mirror of
https://github.com/infiniflow/ragflow.git
synced 2026-01-04 03:25:30 +08:00
Compare commits
45 Commits
v0.23.0
...
6fee60e110
| Author | SHA1 | Date | |
|---|---|---|---|
| 6fee60e110 | |||
| 52f91c2388 | |||
| 348265afc1 | |||
| a7e466142d | |||
| 2fccf3924d | |||
| 4705d07e11 | |||
| 68be3b9a3d | |||
| e2d17d808b | |||
| 95edbd43ba | |||
| b96d553cd8 | |||
| bffdb5fb11 | |||
| 109e782493 | |||
| ff2c70608d | |||
| 5903d1c8f1 | |||
| f0392e7501 | |||
| 4037788e0c | |||
| 59884ab0fb | |||
| 4a6d37f0e8 | |||
| 731e2d5f26 | |||
| df3cbb9b9e | |||
| 5402666b19 | |||
| 4ec6a4e493 | |||
| 2d5ad42128 | |||
| dccda35f65 | |||
| d142b9095e | |||
| c2c079886f | |||
| c3ae1aaecd | |||
| f099bc1236 | |||
| 0b5d1ebefa | |||
| 082c2ed11c | |||
| a764f0a5b2 | |||
| 651d9fff9f | |||
| fddfce303c | |||
| a24fc8291b | |||
| 37e4485415 | |||
| 8d3f9d61da | |||
| 27c55f6514 | |||
| 9883c572cd | |||
| f9619defcc | |||
| 01f0ced1e6 | |||
| 647fb115a0 | |||
| 2114b9e3ad | |||
| 45b96acf6b | |||
| 3305215144 | |||
| 86b03f399a |
22
.github/workflows/release.yml
vendored
22
.github/workflows/release.yml
vendored
@ -10,6 +10,12 @@ on:
|
||||
tags:
|
||||
- "v*.*.*" # normal release
|
||||
|
||||
permissions:
|
||||
contents: write
|
||||
actions: read
|
||||
checks: read
|
||||
statuses: read
|
||||
|
||||
# https://docs.github.com/en/actions/using-jobs/using-concurrency
|
||||
concurrency:
|
||||
group: ${{ github.workflow }}-${{ github.event.pull_request.number || github.ref }}
|
||||
@ -76,6 +82,14 @@ jobs:
|
||||
# The body field does not support environment variable substitution directly.
|
||||
body_path: release_body.md
|
||||
|
||||
- name: Build and push image
|
||||
run: |
|
||||
sudo docker login --username infiniflow --password-stdin <<< ${{ secrets.DOCKERHUB_TOKEN }}
|
||||
sudo docker build --build-arg NEED_MIRROR=1 --build-arg HTTPS_PROXY=${HTTPS_PROXY} --build-arg HTTP_PROXY=${HTTP_PROXY} -t infiniflow/ragflow:${RELEASE_TAG} -f Dockerfile .
|
||||
sudo docker tag infiniflow/ragflow:${RELEASE_TAG} infiniflow/ragflow:latest
|
||||
sudo docker push infiniflow/ragflow:${RELEASE_TAG}
|
||||
sudo docker push infiniflow/ragflow:latest
|
||||
|
||||
- name: Build and push ragflow-sdk
|
||||
if: startsWith(github.ref, 'refs/tags/v')
|
||||
run: |
|
||||
@ -85,11 +99,3 @@ jobs:
|
||||
if: startsWith(github.ref, 'refs/tags/v')
|
||||
run: |
|
||||
cd admin/client && uv build && uv publish --token ${{ secrets.PYPI_API_TOKEN }}
|
||||
|
||||
- name: Build and push image
|
||||
run: |
|
||||
sudo docker login --username infiniflow --password-stdin <<< ${{ secrets.DOCKERHUB_TOKEN }}
|
||||
sudo docker build --build-arg NEED_MIRROR=1 --build-arg HTTPS_PROXY=${HTTPS_PROXY} --build-arg HTTP_PROXY=${HTTP_PROXY} -t infiniflow/ragflow:${RELEASE_TAG} -f Dockerfile .
|
||||
sudo docker tag infiniflow/ragflow:${RELEASE_TAG} infiniflow/ragflow:latest
|
||||
sudo docker push infiniflow/ragflow:${RELEASE_TAG}
|
||||
sudo docker push infiniflow/ragflow:latest
|
||||
|
||||
11
README.md
11
README.md
@ -233,7 +233,7 @@ releases! 🌟
|
||||
* Running on all addresses (0.0.0.0)
|
||||
```
|
||||
|
||||
> If you skip this confirmation step and directly log in to RAGFlow, your browser may prompt a `network anormal`
|
||||
> If you skip this confirmation step and directly log in to RAGFlow, your browser may prompt a `network abnormal`
|
||||
> error because, at that moment, your RAGFlow may not be fully initialized.
|
||||
>
|
||||
5. In your web browser, enter the IP address of your server and log in to RAGFlow.
|
||||
@ -303,6 +303,15 @@ cd ragflow/
|
||||
docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly .
|
||||
```
|
||||
|
||||
Or if you are behind a proxy, you can pass proxy arguments:
|
||||
|
||||
```bash
|
||||
docker build --platform linux/amd64 \
|
||||
--build-arg http_proxy=http://YOUR_PROXY:PORT \
|
||||
--build-arg https_proxy=http://YOUR_PROXY:PORT \
|
||||
-f Dockerfile -t infiniflow/ragflow:nightly .
|
||||
```
|
||||
|
||||
## 🔨 Launch service from source for development
|
||||
|
||||
1. Install `uv` and `pre-commit`, or skip this step if they are already installed:
|
||||
|
||||
11
README_id.md
11
README_id.md
@ -233,7 +233,7 @@ Coba demo kami di [https://demo.ragflow.io](https://demo.ragflow.io).
|
||||
* Running on all addresses (0.0.0.0)
|
||||
```
|
||||
|
||||
> Jika Anda melewatkan langkah ini dan langsung login ke RAGFlow, browser Anda mungkin menampilkan error `network anormal`
|
||||
> Jika Anda melewatkan langkah ini dan langsung login ke RAGFlow, browser Anda mungkin menampilkan error `network abnormal`
|
||||
> karena RAGFlow mungkin belum sepenuhnya siap.
|
||||
>
|
||||
2. Buka browser web Anda, masukkan alamat IP server Anda, dan login ke RAGFlow.
|
||||
@ -277,6 +277,15 @@ cd ragflow/
|
||||
docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly .
|
||||
```
|
||||
|
||||
Jika berada di belakang proxy, Anda dapat melewatkan argumen proxy:
|
||||
|
||||
```bash
|
||||
docker build --platform linux/amd64 \
|
||||
--build-arg http_proxy=http://YOUR_PROXY:PORT \
|
||||
--build-arg https_proxy=http://YOUR_PROXY:PORT \
|
||||
-f Dockerfile -t infiniflow/ragflow:nightly .
|
||||
```
|
||||
|
||||
## 🔨 Menjalankan Aplikasi dari untuk Pengembangan
|
||||
|
||||
1. Instal `uv` dan `pre-commit`, atau lewati langkah ini jika sudah terinstal:
|
||||
|
||||
@ -277,6 +277,15 @@ cd ragflow/
|
||||
docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly .
|
||||
```
|
||||
|
||||
プロキシ環境下にいる場合は、プロキシ引数を指定できます:
|
||||
|
||||
```bash
|
||||
docker build --platform linux/amd64 \
|
||||
--build-arg http_proxy=http://YOUR_PROXY:PORT \
|
||||
--build-arg https_proxy=http://YOUR_PROXY:PORT \
|
||||
-f Dockerfile -t infiniflow/ragflow:nightly .
|
||||
```
|
||||
|
||||
## 🔨 ソースコードからサービスを起動する方法
|
||||
|
||||
1. `uv` と `pre-commit` をインストールする。すでにインストールされている場合は、このステップをスキップしてください:
|
||||
|
||||
11
README_ko.md
11
README_ko.md
@ -214,7 +214,7 @@
|
||||
* Running on all addresses (0.0.0.0)
|
||||
```
|
||||
|
||||
> 만약 확인 단계를 건너뛰고 바로 RAGFlow에 로그인하면, RAGFlow가 완전히 초기화되지 않았기 때문에 브라우저에서 `network anormal` 오류가 발생할 수 있습니다.
|
||||
> 만약 확인 단계를 건너뛰고 바로 RAGFlow에 로그인하면, RAGFlow가 완전히 초기화되지 않았기 때문에 브라우저에서 `network abnormal` 오류가 발생할 수 있습니다.
|
||||
|
||||
2. 웹 브라우저에 서버의 IP 주소를 입력하고 RAGFlow에 로그인하세요.
|
||||
> 기본 설정을 사용할 경우, `http://IP_OF_YOUR_MACHINE`만 입력하면 됩니다 (포트 번호는 제외). 기본 HTTP 서비스 포트 `80`은 기본 구성으로 사용할 때 생략할 수 있습니다.
|
||||
@ -271,6 +271,15 @@ cd ragflow/
|
||||
docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly .
|
||||
```
|
||||
|
||||
프록시 환경인 경우, 프록시 인수를 전달할 수 있습니다:
|
||||
|
||||
```bash
|
||||
docker build --platform linux/amd64 \
|
||||
--build-arg http_proxy=http://YOUR_PROXY:PORT \
|
||||
--build-arg https_proxy=http://YOUR_PROXY:PORT \
|
||||
-f Dockerfile -t infiniflow/ragflow:nightly .
|
||||
```
|
||||
|
||||
## 🔨 소스 코드로 서비스를 시작합니다.
|
||||
|
||||
1. `uv` 와 `pre-commit` 을 설치하거나, 이미 설치된 경우 이 단계를 건너뜁니다:
|
||||
|
||||
@ -232,7 +232,7 @@ Experimente nossa demo em [https://demo.ragflow.io](https://demo.ragflow.io).
|
||||
* Rodando em todos os endereços (0.0.0.0)
|
||||
```
|
||||
|
||||
> Se você pular essa etapa de confirmação e acessar diretamente o RAGFlow, seu navegador pode exibir um erro `network anormal`, pois, nesse momento, seu RAGFlow pode não estar totalmente inicializado.
|
||||
> Se você pular essa etapa de confirmação e acessar diretamente o RAGFlow, seu navegador pode exibir um erro `network abnormal`, pois, nesse momento, seu RAGFlow pode não estar totalmente inicializado.
|
||||
>
|
||||
5. No seu navegador, insira o endereço IP do seu servidor e faça login no RAGFlow.
|
||||
|
||||
@ -294,6 +294,15 @@ cd ragflow/
|
||||
docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly .
|
||||
```
|
||||
|
||||
Se você estiver atrás de um proxy, pode passar argumentos de proxy:
|
||||
|
||||
```bash
|
||||
docker build --platform linux/amd64 \
|
||||
--build-arg http_proxy=http://YOUR_PROXY:PORT \
|
||||
--build-arg https_proxy=http://YOUR_PROXY:PORT \
|
||||
-f Dockerfile -t infiniflow/ragflow:nightly .
|
||||
```
|
||||
|
||||
## 🔨 Lançar o serviço a partir do código-fonte para desenvolvimento
|
||||
|
||||
1. Instale o `uv` e o `pre-commit`, ou pule esta etapa se eles já estiverem instalados:
|
||||
|
||||
@ -125,7 +125,7 @@
|
||||
|
||||
### 🍔 **相容各類異質資料來源**
|
||||
|
||||
- 支援豐富的文件類型,包括 Word 文件、PPT、excel 表格、txt 檔案、圖片、PDF、影印件、影印件、結構化資料、網頁等。
|
||||
- 支援豐富的文件類型,包括 Word 文件、PPT、excel 表格、txt 檔案、圖片、PDF、影印件、複印件、結構化資料、網頁等。
|
||||
|
||||
### 🛀 **全程無憂、自動化的 RAG 工作流程**
|
||||
|
||||
@ -237,7 +237,7 @@
|
||||
* Running on all addresses (0.0.0.0)
|
||||
```
|
||||
|
||||
> 如果您跳過這一步驟系統確認步驟就登入 RAGFlow,你的瀏覽器有可能會提示 `network anormal` 或 `網路異常`,因為 RAGFlow 可能並未完全啟動成功。
|
||||
> 如果您跳過這一步驟系統確認步驟就登入 RAGFlow,你的瀏覽器有可能會提示 `network abnormal` 或 `網路異常`,因為 RAGFlow 可能並未完全啟動成功。
|
||||
>
|
||||
5. 在你的瀏覽器中輸入你的伺服器對應的 IP 位址並登入 RAGFlow。
|
||||
|
||||
@ -303,6 +303,15 @@ cd ragflow/
|
||||
docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly .
|
||||
```
|
||||
|
||||
若您位於代理環境,可傳遞代理參數:
|
||||
|
||||
```bash
|
||||
docker build --platform linux/amd64 \
|
||||
--build-arg http_proxy=http://YOUR_PROXY:PORT \
|
||||
--build-arg https_proxy=http://YOUR_PROXY:PORT \
|
||||
-f Dockerfile -t infiniflow/ragflow:nightly .
|
||||
```
|
||||
|
||||
## 🔨 以原始碼啟動服務
|
||||
|
||||
1. 安裝 `uv` 和 `pre-commit`。如已安裝,可跳過此步驟:
|
||||
|
||||
11
README_zh.md
11
README_zh.md
@ -238,7 +238,7 @@
|
||||
* Running on all addresses (0.0.0.0)
|
||||
```
|
||||
|
||||
> 如果您在没有看到上面的提示信息出来之前,就尝试登录 RAGFlow,你的浏览器有可能会提示 `network anormal` 或 `网络异常`。
|
||||
> 如果您在没有看到上面的提示信息出来之前,就尝试登录 RAGFlow,你的浏览器有可能会提示 `network abnormal` 或 `网络异常`。
|
||||
|
||||
5. 在你的浏览器中输入你的服务器对应的 IP 地址并登录 RAGFlow。
|
||||
> 上面这个例子中,您只需输入 http://IP_OF_YOUR_MACHINE 即可:未改动过配置则无需输入端口(默认的 HTTP 服务端口 80)。
|
||||
@ -302,6 +302,15 @@ cd ragflow/
|
||||
docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly .
|
||||
```
|
||||
|
||||
如果您处在代理环境下,可以传递代理参数:
|
||||
|
||||
```bash
|
||||
docker build --platform linux/amd64 \
|
||||
--build-arg http_proxy=http://YOUR_PROXY:PORT \
|
||||
--build-arg https_proxy=http://YOUR_PROXY:PORT \
|
||||
-f Dockerfile -t infiniflow/ragflow:nightly .
|
||||
```
|
||||
|
||||
## 🔨 以源代码启动服务
|
||||
|
||||
1. 安装 `uv` 和 `pre-commit`。如已经安装,可跳过本步骤:
|
||||
|
||||
@ -33,7 +33,7 @@ from common.connection_utils import timeout
|
||||
from common.misc_utils import get_uuid
|
||||
from common import settings
|
||||
|
||||
from api.db.joint_services.memory_message_service import save_to_memory
|
||||
from api.db.joint_services.memory_message_service import queue_save_to_memory_task
|
||||
|
||||
|
||||
class MessageParam(ComponentParamBase):
|
||||
@ -437,17 +437,4 @@ class Message(ComponentBase):
|
||||
"user_input": self._canvas.get_sys_query(),
|
||||
"agent_response": content
|
||||
}
|
||||
res = []
|
||||
for memory_id in self._param.memory_ids:
|
||||
success, msg = await save_to_memory(memory_id, message_dict)
|
||||
res.append({
|
||||
"memory_id": memory_id,
|
||||
"success": success,
|
||||
"msg": msg
|
||||
})
|
||||
if all([r["success"] for r in res]):
|
||||
return True, "Successfully added to memories."
|
||||
|
||||
error_text = "Some messages failed to add. " + " ".join([f"Add to memory {r['memory_id']} failed, detail: {r['msg']}" for r in res if not r["success"]])
|
||||
logging.error(error_text)
|
||||
return False, error_text
|
||||
return await queue_save_to_memory_task(self._param.memory_ids, message_dict)
|
||||
|
||||
@ -746,6 +746,7 @@ async def change_parser():
|
||||
tenant_id = DocumentService.get_tenant_id(req["doc_id"])
|
||||
if not tenant_id:
|
||||
return get_data_error_result(message="Tenant not found!")
|
||||
DocumentService.delete_chunk_images(doc, tenant_id)
|
||||
if settings.docStoreConn.index_exist(search.index_name(tenant_id), doc.kb_id):
|
||||
settings.docStoreConn.delete({"doc_id": doc.id}, search.index_name(tenant_id), doc.kb_id)
|
||||
return None
|
||||
|
||||
@ -159,7 +159,8 @@ async def delete_memory(memory_id):
|
||||
return get_json_result(message=True, code=RetCode.NOT_FOUND)
|
||||
try:
|
||||
MemoryService.delete_memory(memory_id)
|
||||
MessageService.delete_message({"memory_id": memory_id}, memory.tenant_id, memory_id)
|
||||
if MessageService.has_index(memory.tenant_id, memory_id):
|
||||
MessageService.delete_message({"memory_id": memory_id}, memory.tenant_id, memory_id)
|
||||
return get_json_result(message=True)
|
||||
except Exception as e:
|
||||
logging.error(e)
|
||||
|
||||
@ -1286,6 +1286,9 @@ async def rm_chunk(tenant_id, dataset_id, document_id):
|
||||
if "chunk_ids" in req:
|
||||
unique_chunk_ids, duplicate_messages = check_duplicate_ids(req["chunk_ids"], "chunk")
|
||||
condition["id"] = unique_chunk_ids
|
||||
else:
|
||||
unique_chunk_ids = []
|
||||
duplicate_messages = []
|
||||
chunk_number = settings.docStoreConn.delete(condition, search.index_name(tenant_id), dataset_id)
|
||||
if chunk_number != 0:
|
||||
DocumentService.decrement_chunk_num(document_id, dataset_id, 1, chunk_number, 0)
|
||||
|
||||
@ -177,7 +177,7 @@ def healthz():
|
||||
return jsonify(result), (200 if all_ok else 500)
|
||||
|
||||
|
||||
@manager.route("/ping", methods=["GET"]) # noqa: F821
|
||||
@manager.route("/ping", methods=["GET"]) # noqa: F821
|
||||
def ping():
|
||||
return "pong", 200
|
||||
|
||||
@ -213,7 +213,7 @@ def new_token():
|
||||
if not tenants:
|
||||
return get_data_error_result(message="Tenant not found!")
|
||||
|
||||
tenant_id = [tenant for tenant in tenants if tenant.role == 'owner'][0].tenant_id
|
||||
tenant_id = [tenant for tenant in tenants if tenant.role == "owner"][0].tenant_id
|
||||
obj = {
|
||||
"tenant_id": tenant_id,
|
||||
"token": generate_confirmation_token(),
|
||||
@ -268,13 +268,12 @@ def token_list():
|
||||
if not tenants:
|
||||
return get_data_error_result(message="Tenant not found!")
|
||||
|
||||
tenant_id = [tenant for tenant in tenants if tenant.role == 'owner'][0].tenant_id
|
||||
tenant_id = [tenant for tenant in tenants if tenant.role == "owner"][0].tenant_id
|
||||
objs = APITokenService.query(tenant_id=tenant_id)
|
||||
objs = [o.to_dict() for o in objs]
|
||||
for o in objs:
|
||||
if not o["beta"]:
|
||||
o["beta"] = generate_confirmation_token().replace(
|
||||
"ragflow-", "")[:32]
|
||||
o["beta"] = generate_confirmation_token().replace("ragflow-", "")[:32]
|
||||
APITokenService.filter_update([APIToken.tenant_id == tenant_id, APIToken.token == o["token"]], o)
|
||||
return get_json_result(data=objs)
|
||||
except Exception as e:
|
||||
@ -307,13 +306,19 @@ def rm(token):
|
||||
type: boolean
|
||||
description: Deletion status.
|
||||
"""
|
||||
APITokenService.filter_delete(
|
||||
[APIToken.tenant_id == current_user.id, APIToken.token == token]
|
||||
)
|
||||
return get_json_result(data=True)
|
||||
try:
|
||||
tenants = UserTenantService.query(user_id=current_user.id)
|
||||
if not tenants:
|
||||
return get_data_error_result(message="Tenant not found!")
|
||||
|
||||
tenant_id = tenants[0].tenant_id
|
||||
APITokenService.filter_delete([APIToken.tenant_id == tenant_id, APIToken.token == token])
|
||||
return get_json_result(data=True)
|
||||
except Exception as e:
|
||||
return server_error_response(e)
|
||||
|
||||
|
||||
@manager.route('/config', methods=['GET']) # noqa: F821
|
||||
@manager.route("/config", methods=["GET"]) # noqa: F821
|
||||
def get_config():
|
||||
"""
|
||||
Get system configuration.
|
||||
@ -330,6 +335,4 @@ def get_config():
|
||||
type: integer 0 means disabled, 1 means enabled
|
||||
description: Whether user registration is enabled
|
||||
"""
|
||||
return get_json_result(data={
|
||||
"registerEnabled": settings.REGISTER_ENABLED
|
||||
})
|
||||
return get_json_result(data={"registerEnabled": settings.REGISTER_ENABLED})
|
||||
|
||||
@ -16,9 +16,14 @@
|
||||
import logging
|
||||
from typing import List
|
||||
|
||||
from api.db.services.task_service import TaskService
|
||||
from common import settings
|
||||
from common.time_utils import current_timestamp, timestamp_to_date, format_iso_8601_to_ymd_hms
|
||||
from common.constants import MemoryType, LLMType
|
||||
from common.doc_store.doc_store_base import FusionExpr
|
||||
from common.misc_utils import get_uuid
|
||||
from api.db.db_utils import bulk_insert_into_db
|
||||
from api.db.db_models import Task
|
||||
from api.db.services.memory_service import MemoryService
|
||||
from api.db.services.tenant_llm_service import TenantLLMService
|
||||
from api.db.services.llm_service import LLMBundle
|
||||
@ -82,32 +87,44 @@ async def save_to_memory(memory_id: str, message_dict: dict):
|
||||
"forget_at": None,
|
||||
"status": True
|
||||
} for content in extracted_content]]
|
||||
embedding_model = LLMBundle(tenant_id, llm_type=LLMType.EMBEDDING, llm_name=memory.embd_id)
|
||||
vector_list, _ = embedding_model.encode([msg["content"] for msg in message_list])
|
||||
for idx, msg in enumerate(message_list):
|
||||
msg["content_embed"] = vector_list[idx]
|
||||
vector_dimension = len(vector_list[0])
|
||||
if not MessageService.has_index(tenant_id, memory_id):
|
||||
created = MessageService.create_index(tenant_id, memory_id, vector_size=vector_dimension)
|
||||
if not created:
|
||||
return False, "Failed to create message index."
|
||||
return await embed_and_save(memory, message_list)
|
||||
|
||||
new_msg_size = sum([MessageService.calculate_message_size(m) for m in message_list])
|
||||
current_memory_size = get_memory_size_cache(memory_id, tenant_id)
|
||||
if new_msg_size + current_memory_size > memory.memory_size:
|
||||
size_to_delete = current_memory_size + new_msg_size - memory.memory_size
|
||||
if memory.forgetting_policy == "FIFO":
|
||||
message_ids_to_delete, delete_size = MessageService.pick_messages_to_delete_by_fifo(memory_id, tenant_id, size_to_delete)
|
||||
MessageService.delete_message({"message_id": message_ids_to_delete}, tenant_id, memory_id)
|
||||
decrease_memory_size_cache(memory_id, delete_size)
|
||||
else:
|
||||
return False, "Failed to insert message into memory. Memory size reached limit and cannot decide which to delete."
|
||||
fail_cases = MessageService.insert_message(message_list, tenant_id, memory_id)
|
||||
if fail_cases:
|
||||
return False, "Failed to insert message into memory. Details: " + "; ".join(fail_cases)
|
||||
|
||||
increase_memory_size_cache(memory_id, new_msg_size)
|
||||
return True, "Message saved successfully."
|
||||
async def save_extracted_to_memory_only(memory_id: str, message_dict, source_message_id: int):
|
||||
memory = MemoryService.get_by_memory_id(memory_id)
|
||||
if not memory:
|
||||
return False, f"Memory '{memory_id}' not found."
|
||||
|
||||
if memory.memory_type == MemoryType.RAW.value:
|
||||
return True, f"Memory '{memory_id}' don't need to extract."
|
||||
|
||||
tenant_id = memory.tenant_id
|
||||
extracted_content = await extract_by_llm(
|
||||
tenant_id,
|
||||
memory.llm_id,
|
||||
{"temperature": memory.temperature},
|
||||
get_memory_type_human(memory.memory_type),
|
||||
message_dict.get("user_input", ""),
|
||||
message_dict.get("agent_response", "")
|
||||
)
|
||||
message_list = [{
|
||||
"message_id": REDIS_CONN.generate_auto_increment_id(namespace="memory"),
|
||||
"message_type": content["message_type"],
|
||||
"source_id": source_message_id,
|
||||
"memory_id": memory_id,
|
||||
"user_id": "",
|
||||
"agent_id": message_dict["agent_id"],
|
||||
"session_id": message_dict["session_id"],
|
||||
"content": content["content"],
|
||||
"valid_at": content["valid_at"],
|
||||
"invalid_at": content["invalid_at"] if content["invalid_at"] else None,
|
||||
"forget_at": None,
|
||||
"status": True
|
||||
} for content in extracted_content]
|
||||
if not message_list:
|
||||
return True, "No memory extracted from raw message."
|
||||
|
||||
return await embed_and_save(memory, message_list)
|
||||
|
||||
|
||||
async def extract_by_llm(tenant_id: str, llm_id: str, extract_conf: dict, memory_type: List[str], user_input: str,
|
||||
@ -136,6 +153,36 @@ async def extract_by_llm(tenant_id: str, llm_id: str, extract_conf: dict, memory
|
||||
} for message_type, extracted_content_list in res_json.items() for extracted_content in extracted_content_list]
|
||||
|
||||
|
||||
async def embed_and_save(memory, message_list: list[dict]):
|
||||
embedding_model = LLMBundle(memory.tenant_id, llm_type=LLMType.EMBEDDING, llm_name=memory.embd_id)
|
||||
vector_list, _ = embedding_model.encode([msg["content"] for msg in message_list])
|
||||
for idx, msg in enumerate(message_list):
|
||||
msg["content_embed"] = vector_list[idx]
|
||||
vector_dimension = len(vector_list[0])
|
||||
if not MessageService.has_index(memory.tenant_id, memory.id):
|
||||
created = MessageService.create_index(memory.tenant_id, memory.id, vector_size=vector_dimension)
|
||||
if not created:
|
||||
return False, "Failed to create message index."
|
||||
|
||||
new_msg_size = sum([MessageService.calculate_message_size(m) for m in message_list])
|
||||
current_memory_size = get_memory_size_cache(memory.tenant_id, memory.id)
|
||||
if new_msg_size + current_memory_size > memory.memory_size:
|
||||
size_to_delete = current_memory_size + new_msg_size - memory.memory_size
|
||||
if memory.forgetting_policy == "FIFO":
|
||||
message_ids_to_delete, delete_size = MessageService.pick_messages_to_delete_by_fifo(memory.id, memory.tenant_id,
|
||||
size_to_delete)
|
||||
MessageService.delete_message({"message_id": message_ids_to_delete}, memory.tenant_id, memory.id)
|
||||
decrease_memory_size_cache(memory.id, delete_size)
|
||||
else:
|
||||
return False, "Failed to insert message into memory. Memory size reached limit and cannot decide which to delete."
|
||||
fail_cases = MessageService.insert_message(message_list, memory.tenant_id, memory.id)
|
||||
if fail_cases:
|
||||
return False, "Failed to insert message into memory. Details: " + "; ".join(fail_cases)
|
||||
|
||||
increase_memory_size_cache(memory.id, new_msg_size)
|
||||
return True, "Message saved successfully."
|
||||
|
||||
|
||||
def query_message(filter_dict: dict, params: dict):
|
||||
"""
|
||||
:param filter_dict: {
|
||||
@ -231,3 +278,112 @@ def init_memory_size_cache():
|
||||
def judge_system_prompt_is_default(system_prompt: str, memory_type: int|list[str]):
|
||||
memory_type_list = memory_type if isinstance(memory_type, list) else get_memory_type_human(memory_type)
|
||||
return system_prompt == PromptAssembler.assemble_system_prompt({"memory_type": memory_type_list})
|
||||
|
||||
|
||||
async def queue_save_to_memory_task(memory_ids: list[str], message_dict: dict):
|
||||
"""
|
||||
:param memory_ids:
|
||||
:param message_dict: {
|
||||
"user_id": str,
|
||||
"agent_id": str,
|
||||
"session_id": str,
|
||||
"user_input": str,
|
||||
"agent_response": str
|
||||
}
|
||||
"""
|
||||
def new_task(_memory_id: str, _source_id: int):
|
||||
return {
|
||||
"id": get_uuid(),
|
||||
"doc_id": _memory_id,
|
||||
"task_type": "memory",
|
||||
"progress": 0.0,
|
||||
"digest": str(_source_id)
|
||||
}
|
||||
|
||||
not_found_memory = []
|
||||
failed_memory = []
|
||||
for memory_id in memory_ids:
|
||||
memory = MemoryService.get_by_memory_id(memory_id)
|
||||
if not memory:
|
||||
not_found_memory.append(memory_id)
|
||||
continue
|
||||
|
||||
raw_message_id = REDIS_CONN.generate_auto_increment_id(namespace="memory")
|
||||
raw_message = {
|
||||
"message_id": raw_message_id,
|
||||
"message_type": MemoryType.RAW.name.lower(),
|
||||
"source_id": 0,
|
||||
"memory_id": memory_id,
|
||||
"user_id": "",
|
||||
"agent_id": message_dict["agent_id"],
|
||||
"session_id": message_dict["session_id"],
|
||||
"content": f"User Input: {message_dict.get('user_input')}\nAgent Response: {message_dict.get('agent_response')}",
|
||||
"valid_at": timestamp_to_date(current_timestamp()),
|
||||
"invalid_at": None,
|
||||
"forget_at": None,
|
||||
"status": True
|
||||
}
|
||||
res, msg = await embed_and_save(memory, [raw_message])
|
||||
if not res:
|
||||
failed_memory.append({"memory_id": memory_id, "fail_msg": msg})
|
||||
continue
|
||||
|
||||
task = new_task(memory_id, raw_message_id)
|
||||
bulk_insert_into_db(Task, [task], replace_on_conflict=True)
|
||||
task_message = {
|
||||
"id": task["id"],
|
||||
"task_id": task["id"],
|
||||
"task_type": task["task_type"],
|
||||
"memory_id": memory_id,
|
||||
"source_id": raw_message_id,
|
||||
"message_dict": message_dict
|
||||
}
|
||||
if not REDIS_CONN.queue_product(settings.get_svr_queue_name(priority=0), message=task_message):
|
||||
failed_memory.append({"memory_id": memory_id, "fail_msg": "Can't access Redis."})
|
||||
|
||||
error_msg = ""
|
||||
if not_found_memory:
|
||||
error_msg = f"Memory {not_found_memory} not found."
|
||||
if failed_memory:
|
||||
error_msg += "".join([f"Memory {fm['memory_id']} failed. Detail: {fm['fail_msg']}" for fm in failed_memory])
|
||||
|
||||
if error_msg:
|
||||
return False, error_msg
|
||||
|
||||
return True, "All add to task."
|
||||
|
||||
|
||||
async def handle_save_to_memory_task(task_param: dict):
|
||||
"""
|
||||
:param task_param: {
|
||||
"id": task_id
|
||||
"memory_id": id
|
||||
"source_id": id
|
||||
"message_dict": {
|
||||
"user_id": str,
|
||||
"agent_id": str,
|
||||
"session_id": str,
|
||||
"user_input": str,
|
||||
"agent_response": str
|
||||
}
|
||||
}
|
||||
"""
|
||||
_, task = TaskService.get_by_id(task_param["id"])
|
||||
if not task:
|
||||
return False, f"Task {task_param['id']} is not found."
|
||||
if task.progress == -1:
|
||||
return False, f"Task {task_param['id']} is already failed."
|
||||
now_time = current_timestamp()
|
||||
TaskService.update_by_id(task_param["id"], {"begin_at": timestamp_to_date(now_time)})
|
||||
|
||||
memory_id = task_param["memory_id"]
|
||||
source_id = task_param["source_id"]
|
||||
message_dict = task_param["message_dict"]
|
||||
success, msg = await save_extracted_to_memory_only(memory_id, message_dict, source_id)
|
||||
if success:
|
||||
TaskService.update_progress(task.id, {"progress": 1.0, "progress_msg": msg})
|
||||
return True, msg
|
||||
|
||||
logging.error(msg)
|
||||
TaskService.update_progress(task.id, {"progress": -1, "progress_msg": None})
|
||||
return False, msg
|
||||
|
||||
@ -342,21 +342,7 @@ class DocumentService(CommonService):
|
||||
cls.clear_chunk_num(doc.id)
|
||||
try:
|
||||
TaskService.filter_delete([Task.doc_id == doc.id])
|
||||
page = 0
|
||||
page_size = 1000
|
||||
all_chunk_ids = []
|
||||
while True:
|
||||
chunks = settings.docStoreConn.search(["img_id"], [], {"doc_id": doc.id}, [], OrderByExpr(),
|
||||
page * page_size, page_size, search.index_name(tenant_id),
|
||||
[doc.kb_id])
|
||||
chunk_ids = settings.docStoreConn.get_doc_ids(chunks)
|
||||
if not chunk_ids:
|
||||
break
|
||||
all_chunk_ids.extend(chunk_ids)
|
||||
page += 1
|
||||
for cid in all_chunk_ids:
|
||||
if settings.STORAGE_IMPL.obj_exist(doc.kb_id, cid):
|
||||
settings.STORAGE_IMPL.rm(doc.kb_id, cid)
|
||||
cls.delete_chunk_images(doc, tenant_id)
|
||||
if doc.thumbnail and not doc.thumbnail.startswith(IMG_BASE64_PREFIX):
|
||||
if settings.STORAGE_IMPL.obj_exist(doc.kb_id, doc.thumbnail):
|
||||
settings.STORAGE_IMPL.rm(doc.kb_id, doc.thumbnail)
|
||||
@ -378,6 +364,23 @@ class DocumentService(CommonService):
|
||||
pass
|
||||
return cls.delete_by_id(doc.id)
|
||||
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
def delete_chunk_images(cls, doc, tenant_id):
|
||||
page = 0
|
||||
page_size = 1000
|
||||
while True:
|
||||
chunks = settings.docStoreConn.search(["img_id"], [], {"doc_id": doc.id}, [], OrderByExpr(),
|
||||
page * page_size, page_size, search.index_name(tenant_id),
|
||||
[doc.kb_id])
|
||||
chunk_ids = settings.docStoreConn.get_doc_ids(chunks)
|
||||
if not chunk_ids:
|
||||
break
|
||||
for cid in chunk_ids:
|
||||
if settings.STORAGE_IMPL.obj_exist(doc.kb_id, cid):
|
||||
settings.STORAGE_IMPL.rm(doc.kb_id, cid)
|
||||
page += 1
|
||||
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
def get_newly_uploaded(cls):
|
||||
|
||||
@ -65,6 +65,7 @@ class EvaluationService(CommonService):
|
||||
(success, dataset_id or error_message)
|
||||
"""
|
||||
try:
|
||||
timestamp= current_timestamp()
|
||||
dataset_id = get_uuid()
|
||||
dataset = {
|
||||
"id": dataset_id,
|
||||
@ -73,8 +74,8 @@ class EvaluationService(CommonService):
|
||||
"description": description,
|
||||
"kb_ids": kb_ids,
|
||||
"created_by": user_id,
|
||||
"create_time": current_timestamp(),
|
||||
"update_time": current_timestamp(),
|
||||
"create_time": timestamp,
|
||||
"update_time": timestamp,
|
||||
"status": StatusEnum.VALID.value
|
||||
}
|
||||
|
||||
|
||||
@ -64,10 +64,13 @@ class TenantLangfuseService(CommonService):
|
||||
|
||||
@classmethod
|
||||
def save(cls, **kwargs):
|
||||
kwargs["create_time"] = current_timestamp()
|
||||
kwargs["create_date"] = datetime_format(datetime.now())
|
||||
kwargs["update_time"] = current_timestamp()
|
||||
kwargs["update_date"] = datetime_format(datetime.now())
|
||||
current_ts = current_timestamp()
|
||||
current_date = datetime_format(datetime.now())
|
||||
|
||||
kwargs["create_time"] = current_ts
|
||||
kwargs["create_date"] = current_date
|
||||
kwargs["update_time"] = current_ts
|
||||
kwargs["update_date"] = current_date
|
||||
obj = cls.model.create(**kwargs)
|
||||
return obj
|
||||
|
||||
|
||||
@ -169,11 +169,12 @@ class PipelineOperationLogService(CommonService):
|
||||
operation_status=operation_status,
|
||||
avatar=avatar,
|
||||
)
|
||||
log["create_time"] = current_timestamp()
|
||||
log["create_date"] = datetime_format(datetime.now())
|
||||
log["update_time"] = current_timestamp()
|
||||
log["update_date"] = datetime_format(datetime.now())
|
||||
|
||||
timestamp = current_timestamp()
|
||||
datetime_now = datetime_format(datetime.now())
|
||||
log["create_time"] = timestamp
|
||||
log["create_date"] = datetime_now
|
||||
log["update_time"] = timestamp
|
||||
log["update_date"] = datetime_now
|
||||
with DB.atomic():
|
||||
obj = cls.save(**log)
|
||||
|
||||
|
||||
@ -28,10 +28,13 @@ class SearchService(CommonService):
|
||||
|
||||
@classmethod
|
||||
def save(cls, **kwargs):
|
||||
kwargs["create_time"] = current_timestamp()
|
||||
kwargs["create_date"] = datetime_format(datetime.now())
|
||||
kwargs["update_time"] = current_timestamp()
|
||||
kwargs["update_date"] = datetime_format(datetime.now())
|
||||
current_ts = current_timestamp()
|
||||
current_date = datetime_format(datetime.now())
|
||||
|
||||
kwargs["create_time"] = current_ts
|
||||
kwargs["create_date"] = current_date
|
||||
kwargs["update_time"] = current_ts
|
||||
kwargs["update_date"] = current_date
|
||||
obj = cls.model.create(**kwargs)
|
||||
return obj
|
||||
|
||||
|
||||
@ -116,10 +116,13 @@ class UserService(CommonService):
|
||||
kwargs["password"] = generate_password_hash(
|
||||
str(kwargs["password"]))
|
||||
|
||||
kwargs["create_time"] = current_timestamp()
|
||||
kwargs["create_date"] = datetime_format(datetime.now())
|
||||
kwargs["update_time"] = current_timestamp()
|
||||
kwargs["update_date"] = datetime_format(datetime.now())
|
||||
current_ts = current_timestamp()
|
||||
current_date = datetime_format(datetime.now())
|
||||
|
||||
kwargs["create_time"] = current_ts
|
||||
kwargs["create_date"] = current_date
|
||||
kwargs["update_time"] = current_ts
|
||||
kwargs["update_date"] = current_date
|
||||
obj = cls.model(**kwargs).save(force_insert=True)
|
||||
return obj
|
||||
|
||||
|
||||
@ -42,7 +42,7 @@ def filename_type(filename):
|
||||
if re.match(r".*\.pdf$", filename):
|
||||
return FileType.PDF.value
|
||||
|
||||
if re.match(r".*\.(msg|eml|doc|docx|ppt|pptx|yml|xml|htm|json|jsonl|ldjson|csv|txt|ini|xls|xlsx|wps|rtf|hlp|pages|numbers|key|md|py|js|java|c|cpp|h|php|go|ts|sh|cs|kt|html|sql)$", filename):
|
||||
if re.match(r".*\.(msg|eml|doc|docx|ppt|pptx|yml|xml|htm|json|jsonl|ldjson|csv|txt|ini|xls|xlsx|wps|rtf|hlp|pages|numbers|key|md|mdx|py|js|java|c|cpp|h|php|go|ts|sh|cs|kt|html|sql)$", filename):
|
||||
return FileType.DOC.value
|
||||
|
||||
if re.match(r".*\.(wav|flac|ape|alac|wavpack|wv|mp3|aac|ogg|vorbis|opus)$", filename):
|
||||
|
||||
@ -69,6 +69,7 @@ CONTENT_TYPE_MAP = {
|
||||
# Web
|
||||
"md": "text/markdown",
|
||||
"markdown": "text/markdown",
|
||||
"mdx": "text/markdown",
|
||||
"htm": "text/html",
|
||||
"html": "text/html",
|
||||
"json": "application/json",
|
||||
|
||||
@ -129,14 +129,18 @@ class FileSource(StrEnum):
|
||||
OCI_STORAGE = "oci_storage"
|
||||
GOOGLE_CLOUD_STORAGE = "google_cloud_storage"
|
||||
AIRTABLE = "airtable"
|
||||
ASANA = "asana"
|
||||
GITHUB = "github"
|
||||
GITLAB = "gitlab"
|
||||
IMAP = "imap"
|
||||
|
||||
|
||||
class PipelineTaskType(StrEnum):
|
||||
PARSE = "Parse"
|
||||
DOWNLOAD = "Download"
|
||||
RAPTOR = "RAPTOR"
|
||||
GRAPH_RAG = "GraphRAG"
|
||||
MINDMAP = "Mindmap"
|
||||
MEMORY = "Memory"
|
||||
|
||||
|
||||
VALID_PIPELINE_TASK_TYPES = {PipelineTaskType.PARSE, PipelineTaskType.DOWNLOAD, PipelineTaskType.RAPTOR,
|
||||
|
||||
@ -37,6 +37,8 @@ from .teams_connector import TeamsConnector
|
||||
from .webdav_connector import WebDAVConnector
|
||||
from .moodle_connector import MoodleConnector
|
||||
from .airtable_connector import AirtableConnector
|
||||
from .asana_connector import AsanaConnector
|
||||
from .imap_connector import ImapConnector
|
||||
from .config import BlobType, DocumentSource
|
||||
from .models import Document, TextSection, ImageSection, BasicExpertInfo
|
||||
from .exceptions import (
|
||||
@ -73,4 +75,6 @@ __all__ = [
|
||||
"InsufficientPermissionsError",
|
||||
"UnexpectedValidationError",
|
||||
"AirtableConnector",
|
||||
"AsanaConnector",
|
||||
"ImapConnector"
|
||||
]
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
from datetime import datetime, timezone
|
||||
import logging
|
||||
from typing import Any
|
||||
from typing import Any, Generator
|
||||
|
||||
import requests
|
||||
|
||||
@ -8,8 +8,8 @@ from pyairtable import Api as AirtableApi
|
||||
|
||||
from common.data_source.config import AIRTABLE_CONNECTOR_SIZE_THRESHOLD, INDEX_BATCH_SIZE, DocumentSource
|
||||
from common.data_source.exceptions import ConnectorMissingCredentialError
|
||||
from common.data_source.interfaces import LoadConnector
|
||||
from common.data_source.models import Document, GenerateDocumentsOutput
|
||||
from common.data_source.interfaces import LoadConnector, PollConnector
|
||||
from common.data_source.models import Document, GenerateDocumentsOutput, SecondsSinceUnixEpoch
|
||||
from common.data_source.utils import extract_size_bytes, get_file_ext
|
||||
|
||||
class AirtableClientNotSetUpError(PermissionError):
|
||||
@ -19,7 +19,7 @@ class AirtableClientNotSetUpError(PermissionError):
|
||||
)
|
||||
|
||||
|
||||
class AirtableConnector(LoadConnector):
|
||||
class AirtableConnector(LoadConnector, PollConnector):
|
||||
"""
|
||||
Lightweight Airtable connector.
|
||||
|
||||
@ -132,6 +132,26 @@ class AirtableConnector(LoadConnector):
|
||||
if batch:
|
||||
yield batch
|
||||
|
||||
def poll_source(self, start: SecondsSinceUnixEpoch, end: SecondsSinceUnixEpoch) -> Generator[list[Document], None, None]:
|
||||
"""Poll source to get documents"""
|
||||
start_dt = datetime.fromtimestamp(start, tz=timezone.utc)
|
||||
end_dt = datetime.fromtimestamp(end, tz=timezone.utc)
|
||||
|
||||
for batch in self.load_from_state():
|
||||
filtered: list[Document] = []
|
||||
|
||||
for doc in batch:
|
||||
if not doc.doc_updated_at:
|
||||
continue
|
||||
|
||||
doc_dt = doc.doc_updated_at.astimezone(timezone.utc)
|
||||
|
||||
if start_dt <= doc_dt < end_dt:
|
||||
filtered.append(doc)
|
||||
|
||||
if filtered:
|
||||
yield filtered
|
||||
|
||||
if __name__ == "__main__":
|
||||
import os
|
||||
|
||||
|
||||
454
common/data_source/asana_connector.py
Normal file
454
common/data_source/asana_connector.py
Normal file
@ -0,0 +1,454 @@
|
||||
from collections.abc import Iterator
|
||||
import time
|
||||
from datetime import datetime
|
||||
import logging
|
||||
from typing import Any, Dict
|
||||
import asana
|
||||
import requests
|
||||
from common.data_source.config import CONTINUE_ON_CONNECTOR_FAILURE, INDEX_BATCH_SIZE, DocumentSource
|
||||
from common.data_source.interfaces import LoadConnector, PollConnector
|
||||
from common.data_source.models import Document, GenerateDocumentsOutput, SecondsSinceUnixEpoch
|
||||
from common.data_source.utils import extract_size_bytes, get_file_ext
|
||||
|
||||
|
||||
|
||||
# https://github.com/Asana/python-asana/tree/master?tab=readme-ov-file#documentation-for-api-endpoints
|
||||
class AsanaTask:
|
||||
def __init__(
|
||||
self,
|
||||
id: str,
|
||||
title: str,
|
||||
text: str,
|
||||
link: str,
|
||||
last_modified: datetime,
|
||||
project_gid: str,
|
||||
project_name: str,
|
||||
) -> None:
|
||||
self.id = id
|
||||
self.title = title
|
||||
self.text = text
|
||||
self.link = link
|
||||
self.last_modified = last_modified
|
||||
self.project_gid = project_gid
|
||||
self.project_name = project_name
|
||||
|
||||
def __str__(self) -> str:
|
||||
return f"ID: {self.id}\nTitle: {self.title}\nLast modified: {self.last_modified}\nText: {self.text}"
|
||||
|
||||
|
||||
class AsanaAPI:
|
||||
def __init__(
|
||||
self, api_token: str, workspace_gid: str, team_gid: str | None
|
||||
) -> None:
|
||||
self._user = None
|
||||
self.workspace_gid = workspace_gid
|
||||
self.team_gid = team_gid
|
||||
|
||||
self.configuration = asana.Configuration()
|
||||
self.api_client = asana.ApiClient(self.configuration)
|
||||
self.tasks_api = asana.TasksApi(self.api_client)
|
||||
self.attachments_api = asana.AttachmentsApi(self.api_client)
|
||||
self.stories_api = asana.StoriesApi(self.api_client)
|
||||
self.users_api = asana.UsersApi(self.api_client)
|
||||
self.project_api = asana.ProjectsApi(self.api_client)
|
||||
self.project_memberships_api = asana.ProjectMembershipsApi(self.api_client)
|
||||
self.workspaces_api = asana.WorkspacesApi(self.api_client)
|
||||
|
||||
self.api_error_count = 0
|
||||
self.configuration.access_token = api_token
|
||||
self.task_count = 0
|
||||
|
||||
def get_tasks(
|
||||
self, project_gids: list[str] | None, start_date: str
|
||||
) -> Iterator[AsanaTask]:
|
||||
"""Get all tasks from the projects with the given gids that were modified since the given date.
|
||||
If project_gids is None, get all tasks from all projects in the workspace."""
|
||||
logging.info("Starting to fetch Asana projects")
|
||||
projects = self.project_api.get_projects(
|
||||
opts={
|
||||
"workspace": self.workspace_gid,
|
||||
"opt_fields": "gid,name,archived,modified_at",
|
||||
}
|
||||
)
|
||||
start_seconds = int(time.mktime(datetime.now().timetuple()))
|
||||
projects_list = []
|
||||
project_count = 0
|
||||
for project_info in projects:
|
||||
project_gid = project_info["gid"]
|
||||
if project_gids is None or project_gid in project_gids:
|
||||
projects_list.append(project_gid)
|
||||
else:
|
||||
logging.debug(
|
||||
f"Skipping project: {project_gid} - not in accepted project_gids"
|
||||
)
|
||||
project_count += 1
|
||||
if project_count % 100 == 0:
|
||||
logging.info(f"Processed {project_count} projects")
|
||||
logging.info(f"Found {len(projects_list)} projects to process")
|
||||
for project_gid in projects_list:
|
||||
for task in self._get_tasks_for_project(
|
||||
project_gid, start_date, start_seconds
|
||||
):
|
||||
yield task
|
||||
logging.info(f"Completed fetching {self.task_count} tasks from Asana")
|
||||
if self.api_error_count > 0:
|
||||
logging.warning(
|
||||
f"Encountered {self.api_error_count} API errors during task fetching"
|
||||
)
|
||||
|
||||
def _get_tasks_for_project(
|
||||
self, project_gid: str, start_date: str, start_seconds: int
|
||||
) -> Iterator[AsanaTask]:
|
||||
project = self.project_api.get_project(project_gid, opts={})
|
||||
project_name = project.get("name", project_gid)
|
||||
team = project.get("team") or {}
|
||||
team_gid = team.get("gid")
|
||||
|
||||
if project.get("archived"):
|
||||
logging.info(f"Skipping archived project: {project_name} ({project_gid})")
|
||||
return
|
||||
if not team_gid:
|
||||
logging.info(
|
||||
f"Skipping project without a team: {project_name} ({project_gid})"
|
||||
)
|
||||
return
|
||||
if project.get("privacy_setting") == "private":
|
||||
if self.team_gid and team_gid != self.team_gid:
|
||||
logging.info(
|
||||
f"Skipping private project not in configured team: {project_name} ({project_gid})"
|
||||
)
|
||||
return
|
||||
logging.info(
|
||||
f"Processing private project in configured team: {project_name} ({project_gid})"
|
||||
)
|
||||
|
||||
simple_start_date = start_date.split(".")[0].split("+")[0]
|
||||
logging.info(
|
||||
f"Fetching tasks modified since {simple_start_date} for project: {project_name} ({project_gid})"
|
||||
)
|
||||
|
||||
opts = {
|
||||
"opt_fields": "name,memberships,memberships.project,completed_at,completed_by,created_at,"
|
||||
"created_by,custom_fields,dependencies,due_at,due_on,external,html_notes,liked,likes,"
|
||||
"modified_at,notes,num_hearts,parent,projects,resource_subtype,resource_type,start_on,"
|
||||
"workspace,permalink_url",
|
||||
"modified_since": start_date,
|
||||
}
|
||||
tasks_from_api = self.tasks_api.get_tasks_for_project(project_gid, opts)
|
||||
for data in tasks_from_api:
|
||||
self.task_count += 1
|
||||
if self.task_count % 10 == 0:
|
||||
end_seconds = time.mktime(datetime.now().timetuple())
|
||||
runtime_seconds = end_seconds - start_seconds
|
||||
if runtime_seconds > 0:
|
||||
logging.info(
|
||||
f"Processed {self.task_count} tasks in {runtime_seconds:.0f} seconds "
|
||||
f"({self.task_count / runtime_seconds:.2f} tasks/second)"
|
||||
)
|
||||
|
||||
logging.debug(f"Processing Asana task: {data['name']}")
|
||||
|
||||
text = self._construct_task_text(data)
|
||||
|
||||
try:
|
||||
text += self._fetch_and_add_comments(data["gid"])
|
||||
|
||||
last_modified_date = self.format_date(data["modified_at"])
|
||||
text += f"Last modified: {last_modified_date}\n"
|
||||
|
||||
task = AsanaTask(
|
||||
id=data["gid"],
|
||||
title=data["name"],
|
||||
text=text,
|
||||
link=data["permalink_url"],
|
||||
last_modified=datetime.fromisoformat(data["modified_at"]),
|
||||
project_gid=project_gid,
|
||||
project_name=project_name,
|
||||
)
|
||||
yield task
|
||||
except Exception:
|
||||
logging.error(
|
||||
f"Error processing task {data['gid']} in project {project_gid}",
|
||||
exc_info=True,
|
||||
)
|
||||
self.api_error_count += 1
|
||||
|
||||
def _construct_task_text(self, data: Dict) -> str:
|
||||
text = f"{data['name']}\n\n"
|
||||
|
||||
if data["notes"]:
|
||||
text += f"{data['notes']}\n\n"
|
||||
|
||||
if data["created_by"] and data["created_by"]["gid"]:
|
||||
creator = self.get_user(data["created_by"]["gid"])["name"]
|
||||
created_date = self.format_date(data["created_at"])
|
||||
text += f"Created by: {creator} on {created_date}\n"
|
||||
|
||||
if data["due_on"]:
|
||||
due_date = self.format_date(data["due_on"])
|
||||
text += f"Due date: {due_date}\n"
|
||||
|
||||
if data["completed_at"]:
|
||||
completed_date = self.format_date(data["completed_at"])
|
||||
text += f"Completed on: {completed_date}\n"
|
||||
|
||||
text += "\n"
|
||||
return text
|
||||
|
||||
def _fetch_and_add_comments(self, task_gid: str) -> str:
|
||||
text = ""
|
||||
stories_opts: Dict[str, str] = {}
|
||||
story_start = time.time()
|
||||
stories = self.stories_api.get_stories_for_task(task_gid, stories_opts)
|
||||
|
||||
story_count = 0
|
||||
comment_count = 0
|
||||
|
||||
for story in stories:
|
||||
story_count += 1
|
||||
if story["resource_subtype"] == "comment_added":
|
||||
comment = self.stories_api.get_story(
|
||||
story["gid"], opts={"opt_fields": "text,created_by,created_at"}
|
||||
)
|
||||
commenter = self.get_user(comment["created_by"]["gid"])["name"]
|
||||
text += f"Comment by {commenter}: {comment['text']}\n\n"
|
||||
comment_count += 1
|
||||
|
||||
story_duration = time.time() - story_start
|
||||
logging.debug(
|
||||
f"Processed {story_count} stories (including {comment_count} comments) in {story_duration:.2f} seconds"
|
||||
)
|
||||
|
||||
return text
|
||||
|
||||
def get_attachments(self, task_gid: str) -> list[dict]:
|
||||
"""
|
||||
Fetch full attachment info (including download_url) for a task.
|
||||
"""
|
||||
attachments: list[dict] = []
|
||||
|
||||
try:
|
||||
# Step 1: list attachment compact records
|
||||
for att in self.attachments_api.get_attachments_for_object(
|
||||
parent=task_gid,
|
||||
opts={}
|
||||
):
|
||||
gid = att.get("gid")
|
||||
if not gid:
|
||||
continue
|
||||
|
||||
try:
|
||||
# Step 2: expand to full attachment
|
||||
full = self.attachments_api.get_attachment(
|
||||
attachment_gid=gid,
|
||||
opts={
|
||||
"opt_fields": "name,download_url,size,created_at"
|
||||
}
|
||||
)
|
||||
|
||||
if full.get("download_url"):
|
||||
attachments.append(full)
|
||||
|
||||
except Exception:
|
||||
logging.exception(
|
||||
f"Failed to fetch attachment detail {gid} for task {task_gid}"
|
||||
)
|
||||
self.api_error_count += 1
|
||||
|
||||
except Exception:
|
||||
logging.exception(f"Failed to list attachments for task {task_gid}")
|
||||
self.api_error_count += 1
|
||||
|
||||
return attachments
|
||||
|
||||
def get_accessible_emails(
|
||||
self,
|
||||
workspace_id: str,
|
||||
project_ids: list[str] | None,
|
||||
team_id: str | None,
|
||||
):
|
||||
|
||||
ws_users = self.users_api.get_users(
|
||||
opts={
|
||||
"workspace": workspace_id,
|
||||
"opt_fields": "gid,name,email"
|
||||
}
|
||||
)
|
||||
|
||||
workspace_users = {
|
||||
u["gid"]: u.get("email")
|
||||
for u in ws_users
|
||||
if u.get("email")
|
||||
}
|
||||
|
||||
if not project_ids:
|
||||
return set(workspace_users.values())
|
||||
|
||||
|
||||
project_emails = set()
|
||||
|
||||
for pid in project_ids:
|
||||
project = self.project_api.get_project(
|
||||
pid,
|
||||
opts={"opt_fields": "team,privacy_setting"}
|
||||
)
|
||||
|
||||
if project["privacy_setting"] == "private":
|
||||
if team_id and project.get("team", {}).get("gid") != team_id:
|
||||
continue
|
||||
|
||||
memberships = self.project_memberships_api.get_project_membership(
|
||||
pid,
|
||||
opts={"opt_fields": "user.gid,user.email"}
|
||||
)
|
||||
|
||||
for m in memberships:
|
||||
email = m["user"].get("email")
|
||||
if email:
|
||||
project_emails.add(email)
|
||||
|
||||
return project_emails
|
||||
|
||||
def get_user(self, user_gid: str) -> Dict:
|
||||
if self._user is not None:
|
||||
return self._user
|
||||
self._user = self.users_api.get_user(user_gid, {"opt_fields": "name,email"})
|
||||
|
||||
if not self._user:
|
||||
logging.warning(f"Unable to fetch user information for user_gid: {user_gid}")
|
||||
return {"name": "Unknown"}
|
||||
return self._user
|
||||
|
||||
def format_date(self, date_str: str) -> str:
|
||||
date = datetime.fromisoformat(date_str)
|
||||
return time.strftime("%Y-%m-%d", date.timetuple())
|
||||
|
||||
def get_time(self) -> str:
|
||||
return time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
|
||||
|
||||
|
||||
class AsanaConnector(LoadConnector, PollConnector):
|
||||
def __init__(
|
||||
self,
|
||||
asana_workspace_id: str,
|
||||
asana_project_ids: str | None = None,
|
||||
asana_team_id: str | None = None,
|
||||
batch_size: int = INDEX_BATCH_SIZE,
|
||||
continue_on_failure: bool = CONTINUE_ON_CONNECTOR_FAILURE,
|
||||
) -> None:
|
||||
self.workspace_id = asana_workspace_id
|
||||
self.project_ids_to_index: list[str] | None = (
|
||||
asana_project_ids.split(",") if asana_project_ids else None
|
||||
)
|
||||
self.asana_team_id = asana_team_id if asana_team_id else None
|
||||
self.batch_size = batch_size
|
||||
self.continue_on_failure = continue_on_failure
|
||||
self.size_threshold = None
|
||||
logging.info(
|
||||
f"AsanaConnector initialized with workspace_id: {asana_workspace_id}"
|
||||
)
|
||||
|
||||
def load_credentials(self, credentials: dict[str, Any]) -> dict[str, Any] | None:
|
||||
self.api_token = credentials["asana_api_token_secret"]
|
||||
self.asana_client = AsanaAPI(
|
||||
api_token=self.api_token,
|
||||
workspace_gid=self.workspace_id,
|
||||
team_gid=self.asana_team_id,
|
||||
)
|
||||
self.workspace_users_email = self.asana_client.get_accessible_emails(self.workspace_id, self.project_ids_to_index, self.asana_team_id)
|
||||
logging.info("Asana credentials loaded and API client initialized")
|
||||
return None
|
||||
|
||||
def poll_source(
|
||||
self, start: SecondsSinceUnixEpoch, end: SecondsSinceUnixEpoch | None
|
||||
) -> GenerateDocumentsOutput:
|
||||
start_time = datetime.fromtimestamp(start).isoformat()
|
||||
logging.info(f"Starting Asana poll from {start_time}")
|
||||
docs_batch: list[Document] = []
|
||||
tasks = self.asana_client.get_tasks(self.project_ids_to_index, start_time)
|
||||
for task in tasks:
|
||||
docs = self._task_to_documents(task)
|
||||
docs_batch.extend(docs)
|
||||
|
||||
if len(docs_batch) >= self.batch_size:
|
||||
logging.info(f"Yielding batch of {len(docs_batch)} documents")
|
||||
yield docs_batch
|
||||
docs_batch = []
|
||||
|
||||
if docs_batch:
|
||||
logging.info(f"Yielding final batch of {len(docs_batch)} documents")
|
||||
yield docs_batch
|
||||
|
||||
logging.info("Asana poll completed")
|
||||
|
||||
def load_from_state(self) -> GenerateDocumentsOutput:
|
||||
logging.info("Starting full index of all Asana tasks")
|
||||
return self.poll_source(start=0, end=None)
|
||||
|
||||
def _task_to_documents(self, task: AsanaTask) -> list[Document]:
|
||||
docs: list[Document] = []
|
||||
|
||||
attachments = self.asana_client.get_attachments(task.id)
|
||||
|
||||
for att in attachments:
|
||||
try:
|
||||
resp = requests.get(att["download_url"], timeout=30)
|
||||
resp.raise_for_status()
|
||||
file_blob = resp.content
|
||||
filename = att.get("name", "attachment")
|
||||
size_bytes = extract_size_bytes(att)
|
||||
if (
|
||||
self.size_threshold is not None
|
||||
and isinstance(size_bytes, int)
|
||||
and size_bytes > self.size_threshold
|
||||
):
|
||||
logging.warning(
|
||||
f"{filename} exceeds size threshold of {self.size_threshold}. Skipping."
|
||||
)
|
||||
continue
|
||||
docs.append(
|
||||
Document(
|
||||
id=f"asana:{task.id}:{att['gid']}",
|
||||
blob=file_blob,
|
||||
extension=get_file_ext(filename) or "",
|
||||
size_bytes=size_bytes,
|
||||
doc_updated_at=task.last_modified,
|
||||
source=DocumentSource.ASANA,
|
||||
semantic_identifier=filename,
|
||||
primary_owners=list(self.workspace_users_email),
|
||||
)
|
||||
)
|
||||
except Exception:
|
||||
logging.exception(
|
||||
f"Failed to download attachment {att.get('gid')} for task {task.id}"
|
||||
)
|
||||
|
||||
return docs
|
||||
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
import time
|
||||
import os
|
||||
|
||||
logging.info("Starting Asana connector test")
|
||||
connector = AsanaConnector(
|
||||
os.environ["WORKSPACE_ID"],
|
||||
os.environ["PROJECT_IDS"],
|
||||
os.environ["TEAM_ID"],
|
||||
)
|
||||
connector.load_credentials(
|
||||
{
|
||||
"asana_api_token_secret": os.environ["API_TOKEN"],
|
||||
}
|
||||
)
|
||||
logging.info("Loading all documents from Asana")
|
||||
all_docs = connector.load_from_state()
|
||||
current = time.time()
|
||||
one_day_ago = current - 24 * 60 * 60 # 1 day
|
||||
logging.info("Polling for documents updated in the last 24 hours")
|
||||
latest_docs = connector.poll_source(one_day_ago, current)
|
||||
for docs in all_docs:
|
||||
for doc in docs:
|
||||
print(doc.id)
|
||||
logging.info("Asana connector test completed")
|
||||
@ -54,7 +54,12 @@ class DocumentSource(str, Enum):
|
||||
DROPBOX = "dropbox"
|
||||
BOX = "box"
|
||||
AIRTABLE = "airtable"
|
||||
ASANA = "asana"
|
||||
GITHUB = "github"
|
||||
GITLAB = "gitlab"
|
||||
IMAP = "imap"
|
||||
|
||||
|
||||
class FileOrigin(str, Enum):
|
||||
"""File origins"""
|
||||
CONNECTOR = "connector"
|
||||
@ -231,6 +236,8 @@ _REPLACEMENT_EXPANSIONS = "body.view.value"
|
||||
|
||||
BOX_WEB_OAUTH_REDIRECT_URI = os.environ.get("BOX_WEB_OAUTH_REDIRECT_URI", "http://localhost:9380/v1/connector/box/oauth/web/callback")
|
||||
|
||||
GITHUB_CONNECTOR_BASE_URL = os.environ.get("GITHUB_CONNECTOR_BASE_URL") or None
|
||||
|
||||
class HtmlBasedConnectorTransformLinksStrategy(str, Enum):
|
||||
# remove links entirely
|
||||
STRIP = "strip"
|
||||
@ -256,6 +263,14 @@ AIRTABLE_CONNECTOR_SIZE_THRESHOLD = int(
|
||||
os.environ.get("AIRTABLE_CONNECTOR_SIZE_THRESHOLD", 10 * 1024 * 1024)
|
||||
)
|
||||
|
||||
ASANA_CONNECTOR_SIZE_THRESHOLD = int(
|
||||
os.environ.get("ASANA_CONNECTOR_SIZE_THRESHOLD", 10 * 1024 * 1024)
|
||||
)
|
||||
|
||||
IMAP_CONNECTOR_SIZE_THRESHOLD = int(
|
||||
os.environ.get("IMAP_CONNECTOR_SIZE_THRESHOLD", 10 * 1024 * 1024)
|
||||
)
|
||||
|
||||
_USER_NOT_FOUND = "Unknown Confluence User"
|
||||
|
||||
_COMMENT_EXPANSION_FIELDS = ["body.storage.value"]
|
||||
|
||||
217
common/data_source/connector_runner.py
Normal file
217
common/data_source/connector_runner.py
Normal file
@ -0,0 +1,217 @@
|
||||
import sys
|
||||
import time
|
||||
import logging
|
||||
from collections.abc import Generator
|
||||
from datetime import datetime
|
||||
from typing import Generic
|
||||
from typing import TypeVar
|
||||
from common.data_source.interfaces import (
|
||||
BaseConnector,
|
||||
CheckpointedConnector,
|
||||
CheckpointedConnectorWithPermSync,
|
||||
CheckpointOutput,
|
||||
LoadConnector,
|
||||
PollConnector,
|
||||
)
|
||||
from common.data_source.models import ConnectorCheckpoint, ConnectorFailure, Document
|
||||
|
||||
|
||||
TimeRange = tuple[datetime, datetime]
|
||||
|
||||
CT = TypeVar("CT", bound=ConnectorCheckpoint)
|
||||
|
||||
|
||||
def batched_doc_ids(
|
||||
checkpoint_connector_generator: CheckpointOutput[CT],
|
||||
batch_size: int,
|
||||
) -> Generator[set[str], None, None]:
|
||||
batch: set[str] = set()
|
||||
for document, failure, next_checkpoint in CheckpointOutputWrapper[CT]()(
|
||||
checkpoint_connector_generator
|
||||
):
|
||||
if document is not None:
|
||||
batch.add(document.id)
|
||||
elif (
|
||||
failure and failure.failed_document and failure.failed_document.document_id
|
||||
):
|
||||
batch.add(failure.failed_document.document_id)
|
||||
|
||||
if len(batch) >= batch_size:
|
||||
yield batch
|
||||
batch = set()
|
||||
if len(batch) > 0:
|
||||
yield batch
|
||||
|
||||
|
||||
class CheckpointOutputWrapper(Generic[CT]):
|
||||
"""
|
||||
Wraps a CheckpointOutput generator to give things back in a more digestible format,
|
||||
specifically for Document outputs.
|
||||
The connector format is easier for the connector implementor (e.g. it enforces exactly
|
||||
one new checkpoint is returned AND that the checkpoint is at the end), thus the different
|
||||
formats.
|
||||
"""
|
||||
|
||||
def __init__(self) -> None:
|
||||
self.next_checkpoint: CT | None = None
|
||||
|
||||
def __call__(
|
||||
self,
|
||||
checkpoint_connector_generator: CheckpointOutput[CT],
|
||||
) -> Generator[
|
||||
tuple[Document | None, ConnectorFailure | None, CT | None],
|
||||
None,
|
||||
None,
|
||||
]:
|
||||
# grabs the final return value and stores it in the `next_checkpoint` variable
|
||||
def _inner_wrapper(
|
||||
checkpoint_connector_generator: CheckpointOutput[CT],
|
||||
) -> CheckpointOutput[CT]:
|
||||
self.next_checkpoint = yield from checkpoint_connector_generator
|
||||
return self.next_checkpoint # not used
|
||||
|
||||
for document_or_failure in _inner_wrapper(checkpoint_connector_generator):
|
||||
if isinstance(document_or_failure, Document):
|
||||
yield document_or_failure, None, None
|
||||
elif isinstance(document_or_failure, ConnectorFailure):
|
||||
yield None, document_or_failure, None
|
||||
else:
|
||||
raise ValueError(
|
||||
f"Invalid document_or_failure type: {type(document_or_failure)}"
|
||||
)
|
||||
|
||||
if self.next_checkpoint is None:
|
||||
raise RuntimeError(
|
||||
"Checkpoint is None. This should never happen - the connector should always return a checkpoint."
|
||||
)
|
||||
|
||||
yield None, None, self.next_checkpoint
|
||||
|
||||
|
||||
class ConnectorRunner(Generic[CT]):
|
||||
"""
|
||||
Handles:
|
||||
- Batching
|
||||
- Additional exception logging
|
||||
- Combining different connector types to a single interface
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
connector: BaseConnector,
|
||||
batch_size: int,
|
||||
# cannot be True for non-checkpointed connectors
|
||||
include_permissions: bool,
|
||||
time_range: TimeRange | None = None,
|
||||
):
|
||||
if not isinstance(connector, CheckpointedConnector) and include_permissions:
|
||||
raise ValueError(
|
||||
"include_permissions cannot be True for non-checkpointed connectors"
|
||||
)
|
||||
|
||||
self.connector = connector
|
||||
self.time_range = time_range
|
||||
self.batch_size = batch_size
|
||||
self.include_permissions = include_permissions
|
||||
|
||||
self.doc_batch: list[Document] = []
|
||||
|
||||
def run(self, checkpoint: CT) -> Generator[
|
||||
tuple[list[Document] | None, ConnectorFailure | None, CT | None],
|
||||
None,
|
||||
None,
|
||||
]:
|
||||
"""Adds additional exception logging to the connector."""
|
||||
try:
|
||||
if isinstance(self.connector, CheckpointedConnector):
|
||||
if self.time_range is None:
|
||||
raise ValueError("time_range is required for CheckpointedConnector")
|
||||
|
||||
start = time.monotonic()
|
||||
if self.include_permissions:
|
||||
if not isinstance(
|
||||
self.connector, CheckpointedConnectorWithPermSync
|
||||
):
|
||||
raise ValueError(
|
||||
"Connector does not support permission syncing"
|
||||
)
|
||||
load_from_checkpoint = (
|
||||
self.connector.load_from_checkpoint_with_perm_sync
|
||||
)
|
||||
else:
|
||||
load_from_checkpoint = self.connector.load_from_checkpoint
|
||||
checkpoint_connector_generator = load_from_checkpoint(
|
||||
start=self.time_range[0].timestamp(),
|
||||
end=self.time_range[1].timestamp(),
|
||||
checkpoint=checkpoint,
|
||||
)
|
||||
next_checkpoint: CT | None = None
|
||||
# this is guaranteed to always run at least once with next_checkpoint being non-None
|
||||
for document, failure, next_checkpoint in CheckpointOutputWrapper[CT]()(
|
||||
checkpoint_connector_generator
|
||||
):
|
||||
if document is not None and isinstance(document, Document):
|
||||
self.doc_batch.append(document)
|
||||
|
||||
if failure is not None:
|
||||
yield None, failure, None
|
||||
|
||||
if len(self.doc_batch) >= self.batch_size:
|
||||
yield self.doc_batch, None, None
|
||||
self.doc_batch = []
|
||||
|
||||
# yield remaining documents
|
||||
if len(self.doc_batch) > 0:
|
||||
yield self.doc_batch, None, None
|
||||
self.doc_batch = []
|
||||
|
||||
yield None, None, next_checkpoint
|
||||
|
||||
logging.debug(
|
||||
f"Connector took {time.monotonic() - start} seconds to get to the next checkpoint."
|
||||
)
|
||||
|
||||
else:
|
||||
finished_checkpoint = self.connector.build_dummy_checkpoint()
|
||||
finished_checkpoint.has_more = False
|
||||
|
||||
if isinstance(self.connector, PollConnector):
|
||||
if self.time_range is None:
|
||||
raise ValueError("time_range is required for PollConnector")
|
||||
|
||||
for document_batch in self.connector.poll_source(
|
||||
start=self.time_range[0].timestamp(),
|
||||
end=self.time_range[1].timestamp(),
|
||||
):
|
||||
yield document_batch, None, None
|
||||
|
||||
yield None, None, finished_checkpoint
|
||||
elif isinstance(self.connector, LoadConnector):
|
||||
for document_batch in self.connector.load_from_state():
|
||||
yield document_batch, None, None
|
||||
|
||||
yield None, None, finished_checkpoint
|
||||
else:
|
||||
raise ValueError(f"Invalid connector. type: {type(self.connector)}")
|
||||
except Exception:
|
||||
exc_type, _, exc_traceback = sys.exc_info()
|
||||
|
||||
# Traverse the traceback to find the last frame where the exception was raised
|
||||
tb = exc_traceback
|
||||
if tb is None:
|
||||
logging.error("No traceback found for exception")
|
||||
raise
|
||||
|
||||
while tb.tb_next:
|
||||
tb = tb.tb_next # Move to the next frame in the traceback
|
||||
|
||||
# Get the local variables from the frame where the exception occurred
|
||||
local_vars = tb.tb_frame.f_locals
|
||||
local_vars_str = "\n".join(
|
||||
f"{key}: {value}" for key, value in local_vars.items()
|
||||
)
|
||||
logging.error(
|
||||
f"Error in connector. type: {exc_type};\n"
|
||||
f"local_vars below -> \n{local_vars_str[:1024]}"
|
||||
)
|
||||
raise
|
||||
@ -18,6 +18,7 @@ class UploadMimeTypes:
|
||||
"text/plain",
|
||||
"text/markdown",
|
||||
"text/x-markdown",
|
||||
"text/mdx",
|
||||
"text/x-config",
|
||||
"text/tab-separated-values",
|
||||
"application/json",
|
||||
|
||||
0
common/data_source/github/__init__.py
Normal file
0
common/data_source/github/__init__.py
Normal file
973
common/data_source/github/connector.py
Normal file
973
common/data_source/github/connector.py
Normal file
@ -0,0 +1,973 @@
|
||||
import copy
|
||||
import logging
|
||||
from collections.abc import Callable
|
||||
from collections.abc import Generator
|
||||
from datetime import datetime
|
||||
from datetime import timedelta
|
||||
from datetime import timezone
|
||||
from enum import Enum
|
||||
from typing import Any
|
||||
from typing import cast
|
||||
|
||||
from github import Github, Auth
|
||||
from github import RateLimitExceededException
|
||||
from github import Repository
|
||||
from github.GithubException import GithubException
|
||||
from github.Issue import Issue
|
||||
from github.NamedUser import NamedUser
|
||||
from github.PaginatedList import PaginatedList
|
||||
from github.PullRequest import PullRequest
|
||||
from pydantic import BaseModel
|
||||
from typing_extensions import override
|
||||
from common.data_source.google_util.util import sanitize_filename
|
||||
from common.data_source.config import DocumentSource, GITHUB_CONNECTOR_BASE_URL
|
||||
from common.data_source.exceptions import (
|
||||
ConnectorMissingCredentialError,
|
||||
ConnectorValidationError,
|
||||
CredentialExpiredError,
|
||||
InsufficientPermissionsError,
|
||||
UnexpectedValidationError,
|
||||
)
|
||||
from common.data_source.interfaces import CheckpointedConnectorWithPermSyncGH, CheckpointOutput
|
||||
from common.data_source.models import (
|
||||
ConnectorCheckpoint,
|
||||
ConnectorFailure,
|
||||
Document,
|
||||
DocumentFailure,
|
||||
ExternalAccess,
|
||||
SecondsSinceUnixEpoch,
|
||||
)
|
||||
from common.data_source.connector_runner import ConnectorRunner
|
||||
from .models import SerializedRepository
|
||||
from .rate_limit_utils import sleep_after_rate_limit_exception
|
||||
from .utils import deserialize_repository
|
||||
from .utils import get_external_access_permission
|
||||
|
||||
ITEMS_PER_PAGE = 100
|
||||
CURSOR_LOG_FREQUENCY = 50
|
||||
|
||||
_MAX_NUM_RATE_LIMIT_RETRIES = 5
|
||||
|
||||
ONE_DAY = timedelta(days=1)
|
||||
SLIM_BATCH_SIZE = 100
|
||||
# Cases
|
||||
# X (from start) standard run, no fallback to cursor-based pagination
|
||||
# X (from start) standard run errors, fallback to cursor-based pagination
|
||||
# X error in the middle of a page
|
||||
# X no errors: run to completion
|
||||
# X (from checkpoint) standard run, no fallback to cursor-based pagination
|
||||
# X (from checkpoint) continue from cursor-based pagination
|
||||
# - retrying
|
||||
# - no retrying
|
||||
|
||||
# things to check:
|
||||
# checkpoint state on return
|
||||
# checkpoint progress (no infinite loop)
|
||||
|
||||
|
||||
class DocMetadata(BaseModel):
|
||||
repo: str
|
||||
|
||||
|
||||
def get_nextUrl_key(pag_list: PaginatedList[PullRequest | Issue]) -> str:
|
||||
if "_PaginatedList__nextUrl" in pag_list.__dict__:
|
||||
return "_PaginatedList__nextUrl"
|
||||
for key in pag_list.__dict__:
|
||||
if "__nextUrl" in key:
|
||||
return key
|
||||
for key in pag_list.__dict__:
|
||||
if "nextUrl" in key:
|
||||
return key
|
||||
return ""
|
||||
|
||||
|
||||
def get_nextUrl(
|
||||
pag_list: PaginatedList[PullRequest | Issue], nextUrl_key: str
|
||||
) -> str | None:
|
||||
return getattr(pag_list, nextUrl_key) if nextUrl_key else None
|
||||
|
||||
|
||||
def set_nextUrl(
|
||||
pag_list: PaginatedList[PullRequest | Issue], nextUrl_key: str, nextUrl: str
|
||||
) -> None:
|
||||
if nextUrl_key:
|
||||
setattr(pag_list, nextUrl_key, nextUrl)
|
||||
elif nextUrl:
|
||||
raise ValueError("Next URL key not found: " + str(pag_list.__dict__))
|
||||
|
||||
|
||||
def _paginate_until_error(
|
||||
git_objs: Callable[[], PaginatedList[PullRequest | Issue]],
|
||||
cursor_url: str | None,
|
||||
prev_num_objs: int,
|
||||
cursor_url_callback: Callable[[str | None, int], None],
|
||||
retrying: bool = False,
|
||||
) -> Generator[PullRequest | Issue, None, None]:
|
||||
num_objs = prev_num_objs
|
||||
pag_list = git_objs()
|
||||
nextUrl_key = get_nextUrl_key(pag_list)
|
||||
if cursor_url:
|
||||
set_nextUrl(pag_list, nextUrl_key, cursor_url)
|
||||
elif retrying:
|
||||
# if we are retrying, we want to skip the objects retrieved
|
||||
# over previous calls. Unfortunately, this WILL retrieve all
|
||||
# pages before the one we are resuming from, so we really
|
||||
# don't want this case to be hit often
|
||||
logging.warning(
|
||||
"Retrying from a previous cursor-based pagination call. "
|
||||
"This will retrieve all pages before the one we are resuming from, "
|
||||
"which may take a while and consume many API calls."
|
||||
)
|
||||
pag_list = cast(PaginatedList[PullRequest | Issue], pag_list[prev_num_objs:])
|
||||
num_objs = 0
|
||||
|
||||
try:
|
||||
# this for loop handles cursor-based pagination
|
||||
for issue_or_pr in pag_list:
|
||||
num_objs += 1
|
||||
yield issue_or_pr
|
||||
# used to store the current cursor url in the checkpoint. This value
|
||||
# is updated during iteration over pag_list.
|
||||
cursor_url_callback(get_nextUrl(pag_list, nextUrl_key), num_objs)
|
||||
|
||||
if num_objs % CURSOR_LOG_FREQUENCY == 0:
|
||||
logging.info(
|
||||
f"Retrieved {num_objs} objects with current cursor url: {get_nextUrl(pag_list, nextUrl_key)}"
|
||||
)
|
||||
|
||||
except Exception as e:
|
||||
logging.exception(f"Error during cursor-based pagination: {e}")
|
||||
if num_objs - prev_num_objs > 0:
|
||||
raise
|
||||
|
||||
if get_nextUrl(pag_list, nextUrl_key) is not None and not retrying:
|
||||
logging.info(
|
||||
"Assuming that this error is due to cursor "
|
||||
"expiration because no objects were retrieved. "
|
||||
"Retrying from the first page."
|
||||
)
|
||||
yield from _paginate_until_error(
|
||||
git_objs, None, prev_num_objs, cursor_url_callback, retrying=True
|
||||
)
|
||||
return
|
||||
|
||||
# for no cursor url or if we reach this point after a retry, raise the error
|
||||
raise
|
||||
|
||||
|
||||
def _get_batch_rate_limited(
|
||||
# We pass in a callable because we want git_objs to produce a fresh
|
||||
# PaginatedList each time it's called to avoid using the same object for cursor-based pagination
|
||||
# from a partial offset-based pagination call.
|
||||
git_objs: Callable[[], PaginatedList],
|
||||
page_num: int,
|
||||
cursor_url: str | None,
|
||||
prev_num_objs: int,
|
||||
cursor_url_callback: Callable[[str | None, int], None],
|
||||
github_client: Github,
|
||||
attempt_num: int = 0,
|
||||
) -> Generator[PullRequest | Issue, None, None]:
|
||||
if attempt_num > _MAX_NUM_RATE_LIMIT_RETRIES:
|
||||
raise RuntimeError(
|
||||
"Re-tried fetching batch too many times. Something is going wrong with fetching objects from Github"
|
||||
)
|
||||
try:
|
||||
if cursor_url:
|
||||
# when this is set, we are resuming from an earlier
|
||||
# cursor-based pagination call.
|
||||
yield from _paginate_until_error(
|
||||
git_objs, cursor_url, prev_num_objs, cursor_url_callback
|
||||
)
|
||||
return
|
||||
objs = list(git_objs().get_page(page_num))
|
||||
# fetch all data here to disable lazy loading later
|
||||
# this is needed to capture the rate limit exception here (if one occurs)
|
||||
for obj in objs:
|
||||
if hasattr(obj, "raw_data"):
|
||||
getattr(obj, "raw_data")
|
||||
yield from objs
|
||||
except RateLimitExceededException:
|
||||
sleep_after_rate_limit_exception(github_client)
|
||||
yield from _get_batch_rate_limited(
|
||||
git_objs,
|
||||
page_num,
|
||||
cursor_url,
|
||||
prev_num_objs,
|
||||
cursor_url_callback,
|
||||
github_client,
|
||||
attempt_num + 1,
|
||||
)
|
||||
except GithubException as e:
|
||||
if not (
|
||||
e.status == 422
|
||||
and (
|
||||
"cursor" in (e.message or "")
|
||||
or "cursor" in (e.data or {}).get("message", "")
|
||||
)
|
||||
):
|
||||
raise
|
||||
# Fallback to a cursor-based pagination strategy
|
||||
# This can happen for "large datasets," but there's no documentation
|
||||
# On the error on the web as far as we can tell.
|
||||
# Error message:
|
||||
# "Pagination with the page parameter is not supported for large datasets,
|
||||
# please use cursor based pagination (after/before)"
|
||||
yield from _paginate_until_error(
|
||||
git_objs, cursor_url, prev_num_objs, cursor_url_callback
|
||||
)
|
||||
|
||||
|
||||
def _get_userinfo(user: NamedUser) -> dict[str, str]:
|
||||
def _safe_get(attr_name: str) -> str | None:
|
||||
try:
|
||||
return cast(str | None, getattr(user, attr_name))
|
||||
except GithubException:
|
||||
logging.debug(f"Error getting {attr_name} for user")
|
||||
return None
|
||||
|
||||
return {
|
||||
k: v
|
||||
for k, v in {
|
||||
"login": _safe_get("login"),
|
||||
"name": _safe_get("name"),
|
||||
"email": _safe_get("email"),
|
||||
}.items()
|
||||
if v is not None
|
||||
}
|
||||
|
||||
|
||||
def _convert_pr_to_document(
|
||||
pull_request: PullRequest, repo_external_access: ExternalAccess | None
|
||||
) -> Document:
|
||||
repo_name = pull_request.base.repo.full_name if pull_request.base else ""
|
||||
doc_metadata = DocMetadata(repo=repo_name)
|
||||
file_content_byte = pull_request.body.encode('utf-8') if pull_request.body else b""
|
||||
name = sanitize_filename(pull_request.title, "md")
|
||||
|
||||
return Document(
|
||||
id=pull_request.html_url,
|
||||
blob= file_content_byte,
|
||||
source=DocumentSource.GITHUB,
|
||||
external_access=repo_external_access,
|
||||
semantic_identifier=f"{pull_request.number}:{name}",
|
||||
# updated_at is UTC time but is timezone unaware, explicitly add UTC
|
||||
# as there is logic in indexing to prevent wrong timestamped docs
|
||||
# due to local time discrepancies with UTC
|
||||
doc_updated_at=(
|
||||
pull_request.updated_at.replace(tzinfo=timezone.utc)
|
||||
if pull_request.updated_at
|
||||
else None
|
||||
),
|
||||
extension=".md",
|
||||
# this metadata is used in perm sync
|
||||
size_bytes=len(file_content_byte) if file_content_byte else 0,
|
||||
primary_owners=[],
|
||||
doc_metadata=doc_metadata.model_dump(),
|
||||
metadata={
|
||||
k: [str(vi) for vi in v] if isinstance(v, list) else str(v)
|
||||
for k, v in {
|
||||
"object_type": "PullRequest",
|
||||
"id": pull_request.number,
|
||||
"merged": pull_request.merged,
|
||||
"state": pull_request.state,
|
||||
"user": _get_userinfo(pull_request.user) if pull_request.user else None,
|
||||
"assignees": [
|
||||
_get_userinfo(assignee) for assignee in pull_request.assignees
|
||||
],
|
||||
"repo": (
|
||||
pull_request.base.repo.full_name if pull_request.base else None
|
||||
),
|
||||
"num_commits": str(pull_request.commits),
|
||||
"num_files_changed": str(pull_request.changed_files),
|
||||
"labels": [label.name for label in pull_request.labels],
|
||||
"created_at": (
|
||||
pull_request.created_at.replace(tzinfo=timezone.utc)
|
||||
if pull_request.created_at
|
||||
else None
|
||||
),
|
||||
"updated_at": (
|
||||
pull_request.updated_at.replace(tzinfo=timezone.utc)
|
||||
if pull_request.updated_at
|
||||
else None
|
||||
),
|
||||
"closed_at": (
|
||||
pull_request.closed_at.replace(tzinfo=timezone.utc)
|
||||
if pull_request.closed_at
|
||||
else None
|
||||
),
|
||||
"merged_at": (
|
||||
pull_request.merged_at.replace(tzinfo=timezone.utc)
|
||||
if pull_request.merged_at
|
||||
else None
|
||||
),
|
||||
"merged_by": (
|
||||
_get_userinfo(pull_request.merged_by)
|
||||
if pull_request.merged_by
|
||||
else None
|
||||
),
|
||||
}.items()
|
||||
if v is not None
|
||||
},
|
||||
)
|
||||
|
||||
|
||||
def _fetch_issue_comments(issue: Issue) -> str:
|
||||
comments = issue.get_comments()
|
||||
return "\nComment: ".join(comment.body for comment in comments)
|
||||
|
||||
|
||||
def _convert_issue_to_document(
|
||||
issue: Issue, repo_external_access: ExternalAccess | None
|
||||
) -> Document:
|
||||
repo_name = issue.repository.full_name if issue.repository else ""
|
||||
doc_metadata = DocMetadata(repo=repo_name)
|
||||
file_content_byte = issue.body.encode('utf-8') if issue.body else b""
|
||||
name = sanitize_filename(issue.title, "md")
|
||||
|
||||
return Document(
|
||||
id=issue.html_url,
|
||||
blob=file_content_byte,
|
||||
source=DocumentSource.GITHUB,
|
||||
extension=".md",
|
||||
external_access=repo_external_access,
|
||||
semantic_identifier=f"{issue.number}:{name}",
|
||||
# updated_at is UTC time but is timezone unaware
|
||||
doc_updated_at=issue.updated_at.replace(tzinfo=timezone.utc),
|
||||
# this metadata is used in perm sync
|
||||
doc_metadata=doc_metadata.model_dump(),
|
||||
size_bytes=len(file_content_byte) if file_content_byte else 0,
|
||||
primary_owners=[_get_userinfo(issue.user) if issue.user else None],
|
||||
metadata={
|
||||
k: [str(vi) for vi in v] if isinstance(v, list) else str(v)
|
||||
for k, v in {
|
||||
"object_type": "Issue",
|
||||
"id": issue.number,
|
||||
"state": issue.state,
|
||||
"user": _get_userinfo(issue.user) if issue.user else None,
|
||||
"assignees": [_get_userinfo(assignee) for assignee in issue.assignees],
|
||||
"repo": issue.repository.full_name if issue.repository else None,
|
||||
"labels": [label.name for label in issue.labels],
|
||||
"created_at": (
|
||||
issue.created_at.replace(tzinfo=timezone.utc)
|
||||
if issue.created_at
|
||||
else None
|
||||
),
|
||||
"updated_at": (
|
||||
issue.updated_at.replace(tzinfo=timezone.utc)
|
||||
if issue.updated_at
|
||||
else None
|
||||
),
|
||||
"closed_at": (
|
||||
issue.closed_at.replace(tzinfo=timezone.utc)
|
||||
if issue.closed_at
|
||||
else None
|
||||
),
|
||||
"closed_by": (
|
||||
_get_userinfo(issue.closed_by) if issue.closed_by else None
|
||||
),
|
||||
}.items()
|
||||
if v is not None
|
||||
},
|
||||
)
|
||||
|
||||
|
||||
class GithubConnectorStage(Enum):
|
||||
START = "start"
|
||||
PRS = "prs"
|
||||
ISSUES = "issues"
|
||||
|
||||
|
||||
class GithubConnectorCheckpoint(ConnectorCheckpoint):
|
||||
stage: GithubConnectorStage
|
||||
curr_page: int
|
||||
|
||||
cached_repo_ids: list[int] | None = None
|
||||
cached_repo: SerializedRepository | None = None
|
||||
|
||||
# Used for the fallback cursor-based pagination strategy
|
||||
num_retrieved: int
|
||||
cursor_url: str | None = None
|
||||
|
||||
def reset(self) -> None:
|
||||
"""
|
||||
Resets curr_page, num_retrieved, and cursor_url to their initial values (0, 0, None)
|
||||
"""
|
||||
self.curr_page = 0
|
||||
self.num_retrieved = 0
|
||||
self.cursor_url = None
|
||||
|
||||
|
||||
def make_cursor_url_callback(
|
||||
checkpoint: GithubConnectorCheckpoint,
|
||||
) -> Callable[[str | None, int], None]:
|
||||
def cursor_url_callback(cursor_url: str | None, num_objs: int) -> None:
|
||||
# we want to maintain the old cursor url so code after retrieval
|
||||
# can determine that we are using the fallback cursor-based pagination strategy
|
||||
if cursor_url:
|
||||
checkpoint.cursor_url = cursor_url
|
||||
checkpoint.num_retrieved = num_objs
|
||||
|
||||
return cursor_url_callback
|
||||
|
||||
|
||||
class GithubConnector(CheckpointedConnectorWithPermSyncGH[GithubConnectorCheckpoint]):
|
||||
def __init__(
|
||||
self,
|
||||
repo_owner: str,
|
||||
repositories: str | None = None,
|
||||
state_filter: str = "all",
|
||||
include_prs: bool = True,
|
||||
include_issues: bool = False,
|
||||
) -> None:
|
||||
self.repo_owner = repo_owner
|
||||
self.repositories = repositories
|
||||
self.state_filter = state_filter
|
||||
self.include_prs = include_prs
|
||||
self.include_issues = include_issues
|
||||
self.github_client: Github | None = None
|
||||
|
||||
def load_credentials(self, credentials: dict[str, Any]) -> dict[str, Any] | None:
|
||||
# defaults to 30 items per page, can be set to as high as 100
|
||||
token = credentials["github_access_token"]
|
||||
auth = Auth.Token(token)
|
||||
|
||||
if GITHUB_CONNECTOR_BASE_URL:
|
||||
self.github_client = Github(
|
||||
auth=auth,
|
||||
base_url=GITHUB_CONNECTOR_BASE_URL,
|
||||
per_page=ITEMS_PER_PAGE,
|
||||
)
|
||||
else:
|
||||
self.github_client = Github(
|
||||
auth=auth,
|
||||
per_page=ITEMS_PER_PAGE,
|
||||
)
|
||||
|
||||
return None
|
||||
|
||||
def get_github_repo(
|
||||
self, github_client: Github, attempt_num: int = 0
|
||||
) -> Repository.Repository:
|
||||
if attempt_num > _MAX_NUM_RATE_LIMIT_RETRIES:
|
||||
raise RuntimeError(
|
||||
"Re-tried fetching repo too many times. Something is going wrong with fetching objects from Github"
|
||||
)
|
||||
|
||||
try:
|
||||
return github_client.get_repo(f"{self.repo_owner}/{self.repositories}")
|
||||
except RateLimitExceededException:
|
||||
sleep_after_rate_limit_exception(github_client)
|
||||
return self.get_github_repo(github_client, attempt_num + 1)
|
||||
|
||||
def get_github_repos(
|
||||
self, github_client: Github, attempt_num: int = 0
|
||||
) -> list[Repository.Repository]:
|
||||
"""Get specific repositories based on comma-separated repo_name string."""
|
||||
if attempt_num > _MAX_NUM_RATE_LIMIT_RETRIES:
|
||||
raise RuntimeError(
|
||||
"Re-tried fetching repos too many times. Something is going wrong with fetching objects from Github"
|
||||
)
|
||||
|
||||
try:
|
||||
repos = []
|
||||
# Split repo_name by comma and strip whitespace
|
||||
repo_names = [
|
||||
name.strip() for name in (cast(str, self.repositories)).split(",")
|
||||
]
|
||||
|
||||
for repo_name in repo_names:
|
||||
if repo_name: # Skip empty strings
|
||||
try:
|
||||
repo = github_client.get_repo(f"{self.repo_owner}/{repo_name}")
|
||||
repos.append(repo)
|
||||
except GithubException as e:
|
||||
logging.warning(
|
||||
f"Could not fetch repo {self.repo_owner}/{repo_name}: {e}"
|
||||
)
|
||||
|
||||
return repos
|
||||
except RateLimitExceededException:
|
||||
sleep_after_rate_limit_exception(github_client)
|
||||
return self.get_github_repos(github_client, attempt_num + 1)
|
||||
|
||||
def get_all_repos(
|
||||
self, github_client: Github, attempt_num: int = 0
|
||||
) -> list[Repository.Repository]:
|
||||
if attempt_num > _MAX_NUM_RATE_LIMIT_RETRIES:
|
||||
raise RuntimeError(
|
||||
"Re-tried fetching repos too many times. Something is going wrong with fetching objects from Github"
|
||||
)
|
||||
|
||||
try:
|
||||
# Try to get organization first
|
||||
try:
|
||||
org = github_client.get_organization(self.repo_owner)
|
||||
return list(org.get_repos())
|
||||
|
||||
except GithubException:
|
||||
# If not an org, try as a user
|
||||
user = github_client.get_user(self.repo_owner)
|
||||
return list(user.get_repos())
|
||||
except RateLimitExceededException:
|
||||
sleep_after_rate_limit_exception(github_client)
|
||||
return self.get_all_repos(github_client, attempt_num + 1)
|
||||
|
||||
def _pull_requests_func(
|
||||
self, repo: Repository.Repository
|
||||
) -> Callable[[], PaginatedList[PullRequest]]:
|
||||
return lambda: repo.get_pulls(
|
||||
state=self.state_filter, sort="updated", direction="desc"
|
||||
)
|
||||
|
||||
def _issues_func(
|
||||
self, repo: Repository.Repository
|
||||
) -> Callable[[], PaginatedList[Issue]]:
|
||||
return lambda: repo.get_issues(
|
||||
state=self.state_filter, sort="updated", direction="desc"
|
||||
)
|
||||
|
||||
def _fetch_from_github(
|
||||
self,
|
||||
checkpoint: GithubConnectorCheckpoint,
|
||||
start: datetime | None = None,
|
||||
end: datetime | None = None,
|
||||
include_permissions: bool = False,
|
||||
) -> Generator[Document | ConnectorFailure, None, GithubConnectorCheckpoint]:
|
||||
if self.github_client is None:
|
||||
raise ConnectorMissingCredentialError("GitHub")
|
||||
|
||||
checkpoint = copy.deepcopy(checkpoint)
|
||||
|
||||
# First run of the connector, fetch all repos and store in checkpoint
|
||||
if checkpoint.cached_repo_ids is None:
|
||||
repos = []
|
||||
if self.repositories:
|
||||
if "," in self.repositories:
|
||||
# Multiple repositories specified
|
||||
repos = self.get_github_repos(self.github_client)
|
||||
else:
|
||||
# Single repository (backward compatibility)
|
||||
repos = [self.get_github_repo(self.github_client)]
|
||||
else:
|
||||
# All repositories
|
||||
repos = self.get_all_repos(self.github_client)
|
||||
if not repos:
|
||||
checkpoint.has_more = False
|
||||
return checkpoint
|
||||
|
||||
curr_repo = repos.pop()
|
||||
checkpoint.cached_repo_ids = [repo.id for repo in repos]
|
||||
checkpoint.cached_repo = SerializedRepository(
|
||||
id=curr_repo.id,
|
||||
headers=curr_repo.raw_headers,
|
||||
raw_data=curr_repo.raw_data,
|
||||
)
|
||||
checkpoint.stage = GithubConnectorStage.PRS
|
||||
checkpoint.curr_page = 0
|
||||
# save checkpoint with repo ids retrieved
|
||||
return checkpoint
|
||||
|
||||
if checkpoint.cached_repo is None:
|
||||
raise ValueError("No repo saved in checkpoint")
|
||||
|
||||
# Deserialize the repository from the checkpoint
|
||||
repo = deserialize_repository(checkpoint.cached_repo, self.github_client)
|
||||
|
||||
cursor_url_callback = make_cursor_url_callback(checkpoint)
|
||||
repo_external_access: ExternalAccess | None = None
|
||||
if include_permissions:
|
||||
repo_external_access = get_external_access_permission(
|
||||
repo, self.github_client
|
||||
)
|
||||
if self.include_prs and checkpoint.stage == GithubConnectorStage.PRS:
|
||||
logging.info(f"Fetching PRs for repo: {repo.name}")
|
||||
|
||||
pr_batch = _get_batch_rate_limited(
|
||||
self._pull_requests_func(repo),
|
||||
checkpoint.curr_page,
|
||||
checkpoint.cursor_url,
|
||||
checkpoint.num_retrieved,
|
||||
cursor_url_callback,
|
||||
self.github_client,
|
||||
)
|
||||
checkpoint.curr_page += 1 # NOTE: not used for cursor-based fallback
|
||||
done_with_prs = False
|
||||
num_prs = 0
|
||||
pr = None
|
||||
print("start: ", start)
|
||||
for pr in pr_batch:
|
||||
num_prs += 1
|
||||
print("-"*40)
|
||||
print("PR name", pr.title)
|
||||
print("updated at", pr.updated_at)
|
||||
print("-"*40)
|
||||
print("\n")
|
||||
# we iterate backwards in time, so at this point we stop processing prs
|
||||
if (
|
||||
start is not None
|
||||
and pr.updated_at
|
||||
and pr.updated_at.replace(tzinfo=timezone.utc) <= start
|
||||
):
|
||||
done_with_prs = True
|
||||
break
|
||||
# Skip PRs updated after the end date
|
||||
if (
|
||||
end is not None
|
||||
and pr.updated_at
|
||||
and pr.updated_at.replace(tzinfo=timezone.utc) > end
|
||||
):
|
||||
continue
|
||||
try:
|
||||
yield _convert_pr_to_document(
|
||||
cast(PullRequest, pr), repo_external_access
|
||||
)
|
||||
except Exception as e:
|
||||
error_msg = f"Error converting PR to document: {e}"
|
||||
logging.exception(error_msg)
|
||||
yield ConnectorFailure(
|
||||
failed_document=DocumentFailure(
|
||||
document_id=str(pr.id), document_link=pr.html_url
|
||||
),
|
||||
failure_message=error_msg,
|
||||
exception=e,
|
||||
)
|
||||
continue
|
||||
|
||||
# If we reach this point with a cursor url in the checkpoint, we were using
|
||||
# the fallback cursor-based pagination strategy. That strategy tries to get all
|
||||
# PRs, so having curosr_url set means we are done with prs. However, we need to
|
||||
# return AFTER the checkpoint reset to avoid infinite loops.
|
||||
|
||||
# if we found any PRs on the page and there are more PRs to get, return the checkpoint.
|
||||
# In offset mode, while indexing without time constraints, the pr batch
|
||||
# will be empty when we're done.
|
||||
used_cursor = checkpoint.cursor_url is not None
|
||||
if num_prs > 0 and not done_with_prs and not used_cursor:
|
||||
return checkpoint
|
||||
|
||||
# if we went past the start date during the loop or there are no more
|
||||
# prs to get, we move on to issues
|
||||
checkpoint.stage = GithubConnectorStage.ISSUES
|
||||
checkpoint.reset()
|
||||
|
||||
if used_cursor:
|
||||
# save the checkpoint after changing stage; next run will continue from issues
|
||||
return checkpoint
|
||||
|
||||
checkpoint.stage = GithubConnectorStage.ISSUES
|
||||
|
||||
if self.include_issues and checkpoint.stage == GithubConnectorStage.ISSUES:
|
||||
logging.info(f"Fetching issues for repo: {repo.name}")
|
||||
|
||||
issue_batch = list(
|
||||
_get_batch_rate_limited(
|
||||
self._issues_func(repo),
|
||||
checkpoint.curr_page,
|
||||
checkpoint.cursor_url,
|
||||
checkpoint.num_retrieved,
|
||||
cursor_url_callback,
|
||||
self.github_client,
|
||||
)
|
||||
)
|
||||
checkpoint.curr_page += 1
|
||||
done_with_issues = False
|
||||
num_issues = 0
|
||||
for issue in issue_batch:
|
||||
num_issues += 1
|
||||
issue = cast(Issue, issue)
|
||||
# we iterate backwards in time, so at this point we stop processing prs
|
||||
if (
|
||||
start is not None
|
||||
and issue.updated_at.replace(tzinfo=timezone.utc) <= start
|
||||
):
|
||||
done_with_issues = True
|
||||
break
|
||||
# Skip PRs updated after the end date
|
||||
if (
|
||||
end is not None
|
||||
and issue.updated_at.replace(tzinfo=timezone.utc) > end
|
||||
):
|
||||
continue
|
||||
|
||||
if issue.pull_request is not None:
|
||||
# PRs are handled separately
|
||||
continue
|
||||
|
||||
try:
|
||||
yield _convert_issue_to_document(issue, repo_external_access)
|
||||
except Exception as e:
|
||||
error_msg = f"Error converting issue to document: {e}"
|
||||
logging.exception(error_msg)
|
||||
yield ConnectorFailure(
|
||||
failed_document=DocumentFailure(
|
||||
document_id=str(issue.id),
|
||||
document_link=issue.html_url,
|
||||
),
|
||||
failure_message=error_msg,
|
||||
exception=e,
|
||||
)
|
||||
continue
|
||||
|
||||
# if we found any issues on the page, and we're not done, return the checkpoint.
|
||||
# don't return if we're using cursor-based pagination to avoid infinite loops
|
||||
if num_issues > 0 and not done_with_issues and not checkpoint.cursor_url:
|
||||
return checkpoint
|
||||
|
||||
# if we went past the start date during the loop or there are no more
|
||||
# issues to get, we move on to the next repo
|
||||
checkpoint.stage = GithubConnectorStage.PRS
|
||||
checkpoint.reset()
|
||||
|
||||
checkpoint.has_more = len(checkpoint.cached_repo_ids) > 0
|
||||
if checkpoint.cached_repo_ids:
|
||||
next_id = checkpoint.cached_repo_ids.pop()
|
||||
next_repo = self.github_client.get_repo(next_id)
|
||||
checkpoint.cached_repo = SerializedRepository(
|
||||
id=next_id,
|
||||
headers=next_repo.raw_headers,
|
||||
raw_data=next_repo.raw_data,
|
||||
)
|
||||
checkpoint.stage = GithubConnectorStage.PRS
|
||||
checkpoint.reset()
|
||||
|
||||
if checkpoint.cached_repo_ids:
|
||||
logging.info(
|
||||
f"{len(checkpoint.cached_repo_ids)} repos remaining (IDs: {checkpoint.cached_repo_ids})"
|
||||
)
|
||||
else:
|
||||
logging.info("No more repos remaining")
|
||||
|
||||
return checkpoint
|
||||
|
||||
def _load_from_checkpoint(
|
||||
self,
|
||||
start: SecondsSinceUnixEpoch,
|
||||
end: SecondsSinceUnixEpoch,
|
||||
checkpoint: GithubConnectorCheckpoint,
|
||||
include_permissions: bool = False,
|
||||
) -> CheckpointOutput[GithubConnectorCheckpoint]:
|
||||
start_datetime = datetime.fromtimestamp(start, tz=timezone.utc)
|
||||
# add a day for timezone safety
|
||||
end_datetime = datetime.fromtimestamp(end, tz=timezone.utc) + ONE_DAY
|
||||
|
||||
# Move start time back by 3 hours, since some Issues/PRs are getting dropped
|
||||
# Could be due to delayed processing on GitHub side
|
||||
# The non-updated issues since last poll will be shortcut-ed and not embedded
|
||||
# adjusted_start_datetime = start_datetime - timedelta(hours=3)
|
||||
|
||||
adjusted_start_datetime = start_datetime
|
||||
|
||||
epoch = datetime.fromtimestamp(0, tz=timezone.utc)
|
||||
if adjusted_start_datetime < epoch:
|
||||
adjusted_start_datetime = epoch
|
||||
|
||||
return self._fetch_from_github(
|
||||
checkpoint,
|
||||
start=adjusted_start_datetime,
|
||||
end=end_datetime,
|
||||
include_permissions=include_permissions,
|
||||
)
|
||||
|
||||
@override
|
||||
def load_from_checkpoint(
|
||||
self,
|
||||
start: SecondsSinceUnixEpoch,
|
||||
end: SecondsSinceUnixEpoch,
|
||||
checkpoint: GithubConnectorCheckpoint,
|
||||
) -> CheckpointOutput[GithubConnectorCheckpoint]:
|
||||
return self._load_from_checkpoint(
|
||||
start, end, checkpoint, include_permissions=False
|
||||
)
|
||||
|
||||
@override
|
||||
def load_from_checkpoint_with_perm_sync(
|
||||
self,
|
||||
start: SecondsSinceUnixEpoch,
|
||||
end: SecondsSinceUnixEpoch,
|
||||
checkpoint: GithubConnectorCheckpoint,
|
||||
) -> CheckpointOutput[GithubConnectorCheckpoint]:
|
||||
return self._load_from_checkpoint(
|
||||
start, end, checkpoint, include_permissions=True
|
||||
)
|
||||
|
||||
def validate_connector_settings(self) -> None:
|
||||
if self.github_client is None:
|
||||
raise ConnectorMissingCredentialError("GitHub credentials not loaded.")
|
||||
|
||||
if not self.repo_owner:
|
||||
raise ConnectorValidationError(
|
||||
"Invalid connector settings: 'repo_owner' must be provided."
|
||||
)
|
||||
|
||||
try:
|
||||
if self.repositories:
|
||||
if "," in self.repositories:
|
||||
# Multiple repositories specified
|
||||
repo_names = [name.strip() for name in self.repositories.split(",")]
|
||||
if not repo_names:
|
||||
raise ConnectorValidationError(
|
||||
"Invalid connector settings: No valid repository names provided."
|
||||
)
|
||||
|
||||
# Validate at least one repository exists and is accessible
|
||||
valid_repos = False
|
||||
validation_errors = []
|
||||
|
||||
for repo_name in repo_names:
|
||||
if not repo_name:
|
||||
continue
|
||||
|
||||
try:
|
||||
test_repo = self.github_client.get_repo(
|
||||
f"{self.repo_owner}/{repo_name}"
|
||||
)
|
||||
logging.info(
|
||||
f"Successfully accessed repository: {self.repo_owner}/{repo_name}"
|
||||
)
|
||||
test_repo.get_contents("")
|
||||
valid_repos = True
|
||||
# If at least one repo is valid, we can proceed
|
||||
break
|
||||
except GithubException as e:
|
||||
validation_errors.append(
|
||||
f"Repository '{repo_name}': {e.data.get('message', str(e))}"
|
||||
)
|
||||
|
||||
if not valid_repos:
|
||||
error_msg = (
|
||||
"None of the specified repositories could be accessed: "
|
||||
)
|
||||
error_msg += ", ".join(validation_errors)
|
||||
raise ConnectorValidationError(error_msg)
|
||||
else:
|
||||
# Single repository (backward compatibility)
|
||||
test_repo = self.github_client.get_repo(
|
||||
f"{self.repo_owner}/{self.repositories}"
|
||||
)
|
||||
test_repo.get_contents("")
|
||||
else:
|
||||
# Try to get organization first
|
||||
try:
|
||||
org = self.github_client.get_organization(self.repo_owner)
|
||||
total_count = org.get_repos().totalCount
|
||||
if total_count == 0:
|
||||
raise ConnectorValidationError(
|
||||
f"Found no repos for organization: {self.repo_owner}. "
|
||||
"Does the credential have the right scopes?"
|
||||
)
|
||||
except GithubException as e:
|
||||
# Check for missing SSO
|
||||
MISSING_SSO_ERROR_MESSAGE = "You must grant your Personal Access token access to this organization".lower()
|
||||
if MISSING_SSO_ERROR_MESSAGE in str(e).lower():
|
||||
SSO_GUIDE_LINK = (
|
||||
"https://docs.github.com/en/enterprise-cloud@latest/authentication/"
|
||||
"authenticating-with-saml-single-sign-on/"
|
||||
"authorizing-a-personal-access-token-for-use-with-saml-single-sign-on"
|
||||
)
|
||||
raise ConnectorValidationError(
|
||||
f"Your GitHub token is missing authorization to access the "
|
||||
f"`{self.repo_owner}` organization. Please follow the guide to "
|
||||
f"authorize your token: {SSO_GUIDE_LINK}"
|
||||
)
|
||||
# If not an org, try as a user
|
||||
user = self.github_client.get_user(self.repo_owner)
|
||||
|
||||
# Check if we can access any repos
|
||||
total_count = user.get_repos().totalCount
|
||||
if total_count == 0:
|
||||
raise ConnectorValidationError(
|
||||
f"Found no repos for user: {self.repo_owner}. "
|
||||
"Does the credential have the right scopes?"
|
||||
)
|
||||
|
||||
except RateLimitExceededException:
|
||||
raise UnexpectedValidationError(
|
||||
"Validation failed due to GitHub rate-limits being exceeded. Please try again later."
|
||||
)
|
||||
|
||||
except GithubException as e:
|
||||
if e.status == 401:
|
||||
raise CredentialExpiredError(
|
||||
"GitHub credential appears to be invalid or expired (HTTP 401)."
|
||||
)
|
||||
elif e.status == 403:
|
||||
raise InsufficientPermissionsError(
|
||||
"Your GitHub token does not have sufficient permissions for this repository (HTTP 403)."
|
||||
)
|
||||
elif e.status == 404:
|
||||
if self.repositories:
|
||||
if "," in self.repositories:
|
||||
raise ConnectorValidationError(
|
||||
f"None of the specified GitHub repositories could be found for owner: {self.repo_owner}"
|
||||
)
|
||||
else:
|
||||
raise ConnectorValidationError(
|
||||
f"GitHub repository not found with name: {self.repo_owner}/{self.repositories}"
|
||||
)
|
||||
else:
|
||||
raise ConnectorValidationError(
|
||||
f"GitHub user or organization not found: {self.repo_owner}"
|
||||
)
|
||||
else:
|
||||
raise ConnectorValidationError(
|
||||
f"Unexpected GitHub error (status={e.status}): {e.data}"
|
||||
)
|
||||
|
||||
except Exception as exc:
|
||||
raise Exception(
|
||||
f"Unexpected error during GitHub settings validation: {exc}"
|
||||
)
|
||||
|
||||
def validate_checkpoint_json(
|
||||
self, checkpoint_json: str
|
||||
) -> GithubConnectorCheckpoint:
|
||||
return GithubConnectorCheckpoint.model_validate_json(checkpoint_json)
|
||||
|
||||
def build_dummy_checkpoint(self) -> GithubConnectorCheckpoint:
|
||||
return GithubConnectorCheckpoint(
|
||||
stage=GithubConnectorStage.PRS, curr_page=0, has_more=True, num_retrieved=0
|
||||
)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# Initialize the connector
|
||||
connector = GithubConnector(
|
||||
repo_owner="EvoAgentX",
|
||||
repositories="EvoAgentX",
|
||||
include_issues=True,
|
||||
include_prs=False,
|
||||
)
|
||||
connector.load_credentials(
|
||||
{"github_access_token": "<Your_GitHub_Access_Token>"}
|
||||
)
|
||||
|
||||
if connector.github_client:
|
||||
get_external_access_permission(
|
||||
connector.get_github_repos(connector.github_client).pop(),
|
||||
connector.github_client,
|
||||
)
|
||||
|
||||
# Create a time range from epoch to now
|
||||
end_time = datetime.now(timezone.utc)
|
||||
start_time = datetime.fromtimestamp(0, tz=timezone.utc)
|
||||
time_range = (start_time, end_time)
|
||||
|
||||
# Initialize the runner with a batch size of 10
|
||||
runner: ConnectorRunner[GithubConnectorCheckpoint] = ConnectorRunner(
|
||||
connector, batch_size=10, include_permissions=False, time_range=time_range
|
||||
)
|
||||
|
||||
# Get initial checkpoint
|
||||
checkpoint = connector.build_dummy_checkpoint()
|
||||
|
||||
# Run the connector
|
||||
while checkpoint.has_more:
|
||||
for doc_batch, failure, next_checkpoint in runner.run(checkpoint):
|
||||
if doc_batch:
|
||||
print(f"Retrieved batch of {len(doc_batch)} documents")
|
||||
for doc in doc_batch:
|
||||
print(f"Document: {doc.semantic_identifier}")
|
||||
if failure:
|
||||
print(f"Failure: {failure.failure_message}")
|
||||
if next_checkpoint:
|
||||
checkpoint = next_checkpoint
|
||||
17
common/data_source/github/models.py
Normal file
17
common/data_source/github/models.py
Normal file
@ -0,0 +1,17 @@
|
||||
from typing import Any
|
||||
|
||||
from github import Repository
|
||||
from github.Requester import Requester
|
||||
from pydantic import BaseModel
|
||||
|
||||
|
||||
class SerializedRepository(BaseModel):
|
||||
# id is part of the raw_data as well, just pulled out for convenience
|
||||
id: int
|
||||
headers: dict[str, str | int]
|
||||
raw_data: dict[str, Any]
|
||||
|
||||
def to_Repository(self, requester: Requester) -> Repository.Repository:
|
||||
return Repository.Repository(
|
||||
requester, self.headers, self.raw_data, completed=True
|
||||
)
|
||||
24
common/data_source/github/rate_limit_utils.py
Normal file
24
common/data_source/github/rate_limit_utils.py
Normal file
@ -0,0 +1,24 @@
|
||||
import time
|
||||
import logging
|
||||
from datetime import datetime
|
||||
from datetime import timedelta
|
||||
from datetime import timezone
|
||||
|
||||
from github import Github
|
||||
|
||||
|
||||
def sleep_after_rate_limit_exception(github_client: Github) -> None:
|
||||
"""
|
||||
Sleep until the GitHub rate limit resets.
|
||||
|
||||
Args:
|
||||
github_client: The GitHub client that hit the rate limit
|
||||
"""
|
||||
sleep_time = github_client.get_rate_limit().core.reset.replace(
|
||||
tzinfo=timezone.utc
|
||||
) - datetime.now(tz=timezone.utc)
|
||||
sleep_time += timedelta(minutes=1) # add an extra minute just to be safe
|
||||
logging.info(
|
||||
"Ran into Github rate-limit. Sleeping %s seconds.", sleep_time.seconds
|
||||
)
|
||||
time.sleep(sleep_time.total_seconds())
|
||||
44
common/data_source/github/utils.py
Normal file
44
common/data_source/github/utils.py
Normal file
@ -0,0 +1,44 @@
|
||||
import logging
|
||||
|
||||
from github import Github
|
||||
from github.Repository import Repository
|
||||
|
||||
from common.data_source.models import ExternalAccess
|
||||
|
||||
from .models import SerializedRepository
|
||||
|
||||
|
||||
def get_external_access_permission(
|
||||
repo: Repository, github_client: Github
|
||||
) -> ExternalAccess:
|
||||
"""
|
||||
Get the external access permission for a repository.
|
||||
This functionality requires Enterprise Edition.
|
||||
"""
|
||||
# RAGFlow doesn't implement the Onyx EE external-permissions system.
|
||||
# Default to private/unknown permissions.
|
||||
return ExternalAccess.empty()
|
||||
|
||||
|
||||
def deserialize_repository(
|
||||
cached_repo: SerializedRepository, github_client: Github
|
||||
) -> Repository:
|
||||
"""
|
||||
Deserialize a SerializedRepository back into a Repository object.
|
||||
"""
|
||||
# Try to access the requester - different PyGithub versions may use different attribute names
|
||||
try:
|
||||
# Try to get the requester using getattr to avoid linter errors
|
||||
requester = getattr(github_client, "_requester", None)
|
||||
if requester is None:
|
||||
requester = getattr(github_client, "_Github__requester", None)
|
||||
if requester is None:
|
||||
# If we can't find the requester attribute, we need to fall back to recreating the repo
|
||||
raise AttributeError("Could not find requester attribute")
|
||||
|
||||
return cached_repo.to_Repository(requester)
|
||||
except Exception as e:
|
||||
# If all else fails, re-fetch the repo directly
|
||||
logging.warning("Failed to deserialize repository: %s. Attempting to re-fetch.", e)
|
||||
repo_id = cached_repo.id
|
||||
return github_client.get_repo(repo_id)
|
||||
340
common/data_source/gitlab_connector.py
Normal file
340
common/data_source/gitlab_connector.py
Normal file
@ -0,0 +1,340 @@
|
||||
import fnmatch
|
||||
import itertools
|
||||
from collections import deque
|
||||
from collections.abc import Iterable
|
||||
from collections.abc import Iterator
|
||||
from datetime import datetime
|
||||
from datetime import timezone
|
||||
from typing import Any
|
||||
from typing import TypeVar
|
||||
import gitlab
|
||||
from gitlab.v4.objects import Project
|
||||
|
||||
from common.data_source.config import DocumentSource, INDEX_BATCH_SIZE
|
||||
from common.data_source.exceptions import ConnectorMissingCredentialError
|
||||
from common.data_source.exceptions import ConnectorValidationError
|
||||
from common.data_source.exceptions import CredentialExpiredError
|
||||
from common.data_source.exceptions import InsufficientPermissionsError
|
||||
from common.data_source.exceptions import UnexpectedValidationError
|
||||
from common.data_source.interfaces import GenerateDocumentsOutput
|
||||
from common.data_source.interfaces import LoadConnector
|
||||
from common.data_source.interfaces import PollConnector
|
||||
from common.data_source.interfaces import SecondsSinceUnixEpoch
|
||||
from common.data_source.models import BasicExpertInfo
|
||||
from common.data_source.models import Document
|
||||
from common.data_source.utils import get_file_ext
|
||||
|
||||
T = TypeVar("T")
|
||||
|
||||
|
||||
|
||||
# List of directories/Files to exclude
|
||||
exclude_patterns = [
|
||||
"logs",
|
||||
".github/",
|
||||
".gitlab/",
|
||||
".pre-commit-config.yaml",
|
||||
]
|
||||
|
||||
|
||||
def _batch_gitlab_objects(git_objs: Iterable[T], batch_size: int) -> Iterator[list[T]]:
|
||||
it = iter(git_objs)
|
||||
while True:
|
||||
batch = list(itertools.islice(it, batch_size))
|
||||
if not batch:
|
||||
break
|
||||
yield batch
|
||||
|
||||
|
||||
def get_author(author: Any) -> BasicExpertInfo:
|
||||
return BasicExpertInfo(
|
||||
display_name=author.get("name"),
|
||||
)
|
||||
|
||||
|
||||
def _convert_merge_request_to_document(mr: Any) -> Document:
|
||||
mr_text = mr.description or ""
|
||||
doc = Document(
|
||||
id=mr.web_url,
|
||||
blob=mr_text,
|
||||
source=DocumentSource.GITLAB,
|
||||
semantic_identifier=mr.title,
|
||||
extension=".md",
|
||||
# updated_at is UTC time but is timezone unaware, explicitly add UTC
|
||||
# as there is logic in indexing to prevent wrong timestamped docs
|
||||
# due to local time discrepancies with UTC
|
||||
doc_updated_at=mr.updated_at.replace(tzinfo=timezone.utc),
|
||||
size_bytes=len(mr_text.encode("utf-8")),
|
||||
primary_owners=[get_author(mr.author)],
|
||||
metadata={"state": mr.state, "type": "MergeRequest", "web_url": mr.web_url},
|
||||
)
|
||||
return doc
|
||||
|
||||
|
||||
def _convert_issue_to_document(issue: Any) -> Document:
|
||||
issue_text = issue.description or ""
|
||||
doc = Document(
|
||||
id=issue.web_url,
|
||||
blob=issue_text,
|
||||
source=DocumentSource.GITLAB,
|
||||
semantic_identifier=issue.title,
|
||||
extension=".md",
|
||||
# updated_at is UTC time but is timezone unaware, explicitly add UTC
|
||||
# as there is logic in indexing to prevent wrong timestamped docs
|
||||
# due to local time discrepancies with UTC
|
||||
doc_updated_at=issue.updated_at.replace(tzinfo=timezone.utc),
|
||||
size_bytes=len(issue_text.encode("utf-8")),
|
||||
primary_owners=[get_author(issue.author)],
|
||||
metadata={
|
||||
"state": issue.state,
|
||||
"type": issue.type if issue.type else "Issue",
|
||||
"web_url": issue.web_url,
|
||||
},
|
||||
)
|
||||
return doc
|
||||
|
||||
|
||||
def _convert_code_to_document(
|
||||
project: Project, file: Any, url: str, projectName: str, projectOwner: str
|
||||
) -> Document:
|
||||
|
||||
# Dynamically get the default branch from the project object
|
||||
default_branch = project.default_branch
|
||||
|
||||
# Fetch the file content using the correct branch
|
||||
file_content_obj = project.files.get(
|
||||
file_path=file["path"], ref=default_branch # Use the default branch
|
||||
)
|
||||
# BoxConnector uses raw bytes for blob. Keep the same here.
|
||||
file_content_bytes = file_content_obj.decode()
|
||||
file_url = f"{url}/{projectOwner}/{projectName}/-/blob/{default_branch}/{file['path']}"
|
||||
|
||||
# Try to use the last commit timestamp for incremental sync.
|
||||
# Falls back to "now" if the commit lookup fails.
|
||||
last_commit_at = None
|
||||
try:
|
||||
# Query commit history for this file on the default branch.
|
||||
commits = project.commits.list(
|
||||
ref_name=default_branch,
|
||||
path=file["path"],
|
||||
per_page=1,
|
||||
)
|
||||
if commits:
|
||||
# committed_date is ISO string like "2024-01-01T00:00:00.000+00:00"
|
||||
committed_date = commits[0].committed_date
|
||||
if isinstance(committed_date, str):
|
||||
last_commit_at = datetime.strptime(
|
||||
committed_date, "%Y-%m-%dT%H:%M:%S.%f%z"
|
||||
).astimezone(timezone.utc)
|
||||
elif isinstance(committed_date, datetime):
|
||||
last_commit_at = committed_date.astimezone(timezone.utc)
|
||||
except Exception:
|
||||
last_commit_at = None
|
||||
|
||||
# Create and return a Document object
|
||||
doc = Document(
|
||||
# Use a stable ID so reruns don't create duplicates.
|
||||
id=file_url,
|
||||
blob=file_content_bytes,
|
||||
source=DocumentSource.GITLAB,
|
||||
semantic_identifier=file.get("name"),
|
||||
extension=get_file_ext(file.get("name")),
|
||||
doc_updated_at=last_commit_at or datetime.now(tz=timezone.utc),
|
||||
size_bytes=len(file_content_bytes) if file_content_bytes is not None else 0,
|
||||
primary_owners=[], # Add owners if needed
|
||||
metadata={
|
||||
"type": "CodeFile",
|
||||
"path": file.get("path"),
|
||||
"ref": default_branch,
|
||||
"project": f"{projectOwner}/{projectName}",
|
||||
"web_url": file_url,
|
||||
},
|
||||
)
|
||||
return doc
|
||||
|
||||
|
||||
def _should_exclude(path: str) -> bool:
|
||||
"""Check if a path matches any of the exclude patterns."""
|
||||
return any(fnmatch.fnmatch(path, pattern) for pattern in exclude_patterns)
|
||||
|
||||
|
||||
class GitlabConnector(LoadConnector, PollConnector):
|
||||
def __init__(
|
||||
self,
|
||||
project_owner: str,
|
||||
project_name: str,
|
||||
batch_size: int = INDEX_BATCH_SIZE,
|
||||
state_filter: str = "all",
|
||||
include_mrs: bool = True,
|
||||
include_issues: bool = True,
|
||||
include_code_files: bool = False,
|
||||
) -> None:
|
||||
self.project_owner = project_owner
|
||||
self.project_name = project_name
|
||||
self.batch_size = batch_size
|
||||
self.state_filter = state_filter
|
||||
self.include_mrs = include_mrs
|
||||
self.include_issues = include_issues
|
||||
self.include_code_files = include_code_files
|
||||
self.gitlab_client: gitlab.Gitlab | None = None
|
||||
|
||||
def load_credentials(self, credentials: dict[str, Any]) -> dict[str, Any] | None:
|
||||
self.gitlab_client = gitlab.Gitlab(
|
||||
credentials["gitlab_url"], private_token=credentials["gitlab_access_token"]
|
||||
)
|
||||
return None
|
||||
|
||||
def validate_connector_settings(self) -> None:
|
||||
if self.gitlab_client is None:
|
||||
raise ConnectorMissingCredentialError("GitLab")
|
||||
|
||||
try:
|
||||
self.gitlab_client.auth()
|
||||
self.gitlab_client.projects.get(
|
||||
f"{self.project_owner}/{self.project_name}",
|
||||
lazy=True,
|
||||
)
|
||||
|
||||
except gitlab.exceptions.GitlabAuthenticationError as e:
|
||||
raise CredentialExpiredError(
|
||||
"Invalid or expired GitLab credentials."
|
||||
) from e
|
||||
|
||||
except gitlab.exceptions.GitlabAuthorizationError as e:
|
||||
raise InsufficientPermissionsError(
|
||||
"Insufficient permissions to access GitLab resources."
|
||||
) from e
|
||||
|
||||
except gitlab.exceptions.GitlabGetError as e:
|
||||
raise ConnectorValidationError(
|
||||
"GitLab project not found or not accessible."
|
||||
) from e
|
||||
|
||||
except Exception as e:
|
||||
raise UnexpectedValidationError(
|
||||
f"Unexpected error while validating GitLab settings: {e}"
|
||||
) from e
|
||||
|
||||
def _fetch_from_gitlab(
|
||||
self, start: datetime | None = None, end: datetime | None = None
|
||||
) -> GenerateDocumentsOutput:
|
||||
if self.gitlab_client is None:
|
||||
raise ConnectorMissingCredentialError("Gitlab")
|
||||
project: Project = self.gitlab_client.projects.get(
|
||||
f"{self.project_owner}/{self.project_name}"
|
||||
)
|
||||
|
||||
start_utc = start.astimezone(timezone.utc) if start else None
|
||||
end_utc = end.astimezone(timezone.utc) if end else None
|
||||
|
||||
# Fetch code files
|
||||
if self.include_code_files:
|
||||
# Fetching using BFS as project.report_tree with recursion causing slow load
|
||||
queue = deque([""]) # Start with the root directory
|
||||
while queue:
|
||||
current_path = queue.popleft()
|
||||
files = project.repository_tree(path=current_path, all=True)
|
||||
for file_batch in _batch_gitlab_objects(files, self.batch_size):
|
||||
code_doc_batch: list[Document] = []
|
||||
for file in file_batch:
|
||||
if _should_exclude(file["path"]):
|
||||
continue
|
||||
|
||||
if file["type"] == "blob":
|
||||
|
||||
doc = _convert_code_to_document(
|
||||
project,
|
||||
file,
|
||||
self.gitlab_client.url,
|
||||
self.project_name,
|
||||
self.project_owner,
|
||||
)
|
||||
|
||||
# Apply incremental window filtering for code files too.
|
||||
if start_utc is not None and doc.doc_updated_at <= start_utc:
|
||||
continue
|
||||
if end_utc is not None and doc.doc_updated_at > end_utc:
|
||||
continue
|
||||
|
||||
code_doc_batch.append(doc)
|
||||
elif file["type"] == "tree":
|
||||
queue.append(file["path"])
|
||||
|
||||
if code_doc_batch:
|
||||
yield code_doc_batch
|
||||
|
||||
if self.include_mrs:
|
||||
merge_requests = project.mergerequests.list(
|
||||
state=self.state_filter,
|
||||
order_by="updated_at",
|
||||
sort="desc",
|
||||
iterator=True,
|
||||
)
|
||||
|
||||
for mr_batch in _batch_gitlab_objects(merge_requests, self.batch_size):
|
||||
mr_doc_batch: list[Document] = []
|
||||
for mr in mr_batch:
|
||||
mr.updated_at = datetime.strptime(
|
||||
mr.updated_at, "%Y-%m-%dT%H:%M:%S.%f%z"
|
||||
)
|
||||
if start_utc is not None and mr.updated_at <= start_utc:
|
||||
yield mr_doc_batch
|
||||
return
|
||||
if end_utc is not None and mr.updated_at > end_utc:
|
||||
continue
|
||||
mr_doc_batch.append(_convert_merge_request_to_document(mr))
|
||||
yield mr_doc_batch
|
||||
|
||||
if self.include_issues:
|
||||
issues = project.issues.list(state=self.state_filter, iterator=True)
|
||||
|
||||
for issue_batch in _batch_gitlab_objects(issues, self.batch_size):
|
||||
issue_doc_batch: list[Document] = []
|
||||
for issue in issue_batch:
|
||||
issue.updated_at = datetime.strptime(
|
||||
issue.updated_at, "%Y-%m-%dT%H:%M:%S.%f%z"
|
||||
)
|
||||
# Avoid re-syncing the last-seen item.
|
||||
if start_utc is not None and issue.updated_at <= start_utc:
|
||||
yield issue_doc_batch
|
||||
return
|
||||
if end_utc is not None and issue.updated_at > end_utc:
|
||||
continue
|
||||
issue_doc_batch.append(_convert_issue_to_document(issue))
|
||||
yield issue_doc_batch
|
||||
|
||||
def load_from_state(self) -> GenerateDocumentsOutput:
|
||||
return self._fetch_from_gitlab()
|
||||
|
||||
def poll_source(
|
||||
self, start: SecondsSinceUnixEpoch, end: SecondsSinceUnixEpoch
|
||||
) -> GenerateDocumentsOutput:
|
||||
start_datetime = datetime.fromtimestamp(start, tz=timezone.utc)
|
||||
end_datetime = datetime.fromtimestamp(end, tz=timezone.utc)
|
||||
return self._fetch_from_gitlab(start_datetime, end_datetime)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
import os
|
||||
|
||||
connector = GitlabConnector(
|
||||
# gitlab_url="https://gitlab.com/api/v4",
|
||||
project_owner=os.environ["PROJECT_OWNER"],
|
||||
project_name=os.environ["PROJECT_NAME"],
|
||||
batch_size=INDEX_BATCH_SIZE,
|
||||
state_filter="all",
|
||||
include_mrs=True,
|
||||
include_issues=True,
|
||||
include_code_files=True,
|
||||
)
|
||||
|
||||
connector.load_credentials(
|
||||
{
|
||||
"gitlab_access_token": os.environ["GITLAB_ACCESS_TOKEN"],
|
||||
"gitlab_url": os.environ["GITLAB_URL"],
|
||||
}
|
||||
)
|
||||
document_batches = connector.load_from_state()
|
||||
for f in document_batches:
|
||||
print("Batch:", f)
|
||||
print("Finished loading from state.")
|
||||
@ -191,7 +191,7 @@ def get_credentials_from_env(email: str, oauth: bool = False, source="drive") ->
|
||||
DB_CREDENTIALS_AUTHENTICATION_METHOD: "uploaded",
|
||||
}
|
||||
|
||||
def sanitize_filename(name: str) -> str:
|
||||
def sanitize_filename(name: str, extension: str = "txt") -> str:
|
||||
"""
|
||||
Soft sanitize for MinIO/S3:
|
||||
- Replace only prohibited characters with a space.
|
||||
@ -199,7 +199,7 @@ def sanitize_filename(name: str) -> str:
|
||||
- Collapse multiple spaces.
|
||||
"""
|
||||
if name is None:
|
||||
return "file.txt"
|
||||
return f"file.{extension}"
|
||||
|
||||
name = str(name).strip()
|
||||
|
||||
@ -222,9 +222,8 @@ def sanitize_filename(name: str) -> str:
|
||||
base, ext = os.path.splitext(name)
|
||||
name = base[:180].rstrip() + ext
|
||||
|
||||
# Ensure there is an extension (your original logic)
|
||||
if not os.path.splitext(name)[1]:
|
||||
name += ".txt"
|
||||
name += f".{extension}"
|
||||
|
||||
return name
|
||||
|
||||
|
||||
724
common/data_source/imap_connector.py
Normal file
724
common/data_source/imap_connector.py
Normal file
@ -0,0 +1,724 @@
|
||||
import copy
|
||||
import email
|
||||
from email.header import decode_header
|
||||
import imaplib
|
||||
import logging
|
||||
import os
|
||||
import re
|
||||
from datetime import datetime, timedelta
|
||||
from datetime import timezone
|
||||
from email.message import Message
|
||||
from email.utils import collapse_rfc2231_value, parseaddr
|
||||
from enum import Enum
|
||||
from typing import Any
|
||||
from typing import cast
|
||||
|
||||
import bs4
|
||||
from pydantic import BaseModel
|
||||
|
||||
from common.data_source.config import IMAP_CONNECTOR_SIZE_THRESHOLD, DocumentSource
|
||||
from common.data_source.interfaces import CheckpointOutput, CheckpointedConnectorWithPermSync, CredentialsConnector, CredentialsProviderInterface
|
||||
from common.data_source.models import BasicExpertInfo, ConnectorCheckpoint, Document, ExternalAccess, SecondsSinceUnixEpoch
|
||||
|
||||
_DEFAULT_IMAP_PORT_NUMBER = int(os.environ.get("IMAP_PORT", 993))
|
||||
_IMAP_OKAY_STATUS = "OK"
|
||||
_PAGE_SIZE = 100
|
||||
_USERNAME_KEY = "imap_username"
|
||||
_PASSWORD_KEY = "imap_password"
|
||||
|
||||
class Header(str, Enum):
|
||||
SUBJECT_HEADER = "subject"
|
||||
FROM_HEADER = "from"
|
||||
TO_HEADER = "to"
|
||||
CC_HEADER = "cc"
|
||||
DELIVERED_TO_HEADER = (
|
||||
"Delivered-To" # Used in mailing lists instead of the "to" header.
|
||||
)
|
||||
DATE_HEADER = "date"
|
||||
MESSAGE_ID_HEADER = "Message-ID"
|
||||
|
||||
|
||||
class EmailHeaders(BaseModel):
|
||||
"""
|
||||
Model for email headers extracted from IMAP messages.
|
||||
"""
|
||||
|
||||
id: str
|
||||
subject: str
|
||||
sender: str
|
||||
recipients: str | None
|
||||
cc: str | None
|
||||
date: datetime
|
||||
|
||||
@classmethod
|
||||
def from_email_msg(cls, email_msg: Message) -> "EmailHeaders":
|
||||
def _decode(header: str, default: str | None = None) -> str | None:
|
||||
value = email_msg.get(header, default)
|
||||
if not value:
|
||||
return None
|
||||
|
||||
decoded_fragments = decode_header(value)
|
||||
decoded_strings: list[str] = []
|
||||
|
||||
for decoded_value, encoding in decoded_fragments:
|
||||
if isinstance(decoded_value, bytes):
|
||||
try:
|
||||
decoded_strings.append(
|
||||
decoded_value.decode(encoding or "utf-8", errors="replace")
|
||||
)
|
||||
except LookupError:
|
||||
decoded_strings.append(
|
||||
decoded_value.decode("utf-8", errors="replace")
|
||||
)
|
||||
elif isinstance(decoded_value, str):
|
||||
decoded_strings.append(decoded_value)
|
||||
else:
|
||||
decoded_strings.append(str(decoded_value))
|
||||
|
||||
return "".join(decoded_strings)
|
||||
|
||||
def _parse_date(date_str: str | None) -> datetime | None:
|
||||
if not date_str:
|
||||
return None
|
||||
try:
|
||||
return email.utils.parsedate_to_datetime(date_str)
|
||||
except (TypeError, ValueError):
|
||||
return None
|
||||
|
||||
message_id = _decode(header=Header.MESSAGE_ID_HEADER)
|
||||
if not message_id:
|
||||
message_id = f"<generated-{uuid.uuid4()}@imap.local>"
|
||||
# It's possible for the subject line to not exist or be an empty string.
|
||||
subject = _decode(header=Header.SUBJECT_HEADER) or "Unknown Subject"
|
||||
from_ = _decode(header=Header.FROM_HEADER)
|
||||
to = _decode(header=Header.TO_HEADER)
|
||||
if not to:
|
||||
to = _decode(header=Header.DELIVERED_TO_HEADER)
|
||||
cc = _decode(header=Header.CC_HEADER)
|
||||
date_str = _decode(header=Header.DATE_HEADER)
|
||||
date = _parse_date(date_str=date_str)
|
||||
|
||||
if not date:
|
||||
date = datetime.now(tz=timezone.utc)
|
||||
|
||||
# If any of the above are `None`, model validation will fail.
|
||||
# Therefore, no guards (i.e.: `if <header> is None: raise RuntimeError(..)`) were written.
|
||||
return cls.model_validate(
|
||||
{
|
||||
"id": message_id,
|
||||
"subject": subject,
|
||||
"sender": from_,
|
||||
"recipients": to,
|
||||
"cc": cc,
|
||||
"date": date,
|
||||
}
|
||||
)
|
||||
|
||||
class CurrentMailbox(BaseModel):
|
||||
mailbox: str
|
||||
todo_email_ids: list[str]
|
||||
|
||||
|
||||
# An email has a list of mailboxes.
|
||||
# Each mailbox has a list of email-ids inside of it.
|
||||
#
|
||||
# Usage:
|
||||
# To use this checkpointer, first fetch all the mailboxes.
|
||||
# Then, pop a mailbox and fetch all of its email-ids.
|
||||
# Then, pop each email-id and fetch its content (and parse it, etc..).
|
||||
# When you have popped all email-ids for this mailbox, pop the next mailbox and repeat the above process until you're done.
|
||||
#
|
||||
# For initial checkpointing, set both fields to `None`.
|
||||
class ImapCheckpoint(ConnectorCheckpoint):
|
||||
todo_mailboxes: list[str] | None = None
|
||||
current_mailbox: CurrentMailbox | None = None
|
||||
|
||||
|
||||
class LoginState(str, Enum):
|
||||
LoggedIn = "logged_in"
|
||||
LoggedOut = "logged_out"
|
||||
|
||||
|
||||
class ImapConnector(
|
||||
CredentialsConnector,
|
||||
CheckpointedConnectorWithPermSync,
|
||||
):
|
||||
def __init__(
|
||||
self,
|
||||
host: str,
|
||||
port: int = _DEFAULT_IMAP_PORT_NUMBER,
|
||||
mailboxes: list[str] | None = None,
|
||||
) -> None:
|
||||
self._host = host
|
||||
self._port = port
|
||||
self._mailboxes = mailboxes
|
||||
self._credentials: dict[str, Any] | None = None
|
||||
|
||||
@property
|
||||
def credentials(self) -> dict[str, Any]:
|
||||
if not self._credentials:
|
||||
raise RuntimeError(
|
||||
"Credentials have not been initialized; call `set_credentials_provider` first"
|
||||
)
|
||||
return self._credentials
|
||||
|
||||
def _get_mail_client(self) -> imaplib.IMAP4_SSL:
|
||||
"""
|
||||
Returns a new `imaplib.IMAP4_SSL` instance.
|
||||
|
||||
The `imaplib.IMAP4_SSL` object is supposed to be an "ephemeral" object; it's not something that you can login,
|
||||
logout, then log back into again. I.e., the following will fail:
|
||||
|
||||
```py
|
||||
mail_client.login(..)
|
||||
mail_client.logout();
|
||||
mail_client.login(..)
|
||||
```
|
||||
|
||||
Therefore, you need a fresh, new instance in order to operate with IMAP. This function gives one to you.
|
||||
|
||||
# Notes
|
||||
This function will throw an error if the credentials have not yet been set.
|
||||
"""
|
||||
|
||||
def get_or_raise(name: str) -> str:
|
||||
value = self.credentials.get(name)
|
||||
if not value:
|
||||
raise RuntimeError(f"Credential item {name=} was not found")
|
||||
if not isinstance(value, str):
|
||||
raise RuntimeError(
|
||||
f"Credential item {name=} must be of type str, instead received {type(name)=}"
|
||||
)
|
||||
return value
|
||||
|
||||
username = get_or_raise(_USERNAME_KEY)
|
||||
password = get_or_raise(_PASSWORD_KEY)
|
||||
|
||||
mail_client = imaplib.IMAP4_SSL(host=self._host, port=self._port)
|
||||
status, _data = mail_client.login(user=username, password=password)
|
||||
|
||||
if status != _IMAP_OKAY_STATUS:
|
||||
raise RuntimeError(f"Failed to log into imap server; {status=}")
|
||||
|
||||
return mail_client
|
||||
|
||||
def _load_from_checkpoint(
|
||||
self,
|
||||
start: SecondsSinceUnixEpoch,
|
||||
end: SecondsSinceUnixEpoch,
|
||||
checkpoint: ImapCheckpoint,
|
||||
include_perm_sync: bool,
|
||||
) -> CheckpointOutput[ImapCheckpoint]:
|
||||
checkpoint = cast(ImapCheckpoint, copy.deepcopy(checkpoint))
|
||||
checkpoint.has_more = True
|
||||
|
||||
mail_client = self._get_mail_client()
|
||||
|
||||
if checkpoint.todo_mailboxes is None:
|
||||
# This is the dummy checkpoint.
|
||||
# Fill it with mailboxes first.
|
||||
if self._mailboxes:
|
||||
checkpoint.todo_mailboxes = _sanitize_mailbox_names(self._mailboxes)
|
||||
else:
|
||||
fetched_mailboxes = _fetch_all_mailboxes_for_email_account(
|
||||
mail_client=mail_client
|
||||
)
|
||||
if not fetched_mailboxes:
|
||||
raise RuntimeError(
|
||||
"Failed to find any mailboxes for this email account"
|
||||
)
|
||||
checkpoint.todo_mailboxes = _sanitize_mailbox_names(fetched_mailboxes)
|
||||
|
||||
return checkpoint
|
||||
|
||||
if (
|
||||
not checkpoint.current_mailbox
|
||||
or not checkpoint.current_mailbox.todo_email_ids
|
||||
):
|
||||
if not checkpoint.todo_mailboxes:
|
||||
checkpoint.has_more = False
|
||||
return checkpoint
|
||||
|
||||
mailbox = checkpoint.todo_mailboxes.pop()
|
||||
email_ids = _fetch_email_ids_in_mailbox(
|
||||
mail_client=mail_client,
|
||||
mailbox=mailbox,
|
||||
start=start,
|
||||
end=end,
|
||||
)
|
||||
checkpoint.current_mailbox = CurrentMailbox(
|
||||
mailbox=mailbox,
|
||||
todo_email_ids=email_ids,
|
||||
)
|
||||
|
||||
_select_mailbox(
|
||||
mail_client=mail_client, mailbox=checkpoint.current_mailbox.mailbox
|
||||
)
|
||||
current_todos = cast(
|
||||
list, copy.deepcopy(checkpoint.current_mailbox.todo_email_ids[:_PAGE_SIZE])
|
||||
)
|
||||
checkpoint.current_mailbox.todo_email_ids = (
|
||||
checkpoint.current_mailbox.todo_email_ids[_PAGE_SIZE:]
|
||||
)
|
||||
|
||||
for email_id in current_todos:
|
||||
email_msg = _fetch_email(mail_client=mail_client, email_id=email_id)
|
||||
if not email_msg:
|
||||
logging.warning(f"Failed to fetch message {email_id=}; skipping")
|
||||
continue
|
||||
|
||||
email_headers = EmailHeaders.from_email_msg(email_msg=email_msg)
|
||||
msg_dt = email_headers.date
|
||||
if msg_dt.tzinfo is None:
|
||||
msg_dt = msg_dt.replace(tzinfo=timezone.utc)
|
||||
else:
|
||||
msg_dt = msg_dt.astimezone(timezone.utc)
|
||||
|
||||
start_dt = datetime.fromtimestamp(start, tz=timezone.utc)
|
||||
end_dt = datetime.fromtimestamp(end, tz=timezone.utc)
|
||||
|
||||
if not (start_dt < msg_dt <= end_dt):
|
||||
continue
|
||||
|
||||
email_doc = _convert_email_headers_and_body_into_document(
|
||||
email_msg=email_msg,
|
||||
email_headers=email_headers,
|
||||
include_perm_sync=include_perm_sync,
|
||||
)
|
||||
yield email_doc
|
||||
attachments = extract_attachments(email_msg)
|
||||
for att in attachments:
|
||||
yield attachment_to_document(email_doc, att, email_headers)
|
||||
|
||||
return checkpoint
|
||||
|
||||
# impls for BaseConnector
|
||||
|
||||
def load_credentials(self, credentials: dict[str, Any]) -> dict[str, Any] | None:
|
||||
self._credentials = credentials
|
||||
return None
|
||||
|
||||
def validate_connector_settings(self) -> None:
|
||||
self._get_mail_client()
|
||||
|
||||
# impls for CredentialsConnector
|
||||
|
||||
def set_credentials_provider(
|
||||
self, credentials_provider: CredentialsProviderInterface
|
||||
) -> None:
|
||||
self._credentials = credentials_provider.get_credentials()
|
||||
|
||||
# impls for CheckpointedConnector
|
||||
|
||||
def load_from_checkpoint(
|
||||
self,
|
||||
start: SecondsSinceUnixEpoch,
|
||||
end: SecondsSinceUnixEpoch,
|
||||
checkpoint: ImapCheckpoint,
|
||||
) -> CheckpointOutput[ImapCheckpoint]:
|
||||
return self._load_from_checkpoint(
|
||||
start=start, end=end, checkpoint=checkpoint, include_perm_sync=False
|
||||
)
|
||||
|
||||
def build_dummy_checkpoint(self) -> ImapCheckpoint:
|
||||
return ImapCheckpoint(has_more=True)
|
||||
|
||||
def validate_checkpoint_json(self, checkpoint_json: str) -> ImapCheckpoint:
|
||||
return ImapCheckpoint.model_validate_json(json_data=checkpoint_json)
|
||||
|
||||
# impls for CheckpointedConnectorWithPermSync
|
||||
|
||||
def load_from_checkpoint_with_perm_sync(
|
||||
self,
|
||||
start: SecondsSinceUnixEpoch,
|
||||
end: SecondsSinceUnixEpoch,
|
||||
checkpoint: ImapCheckpoint,
|
||||
) -> CheckpointOutput[ImapCheckpoint]:
|
||||
return self._load_from_checkpoint(
|
||||
start=start, end=end, checkpoint=checkpoint, include_perm_sync=True
|
||||
)
|
||||
|
||||
|
||||
def _fetch_all_mailboxes_for_email_account(mail_client: imaplib.IMAP4_SSL) -> list[str]:
|
||||
status, mailboxes_data = mail_client.list('""', "*")
|
||||
if status != _IMAP_OKAY_STATUS:
|
||||
raise RuntimeError(f"Failed to fetch mailboxes; {status=}")
|
||||
|
||||
mailboxes = []
|
||||
|
||||
for mailboxes_raw in mailboxes_data:
|
||||
if isinstance(mailboxes_raw, bytes):
|
||||
mailboxes_str = mailboxes_raw.decode()
|
||||
elif isinstance(mailboxes_raw, str):
|
||||
mailboxes_str = mailboxes_raw
|
||||
else:
|
||||
logging.warning(
|
||||
f"Expected the mailbox data to be of type str, instead got {type(mailboxes_raw)=} {mailboxes_raw}; skipping"
|
||||
)
|
||||
continue
|
||||
|
||||
# The mailbox LIST response output can be found here:
|
||||
# https://www.rfc-editor.org/rfc/rfc3501.html#section-7.2.2
|
||||
#
|
||||
# The general format is:
|
||||
# `(<name-attributes>) <hierarchy-delimiter> <mailbox-name>`
|
||||
#
|
||||
# The below regex matches on that pattern; from there, we select the 3rd match (index 2), which is the mailbox-name.
|
||||
match = re.match(r'\([^)]*\)\s+"([^"]+)"\s+"?(.+?)"?$', mailboxes_str)
|
||||
if not match:
|
||||
logging.warning(
|
||||
f"Invalid mailbox-data formatting structure: {mailboxes_str=}; skipping"
|
||||
)
|
||||
continue
|
||||
|
||||
mailbox = match.group(2)
|
||||
mailboxes.append(mailbox)
|
||||
if not mailboxes:
|
||||
logging.warning(
|
||||
"No mailboxes parsed from LIST response; falling back to INBOX"
|
||||
)
|
||||
return ["INBOX"]
|
||||
|
||||
return mailboxes
|
||||
|
||||
|
||||
def _select_mailbox(mail_client: imaplib.IMAP4_SSL, mailbox: str) -> bool:
|
||||
try:
|
||||
status, _ = mail_client.select(mailbox=mailbox, readonly=True)
|
||||
if status != _IMAP_OKAY_STATUS:
|
||||
return False
|
||||
return True
|
||||
except Exception:
|
||||
return False
|
||||
|
||||
|
||||
def _fetch_email_ids_in_mailbox(
|
||||
mail_client: imaplib.IMAP4_SSL,
|
||||
mailbox: str,
|
||||
start: SecondsSinceUnixEpoch,
|
||||
end: SecondsSinceUnixEpoch,
|
||||
) -> list[str]:
|
||||
if not _select_mailbox(mail_client, mailbox):
|
||||
logging.warning(f"Skip mailbox: {mailbox}")
|
||||
return []
|
||||
|
||||
start_dt = datetime.fromtimestamp(start, tz=timezone.utc)
|
||||
end_dt = datetime.fromtimestamp(end, tz=timezone.utc) + timedelta(days=1)
|
||||
|
||||
start_str = start_dt.strftime("%d-%b-%Y")
|
||||
end_str = end_dt.strftime("%d-%b-%Y")
|
||||
search_criteria = f'(SINCE "{start_str}" BEFORE "{end_str}")'
|
||||
|
||||
status, email_ids_byte_array = mail_client.search(None, search_criteria)
|
||||
|
||||
if status != _IMAP_OKAY_STATUS or not email_ids_byte_array:
|
||||
raise RuntimeError(f"Failed to fetch email ids; {status=}")
|
||||
|
||||
email_ids: bytes = email_ids_byte_array[0]
|
||||
|
||||
return [email_id.decode() for email_id in email_ids.split()]
|
||||
|
||||
|
||||
def _fetch_email(mail_client: imaplib.IMAP4_SSL, email_id: str) -> Message | None:
|
||||
status, msg_data = mail_client.fetch(message_set=email_id, message_parts="(RFC822)")
|
||||
if status != _IMAP_OKAY_STATUS or not msg_data:
|
||||
return None
|
||||
|
||||
data = msg_data[0]
|
||||
if not isinstance(data, tuple):
|
||||
raise RuntimeError(
|
||||
f"Message data should be a tuple; instead got a {type(data)=} {data=}"
|
||||
)
|
||||
|
||||
_, raw_email = data
|
||||
return email.message_from_bytes(raw_email)
|
||||
|
||||
|
||||
def _convert_email_headers_and_body_into_document(
|
||||
email_msg: Message,
|
||||
email_headers: EmailHeaders,
|
||||
include_perm_sync: bool,
|
||||
) -> Document:
|
||||
sender_name, sender_addr = _parse_singular_addr(raw_header=email_headers.sender)
|
||||
to_addrs = (
|
||||
_parse_addrs(email_headers.recipients)
|
||||
if email_headers.recipients
|
||||
else []
|
||||
)
|
||||
cc_addrs = (
|
||||
_parse_addrs(email_headers.cc)
|
||||
if email_headers.cc
|
||||
else []
|
||||
)
|
||||
all_participants = to_addrs + cc_addrs
|
||||
|
||||
expert_info_map = {
|
||||
recipient_addr: BasicExpertInfo(
|
||||
display_name=recipient_name, email=recipient_addr
|
||||
)
|
||||
for recipient_name, recipient_addr in all_participants
|
||||
}
|
||||
if sender_addr not in expert_info_map:
|
||||
expert_info_map[sender_addr] = BasicExpertInfo(
|
||||
display_name=sender_name, email=sender_addr
|
||||
)
|
||||
|
||||
email_body = _parse_email_body(email_msg=email_msg, email_headers=email_headers)
|
||||
primary_owners = list(expert_info_map.values())
|
||||
external_access = (
|
||||
ExternalAccess(
|
||||
external_user_emails=set(expert_info_map.keys()),
|
||||
external_user_group_ids=set(),
|
||||
is_public=False,
|
||||
)
|
||||
if include_perm_sync
|
||||
else None
|
||||
)
|
||||
return Document(
|
||||
id=email_headers.id,
|
||||
title=email_headers.subject,
|
||||
blob=email_body,
|
||||
size_bytes=len(email_body),
|
||||
semantic_identifier=email_headers.subject,
|
||||
metadata={},
|
||||
extension='.txt',
|
||||
doc_updated_at=email_headers.date,
|
||||
source=DocumentSource.IMAP,
|
||||
primary_owners=primary_owners,
|
||||
external_access=external_access,
|
||||
)
|
||||
|
||||
def extract_attachments(email_msg: Message, max_bytes: int = IMAP_CONNECTOR_SIZE_THRESHOLD):
|
||||
attachments = []
|
||||
|
||||
if not email_msg.is_multipart():
|
||||
return attachments
|
||||
|
||||
for part in email_msg.walk():
|
||||
if part.get_content_maintype() == "multipart":
|
||||
continue
|
||||
|
||||
disposition = (part.get("Content-Disposition") or "").lower()
|
||||
filename = part.get_filename()
|
||||
|
||||
if not (
|
||||
disposition.startswith("attachment")
|
||||
or (disposition.startswith("inline") and filename)
|
||||
):
|
||||
continue
|
||||
|
||||
payload = part.get_payload(decode=True)
|
||||
if not payload:
|
||||
continue
|
||||
|
||||
if len(payload) > max_bytes:
|
||||
continue
|
||||
|
||||
attachments.append({
|
||||
"filename": filename or "attachment.bin",
|
||||
"content_type": part.get_content_type(),
|
||||
"content_bytes": payload,
|
||||
"size_bytes": len(payload),
|
||||
})
|
||||
|
||||
return attachments
|
||||
|
||||
def decode_mime_filename(raw: str | None) -> str | None:
|
||||
if not raw:
|
||||
return None
|
||||
|
||||
try:
|
||||
raw = collapse_rfc2231_value(raw)
|
||||
except Exception:
|
||||
pass
|
||||
|
||||
parts = decode_header(raw)
|
||||
decoded = []
|
||||
|
||||
for value, encoding in parts:
|
||||
if isinstance(value, bytes):
|
||||
decoded.append(value.decode(encoding or "utf-8", errors="replace"))
|
||||
else:
|
||||
decoded.append(value)
|
||||
|
||||
return "".join(decoded)
|
||||
|
||||
def attachment_to_document(
|
||||
parent_doc: Document,
|
||||
att: dict,
|
||||
email_headers: EmailHeaders,
|
||||
):
|
||||
raw_filename = att["filename"]
|
||||
filename = decode_mime_filename(raw_filename) or "attachment.bin"
|
||||
ext = "." + filename.split(".")[-1] if "." in filename else ""
|
||||
|
||||
return Document(
|
||||
id=f"{parent_doc.id}#att:{filename}",
|
||||
source=DocumentSource.IMAP,
|
||||
semantic_identifier=filename,
|
||||
extension=ext,
|
||||
blob=att["content_bytes"],
|
||||
size_bytes=att["size_bytes"],
|
||||
doc_updated_at=email_headers.date,
|
||||
primary_owners=parent_doc.primary_owners,
|
||||
metadata={
|
||||
"parent_email_id": parent_doc.id,
|
||||
"parent_subject": email_headers.subject,
|
||||
"attachment_filename": filename,
|
||||
"attachment_content_type": att["content_type"],
|
||||
},
|
||||
)
|
||||
|
||||
def _parse_email_body(
|
||||
email_msg: Message,
|
||||
email_headers: EmailHeaders,
|
||||
) -> str:
|
||||
body = None
|
||||
for part in email_msg.walk():
|
||||
if part.is_multipart():
|
||||
# Multipart parts are *containers* for other parts, not the actual content itself.
|
||||
# Therefore, we skip until we find the individual parts instead.
|
||||
continue
|
||||
|
||||
charset = part.get_content_charset() or "utf-8"
|
||||
|
||||
try:
|
||||
raw_payload = part.get_payload(decode=True)
|
||||
if not isinstance(raw_payload, bytes):
|
||||
logging.warning(
|
||||
"Payload section from email was expected to be an array of bytes, instead got "
|
||||
f"{type(raw_payload)=}, {raw_payload=}"
|
||||
)
|
||||
continue
|
||||
body = raw_payload.decode(charset)
|
||||
break
|
||||
except (UnicodeDecodeError, LookupError) as e:
|
||||
logging.warning(f"Could not decode part with charset {charset}. Error: {e}")
|
||||
continue
|
||||
|
||||
if not body:
|
||||
logging.warning(
|
||||
f"Email with {email_headers.id=} has an empty body; returning an empty string"
|
||||
)
|
||||
return ""
|
||||
|
||||
soup = bs4.BeautifulSoup(markup=body, features="html.parser")
|
||||
|
||||
return " ".join(str_section for str_section in soup.stripped_strings)
|
||||
|
||||
|
||||
def _sanitize_mailbox_names(mailboxes: list[str]) -> list[str]:
|
||||
"""
|
||||
Mailboxes with special characters in them must be enclosed by double-quotes, as per the IMAP protocol.
|
||||
Just to be safe, we wrap *all* mailboxes with double-quotes.
|
||||
"""
|
||||
return [f'"{mailbox}"' for mailbox in mailboxes if mailbox]
|
||||
|
||||
|
||||
def _parse_addrs(raw_header: str) -> list[tuple[str, str]]:
|
||||
addrs = raw_header.split(",")
|
||||
name_addr_pairs = [parseaddr(addr=addr) for addr in addrs if addr]
|
||||
return [(name, addr) for name, addr in name_addr_pairs if addr]
|
||||
|
||||
|
||||
def _parse_singular_addr(raw_header: str) -> tuple[str, str]:
|
||||
addrs = _parse_addrs(raw_header=raw_header)
|
||||
if not addrs:
|
||||
return ("Unknown", "unknown@example.com")
|
||||
elif len(addrs) >= 2:
|
||||
raise RuntimeError(
|
||||
f"Expected a singular address, but instead got multiple; {raw_header=} {addrs=}"
|
||||
)
|
||||
|
||||
return addrs[0]
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
import time
|
||||
import uuid
|
||||
from types import TracebackType
|
||||
from common.data_source.utils import load_all_docs_from_checkpoint_connector
|
||||
|
||||
|
||||
class OnyxStaticCredentialsProvider(
|
||||
CredentialsProviderInterface["OnyxStaticCredentialsProvider"]
|
||||
):
|
||||
"""Implementation (a very simple one!) to handle static credentials."""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
tenant_id: str | None,
|
||||
connector_name: str,
|
||||
credential_json: dict[str, Any],
|
||||
):
|
||||
self._tenant_id = tenant_id
|
||||
self._connector_name = connector_name
|
||||
self._credential_json = credential_json
|
||||
|
||||
self._provider_key = str(uuid.uuid4())
|
||||
|
||||
def __enter__(self) -> "OnyxStaticCredentialsProvider":
|
||||
return self
|
||||
|
||||
def __exit__(
|
||||
self,
|
||||
exc_type: type[BaseException] | None,
|
||||
exc_value: BaseException | None,
|
||||
traceback: TracebackType | None,
|
||||
) -> None:
|
||||
pass
|
||||
|
||||
def get_tenant_id(self) -> str | None:
|
||||
return self._tenant_id
|
||||
|
||||
def get_provider_key(self) -> str:
|
||||
return self._provider_key
|
||||
|
||||
def get_credentials(self) -> dict[str, Any]:
|
||||
return self._credential_json
|
||||
|
||||
def set_credentials(self, credential_json: dict[str, Any]) -> None:
|
||||
self._credential_json = credential_json
|
||||
|
||||
def is_dynamic(self) -> bool:
|
||||
return False
|
||||
# from tests.daily.connectors.utils import load_all_docs_from_checkpoint_connector
|
||||
# from onyx.connectors.credentials_provider import OnyxStaticCredentialsProvider
|
||||
|
||||
host = os.environ.get("IMAP_HOST")
|
||||
mailboxes_str = os.environ.get("IMAP_MAILBOXES","INBOX")
|
||||
username = os.environ.get("IMAP_USERNAME")
|
||||
password = os.environ.get("IMAP_PASSWORD")
|
||||
|
||||
mailboxes = (
|
||||
[mailbox.strip() for mailbox in mailboxes_str.split(",")]
|
||||
if mailboxes_str
|
||||
else []
|
||||
)
|
||||
|
||||
if not host:
|
||||
raise RuntimeError("`IMAP_HOST` must be set")
|
||||
|
||||
imap_connector = ImapConnector(
|
||||
host=host,
|
||||
mailboxes=mailboxes,
|
||||
)
|
||||
|
||||
imap_connector.set_credentials_provider(
|
||||
OnyxStaticCredentialsProvider(
|
||||
tenant_id=None,
|
||||
connector_name=DocumentSource.IMAP,
|
||||
credential_json={
|
||||
_USERNAME_KEY: username,
|
||||
_PASSWORD_KEY: password,
|
||||
},
|
||||
)
|
||||
)
|
||||
END = time.time()
|
||||
START = END - 1 * 24 * 60 * 60
|
||||
for doc in load_all_docs_from_checkpoint_connector(
|
||||
connector=imap_connector,
|
||||
start=START,
|
||||
end=END,
|
||||
):
|
||||
print(doc.id,doc.extension)
|
||||
@ -5,7 +5,7 @@ from abc import ABC, abstractmethod
|
||||
from enum import IntFlag, auto
|
||||
from types import TracebackType
|
||||
from typing import Any, Dict, Generator, TypeVar, Generic, Callable, TypeAlias
|
||||
|
||||
from collections.abc import Iterator
|
||||
from anthropic import BaseModel
|
||||
|
||||
from common.data_source.models import (
|
||||
@ -16,6 +16,7 @@ from common.data_source.models import (
|
||||
SecondsSinceUnixEpoch, GenerateSlimDocumentOutput
|
||||
)
|
||||
|
||||
GenerateDocumentsOutput = Iterator[list[Document]]
|
||||
|
||||
class LoadConnector(ABC):
|
||||
"""Load connector interface"""
|
||||
@ -236,16 +237,13 @@ class BaseConnector(abc.ABC, Generic[CT]):
|
||||
|
||||
def validate_perm_sync(self) -> None:
|
||||
"""
|
||||
Don't override this; add a function to perm_sync_valid.py in the ee package
|
||||
to do permission sync validation
|
||||
Permission-sync validation hook.
|
||||
|
||||
RAGFlow doesn't ship the Onyx EE permission-sync validation package.
|
||||
Connectors that support permission sync should override
|
||||
`validate_connector_settings()` as needed.
|
||||
"""
|
||||
"""
|
||||
validate_connector_settings_fn = fetch_ee_implementation_or_noop(
|
||||
"onyx.connectors.perm_sync_valid",
|
||||
"validate_perm_sync",
|
||||
noop_return_value=None,
|
||||
)
|
||||
validate_connector_settings_fn(self)"""
|
||||
return None
|
||||
|
||||
def set_allow_images(self, value: bool) -> None:
|
||||
"""Implement if the underlying connector wants to skip/allow image downloading
|
||||
@ -344,6 +342,17 @@ class CheckpointOutputWrapper(Generic[CT]):
|
||||
yield None, None, self.next_checkpoint
|
||||
|
||||
|
||||
class CheckpointedConnectorWithPermSyncGH(CheckpointedConnector[CT]):
|
||||
@abc.abstractmethod
|
||||
def load_from_checkpoint_with_perm_sync(
|
||||
self,
|
||||
start: SecondsSinceUnixEpoch,
|
||||
end: SecondsSinceUnixEpoch,
|
||||
checkpoint: CT,
|
||||
) -> CheckpointOutput[CT]:
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
# Slim connectors retrieve just the ids of documents
|
||||
class SlimConnector(BaseConnector):
|
||||
@abc.abstractmethod
|
||||
|
||||
@ -94,8 +94,10 @@ class Document(BaseModel):
|
||||
blob: bytes
|
||||
doc_updated_at: datetime
|
||||
size_bytes: int
|
||||
externale_access: Optional[ExternalAccess] = None
|
||||
primary_owners: Optional[list] = None
|
||||
metadata: Optional[dict[str, Any]] = None
|
||||
doc_metadata: Optional[dict[str, Any]] = None
|
||||
|
||||
|
||||
class BasicExpertInfo(BaseModel):
|
||||
|
||||
@ -13,6 +13,7 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
import ast
|
||||
import logging
|
||||
from typing import Any, Callable, Dict
|
||||
|
||||
@ -49,8 +50,8 @@ def meta_filter(metas: dict, filters: list[dict], logic: str = "and"):
|
||||
try:
|
||||
if isinstance(input, list):
|
||||
input = input[0]
|
||||
input = float(input)
|
||||
value = float(value)
|
||||
input = ast.literal_eval(input)
|
||||
value = ast.literal_eval(value)
|
||||
except Exception:
|
||||
pass
|
||||
if isinstance(input, str):
|
||||
@ -58,28 +59,41 @@ def meta_filter(metas: dict, filters: list[dict], logic: str = "and"):
|
||||
if isinstance(value, str):
|
||||
value = value.lower()
|
||||
|
||||
for conds in [
|
||||
(operator == "contains", input in value if not isinstance(input, list) else all([i in value for i in input])),
|
||||
(operator == "not contains", input not in value if not isinstance(input, list) else all([i not in value for i in input])),
|
||||
(operator == "in", input in value if not isinstance(input, list) else all([i in value for i in input])),
|
||||
(operator == "not in", input not in value if not isinstance(input, list) else all([i not in value for i in input])),
|
||||
(operator == "start with", str(input).lower().startswith(str(value).lower()) if not isinstance(input, list) else "".join([str(i).lower() for i in input]).startswith(str(value).lower())),
|
||||
(operator == "end with", str(input).lower().endswith(str(value).lower()) if not isinstance(input, list) else "".join([str(i).lower() for i in input]).endswith(str(value).lower())),
|
||||
(operator == "empty", not input),
|
||||
(operator == "not empty", input),
|
||||
(operator == "=", input == value),
|
||||
(operator == "≠", input != value),
|
||||
(operator == ">", input > value),
|
||||
(operator == "<", input < value),
|
||||
(operator == "≥", input >= value),
|
||||
(operator == "≤", input <= value),
|
||||
]:
|
||||
try:
|
||||
if all(conds):
|
||||
ids.extend(docids)
|
||||
break
|
||||
except Exception:
|
||||
pass
|
||||
matched = False
|
||||
try:
|
||||
if operator == "contains":
|
||||
matched = input in value if not isinstance(input, list) else all(i in value for i in input)
|
||||
elif operator == "not contains":
|
||||
matched = input not in value if not isinstance(input, list) else all(i not in value for i in input)
|
||||
elif operator == "in":
|
||||
matched = input in value if not isinstance(input, list) else all(i in value for i in input)
|
||||
elif operator == "not in":
|
||||
matched = input not in value if not isinstance(input, list) else all(i not in value for i in input)
|
||||
elif operator == "start with":
|
||||
matched = str(input).lower().startswith(str(value).lower()) if not isinstance(input, list) else "".join([str(i).lower() for i in input]).startswith(str(value).lower())
|
||||
elif operator == "end with":
|
||||
matched = str(input).lower().endswith(str(value).lower()) if not isinstance(input, list) else "".join([str(i).lower() for i in input]).endswith(str(value).lower())
|
||||
elif operator == "empty":
|
||||
matched = not input
|
||||
elif operator == "not empty":
|
||||
matched = bool(input)
|
||||
elif operator == "=":
|
||||
matched = input == value
|
||||
elif operator == "≠":
|
||||
matched = input != value
|
||||
elif operator == ">":
|
||||
matched = input > value
|
||||
elif operator == "<":
|
||||
matched = input < value
|
||||
elif operator == "≥":
|
||||
matched = input >= value
|
||||
elif operator == "≤":
|
||||
matched = input <= value
|
||||
except Exception:
|
||||
pass
|
||||
|
||||
if matched:
|
||||
ids.extend(docids)
|
||||
return ids
|
||||
|
||||
for k, v2docs in metas.items():
|
||||
|
||||
@ -170,7 +170,7 @@ def init_settings():
|
||||
global DATABASE_TYPE, DATABASE
|
||||
DATABASE_TYPE = os.getenv("DB_TYPE", "mysql")
|
||||
DATABASE = decrypt_database_config(name=DATABASE_TYPE)
|
||||
|
||||
|
||||
global ALLOWED_LLM_FACTORIES, LLM_FACTORY, LLM_BASE_URL
|
||||
llm_settings = get_base_config("user_default_llm", {}) or {}
|
||||
llm_default_models = llm_settings.get("default_models", {}) or {}
|
||||
@ -334,6 +334,9 @@ def init_settings():
|
||||
DOC_BULK_SIZE = int(os.environ.get("DOC_BULK_SIZE", 4))
|
||||
EMBEDDING_BATCH_SIZE = int(os.environ.get("EMBEDDING_BATCH_SIZE", 16))
|
||||
|
||||
os.environ["DOTNET_SYSTEM_GLOBALIZATION_INVARIANT"] = "1"
|
||||
|
||||
|
||||
def check_and_install_torch():
|
||||
global PARALLEL_DEVICES
|
||||
try:
|
||||
|
||||
@ -78,14 +78,21 @@ class DoclingParser(RAGFlowPdfParser):
|
||||
def __images__(self, fnm, zoomin: int = 1, page_from=0, page_to=600, callback=None):
|
||||
self.page_from = page_from
|
||||
self.page_to = page_to
|
||||
bytes_io = None
|
||||
try:
|
||||
opener = pdfplumber.open(fnm) if isinstance(fnm, (str, PathLike)) else pdfplumber.open(BytesIO(fnm))
|
||||
if not isinstance(fnm, (str, PathLike)):
|
||||
bytes_io = BytesIO(fnm)
|
||||
|
||||
opener = pdfplumber.open(fnm) if isinstance(fnm, (str, PathLike)) else pdfplumber.open(bytes_io)
|
||||
with opener as pdf:
|
||||
pages = pdf.pages[page_from:page_to]
|
||||
self.page_images = [p.to_image(resolution=72 * zoomin, antialias=True).original for p in pages]
|
||||
except Exception as e:
|
||||
self.page_images = []
|
||||
self.logger.exception(e)
|
||||
finally:
|
||||
if bytes_io:
|
||||
bytes_io.close()
|
||||
|
||||
def _make_line_tag(self,bbox: _BBox) -> str:
|
||||
if bbox is None:
|
||||
|
||||
@ -476,11 +476,13 @@ class RAGFlowPdfParser:
|
||||
self.boxes = bxs
|
||||
|
||||
def _naive_vertical_merge(self, zoomin=3):
|
||||
bxs = self._assign_column(self.boxes, zoomin)
|
||||
#bxs = self._assign_column(self.boxes, zoomin)
|
||||
bxs = self.boxes
|
||||
|
||||
grouped = defaultdict(list)
|
||||
for b in bxs:
|
||||
grouped[(b["page_number"], b.get("col_id", 0))].append(b)
|
||||
# grouped[(b["page_number"], b.get("col_id", 0))].append(b)
|
||||
grouped[(b["page_number"], "x")].append(b)
|
||||
|
||||
merged_boxes = []
|
||||
for (pg, col), bxs in grouped.items():
|
||||
@ -551,7 +553,7 @@ class RAGFlowPdfParser:
|
||||
|
||||
merged_boxes.extend(bxs)
|
||||
|
||||
self.boxes = sorted(merged_boxes, key=lambda x: (x["page_number"], x.get("col_id", 0), x["top"]))
|
||||
#self.boxes = sorted(merged_boxes, key=lambda x: (x["page_number"], x.get("col_id", 0), x["top"]))
|
||||
|
||||
def _final_reading_order_merge(self, zoomin=3):
|
||||
if not self.boxes:
|
||||
@ -1061,8 +1063,8 @@ class RAGFlowPdfParser:
|
||||
|
||||
self.total_page = len(self.pdf.pages)
|
||||
|
||||
except Exception:
|
||||
logging.exception("RAGFlowPdfParser __images__")
|
||||
except Exception as e:
|
||||
logging.exception(f"RAGFlowPdfParser __images__, exception: {e}")
|
||||
logging.info(f"__images__ dedupe_chars cost {timer() - start}s")
|
||||
|
||||
self.outlines = []
|
||||
@ -1206,7 +1208,7 @@ class RAGFlowPdfParser:
|
||||
start = timer()
|
||||
self._text_merge()
|
||||
self._concat_downward()
|
||||
#self._naive_vertical_merge(zoomin)
|
||||
self._naive_vertical_merge(zoomin)
|
||||
if callback:
|
||||
callback(0.92, "Text merged ({:.2f}s)".format(timer() - start))
|
||||
|
||||
|
||||
@ -16,6 +16,7 @@
|
||||
|
||||
import logging
|
||||
import sys
|
||||
import ast
|
||||
import six
|
||||
import cv2
|
||||
import numpy as np
|
||||
@ -108,7 +109,14 @@ class NormalizeImage:
|
||||
|
||||
def __init__(self, scale=None, mean=None, std=None, order='chw', **kwargs):
|
||||
if isinstance(scale, str):
|
||||
scale = eval(scale)
|
||||
try:
|
||||
scale = float(scale)
|
||||
except ValueError:
|
||||
if '/' in scale:
|
||||
parts = scale.split('/')
|
||||
scale = ast.literal_eval(parts[0]) / ast.literal_eval(parts[1])
|
||||
else:
|
||||
scale = ast.literal_eval(scale)
|
||||
self.scale = np.float32(scale if scale is not None else 1.0 / 255.0)
|
||||
mean = mean if mean is not None else [0.485, 0.456, 0.406]
|
||||
std = std if std is not None else [0.229, 0.224, 0.225]
|
||||
|
||||
@ -1,3 +1,10 @@
|
||||
# -----------------------------------------------------------------------------
|
||||
# SECURITY WARNING: DO NOT DEPLOY WITH DEFAULT PASSWORDS
|
||||
# For non-local deployments, please change all passwords (ELASTIC_PASSWORD,
|
||||
# MYSQL_PASSWORD, MINIO_PASSWORD, etc.) to strong, unique values.
|
||||
# You can generate a random string using: openssl rand -hex 32
|
||||
# -----------------------------------------------------------------------------
|
||||
|
||||
# ------------------------------
|
||||
# docker env var for specifying vector db type at startup
|
||||
# (based on the vector db type, the corresponding docker
|
||||
@ -30,6 +37,7 @@ ES_HOST=es01
|
||||
ES_PORT=1200
|
||||
|
||||
# The password for Elasticsearch.
|
||||
# WARNING: Change this for production!
|
||||
ELASTIC_PASSWORD=infini_rag_flow
|
||||
|
||||
# the hostname where OpenSearch service is exposed, set it not the same as elasticsearch
|
||||
@ -85,6 +93,7 @@ OB_DATAFILE_SIZE=${OB_DATAFILE_SIZE:-20G}
|
||||
OB_LOG_DISK_SIZE=${OB_LOG_DISK_SIZE:-20G}
|
||||
|
||||
# The password for MySQL.
|
||||
# WARNING: Change this for production!
|
||||
MYSQL_PASSWORD=infini_rag_flow
|
||||
# The hostname where the MySQL service is exposed
|
||||
MYSQL_HOST=mysql
|
||||
|
||||
8
docs/basics/_category_.json
Normal file
8
docs/basics/_category_.json
Normal file
@ -0,0 +1,8 @@
|
||||
{
|
||||
"label": "Basics",
|
||||
"position": 2,
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "Basic concepts."
|
||||
}
|
||||
}
|
||||
61
docs/basics/agent_context_engine.md
Normal file
61
docs/basics/agent_context_engine.md
Normal file
@ -0,0 +1,61 @@
|
||||
---
|
||||
sidebar_position: 2
|
||||
slug: /what_is_agent_context_engine
|
||||
---
|
||||
|
||||
# What is Agent context engine?
|
||||
|
||||
From 2025, a silent revolution began beneath the dazzling surface of AI Agents. While the world marveled at agents that could write code, analyze data, and automate workflows, a fundamental bottleneck emerged: why do even the most advanced agents still stumble on simple questions, forget previous conversations, or misuse available tools?
|
||||
|
||||
The answer lies not in the intelligence of the Large Language Model (LLM) itself, but in the quality of the Context it receives. An LLM, no matter how powerful, is only as good as the information we feed it. Today’s cutting-edge agents are often crippled by a cumbersome, manual, and error-prone process of context assembly—a process known as Context Engineering.
|
||||
|
||||
This is where the Agent Context Engine comes in. It is not merely an incremental improvement but a foundational shift, representing the evolution of RAG from a singular technique into the core data and intelligence substrate for the entire Agent ecosystem.
|
||||
|
||||
## Beyond the hype: The reality of today's "intelligent" Agents
|
||||
Today, the “intelligence” behind most AI Agents hides a mountain of human labor. Developers must:
|
||||
|
||||
- Hand-craft elaborate prompt templates
|
||||
- Hard-code document-retrieval logic for every task
|
||||
- Juggle tool descriptions, conversation history, and knowledge snippets inside a tiny context window
|
||||
- Repeat the whole process for each new scenario
|
||||
|
||||
This pattern is called Context Engineering. It is deeply tied to expert know-how, almost impossible to scale, and prohibitively expensive to maintain. When an enterprise needs to keep dozens of distinct agents alive, the artisanal workshop model collapses under its own weight.
|
||||
|
||||
The mission of an Agent Context Engine is to turn Context Engineering from an “art” into an industrial-grade science.
|
||||
|
||||
Deconstructing the Agent Context Engine
|
||||
So, what exactly is an Agent Context Engine? It is a unified, intelligent, and automated platform responsible for the end-to-end process of assembling the optimal context for an LLM or Agent at the moment of inference. It moves from artisanal crafting to industrialized production.
|
||||
At its core, an Agent Context Engine is built on a triumvirate of next-generation retrieval capabilities, seamlessly integrated into a single service layer:
|
||||
|
||||
1. The Knowledge Core (Advanced RAG): This is the evolution of traditional RAG. It moves beyond simple chunk-and-embed to intelligently process static, private enterprise knowledge. Techniques like TreeRAG (building LLM-generated document outlines for "locate-then-expand" retrieval) and GraphRAG (extracting entity networks to find semantically distant connections) work to close the "semantic gap." The engine’s Ingestion Pipeline acts as the ETL for unstructured data, parsing multi-format documents and using LLMs to enrich content with summaries, metadata, and structure before indexing.
|
||||
|
||||
2. The Memory Layer: An Agent’s intelligence is defined by its ability to learn from interaction. The Memory Layer is a specialized retrieval system for dynamic, episodic data: conversation history, user preferences, and the agent’s own internal state (e.g., "waiting for human input"). It manages the lifecycle of this data—storing raw dialogue, triggering summarization into semantic memory, and retrieving relevant past interactions to provide continuity and personalization. Technologically, it is a close sibling to RAG, but focused on a temporal stream of data.
|
||||
|
||||
3. The Tool Orchestrator: As MCP (Model Context Protocol) enables the connection of hundreds of internal services as tools, a new problem arises: tool selection. The Context Engine solves this with Tool Retrieval. Instead of dumping all tool descriptions into the prompt, it maintains an index of tools and—critically—an index of Playbooks or Guidelines (best practices on when and how to use tools). For a given task, it retrieves only the most relevant tools and instructions, transforming the LLM’s job from "searching a haystack" to "following a recipe."
|
||||
|
||||
## Why we need a dedicated engine? The case for a unified substrate
|
||||
|
||||
The necessity of an Agent Context Engine becomes clear when we examine the alternative: siloed, manually wired components.
|
||||
|
||||
- The Data Silo Problem: Knowledge, memory, and tools reside in separate systems, requiring complex integration for each new agent.
|
||||
- The Assembly Line Bottleneck: Developers spend more time on context plumbing than on agent logic, slowing innovation to a crawl.
|
||||
- The "Context Ownership" Dilemma: In manually engineered systems, context logic is buried in code, owned by developers, and opaque to business users. An Engine makes context a configurable, observable, and customer-owned asset.
|
||||
|
||||
The shift from Context Engineering to a Context Platform/Engine marks the maturation of enterprise AI, as summarized in the table below:
|
||||
|
||||
| Dimension | Context engineering (present) | Context engineering/Platform (future) |
|
||||
| ------------------- | -------------------------------------------------------------------------- | --------------------------------------------------------------------------------------------------- |
|
||||
| Context creation | Manual, artisanal work by developers and prompt engineers. | Automated, driven by intelligent ingestion pipelines and configurable rules. |
|
||||
| Context delivery | Hard-coded prompts and static retrieval logic embedded in agent workflows. | Dynamic, real-time retrieval and assembly based on the agent's live state and intent. |
|
||||
| Context maintenance | A development and operational burden, logic locked in code. | A manageable platform function, with visibility and control returned to the business. |
|
||||
|
||||
|
||||
## RAGFlow: A resolute march toward the context engine of Agents
|
||||
|
||||
This is the future RAGFlow is forging.
|
||||
|
||||
We left behind the label of “yet another RAG system” long ago. From DeepDoc—our deeply-optimized, multimodal document parser—to the bleeding-edge architectures that bridge semantic chasms in complex RAG scenarios, all the way to a full-blown, enterprise-grade ingestion pipeline, every evolutionary step RAGFlow takes is a deliberate stride toward the ultimate form: an Agentic Context Engine.
|
||||
|
||||
We believe tomorrow’s enterprise AI advantage will hinge not on who owns the largest model, but on who can feed that model the highest-quality, most real-time, and most relevant context. An Agentic Context Engine is the critical infrastructure that turns this vision into reality.
|
||||
|
||||
In the paradigm shift from “hand-crafted prompts” to “intelligent context,” RAGFlow is determined to be the most steadfast propeller and enabler. We invite every developer, enterprise, and researcher who cares about the future of AI agents to follow RAGFlow’s journey—so together we can witness and build the cornerstone of the next-generation AI stack.
|
||||
107
docs/basics/rag.md
Normal file
107
docs/basics/rag.md
Normal file
@ -0,0 +1,107 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
slug: /what_is_rag
|
||||
---
|
||||
|
||||
# What is Retreival-Augmented-Generation (RAG)?
|
||||
|
||||
Since large language models (LLMs) became the focus of technology, their ability to handle general knowledge has been astonishing. However, when questions shift to internal corporate documents, proprietary knowledge bases, or real-time data, the limitations of LLMs become glaringly apparent: they cannot access private information outside their training data. Retrieval-Augmented Generation (RAG) was born precisely to address this core need. Before an LLM generates an answer, it first retrieves the most relevant context from an external knowledge base and inputs it as "reference material" to the LLM, thereby guiding it to produce accurate answers. In short, RAG elevates LLMs from "relying on memory" to "having evidence to rely on," significantly improving their accuracy and trustworthiness in specialized fields and real-time information queries.
|
||||
|
||||
## Why RAG is important?
|
||||
|
||||
Although LLMs excel in language understanding and generation, they have inherent limitations:
|
||||
|
||||
- Static Knowledge: The model's knowledge is based on a data snapshot from its training time and cannot be automatically updated, making it difficult to perceive the latest information.
|
||||
- Blind Spot to External Data: They cannot directly access corporate private documents, real-time information streams, or domain-specific content.
|
||||
- Hallucination Risk: When lacking accurate evidence, they may still fabricate plausible-sounding but false answers to maintain conversational fluency.
|
||||
|
||||
The introduction of RAG provides LLMs with real-time, credible "factual grounding." Its core mechanism is divided into two stages:
|
||||
|
||||
- Retrieval Stage: Based on the user's question, quickly retrieve the most relevant documents or data fragments from an external knowledge base.
|
||||
- Generation Stage: The LLM organizes and generates the final answer by incorporating the retrieved information as context, combined with its own linguistic capabilities.
|
||||
|
||||
This upgrades LLMs from "speaking from memory" to "speaking with documentation," significantly enhancing reliability in professional and enterprise-level applications.
|
||||
|
||||
## How RAG works?
|
||||
|
||||
Retrieval-Augmented Generation enables LLMs to generate higher-quality responses by leveraging real-time, external, or private data sources through the introduction of an information retrieval mechanism. Its workflow can be divided into following key steps:
|
||||
|
||||
### Data processing and vectorization
|
||||
|
||||
The knowledge required by RAG comes from unstructured data in various formats, such as documents, database records, or API return content. This data typically needs to be chunked, then transformed into vectors via an embedding model, and stored in a vector database.
|
||||
|
||||
Why is Chunking Needed? Indexing entire documents directly faces the following problems:
|
||||
|
||||
- Decreased Retrieval Precision: Vectorizing long documents leads to semantic "averaging," losing details.
|
||||
- Context Length Limitation: LLMs have a finite context window, requiring filtering of the most relevant parts for input.
|
||||
- Cost and Efficiency: Embedding computation and retrieval costs are higher for long texts.
|
||||
|
||||
Therefore, an intelligent chunking strategy is key to balancing information integrity, retrieval granularity, and computational efficiency.
|
||||
|
||||
### Retrieve relevant information
|
||||
|
||||
The user's query is also converted into a vector to perform semantic relevance searches (e.g., calculating cosine similarity) in the vector database, matching and recalling the most relevant text fragments.
|
||||
|
||||
### Context construction and answer generation
|
||||
|
||||
The retrieved relevant content is added to the LLM's context as factual grounding, and the LLM finally generates the answer. Therefore, RAG can be seen as Context Engineering 1.0 for automated context construction.
|
||||
|
||||
## Deep dive into existing RAG architecture: beyond vector retrieval
|
||||
|
||||
An industrial-grade RAG system is far from being as simple as "vector search + LLM"; its complexity and challenges are primarily embedded in the retrieval process.
|
||||
|
||||
### Data complexity: multimodal document processing
|
||||
|
||||
Core Challenge: Corporate knowledge mostly exists in the form of multimodal documents containing text, charts, tables, and formulas. Simple OCR extraction loses a large amount of semantic information.
|
||||
|
||||
Advanced Practice: Leading solutions, such as RAGFlow, tend to use Visual Language Models (VLM) or specialized parsing models like DeepDoc to "translate" multimodal documents into unimodal text rich in structural and semantic information. Converting multimodal information into high-quality unimodal text has become standard practice for advanced RAG.
|
||||
|
||||
### The complexity of chunking: the trade-off between precision and context
|
||||
|
||||
A simple "chunk-embed-retrieve" pipeline has an inherent contradiction:
|
||||
- Semantic Matching requires small text chunks to ensure clear semantic focus.
|
||||
- Context Understanding requires large text chunks to ensure complete and coherent information.
|
||||
|
||||
This forces system design into a difficult trade-off between "precise but fragmented" and "complete but vague."
|
||||
|
||||
Advanced Practice: Leading solutions, such as RAGFlow, employ semantic enhancement techniques like constructing semantic tables of contents and knowledge graphs. These not only address semantic fragmentation caused by physical chunking but also enable the discovery of relevant content across documents based on entity-relationship networks.
|
||||
|
||||
### Why is a vector database insufficient for serving RAG?
|
||||
|
||||
Vector databases excel at semantic similarity search, but RAG requires precise and reliable answers, demanding more capabilities from the retrieval system:
|
||||
- Hybrid Search: Relying solely on vector retrieval may miss exact keyword matches (e.g., product codes, regulation numbers). Hybrid search, combining vector retrieval with keyword retrieval (BM25), ensures both semantic breadth and keyword precision.
|
||||
- Tensor or Multi-Vector Representation: To support cross-modal data, employing tensor or multi-vector representation has become an important trend.
|
||||
- Metadata Filtering: Filtering based on attributes like date, department, and type is a rigid requirement in business scenarios.
|
||||
|
||||
Therefore, the retrieval layer of RAG is a composite system based on vector search but must integrate capabilities like full-text search, re-ranking, and metadata filtering.
|
||||
|
||||
## RAG and memory: Retrieval from the same source but different streams
|
||||
|
||||
Within the agent framework, the essence of the memory mechanism is the same as RAG: both retrieve relevant information from storage based on current needs. The key difference lies in the data source:
|
||||
- RAG: Targets pre-existing static or dynamic private data provided by the user in advance (e.g., documents, databases).
|
||||
- Memory: Targets dynamic data generated or perceived by the agent in real-time during interaction (e.g., conversation history, environmental state, tool execution results).
|
||||
They are highly consistent at the technical base (e.g., vector retrieval, keyword matching) and can be seen as the same retrieval capability applied in different scenarios ("existing knowledge" vs. "interaction memory"). A complete agent system often includes both an RAG module for inherent knowledge and a Memory module for interaction history.
|
||||
|
||||
## RAG applications
|
||||
|
||||
RAG has demonstrated clear value in several typical scenarios:
|
||||
|
||||
1. Enterprise Knowledge Q&A and Internal Search
|
||||
By vectorizing corporate private data and combining it with an LLM, RAG can directly return natural language answers based on authoritative sources, rather than document lists. While meeting intelligent Q&A needs, it inherently aligns with corporate requirements for data security, access control, and compliance.
|
||||
2. Complex Document Understanding and Professional Q&A
|
||||
For structurally complex documents like contracts and regulations, the value of RAG lies in its ability to generate accurate, verifiable answers while maintaining context integrity. Its system accuracy largely depends on text chunking and semantic understanding strategies.
|
||||
3. Dynamic Knowledge Fusion and Decision Support
|
||||
In business scenarios requiring the synthesis of information from multiple sources, RAG evolves into a knowledge orchestration and reasoning support system for business decisions. Through a multi-path recall mechanism, it fuses knowledge from different systems and formats, maintaining factual consistency and logical controllability during the generation phase.
|
||||
|
||||
## The future of RAG
|
||||
|
||||
The evolution of RAG is unfolding along several clear paths:
|
||||
|
||||
1. RAG as the data foundation for Agents
|
||||
RAG and agents have an architecture vs. scenario relationship. For agents to achieve autonomous and reliable decision-making and execution, they must rely on accurate and timely knowledge. RAG provides them with a standardized capability to access private domain knowledge and is an inevitable choice for building knowledge-aware agents.
|
||||
2. Advanced RAG: Using LLMs to optimize retrieval itself
|
||||
The core feature of next-generation RAG is fully utilizing the reasoning capabilities of LLMs to optimize the retrieval process, such as rewriting queries, summarizing or fusing results, or implementing intelligent routing. Empowering every aspect of retrieval with LLMs is key to breaking through current performance bottlenecks.
|
||||
3. Towards context engineering 2.0
|
||||
Current RAG can be viewed as Context Engineering 1.0, whose core is assembling static knowledge context for single Q&A tasks. The forthcoming Context Engineering 2.0 will extend with RAG technology at its core, becoming a system that automatically and dynamically assembles comprehensive context for agents. The context fused by this system will come not only from documents but also include interaction memory, available tools/skills, and real-time environmental information. This marks the transition of agent development from a "handicraft workshop" model to the industrial starting point of automated context engineering.
|
||||
|
||||
The essence of RAG is to build a dedicated, efficient, and trustworthy external data interface for large language models; its core is Retrieval, not Generation. Starting from the practical need to solve private data access, its technical depth is reflected in the optimization of retrieval for complex unstructured data. With its deep integration into agent architectures and its development towards automated context engineering, RAG is evolving from a technology that improves Q&A quality into the core infrastructure for building the next generation of trustworthy, controllable, and scalable intelligent applications.
|
||||
@ -34,7 +34,7 @@ Enabling TOC extraction requires significant memory, computational resources, an
|
||||
|
||||
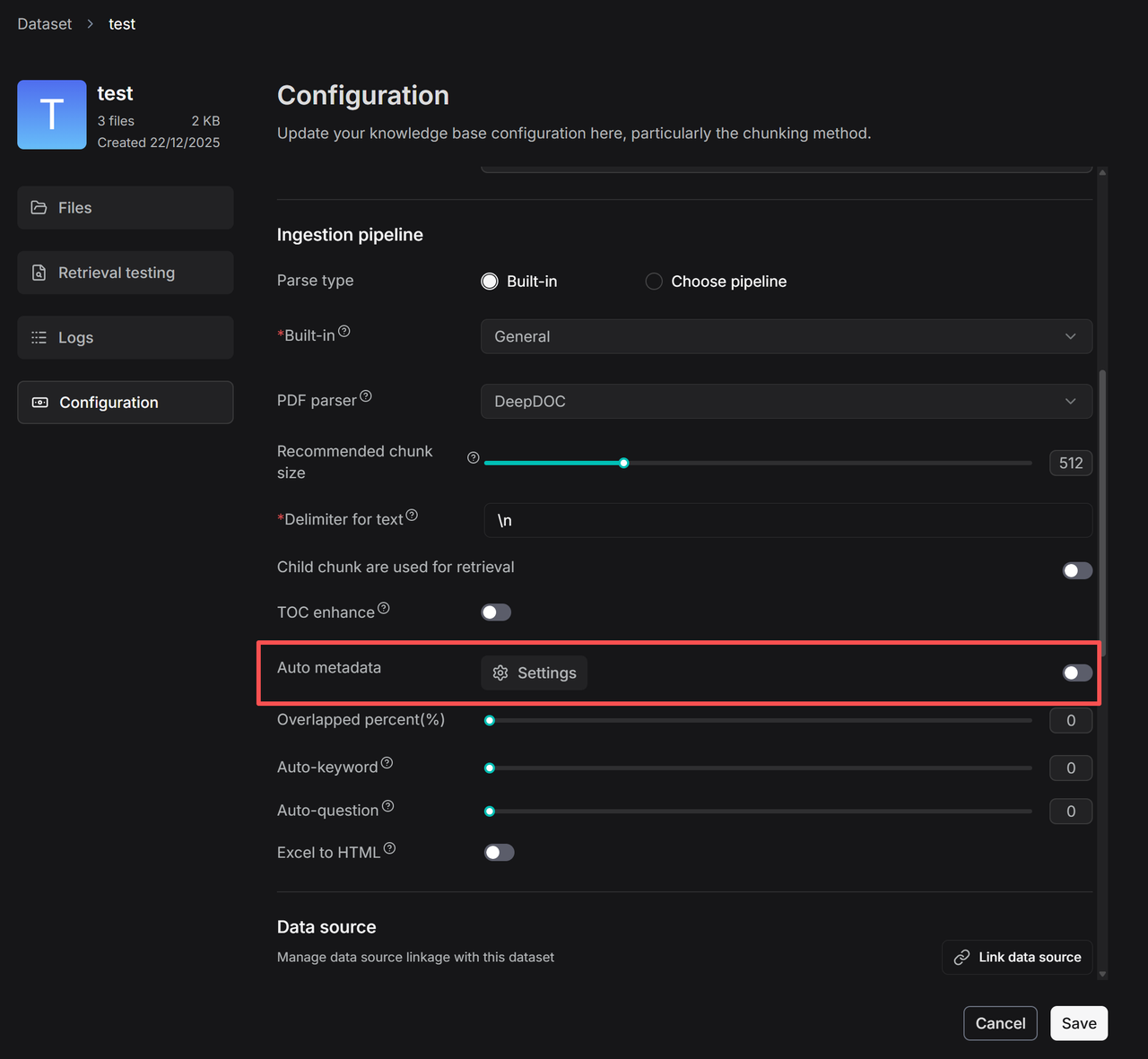
|
||||
|
||||
3. Click **+** to add new fields and enter the congiruation page.
|
||||
3. Click **+** to add new fields and enter the configuration page.
|
||||
|
||||
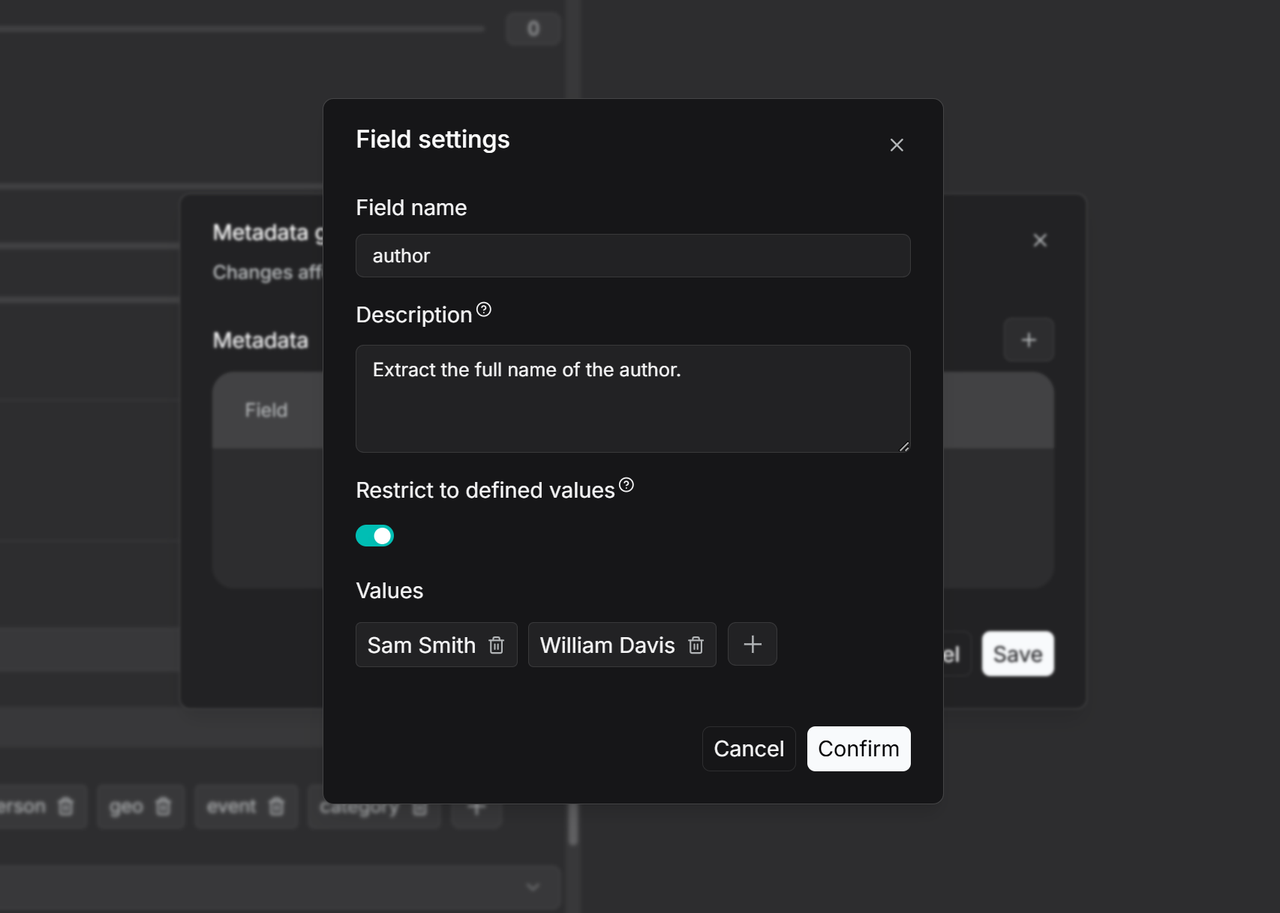
|
||||
|
||||
|
||||
@ -340,13 +340,13 @@ Application startup complete.
|
||||
|
||||
setting->model providers->search->vllm->add ,configure as follow:
|
||||
|
||||

|
||||
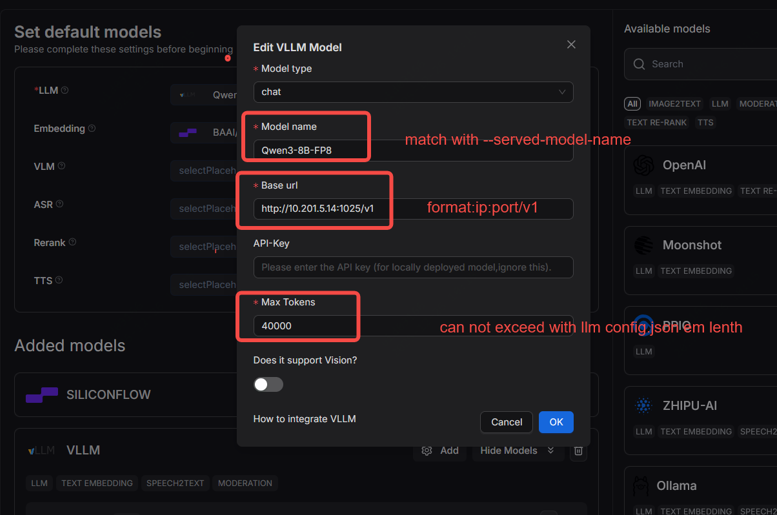
|
||||
|
||||
select vllm chat model as default llm model as follow:
|
||||

|
||||
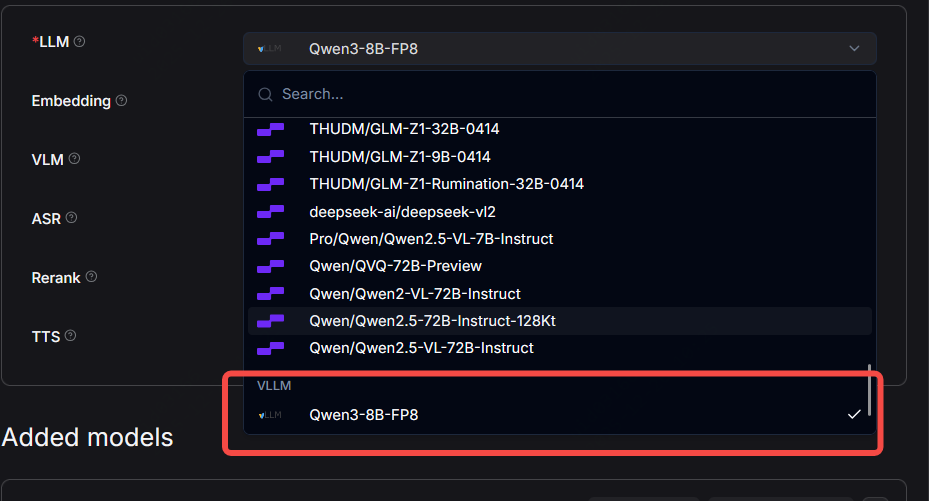
|
||||
### 5.3 chat with vllm chat model
|
||||
create chat->create conversations-chat as follow:
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -1603,7 +1603,7 @@ In streaming mode, not all responses include a reference, as this depends on the
|
||||
|
||||
##### question: `str`
|
||||
|
||||
The question to start an AI-powered conversation. Ifthe **Begin** component takes parameters, a question is not required.
|
||||
The question to start an AI-powered conversation. If the **Begin** component takes parameters, a question is not required.
|
||||
|
||||
##### stream: `bool`
|
||||
|
||||
|
||||
@ -13,61 +13,58 @@ A complete list of models supported by RAGFlow, which will continue to expand.
|
||||
<APITable>
|
||||
```
|
||||
|
||||
| Provider | Chat | Embedding | Rerank | Img2txt | Speech2txt | TTS |
|
||||
| --------------------- | ------------------ | ------------------ | ------------------ | ------------------ | ------------------ | ------------------ |
|
||||
| Anthropic | :heavy_check_mark: | | | | | |
|
||||
| Azure-OpenAI | :heavy_check_mark: | :heavy_check_mark: | | :heavy_check_mark: | :heavy_check_mark: | |
|
||||
| BAAI | | :heavy_check_mark: | :heavy_check_mark: | | | |
|
||||
| BaiChuan | :heavy_check_mark: | :heavy_check_mark: | | | | |
|
||||
| BaiduYiyan | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | | |
|
||||
| Bedrock | :heavy_check_mark: | :heavy_check_mark: | | | | |
|
||||
| Cohere | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | | |
|
||||
| DeepSeek | :heavy_check_mark: | | | | | |
|
||||
| FastEmbed | | :heavy_check_mark: | | | | |
|
||||
| Fish Audio | | | | | | :heavy_check_mark: |
|
||||
| Gemini | :heavy_check_mark: | :heavy_check_mark: | | :heavy_check_mark: | | |
|
||||
| Google Cloud | :heavy_check_mark: | | | | | |
|
||||
| GPUStack | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | | :heavy_check_mark: | :heavy_check_mark: |
|
||||
| Groq | :heavy_check_mark: | | | | | |
|
||||
| HuggingFace | :heavy_check_mark: | :heavy_check_mark: | | | | |
|
||||
| Jina | | :heavy_check_mark: | :heavy_check_mark: | | | |
|
||||
| LeptonAI | :heavy_check_mark: | | | | | |
|
||||
| LocalAI | :heavy_check_mark: | :heavy_check_mark: | | :heavy_check_mark: | | |
|
||||
| LM-Studio | :heavy_check_mark: | :heavy_check_mark: | | :heavy_check_mark: | | |
|
||||
| MiniMax | :heavy_check_mark: | | | | | |
|
||||
| Mistral | :heavy_check_mark: | :heavy_check_mark: | | | | |
|
||||
| ModelScope | :heavy_check_mark: | | | | | |
|
||||
| Moonshot | :heavy_check_mark: | | | :heavy_check_mark: | | |
|
||||
| Novita AI | :heavy_check_mark: | :heavy_check_mark: | | | | |
|
||||
| NVIDIA | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | | |
|
||||
| Ollama | :heavy_check_mark: | :heavy_check_mark: | | :heavy_check_mark: | | |
|
||||
| OpenAI | :heavy_check_mark: | :heavy_check_mark: | | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: |
|
||||
| OpenAI-API-Compatible | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | | |
|
||||
| OpenRouter | :heavy_check_mark: | | | :heavy_check_mark: | | |
|
||||
| PerfXCloud | :heavy_check_mark: | :heavy_check_mark: | | | | |
|
||||
| Replicate | :heavy_check_mark: | :heavy_check_mark: | | | | |
|
||||
| PPIO | :heavy_check_mark: | | | | | |
|
||||
| SILICONFLOW | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | | |
|
||||
| StepFun | :heavy_check_mark: | | | | | |
|
||||
| Tencent Hunyuan | :heavy_check_mark: | | | | | |
|
||||
| Tencent Cloud | | | | | :heavy_check_mark: | |
|
||||
| TogetherAI | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | | |
|
||||
| Tongyi-Qianwen | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: |
|
||||
| Upstage | :heavy_check_mark: | :heavy_check_mark: | | | | |
|
||||
| VLLM | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | | |
|
||||
| VolcEngine | :heavy_check_mark: | | | | | |
|
||||
| Voyage AI | | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | | |
|
||||
| Xinference | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: |
|
||||
| XunFei Spark | :heavy_check_mark: | | | | | :heavy_check_mark: |
|
||||
| xAI | :heavy_check_mark: | | | :heavy_check_mark: | | |
|
||||
| Youdao | | :heavy_check_mark: | :heavy_check_mark: | | | |
|
||||
| ZHIPU-AI | :heavy_check_mark: | :heavy_check_mark: | | :heavy_check_mark: | | |
|
||||
| 01.AI | :heavy_check_mark: | | | | | |
|
||||
| DeepInfra | :heavy_check_mark: | :heavy_check_mark: | | | :heavy_check_mark: | :heavy_check_mark: |
|
||||
| 302.AI | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | | |
|
||||
| CometAPI | :heavy_check_mark: | :heavy_check_mark: | | | | |
|
||||
| DeerAPI | :heavy_check_mark: | :heavy_check_mark: | | :heavy_check_mark: | | :heavy_check_mark: |
|
||||
| Jiekou.AI | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | | | |
|
||||
| Provider | LLM | Image2Text | Speech2text | TTS | Embedding | Rerank | OCR |
|
||||
| --------------------- | ------------------ | ------------------ | ------------------ | ------------------ | ------------------ | ------------------ | ------------------ |
|
||||
| Anthropic | :heavy_check_mark: | | | | | | |
|
||||
| Azure-OpenAI | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | | :heavy_check_mark: | | |
|
||||
| BaiChuan | :heavy_check_mark: | | | | :heavy_check_mark: | | |
|
||||
| BaiduYiyan | :heavy_check_mark: | :heavy_check_mark: | | | :heavy_check_mark: | :heavy_check_mark: | |
|
||||
| Bedrock | :heavy_check_mark: | | | | :heavy_check_mark: | | |
|
||||
| Cohere | :heavy_check_mark: | :heavy_check_mark: | | | :heavy_check_mark: | :heavy_check_mark: | |
|
||||
| DeepSeek | :heavy_check_mark: | | | | | | |
|
||||
| Fish Audio | | | | :heavy_check_mark: | | | |
|
||||
| Gemini | :heavy_check_mark: | :heavy_check_mark: | | | :heavy_check_mark: | | |
|
||||
| Google Cloud | :heavy_check_mark: | | | | | | |
|
||||
| GPUStack | :heavy_check_mark: | | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | |
|
||||
| Groq | :heavy_check_mark: | | | | | | |
|
||||
| HuggingFace | :heavy_check_mark: | | | | :heavy_check_mark: | | |
|
||||
| Jina | | | | | :heavy_check_mark: | :heavy_check_mark: | |
|
||||
| LocalAI | :heavy_check_mark: | :heavy_check_mark: | | | :heavy_check_mark: | | |
|
||||
| LongCat | :heavy_check_mark: | | | | | | |
|
||||
| LM-Studio | :heavy_check_mark: | :heavy_check_mark: | | | :heavy_check_mark: | | |
|
||||
| MiniMax | :heavy_check_mark: | | | | | | |
|
||||
| MinerU | | | | | | | :heavy_check_mark: |
|
||||
| Mistral | :heavy_check_mark: | | | | :heavy_check_mark: | | |
|
||||
| ModelScope | :heavy_check_mark: | | | | | | |
|
||||
| Moonshot | :heavy_check_mark: | :heavy_check_mark: | | | | | |
|
||||
| NovitaAI | :heavy_check_mark: | | | | :heavy_check_mark: | | |
|
||||
| NVIDIA | :heavy_check_mark: | :heavy_check_mark: | | | :heavy_check_mark: | :heavy_check_mark: | |
|
||||
| Ollama | :heavy_check_mark: | :heavy_check_mark: | | | :heavy_check_mark: | | |
|
||||
| OpenAI | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | | |
|
||||
| OpenAI-API-Compatible | :heavy_check_mark: | :heavy_check_mark: | | | :heavy_check_mark: | :heavy_check_mark: | |
|
||||
| OpenRouter | :heavy_check_mark: | :heavy_check_mark: | | | | | |
|
||||
| Replicate | :heavy_check_mark: | | | | :heavy_check_mark: | | |
|
||||
| PPIO | :heavy_check_mark: | | | | | | |
|
||||
| SILICONFLOW | :heavy_check_mark: | :heavy_check_mark: | | | :heavy_check_mark: | :heavy_check_mark: | |
|
||||
| StepFun | :heavy_check_mark: | | | | | | |
|
||||
| Tencent Hunyuan | :heavy_check_mark: | | | | | | |
|
||||
| Tencent Cloud | | | :heavy_check_mark: | | | | |
|
||||
| TogetherAI | :heavy_check_mark: | :heavy_check_mark: | | | :heavy_check_mark: | :heavy_check_mark: | |
|
||||
| TokenPony | :heavy_check_mark: | | | | | | |
|
||||
| Tongyi-Qianwen | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | |
|
||||
| Upstage | :heavy_check_mark: | | | | :heavy_check_mark: | | |
|
||||
| VLLM | :heavy_check_mark: | :heavy_check_mark: | | | :heavy_check_mark: | :heavy_check_mark: | |
|
||||
| VolcEngine | :heavy_check_mark: | | | | | | |
|
||||
| Voyage AI | | :heavy_check_mark: | | | :heavy_check_mark: | :heavy_check_mark: | |
|
||||
| Xinference | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | |
|
||||
| XunFei Spark | :heavy_check_mark: | | | :heavy_check_mark: | | | |
|
||||
| xAI | :heavy_check_mark: | :heavy_check_mark: | | | | | |
|
||||
| ZHIPU-AI | :heavy_check_mark: | :heavy_check_mark: | | | :heavy_check_mark: | | |
|
||||
| DeepInfra | :heavy_check_mark: | | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | | |
|
||||
| 302.AI | :heavy_check_mark: | :heavy_check_mark: | | | :heavy_check_mark: | :heavy_check_mark: | |
|
||||
| CometAPI | :heavy_check_mark: | | | | :heavy_check_mark: | | |
|
||||
| DeerAPI | :heavy_check_mark: | :heavy_check_mark: | | :heavy_check_mark: | :heavy_check_mark: | | |
|
||||
| Jiekou.AI | :heavy_check_mark: | | | | :heavy_check_mark: | :heavy_check_mark: | |
|
||||
|
||||
```mdx-code-block
|
||||
</APITable>
|
||||
|
||||
@ -9,7 +9,7 @@ Key features, improvements and bug fixes in the latest releases.
|
||||
|
||||
## v0.23.0
|
||||
|
||||
Released on December 29, 2025.
|
||||
Released on December 27, 2025.
|
||||
|
||||
### New features
|
||||
|
||||
@ -32,7 +32,7 @@ Released on December 29, 2025.
|
||||
|
||||
### Improvements
|
||||
|
||||
- Bumps RAGFlow's document engine, [Infinity](https://github.com/infiniflow/infinity) to v0.6.13 (backward compatible).
|
||||
- Bumps RAGFlow's document engine, [Infinity](https://github.com/infiniflow/infinity) to v0.6.15 (backward compatible).
|
||||
|
||||
### Data sources
|
||||
|
||||
|
||||
133
helm/README.md
Normal file
133
helm/README.md
Normal file
@ -0,0 +1,133 @@
|
||||
# RAGFlow Helm Chart
|
||||
|
||||
A Helm chart to deploy RAGFlow and its dependencies on Kubernetes.
|
||||
|
||||
- Components: RAGFlow (web/api) and optional dependencies (Infinity/Elasticsearch/OpenSearch, MySQL, MinIO, Redis)
|
||||
- Requirements: Kubernetes >= 1.24, Helm >= 3.10
|
||||
|
||||
## Install
|
||||
|
||||
```bash
|
||||
helm upgrade --install ragflow ./ \
|
||||
--namespace ragflow --create-namespace
|
||||
```
|
||||
|
||||
Uninstall:
|
||||
```bash
|
||||
helm uninstall ragflow -n ragflow
|
||||
```
|
||||
|
||||
## Global Settings
|
||||
|
||||
- `global.repo`: Prepend a global image registry prefix for all images.
|
||||
- Behavior: Replaces the registry part and keeps the image path (e.g., `quay.io/minio/minio` -> `registry.example.com/myproj/minio/minio`).
|
||||
- Example: `global.repo: "registry.example.com/myproj"`
|
||||
- `global.imagePullSecrets`: List of image pull secrets applied to all Pods.
|
||||
- Example:
|
||||
```yaml
|
||||
global:
|
||||
imagePullSecrets:
|
||||
- name: regcred
|
||||
```
|
||||
|
||||
## External Services (MySQL / MinIO / Redis)
|
||||
|
||||
The chart can deploy in-cluster services or connect to external ones. Toggle with `*.enabled`. When disabled, provide host/port via `env.*`.
|
||||
|
||||
- MySQL
|
||||
- `mysql.enabled`: default `true`
|
||||
- If `false`, set:
|
||||
- `env.MYSQL_HOST` (required), `env.MYSQL_PORT` (default `3306`)
|
||||
- `env.MYSQL_DBNAME` (default `rag_flow`), `env.MYSQL_PASSWORD` (required)
|
||||
- `env.MYSQL_USER` (default `root` if omitted)
|
||||
- MinIO
|
||||
- `minio.enabled`: default `true`
|
||||
- Configure:
|
||||
- `env.MINIO_HOST` (optional external host), `env.MINIO_PORT` (default `9000`)
|
||||
- `env.MINIO_ROOT_USER` (default `rag_flow`), `env.MINIO_PASSWORD` (optional)
|
||||
- Redis (Valkey)
|
||||
- `redis.enabled`: default `true`
|
||||
- If `false`, set:
|
||||
- `env.REDIS_HOST` (required), `env.REDIS_PORT` (default `6379`)
|
||||
- `env.REDIS_PASSWORD` (optional; empty disables auth if server allows)
|
||||
|
||||
Notes:
|
||||
- When `*.enabled=true`, the chart renders in-cluster resources and injects corresponding `*_HOST`/`*_PORT` automatically.
|
||||
- Sensitive variables like `MYSQL_PASSWORD` are required; `MINIO_PASSWORD` and `REDIS_PASSWORD` are optional. All secrets are stored in a Secret.
|
||||
|
||||
### Example: use external MySQL, MinIO, and Redis
|
||||
|
||||
```yaml
|
||||
# values.override.yaml
|
||||
mysql:
|
||||
enabled: false # use external MySQL
|
||||
minio:
|
||||
enabled: false # use external MinIO (S3 compatible)
|
||||
redis:
|
||||
enabled: false # use external Redis/Valkey
|
||||
|
||||
env:
|
||||
# MySQL
|
||||
MYSQL_HOST: mydb.example.com
|
||||
MYSQL_PORT: "3306"
|
||||
MYSQL_USER: root
|
||||
MYSQL_DBNAME: rag_flow
|
||||
MYSQL_PASSWORD: "<your-mysql-password>"
|
||||
|
||||
# MinIO
|
||||
MINIO_HOST: s3.example.com
|
||||
MINIO_PORT: "9000"
|
||||
MINIO_ROOT_USER: rag_flow
|
||||
MINIO_PASSWORD: "<your-minio-secret>"
|
||||
|
||||
# Redis
|
||||
REDIS_HOST: redis.example.com
|
||||
REDIS_PORT: "6379"
|
||||
REDIS_PASSWORD: "<your-redis-pass>"
|
||||
```
|
||||
|
||||
Apply:
|
||||
```bash
|
||||
helm upgrade --install ragflow ./helm -n ragflow -f values.override.yaml
|
||||
```
|
||||
|
||||
## Document Engine Selection
|
||||
|
||||
Choose one of `infinity` (default), `elasticsearch`, or `opensearch` via `env.DOC_ENGINE`. The chart renders only the selected engine and sets the appropriate host variables.
|
||||
|
||||
```yaml
|
||||
env:
|
||||
DOC_ENGINE: infinity # or: elasticsearch | opensearch
|
||||
# For elasticsearch
|
||||
ELASTIC_PASSWORD: "<es-pass>"
|
||||
# For opensearch
|
||||
OPENSEARCH_PASSWORD: "<os-pass>"
|
||||
```
|
||||
|
||||
## Ingress
|
||||
|
||||
Expose the web UI via Ingress:
|
||||
|
||||
```yaml
|
||||
ingress:
|
||||
enabled: true
|
||||
className: nginx
|
||||
hosts:
|
||||
- host: ragflow.example.com
|
||||
paths:
|
||||
- path: /
|
||||
pathType: Prefix
|
||||
```
|
||||
|
||||
## Validate the Chart
|
||||
|
||||
```bash
|
||||
helm lint ./helm
|
||||
helm template ragflow ./helm > rendered.yaml
|
||||
```
|
||||
|
||||
## Notes
|
||||
|
||||
- By default, the chart uses `DOC_ENGINE: infinity` and deploys in-cluster MySQL, MinIO, and Redis.
|
||||
- The chart injects derived `*_HOST`/`*_PORT` and required secrets into a single Secret (`<release>-ragflow-env-config`).
|
||||
- `global.repo` and `global.imagePullSecrets` apply to all Pods; per-component `*.image.pullSecrets` still work and are merged with global settings.
|
||||
@ -42,6 +42,31 @@ app.kubernetes.io/version: {{ .Chart.AppVersion | quote }}
|
||||
app.kubernetes.io/managed-by: {{ .Release.Service }}
|
||||
{{- end }}
|
||||
|
||||
{{/*
|
||||
Resolve image repository with optional global repo prefix.
|
||||
If .Values.global.repo is set, replace registry part and keep image path.
|
||||
Detect existing registry by first segment containing '.' or ':' or being 'localhost'.
|
||||
Usage: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.foo.image.repository) }}
|
||||
*/}}
|
||||
{{- define "ragflow.imageRepo" -}}
|
||||
{{- $root := .root -}}
|
||||
{{- $repo := .repo -}}
|
||||
{{- $global := $root.Values.global -}}
|
||||
{{- if and $global $global.repo }}
|
||||
{{- $parts := splitList "/" $repo -}}
|
||||
{{- $first := index $parts 0 -}}
|
||||
{{- $hasRegistry := or (regexMatch "\\." $first) (regexMatch ":" $first) (eq $first "localhost") -}}
|
||||
{{- if $hasRegistry -}}
|
||||
{{- $path := join "/" (rest $parts) -}}
|
||||
{{- printf "%s/%s" $global.repo $path -}}
|
||||
{{- else -}}
|
||||
{{- printf "%s/%s" $global.repo $repo -}}
|
||||
{{- end -}}
|
||||
{{- else -}}
|
||||
{{- $repo -}}
|
||||
{{- end -}}
|
||||
{{- end }}
|
||||
|
||||
{{/*
|
||||
Selector labels
|
||||
*/}}
|
||||
|
||||
@ -32,7 +32,7 @@ spec:
|
||||
{{- include "ragflow.selectorLabels" . | nindent 6 }}
|
||||
app.kubernetes.io/component: elasticsearch
|
||||
{{- with .Values.elasticsearch.deployment.strategy }}
|
||||
strategy:
|
||||
updateStrategy:
|
||||
{{- . | toYaml | nindent 4 }}
|
||||
{{- end }}
|
||||
template:
|
||||
@ -44,9 +44,9 @@ spec:
|
||||
checksum/config-es: {{ include (print $.Template.BasePath "/elasticsearch-config.yaml") . | sha256sum }}
|
||||
checksum/config-env: {{ include (print $.Template.BasePath "/env.yaml") . | sha256sum }}
|
||||
spec:
|
||||
{{- if or .Values.imagePullSecrets .Values.elasticsearch.image.pullSecrets }}
|
||||
{{- if or .Values.global.imagePullSecrets .Values.elasticsearch.image.pullSecrets }}
|
||||
imagePullSecrets:
|
||||
{{- with .Values.imagePullSecrets }}
|
||||
{{- with .Values.global.imagePullSecrets }}
|
||||
{{- toYaml . | nindent 8 }}
|
||||
{{- end }}
|
||||
{{- with .Values.elasticsearch.image.pullSecrets }}
|
||||
@ -55,7 +55,7 @@ spec:
|
||||
{{- end }}
|
||||
initContainers:
|
||||
- name: fix-data-volume-permissions
|
||||
image: {{ .Values.elasticsearch.initContainers.alpine.repository }}:{{ .Values.elasticsearch.initContainers.alpine.tag }}
|
||||
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.elasticsearch.initContainers.alpine.repository) }}:{{ .Values.elasticsearch.initContainers.alpine.tag }}
|
||||
{{- with .Values.elasticsearch.initContainers.alpine.pullPolicy }}
|
||||
imagePullPolicy: {{ . }}
|
||||
{{- end }}
|
||||
@ -67,7 +67,7 @@ spec:
|
||||
- mountPath: /usr/share/elasticsearch/data
|
||||
name: es-data
|
||||
- name: sysctl
|
||||
image: {{ .Values.elasticsearch.initContainers.busybox.repository }}:{{ .Values.elasticsearch.initContainers.busybox.tag }}
|
||||
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.elasticsearch.initContainers.busybox.repository) }}:{{ .Values.elasticsearch.initContainers.busybox.tag }}
|
||||
{{- with .Values.elasticsearch.initContainers.busybox.pullPolicy }}
|
||||
imagePullPolicy: {{ . }}
|
||||
{{- end }}
|
||||
@ -77,7 +77,7 @@ spec:
|
||||
command: ["sysctl", "-w", "vm.max_map_count=262144"]
|
||||
containers:
|
||||
- name: elasticsearch
|
||||
image: {{ .Values.elasticsearch.image.repository }}:{{ .Values.elasticsearch.image.tag }}
|
||||
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.elasticsearch.image.repository) }}:{{ .Values.elasticsearch.image.tag }}
|
||||
{{- with .Values.elasticsearch.image.pullPolicy }}
|
||||
imagePullPolicy: {{ . }}
|
||||
{{- end }}
|
||||
|
||||
@ -9,20 +9,39 @@ metadata:
|
||||
type: Opaque
|
||||
stringData:
|
||||
{{- range $key, $val := .Values.env }}
|
||||
{{- if $val }}
|
||||
{{- if and $val (ne $key "MYSQL_HOST") (ne $key "MYSQL_PORT") (ne $key "MYSQL_USER") (ne $key "MINIO_HOST") (ne $key "MINIO_PORT") (ne $key "REDIS_HOST") (ne $key "REDIS_PORT") }}
|
||||
{{ $key }}: {{ quote $val }}
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
{{- /*
|
||||
Use host names derived from internal cluster DNS
|
||||
*/}}
|
||||
{{- if .Values.redis.enabled }}
|
||||
REDIS_HOST: {{ printf "%s-redis.%s.svc" (include "ragflow.fullname" .) .Release.Namespace }}
|
||||
REDIS_PORT: "6379"
|
||||
{{- else }}
|
||||
REDIS_HOST: {{ required "env.REDIS_HOST is required when redis.enabled=false" .Values.env.REDIS_HOST | quote }}
|
||||
REDIS_PORT: {{ default "6379" .Values.env.REDIS_PORT | quote }}
|
||||
{{- end }}
|
||||
{{- if .Values.mysql.enabled }}
|
||||
MYSQL_HOST: {{ printf "%s-mysql.%s.svc" (include "ragflow.fullname" .) .Release.Namespace }}
|
||||
MYSQL_PORT: "3306"
|
||||
{{- else }}
|
||||
MYSQL_HOST: {{ required "env.MYSQL_HOST is required when mysql.enabled=false" .Values.env.MYSQL_HOST | quote }}
|
||||
MYSQL_PORT: {{ default "3306" .Values.env.MYSQL_PORT | quote }}
|
||||
MYSQL_USER: {{ default "root" .Values.env.MYSQL_USER | quote }}
|
||||
{{- end }}
|
||||
{{- if .Values.minio.enabled }}
|
||||
MINIO_HOST: {{ printf "%s-minio.%s.svc" (include "ragflow.fullname" .) .Release.Namespace }}
|
||||
MINIO_PORT: "9000"
|
||||
{{- else }}
|
||||
MINIO_HOST: {{ default "" .Values.env.MINIO_HOST | quote }}
|
||||
MINIO_PORT: {{ default "9000" .Values.env.MINIO_PORT | quote }}
|
||||
{{- end }}
|
||||
{{- /*
|
||||
Fail if passwords are not provided in release values
|
||||
*/}}
|
||||
REDIS_PASSWORD: {{ .Values.env.REDIS_PASSWORD | required "REDIS_PASSWORD is required" }}
|
||||
REDIS_PASSWORD: {{ default "" .Values.env.REDIS_PASSWORD }}
|
||||
{{- /*
|
||||
NOTE: MySQL uses MYSQL_ROOT_PASSWORD env var but Ragflow container expects
|
||||
MYSQL_PASSWORD so we need to define both as the same value here.
|
||||
@ -31,10 +50,9 @@ stringData:
|
||||
MYSQL_PASSWORD: {{ . }}
|
||||
MYSQL_ROOT_PASSWORD: {{ . }}
|
||||
{{- end }}
|
||||
{{- with .Values.env.MINIO_PASSWORD | required "MINIO_PASSWORD is required" }}
|
||||
MINIO_PASSWORD: {{ . }}
|
||||
MINIO_ROOT_PASSWORD: {{ . }}
|
||||
{{- end }}
|
||||
{{- $minioPass := default "" .Values.env.MINIO_PASSWORD }}
|
||||
MINIO_PASSWORD: {{ $minioPass }}
|
||||
MINIO_ROOT_PASSWORD: {{ $minioPass }}
|
||||
{{- /*
|
||||
Only provide env vars for enabled doc engine
|
||||
*/}}
|
||||
|
||||
@ -32,7 +32,7 @@ spec:
|
||||
{{- include "ragflow.selectorLabels" . | nindent 6 }}
|
||||
app.kubernetes.io/component: infinity
|
||||
{{- with .Values.infinity.deployment.strategy }}
|
||||
strategy:
|
||||
updateStrategy:
|
||||
{{- . | toYaml | nindent 4 }}
|
||||
{{- end }}
|
||||
template:
|
||||
@ -43,9 +43,9 @@ spec:
|
||||
annotations:
|
||||
checksum/config: {{ include (print $.Template.BasePath "/env.yaml") . | sha256sum }}
|
||||
spec:
|
||||
{{- if or .Values.imagePullSecrets .Values.infinity.image.pullSecrets }}
|
||||
{{- if or .Values.global.imagePullSecrets .Values.infinity.image.pullSecrets }}
|
||||
imagePullSecrets:
|
||||
{{- with .Values.imagePullSecrets }}
|
||||
{{- with .Values.global.imagePullSecrets }}
|
||||
{{- toYaml . | nindent 8 }}
|
||||
{{- end }}
|
||||
{{- with .Values.infinity.image.pullSecrets }}
|
||||
@ -54,7 +54,7 @@ spec:
|
||||
{{- end }}
|
||||
containers:
|
||||
- name: infinity
|
||||
image: {{ .Values.infinity.image.repository }}:{{ .Values.infinity.image.tag }}
|
||||
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.infinity.image.repository) }}:{{ .Values.infinity.image.tag }}
|
||||
{{- with .Values.infinity.image.pullPolicy }}
|
||||
imagePullPolicy: {{ . }}
|
||||
{{- end }}
|
||||
|
||||
@ -35,7 +35,7 @@ spec:
|
||||
{{- end }}
|
||||
backend:
|
||||
service:
|
||||
name: {{ $.Release.Name }}
|
||||
name: {{ include "ragflow.fullname" $ }}
|
||||
port:
|
||||
name: http
|
||||
{{- end }}
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
{{- if .Values.minio.enabled }}
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: PersistentVolumeClaim
|
||||
@ -43,9 +44,9 @@ spec:
|
||||
{{- include "ragflow.labels" . | nindent 8 }}
|
||||
app.kubernetes.io/component: minio
|
||||
spec:
|
||||
{{- if or .Values.imagePullSecrets .Values.minio.image.pullSecrets }}
|
||||
{{- if or .Values.global.imagePullSecrets .Values.minio.image.pullSecrets }}
|
||||
imagePullSecrets:
|
||||
{{- with .Values.imagePullSecrets }}
|
||||
{{- with .Values.global.imagePullSecrets }}
|
||||
{{- toYaml . | nindent 8 }}
|
||||
{{- end }}
|
||||
{{- with .Values.minio.image.pullSecrets }}
|
||||
@ -54,7 +55,7 @@ spec:
|
||||
{{- end }}
|
||||
containers:
|
||||
- name: minio
|
||||
image: {{ .Values.minio.image.repository }}:{{ .Values.minio.image.tag }}
|
||||
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.minio.image.repository) }}:{{ .Values.minio.image.tag }}
|
||||
{{- with .Values.minio.image.pullPolicy }}
|
||||
imagePullPolicy: {{ . }}
|
||||
{{- end }}
|
||||
@ -103,3 +104,4 @@ spec:
|
||||
port: 9001
|
||||
targetPort: console
|
||||
type: {{ .Values.minio.service.type }}
|
||||
{{- end }}
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
{{- if .Values.mysql.enabled }}
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: ConfigMap
|
||||
@ -7,3 +8,4 @@ data:
|
||||
init.sql: |-
|
||||
CREATE DATABASE IF NOT EXISTS rag_flow;
|
||||
USE rag_flow;
|
||||
{{- end }}
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
{{- if .Values.mysql.enabled }}
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: PersistentVolumeClaim
|
||||
@ -32,7 +33,7 @@ spec:
|
||||
{{- include "ragflow.selectorLabels" . | nindent 6 }}
|
||||
app.kubernetes.io/component: mysql
|
||||
{{- with .Values.mysql.deployment.strategy }}
|
||||
strategy:
|
||||
updateStrategy:
|
||||
{{- . | toYaml | nindent 4 }}
|
||||
{{- end }}
|
||||
template:
|
||||
@ -44,9 +45,9 @@ spec:
|
||||
checksum/config-mysql: {{ include (print $.Template.BasePath "/mysql-config.yaml") . | sha256sum }}
|
||||
checksum/config-env: {{ include (print $.Template.BasePath "/env.yaml") . | sha256sum }}
|
||||
spec:
|
||||
{{- if or .Values.imagePullSecrets .Values.mysql.image.pullSecrets }}
|
||||
{{- if or .Values.global.imagePullSecrets .Values.mysql.image.pullSecrets }}
|
||||
imagePullSecrets:
|
||||
{{- with .Values.imagePullSecrets }}
|
||||
{{- with .Values.global.imagePullSecrets }}
|
||||
{{- toYaml . | nindent 8 }}
|
||||
{{- end }}
|
||||
{{- with .Values.mysql.image.pullSecrets }}
|
||||
@ -55,7 +56,7 @@ spec:
|
||||
{{- end }}
|
||||
containers:
|
||||
- name: mysql
|
||||
image: {{ .Values.mysql.image.repository }}:{{ .Values.mysql.image.tag }}
|
||||
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.mysql.image.repository) }}:{{ .Values.mysql.image.tag }}
|
||||
{{- with .Values.mysql.image.pullPolicy }}
|
||||
imagePullPolicy: {{ . }}
|
||||
{{- end }}
|
||||
@ -108,3 +109,4 @@ spec:
|
||||
port: 3306
|
||||
targetPort: mysql
|
||||
type: {{ .Values.mysql.service.type }}
|
||||
{{- end }}
|
||||
|
||||
@ -32,7 +32,7 @@ spec:
|
||||
{{- include "ragflow.selectorLabels" . | nindent 6 }}
|
||||
app.kubernetes.io/component: opensearch
|
||||
{{- with .Values.opensearch.deployment.strategy }}
|
||||
strategy:
|
||||
updateStrategy:
|
||||
{{- . | toYaml | nindent 4 }}
|
||||
{{- end }}
|
||||
template:
|
||||
@ -44,9 +44,9 @@ spec:
|
||||
checksum/config-opensearch: {{ include (print $.Template.BasePath "/opensearch-config.yaml") . | sha256sum }}
|
||||
checksum/config-env: {{ include (print $.Template.BasePath "/env.yaml") . | sha256sum }}
|
||||
spec:
|
||||
{{- if or .Values.imagePullSecrets .Values.opensearch.image.pullSecrets }}
|
||||
{{- if or .Values.global.imagePullSecrets .Values.opensearch.image.pullSecrets }}
|
||||
imagePullSecrets:
|
||||
{{- with .Values.imagePullSecrets }}
|
||||
{{- with .Values.global.imagePullSecrets }}
|
||||
{{- toYaml . | nindent 8 }}
|
||||
{{- end }}
|
||||
{{- with .Values.opensearch.image.pullSecrets }}
|
||||
@ -55,7 +55,7 @@ spec:
|
||||
{{- end }}
|
||||
initContainers:
|
||||
- name: fix-data-volume-permissions
|
||||
image: {{ .Values.opensearch.initContainers.alpine.repository }}:{{ .Values.opensearch.initContainers.alpine.tag }}
|
||||
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.opensearch.initContainers.alpine.repository) }}:{{ .Values.opensearch.initContainers.alpine.tag }}
|
||||
{{- with .Values.opensearch.initContainers.alpine.pullPolicy }}
|
||||
imagePullPolicy: {{ . }}
|
||||
{{- end }}
|
||||
@ -67,7 +67,7 @@ spec:
|
||||
- mountPath: /usr/share/opensearch/data
|
||||
name: opensearch-data
|
||||
- name: sysctl
|
||||
image: {{ .Values.opensearch.initContainers.busybox.repository }}:{{ .Values.opensearch.initContainers.busybox.tag }}
|
||||
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.opensearch.initContainers.busybox.repository) }}:{{ .Values.opensearch.initContainers.busybox.tag }}
|
||||
{{- with .Values.opensearch.initContainers.busybox.pullPolicy }}
|
||||
imagePullPolicy: {{ . }}
|
||||
{{- end }}
|
||||
@ -77,7 +77,7 @@ spec:
|
||||
command: ["sysctl", "-w", "vm.max_map_count=262144"]
|
||||
containers:
|
||||
- name: opensearch
|
||||
image: {{ .Values.opensearch.image.repository }}:{{ .Values.opensearch.image.tag }}
|
||||
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.opensearch.image.repository) }}:{{ .Values.opensearch.image.tag }}
|
||||
{{- with .Values.opensearch.image.pullPolicy }}
|
||||
imagePullPolicy: {{ . }}
|
||||
{{- end }}
|
||||
|
||||
@ -25,9 +25,9 @@ spec:
|
||||
checksum/config-env: {{ include (print $.Template.BasePath "/env.yaml") . | sha256sum }}
|
||||
checksum/config-ragflow: {{ include (print $.Template.BasePath "/ragflow_config.yaml") . | sha256sum }}
|
||||
spec:
|
||||
{{- if or .Values.imagePullSecrets .Values.ragflow.image.pullSecrets }}
|
||||
{{- if or .Values.global.imagePullSecrets .Values.ragflow.image.pullSecrets }}
|
||||
imagePullSecrets:
|
||||
{{- with .Values.imagePullSecrets }}
|
||||
{{- with .Values.global.imagePullSecrets }}
|
||||
{{- toYaml . | nindent 8 }}
|
||||
{{- end }}
|
||||
{{- with .Values.ragflow.image.pullSecrets }}
|
||||
@ -36,7 +36,7 @@ spec:
|
||||
{{- end }}
|
||||
containers:
|
||||
- name: ragflow
|
||||
image: {{ .Values.ragflow.image.repository }}:{{ .Values.ragflow.image.tag }}
|
||||
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.ragflow.image.repository) }}:{{ .Values.ragflow.image.tag }}
|
||||
{{- with .Values.ragflow.image.pullPolicy }}
|
||||
imagePullPolicy: {{ . }}
|
||||
{{- end }}
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
{{- if .Values.redis.enabled }}
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
@ -40,9 +41,9 @@ spec:
|
||||
annotations:
|
||||
checksum/config-env: {{ include (print $.Template.BasePath "/env.yaml") . | sha256sum }}
|
||||
spec:
|
||||
{{- if or .Values.imagePullSecrets .Values.redis.image.pullSecrets }}
|
||||
{{- if or .Values.global.imagePullSecrets .Values.redis.image.pullSecrets }}
|
||||
imagePullSecrets:
|
||||
{{- with .Values.imagePullSecrets }}
|
||||
{{- with .Values.global.imagePullSecrets }}
|
||||
{{- toYaml . | nindent 8 }}
|
||||
{{- end }}
|
||||
{{- with .Values.redis.image.pullSecrets }}
|
||||
@ -52,7 +53,7 @@ spec:
|
||||
terminationGracePeriodSeconds: 60
|
||||
containers:
|
||||
- name: redis
|
||||
image: {{ .Values.redis.image.repository }}:{{ .Values.redis.image.tag }}
|
||||
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.redis.image.repository) }}:{{ .Values.redis.image.tag }}
|
||||
{{- with .Values.redis.image.pullPolicy }}
|
||||
imagePullPolicy: {{ . }}
|
||||
{{- end }}
|
||||
@ -131,3 +132,4 @@ spec:
|
||||
matchLabels:
|
||||
{{- include "ragflow.selectorLabels" . | nindent 6 }}
|
||||
app.kubernetes.io/component: redis
|
||||
{{- end }}
|
||||
|
||||
@ -9,7 +9,7 @@ metadata:
|
||||
spec:
|
||||
containers:
|
||||
- name: wget
|
||||
image: busybox
|
||||
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" "busybox") }}
|
||||
command:
|
||||
- 'wget'
|
||||
args:
|
||||
|
||||
@ -1,7 +1,14 @@
|
||||
# Based on docker compose .env file
|
||||
|
||||
# Global image pull secrets configuration
|
||||
imagePullSecrets: []
|
||||
global:
|
||||
# Global image repo prefix to render all images from a mirror/registry.
|
||||
# Example: "registry.example.com/myproj"
|
||||
# When set, template will replace the registry part of each image and keep the path.
|
||||
# Leave empty to use per-image repositories as-is.
|
||||
repo: ""
|
||||
# Global image pull secrets for all pods
|
||||
imagePullSecrets: []
|
||||
|
||||
env:
|
||||
# The type of doc engine to use.
|
||||
@ -27,14 +34,28 @@ env:
|
||||
MYSQL_PASSWORD: infini_rag_flow_helm
|
||||
# The database of the MySQL service to use
|
||||
MYSQL_DBNAME: rag_flow
|
||||
# External MySQL host (only required when mysql.enabled=false)
|
||||
# MYSQL_HOST: ""
|
||||
# External MySQL port (defaults to 3306 if not set)
|
||||
# MYSQL_PORT: "3306"
|
||||
# External MySQL user (only when mysql.enabled=false), default is root if omitted
|
||||
# MYSQL_USER: "root"
|
||||
|
||||
# The username for MinIO.
|
||||
MINIO_ROOT_USER: rag_flow
|
||||
# The password for MinIO
|
||||
MINIO_PASSWORD: infini_rag_flow_helm
|
||||
# External MinIO host
|
||||
# MINIO_HOST: ""
|
||||
# External MinIO port (defaults to 9000 if not set)
|
||||
# MINIO_PORT: "9000"
|
||||
|
||||
# The password for Redis
|
||||
REDIS_PASSWORD: infini_rag_flow_helm
|
||||
# External Redis host (only required when redis.enabled=false)
|
||||
# REDIS_HOST: ""
|
||||
# External Redis port (defaults to 6379 if not set)
|
||||
# REDIS_PORT: "6379"
|
||||
|
||||
# The local time zone.
|
||||
TZ: "Asia/Shanghai"
|
||||
@ -163,6 +184,7 @@ opensearch:
|
||||
type: ClusterIP
|
||||
|
||||
minio:
|
||||
enabled: true
|
||||
image:
|
||||
repository: quay.io/minio/minio
|
||||
tag: RELEASE.2023-12-20T01-00-02Z
|
||||
@ -178,6 +200,7 @@ minio:
|
||||
type: ClusterIP
|
||||
|
||||
mysql:
|
||||
enabled: true
|
||||
image:
|
||||
repository: mysql
|
||||
tag: 8.0.39
|
||||
@ -193,6 +216,7 @@ mysql:
|
||||
type: ClusterIP
|
||||
|
||||
redis:
|
||||
enabled: true
|
||||
image:
|
||||
repository: valkey/valkey
|
||||
tag: 8
|
||||
|
||||
@ -71,7 +71,7 @@ class MessageService:
|
||||
filter_dict["session_id"] = keywords
|
||||
order_by = OrderByExpr()
|
||||
order_by.desc("valid_at")
|
||||
res = settings.msgStoreConn.search(
|
||||
res, total_count = settings.msgStoreConn.search(
|
||||
select_fields=[
|
||||
"message_id", "message_type", "source_id", "memory_id", "user_id", "agent_id", "session_id", "valid_at",
|
||||
"invalid_at", "forget_at", "status"
|
||||
@ -82,13 +82,12 @@ class MessageService:
|
||||
offset=(page-1)*page_size, limit=page_size,
|
||||
index_names=index, memory_ids=[memory_id], agg_fields=[], hide_forgotten=False
|
||||
)
|
||||
if not res:
|
||||
if not total_count:
|
||||
return {
|
||||
"message_list": [],
|
||||
"total_count": 0
|
||||
}
|
||||
|
||||
total_count = settings.msgStoreConn.get_total(res)
|
||||
doc_mapping = settings.msgStoreConn.get_fields(res, [
|
||||
"message_id", "message_type", "source_id", "memory_id", "user_id", "agent_id", "session_id",
|
||||
"valid_at", "invalid_at", "forget_at", "status"
|
||||
@ -107,7 +106,7 @@ class MessageService:
|
||||
}
|
||||
order_by = OrderByExpr()
|
||||
order_by.desc("valid_at")
|
||||
res = settings.msgStoreConn.search(
|
||||
res, total_count = settings.msgStoreConn.search(
|
||||
select_fields=[
|
||||
"message_id", "message_type", "source_id", "memory_id", "user_id", "agent_id", "session_id", "valid_at",
|
||||
"invalid_at", "forget_at", "status", "content"
|
||||
@ -118,7 +117,7 @@ class MessageService:
|
||||
offset=0, limit=limit,
|
||||
index_names=index_names, memory_ids=memory_ids, agg_fields=[]
|
||||
)
|
||||
if not res:
|
||||
if not total_count:
|
||||
return []
|
||||
|
||||
doc_mapping = settings.msgStoreConn.get_fields(res, [
|
||||
@ -136,7 +135,7 @@ class MessageService:
|
||||
|
||||
order_by = OrderByExpr()
|
||||
order_by.desc("valid_at")
|
||||
res = settings.msgStoreConn.search(
|
||||
res, total_count = settings.msgStoreConn.search(
|
||||
select_fields=[
|
||||
"message_id", "message_type", "source_id", "memory_id", "user_id", "agent_id", "session_id",
|
||||
"valid_at",
|
||||
@ -149,7 +148,7 @@ class MessageService:
|
||||
offset=0, limit=top_n,
|
||||
index_names=index_names, memory_ids=memory_ids, agg_fields=[]
|
||||
)
|
||||
if not res:
|
||||
if not total_count:
|
||||
return []
|
||||
|
||||
docs = settings.msgStoreConn.get_fields(res, [
|
||||
@ -195,23 +194,22 @@ class MessageService:
|
||||
select_fields = ["message_id", "content", "content_embed"]
|
||||
_index_name = index_name(uid)
|
||||
res = settings.msgStoreConn.get_forgotten_messages(select_fields, _index_name, memory_id)
|
||||
if not res:
|
||||
return []
|
||||
message_list = settings.msgStoreConn.get_fields(res, select_fields)
|
||||
current_size = 0
|
||||
ids_to_remove = []
|
||||
for message in message_list.values():
|
||||
if current_size < size_to_delete:
|
||||
current_size += cls.calculate_message_size(message)
|
||||
ids_to_remove.append(message["message_id"])
|
||||
else:
|
||||
if res:
|
||||
message_list = settings.msgStoreConn.get_fields(res, select_fields)
|
||||
for message in message_list.values():
|
||||
if current_size < size_to_delete:
|
||||
current_size += cls.calculate_message_size(message)
|
||||
ids_to_remove.append(message["message_id"])
|
||||
else:
|
||||
return ids_to_remove, current_size
|
||||
if current_size >= size_to_delete:
|
||||
return ids_to_remove, current_size
|
||||
if current_size >= size_to_delete:
|
||||
return ids_to_remove, current_size
|
||||
|
||||
order_by = OrderByExpr()
|
||||
order_by.asc("valid_at")
|
||||
res = settings.msgStoreConn.search(
|
||||
res, total_count = settings.msgStoreConn.search(
|
||||
select_fields=select_fields,
|
||||
highlight_fields=[],
|
||||
condition={},
|
||||
@ -240,7 +238,7 @@ class MessageService:
|
||||
order_by = OrderByExpr()
|
||||
order_by.desc("message_id")
|
||||
index_names = [index_name(uid) for uid in uid_list]
|
||||
res = settings.msgStoreConn.search(
|
||||
res, total_count = settings.msgStoreConn.search(
|
||||
select_fields=["message_id"],
|
||||
highlight_fields=[],
|
||||
condition={},
|
||||
@ -250,7 +248,7 @@ class MessageService:
|
||||
index_names=index_names, memory_ids=memory_ids,
|
||||
agg_fields=[], hide_forgotten=False
|
||||
)
|
||||
if not res:
|
||||
if not total_count:
|
||||
return 1
|
||||
|
||||
docs = settings.msgStoreConn.get_fields(res, ["message_id"])
|
||||
|
||||
@ -130,7 +130,7 @@ class ESConnection(ESConnectionBase):
|
||||
|
||||
exist_index_list = [idx for idx in index_names if self.index_exist(idx)]
|
||||
if not exist_index_list:
|
||||
return None
|
||||
return None, 0
|
||||
|
||||
bool_query = Q("bool", must=[], must_not=[])
|
||||
if hide_forgotten:
|
||||
|
||||
@ -149,6 +149,9 @@ dependencies = [
|
||||
# "cryptography==46.0.3",
|
||||
# "jinja2>=3.1.0",
|
||||
"pyairtable>=3.3.0",
|
||||
"pygithub>=2.8.1",
|
||||
"asana>=5.2.2",
|
||||
"python-gitlab>=7.0.0",
|
||||
]
|
||||
|
||||
[dependency-groups]
|
||||
|
||||
@ -13,7 +13,7 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
|
||||
import logging
|
||||
import os
|
||||
import re
|
||||
import tempfile
|
||||
@ -28,13 +28,14 @@ def chunk(filename, binary, tenant_id, lang, callback=None, **kwargs):
|
||||
doc["title_sm_tks"] = rag_tokenizer.fine_grained_tokenize(doc["title_tks"])
|
||||
|
||||
# is it English
|
||||
eng = lang.lower() == "english" # is_english(sections)
|
||||
is_english = lang.lower() == "english" # is_english(sections)
|
||||
try:
|
||||
_, ext = os.path.splitext(filename)
|
||||
if not ext:
|
||||
raise RuntimeError("No extension detected.")
|
||||
|
||||
if ext not in [".da", ".wave", ".wav", ".mp3", ".wav", ".aac", ".flac", ".ogg", ".aiff", ".au", ".midi", ".wma", ".realaudio", ".vqf", ".oggvorbis", ".aac", ".ape"]:
|
||||
if ext not in [".da", ".wave", ".wav", ".mp3", ".wav", ".aac", ".flac", ".ogg", ".aiff", ".au", ".midi", ".wma",
|
||||
".realaudio", ".vqf", ".oggvorbis", ".aac", ".ape"]:
|
||||
raise RuntimeError(f"Extension {ext} is not supported yet.")
|
||||
|
||||
tmp_path = ""
|
||||
@ -48,7 +49,7 @@ def chunk(filename, binary, tenant_id, lang, callback=None, **kwargs):
|
||||
ans = seq2txt_mdl.transcription(tmp_path)
|
||||
callback(0.8, "Sequence2Txt LLM respond: %s ..." % ans[:32])
|
||||
|
||||
tokenize(doc, ans, eng)
|
||||
tokenize(doc, ans, is_english)
|
||||
return [doc]
|
||||
except Exception as e:
|
||||
callback(prog=-1, msg=str(e))
|
||||
@ -56,6 +57,7 @@ def chunk(filename, binary, tenant_id, lang, callback=None, **kwargs):
|
||||
if tmp_path and os.path.exists(tmp_path):
|
||||
try:
|
||||
os.unlink(tmp_path)
|
||||
except Exception:
|
||||
except Exception as e:
|
||||
logging.exception(f"Failed to remove temporary file: {tmp_path}, exception: {e}")
|
||||
pass
|
||||
return []
|
||||
|
||||
@ -22,7 +22,7 @@ from deepdoc.parser.utils import get_text
|
||||
from rag.app import naive
|
||||
from rag.app.naive import by_plaintext, PARSERS
|
||||
from common.parser_config_utils import normalize_layout_recognizer
|
||||
from rag.nlp import bullets_category, is_english,remove_contents_table, \
|
||||
from rag.nlp import bullets_category, is_english, remove_contents_table, \
|
||||
hierarchical_merge, make_colon_as_title, naive_merge, random_choices, tokenize_table, \
|
||||
tokenize_chunks, attach_media_context
|
||||
from rag.nlp import rag_tokenizer
|
||||
@ -91,9 +91,10 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
filename, binary=binary, from_page=from_page, to_page=to_page)
|
||||
remove_contents_table(sections, eng=is_english(
|
||||
random_choices([t for t, _ in sections], k=200)))
|
||||
tbls = vision_figure_parser_docx_wrapper(sections=sections,tbls=tbls,callback=callback,**kwargs)
|
||||
tbls = vision_figure_parser_docx_wrapper(sections=sections, tbls=tbls, callback=callback, **kwargs)
|
||||
# tbls = [((None, lns), None) for lns in tbls]
|
||||
sections=[(item[0],item[1] if item[1] is not None else "") for item in sections if not isinstance(item[1], Image.Image)]
|
||||
sections = [(item[0], item[1] if item[1] is not None else "") for item in sections if
|
||||
not isinstance(item[1], Image.Image)]
|
||||
callback(0.8, "Finish parsing.")
|
||||
|
||||
elif re.search(r"\.pdf$", filename, re.IGNORECASE):
|
||||
@ -109,14 +110,14 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
callback(0.1, "Start to parse.")
|
||||
|
||||
sections, tables, pdf_parser = parser(
|
||||
filename = filename,
|
||||
binary = binary,
|
||||
from_page = from_page,
|
||||
to_page = to_page,
|
||||
lang = lang,
|
||||
callback = callback,
|
||||
pdf_cls = Pdf,
|
||||
layout_recognizer = layout_recognizer,
|
||||
filename=filename,
|
||||
binary=binary,
|
||||
from_page=from_page,
|
||||
to_page=to_page,
|
||||
lang=lang,
|
||||
callback=callback,
|
||||
pdf_cls=Pdf,
|
||||
layout_recognizer=layout_recognizer,
|
||||
mineru_llm_name=parser_model_name,
|
||||
**kwargs
|
||||
)
|
||||
@ -126,7 +127,7 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
|
||||
if name in ["tcadp", "docling", "mineru"]:
|
||||
parser_config["chunk_token_num"] = 0
|
||||
|
||||
|
||||
callback(0.8, "Finish parsing.")
|
||||
elif re.search(r"\.txt$", filename, re.IGNORECASE):
|
||||
callback(0.1, "Start to parse.")
|
||||
@ -175,7 +176,7 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
for ck in hierarchical_merge(bull, sections, 5)]
|
||||
else:
|
||||
sections = [s.split("@") for s, _ in sections]
|
||||
sections = [(pr[0], "@" + pr[1]) if len(pr) == 2 else (pr[0], '') for pr in sections ]
|
||||
sections = [(pr[0], "@" + pr[1]) if len(pr) == 2 else (pr[0], '') for pr in sections]
|
||||
chunks = naive_merge(
|
||||
sections,
|
||||
parser_config.get("chunk_token_num", 256),
|
||||
@ -199,6 +200,9 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
if __name__ == "__main__":
|
||||
import sys
|
||||
|
||||
|
||||
def dummy(prog=None, msg=""):
|
||||
pass
|
||||
|
||||
|
||||
chunk(sys.argv[1], from_page=1, to_page=10, callback=dummy)
|
||||
|
||||
@ -26,13 +26,13 @@ import io
|
||||
|
||||
|
||||
def chunk(
|
||||
filename,
|
||||
binary=None,
|
||||
from_page=0,
|
||||
to_page=100000,
|
||||
lang="Chinese",
|
||||
callback=None,
|
||||
**kwargs,
|
||||
filename,
|
||||
binary=None,
|
||||
from_page=0,
|
||||
to_page=100000,
|
||||
lang="Chinese",
|
||||
callback=None,
|
||||
**kwargs,
|
||||
):
|
||||
"""
|
||||
Only eml is supported
|
||||
@ -93,7 +93,8 @@ def chunk(
|
||||
_add_content(msg, msg.get_content_type())
|
||||
|
||||
sections = TxtParser.parser_txt("\n".join(text_txt)) + [
|
||||
(line, "") for line in HtmlParser.parser_txt("\n".join(html_txt), chunk_token_num=parser_config["chunk_token_num"]) if line
|
||||
(line, "") for line in
|
||||
HtmlParser.parser_txt("\n".join(html_txt), chunk_token_num=parser_config["chunk_token_num"]) if line
|
||||
]
|
||||
|
||||
st = timer()
|
||||
@ -126,7 +127,9 @@ def chunk(
|
||||
if __name__ == "__main__":
|
||||
import sys
|
||||
|
||||
|
||||
def dummy(prog=None, msg=""):
|
||||
pass
|
||||
|
||||
|
||||
chunk(sys.argv[1], callback=dummy)
|
||||
|
||||
@ -29,8 +29,6 @@ from rag.app.naive import by_plaintext, PARSERS
|
||||
from common.parser_config_utils import normalize_layout_recognizer
|
||||
|
||||
|
||||
|
||||
|
||||
class Docx(DocxParser):
|
||||
def __init__(self):
|
||||
pass
|
||||
@ -58,37 +56,36 @@ class Docx(DocxParser):
|
||||
return [line for line in lines if line]
|
||||
|
||||
def __call__(self, filename, binary=None, from_page=0, to_page=100000):
|
||||
self.doc = Document(
|
||||
filename) if not binary else Document(BytesIO(binary))
|
||||
pn = 0
|
||||
lines = []
|
||||
level_set = set()
|
||||
bull = bullets_category([p.text for p in self.doc.paragraphs])
|
||||
for p in self.doc.paragraphs:
|
||||
if pn > to_page:
|
||||
break
|
||||
question_level, p_text = docx_question_level(p, bull)
|
||||
if not p_text.strip("\n"):
|
||||
self.doc = Document(
|
||||
filename) if not binary else Document(BytesIO(binary))
|
||||
pn = 0
|
||||
lines = []
|
||||
level_set = set()
|
||||
bull = bullets_category([p.text for p in self.doc.paragraphs])
|
||||
for p in self.doc.paragraphs:
|
||||
if pn > to_page:
|
||||
break
|
||||
question_level, p_text = docx_question_level(p, bull)
|
||||
if not p_text.strip("\n"):
|
||||
continue
|
||||
lines.append((question_level, p_text))
|
||||
level_set.add(question_level)
|
||||
for run in p.runs:
|
||||
if 'lastRenderedPageBreak' in run._element.xml:
|
||||
pn += 1
|
||||
continue
|
||||
lines.append((question_level, p_text))
|
||||
level_set.add(question_level)
|
||||
for run in p.runs:
|
||||
if 'lastRenderedPageBreak' in run._element.xml:
|
||||
pn += 1
|
||||
continue
|
||||
if 'w:br' in run._element.xml and 'type="page"' in run._element.xml:
|
||||
pn += 1
|
||||
if 'w:br' in run._element.xml and 'type="page"' in run._element.xml:
|
||||
pn += 1
|
||||
|
||||
sorted_levels = sorted(level_set)
|
||||
sorted_levels = sorted(level_set)
|
||||
|
||||
h2_level = sorted_levels[1] if len(sorted_levels) > 1 else 1
|
||||
h2_level = sorted_levels[-2] if h2_level == sorted_levels[-1] and len(sorted_levels) > 2 else h2_level
|
||||
h2_level = sorted_levels[1] if len(sorted_levels) > 1 else 1
|
||||
h2_level = sorted_levels[-2] if h2_level == sorted_levels[-1] and len(sorted_levels) > 2 else h2_level
|
||||
|
||||
root = Node(level=0, depth=h2_level, texts=[])
|
||||
root.build_tree(lines)
|
||||
|
||||
return [element for element in root.get_tree() if element]
|
||||
root = Node(level=0, depth=h2_level, texts=[])
|
||||
root.build_tree(lines)
|
||||
|
||||
return [element for element in root.get_tree() if element]
|
||||
|
||||
def __str__(self) -> str:
|
||||
return f'''
|
||||
@ -121,8 +118,7 @@ class Pdf(PdfParser):
|
||||
start = timer()
|
||||
self._layouts_rec(zoomin)
|
||||
callback(0.67, "Layout analysis ({:.2f}s)".format(timer() - start))
|
||||
logging.debug("layouts:".format(
|
||||
))
|
||||
logging.debug("layouts: {}".format((timer() - start)))
|
||||
self._naive_vertical_merge()
|
||||
|
||||
callback(0.8, "Text extraction ({:.2f}s)".format(timer() - start))
|
||||
@ -154,7 +150,7 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
chunks = Docx()(filename, binary)
|
||||
callback(0.7, "Finish parsing.")
|
||||
return tokenize_chunks(chunks, doc, eng, None)
|
||||
|
||||
|
||||
elif re.search(r"\.pdf$", filename, re.IGNORECASE):
|
||||
layout_recognizer, parser_model_name = normalize_layout_recognizer(
|
||||
parser_config.get("layout_recognize", "DeepDOC")
|
||||
@ -168,14 +164,14 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
callback(0.1, "Start to parse.")
|
||||
|
||||
raw_sections, tables, pdf_parser = parser(
|
||||
filename = filename,
|
||||
binary = binary,
|
||||
from_page = from_page,
|
||||
to_page = to_page,
|
||||
lang = lang,
|
||||
callback = callback,
|
||||
pdf_cls = Pdf,
|
||||
layout_recognizer = layout_recognizer,
|
||||
filename=filename,
|
||||
binary=binary,
|
||||
from_page=from_page,
|
||||
to_page=to_page,
|
||||
lang=lang,
|
||||
callback=callback,
|
||||
pdf_cls=Pdf,
|
||||
layout_recognizer=layout_recognizer,
|
||||
mineru_llm_name=parser_model_name,
|
||||
**kwargs
|
||||
)
|
||||
@ -185,7 +181,7 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
|
||||
if name in ["tcadp", "docling", "mineru"]:
|
||||
parser_config["chunk_token_num"] = 0
|
||||
|
||||
|
||||
for txt, poss in raw_sections:
|
||||
sections.append(txt + poss)
|
||||
|
||||
@ -226,7 +222,6 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
raise NotImplementedError(
|
||||
"file type not supported yet(doc, docx, pdf, txt supported)")
|
||||
|
||||
|
||||
# Remove 'Contents' part
|
||||
remove_contents_table(sections, eng)
|
||||
|
||||
@ -234,7 +229,6 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
bull = bullets_category(sections)
|
||||
res = tree_merge(bull, sections, 2)
|
||||
|
||||
|
||||
if not res:
|
||||
callback(0.99, "No chunk parsed out.")
|
||||
|
||||
@ -243,9 +237,13 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
# chunks = hierarchical_merge(bull, sections, 5)
|
||||
# return tokenize_chunks(["\n".join(ck)for ck in chunks], doc, eng, pdf_parser)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
import sys
|
||||
|
||||
|
||||
def dummy(prog=None, msg=""):
|
||||
pass
|
||||
|
||||
|
||||
chunk(sys.argv[1], callback=dummy)
|
||||
|
||||
@ -20,15 +20,17 @@ import re
|
||||
|
||||
from common.constants import ParserType
|
||||
from io import BytesIO
|
||||
from rag.nlp import rag_tokenizer, tokenize, tokenize_table, bullets_category, title_frequency, tokenize_chunks, docx_question_level, attach_media_context
|
||||
from rag.nlp import rag_tokenizer, tokenize, tokenize_table, bullets_category, title_frequency, tokenize_chunks, \
|
||||
docx_question_level, attach_media_context
|
||||
from common.token_utils import num_tokens_from_string
|
||||
from deepdoc.parser import PdfParser, DocxParser
|
||||
from deepdoc.parser.figure_parser import vision_figure_parser_pdf_wrapper,vision_figure_parser_docx_wrapper
|
||||
from deepdoc.parser.figure_parser import vision_figure_parser_pdf_wrapper, vision_figure_parser_docx_wrapper
|
||||
from docx import Document
|
||||
from PIL import Image
|
||||
from rag.app.naive import by_plaintext, PARSERS
|
||||
from common.parser_config_utils import normalize_layout_recognizer
|
||||
|
||||
|
||||
class Pdf(PdfParser):
|
||||
def __init__(self):
|
||||
self.model_speciess = ParserType.MANUAL.value
|
||||
@ -129,11 +131,11 @@ class Docx(DocxParser):
|
||||
question_level, p_text = 0, ''
|
||||
if from_page <= pn < to_page and p.text.strip():
|
||||
question_level, p_text = docx_question_level(p)
|
||||
if not question_level or question_level > 6: # not a question
|
||||
if not question_level or question_level > 6: # not a question
|
||||
last_answer = f'{last_answer}\n{p_text}'
|
||||
current_image = self.get_picture(self.doc, p)
|
||||
last_image = self.concat_img(last_image, current_image)
|
||||
else: # is a question
|
||||
else: # is a question
|
||||
if last_answer or last_image:
|
||||
sum_question = '\n'.join(question_stack)
|
||||
if sum_question:
|
||||
@ -159,14 +161,14 @@ class Docx(DocxParser):
|
||||
|
||||
tbls = []
|
||||
for tb in self.doc.tables:
|
||||
html= "<table>"
|
||||
html = "<table>"
|
||||
for r in tb.rows:
|
||||
html += "<tr>"
|
||||
i = 0
|
||||
while i < len(r.cells):
|
||||
span = 1
|
||||
c = r.cells[i]
|
||||
for j in range(i+1, len(r.cells)):
|
||||
for j in range(i + 1, len(r.cells)):
|
||||
if c.text == r.cells[j].text:
|
||||
span += 1
|
||||
i = j
|
||||
@ -211,16 +213,16 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
kwargs.pop("parse_method", None)
|
||||
kwargs.pop("mineru_llm_name", None)
|
||||
sections, tbls, pdf_parser = pdf_parser(
|
||||
filename = filename,
|
||||
binary = binary,
|
||||
from_page = from_page,
|
||||
to_page = to_page,
|
||||
lang = lang,
|
||||
callback = callback,
|
||||
pdf_cls = Pdf,
|
||||
layout_recognizer = layout_recognizer,
|
||||
filename=filename,
|
||||
binary=binary,
|
||||
from_page=from_page,
|
||||
to_page=to_page,
|
||||
lang=lang,
|
||||
callback=callback,
|
||||
pdf_cls=Pdf,
|
||||
layout_recognizer=layout_recognizer,
|
||||
mineru_llm_name=parser_model_name,
|
||||
parse_method = "manual",
|
||||
parse_method="manual",
|
||||
**kwargs
|
||||
)
|
||||
|
||||
@ -237,10 +239,10 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
if isinstance(poss, str):
|
||||
poss = pdf_parser.extract_positions(poss)
|
||||
if poss:
|
||||
first = poss[0] # tuple: ([pn], x1, x2, y1, y2)
|
||||
first = poss[0] # tuple: ([pn], x1, x2, y1, y2)
|
||||
pn = first[0]
|
||||
if isinstance(pn, list) and pn:
|
||||
pn = pn[0] # [pn] -> pn
|
||||
pn = pn[0] # [pn] -> pn
|
||||
poss[0] = (pn, *first[1:])
|
||||
|
||||
return (txt, layoutno, poss)
|
||||
@ -289,7 +291,7 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
if not rows:
|
||||
continue
|
||||
sections.append((rows if isinstance(rows, str) else rows[0], -1,
|
||||
[(p[0] + 1 - from_page, p[1], p[2], p[3], p[4]) for p in poss]))
|
||||
[(p[0] + 1 - from_page, p[1], p[2], p[3], p[4]) for p in poss]))
|
||||
|
||||
def tag(pn, left, right, top, bottom):
|
||||
if pn + left + right + top + bottom == 0:
|
||||
@ -312,7 +314,7 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
tk_cnt = num_tokens_from_string(txt)
|
||||
if sec_id > -1:
|
||||
last_sid = sec_id
|
||||
tbls = vision_figure_parser_pdf_wrapper(tbls=tbls,callback=callback,**kwargs)
|
||||
tbls = vision_figure_parser_pdf_wrapper(tbls=tbls, callback=callback, **kwargs)
|
||||
res = tokenize_table(tbls, doc, eng)
|
||||
res.extend(tokenize_chunks(chunks, doc, eng, pdf_parser))
|
||||
table_ctx = max(0, int(parser_config.get("table_context_size", 0) or 0))
|
||||
@ -325,7 +327,7 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
docx_parser = Docx()
|
||||
ti_list, tbls = docx_parser(filename, binary,
|
||||
from_page=0, to_page=10000, callback=callback)
|
||||
tbls = vision_figure_parser_docx_wrapper(sections=ti_list,tbls=tbls,callback=callback,**kwargs)
|
||||
tbls = vision_figure_parser_docx_wrapper(sections=ti_list, tbls=tbls, callback=callback, **kwargs)
|
||||
res = tokenize_table(tbls, doc, eng)
|
||||
for text, image in ti_list:
|
||||
d = copy.deepcopy(doc)
|
||||
|
||||
134
rag/app/naive.py
134
rag/app/naive.py
@ -31,16 +31,20 @@ from common.token_utils import num_tokens_from_string
|
||||
from common.constants import LLMType
|
||||
from api.db.services.llm_service import LLMBundle
|
||||
from rag.utils.file_utils import extract_embed_file, extract_links_from_pdf, extract_links_from_docx, extract_html
|
||||
from deepdoc.parser import DocxParser, ExcelParser, HtmlParser, JsonParser, MarkdownElementExtractor, MarkdownParser, PdfParser, TxtParser
|
||||
from deepdoc.parser.figure_parser import VisionFigureParser,vision_figure_parser_docx_wrapper,vision_figure_parser_pdf_wrapper
|
||||
from deepdoc.parser import DocxParser, ExcelParser, HtmlParser, JsonParser, MarkdownElementExtractor, MarkdownParser, \
|
||||
PdfParser, TxtParser
|
||||
from deepdoc.parser.figure_parser import VisionFigureParser, vision_figure_parser_docx_wrapper, \
|
||||
vision_figure_parser_pdf_wrapper
|
||||
from deepdoc.parser.pdf_parser import PlainParser, VisionParser
|
||||
from deepdoc.parser.docling_parser import DoclingParser
|
||||
from deepdoc.parser.tcadp_parser import TCADPParser
|
||||
from common.parser_config_utils import normalize_layout_recognizer
|
||||
from rag.nlp import concat_img, find_codec, naive_merge, naive_merge_with_images, naive_merge_docx, rag_tokenizer, tokenize_chunks, tokenize_chunks_with_images, tokenize_table, attach_media_context
|
||||
from rag.nlp import concat_img, find_codec, naive_merge, naive_merge_with_images, naive_merge_docx, rag_tokenizer, \
|
||||
tokenize_chunks, tokenize_chunks_with_images, tokenize_table, attach_media_context, append_context2table_image4pdf
|
||||
|
||||
|
||||
def by_deepdoc(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", callback=None, pdf_cls = None, **kwargs):
|
||||
def by_deepdoc(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", callback=None, pdf_cls=None,
|
||||
**kwargs):
|
||||
callback = callback
|
||||
binary = binary
|
||||
pdf_parser = pdf_cls() if pdf_cls else Pdf()
|
||||
@ -58,17 +62,17 @@ def by_deepdoc(filename, binary=None, from_page=0, to_page=100000, lang="Chinese
|
||||
|
||||
|
||||
def by_mineru(
|
||||
filename,
|
||||
binary=None,
|
||||
from_page=0,
|
||||
to_page=100000,
|
||||
lang="Chinese",
|
||||
callback=None,
|
||||
pdf_cls=None,
|
||||
parse_method: str = "raw",
|
||||
mineru_llm_name: str | None = None,
|
||||
tenant_id: str | None = None,
|
||||
**kwargs,
|
||||
filename,
|
||||
binary=None,
|
||||
from_page=0,
|
||||
to_page=100000,
|
||||
lang="Chinese",
|
||||
callback=None,
|
||||
pdf_cls=None,
|
||||
parse_method: str = "raw",
|
||||
mineru_llm_name: str | None = None,
|
||||
tenant_id: str | None = None,
|
||||
**kwargs,
|
||||
):
|
||||
pdf_parser = None
|
||||
if tenant_id:
|
||||
@ -106,7 +110,8 @@ def by_mineru(
|
||||
return None, None, None
|
||||
|
||||
|
||||
def by_docling(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", callback=None, pdf_cls = None, **kwargs):
|
||||
def by_docling(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", callback=None, pdf_cls=None,
|
||||
**kwargs):
|
||||
pdf_parser = DoclingParser()
|
||||
parse_method = kwargs.get("parse_method", "raw")
|
||||
|
||||
@ -125,7 +130,7 @@ def by_docling(filename, binary=None, from_page=0, to_page=100000, lang="Chinese
|
||||
return sections, tables, pdf_parser
|
||||
|
||||
|
||||
def by_tcadp(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", callback=None, pdf_cls = None, **kwargs):
|
||||
def by_tcadp(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", callback=None, pdf_cls=None, **kwargs):
|
||||
tcadp_parser = TCADPParser()
|
||||
|
||||
if not tcadp_parser.check_installation():
|
||||
@ -168,10 +173,10 @@ def by_plaintext(filename, binary=None, from_page=0, to_page=100000, callback=No
|
||||
|
||||
|
||||
PARSERS = {
|
||||
"deepdoc": by_deepdoc,
|
||||
"mineru": by_mineru,
|
||||
"docling": by_docling,
|
||||
"tcadp": by_tcadp,
|
||||
"deepdoc": by_deepdoc,
|
||||
"mineru": by_mineru,
|
||||
"docling": by_docling,
|
||||
"tcadp": by_tcadp,
|
||||
"plaintext": by_plaintext, # default
|
||||
}
|
||||
|
||||
@ -205,8 +210,8 @@ class Docx(DocxParser):
|
||||
except UnicodeDecodeError:
|
||||
logging.info("The recognized image stream appears to be corrupted. Skipping image.")
|
||||
continue
|
||||
except Exception:
|
||||
logging.info("The recognized image stream appears to be corrupted. Skipping image.")
|
||||
except Exception as e:
|
||||
logging.warning(f"The recognized image stream appears to be corrupted. Skipping image, exception: {e}")
|
||||
continue
|
||||
try:
|
||||
image = Image.open(BytesIO(image_blob)).convert('RGB')
|
||||
@ -214,7 +219,8 @@ class Docx(DocxParser):
|
||||
res_img = image
|
||||
else:
|
||||
res_img = concat_img(res_img, image)
|
||||
except Exception:
|
||||
except Exception as e:
|
||||
logging.warning(f"Fail to open or concat images, exception: {e}")
|
||||
continue
|
||||
|
||||
return res_img
|
||||
@ -264,7 +270,7 @@ class Docx(DocxParser):
|
||||
|
||||
# Find the nearest heading paragraph in reverse order
|
||||
nearest_title = None
|
||||
for i in range(len(blocks)-1, -1, -1):
|
||||
for i in range(len(blocks) - 1, -1, -1):
|
||||
block_type, pos, block = blocks[i]
|
||||
if pos >= target_table_pos: # Skip blocks after the table
|
||||
continue
|
||||
@ -293,7 +299,7 @@ class Docx(DocxParser):
|
||||
# Find all parent headings, allowing cross-level search
|
||||
while current_level > 1:
|
||||
found = False
|
||||
for i in range(len(blocks)-1, -1, -1):
|
||||
for i in range(len(blocks) - 1, -1, -1):
|
||||
block_type, pos, block = blocks[i]
|
||||
if pos >= target_table_pos: # Skip blocks after the table
|
||||
continue
|
||||
@ -426,7 +432,8 @@ class Docx(DocxParser):
|
||||
|
||||
try:
|
||||
if inline_images:
|
||||
result = mammoth.convert_to_html(docx_file, convert_image=mammoth.images.img_element(_convert_image_to_base64))
|
||||
result = mammoth.convert_to_html(docx_file,
|
||||
convert_image=mammoth.images.img_element(_convert_image_to_base64))
|
||||
else:
|
||||
result = mammoth.convert_to_html(docx_file)
|
||||
|
||||
@ -480,7 +487,7 @@ class Pdf(PdfParser):
|
||||
tbls = self._extract_table_figure(True, zoomin, True, True)
|
||||
self._naive_vertical_merge()
|
||||
self._concat_downward()
|
||||
self._final_reading_order_merge()
|
||||
# self._final_reading_order_merge()
|
||||
# self._filter_forpages()
|
||||
logging.info("layouts cost: {}s".format(timer() - first_start))
|
||||
return [(b["text"], self._line_tag(b, zoomin)) for b in self.boxes], tbls
|
||||
@ -547,7 +554,8 @@ class Markdown(MarkdownParser):
|
||||
if (src, line_no) not in seen:
|
||||
urls.append({"url": src, "line": line_no})
|
||||
seen.add((src, line_no))
|
||||
except Exception:
|
||||
except Exception as e:
|
||||
logging.error("Failed to extract image urls: {}".format(e))
|
||||
pass
|
||||
|
||||
return urls
|
||||
@ -621,6 +629,7 @@ class Markdown(MarkdownParser):
|
||||
return sections, tbls, section_images
|
||||
return sections, tbls
|
||||
|
||||
|
||||
def load_from_xml_v2(baseURI, rels_item_xml):
|
||||
"""
|
||||
Return |_SerializedRelationships| instance loaded with the
|
||||
@ -636,6 +645,7 @@ def load_from_xml_v2(baseURI, rels_item_xml):
|
||||
srels._srels.append(_SerializedRelationship(baseURI, rel_elm))
|
||||
return srels
|
||||
|
||||
|
||||
def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", callback=None, **kwargs):
|
||||
"""
|
||||
Supported file formats are docx, pdf, excel, txt.
|
||||
@ -651,7 +661,8 @@ def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", ca
|
||||
"parser_config", {
|
||||
"chunk_token_num": 512, "delimiter": "\n!?。;!?", "layout_recognize": "DeepDOC", "analyze_hyperlink": True})
|
||||
|
||||
child_deli = (parser_config.get("children_delimiter") or "").encode('utf-8').decode('unicode_escape').encode('latin1').decode('utf-8')
|
||||
child_deli = (parser_config.get("children_delimiter") or "").encode('utf-8').decode('unicode_escape').encode(
|
||||
'latin1').decode('utf-8')
|
||||
cust_child_deli = re.findall(r"`([^`]+)`", child_deli)
|
||||
child_deli = "|".join(re.sub(r"`([^`]+)`", "", child_deli))
|
||||
if cust_child_deli:
|
||||
@ -685,11 +696,14 @@ def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", ca
|
||||
# Recursively chunk each embedded file and collect results
|
||||
for embed_filename, embed_bytes in embeds:
|
||||
try:
|
||||
sub_res = chunk(embed_filename, binary=embed_bytes, lang=lang, callback=callback, is_root=False, **kwargs) or []
|
||||
sub_res = chunk(embed_filename, binary=embed_bytes, lang=lang, callback=callback, is_root=False,
|
||||
**kwargs) or []
|
||||
embed_res.extend(sub_res)
|
||||
except Exception as e:
|
||||
error_msg = f"Failed to chunk embed {embed_filename}: {e}"
|
||||
logging.error(error_msg)
|
||||
if callback:
|
||||
callback(0.05, f"Failed to chunk embed {embed_filename}: {e}")
|
||||
callback(0.05, error_msg)
|
||||
continue
|
||||
|
||||
if re.search(r"\.docx$", filename, re.IGNORECASE):
|
||||
@ -704,7 +718,8 @@ def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", ca
|
||||
sub_url_res = chunk(url, html_bytes, callback=callback, lang=lang, is_root=False, **kwargs)
|
||||
except Exception as e:
|
||||
logging.info(f"Failed to chunk url in registered file type {url}: {e}")
|
||||
sub_url_res = chunk(f"{index}.html", html_bytes, callback=callback, lang=lang, is_root=False, **kwargs)
|
||||
sub_url_res = chunk(f"{index}.html", html_bytes, callback=callback, lang=lang, is_root=False,
|
||||
**kwargs)
|
||||
url_res.extend(sub_url_res)
|
||||
|
||||
# fix "There is no item named 'word/NULL' in the archive", referring to https://github.com/python-openxml/python-docx/issues/1105#issuecomment-1298075246
|
||||
@ -747,20 +762,23 @@ def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", ca
|
||||
callback(0.1, "Start to parse.")
|
||||
|
||||
sections, tables, pdf_parser = parser(
|
||||
filename = filename,
|
||||
binary = binary,
|
||||
from_page = from_page,
|
||||
to_page = to_page,
|
||||
lang = lang,
|
||||
callback = callback,
|
||||
layout_recognizer = layout_recognizer,
|
||||
mineru_llm_name = parser_model_name,
|
||||
filename=filename,
|
||||
binary=binary,
|
||||
from_page=from_page,
|
||||
to_page=to_page,
|
||||
lang=lang,
|
||||
callback=callback,
|
||||
layout_recognizer=layout_recognizer,
|
||||
mineru_llm_name=parser_model_name,
|
||||
**kwargs
|
||||
)
|
||||
|
||||
if not sections and not tables:
|
||||
return []
|
||||
|
||||
if table_context_size or image_context_size:
|
||||
tables = append_context2table_image4pdf(sections, tables, image_context_size)
|
||||
|
||||
if name in ["tcadp", "docling", "mineru"]:
|
||||
parser_config["chunk_token_num"] = 0
|
||||
|
||||
@ -812,7 +830,7 @@ def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", ca
|
||||
parser_config.get("delimiter", "\n!?;。;!?"))
|
||||
callback(0.8, "Finish parsing.")
|
||||
|
||||
elif re.search(r"\.(md|markdown)$", filename, re.IGNORECASE):
|
||||
elif re.search(r"\.(md|markdown|mdx)$", filename, re.IGNORECASE):
|
||||
callback(0.1, "Start to parse.")
|
||||
markdown_parser = Markdown(int(parser_config.get("chunk_token_num", 128)))
|
||||
sections, tables, section_images = markdown_parser(
|
||||
@ -828,7 +846,8 @@ def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", ca
|
||||
try:
|
||||
vision_model = LLMBundle(kwargs["tenant_id"], LLMType.IMAGE2TEXT)
|
||||
callback(0.2, "Visual model detected. Attempting to enhance figure extraction...")
|
||||
except Exception:
|
||||
except Exception as e:
|
||||
logging.warning(f"Failed to detect figure extraction: {e}")
|
||||
vision_model = None
|
||||
|
||||
if vision_model:
|
||||
@ -846,9 +865,11 @@ def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", ca
|
||||
else:
|
||||
section_images = [None] * len(sections)
|
||||
section_images[idx] = combined_image
|
||||
markdown_vision_parser = VisionFigureParser(vision_model=vision_model, figures_data= [((combined_image, ["markdown image"]), [(0, 0, 0, 0, 0)])], **kwargs)
|
||||
markdown_vision_parser = VisionFigureParser(vision_model=vision_model, figures_data=[
|
||||
((combined_image, ["markdown image"]), [(0, 0, 0, 0, 0)])], **kwargs)
|
||||
boosted_figures = markdown_vision_parser(callback=callback)
|
||||
sections[idx] = (section_text + "\n\n" + "\n\n".join([fig[0][1] for fig in boosted_figures]), sections[idx][1])
|
||||
sections[idx] = (section_text + "\n\n" + "\n\n".join([fig[0][1] for fig in boosted_figures]),
|
||||
sections[idx][1])
|
||||
|
||||
else:
|
||||
logging.warning("No visual model detected. Skipping figure parsing enhancement.")
|
||||
@ -892,8 +913,9 @@ def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", ca
|
||||
sections = [(_, "") for _ in sections if _]
|
||||
callback(0.8, "Finish parsing.")
|
||||
else:
|
||||
callback(0.8, f"tika.parser got empty content from {filename}.")
|
||||
logging.warning(f"tika.parser got empty content from {filename}.")
|
||||
error_msg = f"tika.parser got empty content from {filename}."
|
||||
callback(0.8, error_msg)
|
||||
logging.warning(error_msg)
|
||||
return []
|
||||
else:
|
||||
raise NotImplementedError(
|
||||
@ -945,7 +967,8 @@ def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", ca
|
||||
has_images = merged_images and any(img is not None for img in merged_images)
|
||||
|
||||
if has_images:
|
||||
res.extend(tokenize_chunks_with_images(chunks, doc, is_english, merged_images, child_delimiters_pattern=child_deli))
|
||||
res.extend(tokenize_chunks_with_images(chunks, doc, is_english, merged_images,
|
||||
child_delimiters_pattern=child_deli))
|
||||
else:
|
||||
res.extend(tokenize_chunks(chunks, doc, is_english, pdf_parser, child_delimiters_pattern=child_deli))
|
||||
else:
|
||||
@ -955,10 +978,11 @@ def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", ca
|
||||
|
||||
if section_images:
|
||||
chunks, images = naive_merge_with_images(sections, section_images,
|
||||
int(parser_config.get(
|
||||
"chunk_token_num", 128)), parser_config.get(
|
||||
"delimiter", "\n!?。;!?"))
|
||||
res.extend(tokenize_chunks_with_images(chunks, doc, is_english, images, child_delimiters_pattern=child_deli))
|
||||
int(parser_config.get(
|
||||
"chunk_token_num", 128)), parser_config.get(
|
||||
"delimiter", "\n!?。;!?"))
|
||||
res.extend(
|
||||
tokenize_chunks_with_images(chunks, doc, is_english, images, child_delimiters_pattern=child_deli))
|
||||
else:
|
||||
chunks = naive_merge(
|
||||
sections, int(parser_config.get(
|
||||
@ -985,15 +1009,17 @@ def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", ca
|
||||
res.extend(embed_res)
|
||||
if url_res:
|
||||
res.extend(url_res)
|
||||
if table_context_size or image_context_size:
|
||||
attach_media_context(res, table_context_size, image_context_size)
|
||||
#if table_context_size or image_context_size:
|
||||
# attach_media_context(res, table_context_size, image_context_size)
|
||||
return res
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
import sys
|
||||
|
||||
|
||||
def dummy(prog=None, msg=""):
|
||||
pass
|
||||
|
||||
|
||||
chunk(sys.argv[1], from_page=0, to_page=10, callback=dummy)
|
||||
|
||||
@ -26,6 +26,7 @@ from deepdoc.parser.figure_parser import vision_figure_parser_docx_wrapper
|
||||
from rag.app.naive import by_plaintext, PARSERS
|
||||
from common.parser_config_utils import normalize_layout_recognizer
|
||||
|
||||
|
||||
class Pdf(PdfParser):
|
||||
def __call__(self, filename, binary=None, from_page=0,
|
||||
to_page=100000, zoomin=3, callback=None):
|
||||
@ -95,14 +96,14 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
callback(0.1, "Start to parse.")
|
||||
|
||||
sections, tbls, pdf_parser = parser(
|
||||
filename = filename,
|
||||
binary = binary,
|
||||
from_page = from_page,
|
||||
to_page = to_page,
|
||||
lang = lang,
|
||||
callback = callback,
|
||||
pdf_cls = Pdf,
|
||||
layout_recognizer = layout_recognizer,
|
||||
filename=filename,
|
||||
binary=binary,
|
||||
from_page=from_page,
|
||||
to_page=to_page,
|
||||
lang=lang,
|
||||
callback=callback,
|
||||
pdf_cls=Pdf,
|
||||
layout_recognizer=layout_recognizer,
|
||||
mineru_llm_name=parser_model_name,
|
||||
**kwargs
|
||||
)
|
||||
@ -112,9 +113,9 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
|
||||
if name in ["tcadp", "docling", "mineru"]:
|
||||
parser_config["chunk_token_num"] = 0
|
||||
|
||||
|
||||
callback(0.8, "Finish parsing.")
|
||||
|
||||
|
||||
for (img, rows), poss in tbls:
|
||||
if not rows:
|
||||
continue
|
||||
@ -127,7 +128,7 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
excel_parser = ExcelParser()
|
||||
sections = excel_parser.html(binary, 1000000000)
|
||||
|
||||
elif re.search(r"\.(txt|md|markdown)$", filename, re.IGNORECASE):
|
||||
elif re.search(r"\.(txt|md|markdown|mdx)$", filename, re.IGNORECASE):
|
||||
callback(0.1, "Start to parse.")
|
||||
txt = get_text(filename, binary)
|
||||
sections = txt.split("\n")
|
||||
@ -172,7 +173,9 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
if __name__ == "__main__":
|
||||
import sys
|
||||
|
||||
|
||||
def dummy(prog=None, msg=""):
|
||||
pass
|
||||
|
||||
|
||||
chunk(sys.argv[1], from_page=0, to_page=10, callback=dummy)
|
||||
|
||||
@ -20,7 +20,8 @@ import re
|
||||
|
||||
from deepdoc.parser.figure_parser import vision_figure_parser_pdf_wrapper
|
||||
from common.constants import ParserType
|
||||
from rag.nlp import rag_tokenizer, tokenize, tokenize_table, add_positions, bullets_category, title_frequency, tokenize_chunks, attach_media_context
|
||||
from rag.nlp import rag_tokenizer, tokenize, tokenize_table, add_positions, bullets_category, title_frequency, \
|
||||
tokenize_chunks, attach_media_context
|
||||
from deepdoc.parser import PdfParser
|
||||
import numpy as np
|
||||
from rag.app.naive import by_plaintext, PARSERS
|
||||
@ -66,7 +67,7 @@ class Pdf(PdfParser):
|
||||
# clean mess
|
||||
if column_width < self.page_images[0].size[0] / zoomin / 2:
|
||||
logging.debug("two_column................... {} {}".format(column_width,
|
||||
self.page_images[0].size[0] / zoomin / 2))
|
||||
self.page_images[0].size[0] / zoomin / 2))
|
||||
self.boxes = self.sort_X_by_page(self.boxes, column_width / 2)
|
||||
for b in self.boxes:
|
||||
b["text"] = re.sub(r"([\t ]|\u3000){2,}", " ", b["text"].strip())
|
||||
@ -89,7 +90,7 @@ class Pdf(PdfParser):
|
||||
title = ""
|
||||
authors = []
|
||||
i = 0
|
||||
while i < min(32, len(self.boxes)-1):
|
||||
while i < min(32, len(self.boxes) - 1):
|
||||
b = self.boxes[i]
|
||||
i += 1
|
||||
if b.get("layoutno", "").find("title") >= 0:
|
||||
@ -190,8 +191,8 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
"tables": tables
|
||||
}
|
||||
|
||||
tbls=paper["tables"]
|
||||
tbls=vision_figure_parser_pdf_wrapper(tbls=tbls,callback=callback,**kwargs)
|
||||
tbls = paper["tables"]
|
||||
tbls = vision_figure_parser_pdf_wrapper(tbls=tbls, callback=callback, **kwargs)
|
||||
paper["tables"] = tbls
|
||||
else:
|
||||
raise NotImplementedError("file type not supported yet(pdf supported)")
|
||||
@ -329,6 +330,9 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
if __name__ == "__main__":
|
||||
import sys
|
||||
|
||||
|
||||
def dummy(prog=None, msg=""):
|
||||
pass
|
||||
|
||||
|
||||
chunk(sys.argv[1], callback=dummy)
|
||||
|
||||
@ -51,7 +51,8 @@ def chunk(filename, binary, tenant_id, lang, callback=None, **kwargs):
|
||||
}
|
||||
)
|
||||
cv_mdl = LLMBundle(tenant_id, llm_type=LLMType.IMAGE2TEXT, lang=lang)
|
||||
ans = asyncio.run(cv_mdl.async_chat(system="", history=[], gen_conf={}, video_bytes=binary, filename=filename))
|
||||
ans = asyncio.run(
|
||||
cv_mdl.async_chat(system="", history=[], gen_conf={}, video_bytes=binary, filename=filename))
|
||||
callback(0.8, "CV LLM respond: %s ..." % ans[:32])
|
||||
ans += "\n" + ans
|
||||
tokenize(doc, ans, eng)
|
||||
|
||||
@ -249,7 +249,9 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
if __name__ == "__main__":
|
||||
import sys
|
||||
|
||||
|
||||
def dummy(a, b):
|
||||
pass
|
||||
|
||||
|
||||
chunk(sys.argv[1], callback=dummy)
|
||||
|
||||
@ -102,9 +102,9 @@ class Pdf(PdfParser):
|
||||
self._text_merge()
|
||||
callback(0.67, "Text merged ({:.2f}s)".format(timer() - start))
|
||||
tbls = self._extract_table_figure(True, zoomin, True, True)
|
||||
#self._naive_vertical_merge()
|
||||
# self._naive_vertical_merge()
|
||||
# self._concat_downward()
|
||||
#self._filter_forpages()
|
||||
# self._filter_forpages()
|
||||
logging.debug("layouts: {}".format(timer() - start))
|
||||
sections = [b["text"] for b in self.boxes]
|
||||
bull_x0_list = []
|
||||
@ -114,12 +114,14 @@ class Pdf(PdfParser):
|
||||
qai_list = []
|
||||
last_q, last_a, last_tag = '', '', ''
|
||||
last_index = -1
|
||||
last_box = {'text':''}
|
||||
last_box = {'text': ''}
|
||||
last_bull = None
|
||||
|
||||
def sort_key(element):
|
||||
tbls_pn = element[1][0][0]
|
||||
tbls_top = element[1][0][3]
|
||||
return tbls_pn, tbls_top
|
||||
|
||||
tbls.sort(key=sort_key)
|
||||
tbl_index = 0
|
||||
last_pn, last_bottom = 0, 0
|
||||
@ -133,28 +135,32 @@ class Pdf(PdfParser):
|
||||
tbl_pn, tbl_left, tbl_right, tbl_top, tbl_bottom, tbl_tag, tbl_text = self.get_tbls_info(tbls, tbl_index)
|
||||
if not has_bull: # No question bullet
|
||||
if not last_q:
|
||||
if tbl_pn < line_pn or (tbl_pn == line_pn and tbl_top <= line_top): # image passed
|
||||
if tbl_pn < line_pn or (tbl_pn == line_pn and tbl_top <= line_top): # image passed
|
||||
tbl_index += 1
|
||||
continue
|
||||
else:
|
||||
sum_tag = line_tag
|
||||
sum_section = section
|
||||
while ((tbl_pn == last_pn and tbl_top>= last_bottom) or (tbl_pn > last_pn)) \
|
||||
and ((tbl_pn == line_pn and tbl_top <= line_top) or (tbl_pn < line_pn)): # add image at the middle of current answer
|
||||
while ((tbl_pn == last_pn and tbl_top >= last_bottom) or (tbl_pn > last_pn)) \
|
||||
and ((tbl_pn == line_pn and tbl_top <= line_top) or (
|
||||
tbl_pn < line_pn)): # add image at the middle of current answer
|
||||
sum_tag = f'{tbl_tag}{sum_tag}'
|
||||
sum_section = f'{tbl_text}{sum_section}'
|
||||
tbl_index += 1
|
||||
tbl_pn, tbl_left, tbl_right, tbl_top, tbl_bottom, tbl_tag, tbl_text = self.get_tbls_info(tbls, tbl_index)
|
||||
tbl_pn, tbl_left, tbl_right, tbl_top, tbl_bottom, tbl_tag, tbl_text = self.get_tbls_info(tbls,
|
||||
tbl_index)
|
||||
last_a = f'{last_a}{sum_section}'
|
||||
last_tag = f'{last_tag}{sum_tag}'
|
||||
else:
|
||||
if last_q:
|
||||
while ((tbl_pn == last_pn and tbl_top>= last_bottom) or (tbl_pn > last_pn)) \
|
||||
and ((tbl_pn == line_pn and tbl_top <= line_top) or (tbl_pn < line_pn)): # add image at the end of last answer
|
||||
while ((tbl_pn == last_pn and tbl_top >= last_bottom) or (tbl_pn > last_pn)) \
|
||||
and ((tbl_pn == line_pn and tbl_top <= line_top) or (
|
||||
tbl_pn < line_pn)): # add image at the end of last answer
|
||||
last_tag = f'{last_tag}{tbl_tag}'
|
||||
last_a = f'{last_a}{tbl_text}'
|
||||
tbl_index += 1
|
||||
tbl_pn, tbl_left, tbl_right, tbl_top, tbl_bottom, tbl_tag, tbl_text = self.get_tbls_info(tbls, tbl_index)
|
||||
tbl_pn, tbl_left, tbl_right, tbl_top, tbl_bottom, tbl_tag, tbl_text = self.get_tbls_info(tbls,
|
||||
tbl_index)
|
||||
image, poss = self.crop(last_tag, need_position=True)
|
||||
qai_list.append((last_q, last_a, image, poss))
|
||||
last_q, last_a, last_tag = '', '', ''
|
||||
@ -171,7 +177,7 @@ class Pdf(PdfParser):
|
||||
def get_tbls_info(self, tbls, tbl_index):
|
||||
if tbl_index >= len(tbls):
|
||||
return 1, 0, 0, 0, 0, '@@0\t0\t0\t0\t0##', ''
|
||||
tbl_pn = tbls[tbl_index][1][0][0]+1
|
||||
tbl_pn = tbls[tbl_index][1][0][0] + 1
|
||||
tbl_left = tbls[tbl_index][1][0][1]
|
||||
tbl_right = tbls[tbl_index][1][0][2]
|
||||
tbl_top = tbls[tbl_index][1][0][3]
|
||||
@ -210,11 +216,11 @@ class Docx(DocxParser):
|
||||
question_level, p_text = 0, ''
|
||||
if from_page <= pn < to_page and p.text.strip():
|
||||
question_level, p_text = docx_question_level(p)
|
||||
if not question_level or question_level > 6: # not a question
|
||||
if not question_level or question_level > 6: # not a question
|
||||
last_answer = f'{last_answer}\n{p_text}'
|
||||
current_image = self.get_picture(self.doc, p)
|
||||
last_image = concat_img(last_image, current_image)
|
||||
else: # is a question
|
||||
else: # is a question
|
||||
if last_answer or last_image:
|
||||
sum_question = '\n'.join(question_stack)
|
||||
if sum_question:
|
||||
@ -240,14 +246,14 @@ class Docx(DocxParser):
|
||||
|
||||
tbls = []
|
||||
for tb in self.doc.tables:
|
||||
html= "<table>"
|
||||
html = "<table>"
|
||||
for r in tb.rows:
|
||||
html += "<tr>"
|
||||
i = 0
|
||||
while i < len(r.cells):
|
||||
span = 1
|
||||
c = r.cells[i]
|
||||
for j in range(i+1, len(r.cells)):
|
||||
for j in range(i + 1, len(r.cells)):
|
||||
if c.text == r.cells[j].text:
|
||||
span += 1
|
||||
i = j
|
||||
@ -356,7 +362,7 @@ def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", ca
|
||||
if question:
|
||||
answer += "\n" + lines[i]
|
||||
else:
|
||||
fails.append(str(i+1))
|
||||
fails.append(str(i + 1))
|
||||
elif len(arr) == 2:
|
||||
if question and answer:
|
||||
res.append(beAdoc(deepcopy(doc), question, answer, eng, i))
|
||||
@ -415,7 +421,7 @@ def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", ca
|
||||
res.append(beAdocPdf(deepcopy(doc), q, a, eng, image, poss))
|
||||
return res
|
||||
|
||||
elif re.search(r"\.(md|markdown)$", filename, re.IGNORECASE):
|
||||
elif re.search(r"\.(md|markdown|mdx)$", filename, re.IGNORECASE):
|
||||
callback(0.1, "Start to parse.")
|
||||
txt = get_text(filename, binary)
|
||||
lines = txt.split("\n")
|
||||
@ -429,13 +435,14 @@ def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", ca
|
||||
if not code_block:
|
||||
question_level, question = mdQuestionLevel(line)
|
||||
|
||||
if not question_level or question_level > 6: # not a question
|
||||
if not question_level or question_level > 6: # not a question
|
||||
last_answer = f'{last_answer}\n{line}'
|
||||
else: # is a question
|
||||
else: # is a question
|
||||
if last_answer.strip():
|
||||
sum_question = '\n'.join(question_stack)
|
||||
if sum_question:
|
||||
res.append(beAdoc(deepcopy(doc), sum_question, markdown(last_answer, extensions=['markdown.extensions.tables']), eng, index))
|
||||
res.append(beAdoc(deepcopy(doc), sum_question,
|
||||
markdown(last_answer, extensions=['markdown.extensions.tables']), eng, index))
|
||||
last_answer = ''
|
||||
|
||||
i = question_level
|
||||
@ -447,13 +454,14 @@ def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", ca
|
||||
if last_answer.strip():
|
||||
sum_question = '\n'.join(question_stack)
|
||||
if sum_question:
|
||||
res.append(beAdoc(deepcopy(doc), sum_question, markdown(last_answer, extensions=['markdown.extensions.tables']), eng, index))
|
||||
res.append(beAdoc(deepcopy(doc), sum_question,
|
||||
markdown(last_answer, extensions=['markdown.extensions.tables']), eng, index))
|
||||
return res
|
||||
|
||||
elif re.search(r"\.docx$", filename, re.IGNORECASE):
|
||||
docx_parser = Docx()
|
||||
qai_list, tbls = docx_parser(filename, binary,
|
||||
from_page=0, to_page=10000, callback=callback)
|
||||
from_page=0, to_page=10000, callback=callback)
|
||||
res = tokenize_table(tbls, doc, eng)
|
||||
for i, (q, a, image) in enumerate(qai_list):
|
||||
res.append(beAdocDocx(deepcopy(doc), q, a, eng, image, i))
|
||||
@ -466,6 +474,9 @@ def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", ca
|
||||
if __name__ == "__main__":
|
||||
import sys
|
||||
|
||||
|
||||
def dummy(prog=None, msg=""):
|
||||
pass
|
||||
|
||||
|
||||
chunk(sys.argv[1], from_page=0, to_page=10, callback=dummy)
|
||||
|
||||
@ -64,7 +64,8 @@ def remote_call(filename, binary):
|
||||
del resume[k]
|
||||
|
||||
resume = step_one.refactor(pd.DataFrame([{"resume_content": json.dumps(resume), "tob_resume_id": "x",
|
||||
"updated_at": datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]))
|
||||
"updated_at": datetime.datetime.now().strftime(
|
||||
"%Y-%m-%d %H:%M:%S")}]))
|
||||
resume = step_two.parse(resume)
|
||||
return resume
|
||||
except Exception:
|
||||
@ -171,6 +172,9 @@ def chunk(filename, binary=None, callback=None, **kwargs):
|
||||
if __name__ == "__main__":
|
||||
import sys
|
||||
|
||||
|
||||
def dummy(a, b):
|
||||
pass
|
||||
|
||||
|
||||
chunk(sys.argv[1], callback=dummy)
|
||||
|
||||
@ -42,23 +42,24 @@ class Excel(ExcelParser):
|
||||
else:
|
||||
wb = Excel._load_excel_to_workbook(BytesIO(binary))
|
||||
total = 0
|
||||
for sheetname in wb.sheetnames:
|
||||
total += len(list(wb[sheetname].rows))
|
||||
for sheet_name in wb.sheetnames:
|
||||
total += len(list(wb[sheet_name].rows))
|
||||
res, fails, done = [], [], 0
|
||||
rn = 0
|
||||
flow_images = []
|
||||
pending_cell_images = []
|
||||
tables = []
|
||||
for sheetname in wb.sheetnames:
|
||||
ws = wb[sheetname]
|
||||
images = Excel._extract_images_from_worksheet(ws,sheetname=sheetname)
|
||||
for sheet_name in wb.sheetnames:
|
||||
ws = wb[sheet_name]
|
||||
images = Excel._extract_images_from_worksheet(ws, sheetname=sheet_name)
|
||||
if images:
|
||||
image_descriptions = vision_figure_parser_figure_xlsx_wrapper(images=images, callback=callback, **kwargs)
|
||||
image_descriptions = vision_figure_parser_figure_xlsx_wrapper(images=images, callback=callback,
|
||||
**kwargs)
|
||||
if image_descriptions and len(image_descriptions) == len(images):
|
||||
for i, bf in enumerate(image_descriptions):
|
||||
images[i]["image_description"] = "\n".join(bf[0][1])
|
||||
for img in images:
|
||||
if (img["span_type"] == "single_cell"and img.get("image_description")):
|
||||
if img["span_type"] == "single_cell" and img.get("image_description"):
|
||||
pending_cell_images.append(img)
|
||||
else:
|
||||
flow_images.append(img)
|
||||
@ -66,7 +67,7 @@ class Excel(ExcelParser):
|
||||
try:
|
||||
rows = list(ws.rows)
|
||||
except Exception as e:
|
||||
logging.warning(f"Skip sheet '{sheetname}' due to rows access error: {e}")
|
||||
logging.warning(f"Skip sheet '{sheet_name}' due to rows access error: {e}")
|
||||
continue
|
||||
if not rows:
|
||||
continue
|
||||
@ -113,16 +114,17 @@ class Excel(ExcelParser):
|
||||
tables.append(
|
||||
(
|
||||
(
|
||||
img["image"], # Image.Image
|
||||
[img["image_description"]] # description list (must be list)
|
||||
img["image"], # Image.Image
|
||||
[img["image_description"]] # description list (must be list)
|
||||
),
|
||||
[
|
||||
(0, 0, 0, 0, 0) # dummy position
|
||||
(0, 0, 0, 0, 0) # dummy position
|
||||
]
|
||||
)
|
||||
)
|
||||
callback(0.3, ("Extract records: {}~{}".format(from_page + 1, min(to_page, from_page + rn)) + (f"{len(fails)} failure, line: %s..." % (",".join(fails[:3])) if fails else "")))
|
||||
return res,tables
|
||||
callback(0.3, ("Extract records: {}~{}".format(from_page + 1, min(to_page, from_page + rn)) + (
|
||||
f"{len(fails)} failure, line: %s..." % (",".join(fails[:3])) if fails else "")))
|
||||
return res, tables
|
||||
|
||||
def _parse_headers(self, ws, rows):
|
||||
if len(rows) == 0:
|
||||
@ -301,7 +303,8 @@ class Excel(ExcelParser):
|
||||
def trans_datatime(s):
|
||||
try:
|
||||
return datetime_parse(s.strip()).strftime("%Y-%m-%d %H:%M:%S")
|
||||
except Exception:
|
||||
except Exception as e:
|
||||
logging.warning(f"Failed to parse date from {s}, error: {e}")
|
||||
pass
|
||||
|
||||
|
||||
@ -310,19 +313,21 @@ def trans_bool(s):
|
||||
return "yes"
|
||||
if re.match(r"(false|no|否|⍻|×)$", str(s).strip(), flags=re.IGNORECASE):
|
||||
return "no"
|
||||
return None
|
||||
|
||||
|
||||
def column_data_type(arr):
|
||||
arr = list(arr)
|
||||
counts = {"int": 0, "float": 0, "text": 0, "datetime": 0, "bool": 0}
|
||||
trans = {t: f for f, t in [(int, "int"), (float, "float"), (trans_datatime, "datetime"), (trans_bool, "bool"), (str, "text")]}
|
||||
trans = {t: f for f, t in
|
||||
[(int, "int"), (float, "float"), (trans_datatime, "datetime"), (trans_bool, "bool"), (str, "text")]}
|
||||
float_flag = False
|
||||
for a in arr:
|
||||
if a is None:
|
||||
continue
|
||||
if re.match(r"[+-]?[0-9]+$", str(a).replace("%%", "")) and not str(a).replace("%%", "").startswith("0"):
|
||||
counts["int"] += 1
|
||||
if int(str(a)) > 2**63 - 1:
|
||||
if int(str(a)) > 2 ** 63 - 1:
|
||||
float_flag = True
|
||||
break
|
||||
elif re.match(r"[+-]?[0-9.]{,19}$", str(a).replace("%%", "")) and not str(a).replace("%%", "").startswith("0"):
|
||||
@ -343,8 +348,9 @@ def column_data_type(arr):
|
||||
continue
|
||||
try:
|
||||
arr[i] = trans[ty](str(arr[i]))
|
||||
except Exception:
|
||||
except Exception as e:
|
||||
arr[i] = None
|
||||
logging.warning(f"Column {i}: {e}")
|
||||
# if ty == "text":
|
||||
# if len(arr) > 128 and uni / len(arr) < 0.1:
|
||||
# ty = "keyword"
|
||||
@ -370,7 +376,7 @@ def chunk(filename, binary=None, from_page=0, to_page=10000000000, lang="Chinese
|
||||
if re.search(r"\.xlsx?$", filename, re.IGNORECASE):
|
||||
callback(0.1, "Start to parse.")
|
||||
excel_parser = Excel()
|
||||
dfs,tbls = excel_parser(filename, binary, from_page=from_page, to_page=to_page, callback=callback, **kwargs)
|
||||
dfs, tbls = excel_parser(filename, binary, from_page=from_page, to_page=to_page, callback=callback, **kwargs)
|
||||
elif re.search(r"\.txt$", filename, re.IGNORECASE):
|
||||
callback(0.1, "Start to parse.")
|
||||
txt = get_text(filename, binary)
|
||||
@ -389,7 +395,8 @@ def chunk(filename, binary=None, from_page=0, to_page=10000000000, lang="Chinese
|
||||
continue
|
||||
rows.append(row)
|
||||
|
||||
callback(0.3, ("Extract records: {}~{}".format(from_page, min(len(lines), to_page)) + (f"{len(fails)} failure, line: %s..." % (",".join(fails[:3])) if fails else "")))
|
||||
callback(0.3, ("Extract records: {}~{}".format(from_page, min(len(lines), to_page)) + (
|
||||
f"{len(fails)} failure, line: %s..." % (",".join(fails[:3])) if fails else "")))
|
||||
|
||||
dfs = [pd.DataFrame(np.array(rows), columns=headers)]
|
||||
elif re.search(r"\.csv$", filename, re.IGNORECASE):
|
||||
@ -406,7 +413,7 @@ def chunk(filename, binary=None, from_page=0, to_page=10000000000, lang="Chinese
|
||||
fails = []
|
||||
rows = []
|
||||
|
||||
for i, row in enumerate(all_rows[1 + from_page : 1 + to_page]):
|
||||
for i, row in enumerate(all_rows[1 + from_page: 1 + to_page]):
|
||||
if len(row) != len(headers):
|
||||
fails.append(str(i + from_page))
|
||||
continue
|
||||
@ -415,7 +422,7 @@ def chunk(filename, binary=None, from_page=0, to_page=10000000000, lang="Chinese
|
||||
callback(
|
||||
0.3,
|
||||
(f"Extract records: {from_page}~{from_page + len(rows)}" +
|
||||
(f"{len(fails)} failure, line: {','.join(fails[:3])}..." if fails else ""))
|
||||
(f"{len(fails)} failure, line: {','.join(fails[:3])}..." if fails else ""))
|
||||
)
|
||||
|
||||
dfs = [pd.DataFrame(rows, columns=headers)]
|
||||
@ -445,7 +452,8 @@ def chunk(filename, binary=None, from_page=0, to_page=10000000000, lang="Chinese
|
||||
df[clmns[j]] = cln
|
||||
if ty == "text":
|
||||
txts.extend([str(c) for c in cln if c])
|
||||
clmns_map = [(py_clmns[i].lower() + fieds_map[clmn_tys[i]], str(clmns[i]).replace("_", " ")) for i in range(len(clmns))]
|
||||
clmns_map = [(py_clmns[i].lower() + fieds_map[clmn_tys[i]], str(clmns[i]).replace("_", " ")) for i in
|
||||
range(len(clmns))]
|
||||
|
||||
eng = lang.lower() == "english" # is_english(txts)
|
||||
for ii, row in df.iterrows():
|
||||
@ -477,7 +485,9 @@ def chunk(filename, binary=None, from_page=0, to_page=10000000000, lang="Chinese
|
||||
if __name__ == "__main__":
|
||||
import sys
|
||||
|
||||
|
||||
def dummy(prog=None, msg=""):
|
||||
pass
|
||||
|
||||
|
||||
chunk(sys.argv[1], callback=dummy)
|
||||
|
||||
@ -141,17 +141,20 @@ def label_question(question, kbs):
|
||||
if not tag_kbs:
|
||||
return tags
|
||||
tags = settings.retriever.tag_query(question,
|
||||
list(set([kb.tenant_id for kb in tag_kbs])),
|
||||
tag_kb_ids,
|
||||
all_tags,
|
||||
kb.parser_config.get("topn_tags", 3)
|
||||
)
|
||||
list(set([kb.tenant_id for kb in tag_kbs])),
|
||||
tag_kb_ids,
|
||||
all_tags,
|
||||
kb.parser_config.get("topn_tags", 3)
|
||||
)
|
||||
return tags
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
import sys
|
||||
|
||||
|
||||
def dummy(prog=None, msg=""):
|
||||
pass
|
||||
chunk(sys.argv[1], from_page=0, to_page=10, callback=dummy)
|
||||
|
||||
|
||||
chunk(sys.argv[1], from_page=0, to_page=10, callback=dummy)
|
||||
|
||||
@ -263,7 +263,7 @@ class SparkTTS(Base):
|
||||
raise Exception(error)
|
||||
|
||||
def on_close(self, ws, close_status_code, close_msg):
|
||||
self.audio_queue.put(None) # 放入 None 作为结束标志
|
||||
self.audio_queue.put(None) # None is terminator
|
||||
|
||||
def on_open(self, ws):
|
||||
def run(*args):
|
||||
|
||||
@ -16,7 +16,7 @@
|
||||
|
||||
import logging
|
||||
import random
|
||||
from collections import Counter
|
||||
from collections import Counter, defaultdict
|
||||
|
||||
from common.token_utils import num_tokens_from_string
|
||||
import re
|
||||
@ -273,7 +273,7 @@ def tokenize(d, txt, eng):
|
||||
d["content_sm_ltks"] = rag_tokenizer.fine_grained_tokenize(d["content_ltks"])
|
||||
|
||||
|
||||
def split_with_pattern(d, pattern:str, content:str, eng) -> list:
|
||||
def split_with_pattern(d, pattern: str, content: str, eng) -> list:
|
||||
docs = []
|
||||
txts = [txt for txt in re.split(r"(%s)" % pattern, content, flags=re.DOTALL)]
|
||||
for j in range(0, len(txts), 2):
|
||||
@ -281,7 +281,7 @@ def split_with_pattern(d, pattern:str, content:str, eng) -> list:
|
||||
if not txt:
|
||||
continue
|
||||
if j + 1 < len(txts):
|
||||
txt += txts[j+1]
|
||||
txt += txts[j + 1]
|
||||
dd = copy.deepcopy(d)
|
||||
tokenize(dd, txt, eng)
|
||||
docs.append(dd)
|
||||
@ -304,7 +304,7 @@ def tokenize_chunks(chunks, doc, eng, pdf_parser=None, child_delimiters_pattern=
|
||||
except NotImplementedError:
|
||||
pass
|
||||
else:
|
||||
add_positions(d, [[ii]*5])
|
||||
add_positions(d, [[ii] * 5])
|
||||
|
||||
if child_delimiters_pattern:
|
||||
d["mom_with_weight"] = ck
|
||||
@ -325,7 +325,7 @@ def tokenize_chunks_with_images(chunks, doc, eng, images, child_delimiters_patte
|
||||
logging.debug("-- {}".format(ck))
|
||||
d = copy.deepcopy(doc)
|
||||
d["image"] = image
|
||||
add_positions(d, [[ii]*5])
|
||||
add_positions(d, [[ii] * 5])
|
||||
if child_delimiters_pattern:
|
||||
d["mom_with_weight"] = ck
|
||||
res.extend(split_with_pattern(d, child_delimiters_pattern, ck, eng))
|
||||
@ -658,7 +658,8 @@ def attach_media_context(chunks, table_context_size=0, image_context_size=0):
|
||||
if "content_ltks" in ck:
|
||||
ck["content_ltks"] = rag_tokenizer.tokenize(combined)
|
||||
if "content_sm_ltks" in ck:
|
||||
ck["content_sm_ltks"] = rag_tokenizer.fine_grained_tokenize(ck.get("content_ltks", rag_tokenizer.tokenize(combined)))
|
||||
ck["content_sm_ltks"] = rag_tokenizer.fine_grained_tokenize(
|
||||
ck.get("content_ltks", rag_tokenizer.tokenize(combined)))
|
||||
|
||||
if positioned_indices:
|
||||
chunks[:] = [chunks[i] for i in ordered_indices]
|
||||
@ -666,6 +667,94 @@ def attach_media_context(chunks, table_context_size=0, image_context_size=0):
|
||||
return chunks
|
||||
|
||||
|
||||
def append_context2table_image4pdf(sections: list, tabls: list, table_context_size=0):
|
||||
from deepdoc.parser import PdfParser
|
||||
if table_context_size <=0:
|
||||
return tabls
|
||||
|
||||
page_bucket = defaultdict(list)
|
||||
for i, (txt, poss) in enumerate(sections):
|
||||
poss = PdfParser.extract_positions(poss)
|
||||
for page, left, right, top, bottom in poss:
|
||||
page = page[0]
|
||||
page_bucket[page].append(((left, top, right, bottom), txt))
|
||||
|
||||
def upper_context(page, i):
|
||||
txt = ""
|
||||
if page not in page_bucket:
|
||||
i = -1
|
||||
while num_tokens_from_string(txt) < table_context_size:
|
||||
if i < 0:
|
||||
page -= 1
|
||||
if page < 0 or page not in page_bucket:
|
||||
break
|
||||
i = len(page_bucket[page]) -1
|
||||
blks = page_bucket[page]
|
||||
(_, _, _, _), cnt = blks[i]
|
||||
txts = re.split(r"([。!??;!\n]|\. )", cnt, flags=re.DOTALL)[::-1]
|
||||
for j in range(0, len(txts), 2):
|
||||
txt = (txts[j+1] if j+1<len(txts) else "") + txts[j] + txt
|
||||
if num_tokens_from_string(txt) > table_context_size:
|
||||
break
|
||||
i -= 1
|
||||
return txt
|
||||
|
||||
def lower_context(page, i):
|
||||
txt = ""
|
||||
if page not in page_bucket:
|
||||
return txt
|
||||
while num_tokens_from_string(txt) < table_context_size:
|
||||
if i >= len(page_bucket[page]):
|
||||
page += 1
|
||||
if page not in page_bucket:
|
||||
break
|
||||
i = 0
|
||||
blks = page_bucket[page]
|
||||
(_, _, _, _), cnt = blks[i]
|
||||
txts = re.split(r"([。!??;!\n]|\. )", cnt, flags=re.DOTALL)
|
||||
for j in range(0, len(txts), 2):
|
||||
txt += txts[j] + (txts[j+1] if j+1<len(txts) else "")
|
||||
if num_tokens_from_string(txt) > table_context_size:
|
||||
break
|
||||
i += 1
|
||||
return txt
|
||||
|
||||
res = []
|
||||
for (img, tb), poss in tabls:
|
||||
page, left, top, right, bott = poss[0]
|
||||
_page, _left, _top, _right, _bott = poss[-1]
|
||||
if isinstance(tb, list):
|
||||
tb = "\n".join(tb)
|
||||
|
||||
i = 0
|
||||
blks = page_bucket.get(page, [])
|
||||
_tb = tb
|
||||
while i < len(blks):
|
||||
if i + 1 >= len(blks):
|
||||
if _page > page:
|
||||
page += 1
|
||||
i = 0
|
||||
blks = page_bucket.get(page, [])
|
||||
continue
|
||||
tb = upper_context(page, i) + tb + lower_context(page+1, 0)
|
||||
break
|
||||
(_, t, r, b), txt = blks[i]
|
||||
if b > top:
|
||||
break
|
||||
(_, _t, _r, _b), _txt = blks[i+1]
|
||||
if _t < _bott:
|
||||
i += 1
|
||||
continue
|
||||
|
||||
tb = upper_context(page, i) + tb + lower_context(page, i)
|
||||
break
|
||||
|
||||
if _tb == tb:
|
||||
tb = upper_context(page, -1) + tb + lower_context(page+1, 0)
|
||||
res.append(((img, tb), poss))
|
||||
return res
|
||||
|
||||
|
||||
def add_positions(d, poss):
|
||||
if not poss:
|
||||
return
|
||||
@ -764,8 +853,8 @@ def not_title(txt):
|
||||
return True
|
||||
return re.search(r"[,;,。;!!]", txt)
|
||||
|
||||
def tree_merge(bull, sections, depth):
|
||||
|
||||
def tree_merge(bull, sections, depth):
|
||||
if not sections or bull < 0:
|
||||
return sections
|
||||
if isinstance(sections[0], type("")):
|
||||
@ -777,16 +866,17 @@ def tree_merge(bull, sections, depth):
|
||||
|
||||
def get_level(bull, section):
|
||||
text, layout = section
|
||||
text = re.sub(r"\u3000", " ", text).strip()
|
||||
text = re.sub(r"\u3000", " ", text).strip()
|
||||
|
||||
for i, title in enumerate(BULLET_PATTERN[bull]):
|
||||
if re.match(title, text.strip()):
|
||||
return i+1, text
|
||||
return i + 1, text
|
||||
else:
|
||||
if re.search(r"(title|head)", layout) and not not_title(text):
|
||||
return len(BULLET_PATTERN[bull])+1, text
|
||||
return len(BULLET_PATTERN[bull]) + 1, text
|
||||
else:
|
||||
return len(BULLET_PATTERN[bull])+2, text
|
||||
return len(BULLET_PATTERN[bull]) + 2, text
|
||||
|
||||
level_set = set()
|
||||
lines = []
|
||||
for section in sections:
|
||||
@ -812,8 +902,8 @@ def tree_merge(bull, sections, depth):
|
||||
|
||||
return [element for element in root.get_tree() if element]
|
||||
|
||||
def hierarchical_merge(bull, sections, depth):
|
||||
|
||||
def hierarchical_merge(bull, sections, depth):
|
||||
if not sections or bull < 0:
|
||||
return []
|
||||
if isinstance(sections[0], type("")):
|
||||
@ -922,10 +1012,10 @@ def naive_merge(sections: str | list, chunk_token_num=128, delimiter="\n。;
|
||||
if tnum < 8:
|
||||
pos = ""
|
||||
# Ensure that the length of the merged chunk does not exceed chunk_token_num
|
||||
if cks[-1] == "" or tk_nums[-1] > chunk_token_num * (100 - overlapped_percent)/100.:
|
||||
if cks[-1] == "" or tk_nums[-1] > chunk_token_num * (100 - overlapped_percent) / 100.:
|
||||
if cks:
|
||||
overlapped = RAGFlowPdfParser.remove_tag(cks[-1])
|
||||
t = overlapped[int(len(overlapped)*(100-overlapped_percent)/100.):] + t
|
||||
t = overlapped[int(len(overlapped) * (100 - overlapped_percent) / 100.):] + t
|
||||
if t.find(pos) < 0:
|
||||
t += pos
|
||||
cks.append(t)
|
||||
@ -957,7 +1047,7 @@ def naive_merge(sections: str | list, chunk_token_num=128, delimiter="\n。;
|
||||
return cks
|
||||
|
||||
for sec, pos in sections:
|
||||
add_chunk("\n"+sec, pos)
|
||||
add_chunk("\n" + sec, pos)
|
||||
|
||||
return cks
|
||||
|
||||
@ -978,10 +1068,10 @@ def naive_merge_with_images(texts, images, chunk_token_num=128, delimiter="\n。
|
||||
if tnum < 8:
|
||||
pos = ""
|
||||
# Ensure that the length of the merged chunk does not exceed chunk_token_num
|
||||
if cks[-1] == "" or tk_nums[-1] > chunk_token_num * (100 - overlapped_percent)/100.:
|
||||
if cks[-1] == "" or tk_nums[-1] > chunk_token_num * (100 - overlapped_percent) / 100.:
|
||||
if cks:
|
||||
overlapped = RAGFlowPdfParser.remove_tag(cks[-1])
|
||||
t = overlapped[int(len(overlapped)*(100-overlapped_percent)/100.):] + t
|
||||
t = overlapped[int(len(overlapped) * (100 - overlapped_percent) / 100.):] + t
|
||||
if t.find(pos) < 0:
|
||||
t += pos
|
||||
cks.append(t)
|
||||
@ -1025,9 +1115,9 @@ def naive_merge_with_images(texts, images, chunk_token_num=128, delimiter="\n。
|
||||
if isinstance(text, tuple):
|
||||
text_str = text[0]
|
||||
text_pos = text[1] if len(text) > 1 else ""
|
||||
add_chunk("\n"+text_str, image, text_pos)
|
||||
add_chunk("\n" + text_str, image, text_pos)
|
||||
else:
|
||||
add_chunk("\n"+text, image)
|
||||
add_chunk("\n" + text, image)
|
||||
|
||||
return cks, result_images
|
||||
|
||||
@ -1042,7 +1132,7 @@ def docx_question_level(p, bull=-1):
|
||||
for j, title in enumerate(BULLET_PATTERN[bull]):
|
||||
if re.match(title, txt):
|
||||
return j + 1, txt
|
||||
return len(BULLET_PATTERN[bull])+1, txt
|
||||
return len(BULLET_PATTERN[bull]) + 1, txt
|
||||
|
||||
|
||||
def concat_img(img1, img2):
|
||||
@ -1211,7 +1301,7 @@ class Node:
|
||||
child = node.get_children()
|
||||
|
||||
if level == 0 and texts:
|
||||
tree_list.append("\n".join(titles+texts))
|
||||
tree_list.append("\n".join(titles + texts))
|
||||
|
||||
# Titles within configured depth are accumulated into the current path
|
||||
if 1 <= level <= self.depth:
|
||||
|
||||
@ -205,11 +205,11 @@ class FulltextQueryer(QueryBase):
|
||||
s = 1e-9
|
||||
for k, v in qtwt.items():
|
||||
if k in dtwt:
|
||||
s += v #* dtwt[k]
|
||||
s += v # * dtwt[k]
|
||||
q = 1e-9
|
||||
for k, v in qtwt.items():
|
||||
q += v #* v
|
||||
return s/q #math.sqrt(3. * (s / q / math.log10( len(dtwt.keys()) + 512 )))
|
||||
q += v # * v
|
||||
return s / q # math.sqrt(3. * (s / q / math.log10( len(dtwt.keys()) + 512 )))
|
||||
|
||||
def paragraph(self, content_tks: str, keywords: list = [], keywords_topn=30):
|
||||
if isinstance(content_tks, str):
|
||||
@ -232,4 +232,5 @@ class FulltextQueryer(QueryBase):
|
||||
keywords.append(f"{tk}^{w}")
|
||||
|
||||
return MatchTextExpr(self.query_fields, " ".join(keywords), 100,
|
||||
{"minimum_should_match": min(3, len(keywords) / 10), "original_query": " ".join(origin_keywords)})
|
||||
{"minimum_should_match": min(3, len(keywords) / 10),
|
||||
"original_query": " ".join(origin_keywords)})
|
||||
|
||||
@ -66,7 +66,8 @@ class Dealer:
|
||||
if key in req and req[key] is not None:
|
||||
condition[field] = req[key]
|
||||
# TODO(yzc): `available_int` is nullable however infinity doesn't support nullable columns.
|
||||
for key in ["knowledge_graph_kwd", "available_int", "entity_kwd", "from_entity_kwd", "to_entity_kwd", "removed_kwd"]:
|
||||
for key in ["knowledge_graph_kwd", "available_int", "entity_kwd", "from_entity_kwd", "to_entity_kwd",
|
||||
"removed_kwd"]:
|
||||
if key in req and req[key] is not None:
|
||||
condition[key] = req[key]
|
||||
return condition
|
||||
@ -141,7 +142,8 @@ class Dealer:
|
||||
matchText, _ = self.qryr.question(qst, min_match=0.1)
|
||||
matchDense.extra_options["similarity"] = 0.17
|
||||
res = self.dataStore.search(src, highlightFields, filters, [matchText, matchDense, fusionExpr],
|
||||
orderBy, offset, limit, idx_names, kb_ids, rank_feature=rank_feature)
|
||||
orderBy, offset, limit, idx_names, kb_ids,
|
||||
rank_feature=rank_feature)
|
||||
total = self.dataStore.get_total(res)
|
||||
logging.debug("Dealer.search 2 TOTAL: {}".format(total))
|
||||
|
||||
@ -218,8 +220,9 @@ class Dealer:
|
||||
ans_v, _ = embd_mdl.encode(pieces_)
|
||||
for i in range(len(chunk_v)):
|
||||
if len(ans_v[0]) != len(chunk_v[i]):
|
||||
chunk_v[i] = [0.0]*len(ans_v[0])
|
||||
logging.warning("The dimension of query and chunk do not match: {} vs. {}".format(len(ans_v[0]), len(chunk_v[i])))
|
||||
chunk_v[i] = [0.0] * len(ans_v[0])
|
||||
logging.warning(
|
||||
"The dimension of query and chunk do not match: {} vs. {}".format(len(ans_v[0]), len(chunk_v[i])))
|
||||
|
||||
assert len(ans_v[0]) == len(chunk_v[0]), "The dimension of query and chunk do not match: {} vs. {}".format(
|
||||
len(ans_v[0]), len(chunk_v[0]))
|
||||
@ -273,7 +276,7 @@ class Dealer:
|
||||
if not query_rfea:
|
||||
return np.array([0 for _ in range(len(search_res.ids))]) + pageranks
|
||||
|
||||
q_denor = np.sqrt(np.sum([s*s for t,s in query_rfea.items() if t != PAGERANK_FLD]))
|
||||
q_denor = np.sqrt(np.sum([s * s for t, s in query_rfea.items() if t != PAGERANK_FLD]))
|
||||
for i in search_res.ids:
|
||||
nor, denor = 0, 0
|
||||
if not search_res.field[i].get(TAG_FLD):
|
||||
@ -286,8 +289,8 @@ class Dealer:
|
||||
if denor == 0:
|
||||
rank_fea.append(0)
|
||||
else:
|
||||
rank_fea.append(nor/np.sqrt(denor)/q_denor)
|
||||
return np.array(rank_fea)*10. + pageranks
|
||||
rank_fea.append(nor / np.sqrt(denor) / q_denor)
|
||||
return np.array(rank_fea) * 10. + pageranks
|
||||
|
||||
def rerank(self, sres, query, tkweight=0.3,
|
||||
vtweight=0.7, cfield="content_ltks",
|
||||
@ -358,21 +361,21 @@ class Dealer:
|
||||
rag_tokenizer.tokenize(inst).split())
|
||||
|
||||
def retrieval(
|
||||
self,
|
||||
question,
|
||||
embd_mdl,
|
||||
tenant_ids,
|
||||
kb_ids,
|
||||
page,
|
||||
page_size,
|
||||
similarity_threshold=0.2,
|
||||
vector_similarity_weight=0.3,
|
||||
top=1024,
|
||||
doc_ids=None,
|
||||
aggs=True,
|
||||
rerank_mdl=None,
|
||||
highlight=False,
|
||||
rank_feature: dict | None = {PAGERANK_FLD: 10},
|
||||
self,
|
||||
question,
|
||||
embd_mdl,
|
||||
tenant_ids,
|
||||
kb_ids,
|
||||
page,
|
||||
page_size,
|
||||
similarity_threshold=0.2,
|
||||
vector_similarity_weight=0.3,
|
||||
top=1024,
|
||||
doc_ids=None,
|
||||
aggs=True,
|
||||
rerank_mdl=None,
|
||||
highlight=False,
|
||||
rank_feature: dict | None = {PAGERANK_FLD: 10},
|
||||
):
|
||||
ranks = {"total": 0, "chunks": [], "doc_aggs": {}}
|
||||
if not question:
|
||||
@ -395,7 +398,8 @@ class Dealer:
|
||||
if isinstance(tenant_ids, str):
|
||||
tenant_ids = tenant_ids.split(",")
|
||||
|
||||
sres = self.search(req, [index_name(tid) for tid in tenant_ids], kb_ids, embd_mdl, highlight, rank_feature=rank_feature)
|
||||
sres = self.search(req, [index_name(tid) for tid in tenant_ids], kb_ids, embd_mdl, highlight,
|
||||
rank_feature=rank_feature)
|
||||
|
||||
if rerank_mdl and sres.total > 0:
|
||||
sim, tsim, vsim = self.rerank_by_model(
|
||||
@ -558,13 +562,14 @@ class Dealer:
|
||||
|
||||
def tag_content(self, tenant_id: str, kb_ids: list[str], doc, all_tags, topn_tags=3, keywords_topn=30, S=1000):
|
||||
idx_nm = index_name(tenant_id)
|
||||
match_txt = self.qryr.paragraph(doc["title_tks"] + " " + doc["content_ltks"], doc.get("important_kwd", []), keywords_topn)
|
||||
match_txt = self.qryr.paragraph(doc["title_tks"] + " " + doc["content_ltks"], doc.get("important_kwd", []),
|
||||
keywords_topn)
|
||||
res = self.dataStore.search([], [], {}, [match_txt], OrderByExpr(), 0, 0, idx_nm, kb_ids, ["tag_kwd"])
|
||||
aggs = self.dataStore.get_aggregation(res, "tag_kwd")
|
||||
if not aggs:
|
||||
return False
|
||||
cnt = np.sum([c for _, c in aggs])
|
||||
tag_fea = sorted([(a, round(0.1*(c + 1) / (cnt + S) / max(1e-6, all_tags.get(a, 0.0001)))) for a, c in aggs],
|
||||
tag_fea = sorted([(a, round(0.1 * (c + 1) / (cnt + S) / max(1e-6, all_tags.get(a, 0.0001)))) for a, c in aggs],
|
||||
key=lambda x: x[1] * -1)[:topn_tags]
|
||||
doc[TAG_FLD] = {a.replace(".", "_"): c for a, c in tag_fea if c > 0}
|
||||
return True
|
||||
@ -580,11 +585,11 @@ class Dealer:
|
||||
if not aggs:
|
||||
return {}
|
||||
cnt = np.sum([c for _, c in aggs])
|
||||
tag_fea = sorted([(a, round(0.1*(c + 1) / (cnt + S) / max(1e-6, all_tags.get(a, 0.0001)))) for a, c in aggs],
|
||||
tag_fea = sorted([(a, round(0.1 * (c + 1) / (cnt + S) / max(1e-6, all_tags.get(a, 0.0001)))) for a, c in aggs],
|
||||
key=lambda x: x[1] * -1)[:topn_tags]
|
||||
return {a.replace(".", "_"): max(1, c) for a, c in tag_fea}
|
||||
|
||||
def retrieval_by_toc(self, query:str, chunks:list[dict], tenant_ids:list[str], chat_mdl, topn: int=6):
|
||||
def retrieval_by_toc(self, query: str, chunks: list[dict], tenant_ids: list[str], chat_mdl, topn: int = 6):
|
||||
if not chunks:
|
||||
return []
|
||||
idx_nms = [index_name(tid) for tid in tenant_ids]
|
||||
@ -594,9 +599,10 @@ class Dealer:
|
||||
ranks[ck["doc_id"]] = 0
|
||||
ranks[ck["doc_id"]] += ck["similarity"]
|
||||
doc_id2kb_id[ck["doc_id"]] = ck["kb_id"]
|
||||
doc_id = sorted(ranks.items(), key=lambda x: x[1]*-1.)[0][0]
|
||||
doc_id = sorted(ranks.items(), key=lambda x: x[1] * -1.)[0][0]
|
||||
kb_ids = [doc_id2kb_id[doc_id]]
|
||||
es_res = self.dataStore.search(["content_with_weight"], [], {"doc_id": doc_id, "toc_kwd": "toc"}, [], OrderByExpr(), 0, 128, idx_nms,
|
||||
es_res = self.dataStore.search(["content_with_weight"], [], {"doc_id": doc_id, "toc_kwd": "toc"}, [],
|
||||
OrderByExpr(), 0, 128, idx_nms,
|
||||
kb_ids)
|
||||
toc = []
|
||||
dict_chunks = self.dataStore.get_fields(es_res, ["content_with_weight"])
|
||||
@ -608,7 +614,7 @@ class Dealer:
|
||||
if not toc:
|
||||
return chunks
|
||||
|
||||
ids = asyncio.run(relevant_chunks_with_toc(query, toc, chat_mdl, topn*2))
|
||||
ids = asyncio.run(relevant_chunks_with_toc(query, toc, chat_mdl, topn * 2))
|
||||
if not ids:
|
||||
return chunks
|
||||
|
||||
@ -644,9 +650,9 @@ class Dealer:
|
||||
break
|
||||
chunks.append(d)
|
||||
|
||||
return sorted(chunks, key=lambda x:x["similarity"]*-1)[:topn]
|
||||
return sorted(chunks, key=lambda x: x["similarity"] * -1)[:topn]
|
||||
|
||||
def retrieval_by_children(self, chunks:list[dict], tenant_ids:list[str]):
|
||||
def retrieval_by_children(self, chunks: list[dict], tenant_ids: list[str]):
|
||||
if not chunks:
|
||||
return []
|
||||
idx_nms = [index_name(tid) for tid in tenant_ids]
|
||||
@ -692,4 +698,4 @@ class Dealer:
|
||||
break
|
||||
chunks.append(d)
|
||||
|
||||
return sorted(chunks, key=lambda x:x["similarity"]*-1)
|
||||
return sorted(chunks, key=lambda x: x["similarity"] * -1)
|
||||
|
||||
@ -14,129 +14,131 @@
|
||||
# limitations under the License.
|
||||
#
|
||||
|
||||
m = set(["赵","钱","孙","李",
|
||||
"周","吴","郑","王",
|
||||
"冯","陈","褚","卫",
|
||||
"蒋","沈","韩","杨",
|
||||
"朱","秦","尤","许",
|
||||
"何","吕","施","张",
|
||||
"孔","曹","严","华",
|
||||
"金","魏","陶","姜",
|
||||
"戚","谢","邹","喻",
|
||||
"柏","水","窦","章",
|
||||
"云","苏","潘","葛",
|
||||
"奚","范","彭","郎",
|
||||
"鲁","韦","昌","马",
|
||||
"苗","凤","花","方",
|
||||
"俞","任","袁","柳",
|
||||
"酆","鲍","史","唐",
|
||||
"费","廉","岑","薛",
|
||||
"雷","贺","倪","汤",
|
||||
"滕","殷","罗","毕",
|
||||
"郝","邬","安","常",
|
||||
"乐","于","时","傅",
|
||||
"皮","卞","齐","康",
|
||||
"伍","余","元","卜",
|
||||
"顾","孟","平","黄",
|
||||
"和","穆","萧","尹",
|
||||
"姚","邵","湛","汪",
|
||||
"祁","毛","禹","狄",
|
||||
"米","贝","明","臧",
|
||||
"计","伏","成","戴",
|
||||
"谈","宋","茅","庞",
|
||||
"熊","纪","舒","屈",
|
||||
"项","祝","董","梁",
|
||||
"杜","阮","蓝","闵",
|
||||
"席","季","麻","强",
|
||||
"贾","路","娄","危",
|
||||
"江","童","颜","郭",
|
||||
"梅","盛","林","刁",
|
||||
"钟","徐","邱","骆",
|
||||
"高","夏","蔡","田",
|
||||
"樊","胡","凌","霍",
|
||||
"虞","万","支","柯",
|
||||
"昝","管","卢","莫",
|
||||
"经","房","裘","缪",
|
||||
"干","解","应","宗",
|
||||
"丁","宣","贲","邓",
|
||||
"郁","单","杭","洪",
|
||||
"包","诸","左","石",
|
||||
"崔","吉","钮","龚",
|
||||
"程","嵇","邢","滑",
|
||||
"裴","陆","荣","翁",
|
||||
"荀","羊","於","惠",
|
||||
"甄","曲","家","封",
|
||||
"芮","羿","储","靳",
|
||||
"汲","邴","糜","松",
|
||||
"井","段","富","巫",
|
||||
"乌","焦","巴","弓",
|
||||
"牧","隗","山","谷",
|
||||
"车","侯","宓","蓬",
|
||||
"全","郗","班","仰",
|
||||
"秋","仲","伊","宫",
|
||||
"宁","仇","栾","暴",
|
||||
"甘","钭","厉","戎",
|
||||
"祖","武","符","刘",
|
||||
"景","詹","束","龙",
|
||||
"叶","幸","司","韶",
|
||||
"郜","黎","蓟","薄",
|
||||
"印","宿","白","怀",
|
||||
"蒲","邰","从","鄂",
|
||||
"索","咸","籍","赖",
|
||||
"卓","蔺","屠","蒙",
|
||||
"池","乔","阴","鬱",
|
||||
"胥","能","苍","双",
|
||||
"闻","莘","党","翟",
|
||||
"谭","贡","劳","逄",
|
||||
"姬","申","扶","堵",
|
||||
"冉","宰","郦","雍",
|
||||
"郤","璩","桑","桂",
|
||||
"濮","牛","寿","通",
|
||||
"边","扈","燕","冀",
|
||||
"郏","浦","尚","农",
|
||||
"温","别","庄","晏",
|
||||
"柴","瞿","阎","充",
|
||||
"慕","连","茹","习",
|
||||
"宦","艾","鱼","容",
|
||||
"向","古","易","慎",
|
||||
"戈","廖","庾","终",
|
||||
"暨","居","衡","步",
|
||||
"都","耿","满","弘",
|
||||
"匡","国","文","寇",
|
||||
"广","禄","阙","东",
|
||||
"欧","殳","沃","利",
|
||||
"蔚","越","夔","隆",
|
||||
"师","巩","厍","聂",
|
||||
"晁","勾","敖","融",
|
||||
"冷","訾","辛","阚",
|
||||
"那","简","饶","空",
|
||||
"曾","母","沙","乜",
|
||||
"养","鞠","须","丰",
|
||||
"巢","关","蒯","相",
|
||||
"查","后","荆","红",
|
||||
"游","竺","权","逯",
|
||||
"盖","益","桓","公",
|
||||
"兰","原","乞","西","阿","肖","丑","位","曽","巨","德","代","圆","尉","仵","纳","仝","脱","丘","但","展","迪","付","覃","晗","特","隋","苑","奥","漆","谌","郄","练","扎","邝","渠","信","门","陳","化","原","密","泮","鹿","赫",
|
||||
"万俟","司马","上官","欧阳",
|
||||
"夏侯","诸葛","闻人","东方",
|
||||
"赫连","皇甫","尉迟","公羊",
|
||||
"澹台","公冶","宗政","濮阳",
|
||||
"淳于","单于","太叔","申屠",
|
||||
"公孙","仲孙","轩辕","令狐",
|
||||
"钟离","宇文","长孙","慕容",
|
||||
"鲜于","闾丘","司徒","司空",
|
||||
"亓官","司寇","仉督","子车",
|
||||
"颛孙","端木","巫马","公西",
|
||||
"漆雕","乐正","壤驷","公良",
|
||||
"拓跋","夹谷","宰父","榖梁",
|
||||
"晋","楚","闫","法","汝","鄢","涂","钦",
|
||||
"段干","百里","东郭","南门",
|
||||
"呼延","归","海","羊舌","微","生",
|
||||
"岳","帅","缑","亢","况","后","有","琴",
|
||||
"梁丘","左丘","东门","西门",
|
||||
"商","牟","佘","佴","伯","赏","南宫",
|
||||
"墨","哈","谯","笪","年","爱","阳","佟",
|
||||
"第五","言","福"])
|
||||
m = set(["赵", "钱", "孙", "李",
|
||||
"周", "吴", "郑", "王",
|
||||
"冯", "陈", "褚", "卫",
|
||||
"蒋", "沈", "韩", "杨",
|
||||
"朱", "秦", "尤", "许",
|
||||
"何", "吕", "施", "张",
|
||||
"孔", "曹", "严", "华",
|
||||
"金", "魏", "陶", "姜",
|
||||
"戚", "谢", "邹", "喻",
|
||||
"柏", "水", "窦", "章",
|
||||
"云", "苏", "潘", "葛",
|
||||
"奚", "范", "彭", "郎",
|
||||
"鲁", "韦", "昌", "马",
|
||||
"苗", "凤", "花", "方",
|
||||
"俞", "任", "袁", "柳",
|
||||
"酆", "鲍", "史", "唐",
|
||||
"费", "廉", "岑", "薛",
|
||||
"雷", "贺", "倪", "汤",
|
||||
"滕", "殷", "罗", "毕",
|
||||
"郝", "邬", "安", "常",
|
||||
"乐", "于", "时", "傅",
|
||||
"皮", "卞", "齐", "康",
|
||||
"伍", "余", "元", "卜",
|
||||
"顾", "孟", "平", "黄",
|
||||
"和", "穆", "萧", "尹",
|
||||
"姚", "邵", "湛", "汪",
|
||||
"祁", "毛", "禹", "狄",
|
||||
"米", "贝", "明", "臧",
|
||||
"计", "伏", "成", "戴",
|
||||
"谈", "宋", "茅", "庞",
|
||||
"熊", "纪", "舒", "屈",
|
||||
"项", "祝", "董", "梁",
|
||||
"杜", "阮", "蓝", "闵",
|
||||
"席", "季", "麻", "强",
|
||||
"贾", "路", "娄", "危",
|
||||
"江", "童", "颜", "郭",
|
||||
"梅", "盛", "林", "刁",
|
||||
"钟", "徐", "邱", "骆",
|
||||
"高", "夏", "蔡", "田",
|
||||
"樊", "胡", "凌", "霍",
|
||||
"虞", "万", "支", "柯",
|
||||
"昝", "管", "卢", "莫",
|
||||
"经", "房", "裘", "缪",
|
||||
"干", "解", "应", "宗",
|
||||
"丁", "宣", "贲", "邓",
|
||||
"郁", "单", "杭", "洪",
|
||||
"包", "诸", "左", "石",
|
||||
"崔", "吉", "钮", "龚",
|
||||
"程", "嵇", "邢", "滑",
|
||||
"裴", "陆", "荣", "翁",
|
||||
"荀", "羊", "於", "惠",
|
||||
"甄", "曲", "家", "封",
|
||||
"芮", "羿", "储", "靳",
|
||||
"汲", "邴", "糜", "松",
|
||||
"井", "段", "富", "巫",
|
||||
"乌", "焦", "巴", "弓",
|
||||
"牧", "隗", "山", "谷",
|
||||
"车", "侯", "宓", "蓬",
|
||||
"全", "郗", "班", "仰",
|
||||
"秋", "仲", "伊", "宫",
|
||||
"宁", "仇", "栾", "暴",
|
||||
"甘", "钭", "厉", "戎",
|
||||
"祖", "武", "符", "刘",
|
||||
"景", "詹", "束", "龙",
|
||||
"叶", "幸", "司", "韶",
|
||||
"郜", "黎", "蓟", "薄",
|
||||
"印", "宿", "白", "怀",
|
||||
"蒲", "邰", "从", "鄂",
|
||||
"索", "咸", "籍", "赖",
|
||||
"卓", "蔺", "屠", "蒙",
|
||||
"池", "乔", "阴", "鬱",
|
||||
"胥", "能", "苍", "双",
|
||||
"闻", "莘", "党", "翟",
|
||||
"谭", "贡", "劳", "逄",
|
||||
"姬", "申", "扶", "堵",
|
||||
"冉", "宰", "郦", "雍",
|
||||
"郤", "璩", "桑", "桂",
|
||||
"濮", "牛", "寿", "通",
|
||||
"边", "扈", "燕", "冀",
|
||||
"郏", "浦", "尚", "农",
|
||||
"温", "别", "庄", "晏",
|
||||
"柴", "瞿", "阎", "充",
|
||||
"慕", "连", "茹", "习",
|
||||
"宦", "艾", "鱼", "容",
|
||||
"向", "古", "易", "慎",
|
||||
"戈", "廖", "庾", "终",
|
||||
"暨", "居", "衡", "步",
|
||||
"都", "耿", "满", "弘",
|
||||
"匡", "国", "文", "寇",
|
||||
"广", "禄", "阙", "东",
|
||||
"欧", "殳", "沃", "利",
|
||||
"蔚", "越", "夔", "隆",
|
||||
"师", "巩", "厍", "聂",
|
||||
"晁", "勾", "敖", "融",
|
||||
"冷", "訾", "辛", "阚",
|
||||
"那", "简", "饶", "空",
|
||||
"曾", "母", "沙", "乜",
|
||||
"养", "鞠", "须", "丰",
|
||||
"巢", "关", "蒯", "相",
|
||||
"查", "后", "荆", "红",
|
||||
"游", "竺", "权", "逯",
|
||||
"盖", "益", "桓", "公",
|
||||
"兰", "原", "乞", "西", "阿", "肖", "丑", "位", "曽", "巨", "德", "代", "圆", "尉", "仵", "纳", "仝", "脱",
|
||||
"丘", "但", "展", "迪", "付", "覃", "晗", "特", "隋", "苑", "奥", "漆", "谌", "郄", "练", "扎", "邝", "渠",
|
||||
"信", "门", "陳", "化", "原", "密", "泮", "鹿", "赫",
|
||||
"万俟", "司马", "上官", "欧阳",
|
||||
"夏侯", "诸葛", "闻人", "东方",
|
||||
"赫连", "皇甫", "尉迟", "公羊",
|
||||
"澹台", "公冶", "宗政", "濮阳",
|
||||
"淳于", "单于", "太叔", "申屠",
|
||||
"公孙", "仲孙", "轩辕", "令狐",
|
||||
"钟离", "宇文", "长孙", "慕容",
|
||||
"鲜于", "闾丘", "司徒", "司空",
|
||||
"亓官", "司寇", "仉督", "子车",
|
||||
"颛孙", "端木", "巫马", "公西",
|
||||
"漆雕", "乐正", "壤驷", "公良",
|
||||
"拓跋", "夹谷", "宰父", "榖梁",
|
||||
"晋", "楚", "闫", "法", "汝", "鄢", "涂", "钦",
|
||||
"段干", "百里", "东郭", "南门",
|
||||
"呼延", "归", "海", "羊舌", "微", "生",
|
||||
"岳", "帅", "缑", "亢", "况", "后", "有", "琴",
|
||||
"梁丘", "左丘", "东门", "西门",
|
||||
"商", "牟", "佘", "佴", "伯", "赏", "南宫",
|
||||
"墨", "哈", "谯", "笪", "年", "爱", "阳", "佟",
|
||||
"第五", "言", "福"])
|
||||
|
||||
def isit(n):return n.strip() in m
|
||||
|
||||
def isit(n): return n.strip() in m
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
#
|
||||
#
|
||||
# Copyright 2024 The InfiniFlow Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
@ -108,13 +108,14 @@ class Dealer:
|
||||
if re.match(p, t):
|
||||
tk = "#"
|
||||
break
|
||||
#tk = re.sub(r"([\+\\-])", r"\\\1", tk)
|
||||
# tk = re.sub(r"([\+\\-])", r"\\\1", tk)
|
||||
if tk != "#" and tk:
|
||||
res.append(tk)
|
||||
return res
|
||||
|
||||
def token_merge(self, tks):
|
||||
def one_term(t): return len(t) == 1 or re.match(r"[0-9a-z]{1,2}$", t)
|
||||
def one_term(t):
|
||||
return len(t) == 1 or re.match(r"[0-9a-z]{1,2}$", t)
|
||||
|
||||
res, i = [], 0
|
||||
while i < len(tks):
|
||||
@ -152,8 +153,8 @@ class Dealer:
|
||||
tks = []
|
||||
for t in re.sub(r"[ \t]+", " ", txt).split():
|
||||
if tks and re.match(r".*[a-zA-Z]$", tks[-1]) and \
|
||||
re.match(r".*[a-zA-Z]$", t) and tks and \
|
||||
self.ne.get(t, "") != "func" and self.ne.get(tks[-1], "") != "func":
|
||||
re.match(r".*[a-zA-Z]$", t) and tks and \
|
||||
self.ne.get(t, "") != "func" and self.ne.get(tks[-1], "") != "func":
|
||||
tks[-1] = tks[-1] + " " + t
|
||||
else:
|
||||
tks.append(t)
|
||||
@ -220,14 +221,15 @@ class Dealer:
|
||||
|
||||
return 3
|
||||
|
||||
def idf(s, N): return math.log10(10 + ((N - s + 0.5) / (s + 0.5)))
|
||||
def idf(s, N):
|
||||
return math.log10(10 + ((N - s + 0.5) / (s + 0.5)))
|
||||
|
||||
tw = []
|
||||
if not preprocess:
|
||||
idf1 = np.array([idf(freq(t), 10000000) for t in tks])
|
||||
idf2 = np.array([idf(df(t), 1000000000) for t in tks])
|
||||
wts = (0.3 * idf1 + 0.7 * idf2) * \
|
||||
np.array([ner(t) * postag(t) for t in tks])
|
||||
np.array([ner(t) * postag(t) for t in tks])
|
||||
wts = [s for s in wts]
|
||||
tw = list(zip(tks, wts))
|
||||
else:
|
||||
@ -236,7 +238,7 @@ class Dealer:
|
||||
idf1 = np.array([idf(freq(t), 10000000) for t in tt])
|
||||
idf2 = np.array([idf(df(t), 1000000000) for t in tt])
|
||||
wts = (0.3 * idf1 + 0.7 * idf2) * \
|
||||
np.array([ner(t) * postag(t) for t in tt])
|
||||
np.array([ner(t) * postag(t) for t in tt])
|
||||
wts = [s for s in wts]
|
||||
tw.extend(zip(tt, wts))
|
||||
|
||||
|
||||
@ -3,4 +3,4 @@ from . import generator
|
||||
__all__ = [name for name in dir(generator)
|
||||
if not name.startswith('_')]
|
||||
|
||||
globals().update({name: getattr(generator, name) for name in __all__})
|
||||
globals().update({name: getattr(generator, name) for name in __all__})
|
||||
|
||||
@ -28,17 +28,16 @@ from rag.prompts.template import load_prompt
|
||||
from common.constants import TAG_FLD
|
||||
from common.token_utils import encoder, num_tokens_from_string
|
||||
|
||||
|
||||
STOP_TOKEN="<|STOP|>"
|
||||
COMPLETE_TASK="complete_task"
|
||||
STOP_TOKEN = "<|STOP|>"
|
||||
COMPLETE_TASK = "complete_task"
|
||||
INPUT_UTILIZATION = 0.5
|
||||
|
||||
|
||||
def get_value(d, k1, k2):
|
||||
return d.get(k1, d.get(k2))
|
||||
|
||||
|
||||
def chunks_format(reference):
|
||||
|
||||
return [
|
||||
{
|
||||
"id": get_value(chunk, "chunk_id", "id"),
|
||||
@ -126,7 +125,7 @@ def kb_prompt(kbinfos, max_tokens, hash_id=False):
|
||||
for i, ck in enumerate(kbinfos["chunks"][:chunks_num]):
|
||||
cnt = "\nID: {}".format(i if not hash_id else hash_str2int(get_value(ck, "id", "chunk_id"), 500))
|
||||
cnt += draw_node("Title", get_value(ck, "docnm_kwd", "document_name"))
|
||||
cnt += draw_node("URL", ck['url']) if "url" in ck else ""
|
||||
cnt += draw_node("URL", ck['url']) if "url" in ck else ""
|
||||
for k, v in docs.get(get_value(ck, "doc_id", "document_id"), {}).items():
|
||||
cnt += draw_node(k, v)
|
||||
cnt += "\n└── Content:\n"
|
||||
@ -173,7 +172,7 @@ ASK_SUMMARY = load_prompt("ask_summary")
|
||||
PROMPT_JINJA_ENV = jinja2.Environment(autoescape=False, trim_blocks=True, lstrip_blocks=True)
|
||||
|
||||
|
||||
def citation_prompt(user_defined_prompts: dict={}) -> str:
|
||||
def citation_prompt(user_defined_prompts: dict = {}) -> str:
|
||||
template = PROMPT_JINJA_ENV.from_string(user_defined_prompts.get("citation_guidelines", CITATION_PROMPT_TEMPLATE))
|
||||
return template.render()
|
||||
|
||||
@ -258,9 +257,11 @@ async def cross_languages(tenant_id, llm_id, query, languages=[]):
|
||||
chat_mdl = LLMBundle(tenant_id, LLMType.CHAT, llm_id)
|
||||
|
||||
rendered_sys_prompt = PROMPT_JINJA_ENV.from_string(CROSS_LANGUAGES_SYS_PROMPT_TEMPLATE).render()
|
||||
rendered_user_prompt = PROMPT_JINJA_ENV.from_string(CROSS_LANGUAGES_USER_PROMPT_TEMPLATE).render(query=query, languages=languages)
|
||||
rendered_user_prompt = PROMPT_JINJA_ENV.from_string(CROSS_LANGUAGES_USER_PROMPT_TEMPLATE).render(query=query,
|
||||
languages=languages)
|
||||
|
||||
ans = await chat_mdl.async_chat(rendered_sys_prompt, [{"role": "user", "content": rendered_user_prompt}], {"temperature": 0.2})
|
||||
ans = await chat_mdl.async_chat(rendered_sys_prompt, [{"role": "user", "content": rendered_user_prompt}],
|
||||
{"temperature": 0.2})
|
||||
ans = re.sub(r"^.*</think>", "", ans, flags=re.DOTALL)
|
||||
if ans.find("**ERROR**") >= 0:
|
||||
return query
|
||||
@ -332,7 +333,8 @@ def tool_schema(tools_description: list[dict], complete_task=False):
|
||||
"description": "When you have the final answer and are ready to complete the task, call this function with your answer",
|
||||
"parameters": {
|
||||
"type": "object",
|
||||
"properties": {"answer":{"type":"string", "description": "The final answer to the user's question"}},
|
||||
"properties": {
|
||||
"answer": {"type": "string", "description": "The final answer to the user's question"}},
|
||||
"required": ["answer"]
|
||||
}
|
||||
}
|
||||
@ -341,7 +343,8 @@ def tool_schema(tools_description: list[dict], complete_task=False):
|
||||
name = tool["function"]["name"]
|
||||
desc[name] = tool
|
||||
|
||||
return "\n\n".join([f"## {i+1}. {fnm}\n{json.dumps(des, ensure_ascii=False, indent=4)}" for i, (fnm, des) in enumerate(desc.items())])
|
||||
return "\n\n".join([f"## {i + 1}. {fnm}\n{json.dumps(des, ensure_ascii=False, indent=4)}" for i, (fnm, des) in
|
||||
enumerate(desc.items())])
|
||||
|
||||
|
||||
def form_history(history, limit=-6):
|
||||
@ -350,14 +353,14 @@ def form_history(history, limit=-6):
|
||||
if h["role"] == "system":
|
||||
continue
|
||||
role = "USER"
|
||||
if h["role"].upper()!= role:
|
||||
if h["role"].upper() != role:
|
||||
role = "AGENT"
|
||||
context += f"\n{role}: {h['content'][:2048] + ('...' if len(h['content'])>2048 else '')}"
|
||||
context += f"\n{role}: {h['content'][:2048] + ('...' if len(h['content']) > 2048 else '')}"
|
||||
return context
|
||||
|
||||
|
||||
|
||||
async def analyze_task_async(chat_mdl, prompt, task_name, tools_description: list[dict], user_defined_prompts: dict={}):
|
||||
async def analyze_task_async(chat_mdl, prompt, task_name, tools_description: list[dict],
|
||||
user_defined_prompts: dict = {}):
|
||||
tools_desc = tool_schema(tools_description)
|
||||
context = ""
|
||||
|
||||
@ -375,7 +378,8 @@ async def analyze_task_async(chat_mdl, prompt, task_name, tools_description: lis
|
||||
return kwd
|
||||
|
||||
|
||||
async def next_step_async(chat_mdl, history:list, tools_description: list[dict], task_desc, user_defined_prompts: dict={}):
|
||||
async def next_step_async(chat_mdl, history: list, tools_description: list[dict], task_desc,
|
||||
user_defined_prompts: dict = {}):
|
||||
if not tools_description:
|
||||
return "", 0
|
||||
desc = tool_schema(tools_description)
|
||||
@ -396,7 +400,7 @@ async def next_step_async(chat_mdl, history:list, tools_description: list[dict],
|
||||
return json_str, tk_cnt
|
||||
|
||||
|
||||
async def reflect_async(chat_mdl, history: list[dict], tool_call_res: list[Tuple], user_defined_prompts: dict={}):
|
||||
async def reflect_async(chat_mdl, history: list[dict], tool_call_res: list[Tuple], user_defined_prompts: dict = {}):
|
||||
tool_calls = [{"name": p[0], "result": p[1]} for p in tool_call_res]
|
||||
goal = history[1]["content"]
|
||||
template = PROMPT_JINJA_ENV.from_string(user_defined_prompts.get("reflection", REFLECT))
|
||||
@ -419,7 +423,7 @@ async def reflect_async(chat_mdl, history: list[dict], tool_call_res: list[Tuple
|
||||
|
||||
|
||||
def form_message(system_prompt, user_prompt):
|
||||
return [{"role": "system", "content": system_prompt},{"role": "user", "content": user_prompt}]
|
||||
return [{"role": "system", "content": system_prompt}, {"role": "user", "content": user_prompt}]
|
||||
|
||||
|
||||
def structured_output_prompt(schema=None) -> str:
|
||||
@ -427,27 +431,29 @@ def structured_output_prompt(schema=None) -> str:
|
||||
return template.render(schema=schema)
|
||||
|
||||
|
||||
async def tool_call_summary(chat_mdl, name: str, params: dict, result: str, user_defined_prompts: dict={}) -> str:
|
||||
async def tool_call_summary(chat_mdl, name: str, params: dict, result: str, user_defined_prompts: dict = {}) -> str:
|
||||
template = PROMPT_JINJA_ENV.from_string(SUMMARY4MEMORY)
|
||||
system_prompt = template.render(name=name,
|
||||
params=json.dumps(params, ensure_ascii=False, indent=2),
|
||||
result=result)
|
||||
params=json.dumps(params, ensure_ascii=False, indent=2),
|
||||
result=result)
|
||||
user_prompt = "→ Summary: "
|
||||
_, msg = message_fit_in(form_message(system_prompt, user_prompt), chat_mdl.max_length)
|
||||
ans = await chat_mdl.async_chat(msg[0]["content"], msg[1:])
|
||||
return re.sub(r"^.*</think>", "", ans, flags=re.DOTALL)
|
||||
|
||||
|
||||
async def rank_memories_async(chat_mdl, goal:str, sub_goal:str, tool_call_summaries: list[str], user_defined_prompts: dict={}):
|
||||
async def rank_memories_async(chat_mdl, goal: str, sub_goal: str, tool_call_summaries: list[str],
|
||||
user_defined_prompts: dict = {}):
|
||||
template = PROMPT_JINJA_ENV.from_string(RANK_MEMORY)
|
||||
system_prompt = template.render(goal=goal, sub_goal=sub_goal, results=[{"i": i, "content": s} for i,s in enumerate(tool_call_summaries)])
|
||||
system_prompt = template.render(goal=goal, sub_goal=sub_goal,
|
||||
results=[{"i": i, "content": s} for i, s in enumerate(tool_call_summaries)])
|
||||
user_prompt = " → rank: "
|
||||
_, msg = message_fit_in(form_message(system_prompt, user_prompt), chat_mdl.max_length)
|
||||
ans = await chat_mdl.async_chat(msg[0]["content"], msg[1:], stop="<|stop|>")
|
||||
return re.sub(r"^.*</think>", "", ans, flags=re.DOTALL)
|
||||
|
||||
|
||||
async def gen_meta_filter(chat_mdl, meta_data:dict, query: str) -> dict:
|
||||
async def gen_meta_filter(chat_mdl, meta_data: dict, query: str) -> dict:
|
||||
meta_data_structure = {}
|
||||
for key, values in meta_data.items():
|
||||
meta_data_structure[key] = list(values.keys()) if isinstance(values, dict) else values
|
||||
@ -471,13 +477,13 @@ async def gen_meta_filter(chat_mdl, meta_data:dict, query: str) -> dict:
|
||||
return {"conditions": []}
|
||||
|
||||
|
||||
async def gen_json(system_prompt:str, user_prompt:str, chat_mdl, gen_conf = None):
|
||||
async def gen_json(system_prompt: str, user_prompt: str, chat_mdl, gen_conf=None):
|
||||
from graphrag.utils import get_llm_cache, set_llm_cache
|
||||
cached = get_llm_cache(chat_mdl.llm_name, system_prompt, user_prompt, gen_conf)
|
||||
if cached:
|
||||
return json_repair.loads(cached)
|
||||
_, msg = message_fit_in(form_message(system_prompt, user_prompt), chat_mdl.max_length)
|
||||
ans = await chat_mdl.async_chat(msg[0]["content"], msg[1:],gen_conf=gen_conf)
|
||||
ans = await chat_mdl.async_chat(msg[0]["content"], msg[1:], gen_conf=gen_conf)
|
||||
ans = re.sub(r"(^.*</think>|```json\n|```\n*$)", "", ans, flags=re.DOTALL)
|
||||
try:
|
||||
res = json_repair.loads(ans)
|
||||
@ -488,10 +494,13 @@ async def gen_json(system_prompt:str, user_prompt:str, chat_mdl, gen_conf = None
|
||||
|
||||
|
||||
TOC_DETECTION = load_prompt("toc_detection")
|
||||
async def detect_table_of_contents(page_1024:list[str], chat_mdl):
|
||||
|
||||
|
||||
async def detect_table_of_contents(page_1024: list[str], chat_mdl):
|
||||
toc_secs = []
|
||||
for i, sec in enumerate(page_1024[:22]):
|
||||
ans = await gen_json(PROMPT_JINJA_ENV.from_string(TOC_DETECTION).render(page_txt=sec), "Only JSON please.", chat_mdl)
|
||||
ans = await gen_json(PROMPT_JINJA_ENV.from_string(TOC_DETECTION).render(page_txt=sec), "Only JSON please.",
|
||||
chat_mdl)
|
||||
if toc_secs and not ans["exists"]:
|
||||
break
|
||||
toc_secs.append(sec)
|
||||
@ -500,14 +509,17 @@ async def detect_table_of_contents(page_1024:list[str], chat_mdl):
|
||||
|
||||
TOC_EXTRACTION = load_prompt("toc_extraction")
|
||||
TOC_EXTRACTION_CONTINUE = load_prompt("toc_extraction_continue")
|
||||
|
||||
|
||||
async def extract_table_of_contents(toc_pages, chat_mdl):
|
||||
if not toc_pages:
|
||||
return []
|
||||
|
||||
return await gen_json(PROMPT_JINJA_ENV.from_string(TOC_EXTRACTION).render(toc_page="\n".join(toc_pages)), "Only JSON please.", chat_mdl)
|
||||
return await gen_json(PROMPT_JINJA_ENV.from_string(TOC_EXTRACTION).render(toc_page="\n".join(toc_pages)),
|
||||
"Only JSON please.", chat_mdl)
|
||||
|
||||
|
||||
async def toc_index_extractor(toc:list[dict], content:str, chat_mdl):
|
||||
async def toc_index_extractor(toc: list[dict], content: str, chat_mdl):
|
||||
tob_extractor_prompt = """
|
||||
You are given a table of contents in a json format and several pages of a document, your job is to add the physical_index to the table of contents in the json format.
|
||||
|
||||
@ -529,18 +541,21 @@ async def toc_index_extractor(toc:list[dict], content:str, chat_mdl):
|
||||
If the title of the section are not in the provided pages, do not add the physical_index to it.
|
||||
Directly return the final JSON structure. Do not output anything else."""
|
||||
|
||||
prompt = tob_extractor_prompt + '\nTable of contents:\n' + json.dumps(toc, ensure_ascii=False, indent=2) + '\nDocument pages:\n' + content
|
||||
prompt = tob_extractor_prompt + '\nTable of contents:\n' + json.dumps(toc, ensure_ascii=False,
|
||||
indent=2) + '\nDocument pages:\n' + content
|
||||
return await gen_json(prompt, "Only JSON please.", chat_mdl)
|
||||
|
||||
|
||||
TOC_INDEX = load_prompt("toc_index")
|
||||
|
||||
|
||||
async def table_of_contents_index(toc_arr: list[dict], sections: list[str], chat_mdl):
|
||||
if not toc_arr or not sections:
|
||||
return []
|
||||
|
||||
toc_map = {}
|
||||
for i, it in enumerate(toc_arr):
|
||||
k1 = (it["structure"]+it["title"]).replace(" ", "")
|
||||
k1 = (it["structure"] + it["title"]).replace(" ", "")
|
||||
k2 = it["title"].strip()
|
||||
if k1 not in toc_map:
|
||||
toc_map[k1] = []
|
||||
@ -558,6 +573,7 @@ async def table_of_contents_index(toc_arr: list[dict], sections: list[str], chat
|
||||
toc_arr[j]["indices"].append(i)
|
||||
|
||||
all_pathes = []
|
||||
|
||||
def dfs(start, path):
|
||||
nonlocal all_pathes
|
||||
if start >= len(toc_arr):
|
||||
@ -565,7 +581,7 @@ async def table_of_contents_index(toc_arr: list[dict], sections: list[str], chat
|
||||
all_pathes.append(path)
|
||||
return
|
||||
if not toc_arr[start]["indices"]:
|
||||
dfs(start+1, path)
|
||||
dfs(start + 1, path)
|
||||
return
|
||||
added = False
|
||||
for j in toc_arr[start]["indices"]:
|
||||
@ -574,12 +590,12 @@ async def table_of_contents_index(toc_arr: list[dict], sections: list[str], chat
|
||||
_path = deepcopy(path)
|
||||
_path.append((j, start))
|
||||
added = True
|
||||
dfs(start+1, _path)
|
||||
dfs(start + 1, _path)
|
||||
if not added and path:
|
||||
all_pathes.append(path)
|
||||
|
||||
dfs(0, [])
|
||||
path = max(all_pathes, key=lambda x:len(x))
|
||||
path = max(all_pathes, key=lambda x: len(x))
|
||||
for it in toc_arr:
|
||||
it["indices"] = []
|
||||
for j, i in path:
|
||||
@ -588,24 +604,24 @@ async def table_of_contents_index(toc_arr: list[dict], sections: list[str], chat
|
||||
|
||||
i = 0
|
||||
while i < len(toc_arr):
|
||||
it = toc_arr[i]
|
||||
it = toc_arr[i]
|
||||
if it["indices"]:
|
||||
i += 1
|
||||
continue
|
||||
|
||||
if i>0 and toc_arr[i-1]["indices"]:
|
||||
st_i = toc_arr[i-1]["indices"][-1]
|
||||
if i > 0 and toc_arr[i - 1]["indices"]:
|
||||
st_i = toc_arr[i - 1]["indices"][-1]
|
||||
else:
|
||||
st_i = 0
|
||||
e = i + 1
|
||||
while e <len(toc_arr) and not toc_arr[e]["indices"]:
|
||||
while e < len(toc_arr) and not toc_arr[e]["indices"]:
|
||||
e += 1
|
||||
if e >= len(toc_arr):
|
||||
e = len(sections)
|
||||
else:
|
||||
e = toc_arr[e]["indices"][0]
|
||||
|
||||
for j in range(st_i, min(e+1, len(sections))):
|
||||
for j in range(st_i, min(e + 1, len(sections))):
|
||||
ans = await gen_json(PROMPT_JINJA_ENV.from_string(TOC_INDEX).render(
|
||||
structure=it["structure"],
|
||||
title=it["title"],
|
||||
@ -656,11 +672,15 @@ async def toc_transformer(toc_pages, chat_mdl):
|
||||
|
||||
toc_content = "\n".join(toc_pages)
|
||||
prompt = init_prompt + '\n Given table of contents\n:' + toc_content
|
||||
|
||||
def clean_toc(arr):
|
||||
for a in arr:
|
||||
a["title"] = re.sub(r"[.·….]{2,}", "", a["title"])
|
||||
|
||||
last_complete = await gen_json(prompt, "Only JSON please.", chat_mdl)
|
||||
if_complete = await check_if_toc_transformation_is_complete(toc_content, json.dumps(last_complete, ensure_ascii=False, indent=2), chat_mdl)
|
||||
if_complete = await check_if_toc_transformation_is_complete(toc_content,
|
||||
json.dumps(last_complete, ensure_ascii=False, indent=2),
|
||||
chat_mdl)
|
||||
clean_toc(last_complete)
|
||||
if if_complete == "yes":
|
||||
return last_complete
|
||||
@ -682,13 +702,17 @@ async def toc_transformer(toc_pages, chat_mdl):
|
||||
break
|
||||
clean_toc(new_complete)
|
||||
last_complete.extend(new_complete)
|
||||
if_complete = await check_if_toc_transformation_is_complete(toc_content, json.dumps(last_complete, ensure_ascii=False, indent=2), chat_mdl)
|
||||
if_complete = await check_if_toc_transformation_is_complete(toc_content,
|
||||
json.dumps(last_complete, ensure_ascii=False,
|
||||
indent=2), chat_mdl)
|
||||
|
||||
return last_complete
|
||||
|
||||
|
||||
TOC_LEVELS = load_prompt("assign_toc_levels")
|
||||
async def assign_toc_levels(toc_secs, chat_mdl, gen_conf = {"temperature": 0.2}):
|
||||
|
||||
|
||||
async def assign_toc_levels(toc_secs, chat_mdl, gen_conf={"temperature": 0.2}):
|
||||
if not toc_secs:
|
||||
return []
|
||||
return await gen_json(
|
||||
@ -701,18 +725,21 @@ async def assign_toc_levels(toc_secs, chat_mdl, gen_conf = {"temperature": 0.2})
|
||||
|
||||
TOC_FROM_TEXT_SYSTEM = load_prompt("toc_from_text_system")
|
||||
TOC_FROM_TEXT_USER = load_prompt("toc_from_text_user")
|
||||
|
||||
|
||||
# Generate TOC from text chunks with text llms
|
||||
async def gen_toc_from_text(txt_info: dict, chat_mdl, callback=None):
|
||||
if callback:
|
||||
callback(msg="")
|
||||
try:
|
||||
ans = await gen_json(
|
||||
PROMPT_JINJA_ENV.from_string(TOC_FROM_TEXT_SYSTEM).render(),
|
||||
PROMPT_JINJA_ENV.from_string(TOC_FROM_TEXT_USER).render(text="\n".join([json.dumps(d, ensure_ascii=False) for d in txt_info["chunks"]])),
|
||||
PROMPT_JINJA_ENV.from_string(TOC_FROM_TEXT_USER).render(
|
||||
text="\n".join([json.dumps(d, ensure_ascii=False) for d in txt_info["chunks"]])),
|
||||
chat_mdl,
|
||||
gen_conf={"temperature": 0.0, "top_p": 0.9}
|
||||
)
|
||||
txt_info["toc"] = ans if ans and not isinstance(ans, str) else []
|
||||
if callback:
|
||||
callback(msg="")
|
||||
except Exception as e:
|
||||
logging.exception(e)
|
||||
|
||||
@ -743,7 +770,7 @@ async def run_toc_from_text(chunks, chat_mdl, callback=None):
|
||||
TOC_FROM_TEXT_USER + TOC_FROM_TEXT_SYSTEM
|
||||
)
|
||||
|
||||
input_budget = 1024 if input_budget > 1024 else input_budget
|
||||
input_budget = 1024 if input_budget > 1024 else input_budget
|
||||
chunk_sections = split_chunks(chunks, input_budget)
|
||||
titles = []
|
||||
|
||||
@ -798,7 +825,7 @@ async def run_toc_from_text(chunks, chat_mdl, callback=None):
|
||||
if sorted_list:
|
||||
max_lvl = sorted_list[-1]
|
||||
merged = []
|
||||
for _ , (toc_item, src_item) in enumerate(zip(toc_with_levels, filtered)):
|
||||
for _, (toc_item, src_item) in enumerate(zip(toc_with_levels, filtered)):
|
||||
if prune and toc_item.get("level", "0") >= max_lvl:
|
||||
continue
|
||||
merged.append({
|
||||
@ -812,12 +839,15 @@ async def run_toc_from_text(chunks, chat_mdl, callback=None):
|
||||
|
||||
TOC_RELEVANCE_SYSTEM = load_prompt("toc_relevance_system")
|
||||
TOC_RELEVANCE_USER = load_prompt("toc_relevance_user")
|
||||
async def relevant_chunks_with_toc(query: str, toc:list[dict], chat_mdl, topn: int=6):
|
||||
|
||||
|
||||
async def relevant_chunks_with_toc(query: str, toc: list[dict], chat_mdl, topn: int = 6):
|
||||
import numpy as np
|
||||
try:
|
||||
ans = await gen_json(
|
||||
PROMPT_JINJA_ENV.from_string(TOC_RELEVANCE_SYSTEM).render(),
|
||||
PROMPT_JINJA_ENV.from_string(TOC_RELEVANCE_USER).render(query=query, toc_json="[\n%s\n]\n"%"\n".join([json.dumps({"level": d["level"], "title":d["title"]}, ensure_ascii=False) for d in toc])),
|
||||
PROMPT_JINJA_ENV.from_string(TOC_RELEVANCE_USER).render(query=query, toc_json="[\n%s\n]\n" % "\n".join(
|
||||
[json.dumps({"level": d["level"], "title": d["title"]}, ensure_ascii=False) for d in toc])),
|
||||
chat_mdl,
|
||||
gen_conf={"temperature": 0.0, "top_p": 0.9}
|
||||
)
|
||||
@ -828,17 +858,19 @@ async def relevant_chunks_with_toc(query: str, toc:list[dict], chat_mdl, topn: i
|
||||
for id in ti.get("ids", []):
|
||||
if id not in id2score:
|
||||
id2score[id] = []
|
||||
id2score[id].append(sc["score"]/5.)
|
||||
id2score[id].append(sc["score"] / 5.)
|
||||
for id in id2score.keys():
|
||||
id2score[id] = np.mean(id2score[id])
|
||||
return [(id, sc) for id, sc in list(id2score.items()) if sc>=0.3][:topn]
|
||||
return [(id, sc) for id, sc in list(id2score.items()) if sc >= 0.3][:topn]
|
||||
except Exception as e:
|
||||
logging.exception(e)
|
||||
return []
|
||||
|
||||
|
||||
META_DATA = load_prompt("meta_data")
|
||||
async def gen_metadata(chat_mdl, schema:dict, content:str):
|
||||
|
||||
|
||||
async def gen_metadata(chat_mdl, schema: dict, content: str):
|
||||
template = PROMPT_JINJA_ENV.from_string(META_DATA)
|
||||
for k, desc in schema["properties"].items():
|
||||
if "enum" in desc and not desc.get("enum"):
|
||||
@ -849,4 +881,4 @@ async def gen_metadata(chat_mdl, schema:dict, content:str):
|
||||
user_prompt = "Output: "
|
||||
_, msg = message_fit_in(form_message(system_prompt, user_prompt), chat_mdl.max_length)
|
||||
ans = await chat_mdl.async_chat(msg[0]["content"], msg[1:])
|
||||
return re.sub(r"^.*</think>", "", ans, flags=re.DOTALL)
|
||||
return re.sub(r"^.*</think>", "", ans, flags=re.DOTALL)
|
||||
|
||||
@ -1,6 +1,5 @@
|
||||
import os
|
||||
|
||||
|
||||
PROMPT_DIR = os.path.dirname(__file__)
|
||||
|
||||
_loaded_prompts = {}
|
||||
|
||||
@ -48,13 +48,15 @@ def main():
|
||||
REDIS_CONN.transaction(key, file_bin, 12 * 60)
|
||||
logging.info("CACHE: {}".format(loc))
|
||||
except Exception as e:
|
||||
traceback.print_stack(e)
|
||||
logging.error(f"Error to get data from REDIS: {e}")
|
||||
traceback.print_stack()
|
||||
except Exception as e:
|
||||
traceback.print_stack(e)
|
||||
logging.error(f"Error to check REDIS connection: {e}")
|
||||
traceback.print_stack()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
while True:
|
||||
main()
|
||||
close_connection()
|
||||
time.sleep(1)
|
||||
time.sleep(1)
|
||||
|
||||
@ -19,16 +19,15 @@ import requests
|
||||
import base64
|
||||
import asyncio
|
||||
|
||||
URL = '{YOUR_IP_ADDRESS:PORT}/v1/api/completion_aibotk' # Default: https://demo.ragflow.io/v1/api/completion_aibotk
|
||||
URL = '{YOUR_IP_ADDRESS:PORT}/v1/api/completion_aibotk' # Default: https://demo.ragflow.io/v1/api/completion_aibotk
|
||||
|
||||
JSON_DATA = {
|
||||
"conversation_id": "xxxxxxxxxxxxxxxxxxxxxxxxxxx", # Get conversation id from /api/new_conversation
|
||||
"Authorization": "ragflow-xxxxxxxxxxxxxxxxxxxxxxxxxxxxx", # RAGFlow Assistant Chat Bot API Key
|
||||
"word": "" # User question, don't need to initialize
|
||||
"conversation_id": "xxxxxxxxxxxxxxxxxxxxxxxxxxx", # Get conversation id from /api/new_conversation
|
||||
"Authorization": "ragflow-xxxxxxxxxxxxxxxxxxxxxxxxxxxxx", # RAGFlow Assistant Chat Bot API Key
|
||||
"word": "" # User question, don't need to initialize
|
||||
}
|
||||
|
||||
DISCORD_BOT_KEY = "xxxxxxxxxxxxxxxxxxxxxxxxxx" #Get DISCORD_BOT_KEY from Discord Application
|
||||
|
||||
DISCORD_BOT_KEY = "xxxxxxxxxxxxxxxxxxxxxxxxxx" # Get DISCORD_BOT_KEY from Discord Application
|
||||
|
||||
intents = discord.Intents.default()
|
||||
intents.message_content = True
|
||||
@ -50,7 +49,7 @@ async def on_message(message):
|
||||
if len(message.content.split('> ')) == 1:
|
||||
await message.channel.send("Hi~ How can I help you? ")
|
||||
else:
|
||||
JSON_DATA['word']=message.content.split('> ')[1]
|
||||
JSON_DATA['word'] = message.content.split('> ')[1]
|
||||
response = requests.post(URL, json=JSON_DATA)
|
||||
response_data = response.json().get('data', [])
|
||||
image_bool = False
|
||||
@ -61,9 +60,9 @@ async def on_message(message):
|
||||
if i['type'] == 3:
|
||||
image_bool = True
|
||||
image_data = base64.b64decode(i['url'])
|
||||
with open('tmp_image.png','wb') as file:
|
||||
with open('tmp_image.png', 'wb') as file:
|
||||
file.write(image_data)
|
||||
image= discord.File('tmp_image.png')
|
||||
image = discord.File('tmp_image.png')
|
||||
|
||||
await message.channel.send(f"{message.author.mention}{res}")
|
||||
|
||||
|
||||
@ -38,12 +38,26 @@ from api.db.services.connector_service import ConnectorService, SyncLogsService
|
||||
from api.db.services.knowledgebase_service import KnowledgebaseService
|
||||
from common import settings
|
||||
from common.config_utils import show_configs
|
||||
from common.data_source import BlobStorageConnector, NotionConnector, DiscordConnector, GoogleDriveConnector, MoodleConnector, JiraConnector, DropboxConnector, WebDAVConnector, AirtableConnector
|
||||
from common.data_source import (
|
||||
BlobStorageConnector,
|
||||
NotionConnector,
|
||||
DiscordConnector,
|
||||
GoogleDriveConnector,
|
||||
MoodleConnector,
|
||||
JiraConnector,
|
||||
DropboxConnector,
|
||||
WebDAVConnector,
|
||||
AirtableConnector,
|
||||
AsanaConnector,
|
||||
ImapConnector
|
||||
)
|
||||
from common.constants import FileSource, TaskStatus
|
||||
from common.data_source.config import INDEX_BATCH_SIZE
|
||||
from common.data_source.confluence_connector import ConfluenceConnector
|
||||
from common.data_source.gmail_connector import GmailConnector
|
||||
from common.data_source.box_connector import BoxConnector
|
||||
from common.data_source.github.connector import GithubConnector
|
||||
from common.data_source.gitlab_connector import GitlabConnector
|
||||
from common.data_source.interfaces import CheckpointOutputWrapper
|
||||
from common.log_utils import init_root_logger
|
||||
from common.signal_utils import start_tracemalloc_and_snapshot, stop_tracemalloc
|
||||
@ -96,7 +110,7 @@ class SyncBase:
|
||||
if task["poll_range_start"]:
|
||||
next_update = task["poll_range_start"]
|
||||
|
||||
for document_batch in document_batch_generator:
|
||||
async for document_batch in document_batch_generator:
|
||||
if not document_batch:
|
||||
continue
|
||||
|
||||
@ -161,6 +175,7 @@ class SyncBase:
|
||||
def _get_source_prefix(self):
|
||||
return ""
|
||||
|
||||
|
||||
class _BlobLikeBase(SyncBase):
|
||||
DEFAULT_BUCKET_TYPE: str = "s3"
|
||||
|
||||
@ -199,22 +214,27 @@ class _BlobLikeBase(SyncBase):
|
||||
)
|
||||
return document_batch_generator
|
||||
|
||||
|
||||
class S3(_BlobLikeBase):
|
||||
SOURCE_NAME: str = FileSource.S3
|
||||
DEFAULT_BUCKET_TYPE: str = "s3"
|
||||
|
||||
|
||||
class R2(_BlobLikeBase):
|
||||
SOURCE_NAME: str = FileSource.R2
|
||||
DEFAULT_BUCKET_TYPE: str = "r2"
|
||||
|
||||
|
||||
class OCI_STORAGE(_BlobLikeBase):
|
||||
SOURCE_NAME: str = FileSource.OCI_STORAGE
|
||||
DEFAULT_BUCKET_TYPE: str = "oci_storage"
|
||||
|
||||
|
||||
class GOOGLE_CLOUD_STORAGE(_BlobLikeBase):
|
||||
SOURCE_NAME: str = FileSource.GOOGLE_CLOUD_STORAGE
|
||||
DEFAULT_BUCKET_TYPE: str = "google_cloud_storage"
|
||||
|
||||
|
||||
class Confluence(SyncBase):
|
||||
SOURCE_NAME: str = FileSource.CONFLUENCE
|
||||
|
||||
@ -248,7 +268,9 @@ class Confluence(SyncBase):
|
||||
index_recursively=index_recursively,
|
||||
)
|
||||
|
||||
credentials_provider = StaticCredentialsProvider(tenant_id=task["tenant_id"], connector_name=DocumentSource.CONFLUENCE, credential_json=self.conf["credentials"])
|
||||
credentials_provider = StaticCredentialsProvider(tenant_id=task["tenant_id"],
|
||||
connector_name=DocumentSource.CONFLUENCE,
|
||||
credential_json=self.conf["credentials"])
|
||||
self.connector.set_credentials_provider(credentials_provider)
|
||||
|
||||
# Determine the time range for synchronization based on reindex or poll_range_start
|
||||
@ -280,7 +302,8 @@ class Confluence(SyncBase):
|
||||
doc_generator = wrapper(self.connector.load_from_checkpoint(start_time, end_time, checkpoint))
|
||||
for document, failure, next_checkpoint in doc_generator:
|
||||
if failure is not None:
|
||||
logging.warning("Confluence connector failure: %s", getattr(failure, "failure_message", failure))
|
||||
logging.warning("Confluence connector failure: %s",
|
||||
getattr(failure, "failure_message", failure))
|
||||
continue
|
||||
if document is not None:
|
||||
pending_docs.append(document)
|
||||
@ -300,7 +323,7 @@ class Confluence(SyncBase):
|
||||
async def async_wrapper():
|
||||
for batch in document_batches():
|
||||
yield batch
|
||||
|
||||
|
||||
logging.info("Connect to Confluence: {} {}".format(self.conf["wiki_base"], begin_info))
|
||||
return async_wrapper()
|
||||
|
||||
@ -314,10 +337,12 @@ class Notion(SyncBase):
|
||||
document_generator = (
|
||||
self.connector.load_from_state()
|
||||
if task["reindex"] == "1" or not task["poll_range_start"]
|
||||
else self.connector.poll_source(task["poll_range_start"].timestamp(), datetime.now(timezone.utc).timestamp())
|
||||
else self.connector.poll_source(task["poll_range_start"].timestamp(),
|
||||
datetime.now(timezone.utc).timestamp())
|
||||
)
|
||||
|
||||
begin_info = "totally" if task["reindex"] == "1" or not task["poll_range_start"] else "from {}".format(task["poll_range_start"])
|
||||
begin_info = "totally" if task["reindex"] == "1" or not task["poll_range_start"] else "from {}".format(
|
||||
task["poll_range_start"])
|
||||
logging.info("Connect to Notion: root({}) {}".format(self.conf["root_page_id"], begin_info))
|
||||
return document_generator
|
||||
|
||||
@ -340,10 +365,12 @@ class Discord(SyncBase):
|
||||
document_generator = (
|
||||
self.connector.load_from_state()
|
||||
if task["reindex"] == "1" or not task["poll_range_start"]
|
||||
else self.connector.poll_source(task["poll_range_start"].timestamp(), datetime.now(timezone.utc).timestamp())
|
||||
else self.connector.poll_source(task["poll_range_start"].timestamp(),
|
||||
datetime.now(timezone.utc).timestamp())
|
||||
)
|
||||
|
||||
begin_info = "totally" if task["reindex"] == "1" or not task["poll_range_start"] else "from {}".format(task["poll_range_start"])
|
||||
begin_info = "totally" if task["reindex"] == "1" or not task["poll_range_start"] else "from {}".format(
|
||||
task["poll_range_start"])
|
||||
logging.info("Connect to Discord: servers({}), channel({}) {}".format(server_ids, channel_names, begin_info))
|
||||
return document_generator
|
||||
|
||||
@ -485,7 +512,8 @@ class GoogleDrive(SyncBase):
|
||||
doc_generator = wrapper(self.connector.load_from_checkpoint(start_time, end_time, checkpoint))
|
||||
for document, failure, next_checkpoint in doc_generator:
|
||||
if failure is not None:
|
||||
logging.warning("Google Drive connector failure: %s", getattr(failure, "failure_message", failure))
|
||||
logging.warning("Google Drive connector failure: %s",
|
||||
getattr(failure, "failure_message", failure))
|
||||
continue
|
||||
if document is not None:
|
||||
pending_docs.append(document)
|
||||
@ -646,10 +674,10 @@ class WebDAV(SyncBase):
|
||||
remote_path=self.conf.get("remote_path", "/")
|
||||
)
|
||||
self.connector.load_credentials(self.conf["credentials"])
|
||||
|
||||
|
||||
logging.info(f"Task info: reindex={task['reindex']}, poll_range_start={task['poll_range_start']}")
|
||||
|
||||
if task["reindex"]=="1" or not task["poll_range_start"]:
|
||||
|
||||
if task["reindex"] == "1" or not task["poll_range_start"]:
|
||||
logging.info("Using load_from_state (full sync)")
|
||||
document_batch_generator = self.connector.load_from_state()
|
||||
begin_info = "totally"
|
||||
@ -659,14 +687,15 @@ class WebDAV(SyncBase):
|
||||
logging.info(f"Polling WebDAV from {task['poll_range_start']} (ts: {start_ts}) to now (ts: {end_ts})")
|
||||
document_batch_generator = self.connector.poll_source(start_ts, end_ts)
|
||||
begin_info = "from {}".format(task["poll_range_start"])
|
||||
|
||||
|
||||
logging.info("Connect to WebDAV: {}(path: {}) {}".format(
|
||||
self.conf["base_url"],
|
||||
self.conf.get("remote_path", "/"),
|
||||
begin_info
|
||||
))
|
||||
return document_batch_generator
|
||||
|
||||
|
||||
|
||||
class Moodle(SyncBase):
|
||||
SOURCE_NAME: str = FileSource.MOODLE
|
||||
|
||||
@ -675,24 +704,21 @@ class Moodle(SyncBase):
|
||||
moodle_url=self.conf["moodle_url"],
|
||||
batch_size=self.conf.get("batch_size", INDEX_BATCH_SIZE)
|
||||
)
|
||||
|
||||
|
||||
self.connector.load_credentials(self.conf["credentials"])
|
||||
|
||||
# Determine the time range for synchronization based on reindex or poll_range_start
|
||||
if task["reindex"] == "1" or not task.get("poll_range_start"):
|
||||
poll_start = task.get("poll_range_start")
|
||||
|
||||
if task["reindex"] == "1" or poll_start is None:
|
||||
document_generator = self.connector.load_from_state()
|
||||
begin_info = "totally"
|
||||
else:
|
||||
poll_start = task["poll_range_start"]
|
||||
if poll_start is None:
|
||||
document_generator = self.connector.load_from_state()
|
||||
begin_info = "totally"
|
||||
else:
|
||||
document_generator = self.connector.poll_source(
|
||||
poll_start.timestamp(),
|
||||
datetime.now(timezone.utc).timestamp()
|
||||
)
|
||||
begin_info = "from {}".format(poll_start)
|
||||
document_generator = self.connector.poll_source(
|
||||
poll_start.timestamp(),
|
||||
datetime.now(timezone.utc).timestamp(),
|
||||
)
|
||||
begin_info = f"from {poll_start}"
|
||||
|
||||
logging.info("Connect to Moodle: {} {}".format(self.conf["moodle_url"], begin_info))
|
||||
return document_generator
|
||||
@ -718,27 +744,25 @@ class BOX(SyncBase):
|
||||
token = AccessToken(
|
||||
access_token=credential['access_token'],
|
||||
refresh_token=credential['refresh_token'],
|
||||
)
|
||||
)
|
||||
auth.token_storage.store(token)
|
||||
|
||||
self.connector.load_credentials(auth)
|
||||
if task["reindex"] == "1" or not task["poll_range_start"]:
|
||||
poll_start = task["poll_range_start"]
|
||||
|
||||
if task["reindex"] == "1" or poll_start is None:
|
||||
document_generator = self.connector.load_from_state()
|
||||
begin_info = "totally"
|
||||
else:
|
||||
poll_start = task["poll_range_start"]
|
||||
if poll_start is None:
|
||||
document_generator = self.connector.load_from_state()
|
||||
begin_info = "totally"
|
||||
else:
|
||||
document_generator = self.connector.poll_source(
|
||||
poll_start.timestamp(),
|
||||
datetime.now(timezone.utc).timestamp()
|
||||
)
|
||||
begin_info = "from {}".format(poll_start)
|
||||
document_generator = self.connector.poll_source(
|
||||
poll_start.timestamp(),
|
||||
datetime.now(timezone.utc).timestamp(),
|
||||
)
|
||||
begin_info = f"from {poll_start}"
|
||||
logging.info("Connect to Box: folder_id({}) {}".format(self.conf["folder_id"], begin_info))
|
||||
return document_generator
|
||||
|
||||
|
||||
class Airtable(SyncBase):
|
||||
SOURCE_NAME: str = FileSource.AIRTABLE
|
||||
|
||||
@ -760,6 +784,44 @@ class Airtable(SyncBase):
|
||||
{"airtable_access_token": credentials["airtable_access_token"]}
|
||||
)
|
||||
|
||||
poll_start = task.get("poll_range_start")
|
||||
|
||||
if task.get("reindex") == "1" or poll_start is None:
|
||||
document_generator = self.connector.load_from_state()
|
||||
begin_info = "totally"
|
||||
else:
|
||||
document_generator = self.connector.poll_source(
|
||||
poll_start.timestamp(),
|
||||
datetime.now(timezone.utc).timestamp(),
|
||||
)
|
||||
begin_info = f"from {poll_start}"
|
||||
|
||||
logging.info(
|
||||
"Connect to Airtable: base_id(%s), table(%s) %s",
|
||||
self.conf.get("base_id"),
|
||||
self.conf.get("table_name_or_id"),
|
||||
begin_info,
|
||||
)
|
||||
|
||||
return document_generator
|
||||
|
||||
class Asana(SyncBase):
|
||||
SOURCE_NAME: str = FileSource.ASANA
|
||||
|
||||
async def _generate(self, task: dict):
|
||||
self.connector = AsanaConnector(
|
||||
self.conf.get("asana_workspace_id"),
|
||||
self.conf.get("asana_project_ids"),
|
||||
self.conf.get("asana_team_id"),
|
||||
)
|
||||
credentials = self.conf.get("credentials", {})
|
||||
if "asana_api_token_secret" not in credentials:
|
||||
raise ValueError("Missing asana_api_token_secret in credentials")
|
||||
|
||||
self.connector.load_credentials(
|
||||
{"asana_api_token_secret": credentials["asana_api_token_secret"]}
|
||||
)
|
||||
|
||||
if task.get("reindex") == "1" or not task.get("poll_range_start"):
|
||||
document_generator = self.connector.load_from_state()
|
||||
begin_info = "totally"
|
||||
@ -776,14 +838,190 @@ class Airtable(SyncBase):
|
||||
begin_info = f"from {poll_start}"
|
||||
|
||||
logging.info(
|
||||
"Connect to Airtable: base_id(%s), table(%s) %s",
|
||||
self.conf.get("base_id"),
|
||||
self.conf.get("table_name_or_id"),
|
||||
"Connect to Asana: workspace_id(%s), project_ids(%s), team_id(%s) %s",
|
||||
self.conf.get("asana_workspace_id"),
|
||||
self.conf.get("asana_project_ids"),
|
||||
self.conf.get("asana_team_id"),
|
||||
begin_info,
|
||||
)
|
||||
|
||||
return document_generator
|
||||
|
||||
class Github(SyncBase):
|
||||
SOURCE_NAME: str = FileSource.GITHUB
|
||||
|
||||
async def _generate(self, task: dict):
|
||||
"""
|
||||
Sync files from Github repositories.
|
||||
"""
|
||||
from common.data_source.connector_runner import ConnectorRunner
|
||||
|
||||
self.connector = GithubConnector(
|
||||
repo_owner=self.conf.get("repository_owner"),
|
||||
repositories=self.conf.get("repository_name"),
|
||||
include_prs=self.conf.get("include_pull_requests", False),
|
||||
include_issues=self.conf.get("include_issues", False),
|
||||
)
|
||||
|
||||
credentials = self.conf.get("credentials", {})
|
||||
if "github_access_token" not in credentials:
|
||||
raise ValueError("Missing github_access_token in credentials")
|
||||
|
||||
self.connector.load_credentials(
|
||||
{"github_access_token": credentials["github_access_token"]}
|
||||
)
|
||||
|
||||
if task.get("reindex") == "1" or not task.get("poll_range_start"):
|
||||
start_time = datetime.fromtimestamp(0, tz=timezone.utc)
|
||||
begin_info = "totally"
|
||||
else:
|
||||
start_time = task.get("poll_range_start")
|
||||
begin_info = f"from {start_time}"
|
||||
|
||||
end_time = datetime.now(timezone.utc)
|
||||
|
||||
runner = ConnectorRunner(
|
||||
connector=self.connector,
|
||||
batch_size=self.conf.get("batch_size", INDEX_BATCH_SIZE),
|
||||
include_permissions=False,
|
||||
time_range=(start_time, end_time)
|
||||
)
|
||||
|
||||
def document_batches():
|
||||
checkpoint = self.connector.build_dummy_checkpoint()
|
||||
|
||||
while checkpoint.has_more:
|
||||
for doc_batch, failure, next_checkpoint in runner.run(checkpoint):
|
||||
if failure is not None:
|
||||
logging.warning(
|
||||
"Github connector failure: %s",
|
||||
getattr(failure, "failure_message", failure),
|
||||
)
|
||||
continue
|
||||
if doc_batch is not None:
|
||||
yield doc_batch
|
||||
if next_checkpoint is not None:
|
||||
checkpoint = next_checkpoint
|
||||
|
||||
async def async_wrapper():
|
||||
for batch in document_batches():
|
||||
yield batch
|
||||
|
||||
logging.info(
|
||||
"Connect to Github: org_name(%s), repo_names(%s) for %s",
|
||||
self.conf.get("repository_owner"),
|
||||
self.conf.get("repository_name"),
|
||||
begin_info,
|
||||
)
|
||||
|
||||
return async_wrapper()
|
||||
|
||||
class IMAP(SyncBase):
|
||||
SOURCE_NAME: str = FileSource.IMAP
|
||||
|
||||
async def _generate(self, task):
|
||||
from common.data_source.config import DocumentSource
|
||||
from common.data_source.interfaces import StaticCredentialsProvider
|
||||
self.connector = ImapConnector(
|
||||
host=self.conf.get("imap_host"),
|
||||
port=self.conf.get("imap_port"),
|
||||
mailboxes=self.conf.get("imap_mailbox"),
|
||||
)
|
||||
credentials_provider = StaticCredentialsProvider(tenant_id=task["tenant_id"], connector_name=DocumentSource.IMAP, credential_json=self.conf["credentials"])
|
||||
self.connector.set_credentials_provider(credentials_provider)
|
||||
end_time = datetime.now(timezone.utc).timestamp()
|
||||
if task["reindex"] == "1" or not task["poll_range_start"]:
|
||||
start_time = end_time - self.conf.get("poll_range",30) * 24 * 60 * 60
|
||||
begin_info = "totally"
|
||||
else:
|
||||
start_time = task["poll_range_start"].timestamp()
|
||||
begin_info = f"from {task['poll_range_start']}"
|
||||
raw_batch_size = self.conf.get("sync_batch_size") or self.conf.get("batch_size") or INDEX_BATCH_SIZE
|
||||
try:
|
||||
batch_size = int(raw_batch_size)
|
||||
except (TypeError, ValueError):
|
||||
batch_size = INDEX_BATCH_SIZE
|
||||
if batch_size <= 0:
|
||||
batch_size = INDEX_BATCH_SIZE
|
||||
|
||||
def document_batches():
|
||||
checkpoint = self.connector.build_dummy_checkpoint()
|
||||
pending_docs = []
|
||||
iterations = 0
|
||||
iteration_limit = 100_000
|
||||
while checkpoint.has_more:
|
||||
wrapper = CheckpointOutputWrapper()
|
||||
doc_generator = wrapper(self.connector.load_from_checkpoint(start_time, end_time, checkpoint))
|
||||
for document, failure, next_checkpoint in doc_generator:
|
||||
if failure is not None:
|
||||
logging.warning("IMAP connector failure: %s", getattr(failure, "failure_message", failure))
|
||||
continue
|
||||
if document is not None:
|
||||
pending_docs.append(document)
|
||||
if len(pending_docs) >= batch_size:
|
||||
yield pending_docs
|
||||
pending_docs = []
|
||||
if next_checkpoint is not None:
|
||||
checkpoint = next_checkpoint
|
||||
|
||||
iterations += 1
|
||||
if iterations > iteration_limit:
|
||||
raise RuntimeError("Too many iterations while loading IMAP documents.")
|
||||
|
||||
if pending_docs:
|
||||
yield pending_docs
|
||||
|
||||
logging.info(
|
||||
"Connect to IMAP: host(%s) port(%s) user(%s) folder(%s) %s",
|
||||
self.conf["imap_host"],
|
||||
self.conf["imap_port"],
|
||||
self.conf["credentials"]["imap_username"],
|
||||
self.conf["imap_mailbox"],
|
||||
begin_info
|
||||
)
|
||||
return document_batches()
|
||||
|
||||
|
||||
class Gitlab(SyncBase):
|
||||
SOURCE_NAME: str = FileSource.GITLAB
|
||||
|
||||
async def _generate(self, task: dict):
|
||||
"""
|
||||
Sync files from GitLab attachments.
|
||||
"""
|
||||
|
||||
self.connector = GitlabConnector(
|
||||
project_owner= self.conf.get("project_owner"),
|
||||
project_name= self.conf.get("project_name"),
|
||||
include_mrs = self.conf.get("include_mrs", False),
|
||||
include_issues = self.conf.get("include_issues", False),
|
||||
include_code_files= self.conf.get("include_code_files", False),
|
||||
)
|
||||
|
||||
self.connector.load_credentials(
|
||||
{
|
||||
"gitlab_access_token": self.conf.get("credentials", {}).get("gitlab_access_token"),
|
||||
"gitlab_url": self.conf.get("credentials", {}).get("gitlab_url"),
|
||||
}
|
||||
)
|
||||
|
||||
if task["reindex"] == "1" or not task["poll_range_start"]:
|
||||
document_generator = self.connector.load_from_state()
|
||||
begin_info = "totally"
|
||||
else:
|
||||
poll_start = task["poll_range_start"]
|
||||
if poll_start is None:
|
||||
document_generator = self.connector.load_from_state()
|
||||
begin_info = "totally"
|
||||
else:
|
||||
document_generator = self.connector.poll_source(
|
||||
poll_start.timestamp(),
|
||||
datetime.now(timezone.utc).timestamp()
|
||||
)
|
||||
begin_info = "from {}".format(poll_start)
|
||||
logging.info("Connect to Gitlab: ({}) {}".format(self.conf["project_name"], begin_info))
|
||||
return document_generator
|
||||
|
||||
func_factory = {
|
||||
FileSource.S3: S3,
|
||||
FileSource.R2: R2,
|
||||
@ -803,6 +1041,10 @@ func_factory = {
|
||||
FileSource.WEBDAV: WebDAV,
|
||||
FileSource.BOX: BOX,
|
||||
FileSource.AIRTABLE: Airtable,
|
||||
FileSource.ASANA: Asana,
|
||||
FileSource.IMAP: IMAP,
|
||||
FileSource.GITHUB: Github,
|
||||
FileSource.GITLAB: Gitlab,
|
||||
}
|
||||
|
||||
|
||||
|
||||
@ -26,6 +26,7 @@ import time
|
||||
from api.db import PIPELINE_SPECIAL_PROGRESS_FREEZE_TASK_TYPES
|
||||
from api.db.services.knowledgebase_service import KnowledgebaseService
|
||||
from api.db.services.pipeline_operation_log_service import PipelineOperationLogService
|
||||
from api.db.joint_services.memory_message_service import handle_save_to_memory_task
|
||||
from common.connection_utils import timeout
|
||||
from common.metadata_utils import update_metadata_to, metadata_schema
|
||||
from rag.utils.base64_image import image2id
|
||||
@ -92,10 +93,11 @@ FACTORY = {
|
||||
}
|
||||
|
||||
TASK_TYPE_TO_PIPELINE_TASK_TYPE = {
|
||||
"dataflow" : PipelineTaskType.PARSE,
|
||||
"dataflow": PipelineTaskType.PARSE,
|
||||
"raptor": PipelineTaskType.RAPTOR,
|
||||
"graphrag": PipelineTaskType.GRAPH_RAG,
|
||||
"mindmap": PipelineTaskType.MINDMAP,
|
||||
"memory": PipelineTaskType.MEMORY,
|
||||
}
|
||||
|
||||
UNACKED_ITERATOR = None
|
||||
@ -157,8 +159,8 @@ def set_progress(task_id, from_page=0, to_page=-1, prog=None, msg="Processing...
|
||||
logging.info(f"set_progress({task_id}), progress: {prog}, progress_msg: {msg}")
|
||||
except DoesNotExist:
|
||||
logging.warning(f"set_progress({task_id}) got exception DoesNotExist")
|
||||
except Exception:
|
||||
logging.exception(f"set_progress({task_id}), progress: {prog}, progress_msg: {msg}, got exception")
|
||||
except Exception as e:
|
||||
logging.exception(f"set_progress({task_id}), progress: {prog}, progress_msg: {msg}, got exception: {e}")
|
||||
|
||||
|
||||
async def collect():
|
||||
@ -166,6 +168,7 @@ async def collect():
|
||||
global UNACKED_ITERATOR
|
||||
|
||||
svr_queue_names = settings.get_svr_queue_names()
|
||||
redis_msg = None
|
||||
try:
|
||||
if not UNACKED_ITERATOR:
|
||||
UNACKED_ITERATOR = REDIS_CONN.get_unacked_iterator(svr_queue_names, SVR_CONSUMER_GROUP_NAME, CONSUMER_NAME)
|
||||
@ -176,8 +179,8 @@ async def collect():
|
||||
redis_msg = REDIS_CONN.queue_consumer(svr_queue_name, SVR_CONSUMER_GROUP_NAME, CONSUMER_NAME)
|
||||
if redis_msg:
|
||||
break
|
||||
except Exception:
|
||||
logging.exception("collect got exception")
|
||||
except Exception as e:
|
||||
logging.exception(f"collect got exception: {e}")
|
||||
return None, None
|
||||
|
||||
if not redis_msg:
|
||||
@ -196,6 +199,9 @@ async def collect():
|
||||
if task:
|
||||
task["doc_id"] = msg["doc_id"]
|
||||
task["doc_ids"] = msg.get("doc_ids", []) or []
|
||||
elif msg.get("task_type") == PipelineTaskType.MEMORY.lower():
|
||||
_, task_obj = TaskService.get_by_id(msg["id"])
|
||||
task = task_obj.to_dict()
|
||||
else:
|
||||
task = TaskService.get_task(msg["id"])
|
||||
|
||||
@ -214,6 +220,10 @@ async def collect():
|
||||
task["tenant_id"] = msg["tenant_id"]
|
||||
task["dataflow_id"] = msg["dataflow_id"]
|
||||
task["kb_id"] = msg.get("kb_id", "")
|
||||
if task_type[:6] == "memory":
|
||||
task["memory_id"] = msg["memory_id"]
|
||||
task["source_id"] = msg["source_id"]
|
||||
task["message_dict"] = msg["message_dict"]
|
||||
return redis_msg, task
|
||||
|
||||
|
||||
@ -221,7 +231,7 @@ async def get_storage_binary(bucket, name):
|
||||
return await asyncio.to_thread(settings.STORAGE_IMPL.get, bucket, name)
|
||||
|
||||
|
||||
@timeout(60*80, 1)
|
||||
@timeout(60 * 80, 1)
|
||||
async def build_chunks(task, progress_callback):
|
||||
if task["size"] > settings.DOC_MAXIMUM_SIZE:
|
||||
set_progress(task["id"], prog=-1, msg="File size exceeds( <= %dMb )" %
|
||||
@ -283,7 +293,8 @@ async def build_chunks(task, progress_callback):
|
||||
try:
|
||||
d = copy.deepcopy(document)
|
||||
d.update(chunk)
|
||||
d["id"] = xxhash.xxh64((chunk["content_with_weight"] + str(d["doc_id"])).encode("utf-8", "surrogatepass")).hexdigest()
|
||||
d["id"] = xxhash.xxh64(
|
||||
(chunk["content_with_weight"] + str(d["doc_id"])).encode("utf-8", "surrogatepass")).hexdigest()
|
||||
d["create_time"] = str(datetime.now()).replace("T", " ")[:19]
|
||||
d["create_timestamp_flt"] = datetime.now().timestamp()
|
||||
if not d.get("image"):
|
||||
@ -321,6 +332,9 @@ async def build_chunks(task, progress_callback):
|
||||
async def doc_keyword_extraction(chat_mdl, d, topn):
|
||||
cached = get_llm_cache(chat_mdl.llm_name, d["content_with_weight"], "keywords", {"topn": topn})
|
||||
if not cached:
|
||||
if has_canceled(task["id"]):
|
||||
progress_callback(-1, msg="Task has been canceled.")
|
||||
return
|
||||
async with chat_limiter:
|
||||
cached = await keyword_extraction(chat_mdl, d["content_with_weight"], topn)
|
||||
set_llm_cache(chat_mdl.llm_name, d["content_with_weight"], cached, "keywords", {"topn": topn})
|
||||
@ -328,9 +342,11 @@ async def build_chunks(task, progress_callback):
|
||||
d["important_kwd"] = cached.split(",")
|
||||
d["important_tks"] = rag_tokenizer.tokenize(" ".join(d["important_kwd"]))
|
||||
return
|
||||
|
||||
tasks = []
|
||||
for d in docs:
|
||||
tasks.append(asyncio.create_task(doc_keyword_extraction(chat_mdl, d, task["parser_config"]["auto_keywords"])))
|
||||
tasks.append(
|
||||
asyncio.create_task(doc_keyword_extraction(chat_mdl, d, task["parser_config"]["auto_keywords"])))
|
||||
try:
|
||||
await asyncio.gather(*tasks, return_exceptions=False)
|
||||
except Exception as e:
|
||||
@ -349,15 +365,20 @@ async def build_chunks(task, progress_callback):
|
||||
async def doc_question_proposal(chat_mdl, d, topn):
|
||||
cached = get_llm_cache(chat_mdl.llm_name, d["content_with_weight"], "question", {"topn": topn})
|
||||
if not cached:
|
||||
if has_canceled(task["id"]):
|
||||
progress_callback(-1, msg="Task has been canceled.")
|
||||
return
|
||||
async with chat_limiter:
|
||||
cached = await question_proposal(chat_mdl, d["content_with_weight"], topn)
|
||||
set_llm_cache(chat_mdl.llm_name, d["content_with_weight"], cached, "question", {"topn": topn})
|
||||
if cached:
|
||||
d["question_kwd"] = cached.split("\n")
|
||||
d["question_tks"] = rag_tokenizer.tokenize("\n".join(d["question_kwd"]))
|
||||
|
||||
tasks = []
|
||||
for d in docs:
|
||||
tasks.append(asyncio.create_task(doc_question_proposal(chat_mdl, d, task["parser_config"]["auto_questions"])))
|
||||
tasks.append(
|
||||
asyncio.create_task(doc_question_proposal(chat_mdl, d, task["parser_config"]["auto_questions"])))
|
||||
try:
|
||||
await asyncio.gather(*tasks, return_exceptions=False)
|
||||
except Exception as e:
|
||||
@ -374,15 +395,21 @@ async def build_chunks(task, progress_callback):
|
||||
chat_mdl = LLMBundle(task["tenant_id"], LLMType.CHAT, llm_name=task["llm_id"], lang=task["language"])
|
||||
|
||||
async def gen_metadata_task(chat_mdl, d):
|
||||
cached = get_llm_cache(chat_mdl.llm_name, d["content_with_weight"], "metadata", task["parser_config"]["metadata"])
|
||||
cached = get_llm_cache(chat_mdl.llm_name, d["content_with_weight"], "metadata",
|
||||
task["parser_config"]["metadata"])
|
||||
if not cached:
|
||||
if has_canceled(task["id"]):
|
||||
progress_callback(-1, msg="Task has been canceled.")
|
||||
return
|
||||
async with chat_limiter:
|
||||
cached = await gen_metadata(chat_mdl,
|
||||
metadata_schema(task["parser_config"]["metadata"]),
|
||||
d["content_with_weight"])
|
||||
set_llm_cache(chat_mdl.llm_name, d["content_with_weight"], cached, "metadata", task["parser_config"]["metadata"])
|
||||
set_llm_cache(chat_mdl.llm_name, d["content_with_weight"], cached, "metadata",
|
||||
task["parser_config"]["metadata"])
|
||||
if cached:
|
||||
d["metadata_obj"] = cached
|
||||
|
||||
tasks = []
|
||||
for d in docs:
|
||||
tasks.append(asyncio.create_task(gen_metadata_task(chat_mdl, d)))
|
||||
@ -430,7 +457,8 @@ async def build_chunks(task, progress_callback):
|
||||
if task_canceled:
|
||||
progress_callback(-1, msg="Task has been canceled.")
|
||||
return None
|
||||
if settings.retriever.tag_content(tenant_id, kb_ids, d, all_tags, topn_tags=topn_tags, S=S) and len(d[TAG_FLD]) > 0:
|
||||
if settings.retriever.tag_content(tenant_id, kb_ids, d, all_tags, topn_tags=topn_tags, S=S) and len(
|
||||
d[TAG_FLD]) > 0:
|
||||
examples.append({"content": d["content_with_weight"], TAG_FLD: d[TAG_FLD]})
|
||||
else:
|
||||
docs_to_tag.append(d)
|
||||
@ -438,7 +466,10 @@ async def build_chunks(task, progress_callback):
|
||||
async def doc_content_tagging(chat_mdl, d, topn_tags):
|
||||
cached = get_llm_cache(chat_mdl.llm_name, d["content_with_weight"], all_tags, {"topn": topn_tags})
|
||||
if not cached:
|
||||
picked_examples = random.choices(examples, k=2) if len(examples)>2 else examples
|
||||
if has_canceled(task["id"]):
|
||||
progress_callback(-1, msg="Task has been canceled.")
|
||||
return
|
||||
picked_examples = random.choices(examples, k=2) if len(examples) > 2 else examples
|
||||
if not picked_examples:
|
||||
picked_examples.append({"content": "This is an example", TAG_FLD: {'example': 1}})
|
||||
async with chat_limiter:
|
||||
@ -454,6 +485,7 @@ async def build_chunks(task, progress_callback):
|
||||
if cached:
|
||||
set_llm_cache(chat_mdl.llm_name, d["content_with_weight"], cached, all_tags, {"topn": topn_tags})
|
||||
d[TAG_FLD] = json.loads(cached)
|
||||
|
||||
tasks = []
|
||||
for d in docs_to_tag:
|
||||
tasks.append(asyncio.create_task(doc_content_tagging(chat_mdl, d, topn_tags)))
|
||||
@ -473,21 +505,22 @@ async def build_chunks(task, progress_callback):
|
||||
def build_TOC(task, docs, progress_callback):
|
||||
progress_callback(msg="Start to generate table of content ...")
|
||||
chat_mdl = LLMBundle(task["tenant_id"], LLMType.CHAT, llm_name=task["llm_id"], lang=task["language"])
|
||||
docs = sorted(docs, key=lambda d:(
|
||||
docs = sorted(docs, key=lambda d: (
|
||||
d.get("page_num_int", 0)[0] if isinstance(d.get("page_num_int", 0), list) else d.get("page_num_int", 0),
|
||||
d.get("top_int", 0)[0] if isinstance(d.get("top_int", 0), list) else d.get("top_int", 0)
|
||||
))
|
||||
toc: list[dict] = asyncio.run(run_toc_from_text([d["content_with_weight"] for d in docs], chat_mdl, progress_callback))
|
||||
logging.info("------------ T O C -------------\n"+json.dumps(toc, ensure_ascii=False, indent=' '))
|
||||
toc: list[dict] = asyncio.run(
|
||||
run_toc_from_text([d["content_with_weight"] for d in docs], chat_mdl, progress_callback))
|
||||
logging.info("------------ T O C -------------\n" + json.dumps(toc, ensure_ascii=False, indent=' '))
|
||||
ii = 0
|
||||
while ii < len(toc):
|
||||
try:
|
||||
idx = int(toc[ii]["chunk_id"])
|
||||
del toc[ii]["chunk_id"]
|
||||
toc[ii]["ids"] = [docs[idx]["id"]]
|
||||
if ii == len(toc) -1:
|
||||
if ii == len(toc) - 1:
|
||||
break
|
||||
for jj in range(idx+1, int(toc[ii+1]["chunk_id"])+1):
|
||||
for jj in range(idx + 1, int(toc[ii + 1]["chunk_id"]) + 1):
|
||||
toc[ii]["ids"].append(docs[jj]["id"])
|
||||
except Exception as e:
|
||||
logging.exception(e)
|
||||
@ -499,7 +532,8 @@ def build_TOC(task, docs, progress_callback):
|
||||
d["toc_kwd"] = "toc"
|
||||
d["available_int"] = 0
|
||||
d["page_num_int"] = [100000000]
|
||||
d["id"] = xxhash.xxh64((d["content_with_weight"] + str(d["doc_id"])).encode("utf-8", "surrogatepass")).hexdigest()
|
||||
d["id"] = xxhash.xxh64(
|
||||
(d["content_with_weight"] + str(d["doc_id"])).encode("utf-8", "surrogatepass")).hexdigest()
|
||||
return d
|
||||
return None
|
||||
|
||||
@ -532,12 +566,12 @@ async def embedding(docs, mdl, parser_config=None, callback=None):
|
||||
@timeout(60)
|
||||
def batch_encode(txts):
|
||||
nonlocal mdl
|
||||
return mdl.encode([truncate(c, mdl.max_length-10) for c in txts])
|
||||
return mdl.encode([truncate(c, mdl.max_length - 10) for c in txts])
|
||||
|
||||
cnts_ = np.array([])
|
||||
for i in range(0, len(cnts), settings.EMBEDDING_BATCH_SIZE):
|
||||
async with embed_limiter:
|
||||
vts, c = await asyncio.to_thread(batch_encode, cnts[i : i + settings.EMBEDDING_BATCH_SIZE])
|
||||
vts, c = await asyncio.to_thread(batch_encode, cnts[i: i + settings.EMBEDDING_BATCH_SIZE])
|
||||
if len(cnts_) == 0:
|
||||
cnts_ = vts
|
||||
else:
|
||||
@ -545,7 +579,7 @@ async def embedding(docs, mdl, parser_config=None, callback=None):
|
||||
tk_count += c
|
||||
callback(prog=0.7 + 0.2 * (i + 1) / len(cnts), msg="")
|
||||
cnts = cnts_
|
||||
filename_embd_weight = parser_config.get("filename_embd_weight", 0.1) # due to the db support none value
|
||||
filename_embd_weight = parser_config.get("filename_embd_weight", 0.1) # due to the db support none value
|
||||
if not filename_embd_weight:
|
||||
filename_embd_weight = 0.1
|
||||
title_w = float(filename_embd_weight)
|
||||
@ -588,7 +622,8 @@ async def run_dataflow(task: dict):
|
||||
return
|
||||
|
||||
if not chunks:
|
||||
PipelineOperationLogService.create(document_id=doc_id, pipeline_id=dataflow_id, task_type=PipelineTaskType.PARSE, dsl=str(pipeline))
|
||||
PipelineOperationLogService.create(document_id=doc_id, pipeline_id=dataflow_id,
|
||||
task_type=PipelineTaskType.PARSE, dsl=str(pipeline))
|
||||
return
|
||||
|
||||
embedding_token_consumption = chunks.get("embedding_token_consumption", 0)
|
||||
@ -610,25 +645,27 @@ async def run_dataflow(task: dict):
|
||||
e, kb = KnowledgebaseService.get_by_id(task["kb_id"])
|
||||
embedding_id = kb.embd_id
|
||||
embedding_model = LLMBundle(task["tenant_id"], LLMType.EMBEDDING, llm_name=embedding_id)
|
||||
|
||||
@timeout(60)
|
||||
def batch_encode(txts):
|
||||
nonlocal embedding_model
|
||||
return embedding_model.encode([truncate(c, embedding_model.max_length - 10) for c in txts])
|
||||
|
||||
vects = np.array([])
|
||||
texts = [o.get("questions", o.get("summary", o["text"])) for o in chunks]
|
||||
delta = 0.20/(len(texts)//settings.EMBEDDING_BATCH_SIZE+1)
|
||||
delta = 0.20 / (len(texts) // settings.EMBEDDING_BATCH_SIZE + 1)
|
||||
prog = 0.8
|
||||
for i in range(0, len(texts), settings.EMBEDDING_BATCH_SIZE):
|
||||
async with embed_limiter:
|
||||
vts, c = await asyncio.to_thread(batch_encode, texts[i : i + settings.EMBEDDING_BATCH_SIZE])
|
||||
vts, c = await asyncio.to_thread(batch_encode, texts[i: i + settings.EMBEDDING_BATCH_SIZE])
|
||||
if len(vects) == 0:
|
||||
vects = vts
|
||||
else:
|
||||
vects = np.concatenate((vects, vts), axis=0)
|
||||
embedding_token_consumption += c
|
||||
prog += delta
|
||||
if i % (len(texts)//settings.EMBEDDING_BATCH_SIZE/100+1) == 1:
|
||||
set_progress(task_id, prog=prog, msg=f"{i+1} / {len(texts)//settings.EMBEDDING_BATCH_SIZE}")
|
||||
if i % (len(texts) // settings.EMBEDDING_BATCH_SIZE / 100 + 1) == 1:
|
||||
set_progress(task_id, prog=prog, msg=f"{i + 1} / {len(texts) // settings.EMBEDDING_BATCH_SIZE}")
|
||||
|
||||
assert len(vects) == len(chunks)
|
||||
for i, ck in enumerate(chunks):
|
||||
@ -636,10 +673,10 @@ async def run_dataflow(task: dict):
|
||||
ck["q_%d_vec" % len(v)] = v
|
||||
except Exception as e:
|
||||
set_progress(task_id, prog=-1, msg=f"[ERROR]: {e}")
|
||||
PipelineOperationLogService.create(document_id=doc_id, pipeline_id=dataflow_id, task_type=PipelineTaskType.PARSE, dsl=str(pipeline))
|
||||
PipelineOperationLogService.create(document_id=doc_id, pipeline_id=dataflow_id,
|
||||
task_type=PipelineTaskType.PARSE, dsl=str(pipeline))
|
||||
return
|
||||
|
||||
|
||||
metadata = {}
|
||||
for ck in chunks:
|
||||
ck["doc_id"] = doc_id
|
||||
@ -686,15 +723,19 @@ async def run_dataflow(task: dict):
|
||||
set_progress(task_id, prog=0.82, msg="[DOC Engine]:\nStart to index...")
|
||||
e = await insert_es(task_id, task["tenant_id"], task["kb_id"], chunks, partial(set_progress, task_id, 0, 100000000))
|
||||
if not e:
|
||||
PipelineOperationLogService.create(document_id=doc_id, pipeline_id=dataflow_id, task_type=PipelineTaskType.PARSE, dsl=str(pipeline))
|
||||
PipelineOperationLogService.create(document_id=doc_id, pipeline_id=dataflow_id,
|
||||
task_type=PipelineTaskType.PARSE, dsl=str(pipeline))
|
||||
return
|
||||
|
||||
time_cost = timer() - start_ts
|
||||
task_time_cost = timer() - task_start_ts
|
||||
set_progress(task_id, prog=1., msg="Indexing done ({:.2f}s). Task done ({:.2f}s)".format(time_cost, task_time_cost))
|
||||
DocumentService.increment_chunk_num(doc_id, task_dataset_id, embedding_token_consumption, len(chunks), task_time_cost)
|
||||
logging.info("[Done], chunks({}), token({}), elapsed:{:.2f}".format(len(chunks), embedding_token_consumption, task_time_cost))
|
||||
PipelineOperationLogService.create(document_id=doc_id, pipeline_id=dataflow_id, task_type=PipelineTaskType.PARSE, dsl=str(pipeline))
|
||||
DocumentService.increment_chunk_num(doc_id, task_dataset_id, embedding_token_consumption, len(chunks),
|
||||
task_time_cost)
|
||||
logging.info("[Done], chunks({}), token({}), elapsed:{:.2f}".format(len(chunks), embedding_token_consumption,
|
||||
task_time_cost))
|
||||
PipelineOperationLogService.create(document_id=doc_id, pipeline_id=dataflow_id, task_type=PipelineTaskType.PARSE,
|
||||
dsl=str(pipeline))
|
||||
|
||||
|
||||
@timeout(3600)
|
||||
@ -702,7 +743,7 @@ async def run_raptor_for_kb(row, kb_parser_config, chat_mdl, embd_mdl, vector_si
|
||||
fake_doc_id = GRAPH_RAPTOR_FAKE_DOC_ID
|
||||
|
||||
raptor_config = kb_parser_config.get("raptor", {})
|
||||
vctr_nm = "q_%d_vec"%vector_size
|
||||
vctr_nm = "q_%d_vec" % vector_size
|
||||
|
||||
res = []
|
||||
tk_count = 0
|
||||
@ -747,17 +788,17 @@ async def run_raptor_for_kb(row, kb_parser_config, chat_mdl, embd_mdl, vector_si
|
||||
for x, doc_id in enumerate(doc_ids):
|
||||
chunks = []
|
||||
for d in settings.retriever.chunk_list(doc_id, row["tenant_id"], [str(row["kb_id"])],
|
||||
fields=["content_with_weight", vctr_nm],
|
||||
sort_by_position=True):
|
||||
fields=["content_with_weight", vctr_nm],
|
||||
sort_by_position=True):
|
||||
chunks.append((d["content_with_weight"], np.array(d[vctr_nm])))
|
||||
await generate(chunks, doc_id)
|
||||
callback(prog=(x+1.)/len(doc_ids))
|
||||
callback(prog=(x + 1.) / len(doc_ids))
|
||||
else:
|
||||
chunks = []
|
||||
for doc_id in doc_ids:
|
||||
for d in settings.retriever.chunk_list(doc_id, row["tenant_id"], [str(row["kb_id"])],
|
||||
fields=["content_with_weight", vctr_nm],
|
||||
sort_by_position=True):
|
||||
fields=["content_with_weight", vctr_nm],
|
||||
sort_by_position=True):
|
||||
chunks.append((d["content_with_weight"], np.array(d[vctr_nm])))
|
||||
|
||||
await generate(chunks, fake_doc_id)
|
||||
@ -792,19 +833,22 @@ async def insert_es(task_id, task_tenant_id, task_dataset_id, chunks, progress_c
|
||||
mom_ck["available_int"] = 0
|
||||
flds = list(mom_ck.keys())
|
||||
for fld in flds:
|
||||
if fld not in ["id", "content_with_weight", "doc_id", "docnm_kwd", "kb_id", "available_int", "position_int"]:
|
||||
if fld not in ["id", "content_with_weight", "doc_id", "docnm_kwd", "kb_id", "available_int",
|
||||
"position_int"]:
|
||||
del mom_ck[fld]
|
||||
mothers.append(mom_ck)
|
||||
|
||||
for b in range(0, len(mothers), settings.DOC_BULK_SIZE):
|
||||
await asyncio.to_thread(settings.docStoreConn.insert,mothers[b:b + settings.DOC_BULK_SIZE],search.index_name(task_tenant_id),task_dataset_id,)
|
||||
await asyncio.to_thread(settings.docStoreConn.insert, mothers[b:b + settings.DOC_BULK_SIZE],
|
||||
search.index_name(task_tenant_id), task_dataset_id, )
|
||||
task_canceled = has_canceled(task_id)
|
||||
if task_canceled:
|
||||
progress_callback(-1, msg="Task has been canceled.")
|
||||
return False
|
||||
|
||||
for b in range(0, len(chunks), settings.DOC_BULK_SIZE):
|
||||
doc_store_result = await asyncio.to_thread(settings.docStoreConn.insert,chunks[b:b + settings.DOC_BULK_SIZE],search.index_name(task_tenant_id),task_dataset_id,)
|
||||
doc_store_result = await asyncio.to_thread(settings.docStoreConn.insert, chunks[b:b + settings.DOC_BULK_SIZE],
|
||||
search.index_name(task_tenant_id), task_dataset_id, )
|
||||
task_canceled = has_canceled(task_id)
|
||||
if task_canceled:
|
||||
progress_callback(-1, msg="Task has been canceled.")
|
||||
@ -821,7 +865,8 @@ async def insert_es(task_id, task_tenant_id, task_dataset_id, chunks, progress_c
|
||||
TaskService.update_chunk_ids(task_id, chunk_ids_str)
|
||||
except DoesNotExist:
|
||||
logging.warning(f"do_handle_task update_chunk_ids failed since task {task_id} is unknown.")
|
||||
doc_store_result = await asyncio.to_thread(settings.docStoreConn.delete,{"id": chunk_ids},search.index_name(task_tenant_id),task_dataset_id,)
|
||||
doc_store_result = await asyncio.to_thread(settings.docStoreConn.delete, {"id": chunk_ids},
|
||||
search.index_name(task_tenant_id), task_dataset_id, )
|
||||
tasks = []
|
||||
for chunk_id in chunk_ids:
|
||||
tasks.append(asyncio.create_task(delete_image(task_dataset_id, chunk_id)))
|
||||
@ -838,10 +883,14 @@ async def insert_es(task_id, task_tenant_id, task_dataset_id, chunks, progress_c
|
||||
return True
|
||||
|
||||
|
||||
@timeout(60*60*3, 1)
|
||||
@timeout(60 * 60 * 3, 1)
|
||||
async def do_handle_task(task):
|
||||
task_type = task.get("task_type", "")
|
||||
|
||||
if task_type == "memory":
|
||||
await handle_save_to_memory_task(task)
|
||||
return
|
||||
|
||||
if task_type == "dataflow" and task.get("doc_id", "") == CANVAS_DEBUG_DOC_ID:
|
||||
await run_dataflow(task)
|
||||
return
|
||||
@ -914,7 +963,7 @@ async def do_handle_task(task):
|
||||
},
|
||||
}
|
||||
)
|
||||
if not KnowledgebaseService.update_by_id(kb.id, {"parser_config":kb_parser_config}):
|
||||
if not KnowledgebaseService.update_by_id(kb.id, {"parser_config": kb_parser_config}):
|
||||
progress_callback(prog=-1.0, msg="Internal error: Invalid RAPTOR configuration")
|
||||
return
|
||||
|
||||
@ -943,7 +992,7 @@ async def do_handle_task(task):
|
||||
doc_ids=task.get("doc_ids", []),
|
||||
)
|
||||
if fake_doc_ids := task.get("doc_ids", []):
|
||||
task_doc_id = fake_doc_ids[0] # use the first document ID to represent this task for logging purposes
|
||||
task_doc_id = fake_doc_ids[0] # use the first document ID to represent this task for logging purposes
|
||||
# Either using graphrag or Standard chunking methods
|
||||
elif task_type == "graphrag":
|
||||
ok, kb = KnowledgebaseService.get_by_id(task_dataset_id)
|
||||
@ -968,11 +1017,10 @@ async def do_handle_task(task):
|
||||
}
|
||||
}
|
||||
)
|
||||
if not KnowledgebaseService.update_by_id(kb.id, {"parser_config":kb_parser_config}):
|
||||
if not KnowledgebaseService.update_by_id(kb.id, {"parser_config": kb_parser_config}):
|
||||
progress_callback(prog=-1.0, msg="Internal error: Invalid GraphRAG configuration")
|
||||
return
|
||||
|
||||
|
||||
graphrag_conf = kb_parser_config.get("graphrag", {})
|
||||
start_ts = timer()
|
||||
chat_model = LLMBundle(task_tenant_id, LLMType.CHAT, llm_name=task_llm_id, lang=task_language)
|
||||
@ -1028,9 +1076,9 @@ async def do_handle_task(task):
|
||||
async def _maybe_insert_es(_chunks):
|
||||
if has_canceled(task_id):
|
||||
return True
|
||||
e = await insert_es(task_id, task_tenant_id, task_dataset_id, _chunks, progress_callback)
|
||||
return bool(e)
|
||||
|
||||
insert_result = await insert_es(task_id, task_tenant_id, task_dataset_id, _chunks, progress_callback)
|
||||
return bool(insert_result)
|
||||
|
||||
try:
|
||||
if not await _maybe_insert_es(chunks):
|
||||
return
|
||||
@ -1079,13 +1127,12 @@ async def do_handle_task(task):
|
||||
search.index_name(task_tenant_id),
|
||||
task_dataset_id,
|
||||
)
|
||||
except Exception:
|
||||
except Exception as e:
|
||||
logging.exception(
|
||||
f"Remove doc({task_doc_id}) from docStore failed when task({task_id}) canceled."
|
||||
)
|
||||
f"Remove doc({task_doc_id}) from docStore failed when task({task_id}) canceled, exception: {e}")
|
||||
|
||||
|
||||
async def handle_task():
|
||||
|
||||
global DONE_TASKS, FAILED_TASKS
|
||||
redis_msg, task = await collect()
|
||||
if not task:
|
||||
@ -1093,25 +1140,27 @@ async def handle_task():
|
||||
return
|
||||
|
||||
task_type = task["task_type"]
|
||||
pipeline_task_type = TASK_TYPE_TO_PIPELINE_TASK_TYPE.get(task_type, PipelineTaskType.PARSE) or PipelineTaskType.PARSE
|
||||
|
||||
pipeline_task_type = TASK_TYPE_TO_PIPELINE_TASK_TYPE.get(task_type,
|
||||
PipelineTaskType.PARSE) or PipelineTaskType.PARSE
|
||||
task_id = task["id"]
|
||||
try:
|
||||
logging.info(f"handle_task begin for task {json.dumps(task)}")
|
||||
CURRENT_TASKS[task["id"]] = copy.deepcopy(task)
|
||||
await do_handle_task(task)
|
||||
DONE_TASKS += 1
|
||||
CURRENT_TASKS.pop(task["id"], None)
|
||||
CURRENT_TASKS.pop(task_id, None)
|
||||
logging.info(f"handle_task done for task {json.dumps(task)}")
|
||||
except Exception as e:
|
||||
FAILED_TASKS += 1
|
||||
CURRENT_TASKS.pop(task["id"], None)
|
||||
CURRENT_TASKS.pop(task_id, None)
|
||||
try:
|
||||
err_msg = str(e)
|
||||
while isinstance(e, exceptiongroup.ExceptionGroup):
|
||||
e = e.exceptions[0]
|
||||
err_msg += ' -- ' + str(e)
|
||||
set_progress(task["id"], prog=-1, msg=f"[Exception]: {err_msg}")
|
||||
except Exception:
|
||||
set_progress(task_id, prog=-1, msg=f"[Exception]: {err_msg}")
|
||||
except Exception as e:
|
||||
logging.exception(f"[Exception]: {str(e)}")
|
||||
pass
|
||||
logging.exception(f"handle_task got exception for task {json.dumps(task)}")
|
||||
finally:
|
||||
@ -1119,7 +1168,9 @@ async def handle_task():
|
||||
if task_type in ["graphrag", "raptor", "mindmap"]:
|
||||
task_document_ids = task["doc_ids"]
|
||||
if not task.get("dataflow_id", ""):
|
||||
PipelineOperationLogService.record_pipeline_operation(document_id=task["doc_id"], pipeline_id="", task_type=pipeline_task_type, fake_document_ids=task_document_ids)
|
||||
PipelineOperationLogService.record_pipeline_operation(document_id=task["doc_id"], pipeline_id="",
|
||||
task_type=pipeline_task_type,
|
||||
fake_document_ids=task_document_ids)
|
||||
|
||||
redis_msg.ack()
|
||||
|
||||
@ -1182,8 +1233,8 @@ async def report_status():
|
||||
logging.info(f"{consumer_name} expired, removed")
|
||||
REDIS_CONN.srem("TASKEXE", consumer_name)
|
||||
REDIS_CONN.delete(consumer_name)
|
||||
except Exception:
|
||||
logging.exception("report_status got exception")
|
||||
except Exception as e:
|
||||
logging.exception(f"report_status got exception: {e}")
|
||||
finally:
|
||||
redis_lock.release()
|
||||
await asyncio.sleep(30)
|
||||
@ -1249,6 +1300,7 @@ async def main():
|
||||
await asyncio.gather(report_task, return_exceptions=True)
|
||||
logging.error("BUG!!! You should not reach here!!!")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
faulthandler.enable()
|
||||
init_root_logger(CONSUMER_NAME)
|
||||
|
||||
@ -42,8 +42,10 @@ class RAGFlowAzureSpnBlob:
|
||||
pass
|
||||
|
||||
try:
|
||||
credentials = ClientSecretCredential(tenant_id=self.tenant_id, client_id=self.client_id, client_secret=self.secret, authority=AzureAuthorityHosts.AZURE_CHINA)
|
||||
self.conn = FileSystemClient(account_url=self.account_url, file_system_name=self.container_name, credential=credentials)
|
||||
credentials = ClientSecretCredential(tenant_id=self.tenant_id, client_id=self.client_id,
|
||||
client_secret=self.secret, authority=AzureAuthorityHosts.AZURE_CHINA)
|
||||
self.conn = FileSystemClient(account_url=self.account_url, file_system_name=self.container_name,
|
||||
credential=credentials)
|
||||
except Exception:
|
||||
logging.exception("Fail to connect %s" % self.account_url)
|
||||
|
||||
@ -104,4 +106,4 @@ class RAGFlowAzureSpnBlob:
|
||||
logging.exception(f"fail get {bucket}/{fnm}")
|
||||
self.__open__()
|
||||
time.sleep(1)
|
||||
return None
|
||||
return None
|
||||
|
||||
@ -25,7 +25,8 @@ from PIL import Image
|
||||
test_image_base64 = "iVBORw0KGgoAAAANSUhEUgAAAGQAAABkCAIAAAD/gAIDAAAA6ElEQVR4nO3QwQ3AIBDAsIP9d25XIC+EZE8QZc18w5l9O+AlZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBT+IYAHHLHkdEgAAAABJRU5ErkJggg=="
|
||||
test_image = base64.b64decode(test_image_base64)
|
||||
|
||||
async def image2id(d: dict, storage_put_func: partial, objname:str, bucket:str="imagetemps"):
|
||||
|
||||
async def image2id(d: dict, storage_put_func: partial, objname: str, bucket: str = "imagetemps"):
|
||||
import logging
|
||||
from io import BytesIO
|
||||
from rag.svr.task_executor import minio_limiter
|
||||
@ -74,7 +75,7 @@ async def image2id(d: dict, storage_put_func: partial, objname:str, bucket:str="
|
||||
del d["image"]
|
||||
|
||||
|
||||
def id2image(image_id:str|None, storage_get_func: partial):
|
||||
def id2image(image_id: str | None, storage_get_func: partial):
|
||||
if not image_id:
|
||||
return
|
||||
arr = image_id.split("-")
|
||||
|
||||
@ -16,11 +16,13 @@
|
||||
|
||||
import logging
|
||||
from common.crypto_utils import CryptoUtil
|
||||
|
||||
|
||||
# from common.decorator import singleton
|
||||
|
||||
class EncryptedStorageWrapper:
|
||||
"""Encrypted storage wrapper that wraps existing storage implementations to provide transparent encryption"""
|
||||
|
||||
|
||||
def __init__(self, storage_impl, algorithm="aes-256-cbc", key=None, iv=None):
|
||||
"""
|
||||
Initialize encrypted storage wrapper
|
||||
@ -34,16 +36,16 @@ class EncryptedStorageWrapper:
|
||||
self.storage_impl = storage_impl
|
||||
self.crypto = CryptoUtil(algorithm=algorithm, key=key, iv=iv)
|
||||
self.encryption_enabled = True
|
||||
|
||||
|
||||
# Check if storage implementation has required methods
|
||||
# todo: Consider abstracting a storage base class to ensure these methods exist
|
||||
required_methods = ["put", "get", "rm", "obj_exist", "health"]
|
||||
for method in required_methods:
|
||||
if not hasattr(storage_impl, method):
|
||||
raise AttributeError(f"Storage implementation missing required method: {method}")
|
||||
|
||||
|
||||
logging.info(f"EncryptedStorageWrapper initialized with algorithm: {algorithm}")
|
||||
|
||||
|
||||
def put(self, bucket, fnm, binary, tenant_id=None):
|
||||
"""
|
||||
Encrypt and store data
|
||||
@ -59,15 +61,15 @@ class EncryptedStorageWrapper:
|
||||
"""
|
||||
if not self.encryption_enabled:
|
||||
return self.storage_impl.put(bucket, fnm, binary, tenant_id)
|
||||
|
||||
|
||||
try:
|
||||
encrypted_binary = self.crypto.encrypt(binary)
|
||||
|
||||
|
||||
return self.storage_impl.put(bucket, fnm, encrypted_binary, tenant_id)
|
||||
except Exception as e:
|
||||
logging.exception(f"Failed to encrypt and store data: {bucket}/{fnm}, error: {str(e)}")
|
||||
raise
|
||||
|
||||
|
||||
def get(self, bucket, fnm, tenant_id=None):
|
||||
"""
|
||||
Retrieve and decrypt data
|
||||
@ -83,21 +85,21 @@ class EncryptedStorageWrapper:
|
||||
try:
|
||||
# Get encrypted data
|
||||
encrypted_binary = self.storage_impl.get(bucket, fnm, tenant_id)
|
||||
|
||||
|
||||
if encrypted_binary is None:
|
||||
return None
|
||||
|
||||
|
||||
if not self.encryption_enabled:
|
||||
return encrypted_binary
|
||||
|
||||
|
||||
# Decrypt data
|
||||
decrypted_binary = self.crypto.decrypt(encrypted_binary)
|
||||
return decrypted_binary
|
||||
|
||||
|
||||
except Exception as e:
|
||||
logging.exception(f"Failed to get and decrypt data: {bucket}/{fnm}, error: {str(e)}")
|
||||
raise
|
||||
|
||||
|
||||
def rm(self, bucket, fnm, tenant_id=None):
|
||||
"""
|
||||
Delete data (same as original storage implementation, no decryption needed)
|
||||
@ -111,7 +113,7 @@ class EncryptedStorageWrapper:
|
||||
Deletion result
|
||||
"""
|
||||
return self.storage_impl.rm(bucket, fnm, tenant_id)
|
||||
|
||||
|
||||
def obj_exist(self, bucket, fnm, tenant_id=None):
|
||||
"""
|
||||
Check if object exists (same as original storage implementation, no decryption needed)
|
||||
@ -125,7 +127,7 @@ class EncryptedStorageWrapper:
|
||||
Whether the object exists
|
||||
"""
|
||||
return self.storage_impl.obj_exist(bucket, fnm, tenant_id)
|
||||
|
||||
|
||||
def health(self):
|
||||
"""
|
||||
Health check (uses the original storage implementation's method)
|
||||
@ -134,7 +136,7 @@ class EncryptedStorageWrapper:
|
||||
Health check result
|
||||
"""
|
||||
return self.storage_impl.health()
|
||||
|
||||
|
||||
def bucket_exists(self, bucket):
|
||||
"""
|
||||
Check if bucket exists (if the original storage implementation has this method)
|
||||
@ -148,7 +150,7 @@ class EncryptedStorageWrapper:
|
||||
if hasattr(self.storage_impl, "bucket_exists"):
|
||||
return self.storage_impl.bucket_exists(bucket)
|
||||
return False
|
||||
|
||||
|
||||
def get_presigned_url(self, bucket, fnm, expires, tenant_id=None):
|
||||
"""
|
||||
Get presigned URL (if the original storage implementation has this method)
|
||||
@ -165,7 +167,7 @@ class EncryptedStorageWrapper:
|
||||
if hasattr(self.storage_impl, "get_presigned_url"):
|
||||
return self.storage_impl.get_presigned_url(bucket, fnm, expires, tenant_id)
|
||||
return None
|
||||
|
||||
|
||||
def scan(self, bucket, fnm, tenant_id=None):
|
||||
"""
|
||||
Scan objects (if the original storage implementation has this method)
|
||||
@ -181,7 +183,7 @@ class EncryptedStorageWrapper:
|
||||
if hasattr(self.storage_impl, "scan"):
|
||||
return self.storage_impl.scan(bucket, fnm, tenant_id)
|
||||
return None
|
||||
|
||||
|
||||
def copy(self, src_bucket, src_path, dest_bucket, dest_path):
|
||||
"""
|
||||
Copy object (if the original storage implementation has this method)
|
||||
@ -198,7 +200,7 @@ class EncryptedStorageWrapper:
|
||||
if hasattr(self.storage_impl, "copy"):
|
||||
return self.storage_impl.copy(src_bucket, src_path, dest_bucket, dest_path)
|
||||
return False
|
||||
|
||||
|
||||
def move(self, src_bucket, src_path, dest_bucket, dest_path):
|
||||
"""
|
||||
Move object (if the original storage implementation has this method)
|
||||
@ -215,7 +217,7 @@ class EncryptedStorageWrapper:
|
||||
if hasattr(self.storage_impl, "move"):
|
||||
return self.storage_impl.move(src_bucket, src_path, dest_bucket, dest_path)
|
||||
return False
|
||||
|
||||
|
||||
def remove_bucket(self, bucket):
|
||||
"""
|
||||
Remove bucket (if the original storage implementation has this method)
|
||||
@ -229,17 +231,18 @@ class EncryptedStorageWrapper:
|
||||
if hasattr(self.storage_impl, "remove_bucket"):
|
||||
return self.storage_impl.remove_bucket(bucket)
|
||||
return False
|
||||
|
||||
|
||||
def enable_encryption(self):
|
||||
"""Enable encryption"""
|
||||
self.encryption_enabled = True
|
||||
logging.info("Encryption enabled")
|
||||
|
||||
|
||||
def disable_encryption(self):
|
||||
"""Disable encryption"""
|
||||
self.encryption_enabled = False
|
||||
logging.info("Encryption disabled")
|
||||
|
||||
|
||||
# Create singleton wrapper function
|
||||
def create_encrypted_storage(storage_impl, algorithm=None, key=None, encryption_enabled=True):
|
||||
"""
|
||||
@ -255,12 +258,12 @@ def create_encrypted_storage(storage_impl, algorithm=None, key=None, encryption_
|
||||
Encrypted storage wrapper instance
|
||||
"""
|
||||
wrapper = EncryptedStorageWrapper(storage_impl, algorithm=algorithm, key=key)
|
||||
|
||||
|
||||
wrapper.encryption_enabled = encryption_enabled
|
||||
|
||||
|
||||
if encryption_enabled:
|
||||
logging.info("Encryption enabled in storage wrapper")
|
||||
else:
|
||||
logging.info("Encryption disabled in storage wrapper")
|
||||
|
||||
|
||||
return wrapper
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user