mirror of
https://github.com/infiniflow/ragflow.git
synced 2026-01-04 03:25:30 +08:00
Compare commits
24 Commits
v0.23.0
...
4ec6a4e493
| Author | SHA1 | Date | |
|---|---|---|---|
| 4ec6a4e493 | |||
| 2d5ad42128 | |||
| dccda35f65 | |||
| d142b9095e | |||
| c2c079886f | |||
| c3ae1aaecd | |||
| f099bc1236 | |||
| 0b5d1ebefa | |||
| 082c2ed11c | |||
| a764f0a5b2 | |||
| 651d9fff9f | |||
| fddfce303c | |||
| a24fc8291b | |||
| 37e4485415 | |||
| 8d3f9d61da | |||
| 27c55f6514 | |||
| 9883c572cd | |||
| f9619defcc | |||
| 01f0ced1e6 | |||
| 647fb115a0 | |||
| 2114b9e3ad | |||
| 45b96acf6b | |||
| 3305215144 | |||
| 86b03f399a |
@ -303,6 +303,15 @@ cd ragflow/
|
||||
docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly .
|
||||
```
|
||||
|
||||
Or if you are behind a proxy, you can pass proxy arguments:
|
||||
|
||||
```bash
|
||||
docker build --platform linux/amd64 \
|
||||
--build-arg http_proxy=http://YOUR_PROXY:PORT \
|
||||
--build-arg https_proxy=http://YOUR_PROXY:PORT \
|
||||
-f Dockerfile -t infiniflow/ragflow:nightly .
|
||||
```
|
||||
|
||||
## 🔨 Launch service from source for development
|
||||
|
||||
1. Install `uv` and `pre-commit`, or skip this step if they are already installed:
|
||||
|
||||
@ -277,6 +277,15 @@ cd ragflow/
|
||||
docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly .
|
||||
```
|
||||
|
||||
Jika berada di belakang proxy, Anda dapat melewatkan argumen proxy:
|
||||
|
||||
```bash
|
||||
docker build --platform linux/amd64 \
|
||||
--build-arg http_proxy=http://YOUR_PROXY:PORT \
|
||||
--build-arg https_proxy=http://YOUR_PROXY:PORT \
|
||||
-f Dockerfile -t infiniflow/ragflow:nightly .
|
||||
```
|
||||
|
||||
## 🔨 Menjalankan Aplikasi dari untuk Pengembangan
|
||||
|
||||
1. Instal `uv` dan `pre-commit`, atau lewati langkah ini jika sudah terinstal:
|
||||
|
||||
@ -277,6 +277,15 @@ cd ragflow/
|
||||
docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly .
|
||||
```
|
||||
|
||||
プロキシ環境下にいる場合は、プロキシ引数を指定できます:
|
||||
|
||||
```bash
|
||||
docker build --platform linux/amd64 \
|
||||
--build-arg http_proxy=http://YOUR_PROXY:PORT \
|
||||
--build-arg https_proxy=http://YOUR_PROXY:PORT \
|
||||
-f Dockerfile -t infiniflow/ragflow:nightly .
|
||||
```
|
||||
|
||||
## 🔨 ソースコードからサービスを起動する方法
|
||||
|
||||
1. `uv` と `pre-commit` をインストールする。すでにインストールされている場合は、このステップをスキップしてください:
|
||||
|
||||
@ -271,6 +271,15 @@ cd ragflow/
|
||||
docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly .
|
||||
```
|
||||
|
||||
프록시 환경인 경우, 프록시 인수를 전달할 수 있습니다:
|
||||
|
||||
```bash
|
||||
docker build --platform linux/amd64 \
|
||||
--build-arg http_proxy=http://YOUR_PROXY:PORT \
|
||||
--build-arg https_proxy=http://YOUR_PROXY:PORT \
|
||||
-f Dockerfile -t infiniflow/ragflow:nightly .
|
||||
```
|
||||
|
||||
## 🔨 소스 코드로 서비스를 시작합니다.
|
||||
|
||||
1. `uv` 와 `pre-commit` 을 설치하거나, 이미 설치된 경우 이 단계를 건너뜁니다:
|
||||
|
||||
@ -294,6 +294,15 @@ cd ragflow/
|
||||
docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly .
|
||||
```
|
||||
|
||||
Se você estiver atrás de um proxy, pode passar argumentos de proxy:
|
||||
|
||||
```bash
|
||||
docker build --platform linux/amd64 \
|
||||
--build-arg http_proxy=http://YOUR_PROXY:PORT \
|
||||
--build-arg https_proxy=http://YOUR_PROXY:PORT \
|
||||
-f Dockerfile -t infiniflow/ragflow:nightly .
|
||||
```
|
||||
|
||||
## 🔨 Lançar o serviço a partir do código-fonte para desenvolvimento
|
||||
|
||||
1. Instale o `uv` e o `pre-commit`, ou pule esta etapa se eles já estiverem instalados:
|
||||
|
||||
@ -303,6 +303,15 @@ cd ragflow/
|
||||
docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly .
|
||||
```
|
||||
|
||||
若您位於代理環境,可傳遞代理參數:
|
||||
|
||||
```bash
|
||||
docker build --platform linux/amd64 \
|
||||
--build-arg http_proxy=http://YOUR_PROXY:PORT \
|
||||
--build-arg https_proxy=http://YOUR_PROXY:PORT \
|
||||
-f Dockerfile -t infiniflow/ragflow:nightly .
|
||||
```
|
||||
|
||||
## 🔨 以原始碼啟動服務
|
||||
|
||||
1. 安裝 `uv` 和 `pre-commit`。如已安裝,可跳過此步驟:
|
||||
|
||||
@ -302,6 +302,15 @@ cd ragflow/
|
||||
docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly .
|
||||
```
|
||||
|
||||
如果您处在代理环境下,可以传递代理参数:
|
||||
|
||||
```bash
|
||||
docker build --platform linux/amd64 \
|
||||
--build-arg http_proxy=http://YOUR_PROXY:PORT \
|
||||
--build-arg https_proxy=http://YOUR_PROXY:PORT \
|
||||
-f Dockerfile -t infiniflow/ragflow:nightly .
|
||||
```
|
||||
|
||||
## 🔨 以源代码启动服务
|
||||
|
||||
1. 安装 `uv` 和 `pre-commit`。如已经安装,可跳过本步骤:
|
||||
|
||||
@ -746,6 +746,7 @@ async def change_parser():
|
||||
tenant_id = DocumentService.get_tenant_id(req["doc_id"])
|
||||
if not tenant_id:
|
||||
return get_data_error_result(message="Tenant not found!")
|
||||
DocumentService.delete_chunk_images(doc, tenant_id)
|
||||
if settings.docStoreConn.index_exist(search.index_name(tenant_id), doc.kb_id):
|
||||
settings.docStoreConn.delete({"doc_id": doc.id}, search.index_name(tenant_id), doc.kb_id)
|
||||
return None
|
||||
|
||||
@ -1286,6 +1286,9 @@ async def rm_chunk(tenant_id, dataset_id, document_id):
|
||||
if "chunk_ids" in req:
|
||||
unique_chunk_ids, duplicate_messages = check_duplicate_ids(req["chunk_ids"], "chunk")
|
||||
condition["id"] = unique_chunk_ids
|
||||
else:
|
||||
unique_chunk_ids = []
|
||||
duplicate_messages = []
|
||||
chunk_number = settings.docStoreConn.delete(condition, search.index_name(tenant_id), dataset_id)
|
||||
if chunk_number != 0:
|
||||
DocumentService.decrement_chunk_num(document_id, dataset_id, 1, chunk_number, 0)
|
||||
|
||||
@ -342,21 +342,7 @@ class DocumentService(CommonService):
|
||||
cls.clear_chunk_num(doc.id)
|
||||
try:
|
||||
TaskService.filter_delete([Task.doc_id == doc.id])
|
||||
page = 0
|
||||
page_size = 1000
|
||||
all_chunk_ids = []
|
||||
while True:
|
||||
chunks = settings.docStoreConn.search(["img_id"], [], {"doc_id": doc.id}, [], OrderByExpr(),
|
||||
page * page_size, page_size, search.index_name(tenant_id),
|
||||
[doc.kb_id])
|
||||
chunk_ids = settings.docStoreConn.get_doc_ids(chunks)
|
||||
if not chunk_ids:
|
||||
break
|
||||
all_chunk_ids.extend(chunk_ids)
|
||||
page += 1
|
||||
for cid in all_chunk_ids:
|
||||
if settings.STORAGE_IMPL.obj_exist(doc.kb_id, cid):
|
||||
settings.STORAGE_IMPL.rm(doc.kb_id, cid)
|
||||
cls.delete_chunk_images(doc, tenant_id)
|
||||
if doc.thumbnail and not doc.thumbnail.startswith(IMG_BASE64_PREFIX):
|
||||
if settings.STORAGE_IMPL.obj_exist(doc.kb_id, doc.thumbnail):
|
||||
settings.STORAGE_IMPL.rm(doc.kb_id, doc.thumbnail)
|
||||
@ -378,6 +364,23 @@ class DocumentService(CommonService):
|
||||
pass
|
||||
return cls.delete_by_id(doc.id)
|
||||
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
def delete_chunk_images(cls, doc, tenant_id):
|
||||
page = 0
|
||||
page_size = 1000
|
||||
while True:
|
||||
chunks = settings.docStoreConn.search(["img_id"], [], {"doc_id": doc.id}, [], OrderByExpr(),
|
||||
page * page_size, page_size, search.index_name(tenant_id),
|
||||
[doc.kb_id])
|
||||
chunk_ids = settings.docStoreConn.get_doc_ids(chunks)
|
||||
if not chunk_ids:
|
||||
break
|
||||
for cid in chunk_ids:
|
||||
if settings.STORAGE_IMPL.obj_exist(doc.kb_id, cid):
|
||||
settings.STORAGE_IMPL.rm(doc.kb_id, cid)
|
||||
page += 1
|
||||
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
def get_newly_uploaded(cls):
|
||||
|
||||
@ -65,6 +65,7 @@ class EvaluationService(CommonService):
|
||||
(success, dataset_id or error_message)
|
||||
"""
|
||||
try:
|
||||
timestamp= current_timestamp()
|
||||
dataset_id = get_uuid()
|
||||
dataset = {
|
||||
"id": dataset_id,
|
||||
@ -73,8 +74,8 @@ class EvaluationService(CommonService):
|
||||
"description": description,
|
||||
"kb_ids": kb_ids,
|
||||
"created_by": user_id,
|
||||
"create_time": current_timestamp(),
|
||||
"update_time": current_timestamp(),
|
||||
"create_time": timestamp,
|
||||
"update_time": timestamp,
|
||||
"status": StatusEnum.VALID.value
|
||||
}
|
||||
|
||||
|
||||
@ -64,10 +64,13 @@ class TenantLangfuseService(CommonService):
|
||||
|
||||
@classmethod
|
||||
def save(cls, **kwargs):
|
||||
kwargs["create_time"] = current_timestamp()
|
||||
kwargs["create_date"] = datetime_format(datetime.now())
|
||||
kwargs["update_time"] = current_timestamp()
|
||||
kwargs["update_date"] = datetime_format(datetime.now())
|
||||
current_ts = current_timestamp()
|
||||
current_date = datetime_format(datetime.now())
|
||||
|
||||
kwargs["create_time"] = current_ts
|
||||
kwargs["create_date"] = current_date
|
||||
kwargs["update_time"] = current_ts
|
||||
kwargs["update_date"] = current_date
|
||||
obj = cls.model.create(**kwargs)
|
||||
return obj
|
||||
|
||||
|
||||
@ -169,11 +169,12 @@ class PipelineOperationLogService(CommonService):
|
||||
operation_status=operation_status,
|
||||
avatar=avatar,
|
||||
)
|
||||
log["create_time"] = current_timestamp()
|
||||
log["create_date"] = datetime_format(datetime.now())
|
||||
log["update_time"] = current_timestamp()
|
||||
log["update_date"] = datetime_format(datetime.now())
|
||||
|
||||
timestamp = current_timestamp()
|
||||
datetime_now = datetime_format(datetime.now())
|
||||
log["create_time"] = timestamp
|
||||
log["create_date"] = datetime_now
|
||||
log["update_time"] = timestamp
|
||||
log["update_date"] = datetime_now
|
||||
with DB.atomic():
|
||||
obj = cls.save(**log)
|
||||
|
||||
|
||||
@ -28,10 +28,13 @@ class SearchService(CommonService):
|
||||
|
||||
@classmethod
|
||||
def save(cls, **kwargs):
|
||||
kwargs["create_time"] = current_timestamp()
|
||||
kwargs["create_date"] = datetime_format(datetime.now())
|
||||
kwargs["update_time"] = current_timestamp()
|
||||
kwargs["update_date"] = datetime_format(datetime.now())
|
||||
current_ts = current_timestamp()
|
||||
current_date = datetime_format(datetime.now())
|
||||
|
||||
kwargs["create_time"] = current_ts
|
||||
kwargs["create_date"] = current_date
|
||||
kwargs["update_time"] = current_ts
|
||||
kwargs["update_date"] = current_date
|
||||
obj = cls.model.create(**kwargs)
|
||||
return obj
|
||||
|
||||
|
||||
@ -116,10 +116,13 @@ class UserService(CommonService):
|
||||
kwargs["password"] = generate_password_hash(
|
||||
str(kwargs["password"]))
|
||||
|
||||
kwargs["create_time"] = current_timestamp()
|
||||
kwargs["create_date"] = datetime_format(datetime.now())
|
||||
kwargs["update_time"] = current_timestamp()
|
||||
kwargs["update_date"] = datetime_format(datetime.now())
|
||||
current_ts = current_timestamp()
|
||||
current_date = datetime_format(datetime.now())
|
||||
|
||||
kwargs["create_time"] = current_ts
|
||||
kwargs["create_date"] = current_date
|
||||
kwargs["update_time"] = current_ts
|
||||
kwargs["update_date"] = current_date
|
||||
obj = cls.model(**kwargs).save(force_insert=True)
|
||||
return obj
|
||||
|
||||
|
||||
@ -42,7 +42,7 @@ def filename_type(filename):
|
||||
if re.match(r".*\.pdf$", filename):
|
||||
return FileType.PDF.value
|
||||
|
||||
if re.match(r".*\.(msg|eml|doc|docx|ppt|pptx|yml|xml|htm|json|jsonl|ldjson|csv|txt|ini|xls|xlsx|wps|rtf|hlp|pages|numbers|key|md|py|js|java|c|cpp|h|php|go|ts|sh|cs|kt|html|sql)$", filename):
|
||||
if re.match(r".*\.(msg|eml|doc|docx|ppt|pptx|yml|xml|htm|json|jsonl|ldjson|csv|txt|ini|xls|xlsx|wps|rtf|hlp|pages|numbers|key|md|mdx|py|js|java|c|cpp|h|php|go|ts|sh|cs|kt|html|sql)$", filename):
|
||||
return FileType.DOC.value
|
||||
|
||||
if re.match(r".*\.(wav|flac|ape|alac|wavpack|wv|mp3|aac|ogg|vorbis|opus)$", filename):
|
||||
|
||||
@ -69,6 +69,7 @@ CONTENT_TYPE_MAP = {
|
||||
# Web
|
||||
"md": "text/markdown",
|
||||
"markdown": "text/markdown",
|
||||
"mdx": "text/markdown",
|
||||
"htm": "text/html",
|
||||
"html": "text/html",
|
||||
"json": "application/json",
|
||||
|
||||
@ -129,7 +129,8 @@ class FileSource(StrEnum):
|
||||
OCI_STORAGE = "oci_storage"
|
||||
GOOGLE_CLOUD_STORAGE = "google_cloud_storage"
|
||||
AIRTABLE = "airtable"
|
||||
|
||||
ASANA = "asana"
|
||||
GITLAB = "gitlab"
|
||||
|
||||
class PipelineTaskType(StrEnum):
|
||||
PARSE = "Parse"
|
||||
|
||||
@ -37,6 +37,7 @@ from .teams_connector import TeamsConnector
|
||||
from .webdav_connector import WebDAVConnector
|
||||
from .moodle_connector import MoodleConnector
|
||||
from .airtable_connector import AirtableConnector
|
||||
from .asana_connector import AsanaConnector
|
||||
from .config import BlobType, DocumentSource
|
||||
from .models import Document, TextSection, ImageSection, BasicExpertInfo
|
||||
from .exceptions import (
|
||||
@ -73,4 +74,5 @@ __all__ = [
|
||||
"InsufficientPermissionsError",
|
||||
"UnexpectedValidationError",
|
||||
"AirtableConnector",
|
||||
"AsanaConnector",
|
||||
]
|
||||
|
||||
454
common/data_source/asana_connector.py
Normal file
454
common/data_source/asana_connector.py
Normal file
@ -0,0 +1,454 @@
|
||||
from collections.abc import Iterator
|
||||
import time
|
||||
from datetime import datetime
|
||||
import logging
|
||||
from typing import Any, Dict
|
||||
import asana
|
||||
import requests
|
||||
from common.data_source.config import CONTINUE_ON_CONNECTOR_FAILURE, INDEX_BATCH_SIZE, DocumentSource
|
||||
from common.data_source.interfaces import LoadConnector, PollConnector
|
||||
from common.data_source.models import Document, GenerateDocumentsOutput, SecondsSinceUnixEpoch
|
||||
from common.data_source.utils import extract_size_bytes, get_file_ext
|
||||
|
||||
|
||||
|
||||
# https://github.com/Asana/python-asana/tree/master?tab=readme-ov-file#documentation-for-api-endpoints
|
||||
class AsanaTask:
|
||||
def __init__(
|
||||
self,
|
||||
id: str,
|
||||
title: str,
|
||||
text: str,
|
||||
link: str,
|
||||
last_modified: datetime,
|
||||
project_gid: str,
|
||||
project_name: str,
|
||||
) -> None:
|
||||
self.id = id
|
||||
self.title = title
|
||||
self.text = text
|
||||
self.link = link
|
||||
self.last_modified = last_modified
|
||||
self.project_gid = project_gid
|
||||
self.project_name = project_name
|
||||
|
||||
def __str__(self) -> str:
|
||||
return f"ID: {self.id}\nTitle: {self.title}\nLast modified: {self.last_modified}\nText: {self.text}"
|
||||
|
||||
|
||||
class AsanaAPI:
|
||||
def __init__(
|
||||
self, api_token: str, workspace_gid: str, team_gid: str | None
|
||||
) -> None:
|
||||
self._user = None
|
||||
self.workspace_gid = workspace_gid
|
||||
self.team_gid = team_gid
|
||||
|
||||
self.configuration = asana.Configuration()
|
||||
self.api_client = asana.ApiClient(self.configuration)
|
||||
self.tasks_api = asana.TasksApi(self.api_client)
|
||||
self.attachments_api = asana.AttachmentsApi(self.api_client)
|
||||
self.stories_api = asana.StoriesApi(self.api_client)
|
||||
self.users_api = asana.UsersApi(self.api_client)
|
||||
self.project_api = asana.ProjectsApi(self.api_client)
|
||||
self.project_memberships_api = asana.ProjectMembershipsApi(self.api_client)
|
||||
self.workspaces_api = asana.WorkspacesApi(self.api_client)
|
||||
|
||||
self.api_error_count = 0
|
||||
self.configuration.access_token = api_token
|
||||
self.task_count = 0
|
||||
|
||||
def get_tasks(
|
||||
self, project_gids: list[str] | None, start_date: str
|
||||
) -> Iterator[AsanaTask]:
|
||||
"""Get all tasks from the projects with the given gids that were modified since the given date.
|
||||
If project_gids is None, get all tasks from all projects in the workspace."""
|
||||
logging.info("Starting to fetch Asana projects")
|
||||
projects = self.project_api.get_projects(
|
||||
opts={
|
||||
"workspace": self.workspace_gid,
|
||||
"opt_fields": "gid,name,archived,modified_at",
|
||||
}
|
||||
)
|
||||
start_seconds = int(time.mktime(datetime.now().timetuple()))
|
||||
projects_list = []
|
||||
project_count = 0
|
||||
for project_info in projects:
|
||||
project_gid = project_info["gid"]
|
||||
if project_gids is None or project_gid in project_gids:
|
||||
projects_list.append(project_gid)
|
||||
else:
|
||||
logging.debug(
|
||||
f"Skipping project: {project_gid} - not in accepted project_gids"
|
||||
)
|
||||
project_count += 1
|
||||
if project_count % 100 == 0:
|
||||
logging.info(f"Processed {project_count} projects")
|
||||
logging.info(f"Found {len(projects_list)} projects to process")
|
||||
for project_gid in projects_list:
|
||||
for task in self._get_tasks_for_project(
|
||||
project_gid, start_date, start_seconds
|
||||
):
|
||||
yield task
|
||||
logging.info(f"Completed fetching {self.task_count} tasks from Asana")
|
||||
if self.api_error_count > 0:
|
||||
logging.warning(
|
||||
f"Encountered {self.api_error_count} API errors during task fetching"
|
||||
)
|
||||
|
||||
def _get_tasks_for_project(
|
||||
self, project_gid: str, start_date: str, start_seconds: int
|
||||
) -> Iterator[AsanaTask]:
|
||||
project = self.project_api.get_project(project_gid, opts={})
|
||||
project_name = project.get("name", project_gid)
|
||||
team = project.get("team") or {}
|
||||
team_gid = team.get("gid")
|
||||
|
||||
if project.get("archived"):
|
||||
logging.info(f"Skipping archived project: {project_name} ({project_gid})")
|
||||
return
|
||||
if not team_gid:
|
||||
logging.info(
|
||||
f"Skipping project without a team: {project_name} ({project_gid})"
|
||||
)
|
||||
return
|
||||
if project.get("privacy_setting") == "private":
|
||||
if self.team_gid and team_gid != self.team_gid:
|
||||
logging.info(
|
||||
f"Skipping private project not in configured team: {project_name} ({project_gid})"
|
||||
)
|
||||
return
|
||||
logging.info(
|
||||
f"Processing private project in configured team: {project_name} ({project_gid})"
|
||||
)
|
||||
|
||||
simple_start_date = start_date.split(".")[0].split("+")[0]
|
||||
logging.info(
|
||||
f"Fetching tasks modified since {simple_start_date} for project: {project_name} ({project_gid})"
|
||||
)
|
||||
|
||||
opts = {
|
||||
"opt_fields": "name,memberships,memberships.project,completed_at,completed_by,created_at,"
|
||||
"created_by,custom_fields,dependencies,due_at,due_on,external,html_notes,liked,likes,"
|
||||
"modified_at,notes,num_hearts,parent,projects,resource_subtype,resource_type,start_on,"
|
||||
"workspace,permalink_url",
|
||||
"modified_since": start_date,
|
||||
}
|
||||
tasks_from_api = self.tasks_api.get_tasks_for_project(project_gid, opts)
|
||||
for data in tasks_from_api:
|
||||
self.task_count += 1
|
||||
if self.task_count % 10 == 0:
|
||||
end_seconds = time.mktime(datetime.now().timetuple())
|
||||
runtime_seconds = end_seconds - start_seconds
|
||||
if runtime_seconds > 0:
|
||||
logging.info(
|
||||
f"Processed {self.task_count} tasks in {runtime_seconds:.0f} seconds "
|
||||
f"({self.task_count / runtime_seconds:.2f} tasks/second)"
|
||||
)
|
||||
|
||||
logging.debug(f"Processing Asana task: {data['name']}")
|
||||
|
||||
text = self._construct_task_text(data)
|
||||
|
||||
try:
|
||||
text += self._fetch_and_add_comments(data["gid"])
|
||||
|
||||
last_modified_date = self.format_date(data["modified_at"])
|
||||
text += f"Last modified: {last_modified_date}\n"
|
||||
|
||||
task = AsanaTask(
|
||||
id=data["gid"],
|
||||
title=data["name"],
|
||||
text=text,
|
||||
link=data["permalink_url"],
|
||||
last_modified=datetime.fromisoformat(data["modified_at"]),
|
||||
project_gid=project_gid,
|
||||
project_name=project_name,
|
||||
)
|
||||
yield task
|
||||
except Exception:
|
||||
logging.error(
|
||||
f"Error processing task {data['gid']} in project {project_gid}",
|
||||
exc_info=True,
|
||||
)
|
||||
self.api_error_count += 1
|
||||
|
||||
def _construct_task_text(self, data: Dict) -> str:
|
||||
text = f"{data['name']}\n\n"
|
||||
|
||||
if data["notes"]:
|
||||
text += f"{data['notes']}\n\n"
|
||||
|
||||
if data["created_by"] and data["created_by"]["gid"]:
|
||||
creator = self.get_user(data["created_by"]["gid"])["name"]
|
||||
created_date = self.format_date(data["created_at"])
|
||||
text += f"Created by: {creator} on {created_date}\n"
|
||||
|
||||
if data["due_on"]:
|
||||
due_date = self.format_date(data["due_on"])
|
||||
text += f"Due date: {due_date}\n"
|
||||
|
||||
if data["completed_at"]:
|
||||
completed_date = self.format_date(data["completed_at"])
|
||||
text += f"Completed on: {completed_date}\n"
|
||||
|
||||
text += "\n"
|
||||
return text
|
||||
|
||||
def _fetch_and_add_comments(self, task_gid: str) -> str:
|
||||
text = ""
|
||||
stories_opts: Dict[str, str] = {}
|
||||
story_start = time.time()
|
||||
stories = self.stories_api.get_stories_for_task(task_gid, stories_opts)
|
||||
|
||||
story_count = 0
|
||||
comment_count = 0
|
||||
|
||||
for story in stories:
|
||||
story_count += 1
|
||||
if story["resource_subtype"] == "comment_added":
|
||||
comment = self.stories_api.get_story(
|
||||
story["gid"], opts={"opt_fields": "text,created_by,created_at"}
|
||||
)
|
||||
commenter = self.get_user(comment["created_by"]["gid"])["name"]
|
||||
text += f"Comment by {commenter}: {comment['text']}\n\n"
|
||||
comment_count += 1
|
||||
|
||||
story_duration = time.time() - story_start
|
||||
logging.debug(
|
||||
f"Processed {story_count} stories (including {comment_count} comments) in {story_duration:.2f} seconds"
|
||||
)
|
||||
|
||||
return text
|
||||
|
||||
def get_attachments(self, task_gid: str) -> list[dict]:
|
||||
"""
|
||||
Fetch full attachment info (including download_url) for a task.
|
||||
"""
|
||||
attachments: list[dict] = []
|
||||
|
||||
try:
|
||||
# Step 1: list attachment compact records
|
||||
for att in self.attachments_api.get_attachments_for_object(
|
||||
parent=task_gid,
|
||||
opts={}
|
||||
):
|
||||
gid = att.get("gid")
|
||||
if not gid:
|
||||
continue
|
||||
|
||||
try:
|
||||
# Step 2: expand to full attachment
|
||||
full = self.attachments_api.get_attachment(
|
||||
attachment_gid=gid,
|
||||
opts={
|
||||
"opt_fields": "name,download_url,size,created_at"
|
||||
}
|
||||
)
|
||||
|
||||
if full.get("download_url"):
|
||||
attachments.append(full)
|
||||
|
||||
except Exception:
|
||||
logging.exception(
|
||||
f"Failed to fetch attachment detail {gid} for task {task_gid}"
|
||||
)
|
||||
self.api_error_count += 1
|
||||
|
||||
except Exception:
|
||||
logging.exception(f"Failed to list attachments for task {task_gid}")
|
||||
self.api_error_count += 1
|
||||
|
||||
return attachments
|
||||
|
||||
def get_accessible_emails(
|
||||
self,
|
||||
workspace_id: str,
|
||||
project_ids: list[str] | None,
|
||||
team_id: str | None,
|
||||
):
|
||||
|
||||
ws_users = self.users_api.get_users(
|
||||
opts={
|
||||
"workspace": workspace_id,
|
||||
"opt_fields": "gid,name,email"
|
||||
}
|
||||
)
|
||||
|
||||
workspace_users = {
|
||||
u["gid"]: u.get("email")
|
||||
for u in ws_users
|
||||
if u.get("email")
|
||||
}
|
||||
|
||||
if not project_ids:
|
||||
return set(workspace_users.values())
|
||||
|
||||
|
||||
project_emails = set()
|
||||
|
||||
for pid in project_ids:
|
||||
project = self.project_api.get_project(
|
||||
pid,
|
||||
opts={"opt_fields": "team,privacy_setting"}
|
||||
)
|
||||
|
||||
if project["privacy_setting"] == "private":
|
||||
if team_id and project.get("team", {}).get("gid") != team_id:
|
||||
continue
|
||||
|
||||
memberships = self.project_memberships_api.get_project_membership(
|
||||
pid,
|
||||
opts={"opt_fields": "user.gid,user.email"}
|
||||
)
|
||||
|
||||
for m in memberships:
|
||||
email = m["user"].get("email")
|
||||
if email:
|
||||
project_emails.add(email)
|
||||
|
||||
return project_emails
|
||||
|
||||
def get_user(self, user_gid: str) -> Dict:
|
||||
if self._user is not None:
|
||||
return self._user
|
||||
self._user = self.users_api.get_user(user_gid, {"opt_fields": "name,email"})
|
||||
|
||||
if not self._user:
|
||||
logging.warning(f"Unable to fetch user information for user_gid: {user_gid}")
|
||||
return {"name": "Unknown"}
|
||||
return self._user
|
||||
|
||||
def format_date(self, date_str: str) -> str:
|
||||
date = datetime.fromisoformat(date_str)
|
||||
return time.strftime("%Y-%m-%d", date.timetuple())
|
||||
|
||||
def get_time(self) -> str:
|
||||
return time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
|
||||
|
||||
|
||||
class AsanaConnector(LoadConnector, PollConnector):
|
||||
def __init__(
|
||||
self,
|
||||
asana_workspace_id: str,
|
||||
asana_project_ids: str | None = None,
|
||||
asana_team_id: str | None = None,
|
||||
batch_size: int = INDEX_BATCH_SIZE,
|
||||
continue_on_failure: bool = CONTINUE_ON_CONNECTOR_FAILURE,
|
||||
) -> None:
|
||||
self.workspace_id = asana_workspace_id
|
||||
self.project_ids_to_index: list[str] | None = (
|
||||
asana_project_ids.split(",") if asana_project_ids else None
|
||||
)
|
||||
self.asana_team_id = asana_team_id if asana_team_id else None
|
||||
self.batch_size = batch_size
|
||||
self.continue_on_failure = continue_on_failure
|
||||
self.size_threshold = None
|
||||
logging.info(
|
||||
f"AsanaConnector initialized with workspace_id: {asana_workspace_id}"
|
||||
)
|
||||
|
||||
def load_credentials(self, credentials: dict[str, Any]) -> dict[str, Any] | None:
|
||||
self.api_token = credentials["asana_api_token_secret"]
|
||||
self.asana_client = AsanaAPI(
|
||||
api_token=self.api_token,
|
||||
workspace_gid=self.workspace_id,
|
||||
team_gid=self.asana_team_id,
|
||||
)
|
||||
self.workspace_users_email = self.asana_client.get_accessible_emails(self.workspace_id, self.project_ids_to_index, self.asana_team_id)
|
||||
logging.info("Asana credentials loaded and API client initialized")
|
||||
return None
|
||||
|
||||
def poll_source(
|
||||
self, start: SecondsSinceUnixEpoch, end: SecondsSinceUnixEpoch | None
|
||||
) -> GenerateDocumentsOutput:
|
||||
start_time = datetime.fromtimestamp(start).isoformat()
|
||||
logging.info(f"Starting Asana poll from {start_time}")
|
||||
docs_batch: list[Document] = []
|
||||
tasks = self.asana_client.get_tasks(self.project_ids_to_index, start_time)
|
||||
for task in tasks:
|
||||
docs = self._task_to_documents(task)
|
||||
docs_batch.extend(docs)
|
||||
|
||||
if len(docs_batch) >= self.batch_size:
|
||||
logging.info(f"Yielding batch of {len(docs_batch)} documents")
|
||||
yield docs_batch
|
||||
docs_batch = []
|
||||
|
||||
if docs_batch:
|
||||
logging.info(f"Yielding final batch of {len(docs_batch)} documents")
|
||||
yield docs_batch
|
||||
|
||||
logging.info("Asana poll completed")
|
||||
|
||||
def load_from_state(self) -> GenerateDocumentsOutput:
|
||||
logging.info("Starting full index of all Asana tasks")
|
||||
return self.poll_source(start=0, end=None)
|
||||
|
||||
def _task_to_documents(self, task: AsanaTask) -> list[Document]:
|
||||
docs: list[Document] = []
|
||||
|
||||
attachments = self.asana_client.get_attachments(task.id)
|
||||
|
||||
for att in attachments:
|
||||
try:
|
||||
resp = requests.get(att["download_url"], timeout=30)
|
||||
resp.raise_for_status()
|
||||
file_blob = resp.content
|
||||
filename = att.get("name", "attachment")
|
||||
size_bytes = extract_size_bytes(att)
|
||||
if (
|
||||
self.size_threshold is not None
|
||||
and isinstance(size_bytes, int)
|
||||
and size_bytes > self.size_threshold
|
||||
):
|
||||
logging.warning(
|
||||
f"{filename} exceeds size threshold of {self.size_threshold}. Skipping."
|
||||
)
|
||||
continue
|
||||
docs.append(
|
||||
Document(
|
||||
id=f"asana:{task.id}:{att['gid']}",
|
||||
blob=file_blob,
|
||||
extension=get_file_ext(filename) or "",
|
||||
size_bytes=size_bytes,
|
||||
doc_updated_at=task.last_modified,
|
||||
source=DocumentSource.ASANA,
|
||||
semantic_identifier=filename,
|
||||
primary_owners=list(self.workspace_users_email),
|
||||
)
|
||||
)
|
||||
except Exception:
|
||||
logging.exception(
|
||||
f"Failed to download attachment {att.get('gid')} for task {task.id}"
|
||||
)
|
||||
|
||||
return docs
|
||||
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
import time
|
||||
import os
|
||||
|
||||
logging.info("Starting Asana connector test")
|
||||
connector = AsanaConnector(
|
||||
os.environ["WORKSPACE_ID"],
|
||||
os.environ["PROJECT_IDS"],
|
||||
os.environ["TEAM_ID"],
|
||||
)
|
||||
connector.load_credentials(
|
||||
{
|
||||
"asana_api_token_secret": os.environ["API_TOKEN"],
|
||||
}
|
||||
)
|
||||
logging.info("Loading all documents from Asana")
|
||||
all_docs = connector.load_from_state()
|
||||
current = time.time()
|
||||
one_day_ago = current - 24 * 60 * 60 # 1 day
|
||||
logging.info("Polling for documents updated in the last 24 hours")
|
||||
latest_docs = connector.poll_source(one_day_ago, current)
|
||||
for docs in all_docs:
|
||||
for doc in docs:
|
||||
print(doc.id)
|
||||
logging.info("Asana connector test completed")
|
||||
@ -54,6 +54,9 @@ class DocumentSource(str, Enum):
|
||||
DROPBOX = "dropbox"
|
||||
BOX = "box"
|
||||
AIRTABLE = "airtable"
|
||||
ASANA = "asana"
|
||||
GITHUB = "github"
|
||||
GITLAB = "gitlab"
|
||||
|
||||
class FileOrigin(str, Enum):
|
||||
"""File origins"""
|
||||
@ -256,6 +259,10 @@ AIRTABLE_CONNECTOR_SIZE_THRESHOLD = int(
|
||||
os.environ.get("AIRTABLE_CONNECTOR_SIZE_THRESHOLD", 10 * 1024 * 1024)
|
||||
)
|
||||
|
||||
ASANA_CONNECTOR_SIZE_THRESHOLD = int(
|
||||
os.environ.get("ASANA_CONNECTOR_SIZE_THRESHOLD", 10 * 1024 * 1024)
|
||||
)
|
||||
|
||||
_USER_NOT_FOUND = "Unknown Confluence User"
|
||||
|
||||
_COMMENT_EXPANSION_FIELDS = ["body.storage.value"]
|
||||
|
||||
@ -18,6 +18,7 @@ class UploadMimeTypes:
|
||||
"text/plain",
|
||||
"text/markdown",
|
||||
"text/x-markdown",
|
||||
"text/mdx",
|
||||
"text/x-config",
|
||||
"text/tab-separated-values",
|
||||
"application/json",
|
||||
|
||||
340
common/data_source/gitlab_connector.py
Normal file
340
common/data_source/gitlab_connector.py
Normal file
@ -0,0 +1,340 @@
|
||||
import fnmatch
|
||||
import itertools
|
||||
from collections import deque
|
||||
from collections.abc import Iterable
|
||||
from collections.abc import Iterator
|
||||
from datetime import datetime
|
||||
from datetime import timezone
|
||||
from typing import Any
|
||||
from typing import TypeVar
|
||||
import gitlab
|
||||
from gitlab.v4.objects import Project
|
||||
|
||||
from common.data_source.config import DocumentSource, INDEX_BATCH_SIZE
|
||||
from common.data_source.exceptions import ConnectorMissingCredentialError
|
||||
from common.data_source.exceptions import ConnectorValidationError
|
||||
from common.data_source.exceptions import CredentialExpiredError
|
||||
from common.data_source.exceptions import InsufficientPermissionsError
|
||||
from common.data_source.exceptions import UnexpectedValidationError
|
||||
from common.data_source.interfaces import GenerateDocumentsOutput
|
||||
from common.data_source.interfaces import LoadConnector
|
||||
from common.data_source.interfaces import PollConnector
|
||||
from common.data_source.interfaces import SecondsSinceUnixEpoch
|
||||
from common.data_source.models import BasicExpertInfo
|
||||
from common.data_source.models import Document
|
||||
from common.data_source.utils import get_file_ext
|
||||
|
||||
T = TypeVar("T")
|
||||
|
||||
|
||||
|
||||
# List of directories/Files to exclude
|
||||
exclude_patterns = [
|
||||
"logs",
|
||||
".github/",
|
||||
".gitlab/",
|
||||
".pre-commit-config.yaml",
|
||||
]
|
||||
|
||||
|
||||
def _batch_gitlab_objects(git_objs: Iterable[T], batch_size: int) -> Iterator[list[T]]:
|
||||
it = iter(git_objs)
|
||||
while True:
|
||||
batch = list(itertools.islice(it, batch_size))
|
||||
if not batch:
|
||||
break
|
||||
yield batch
|
||||
|
||||
|
||||
def get_author(author: Any) -> BasicExpertInfo:
|
||||
return BasicExpertInfo(
|
||||
display_name=author.get("name"),
|
||||
)
|
||||
|
||||
|
||||
def _convert_merge_request_to_document(mr: Any) -> Document:
|
||||
mr_text = mr.description or ""
|
||||
doc = Document(
|
||||
id=mr.web_url,
|
||||
blob=mr_text,
|
||||
source=DocumentSource.GITLAB,
|
||||
semantic_identifier=mr.title,
|
||||
extension=".md",
|
||||
# updated_at is UTC time but is timezone unaware, explicitly add UTC
|
||||
# as there is logic in indexing to prevent wrong timestamped docs
|
||||
# due to local time discrepancies with UTC
|
||||
doc_updated_at=mr.updated_at.replace(tzinfo=timezone.utc),
|
||||
size_bytes=len(mr_text.encode("utf-8")),
|
||||
primary_owners=[get_author(mr.author)],
|
||||
metadata={"state": mr.state, "type": "MergeRequest", "web_url": mr.web_url},
|
||||
)
|
||||
return doc
|
||||
|
||||
|
||||
def _convert_issue_to_document(issue: Any) -> Document:
|
||||
issue_text = issue.description or ""
|
||||
doc = Document(
|
||||
id=issue.web_url,
|
||||
blob=issue_text,
|
||||
source=DocumentSource.GITLAB,
|
||||
semantic_identifier=issue.title,
|
||||
extension=".md",
|
||||
# updated_at is UTC time but is timezone unaware, explicitly add UTC
|
||||
# as there is logic in indexing to prevent wrong timestamped docs
|
||||
# due to local time discrepancies with UTC
|
||||
doc_updated_at=issue.updated_at.replace(tzinfo=timezone.utc),
|
||||
size_bytes=len(issue_text.encode("utf-8")),
|
||||
primary_owners=[get_author(issue.author)],
|
||||
metadata={
|
||||
"state": issue.state,
|
||||
"type": issue.type if issue.type else "Issue",
|
||||
"web_url": issue.web_url,
|
||||
},
|
||||
)
|
||||
return doc
|
||||
|
||||
|
||||
def _convert_code_to_document(
|
||||
project: Project, file: Any, url: str, projectName: str, projectOwner: str
|
||||
) -> Document:
|
||||
|
||||
# Dynamically get the default branch from the project object
|
||||
default_branch = project.default_branch
|
||||
|
||||
# Fetch the file content using the correct branch
|
||||
file_content_obj = project.files.get(
|
||||
file_path=file["path"], ref=default_branch # Use the default branch
|
||||
)
|
||||
# BoxConnector uses raw bytes for blob. Keep the same here.
|
||||
file_content_bytes = file_content_obj.decode()
|
||||
file_url = f"{url}/{projectOwner}/{projectName}/-/blob/{default_branch}/{file['path']}"
|
||||
|
||||
# Try to use the last commit timestamp for incremental sync.
|
||||
# Falls back to "now" if the commit lookup fails.
|
||||
last_commit_at = None
|
||||
try:
|
||||
# Query commit history for this file on the default branch.
|
||||
commits = project.commits.list(
|
||||
ref_name=default_branch,
|
||||
path=file["path"],
|
||||
per_page=1,
|
||||
)
|
||||
if commits:
|
||||
# committed_date is ISO string like "2024-01-01T00:00:00.000+00:00"
|
||||
committed_date = commits[0].committed_date
|
||||
if isinstance(committed_date, str):
|
||||
last_commit_at = datetime.strptime(
|
||||
committed_date, "%Y-%m-%dT%H:%M:%S.%f%z"
|
||||
).astimezone(timezone.utc)
|
||||
elif isinstance(committed_date, datetime):
|
||||
last_commit_at = committed_date.astimezone(timezone.utc)
|
||||
except Exception:
|
||||
last_commit_at = None
|
||||
|
||||
# Create and return a Document object
|
||||
doc = Document(
|
||||
# Use a stable ID so reruns don't create duplicates.
|
||||
id=file_url,
|
||||
blob=file_content_bytes,
|
||||
source=DocumentSource.GITLAB,
|
||||
semantic_identifier=file.get("name"),
|
||||
extension=get_file_ext(file.get("name")),
|
||||
doc_updated_at=last_commit_at or datetime.now(tz=timezone.utc),
|
||||
size_bytes=len(file_content_bytes) if file_content_bytes is not None else 0,
|
||||
primary_owners=[], # Add owners if needed
|
||||
metadata={
|
||||
"type": "CodeFile",
|
||||
"path": file.get("path"),
|
||||
"ref": default_branch,
|
||||
"project": f"{projectOwner}/{projectName}",
|
||||
"web_url": file_url,
|
||||
},
|
||||
)
|
||||
return doc
|
||||
|
||||
|
||||
def _should_exclude(path: str) -> bool:
|
||||
"""Check if a path matches any of the exclude patterns."""
|
||||
return any(fnmatch.fnmatch(path, pattern) for pattern in exclude_patterns)
|
||||
|
||||
|
||||
class GitlabConnector(LoadConnector, PollConnector):
|
||||
def __init__(
|
||||
self,
|
||||
project_owner: str,
|
||||
project_name: str,
|
||||
batch_size: int = INDEX_BATCH_SIZE,
|
||||
state_filter: str = "all",
|
||||
include_mrs: bool = True,
|
||||
include_issues: bool = True,
|
||||
include_code_files: bool = False,
|
||||
) -> None:
|
||||
self.project_owner = project_owner
|
||||
self.project_name = project_name
|
||||
self.batch_size = batch_size
|
||||
self.state_filter = state_filter
|
||||
self.include_mrs = include_mrs
|
||||
self.include_issues = include_issues
|
||||
self.include_code_files = include_code_files
|
||||
self.gitlab_client: gitlab.Gitlab | None = None
|
||||
|
||||
def load_credentials(self, credentials: dict[str, Any]) -> dict[str, Any] | None:
|
||||
self.gitlab_client = gitlab.Gitlab(
|
||||
credentials["gitlab_url"], private_token=credentials["gitlab_access_token"]
|
||||
)
|
||||
return None
|
||||
|
||||
def validate_connector_settings(self) -> None:
|
||||
if self.gitlab_client is None:
|
||||
raise ConnectorMissingCredentialError("GitLab")
|
||||
|
||||
try:
|
||||
self.gitlab_client.auth()
|
||||
self.gitlab_client.projects.get(
|
||||
f"{self.project_owner}/{self.project_name}",
|
||||
lazy=True,
|
||||
)
|
||||
|
||||
except gitlab.exceptions.GitlabAuthenticationError as e:
|
||||
raise CredentialExpiredError(
|
||||
"Invalid or expired GitLab credentials."
|
||||
) from e
|
||||
|
||||
except gitlab.exceptions.GitlabAuthorizationError as e:
|
||||
raise InsufficientPermissionsError(
|
||||
"Insufficient permissions to access GitLab resources."
|
||||
) from e
|
||||
|
||||
except gitlab.exceptions.GitlabGetError as e:
|
||||
raise ConnectorValidationError(
|
||||
"GitLab project not found or not accessible."
|
||||
) from e
|
||||
|
||||
except Exception as e:
|
||||
raise UnexpectedValidationError(
|
||||
f"Unexpected error while validating GitLab settings: {e}"
|
||||
) from e
|
||||
|
||||
def _fetch_from_gitlab(
|
||||
self, start: datetime | None = None, end: datetime | None = None
|
||||
) -> GenerateDocumentsOutput:
|
||||
if self.gitlab_client is None:
|
||||
raise ConnectorMissingCredentialError("Gitlab")
|
||||
project: Project = self.gitlab_client.projects.get(
|
||||
f"{self.project_owner}/{self.project_name}"
|
||||
)
|
||||
|
||||
start_utc = start.astimezone(timezone.utc) if start else None
|
||||
end_utc = end.astimezone(timezone.utc) if end else None
|
||||
|
||||
# Fetch code files
|
||||
if self.include_code_files:
|
||||
# Fetching using BFS as project.report_tree with recursion causing slow load
|
||||
queue = deque([""]) # Start with the root directory
|
||||
while queue:
|
||||
current_path = queue.popleft()
|
||||
files = project.repository_tree(path=current_path, all=True)
|
||||
for file_batch in _batch_gitlab_objects(files, self.batch_size):
|
||||
code_doc_batch: list[Document] = []
|
||||
for file in file_batch:
|
||||
if _should_exclude(file["path"]):
|
||||
continue
|
||||
|
||||
if file["type"] == "blob":
|
||||
|
||||
doc = _convert_code_to_document(
|
||||
project,
|
||||
file,
|
||||
self.gitlab_client.url,
|
||||
self.project_name,
|
||||
self.project_owner,
|
||||
)
|
||||
|
||||
# Apply incremental window filtering for code files too.
|
||||
if start_utc is not None and doc.doc_updated_at <= start_utc:
|
||||
continue
|
||||
if end_utc is not None and doc.doc_updated_at > end_utc:
|
||||
continue
|
||||
|
||||
code_doc_batch.append(doc)
|
||||
elif file["type"] == "tree":
|
||||
queue.append(file["path"])
|
||||
|
||||
if code_doc_batch:
|
||||
yield code_doc_batch
|
||||
|
||||
if self.include_mrs:
|
||||
merge_requests = project.mergerequests.list(
|
||||
state=self.state_filter,
|
||||
order_by="updated_at",
|
||||
sort="desc",
|
||||
iterator=True,
|
||||
)
|
||||
|
||||
for mr_batch in _batch_gitlab_objects(merge_requests, self.batch_size):
|
||||
mr_doc_batch: list[Document] = []
|
||||
for mr in mr_batch:
|
||||
mr.updated_at = datetime.strptime(
|
||||
mr.updated_at, "%Y-%m-%dT%H:%M:%S.%f%z"
|
||||
)
|
||||
if start_utc is not None and mr.updated_at <= start_utc:
|
||||
yield mr_doc_batch
|
||||
return
|
||||
if end_utc is not None and mr.updated_at > end_utc:
|
||||
continue
|
||||
mr_doc_batch.append(_convert_merge_request_to_document(mr))
|
||||
yield mr_doc_batch
|
||||
|
||||
if self.include_issues:
|
||||
issues = project.issues.list(state=self.state_filter, iterator=True)
|
||||
|
||||
for issue_batch in _batch_gitlab_objects(issues, self.batch_size):
|
||||
issue_doc_batch: list[Document] = []
|
||||
for issue in issue_batch:
|
||||
issue.updated_at = datetime.strptime(
|
||||
issue.updated_at, "%Y-%m-%dT%H:%M:%S.%f%z"
|
||||
)
|
||||
# Avoid re-syncing the last-seen item.
|
||||
if start_utc is not None and issue.updated_at <= start_utc:
|
||||
yield issue_doc_batch
|
||||
return
|
||||
if end_utc is not None and issue.updated_at > end_utc:
|
||||
continue
|
||||
issue_doc_batch.append(_convert_issue_to_document(issue))
|
||||
yield issue_doc_batch
|
||||
|
||||
def load_from_state(self) -> GenerateDocumentsOutput:
|
||||
return self._fetch_from_gitlab()
|
||||
|
||||
def poll_source(
|
||||
self, start: SecondsSinceUnixEpoch, end: SecondsSinceUnixEpoch
|
||||
) -> GenerateDocumentsOutput:
|
||||
start_datetime = datetime.fromtimestamp(start, tz=timezone.utc)
|
||||
end_datetime = datetime.fromtimestamp(end, tz=timezone.utc)
|
||||
return self._fetch_from_gitlab(start_datetime, end_datetime)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
import os
|
||||
|
||||
connector = GitlabConnector(
|
||||
# gitlab_url="https://gitlab.com/api/v4",
|
||||
project_owner=os.environ["PROJECT_OWNER"],
|
||||
project_name=os.environ["PROJECT_NAME"],
|
||||
batch_size=INDEX_BATCH_SIZE,
|
||||
state_filter="all",
|
||||
include_mrs=True,
|
||||
include_issues=True,
|
||||
include_code_files=True,
|
||||
)
|
||||
|
||||
connector.load_credentials(
|
||||
{
|
||||
"gitlab_access_token": os.environ["GITLAB_ACCESS_TOKEN"],
|
||||
"gitlab_url": os.environ["GITLAB_URL"],
|
||||
}
|
||||
)
|
||||
document_batches = connector.load_from_state()
|
||||
for f in document_batches:
|
||||
print("Batch:", f)
|
||||
print("Finished loading from state.")
|
||||
@ -5,7 +5,7 @@ from abc import ABC, abstractmethod
|
||||
from enum import IntFlag, auto
|
||||
from types import TracebackType
|
||||
from typing import Any, Dict, Generator, TypeVar, Generic, Callable, TypeAlias
|
||||
|
||||
from collections.abc import Iterator
|
||||
from anthropic import BaseModel
|
||||
|
||||
from common.data_source.models import (
|
||||
@ -16,6 +16,7 @@ from common.data_source.models import (
|
||||
SecondsSinceUnixEpoch, GenerateSlimDocumentOutput
|
||||
)
|
||||
|
||||
GenerateDocumentsOutput = Iterator[list[Document]]
|
||||
|
||||
class LoadConnector(ABC):
|
||||
"""Load connector interface"""
|
||||
|
||||
@ -78,14 +78,21 @@ class DoclingParser(RAGFlowPdfParser):
|
||||
def __images__(self, fnm, zoomin: int = 1, page_from=0, page_to=600, callback=None):
|
||||
self.page_from = page_from
|
||||
self.page_to = page_to
|
||||
bytes_io = None
|
||||
try:
|
||||
opener = pdfplumber.open(fnm) if isinstance(fnm, (str, PathLike)) else pdfplumber.open(BytesIO(fnm))
|
||||
if not isinstance(fnm, (str, PathLike)):
|
||||
bytes_io = BytesIO(fnm)
|
||||
|
||||
opener = pdfplumber.open(fnm) if isinstance(fnm, (str, PathLike)) else pdfplumber.open(bytes_io)
|
||||
with opener as pdf:
|
||||
pages = pdf.pages[page_from:page_to]
|
||||
self.page_images = [p.to_image(resolution=72 * zoomin, antialias=True).original for p in pages]
|
||||
except Exception as e:
|
||||
self.page_images = []
|
||||
self.logger.exception(e)
|
||||
finally:
|
||||
if bytes_io:
|
||||
bytes_io.close()
|
||||
|
||||
def _make_line_tag(self,bbox: _BBox) -> str:
|
||||
if bbox is None:
|
||||
|
||||
@ -16,6 +16,7 @@
|
||||
|
||||
import logging
|
||||
import sys
|
||||
import ast
|
||||
import six
|
||||
import cv2
|
||||
import numpy as np
|
||||
@ -108,7 +109,14 @@ class NormalizeImage:
|
||||
|
||||
def __init__(self, scale=None, mean=None, std=None, order='chw', **kwargs):
|
||||
if isinstance(scale, str):
|
||||
scale = eval(scale)
|
||||
try:
|
||||
scale = float(scale)
|
||||
except ValueError:
|
||||
if '/' in scale:
|
||||
parts = scale.split('/')
|
||||
scale = ast.literal_eval(parts[0]) / ast.literal_eval(parts[1])
|
||||
else:
|
||||
scale = ast.literal_eval(scale)
|
||||
self.scale = np.float32(scale if scale is not None else 1.0 / 255.0)
|
||||
mean = mean if mean is not None else [0.485, 0.456, 0.406]
|
||||
std = std if std is not None else [0.229, 0.224, 0.225]
|
||||
|
||||
@ -1,3 +1,10 @@
|
||||
# -----------------------------------------------------------------------------
|
||||
# SECURITY WARNING: DO NOT DEPLOY WITH DEFAULT PASSWORDS
|
||||
# For non-local deployments, please change all passwords (ELASTIC_PASSWORD,
|
||||
# MYSQL_PASSWORD, MINIO_PASSWORD, etc.) to strong, unique values.
|
||||
# You can generate a random string using: openssl rand -hex 32
|
||||
# -----------------------------------------------------------------------------
|
||||
|
||||
# ------------------------------
|
||||
# docker env var for specifying vector db type at startup
|
||||
# (based on the vector db type, the corresponding docker
|
||||
@ -30,6 +37,7 @@ ES_HOST=es01
|
||||
ES_PORT=1200
|
||||
|
||||
# The password for Elasticsearch.
|
||||
# WARNING: Change this for production!
|
||||
ELASTIC_PASSWORD=infini_rag_flow
|
||||
|
||||
# the hostname where OpenSearch service is exposed, set it not the same as elasticsearch
|
||||
@ -85,6 +93,7 @@ OB_DATAFILE_SIZE=${OB_DATAFILE_SIZE:-20G}
|
||||
OB_LOG_DISK_SIZE=${OB_LOG_DISK_SIZE:-20G}
|
||||
|
||||
# The password for MySQL.
|
||||
# WARNING: Change this for production!
|
||||
MYSQL_PASSWORD=infini_rag_flow
|
||||
# The hostname where the MySQL service is exposed
|
||||
MYSQL_HOST=mysql
|
||||
|
||||
@ -34,7 +34,7 @@ Enabling TOC extraction requires significant memory, computational resources, an
|
||||
|
||||
|
||||
|
||||
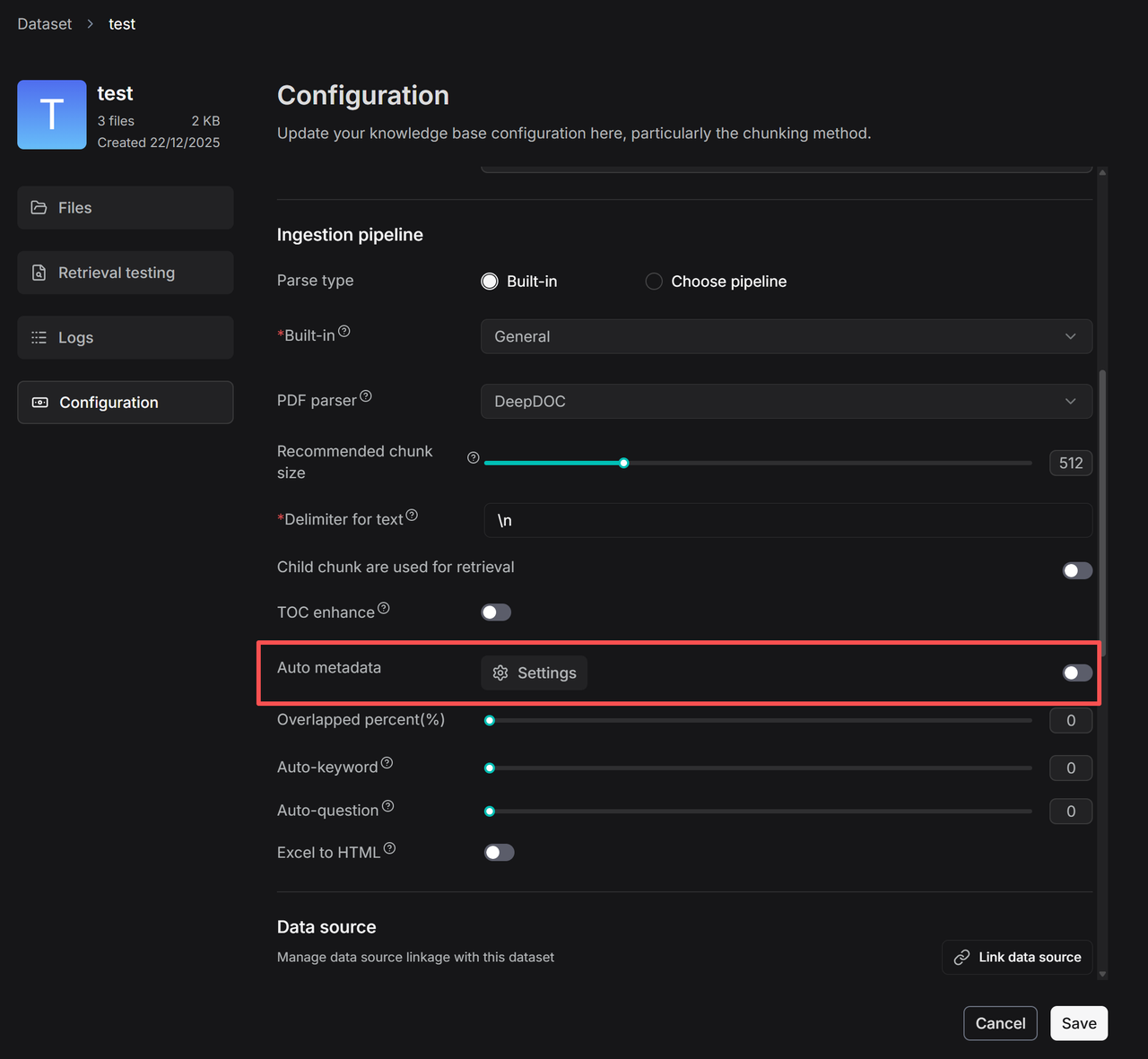
3. Click **+** to add new fields and enter the congiruation page.
|
||||
3. Click **+** to add new fields and enter the configuration page.
|
||||
|
||||
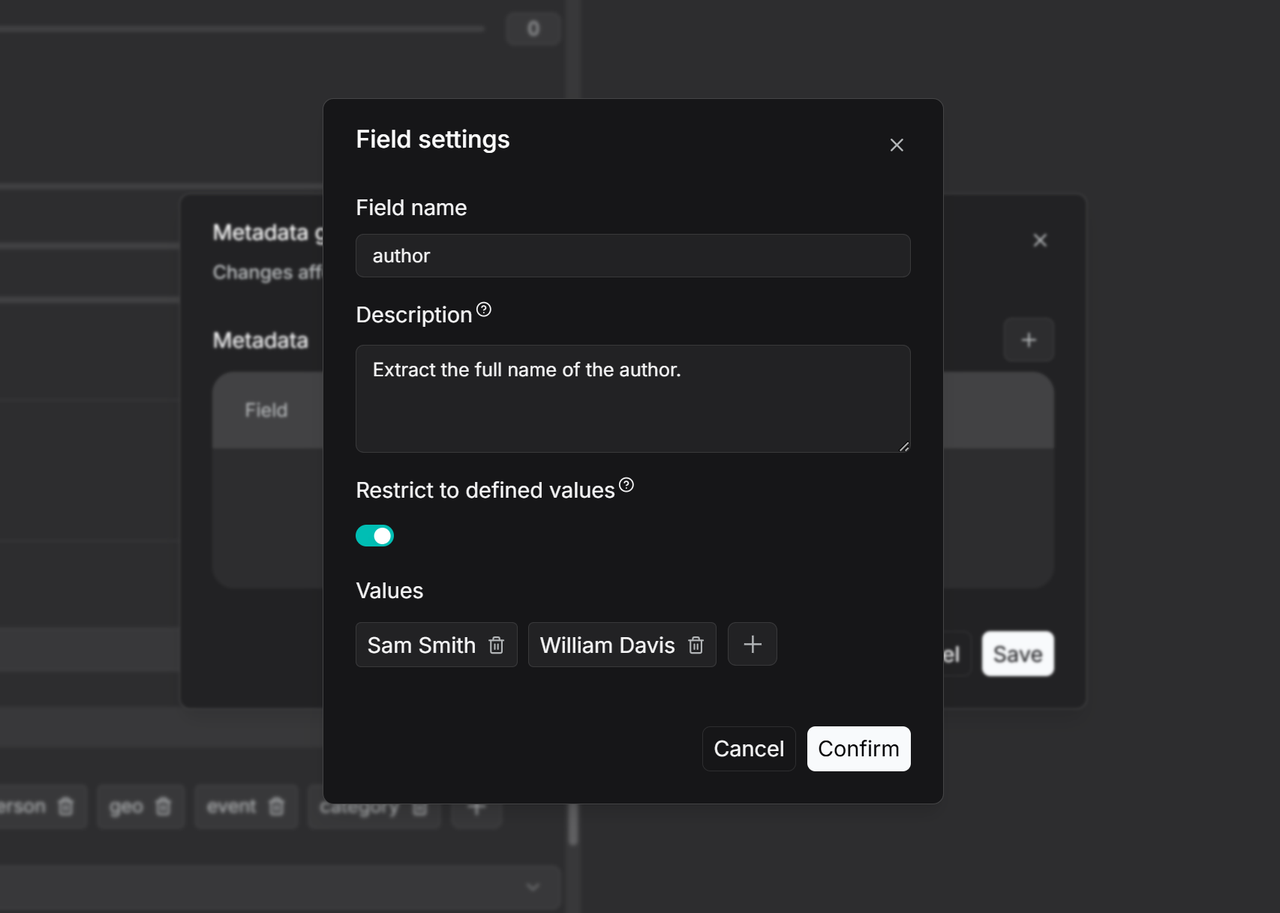
|
||||
|
||||
|
||||
@ -340,13 +340,13 @@ Application startup complete.
|
||||
|
||||
setting->model providers->search->vllm->add ,configure as follow:
|
||||
|
||||

|
||||
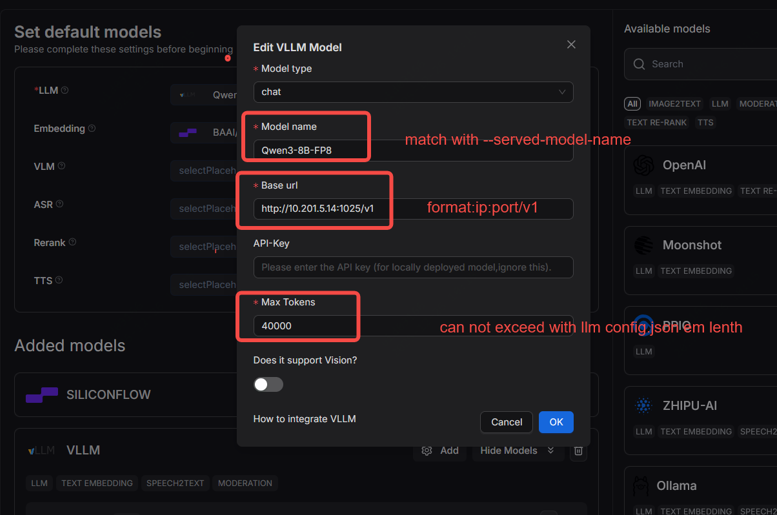
|
||||
|
||||
select vllm chat model as default llm model as follow:
|
||||

|
||||
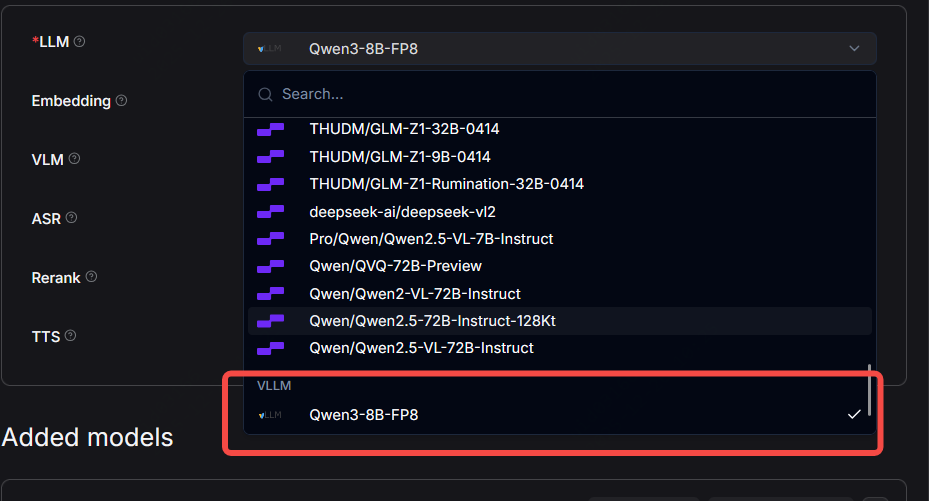
|
||||
### 5.3 chat with vllm chat model
|
||||
create chat->create conversations-chat as follow:
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -1603,7 +1603,7 @@ In streaming mode, not all responses include a reference, as this depends on the
|
||||
|
||||
##### question: `str`
|
||||
|
||||
The question to start an AI-powered conversation. Ifthe **Begin** component takes parameters, a question is not required.
|
||||
The question to start an AI-powered conversation. If the **Begin** component takes parameters, a question is not required.
|
||||
|
||||
##### stream: `bool`
|
||||
|
||||
|
||||
@ -9,7 +9,7 @@ Key features, improvements and bug fixes in the latest releases.
|
||||
|
||||
## v0.23.0
|
||||
|
||||
Released on December 29, 2025.
|
||||
Released on December 27, 2025.
|
||||
|
||||
### New features
|
||||
|
||||
@ -32,7 +32,7 @@ Released on December 29, 2025.
|
||||
|
||||
### Improvements
|
||||
|
||||
- Bumps RAGFlow's document engine, [Infinity](https://github.com/infiniflow/infinity) to v0.6.13 (backward compatible).
|
||||
- Bumps RAGFlow's document engine, [Infinity](https://github.com/infiniflow/infinity) to v0.6.15 (backward compatible).
|
||||
|
||||
### Data sources
|
||||
|
||||
|
||||
133
helm/README.md
Normal file
133
helm/README.md
Normal file
@ -0,0 +1,133 @@
|
||||
# RAGFlow Helm Chart
|
||||
|
||||
A Helm chart to deploy RAGFlow and its dependencies on Kubernetes.
|
||||
|
||||
- Components: RAGFlow (web/api) and optional dependencies (Infinity/Elasticsearch/OpenSearch, MySQL, MinIO, Redis)
|
||||
- Requirements: Kubernetes >= 1.24, Helm >= 3.10
|
||||
|
||||
## Install
|
||||
|
||||
```bash
|
||||
helm upgrade --install ragflow ./ \
|
||||
--namespace ragflow --create-namespace
|
||||
```
|
||||
|
||||
Uninstall:
|
||||
```bash
|
||||
helm uninstall ragflow -n ragflow
|
||||
```
|
||||
|
||||
## Global Settings
|
||||
|
||||
- `global.repo`: Prepend a global image registry prefix for all images.
|
||||
- Behavior: Replaces the registry part and keeps the image path (e.g., `quay.io/minio/minio` -> `registry.example.com/myproj/minio/minio`).
|
||||
- Example: `global.repo: "registry.example.com/myproj"`
|
||||
- `global.imagePullSecrets`: List of image pull secrets applied to all Pods.
|
||||
- Example:
|
||||
```yaml
|
||||
global:
|
||||
imagePullSecrets:
|
||||
- name: regcred
|
||||
```
|
||||
|
||||
## External Services (MySQL / MinIO / Redis)
|
||||
|
||||
The chart can deploy in-cluster services or connect to external ones. Toggle with `*.enabled`. When disabled, provide host/port via `env.*`.
|
||||
|
||||
- MySQL
|
||||
- `mysql.enabled`: default `true`
|
||||
- If `false`, set:
|
||||
- `env.MYSQL_HOST` (required), `env.MYSQL_PORT` (default `3306`)
|
||||
- `env.MYSQL_DBNAME` (default `rag_flow`), `env.MYSQL_PASSWORD` (required)
|
||||
- `env.MYSQL_USER` (default `root` if omitted)
|
||||
- MinIO
|
||||
- `minio.enabled`: default `true`
|
||||
- Configure:
|
||||
- `env.MINIO_HOST` (optional external host), `env.MINIO_PORT` (default `9000`)
|
||||
- `env.MINIO_ROOT_USER` (default `rag_flow`), `env.MINIO_PASSWORD` (optional)
|
||||
- Redis (Valkey)
|
||||
- `redis.enabled`: default `true`
|
||||
- If `false`, set:
|
||||
- `env.REDIS_HOST` (required), `env.REDIS_PORT` (default `6379`)
|
||||
- `env.REDIS_PASSWORD` (optional; empty disables auth if server allows)
|
||||
|
||||
Notes:
|
||||
- When `*.enabled=true`, the chart renders in-cluster resources and injects corresponding `*_HOST`/`*_PORT` automatically.
|
||||
- Sensitive variables like `MYSQL_PASSWORD` are required; `MINIO_PASSWORD` and `REDIS_PASSWORD` are optional. All secrets are stored in a Secret.
|
||||
|
||||
### Example: use external MySQL, MinIO, and Redis
|
||||
|
||||
```yaml
|
||||
# values.override.yaml
|
||||
mysql:
|
||||
enabled: false # use external MySQL
|
||||
minio:
|
||||
enabled: false # use external MinIO (S3 compatible)
|
||||
redis:
|
||||
enabled: false # use external Redis/Valkey
|
||||
|
||||
env:
|
||||
# MySQL
|
||||
MYSQL_HOST: mydb.example.com
|
||||
MYSQL_PORT: "3306"
|
||||
MYSQL_USER: root
|
||||
MYSQL_DBNAME: rag_flow
|
||||
MYSQL_PASSWORD: "<your-mysql-password>"
|
||||
|
||||
# MinIO
|
||||
MINIO_HOST: s3.example.com
|
||||
MINIO_PORT: "9000"
|
||||
MINIO_ROOT_USER: rag_flow
|
||||
MINIO_PASSWORD: "<your-minio-secret>"
|
||||
|
||||
# Redis
|
||||
REDIS_HOST: redis.example.com
|
||||
REDIS_PORT: "6379"
|
||||
REDIS_PASSWORD: "<your-redis-pass>"
|
||||
```
|
||||
|
||||
Apply:
|
||||
```bash
|
||||
helm upgrade --install ragflow ./helm -n ragflow -f values.override.yaml
|
||||
```
|
||||
|
||||
## Document Engine Selection
|
||||
|
||||
Choose one of `infinity` (default), `elasticsearch`, or `opensearch` via `env.DOC_ENGINE`. The chart renders only the selected engine and sets the appropriate host variables.
|
||||
|
||||
```yaml
|
||||
env:
|
||||
DOC_ENGINE: infinity # or: elasticsearch | opensearch
|
||||
# For elasticsearch
|
||||
ELASTIC_PASSWORD: "<es-pass>"
|
||||
# For opensearch
|
||||
OPENSEARCH_PASSWORD: "<os-pass>"
|
||||
```
|
||||
|
||||
## Ingress
|
||||
|
||||
Expose the web UI via Ingress:
|
||||
|
||||
```yaml
|
||||
ingress:
|
||||
enabled: true
|
||||
className: nginx
|
||||
hosts:
|
||||
- host: ragflow.example.com
|
||||
paths:
|
||||
- path: /
|
||||
pathType: Prefix
|
||||
```
|
||||
|
||||
## Validate the Chart
|
||||
|
||||
```bash
|
||||
helm lint ./helm
|
||||
helm template ragflow ./helm > rendered.yaml
|
||||
```
|
||||
|
||||
## Notes
|
||||
|
||||
- By default, the chart uses `DOC_ENGINE: infinity` and deploys in-cluster MySQL, MinIO, and Redis.
|
||||
- The chart injects derived `*_HOST`/`*_PORT` and required secrets into a single Secret (`<release>-ragflow-env-config`).
|
||||
- `global.repo` and `global.imagePullSecrets` apply to all Pods; per-component `*.image.pullSecrets` still work and are merged with global settings.
|
||||
@ -42,6 +42,31 @@ app.kubernetes.io/version: {{ .Chart.AppVersion | quote }}
|
||||
app.kubernetes.io/managed-by: {{ .Release.Service }}
|
||||
{{- end }}
|
||||
|
||||
{{/*
|
||||
Resolve image repository with optional global repo prefix.
|
||||
If .Values.global.repo is set, replace registry part and keep image path.
|
||||
Detect existing registry by first segment containing '.' or ':' or being 'localhost'.
|
||||
Usage: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.foo.image.repository) }}
|
||||
*/}}
|
||||
{{- define "ragflow.imageRepo" -}}
|
||||
{{- $root := .root -}}
|
||||
{{- $repo := .repo -}}
|
||||
{{- $global := $root.Values.global -}}
|
||||
{{- if and $global $global.repo }}
|
||||
{{- $parts := splitList "/" $repo -}}
|
||||
{{- $first := index $parts 0 -}}
|
||||
{{- $hasRegistry := or (regexMatch "\\." $first) (regexMatch ":" $first) (eq $first "localhost") -}}
|
||||
{{- if $hasRegistry -}}
|
||||
{{- $path := join "/" (rest $parts) -}}
|
||||
{{- printf "%s/%s" $global.repo $path -}}
|
||||
{{- else -}}
|
||||
{{- printf "%s/%s" $global.repo $repo -}}
|
||||
{{- end -}}
|
||||
{{- else -}}
|
||||
{{- $repo -}}
|
||||
{{- end -}}
|
||||
{{- end }}
|
||||
|
||||
{{/*
|
||||
Selector labels
|
||||
*/}}
|
||||
|
||||
@ -32,7 +32,7 @@ spec:
|
||||
{{- include "ragflow.selectorLabels" . | nindent 6 }}
|
||||
app.kubernetes.io/component: elasticsearch
|
||||
{{- with .Values.elasticsearch.deployment.strategy }}
|
||||
strategy:
|
||||
updateStrategy:
|
||||
{{- . | toYaml | nindent 4 }}
|
||||
{{- end }}
|
||||
template:
|
||||
@ -44,9 +44,9 @@ spec:
|
||||
checksum/config-es: {{ include (print $.Template.BasePath "/elasticsearch-config.yaml") . | sha256sum }}
|
||||
checksum/config-env: {{ include (print $.Template.BasePath "/env.yaml") . | sha256sum }}
|
||||
spec:
|
||||
{{- if or .Values.imagePullSecrets .Values.elasticsearch.image.pullSecrets }}
|
||||
{{- if or .Values.global.imagePullSecrets .Values.elasticsearch.image.pullSecrets }}
|
||||
imagePullSecrets:
|
||||
{{- with .Values.imagePullSecrets }}
|
||||
{{- with .Values.global.imagePullSecrets }}
|
||||
{{- toYaml . | nindent 8 }}
|
||||
{{- end }}
|
||||
{{- with .Values.elasticsearch.image.pullSecrets }}
|
||||
@ -55,7 +55,7 @@ spec:
|
||||
{{- end }}
|
||||
initContainers:
|
||||
- name: fix-data-volume-permissions
|
||||
image: {{ .Values.elasticsearch.initContainers.alpine.repository }}:{{ .Values.elasticsearch.initContainers.alpine.tag }}
|
||||
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.elasticsearch.initContainers.alpine.repository) }}:{{ .Values.elasticsearch.initContainers.alpine.tag }}
|
||||
{{- with .Values.elasticsearch.initContainers.alpine.pullPolicy }}
|
||||
imagePullPolicy: {{ . }}
|
||||
{{- end }}
|
||||
@ -67,7 +67,7 @@ spec:
|
||||
- mountPath: /usr/share/elasticsearch/data
|
||||
name: es-data
|
||||
- name: sysctl
|
||||
image: {{ .Values.elasticsearch.initContainers.busybox.repository }}:{{ .Values.elasticsearch.initContainers.busybox.tag }}
|
||||
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.elasticsearch.initContainers.busybox.repository) }}:{{ .Values.elasticsearch.initContainers.busybox.tag }}
|
||||
{{- with .Values.elasticsearch.initContainers.busybox.pullPolicy }}
|
||||
imagePullPolicy: {{ . }}
|
||||
{{- end }}
|
||||
@ -77,7 +77,7 @@ spec:
|
||||
command: ["sysctl", "-w", "vm.max_map_count=262144"]
|
||||
containers:
|
||||
- name: elasticsearch
|
||||
image: {{ .Values.elasticsearch.image.repository }}:{{ .Values.elasticsearch.image.tag }}
|
||||
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.elasticsearch.image.repository) }}:{{ .Values.elasticsearch.image.tag }}
|
||||
{{- with .Values.elasticsearch.image.pullPolicy }}
|
||||
imagePullPolicy: {{ . }}
|
||||
{{- end }}
|
||||
|
||||
@ -9,20 +9,39 @@ metadata:
|
||||
type: Opaque
|
||||
stringData:
|
||||
{{- range $key, $val := .Values.env }}
|
||||
{{- if $val }}
|
||||
{{- if and $val (ne $key "MYSQL_HOST") (ne $key "MYSQL_PORT") (ne $key "MYSQL_USER") (ne $key "MINIO_HOST") (ne $key "MINIO_PORT") (ne $key "REDIS_HOST") (ne $key "REDIS_PORT") }}
|
||||
{{ $key }}: {{ quote $val }}
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
{{- /*
|
||||
Use host names derived from internal cluster DNS
|
||||
*/}}
|
||||
{{- if .Values.redis.enabled }}
|
||||
REDIS_HOST: {{ printf "%s-redis.%s.svc" (include "ragflow.fullname" .) .Release.Namespace }}
|
||||
REDIS_PORT: "6379"
|
||||
{{- else }}
|
||||
REDIS_HOST: {{ required "env.REDIS_HOST is required when redis.enabled=false" .Values.env.REDIS_HOST | quote }}
|
||||
REDIS_PORT: {{ default "6379" .Values.env.REDIS_PORT | quote }}
|
||||
{{- end }}
|
||||
{{- if .Values.mysql.enabled }}
|
||||
MYSQL_HOST: {{ printf "%s-mysql.%s.svc" (include "ragflow.fullname" .) .Release.Namespace }}
|
||||
MYSQL_PORT: "3306"
|
||||
{{- else }}
|
||||
MYSQL_HOST: {{ required "env.MYSQL_HOST is required when mysql.enabled=false" .Values.env.MYSQL_HOST | quote }}
|
||||
MYSQL_PORT: {{ default "3306" .Values.env.MYSQL_PORT | quote }}
|
||||
MYSQL_USER: {{ default "root" .Values.env.MYSQL_USER | quote }}
|
||||
{{- end }}
|
||||
{{- if .Values.minio.enabled }}
|
||||
MINIO_HOST: {{ printf "%s-minio.%s.svc" (include "ragflow.fullname" .) .Release.Namespace }}
|
||||
MINIO_PORT: "9000"
|
||||
{{- else }}
|
||||
MINIO_HOST: {{ default "" .Values.env.MINIO_HOST | quote }}
|
||||
MINIO_PORT: {{ default "9000" .Values.env.MINIO_PORT | quote }}
|
||||
{{- end }}
|
||||
{{- /*
|
||||
Fail if passwords are not provided in release values
|
||||
*/}}
|
||||
REDIS_PASSWORD: {{ .Values.env.REDIS_PASSWORD | required "REDIS_PASSWORD is required" }}
|
||||
REDIS_PASSWORD: {{ default "" .Values.env.REDIS_PASSWORD }}
|
||||
{{- /*
|
||||
NOTE: MySQL uses MYSQL_ROOT_PASSWORD env var but Ragflow container expects
|
||||
MYSQL_PASSWORD so we need to define both as the same value here.
|
||||
@ -31,10 +50,9 @@ stringData:
|
||||
MYSQL_PASSWORD: {{ . }}
|
||||
MYSQL_ROOT_PASSWORD: {{ . }}
|
||||
{{- end }}
|
||||
{{- with .Values.env.MINIO_PASSWORD | required "MINIO_PASSWORD is required" }}
|
||||
MINIO_PASSWORD: {{ . }}
|
||||
MINIO_ROOT_PASSWORD: {{ . }}
|
||||
{{- end }}
|
||||
{{- $minioPass := default "" .Values.env.MINIO_PASSWORD }}
|
||||
MINIO_PASSWORD: {{ $minioPass }}
|
||||
MINIO_ROOT_PASSWORD: {{ $minioPass }}
|
||||
{{- /*
|
||||
Only provide env vars for enabled doc engine
|
||||
*/}}
|
||||
|
||||
@ -32,7 +32,7 @@ spec:
|
||||
{{- include "ragflow.selectorLabels" . | nindent 6 }}
|
||||
app.kubernetes.io/component: infinity
|
||||
{{- with .Values.infinity.deployment.strategy }}
|
||||
strategy:
|
||||
updateStrategy:
|
||||
{{- . | toYaml | nindent 4 }}
|
||||
{{- end }}
|
||||
template:
|
||||
@ -43,9 +43,9 @@ spec:
|
||||
annotations:
|
||||
checksum/config: {{ include (print $.Template.BasePath "/env.yaml") . | sha256sum }}
|
||||
spec:
|
||||
{{- if or .Values.imagePullSecrets .Values.infinity.image.pullSecrets }}
|
||||
{{- if or .Values.global.imagePullSecrets .Values.infinity.image.pullSecrets }}
|
||||
imagePullSecrets:
|
||||
{{- with .Values.imagePullSecrets }}
|
||||
{{- with .Values.global.imagePullSecrets }}
|
||||
{{- toYaml . | nindent 8 }}
|
||||
{{- end }}
|
||||
{{- with .Values.infinity.image.pullSecrets }}
|
||||
@ -54,7 +54,7 @@ spec:
|
||||
{{- end }}
|
||||
containers:
|
||||
- name: infinity
|
||||
image: {{ .Values.infinity.image.repository }}:{{ .Values.infinity.image.tag }}
|
||||
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.infinity.image.repository) }}:{{ .Values.infinity.image.tag }}
|
||||
{{- with .Values.infinity.image.pullPolicy }}
|
||||
imagePullPolicy: {{ . }}
|
||||
{{- end }}
|
||||
|
||||
@ -35,7 +35,7 @@ spec:
|
||||
{{- end }}
|
||||
backend:
|
||||
service:
|
||||
name: {{ $.Release.Name }}
|
||||
name: {{ include "ragflow.fullname" $ }}
|
||||
port:
|
||||
name: http
|
||||
{{- end }}
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
{{- if .Values.minio.enabled }}
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: PersistentVolumeClaim
|
||||
@ -43,9 +44,9 @@ spec:
|
||||
{{- include "ragflow.labels" . | nindent 8 }}
|
||||
app.kubernetes.io/component: minio
|
||||
spec:
|
||||
{{- if or .Values.imagePullSecrets .Values.minio.image.pullSecrets }}
|
||||
{{- if or .Values.global.imagePullSecrets .Values.minio.image.pullSecrets }}
|
||||
imagePullSecrets:
|
||||
{{- with .Values.imagePullSecrets }}
|
||||
{{- with .Values.global.imagePullSecrets }}
|
||||
{{- toYaml . | nindent 8 }}
|
||||
{{- end }}
|
||||
{{- with .Values.minio.image.pullSecrets }}
|
||||
@ -54,7 +55,7 @@ spec:
|
||||
{{- end }}
|
||||
containers:
|
||||
- name: minio
|
||||
image: {{ .Values.minio.image.repository }}:{{ .Values.minio.image.tag }}
|
||||
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.minio.image.repository) }}:{{ .Values.minio.image.tag }}
|
||||
{{- with .Values.minio.image.pullPolicy }}
|
||||
imagePullPolicy: {{ . }}
|
||||
{{- end }}
|
||||
@ -103,3 +104,4 @@ spec:
|
||||
port: 9001
|
||||
targetPort: console
|
||||
type: {{ .Values.minio.service.type }}
|
||||
{{- end }}
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
{{- if .Values.mysql.enabled }}
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: ConfigMap
|
||||
@ -7,3 +8,4 @@ data:
|
||||
init.sql: |-
|
||||
CREATE DATABASE IF NOT EXISTS rag_flow;
|
||||
USE rag_flow;
|
||||
{{- end }}
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
{{- if .Values.mysql.enabled }}
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: PersistentVolumeClaim
|
||||
@ -32,7 +33,7 @@ spec:
|
||||
{{- include "ragflow.selectorLabels" . | nindent 6 }}
|
||||
app.kubernetes.io/component: mysql
|
||||
{{- with .Values.mysql.deployment.strategy }}
|
||||
strategy:
|
||||
updateStrategy:
|
||||
{{- . | toYaml | nindent 4 }}
|
||||
{{- end }}
|
||||
template:
|
||||
@ -44,9 +45,9 @@ spec:
|
||||
checksum/config-mysql: {{ include (print $.Template.BasePath "/mysql-config.yaml") . | sha256sum }}
|
||||
checksum/config-env: {{ include (print $.Template.BasePath "/env.yaml") . | sha256sum }}
|
||||
spec:
|
||||
{{- if or .Values.imagePullSecrets .Values.mysql.image.pullSecrets }}
|
||||
{{- if or .Values.global.imagePullSecrets .Values.mysql.image.pullSecrets }}
|
||||
imagePullSecrets:
|
||||
{{- with .Values.imagePullSecrets }}
|
||||
{{- with .Values.global.imagePullSecrets }}
|
||||
{{- toYaml . | nindent 8 }}
|
||||
{{- end }}
|
||||
{{- with .Values.mysql.image.pullSecrets }}
|
||||
@ -55,7 +56,7 @@ spec:
|
||||
{{- end }}
|
||||
containers:
|
||||
- name: mysql
|
||||
image: {{ .Values.mysql.image.repository }}:{{ .Values.mysql.image.tag }}
|
||||
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.mysql.image.repository) }}:{{ .Values.mysql.image.tag }}
|
||||
{{- with .Values.mysql.image.pullPolicy }}
|
||||
imagePullPolicy: {{ . }}
|
||||
{{- end }}
|
||||
@ -108,3 +109,4 @@ spec:
|
||||
port: 3306
|
||||
targetPort: mysql
|
||||
type: {{ .Values.mysql.service.type }}
|
||||
{{- end }}
|
||||
|
||||
@ -32,7 +32,7 @@ spec:
|
||||
{{- include "ragflow.selectorLabels" . | nindent 6 }}
|
||||
app.kubernetes.io/component: opensearch
|
||||
{{- with .Values.opensearch.deployment.strategy }}
|
||||
strategy:
|
||||
updateStrategy:
|
||||
{{- . | toYaml | nindent 4 }}
|
||||
{{- end }}
|
||||
template:
|
||||
@ -44,9 +44,9 @@ spec:
|
||||
checksum/config-opensearch: {{ include (print $.Template.BasePath "/opensearch-config.yaml") . | sha256sum }}
|
||||
checksum/config-env: {{ include (print $.Template.BasePath "/env.yaml") . | sha256sum }}
|
||||
spec:
|
||||
{{- if or .Values.imagePullSecrets .Values.opensearch.image.pullSecrets }}
|
||||
{{- if or .Values.global.imagePullSecrets .Values.opensearch.image.pullSecrets }}
|
||||
imagePullSecrets:
|
||||
{{- with .Values.imagePullSecrets }}
|
||||
{{- with .Values.global.imagePullSecrets }}
|
||||
{{- toYaml . | nindent 8 }}
|
||||
{{- end }}
|
||||
{{- with .Values.opensearch.image.pullSecrets }}
|
||||
@ -55,7 +55,7 @@ spec:
|
||||
{{- end }}
|
||||
initContainers:
|
||||
- name: fix-data-volume-permissions
|
||||
image: {{ .Values.opensearch.initContainers.alpine.repository }}:{{ .Values.opensearch.initContainers.alpine.tag }}
|
||||
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.opensearch.initContainers.alpine.repository) }}:{{ .Values.opensearch.initContainers.alpine.tag }}
|
||||
{{- with .Values.opensearch.initContainers.alpine.pullPolicy }}
|
||||
imagePullPolicy: {{ . }}
|
||||
{{- end }}
|
||||
@ -67,7 +67,7 @@ spec:
|
||||
- mountPath: /usr/share/opensearch/data
|
||||
name: opensearch-data
|
||||
- name: sysctl
|
||||
image: {{ .Values.opensearch.initContainers.busybox.repository }}:{{ .Values.opensearch.initContainers.busybox.tag }}
|
||||
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.opensearch.initContainers.busybox.repository) }}:{{ .Values.opensearch.initContainers.busybox.tag }}
|
||||
{{- with .Values.opensearch.initContainers.busybox.pullPolicy }}
|
||||
imagePullPolicy: {{ . }}
|
||||
{{- end }}
|
||||
@ -77,7 +77,7 @@ spec:
|
||||
command: ["sysctl", "-w", "vm.max_map_count=262144"]
|
||||
containers:
|
||||
- name: opensearch
|
||||
image: {{ .Values.opensearch.image.repository }}:{{ .Values.opensearch.image.tag }}
|
||||
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.opensearch.image.repository) }}:{{ .Values.opensearch.image.tag }}
|
||||
{{- with .Values.opensearch.image.pullPolicy }}
|
||||
imagePullPolicy: {{ . }}
|
||||
{{- end }}
|
||||
|
||||
@ -25,9 +25,9 @@ spec:
|
||||
checksum/config-env: {{ include (print $.Template.BasePath "/env.yaml") . | sha256sum }}
|
||||
checksum/config-ragflow: {{ include (print $.Template.BasePath "/ragflow_config.yaml") . | sha256sum }}
|
||||
spec:
|
||||
{{- if or .Values.imagePullSecrets .Values.ragflow.image.pullSecrets }}
|
||||
{{- if or .Values.global.imagePullSecrets .Values.ragflow.image.pullSecrets }}
|
||||
imagePullSecrets:
|
||||
{{- with .Values.imagePullSecrets }}
|
||||
{{- with .Values.global.imagePullSecrets }}
|
||||
{{- toYaml . | nindent 8 }}
|
||||
{{- end }}
|
||||
{{- with .Values.ragflow.image.pullSecrets }}
|
||||
@ -36,7 +36,7 @@ spec:
|
||||
{{- end }}
|
||||
containers:
|
||||
- name: ragflow
|
||||
image: {{ .Values.ragflow.image.repository }}:{{ .Values.ragflow.image.tag }}
|
||||
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.ragflow.image.repository) }}:{{ .Values.ragflow.image.tag }}
|
||||
{{- with .Values.ragflow.image.pullPolicy }}
|
||||
imagePullPolicy: {{ . }}
|
||||
{{- end }}
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
{{- if .Values.redis.enabled }}
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
@ -40,9 +41,9 @@ spec:
|
||||
annotations:
|
||||
checksum/config-env: {{ include (print $.Template.BasePath "/env.yaml") . | sha256sum }}
|
||||
spec:
|
||||
{{- if or .Values.imagePullSecrets .Values.redis.image.pullSecrets }}
|
||||
{{- if or .Values.global.imagePullSecrets .Values.redis.image.pullSecrets }}
|
||||
imagePullSecrets:
|
||||
{{- with .Values.imagePullSecrets }}
|
||||
{{- with .Values.global.imagePullSecrets }}
|
||||
{{- toYaml . | nindent 8 }}
|
||||
{{- end }}
|
||||
{{- with .Values.redis.image.pullSecrets }}
|
||||
@ -52,7 +53,7 @@ spec:
|
||||
terminationGracePeriodSeconds: 60
|
||||
containers:
|
||||
- name: redis
|
||||
image: {{ .Values.redis.image.repository }}:{{ .Values.redis.image.tag }}
|
||||
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.redis.image.repository) }}:{{ .Values.redis.image.tag }}
|
||||
{{- with .Values.redis.image.pullPolicy }}
|
||||
imagePullPolicy: {{ . }}
|
||||
{{- end }}
|
||||
@ -131,3 +132,4 @@ spec:
|
||||
matchLabels:
|
||||
{{- include "ragflow.selectorLabels" . | nindent 6 }}
|
||||
app.kubernetes.io/component: redis
|
||||
{{- end }}
|
||||
|
||||
@ -9,7 +9,7 @@ metadata:
|
||||
spec:
|
||||
containers:
|
||||
- name: wget
|
||||
image: busybox
|
||||
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" "busybox") }}
|
||||
command:
|
||||
- 'wget'
|
||||
args:
|
||||
|
||||
@ -1,7 +1,14 @@
|
||||
# Based on docker compose .env file
|
||||
|
||||
# Global image pull secrets configuration
|
||||
imagePullSecrets: []
|
||||
global:
|
||||
# Global image repo prefix to render all images from a mirror/registry.
|
||||
# Example: "registry.example.com/myproj"
|
||||
# When set, template will replace the registry part of each image and keep the path.
|
||||
# Leave empty to use per-image repositories as-is.
|
||||
repo: ""
|
||||
# Global image pull secrets for all pods
|
||||
imagePullSecrets: []
|
||||
|
||||
env:
|
||||
# The type of doc engine to use.
|
||||
@ -27,14 +34,28 @@ env:
|
||||
MYSQL_PASSWORD: infini_rag_flow_helm
|
||||
# The database of the MySQL service to use
|
||||
MYSQL_DBNAME: rag_flow
|
||||
# External MySQL host (only required when mysql.enabled=false)
|
||||
# MYSQL_HOST: ""
|
||||
# External MySQL port (defaults to 3306 if not set)
|
||||
# MYSQL_PORT: "3306"
|
||||
# External MySQL user (only when mysql.enabled=false), default is root if omitted
|
||||
# MYSQL_USER: "root"
|
||||
|
||||
# The username for MinIO.
|
||||
MINIO_ROOT_USER: rag_flow
|
||||
# The password for MinIO
|
||||
MINIO_PASSWORD: infini_rag_flow_helm
|
||||
# External MinIO host
|
||||
# MINIO_HOST: ""
|
||||
# External MinIO port (defaults to 9000 if not set)
|
||||
# MINIO_PORT: "9000"
|
||||
|
||||
# The password for Redis
|
||||
REDIS_PASSWORD: infini_rag_flow_helm
|
||||
# External Redis host (only required when redis.enabled=false)
|
||||
# REDIS_HOST: ""
|
||||
# External Redis port (defaults to 6379 if not set)
|
||||
# REDIS_PORT: "6379"
|
||||
|
||||
# The local time zone.
|
||||
TZ: "Asia/Shanghai"
|
||||
@ -163,6 +184,7 @@ opensearch:
|
||||
type: ClusterIP
|
||||
|
||||
minio:
|
||||
enabled: true
|
||||
image:
|
||||
repository: quay.io/minio/minio
|
||||
tag: RELEASE.2023-12-20T01-00-02Z
|
||||
@ -178,6 +200,7 @@ minio:
|
||||
type: ClusterIP
|
||||
|
||||
mysql:
|
||||
enabled: true
|
||||
image:
|
||||
repository: mysql
|
||||
tag: 8.0.39
|
||||
@ -193,6 +216,7 @@ mysql:
|
||||
type: ClusterIP
|
||||
|
||||
redis:
|
||||
enabled: true
|
||||
image:
|
||||
repository: valkey/valkey
|
||||
tag: 8
|
||||
|
||||
@ -71,7 +71,7 @@ class MessageService:
|
||||
filter_dict["session_id"] = keywords
|
||||
order_by = OrderByExpr()
|
||||
order_by.desc("valid_at")
|
||||
res = settings.msgStoreConn.search(
|
||||
res, total_count = settings.msgStoreConn.search(
|
||||
select_fields=[
|
||||
"message_id", "message_type", "source_id", "memory_id", "user_id", "agent_id", "session_id", "valid_at",
|
||||
"invalid_at", "forget_at", "status"
|
||||
@ -82,13 +82,12 @@ class MessageService:
|
||||
offset=(page-1)*page_size, limit=page_size,
|
||||
index_names=index, memory_ids=[memory_id], agg_fields=[], hide_forgotten=False
|
||||
)
|
||||
if not res:
|
||||
if not total_count:
|
||||
return {
|
||||
"message_list": [],
|
||||
"total_count": 0
|
||||
}
|
||||
|
||||
total_count = settings.msgStoreConn.get_total(res)
|
||||
doc_mapping = settings.msgStoreConn.get_fields(res, [
|
||||
"message_id", "message_type", "source_id", "memory_id", "user_id", "agent_id", "session_id",
|
||||
"valid_at", "invalid_at", "forget_at", "status"
|
||||
@ -107,7 +106,7 @@ class MessageService:
|
||||
}
|
||||
order_by = OrderByExpr()
|
||||
order_by.desc("valid_at")
|
||||
res = settings.msgStoreConn.search(
|
||||
res, total_count = settings.msgStoreConn.search(
|
||||
select_fields=[
|
||||
"message_id", "message_type", "source_id", "memory_id", "user_id", "agent_id", "session_id", "valid_at",
|
||||
"invalid_at", "forget_at", "status", "content"
|
||||
@ -118,7 +117,7 @@ class MessageService:
|
||||
offset=0, limit=limit,
|
||||
index_names=index_names, memory_ids=memory_ids, agg_fields=[]
|
||||
)
|
||||
if not res:
|
||||
if not total_count:
|
||||
return []
|
||||
|
||||
doc_mapping = settings.msgStoreConn.get_fields(res, [
|
||||
@ -136,7 +135,7 @@ class MessageService:
|
||||
|
||||
order_by = OrderByExpr()
|
||||
order_by.desc("valid_at")
|
||||
res = settings.msgStoreConn.search(
|
||||
res, total_count = settings.msgStoreConn.search(
|
||||
select_fields=[
|
||||
"message_id", "message_type", "source_id", "memory_id", "user_id", "agent_id", "session_id",
|
||||
"valid_at",
|
||||
@ -149,7 +148,7 @@ class MessageService:
|
||||
offset=0, limit=top_n,
|
||||
index_names=index_names, memory_ids=memory_ids, agg_fields=[]
|
||||
)
|
||||
if not res:
|
||||
if not total_count:
|
||||
return []
|
||||
|
||||
docs = settings.msgStoreConn.get_fields(res, [
|
||||
@ -195,23 +194,22 @@ class MessageService:
|
||||
select_fields = ["message_id", "content", "content_embed"]
|
||||
_index_name = index_name(uid)
|
||||
res = settings.msgStoreConn.get_forgotten_messages(select_fields, _index_name, memory_id)
|
||||
if not res:
|
||||
return []
|
||||
message_list = settings.msgStoreConn.get_fields(res, select_fields)
|
||||
current_size = 0
|
||||
ids_to_remove = []
|
||||
for message in message_list.values():
|
||||
if current_size < size_to_delete:
|
||||
current_size += cls.calculate_message_size(message)
|
||||
ids_to_remove.append(message["message_id"])
|
||||
else:
|
||||
if res:
|
||||
message_list = settings.msgStoreConn.get_fields(res, select_fields)
|
||||
for message in message_list.values():
|
||||
if current_size < size_to_delete:
|
||||
current_size += cls.calculate_message_size(message)
|
||||
ids_to_remove.append(message["message_id"])
|
||||
else:
|
||||
return ids_to_remove, current_size
|
||||
if current_size >= size_to_delete:
|
||||
return ids_to_remove, current_size
|
||||
if current_size >= size_to_delete:
|
||||
return ids_to_remove, current_size
|
||||
|
||||
order_by = OrderByExpr()
|
||||
order_by.asc("valid_at")
|
||||
res = settings.msgStoreConn.search(
|
||||
res, total_count = settings.msgStoreConn.search(
|
||||
select_fields=select_fields,
|
||||
highlight_fields=[],
|
||||
condition={},
|
||||
@ -240,7 +238,7 @@ class MessageService:
|
||||
order_by = OrderByExpr()
|
||||
order_by.desc("message_id")
|
||||
index_names = [index_name(uid) for uid in uid_list]
|
||||
res = settings.msgStoreConn.search(
|
||||
res, total_count = settings.msgStoreConn.search(
|
||||
select_fields=["message_id"],
|
||||
highlight_fields=[],
|
||||
condition={},
|
||||
@ -250,7 +248,7 @@ class MessageService:
|
||||
index_names=index_names, memory_ids=memory_ids,
|
||||
agg_fields=[], hide_forgotten=False
|
||||
)
|
||||
if not res:
|
||||
if not total_count:
|
||||
return 1
|
||||
|
||||
docs = settings.msgStoreConn.get_fields(res, ["message_id"])
|
||||
|
||||
@ -130,7 +130,7 @@ class ESConnection(ESConnectionBase):
|
||||
|
||||
exist_index_list = [idx for idx in index_names if self.index_exist(idx)]
|
||||
if not exist_index_list:
|
||||
return None
|
||||
return None, 0
|
||||
|
||||
bool_query = Q("bool", must=[], must_not=[])
|
||||
if hide_forgotten:
|
||||
|
||||
@ -149,6 +149,8 @@ dependencies = [
|
||||
# "cryptography==46.0.3",
|
||||
# "jinja2>=3.1.0",
|
||||
"pyairtable>=3.3.0",
|
||||
"asana>=5.2.2",
|
||||
"python-gitlab>=7.0.0",
|
||||
]
|
||||
|
||||
[dependency-groups]
|
||||
|
||||
@ -34,7 +34,8 @@ def chunk(filename, binary, tenant_id, lang, callback=None, **kwargs):
|
||||
if not ext:
|
||||
raise RuntimeError("No extension detected.")
|
||||
|
||||
if ext not in [".da", ".wave", ".wav", ".mp3", ".wav", ".aac", ".flac", ".ogg", ".aiff", ".au", ".midi", ".wma", ".realaudio", ".vqf", ".oggvorbis", ".aac", ".ape"]:
|
||||
if ext not in [".da", ".wave", ".wav", ".mp3", ".wav", ".aac", ".flac", ".ogg", ".aiff", ".au", ".midi", ".wma",
|
||||
".realaudio", ".vqf", ".oggvorbis", ".aac", ".ape"]:
|
||||
raise RuntimeError(f"Extension {ext} is not supported yet.")
|
||||
|
||||
tmp_path = ""
|
||||
|
||||
@ -22,7 +22,7 @@ from deepdoc.parser.utils import get_text
|
||||
from rag.app import naive
|
||||
from rag.app.naive import by_plaintext, PARSERS
|
||||
from common.parser_config_utils import normalize_layout_recognizer
|
||||
from rag.nlp import bullets_category, is_english,remove_contents_table, \
|
||||
from rag.nlp import bullets_category, is_english, remove_contents_table, \
|
||||
hierarchical_merge, make_colon_as_title, naive_merge, random_choices, tokenize_table, \
|
||||
tokenize_chunks, attach_media_context
|
||||
from rag.nlp import rag_tokenizer
|
||||
@ -91,9 +91,10 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
filename, binary=binary, from_page=from_page, to_page=to_page)
|
||||
remove_contents_table(sections, eng=is_english(
|
||||
random_choices([t for t, _ in sections], k=200)))
|
||||
tbls = vision_figure_parser_docx_wrapper(sections=sections,tbls=tbls,callback=callback,**kwargs)
|
||||
tbls = vision_figure_parser_docx_wrapper(sections=sections, tbls=tbls, callback=callback, **kwargs)
|
||||
# tbls = [((None, lns), None) for lns in tbls]
|
||||
sections=[(item[0],item[1] if item[1] is not None else "") for item in sections if not isinstance(item[1], Image.Image)]
|
||||
sections = [(item[0], item[1] if item[1] is not None else "") for item in sections if
|
||||
not isinstance(item[1], Image.Image)]
|
||||
callback(0.8, "Finish parsing.")
|
||||
|
||||
elif re.search(r"\.pdf$", filename, re.IGNORECASE):
|
||||
@ -109,14 +110,14 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
callback(0.1, "Start to parse.")
|
||||
|
||||
sections, tables, pdf_parser = parser(
|
||||
filename = filename,
|
||||
binary = binary,
|
||||
from_page = from_page,
|
||||
to_page = to_page,
|
||||
lang = lang,
|
||||
callback = callback,
|
||||
pdf_cls = Pdf,
|
||||
layout_recognizer = layout_recognizer,
|
||||
filename=filename,
|
||||
binary=binary,
|
||||
from_page=from_page,
|
||||
to_page=to_page,
|
||||
lang=lang,
|
||||
callback=callback,
|
||||
pdf_cls=Pdf,
|
||||
layout_recognizer=layout_recognizer,
|
||||
mineru_llm_name=parser_model_name,
|
||||
**kwargs
|
||||
)
|
||||
@ -126,7 +127,7 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
|
||||
if name in ["tcadp", "docling", "mineru"]:
|
||||
parser_config["chunk_token_num"] = 0
|
||||
|
||||
|
||||
callback(0.8, "Finish parsing.")
|
||||
elif re.search(r"\.txt$", filename, re.IGNORECASE):
|
||||
callback(0.1, "Start to parse.")
|
||||
@ -175,7 +176,7 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
for ck in hierarchical_merge(bull, sections, 5)]
|
||||
else:
|
||||
sections = [s.split("@") for s, _ in sections]
|
||||
sections = [(pr[0], "@" + pr[1]) if len(pr) == 2 else (pr[0], '') for pr in sections ]
|
||||
sections = [(pr[0], "@" + pr[1]) if len(pr) == 2 else (pr[0], '') for pr in sections]
|
||||
chunks = naive_merge(
|
||||
sections,
|
||||
parser_config.get("chunk_token_num", 256),
|
||||
@ -199,6 +200,9 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
if __name__ == "__main__":
|
||||
import sys
|
||||
|
||||
|
||||
def dummy(prog=None, msg=""):
|
||||
pass
|
||||
|
||||
|
||||
chunk(sys.argv[1], from_page=1, to_page=10, callback=dummy)
|
||||
|
||||
@ -26,13 +26,13 @@ import io
|
||||
|
||||
|
||||
def chunk(
|
||||
filename,
|
||||
binary=None,
|
||||
from_page=0,
|
||||
to_page=100000,
|
||||
lang="Chinese",
|
||||
callback=None,
|
||||
**kwargs,
|
||||
filename,
|
||||
binary=None,
|
||||
from_page=0,
|
||||
to_page=100000,
|
||||
lang="Chinese",
|
||||
callback=None,
|
||||
**kwargs,
|
||||
):
|
||||
"""
|
||||
Only eml is supported
|
||||
@ -93,7 +93,8 @@ def chunk(
|
||||
_add_content(msg, msg.get_content_type())
|
||||
|
||||
sections = TxtParser.parser_txt("\n".join(text_txt)) + [
|
||||
(line, "") for line in HtmlParser.parser_txt("\n".join(html_txt), chunk_token_num=parser_config["chunk_token_num"]) if line
|
||||
(line, "") for line in
|
||||
HtmlParser.parser_txt("\n".join(html_txt), chunk_token_num=parser_config["chunk_token_num"]) if line
|
||||
]
|
||||
|
||||
st = timer()
|
||||
@ -126,7 +127,9 @@ def chunk(
|
||||
if __name__ == "__main__":
|
||||
import sys
|
||||
|
||||
|
||||
def dummy(prog=None, msg=""):
|
||||
pass
|
||||
|
||||
|
||||
chunk(sys.argv[1], callback=dummy)
|
||||
|
||||
@ -29,8 +29,6 @@ from rag.app.naive import by_plaintext, PARSERS
|
||||
from common.parser_config_utils import normalize_layout_recognizer
|
||||
|
||||
|
||||
|
||||
|
||||
class Docx(DocxParser):
|
||||
def __init__(self):
|
||||
pass
|
||||
@ -58,37 +56,36 @@ class Docx(DocxParser):
|
||||
return [line for line in lines if line]
|
||||
|
||||
def __call__(self, filename, binary=None, from_page=0, to_page=100000):
|
||||
self.doc = Document(
|
||||
filename) if not binary else Document(BytesIO(binary))
|
||||
pn = 0
|
||||
lines = []
|
||||
level_set = set()
|
||||
bull = bullets_category([p.text for p in self.doc.paragraphs])
|
||||
for p in self.doc.paragraphs:
|
||||
if pn > to_page:
|
||||
break
|
||||
question_level, p_text = docx_question_level(p, bull)
|
||||
if not p_text.strip("\n"):
|
||||
self.doc = Document(
|
||||
filename) if not binary else Document(BytesIO(binary))
|
||||
pn = 0
|
||||
lines = []
|
||||
level_set = set()
|
||||
bull = bullets_category([p.text for p in self.doc.paragraphs])
|
||||
for p in self.doc.paragraphs:
|
||||
if pn > to_page:
|
||||
break
|
||||
question_level, p_text = docx_question_level(p, bull)
|
||||
if not p_text.strip("\n"):
|
||||
continue
|
||||
lines.append((question_level, p_text))
|
||||
level_set.add(question_level)
|
||||
for run in p.runs:
|
||||
if 'lastRenderedPageBreak' in run._element.xml:
|
||||
pn += 1
|
||||
continue
|
||||
lines.append((question_level, p_text))
|
||||
level_set.add(question_level)
|
||||
for run in p.runs:
|
||||
if 'lastRenderedPageBreak' in run._element.xml:
|
||||
pn += 1
|
||||
continue
|
||||
if 'w:br' in run._element.xml and 'type="page"' in run._element.xml:
|
||||
pn += 1
|
||||
if 'w:br' in run._element.xml and 'type="page"' in run._element.xml:
|
||||
pn += 1
|
||||
|
||||
sorted_levels = sorted(level_set)
|
||||
sorted_levels = sorted(level_set)
|
||||
|
||||
h2_level = sorted_levels[1] if len(sorted_levels) > 1 else 1
|
||||
h2_level = sorted_levels[-2] if h2_level == sorted_levels[-1] and len(sorted_levels) > 2 else h2_level
|
||||
h2_level = sorted_levels[1] if len(sorted_levels) > 1 else 1
|
||||
h2_level = sorted_levels[-2] if h2_level == sorted_levels[-1] and len(sorted_levels) > 2 else h2_level
|
||||
|
||||
root = Node(level=0, depth=h2_level, texts=[])
|
||||
root.build_tree(lines)
|
||||
|
||||
return [element for element in root.get_tree() if element]
|
||||
root = Node(level=0, depth=h2_level, texts=[])
|
||||
root.build_tree(lines)
|
||||
|
||||
return [element for element in root.get_tree() if element]
|
||||
|
||||
def __str__(self) -> str:
|
||||
return f'''
|
||||
@ -121,8 +118,7 @@ class Pdf(PdfParser):
|
||||
start = timer()
|
||||
self._layouts_rec(zoomin)
|
||||
callback(0.67, "Layout analysis ({:.2f}s)".format(timer() - start))
|
||||
logging.debug("layouts:".format(
|
||||
))
|
||||
logging.debug("layouts: {}".format((timer() - start)))
|
||||
self._naive_vertical_merge()
|
||||
|
||||
callback(0.8, "Text extraction ({:.2f}s)".format(timer() - start))
|
||||
@ -154,7 +150,7 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
chunks = Docx()(filename, binary)
|
||||
callback(0.7, "Finish parsing.")
|
||||
return tokenize_chunks(chunks, doc, eng, None)
|
||||
|
||||
|
||||
elif re.search(r"\.pdf$", filename, re.IGNORECASE):
|
||||
layout_recognizer, parser_model_name = normalize_layout_recognizer(
|
||||
parser_config.get("layout_recognize", "DeepDOC")
|
||||
@ -168,14 +164,14 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
callback(0.1, "Start to parse.")
|
||||
|
||||
raw_sections, tables, pdf_parser = parser(
|
||||
filename = filename,
|
||||
binary = binary,
|
||||
from_page = from_page,
|
||||
to_page = to_page,
|
||||
lang = lang,
|
||||
callback = callback,
|
||||
pdf_cls = Pdf,
|
||||
layout_recognizer = layout_recognizer,
|
||||
filename=filename,
|
||||
binary=binary,
|
||||
from_page=from_page,
|
||||
to_page=to_page,
|
||||
lang=lang,
|
||||
callback=callback,
|
||||
pdf_cls=Pdf,
|
||||
layout_recognizer=layout_recognizer,
|
||||
mineru_llm_name=parser_model_name,
|
||||
**kwargs
|
||||
)
|
||||
@ -185,7 +181,7 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
|
||||
if name in ["tcadp", "docling", "mineru"]:
|
||||
parser_config["chunk_token_num"] = 0
|
||||
|
||||
|
||||
for txt, poss in raw_sections:
|
||||
sections.append(txt + poss)
|
||||
|
||||
@ -226,7 +222,6 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
raise NotImplementedError(
|
||||
"file type not supported yet(doc, docx, pdf, txt supported)")
|
||||
|
||||
|
||||
# Remove 'Contents' part
|
||||
remove_contents_table(sections, eng)
|
||||
|
||||
@ -234,7 +229,6 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
bull = bullets_category(sections)
|
||||
res = tree_merge(bull, sections, 2)
|
||||
|
||||
|
||||
if not res:
|
||||
callback(0.99, "No chunk parsed out.")
|
||||
|
||||
@ -243,9 +237,13 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
# chunks = hierarchical_merge(bull, sections, 5)
|
||||
# return tokenize_chunks(["\n".join(ck)for ck in chunks], doc, eng, pdf_parser)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
import sys
|
||||
|
||||
|
||||
def dummy(prog=None, msg=""):
|
||||
pass
|
||||
|
||||
|
||||
chunk(sys.argv[1], callback=dummy)
|
||||
|
||||
@ -20,15 +20,17 @@ import re
|
||||
|
||||
from common.constants import ParserType
|
||||
from io import BytesIO
|
||||
from rag.nlp import rag_tokenizer, tokenize, tokenize_table, bullets_category, title_frequency, tokenize_chunks, docx_question_level, attach_media_context
|
||||
from rag.nlp import rag_tokenizer, tokenize, tokenize_table, bullets_category, title_frequency, tokenize_chunks, \
|
||||
docx_question_level, attach_media_context
|
||||
from common.token_utils import num_tokens_from_string
|
||||
from deepdoc.parser import PdfParser, DocxParser
|
||||
from deepdoc.parser.figure_parser import vision_figure_parser_pdf_wrapper,vision_figure_parser_docx_wrapper
|
||||
from deepdoc.parser.figure_parser import vision_figure_parser_pdf_wrapper, vision_figure_parser_docx_wrapper
|
||||
from docx import Document
|
||||
from PIL import Image
|
||||
from rag.app.naive import by_plaintext, PARSERS
|
||||
from common.parser_config_utils import normalize_layout_recognizer
|
||||
|
||||
|
||||
class Pdf(PdfParser):
|
||||
def __init__(self):
|
||||
self.model_speciess = ParserType.MANUAL.value
|
||||
@ -129,11 +131,11 @@ class Docx(DocxParser):
|
||||
question_level, p_text = 0, ''
|
||||
if from_page <= pn < to_page and p.text.strip():
|
||||
question_level, p_text = docx_question_level(p)
|
||||
if not question_level or question_level > 6: # not a question
|
||||
if not question_level or question_level > 6: # not a question
|
||||
last_answer = f'{last_answer}\n{p_text}'
|
||||
current_image = self.get_picture(self.doc, p)
|
||||
last_image = self.concat_img(last_image, current_image)
|
||||
else: # is a question
|
||||
else: # is a question
|
||||
if last_answer or last_image:
|
||||
sum_question = '\n'.join(question_stack)
|
||||
if sum_question:
|
||||
@ -159,14 +161,14 @@ class Docx(DocxParser):
|
||||
|
||||
tbls = []
|
||||
for tb in self.doc.tables:
|
||||
html= "<table>"
|
||||
html = "<table>"
|
||||
for r in tb.rows:
|
||||
html += "<tr>"
|
||||
i = 0
|
||||
while i < len(r.cells):
|
||||
span = 1
|
||||
c = r.cells[i]
|
||||
for j in range(i+1, len(r.cells)):
|
||||
for j in range(i + 1, len(r.cells)):
|
||||
if c.text == r.cells[j].text:
|
||||
span += 1
|
||||
i = j
|
||||
@ -211,16 +213,16 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
kwargs.pop("parse_method", None)
|
||||
kwargs.pop("mineru_llm_name", None)
|
||||
sections, tbls, pdf_parser = pdf_parser(
|
||||
filename = filename,
|
||||
binary = binary,
|
||||
from_page = from_page,
|
||||
to_page = to_page,
|
||||
lang = lang,
|
||||
callback = callback,
|
||||
pdf_cls = Pdf,
|
||||
layout_recognizer = layout_recognizer,
|
||||
filename=filename,
|
||||
binary=binary,
|
||||
from_page=from_page,
|
||||
to_page=to_page,
|
||||
lang=lang,
|
||||
callback=callback,
|
||||
pdf_cls=Pdf,
|
||||
layout_recognizer=layout_recognizer,
|
||||
mineru_llm_name=parser_model_name,
|
||||
parse_method = "manual",
|
||||
parse_method="manual",
|
||||
**kwargs
|
||||
)
|
||||
|
||||
@ -237,10 +239,10 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
if isinstance(poss, str):
|
||||
poss = pdf_parser.extract_positions(poss)
|
||||
if poss:
|
||||
first = poss[0] # tuple: ([pn], x1, x2, y1, y2)
|
||||
first = poss[0] # tuple: ([pn], x1, x2, y1, y2)
|
||||
pn = first[0]
|
||||
if isinstance(pn, list) and pn:
|
||||
pn = pn[0] # [pn] -> pn
|
||||
pn = pn[0] # [pn] -> pn
|
||||
poss[0] = (pn, *first[1:])
|
||||
|
||||
return (txt, layoutno, poss)
|
||||
@ -289,7 +291,7 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
if not rows:
|
||||
continue
|
||||
sections.append((rows if isinstance(rows, str) else rows[0], -1,
|
||||
[(p[0] + 1 - from_page, p[1], p[2], p[3], p[4]) for p in poss]))
|
||||
[(p[0] + 1 - from_page, p[1], p[2], p[3], p[4]) for p in poss]))
|
||||
|
||||
def tag(pn, left, right, top, bottom):
|
||||
if pn + left + right + top + bottom == 0:
|
||||
@ -312,7 +314,7 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
tk_cnt = num_tokens_from_string(txt)
|
||||
if sec_id > -1:
|
||||
last_sid = sec_id
|
||||
tbls = vision_figure_parser_pdf_wrapper(tbls=tbls,callback=callback,**kwargs)
|
||||
tbls = vision_figure_parser_pdf_wrapper(tbls=tbls, callback=callback, **kwargs)
|
||||
res = tokenize_table(tbls, doc, eng)
|
||||
res.extend(tokenize_chunks(chunks, doc, eng, pdf_parser))
|
||||
table_ctx = max(0, int(parser_config.get("table_context_size", 0) or 0))
|
||||
@ -325,7 +327,7 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
docx_parser = Docx()
|
||||
ti_list, tbls = docx_parser(filename, binary,
|
||||
from_page=0, to_page=10000, callback=callback)
|
||||
tbls = vision_figure_parser_docx_wrapper(sections=ti_list,tbls=tbls,callback=callback,**kwargs)
|
||||
tbls = vision_figure_parser_docx_wrapper(sections=ti_list, tbls=tbls, callback=callback, **kwargs)
|
||||
res = tokenize_table(tbls, doc, eng)
|
||||
for text, image in ti_list:
|
||||
d = copy.deepcopy(doc)
|
||||
|
||||
103
rag/app/naive.py
103
rag/app/naive.py
@ -31,16 +31,20 @@ from common.token_utils import num_tokens_from_string
|
||||
from common.constants import LLMType
|
||||
from api.db.services.llm_service import LLMBundle
|
||||
from rag.utils.file_utils import extract_embed_file, extract_links_from_pdf, extract_links_from_docx, extract_html
|
||||
from deepdoc.parser import DocxParser, ExcelParser, HtmlParser, JsonParser, MarkdownElementExtractor, MarkdownParser, PdfParser, TxtParser
|
||||
from deepdoc.parser.figure_parser import VisionFigureParser,vision_figure_parser_docx_wrapper,vision_figure_parser_pdf_wrapper
|
||||
from deepdoc.parser import DocxParser, ExcelParser, HtmlParser, JsonParser, MarkdownElementExtractor, MarkdownParser, \
|
||||
PdfParser, TxtParser
|
||||
from deepdoc.parser.figure_parser import VisionFigureParser, vision_figure_parser_docx_wrapper, \
|
||||
vision_figure_parser_pdf_wrapper
|
||||
from deepdoc.parser.pdf_parser import PlainParser, VisionParser
|
||||
from deepdoc.parser.docling_parser import DoclingParser
|
||||
from deepdoc.parser.tcadp_parser import TCADPParser
|
||||
from common.parser_config_utils import normalize_layout_recognizer
|
||||
from rag.nlp import concat_img, find_codec, naive_merge, naive_merge_with_images, naive_merge_docx, rag_tokenizer, tokenize_chunks, tokenize_chunks_with_images, tokenize_table, attach_media_context
|
||||
from rag.nlp import concat_img, find_codec, naive_merge, naive_merge_with_images, naive_merge_docx, rag_tokenizer, \
|
||||
tokenize_chunks, tokenize_chunks_with_images, tokenize_table, attach_media_context
|
||||
|
||||
|
||||
def by_deepdoc(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", callback=None, pdf_cls = None, **kwargs):
|
||||
def by_deepdoc(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", callback=None, pdf_cls=None,
|
||||
**kwargs):
|
||||
callback = callback
|
||||
binary = binary
|
||||
pdf_parser = pdf_cls() if pdf_cls else Pdf()
|
||||
@ -58,17 +62,17 @@ def by_deepdoc(filename, binary=None, from_page=0, to_page=100000, lang="Chinese
|
||||
|
||||
|
||||
def by_mineru(
|
||||
filename,
|
||||
binary=None,
|
||||
from_page=0,
|
||||
to_page=100000,
|
||||
lang="Chinese",
|
||||
callback=None,
|
||||
pdf_cls=None,
|
||||
parse_method: str = "raw",
|
||||
mineru_llm_name: str | None = None,
|
||||
tenant_id: str | None = None,
|
||||
**kwargs,
|
||||
filename,
|
||||
binary=None,
|
||||
from_page=0,
|
||||
to_page=100000,
|
||||
lang="Chinese",
|
||||
callback=None,
|
||||
pdf_cls=None,
|
||||
parse_method: str = "raw",
|
||||
mineru_llm_name: str | None = None,
|
||||
tenant_id: str | None = None,
|
||||
**kwargs,
|
||||
):
|
||||
pdf_parser = None
|
||||
if tenant_id:
|
||||
@ -106,7 +110,8 @@ def by_mineru(
|
||||
return None, None, None
|
||||
|
||||
|
||||
def by_docling(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", callback=None, pdf_cls = None, **kwargs):
|
||||
def by_docling(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", callback=None, pdf_cls=None,
|
||||
**kwargs):
|
||||
pdf_parser = DoclingParser()
|
||||
parse_method = kwargs.get("parse_method", "raw")
|
||||
|
||||
@ -125,7 +130,7 @@ def by_docling(filename, binary=None, from_page=0, to_page=100000, lang="Chinese
|
||||
return sections, tables, pdf_parser
|
||||
|
||||
|
||||
def by_tcadp(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", callback=None, pdf_cls = None, **kwargs):
|
||||
def by_tcadp(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", callback=None, pdf_cls=None, **kwargs):
|
||||
tcadp_parser = TCADPParser()
|
||||
|
||||
if not tcadp_parser.check_installation():
|
||||
@ -168,10 +173,10 @@ def by_plaintext(filename, binary=None, from_page=0, to_page=100000, callback=No
|
||||
|
||||
|
||||
PARSERS = {
|
||||
"deepdoc": by_deepdoc,
|
||||
"mineru": by_mineru,
|
||||
"docling": by_docling,
|
||||
"tcadp": by_tcadp,
|
||||
"deepdoc": by_deepdoc,
|
||||
"mineru": by_mineru,
|
||||
"docling": by_docling,
|
||||
"tcadp": by_tcadp,
|
||||
"plaintext": by_plaintext, # default
|
||||
}
|
||||
|
||||
@ -264,7 +269,7 @@ class Docx(DocxParser):
|
||||
|
||||
# Find the nearest heading paragraph in reverse order
|
||||
nearest_title = None
|
||||
for i in range(len(blocks)-1, -1, -1):
|
||||
for i in range(len(blocks) - 1, -1, -1):
|
||||
block_type, pos, block = blocks[i]
|
||||
if pos >= target_table_pos: # Skip blocks after the table
|
||||
continue
|
||||
@ -293,7 +298,7 @@ class Docx(DocxParser):
|
||||
# Find all parent headings, allowing cross-level search
|
||||
while current_level > 1:
|
||||
found = False
|
||||
for i in range(len(blocks)-1, -1, -1):
|
||||
for i in range(len(blocks) - 1, -1, -1):
|
||||
block_type, pos, block = blocks[i]
|
||||
if pos >= target_table_pos: # Skip blocks after the table
|
||||
continue
|
||||
@ -426,7 +431,8 @@ class Docx(DocxParser):
|
||||
|
||||
try:
|
||||
if inline_images:
|
||||
result = mammoth.convert_to_html(docx_file, convert_image=mammoth.images.img_element(_convert_image_to_base64))
|
||||
result = mammoth.convert_to_html(docx_file,
|
||||
convert_image=mammoth.images.img_element(_convert_image_to_base64))
|
||||
else:
|
||||
result = mammoth.convert_to_html(docx_file)
|
||||
|
||||
@ -621,6 +627,7 @@ class Markdown(MarkdownParser):
|
||||
return sections, tbls, section_images
|
||||
return sections, tbls
|
||||
|
||||
|
||||
def load_from_xml_v2(baseURI, rels_item_xml):
|
||||
"""
|
||||
Return |_SerializedRelationships| instance loaded with the
|
||||
@ -636,6 +643,7 @@ def load_from_xml_v2(baseURI, rels_item_xml):
|
||||
srels._srels.append(_SerializedRelationship(baseURI, rel_elm))
|
||||
return srels
|
||||
|
||||
|
||||
def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", callback=None, **kwargs):
|
||||
"""
|
||||
Supported file formats are docx, pdf, excel, txt.
|
||||
@ -651,7 +659,8 @@ def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", ca
|
||||
"parser_config", {
|
||||
"chunk_token_num": 512, "delimiter": "\n!?。;!?", "layout_recognize": "DeepDOC", "analyze_hyperlink": True})
|
||||
|
||||
child_deli = (parser_config.get("children_delimiter") or "").encode('utf-8').decode('unicode_escape').encode('latin1').decode('utf-8')
|
||||
child_deli = (parser_config.get("children_delimiter") or "").encode('utf-8').decode('unicode_escape').encode(
|
||||
'latin1').decode('utf-8')
|
||||
cust_child_deli = re.findall(r"`([^`]+)`", child_deli)
|
||||
child_deli = "|".join(re.sub(r"`([^`]+)`", "", child_deli))
|
||||
if cust_child_deli:
|
||||
@ -685,7 +694,8 @@ def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", ca
|
||||
# Recursively chunk each embedded file and collect results
|
||||
for embed_filename, embed_bytes in embeds:
|
||||
try:
|
||||
sub_res = chunk(embed_filename, binary=embed_bytes, lang=lang, callback=callback, is_root=False, **kwargs) or []
|
||||
sub_res = chunk(embed_filename, binary=embed_bytes, lang=lang, callback=callback, is_root=False,
|
||||
**kwargs) or []
|
||||
embed_res.extend(sub_res)
|
||||
except Exception as e:
|
||||
if callback:
|
||||
@ -704,7 +714,8 @@ def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", ca
|
||||
sub_url_res = chunk(url, html_bytes, callback=callback, lang=lang, is_root=False, **kwargs)
|
||||
except Exception as e:
|
||||
logging.info(f"Failed to chunk url in registered file type {url}: {e}")
|
||||
sub_url_res = chunk(f"{index}.html", html_bytes, callback=callback, lang=lang, is_root=False, **kwargs)
|
||||
sub_url_res = chunk(f"{index}.html", html_bytes, callback=callback, lang=lang, is_root=False,
|
||||
**kwargs)
|
||||
url_res.extend(sub_url_res)
|
||||
|
||||
# fix "There is no item named 'word/NULL' in the archive", referring to https://github.com/python-openxml/python-docx/issues/1105#issuecomment-1298075246
|
||||
@ -747,14 +758,14 @@ def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", ca
|
||||
callback(0.1, "Start to parse.")
|
||||
|
||||
sections, tables, pdf_parser = parser(
|
||||
filename = filename,
|
||||
binary = binary,
|
||||
from_page = from_page,
|
||||
to_page = to_page,
|
||||
lang = lang,
|
||||
callback = callback,
|
||||
layout_recognizer = layout_recognizer,
|
||||
mineru_llm_name = parser_model_name,
|
||||
filename=filename,
|
||||
binary=binary,
|
||||
from_page=from_page,
|
||||
to_page=to_page,
|
||||
lang=lang,
|
||||
callback=callback,
|
||||
layout_recognizer=layout_recognizer,
|
||||
mineru_llm_name=parser_model_name,
|
||||
**kwargs
|
||||
)
|
||||
|
||||
@ -812,7 +823,7 @@ def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", ca
|
||||
parser_config.get("delimiter", "\n!?;。;!?"))
|
||||
callback(0.8, "Finish parsing.")
|
||||
|
||||
elif re.search(r"\.(md|markdown)$", filename, re.IGNORECASE):
|
||||
elif re.search(r"\.(md|markdown|mdx)$", filename, re.IGNORECASE):
|
||||
callback(0.1, "Start to parse.")
|
||||
markdown_parser = Markdown(int(parser_config.get("chunk_token_num", 128)))
|
||||
sections, tables, section_images = markdown_parser(
|
||||
@ -846,9 +857,11 @@ def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", ca
|
||||
else:
|
||||
section_images = [None] * len(sections)
|
||||
section_images[idx] = combined_image
|
||||
markdown_vision_parser = VisionFigureParser(vision_model=vision_model, figures_data= [((combined_image, ["markdown image"]), [(0, 0, 0, 0, 0)])], **kwargs)
|
||||
markdown_vision_parser = VisionFigureParser(vision_model=vision_model, figures_data=[
|
||||
((combined_image, ["markdown image"]), [(0, 0, 0, 0, 0)])], **kwargs)
|
||||
boosted_figures = markdown_vision_parser(callback=callback)
|
||||
sections[idx] = (section_text + "\n\n" + "\n\n".join([fig[0][1] for fig in boosted_figures]), sections[idx][1])
|
||||
sections[idx] = (section_text + "\n\n" + "\n\n".join([fig[0][1] for fig in boosted_figures]),
|
||||
sections[idx][1])
|
||||
|
||||
else:
|
||||
logging.warning("No visual model detected. Skipping figure parsing enhancement.")
|
||||
@ -945,7 +958,8 @@ def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", ca
|
||||
has_images = merged_images and any(img is not None for img in merged_images)
|
||||
|
||||
if has_images:
|
||||
res.extend(tokenize_chunks_with_images(chunks, doc, is_english, merged_images, child_delimiters_pattern=child_deli))
|
||||
res.extend(tokenize_chunks_with_images(chunks, doc, is_english, merged_images,
|
||||
child_delimiters_pattern=child_deli))
|
||||
else:
|
||||
res.extend(tokenize_chunks(chunks, doc, is_english, pdf_parser, child_delimiters_pattern=child_deli))
|
||||
else:
|
||||
@ -955,10 +969,11 @@ def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", ca
|
||||
|
||||
if section_images:
|
||||
chunks, images = naive_merge_with_images(sections, section_images,
|
||||
int(parser_config.get(
|
||||
"chunk_token_num", 128)), parser_config.get(
|
||||
"delimiter", "\n!?。;!?"))
|
||||
res.extend(tokenize_chunks_with_images(chunks, doc, is_english, images, child_delimiters_pattern=child_deli))
|
||||
int(parser_config.get(
|
||||
"chunk_token_num", 128)), parser_config.get(
|
||||
"delimiter", "\n!?。;!?"))
|
||||
res.extend(
|
||||
tokenize_chunks_with_images(chunks, doc, is_english, images, child_delimiters_pattern=child_deli))
|
||||
else:
|
||||
chunks = naive_merge(
|
||||
sections, int(parser_config.get(
|
||||
@ -993,7 +1008,9 @@ def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", ca
|
||||
if __name__ == "__main__":
|
||||
import sys
|
||||
|
||||
|
||||
def dummy(prog=None, msg=""):
|
||||
pass
|
||||
|
||||
|
||||
chunk(sys.argv[1], from_page=0, to_page=10, callback=dummy)
|
||||
|
||||
@ -26,6 +26,7 @@ from deepdoc.parser.figure_parser import vision_figure_parser_docx_wrapper
|
||||
from rag.app.naive import by_plaintext, PARSERS
|
||||
from common.parser_config_utils import normalize_layout_recognizer
|
||||
|
||||
|
||||
class Pdf(PdfParser):
|
||||
def __call__(self, filename, binary=None, from_page=0,
|
||||
to_page=100000, zoomin=3, callback=None):
|
||||
@ -95,14 +96,14 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
callback(0.1, "Start to parse.")
|
||||
|
||||
sections, tbls, pdf_parser = parser(
|
||||
filename = filename,
|
||||
binary = binary,
|
||||
from_page = from_page,
|
||||
to_page = to_page,
|
||||
lang = lang,
|
||||
callback = callback,
|
||||
pdf_cls = Pdf,
|
||||
layout_recognizer = layout_recognizer,
|
||||
filename=filename,
|
||||
binary=binary,
|
||||
from_page=from_page,
|
||||
to_page=to_page,
|
||||
lang=lang,
|
||||
callback=callback,
|
||||
pdf_cls=Pdf,
|
||||
layout_recognizer=layout_recognizer,
|
||||
mineru_llm_name=parser_model_name,
|
||||
**kwargs
|
||||
)
|
||||
@ -112,9 +113,9 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
|
||||
if name in ["tcadp", "docling", "mineru"]:
|
||||
parser_config["chunk_token_num"] = 0
|
||||
|
||||
|
||||
callback(0.8, "Finish parsing.")
|
||||
|
||||
|
||||
for (img, rows), poss in tbls:
|
||||
if not rows:
|
||||
continue
|
||||
@ -127,7 +128,7 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
excel_parser = ExcelParser()
|
||||
sections = excel_parser.html(binary, 1000000000)
|
||||
|
||||
elif re.search(r"\.(txt|md|markdown)$", filename, re.IGNORECASE):
|
||||
elif re.search(r"\.(txt|md|markdown|mdx)$", filename, re.IGNORECASE):
|
||||
callback(0.1, "Start to parse.")
|
||||
txt = get_text(filename, binary)
|
||||
sections = txt.split("\n")
|
||||
@ -172,7 +173,9 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
if __name__ == "__main__":
|
||||
import sys
|
||||
|
||||
|
||||
def dummy(prog=None, msg=""):
|
||||
pass
|
||||
|
||||
|
||||
chunk(sys.argv[1], from_page=0, to_page=10, callback=dummy)
|
||||
|
||||
@ -20,7 +20,8 @@ import re
|
||||
|
||||
from deepdoc.parser.figure_parser import vision_figure_parser_pdf_wrapper
|
||||
from common.constants import ParserType
|
||||
from rag.nlp import rag_tokenizer, tokenize, tokenize_table, add_positions, bullets_category, title_frequency, tokenize_chunks, attach_media_context
|
||||
from rag.nlp import rag_tokenizer, tokenize, tokenize_table, add_positions, bullets_category, title_frequency, \
|
||||
tokenize_chunks, attach_media_context
|
||||
from deepdoc.parser import PdfParser
|
||||
import numpy as np
|
||||
from rag.app.naive import by_plaintext, PARSERS
|
||||
@ -66,7 +67,7 @@ class Pdf(PdfParser):
|
||||
# clean mess
|
||||
if column_width < self.page_images[0].size[0] / zoomin / 2:
|
||||
logging.debug("two_column................... {} {}".format(column_width,
|
||||
self.page_images[0].size[0] / zoomin / 2))
|
||||
self.page_images[0].size[0] / zoomin / 2))
|
||||
self.boxes = self.sort_X_by_page(self.boxes, column_width / 2)
|
||||
for b in self.boxes:
|
||||
b["text"] = re.sub(r"([\t ]|\u3000){2,}", " ", b["text"].strip())
|
||||
@ -89,7 +90,7 @@ class Pdf(PdfParser):
|
||||
title = ""
|
||||
authors = []
|
||||
i = 0
|
||||
while i < min(32, len(self.boxes)-1):
|
||||
while i < min(32, len(self.boxes) - 1):
|
||||
b = self.boxes[i]
|
||||
i += 1
|
||||
if b.get("layoutno", "").find("title") >= 0:
|
||||
@ -190,8 +191,8 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
"tables": tables
|
||||
}
|
||||
|
||||
tbls=paper["tables"]
|
||||
tbls=vision_figure_parser_pdf_wrapper(tbls=tbls,callback=callback,**kwargs)
|
||||
tbls = paper["tables"]
|
||||
tbls = vision_figure_parser_pdf_wrapper(tbls=tbls, callback=callback, **kwargs)
|
||||
paper["tables"] = tbls
|
||||
else:
|
||||
raise NotImplementedError("file type not supported yet(pdf supported)")
|
||||
@ -329,6 +330,9 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
if __name__ == "__main__":
|
||||
import sys
|
||||
|
||||
|
||||
def dummy(prog=None, msg=""):
|
||||
pass
|
||||
|
||||
|
||||
chunk(sys.argv[1], callback=dummy)
|
||||
|
||||
@ -51,7 +51,8 @@ def chunk(filename, binary, tenant_id, lang, callback=None, **kwargs):
|
||||
}
|
||||
)
|
||||
cv_mdl = LLMBundle(tenant_id, llm_type=LLMType.IMAGE2TEXT, lang=lang)
|
||||
ans = asyncio.run(cv_mdl.async_chat(system="", history=[], gen_conf={}, video_bytes=binary, filename=filename))
|
||||
ans = asyncio.run(
|
||||
cv_mdl.async_chat(system="", history=[], gen_conf={}, video_bytes=binary, filename=filename))
|
||||
callback(0.8, "CV LLM respond: %s ..." % ans[:32])
|
||||
ans += "\n" + ans
|
||||
tokenize(doc, ans, eng)
|
||||
|
||||
@ -249,7 +249,9 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
if __name__ == "__main__":
|
||||
import sys
|
||||
|
||||
|
||||
def dummy(a, b):
|
||||
pass
|
||||
|
||||
|
||||
chunk(sys.argv[1], callback=dummy)
|
||||
|
||||
@ -102,9 +102,9 @@ class Pdf(PdfParser):
|
||||
self._text_merge()
|
||||
callback(0.67, "Text merged ({:.2f}s)".format(timer() - start))
|
||||
tbls = self._extract_table_figure(True, zoomin, True, True)
|
||||
#self._naive_vertical_merge()
|
||||
# self._naive_vertical_merge()
|
||||
# self._concat_downward()
|
||||
#self._filter_forpages()
|
||||
# self._filter_forpages()
|
||||
logging.debug("layouts: {}".format(timer() - start))
|
||||
sections = [b["text"] for b in self.boxes]
|
||||
bull_x0_list = []
|
||||
@ -114,12 +114,14 @@ class Pdf(PdfParser):
|
||||
qai_list = []
|
||||
last_q, last_a, last_tag = '', '', ''
|
||||
last_index = -1
|
||||
last_box = {'text':''}
|
||||
last_box = {'text': ''}
|
||||
last_bull = None
|
||||
|
||||
def sort_key(element):
|
||||
tbls_pn = element[1][0][0]
|
||||
tbls_top = element[1][0][3]
|
||||
return tbls_pn, tbls_top
|
||||
|
||||
tbls.sort(key=sort_key)
|
||||
tbl_index = 0
|
||||
last_pn, last_bottom = 0, 0
|
||||
@ -133,28 +135,32 @@ class Pdf(PdfParser):
|
||||
tbl_pn, tbl_left, tbl_right, tbl_top, tbl_bottom, tbl_tag, tbl_text = self.get_tbls_info(tbls, tbl_index)
|
||||
if not has_bull: # No question bullet
|
||||
if not last_q:
|
||||
if tbl_pn < line_pn or (tbl_pn == line_pn and tbl_top <= line_top): # image passed
|
||||
if tbl_pn < line_pn or (tbl_pn == line_pn and tbl_top <= line_top): # image passed
|
||||
tbl_index += 1
|
||||
continue
|
||||
else:
|
||||
sum_tag = line_tag
|
||||
sum_section = section
|
||||
while ((tbl_pn == last_pn and tbl_top>= last_bottom) or (tbl_pn > last_pn)) \
|
||||
and ((tbl_pn == line_pn and tbl_top <= line_top) or (tbl_pn < line_pn)): # add image at the middle of current answer
|
||||
while ((tbl_pn == last_pn and tbl_top >= last_bottom) or (tbl_pn > last_pn)) \
|
||||
and ((tbl_pn == line_pn and tbl_top <= line_top) or (
|
||||
tbl_pn < line_pn)): # add image at the middle of current answer
|
||||
sum_tag = f'{tbl_tag}{sum_tag}'
|
||||
sum_section = f'{tbl_text}{sum_section}'
|
||||
tbl_index += 1
|
||||
tbl_pn, tbl_left, tbl_right, tbl_top, tbl_bottom, tbl_tag, tbl_text = self.get_tbls_info(tbls, tbl_index)
|
||||
tbl_pn, tbl_left, tbl_right, tbl_top, tbl_bottom, tbl_tag, tbl_text = self.get_tbls_info(tbls,
|
||||
tbl_index)
|
||||
last_a = f'{last_a}{sum_section}'
|
||||
last_tag = f'{last_tag}{sum_tag}'
|
||||
else:
|
||||
if last_q:
|
||||
while ((tbl_pn == last_pn and tbl_top>= last_bottom) or (tbl_pn > last_pn)) \
|
||||
and ((tbl_pn == line_pn and tbl_top <= line_top) or (tbl_pn < line_pn)): # add image at the end of last answer
|
||||
while ((tbl_pn == last_pn and tbl_top >= last_bottom) or (tbl_pn > last_pn)) \
|
||||
and ((tbl_pn == line_pn and tbl_top <= line_top) or (
|
||||
tbl_pn < line_pn)): # add image at the end of last answer
|
||||
last_tag = f'{last_tag}{tbl_tag}'
|
||||
last_a = f'{last_a}{tbl_text}'
|
||||
tbl_index += 1
|
||||
tbl_pn, tbl_left, tbl_right, tbl_top, tbl_bottom, tbl_tag, tbl_text = self.get_tbls_info(tbls, tbl_index)
|
||||
tbl_pn, tbl_left, tbl_right, tbl_top, tbl_bottom, tbl_tag, tbl_text = self.get_tbls_info(tbls,
|
||||
tbl_index)
|
||||
image, poss = self.crop(last_tag, need_position=True)
|
||||
qai_list.append((last_q, last_a, image, poss))
|
||||
last_q, last_a, last_tag = '', '', ''
|
||||
@ -171,7 +177,7 @@ class Pdf(PdfParser):
|
||||
def get_tbls_info(self, tbls, tbl_index):
|
||||
if tbl_index >= len(tbls):
|
||||
return 1, 0, 0, 0, 0, '@@0\t0\t0\t0\t0##', ''
|
||||
tbl_pn = tbls[tbl_index][1][0][0]+1
|
||||
tbl_pn = tbls[tbl_index][1][0][0] + 1
|
||||
tbl_left = tbls[tbl_index][1][0][1]
|
||||
tbl_right = tbls[tbl_index][1][0][2]
|
||||
tbl_top = tbls[tbl_index][1][0][3]
|
||||
@ -210,11 +216,11 @@ class Docx(DocxParser):
|
||||
question_level, p_text = 0, ''
|
||||
if from_page <= pn < to_page and p.text.strip():
|
||||
question_level, p_text = docx_question_level(p)
|
||||
if not question_level or question_level > 6: # not a question
|
||||
if not question_level or question_level > 6: # not a question
|
||||
last_answer = f'{last_answer}\n{p_text}'
|
||||
current_image = self.get_picture(self.doc, p)
|
||||
last_image = concat_img(last_image, current_image)
|
||||
else: # is a question
|
||||
else: # is a question
|
||||
if last_answer or last_image:
|
||||
sum_question = '\n'.join(question_stack)
|
||||
if sum_question:
|
||||
@ -240,14 +246,14 @@ class Docx(DocxParser):
|
||||
|
||||
tbls = []
|
||||
for tb in self.doc.tables:
|
||||
html= "<table>"
|
||||
html = "<table>"
|
||||
for r in tb.rows:
|
||||
html += "<tr>"
|
||||
i = 0
|
||||
while i < len(r.cells):
|
||||
span = 1
|
||||
c = r.cells[i]
|
||||
for j in range(i+1, len(r.cells)):
|
||||
for j in range(i + 1, len(r.cells)):
|
||||
if c.text == r.cells[j].text:
|
||||
span += 1
|
||||
i = j
|
||||
@ -356,7 +362,7 @@ def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", ca
|
||||
if question:
|
||||
answer += "\n" + lines[i]
|
||||
else:
|
||||
fails.append(str(i+1))
|
||||
fails.append(str(i + 1))
|
||||
elif len(arr) == 2:
|
||||
if question and answer:
|
||||
res.append(beAdoc(deepcopy(doc), question, answer, eng, i))
|
||||
@ -415,7 +421,7 @@ def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", ca
|
||||
res.append(beAdocPdf(deepcopy(doc), q, a, eng, image, poss))
|
||||
return res
|
||||
|
||||
elif re.search(r"\.(md|markdown)$", filename, re.IGNORECASE):
|
||||
elif re.search(r"\.(md|markdown|mdx)$", filename, re.IGNORECASE):
|
||||
callback(0.1, "Start to parse.")
|
||||
txt = get_text(filename, binary)
|
||||
lines = txt.split("\n")
|
||||
@ -429,13 +435,14 @@ def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", ca
|
||||
if not code_block:
|
||||
question_level, question = mdQuestionLevel(line)
|
||||
|
||||
if not question_level or question_level > 6: # not a question
|
||||
if not question_level or question_level > 6: # not a question
|
||||
last_answer = f'{last_answer}\n{line}'
|
||||
else: # is a question
|
||||
else: # is a question
|
||||
if last_answer.strip():
|
||||
sum_question = '\n'.join(question_stack)
|
||||
if sum_question:
|
||||
res.append(beAdoc(deepcopy(doc), sum_question, markdown(last_answer, extensions=['markdown.extensions.tables']), eng, index))
|
||||
res.append(beAdoc(deepcopy(doc), sum_question,
|
||||
markdown(last_answer, extensions=['markdown.extensions.tables']), eng, index))
|
||||
last_answer = ''
|
||||
|
||||
i = question_level
|
||||
@ -447,13 +454,14 @@ def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", ca
|
||||
if last_answer.strip():
|
||||
sum_question = '\n'.join(question_stack)
|
||||
if sum_question:
|
||||
res.append(beAdoc(deepcopy(doc), sum_question, markdown(last_answer, extensions=['markdown.extensions.tables']), eng, index))
|
||||
res.append(beAdoc(deepcopy(doc), sum_question,
|
||||
markdown(last_answer, extensions=['markdown.extensions.tables']), eng, index))
|
||||
return res
|
||||
|
||||
elif re.search(r"\.docx$", filename, re.IGNORECASE):
|
||||
docx_parser = Docx()
|
||||
qai_list, tbls = docx_parser(filename, binary,
|
||||
from_page=0, to_page=10000, callback=callback)
|
||||
from_page=0, to_page=10000, callback=callback)
|
||||
res = tokenize_table(tbls, doc, eng)
|
||||
for i, (q, a, image) in enumerate(qai_list):
|
||||
res.append(beAdocDocx(deepcopy(doc), q, a, eng, image, i))
|
||||
@ -466,6 +474,9 @@ def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", ca
|
||||
if __name__ == "__main__":
|
||||
import sys
|
||||
|
||||
|
||||
def dummy(prog=None, msg=""):
|
||||
pass
|
||||
|
||||
|
||||
chunk(sys.argv[1], from_page=0, to_page=10, callback=dummy)
|
||||
|
||||
@ -64,7 +64,8 @@ def remote_call(filename, binary):
|
||||
del resume[k]
|
||||
|
||||
resume = step_one.refactor(pd.DataFrame([{"resume_content": json.dumps(resume), "tob_resume_id": "x",
|
||||
"updated_at": datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")}]))
|
||||
"updated_at": datetime.datetime.now().strftime(
|
||||
"%Y-%m-%d %H:%M:%S")}]))
|
||||
resume = step_two.parse(resume)
|
||||
return resume
|
||||
except Exception:
|
||||
@ -171,6 +172,9 @@ def chunk(filename, binary=None, callback=None, **kwargs):
|
||||
if __name__ == "__main__":
|
||||
import sys
|
||||
|
||||
|
||||
def dummy(a, b):
|
||||
pass
|
||||
|
||||
|
||||
chunk(sys.argv[1], callback=dummy)
|
||||
|
||||
@ -51,14 +51,15 @@ class Excel(ExcelParser):
|
||||
tables = []
|
||||
for sheetname in wb.sheetnames:
|
||||
ws = wb[sheetname]
|
||||
images = Excel._extract_images_from_worksheet(ws,sheetname=sheetname)
|
||||
images = Excel._extract_images_from_worksheet(ws, sheetname=sheetname)
|
||||
if images:
|
||||
image_descriptions = vision_figure_parser_figure_xlsx_wrapper(images=images, callback=callback, **kwargs)
|
||||
image_descriptions = vision_figure_parser_figure_xlsx_wrapper(images=images, callback=callback,
|
||||
**kwargs)
|
||||
if image_descriptions and len(image_descriptions) == len(images):
|
||||
for i, bf in enumerate(image_descriptions):
|
||||
images[i]["image_description"] = "\n".join(bf[0][1])
|
||||
for img in images:
|
||||
if (img["span_type"] == "single_cell"and img.get("image_description")):
|
||||
if (img["span_type"] == "single_cell" and img.get("image_description")):
|
||||
pending_cell_images.append(img)
|
||||
else:
|
||||
flow_images.append(img)
|
||||
@ -113,16 +114,17 @@ class Excel(ExcelParser):
|
||||
tables.append(
|
||||
(
|
||||
(
|
||||
img["image"], # Image.Image
|
||||
[img["image_description"]] # description list (must be list)
|
||||
img["image"], # Image.Image
|
||||
[img["image_description"]] # description list (must be list)
|
||||
),
|
||||
[
|
||||
(0, 0, 0, 0, 0) # dummy position
|
||||
(0, 0, 0, 0, 0) # dummy position
|
||||
]
|
||||
)
|
||||
)
|
||||
callback(0.3, ("Extract records: {}~{}".format(from_page + 1, min(to_page, from_page + rn)) + (f"{len(fails)} failure, line: %s..." % (",".join(fails[:3])) if fails else "")))
|
||||
return res,tables
|
||||
callback(0.3, ("Extract records: {}~{}".format(from_page + 1, min(to_page, from_page + rn)) + (
|
||||
f"{len(fails)} failure, line: %s..." % (",".join(fails[:3])) if fails else "")))
|
||||
return res, tables
|
||||
|
||||
def _parse_headers(self, ws, rows):
|
||||
if len(rows) == 0:
|
||||
@ -315,14 +317,15 @@ def trans_bool(s):
|
||||
def column_data_type(arr):
|
||||
arr = list(arr)
|
||||
counts = {"int": 0, "float": 0, "text": 0, "datetime": 0, "bool": 0}
|
||||
trans = {t: f for f, t in [(int, "int"), (float, "float"), (trans_datatime, "datetime"), (trans_bool, "bool"), (str, "text")]}
|
||||
trans = {t: f for f, t in
|
||||
[(int, "int"), (float, "float"), (trans_datatime, "datetime"), (trans_bool, "bool"), (str, "text")]}
|
||||
float_flag = False
|
||||
for a in arr:
|
||||
if a is None:
|
||||
continue
|
||||
if re.match(r"[+-]?[0-9]+$", str(a).replace("%%", "")) and not str(a).replace("%%", "").startswith("0"):
|
||||
counts["int"] += 1
|
||||
if int(str(a)) > 2**63 - 1:
|
||||
if int(str(a)) > 2 ** 63 - 1:
|
||||
float_flag = True
|
||||
break
|
||||
elif re.match(r"[+-]?[0-9.]{,19}$", str(a).replace("%%", "")) and not str(a).replace("%%", "").startswith("0"):
|
||||
@ -370,7 +373,7 @@ def chunk(filename, binary=None, from_page=0, to_page=10000000000, lang="Chinese
|
||||
if re.search(r"\.xlsx?$", filename, re.IGNORECASE):
|
||||
callback(0.1, "Start to parse.")
|
||||
excel_parser = Excel()
|
||||
dfs,tbls = excel_parser(filename, binary, from_page=from_page, to_page=to_page, callback=callback, **kwargs)
|
||||
dfs, tbls = excel_parser(filename, binary, from_page=from_page, to_page=to_page, callback=callback, **kwargs)
|
||||
elif re.search(r"\.txt$", filename, re.IGNORECASE):
|
||||
callback(0.1, "Start to parse.")
|
||||
txt = get_text(filename, binary)
|
||||
@ -389,7 +392,8 @@ def chunk(filename, binary=None, from_page=0, to_page=10000000000, lang="Chinese
|
||||
continue
|
||||
rows.append(row)
|
||||
|
||||
callback(0.3, ("Extract records: {}~{}".format(from_page, min(len(lines), to_page)) + (f"{len(fails)} failure, line: %s..." % (",".join(fails[:3])) if fails else "")))
|
||||
callback(0.3, ("Extract records: {}~{}".format(from_page, min(len(lines), to_page)) + (
|
||||
f"{len(fails)} failure, line: %s..." % (",".join(fails[:3])) if fails else "")))
|
||||
|
||||
dfs = [pd.DataFrame(np.array(rows), columns=headers)]
|
||||
elif re.search(r"\.csv$", filename, re.IGNORECASE):
|
||||
@ -406,7 +410,7 @@ def chunk(filename, binary=None, from_page=0, to_page=10000000000, lang="Chinese
|
||||
fails = []
|
||||
rows = []
|
||||
|
||||
for i, row in enumerate(all_rows[1 + from_page : 1 + to_page]):
|
||||
for i, row in enumerate(all_rows[1 + from_page: 1 + to_page]):
|
||||
if len(row) != len(headers):
|
||||
fails.append(str(i + from_page))
|
||||
continue
|
||||
@ -415,7 +419,7 @@ def chunk(filename, binary=None, from_page=0, to_page=10000000000, lang="Chinese
|
||||
callback(
|
||||
0.3,
|
||||
(f"Extract records: {from_page}~{from_page + len(rows)}" +
|
||||
(f"{len(fails)} failure, line: {','.join(fails[:3])}..." if fails else ""))
|
||||
(f"{len(fails)} failure, line: {','.join(fails[:3])}..." if fails else ""))
|
||||
)
|
||||
|
||||
dfs = [pd.DataFrame(rows, columns=headers)]
|
||||
@ -445,7 +449,8 @@ def chunk(filename, binary=None, from_page=0, to_page=10000000000, lang="Chinese
|
||||
df[clmns[j]] = cln
|
||||
if ty == "text":
|
||||
txts.extend([str(c) for c in cln if c])
|
||||
clmns_map = [(py_clmns[i].lower() + fieds_map[clmn_tys[i]], str(clmns[i]).replace("_", " ")) for i in range(len(clmns))]
|
||||
clmns_map = [(py_clmns[i].lower() + fieds_map[clmn_tys[i]], str(clmns[i]).replace("_", " ")) for i in
|
||||
range(len(clmns))]
|
||||
|
||||
eng = lang.lower() == "english" # is_english(txts)
|
||||
for ii, row in df.iterrows():
|
||||
@ -477,7 +482,9 @@ def chunk(filename, binary=None, from_page=0, to_page=10000000000, lang="Chinese
|
||||
if __name__ == "__main__":
|
||||
import sys
|
||||
|
||||
|
||||
def dummy(prog=None, msg=""):
|
||||
pass
|
||||
|
||||
|
||||
chunk(sys.argv[1], callback=dummy)
|
||||
|
||||
@ -141,17 +141,20 @@ def label_question(question, kbs):
|
||||
if not tag_kbs:
|
||||
return tags
|
||||
tags = settings.retriever.tag_query(question,
|
||||
list(set([kb.tenant_id for kb in tag_kbs])),
|
||||
tag_kb_ids,
|
||||
all_tags,
|
||||
kb.parser_config.get("topn_tags", 3)
|
||||
)
|
||||
list(set([kb.tenant_id for kb in tag_kbs])),
|
||||
tag_kb_ids,
|
||||
all_tags,
|
||||
kb.parser_config.get("topn_tags", 3)
|
||||
)
|
||||
return tags
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
import sys
|
||||
|
||||
|
||||
def dummy(prog=None, msg=""):
|
||||
pass
|
||||
chunk(sys.argv[1], from_page=0, to_page=10, callback=dummy)
|
||||
|
||||
|
||||
chunk(sys.argv[1], from_page=0, to_page=10, callback=dummy)
|
||||
|
||||
@ -263,7 +263,7 @@ class SparkTTS(Base):
|
||||
raise Exception(error)
|
||||
|
||||
def on_close(self, ws, close_status_code, close_msg):
|
||||
self.audio_queue.put(None) # 放入 None 作为结束标志
|
||||
self.audio_queue.put(None) # None is terminator
|
||||
|
||||
def on_open(self, ws):
|
||||
def run(*args):
|
||||
|
||||
@ -273,7 +273,7 @@ def tokenize(d, txt, eng):
|
||||
d["content_sm_ltks"] = rag_tokenizer.fine_grained_tokenize(d["content_ltks"])
|
||||
|
||||
|
||||
def split_with_pattern(d, pattern:str, content:str, eng) -> list:
|
||||
def split_with_pattern(d, pattern: str, content: str, eng) -> list:
|
||||
docs = []
|
||||
txts = [txt for txt in re.split(r"(%s)" % pattern, content, flags=re.DOTALL)]
|
||||
for j in range(0, len(txts), 2):
|
||||
@ -281,7 +281,7 @@ def split_with_pattern(d, pattern:str, content:str, eng) -> list:
|
||||
if not txt:
|
||||
continue
|
||||
if j + 1 < len(txts):
|
||||
txt += txts[j+1]
|
||||
txt += txts[j + 1]
|
||||
dd = copy.deepcopy(d)
|
||||
tokenize(dd, txt, eng)
|
||||
docs.append(dd)
|
||||
@ -304,7 +304,7 @@ def tokenize_chunks(chunks, doc, eng, pdf_parser=None, child_delimiters_pattern=
|
||||
except NotImplementedError:
|
||||
pass
|
||||
else:
|
||||
add_positions(d, [[ii]*5])
|
||||
add_positions(d, [[ii] * 5])
|
||||
|
||||
if child_delimiters_pattern:
|
||||
d["mom_with_weight"] = ck
|
||||
@ -325,7 +325,7 @@ def tokenize_chunks_with_images(chunks, doc, eng, images, child_delimiters_patte
|
||||
logging.debug("-- {}".format(ck))
|
||||
d = copy.deepcopy(doc)
|
||||
d["image"] = image
|
||||
add_positions(d, [[ii]*5])
|
||||
add_positions(d, [[ii] * 5])
|
||||
if child_delimiters_pattern:
|
||||
d["mom_with_weight"] = ck
|
||||
res.extend(split_with_pattern(d, child_delimiters_pattern, ck, eng))
|
||||
@ -658,7 +658,8 @@ def attach_media_context(chunks, table_context_size=0, image_context_size=0):
|
||||
if "content_ltks" in ck:
|
||||
ck["content_ltks"] = rag_tokenizer.tokenize(combined)
|
||||
if "content_sm_ltks" in ck:
|
||||
ck["content_sm_ltks"] = rag_tokenizer.fine_grained_tokenize(ck.get("content_ltks", rag_tokenizer.tokenize(combined)))
|
||||
ck["content_sm_ltks"] = rag_tokenizer.fine_grained_tokenize(
|
||||
ck.get("content_ltks", rag_tokenizer.tokenize(combined)))
|
||||
|
||||
if positioned_indices:
|
||||
chunks[:] = [chunks[i] for i in ordered_indices]
|
||||
@ -764,8 +765,8 @@ def not_title(txt):
|
||||
return True
|
||||
return re.search(r"[,;,。;!!]", txt)
|
||||
|
||||
def tree_merge(bull, sections, depth):
|
||||
|
||||
def tree_merge(bull, sections, depth):
|
||||
if not sections or bull < 0:
|
||||
return sections
|
||||
if isinstance(sections[0], type("")):
|
||||
@ -777,16 +778,17 @@ def tree_merge(bull, sections, depth):
|
||||
|
||||
def get_level(bull, section):
|
||||
text, layout = section
|
||||
text = re.sub(r"\u3000", " ", text).strip()
|
||||
text = re.sub(r"\u3000", " ", text).strip()
|
||||
|
||||
for i, title in enumerate(BULLET_PATTERN[bull]):
|
||||
if re.match(title, text.strip()):
|
||||
return i+1, text
|
||||
return i + 1, text
|
||||
else:
|
||||
if re.search(r"(title|head)", layout) and not not_title(text):
|
||||
return len(BULLET_PATTERN[bull])+1, text
|
||||
return len(BULLET_PATTERN[bull]) + 1, text
|
||||
else:
|
||||
return len(BULLET_PATTERN[bull])+2, text
|
||||
return len(BULLET_PATTERN[bull]) + 2, text
|
||||
|
||||
level_set = set()
|
||||
lines = []
|
||||
for section in sections:
|
||||
@ -812,8 +814,8 @@ def tree_merge(bull, sections, depth):
|
||||
|
||||
return [element for element in root.get_tree() if element]
|
||||
|
||||
def hierarchical_merge(bull, sections, depth):
|
||||
|
||||
def hierarchical_merge(bull, sections, depth):
|
||||
if not sections or bull < 0:
|
||||
return []
|
||||
if isinstance(sections[0], type("")):
|
||||
@ -922,10 +924,10 @@ def naive_merge(sections: str | list, chunk_token_num=128, delimiter="\n。;
|
||||
if tnum < 8:
|
||||
pos = ""
|
||||
# Ensure that the length of the merged chunk does not exceed chunk_token_num
|
||||
if cks[-1] == "" or tk_nums[-1] > chunk_token_num * (100 - overlapped_percent)/100.:
|
||||
if cks[-1] == "" or tk_nums[-1] > chunk_token_num * (100 - overlapped_percent) / 100.:
|
||||
if cks:
|
||||
overlapped = RAGFlowPdfParser.remove_tag(cks[-1])
|
||||
t = overlapped[int(len(overlapped)*(100-overlapped_percent)/100.):] + t
|
||||
t = overlapped[int(len(overlapped) * (100 - overlapped_percent) / 100.):] + t
|
||||
if t.find(pos) < 0:
|
||||
t += pos
|
||||
cks.append(t)
|
||||
@ -957,7 +959,7 @@ def naive_merge(sections: str | list, chunk_token_num=128, delimiter="\n。;
|
||||
return cks
|
||||
|
||||
for sec, pos in sections:
|
||||
add_chunk("\n"+sec, pos)
|
||||
add_chunk("\n" + sec, pos)
|
||||
|
||||
return cks
|
||||
|
||||
@ -978,10 +980,10 @@ def naive_merge_with_images(texts, images, chunk_token_num=128, delimiter="\n。
|
||||
if tnum < 8:
|
||||
pos = ""
|
||||
# Ensure that the length of the merged chunk does not exceed chunk_token_num
|
||||
if cks[-1] == "" or tk_nums[-1] > chunk_token_num * (100 - overlapped_percent)/100.:
|
||||
if cks[-1] == "" or tk_nums[-1] > chunk_token_num * (100 - overlapped_percent) / 100.:
|
||||
if cks:
|
||||
overlapped = RAGFlowPdfParser.remove_tag(cks[-1])
|
||||
t = overlapped[int(len(overlapped)*(100-overlapped_percent)/100.):] + t
|
||||
t = overlapped[int(len(overlapped) * (100 - overlapped_percent) / 100.):] + t
|
||||
if t.find(pos) < 0:
|
||||
t += pos
|
||||
cks.append(t)
|
||||
@ -1025,9 +1027,9 @@ def naive_merge_with_images(texts, images, chunk_token_num=128, delimiter="\n。
|
||||
if isinstance(text, tuple):
|
||||
text_str = text[0]
|
||||
text_pos = text[1] if len(text) > 1 else ""
|
||||
add_chunk("\n"+text_str, image, text_pos)
|
||||
add_chunk("\n" + text_str, image, text_pos)
|
||||
else:
|
||||
add_chunk("\n"+text, image)
|
||||
add_chunk("\n" + text, image)
|
||||
|
||||
return cks, result_images
|
||||
|
||||
@ -1042,7 +1044,7 @@ def docx_question_level(p, bull=-1):
|
||||
for j, title in enumerate(BULLET_PATTERN[bull]):
|
||||
if re.match(title, txt):
|
||||
return j + 1, txt
|
||||
return len(BULLET_PATTERN[bull])+1, txt
|
||||
return len(BULLET_PATTERN[bull]) + 1, txt
|
||||
|
||||
|
||||
def concat_img(img1, img2):
|
||||
@ -1211,7 +1213,7 @@ class Node:
|
||||
child = node.get_children()
|
||||
|
||||
if level == 0 and texts:
|
||||
tree_list.append("\n".join(titles+texts))
|
||||
tree_list.append("\n".join(titles + texts))
|
||||
|
||||
# Titles within configured depth are accumulated into the current path
|
||||
if 1 <= level <= self.depth:
|
||||
|
||||
@ -205,11 +205,11 @@ class FulltextQueryer(QueryBase):
|
||||
s = 1e-9
|
||||
for k, v in qtwt.items():
|
||||
if k in dtwt:
|
||||
s += v #* dtwt[k]
|
||||
s += v # * dtwt[k]
|
||||
q = 1e-9
|
||||
for k, v in qtwt.items():
|
||||
q += v #* v
|
||||
return s/q #math.sqrt(3. * (s / q / math.log10( len(dtwt.keys()) + 512 )))
|
||||
q += v # * v
|
||||
return s / q # math.sqrt(3. * (s / q / math.log10( len(dtwt.keys()) + 512 )))
|
||||
|
||||
def paragraph(self, content_tks: str, keywords: list = [], keywords_topn=30):
|
||||
if isinstance(content_tks, str):
|
||||
@ -232,4 +232,5 @@ class FulltextQueryer(QueryBase):
|
||||
keywords.append(f"{tk}^{w}")
|
||||
|
||||
return MatchTextExpr(self.query_fields, " ".join(keywords), 100,
|
||||
{"minimum_should_match": min(3, len(keywords) / 10), "original_query": " ".join(origin_keywords)})
|
||||
{"minimum_should_match": min(3, len(keywords) / 10),
|
||||
"original_query": " ".join(origin_keywords)})
|
||||
|
||||
@ -66,7 +66,8 @@ class Dealer:
|
||||
if key in req and req[key] is not None:
|
||||
condition[field] = req[key]
|
||||
# TODO(yzc): `available_int` is nullable however infinity doesn't support nullable columns.
|
||||
for key in ["knowledge_graph_kwd", "available_int", "entity_kwd", "from_entity_kwd", "to_entity_kwd", "removed_kwd"]:
|
||||
for key in ["knowledge_graph_kwd", "available_int", "entity_kwd", "from_entity_kwd", "to_entity_kwd",
|
||||
"removed_kwd"]:
|
||||
if key in req and req[key] is not None:
|
||||
condition[key] = req[key]
|
||||
return condition
|
||||
@ -141,7 +142,8 @@ class Dealer:
|
||||
matchText, _ = self.qryr.question(qst, min_match=0.1)
|
||||
matchDense.extra_options["similarity"] = 0.17
|
||||
res = self.dataStore.search(src, highlightFields, filters, [matchText, matchDense, fusionExpr],
|
||||
orderBy, offset, limit, idx_names, kb_ids, rank_feature=rank_feature)
|
||||
orderBy, offset, limit, idx_names, kb_ids,
|
||||
rank_feature=rank_feature)
|
||||
total = self.dataStore.get_total(res)
|
||||
logging.debug("Dealer.search 2 TOTAL: {}".format(total))
|
||||
|
||||
@ -218,8 +220,9 @@ class Dealer:
|
||||
ans_v, _ = embd_mdl.encode(pieces_)
|
||||
for i in range(len(chunk_v)):
|
||||
if len(ans_v[0]) != len(chunk_v[i]):
|
||||
chunk_v[i] = [0.0]*len(ans_v[0])
|
||||
logging.warning("The dimension of query and chunk do not match: {} vs. {}".format(len(ans_v[0]), len(chunk_v[i])))
|
||||
chunk_v[i] = [0.0] * len(ans_v[0])
|
||||
logging.warning(
|
||||
"The dimension of query and chunk do not match: {} vs. {}".format(len(ans_v[0]), len(chunk_v[i])))
|
||||
|
||||
assert len(ans_v[0]) == len(chunk_v[0]), "The dimension of query and chunk do not match: {} vs. {}".format(
|
||||
len(ans_v[0]), len(chunk_v[0]))
|
||||
@ -273,7 +276,7 @@ class Dealer:
|
||||
if not query_rfea:
|
||||
return np.array([0 for _ in range(len(search_res.ids))]) + pageranks
|
||||
|
||||
q_denor = np.sqrt(np.sum([s*s for t,s in query_rfea.items() if t != PAGERANK_FLD]))
|
||||
q_denor = np.sqrt(np.sum([s * s for t, s in query_rfea.items() if t != PAGERANK_FLD]))
|
||||
for i in search_res.ids:
|
||||
nor, denor = 0, 0
|
||||
if not search_res.field[i].get(TAG_FLD):
|
||||
@ -286,8 +289,8 @@ class Dealer:
|
||||
if denor == 0:
|
||||
rank_fea.append(0)
|
||||
else:
|
||||
rank_fea.append(nor/np.sqrt(denor)/q_denor)
|
||||
return np.array(rank_fea)*10. + pageranks
|
||||
rank_fea.append(nor / np.sqrt(denor) / q_denor)
|
||||
return np.array(rank_fea) * 10. + pageranks
|
||||
|
||||
def rerank(self, sres, query, tkweight=0.3,
|
||||
vtweight=0.7, cfield="content_ltks",
|
||||
@ -358,21 +361,21 @@ class Dealer:
|
||||
rag_tokenizer.tokenize(inst).split())
|
||||
|
||||
def retrieval(
|
||||
self,
|
||||
question,
|
||||
embd_mdl,
|
||||
tenant_ids,
|
||||
kb_ids,
|
||||
page,
|
||||
page_size,
|
||||
similarity_threshold=0.2,
|
||||
vector_similarity_weight=0.3,
|
||||
top=1024,
|
||||
doc_ids=None,
|
||||
aggs=True,
|
||||
rerank_mdl=None,
|
||||
highlight=False,
|
||||
rank_feature: dict | None = {PAGERANK_FLD: 10},
|
||||
self,
|
||||
question,
|
||||
embd_mdl,
|
||||
tenant_ids,
|
||||
kb_ids,
|
||||
page,
|
||||
page_size,
|
||||
similarity_threshold=0.2,
|
||||
vector_similarity_weight=0.3,
|
||||
top=1024,
|
||||
doc_ids=None,
|
||||
aggs=True,
|
||||
rerank_mdl=None,
|
||||
highlight=False,
|
||||
rank_feature: dict | None = {PAGERANK_FLD: 10},
|
||||
):
|
||||
ranks = {"total": 0, "chunks": [], "doc_aggs": {}}
|
||||
if not question:
|
||||
@ -395,7 +398,8 @@ class Dealer:
|
||||
if isinstance(tenant_ids, str):
|
||||
tenant_ids = tenant_ids.split(",")
|
||||
|
||||
sres = self.search(req, [index_name(tid) for tid in tenant_ids], kb_ids, embd_mdl, highlight, rank_feature=rank_feature)
|
||||
sres = self.search(req, [index_name(tid) for tid in tenant_ids], kb_ids, embd_mdl, highlight,
|
||||
rank_feature=rank_feature)
|
||||
|
||||
if rerank_mdl and sres.total > 0:
|
||||
sim, tsim, vsim = self.rerank_by_model(
|
||||
@ -558,13 +562,14 @@ class Dealer:
|
||||
|
||||
def tag_content(self, tenant_id: str, kb_ids: list[str], doc, all_tags, topn_tags=3, keywords_topn=30, S=1000):
|
||||
idx_nm = index_name(tenant_id)
|
||||
match_txt = self.qryr.paragraph(doc["title_tks"] + " " + doc["content_ltks"], doc.get("important_kwd", []), keywords_topn)
|
||||
match_txt = self.qryr.paragraph(doc["title_tks"] + " " + doc["content_ltks"], doc.get("important_kwd", []),
|
||||
keywords_topn)
|
||||
res = self.dataStore.search([], [], {}, [match_txt], OrderByExpr(), 0, 0, idx_nm, kb_ids, ["tag_kwd"])
|
||||
aggs = self.dataStore.get_aggregation(res, "tag_kwd")
|
||||
if not aggs:
|
||||
return False
|
||||
cnt = np.sum([c for _, c in aggs])
|
||||
tag_fea = sorted([(a, round(0.1*(c + 1) / (cnt + S) / max(1e-6, all_tags.get(a, 0.0001)))) for a, c in aggs],
|
||||
tag_fea = sorted([(a, round(0.1 * (c + 1) / (cnt + S) / max(1e-6, all_tags.get(a, 0.0001)))) for a, c in aggs],
|
||||
key=lambda x: x[1] * -1)[:topn_tags]
|
||||
doc[TAG_FLD] = {a.replace(".", "_"): c for a, c in tag_fea if c > 0}
|
||||
return True
|
||||
@ -580,11 +585,11 @@ class Dealer:
|
||||
if not aggs:
|
||||
return {}
|
||||
cnt = np.sum([c for _, c in aggs])
|
||||
tag_fea = sorted([(a, round(0.1*(c + 1) / (cnt + S) / max(1e-6, all_tags.get(a, 0.0001)))) for a, c in aggs],
|
||||
tag_fea = sorted([(a, round(0.1 * (c + 1) / (cnt + S) / max(1e-6, all_tags.get(a, 0.0001)))) for a, c in aggs],
|
||||
key=lambda x: x[1] * -1)[:topn_tags]
|
||||
return {a.replace(".", "_"): max(1, c) for a, c in tag_fea}
|
||||
|
||||
def retrieval_by_toc(self, query:str, chunks:list[dict], tenant_ids:list[str], chat_mdl, topn: int=6):
|
||||
def retrieval_by_toc(self, query: str, chunks: list[dict], tenant_ids: list[str], chat_mdl, topn: int = 6):
|
||||
if not chunks:
|
||||
return []
|
||||
idx_nms = [index_name(tid) for tid in tenant_ids]
|
||||
@ -594,9 +599,10 @@ class Dealer:
|
||||
ranks[ck["doc_id"]] = 0
|
||||
ranks[ck["doc_id"]] += ck["similarity"]
|
||||
doc_id2kb_id[ck["doc_id"]] = ck["kb_id"]
|
||||
doc_id = sorted(ranks.items(), key=lambda x: x[1]*-1.)[0][0]
|
||||
doc_id = sorted(ranks.items(), key=lambda x: x[1] * -1.)[0][0]
|
||||
kb_ids = [doc_id2kb_id[doc_id]]
|
||||
es_res = self.dataStore.search(["content_with_weight"], [], {"doc_id": doc_id, "toc_kwd": "toc"}, [], OrderByExpr(), 0, 128, idx_nms,
|
||||
es_res = self.dataStore.search(["content_with_weight"], [], {"doc_id": doc_id, "toc_kwd": "toc"}, [],
|
||||
OrderByExpr(), 0, 128, idx_nms,
|
||||
kb_ids)
|
||||
toc = []
|
||||
dict_chunks = self.dataStore.get_fields(es_res, ["content_with_weight"])
|
||||
@ -608,7 +614,7 @@ class Dealer:
|
||||
if not toc:
|
||||
return chunks
|
||||
|
||||
ids = asyncio.run(relevant_chunks_with_toc(query, toc, chat_mdl, topn*2))
|
||||
ids = asyncio.run(relevant_chunks_with_toc(query, toc, chat_mdl, topn * 2))
|
||||
if not ids:
|
||||
return chunks
|
||||
|
||||
@ -644,9 +650,9 @@ class Dealer:
|
||||
break
|
||||
chunks.append(d)
|
||||
|
||||
return sorted(chunks, key=lambda x:x["similarity"]*-1)[:topn]
|
||||
return sorted(chunks, key=lambda x: x["similarity"] * -1)[:topn]
|
||||
|
||||
def retrieval_by_children(self, chunks:list[dict], tenant_ids:list[str]):
|
||||
def retrieval_by_children(self, chunks: list[dict], tenant_ids: list[str]):
|
||||
if not chunks:
|
||||
return []
|
||||
idx_nms = [index_name(tid) for tid in tenant_ids]
|
||||
@ -692,4 +698,4 @@ class Dealer:
|
||||
break
|
||||
chunks.append(d)
|
||||
|
||||
return sorted(chunks, key=lambda x:x["similarity"]*-1)
|
||||
return sorted(chunks, key=lambda x: x["similarity"] * -1)
|
||||
|
||||
@ -14,129 +14,131 @@
|
||||
# limitations under the License.
|
||||
#
|
||||
|
||||
m = set(["赵","钱","孙","李",
|
||||
"周","吴","郑","王",
|
||||
"冯","陈","褚","卫",
|
||||
"蒋","沈","韩","杨",
|
||||
"朱","秦","尤","许",
|
||||
"何","吕","施","张",
|
||||
"孔","曹","严","华",
|
||||
"金","魏","陶","姜",
|
||||
"戚","谢","邹","喻",
|
||||
"柏","水","窦","章",
|
||||
"云","苏","潘","葛",
|
||||
"奚","范","彭","郎",
|
||||
"鲁","韦","昌","马",
|
||||
"苗","凤","花","方",
|
||||
"俞","任","袁","柳",
|
||||
"酆","鲍","史","唐",
|
||||
"费","廉","岑","薛",
|
||||
"雷","贺","倪","汤",
|
||||
"滕","殷","罗","毕",
|
||||
"郝","邬","安","常",
|
||||
"乐","于","时","傅",
|
||||
"皮","卞","齐","康",
|
||||
"伍","余","元","卜",
|
||||
"顾","孟","平","黄",
|
||||
"和","穆","萧","尹",
|
||||
"姚","邵","湛","汪",
|
||||
"祁","毛","禹","狄",
|
||||
"米","贝","明","臧",
|
||||
"计","伏","成","戴",
|
||||
"谈","宋","茅","庞",
|
||||
"熊","纪","舒","屈",
|
||||
"项","祝","董","梁",
|
||||
"杜","阮","蓝","闵",
|
||||
"席","季","麻","强",
|
||||
"贾","路","娄","危",
|
||||
"江","童","颜","郭",
|
||||
"梅","盛","林","刁",
|
||||
"钟","徐","邱","骆",
|
||||
"高","夏","蔡","田",
|
||||
"樊","胡","凌","霍",
|
||||
"虞","万","支","柯",
|
||||
"昝","管","卢","莫",
|
||||
"经","房","裘","缪",
|
||||
"干","解","应","宗",
|
||||
"丁","宣","贲","邓",
|
||||
"郁","单","杭","洪",
|
||||
"包","诸","左","石",
|
||||
"崔","吉","钮","龚",
|
||||
"程","嵇","邢","滑",
|
||||
"裴","陆","荣","翁",
|
||||
"荀","羊","於","惠",
|
||||
"甄","曲","家","封",
|
||||
"芮","羿","储","靳",
|
||||
"汲","邴","糜","松",
|
||||
"井","段","富","巫",
|
||||
"乌","焦","巴","弓",
|
||||
"牧","隗","山","谷",
|
||||
"车","侯","宓","蓬",
|
||||
"全","郗","班","仰",
|
||||
"秋","仲","伊","宫",
|
||||
"宁","仇","栾","暴",
|
||||
"甘","钭","厉","戎",
|
||||
"祖","武","符","刘",
|
||||
"景","詹","束","龙",
|
||||
"叶","幸","司","韶",
|
||||
"郜","黎","蓟","薄",
|
||||
"印","宿","白","怀",
|
||||
"蒲","邰","从","鄂",
|
||||
"索","咸","籍","赖",
|
||||
"卓","蔺","屠","蒙",
|
||||
"池","乔","阴","鬱",
|
||||
"胥","能","苍","双",
|
||||
"闻","莘","党","翟",
|
||||
"谭","贡","劳","逄",
|
||||
"姬","申","扶","堵",
|
||||
"冉","宰","郦","雍",
|
||||
"郤","璩","桑","桂",
|
||||
"濮","牛","寿","通",
|
||||
"边","扈","燕","冀",
|
||||
"郏","浦","尚","农",
|
||||
"温","别","庄","晏",
|
||||
"柴","瞿","阎","充",
|
||||
"慕","连","茹","习",
|
||||
"宦","艾","鱼","容",
|
||||
"向","古","易","慎",
|
||||
"戈","廖","庾","终",
|
||||
"暨","居","衡","步",
|
||||
"都","耿","满","弘",
|
||||
"匡","国","文","寇",
|
||||
"广","禄","阙","东",
|
||||
"欧","殳","沃","利",
|
||||
"蔚","越","夔","隆",
|
||||
"师","巩","厍","聂",
|
||||
"晁","勾","敖","融",
|
||||
"冷","訾","辛","阚",
|
||||
"那","简","饶","空",
|
||||
"曾","母","沙","乜",
|
||||
"养","鞠","须","丰",
|
||||
"巢","关","蒯","相",
|
||||
"查","后","荆","红",
|
||||
"游","竺","权","逯",
|
||||
"盖","益","桓","公",
|
||||
"兰","原","乞","西","阿","肖","丑","位","曽","巨","德","代","圆","尉","仵","纳","仝","脱","丘","但","展","迪","付","覃","晗","特","隋","苑","奥","漆","谌","郄","练","扎","邝","渠","信","门","陳","化","原","密","泮","鹿","赫",
|
||||
"万俟","司马","上官","欧阳",
|
||||
"夏侯","诸葛","闻人","东方",
|
||||
"赫连","皇甫","尉迟","公羊",
|
||||
"澹台","公冶","宗政","濮阳",
|
||||
"淳于","单于","太叔","申屠",
|
||||
"公孙","仲孙","轩辕","令狐",
|
||||
"钟离","宇文","长孙","慕容",
|
||||
"鲜于","闾丘","司徒","司空",
|
||||
"亓官","司寇","仉督","子车",
|
||||
"颛孙","端木","巫马","公西",
|
||||
"漆雕","乐正","壤驷","公良",
|
||||
"拓跋","夹谷","宰父","榖梁",
|
||||
"晋","楚","闫","法","汝","鄢","涂","钦",
|
||||
"段干","百里","东郭","南门",
|
||||
"呼延","归","海","羊舌","微","生",
|
||||
"岳","帅","缑","亢","况","后","有","琴",
|
||||
"梁丘","左丘","东门","西门",
|
||||
"商","牟","佘","佴","伯","赏","南宫",
|
||||
"墨","哈","谯","笪","年","爱","阳","佟",
|
||||
"第五","言","福"])
|
||||
m = set(["赵", "钱", "孙", "李",
|
||||
"周", "吴", "郑", "王",
|
||||
"冯", "陈", "褚", "卫",
|
||||
"蒋", "沈", "韩", "杨",
|
||||
"朱", "秦", "尤", "许",
|
||||
"何", "吕", "施", "张",
|
||||
"孔", "曹", "严", "华",
|
||||
"金", "魏", "陶", "姜",
|
||||
"戚", "谢", "邹", "喻",
|
||||
"柏", "水", "窦", "章",
|
||||
"云", "苏", "潘", "葛",
|
||||
"奚", "范", "彭", "郎",
|
||||
"鲁", "韦", "昌", "马",
|
||||
"苗", "凤", "花", "方",
|
||||
"俞", "任", "袁", "柳",
|
||||
"酆", "鲍", "史", "唐",
|
||||
"费", "廉", "岑", "薛",
|
||||
"雷", "贺", "倪", "汤",
|
||||
"滕", "殷", "罗", "毕",
|
||||
"郝", "邬", "安", "常",
|
||||
"乐", "于", "时", "傅",
|
||||
"皮", "卞", "齐", "康",
|
||||
"伍", "余", "元", "卜",
|
||||
"顾", "孟", "平", "黄",
|
||||
"和", "穆", "萧", "尹",
|
||||
"姚", "邵", "湛", "汪",
|
||||
"祁", "毛", "禹", "狄",
|
||||
"米", "贝", "明", "臧",
|
||||
"计", "伏", "成", "戴",
|
||||
"谈", "宋", "茅", "庞",
|
||||
"熊", "纪", "舒", "屈",
|
||||
"项", "祝", "董", "梁",
|
||||
"杜", "阮", "蓝", "闵",
|
||||
"席", "季", "麻", "强",
|
||||
"贾", "路", "娄", "危",
|
||||
"江", "童", "颜", "郭",
|
||||
"梅", "盛", "林", "刁",
|
||||
"钟", "徐", "邱", "骆",
|
||||
"高", "夏", "蔡", "田",
|
||||
"樊", "胡", "凌", "霍",
|
||||
"虞", "万", "支", "柯",
|
||||
"昝", "管", "卢", "莫",
|
||||
"经", "房", "裘", "缪",
|
||||
"干", "解", "应", "宗",
|
||||
"丁", "宣", "贲", "邓",
|
||||
"郁", "单", "杭", "洪",
|
||||
"包", "诸", "左", "石",
|
||||
"崔", "吉", "钮", "龚",
|
||||
"程", "嵇", "邢", "滑",
|
||||
"裴", "陆", "荣", "翁",
|
||||
"荀", "羊", "於", "惠",
|
||||
"甄", "曲", "家", "封",
|
||||
"芮", "羿", "储", "靳",
|
||||
"汲", "邴", "糜", "松",
|
||||
"井", "段", "富", "巫",
|
||||
"乌", "焦", "巴", "弓",
|
||||
"牧", "隗", "山", "谷",
|
||||
"车", "侯", "宓", "蓬",
|
||||
"全", "郗", "班", "仰",
|
||||
"秋", "仲", "伊", "宫",
|
||||
"宁", "仇", "栾", "暴",
|
||||
"甘", "钭", "厉", "戎",
|
||||
"祖", "武", "符", "刘",
|
||||
"景", "詹", "束", "龙",
|
||||
"叶", "幸", "司", "韶",
|
||||
"郜", "黎", "蓟", "薄",
|
||||
"印", "宿", "白", "怀",
|
||||
"蒲", "邰", "从", "鄂",
|
||||
"索", "咸", "籍", "赖",
|
||||
"卓", "蔺", "屠", "蒙",
|
||||
"池", "乔", "阴", "鬱",
|
||||
"胥", "能", "苍", "双",
|
||||
"闻", "莘", "党", "翟",
|
||||
"谭", "贡", "劳", "逄",
|
||||
"姬", "申", "扶", "堵",
|
||||
"冉", "宰", "郦", "雍",
|
||||
"郤", "璩", "桑", "桂",
|
||||
"濮", "牛", "寿", "通",
|
||||
"边", "扈", "燕", "冀",
|
||||
"郏", "浦", "尚", "农",
|
||||
"温", "别", "庄", "晏",
|
||||
"柴", "瞿", "阎", "充",
|
||||
"慕", "连", "茹", "习",
|
||||
"宦", "艾", "鱼", "容",
|
||||
"向", "古", "易", "慎",
|
||||
"戈", "廖", "庾", "终",
|
||||
"暨", "居", "衡", "步",
|
||||
"都", "耿", "满", "弘",
|
||||
"匡", "国", "文", "寇",
|
||||
"广", "禄", "阙", "东",
|
||||
"欧", "殳", "沃", "利",
|
||||
"蔚", "越", "夔", "隆",
|
||||
"师", "巩", "厍", "聂",
|
||||
"晁", "勾", "敖", "融",
|
||||
"冷", "訾", "辛", "阚",
|
||||
"那", "简", "饶", "空",
|
||||
"曾", "母", "沙", "乜",
|
||||
"养", "鞠", "须", "丰",
|
||||
"巢", "关", "蒯", "相",
|
||||
"查", "后", "荆", "红",
|
||||
"游", "竺", "权", "逯",
|
||||
"盖", "益", "桓", "公",
|
||||
"兰", "原", "乞", "西", "阿", "肖", "丑", "位", "曽", "巨", "德", "代", "圆", "尉", "仵", "纳", "仝", "脱",
|
||||
"丘", "但", "展", "迪", "付", "覃", "晗", "特", "隋", "苑", "奥", "漆", "谌", "郄", "练", "扎", "邝", "渠",
|
||||
"信", "门", "陳", "化", "原", "密", "泮", "鹿", "赫",
|
||||
"万俟", "司马", "上官", "欧阳",
|
||||
"夏侯", "诸葛", "闻人", "东方",
|
||||
"赫连", "皇甫", "尉迟", "公羊",
|
||||
"澹台", "公冶", "宗政", "濮阳",
|
||||
"淳于", "单于", "太叔", "申屠",
|
||||
"公孙", "仲孙", "轩辕", "令狐",
|
||||
"钟离", "宇文", "长孙", "慕容",
|
||||
"鲜于", "闾丘", "司徒", "司空",
|
||||
"亓官", "司寇", "仉督", "子车",
|
||||
"颛孙", "端木", "巫马", "公西",
|
||||
"漆雕", "乐正", "壤驷", "公良",
|
||||
"拓跋", "夹谷", "宰父", "榖梁",
|
||||
"晋", "楚", "闫", "法", "汝", "鄢", "涂", "钦",
|
||||
"段干", "百里", "东郭", "南门",
|
||||
"呼延", "归", "海", "羊舌", "微", "生",
|
||||
"岳", "帅", "缑", "亢", "况", "后", "有", "琴",
|
||||
"梁丘", "左丘", "东门", "西门",
|
||||
"商", "牟", "佘", "佴", "伯", "赏", "南宫",
|
||||
"墨", "哈", "谯", "笪", "年", "爱", "阳", "佟",
|
||||
"第五", "言", "福"])
|
||||
|
||||
def isit(n):return n.strip() in m
|
||||
|
||||
def isit(n): return n.strip() in m
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
#
|
||||
#
|
||||
# Copyright 2024 The InfiniFlow Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
@ -108,13 +108,14 @@ class Dealer:
|
||||
if re.match(p, t):
|
||||
tk = "#"
|
||||
break
|
||||
#tk = re.sub(r"([\+\\-])", r"\\\1", tk)
|
||||
# tk = re.sub(r"([\+\\-])", r"\\\1", tk)
|
||||
if tk != "#" and tk:
|
||||
res.append(tk)
|
||||
return res
|
||||
|
||||
def token_merge(self, tks):
|
||||
def one_term(t): return len(t) == 1 or re.match(r"[0-9a-z]{1,2}$", t)
|
||||
def one_term(t):
|
||||
return len(t) == 1 or re.match(r"[0-9a-z]{1,2}$", t)
|
||||
|
||||
res, i = [], 0
|
||||
while i < len(tks):
|
||||
@ -152,8 +153,8 @@ class Dealer:
|
||||
tks = []
|
||||
for t in re.sub(r"[ \t]+", " ", txt).split():
|
||||
if tks and re.match(r".*[a-zA-Z]$", tks[-1]) and \
|
||||
re.match(r".*[a-zA-Z]$", t) and tks and \
|
||||
self.ne.get(t, "") != "func" and self.ne.get(tks[-1], "") != "func":
|
||||
re.match(r".*[a-zA-Z]$", t) and tks and \
|
||||
self.ne.get(t, "") != "func" and self.ne.get(tks[-1], "") != "func":
|
||||
tks[-1] = tks[-1] + " " + t
|
||||
else:
|
||||
tks.append(t)
|
||||
@ -220,14 +221,15 @@ class Dealer:
|
||||
|
||||
return 3
|
||||
|
||||
def idf(s, N): return math.log10(10 + ((N - s + 0.5) / (s + 0.5)))
|
||||
def idf(s, N):
|
||||
return math.log10(10 + ((N - s + 0.5) / (s + 0.5)))
|
||||
|
||||
tw = []
|
||||
if not preprocess:
|
||||
idf1 = np.array([idf(freq(t), 10000000) for t in tks])
|
||||
idf2 = np.array([idf(df(t), 1000000000) for t in tks])
|
||||
wts = (0.3 * idf1 + 0.7 * idf2) * \
|
||||
np.array([ner(t) * postag(t) for t in tks])
|
||||
np.array([ner(t) * postag(t) for t in tks])
|
||||
wts = [s for s in wts]
|
||||
tw = list(zip(tks, wts))
|
||||
else:
|
||||
@ -236,7 +238,7 @@ class Dealer:
|
||||
idf1 = np.array([idf(freq(t), 10000000) for t in tt])
|
||||
idf2 = np.array([idf(df(t), 1000000000) for t in tt])
|
||||
wts = (0.3 * idf1 + 0.7 * idf2) * \
|
||||
np.array([ner(t) * postag(t) for t in tt])
|
||||
np.array([ner(t) * postag(t) for t in tt])
|
||||
wts = [s for s in wts]
|
||||
tw.extend(zip(tt, wts))
|
||||
|
||||
|
||||
@ -3,4 +3,4 @@ from . import generator
|
||||
__all__ = [name for name in dir(generator)
|
||||
if not name.startswith('_')]
|
||||
|
||||
globals().update({name: getattr(generator, name) for name in __all__})
|
||||
globals().update({name: getattr(generator, name) for name in __all__})
|
||||
|
||||
@ -28,17 +28,16 @@ from rag.prompts.template import load_prompt
|
||||
from common.constants import TAG_FLD
|
||||
from common.token_utils import encoder, num_tokens_from_string
|
||||
|
||||
|
||||
STOP_TOKEN="<|STOP|>"
|
||||
COMPLETE_TASK="complete_task"
|
||||
STOP_TOKEN = "<|STOP|>"
|
||||
COMPLETE_TASK = "complete_task"
|
||||
INPUT_UTILIZATION = 0.5
|
||||
|
||||
|
||||
def get_value(d, k1, k2):
|
||||
return d.get(k1, d.get(k2))
|
||||
|
||||
|
||||
def chunks_format(reference):
|
||||
|
||||
return [
|
||||
{
|
||||
"id": get_value(chunk, "chunk_id", "id"),
|
||||
@ -126,7 +125,7 @@ def kb_prompt(kbinfos, max_tokens, hash_id=False):
|
||||
for i, ck in enumerate(kbinfos["chunks"][:chunks_num]):
|
||||
cnt = "\nID: {}".format(i if not hash_id else hash_str2int(get_value(ck, "id", "chunk_id"), 500))
|
||||
cnt += draw_node("Title", get_value(ck, "docnm_kwd", "document_name"))
|
||||
cnt += draw_node("URL", ck['url']) if "url" in ck else ""
|
||||
cnt += draw_node("URL", ck['url']) if "url" in ck else ""
|
||||
for k, v in docs.get(get_value(ck, "doc_id", "document_id"), {}).items():
|
||||
cnt += draw_node(k, v)
|
||||
cnt += "\n└── Content:\n"
|
||||
@ -173,7 +172,7 @@ ASK_SUMMARY = load_prompt("ask_summary")
|
||||
PROMPT_JINJA_ENV = jinja2.Environment(autoescape=False, trim_blocks=True, lstrip_blocks=True)
|
||||
|
||||
|
||||
def citation_prompt(user_defined_prompts: dict={}) -> str:
|
||||
def citation_prompt(user_defined_prompts: dict = {}) -> str:
|
||||
template = PROMPT_JINJA_ENV.from_string(user_defined_prompts.get("citation_guidelines", CITATION_PROMPT_TEMPLATE))
|
||||
return template.render()
|
||||
|
||||
@ -258,9 +257,11 @@ async def cross_languages(tenant_id, llm_id, query, languages=[]):
|
||||
chat_mdl = LLMBundle(tenant_id, LLMType.CHAT, llm_id)
|
||||
|
||||
rendered_sys_prompt = PROMPT_JINJA_ENV.from_string(CROSS_LANGUAGES_SYS_PROMPT_TEMPLATE).render()
|
||||
rendered_user_prompt = PROMPT_JINJA_ENV.from_string(CROSS_LANGUAGES_USER_PROMPT_TEMPLATE).render(query=query, languages=languages)
|
||||
rendered_user_prompt = PROMPT_JINJA_ENV.from_string(CROSS_LANGUAGES_USER_PROMPT_TEMPLATE).render(query=query,
|
||||
languages=languages)
|
||||
|
||||
ans = await chat_mdl.async_chat(rendered_sys_prompt, [{"role": "user", "content": rendered_user_prompt}], {"temperature": 0.2})
|
||||
ans = await chat_mdl.async_chat(rendered_sys_prompt, [{"role": "user", "content": rendered_user_prompt}],
|
||||
{"temperature": 0.2})
|
||||
ans = re.sub(r"^.*</think>", "", ans, flags=re.DOTALL)
|
||||
if ans.find("**ERROR**") >= 0:
|
||||
return query
|
||||
@ -332,7 +333,8 @@ def tool_schema(tools_description: list[dict], complete_task=False):
|
||||
"description": "When you have the final answer and are ready to complete the task, call this function with your answer",
|
||||
"parameters": {
|
||||
"type": "object",
|
||||
"properties": {"answer":{"type":"string", "description": "The final answer to the user's question"}},
|
||||
"properties": {
|
||||
"answer": {"type": "string", "description": "The final answer to the user's question"}},
|
||||
"required": ["answer"]
|
||||
}
|
||||
}
|
||||
@ -341,7 +343,8 @@ def tool_schema(tools_description: list[dict], complete_task=False):
|
||||
name = tool["function"]["name"]
|
||||
desc[name] = tool
|
||||
|
||||
return "\n\n".join([f"## {i+1}. {fnm}\n{json.dumps(des, ensure_ascii=False, indent=4)}" for i, (fnm, des) in enumerate(desc.items())])
|
||||
return "\n\n".join([f"## {i + 1}. {fnm}\n{json.dumps(des, ensure_ascii=False, indent=4)}" for i, (fnm, des) in
|
||||
enumerate(desc.items())])
|
||||
|
||||
|
||||
def form_history(history, limit=-6):
|
||||
@ -350,14 +353,14 @@ def form_history(history, limit=-6):
|
||||
if h["role"] == "system":
|
||||
continue
|
||||
role = "USER"
|
||||
if h["role"].upper()!= role:
|
||||
if h["role"].upper() != role:
|
||||
role = "AGENT"
|
||||
context += f"\n{role}: {h['content'][:2048] + ('...' if len(h['content'])>2048 else '')}"
|
||||
context += f"\n{role}: {h['content'][:2048] + ('...' if len(h['content']) > 2048 else '')}"
|
||||
return context
|
||||
|
||||
|
||||
|
||||
async def analyze_task_async(chat_mdl, prompt, task_name, tools_description: list[dict], user_defined_prompts: dict={}):
|
||||
async def analyze_task_async(chat_mdl, prompt, task_name, tools_description: list[dict],
|
||||
user_defined_prompts: dict = {}):
|
||||
tools_desc = tool_schema(tools_description)
|
||||
context = ""
|
||||
|
||||
@ -375,7 +378,8 @@ async def analyze_task_async(chat_mdl, prompt, task_name, tools_description: lis
|
||||
return kwd
|
||||
|
||||
|
||||
async def next_step_async(chat_mdl, history:list, tools_description: list[dict], task_desc, user_defined_prompts: dict={}):
|
||||
async def next_step_async(chat_mdl, history: list, tools_description: list[dict], task_desc,
|
||||
user_defined_prompts: dict = {}):
|
||||
if not tools_description:
|
||||
return "", 0
|
||||
desc = tool_schema(tools_description)
|
||||
@ -396,7 +400,7 @@ async def next_step_async(chat_mdl, history:list, tools_description: list[dict],
|
||||
return json_str, tk_cnt
|
||||
|
||||
|
||||
async def reflect_async(chat_mdl, history: list[dict], tool_call_res: list[Tuple], user_defined_prompts: dict={}):
|
||||
async def reflect_async(chat_mdl, history: list[dict], tool_call_res: list[Tuple], user_defined_prompts: dict = {}):
|
||||
tool_calls = [{"name": p[0], "result": p[1]} for p in tool_call_res]
|
||||
goal = history[1]["content"]
|
||||
template = PROMPT_JINJA_ENV.from_string(user_defined_prompts.get("reflection", REFLECT))
|
||||
@ -419,7 +423,7 @@ async def reflect_async(chat_mdl, history: list[dict], tool_call_res: list[Tuple
|
||||
|
||||
|
||||
def form_message(system_prompt, user_prompt):
|
||||
return [{"role": "system", "content": system_prompt},{"role": "user", "content": user_prompt}]
|
||||
return [{"role": "system", "content": system_prompt}, {"role": "user", "content": user_prompt}]
|
||||
|
||||
|
||||
def structured_output_prompt(schema=None) -> str:
|
||||
@ -427,27 +431,29 @@ def structured_output_prompt(schema=None) -> str:
|
||||
return template.render(schema=schema)
|
||||
|
||||
|
||||
async def tool_call_summary(chat_mdl, name: str, params: dict, result: str, user_defined_prompts: dict={}) -> str:
|
||||
async def tool_call_summary(chat_mdl, name: str, params: dict, result: str, user_defined_prompts: dict = {}) -> str:
|
||||
template = PROMPT_JINJA_ENV.from_string(SUMMARY4MEMORY)
|
||||
system_prompt = template.render(name=name,
|
||||
params=json.dumps(params, ensure_ascii=False, indent=2),
|
||||
result=result)
|
||||
params=json.dumps(params, ensure_ascii=False, indent=2),
|
||||
result=result)
|
||||
user_prompt = "→ Summary: "
|
||||
_, msg = message_fit_in(form_message(system_prompt, user_prompt), chat_mdl.max_length)
|
||||
ans = await chat_mdl.async_chat(msg[0]["content"], msg[1:])
|
||||
return re.sub(r"^.*</think>", "", ans, flags=re.DOTALL)
|
||||
|
||||
|
||||
async def rank_memories_async(chat_mdl, goal:str, sub_goal:str, tool_call_summaries: list[str], user_defined_prompts: dict={}):
|
||||
async def rank_memories_async(chat_mdl, goal: str, sub_goal: str, tool_call_summaries: list[str],
|
||||
user_defined_prompts: dict = {}):
|
||||
template = PROMPT_JINJA_ENV.from_string(RANK_MEMORY)
|
||||
system_prompt = template.render(goal=goal, sub_goal=sub_goal, results=[{"i": i, "content": s} for i,s in enumerate(tool_call_summaries)])
|
||||
system_prompt = template.render(goal=goal, sub_goal=sub_goal,
|
||||
results=[{"i": i, "content": s} for i, s in enumerate(tool_call_summaries)])
|
||||
user_prompt = " → rank: "
|
||||
_, msg = message_fit_in(form_message(system_prompt, user_prompt), chat_mdl.max_length)
|
||||
ans = await chat_mdl.async_chat(msg[0]["content"], msg[1:], stop="<|stop|>")
|
||||
return re.sub(r"^.*</think>", "", ans, flags=re.DOTALL)
|
||||
|
||||
|
||||
async def gen_meta_filter(chat_mdl, meta_data:dict, query: str) -> dict:
|
||||
async def gen_meta_filter(chat_mdl, meta_data: dict, query: str) -> dict:
|
||||
meta_data_structure = {}
|
||||
for key, values in meta_data.items():
|
||||
meta_data_structure[key] = list(values.keys()) if isinstance(values, dict) else values
|
||||
@ -471,13 +477,13 @@ async def gen_meta_filter(chat_mdl, meta_data:dict, query: str) -> dict:
|
||||
return {"conditions": []}
|
||||
|
||||
|
||||
async def gen_json(system_prompt:str, user_prompt:str, chat_mdl, gen_conf = None):
|
||||
async def gen_json(system_prompt: str, user_prompt: str, chat_mdl, gen_conf=None):
|
||||
from graphrag.utils import get_llm_cache, set_llm_cache
|
||||
cached = get_llm_cache(chat_mdl.llm_name, system_prompt, user_prompt, gen_conf)
|
||||
if cached:
|
||||
return json_repair.loads(cached)
|
||||
_, msg = message_fit_in(form_message(system_prompt, user_prompt), chat_mdl.max_length)
|
||||
ans = await chat_mdl.async_chat(msg[0]["content"], msg[1:],gen_conf=gen_conf)
|
||||
ans = await chat_mdl.async_chat(msg[0]["content"], msg[1:], gen_conf=gen_conf)
|
||||
ans = re.sub(r"(^.*</think>|```json\n|```\n*$)", "", ans, flags=re.DOTALL)
|
||||
try:
|
||||
res = json_repair.loads(ans)
|
||||
@ -488,10 +494,13 @@ async def gen_json(system_prompt:str, user_prompt:str, chat_mdl, gen_conf = None
|
||||
|
||||
|
||||
TOC_DETECTION = load_prompt("toc_detection")
|
||||
async def detect_table_of_contents(page_1024:list[str], chat_mdl):
|
||||
|
||||
|
||||
async def detect_table_of_contents(page_1024: list[str], chat_mdl):
|
||||
toc_secs = []
|
||||
for i, sec in enumerate(page_1024[:22]):
|
||||
ans = await gen_json(PROMPT_JINJA_ENV.from_string(TOC_DETECTION).render(page_txt=sec), "Only JSON please.", chat_mdl)
|
||||
ans = await gen_json(PROMPT_JINJA_ENV.from_string(TOC_DETECTION).render(page_txt=sec), "Only JSON please.",
|
||||
chat_mdl)
|
||||
if toc_secs and not ans["exists"]:
|
||||
break
|
||||
toc_secs.append(sec)
|
||||
@ -500,14 +509,17 @@ async def detect_table_of_contents(page_1024:list[str], chat_mdl):
|
||||
|
||||
TOC_EXTRACTION = load_prompt("toc_extraction")
|
||||
TOC_EXTRACTION_CONTINUE = load_prompt("toc_extraction_continue")
|
||||
|
||||
|
||||
async def extract_table_of_contents(toc_pages, chat_mdl):
|
||||
if not toc_pages:
|
||||
return []
|
||||
|
||||
return await gen_json(PROMPT_JINJA_ENV.from_string(TOC_EXTRACTION).render(toc_page="\n".join(toc_pages)), "Only JSON please.", chat_mdl)
|
||||
return await gen_json(PROMPT_JINJA_ENV.from_string(TOC_EXTRACTION).render(toc_page="\n".join(toc_pages)),
|
||||
"Only JSON please.", chat_mdl)
|
||||
|
||||
|
||||
async def toc_index_extractor(toc:list[dict], content:str, chat_mdl):
|
||||
async def toc_index_extractor(toc: list[dict], content: str, chat_mdl):
|
||||
tob_extractor_prompt = """
|
||||
You are given a table of contents in a json format and several pages of a document, your job is to add the physical_index to the table of contents in the json format.
|
||||
|
||||
@ -529,18 +541,21 @@ async def toc_index_extractor(toc:list[dict], content:str, chat_mdl):
|
||||
If the title of the section are not in the provided pages, do not add the physical_index to it.
|
||||
Directly return the final JSON structure. Do not output anything else."""
|
||||
|
||||
prompt = tob_extractor_prompt + '\nTable of contents:\n' + json.dumps(toc, ensure_ascii=False, indent=2) + '\nDocument pages:\n' + content
|
||||
prompt = tob_extractor_prompt + '\nTable of contents:\n' + json.dumps(toc, ensure_ascii=False,
|
||||
indent=2) + '\nDocument pages:\n' + content
|
||||
return await gen_json(prompt, "Only JSON please.", chat_mdl)
|
||||
|
||||
|
||||
TOC_INDEX = load_prompt("toc_index")
|
||||
|
||||
|
||||
async def table_of_contents_index(toc_arr: list[dict], sections: list[str], chat_mdl):
|
||||
if not toc_arr or not sections:
|
||||
return []
|
||||
|
||||
toc_map = {}
|
||||
for i, it in enumerate(toc_arr):
|
||||
k1 = (it["structure"]+it["title"]).replace(" ", "")
|
||||
k1 = (it["structure"] + it["title"]).replace(" ", "")
|
||||
k2 = it["title"].strip()
|
||||
if k1 not in toc_map:
|
||||
toc_map[k1] = []
|
||||
@ -558,6 +573,7 @@ async def table_of_contents_index(toc_arr: list[dict], sections: list[str], chat
|
||||
toc_arr[j]["indices"].append(i)
|
||||
|
||||
all_pathes = []
|
||||
|
||||
def dfs(start, path):
|
||||
nonlocal all_pathes
|
||||
if start >= len(toc_arr):
|
||||
@ -565,7 +581,7 @@ async def table_of_contents_index(toc_arr: list[dict], sections: list[str], chat
|
||||
all_pathes.append(path)
|
||||
return
|
||||
if not toc_arr[start]["indices"]:
|
||||
dfs(start+1, path)
|
||||
dfs(start + 1, path)
|
||||
return
|
||||
added = False
|
||||
for j in toc_arr[start]["indices"]:
|
||||
@ -574,12 +590,12 @@ async def table_of_contents_index(toc_arr: list[dict], sections: list[str], chat
|
||||
_path = deepcopy(path)
|
||||
_path.append((j, start))
|
||||
added = True
|
||||
dfs(start+1, _path)
|
||||
dfs(start + 1, _path)
|
||||
if not added and path:
|
||||
all_pathes.append(path)
|
||||
|
||||
dfs(0, [])
|
||||
path = max(all_pathes, key=lambda x:len(x))
|
||||
path = max(all_pathes, key=lambda x: len(x))
|
||||
for it in toc_arr:
|
||||
it["indices"] = []
|
||||
for j, i in path:
|
||||
@ -588,24 +604,24 @@ async def table_of_contents_index(toc_arr: list[dict], sections: list[str], chat
|
||||
|
||||
i = 0
|
||||
while i < len(toc_arr):
|
||||
it = toc_arr[i]
|
||||
it = toc_arr[i]
|
||||
if it["indices"]:
|
||||
i += 1
|
||||
continue
|
||||
|
||||
if i>0 and toc_arr[i-1]["indices"]:
|
||||
st_i = toc_arr[i-1]["indices"][-1]
|
||||
if i > 0 and toc_arr[i - 1]["indices"]:
|
||||
st_i = toc_arr[i - 1]["indices"][-1]
|
||||
else:
|
||||
st_i = 0
|
||||
e = i + 1
|
||||
while e <len(toc_arr) and not toc_arr[e]["indices"]:
|
||||
while e < len(toc_arr) and not toc_arr[e]["indices"]:
|
||||
e += 1
|
||||
if e >= len(toc_arr):
|
||||
e = len(sections)
|
||||
else:
|
||||
e = toc_arr[e]["indices"][0]
|
||||
|
||||
for j in range(st_i, min(e+1, len(sections))):
|
||||
for j in range(st_i, min(e + 1, len(sections))):
|
||||
ans = await gen_json(PROMPT_JINJA_ENV.from_string(TOC_INDEX).render(
|
||||
structure=it["structure"],
|
||||
title=it["title"],
|
||||
@ -656,11 +672,15 @@ async def toc_transformer(toc_pages, chat_mdl):
|
||||
|
||||
toc_content = "\n".join(toc_pages)
|
||||
prompt = init_prompt + '\n Given table of contents\n:' + toc_content
|
||||
|
||||
def clean_toc(arr):
|
||||
for a in arr:
|
||||
a["title"] = re.sub(r"[.·….]{2,}", "", a["title"])
|
||||
|
||||
last_complete = await gen_json(prompt, "Only JSON please.", chat_mdl)
|
||||
if_complete = await check_if_toc_transformation_is_complete(toc_content, json.dumps(last_complete, ensure_ascii=False, indent=2), chat_mdl)
|
||||
if_complete = await check_if_toc_transformation_is_complete(toc_content,
|
||||
json.dumps(last_complete, ensure_ascii=False, indent=2),
|
||||
chat_mdl)
|
||||
clean_toc(last_complete)
|
||||
if if_complete == "yes":
|
||||
return last_complete
|
||||
@ -682,13 +702,17 @@ async def toc_transformer(toc_pages, chat_mdl):
|
||||
break
|
||||
clean_toc(new_complete)
|
||||
last_complete.extend(new_complete)
|
||||
if_complete = await check_if_toc_transformation_is_complete(toc_content, json.dumps(last_complete, ensure_ascii=False, indent=2), chat_mdl)
|
||||
if_complete = await check_if_toc_transformation_is_complete(toc_content,
|
||||
json.dumps(last_complete, ensure_ascii=False,
|
||||
indent=2), chat_mdl)
|
||||
|
||||
return last_complete
|
||||
|
||||
|
||||
TOC_LEVELS = load_prompt("assign_toc_levels")
|
||||
async def assign_toc_levels(toc_secs, chat_mdl, gen_conf = {"temperature": 0.2}):
|
||||
|
||||
|
||||
async def assign_toc_levels(toc_secs, chat_mdl, gen_conf={"temperature": 0.2}):
|
||||
if not toc_secs:
|
||||
return []
|
||||
return await gen_json(
|
||||
@ -701,12 +725,15 @@ async def assign_toc_levels(toc_secs, chat_mdl, gen_conf = {"temperature": 0.2})
|
||||
|
||||
TOC_FROM_TEXT_SYSTEM = load_prompt("toc_from_text_system")
|
||||
TOC_FROM_TEXT_USER = load_prompt("toc_from_text_user")
|
||||
|
||||
|
||||
# Generate TOC from text chunks with text llms
|
||||
async def gen_toc_from_text(txt_info: dict, chat_mdl, callback=None):
|
||||
try:
|
||||
ans = await gen_json(
|
||||
PROMPT_JINJA_ENV.from_string(TOC_FROM_TEXT_SYSTEM).render(),
|
||||
PROMPT_JINJA_ENV.from_string(TOC_FROM_TEXT_USER).render(text="\n".join([json.dumps(d, ensure_ascii=False) for d in txt_info["chunks"]])),
|
||||
PROMPT_JINJA_ENV.from_string(TOC_FROM_TEXT_USER).render(
|
||||
text="\n".join([json.dumps(d, ensure_ascii=False) for d in txt_info["chunks"]])),
|
||||
chat_mdl,
|
||||
gen_conf={"temperature": 0.0, "top_p": 0.9}
|
||||
)
|
||||
@ -743,7 +770,7 @@ async def run_toc_from_text(chunks, chat_mdl, callback=None):
|
||||
TOC_FROM_TEXT_USER + TOC_FROM_TEXT_SYSTEM
|
||||
)
|
||||
|
||||
input_budget = 1024 if input_budget > 1024 else input_budget
|
||||
input_budget = 1024 if input_budget > 1024 else input_budget
|
||||
chunk_sections = split_chunks(chunks, input_budget)
|
||||
titles = []
|
||||
|
||||
@ -798,7 +825,7 @@ async def run_toc_from_text(chunks, chat_mdl, callback=None):
|
||||
if sorted_list:
|
||||
max_lvl = sorted_list[-1]
|
||||
merged = []
|
||||
for _ , (toc_item, src_item) in enumerate(zip(toc_with_levels, filtered)):
|
||||
for _, (toc_item, src_item) in enumerate(zip(toc_with_levels, filtered)):
|
||||
if prune and toc_item.get("level", "0") >= max_lvl:
|
||||
continue
|
||||
merged.append({
|
||||
@ -812,12 +839,15 @@ async def run_toc_from_text(chunks, chat_mdl, callback=None):
|
||||
|
||||
TOC_RELEVANCE_SYSTEM = load_prompt("toc_relevance_system")
|
||||
TOC_RELEVANCE_USER = load_prompt("toc_relevance_user")
|
||||
async def relevant_chunks_with_toc(query: str, toc:list[dict], chat_mdl, topn: int=6):
|
||||
|
||||
|
||||
async def relevant_chunks_with_toc(query: str, toc: list[dict], chat_mdl, topn: int = 6):
|
||||
import numpy as np
|
||||
try:
|
||||
ans = await gen_json(
|
||||
PROMPT_JINJA_ENV.from_string(TOC_RELEVANCE_SYSTEM).render(),
|
||||
PROMPT_JINJA_ENV.from_string(TOC_RELEVANCE_USER).render(query=query, toc_json="[\n%s\n]\n"%"\n".join([json.dumps({"level": d["level"], "title":d["title"]}, ensure_ascii=False) for d in toc])),
|
||||
PROMPT_JINJA_ENV.from_string(TOC_RELEVANCE_USER).render(query=query, toc_json="[\n%s\n]\n" % "\n".join(
|
||||
[json.dumps({"level": d["level"], "title": d["title"]}, ensure_ascii=False) for d in toc])),
|
||||
chat_mdl,
|
||||
gen_conf={"temperature": 0.0, "top_p": 0.9}
|
||||
)
|
||||
@ -828,17 +858,19 @@ async def relevant_chunks_with_toc(query: str, toc:list[dict], chat_mdl, topn: i
|
||||
for id in ti.get("ids", []):
|
||||
if id not in id2score:
|
||||
id2score[id] = []
|
||||
id2score[id].append(sc["score"]/5.)
|
||||
id2score[id].append(sc["score"] / 5.)
|
||||
for id in id2score.keys():
|
||||
id2score[id] = np.mean(id2score[id])
|
||||
return [(id, sc) for id, sc in list(id2score.items()) if sc>=0.3][:topn]
|
||||
return [(id, sc) for id, sc in list(id2score.items()) if sc >= 0.3][:topn]
|
||||
except Exception as e:
|
||||
logging.exception(e)
|
||||
return []
|
||||
|
||||
|
||||
META_DATA = load_prompt("meta_data")
|
||||
async def gen_metadata(chat_mdl, schema:dict, content:str):
|
||||
|
||||
|
||||
async def gen_metadata(chat_mdl, schema: dict, content: str):
|
||||
template = PROMPT_JINJA_ENV.from_string(META_DATA)
|
||||
for k, desc in schema["properties"].items():
|
||||
if "enum" in desc and not desc.get("enum"):
|
||||
@ -849,4 +881,4 @@ async def gen_metadata(chat_mdl, schema:dict, content:str):
|
||||
user_prompt = "Output: "
|
||||
_, msg = message_fit_in(form_message(system_prompt, user_prompt), chat_mdl.max_length)
|
||||
ans = await chat_mdl.async_chat(msg[0]["content"], msg[1:])
|
||||
return re.sub(r"^.*</think>", "", ans, flags=re.DOTALL)
|
||||
return re.sub(r"^.*</think>", "", ans, flags=re.DOTALL)
|
||||
|
||||
@ -1,6 +1,5 @@
|
||||
import os
|
||||
|
||||
|
||||
PROMPT_DIR = os.path.dirname(__file__)
|
||||
|
||||
_loaded_prompts = {}
|
||||
|
||||
@ -48,13 +48,15 @@ def main():
|
||||
REDIS_CONN.transaction(key, file_bin, 12 * 60)
|
||||
logging.info("CACHE: {}".format(loc))
|
||||
except Exception as e:
|
||||
traceback.print_stack(e)
|
||||
logging.error(f"Error to get data from REDIS: {e}")
|
||||
traceback.print_stack()
|
||||
except Exception as e:
|
||||
traceback.print_stack(e)
|
||||
logging.error(f"Error to check REDIS connection: {e}")
|
||||
traceback.print_stack()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
while True:
|
||||
main()
|
||||
close_connection()
|
||||
time.sleep(1)
|
||||
time.sleep(1)
|
||||
|
||||
@ -19,16 +19,15 @@ import requests
|
||||
import base64
|
||||
import asyncio
|
||||
|
||||
URL = '{YOUR_IP_ADDRESS:PORT}/v1/api/completion_aibotk' # Default: https://demo.ragflow.io/v1/api/completion_aibotk
|
||||
URL = '{YOUR_IP_ADDRESS:PORT}/v1/api/completion_aibotk' # Default: https://demo.ragflow.io/v1/api/completion_aibotk
|
||||
|
||||
JSON_DATA = {
|
||||
"conversation_id": "xxxxxxxxxxxxxxxxxxxxxxxxxxx", # Get conversation id from /api/new_conversation
|
||||
"Authorization": "ragflow-xxxxxxxxxxxxxxxxxxxxxxxxxxxxx", # RAGFlow Assistant Chat Bot API Key
|
||||
"word": "" # User question, don't need to initialize
|
||||
"conversation_id": "xxxxxxxxxxxxxxxxxxxxxxxxxxx", # Get conversation id from /api/new_conversation
|
||||
"Authorization": "ragflow-xxxxxxxxxxxxxxxxxxxxxxxxxxxxx", # RAGFlow Assistant Chat Bot API Key
|
||||
"word": "" # User question, don't need to initialize
|
||||
}
|
||||
|
||||
DISCORD_BOT_KEY = "xxxxxxxxxxxxxxxxxxxxxxxxxx" #Get DISCORD_BOT_KEY from Discord Application
|
||||
|
||||
DISCORD_BOT_KEY = "xxxxxxxxxxxxxxxxxxxxxxxxxx" # Get DISCORD_BOT_KEY from Discord Application
|
||||
|
||||
intents = discord.Intents.default()
|
||||
intents.message_content = True
|
||||
@ -50,7 +49,7 @@ async def on_message(message):
|
||||
if len(message.content.split('> ')) == 1:
|
||||
await message.channel.send("Hi~ How can I help you? ")
|
||||
else:
|
||||
JSON_DATA['word']=message.content.split('> ')[1]
|
||||
JSON_DATA['word'] = message.content.split('> ')[1]
|
||||
response = requests.post(URL, json=JSON_DATA)
|
||||
response_data = response.json().get('data', [])
|
||||
image_bool = False
|
||||
@ -61,9 +60,9 @@ async def on_message(message):
|
||||
if i['type'] == 3:
|
||||
image_bool = True
|
||||
image_data = base64.b64decode(i['url'])
|
||||
with open('tmp_image.png','wb') as file:
|
||||
with open('tmp_image.png', 'wb') as file:
|
||||
file.write(image_data)
|
||||
image= discord.File('tmp_image.png')
|
||||
image = discord.File('tmp_image.png')
|
||||
|
||||
await message.channel.send(f"{message.author.mention}{res}")
|
||||
|
||||
|
||||
@ -38,12 +38,24 @@ from api.db.services.connector_service import ConnectorService, SyncLogsService
|
||||
from api.db.services.knowledgebase_service import KnowledgebaseService
|
||||
from common import settings
|
||||
from common.config_utils import show_configs
|
||||
from common.data_source import BlobStorageConnector, NotionConnector, DiscordConnector, GoogleDriveConnector, MoodleConnector, JiraConnector, DropboxConnector, WebDAVConnector, AirtableConnector
|
||||
from common.data_source import (
|
||||
BlobStorageConnector,
|
||||
NotionConnector,
|
||||
DiscordConnector,
|
||||
GoogleDriveConnector,
|
||||
MoodleConnector,
|
||||
JiraConnector,
|
||||
DropboxConnector,
|
||||
WebDAVConnector,
|
||||
AirtableConnector,
|
||||
AsanaConnector,
|
||||
)
|
||||
from common.constants import FileSource, TaskStatus
|
||||
from common.data_source.config import INDEX_BATCH_SIZE
|
||||
from common.data_source.confluence_connector import ConfluenceConnector
|
||||
from common.data_source.gmail_connector import GmailConnector
|
||||
from common.data_source.box_connector import BoxConnector
|
||||
from common.data_source.gitlab_connector import GitlabConnector
|
||||
from common.data_source.interfaces import CheckpointOutputWrapper
|
||||
from common.log_utils import init_root_logger
|
||||
from common.signal_utils import start_tracemalloc_and_snapshot, stop_tracemalloc
|
||||
@ -96,7 +108,7 @@ class SyncBase:
|
||||
if task["poll_range_start"]:
|
||||
next_update = task["poll_range_start"]
|
||||
|
||||
for document_batch in document_batch_generator:
|
||||
for document_batch in document_batch_generator:
|
||||
if not document_batch:
|
||||
continue
|
||||
|
||||
@ -161,6 +173,7 @@ class SyncBase:
|
||||
def _get_source_prefix(self):
|
||||
return ""
|
||||
|
||||
|
||||
class _BlobLikeBase(SyncBase):
|
||||
DEFAULT_BUCKET_TYPE: str = "s3"
|
||||
|
||||
@ -199,22 +212,27 @@ class _BlobLikeBase(SyncBase):
|
||||
)
|
||||
return document_batch_generator
|
||||
|
||||
|
||||
class S3(_BlobLikeBase):
|
||||
SOURCE_NAME: str = FileSource.S3
|
||||
DEFAULT_BUCKET_TYPE: str = "s3"
|
||||
|
||||
|
||||
class R2(_BlobLikeBase):
|
||||
SOURCE_NAME: str = FileSource.R2
|
||||
DEFAULT_BUCKET_TYPE: str = "r2"
|
||||
|
||||
|
||||
class OCI_STORAGE(_BlobLikeBase):
|
||||
SOURCE_NAME: str = FileSource.OCI_STORAGE
|
||||
DEFAULT_BUCKET_TYPE: str = "oci_storage"
|
||||
|
||||
|
||||
class GOOGLE_CLOUD_STORAGE(_BlobLikeBase):
|
||||
SOURCE_NAME: str = FileSource.GOOGLE_CLOUD_STORAGE
|
||||
DEFAULT_BUCKET_TYPE: str = "google_cloud_storage"
|
||||
|
||||
|
||||
class Confluence(SyncBase):
|
||||
SOURCE_NAME: str = FileSource.CONFLUENCE
|
||||
|
||||
@ -248,7 +266,9 @@ class Confluence(SyncBase):
|
||||
index_recursively=index_recursively,
|
||||
)
|
||||
|
||||
credentials_provider = StaticCredentialsProvider(tenant_id=task["tenant_id"], connector_name=DocumentSource.CONFLUENCE, credential_json=self.conf["credentials"])
|
||||
credentials_provider = StaticCredentialsProvider(tenant_id=task["tenant_id"],
|
||||
connector_name=DocumentSource.CONFLUENCE,
|
||||
credential_json=self.conf["credentials"])
|
||||
self.connector.set_credentials_provider(credentials_provider)
|
||||
|
||||
# Determine the time range for synchronization based on reindex or poll_range_start
|
||||
@ -280,7 +300,8 @@ class Confluence(SyncBase):
|
||||
doc_generator = wrapper(self.connector.load_from_checkpoint(start_time, end_time, checkpoint))
|
||||
for document, failure, next_checkpoint in doc_generator:
|
||||
if failure is not None:
|
||||
logging.warning("Confluence connector failure: %s", getattr(failure, "failure_message", failure))
|
||||
logging.warning("Confluence connector failure: %s",
|
||||
getattr(failure, "failure_message", failure))
|
||||
continue
|
||||
if document is not None:
|
||||
pending_docs.append(document)
|
||||
@ -300,7 +321,7 @@ class Confluence(SyncBase):
|
||||
async def async_wrapper():
|
||||
for batch in document_batches():
|
||||
yield batch
|
||||
|
||||
|
||||
logging.info("Connect to Confluence: {} {}".format(self.conf["wiki_base"], begin_info))
|
||||
return async_wrapper()
|
||||
|
||||
@ -314,10 +335,12 @@ class Notion(SyncBase):
|
||||
document_generator = (
|
||||
self.connector.load_from_state()
|
||||
if task["reindex"] == "1" or not task["poll_range_start"]
|
||||
else self.connector.poll_source(task["poll_range_start"].timestamp(), datetime.now(timezone.utc).timestamp())
|
||||
else self.connector.poll_source(task["poll_range_start"].timestamp(),
|
||||
datetime.now(timezone.utc).timestamp())
|
||||
)
|
||||
|
||||
begin_info = "totally" if task["reindex"] == "1" or not task["poll_range_start"] else "from {}".format(task["poll_range_start"])
|
||||
begin_info = "totally" if task["reindex"] == "1" or not task["poll_range_start"] else "from {}".format(
|
||||
task["poll_range_start"])
|
||||
logging.info("Connect to Notion: root({}) {}".format(self.conf["root_page_id"], begin_info))
|
||||
return document_generator
|
||||
|
||||
@ -340,10 +363,12 @@ class Discord(SyncBase):
|
||||
document_generator = (
|
||||
self.connector.load_from_state()
|
||||
if task["reindex"] == "1" or not task["poll_range_start"]
|
||||
else self.connector.poll_source(task["poll_range_start"].timestamp(), datetime.now(timezone.utc).timestamp())
|
||||
else self.connector.poll_source(task["poll_range_start"].timestamp(),
|
||||
datetime.now(timezone.utc).timestamp())
|
||||
)
|
||||
|
||||
begin_info = "totally" if task["reindex"] == "1" or not task["poll_range_start"] else "from {}".format(task["poll_range_start"])
|
||||
begin_info = "totally" if task["reindex"] == "1" or not task["poll_range_start"] else "from {}".format(
|
||||
task["poll_range_start"])
|
||||
logging.info("Connect to Discord: servers({}), channel({}) {}".format(server_ids, channel_names, begin_info))
|
||||
return document_generator
|
||||
|
||||
@ -485,7 +510,8 @@ class GoogleDrive(SyncBase):
|
||||
doc_generator = wrapper(self.connector.load_from_checkpoint(start_time, end_time, checkpoint))
|
||||
for document, failure, next_checkpoint in doc_generator:
|
||||
if failure is not None:
|
||||
logging.warning("Google Drive connector failure: %s", getattr(failure, "failure_message", failure))
|
||||
logging.warning("Google Drive connector failure: %s",
|
||||
getattr(failure, "failure_message", failure))
|
||||
continue
|
||||
if document is not None:
|
||||
pending_docs.append(document)
|
||||
@ -646,10 +672,10 @@ class WebDAV(SyncBase):
|
||||
remote_path=self.conf.get("remote_path", "/")
|
||||
)
|
||||
self.connector.load_credentials(self.conf["credentials"])
|
||||
|
||||
|
||||
logging.info(f"Task info: reindex={task['reindex']}, poll_range_start={task['poll_range_start']}")
|
||||
|
||||
if task["reindex"]=="1" or not task["poll_range_start"]:
|
||||
|
||||
if task["reindex"] == "1" or not task["poll_range_start"]:
|
||||
logging.info("Using load_from_state (full sync)")
|
||||
document_batch_generator = self.connector.load_from_state()
|
||||
begin_info = "totally"
|
||||
@ -659,14 +685,15 @@ class WebDAV(SyncBase):
|
||||
logging.info(f"Polling WebDAV from {task['poll_range_start']} (ts: {start_ts}) to now (ts: {end_ts})")
|
||||
document_batch_generator = self.connector.poll_source(start_ts, end_ts)
|
||||
begin_info = "from {}".format(task["poll_range_start"])
|
||||
|
||||
|
||||
logging.info("Connect to WebDAV: {}(path: {}) {}".format(
|
||||
self.conf["base_url"],
|
||||
self.conf.get("remote_path", "/"),
|
||||
begin_info
|
||||
))
|
||||
return document_batch_generator
|
||||
|
||||
|
||||
|
||||
class Moodle(SyncBase):
|
||||
SOURCE_NAME: str = FileSource.MOODLE
|
||||
|
||||
@ -675,7 +702,7 @@ class Moodle(SyncBase):
|
||||
moodle_url=self.conf["moodle_url"],
|
||||
batch_size=self.conf.get("batch_size", INDEX_BATCH_SIZE)
|
||||
)
|
||||
|
||||
|
||||
self.connector.load_credentials(self.conf["credentials"])
|
||||
|
||||
# Determine the time range for synchronization based on reindex or poll_range_start
|
||||
@ -689,7 +716,7 @@ class Moodle(SyncBase):
|
||||
begin_info = "totally"
|
||||
else:
|
||||
document_generator = self.connector.poll_source(
|
||||
poll_start.timestamp(),
|
||||
poll_start.timestamp(),
|
||||
datetime.now(timezone.utc).timestamp()
|
||||
)
|
||||
begin_info = "from {}".format(poll_start)
|
||||
@ -718,7 +745,7 @@ class BOX(SyncBase):
|
||||
token = AccessToken(
|
||||
access_token=credential['access_token'],
|
||||
refresh_token=credential['refresh_token'],
|
||||
)
|
||||
)
|
||||
auth.token_storage.store(token)
|
||||
|
||||
self.connector.load_credentials(auth)
|
||||
@ -739,6 +766,7 @@ class BOX(SyncBase):
|
||||
logging.info("Connect to Box: folder_id({}) {}".format(self.conf["folder_id"], begin_info))
|
||||
return document_generator
|
||||
|
||||
|
||||
class Airtable(SyncBase):
|
||||
SOURCE_NAME: str = FileSource.AIRTABLE
|
||||
|
||||
@ -784,6 +812,90 @@ class Airtable(SyncBase):
|
||||
|
||||
return document_generator
|
||||
|
||||
class Asana(SyncBase):
|
||||
SOURCE_NAME: str = FileSource.ASANA
|
||||
|
||||
async def _generate(self, task: dict):
|
||||
self.connector = AsanaConnector(
|
||||
self.conf.get("asana_workspace_id"),
|
||||
self.conf.get("asana_project_ids"),
|
||||
self.conf.get("asana_team_id"),
|
||||
)
|
||||
credentials = self.conf.get("credentials", {})
|
||||
if "asana_api_token_secret" not in credentials:
|
||||
raise ValueError("Missing asana_api_token_secret in credentials")
|
||||
|
||||
self.connector.load_credentials(
|
||||
{"asana_api_token_secret": credentials["asana_api_token_secret"]}
|
||||
)
|
||||
|
||||
if task.get("reindex") == "1" or not task.get("poll_range_start"):
|
||||
document_generator = self.connector.load_from_state()
|
||||
begin_info = "totally"
|
||||
else:
|
||||
poll_start = task.get("poll_range_start")
|
||||
if poll_start is None:
|
||||
document_generator = self.connector.load_from_state()
|
||||
begin_info = "totally"
|
||||
else:
|
||||
document_generator = self.connector.poll_source(
|
||||
poll_start.timestamp(),
|
||||
datetime.now(timezone.utc).timestamp(),
|
||||
)
|
||||
begin_info = f"from {poll_start}"
|
||||
|
||||
logging.info(
|
||||
"Connect to Asana: workspace_id(%s), project_ids(%s), team_id(%s) %s",
|
||||
self.conf.get("asana_workspace_id"),
|
||||
self.conf.get("asana_project_ids"),
|
||||
self.conf.get("asana_team_id"),
|
||||
begin_info,
|
||||
)
|
||||
|
||||
return document_generator
|
||||
|
||||
|
||||
|
||||
class Gitlab(SyncBase):
|
||||
SOURCE_NAME: str = FileSource.GITLAB
|
||||
|
||||
async def _generate(self, task: dict):
|
||||
"""
|
||||
Sync files from GitLab attachments.
|
||||
"""
|
||||
|
||||
self.connector = GitlabConnector(
|
||||
project_owner= self.conf.get("project_owner"),
|
||||
project_name= self.conf.get("project_name"),
|
||||
include_mrs = self.conf.get("include_mrs", False),
|
||||
include_issues = self.conf.get("include_issues", False),
|
||||
include_code_files= self.conf.get("include_code_files", False),
|
||||
)
|
||||
|
||||
self.connector.load_credentials(
|
||||
{
|
||||
"gitlab_access_token": self.conf.get("credentials", {}).get("gitlab_access_token"),
|
||||
"gitlab_url": self.conf.get("credentials", {}).get("gitlab_url"),
|
||||
}
|
||||
)
|
||||
|
||||
if task["reindex"] == "1" or not task["poll_range_start"]:
|
||||
document_generator = self.connector.load_from_state()
|
||||
begin_info = "totally"
|
||||
else:
|
||||
poll_start = task["poll_range_start"]
|
||||
if poll_start is None:
|
||||
document_generator = self.connector.load_from_state()
|
||||
begin_info = "totally"
|
||||
else:
|
||||
document_generator = self.connector.poll_source(
|
||||
poll_start.timestamp(),
|
||||
datetime.now(timezone.utc).timestamp()
|
||||
)
|
||||
begin_info = "from {}".format(poll_start)
|
||||
logging.info("Connect to Gitlab: ({}) {}".format(self.conf["project_name"], begin_info))
|
||||
return document_generator
|
||||
|
||||
func_factory = {
|
||||
FileSource.S3: S3,
|
||||
FileSource.R2: R2,
|
||||
@ -803,6 +915,8 @@ func_factory = {
|
||||
FileSource.WEBDAV: WebDAV,
|
||||
FileSource.BOX: BOX,
|
||||
FileSource.AIRTABLE: Airtable,
|
||||
FileSource.GITLAB: Gitlab,
|
||||
FileSource.ASANA: Asana,
|
||||
}
|
||||
|
||||
|
||||
|
||||
@ -92,7 +92,7 @@ FACTORY = {
|
||||
}
|
||||
|
||||
TASK_TYPE_TO_PIPELINE_TASK_TYPE = {
|
||||
"dataflow" : PipelineTaskType.PARSE,
|
||||
"dataflow": PipelineTaskType.PARSE,
|
||||
"raptor": PipelineTaskType.RAPTOR,
|
||||
"graphrag": PipelineTaskType.GRAPH_RAG,
|
||||
"mindmap": PipelineTaskType.MINDMAP,
|
||||
@ -221,7 +221,7 @@ async def get_storage_binary(bucket, name):
|
||||
return await asyncio.to_thread(settings.STORAGE_IMPL.get, bucket, name)
|
||||
|
||||
|
||||
@timeout(60*80, 1)
|
||||
@timeout(60 * 80, 1)
|
||||
async def build_chunks(task, progress_callback):
|
||||
if task["size"] > settings.DOC_MAXIMUM_SIZE:
|
||||
set_progress(task["id"], prog=-1, msg="File size exceeds( <= %dMb )" %
|
||||
@ -283,7 +283,8 @@ async def build_chunks(task, progress_callback):
|
||||
try:
|
||||
d = copy.deepcopy(document)
|
||||
d.update(chunk)
|
||||
d["id"] = xxhash.xxh64((chunk["content_with_weight"] + str(d["doc_id"])).encode("utf-8", "surrogatepass")).hexdigest()
|
||||
d["id"] = xxhash.xxh64(
|
||||
(chunk["content_with_weight"] + str(d["doc_id"])).encode("utf-8", "surrogatepass")).hexdigest()
|
||||
d["create_time"] = str(datetime.now()).replace("T", " ")[:19]
|
||||
d["create_timestamp_flt"] = datetime.now().timestamp()
|
||||
if not d.get("image"):
|
||||
@ -328,9 +329,11 @@ async def build_chunks(task, progress_callback):
|
||||
d["important_kwd"] = cached.split(",")
|
||||
d["important_tks"] = rag_tokenizer.tokenize(" ".join(d["important_kwd"]))
|
||||
return
|
||||
|
||||
tasks = []
|
||||
for d in docs:
|
||||
tasks.append(asyncio.create_task(doc_keyword_extraction(chat_mdl, d, task["parser_config"]["auto_keywords"])))
|
||||
tasks.append(
|
||||
asyncio.create_task(doc_keyword_extraction(chat_mdl, d, task["parser_config"]["auto_keywords"])))
|
||||
try:
|
||||
await asyncio.gather(*tasks, return_exceptions=False)
|
||||
except Exception as e:
|
||||
@ -355,9 +358,11 @@ async def build_chunks(task, progress_callback):
|
||||
if cached:
|
||||
d["question_kwd"] = cached.split("\n")
|
||||
d["question_tks"] = rag_tokenizer.tokenize("\n".join(d["question_kwd"]))
|
||||
|
||||
tasks = []
|
||||
for d in docs:
|
||||
tasks.append(asyncio.create_task(doc_question_proposal(chat_mdl, d, task["parser_config"]["auto_questions"])))
|
||||
tasks.append(
|
||||
asyncio.create_task(doc_question_proposal(chat_mdl, d, task["parser_config"]["auto_questions"])))
|
||||
try:
|
||||
await asyncio.gather(*tasks, return_exceptions=False)
|
||||
except Exception as e:
|
||||
@ -374,15 +379,18 @@ async def build_chunks(task, progress_callback):
|
||||
chat_mdl = LLMBundle(task["tenant_id"], LLMType.CHAT, llm_name=task["llm_id"], lang=task["language"])
|
||||
|
||||
async def gen_metadata_task(chat_mdl, d):
|
||||
cached = get_llm_cache(chat_mdl.llm_name, d["content_with_weight"], "metadata", task["parser_config"]["metadata"])
|
||||
cached = get_llm_cache(chat_mdl.llm_name, d["content_with_weight"], "metadata",
|
||||
task["parser_config"]["metadata"])
|
||||
if not cached:
|
||||
async with chat_limiter:
|
||||
cached = await gen_metadata(chat_mdl,
|
||||
metadata_schema(task["parser_config"]["metadata"]),
|
||||
d["content_with_weight"])
|
||||
set_llm_cache(chat_mdl.llm_name, d["content_with_weight"], cached, "metadata", task["parser_config"]["metadata"])
|
||||
set_llm_cache(chat_mdl.llm_name, d["content_with_weight"], cached, "metadata",
|
||||
task["parser_config"]["metadata"])
|
||||
if cached:
|
||||
d["metadata_obj"] = cached
|
||||
|
||||
tasks = []
|
||||
for d in docs:
|
||||
tasks.append(asyncio.create_task(gen_metadata_task(chat_mdl, d)))
|
||||
@ -430,7 +438,8 @@ async def build_chunks(task, progress_callback):
|
||||
if task_canceled:
|
||||
progress_callback(-1, msg="Task has been canceled.")
|
||||
return None
|
||||
if settings.retriever.tag_content(tenant_id, kb_ids, d, all_tags, topn_tags=topn_tags, S=S) and len(d[TAG_FLD]) > 0:
|
||||
if settings.retriever.tag_content(tenant_id, kb_ids, d, all_tags, topn_tags=topn_tags, S=S) and len(
|
||||
d[TAG_FLD]) > 0:
|
||||
examples.append({"content": d["content_with_weight"], TAG_FLD: d[TAG_FLD]})
|
||||
else:
|
||||
docs_to_tag.append(d)
|
||||
@ -438,7 +447,7 @@ async def build_chunks(task, progress_callback):
|
||||
async def doc_content_tagging(chat_mdl, d, topn_tags):
|
||||
cached = get_llm_cache(chat_mdl.llm_name, d["content_with_weight"], all_tags, {"topn": topn_tags})
|
||||
if not cached:
|
||||
picked_examples = random.choices(examples, k=2) if len(examples)>2 else examples
|
||||
picked_examples = random.choices(examples, k=2) if len(examples) > 2 else examples
|
||||
if not picked_examples:
|
||||
picked_examples.append({"content": "This is an example", TAG_FLD: {'example': 1}})
|
||||
async with chat_limiter:
|
||||
@ -454,6 +463,7 @@ async def build_chunks(task, progress_callback):
|
||||
if cached:
|
||||
set_llm_cache(chat_mdl.llm_name, d["content_with_weight"], cached, all_tags, {"topn": topn_tags})
|
||||
d[TAG_FLD] = json.loads(cached)
|
||||
|
||||
tasks = []
|
||||
for d in docs_to_tag:
|
||||
tasks.append(asyncio.create_task(doc_content_tagging(chat_mdl, d, topn_tags)))
|
||||
@ -473,21 +483,22 @@ async def build_chunks(task, progress_callback):
|
||||
def build_TOC(task, docs, progress_callback):
|
||||
progress_callback(msg="Start to generate table of content ...")
|
||||
chat_mdl = LLMBundle(task["tenant_id"], LLMType.CHAT, llm_name=task["llm_id"], lang=task["language"])
|
||||
docs = sorted(docs, key=lambda d:(
|
||||
docs = sorted(docs, key=lambda d: (
|
||||
d.get("page_num_int", 0)[0] if isinstance(d.get("page_num_int", 0), list) else d.get("page_num_int", 0),
|
||||
d.get("top_int", 0)[0] if isinstance(d.get("top_int", 0), list) else d.get("top_int", 0)
|
||||
))
|
||||
toc: list[dict] = asyncio.run(run_toc_from_text([d["content_with_weight"] for d in docs], chat_mdl, progress_callback))
|
||||
logging.info("------------ T O C -------------\n"+json.dumps(toc, ensure_ascii=False, indent=' '))
|
||||
toc: list[dict] = asyncio.run(
|
||||
run_toc_from_text([d["content_with_weight"] for d in docs], chat_mdl, progress_callback))
|
||||
logging.info("------------ T O C -------------\n" + json.dumps(toc, ensure_ascii=False, indent=' '))
|
||||
ii = 0
|
||||
while ii < len(toc):
|
||||
try:
|
||||
idx = int(toc[ii]["chunk_id"])
|
||||
del toc[ii]["chunk_id"]
|
||||
toc[ii]["ids"] = [docs[idx]["id"]]
|
||||
if ii == len(toc) -1:
|
||||
if ii == len(toc) - 1:
|
||||
break
|
||||
for jj in range(idx+1, int(toc[ii+1]["chunk_id"])+1):
|
||||
for jj in range(idx + 1, int(toc[ii + 1]["chunk_id"]) + 1):
|
||||
toc[ii]["ids"].append(docs[jj]["id"])
|
||||
except Exception as e:
|
||||
logging.exception(e)
|
||||
@ -499,7 +510,8 @@ def build_TOC(task, docs, progress_callback):
|
||||
d["toc_kwd"] = "toc"
|
||||
d["available_int"] = 0
|
||||
d["page_num_int"] = [100000000]
|
||||
d["id"] = xxhash.xxh64((d["content_with_weight"] + str(d["doc_id"])).encode("utf-8", "surrogatepass")).hexdigest()
|
||||
d["id"] = xxhash.xxh64(
|
||||
(d["content_with_weight"] + str(d["doc_id"])).encode("utf-8", "surrogatepass")).hexdigest()
|
||||
return d
|
||||
return None
|
||||
|
||||
@ -532,12 +544,12 @@ async def embedding(docs, mdl, parser_config=None, callback=None):
|
||||
@timeout(60)
|
||||
def batch_encode(txts):
|
||||
nonlocal mdl
|
||||
return mdl.encode([truncate(c, mdl.max_length-10) for c in txts])
|
||||
return mdl.encode([truncate(c, mdl.max_length - 10) for c in txts])
|
||||
|
||||
cnts_ = np.array([])
|
||||
for i in range(0, len(cnts), settings.EMBEDDING_BATCH_SIZE):
|
||||
async with embed_limiter:
|
||||
vts, c = await asyncio.to_thread(batch_encode, cnts[i : i + settings.EMBEDDING_BATCH_SIZE])
|
||||
vts, c = await asyncio.to_thread(batch_encode, cnts[i: i + settings.EMBEDDING_BATCH_SIZE])
|
||||
if len(cnts_) == 0:
|
||||
cnts_ = vts
|
||||
else:
|
||||
@ -545,7 +557,7 @@ async def embedding(docs, mdl, parser_config=None, callback=None):
|
||||
tk_count += c
|
||||
callback(prog=0.7 + 0.2 * (i + 1) / len(cnts), msg="")
|
||||
cnts = cnts_
|
||||
filename_embd_weight = parser_config.get("filename_embd_weight", 0.1) # due to the db support none value
|
||||
filename_embd_weight = parser_config.get("filename_embd_weight", 0.1) # due to the db support none value
|
||||
if not filename_embd_weight:
|
||||
filename_embd_weight = 0.1
|
||||
title_w = float(filename_embd_weight)
|
||||
@ -588,7 +600,8 @@ async def run_dataflow(task: dict):
|
||||
return
|
||||
|
||||
if not chunks:
|
||||
PipelineOperationLogService.create(document_id=doc_id, pipeline_id=dataflow_id, task_type=PipelineTaskType.PARSE, dsl=str(pipeline))
|
||||
PipelineOperationLogService.create(document_id=doc_id, pipeline_id=dataflow_id,
|
||||
task_type=PipelineTaskType.PARSE, dsl=str(pipeline))
|
||||
return
|
||||
|
||||
embedding_token_consumption = chunks.get("embedding_token_consumption", 0)
|
||||
@ -610,25 +623,27 @@ async def run_dataflow(task: dict):
|
||||
e, kb = KnowledgebaseService.get_by_id(task["kb_id"])
|
||||
embedding_id = kb.embd_id
|
||||
embedding_model = LLMBundle(task["tenant_id"], LLMType.EMBEDDING, llm_name=embedding_id)
|
||||
|
||||
@timeout(60)
|
||||
def batch_encode(txts):
|
||||
nonlocal embedding_model
|
||||
return embedding_model.encode([truncate(c, embedding_model.max_length - 10) for c in txts])
|
||||
|
||||
vects = np.array([])
|
||||
texts = [o.get("questions", o.get("summary", o["text"])) for o in chunks]
|
||||
delta = 0.20/(len(texts)//settings.EMBEDDING_BATCH_SIZE+1)
|
||||
delta = 0.20 / (len(texts) // settings.EMBEDDING_BATCH_SIZE + 1)
|
||||
prog = 0.8
|
||||
for i in range(0, len(texts), settings.EMBEDDING_BATCH_SIZE):
|
||||
async with embed_limiter:
|
||||
vts, c = await asyncio.to_thread(batch_encode, texts[i : i + settings.EMBEDDING_BATCH_SIZE])
|
||||
vts, c = await asyncio.to_thread(batch_encode, texts[i: i + settings.EMBEDDING_BATCH_SIZE])
|
||||
if len(vects) == 0:
|
||||
vects = vts
|
||||
else:
|
||||
vects = np.concatenate((vects, vts), axis=0)
|
||||
embedding_token_consumption += c
|
||||
prog += delta
|
||||
if i % (len(texts)//settings.EMBEDDING_BATCH_SIZE/100+1) == 1:
|
||||
set_progress(task_id, prog=prog, msg=f"{i+1} / {len(texts)//settings.EMBEDDING_BATCH_SIZE}")
|
||||
if i % (len(texts) // settings.EMBEDDING_BATCH_SIZE / 100 + 1) == 1:
|
||||
set_progress(task_id, prog=prog, msg=f"{i + 1} / {len(texts) // settings.EMBEDDING_BATCH_SIZE}")
|
||||
|
||||
assert len(vects) == len(chunks)
|
||||
for i, ck in enumerate(chunks):
|
||||
@ -636,10 +651,10 @@ async def run_dataflow(task: dict):
|
||||
ck["q_%d_vec" % len(v)] = v
|
||||
except Exception as e:
|
||||
set_progress(task_id, prog=-1, msg=f"[ERROR]: {e}")
|
||||
PipelineOperationLogService.create(document_id=doc_id, pipeline_id=dataflow_id, task_type=PipelineTaskType.PARSE, dsl=str(pipeline))
|
||||
PipelineOperationLogService.create(document_id=doc_id, pipeline_id=dataflow_id,
|
||||
task_type=PipelineTaskType.PARSE, dsl=str(pipeline))
|
||||
return
|
||||
|
||||
|
||||
metadata = {}
|
||||
for ck in chunks:
|
||||
ck["doc_id"] = doc_id
|
||||
@ -686,15 +701,19 @@ async def run_dataflow(task: dict):
|
||||
set_progress(task_id, prog=0.82, msg="[DOC Engine]:\nStart to index...")
|
||||
e = await insert_es(task_id, task["tenant_id"], task["kb_id"], chunks, partial(set_progress, task_id, 0, 100000000))
|
||||
if not e:
|
||||
PipelineOperationLogService.create(document_id=doc_id, pipeline_id=dataflow_id, task_type=PipelineTaskType.PARSE, dsl=str(pipeline))
|
||||
PipelineOperationLogService.create(document_id=doc_id, pipeline_id=dataflow_id,
|
||||
task_type=PipelineTaskType.PARSE, dsl=str(pipeline))
|
||||
return
|
||||
|
||||
time_cost = timer() - start_ts
|
||||
task_time_cost = timer() - task_start_ts
|
||||
set_progress(task_id, prog=1., msg="Indexing done ({:.2f}s). Task done ({:.2f}s)".format(time_cost, task_time_cost))
|
||||
DocumentService.increment_chunk_num(doc_id, task_dataset_id, embedding_token_consumption, len(chunks), task_time_cost)
|
||||
logging.info("[Done], chunks({}), token({}), elapsed:{:.2f}".format(len(chunks), embedding_token_consumption, task_time_cost))
|
||||
PipelineOperationLogService.create(document_id=doc_id, pipeline_id=dataflow_id, task_type=PipelineTaskType.PARSE, dsl=str(pipeline))
|
||||
DocumentService.increment_chunk_num(doc_id, task_dataset_id, embedding_token_consumption, len(chunks),
|
||||
task_time_cost)
|
||||
logging.info("[Done], chunks({}), token({}), elapsed:{:.2f}".format(len(chunks), embedding_token_consumption,
|
||||
task_time_cost))
|
||||
PipelineOperationLogService.create(document_id=doc_id, pipeline_id=dataflow_id, task_type=PipelineTaskType.PARSE,
|
||||
dsl=str(pipeline))
|
||||
|
||||
|
||||
@timeout(3600)
|
||||
@ -702,7 +721,7 @@ async def run_raptor_for_kb(row, kb_parser_config, chat_mdl, embd_mdl, vector_si
|
||||
fake_doc_id = GRAPH_RAPTOR_FAKE_DOC_ID
|
||||
|
||||
raptor_config = kb_parser_config.get("raptor", {})
|
||||
vctr_nm = "q_%d_vec"%vector_size
|
||||
vctr_nm = "q_%d_vec" % vector_size
|
||||
|
||||
res = []
|
||||
tk_count = 0
|
||||
@ -747,17 +766,17 @@ async def run_raptor_for_kb(row, kb_parser_config, chat_mdl, embd_mdl, vector_si
|
||||
for x, doc_id in enumerate(doc_ids):
|
||||
chunks = []
|
||||
for d in settings.retriever.chunk_list(doc_id, row["tenant_id"], [str(row["kb_id"])],
|
||||
fields=["content_with_weight", vctr_nm],
|
||||
sort_by_position=True):
|
||||
fields=["content_with_weight", vctr_nm],
|
||||
sort_by_position=True):
|
||||
chunks.append((d["content_with_weight"], np.array(d[vctr_nm])))
|
||||
await generate(chunks, doc_id)
|
||||
callback(prog=(x+1.)/len(doc_ids))
|
||||
callback(prog=(x + 1.) / len(doc_ids))
|
||||
else:
|
||||
chunks = []
|
||||
for doc_id in doc_ids:
|
||||
for d in settings.retriever.chunk_list(doc_id, row["tenant_id"], [str(row["kb_id"])],
|
||||
fields=["content_with_weight", vctr_nm],
|
||||
sort_by_position=True):
|
||||
fields=["content_with_weight", vctr_nm],
|
||||
sort_by_position=True):
|
||||
chunks.append((d["content_with_weight"], np.array(d[vctr_nm])))
|
||||
|
||||
await generate(chunks, fake_doc_id)
|
||||
@ -792,19 +811,22 @@ async def insert_es(task_id, task_tenant_id, task_dataset_id, chunks, progress_c
|
||||
mom_ck["available_int"] = 0
|
||||
flds = list(mom_ck.keys())
|
||||
for fld in flds:
|
||||
if fld not in ["id", "content_with_weight", "doc_id", "docnm_kwd", "kb_id", "available_int", "position_int"]:
|
||||
if fld not in ["id", "content_with_weight", "doc_id", "docnm_kwd", "kb_id", "available_int",
|
||||
"position_int"]:
|
||||
del mom_ck[fld]
|
||||
mothers.append(mom_ck)
|
||||
|
||||
for b in range(0, len(mothers), settings.DOC_BULK_SIZE):
|
||||
await asyncio.to_thread(settings.docStoreConn.insert,mothers[b:b + settings.DOC_BULK_SIZE],search.index_name(task_tenant_id),task_dataset_id,)
|
||||
await asyncio.to_thread(settings.docStoreConn.insert, mothers[b:b + settings.DOC_BULK_SIZE],
|
||||
search.index_name(task_tenant_id), task_dataset_id, )
|
||||
task_canceled = has_canceled(task_id)
|
||||
if task_canceled:
|
||||
progress_callback(-1, msg="Task has been canceled.")
|
||||
return False
|
||||
|
||||
for b in range(0, len(chunks), settings.DOC_BULK_SIZE):
|
||||
doc_store_result = await asyncio.to_thread(settings.docStoreConn.insert,chunks[b:b + settings.DOC_BULK_SIZE],search.index_name(task_tenant_id),task_dataset_id,)
|
||||
doc_store_result = await asyncio.to_thread(settings.docStoreConn.insert, chunks[b:b + settings.DOC_BULK_SIZE],
|
||||
search.index_name(task_tenant_id), task_dataset_id, )
|
||||
task_canceled = has_canceled(task_id)
|
||||
if task_canceled:
|
||||
progress_callback(-1, msg="Task has been canceled.")
|
||||
@ -821,7 +843,8 @@ async def insert_es(task_id, task_tenant_id, task_dataset_id, chunks, progress_c
|
||||
TaskService.update_chunk_ids(task_id, chunk_ids_str)
|
||||
except DoesNotExist:
|
||||
logging.warning(f"do_handle_task update_chunk_ids failed since task {task_id} is unknown.")
|
||||
doc_store_result = await asyncio.to_thread(settings.docStoreConn.delete,{"id": chunk_ids},search.index_name(task_tenant_id),task_dataset_id,)
|
||||
doc_store_result = await asyncio.to_thread(settings.docStoreConn.delete, {"id": chunk_ids},
|
||||
search.index_name(task_tenant_id), task_dataset_id, )
|
||||
tasks = []
|
||||
for chunk_id in chunk_ids:
|
||||
tasks.append(asyncio.create_task(delete_image(task_dataset_id, chunk_id)))
|
||||
@ -838,7 +861,7 @@ async def insert_es(task_id, task_tenant_id, task_dataset_id, chunks, progress_c
|
||||
return True
|
||||
|
||||
|
||||
@timeout(60*60*3, 1)
|
||||
@timeout(60 * 60 * 3, 1)
|
||||
async def do_handle_task(task):
|
||||
task_type = task.get("task_type", "")
|
||||
|
||||
@ -914,7 +937,7 @@ async def do_handle_task(task):
|
||||
},
|
||||
}
|
||||
)
|
||||
if not KnowledgebaseService.update_by_id(kb.id, {"parser_config":kb_parser_config}):
|
||||
if not KnowledgebaseService.update_by_id(kb.id, {"parser_config": kb_parser_config}):
|
||||
progress_callback(prog=-1.0, msg="Internal error: Invalid RAPTOR configuration")
|
||||
return
|
||||
|
||||
@ -943,7 +966,7 @@ async def do_handle_task(task):
|
||||
doc_ids=task.get("doc_ids", []),
|
||||
)
|
||||
if fake_doc_ids := task.get("doc_ids", []):
|
||||
task_doc_id = fake_doc_ids[0] # use the first document ID to represent this task for logging purposes
|
||||
task_doc_id = fake_doc_ids[0] # use the first document ID to represent this task for logging purposes
|
||||
# Either using graphrag or Standard chunking methods
|
||||
elif task_type == "graphrag":
|
||||
ok, kb = KnowledgebaseService.get_by_id(task_dataset_id)
|
||||
@ -968,11 +991,10 @@ async def do_handle_task(task):
|
||||
}
|
||||
}
|
||||
)
|
||||
if not KnowledgebaseService.update_by_id(kb.id, {"parser_config":kb_parser_config}):
|
||||
if not KnowledgebaseService.update_by_id(kb.id, {"parser_config": kb_parser_config}):
|
||||
progress_callback(prog=-1.0, msg="Internal error: Invalid GraphRAG configuration")
|
||||
return
|
||||
|
||||
|
||||
graphrag_conf = kb_parser_config.get("graphrag", {})
|
||||
start_ts = timer()
|
||||
chat_model = LLMBundle(task_tenant_id, LLMType.CHAT, llm_name=task_llm_id, lang=task_language)
|
||||
@ -1030,7 +1052,7 @@ async def do_handle_task(task):
|
||||
return True
|
||||
e = await insert_es(task_id, task_tenant_id, task_dataset_id, _chunks, progress_callback)
|
||||
return bool(e)
|
||||
|
||||
|
||||
try:
|
||||
if not await _maybe_insert_es(chunks):
|
||||
return
|
||||
@ -1084,8 +1106,8 @@ async def do_handle_task(task):
|
||||
f"Remove doc({task_doc_id}) from docStore failed when task({task_id}) canceled."
|
||||
)
|
||||
|
||||
async def handle_task():
|
||||
|
||||
async def handle_task():
|
||||
global DONE_TASKS, FAILED_TASKS
|
||||
redis_msg, task = await collect()
|
||||
if not task:
|
||||
@ -1093,7 +1115,8 @@ async def handle_task():
|
||||
return
|
||||
|
||||
task_type = task["task_type"]
|
||||
pipeline_task_type = TASK_TYPE_TO_PIPELINE_TASK_TYPE.get(task_type, PipelineTaskType.PARSE) or PipelineTaskType.PARSE
|
||||
pipeline_task_type = TASK_TYPE_TO_PIPELINE_TASK_TYPE.get(task_type,
|
||||
PipelineTaskType.PARSE) or PipelineTaskType.PARSE
|
||||
|
||||
try:
|
||||
logging.info(f"handle_task begin for task {json.dumps(task)}")
|
||||
@ -1119,7 +1142,9 @@ async def handle_task():
|
||||
if task_type in ["graphrag", "raptor", "mindmap"]:
|
||||
task_document_ids = task["doc_ids"]
|
||||
if not task.get("dataflow_id", ""):
|
||||
PipelineOperationLogService.record_pipeline_operation(document_id=task["doc_id"], pipeline_id="", task_type=pipeline_task_type, fake_document_ids=task_document_ids)
|
||||
PipelineOperationLogService.record_pipeline_operation(document_id=task["doc_id"], pipeline_id="",
|
||||
task_type=pipeline_task_type,
|
||||
fake_document_ids=task_document_ids)
|
||||
|
||||
redis_msg.ack()
|
||||
|
||||
@ -1249,6 +1274,7 @@ async def main():
|
||||
await asyncio.gather(report_task, return_exceptions=True)
|
||||
logging.error("BUG!!! You should not reach here!!!")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
faulthandler.enable()
|
||||
init_root_logger(CONSUMER_NAME)
|
||||
|
||||
@ -42,8 +42,10 @@ class RAGFlowAzureSpnBlob:
|
||||
pass
|
||||
|
||||
try:
|
||||
credentials = ClientSecretCredential(tenant_id=self.tenant_id, client_id=self.client_id, client_secret=self.secret, authority=AzureAuthorityHosts.AZURE_CHINA)
|
||||
self.conn = FileSystemClient(account_url=self.account_url, file_system_name=self.container_name, credential=credentials)
|
||||
credentials = ClientSecretCredential(tenant_id=self.tenant_id, client_id=self.client_id,
|
||||
client_secret=self.secret, authority=AzureAuthorityHosts.AZURE_CHINA)
|
||||
self.conn = FileSystemClient(account_url=self.account_url, file_system_name=self.container_name,
|
||||
credential=credentials)
|
||||
except Exception:
|
||||
logging.exception("Fail to connect %s" % self.account_url)
|
||||
|
||||
@ -104,4 +106,4 @@ class RAGFlowAzureSpnBlob:
|
||||
logging.exception(f"fail get {bucket}/{fnm}")
|
||||
self.__open__()
|
||||
time.sleep(1)
|
||||
return None
|
||||
return None
|
||||
|
||||
@ -25,7 +25,8 @@ from PIL import Image
|
||||
test_image_base64 = "iVBORw0KGgoAAAANSUhEUgAAAGQAAABkCAIAAAD/gAIDAAAA6ElEQVR4nO3QwQ3AIBDAsIP9d25XIC+EZE8QZc18w5l9O+AlZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBT+IYAHHLHkdEgAAAABJRU5ErkJggg=="
|
||||
test_image = base64.b64decode(test_image_base64)
|
||||
|
||||
async def image2id(d: dict, storage_put_func: partial, objname:str, bucket:str="imagetemps"):
|
||||
|
||||
async def image2id(d: dict, storage_put_func: partial, objname: str, bucket: str = "imagetemps"):
|
||||
import logging
|
||||
from io import BytesIO
|
||||
from rag.svr.task_executor import minio_limiter
|
||||
@ -74,7 +75,7 @@ async def image2id(d: dict, storage_put_func: partial, objname:str, bucket:str="
|
||||
del d["image"]
|
||||
|
||||
|
||||
def id2image(image_id:str|None, storage_get_func: partial):
|
||||
def id2image(image_id: str | None, storage_get_func: partial):
|
||||
if not image_id:
|
||||
return
|
||||
arr = image_id.split("-")
|
||||
|
||||
@ -16,11 +16,13 @@
|
||||
|
||||
import logging
|
||||
from common.crypto_utils import CryptoUtil
|
||||
|
||||
|
||||
# from common.decorator import singleton
|
||||
|
||||
class EncryptedStorageWrapper:
|
||||
"""Encrypted storage wrapper that wraps existing storage implementations to provide transparent encryption"""
|
||||
|
||||
|
||||
def __init__(self, storage_impl, algorithm="aes-256-cbc", key=None, iv=None):
|
||||
"""
|
||||
Initialize encrypted storage wrapper
|
||||
@ -34,16 +36,16 @@ class EncryptedStorageWrapper:
|
||||
self.storage_impl = storage_impl
|
||||
self.crypto = CryptoUtil(algorithm=algorithm, key=key, iv=iv)
|
||||
self.encryption_enabled = True
|
||||
|
||||
|
||||
# Check if storage implementation has required methods
|
||||
# todo: Consider abstracting a storage base class to ensure these methods exist
|
||||
required_methods = ["put", "get", "rm", "obj_exist", "health"]
|
||||
for method in required_methods:
|
||||
if not hasattr(storage_impl, method):
|
||||
raise AttributeError(f"Storage implementation missing required method: {method}")
|
||||
|
||||
|
||||
logging.info(f"EncryptedStorageWrapper initialized with algorithm: {algorithm}")
|
||||
|
||||
|
||||
def put(self, bucket, fnm, binary, tenant_id=None):
|
||||
"""
|
||||
Encrypt and store data
|
||||
@ -59,15 +61,15 @@ class EncryptedStorageWrapper:
|
||||
"""
|
||||
if not self.encryption_enabled:
|
||||
return self.storage_impl.put(bucket, fnm, binary, tenant_id)
|
||||
|
||||
|
||||
try:
|
||||
encrypted_binary = self.crypto.encrypt(binary)
|
||||
|
||||
|
||||
return self.storage_impl.put(bucket, fnm, encrypted_binary, tenant_id)
|
||||
except Exception as e:
|
||||
logging.exception(f"Failed to encrypt and store data: {bucket}/{fnm}, error: {str(e)}")
|
||||
raise
|
||||
|
||||
|
||||
def get(self, bucket, fnm, tenant_id=None):
|
||||
"""
|
||||
Retrieve and decrypt data
|
||||
@ -83,21 +85,21 @@ class EncryptedStorageWrapper:
|
||||
try:
|
||||
# Get encrypted data
|
||||
encrypted_binary = self.storage_impl.get(bucket, fnm, tenant_id)
|
||||
|
||||
|
||||
if encrypted_binary is None:
|
||||
return None
|
||||
|
||||
|
||||
if not self.encryption_enabled:
|
||||
return encrypted_binary
|
||||
|
||||
|
||||
# Decrypt data
|
||||
decrypted_binary = self.crypto.decrypt(encrypted_binary)
|
||||
return decrypted_binary
|
||||
|
||||
|
||||
except Exception as e:
|
||||
logging.exception(f"Failed to get and decrypt data: {bucket}/{fnm}, error: {str(e)}")
|
||||
raise
|
||||
|
||||
|
||||
def rm(self, bucket, fnm, tenant_id=None):
|
||||
"""
|
||||
Delete data (same as original storage implementation, no decryption needed)
|
||||
@ -111,7 +113,7 @@ class EncryptedStorageWrapper:
|
||||
Deletion result
|
||||
"""
|
||||
return self.storage_impl.rm(bucket, fnm, tenant_id)
|
||||
|
||||
|
||||
def obj_exist(self, bucket, fnm, tenant_id=None):
|
||||
"""
|
||||
Check if object exists (same as original storage implementation, no decryption needed)
|
||||
@ -125,7 +127,7 @@ class EncryptedStorageWrapper:
|
||||
Whether the object exists
|
||||
"""
|
||||
return self.storage_impl.obj_exist(bucket, fnm, tenant_id)
|
||||
|
||||
|
||||
def health(self):
|
||||
"""
|
||||
Health check (uses the original storage implementation's method)
|
||||
@ -134,7 +136,7 @@ class EncryptedStorageWrapper:
|
||||
Health check result
|
||||
"""
|
||||
return self.storage_impl.health()
|
||||
|
||||
|
||||
def bucket_exists(self, bucket):
|
||||
"""
|
||||
Check if bucket exists (if the original storage implementation has this method)
|
||||
@ -148,7 +150,7 @@ class EncryptedStorageWrapper:
|
||||
if hasattr(self.storage_impl, "bucket_exists"):
|
||||
return self.storage_impl.bucket_exists(bucket)
|
||||
return False
|
||||
|
||||
|
||||
def get_presigned_url(self, bucket, fnm, expires, tenant_id=None):
|
||||
"""
|
||||
Get presigned URL (if the original storage implementation has this method)
|
||||
@ -165,7 +167,7 @@ class EncryptedStorageWrapper:
|
||||
if hasattr(self.storage_impl, "get_presigned_url"):
|
||||
return self.storage_impl.get_presigned_url(bucket, fnm, expires, tenant_id)
|
||||
return None
|
||||
|
||||
|
||||
def scan(self, bucket, fnm, tenant_id=None):
|
||||
"""
|
||||
Scan objects (if the original storage implementation has this method)
|
||||
@ -181,7 +183,7 @@ class EncryptedStorageWrapper:
|
||||
if hasattr(self.storage_impl, "scan"):
|
||||
return self.storage_impl.scan(bucket, fnm, tenant_id)
|
||||
return None
|
||||
|
||||
|
||||
def copy(self, src_bucket, src_path, dest_bucket, dest_path):
|
||||
"""
|
||||
Copy object (if the original storage implementation has this method)
|
||||
@ -198,7 +200,7 @@ class EncryptedStorageWrapper:
|
||||
if hasattr(self.storage_impl, "copy"):
|
||||
return self.storage_impl.copy(src_bucket, src_path, dest_bucket, dest_path)
|
||||
return False
|
||||
|
||||
|
||||
def move(self, src_bucket, src_path, dest_bucket, dest_path):
|
||||
"""
|
||||
Move object (if the original storage implementation has this method)
|
||||
@ -215,7 +217,7 @@ class EncryptedStorageWrapper:
|
||||
if hasattr(self.storage_impl, "move"):
|
||||
return self.storage_impl.move(src_bucket, src_path, dest_bucket, dest_path)
|
||||
return False
|
||||
|
||||
|
||||
def remove_bucket(self, bucket):
|
||||
"""
|
||||
Remove bucket (if the original storage implementation has this method)
|
||||
@ -229,17 +231,18 @@ class EncryptedStorageWrapper:
|
||||
if hasattr(self.storage_impl, "remove_bucket"):
|
||||
return self.storage_impl.remove_bucket(bucket)
|
||||
return False
|
||||
|
||||
|
||||
def enable_encryption(self):
|
||||
"""Enable encryption"""
|
||||
self.encryption_enabled = True
|
||||
logging.info("Encryption enabled")
|
||||
|
||||
|
||||
def disable_encryption(self):
|
||||
"""Disable encryption"""
|
||||
self.encryption_enabled = False
|
||||
logging.info("Encryption disabled")
|
||||
|
||||
|
||||
# Create singleton wrapper function
|
||||
def create_encrypted_storage(storage_impl, algorithm=None, key=None, encryption_enabled=True):
|
||||
"""
|
||||
@ -255,12 +258,12 @@ def create_encrypted_storage(storage_impl, algorithm=None, key=None, encryption_
|
||||
Encrypted storage wrapper instance
|
||||
"""
|
||||
wrapper = EncryptedStorageWrapper(storage_impl, algorithm=algorithm, key=key)
|
||||
|
||||
|
||||
wrapper.encryption_enabled = encryption_enabled
|
||||
|
||||
|
||||
if encryption_enabled:
|
||||
logging.info("Encryption enabled in storage wrapper")
|
||||
else:
|
||||
logging.info("Encryption disabled in storage wrapper")
|
||||
|
||||
|
||||
return wrapper
|
||||
|
||||
@ -32,7 +32,6 @@ ATTEMPT_TIME = 2
|
||||
|
||||
@singleton
|
||||
class ESConnection(ESConnectionBase):
|
||||
|
||||
"""
|
||||
CRUD operations
|
||||
"""
|
||||
@ -82,8 +81,9 @@ class ESConnection(ESConnectionBase):
|
||||
vector_similarity_weight = 0.5
|
||||
for m in match_expressions:
|
||||
if isinstance(m, FusionExpr) and m.method == "weighted_sum" and "weights" in m.fusion_params:
|
||||
assert len(match_expressions) == 3 and isinstance(match_expressions[0], MatchTextExpr) and isinstance(match_expressions[1],
|
||||
MatchDenseExpr) and isinstance(
|
||||
assert len(match_expressions) == 3 and isinstance(match_expressions[0], MatchTextExpr) and isinstance(
|
||||
match_expressions[1],
|
||||
MatchDenseExpr) and isinstance(
|
||||
match_expressions[2], FusionExpr)
|
||||
weights = m.fusion_params["weights"]
|
||||
vector_similarity_weight = get_float(weights.split(",")[1])
|
||||
@ -93,9 +93,9 @@ class ESConnection(ESConnectionBase):
|
||||
if isinstance(minimum_should_match, float):
|
||||
minimum_should_match = str(int(minimum_should_match * 100)) + "%"
|
||||
bool_query.must.append(Q("query_string", fields=m.fields,
|
||||
type="best_fields", query=m.matching_text,
|
||||
minimum_should_match=minimum_should_match,
|
||||
boost=1))
|
||||
type="best_fields", query=m.matching_text,
|
||||
minimum_should_match=minimum_should_match,
|
||||
boost=1))
|
||||
bool_query.boost = 1.0 - vector_similarity_weight
|
||||
|
||||
elif isinstance(m, MatchDenseExpr):
|
||||
@ -146,7 +146,7 @@ class ESConnection(ESConnectionBase):
|
||||
|
||||
for i in range(ATTEMPT_TIME):
|
||||
try:
|
||||
#print(json.dumps(q, ensure_ascii=False))
|
||||
# print(json.dumps(q, ensure_ascii=False))
|
||||
res = self.es.search(index=index_names,
|
||||
body=q,
|
||||
timeout="600s",
|
||||
@ -220,13 +220,15 @@ class ESConnection(ESConnectionBase):
|
||||
try:
|
||||
self.es.update(index=index_name, id=chunk_id, script=f"ctx._source.remove(\"{k}\");")
|
||||
except Exception:
|
||||
self.logger.exception(f"ESConnection.update(index={index_name}, id={chunk_id}, doc={json.dumps(condition, ensure_ascii=False)}) got exception")
|
||||
self.logger.exception(
|
||||
f"ESConnection.update(index={index_name}, id={chunk_id}, doc={json.dumps(condition, ensure_ascii=False)}) got exception")
|
||||
try:
|
||||
self.es.update(index=index_name, id=chunk_id, doc=doc)
|
||||
return True
|
||||
except Exception as e:
|
||||
self.logger.exception(
|
||||
f"ESConnection.update(index={index_name}, id={chunk_id}, doc={json.dumps(condition, ensure_ascii=False)}) got exception: " + str(e))
|
||||
f"ESConnection.update(index={index_name}, id={chunk_id}, doc={json.dumps(condition, ensure_ascii=False)}) got exception: " + str(
|
||||
e))
|
||||
break
|
||||
return False
|
||||
|
||||
|
||||
@ -25,18 +25,23 @@ import PyPDF2
|
||||
from docx import Document
|
||||
import olefile
|
||||
|
||||
|
||||
def _is_zip(h: bytes) -> bool:
|
||||
return h.startswith(b"PK\x03\x04") or h.startswith(b"PK\x05\x06") or h.startswith(b"PK\x07\x08")
|
||||
|
||||
|
||||
def _is_pdf(h: bytes) -> bool:
|
||||
return h.startswith(b"%PDF-")
|
||||
|
||||
|
||||
def _is_ole(h: bytes) -> bool:
|
||||
return h.startswith(b"\xD0\xCF\x11\xE0\xA1\xB1\x1A\xE1")
|
||||
|
||||
|
||||
def _sha10(b: bytes) -> str:
|
||||
return hashlib.sha256(b).hexdigest()[:10]
|
||||
|
||||
|
||||
def _guess_ext(b: bytes) -> str:
|
||||
h = b[:8]
|
||||
if _is_zip(h):
|
||||
@ -58,13 +63,14 @@ def _guess_ext(b: bytes) -> str:
|
||||
return ".doc"
|
||||
return ".bin"
|
||||
|
||||
|
||||
# Try to extract the real embedded payload from OLE's Ole10Native
|
||||
def _extract_ole10native_payload(data: bytes) -> bytes:
|
||||
try:
|
||||
pos = 0
|
||||
if len(data) < 4:
|
||||
return data
|
||||
_ = int.from_bytes(data[pos:pos+4], "little")
|
||||
_ = int.from_bytes(data[pos:pos + 4], "little")
|
||||
pos += 4
|
||||
# filename/src/tmp (NUL-terminated ANSI)
|
||||
for _ in range(3):
|
||||
@ -74,14 +80,15 @@ def _extract_ole10native_payload(data: bytes) -> bytes:
|
||||
pos += 4
|
||||
if pos + 4 > len(data):
|
||||
return data
|
||||
size = int.from_bytes(data[pos:pos+4], "little")
|
||||
size = int.from_bytes(data[pos:pos + 4], "little")
|
||||
pos += 4
|
||||
if pos + size <= len(data):
|
||||
return data[pos:pos+size]
|
||||
return data[pos:pos + size]
|
||||
except Exception:
|
||||
pass
|
||||
return data
|
||||
|
||||
|
||||
def extract_embed_file(target: Union[bytes, bytearray]) -> List[Tuple[str, bytes]]:
|
||||
"""
|
||||
Only extract the 'first layer' of embedding, returning raw (filename, bytes).
|
||||
@ -163,7 +170,7 @@ def extract_links_from_docx(docx_bytes: bytes):
|
||||
# Each relationship may represent a hyperlink, image, footer, etc.
|
||||
for rel in document.part.rels.values():
|
||||
if rel.reltype == (
|
||||
"http://schemas.openxmlformats.org/officeDocument/2006/relationships/hyperlink"
|
||||
"http://schemas.openxmlformats.org/officeDocument/2006/relationships/hyperlink"
|
||||
):
|
||||
links.add(rel.target_ref)
|
||||
|
||||
@ -198,6 +205,8 @@ def extract_links_from_pdf(pdf_bytes: bytes):
|
||||
|
||||
|
||||
_GLOBAL_SESSION: Optional[requests.Session] = None
|
||||
|
||||
|
||||
def _get_session(headers: Optional[Dict[str, str]] = None) -> requests.Session:
|
||||
"""Get or create a global reusable session."""
|
||||
global _GLOBAL_SESSION
|
||||
@ -216,10 +225,10 @@ def _get_session(headers: Optional[Dict[str, str]] = None) -> requests.Session:
|
||||
|
||||
|
||||
def extract_html(
|
||||
url: str,
|
||||
timeout: float = 60.0,
|
||||
headers: Optional[Dict[str, str]] = None,
|
||||
max_retries: int = 2,
|
||||
url: str,
|
||||
timeout: float = 60.0,
|
||||
headers: Optional[Dict[str, str]] = None,
|
||||
max_retries: int = 2,
|
||||
) -> Tuple[Optional[bytes], Dict[str, str]]:
|
||||
"""
|
||||
Extract the full HTML page as raw bytes from a given URL.
|
||||
@ -260,4 +269,4 @@ def extract_html(
|
||||
metadata["error"] = f"Request failed: {e}"
|
||||
continue
|
||||
|
||||
return None, metadata
|
||||
return None, metadata
|
||||
|
||||
@ -204,4 +204,4 @@ class RAGFlowGCS:
|
||||
return False
|
||||
except Exception:
|
||||
logging.exception(f"Fail to move {src_bucket}/{src_path} -> {dest_bucket}/{dest_path}")
|
||||
return False
|
||||
return False
|
||||
|
||||
@ -28,7 +28,6 @@ from common.doc_store.infinity_conn_base import InfinityConnectionBase
|
||||
|
||||
@singleton
|
||||
class InfinityConnection(InfinityConnectionBase):
|
||||
|
||||
"""
|
||||
Dataframe and fields convert
|
||||
"""
|
||||
@ -83,24 +82,23 @@ class InfinityConnection(InfinityConnectionBase):
|
||||
tokens[0] = field
|
||||
return "^".join(tokens)
|
||||
|
||||
|
||||
"""
|
||||
CRUD operations
|
||||
"""
|
||||
|
||||
def search(
|
||||
self,
|
||||
select_fields: list[str],
|
||||
highlight_fields: list[str],
|
||||
condition: dict,
|
||||
match_expressions: list[MatchExpr],
|
||||
order_by: OrderByExpr,
|
||||
offset: int,
|
||||
limit: int,
|
||||
index_names: str | list[str],
|
||||
knowledgebase_ids: list[str],
|
||||
agg_fields: list[str] | None = None,
|
||||
rank_feature: dict | None = None,
|
||||
self,
|
||||
select_fields: list[str],
|
||||
highlight_fields: list[str],
|
||||
condition: dict,
|
||||
match_expressions: list[MatchExpr],
|
||||
order_by: OrderByExpr,
|
||||
offset: int,
|
||||
limit: int,
|
||||
index_names: str | list[str],
|
||||
knowledgebase_ids: list[str],
|
||||
agg_fields: list[str] | None = None,
|
||||
rank_feature: dict | None = None,
|
||||
) -> tuple[pd.DataFrame, int]:
|
||||
"""
|
||||
BUG: Infinity returns empty for a highlight field if the query string doesn't use that field.
|
||||
@ -159,7 +157,8 @@ class InfinityConnection(InfinityConnectionBase):
|
||||
if table_found:
|
||||
break
|
||||
if not table_found:
|
||||
self.logger.error(f"No valid tables found for indexNames {index_names} and knowledgebaseIds {knowledgebase_ids}")
|
||||
self.logger.error(
|
||||
f"No valid tables found for indexNames {index_names} and knowledgebaseIds {knowledgebase_ids}")
|
||||
return pd.DataFrame(), 0
|
||||
|
||||
for matchExpr in match_expressions:
|
||||
@ -280,7 +279,8 @@ class InfinityConnection(InfinityConnectionBase):
|
||||
try:
|
||||
table_instance = db_instance.get_table(table_name)
|
||||
except Exception:
|
||||
self.logger.warning(f"Table not found: {table_name}, this dataset isn't created in Infinity. Maybe it is created in other document engine.")
|
||||
self.logger.warning(
|
||||
f"Table not found: {table_name}, this dataset isn't created in Infinity. Maybe it is created in other document engine.")
|
||||
continue
|
||||
kb_res, _ = table_instance.output(["*"]).filter(f"id = '{chunk_id}'").to_df()
|
||||
self.logger.debug(f"INFINITY get table: {str(table_list)}, result: {str(kb_res)}")
|
||||
@ -288,7 +288,9 @@ class InfinityConnection(InfinityConnectionBase):
|
||||
self.connPool.release_conn(inf_conn)
|
||||
res = self.concat_dataframes(df_list, ["id"])
|
||||
fields = set(res.columns.tolist())
|
||||
for field in ["docnm_kwd", "title_tks", "title_sm_tks", "important_kwd", "important_tks", "question_kwd", "question_tks","content_with_weight", "content_ltks", "content_sm_ltks", "authors_tks", "authors_sm_tks"]:
|
||||
for field in ["docnm_kwd", "title_tks", "title_sm_tks", "important_kwd", "important_tks", "question_kwd",
|
||||
"question_tks", "content_with_weight", "content_ltks", "content_sm_ltks", "authors_tks",
|
||||
"authors_sm_tks"]:
|
||||
fields.add(field)
|
||||
res_fields = self.get_fields(res, list(fields))
|
||||
return res_fields.get(chunk_id, None)
|
||||
@ -379,7 +381,9 @@ class InfinityConnection(InfinityConnectionBase):
|
||||
d[k] = "_".join(f"{num:08x}" for num in v)
|
||||
else:
|
||||
d[k] = v
|
||||
for k in ["docnm_kwd", "title_tks", "title_sm_tks", "important_kwd", "important_tks", "content_with_weight", "content_ltks", "content_sm_ltks", "authors_tks", "authors_sm_tks", "question_kwd", "question_tks"]:
|
||||
for k in ["docnm_kwd", "title_tks", "title_sm_tks", "important_kwd", "important_tks", "content_with_weight",
|
||||
"content_ltks", "content_sm_ltks", "authors_tks", "authors_sm_tks", "question_kwd",
|
||||
"question_tks"]:
|
||||
if k in d:
|
||||
del d[k]
|
||||
|
||||
@ -478,7 +482,8 @@ class InfinityConnection(InfinityConnectionBase):
|
||||
del new_value[k]
|
||||
else:
|
||||
new_value[k] = v
|
||||
for k in ["docnm_kwd", "title_tks", "title_sm_tks", "important_kwd", "important_tks", "content_with_weight", "content_ltks", "content_sm_ltks", "authors_tks", "authors_sm_tks", "question_kwd", "question_tks"]:
|
||||
for k in ["docnm_kwd", "title_tks", "title_sm_tks", "important_kwd", "important_tks", "content_with_weight",
|
||||
"content_ltks", "content_sm_ltks", "authors_tks", "authors_sm_tks", "question_kwd", "question_tks"]:
|
||||
if k in new_value:
|
||||
del new_value[k]
|
||||
|
||||
@ -502,7 +507,8 @@ class InfinityConnection(InfinityConnectionBase):
|
||||
self.logger.debug(f"INFINITY update table {table_name}, filter {filter}, newValue {new_value}.")
|
||||
for update_kv, ids in remove_opt.items():
|
||||
k, v = json.loads(update_kv)
|
||||
table_instance.update(filter + " AND id in ({0})".format(",".join([f"'{id}'" for id in ids])), {k: "###".join(v)})
|
||||
table_instance.update(filter + " AND id in ({0})".format(",".join([f"'{id}'" for id in ids])),
|
||||
{k: "###".join(v)})
|
||||
|
||||
table_instance.update(filter, new_value)
|
||||
self.connPool.release_conn(inf_conn)
|
||||
@ -561,7 +567,7 @@ class InfinityConnection(InfinityConnectionBase):
|
||||
def to_position_int(v):
|
||||
if v:
|
||||
arr = [int(hex_val, 16) for hex_val in v.split("_")]
|
||||
v = [arr[i : i + 5] for i in range(0, len(arr), 5)]
|
||||
v = [arr[i: i + 5] for i in range(0, len(arr), 5)]
|
||||
else:
|
||||
v = []
|
||||
return v
|
||||
|
||||
@ -46,6 +46,7 @@ class RAGFlowMinio:
|
||||
# pass original identifier forward for use by other decorators
|
||||
kwargs['_orig_bucket'] = original_bucket
|
||||
return method(self, actual_bucket, *args, **kwargs)
|
||||
|
||||
return wrapper
|
||||
|
||||
@staticmethod
|
||||
@ -71,6 +72,7 @@ class RAGFlowMinio:
|
||||
fnm = f"{orig_bucket}/{fnm}"
|
||||
|
||||
return method(self, bucket, fnm, *args, **kwargs)
|
||||
|
||||
return wrapper
|
||||
|
||||
def __open__(self):
|
||||
|
||||
@ -37,7 +37,8 @@ from common import settings
|
||||
from common.constants import PAGERANK_FLD, TAG_FLD
|
||||
from common.decorator import singleton
|
||||
from common.float_utils import get_float
|
||||
from common.doc_store.doc_store_base import DocStoreConnection, MatchExpr, OrderByExpr, FusionExpr, MatchTextExpr, MatchDenseExpr
|
||||
from common.doc_store.doc_store_base import DocStoreConnection, MatchExpr, OrderByExpr, FusionExpr, MatchTextExpr, \
|
||||
MatchDenseExpr
|
||||
from rag.nlp import rag_tokenizer
|
||||
|
||||
ATTEMPT_TIME = 2
|
||||
@ -719,19 +720,19 @@ class OBConnection(DocStoreConnection):
|
||||
"""
|
||||
|
||||
def search(
|
||||
self,
|
||||
selectFields: list[str],
|
||||
highlightFields: list[str],
|
||||
condition: dict,
|
||||
matchExprs: list[MatchExpr],
|
||||
orderBy: OrderByExpr,
|
||||
offset: int,
|
||||
limit: int,
|
||||
indexNames: str | list[str],
|
||||
knowledgebaseIds: list[str],
|
||||
aggFields: list[str] = [],
|
||||
rank_feature: dict | None = None,
|
||||
**kwargs,
|
||||
self,
|
||||
selectFields: list[str],
|
||||
highlightFields: list[str],
|
||||
condition: dict,
|
||||
matchExprs: list[MatchExpr],
|
||||
orderBy: OrderByExpr,
|
||||
offset: int,
|
||||
limit: int,
|
||||
indexNames: str | list[str],
|
||||
knowledgebaseIds: list[str],
|
||||
aggFields: list[str] = [],
|
||||
rank_feature: dict | None = None,
|
||||
**kwargs,
|
||||
):
|
||||
if isinstance(indexNames, str):
|
||||
indexNames = indexNames.split(",")
|
||||
@ -1546,7 +1547,7 @@ class OBConnection(DocStoreConnection):
|
||||
flags=re.IGNORECASE | re.MULTILINE,
|
||||
)
|
||||
if len(re.findall(r'</em><em>', highlighted_txt)) > 0 or len(
|
||||
re.findall(r'</em>\s*<em>', highlighted_txt)) > 0:
|
||||
re.findall(r'</em>\s*<em>', highlighted_txt)) > 0:
|
||||
return highlighted_txt
|
||||
else:
|
||||
return None
|
||||
@ -1565,9 +1566,9 @@ class OBConnection(DocStoreConnection):
|
||||
if token_pos != -1:
|
||||
if token in keywords:
|
||||
highlighted_txt = (
|
||||
highlighted_txt[:token_pos] +
|
||||
f'<em>{token}</em>' +
|
||||
highlighted_txt[token_pos + len(token):]
|
||||
highlighted_txt[:token_pos] +
|
||||
f'<em>{token}</em>' +
|
||||
highlighted_txt[token_pos + len(token):]
|
||||
)
|
||||
last_pos = token_pos
|
||||
return re.sub(r'</em><em>', '', highlighted_txt)
|
||||
|
||||
@ -6,7 +6,6 @@ from urllib.parse import quote_plus
|
||||
from common.config_utils import get_base_config
|
||||
from common.decorator import singleton
|
||||
|
||||
|
||||
CREATE_TABLE_SQL = """
|
||||
CREATE TABLE IF NOT EXISTS `{}` (
|
||||
`key` VARCHAR(255) PRIMARY KEY,
|
||||
@ -36,7 +35,8 @@ def get_opendal_config():
|
||||
"table": opendal_config.get("config", {}).get("oss_table", "opendal_storage"),
|
||||
"max_allowed_packet": str(max_packet)
|
||||
}
|
||||
kwargs["connection_string"] = f"mysql://{kwargs['user']}:{quote_plus(kwargs['password'])}@{kwargs['host']}:{kwargs['port']}/{kwargs['database']}?max_allowed_packet={max_packet}"
|
||||
kwargs[
|
||||
"connection_string"] = f"mysql://{kwargs['user']}:{quote_plus(kwargs['password'])}@{kwargs['host']}:{kwargs['port']}/{kwargs['database']}?max_allowed_packet={max_packet}"
|
||||
else:
|
||||
scheme = opendal_config.get("scheme")
|
||||
config_data = opendal_config.get("config", {})
|
||||
@ -61,7 +61,7 @@ def get_opendal_config():
|
||||
del kwargs["password"]
|
||||
if "connection_string" in kwargs:
|
||||
del kwargs["connection_string"]
|
||||
return kwargs
|
||||
return kwargs
|
||||
except Exception as e:
|
||||
logging.error("Failed to load OpenDAL configuration from yaml: %s", str(e))
|
||||
raise
|
||||
@ -99,7 +99,6 @@ class OpenDALStorage:
|
||||
def obj_exist(self, bucket, fnm, tenant_id=None):
|
||||
return self._operator.exists(f"{bucket}/{fnm}")
|
||||
|
||||
|
||||
def init_db_config(self):
|
||||
try:
|
||||
conn = pymysql.connect(
|
||||
|
||||
@ -26,7 +26,8 @@ from opensearchpy import UpdateByQuery, Q, Search, Index
|
||||
from opensearchpy import ConnectionTimeout
|
||||
from common.decorator import singleton
|
||||
from common.file_utils import get_project_base_directory
|
||||
from common.doc_store.doc_store_base import DocStoreConnection, MatchExpr, OrderByExpr, MatchTextExpr, MatchDenseExpr, FusionExpr
|
||||
from common.doc_store.doc_store_base import DocStoreConnection, MatchExpr, OrderByExpr, MatchTextExpr, MatchDenseExpr, \
|
||||
FusionExpr
|
||||
from rag.nlp import is_english, rag_tokenizer
|
||||
from common.constants import PAGERANK_FLD, TAG_FLD
|
||||
from common import settings
|
||||
@ -189,7 +190,7 @@ class OSConnection(DocStoreConnection):
|
||||
minimum_should_match=minimum_should_match,
|
||||
boost=1))
|
||||
bqry.boost = 1.0 - vector_similarity_weight
|
||||
|
||||
|
||||
# Elasticsearch has the encapsulation of KNN_search in python sdk
|
||||
# while the Python SDK for OpenSearch does not provide encapsulation for KNN_search,
|
||||
# the following codes implement KNN_search in OpenSearch using DSL
|
||||
@ -216,7 +217,7 @@ class OSConnection(DocStoreConnection):
|
||||
if bqry:
|
||||
s = s.query(bqry)
|
||||
for field in highlightFields:
|
||||
s = s.highlight(field,force_source=True,no_match_size=30,require_field_match=False)
|
||||
s = s.highlight(field, force_source=True, no_match_size=30, require_field_match=False)
|
||||
|
||||
if orderBy:
|
||||
orders = list()
|
||||
@ -239,10 +240,10 @@ class OSConnection(DocStoreConnection):
|
||||
s = s[offset:offset + limit]
|
||||
q = s.to_dict()
|
||||
logger.debug(f"OSConnection.search {str(indexNames)} query: " + json.dumps(q))
|
||||
|
||||
|
||||
if use_knn:
|
||||
del q["query"]
|
||||
q["query"] = {"knn" : knn_query}
|
||||
q["query"] = {"knn": knn_query}
|
||||
|
||||
for i in range(ATTEMPT_TIME):
|
||||
try:
|
||||
@ -328,7 +329,7 @@ class OSConnection(DocStoreConnection):
|
||||
chunkId = condition["id"]
|
||||
for i in range(ATTEMPT_TIME):
|
||||
try:
|
||||
self.os.update(index=indexName, id=chunkId, body={"doc":doc})
|
||||
self.os.update(index=indexName, id=chunkId, body={"doc": doc})
|
||||
return True
|
||||
except Exception as e:
|
||||
logger.exception(
|
||||
@ -435,7 +436,7 @@ class OSConnection(DocStoreConnection):
|
||||
logger.debug("OSConnection.delete query: " + json.dumps(qry.to_dict()))
|
||||
for _ in range(ATTEMPT_TIME):
|
||||
try:
|
||||
#print(Search().query(qry).to_dict(), flush=True)
|
||||
# print(Search().query(qry).to_dict(), flush=True)
|
||||
res = self.os.delete_by_query(
|
||||
index=indexName,
|
||||
body=Search().query(qry).to_dict(),
|
||||
|
||||
@ -42,14 +42,16 @@ class RAGFlowOSS:
|
||||
# If there is a default bucket, use the default bucket
|
||||
actual_bucket = self.bucket if self.bucket else bucket
|
||||
return method(self, actual_bucket, *args, **kwargs)
|
||||
|
||||
return wrapper
|
||||
|
||||
|
||||
@staticmethod
|
||||
def use_prefix_path(method):
|
||||
def wrapper(self, bucket, fnm, *args, **kwargs):
|
||||
# If the prefix path is set, use the prefix path
|
||||
fnm = f"{self.prefix_path}/{fnm}" if self.prefix_path else fnm
|
||||
return method(self, bucket, fnm, *args, **kwargs)
|
||||
|
||||
return wrapper
|
||||
|
||||
def __open__(self):
|
||||
@ -171,4 +173,3 @@ class RAGFlowOSS:
|
||||
self.__open__()
|
||||
time.sleep(1)
|
||||
return None
|
||||
|
||||
|
||||
@ -21,7 +21,6 @@ Utility functions for Raptor processing decisions.
|
||||
import logging
|
||||
from typing import Optional
|
||||
|
||||
|
||||
# File extensions for structured data types
|
||||
EXCEL_EXTENSIONS = {".xls", ".xlsx", ".xlsm", ".xlsb"}
|
||||
CSV_EXTENSIONS = {".csv", ".tsv"}
|
||||
@ -40,12 +39,12 @@ def is_structured_file_type(file_type: Optional[str]) -> bool:
|
||||
"""
|
||||
if not file_type:
|
||||
return False
|
||||
|
||||
|
||||
# Normalize to lowercase and ensure leading dot
|
||||
file_type = file_type.lower()
|
||||
if not file_type.startswith("."):
|
||||
file_type = f".{file_type}"
|
||||
|
||||
|
||||
return file_type in STRUCTURED_EXTENSIONS
|
||||
|
||||
|
||||
@ -61,23 +60,23 @@ def is_tabular_pdf(parser_id: str = "", parser_config: Optional[dict] = None) ->
|
||||
True if PDF is being parsed as tabular data
|
||||
"""
|
||||
parser_config = parser_config or {}
|
||||
|
||||
|
||||
# If using table parser, it's tabular
|
||||
if parser_id and parser_id.lower() == "table":
|
||||
return True
|
||||
|
||||
|
||||
# Check if html4excel is enabled (Excel-like table parsing)
|
||||
if parser_config.get("html4excel", False):
|
||||
return True
|
||||
|
||||
|
||||
return False
|
||||
|
||||
|
||||
def should_skip_raptor(
|
||||
file_type: Optional[str] = None,
|
||||
parser_id: str = "",
|
||||
parser_config: Optional[dict] = None,
|
||||
raptor_config: Optional[dict] = None
|
||||
file_type: Optional[str] = None,
|
||||
parser_id: str = "",
|
||||
parser_config: Optional[dict] = None,
|
||||
raptor_config: Optional[dict] = None
|
||||
) -> bool:
|
||||
"""
|
||||
Determine if Raptor should be skipped for a given document.
|
||||
@ -97,30 +96,30 @@ def should_skip_raptor(
|
||||
"""
|
||||
parser_config = parser_config or {}
|
||||
raptor_config = raptor_config or {}
|
||||
|
||||
|
||||
# Check if auto-disable is explicitly disabled in config
|
||||
if raptor_config.get("auto_disable_for_structured_data", True) is False:
|
||||
logging.info("Raptor auto-disable is turned off via configuration")
|
||||
return False
|
||||
|
||||
|
||||
# Check for Excel/CSV files
|
||||
if is_structured_file_type(file_type):
|
||||
logging.info(f"Skipping Raptor for structured file type: {file_type}")
|
||||
return True
|
||||
|
||||
|
||||
# Check for tabular PDFs
|
||||
if file_type and file_type.lower() in [".pdf", "pdf"]:
|
||||
if is_tabular_pdf(parser_id, parser_config):
|
||||
logging.info(f"Skipping Raptor for tabular PDF (parser_id={parser_id})")
|
||||
return True
|
||||
|
||||
|
||||
return False
|
||||
|
||||
|
||||
def get_skip_reason(
|
||||
file_type: Optional[str] = None,
|
||||
parser_id: str = "",
|
||||
parser_config: Optional[dict] = None
|
||||
file_type: Optional[str] = None,
|
||||
parser_id: str = "",
|
||||
parser_config: Optional[dict] = None
|
||||
) -> str:
|
||||
"""
|
||||
Get a human-readable reason why Raptor was skipped.
|
||||
@ -134,12 +133,12 @@ def get_skip_reason(
|
||||
Reason string, or empty string if Raptor should not be skipped
|
||||
"""
|
||||
parser_config = parser_config or {}
|
||||
|
||||
|
||||
if is_structured_file_type(file_type):
|
||||
return f"Structured data file ({file_type}) - Raptor auto-disabled"
|
||||
|
||||
|
||||
if file_type and file_type.lower() in [".pdf", "pdf"]:
|
||||
if is_tabular_pdf(parser_id, parser_config):
|
||||
return f"Tabular PDF (parser={parser_id}) - Raptor auto-disabled"
|
||||
|
||||
|
||||
return ""
|
||||
|
||||
@ -33,6 +33,7 @@ except Exception:
|
||||
except Exception:
|
||||
REDIS = {}
|
||||
|
||||
|
||||
class RedisMsg:
|
||||
def __init__(self, consumer, queue_name, group_name, msg_id, message):
|
||||
self.__consumer = consumer
|
||||
@ -278,7 +279,8 @@ class RedisDB:
|
||||
def decrby(self, key: str, decrement: int):
|
||||
return self.REDIS.decrby(key, decrement)
|
||||
|
||||
def generate_auto_increment_id(self, key_prefix: str = "id_generator", namespace: str = "default", increment: int = 1, ensure_minimum: int | None = None) -> int:
|
||||
def generate_auto_increment_id(self, key_prefix: str = "id_generator", namespace: str = "default",
|
||||
increment: int = 1, ensure_minimum: int | None = None) -> int:
|
||||
redis_key = f"{key_prefix}:{namespace}"
|
||||
|
||||
try:
|
||||
|
||||
@ -46,6 +46,7 @@ class RAGFlowS3:
|
||||
# If there is a default bucket, use the default bucket
|
||||
actual_bucket = self.bucket if self.bucket else bucket
|
||||
return method(self, actual_bucket, *args, **kwargs)
|
||||
|
||||
return wrapper
|
||||
|
||||
@staticmethod
|
||||
@ -57,6 +58,7 @@ class RAGFlowS3:
|
||||
if self.prefix_path:
|
||||
fnm = f"{self.prefix_path}/{bucket}/{fnm}"
|
||||
return method(self, bucket, fnm, *args, **kwargs)
|
||||
|
||||
return wrapper
|
||||
|
||||
def __open__(self):
|
||||
@ -81,16 +83,16 @@ class RAGFlowS3:
|
||||
s3_params['region_name'] = self.region_name
|
||||
if self.endpoint_url:
|
||||
s3_params['endpoint_url'] = self.endpoint_url
|
||||
|
||||
|
||||
# Configure signature_version and addressing_style through Config object
|
||||
if self.signature_version:
|
||||
config_kwargs['signature_version'] = self.signature_version
|
||||
if self.addressing_style:
|
||||
config_kwargs['s3'] = {'addressing_style': self.addressing_style}
|
||||
|
||||
|
||||
if config_kwargs:
|
||||
s3_params['config'] = Config(**config_kwargs)
|
||||
|
||||
|
||||
self.conn = [boto3.client('s3', **s3_params)]
|
||||
except Exception:
|
||||
logging.exception(f"Fail to connect at region {self.region_name} or endpoint {self.endpoint_url}")
|
||||
@ -184,9 +186,9 @@ class RAGFlowS3:
|
||||
for _ in range(10):
|
||||
try:
|
||||
r = self.conn[0].generate_presigned_url('get_object',
|
||||
Params={'Bucket': bucket,
|
||||
'Key': fnm},
|
||||
ExpiresIn=expires)
|
||||
Params={'Bucket': bucket,
|
||||
'Key': fnm},
|
||||
ExpiresIn=expires)
|
||||
|
||||
return r
|
||||
except Exception:
|
||||
|
||||
@ -30,7 +30,8 @@ class Tavily:
|
||||
search_depth="advanced",
|
||||
max_results=6
|
||||
)
|
||||
return [{"url": res["url"], "title": res["title"], "content": res["content"], "score": res["score"]} for res in response["results"]]
|
||||
return [{"url": res["url"], "title": res["title"], "content": res["content"], "score": res["score"]} for res
|
||||
in response["results"]]
|
||||
except Exception as e:
|
||||
logging.exception(e)
|
||||
|
||||
@ -64,5 +65,5 @@ class Tavily:
|
||||
"count": 1,
|
||||
"url": r["url"]
|
||||
})
|
||||
logging.info("[Tavily]R: "+r["content"][:128]+"...")
|
||||
return {"chunks": chunks, "doc_aggs": aggs}
|
||||
logging.info("[Tavily]R: " + r["content"][:128] + "...")
|
||||
return {"chunks": chunks, "doc_aggs": aggs}
|
||||
|
||||
32
uv.lock
generated
32
uv.lock
generated
@ -345,6 +345,21 @@ wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/b7/7b/7bf42178d227b26d3daf94cdd22a72a4ed5bf235548c4f5aea49c51c6458/arxiv-2.1.3-py3-none-any.whl", hash = "sha256:6f43673ab770a9e848d7d4fc1894824df55edeac3c3572ea280c9ba2e3c0f39f", size = 11478, upload-time = "2024-06-25T02:56:17.032Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "asana"
|
||||
version = "5.2.2"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
dependencies = [
|
||||
{ name = "certifi" },
|
||||
{ name = "python-dateutil" },
|
||||
{ name = "six" },
|
||||
{ name = "urllib3" },
|
||||
]
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/db/59/af14efdd03d332c33d4a77aed8f1f7151e3de5c2441e4bea3b1c6dbcc9d7/asana-5.2.2.tar.gz", hash = "sha256:d280ce2e8edf0355ccf21e548d887617ca8c926e1cb41309b8a173ca3181632c", size = 126424, upload-time = "2025-09-24T21:31:04.055Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/26/5e/337125441af40aba86b087dee3dbe829413b6e42eac74defae2076926dbe/asana-5.2.2-py3-none-any.whl", hash = "sha256:1c8d15949a6cb9aa12363a5b7cfc6c0544cb3ae77290dd2e3255c0ec70668458", size = 203161, upload-time = "2025-09-24T21:31:02.401Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "aspose-slides"
|
||||
version = "24.7.0"
|
||||
@ -5856,6 +5871,19 @@ wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/6a/3e/b68c118422ec867fa7ab88444e1274aa40681c606d59ac27de5a5588f082/python_dotenv-1.0.1-py3-none-any.whl", hash = "sha256:f7b63ef50f1b690dddf550d03497b66d609393b40b564ed0d674909a68ebf16a", size = 19863, upload-time = "2024-01-23T06:32:58.246Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "python-gitlab"
|
||||
version = "7.0.0"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
dependencies = [
|
||||
{ name = "requests" },
|
||||
{ name = "requests-toolbelt" },
|
||||
]
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/5e/c4/0b613303b4f0fcda69b3d2e03d0a1fb1b6b079a7c7832e03a8d92461e9fe/python_gitlab-7.0.0.tar.gz", hash = "sha256:e4d934430f64efc09e6208b782c61cc0a3389527765e03ffbef17f4323dce441", size = 400568, upload-time = "2025-10-29T15:06:02.069Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/4f/9e/811edc46a15f8deb828cba7ef8aab3451dc11ca72d033f3df72a5af865d9/python_gitlab-7.0.0-py3-none-any.whl", hash = "sha256:712a6c8c5e79e7e66f6dabb25d8fe7831a6b238d4a5132f8231df6b3b890ceff", size = 144415, upload-time = "2025-10-29T15:06:00.232Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "python-multipart"
|
||||
version = "0.0.20"
|
||||
@ -6089,6 +6117,7 @@ dependencies = [
|
||||
{ name = "akshare" },
|
||||
{ name = "anthropic" },
|
||||
{ name = "arxiv" },
|
||||
{ name = "asana" },
|
||||
{ name = "aspose-slides", marker = "platform_machine == 'x86_64' or (platform_machine == 'arm64' and sys_platform == 'darwin')" },
|
||||
{ name = "atlassian-python-api" },
|
||||
{ name = "azure-identity" },
|
||||
@ -6162,6 +6191,7 @@ dependencies = [
|
||||
{ name = "pypdf2" },
|
||||
{ name = "python-calamine" },
|
||||
{ name = "python-docx" },
|
||||
{ name = "python-gitlab" },
|
||||
{ name = "python-pptx" },
|
||||
{ name = "pywencai" },
|
||||
{ name = "qianfan" },
|
||||
@ -6219,6 +6249,7 @@ requires-dist = [
|
||||
{ name = "akshare", specifier = ">=1.15.78,<2.0.0" },
|
||||
{ name = "anthropic", specifier = "==0.34.1" },
|
||||
{ name = "arxiv", specifier = "==2.1.3" },
|
||||
{ name = "asana", specifier = ">=5.2.2" },
|
||||
{ name = "aspose-slides", marker = "platform_machine == 'x86_64' or (platform_machine == 'arm64' and sys_platform == 'darwin')", specifier = "==24.7.0" },
|
||||
{ name = "atlassian-python-api", specifier = "==4.0.7" },
|
||||
{ name = "azure-identity", specifier = "==1.17.1" },
|
||||
@ -6291,6 +6322,7 @@ requires-dist = [
|
||||
{ name = "pypdf2", specifier = ">=3.0.1,<4.0.0" },
|
||||
{ name = "python-calamine", specifier = ">=0.4.0" },
|
||||
{ name = "python-docx", specifier = ">=1.1.2,<2.0.0" },
|
||||
{ name = "python-gitlab", specifier = ">=7.0.0" },
|
||||
{ name = "python-pptx", specifier = ">=1.0.2,<2.0.0" },
|
||||
{ name = "pywencai", specifier = ">=0.13.1,<1.0.0" },
|
||||
{ name = "qianfan", specifier = "==0.4.6" },
|
||||
|
||||
5
web/src/assets/svg/data-source/asana.svg
Normal file
5
web/src/assets/svg/data-source/asana.svg
Normal file
{kind=link}
@ -0,0 +1,5 @@
|
||||
<svg fill="none" xmlns="http://www.w3.org/2000/svg" viewBox="8 16 20 17">
|
||||
<path fill-rule="evenodd" clip-rule="evenodd"
|
||||
d="M23.3789 24.9999C21.1719 24.9999 19.3826 26.7908 19.3826 29.0001C19.3826 31.2091 21.1719 33 23.3789 33C25.586 33 27.3752 31.2091 27.3752 29.0001C27.3752 26.7908 25.586 24.9999 23.3789 24.9999ZM12.9963 25.0003C10.7892 25.0003 9 26.7908 9 29C9 31.2091 10.7892 33 12.9963 33C15.2034 33 16.9927 31.2091 16.9927 29C16.9927 26.7908 15.2034 25.0003 12.9963 25.0003ZM22.1838 19.9999C22.1838 22.2091 20.3947 24.0002 18.1876 24.0002C15.9805 24.0002 14.1913 22.2091 14.1913 19.9999C14.1913 17.791 15.9805 16 18.1876 16C20.3947 16 22.1838 17.791 22.1838 19.9999Z"
|
||||
fill="#FF584A"></path>
|
||||
</svg>
|
||||
|
After Width: | Height: | Size: 724 B |
2
web/src/assets/svg/data-source/gitlab.svg
Normal file
2
web/src/assets/svg/data-source/gitlab.svg
Normal file
{kind=link}
@ -0,0 +1,2 @@
|
||||
<?xml version="1.0" encoding="utf-8"?><!-- Uploaded to: SVG Repo, www.svgrepo.com, Generator: SVG Repo Mixer Tools -->
|
||||
<svg width="800px" height="800px" viewBox="0 0 32 32" xmlns="http://www.w3.org/2000/svg"><title>file_type_gitlab</title><polygon points="16 28.896 16 28.896 21.156 13.029 10.844 13.029 16 28.896" style="fill:#e24329"/><polygon points="16 28.896 10.844 13.029 3.619 13.029 16 28.896" style="fill:#fc6d26"/><path d="M3.619,13.029h0L2.052,17.851a1.067,1.067,0,0,0,.388,1.193L16,28.9,3.619,13.029Z" style="fill:#fca326"/><path d="M3.619,13.029h7.225L7.739,3.473a.534.534,0,0,0-1.015,0L3.619,13.029Z" style="fill:#e24329"/><polygon points="16 28.896 21.156 13.029 28.381 13.029 16 28.896" style="fill:#fc6d26"/><path d="M28.381,13.029h0l1.567,4.822a1.067,1.067,0,0,1-.388,1.193L16,28.9,28.381,13.029Z" style="fill:#fca326"/><path d="M28.381,13.029H21.156l3.105-9.557a.534.534,0,0,1,1.015,0l3.105,9.557Z" style="fill:#e24329"/></svg>
|
||||
|
After Width: | Height: | Size: 946 B |
10
web/src/assets/svg/file-icon/mdx.svg
Normal file
10
web/src/assets/svg/file-icon/mdx.svg
Normal file
{kind=link}
@ -0,0 +1,10 @@
|
||||
<svg width="40" height="40" viewBox="0 0 40 40" fill="none" xmlns="http://www.w3.org/2000/svg">
|
||||
<path
|
||||
d="M35 39.25H11C9.20507 39.25 7.75 37.7949 7.75 36V4C7.75 2.20508 9.20508 0.75 11 0.75H27C27.1212 0.75 27.2375 0.798159 27.3232 0.883883L38.1161 11.6768C38.2018 11.7625 38.25 11.8788 38.25 12V36C38.25 37.7949 36.7949 39.25 35 39.25Z"
|
||||
stroke="#D0D5DD" stroke-width="1.5" />
|
||||
<path d="M27 0.5V8C27 10.2091 28.7909 12 31 12H38.5" stroke="#D0D5DD" stroke-width="1.5" />
|
||||
<rect x="1.7" y="18" width="31" height="16" rx="2" fill="#444CE7" />
|
||||
<path
|
||||
d="M5.91921 22.7273H7.81552L9.81836 27.6136H9.90359L11.9064 22.7273H13.8027V30H12.3113V25.2663H12.2509L10.3688 29.9645H9.35316L7.47106 25.2486H7.41069V30H5.91921V22.7273ZM17.6477 30H15.0696V22.7273H17.669C18.4006 22.7273 19.0303 22.8729 19.5582 23.1641C20.0862 23.4529 20.4922 23.8684 20.7763 24.4105C21.0627 24.9527 21.206 25.6013 21.206 26.3565C21.206 27.1141 21.0627 27.7652 20.7763 28.3097C20.4922 28.8542 20.0838 29.272 19.5511 29.5632C19.0208 29.8544 18.3864 30 17.6477 30ZM16.6072 28.6825H17.5838C18.0384 28.6825 18.4207 28.602 18.7308 28.4411C19.0433 28.2777 19.2777 28.0256 19.4339 27.6847C19.5926 27.3414 19.6719 26.8987 19.6719 26.3565C19.6719 25.8191 19.5926 25.38 19.4339 25.0391C19.2777 24.6982 19.0445 24.4472 18.7344 24.2862C18.4242 24.1252 18.0419 24.0447 17.5874 24.0447H16.6072V28.6825Z M21.5 22.7273H23.1L27.5 30H25.9L21.5 22.7273Z M25.9 22.7273H27.5L23.1 30H21.5L25.9 22.7273Z"
|
||||
fill="white" />
|
||||
</svg>
|
||||
|
After Width: | Height: | Size: 1.5 KiB |
@ -65,7 +65,10 @@ const ParserListMap = new Map([
|
||||
'knowledge_graph',
|
||||
],
|
||||
],
|
||||
[['md'], ['naive', 'qa', 'knowledge_graph']],
|
||||
[
|
||||
['md', 'mdx'],
|
||||
['naive', 'qa', 'knowledge_graph'],
|
||||
],
|
||||
[['json'], ['naive', 'knowledge_graph']],
|
||||
[['eml'], ['email']],
|
||||
]);
|
||||
|
||||
@ -82,7 +82,7 @@ const Preview = ({
|
||||
<CSVFileViewer className={className} url={url} />
|
||||
</section>
|
||||
)}
|
||||
{['md'].indexOf(fileType) > -1 && (
|
||||
{['md', 'mdx'].indexOf(fileType) > -1 && (
|
||||
<section>
|
||||
<Md className={className} url={url} />
|
||||
</section>
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
import { zodResolver } from '@hookform/resolvers/zod';
|
||||
import {
|
||||
forwardRef,
|
||||
useCallback,
|
||||
useEffect,
|
||||
useImperativeHandle,
|
||||
useMemo,
|
||||
@ -35,8 +36,20 @@ import { cn } from '@/lib/utils';
|
||||
import { t } from 'i18next';
|
||||
import { Loader } from 'lucide-react';
|
||||
import { MultiSelect, MultiSelectOptionType } from './ui/multi-select';
|
||||
import { Segmented } from './ui/segmented';
|
||||
import { Switch } from './ui/switch';
|
||||
|
||||
const getNestedValue = (obj: any, path: string) => {
|
||||
return path.split('.').reduce((current, key) => {
|
||||
return current && current[key] !== undefined ? current[key] : undefined;
|
||||
}, obj);
|
||||
};
|
||||
|
||||
/**
|
||||
* Properties of this field will be treated as static attributes and will be filtered out during form submission.
|
||||
*/
|
||||
export const FilterFormField = 'RAG_DY_STATIC';
|
||||
|
||||
// Field type enumeration
|
||||
export enum FormFieldType {
|
||||
Text = 'text',
|
||||
@ -49,6 +62,7 @@ export enum FormFieldType {
|
||||
Checkbox = 'checkbox',
|
||||
Switch = 'switch',
|
||||
Tag = 'tag',
|
||||
Segmented = 'segmented',
|
||||
Custom = 'custom',
|
||||
}
|
||||
|
||||
@ -138,6 +152,9 @@ export const generateSchema = (fields: FormFieldConfig[]): ZodSchema<any> => {
|
||||
});
|
||||
}
|
||||
break;
|
||||
case FormFieldType.Segmented:
|
||||
fieldSchema = z.string();
|
||||
break;
|
||||
case FormFieldType.Number:
|
||||
fieldSchema = z.coerce.number();
|
||||
if (field.validation?.min !== undefined) {
|
||||
@ -359,6 +376,34 @@ export const RenderField = ({
|
||||
);
|
||||
}
|
||||
switch (field.type) {
|
||||
case FormFieldType.Segmented:
|
||||
return (
|
||||
<RAGFlowFormItem
|
||||
{...field}
|
||||
labelClassName={labelClassName || field.labelClassName}
|
||||
>
|
||||
{(fieldProps) => {
|
||||
const finalFieldProps = field.onChange
|
||||
? {
|
||||
...fieldProps,
|
||||
onChange: (value: any) => {
|
||||
fieldProps.onChange(value);
|
||||
field.onChange?.(value);
|
||||
},
|
||||
}
|
||||
: fieldProps;
|
||||
return (
|
||||
<Segmented
|
||||
{...finalFieldProps}
|
||||
options={field.options || []}
|
||||
className="w-full"
|
||||
itemClassName="flex-1 justify-center"
|
||||
disabled={field.disabled}
|
||||
/>
|
||||
);
|
||||
}}
|
||||
</RAGFlowFormItem>
|
||||
);
|
||||
case FormFieldType.Textarea:
|
||||
return (
|
||||
<RAGFlowFormItem
|
||||
@ -621,7 +666,6 @@ const DynamicForm = {
|
||||
useMemo(() => {
|
||||
setFields(originFields);
|
||||
}, [originFields]);
|
||||
const schema = useMemo(() => generateSchema(fields), [fields]);
|
||||
|
||||
const defaultValues = useMemo(() => {
|
||||
const value = {
|
||||
@ -634,17 +678,31 @@ const DynamicForm = {
|
||||
// Initialize form
|
||||
const form = useForm<T>({
|
||||
resolver: async (data, context, options) => {
|
||||
const zodResult = await zodResolver(schema)(data, context, options);
|
||||
// Filter out fields that should not render
|
||||
const activeFields = fields.filter(
|
||||
(field) => !field.shouldRender || field.shouldRender(data),
|
||||
);
|
||||
|
||||
const activeSchema = generateSchema(activeFields);
|
||||
const zodResult = await zodResolver(activeSchema)(
|
||||
data,
|
||||
context,
|
||||
options,
|
||||
);
|
||||
|
||||
let combinedErrors = { ...zodResult.errors };
|
||||
|
||||
const fieldErrors: Record<string, { type: string; message: string }> =
|
||||
{};
|
||||
for (const field of fields) {
|
||||
if (field.customValidate && data[field.name] !== undefined) {
|
||||
if (
|
||||
field.customValidate &&
|
||||
getNestedValue(data, field.name) !== undefined &&
|
||||
(!field.shouldRender || field.shouldRender(data))
|
||||
) {
|
||||
try {
|
||||
const result = await field.customValidate(
|
||||
data[field.name],
|
||||
getNestedValue(data, field.name),
|
||||
data,
|
||||
);
|
||||
if (typeof result === 'string') {
|
||||
@ -676,7 +734,6 @@ const DynamicForm = {
|
||||
...fieldErrors,
|
||||
} as any;
|
||||
|
||||
console.log('combinedErrors', combinedErrors);
|
||||
for (const key in combinedErrors) {
|
||||
if (Array.isArray(combinedErrors[key])) {
|
||||
combinedErrors[key] = combinedErrors[key][0];
|
||||
@ -724,11 +781,61 @@ const DynamicForm = {
|
||||
};
|
||||
}, [fields, form]);
|
||||
|
||||
const filterActiveValues = useCallback(
|
||||
(allValues: any) => {
|
||||
const filteredValues: any = {};
|
||||
|
||||
fields.forEach((field) => {
|
||||
if (
|
||||
!field.shouldRender ||
|
||||
(field.shouldRender(allValues) &&
|
||||
field.name?.indexOf(FilterFormField) < 0)
|
||||
) {
|
||||
const keys = field.name.split('.');
|
||||
let current = allValues;
|
||||
let exists = true;
|
||||
|
||||
for (const key of keys) {
|
||||
if (current && current[key] !== undefined) {
|
||||
current = current[key];
|
||||
} else {
|
||||
exists = false;
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
if (exists) {
|
||||
let target = filteredValues;
|
||||
for (let i = 0; i < keys.length - 1; i++) {
|
||||
const key = keys[i];
|
||||
if (!target[key]) {
|
||||
target[key] = {};
|
||||
}
|
||||
target = target[key];
|
||||
}
|
||||
target[keys[keys.length - 1]] = getNestedValue(
|
||||
allValues,
|
||||
field.name,
|
||||
);
|
||||
}
|
||||
}
|
||||
});
|
||||
|
||||
return filteredValues;
|
||||
},
|
||||
[fields],
|
||||
);
|
||||
|
||||
// Expose form methods via ref
|
||||
useImperativeHandle(
|
||||
ref,
|
||||
() => ({
|
||||
submit: form.handleSubmit(onSubmit),
|
||||
submit: () => {
|
||||
form.handleSubmit((values) => {
|
||||
const filteredValues = filterActiveValues(values);
|
||||
onSubmit(filteredValues);
|
||||
})();
|
||||
},
|
||||
getValues: form.getValues,
|
||||
reset: (values?: T) => {
|
||||
if (values) {
|
||||
@ -771,9 +878,9 @@ const DynamicForm = {
|
||||
// }, 0);
|
||||
},
|
||||
}),
|
||||
[form],
|
||||
[form, onSubmit, filterActiveValues],
|
||||
);
|
||||
|
||||
(form as any).filterActiveValues = filterActiveValues;
|
||||
useEffect(() => {
|
||||
if (formDefaultValues && Object.keys(formDefaultValues).length > 0) {
|
||||
form.reset({
|
||||
@ -795,7 +902,10 @@ const DynamicForm = {
|
||||
className={`space-y-6 ${className}`}
|
||||
onSubmit={(e) => {
|
||||
e.preventDefault();
|
||||
form.handleSubmit(onSubmit)(e);
|
||||
form.handleSubmit((values) => {
|
||||
const filteredValues = filterActiveValues(values);
|
||||
onSubmit(filteredValues);
|
||||
})(e);
|
||||
}}
|
||||
>
|
||||
<>
|
||||
@ -844,10 +954,23 @@ const DynamicForm = {
|
||||
try {
|
||||
let beValid = await form.formControl.trigger();
|
||||
console.log('form valid', beValid, form, form.formControl);
|
||||
if (beValid) {
|
||||
// if (beValid) {
|
||||
// form.handleSubmit(async (values) => {
|
||||
// console.log('form values', values);
|
||||
// submitFunc?.(values);
|
||||
// })();
|
||||
// }
|
||||
|
||||
if (beValid && submitFunc) {
|
||||
form.handleSubmit(async (values) => {
|
||||
console.log('form values', values);
|
||||
submitFunc?.(values);
|
||||
const filteredValues = (form as any).filterActiveValues
|
||||
? (form as any).filterActiveValues(values)
|
||||
: values;
|
||||
console.log(
|
||||
'filtered form values in saving button',
|
||||
filteredValues,
|
||||
);
|
||||
submitFunc(filteredValues);
|
||||
})();
|
||||
}
|
||||
} catch (e) {
|
||||
|
||||
@ -1028,7 +1028,7 @@ function getFileIcon(file: File) {
|
||||
|
||||
if (
|
||||
type.startsWith('text/') ||
|
||||
['txt', 'md', 'rtf', 'pdf'].includes(extension)
|
||||
['txt', 'md', 'mdx', 'rtf', 'pdf'].includes(extension)
|
||||
) {
|
||||
return <FileTextIcon />;
|
||||
}
|
||||
|
||||
@ -213,7 +213,7 @@ const MarkdownContent = ({
|
||||
return (
|
||||
<HoverCard key={i}>
|
||||
<HoverCardTrigger>
|
||||
<span className="text-text-secondary bg-bg-card rounded-2xl px-1 mx-1">
|
||||
<span className="text-text-secondary bg-bg-card rounded-2xl px-1 mx-1 text-nowrap">
|
||||
Fig. {chunkIndex + 1}
|
||||
</span>
|
||||
</HoverCardTrigger>
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user