mirror of
https://github.com/infiniflow/ragflow.git
synced 2025-12-31 01:01:30 +08:00
Compare commits
71 Commits
v0.22.1
...
8604c4f57c
| Author | SHA1 | Date | |
|---|---|---|---|
| 8604c4f57c | |||
| a674338c21 | |||
| 89d82ff031 | |||
| c71d25f744 | |||
| f57f32cf3a | |||
| b6314164c5 | |||
| 856201c0f2 | |||
| 9d8b96c1d0 | |||
| 7c3c185038 | |||
| a9259917c6 | |||
| 8c28587821 | |||
| 12979a3f21 | |||
| 376eb15c63 | |||
| 89ba7abe30 | |||
| 2fd5ac1031 | |||
| 40e84ca41a | |||
| a28c672695 | |||
| 74e0b58d89 | |||
| 7c20c964b4 | |||
| 5d0981d046 | |||
| a793dd2ea8 | |||
| 915e385244 | |||
| 7a344a32f9 | |||
| 8c1ee3845a | |||
| 8c751d5afc | |||
| f5faf0c94f | |||
| af72e8dc33 | |||
| bcd70affb5 | |||
| 6987e9f23b | |||
| 41665b0865 | |||
| d1744aaaf3 | |||
| d5f8548200 | |||
| 4d8698624c | |||
| 1009819801 | |||
| 8fe782f4ea | |||
| 7140950e93 | |||
| 0181747881 | |||
| 3c41159d26 | |||
| e0e1d04da5 | |||
| f0a14f5fce | |||
| 174a2578e8 | |||
| a0959b9d38 | |||
| 13299197b8 | |||
| 249296e417 | |||
| db0f6840d9 | |||
| 1033a3ae26 | |||
| 1845daf41f | |||
| 4c8f9f0d77 | |||
| cc00c3ec93 | |||
| 653b785958 | |||
| 971c1bcba7 | |||
| 065917bf1c | |||
| 820934fc77 | |||
| d3d2ccc76c | |||
| c8ab9079b3 | |||
| 0d5589bfda | |||
| b846a0f547 | |||
| 69578ebfce | |||
| 06cef71ba6 | |||
| d2b1da0e26 | |||
| 7c6d30f4c8 | |||
| ea0352ee4a | |||
| fa5cf10f56 | |||
| 3fe71ab7dd | |||
| 9f715d6bc2 | |||
| 48de3b26ba | |||
| 273c4bc4d3 | |||
| 420c97199a | |||
| ecf0322165 | |||
| 38234aca53 | |||
| 1c06ec39ca |
4
.github/workflows/tests.yml
vendored
4
.github/workflows/tests.yml
vendored
@ -31,7 +31,7 @@ jobs:
|
||||
name: ragflow_tests
|
||||
# https://docs.github.com/en/actions/using-jobs/using-conditions-to-control-job-execution
|
||||
# https://github.com/orgs/community/discussions/26261
|
||||
if: ${{ github.event_name != 'pull_request_target' || contains(github.event.pull_request.labels.*.name, 'ci') }}
|
||||
if: ${{ github.event_name != 'pull_request_target' || (contains(github.event.pull_request.labels.*.name, 'ci') && github.event.pull_request.mergeable == true) }}
|
||||
runs-on: [ "self-hosted", "ragflow-test" ]
|
||||
steps:
|
||||
# https://github.com/hmarr/debug-action
|
||||
@ -193,7 +193,7 @@ jobs:
|
||||
echo "HOST_ADDRESS=http://host.docker.internal:${SVR_HTTP_PORT}" >> ${GITHUB_ENV}
|
||||
|
||||
sudo docker compose -f docker/docker-compose.yml -p ${GITHUB_RUN_ID} up -d
|
||||
uv sync --python 3.10 --only-group test --no-default-groups --frozen && uv pip install sdk/python
|
||||
uv sync --python 3.10 --only-group test --no-default-groups --frozen && uv pip install sdk/python --group test
|
||||
|
||||
- name: Run sdk tests against Elasticsearch
|
||||
run: |
|
||||
|
||||
@ -86,7 +86,7 @@ Try our demo at [https://demo.ragflow.io](https://demo.ragflow.io).
|
||||
## 🔥 Latest Updates
|
||||
|
||||
- 2025-11-19 Supports Gemini 3 Pro.
|
||||
- 2025-11-12 Supports data synchronization from Confluence, AWS S3, Discord, Google Drive.
|
||||
- 2025-11-12 Supports data synchronization from Confluence, S3, Notion, Discord, Google Drive.
|
||||
- 2025-10-23 Supports MinerU & Docling as document parsing methods.
|
||||
- 2025-10-15 Supports orchestrable ingestion pipeline.
|
||||
- 2025-08-08 Supports OpenAI's latest GPT-5 series models.
|
||||
|
||||
@ -86,7 +86,7 @@ Coba demo kami di [https://demo.ragflow.io](https://demo.ragflow.io).
|
||||
## 🔥 Pembaruan Terbaru
|
||||
|
||||
- 2025-11-19 Mendukung Gemini 3 Pro.
|
||||
- 2025-11-12 Mendukung sinkronisasi data dari Confluence, AWS S3, Discord, Google Drive.
|
||||
- 2025-11-12 Mendukung sinkronisasi data dari Confluence, S3, Notion, Discord, Google Drive.
|
||||
- 2025-10-23 Mendukung MinerU & Docling sebagai metode penguraian dokumen.
|
||||
- 2025-10-15 Dukungan untuk jalur data yang terorkestrasi.
|
||||
- 2025-08-08 Mendukung model seri GPT-5 terbaru dari OpenAI.
|
||||
|
||||
@ -67,7 +67,7 @@
|
||||
## 🔥 最新情報
|
||||
|
||||
- 2025-11-19 Gemini 3 Proをサポートしています
|
||||
- 2025-11-12 Confluence、AWS S3、Discord、Google Drive からのデータ同期をサポートします。
|
||||
- 2025-11-12 Confluence、S3、Notion、Discord、Google Drive からのデータ同期をサポートします。
|
||||
- 2025-10-23 ドキュメント解析方法として MinerU と Docling をサポートします。
|
||||
- 2025-10-15 オーケストレーションされたデータパイプラインのサポート。
|
||||
- 2025-08-08 OpenAI の最新 GPT-5 シリーズモデルをサポートします。
|
||||
|
||||
@ -68,7 +68,7 @@
|
||||
## 🔥 업데이트
|
||||
|
||||
- 2025-11-19 Gemini 3 Pro를 지원합니다.
|
||||
- 2025-11-12 Confluence, AWS S3, Discord, Google Drive에서 데이터 동기화를 지원합니다.
|
||||
- 2025-11-12 Confluence, S3, Notion, Discord, Google Drive에서 데이터 동기화를 지원합니다.
|
||||
- 2025-10-23 문서 파싱 방법으로 MinerU 및 Docling을 지원합니다.
|
||||
- 2025-10-15 조정된 데이터 파이프라인 지원.
|
||||
- 2025-08-08 OpenAI의 최신 GPT-5 시리즈 모델을 지원합니다.
|
||||
|
||||
@ -87,7 +87,7 @@ Experimente nossa demo em [https://demo.ragflow.io](https://demo.ragflow.io).
|
||||
## 🔥 Últimas Atualizações
|
||||
|
||||
- 19-11-2025 Suporta Gemini 3 Pro.
|
||||
- 12-11-2025 Suporta a sincronização de dados do Confluence, AWS S3, Discord e Google Drive.
|
||||
- 12-11-2025 Suporta a sincronização de dados do Confluence, S3, Notion, Discord e Google Drive.
|
||||
- 23-10-2025 Suporta MinerU e Docling como métodos de análise de documentos.
|
||||
- 15-10-2025 Suporte para pipelines de dados orquestrados.
|
||||
- 08-08-2025 Suporta a mais recente série GPT-5 da OpenAI.
|
||||
|
||||
@ -86,7 +86,7 @@
|
||||
## 🔥 近期更新
|
||||
|
||||
- 2025-11-19 支援 Gemini 3 Pro.
|
||||
- 2025-11-12 支援從 Confluence、AWS S3、Discord、Google Drive 進行資料同步。
|
||||
- 2025-11-12 支援從 Confluence、S3、Notion、Discord、Google Drive 進行資料同步。
|
||||
- 2025-10-23 支援 MinerU 和 Docling 作為文件解析方法。
|
||||
- 2025-10-15 支援可編排的資料管道。
|
||||
- 2025-08-08 支援 OpenAI 最新的 GPT-5 系列模型。
|
||||
|
||||
@ -86,7 +86,7 @@
|
||||
## 🔥 近期更新
|
||||
|
||||
- 2025-11-19 支持 Gemini 3 Pro.
|
||||
- 2025-11-12 支持从 Confluence、AWS S3、Discord、Google Drive 进行数据同步。
|
||||
- 2025-11-12 支持从 Confluence、S3、Notion、Discord、Google Drive 进行数据同步。
|
||||
- 2025-10-23 支持 MinerU 和 Docling 作为文档解析方法。
|
||||
- 2025-10-15 支持可编排的数据管道。
|
||||
- 2025-08-08 支持 OpenAI 最新的 GPT-5 系列模型。
|
||||
|
||||
@ -8,7 +8,7 @@ readme = "README.md"
|
||||
requires-python = ">=3.10,<3.13"
|
||||
dependencies = [
|
||||
"requests>=2.30.0,<3.0.0",
|
||||
"beartype>=0.18.5,<0.19.0",
|
||||
"beartype>=0.20.0,<1.0.0",
|
||||
"pycryptodomex>=3.10.0",
|
||||
"lark>=1.1.0",
|
||||
]
|
||||
|
||||
298
admin/client/uv.lock
generated
Normal file
298
admin/client/uv.lock
generated
Normal file
@ -0,0 +1,298 @@
|
||||
version = 1
|
||||
revision = 3
|
||||
requires-python = ">=3.10, <3.13"
|
||||
|
||||
[[package]]
|
||||
name = "beartype"
|
||||
version = "0.22.6"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/88/e2/105ceb1704cb80fe4ab3872529ab7b6f365cf7c74f725e6132d0efcf1560/beartype-0.22.6.tar.gz", hash = "sha256:97fbda69c20b48c5780ac2ca60ce3c1bb9af29b3a1a0216898ffabdd523e48f4", size = 1588975, upload-time = "2025-11-20T04:47:14.736Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/98/c9/ceecc71fe2c9495a1d8e08d44f5f31f5bca1350d5b2e27a4b6265424f59e/beartype-0.22.6-py3-none-any.whl", hash = "sha256:0584bc46a2ea2a871509679278cda992eadde676c01356ab0ac77421f3c9a093", size = 1324807, upload-time = "2025-11-20T04:47:11.837Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "certifi"
|
||||
version = "2025.11.12"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/a2/8c/58f469717fa48465e4a50c014a0400602d3c437d7c0c468e17ada824da3a/certifi-2025.11.12.tar.gz", hash = "sha256:d8ab5478f2ecd78af242878415affce761ca6bc54a22a27e026d7c25357c3316", size = 160538, upload-time = "2025-11-12T02:54:51.517Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/70/7d/9bc192684cea499815ff478dfcdc13835ddf401365057044fb721ec6bddb/certifi-2025.11.12-py3-none-any.whl", hash = "sha256:97de8790030bbd5c2d96b7ec782fc2f7820ef8dba6db909ccf95449f2d062d4b", size = 159438, upload-time = "2025-11-12T02:54:49.735Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "charset-normalizer"
|
||||
version = "3.4.4"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/13/69/33ddede1939fdd074bce5434295f38fae7136463422fe4fd3e0e89b98062/charset_normalizer-3.4.4.tar.gz", hash = "sha256:94537985111c35f28720e43603b8e7b43a6ecfb2ce1d3058bbe955b73404e21a", size = 129418, upload-time = "2025-10-14T04:42:32.879Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/1f/b8/6d51fc1d52cbd52cd4ccedd5b5b2f0f6a11bbf6765c782298b0f3e808541/charset_normalizer-3.4.4-cp310-cp310-macosx_10_9_universal2.whl", hash = "sha256:e824f1492727fa856dd6eda4f7cee25f8518a12f3c4a56a74e8095695089cf6d", size = 209709, upload-time = "2025-10-14T04:40:11.385Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/5c/af/1f9d7f7faafe2ddfb6f72a2e07a548a629c61ad510fe60f9630309908fef/charset_normalizer-3.4.4-cp310-cp310-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:4bd5d4137d500351a30687c2d3971758aac9a19208fc110ccb9d7188fbe709e8", size = 148814, upload-time = "2025-10-14T04:40:13.135Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/79/3d/f2e3ac2bbc056ca0c204298ea4e3d9db9b4afe437812638759db2c976b5f/charset_normalizer-3.4.4-cp310-cp310-manylinux2014_armv7l.manylinux_2_17_armv7l.manylinux_2_31_armv7l.whl", hash = "sha256:027f6de494925c0ab2a55eab46ae5129951638a49a34d87f4c3eda90f696b4ad", size = 144467, upload-time = "2025-10-14T04:40:14.728Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/ec/85/1bf997003815e60d57de7bd972c57dc6950446a3e4ccac43bc3070721856/charset_normalizer-3.4.4-cp310-cp310-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:f820802628d2694cb7e56db99213f930856014862f3fd943d290ea8438d07ca8", size = 162280, upload-time = "2025-10-14T04:40:16.14Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/3e/8e/6aa1952f56b192f54921c436b87f2aaf7c7a7c3d0d1a765547d64fd83c13/charset_normalizer-3.4.4-cp310-cp310-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:798d75d81754988d2565bff1b97ba5a44411867c0cf32b77a7e8f8d84796b10d", size = 159454, upload-time = "2025-10-14T04:40:17.567Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/36/3b/60cbd1f8e93aa25d1c669c649b7a655b0b5fb4c571858910ea9332678558/charset_normalizer-3.4.4-cp310-cp310-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:9d1bb833febdff5c8927f922386db610b49db6e0d4f4ee29601d71e7c2694313", size = 153609, upload-time = "2025-10-14T04:40:19.08Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/64/91/6a13396948b8fd3c4b4fd5bc74d045f5637d78c9675585e8e9fbe5636554/charset_normalizer-3.4.4-cp310-cp310-manylinux_2_31_riscv64.manylinux_2_39_riscv64.whl", hash = "sha256:9cd98cdc06614a2f768d2b7286d66805f94c48cde050acdbbb7db2600ab3197e", size = 151849, upload-time = "2025-10-14T04:40:20.607Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/b7/7a/59482e28b9981d105691e968c544cc0df3b7d6133152fb3dcdc8f135da7a/charset_normalizer-3.4.4-cp310-cp310-musllinux_1_2_aarch64.whl", hash = "sha256:077fbb858e903c73f6c9db43374fd213b0b6a778106bc7032446a8e8b5b38b93", size = 151586, upload-time = "2025-10-14T04:40:21.719Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/92/59/f64ef6a1c4bdd2baf892b04cd78792ed8684fbc48d4c2afe467d96b4df57/charset_normalizer-3.4.4-cp310-cp310-musllinux_1_2_armv7l.whl", hash = "sha256:244bfb999c71b35de57821b8ea746b24e863398194a4014e4c76adc2bbdfeff0", size = 145290, upload-time = "2025-10-14T04:40:23.069Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/6b/63/3bf9f279ddfa641ffa1962b0db6a57a9c294361cc2f5fcac997049a00e9c/charset_normalizer-3.4.4-cp310-cp310-musllinux_1_2_ppc64le.whl", hash = "sha256:64b55f9dce520635f018f907ff1b0df1fdc31f2795a922fb49dd14fbcdf48c84", size = 163663, upload-time = "2025-10-14T04:40:24.17Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/ed/09/c9e38fc8fa9e0849b172b581fd9803bdf6e694041127933934184e19f8c3/charset_normalizer-3.4.4-cp310-cp310-musllinux_1_2_riscv64.whl", hash = "sha256:faa3a41b2b66b6e50f84ae4a68c64fcd0c44355741c6374813a800cd6695db9e", size = 151964, upload-time = "2025-10-14T04:40:25.368Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/d2/d1/d28b747e512d0da79d8b6a1ac18b7ab2ecfd81b2944c4c710e166d8dd09c/charset_normalizer-3.4.4-cp310-cp310-musllinux_1_2_s390x.whl", hash = "sha256:6515f3182dbe4ea06ced2d9e8666d97b46ef4c75e326b79bb624110f122551db", size = 161064, upload-time = "2025-10-14T04:40:26.806Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/bb/9a/31d62b611d901c3b9e5500c36aab0ff5eb442043fb3a1c254200d3d397d9/charset_normalizer-3.4.4-cp310-cp310-musllinux_1_2_x86_64.whl", hash = "sha256:cc00f04ed596e9dc0da42ed17ac5e596c6ccba999ba6bd92b0e0aef2f170f2d6", size = 155015, upload-time = "2025-10-14T04:40:28.284Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/1f/f3/107e008fa2bff0c8b9319584174418e5e5285fef32f79d8ee6a430d0039c/charset_normalizer-3.4.4-cp310-cp310-win32.whl", hash = "sha256:f34be2938726fc13801220747472850852fe6b1ea75869a048d6f896838c896f", size = 99792, upload-time = "2025-10-14T04:40:29.613Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/eb/66/e396e8a408843337d7315bab30dbf106c38966f1819f123257f5520f8a96/charset_normalizer-3.4.4-cp310-cp310-win_amd64.whl", hash = "sha256:a61900df84c667873b292c3de315a786dd8dac506704dea57bc957bd31e22c7d", size = 107198, upload-time = "2025-10-14T04:40:30.644Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/b5/58/01b4f815bf0312704c267f2ccb6e5d42bcc7752340cd487bc9f8c3710597/charset_normalizer-3.4.4-cp310-cp310-win_arm64.whl", hash = "sha256:cead0978fc57397645f12578bfd2d5ea9138ea0fac82b2f63f7f7c6877986a69", size = 100262, upload-time = "2025-10-14T04:40:32.108Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/ed/27/c6491ff4954e58a10f69ad90aca8a1b6fe9c5d3c6f380907af3c37435b59/charset_normalizer-3.4.4-cp311-cp311-macosx_10_9_universal2.whl", hash = "sha256:6e1fcf0720908f200cd21aa4e6750a48ff6ce4afe7ff5a79a90d5ed8a08296f8", size = 206988, upload-time = "2025-10-14T04:40:33.79Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/94/59/2e87300fe67ab820b5428580a53cad894272dbb97f38a7a814a2a1ac1011/charset_normalizer-3.4.4-cp311-cp311-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:5f819d5fe9234f9f82d75bdfa9aef3a3d72c4d24a6e57aeaebba32a704553aa0", size = 147324, upload-time = "2025-10-14T04:40:34.961Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/07/fb/0cf61dc84b2b088391830f6274cb57c82e4da8bbc2efeac8c025edb88772/charset_normalizer-3.4.4-cp311-cp311-manylinux2014_armv7l.manylinux_2_17_armv7l.manylinux_2_31_armv7l.whl", hash = "sha256:a59cb51917aa591b1c4e6a43c132f0cdc3c76dbad6155df4e28ee626cc77a0a3", size = 142742, upload-time = "2025-10-14T04:40:36.105Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/62/8b/171935adf2312cd745d290ed93cf16cf0dfe320863ab7cbeeae1dcd6535f/charset_normalizer-3.4.4-cp311-cp311-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:8ef3c867360f88ac904fd3f5e1f902f13307af9052646963ee08ff4f131adafc", size = 160863, upload-time = "2025-10-14T04:40:37.188Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/09/73/ad875b192bda14f2173bfc1bc9a55e009808484a4b256748d931b6948442/charset_normalizer-3.4.4-cp311-cp311-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:d9e45d7faa48ee908174d8fe84854479ef838fc6a705c9315372eacbc2f02897", size = 157837, upload-time = "2025-10-14T04:40:38.435Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/6d/fc/de9cce525b2c5b94b47c70a4b4fb19f871b24995c728e957ee68ab1671ea/charset_normalizer-3.4.4-cp311-cp311-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:840c25fb618a231545cbab0564a799f101b63b9901f2569faecd6b222ac72381", size = 151550, upload-time = "2025-10-14T04:40:40.053Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/55/c2/43edd615fdfba8c6f2dfbd459b25a6b3b551f24ea21981e23fb768503ce1/charset_normalizer-3.4.4-cp311-cp311-manylinux_2_31_riscv64.manylinux_2_39_riscv64.whl", hash = "sha256:ca5862d5b3928c4940729dacc329aa9102900382fea192fc5e52eb69d6093815", size = 149162, upload-time = "2025-10-14T04:40:41.163Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/03/86/bde4ad8b4d0e9429a4e82c1e8f5c659993a9a863ad62c7df05cf7b678d75/charset_normalizer-3.4.4-cp311-cp311-musllinux_1_2_aarch64.whl", hash = "sha256:d9c7f57c3d666a53421049053eaacdd14bbd0a528e2186fcb2e672effd053bb0", size = 150019, upload-time = "2025-10-14T04:40:42.276Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/1f/86/a151eb2af293a7e7bac3a739b81072585ce36ccfb4493039f49f1d3cae8c/charset_normalizer-3.4.4-cp311-cp311-musllinux_1_2_armv7l.whl", hash = "sha256:277e970e750505ed74c832b4bf75dac7476262ee2a013f5574dd49075879e161", size = 143310, upload-time = "2025-10-14T04:40:43.439Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/b5/fe/43dae6144a7e07b87478fdfc4dbe9efd5defb0e7ec29f5f58a55aeef7bf7/charset_normalizer-3.4.4-cp311-cp311-musllinux_1_2_ppc64le.whl", hash = "sha256:31fd66405eaf47bb62e8cd575dc621c56c668f27d46a61d975a249930dd5e2a4", size = 162022, upload-time = "2025-10-14T04:40:44.547Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/80/e6/7aab83774f5d2bca81f42ac58d04caf44f0cc2b65fc6db2b3b2e8a05f3b3/charset_normalizer-3.4.4-cp311-cp311-musllinux_1_2_riscv64.whl", hash = "sha256:0d3d8f15c07f86e9ff82319b3d9ef6f4bf907608f53fe9d92b28ea9ae3d1fd89", size = 149383, upload-time = "2025-10-14T04:40:46.018Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/4f/e8/b289173b4edae05c0dde07f69f8db476a0b511eac556dfe0d6bda3c43384/charset_normalizer-3.4.4-cp311-cp311-musllinux_1_2_s390x.whl", hash = "sha256:9f7fcd74d410a36883701fafa2482a6af2ff5ba96b9a620e9e0721e28ead5569", size = 159098, upload-time = "2025-10-14T04:40:47.081Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/d8/df/fe699727754cae3f8478493c7f45f777b17c3ef0600e28abfec8619eb49c/charset_normalizer-3.4.4-cp311-cp311-musllinux_1_2_x86_64.whl", hash = "sha256:ebf3e58c7ec8a8bed6d66a75d7fb37b55e5015b03ceae72a8e7c74495551e224", size = 152991, upload-time = "2025-10-14T04:40:48.246Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/1a/86/584869fe4ddb6ffa3bd9f491b87a01568797fb9bd8933f557dba9771beaf/charset_normalizer-3.4.4-cp311-cp311-win32.whl", hash = "sha256:eecbc200c7fd5ddb9a7f16c7decb07b566c29fa2161a16cf67b8d068bd21690a", size = 99456, upload-time = "2025-10-14T04:40:49.376Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/65/f6/62fdd5feb60530f50f7e38b4f6a1d5203f4d16ff4f9f0952962c044e919a/charset_normalizer-3.4.4-cp311-cp311-win_amd64.whl", hash = "sha256:5ae497466c7901d54b639cf42d5b8c1b6a4fead55215500d2f486d34db48d016", size = 106978, upload-time = "2025-10-14T04:40:50.844Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/7a/9d/0710916e6c82948b3be62d9d398cb4fcf4e97b56d6a6aeccd66c4b2f2bd5/charset_normalizer-3.4.4-cp311-cp311-win_arm64.whl", hash = "sha256:65e2befcd84bc6f37095f5961e68a6f077bf44946771354a28ad434c2cce0ae1", size = 99969, upload-time = "2025-10-14T04:40:52.272Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/f3/85/1637cd4af66fa687396e757dec650f28025f2a2f5a5531a3208dc0ec43f2/charset_normalizer-3.4.4-cp312-cp312-macosx_10_13_universal2.whl", hash = "sha256:0a98e6759f854bd25a58a73fa88833fba3b7c491169f86ce1180c948ab3fd394", size = 208425, upload-time = "2025-10-14T04:40:53.353Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/9d/6a/04130023fef2a0d9c62d0bae2649b69f7b7d8d24ea5536feef50551029df/charset_normalizer-3.4.4-cp312-cp312-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:b5b290ccc2a263e8d185130284f8501e3e36c5e02750fc6b6bdeb2e9e96f1e25", size = 148162, upload-time = "2025-10-14T04:40:54.558Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/78/29/62328d79aa60da22c9e0b9a66539feae06ca0f5a4171ac4f7dc285b83688/charset_normalizer-3.4.4-cp312-cp312-manylinux2014_armv7l.manylinux_2_17_armv7l.manylinux_2_31_armv7l.whl", hash = "sha256:74bb723680f9f7a6234dcf67aea57e708ec1fbdf5699fb91dfd6f511b0a320ef", size = 144558, upload-time = "2025-10-14T04:40:55.677Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/86/bb/b32194a4bf15b88403537c2e120b817c61cd4ecffa9b6876e941c3ee38fe/charset_normalizer-3.4.4-cp312-cp312-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:f1e34719c6ed0b92f418c7c780480b26b5d9c50349e9a9af7d76bf757530350d", size = 161497, upload-time = "2025-10-14T04:40:57.217Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/19/89/a54c82b253d5b9b111dc74aca196ba5ccfcca8242d0fb64146d4d3183ff1/charset_normalizer-3.4.4-cp312-cp312-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:2437418e20515acec67d86e12bf70056a33abdacb5cb1655042f6538d6b085a8", size = 159240, upload-time = "2025-10-14T04:40:58.358Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/c0/10/d20b513afe03acc89ec33948320a5544d31f21b05368436d580dec4e234d/charset_normalizer-3.4.4-cp312-cp312-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:11d694519d7f29d6cd09f6ac70028dba10f92f6cdd059096db198c283794ac86", size = 153471, upload-time = "2025-10-14T04:40:59.468Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/61/fa/fbf177b55bdd727010f9c0a3c49eefa1d10f960e5f09d1d887bf93c2e698/charset_normalizer-3.4.4-cp312-cp312-manylinux_2_31_riscv64.manylinux_2_39_riscv64.whl", hash = "sha256:ac1c4a689edcc530fc9d9aa11f5774b9e2f33f9a0c6a57864e90908f5208d30a", size = 150864, upload-time = "2025-10-14T04:41:00.623Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/05/12/9fbc6a4d39c0198adeebbde20b619790e9236557ca59fc40e0e3cebe6f40/charset_normalizer-3.4.4-cp312-cp312-musllinux_1_2_aarch64.whl", hash = "sha256:21d142cc6c0ec30d2efee5068ca36c128a30b0f2c53c1c07bd78cb6bc1d3be5f", size = 150647, upload-time = "2025-10-14T04:41:01.754Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/ad/1f/6a9a593d52e3e8c5d2b167daf8c6b968808efb57ef4c210acb907c365bc4/charset_normalizer-3.4.4-cp312-cp312-musllinux_1_2_armv7l.whl", hash = "sha256:5dbe56a36425d26d6cfb40ce79c314a2e4dd6211d51d6d2191c00bed34f354cc", size = 145110, upload-time = "2025-10-14T04:41:03.231Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/30/42/9a52c609e72471b0fc54386dc63c3781a387bb4fe61c20231a4ebcd58bdd/charset_normalizer-3.4.4-cp312-cp312-musllinux_1_2_ppc64le.whl", hash = "sha256:5bfbb1b9acf3334612667b61bd3002196fe2a1eb4dd74d247e0f2a4d50ec9bbf", size = 162839, upload-time = "2025-10-14T04:41:04.715Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/c4/5b/c0682bbf9f11597073052628ddd38344a3d673fda35a36773f7d19344b23/charset_normalizer-3.4.4-cp312-cp312-musllinux_1_2_riscv64.whl", hash = "sha256:d055ec1e26e441f6187acf818b73564e6e6282709e9bcb5b63f5b23068356a15", size = 150667, upload-time = "2025-10-14T04:41:05.827Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/e4/24/a41afeab6f990cf2daf6cb8c67419b63b48cf518e4f56022230840c9bfb2/charset_normalizer-3.4.4-cp312-cp312-musllinux_1_2_s390x.whl", hash = "sha256:af2d8c67d8e573d6de5bc30cdb27e9b95e49115cd9baad5ddbd1a6207aaa82a9", size = 160535, upload-time = "2025-10-14T04:41:06.938Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/2a/e5/6a4ce77ed243c4a50a1fecca6aaaab419628c818a49434be428fe24c9957/charset_normalizer-3.4.4-cp312-cp312-musllinux_1_2_x86_64.whl", hash = "sha256:780236ac706e66881f3b7f2f32dfe90507a09e67d1d454c762cf642e6e1586e0", size = 154816, upload-time = "2025-10-14T04:41:08.101Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/a8/ef/89297262b8092b312d29cdb2517cb1237e51db8ecef2e9af5edbe7b683b1/charset_normalizer-3.4.4-cp312-cp312-win32.whl", hash = "sha256:5833d2c39d8896e4e19b689ffc198f08ea58116bee26dea51e362ecc7cd3ed26", size = 99694, upload-time = "2025-10-14T04:41:09.23Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/3d/2d/1e5ed9dd3b3803994c155cd9aacb60c82c331bad84daf75bcb9c91b3295e/charset_normalizer-3.4.4-cp312-cp312-win_amd64.whl", hash = "sha256:a79cfe37875f822425b89a82333404539ae63dbdddf97f84dcbc3d339aae9525", size = 107131, upload-time = "2025-10-14T04:41:10.467Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/d0/d9/0ed4c7098a861482a7b6a95603edce4c0d9db2311af23da1fb2b75ec26fc/charset_normalizer-3.4.4-cp312-cp312-win_arm64.whl", hash = "sha256:376bec83a63b8021bb5c8ea75e21c4ccb86e7e45ca4eb81146091b56599b80c3", size = 100390, upload-time = "2025-10-14T04:41:11.915Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/0a/4c/925909008ed5a988ccbb72dcc897407e5d6d3bd72410d69e051fc0c14647/charset_normalizer-3.4.4-py3-none-any.whl", hash = "sha256:7a32c560861a02ff789ad905a2fe94e3f840803362c84fecf1851cb4cf3dc37f", size = 53402, upload-time = "2025-10-14T04:42:31.76Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "colorama"
|
||||
version = "0.4.6"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/d8/53/6f443c9a4a8358a93a6792e2acffb9d9d5cb0a5cfd8802644b7b1c9a02e4/colorama-0.4.6.tar.gz", hash = "sha256:08695f5cb7ed6e0531a20572697297273c47b8cae5a63ffc6d6ed5c201be6e44", size = 27697, upload-time = "2022-10-25T02:36:22.414Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/d1/d6/3965ed04c63042e047cb6a3e6ed1a63a35087b6a609aa3a15ed8ac56c221/colorama-0.4.6-py2.py3-none-any.whl", hash = "sha256:4f1d9991f5acc0ca119f9d443620b77f9d6b33703e51011c16baf57afb285fc6", size = 25335, upload-time = "2022-10-25T02:36:20.889Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "exceptiongroup"
|
||||
version = "1.3.1"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
dependencies = [
|
||||
{ name = "typing-extensions" },
|
||||
]
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/50/79/66800aadf48771f6b62f7eb014e352e5d06856655206165d775e675a02c9/exceptiongroup-1.3.1.tar.gz", hash = "sha256:8b412432c6055b0b7d14c310000ae93352ed6754f70fa8f7c34141f91c4e3219", size = 30371, upload-time = "2025-11-21T23:01:54.787Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/8a/0e/97c33bf5009bdbac74fd2beace167cab3f978feb69cc36f1ef79360d6c4e/exceptiongroup-1.3.1-py3-none-any.whl", hash = "sha256:a7a39a3bd276781e98394987d3a5701d0c4edffb633bb7a5144577f82c773598", size = 16740, upload-time = "2025-11-21T23:01:53.443Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "idna"
|
||||
version = "3.11"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/6f/6d/0703ccc57f3a7233505399edb88de3cbd678da106337b9fcde432b65ed60/idna-3.11.tar.gz", hash = "sha256:795dafcc9c04ed0c1fb032c2aa73654d8e8c5023a7df64a53f39190ada629902", size = 194582, upload-time = "2025-10-12T14:55:20.501Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/0e/61/66938bbb5fc52dbdf84594873d5b51fb1f7c7794e9c0f5bd885f30bc507b/idna-3.11-py3-none-any.whl", hash = "sha256:771a87f49d9defaf64091e6e6fe9c18d4833f140bd19464795bc32d966ca37ea", size = 71008, upload-time = "2025-10-12T14:55:18.883Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "iniconfig"
|
||||
version = "2.3.0"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/72/34/14ca021ce8e5dfedc35312d08ba8bf51fdd999c576889fc2c24cb97f4f10/iniconfig-2.3.0.tar.gz", hash = "sha256:c76315c77db068650d49c5b56314774a7804df16fee4402c1f19d6d15d8c4730", size = 20503, upload-time = "2025-10-18T21:55:43.219Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/cb/b1/3846dd7f199d53cb17f49cba7e651e9ce294d8497c8c150530ed11865bb8/iniconfig-2.3.0-py3-none-any.whl", hash = "sha256:f631c04d2c48c52b84d0d0549c99ff3859c98df65b3101406327ecc7d53fbf12", size = 7484, upload-time = "2025-10-18T21:55:41.639Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "lark"
|
||||
version = "1.3.1"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/da/34/28fff3ab31ccff1fd4f6c7c7b0ceb2b6968d8ea4950663eadcb5720591a0/lark-1.3.1.tar.gz", hash = "sha256:b426a7a6d6d53189d318f2b6236ab5d6429eaf09259f1ca33eb716eed10d2905", size = 382732, upload-time = "2025-10-27T18:25:56.653Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/82/3d/14ce75ef66813643812f3093ab17e46d3a206942ce7376d31ec2d36229e7/lark-1.3.1-py3-none-any.whl", hash = "sha256:c629b661023a014c37da873b4ff58a817398d12635d3bbb2c5a03be7fe5d1e12", size = 113151, upload-time = "2025-10-27T18:25:54.882Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "packaging"
|
||||
version = "25.0"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/a1/d4/1fc4078c65507b51b96ca8f8c3ba19e6a61c8253c72794544580a7b6c24d/packaging-25.0.tar.gz", hash = "sha256:d443872c98d677bf60f6a1f2f8c1cb748e8fe762d2bf9d3148b5599295b0fc4f", size = 165727, upload-time = "2025-04-19T11:48:59.673Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/20/12/38679034af332785aac8774540895e234f4d07f7545804097de4b666afd8/packaging-25.0-py3-none-any.whl", hash = "sha256:29572ef2b1f17581046b3a2227d5c611fb25ec70ca1ba8554b24b0e69331a484", size = 66469, upload-time = "2025-04-19T11:48:57.875Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "pluggy"
|
||||
version = "1.6.0"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/f9/e2/3e91f31a7d2b083fe6ef3fa267035b518369d9511ffab804f839851d2779/pluggy-1.6.0.tar.gz", hash = "sha256:7dcc130b76258d33b90f61b658791dede3486c3e6bfb003ee5c9bfb396dd22f3", size = 69412, upload-time = "2025-05-15T12:30:07.975Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/54/20/4d324d65cc6d9205fabedc306948156824eb9f0ee1633355a8f7ec5c66bf/pluggy-1.6.0-py3-none-any.whl", hash = "sha256:e920276dd6813095e9377c0bc5566d94c932c33b27a3e3945d8389c374dd4746", size = 20538, upload-time = "2025-05-15T12:30:06.134Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "pycryptodomex"
|
||||
version = "3.23.0"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/c9/85/e24bf90972a30b0fcd16c73009add1d7d7cd9140c2498a68252028899e41/pycryptodomex-3.23.0.tar.gz", hash = "sha256:71909758f010c82bc99b0abf4ea12012c98962fbf0583c2164f8b84533c2e4da", size = 4922157, upload-time = "2025-05-17T17:23:41.434Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/dd/9c/1a8f35daa39784ed8adf93a694e7e5dc15c23c741bbda06e1d45f8979e9e/pycryptodomex-3.23.0-cp37-abi3-macosx_10_9_universal2.whl", hash = "sha256:06698f957fe1ab229a99ba2defeeae1c09af185baa909a31a5d1f9d42b1aaed6", size = 2499240, upload-time = "2025-05-17T17:22:46.953Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/7a/62/f5221a191a97157d240cf6643747558759126c76ee92f29a3f4aee3197a5/pycryptodomex-3.23.0-cp37-abi3-macosx_10_9_x86_64.whl", hash = "sha256:b2c2537863eccef2d41061e82a881dcabb04944c5c06c5aa7110b577cc487545", size = 1644042, upload-time = "2025-05-17T17:22:49.098Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/8c/fd/5a054543c8988d4ed7b612721d7e78a4b9bf36bc3c5ad45ef45c22d0060e/pycryptodomex-3.23.0-cp37-abi3-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:43c446e2ba8df8889e0e16f02211c25b4934898384c1ec1ec04d7889c0333587", size = 2186227, upload-time = "2025-05-17T17:22:51.139Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/c8/a9/8862616a85cf450d2822dbd4fff1fcaba90877907a6ff5bc2672cafe42f8/pycryptodomex-3.23.0-cp37-abi3-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:f489c4765093fb60e2edafdf223397bc716491b2b69fe74367b70d6999257a5c", size = 2272578, upload-time = "2025-05-17T17:22:53.676Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/46/9f/bda9c49a7c1842820de674ab36c79f4fbeeee03f8ff0e4f3546c3889076b/pycryptodomex-3.23.0-cp37-abi3-manylinux_2_5_i686.manylinux1_i686.manylinux_2_17_i686.manylinux2014_i686.whl", hash = "sha256:bdc69d0d3d989a1029df0eed67cc5e8e5d968f3724f4519bd03e0ec68df7543c", size = 2312166, upload-time = "2025-05-17T17:22:56.585Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/03/cc/870b9bf8ca92866ca0186534801cf8d20554ad2a76ca959538041b7a7cf4/pycryptodomex-3.23.0-cp37-abi3-musllinux_1_2_aarch64.whl", hash = "sha256:6bbcb1dd0f646484939e142462d9e532482bc74475cecf9c4903d4e1cd21f003", size = 2185467, upload-time = "2025-05-17T17:22:59.237Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/96/e3/ce9348236d8e669fea5dd82a90e86be48b9c341210f44e25443162aba187/pycryptodomex-3.23.0-cp37-abi3-musllinux_1_2_i686.whl", hash = "sha256:8a4fcd42ccb04c31268d1efeecfccfd1249612b4de6374205376b8f280321744", size = 2346104, upload-time = "2025-05-17T17:23:02.112Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/a5/e9/e869bcee87beb89040263c416a8a50204f7f7a83ac11897646c9e71e0daf/pycryptodomex-3.23.0-cp37-abi3-musllinux_1_2_x86_64.whl", hash = "sha256:55ccbe27f049743a4caf4f4221b166560d3438d0b1e5ab929e07ae1702a4d6fd", size = 2271038, upload-time = "2025-05-17T17:23:04.872Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/8d/67/09ee8500dd22614af5fbaa51a4aee6e342b5fa8aecf0a6cb9cbf52fa6d45/pycryptodomex-3.23.0-cp37-abi3-win32.whl", hash = "sha256:189afbc87f0b9f158386bf051f720e20fa6145975f1e76369303d0f31d1a8d7c", size = 1771969, upload-time = "2025-05-17T17:23:07.115Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/69/96/11f36f71a865dd6df03716d33bd07a67e9d20f6b8d39820470b766af323c/pycryptodomex-3.23.0-cp37-abi3-win_amd64.whl", hash = "sha256:52e5ca58c3a0b0bd5e100a9fbc8015059b05cffc6c66ce9d98b4b45e023443b9", size = 1803124, upload-time = "2025-05-17T17:23:09.267Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/f9/93/45c1cdcbeb182ccd2e144c693eaa097763b08b38cded279f0053ed53c553/pycryptodomex-3.23.0-cp37-abi3-win_arm64.whl", hash = "sha256:02d87b80778c171445d67e23d1caef279bf4b25c3597050ccd2e13970b57fd51", size = 1707161, upload-time = "2025-05-17T17:23:11.414Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/f3/b8/3e76d948c3c4ac71335bbe75dac53e154b40b0f8f1f022dfa295257a0c96/pycryptodomex-3.23.0-pp310-pypy310_pp73-macosx_10_15_x86_64.whl", hash = "sha256:ebfff755c360d674306e5891c564a274a47953562b42fb74a5c25b8fc1fb1cb5", size = 1627695, upload-time = "2025-05-17T17:23:17.38Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/6a/cf/80f4297a4820dfdfd1c88cf6c4666a200f204b3488103d027b5edd9176ec/pycryptodomex-3.23.0-pp310-pypy310_pp73-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:eca54f4bb349d45afc17e3011ed4264ef1cc9e266699874cdd1349c504e64798", size = 1675772, upload-time = "2025-05-17T17:23:19.202Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/d1/42/1e969ee0ad19fe3134b0e1b856c39bd0b70d47a4d0e81c2a8b05727394c9/pycryptodomex-3.23.0-pp310-pypy310_pp73-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:4f2596e643d4365e14d0879dc5aafe6355616c61c2176009270f3048f6d9a61f", size = 1668083, upload-time = "2025-05-17T17:23:21.867Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/6e/c3/1de4f7631fea8a992a44ba632aa40e0008764c0fb9bf2854b0acf78c2cf2/pycryptodomex-3.23.0-pp310-pypy310_pp73-manylinux_2_5_i686.manylinux1_i686.manylinux_2_17_i686.manylinux2014_i686.whl", hash = "sha256:fdfac7cda115bca3a5abb2f9e43bc2fb66c2b65ab074913643803ca7083a79ea", size = 1706056, upload-time = "2025-05-17T17:23:24.031Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/f2/5f/af7da8e6f1e42b52f44a24d08b8e4c726207434e2593732d39e7af5e7256/pycryptodomex-3.23.0-pp310-pypy310_pp73-win_amd64.whl", hash = "sha256:14c37aaece158d0ace436f76a7bb19093db3b4deade9797abfc39ec6cd6cc2fe", size = 1806478, upload-time = "2025-05-17T17:23:26.066Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "pygments"
|
||||
version = "2.19.2"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/b0/77/a5b8c569bf593b0140bde72ea885a803b82086995367bf2037de0159d924/pygments-2.19.2.tar.gz", hash = "sha256:636cb2477cec7f8952536970bc533bc43743542f70392ae026374600add5b887", size = 4968631, upload-time = "2025-06-21T13:39:12.283Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/c7/21/705964c7812476f378728bdf590ca4b771ec72385c533964653c68e86bdc/pygments-2.19.2-py3-none-any.whl", hash = "sha256:86540386c03d588bb81d44bc3928634ff26449851e99741617ecb9037ee5ec0b", size = 1225217, upload-time = "2025-06-21T13:39:07.939Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "pytest"
|
||||
version = "9.0.1"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
dependencies = [
|
||||
{ name = "colorama", marker = "sys_platform == 'win32'" },
|
||||
{ name = "exceptiongroup", marker = "python_full_version < '3.11'" },
|
||||
{ name = "iniconfig" },
|
||||
{ name = "packaging" },
|
||||
{ name = "pluggy" },
|
||||
{ name = "pygments" },
|
||||
{ name = "tomli", marker = "python_full_version < '3.11'" },
|
||||
]
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/07/56/f013048ac4bc4c1d9be45afd4ab209ea62822fb1598f40687e6bf45dcea4/pytest-9.0.1.tar.gz", hash = "sha256:3e9c069ea73583e255c3b21cf46b8d3c56f6e3a1a8f6da94ccb0fcf57b9d73c8", size = 1564125, upload-time = "2025-11-12T13:05:09.333Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/0b/8b/6300fb80f858cda1c51ffa17075df5d846757081d11ab4aa35cef9e6258b/pytest-9.0.1-py3-none-any.whl", hash = "sha256:67be0030d194df2dfa7b556f2e56fb3c3315bd5c8822c6951162b92b32ce7dad", size = 373668, upload-time = "2025-11-12T13:05:07.379Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "ragflow-cli"
|
||||
version = "0.22.1"
|
||||
source = { virtual = "." }
|
||||
dependencies = [
|
||||
{ name = "beartype" },
|
||||
{ name = "lark" },
|
||||
{ name = "pycryptodomex" },
|
||||
{ name = "requests" },
|
||||
]
|
||||
|
||||
[package.dev-dependencies]
|
||||
test = [
|
||||
{ name = "pytest" },
|
||||
{ name = "requests" },
|
||||
{ name = "requests-toolbelt" },
|
||||
]
|
||||
|
||||
[package.metadata]
|
||||
requires-dist = [
|
||||
{ name = "beartype", specifier = ">=0.20.0,<1.0.0" },
|
||||
{ name = "lark", specifier = ">=1.1.0" },
|
||||
{ name = "pycryptodomex", specifier = ">=3.10.0" },
|
||||
{ name = "requests", specifier = ">=2.30.0,<3.0.0" },
|
||||
]
|
||||
|
||||
[package.metadata.requires-dev]
|
||||
test = [
|
||||
{ name = "pytest", specifier = ">=8.3.5" },
|
||||
{ name = "requests", specifier = ">=2.32.3" },
|
||||
{ name = "requests-toolbelt", specifier = ">=1.0.0" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "requests"
|
||||
version = "2.32.5"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
dependencies = [
|
||||
{ name = "certifi" },
|
||||
{ name = "charset-normalizer" },
|
||||
{ name = "idna" },
|
||||
{ name = "urllib3" },
|
||||
]
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/c9/74/b3ff8e6c8446842c3f5c837e9c3dfcfe2018ea6ecef224c710c85ef728f4/requests-2.32.5.tar.gz", hash = "sha256:dbba0bac56e100853db0ea71b82b4dfd5fe2bf6d3754a8893c3af500cec7d7cf", size = 134517, upload-time = "2025-08-18T20:46:02.573Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/1e/db/4254e3eabe8020b458f1a747140d32277ec7a271daf1d235b70dc0b4e6e3/requests-2.32.5-py3-none-any.whl", hash = "sha256:2462f94637a34fd532264295e186976db0f5d453d1cdd31473c85a6a161affb6", size = 64738, upload-time = "2025-08-18T20:46:00.542Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "requests-toolbelt"
|
||||
version = "1.0.0"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
dependencies = [
|
||||
{ name = "requests" },
|
||||
]
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/f3/61/d7545dafb7ac2230c70d38d31cbfe4cc64f7144dc41f6e4e4b78ecd9f5bb/requests-toolbelt-1.0.0.tar.gz", hash = "sha256:7681a0a3d047012b5bdc0ee37d7f8f07ebe76ab08caeccfc3921ce23c88d5bc6", size = 206888, upload-time = "2023-05-01T04:11:33.229Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/3f/51/d4db610ef29373b879047326cbf6fa98b6c1969d6f6dc423279de2b1be2c/requests_toolbelt-1.0.0-py2.py3-none-any.whl", hash = "sha256:cccfdd665f0a24fcf4726e690f65639d272bb0637b9b92dfd91a5568ccf6bd06", size = 54481, upload-time = "2023-05-01T04:11:28.427Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "tomli"
|
||||
version = "2.3.0"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/52/ed/3f73f72945444548f33eba9a87fc7a6e969915e7b1acc8260b30e1f76a2f/tomli-2.3.0.tar.gz", hash = "sha256:64be704a875d2a59753d80ee8a533c3fe183e3f06807ff7dc2232938ccb01549", size = 17392, upload-time = "2025-10-08T22:01:47.119Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/b3/2e/299f62b401438d5fe1624119c723f5d877acc86a4c2492da405626665f12/tomli-2.3.0-cp311-cp311-macosx_10_9_x86_64.whl", hash = "sha256:88bd15eb972f3664f5ed4b57c1634a97153b4bac4479dcb6a495f41921eb7f45", size = 153236, upload-time = "2025-10-08T22:01:00.137Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/86/7f/d8fffe6a7aefdb61bced88fcb5e280cfd71e08939da5894161bd71bea022/tomli-2.3.0-cp311-cp311-macosx_11_0_arm64.whl", hash = "sha256:883b1c0d6398a6a9d29b508c331fa56adbcdff647f6ace4dfca0f50e90dfd0ba", size = 148084, upload-time = "2025-10-08T22:01:01.63Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/47/5c/24935fb6a2ee63e86d80e4d3b58b222dafaf438c416752c8b58537c8b89a/tomli-2.3.0-cp311-cp311-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:d1381caf13ab9f300e30dd8feadb3de072aeb86f1d34a8569453ff32a7dea4bf", size = 234832, upload-time = "2025-10-08T22:01:02.543Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/89/da/75dfd804fc11e6612846758a23f13271b76d577e299592b4371a4ca4cd09/tomli-2.3.0-cp311-cp311-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:a0e285d2649b78c0d9027570d4da3425bdb49830a6156121360b3f8511ea3441", size = 242052, upload-time = "2025-10-08T22:01:03.836Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/70/8c/f48ac899f7b3ca7eb13af73bacbc93aec37f9c954df3c08ad96991c8c373/tomli-2.3.0-cp311-cp311-musllinux_1_2_aarch64.whl", hash = "sha256:0a154a9ae14bfcf5d8917a59b51ffd5a3ac1fd149b71b47a3a104ca4edcfa845", size = 239555, upload-time = "2025-10-08T22:01:04.834Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/ba/28/72f8afd73f1d0e7829bfc093f4cb98ce0a40ffc0cc997009ee1ed94ba705/tomli-2.3.0-cp311-cp311-musllinux_1_2_x86_64.whl", hash = "sha256:74bf8464ff93e413514fefd2be591c3b0b23231a77f901db1eb30d6f712fc42c", size = 245128, upload-time = "2025-10-08T22:01:05.84Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/b6/eb/a7679c8ac85208706d27436e8d421dfa39d4c914dcf5fa8083a9305f58d9/tomli-2.3.0-cp311-cp311-win32.whl", hash = "sha256:00b5f5d95bbfc7d12f91ad8c593a1659b6387b43f054104cda404be6bda62456", size = 96445, upload-time = "2025-10-08T22:01:06.896Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/0a/fe/3d3420c4cb1ad9cb462fb52967080575f15898da97e21cb6f1361d505383/tomli-2.3.0-cp311-cp311-win_amd64.whl", hash = "sha256:4dc4ce8483a5d429ab602f111a93a6ab1ed425eae3122032db7e9acf449451be", size = 107165, upload-time = "2025-10-08T22:01:08.107Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/ff/b7/40f36368fcabc518bb11c8f06379a0fd631985046c038aca08c6d6a43c6e/tomli-2.3.0-cp312-cp312-macosx_10_13_x86_64.whl", hash = "sha256:d7d86942e56ded512a594786a5ba0a5e521d02529b3826e7761a05138341a2ac", size = 154891, upload-time = "2025-10-08T22:01:09.082Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/f9/3f/d9dd692199e3b3aab2e4e4dd948abd0f790d9ded8cd10cbaae276a898434/tomli-2.3.0-cp312-cp312-macosx_11_0_arm64.whl", hash = "sha256:73ee0b47d4dad1c5e996e3cd33b8a76a50167ae5f96a2607cbe8cc773506ab22", size = 148796, upload-time = "2025-10-08T22:01:10.266Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/60/83/59bff4996c2cf9f9387a0f5a3394629c7efa5ef16142076a23a90f1955fa/tomli-2.3.0-cp312-cp312-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:792262b94d5d0a466afb5bc63c7daa9d75520110971ee269152083270998316f", size = 242121, upload-time = "2025-10-08T22:01:11.332Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/45/e5/7c5119ff39de8693d6baab6c0b6dcb556d192c165596e9fc231ea1052041/tomli-2.3.0-cp312-cp312-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:4f195fe57ecceac95a66a75ac24d9d5fbc98ef0962e09b2eddec5d39375aae52", size = 250070, upload-time = "2025-10-08T22:01:12.498Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/45/12/ad5126d3a278f27e6701abde51d342aa78d06e27ce2bb596a01f7709a5a2/tomli-2.3.0-cp312-cp312-musllinux_1_2_aarch64.whl", hash = "sha256:e31d432427dcbf4d86958c184b9bfd1e96b5b71f8eb17e6d02531f434fd335b8", size = 245859, upload-time = "2025-10-08T22:01:13.551Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/fb/a1/4d6865da6a71c603cfe6ad0e6556c73c76548557a8d658f9e3b142df245f/tomli-2.3.0-cp312-cp312-musllinux_1_2_x86_64.whl", hash = "sha256:7b0882799624980785240ab732537fcfc372601015c00f7fc367c55308c186f6", size = 250296, upload-time = "2025-10-08T22:01:14.614Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/a0/b7/a7a7042715d55c9ba6e8b196d65d2cb662578b4d8cd17d882d45322b0d78/tomli-2.3.0-cp312-cp312-win32.whl", hash = "sha256:ff72b71b5d10d22ecb084d345fc26f42b5143c5533db5e2eaba7d2d335358876", size = 97124, upload-time = "2025-10-08T22:01:15.629Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/06/1e/f22f100db15a68b520664eb3328fb0ae4e90530887928558112c8d1f4515/tomli-2.3.0-cp312-cp312-win_amd64.whl", hash = "sha256:1cb4ed918939151a03f33d4242ccd0aa5f11b3547d0cf30f7c74a408a5b99878", size = 107698, upload-time = "2025-10-08T22:01:16.51Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/77/b8/0135fadc89e73be292b473cb820b4f5a08197779206b33191e801feeae40/tomli-2.3.0-py3-none-any.whl", hash = "sha256:e95b1af3c5b07d9e643909b5abbec77cd9f1217e6d0bca72b0234736b9fb1f1b", size = 14408, upload-time = "2025-10-08T22:01:46.04Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "typing-extensions"
|
||||
version = "4.15.0"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/72/94/1a15dd82efb362ac84269196e94cf00f187f7ed21c242792a923cdb1c61f/typing_extensions-4.15.0.tar.gz", hash = "sha256:0cea48d173cc12fa28ecabc3b837ea3cf6f38c6d1136f85cbaaf598984861466", size = 109391, upload-time = "2025-08-25T13:49:26.313Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/18/67/36e9267722cc04a6b9f15c7f3441c2363321a3ea07da7ae0c0707beb2a9c/typing_extensions-4.15.0-py3-none-any.whl", hash = "sha256:f0fa19c6845758ab08074a0cfa8b7aecb71c999ca73d62883bc25cc018c4e548", size = 44614, upload-time = "2025-08-25T13:49:24.86Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "urllib3"
|
||||
version = "2.5.0"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/15/22/9ee70a2574a4f4599c47dd506532914ce044817c7752a79b6a51286319bc/urllib3-2.5.0.tar.gz", hash = "sha256:3fc47733c7e419d4bc3f6b3dc2b4f890bb743906a30d56ba4a5bfa4bbff92760", size = 393185, upload-time = "2025-06-18T14:07:41.644Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/a7/c2/fe1e52489ae3122415c51f387e221dd0773709bad6c6cdaa599e8a2c5185/urllib3-2.5.0-py3-none-any.whl", hash = "sha256:e6b01673c0fa6a13e374b50871808eb3bf7046c4b125b216f6bf1cc604cff0dc", size = 129795, upload-time = "2025-06-18T14:07:40.39Z" },
|
||||
]
|
||||
@ -20,6 +20,7 @@ import logging
|
||||
import time
|
||||
import threading
|
||||
import traceback
|
||||
import faulthandler
|
||||
|
||||
from flask import Flask
|
||||
from flask_login import LoginManager
|
||||
@ -37,6 +38,7 @@ from common.versions import get_ragflow_version
|
||||
stop_event = threading.Event()
|
||||
|
||||
if __name__ == '__main__':
|
||||
faulthandler.enable()
|
||||
init_root_logger("admin_service")
|
||||
logging.info(r"""
|
||||
____ ___ ______________ ___ __ _
|
||||
|
||||
@ -206,17 +206,28 @@ class Graph:
|
||||
for key in path.split('.'):
|
||||
if cur is None:
|
||||
return None
|
||||
|
||||
if isinstance(cur, str):
|
||||
try:
|
||||
cur = json.loads(cur)
|
||||
except Exception:
|
||||
return None
|
||||
|
||||
if isinstance(cur, dict):
|
||||
cur = cur.get(key)
|
||||
else:
|
||||
cur = getattr(cur, key, None)
|
||||
continue
|
||||
|
||||
if isinstance(cur, (list, tuple)):
|
||||
try:
|
||||
idx = int(key)
|
||||
cur = cur[idx]
|
||||
except Exception:
|
||||
return None
|
||||
continue
|
||||
|
||||
cur = getattr(cur, key, None)
|
||||
return cur
|
||||
|
||||
|
||||
def set_variable_value(self, exp: str,value):
|
||||
exp = exp.strip("{").strip("}").strip(" ").strip("{").strip("}")
|
||||
if exp.find("@") < 0:
|
||||
@ -270,6 +281,7 @@ class Canvas(Graph):
|
||||
"sys.conversation_turns": 0,
|
||||
"sys.files": []
|
||||
}
|
||||
self.variables = {}
|
||||
super().__init__(dsl, tenant_id, task_id)
|
||||
|
||||
def load(self):
|
||||
@ -284,6 +296,10 @@ class Canvas(Graph):
|
||||
"sys.conversation_turns": 0,
|
||||
"sys.files": []
|
||||
}
|
||||
if "variables" in self.dsl:
|
||||
self.variables = self.dsl["variables"]
|
||||
else:
|
||||
self.variables = {}
|
||||
|
||||
self.retrieval = self.dsl["retrieval"]
|
||||
self.memory = self.dsl.get("memory", [])
|
||||
@ -300,8 +316,9 @@ class Canvas(Graph):
|
||||
self.history = []
|
||||
self.retrieval = []
|
||||
self.memory = []
|
||||
print(self.variables)
|
||||
for k in self.globals.keys():
|
||||
if k.startswith("sys.") or k.startswith("env."):
|
||||
if k.startswith("sys."):
|
||||
if isinstance(self.globals[k], str):
|
||||
self.globals[k] = ""
|
||||
elif isinstance(self.globals[k], int):
|
||||
@ -314,6 +331,29 @@ class Canvas(Graph):
|
||||
self.globals[k] = {}
|
||||
else:
|
||||
self.globals[k] = None
|
||||
if k.startswith("env."):
|
||||
key = k[4:]
|
||||
if key in self.variables:
|
||||
variable = self.variables[key]
|
||||
if variable["value"]:
|
||||
self.globals[k] = variable["value"]
|
||||
else:
|
||||
if variable["type"] == "string":
|
||||
self.globals[k] = ""
|
||||
elif variable["type"] == "number":
|
||||
self.globals[k] = 0
|
||||
elif variable["type"] == "boolean":
|
||||
self.globals[k] = False
|
||||
elif variable["type"] == "object":
|
||||
self.globals[k] = {}
|
||||
elif variable["type"].startswith("array"):
|
||||
self.globals[k] = []
|
||||
else:
|
||||
self.globals[k] = ""
|
||||
else:
|
||||
self.globals[k] = ""
|
||||
print(self.globals)
|
||||
|
||||
|
||||
async def run(self, **kwargs):
|
||||
st = time.perf_counter()
|
||||
@ -440,7 +480,7 @@ class Canvas(Graph):
|
||||
|
||||
if isinstance(cpn_obj.output("attachment"), tuple):
|
||||
yield decorate("message", {"attachment": cpn_obj.output("attachment")})
|
||||
|
||||
|
||||
yield decorate("message_end", {"reference": self.get_reference() if cite else None})
|
||||
|
||||
while partials:
|
||||
@ -462,7 +502,7 @@ class Canvas(Graph):
|
||||
else:
|
||||
self.error = cpn_obj.error()
|
||||
|
||||
if cpn_obj.component_name.lower() != "iteration":
|
||||
if cpn_obj.component_name.lower() not in ("iteration","loop"):
|
||||
if isinstance(cpn_obj.output("content"), partial):
|
||||
if self.error:
|
||||
cpn_obj.set_output("content", None)
|
||||
@ -487,14 +527,16 @@ class Canvas(Graph):
|
||||
for cpn_id in cpn_ids:
|
||||
_append_path(cpn_id)
|
||||
|
||||
if cpn_obj.component_name.lower() == "iterationitem" and cpn_obj.end():
|
||||
if cpn_obj.component_name.lower() in ("iterationitem","loopitem") and cpn_obj.end():
|
||||
iter = cpn_obj.get_parent()
|
||||
yield _node_finished(iter)
|
||||
_extend_path(self.get_component(cpn["parent_id"])["downstream"])
|
||||
elif cpn_obj.component_name.lower() in ["categorize", "switch"]:
|
||||
_extend_path(cpn_obj.output("_next"))
|
||||
elif cpn_obj.component_name.lower() == "iteration":
|
||||
elif cpn_obj.component_name.lower() in ("iteration", "loop"):
|
||||
_append_path(cpn_obj.get_start())
|
||||
elif cpn_obj.component_name.lower() == "exitloop" and cpn_obj.get_parent().component_name.lower() == "loop":
|
||||
_extend_path(self.get_component(cpn["parent_id"])["downstream"])
|
||||
elif not cpn["downstream"] and cpn_obj.get_parent():
|
||||
_append_path(cpn_obj.get_parent().get_start())
|
||||
else:
|
||||
@ -647,4 +689,3 @@ class Canvas(Graph):
|
||||
|
||||
def get_component_thoughts(self, cpn_id) -> str:
|
||||
return self.components.get(cpn_id)["obj"].thoughts()
|
||||
|
||||
|
||||
@ -13,6 +13,7 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
import json
|
||||
import logging
|
||||
import os
|
||||
import re
|
||||
@ -29,7 +30,7 @@ from api.db.services.tenant_llm_service import TenantLLMService
|
||||
from api.db.services.mcp_server_service import MCPServerService
|
||||
from common.connection_utils import timeout
|
||||
from rag.prompts.generator import next_step, COMPLETE_TASK, analyze_task, \
|
||||
citation_prompt, reflect, rank_memories, kb_prompt, citation_plus, full_question, message_fit_in
|
||||
citation_prompt, reflect, rank_memories, kb_prompt, citation_plus, full_question, message_fit_in, structured_output_prompt
|
||||
from common.mcp_tool_call_conn import MCPToolCallSession, mcp_tool_metadata_to_openai_tool
|
||||
from agent.component.llm import LLMParam, LLM
|
||||
|
||||
@ -137,6 +138,29 @@ class Agent(LLM, ToolBase):
|
||||
res.update(cpn.get_input_form())
|
||||
return res
|
||||
|
||||
def _get_output_schema(self):
|
||||
try:
|
||||
cand = self._param.outputs.get("structured")
|
||||
except Exception:
|
||||
return None
|
||||
|
||||
if isinstance(cand, dict):
|
||||
if isinstance(cand.get("properties"), dict) and len(cand["properties"]) > 0:
|
||||
return cand
|
||||
for k in ("schema", "structured"):
|
||||
if isinstance(cand.get(k), dict) and isinstance(cand[k].get("properties"), dict) and len(cand[k]["properties"]) > 0:
|
||||
return cand[k]
|
||||
|
||||
return None
|
||||
|
||||
def _force_format_to_schema(self, text: str, schema_prompt: str) -> str:
|
||||
fmt_msgs = [
|
||||
{"role": "system", "content": schema_prompt + "\nIMPORTANT: Output ONLY valid JSON. No markdown, no extra text."},
|
||||
{"role": "user", "content": text},
|
||||
]
|
||||
_, fmt_msgs = message_fit_in(fmt_msgs, int(self.chat_mdl.max_length * 0.97))
|
||||
return self._generate(fmt_msgs)
|
||||
|
||||
@timeout(int(os.environ.get("COMPONENT_EXEC_TIMEOUT", 20*60)))
|
||||
def _invoke(self, **kwargs):
|
||||
if self.check_if_canceled("Agent processing"):
|
||||
@ -160,17 +184,22 @@ class Agent(LLM, ToolBase):
|
||||
return LLM._invoke(self, **kwargs)
|
||||
|
||||
prompt, msg, user_defined_prompt = self._prepare_prompt_variables()
|
||||
output_schema = self._get_output_schema()
|
||||
schema_prompt = ""
|
||||
if output_schema:
|
||||
schema = json.dumps(output_schema, ensure_ascii=False, indent=2)
|
||||
schema_prompt = structured_output_prompt(schema)
|
||||
|
||||
downstreams = self._canvas.get_component(self._id)["downstream"] if self._canvas.get_component(self._id) else []
|
||||
ex = self.exception_handler()
|
||||
if any([self._canvas.get_component_obj(cid).component_name.lower()=="message" for cid in downstreams]) and not (ex and ex["goto"]):
|
||||
if any([self._canvas.get_component_obj(cid).component_name.lower()=="message" for cid in downstreams]) and not (ex and ex["goto"]) and not output_schema:
|
||||
self.set_output("content", partial(self.stream_output_with_tools, prompt, msg, user_defined_prompt))
|
||||
return
|
||||
|
||||
_, msg = message_fit_in([{"role": "system", "content": prompt}, *msg], int(self.chat_mdl.max_length * 0.97))
|
||||
use_tools = []
|
||||
ans = ""
|
||||
for delta_ans, tk in self._react_with_tools_streamly(prompt, msg, use_tools, user_defined_prompt):
|
||||
for delta_ans, tk in self._react_with_tools_streamly(prompt, msg, use_tools, user_defined_prompt,schema_prompt=schema_prompt):
|
||||
if self.check_if_canceled("Agent processing"):
|
||||
return
|
||||
ans += delta_ans
|
||||
@ -183,6 +212,28 @@ class Agent(LLM, ToolBase):
|
||||
self.set_output("_ERROR", ans)
|
||||
return
|
||||
|
||||
if output_schema:
|
||||
error = ""
|
||||
for _ in range(self._param.max_retries + 1):
|
||||
try:
|
||||
def clean_formated_answer(ans: str) -> str:
|
||||
ans = re.sub(r"^.*</think>", "", ans, flags=re.DOTALL)
|
||||
ans = re.sub(r"^.*```json", "", ans, flags=re.DOTALL)
|
||||
return re.sub(r"```\n*$", "", ans, flags=re.DOTALL)
|
||||
obj = json_repair.loads(clean_formated_answer(ans))
|
||||
self.set_output("structured", obj)
|
||||
if use_tools:
|
||||
self.set_output("use_tools", use_tools)
|
||||
return obj
|
||||
except Exception:
|
||||
error = "The answer cannot be parsed as JSON"
|
||||
ans = self._force_format_to_schema(ans, schema_prompt)
|
||||
if ans.find("**ERROR**") >= 0:
|
||||
continue
|
||||
|
||||
self.set_output("_ERROR", error)
|
||||
return
|
||||
|
||||
self.set_output("content", ans)
|
||||
if use_tools:
|
||||
self.set_output("use_tools", use_tools)
|
||||
@ -219,7 +270,7 @@ class Agent(LLM, ToolBase):
|
||||
]):
|
||||
yield delta_ans
|
||||
|
||||
def _react_with_tools_streamly(self, prompt, history: list[dict], use_tools, user_defined_prompt={}):
|
||||
def _react_with_tools_streamly(self, prompt, history: list[dict], use_tools, user_defined_prompt={}, schema_prompt: str = ""):
|
||||
token_count = 0
|
||||
tool_metas = self.tool_meta
|
||||
hist = deepcopy(history)
|
||||
@ -256,9 +307,13 @@ class Agent(LLM, ToolBase):
|
||||
def complete():
|
||||
nonlocal hist
|
||||
need2cite = self._param.cite and self._canvas.get_reference()["chunks"] and self._id.find("-->") < 0
|
||||
if schema_prompt:
|
||||
need2cite = False
|
||||
cited = False
|
||||
if hist[0]["role"] == "system" and need2cite:
|
||||
if len(hist) < 7:
|
||||
if hist and hist[0]["role"] == "system":
|
||||
if schema_prompt:
|
||||
hist[0]["content"] += "\n" + schema_prompt
|
||||
if need2cite and len(hist) < 7:
|
||||
hist[0]["content"] += citation_prompt()
|
||||
cited = True
|
||||
yield "", token_count
|
||||
@ -369,7 +424,7 @@ Respond immediately with your final comprehensive answer.
|
||||
"""
|
||||
for k in self._param.outputs.keys():
|
||||
self._param.outputs[k]["value"] = None
|
||||
|
||||
|
||||
for k, cpn in self.tools.items():
|
||||
if hasattr(cpn, "reset") and callable(cpn.reset):
|
||||
cpn.reset()
|
||||
|
||||
32
agent/component/exit_loop.py
Normal file
32
agent/component/exit_loop.py
Normal file
@ -0,0 +1,32 @@
|
||||
#
|
||||
# Copyright 2024 The InfiniFlow Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
from abc import ABC
|
||||
from agent.component.base import ComponentBase, ComponentParamBase
|
||||
|
||||
|
||||
class ExitLoopParam(ComponentParamBase, ABC):
|
||||
def check(self):
|
||||
return True
|
||||
|
||||
|
||||
class ExitLoop(ComponentBase, ABC):
|
||||
component_name = "ExitLoop"
|
||||
|
||||
def _invoke(self, **kwargs):
|
||||
pass
|
||||
|
||||
def thoughts(self) -> str:
|
||||
return ""
|
||||
@ -32,7 +32,7 @@ class IterationParam(ComponentParamBase):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.items_ref = ""
|
||||
self.veriable={}
|
||||
self.variable={}
|
||||
|
||||
def get_input_form(self) -> dict[str, dict]:
|
||||
return {
|
||||
|
||||
@ -222,7 +222,7 @@ class LLM(ComponentBase):
|
||||
output_structure = self._param.outputs['structured']
|
||||
except Exception:
|
||||
pass
|
||||
if output_structure and isinstance(output_structure, dict) and output_structure.get("properties"):
|
||||
if output_structure and isinstance(output_structure, dict) and output_structure.get("properties") and len(output_structure["properties"]) > 0:
|
||||
schema=json.dumps(output_structure, ensure_ascii=False, indent=2)
|
||||
prompt += structured_output_prompt(schema)
|
||||
for _ in range(self._param.max_retries+1):
|
||||
|
||||
80
agent/component/loop.py
Normal file
80
agent/component/loop.py
Normal file
@ -0,0 +1,80 @@
|
||||
#
|
||||
# Copyright 2024 The InfiniFlow Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
from abc import ABC
|
||||
from agent.component.base import ComponentBase, ComponentParamBase
|
||||
|
||||
|
||||
class LoopParam(ComponentParamBase):
|
||||
"""
|
||||
Define the Loop component parameters.
|
||||
"""
|
||||
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.loop_variables = []
|
||||
self.loop_termination_condition=[]
|
||||
self.maximum_loop_count = 0
|
||||
|
||||
def get_input_form(self) -> dict[str, dict]:
|
||||
return {
|
||||
"items": {
|
||||
"type": "json",
|
||||
"name": "Items"
|
||||
}
|
||||
}
|
||||
|
||||
def check(self):
|
||||
return True
|
||||
|
||||
|
||||
class Loop(ComponentBase, ABC):
|
||||
component_name = "Loop"
|
||||
|
||||
def get_start(self):
|
||||
for cid in self._canvas.components.keys():
|
||||
if self._canvas.get_component(cid)["obj"].component_name.lower() != "loopitem":
|
||||
continue
|
||||
if self._canvas.get_component(cid)["parent_id"] == self._id:
|
||||
return cid
|
||||
|
||||
def _invoke(self, **kwargs):
|
||||
if self.check_if_canceled("Loop processing"):
|
||||
return
|
||||
|
||||
for item in self._param.loop_variables:
|
||||
if any([not item.get("variable"), not item.get("input_mode"), not item.get("value"),not item.get("type")]):
|
||||
assert "Loop Variable is not complete."
|
||||
if item["input_mode"]=="variable":
|
||||
self.set_output(item["variable"],self._canvas.get_variable_value(item["value"]))
|
||||
elif item["input_mode"]=="constant":
|
||||
self.set_output(item["variable"],item["value"])
|
||||
else:
|
||||
if item["type"] == "number":
|
||||
self.set_output(item["variable"], 0)
|
||||
elif item["type"] == "string":
|
||||
self.set_output(item["variable"], "")
|
||||
elif item["type"] == "boolean":
|
||||
self.set_output(item["variable"], False)
|
||||
elif item["type"].startswith("object"):
|
||||
self.set_output(item["variable"], {})
|
||||
elif item["type"].startswith("array"):
|
||||
self.set_output(item["variable"], [])
|
||||
else:
|
||||
self.set_output(item["variable"], "")
|
||||
|
||||
|
||||
def thoughts(self) -> str:
|
||||
return "Loop from canvas."
|
||||
163
agent/component/loopitem.py
Normal file
163
agent/component/loopitem.py
Normal file
@ -0,0 +1,163 @@
|
||||
#
|
||||
# Copyright 2024 The InfiniFlow Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
from abc import ABC
|
||||
from agent.component.base import ComponentBase, ComponentParamBase
|
||||
|
||||
|
||||
class LoopItemParam(ComponentParamBase):
|
||||
"""
|
||||
Define the LoopItem component parameters.
|
||||
"""
|
||||
def check(self):
|
||||
return True
|
||||
|
||||
class LoopItem(ComponentBase, ABC):
|
||||
component_name = "LoopItem"
|
||||
|
||||
def __init__(self, canvas, id, param: ComponentParamBase):
|
||||
super().__init__(canvas, id, param)
|
||||
self._idx = 0
|
||||
|
||||
|
||||
def _invoke(self, **kwargs):
|
||||
if self.check_if_canceled("LoopItem processing"):
|
||||
return
|
||||
parent = self.get_parent()
|
||||
maximum_loop_count = parent._param.maximum_loop_count
|
||||
if self._idx >= maximum_loop_count:
|
||||
self._idx = -1
|
||||
return
|
||||
if self._idx > 0:
|
||||
if self.check_if_canceled("LoopItem processing"):
|
||||
return
|
||||
self._idx += 1
|
||||
|
||||
def evaluate_condition(self,var, operator, value):
|
||||
if isinstance(var, str):
|
||||
if operator == "contains":
|
||||
return value in var
|
||||
elif operator == "not contains":
|
||||
return value not in var
|
||||
elif operator == "start with":
|
||||
return var.startswith(value)
|
||||
elif operator == "end with":
|
||||
return var.endswith(value)
|
||||
elif operator == "is":
|
||||
return var == value
|
||||
elif operator == "is not":
|
||||
return var != value
|
||||
elif operator == "empty":
|
||||
return var == ""
|
||||
elif operator == "not empty":
|
||||
return var != ""
|
||||
|
||||
elif isinstance(var, (int, float)):
|
||||
if operator == "=":
|
||||
return var == value
|
||||
elif operator == "≠":
|
||||
return var != value
|
||||
elif operator == ">":
|
||||
return var > value
|
||||
elif operator == "<":
|
||||
return var < value
|
||||
elif operator == "≥":
|
||||
return var >= value
|
||||
elif operator == "≤":
|
||||
return var <= value
|
||||
elif operator == "empty":
|
||||
return var is None
|
||||
elif operator == "not empty":
|
||||
return var is not None
|
||||
|
||||
elif isinstance(var, bool):
|
||||
if operator == "is":
|
||||
return var is value
|
||||
elif operator == "is not":
|
||||
return var is not value
|
||||
elif operator == "empty":
|
||||
return var is None
|
||||
elif operator == "not empty":
|
||||
return var is not None
|
||||
|
||||
elif isinstance(var, dict):
|
||||
if operator == "empty":
|
||||
return len(var) == 0
|
||||
elif operator == "not empty":
|
||||
return len(var) > 0
|
||||
|
||||
elif isinstance(var, list):
|
||||
if operator == "contains":
|
||||
return value in var
|
||||
elif operator == "not contains":
|
||||
return value not in var
|
||||
|
||||
elif operator == "is":
|
||||
return var == value
|
||||
elif operator == "is not":
|
||||
return var != value
|
||||
|
||||
elif operator == "empty":
|
||||
return len(var) == 0
|
||||
elif operator == "not empty":
|
||||
return len(var) > 0
|
||||
|
||||
raise Exception(f"Invalid operator: {operator}")
|
||||
|
||||
def end(self):
|
||||
if self._idx == -1:
|
||||
return True
|
||||
parent = self.get_parent()
|
||||
logical_operator = parent._param.logical_operator if hasattr(parent._param, "logical_operator") else "and"
|
||||
conditions = []
|
||||
for item in parent._param.loop_termination_condition:
|
||||
if not item.get("variable") or not item.get("operator"):
|
||||
raise ValueError("Loop condition is incomplete.")
|
||||
var = self._canvas.get_variable_value(item["variable"])
|
||||
operator = item["operator"]
|
||||
input_mode = item.get("input_mode", "constant")
|
||||
|
||||
if input_mode == "variable":
|
||||
value = self._canvas.get_variable_value(item.get("value", ""))
|
||||
elif input_mode == "constant":
|
||||
value = item.get("value", "")
|
||||
else:
|
||||
raise ValueError("Invalid input mode.")
|
||||
conditions.append(self.evaluate_condition(var, operator, value))
|
||||
should_end = (
|
||||
all(conditions) if logical_operator == "and"
|
||||
else any(conditions) if logical_operator == "or"
|
||||
else None
|
||||
)
|
||||
if should_end is None:
|
||||
raise ValueError("Invalid logical operator,should be 'and' or 'or'.")
|
||||
|
||||
if should_end:
|
||||
self._idx = -1
|
||||
return True
|
||||
|
||||
return False
|
||||
|
||||
def next(self):
|
||||
if self._idx == -1:
|
||||
self._idx = 0
|
||||
else:
|
||||
self._idx += 1
|
||||
if self._idx >= len(self._items):
|
||||
self._idx = -1
|
||||
return False
|
||||
|
||||
def thoughts(self) -> str:
|
||||
return "Next turn..."
|
||||
@ -13,16 +13,20 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
import ast
|
||||
import base64
|
||||
import json
|
||||
import logging
|
||||
import os
|
||||
from abc import ABC
|
||||
from strenum import StrEnum
|
||||
from typing import Optional
|
||||
|
||||
from pydantic import BaseModel, Field, field_validator
|
||||
from agent.tools.base import ToolParamBase, ToolBase, ToolMeta
|
||||
from common.connection_utils import timeout
|
||||
from strenum import StrEnum
|
||||
|
||||
from agent.tools.base import ToolBase, ToolMeta, ToolParamBase
|
||||
from common import settings
|
||||
from common.connection_utils import timeout
|
||||
|
||||
|
||||
class Language(StrEnum):
|
||||
@ -62,7 +66,7 @@ class CodeExecParam(ToolParamBase):
|
||||
"""
|
||||
|
||||
def __init__(self):
|
||||
self.meta:ToolMeta = {
|
||||
self.meta: ToolMeta = {
|
||||
"name": "execute_code",
|
||||
"description": """
|
||||
This tool has a sandbox that can execute code written in 'Python'/'Javascript'. It recieves a piece of code and return a Json string.
|
||||
@ -99,16 +103,12 @@ module.exports = { main };
|
||||
"enum": ["python", "javascript"],
|
||||
"required": True,
|
||||
},
|
||||
"script": {
|
||||
"type": "string",
|
||||
"description": "A piece of code in right format. There MUST be main function.",
|
||||
"required": True
|
||||
}
|
||||
}
|
||||
"script": {"type": "string", "description": "A piece of code in right format. There MUST be main function.", "required": True},
|
||||
},
|
||||
}
|
||||
super().__init__()
|
||||
self.lang = Language.PYTHON.value
|
||||
self.script = "def main(arg1: str, arg2: str) -> dict: return {\"result\": arg1 + arg2}"
|
||||
self.script = 'def main(arg1: str, arg2: str) -> dict: return {"result": arg1 + arg2}'
|
||||
self.arguments = {}
|
||||
self.outputs = {"result": {"value": "", "type": "string"}}
|
||||
|
||||
@ -119,17 +119,14 @@ module.exports = { main };
|
||||
def get_input_form(self) -> dict[str, dict]:
|
||||
res = {}
|
||||
for k, v in self.arguments.items():
|
||||
res[k] = {
|
||||
"type": "line",
|
||||
"name": k
|
||||
}
|
||||
res[k] = {"type": "line", "name": k}
|
||||
return res
|
||||
|
||||
|
||||
class CodeExec(ToolBase, ABC):
|
||||
component_name = "CodeExec"
|
||||
|
||||
@timeout(int(os.environ.get("COMPONENT_EXEC_TIMEOUT", 10*60)))
|
||||
@timeout(int(os.environ.get("COMPONENT_EXEC_TIMEOUT", 10 * 60)))
|
||||
def _invoke(self, **kwargs):
|
||||
if self.check_if_canceled("CodeExec processing"):
|
||||
return
|
||||
@ -138,17 +135,12 @@ class CodeExec(ToolBase, ABC):
|
||||
script = kwargs.get("script", self._param.script)
|
||||
arguments = {}
|
||||
for k, v in self._param.arguments.items():
|
||||
|
||||
if kwargs.get(k):
|
||||
arguments[k] = kwargs[k]
|
||||
continue
|
||||
arguments[k] = self._canvas.get_variable_value(v) if v else None
|
||||
|
||||
self._execute_code(
|
||||
language=lang,
|
||||
code=script,
|
||||
arguments=arguments
|
||||
)
|
||||
self._execute_code(language=lang, code=script, arguments=arguments)
|
||||
|
||||
def _execute_code(self, language: str, code: str, arguments: dict):
|
||||
import requests
|
||||
@ -169,7 +161,7 @@ class CodeExec(ToolBase, ABC):
|
||||
if self.check_if_canceled("CodeExec execution"):
|
||||
return "Task has been canceled"
|
||||
|
||||
resp = requests.post(url=f"http://{settings.SANDBOX_HOST}:9385/run", json=code_req, timeout=int(os.environ.get("COMPONENT_EXEC_TIMEOUT", 10*60)))
|
||||
resp = requests.post(url=f"http://{settings.SANDBOX_HOST}:9385/run", json=code_req, timeout=int(os.environ.get("COMPONENT_EXEC_TIMEOUT", 10 * 60)))
|
||||
logging.info(f"http://{settings.SANDBOX_HOST}:9385/run, code_req: {code_req}, resp.status_code {resp.status_code}:")
|
||||
|
||||
if self.check_if_canceled("CodeExec execution"):
|
||||
@ -183,35 +175,10 @@ class CodeExec(ToolBase, ABC):
|
||||
if stderr:
|
||||
self.set_output("_ERROR", stderr)
|
||||
return
|
||||
try:
|
||||
rt = eval(body.get("stdout", ""))
|
||||
except Exception:
|
||||
rt = body.get("stdout", "")
|
||||
logging.info(f"http://{settings.SANDBOX_HOST}:9385/run -> {rt}")
|
||||
if isinstance(rt, tuple):
|
||||
for i, (k, o) in enumerate(self._param.outputs.items()):
|
||||
if self.check_if_canceled("CodeExec execution"):
|
||||
return
|
||||
|
||||
if k.find("_") == 0:
|
||||
continue
|
||||
o["value"] = rt[i]
|
||||
elif isinstance(rt, dict):
|
||||
for i, (k, o) in enumerate(self._param.outputs.items()):
|
||||
if self.check_if_canceled("CodeExec execution"):
|
||||
return
|
||||
|
||||
if k not in rt or k.find("_") == 0:
|
||||
continue
|
||||
o["value"] = rt[k]
|
||||
else:
|
||||
for i, (k, o) in enumerate(self._param.outputs.items()):
|
||||
if self.check_if_canceled("CodeExec execution"):
|
||||
return
|
||||
|
||||
if k.find("_") == 0:
|
||||
continue
|
||||
o["value"] = rt
|
||||
raw_stdout = body.get("stdout", "")
|
||||
parsed_stdout = self._deserialize_stdout(raw_stdout)
|
||||
logging.info(f"[CodeExec]: http://{settings.SANDBOX_HOST}:9385/run -> {parsed_stdout}")
|
||||
self._populate_outputs(parsed_stdout, raw_stdout)
|
||||
else:
|
||||
self.set_output("_ERROR", "There is no response from sandbox")
|
||||
|
||||
@ -228,3 +195,149 @@ class CodeExec(ToolBase, ABC):
|
||||
|
||||
def thoughts(self) -> str:
|
||||
return "Running a short script to process data."
|
||||
|
||||
def _deserialize_stdout(self, stdout: str):
|
||||
text = str(stdout).strip()
|
||||
if not text:
|
||||
return ""
|
||||
for loader in (json.loads, ast.literal_eval):
|
||||
try:
|
||||
return loader(text)
|
||||
except Exception:
|
||||
continue
|
||||
return text
|
||||
|
||||
def _coerce_output_value(self, value, expected_type: Optional[str]):
|
||||
if expected_type is None:
|
||||
return value
|
||||
|
||||
etype = expected_type.strip().lower()
|
||||
inner_type = None
|
||||
if etype.startswith("array<") and etype.endswith(">"):
|
||||
inner_type = etype[6:-1].strip()
|
||||
etype = "array"
|
||||
|
||||
try:
|
||||
if etype == "string":
|
||||
return "" if value is None else str(value)
|
||||
|
||||
if etype == "number":
|
||||
if value is None or value == "":
|
||||
return None
|
||||
if isinstance(value, (int, float)):
|
||||
return value
|
||||
if isinstance(value, str):
|
||||
try:
|
||||
return float(value)
|
||||
except Exception:
|
||||
return value
|
||||
return float(value)
|
||||
|
||||
if etype == "boolean":
|
||||
if isinstance(value, bool):
|
||||
return value
|
||||
if isinstance(value, str):
|
||||
lv = value.lower()
|
||||
if lv in ("true", "1", "yes", "y", "on"):
|
||||
return True
|
||||
if lv in ("false", "0", "no", "n", "off"):
|
||||
return False
|
||||
return bool(value)
|
||||
|
||||
if etype == "array":
|
||||
candidate = value
|
||||
if isinstance(candidate, str):
|
||||
parsed = self._deserialize_stdout(candidate)
|
||||
candidate = parsed
|
||||
if isinstance(candidate, tuple):
|
||||
candidate = list(candidate)
|
||||
if not isinstance(candidate, list):
|
||||
candidate = [] if candidate is None else [candidate]
|
||||
|
||||
if inner_type == "string":
|
||||
return ["" if v is None else str(v) for v in candidate]
|
||||
if inner_type == "number":
|
||||
coerced = []
|
||||
for v in candidate:
|
||||
try:
|
||||
if v is None or v == "":
|
||||
coerced.append(None)
|
||||
elif isinstance(v, (int, float)):
|
||||
coerced.append(v)
|
||||
else:
|
||||
coerced.append(float(v))
|
||||
except Exception:
|
||||
coerced.append(v)
|
||||
return coerced
|
||||
return candidate
|
||||
|
||||
if etype == "object":
|
||||
if isinstance(value, dict):
|
||||
return value
|
||||
if isinstance(value, str):
|
||||
parsed = self._deserialize_stdout(value)
|
||||
if isinstance(parsed, dict):
|
||||
return parsed
|
||||
return value
|
||||
except Exception:
|
||||
return value
|
||||
|
||||
return value
|
||||
|
||||
def _populate_outputs(self, parsed_stdout, raw_stdout: str):
|
||||
outputs_items = list(self._param.outputs.items())
|
||||
logging.info(f"[CodeExec]: outputs schema keys: {[k for k, _ in outputs_items]}")
|
||||
if not outputs_items:
|
||||
return
|
||||
|
||||
if isinstance(parsed_stdout, dict):
|
||||
for key, meta in outputs_items:
|
||||
if key.startswith("_"):
|
||||
continue
|
||||
val = self._get_by_path(parsed_stdout, key)
|
||||
coerced = self._coerce_output_value(val, meta.get("type"))
|
||||
logging.info(f"[CodeExec]: populate dict key='{key}' raw='{val}' coerced='{coerced}'")
|
||||
self.set_output(key, coerced)
|
||||
return
|
||||
|
||||
if isinstance(parsed_stdout, (list, tuple)):
|
||||
for idx, (key, meta) in enumerate(outputs_items):
|
||||
if key.startswith("_"):
|
||||
continue
|
||||
val = parsed_stdout[idx] if idx < len(parsed_stdout) else None
|
||||
coerced = self._coerce_output_value(val, meta.get("type"))
|
||||
logging.info(f"[CodeExec]: populate list key='{key}' raw='{val}' coerced='{coerced}'")
|
||||
self.set_output(key, coerced)
|
||||
return
|
||||
|
||||
default_val = parsed_stdout if parsed_stdout is not None else raw_stdout
|
||||
for idx, (key, meta) in enumerate(outputs_items):
|
||||
if key.startswith("_"):
|
||||
continue
|
||||
val = default_val if idx == 0 else None
|
||||
coerced = self._coerce_output_value(val, meta.get("type"))
|
||||
logging.info(f"[CodeExec]: populate scalar key='{key}' raw='{val}' coerced='{coerced}'")
|
||||
self.set_output(key, coerced)
|
||||
|
||||
def _get_by_path(self, data, path: str):
|
||||
if not path:
|
||||
return None
|
||||
cur = data
|
||||
for part in path.split("."):
|
||||
part = part.strip()
|
||||
if not part:
|
||||
return None
|
||||
if isinstance(cur, dict):
|
||||
cur = cur.get(part)
|
||||
elif isinstance(cur, list):
|
||||
try:
|
||||
idx = int(part)
|
||||
cur = cur[idx]
|
||||
except Exception:
|
||||
return None
|
||||
else:
|
||||
return None
|
||||
if cur is None:
|
||||
return None
|
||||
logging.info(f"[CodeExec]: resolve path '{path}' -> {cur}")
|
||||
return cur
|
||||
|
||||
@ -132,12 +132,12 @@ class Retrieval(ToolBase, ABC):
|
||||
metas = DocumentService.get_meta_by_kbs(kb_ids)
|
||||
if self._param.meta_data_filter.get("method") == "auto":
|
||||
chat_mdl = LLMBundle(self._canvas.get_tenant_id(), LLMType.CHAT)
|
||||
filters = gen_meta_filter(chat_mdl, metas, query)
|
||||
doc_ids.extend(meta_filter(metas, filters))
|
||||
filters: dict = gen_meta_filter(chat_mdl, metas, query)
|
||||
doc_ids.extend(meta_filter(metas, filters["conditions"], filters.get("logic", "and")))
|
||||
if not doc_ids:
|
||||
doc_ids = None
|
||||
elif self._param.meta_data_filter.get("method") == "manual":
|
||||
filters=self._param.meta_data_filter["manual"]
|
||||
filters = self._param.meta_data_filter["manual"]
|
||||
for flt in filters:
|
||||
pat = re.compile(self.variable_ref_patt)
|
||||
s = flt["value"]
|
||||
@ -165,9 +165,9 @@ class Retrieval(ToolBase, ABC):
|
||||
|
||||
out_parts.append(s[last:])
|
||||
flt["value"] = "".join(out_parts)
|
||||
doc_ids.extend(meta_filter(metas, filters))
|
||||
if not doc_ids:
|
||||
doc_ids = None
|
||||
doc_ids.extend(meta_filter(metas, filters, self._param.meta_data_filter.get("logic", "and")))
|
||||
if filters and not doc_ids:
|
||||
doc_ids = ["-999"]
|
||||
|
||||
if self._param.cross_languages:
|
||||
query = cross_languages(kbs[0].tenant_id, None, query, self._param.cross_languages)
|
||||
|
||||
@ -24,7 +24,7 @@ from flasgger import Swagger
|
||||
from itsdangerous.url_safe import URLSafeTimedSerializer as Serializer
|
||||
from quart_cors import cors
|
||||
from common.constants import StatusEnum
|
||||
from api.db.db_models import close_connection
|
||||
from api.db.db_models import close_connection, APIToken
|
||||
from api.db.services import UserService
|
||||
from api.utils.json_encode import CustomJSONEncoder
|
||||
from api.utils import commands
|
||||
@ -124,6 +124,10 @@ def _load_user():
|
||||
user = UserService.query(
|
||||
access_token=access_token, status=StatusEnum.VALID.value
|
||||
)
|
||||
if not user and len(authorization.split()) == 2:
|
||||
objs = APIToken.query(token=authorization.split()[1])
|
||||
if objs:
|
||||
user = UserService.query(id=objs[0].tenant_id, status=StatusEnum.VALID.value)
|
||||
if user:
|
||||
if not user[0].access_token or not user[0].access_token.strip():
|
||||
logging.warning(f"User {user[0].email} has empty access_token in database")
|
||||
|
||||
@ -305,14 +305,14 @@ async def retrieval_test():
|
||||
metas = DocumentService.get_meta_by_kbs(kb_ids)
|
||||
if meta_data_filter.get("method") == "auto":
|
||||
chat_mdl = LLMBundle(current_user.id, LLMType.CHAT, llm_name=search_config.get("chat_id", ""))
|
||||
filters = gen_meta_filter(chat_mdl, metas, question)
|
||||
doc_ids.extend(meta_filter(metas, filters))
|
||||
filters: dict = gen_meta_filter(chat_mdl, metas, question)
|
||||
doc_ids.extend(meta_filter(metas, filters["conditions"], filters.get("logic", "and")))
|
||||
if not doc_ids:
|
||||
doc_ids = None
|
||||
elif meta_data_filter.get("method") == "manual":
|
||||
doc_ids.extend(meta_filter(metas, meta_data_filter["manual"]))
|
||||
if not doc_ids:
|
||||
doc_ids = None
|
||||
doc_ids.extend(meta_filter(metas, meta_data_filter["manual"], meta_data_filter.get("logic", "and")))
|
||||
if meta_data_filter["manual"] and not doc_ids:
|
||||
doc_ids = ["-999"]
|
||||
|
||||
try:
|
||||
tenants = UserTenantService.query(user_id=current_user.id)
|
||||
|
||||
@ -125,8 +125,8 @@ async def upload():
|
||||
@validate_request("name")
|
||||
async def create():
|
||||
req = await request.json
|
||||
pf_id = await request.json.get("parent_id")
|
||||
input_file_type = await request.json.get("type")
|
||||
pf_id = req.get("parent_id")
|
||||
input_file_type = req.get("type")
|
||||
if not pf_id:
|
||||
root_folder = FileService.get_root_folder(current_user.id)
|
||||
pf_id = root_folder["id"]
|
||||
|
||||
@ -159,10 +159,10 @@ async def webhook(tenant_id: str, agent_id: str):
|
||||
data=False, message=str(e),
|
||||
code=RetCode.EXCEPTION_ERROR)
|
||||
|
||||
def sse():
|
||||
async def sse():
|
||||
nonlocal canvas
|
||||
try:
|
||||
for ans in canvas.run(query=req.get("query", ""), files=req.get("files", []), user_id=req.get("user_id", tenant_id), webhook_payload=req):
|
||||
async for ans in canvas.run(query=req.get("query", ""), files=req.get("files", []), user_id=req.get("user_id", tenant_id), webhook_payload=req):
|
||||
yield "data:" + json.dumps(ans, ensure_ascii=False) + "\n\n"
|
||||
|
||||
cvs.dsl = json.loads(str(canvas))
|
||||
|
||||
@ -120,7 +120,7 @@ async def retrieval(tenant_id):
|
||||
retrieval_setting = req.get("retrieval_setting", {})
|
||||
similarity_threshold = float(retrieval_setting.get("score_threshold", 0.0))
|
||||
top = int(retrieval_setting.get("top_k", 1024))
|
||||
metadata_condition = req.get("metadata_condition", {})
|
||||
metadata_condition = req.get("metadata_condition", {}) or {}
|
||||
metas = DocumentService.get_meta_by_kbs([kb_id])
|
||||
|
||||
doc_ids = []
|
||||
@ -132,7 +132,7 @@ async def retrieval(tenant_id):
|
||||
|
||||
embd_mdl = LLMBundle(kb.tenant_id, LLMType.EMBEDDING.value, llm_name=kb.embd_id)
|
||||
if metadata_condition:
|
||||
doc_ids.extend(meta_filter(metas, convert_conditions(metadata_condition)))
|
||||
doc_ids.extend(meta_filter(metas, convert_conditions(metadata_condition), metadata_condition.get("logic", "and")))
|
||||
if not doc_ids and metadata_condition:
|
||||
doc_ids = ["-999"]
|
||||
ranks = settings.retriever.retrieval(
|
||||
|
||||
@ -1289,7 +1289,7 @@ async def update_chunk(tenant_id, dataset_id, document_id, chunk_id):
|
||||
return get_error_data_result(message=f"You don't own the document {document_id}.")
|
||||
doc = doc[0]
|
||||
req = await request_json()
|
||||
if "content" in req:
|
||||
if "content" in req and req["content"] is not None:
|
||||
content = req["content"]
|
||||
else:
|
||||
content = chunk.get("content_with_weight", "")
|
||||
@ -1434,6 +1434,7 @@ async def retrieval_test(tenant_id):
|
||||
question = req["question"]
|
||||
doc_ids = req.get("document_ids", [])
|
||||
use_kg = req.get("use_kg", False)
|
||||
toc_enhance = req.get("toc_enhance", False)
|
||||
langs = req.get("cross_languages", [])
|
||||
if not isinstance(doc_ids, list):
|
||||
return get_error_data_result("`documents` should be a list")
|
||||
@ -1442,9 +1443,11 @@ async def retrieval_test(tenant_id):
|
||||
if doc_id not in doc_ids_list:
|
||||
return get_error_data_result(f"The datasets don't own the document {doc_id}")
|
||||
if not doc_ids:
|
||||
metadata_condition = req.get("metadata_condition", {})
|
||||
metadata_condition = req.get("metadata_condition", {}) or {}
|
||||
metas = DocumentService.get_meta_by_kbs(kb_ids)
|
||||
doc_ids = meta_filter(metas, convert_conditions(metadata_condition))
|
||||
doc_ids = meta_filter(metas, convert_conditions(metadata_condition), metadata_condition.get("logic", "and"))
|
||||
if metadata_condition and not doc_ids:
|
||||
doc_ids = ["-999"]
|
||||
similarity_threshold = float(req.get("similarity_threshold", 0.2))
|
||||
vector_similarity_weight = float(req.get("vector_similarity_weight", 0.3))
|
||||
top = int(req.get("top_k", 1024))
|
||||
@ -1485,6 +1488,11 @@ async def retrieval_test(tenant_id):
|
||||
highlight=highlight,
|
||||
rank_feature=label_question(question, kbs),
|
||||
)
|
||||
if toc_enhance:
|
||||
chat_mdl = LLMBundle(kb.tenant_id, LLMType.CHAT)
|
||||
cks = settings.retriever.retrieval_by_toc(question, ranks["chunks"], tenant_ids, chat_mdl, size)
|
||||
if cks:
|
||||
ranks["chunks"] = cks
|
||||
if use_kg:
|
||||
ck = settings.kg_retriever.retrieval(question, [k.tenant_id for k in kbs], kb_ids, embd_mdl, LLMBundle(kb.tenant_id, LLMType.CHAT))
|
||||
if ck["content_with_weight"]:
|
||||
|
||||
@ -31,7 +31,7 @@ from api.db.services.file_service import FileService
|
||||
from api.utils.api_utils import get_json_result
|
||||
from api.utils.file_utils import filename_type
|
||||
from common import settings
|
||||
|
||||
from common.constants import RetCode
|
||||
|
||||
@manager.route('/file/upload', methods=['POST']) # noqa: F821
|
||||
@token_required
|
||||
@ -86,19 +86,19 @@ async def upload(tenant_id):
|
||||
pf_id = root_folder["id"]
|
||||
|
||||
if 'file' not in files:
|
||||
return get_json_result(data=False, message='No file part!', code=400)
|
||||
return get_json_result(data=False, message='No file part!', code=RetCode.BAD_REQUEST)
|
||||
file_objs = files.getlist('file')
|
||||
|
||||
for file_obj in file_objs:
|
||||
if file_obj.filename == '':
|
||||
return get_json_result(data=False, message='No selected file!', code=400)
|
||||
return get_json_result(data=False, message='No selected file!', code=RetCode.BAD_REQUEST)
|
||||
|
||||
file_res = []
|
||||
|
||||
try:
|
||||
e, pf_folder = FileService.get_by_id(pf_id)
|
||||
if not e:
|
||||
return get_json_result(data=False, message="Can't find this folder!", code=404)
|
||||
return get_json_result(data=False, message="Can't find this folder!", code=RetCode.NOT_FOUND)
|
||||
|
||||
for file_obj in file_objs:
|
||||
# Handle file path
|
||||
@ -114,13 +114,13 @@ async def upload(tenant_id):
|
||||
if file_len != len_id_list:
|
||||
e, file = FileService.get_by_id(file_id_list[len_id_list - 1])
|
||||
if not e:
|
||||
return get_json_result(data=False, message="Folder not found!", code=404)
|
||||
return get_json_result(data=False, message="Folder not found!", code=RetCode.NOT_FOUND)
|
||||
last_folder = FileService.create_folder(file, file_id_list[len_id_list - 1], file_obj_names,
|
||||
len_id_list)
|
||||
else:
|
||||
e, file = FileService.get_by_id(file_id_list[len_id_list - 2])
|
||||
if not e:
|
||||
return get_json_result(data=False, message="Folder not found!", code=404)
|
||||
return get_json_result(data=False, message="Folder not found!", code=RetCode.NOT_FOUND)
|
||||
last_folder = FileService.create_folder(file, file_id_list[len_id_list - 2], file_obj_names,
|
||||
len_id_list)
|
||||
|
||||
@ -202,7 +202,7 @@ async def create(tenant_id):
|
||||
|
||||
try:
|
||||
if not FileService.is_parent_folder_exist(pf_id):
|
||||
return get_json_result(data=False, message="Parent Folder Doesn't Exist!", code=400)
|
||||
return get_json_result(data=False, message="Parent Folder Doesn't Exist!", code=RetCode.BAD_REQUEST)
|
||||
if FileService.query(name=req["name"], parent_id=pf_id):
|
||||
return get_json_result(data=False, message="Duplicated folder name in the same folder.", code=409)
|
||||
|
||||
@ -306,13 +306,13 @@ def list_files(tenant_id):
|
||||
try:
|
||||
e, file = FileService.get_by_id(pf_id)
|
||||
if not e:
|
||||
return get_json_result(message="Folder not found!", code=404)
|
||||
return get_json_result(message="Folder not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
files, total = FileService.get_by_pf_id(tenant_id, pf_id, page_number, items_per_page, orderby, desc, keywords)
|
||||
|
||||
parent_folder = FileService.get_parent_folder(pf_id)
|
||||
if not parent_folder:
|
||||
return get_json_result(message="File not found!", code=404)
|
||||
return get_json_result(message="File not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
return get_json_result(data={"total": total, "files": files, "parent_folder": parent_folder.to_json()})
|
||||
except Exception as e:
|
||||
@ -392,7 +392,7 @@ def get_parent_folder():
|
||||
try:
|
||||
e, file = FileService.get_by_id(file_id)
|
||||
if not e:
|
||||
return get_json_result(message="Folder not found!", code=404)
|
||||
return get_json_result(message="Folder not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
parent_folder = FileService.get_parent_folder(file_id)
|
||||
return get_json_result(data={"parent_folder": parent_folder.to_json()})
|
||||
@ -439,7 +439,7 @@ def get_all_parent_folders(tenant_id):
|
||||
try:
|
||||
e, file = FileService.get_by_id(file_id)
|
||||
if not e:
|
||||
return get_json_result(message="Folder not found!", code=404)
|
||||
return get_json_result(message="Folder not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
parent_folders = FileService.get_all_parent_folders(file_id)
|
||||
parent_folders_res = [folder.to_json() for folder in parent_folders]
|
||||
@ -487,34 +487,34 @@ async def rm(tenant_id):
|
||||
for file_id in file_ids:
|
||||
e, file = FileService.get_by_id(file_id)
|
||||
if not e:
|
||||
return get_json_result(message="File or Folder not found!", code=404)
|
||||
return get_json_result(message="File or Folder not found!", code=RetCode.NOT_FOUND)
|
||||
if not file.tenant_id:
|
||||
return get_json_result(message="Tenant not found!", code=404)
|
||||
return get_json_result(message="Tenant not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
if file.type == FileType.FOLDER.value:
|
||||
file_id_list = FileService.get_all_innermost_file_ids(file_id, [])
|
||||
for inner_file_id in file_id_list:
|
||||
e, file = FileService.get_by_id(inner_file_id)
|
||||
if not e:
|
||||
return get_json_result(message="File not found!", code=404)
|
||||
return get_json_result(message="File not found!", code=RetCode.NOT_FOUND)
|
||||
settings.STORAGE_IMPL.rm(file.parent_id, file.location)
|
||||
FileService.delete_folder_by_pf_id(tenant_id, file_id)
|
||||
else:
|
||||
settings.STORAGE_IMPL.rm(file.parent_id, file.location)
|
||||
if not FileService.delete(file):
|
||||
return get_json_result(message="Database error (File removal)!", code=500)
|
||||
return get_json_result(message="Database error (File removal)!", code=RetCode.SERVER_ERROR)
|
||||
|
||||
informs = File2DocumentService.get_by_file_id(file_id)
|
||||
for inform in informs:
|
||||
doc_id = inform.document_id
|
||||
e, doc = DocumentService.get_by_id(doc_id)
|
||||
if not e:
|
||||
return get_json_result(message="Document not found!", code=404)
|
||||
return get_json_result(message="Document not found!", code=RetCode.NOT_FOUND)
|
||||
tenant_id = DocumentService.get_tenant_id(doc_id)
|
||||
if not tenant_id:
|
||||
return get_json_result(message="Tenant not found!", code=404)
|
||||
return get_json_result(message="Tenant not found!", code=RetCode.NOT_FOUND)
|
||||
if not DocumentService.remove_document(doc, tenant_id):
|
||||
return get_json_result(message="Database error (Document removal)!", code=500)
|
||||
return get_json_result(message="Database error (Document removal)!", code=RetCode.SERVER_ERROR)
|
||||
File2DocumentService.delete_by_file_id(file_id)
|
||||
|
||||
return get_json_result(data=True)
|
||||
@ -560,23 +560,23 @@ async def rename(tenant_id):
|
||||
try:
|
||||
e, file = FileService.get_by_id(req["file_id"])
|
||||
if not e:
|
||||
return get_json_result(message="File not found!", code=404)
|
||||
return get_json_result(message="File not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
if file.type != FileType.FOLDER.value and pathlib.Path(req["name"].lower()).suffix != pathlib.Path(
|
||||
file.name.lower()).suffix:
|
||||
return get_json_result(data=False, message="The extension of file can't be changed", code=400)
|
||||
return get_json_result(data=False, message="The extension of file can't be changed", code=RetCode.BAD_REQUEST)
|
||||
|
||||
for existing_file in FileService.query(name=req["name"], pf_id=file.parent_id):
|
||||
if existing_file.name == req["name"]:
|
||||
return get_json_result(data=False, message="Duplicated file name in the same folder.", code=409)
|
||||
|
||||
if not FileService.update_by_id(req["file_id"], {"name": req["name"]}):
|
||||
return get_json_result(message="Database error (File rename)!", code=500)
|
||||
return get_json_result(message="Database error (File rename)!", code=RetCode.SERVER_ERROR)
|
||||
|
||||
informs = File2DocumentService.get_by_file_id(req["file_id"])
|
||||
if informs:
|
||||
if not DocumentService.update_by_id(informs[0].document_id, {"name": req["name"]}):
|
||||
return get_json_result(message="Database error (Document rename)!", code=500)
|
||||
return get_json_result(message="Database error (Document rename)!", code=RetCode.SERVER_ERROR)
|
||||
|
||||
return get_json_result(data=True)
|
||||
except Exception as e:
|
||||
@ -606,13 +606,13 @@ async def get(tenant_id, file_id):
|
||||
description: File stream
|
||||
schema:
|
||||
type: file
|
||||
404:
|
||||
RetCode.NOT_FOUND:
|
||||
description: File not found
|
||||
"""
|
||||
try:
|
||||
e, file = FileService.get_by_id(file_id)
|
||||
if not e:
|
||||
return get_json_result(message="Document not found!", code=404)
|
||||
return get_json_result(message="Document not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
blob = settings.STORAGE_IMPL.get(file.parent_id, file.location)
|
||||
if not blob:
|
||||
@ -677,13 +677,13 @@ async def move(tenant_id):
|
||||
for file_id in file_ids:
|
||||
file = files_dict[file_id]
|
||||
if not file:
|
||||
return get_json_result(message="File or Folder not found!", code=404)
|
||||
return get_json_result(message="File or Folder not found!", code=RetCode.NOT_FOUND)
|
||||
if not file.tenant_id:
|
||||
return get_json_result(message="Tenant not found!", code=404)
|
||||
return get_json_result(message="Tenant not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
fe, _ = FileService.get_by_id(parent_id)
|
||||
if not fe:
|
||||
return get_json_result(message="Parent Folder not found!", code=404)
|
||||
return get_json_result(message="Parent Folder not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
FileService.move_file(file_ids, parent_id)
|
||||
return get_json_result(data=True)
|
||||
@ -705,7 +705,7 @@ async def convert(tenant_id):
|
||||
for file_id in file_ids:
|
||||
file = files_set[file_id]
|
||||
if not file:
|
||||
return get_json_result(message="File not found!", code=404)
|
||||
return get_json_result(message="File not found!", code=RetCode.NOT_FOUND)
|
||||
file_ids_list = [file_id]
|
||||
if file.type == FileType.FOLDER.value:
|
||||
file_ids_list = FileService.get_all_innermost_file_ids(file_id, [])
|
||||
@ -716,13 +716,13 @@ async def convert(tenant_id):
|
||||
doc_id = inform.document_id
|
||||
e, doc = DocumentService.get_by_id(doc_id)
|
||||
if not e:
|
||||
return get_json_result(message="Document not found!", code=404)
|
||||
return get_json_result(message="Document not found!", code=RetCode.NOT_FOUND)
|
||||
tenant_id = DocumentService.get_tenant_id(doc_id)
|
||||
if not tenant_id:
|
||||
return get_json_result(message="Tenant not found!", code=404)
|
||||
return get_json_result(message="Tenant not found!", code=RetCode.NOT_FOUND)
|
||||
if not DocumentService.remove_document(doc, tenant_id):
|
||||
return get_json_result(
|
||||
message="Database error (Document removal)!", code=404)
|
||||
message="Database error (Document removal)!", code=RetCode.NOT_FOUND)
|
||||
File2DocumentService.delete_by_file_id(id)
|
||||
|
||||
# insert
|
||||
@ -730,11 +730,11 @@ async def convert(tenant_id):
|
||||
e, kb = KnowledgebaseService.get_by_id(kb_id)
|
||||
if not e:
|
||||
return get_json_result(
|
||||
message="Can't find this knowledgebase!", code=404)
|
||||
message="Can't find this knowledgebase!", code=RetCode.NOT_FOUND)
|
||||
e, file = FileService.get_by_id(id)
|
||||
if not e:
|
||||
return get_json_result(
|
||||
message="Can't find this file!", code=404)
|
||||
message="Can't find this file!", code=RetCode.NOT_FOUND)
|
||||
|
||||
doc = DocumentService.insert({
|
||||
"id": get_uuid(),
|
||||
|
||||
@ -428,17 +428,15 @@ async def agents_completion_openai_compatibility(tenant_id, agent_id):
|
||||
return resp
|
||||
else:
|
||||
# For non-streaming, just return the response directly
|
||||
response = next(
|
||||
completion_openai(
|
||||
async for response in completion_openai(
|
||||
tenant_id,
|
||||
agent_id,
|
||||
question,
|
||||
session_id=req.pop("session_id", req.get("id", "")) or req.get("metadata", {}).get("id", ""),
|
||||
stream=False,
|
||||
**req,
|
||||
)
|
||||
)
|
||||
return jsonify(response)
|
||||
):
|
||||
return jsonify(response)
|
||||
|
||||
|
||||
@manager.route("/agents/<agent_id>/completions", methods=["POST"]) # noqa: F821
|
||||
@ -448,8 +446,8 @@ async def agent_completions(tenant_id, agent_id):
|
||||
|
||||
if req.get("stream", True):
|
||||
|
||||
def generate():
|
||||
for answer in agent_completion(tenant_id=tenant_id, agent_id=agent_id, **req):
|
||||
async def generate():
|
||||
async for answer in agent_completion(tenant_id=tenant_id, agent_id=agent_id, **req):
|
||||
if isinstance(answer, str):
|
||||
try:
|
||||
ans = json.loads(answer[5:]) # remove "data:"
|
||||
@ -473,7 +471,7 @@ async def agent_completions(tenant_id, agent_id):
|
||||
full_content = ""
|
||||
reference = {}
|
||||
final_ans = ""
|
||||
for answer in agent_completion(tenant_id=tenant_id, agent_id=agent_id, **req):
|
||||
async for answer in agent_completion(tenant_id=tenant_id, agent_id=agent_id, **req):
|
||||
try:
|
||||
ans = json.loads(answer[5:])
|
||||
|
||||
@ -875,7 +873,7 @@ async def agent_bot_completions(agent_id):
|
||||
resp.headers.add_header("Content-Type", "text/event-stream; charset=utf-8")
|
||||
return resp
|
||||
|
||||
for answer in agent_completion(objs[0].tenant_id, agent_id, **req):
|
||||
async for answer in agent_completion(objs[0].tenant_id, agent_id, **req):
|
||||
return get_result(data=answer)
|
||||
|
||||
|
||||
@ -977,14 +975,14 @@ async def retrieval_test_embedded():
|
||||
metas = DocumentService.get_meta_by_kbs(kb_ids)
|
||||
if meta_data_filter.get("method") == "auto":
|
||||
chat_mdl = LLMBundle(tenant_id, LLMType.CHAT, llm_name=search_config.get("chat_id", ""))
|
||||
filters = gen_meta_filter(chat_mdl, metas, question)
|
||||
doc_ids.extend(meta_filter(metas, filters))
|
||||
filters: dict = gen_meta_filter(chat_mdl, metas, question)
|
||||
doc_ids.extend(meta_filter(metas, filters["conditions"], filters.get("logic", "and")))
|
||||
if not doc_ids:
|
||||
doc_ids = None
|
||||
elif meta_data_filter.get("method") == "manual":
|
||||
doc_ids.extend(meta_filter(metas, meta_data_filter["manual"]))
|
||||
if not doc_ids:
|
||||
doc_ids = None
|
||||
doc_ids.extend(meta_filter(metas, meta_data_filter["manual"], meta_data_filter.get("logic", "and")))
|
||||
if meta_data_filter["manual"] and not doc_ids:
|
||||
doc_ids = ["-999"]
|
||||
|
||||
try:
|
||||
tenants = UserTenantService.query(user_id=tenant_id)
|
||||
|
||||
@ -749,7 +749,7 @@ class Knowledgebase(DataBaseModel):
|
||||
|
||||
parser_id = CharField(max_length=32, null=False, help_text="default parser ID", default=ParserType.NAIVE.value, index=True)
|
||||
pipeline_id = CharField(max_length=32, null=True, help_text="Pipeline ID", index=True)
|
||||
parser_config = JSONField(null=False, default={"pages": [[1, 1000000]]})
|
||||
parser_config = JSONField(null=False, default={"pages": [[1, 1000000]], "table_context_size": 0, "image_context_size": 0})
|
||||
pagerank = IntegerField(default=0, index=False)
|
||||
|
||||
graphrag_task_id = CharField(max_length=32, null=True, help_text="Graph RAG task ID", index=True)
|
||||
@ -774,7 +774,7 @@ class Document(DataBaseModel):
|
||||
kb_id = CharField(max_length=256, null=False, index=True)
|
||||
parser_id = CharField(max_length=32, null=False, help_text="default parser ID", index=True)
|
||||
pipeline_id = CharField(max_length=32, null=True, help_text="pipeline ID", index=True)
|
||||
parser_config = JSONField(null=False, default={"pages": [[1, 1000000]]})
|
||||
parser_config = JSONField(null=False, default={"pages": [[1, 1000000]], "table_context_size": 0, "image_context_size": 0})
|
||||
source_type = CharField(max_length=128, null=False, default="local", help_text="where dose this document come from", index=True)
|
||||
type = CharField(max_length=32, null=False, help_text="file extension", index=True)
|
||||
created_by = CharField(max_length=32, null=False, help_text="who created it", index=True)
|
||||
|
||||
@ -34,14 +34,17 @@ from common.file_utils import get_project_base_directory
|
||||
from common import settings
|
||||
from api.common.base64 import encode_to_base64
|
||||
|
||||
DEFAULT_SUPERUSER_NICKNAME = os.getenv("DEFAULT_SUPERUSER_NICKNAME", "admin")
|
||||
DEFAULT_SUPERUSER_EMAIL = os.getenv("DEFAULT_SUPERUSER_EMAIL", "admin@ragflow.io")
|
||||
DEFAULT_SUPERUSER_PASSWORD = os.getenv("DEFAULT_SUPERUSER_PASSWORD", "admin")
|
||||
|
||||
def init_superuser():
|
||||
def init_superuser(nickname=DEFAULT_SUPERUSER_NICKNAME, email=DEFAULT_SUPERUSER_EMAIL, password=DEFAULT_SUPERUSER_PASSWORD, role=UserTenantRole.OWNER):
|
||||
user_info = {
|
||||
"id": uuid.uuid1().hex,
|
||||
"password": encode_to_base64("admin"),
|
||||
"nickname": "admin",
|
||||
"password": encode_to_base64(password),
|
||||
"nickname": nickname,
|
||||
"is_superuser": True,
|
||||
"email": "admin@ragflow.io",
|
||||
"email": email,
|
||||
"creator": "system",
|
||||
"status": "1",
|
||||
}
|
||||
@ -58,7 +61,7 @@ def init_superuser():
|
||||
"tenant_id": user_info["id"],
|
||||
"user_id": user_info["id"],
|
||||
"invited_by": user_info["id"],
|
||||
"role": UserTenantRole.OWNER
|
||||
"role": role
|
||||
}
|
||||
|
||||
tenant_llm = get_init_tenant_llm(user_info["id"])
|
||||
@ -70,7 +73,7 @@ def init_superuser():
|
||||
UserTenantService.insert(**usr_tenant)
|
||||
TenantLLMService.insert_many(tenant_llm)
|
||||
logging.info(
|
||||
"Super user initialized. email: admin@ragflow.io, password: admin. Changing the password after login is strongly recommended.")
|
||||
f"Super user initialized. email: {email}, password: {password}. Changing the password after login is strongly recommended.")
|
||||
|
||||
chat_mdl = LLMBundle(tenant["id"], LLMType.CHAT, tenant["llm_id"])
|
||||
msg = chat_mdl.chat(system="", history=[
|
||||
|
||||
@ -177,7 +177,7 @@ class UserCanvasService(CommonService):
|
||||
return True
|
||||
|
||||
|
||||
def completion(tenant_id, agent_id, session_id=None, **kwargs):
|
||||
async def completion(tenant_id, agent_id, session_id=None, **kwargs):
|
||||
query = kwargs.get("query", "") or kwargs.get("question", "")
|
||||
files = kwargs.get("files", [])
|
||||
inputs = kwargs.get("inputs", {})
|
||||
@ -219,10 +219,14 @@ def completion(tenant_id, agent_id, session_id=None, **kwargs):
|
||||
"id": message_id
|
||||
})
|
||||
txt = ""
|
||||
for ans in canvas.run(query=query, files=files, user_id=user_id, inputs=inputs):
|
||||
async for ans in canvas.run(query=query, files=files, user_id=user_id, inputs=inputs):
|
||||
ans["session_id"] = session_id
|
||||
if ans["event"] == "message":
|
||||
txt += ans["data"]["content"]
|
||||
if ans["data"].get("start_to_think", False):
|
||||
txt += "<think>"
|
||||
elif ans["data"].get("end_to_think", False):
|
||||
txt += "</think>"
|
||||
yield "data:" + json.dumps(ans, ensure_ascii=False) + "\n\n"
|
||||
|
||||
conv.message.append({"role": "assistant", "content": txt, "created_at": time.time(), "id": message_id})
|
||||
@ -233,7 +237,7 @@ def completion(tenant_id, agent_id, session_id=None, **kwargs):
|
||||
API4ConversationService.append_message(conv["id"], conv)
|
||||
|
||||
|
||||
def completion_openai(tenant_id, agent_id, question, session_id=None, stream=True, **kwargs):
|
||||
async def completion_openai(tenant_id, agent_id, question, session_id=None, stream=True, **kwargs):
|
||||
tiktoken_encoder = tiktoken.get_encoding("cl100k_base")
|
||||
prompt_tokens = len(tiktoken_encoder.encode(str(question)))
|
||||
user_id = kwargs.get("user_id", "")
|
||||
@ -241,7 +245,7 @@ def completion_openai(tenant_id, agent_id, question, session_id=None, stream=Tru
|
||||
if stream:
|
||||
completion_tokens = 0
|
||||
try:
|
||||
for ans in completion(
|
||||
async for ans in completion(
|
||||
tenant_id=tenant_id,
|
||||
agent_id=agent_id,
|
||||
session_id=session_id,
|
||||
@ -300,7 +304,7 @@ def completion_openai(tenant_id, agent_id, question, session_id=None, stream=Tru
|
||||
try:
|
||||
all_content = ""
|
||||
reference = {}
|
||||
for ans in completion(
|
||||
async for ans in completion(
|
||||
tenant_id=tenant_id,
|
||||
agent_id=agent_id,
|
||||
session_id=session_id,
|
||||
|
||||
@ -15,6 +15,7 @@
|
||||
#
|
||||
import logging
|
||||
from datetime import datetime
|
||||
import os
|
||||
from typing import Tuple, List
|
||||
|
||||
from anthropic import BaseModel
|
||||
@ -103,7 +104,8 @@ class SyncLogsService(CommonService):
|
||||
Knowledgebase.avatar.alias("kb_avatar"),
|
||||
Connector2Kb.auto_parse,
|
||||
cls.model.from_beginning.alias("reindex"),
|
||||
cls.model.status
|
||||
cls.model.status,
|
||||
cls.model.update_time
|
||||
]
|
||||
if not connector_id:
|
||||
fields.append(Connector.config)
|
||||
@ -116,7 +118,11 @@ class SyncLogsService(CommonService):
|
||||
if connector_id:
|
||||
query = query.where(cls.model.connector_id == connector_id)
|
||||
else:
|
||||
interval_expr = SQL("INTERVAL `t2`.`refresh_freq` MINUTE")
|
||||
database_type = os.getenv("DB_TYPE", "mysql")
|
||||
if "postgres" in database_type.lower():
|
||||
interval_expr = SQL("make_interval(mins => t2.refresh_freq)")
|
||||
else:
|
||||
interval_expr = SQL("INTERVAL `t2`.`refresh_freq` MINUTE")
|
||||
query = query.where(
|
||||
Connector.input_type == InputType.POLL,
|
||||
Connector.status == TaskStatus.SCHEDULE,
|
||||
@ -208,9 +214,21 @@ class SyncLogsService(CommonService):
|
||||
err, doc_blob_pairs = FileService.upload_document(kb, files, tenant_id, src)
|
||||
errs.extend(err)
|
||||
|
||||
# Create a mapping from filename to metadata for later use
|
||||
metadata_map = {}
|
||||
for d in docs:
|
||||
if d.get("metadata"):
|
||||
filename = d["semantic_identifier"]+(f"{d['extension']}" if d["semantic_identifier"][::-1].find(d['extension'][::-1])<0 else "")
|
||||
metadata_map[filename] = d["metadata"]
|
||||
|
||||
kb_table_num_map = {}
|
||||
for doc, _ in doc_blob_pairs:
|
||||
doc_ids.append(doc["id"])
|
||||
|
||||
# Set metadata if available for this document
|
||||
if doc["name"] in metadata_map:
|
||||
DocumentService.update_by_id(doc["id"], {"meta_fields": metadata_map[doc["name"]]})
|
||||
|
||||
if not auto_parse or auto_parse == "0":
|
||||
continue
|
||||
DocumentService.run(tenant_id, doc, kb_table_num_map)
|
||||
|
||||
@ -287,7 +287,7 @@ def convert_conditions(metadata_condition):
|
||||
]
|
||||
|
||||
|
||||
def meta_filter(metas: dict, filters: list[dict]):
|
||||
def meta_filter(metas: dict, filters: list[dict], logic: str = "and"):
|
||||
doc_ids = set([])
|
||||
|
||||
def filter_out(v2docs, operator, value):
|
||||
@ -304,6 +304,8 @@ def meta_filter(metas: dict, filters: list[dict]):
|
||||
for conds in [
|
||||
(operator == "contains", str(value).lower() in str(input).lower()),
|
||||
(operator == "not contains", str(value).lower() not in str(input).lower()),
|
||||
(operator == "in", str(input).lower() in str(value).lower()),
|
||||
(operator == "not in", str(input).lower() not in str(value).lower()),
|
||||
(operator == "start with", str(input).lower().startswith(str(value).lower())),
|
||||
(operator == "end with", str(input).lower().endswith(str(value).lower())),
|
||||
(operator == "empty", not input),
|
||||
@ -331,7 +333,10 @@ def meta_filter(metas: dict, filters: list[dict]):
|
||||
if not doc_ids:
|
||||
doc_ids = set(ids)
|
||||
else:
|
||||
doc_ids = doc_ids & set(ids)
|
||||
if logic == "and":
|
||||
doc_ids = doc_ids & set(ids)
|
||||
else:
|
||||
doc_ids = doc_ids | set(ids)
|
||||
if not doc_ids:
|
||||
return []
|
||||
return list(doc_ids)
|
||||
@ -407,14 +412,15 @@ def chat(dialog, messages, stream=True, **kwargs):
|
||||
if dialog.meta_data_filter:
|
||||
metas = DocumentService.get_meta_by_kbs(dialog.kb_ids)
|
||||
if dialog.meta_data_filter.get("method") == "auto":
|
||||
filters = gen_meta_filter(chat_mdl, metas, questions[-1])
|
||||
attachments.extend(meta_filter(metas, filters))
|
||||
filters: dict = gen_meta_filter(chat_mdl, metas, questions[-1])
|
||||
attachments.extend(meta_filter(metas, filters["conditions"], filters.get("logic", "and")))
|
||||
if not attachments:
|
||||
attachments = None
|
||||
elif dialog.meta_data_filter.get("method") == "manual":
|
||||
attachments.extend(meta_filter(metas, dialog.meta_data_filter["manual"]))
|
||||
if not attachments:
|
||||
attachments = None
|
||||
conds = dialog.meta_data_filter["manual"]
|
||||
attachments.extend(meta_filter(metas, conds, dialog.meta_data_filter.get("logic", "and")))
|
||||
if conds and not attachments:
|
||||
attachments = ["-999"]
|
||||
|
||||
if prompt_config.get("keyword", False):
|
||||
questions[-1] += keyword_extraction(chat_mdl, questions[-1])
|
||||
@ -778,14 +784,14 @@ def ask(question, kb_ids, tenant_id, chat_llm_name=None, search_config={}):
|
||||
if meta_data_filter:
|
||||
metas = DocumentService.get_meta_by_kbs(kb_ids)
|
||||
if meta_data_filter.get("method") == "auto":
|
||||
filters = gen_meta_filter(chat_mdl, metas, question)
|
||||
doc_ids.extend(meta_filter(metas, filters))
|
||||
filters: dict = gen_meta_filter(chat_mdl, metas, question)
|
||||
doc_ids.extend(meta_filter(metas, filters["conditions"], filters.get("logic", "and")))
|
||||
if not doc_ids:
|
||||
doc_ids = None
|
||||
elif meta_data_filter.get("method") == "manual":
|
||||
doc_ids.extend(meta_filter(metas, meta_data_filter["manual"]))
|
||||
if not doc_ids:
|
||||
doc_ids = None
|
||||
doc_ids.extend(meta_filter(metas, meta_data_filter["manual"], meta_data_filter.get("logic", "and")))
|
||||
if meta_data_filter["manual"] and not doc_ids:
|
||||
doc_ids = ["-999"]
|
||||
|
||||
kbinfos = retriever.retrieval(
|
||||
question=question,
|
||||
@ -853,14 +859,14 @@ def gen_mindmap(question, kb_ids, tenant_id, search_config={}):
|
||||
if meta_data_filter:
|
||||
metas = DocumentService.get_meta_by_kbs(kb_ids)
|
||||
if meta_data_filter.get("method") == "auto":
|
||||
filters = gen_meta_filter(chat_mdl, metas, question)
|
||||
doc_ids.extend(meta_filter(metas, filters))
|
||||
filters: dict = gen_meta_filter(chat_mdl, metas, question)
|
||||
doc_ids.extend(meta_filter(metas, filters["conditions"], filters.get("logic", "and")))
|
||||
if not doc_ids:
|
||||
doc_ids = None
|
||||
elif meta_data_filter.get("method") == "manual":
|
||||
doc_ids.extend(meta_filter(metas, meta_data_filter["manual"]))
|
||||
if not doc_ids:
|
||||
doc_ids = None
|
||||
doc_ids.extend(meta_filter(metas, meta_data_filter["manual"], meta_data_filter.get("logic", "and")))
|
||||
if meta_data_filter["manual"] and not doc_ids:
|
||||
doc_ids = ["-999"]
|
||||
|
||||
ranks = settings.retriever.retrieval(
|
||||
question=question,
|
||||
|
||||
@ -923,7 +923,7 @@ def doc_upload_and_parse(conversation_id, file_objs, user_id):
|
||||
ParserType.AUDIO.value: audio,
|
||||
ParserType.EMAIL.value: email
|
||||
}
|
||||
parser_config = {"chunk_token_num": 4096, "delimiter": "\n!?;。;!?", "layout_recognize": "Plain Text"}
|
||||
parser_config = {"chunk_token_num": 4096, "delimiter": "\n!?;。;!?", "layout_recognize": "Plain Text", "table_context_size": 0, "image_context_size": 0}
|
||||
exe = ThreadPoolExecutor(max_workers=12)
|
||||
threads = []
|
||||
doc_nm = {}
|
||||
|
||||
@ -20,7 +20,6 @@
|
||||
|
||||
from common.log_utils import init_root_logger
|
||||
from plugin import GlobalPluginManager
|
||||
init_root_logger("ragflow_server")
|
||||
|
||||
import logging
|
||||
import os
|
||||
@ -30,6 +29,7 @@ import time
|
||||
import traceback
|
||||
import threading
|
||||
import uuid
|
||||
import faulthandler
|
||||
|
||||
from api.apps import app, smtp_mail_server
|
||||
from api.db.runtime_config import RuntimeConfig
|
||||
@ -37,7 +37,7 @@ from api.db.services.document_service import DocumentService
|
||||
from common.file_utils import get_project_base_directory
|
||||
from common import settings
|
||||
from api.db.db_models import init_database_tables as init_web_db
|
||||
from api.db.init_data import init_web_data
|
||||
from api.db.init_data import init_web_data, init_superuser
|
||||
from common.versions import get_ragflow_version
|
||||
from common.config_utils import show_configs
|
||||
from common.mcp_tool_call_conn import shutdown_all_mcp_sessions
|
||||
@ -73,6 +73,8 @@ def signal_handler(sig, frame):
|
||||
sys.exit(0)
|
||||
|
||||
if __name__ == '__main__':
|
||||
faulthandler.enable()
|
||||
init_root_logger("ragflow_server")
|
||||
logging.info(r"""
|
||||
____ ___ ______ ______ __
|
||||
/ __ \ / | / ____// ____// /____ _ __
|
||||
@ -109,11 +111,16 @@ if __name__ == '__main__':
|
||||
parser.add_argument(
|
||||
"--debug", default=False, help="debug mode", action="store_true"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--init-superuser", default=False, help="init superuser", action="store_true"
|
||||
)
|
||||
args = parser.parse_args()
|
||||
if args.version:
|
||||
print(get_ragflow_version())
|
||||
sys.exit(0)
|
||||
|
||||
if args.init_superuser:
|
||||
init_superuser()
|
||||
RuntimeConfig.DEBUG = args.debug
|
||||
if RuntimeConfig.DEBUG:
|
||||
logging.info("run on debug mode")
|
||||
|
||||
@ -89,7 +89,8 @@ def get_data_error_result(code=RetCode.DATA_ERROR, message="Sorry! Data missing!
|
||||
|
||||
|
||||
def server_error_response(e):
|
||||
logging.exception(e)
|
||||
# Quart invokes this handler outside the original except block, so we must pass exc_info manually.
|
||||
logging.error("Unhandled exception during request", exc_info=(type(e), e, e.__traceback__))
|
||||
try:
|
||||
msg = repr(e).lower()
|
||||
if getattr(e, "code", None) == 401 or ("unauthorized" in msg) or ("401" in msg):
|
||||
@ -312,6 +313,10 @@ def get_parser_config(chunk_method, parser_config):
|
||||
chunk_method = "naive"
|
||||
|
||||
# Define default configurations for each chunking method
|
||||
base_defaults = {
|
||||
"table_context_size": 0,
|
||||
"image_context_size": 0,
|
||||
}
|
||||
key_mapping = {
|
||||
"naive": {
|
||||
"layout_recognize": "DeepDOC",
|
||||
@ -364,16 +369,19 @@ def get_parser_config(chunk_method, parser_config):
|
||||
|
||||
default_config = key_mapping[chunk_method]
|
||||
|
||||
# If no parser_config provided, return default
|
||||
# If no parser_config provided, return default merged with base defaults
|
||||
if not parser_config:
|
||||
return default_config
|
||||
if default_config is None:
|
||||
return deep_merge(base_defaults, {})
|
||||
return deep_merge(base_defaults, default_config)
|
||||
|
||||
# If parser_config is provided, merge with defaults to ensure required fields exist
|
||||
if default_config is None:
|
||||
return parser_config
|
||||
return deep_merge(base_defaults, parser_config)
|
||||
|
||||
# Ensure raptor and graphrag fields have default values if not provided
|
||||
merged_config = deep_merge(default_config, parser_config)
|
||||
merged_config = deep_merge(base_defaults, default_config)
|
||||
merged_config = deep_merge(merged_config, parser_config)
|
||||
|
||||
return merged_config
|
||||
|
||||
|
||||
@ -49,6 +49,7 @@ class RetCode(IntEnum, CustomEnum):
|
||||
RUNNING = 106
|
||||
PERMISSION_ERROR = 108
|
||||
AUTHENTICATION_ERROR = 109
|
||||
BAD_REQUEST = 400
|
||||
UNAUTHORIZED = 401
|
||||
SERVER_ERROR = 500
|
||||
FORBIDDEN = 403
|
||||
@ -118,6 +119,9 @@ class FileSource(StrEnum):
|
||||
SHAREPOINT = "sharepoint"
|
||||
SLACK = "slack"
|
||||
TEAMS = "teams"
|
||||
WEBDAV = "webdav"
|
||||
MOODLE = "moodle"
|
||||
DROPBOX = "dropbox"
|
||||
|
||||
|
||||
class PipelineTaskType(StrEnum):
|
||||
|
||||
@ -14,6 +14,8 @@ from .google_drive.connector import GoogleDriveConnector
|
||||
from .jira.connector import JiraConnector
|
||||
from .sharepoint_connector import SharePointConnector
|
||||
from .teams_connector import TeamsConnector
|
||||
from .webdav_connector import WebDAVConnector
|
||||
from .moodle_connector import MoodleConnector
|
||||
from .config import BlobType, DocumentSource
|
||||
from .models import Document, TextSection, ImageSection, BasicExpertInfo
|
||||
from .exceptions import (
|
||||
@ -36,6 +38,8 @@ __all__ = [
|
||||
"JiraConnector",
|
||||
"SharePointConnector",
|
||||
"TeamsConnector",
|
||||
"WebDAVConnector",
|
||||
"MoodleConnector",
|
||||
"BlobType",
|
||||
"DocumentSource",
|
||||
"Document",
|
||||
|
||||
@ -90,7 +90,7 @@ class BlobStorageConnector(LoadConnector, PollConnector):
|
||||
elif self.bucket_type == BlobType.S3_COMPATIBLE:
|
||||
if not all(
|
||||
credentials.get(key)
|
||||
for key in ["endpoint_url", "aws_access_key_id", "aws_secret_access_key"]
|
||||
for key in ["endpoint_url", "aws_access_key_id", "aws_secret_access_key", "addressing_style"]
|
||||
):
|
||||
raise ConnectorMissingCredentialError("S3 Compatible Storage")
|
||||
|
||||
|
||||
@ -48,7 +48,10 @@ class DocumentSource(str, Enum):
|
||||
GOOGLE_DRIVE = "google_drive"
|
||||
GMAIL = "gmail"
|
||||
DISCORD = "discord"
|
||||
WEBDAV = "webdav"
|
||||
MOODLE = "moodle"
|
||||
S3_COMPATIBLE = "s3_compatible"
|
||||
DROPBOX = "dropbox"
|
||||
|
||||
|
||||
class FileOrigin(str, Enum):
|
||||
|
||||
@ -1562,6 +1562,7 @@ class ConfluenceConnector(
|
||||
size_bytes=len(page_content.encode("utf-8")), # Calculate size in bytes
|
||||
doc_updated_at=datetime_from_string(page["version"]["when"]),
|
||||
primary_owners=primary_owners if primary_owners else None,
|
||||
metadata=metadata if metadata else None,
|
||||
)
|
||||
except Exception as e:
|
||||
logging.error(f"Error converting page {page.get('id', 'unknown')}: {e}")
|
||||
|
||||
@ -65,6 +65,7 @@ def _convert_message_to_document(
|
||||
blob=message.content.encode("utf-8"),
|
||||
extension=".txt",
|
||||
size_bytes=len(message.content.encode("utf-8")),
|
||||
metadata=metadata if metadata else None,
|
||||
)
|
||||
|
||||
|
||||
|
||||
@ -1,13 +1,24 @@
|
||||
"""Dropbox connector"""
|
||||
|
||||
import logging
|
||||
from datetime import timezone
|
||||
from typing import Any
|
||||
|
||||
from dropbox import Dropbox
|
||||
from dropbox.exceptions import ApiError, AuthError
|
||||
from dropbox.files import FileMetadata, FolderMetadata
|
||||
|
||||
from common.data_source.config import INDEX_BATCH_SIZE
|
||||
from common.data_source.exceptions import ConnectorValidationError, InsufficientPermissionsError, ConnectorMissingCredentialError
|
||||
from common.data_source.config import INDEX_BATCH_SIZE, DocumentSource
|
||||
from common.data_source.exceptions import (
|
||||
ConnectorMissingCredentialError,
|
||||
ConnectorValidationError,
|
||||
InsufficientPermissionsError,
|
||||
)
|
||||
from common.data_source.interfaces import LoadConnector, PollConnector, SecondsSinceUnixEpoch
|
||||
from common.data_source.models import Document, GenerateDocumentsOutput
|
||||
from common.data_source.utils import get_file_ext
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
class DropboxConnector(LoadConnector, PollConnector):
|
||||
@ -19,29 +30,29 @@ class DropboxConnector(LoadConnector, PollConnector):
|
||||
|
||||
def load_credentials(self, credentials: dict[str, Any]) -> dict[str, Any] | None:
|
||||
"""Load Dropbox credentials"""
|
||||
try:
|
||||
access_token = credentials.get("dropbox_access_token")
|
||||
if not access_token:
|
||||
raise ConnectorMissingCredentialError("Dropbox access token is required")
|
||||
|
||||
self.dropbox_client = Dropbox(access_token)
|
||||
return None
|
||||
except Exception as e:
|
||||
raise ConnectorMissingCredentialError(f"Dropbox: {e}")
|
||||
access_token = credentials.get("dropbox_access_token")
|
||||
if not access_token:
|
||||
raise ConnectorMissingCredentialError("Dropbox access token is required")
|
||||
|
||||
self.dropbox_client = Dropbox(access_token)
|
||||
return None
|
||||
|
||||
def validate_connector_settings(self) -> None:
|
||||
"""Validate Dropbox connector settings"""
|
||||
if not self.dropbox_client:
|
||||
if self.dropbox_client is None:
|
||||
raise ConnectorMissingCredentialError("Dropbox")
|
||||
|
||||
|
||||
try:
|
||||
# Test connection by getting current account info
|
||||
self.dropbox_client.users_get_current_account()
|
||||
except (AuthError, ApiError) as e:
|
||||
if "invalid_access_token" in str(e).lower():
|
||||
raise InsufficientPermissionsError("Invalid Dropbox access token")
|
||||
else:
|
||||
raise ConnectorValidationError(f"Dropbox validation error: {e}")
|
||||
self.dropbox_client.files_list_folder(path="", limit=1)
|
||||
except AuthError as e:
|
||||
logger.exception("[Dropbox]: Failed to validate Dropbox credentials")
|
||||
raise ConnectorValidationError(f"Dropbox credential is invalid: {e}")
|
||||
except ApiError as e:
|
||||
if e.error is not None and "insufficient_permissions" in str(e.error).lower():
|
||||
raise InsufficientPermissionsError("Your Dropbox token does not have sufficient permissions.")
|
||||
raise ConnectorValidationError(f"Unexpected Dropbox error during validation: {e.user_message_text or e}")
|
||||
except Exception as e:
|
||||
raise ConnectorValidationError(f"Unexpected error during Dropbox settings validation: {e}")
|
||||
|
||||
def _download_file(self, path: str) -> bytes:
|
||||
"""Download a single file from Dropbox."""
|
||||
@ -54,26 +65,105 @@ class DropboxConnector(LoadConnector, PollConnector):
|
||||
"""Create a shared link for a file in Dropbox."""
|
||||
if self.dropbox_client is None:
|
||||
raise ConnectorMissingCredentialError("Dropbox")
|
||||
|
||||
|
||||
try:
|
||||
# Try to get existing shared links first
|
||||
shared_links = self.dropbox_client.sharing_list_shared_links(path=path)
|
||||
if shared_links.links:
|
||||
return shared_links.links[0].url
|
||||
|
||||
# Create a new shared link
|
||||
link_settings = self.dropbox_client.sharing_create_shared_link_with_settings(path)
|
||||
return link_settings.url
|
||||
except Exception:
|
||||
# Fallback to basic link format
|
||||
return f"https://www.dropbox.com/home{path}"
|
||||
|
||||
def poll_source(self, start: SecondsSinceUnixEpoch, end: SecondsSinceUnixEpoch) -> Any:
|
||||
link_metadata = self.dropbox_client.sharing_create_shared_link_with_settings(path)
|
||||
return link_metadata.url
|
||||
except ApiError as err:
|
||||
logger.exception(f"[Dropbox]: Failed to create a shared link for {path}: {err}")
|
||||
return ""
|
||||
|
||||
def _yield_files_recursive(
|
||||
self,
|
||||
path: str,
|
||||
start: SecondsSinceUnixEpoch | None,
|
||||
end: SecondsSinceUnixEpoch | None,
|
||||
) -> GenerateDocumentsOutput:
|
||||
"""Yield files in batches from a specified Dropbox folder, including subfolders."""
|
||||
if self.dropbox_client is None:
|
||||
raise ConnectorMissingCredentialError("Dropbox")
|
||||
|
||||
result = self.dropbox_client.files_list_folder(
|
||||
path,
|
||||
limit=self.batch_size,
|
||||
recursive=False,
|
||||
include_non_downloadable_files=False,
|
||||
)
|
||||
|
||||
while True:
|
||||
batch: list[Document] = []
|
||||
for entry in result.entries:
|
||||
if isinstance(entry, FileMetadata):
|
||||
modified_time = entry.client_modified
|
||||
if modified_time.tzinfo is None:
|
||||
modified_time = modified_time.replace(tzinfo=timezone.utc)
|
||||
else:
|
||||
modified_time = modified_time.astimezone(timezone.utc)
|
||||
|
||||
time_as_seconds = modified_time.timestamp()
|
||||
if start is not None and time_as_seconds <= start:
|
||||
continue
|
||||
if end is not None and time_as_seconds > end:
|
||||
continue
|
||||
|
||||
try:
|
||||
downloaded_file = self._download_file(entry.path_display)
|
||||
except Exception:
|
||||
logger.exception(f"[Dropbox]: Error downloading file {entry.path_display}")
|
||||
continue
|
||||
|
||||
batch.append(
|
||||
Document(
|
||||
id=f"dropbox:{entry.id}",
|
||||
blob=downloaded_file,
|
||||
source=DocumentSource.DROPBOX,
|
||||
semantic_identifier=entry.name,
|
||||
extension=get_file_ext(entry.name),
|
||||
doc_updated_at=modified_time,
|
||||
size_bytes=entry.size if getattr(entry, "size", None) is not None else len(downloaded_file),
|
||||
)
|
||||
)
|
||||
|
||||
elif isinstance(entry, FolderMetadata):
|
||||
yield from self._yield_files_recursive(entry.path_lower, start, end)
|
||||
|
||||
if batch:
|
||||
yield batch
|
||||
|
||||
if not result.has_more:
|
||||
break
|
||||
|
||||
result = self.dropbox_client.files_list_folder_continue(result.cursor)
|
||||
|
||||
def poll_source(self, start: SecondsSinceUnixEpoch, end: SecondsSinceUnixEpoch) -> GenerateDocumentsOutput:
|
||||
"""Poll Dropbox for recent file changes"""
|
||||
# Simplified implementation - in production this would handle actual polling
|
||||
return []
|
||||
if self.dropbox_client is None:
|
||||
raise ConnectorMissingCredentialError("Dropbox")
|
||||
|
||||
def load_from_state(self) -> Any:
|
||||
for batch in self._yield_files_recursive("", start, end):
|
||||
yield batch
|
||||
|
||||
def load_from_state(self) -> GenerateDocumentsOutput:
|
||||
"""Load files from Dropbox state"""
|
||||
# Simplified implementation
|
||||
return []
|
||||
return self._yield_files_recursive("", None, None)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
import os
|
||||
|
||||
logging.basicConfig(level=logging.DEBUG)
|
||||
connector = DropboxConnector()
|
||||
connector.load_credentials({"dropbox_access_token": os.environ.get("DROPBOX_ACCESS_TOKEN")})
|
||||
connector.validate_connector_settings()
|
||||
document_batches = connector.load_from_state()
|
||||
try:
|
||||
first_batch = next(document_batches)
|
||||
print(f"Loaded {len(first_batch)} documents in first batch.")
|
||||
for doc in first_batch:
|
||||
print(f"- {doc.semantic_identifier} ({doc.size_bytes} bytes)")
|
||||
except StopIteration:
|
||||
print("No documents available in Dropbox.")
|
||||
|
||||
@ -94,6 +94,7 @@ class Document(BaseModel):
|
||||
blob: bytes
|
||||
doc_updated_at: datetime
|
||||
size_bytes: int
|
||||
metadata: Optional[dict[str, Any]] = None
|
||||
|
||||
|
||||
class BasicExpertInfo(BaseModel):
|
||||
|
||||
378
common/data_source/moodle_connector.py
Normal file
378
common/data_source/moodle_connector.py
Normal file
@ -0,0 +1,378 @@
|
||||
from __future__ import annotations
|
||||
|
||||
import logging
|
||||
import os
|
||||
from collections.abc import Generator
|
||||
from datetime import datetime, timezone
|
||||
from retry import retry
|
||||
from typing import Any, Optional
|
||||
|
||||
from markdownify import markdownify as md
|
||||
from moodle import Moodle as MoodleClient, MoodleException
|
||||
|
||||
from common.data_source.config import INDEX_BATCH_SIZE
|
||||
from common.data_source.exceptions import (
|
||||
ConnectorMissingCredentialError,
|
||||
CredentialExpiredError,
|
||||
InsufficientPermissionsError,
|
||||
ConnectorValidationError,
|
||||
)
|
||||
from common.data_source.interfaces import LoadConnector, PollConnector, SecondsSinceUnixEpoch
|
||||
from common.data_source.models import Document
|
||||
from common.data_source.utils import batch_generator, rl_requests
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
class MoodleConnector(LoadConnector, PollConnector):
|
||||
"""Moodle LMS connector for accessing course content"""
|
||||
|
||||
def __init__(self, moodle_url: str, batch_size: int = INDEX_BATCH_SIZE) -> None:
|
||||
self.moodle_url = moodle_url.rstrip("/")
|
||||
self.batch_size = batch_size
|
||||
self.moodle_client: Optional[MoodleClient] = None
|
||||
|
||||
def _add_token_to_url(self, file_url: str) -> str:
|
||||
"""Append Moodle token to URL if missing"""
|
||||
if not self.moodle_client:
|
||||
return file_url
|
||||
token = getattr(self.moodle_client, "token", "")
|
||||
if "token=" in file_url.lower():
|
||||
return file_url
|
||||
delimiter = "&" if "?" in file_url else "?"
|
||||
return f"{file_url}{delimiter}token={token}"
|
||||
|
||||
def _log_error(self, context: str, error: Exception, level: str = "warning") -> None:
|
||||
"""Simplified logging wrapper"""
|
||||
msg = f"{context}: {error}"
|
||||
if level == "error":
|
||||
logger.error(msg)
|
||||
else:
|
||||
logger.warning(msg)
|
||||
|
||||
def _get_latest_timestamp(self, *timestamps: int) -> int:
|
||||
"""Return latest valid timestamp"""
|
||||
return max((t for t in timestamps if t and t > 0), default=0)
|
||||
|
||||
def _yield_in_batches(
|
||||
self, generator: Generator[Document, None, None]
|
||||
) -> Generator[list[Document], None, None]:
|
||||
for batch in batch_generator(generator, self.batch_size):
|
||||
yield batch
|
||||
|
||||
def load_credentials(self, credentials: dict[str, Any]) -> None:
|
||||
token = credentials.get("moodle_token")
|
||||
if not token:
|
||||
raise ConnectorMissingCredentialError("Moodle API token is required")
|
||||
|
||||
try:
|
||||
self.moodle_client = MoodleClient(
|
||||
self.moodle_url + "/webservice/rest/server.php", token
|
||||
)
|
||||
self.moodle_client.core.webservice.get_site_info()
|
||||
except MoodleException as e:
|
||||
if "invalidtoken" in str(e).lower():
|
||||
raise CredentialExpiredError("Moodle token is invalid or expired")
|
||||
raise ConnectorMissingCredentialError(f"Failed to initialize Moodle client: {e}")
|
||||
|
||||
def validate_connector_settings(self) -> None:
|
||||
if not self.moodle_client:
|
||||
raise ConnectorMissingCredentialError("Moodle client not initialized")
|
||||
|
||||
try:
|
||||
site_info = self.moodle_client.core.webservice.get_site_info()
|
||||
if not site_info.sitename:
|
||||
raise InsufficientPermissionsError("Invalid Moodle API response")
|
||||
except MoodleException as e:
|
||||
msg = str(e).lower()
|
||||
if "invalidtoken" in msg:
|
||||
raise CredentialExpiredError("Moodle token is invalid or expired")
|
||||
if "accessexception" in msg:
|
||||
raise InsufficientPermissionsError(
|
||||
"Insufficient permissions. Ensure web services are enabled and permissions are correct."
|
||||
)
|
||||
raise ConnectorValidationError(f"Moodle validation error: {e}")
|
||||
except Exception as e:
|
||||
raise ConnectorValidationError(f"Unexpected validation error: {e}")
|
||||
|
||||
# -------------------------------------------------------------------------
|
||||
# Data loading & polling
|
||||
# -------------------------------------------------------------------------
|
||||
|
||||
def load_from_state(self) -> Generator[list[Document], None, None]:
|
||||
if not self.moodle_client:
|
||||
raise ConnectorMissingCredentialError("Moodle client not initialized")
|
||||
|
||||
logger.info("Starting full load from Moodle workspace")
|
||||
courses = self._get_enrolled_courses()
|
||||
if not courses:
|
||||
logger.warning("No courses found to process")
|
||||
return
|
||||
|
||||
yield from self._yield_in_batches(self._process_courses(courses))
|
||||
|
||||
def poll_source(
|
||||
self, start: SecondsSinceUnixEpoch, end: SecondsSinceUnixEpoch
|
||||
) -> Generator[list[Document], None, None]:
|
||||
if not self.moodle_client:
|
||||
raise ConnectorMissingCredentialError("Moodle client not initialized")
|
||||
|
||||
logger.info(
|
||||
f"Polling Moodle updates between {datetime.fromtimestamp(start)} and {datetime.fromtimestamp(end)}"
|
||||
)
|
||||
courses = self._get_enrolled_courses()
|
||||
if not courses:
|
||||
logger.warning("No courses found to poll")
|
||||
return
|
||||
|
||||
yield from self._yield_in_batches(self._get_updated_content(courses, start, end))
|
||||
|
||||
@retry(tries=3, delay=1, backoff=2)
|
||||
def _get_enrolled_courses(self) -> list:
|
||||
if not self.moodle_client:
|
||||
raise ConnectorMissingCredentialError("Moodle client not initialized")
|
||||
|
||||
try:
|
||||
return self.moodle_client.core.course.get_courses()
|
||||
except MoodleException as e:
|
||||
self._log_error("fetching courses", e, "error")
|
||||
raise ConnectorValidationError(f"Failed to fetch courses: {e}")
|
||||
|
||||
@retry(tries=3, delay=1, backoff=2)
|
||||
def _get_course_contents(self, course_id: int):
|
||||
if not self.moodle_client:
|
||||
raise ConnectorMissingCredentialError("Moodle client not initialized")
|
||||
|
||||
try:
|
||||
return self.moodle_client.core.course.get_contents(courseid=course_id)
|
||||
except MoodleException as e:
|
||||
self._log_error(f"fetching course contents for {course_id}", e)
|
||||
return []
|
||||
|
||||
def _process_courses(self, courses) -> Generator[Document, None, None]:
|
||||
for course in courses:
|
||||
try:
|
||||
contents = self._get_course_contents(course.id)
|
||||
for section in contents:
|
||||
for module in section.modules:
|
||||
doc = self._process_module(course, section, module)
|
||||
if doc:
|
||||
yield doc
|
||||
except Exception as e:
|
||||
self._log_error(f"processing course {course.fullname}", e)
|
||||
|
||||
def _get_updated_content(
|
||||
self, courses, start: float, end: float
|
||||
) -> Generator[Document, None, None]:
|
||||
for course in courses:
|
||||
try:
|
||||
contents = self._get_course_contents(course.id)
|
||||
for section in contents:
|
||||
for module in section.modules:
|
||||
times = [
|
||||
getattr(module, "timecreated", 0),
|
||||
getattr(module, "timemodified", 0),
|
||||
]
|
||||
if hasattr(module, "contents"):
|
||||
times.extend(
|
||||
getattr(c, "timemodified", 0)
|
||||
for c in module.contents
|
||||
if c and getattr(c, "timemodified", 0)
|
||||
)
|
||||
last_mod = self._get_latest_timestamp(*times)
|
||||
if start < last_mod <= end:
|
||||
doc = self._process_module(course, section, module)
|
||||
if doc:
|
||||
yield doc
|
||||
except Exception as e:
|
||||
self._log_error(f"polling course {course.fullname}", e)
|
||||
|
||||
def _process_module(
|
||||
self, course, section, module
|
||||
) -> Optional[Document]:
|
||||
try:
|
||||
mtype = module.modname
|
||||
if mtype in ["label", "url"]:
|
||||
return None
|
||||
if mtype == "resource":
|
||||
return self._process_resource(course, section, module)
|
||||
if mtype == "forum":
|
||||
return self._process_forum(course, section, module)
|
||||
if mtype == "page":
|
||||
return self._process_page(course, section, module)
|
||||
if mtype in ["assign", "quiz"]:
|
||||
return self._process_activity(course, section, module)
|
||||
if mtype == "book":
|
||||
return self._process_book(course, section, module)
|
||||
except Exception as e:
|
||||
self._log_error(f"processing module {getattr(module, 'name', '?')}", e)
|
||||
return None
|
||||
|
||||
def _process_resource(self, course, section, module) -> Optional[Document]:
|
||||
if not getattr(module, "contents", None):
|
||||
return None
|
||||
|
||||
file_info = module.contents[0]
|
||||
if not getattr(file_info, "fileurl", None):
|
||||
return None
|
||||
|
||||
file_name = os.path.basename(file_info.filename)
|
||||
ts = self._get_latest_timestamp(
|
||||
getattr(module, "timecreated", 0),
|
||||
getattr(module, "timemodified", 0),
|
||||
getattr(file_info, "timemodified", 0),
|
||||
)
|
||||
|
||||
try:
|
||||
resp = rl_requests.get(self._add_token_to_url(file_info.fileurl), timeout=60)
|
||||
resp.raise_for_status()
|
||||
blob = resp.content
|
||||
ext = os.path.splitext(file_name)[1] or ".bin"
|
||||
semantic_id = f"{course.fullname} / {section.name} / {file_name}"
|
||||
return Document(
|
||||
id=f"moodle_resource_{module.id}",
|
||||
source="moodle",
|
||||
semantic_identifier=semantic_id,
|
||||
extension=ext,
|
||||
blob=blob,
|
||||
doc_updated_at=datetime.fromtimestamp(ts or 0, tz=timezone.utc),
|
||||
size_bytes=len(blob),
|
||||
)
|
||||
except Exception as e:
|
||||
self._log_error(f"downloading resource {file_name}", e, "error")
|
||||
return None
|
||||
|
||||
def _process_forum(self, course, section, module) -> Optional[Document]:
|
||||
if not self.moodle_client or not getattr(module, "instance", None):
|
||||
return None
|
||||
|
||||
try:
|
||||
result = self.moodle_client.mod.forum.get_forum_discussions(forumid=module.instance)
|
||||
disc_list = getattr(result, "discussions", [])
|
||||
if not disc_list:
|
||||
return None
|
||||
|
||||
markdown = [f"# {module.name}\n"]
|
||||
latest_ts = self._get_latest_timestamp(
|
||||
getattr(module, "timecreated", 0),
|
||||
getattr(module, "timemodified", 0),
|
||||
)
|
||||
|
||||
for d in disc_list:
|
||||
markdown.append(f"## {d.name}\n\n{md(d.message or '')}\n\n---\n")
|
||||
latest_ts = max(latest_ts, getattr(d, "timemodified", 0))
|
||||
|
||||
blob = "\n".join(markdown).encode("utf-8")
|
||||
semantic_id = f"{course.fullname} / {section.name} / {module.name}"
|
||||
return Document(
|
||||
id=f"moodle_forum_{module.id}",
|
||||
source="moodle",
|
||||
semantic_identifier=semantic_id,
|
||||
extension=".md",
|
||||
blob=blob,
|
||||
doc_updated_at=datetime.fromtimestamp(latest_ts or 0, tz=timezone.utc),
|
||||
size_bytes=len(blob),
|
||||
)
|
||||
except Exception as e:
|
||||
self._log_error(f"processing forum {module.name}", e)
|
||||
return None
|
||||
|
||||
def _process_page(self, course, section, module) -> Optional[Document]:
|
||||
if not getattr(module, "contents", None):
|
||||
return None
|
||||
|
||||
file_info = module.contents[0]
|
||||
if not getattr(file_info, "fileurl", None):
|
||||
return None
|
||||
|
||||
file_name = os.path.basename(file_info.filename)
|
||||
ts = self._get_latest_timestamp(
|
||||
getattr(module, "timecreated", 0),
|
||||
getattr(module, "timemodified", 0),
|
||||
getattr(file_info, "timemodified", 0),
|
||||
)
|
||||
|
||||
try:
|
||||
resp = rl_requests.get(self._add_token_to_url(file_info.fileurl), timeout=60)
|
||||
resp.raise_for_status()
|
||||
blob = resp.content
|
||||
ext = os.path.splitext(file_name)[1] or ".html"
|
||||
semantic_id = f"{course.fullname} / {section.name} / {module.name}"
|
||||
return Document(
|
||||
id=f"moodle_page_{module.id}",
|
||||
source="moodle",
|
||||
semantic_identifier=semantic_id,
|
||||
extension=ext,
|
||||
blob=blob,
|
||||
doc_updated_at=datetime.fromtimestamp(ts or 0, tz=timezone.utc),
|
||||
size_bytes=len(blob),
|
||||
)
|
||||
except Exception as e:
|
||||
self._log_error(f"processing page {file_name}", e, "error")
|
||||
return None
|
||||
|
||||
def _process_activity(self, course, section, module) -> Optional[Document]:
|
||||
desc = getattr(module, "description", "")
|
||||
if not desc:
|
||||
return None
|
||||
|
||||
mtype, mname = module.modname, module.name
|
||||
markdown = f"# {mname}\n\n**Type:** {mtype.capitalize()}\n\n{md(desc)}"
|
||||
ts = self._get_latest_timestamp(
|
||||
getattr(module, "timecreated", 0),
|
||||
getattr(module, "timemodified", 0),
|
||||
getattr(module, "added", 0),
|
||||
)
|
||||
|
||||
semantic_id = f"{course.fullname} / {section.name} / {mname}"
|
||||
blob = markdown.encode("utf-8")
|
||||
return Document(
|
||||
id=f"moodle_{mtype}_{module.id}",
|
||||
source="moodle",
|
||||
semantic_identifier=semantic_id,
|
||||
extension=".md",
|
||||
blob=blob,
|
||||
doc_updated_at=datetime.fromtimestamp(ts or 0, tz=timezone.utc),
|
||||
size_bytes=len(blob),
|
||||
)
|
||||
|
||||
def _process_book(self, course, section, module) -> Optional[Document]:
|
||||
if not getattr(module, "contents", None):
|
||||
return None
|
||||
|
||||
contents = module.contents
|
||||
chapters = [
|
||||
c for c in contents
|
||||
if getattr(c, "fileurl", None) and os.path.basename(c.filename) == "index.html"
|
||||
]
|
||||
if not chapters:
|
||||
return None
|
||||
|
||||
latest_ts = self._get_latest_timestamp(
|
||||
getattr(module, "timecreated", 0),
|
||||
getattr(module, "timemodified", 0),
|
||||
*[getattr(c, "timecreated", 0) for c in contents],
|
||||
*[getattr(c, "timemodified", 0) for c in contents],
|
||||
)
|
||||
|
||||
markdown_parts = [f"# {module.name}\n"]
|
||||
for ch in chapters:
|
||||
try:
|
||||
resp = rl_requests.get(self._add_token_to_url(ch.fileurl), timeout=60)
|
||||
resp.raise_for_status()
|
||||
html = resp.content.decode("utf-8", errors="ignore")
|
||||
markdown_parts.append(md(html) + "\n\n---\n")
|
||||
except Exception as e:
|
||||
self._log_error(f"processing book chapter {ch.filename}", e)
|
||||
|
||||
blob = "\n".join(markdown_parts).encode("utf-8")
|
||||
semantic_id = f"{course.fullname} / {section.name} / {module.name}"
|
||||
return Document(
|
||||
id=f"moodle_book_{module.id}",
|
||||
source="moodle",
|
||||
semantic_identifier=semantic_id,
|
||||
extension=".md",
|
||||
blob=blob,
|
||||
doc_updated_at=datetime.fromtimestamp(latest_ts or 0, tz=timezone.utc),
|
||||
size_bytes=len(blob),
|
||||
)
|
||||
@ -1,38 +1,45 @@
|
||||
import html
|
||||
import logging
|
||||
from collections.abc import Generator
|
||||
from datetime import datetime, timezone
|
||||
from pathlib import Path
|
||||
from typing import Any, Optional
|
||||
from urllib.parse import urlparse
|
||||
|
||||
from retry import retry
|
||||
|
||||
from common.data_source.config import (
|
||||
INDEX_BATCH_SIZE,
|
||||
DocumentSource, NOTION_CONNECTOR_DISABLE_RECURSIVE_PAGE_LOOKUP
|
||||
NOTION_CONNECTOR_DISABLE_RECURSIVE_PAGE_LOOKUP,
|
||||
DocumentSource,
|
||||
)
|
||||
from common.data_source.exceptions import (
|
||||
ConnectorMissingCredentialError,
|
||||
ConnectorValidationError,
|
||||
CredentialExpiredError,
|
||||
InsufficientPermissionsError,
|
||||
UnexpectedValidationError,
|
||||
)
|
||||
from common.data_source.interfaces import (
|
||||
LoadConnector,
|
||||
PollConnector,
|
||||
SecondsSinceUnixEpoch
|
||||
SecondsSinceUnixEpoch,
|
||||
)
|
||||
from common.data_source.models import (
|
||||
Document,
|
||||
TextSection, GenerateDocumentsOutput
|
||||
)
|
||||
from common.data_source.exceptions import (
|
||||
ConnectorValidationError,
|
||||
CredentialExpiredError,
|
||||
InsufficientPermissionsError,
|
||||
UnexpectedValidationError, ConnectorMissingCredentialError
|
||||
)
|
||||
from common.data_source.models import (
|
||||
NotionPage,
|
||||
GenerateDocumentsOutput,
|
||||
NotionBlock,
|
||||
NotionSearchResponse
|
||||
NotionPage,
|
||||
NotionSearchResponse,
|
||||
TextSection,
|
||||
)
|
||||
from common.data_source.utils import (
|
||||
rl_requests,
|
||||
batch_generator,
|
||||
datetime_from_string,
|
||||
fetch_notion_data,
|
||||
filter_pages_by_time,
|
||||
properties_to_str,
|
||||
filter_pages_by_time, datetime_from_string
|
||||
rl_requests,
|
||||
)
|
||||
|
||||
|
||||
@ -61,11 +68,9 @@ class NotionConnector(LoadConnector, PollConnector):
|
||||
self.recursive_index_enabled = recursive_index_enabled or bool(root_page_id)
|
||||
|
||||
@retry(tries=3, delay=1, backoff=2)
|
||||
def _fetch_child_blocks(
|
||||
self, block_id: str, cursor: Optional[str] = None
|
||||
) -> dict[str, Any] | None:
|
||||
def _fetch_child_blocks(self, block_id: str, cursor: Optional[str] = None) -> dict[str, Any] | None:
|
||||
"""Fetch all child blocks via the Notion API."""
|
||||
logging.debug(f"Fetching children of block with ID '{block_id}'")
|
||||
logging.debug(f"[Notion]: Fetching children of block with ID {block_id}")
|
||||
block_url = f"https://api.notion.com/v1/blocks/{block_id}/children"
|
||||
query_params = {"start_cursor": cursor} if cursor else None
|
||||
|
||||
@ -79,49 +84,42 @@ class NotionConnector(LoadConnector, PollConnector):
|
||||
response.raise_for_status()
|
||||
return response.json()
|
||||
except Exception as e:
|
||||
if hasattr(e, 'response') and e.response.status_code == 404:
|
||||
logging.error(
|
||||
f"Unable to access block with ID '{block_id}'. "
|
||||
f"This is likely due to the block not being shared with the integration."
|
||||
)
|
||||
if hasattr(e, "response") and e.response.status_code == 404:
|
||||
logging.error(f"[Notion]: Unable to access block with ID {block_id}. This is likely due to the block not being shared with the integration.")
|
||||
return None
|
||||
else:
|
||||
logging.exception(f"Error fetching blocks: {e}")
|
||||
logging.exception(f"[Notion]: Error fetching blocks: {e}")
|
||||
raise
|
||||
|
||||
@retry(tries=3, delay=1, backoff=2)
|
||||
def _fetch_page(self, page_id: str) -> NotionPage:
|
||||
"""Fetch a page from its ID via the Notion API."""
|
||||
logging.debug(f"Fetching page for ID '{page_id}'")
|
||||
logging.debug(f"[Notion]: Fetching page for ID {page_id}")
|
||||
page_url = f"https://api.notion.com/v1/pages/{page_id}"
|
||||
|
||||
try:
|
||||
data = fetch_notion_data(page_url, self.headers, "GET")
|
||||
return NotionPage(**data)
|
||||
except Exception as e:
|
||||
logging.warning(f"Failed to fetch page, trying database for ID '{page_id}': {e}")
|
||||
logging.warning(f"[Notion]: Failed to fetch page, trying database for ID {page_id}: {e}")
|
||||
return self._fetch_database_as_page(page_id)
|
||||
|
||||
@retry(tries=3, delay=1, backoff=2)
|
||||
def _fetch_database_as_page(self, database_id: str) -> NotionPage:
|
||||
"""Attempt to fetch a database as a page."""
|
||||
logging.debug(f"Fetching database for ID '{database_id}' as a page")
|
||||
logging.debug(f"[Notion]: Fetching database for ID {database_id} as a page")
|
||||
database_url = f"https://api.notion.com/v1/databases/{database_id}"
|
||||
|
||||
data = fetch_notion_data(database_url, self.headers, "GET")
|
||||
database_name = data.get("title")
|
||||
database_name = (
|
||||
database_name[0].get("text", {}).get("content") if database_name else None
|
||||
)
|
||||
database_name = database_name[0].get("text", {}).get("content") if database_name else None
|
||||
|
||||
return NotionPage(**data, database_name=database_name)
|
||||
|
||||
@retry(tries=3, delay=1, backoff=2)
|
||||
def _fetch_database(
|
||||
self, database_id: str, cursor: Optional[str] = None
|
||||
) -> dict[str, Any]:
|
||||
def _fetch_database(self, database_id: str, cursor: Optional[str] = None) -> dict[str, Any]:
|
||||
"""Fetch a database from its ID via the Notion API."""
|
||||
logging.debug(f"Fetching database for ID '{database_id}'")
|
||||
logging.debug(f"[Notion]: Fetching database for ID {database_id}")
|
||||
block_url = f"https://api.notion.com/v1/databases/{database_id}/query"
|
||||
body = {"start_cursor": cursor} if cursor else None
|
||||
|
||||
@ -129,17 +127,12 @@ class NotionConnector(LoadConnector, PollConnector):
|
||||
data = fetch_notion_data(block_url, self.headers, "POST", body)
|
||||
return data
|
||||
except Exception as e:
|
||||
if hasattr(e, 'response') and e.response.status_code in [404, 400]:
|
||||
logging.error(
|
||||
f"Unable to access database with ID '{database_id}'. "
|
||||
f"This is likely due to the database not being shared with the integration."
|
||||
)
|
||||
if hasattr(e, "response") and e.response.status_code in [404, 400]:
|
||||
logging.error(f"[Notion]: Unable to access database with ID {database_id}. This is likely due to the database not being shared with the integration.")
|
||||
return {"results": [], "next_cursor": None}
|
||||
raise
|
||||
|
||||
def _read_pages_from_database(
|
||||
self, database_id: str
|
||||
) -> tuple[list[NotionBlock], list[str]]:
|
||||
def _read_pages_from_database(self, database_id: str) -> tuple[list[NotionBlock], list[str]]:
|
||||
"""Returns a list of top level blocks and all page IDs in the database."""
|
||||
result_blocks: list[NotionBlock] = []
|
||||
result_pages: list[str] = []
|
||||
@ -158,10 +151,10 @@ class NotionConnector(LoadConnector, PollConnector):
|
||||
|
||||
if self.recursive_index_enabled:
|
||||
if obj_type == "page":
|
||||
logging.debug(f"Found page with ID '{obj_id}' in database '{database_id}'")
|
||||
logging.debug(f"[Notion]: Found page with ID {obj_id} in database {database_id}")
|
||||
result_pages.append(result["id"])
|
||||
elif obj_type == "database":
|
||||
logging.debug(f"Found database with ID '{obj_id}' in database '{database_id}'")
|
||||
logging.debug(f"[Notion]: Found database with ID {obj_id} in database {database_id}")
|
||||
_, child_pages = self._read_pages_from_database(obj_id)
|
||||
result_pages.extend(child_pages)
|
||||
|
||||
@ -172,44 +165,229 @@ class NotionConnector(LoadConnector, PollConnector):
|
||||
|
||||
return result_blocks, result_pages
|
||||
|
||||
def _read_blocks(self, base_block_id: str) -> tuple[list[NotionBlock], list[str]]:
|
||||
"""Reads all child blocks for the specified block, returns blocks and child page ids."""
|
||||
def _extract_rich_text(self, rich_text_array: list[dict[str, Any]]) -> str:
|
||||
collected_text: list[str] = []
|
||||
for rich_text in rich_text_array:
|
||||
content = ""
|
||||
r_type = rich_text.get("type")
|
||||
|
||||
if r_type == "equation":
|
||||
expr = rich_text.get("equation", {}).get("expression")
|
||||
if expr:
|
||||
content = expr
|
||||
elif r_type == "mention":
|
||||
mention = rich_text.get("mention", {}) or {}
|
||||
mention_type = mention.get("type")
|
||||
mention_value = mention.get(mention_type, {}) if mention_type else {}
|
||||
if mention_type == "date":
|
||||
start = mention_value.get("start")
|
||||
end = mention_value.get("end")
|
||||
if start and end:
|
||||
content = f"{start} - {end}"
|
||||
elif start:
|
||||
content = start
|
||||
elif mention_type in {"page", "database"}:
|
||||
content = mention_value.get("id", rich_text.get("plain_text", ""))
|
||||
elif mention_type == "link_preview":
|
||||
content = mention_value.get("url", rich_text.get("plain_text", ""))
|
||||
else:
|
||||
content = rich_text.get("plain_text", "") or str(mention_value)
|
||||
else:
|
||||
if rich_text.get("plain_text"):
|
||||
content = rich_text["plain_text"]
|
||||
elif "text" in rich_text and rich_text["text"].get("content"):
|
||||
content = rich_text["text"]["content"]
|
||||
|
||||
href = rich_text.get("href")
|
||||
if content and href:
|
||||
content = f"{content} ({href})"
|
||||
|
||||
if content:
|
||||
collected_text.append(content)
|
||||
|
||||
return "".join(collected_text).strip()
|
||||
|
||||
def _build_table_html(self, table_block_id: str) -> str | None:
|
||||
rows: list[str] = []
|
||||
cursor = None
|
||||
while True:
|
||||
data = self._fetch_child_blocks(table_block_id, cursor)
|
||||
if data is None:
|
||||
break
|
||||
|
||||
for result in data["results"]:
|
||||
if result.get("type") != "table_row":
|
||||
continue
|
||||
cells_html: list[str] = []
|
||||
for cell in result["table_row"].get("cells", []):
|
||||
cell_text = self._extract_rich_text(cell)
|
||||
cell_html = html.escape(cell_text) if cell_text else ""
|
||||
cells_html.append(f"<td>{cell_html}</td>")
|
||||
rows.append(f"<tr>{''.join(cells_html)}</tr>")
|
||||
|
||||
if data.get("next_cursor") is None:
|
||||
break
|
||||
cursor = data["next_cursor"]
|
||||
|
||||
if not rows:
|
||||
return None
|
||||
return "<table>\n" + "\n".join(rows) + "\n</table>"
|
||||
|
||||
def _download_file(self, url: str) -> bytes | None:
|
||||
try:
|
||||
response = rl_requests.get(url, timeout=60)
|
||||
response.raise_for_status()
|
||||
return response.content
|
||||
except Exception as exc:
|
||||
logging.warning(f"[Notion]: Failed to download Notion file from {url}: {exc}")
|
||||
return None
|
||||
|
||||
def _extract_file_metadata(self, result_obj: dict[str, Any], block_id: str) -> tuple[str | None, str, str | None]:
|
||||
file_source_type = result_obj.get("type")
|
||||
file_source = result_obj.get(file_source_type, {}) if file_source_type else {}
|
||||
url = file_source.get("url")
|
||||
|
||||
name = result_obj.get("name") or file_source.get("name")
|
||||
if url and not name:
|
||||
parsed_name = Path(urlparse(url).path).name
|
||||
name = parsed_name or f"notion_file_{block_id}"
|
||||
elif not name:
|
||||
name = f"notion_file_{block_id}"
|
||||
|
||||
caption = self._extract_rich_text(result_obj.get("caption", [])) if "caption" in result_obj else None
|
||||
|
||||
return url, name, caption
|
||||
|
||||
def _build_attachment_document(
|
||||
self,
|
||||
block_id: str,
|
||||
url: str,
|
||||
name: str,
|
||||
caption: Optional[str],
|
||||
page_last_edited_time: Optional[str],
|
||||
) -> Document | None:
|
||||
file_bytes = self._download_file(url)
|
||||
if file_bytes is None:
|
||||
return None
|
||||
|
||||
extension = Path(name).suffix or Path(urlparse(url).path).suffix or ".bin"
|
||||
if extension and not extension.startswith("."):
|
||||
extension = f".{extension}"
|
||||
if not extension:
|
||||
extension = ".bin"
|
||||
|
||||
updated_at = datetime_from_string(page_last_edited_time) if page_last_edited_time else datetime.now(timezone.utc)
|
||||
semantic_identifier = caption or name or f"Notion file {block_id}"
|
||||
|
||||
return Document(
|
||||
id=block_id,
|
||||
blob=file_bytes,
|
||||
source=DocumentSource.NOTION,
|
||||
semantic_identifier=semantic_identifier,
|
||||
extension=extension,
|
||||
size_bytes=len(file_bytes),
|
||||
doc_updated_at=updated_at,
|
||||
)
|
||||
|
||||
def _read_blocks(self, base_block_id: str, page_last_edited_time: Optional[str] = None) -> tuple[list[NotionBlock], list[str], list[Document]]:
|
||||
result_blocks: list[NotionBlock] = []
|
||||
child_pages: list[str] = []
|
||||
attachments: list[Document] = []
|
||||
cursor = None
|
||||
|
||||
while True:
|
||||
data = self._fetch_child_blocks(base_block_id, cursor)
|
||||
|
||||
if data is None:
|
||||
return result_blocks, child_pages
|
||||
return result_blocks, child_pages, attachments
|
||||
|
||||
for result in data["results"]:
|
||||
logging.debug(f"Found child block for block with ID '{base_block_id}': {result}")
|
||||
logging.debug(f"[Notion]: Found child block for block with ID {base_block_id}: {result}")
|
||||
result_block_id = result["id"]
|
||||
result_type = result["type"]
|
||||
result_obj = result[result_type]
|
||||
|
||||
if result_type in ["ai_block", "unsupported", "external_object_instance_page"]:
|
||||
logging.warning(f"Skipping unsupported block type '{result_type}'")
|
||||
logging.warning(f"[Notion]: Skipping unsupported block type {result_type}")
|
||||
continue
|
||||
|
||||
if result_type == "table":
|
||||
table_html = self._build_table_html(result_block_id)
|
||||
if table_html:
|
||||
result_blocks.append(
|
||||
NotionBlock(
|
||||
id=result_block_id,
|
||||
text=table_html,
|
||||
prefix="\n\n",
|
||||
)
|
||||
)
|
||||
continue
|
||||
|
||||
if result_type == "equation":
|
||||
expr = result_obj.get("expression")
|
||||
if expr:
|
||||
result_blocks.append(
|
||||
NotionBlock(
|
||||
id=result_block_id,
|
||||
text=expr,
|
||||
prefix="\n",
|
||||
)
|
||||
)
|
||||
continue
|
||||
|
||||
cur_result_text_arr = []
|
||||
if "rich_text" in result_obj:
|
||||
for rich_text in result_obj["rich_text"]:
|
||||
if "text" in rich_text:
|
||||
text = rich_text["text"]["content"]
|
||||
cur_result_text_arr.append(text)
|
||||
text = self._extract_rich_text(result_obj["rich_text"])
|
||||
if text:
|
||||
cur_result_text_arr.append(text)
|
||||
|
||||
if result_type == "bulleted_list_item":
|
||||
if cur_result_text_arr:
|
||||
cur_result_text_arr[0] = f"- {cur_result_text_arr[0]}"
|
||||
else:
|
||||
cur_result_text_arr = ["- "]
|
||||
|
||||
if result_type == "numbered_list_item":
|
||||
if cur_result_text_arr:
|
||||
cur_result_text_arr[0] = f"1. {cur_result_text_arr[0]}"
|
||||
else:
|
||||
cur_result_text_arr = ["1. "]
|
||||
|
||||
if result_type == "to_do":
|
||||
checked = result_obj.get("checked")
|
||||
checkbox_prefix = "[x]" if checked else "[ ]"
|
||||
if cur_result_text_arr:
|
||||
cur_result_text_arr = [f"{checkbox_prefix} {cur_result_text_arr[0]}"] + cur_result_text_arr[1:]
|
||||
else:
|
||||
cur_result_text_arr = [checkbox_prefix]
|
||||
|
||||
if result_type in {"file", "image", "pdf", "video", "audio"}:
|
||||
file_url, file_name, caption = self._extract_file_metadata(result_obj, result_block_id)
|
||||
if file_url:
|
||||
attachment_doc = self._build_attachment_document(
|
||||
block_id=result_block_id,
|
||||
url=file_url,
|
||||
name=file_name,
|
||||
caption=caption,
|
||||
page_last_edited_time=page_last_edited_time,
|
||||
)
|
||||
if attachment_doc:
|
||||
attachments.append(attachment_doc)
|
||||
|
||||
attachment_label = caption or file_name
|
||||
if attachment_label:
|
||||
cur_result_text_arr.append(f"{result_type.capitalize()}: {attachment_label}")
|
||||
|
||||
if result["has_children"]:
|
||||
if result_type == "child_page":
|
||||
child_pages.append(result_block_id)
|
||||
else:
|
||||
logging.debug(f"Entering sub-block: {result_block_id}")
|
||||
subblocks, subblock_child_pages = self._read_blocks(result_block_id)
|
||||
logging.debug(f"Finished sub-block: {result_block_id}")
|
||||
logging.debug(f"[Notion]: Entering sub-block: {result_block_id}")
|
||||
subblocks, subblock_child_pages, subblock_attachments = self._read_blocks(result_block_id, page_last_edited_time)
|
||||
logging.debug(f"[Notion]: Finished sub-block: {result_block_id}")
|
||||
result_blocks.extend(subblocks)
|
||||
child_pages.extend(subblock_child_pages)
|
||||
attachments.extend(subblock_attachments)
|
||||
|
||||
if result_type == "child_database":
|
||||
inner_blocks, inner_child_pages = self._read_pages_from_database(result_block_id)
|
||||
@ -231,7 +409,7 @@ class NotionConnector(LoadConnector, PollConnector):
|
||||
|
||||
cursor = data["next_cursor"]
|
||||
|
||||
return result_blocks, child_pages
|
||||
return result_blocks, child_pages, attachments
|
||||
|
||||
def _read_page_title(self, page: NotionPage) -> Optional[str]:
|
||||
"""Extracts the title from a Notion page."""
|
||||
@ -245,9 +423,7 @@ class NotionConnector(LoadConnector, PollConnector):
|
||||
|
||||
return None
|
||||
|
||||
def _read_pages(
|
||||
self, pages: list[NotionPage]
|
||||
) -> Generator[Document, None, None]:
|
||||
def _read_pages(self, pages: list[NotionPage], start: SecondsSinceUnixEpoch | None = None, end: SecondsSinceUnixEpoch | None = None) -> Generator[Document, None, None]:
|
||||
"""Reads pages for rich text content and generates Documents."""
|
||||
all_child_page_ids: list[str] = []
|
||||
|
||||
@ -255,11 +431,17 @@ class NotionConnector(LoadConnector, PollConnector):
|
||||
if isinstance(page, dict):
|
||||
page = NotionPage(**page)
|
||||
if page.id in self.indexed_pages:
|
||||
logging.debug(f"Already indexed page with ID '{page.id}'. Skipping.")
|
||||
logging.debug(f"[Notion]: Already indexed page with ID {page.id}. Skipping.")
|
||||
continue
|
||||
|
||||
logging.info(f"Reading page with ID '{page.id}', with url {page.url}")
|
||||
page_blocks, child_page_ids = self._read_blocks(page.id)
|
||||
if start is not None and end is not None:
|
||||
page_ts = datetime_from_string(page.last_edited_time).timestamp()
|
||||
if not (page_ts > start and page_ts <= end):
|
||||
logging.debug(f"[Notion]: Skipping page {page.id} outside polling window.")
|
||||
continue
|
||||
|
||||
logging.info(f"[Notion]: Reading page with ID {page.id}, with url {page.url}")
|
||||
page_blocks, child_page_ids, attachment_docs = self._read_blocks(page.id, page.last_edited_time)
|
||||
all_child_page_ids.extend(child_page_ids)
|
||||
self.indexed_pages.add(page.id)
|
||||
|
||||
@ -268,14 +450,12 @@ class NotionConnector(LoadConnector, PollConnector):
|
||||
|
||||
if not page_blocks:
|
||||
if not raw_page_title:
|
||||
logging.warning(f"No blocks OR title found for page with ID '{page.id}'. Skipping.")
|
||||
logging.warning(f"[Notion]: No blocks OR title found for page with ID {page.id}. Skipping.")
|
||||
continue
|
||||
|
||||
text = page_title
|
||||
if page.properties:
|
||||
text += "\n\n" + "\n".join(
|
||||
[f"{key}: {value}" for key, value in page.properties.items()]
|
||||
)
|
||||
text += "\n\n" + "\n".join([f"{key}: {value}" for key, value in page.properties.items()])
|
||||
sections = [TextSection(link=page.url, text=text)]
|
||||
else:
|
||||
sections = [
|
||||
@ -286,45 +466,39 @@ class NotionConnector(LoadConnector, PollConnector):
|
||||
for block in page_blocks
|
||||
]
|
||||
|
||||
blob = ("\n".join([sec.text for sec in sections])).encode("utf-8")
|
||||
joined_text = "\n".join(sec.text for sec in sections)
|
||||
blob = joined_text.encode("utf-8")
|
||||
yield Document(
|
||||
id=page.id,
|
||||
blob=blob,
|
||||
source=DocumentSource.NOTION,
|
||||
semantic_identifier=page_title,
|
||||
extension=".txt",
|
||||
size_bytes=len(blob),
|
||||
doc_updated_at=datetime_from_string(page.last_edited_time)
|
||||
id=page.id, blob=blob, source=DocumentSource.NOTION, semantic_identifier=page_title, extension=".txt", size_bytes=len(blob), doc_updated_at=datetime_from_string(page.last_edited_time)
|
||||
)
|
||||
|
||||
for attachment_doc in attachment_docs:
|
||||
yield attachment_doc
|
||||
|
||||
if self.recursive_index_enabled and all_child_page_ids:
|
||||
for child_page_batch_ids in batch_generator(all_child_page_ids, INDEX_BATCH_SIZE):
|
||||
child_page_batch = [
|
||||
self._fetch_page(page_id)
|
||||
for page_id in child_page_batch_ids
|
||||
if page_id not in self.indexed_pages
|
||||
]
|
||||
yield from self._read_pages(child_page_batch)
|
||||
child_page_batch = [self._fetch_page(page_id) for page_id in child_page_batch_ids if page_id not in self.indexed_pages]
|
||||
yield from self._read_pages(child_page_batch, start, end)
|
||||
|
||||
@retry(tries=3, delay=1, backoff=2)
|
||||
def _search_notion(self, query_dict: dict[str, Any]) -> NotionSearchResponse:
|
||||
"""Search for pages from a Notion database."""
|
||||
logging.debug(f"Searching for pages in Notion with query_dict: {query_dict}")
|
||||
logging.debug(f"[Notion]: Searching for pages in Notion with query_dict: {query_dict}")
|
||||
data = fetch_notion_data("https://api.notion.com/v1/search", self.headers, "POST", query_dict)
|
||||
return NotionSearchResponse(**data)
|
||||
|
||||
def _recursive_load(self) -> Generator[list[Document], None, None]:
|
||||
def _recursive_load(self, start: SecondsSinceUnixEpoch | None = None, end: SecondsSinceUnixEpoch | None = None) -> Generator[list[Document], None, None]:
|
||||
"""Recursively load pages starting from root page ID."""
|
||||
if self.root_page_id is None or not self.recursive_index_enabled:
|
||||
raise RuntimeError("Recursive page lookup is not enabled")
|
||||
|
||||
logging.info(f"Recursively loading pages from Notion based on root page with ID: {self.root_page_id}")
|
||||
logging.info(f"[Notion]: Recursively loading pages from Notion based on root page with ID: {self.root_page_id}")
|
||||
pages = [self._fetch_page(page_id=self.root_page_id)]
|
||||
yield from batch_generator(self._read_pages(pages), self.batch_size)
|
||||
yield from batch_generator(self._read_pages(pages, start, end), self.batch_size)
|
||||
|
||||
def load_credentials(self, credentials: dict[str, Any]) -> dict[str, Any] | None:
|
||||
"""Applies integration token to headers."""
|
||||
self.headers["Authorization"] = f'Bearer {credentials["notion_integration_token"]}'
|
||||
self.headers["Authorization"] = f"Bearer {credentials['notion_integration_token']}"
|
||||
return None
|
||||
|
||||
def load_from_state(self) -> GenerateDocumentsOutput:
|
||||
@ -348,12 +522,10 @@ class NotionConnector(LoadConnector, PollConnector):
|
||||
else:
|
||||
break
|
||||
|
||||
def poll_source(
|
||||
self, start: SecondsSinceUnixEpoch, end: SecondsSinceUnixEpoch
|
||||
) -> GenerateDocumentsOutput:
|
||||
def poll_source(self, start: SecondsSinceUnixEpoch, end: SecondsSinceUnixEpoch) -> GenerateDocumentsOutput:
|
||||
"""Poll Notion for updated pages within a time period."""
|
||||
if self.recursive_index_enabled and self.root_page_id:
|
||||
yield from self._recursive_load()
|
||||
yield from self._recursive_load(start, end)
|
||||
return
|
||||
|
||||
query_dict = {
|
||||
@ -367,7 +539,7 @@ class NotionConnector(LoadConnector, PollConnector):
|
||||
pages = filter_pages_by_time(db_res.results, start, end, "last_edited_time")
|
||||
|
||||
if pages:
|
||||
yield from batch_generator(self._read_pages(pages), self.batch_size)
|
||||
yield from batch_generator(self._read_pages(pages, start, end), self.batch_size)
|
||||
if db_res.has_more:
|
||||
query_dict["start_cursor"] = db_res.next_cursor
|
||||
else:
|
||||
|
||||
@ -312,12 +312,15 @@ def create_s3_client(bucket_type: BlobType, credentials: dict[str, Any], europea
|
||||
region_name=credentials["region"],
|
||||
)
|
||||
elif bucket_type == BlobType.S3_COMPATIBLE:
|
||||
addressing_style = credentials.get("addressing_style", "virtual")
|
||||
|
||||
return boto3.client(
|
||||
"s3",
|
||||
endpoint_url=credentials["endpoint_url"],
|
||||
aws_access_key_id=credentials["aws_access_key_id"],
|
||||
aws_secret_access_key=credentials["aws_secret_access_key"],
|
||||
)
|
||||
config=Config(s3={'addressing_style': addressing_style}),
|
||||
)
|
||||
|
||||
else:
|
||||
raise ValueError(f"Unsupported bucket type: {bucket_type}")
|
||||
|
||||
370
common/data_source/webdav_connector.py
Normal file
370
common/data_source/webdav_connector.py
Normal file
@ -0,0 +1,370 @@
|
||||
"""WebDAV connector"""
|
||||
import logging
|
||||
import os
|
||||
from datetime import datetime, timezone
|
||||
from typing import Any, Optional
|
||||
|
||||
from webdav4.client import Client as WebDAVClient
|
||||
|
||||
from common.data_source.utils import (
|
||||
get_file_ext,
|
||||
)
|
||||
from common.data_source.config import DocumentSource, INDEX_BATCH_SIZE, BLOB_STORAGE_SIZE_THRESHOLD
|
||||
from common.data_source.exceptions import (
|
||||
ConnectorMissingCredentialError,
|
||||
ConnectorValidationError,
|
||||
CredentialExpiredError,
|
||||
InsufficientPermissionsError
|
||||
)
|
||||
from common.data_source.interfaces import LoadConnector, PollConnector
|
||||
from common.data_source.models import Document, SecondsSinceUnixEpoch, GenerateDocumentsOutput
|
||||
|
||||
|
||||
class WebDAVConnector(LoadConnector, PollConnector):
|
||||
"""WebDAV connector for syncing files from WebDAV servers"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
base_url: str,
|
||||
remote_path: str = "/",
|
||||
batch_size: int = INDEX_BATCH_SIZE,
|
||||
) -> None:
|
||||
"""Initialize WebDAV connector
|
||||
|
||||
Args:
|
||||
base_url: Base URL of the WebDAV server (e.g., "https://webdav.example.com")
|
||||
remote_path: Remote path to sync from (default: "/")
|
||||
batch_size: Number of documents per batch
|
||||
"""
|
||||
self.base_url = base_url.rstrip("/")
|
||||
if not remote_path:
|
||||
remote_path = "/"
|
||||
if not remote_path.startswith("/"):
|
||||
remote_path = f"/{remote_path}"
|
||||
if remote_path.endswith("/") and remote_path != "/":
|
||||
remote_path = remote_path.rstrip("/")
|
||||
self.remote_path = remote_path
|
||||
self.batch_size = batch_size
|
||||
self.client: Optional[WebDAVClient] = None
|
||||
self._allow_images: bool | None = None
|
||||
self.size_threshold: int | None = BLOB_STORAGE_SIZE_THRESHOLD
|
||||
|
||||
def set_allow_images(self, allow_images: bool) -> None:
|
||||
"""Set whether to process images"""
|
||||
logging.info(f"Setting allow_images to {allow_images}.")
|
||||
self._allow_images = allow_images
|
||||
|
||||
def load_credentials(self, credentials: dict[str, Any]) -> dict[str, Any] | None:
|
||||
"""Load credentials and initialize WebDAV client
|
||||
|
||||
Args:
|
||||
credentials: Dictionary containing 'username' and 'password'
|
||||
|
||||
Returns:
|
||||
None
|
||||
|
||||
Raises:
|
||||
ConnectorMissingCredentialError: If required credentials are missing
|
||||
"""
|
||||
logging.debug(f"Loading credentials for WebDAV server {self.base_url}")
|
||||
|
||||
username = credentials.get("username")
|
||||
password = credentials.get("password")
|
||||
|
||||
if not username or not password:
|
||||
raise ConnectorMissingCredentialError(
|
||||
"WebDAV requires 'username' and 'password' credentials"
|
||||
)
|
||||
|
||||
try:
|
||||
# Initialize WebDAV client
|
||||
self.client = WebDAVClient(
|
||||
base_url=self.base_url,
|
||||
auth=(username, password)
|
||||
)
|
||||
|
||||
# Test connection
|
||||
self.client.exists(self.remote_path)
|
||||
|
||||
except Exception as e:
|
||||
logging.error(f"Failed to connect to WebDAV server: {e}")
|
||||
raise ConnectorMissingCredentialError(
|
||||
f"Failed to authenticate with WebDAV server: {e}"
|
||||
)
|
||||
|
||||
return None
|
||||
|
||||
def _list_files_recursive(
|
||||
self,
|
||||
path: str,
|
||||
start: datetime,
|
||||
end: datetime,
|
||||
) -> list[tuple[str, dict]]:
|
||||
"""Recursively list all files in the given path
|
||||
|
||||
Args:
|
||||
path: Path to list files from
|
||||
start: Start datetime for filtering
|
||||
end: End datetime for filtering
|
||||
|
||||
Returns:
|
||||
List of tuples containing (file_path, file_info)
|
||||
"""
|
||||
if self.client is None:
|
||||
raise ConnectorMissingCredentialError("WebDAV client not initialized")
|
||||
|
||||
files = []
|
||||
|
||||
try:
|
||||
logging.debug(f"Listing directory: {path}")
|
||||
for item in self.client.ls(path, detail=True):
|
||||
item_path = item['name']
|
||||
|
||||
if item_path == path or item_path == path + '/':
|
||||
continue
|
||||
|
||||
logging.debug(f"Found item: {item_path}, type: {item.get('type')}")
|
||||
|
||||
if item.get('type') == 'directory':
|
||||
try:
|
||||
files.extend(self._list_files_recursive(item_path, start, end))
|
||||
except Exception as e:
|
||||
logging.error(f"Error recursing into directory {item_path}: {e}")
|
||||
continue
|
||||
else:
|
||||
try:
|
||||
modified_time = item.get('modified')
|
||||
if modified_time:
|
||||
if isinstance(modified_time, datetime):
|
||||
modified = modified_time
|
||||
if modified.tzinfo is None:
|
||||
modified = modified.replace(tzinfo=timezone.utc)
|
||||
elif isinstance(modified_time, str):
|
||||
try:
|
||||
modified = datetime.strptime(modified_time, '%a, %d %b %Y %H:%M:%S %Z')
|
||||
modified = modified.replace(tzinfo=timezone.utc)
|
||||
except (ValueError, TypeError):
|
||||
try:
|
||||
modified = datetime.fromisoformat(modified_time.replace('Z', '+00:00'))
|
||||
except (ValueError, TypeError):
|
||||
logging.warning(f"Could not parse modified time for {item_path}: {modified_time}")
|
||||
modified = datetime.now(timezone.utc)
|
||||
else:
|
||||
modified = datetime.now(timezone.utc)
|
||||
else:
|
||||
modified = datetime.now(timezone.utc)
|
||||
|
||||
|
||||
logging.debug(f"File {item_path}: modified={modified}, start={start}, end={end}, include={start < modified <= end}")
|
||||
if start < modified <= end:
|
||||
files.append((item_path, item))
|
||||
else:
|
||||
logging.debug(f"File {item_path} filtered out by time range")
|
||||
except Exception as e:
|
||||
logging.error(f"Error processing file {item_path}: {e}")
|
||||
continue
|
||||
|
||||
except Exception as e:
|
||||
logging.error(f"Error listing directory {path}: {e}")
|
||||
|
||||
return files
|
||||
|
||||
def _yield_webdav_documents(
|
||||
self,
|
||||
start: datetime,
|
||||
end: datetime,
|
||||
) -> GenerateDocumentsOutput:
|
||||
"""Generate documents from WebDAV server
|
||||
|
||||
Args:
|
||||
start: Start datetime for filtering
|
||||
end: End datetime for filtering
|
||||
|
||||
Yields:
|
||||
Batches of documents
|
||||
"""
|
||||
if self.client is None:
|
||||
raise ConnectorMissingCredentialError("WebDAV client not initialized")
|
||||
|
||||
logging.info(f"Searching for files in {self.remote_path} between {start} and {end}")
|
||||
files = self._list_files_recursive(self.remote_path, start, end)
|
||||
logging.info(f"Found {len(files)} files matching time criteria")
|
||||
|
||||
batch: list[Document] = []
|
||||
for file_path, file_info in files:
|
||||
file_name = os.path.basename(file_path)
|
||||
|
||||
size_bytes = file_info.get('size', 0)
|
||||
if (
|
||||
self.size_threshold is not None
|
||||
and isinstance(size_bytes, int)
|
||||
and size_bytes > self.size_threshold
|
||||
):
|
||||
logging.warning(
|
||||
f"{file_name} exceeds size threshold of {self.size_threshold}. Skipping."
|
||||
)
|
||||
continue
|
||||
|
||||
try:
|
||||
logging.debug(f"Downloading file: {file_path}")
|
||||
from io import BytesIO
|
||||
buffer = BytesIO()
|
||||
self.client.download_fileobj(file_path, buffer)
|
||||
blob = buffer.getvalue()
|
||||
|
||||
if blob is None or len(blob) == 0:
|
||||
logging.warning(f"Downloaded content is empty for {file_path}")
|
||||
continue
|
||||
|
||||
modified_time = file_info.get('modified')
|
||||
if modified_time:
|
||||
if isinstance(modified_time, datetime):
|
||||
modified = modified_time
|
||||
if modified.tzinfo is None:
|
||||
modified = modified.replace(tzinfo=timezone.utc)
|
||||
elif isinstance(modified_time, str):
|
||||
try:
|
||||
modified = datetime.strptime(modified_time, '%a, %d %b %Y %H:%M:%S %Z')
|
||||
modified = modified.replace(tzinfo=timezone.utc)
|
||||
except (ValueError, TypeError):
|
||||
try:
|
||||
modified = datetime.fromisoformat(modified_time.replace('Z', '+00:00'))
|
||||
except (ValueError, TypeError):
|
||||
logging.warning(f"Could not parse modified time for {file_path}: {modified_time}")
|
||||
modified = datetime.now(timezone.utc)
|
||||
else:
|
||||
modified = datetime.now(timezone.utc)
|
||||
else:
|
||||
modified = datetime.now(timezone.utc)
|
||||
|
||||
batch.append(
|
||||
Document(
|
||||
id=f"webdav:{self.base_url}:{file_path}",
|
||||
blob=blob,
|
||||
source=DocumentSource.WEBDAV,
|
||||
semantic_identifier=file_name,
|
||||
extension=get_file_ext(file_name),
|
||||
doc_updated_at=modified,
|
||||
size_bytes=size_bytes if size_bytes else 0
|
||||
)
|
||||
)
|
||||
|
||||
if len(batch) == self.batch_size:
|
||||
yield batch
|
||||
batch = []
|
||||
|
||||
except Exception as e:
|
||||
logging.exception(f"Error downloading file {file_path}: {e}")
|
||||
|
||||
if batch:
|
||||
yield batch
|
||||
|
||||
def load_from_state(self) -> GenerateDocumentsOutput:
|
||||
"""Load all documents from WebDAV server
|
||||
|
||||
Yields:
|
||||
Batches of documents
|
||||
"""
|
||||
logging.debug(f"Loading documents from WebDAV server {self.base_url}")
|
||||
return self._yield_webdav_documents(
|
||||
start=datetime(1970, 1, 1, tzinfo=timezone.utc),
|
||||
end=datetime.now(timezone.utc),
|
||||
)
|
||||
|
||||
def poll_source(
|
||||
self, start: SecondsSinceUnixEpoch, end: SecondsSinceUnixEpoch
|
||||
) -> GenerateDocumentsOutput:
|
||||
"""Poll WebDAV server for updated documents
|
||||
|
||||
Args:
|
||||
start: Start timestamp (seconds since Unix epoch)
|
||||
end: End timestamp (seconds since Unix epoch)
|
||||
|
||||
Yields:
|
||||
Batches of documents
|
||||
"""
|
||||
if self.client is None:
|
||||
raise ConnectorMissingCredentialError("WebDAV client not initialized")
|
||||
|
||||
start_datetime = datetime.fromtimestamp(start, tz=timezone.utc)
|
||||
end_datetime = datetime.fromtimestamp(end, tz=timezone.utc)
|
||||
|
||||
for batch in self._yield_webdav_documents(start_datetime, end_datetime):
|
||||
yield batch
|
||||
|
||||
def validate_connector_settings(self) -> None:
|
||||
"""Validate WebDAV connector settings
|
||||
|
||||
Raises:
|
||||
ConnectorMissingCredentialError: If credentials are not loaded
|
||||
ConnectorValidationError: If settings are invalid
|
||||
"""
|
||||
if self.client is None:
|
||||
raise ConnectorMissingCredentialError(
|
||||
"WebDAV credentials not loaded."
|
||||
)
|
||||
|
||||
if not self.base_url:
|
||||
raise ConnectorValidationError(
|
||||
"No base URL was provided in connector settings."
|
||||
)
|
||||
|
||||
try:
|
||||
if not self.client.exists(self.remote_path):
|
||||
raise ConnectorValidationError(
|
||||
f"Remote path '{self.remote_path}' does not exist on WebDAV server."
|
||||
)
|
||||
|
||||
except Exception as e:
|
||||
error_message = str(e)
|
||||
|
||||
if "401" in error_message or "unauthorized" in error_message.lower():
|
||||
raise CredentialExpiredError(
|
||||
"WebDAV credentials appear invalid or expired."
|
||||
)
|
||||
|
||||
if "403" in error_message or "forbidden" in error_message.lower():
|
||||
raise InsufficientPermissionsError(
|
||||
f"Insufficient permissions to access path '{self.remote_path}' on WebDAV server."
|
||||
)
|
||||
|
||||
if "404" in error_message or "not found" in error_message.lower():
|
||||
raise ConnectorValidationError(
|
||||
f"Remote path '{self.remote_path}' does not exist on WebDAV server."
|
||||
)
|
||||
|
||||
raise ConnectorValidationError(
|
||||
f"Unexpected WebDAV client error: {e}"
|
||||
)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
credentials_dict = {
|
||||
"username": os.environ.get("WEBDAV_USERNAME"),
|
||||
"password": os.environ.get("WEBDAV_PASSWORD"),
|
||||
}
|
||||
|
||||
connector = WebDAVConnector(
|
||||
base_url=os.environ.get("WEBDAV_URL") or "https://webdav.example.com",
|
||||
remote_path=os.environ.get("WEBDAV_PATH") or "/",
|
||||
)
|
||||
|
||||
try:
|
||||
connector.load_credentials(credentials_dict)
|
||||
connector.validate_connector_settings()
|
||||
|
||||
document_batch_generator = connector.load_from_state()
|
||||
for document_batch in document_batch_generator:
|
||||
print("First batch of documents:")
|
||||
for doc in document_batch:
|
||||
print(f"Document ID: {doc.id}")
|
||||
print(f"Semantic Identifier: {doc.semantic_identifier}")
|
||||
print(f"Source: {doc.source}")
|
||||
print(f"Updated At: {doc.doc_updated_at}")
|
||||
print("---")
|
||||
break
|
||||
|
||||
except ConnectorMissingCredentialError as e:
|
||||
print(f"Error: {e}")
|
||||
except Exception as e:
|
||||
print(f"An unexpected error occurred: {e}")
|
||||
@ -27,6 +27,7 @@ from common.constants import SVR_QUEUE_NAME, Storage
|
||||
import rag.utils
|
||||
import rag.utils.es_conn
|
||||
import rag.utils.infinity_conn
|
||||
import rag.utils.ob_conn
|
||||
import rag.utils.opensearch_conn
|
||||
from rag.utils.azure_sas_conn import RAGFlowAzureSasBlob
|
||||
from rag.utils.azure_spn_conn import RAGFlowAzureSpnBlob
|
||||
@ -73,6 +74,8 @@ GITHUB_OAUTH = None
|
||||
FEISHU_OAUTH = None
|
||||
OAUTH_CONFIG = None
|
||||
DOC_ENGINE = os.getenv('DOC_ENGINE', 'elasticsearch')
|
||||
DOC_ENGINE_INFINITY = (DOC_ENGINE.lower() == "infinity")
|
||||
|
||||
|
||||
docStoreConn = None
|
||||
|
||||
@ -103,6 +106,7 @@ INFINITY = {}
|
||||
AZURE = {}
|
||||
S3 = {}
|
||||
MINIO = {}
|
||||
OB = {}
|
||||
OSS = {}
|
||||
OS = {}
|
||||
|
||||
@ -137,7 +141,7 @@ def _get_or_create_secret_key():
|
||||
import logging
|
||||
|
||||
new_key = secrets.token_hex(32)
|
||||
logging.warning(f"SECURITY WARNING: Using auto-generated SECRET_KEY. Generated key: {new_key}")
|
||||
logging.warning("SECURITY WARNING: Using auto-generated SECRET_KEY.")
|
||||
return new_key
|
||||
|
||||
class StorageFactory:
|
||||
@ -227,9 +231,9 @@ def init_settings():
|
||||
FEISHU_OAUTH = get_base_config("oauth", {}).get("feishu")
|
||||
OAUTH_CONFIG = get_base_config("oauth", {})
|
||||
|
||||
global DOC_ENGINE, docStoreConn, ES, OS, INFINITY
|
||||
global DOC_ENGINE, DOC_ENGINE_INFINITY, docStoreConn, ES, OB, OS, INFINITY
|
||||
DOC_ENGINE = os.environ.get("DOC_ENGINE", "elasticsearch")
|
||||
# DOC_ENGINE = os.environ.get('DOC_ENGINE', "opensearch")
|
||||
DOC_ENGINE_INFINITY = (DOC_ENGINE.lower() == "infinity")
|
||||
lower_case_doc_engine = DOC_ENGINE.lower()
|
||||
if lower_case_doc_engine == "elasticsearch":
|
||||
ES = get_base_config("es", {})
|
||||
@ -240,6 +244,9 @@ def init_settings():
|
||||
elif lower_case_doc_engine == "opensearch":
|
||||
OS = get_base_config("os", {})
|
||||
docStoreConn = rag.utils.opensearch_conn.OSConnection()
|
||||
elif lower_case_doc_engine == "oceanbase":
|
||||
OB = get_base_config("oceanbase", {})
|
||||
docStoreConn = rag.utils.ob_conn.OBConnection()
|
||||
else:
|
||||
raise Exception(f"Not supported doc engine: {DOC_ENGINE}")
|
||||
|
||||
|
||||
@ -35,6 +35,12 @@ def num_tokens_from_string(string: str) -> int:
|
||||
return 0
|
||||
|
||||
def total_token_count_from_response(resp):
|
||||
"""
|
||||
Extract token count from LLM response in various formats.
|
||||
|
||||
Handles None responses and different response structures from various LLM providers.
|
||||
Returns 0 if token count cannot be determined.
|
||||
"""
|
||||
if resp is None:
|
||||
return 0
|
||||
|
||||
@ -50,19 +56,19 @@ def total_token_count_from_response(resp):
|
||||
except Exception:
|
||||
pass
|
||||
|
||||
if 'usage' in resp and 'total_tokens' in resp['usage']:
|
||||
if isinstance(resp, dict) and 'usage' in resp and 'total_tokens' in resp['usage']:
|
||||
try:
|
||||
return resp["usage"]["total_tokens"]
|
||||
except Exception:
|
||||
pass
|
||||
|
||||
if 'usage' in resp and 'input_tokens' in resp['usage'] and 'output_tokens' in resp['usage']:
|
||||
if isinstance(resp, dict) and 'usage' in resp and 'input_tokens' in resp['usage'] and 'output_tokens' in resp['usage']:
|
||||
try:
|
||||
return resp["usage"]["input_tokens"] + resp["usage"]["output_tokens"]
|
||||
except Exception:
|
||||
pass
|
||||
|
||||
if 'meta' in resp and 'tokens' in resp['meta'] and 'input_tokens' in resp['meta']['tokens'] and 'output_tokens' in resp['meta']['tokens']:
|
||||
if isinstance(resp, dict) and 'meta' in resp and 'tokens' in resp['meta'] and 'input_tokens' in resp['meta']['tokens'] and 'output_tokens' in resp['meta']['tokens']:
|
||||
try:
|
||||
return resp["meta"]["tokens"]["input_tokens"] + resp["meta"]["tokens"]["output_tokens"]
|
||||
except Exception:
|
||||
|
||||
@ -5,20 +5,13 @@
|
||||
"create_time": {"type": "varchar", "default": ""},
|
||||
"create_timestamp_flt": {"type": "float", "default": 0.0},
|
||||
"img_id": {"type": "varchar", "default": ""},
|
||||
"docnm_kwd": {"type": "varchar", "default": ""},
|
||||
"title_tks": {"type": "varchar", "default": "", "analyzer": "whitespace"},
|
||||
"title_sm_tks": {"type": "varchar", "default": "", "analyzer": "whitespace"},
|
||||
"docnm": {"type": "varchar", "default": "", "analyzer": ["rag-coarse", "rag-fine"], "comment": "docnm_kwd, title_tks, title_sm_tks"},
|
||||
"name_kwd": {"type": "varchar", "default": "", "analyzer": "whitespace-#"},
|
||||
"important_kwd": {"type": "varchar", "default": "", "analyzer": "whitespace-#"},
|
||||
"tag_kwd": {"type": "varchar", "default": "", "analyzer": "whitespace-#"},
|
||||
"important_tks": {"type": "varchar", "default": "", "analyzer": "whitespace"},
|
||||
"question_kwd": {"type": "varchar", "default": "", "analyzer": "whitespace-#"},
|
||||
"question_tks": {"type": "varchar", "default": "", "analyzer": "whitespace"},
|
||||
"content_with_weight": {"type": "varchar", "default": ""},
|
||||
"content_ltks": {"type": "varchar", "default": "", "analyzer": "whitespace"},
|
||||
"content_sm_ltks": {"type": "varchar", "default": "", "analyzer": "whitespace"},
|
||||
"authors_tks": {"type": "varchar", "default": "", "analyzer": "whitespace"},
|
||||
"authors_sm_tks": {"type": "varchar", "default": "", "analyzer": "whitespace"},
|
||||
"important_keywords": {"type": "varchar", "default": "", "analyzer": ["rag-coarse", "rag-fine"], "comment": "important_kwd, important_tks"},
|
||||
"questions": {"type": "varchar", "default": "", "analyzer": ["rag-coarse", "rag-fine"], "comment": "question_kwd, question_tks"},
|
||||
"content": {"type": "varchar", "default": "", "analyzer": ["rag-coarse", "rag-fine"], "comment": "content_with_weight, content_ltks, content_sm_ltks"},
|
||||
"authors": {"type": "varchar", "default": "", "analyzer": ["rag-coarse", "rag-fine"], "comment": "authors_tks, authors_sm_tks"},
|
||||
"page_num_int": {"type": "varchar", "default": ""},
|
||||
"top_int": {"type": "varchar", "default": ""},
|
||||
"position_int": {"type": "varchar", "default": ""},
|
||||
|
||||
@ -7,6 +7,20 @@
|
||||
"status": "1",
|
||||
"rank": "999",
|
||||
"llm": [
|
||||
{
|
||||
"llm_name": "gpt-5.1",
|
||||
"tags": "LLM,CHAT,400k,IMAGE2TEXT",
|
||||
"max_tokens": 400000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "gpt-5.1-chat-latest",
|
||||
"tags": "LLM,CHAT,400k,IMAGE2TEXT",
|
||||
"max_tokens": 400000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "gpt-5",
|
||||
"tags": "LLM,CHAT,400k,IMAGE2TEXT",
|
||||
@ -3218,6 +3232,13 @@
|
||||
"status": "1",
|
||||
"rank": "990",
|
||||
"llm": [
|
||||
{
|
||||
"llm_name": "claude-opus-4-5-20251101",
|
||||
"tags": "LLM,CHAT,IMAGE2TEXT,200k",
|
||||
"max_tokens": 204800,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "claude-opus-4-1-20250805",
|
||||
"tags": "LLM,CHAT,IMAGE2TEXT,200k",
|
||||
|
||||
@ -28,6 +28,14 @@ os:
|
||||
infinity:
|
||||
uri: 'localhost:23817'
|
||||
db_name: 'default_db'
|
||||
oceanbase:
|
||||
scheme: 'oceanbase' # set 'mysql' to create connection using mysql config
|
||||
config:
|
||||
db_name: 'test'
|
||||
user: 'root@ragflow'
|
||||
password: 'infini_rag_flow'
|
||||
host: 'localhost'
|
||||
port: 2881
|
||||
redis:
|
||||
db: 1
|
||||
password: 'infini_rag_flow'
|
||||
@ -139,5 +147,3 @@ user_default_llm:
|
||||
# secret_id: 'tencent_secret_id'
|
||||
# secret_key: 'tencent_secret_key'
|
||||
# region: 'tencent_region'
|
||||
# table_result_type: '1'
|
||||
# markdown_image_response_type: '1'
|
||||
|
||||
@ -187,7 +187,7 @@ class DoclingParser(RAGFlowPdfParser):
|
||||
bbox = _BBox(int(pn), bb[0], bb[1], bb[2], bb[3])
|
||||
yield (DoclingContentType.EQUATION.value, text, bbox)
|
||||
|
||||
def _transfer_to_sections(self, doc) -> list[tuple[str, str]]:
|
||||
def _transfer_to_sections(self, doc, parse_method: str) -> list[tuple[str, str]]:
|
||||
sections: list[tuple[str, str]] = []
|
||||
for typ, payload, bbox in self._iter_doc_items(doc):
|
||||
if typ == DoclingContentType.TEXT.value:
|
||||
@ -200,7 +200,12 @@ class DoclingParser(RAGFlowPdfParser):
|
||||
continue
|
||||
|
||||
tag = self._make_line_tag(bbox) if isinstance(bbox,_BBox) else ""
|
||||
sections.append((section, tag))
|
||||
if parse_method == "manual":
|
||||
sections.append((section, typ, tag))
|
||||
elif parse_method == "paper":
|
||||
sections.append((section + tag, typ))
|
||||
else:
|
||||
sections.append((section, tag))
|
||||
return sections
|
||||
|
||||
def cropout_docling_table(self, page_no: int, bbox: tuple[float, float, float, float], zoomin: int = 1):
|
||||
@ -282,7 +287,8 @@ class DoclingParser(RAGFlowPdfParser):
|
||||
output_dir: Optional[str] = None,
|
||||
lang: Optional[str] = None,
|
||||
method: str = "auto",
|
||||
delete_output: bool = True,
|
||||
delete_output: bool = True,
|
||||
parse_method: str = "raw"
|
||||
):
|
||||
|
||||
if not self.check_installation():
|
||||
@ -318,7 +324,7 @@ class DoclingParser(RAGFlowPdfParser):
|
||||
if callback:
|
||||
callback(0.7, f"[Docling] Parsed doc: {getattr(doc, 'num_pages', 'n/a')} pages")
|
||||
|
||||
sections = self._transfer_to_sections(doc)
|
||||
sections = self._transfer_to_sections(doc, parse_method=parse_method)
|
||||
tables = self._transfer_to_tables(doc)
|
||||
|
||||
if callback:
|
||||
|
||||
@ -138,7 +138,6 @@ class RAGFlowHtmlParser:
|
||||
"metadata": {"table_id": table_id, "index": table_list.index(t)}})
|
||||
return table_info_list
|
||||
else:
|
||||
block_id = None
|
||||
if str.lower(element.name) in BLOCK_TAGS:
|
||||
block_id = str(uuid.uuid1())
|
||||
for child in element.children:
|
||||
@ -172,7 +171,7 @@ class RAGFlowHtmlParser:
|
||||
if tag_name == "table":
|
||||
table_info_list.append(item)
|
||||
else:
|
||||
current_content += (" " if current_content else "" + content)
|
||||
current_content += (" " if current_content else "") + content
|
||||
if current_content:
|
||||
block_content.append(current_content)
|
||||
return block_content, table_info_list
|
||||
|
||||
@ -72,9 +72,8 @@ class RAGFlowMarkdownParser:
|
||||
|
||||
# Replace any TAGS e.g. <table ...> to <table>
|
||||
TAGS = ["table", "td", "tr", "th", "tbody", "thead", "div"]
|
||||
table_with_attributes_pattern = re.compile(
|
||||
rf"<(?:{'|'.join(TAGS)})[^>]*>", re.IGNORECASE
|
||||
)
|
||||
table_with_attributes_pattern = re.compile(rf"<(?:{'|'.join(TAGS)})[^>]*>", re.IGNORECASE)
|
||||
|
||||
def replace_tag(m):
|
||||
tag_name = re.match(r"<(\w+)", m.group()).group(1)
|
||||
return "<{}>".format(tag_name)
|
||||
@ -128,23 +127,48 @@ class MarkdownElementExtractor:
|
||||
self.markdown_content = markdown_content
|
||||
self.lines = markdown_content.split("\n")
|
||||
|
||||
def get_delimiters(self,delimiters):
|
||||
def get_delimiters(self, delimiters):
|
||||
toks = re.findall(r"`([^`]+)`", delimiters)
|
||||
toks = sorted(set(toks), key=lambda x: -len(x))
|
||||
return "|".join(re.escape(t) for t in toks if t)
|
||||
|
||||
def extract_elements(self,delimiter=None):
|
||||
|
||||
def extract_elements(self, delimiter=None, include_meta=False):
|
||||
"""Extract individual elements (headers, code blocks, lists, etc.)"""
|
||||
sections = []
|
||||
|
||||
i = 0
|
||||
dels=""
|
||||
dels = ""
|
||||
if delimiter:
|
||||
dels = self.get_delimiters(delimiter)
|
||||
if len(dels) > 0:
|
||||
text = "\n".join(self.lines)
|
||||
parts = re.split(dels, text)
|
||||
sections = [p.strip() for p in parts if p and p.strip()]
|
||||
if include_meta:
|
||||
pattern = re.compile(dels)
|
||||
last_end = 0
|
||||
for m in pattern.finditer(text):
|
||||
part = text[last_end : m.start()]
|
||||
if part and part.strip():
|
||||
sections.append(
|
||||
{
|
||||
"content": part.strip(),
|
||||
"start_line": text.count("\n", 0, last_end),
|
||||
"end_line": text.count("\n", 0, m.start()),
|
||||
}
|
||||
)
|
||||
last_end = m.end()
|
||||
|
||||
part = text[last_end:]
|
||||
if part and part.strip():
|
||||
sections.append(
|
||||
{
|
||||
"content": part.strip(),
|
||||
"start_line": text.count("\n", 0, last_end),
|
||||
"end_line": text.count("\n", 0, len(text)),
|
||||
}
|
||||
)
|
||||
else:
|
||||
parts = re.split(dels, text)
|
||||
sections = [p.strip() for p in parts if p and p.strip()]
|
||||
return sections
|
||||
while i < len(self.lines):
|
||||
line = self.lines[i]
|
||||
@ -152,32 +176,35 @@ class MarkdownElementExtractor:
|
||||
if re.match(r"^#{1,6}\s+.*$", line):
|
||||
# header
|
||||
element = self._extract_header(i)
|
||||
sections.append(element["content"])
|
||||
sections.append(element if include_meta else element["content"])
|
||||
i = element["end_line"] + 1
|
||||
elif line.strip().startswith("```"):
|
||||
# code block
|
||||
element = self._extract_code_block(i)
|
||||
sections.append(element["content"])
|
||||
sections.append(element if include_meta else element["content"])
|
||||
i = element["end_line"] + 1
|
||||
elif re.match(r"^\s*[-*+]\s+.*$", line) or re.match(r"^\s*\d+\.\s+.*$", line):
|
||||
# list block
|
||||
element = self._extract_list_block(i)
|
||||
sections.append(element["content"])
|
||||
sections.append(element if include_meta else element["content"])
|
||||
i = element["end_line"] + 1
|
||||
elif line.strip().startswith(">"):
|
||||
# blockquote
|
||||
element = self._extract_blockquote(i)
|
||||
sections.append(element["content"])
|
||||
sections.append(element if include_meta else element["content"])
|
||||
i = element["end_line"] + 1
|
||||
elif line.strip():
|
||||
# text block (paragraphs and inline elements until next block element)
|
||||
element = self._extract_text_block(i)
|
||||
sections.append(element["content"])
|
||||
sections.append(element if include_meta else element["content"])
|
||||
i = element["end_line"] + 1
|
||||
else:
|
||||
i += 1
|
||||
|
||||
sections = [section for section in sections if section.strip()]
|
||||
if include_meta:
|
||||
sections = [section for section in sections if section["content"].strip()]
|
||||
else:
|
||||
sections = [section for section in sections if section.strip()]
|
||||
return sections
|
||||
|
||||
def _extract_header(self, start_pos):
|
||||
|
||||
@ -476,7 +476,7 @@ class MinerUParser(RAGFlowPdfParser):
|
||||
item[key] = str((subdir / item[key]).resolve())
|
||||
return data
|
||||
|
||||
def _transfer_to_sections(self, outputs: list[dict[str, Any]]):
|
||||
def _transfer_to_sections(self, outputs: list[dict[str, Any]], parse_method: str = None):
|
||||
sections = []
|
||||
for output in outputs:
|
||||
match output["type"]:
|
||||
@ -497,7 +497,11 @@ class MinerUParser(RAGFlowPdfParser):
|
||||
case MinerUContentType.DISCARDED:
|
||||
pass
|
||||
|
||||
if section:
|
||||
if section and parse_method == "manual":
|
||||
sections.append((section, output["type"], self._line_tag(output)))
|
||||
elif section and parse_method == "paper":
|
||||
sections.append((section + self._line_tag(output), output["type"]))
|
||||
else:
|
||||
sections.append((section, self._line_tag(output)))
|
||||
return sections
|
||||
|
||||
@ -516,6 +520,7 @@ class MinerUParser(RAGFlowPdfParser):
|
||||
method: str = "auto",
|
||||
server_url: Optional[str] = None,
|
||||
delete_output: bool = True,
|
||||
parse_method: str = "raw"
|
||||
) -> tuple:
|
||||
import shutil
|
||||
|
||||
@ -565,7 +570,8 @@ class MinerUParser(RAGFlowPdfParser):
|
||||
self.logger.info(f"[MinerU] Parsed {len(outputs)} blocks from PDF.")
|
||||
if callback:
|
||||
callback(0.75, f"[MinerU] Parsed {len(outputs)} blocks from PDF.")
|
||||
return self._transfer_to_sections(outputs), self._transfer_to_tables(outputs)
|
||||
|
||||
return self._transfer_to_sections(outputs, parse_method), self._transfer_to_tables(outputs)
|
||||
finally:
|
||||
if temp_pdf and temp_pdf.exists():
|
||||
try:
|
||||
|
||||
@ -33,6 +33,8 @@ import xgboost as xgb
|
||||
from huggingface_hub import snapshot_download
|
||||
from PIL import Image
|
||||
from pypdf import PdfReader as pdf2_read
|
||||
from sklearn.cluster import KMeans
|
||||
from sklearn.metrics import silhouette_score
|
||||
|
||||
from common.file_utils import get_project_base_directory
|
||||
from common.misc_utils import pip_install_torch
|
||||
@ -353,7 +355,6 @@ class RAGFlowPdfParser:
|
||||
def _assign_column(self, boxes, zoomin=3):
|
||||
if not boxes:
|
||||
return boxes
|
||||
|
||||
if all("col_id" in b for b in boxes):
|
||||
return boxes
|
||||
|
||||
@ -361,61 +362,79 @@ class RAGFlowPdfParser:
|
||||
for b in boxes:
|
||||
by_page[b["page_number"]].append(b)
|
||||
|
||||
page_info = {} # pg -> dict(page_w, left_edge, cand_cols)
|
||||
counter = Counter()
|
||||
page_cols = {}
|
||||
|
||||
for pg, bxs in by_page.items():
|
||||
if not bxs:
|
||||
page_info[pg] = {"page_w": 1.0, "left_edge": 0.0, "cand": 1}
|
||||
counter[1] += 1
|
||||
page_cols[pg] = 1
|
||||
continue
|
||||
|
||||
if hasattr(self, "page_images") and self.page_images and len(self.page_images) >= pg:
|
||||
page_w = self.page_images[pg - 1].size[0] / max(1, zoomin)
|
||||
left_edge = 0.0
|
||||
else:
|
||||
xs0 = [box["x0"] for box in bxs]
|
||||
xs1 = [box["x1"] for box in bxs]
|
||||
left_edge = float(min(xs0))
|
||||
page_w = max(1.0, float(max(xs1) - left_edge))
|
||||
x0s_raw = np.array([b["x0"] for b in bxs], dtype=float)
|
||||
|
||||
widths = [max(1.0, (box["x1"] - box["x0"])) for box in bxs]
|
||||
median_w = float(np.median(widths)) if widths else 1.0
|
||||
min_x0 = np.min(x0s_raw)
|
||||
max_x1 = np.max([b["x1"] for b in bxs])
|
||||
width = max_x1 - min_x0
|
||||
|
||||
raw_cols = int(page_w / max(1.0, median_w))
|
||||
INDENT_TOL = width * 0.12
|
||||
x0s = []
|
||||
for x in x0s_raw:
|
||||
if abs(x - min_x0) < INDENT_TOL:
|
||||
x0s.append([min_x0])
|
||||
else:
|
||||
x0s.append([x])
|
||||
x0s = np.array(x0s, dtype=float)
|
||||
|
||||
max_try = min(4, len(bxs))
|
||||
if max_try < 2:
|
||||
max_try = 1
|
||||
best_k = 1
|
||||
best_score = -1
|
||||
|
||||
# cand = raw_cols if (raw_cols >= 2 and median_w < page_w / raw_cols * 0.8) else 1
|
||||
cand = raw_cols
|
||||
for k in range(1, max_try + 1):
|
||||
km = KMeans(n_clusters=k, n_init="auto")
|
||||
labels = km.fit_predict(x0s)
|
||||
|
||||
page_info[pg] = {"page_w": page_w, "left_edge": left_edge, "cand": cand}
|
||||
counter[cand] += 1
|
||||
centers = np.sort(km.cluster_centers_.flatten())
|
||||
if len(centers) > 1:
|
||||
try:
|
||||
score = silhouette_score(x0s, labels)
|
||||
except ValueError:
|
||||
continue
|
||||
else:
|
||||
score = 0
|
||||
if score > best_score:
|
||||
best_score = score
|
||||
best_k = k
|
||||
|
||||
logging.info(f"[Page {pg}] median_w={median_w:.2f}, page_w={page_w:.2f}, raw_cols={raw_cols}, cand={cand}")
|
||||
page_cols[pg] = best_k
|
||||
logging.info(f"[Page {pg}] best_score={best_score:.2f}, best_k={best_k}")
|
||||
|
||||
global_cols = counter.most_common(1)[0][0]
|
||||
|
||||
global_cols = Counter(page_cols.values()).most_common(1)[0][0]
|
||||
logging.info(f"Global column_num decided by majority: {global_cols}")
|
||||
|
||||
|
||||
for pg, bxs in by_page.items():
|
||||
if not bxs:
|
||||
continue
|
||||
k = page_cols[pg]
|
||||
if len(bxs) < k:
|
||||
k = 1
|
||||
x0s = np.array([[b["x0"]] for b in bxs], dtype=float)
|
||||
km = KMeans(n_clusters=k, n_init="auto")
|
||||
labels = km.fit_predict(x0s)
|
||||
|
||||
page_w = page_info[pg]["page_w"]
|
||||
left_edge = page_info[pg]["left_edge"]
|
||||
centers = km.cluster_centers_.flatten()
|
||||
order = np.argsort(centers)
|
||||
|
||||
if global_cols == 1:
|
||||
for box in bxs:
|
||||
box["col_id"] = 0
|
||||
continue
|
||||
remap = {orig: new for new, orig in enumerate(order)}
|
||||
|
||||
for box in bxs:
|
||||
w = box["x1"] - box["x0"]
|
||||
if w >= 0.8 * page_w:
|
||||
box["col_id"] = 0
|
||||
continue
|
||||
cx = 0.5 * (box["x0"] + box["x1"])
|
||||
norm_cx = (cx - left_edge) / page_w
|
||||
norm_cx = max(0.0, min(norm_cx, 0.999999))
|
||||
box["col_id"] = int(min(global_cols - 1, norm_cx * global_cols))
|
||||
for b, lb in zip(bxs, labels):
|
||||
b["col_id"] = remap[lb]
|
||||
|
||||
grouped = defaultdict(list)
|
||||
for b in bxs:
|
||||
grouped[b["col_id"]].append(b)
|
||||
|
||||
return boxes
|
||||
|
||||
@ -1071,7 +1090,7 @@ class RAGFlowPdfParser:
|
||||
|
||||
logging.debug("Images converted.")
|
||||
self.is_english = [
|
||||
re.search(r"[a-zA-Z0-9,/¸;:'\[\]\(\)!@#$%^&*\"?<>._-]{30,}", "".join(random.choices([c["text"] for c in self.page_chars[i]], k=min(100, len(self.page_chars[i])))))
|
||||
re.search(r"[ a-zA-Z0-9,/¸;:'\[\]\(\)!@#$%^&*\"?<>._-]{30,}", "".join(random.choices([c["text"] for c in self.page_chars[i]], k=min(100, len(self.page_chars[i])))))
|
||||
for i in range(len(self.page_chars))
|
||||
]
|
||||
if sum([1 if e else 0 for e in self.is_english]) > len(self.page_images) / 2:
|
||||
@ -1128,7 +1147,7 @@ class RAGFlowPdfParser:
|
||||
|
||||
if not self.is_english and not any([c for c in self.page_chars]) and self.boxes:
|
||||
bxes = [b for bxs in self.boxes for b in bxs]
|
||||
self.is_english = re.search(r"[\na-zA-Z0-9,/¸;:'\[\]\(\)!@#$%^&*\"?<>._-]{30,}", "".join([b["text"] for b in random.choices(bxes, k=min(30, len(bxes)))]))
|
||||
self.is_english = re.search(r"[ \na-zA-Z0-9,/¸;:'\[\]\(\)!@#$%^&*\"?<>._-]{30,}", "".join([b["text"] for b in random.choices(bxes, k=min(30, len(bxes)))]))
|
||||
|
||||
logging.debug(f"Is it English: {self.is_english}")
|
||||
|
||||
@ -1303,7 +1322,10 @@ class RAGFlowPdfParser:
|
||||
|
||||
positions = []
|
||||
for ii, (pns, left, right, top, bottom) in enumerate(poss):
|
||||
right = left + max_width
|
||||
if 0 < ii < len(poss) - 1:
|
||||
right = max(left + 10, right)
|
||||
else:
|
||||
right = left + max_width
|
||||
bottom *= ZM
|
||||
for pn in pns[1:]:
|
||||
if 0 <= pn - 1 < page_count:
|
||||
|
||||
@ -192,12 +192,16 @@ class TencentCloudAPIClient:
|
||||
|
||||
|
||||
class TCADPParser(RAGFlowPdfParser):
|
||||
def __init__(self, secret_id: str = None, secret_key: str = None, region: str = "ap-guangzhou"):
|
||||
def __init__(self, secret_id: str = None, secret_key: str = None, region: str = "ap-guangzhou",
|
||||
table_result_type: str = None, markdown_image_response_type: str = None):
|
||||
super().__init__()
|
||||
|
||||
# First initialize logger
|
||||
self.logger = logging.getLogger(self.__class__.__name__)
|
||||
|
||||
# Log received parameters
|
||||
self.logger.info(f"[TCADP] Initializing with parameters - table_result_type: {table_result_type}, markdown_image_response_type: {markdown_image_response_type}")
|
||||
|
||||
# Priority: read configuration from RAGFlow configuration system (service_conf.yaml)
|
||||
try:
|
||||
tcadp_parser = get_base_config("tcadp_config", {})
|
||||
@ -205,14 +209,30 @@ class TCADPParser(RAGFlowPdfParser):
|
||||
self.secret_id = secret_id or tcadp_parser.get("secret_id")
|
||||
self.secret_key = secret_key or tcadp_parser.get("secret_key")
|
||||
self.region = region or tcadp_parser.get("region", "ap-guangzhou")
|
||||
self.table_result_type = tcadp_parser.get("table_result_type", "1")
|
||||
self.markdown_image_response_type = tcadp_parser.get("markdown_image_response_type", "1")
|
||||
self.logger.info("[TCADP] Configuration read from service_conf.yaml")
|
||||
# Set table_result_type and markdown_image_response_type from config or parameters
|
||||
self.table_result_type = table_result_type if table_result_type is not None else tcadp_parser.get("table_result_type", "1")
|
||||
self.markdown_image_response_type = markdown_image_response_type if markdown_image_response_type is not None else tcadp_parser.get("markdown_image_response_type", "1")
|
||||
|
||||
else:
|
||||
self.logger.error("[TCADP] Please configure tcadp_config in service_conf.yaml first")
|
||||
# If config file is empty, use provided parameters or defaults
|
||||
self.secret_id = secret_id
|
||||
self.secret_key = secret_key
|
||||
self.region = region or "ap-guangzhou"
|
||||
self.table_result_type = table_result_type if table_result_type is not None else "1"
|
||||
self.markdown_image_response_type = markdown_image_response_type if markdown_image_response_type is not None else "1"
|
||||
|
||||
except ImportError:
|
||||
self.logger.info("[TCADP] Configuration module import failed")
|
||||
# If config file is not available, use provided parameters or defaults
|
||||
self.secret_id = secret_id
|
||||
self.secret_key = secret_key
|
||||
self.region = region or "ap-guangzhou"
|
||||
self.table_result_type = table_result_type if table_result_type is not None else "1"
|
||||
self.markdown_image_response_type = markdown_image_response_type if markdown_image_response_type is not None else "1"
|
||||
|
||||
# Log final values
|
||||
self.logger.info(f"[TCADP] Final values - table_result_type: {self.table_result_type}, markdown_image_response_type: {self.markdown_image_response_type}")
|
||||
|
||||
if not self.secret_id or not self.secret_key:
|
||||
raise ValueError("[TCADP] Please set Tencent Cloud API keys, configure tcadp_config in service_conf.yaml")
|
||||
@ -400,6 +420,8 @@ class TCADPParser(RAGFlowPdfParser):
|
||||
"TableResultType": self.table_result_type,
|
||||
"MarkdownImageResponseType": self.markdown_image_response_type
|
||||
}
|
||||
|
||||
self.logger.info(f"[TCADP] API request config - TableResultType: {self.table_result_type}, MarkdownImageResponseType: {self.markdown_image_response_type}")
|
||||
|
||||
result = client.reconstruct_document_sse(
|
||||
file_type=file_type,
|
||||
|
||||
@ -17,7 +17,7 @@
|
||||
import logging
|
||||
import math
|
||||
import os
|
||||
import re
|
||||
# import re
|
||||
from collections import Counter
|
||||
from copy import deepcopy
|
||||
|
||||
@ -62,8 +62,9 @@ class LayoutRecognizer(Recognizer):
|
||||
|
||||
def __call__(self, image_list, ocr_res, scale_factor=3, thr=0.2, batch_size=16, drop=True):
|
||||
def __is_garbage(b):
|
||||
patt = [r"^•+$", "^[0-9]{1,2} / ?[0-9]{1,2}$", r"^[0-9]{1,2} of [0-9]{1,2}$", "^http://[^ ]{12,}", "\\(cid *: *[0-9]+ *\\)"]
|
||||
return any([re.search(p, b["text"]) for p in patt])
|
||||
return False
|
||||
# patt = [r"^•+$", "^[0-9]{1,2} / ?[0-9]{1,2}$", r"^[0-9]{1,2} of [0-9]{1,2}$", "^http://[^ ]{12,}", "\\(cid *: *[0-9]+ *\\)"]
|
||||
# return any([re.search(p, b["text"]) for p in patt])
|
||||
|
||||
if self.client:
|
||||
layouts = self.client.predict(image_list)
|
||||
|
||||
31
docker/.env
31
docker/.env
@ -7,6 +7,7 @@
|
||||
# Available options:
|
||||
# - `elasticsearch` (default)
|
||||
# - `infinity` (https://github.com/infiniflow/infinity)
|
||||
# - `oceanbase` (https://github.com/oceanbase/oceanbase)
|
||||
# - `opensearch` (https://github.com/opensearch-project/OpenSearch)
|
||||
DOC_ENGINE=${DOC_ENGINE:-elasticsearch}
|
||||
|
||||
@ -62,6 +63,27 @@ INFINITY_THRIFT_PORT=23817
|
||||
INFINITY_HTTP_PORT=23820
|
||||
INFINITY_PSQL_PORT=5432
|
||||
|
||||
# The hostname where the OceanBase service is exposed
|
||||
OCEANBASE_HOST=oceanbase
|
||||
# The port used to expose the OceanBase service
|
||||
OCEANBASE_PORT=2881
|
||||
# The username for OceanBase
|
||||
OCEANBASE_USER=root@ragflow
|
||||
# The password for OceanBase
|
||||
OCEANBASE_PASSWORD=infini_rag_flow
|
||||
# The doc database of the OceanBase service to use
|
||||
OCEANBASE_DOC_DBNAME=ragflow_doc
|
||||
|
||||
# OceanBase container configuration
|
||||
OB_CLUSTER_NAME=${OB_CLUSTER_NAME:-ragflow}
|
||||
OB_TENANT_NAME=${OB_TENANT_NAME:-ragflow}
|
||||
OB_SYS_PASSWORD=${OCEANBASE_PASSWORD:-infini_rag_flow}
|
||||
OB_TENANT_PASSWORD=${OCEANBASE_PASSWORD:-infini_rag_flow}
|
||||
OB_MEMORY_LIMIT=${OB_MEMORY_LIMIT:-10G}
|
||||
OB_SYSTEM_MEMORY=${OB_SYSTEM_MEMORY:-2G}
|
||||
OB_DATAFILE_SIZE=${OB_DATAFILE_SIZE:-20G}
|
||||
OB_LOG_DISK_SIZE=${OB_LOG_DISK_SIZE:-20G}
|
||||
|
||||
# The password for MySQL.
|
||||
MYSQL_PASSWORD=infini_rag_flow
|
||||
# The hostname where the MySQL service is exposed
|
||||
@ -208,9 +230,16 @@ REGISTER_ENABLED=1
|
||||
# SANDBOX_MAX_MEMORY=256m # b, k, m, g
|
||||
# SANDBOX_TIMEOUT=10s # s, m, 1m30s
|
||||
|
||||
# Enable DocLing and Mineru
|
||||
# Enable DocLing
|
||||
USE_DOCLING=false
|
||||
|
||||
# Enable Mineru
|
||||
USE_MINERU=false
|
||||
MINERU_EXECUTABLE="$HOME/uv_tools/.venv/bin/mineru"
|
||||
MINERU_DELETE_OUTPUT=0 # keep output directory
|
||||
MINERU_BACKEND=pipeline # or another backend you prefer
|
||||
|
||||
|
||||
|
||||
# pptx support
|
||||
DOTNET_SYSTEM_GLOBALIZATION_INVARIANT=1
|
||||
@ -138,6 +138,15 @@ The [.env](./.env) file contains important environment variables for Docker.
|
||||
- `password`: The password for MinIO.
|
||||
- `host`: The MinIO serving IP *and* port inside the Docker container. Defaults to `minio:9000`.
|
||||
|
||||
- `oceanbase`
|
||||
- `scheme`: The connection scheme. Set to `mysql` to use mysql config, or other values to use config below.
|
||||
- `config`:
|
||||
- `db_name`: The OceanBase database name.
|
||||
- `user`: The username for OceanBase.
|
||||
- `password`: The password for OceanBase.
|
||||
- `host`: The hostname of the OceanBase service.
|
||||
- `port`: The port of OceanBase.
|
||||
|
||||
- `oss`
|
||||
- `access_key`: The access key ID used to authenticate requests to the OSS service.
|
||||
- `secret_key`: The secret access key used to authenticate requests to the OSS service.
|
||||
|
||||
@ -72,7 +72,7 @@ services:
|
||||
infinity:
|
||||
profiles:
|
||||
- infinity
|
||||
image: infiniflow/infinity:v0.6.5
|
||||
image: infiniflow/infinity:v0.6.7
|
||||
volumes:
|
||||
- infinity_data:/var/infinity
|
||||
- ./infinity_conf.toml:/infinity_conf.toml
|
||||
@ -96,6 +96,31 @@ services:
|
||||
retries: 120
|
||||
restart: on-failure
|
||||
|
||||
oceanbase:
|
||||
profiles:
|
||||
- oceanbase
|
||||
image: oceanbase/oceanbase-ce:4.4.1.0-100000032025101610
|
||||
volumes:
|
||||
- ./oceanbase/data:/root/ob
|
||||
- ./oceanbase/conf:/root/.obd/cluster
|
||||
- ./oceanbase/init.d:/root/boot/init.d
|
||||
ports:
|
||||
- ${OCEANBASE_PORT:-2881}:2881
|
||||
env_file: .env
|
||||
environment:
|
||||
- MODE=normal
|
||||
- OB_SERVER_IP=127.0.0.1
|
||||
mem_limit: ${MEM_LIMIT}
|
||||
healthcheck:
|
||||
test: [ 'CMD-SHELL', 'obclient -h127.0.0.1 -P2881 -uroot@${OB_TENANT_NAME:-ragflow} -p${OB_TENANT_PASSWORD:-infini_rag_flow} -e "CREATE DATABASE IF NOT EXISTS ${OCEANBASE_DOC_DBNAME:-ragflow_doc};"' ]
|
||||
interval: 10s
|
||||
retries: 30
|
||||
start_period: 30s
|
||||
timeout: 10s
|
||||
networks:
|
||||
- ragflow
|
||||
restart: on-failure
|
||||
|
||||
sandbox-executor-manager:
|
||||
profiles:
|
||||
- sandbox
|
||||
@ -154,7 +179,7 @@ services:
|
||||
|
||||
minio:
|
||||
image: quay.io/minio/minio:RELEASE.2025-06-13T11-33-47Z
|
||||
command: server --console-address ":9001" /data
|
||||
command: ["server", "--console-address", ":9001", "/data"]
|
||||
ports:
|
||||
- ${MINIO_PORT}:9000
|
||||
- ${MINIO_CONSOLE_PORT}:9001
|
||||
@ -176,7 +201,7 @@ services:
|
||||
redis:
|
||||
# swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/valkey/valkey:8
|
||||
image: valkey/valkey:8
|
||||
command: redis-server --requirepass ${REDIS_PASSWORD} --maxmemory 128mb --maxmemory-policy allkeys-lru
|
||||
command: ["redis-server", "--requirepass", "${REDIS_PASSWORD}", "--maxmemory", "128mb", "--maxmemory-policy", "allkeys-lru"]
|
||||
env_file: .env
|
||||
ports:
|
||||
- ${REDIS_PORT}:6379
|
||||
@ -256,6 +281,8 @@ volumes:
|
||||
driver: local
|
||||
infinity_data:
|
||||
driver: local
|
||||
ob_data:
|
||||
driver: local
|
||||
mysql_data:
|
||||
driver: local
|
||||
minio_data:
|
||||
|
||||
@ -13,6 +13,7 @@ function usage() {
|
||||
echo " --disable-datasync Disables synchronization of datasource workers."
|
||||
echo " --enable-mcpserver Enables the MCP server."
|
||||
echo " --enable-adminserver Enables the Admin server."
|
||||
echo " --init-superuser Initializes the superuser."
|
||||
echo " --consumer-no-beg=<num> Start range for consumers (if using range-based)."
|
||||
echo " --consumer-no-end=<num> End range for consumers (if using range-based)."
|
||||
echo " --workers=<num> Number of task executors to run (if range is not used)."
|
||||
@ -24,6 +25,7 @@ function usage() {
|
||||
echo " $0 --disable-webserver --workers=2 --host-id=myhost123"
|
||||
echo " $0 --enable-mcpserver"
|
||||
echo " $0 --enable-adminserver"
|
||||
echo " $0 --init-superuser"
|
||||
exit 1
|
||||
}
|
||||
|
||||
@ -32,6 +34,7 @@ ENABLE_TASKEXECUTOR=1 # Default to enable task executor
|
||||
ENABLE_DATASYNC=1
|
||||
ENABLE_MCP_SERVER=0
|
||||
ENABLE_ADMIN_SERVER=0 # Default close admin server
|
||||
INIT_SUPERUSER_ARGS="" # Default to not initialize superuser
|
||||
CONSUMER_NO_BEG=0
|
||||
CONSUMER_NO_END=0
|
||||
WORKERS=1
|
||||
@ -83,6 +86,10 @@ for arg in "$@"; do
|
||||
ENABLE_ADMIN_SERVER=1
|
||||
shift
|
||||
;;
|
||||
--init-superuser)
|
||||
INIT_SUPERUSER_ARGS="--init-superuser"
|
||||
shift
|
||||
;;
|
||||
--mcp-host=*)
|
||||
MCP_HOST="${arg#*=}"
|
||||
shift
|
||||
@ -240,7 +247,7 @@ if [[ "${ENABLE_WEBSERVER}" -eq 1 ]]; then
|
||||
|
||||
echo "Starting ragflow_server..."
|
||||
while true; do
|
||||
"$PY" api/ragflow_server.py &
|
||||
"$PY" api/ragflow_server.py ${INIT_SUPERUSER_ARGS} &
|
||||
wait;
|
||||
sleep 1;
|
||||
done &
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
[general]
|
||||
version = "0.6.5"
|
||||
version = "0.6.7"
|
||||
time_zone = "utc-8"
|
||||
|
||||
[network]
|
||||
@ -54,4 +54,3 @@ memindex_memory_quota = "1GB"
|
||||
wal_dir = "/var/infinity/wal"
|
||||
|
||||
[resource]
|
||||
resource_dir = "/var/infinity/resource"
|
||||
|
||||
@ -23,12 +23,12 @@ server {
|
||||
gzip_disable "MSIE [1-6]\.";
|
||||
|
||||
location ~ ^/api/v1/admin {
|
||||
proxy_pass http://ragflow:9381;
|
||||
proxy_pass http://localhost:9381;
|
||||
include proxy.conf;
|
||||
}
|
||||
|
||||
location ~ ^/(v1|api) {
|
||||
proxy_pass http://ragflow:9380;
|
||||
proxy_pass http://localhost:9380;
|
||||
include proxy.conf;
|
||||
}
|
||||
|
||||
|
||||
1
docker/oceanbase/init.d/vec_memory.sql
Normal file
1
docker/oceanbase/init.d/vec_memory.sql
Normal file
@ -0,0 +1 @@
|
||||
ALTER SYSTEM SET ob_vector_memory_limit_percentage = 30;
|
||||
@ -28,6 +28,14 @@ os:
|
||||
infinity:
|
||||
uri: '${INFINITY_HOST:-infinity}:23817'
|
||||
db_name: 'default_db'
|
||||
oceanbase:
|
||||
scheme: 'oceanbase' # set 'mysql' to create connection using mysql config
|
||||
config:
|
||||
db_name: '${OCEANBASE_DOC_DBNAME:-test}'
|
||||
user: '${OCEANBASE_USER:-root@ragflow}'
|
||||
password: '${OCEANBASE_PASSWORD:-infini_rag_flow}'
|
||||
host: '${OCEANBASE_HOST:-oceanbase}'
|
||||
port: ${OCEANBASE_PORT:-2881}
|
||||
redis:
|
||||
db: 1
|
||||
password: '${REDIS_PASSWORD:-infini_rag_flow}'
|
||||
@ -142,5 +150,3 @@ user_default_llm:
|
||||
# secret_id: '${TENCENT_SECRET_ID}'
|
||||
# secret_key: '${TENCENT_SECRET_KEY}'
|
||||
# region: '${TENCENT_REGION}'
|
||||
# table_result_type: '1'
|
||||
# markdown_image_response_type: '1'
|
||||
|
||||
12
docs/faq.mdx
12
docs/faq.mdx
@ -323,9 +323,9 @@ The status of a Docker container status does not necessarily reflect the status
|
||||
|
||||
2. Follow [this document](./guides/run_health_check.md) to check the health status of the Elasticsearch service.
|
||||
|
||||
:::danger IMPORTANT
|
||||
The status of a Docker container status does not necessarily reflect the status of the service. You may find that your services are unhealthy even when the corresponding Docker containers are up running. Possible reasons for this include network failures, incorrect port numbers, or DNS issues.
|
||||
:::
|
||||
:::danger IMPORTANT
|
||||
The status of a Docker container status does not necessarily reflect the status of the service. You may find that your services are unhealthy even when the corresponding Docker containers are up running. Possible reasons for this include network failures, incorrect port numbers, or DNS issues.
|
||||
:::
|
||||
|
||||
3. If your container keeps restarting, ensure `vm.max_map_count` >= 262144 as per [this README](https://github.com/infiniflow/ragflow?tab=readme-ov-file#-start-up-the-server). Updating the `vm.max_map_count` value in **/etc/sysctl.conf** is required, if you wish to keep your change permanent. Note that this configuration works only for Linux.
|
||||
|
||||
@ -456,9 +456,9 @@ To switch your document engine from Elasticsearch to [Infinity](https://github.c
|
||||
```bash
|
||||
$ docker compose -f docker/docker-compose.yml down -v
|
||||
```
|
||||
:::caution WARNING
|
||||
`-v` will delete all Docker container volumes, and the existing data will be cleared.
|
||||
:::
|
||||
:::caution WARNING
|
||||
`-v` will delete all Docker container volumes, and the existing data will be cleared.
|
||||
:::
|
||||
|
||||
2. In **docker/.env**, set `DOC_ENGINE=${DOC_ENGINE:-infinity}`
|
||||
3. Restart your Docker image:
|
||||
|
||||
@ -22,7 +22,7 @@ An **Agent** component is essential when you need the LLM to assist with summari
|
||||
|
||||
1. Ensure you have a chat model properly configured:
|
||||
|
||||

|
||||

|
||||
|
||||
2. If your Agent involves dataset retrieval, ensure you [have properly configured your target dataset(s)](../../dataset/configure_knowledge_base.md).
|
||||
|
||||
@ -91,7 +91,7 @@ Update your MCP server's name, URL (including the API key), server type, and oth
|
||||
|
||||
*The target MCP server appears below your Agent component, and your Agent will autonomously decide when to invoke the available tools it offers.*
|
||||
|
||||
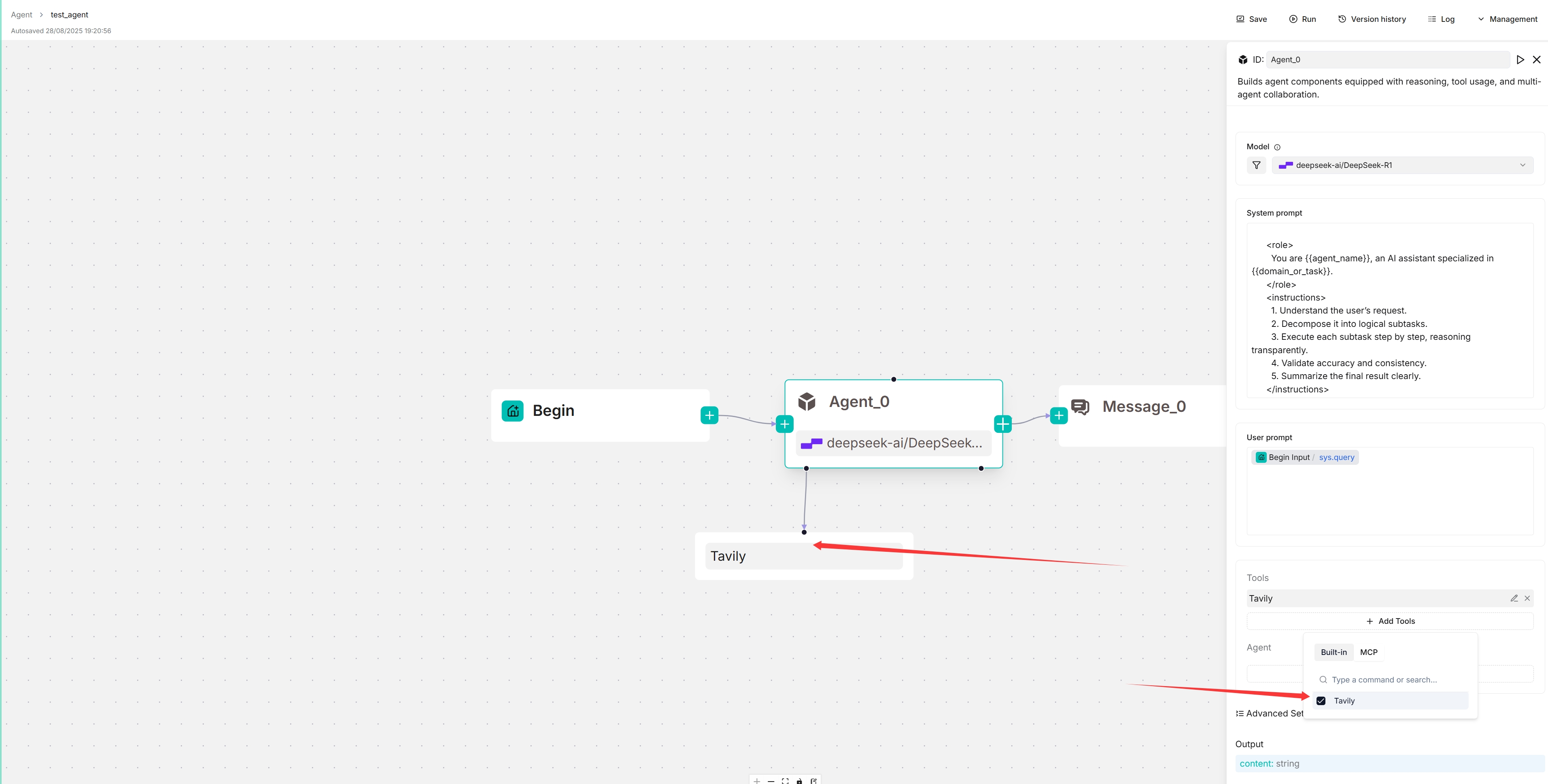
|
||||

|
||||
|
||||
### 5. Update system prompt to specify trigger conditions (Optional)
|
||||
|
||||
|
||||
@ -62,9 +62,9 @@ docker build -t sandbox-executor-manager:latest ./executor_manager
|
||||
|
||||
3. Add the following entry to your /etc/hosts file to resolve the executor manager service:
|
||||
|
||||
```bash
|
||||
127.0.0.1 es01 infinity mysql minio redis sandbox-executor-manager
|
||||
```
|
||||
```bash
|
||||
127.0.0.1 es01 infinity mysql minio redis sandbox-executor-manager
|
||||
```
|
||||
|
||||
4. Start the RAGFlow service as usual.
|
||||
|
||||
@ -74,24 +74,24 @@ docker build -t sandbox-executor-manager:latest ./executor_manager
|
||||
|
||||
1. Initialize the environment variables:
|
||||
|
||||
```bash
|
||||
cp .env.example .env
|
||||
```
|
||||
```bash
|
||||
cp .env.example .env
|
||||
```
|
||||
|
||||
2. Launch the sandbox services with Docker Compose:
|
||||
|
||||
```bash
|
||||
docker compose -f docker-compose.yml up
|
||||
```
|
||||
```bash
|
||||
docker compose -f docker-compose.yml up
|
||||
```
|
||||
|
||||
3. Test the sandbox setup:
|
||||
|
||||
```bash
|
||||
source .venv/bin/activate
|
||||
export PYTHONPATH=$(pwd)
|
||||
uv pip install -r executor_manager/requirements.txt
|
||||
uv run tests/sandbox_security_tests_full.py
|
||||
```
|
||||
```bash
|
||||
source .venv/bin/activate
|
||||
export PYTHONPATH=$(pwd)
|
||||
uv pip install -r executor_manager/requirements.txt
|
||||
uv run tests/sandbox_security_tests_full.py
|
||||
```
|
||||
|
||||
### Using Makefile
|
||||
|
||||
|
||||
@ -83,13 +83,13 @@ You start an AI conversation by creating an assistant.
|
||||
|
||||
1. Click the light bulb icon above the answer to view the expanded system prompt:
|
||||
|
||||
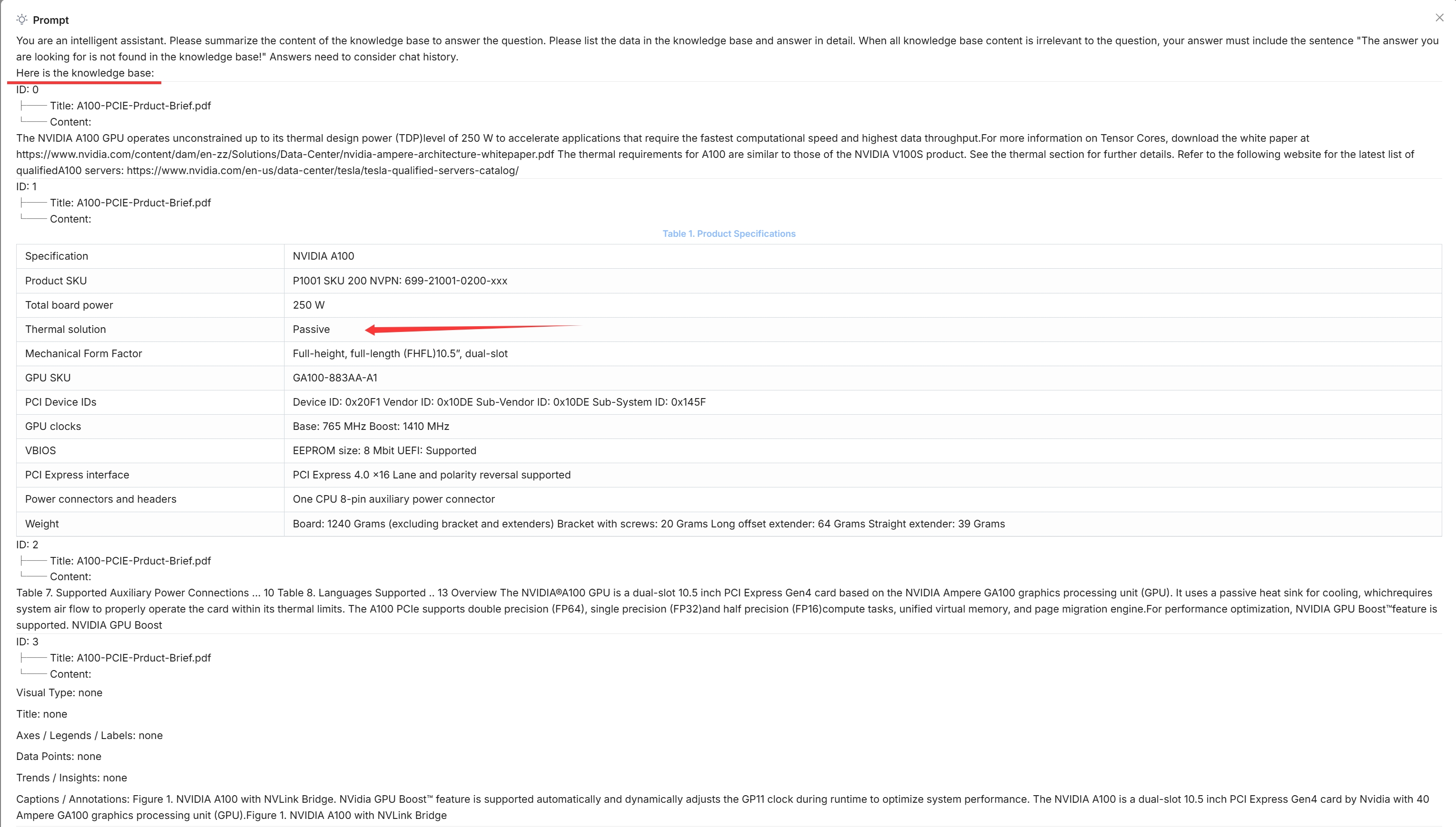
|
||||

|
||||
|
||||
*The light bulb icon is available only for the current dialogue.*
|
||||
|
||||
2. Scroll down the expanded prompt to view the time consumed for each task:
|
||||
|
||||

|
||||

|
||||
:::
|
||||
|
||||
## Update settings of an existing chat assistant
|
||||
|
||||
@ -56,9 +56,9 @@ Once a tag set is created, you can apply it to your dataset:
|
||||
1. Navigate to the **Configuration** page of your dataset.
|
||||
2. Select the tag set from the **Tag sets** dropdown and click **Save** to confirm.
|
||||
|
||||
:::tip NOTE
|
||||
If the tag set is missing from the dropdown, check that it has been created or configured correctly.
|
||||
:::
|
||||
:::tip NOTE
|
||||
If the tag set is missing from the dropdown, check that it has been created or configured correctly.
|
||||
:::
|
||||
|
||||
3. Re-parse your documents to start the auto-tagging process.
|
||||
_In an AI chat scenario using auto-tagged datasets, each query will be tagged using the corresponding tag set(s) and chunks with these tags will have a higher chance to be retrieved._
|
||||
|
||||
@ -39,8 +39,10 @@ If you have not installed Docker on your local machine (Windows, Mac, or Linux),
|
||||
|
||||
This section provides instructions on setting up the RAGFlow server on Linux. If you are on a different operating system, no worries. Most steps are alike.
|
||||
|
||||
1. Ensure `vm.max_map_count` ≥ 262144.
|
||||
|
||||
<details>
|
||||
<summary>1. Ensure <code>vm.max_map_count</code> ≥ 262144:</summary>
|
||||
<summary>Expand to show details:</summary>
|
||||
|
||||
`vm.max_map_count`. This value sets the maximum number of memory map areas a process may have. Its default value is 65530. While most applications require fewer than a thousand maps, reducing this value can result in abnormal behaviors, and the system will throw out-of-memory errors when a process reaches the limitation.
|
||||
|
||||
@ -194,22 +196,22 @@ This section provides instructions on setting up the RAGFlow server on Linux. If
|
||||
$ docker compose -f docker-compose.yml up -d
|
||||
```
|
||||
|
||||
```mdx-code-block
|
||||
<APITable>
|
||||
```
|
||||
```mdx-code-block
|
||||
<APITable>
|
||||
```
|
||||
|
||||
| RAGFlow image tag | Image size (GB) | Stable? |
|
||||
| ------------------- | --------------- | ------------------------ |
|
||||
| v0.22.1 | ≈2 | Stable release |
|
||||
| nightly | ≈2 | _Unstable_ nightly build |
|
||||
| RAGFlow image tag | Image size (GB) | Stable? |
|
||||
| ------------------- | --------------- | ------------------------ |
|
||||
| v0.22.1 | ≈2 | Stable release |
|
||||
| nightly | ≈2 | _Unstable_ nightly build |
|
||||
|
||||
```mdx-code-block
|
||||
</APITable>
|
||||
```
|
||||
```mdx-code-block
|
||||
</APITable>
|
||||
```
|
||||
|
||||
:::tip NOTE
|
||||
The image size shown refers to the size of the *downloaded* Docker image, which is compressed. When Docker runs the image, it unpacks it, resulting in significantly greater disk usage. A Docker image will expand to around 7 GB once unpacked.
|
||||
:::
|
||||
:::tip NOTE
|
||||
The image size shown refers to the size of the *downloaded* Docker image, which is compressed. When Docker runs the image, it unpacks it, resulting in significantly greater disk usage. A Docker image will expand to around 7 GB once unpacked.
|
||||
:::
|
||||
|
||||
4. Check the server status after having the server up and running:
|
||||
|
||||
@ -229,15 +231,15 @@ The image size shown refers to the size of the *downloaded* Docker image, which
|
||||
* Running on all addresses (0.0.0.0)
|
||||
```
|
||||
|
||||
:::danger IMPORTANT
|
||||
If you skip this confirmation step and directly log in to RAGFlow, your browser may prompt a `network anomaly` error because, at that moment, your RAGFlow may not be fully initialized.
|
||||
:::
|
||||
:::danger IMPORTANT
|
||||
If you skip this confirmation step and directly log in to RAGFlow, your browser may prompt a `network anomaly` error because, at that moment, your RAGFlow may not be fully initialized.
|
||||
:::
|
||||
|
||||
5. In your web browser, enter the IP address of your server and log in to RAGFlow.
|
||||
|
||||
:::caution WARNING
|
||||
With the default settings, you only need to enter `http://IP_OF_YOUR_MACHINE` (**sans** port number) as the default HTTP serving port `80` can be omitted when using the default configurations.
|
||||
:::
|
||||
:::caution WARNING
|
||||
With the default settings, you only need to enter `http://IP_OF_YOUR_MACHINE` (**sans** port number) as the default HTTP serving port `80` can be omitted when using the default configurations.
|
||||
:::
|
||||
|
||||
## Configure LLMs
|
||||
|
||||
@ -278,9 +280,9 @@ To create your first dataset:
|
||||
|
||||
3. RAGFlow offers multiple chunk templates that cater to different document layouts and file formats. Select the embedding model and chunking method (template) for your dataset.
|
||||
|
||||
:::danger IMPORTANT
|
||||
Once you have selected an embedding model and used it to parse a file, you are no longer allowed to change it. The obvious reason is that we must ensure that all files in a specific dataset are parsed using the *same* embedding model (ensure that they are being compared in the same embedding space).
|
||||
:::
|
||||
:::danger IMPORTANT
|
||||
Once you have selected an embedding model and used it to parse a file, you are no longer allowed to change it. The obvious reason is that we must ensure that all files in a specific dataset are parsed using the *same* embedding model (ensure that they are being compared in the same embedding space).
|
||||
:::
|
||||
|
||||
_You are taken to the **Dataset** page of your dataset._
|
||||
|
||||
@ -290,10 +292,10 @@ Once you have selected an embedding model and used it to parse a file, you are n
|
||||
|
||||
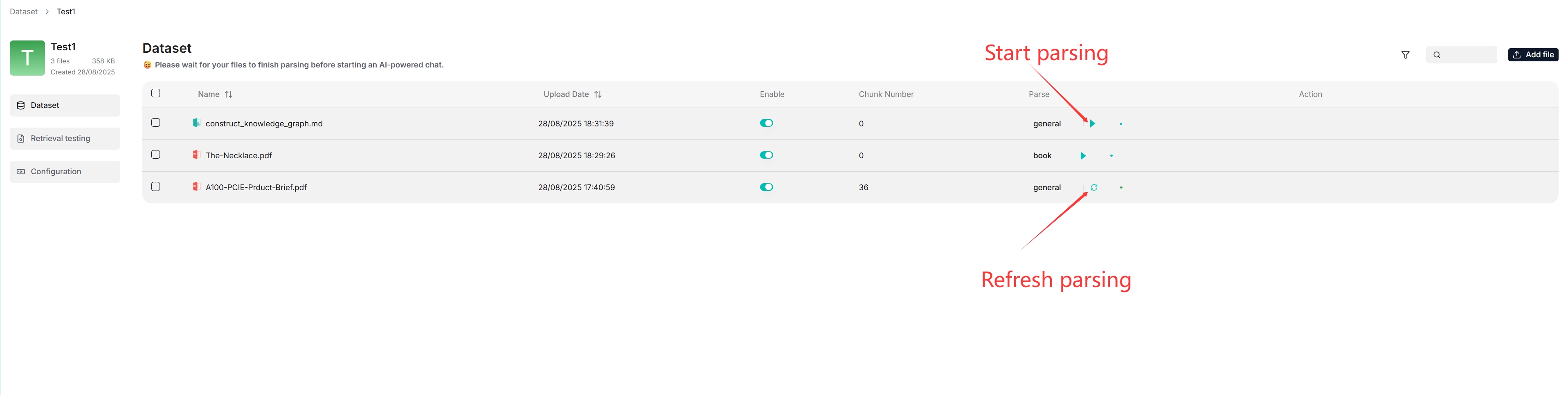
|
||||
|
||||
:::caution NOTE
|
||||
- If your file parsing gets stuck at below 1%, see [this FAQ](./faq.mdx#why-does-my-document-parsing-stall-at-under-one-percent).
|
||||
- If your file parsing gets stuck at near completion, see [this FAQ](./faq.mdx#why-does-my-pdf-parsing-stall-near-completion-while-the-log-does-not-show-any-error)
|
||||
:::
|
||||
:::caution NOTE
|
||||
- If your file parsing gets stuck at below 1%, see [this FAQ](./faq.mdx#why-does-my-document-parsing-stall-at-under-one-percent).
|
||||
- If your file parsing gets stuck at near completion, see [this FAQ](./faq.mdx#why-does-my-pdf-parsing-stall-near-completion-while-the-log-does-not-show-any-error)
|
||||
:::
|
||||
|
||||
## Intervene with file parsing
|
||||
|
||||
@ -311,9 +313,9 @@ RAGFlow features visibility and explainability, allowing you to view the chunkin
|
||||
|
||||
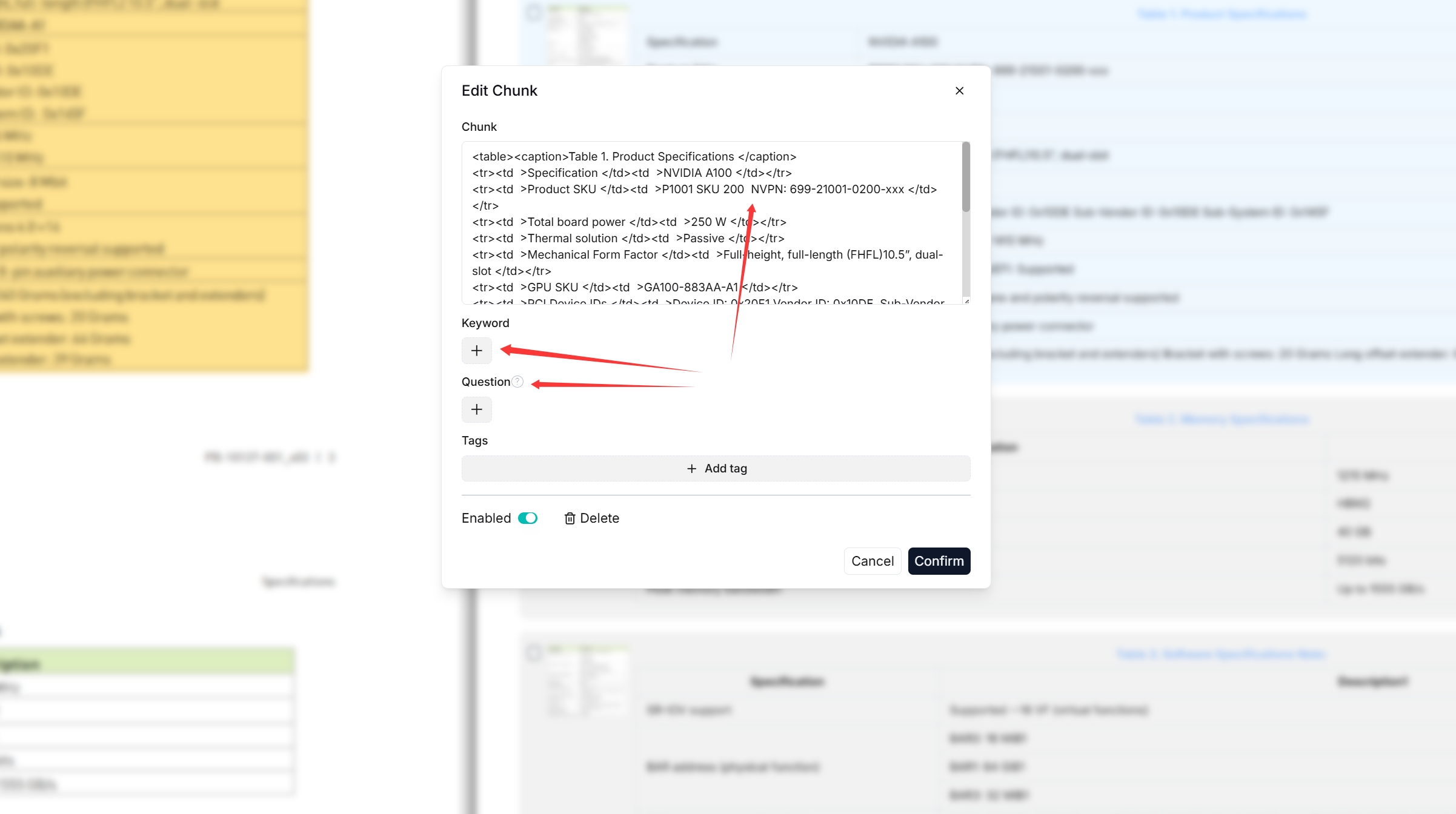
|
||||
|
||||
:::caution NOTE
|
||||
You can add keywords or questions to a file chunk to improve its ranking for queries containing those keywords. This action increases its keyword weight and can improve its position in search list.
|
||||
:::
|
||||
:::caution NOTE
|
||||
You can add keywords or questions to a file chunk to improve its ranking for queries containing those keywords. This action increases its keyword weight and can improve its position in search list.
|
||||
:::
|
||||
|
||||
4. In Retrieval testing, ask a quick question in **Test text** to double check if your configurations work:
|
||||
|
||||
|
||||
@ -2072,6 +2072,7 @@ Retrieves chunks from specified datasets.
|
||||
- `"cross_languages"`: `list[string]`
|
||||
- `"metadata_condition"`: `object`
|
||||
- `"use_kg"`: `boolean`
|
||||
- `"toc_enhance"`: `boolean`
|
||||
##### Request example
|
||||
|
||||
```bash
|
||||
@ -2085,6 +2086,7 @@ curl --request POST \
|
||||
"dataset_ids": ["b2a62730759d11ef987d0242ac120004"],
|
||||
"document_ids": ["77df9ef4759a11ef8bdd0242ac120004"],
|
||||
"metadata_condition": {
|
||||
"logic": "and",
|
||||
"conditions": [
|
||||
{
|
||||
"name": "author",
|
||||
@ -2120,7 +2122,9 @@ curl --request POST \
|
||||
- `"top_k"`: (*Body parameter*), `integer`
|
||||
The number of chunks engaged in vector cosine computation. Defaults to `1024`.
|
||||
- `"use_kg"`: (*Body parameter*), `boolean`
|
||||
The search includes text chunks related to the knowledge graph of the selected dataset to handle complex multi-hop queries. Defaults to `False`.
|
||||
Whether to search chunks related to the generated knowledge graph for multi-hop queries. Defaults to `False`. Before enabling this, ensure you have successfully constructed a knowledge graph for the specified datasets. See [here](https://ragflow.io/docs/dev/construct_knowledge_graph) for details.
|
||||
- `"toc_enhance"`: (*Body parameter*), `boolean`
|
||||
Whether to search chunks with extracted table of content. Defaults to `False`. Before enabling this, ensure you have enabled `TOC_Enhance` and successfully extracted table of contents for the specified datasets. See [here](https://ragflow.io/docs/dev/enable_table_of_contents) for details.
|
||||
- `"rerank_id"`: (*Body parameter*), `integer`
|
||||
The ID of the rerank model.
|
||||
- `"keyword"`: (*Body parameter*), `boolean`
|
||||
@ -2135,6 +2139,9 @@ curl --request POST \
|
||||
The languages that should be translated into, in order to achieve keywords retrievals in different languages.
|
||||
- `"metadata_condition"`: (*Body parameter*), `object`
|
||||
The metadata condition used for filtering chunks:
|
||||
- `"logic"`: (*Body parameter*), `string`
|
||||
- `"and"`: Return only results that satisfy *every* condition (default).
|
||||
- `"or"`: Return results that satisfy *any* condition.
|
||||
- `"conditions"`: (*Body parameter*), `array`
|
||||
A list of metadata filter conditions.
|
||||
- `"name"`: `string` - The metadata field name to filter by, e.g., `"author"`, `"company"`, `"url"`. Ensure this parameter before use. See [Set metadata](../guides/dataset/set_metadata.md) for details.
|
||||
|
||||
@ -96,7 +96,7 @@ ragflow:
|
||||
infinity:
|
||||
image:
|
||||
repository: infiniflow/infinity
|
||||
tag: v0.6.5
|
||||
tag: v0.6.7
|
||||
pullPolicy: IfNotPresent
|
||||
pullSecrets: []
|
||||
storage:
|
||||
|
||||
@ -16,7 +16,7 @@ dependencies = [
|
||||
"arxiv==2.1.3",
|
||||
"aspose-slides>=25.10.0,<26.0.0; platform_machine == 'x86_64' or (sys_platform == 'darwin' and platform_machine == 'arm64')",
|
||||
"atlassian-python-api==4.0.7",
|
||||
"beartype>=0.18.5,<0.19.0",
|
||||
"beartype>=0.20.0,<1.0.0",
|
||||
"bio==1.7.1",
|
||||
"blinker==1.7.0",
|
||||
"boto3==1.34.140",
|
||||
@ -49,7 +49,7 @@ dependencies = [
|
||||
"html-text==0.6.2",
|
||||
"httpx[socks]>=0.28.1,<0.29.0",
|
||||
"huggingface-hub>=0.25.0,<0.26.0",
|
||||
"infinity-sdk==0.6.5",
|
||||
"infinity-sdk==0.6.7",
|
||||
"infinity-emb>=0.0.66,<0.0.67",
|
||||
"itsdangerous==2.1.2",
|
||||
"json-repair==0.35.0",
|
||||
@ -80,7 +80,7 @@ dependencies = [
|
||||
"pyclipper==1.3.0.post5",
|
||||
"pycryptodomex==3.20.0",
|
||||
"pymysql>=1.1.1,<2.0.0",
|
||||
"pypdf==6.0.0",
|
||||
"pypdf==6.4.0",
|
||||
"python-dotenv==1.0.1",
|
||||
"python-dateutil==2.8.2",
|
||||
"python-pptx>=1.0.2,<2.0.0",
|
||||
@ -116,6 +116,7 @@ dependencies = [
|
||||
"google-genai>=1.41.0,<2.0.0",
|
||||
"volcengine==1.0.194",
|
||||
"voyageai==0.2.3",
|
||||
"webdav4>=0.10.0,<0.11.0",
|
||||
"webdriver-manager==4.0.1",
|
||||
"werkzeug==3.0.6",
|
||||
"wikipedia==1.4.0",
|
||||
@ -127,13 +128,13 @@ dependencies = [
|
||||
"google-generativeai>=0.8.1,<0.9.0", # Needed for cv_model and embedding_model
|
||||
"python-docx>=1.1.2,<2.0.0",
|
||||
"pypdf2>=3.0.1,<4.0.0",
|
||||
"graspologic>=3.4.1,<4.0.0",
|
||||
"graspologic @ git+https://github.com/yuzhichang/graspologic.git@38e680cab72bc9fb68a7992c3bcc2d53b24e42fd",
|
||||
"mini-racer>=0.12.4,<0.13.0",
|
||||
"pyodbc>=5.2.0,<6.0.0",
|
||||
"pyicu>=2.15.3,<3.0.0",
|
||||
"flasgger>=0.9.7.1,<0.10.0",
|
||||
"xxhash>=3.5.0,<4.0.0",
|
||||
"trio>=0.29.0",
|
||||
"trio>=0.17.0,<0.29.0",
|
||||
"langfuse>=2.60.0",
|
||||
"debugpy>=1.8.13",
|
||||
"mcp>=1.9.4",
|
||||
@ -148,7 +149,10 @@ dependencies = [
|
||||
"markdownify>=1.2.0",
|
||||
"captcha>=0.7.1",
|
||||
"pip>=25.2",
|
||||
"moodlepy>=0.23.0",
|
||||
"pypandoc>=1.16",
|
||||
"pyobvector==0.2.18",
|
||||
"exceptiongroup>=1.3.0,<2.0.0"
|
||||
]
|
||||
|
||||
[dependency-groups]
|
||||
|
||||
@ -23,7 +23,7 @@ from rag.app import naive
|
||||
from rag.app.naive import by_plaintext, PARSERS
|
||||
from rag.nlp import bullets_category, is_english,remove_contents_table, \
|
||||
hierarchical_merge, make_colon_as_title, naive_merge, random_choices, tokenize_table, \
|
||||
tokenize_chunks
|
||||
tokenize_chunks, attach_media_context
|
||||
from rag.nlp import rag_tokenizer
|
||||
from deepdoc.parser import PdfParser, HtmlParser
|
||||
from deepdoc.parser.figure_parser import vision_figure_parser_docx_wrapper
|
||||
@ -113,6 +113,7 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
lang = lang,
|
||||
callback = callback,
|
||||
pdf_cls = Pdf,
|
||||
layout_recognizer = layout_recognizer,
|
||||
**kwargs
|
||||
)
|
||||
|
||||
@ -174,6 +175,10 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
|
||||
res = tokenize_table(tbls, doc, eng)
|
||||
res.extend(tokenize_chunks(chunks, doc, eng, pdf_parser))
|
||||
table_ctx = max(0, int(parser_config.get("table_context_size", 0) or 0))
|
||||
image_ctx = max(0, int(parser_config.get("image_context_size", 0) or 0))
|
||||
if table_ctx or image_ctx:
|
||||
attach_media_context(res, table_ctx, image_ctx)
|
||||
|
||||
return res
|
||||
|
||||
|
||||
@ -51,9 +51,11 @@ def chunk(
|
||||
attachment_res = []
|
||||
|
||||
if binary:
|
||||
msg = BytesParser(policy=policy.default).parse(io.BytesIO(binary))
|
||||
with io.BytesIO(binary) as buffer:
|
||||
msg = BytesParser(policy=policy.default).parse(buffer)
|
||||
else:
|
||||
msg = BytesParser(policy=policy.default).parse(open(filename, "rb"))
|
||||
with open(filename, "rb") as buffer:
|
||||
msg = BytesParser(policy=policy.default).parse(buffer)
|
||||
|
||||
text_txt, html_txt = [], []
|
||||
# get the email header info
|
||||
|
||||
@ -172,6 +172,7 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
lang = lang,
|
||||
callback = callback,
|
||||
pdf_cls = Pdf,
|
||||
layout_recognizer = layout_recognizer,
|
||||
**kwargs
|
||||
)
|
||||
|
||||
|
||||
@ -20,7 +20,7 @@ import re
|
||||
|
||||
from common.constants import ParserType
|
||||
from io import BytesIO
|
||||
from rag.nlp import rag_tokenizer, tokenize, tokenize_table, bullets_category, title_frequency, tokenize_chunks, docx_question_level
|
||||
from rag.nlp import rag_tokenizer, tokenize, tokenize_table, bullets_category, title_frequency, tokenize_chunks, docx_question_level, attach_media_context
|
||||
from common.token_utils import num_tokens_from_string
|
||||
from deepdoc.parser import PdfParser, DocxParser
|
||||
from deepdoc.parser.figure_parser import vision_figure_parser_pdf_wrapper,vision_figure_parser_docx_wrapper
|
||||
@ -155,7 +155,7 @@ class Docx(DocxParser):
|
||||
sum_question = '\n'.join(question_stack)
|
||||
if sum_question:
|
||||
ti_list.append((f'{sum_question}\n{last_answer}', last_image))
|
||||
|
||||
|
||||
tbls = []
|
||||
for tb in self.doc.tables:
|
||||
html= "<table>"
|
||||
@ -213,6 +213,8 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
lang = lang,
|
||||
callback = callback,
|
||||
pdf_cls = Pdf,
|
||||
layout_recognizer = layout_recognizer,
|
||||
parse_method = "manual",
|
||||
**kwargs
|
||||
)
|
||||
|
||||
@ -225,18 +227,18 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
elif len(section) != 3:
|
||||
raise ValueError(f"Unexpected section length: {len(section)} (value={section!r})")
|
||||
|
||||
txt, sec_id, poss = section
|
||||
txt, layoutno, poss = section
|
||||
if isinstance(poss, str):
|
||||
poss = pdf_parser.extract_positions(poss)
|
||||
first = poss[0] # tuple: ([pn], x1, x2, y1, y2)
|
||||
pn = first[0]
|
||||
pn = first[0]
|
||||
|
||||
if isinstance(pn, list):
|
||||
pn = pn[0] # [pn] -> pn
|
||||
poss[0] = (pn, *first[1:])
|
||||
|
||||
return (txt, sec_id, poss)
|
||||
|
||||
return (txt, layoutno, poss)
|
||||
|
||||
|
||||
sections = [_normalize_section(sec) for sec in sections]
|
||||
|
||||
@ -245,7 +247,7 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
|
||||
if name in ["tcadp", "docling", "mineru"]:
|
||||
parser_config["chunk_token_num"] = 0
|
||||
|
||||
|
||||
callback(0.8, "Finish parsing.")
|
||||
|
||||
if len(sections) > 0 and len(pdf_parser.outlines) / len(sections) > 0.03:
|
||||
@ -308,6 +310,10 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
tbls=vision_figure_parser_pdf_wrapper(tbls=tbls,callback=callback,**kwargs)
|
||||
res = tokenize_table(tbls, doc, eng)
|
||||
res.extend(tokenize_chunks(chunks, doc, eng, pdf_parser))
|
||||
table_ctx = max(0, int(parser_config.get("table_context_size", 0) or 0))
|
||||
image_ctx = max(0, int(parser_config.get("image_context_size", 0) or 0))
|
||||
if table_ctx or image_ctx:
|
||||
attach_media_context(res, table_ctx, image_ctx)
|
||||
return res
|
||||
|
||||
elif re.search(r"\.docx?$", filename, re.IGNORECASE):
|
||||
@ -323,10 +329,14 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
d["doc_type_kwd"] = "image"
|
||||
tokenize(d, text, eng)
|
||||
res.append(d)
|
||||
table_ctx = max(0, int(parser_config.get("table_context_size", 0) or 0))
|
||||
image_ctx = max(0, int(parser_config.get("image_context_size", 0) or 0))
|
||||
if table_ctx or image_ctx:
|
||||
attach_media_context(res, table_ctx, image_ctx)
|
||||
return res
|
||||
else:
|
||||
raise NotImplementedError("file type not supported yet(pdf and docx supported)")
|
||||
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
import sys
|
||||
|
||||
293
rag/app/naive.py
293
rag/app/naive.py
@ -26,6 +26,7 @@ from docx.opc.pkgreader import _SerializedRelationships, _SerializedRelationship
|
||||
from docx.opc.oxml import parse_xml
|
||||
from markdown import markdown
|
||||
from PIL import Image
|
||||
from common.token_utils import num_tokens_from_string
|
||||
|
||||
from common.constants import LLMType
|
||||
from api.db.services.llm_service import LLMBundle
|
||||
@ -36,7 +37,7 @@ from deepdoc.parser.pdf_parser import PlainParser, VisionParser
|
||||
from deepdoc.parser.mineru_parser import MinerUParser
|
||||
from deepdoc.parser.docling_parser import DoclingParser
|
||||
from deepdoc.parser.tcadp_parser import TCADPParser
|
||||
from rag.nlp import concat_img, find_codec, naive_merge, naive_merge_with_images, naive_merge_docx, rag_tokenizer, tokenize_chunks, tokenize_chunks_with_images, tokenize_table
|
||||
from rag.nlp import concat_img, find_codec, naive_merge, naive_merge_with_images, naive_merge_docx, rag_tokenizer, tokenize_chunks, tokenize_chunks_with_images, tokenize_table, attach_media_context
|
||||
|
||||
def by_deepdoc(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", callback=None, pdf_cls = None ,**kwargs):
|
||||
callback = callback
|
||||
@ -59,6 +60,7 @@ def by_mineru(filename, binary=None, from_page=0, to_page=100000, lang="Chinese"
|
||||
mineru_executable = os.environ.get("MINERU_EXECUTABLE", "mineru")
|
||||
mineru_api = os.environ.get("MINERU_APISERVER", "http://host.docker.internal:9987")
|
||||
pdf_parser = MinerUParser(mineru_path=mineru_executable, mineru_api=mineru_api)
|
||||
parse_method = kwargs.get("parse_method", "raw")
|
||||
|
||||
if not pdf_parser.check_installation():
|
||||
callback(-1, "MinerU not found.")
|
||||
@ -72,12 +74,14 @@ def by_mineru(filename, binary=None, from_page=0, to_page=100000, lang="Chinese"
|
||||
backend=os.environ.get("MINERU_BACKEND", "pipeline"),
|
||||
server_url=os.environ.get("MINERU_SERVER_URL", ""),
|
||||
delete_output=bool(int(os.environ.get("MINERU_DELETE_OUTPUT", 1))),
|
||||
parse_method=parse_method
|
||||
)
|
||||
return sections, tables, pdf_parser
|
||||
|
||||
|
||||
def by_docling(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", callback=None, pdf_cls = None ,**kwargs):
|
||||
pdf_parser = DoclingParser()
|
||||
parse_method = kwargs.get("parse_method", "raw")
|
||||
|
||||
if not pdf_parser.check_installation():
|
||||
callback(-1, "Docling not found.")
|
||||
@ -89,6 +93,7 @@ def by_docling(filename, binary=None, from_page=0, to_page=100000, lang="Chinese
|
||||
callback=callback,
|
||||
output_dir=os.environ.get("MINERU_OUTPUT_DIR", ""),
|
||||
delete_output=bool(int(os.environ.get("MINERU_DELETE_OUTPUT", 1))),
|
||||
parse_method=parse_method
|
||||
)
|
||||
return sections, tables, pdf_parser
|
||||
|
||||
@ -116,7 +121,7 @@ def by_plaintext(filename, binary=None, from_page=0, to_page=100000, callback=No
|
||||
else:
|
||||
vision_model = LLMBundle(kwargs["tenant_id"], LLMType.IMAGE2TEXT, llm_name=kwargs.get("layout_recognizer", ""), lang=kwargs.get("lang", "Chinese"))
|
||||
pdf_parser = VisionParser(vision_model=vision_model, **kwargs)
|
||||
|
||||
|
||||
sections, tables = pdf_parser(
|
||||
filename if not binary else binary,
|
||||
from_page=from_page,
|
||||
@ -460,51 +465,88 @@ class Markdown(MarkdownParser):
|
||||
html_content = markdown(text)
|
||||
soup = BeautifulSoup(html_content, 'html.parser')
|
||||
return soup
|
||||
|
||||
def get_picture_urls(self, soup):
|
||||
if soup:
|
||||
return [img.get('src') for img in soup.find_all('img') if img.get('src')]
|
||||
return []
|
||||
|
||||
def get_hyperlink_urls(self, soup):
|
||||
if soup:
|
||||
return set([a.get('href') for a in soup.find_all('a') if a.get('href')])
|
||||
return []
|
||||
|
||||
def get_pictures(self, text):
|
||||
"""Download and open all images from markdown text."""
|
||||
|
||||
def extract_image_urls_with_lines(self, text):
|
||||
md_img_re = re.compile(r"!\[[^\]]*\]\(([^)\s]+)")
|
||||
html_img_re = re.compile(r'src=["\\\']([^"\\\'>\\s]+)', re.IGNORECASE)
|
||||
urls = []
|
||||
seen = set()
|
||||
lines = text.splitlines()
|
||||
for idx, line in enumerate(lines):
|
||||
for url in md_img_re.findall(line):
|
||||
if (url, idx) not in seen:
|
||||
urls.append({"url": url, "line": idx})
|
||||
seen.add((url, idx))
|
||||
for url in html_img_re.findall(line):
|
||||
if (url, idx) not in seen:
|
||||
urls.append({"url": url, "line": idx})
|
||||
seen.add((url, idx))
|
||||
|
||||
# cross-line
|
||||
try:
|
||||
from bs4 import BeautifulSoup
|
||||
|
||||
soup = BeautifulSoup(text, 'html.parser')
|
||||
newline_offsets = [m.start() for m in re.finditer(r"\n", text)] + [len(text)]
|
||||
for img_tag in soup.find_all('img'):
|
||||
src = img_tag.get('src')
|
||||
if not src:
|
||||
continue
|
||||
|
||||
tag_str = str(img_tag)
|
||||
pos = text.find(tag_str)
|
||||
if pos == -1:
|
||||
# fallback
|
||||
pos = max(text.find(src), 0)
|
||||
line_no = 0
|
||||
for i, off in enumerate(newline_offsets):
|
||||
if pos <= off:
|
||||
line_no = i
|
||||
break
|
||||
if (src, line_no) not in seen:
|
||||
urls.append({"url": src, "line": line_no})
|
||||
seen.add((src, line_no))
|
||||
except Exception:
|
||||
pass
|
||||
|
||||
return urls
|
||||
|
||||
def load_images_from_urls(self, urls, cache=None):
|
||||
import requests
|
||||
soup = self.md_to_html(text)
|
||||
image_urls = self.get_picture_urls(soup)
|
||||
from pathlib import Path
|
||||
|
||||
cache = cache or {}
|
||||
images = []
|
||||
# Find all image URLs in text
|
||||
for url in image_urls:
|
||||
if not url:
|
||||
for url in urls:
|
||||
if url in cache:
|
||||
if cache[url]:
|
||||
images.append(cache[url])
|
||||
continue
|
||||
img_obj = None
|
||||
try:
|
||||
# check if the url is a local file or a remote URL
|
||||
if url.startswith(('http://', 'https://')):
|
||||
# For remote URLs, download the image
|
||||
response = requests.get(url, stream=True, timeout=30)
|
||||
if response.status_code == 200 and response.headers['Content-Type'] and response.headers['Content-Type'].startswith('image/'):
|
||||
img = Image.open(BytesIO(response.content)).convert('RGB')
|
||||
images.append(img)
|
||||
if response.status_code == 200 and response.headers.get('Content-Type', '').startswith('image/'):
|
||||
img_obj = Image.open(BytesIO(response.content)).convert('RGB')
|
||||
else:
|
||||
# For local file paths, open the image directly
|
||||
from pathlib import Path
|
||||
local_path = Path(url)
|
||||
if not local_path.exists():
|
||||
if local_path.exists():
|
||||
img_obj = Image.open(url).convert('RGB')
|
||||
else:
|
||||
logging.warning(f"Local image file not found: {url}")
|
||||
continue
|
||||
img = Image.open(url).convert('RGB')
|
||||
images.append(img)
|
||||
except Exception as e:
|
||||
logging.error(f"Failed to download/open image from {url}: {e}")
|
||||
continue
|
||||
cache[url] = img_obj
|
||||
if img_obj:
|
||||
images.append(img_obj)
|
||||
return images, cache
|
||||
|
||||
return images if images else None
|
||||
|
||||
def __call__(self, filename, binary=None, separate_tables=True,delimiter=None):
|
||||
def __call__(self, filename, binary=None, separate_tables=True, delimiter=None, return_section_images=False):
|
||||
if binary:
|
||||
encoding = find_codec(binary)
|
||||
txt = binary.decode(encoding, errors="ignore")
|
||||
@ -516,11 +558,31 @@ class Markdown(MarkdownParser):
|
||||
# To eliminate duplicate tables in chunking result, uncomment code below and set separate_tables to True in line 410.
|
||||
# extractor = MarkdownElementExtractor(remainder)
|
||||
extractor = MarkdownElementExtractor(txt)
|
||||
element_sections = extractor.extract_elements(delimiter)
|
||||
sections = [(element, "") for element in element_sections]
|
||||
image_refs = self.extract_image_urls_with_lines(txt)
|
||||
element_sections = extractor.extract_elements(delimiter, include_meta=True)
|
||||
|
||||
sections = []
|
||||
section_images = []
|
||||
image_cache = {}
|
||||
for element in element_sections:
|
||||
content = element["content"]
|
||||
start_line = element["start_line"]
|
||||
end_line = element["end_line"]
|
||||
urls_in_section = [ref["url"] for ref in image_refs if start_line <= ref["line"] <= end_line]
|
||||
imgs = []
|
||||
if urls_in_section:
|
||||
imgs, image_cache = self.load_images_from_urls(urls_in_section, image_cache)
|
||||
combined_image = None
|
||||
if imgs:
|
||||
combined_image = reduce(concat_img, imgs) if len(imgs) > 1 else imgs[0]
|
||||
sections.append((content, ""))
|
||||
section_images.append(combined_image)
|
||||
|
||||
tbls = []
|
||||
for table in tables:
|
||||
tbls.append(((None, markdown(table, extensions=['markdown.extensions.tables'])), ""))
|
||||
if return_section_images:
|
||||
return sections, tbls, section_images
|
||||
return sections, tbls
|
||||
|
||||
def load_from_xml_v2(baseURI, rels_item_xml):
|
||||
@ -554,6 +616,9 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
parser_config = kwargs.get(
|
||||
"parser_config", {
|
||||
"chunk_token_num": 512, "delimiter": "\n!?。;!?", "layout_recognize": "DeepDOC", "analyze_hyperlink": True})
|
||||
table_context_size = max(0, int(parser_config.get("table_context_size", 0) or 0))
|
||||
image_context_size = max(0, int(parser_config.get("image_context_size", 0) or 0))
|
||||
final_sections = False
|
||||
doc = {
|
||||
"docnm_kwd": filename,
|
||||
"title_tks": rag_tokenizer.tokenize(re.sub(r"\.[a-zA-Z]+$", "", filename))
|
||||
@ -602,7 +667,7 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
_SerializedRelationships.load_from_xml = load_from_xml_v2
|
||||
sections, tables = Docx()(filename, binary)
|
||||
|
||||
tables=vision_figure_parser_docx_wrapper(sections=sections,tbls=tables,callback=callback,**kwargs)
|
||||
tables = vision_figure_parser_docx_wrapper(sections=sections, tbls=tables, callback=callback, **kwargs)
|
||||
|
||||
res = tokenize_table(tables, doc, is_english)
|
||||
callback(0.8, "Finish parsing.")
|
||||
@ -623,6 +688,8 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
logging.info("naive_merge({}): {}".format(filename, timer() - st))
|
||||
res.extend(embed_res)
|
||||
res.extend(url_res)
|
||||
if table_context_size or image_context_size:
|
||||
attach_media_context(res, table_context_size, image_context_size)
|
||||
return res
|
||||
|
||||
elif re.search(r"\.pdf$", filename, re.IGNORECASE):
|
||||
@ -653,18 +720,47 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
|
||||
if name in ["tcadp", "docling", "mineru"]:
|
||||
parser_config["chunk_token_num"] = 0
|
||||
|
||||
|
||||
res = tokenize_table(tables, doc, is_english)
|
||||
callback(0.8, "Finish parsing.")
|
||||
|
||||
elif re.search(r"\.(csv|xlsx?)$", filename, re.IGNORECASE):
|
||||
callback(0.1, "Start to parse.")
|
||||
excel_parser = ExcelParser()
|
||||
if parser_config.get("html4excel"):
|
||||
sections = [(_, "") for _ in excel_parser.html(binary, 12) if _]
|
||||
|
||||
# Check if tcadp_parser is selected for spreadsheet files
|
||||
layout_recognizer = parser_config.get("layout_recognize", "DeepDOC")
|
||||
if layout_recognizer == "TCADP Parser":
|
||||
table_result_type = parser_config.get("table_result_type", "1")
|
||||
markdown_image_response_type = parser_config.get("markdown_image_response_type", "1")
|
||||
tcadp_parser = TCADPParser(
|
||||
table_result_type=table_result_type,
|
||||
markdown_image_response_type=markdown_image_response_type
|
||||
)
|
||||
if not tcadp_parser.check_installation():
|
||||
callback(-1, "TCADP parser not available. Please check Tencent Cloud API configuration.")
|
||||
return res
|
||||
|
||||
# Determine file type based on extension
|
||||
file_type = "XLSX" if re.search(r"\.xlsx?$", filename, re.IGNORECASE) else "CSV"
|
||||
|
||||
sections, tables = tcadp_parser.parse_pdf(
|
||||
filepath=filename,
|
||||
binary=binary,
|
||||
callback=callback,
|
||||
output_dir=os.environ.get("TCADP_OUTPUT_DIR", ""),
|
||||
file_type=file_type
|
||||
)
|
||||
parser_config["chunk_token_num"] = 0
|
||||
res = tokenize_table(tables, doc, is_english)
|
||||
callback(0.8, "Finish parsing.")
|
||||
else:
|
||||
sections = [(_, "") for _ in excel_parser(binary) if _]
|
||||
parser_config["chunk_token_num"] = 12800
|
||||
# Default DeepDOC parser
|
||||
excel_parser = ExcelParser()
|
||||
if parser_config.get("html4excel"):
|
||||
sections = [(_, "") for _ in excel_parser.html(binary, 12) if _]
|
||||
parser_config["chunk_token_num"] = 0
|
||||
else:
|
||||
sections = [(_, "") for _ in excel_parser(binary) if _]
|
||||
|
||||
elif re.search(r"\.(txt|py|js|java|c|cpp|h|php|go|ts|sh|cs|kt|sql)$", filename, re.IGNORECASE):
|
||||
callback(0.1, "Start to parse.")
|
||||
@ -676,7 +772,15 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
elif re.search(r"\.(md|markdown)$", filename, re.IGNORECASE):
|
||||
callback(0.1, "Start to parse.")
|
||||
markdown_parser = Markdown(int(parser_config.get("chunk_token_num", 128)))
|
||||
sections, tables = markdown_parser(filename, binary, separate_tables=False,delimiter=parser_config.get("delimiter", "\n!?;。;!?"))
|
||||
sections, tables, section_images = markdown_parser(
|
||||
filename,
|
||||
binary,
|
||||
separate_tables=False,
|
||||
delimiter=parser_config.get("delimiter", "\n!?;。;!?"),
|
||||
return_section_images=True,
|
||||
)
|
||||
|
||||
final_sections = True
|
||||
|
||||
try:
|
||||
vision_model = LLMBundle(kwargs["tenant_id"], LLMType.IMAGE2TEXT)
|
||||
@ -686,19 +790,22 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
|
||||
if vision_model:
|
||||
# Process images for each section
|
||||
section_images = []
|
||||
for idx, (section_text, _) in enumerate(sections):
|
||||
images = markdown_parser.get_pictures(section_text) if section_text else None
|
||||
images = []
|
||||
if section_images and len(section_images) > idx and section_images[idx] is not None:
|
||||
images.append(section_images[idx])
|
||||
|
||||
if images:
|
||||
if images and len(images) > 0:
|
||||
# If multiple images found, combine them using concat_img
|
||||
combined_image = reduce(concat_img, images) if len(images) > 1 else images[0]
|
||||
section_images.append(combined_image)
|
||||
if section_images:
|
||||
section_images[idx] = combined_image
|
||||
else:
|
||||
section_images = [None] * len(sections)
|
||||
section_images[idx] = combined_image
|
||||
markdown_vision_parser = VisionFigureParser(vision_model=vision_model, figures_data= [((combined_image, ["markdown image"]), [(0, 0, 0, 0, 0)])], **kwargs)
|
||||
boosted_figures = markdown_vision_parser(callback=callback)
|
||||
sections[idx] = (section_text + "\n\n" + "\n\n".join([fig[0][1] for fig in boosted_figures]), sections[idx][1])
|
||||
else:
|
||||
section_images.append(None)
|
||||
|
||||
else:
|
||||
logging.warning("No visual model detected. Skipping figure parsing enhancement.")
|
||||
@ -750,31 +857,81 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
"file type not supported yet(pdf, xlsx, doc, docx, txt supported)")
|
||||
|
||||
st = timer()
|
||||
if section_images:
|
||||
# if all images are None, set section_images to None
|
||||
if all(image is None for image in section_images):
|
||||
section_images = None
|
||||
if final_sections:
|
||||
merged_chunks = []
|
||||
merged_images = []
|
||||
chunk_limit = max(0, int(parser_config.get("chunk_token_num", 128)))
|
||||
overlapped_percent = int(parser_config.get("overlapped_percent", 0))
|
||||
overlapped_percent = max(0, min(overlapped_percent, 90))
|
||||
|
||||
if section_images:
|
||||
chunks, images = naive_merge_with_images(sections, section_images,
|
||||
int(parser_config.get(
|
||||
"chunk_token_num", 128)), parser_config.get(
|
||||
"delimiter", "\n!?。;!?"))
|
||||
current_text = ""
|
||||
current_tokens = 0
|
||||
current_image = None
|
||||
|
||||
for idx, sec in enumerate(sections):
|
||||
text = sec[0] if isinstance(sec, tuple) else sec
|
||||
sec_tokens = num_tokens_from_string(text)
|
||||
sec_image = section_images[idx] if section_images and idx < len(section_images) else None
|
||||
|
||||
if current_text and current_tokens + sec_tokens > chunk_limit:
|
||||
merged_chunks.append(current_text)
|
||||
merged_images.append(current_image)
|
||||
overlap_part = ""
|
||||
if overlapped_percent > 0:
|
||||
overlap_len = int(len(current_text) * overlapped_percent / 100)
|
||||
if overlap_len > 0:
|
||||
overlap_part = current_text[-overlap_len:]
|
||||
current_text = overlap_part
|
||||
current_tokens = num_tokens_from_string(current_text)
|
||||
current_image = current_image if overlap_part else None
|
||||
|
||||
if current_text:
|
||||
current_text += "\n" + text
|
||||
else:
|
||||
current_text = text
|
||||
current_tokens += sec_tokens
|
||||
|
||||
if sec_image:
|
||||
current_image = concat_img(current_image, sec_image) if current_image else sec_image
|
||||
|
||||
if current_text:
|
||||
merged_chunks.append(current_text)
|
||||
merged_images.append(current_image)
|
||||
|
||||
chunks = merged_chunks
|
||||
has_images = merged_images and any(img is not None for img in merged_images)
|
||||
if kwargs.get("section_only", False):
|
||||
chunks.extend(embed_res)
|
||||
return chunks
|
||||
|
||||
res.extend(tokenize_chunks_with_images(chunks, doc, is_english, images))
|
||||
if has_images:
|
||||
res.extend(tokenize_chunks_with_images(chunks, doc, is_english, merged_images))
|
||||
else:
|
||||
res.extend(tokenize_chunks(chunks, doc, is_english, pdf_parser))
|
||||
else:
|
||||
chunks = naive_merge(
|
||||
sections, int(parser_config.get(
|
||||
"chunk_token_num", 128)), parser_config.get(
|
||||
"delimiter", "\n!?。;!?"))
|
||||
if kwargs.get("section_only", False):
|
||||
chunks.extend(embed_res)
|
||||
return chunks
|
||||
if section_images:
|
||||
if all(image is None for image in section_images):
|
||||
section_images = None
|
||||
|
||||
res.extend(tokenize_chunks(chunks, doc, is_english, pdf_parser))
|
||||
if section_images:
|
||||
chunks, images = naive_merge_with_images(sections, section_images,
|
||||
int(parser_config.get(
|
||||
"chunk_token_num", 128)), parser_config.get(
|
||||
"delimiter", "\n!?。;!?"))
|
||||
if kwargs.get("section_only", False):
|
||||
chunks.extend(embed_res)
|
||||
return chunks
|
||||
|
||||
res.extend(tokenize_chunks_with_images(chunks, doc, is_english, images))
|
||||
else:
|
||||
chunks = naive_merge(
|
||||
sections, int(parser_config.get(
|
||||
"chunk_token_num", 128)), parser_config.get(
|
||||
"delimiter", "\n!?。;!?"))
|
||||
if kwargs.get("section_only", False):
|
||||
chunks.extend(embed_res)
|
||||
return chunks
|
||||
|
||||
res.extend(tokenize_chunks(chunks, doc, is_english, pdf_parser))
|
||||
|
||||
if urls and parser_config.get("analyze_hyperlink", False) and is_root:
|
||||
for index, url in enumerate(urls):
|
||||
@ -787,13 +944,15 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
logging.info(f"Failed to chunk url in registered file type {url}: {e}")
|
||||
sub_url_res = chunk(f"{index}.html", html_bytes, callback=callback, lang=lang, is_root=False, **kwargs)
|
||||
url_res.extend(sub_url_res)
|
||||
|
||||
|
||||
logging.info("naive_merge({}): {}".format(filename, timer() - st))
|
||||
|
||||
|
||||
if embed_res:
|
||||
res.extend(embed_res)
|
||||
if url_res:
|
||||
res.extend(url_res)
|
||||
if table_context_size or image_context_size:
|
||||
attach_media_context(res, table_context_size, image_context_size)
|
||||
return res
|
||||
|
||||
|
||||
|
||||
@ -99,6 +99,7 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
lang = lang,
|
||||
callback = callback,
|
||||
pdf_cls = Pdf,
|
||||
layout_recognizer = layout_recognizer,
|
||||
**kwargs
|
||||
)
|
||||
|
||||
|
||||
@ -20,9 +20,11 @@ import re
|
||||
|
||||
from deepdoc.parser.figure_parser import vision_figure_parser_pdf_wrapper
|
||||
from common.constants import ParserType
|
||||
from rag.nlp import rag_tokenizer, tokenize, tokenize_table, add_positions, bullets_category, title_frequency, tokenize_chunks
|
||||
from deepdoc.parser import PdfParser, PlainParser
|
||||
from rag.nlp import rag_tokenizer, tokenize, tokenize_table, add_positions, bullets_category, title_frequency, tokenize_chunks, attach_media_context
|
||||
from deepdoc.parser import PdfParser
|
||||
import numpy as np
|
||||
from rag.app.naive import by_plaintext, PARSERS
|
||||
|
||||
|
||||
class Pdf(PdfParser):
|
||||
def __init__(self):
|
||||
@ -147,19 +149,40 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
"parser_config", {
|
||||
"chunk_token_num": 512, "delimiter": "\n!?。;!?", "layout_recognize": "DeepDOC"})
|
||||
if re.search(r"\.pdf$", filename, re.IGNORECASE):
|
||||
if parser_config.get("layout_recognize", "DeepDOC") == "Plain Text":
|
||||
pdf_parser = PlainParser()
|
||||
layout_recognizer = parser_config.get("layout_recognize", "DeepDOC")
|
||||
|
||||
if isinstance(layout_recognizer, bool):
|
||||
layout_recognizer = "DeepDOC" if layout_recognizer else "Plain Text"
|
||||
|
||||
name = layout_recognizer.strip().lower()
|
||||
pdf_parser = PARSERS.get(name, by_plaintext)
|
||||
callback(0.1, "Start to parse.")
|
||||
|
||||
if name == "deepdoc":
|
||||
pdf_parser = Pdf()
|
||||
paper = pdf_parser(filename if not binary else binary,
|
||||
from_page=from_page, to_page=to_page, callback=callback)
|
||||
else:
|
||||
sections, tables, pdf_parser = pdf_parser(
|
||||
filename=filename,
|
||||
binary=binary,
|
||||
from_page=from_page,
|
||||
to_page=to_page,
|
||||
lang=lang,
|
||||
callback=callback,
|
||||
pdf_cls=Pdf,
|
||||
parse_method="paper",
|
||||
**kwargs
|
||||
)
|
||||
|
||||
paper = {
|
||||
"title": filename,
|
||||
"authors": " ",
|
||||
"abstract": "",
|
||||
"sections": pdf_parser(filename if not binary else binary, from_page=from_page, to_page=to_page)[0],
|
||||
"tables": []
|
||||
"sections": sections,
|
||||
"tables": tables
|
||||
}
|
||||
else:
|
||||
pdf_parser = Pdf()
|
||||
paper = pdf_parser(filename if not binary else binary,
|
||||
from_page=from_page, to_page=to_page, callback=callback)
|
||||
|
||||
tbls=paper["tables"]
|
||||
tbls=vision_figure_parser_pdf_wrapper(tbls=tbls,callback=callback,**kwargs)
|
||||
paper["tables"] = tbls
|
||||
@ -211,6 +234,10 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
chunks.append(txt)
|
||||
last_sid = sec_id
|
||||
res.extend(tokenize_chunks(chunks, doc, eng, pdf_parser))
|
||||
table_ctx = max(0, int(parser_config.get("table_context_size", 0) or 0))
|
||||
image_ctx = max(0, int(parser_config.get("image_context_size", 0) or 0))
|
||||
if table_ctx or image_ctx:
|
||||
attach_media_context(res, table_ctx, image_ctx)
|
||||
return res
|
||||
|
||||
|
||||
|
||||
@ -20,11 +20,11 @@ import re
|
||||
import numpy as np
|
||||
from PIL import Image
|
||||
|
||||
from common.constants import LLMType
|
||||
from api.db.services.llm_service import LLMBundle
|
||||
from deepdoc.vision import OCR
|
||||
from rag.nlp import rag_tokenizer, tokenize
|
||||
from common.constants import LLMType
|
||||
from common.string_utils import clean_markdown_block
|
||||
from deepdoc.vision import OCR
|
||||
from rag.nlp import attach_media_context, rag_tokenizer, tokenize
|
||||
|
||||
ocr = OCR()
|
||||
|
||||
@ -39,9 +39,16 @@ def chunk(filename, binary, tenant_id, lang, callback=None, **kwargs):
|
||||
}
|
||||
eng = lang.lower() == "english"
|
||||
|
||||
parser_config = kwargs.get("parser_config", {}) or {}
|
||||
image_ctx = max(0, int(parser_config.get("image_context_size", 0) or 0))
|
||||
|
||||
if any(filename.lower().endswith(ext) for ext in VIDEO_EXTS):
|
||||
try:
|
||||
doc.update({"doc_type_kwd": "video"})
|
||||
doc.update(
|
||||
{
|
||||
"doc_type_kwd": "video",
|
||||
}
|
||||
)
|
||||
cv_mdl = LLMBundle(tenant_id, llm_type=LLMType.IMAGE2TEXT, lang=lang)
|
||||
ans = cv_mdl.chat(system="", history=[], gen_conf={}, video_bytes=binary, filename=filename)
|
||||
callback(0.8, "CV LLM respond: %s ..." % ans[:32])
|
||||
@ -64,7 +71,7 @@ def chunk(filename, binary, tenant_id, lang, callback=None, **kwargs):
|
||||
if (eng and len(txt.split()) > 32) or len(txt) > 32:
|
||||
tokenize(doc, txt, eng)
|
||||
callback(0.8, "OCR results is too long to use CV LLM.")
|
||||
return [doc]
|
||||
return attach_media_context([doc], 0, image_ctx)
|
||||
|
||||
try:
|
||||
callback(0.4, "Use CV LLM to describe the picture.")
|
||||
@ -76,7 +83,7 @@ def chunk(filename, binary, tenant_id, lang, callback=None, **kwargs):
|
||||
callback(0.8, "CV LLM respond: %s ..." % ans[:32])
|
||||
txt += "\n" + ans
|
||||
tokenize(doc, txt, eng)
|
||||
return [doc]
|
||||
return attach_media_context([doc], 0, image_ctx)
|
||||
except Exception as e:
|
||||
callback(prog=-1, msg=str(e))
|
||||
|
||||
@ -103,7 +110,7 @@ def vision_llm_chunk(binary, vision_model, prompt=None, callback=None):
|
||||
img_binary.seek(0)
|
||||
img_binary.truncate()
|
||||
img.save(img_binary, format="PNG")
|
||||
|
||||
|
||||
img_binary.seek(0)
|
||||
ans = clean_markdown_block(vision_model.describe_with_prompt(img_binary.read(), prompt))
|
||||
txt += "\n" + ans
|
||||
|
||||
@ -142,6 +142,7 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
lang = lang,
|
||||
callback = callback,
|
||||
pdf_cls = Pdf,
|
||||
layout_recognizer = layout_recognizer,
|
||||
**kwargs
|
||||
)
|
||||
|
||||
|
||||
@ -16,18 +16,19 @@ import io
|
||||
import json
|
||||
import os
|
||||
import random
|
||||
import re
|
||||
from functools import partial
|
||||
|
||||
import trio
|
||||
import numpy as np
|
||||
import trio
|
||||
from PIL import Image
|
||||
|
||||
from common.constants import LLMType
|
||||
from api.db.services.file2document_service import File2DocumentService
|
||||
from api.db.services.file_service import FileService
|
||||
from api.db.services.llm_service import LLMBundle
|
||||
from common import settings
|
||||
from common.constants import LLMType
|
||||
from common.misc_utils import get_uuid
|
||||
from rag.utils.base64_image import image2id
|
||||
from deepdoc.parser import ExcelParser
|
||||
from deepdoc.parser.mineru_parser import MinerUParser
|
||||
from deepdoc.parser.pdf_parser import PlainParser, RAGFlowPdfParser, VisionParser
|
||||
@ -36,7 +37,8 @@ from rag.app.naive import Docx
|
||||
from rag.flow.base import ProcessBase, ProcessParamBase
|
||||
from rag.flow.parser.schema import ParserFromUpstream
|
||||
from rag.llm.cv_model import Base as VLM
|
||||
from common import settings
|
||||
from rag.nlp import attach_media_context
|
||||
from rag.utils.base64_image import image2id
|
||||
|
||||
|
||||
class ParserParam(ProcessParamBase):
|
||||
@ -60,15 +62,18 @@ class ParserParam(ProcessParamBase):
|
||||
"json",
|
||||
],
|
||||
"image": [
|
||||
"text"
|
||||
"text",
|
||||
],
|
||||
"email": [
|
||||
"text",
|
||||
"json",
|
||||
],
|
||||
"email": ["text", "json"],
|
||||
"text&markdown": [
|
||||
"text",
|
||||
"json"
|
||||
"json",
|
||||
],
|
||||
"audio": [
|
||||
"json"
|
||||
"json",
|
||||
],
|
||||
"video": [],
|
||||
}
|
||||
@ -81,14 +86,19 @@ class ParserParam(ProcessParamBase):
|
||||
"pdf",
|
||||
],
|
||||
"output_format": "json",
|
||||
"table_context_size": 0,
|
||||
"image_context_size": 0,
|
||||
},
|
||||
"spreadsheet": {
|
||||
"parse_method": "deepdoc", # deepdoc/tcadp_parser
|
||||
"output_format": "html",
|
||||
"suffix": [
|
||||
"xls",
|
||||
"xlsx",
|
||||
"csv",
|
||||
],
|
||||
"table_context_size": 0,
|
||||
"image_context_size": 0,
|
||||
},
|
||||
"word": {
|
||||
"suffix": [
|
||||
@ -96,16 +106,24 @@ class ParserParam(ProcessParamBase):
|
||||
"docx",
|
||||
],
|
||||
"output_format": "json",
|
||||
"table_context_size": 0,
|
||||
"image_context_size": 0,
|
||||
},
|
||||
"text&markdown": {
|
||||
"suffix": ["md", "markdown", "mdx", "txt"],
|
||||
"output_format": "json",
|
||||
"table_context_size": 0,
|
||||
"image_context_size": 0,
|
||||
},
|
||||
"slides": {
|
||||
"parse_method": "deepdoc", # deepdoc/tcadp_parser
|
||||
"suffix": [
|
||||
"pptx",
|
||||
"ppt",
|
||||
],
|
||||
"output_format": "json",
|
||||
"table_context_size": 0,
|
||||
"image_context_size": 0,
|
||||
},
|
||||
"image": {
|
||||
"parse_method": "ocr",
|
||||
@ -117,13 +135,14 @@ class ParserParam(ProcessParamBase):
|
||||
},
|
||||
"email": {
|
||||
"suffix": [
|
||||
"eml", "msg"
|
||||
"eml",
|
||||
"msg",
|
||||
],
|
||||
"fields": ["from", "to", "cc", "bcc", "date", "subject", "body", "attachments", "metadata"],
|
||||
"output_format": "json",
|
||||
},
|
||||
"audio": {
|
||||
"suffix":[
|
||||
"suffix": [
|
||||
"da",
|
||||
"wave",
|
||||
"wav",
|
||||
@ -138,15 +157,15 @@ class ParserParam(ProcessParamBase):
|
||||
"realaudio",
|
||||
"vqf",
|
||||
"oggvorbis",
|
||||
"ape"
|
||||
"ape",
|
||||
],
|
||||
"output_format": "text",
|
||||
},
|
||||
"video": {
|
||||
"suffix":[
|
||||
"suffix": [
|
||||
"mp4",
|
||||
"avi",
|
||||
"mkv"
|
||||
"mkv",
|
||||
],
|
||||
"output_format": "text",
|
||||
},
|
||||
@ -245,14 +264,19 @@ class Parser(ProcessBase):
|
||||
bboxes.append(box)
|
||||
elif conf.get("parse_method").lower() == "tcadp parser":
|
||||
# ADP is a document parsing tool using Tencent Cloud API
|
||||
tcadp_parser = TCADPParser()
|
||||
table_result_type = conf.get("table_result_type", "1")
|
||||
markdown_image_response_type = conf.get("markdown_image_response_type", "1")
|
||||
tcadp_parser = TCADPParser(
|
||||
table_result_type=table_result_type,
|
||||
markdown_image_response_type=markdown_image_response_type,
|
||||
)
|
||||
sections, _ = tcadp_parser.parse_pdf(
|
||||
filepath=name,
|
||||
binary=blob,
|
||||
callback=self.callback,
|
||||
file_type="PDF",
|
||||
file_start_page=1,
|
||||
file_end_page=1000
|
||||
file_end_page=1000,
|
||||
)
|
||||
bboxes = []
|
||||
for section, position_tag in sections:
|
||||
@ -260,17 +284,20 @@ class Parser(ProcessBase):
|
||||
# Extract position information from TCADP's position tag
|
||||
# Format: @@{page_number}\t{x0}\t{x1}\t{top}\t{bottom}##
|
||||
import re
|
||||
|
||||
match = re.match(r"@@([0-9-]+)\t([0-9.]+)\t([0-9.]+)\t([0-9.]+)\t([0-9.]+)##", position_tag)
|
||||
if match:
|
||||
pn, x0, x1, top, bott = match.groups()
|
||||
bboxes.append({
|
||||
"page_number": int(pn.split('-')[0]), # Take the first page number
|
||||
"x0": float(x0),
|
||||
"x1": float(x1),
|
||||
"top": float(top),
|
||||
"bottom": float(bott),
|
||||
"text": section
|
||||
})
|
||||
bboxes.append(
|
||||
{
|
||||
"page_number": int(pn.split("-")[0]), # Take the first page number
|
||||
"x0": float(x0),
|
||||
"x1": float(x1),
|
||||
"top": float(top),
|
||||
"bottom": float(bott),
|
||||
"text": section,
|
||||
}
|
||||
)
|
||||
else:
|
||||
# If no position info, add as text without position
|
||||
bboxes.append({"text": section})
|
||||
@ -282,7 +309,30 @@ class Parser(ProcessBase):
|
||||
bboxes = []
|
||||
for t, poss in lines:
|
||||
for pn, x0, x1, top, bott in RAGFlowPdfParser.extract_positions(poss):
|
||||
bboxes.append({"page_number": int(pn[0]), "x0": float(x0), "x1": float(x1), "top": float(top), "bottom": float(bott), "text": t})
|
||||
bboxes.append(
|
||||
{
|
||||
"page_number": int(pn[0]),
|
||||
"x0": float(x0),
|
||||
"x1": float(x1),
|
||||
"top": float(top),
|
||||
"bottom": float(bott),
|
||||
"text": t,
|
||||
}
|
||||
)
|
||||
|
||||
for b in bboxes:
|
||||
text_val = b.get("text", "")
|
||||
has_text = isinstance(text_val, str) and text_val.strip()
|
||||
layout = b.get("layout_type")
|
||||
if layout == "figure" or (b.get("image") and not has_text):
|
||||
b["doc_type_kwd"] = "image"
|
||||
elif layout == "table":
|
||||
b["doc_type_kwd"] = "table"
|
||||
|
||||
table_ctx = conf.get("table_context_size", 0) or 0
|
||||
image_ctx = conf.get("image_context_size", 0) or 0
|
||||
if table_ctx or image_ctx:
|
||||
bboxes = attach_media_context(bboxes, table_ctx, image_ctx)
|
||||
|
||||
if conf.get("output_format") == "json":
|
||||
self.set_output("json", bboxes)
|
||||
@ -301,14 +351,91 @@ class Parser(ProcessBase):
|
||||
self.callback(random.randint(1, 5) / 100.0, "Start to work on a Spreadsheet.")
|
||||
conf = self._param.setups["spreadsheet"]
|
||||
self.set_output("output_format", conf["output_format"])
|
||||
spreadsheet_parser = ExcelParser()
|
||||
if conf.get("output_format") == "html":
|
||||
htmls = spreadsheet_parser.html(blob, 1000000000)
|
||||
self.set_output("html", htmls[0])
|
||||
elif conf.get("output_format") == "json":
|
||||
self.set_output("json", [{"text": txt} for txt in spreadsheet_parser(blob) if txt])
|
||||
elif conf.get("output_format") == "markdown":
|
||||
self.set_output("markdown", spreadsheet_parser.markdown(blob))
|
||||
|
||||
parse_method = conf.get("parse_method", "deepdoc")
|
||||
|
||||
# Handle TCADP parser
|
||||
if parse_method.lower() == "tcadp parser":
|
||||
table_result_type = conf.get("table_result_type", "1")
|
||||
markdown_image_response_type = conf.get("markdown_image_response_type", "1")
|
||||
tcadp_parser = TCADPParser(
|
||||
table_result_type=table_result_type,
|
||||
markdown_image_response_type=markdown_image_response_type,
|
||||
)
|
||||
if not tcadp_parser.check_installation():
|
||||
raise RuntimeError("TCADP parser not available. Please check Tencent Cloud API configuration.")
|
||||
|
||||
# Determine file type based on extension
|
||||
if re.search(r"\.xlsx?$", name, re.IGNORECASE):
|
||||
file_type = "XLSX"
|
||||
else:
|
||||
file_type = "CSV"
|
||||
|
||||
self.callback(0.2, f"Using TCADP parser for {file_type} file.")
|
||||
sections, tables = tcadp_parser.parse_pdf(
|
||||
filepath=name,
|
||||
binary=blob,
|
||||
callback=self.callback,
|
||||
file_type=file_type,
|
||||
file_start_page=1,
|
||||
file_end_page=1000,
|
||||
)
|
||||
|
||||
# Process TCADP parser output based on configured output_format
|
||||
output_format = conf.get("output_format", "html")
|
||||
|
||||
if output_format == "html":
|
||||
# For HTML output, combine sections and tables into HTML
|
||||
html_content = ""
|
||||
for section, position_tag in sections:
|
||||
if section:
|
||||
html_content += section + "\n"
|
||||
for table in tables:
|
||||
if table:
|
||||
html_content += table + "\n"
|
||||
|
||||
self.set_output("html", html_content)
|
||||
|
||||
elif output_format == "json":
|
||||
# For JSON output, create a list of text items
|
||||
result = []
|
||||
# Add sections as text
|
||||
for section, position_tag in sections:
|
||||
if section:
|
||||
result.append({"text": section})
|
||||
# Add tables as text
|
||||
for table in tables:
|
||||
if table:
|
||||
result.append({"text": table, "doc_type_kwd": "table"})
|
||||
|
||||
table_ctx = conf.get("table_context_size", 0) or 0
|
||||
image_ctx = conf.get("image_context_size", 0) or 0
|
||||
if table_ctx or image_ctx:
|
||||
result = attach_media_context(result, table_ctx, image_ctx)
|
||||
|
||||
self.set_output("json", result)
|
||||
|
||||
elif output_format == "markdown":
|
||||
# For markdown output, combine into markdown
|
||||
md_content = ""
|
||||
for section, position_tag in sections:
|
||||
if section:
|
||||
md_content += section + "\n\n"
|
||||
for table in tables:
|
||||
if table:
|
||||
md_content += table + "\n\n"
|
||||
|
||||
self.set_output("markdown", md_content)
|
||||
else:
|
||||
# Default DeepDOC parser
|
||||
spreadsheet_parser = ExcelParser()
|
||||
if conf.get("output_format") == "html":
|
||||
htmls = spreadsheet_parser.html(blob, 1000000000)
|
||||
self.set_output("html", htmls[0])
|
||||
elif conf.get("output_format") == "json":
|
||||
self.set_output("json", [{"text": txt} for txt in spreadsheet_parser(blob) if txt])
|
||||
elif conf.get("output_format") == "markdown":
|
||||
self.set_output("markdown", spreadsheet_parser.markdown(blob))
|
||||
|
||||
def _word(self, name, blob):
|
||||
self.callback(random.randint(1, 5) / 100.0, "Start to work on a Word Processor Document")
|
||||
@ -319,29 +446,91 @@ class Parser(ProcessBase):
|
||||
if conf.get("output_format") == "json":
|
||||
sections, tbls = docx_parser(name, binary=blob)
|
||||
sections = [{"text": section[0], "image": section[1]} for section in sections if section]
|
||||
sections.extend([{"text": tb, "image": None} for ((_,tb), _) in tbls])
|
||||
sections.extend([{"text": tb, "image": None, "doc_type_kwd": "table"} for ((_, tb), _) in tbls])
|
||||
|
||||
table_ctx = conf.get("table_context_size", 0) or 0
|
||||
image_ctx = conf.get("image_context_size", 0) or 0
|
||||
if table_ctx or image_ctx:
|
||||
sections = attach_media_context(sections, table_ctx, image_ctx)
|
||||
|
||||
self.set_output("json", sections)
|
||||
elif conf.get("output_format") == "markdown":
|
||||
markdown_text = docx_parser.to_markdown(name, binary=blob)
|
||||
self.set_output("markdown", markdown_text)
|
||||
|
||||
def _slides(self, name, blob):
|
||||
from deepdoc.parser.ppt_parser import RAGFlowPptParser as ppt_parser
|
||||
|
||||
self.callback(random.randint(1, 5) / 100.0, "Start to work on a PowerPoint Document")
|
||||
|
||||
conf = self._param.setups["slides"]
|
||||
self.set_output("output_format", conf["output_format"])
|
||||
|
||||
ppt_parser = ppt_parser()
|
||||
txts = ppt_parser(blob, 0, 100000, None)
|
||||
parse_method = conf.get("parse_method", "deepdoc")
|
||||
|
||||
sections = [{"text": section} for section in txts if section.strip()]
|
||||
# Handle TCADP parser
|
||||
if parse_method.lower() == "tcadp parser":
|
||||
table_result_type = conf.get("table_result_type", "1")
|
||||
markdown_image_response_type = conf.get("markdown_image_response_type", "1")
|
||||
tcadp_parser = TCADPParser(
|
||||
table_result_type=table_result_type,
|
||||
markdown_image_response_type=markdown_image_response_type,
|
||||
)
|
||||
if not tcadp_parser.check_installation():
|
||||
raise RuntimeError("TCADP parser not available. Please check Tencent Cloud API configuration.")
|
||||
|
||||
# json
|
||||
assert conf.get("output_format") == "json", "have to be json for ppt"
|
||||
if conf.get("output_format") == "json":
|
||||
self.set_output("json", sections)
|
||||
# Determine file type based on extension
|
||||
if re.search(r"\.pptx?$", name, re.IGNORECASE):
|
||||
file_type = "PPTX"
|
||||
else:
|
||||
file_type = "PPT"
|
||||
|
||||
self.callback(0.2, f"Using TCADP parser for {file_type} file.")
|
||||
|
||||
sections, tables = tcadp_parser.parse_pdf(
|
||||
filepath=name,
|
||||
binary=blob,
|
||||
callback=self.callback,
|
||||
file_type=file_type,
|
||||
file_start_page=1,
|
||||
file_end_page=1000,
|
||||
)
|
||||
|
||||
# Process TCADP parser output - PPT only supports json format
|
||||
output_format = conf.get("output_format", "json")
|
||||
if output_format == "json":
|
||||
# For JSON output, create a list of text items
|
||||
result = []
|
||||
# Add sections as text
|
||||
for section, position_tag in sections:
|
||||
if section:
|
||||
result.append({"text": section})
|
||||
# Add tables as text
|
||||
for table in tables:
|
||||
if table:
|
||||
result.append({"text": table, "doc_type_kwd": "table"})
|
||||
|
||||
table_ctx = conf.get("table_context_size", 0) or 0
|
||||
image_ctx = conf.get("image_context_size", 0) or 0
|
||||
if table_ctx or image_ctx:
|
||||
result = attach_media_context(result, table_ctx, image_ctx)
|
||||
|
||||
self.set_output("json", result)
|
||||
else:
|
||||
# Default DeepDOC parser (supports .pptx format)
|
||||
from deepdoc.parser.ppt_parser import RAGFlowPptParser as ppt_parser
|
||||
|
||||
ppt_parser = ppt_parser()
|
||||
txts = ppt_parser(blob, 0, 100000, None)
|
||||
|
||||
sections = [{"text": section} for section in txts if section.strip()]
|
||||
|
||||
# json
|
||||
assert conf.get("output_format") == "json", "have to be json for ppt"
|
||||
if conf.get("output_format") == "json":
|
||||
table_ctx = conf.get("table_context_size", 0) or 0
|
||||
image_ctx = conf.get("image_context_size", 0) or 0
|
||||
if table_ctx or image_ctx:
|
||||
sections = attach_media_context(sections, table_ctx, image_ctx)
|
||||
self.set_output("json", sections)
|
||||
|
||||
def _markdown(self, name, blob):
|
||||
from functools import reduce
|
||||
@ -354,17 +543,25 @@ class Parser(ProcessBase):
|
||||
self.set_output("output_format", conf["output_format"])
|
||||
|
||||
markdown_parser = naive_markdown_parser()
|
||||
sections, tables = markdown_parser(name, blob, separate_tables=False)
|
||||
sections, tables, section_images = markdown_parser(
|
||||
name,
|
||||
blob,
|
||||
separate_tables=False,
|
||||
delimiter=conf.get("delimiter"),
|
||||
return_section_images=True,
|
||||
)
|
||||
|
||||
if conf.get("output_format") == "json":
|
||||
json_results = []
|
||||
|
||||
for section_text, _ in sections:
|
||||
for idx, (section_text, _) in enumerate(sections):
|
||||
json_result = {
|
||||
"text": section_text,
|
||||
}
|
||||
|
||||
images = markdown_parser.get_pictures(section_text) if section_text else None
|
||||
images = []
|
||||
if section_images and len(section_images) > idx and section_images[idx] is not None:
|
||||
images.append(section_images[idx])
|
||||
if images:
|
||||
# If multiple images found, combine them using concat_img
|
||||
combined_image = reduce(concat_img, images) if len(images) > 1 else images[0]
|
||||
@ -372,11 +569,15 @@ class Parser(ProcessBase):
|
||||
|
||||
json_results.append(json_result)
|
||||
|
||||
table_ctx = conf.get("table_context_size", 0) or 0
|
||||
image_ctx = conf.get("image_context_size", 0) or 0
|
||||
if table_ctx or image_ctx:
|
||||
json_results = attach_media_context(json_results, table_ctx, image_ctx)
|
||||
|
||||
self.set_output("json", json_results)
|
||||
else:
|
||||
self.set_output("text", "\n".join([section_text for section_text, _ in sections]))
|
||||
|
||||
|
||||
def _image(self, name, blob):
|
||||
from deepdoc.vision import OCR
|
||||
|
||||
@ -452,7 +653,7 @@ class Parser(ProcessBase):
|
||||
from email.parser import BytesParser
|
||||
|
||||
msg = BytesParser(policy=policy.default).parse(io.BytesIO(blob))
|
||||
email_content['metadata'] = {}
|
||||
email_content["metadata"] = {}
|
||||
# handle header info
|
||||
for header, value in msg.items():
|
||||
# get fields like from, to, cc, bcc, date, subject
|
||||
@ -464,6 +665,7 @@ class Parser(ProcessBase):
|
||||
# get body
|
||||
if "body" in target_fields:
|
||||
body_text, body_html = [], []
|
||||
|
||||
def _add_content(m, content_type):
|
||||
def _decode_payload(payload, charset, target_list):
|
||||
try:
|
||||
@ -505,14 +707,17 @@ class Parser(ProcessBase):
|
||||
if dispositions[0].lower() == "attachment":
|
||||
filename = part.get_filename()
|
||||
payload = part.get_payload(decode=True).decode(part.get_content_charset())
|
||||
attachments.append({
|
||||
"filename": filename,
|
||||
"payload": payload,
|
||||
})
|
||||
attachments.append(
|
||||
{
|
||||
"filename": filename,
|
||||
"payload": payload,
|
||||
}
|
||||
)
|
||||
email_content["attachments"] = attachments
|
||||
else:
|
||||
# handle msg file
|
||||
import extract_msg
|
||||
|
||||
print("handle a msg file.")
|
||||
msg = extract_msg.Message(blob)
|
||||
# handle header info
|
||||
@ -526,9 +731,9 @@ class Parser(ProcessBase):
|
||||
}
|
||||
email_content.update({k: v for k, v in basic_content.items() if k in target_fields})
|
||||
# get metadata
|
||||
email_content['metadata'] = {
|
||||
'message_id': msg.messageId,
|
||||
'in_reply_to': msg.inReplyTo,
|
||||
email_content["metadata"] = {
|
||||
"message_id": msg.messageId,
|
||||
"in_reply_to": msg.inReplyTo,
|
||||
}
|
||||
# get body
|
||||
if "body" in target_fields:
|
||||
@ -539,29 +744,31 @@ class Parser(ProcessBase):
|
||||
if "attachments" in target_fields:
|
||||
attachments = []
|
||||
for t in msg.attachments:
|
||||
attachments.append({
|
||||
"filename": t.name,
|
||||
"payload": t.data.decode("utf-8")
|
||||
})
|
||||
attachments.append(
|
||||
{
|
||||
"filename": t.name,
|
||||
"payload": t.data.decode("utf-8"),
|
||||
}
|
||||
)
|
||||
email_content["attachments"] = attachments
|
||||
|
||||
if conf["output_format"] == "json":
|
||||
self.set_output("json", [email_content])
|
||||
else:
|
||||
content_txt = ''
|
||||
content_txt = ""
|
||||
for k, v in email_content.items():
|
||||
if isinstance(v, str):
|
||||
# basic info
|
||||
content_txt += f'{k}:{v}' + "\n"
|
||||
content_txt += f"{k}:{v}" + "\n"
|
||||
elif isinstance(v, dict):
|
||||
# metadata
|
||||
content_txt += f'{k}:{json.dumps(v)}' + "\n"
|
||||
content_txt += f"{k}:{json.dumps(v)}" + "\n"
|
||||
elif isinstance(v, list):
|
||||
# attachments or others
|
||||
for fb in v:
|
||||
if isinstance(fb, dict):
|
||||
# attachments
|
||||
content_txt += f'{fb["filename"]}:{fb["payload"]}' + "\n"
|
||||
content_txt += f"{fb['filename']}:{fb['payload']}" + "\n"
|
||||
else:
|
||||
# str, usually plain text
|
||||
content_txt += fb
|
||||
@ -579,6 +786,7 @@ class Parser(ProcessBase):
|
||||
"video": self._video,
|
||||
"email": self._email,
|
||||
}
|
||||
|
||||
try:
|
||||
from_upstream = ParserFromUpstream.model_validate(kwargs)
|
||||
except Exception as e:
|
||||
|
||||
@ -132,6 +132,11 @@ class Base(ABC):
|
||||
|
||||
gen_conf = {k: v for k, v in gen_conf.items() if k in allowed_conf}
|
||||
|
||||
model_name_lower = (self.model_name or "").lower()
|
||||
# gpt-5 and gpt-5.1 endpoints have inconsistent parameter support, clear custom generation params to prevent unexpected issues
|
||||
if "gpt-5" in model_name_lower:
|
||||
gen_conf = {}
|
||||
|
||||
return gen_conf
|
||||
|
||||
def _chat(self, history, gen_conf, **kwargs):
|
||||
@ -1635,6 +1640,15 @@ class LiteLLMBase(ABC):
|
||||
provider_cfg["allow_fallbacks"] = False
|
||||
extra_body["provider"] = provider_cfg
|
||||
completion_args.update({"extra_body": extra_body})
|
||||
|
||||
# Ollama deployments commonly sit behind a reverse proxy that enforces
|
||||
# Bearer auth. Ensure the Authorization header is set when an API key
|
||||
# is provided, while respecting any user-supplied headers. #11350
|
||||
extra_headers = deepcopy(completion_args.get("extra_headers") or {})
|
||||
if self.provider == SupportedLiteLLMProvider.Ollama and self.api_key and "Authorization" not in extra_headers:
|
||||
extra_headers["Authorization"] = f"Bearer {self.api_key}"
|
||||
if extra_headers:
|
||||
completion_args["extra_headers"] = extra_headers
|
||||
return completion_args
|
||||
|
||||
def chat_with_tools(self, system: str, history: list, gen_conf: dict = {}):
|
||||
|
||||
@ -200,8 +200,7 @@ class GptV4(Base):
|
||||
res = self.client.chat.completions.create(
|
||||
model=self.model_name,
|
||||
messages=self.prompt(b64),
|
||||
extra_body=self.extra_body,
|
||||
unused=None,
|
||||
extra_body=self.extra_body
|
||||
)
|
||||
return res.choices[0].message.content.strip(), total_token_count_from_response(res)
|
||||
|
||||
@ -284,6 +283,8 @@ class QWenCV(GptV4):
|
||||
model=self.model_name,
|
||||
messages=messages,
|
||||
)
|
||||
if response.get("message"):
|
||||
raise Exception(response["message"])
|
||||
summary = response["output"]["choices"][0]["message"].content[0]["text"]
|
||||
return summary, num_tokens_from_string(summary)
|
||||
|
||||
|
||||
@ -234,7 +234,11 @@ class CoHereRerank(Base):
|
||||
def __init__(self, key, model_name, base_url=None):
|
||||
from cohere import Client
|
||||
|
||||
self.client = Client(api_key=key, base_url=base_url)
|
||||
# Only pass base_url if it's a non-empty string, otherwise use default Cohere API endpoint
|
||||
client_kwargs = {"api_key": key}
|
||||
if base_url and base_url.strip():
|
||||
client_kwargs["base_url"] = base_url
|
||||
self.client = Client(**client_kwargs)
|
||||
self.model_name = model_name.split("___")[0]
|
||||
|
||||
def similarity(self, query: str, texts: list):
|
||||
|
||||
@ -318,6 +318,7 @@ def tokenize_table(tbls, doc, eng, batch_size=10):
|
||||
d = copy.deepcopy(doc)
|
||||
tokenize(d, rows, eng)
|
||||
d["content_with_weight"] = rows
|
||||
d["doc_type_kwd"] = "table"
|
||||
if img:
|
||||
d["image"] = img
|
||||
d["doc_type_kwd"] = "image"
|
||||
@ -330,6 +331,7 @@ def tokenize_table(tbls, doc, eng, batch_size=10):
|
||||
d = copy.deepcopy(doc)
|
||||
r = de.join(rows[i:i + batch_size])
|
||||
tokenize(d, r, eng)
|
||||
d["doc_type_kwd"] = "table"
|
||||
if img:
|
||||
d["image"] = img
|
||||
d["doc_type_kwd"] = "image"
|
||||
@ -338,6 +340,194 @@ def tokenize_table(tbls, doc, eng, batch_size=10):
|
||||
return res
|
||||
|
||||
|
||||
def attach_media_context(chunks, table_context_size=0, image_context_size=0):
|
||||
"""
|
||||
Attach surrounding text chunk content to media chunks (table/image).
|
||||
Best-effort ordering: if positional info exists on any chunk, use it to
|
||||
order chunks before collecting context; otherwise keep original order.
|
||||
"""
|
||||
if not chunks or (table_context_size <= 0 and image_context_size <= 0):
|
||||
return chunks
|
||||
|
||||
def is_image_chunk(ck):
|
||||
if ck.get("doc_type_kwd") == "image":
|
||||
return True
|
||||
|
||||
text_val = ck.get("content_with_weight") if isinstance(ck.get("content_with_weight"), str) else ck.get("text")
|
||||
has_text = isinstance(text_val, str) and text_val.strip()
|
||||
return bool(ck.get("image")) and not has_text
|
||||
|
||||
def is_table_chunk(ck):
|
||||
return ck.get("doc_type_kwd") == "table"
|
||||
|
||||
def is_text_chunk(ck):
|
||||
return not is_image_chunk(ck) and not is_table_chunk(ck)
|
||||
|
||||
def get_text(ck):
|
||||
if isinstance(ck.get("content_with_weight"), str):
|
||||
return ck["content_with_weight"]
|
||||
if isinstance(ck.get("text"), str):
|
||||
return ck["text"]
|
||||
return ""
|
||||
|
||||
def split_sentences(text):
|
||||
pattern = r"([.。!?!?;;::\n])"
|
||||
parts = re.split(pattern, text)
|
||||
sentences = []
|
||||
buf = ""
|
||||
for p in parts:
|
||||
if not p:
|
||||
continue
|
||||
if re.fullmatch(pattern, p):
|
||||
buf += p
|
||||
sentences.append(buf)
|
||||
buf = ""
|
||||
else:
|
||||
buf += p
|
||||
if buf:
|
||||
sentences.append(buf)
|
||||
return sentences
|
||||
|
||||
def trim_to_tokens(text, token_budget, from_tail=False):
|
||||
if token_budget <= 0 or not text:
|
||||
return ""
|
||||
sentences = split_sentences(text)
|
||||
if not sentences:
|
||||
return ""
|
||||
|
||||
collected = []
|
||||
remaining = token_budget
|
||||
seq = reversed(sentences) if from_tail else sentences
|
||||
for s in seq:
|
||||
tks = num_tokens_from_string(s)
|
||||
if tks <= 0:
|
||||
continue
|
||||
if tks > remaining:
|
||||
collected.append(s)
|
||||
break
|
||||
collected.append(s)
|
||||
remaining -= tks
|
||||
|
||||
if from_tail:
|
||||
collected = list(reversed(collected))
|
||||
return "".join(collected)
|
||||
|
||||
def extract_position(ck):
|
||||
pn = None
|
||||
top = None
|
||||
left = None
|
||||
try:
|
||||
if ck.get("page_num_int"):
|
||||
pn = ck["page_num_int"][0]
|
||||
elif ck.get("page_number") is not None:
|
||||
pn = ck.get("page_number")
|
||||
|
||||
if ck.get("top_int"):
|
||||
top = ck["top_int"][0]
|
||||
elif ck.get("top") is not None:
|
||||
top = ck.get("top")
|
||||
|
||||
if ck.get("position_int"):
|
||||
left = ck["position_int"][0][1]
|
||||
elif ck.get("x0") is not None:
|
||||
left = ck.get("x0")
|
||||
except Exception:
|
||||
pn = top = left = None
|
||||
return pn, top, left
|
||||
|
||||
indexed = list(enumerate(chunks))
|
||||
positioned_indices = []
|
||||
unpositioned_indices = []
|
||||
for idx, ck in indexed:
|
||||
pn, top, left = extract_position(ck)
|
||||
if pn is not None and top is not None:
|
||||
positioned_indices.append((idx, pn, top, left if left is not None else 0))
|
||||
else:
|
||||
unpositioned_indices.append(idx)
|
||||
|
||||
if positioned_indices:
|
||||
positioned_indices.sort(key=lambda x: (int(x[1]), int(x[2]), int(x[3]), x[0]))
|
||||
ordered_indices = [i for i, _, _, _ in positioned_indices] + unpositioned_indices
|
||||
else:
|
||||
ordered_indices = [idx for idx, _ in indexed]
|
||||
|
||||
total = len(ordered_indices)
|
||||
for sorted_pos, idx in enumerate(ordered_indices):
|
||||
ck = chunks[idx]
|
||||
token_budget = image_context_size if is_image_chunk(ck) else table_context_size if is_table_chunk(ck) else 0
|
||||
if token_budget <= 0:
|
||||
continue
|
||||
|
||||
prev_ctx = []
|
||||
remaining_prev = token_budget
|
||||
for prev_idx in range(sorted_pos - 1, -1, -1):
|
||||
if remaining_prev <= 0:
|
||||
break
|
||||
neighbor_idx = ordered_indices[prev_idx]
|
||||
if not is_text_chunk(chunks[neighbor_idx]):
|
||||
break
|
||||
txt = get_text(chunks[neighbor_idx])
|
||||
if not txt:
|
||||
continue
|
||||
tks = num_tokens_from_string(txt)
|
||||
if tks <= 0:
|
||||
continue
|
||||
if tks > remaining_prev:
|
||||
txt = trim_to_tokens(txt, remaining_prev, from_tail=True)
|
||||
tks = num_tokens_from_string(txt)
|
||||
prev_ctx.append(txt)
|
||||
remaining_prev -= tks
|
||||
prev_ctx.reverse()
|
||||
|
||||
next_ctx = []
|
||||
remaining_next = token_budget
|
||||
for next_idx in range(sorted_pos + 1, total):
|
||||
if remaining_next <= 0:
|
||||
break
|
||||
neighbor_idx = ordered_indices[next_idx]
|
||||
if not is_text_chunk(chunks[neighbor_idx]):
|
||||
break
|
||||
txt = get_text(chunks[neighbor_idx])
|
||||
if not txt:
|
||||
continue
|
||||
tks = num_tokens_from_string(txt)
|
||||
if tks <= 0:
|
||||
continue
|
||||
if tks > remaining_next:
|
||||
txt = trim_to_tokens(txt, remaining_next, from_tail=False)
|
||||
tks = num_tokens_from_string(txt)
|
||||
next_ctx.append(txt)
|
||||
remaining_next -= tks
|
||||
|
||||
if not prev_ctx and not next_ctx:
|
||||
continue
|
||||
|
||||
self_text = get_text(ck)
|
||||
pieces = [*prev_ctx]
|
||||
if self_text:
|
||||
pieces.append(self_text)
|
||||
pieces.extend(next_ctx)
|
||||
combined = "\n".join(pieces)
|
||||
|
||||
original = ck.get("content_with_weight")
|
||||
if "content_with_weight" in ck:
|
||||
ck["content_with_weight"] = combined
|
||||
elif "text" in ck:
|
||||
original = ck.get("text")
|
||||
ck["text"] = combined
|
||||
|
||||
if combined != original:
|
||||
if "content_ltks" in ck:
|
||||
ck["content_ltks"] = rag_tokenizer.tokenize(combined)
|
||||
if "content_sm_ltks" in ck:
|
||||
ck["content_sm_ltks"] = rag_tokenizer.fine_grained_tokenize(ck.get("content_ltks", rag_tokenizer.tokenize(combined)))
|
||||
|
||||
if positioned_indices:
|
||||
chunks[:] = [chunks[i] for i in ordered_indices]
|
||||
|
||||
return chunks
|
||||
|
||||
|
||||
def add_positions(d, poss):
|
||||
if not poss:
|
||||
return
|
||||
@ -437,16 +627,16 @@ def not_title(txt):
|
||||
return re.search(r"[,;,。;!!]", txt)
|
||||
|
||||
def tree_merge(bull, sections, depth):
|
||||
|
||||
|
||||
if not sections or bull < 0:
|
||||
return sections
|
||||
if isinstance(sections[0], type("")):
|
||||
sections = [(s, "") for s in sections]
|
||||
|
||||
|
||||
# filter out position information in pdf sections
|
||||
sections = [(t, o) for t, o in sections if
|
||||
t and len(t.split("@")[0].strip()) > 1 and not re.match(r"[0-9]+$", t.split("@")[0].strip())]
|
||||
|
||||
|
||||
def get_level(bull, section):
|
||||
text, layout = section
|
||||
text = re.sub(r"\u3000", " ", text).strip()
|
||||
@ -465,7 +655,7 @@ def tree_merge(bull, sections, depth):
|
||||
level, text = get_level(bull, section)
|
||||
if not text.strip("\n"):
|
||||
continue
|
||||
|
||||
|
||||
lines.append((level, text))
|
||||
level_set.add(level)
|
||||
|
||||
@ -608,16 +798,28 @@ def naive_merge(sections: str | list, chunk_token_num=128, delimiter="\n。;
|
||||
cks[-1] += t
|
||||
tk_nums[-1] += tnum
|
||||
|
||||
dels = get_delimiters(delimiter)
|
||||
custom_delimiters = [m.group(1) for m in re.finditer(r"`([^`]+)`", delimiter)]
|
||||
has_custom = bool(custom_delimiters)
|
||||
if has_custom:
|
||||
custom_pattern = "|".join(re.escape(t) for t in sorted(set(custom_delimiters), key=len, reverse=True))
|
||||
cks, tk_nums = [], []
|
||||
for sec, pos in sections:
|
||||
split_sec = re.split(r"(%s)" % custom_pattern, sec, flags=re.DOTALL)
|
||||
for sub_sec in split_sec:
|
||||
if re.fullmatch(custom_pattern, sub_sec or ""):
|
||||
continue
|
||||
text = "\n" + sub_sec
|
||||
local_pos = pos
|
||||
if num_tokens_from_string(text) < 8:
|
||||
local_pos = ""
|
||||
if local_pos and text.find(local_pos) < 0:
|
||||
text += local_pos
|
||||
cks.append(text)
|
||||
tk_nums.append(num_tokens_from_string(text))
|
||||
return cks
|
||||
|
||||
for sec, pos in sections:
|
||||
if num_tokens_from_string(sec) < chunk_token_num:
|
||||
add_chunk("\n"+sec, pos)
|
||||
continue
|
||||
split_sec = re.split(r"(%s)" % dels, sec, flags=re.DOTALL)
|
||||
for sub_sec in split_sec:
|
||||
if re.match(f"^{dels}$", sub_sec):
|
||||
continue
|
||||
add_chunk("\n"+sub_sec, pos)
|
||||
add_chunk("\n"+sec, pos)
|
||||
|
||||
return cks
|
||||
|
||||
@ -657,26 +859,41 @@ def naive_merge_with_images(texts, images, chunk_token_num=128, delimiter="\n。
|
||||
result_images[-1] = concat_img(result_images[-1], image)
|
||||
tk_nums[-1] += tnum
|
||||
|
||||
dels = get_delimiters(delimiter)
|
||||
custom_delimiters = [m.group(1) for m in re.finditer(r"`([^`]+)`", delimiter)]
|
||||
has_custom = bool(custom_delimiters)
|
||||
if has_custom:
|
||||
custom_pattern = "|".join(re.escape(t) for t in sorted(set(custom_delimiters), key=len, reverse=True))
|
||||
cks, result_images, tk_nums = [], [], []
|
||||
for text, image in zip(texts, images):
|
||||
text_str = text[0] if isinstance(text, tuple) else text
|
||||
text_pos = text[1] if isinstance(text, tuple) and len(text) > 1 else ""
|
||||
split_sec = re.split(r"(%s)" % custom_pattern, text_str)
|
||||
for sub_sec in split_sec:
|
||||
if re.fullmatch(custom_pattern, sub_sec or ""):
|
||||
continue
|
||||
text_seg = "\n" + sub_sec
|
||||
local_pos = text_pos
|
||||
if num_tokens_from_string(text_seg) < 8:
|
||||
local_pos = ""
|
||||
if local_pos and text_seg.find(local_pos) < 0:
|
||||
text_seg += local_pos
|
||||
cks.append(text_seg)
|
||||
result_images.append(image)
|
||||
tk_nums.append(num_tokens_from_string(text_seg))
|
||||
return cks, result_images
|
||||
|
||||
for text, image in zip(texts, images):
|
||||
# if text is tuple, unpack it
|
||||
if isinstance(text, tuple):
|
||||
text_str = text[0]
|
||||
text_pos = text[1] if len(text) > 1 else ""
|
||||
split_sec = re.split(r"(%s)" % dels, text_str)
|
||||
for sub_sec in split_sec:
|
||||
if re.match(f"^{dels}$", sub_sec):
|
||||
continue
|
||||
add_chunk("\n"+sub_sec, image, text_pos)
|
||||
add_chunk("\n"+text_str, image, text_pos)
|
||||
else:
|
||||
split_sec = re.split(r"(%s)" % dels, text)
|
||||
for sub_sec in split_sec:
|
||||
if re.match(f"^{dels}$", sub_sec):
|
||||
continue
|
||||
add_chunk("\n"+sub_sec, image)
|
||||
add_chunk("\n"+text, image)
|
||||
|
||||
return cks, result_images
|
||||
|
||||
|
||||
def docx_question_level(p, bull=-1):
|
||||
txt = re.sub(r"\u3000", " ", p.text).strip()
|
||||
if p.style.name.startswith('Heading'):
|
||||
@ -748,15 +965,25 @@ def naive_merge_docx(sections, chunk_token_num=128, delimiter="\n。;!?"):
|
||||
images[-1] = concat_img(images[-1], image)
|
||||
tk_nums[-1] += tnum
|
||||
|
||||
dels = get_delimiters(delimiter)
|
||||
pattern = r"(%s)" % dels
|
||||
custom_delimiters = [m.group(1) for m in re.finditer(r"`([^`]+)`", delimiter)]
|
||||
has_custom = bool(custom_delimiters)
|
||||
if has_custom:
|
||||
custom_pattern = "|".join(re.escape(t) for t in sorted(set(custom_delimiters), key=len, reverse=True))
|
||||
cks, images, tk_nums = [], [], []
|
||||
pattern = r"(%s)" % custom_pattern
|
||||
for sec, image in sections:
|
||||
split_sec = re.split(pattern, sec)
|
||||
for sub_sec in split_sec:
|
||||
if not sub_sec or re.fullmatch(custom_pattern, sub_sec):
|
||||
continue
|
||||
text_seg = "\n" + sub_sec
|
||||
cks.append(text_seg)
|
||||
images.append(image)
|
||||
tk_nums.append(num_tokens_from_string(text_seg))
|
||||
return cks, images
|
||||
|
||||
for sec, image in sections:
|
||||
split_sec = re.split(pattern, sec)
|
||||
for sub_sec in split_sec:
|
||||
if not sub_sec or re.match(f"^{dels}$", sub_sec):
|
||||
continue
|
||||
add_chunk("\n" + sub_sec, image, "")
|
||||
add_chunk("\n" + sec, image, "")
|
||||
|
||||
return cks, images
|
||||
|
||||
@ -784,12 +1011,13 @@ def get_delimiters(delimiters: str):
|
||||
|
||||
return dels_pattern
|
||||
|
||||
|
||||
class Node:
|
||||
def __init__(self, level, depth=-1, texts=None):
|
||||
self.level = level
|
||||
self.depth = depth
|
||||
self.texts = texts or []
|
||||
self.children = []
|
||||
self.children = []
|
||||
|
||||
def add_child(self, child_node):
|
||||
self.children.append(child_node)
|
||||
@ -835,7 +1063,7 @@ class Node:
|
||||
return self
|
||||
|
||||
def get_tree(self):
|
||||
tree_list = []
|
||||
tree_list = []
|
||||
self._dfs(self, tree_list, [])
|
||||
return tree_list
|
||||
|
||||
@ -860,7 +1088,7 @@ class Node:
|
||||
# A leaf title within depth emits its title path as a chunk (header-only section)
|
||||
elif not child and (1 <= level <= self.depth):
|
||||
tree_list.append("\n".join(path_titles))
|
||||
|
||||
|
||||
# Recurse into children with the updated title path
|
||||
for c in child:
|
||||
self._dfs(c, tree_list, path_titles)
|
||||
self._dfs(c, tree_list, path_titles)
|
||||
|
||||
@ -83,6 +83,7 @@ class FulltextQueryer:
|
||||
return txt
|
||||
|
||||
def question(self, txt, tbl="qa", min_match: float = 0.6):
|
||||
original_query = txt
|
||||
txt = FulltextQueryer.add_space_between_eng_zh(txt)
|
||||
txt = re.sub(
|
||||
r"[ :|\r\n\t,,。??/`!!&^%%()\[\]{}<>]+",
|
||||
@ -127,7 +128,7 @@ class FulltextQueryer:
|
||||
q.append(txt)
|
||||
query = " ".join(q)
|
||||
return MatchTextExpr(
|
||||
self.query_fields, query, 100
|
||||
self.query_fields, query, 100, {"original_query": original_query}
|
||||
), keywords
|
||||
|
||||
def need_fine_grained_tokenize(tk):
|
||||
@ -212,7 +213,7 @@ class FulltextQueryer:
|
||||
if not query:
|
||||
query = otxt
|
||||
return MatchTextExpr(
|
||||
self.query_fields, query, 100, {"minimum_should_match": min_match}
|
||||
self.query_fields, query, 100, {"minimum_should_match": min_match, "original_query": original_query}
|
||||
), keywords
|
||||
return None, keywords
|
||||
|
||||
@ -259,6 +260,7 @@ class FulltextQueryer:
|
||||
content_tks = [c.strip() for c in content_tks.strip() if c.strip()]
|
||||
tks_w = self.tw.weights(content_tks, preprocess=False)
|
||||
|
||||
origin_keywords = keywords.copy()
|
||||
keywords = [f'"{k.strip()}"' for k in keywords]
|
||||
for tk, w in sorted(tks_w, key=lambda x: x[1] * -1)[:keywords_topn]:
|
||||
tk_syns = self.syn.lookup(tk)
|
||||
@ -274,4 +276,4 @@ class FulltextQueryer:
|
||||
keywords.append(f"{tk}^{w}")
|
||||
|
||||
return MatchTextExpr(self.query_fields, " ".join(keywords), 100,
|
||||
{"minimum_should_match": min(3, len(keywords) // 10)})
|
||||
{"minimum_should_match": min(3, len(keywords) / 10), "original_query": " ".join(origin_keywords)})
|
||||
|
||||
@ -26,6 +26,7 @@ from hanziconv import HanziConv
|
||||
from nltk import word_tokenize
|
||||
from nltk.stem import PorterStemmer, WordNetLemmatizer
|
||||
from common.file_utils import get_project_base_directory
|
||||
from common import settings
|
||||
|
||||
|
||||
class RagTokenizer:
|
||||
@ -38,7 +39,7 @@ class RagTokenizer:
|
||||
def _load_dict(self, fnm):
|
||||
logging.info(f"[HUQIE]:Build trie from {fnm}")
|
||||
try:
|
||||
of = open(fnm, "r", encoding='utf-8')
|
||||
of = open(fnm, "r", encoding="utf-8")
|
||||
while True:
|
||||
line = of.readline()
|
||||
if not line:
|
||||
@ -46,7 +47,7 @@ class RagTokenizer:
|
||||
line = re.sub(r"[\r\n]+", "", line)
|
||||
line = re.split(r"[ \t]", line)
|
||||
k = self.key_(line[0])
|
||||
F = int(math.log(float(line[1]) / self.DENOMINATOR) + .5)
|
||||
F = int(math.log(float(line[1]) / self.DENOMINATOR) + 0.5)
|
||||
if k not in self.trie_ or self.trie_[k][0] < F:
|
||||
self.trie_[self.key_(line[0])] = (F, line[2])
|
||||
self.trie_[self.rkey_(line[0])] = 1
|
||||
@ -106,8 +107,8 @@ class RagTokenizer:
|
||||
if inside_code == 0x3000:
|
||||
inside_code = 0x0020
|
||||
else:
|
||||
inside_code -= 0xfee0
|
||||
if inside_code < 0x0020 or inside_code > 0x7e: # After the conversion, if it's not a half-width character, return the original character.
|
||||
inside_code -= 0xFEE0
|
||||
if inside_code < 0x0020 or inside_code > 0x7E: # After the conversion, if it's not a half-width character, return the original character.
|
||||
rstring += uchar
|
||||
else:
|
||||
rstring += chr(inside_code)
|
||||
@ -124,14 +125,14 @@ class RagTokenizer:
|
||||
if s < len(chars):
|
||||
copy_pretks = copy.deepcopy(preTks)
|
||||
remaining = "".join(chars[s:])
|
||||
copy_pretks.append((remaining, (-12, '')))
|
||||
copy_pretks.append((remaining, (-12, "")))
|
||||
tkslist.append(copy_pretks)
|
||||
return s
|
||||
|
||||
|
||||
state_key = (s, tuple(tk[0] for tk in preTks)) if preTks else (s, None)
|
||||
if state_key in _memo:
|
||||
return _memo[state_key]
|
||||
|
||||
|
||||
res = s
|
||||
if s >= len(chars):
|
||||
tkslist.append(preTks)
|
||||
@ -155,23 +156,23 @@ class RagTokenizer:
|
||||
if k in self.trie_:
|
||||
copy_pretks.append((t, self.trie_[k]))
|
||||
else:
|
||||
copy_pretks.append((t, (-12, '')))
|
||||
copy_pretks.append((t, (-12, "")))
|
||||
next_res = self.dfs_(chars, mid, copy_pretks, tkslist, _depth + 1, _memo)
|
||||
res = max(res, next_res)
|
||||
_memo[state_key] = res
|
||||
return res
|
||||
|
||||
|
||||
S = s + 1
|
||||
if s + 2 <= len(chars):
|
||||
t1 = "".join(chars[s:s + 1])
|
||||
t2 = "".join(chars[s:s + 2])
|
||||
t1 = "".join(chars[s : s + 1])
|
||||
t2 = "".join(chars[s : s + 2])
|
||||
if self.trie_.has_keys_with_prefix(self.key_(t1)) and not self.trie_.has_keys_with_prefix(self.key_(t2)):
|
||||
S = s + 2
|
||||
if len(preTks) > 2 and len(preTks[-1][0]) == 1 and len(preTks[-2][0]) == 1 and len(preTks[-3][0]) == 1:
|
||||
t1 = preTks[-1][0] + "".join(chars[s:s + 1])
|
||||
t1 = preTks[-1][0] + "".join(chars[s : s + 1])
|
||||
if self.trie_.has_keys_with_prefix(self.key_(t1)):
|
||||
S = s + 2
|
||||
|
||||
|
||||
for e in range(S, len(chars) + 1):
|
||||
t = "".join(chars[s:e])
|
||||
k = self.key_(t)
|
||||
@ -181,18 +182,18 @@ class RagTokenizer:
|
||||
pretks = copy.deepcopy(preTks)
|
||||
pretks.append((t, self.trie_[k]))
|
||||
res = max(res, self.dfs_(chars, e, pretks, tkslist, _depth + 1, _memo))
|
||||
|
||||
|
||||
if res > s:
|
||||
_memo[state_key] = res
|
||||
return res
|
||||
|
||||
t = "".join(chars[s:s + 1])
|
||||
|
||||
t = "".join(chars[s : s + 1])
|
||||
k = self.key_(t)
|
||||
copy_pretks = copy.deepcopy(preTks)
|
||||
if k in self.trie_:
|
||||
copy_pretks.append((t, self.trie_[k]))
|
||||
else:
|
||||
copy_pretks.append((t, (-12, '')))
|
||||
copy_pretks.append((t, (-12, "")))
|
||||
result = self.dfs_(chars, s + 1, copy_pretks, tkslist, _depth + 1, _memo)
|
||||
_memo[state_key] = result
|
||||
return result
|
||||
@ -216,7 +217,7 @@ class RagTokenizer:
|
||||
F += freq
|
||||
L += 0 if len(tk) < 2 else 1
|
||||
tks.append(tk)
|
||||
#F /= len(tks)
|
||||
# F /= len(tks)
|
||||
L /= len(tks)
|
||||
logging.debug("[SC] {} {} {} {} {}".format(tks, len(tks), L, F, B / len(tks) + L + F))
|
||||
return tks, B / len(tks) + L + F
|
||||
@ -252,8 +253,7 @@ class RagTokenizer:
|
||||
while s < len(line):
|
||||
e = s + 1
|
||||
t = line[s:e]
|
||||
while e < len(line) and self.trie_.has_keys_with_prefix(
|
||||
self.key_(t)):
|
||||
while e < len(line) and self.trie_.has_keys_with_prefix(self.key_(t)):
|
||||
e += 1
|
||||
t = line[s:e]
|
||||
|
||||
@ -264,7 +264,7 @@ class RagTokenizer:
|
||||
if self.key_(t) in self.trie_:
|
||||
res.append((t, self.trie_[self.key_(t)]))
|
||||
else:
|
||||
res.append((t, (0, '')))
|
||||
res.append((t, (0, "")))
|
||||
|
||||
s = e
|
||||
|
||||
@ -287,7 +287,7 @@ class RagTokenizer:
|
||||
if self.key_(t) in self.trie_:
|
||||
res.append((t, self.trie_[self.key_(t)]))
|
||||
else:
|
||||
res.append((t, (0, '')))
|
||||
res.append((t, (0, "")))
|
||||
|
||||
s -= 1
|
||||
|
||||
@ -310,28 +310,29 @@ class RagTokenizer:
|
||||
if _zh == zh:
|
||||
e += 1
|
||||
continue
|
||||
txt_lang_pairs.append((a[s: e], zh))
|
||||
txt_lang_pairs.append((a[s:e], zh))
|
||||
s = e
|
||||
e = s + 1
|
||||
zh = _zh
|
||||
if s >= len(a):
|
||||
continue
|
||||
txt_lang_pairs.append((a[s: e], zh))
|
||||
txt_lang_pairs.append((a[s:e], zh))
|
||||
return txt_lang_pairs
|
||||
|
||||
def tokenize(self, line):
|
||||
def tokenize(self, line: str) -> str:
|
||||
if settings.DOC_ENGINE_INFINITY:
|
||||
return line
|
||||
line = re.sub(r"\W+", " ", line)
|
||||
line = self._strQ2B(line).lower()
|
||||
line = self._tradi2simp(line)
|
||||
|
||||
arr = self._split_by_lang(line)
|
||||
res = []
|
||||
for L,lang in arr:
|
||||
for L, lang in arr:
|
||||
if not lang:
|
||||
res.extend([self.stemmer.stem(self.lemmatizer.lemmatize(t)) for t in word_tokenize(L)])
|
||||
continue
|
||||
if len(L) < 2 or re.match(
|
||||
r"[a-z\.-]+$", L) or re.match(r"[0-9\.-]+$", L):
|
||||
if len(L) < 2 or re.match(r"[a-z\.-]+$", L) or re.match(r"[0-9\.-]+$", L):
|
||||
res.append(L)
|
||||
continue
|
||||
|
||||
@ -347,7 +348,7 @@ class RagTokenizer:
|
||||
while i + same < len(tks1) and j + same < len(tks) and tks1[i + same] == tks[j + same]:
|
||||
same += 1
|
||||
if same > 0:
|
||||
res.append(" ".join(tks[j: j + same]))
|
||||
res.append(" ".join(tks[j : j + same]))
|
||||
_i = i + same
|
||||
_j = j + same
|
||||
j = _j + 1
|
||||
@ -374,7 +375,7 @@ class RagTokenizer:
|
||||
same = 1
|
||||
while i + same < len(tks1) and j + same < len(tks) and tks1[i + same] == tks[j + same]:
|
||||
same += 1
|
||||
res.append(" ".join(tks[j: j + same]))
|
||||
res.append(" ".join(tks[j : j + same]))
|
||||
_i = i + same
|
||||
_j = j + same
|
||||
j = _j + 1
|
||||
@ -391,7 +392,9 @@ class RagTokenizer:
|
||||
logging.debug("[TKS] {}".format(self.merge_(res)))
|
||||
return self.merge_(res)
|
||||
|
||||
def fine_grained_tokenize(self, tks):
|
||||
def fine_grained_tokenize(self, tks: str) -> str:
|
||||
if settings.DOC_ENGINE_INFINITY:
|
||||
return tks
|
||||
tks = tks.split()
|
||||
zh_num = len([1 for c in tks if c and is_chinese(c[0])])
|
||||
if zh_num < len(tks) * 0.2:
|
||||
@ -433,21 +436,21 @@ class RagTokenizer:
|
||||
|
||||
|
||||
def is_chinese(s):
|
||||
if s >= u'\u4e00' and s <= u'\u9fa5':
|
||||
if s >= "\u4e00" and s <= "\u9fa5":
|
||||
return True
|
||||
else:
|
||||
return False
|
||||
|
||||
|
||||
def is_number(s):
|
||||
if s >= u'\u0030' and s <= u'\u0039':
|
||||
if s >= "\u0030" and s <= "\u0039":
|
||||
return True
|
||||
else:
|
||||
return False
|
||||
|
||||
|
||||
def is_alphabet(s):
|
||||
if (u'\u0041' <= s <= u'\u005a') or (u'\u0061' <= s <= u'\u007a'):
|
||||
if ("\u0041" <= s <= "\u005a") or ("\u0061" <= s <= "\u007a"):
|
||||
return True
|
||||
else:
|
||||
return False
|
||||
@ -456,8 +459,7 @@ def is_alphabet(s):
|
||||
def naive_qie(txt):
|
||||
tks = []
|
||||
for t in txt.split():
|
||||
if tks and re.match(r".*[a-zA-Z]$", tks[-1]
|
||||
) and re.match(r".*[a-zA-Z]$", t):
|
||||
if tks and re.match(r".*[a-zA-Z]$", tks[-1]) and re.match(r".*[a-zA-Z]$", t):
|
||||
tks.append(" ")
|
||||
tks.append(t)
|
||||
return tks
|
||||
@ -473,43 +475,35 @@ add_user_dict = tokenizer.add_user_dict
|
||||
tradi2simp = tokenizer._tradi2simp
|
||||
strQ2B = tokenizer._strQ2B
|
||||
|
||||
if __name__ == '__main__':
|
||||
if __name__ == "__main__":
|
||||
tknzr = RagTokenizer(debug=True)
|
||||
# huqie.add_user_dict("/tmp/tmp.new.tks.dict")
|
||||
tks = tknzr.tokenize(
|
||||
"哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈")
|
||||
logging.info(tknzr.fine_grained_tokenize(tks))
|
||||
tks = tknzr.tokenize(
|
||||
"公开征求意见稿提出,境外投资者可使用自有人民币或外汇投资。使用外汇投资的,可通过债券持有人在香港人民币业务清算行及香港地区经批准可进入境内银行间外汇市场进行交易的境外人民币业务参加行(以下统称香港结算行)办理外汇资金兑换。香港结算行由此所产生的头寸可到境内银行间外汇市场平盘。使用外汇投资的,在其投资的债券到期或卖出后,原则上应兑换回外汇。")
|
||||
logging.info(tknzr.fine_grained_tokenize(tks))
|
||||
tks = tknzr.tokenize(
|
||||
"多校划片就是一个小区对应多个小学初中,让买了学区房的家庭也不确定到底能上哪个学校。目的是通过这种方式为学区房降温,把就近入学落到实处。南京市长江大桥")
|
||||
logging.info(tknzr.fine_grained_tokenize(tks))
|
||||
tks = tknzr.tokenize(
|
||||
"实际上当时他们已经将业务中心偏移到安全部门和针对政府企业的部门 Scripts are compiled and cached aaaaaaaaa")
|
||||
logging.info(tknzr.fine_grained_tokenize(tks))
|
||||
tks = tknzr.tokenize("虽然我不怎么玩")
|
||||
logging.info(tknzr.fine_grained_tokenize(tks))
|
||||
tks = tknzr.tokenize("蓝月亮如何在外资夹击中生存,那是全宇宙最有意思的")
|
||||
logging.info(tknzr.fine_grained_tokenize(tks))
|
||||
tks = tknzr.tokenize(
|
||||
"涡轮增压发动机num最大功率,不像别的共享买车锁电子化的手段,我们接过来是否有意义,黄黄爱美食,不过,今天阿奇要讲到的这家农贸市场,说实话,还真蛮有特色的!不仅环境好,还打出了")
|
||||
logging.info(tknzr.fine_grained_tokenize(tks))
|
||||
tks = tknzr.tokenize("这周日你去吗?这周日你有空吗?")
|
||||
logging.info(tknzr.fine_grained_tokenize(tks))
|
||||
tks = tknzr.tokenize("Unity3D开发经验 测试开发工程师 c++双11双11 985 211 ")
|
||||
logging.info(tknzr.fine_grained_tokenize(tks))
|
||||
tks = tknzr.tokenize(
|
||||
"数据分析项目经理|数据分析挖掘|数据分析方向|商品数据分析|搜索数据分析 sql python hive tableau Cocos2d-")
|
||||
logging.info(tknzr.fine_grained_tokenize(tks))
|
||||
texts = [
|
||||
"over_the_past.pdf",
|
||||
"哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈",
|
||||
"公开征求意见稿提出,境外投资者可使用自有人民币或外汇投资。使用外汇投资的,可通过债券持有人在香港人民币业务清算行及香港地区经批准可进入境内银行间外汇市场进行交易的境外人民币业务参加行(以下统称香港结算行)办理外汇资金兑换。香港结算行由此所产生的头寸可到境内银行间外汇市场平盘。使用外汇投资的,在其投资的债券到期或卖出后,原则上应兑换回外汇。",
|
||||
"多校划片就是一个小区对应多个小学初中,让买了学区房的家庭也不确定到底能上哪个学校。目的是通过这种方式为学区房降温,把就近入学落到实处。南京市长江大桥",
|
||||
"实际上当时他们已经将业务中心偏移到安全部门和针对政府企业的部门 Scripts are compiled and cached aaaaaaaaa",
|
||||
"虽然我不怎么玩",
|
||||
"蓝月亮如何在外资夹击中生存,那是全宇宙最有意思的",
|
||||
"涡轮增压发动机num最大功率,不像别的共享买车锁电子化的手段,我们接过来是否有意义,黄黄爱美食,不过,今天阿奇要讲到的这家农贸市场,说实话,还真蛮有特色的!不仅环境好,还打出了",
|
||||
"这周日你去吗?这周日你有空吗?",
|
||||
"Unity3D开发经验 测试开发工程师 c++双11双11 985 211 ",
|
||||
"数据分析项目经理|数据分析挖掘|数据分析方向|商品数据分析|搜索数据分析 sql python hive tableau Cocos2d-",
|
||||
]
|
||||
for text in texts:
|
||||
print(text)
|
||||
tks1 = tknzr.tokenize(text)
|
||||
tks2 = tknzr.fine_grained_tokenize(tks1)
|
||||
print(tks1)
|
||||
print(tks2)
|
||||
if len(sys.argv) < 2:
|
||||
sys.exit()
|
||||
tknzr.DEBUG = False
|
||||
tknzr.load_user_dict(sys.argv[1])
|
||||
of = open(sys.argv[2], "r")
|
||||
while True:
|
||||
line = of.readline()
|
||||
if not line:
|
||||
break
|
||||
logging.info(tknzr.tokenize(line))
|
||||
print(tknzr.tokenize(line))
|
||||
of.close()
|
||||
|
||||
@ -17,7 +17,6 @@ import json
|
||||
import logging
|
||||
import re
|
||||
import math
|
||||
import os
|
||||
from collections import OrderedDict
|
||||
from dataclasses import dataclass
|
||||
|
||||
@ -28,6 +27,7 @@ from rag.utils.doc_store_conn import DocStoreConnection, MatchDenseExpr, FusionE
|
||||
from common.string_utils import remove_redundant_spaces
|
||||
from common.float_utils import get_float
|
||||
from common.constants import PAGERANK_FLD, TAG_FLD
|
||||
from common import settings
|
||||
|
||||
|
||||
def index_name(uid): return f"ragflow_{uid}"
|
||||
@ -120,7 +120,8 @@ class Dealer:
|
||||
else:
|
||||
matchDense = self.get_vector(qst, emb_mdl, topk, req.get("similarity", 0.1))
|
||||
q_vec = matchDense.embedding_data
|
||||
src.append(f"q_{len(q_vec)}_vec")
|
||||
if not settings.DOC_ENGINE_INFINITY:
|
||||
src.append(f"q_{len(q_vec)}_vec")
|
||||
|
||||
fusionExpr = FusionExpr("weighted_sum", topk, {"weights": "0.05,0.95"})
|
||||
matchExprs = [matchText, matchDense, fusionExpr]
|
||||
@ -355,75 +356,101 @@ class Dealer:
|
||||
rag_tokenizer.tokenize(ans).split(),
|
||||
rag_tokenizer.tokenize(inst).split())
|
||||
|
||||
def retrieval(self, question, embd_mdl, tenant_ids, kb_ids, page, page_size, similarity_threshold=0.2,
|
||||
vector_similarity_weight=0.3, top=1024, doc_ids=None, aggs=True,
|
||||
rerank_mdl=None, highlight=False,
|
||||
rank_feature: dict | None = {PAGERANK_FLD: 10}):
|
||||
def retrieval(
|
||||
self,
|
||||
question,
|
||||
embd_mdl,
|
||||
tenant_ids,
|
||||
kb_ids,
|
||||
page,
|
||||
page_size,
|
||||
similarity_threshold=0.2,
|
||||
vector_similarity_weight=0.3,
|
||||
top=1024,
|
||||
doc_ids=None,
|
||||
aggs=True,
|
||||
rerank_mdl=None,
|
||||
highlight=False,
|
||||
rank_feature: dict | None = {PAGERANK_FLD: 10},
|
||||
):
|
||||
ranks = {"total": 0, "chunks": [], "doc_aggs": {}}
|
||||
if not question:
|
||||
return ranks
|
||||
|
||||
# Ensure RERANK_LIMIT is multiple of page_size
|
||||
RERANK_LIMIT = math.ceil(64/page_size) * page_size if page_size>1 else 1
|
||||
req = {"kb_ids": kb_ids, "doc_ids": doc_ids, "page": math.ceil(page_size*page/RERANK_LIMIT), "size": RERANK_LIMIT,
|
||||
"question": question, "vector": True, "topk": top,
|
||||
"similarity": similarity_threshold,
|
||||
"available_int": 1}
|
||||
|
||||
RERANK_LIMIT = math.ceil(64 / page_size) * page_size if page_size > 1 else 1
|
||||
req = {
|
||||
"kb_ids": kb_ids,
|
||||
"doc_ids": doc_ids,
|
||||
"page": math.ceil(page_size * page / RERANK_LIMIT),
|
||||
"size": RERANK_LIMIT,
|
||||
"question": question,
|
||||
"vector": True,
|
||||
"topk": top,
|
||||
"similarity": similarity_threshold,
|
||||
"available_int": 1,
|
||||
}
|
||||
|
||||
if isinstance(tenant_ids, str):
|
||||
tenant_ids = tenant_ids.split(",")
|
||||
|
||||
sres = self.search(req, [index_name(tid) for tid in tenant_ids],
|
||||
kb_ids, embd_mdl, highlight, rank_feature=rank_feature)
|
||||
sres = self.search(req, [index_name(tid) for tid in tenant_ids], kb_ids, embd_mdl, highlight, rank_feature=rank_feature)
|
||||
|
||||
if rerank_mdl and sres.total > 0:
|
||||
sim, tsim, vsim = self.rerank_by_model(rerank_mdl,
|
||||
sres, question, 1 - vector_similarity_weight,
|
||||
vector_similarity_weight,
|
||||
rank_feature=rank_feature)
|
||||
sim, tsim, vsim = self.rerank_by_model(
|
||||
rerank_mdl,
|
||||
sres,
|
||||
question,
|
||||
1 - vector_similarity_weight,
|
||||
vector_similarity_weight,
|
||||
rank_feature=rank_feature,
|
||||
)
|
||||
else:
|
||||
lower_case_doc_engine = os.getenv('DOC_ENGINE', 'elasticsearch')
|
||||
if lower_case_doc_engine in ["elasticsearch","opensearch"]:
|
||||
# ElasticSearch doesn't normalize each way score before fusion.
|
||||
sim, tsim, vsim = self.rerank(
|
||||
sres, question, 1 - vector_similarity_weight, vector_similarity_weight,
|
||||
rank_feature=rank_feature)
|
||||
else:
|
||||
if settings.DOC_ENGINE_INFINITY:
|
||||
# Don't need rerank here since Infinity normalizes each way score before fusion.
|
||||
sim = [sres.field[id].get("_score", 0.0) for id in sres.ids]
|
||||
sim = [s if s is not None else 0. for s in sim]
|
||||
sim = [s if s is not None else 0.0 for s in sim]
|
||||
tsim = sim
|
||||
vsim = sim
|
||||
# Already paginated in search function
|
||||
max_pages = RERANK_LIMIT // page_size
|
||||
page_index = (page % max_pages) - 1
|
||||
begin = max(page_index * page_size, 0)
|
||||
sim = sim[begin : begin + page_size]
|
||||
else:
|
||||
# ElasticSearch doesn't normalize each way score before fusion.
|
||||
sim, tsim, vsim = self.rerank(
|
||||
sres,
|
||||
question,
|
||||
1 - vector_similarity_weight,
|
||||
vector_similarity_weight,
|
||||
rank_feature=rank_feature,
|
||||
)
|
||||
|
||||
sim_np = np.array(sim, dtype=np.float64)
|
||||
idx = np.argsort(sim_np * -1)
|
||||
if sim_np.size == 0:
|
||||
return ranks
|
||||
|
||||
sorted_idx = np.argsort(sim_np * -1)
|
||||
|
||||
valid_idx = [int(i) for i in sorted_idx if sim_np[i] >= similarity_threshold]
|
||||
filtered_count = len(valid_idx)
|
||||
ranks["total"] = int(filtered_count)
|
||||
|
||||
if filtered_count == 0:
|
||||
return ranks
|
||||
|
||||
max_pages = max(RERANK_LIMIT // max(page_size, 1), 1)
|
||||
page_index = (page - 1) % max_pages
|
||||
begin = page_index * page_size
|
||||
end = begin + page_size
|
||||
page_idx = valid_idx[begin:end]
|
||||
|
||||
dim = len(sres.query_vector)
|
||||
vector_column = f"q_{dim}_vec"
|
||||
zero_vector = [0.0] * dim
|
||||
filtered_count = (sim_np >= similarity_threshold).sum()
|
||||
ranks["total"] = int(filtered_count) # Convert from np.int64 to Python int otherwise JSON serializable error
|
||||
for i in idx:
|
||||
if np.float64(sim[i]) < similarity_threshold:
|
||||
break
|
||||
|
||||
for i in page_idx:
|
||||
id = sres.ids[i]
|
||||
chunk = sres.field[id]
|
||||
dnm = chunk.get("docnm_kwd", "")
|
||||
did = chunk.get("doc_id", "")
|
||||
|
||||
if len(ranks["chunks"]) >= page_size:
|
||||
if aggs:
|
||||
if dnm not in ranks["doc_aggs"]:
|
||||
ranks["doc_aggs"][dnm] = {"doc_id": did, "count": 0}
|
||||
ranks["doc_aggs"][dnm]["count"] += 1
|
||||
continue
|
||||
break
|
||||
|
||||
position_int = chunk.get("position_int", [])
|
||||
d = {
|
||||
"chunk_id": id,
|
||||
@ -434,12 +461,12 @@ class Dealer:
|
||||
"kb_id": chunk["kb_id"],
|
||||
"important_kwd": chunk.get("important_kwd", []),
|
||||
"image_id": chunk.get("img_id", ""),
|
||||
"similarity": sim[i],
|
||||
"vector_similarity": vsim[i],
|
||||
"term_similarity": tsim[i],
|
||||
"similarity": float(sim_np[i]),
|
||||
"vector_similarity": float(vsim[i]),
|
||||
"term_similarity": float(tsim[i]),
|
||||
"vector": chunk.get(vector_column, zero_vector),
|
||||
"positions": position_int,
|
||||
"doc_type_kwd": chunk.get("doc_type_kwd", "")
|
||||
"doc_type_kwd": chunk.get("doc_type_kwd", ""),
|
||||
}
|
||||
if highlight and sres.highlight:
|
||||
if id in sres.highlight:
|
||||
@ -447,15 +474,30 @@ class Dealer:
|
||||
else:
|
||||
d["highlight"] = d["content_with_weight"]
|
||||
ranks["chunks"].append(d)
|
||||
if dnm not in ranks["doc_aggs"]:
|
||||
ranks["doc_aggs"][dnm] = {"doc_id": did, "count": 0}
|
||||
ranks["doc_aggs"][dnm]["count"] += 1
|
||||
ranks["doc_aggs"] = [{"doc_name": k,
|
||||
"doc_id": v["doc_id"],
|
||||
"count": v["count"]} for k,
|
||||
v in sorted(ranks["doc_aggs"].items(),
|
||||
key=lambda x: x[1]["count"] * -1)]
|
||||
ranks["chunks"] = ranks["chunks"][:page_size]
|
||||
|
||||
if aggs:
|
||||
for i in valid_idx:
|
||||
id = sres.ids[i]
|
||||
chunk = sres.field[id]
|
||||
dnm = chunk.get("docnm_kwd", "")
|
||||
did = chunk.get("doc_id", "")
|
||||
if dnm not in ranks["doc_aggs"]:
|
||||
ranks["doc_aggs"][dnm] = {"doc_id": did, "count": 0}
|
||||
ranks["doc_aggs"][dnm]["count"] += 1
|
||||
|
||||
ranks["doc_aggs"] = [
|
||||
{
|
||||
"doc_name": k,
|
||||
"doc_id": v["doc_id"],
|
||||
"count": v["count"],
|
||||
}
|
||||
for k, v in sorted(
|
||||
ranks["doc_aggs"].items(),
|
||||
key=lambda x: x[1]["count"] * -1,
|
||||
)
|
||||
]
|
||||
else:
|
||||
ranks["doc_aggs"] = []
|
||||
|
||||
return ranks
|
||||
|
||||
@ -564,7 +606,7 @@ class Dealer:
|
||||
ids = relevant_chunks_with_toc(query, toc, chat_mdl, topn*2)
|
||||
if not ids:
|
||||
return chunks
|
||||
|
||||
|
||||
vector_size = 1024
|
||||
id2idx = {ck["chunk_id"]: i for i, ck in enumerate(chunks)}
|
||||
for cid, sim in ids:
|
||||
|
||||
@ -429,7 +429,7 @@ def rank_memories(chat_mdl, goal:str, sub_goal:str, tool_call_summaries: list[st
|
||||
return re.sub(r"^.*</think>", "", ans, flags=re.DOTALL)
|
||||
|
||||
|
||||
def gen_meta_filter(chat_mdl, meta_data:dict, query: str) -> list:
|
||||
def gen_meta_filter(chat_mdl, meta_data:dict, query: str) -> dict:
|
||||
sys_prompt = PROMPT_JINJA_ENV.from_string(META_FILTER).render(
|
||||
current_date=datetime.datetime.today().strftime('%Y-%m-%d'),
|
||||
metadata_keys=json.dumps(meta_data),
|
||||
@ -440,11 +440,13 @@ def gen_meta_filter(chat_mdl, meta_data:dict, query: str) -> list:
|
||||
ans = re.sub(r"(^.*</think>|```json\n|```\n*$)", "", ans, flags=re.DOTALL)
|
||||
try:
|
||||
ans = json_repair.loads(ans)
|
||||
assert isinstance(ans, list), ans
|
||||
assert isinstance(ans, dict), ans
|
||||
assert "conditions" in ans and isinstance(ans["conditions"], list), ans
|
||||
return ans
|
||||
except Exception:
|
||||
logging.exception(f"Loading json failure: {ans}")
|
||||
return []
|
||||
|
||||
return {"conditions": []}
|
||||
|
||||
|
||||
def gen_json(system_prompt:str, user_prompt:str, chat_mdl, gen_conf = None):
|
||||
|
||||
@ -9,11 +9,13 @@ You are a metadata filtering condition generator. Analyze the user's question an
|
||||
}
|
||||
|
||||
2. **Output Requirements**:
|
||||
- Always output a JSON array of filter objects
|
||||
- Each object must have:
|
||||
- Always output a JSON dictionary with only 2 keys: 'conditions'(filter objects) and 'logic' between the conditions ('and' or 'or').
|
||||
- Each filter object in conditions must have:
|
||||
"key": (metadata attribute name),
|
||||
"value": (string value to compare),
|
||||
"op": (operator from allowed list)
|
||||
- Logic between all the conditions: 'and'(Intersection of results for each condition) / 'or' (union of results for all conditions)
|
||||
|
||||
|
||||
3. **Operator Guide**:
|
||||
- Use these operators only: ["contains", "not contains", "start with", "end with", "empty", "not empty", "=", "≠", ">", "<", "≥", "≤"]
|
||||
@ -32,22 +34,101 @@ You are a metadata filtering condition generator. Analyze the user's question an
|
||||
- Attribute doesn't exist in metadata
|
||||
- Value has no match in metadata
|
||||
|
||||
5. **Example**:
|
||||
- User query: "上市日期七月份的有哪些商品,不要蓝色的"
|
||||
5. **Example A**:
|
||||
- User query: "上市日期七月份的有哪些新品,不要蓝色的,只看鞋子和帽子"
|
||||
- Metadata: { "color": {...}, "listing_date": {...} }
|
||||
- Output:
|
||||
[
|
||||
{
|
||||
"logic": "and",
|
||||
"conditions": [
|
||||
{"key": "listing_date", "value": "2025-07-01", "op": "≥"},
|
||||
{"key": "listing_date", "value": "2025-08-01", "op": "<"},
|
||||
{"key": "color", "value": "blue", "op": "≠"}
|
||||
{"key": "color", "value": "blue", "op": "≠"},
|
||||
{"key": "category", "value": "shoes, hat", "op": "in"}
|
||||
]
|
||||
}
|
||||
|
||||
6. **Final Output**:
|
||||
- ONLY output valid JSON array
|
||||
6. **Example B**:
|
||||
- User query: "It must be from China or India. Otherwise, it must not be blue or red."
|
||||
- Metadata: { "color": {...}, "country": {...} }
|
||||
-
|
||||
- Output:
|
||||
{
|
||||
"logic": "or",
|
||||
"conditions": [
|
||||
{"key": "color", "value": "blue, red", "op": "not in"},
|
||||
{"key": "country", "value": "china, india", "op": "in"},
|
||||
]
|
||||
}
|
||||
|
||||
7. **Final Output**:
|
||||
- ONLY output valid JSON dictionary
|
||||
- NO additional text/explanations
|
||||
- Json schema is as following:
|
||||
```json
|
||||
{
|
||||
"type": "object",
|
||||
"properties": {
|
||||
"logic": {
|
||||
"type": "string",
|
||||
"description": "Logic relationship between all the conditions, the default is 'and'.",
|
||||
"enum": [
|
||||
"and",
|
||||
"or"
|
||||
]
|
||||
},
|
||||
"conditions": {
|
||||
"type": "array",
|
||||
"items": {
|
||||
"type": "object",
|
||||
"properties": {
|
||||
"key": {
|
||||
"type": "string",
|
||||
"description": "Metadata attribute name."
|
||||
},
|
||||
"value": {
|
||||
"type": "string",
|
||||
"description": "Value to compare."
|
||||
},
|
||||
"op": {
|
||||
"type": "string",
|
||||
"description": "Operator from allowed list.",
|
||||
"enum": [
|
||||
"contains",
|
||||
"not contains",
|
||||
"in",
|
||||
"not in",
|
||||
"start with",
|
||||
"end with",
|
||||
"empty",
|
||||
"not empty",
|
||||
"=",
|
||||
"≠",
|
||||
">",
|
||||
"<",
|
||||
"≥",
|
||||
"≤"
|
||||
]
|
||||
}
|
||||
},
|
||||
"required": [
|
||||
"key",
|
||||
"value",
|
||||
"op"
|
||||
],
|
||||
"additionalProperties": false
|
||||
}
|
||||
}
|
||||
},
|
||||
"required": [
|
||||
"conditions"
|
||||
],
|
||||
"additionalProperties": false
|
||||
}
|
||||
```
|
||||
|
||||
**Current Task**:
|
||||
- Today's date: {{current_date}}
|
||||
- Available metadata keys: {{metadata_keys}}
|
||||
- User query: "{{user_question}}"
|
||||
- Today's date: {{ current_date }}
|
||||
- Available metadata keys: {{ metadata_keys }}
|
||||
- User query: "{{ user_question }}"
|
||||
|
||||
|
||||
@ -37,14 +37,8 @@ from api.db.services.connector_service import ConnectorService, SyncLogsService
|
||||
from api.db.services.knowledgebase_service import KnowledgebaseService
|
||||
from common import settings
|
||||
from common.config_utils import show_configs
|
||||
from common.data_source import BlobStorageConnector, NotionConnector, DiscordConnector, GoogleDriveConnector, MoodleConnector, JiraConnector, DropboxConnector, WebDAVConnector
|
||||
from common.constants import FileSource, TaskStatus
|
||||
from common.data_source import (
|
||||
BlobStorageConnector,
|
||||
DiscordConnector,
|
||||
GoogleDriveConnector,
|
||||
JiraConnector,
|
||||
NotionConnector,
|
||||
)
|
||||
from common.data_source.config import INDEX_BATCH_SIZE
|
||||
from common.data_source.confluence_connector import ConfluenceConnector
|
||||
from common.data_source.interfaces import CheckpointOutputWrapper
|
||||
@ -73,14 +67,17 @@ class SyncBase:
|
||||
next_update = datetime(1970, 1, 1, tzinfo=timezone.utc)
|
||||
if task["poll_range_start"]:
|
||||
next_update = task["poll_range_start"]
|
||||
|
||||
failed_docs = 0
|
||||
for document_batch in document_batch_generator:
|
||||
if not document_batch:
|
||||
continue
|
||||
min_update = min([doc.doc_updated_at for doc in document_batch])
|
||||
max_update = max([doc.doc_updated_at for doc in document_batch])
|
||||
next_update = max([next_update, max_update])
|
||||
docs = [
|
||||
{
|
||||
docs = []
|
||||
for doc in document_batch:
|
||||
doc_dict = {
|
||||
"id": doc.id,
|
||||
"connector_id": task["connector_id"],
|
||||
"source": self.SOURCE_NAME,
|
||||
@ -90,16 +87,35 @@ class SyncBase:
|
||||
"doc_updated_at": doc.doc_updated_at,
|
||||
"blob": doc.blob,
|
||||
}
|
||||
for doc in document_batch
|
||||
]
|
||||
# Add metadata if present
|
||||
if doc.metadata:
|
||||
doc_dict["metadata"] = doc.metadata
|
||||
docs.append(doc_dict)
|
||||
|
||||
e, kb = KnowledgebaseService.get_by_id(task["kb_id"])
|
||||
err, dids = SyncLogsService.duplicate_and_parse(kb, docs, task["tenant_id"], f"{self.SOURCE_NAME}/{task['connector_id']}", task["auto_parse"])
|
||||
SyncLogsService.increase_docs(task["id"], min_update, max_update, len(docs), "\n".join(err), len(err))
|
||||
doc_num += len(docs)
|
||||
try:
|
||||
e, kb = KnowledgebaseService.get_by_id(task["kb_id"])
|
||||
err, dids = SyncLogsService.duplicate_and_parse(kb, docs, task["tenant_id"], f"{self.SOURCE_NAME}/{task['connector_id']}", task["auto_parse"])
|
||||
SyncLogsService.increase_docs(task["id"], min_update, max_update, len(docs), "\n".join(err), len(err))
|
||||
doc_num += len(docs)
|
||||
except Exception as batch_ex:
|
||||
error_msg = str(batch_ex)
|
||||
error_code = getattr(batch_ex, 'args', (None,))[0] if hasattr(batch_ex, 'args') else None
|
||||
|
||||
if error_code == 1267 or "collation" in error_msg.lower():
|
||||
logging.warning(f"Skipping {len(docs)} document(s) due to database collation conflict (error 1267)")
|
||||
for doc in docs:
|
||||
logging.debug(f"Skipped: {doc['semantic_identifier']}")
|
||||
else:
|
||||
logging.error(f"Error processing batch of {len(docs)} documents: {error_msg}")
|
||||
|
||||
failed_docs += len(docs)
|
||||
continue
|
||||
|
||||
prefix = "[Jira] " if self.SOURCE_NAME == FileSource.JIRA else ""
|
||||
logging.info(f"{prefix}{doc_num} docs synchronized till {next_update}")
|
||||
if failed_docs > 0:
|
||||
logging.info(f"{prefix}{doc_num} docs synchronized till {next_update} ({failed_docs} skipped)")
|
||||
else:
|
||||
logging.info(f"{prefix}{doc_num} docs synchronized till {next_update}")
|
||||
SyncLogsService.done(task["id"], task["connector_id"])
|
||||
task["poll_range_start"] = next_update
|
||||
|
||||
@ -217,6 +233,27 @@ class Gmail(SyncBase):
|
||||
pass
|
||||
|
||||
|
||||
class Dropbox(SyncBase):
|
||||
SOURCE_NAME: str = FileSource.DROPBOX
|
||||
|
||||
async def _generate(self, task: dict):
|
||||
self.connector = DropboxConnector(batch_size=self.conf.get("batch_size", INDEX_BATCH_SIZE))
|
||||
self.connector.load_credentials(self.conf["credentials"])
|
||||
|
||||
if task["reindex"] == "1" or not task["poll_range_start"]:
|
||||
document_generator = self.connector.load_from_state()
|
||||
begin_info = "totally"
|
||||
else:
|
||||
poll_start = task["poll_range_start"]
|
||||
document_generator = self.connector.poll_source(
|
||||
poll_start.timestamp(), datetime.now(timezone.utc).timestamp()
|
||||
)
|
||||
begin_info = f"from {poll_start}"
|
||||
|
||||
logging.info(f"[Dropbox] Connect to Dropbox {begin_info}")
|
||||
return document_generator
|
||||
|
||||
|
||||
class GoogleDrive(SyncBase):
|
||||
SOURCE_NAME: str = FileSource.GOOGLE_DRIVE
|
||||
|
||||
@ -418,6 +455,67 @@ class Teams(SyncBase):
|
||||
pass
|
||||
|
||||
|
||||
class WebDAV(SyncBase):
|
||||
SOURCE_NAME: str = FileSource.WEBDAV
|
||||
|
||||
async def _generate(self, task: dict):
|
||||
self.connector = WebDAVConnector(
|
||||
base_url=self.conf["base_url"],
|
||||
remote_path=self.conf.get("remote_path", "/")
|
||||
)
|
||||
self.connector.load_credentials(self.conf["credentials"])
|
||||
|
||||
logging.info(f"Task info: reindex={task['reindex']}, poll_range_start={task['poll_range_start']}")
|
||||
|
||||
if task["reindex"]=="1" or not task["poll_range_start"]:
|
||||
logging.info("Using load_from_state (full sync)")
|
||||
document_batch_generator = self.connector.load_from_state()
|
||||
begin_info = "totally"
|
||||
else:
|
||||
start_ts = task["poll_range_start"].timestamp()
|
||||
end_ts = datetime.now(timezone.utc).timestamp()
|
||||
logging.info(f"Polling WebDAV from {task['poll_range_start']} (ts: {start_ts}) to now (ts: {end_ts})")
|
||||
document_batch_generator = self.connector.poll_source(start_ts, end_ts)
|
||||
begin_info = "from {}".format(task["poll_range_start"])
|
||||
|
||||
logging.info("Connect to WebDAV: {}(path: {}) {}".format(
|
||||
self.conf["base_url"],
|
||||
self.conf.get("remote_path", "/"),
|
||||
begin_info
|
||||
))
|
||||
return document_batch_generator
|
||||
|
||||
class Moodle(SyncBase):
|
||||
SOURCE_NAME: str = FileSource.MOODLE
|
||||
|
||||
async def _generate(self, task: dict):
|
||||
self.connector = MoodleConnector(
|
||||
moodle_url=self.conf["moodle_url"],
|
||||
batch_size=self.conf.get("batch_size", INDEX_BATCH_SIZE)
|
||||
)
|
||||
|
||||
self.connector.load_credentials(self.conf["credentials"])
|
||||
|
||||
# Determine the time range for synchronization based on reindex or poll_range_start
|
||||
if task["reindex"] == "1" or not task.get("poll_range_start"):
|
||||
document_generator = self.connector.load_from_state()
|
||||
begin_info = "totally"
|
||||
else:
|
||||
poll_start = task["poll_range_start"]
|
||||
if poll_start is None:
|
||||
document_generator = self.connector.load_from_state()
|
||||
begin_info = "totally"
|
||||
else:
|
||||
document_generator = self.connector.poll_source(
|
||||
poll_start.timestamp(),
|
||||
datetime.now(timezone.utc).timestamp()
|
||||
)
|
||||
begin_info = "from {}".format(poll_start)
|
||||
|
||||
logging.info("Connect to Moodle: {} {}".format(self.conf["moodle_url"], begin_info))
|
||||
return document_generator
|
||||
|
||||
|
||||
func_factory = {
|
||||
FileSource.S3: S3,
|
||||
FileSource.NOTION: Notion,
|
||||
@ -429,6 +527,9 @@ func_factory = {
|
||||
FileSource.SHAREPOINT: SharePoint,
|
||||
FileSource.SLACK: Slack,
|
||||
FileSource.TEAMS: Teams,
|
||||
FileSource.MOODLE: Moodle,
|
||||
FileSource.DROPBOX: Dropbox,
|
||||
FileSource.WEBDAV: WebDAV,
|
||||
}
|
||||
|
||||
|
||||
|
||||
@ -44,11 +44,56 @@ logger = logging.getLogger("ragflow.infinity_conn")
|
||||
|
||||
|
||||
def field_keyword(field_name: str):
|
||||
# The "docnm_kwd" field is always a string, not list.
|
||||
if field_name == "source_id" or (field_name.endswith("_kwd") and field_name != "docnm_kwd" and field_name != "knowledge_graph_kwd"):
|
||||
# Treat "*_kwd" tag-like columns as keyword lists except knowledge_graph_kwd; source_id is also keyword-like.
|
||||
if field_name == "source_id" or (field_name.endswith("_kwd") and field_name not in ["knowledge_graph_kwd", "docnm_kwd", "important_kwd", "question_kwd"]):
|
||||
return True
|
||||
return False
|
||||
|
||||
def convert_select_fields(output_fields: list[str]) -> list[str]:
|
||||
for i, field in enumerate(output_fields):
|
||||
if field in ["docnm_kwd", "title_tks", "title_sm_tks"]:
|
||||
output_fields[i] = "docnm"
|
||||
elif field in ["important_kwd", "important_tks"]:
|
||||
output_fields[i] = "important_keywords"
|
||||
elif field in ["question_kwd", "question_tks"]:
|
||||
output_fields[i] = "questions"
|
||||
elif field in ["content_with_weight", "content_ltks", "content_sm_ltks"]:
|
||||
output_fields[i] = "content"
|
||||
elif field in ["authors_tks", "authors_sm_tks"]:
|
||||
output_fields[i] = "authors"
|
||||
return list(set(output_fields))
|
||||
|
||||
def convert_matching_field(field_weightstr: str) -> str:
|
||||
tokens = field_weightstr.split("^")
|
||||
field = tokens[0]
|
||||
if field == "docnm_kwd" or field == "title_tks":
|
||||
field = "docnm@ft_docnm_rag_coarse"
|
||||
elif field == "title_sm_tks":
|
||||
field = "docnm@ft_docnm_rag_fine"
|
||||
elif field == "important_kwd":
|
||||
field = "important_keywords@ft_important_keywords_rag_coarse"
|
||||
elif field == "important_tks":
|
||||
field = "important_keywords@ft_important_keywords_rag_fine"
|
||||
elif field == "question_kwd":
|
||||
field = "questions@ft_questions_rag_coarse"
|
||||
elif field == "question_tks":
|
||||
field = "questions@ft_questions_rag_fine"
|
||||
elif field == "content_with_weight" or field == "content_ltks":
|
||||
field = "content@ft_content_rag_coarse"
|
||||
elif field == "content_sm_ltks":
|
||||
field = "content@ft_content_rag_fine"
|
||||
elif field == "authors_tks":
|
||||
field = "authors@ft_authors_rag_coarse"
|
||||
elif field == "authors_sm_tks":
|
||||
field = "authors@ft_authors_rag_fine"
|
||||
tokens[0] = field
|
||||
return "^".join(tokens)
|
||||
|
||||
def list2str(lst: str|list, sep: str = " ") -> str:
|
||||
if isinstance(lst, str):
|
||||
return lst
|
||||
return sep.join(lst)
|
||||
|
||||
|
||||
def equivalent_condition_to_str(condition: dict, table_instance=None) -> str | None:
|
||||
assert "_id" not in condition
|
||||
@ -77,13 +122,13 @@ def equivalent_condition_to_str(condition: dict, table_instance=None) -> str | N
|
||||
for item in v:
|
||||
if isinstance(item, str):
|
||||
item = item.replace("'", "''")
|
||||
inCond.append(f"filter_fulltext('{k}', '{item}')")
|
||||
inCond.append(f"filter_fulltext('{convert_matching_field(k)}', '{item}')")
|
||||
if inCond:
|
||||
strInCond = " or ".join(inCond)
|
||||
strInCond = f"({strInCond})"
|
||||
cond.append(strInCond)
|
||||
else:
|
||||
cond.append(f"filter_fulltext('{k}', '{v}')")
|
||||
cond.append(f"filter_fulltext('{convert_matching_field(k)}', '{v}')")
|
||||
elif isinstance(v, list):
|
||||
inCond = list()
|
||||
for item in v:
|
||||
@ -181,11 +226,15 @@ class InfinityConnection(DocStoreConnection):
|
||||
logger.info(f"INFINITY added following column to table {table_name}: {field_name} {field_info}")
|
||||
if field_info["type"] != "varchar" or "analyzer" not in field_info:
|
||||
continue
|
||||
inf_table.create_index(
|
||||
f"text_idx_{field_name}",
|
||||
IndexInfo(field_name, IndexType.FullText, {"ANALYZER": field_info["analyzer"]}),
|
||||
ConflictType.Ignore,
|
||||
)
|
||||
analyzers = field_info["analyzer"]
|
||||
if isinstance(analyzers, str):
|
||||
analyzers = [analyzers]
|
||||
for analyzer in analyzers:
|
||||
inf_table.create_index(
|
||||
f"ft_{re.sub(r'[^a-zA-Z0-9]', '_', field_name)}_{re.sub(r'[^a-zA-Z0-9]', '_', analyzer)}",
|
||||
IndexInfo(field_name, IndexType.FullText, {"ANALYZER": analyzer}),
|
||||
ConflictType.Ignore,
|
||||
)
|
||||
|
||||
"""
|
||||
Database operations
|
||||
@ -245,11 +294,15 @@ class InfinityConnection(DocStoreConnection):
|
||||
for field_name, field_info in schema.items():
|
||||
if field_info["type"] != "varchar" or "analyzer" not in field_info:
|
||||
continue
|
||||
inf_table.create_index(
|
||||
f"text_idx_{field_name}",
|
||||
IndexInfo(field_name, IndexType.FullText, {"ANALYZER": field_info["analyzer"]}),
|
||||
ConflictType.Ignore,
|
||||
)
|
||||
analyzers = field_info["analyzer"]
|
||||
if isinstance(analyzers, str):
|
||||
analyzers = [analyzers]
|
||||
for analyzer in analyzers:
|
||||
inf_table.create_index(
|
||||
f"ft_{re.sub(r'[^a-zA-Z0-9]', '_', field_name)}_{re.sub(r'[^a-zA-Z0-9]', '_', analyzer)}",
|
||||
IndexInfo(field_name, IndexType.FullText, {"ANALYZER": analyzer}),
|
||||
ConflictType.Ignore,
|
||||
)
|
||||
self.connPool.release_conn(inf_conn)
|
||||
logger.info(f"INFINITY created table {table_name}, vector size {vectorSize}")
|
||||
|
||||
@ -302,6 +355,7 @@ class InfinityConnection(DocStoreConnection):
|
||||
df_list = list()
|
||||
table_list = list()
|
||||
output = selectFields.copy()
|
||||
output = convert_select_fields(output)
|
||||
for essential_field in ["id"] + aggFields:
|
||||
if essential_field not in output:
|
||||
output.append(essential_field)
|
||||
@ -352,6 +406,7 @@ class InfinityConnection(DocStoreConnection):
|
||||
if isinstance(matchExpr, MatchTextExpr):
|
||||
if filter_cond and "filter" not in matchExpr.extra_options:
|
||||
matchExpr.extra_options.update({"filter": filter_cond})
|
||||
matchExpr.fields = [convert_matching_field(field) for field in matchExpr.fields]
|
||||
fields = ",".join(matchExpr.fields)
|
||||
filter_fulltext = f"filter_fulltext('{fields}', '{matchExpr.matching_text}')"
|
||||
if filter_cond:
|
||||
@ -470,7 +525,10 @@ class InfinityConnection(DocStoreConnection):
|
||||
df_list.append(kb_res)
|
||||
self.connPool.release_conn(inf_conn)
|
||||
res = concat_dataframes(df_list, ["id"])
|
||||
res_fields = self.get_fields(res, res.columns.tolist())
|
||||
fields = set(res.columns.tolist())
|
||||
for field in ["docnm_kwd", "title_tks", "title_sm_tks", "important_kwd", "important_tks", "question_kwd", "question_tks","content_with_weight", "content_ltks", "content_sm_ltks", "authors_tks", "authors_sm_tks"]:
|
||||
fields.add(field)
|
||||
res_fields = self.get_fields(res, list(fields))
|
||||
return res_fields.get(chunkId, None)
|
||||
|
||||
def insert(self, documents: list[dict], indexName: str, knowledgebaseId: str = None) -> list[str]:
|
||||
@ -508,8 +566,39 @@ class InfinityConnection(DocStoreConnection):
|
||||
for d in docs:
|
||||
assert "_id" not in d
|
||||
assert "id" in d
|
||||
for k, v in d.items():
|
||||
if field_keyword(k):
|
||||
for k, v in list(d.items()):
|
||||
if k == "docnm_kwd":
|
||||
d["docnm"] = v
|
||||
elif k == "title_kwd":
|
||||
if not d.get("docnm_kwd"):
|
||||
d["docnm"] = list2str(v)
|
||||
elif k == "title_sm_tks":
|
||||
if not d.get("docnm_kwd"):
|
||||
d["docnm"] = list2str(v)
|
||||
elif k == "important_kwd":
|
||||
d["important_keywords"] = list2str(v)
|
||||
elif k == "important_tks":
|
||||
if not d.get("important_kwd"):
|
||||
d["important_keywords"] = v
|
||||
elif k == "content_with_weight":
|
||||
d["content"] = v
|
||||
elif k == "content_ltks":
|
||||
if not d.get("content_with_weight"):
|
||||
d["content"] = v
|
||||
elif k == "content_sm_ltks":
|
||||
if not d.get("content_with_weight"):
|
||||
d["content"] = v
|
||||
elif k == "authors_tks":
|
||||
d["authors"] = v
|
||||
elif k == "authors_sm_tks":
|
||||
if not d.get("authors_tks"):
|
||||
d["authors"] = v
|
||||
elif k == "question_kwd":
|
||||
d["questions"] = list2str(v, "\n")
|
||||
elif k == "question_tks":
|
||||
if not d.get("question_kwd"):
|
||||
d["questions"] = list2str(v)
|
||||
elif field_keyword(k):
|
||||
if isinstance(v, list):
|
||||
d[k] = "###".join(v)
|
||||
else:
|
||||
@ -528,6 +617,9 @@ class InfinityConnection(DocStoreConnection):
|
||||
d[k] = "_".join(f"{num:08x}" for num in v)
|
||||
else:
|
||||
d[k] = v
|
||||
for k in ["docnm_kwd", "title_tks", "title_sm_tks", "important_kwd", "important_tks", "content_with_weight", "content_ltks", "content_sm_ltks", "authors_tks", "authors_sm_tks", "question_kwd", "question_tks"]:
|
||||
if k in d:
|
||||
del d[k]
|
||||
|
||||
for n, vs in embedding_clmns:
|
||||
if n in d:
|
||||
@ -562,7 +654,38 @@ class InfinityConnection(DocStoreConnection):
|
||||
filter = equivalent_condition_to_str(condition, table_instance)
|
||||
removeValue = {}
|
||||
for k, v in list(newValue.items()):
|
||||
if field_keyword(k):
|
||||
if k == "docnm_kwd":
|
||||
newValue["docnm"] = list2str(v)
|
||||
elif k == "title_kwd":
|
||||
if not newValue.get("docnm_kwd"):
|
||||
newValue["docnm"] = list2str(v)
|
||||
elif k == "title_sm_tks":
|
||||
if not newValue.get("docnm_kwd"):
|
||||
newValue["docnm"] = v
|
||||
elif k == "important_kwd":
|
||||
newValue["important_keywords"] = list2str(v)
|
||||
elif k == "important_tks":
|
||||
if not newValue.get("important_kwd"):
|
||||
newValue["important_keywords"] = v
|
||||
elif k == "content_with_weight":
|
||||
newValue["content"] = v
|
||||
elif k == "content_ltks":
|
||||
if not newValue.get("content_with_weight"):
|
||||
newValue["content"] = v
|
||||
elif k == "content_sm_ltks":
|
||||
if not newValue.get("content_with_weight"):
|
||||
newValue["content"] = v
|
||||
elif k == "authors_tks":
|
||||
newValue["authors"] = v
|
||||
elif k == "authors_sm_tks":
|
||||
if not newValue.get("authors_tks"):
|
||||
newValue["authors"] = v
|
||||
elif k == "question_kwd":
|
||||
newValue["questions"] = "\n".join(v)
|
||||
elif k == "question_tks":
|
||||
if not newValue.get("question_kwd"):
|
||||
newValue["questions"] = list2str(v)
|
||||
elif field_keyword(k):
|
||||
if isinstance(v, list):
|
||||
newValue[k] = "###".join(v)
|
||||
else:
|
||||
@ -593,6 +716,9 @@ class InfinityConnection(DocStoreConnection):
|
||||
del newValue[k]
|
||||
else:
|
||||
newValue[k] = v
|
||||
for k in ["docnm_kwd", "title_tks", "title_sm_tks", "important_kwd", "important_tks", "content_with_weight", "content_ltks", "content_sm_ltks", "authors_tks", "authors_sm_tks", "question_kwd", "question_tks"]:
|
||||
if k in newValue:
|
||||
del newValue[k]
|
||||
|
||||
remove_opt = {} # "[k,new_value]": [id_to_update, ...]
|
||||
if removeValue:
|
||||
@ -656,22 +782,45 @@ class InfinityConnection(DocStoreConnection):
|
||||
return {}
|
||||
fieldsAll = fields.copy()
|
||||
fieldsAll.append("id")
|
||||
fieldsAll = set(fieldsAll)
|
||||
if "docnm" in res.columns:
|
||||
for field in ["docnm_kwd", "title_tks", "title_sm_tks"]:
|
||||
if field in fieldsAll:
|
||||
res[field] = res["docnm"]
|
||||
if "important_keywords" in res.columns:
|
||||
if "important_kwd" in fieldsAll:
|
||||
res["important_kwd"] = res["important_keywords"].apply(lambda v: v.split())
|
||||
if "important_tks" in fieldsAll:
|
||||
res["important_tks"] = res["important_keywords"]
|
||||
if "questions" in res.columns:
|
||||
if "question_kwd" in fieldsAll:
|
||||
res["question_kwd"] = res["questions"].apply(lambda v: v.splitlines())
|
||||
if "question_tks" in fieldsAll:
|
||||
res["question_tks"] = res["questions"]
|
||||
if "content" in res.columns:
|
||||
for field in ["content_with_weight", "content_ltks", "content_sm_ltks"]:
|
||||
if field in fieldsAll:
|
||||
res[field] = res["content"]
|
||||
if "authors" in res.columns:
|
||||
for field in ["authors_tks", "authors_sm_tks"]:
|
||||
if field in fieldsAll:
|
||||
res[field] = res["authors"]
|
||||
|
||||
column_map = {col.lower(): col for col in res.columns}
|
||||
matched_columns = {column_map[col.lower()]: col for col in set(fieldsAll) if col.lower() in column_map}
|
||||
none_columns = [col for col in set(fieldsAll) if col.lower() not in column_map]
|
||||
matched_columns = {column_map[col.lower()]: col for col in fieldsAll if col.lower() in column_map}
|
||||
none_columns = [col for col in fieldsAll if col.lower() not in column_map]
|
||||
|
||||
res2 = res[matched_columns.keys()]
|
||||
res2 = res2.rename(columns=matched_columns)
|
||||
res2.drop_duplicates(subset=["id"], inplace=True)
|
||||
|
||||
for column in res2.columns:
|
||||
for column in list(res2.columns):
|
||||
k = column.lower()
|
||||
if field_keyword(k):
|
||||
res2[column] = res2[column].apply(lambda v: [kwd for kwd in v.split("###") if kwd])
|
||||
elif re.search(r"_feas$", k):
|
||||
res2[column] = res2[column].apply(lambda v: json.loads(v) if v else {})
|
||||
elif k == "position_int":
|
||||
|
||||
def to_position_int(v):
|
||||
if v:
|
||||
arr = [int(hex_val, 16) for hex_val in v.split("_")]
|
||||
@ -685,6 +834,9 @@ class InfinityConnection(DocStoreConnection):
|
||||
res2[column] = res2[column].apply(lambda v: [int(hex_val, 16) for hex_val in v.split("_")] if v else [])
|
||||
else:
|
||||
pass
|
||||
for column in ["docnm", "important_keywords", "questions", "content", "authors"]:
|
||||
if column in res2:
|
||||
del res2[column]
|
||||
for column in none_columns:
|
||||
res2[column] = None
|
||||
|
||||
|
||||
1562
rag/utils/ob_conn.py
Normal file
1562
rag/utils/ob_conn.py
Normal file
File diff suppressed because it is too large
Load Diff
@ -1,11 +0,0 @@
|
||||
# ragflow-sdk
|
||||
|
||||
# build and publish python SDK to pypi.org
|
||||
|
||||
```shell
|
||||
uv build
|
||||
uv pip install twine
|
||||
export TWINE_USERNAME="__token__"
|
||||
export TWINE_PASSWORD=$YOUR_PYPI_API_TOKEN
|
||||
twine upload dist/*.whl
|
||||
```
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user