mirror of
https://github.com/infiniflow/ragflow.git
synced 2026-01-04 03:25:30 +08:00
Compare commits
152 Commits
v0.20.4
...
c8b79dfed4
| Author | SHA1 | Date | |
|---|---|---|---|
| c8b79dfed4 | |||
| da80fa40bc | |||
| 94dbd4aac9 | |||
| ca9f30e1a1 | |||
| 2e4295d5ca | |||
| d11b1628a1 | |||
| 45f9f428db | |||
| 902703d145 | |||
| 7ccca2143c | |||
| 70ce02faf4 | |||
| 3f1741c8c6 | |||
| 6c24ad7966 | |||
| 4846589599 | |||
| a24547aa66 | |||
| a04c5247ab | |||
| ed6a76dcc0 | |||
| a0ccbec8bd | |||
| 4693c5382a | |||
| ff3b4d0dcd | |||
| 62d35b1b73 | |||
| 91b609447d | |||
| c353840244 | |||
| f12b9fdcd4 | |||
| 80ede65bbe | |||
| 52cf186028 | |||
| ea0f1d47a5 | |||
| 9fe7c92217 | |||
| d353f7f7f8 | |||
| f3738b06f1 | |||
| 5a8bc88147 | |||
| 04ef5b2783 | |||
| c9ea22ef69 | |||
| 152111fd9d | |||
| 86f6da2f74 | |||
| 8c00cbc87a | |||
| 41e808f4e6 | |||
| bc0281040b | |||
| 341a7b1473 | |||
| c29c395390 | |||
| a23a0f230c | |||
| 2a88ce6be1 | |||
| 664b781d62 | |||
| 65571e5254 | |||
| aa30f20730 | |||
| b9b278d441 | |||
| e1d86cfee3 | |||
| 8ebd07337f | |||
| dd584d57b0 | |||
| 3d39b96c6f | |||
| 179091b1a4 | |||
| d14d92a900 | |||
| 1936ad82d2 | |||
| 8a09f07186 | |||
| df8d31451b | |||
| fc95d113c3 | |||
| 7d14455fbe | |||
| bbe6ed3b90 | |||
| 127af4e45c | |||
| 41cdba19ba | |||
| 0d9c1f1c3c | |||
| e650f0d368 | |||
| 067b4fc012 | |||
| 38ff2ffc01 | |||
| a9cc992d13 | |||
| 5cf2c97908 | |||
| 81fede0041 | |||
| 07a83f93d5 | |||
| 1a904edd94 | |||
| 906969fe4e | |||
| 776ea078a6 | |||
| fcdde26a7f | |||
| 79076ffb5f | |||
| e8dcdfb9f0 | |||
| c4f43a395d | |||
| a255c78b59 | |||
| 936f27e9e5 | |||
| 2616f651c9 | |||
| e8018fde83 | |||
| f514482c0a | |||
| e9ee9269f5 | |||
| cf18231713 | |||
| f48aed6d4a | |||
| b524cf0ec8 | |||
| 994517495f | |||
| 63781bde3f | |||
| 91d6fb8061 | |||
| 45f52e85d7 | |||
| 9aa8cfb73a | |||
| 79ca25ec7e | |||
| 6ff7cfe005 | |||
| 4e16936fa4 | |||
| 677c99b090 | |||
| 8e30a75e5c | |||
| b14052e5a2 | |||
| ddaed541ff | |||
| 1ee9c0b8d9 | |||
| 9b724b3b5e | |||
| 3b1ee769eb | |||
| 41cb94324a | |||
| 982ec24fa7 | |||
| 1f7a035340 | |||
| d04ae3f943 | |||
| abd19b0f48 | |||
| aa1251af9a | |||
| 483f3aa71d | |||
| 72bb79e8dd | |||
| 927a195008 | |||
| d13dc0c24d | |||
| 37ac7576f1 | |||
| c832e0b858 | |||
| 5d015e48c1 | |||
| b58e882eaa | |||
| 1bc33009c7 | |||
| cb731dce34 | |||
| 1595cdc48f | |||
| 4179ecd469 | |||
| cb14dafaca | |||
| c2567844ea | |||
| 757c5376be | |||
| 79968c37a8 | |||
| 2e00d8d3d4 | |||
| 0b456a18a3 | |||
| dd8e660f0a | |||
| 98ee3dee74 | |||
| d4b0cd8599 | |||
| 3398dac906 | |||
| 7eb25e0de6 | |||
| bed77ee28f | |||
| 56cd576876 | |||
| 4fbad2828c | |||
| e997bf6507 | |||
| 209b731541 | |||
| c47a38773c | |||
| fcd18d7d87 | |||
| fe9adbf0a5 | |||
| c7f7adf029 | |||
| c27172b3bc | |||
| a246949b77 | |||
| 0a954d720a | |||
| f89e55ec42 | |||
| 5fe8cf6018 | |||
| 4720849ac0 | |||
| d7721833e7 | |||
| 7332f1d0f3 | |||
| 2d101561f8 | |||
| 59590e9aae | |||
| bb9b9b8357 | |||
| a4b368e53f | |||
| c461261f0b | |||
| a1633e0a2f | |||
| 369add35b8 | |||
| 5abd0bbac1 |
8
.github/workflows/release.yml
vendored
8
.github/workflows/release.yml
vendored
@ -88,7 +88,9 @@ jobs:
|
||||
with:
|
||||
context: .
|
||||
push: true
|
||||
tags: infiniflow/ragflow:${{ env.RELEASE_TAG }}
|
||||
tags: |
|
||||
infiniflow/ragflow:${{ env.RELEASE_TAG }}
|
||||
infiniflow/ragflow:latest-full
|
||||
file: Dockerfile
|
||||
platforms: linux/amd64
|
||||
|
||||
@ -98,7 +100,9 @@ jobs:
|
||||
with:
|
||||
context: .
|
||||
push: true
|
||||
tags: infiniflow/ragflow:${{ env.RELEASE_TAG }}-slim
|
||||
tags: |
|
||||
infiniflow/ragflow:${{ env.RELEASE_TAG }}-slim
|
||||
infiniflow/ragflow:latest-slim
|
||||
file: Dockerfile
|
||||
build-args: LIGHTEN=1
|
||||
platforms: linux/amd64
|
||||
|
||||
1
.github/workflows/tests.yml
vendored
1
.github/workflows/tests.yml
vendored
@ -67,6 +67,7 @@ jobs:
|
||||
|
||||
- name: Start ragflow:nightly-slim
|
||||
run: |
|
||||
sudo docker compose -f docker/docker-compose.yml down --volumes --remove-orphans
|
||||
echo -e "\nRAGFLOW_IMAGE=infiniflow/ragflow:nightly-slim" >> docker/.env
|
||||
sudo docker compose -f docker/docker-compose.yml up -d
|
||||
|
||||
|
||||
19
README.md
19
README.md
@ -22,7 +22,7 @@
|
||||
<img alt="Static Badge" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
||||
</a>
|
||||
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
||||
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.20.4">
|
||||
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.20.5">
|
||||
</a>
|
||||
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
||||
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Latest%20Release" alt="Latest Release">
|
||||
@ -71,10 +71,7 @@
|
||||
|
||||
## 💡 What is RAGFlow?
|
||||
|
||||
[RAGFlow](https://ragflow.io/) is an open-source RAG (Retrieval-Augmented Generation) engine based on deep document
|
||||
understanding. It offers a streamlined RAG workflow for businesses of any scale, combining LLM (Large Language Models)
|
||||
to provide truthful question-answering capabilities, backed by well-founded citations from various complex formatted
|
||||
data.
|
||||
[RAGFlow](https://ragflow.io/) is a leading open-source Retrieval-Augmented Generation (RAG) engine that fuses cutting-edge RAG with Agent capabilities to create a superior context layer for LLMs. It offers a streamlined RAG workflow adaptable to enterprises of any scale. Powered by a converged context engine and pre-built agent templates, RAGFlow enables developers to transform complex data into high-fidelity, production-ready AI systems with exceptional efficiency and precision.
|
||||
|
||||
## 🎮 Demo
|
||||
|
||||
@ -190,7 +187,7 @@ releases! 🌟
|
||||
> All Docker images are built for x86 platforms. We don't currently offer Docker images for ARM64.
|
||||
> If you are on an ARM64 platform, follow [this guide](https://ragflow.io/docs/dev/build_docker_image) to build a Docker image compatible with your system.
|
||||
|
||||
> The command below downloads the `v0.20.4-slim` edition of the RAGFlow Docker image. See the following table for descriptions of different RAGFlow editions. To download a RAGFlow edition different from `v0.20.4-slim`, update the `RAGFLOW_IMAGE` variable accordingly in **docker/.env** before using `docker compose` to start the server. For example: set `RAGFLOW_IMAGE=infiniflow/ragflow:v0.20.4` for the full edition `v0.20.4`.
|
||||
> The command below downloads the `v0.20.5-slim` edition of the RAGFlow Docker image. See the following table for descriptions of different RAGFlow editions. To download a RAGFlow edition different from `v0.20.5-slim`, update the `RAGFLOW_IMAGE` variable accordingly in **docker/.env** before using `docker compose` to start the server. For example: set `RAGFLOW_IMAGE=infiniflow/ragflow:v0.20.5` for the full edition `v0.20.5`.
|
||||
|
||||
```bash
|
||||
$ cd ragflow/docker
|
||||
@ -203,8 +200,8 @@ releases! 🌟
|
||||
|
||||
| RAGFlow image tag | Image size (GB) | Has embedding models? | Stable? |
|
||||
|-------------------|-----------------|-----------------------|--------------------------|
|
||||
| v0.20.4 | ≈9 | :heavy_check_mark: | Stable release |
|
||||
| v0.20.4-slim | ≈2 | ❌ | Stable release |
|
||||
| v0.20.5 | ≈9 | :heavy_check_mark: | Stable release |
|
||||
| v0.20.5-slim | ≈2 | ❌ | Stable release |
|
||||
| nightly | ≈9 | :heavy_check_mark: | _Unstable_ nightly build |
|
||||
| nightly-slim | ≈2 | ❌ | _Unstable_ nightly build |
|
||||
|
||||
@ -307,7 +304,7 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
|
||||
## 🔨 Launch service from source for development
|
||||
|
||||
1. Install uv, or skip this step if it is already installed:
|
||||
1. Install `uv` and `pre-commit`, or skip this step if they are already installed:
|
||||
|
||||
```bash
|
||||
pipx install uv pre-commit
|
||||
@ -348,8 +345,10 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
sudo apt-get install libjemalloc-dev
|
||||
# centos
|
||||
sudo yum install jemalloc
|
||||
# mac
|
||||
sudo brew install jemalloc
|
||||
```
|
||||
|
||||
|
||||
6. Launch backend service:
|
||||
|
||||
```bash
|
||||
|
||||
14
README_id.md
14
README_id.md
@ -22,7 +22,7 @@
|
||||
<img alt="Lencana Daring" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
||||
</a>
|
||||
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
||||
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.20.4">
|
||||
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.20.5">
|
||||
</a>
|
||||
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
||||
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Rilis%20Terbaru" alt="Rilis Terbaru">
|
||||
@ -67,7 +67,7 @@
|
||||
|
||||
## 💡 Apa Itu RAGFlow?
|
||||
|
||||
[RAGFlow](https://ragflow.io/) adalah mesin RAG (Retrieval-Augmented Generation) open-source berbasis pemahaman dokumen yang mendalam. Platform ini menyediakan alur kerja RAG yang efisien untuk bisnis dengan berbagai skala, menggabungkan LLM (Large Language Models) untuk menyediakan kemampuan tanya-jawab yang benar dan didukung oleh referensi dari data terstruktur kompleks.
|
||||
[RAGFlow](https://ragflow.io/) adalah mesin RAG (Retrieval-Augmented Generation) open-source terkemuka yang mengintegrasikan teknologi RAG mutakhir dengan kemampuan Agent untuk menciptakan lapisan kontekstual superior bagi LLM. Menyediakan alur kerja RAG yang efisien dan dapat diadaptasi untuk perusahaan segala skala. Didukung oleh mesin konteks terkonvergensi dan template Agent yang telah dipra-bangun, RAGFlow memungkinkan pengembang mengubah data kompleks menjadi sistem AI kesetiaan-tinggi dan siap-produksi dengan efisiensi dan presisi yang luar biasa.
|
||||
|
||||
## 🎮 Demo
|
||||
|
||||
@ -181,7 +181,7 @@ Coba demo kami di [https://demo.ragflow.io](https://demo.ragflow.io).
|
||||
> Semua gambar Docker dibangun untuk platform x86. Saat ini, kami tidak menawarkan gambar Docker untuk ARM64.
|
||||
> Jika Anda menggunakan platform ARM64, [silakan gunakan panduan ini untuk membangun gambar Docker yang kompatibel dengan sistem Anda](https://ragflow.io/docs/dev/build_docker_image).
|
||||
|
||||
> Perintah di bawah ini mengunduh edisi v0.20.4-slim dari gambar Docker RAGFlow. Silakan merujuk ke tabel berikut untuk deskripsi berbagai edisi RAGFlow. Untuk mengunduh edisi RAGFlow yang berbeda dari v0.20.4-slim, perbarui variabel RAGFLOW_IMAGE di docker/.env sebelum menggunakan docker compose untuk memulai server. Misalnya, atur RAGFLOW_IMAGE=infiniflow/ragflow:v0.20.4 untuk edisi lengkap v0.20.4.
|
||||
> Perintah di bawah ini mengunduh edisi v0.20.5-slim dari gambar Docker RAGFlow. Silakan merujuk ke tabel berikut untuk deskripsi berbagai edisi RAGFlow. Untuk mengunduh edisi RAGFlow yang berbeda dari v0.20.5-slim, perbarui variabel RAGFLOW_IMAGE di docker/.env sebelum menggunakan docker compose untuk memulai server. Misalnya, atur RAGFLOW_IMAGE=infiniflow/ragflow:v0.20.5 untuk edisi lengkap v0.20.5.
|
||||
|
||||
```bash
|
||||
$ cd ragflow/docker
|
||||
@ -194,8 +194,8 @@ $ docker compose -f docker-compose.yml up -d
|
||||
|
||||
| RAGFlow image tag | Image size (GB) | Has embedding models? | Stable? |
|
||||
| ----------------- | --------------- | --------------------- | ------------------------ |
|
||||
| v0.20.4 | ≈9 | :heavy_check_mark: | Stable release |
|
||||
| v0.20.4-slim | ≈2 | ❌ | Stable release |
|
||||
| v0.20.5 | ≈9 | :heavy_check_mark: | Stable release |
|
||||
| v0.20.5-slim | ≈2 | ❌ | Stable release |
|
||||
| nightly | ≈9 | :heavy_check_mark: | _Unstable_ nightly build |
|
||||
| nightly-slim | ≈2 | ❌ | _Unstable_ nightly build |
|
||||
|
||||
@ -271,7 +271,7 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
|
||||
## 🔨 Menjalankan Aplikasi dari untuk Pengembangan
|
||||
|
||||
1. Instal uv, atau lewati langkah ini jika sudah terinstal:
|
||||
1. Instal `uv` dan `pre-commit`, atau lewati langkah ini jika sudah terinstal:
|
||||
|
||||
```bash
|
||||
pipx install uv pre-commit
|
||||
@ -312,6 +312,8 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
sudo apt-get install libjemalloc-dev
|
||||
# centos
|
||||
sudo yum install jemalloc
|
||||
# mac
|
||||
sudo brew install jemalloc
|
||||
```
|
||||
|
||||
6. Jalankan aplikasi backend:
|
||||
|
||||
16
README_ja.md
16
README_ja.md
@ -22,7 +22,7 @@
|
||||
<img alt="Static Badge" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
||||
</a>
|
||||
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
||||
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.20.4">
|
||||
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.20.5">
|
||||
</a>
|
||||
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
||||
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Latest%20Release" alt="Latest Release">
|
||||
@ -47,7 +47,7 @@
|
||||
|
||||
## 💡 RAGFlow とは?
|
||||
|
||||
[RAGFlow](https://ragflow.io/) は、深い文書理解に基づいたオープンソースの RAG (Retrieval-Augmented Generation) エンジンである。LLM(大規模言語モデル)を組み合わせることで、様々な複雑なフォーマットのデータから根拠のある引用に裏打ちされた、信頼できる質問応答機能を実現し、あらゆる規模のビジネスに適した RAG ワークフローを提供します。
|
||||
[RAGFlow](https://ragflow.io/) は、先進的なRAG(Retrieval-Augmented Generation)技術と Agent 機能を融合し、大規模言語モデル(LLM)に優れたコンテキスト層を構築する最先端のオープンソース RAG エンジンです。あらゆる規模の企業に対応可能な合理化された RAG ワークフローを提供し、統合型コンテキストエンジンと事前構築されたAgentテンプレートにより、開発者が複雑なデータを驚異的な効率性と精度で高精細なプロダクションレディAIシステムへ変換することを可能にします。
|
||||
|
||||
## 🎮 Demo
|
||||
|
||||
@ -160,7 +160,7 @@
|
||||
> 現在、公式に提供されているすべての Docker イメージは x86 アーキテクチャ向けにビルドされており、ARM64 用の Docker イメージは提供されていません。
|
||||
> ARM64 アーキテクチャのオペレーティングシステムを使用している場合は、[このドキュメント](https://ragflow.io/docs/dev/build_docker_image)を参照して Docker イメージを自分でビルドしてください。
|
||||
|
||||
> 以下のコマンドは、RAGFlow Docker イメージの v0.20.4-slim エディションをダウンロードします。異なる RAGFlow エディションの説明については、以下の表を参照してください。v0.20.4-slim とは異なるエディションをダウンロードするには、docker/.env ファイルの RAGFLOW_IMAGE 変数を適宜更新し、docker compose を使用してサーバーを起動してください。例えば、完全版 v0.20.4 をダウンロードするには、RAGFLOW_IMAGE=infiniflow/ragflow:v0.20.4 と設定します。
|
||||
> 以下のコマンドは、RAGFlow Docker イメージの v0.20.5-slim エディションをダウンロードします。異なる RAGFlow エディションの説明については、以下の表を参照してください。v0.20.5-slim とは異なるエディションをダウンロードするには、docker/.env ファイルの RAGFLOW_IMAGE 変数を適宜更新し、docker compose を使用してサーバーを起動してください。例えば、完全版 v0.20.5 をダウンロードするには、RAGFLOW_IMAGE=infiniflow/ragflow:v0.20.5 と設定します。
|
||||
|
||||
```bash
|
||||
$ cd ragflow/docker
|
||||
@ -173,8 +173,8 @@
|
||||
|
||||
| RAGFlow image tag | Image size (GB) | Has embedding models? | Stable? |
|
||||
| ----------------- | --------------- | --------------------- | ------------------------ |
|
||||
| v0.20.4 | ≈9 | :heavy_check_mark: | Stable release |
|
||||
| v0.20.4-slim | ≈2 | ❌ | Stable release |
|
||||
| v0.20.5 | ≈9 | :heavy_check_mark: | Stable release |
|
||||
| v0.20.5-slim | ≈2 | ❌ | Stable release |
|
||||
| nightly | ≈9 | :heavy_check_mark: | _Unstable_ nightly build |
|
||||
| nightly-slim | ≈2 | ❌ | _Unstable_ nightly build |
|
||||
|
||||
@ -266,7 +266,7 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
|
||||
## 🔨 ソースコードからサービスを起動する方法
|
||||
|
||||
1. uv をインストールする。すでにインストールされている場合は、このステップをスキップしてください:
|
||||
1. `uv` と `pre-commit` をインストールする。すでにインストールされている場合は、このステップをスキップしてください:
|
||||
|
||||
```bash
|
||||
pipx install uv pre-commit
|
||||
@ -301,12 +301,14 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
```
|
||||
|
||||
5. オペレーティングシステムにjemallocがない場合は、次のようにインストールします:
|
||||
|
||||
|
||||
```bash
|
||||
# ubuntu
|
||||
sudo apt-get install libjemalloc-dev
|
||||
# centos
|
||||
sudo yum install jemalloc
|
||||
# mac
|
||||
sudo brew install jemalloc
|
||||
```
|
||||
|
||||
6. バックエンドサービスを起動する:
|
||||
|
||||
16
README_ko.md
16
README_ko.md
@ -22,7 +22,7 @@
|
||||
<img alt="Static Badge" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
||||
</a>
|
||||
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
||||
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.20.4">
|
||||
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.20.5">
|
||||
</a>
|
||||
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
||||
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Latest%20Release" alt="Latest Release">
|
||||
@ -47,7 +47,7 @@
|
||||
|
||||
## 💡 RAGFlow란?
|
||||
|
||||
[RAGFlow](https://ragflow.io/)는 심층 문서 이해에 기반한 오픈소스 RAG (Retrieval-Augmented Generation) 엔진입니다. 이 엔진은 대규모 언어 모델(LLM)과 결합하여 정확한 질문 응답 기능을 제공하며, 다양한 복잡한 형식의 데이터에서 신뢰할 수 있는 출처를 바탕으로 한 인용을 통해 이를 뒷받침합니다. RAGFlow는 규모에 상관없이 모든 기업에 최적화된 RAG 워크플로우를 제공합니다.
|
||||
[RAGFlow](https://ragflow.io/) 는 최첨단 RAG(Retrieval-Augmented Generation)와 Agent 기능을 융합하여 대규모 언어 모델(LLM)을 위한 우수한 컨텍스트 계층을 생성하는 선도적인 오픈소스 RAG 엔진입니다. 모든 규모의 기업에 적용 가능한 효율적인 RAG 워크플로를 제공하며, 통합 컨텍스트 엔진과 사전 구축된 Agent 템플릿을 통해 개발자들이 복잡한 데이터를 예외적인 효율성과 정밀도로 고급 구현도의 프로덕션 준비 완료 AI 시스템으로 변환할 수 있도록 지원합니다.
|
||||
|
||||
## 🎮 데모
|
||||
|
||||
@ -160,7 +160,7 @@
|
||||
> 모든 Docker 이미지는 x86 플랫폼을 위해 빌드되었습니다. 우리는 현재 ARM64 플랫폼을 위한 Docker 이미지를 제공하지 않습니다.
|
||||
> ARM64 플랫폼을 사용 중이라면, [시스템과 호환되는 Docker 이미지를 빌드하려면 이 가이드를 사용해 주세요](https://ragflow.io/docs/dev/build_docker_image).
|
||||
|
||||
> 아래 명령어는 RAGFlow Docker 이미지의 v0.20.4-slim 버전을 다운로드합니다. 다양한 RAGFlow 버전에 대한 설명은 다음 표를 참조하십시오. v0.20.4-slim과 다른 RAGFlow 버전을 다운로드하려면, docker/.env 파일에서 RAGFLOW_IMAGE 변수를 적절히 업데이트한 후 docker compose를 사용하여 서버를 시작하십시오. 예를 들어, 전체 버전인 v0.20.4을 다운로드하려면 RAGFLOW_IMAGE=infiniflow/ragflow:v0.20.4로 설정합니다.
|
||||
> 아래 명령어는 RAGFlow Docker 이미지의 v0.20.5-slim 버전을 다운로드합니다. 다양한 RAGFlow 버전에 대한 설명은 다음 표를 참조하십시오. v0.20.5-slim과 다른 RAGFlow 버전을 다운로드하려면, docker/.env 파일에서 RAGFLOW_IMAGE 변수를 적절히 업데이트한 후 docker compose를 사용하여 서버를 시작하십시오. 예를 들어, 전체 버전인 v0.20.5을 다운로드하려면 RAGFLOW_IMAGE=infiniflow/ragflow:v0.20.5로 설정합니다.
|
||||
|
||||
```bash
|
||||
$ cd ragflow/docker
|
||||
@ -173,8 +173,8 @@
|
||||
|
||||
| RAGFlow image tag | Image size (GB) | Has embedding models? | Stable? |
|
||||
| ----------------- | --------------- | --------------------- | ------------------------ |
|
||||
| v0.20.4 | ≈9 | :heavy_check_mark: | Stable release |
|
||||
| v0.20.4-slim | ≈2 | ❌ | Stable release |
|
||||
| v0.20.5 | ≈9 | :heavy_check_mark: | Stable release |
|
||||
| v0.20.5-slim | ≈2 | ❌ | Stable release |
|
||||
| nightly | ≈9 | :heavy_check_mark: | _Unstable_ nightly build |
|
||||
| nightly-slim | ≈2 | ❌ | _Unstable_ nightly build |
|
||||
|
||||
@ -265,7 +265,7 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
|
||||
## 🔨 소스 코드로 서비스를 시작합니다.
|
||||
|
||||
1. uv를 설치하거나 이미 설치된 경우 이 단계를 건너뜁니다:
|
||||
1. `uv` 와 `pre-commit` 을 설치하거나, 이미 설치된 경우 이 단계를 건너뜁니다:
|
||||
|
||||
```bash
|
||||
pipx install uv pre-commit
|
||||
@ -306,6 +306,8 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
sudo apt-get install libjemalloc-dev
|
||||
# centos
|
||||
sudo yum install jemalloc
|
||||
# mac
|
||||
sudo brew install jemalloc
|
||||
```
|
||||
|
||||
6. 백엔드 서비스를 시작합니다:
|
||||
@ -339,7 +341,7 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
```bash
|
||||
pkill -f "ragflow_server.py|task_executor.py"
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 📚 문서
|
||||
|
||||
|
||||
@ -22,7 +22,7 @@
|
||||
<img alt="Badge Estático" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
||||
</a>
|
||||
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
||||
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.20.4">
|
||||
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.20.5">
|
||||
</a>
|
||||
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
||||
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Última%20Relese" alt="Última Versão">
|
||||
@ -67,7 +67,7 @@
|
||||
|
||||
## 💡 O que é o RAGFlow?
|
||||
|
||||
[RAGFlow](https://ragflow.io/) é um mecanismo RAG (Geração Aumentada por Recuperação) de código aberto baseado em entendimento profundo de documentos. Ele oferece um fluxo de trabalho RAG simplificado para empresas de qualquer porte, combinando LLMs (Modelos de Linguagem de Grande Escala) para fornecer capacidades de perguntas e respostas verídicas, respaldadas por citações bem fundamentadas de diversos dados complexos formatados.
|
||||
[RAGFlow](https://ragflow.io/) é um mecanismo de RAG (Retrieval-Augmented Generation) open-source líder que fusiona tecnologias RAG de ponta com funcionalidades Agent para criar uma camada contextual superior para LLMs. Oferece um fluxo de trabalho RAG otimizado adaptável a empresas de qualquer escala. Alimentado por um motor de contexto convergente e modelos Agent pré-construídos, o RAGFlow permite que desenvolvedores transformem dados complexos em sistemas de IA de alta fidelidade e pronto para produção com excepcional eficiência e precisão.
|
||||
|
||||
## 🎮 Demo
|
||||
|
||||
@ -180,7 +180,7 @@ Experimente nossa demo em [https://demo.ragflow.io](https://demo.ragflow.io).
|
||||
> Todas as imagens Docker são construídas para plataformas x86. Atualmente, não oferecemos imagens Docker para ARM64.
|
||||
> Se você estiver usando uma plataforma ARM64, por favor, utilize [este guia](https://ragflow.io/docs/dev/build_docker_image) para construir uma imagem Docker compatível com o seu sistema.
|
||||
|
||||
> O comando abaixo baixa a edição `v0.20.4-slim` da imagem Docker do RAGFlow. Consulte a tabela a seguir para descrições de diferentes edições do RAGFlow. Para baixar uma edição do RAGFlow diferente da `v0.20.4-slim`, atualize a variável `RAGFLOW_IMAGE` conforme necessário no **docker/.env** antes de usar `docker compose` para iniciar o servidor. Por exemplo: defina `RAGFLOW_IMAGE=infiniflow/ragflow:v0.20.4` para a edição completa `v0.20.4`.
|
||||
> O comando abaixo baixa a edição `v0.20.5-slim` da imagem Docker do RAGFlow. Consulte a tabela a seguir para descrições de diferentes edições do RAGFlow. Para baixar uma edição do RAGFlow diferente da `v0.20.5-slim`, atualize a variável `RAGFLOW_IMAGE` conforme necessário no **docker/.env** antes de usar `docker compose` para iniciar o servidor. Por exemplo: defina `RAGFLOW_IMAGE=infiniflow/ragflow:v0.20.5` para a edição completa `v0.20.5`.
|
||||
|
||||
```bash
|
||||
$ cd ragflow/docker
|
||||
@ -193,8 +193,8 @@ Experimente nossa demo em [https://demo.ragflow.io](https://demo.ragflow.io).
|
||||
|
||||
| Tag da imagem RAGFlow | Tamanho da imagem (GB) | Possui modelos de incorporação? | Estável? |
|
||||
| --------------------- | ---------------------- | ------------------------------- | ------------------------ |
|
||||
| v0.20.4 | ~9 | :heavy_check_mark: | Lançamento estável |
|
||||
| v0.20.4-slim | ~2 | ❌ | Lançamento estável |
|
||||
| v0.20.5 | ~9 | :heavy_check_mark: | Lançamento estável |
|
||||
| v0.20.5-slim | ~2 | ❌ | Lançamento estável |
|
||||
| nightly | ~9 | :heavy_check_mark: | _Instável_ build noturno |
|
||||
| nightly-slim | ~2 | ❌ | _Instável_ build noturno |
|
||||
|
||||
@ -289,7 +289,7 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
|
||||
## 🔨 Lançar o serviço a partir do código-fonte para desenvolvimento
|
||||
|
||||
1. Instale o `uv`, ou pule esta etapa se ele já estiver instalado:
|
||||
1. Instale o `uv` e o `pre-commit`, ou pule esta etapa se eles já estiverem instalados:
|
||||
|
||||
```bash
|
||||
pipx install uv pre-commit
|
||||
@ -330,6 +330,8 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
sudo apt-get install libjemalloc-dev
|
||||
# centos
|
||||
sudo yum instalar jemalloc
|
||||
# mac
|
||||
sudo brew install jemalloc
|
||||
```
|
||||
|
||||
6. Lance o serviço de back-end:
|
||||
|
||||
@ -22,7 +22,7 @@
|
||||
<img alt="Static Badge" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
||||
</a>
|
||||
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
||||
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.20.4">
|
||||
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.20.5">
|
||||
</a>
|
||||
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
||||
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Latest%20Release" alt="Latest Release">
|
||||
@ -70,7 +70,7 @@
|
||||
|
||||
## 💡 RAGFlow 是什麼?
|
||||
|
||||
[RAGFlow](https://ragflow.io/) 是一款基於深度文件理解所建構的開源 RAG(Retrieval-Augmented Generation)引擎。 RAGFlow 可以為各種規模的企業及個人提供一套精簡的 RAG 工作流程,結合大語言模型(LLM)針對用戶各類不同的複雜格式數據提供可靠的問答以及有理有據的引用。
|
||||
[RAGFlow](https://ragflow.io/) 是一款領先的開源 RAG(Retrieval-Augmented Generation)引擎,通過融合前沿的 RAG 技術與 Agent 能力,為大型語言模型提供卓越的上下文層。它提供可適配任意規模企業的端到端 RAG 工作流,憑藉融合式上下文引擎與預置的 Agent 模板,助力開發者以極致效率與精度將複雜數據轉化為高可信、生產級的人工智能系統。
|
||||
|
||||
## 🎮 Demo 試用
|
||||
|
||||
@ -183,7 +183,7 @@
|
||||
> 所有 Docker 映像檔都是為 x86 平台建置的。目前,我們不提供 ARM64 平台的 Docker 映像檔。
|
||||
> 如果您使用的是 ARM64 平台,請使用 [這份指南](https://ragflow.io/docs/dev/build_docker_image) 來建置適合您系統的 Docker 映像檔。
|
||||
|
||||
> 執行以下指令會自動下載 RAGFlow slim Docker 映像 `v0.20.4-slim`。請參考下表查看不同 Docker 發行版的說明。如需下載不同於 `v0.20.4-slim` 的 Docker 映像,請在執行 `docker compose` 啟動服務之前先更新 **docker/.env** 檔案內的 `RAGFLOW_IMAGE` 變數。例如,你可以透過設定 `RAGFLOW_IMAGE=infiniflow/ragflow:v0.20.4` 來下載 RAGFlow 鏡像的 `v0.20.4` 完整發行版。
|
||||
> 執行以下指令會自動下載 RAGFlow slim Docker 映像 `v0.20.5-slim`。請參考下表查看不同 Docker 發行版的說明。如需下載不同於 `v0.20.5-slim` 的 Docker 映像,請在執行 `docker compose` 啟動服務之前先更新 **docker/.env** 檔案內的 `RAGFLOW_IMAGE` 變數。例如,你可以透過設定 `RAGFLOW_IMAGE=infiniflow/ragflow:v0.20.5` 來下載 RAGFlow 鏡像的 `v0.20.5` 完整發行版。
|
||||
|
||||
```bash
|
||||
$ cd ragflow/docker
|
||||
@ -196,8 +196,8 @@
|
||||
|
||||
| RAGFlow image tag | Image size (GB) | Has embedding models? | Stable? |
|
||||
| ----------------- | --------------- | --------------------- | ------------------------ |
|
||||
| v0.20.4 | ≈9 | :heavy_check_mark: | Stable release |
|
||||
| v0.20.4-slim | ≈2 | ❌ | Stable release |
|
||||
| v0.20.5 | ≈9 | :heavy_check_mark: | Stable release |
|
||||
| v0.20.5-slim | ≈2 | ❌ | Stable release |
|
||||
| nightly | ≈9 | :heavy_check_mark: | _Unstable_ nightly build |
|
||||
| nightly-slim | ≈2 | ❌ | _Unstable_ nightly build |
|
||||
|
||||
@ -301,7 +301,7 @@ docker build --platform linux/amd64 --build-arg NEED_MIRROR=1 -f Dockerfile -t i
|
||||
|
||||
## 🔨 以原始碼啟動服務
|
||||
|
||||
1. 安裝 uv。如已安裝,可跳過此步驟:
|
||||
1. 安裝 `uv` 和 `pre-commit`。如已安裝,可跳過此步驟:
|
||||
|
||||
```bash
|
||||
pipx install uv pre-commit
|
||||
@ -343,6 +343,8 @@ docker build --platform linux/amd64 --build-arg NEED_MIRROR=1 -f Dockerfile -t i
|
||||
sudo apt-get install libjemalloc-dev
|
||||
# centos
|
||||
sudo yum install jemalloc
|
||||
# mac
|
||||
sudo brew install jemalloc
|
||||
```
|
||||
|
||||
6. 啟動後端服務:
|
||||
|
||||
14
README_zh.md
14
README_zh.md
@ -22,7 +22,7 @@
|
||||
<img alt="Static Badge" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
||||
</a>
|
||||
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
||||
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.20.4">
|
||||
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.20.5">
|
||||
</a>
|
||||
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
||||
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Latest%20Release" alt="Latest Release">
|
||||
@ -70,7 +70,7 @@
|
||||
|
||||
## 💡 RAGFlow 是什么?
|
||||
|
||||
[RAGFlow](https://ragflow.io/) 是一款基于深度文档理解构建的开源 RAG(Retrieval-Augmented Generation)引擎。RAGFlow 可以为各种规模的企业及个人提供一套精简的 RAG 工作流程,结合大语言模型(LLM)针对用户各类不同的复杂格式数据提供可靠的问答以及有理有据的引用。
|
||||
[RAGFlow](https://ragflow.io/) 是一款领先的开源检索增强生成(RAG)引擎,通过融合前沿的 RAG 技术与 Agent 能力,为大型语言模型提供卓越的上下文层。它提供可适配任意规模企业的端到端 RAG 工作流,凭借融合式上下文引擎与预置的 Agent 模板,助力开发者以极致效率与精度将复杂数据转化为高可信、生产级的人工智能系统。
|
||||
|
||||
## 🎮 Demo 试用
|
||||
|
||||
@ -183,7 +183,7 @@
|
||||
> 请注意,目前官方提供的所有 Docker 镜像均基于 x86 架构构建,并不提供基于 ARM64 的 Docker 镜像。
|
||||
> 如果你的操作系统是 ARM64 架构,请参考[这篇文档](https://ragflow.io/docs/dev/build_docker_image)自行构建 Docker 镜像。
|
||||
|
||||
> 运行以下命令会自动下载 RAGFlow slim Docker 镜像 `v0.20.4-slim`。请参考下表查看不同 Docker 发行版的描述。如需下载不同于 `v0.20.4-slim` 的 Docker 镜像,请在运行 `docker compose` 启动服务之前先更新 **docker/.env** 文件内的 `RAGFLOW_IMAGE` 变量。比如,你可以通过设置 `RAGFLOW_IMAGE=infiniflow/ragflow:v0.20.4` 来下载 RAGFlow 镜像的 `v0.20.4` 完整发行版。
|
||||
> 运行以下命令会自动下载 RAGFlow slim Docker 镜像 `v0.20.5-slim`。请参考下表查看不同 Docker 发行版的描述。如需下载不同于 `v0.20.5-slim` 的 Docker 镜像,请在运行 `docker compose` 启动服务之前先更新 **docker/.env** 文件内的 `RAGFLOW_IMAGE` 变量。比如,你可以通过设置 `RAGFLOW_IMAGE=infiniflow/ragflow:v0.20.5` 来下载 RAGFlow 镜像的 `v0.20.5` 完整发行版。
|
||||
|
||||
```bash
|
||||
$ cd ragflow/docker
|
||||
@ -196,8 +196,8 @@
|
||||
|
||||
| RAGFlow image tag | Image size (GB) | Has embedding models? | Stable? |
|
||||
| ----------------- | --------------- | --------------------- | ------------------------ |
|
||||
| v0.20.4 | ≈9 | :heavy_check_mark: | Stable release |
|
||||
| v0.20.4-slim | ≈2 | ❌ | Stable release |
|
||||
| v0.20.5 | ≈9 | :heavy_check_mark: | Stable release |
|
||||
| v0.20.5-slim | ≈2 | ❌ | Stable release |
|
||||
| nightly | ≈9 | :heavy_check_mark: | _Unstable_ nightly build |
|
||||
| nightly-slim | ≈2 | ❌ | _Unstable_ nightly build |
|
||||
|
||||
@ -301,7 +301,7 @@ docker build --platform linux/amd64 --build-arg NEED_MIRROR=1 -f Dockerfile -t i
|
||||
|
||||
## 🔨 以源代码启动服务
|
||||
|
||||
1. 安装 uv。如已经安装,可跳过本步骤:
|
||||
1. 安装 `uv` 和 `pre-commit`。如已经安装,可跳过本步骤:
|
||||
|
||||
```bash
|
||||
pipx install uv pre-commit
|
||||
@ -342,6 +342,8 @@ docker build --platform linux/amd64 --build-arg NEED_MIRROR=1 -f Dockerfile -t i
|
||||
sudo apt-get install libjemalloc-dev
|
||||
# centos
|
||||
sudo yum install jemalloc
|
||||
# mac
|
||||
sudo brew install jemalloc
|
||||
```
|
||||
|
||||
6. 启动后端服务:
|
||||
|
||||
101
admin/README.md
Normal file
101
admin/README.md
Normal file
@ -0,0 +1,101 @@
|
||||
# RAGFlow Admin Service & CLI
|
||||
|
||||
### Introduction
|
||||
|
||||
Admin Service is a dedicated management component designed to monitor, maintain, and administrate the RAGFlow system. It provides comprehensive tools for ensuring system stability, performing operational tasks, and managing users and permissions efficiently.
|
||||
|
||||
The service offers real-time monitoring of critical components, including the RAGFlow server, Task Executor processes, and dependent services such as MySQL, Elasticsearch, Redis, and MinIO. It automatically checks their health status, resource usage, and uptime, and performs restarts in case of failures to minimize downtime.
|
||||
|
||||
For user and system management, it supports listing, creating, modifying, and deleting users and their associated resources like knowledge bases and Agents.
|
||||
|
||||
Built with scalability and reliability in mind, the Admin Service ensures smooth system operation and simplifies maintenance workflows.
|
||||
|
||||
It consists of a server-side Service and a command-line client (CLI), both implemented in Python. User commands are parsed using the Lark parsing toolkit.
|
||||
|
||||
- **Admin Service**: A backend service that interfaces with the RAGFlow system to execute administrative operations and monitor its status.
|
||||
- **Admin CLI**: A command-line interface that allows users to connect to the Admin Service and issue commands for system management.
|
||||
|
||||
### Starting the Admin Service
|
||||
|
||||
1. Before start Admin Service, please make sure RAGFlow system is already started.
|
||||
|
||||
2. Run the service script:
|
||||
```bash
|
||||
python admin/admin_server.py
|
||||
```
|
||||
The service will start and listen for incoming connections from the CLI on the configured port.
|
||||
|
||||
### Using the Admin CLI
|
||||
|
||||
1. Ensure the Admin Service is running.
|
||||
2. Launch the CLI client:
|
||||
```bash
|
||||
python admin/admin_client.py -h 0.0.0.0 -p 9381
|
||||
|
||||
## Supported Commands
|
||||
|
||||
Commands are case-insensitive and must be terminated with a semicolon (`;`).
|
||||
|
||||
### Service Management Commands
|
||||
|
||||
- `LIST SERVICES;`
|
||||
- Lists all available services within the RAGFlow system.
|
||||
- `SHOW SERVICE <id>;`
|
||||
- Shows detailed status information for the service identified by `<id>`.
|
||||
- `STARTUP SERVICE <id>;`
|
||||
- Attempts to start the service identified by `<id>`.
|
||||
- `SHUTDOWN SERVICE <id>;`
|
||||
- Attempts to gracefully shut down the service identified by `<id>`.
|
||||
- `RESTART SERVICE <id>;`
|
||||
- Attempts to restart the service identified by `<id>`.
|
||||
|
||||
### User Management Commands
|
||||
|
||||
- `LIST USERS;`
|
||||
- Lists all users known to the system.
|
||||
- `SHOW USER '<username>';`
|
||||
- Shows details and permissions for the specified user. The username must be enclosed in single or double quotes.
|
||||
- `DROP USER '<username>';`
|
||||
- Removes the specified user from the system. Use with caution.
|
||||
- `ALTER USER PASSWORD '<username>' '<new_password>';`
|
||||
- Changes the password for the specified user.
|
||||
|
||||
### Data and Agent Commands
|
||||
|
||||
- `LIST DATASETS OF '<username>';`
|
||||
- Lists the datasets associated with the specified user.
|
||||
- `LIST AGENTS OF '<username>';`
|
||||
- Lists the agents associated with the specified user.
|
||||
|
||||
### Meta-Commands
|
||||
|
||||
Meta-commands are prefixed with a backslash (`\`).
|
||||
|
||||
- `\?` or `\help`
|
||||
- Shows help information for the available commands.
|
||||
- `\q` or `\quit`
|
||||
- Exits the CLI application.
|
||||
|
||||
## Examples
|
||||
|
||||
```commandline
|
||||
admin> list users;
|
||||
+-------------------------------+------------------------+-----------+-------------+
|
||||
| create_date | email | is_active | nickname |
|
||||
+-------------------------------+------------------------+-----------+-------------+
|
||||
| Fri, 22 Nov 2024 16:03:41 GMT | jeffery@infiniflow.org | 1 | Jeffery |
|
||||
| Fri, 22 Nov 2024 16:10:55 GMT | aya@infiniflow.org | 1 | Waterdancer |
|
||||
+-------------------------------+------------------------+-----------+-------------+
|
||||
|
||||
admin> list services;
|
||||
+-------------------------------------------------------------------------------------------+-----------+----+---------------+-------+----------------+
|
||||
| extra | host | id | name | port | service_type |
|
||||
+-------------------------------------------------------------------------------------------+-----------+----+---------------+-------+----------------+
|
||||
| {} | 0.0.0.0 | 0 | ragflow_0 | 9380 | ragflow_server |
|
||||
| {'meta_type': 'mysql', 'password': 'infini_rag_flow', 'username': 'root'} | localhost | 1 | mysql | 5455 | meta_data |
|
||||
| {'password': 'infini_rag_flow', 'store_type': 'minio', 'user': 'rag_flow'} | localhost | 2 | minio | 9000 | file_store |
|
||||
| {'password': 'infini_rag_flow', 'retrieval_type': 'elasticsearch', 'username': 'elastic'} | localhost | 3 | elasticsearch | 1200 | retrieval |
|
||||
| {'db_name': 'default_db', 'retrieval_type': 'infinity'} | localhost | 4 | infinity | 23817 | retrieval |
|
||||
| {'database': 1, 'mq_type': 'redis', 'password': 'infini_rag_flow'} | localhost | 5 | redis | 6379 | message_queue |
|
||||
+-------------------------------------------------------------------------------------------+-----------+----+---------------+-------+----------------+
|
||||
```
|
||||
471
admin/admin_client.py
Normal file
471
admin/admin_client.py
Normal file
@ -0,0 +1,471 @@
|
||||
import argparse
|
||||
import base64
|
||||
from typing import Dict, List, Any
|
||||
from lark import Lark, Transformer, Tree
|
||||
import requests
|
||||
from requests.auth import HTTPBasicAuth
|
||||
|
||||
GRAMMAR = r"""
|
||||
start: command
|
||||
|
||||
command: sql_command | meta_command
|
||||
|
||||
sql_command: list_services
|
||||
| show_service
|
||||
| startup_service
|
||||
| shutdown_service
|
||||
| restart_service
|
||||
| list_users
|
||||
| show_user
|
||||
| drop_user
|
||||
| alter_user
|
||||
| list_datasets
|
||||
| list_agents
|
||||
|
||||
// meta command definition
|
||||
meta_command: "\\" meta_command_name [meta_args]
|
||||
|
||||
meta_command_name: /[a-zA-Z?]+/
|
||||
meta_args: (meta_arg)+
|
||||
|
||||
meta_arg: /[^\\s"']+/ | quoted_string
|
||||
|
||||
// command definition
|
||||
|
||||
LIST: "LIST"i
|
||||
SERVICES: "SERVICES"i
|
||||
SHOW: "SHOW"i
|
||||
SERVICE: "SERVICE"i
|
||||
SHUTDOWN: "SHUTDOWN"i
|
||||
STARTUP: "STARTUP"i
|
||||
RESTART: "RESTART"i
|
||||
USERS: "USERS"i
|
||||
DROP: "DROP"i
|
||||
USER: "USER"i
|
||||
ALTER: "ALTER"i
|
||||
PASSWORD: "PASSWORD"i
|
||||
DATASETS: "DATASETS"i
|
||||
OF: "OF"i
|
||||
AGENTS: "AGENTS"i
|
||||
|
||||
list_services: LIST SERVICES ";"
|
||||
show_service: SHOW SERVICE NUMBER ";"
|
||||
startup_service: STARTUP SERVICE NUMBER ";"
|
||||
shutdown_service: SHUTDOWN SERVICE NUMBER ";"
|
||||
restart_service: RESTART SERVICE NUMBER ";"
|
||||
|
||||
list_users: LIST USERS ";"
|
||||
drop_user: DROP USER quoted_string ";"
|
||||
alter_user: ALTER USER PASSWORD quoted_string quoted_string ";"
|
||||
show_user: SHOW USER quoted_string ";"
|
||||
|
||||
list_datasets: LIST DATASETS OF quoted_string ";"
|
||||
list_agents: LIST AGENTS OF quoted_string ";"
|
||||
|
||||
identifier: WORD
|
||||
quoted_string: QUOTED_STRING
|
||||
|
||||
QUOTED_STRING: /'[^']+'/ | /"[^"]+"/
|
||||
WORD: /[a-zA-Z0-9_\-\.]+/
|
||||
NUMBER: /[0-9]+/
|
||||
|
||||
%import common.WS
|
||||
%ignore WS
|
||||
"""
|
||||
|
||||
|
||||
class AdminTransformer(Transformer):
|
||||
|
||||
def start(self, items):
|
||||
return items[0]
|
||||
|
||||
def command(self, items):
|
||||
return items[0]
|
||||
|
||||
def list_services(self, items):
|
||||
result = {'type': 'list_services'}
|
||||
return result
|
||||
|
||||
def show_service(self, items):
|
||||
service_id = int(items[2])
|
||||
return {"type": "show_service", "number": service_id}
|
||||
|
||||
def startup_service(self, items):
|
||||
service_id = int(items[2])
|
||||
return {"type": "startup_service", "number": service_id}
|
||||
|
||||
def shutdown_service(self, items):
|
||||
service_id = int(items[2])
|
||||
return {"type": "shutdown_service", "number": service_id}
|
||||
|
||||
def restart_service(self, items):
|
||||
service_id = int(items[2])
|
||||
return {"type": "restart_service", "number": service_id}
|
||||
|
||||
def list_users(self, items):
|
||||
return {"type": "list_users"}
|
||||
|
||||
def show_user(self, items):
|
||||
user_name = items[2]
|
||||
return {"type": "show_user", "username": user_name}
|
||||
|
||||
def drop_user(self, items):
|
||||
user_name = items[2]
|
||||
return {"type": "drop_user", "username": user_name}
|
||||
|
||||
def alter_user(self, items):
|
||||
user_name = items[3]
|
||||
new_password = items[4]
|
||||
return {"type": "alter_user", "username": user_name, "password": new_password}
|
||||
|
||||
def list_datasets(self, items):
|
||||
user_name = items[3]
|
||||
return {"type": "list_datasets", "username": user_name}
|
||||
|
||||
def list_agents(self, items):
|
||||
user_name = items[3]
|
||||
return {"type": "list_agents", "username": user_name}
|
||||
|
||||
def meta_command(self, items):
|
||||
command_name = str(items[0]).lower()
|
||||
args = items[1:] if len(items) > 1 else []
|
||||
|
||||
# handle quoted parameter
|
||||
parsed_args = []
|
||||
for arg in args:
|
||||
if hasattr(arg, 'value'):
|
||||
parsed_args.append(arg.value)
|
||||
else:
|
||||
parsed_args.append(str(arg))
|
||||
|
||||
return {'type': 'meta', 'command': command_name, 'args': parsed_args}
|
||||
|
||||
def meta_command_name(self, items):
|
||||
return items[0]
|
||||
|
||||
def meta_args(self, items):
|
||||
return items
|
||||
|
||||
|
||||
def encode_to_base64(input_string):
|
||||
base64_encoded = base64.b64encode(input_string.encode('utf-8'))
|
||||
return base64_encoded.decode('utf-8')
|
||||
|
||||
|
||||
class AdminCommandParser:
|
||||
def __init__(self):
|
||||
self.parser = Lark(GRAMMAR, start='start', parser='lalr', transformer=AdminTransformer())
|
||||
self.command_history = []
|
||||
|
||||
def parse_command(self, command_str: str) -> Dict[str, Any]:
|
||||
if not command_str.strip():
|
||||
return {'type': 'empty'}
|
||||
|
||||
self.command_history.append(command_str)
|
||||
|
||||
try:
|
||||
result = self.parser.parse(command_str)
|
||||
return result
|
||||
except Exception as e:
|
||||
return {'type': 'error', 'message': f'Parse error: {str(e)}'}
|
||||
|
||||
|
||||
class AdminCLI:
|
||||
def __init__(self):
|
||||
self.parser = AdminCommandParser()
|
||||
self.is_interactive = False
|
||||
self.admin_account = "admin@ragflow.io"
|
||||
self.admin_password: str = "admin"
|
||||
self.host: str = ""
|
||||
self.port: int = 0
|
||||
|
||||
def verify_admin(self, args):
|
||||
|
||||
conn_info = self._parse_connection_args(args)
|
||||
if 'error' in conn_info:
|
||||
print(f"Error: {conn_info['error']}")
|
||||
return
|
||||
|
||||
self.host = conn_info['host']
|
||||
self.port = conn_info['port']
|
||||
print(f"Attempt to access ip: {self.host}, port: {self.port}")
|
||||
url = f'http://{self.host}:{self.port}/api/v1/admin/auth'
|
||||
|
||||
try_count = 0
|
||||
while True:
|
||||
try_count += 1
|
||||
if try_count > 3:
|
||||
return False
|
||||
|
||||
admin_passwd = input(f"password for {self.admin_account}: ").strip()
|
||||
try:
|
||||
self.admin_password = encode_to_base64(admin_passwd)
|
||||
response = requests.get(url, auth=HTTPBasicAuth(self.admin_account, self.admin_password))
|
||||
if response.status_code == 200:
|
||||
res_json = response.json()
|
||||
error_code = res_json.get('code', -1)
|
||||
if error_code == 0:
|
||||
print("Authentication successful.")
|
||||
return True
|
||||
else:
|
||||
error_message = res_json.get('message', 'Unknown error')
|
||||
print(f"Authentication failed: {error_message}, try again")
|
||||
continue
|
||||
else:
|
||||
print(f"Bad response,status: {response.status_code}, try again")
|
||||
except Exception:
|
||||
print(f"Can't access {self.host}, port: {self.port}")
|
||||
|
||||
def _print_table_simple(self, data):
|
||||
if not data:
|
||||
print("No data to print")
|
||||
return
|
||||
|
||||
columns = list(data[0].keys())
|
||||
col_widths = {}
|
||||
|
||||
for col in columns:
|
||||
max_width = len(str(col))
|
||||
for item in data:
|
||||
value_len = len(str(item.get(col, '')))
|
||||
if value_len > max_width:
|
||||
max_width = value_len
|
||||
col_widths[col] = max(2, max_width)
|
||||
|
||||
# Generate delimiter
|
||||
separator = "+" + "+".join(["-" * (col_widths[col] + 2) for col in columns]) + "+"
|
||||
|
||||
# Print header
|
||||
print(separator)
|
||||
header = "|" + "|".join([f" {col:<{col_widths[col]}} " for col in columns]) + "|"
|
||||
print(header)
|
||||
print(separator)
|
||||
|
||||
# Print data
|
||||
for item in data:
|
||||
row = "|"
|
||||
for col in columns:
|
||||
value = str(item.get(col, ''))
|
||||
if len(value) > col_widths[col]:
|
||||
value = value[:col_widths[col] - 3] + "..."
|
||||
row += f" {value:<{col_widths[col]}} |"
|
||||
print(row)
|
||||
|
||||
print(separator)
|
||||
|
||||
def run_interactive(self):
|
||||
|
||||
self.is_interactive = True
|
||||
print("RAGFlow Admin command line interface - Type '\\?' for help, '\\q' to quit")
|
||||
|
||||
while True:
|
||||
try:
|
||||
command = input("admin> ").strip()
|
||||
if not command:
|
||||
continue
|
||||
|
||||
print(f"command: {command}")
|
||||
result = self.parser.parse_command(command)
|
||||
self.execute_command(result)
|
||||
|
||||
if isinstance(result, Tree):
|
||||
continue
|
||||
|
||||
if result.get('type') == 'meta' and result.get('command') in ['q', 'quit', 'exit']:
|
||||
break
|
||||
|
||||
except KeyboardInterrupt:
|
||||
print("\nUse '\\q' to quit")
|
||||
except EOFError:
|
||||
print("\nGoodbye!")
|
||||
break
|
||||
|
||||
def run_single_command(self, args):
|
||||
conn_info = self._parse_connection_args(args)
|
||||
if 'error' in conn_info:
|
||||
print(f"Error: {conn_info['error']}")
|
||||
return
|
||||
|
||||
def _parse_connection_args(self, args: List[str]) -> Dict[str, Any]:
|
||||
parser = argparse.ArgumentParser(description='Admin CLI Client', add_help=False)
|
||||
parser.add_argument('-h', '--host', default='localhost', help='Admin service host')
|
||||
parser.add_argument('-p', '--port', type=int, default=8080, help='Admin service port')
|
||||
|
||||
try:
|
||||
parsed_args, remaining_args = parser.parse_known_args(args)
|
||||
return {
|
||||
'host': parsed_args.host,
|
||||
'port': parsed_args.port,
|
||||
}
|
||||
except SystemExit:
|
||||
return {'error': 'Invalid connection arguments'}
|
||||
|
||||
def execute_command(self, parsed_command: Dict[str, Any]):
|
||||
|
||||
command_dict: dict
|
||||
if isinstance(parsed_command, Tree):
|
||||
command_dict = parsed_command.children[0]
|
||||
else:
|
||||
if parsed_command['type'] == 'error':
|
||||
print(f"Error: {parsed_command['message']}")
|
||||
return
|
||||
else:
|
||||
command_dict = parsed_command
|
||||
|
||||
# print(f"Parsed command: {command_dict}")
|
||||
|
||||
command_type = command_dict['type']
|
||||
|
||||
match command_type:
|
||||
case 'list_services':
|
||||
self._handle_list_services(command_dict)
|
||||
case 'show_service':
|
||||
self._handle_show_service(command_dict)
|
||||
case 'restart_service':
|
||||
self._handle_restart_service(command_dict)
|
||||
case 'shutdown_service':
|
||||
self._handle_shutdown_service(command_dict)
|
||||
case 'startup_service':
|
||||
self._handle_startup_service(command_dict)
|
||||
case 'list_users':
|
||||
self._handle_list_users(command_dict)
|
||||
case 'show_user':
|
||||
self._handle_show_user(command_dict)
|
||||
case 'drop_user':
|
||||
self._handle_drop_user(command_dict)
|
||||
case 'alter_user':
|
||||
self._handle_alter_user(command_dict)
|
||||
case 'list_datasets':
|
||||
self._handle_list_datasets(command_dict)
|
||||
case 'list_agents':
|
||||
self._handle_list_agents(command_dict)
|
||||
case 'meta':
|
||||
self._handle_meta_command(command_dict)
|
||||
case _:
|
||||
print(f"Command '{command_type}' would be executed with API")
|
||||
|
||||
def _handle_list_services(self, command):
|
||||
print("Listing all services")
|
||||
|
||||
url = f'http://{self.host}:{self.port}/api/v1/admin/services'
|
||||
response = requests.get(url, auth=HTTPBasicAuth(self.admin_account, self.admin_password))
|
||||
res_json = dict
|
||||
if response.status_code == 200:
|
||||
res_json = response.json()
|
||||
self._print_table_simple(res_json['data'])
|
||||
else:
|
||||
print(f"Fail to get all users, code: {res_json['code']}, message: {res_json['message']}")
|
||||
|
||||
def _handle_show_service(self, command):
|
||||
service_id: int = command['number']
|
||||
print(f"Showing service: {service_id}")
|
||||
|
||||
def _handle_restart_service(self, command):
|
||||
service_id: int = command['number']
|
||||
print(f"Restart service {service_id}")
|
||||
|
||||
def _handle_shutdown_service(self, command):
|
||||
service_id: int = command['number']
|
||||
print(f"Shutdown service {service_id}")
|
||||
|
||||
def _handle_startup_service(self, command):
|
||||
service_id: int = command['number']
|
||||
print(f"Startup service {service_id}")
|
||||
|
||||
def _handle_list_users(self, command):
|
||||
print("Listing all users")
|
||||
|
||||
url = f'http://{self.host}:{self.port}/api/v1/admin/users'
|
||||
response = requests.get(url, auth=HTTPBasicAuth(self.admin_account, self.admin_password))
|
||||
res_json = dict
|
||||
if response.status_code == 200:
|
||||
res_json = response.json()
|
||||
self._print_table_simple(res_json['data'])
|
||||
else:
|
||||
print(f"Fail to get all users, code: {res_json['code']}, message: {res_json['message']}")
|
||||
|
||||
def _handle_show_user(self, command):
|
||||
username_tree: Tree = command['username']
|
||||
username: str = username_tree.children[0].strip("'\"")
|
||||
print(f"Showing user: {username}")
|
||||
|
||||
def _handle_drop_user(self, command):
|
||||
username_tree: Tree = command['username']
|
||||
username: str = username_tree.children[0].strip("'\"")
|
||||
print(f"Drop user: {username}")
|
||||
|
||||
def _handle_alter_user(self, command):
|
||||
username_tree: Tree = command['username']
|
||||
username: str = username_tree.children[0].strip("'\"")
|
||||
password_tree: Tree = command['password']
|
||||
password: str = password_tree.children[0].strip("'\"")
|
||||
print(f"Alter user: {username}, password: {password}")
|
||||
|
||||
def _handle_list_datasets(self, command):
|
||||
username_tree: Tree = command['username']
|
||||
username: str = username_tree.children[0].strip("'\"")
|
||||
print(f"Listing all datasets of user: {username}")
|
||||
|
||||
def _handle_list_agents(self, command):
|
||||
username_tree: Tree = command['username']
|
||||
username: str = username_tree.children[0].strip("'\"")
|
||||
print(f"Listing all agents of user: {username}")
|
||||
|
||||
def _handle_meta_command(self, command):
|
||||
meta_command = command['command']
|
||||
args = command.get('args', [])
|
||||
|
||||
if meta_command in ['?', 'h', 'help']:
|
||||
self.show_help()
|
||||
elif meta_command in ['q', 'quit', 'exit']:
|
||||
print("Goodbye!")
|
||||
else:
|
||||
print(f"Meta command '{meta_command}' with args {args}")
|
||||
|
||||
def show_help(self):
|
||||
"""Help info"""
|
||||
help_text = """
|
||||
Commands:
|
||||
LIST SERVICES
|
||||
SHOW SERVICE <service>
|
||||
STARTUP SERVICE <service>
|
||||
SHUTDOWN SERVICE <service>
|
||||
RESTART SERVICE <service>
|
||||
LIST USERS
|
||||
SHOW USER <user>
|
||||
DROP USER <user>
|
||||
CREATE USER <user> <password>
|
||||
ALTER USER PASSWORD <user> <new_password>
|
||||
LIST DATASETS OF <user>
|
||||
LIST AGENTS OF <user>
|
||||
|
||||
Meta Commands:
|
||||
\\?, \\h, \\help Show this help
|
||||
\\q, \\quit, \\exit Quit the CLI
|
||||
"""
|
||||
print(help_text)
|
||||
|
||||
|
||||
def main():
|
||||
import sys
|
||||
|
||||
cli = AdminCLI()
|
||||
|
||||
if len(sys.argv) == 1 or (len(sys.argv) > 1 and sys.argv[1] == '-'):
|
||||
print(r"""
|
||||
____ ___ ______________ ___ __ _
|
||||
/ __ \/ | / ____/ ____/ /___ _ __ / | ____/ /___ ___ (_)___
|
||||
/ /_/ / /| |/ / __/ /_ / / __ \ | /| / / / /| |/ __ / __ `__ \/ / __ \
|
||||
/ _, _/ ___ / /_/ / __/ / / /_/ / |/ |/ / / ___ / /_/ / / / / / / / / / /
|
||||
/_/ |_/_/ |_\____/_/ /_/\____/|__/|__/ /_/ |_\__,_/_/ /_/ /_/_/_/ /_/
|
||||
""")
|
||||
if cli.verify_admin(sys.argv):
|
||||
cli.run_interactive()
|
||||
else:
|
||||
if cli.verify_admin(sys.argv):
|
||||
cli.run_interactive()
|
||||
# cli.run_single_command(sys.argv[1:])
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
46
admin/admin_server.py
Normal file
46
admin/admin_server.py
Normal file
@ -0,0 +1,46 @@
|
||||
|
||||
import os
|
||||
import signal
|
||||
import logging
|
||||
import time
|
||||
import threading
|
||||
import traceback
|
||||
from werkzeug.serving import run_simple
|
||||
from flask import Flask
|
||||
from routes import admin_bp
|
||||
from api.utils.log_utils import init_root_logger
|
||||
from api.constants import SERVICE_CONF
|
||||
from config import load_configurations, SERVICE_CONFIGS
|
||||
|
||||
stop_event = threading.Event()
|
||||
|
||||
if __name__ == '__main__':
|
||||
init_root_logger("admin_service")
|
||||
logging.info(r"""
|
||||
____ ___ ______________ ___ __ _
|
||||
/ __ \/ | / ____/ ____/ /___ _ __ / | ____/ /___ ___ (_)___
|
||||
/ /_/ / /| |/ / __/ /_ / / __ \ | /| / / / /| |/ __ / __ `__ \/ / __ \
|
||||
/ _, _/ ___ / /_/ / __/ / / /_/ / |/ |/ / / ___ / /_/ / / / / / / / / / /
|
||||
/_/ |_/_/ |_\____/_/ /_/\____/|__/|__/ /_/ |_\__,_/_/ /_/ /_/_/_/ /_/
|
||||
""")
|
||||
|
||||
app = Flask(__name__)
|
||||
app.register_blueprint(admin_bp)
|
||||
|
||||
SERVICE_CONFIGS.configs = load_configurations(SERVICE_CONF)
|
||||
|
||||
try:
|
||||
logging.info("RAGFlow Admin service start...")
|
||||
run_simple(
|
||||
hostname="0.0.0.0",
|
||||
port=9381,
|
||||
application=app,
|
||||
threaded=True,
|
||||
use_reloader=True,
|
||||
use_debugger=True,
|
||||
)
|
||||
except Exception:
|
||||
traceback.print_exc()
|
||||
stop_event.set()
|
||||
time.sleep(1)
|
||||
os.kill(os.getpid(), signal.SIGKILL)
|
||||
57
admin/auth.py
Normal file
57
admin/auth.py
Normal file
@ -0,0 +1,57 @@
|
||||
import logging
|
||||
import uuid
|
||||
from functools import wraps
|
||||
from flask import request, jsonify
|
||||
|
||||
from exceptions import AdminException
|
||||
from api.db.init_data import encode_to_base64
|
||||
from api.db.services import UserService
|
||||
|
||||
|
||||
def check_admin(username: str, password: str):
|
||||
users = UserService.query(email=username)
|
||||
if not users:
|
||||
logging.info(f"Username: {username} is not registered!")
|
||||
user_info = {
|
||||
"id": uuid.uuid1().hex,
|
||||
"password": encode_to_base64("admin"),
|
||||
"nickname": "admin",
|
||||
"is_superuser": True,
|
||||
"email": "admin@ragflow.io",
|
||||
"creator": "system",
|
||||
"status": "1",
|
||||
}
|
||||
if not UserService.save(**user_info):
|
||||
raise AdminException("Can't init admin.", 500)
|
||||
|
||||
user = UserService.query_user(username, password)
|
||||
if user:
|
||||
return True
|
||||
else:
|
||||
return False
|
||||
|
||||
|
||||
def login_verify(f):
|
||||
@wraps(f)
|
||||
def decorated(*args, **kwargs):
|
||||
auth = request.authorization
|
||||
if not auth or 'username' not in auth.parameters or 'password' not in auth.parameters:
|
||||
return jsonify({
|
||||
"code": 401,
|
||||
"message": "Authentication required",
|
||||
"data": None
|
||||
}), 200
|
||||
|
||||
username = auth.parameters['username']
|
||||
password = auth.parameters['password']
|
||||
# TODO: to check the username and password from DB
|
||||
if check_admin(username, password) is False:
|
||||
return jsonify({
|
||||
"code": 403,
|
||||
"message": "Access denied",
|
||||
"data": None
|
||||
}), 200
|
||||
|
||||
return f(*args, **kwargs)
|
||||
|
||||
return decorated
|
||||
280
admin/config.py
Normal file
280
admin/config.py
Normal file
@ -0,0 +1,280 @@
|
||||
import logging
|
||||
import threading
|
||||
from enum import Enum
|
||||
|
||||
from pydantic import BaseModel
|
||||
from typing import Any
|
||||
from api.utils import read_config
|
||||
from urllib.parse import urlparse
|
||||
|
||||
|
||||
class ServiceConfigs:
|
||||
def __init__(self):
|
||||
self.configs = []
|
||||
self.lock = threading.Lock()
|
||||
|
||||
|
||||
SERVICE_CONFIGS = ServiceConfigs
|
||||
|
||||
|
||||
class ServiceType(Enum):
|
||||
METADATA = "metadata"
|
||||
RETRIEVAL = "retrieval"
|
||||
MESSAGE_QUEUE = "message_queue"
|
||||
RAGFLOW_SERVER = "ragflow_server"
|
||||
TASK_EXECUTOR = "task_executor"
|
||||
FILE_STORE = "file_store"
|
||||
|
||||
|
||||
class BaseConfig(BaseModel):
|
||||
id: int
|
||||
name: str
|
||||
host: str
|
||||
port: int
|
||||
service_type: str
|
||||
|
||||
def to_dict(self) -> dict[str, Any]:
|
||||
return {'id': self.id, 'name': self.name, 'host': self.host, 'port': self.port, 'service_type': self.service_type}
|
||||
|
||||
|
||||
class MetaConfig(BaseConfig):
|
||||
meta_type: str
|
||||
|
||||
def to_dict(self) -> dict[str, Any]:
|
||||
result = super().to_dict()
|
||||
if 'extra' not in result:
|
||||
result['extra'] = dict()
|
||||
extra_dict = result['extra'].copy()
|
||||
extra_dict['meta_type'] = self.meta_type
|
||||
result['extra'] = extra_dict
|
||||
return result
|
||||
|
||||
|
||||
class MySQLConfig(MetaConfig):
|
||||
username: str
|
||||
password: str
|
||||
|
||||
def to_dict(self) -> dict[str, Any]:
|
||||
result = super().to_dict()
|
||||
if 'extra' not in result:
|
||||
result['extra'] = dict()
|
||||
extra_dict = result['extra'].copy()
|
||||
extra_dict['username'] = self.username
|
||||
extra_dict['password'] = self.password
|
||||
result['extra'] = extra_dict
|
||||
return result
|
||||
|
||||
|
||||
class PostgresConfig(MetaConfig):
|
||||
|
||||
def to_dict(self) -> dict[str, Any]:
|
||||
result = super().to_dict()
|
||||
if 'extra' not in result:
|
||||
result['extra'] = dict()
|
||||
return result
|
||||
|
||||
|
||||
class RetrievalConfig(BaseConfig):
|
||||
retrieval_type: str
|
||||
|
||||
def to_dict(self) -> dict[str, Any]:
|
||||
result = super().to_dict()
|
||||
if 'extra' not in result:
|
||||
result['extra'] = dict()
|
||||
extra_dict = result['extra'].copy()
|
||||
extra_dict['retrieval_type'] = self.retrieval_type
|
||||
result['extra'] = extra_dict
|
||||
return result
|
||||
|
||||
|
||||
class InfinityConfig(RetrievalConfig):
|
||||
db_name: str
|
||||
|
||||
def to_dict(self) -> dict[str, Any]:
|
||||
result = super().to_dict()
|
||||
if 'extra' not in result:
|
||||
result['extra'] = dict()
|
||||
extra_dict = result['extra'].copy()
|
||||
extra_dict['db_name'] = self.db_name
|
||||
result['extra'] = extra_dict
|
||||
return result
|
||||
|
||||
|
||||
class ElasticsearchConfig(RetrievalConfig):
|
||||
username: str
|
||||
password: str
|
||||
|
||||
def to_dict(self) -> dict[str, Any]:
|
||||
result = super().to_dict()
|
||||
if 'extra' not in result:
|
||||
result['extra'] = dict()
|
||||
extra_dict = result['extra'].copy()
|
||||
extra_dict['username'] = self.username
|
||||
extra_dict['password'] = self.password
|
||||
result['extra'] = extra_dict
|
||||
return result
|
||||
|
||||
|
||||
class MessageQueueConfig(BaseConfig):
|
||||
mq_type: str
|
||||
|
||||
def to_dict(self) -> dict[str, Any]:
|
||||
result = super().to_dict()
|
||||
if 'extra' not in result:
|
||||
result['extra'] = dict()
|
||||
extra_dict = result['extra'].copy()
|
||||
extra_dict['mq_type'] = self.mq_type
|
||||
result['extra'] = extra_dict
|
||||
return result
|
||||
|
||||
|
||||
class RedisConfig(MessageQueueConfig):
|
||||
database: int
|
||||
password: str
|
||||
|
||||
def to_dict(self) -> dict[str, Any]:
|
||||
result = super().to_dict()
|
||||
if 'extra' not in result:
|
||||
result['extra'] = dict()
|
||||
extra_dict = result['extra'].copy()
|
||||
extra_dict['database'] = self.database
|
||||
extra_dict['password'] = self.password
|
||||
result['extra'] = extra_dict
|
||||
return result
|
||||
|
||||
|
||||
class RabbitMQConfig(MessageQueueConfig):
|
||||
|
||||
def to_dict(self) -> dict[str, Any]:
|
||||
result = super().to_dict()
|
||||
if 'extra' not in result:
|
||||
result['extra'] = dict()
|
||||
return result
|
||||
|
||||
|
||||
class RAGFlowServerConfig(BaseConfig):
|
||||
|
||||
def to_dict(self) -> dict[str, Any]:
|
||||
result = super().to_dict()
|
||||
if 'extra' not in result:
|
||||
result['extra'] = dict()
|
||||
return result
|
||||
|
||||
|
||||
class TaskExecutorConfig(BaseConfig):
|
||||
|
||||
def to_dict(self) -> dict[str, Any]:
|
||||
result = super().to_dict()
|
||||
if 'extra' not in result:
|
||||
result['extra'] = dict()
|
||||
return result
|
||||
|
||||
|
||||
class FileStoreConfig(BaseConfig):
|
||||
store_type: str
|
||||
|
||||
def to_dict(self) -> dict[str, Any]:
|
||||
result = super().to_dict()
|
||||
if 'extra' not in result:
|
||||
result['extra'] = dict()
|
||||
extra_dict = result['extra'].copy()
|
||||
extra_dict['store_type'] = self.store_type
|
||||
result['extra'] = extra_dict
|
||||
return result
|
||||
|
||||
|
||||
class MinioConfig(FileStoreConfig):
|
||||
user: str
|
||||
password: str
|
||||
|
||||
def to_dict(self) -> dict[str, Any]:
|
||||
result = super().to_dict()
|
||||
if 'extra' not in result:
|
||||
result['extra'] = dict()
|
||||
extra_dict = result['extra'].copy()
|
||||
extra_dict['user'] = self.user
|
||||
extra_dict['password'] = self.password
|
||||
result['extra'] = extra_dict
|
||||
return result
|
||||
|
||||
|
||||
def load_configurations(config_path: str) -> list[BaseConfig]:
|
||||
raw_configs = read_config(config_path)
|
||||
configurations = []
|
||||
ragflow_count = 0
|
||||
id_count = 0
|
||||
for k, v in raw_configs.items():
|
||||
match (k):
|
||||
case "ragflow":
|
||||
name: str = f'ragflow_{ragflow_count}'
|
||||
host: str = v['host']
|
||||
http_port: int = v['http_port']
|
||||
config = RAGFlowServerConfig(id=id_count, name=name, host=host, port=http_port, service_type="ragflow_server")
|
||||
configurations.append(config)
|
||||
id_count += 1
|
||||
case "es":
|
||||
name: str = 'elasticsearch'
|
||||
url = v['hosts']
|
||||
parsed = urlparse(url)
|
||||
host: str = parsed.hostname
|
||||
port: int = parsed.port
|
||||
username: str = v.get('username')
|
||||
password: str = v.get('password')
|
||||
config = ElasticsearchConfig(id=id_count, name=name, host=host, port=port, service_type="retrieval",
|
||||
retrieval_type="elasticsearch",
|
||||
username=username, password=password)
|
||||
configurations.append(config)
|
||||
id_count += 1
|
||||
|
||||
case "infinity":
|
||||
name: str = 'infinity'
|
||||
url = v['uri']
|
||||
parts = url.split(':', 1)
|
||||
host = parts[0]
|
||||
port = int(parts[1])
|
||||
database: str = v.get('db_name', 'default_db')
|
||||
config = InfinityConfig(id=id_count, name=name, host=host, port=port, service_type="retrieval", retrieval_type="infinity",
|
||||
db_name=database)
|
||||
configurations.append(config)
|
||||
id_count += 1
|
||||
case "minio":
|
||||
name: str = 'minio'
|
||||
url = v['host']
|
||||
parts = url.split(':', 1)
|
||||
host = parts[0]
|
||||
port = int(parts[1])
|
||||
user = v.get('user')
|
||||
password = v.get('password')
|
||||
config = MinioConfig(id=id_count, name=name, host=host, port=port, user=user, password=password, service_type="file_store",
|
||||
store_type="minio")
|
||||
configurations.append(config)
|
||||
id_count += 1
|
||||
case "redis":
|
||||
name: str = 'redis'
|
||||
url = v['host']
|
||||
parts = url.split(':', 1)
|
||||
host = parts[0]
|
||||
port = int(parts[1])
|
||||
password = v.get('password')
|
||||
db: int = v.get('db')
|
||||
config = RedisConfig(id=id_count, name=name, host=host, port=port, password=password, database=db,
|
||||
service_type="message_queue", mq_type="redis")
|
||||
configurations.append(config)
|
||||
id_count += 1
|
||||
case "mysql":
|
||||
name: str = 'mysql'
|
||||
host: str = v.get('host')
|
||||
port: int = v.get('port')
|
||||
username = v.get('user')
|
||||
password = v.get('password')
|
||||
config = MySQLConfig(id=id_count, name=name, host=host, port=port, username=username, password=password,
|
||||
service_type="meta_data", meta_type="mysql")
|
||||
configurations.append(config)
|
||||
id_count += 1
|
||||
case "admin":
|
||||
pass
|
||||
case _:
|
||||
logging.warning(f"Unknown configuration key: {k}")
|
||||
continue
|
||||
|
||||
return configurations
|
||||
17
admin/exceptions.py
Normal file
17
admin/exceptions.py
Normal file
@ -0,0 +1,17 @@
|
||||
class AdminException(Exception):
|
||||
def __init__(self, message, code=400):
|
||||
super().__init__(message)
|
||||
self.code = code
|
||||
self.message = message
|
||||
|
||||
class UserNotFoundError(AdminException):
|
||||
def __init__(self, username):
|
||||
super().__init__(f"User '{username}' not found", 404)
|
||||
|
||||
class UserAlreadyExistsError(AdminException):
|
||||
def __init__(self, username):
|
||||
super().__init__(f"User '{username}' already exists", 409)
|
||||
|
||||
class CannotDeleteAdminError(AdminException):
|
||||
def __init__(self):
|
||||
super().__init__("Cannot delete admin account", 403)
|
||||
0
admin/models.py
Normal file
0
admin/models.py
Normal file
15
admin/responses.py
Normal file
15
admin/responses.py
Normal file
@ -0,0 +1,15 @@
|
||||
from flask import jsonify
|
||||
|
||||
def success_response(data=None, message="Success", code = 0):
|
||||
return jsonify({
|
||||
"code": code,
|
||||
"message": message,
|
||||
"data": data
|
||||
}), 200
|
||||
|
||||
def error_response(message="Error", code=-1, data=None):
|
||||
return jsonify({
|
||||
"code": code,
|
||||
"message": message,
|
||||
"data": data
|
||||
}), 400
|
||||
141
admin/routes.py
Normal file
141
admin/routes.py
Normal file
@ -0,0 +1,141 @@
|
||||
from flask import Blueprint, request
|
||||
from auth import login_verify
|
||||
from responses import success_response, error_response
|
||||
from services import UserMgr, ServiceMgr
|
||||
from exceptions import AdminException
|
||||
|
||||
admin_bp = Blueprint('admin', __name__, url_prefix='/api/v1/admin')
|
||||
|
||||
|
||||
@admin_bp.route('/auth', methods=['GET'])
|
||||
@login_verify
|
||||
def auth_admin():
|
||||
try:
|
||||
return success_response(None, "Admin is authorized", 0)
|
||||
except Exception as e:
|
||||
return error_response(str(e), 500)
|
||||
|
||||
|
||||
@admin_bp.route('/users', methods=['GET'])
|
||||
@login_verify
|
||||
def list_users():
|
||||
try:
|
||||
users = UserMgr.get_all_users()
|
||||
return success_response(users, "Get all users", 0)
|
||||
except Exception as e:
|
||||
return error_response(str(e), 500)
|
||||
|
||||
|
||||
@admin_bp.route('/users', methods=['POST'])
|
||||
@login_verify
|
||||
def create_user():
|
||||
try:
|
||||
data = request.get_json()
|
||||
if not data or 'username' not in data or 'password' not in data:
|
||||
return error_response("Username and password are required", 400)
|
||||
|
||||
username = data['username']
|
||||
password = data['password']
|
||||
role = data.get('role', 'user')
|
||||
|
||||
user = UserMgr.create_user(username, password, role)
|
||||
return success_response(user, "User created successfully", 201)
|
||||
|
||||
except AdminException as e:
|
||||
return error_response(e.message, e.code)
|
||||
except Exception as e:
|
||||
return error_response(str(e), 500)
|
||||
|
||||
|
||||
@admin_bp.route('/users/<username>', methods=['DELETE'])
|
||||
@login_verify
|
||||
def delete_user(username):
|
||||
try:
|
||||
UserMgr.delete_user(username)
|
||||
return success_response(None, "User and all data deleted successfully")
|
||||
|
||||
except AdminException as e:
|
||||
return error_response(e.message, e.code)
|
||||
except Exception as e:
|
||||
return error_response(str(e), 500)
|
||||
|
||||
|
||||
@admin_bp.route('/users/<username>/password', methods=['PUT'])
|
||||
@login_verify
|
||||
def change_password(username):
|
||||
try:
|
||||
data = request.get_json()
|
||||
if not data or 'new_password' not in data:
|
||||
return error_response("New password is required", 400)
|
||||
|
||||
new_password = data['new_password']
|
||||
UserMgr.update_user_password(username, new_password)
|
||||
return success_response(None, "Password updated successfully")
|
||||
|
||||
except AdminException as e:
|
||||
return error_response(e.message, e.code)
|
||||
except Exception as e:
|
||||
return error_response(str(e), 500)
|
||||
|
||||
|
||||
@admin_bp.route('/users/<username>', methods=['GET'])
|
||||
@login_verify
|
||||
def get_user_details(username):
|
||||
try:
|
||||
user_details = UserMgr.get_user_details(username)
|
||||
return success_response(user_details)
|
||||
|
||||
except AdminException as e:
|
||||
return error_response(e.message, e.code)
|
||||
except Exception as e:
|
||||
return error_response(str(e), 500)
|
||||
|
||||
|
||||
@admin_bp.route('/services', methods=['GET'])
|
||||
@login_verify
|
||||
def get_services():
|
||||
try:
|
||||
services = ServiceMgr.get_all_services()
|
||||
return success_response(services, "Get all services", 0)
|
||||
except Exception as e:
|
||||
return error_response(str(e), 500)
|
||||
|
||||
|
||||
@admin_bp.route('/service_types/<service_type>', methods=['GET'])
|
||||
@login_verify
|
||||
def get_services_by_type(service_type_str):
|
||||
try:
|
||||
services = ServiceMgr.get_services_by_type(service_type_str)
|
||||
return success_response(services)
|
||||
except Exception as e:
|
||||
return error_response(str(e), 500)
|
||||
|
||||
|
||||
@admin_bp.route('/services/<service_id>', methods=['GET'])
|
||||
@login_verify
|
||||
def get_service(service_id):
|
||||
try:
|
||||
services = ServiceMgr.get_service_details(service_id)
|
||||
return success_response(services)
|
||||
except Exception as e:
|
||||
return error_response(str(e), 500)
|
||||
|
||||
|
||||
@admin_bp.route('/services/<service_id>', methods=['DELETE'])
|
||||
@login_verify
|
||||
def shutdown_service(service_id):
|
||||
try:
|
||||
services = ServiceMgr.shutdown_service(service_id)
|
||||
return success_response(services)
|
||||
except Exception as e:
|
||||
return error_response(str(e), 500)
|
||||
|
||||
|
||||
@admin_bp.route('/services/<service_id>', methods=['PUT'])
|
||||
@login_verify
|
||||
def restart_service(service_id):
|
||||
try:
|
||||
services = ServiceMgr.restart_service(service_id)
|
||||
return success_response(services)
|
||||
except Exception as e:
|
||||
return error_response(str(e), 500)
|
||||
54
admin/services.py
Normal file
54
admin/services.py
Normal file
@ -0,0 +1,54 @@
|
||||
from api.db.services import UserService
|
||||
from exceptions import AdminException
|
||||
from config import SERVICE_CONFIGS
|
||||
|
||||
class UserMgr:
|
||||
@staticmethod
|
||||
def get_all_users():
|
||||
users = UserService.get_all_users()
|
||||
result = []
|
||||
for user in users:
|
||||
result.append({'email': user.email, 'nickname': user.nickname, 'create_date': user.create_date, 'is_active': user.is_active})
|
||||
return result
|
||||
|
||||
@staticmethod
|
||||
def get_user_details(username):
|
||||
raise AdminException("get_user_details: not implemented")
|
||||
|
||||
@staticmethod
|
||||
def create_user(username, password, role="user"):
|
||||
raise AdminException("create_user: not implemented")
|
||||
|
||||
@staticmethod
|
||||
def delete_user(username):
|
||||
raise AdminException("delete_user: not implemented")
|
||||
|
||||
@staticmethod
|
||||
def update_user_password(username, new_password):
|
||||
raise AdminException("update_user_password: not implemented")
|
||||
|
||||
class ServiceMgr:
|
||||
|
||||
@staticmethod
|
||||
def get_all_services():
|
||||
result = []
|
||||
configs = SERVICE_CONFIGS.configs
|
||||
for config in configs:
|
||||
result.append(config.to_dict())
|
||||
return result
|
||||
|
||||
@staticmethod
|
||||
def get_services_by_type(service_type_str: str):
|
||||
raise AdminException("get_services_by_type: not implemented")
|
||||
|
||||
@staticmethod
|
||||
def get_service_details(service_id: int):
|
||||
raise AdminException("get_service_details: not implemented")
|
||||
|
||||
@staticmethod
|
||||
def shutdown_service(service_id: int):
|
||||
raise AdminException("shutdown_service: not implemented")
|
||||
|
||||
@staticmethod
|
||||
def restart_service(service_id: int):
|
||||
raise AdminException("restart_service: not implemented")
|
||||
248
agent/canvas.py
248
agent/canvas.py
@ -16,6 +16,7 @@
|
||||
import base64
|
||||
import json
|
||||
import logging
|
||||
import re
|
||||
import time
|
||||
from concurrent.futures import ThreadPoolExecutor
|
||||
from copy import deepcopy
|
||||
@ -29,83 +30,52 @@ from api.utils import get_uuid, hash_str2int
|
||||
from rag.prompts.prompts import chunks_format
|
||||
from rag.utils.redis_conn import REDIS_CONN
|
||||
|
||||
|
||||
class Canvas:
|
||||
class Graph:
|
||||
"""
|
||||
dsl = {
|
||||
"components": {
|
||||
"begin": {
|
||||
"obj":{
|
||||
"component_name": "Begin",
|
||||
"params": {},
|
||||
},
|
||||
"downstream": ["answer_0"],
|
||||
"upstream": [],
|
||||
},
|
||||
"retrieval_0": {
|
||||
"obj": {
|
||||
"component_name": "Retrieval",
|
||||
"params": {}
|
||||
},
|
||||
"downstream": ["generate_0"],
|
||||
"upstream": ["answer_0"],
|
||||
},
|
||||
"generate_0": {
|
||||
"obj": {
|
||||
"component_name": "Generate",
|
||||
"params": {}
|
||||
},
|
||||
"downstream": ["answer_0"],
|
||||
"upstream": ["retrieval_0"],
|
||||
}
|
||||
},
|
||||
"history": [],
|
||||
"path": ["begin"],
|
||||
"retrieval": {"chunks": [], "doc_aggs": []},
|
||||
"globals": {
|
||||
"sys.query": "",
|
||||
"sys.user_id": tenant_id,
|
||||
"sys.conversation_turns": 0,
|
||||
"sys.files": []
|
||||
}
|
||||
}
|
||||
"""
|
||||
|
||||
def __init__(self, dsl: str, tenant_id=None, task_id=None):
|
||||
self.path = []
|
||||
self.history = []
|
||||
self.components = {}
|
||||
self.error = ""
|
||||
self.globals = {
|
||||
"sys.query": "",
|
||||
"sys.user_id": tenant_id,
|
||||
"sys.conversation_turns": 0,
|
||||
"sys.files": []
|
||||
}
|
||||
self.dsl = json.loads(dsl) if dsl else {
|
||||
dsl = {
|
||||
"components": {
|
||||
"begin": {
|
||||
"obj": {
|
||||
"obj":{
|
||||
"component_name": "Begin",
|
||||
"params": {
|
||||
"prologue": "Hi there!"
|
||||
}
|
||||
"params": {},
|
||||
},
|
||||
"downstream": [],
|
||||
"downstream": ["answer_0"],
|
||||
"upstream": [],
|
||||
"parent_id": ""
|
||||
},
|
||||
"retrieval_0": {
|
||||
"obj": {
|
||||
"component_name": "Retrieval",
|
||||
"params": {}
|
||||
},
|
||||
"downstream": ["generate_0"],
|
||||
"upstream": ["answer_0"],
|
||||
},
|
||||
"generate_0": {
|
||||
"obj": {
|
||||
"component_name": "Generate",
|
||||
"params": {}
|
||||
},
|
||||
"downstream": ["answer_0"],
|
||||
"upstream": ["retrieval_0"],
|
||||
}
|
||||
},
|
||||
"history": [],
|
||||
"path": [],
|
||||
"retrieval": [],
|
||||
"path": ["begin"],
|
||||
"retrieval": {"chunks": [], "doc_aggs": []},
|
||||
"globals": {
|
||||
"sys.query": "",
|
||||
"sys.user_id": "",
|
||||
"sys.user_id": tenant_id,
|
||||
"sys.conversation_turns": 0,
|
||||
"sys.files": []
|
||||
}
|
||||
}
|
||||
"""
|
||||
|
||||
def __init__(self, dsl: str, tenant_id=None, task_id=None):
|
||||
self.path = []
|
||||
self.components = {}
|
||||
self.error = ""
|
||||
self.dsl = json.loads(dsl)
|
||||
self._tenant_id = tenant_id
|
||||
self.task_id = task_id if task_id else get_uuid()
|
||||
self.load()
|
||||
@ -116,8 +86,6 @@ class Canvas:
|
||||
for k, cpn in self.components.items():
|
||||
cpn_nms.add(cpn["obj"]["component_name"])
|
||||
|
||||
assert "Begin" in cpn_nms, "There have to be an 'Begin' component."
|
||||
|
||||
for k, cpn in self.components.items():
|
||||
cpn_nms.add(cpn["obj"]["component_name"])
|
||||
param = component_class(cpn["obj"]["component_name"] + "Param")()
|
||||
@ -130,27 +98,10 @@ class Canvas:
|
||||
cpn["obj"] = component_class(cpn["obj"]["component_name"])(self, k, param)
|
||||
|
||||
self.path = self.dsl["path"]
|
||||
self.history = self.dsl["history"]
|
||||
if "globals" in self.dsl:
|
||||
self.globals = self.dsl["globals"]
|
||||
else:
|
||||
self.globals = {
|
||||
"sys.query": "",
|
||||
"sys.user_id": "",
|
||||
"sys.conversation_turns": 0,
|
||||
"sys.files": []
|
||||
}
|
||||
|
||||
self.retrieval = self.dsl["retrieval"]
|
||||
self.memory = self.dsl.get("memory", [])
|
||||
|
||||
def __str__(self):
|
||||
self.dsl["path"] = self.path
|
||||
self.dsl["history"] = self.history
|
||||
self.dsl["globals"] = self.globals
|
||||
self.dsl["task_id"] = self.task_id
|
||||
self.dsl["retrieval"] = self.retrieval
|
||||
self.dsl["memory"] = self.memory
|
||||
dsl = {
|
||||
"components": {}
|
||||
}
|
||||
@ -169,14 +120,79 @@ class Canvas:
|
||||
dsl["components"][k][c] = deepcopy(cpn[c])
|
||||
return json.dumps(dsl, ensure_ascii=False)
|
||||
|
||||
def reset(self, mem=False):
|
||||
def reset(self):
|
||||
self.path = []
|
||||
for k, cpn in self.components.items():
|
||||
self.components[k]["obj"].reset()
|
||||
try:
|
||||
REDIS_CONN.delete(f"{self.task_id}-logs")
|
||||
except Exception as e:
|
||||
logging.exception(e)
|
||||
|
||||
def get_component_name(self, cid):
|
||||
for n in self.dsl.get("graph", {}).get("nodes", []):
|
||||
if cid == n["id"]:
|
||||
return n["data"]["name"]
|
||||
return ""
|
||||
|
||||
def run(self, **kwargs):
|
||||
raise NotImplementedError()
|
||||
|
||||
def get_component(self, cpn_id) -> Union[None, dict[str, Any]]:
|
||||
return self.components.get(cpn_id)
|
||||
|
||||
def get_component_obj(self, cpn_id) -> ComponentBase:
|
||||
return self.components.get(cpn_id)["obj"]
|
||||
|
||||
def get_component_type(self, cpn_id) -> str:
|
||||
return self.components.get(cpn_id)["obj"].component_name
|
||||
|
||||
def get_component_input_form(self, cpn_id) -> dict:
|
||||
return self.components.get(cpn_id)["obj"].get_input_form()
|
||||
|
||||
def get_tenant_id(self):
|
||||
return self._tenant_id
|
||||
|
||||
|
||||
class Canvas(Graph):
|
||||
|
||||
def __init__(self, dsl: str, tenant_id=None, task_id=None):
|
||||
self.globals = {
|
||||
"sys.query": "",
|
||||
"sys.user_id": tenant_id,
|
||||
"sys.conversation_turns": 0,
|
||||
"sys.files": []
|
||||
}
|
||||
super().__init__(dsl, tenant_id, task_id)
|
||||
|
||||
def load(self):
|
||||
super().load()
|
||||
self.history = self.dsl["history"]
|
||||
if "globals" in self.dsl:
|
||||
self.globals = self.dsl["globals"]
|
||||
else:
|
||||
self.globals = {
|
||||
"sys.query": "",
|
||||
"sys.user_id": "",
|
||||
"sys.conversation_turns": 0,
|
||||
"sys.files": []
|
||||
}
|
||||
|
||||
self.retrieval = self.dsl["retrieval"]
|
||||
self.memory = self.dsl.get("memory", [])
|
||||
|
||||
def __str__(self):
|
||||
self.dsl["history"] = self.history
|
||||
self.dsl["retrieval"] = self.retrieval
|
||||
self.dsl["memory"] = self.memory
|
||||
return super().__str__()
|
||||
|
||||
def reset(self, mem=False):
|
||||
super().reset()
|
||||
if not mem:
|
||||
self.history = []
|
||||
self.retrieval = []
|
||||
self.memory = []
|
||||
for k, cpn in self.components.items():
|
||||
self.components[k]["obj"].reset()
|
||||
|
||||
for k in self.globals.keys():
|
||||
if isinstance(self.globals[k], str):
|
||||
@ -192,22 +208,13 @@ class Canvas:
|
||||
else:
|
||||
self.globals[k] = None
|
||||
|
||||
try:
|
||||
REDIS_CONN.delete(f"{self.task_id}-logs")
|
||||
except Exception as e:
|
||||
logging.exception(e)
|
||||
|
||||
def get_component_name(self, cid):
|
||||
for n in self.dsl.get("graph", {}).get("nodes", []):
|
||||
if cid == n["id"]:
|
||||
return n["data"]["name"]
|
||||
return ""
|
||||
|
||||
def run(self, **kwargs):
|
||||
st = time.perf_counter()
|
||||
self.message_id = get_uuid()
|
||||
created_at = int(time.time())
|
||||
self.add_user_input(kwargs.get("query"))
|
||||
for k, cpn in self.components.items():
|
||||
self.components[k]["obj"].reset(True)
|
||||
|
||||
for k in kwargs.keys():
|
||||
if k in ["query", "user_id", "files"] and kwargs[k]:
|
||||
@ -294,9 +301,11 @@ class Canvas:
|
||||
yield decorate("message", {"content": m})
|
||||
_m += m
|
||||
cpn_obj.set_output("content", _m)
|
||||
cite = re.search(r"\[ID:[ 0-9]+\]", _m)
|
||||
else:
|
||||
yield decorate("message", {"content": cpn_obj.output("content")})
|
||||
yield decorate("message_end", {"reference": self.get_reference()})
|
||||
cite = re.search(r"\[ID:[ 0-9]+\]", cpn_obj.output("content"))
|
||||
yield decorate("message_end", {"reference": self.get_reference() if cite else None})
|
||||
|
||||
while partials:
|
||||
_cpn_obj = self.get_component_obj(partials[0])
|
||||
@ -386,18 +395,6 @@ class Canvas:
|
||||
})
|
||||
self.history.append(("assistant", self.get_component_obj(self.path[-1]).output()))
|
||||
|
||||
def get_component(self, cpn_id) -> Union[None, dict[str, Any]]:
|
||||
return self.components.get(cpn_id)
|
||||
|
||||
def get_component_obj(self, cpn_id) -> ComponentBase:
|
||||
return self.components.get(cpn_id)["obj"]
|
||||
|
||||
def get_component_type(self, cpn_id) -> str:
|
||||
return self.components.get(cpn_id)["obj"].component_name
|
||||
|
||||
def get_component_input_form(self, cpn_id) -> dict:
|
||||
return self.components.get(cpn_id)["obj"].get_input_form()
|
||||
|
||||
def is_reff(self, exp: str) -> bool:
|
||||
exp = exp.strip("{").strip("}")
|
||||
if exp.find("@") < 0:
|
||||
@ -419,9 +416,6 @@ class Canvas:
|
||||
raise Exception(f"Can't find variable: '{cpn_id}@{var_nm}'")
|
||||
return cpn["obj"].output(var_nm)
|
||||
|
||||
def get_tenant_id(self):
|
||||
return self._tenant_id
|
||||
|
||||
def get_history(self, window_size):
|
||||
convs = []
|
||||
if window_size <= 0:
|
||||
@ -436,36 +430,6 @@ class Canvas:
|
||||
def add_user_input(self, question):
|
||||
self.history.append(("user", question))
|
||||
|
||||
def _find_loop(self, max_loops=6):
|
||||
path = self.path[-1][::-1]
|
||||
if len(path) < 2:
|
||||
return False
|
||||
|
||||
for i in range(len(path)):
|
||||
if path[i].lower().find("answer") == 0 or path[i].lower().find("iterationitem") == 0:
|
||||
path = path[:i]
|
||||
break
|
||||
|
||||
if len(path) < 2:
|
||||
return False
|
||||
|
||||
for loc in range(2, len(path) // 2):
|
||||
pat = ",".join(path[0:loc])
|
||||
path_str = ",".join(path)
|
||||
if len(pat) >= len(path_str):
|
||||
return False
|
||||
loop = max_loops
|
||||
while path_str.find(pat) == 0 and loop >= 0:
|
||||
loop -= 1
|
||||
if len(pat)+1 >= len(path_str):
|
||||
return False
|
||||
path_str = path_str[len(pat)+1:]
|
||||
if loop < 0:
|
||||
pat = " => ".join([p.split(":")[0] for p in path[0:loc]])
|
||||
return pat + " => " + pat
|
||||
|
||||
return False
|
||||
|
||||
def get_prologue(self):
|
||||
return self.components["begin"]["obj"]._param.prologue
|
||||
|
||||
@ -520,7 +484,7 @@ class Canvas:
|
||||
except Exception as e:
|
||||
logging.exception(e)
|
||||
|
||||
def add_refernce(self, chunks: list[object], doc_infos: list[object]):
|
||||
def add_reference(self, chunks: list[object], doc_infos: list[object]):
|
||||
if not self.retrieval:
|
||||
self.retrieval = [{"chunks": {}, "doc_aggs": {}}]
|
||||
|
||||
|
||||
@ -50,8 +50,9 @@ del _package_path, _import_submodules, _extract_classes_from_module
|
||||
|
||||
|
||||
def component_class(class_name):
|
||||
m = importlib.import_module("agent.component")
|
||||
try:
|
||||
return getattr(m, class_name)
|
||||
except Exception:
|
||||
return getattr(importlib.import_module("agent.tools"), class_name)
|
||||
for mdl in ["agent.component", "agent.tools", "rag.flow"]:
|
||||
try:
|
||||
return getattr(importlib.import_module(mdl), class_name)
|
||||
except Exception:
|
||||
pass
|
||||
assert False, f"Can't import {class_name}"
|
||||
|
||||
@ -155,18 +155,18 @@ class Agent(LLM, ToolBase):
|
||||
if not self.tools:
|
||||
return LLM._invoke(self, **kwargs)
|
||||
|
||||
prompt, msg = self._prepare_prompt_variables()
|
||||
prompt, msg, user_defined_prompt = self._prepare_prompt_variables()
|
||||
|
||||
downstreams = self._canvas.get_component(self._id)["downstream"] if self._canvas.get_component(self._id) else []
|
||||
ex = self.exception_handler()
|
||||
if any([self._canvas.get_component_obj(cid).component_name.lower()=="message" for cid in downstreams]) and not self._param.output_structure and not (ex and ex["goto"]):
|
||||
self.set_output("content", partial(self.stream_output_with_tools, prompt, msg))
|
||||
self.set_output("content", partial(self.stream_output_with_tools, prompt, msg, user_defined_prompt))
|
||||
return
|
||||
|
||||
_, msg = message_fit_in([{"role": "system", "content": prompt}, *msg], int(self.chat_mdl.max_length * 0.97))
|
||||
use_tools = []
|
||||
ans = ""
|
||||
for delta_ans, tk in self._react_with_tools_streamly(prompt, msg, use_tools):
|
||||
for delta_ans, tk in self._react_with_tools_streamly(prompt, msg, use_tools, user_defined_prompt):
|
||||
ans += delta_ans
|
||||
|
||||
if ans.find("**ERROR**") >= 0:
|
||||
@ -182,11 +182,11 @@ class Agent(LLM, ToolBase):
|
||||
self.set_output("use_tools", use_tools)
|
||||
return ans
|
||||
|
||||
def stream_output_with_tools(self, prompt, msg):
|
||||
def stream_output_with_tools(self, prompt, msg, user_defined_prompt={}):
|
||||
_, msg = message_fit_in([{"role": "system", "content": prompt}, *msg], int(self.chat_mdl.max_length * 0.97))
|
||||
answer_without_toolcall = ""
|
||||
use_tools = []
|
||||
for delta_ans,_ in self._react_with_tools_streamly(prompt, msg, use_tools):
|
||||
for delta_ans,_ in self._react_with_tools_streamly(prompt, msg, use_tools, user_defined_prompt):
|
||||
if delta_ans.find("**ERROR**") >= 0:
|
||||
if self.get_exception_default_value():
|
||||
self.set_output("content", self.get_exception_default_value())
|
||||
@ -209,7 +209,7 @@ class Agent(LLM, ToolBase):
|
||||
]):
|
||||
yield delta_ans
|
||||
|
||||
def _react_with_tools_streamly(self, prompt, history: list[dict], use_tools):
|
||||
def _react_with_tools_streamly(self, prompt, history: list[dict], use_tools, user_defined_prompt={}):
|
||||
token_count = 0
|
||||
tool_metas = self.tool_meta
|
||||
hist = deepcopy(history)
|
||||
@ -230,7 +230,7 @@ class Agent(LLM, ToolBase):
|
||||
# last_calling,
|
||||
# last_calling != name
|
||||
#]):
|
||||
# self.toolcall_session.get_tool_obj(name).add2system_prompt(f"The chat history with other agents are as following: \n" + self.get_useful_memory(user_request, str(args["user_prompt"])))
|
||||
# self.toolcall_session.get_tool_obj(name).add2system_prompt(f"The chat history with other agents are as following: \n" + self.get_useful_memory(user_request, str(args["user_prompt"]),user_defined_prompt))
|
||||
last_calling = name
|
||||
tool_response = self.toolcall_session.tool_call(name, args)
|
||||
use_tools.append({
|
||||
@ -239,7 +239,7 @@ class Agent(LLM, ToolBase):
|
||||
"results": tool_response
|
||||
})
|
||||
# self.callback("add_memory", {}, "...")
|
||||
#self.add_memory(hist[-2]["content"], hist[-1]["content"], name, args, str(tool_response))
|
||||
#self.add_memory(hist[-2]["content"], hist[-1]["content"], name, args, str(tool_response), user_defined_prompt)
|
||||
|
||||
return name, tool_response
|
||||
|
||||
@ -279,10 +279,10 @@ class Agent(LLM, ToolBase):
|
||||
hist.append({"role": "user", "content": content})
|
||||
|
||||
st = timer()
|
||||
task_desc = analyze_task(self.chat_mdl, prompt, user_request, tool_metas)
|
||||
task_desc = analyze_task(self.chat_mdl, prompt, user_request, tool_metas, user_defined_prompt)
|
||||
self.callback("analyze_task", {}, task_desc, elapsed_time=timer()-st)
|
||||
for _ in range(self._param.max_rounds + 1):
|
||||
response, tk = next_step(self.chat_mdl, hist, tool_metas, task_desc)
|
||||
response, tk = next_step(self.chat_mdl, hist, tool_metas, task_desc, user_defined_prompt)
|
||||
# self.callback("next_step", {}, str(response)[:256]+"...")
|
||||
token_count += tk
|
||||
hist.append({"role": "assistant", "content": response})
|
||||
@ -307,7 +307,7 @@ class Agent(LLM, ToolBase):
|
||||
thr.append(executor.submit(use_tool, name, args))
|
||||
|
||||
st = timer()
|
||||
reflection = reflect(self.chat_mdl, hist, [th.result() for th in thr])
|
||||
reflection = reflect(self.chat_mdl, hist, [th.result() for th in thr], user_defined_prompt)
|
||||
append_user_content(hist, reflection)
|
||||
self.callback("reflection", {}, str(reflection), elapsed_time=timer()-st)
|
||||
|
||||
@ -334,10 +334,10 @@ Respond immediately with your final comprehensive answer.
|
||||
for txt, tkcnt in complete():
|
||||
yield txt, tkcnt
|
||||
|
||||
def get_useful_memory(self, goal: str, sub_goal:str, topn=3) -> str:
|
||||
def get_useful_memory(self, goal: str, sub_goal:str, topn=3, user_defined_prompt:dict={}) -> str:
|
||||
# self.callback("get_useful_memory", {"topn": 3}, "...")
|
||||
mems = self._canvas.get_memory()
|
||||
rank = rank_memories(self.chat_mdl, goal, sub_goal, [summ for (user, assist, summ) in mems])
|
||||
rank = rank_memories(self.chat_mdl, goal, sub_goal, [summ for (user, assist, summ) in mems], user_defined_prompt)
|
||||
try:
|
||||
rank = json_repair.loads(re.sub(r"```.*", "", rank))[:topn]
|
||||
mems = [mems[r] for r in rank]
|
||||
|
||||
@ -16,7 +16,7 @@
|
||||
|
||||
import re
|
||||
import time
|
||||
from abc import ABC, abstractmethod
|
||||
from abc import ABC
|
||||
import builtins
|
||||
import json
|
||||
import os
|
||||
@ -410,8 +410,8 @@ class ComponentBase(ABC):
|
||||
)
|
||||
|
||||
def __init__(self, canvas, id, param: ComponentParamBase):
|
||||
from agent.canvas import Canvas # Local import to avoid cyclic dependency
|
||||
assert isinstance(canvas, Canvas), "canvas must be an instance of Canvas"
|
||||
from agent.canvas import Graph # Local import to avoid cyclic dependency
|
||||
assert isinstance(canvas, Graph), "canvas must be an instance of Canvas"
|
||||
self._canvas = canvas
|
||||
self._id = id
|
||||
self._param = param
|
||||
@ -448,9 +448,11 @@ class ComponentBase(ABC):
|
||||
def error(self):
|
||||
return self._param.outputs.get("_ERROR", {}).get("value")
|
||||
|
||||
def reset(self):
|
||||
def reset(self, only_output=False):
|
||||
for k in self._param.outputs.keys():
|
||||
self._param.outputs[k]["value"] = None
|
||||
if only_output:
|
||||
return
|
||||
for k in self._param.inputs.keys():
|
||||
self._param.inputs[k]["value"] = None
|
||||
self._param.debug_inputs = {}
|
||||
@ -526,6 +528,10 @@ class ComponentBase(ABC):
|
||||
cpn_nms = self._canvas.get_component(self._id)['upstream']
|
||||
return cpn_nms
|
||||
|
||||
def get_downstream(self) -> List[str]:
|
||||
cpn_nms = self._canvas.get_component(self._id)['downstream']
|
||||
return cpn_nms
|
||||
|
||||
@staticmethod
|
||||
def string_format(content: str, kv: dict[str, str]) -> str:
|
||||
for n, v in kv.items():
|
||||
@ -554,6 +560,5 @@ class ComponentBase(ABC):
|
||||
def set_exception_default_value(self):
|
||||
self.set_output("result", self.get_exception_default_value())
|
||||
|
||||
@abstractmethod
|
||||
def thoughts(self) -> str:
|
||||
...
|
||||
raise NotImplementedError()
|
||||
|
||||
@ -17,6 +17,7 @@ import json
|
||||
import logging
|
||||
import os
|
||||
import re
|
||||
from copy import deepcopy
|
||||
from typing import Any, Generator
|
||||
import json_repair
|
||||
from functools import partial
|
||||
@ -141,15 +142,26 @@ class LLM(ComponentBase):
|
||||
for p in self._param.prompts:
|
||||
if msg and msg[-1]["role"] == p["role"]:
|
||||
continue
|
||||
msg.append(p)
|
||||
msg.append(deepcopy(p))
|
||||
|
||||
sys_prompt = self.string_format(sys_prompt, args)
|
||||
user_defined_prompt, sys_prompt = self._extract_prompts(sys_prompt)
|
||||
for m in msg:
|
||||
m["content"] = self.string_format(m["content"], args)
|
||||
if self._param.cite and self._canvas.get_reference()["chunks"]:
|
||||
sys_prompt += citation_prompt()
|
||||
sys_prompt += citation_prompt(user_defined_prompt)
|
||||
|
||||
return sys_prompt, msg
|
||||
return sys_prompt, msg, user_defined_prompt
|
||||
|
||||
def _extract_prompts(self, sys_prompt):
|
||||
pts = {}
|
||||
for tag in ["TASK_ANALYSIS", "PLAN_GENERATION", "REFLECTION", "CONTEXT_SUMMARY", "CONTEXT_RANKING", "CITATION_GUIDELINES"]:
|
||||
r = re.search(rf"<{tag}>(.*?)</{tag}>", sys_prompt, flags=re.DOTALL|re.IGNORECASE)
|
||||
if not r:
|
||||
continue
|
||||
pts[tag.lower()] = r.group(1)
|
||||
sys_prompt = re.sub(rf"<{tag}>(.*?)</{tag}>", "", sys_prompt, flags=re.DOTALL|re.IGNORECASE)
|
||||
return pts, sys_prompt
|
||||
|
||||
def _generate(self, msg:list[dict], **kwargs) -> str:
|
||||
if not self.imgs:
|
||||
@ -197,7 +209,7 @@ class LLM(ComponentBase):
|
||||
ans = re.sub(r"^.*```json", "", ans, flags=re.DOTALL)
|
||||
return re.sub(r"```\n*$", "", ans, flags=re.DOTALL)
|
||||
|
||||
prompt, msg = self._prepare_prompt_variables()
|
||||
prompt, msg, _ = self._prepare_prompt_variables()
|
||||
error = ""
|
||||
|
||||
if self._param.output_structure:
|
||||
@ -261,11 +273,11 @@ class LLM(ComponentBase):
|
||||
answer += ans
|
||||
self.set_output("content", answer)
|
||||
|
||||
def add_memory(self, user:str, assist:str, func_name: str, params: dict, results: str):
|
||||
summ = tool_call_summary(self.chat_mdl, func_name, params, results)
|
||||
def add_memory(self, user:str, assist:str, func_name: str, params: dict, results: str, user_defined_prompt:dict={}):
|
||||
summ = tool_call_summary(self.chat_mdl, func_name, params, results, user_defined_prompt)
|
||||
logging.info(f"[MEMORY]: {summ}")
|
||||
self._canvas.add_memory(user, assist, summ)
|
||||
|
||||
def thoughts(self) -> str:
|
||||
_, msg = self._prepare_prompt_variables()
|
||||
_, msg,_ = self._prepare_prompt_variables()
|
||||
return "⌛Give me a moment—starting from: \n\n" + re.sub(r"(User's query:|[\\]+)", '', msg[-1]['content'], flags=re.DOTALL) + "\n\nI’ll figure out our best next move."
|
||||
@ -1,8 +1,12 @@
|
||||
{
|
||||
"id": 19,
|
||||
"title": "Choose Your Knowledge Base Agent",
|
||||
"description": "Select your desired knowledge base from the dropdown menu. The Agent will only retrieve from the selected knowledge base and use this content to generate responses.",
|
||||
"canvas_type": "Agent",
|
||||
"title": {
|
||||
"en": "Choose Your Knowledge Base Agent",
|
||||
"zh": "选择知识库智能体"},
|
||||
"description": {
|
||||
"en": "Select your desired knowledge base from the dropdown menu. The Agent will only retrieve from the selected knowledge base and use this content to generate responses.",
|
||||
"zh": "从下拉菜单中选择知识库,智能体将仅根据所选知识库内容生成回答。"},
|
||||
"canvas_type": "Agent",
|
||||
"dsl": {
|
||||
"components": {
|
||||
"Agent:BraveParksJoke": {
|
||||
|
||||
@ -1,8 +1,12 @@
|
||||
{
|
||||
"id": 18,
|
||||
"title": "Choose Your Knowledge Base Workflow",
|
||||
"description": "Select your desired knowledge base from the dropdown menu. The retrieval assistant will only use data from your selected knowledge base to generate responses.",
|
||||
"canvas_type": "Other",
|
||||
"title": {
|
||||
"en": "Choose Your Knowledge Base Workflow",
|
||||
"zh": "选择知识库工作流"},
|
||||
"description": {
|
||||
"en": "Select your desired knowledge base from the dropdown menu. The retrieval assistant will only use data from your selected knowledge base to generate responses.",
|
||||
"zh": "从下拉菜单中选择知识库,工作流将仅根据所选知识库内容生成回答。"},
|
||||
"canvas_type": "Other",
|
||||
"dsl": {
|
||||
"components": {
|
||||
"Agent:ProudDingosShout": {
|
||||
|
||||
@ -1,9 +1,13 @@
|
||||
|
||||
{
|
||||
"id": 11,
|
||||
"title": "Customer Review Analysis",
|
||||
"description": "Automatically classify customer reviews using LLM (Large Language Model) and route them via email to the relevant departments.",
|
||||
"canvas_type": "Customer Support",
|
||||
"title": {
|
||||
"en": "Customer Review Analysis",
|
||||
"zh": "客户评价分析"},
|
||||
"description": {
|
||||
"en": "Automatically classify customer reviews using LLM (Large Language Model) and route them via email to the relevant departments.",
|
||||
"zh": "大模型将自动分类客户评价,并通过电子邮件将结果发送到相关部门。"},
|
||||
"canvas_type": "Customer Support",
|
||||
"dsl": {
|
||||
"components": {
|
||||
"Categorize:FourTeamsFold": {
|
||||
|
||||
File diff suppressed because one or more lines are too long
@ -1,8 +1,12 @@
|
||||
|
||||
{
|
||||
"id": 10,
|
||||
"title": "Customer Support",
|
||||
"description": "This is an intelligent customer service processing system workflow based on user intent classification. It uses LLM to identify user demand types and transfers them to the corresponding professional agent for processing.",
|
||||
"title": {
|
||||
"en":"Customer Support",
|
||||
"zh": "客户支持"},
|
||||
"description": {
|
||||
"en": "This is an intelligent customer service processing system workflow based on user intent classification. It uses LLM to identify user demand types and transfers them to the corresponding professional agent for processing.",
|
||||
"zh": "工作流系统,用于智能客服场景。基于用户意图分类。使用大模型识别用户需求类型,并将需求转移给相应的智能体进行处理。"},
|
||||
"canvas_type": "Customer Support",
|
||||
"dsl": {
|
||||
"components": {
|
||||
|
||||
@ -1,8 +1,12 @@
|
||||
|
||||
{
|
||||
"id": 15,
|
||||
"title": "CV Analysis and Candidate Evaluation",
|
||||
"description": "This is a workflow that helps companies evaluate resumes, HR uploads a job description first, then submits multiple resumes via the chat window for evaluation.",
|
||||
"title": {
|
||||
"en": "CV Analysis and Candidate Evaluation",
|
||||
"zh": "简历分析和候选人评估"},
|
||||
"description": {
|
||||
"en": "This is a workflow that helps companies evaluate resumes, HR uploads a job description first, then submits multiple resumes via the chat window for evaluation.",
|
||||
"zh": "帮助公司评估简历的工作流。HR首先上传职位描述,通过聊天窗口提交多份简历进行评估。"},
|
||||
"canvas_type": "Other",
|
||||
"dsl": {
|
||||
"components": {
|
||||
|
||||
File diff suppressed because one or more lines are too long
@ -1,8 +1,12 @@
|
||||
|
||||
{
|
||||
"id": 1,
|
||||
"title": "Deep Research",
|
||||
"description": "For professionals in sales, marketing, policy, or consulting, the Multi-Agent Deep Research Agent conducts structured, multi-step investigations across diverse sources and delivers consulting-style reports with clear citations.",
|
||||
"title": {
|
||||
"en": "Deep Research",
|
||||
"zh": "深度研究"},
|
||||
"description": {
|
||||
"en": "For professionals in sales, marketing, policy, or consulting, the Multi-Agent Deep Research Agent conducts structured, multi-step investigations across diverse sources and delivers consulting-style reports with clear citations.",
|
||||
"zh": "专为销售、市场、政策或咨询领域的专业人士设计,多智能体的深度研究会结合多源信息进行结构化、多步骤地回答问题,并附带有清晰的引用。"},
|
||||
"canvas_type": "Recommended",
|
||||
"dsl": {
|
||||
"components": {
|
||||
|
||||
@ -1,8 +1,12 @@
|
||||
|
||||
{
|
||||
"id": 6,
|
||||
"title": "Deep Research",
|
||||
"description": "For professionals in sales, marketing, policy, or consulting, the Multi-Agent Deep Research Agent conducts structured, multi-step investigations across diverse sources and delivers consulting-style reports with clear citations.",
|
||||
"title": {
|
||||
"en": "Deep Research",
|
||||
"zh": "深度研究"},
|
||||
"description": {
|
||||
"en": "For professionals in sales, marketing, policy, or consulting, the Multi-Agent Deep Research Agent conducts structured, multi-step investigations across diverse sources and delivers consulting-style reports with clear citations.",
|
||||
"zh": "专为销售、市场、政策或咨询领域的专业人士设计,多智能体的深度研究会结合多源信息进行结构化、多步骤地回答问题,并附带有清晰的引用。"},
|
||||
"canvas_type": "Agent",
|
||||
"dsl": {
|
||||
"components": {
|
||||
|
||||
@ -1,7 +1,13 @@
|
||||
{
|
||||
"id": 22,
|
||||
"title": "Ecommerce Customer Service Workflow",
|
||||
"description": "This template helps e-commerce platforms address complex customer needs, such as comparing product features, providing usage support, and coordinating home installation services.",
|
||||
"title": {
|
||||
"en": "Ecommerce Customer Service Workflow",
|
||||
"zh": "电子商务客户服务工作流程"
|
||||
},
|
||||
"description": {
|
||||
"en": "This template helps e-commerce platforms address complex customer needs, such as comparing product features, providing usage support, and coordinating home installation services.",
|
||||
"zh": "该模板可帮助电子商务平台解决复杂的客户需求,例如比较产品功能、提供使用支持和协调家庭安装服务。"
|
||||
},
|
||||
"canvas_type": "Customer Support",
|
||||
"dsl": {
|
||||
"components": {
|
||||
|
||||
@ -1,7 +1,11 @@
|
||||
{
|
||||
"id": 8,
|
||||
"title": "Generate SEO Blog",
|
||||
"description": "This is a multi-agent version of the SEO blog generation workflow. It simulates a small team of AI “writers”, where each agent plays a specialized role — just like a real editorial team.",
|
||||
"title": {
|
||||
"en": "Generate SEO Blog",
|
||||
"zh": "生成SEO博客"},
|
||||
"description": {
|
||||
"en": "This is a multi-agent version of the SEO blog generation workflow. It simulates a small team of AI “writers”, where each agent plays a specialized role — just like a real editorial team.",
|
||||
"zh": "多智能体架构可根据简单的用户输入自动生成完整的SEO博客文章。模拟小型“作家”团队,其中每个智能体扮演一个专业角色——就像真正的编辑团队。"},
|
||||
"canvas_type": "Agent",
|
||||
"dsl": {
|
||||
"components": {
|
||||
|
||||
@ -1,7 +1,11 @@
|
||||
{
|
||||
"id": 13,
|
||||
"title": "ImageLingo",
|
||||
"description": "ImageLingo lets you snap any photo containing text—menus, signs, or documents—and instantly recognize and translate it into your language of choice using advanced AI-powered translation technology.",
|
||||
"title": {
|
||||
"en": "ImageLingo",
|
||||
"zh": "图片解析"},
|
||||
"description": {
|
||||
"en": "ImageLingo lets you snap any photo containing text—menus, signs, or documents—and instantly recognize and translate it into your language of choice using advanced AI-powered translation technology.",
|
||||
"zh": "多模态大模型允许您拍摄任何包含文本的照片——菜单、标志或文档——立即识别并转换成您选择的语言。"},
|
||||
"canvas_type": "Consumer App",
|
||||
"dsl": {
|
||||
"components": {
|
||||
|
||||
@ -1,7 +1,11 @@
|
||||
{
|
||||
"id": 20,
|
||||
"title": "Report Agent Using Knowledge Base",
|
||||
"description": "A report generation assistant using local knowledge base, with advanced capabilities in task planning, reasoning, and reflective analysis. Recommended for academic research paper Q&A",
|
||||
"title": {
|
||||
"en": "Report Agent Using Knowledge Base",
|
||||
"zh": "知识库检索智能体"},
|
||||
"description": {
|
||||
"en": "A report generation assistant using local knowledge base, with advanced capabilities in task planning, reasoning, and reflective analysis. Recommended for academic research paper Q&A",
|
||||
"zh": "一个使用本地知识库的报告生成助手,具备高级能力,包括任务规划、推理和反思性分析。推荐用于学术研究论文问答。"},
|
||||
"canvas_type": "Agent",
|
||||
"dsl": {
|
||||
"components": {
|
||||
|
||||
331
agent/templates/knowledge_base_report_r.json
Normal file
331
agent/templates/knowledge_base_report_r.json
Normal file
@ -0,0 +1,331 @@
|
||||
{
|
||||
"id": 21,
|
||||
"title": {
|
||||
"en": "Report Agent Using Knowledge Base",
|
||||
"zh": "知识库检索智能体"},
|
||||
"description": {
|
||||
"en": "A report generation assistant using local knowledge base, with advanced capabilities in task planning, reasoning, and reflective analysis. Recommended for academic research paper Q&A",
|
||||
"zh": "一个使用本地知识库的报告生成助手,具备高级能力,包括任务规划、推理和反思性分析。推荐用于学术研究论文问答。"},
|
||||
"canvas_type": "Recommended",
|
||||
"dsl": {
|
||||
"components": {
|
||||
"Agent:NewPumasLick": {
|
||||
"downstream": [
|
||||
"Message:OrangeYearsShine"
|
||||
],
|
||||
"obj": {
|
||||
"component_name": "Agent",
|
||||
"params": {
|
||||
"delay_after_error": 1,
|
||||
"description": "",
|
||||
"exception_comment": "",
|
||||
"exception_default_value": "",
|
||||
"exception_goto": [],
|
||||
"exception_method": null,
|
||||
"frequencyPenaltyEnabled": false,
|
||||
"frequency_penalty": 0.5,
|
||||
"llm_id": "qwen3-235b-a22b-instruct-2507@Tongyi-Qianwen",
|
||||
"maxTokensEnabled": true,
|
||||
"max_retries": 3,
|
||||
"max_rounds": 3,
|
||||
"max_tokens": 128000,
|
||||
"mcp": [],
|
||||
"message_history_window_size": 12,
|
||||
"outputs": {
|
||||
"content": {
|
||||
"type": "string",
|
||||
"value": ""
|
||||
}
|
||||
},
|
||||
"parameter": "Precise",
|
||||
"presencePenaltyEnabled": false,
|
||||
"presence_penalty": 0.5,
|
||||
"prompts": [
|
||||
{
|
||||
"content": "# User Query\n {sys.query}",
|
||||
"role": "user"
|
||||
}
|
||||
],
|
||||
"sys_prompt": "## Role & Task\nYou are a **\u201cKnowledge Base Retrieval Q\\&A Agent\u201d** whose goal is to break down the user\u2019s question into retrievable subtasks, and then produce a multi-source-verified, structured, and actionable research report using the internal knowledge base.\n## Execution Framework (Detailed Steps & Key Points)\n1. **Assessment & Decomposition**\n * Actions:\n * Automatically extract: main topic, subtopics, entities (people/organizations/products/technologies), time window, geographic/business scope.\n * Output as a list: N facts/data points that must be collected (*N* ranges from 5\u201320 depending on question complexity).\n2. **Query Type Determination (Rule-Based)**\n * Example rules:\n * If the question involves a single issue but requests \u201cmethod comparison/multiple explanations\u201d \u2192 use **depth-first**.\n * If the question can naturally be split into \u22653 independent sub-questions \u2192 use **breadth-first**.\n * If the question can be answered by a single fact/specification/definition \u2192 use **simple query**.\n3. **Research Plan Formulation**\n * Depth-first: define 3\u20135 perspectives (methodology/stakeholders/time dimension/technical route, etc.), assign search keywords, target document types, and output format for each perspective.\n * Breadth-first: list subtasks, prioritize them, and assign search terms.\n * Simple query: directly provide the search sentence and required fields.\n4. **Retrieval Execution**\n * After retrieval: perform coverage check (does it contain the key facts?) and quality check (source diversity, authority, latest update time).\n * If standards are not met, automatically loop: rewrite queries (synonyms/cross-domain terms) and retry \u22643 times, or flag as requiring external search.\n5. **Integration & Reasoning**\n * Build the answer using a **fact\u2013evidence\u2013reasoning** chain. For each conclusion, attach 1\u20132 strongest pieces of evidence.\n---\n## Quality Gate Checklist (Verify at Each Stage)\n* **Stage 1 (Decomposition)**:\n * [ ] Key concepts and expected outputs identified\n * [ ] Required facts/data points listed\n* **Stage 2 (Retrieval)**:\n * [ ] Meets quality standards (see above)\n * [ ] If not met: execute query iteration\n* **Stage 3 (Generation)**:\n * [ ] Each conclusion has at least one direct evidence source\n * [ ] State assumptions/uncertainties\n * [ ] Provide next-step suggestions or experiment/retrieval plans\n * [ ] Final length and depth match user expectations (comply with word count/format if specified)\n---\n## Core Principles\n1. **Strict reliance on the knowledge base**: answers must be **fully bounded** by the content retrieved from the knowledge base.\n2. **No fabrication**: do not generate, infer, or create information that is not explicitly present in the knowledge base.\n3. **Accuracy first**: prefer incompleteness over inaccurate content.\n4. **Output format**:\n * Hierarchically clear modular structure\n * Logical grouping according to the MECE principle\n * Professionally presented formatting\n * Step-by-step cognitive guidance\n * Reasonable use of headings and dividers for clarity\n * *Italicize* key parameters\n * **Bold** critical information\n5. **LaTeX formula requirements**:\n * Inline formulas: start and end with `$`\n * Block formulas: start and end with `$$`, each `$$` on its own line\n * Block formula content must comply with LaTeX math syntax\n * Verify formula correctness\n---\n## Additional Notes (Interaction & Failure Strategy)\n* If the knowledge base does not cover critical facts: explicitly inform the user (with sample wording)\n* For time-sensitive issues: enforce time filtering in the search request, and indicate the latest retrieval date in the answer.\n* Language requirement: answer in the user\u2019s preferred language\n",
|
||||
"temperature": "0.1",
|
||||
"temperatureEnabled": true,
|
||||
"tools": [
|
||||
{
|
||||
"component_name": "Retrieval",
|
||||
"name": "Retrieval",
|
||||
"params": {
|
||||
"cross_languages": [],
|
||||
"description": "",
|
||||
"empty_response": "",
|
||||
"kb_ids": [],
|
||||
"keywords_similarity_weight": 0.7,
|
||||
"outputs": {
|
||||
"formalized_content": {
|
||||
"type": "string",
|
||||
"value": ""
|
||||
}
|
||||
},
|
||||
"rerank_id": "",
|
||||
"similarity_threshold": 0.2,
|
||||
"top_k": 1024,
|
||||
"top_n": 8,
|
||||
"use_kg": false
|
||||
}
|
||||
}
|
||||
],
|
||||
"topPEnabled": false,
|
||||
"top_p": 0.75,
|
||||
"user_prompt": "",
|
||||
"visual_files_var": ""
|
||||
}
|
||||
},
|
||||
"upstream": [
|
||||
"begin"
|
||||
]
|
||||
},
|
||||
"Message:OrangeYearsShine": {
|
||||
"downstream": [],
|
||||
"obj": {
|
||||
"component_name": "Message",
|
||||
"params": {
|
||||
"content": [
|
||||
"{Agent:NewPumasLick@content}"
|
||||
]
|
||||
}
|
||||
},
|
||||
"upstream": [
|
||||
"Agent:NewPumasLick"
|
||||
]
|
||||
},
|
||||
"begin": {
|
||||
"downstream": [
|
||||
"Agent:NewPumasLick"
|
||||
],
|
||||
"obj": {
|
||||
"component_name": "Begin",
|
||||
"params": {
|
||||
"enablePrologue": true,
|
||||
"inputs": {},
|
||||
"mode": "conversational",
|
||||
"prologue": "\u4f60\u597d\uff01 \u6211\u662f\u4f60\u7684\u52a9\u7406\uff0c\u6709\u4ec0\u4e48\u53ef\u4ee5\u5e2e\u5230\u4f60\u7684\u5417\uff1f"
|
||||
}
|
||||
},
|
||||
"upstream": []
|
||||
}
|
||||
},
|
||||
"globals": {
|
||||
"sys.conversation_turns": 0,
|
||||
"sys.files": [],
|
||||
"sys.query": "",
|
||||
"sys.user_id": ""
|
||||
},
|
||||
"graph": {
|
||||
"edges": [
|
||||
{
|
||||
"data": {
|
||||
"isHovered": false
|
||||
},
|
||||
"id": "xy-edge__beginstart-Agent:NewPumasLickend",
|
||||
"source": "begin",
|
||||
"sourceHandle": "start",
|
||||
"target": "Agent:NewPumasLick",
|
||||
"targetHandle": "end"
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"isHovered": false
|
||||
},
|
||||
"id": "xy-edge__Agent:NewPumasLickstart-Message:OrangeYearsShineend",
|
||||
"markerEnd": "logo",
|
||||
"source": "Agent:NewPumasLick",
|
||||
"sourceHandle": "start",
|
||||
"style": {
|
||||
"stroke": "rgba(91, 93, 106, 1)",
|
||||
"strokeWidth": 1
|
||||
},
|
||||
"target": "Message:OrangeYearsShine",
|
||||
"targetHandle": "end",
|
||||
"type": "buttonEdge",
|
||||
"zIndex": 1001
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"isHovered": false
|
||||
},
|
||||
"id": "xy-edge__Agent:NewPumasLicktool-Tool:AllBirdsNailend",
|
||||
"selected": false,
|
||||
"source": "Agent:NewPumasLick",
|
||||
"sourceHandle": "tool",
|
||||
"target": "Tool:AllBirdsNail",
|
||||
"targetHandle": "end"
|
||||
}
|
||||
],
|
||||
"nodes": [
|
||||
{
|
||||
"data": {
|
||||
"form": {
|
||||
"enablePrologue": true,
|
||||
"inputs": {},
|
||||
"mode": "conversational",
|
||||
"prologue": "\u4f60\u597d\uff01 \u6211\u662f\u4f60\u7684\u52a9\u7406\uff0c\u6709\u4ec0\u4e48\u53ef\u4ee5\u5e2e\u5230\u4f60\u7684\u5417\uff1f"
|
||||
},
|
||||
"label": "Begin",
|
||||
"name": "begin"
|
||||
},
|
||||
"dragging": false,
|
||||
"id": "begin",
|
||||
"measured": {
|
||||
"height": 48,
|
||||
"width": 200
|
||||
},
|
||||
"position": {
|
||||
"x": -9.569875358221438,
|
||||
"y": 205.84018385864917
|
||||
},
|
||||
"selected": false,
|
||||
"sourcePosition": "left",
|
||||
"targetPosition": "right",
|
||||
"type": "beginNode"
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"form": {
|
||||
"content": [
|
||||
"{Agent:NewPumasLick@content}"
|
||||
]
|
||||
},
|
||||
"label": "Message",
|
||||
"name": "Response"
|
||||
},
|
||||
"dragging": false,
|
||||
"id": "Message:OrangeYearsShine",
|
||||
"measured": {
|
||||
"height": 56,
|
||||
"width": 200
|
||||
},
|
||||
"position": {
|
||||
"x": 734.4061285881053,
|
||||
"y": 199.9706031723009
|
||||
},
|
||||
"selected": false,
|
||||
"sourcePosition": "right",
|
||||
"targetPosition": "left",
|
||||
"type": "messageNode"
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"form": {
|
||||
"delay_after_error": 1,
|
||||
"description": "",
|
||||
"exception_comment": "",
|
||||
"exception_default_value": "",
|
||||
"exception_goto": [],
|
||||
"exception_method": null,
|
||||
"frequencyPenaltyEnabled": false,
|
||||
"frequency_penalty": 0.5,
|
||||
"llm_id": "qwen3-235b-a22b-instruct-2507@Tongyi-Qianwen",
|
||||
"maxTokensEnabled": true,
|
||||
"max_retries": 3,
|
||||
"max_rounds": 3,
|
||||
"max_tokens": 128000,
|
||||
"mcp": [],
|
||||
"message_history_window_size": 12,
|
||||
"outputs": {
|
||||
"content": {
|
||||
"type": "string",
|
||||
"value": ""
|
||||
}
|
||||
},
|
||||
"parameter": "Precise",
|
||||
"presencePenaltyEnabled": false,
|
||||
"presence_penalty": 0.5,
|
||||
"prompts": [
|
||||
{
|
||||
"content": "# User Query\n {sys.query}",
|
||||
"role": "user"
|
||||
}
|
||||
],
|
||||
"sys_prompt": "## Role & Task\nYou are a **\u201cKnowledge Base Retrieval Q\\&A Agent\u201d** whose goal is to break down the user\u2019s question into retrievable subtasks, and then produce a multi-source-verified, structured, and actionable research report using the internal knowledge base.\n## Execution Framework (Detailed Steps & Key Points)\n1. **Assessment & Decomposition**\n * Actions:\n * Automatically extract: main topic, subtopics, entities (people/organizations/products/technologies), time window, geographic/business scope.\n * Output as a list: N facts/data points that must be collected (*N* ranges from 5\u201320 depending on question complexity).\n2. **Query Type Determination (Rule-Based)**\n * Example rules:\n * If the question involves a single issue but requests \u201cmethod comparison/multiple explanations\u201d \u2192 use **depth-first**.\n * If the question can naturally be split into \u22653 independent sub-questions \u2192 use **breadth-first**.\n * If the question can be answered by a single fact/specification/definition \u2192 use **simple query**.\n3. **Research Plan Formulation**\n * Depth-first: define 3\u20135 perspectives (methodology/stakeholders/time dimension/technical route, etc.), assign search keywords, target document types, and output format for each perspective.\n * Breadth-first: list subtasks, prioritize them, and assign search terms.\n * Simple query: directly provide the search sentence and required fields.\n4. **Retrieval Execution**\n * After retrieval: perform coverage check (does it contain the key facts?) and quality check (source diversity, authority, latest update time).\n * If standards are not met, automatically loop: rewrite queries (synonyms/cross-domain terms) and retry \u22643 times, or flag as requiring external search.\n5. **Integration & Reasoning**\n * Build the answer using a **fact\u2013evidence\u2013reasoning** chain. For each conclusion, attach 1\u20132 strongest pieces of evidence.\n---\n## Quality Gate Checklist (Verify at Each Stage)\n* **Stage 1 (Decomposition)**:\n * [ ] Key concepts and expected outputs identified\n * [ ] Required facts/data points listed\n* **Stage 2 (Retrieval)**:\n * [ ] Meets quality standards (see above)\n * [ ] If not met: execute query iteration\n* **Stage 3 (Generation)**:\n * [ ] Each conclusion has at least one direct evidence source\n * [ ] State assumptions/uncertainties\n * [ ] Provide next-step suggestions or experiment/retrieval plans\n * [ ] Final length and depth match user expectations (comply with word count/format if specified)\n---\n## Core Principles\n1. **Strict reliance on the knowledge base**: answers must be **fully bounded** by the content retrieved from the knowledge base.\n2. **No fabrication**: do not generate, infer, or create information that is not explicitly present in the knowledge base.\n3. **Accuracy first**: prefer incompleteness over inaccurate content.\n4. **Output format**:\n * Hierarchically clear modular structure\n * Logical grouping according to the MECE principle\n * Professionally presented formatting\n * Step-by-step cognitive guidance\n * Reasonable use of headings and dividers for clarity\n * *Italicize* key parameters\n * **Bold** critical information\n5. **LaTeX formula requirements**:\n * Inline formulas: start and end with `$`\n * Block formulas: start and end with `$$`, each `$$` on its own line\n * Block formula content must comply with LaTeX math syntax\n * Verify formula correctness\n---\n## Additional Notes (Interaction & Failure Strategy)\n* If the knowledge base does not cover critical facts: explicitly inform the user (with sample wording)\n* For time-sensitive issues: enforce time filtering in the search request, and indicate the latest retrieval date in the answer.\n* Language requirement: answer in the user\u2019s preferred language\n",
|
||||
"temperature": "0.1",
|
||||
"temperatureEnabled": true,
|
||||
"tools": [
|
||||
{
|
||||
"component_name": "Retrieval",
|
||||
"name": "Retrieval",
|
||||
"params": {
|
||||
"cross_languages": [],
|
||||
"description": "",
|
||||
"empty_response": "",
|
||||
"kb_ids": [],
|
||||
"keywords_similarity_weight": 0.7,
|
||||
"outputs": {
|
||||
"formalized_content": {
|
||||
"type": "string",
|
||||
"value": ""
|
||||
}
|
||||
},
|
||||
"rerank_id": "",
|
||||
"similarity_threshold": 0.2,
|
||||
"top_k": 1024,
|
||||
"top_n": 8,
|
||||
"use_kg": false
|
||||
}
|
||||
}
|
||||
],
|
||||
"topPEnabled": false,
|
||||
"top_p": 0.75,
|
||||
"user_prompt": "",
|
||||
"visual_files_var": ""
|
||||
},
|
||||
"label": "Agent",
|
||||
"name": "Knowledge Base Agent"
|
||||
},
|
||||
"dragging": false,
|
||||
"id": "Agent:NewPumasLick",
|
||||
"measured": {
|
||||
"height": 84,
|
||||
"width": 200
|
||||
},
|
||||
"position": {
|
||||
"x": 347.00048227952215,
|
||||
"y": 186.49109364794631
|
||||
},
|
||||
"selected": false,
|
||||
"sourcePosition": "right",
|
||||
"targetPosition": "left",
|
||||
"type": "agentNode"
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"form": {
|
||||
"description": "This is an agent for a specific task.",
|
||||
"user_prompt": "This is the order you need to send to the agent."
|
||||
},
|
||||
"label": "Tool",
|
||||
"name": "flow.tool_10"
|
||||
},
|
||||
"dragging": false,
|
||||
"id": "Tool:AllBirdsNail",
|
||||
"measured": {
|
||||
"height": 48,
|
||||
"width": 200
|
||||
},
|
||||
"position": {
|
||||
"x": 220.24819746977118,
|
||||
"y": 403.31576836482583
|
||||
},
|
||||
"selected": false,
|
||||
"sourcePosition": "right",
|
||||
"targetPosition": "left",
|
||||
"type": "toolNode"
|
||||
}
|
||||
]
|
||||
},
|
||||
"history": [],
|
||||
"memory": [],
|
||||
"messages": [],
|
||||
"path": [],
|
||||
"retrieval": []
|
||||
},
|
||||
"avatar": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAADAAAAAwCAYAAABXAvmHAAAH0klEQVR4nO2ZC1BU1wGG/3uRp/IygG+DGK0GOjE1U6cxI4tT03Y0E+kENbaJbKpj60wzgNMwnTjuEtu0miGasY+0krI202kMVEnVxtoOLG00oVa0LajVBDcSEI0REFBgkZv/3GWXfdzdvctuHs7kmzmec9//d+45914XCXc4Xwjk1+59VJGGF7C5QAFSWBvgyWmWLl7IKiny6QNL173B5YjB84bOyrpKA4B1DLySdQpLKAiZGtZ7a/KMVoQJz6UfEZyhTWwaEBmssiLvCueu6BJg8EwFqGTTAC+uvNWC9w82sRWcux/JwaSHstjywcogRt4RG0KExwWG4QsVYCebKSwe3L5lR9OOWjyzfg2WL/0a1/jncO3b2FHxGnKeWYqo+Giu8UEMrWJKWBACPMY/DG+63txhvnKshUu+DF2/hayMDFRsL+VScDb++AVc6OjAuInxXPJl2tfnIikrzUyJMi7qQmLRhOEr2fOFbX/7P6STF7BqoWevfdij4NWGQfx+57OYO2sG1wSnsek8Nm15EU8sikF6ouelXz9ph7JwDqYt+5IIZaGEkauDIrH4wPBmhjexCSEws+VdVG1M4NIoj+2xYzBuJtavWcEl/VS8dggx/ZdQvcGzQwp+cxOXsu5RBQQMVkYJM4LA/Txh+ELFMWFVPARS5kFiabZdx8Olh7l17BzdvhzZmROhdJ3j6D/nIyBgOCMlLAgA9xmF4TMV4BSbrgnrLiBl5rOsRCRRbDUsBzQFiJjY91PCBj9w+yiP1lXWsTLAjc9YQGB9I8+Yx1oTiUWFvW9QgDo2PdASaDp/EQ8/sRnhcPTVcuTMncXwQQVESL9DidscaPW+QEtAICRu9PSxFTpJiePV8AI9AsTvXZBY/Pa+wJ9ApNApIILm8S5Y4QXXQwhYFH6csemDP4G3G5v579i5d04mknknQhDYS4HCrCVr/mC3D305KnbCEpvVIia5Onw6WaWw+KAl0Np+FUXbdiMcyoqfUoeRHoFrJ1uRtnBG1/9Mf/3LtElp+VwF2wcd7woJib1vUPwMH4GWQCQJJtBa/V9cPmFD8uQUpMdNGDhY8bNYrobh8acHu270/l0ImJWRt64Wn6WACN9z5gq2lXwPW8pfweT0icP/fH23vO9QLYq3/QKyLBmFQI3CUcT9NdESEEPItKsSN3r7MBaSJoxHWZERM6ZmMLy2gDP8/pd/og418dTL37hFSUpMUC5f+UiWZcnY9s5+ixCwUiCXx2iiJdDNx6f4pgkH8Q3lbxK7h8+enoHha1cRNdMp8axiHxo6+/5bVdk8DSROYIW1X7QEIom3wHD3gEf4vu1bVYEJZeWQ0zJQvmcfyiv2QZak6raG/QWfK4Ez9mTc5v8xPMJfuojoxXmIX/9DOMe+FCWbcHu4BJJ0YEwCx0824bFNW9HesB+CqYu+jepfPYcHF+aoPXS8sQl/+vU2bgmOU2C+qRc9/YrrPPbGBtzavd0nvCxLxui4pJrBm911PFwak4CYA80cj+JCAiGUzYkmxrSY4N2c3GLi6UEIFL/wRxxqkhmHnTEpDQcrfq6ea+hcE8bNy3GFzyq4H22HW1Kd4WMSkg1jmsSRpKj0Rzhy4gNUv/y8Gjrv8SJK3OWScA+fMn/ysVPPvTmeh6nh1TcxBUJ+jEaKYr7N36x7h+Edj0pB6+WrLokn87+BrTt/p4ZPzZ6MM7/8R2//h33vOcNzdwgBMwVMbGvySQmo4a0NqOZccU7YmGXLEfPQUlUid/XT6B8YdIU/99vjsPcOdEhDsfOd4QVCwKB8yp8SWuG1njbTl83DpMWz1PCKAswuWPDI0e8WebyAJBbxNdrF7cls+hBpAb3h3XtehL/3+4u7D35rQwpP4YFTwMJ91rHpQyQFQgmf9sAMNL9Ur4afv/FBjIuPVj+n4YVTwMD96tj0IVICoYYXv/q1VJ1Sl8UveQyaRwErvOB6B5SwKhqP00gI6A0vhsycJ7/KIzxhyHqGN0ADbnNAAYOicRfCFdAb/p50Gbfuc/wy5w1D5lOghk0fuG0USlgVr7sQjoDe8C8WxKGKPy2KjzlvAQb02/sCbh+FApngX1QUtyeSuwDi0hxFByV7L+LIf3r5kvpp4PBr07Hqvn71Y85bgOG6WS2ggA1+4D6eUKKQApVsqngI6KSkqh9HzsoM/3zg8Oz5VQ9E8wjf30YFDGdkeAsCwH18oYRZGXk7C4HuYxcwe6rjQsFovzaEvoFxqNkTOPzMjGikJso8wsF77XYkLx6dAwxWxvBmBIH7aUMJi8J3w0DnTVz7dyvX6KPzVBt+kL8cmzesRq9ps2Z48bRJmOIapS7E4zM2lXNt5CcU6ID7+ocSZkqY2NRN6ysnsHbJEpR8ZwV6t5Yg+iuLELf2KVd48VwXQf3BQGUMb4ZOuH9gKFEIYJfiNrEDcXZHHV4q3YRv5i7ikgM94RlETNgihrcgBHhccCiRCf7VhBK5rAPyr9I/Y/WKPEyfksH/9NjQ2dODhsYzwcLXsypkeBtCRGLRDUUMAMyKHxEx4dtrzyP97nQMygripiQiKi4aSbPvQmKW7+OXF69ntYvBa1iPCYklZEZECsGm4ja0Ops7EJsaj4SprlU+8IJiqIjAFga3Ikx4vvAYkTGALxyWFArlsnbBC9Sz6mI5zWKNRGh3JJY7mjte4GOz+r4tkRbxQQAAAABJRU5ErkJggg=="
|
||||
}
|
||||
@ -1,7 +1,11 @@
|
||||
{
|
||||
"id": 12,
|
||||
"title": "Generate SEO Blog",
|
||||
"description": "This workflow automatically generates a complete SEO-optimized blog article based on a simple user input. You don’t need any writing experience. Just provide a topic or short request — the system will handle the rest.",
|
||||
"title": {
|
||||
"en": "Generate SEO Blog",
|
||||
"zh": "生成SEO博客"},
|
||||
"description": {
|
||||
"en": "This workflow automatically generates a complete SEO-optimized blog article based on a simple user input. You don’t need any writing experience. Just provide a topic or short request — the system will handle the rest.",
|
||||
"zh": "此工作流根据简单的用户输入自动生成完整的SEO博客文章。你无需任何写作经验,只需提供一个主题或简短请求,系统将处理其余部分。"},
|
||||
"canvas_type": "Marketing",
|
||||
"dsl": {
|
||||
"components": {
|
||||
|
||||
@ -1,7 +1,11 @@
|
||||
{
|
||||
"id": 4,
|
||||
"title": "Generate SEO Blog",
|
||||
"description": "This workflow automatically generates a complete SEO-optimized blog article based on a simple user input. You don’t need any writing experience. Just provide a topic or short request — the system will handle the rest.",
|
||||
"title": {
|
||||
"en": "Generate SEO Blog",
|
||||
"zh": "生成SEO博客"},
|
||||
"description": {
|
||||
"en": "This workflow automatically generates a complete SEO-optimized blog article based on a simple user input. You don’t need any writing experience. Just provide a topic or short request — the system will handle the rest.",
|
||||
"zh": "此工作流根据简单的用户输入自动生成完整的SEO博客文章。你无需任何写作经验,只需提供一个主题或简短请求,系统将处理其余部分。"},
|
||||
"canvas_type": "Recommended",
|
||||
"dsl": {
|
||||
"components": {
|
||||
|
||||
@ -1,7 +1,11 @@
|
||||
{
|
||||
"id": 17,
|
||||
"title": "SQL Assistant",
|
||||
"description": "SQL Assistant is an AI-powered tool that lets business users turn plain-English questions into fully formed SQL queries. Simply type your question (e.g., “Show me last quarter’s top 10 products by revenue”) and SQL Assistant generates the exact SQL, runs it against your database, and returns the results in seconds. ",
|
||||
"title": {
|
||||
"en": "SQL Assistant",
|
||||
"zh": "SQL助理"},
|
||||
"description": {
|
||||
"en": "SQL Assistant is an AI-powered tool that lets business users turn plain-English questions into fully formed SQL queries. Simply type your question (e.g., “Show me last quarter’s top 10 products by revenue”) and SQL Assistant generates the exact SQL, runs it against your database, and returns the results in seconds. ",
|
||||
"zh": "用户能够将简单文本问题转化为完整的SQL查询并输出结果。只需输入您的问题(例如,“展示上个季度前十名按收入排序的产品”),SQL助理就会生成精确的SQL语句,对其运行您的数据库,并几秒钟内返回结果。"},
|
||||
"canvas_type": "Marketing",
|
||||
"dsl": {
|
||||
"components": {
|
||||
@ -79,7 +83,7 @@
|
||||
},
|
||||
"password": "20010812Yy!",
|
||||
"port": 3306,
|
||||
"sql": "Agent:WickedGoatsDivide@content",
|
||||
"sql": "{Agent:WickedGoatsDivide@content}",
|
||||
"username": "13637682833@163.com"
|
||||
}
|
||||
},
|
||||
@ -110,9 +114,7 @@
|
||||
"params": {
|
||||
"cross_languages": [],
|
||||
"empty_response": "",
|
||||
"kb_ids": [
|
||||
"ed31364c727211f0bdb2bafe6e7908e6"
|
||||
],
|
||||
"kb_ids": [],
|
||||
"keywords_similarity_weight": 0.7,
|
||||
"outputs": {
|
||||
"formalized_content": {
|
||||
@ -120,7 +122,7 @@
|
||||
"value": ""
|
||||
}
|
||||
},
|
||||
"query": "sys.query",
|
||||
"query": "{sys.query}",
|
||||
"rerank_id": "",
|
||||
"similarity_threshold": 0.2,
|
||||
"top_k": 1024,
|
||||
@ -141,9 +143,7 @@
|
||||
"params": {
|
||||
"cross_languages": [],
|
||||
"empty_response": "",
|
||||
"kb_ids": [
|
||||
"0f968106727311f08357bafe6e7908e6"
|
||||
],
|
||||
"kb_ids": [],
|
||||
"keywords_similarity_weight": 0.7,
|
||||
"outputs": {
|
||||
"formalized_content": {
|
||||
@ -151,7 +151,7 @@
|
||||
"value": ""
|
||||
}
|
||||
},
|
||||
"query": "sys.query",
|
||||
"query": "{sys.query}",
|
||||
"rerank_id": "",
|
||||
"similarity_threshold": 0.2,
|
||||
"top_k": 1024,
|
||||
@ -172,9 +172,7 @@
|
||||
"params": {
|
||||
"cross_languages": [],
|
||||
"empty_response": "",
|
||||
"kb_ids": [
|
||||
"4ad1f9d0727311f0827dbafe6e7908e6"
|
||||
],
|
||||
"kb_ids": [],
|
||||
"keywords_similarity_weight": 0.7,
|
||||
"outputs": {
|
||||
"formalized_content": {
|
||||
@ -182,7 +180,7 @@
|
||||
"value": ""
|
||||
}
|
||||
},
|
||||
"query": "sys.query",
|
||||
"query": "{sys.query}",
|
||||
"rerank_id": "",
|
||||
"similarity_threshold": 0.2,
|
||||
"top_k": 1024,
|
||||
@ -343,9 +341,7 @@
|
||||
"form": {
|
||||
"cross_languages": [],
|
||||
"empty_response": "",
|
||||
"kb_ids": [
|
||||
"ed31364c727211f0bdb2bafe6e7908e6"
|
||||
],
|
||||
"kb_ids": [],
|
||||
"keywords_similarity_weight": 0.7,
|
||||
"outputs": {
|
||||
"formalized_content": {
|
||||
@ -353,7 +349,7 @@
|
||||
"value": ""
|
||||
}
|
||||
},
|
||||
"query": "sys.query",
|
||||
"query": "{sys.query}",
|
||||
"rerank_id": "",
|
||||
"similarity_threshold": 0.2,
|
||||
"top_k": 1024,
|
||||
@ -383,9 +379,7 @@
|
||||
"form": {
|
||||
"cross_languages": [],
|
||||
"empty_response": "",
|
||||
"kb_ids": [
|
||||
"0f968106727311f08357bafe6e7908e6"
|
||||
],
|
||||
"kb_ids": [],
|
||||
"keywords_similarity_weight": 0.7,
|
||||
"outputs": {
|
||||
"formalized_content": {
|
||||
@ -393,7 +387,7 @@
|
||||
"value": ""
|
||||
}
|
||||
},
|
||||
"query": "sys.query",
|
||||
"query": "{sys.query}",
|
||||
"rerank_id": "",
|
||||
"similarity_threshold": 0.2,
|
||||
"top_k": 1024,
|
||||
@ -423,9 +417,7 @@
|
||||
"form": {
|
||||
"cross_languages": [],
|
||||
"empty_response": "",
|
||||
"kb_ids": [
|
||||
"4ad1f9d0727311f0827dbafe6e7908e6"
|
||||
],
|
||||
"kb_ids": [],
|
||||
"keywords_similarity_weight": 0.7,
|
||||
"outputs": {
|
||||
"formalized_content": {
|
||||
@ -433,7 +425,7 @@
|
||||
"value": ""
|
||||
}
|
||||
},
|
||||
"query": "sys.query",
|
||||
"query": "{sys.query}",
|
||||
"rerank_id": "",
|
||||
"similarity_threshold": 0.2,
|
||||
"top_k": 1024,
|
||||
@ -535,7 +527,7 @@
|
||||
},
|
||||
"password": "20010812Yy!",
|
||||
"port": 3306,
|
||||
"sql": "Agent:WickedGoatsDivide@content",
|
||||
"sql": "{Agent:WickedGoatsDivide@content}",
|
||||
"username": "13637682833@163.com"
|
||||
},
|
||||
"label": "ExeSQL",
|
||||
|
||||
File diff suppressed because one or more lines are too long
@ -1,8 +1,12 @@
|
||||
|
||||
{
|
||||
"id": 9,
|
||||
"title": "Technical Docs QA",
|
||||
"description": "This is a document question-and-answer system based on a knowledge base. When a user asks a question, it retrieves relevant document content to provide accurate answers.",
|
||||
"title": {
|
||||
"en": "Technical Docs QA",
|
||||
"zh": "技术文档问答"},
|
||||
"description": {
|
||||
"en": "This is a document question-and-answer system based on a knowledge base. When a user asks a question, it retrieves relevant document content to provide accurate answers.",
|
||||
"zh": "基于知识库的文档问答系统,当用户提出问题时,会检索相关本地文档并提供准确回答。"},
|
||||
"canvas_type": "Customer Support",
|
||||
"dsl": {
|
||||
"components": {
|
||||
|
||||
@ -1,9 +1,13 @@
|
||||
|
||||
{
|
||||
"id": 14,
|
||||
"title": "Trip Planner",
|
||||
"description": "This smart trip planner utilizes LLM technology to automatically generate customized travel itineraries, with optional tool integration for enhanced reliability.",
|
||||
"canvas_type": "Consumer App",
|
||||
"title": {
|
||||
"en": "Trip Planner",
|
||||
"zh": "旅行规划"},
|
||||
"description": {
|
||||
"en": "This smart trip planner utilizes LLM technology to automatically generate customized travel itineraries, with optional tool integration for enhanced reliability.",
|
||||
"zh": "智能旅行规划将利用大模型自动生成定制化的旅行行程,附带可选工具集成,以增强可靠性。"},
|
||||
"canvas_type": "Consumer App",
|
||||
"dsl": {
|
||||
"components": {
|
||||
"Agent:OddGuestsPump": {
|
||||
|
||||
@ -1,9 +1,13 @@
|
||||
|
||||
{
|
||||
"id": 16,
|
||||
"title": "WebSearch Assistant",
|
||||
"description": "A chat assistant template that integrates information extracted from a knowledge base and web searches to respond to queries. Let's start by setting up your knowledge base in 'Retrieval'!",
|
||||
"canvas_type": "Other",
|
||||
"title": {
|
||||
"en": "WebSearch Assistant",
|
||||
"zh": "网页搜索助手"},
|
||||
"description": {
|
||||
"en": "A chat assistant template that integrates information extracted from a knowledge base and web searches to respond to queries. Let's start by setting up your knowledge base in 'Retrieval'!",
|
||||
"zh": "集成了从知识库和网络搜索中提取的信息回答用户问题。让我们从设置您的知识库开始检索!"},
|
||||
"canvas_type": "Other",
|
||||
"dsl": {
|
||||
"components": {
|
||||
"Agent:SmartSchoolsCross": {
|
||||
|
||||
@ -166,7 +166,7 @@ class ToolBase(ComponentBase):
|
||||
"count": 1,
|
||||
"url": url
|
||||
})
|
||||
self._canvas.add_refernce(chunks, aggs)
|
||||
self._canvas.add_reference(chunks, aggs)
|
||||
self.set_output("formalized_content", "\n".join(kb_prompt({"chunks": chunks, "doc_aggs": aggs}, 200000, True)))
|
||||
|
||||
def thoughts(self) -> str:
|
||||
|
||||
@ -157,7 +157,7 @@ class CodeExec(ToolBase, ABC):
|
||||
|
||||
try:
|
||||
resp = requests.post(url=f"http://{settings.SANDBOX_HOST}:9385/run", json=code_req, timeout=os.environ.get("COMPONENT_EXEC_TIMEOUT", 10*60))
|
||||
logging.info(f"http://{settings.SANDBOX_HOST}:9385/run", code_req, resp.status_code)
|
||||
logging.info(f"http://{settings.SANDBOX_HOST}:9385/run, code_req: {code_req}, resp.status_code {resp.status_code}:")
|
||||
if resp.status_code != 200:
|
||||
resp.raise_for_status()
|
||||
body = resp.json()
|
||||
|
||||
@ -16,9 +16,8 @@
|
||||
from abc import ABC
|
||||
import asyncio
|
||||
from crawl4ai import AsyncWebCrawler
|
||||
|
||||
from agent.tools.base import ToolParamBase, ToolBase
|
||||
from api.utils.web_utils import is_valid_url
|
||||
|
||||
|
||||
|
||||
class CrawlerParam(ToolParamBase):
|
||||
@ -39,6 +38,7 @@ class Crawler(ToolBase, ABC):
|
||||
component_name = "Crawler"
|
||||
|
||||
def _run(self, history, **kwargs):
|
||||
from api.utils.web_utils import is_valid_url
|
||||
ans = self.get_input()
|
||||
ans = " - ".join(ans["content"]) if "content" in ans else ""
|
||||
if not is_valid_url(ans):
|
||||
@ -64,5 +64,5 @@ class Crawler(ToolBase, ABC):
|
||||
elif self._param.extract_type == 'markdown':
|
||||
return result.markdown
|
||||
elif self._param.extract_type == 'content':
|
||||
result.extracted_content
|
||||
return result.extracted_content
|
||||
return result.markdown
|
||||
|
||||
@ -43,7 +43,7 @@ class DeepLParam(ComponentParamBase):
|
||||
|
||||
|
||||
class DeepL(ComponentBase, ABC):
|
||||
component_name = "GitHub"
|
||||
component_name = "DeepL"
|
||||
|
||||
def _run(self, history, **kwargs):
|
||||
ans = self.get_input()
|
||||
|
||||
@ -13,6 +13,7 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
import json
|
||||
import os
|
||||
import re
|
||||
from abc import ABC
|
||||
@ -52,7 +53,7 @@ class ExeSQLParam(ToolParamBase):
|
||||
self.max_records = 1024
|
||||
|
||||
def check(self):
|
||||
self.check_valid_value(self.db_type, "Choose DB type", ['mysql', 'postgresql', 'mariadb', 'mssql'])
|
||||
self.check_valid_value(self.db_type, "Choose DB type", ['mysql', 'postgres', 'mariadb', 'mssql'])
|
||||
self.check_empty(self.database, "Database name")
|
||||
self.check_empty(self.username, "database username")
|
||||
self.check_empty(self.host, "IP Address")
|
||||
@ -93,12 +94,24 @@ class ExeSQL(ToolBase, ABC):
|
||||
sql = kwargs.get("sql")
|
||||
if not sql:
|
||||
raise Exception("SQL for `ExeSQL` MUST not be empty.")
|
||||
sqls = sql.split(";")
|
||||
|
||||
vars = self.get_input_elements_from_text(sql)
|
||||
args = {}
|
||||
for k, o in vars.items():
|
||||
args[k] = o["value"]
|
||||
if not isinstance(args[k], str):
|
||||
try:
|
||||
args[k] = json.dumps(args[k], ensure_ascii=False)
|
||||
except Exception:
|
||||
args[k] = str(args[k])
|
||||
self.set_input_value(k, args[k])
|
||||
sql = self.string_format(sql, args)
|
||||
|
||||
sqls = sql.split(";")
|
||||
if self._param.db_type in ["mysql", "mariadb"]:
|
||||
db = pymysql.connect(db=self._param.database, user=self._param.username, host=self._param.host,
|
||||
port=self._param.port, password=self._param.password)
|
||||
elif self._param.db_type == 'postgresql':
|
||||
elif self._param.db_type == 'postgres':
|
||||
db = psycopg2.connect(dbname=self._param.database, user=self._param.username, host=self._param.host,
|
||||
port=self._param.port, password=self._param.password)
|
||||
elif self._param.db_type == 'mssql':
|
||||
|
||||
@ -163,9 +163,16 @@ class Retrieval(ToolBase, ABC):
|
||||
self.set_output("formalized_content", self._param.empty_response)
|
||||
return
|
||||
|
||||
self._canvas.add_refernce(kbinfos["chunks"], kbinfos["doc_aggs"])
|
||||
# Format the chunks for JSON output (similar to how other tools do it)
|
||||
json_output = kbinfos["chunks"].copy()
|
||||
|
||||
self._canvas.add_reference(kbinfos["chunks"], kbinfos["doc_aggs"])
|
||||
form_cnt = "\n".join(kb_prompt(kbinfos, 200000, True))
|
||||
|
||||
# Set both formalized content and JSON output
|
||||
self.set_output("formalized_content", form_cnt)
|
||||
self.set_output("json", json_output)
|
||||
|
||||
return form_cnt
|
||||
|
||||
def thoughts(self) -> str:
|
||||
|
||||
156
agent/tools/searxng.py
Normal file
156
agent/tools/searxng.py
Normal file
@ -0,0 +1,156 @@
|
||||
#
|
||||
# Copyright 2024 The InfiniFlow Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
import logging
|
||||
import os
|
||||
import time
|
||||
from abc import ABC
|
||||
import requests
|
||||
from agent.tools.base import ToolMeta, ToolParamBase, ToolBase
|
||||
from api.utils.api_utils import timeout
|
||||
|
||||
|
||||
class SearXNGParam(ToolParamBase):
|
||||
"""
|
||||
Define the SearXNG component parameters.
|
||||
"""
|
||||
|
||||
def __init__(self):
|
||||
self.meta: ToolMeta = {
|
||||
"name": "searxng_search",
|
||||
"description": "SearXNG is a privacy-focused metasearch engine that aggregates results from multiple search engines without tracking users. It provides comprehensive web search capabilities.",
|
||||
"parameters": {
|
||||
"query": {
|
||||
"type": "string",
|
||||
"description": "The search keywords to execute with SearXNG. The keywords should be the most important words/terms(includes synonyms) from the original request.",
|
||||
"default": "{sys.query}",
|
||||
"required": True
|
||||
},
|
||||
"searxng_url": {
|
||||
"type": "string",
|
||||
"description": "The base URL of your SearXNG instance (e.g., http://localhost:4000). This is required to connect to your SearXNG server.",
|
||||
"required": False,
|
||||
"default": ""
|
||||
}
|
||||
}
|
||||
}
|
||||
super().__init__()
|
||||
self.top_n = 10
|
||||
self.searxng_url = ""
|
||||
|
||||
def check(self):
|
||||
# Keep validation lenient so opening try-run panel won't fail without URL.
|
||||
# Coerce top_n to int if it comes as string from UI.
|
||||
try:
|
||||
if isinstance(self.top_n, str):
|
||||
self.top_n = int(self.top_n.strip())
|
||||
except Exception:
|
||||
pass
|
||||
self.check_positive_integer(self.top_n, "Top N")
|
||||
|
||||
def get_input_form(self) -> dict[str, dict]:
|
||||
return {
|
||||
"query": {
|
||||
"name": "Query",
|
||||
"type": "line"
|
||||
},
|
||||
"searxng_url": {
|
||||
"name": "SearXNG URL",
|
||||
"type": "line",
|
||||
"placeholder": "http://localhost:4000"
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
class SearXNG(ToolBase, ABC):
|
||||
component_name = "SearXNG"
|
||||
|
||||
@timeout(os.environ.get("COMPONENT_EXEC_TIMEOUT", 12))
|
||||
def _invoke(self, **kwargs):
|
||||
# Gracefully handle try-run without inputs
|
||||
query = kwargs.get("query")
|
||||
if not query or not isinstance(query, str) or not query.strip():
|
||||
self.set_output("formalized_content", "")
|
||||
return ""
|
||||
|
||||
searxng_url = (kwargs.get("searxng_url") or getattr(self._param, "searxng_url", "") or "").strip()
|
||||
# In try-run, if no URL configured, just return empty instead of raising
|
||||
if not searxng_url:
|
||||
self.set_output("formalized_content", "")
|
||||
return ""
|
||||
|
||||
last_e = ""
|
||||
for _ in range(self._param.max_retries+1):
|
||||
try:
|
||||
# 构建搜索参数
|
||||
search_params = {
|
||||
'q': query,
|
||||
'format': 'json',
|
||||
'categories': 'general',
|
||||
'language': 'auto',
|
||||
'safesearch': 1,
|
||||
'pageno': 1
|
||||
}
|
||||
|
||||
# 发送搜索请求
|
||||
response = requests.get(
|
||||
f"{searxng_url}/search",
|
||||
params=search_params,
|
||||
timeout=10
|
||||
)
|
||||
response.raise_for_status()
|
||||
|
||||
data = response.json()
|
||||
|
||||
# 验证响应数据
|
||||
if not data or not isinstance(data, dict):
|
||||
raise ValueError("Invalid response from SearXNG")
|
||||
|
||||
results = data.get("results", [])
|
||||
if not isinstance(results, list):
|
||||
raise ValueError("Invalid results format from SearXNG")
|
||||
|
||||
# 限制结果数量
|
||||
results = results[:self._param.top_n]
|
||||
|
||||
# 处理搜索结果
|
||||
self._retrieve_chunks(results,
|
||||
get_title=lambda r: r.get("title", ""),
|
||||
get_url=lambda r: r.get("url", ""),
|
||||
get_content=lambda r: r.get("content", ""))
|
||||
|
||||
self.set_output("json", results)
|
||||
return self.output("formalized_content")
|
||||
|
||||
except requests.RequestException as e:
|
||||
last_e = f"Network error: {e}"
|
||||
logging.exception(f"SearXNG network error: {e}")
|
||||
time.sleep(self._param.delay_after_error)
|
||||
except Exception as e:
|
||||
last_e = str(e)
|
||||
logging.exception(f"SearXNG error: {e}")
|
||||
time.sleep(self._param.delay_after_error)
|
||||
|
||||
if last_e:
|
||||
self.set_output("_ERROR", last_e)
|
||||
return f"SearXNG error: {last_e}"
|
||||
|
||||
assert False, self.output()
|
||||
|
||||
def thoughts(self) -> str:
|
||||
return """
|
||||
Keywords: {}
|
||||
Searching with SearXNG for relevant results...
|
||||
""".format(self.get_input().get("query", "-_-!"))
|
||||
@ -24,7 +24,7 @@ from flask import request, Response
|
||||
from flask_login import login_required, current_user
|
||||
|
||||
from agent.component import LLM
|
||||
from api.db import FileType
|
||||
from api.db import CanvasCategory, FileType
|
||||
from api.db.services.canvas_service import CanvasTemplateService, UserCanvasService, API4ConversationService
|
||||
from api.db.services.document_service import DocumentService
|
||||
from api.db.services.file_service import FileService
|
||||
@ -45,14 +45,14 @@ from rag.utils.redis_conn import REDIS_CONN
|
||||
@manager.route('/templates', methods=['GET']) # noqa: F821
|
||||
@login_required
|
||||
def templates():
|
||||
return get_json_result(data=[c.to_dict() for c in CanvasTemplateService.get_all()])
|
||||
return get_json_result(data=[c.to_dict() for c in CanvasTemplateService.query(canvas_category=CanvasCategory.Agent)])
|
||||
|
||||
|
||||
@manager.route('/list', methods=['GET']) # noqa: F821
|
||||
@login_required
|
||||
def canvas_list():
|
||||
return get_json_result(data=sorted([c.to_dict() for c in \
|
||||
UserCanvasService.query(user_id=current_user.id)], key=lambda x: x["update_time"]*-1)
|
||||
UserCanvasService.query(user_id=current_user.id, canvas_category=CanvasCategory.Agent)], key=lambda x: x["update_time"]*-1)
|
||||
)
|
||||
|
||||
|
||||
@ -79,7 +79,7 @@ def save():
|
||||
req["dsl"] = json.loads(req["dsl"])
|
||||
if "id" not in req:
|
||||
req["user_id"] = current_user.id
|
||||
if UserCanvasService.query(user_id=current_user.id, title=req["title"].strip()):
|
||||
if UserCanvasService.query(user_id=current_user.id, title=req["title"].strip(), canvas_category=CanvasCategory.Agent):
|
||||
return get_data_error_result(message=f"{req['title'].strip()} already exists.")
|
||||
req["id"] = get_uuid()
|
||||
if not UserCanvasService.save(**req):
|
||||
@ -91,7 +91,7 @@ def save():
|
||||
code=RetCode.OPERATING_ERROR)
|
||||
UserCanvasService.update_by_id(req["id"], req)
|
||||
# save version
|
||||
UserCanvasVersionService.insert( user_canvas_id=req["id"], dsl=req["dsl"], title="{0}_{1}".format(req["title"], time.strftime("%Y_%m_%d_%H_%M_%S")))
|
||||
UserCanvasVersionService.insert(user_canvas_id=req["id"], dsl=req["dsl"], title="{0}_{1}".format(req["title"], time.strftime("%Y_%m_%d_%H_%M_%S")))
|
||||
UserCanvasVersionService.delete_all_versions(req["id"])
|
||||
return get_json_result(data=req)
|
||||
|
||||
@ -332,7 +332,7 @@ def test_db_connect():
|
||||
if req["db_type"] in ["mysql", "mariadb"]:
|
||||
db = MySQLDatabase(req["database"], user=req["username"], host=req["host"], port=req["port"],
|
||||
password=req["password"])
|
||||
elif req["db_type"] == 'postgresql':
|
||||
elif req["db_type"] == 'postgres':
|
||||
db = PostgresqlDatabase(req["database"], user=req["username"], host=req["host"], port=req["port"],
|
||||
password=req["password"])
|
||||
elif req["db_type"] == 'mssql':
|
||||
@ -395,7 +395,7 @@ def list_canvas():
|
||||
tenants = TenantService.get_joined_tenants_by_user_id(current_user.id)
|
||||
canvas, total = UserCanvasService.get_by_tenant_ids(
|
||||
[m["tenant_id"] for m in tenants], current_user.id, page_number,
|
||||
items_per_page, orderby, desc, keywords)
|
||||
items_per_page, orderby, desc, keywords, canvas_category=CanvasCategory.Agent)
|
||||
return get_json_result(data={"canvas": canvas, "total": total})
|
||||
except Exception as e:
|
||||
return server_error_response(e)
|
||||
@ -418,12 +418,10 @@ def setting():
|
||||
return get_data_error_result(message="canvas not found.")
|
||||
flow = flow.to_dict()
|
||||
flow["title"] = req["title"]
|
||||
if req["description"]:
|
||||
flow["description"] = req["description"]
|
||||
if req["permission"]:
|
||||
flow["permission"] = req["permission"]
|
||||
if req["avatar"]:
|
||||
flow["avatar"] = req["avatar"]
|
||||
|
||||
for key in ["description", "permission", "avatar"]:
|
||||
if value := req.get(key):
|
||||
flow[key] = value
|
||||
|
||||
num= UserCanvasService.update_by_id(req["id"], flow)
|
||||
return get_json_result(data=num)
|
||||
@ -472,3 +470,16 @@ def sessions(canvas_id):
|
||||
except Exception as e:
|
||||
return server_error_response(e)
|
||||
|
||||
|
||||
@manager.route('/prompts', methods=['GET']) # noqa: F821
|
||||
@login_required
|
||||
def prompts():
|
||||
from rag.prompts.prompts import ANALYZE_TASK_SYSTEM, ANALYZE_TASK_USER, NEXT_STEP, REFLECT, CITATION_PROMPT_TEMPLATE
|
||||
return get_json_result(data={
|
||||
"task_analysis": ANALYZE_TASK_SYSTEM +"\n\n"+ ANALYZE_TASK_USER,
|
||||
"plan_generation": NEXT_STEP,
|
||||
"reflection": REFLECT,
|
||||
#"context_summary": SUMMARY4MEMORY,
|
||||
#"context_ranking": RANK_MEMORY,
|
||||
"citation_guidelines": CITATION_PROMPT_TEMPLATE
|
||||
})
|
||||
|
||||
@ -93,6 +93,7 @@ def list_chunk():
|
||||
def get():
|
||||
chunk_id = request.args["chunk_id"]
|
||||
try:
|
||||
chunk = None
|
||||
tenants = UserTenantService.query(user_id=current_user.id)
|
||||
if not tenants:
|
||||
return get_data_error_result(message="Tenant not found!")
|
||||
@ -290,6 +291,10 @@ def retrieval_test():
|
||||
kb_ids = req["kb_id"]
|
||||
if isinstance(kb_ids, str):
|
||||
kb_ids = [kb_ids]
|
||||
if not kb_ids:
|
||||
return get_json_result(data=False, message='Please specify dataset firstly.',
|
||||
code=settings.RetCode.DATA_ERROR)
|
||||
|
||||
doc_ids = req.get("doc_ids", [])
|
||||
use_kg = req.get("use_kg", False)
|
||||
top = int(req.get("top_k", 1024))
|
||||
|
||||
@ -400,6 +400,8 @@ def related_questions():
|
||||
chat_mdl = LLMBundle(current_user.id, LLMType.CHAT, chat_id)
|
||||
|
||||
gen_conf = search_config.get("llm_setting", {"temperature": 0.9})
|
||||
if "parameter" in gen_conf:
|
||||
del gen_conf["parameter"]
|
||||
prompt = load_prompt("related_question")
|
||||
ans = chat_mdl.chat(
|
||||
prompt,
|
||||
|
||||
353
api/apps/dataflow_app.py
Normal file
353
api/apps/dataflow_app.py
Normal file
@ -0,0 +1,353 @@
|
||||
#
|
||||
# Copyright 2024 The InfiniFlow Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
import json
|
||||
import re
|
||||
import sys
|
||||
import time
|
||||
from functools import partial
|
||||
|
||||
import trio
|
||||
from flask import request
|
||||
from flask_login import current_user, login_required
|
||||
|
||||
from agent.canvas import Canvas
|
||||
from agent.component import LLM
|
||||
from api.db import CanvasCategory, FileType
|
||||
from api.db.services.canvas_service import CanvasTemplateService, UserCanvasService
|
||||
from api.db.services.document_service import DocumentService
|
||||
from api.db.services.file_service import FileService
|
||||
from api.db.services.task_service import queue_dataflow
|
||||
from api.db.services.user_canvas_version import UserCanvasVersionService
|
||||
from api.db.services.user_service import TenantService
|
||||
from api.settings import RetCode
|
||||
from api.utils import get_uuid
|
||||
from api.utils.api_utils import get_data_error_result, get_json_result, server_error_response, validate_request
|
||||
from api.utils.file_utils import filename_type, read_potential_broken_pdf
|
||||
from rag.flow.pipeline import Pipeline
|
||||
|
||||
|
||||
@manager.route("/templates", methods=["GET"]) # noqa: F821
|
||||
@login_required
|
||||
def templates():
|
||||
return get_json_result(data=[c.to_dict() for c in CanvasTemplateService.query(canvas_category=CanvasCategory.DataFlow)])
|
||||
|
||||
|
||||
@manager.route("/list", methods=["GET"]) # noqa: F821
|
||||
@login_required
|
||||
def canvas_list():
|
||||
return get_json_result(data=sorted([c.to_dict() for c in UserCanvasService.query(user_id=current_user.id, canvas_category=CanvasCategory.DataFlow)], key=lambda x: x["update_time"] * -1))
|
||||
|
||||
|
||||
@manager.route("/rm", methods=["POST"]) # noqa: F821
|
||||
@validate_request("canvas_ids")
|
||||
@login_required
|
||||
def rm():
|
||||
for i in request.json["canvas_ids"]:
|
||||
if not UserCanvasService.accessible(i, current_user.id):
|
||||
return get_json_result(data=False, message="Only owner of canvas authorized for this operation.", code=RetCode.OPERATING_ERROR)
|
||||
UserCanvasService.delete_by_id(i)
|
||||
return get_json_result(data=True)
|
||||
|
||||
|
||||
@manager.route("/set", methods=["POST"]) # noqa: F821
|
||||
@validate_request("dsl", "title")
|
||||
@login_required
|
||||
def save():
|
||||
req = request.json
|
||||
if not isinstance(req["dsl"], str):
|
||||
req["dsl"] = json.dumps(req["dsl"], ensure_ascii=False)
|
||||
req["dsl"] = json.loads(req["dsl"])
|
||||
req["canvas_category"] = CanvasCategory.DataFlow
|
||||
if "id" not in req:
|
||||
req["user_id"] = current_user.id
|
||||
if UserCanvasService.query(user_id=current_user.id, title=req["title"].strip(), canvas_category=CanvasCategory.DataFlow):
|
||||
return get_data_error_result(message=f"{req['title'].strip()} already exists.")
|
||||
req["id"] = get_uuid()
|
||||
|
||||
if not UserCanvasService.save(**req):
|
||||
return get_data_error_result(message="Fail to save canvas.")
|
||||
else:
|
||||
if not UserCanvasService.accessible(req["id"], current_user.id):
|
||||
return get_json_result(data=False, message="Only owner of canvas authorized for this operation.", code=RetCode.OPERATING_ERROR)
|
||||
UserCanvasService.update_by_id(req["id"], req)
|
||||
# save version
|
||||
UserCanvasVersionService.insert(user_canvas_id=req["id"], dsl=req["dsl"], title="{0}_{1}".format(req["title"], time.strftime("%Y_%m_%d_%H_%M_%S")))
|
||||
UserCanvasVersionService.delete_all_versions(req["id"])
|
||||
return get_json_result(data=req)
|
||||
|
||||
|
||||
@manager.route("/get/<canvas_id>", methods=["GET"]) # noqa: F821
|
||||
@login_required
|
||||
def get(canvas_id):
|
||||
if not UserCanvasService.accessible(canvas_id, current_user.id):
|
||||
return get_data_error_result(message="canvas not found.")
|
||||
e, c = UserCanvasService.get_by_tenant_id(canvas_id)
|
||||
return get_json_result(data=c)
|
||||
|
||||
|
||||
@manager.route("/run", methods=["POST"]) # noqa: F821
|
||||
@validate_request("id")
|
||||
@login_required
|
||||
def run():
|
||||
req = request.json
|
||||
flow_id = req.get("id", "")
|
||||
doc_id = req.get("doc_id", "")
|
||||
if not all([flow_id, doc_id]):
|
||||
return get_data_error_result(message="id and doc_id are required.")
|
||||
|
||||
if not DocumentService.get_by_id(doc_id):
|
||||
return get_data_error_result(message=f"Document for {doc_id} not found.")
|
||||
|
||||
user_id = req.get("user_id", current_user.id)
|
||||
if not UserCanvasService.accessible(flow_id, current_user.id):
|
||||
return get_json_result(data=False, message="Only owner of canvas authorized for this operation.", code=RetCode.OPERATING_ERROR)
|
||||
|
||||
e, cvs = UserCanvasService.get_by_id(flow_id)
|
||||
if not e:
|
||||
return get_data_error_result(message="canvas not found.")
|
||||
|
||||
if not isinstance(cvs.dsl, str):
|
||||
cvs.dsl = json.dumps(cvs.dsl, ensure_ascii=False)
|
||||
|
||||
task_id = get_uuid()
|
||||
|
||||
ok, error_message = queue_dataflow(dsl=cvs.dsl, tenant_id=user_id, doc_id=doc_id, task_id=task_id, flow_id=flow_id, priority=0)
|
||||
if not ok:
|
||||
return server_error_response(error_message)
|
||||
|
||||
return get_json_result(data={"task_id": task_id, "flow_id": flow_id})
|
||||
|
||||
|
||||
@manager.route("/reset", methods=["POST"]) # noqa: F821
|
||||
@validate_request("id")
|
||||
@login_required
|
||||
def reset():
|
||||
req = request.json
|
||||
flow_id = req.get("id", "")
|
||||
if not flow_id:
|
||||
return get_data_error_result(message="id is required.")
|
||||
|
||||
if not UserCanvasService.accessible(flow_id, current_user.id):
|
||||
return get_json_result(data=False, message="Only owner of canvas authorized for this operation.", code=RetCode.OPERATING_ERROR)
|
||||
|
||||
task_id = req.get("task_id", "")
|
||||
|
||||
try:
|
||||
e, user_canvas = UserCanvasService.get_by_id(req["id"])
|
||||
if not e:
|
||||
return get_data_error_result(message="canvas not found.")
|
||||
|
||||
dataflow = Pipeline(dsl=json.dumps(user_canvas.dsl), tenant_id=current_user.id, flow_id=flow_id, task_id=task_id)
|
||||
dataflow.reset()
|
||||
req["dsl"] = json.loads(str(dataflow))
|
||||
UserCanvasService.update_by_id(req["id"], {"dsl": req["dsl"]})
|
||||
return get_json_result(data=req["dsl"])
|
||||
except Exception as e:
|
||||
return server_error_response(e)
|
||||
|
||||
|
||||
@manager.route("/upload/<canvas_id>", methods=["POST"]) # noqa: F821
|
||||
def upload(canvas_id):
|
||||
e, cvs = UserCanvasService.get_by_tenant_id(canvas_id)
|
||||
if not e:
|
||||
return get_data_error_result(message="canvas not found.")
|
||||
|
||||
user_id = cvs["user_id"]
|
||||
|
||||
def structured(filename, filetype, blob, content_type):
|
||||
nonlocal user_id
|
||||
if filetype == FileType.PDF.value:
|
||||
blob = read_potential_broken_pdf(blob)
|
||||
|
||||
location = get_uuid()
|
||||
FileService.put_blob(user_id, location, blob)
|
||||
|
||||
return {
|
||||
"id": location,
|
||||
"name": filename,
|
||||
"size": sys.getsizeof(blob),
|
||||
"extension": filename.split(".")[-1].lower(),
|
||||
"mime_type": content_type,
|
||||
"created_by": user_id,
|
||||
"created_at": time.time(),
|
||||
"preview_url": None,
|
||||
}
|
||||
|
||||
if request.args.get("url"):
|
||||
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CrawlResult, DefaultMarkdownGenerator, PruningContentFilter
|
||||
|
||||
try:
|
||||
url = request.args.get("url")
|
||||
filename = re.sub(r"\?.*", "", url.split("/")[-1])
|
||||
|
||||
async def adownload():
|
||||
browser_config = BrowserConfig(
|
||||
headless=True,
|
||||
verbose=False,
|
||||
)
|
||||
async with AsyncWebCrawler(config=browser_config) as crawler:
|
||||
crawler_config = CrawlerRunConfig(markdown_generator=DefaultMarkdownGenerator(content_filter=PruningContentFilter()), pdf=True, screenshot=False)
|
||||
result: CrawlResult = await crawler.arun(url=url, config=crawler_config)
|
||||
return result
|
||||
|
||||
page = trio.run(adownload())
|
||||
if page.pdf:
|
||||
if filename.split(".")[-1].lower() != "pdf":
|
||||
filename += ".pdf"
|
||||
return get_json_result(data=structured(filename, "pdf", page.pdf, page.response_headers["content-type"]))
|
||||
|
||||
return get_json_result(data=structured(filename, "html", str(page.markdown).encode("utf-8"), page.response_headers["content-type"], user_id))
|
||||
|
||||
except Exception as e:
|
||||
return server_error_response(e)
|
||||
|
||||
file = request.files["file"]
|
||||
try:
|
||||
DocumentService.check_doc_health(user_id, file.filename)
|
||||
return get_json_result(data=structured(file.filename, filename_type(file.filename), file.read(), file.content_type))
|
||||
except Exception as e:
|
||||
return server_error_response(e)
|
||||
|
||||
|
||||
@manager.route("/input_form", methods=["GET"]) # noqa: F821
|
||||
@login_required
|
||||
def input_form():
|
||||
flow_id = request.args.get("id")
|
||||
cpn_id = request.args.get("component_id")
|
||||
try:
|
||||
e, user_canvas = UserCanvasService.get_by_id(flow_id)
|
||||
if not e:
|
||||
return get_data_error_result(message="canvas not found.")
|
||||
if not UserCanvasService.query(user_id=current_user.id, id=flow_id):
|
||||
return get_json_result(data=False, message="Only owner of canvas authorized for this operation.", code=RetCode.OPERATING_ERROR)
|
||||
|
||||
dataflow = Pipeline(dsl=json.dumps(user_canvas.dsl), tenant_id=current_user.id, flow_id=flow_id, task_id="")
|
||||
|
||||
return get_json_result(data=dataflow.get_component_input_form(cpn_id))
|
||||
except Exception as e:
|
||||
return server_error_response(e)
|
||||
|
||||
|
||||
@manager.route("/debug", methods=["POST"]) # noqa: F821
|
||||
@validate_request("id", "component_id", "params")
|
||||
@login_required
|
||||
def debug():
|
||||
req = request.json
|
||||
if not UserCanvasService.accessible(req["id"], current_user.id):
|
||||
return get_json_result(data=False, message="Only owner of canvas authorized for this operation.", code=RetCode.OPERATING_ERROR)
|
||||
try:
|
||||
e, user_canvas = UserCanvasService.get_by_id(req["id"])
|
||||
canvas = Canvas(json.dumps(user_canvas.dsl), current_user.id)
|
||||
canvas.reset()
|
||||
canvas.message_id = get_uuid()
|
||||
component = canvas.get_component(req["component_id"])["obj"]
|
||||
component.reset()
|
||||
|
||||
if isinstance(component, LLM):
|
||||
component.set_debug_inputs(req["params"])
|
||||
component.invoke(**{k: o["value"] for k, o in req["params"].items()})
|
||||
outputs = component.output()
|
||||
for k in outputs.keys():
|
||||
if isinstance(outputs[k], partial):
|
||||
txt = ""
|
||||
for c in outputs[k]():
|
||||
txt += c
|
||||
outputs[k] = txt
|
||||
return get_json_result(data=outputs)
|
||||
except Exception as e:
|
||||
return server_error_response(e)
|
||||
|
||||
|
||||
# api get list version dsl of canvas
|
||||
@manager.route("/getlistversion/<canvas_id>", methods=["GET"]) # noqa: F821
|
||||
@login_required
|
||||
def getlistversion(canvas_id):
|
||||
try:
|
||||
list = sorted([c.to_dict() for c in UserCanvasVersionService.list_by_canvas_id(canvas_id)], key=lambda x: x["update_time"] * -1)
|
||||
return get_json_result(data=list)
|
||||
except Exception as e:
|
||||
return get_data_error_result(message=f"Error getting history files: {e}")
|
||||
|
||||
|
||||
# api get version dsl of canvas
|
||||
@manager.route("/getversion/<version_id>", methods=["GET"]) # noqa: F821
|
||||
@login_required
|
||||
def getversion(version_id):
|
||||
try:
|
||||
e, version = UserCanvasVersionService.get_by_id(version_id)
|
||||
if version:
|
||||
return get_json_result(data=version.to_dict())
|
||||
except Exception as e:
|
||||
return get_json_result(data=f"Error getting history file: {e}")
|
||||
|
||||
|
||||
@manager.route("/listteam", methods=["GET"]) # noqa: F821
|
||||
@login_required
|
||||
def list_canvas():
|
||||
keywords = request.args.get("keywords", "")
|
||||
page_number = int(request.args.get("page", 1))
|
||||
items_per_page = int(request.args.get("page_size", 150))
|
||||
orderby = request.args.get("orderby", "create_time")
|
||||
desc = request.args.get("desc", True)
|
||||
try:
|
||||
tenants = TenantService.get_joined_tenants_by_user_id(current_user.id)
|
||||
canvas, total = UserCanvasService.get_by_tenant_ids(
|
||||
[m["tenant_id"] for m in tenants], current_user.id, page_number, items_per_page, orderby, desc, keywords, canvas_category=CanvasCategory.DataFlow
|
||||
)
|
||||
return get_json_result(data={"canvas": canvas, "total": total})
|
||||
except Exception as e:
|
||||
return server_error_response(e)
|
||||
|
||||
|
||||
@manager.route("/setting", methods=["POST"]) # noqa: F821
|
||||
@validate_request("id", "title", "permission")
|
||||
@login_required
|
||||
def setting():
|
||||
req = request.json
|
||||
req["user_id"] = current_user.id
|
||||
|
||||
if not UserCanvasService.accessible(req["id"], current_user.id):
|
||||
return get_json_result(data=False, message="Only owner of canvas authorized for this operation.", code=RetCode.OPERATING_ERROR)
|
||||
|
||||
e, flow = UserCanvasService.get_by_id(req["id"])
|
||||
if not e:
|
||||
return get_data_error_result(message="canvas not found.")
|
||||
flow = flow.to_dict()
|
||||
flow["title"] = req["title"]
|
||||
for key in ("description", "permission", "avatar"):
|
||||
if value := req.get(key):
|
||||
flow[key] = value
|
||||
|
||||
num = UserCanvasService.update_by_id(req["id"], flow)
|
||||
return get_json_result(data=num)
|
||||
|
||||
|
||||
@manager.route("/trace", methods=["GET"]) # noqa: F821
|
||||
def trace():
|
||||
dataflow_id = request.args.get("dataflow_id")
|
||||
task_id = request.args.get("task_id")
|
||||
if not all([dataflow_id, task_id]):
|
||||
return get_data_error_result(message="dataflow_id and task_id are required.")
|
||||
|
||||
e, dataflow_canvas = UserCanvasService.get_by_id(dataflow_id)
|
||||
if not e:
|
||||
return get_data_error_result(message="dataflow not found.")
|
||||
|
||||
dsl_str = json.dumps(dataflow_canvas.dsl, ensure_ascii=False)
|
||||
dataflow = Pipeline(dsl=dsl_str, tenant_id=dataflow_canvas.user_id, flow_id=dataflow_id, task_id=task_id)
|
||||
log = dataflow.fetch_logs()
|
||||
|
||||
return get_json_result(data=log)
|
||||
@ -66,7 +66,7 @@ def set_dialog():
|
||||
|
||||
if not is_create:
|
||||
if not req.get("kb_ids", []) and not prompt_config.get("tavily_api_key") and "{knowledge}" in prompt_config['system']:
|
||||
return get_data_error_result(message="Please remove `{knowledge}` in system prompt since no knowledge base/Tavily used here.")
|
||||
return get_data_error_result(message="Please remove `{knowledge}` in system prompt since no knowledge base / Tavily used here.")
|
||||
|
||||
for p in prompt_config["parameters"]:
|
||||
if p["optional"]:
|
||||
|
||||
@ -456,8 +456,7 @@ def run():
|
||||
cancel_all_task_of(id)
|
||||
else:
|
||||
return get_data_error_result(message="Cannot cancel a task that is not in RUNNING status")
|
||||
|
||||
if str(req["run"]) == TaskStatus.RUNNING.value and str(doc.run) == TaskStatus.DONE.value:
|
||||
if all([("delete" not in req or req["delete"]), str(req["run"]) == TaskStatus.RUNNING.value, str(doc.run) == TaskStatus.DONE.value]):
|
||||
DocumentService.clear_chunk_num_when_rerun(doc.id)
|
||||
|
||||
DocumentService.update_by_id(id, info)
|
||||
@ -683,7 +682,7 @@ def set_meta():
|
||||
meta = json.loads(req["meta"])
|
||||
if not isinstance(meta, dict):
|
||||
return get_json_result(data=False, message="Only dictionary type supported.", code=settings.RetCode.ARGUMENT_ERROR)
|
||||
for k,v in meta.items():
|
||||
for k, v in meta.items():
|
||||
if not isinstance(v, str) and not isinstance(v, int) and not isinstance(v, float):
|
||||
return get_json_result(data=False, message=f"The type is not supported: {v}", code=settings.RetCode.ARGUMENT_ERROR)
|
||||
except Exception as e:
|
||||
|
||||
@ -379,3 +379,19 @@ def get_meta():
|
||||
code=settings.RetCode.AUTHENTICATION_ERROR
|
||||
)
|
||||
return get_json_result(data=DocumentService.get_meta_by_kbs(kb_ids))
|
||||
|
||||
|
||||
@manager.route("/basic_info", methods=["GET"]) # noqa: F821
|
||||
@login_required
|
||||
def get_basic_info():
|
||||
kb_id = request.args.get("kb_id", "")
|
||||
if not KnowledgebaseService.accessible(kb_id, current_user.id):
|
||||
return get_json_result(
|
||||
data=False,
|
||||
message='No authorization.',
|
||||
code=settings.RetCode.AUTHENTICATION_ERROR
|
||||
)
|
||||
|
||||
basic_info = DocumentService.knowledgebase_basic_info(kb_id)
|
||||
|
||||
return get_json_result(data=basic_info)
|
||||
|
||||
@ -243,7 +243,7 @@ def add_llm():
|
||||
model_name=mdl_nm,
|
||||
base_url=llm["api_base"]
|
||||
)
|
||||
arr, tc = mdl.similarity("Hello~ Ragflower!", ["Hi, there!", "Ohh, my friend!"])
|
||||
arr, tc = mdl.similarity("Hello~ RAGFlower!", ["Hi, there!", "Ohh, my friend!"])
|
||||
if len(arr) == 0:
|
||||
raise Exception("Not known.")
|
||||
except KeyError:
|
||||
@ -271,7 +271,7 @@ def add_llm():
|
||||
key=llm["api_key"], model_name=mdl_nm, base_url=llm["api_base"]
|
||||
)
|
||||
try:
|
||||
for resp in mdl.tts("Hello~ Ragflower!"):
|
||||
for resp in mdl.tts("Hello~ RAGFlower!"):
|
||||
pass
|
||||
except RuntimeError as e:
|
||||
msg += f"\nFail to access model({factory}/{mdl_nm})." + str(e)
|
||||
|
||||
@ -82,7 +82,7 @@ def create() -> Response:
|
||||
|
||||
server_name = req.get("name", "")
|
||||
if not server_name or len(server_name.encode("utf-8")) > 255:
|
||||
return get_data_error_result(message=f"Invaild MCP name or length is {len(server_name)} which is large than 255.")
|
||||
return get_data_error_result(message=f"Invalid MCP name or length is {len(server_name)} which is large than 255.")
|
||||
|
||||
e, _ = MCPServerService.get_by_name_and_tenant(name=server_name, tenant_id=current_user.id)
|
||||
if e:
|
||||
@ -90,7 +90,7 @@ def create() -> Response:
|
||||
|
||||
url = req.get("url", "")
|
||||
if not url:
|
||||
return get_data_error_result(message="Invaild url.")
|
||||
return get_data_error_result(message="Invalid url.")
|
||||
|
||||
headers = safe_json_parse(req.get("headers", {}))
|
||||
req["headers"] = headers
|
||||
@ -141,10 +141,10 @@ def update() -> Response:
|
||||
return get_data_error_result(message="Unsupported MCP server type.")
|
||||
server_name = req.get("name", mcp_server.name)
|
||||
if server_name and len(server_name.encode("utf-8")) > 255:
|
||||
return get_data_error_result(message=f"Invaild MCP name or length is {len(server_name)} which is large than 255.")
|
||||
return get_data_error_result(message=f"Invalid MCP name or length is {len(server_name)} which is large than 255.")
|
||||
url = req.get("url", mcp_server.url)
|
||||
if not url:
|
||||
return get_data_error_result(message="Invaild url.")
|
||||
return get_data_error_result(message="Invalid url.")
|
||||
|
||||
headers = safe_json_parse(req.get("headers", mcp_server.headers))
|
||||
req["headers"] = headers
|
||||
@ -218,7 +218,7 @@ def import_multiple() -> Response:
|
||||
continue
|
||||
|
||||
if not server_name or len(server_name.encode("utf-8")) > 255:
|
||||
results.append({"server": server_name, "success": False, "message": f"Invaild MCP name or length is {len(server_name)} which is large than 255."})
|
||||
results.append({"server": server_name, "success": False, "message": f"Invalid MCP name or length is {len(server_name)} which is large than 255."})
|
||||
continue
|
||||
|
||||
base_name = server_name
|
||||
@ -409,7 +409,7 @@ def test_mcp() -> Response:
|
||||
|
||||
url = req.get("url", "")
|
||||
if not url:
|
||||
return get_data_error_result(message="Invaild MCP url.")
|
||||
return get_data_error_result(message="Invalid MCP url.")
|
||||
|
||||
server_type = req.get("server_type", "")
|
||||
if server_type not in VALID_MCP_SERVER_TYPES:
|
||||
|
||||
@ -24,7 +24,7 @@ from api.db.services.llm_service import LLMBundle
|
||||
from api import settings
|
||||
from api.utils.api_utils import validate_request, build_error_result, apikey_required
|
||||
from rag.app.tag import label_question
|
||||
from api.db.services.dialog_service import meta_filter
|
||||
from api.db.services.dialog_service import meta_filter, convert_conditions
|
||||
|
||||
|
||||
@manager.route('/dify/retrieval', methods=['POST']) # noqa: F821
|
||||
@ -74,7 +74,6 @@ def retrieval(tenant_id):
|
||||
[tenant_id],
|
||||
[kb_id],
|
||||
embd_mdl,
|
||||
doc_ids,
|
||||
LLMBundle(kb.tenant_id, LLMType.CHAT))
|
||||
if ck["content_with_weight"]:
|
||||
ranks["chunks"].insert(0, ck)
|
||||
@ -102,19 +101,4 @@ def retrieval(tenant_id):
|
||||
logging.exception(e)
|
||||
return build_error_result(message=str(e), code=settings.RetCode.SERVER_ERROR)
|
||||
|
||||
def convert_conditions(metadata_condition):
|
||||
if metadata_condition is None:
|
||||
metadata_condition = {}
|
||||
op_mapping = {
|
||||
"is": "=",
|
||||
"not is": "≠"
|
||||
}
|
||||
return [
|
||||
{
|
||||
"op": op_mapping.get(cond["comparison_operator"], cond["comparison_operator"]),
|
||||
"key": cond["name"],
|
||||
"value": cond["value"]
|
||||
}
|
||||
for cond in metadata_condition.get("conditions", [])
|
||||
]
|
||||
|
||||
|
||||
@ -35,6 +35,7 @@ from api.db.services.knowledgebase_service import KnowledgebaseService
|
||||
from api.db.services.llm_service import LLMBundle
|
||||
from api.db.services.tenant_llm_service import TenantLLMService
|
||||
from api.db.services.task_service import TaskService, queue_tasks
|
||||
from api.db.services.dialog_service import meta_filter, convert_conditions
|
||||
from api.utils.api_utils import check_duplicate_ids, construct_json_result, get_error_data_result, get_parser_config, get_result, server_error_response, token_required
|
||||
from rag.app.qa import beAdoc, rmPrefix
|
||||
from rag.app.tag import label_question
|
||||
@ -1350,6 +1351,9 @@ def retrieval_test(tenant_id):
|
||||
highlight:
|
||||
type: boolean
|
||||
description: Whether to highlight matched content.
|
||||
metadata_condition:
|
||||
type: object
|
||||
description: metadata filter condition.
|
||||
- in: header
|
||||
name: Authorization
|
||||
type: string
|
||||
@ -1413,6 +1417,10 @@ def retrieval_test(tenant_id):
|
||||
for doc_id in doc_ids:
|
||||
if doc_id not in doc_ids_list:
|
||||
return get_error_data_result(f"The datasets don't own the document {doc_id}")
|
||||
if not doc_ids:
|
||||
metadata_condition = req.get("metadata_condition", {})
|
||||
metas = DocumentService.get_meta_by_kbs(kb_ids)
|
||||
doc_ids = meta_filter(metas, convert_conditions(metadata_condition))
|
||||
similarity_threshold = float(req.get("similarity_threshold", 0.2))
|
||||
vector_similarity_weight = float(req.get("vector_similarity_weight", 0.3))
|
||||
top = int(req.get("top_k", 1024))
|
||||
|
||||
@ -3,9 +3,11 @@ import re
|
||||
|
||||
import flask
|
||||
from flask import request
|
||||
from pathlib import Path
|
||||
|
||||
from api.db.services.document_service import DocumentService
|
||||
from api.db.services.file2document_service import File2DocumentService
|
||||
from api.db.services.knowledgebase_service import KnowledgebaseService
|
||||
from api.utils.api_utils import server_error_response, token_required
|
||||
from api.utils import get_uuid
|
||||
from api.db import FileType
|
||||
@ -666,3 +668,71 @@ def move(tenant_id):
|
||||
return get_json_result(data=True)
|
||||
except Exception as e:
|
||||
return server_error_response(e)
|
||||
|
||||
@manager.route('/file/convert', methods=['POST']) # noqa: F821
|
||||
@token_required
|
||||
def convert(tenant_id):
|
||||
req = request.json
|
||||
kb_ids = req["kb_ids"]
|
||||
file_ids = req["file_ids"]
|
||||
file2documents = []
|
||||
|
||||
try:
|
||||
files = FileService.get_by_ids(file_ids)
|
||||
files_set = dict({file.id: file for file in files})
|
||||
for file_id in file_ids:
|
||||
file = files_set[file_id]
|
||||
if not file:
|
||||
return get_json_result(message="File not found!", code=404)
|
||||
file_ids_list = [file_id]
|
||||
if file.type == FileType.FOLDER.value:
|
||||
file_ids_list = FileService.get_all_innermost_file_ids(file_id, [])
|
||||
for id in file_ids_list:
|
||||
informs = File2DocumentService.get_by_file_id(id)
|
||||
# delete
|
||||
for inform in informs:
|
||||
doc_id = inform.document_id
|
||||
e, doc = DocumentService.get_by_id(doc_id)
|
||||
if not e:
|
||||
return get_json_result(message="Document not found!", code=404)
|
||||
tenant_id = DocumentService.get_tenant_id(doc_id)
|
||||
if not tenant_id:
|
||||
return get_json_result(message="Tenant not found!", code=404)
|
||||
if not DocumentService.remove_document(doc, tenant_id):
|
||||
return get_json_result(
|
||||
message="Database error (Document removal)!", code=404)
|
||||
File2DocumentService.delete_by_file_id(id)
|
||||
|
||||
# insert
|
||||
for kb_id in kb_ids:
|
||||
e, kb = KnowledgebaseService.get_by_id(kb_id)
|
||||
if not e:
|
||||
return get_json_result(
|
||||
message="Can't find this knowledgebase!", code=404)
|
||||
e, file = FileService.get_by_id(id)
|
||||
if not e:
|
||||
return get_json_result(
|
||||
message="Can't find this file!", code=404)
|
||||
|
||||
doc = DocumentService.insert({
|
||||
"id": get_uuid(),
|
||||
"kb_id": kb.id,
|
||||
"parser_id": FileService.get_parser(file.type, file.name, kb.parser_id),
|
||||
"parser_config": kb.parser_config,
|
||||
"created_by": tenant_id,
|
||||
"type": file.type,
|
||||
"name": file.name,
|
||||
"suffix": Path(file.name).suffix.lstrip("."),
|
||||
"location": file.location,
|
||||
"size": file.size
|
||||
})
|
||||
file2document = File2DocumentService.insert({
|
||||
"id": get_uuid(),
|
||||
"file_id": id,
|
||||
"document_id": doc.id,
|
||||
})
|
||||
|
||||
file2documents.append(file2document.to_json())
|
||||
return get_json_result(data=file2documents)
|
||||
except Exception as e:
|
||||
return server_error_response(e)
|
||||
@ -414,7 +414,7 @@ def agents_completion_openai_compatibility(tenant_id, agent_id):
|
||||
tenant_id,
|
||||
agent_id,
|
||||
question,
|
||||
session_id=req.get("id", req.get("metadata", {}).get("id", "")),
|
||||
session_id=req.pop("session_id", req.get("id", "")) or req.get("metadata", {}).get("id", ""),
|
||||
stream=True,
|
||||
**req,
|
||||
),
|
||||
@ -432,7 +432,7 @@ def agents_completion_openai_compatibility(tenant_id, agent_id):
|
||||
tenant_id,
|
||||
agent_id,
|
||||
question,
|
||||
session_id=req.get("id", req.get("metadata", {}).get("id", "")),
|
||||
session_id=req.pop("session_id", req.get("id", "")) or req.get("metadata", {}).get("id", ""),
|
||||
stream=False,
|
||||
**req,
|
||||
)
|
||||
@ -445,7 +445,6 @@ def agents_completion_openai_compatibility(tenant_id, agent_id):
|
||||
def agent_completions(tenant_id, agent_id):
|
||||
req = request.json
|
||||
|
||||
ans = {}
|
||||
if req.get("stream", True):
|
||||
|
||||
def generate():
|
||||
@ -456,14 +455,13 @@ def agent_completions(tenant_id, agent_id):
|
||||
except Exception:
|
||||
continue
|
||||
|
||||
if ans.get("event") != "message" or not ans.get("data", {}).get("reference", None):
|
||||
if ans.get("event") not in ["message", "message_end"]:
|
||||
continue
|
||||
|
||||
yield answer
|
||||
|
||||
yield "data:[DONE]\n\n"
|
||||
|
||||
if req.get("stream", True):
|
||||
resp = Response(generate(), mimetype="text/event-stream")
|
||||
resp.headers.add_header("Cache-control", "no-cache")
|
||||
resp.headers.add_header("Connection", "keep-alive")
|
||||
@ -472,6 +470,8 @@ def agent_completions(tenant_id, agent_id):
|
||||
return resp
|
||||
|
||||
full_content = ""
|
||||
reference = {}
|
||||
final_ans = ""
|
||||
for answer in agent_completion(tenant_id=tenant_id, agent_id=agent_id, **req):
|
||||
try:
|
||||
ans = json.loads(answer[5:])
|
||||
@ -480,11 +480,14 @@ def agent_completions(tenant_id, agent_id):
|
||||
full_content += ans["data"]["content"]
|
||||
|
||||
if ans.get("data", {}).get("reference", None):
|
||||
ans["data"]["content"] = full_content
|
||||
return get_result(data=ans)
|
||||
reference.update(ans["data"]["reference"])
|
||||
|
||||
final_ans = ans
|
||||
except Exception as e:
|
||||
return get_result(data=f"**ERROR**: {str(e)}")
|
||||
return get_result(data=ans)
|
||||
final_ans["data"]["content"] = full_content
|
||||
final_ans["data"]["reference"] = reference
|
||||
return get_result(data=final_ans)
|
||||
|
||||
|
||||
@manager.route("/chats/<chat_id>/sessions", methods=["GET"]) # noqa: F821
|
||||
@ -938,6 +941,9 @@ def retrieval_test_embedded():
|
||||
kb_ids = req["kb_id"]
|
||||
if isinstance(kb_ids, str):
|
||||
kb_ids = [kb_ids]
|
||||
if not kb_ids:
|
||||
return get_json_result(data=False, message='Please specify dataset firstly.',
|
||||
code=settings.RetCode.DATA_ERROR)
|
||||
doc_ids = req.get("doc_ids", [])
|
||||
similarity_threshold = float(req.get("similarity_threshold", 0.0))
|
||||
vector_similarity_weight = float(req.get("vector_similarity_weight", 0.3))
|
||||
|
||||
@ -43,7 +43,7 @@ def create():
|
||||
return get_data_error_result(message=f"Search name length is {len(search_name)} which is large than 255.")
|
||||
e, _ = TenantService.get_by_id(current_user.id)
|
||||
if not e:
|
||||
return get_data_error_result(message="Authorizationd identity.")
|
||||
return get_data_error_result(message="Authorized identity.")
|
||||
|
||||
search_name = search_name.strip()
|
||||
search_name = duplicate_name(SearchService.query, name=search_name, tenant_id=current_user.id, status=StatusEnum.VALID.value)
|
||||
@ -78,7 +78,7 @@ def update():
|
||||
tenant_id = req["tenant_id"]
|
||||
e, _ = TenantService.get_by_id(tenant_id)
|
||||
if not e:
|
||||
return get_data_error_result(message="Authorizationd identity.")
|
||||
return get_data_error_result(message="Authorized identity.")
|
||||
|
||||
search_id = req["search_id"]
|
||||
if not SearchService.accessible4deletion(search_id, current_user.id):
|
||||
|
||||
@ -36,6 +36,8 @@ from rag.utils.storage_factory import STORAGE_IMPL, STORAGE_IMPL_TYPE
|
||||
from timeit import default_timer as timer
|
||||
|
||||
from rag.utils.redis_conn import REDIS_CONN
|
||||
from flask import jsonify
|
||||
from api.utils.health_utils import run_health_checks
|
||||
|
||||
@manager.route("/version", methods=["GET"]) # noqa: F821
|
||||
@login_required
|
||||
@ -169,6 +171,12 @@ def status():
|
||||
return get_json_result(data=res)
|
||||
|
||||
|
||||
@manager.route("/healthz", methods=["GET"]) # noqa: F821
|
||||
def healthz():
|
||||
result, all_ok = run_health_checks()
|
||||
return jsonify(result), (200 if all_ok else 500)
|
||||
|
||||
|
||||
@manager.route("/new_token", methods=["POST"]) # noqa: F821
|
||||
@login_required
|
||||
def new_token():
|
||||
|
||||
@ -74,8 +74,10 @@ class TaskStatus(StrEnum):
|
||||
DONE = "3"
|
||||
FAIL = "4"
|
||||
|
||||
|
||||
VALID_TASK_STATUS = {TaskStatus.UNSTART, TaskStatus.RUNNING, TaskStatus.CANCEL, TaskStatus.DONE, TaskStatus.FAIL}
|
||||
|
||||
|
||||
class ParserType(StrEnum):
|
||||
PRESENTATION = "presentation"
|
||||
LAWS = "laws"
|
||||
@ -105,10 +107,19 @@ class CanvasType(StrEnum):
|
||||
DocBot = "docbot"
|
||||
|
||||
|
||||
class CanvasCategory(StrEnum):
|
||||
Agent = "agent_canvas"
|
||||
DataFlow = "dataflow_canvas"
|
||||
|
||||
VALID_CAVAS_CATEGORIES = {CanvasCategory.Agent, CanvasCategory.DataFlow}
|
||||
|
||||
|
||||
class MCPServerType(StrEnum):
|
||||
SSE = "sse"
|
||||
STREAMABLE_HTTP = "streamable-http"
|
||||
|
||||
|
||||
VALID_MCP_SERVER_TYPES = {MCPServerType.SSE, MCPServerType.STREAMABLE_HTTP}
|
||||
|
||||
|
||||
KNOWLEDGEBASE_FOLDER_NAME=".knowledgebase"
|
||||
|
||||
@ -245,22 +245,21 @@ class JsonSerializedField(SerializedField):
|
||||
|
||||
class RetryingPooledMySQLDatabase(PooledMySQLDatabase):
|
||||
def __init__(self, *args, **kwargs):
|
||||
self.max_retries = kwargs.pop('max_retries', 5)
|
||||
self.retry_delay = kwargs.pop('retry_delay', 1)
|
||||
self.max_retries = kwargs.pop("max_retries", 5)
|
||||
self.retry_delay = kwargs.pop("retry_delay", 1)
|
||||
super().__init__(*args, **kwargs)
|
||||
|
||||
def execute_sql(self, sql, params=None, commit=True):
|
||||
from peewee import OperationalError
|
||||
|
||||
for attempt in range(self.max_retries + 1):
|
||||
try:
|
||||
return super().execute_sql(sql, params, commit)
|
||||
except OperationalError as e:
|
||||
if e.args[0] in (2013, 2006) and attempt < self.max_retries:
|
||||
logging.warning(
|
||||
f"Lost connection (attempt {attempt+1}/{self.max_retries}): {e}"
|
||||
)
|
||||
logging.warning(f"Lost connection (attempt {attempt + 1}/{self.max_retries}): {e}")
|
||||
self._handle_connection_loss()
|
||||
time.sleep(self.retry_delay * (2 ** attempt))
|
||||
time.sleep(self.retry_delay * (2**attempt))
|
||||
else:
|
||||
logging.error(f"DB execution failure: {e}")
|
||||
raise
|
||||
@ -272,16 +271,15 @@ class RetryingPooledMySQLDatabase(PooledMySQLDatabase):
|
||||
|
||||
def begin(self):
|
||||
from peewee import OperationalError
|
||||
|
||||
for attempt in range(self.max_retries + 1):
|
||||
try:
|
||||
return super().begin()
|
||||
except OperationalError as e:
|
||||
if e.args[0] in (2013, 2006) and attempt < self.max_retries:
|
||||
logging.warning(
|
||||
f"Lost connection during transaction (attempt {attempt+1}/{self.max_retries})"
|
||||
)
|
||||
logging.warning(f"Lost connection during transaction (attempt {attempt + 1}/{self.max_retries})")
|
||||
self._handle_connection_loss()
|
||||
time.sleep(self.retry_delay * (2 ** attempt))
|
||||
time.sleep(self.retry_delay * (2**attempt))
|
||||
else:
|
||||
raise
|
||||
|
||||
@ -815,6 +813,7 @@ class UserCanvas(DataBaseModel):
|
||||
permission = CharField(max_length=16, null=False, help_text="me|team", default="me", index=True)
|
||||
description = TextField(null=True, help_text="Canvas description")
|
||||
canvas_type = CharField(max_length=32, null=True, help_text="Canvas type", index=True)
|
||||
canvas_category = CharField(max_length=32, null=False, default="agent_canvas", help_text="Canvas category: agent_canvas|dataflow_canvas", index=True)
|
||||
dsl = JSONField(null=True, default={})
|
||||
|
||||
class Meta:
|
||||
@ -824,10 +823,10 @@ class UserCanvas(DataBaseModel):
|
||||
class CanvasTemplate(DataBaseModel):
|
||||
id = CharField(max_length=32, primary_key=True)
|
||||
avatar = TextField(null=True, help_text="avatar base64 string")
|
||||
title = CharField(max_length=255, null=True, help_text="Canvas title")
|
||||
|
||||
description = TextField(null=True, help_text="Canvas description")
|
||||
title = JSONField(null=True, default=dict, help_text="Canvas title")
|
||||
description = JSONField(null=True, default=dict, help_text="Canvas description")
|
||||
canvas_type = CharField(max_length=32, null=True, help_text="Canvas type", index=True)
|
||||
canvas_category = CharField(max_length=32, null=False, default="agent_canvas", help_text="Canvas category: agent_canvas|dataflow_canvas", index=True)
|
||||
dsl = JSONField(null=True, default={})
|
||||
|
||||
class Meta:
|
||||
@ -1021,4 +1020,21 @@ def migrate_db():
|
||||
migrate(migrator.add_column("dialog", "meta_data_filter", JSONField(null=True, default={})))
|
||||
except Exception:
|
||||
pass
|
||||
|
||||
try:
|
||||
migrate(migrator.alter_column_type("canvas_template", "title", JSONField(null=True, default=dict, help_text="Canvas title")))
|
||||
except Exception:
|
||||
pass
|
||||
try:
|
||||
migrate(migrator.alter_column_type("canvas_template", "description", JSONField(null=True, default=dict, help_text="Canvas description")))
|
||||
except Exception:
|
||||
pass
|
||||
try:
|
||||
migrate(migrator.add_column("user_canvas", "canvas_category", CharField(max_length=32, null=False, default="agent_canvas", help_text="agent_canvas|dataflow_canvas", index=True)))
|
||||
except Exception:
|
||||
pass
|
||||
try:
|
||||
migrate(migrator.add_column("canvas_template", "canvas_category", CharField(max_length=32, null=False, default="agent_canvas", help_text="agent_canvas|dataflow_canvas", index=True)))
|
||||
except Exception:
|
||||
pass
|
||||
logging.disable(logging.NOTSET)
|
||||
|
||||
@ -144,8 +144,9 @@ def init_llm_factory():
|
||||
except Exception:
|
||||
pass
|
||||
break
|
||||
doc_count = DocumentService.get_all_kb_doc_count()
|
||||
for kb_id in KnowledgebaseService.get_all_ids():
|
||||
KnowledgebaseService.update_document_number_in_init(kb_id=kb_id, doc_num=DocumentService.get_kb_doc_count(kb_id))
|
||||
KnowledgebaseService.update_document_number_in_init(kb_id=kb_id, doc_num=doc_count.get(kb_id, 0))
|
||||
|
||||
|
||||
|
||||
|
||||
@ -18,7 +18,7 @@ import logging
|
||||
import time
|
||||
from uuid import uuid4
|
||||
from agent.canvas import Canvas
|
||||
from api.db import TenantPermission
|
||||
from api.db import CanvasCategory, TenantPermission
|
||||
from api.db.db_models import DB, CanvasTemplate, User, UserCanvas, API4Conversation
|
||||
from api.db.services.api_service import API4ConversationService
|
||||
from api.db.services.common_service import CommonService
|
||||
@ -31,6 +31,12 @@ from peewee import fn
|
||||
class CanvasTemplateService(CommonService):
|
||||
model = CanvasTemplate
|
||||
|
||||
class DataFlowTemplateService(CommonService):
|
||||
"""
|
||||
Alias of CanvasTemplateService
|
||||
"""
|
||||
model = CanvasTemplate
|
||||
|
||||
|
||||
class UserCanvasService(CommonService):
|
||||
model = UserCanvas
|
||||
@ -38,13 +44,14 @@ class UserCanvasService(CommonService):
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
def get_list(cls, tenant_id,
|
||||
page_number, items_per_page, orderby, desc, id, title):
|
||||
page_number, items_per_page, orderby, desc, id, title, canvas_category=CanvasCategory.Agent):
|
||||
agents = cls.model.select()
|
||||
if id:
|
||||
agents = agents.where(cls.model.id == id)
|
||||
if title:
|
||||
agents = agents.where(cls.model.title == title)
|
||||
agents = agents.where(cls.model.user_id == tenant_id)
|
||||
agents = agents.where(cls.model.canvas_category == canvas_category)
|
||||
if desc:
|
||||
agents = agents.order_by(cls.model.getter_by(orderby).desc())
|
||||
else:
|
||||
@ -71,6 +78,7 @@ class UserCanvasService(CommonService):
|
||||
cls.model.create_time,
|
||||
cls.model.create_date,
|
||||
cls.model.update_date,
|
||||
cls.model.canvas_category,
|
||||
User.nickname,
|
||||
User.avatar.alias('tenant_avatar'),
|
||||
]
|
||||
@ -87,7 +95,7 @@ class UserCanvasService(CommonService):
|
||||
@DB.connection_context()
|
||||
def get_by_tenant_ids(cls, joined_tenant_ids, user_id,
|
||||
page_number, items_per_page,
|
||||
orderby, desc, keywords,
|
||||
orderby, desc, keywords, canvas_category=CanvasCategory.Agent,
|
||||
):
|
||||
fields = [
|
||||
cls.model.id,
|
||||
@ -98,7 +106,8 @@ class UserCanvasService(CommonService):
|
||||
cls.model.permission,
|
||||
User.nickname,
|
||||
User.avatar.alias('tenant_avatar'),
|
||||
cls.model.update_time
|
||||
cls.model.update_time,
|
||||
cls.model.canvas_category,
|
||||
]
|
||||
if keywords:
|
||||
agents = cls.model.select(*fields).join(User, on=(cls.model.user_id == User.id)).where(
|
||||
@ -113,6 +122,7 @@ class UserCanvasService(CommonService):
|
||||
TenantPermission.TEAM.value)) | (
|
||||
cls.model.user_id == user_id))
|
||||
)
|
||||
agents = agents.where(cls.model.canvas_category == canvas_category)
|
||||
if desc:
|
||||
agents = agents.order_by(cls.model.getter_by(orderby).desc())
|
||||
else:
|
||||
@ -213,26 +223,33 @@ def completionOpenAI(tenant_id, agent_id, question, session_id=None, stream=True
|
||||
except Exception as e:
|
||||
logging.exception(f"Agent OpenAI-Compatible completionOpenAI parse answer failed: {e}")
|
||||
continue
|
||||
if ans.get("event") != "message" or not ans.get("data", {}).get("reference", None):
|
||||
if ans.get("event") not in ["message", "message_end"]:
|
||||
continue
|
||||
content_piece = ans["data"]["content"]
|
||||
|
||||
content_piece = ""
|
||||
if ans["event"] == "message":
|
||||
content_piece = ans["data"]["content"]
|
||||
|
||||
completion_tokens += len(tiktokenenc.encode(content_piece))
|
||||
|
||||
yield "data: " + json.dumps(
|
||||
get_data_openai(
|
||||
openai_data = get_data_openai(
|
||||
id=session_id or str(uuid4()),
|
||||
model=agent_id,
|
||||
content=content_piece,
|
||||
prompt_tokens=prompt_tokens,
|
||||
completion_tokens=completion_tokens,
|
||||
stream=True
|
||||
),
|
||||
ensure_ascii=False
|
||||
) + "\n\n"
|
||||
)
|
||||
|
||||
if ans.get("data", {}).get("reference", None):
|
||||
openai_data["choices"][0]["delta"]["reference"] = ans["data"]["reference"]
|
||||
|
||||
yield "data: " + json.dumps(openai_data, ensure_ascii=False) + "\n\n"
|
||||
|
||||
yield "data: [DONE]\n\n"
|
||||
|
||||
except Exception as e:
|
||||
logging.exception(e)
|
||||
yield "data: " + json.dumps(
|
||||
get_data_openai(
|
||||
id=session_id or str(uuid4()),
|
||||
@ -250,6 +267,7 @@ def completionOpenAI(tenant_id, agent_id, question, session_id=None, stream=True
|
||||
else:
|
||||
try:
|
||||
all_content = ""
|
||||
reference = {}
|
||||
for ans in completion(
|
||||
tenant_id=tenant_id,
|
||||
agent_id=agent_id,
|
||||
@ -260,13 +278,18 @@ def completionOpenAI(tenant_id, agent_id, question, session_id=None, stream=True
|
||||
):
|
||||
if isinstance(ans, str):
|
||||
ans = json.loads(ans[5:])
|
||||
if ans.get("event") != "message" or not ans.get("data", {}).get("reference", None):
|
||||
if ans.get("event") not in ["message", "message_end"]:
|
||||
continue
|
||||
all_content += ans["data"]["content"]
|
||||
|
||||
if ans["event"] == "message":
|
||||
all_content += ans["data"]["content"]
|
||||
|
||||
if ans.get("data", {}).get("reference", None):
|
||||
reference.update(ans["data"]["reference"])
|
||||
|
||||
completion_tokens = len(tiktokenenc.encode(all_content))
|
||||
|
||||
yield get_data_openai(
|
||||
openai_data = get_data_openai(
|
||||
id=session_id or str(uuid4()),
|
||||
model=agent_id,
|
||||
prompt_tokens=prompt_tokens,
|
||||
@ -276,7 +299,12 @@ def completionOpenAI(tenant_id, agent_id, question, session_id=None, stream=True
|
||||
param=None
|
||||
)
|
||||
|
||||
if reference:
|
||||
openai_data["choices"][0]["message"]["reference"] = reference
|
||||
|
||||
yield openai_data
|
||||
except Exception as e:
|
||||
logging.exception(e)
|
||||
yield get_data_openai(
|
||||
id=session_id or str(uuid4()),
|
||||
model=agent_id,
|
||||
|
||||
@ -21,11 +21,9 @@ from copy import deepcopy
|
||||
from datetime import datetime
|
||||
from functools import partial
|
||||
from timeit import default_timer as timer
|
||||
|
||||
import trio
|
||||
from langfuse import Langfuse
|
||||
from peewee import fn
|
||||
|
||||
from agentic_reasoning import DeepResearcher
|
||||
from api import settings
|
||||
from api.db import LLMType, ParserType, StatusEnum
|
||||
@ -255,6 +253,23 @@ def repair_bad_citation_formats(answer: str, kbinfos: dict, idx: set):
|
||||
return answer, idx
|
||||
|
||||
|
||||
def convert_conditions(metadata_condition):
|
||||
if metadata_condition is None:
|
||||
metadata_condition = {}
|
||||
op_mapping = {
|
||||
"is": "=",
|
||||
"not is": "≠"
|
||||
}
|
||||
return [
|
||||
{
|
||||
"op": op_mapping.get(cond["comparison_operator"], cond["comparison_operator"]),
|
||||
"key": cond["name"],
|
||||
"value": cond["value"]
|
||||
}
|
||||
for cond in metadata_condition.get("conditions", [])
|
||||
]
|
||||
|
||||
|
||||
def meta_filter(metas: dict, filters: list[dict]):
|
||||
doc_ids = set([])
|
||||
|
||||
@ -350,7 +365,7 @@ def chat(dialog, messages, stream=True, **kwargs):
|
||||
# try to use sql if field mapping is good to go
|
||||
if field_map:
|
||||
logging.debug("Use SQL to retrieval:{}".format(questions[-1]))
|
||||
ans = use_sql(questions[-1], field_map, dialog.tenant_id, chat_mdl, prompt_config.get("quote", True))
|
||||
ans = use_sql(questions[-1], field_map, dialog.tenant_id, chat_mdl, prompt_config.get("quote", True), dialog.kb_ids)
|
||||
if ans:
|
||||
yield ans
|
||||
return
|
||||
@ -578,7 +593,7 @@ def chat(dialog, messages, stream=True, **kwargs):
|
||||
yield res
|
||||
|
||||
|
||||
def use_sql(question, field_map, tenant_id, chat_mdl, quota=True):
|
||||
def use_sql(question, field_map, tenant_id, chat_mdl, quota=True, kb_ids=None):
|
||||
sys_prompt = "You are a Database Administrator. You need to check the fields of the following tables based on the user's list of questions and write the SQL corresponding to the last question."
|
||||
user_prompt = """
|
||||
Table name: {};
|
||||
@ -615,6 +630,13 @@ Please write the SQL, only SQL, without any other explanations or text.
|
||||
flds.append(k)
|
||||
sql = "select doc_id,docnm_kwd," + ",".join(flds) + sql[8:]
|
||||
|
||||
if kb_ids:
|
||||
kb_filter = "(" + " OR ".join([f"kb_id = '{kb_id}'" for kb_id in kb_ids]) + ")"
|
||||
if "where" not in sql.lower():
|
||||
sql += f" WHERE {kb_filter}"
|
||||
else:
|
||||
sql += f" AND {kb_filter}"
|
||||
|
||||
logging.debug(f"{question} get SQL(refined): {sql}")
|
||||
tried_times += 1
|
||||
return settings.retrievaler.sql_retrieval(sql, format="json"), sql
|
||||
@ -821,4 +843,4 @@ def gen_mindmap(question, kb_ids, tenant_id, search_config={}):
|
||||
)
|
||||
mindmap = MindMapExtractor(chat_mdl)
|
||||
mind_map = trio.run(mindmap, [c["content_with_weight"] for c in ranks["chunks"]])
|
||||
return mind_map.output
|
||||
return mind_map.output
|
||||
|
||||
@ -24,7 +24,7 @@ from io import BytesIO
|
||||
|
||||
import trio
|
||||
import xxhash
|
||||
from peewee import fn
|
||||
from peewee import fn, Case
|
||||
|
||||
from api import settings
|
||||
from api.constants import IMG_BASE64_PREFIX, FILE_NAME_LEN_LIMIT
|
||||
@ -660,8 +660,16 @@ class DocumentService(CommonService):
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
def get_kb_doc_count(cls, kb_id):
|
||||
return len(cls.model.select(cls.model.id).where(
|
||||
cls.model.kb_id == kb_id).dicts())
|
||||
return cls.model.select().where(cls.model.kb_id == kb_id).count()
|
||||
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
def get_all_kb_doc_count(cls):
|
||||
result = {}
|
||||
rows = cls.model.select(cls.model.kb_id, fn.COUNT(cls.model.id).alias('count')).group_by(cls.model.kb_id)
|
||||
for row in rows:
|
||||
result[row.kb_id] = row.count
|
||||
return result
|
||||
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
@ -674,6 +682,53 @@ class DocumentService(CommonService):
|
||||
return False
|
||||
|
||||
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
def knowledgebase_basic_info(cls, kb_id: str) -> dict[str, int]:
|
||||
# cancelled: run == "2" but progress can vary
|
||||
cancelled = (
|
||||
cls.model.select(fn.COUNT(1))
|
||||
.where((cls.model.kb_id == kb_id) & (cls.model.run == TaskStatus.CANCEL))
|
||||
.scalar()
|
||||
)
|
||||
|
||||
row = (
|
||||
cls.model.select(
|
||||
# finished: progress == 1
|
||||
fn.COALESCE(fn.SUM(Case(None, [(cls.model.progress == 1, 1)], 0)), 0).alias("finished"),
|
||||
|
||||
# failed: progress == -1
|
||||
fn.COALESCE(fn.SUM(Case(None, [(cls.model.progress == -1, 1)], 0)), 0).alias("failed"),
|
||||
|
||||
# processing: 0 <= progress < 1
|
||||
fn.COALESCE(
|
||||
fn.SUM(
|
||||
Case(
|
||||
None,
|
||||
[
|
||||
(((cls.model.progress == 0) | ((cls.model.progress > 0) & (cls.model.progress < 1))), 1),
|
||||
],
|
||||
0,
|
||||
)
|
||||
),
|
||||
0,
|
||||
).alias("processing"),
|
||||
)
|
||||
.where(
|
||||
(cls.model.kb_id == kb_id)
|
||||
& ((cls.model.run.is_null(True)) | (cls.model.run != TaskStatus.CANCEL))
|
||||
)
|
||||
.dicts()
|
||||
.get()
|
||||
)
|
||||
|
||||
return {
|
||||
"processing": int(row["processing"]),
|
||||
"finished": int(row["finished"]),
|
||||
"failed": int(row["failed"]),
|
||||
"cancelled": int(cancelled),
|
||||
}
|
||||
|
||||
def queue_raptor_o_graphrag_tasks(doc, ty, priority):
|
||||
chunking_config = DocumentService.get_chunking_config(doc["id"])
|
||||
hasher = xxhash.xxh64()
|
||||
@ -702,6 +757,8 @@ def queue_raptor_o_graphrag_tasks(doc, ty, priority):
|
||||
|
||||
def get_queue_length(priority):
|
||||
group_info = REDIS_CONN.queue_info(get_svr_queue_name(priority), SVR_CONSUMER_GROUP_NAME)
|
||||
if not group_info:
|
||||
return 0
|
||||
return int(group_info.get("lag", 0) or 0)
|
||||
|
||||
|
||||
@ -847,3 +904,4 @@ def doc_upload_and_parse(conversation_id, file_objs, user_id):
|
||||
doc_id, kb.id, token_counts[doc_id], chunk_counts[doc_id], 0)
|
||||
|
||||
return [d["id"] for d, _ in files]
|
||||
|
||||
|
||||
@ -54,15 +54,15 @@ def trim_header_by_lines(text: str, max_length) -> str:
|
||||
|
||||
class TaskService(CommonService):
|
||||
"""Service class for managing document processing tasks.
|
||||
|
||||
|
||||
This class extends CommonService to provide specialized functionality for document
|
||||
processing task management, including task creation, progress tracking, and chunk
|
||||
management. It handles various document types (PDF, Excel, etc.) and manages their
|
||||
processing lifecycle.
|
||||
|
||||
|
||||
The class implements a robust task queue system with retry mechanisms and progress
|
||||
tracking, supporting both synchronous and asynchronous task execution.
|
||||
|
||||
|
||||
Attributes:
|
||||
model: The Task model class for database operations.
|
||||
"""
|
||||
@ -72,14 +72,14 @@ class TaskService(CommonService):
|
||||
@DB.connection_context()
|
||||
def get_task(cls, task_id):
|
||||
"""Retrieve detailed task information by task ID.
|
||||
|
||||
|
||||
This method fetches comprehensive task details including associated document,
|
||||
knowledge base, and tenant information. It also handles task retry logic and
|
||||
progress updates.
|
||||
|
||||
|
||||
Args:
|
||||
task_id (str): The unique identifier of the task to retrieve.
|
||||
|
||||
|
||||
Returns:
|
||||
dict: Task details dictionary containing all task information and related metadata.
|
||||
Returns None if task is not found or has exceeded retry limit.
|
||||
@ -139,13 +139,13 @@ class TaskService(CommonService):
|
||||
@DB.connection_context()
|
||||
def get_tasks(cls, doc_id: str):
|
||||
"""Retrieve all tasks associated with a document.
|
||||
|
||||
|
||||
This method fetches all processing tasks for a given document, ordered by page
|
||||
number and creation time. It includes task progress and chunk information.
|
||||
|
||||
|
||||
Args:
|
||||
doc_id (str): The unique identifier of the document.
|
||||
|
||||
|
||||
Returns:
|
||||
list[dict]: List of task dictionaries containing task details.
|
||||
Returns None if no tasks are found.
|
||||
@ -170,10 +170,10 @@ class TaskService(CommonService):
|
||||
@DB.connection_context()
|
||||
def update_chunk_ids(cls, id: str, chunk_ids: str):
|
||||
"""Update the chunk IDs associated with a task.
|
||||
|
||||
|
||||
This method updates the chunk_ids field of a task, which stores the IDs of
|
||||
processed document chunks in a space-separated string format.
|
||||
|
||||
|
||||
Args:
|
||||
id (str): The unique identifier of the task.
|
||||
chunk_ids (str): Space-separated string of chunk identifiers.
|
||||
@ -184,11 +184,11 @@ class TaskService(CommonService):
|
||||
@DB.connection_context()
|
||||
def get_ongoing_doc_name(cls):
|
||||
"""Get names of documents that are currently being processed.
|
||||
|
||||
|
||||
This method retrieves information about documents that are in the processing state,
|
||||
including their locations and associated IDs. It uses database locking to ensure
|
||||
thread safety when accessing the task information.
|
||||
|
||||
|
||||
Returns:
|
||||
list[tuple]: A list of tuples, each containing (parent_id/kb_id, location)
|
||||
for documents currently being processed. Returns empty list if
|
||||
@ -238,14 +238,14 @@ class TaskService(CommonService):
|
||||
@DB.connection_context()
|
||||
def do_cancel(cls, id):
|
||||
"""Check if a task should be cancelled based on its document status.
|
||||
|
||||
|
||||
This method determines whether a task should be cancelled by checking the
|
||||
associated document's run status and progress. A task should be cancelled
|
||||
if its document is marked for cancellation or has negative progress.
|
||||
|
||||
|
||||
Args:
|
||||
id (str): The unique identifier of the task to check.
|
||||
|
||||
|
||||
Returns:
|
||||
bool: True if the task should be cancelled, False otherwise.
|
||||
"""
|
||||
@ -311,18 +311,18 @@ class TaskService(CommonService):
|
||||
|
||||
def queue_tasks(doc: dict, bucket: str, name: str, priority: int):
|
||||
"""Create and queue document processing tasks.
|
||||
|
||||
|
||||
This function creates processing tasks for a document based on its type and configuration.
|
||||
It handles different document types (PDF, Excel, etc.) differently and manages task
|
||||
chunking and configuration. It also implements task reuse optimization by checking
|
||||
for previously completed tasks.
|
||||
|
||||
|
||||
Args:
|
||||
doc (dict): Document dictionary containing metadata and configuration.
|
||||
bucket (str): Storage bucket name where the document is stored.
|
||||
name (str): File name of the document.
|
||||
priority (int, optional): Priority level for task queueing (default is 0).
|
||||
|
||||
|
||||
Note:
|
||||
- For PDF documents, tasks are created per page range based on configuration
|
||||
- For Excel documents, tasks are created per row range
|
||||
@ -410,19 +410,19 @@ def queue_tasks(doc: dict, bucket: str, name: str, priority: int):
|
||||
|
||||
def reuse_prev_task_chunks(task: dict, prev_tasks: list[dict], chunking_config: dict):
|
||||
"""Attempt to reuse chunks from previous tasks for optimization.
|
||||
|
||||
|
||||
This function checks if chunks from previously completed tasks can be reused for
|
||||
the current task, which can significantly improve processing efficiency. It matches
|
||||
tasks based on page ranges and configuration digests.
|
||||
|
||||
|
||||
Args:
|
||||
task (dict): Current task dictionary to potentially reuse chunks for.
|
||||
prev_tasks (list[dict]): List of previous task dictionaries to check for reuse.
|
||||
chunking_config (dict): Configuration dictionary for chunk processing.
|
||||
|
||||
|
||||
Returns:
|
||||
int: Number of chunks successfully reused. Returns 0 if no chunks could be reused.
|
||||
|
||||
|
||||
Note:
|
||||
Chunks can only be reused if:
|
||||
- A previous task exists with matching page range and configuration digest
|
||||
@ -470,3 +470,39 @@ def has_canceled(task_id):
|
||||
except Exception as e:
|
||||
logging.exception(e)
|
||||
return False
|
||||
|
||||
|
||||
def queue_dataflow(dsl:str, tenant_id:str, doc_id:str, task_id:str, flow_id:str, priority: int, callback=None) -> tuple[bool, str]:
|
||||
"""
|
||||
Returns a tuple (success: bool, error_message: str).
|
||||
"""
|
||||
_ = callback
|
||||
|
||||
task = dict(
|
||||
id=get_uuid() if not task_id else task_id,
|
||||
doc_id=doc_id,
|
||||
from_page=0,
|
||||
to_page=100000000,
|
||||
task_type="dataflow",
|
||||
priority=priority,
|
||||
)
|
||||
|
||||
TaskService.model.delete().where(TaskService.model.id == task["id"]).execute()
|
||||
bulk_insert_into_db(model=Task, data_source=[task], replace_on_conflict=True)
|
||||
|
||||
kb_id = DocumentService.get_knowledgebase_id(doc_id)
|
||||
if not kb_id:
|
||||
return False, f"Can't find KB of this document: {doc_id}"
|
||||
|
||||
task["kb_id"] = kb_id
|
||||
task["tenant_id"] = tenant_id
|
||||
task["task_type"] = "dataflow"
|
||||
task["dsl"] = dsl
|
||||
task["dataflow_id"] = get_uuid() if not flow_id else flow_id
|
||||
|
||||
if not REDIS_CONN.queue_product(
|
||||
get_svr_queue_name(priority), message=task
|
||||
):
|
||||
return False, "Can't access Redis. Please check the Redis' status."
|
||||
|
||||
return True, ""
|
||||
|
||||
@ -45,22 +45,22 @@ class UserService(CommonService):
|
||||
def query(cls, cols=None, reverse=None, order_by=None, **kwargs):
|
||||
if 'access_token' in kwargs:
|
||||
access_token = kwargs['access_token']
|
||||
|
||||
|
||||
# Reject empty, None, or whitespace-only access tokens
|
||||
if not access_token or not str(access_token).strip():
|
||||
logging.warning("UserService.query: Rejecting empty access_token query")
|
||||
return cls.model.select().where(cls.model.id == "INVALID_EMPTY_TOKEN") # Returns empty result
|
||||
|
||||
|
||||
# Reject tokens that are too short (should be UUID, 32+ chars)
|
||||
if len(str(access_token).strip()) < 32:
|
||||
logging.warning(f"UserService.query: Rejecting short access_token query: {len(str(access_token))} chars")
|
||||
return cls.model.select().where(cls.model.id == "INVALID_SHORT_TOKEN") # Returns empty result
|
||||
|
||||
|
||||
# Reject tokens that start with "INVALID_" (from logout)
|
||||
if str(access_token).startswith("INVALID_"):
|
||||
logging.warning("UserService.query: Rejecting invalidated access_token")
|
||||
return cls.model.select().where(cls.model.id == "INVALID_LOGOUT_TOKEN") # Returns empty result
|
||||
|
||||
|
||||
# Call parent query method for valid requests
|
||||
return super().query(cols=cols, reverse=reverse, order_by=order_by, **kwargs)
|
||||
|
||||
@ -133,6 +133,19 @@ class UserService(CommonService):
|
||||
cls.model.update(user_dict).where(
|
||||
cls.model.id == user_id).execute()
|
||||
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
def is_admin(cls, user_id):
|
||||
return cls.model.select().where(
|
||||
cls.model.id == user_id,
|
||||
cls.model.is_superuser == 1).count() > 0
|
||||
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
def get_all_users(cls):
|
||||
users = cls.model.select()
|
||||
return list(users)
|
||||
|
||||
|
||||
class TenantService(CommonService):
|
||||
"""Service class for managing tenant-related database operations.
|
||||
|
||||
@ -56,6 +56,30 @@ from rag.utils.mcp_tool_call_conn import MCPToolCallSession, close_multiple_mcp_
|
||||
|
||||
requests.models.complexjson.dumps = functools.partial(json.dumps, cls=CustomJSONEncoder)
|
||||
|
||||
def serialize_for_json(obj):
|
||||
"""
|
||||
Recursively serialize objects to make them JSON serializable.
|
||||
Handles ModelMetaclass and other non-serializable objects.
|
||||
"""
|
||||
if hasattr(obj, '__dict__'):
|
||||
# For objects with __dict__, try to serialize their attributes
|
||||
try:
|
||||
return {key: serialize_for_json(value) for key, value in obj.__dict__.items()
|
||||
if not key.startswith('_')}
|
||||
except (AttributeError, TypeError):
|
||||
return str(obj)
|
||||
elif hasattr(obj, '__name__'):
|
||||
# For classes and metaclasses, return their name
|
||||
return f"<{obj.__module__}.{obj.__name__}>" if hasattr(obj, '__module__') else f"<{obj.__name__}>"
|
||||
elif isinstance(obj, (list, tuple)):
|
||||
return [serialize_for_json(item) for item in obj]
|
||||
elif isinstance(obj, dict):
|
||||
return {key: serialize_for_json(value) for key, value in obj.items()}
|
||||
elif isinstance(obj, (str, int, float, bool)) or obj is None:
|
||||
return obj
|
||||
else:
|
||||
# Fallback: convert to string representation
|
||||
return str(obj)
|
||||
|
||||
def request(**kwargs):
|
||||
sess = requests.Session()
|
||||
@ -128,7 +152,11 @@ def server_error_response(e):
|
||||
except BaseException:
|
||||
pass
|
||||
if len(e.args) > 1:
|
||||
return get_json_result(code=settings.RetCode.EXCEPTION_ERROR, message=repr(e.args[0]), data=e.args[1])
|
||||
try:
|
||||
serialized_data = serialize_for_json(e.args[1])
|
||||
return get_json_result(code= settings.RetCode.EXCEPTION_ERROR, message=repr(e.args[0]), data=serialized_data)
|
||||
except Exception:
|
||||
return get_json_result(code=settings.RetCode.EXCEPTION_ERROR, message=repr(e.args[0]), data=None)
|
||||
if repr(e).find("index_not_found_exception") >= 0:
|
||||
return get_json_result(code=settings.RetCode.EXCEPTION_ERROR, message="No chunk found, please upload file and parse it.")
|
||||
|
||||
@ -292,6 +320,8 @@ def construct_error_response(e):
|
||||
def token_required(func):
|
||||
@wraps(func)
|
||||
def decorated_function(*args, **kwargs):
|
||||
if os.environ.get("DISABLE_SDK"):
|
||||
return get_json_result(data=False, message="`Authorization` can't be empty")
|
||||
authorization_str = flask_request.headers.get("Authorization")
|
||||
if not authorization_str:
|
||||
return get_json_result(data=False, message="`Authorization` can't be empty")
|
||||
|
||||
107
api/utils/health_utils.py
Normal file
107
api/utils/health_utils.py
Normal file
@ -0,0 +1,107 @@
|
||||
#
|
||||
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
|
||||
|
||||
from timeit import default_timer as timer
|
||||
|
||||
from api import settings
|
||||
from api.db.db_models import DB
|
||||
from rag.utils.redis_conn import REDIS_CONN
|
||||
from rag.utils.storage_factory import STORAGE_IMPL
|
||||
|
||||
|
||||
def _ok_nok(ok: bool) -> str:
|
||||
return "ok" if ok else "nok"
|
||||
|
||||
|
||||
def check_db() -> tuple[bool, dict]:
|
||||
st = timer()
|
||||
try:
|
||||
# lightweight probe; works for MySQL/Postgres
|
||||
DB.execute_sql("SELECT 1")
|
||||
return True, {"elapsed": f"{(timer() - st) * 1000.0:.1f}"}
|
||||
except Exception as e:
|
||||
return False, {"elapsed": f"{(timer() - st) * 1000.0:.1f}", "error": str(e)}
|
||||
|
||||
|
||||
def check_redis() -> tuple[bool, dict]:
|
||||
st = timer()
|
||||
try:
|
||||
ok = bool(REDIS_CONN.health())
|
||||
return ok, {"elapsed": f"{(timer() - st) * 1000.0:.1f}"}
|
||||
except Exception as e:
|
||||
return False, {"elapsed": f"{(timer() - st) * 1000.0:.1f}", "error": str(e)}
|
||||
|
||||
|
||||
def check_doc_engine() -> tuple[bool, dict]:
|
||||
st = timer()
|
||||
try:
|
||||
meta = settings.docStoreConn.health()
|
||||
# treat any successful call as ok
|
||||
return True, {"elapsed": f"{(timer() - st) * 1000.0:.1f}", **(meta or {})}
|
||||
except Exception as e:
|
||||
return False, {"elapsed": f"{(timer() - st) * 1000.0:.1f}", "error": str(e)}
|
||||
|
||||
|
||||
def check_storage() -> tuple[bool, dict]:
|
||||
st = timer()
|
||||
try:
|
||||
STORAGE_IMPL.health()
|
||||
return True, {"elapsed": f"{(timer() - st) * 1000.0:.1f}"}
|
||||
except Exception as e:
|
||||
return False, {"elapsed": f"{(timer() - st) * 1000.0:.1f}", "error": str(e)}
|
||||
|
||||
|
||||
|
||||
|
||||
def run_health_checks() -> tuple[dict, bool]:
|
||||
result: dict[str, str | dict] = {}
|
||||
|
||||
db_ok, db_meta = check_db()
|
||||
result["db"] = _ok_nok(db_ok)
|
||||
if not db_ok:
|
||||
result.setdefault("_meta", {})["db"] = db_meta
|
||||
|
||||
try:
|
||||
redis_ok, redis_meta = check_redis()
|
||||
result["redis"] = _ok_nok(redis_ok)
|
||||
if not redis_ok:
|
||||
result.setdefault("_meta", {})["redis"] = redis_meta
|
||||
except Exception:
|
||||
result["redis"] = "nok"
|
||||
|
||||
try:
|
||||
doc_ok, doc_meta = check_doc_engine()
|
||||
result["doc_engine"] = _ok_nok(doc_ok)
|
||||
if not doc_ok:
|
||||
result.setdefault("_meta", {})["doc_engine"] = doc_meta
|
||||
except Exception:
|
||||
result["doc_engine"] = "nok"
|
||||
|
||||
try:
|
||||
sto_ok, sto_meta = check_storage()
|
||||
result["storage"] = _ok_nok(sto_ok)
|
||||
if not sto_ok:
|
||||
result.setdefault("_meta", {})["storage"] = sto_meta
|
||||
except Exception:
|
||||
result["storage"] = "nok"
|
||||
|
||||
|
||||
all_ok = (result.get("db") == "ok") and (result.get("redis") == "ok") and (result.get("doc_engine") == "ok") and (result.get("storage") == "ok")
|
||||
result["status"] = "ok" if all_ok else "nok"
|
||||
return result, all_ok
|
||||
|
||||
|
||||
19
chat_demo/index.html
Normal file
19
chat_demo/index.html
Normal file
@ -0,0 +1,19 @@
|
||||
<iframe src="http://localhost:9222/next-chats/widget?shared_id=9dcfc68696c611f0bb789b9b8b765d12&from=chat&auth=U4MDU3NzkwOTZjNzExZjBiYjc4OWI5Yj&mode=master&streaming=false"
|
||||
style="position:fixed;bottom:0;right:0;width:100px;height:100px;border:none;background:transparent;z-index:9999"
|
||||
frameborder="0" allow="microphone;camera"></iframe>
|
||||
<script>
|
||||
window.addEventListener('message',e=>{
|
||||
if(e.origin!=='http://localhost:9222')return;
|
||||
if(e.data.type==='CREATE_CHAT_WINDOW'){
|
||||
if(document.getElementById('chat-win'))return;
|
||||
const i=document.createElement('iframe');
|
||||
i.id='chat-win';i.src=e.data.src;
|
||||
i.style.cssText='position:fixed;bottom:104px;right:24px;width:380px;height:500px;border:none;background:transparent;z-index:9998;display:none';
|
||||
i.frameBorder='0';i.allow='microphone;camera';
|
||||
document.body.appendChild(i);
|
||||
}else if(e.data.type==='TOGGLE_CHAT'){
|
||||
const w=document.getElementById('chat-win');
|
||||
if(w)w.style.display=e.data.isOpen?'block':'none';
|
||||
}else if(e.data.type==='SCROLL_PASSTHROUGH')window.scrollBy(0,e.data.deltaY);
|
||||
});
|
||||
</script>
|
||||
154
chat_demo/widget_demo.html
Normal file
154
chat_demo/widget_demo.html
Normal file
@ -0,0 +1,154 @@
|
||||
<!DOCTYPE html>
|
||||
<html lang="en">
|
||||
<head>
|
||||
<meta charset="UTF-8">
|
||||
<meta name="viewport" content="width=device-width, initial-scale=1.0">
|
||||
<title>Floating Chat Widget Demo</title>
|
||||
<style>
|
||||
body {
|
||||
font-family: Arial, sans-serif;
|
||||
margin: 0;
|
||||
padding: 40px;
|
||||
background: linear-gradient(135deg, #667eea 0%, #764ba2 100%);
|
||||
min-height: 100vh;
|
||||
color: white;
|
||||
}
|
||||
|
||||
.demo-content {
|
||||
max-width: 800px;
|
||||
margin: 0 auto;
|
||||
}
|
||||
|
||||
.demo-content h1 {
|
||||
text-align: center;
|
||||
font-size: 2.5rem;
|
||||
margin-bottom: 2rem;
|
||||
}
|
||||
|
||||
.demo-content p {
|
||||
font-size: 1.2rem;
|
||||
line-height: 1.6;
|
||||
margin-bottom: 1.5rem;
|
||||
}
|
||||
|
||||
.feature-list {
|
||||
background: rgba(255, 255, 255, 0.1);
|
||||
border-radius: 10px;
|
||||
padding: 2rem;
|
||||
margin: 2rem 0;
|
||||
}
|
||||
|
||||
.feature-list h3 {
|
||||
margin-top: 0;
|
||||
font-size: 1.5rem;
|
||||
}
|
||||
|
||||
.feature-list ul {
|
||||
list-style-type: none;
|
||||
padding: 0;
|
||||
}
|
||||
|
||||
.feature-list li {
|
||||
padding: 0.5rem 0;
|
||||
padding-left: 1.5rem;
|
||||
position: relative;
|
||||
}
|
||||
|
||||
.feature-list li:before {
|
||||
content: "✓";
|
||||
position: absolute;
|
||||
left: 0;
|
||||
color: #4ade80;
|
||||
font-weight: bold;
|
||||
}
|
||||
</style>
|
||||
</head>
|
||||
<body>
|
||||
<div class="demo-content">
|
||||
<h1>🚀 Floating Chat Widget Demo</h1>
|
||||
|
||||
<p>
|
||||
Welcome to our demo page! This page simulates a real website with content.
|
||||
Look for the floating chat button in the bottom-right corner - just like Intercom!
|
||||
</p>
|
||||
|
||||
<div class="feature-list">
|
||||
<h3>🎯 Widget Features</h3>
|
||||
<ul>
|
||||
<li>Floating button that stays visible while scrolling</li>
|
||||
<li>Click to open/close the chat window</li>
|
||||
<li>Minimize button to collapse the chat</li>
|
||||
<li>Professional Intercom-style design</li>
|
||||
<li>Unread message indicator (red badge)</li>
|
||||
<li>Transparent background integration</li>
|
||||
<li>Responsive design for all screen sizes</li>
|
||||
</ul>
|
||||
</div>
|
||||
|
||||
<p>
|
||||
The chat widget is completely separate from your website's content and won't
|
||||
interfere with your existing layout or functionality. It's designed to be
|
||||
lightweight and performant.
|
||||
</p>
|
||||
|
||||
<p>
|
||||
Try scrolling this page - notice how the chat button stays in position.
|
||||
Click it to start a conversation with our AI assistant!
|
||||
</p>
|
||||
|
||||
<div class="feature-list">
|
||||
<h3>🔧 Implementation</h3>
|
||||
<ul>
|
||||
<li>Simple iframe embed - just copy and paste</li>
|
||||
<li>No JavaScript dependencies required</li>
|
||||
<li>Works on any website or platform</li>
|
||||
<li>Customizable appearance and behavior</li>
|
||||
<li>Secure and privacy-focused</li>
|
||||
</ul>
|
||||
</div>
|
||||
|
||||
<p>
|
||||
This is just placeholder content to demonstrate how the widget integrates
|
||||
seamlessly with your existing website content. The widget floats above
|
||||
everything else without disrupting your user experience.
|
||||
</p>
|
||||
|
||||
<p style="margin-top: 4rem; text-align: center; font-style: italic;">
|
||||
🎉 Ready to add this to your website? Get your embed code from the admin panel!
|
||||
</p>
|
||||
</div>
|
||||
|
||||
<iframe id="main-widget" src="http://localhost:9222/next-chats/widget?shared_id=9dcfc68696c611f0bb789b9b8b765d12&from=chat&auth=U4MDU3NzkwOTZjNzExZjBiYjc4OWI5Yj&visible_avatar=1&locale=zh&mode=master&streaming=false"
|
||||
style="position:fixed;bottom:0;right:0;width:100px;height:100px;border:none;background:transparent;z-index:9999;opacity:0;transition:opacity 0.2s ease"
|
||||
frameborder="0" allow="microphone;camera"></iframe>
|
||||
<script>
|
||||
window.addEventListener('message',e=>{
|
||||
if(e.origin!=='http://localhost:9222')return;
|
||||
if(e.data.type==='WIDGET_READY'){
|
||||
// Show the main widget when React is ready
|
||||
const mainWidget = document.getElementById('main-widget');
|
||||
if(mainWidget) mainWidget.style.opacity = '1';
|
||||
}else if(e.data.type==='CREATE_CHAT_WINDOW'){
|
||||
if(document.getElementById('chat-win'))return;
|
||||
const i=document.createElement('iframe');
|
||||
i.id='chat-win';i.src=e.data.src;
|
||||
i.style.cssText='position:fixed;bottom:104px;right:24px;width:380px;height:500px;border:none;background:transparent;z-index:9998;display:none;opacity:0;transition:opacity 0.2s ease';
|
||||
i.frameBorder='0';i.allow='microphone;camera';
|
||||
document.body.appendChild(i);
|
||||
}else if(e.data.type==='TOGGLE_CHAT'){
|
||||
const w=document.getElementById('chat-win');
|
||||
if(w){
|
||||
if(e.data.isOpen){
|
||||
w.style.display='block';
|
||||
// Wait for the iframe content to be ready before showing
|
||||
setTimeout(() => w.style.opacity='1', 100);
|
||||
}else{
|
||||
w.style.opacity='0';
|
||||
setTimeout(() => w.style.display='none', 200);
|
||||
}
|
||||
}
|
||||
}else if(e.data.type==='SCROLL_PASSTHROUGH')window.scrollBy(0,e.data.deltaY);
|
||||
});
|
||||
</script>
|
||||
</body>
|
||||
</html>
|
||||
@ -219,6 +219,70 @@
|
||||
}
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "TokenPony",
|
||||
"logo": "",
|
||||
"tags": "LLM",
|
||||
"status": "1",
|
||||
"llm": [
|
||||
{
|
||||
"llm_name": "qwen3-8b",
|
||||
"tags": "LLM,CHAT,131k",
|
||||
"max_tokens": 131000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "deepseek-v3-0324",
|
||||
"tags": "LLM,CHAT,128k",
|
||||
"max_tokens": 128000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "qwen3-32b",
|
||||
"tags": "LLM,CHAT,131k",
|
||||
"max_tokens": 131000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "kimi-k2-instruct",
|
||||
"tags": "LLM,CHAT,128K",
|
||||
"max_tokens": 128000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "deepseek-r1-0528",
|
||||
"tags": "LLM,CHAT,164k",
|
||||
"max_tokens": 164000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "qwen3-coder-480b",
|
||||
"tags": "LLM,CHAT,1024k",
|
||||
"max_tokens": 1024000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "glm-4.5",
|
||||
"tags": "LLM,CHAT,131K",
|
||||
"max_tokens": 131000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "deepseek-v3.1",
|
||||
"tags": "LLM,CHAT,128k",
|
||||
"max_tokens": 128000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
}
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "Tongyi-Qianwen",
|
||||
"logo": "",
|
||||
@ -302,6 +366,20 @@
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "qwen-plus-2025-07-28",
|
||||
"tags": "LLM,CHAT,132k",
|
||||
"max_tokens": 131072,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "qwen-plus-2025-07-14",
|
||||
"tags": "LLM,CHAT,132k",
|
||||
"max_tokens": 131072,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "qwq-plus-latest",
|
||||
"tags": "LLM,CHAT,132k",
|
||||
@ -309,6 +387,27 @@
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "qwen-flash",
|
||||
"tags": "LLM,CHAT,1M",
|
||||
"max_tokens": 1000000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "qwen-flash-2025-07-28",
|
||||
"tags": "LLM,CHAT,1M",
|
||||
"max_tokens": 1000000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "qwen3-max-preview",
|
||||
"tags": "LLM,CHAT,256k",
|
||||
"max_tokens": 256000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "qwen3-coder-480b-a35b-instruct",
|
||||
"tags": "LLM,CHAT,256k",
|
||||
@ -590,7 +689,7 @@
|
||||
},
|
||||
{
|
||||
"llm_name": "glm-4",
|
||||
"tags":"LLM,CHAT,128K",
|
||||
"tags": "LLM,CHAT,128K",
|
||||
"max_tokens": 128000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
@ -720,6 +819,20 @@
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "kimi-k2-0905-preview",
|
||||
"tags": "LLM,CHAT,256k",
|
||||
"max_tokens": 262144,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "kimi-k2-turbo-preview",
|
||||
"tags": "LLM,CHAT,256k",
|
||||
"max_tokens": 262144,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "kimi-latest",
|
||||
"tags": "LLM,CHAT,8k,32k,128k",
|
||||
@ -2662,21 +2775,21 @@
|
||||
"status": "1",
|
||||
"llm": [
|
||||
{
|
||||
"llm_name": "Qwen3-Embedding-8B",
|
||||
"llm_name": "Qwen/Qwen3-Embedding-8B",
|
||||
"tags": "TEXT EMBEDDING,TEXT RE-RANK,32k",
|
||||
"max_tokens": 32000,
|
||||
"model_type": "embedding",
|
||||
"is_tools": false
|
||||
},
|
||||
{
|
||||
"llm_name": "Qwen3-Embedding-4B",
|
||||
"llm_name": "Qwen/Qwen3-Embedding-4B",
|
||||
"tags": "TEXT EMBEDDING,TEXT RE-RANK,32k",
|
||||
"max_tokens": 32000,
|
||||
"model_type": "embedding",
|
||||
"is_tools": false
|
||||
},
|
||||
{
|
||||
"llm_name": "Qwen3-Embedding-0.6B",
|
||||
"llm_name": "Qwen/Qwen3-Embedding-0.6B",
|
||||
"tags": "TEXT EMBEDDING,TEXT RE-RANK,32k",
|
||||
"max_tokens": 32000,
|
||||
"model_type": "embedding",
|
||||
@ -2759,6 +2872,20 @@
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "Pro/deepseek-ai/DeepSeek-V3.1",
|
||||
"tags": "LLM,CHAT,160k",
|
||||
"max_tokens": 160000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "deepseek-ai/DeepSeek-V3.1",
|
||||
"tags": "LLM,CHAT,160",
|
||||
"max_tokens": 160000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "deepseek-ai/DeepSeek-R1-Distill-Qwen-32B",
|
||||
"tags": "LLM,CHAT,32k",
|
||||
@ -4413,6 +4540,288 @@
|
||||
"is_tools": false
|
||||
}
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "CometAPI",
|
||||
"logo": "",
|
||||
"tags": "LLM,TEXT EMBEDDING,IMAGE2TEXT",
|
||||
"status": "1",
|
||||
"llm": [
|
||||
{
|
||||
"llm_name": "gpt-5-chat-latest",
|
||||
"tags": "LLM,CHAT,400k",
|
||||
"max_tokens": 400000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "chatgpt-4o-latest",
|
||||
"tags": "LLM,CHAT,128k",
|
||||
"max_tokens": 128000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "gpt-5-mini",
|
||||
"tags": "LLM,CHAT,400k",
|
||||
"max_tokens": 400000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "gpt-5-nano",
|
||||
"tags": "LLM,CHAT,400k",
|
||||
"max_tokens": 400000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "gpt-5",
|
||||
"tags": "LLM,CHAT,400k",
|
||||
"max_tokens": 400000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "gpt-4.1-mini",
|
||||
"tags": "LLM,CHAT,1M",
|
||||
"max_tokens": 1047576,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "gpt-4.1-nano",
|
||||
"tags": "LLM,CHAT,1M",
|
||||
"max_tokens": 1047576,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "gpt-4.1",
|
||||
"tags": "LLM,CHAT,1M",
|
||||
"max_tokens": 1047576,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "gpt-4o-mini",
|
||||
"tags": "LLM,CHAT,128k",
|
||||
"max_tokens": 128000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "o4-mini-2025-04-16",
|
||||
"tags": "LLM,CHAT,200k",
|
||||
"max_tokens": 200000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "o3-pro-2025-06-10",
|
||||
"tags": "LLM,CHAT,200k",
|
||||
"max_tokens": 200000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "claude-opus-4-1-20250805",
|
||||
"tags": "LLM,CHAT,200k,IMAGE2TEXT",
|
||||
"max_tokens": 200000,
|
||||
"model_type": "image2text",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "claude-opus-4-1-20250805-thinking",
|
||||
"tags": "LLM,CHAT,200k,IMAGE2TEXT",
|
||||
"max_tokens": 200000,
|
||||
"model_type": "image2text",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "claude-sonnet-4-20250514",
|
||||
"tags": "LLM,CHAT,200k,IMAGE2TEXT",
|
||||
"max_tokens": 200000,
|
||||
"model_type": "image2text",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "claude-sonnet-4-20250514-thinking",
|
||||
"tags": "LLM,CHAT,200k,IMAGE2TEXT",
|
||||
"max_tokens": 200000,
|
||||
"model_type": "image2text",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "claude-3-7-sonnet-latest",
|
||||
"tags": "LLM,CHAT,200k",
|
||||
"max_tokens": 200000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "claude-3-5-haiku-latest",
|
||||
"tags": "LLM,CHAT,200k",
|
||||
"max_tokens": 200000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "gemini-2.5-pro",
|
||||
"tags": "LLM,CHAT,1M,IMAGE2TEXT",
|
||||
"max_tokens": 1000000,
|
||||
"model_type": "image2text",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "gemini-2.5-flash",
|
||||
"tags": "LLM,CHAT,1M,IMAGE2TEXT",
|
||||
"max_tokens": 1000000,
|
||||
"model_type": "image2text",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "gemini-2.5-flash-lite",
|
||||
"tags": "LLM,CHAT,1M,IMAGE2TEXT",
|
||||
"max_tokens": 1000000,
|
||||
"model_type": "image2text",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "gemini-2.0-flash",
|
||||
"tags": "LLM,CHAT,1M,IMAGE2TEXT",
|
||||
"max_tokens": 1000000,
|
||||
"model_type": "image2text",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "grok-4-0709",
|
||||
"tags": "LLM,CHAT,131k",
|
||||
"max_tokens": 131072,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "grok-3",
|
||||
"tags": "LLM,CHAT,131k",
|
||||
"max_tokens": 131072,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "grok-3-mini",
|
||||
"tags": "LLM,CHAT,131k",
|
||||
"max_tokens": 131072,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "grok-2-image-1212",
|
||||
"tags": "LLM,CHAT,32k,IMAGE2TEXT",
|
||||
"max_tokens": 32768,
|
||||
"model_type": "image2text",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "deepseek-v3.1",
|
||||
"tags": "LLM,CHAT,64k",
|
||||
"max_tokens": 64000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "deepseek-v3",
|
||||
"tags": "LLM,CHAT,64k",
|
||||
"max_tokens": 64000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "deepseek-r1-0528",
|
||||
"tags": "LLM,CHAT,164k",
|
||||
"max_tokens": 164000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "deepseek-chat",
|
||||
"tags": "LLM,CHAT,32k",
|
||||
"max_tokens": 32000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "deepseek-reasoner",
|
||||
"tags": "LLM,CHAT,64k",
|
||||
"max_tokens": 64000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "qwen3-30b-a3b",
|
||||
"tags": "LLM,CHAT,128k",
|
||||
"max_tokens": 128000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "qwen3-coder-plus-2025-07-22",
|
||||
"tags": "LLM,CHAT,128k",
|
||||
"max_tokens": 128000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "text-embedding-ada-002",
|
||||
"tags": "TEXT EMBEDDING,8K",
|
||||
"max_tokens": 8191,
|
||||
"model_type": "embedding",
|
||||
"is_tools": false
|
||||
},
|
||||
{
|
||||
"llm_name": "text-embedding-3-small",
|
||||
"tags": "TEXT EMBEDDING,8K",
|
||||
"max_tokens": 8191,
|
||||
"model_type": "embedding",
|
||||
"is_tools": false
|
||||
},
|
||||
{
|
||||
"llm_name": "text-embedding-3-large",
|
||||
"tags": "TEXT EMBEDDING,8K",
|
||||
"max_tokens": 8191,
|
||||
"model_type": "embedding",
|
||||
"is_tools": false
|
||||
},
|
||||
{
|
||||
"llm_name": "whisper-1",
|
||||
"tags": "SPEECH2TEXT",
|
||||
"max_tokens": 26214400,
|
||||
"model_type": "speech2text",
|
||||
"is_tools": false
|
||||
},
|
||||
{
|
||||
"llm_name": "tts-1",
|
||||
"tags": "TTS",
|
||||
"max_tokens": 2048,
|
||||
"model_type": "tts",
|
||||
"is_tools": false
|
||||
}
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "Meituan",
|
||||
"logo": "",
|
||||
"tags": "LLM",
|
||||
"status": "1",
|
||||
"llm": [
|
||||
{
|
||||
"llm_name": "LongCat-Flash-Chat",
|
||||
"tags": "LLM,CHAT,8000",
|
||||
"max_tokens": 8000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
@ -1,6 +1,9 @@
|
||||
ragflow:
|
||||
host: 0.0.0.0
|
||||
http_port: 9380
|
||||
admin:
|
||||
host: 0.0.0.0
|
||||
http_port: 9381
|
||||
mysql:
|
||||
name: 'rag_flow'
|
||||
user: 'root'
|
||||
|
||||
@ -22,10 +22,10 @@ from openpyxl import Workbook, load_workbook
|
||||
from rag.nlp import find_codec
|
||||
|
||||
# copied from `/openpyxl/cell/cell.py`
|
||||
ILLEGAL_CHARACTERS_RE = re.compile(r'[\000-\010]|[\013-\014]|[\016-\037]')
|
||||
ILLEGAL_CHARACTERS_RE = re.compile(r"[\000-\010]|[\013-\014]|[\016-\037]")
|
||||
|
||||
|
||||
class RAGFlowExcelParser:
|
||||
|
||||
@staticmethod
|
||||
def _load_excel_to_workbook(file_like_object):
|
||||
if isinstance(file_like_object, bytes):
|
||||
@ -36,7 +36,7 @@ class RAGFlowExcelParser:
|
||||
file_head = file_like_object.read(4)
|
||||
file_like_object.seek(0)
|
||||
|
||||
if not (file_head.startswith(b'PK\x03\x04') or file_head.startswith(b'\xD0\xCF\x11\xE0')):
|
||||
if not (file_head.startswith(b"PK\x03\x04") or file_head.startswith(b"\xd0\xcf\x11\xe0")):
|
||||
logging.info("Not an Excel file, converting CSV to Excel Workbook")
|
||||
|
||||
try:
|
||||
@ -48,7 +48,7 @@ class RAGFlowExcelParser:
|
||||
raise Exception(f"Failed to parse CSV and convert to Excel Workbook: {e_csv}")
|
||||
|
||||
try:
|
||||
return load_workbook(file_like_object,data_only= True)
|
||||
return load_workbook(file_like_object, data_only=True)
|
||||
except Exception as e:
|
||||
logging.info(f"openpyxl load error: {e}, try pandas instead")
|
||||
try:
|
||||
@ -59,7 +59,7 @@ class RAGFlowExcelParser:
|
||||
except Exception as ex:
|
||||
logging.info(f"pandas with default engine load error: {ex}, try calamine instead")
|
||||
file_like_object.seek(0)
|
||||
df = pd.read_excel(file_like_object, engine='calamine')
|
||||
df = pd.read_excel(file_like_object, engine="calamine")
|
||||
return RAGFlowExcelParser._dataframe_to_workbook(df)
|
||||
except Exception as e_pandas:
|
||||
raise Exception(f"pandas.read_excel error: {e_pandas}, original openpyxl error: {e}")
|
||||
@ -116,21 +116,33 @@ class RAGFlowExcelParser:
|
||||
tb = ""
|
||||
tb += f"<table><caption>{sheetname}</caption>"
|
||||
tb += tb_rows_0
|
||||
for r in list(
|
||||
rows[1 + chunk_i * chunk_rows: min(1 + (chunk_i + 1) * chunk_rows, len(rows))]
|
||||
):
|
||||
for r in list(rows[1 + chunk_i * chunk_rows : min(1 + (chunk_i + 1) * chunk_rows, len(rows))]):
|
||||
tb += "<tr>"
|
||||
for i, c in enumerate(r):
|
||||
if c.value is None:
|
||||
tb += "<td></td>"
|
||||
else:
|
||||
tb += f"<td>{c.value}</td>"
|
||||
tb += f"<td>{escape(_fmt(c.value))}</td>"
|
||||
tb += "</tr>"
|
||||
tb += "</table>\n"
|
||||
tb_chunks.append(tb)
|
||||
|
||||
return tb_chunks
|
||||
|
||||
def markdown(self, fnm):
|
||||
import pandas as pd
|
||||
|
||||
file_like_object = BytesIO(fnm) if not isinstance(fnm, str) else fnm
|
||||
try:
|
||||
file_like_object.seek(0)
|
||||
df = pd.read_excel(file_like_object)
|
||||
except Exception as e:
|
||||
logging.warning(f"Parse spreadsheet error: {e}, trying to interpret as CSV file")
|
||||
file_like_object.seek(0)
|
||||
df = pd.read_csv(file_like_object)
|
||||
df = df.replace(r"^\s*$", "", regex=True)
|
||||
return df.to_markdown(index=False)
|
||||
|
||||
def __call__(self, fnm):
|
||||
file_like_object = BytesIO(fnm) if not isinstance(fnm, str) else fnm
|
||||
wb = RAGFlowExcelParser._load_excel_to_workbook(file_like_object)
|
||||
|
||||
@ -37,7 +37,7 @@ TITLE_TAGS = {"h1": "#", "h2": "##", "h3": "###", "h4": "#####", "h5": "#####",
|
||||
|
||||
|
||||
class RAGFlowHtmlParser:
|
||||
def __call__(self, fnm, binary=None, chunk_token_num=None):
|
||||
def __call__(self, fnm, binary=None, chunk_token_num=512):
|
||||
if binary:
|
||||
encoding = find_codec(binary)
|
||||
txt = binary.decode(encoding, errors="ignore")
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@ -16,24 +16,28 @@
|
||||
import io
|
||||
import sys
|
||||
import threading
|
||||
|
||||
import pdfplumber
|
||||
|
||||
from .ocr import OCR
|
||||
from .recognizer import Recognizer
|
||||
from .layout_recognizer import AscendLayoutRecognizer
|
||||
from .layout_recognizer import LayoutRecognizer4YOLOv10 as LayoutRecognizer
|
||||
from .table_structure_recognizer import TableStructureRecognizer
|
||||
|
||||
|
||||
LOCK_KEY_pdfplumber = "global_shared_lock_pdfplumber"
|
||||
if LOCK_KEY_pdfplumber not in sys.modules:
|
||||
sys.modules[LOCK_KEY_pdfplumber] = threading.Lock()
|
||||
|
||||
|
||||
def init_in_out(args):
|
||||
from PIL import Image
|
||||
import os
|
||||
import traceback
|
||||
|
||||
from PIL import Image
|
||||
|
||||
from api.utils.file_utils import traversal_files
|
||||
|
||||
images = []
|
||||
outputs = []
|
||||
|
||||
@ -44,8 +48,7 @@ def init_in_out(args):
|
||||
nonlocal outputs, images
|
||||
with sys.modules[LOCK_KEY_pdfplumber]:
|
||||
pdf = pdfplumber.open(fnm)
|
||||
images = [p.to_image(resolution=72 * zoomin).annotated for i, p in
|
||||
enumerate(pdf.pages)]
|
||||
images = [p.to_image(resolution=72 * zoomin).annotated for i, p in enumerate(pdf.pages)]
|
||||
|
||||
for i, page in enumerate(images):
|
||||
outputs.append(os.path.split(fnm)[-1] + f"_{i}.jpg")
|
||||
@ -57,10 +60,10 @@ def init_in_out(args):
|
||||
pdf_pages(fnm)
|
||||
return
|
||||
try:
|
||||
fp = open(fnm, 'rb')
|
||||
fp = open(fnm, "rb")
|
||||
binary = fp.read()
|
||||
fp.close()
|
||||
images.append(Image.open(io.BytesIO(binary)).convert('RGB'))
|
||||
images.append(Image.open(io.BytesIO(binary)).convert("RGB"))
|
||||
outputs.append(os.path.split(fnm)[-1])
|
||||
except Exception:
|
||||
traceback.print_exc()
|
||||
@ -81,6 +84,7 @@ __all__ = [
|
||||
"OCR",
|
||||
"Recognizer",
|
||||
"LayoutRecognizer",
|
||||
"AscendLayoutRecognizer",
|
||||
"TableStructureRecognizer",
|
||||
"init_in_out",
|
||||
]
|
||||
|
||||
@ -14,6 +14,8 @@
|
||||
# limitations under the License.
|
||||
#
|
||||
|
||||
import logging
|
||||
import math
|
||||
import os
|
||||
import re
|
||||
from collections import Counter
|
||||
@ -45,28 +47,22 @@ class LayoutRecognizer(Recognizer):
|
||||
|
||||
def __init__(self, domain):
|
||||
try:
|
||||
model_dir = os.path.join(
|
||||
get_project_base_directory(),
|
||||
"rag/res/deepdoc")
|
||||
model_dir = os.path.join(get_project_base_directory(), "rag/res/deepdoc")
|
||||
super().__init__(self.labels, domain, model_dir)
|
||||
except Exception:
|
||||
model_dir = snapshot_download(repo_id="InfiniFlow/deepdoc",
|
||||
local_dir=os.path.join(get_project_base_directory(), "rag/res/deepdoc"),
|
||||
local_dir_use_symlinks=False)
|
||||
model_dir = snapshot_download(repo_id="InfiniFlow/deepdoc", local_dir=os.path.join(get_project_base_directory(), "rag/res/deepdoc"), local_dir_use_symlinks=False)
|
||||
super().__init__(self.labels, domain, model_dir)
|
||||
|
||||
self.garbage_layouts = ["footer", "header", "reference"]
|
||||
self.client = None
|
||||
if os.environ.get("TENSORRT_DLA_SVR"):
|
||||
from deepdoc.vision.dla_cli import DLAClient
|
||||
|
||||
self.client = DLAClient(os.environ["TENSORRT_DLA_SVR"])
|
||||
|
||||
def __call__(self, image_list, ocr_res, scale_factor=3, thr=0.2, batch_size=16, drop=True):
|
||||
def __is_garbage(b):
|
||||
patt = [r"^•+$", "^[0-9]{1,2} / ?[0-9]{1,2}$",
|
||||
r"^[0-9]{1,2} of [0-9]{1,2}$", "^http://[^ ]{12,}",
|
||||
"\\(cid *: *[0-9]+ *\\)"
|
||||
]
|
||||
patt = [r"^•+$", "^[0-9]{1,2} / ?[0-9]{1,2}$", r"^[0-9]{1,2} of [0-9]{1,2}$", "^http://[^ ]{12,}", "\\(cid *: *[0-9]+ *\\)"]
|
||||
return any([re.search(p, b["text"]) for p in patt])
|
||||
|
||||
if self.client:
|
||||
@ -82,18 +78,23 @@ class LayoutRecognizer(Recognizer):
|
||||
page_layout = []
|
||||
for pn, lts in enumerate(layouts):
|
||||
bxs = ocr_res[pn]
|
||||
lts = [{"type": b["type"],
|
||||
lts = [
|
||||
{
|
||||
"type": b["type"],
|
||||
"score": float(b["score"]),
|
||||
"x0": b["bbox"][0] / scale_factor, "x1": b["bbox"][2] / scale_factor,
|
||||
"top": b["bbox"][1] / scale_factor, "bottom": b["bbox"][-1] / scale_factor,
|
||||
"x0": b["bbox"][0] / scale_factor,
|
||||
"x1": b["bbox"][2] / scale_factor,
|
||||
"top": b["bbox"][1] / scale_factor,
|
||||
"bottom": b["bbox"][-1] / scale_factor,
|
||||
"page_number": pn,
|
||||
} for b in lts if float(b["score"]) >= 0.4 or b["type"] not in self.garbage_layouts]
|
||||
lts = self.sort_Y_firstly(lts, np.mean(
|
||||
[lt["bottom"] - lt["top"] for lt in lts]) / 2)
|
||||
}
|
||||
for b in lts
|
||||
if float(b["score"]) >= 0.4 or b["type"] not in self.garbage_layouts
|
||||
]
|
||||
lts = self.sort_Y_firstly(lts, np.mean([lt["bottom"] - lt["top"] for lt in lts]) / 2)
|
||||
lts = self.layouts_cleanup(bxs, lts)
|
||||
page_layout.append(lts)
|
||||
|
||||
# Tag layout type, layouts are ready
|
||||
def findLayout(ty):
|
||||
nonlocal bxs, lts, self
|
||||
lts_ = [lt for lt in lts if lt["type"] == ty]
|
||||
@ -106,21 +107,17 @@ class LayoutRecognizer(Recognizer):
|
||||
bxs.pop(i)
|
||||
continue
|
||||
|
||||
ii = self.find_overlapped_with_threshold(bxs[i], lts_,
|
||||
thr=0.4)
|
||||
if ii is None: # belong to nothing
|
||||
ii = self.find_overlapped_with_threshold(bxs[i], lts_, thr=0.4)
|
||||
if ii is None:
|
||||
bxs[i]["layout_type"] = ""
|
||||
i += 1
|
||||
continue
|
||||
lts_[ii]["visited"] = True
|
||||
keep_feats = [
|
||||
lts_[
|
||||
ii]["type"] == "footer" and bxs[i]["bottom"] < image_list[pn].size[1] * 0.9 / scale_factor,
|
||||
lts_[
|
||||
ii]["type"] == "header" and bxs[i]["top"] > image_list[pn].size[1] * 0.1 / scale_factor,
|
||||
lts_[ii]["type"] == "footer" and bxs[i]["bottom"] < image_list[pn].size[1] * 0.9 / scale_factor,
|
||||
lts_[ii]["type"] == "header" and bxs[i]["top"] > image_list[pn].size[1] * 0.1 / scale_factor,
|
||||
]
|
||||
if drop and lts_[
|
||||
ii]["type"] in self.garbage_layouts and not any(keep_feats):
|
||||
if drop and lts_[ii]["type"] in self.garbage_layouts and not any(keep_feats):
|
||||
if lts_[ii]["type"] not in garbages:
|
||||
garbages[lts_[ii]["type"]] = []
|
||||
garbages[lts_[ii]["type"]].append(bxs[i]["text"])
|
||||
@ -128,17 +125,14 @@ class LayoutRecognizer(Recognizer):
|
||||
continue
|
||||
|
||||
bxs[i]["layoutno"] = f"{ty}-{ii}"
|
||||
bxs[i]["layout_type"] = lts_[ii]["type"] if lts_[
|
||||
ii]["type"] != "equation" else "figure"
|
||||
bxs[i]["layout_type"] = lts_[ii]["type"] if lts_[ii]["type"] != "equation" else "figure"
|
||||
i += 1
|
||||
|
||||
for lt in ["footer", "header", "reference", "figure caption",
|
||||
"table caption", "title", "table", "text", "figure", "equation"]:
|
||||
for lt in ["footer", "header", "reference", "figure caption", "table caption", "title", "table", "text", "figure", "equation"]:
|
||||
findLayout(lt)
|
||||
|
||||
# add box to figure layouts which has not text box
|
||||
for i, lt in enumerate(
|
||||
[lt for lt in lts if lt["type"] in ["figure", "equation"]]):
|
||||
for i, lt in enumerate([lt for lt in lts if lt["type"] in ["figure", "equation"]]):
|
||||
if lt.get("visited"):
|
||||
continue
|
||||
lt = deepcopy(lt)
|
||||
@ -206,13 +200,11 @@ class LayoutRecognizer4YOLOv10(LayoutRecognizer):
|
||||
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
|
||||
top, bottom = int(round(dh - 0.1)) if self.center else 0, int(round(dh + 0.1))
|
||||
left, right = int(round(dw - 0.1)) if self.center else 0, int(round(dw + 0.1))
|
||||
img = cv2.copyMakeBorder(
|
||||
img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=(114, 114, 114)
|
||||
) # add border
|
||||
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=(114, 114, 114)) # add border
|
||||
img /= 255.0
|
||||
img = img.transpose(2, 0, 1)
|
||||
img = img[np.newaxis, :, :, :].astype(np.float32)
|
||||
inputs.append({self.input_names[0]: img, "scale_factor": [shape[1]/ww, shape[0]/hh, dw, dh]})
|
||||
inputs.append({self.input_names[0]: img, "scale_factor": [shape[1] / ww, shape[0] / hh, dw, dh]})
|
||||
|
||||
return inputs
|
||||
|
||||
@ -230,8 +222,7 @@ class LayoutRecognizer4YOLOv10(LayoutRecognizer):
|
||||
boxes[:, 2] -= inputs["scale_factor"][2]
|
||||
boxes[:, 1] -= inputs["scale_factor"][3]
|
||||
boxes[:, 3] -= inputs["scale_factor"][3]
|
||||
input_shape = np.array([inputs["scale_factor"][0], inputs["scale_factor"][1], inputs["scale_factor"][0],
|
||||
inputs["scale_factor"][1]])
|
||||
input_shape = np.array([inputs["scale_factor"][0], inputs["scale_factor"][1], inputs["scale_factor"][0], inputs["scale_factor"][1]])
|
||||
boxes = np.multiply(boxes, input_shape, dtype=np.float32)
|
||||
|
||||
unique_class_ids = np.unique(class_ids)
|
||||
@ -243,8 +234,223 @@ class LayoutRecognizer4YOLOv10(LayoutRecognizer):
|
||||
class_keep_boxes = nms(class_boxes, class_scores, 0.45)
|
||||
indices.extend(class_indices[class_keep_boxes])
|
||||
|
||||
return [{
|
||||
"type": self.label_list[class_ids[i]].lower(),
|
||||
"bbox": [float(t) for t in boxes[i].tolist()],
|
||||
"score": float(scores[i])
|
||||
} for i in indices]
|
||||
return [{"type": self.label_list[class_ids[i]].lower(), "bbox": [float(t) for t in boxes[i].tolist()], "score": float(scores[i])} for i in indices]
|
||||
|
||||
|
||||
class AscendLayoutRecognizer(Recognizer):
|
||||
labels = [
|
||||
"title",
|
||||
"Text",
|
||||
"Reference",
|
||||
"Figure",
|
||||
"Figure caption",
|
||||
"Table",
|
||||
"Table caption",
|
||||
"Table caption",
|
||||
"Equation",
|
||||
"Figure caption",
|
||||
]
|
||||
|
||||
def __init__(self, domain):
|
||||
from ais_bench.infer.interface import InferSession
|
||||
|
||||
model_dir = os.path.join(get_project_base_directory(), "rag/res/deepdoc")
|
||||
model_file_path = os.path.join(model_dir, domain + ".om")
|
||||
|
||||
if not os.path.exists(model_file_path):
|
||||
raise ValueError(f"Model file not found: {model_file_path}")
|
||||
|
||||
device_id = int(os.getenv("ASCEND_LAYOUT_RECOGNIZER_DEVICE_ID", 0))
|
||||
self.session = InferSession(device_id=device_id, model_path=model_file_path)
|
||||
self.input_shape = self.session.get_inputs()[0].shape[2:4] # H,W
|
||||
self.garbage_layouts = ["footer", "header", "reference"]
|
||||
|
||||
def preprocess(self, image_list):
|
||||
inputs = []
|
||||
H, W = self.input_shape
|
||||
for img in image_list:
|
||||
h, w = img.shape[:2]
|
||||
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB).astype(np.float32)
|
||||
|
||||
r = min(H / h, W / w)
|
||||
new_unpad = (int(round(w * r)), int(round(h * r)))
|
||||
dw, dh = (W - new_unpad[0]) / 2.0, (H - new_unpad[1]) / 2.0
|
||||
|
||||
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
|
||||
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
|
||||
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
|
||||
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=(114, 114, 114))
|
||||
|
||||
img /= 255.0
|
||||
img = img.transpose(2, 0, 1)[np.newaxis, :, :, :].astype(np.float32)
|
||||
|
||||
inputs.append(
|
||||
{
|
||||
"image": img,
|
||||
"scale_factor": [w / new_unpad[0], h / new_unpad[1]],
|
||||
"pad": [dw, dh],
|
||||
"orig_shape": [h, w],
|
||||
}
|
||||
)
|
||||
return inputs
|
||||
|
||||
def postprocess(self, boxes, inputs, thr=0.25):
|
||||
arr = np.squeeze(boxes)
|
||||
if arr.ndim == 1:
|
||||
arr = arr.reshape(1, -1)
|
||||
|
||||
results = []
|
||||
if arr.shape[1] == 6:
|
||||
# [x1,y1,x2,y2,score,cls]
|
||||
m = arr[:, 4] >= thr
|
||||
arr = arr[m]
|
||||
if arr.size == 0:
|
||||
return []
|
||||
xyxy = arr[:, :4].astype(np.float32)
|
||||
scores = arr[:, 4].astype(np.float32)
|
||||
cls_ids = arr[:, 5].astype(np.int32)
|
||||
|
||||
if "pad" in inputs:
|
||||
dw, dh = inputs["pad"]
|
||||
sx, sy = inputs["scale_factor"]
|
||||
xyxy[:, [0, 2]] -= dw
|
||||
xyxy[:, [1, 3]] -= dh
|
||||
xyxy *= np.array([sx, sy, sx, sy], dtype=np.float32)
|
||||
else:
|
||||
# backup
|
||||
sx, sy = inputs["scale_factor"]
|
||||
xyxy *= np.array([sx, sy, sx, sy], dtype=np.float32)
|
||||
|
||||
keep_indices = []
|
||||
for c in np.unique(cls_ids):
|
||||
idx = np.where(cls_ids == c)[0]
|
||||
k = nms(xyxy[idx], scores[idx], 0.45)
|
||||
keep_indices.extend(idx[k])
|
||||
|
||||
for i in keep_indices:
|
||||
cid = int(cls_ids[i])
|
||||
if 0 <= cid < len(self.labels):
|
||||
results.append({"type": self.labels[cid].lower(), "bbox": [float(t) for t in xyxy[i].tolist()], "score": float(scores[i])})
|
||||
return results
|
||||
|
||||
raise ValueError(f"Unexpected output shape: {arr.shape}")
|
||||
|
||||
def __call__(self, image_list, ocr_res, scale_factor=3, thr=0.2, batch_size=16, drop=True):
|
||||
import re
|
||||
from collections import Counter
|
||||
|
||||
assert len(image_list) == len(ocr_res)
|
||||
|
||||
images = [np.array(im) if not isinstance(im, np.ndarray) else im for im in image_list]
|
||||
layouts_all_pages = [] # list of list[{"type","score","bbox":[x1,y1,x2,y2]}]
|
||||
|
||||
conf_thr = max(thr, 0.08)
|
||||
|
||||
batch_loop_cnt = math.ceil(float(len(images)) / batch_size)
|
||||
for bi in range(batch_loop_cnt):
|
||||
s = bi * batch_size
|
||||
e = min((bi + 1) * batch_size, len(images))
|
||||
batch_images = images[s:e]
|
||||
|
||||
inputs_list = self.preprocess(batch_images)
|
||||
logging.debug("preprocess done")
|
||||
|
||||
for ins in inputs_list:
|
||||
feeds = [ins["image"]]
|
||||
out_list = self.session.infer(feeds=feeds, mode="static")
|
||||
|
||||
for out in out_list:
|
||||
lts = self.postprocess(out, ins, conf_thr)
|
||||
|
||||
page_lts = []
|
||||
for b in lts:
|
||||
if float(b["score"]) >= 0.4 or b["type"] not in self.garbage_layouts:
|
||||
x0, y0, x1, y1 = b["bbox"]
|
||||
page_lts.append(
|
||||
{
|
||||
"type": b["type"],
|
||||
"score": float(b["score"]),
|
||||
"x0": float(x0) / scale_factor,
|
||||
"x1": float(x1) / scale_factor,
|
||||
"top": float(y0) / scale_factor,
|
||||
"bottom": float(y1) / scale_factor,
|
||||
"page_number": len(layouts_all_pages),
|
||||
}
|
||||
)
|
||||
layouts_all_pages.append(page_lts)
|
||||
|
||||
def _is_garbage_text(box):
|
||||
patt = [r"^•+$", r"^[0-9]{1,2} / ?[0-9]{1,2}$", r"^[0-9]{1,2} of [0-9]{1,2}$", r"^http://[^ ]{12,}", r"\(cid *: *[0-9]+ *\)"]
|
||||
return any(re.search(p, box.get("text", "")) for p in patt)
|
||||
|
||||
boxes_out = []
|
||||
page_layout = []
|
||||
garbages = {}
|
||||
|
||||
for pn, lts in enumerate(layouts_all_pages):
|
||||
if lts:
|
||||
avg_h = np.mean([lt["bottom"] - lt["top"] for lt in lts])
|
||||
lts = self.sort_Y_firstly(lts, avg_h / 2 if avg_h > 0 else 0)
|
||||
|
||||
bxs = ocr_res[pn]
|
||||
lts = self.layouts_cleanup(bxs, lts)
|
||||
page_layout.append(lts)
|
||||
|
||||
def _tag_layout(ty):
|
||||
nonlocal bxs, lts
|
||||
lts_of_ty = [lt for lt in lts if lt["type"] == ty]
|
||||
i = 0
|
||||
while i < len(bxs):
|
||||
if bxs[i].get("layout_type"):
|
||||
i += 1
|
||||
continue
|
||||
if _is_garbage_text(bxs[i]):
|
||||
bxs.pop(i)
|
||||
continue
|
||||
|
||||
ii = self.find_overlapped_with_threshold(bxs[i], lts_of_ty, thr=0.4)
|
||||
if ii is None:
|
||||
bxs[i]["layout_type"] = ""
|
||||
i += 1
|
||||
continue
|
||||
|
||||
lts_of_ty[ii]["visited"] = True
|
||||
|
||||
keep_feats = [
|
||||
lts_of_ty[ii]["type"] == "footer" and bxs[i]["bottom"] < image_list[pn].shape[0] * 0.9 / scale_factor,
|
||||
lts_of_ty[ii]["type"] == "header" and bxs[i]["top"] > image_list[pn].shape[0] * 0.1 / scale_factor,
|
||||
]
|
||||
if drop and lts_of_ty[ii]["type"] in self.garbage_layouts and not any(keep_feats):
|
||||
garbages.setdefault(lts_of_ty[ii]["type"], []).append(bxs[i].get("text", ""))
|
||||
bxs.pop(i)
|
||||
continue
|
||||
|
||||
bxs[i]["layoutno"] = f"{ty}-{ii}"
|
||||
bxs[i]["layout_type"] = lts_of_ty[ii]["type"] if lts_of_ty[ii]["type"] != "equation" else "figure"
|
||||
i += 1
|
||||
|
||||
for ty in ["footer", "header", "reference", "figure caption", "table caption", "title", "table", "text", "figure", "equation"]:
|
||||
_tag_layout(ty)
|
||||
|
||||
figs = [lt for lt in lts if lt["type"] in ["figure", "equation"]]
|
||||
for i, lt in enumerate(figs):
|
||||
if lt.get("visited"):
|
||||
continue
|
||||
lt = deepcopy(lt)
|
||||
lt.pop("type", None)
|
||||
lt["text"] = ""
|
||||
lt["layout_type"] = "figure"
|
||||
lt["layoutno"] = f"figure-{i}"
|
||||
bxs.append(lt)
|
||||
|
||||
boxes_out.extend(bxs)
|
||||
|
||||
garbag_set = set()
|
||||
for k, lst in garbages.items():
|
||||
cnt = Counter(lst)
|
||||
for g, c in cnt.items():
|
||||
if c > 1:
|
||||
garbag_set.add(g)
|
||||
|
||||
ocr_res_new = [b for b in boxes_out if b["text"].strip() not in garbag_set]
|
||||
return ocr_res_new, page_layout
|
||||
|
||||
@ -13,7 +13,7 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
|
||||
import gc
|
||||
import logging
|
||||
import copy
|
||||
import time
|
||||
@ -348,6 +348,13 @@ class TextRecognizer:
|
||||
|
||||
return img
|
||||
|
||||
def close(self):
|
||||
# close session and release manually
|
||||
logging.info('Close TextRecognizer.')
|
||||
if hasattr(self, "predictor"):
|
||||
del self.predictor
|
||||
gc.collect()
|
||||
|
||||
def __call__(self, img_list):
|
||||
img_num = len(img_list)
|
||||
# Calculate the aspect ratio of all text bars
|
||||
@ -395,6 +402,9 @@ class TextRecognizer:
|
||||
|
||||
return rec_res, time.time() - st
|
||||
|
||||
def __del__(self):
|
||||
self.close()
|
||||
|
||||
|
||||
class TextDetector:
|
||||
def __init__(self, model_dir, device_id: int | None = None):
|
||||
@ -479,6 +489,12 @@ class TextDetector:
|
||||
dt_boxes = np.array(dt_boxes_new)
|
||||
return dt_boxes
|
||||
|
||||
def close(self):
|
||||
logging.info("Close TextDetector.")
|
||||
if hasattr(self, "predictor"):
|
||||
del self.predictor
|
||||
gc.collect()
|
||||
|
||||
def __call__(self, img):
|
||||
ori_im = img.copy()
|
||||
data = {'image': img}
|
||||
@ -508,6 +524,9 @@ class TextDetector:
|
||||
|
||||
return dt_boxes, time.time() - st
|
||||
|
||||
def __del__(self):
|
||||
self.close()
|
||||
|
||||
|
||||
class OCR:
|
||||
def __init__(self, model_dir=None):
|
||||
|
||||
@ -13,7 +13,7 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
|
||||
import gc
|
||||
import logging
|
||||
import os
|
||||
import math
|
||||
@ -406,6 +406,12 @@ class Recognizer:
|
||||
"score": float(scores[i])
|
||||
} for i in indices]
|
||||
|
||||
def close(self):
|
||||
logging.info("Close recognizer.")
|
||||
if hasattr(self, "ort_sess"):
|
||||
del self.ort_sess
|
||||
gc.collect()
|
||||
|
||||
def __call__(self, image_list, thr=0.7, batch_size=16):
|
||||
res = []
|
||||
images = []
|
||||
@ -430,5 +436,7 @@ class Recognizer:
|
||||
|
||||
return res
|
||||
|
||||
def __del__(self):
|
||||
self.close()
|
||||
|
||||
|
||||
|
||||
@ -31,11 +31,11 @@ def save_results(image_list, results, labels, output_dir='output/', threshold=0.
|
||||
logging.debug("save result to: " + out_path)
|
||||
|
||||
|
||||
def draw_box(im, result, lables, threshold=0.5):
|
||||
def draw_box(im, result, labels, threshold=0.5):
|
||||
draw_thickness = min(im.size) // 320
|
||||
draw = ImageDraw.Draw(im)
|
||||
color_list = get_color_map_list(len(lables))
|
||||
clsid2color = {n.lower():color_list[i] for i,n in enumerate(lables)}
|
||||
color_list = get_color_map_list(len(labels))
|
||||
clsid2color = {n.lower():color_list[i] for i,n in enumerate(labels)}
|
||||
result = [r for r in result if r["score"] >= threshold]
|
||||
|
||||
for dt in result:
|
||||
|
||||
@ -23,6 +23,7 @@ from huggingface_hub import snapshot_download
|
||||
|
||||
from api.utils.file_utils import get_project_base_directory
|
||||
from rag.nlp import rag_tokenizer
|
||||
|
||||
from .recognizer import Recognizer
|
||||
|
||||
|
||||
@ -38,31 +39,49 @@ class TableStructureRecognizer(Recognizer):
|
||||
|
||||
def __init__(self):
|
||||
try:
|
||||
super().__init__(self.labels, "tsr", os.path.join(
|
||||
get_project_base_directory(),
|
||||
"rag/res/deepdoc"))
|
||||
super().__init__(self.labels, "tsr", os.path.join(get_project_base_directory(), "rag/res/deepdoc"))
|
||||
except Exception:
|
||||
super().__init__(self.labels, "tsr", snapshot_download(repo_id="InfiniFlow/deepdoc",
|
||||
local_dir=os.path.join(get_project_base_directory(), "rag/res/deepdoc"),
|
||||
local_dir_use_symlinks=False))
|
||||
super().__init__(
|
||||
self.labels,
|
||||
"tsr",
|
||||
snapshot_download(
|
||||
repo_id="InfiniFlow/deepdoc",
|
||||
local_dir=os.path.join(get_project_base_directory(), "rag/res/deepdoc"),
|
||||
local_dir_use_symlinks=False,
|
||||
),
|
||||
)
|
||||
|
||||
def __call__(self, images, thr=0.2):
|
||||
tbls = super().__call__(images, thr)
|
||||
table_structure_recognizer_type = os.getenv("TABLE_STRUCTURE_RECOGNIZER_TYPE", "onnx").lower()
|
||||
if table_structure_recognizer_type not in ["onnx", "ascend"]:
|
||||
raise RuntimeError("Unsupported table structure recognizer type.")
|
||||
|
||||
if table_structure_recognizer_type == "onnx":
|
||||
logging.debug("Using Onnx table structure recognizer", flush=True)
|
||||
tbls = super().__call__(images, thr)
|
||||
else: # ascend
|
||||
logging.debug("Using Ascend table structure recognizer", flush=True)
|
||||
tbls = self._run_ascend_tsr(images, thr)
|
||||
|
||||
res = []
|
||||
# align left&right for rows, align top&bottom for columns
|
||||
for tbl in tbls:
|
||||
lts = [{"label": b["type"],
|
||||
lts = [
|
||||
{
|
||||
"label": b["type"],
|
||||
"score": b["score"],
|
||||
"x0": b["bbox"][0], "x1": b["bbox"][2],
|
||||
"top": b["bbox"][1], "bottom": b["bbox"][-1]
|
||||
} for b in tbl]
|
||||
"x0": b["bbox"][0],
|
||||
"x1": b["bbox"][2],
|
||||
"top": b["bbox"][1],
|
||||
"bottom": b["bbox"][-1],
|
||||
}
|
||||
for b in tbl
|
||||
]
|
||||
if not lts:
|
||||
continue
|
||||
|
||||
left = [b["x0"] for b in lts if b["label"].find(
|
||||
"row") > 0 or b["label"].find("header") > 0]
|
||||
right = [b["x1"] for b in lts if b["label"].find(
|
||||
"row") > 0 or b["label"].find("header") > 0]
|
||||
left = [b["x0"] for b in lts if b["label"].find("row") > 0 or b["label"].find("header") > 0]
|
||||
right = [b["x1"] for b in lts if b["label"].find("row") > 0 or b["label"].find("header") > 0]
|
||||
if not left:
|
||||
continue
|
||||
left = np.mean(left) if len(left) > 4 else np.min(left)
|
||||
@ -93,11 +112,8 @@ class TableStructureRecognizer(Recognizer):
|
||||
|
||||
@staticmethod
|
||||
def is_caption(bx):
|
||||
patt = [
|
||||
r"[图表]+[ 0-9::]{2,}"
|
||||
]
|
||||
if any([re.match(p, bx["text"].strip()) for p in patt]) \
|
||||
or bx.get("layout_type", "").find("caption") >= 0:
|
||||
patt = [r"[图表]+[ 0-9::]{2,}"]
|
||||
if any([re.match(p, bx["text"].strip()) for p in patt]) or bx.get("layout_type", "").find("caption") >= 0:
|
||||
return True
|
||||
return False
|
||||
|
||||
@ -115,7 +131,7 @@ class TableStructureRecognizer(Recognizer):
|
||||
(r"^[0-9A-Z/\._~-]+$", "Ca"),
|
||||
(r"^[A-Z]*[a-z' -]+$", "En"),
|
||||
(r"^[0-9.,+-]+[0-9A-Za-z/$¥%<>()()' -]+$", "NE"),
|
||||
(r"^.{1}$", "Sg")
|
||||
(r"^.{1}$", "Sg"),
|
||||
]
|
||||
for p, n in patt:
|
||||
if re.search(p, b["text"].strip()):
|
||||
@ -156,21 +172,19 @@ class TableStructureRecognizer(Recognizer):
|
||||
rowh = [b["R_bott"] - b["R_top"] for b in boxes if "R" in b]
|
||||
rowh = np.min(rowh) if rowh else 0
|
||||
boxes = Recognizer.sort_R_firstly(boxes, rowh / 2)
|
||||
#for b in boxes:print(b)
|
||||
# for b in boxes:print(b)
|
||||
boxes[0]["rn"] = 0
|
||||
rows = [[boxes[0]]]
|
||||
btm = boxes[0]["bottom"]
|
||||
for b in boxes[1:]:
|
||||
b["rn"] = len(rows) - 1
|
||||
lst_r = rows[-1]
|
||||
if lst_r[-1].get("R", "") != b.get("R", "") \
|
||||
or (b["top"] >= btm - 3 and lst_r[-1].get("R", "-1") != b.get("R", "-2")
|
||||
): # new row
|
||||
if lst_r[-1].get("R", "") != b.get("R", "") or (b["top"] >= btm - 3 and lst_r[-1].get("R", "-1") != b.get("R", "-2")): # new row
|
||||
btm = b["bottom"]
|
||||
b["rn"] += 1
|
||||
rows.append([b])
|
||||
continue
|
||||
btm = (btm + b["bottom"]) / 2.
|
||||
btm = (btm + b["bottom"]) / 2.0
|
||||
rows[-1].append(b)
|
||||
|
||||
colwm = [b["C_right"] - b["C_left"] for b in boxes if "C" in b]
|
||||
@ -186,14 +200,14 @@ class TableStructureRecognizer(Recognizer):
|
||||
for b in boxes[1:]:
|
||||
b["cn"] = len(cols) - 1
|
||||
lst_c = cols[-1]
|
||||
if (int(b.get("C", "1")) - int(lst_c[-1].get("C", "1")) == 1 and b["page_number"] == lst_c[-1][
|
||||
"page_number"]) \
|
||||
or (b["x0"] >= right and lst_c[-1].get("C", "-1") != b.get("C", "-2")): # new col
|
||||
if (int(b.get("C", "1")) - int(lst_c[-1].get("C", "1")) == 1 and b["page_number"] == lst_c[-1]["page_number"]) or (
|
||||
b["x0"] >= right and lst_c[-1].get("C", "-1") != b.get("C", "-2")
|
||||
): # new col
|
||||
right = b["x1"]
|
||||
b["cn"] += 1
|
||||
cols.append([b])
|
||||
continue
|
||||
right = (right + b["x1"]) / 2.
|
||||
right = (right + b["x1"]) / 2.0
|
||||
cols[-1].append(b)
|
||||
|
||||
tbl = [[[] for _ in range(len(cols))] for _ in range(len(rows))]
|
||||
@ -214,10 +228,8 @@ class TableStructureRecognizer(Recognizer):
|
||||
if e > 1:
|
||||
j += 1
|
||||
continue
|
||||
f = (j > 0 and tbl[ii][j - 1] and tbl[ii]
|
||||
[j - 1][0].get("text")) or j == 0
|
||||
ff = (j + 1 < len(tbl[ii]) and tbl[ii][j + 1] and tbl[ii]
|
||||
[j + 1][0].get("text")) or j + 1 >= len(tbl[ii])
|
||||
f = (j > 0 and tbl[ii][j - 1] and tbl[ii][j - 1][0].get("text")) or j == 0
|
||||
ff = (j + 1 < len(tbl[ii]) and tbl[ii][j + 1] and tbl[ii][j + 1][0].get("text")) or j + 1 >= len(tbl[ii])
|
||||
if f and ff:
|
||||
j += 1
|
||||
continue
|
||||
@ -228,13 +240,11 @@ class TableStructureRecognizer(Recognizer):
|
||||
if j > 0 and not f:
|
||||
for i in range(len(tbl)):
|
||||
if tbl[i][j - 1]:
|
||||
left = min(left, np.min(
|
||||
[bx["x0"] - a["x1"] for a in tbl[i][j - 1]]))
|
||||
left = min(left, np.min([bx["x0"] - a["x1"] for a in tbl[i][j - 1]]))
|
||||
if j + 1 < len(tbl[0]) and not ff:
|
||||
for i in range(len(tbl)):
|
||||
if tbl[i][j + 1]:
|
||||
right = min(right, np.min(
|
||||
[a["x0"] - bx["x1"] for a in tbl[i][j + 1]]))
|
||||
right = min(right, np.min([a["x0"] - bx["x1"] for a in tbl[i][j + 1]]))
|
||||
assert left < 100000 or right < 100000
|
||||
if left < right:
|
||||
for jj in range(j, len(tbl[0])):
|
||||
@ -260,8 +270,7 @@ class TableStructureRecognizer(Recognizer):
|
||||
for i in range(len(tbl)):
|
||||
tbl[i].pop(j)
|
||||
cols.pop(j)
|
||||
assert len(cols) == len(tbl[0]), "Column NO. miss matched: %d vs %d" % (
|
||||
len(cols), len(tbl[0]))
|
||||
assert len(cols) == len(tbl[0]), "Column NO. miss matched: %d vs %d" % (len(cols), len(tbl[0]))
|
||||
|
||||
if len(cols) >= 4:
|
||||
# remove single in row
|
||||
@ -277,10 +286,8 @@ class TableStructureRecognizer(Recognizer):
|
||||
if e > 1:
|
||||
i += 1
|
||||
continue
|
||||
f = (i > 0 and tbl[i - 1][jj] and tbl[i - 1]
|
||||
[jj][0].get("text")) or i == 0
|
||||
ff = (i + 1 < len(tbl) and tbl[i + 1][jj] and tbl[i + 1]
|
||||
[jj][0].get("text")) or i + 1 >= len(tbl)
|
||||
f = (i > 0 and tbl[i - 1][jj] and tbl[i - 1][jj][0].get("text")) or i == 0
|
||||
ff = (i + 1 < len(tbl) and tbl[i + 1][jj] and tbl[i + 1][jj][0].get("text")) or i + 1 >= len(tbl)
|
||||
if f and ff:
|
||||
i += 1
|
||||
continue
|
||||
@ -292,13 +299,11 @@ class TableStructureRecognizer(Recognizer):
|
||||
if i > 0 and not f:
|
||||
for j in range(len(tbl[i - 1])):
|
||||
if tbl[i - 1][j]:
|
||||
up = min(up, np.min(
|
||||
[bx["top"] - a["bottom"] for a in tbl[i - 1][j]]))
|
||||
up = min(up, np.min([bx["top"] - a["bottom"] for a in tbl[i - 1][j]]))
|
||||
if i + 1 < len(tbl) and not ff:
|
||||
for j in range(len(tbl[i + 1])):
|
||||
if tbl[i + 1][j]:
|
||||
down = min(down, np.min(
|
||||
[a["top"] - bx["bottom"] for a in tbl[i + 1][j]]))
|
||||
down = min(down, np.min([a["top"] - bx["bottom"] for a in tbl[i + 1][j]]))
|
||||
assert up < 100000 or down < 100000
|
||||
if up < down:
|
||||
for ii in range(i, len(tbl)):
|
||||
@ -333,22 +338,15 @@ class TableStructureRecognizer(Recognizer):
|
||||
cnt += 1
|
||||
if max_type == "Nu" and arr[0]["btype"] == "Nu":
|
||||
continue
|
||||
if any([a.get("H") for a in arr]) \
|
||||
or (max_type == "Nu" and arr[0]["btype"] != "Nu"):
|
||||
if any([a.get("H") for a in arr]) or (max_type == "Nu" and arr[0]["btype"] != "Nu"):
|
||||
h += 1
|
||||
if h / cnt > 0.5:
|
||||
hdset.add(i)
|
||||
|
||||
if html:
|
||||
return TableStructureRecognizer.__html_table(cap, hdset,
|
||||
TableStructureRecognizer.__cal_spans(boxes, rows,
|
||||
cols, tbl, True)
|
||||
)
|
||||
return TableStructureRecognizer.__html_table(cap, hdset, TableStructureRecognizer.__cal_spans(boxes, rows, cols, tbl, True))
|
||||
|
||||
return TableStructureRecognizer.__desc_table(cap, hdset,
|
||||
TableStructureRecognizer.__cal_spans(boxes, rows, cols, tbl,
|
||||
False),
|
||||
is_english)
|
||||
return TableStructureRecognizer.__desc_table(cap, hdset, TableStructureRecognizer.__cal_spans(boxes, rows, cols, tbl, False), is_english)
|
||||
|
||||
@staticmethod
|
||||
def __html_table(cap, hdset, tbl):
|
||||
@ -367,10 +365,8 @@ class TableStructureRecognizer(Recognizer):
|
||||
continue
|
||||
txt = ""
|
||||
if arr:
|
||||
h = min(np.min([c["bottom"] - c["top"]
|
||||
for c in arr]) / 2, 10)
|
||||
txt = " ".join([c["text"]
|
||||
for c in Recognizer.sort_Y_firstly(arr, h)])
|
||||
h = min(np.min([c["bottom"] - c["top"] for c in arr]) / 2, 10)
|
||||
txt = " ".join([c["text"] for c in Recognizer.sort_Y_firstly(arr, h)])
|
||||
txts.append(txt)
|
||||
sp = ""
|
||||
if arr[0].get("colspan"):
|
||||
@ -436,15 +432,11 @@ class TableStructureRecognizer(Recognizer):
|
||||
if headers[j][k].find(headers[j - 1][k]) >= 0:
|
||||
continue
|
||||
if len(headers[j][k]) > len(headers[j - 1][k]):
|
||||
headers[j][k] += (de if headers[j][k]
|
||||
else "") + headers[j - 1][k]
|
||||
headers[j][k] += (de if headers[j][k] else "") + headers[j - 1][k]
|
||||
else:
|
||||
headers[j][k] = headers[j - 1][k] \
|
||||
+ (de if headers[j - 1][k] else "") \
|
||||
+ headers[j][k]
|
||||
headers[j][k] = headers[j - 1][k] + (de if headers[j - 1][k] else "") + headers[j][k]
|
||||
|
||||
logging.debug(
|
||||
f">>>>>>>>>>>>>>>>>{cap}:SIZE:{rowno}X{clmno} Header: {hdr_rowno}")
|
||||
logging.debug(f">>>>>>>>>>>>>>>>>{cap}:SIZE:{rowno}X{clmno} Header: {hdr_rowno}")
|
||||
row_txt = []
|
||||
for i in range(rowno):
|
||||
if i in hdr_rowno:
|
||||
@ -503,14 +495,10 @@ class TableStructureRecognizer(Recognizer):
|
||||
@staticmethod
|
||||
def __cal_spans(boxes, rows, cols, tbl, html=True):
|
||||
# caculate span
|
||||
clft = [np.mean([c.get("C_left", c["x0"]) for c in cln])
|
||||
for cln in cols]
|
||||
crgt = [np.mean([c.get("C_right", c["x1"]) for c in cln])
|
||||
for cln in cols]
|
||||
rtop = [np.mean([c.get("R_top", c["top"]) for c in row])
|
||||
for row in rows]
|
||||
rbtm = [np.mean([c.get("R_btm", c["bottom"])
|
||||
for c in row]) for row in rows]
|
||||
clft = [np.mean([c.get("C_left", c["x0"]) for c in cln]) for cln in cols]
|
||||
crgt = [np.mean([c.get("C_right", c["x1"]) for c in cln]) for cln in cols]
|
||||
rtop = [np.mean([c.get("R_top", c["top"]) for c in row]) for row in rows]
|
||||
rbtm = [np.mean([c.get("R_btm", c["bottom"]) for c in row]) for row in rows]
|
||||
for b in boxes:
|
||||
if "SP" not in b:
|
||||
continue
|
||||
@ -585,3 +573,40 @@ class TableStructureRecognizer(Recognizer):
|
||||
tbl[rowspan[0]][colspan[0]] = arr
|
||||
|
||||
return tbl
|
||||
|
||||
def _run_ascend_tsr(self, image_list, thr=0.2, batch_size=16):
|
||||
import math
|
||||
|
||||
from ais_bench.infer.interface import InferSession
|
||||
|
||||
model_dir = os.path.join(get_project_base_directory(), "rag/res/deepdoc")
|
||||
model_file_path = os.path.join(model_dir, "tsr.om")
|
||||
|
||||
if not os.path.exists(model_file_path):
|
||||
raise ValueError(f"Model file not found: {model_file_path}")
|
||||
|
||||
device_id = int(os.getenv("ASCEND_LAYOUT_RECOGNIZER_DEVICE_ID", 0))
|
||||
session = InferSession(device_id=device_id, model_path=model_file_path)
|
||||
|
||||
images = [np.array(im) if not isinstance(im, np.ndarray) else im for im in image_list]
|
||||
results = []
|
||||
|
||||
conf_thr = max(thr, 0.08)
|
||||
|
||||
batch_loop_cnt = math.ceil(float(len(images)) / batch_size)
|
||||
for bi in range(batch_loop_cnt):
|
||||
s = bi * batch_size
|
||||
e = min((bi + 1) * batch_size, len(images))
|
||||
batch_images = images[s:e]
|
||||
|
||||
inputs_list = self.preprocess(batch_images)
|
||||
for ins in inputs_list:
|
||||
feeds = []
|
||||
if "image" in ins:
|
||||
feeds.append(ins["image"])
|
||||
else:
|
||||
feeds.append(ins[self.input_names[0]])
|
||||
output_list = session.infer(feeds=feeds, mode="static")
|
||||
bb = self.postprocess(output_list, ins, conf_thr)
|
||||
results.append(bb)
|
||||
return results
|
||||
|
||||
10
docker/.env
10
docker/.env
@ -93,13 +93,13 @@ REDIS_PASSWORD=infini_rag_flow
|
||||
SVR_HTTP_PORT=9380
|
||||
|
||||
# The RAGFlow Docker image to download.
|
||||
# Defaults to the v0.20.4-slim edition, which is the RAGFlow Docker image without embedding models.
|
||||
RAGFLOW_IMAGE=infiniflow/ragflow:v0.20.4-slim
|
||||
# Defaults to the v0.20.5-slim edition, which is the RAGFlow Docker image without embedding models.
|
||||
RAGFLOW_IMAGE=infiniflow/ragflow:v0.20.5-slim
|
||||
#
|
||||
# To download the RAGFlow Docker image with embedding models, uncomment the following line instead:
|
||||
# RAGFLOW_IMAGE=infiniflow/ragflow:v0.20.4
|
||||
# RAGFLOW_IMAGE=infiniflow/ragflow:v0.20.5
|
||||
#
|
||||
# The Docker image of the v0.20.4 edition includes built-in embedding models:
|
||||
# The Docker image of the v0.20.5 edition includes built-in embedding models:
|
||||
# - BAAI/bge-large-zh-v1.5
|
||||
# - maidalun1020/bce-embedding-base_v1
|
||||
#
|
||||
@ -115,7 +115,7 @@ RAGFLOW_IMAGE=infiniflow/ragflow:v0.20.4-slim
|
||||
# RAGFLOW_IMAGE=registry.cn-hangzhou.aliyuncs.com/infiniflow/ragflow:nightly
|
||||
|
||||
# The local time zone.
|
||||
TIMEZONE='Asia/Shanghai'
|
||||
TIMEZONE=Asia/Shanghai
|
||||
|
||||
# Uncomment the following line if you have limited access to huggingface.co:
|
||||
# HF_ENDPOINT=https://hf-mirror.com
|
||||
|
||||
@ -79,8 +79,8 @@ The [.env](./.env) file contains important environment variables for Docker.
|
||||
- `RAGFLOW-IMAGE`
|
||||
The Docker image edition. Available editions:
|
||||
|
||||
- `infiniflow/ragflow:v0.20.4-slim` (default): The RAGFlow Docker image without embedding models.
|
||||
- `infiniflow/ragflow:v0.20.4`: The RAGFlow Docker image with embedding models including:
|
||||
- `infiniflow/ragflow:v0.20.5-slim` (default): The RAGFlow Docker image without embedding models.
|
||||
- `infiniflow/ragflow:v0.20.5`: The RAGFlow Docker image with embedding models including:
|
||||
- Built-in embedding models:
|
||||
- `BAAI/bge-large-zh-v1.5`
|
||||
- `maidalun1020/bce-embedding-base_v1`
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
ragflow:
|
||||
host: ${RAGFLOW_HOST:-0.0.0.0}
|
||||
http_port: 9380
|
||||
admin:
|
||||
host: ${RAGFLOW_HOST:-0.0.0.0}
|
||||
http_port: 9381
|
||||
mysql:
|
||||
name: '${MYSQL_DBNAME:-rag_flow}'
|
||||
user: '${MYSQL_USER:-root}'
|
||||
@ -29,7 +32,6 @@ redis:
|
||||
db: 1
|
||||
password: '${REDIS_PASSWORD:-infini_rag_flow}'
|
||||
host: '${REDIS_HOST:-redis}:6379'
|
||||
|
||||
# postgres:
|
||||
# name: '${POSTGRES_DBNAME:-rag_flow}'
|
||||
# user: '${POSTGRES_USER:-rag_flow}'
|
||||
@ -65,15 +67,26 @@ redis:
|
||||
# secret: 'secret'
|
||||
# tenant_id: 'tenant_id'
|
||||
# container_name: 'container_name'
|
||||
# The OSS object storage uses the MySQL configuration above by default. If you need to switch to another object storage service, please uncomment and configure the following parameters.
|
||||
# opendal:
|
||||
# scheme: 'mysql' # Storage type, such as s3, oss, azure, etc.
|
||||
# config:
|
||||
# oss_table: 'opendal_storage'
|
||||
# user_default_llm:
|
||||
# factory: 'Tongyi-Qianwen'
|
||||
# api_key: 'sk-xxxxxxxxxxxxx'
|
||||
# base_url: ''
|
||||
# factory: 'BAAI'
|
||||
# api_key: 'backup'
|
||||
# base_url: 'backup_base_url'
|
||||
# default_models:
|
||||
# chat_model: 'qwen-plus'
|
||||
# embedding_model: 'BAAI/bge-large-zh-v1.5@BAAI'
|
||||
# rerank_model: ''
|
||||
# asr_model: ''
|
||||
# chat_model:
|
||||
# name: 'qwen2.5-7b-instruct'
|
||||
# factory: 'xxxx'
|
||||
# api_key: 'xxxx'
|
||||
# base_url: 'https://api.xx.com'
|
||||
# embedding_model:
|
||||
# name: 'bge-m3'
|
||||
# rerank_model: 'bge-reranker-v2'
|
||||
# asr_model:
|
||||
# model: 'whisper-large-v3' # alias of name
|
||||
# image2text_model: ''
|
||||
# oauth:
|
||||
# oauth2:
|
||||
@ -109,3 +122,14 @@ redis:
|
||||
# switch: false
|
||||
# component: false
|
||||
# dataset: false
|
||||
# smtp:
|
||||
# mail_server: ""
|
||||
# mail_port: 465
|
||||
# mail_use_ssl: true
|
||||
# mail_use_tls: false
|
||||
# mail_username: ""
|
||||
# mail_password: ""
|
||||
# mail_default_sender:
|
||||
# - "RAGFlow" # display name
|
||||
# - "" # sender email address
|
||||
# mail_frontend_url: "https://your-frontend.example.com"
|
||||
|
||||
@ -99,8 +99,8 @@ RAGFlow utilizes MinIO as its object storage solution, leveraging its scalabilit
|
||||
- `RAGFLOW-IMAGE`
|
||||
The Docker image edition. Available editions:
|
||||
|
||||
- `infiniflow/ragflow:v0.20.4-slim` (default): The RAGFlow Docker image without embedding models.
|
||||
- `infiniflow/ragflow:v0.20.4`: The RAGFlow Docker image with embedding models including:
|
||||
- `infiniflow/ragflow:v0.20.5-slim` (default): The RAGFlow Docker image without embedding models.
|
||||
- `infiniflow/ragflow:v0.20.5`: The RAGFlow Docker image with embedding models including:
|
||||
- Built-in embedding models:
|
||||
- `BAAI/bge-large-zh-v1.5`
|
||||
- `maidalun1020/bce-embedding-base_v1`
|
||||
|
||||
@ -77,7 +77,7 @@ After building the infiniflow/ragflow:nightly-slim image, you are ready to launc
|
||||
|
||||
1. Edit Docker Compose Configuration
|
||||
|
||||
Open the `docker/.env` file. Find the `RAGFLOW_IMAGE` setting and change the image reference from `infiniflow/ragflow:v0.20.4-slim` to `infiniflow/ragflow:nightly-slim` to use the pre-built image.
|
||||
Open the `docker/.env` file. Find the `RAGFLOW_IMAGE` setting and change the image reference from `infiniflow/ragflow:v0.20.5-slim` to `infiniflow/ragflow:nightly-slim` to use the pre-built image.
|
||||
|
||||
|
||||
2. Launch the Service
|
||||
|
||||
23
docs/faq.mdx
23
docs/faq.mdx
@ -30,17 +30,17 @@ The "garbage in garbage out" status quo remains unchanged despite the fact that
|
||||
|
||||
Each RAGFlow release is available in two editions:
|
||||
|
||||
- **Slim edition**: excludes built-in embedding models and is identified by a **-slim** suffix added to the version name. Example: `infiniflow/ragflow:v0.20.4-slim`
|
||||
- **Full edition**: includes built-in embedding models and has no suffix added to the version name. Example: `infiniflow/ragflow:v0.20.4`
|
||||
- **Slim edition**: excludes built-in embedding models and is identified by a **-slim** suffix added to the version name. Example: `infiniflow/ragflow:v0.20.5-slim`
|
||||
- **Full edition**: includes built-in embedding models and has no suffix added to the version name. Example: `infiniflow/ragflow:v0.20.5`
|
||||
|
||||
---
|
||||
|
||||
### Which embedding models can be deployed locally?
|
||||
|
||||
RAGFlow offers two Docker image editions, `v0.20.4-slim` and `v0.20.4`:
|
||||
RAGFlow offers two Docker image editions, `v0.20.5-slim` and `v0.20.5`:
|
||||
|
||||
- `infiniflow/ragflow:v0.20.4-slim` (default): The RAGFlow Docker image without embedding models.
|
||||
- `infiniflow/ragflow:v0.20.4`: The RAGFlow Docker image with embedding models including:
|
||||
- `infiniflow/ragflow:v0.20.5-slim` (default): The RAGFlow Docker image without embedding models.
|
||||
- `infiniflow/ragflow:v0.20.5`: The RAGFlow Docker image with embedding models including:
|
||||
- Built-in embedding models:
|
||||
- `BAAI/bge-large-zh-v1.5`
|
||||
- `maidalun1020/bce-embedding-base_v1`
|
||||
@ -507,3 +507,16 @@ All uploaded files are stored in Minio, RAGFlow's object storage solution. For i
|
||||
You can control the batch size for document parsing and embedding by setting the environment variables `DOC_BULK_SIZE` and `EMBEDDING_BATCH_SIZE`. Increasing these values may improve throughput for large-scale data processing, but will also increase memory usage. Adjust them according to your hardware resources.
|
||||
|
||||
---
|
||||
|
||||
### How to accelerate the question-answering speed of my chat assistant?
|
||||
|
||||
See [here](./guides/chat/best_practices/accelerate_question_answering.mdx).
|
||||
|
||||
---
|
||||
|
||||
### How to accelerate the question-answering speed of my Agent?
|
||||
|
||||
See [here](./guides/agent/best_practices/accelerate_agent_question_answering.md).
|
||||
|
||||
---
|
||||
|
||||
|
||||
@ -9,7 +9,7 @@ The component equipped with reasoning, tool usage, and multi-agent collaboration
|
||||
|
||||
---
|
||||
|
||||
An **Agent** component fine-tunes the LLM and sets its prompt. From v0.20.4 onwards, an **Agent** component is able to work independently and with the following capabilities:
|
||||
An **Agent** component fine-tunes the LLM and sets its prompt. From v0.20.5 onwards, an **Agent** component is able to work independently and with the following capabilities:
|
||||
|
||||
- Autonomous reasoning with reflection and adjustment based on environmental feedback.
|
||||
- Use of tools or subagents to complete tasks.
|
||||
@ -18,6 +18,92 @@ An **Agent** component fine-tunes the LLM and sets its prompt. From v0.20.4 onwa
|
||||
|
||||
An **Agent** component is essential when you need the LLM to assist with summarizing, translating, or controlling various tasks.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
1. Ensure you have a chat model properly configured:
|
||||
|
||||

|
||||
|
||||
2. If your Agent involves dataset retrieval, ensure you [have properly configured your target knowledge base(s)](../../dataset/configure_knowledge_base.md).
|
||||
|
||||
## Quickstart
|
||||
|
||||
### 1. Click on an **Agent** component to show its configuration panel
|
||||
|
||||
The corresponding configuration panel appears to the right of the canvas. Use this panel to define and fine-tune the **Agent** component's behavior.
|
||||
|
||||
### 2. Select your model
|
||||
|
||||
Click **Model**, and select a chat model from the dropdown menu.
|
||||
|
||||
:::tip NOTE
|
||||
If no model appears, check if your have added a chat model on the **Model providers** page.
|
||||
:::
|
||||
|
||||
### 3. Update system prompt (Optional)
|
||||
|
||||
The system prompt typically defines your model's role. You can either keep the system prompt as is or customize it to override the default.
|
||||
|
||||
|
||||
### 4. Update user prompt
|
||||
|
||||
The user prompt typically defines your model's task. You will find the `sys.query` variable auto-populated. Type `/` or click **(x)** to view or add variables.
|
||||
|
||||
In this quickstart, we assume your **Agent** component is used standalone (without tools or sub-Agents below), then you may also need to specify retrieved chunks using the `formalized_content` variable:
|
||||
|
||||
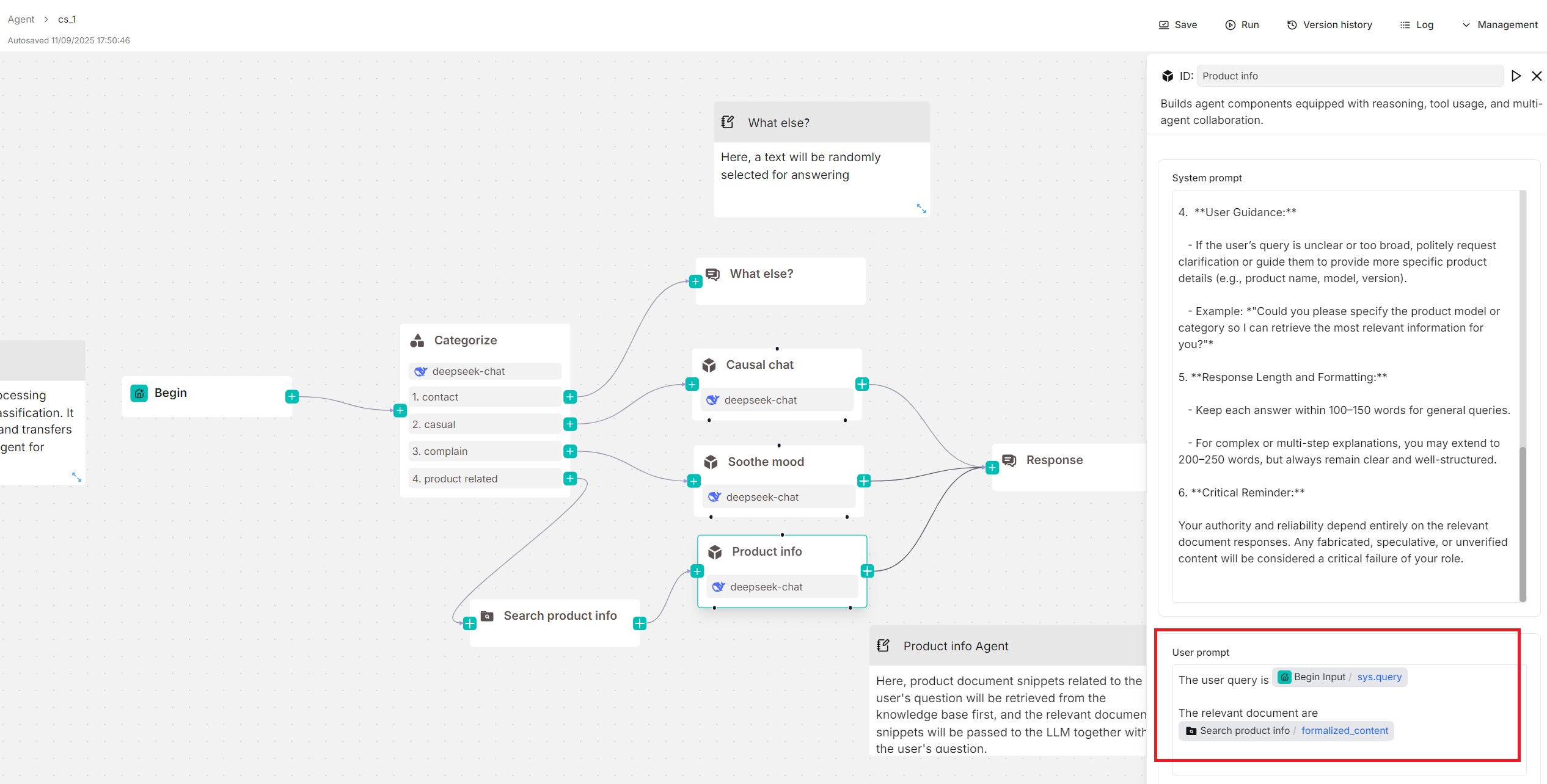
|
||||
|
||||
### 5. Skip Tools and Agent
|
||||
|
||||
The **+ Add tools** and **+ Add agent** sections are used *only* when you need to configure your **Agent** component as a planner (with tools or sub-Agents beneath). In this quickstart, we assume your **Agent** component is used standalone (without tools or sub-Agents beneath).
|
||||
|
||||
### 6. Choose the next component
|
||||
|
||||
When necessary, click the **+** button on the **Agent** component to choose the next component in the worflow from the dropdown list.
|
||||
|
||||
## Connect to an MCP server as a client
|
||||
|
||||
:::danger IMPORTANT
|
||||
In this section, we assume your **Agent** will be configured as a planner, with a Tavily tool beneath it.
|
||||
:::
|
||||
|
||||
### 1. Navigate to the MCP configuration page
|
||||
|
||||

|
||||
|
||||
### 2. Configure your Tavily MCP server
|
||||
|
||||
Update your MCP server's name, URL (including the API key), server type, and other necessary settings. When configured correctly, the available tools will be displayed.
|
||||
|
||||
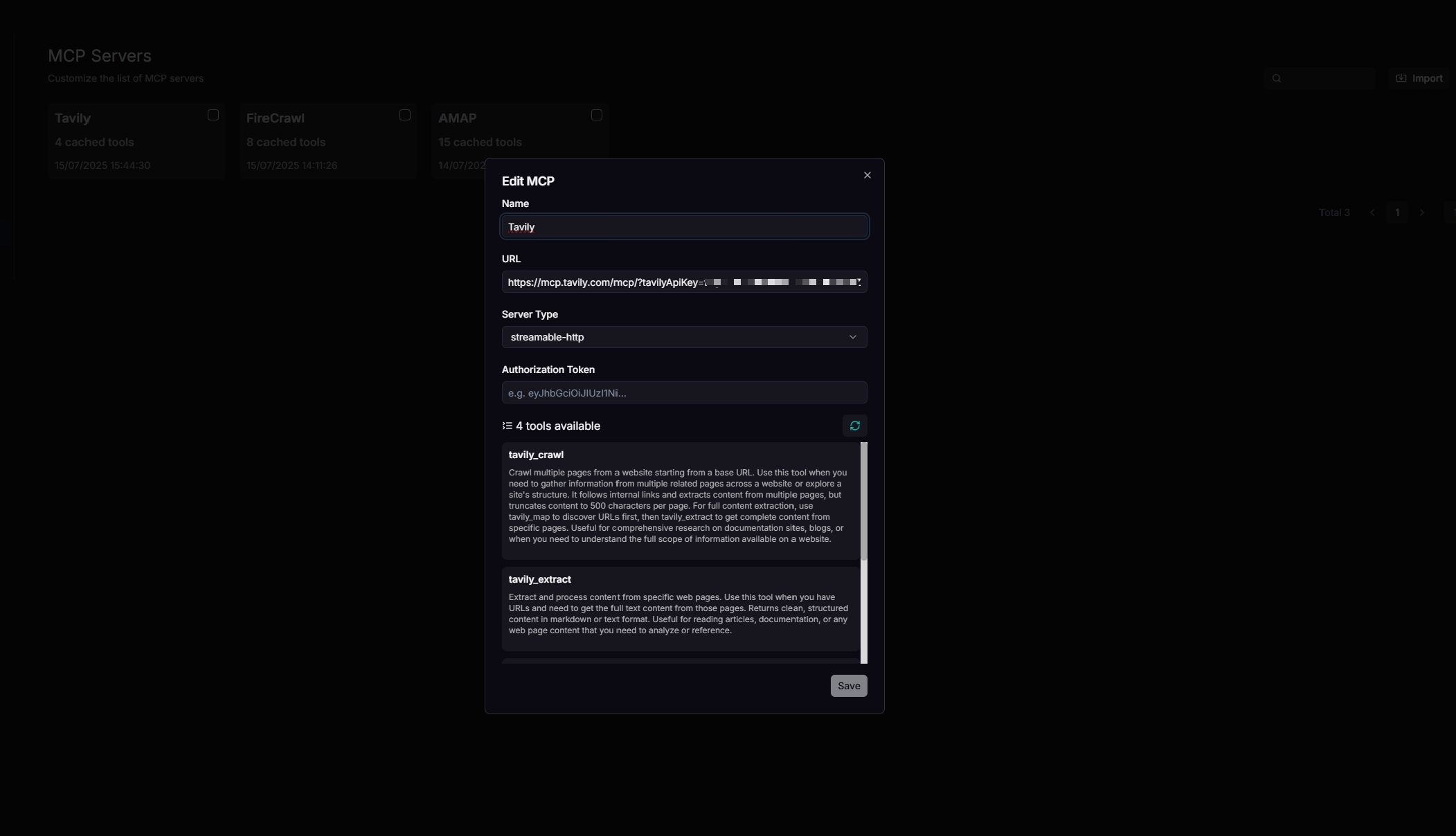
|
||||
|
||||
### 3. Navigate to your Agent's editing page
|
||||
|
||||
### 4. Connect to your MCP server
|
||||
|
||||
1. Click **+ Add tools**:
|
||||
|
||||
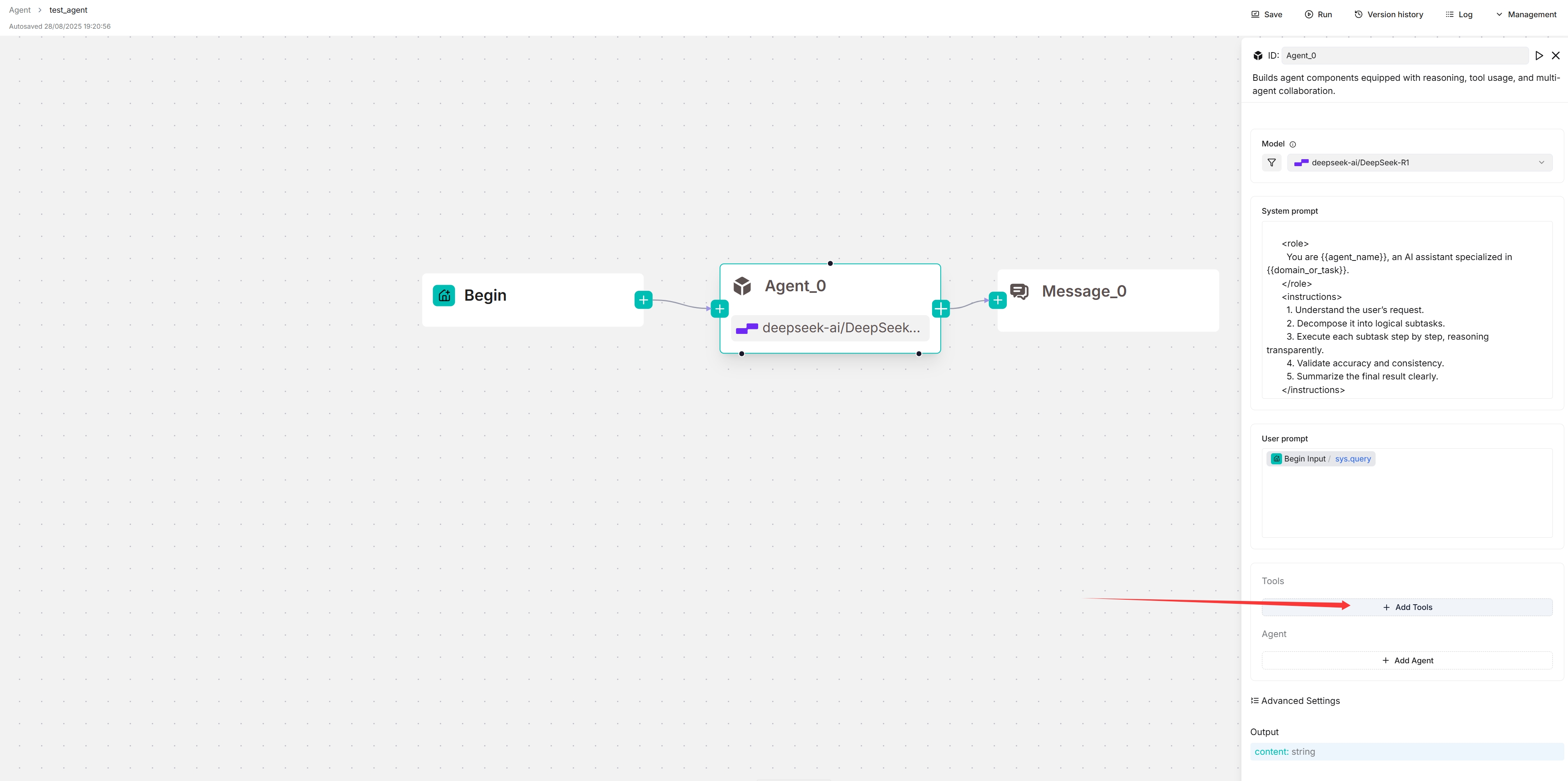
|
||||
|
||||
2. Click **MCP** to show the available MCP servers.
|
||||
|
||||
3. Select your MCP server:
|
||||
|
||||
*The target MCP server appears below your Agent component, and your Agent will autonomously decide when to invoke the available tools it offers.*
|
||||
|
||||
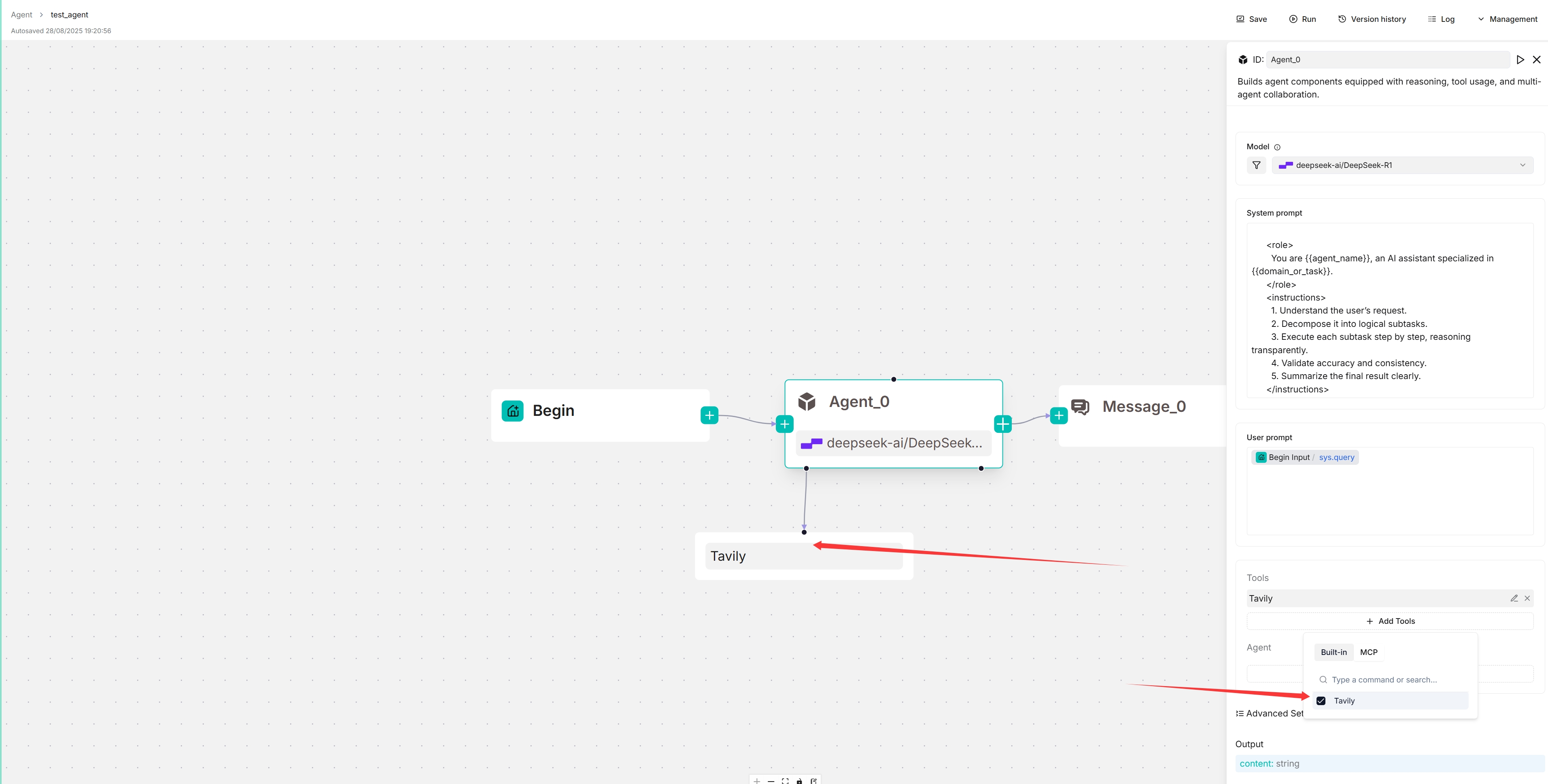
|
||||
|
||||
### 5. Update system prompt to specify trigger conditions (Optional)
|
||||
|
||||
To ensure reliable tool calls, you may specify within the system prompt which tasks should trigger each tool call.
|
||||
|
||||
### 6. View the availabe tools of your MCP server
|
||||
|
||||
On the canvas, click the newly-populated Tavily server to view and select its available tools:
|
||||
|
||||
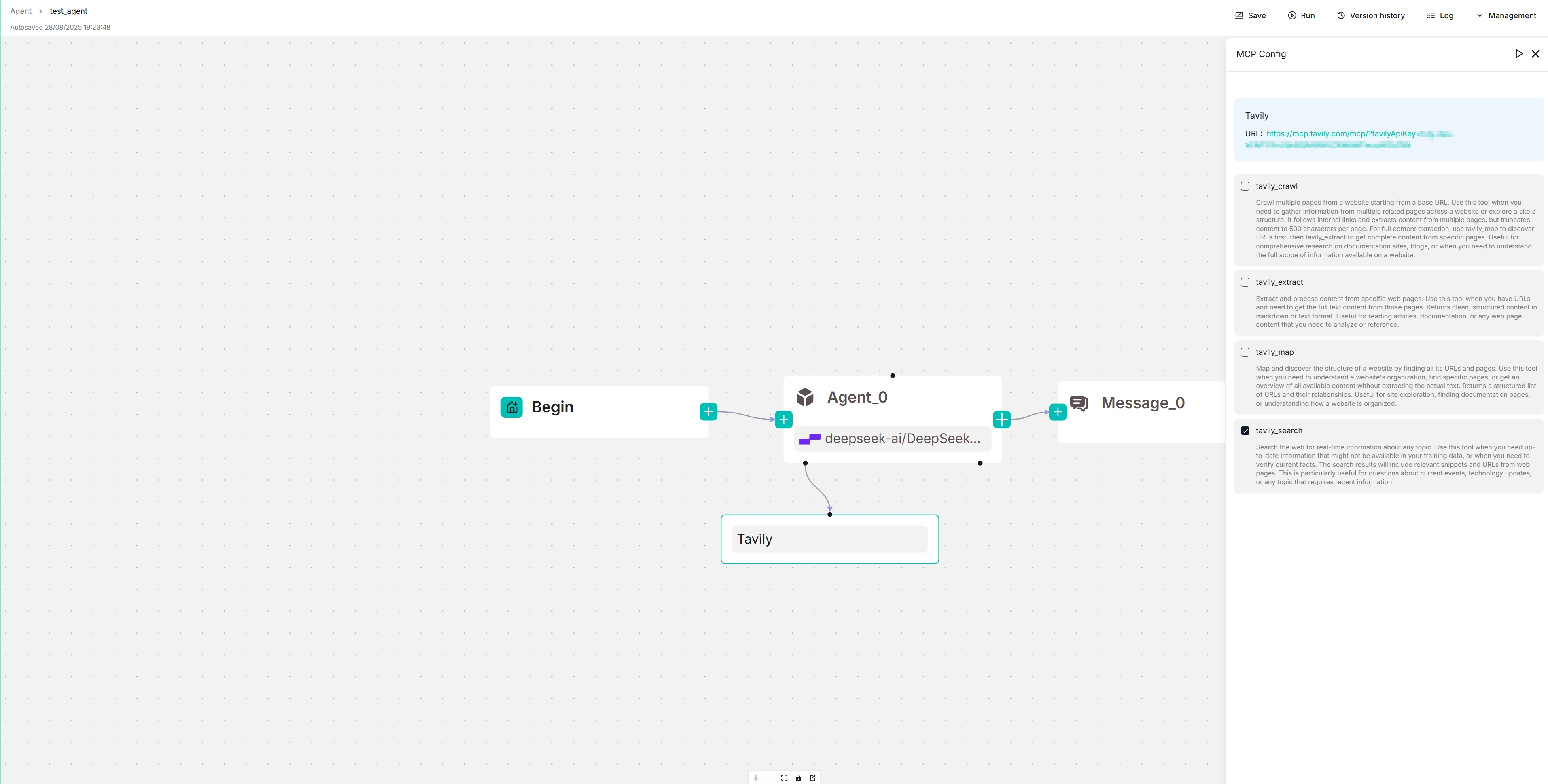
|
||||
|
||||
|
||||
## Configurations
|
||||
|
||||
### Model
|
||||
@ -57,13 +143,50 @@ Click the dropdown menu of **Model** to show the model configuration window.
|
||||
|
||||
Typically, you use the system prompt to describe the task for the LLM, specify how it should respond, and outline other miscellaneous requirements. We do not plan to elaborate on this topic, as it can be as extensive as prompt engineering. However, please be aware that the system prompt is often used in conjunction with keys (variables), which serve as various data inputs for the LLM.
|
||||
|
||||
:::danger IMPORTANT
|
||||
An **Agent** component relies on keys (variables) to specify its data inputs. Its immediate upstream component is *not* necessarily its data input, and the arrows in the workflow indicate *only* the processing sequence. Keys in a **Agent** component are used in conjunction with the system prompt to specify data inputs for the LLM. Use a forward slash `/` or the **(x)** button to show the keys to use.
|
||||
:::
|
||||
|
||||
#### Advanced usage
|
||||
|
||||
From v0.20.5 onwards, four framework-level prompt blocks are available in the **System prompt** field, enabling you to customize and *override* prompts at the framework level. Type `/` or click **(x)** to view them; they appear under the **Framework** entry in the dropdown menu.
|
||||
|
||||
- `task_analysis` prompt block
|
||||
- This block is responsible for analyzing tasks — either a user task or a task assigned by the lead Agent when the **Agent** component is acting as a Sub-Agent.
|
||||
- Reference design: [analyze_task_system.md](https://github.com/infiniflow/ragflow/blob/main/rag/prompts/analyze_task_system.md) and [analyze_task_user.md](https://github.com/infiniflow/ragflow/blob/main/rag/prompts/analyze_task_user.md)
|
||||
- Available *only* when this **Agent** component is acting as a planner, with either tools or sub-Agents under it.
|
||||
- Input variables:
|
||||
- `agent_prompt`: The system prompt.
|
||||
- `task`: The user prompt for either a lead Agent or a sub-Agent. The lead Agent's user prompt is defined by the user, while a sub-Agent's user prompt is defined by the lead Agent when delegating tasks.
|
||||
- `tool_desc`: A description of the tools and sub_Agents that can be called.
|
||||
- `context`: The operational context, which stores interactions between the Agent, tools, and sub-agents; initially empty.
|
||||
- `plan_generation` prompt block
|
||||
- This block creates a plan for the **Agent** component to execute next, based on the task analysis results.
|
||||
- Reference design: [next_step.md](https://github.com/infiniflow/ragflow/blob/main/rag/prompts/next_step.md)
|
||||
- Available *only* when this **Agent** component is acting as a planner, with either tools or sub-Agents under it.
|
||||
- Input variables:
|
||||
- `task_analysis`: The analysis result of the current task.
|
||||
- `desc`: A description of the tools or sub-Agents currently being called.
|
||||
- `today`: The date of today.
|
||||
- `reflection` prompt block
|
||||
- This block enables the **Agent** component to reflect, improving task accuracy and efficiency.
|
||||
- Reference design: [reflect.md](https://github.com/infiniflow/ragflow/blob/main/rag/prompts/reflect.md)
|
||||
- Available *only* when this **Agent** component is acting as a planner, with either tools or sub-Agents under it.
|
||||
- Input variables:
|
||||
- `goal`: The goal of the current task. It is the user prompt for either a lead Agent or a sub-Agent. The lead Agent's user prompt is defined by the user, while a sub-Agent's user prompt is defined by the lead Agent.
|
||||
- `tool_calls`: The history of tool calling
|
||||
- `call.name`:The name of the tool called.
|
||||
- `call.result`:The result of tool calling
|
||||
- `citation_guidelines` prompt block
|
||||
- Reference design: [citation_prompt.md](https://github.com/infiniflow/ragflow/blob/main/rag/prompts/citation_prompt.md)
|
||||
|
||||
*The screenshots below show the framework prompt blocks available to an **Agent** component, both as a standalone and as a planner (with a Tavily tool below):*
|
||||
|
||||
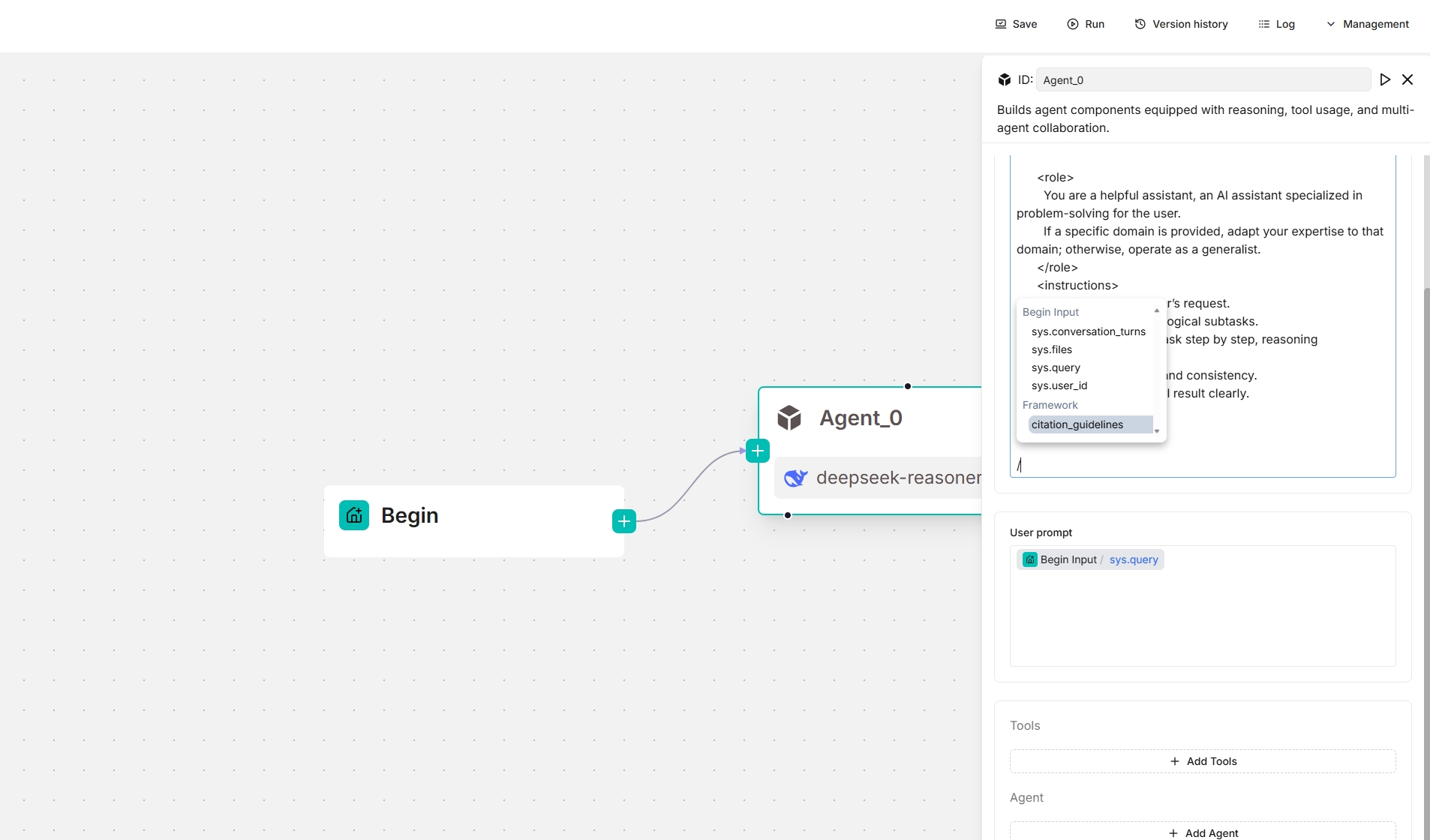
|
||||
|
||||
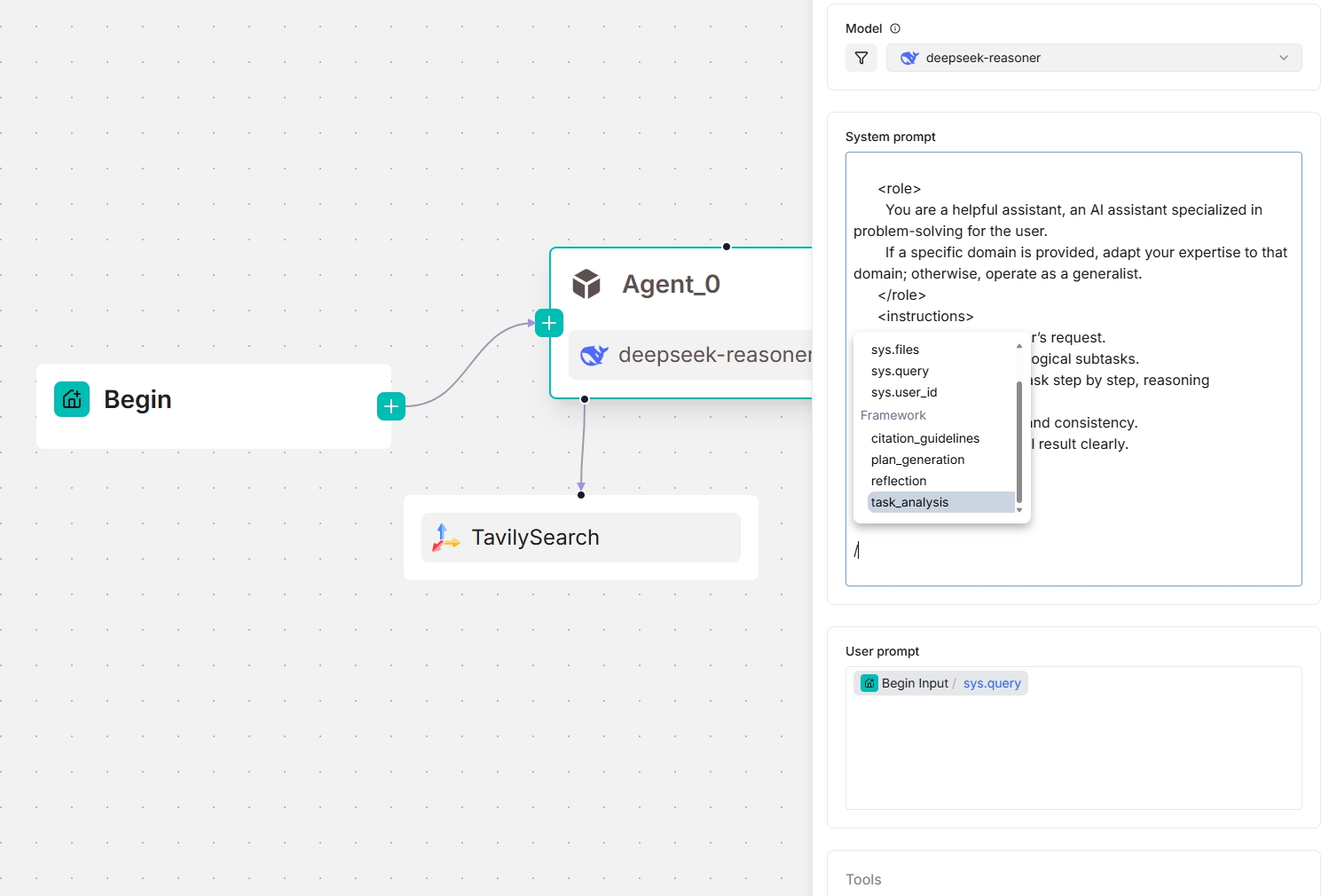
|
||||
|
||||
### User prompt
|
||||
|
||||
The user-defined prompt. Defaults to `sys.query`, the user query.
|
||||
The user-defined prompt. Defaults to `sys.query`, the user query. As a general rule, when using the **Agent** component as a standalone module (not as a planner), you usually need to specify the corresponding **Retrieval** component’s output variable (`formalized_content`) here as part of the input to the LLM.
|
||||
|
||||
|
||||
### Tools
|
||||
@ -90,7 +213,7 @@ Defines the maximum number of attempts the agent will make to retry a failed tas
|
||||
|
||||
The waiting period in seconds that the agent observes before retrying a failed task, helping to prevent immediate repeated attempts and allowing system conditions to improve. Defaults to 1 second.
|
||||
|
||||
### Max rounds
|
||||
### Max reflection rounds
|
||||
|
||||
Defines the maximum number reflection rounds of the selected chat model. Defaults to 1 round.
|
||||
|
||||
@ -100,4 +223,10 @@ Increasing this value will significantly extend your agent's response time.
|
||||
|
||||
### Output
|
||||
|
||||
The global variable name for the output of the **Agent** component, which can be referenced by other components in the workflow.
|
||||
The global variable name for the output of the **Agent** component, which can be referenced by other components in the workflow.
|
||||
|
||||
## Frequently asked questions
|
||||
|
||||
### Why does it take so long for my Agent to respond?
|
||||
|
||||
See [here](../best_practices/accelerate_agent_question_answering.md) for details.
|
||||
@ -13,6 +13,32 @@ A component that enables users to integrate Python or JavaScript codes into thei
|
||||
|
||||
A **Code** component is essential when you need to integrate complex code logic (Python or JavaScript) into your Agent for dynamic data processing.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
### 1. Ensure gVisor is properly installed
|
||||
|
||||
We use gVisor to isolate code execution from the host system. Please follow [the official installation guide](https://gvisor.dev/docs/user_guide/install/) to install gVisor, ensuring your operating system is compatible before proceeding.
|
||||
|
||||
### 2. Ensure Sandbox is properly installed
|
||||
|
||||
RAGFlow Sandbox is a secure, pluggable code execution backend. It serves as the code executor for the **Code** component. Please follow the [instructions here](https://github.com/infiniflow/ragflow/tree/main/sandbox) to install RAGFlow Sandbox.
|
||||
|
||||
:::tip NOTE
|
||||
If your RAGFlow Sandbox is not working, please be sure to consult the [Troubleshooting](#troubleshooting) section in this document. We assure you that it addresses 99.99% of the issues!
|
||||
:::
|
||||
|
||||
### 3. (Optional) Install necessary dependencies
|
||||
|
||||
If you need to import your own Python or JavaScript packages into Sandbox, please follow the commands provided in the [How to import my own Python or JavaScript packages into Sandbox?](#how-to-import-my-own-python-or-javascript-packages-into-sandbox) section to install the additional dependencies.
|
||||
|
||||
### 4. Enable Sandbox-specific settings in RAGFlow
|
||||
|
||||
Ensure all Sandbox-specific settings are enabled in **ragflow/docker/.env**.
|
||||
|
||||
### 5. Restart the service after making changes
|
||||
|
||||
Any changes to the configuration or environment *require* a full service restart to take effect.
|
||||
|
||||
## Configurations
|
||||
|
||||
### Input
|
||||
@ -23,6 +49,10 @@ You can specify multiple input sources for the **Code** component. Click **+ Add
|
||||
|
||||
This field allows you to enter and edit your source code.
|
||||
|
||||
:::danger IMPORTANT
|
||||
If your code implementation includes defined variables, whether input or output variables, ensure they are also specified in the corresponding **Input** or **Output** sections.
|
||||
:::
|
||||
|
||||
#### A Python code example
|
||||
|
||||
```Python
|
||||
@ -51,8 +81,125 @@ This field allows you to enter and edit your source code.
|
||||
|
||||
You define the output variable(s) of the **Code** component here.
|
||||
|
||||
:::danger IMPORTANT
|
||||
If you define output variables here, ensure they are also defined in your code implementation; otherwise, their values will be `null`. The following are two examples:
|
||||
|
||||
|
||||
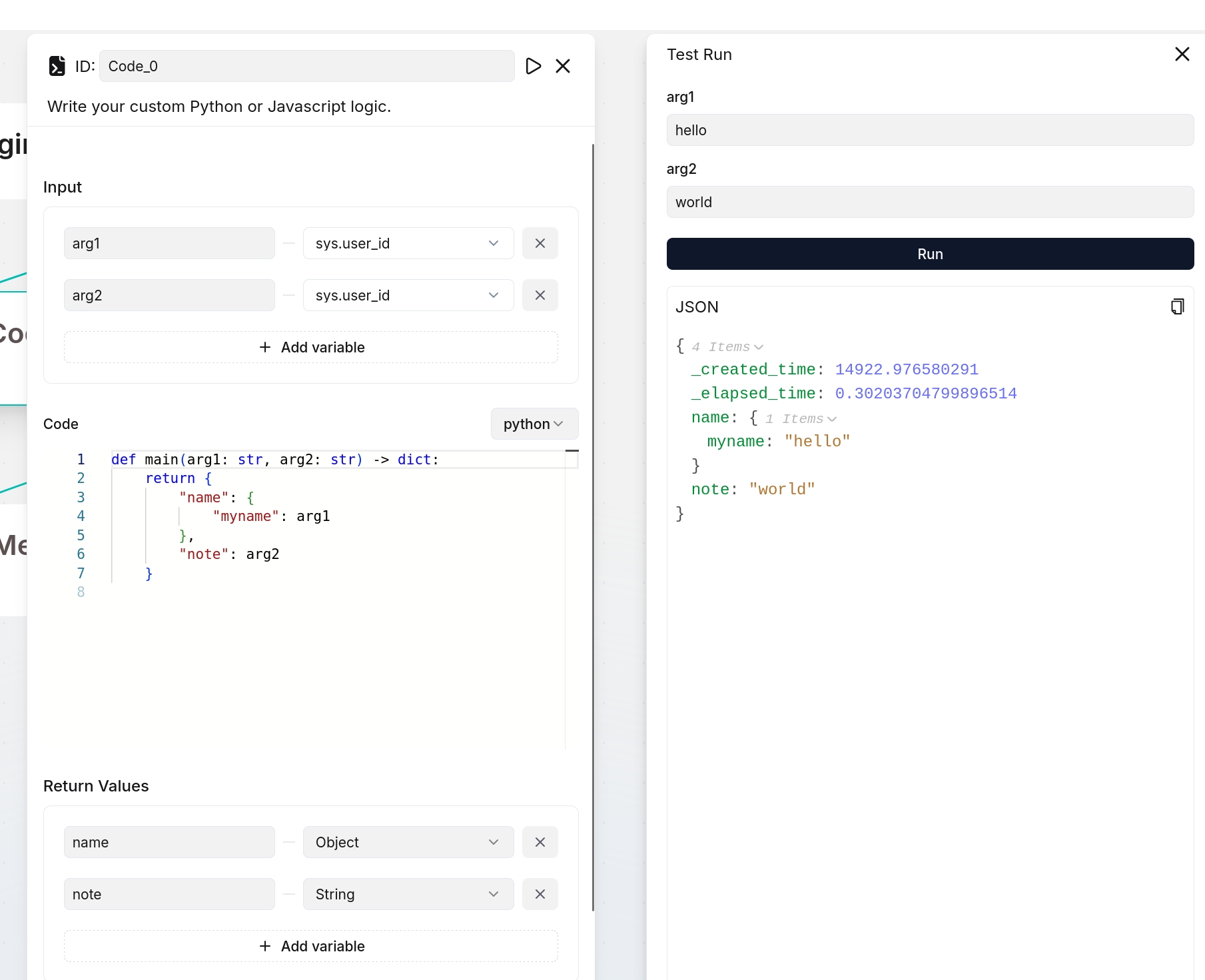
|
||||
|
||||
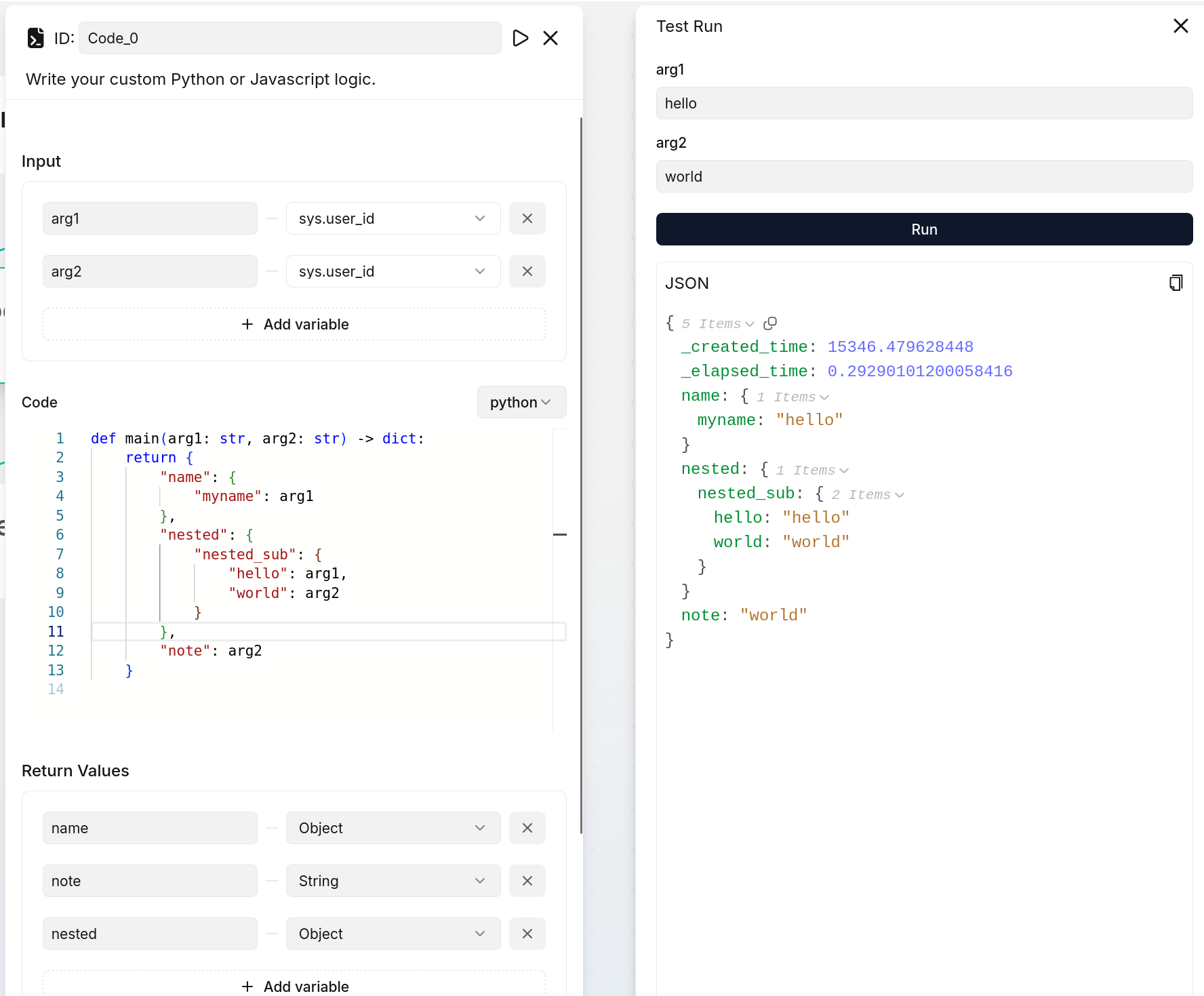
|
||||
:::
|
||||
|
||||
### Output
|
||||
|
||||
The defined output variable(s) will be auto-populated here.
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
### `HTTPConnectionPool(host='sandbox-executor-manager', port=9385): Read timed out.`
|
||||
|
||||
**Root cause**
|
||||
|
||||
- You did not properly install gVisor and `runsc` was not recognized as a valid Docker runtime.
|
||||
- You did not pull the required base images for the runners and no runner was started.
|
||||
|
||||
**Solution**
|
||||
|
||||
For the gVisor issue:
|
||||
|
||||
1. Install [gVisor](https://gvisor.dev/docs/user_guide/install/).
|
||||
2. Restart Docker.
|
||||
3. Run the following to double check:
|
||||
|
||||
```bash
|
||||
docker run --rm --runtime=runsc hello-world
|
||||
```
|
||||
|
||||
For the base image issue, pull the required base images:
|
||||
|
||||
```bash
|
||||
docker pull infiniflow/sandbox-base-nodejs:latest
|
||||
docker pull infiniflow/sandbox-base-python:latest
|
||||
```
|
||||
|
||||
### `HTTPConnectionPool(host='none', port=9385): Max retries exceeded.`
|
||||
|
||||
**Root cause**
|
||||
|
||||
`sandbox-executor-manager` is not mapped in `/etc/hosts`.
|
||||
|
||||
**Solution**
|
||||
|
||||
Add a new entry to `/etc/hosts`:
|
||||
|
||||
`127.0.0.1 es01 infinity mysql minio redis sandbox-executor-manager`
|
||||
|
||||
### `Container pool is busy`
|
||||
|
||||
**Root cause**
|
||||
|
||||
All runners are currently in use, executing tasks.
|
||||
|
||||
**Solution**
|
||||
|
||||
Please try again shortly or increase the pool size in the configuration to improve availability and reduce waiting times.
|
||||
|
||||
|
||||
## Frequently asked questions
|
||||
|
||||
### How to import my own Python or JavaScript packages into Sandbox?
|
||||
|
||||
To import your Python packages, update **sandbox_base_image/python/requirements.txt** to install the required dependencies. For example, to add the `openpyxl` package, proceed with the following command lines:
|
||||
|
||||
```bash {4,6}
|
||||
(ragflow) ➜ ragflow/sandbox main ✓ pwd # make sure you are in the right directory
|
||||
/home/infiniflow/workspace/ragflow/sandbox
|
||||
|
||||
(ragflow) ➜ ragflow/sandbox main ✓ echo "openpyxl" >> sandbox_base_image/python/requirements.txt # add the package to the requirements.txt file
|
||||
|
||||
(ragflow) ➜ ragflow/sandbox main ✗ cat sandbox_base_image/python/requirements.txt # make sure the package is added
|
||||
numpy
|
||||
pandas
|
||||
requests
|
||||
openpyxl # here it is
|
||||
|
||||
(ragflow) ➜ ragflow/sandbox main ✗ make # rebuild the docker image, this command will rebuild the iamge and start the service immediately. To build image only, using `make build` instead.
|
||||
|
||||
(ragflow) ➜ ragflow/sandbox main ✗ docker exec -it sandbox_python_0 /bin/bash # entering container to check if the package is installed
|
||||
|
||||
|
||||
# in the container
|
||||
nobody@ffd8a7dd19da:/workspace$ python # launch python shell
|
||||
Python 3.11.13 (main, Aug 12 2025, 22:46:03) [GCC 12.2.0] on linux
|
||||
Type "help", "copyright", "credits" or "license" for more information.
|
||||
>>> import openpyxl # import the package to verify installation
|
||||
>>>
|
||||
# That's okay!
|
||||
```
|
||||
|
||||
To import your JavaScript packages, navigate to `sandbox_base_image/nodejs` and use `npm` to install the required packages. For example, to add the `lodash` package, run the following commands:
|
||||
|
||||
```bash
|
||||
(ragflow) ➜ ragflow/sandbox main ✓ pwd
|
||||
/home/infiniflow/workspace/ragflow/sandbox
|
||||
|
||||
(ragflow) ➜ ragflow/sandbox main ✓ cd sandbox_base_image/nodejs
|
||||
|
||||
(ragflow) ➜ ragflow/sandbox/sandbox_base_image/nodejs main ✓ npm install lodash
|
||||
|
||||
(ragflow) ➜ ragflow/sandbox/sandbox_base_image/nodejs main ✓ cd ../.. # go back to sandbox root directory
|
||||
|
||||
(ragflow) ➜ ragflow/sandbox main ✗ make # rebuild the docker image, this command will rebuild the iamge and start the service immediately. To build image only, using `make build` instead.
|
||||
|
||||
(ragflow) ➜ ragflow/sandbox main ✗ docker exec -it sandbox_nodejs_0 /bin/bash # entering container to check if the package is installed
|
||||
|
||||
# in the container
|
||||
nobody@dd4bbcabef63:/workspace$ npm list lodash # verify via npm list
|
||||
/workspace
|
||||
`-- lodash@4.17.21 extraneous
|
||||
|
||||
nobody@dd4bbcabef63:/workspace$ ls node_modules | grep lodash # or verify via listing node_modules
|
||||
lodash
|
||||
|
||||
# That's okay!
|
||||
```
|
||||
|
||||
79
docs/guides/agent/agent_component_reference/execute_sql.md
Normal file
79
docs/guides/agent/agent_component_reference/execute_sql.md
Normal file
@ -0,0 +1,79 @@
|
||||
---
|
||||
sidebar_position: 25
|
||||
slug: /execute_sql
|
||||
---
|
||||
|
||||
# Execute SQL tool
|
||||
|
||||
A tool that execute SQL queries on a specified relational database.
|
||||
|
||||
---
|
||||
|
||||
The **Execute SQL** tool enables you to connect to a relational database and run SQL queries, whether entered directly or generated by the system’s Text2SQL capability via an **Agent** component.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- A database instance properly configured and running.
|
||||
- The database must be one of the following types:
|
||||
- MySQL
|
||||
- PostgreSQL
|
||||
- MariaDB
|
||||
- Microsoft SQL Server
|
||||
|
||||
## Examples
|
||||
|
||||
You can pair an **Agent** component with the **Execute SQL** tool, with the **Agent** generating SQL statements and the **Execute SQL** tool handling database connection and query execution. An example of this setup can be found in the **SQL Assistant** Agent template shown below:
|
||||
|
||||
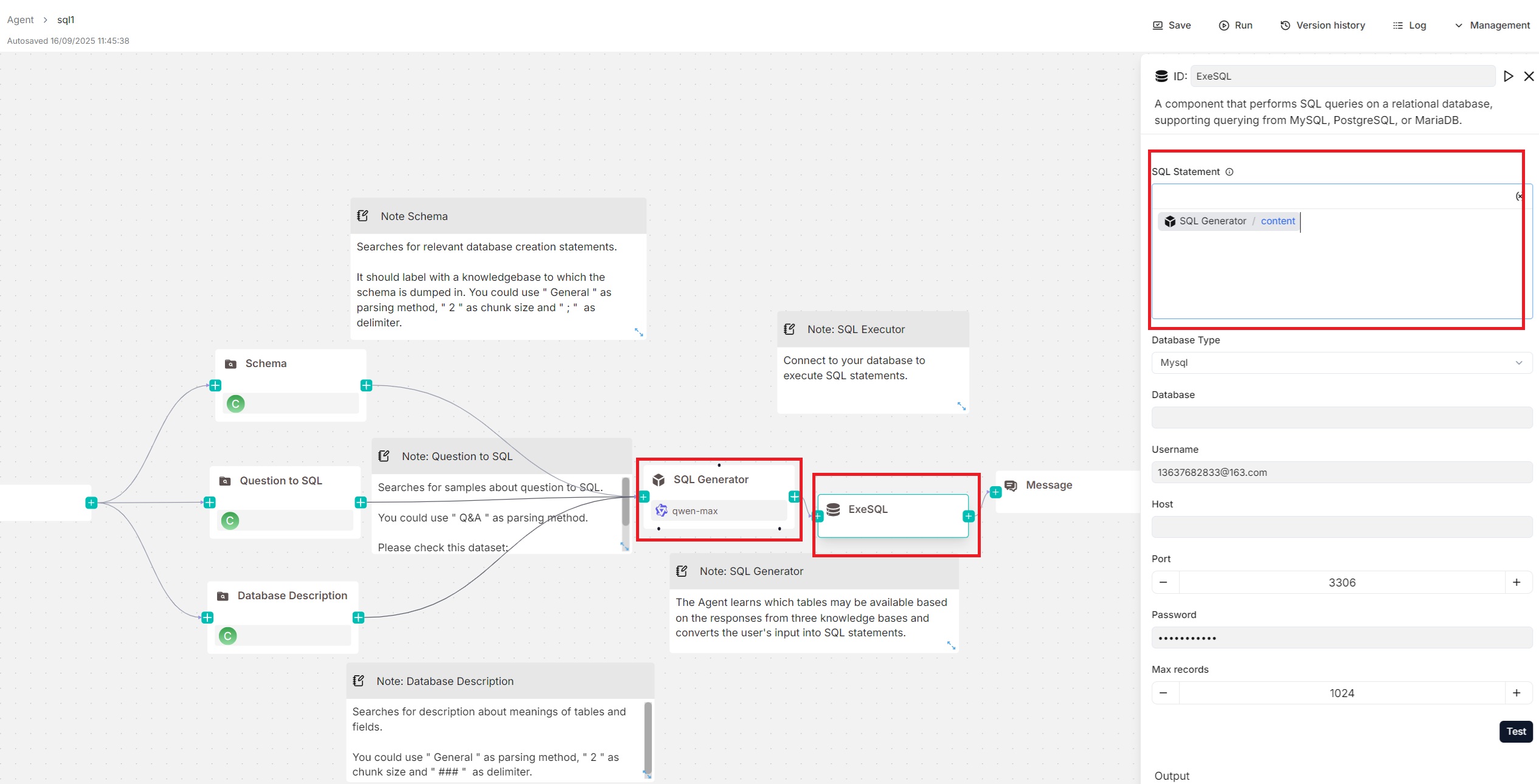
|
||||
|
||||
## Configurations
|
||||
|
||||
### SQL statement
|
||||
|
||||
This text input field allows you to write static SQL queries, such as `SELECT * FROM my_table`, and dynamic SQL queries using variables.
|
||||
|
||||
:::tip NOTE
|
||||
Click **(x)** or type `/` to insert variables.
|
||||
:::
|
||||
|
||||
For dynamic SQL queries, you can include variables in your SQL queries, such as `SELECT * FROM /sys.query`; if an **Agent** component is paired with the **Execute SQL** tool to generate SQL tasks (see the [Examples](#examples) section), you can directly insert that **Agent**'s output, `content`, into this field.
|
||||
|
||||
### Database type
|
||||
|
||||
The supported database type. Currently the following database types are available:
|
||||
|
||||
- MySQL
|
||||
- PostreSQL
|
||||
- MariaDB
|
||||
- Microsoft SQL Server (Myssql)
|
||||
|
||||
### Database
|
||||
|
||||
Appears only when you select **Split** as method.
|
||||
|
||||
### Username
|
||||
|
||||
The username with access privileges to the database.
|
||||
|
||||
### Host
|
||||
|
||||
The IP address of the database server.
|
||||
|
||||
### Port
|
||||
|
||||
The port number on which the database server is listening.
|
||||
|
||||
### Password
|
||||
|
||||
The password for the database user.
|
||||
|
||||
### Max records
|
||||
|
||||
The maximum number of records returned by the SQL query to control response size and improve efficiency. Defaults to `1024`.
|
||||
|
||||
### Output
|
||||
|
||||
The **Execute SQL** tool provides two output variables:
|
||||
|
||||
- `formalized_content`: A string. If you reference this variable in a **Message** component, the returned records are displayed as a table.
|
||||
- `json`: An object array. If you reference this variable in a **Message** component, the returned records will be presented as key-value pairs.
|
||||
@ -9,19 +9,70 @@ A component that retrieves information from specified datasets.
|
||||
|
||||
## Scenarios
|
||||
|
||||
A **Retrieval** component is essential in most RAG scenarios, where information is extracted from designated knowledge bases before being sent to the LLM for content generation. As of v0.20.4, a **Retrieval** component can operate either as a workflow component or as a tool of an **Agent**, enabling the Agent to control its invocation and search queries.
|
||||
A **Retrieval** component is essential in most RAG scenarios, where information is extracted from designated knowledge bases before being sent to the LLM for content generation. A **Retrieval** component can operate either as a standalone workflow module or as a tool for an **Agent** component. In the latter role, the **Agent** component has autonomous control over when to invoke it for query and retrieval.
|
||||
|
||||
The following screenshot shows a reference design using the **Retrieval** component, where the component serves as a tool for an **Agent** component. You can find it from the **Report Agent Using Knowledge Base** Agent template.
|
||||
|
||||
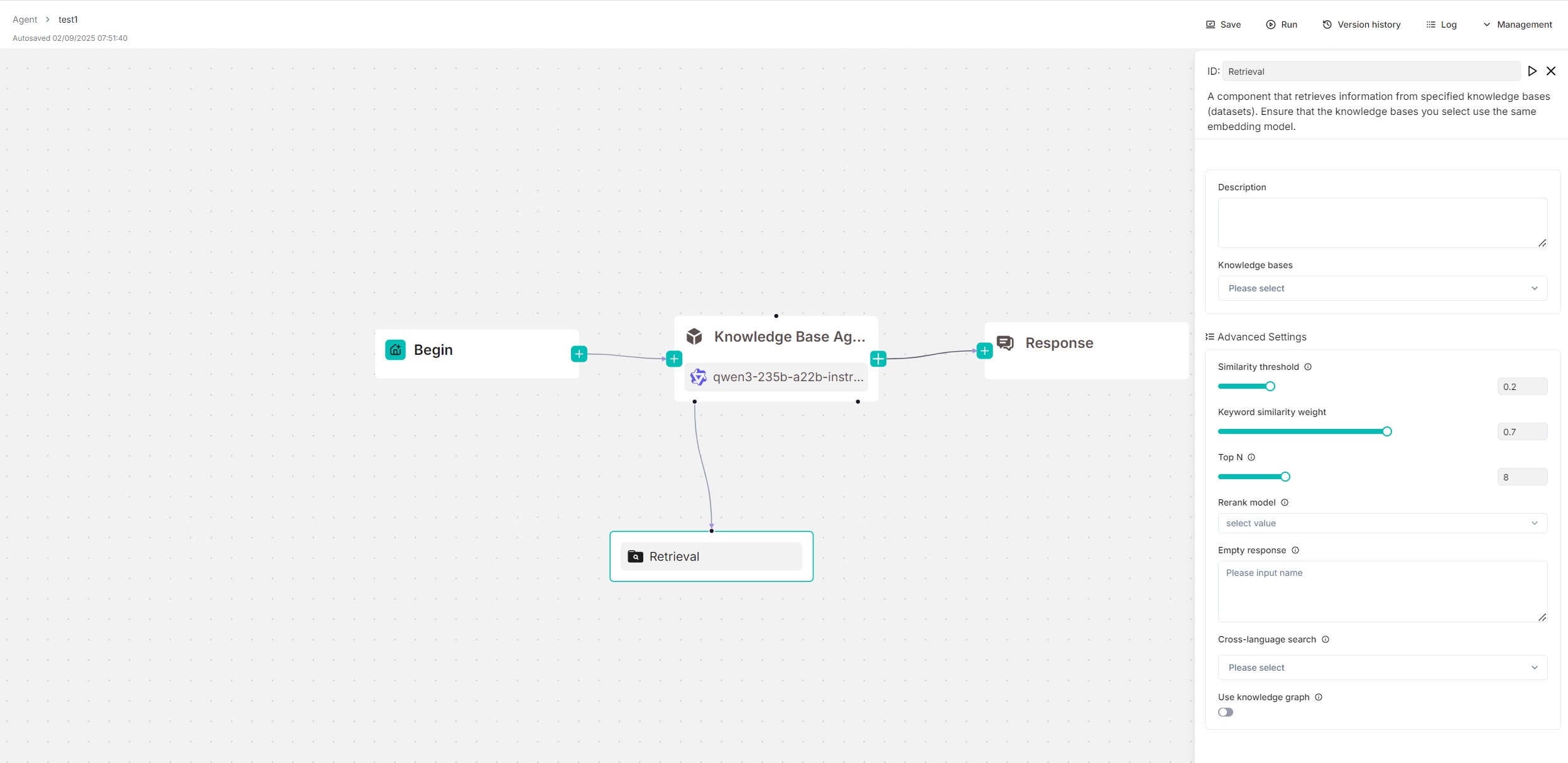
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Ensure you [have properly configured your target knowledge base(s)](../../dataset/configure_knowledge_base.md).
|
||||
|
||||
## Quickstart
|
||||
|
||||
### 1. Click on a **Retrieval** component to show its configuration panel
|
||||
|
||||
The corresponding configuration panel appears to the right of the canvas. Use this panel to define and fine-tune the **Retrieval** component's search behavior.
|
||||
|
||||
### 2. Input query variable(s)
|
||||
|
||||
The **Retrieval** component depends on query variables to specify its queries.
|
||||
|
||||
:::caution IMPORTANT
|
||||
- If you use the **Retrieval** component as a standalone workflow module, input query variables in the **Input Variables** text box.
|
||||
- If it is used as a tool for an **Agent** component, input the query variables in the **Agent** component's **User prompt** field.
|
||||
:::
|
||||
|
||||
By default, you can use `sys.query`, which is the user query and the default output of the **Begin** component. All global variables defined before the **Retrieval** component can also be used as query statements. Use the `(x)` button or type `/` to show all the available query variables.
|
||||
|
||||
### 3. Select knowledge base(s) to query
|
||||
|
||||
You can specify one or multiple knowledge bases to retrieve data from. If selecting mutiple, ensure they use the same embedding model.
|
||||
|
||||
### 4. Expand **Advanced Settings** to configure the retrieval method
|
||||
|
||||
By default, a combination of weighted keyword similarity and weighted vector cosine similarity is used for retrieval. If a rerank model is selected, a combination of weighted keyword similarity and weighted reranking score will be used instead.
|
||||
|
||||
As a starter, you can skip this step to stay with the default retrieval method.
|
||||
|
||||
:::caution WARNING
|
||||
Using a rerank model will *significantly* increase the system's response time. If you must use a rerank model, ensure you use a SaaS reranker; if you prefer a locally deployed rerank model, ensure you start RAGFlow with **docker-compose-gpu.yml**.
|
||||
:::
|
||||
|
||||
### 5. Enable cross-language search
|
||||
|
||||
If your user query is different from the languages of the knowledge bases, you can select the target languages in the **Cross-language search** dropdown menu. The model will then translates queries to ensure accurate matching of semantic meaning across languages.
|
||||
|
||||
|
||||
### 6. Test retrieval results
|
||||
|
||||
Click the **Run** button on the top of canvas to test the retrieval results.
|
||||
|
||||
### 7. Choose the next component
|
||||
|
||||
When necessary, click the **+** button on the **Retrieval** component to choose the next component in the worflow from the dropdown list.
|
||||
|
||||
|
||||
## Configurations
|
||||
|
||||
Click on a **Retrieval** component to open its configuration window.
|
||||
|
||||
### Query variables
|
||||
|
||||
*Mandatory*
|
||||
|
||||
Select the query source for retrieval.
|
||||
Select the query source for retrieval. Defaults to `sys.query`, which is the default output of the **Begin** component.
|
||||
|
||||
The **Retrieval** component relies on query variables to specify its data inputs (queries). All global variables defined before the **Retrieval** component are available in the dropdown list.
|
||||
The **Retrieval** component relies on query variables to specify its queries. All global variables defined before the **Retrieval** component can also be used as queries. Use the `(x)` button or type `/` to show all the available query variables.
|
||||
|
||||
### Knowledge bases
|
||||
|
||||
@ -72,8 +123,23 @@ Select one or more languages for cross‑language search. If no language is sele
|
||||
|
||||
### Use knowledge graph
|
||||
|
||||
:::caution IMPORTANT
|
||||
Before enabling this feature, ensure you have properly [constructed a knowledge graph from each target knowledge base](../../dataset/construct_knowledge_graph.md).
|
||||
:::
|
||||
|
||||
Whether to use knowledge graph(s) in the specified knowledge base(s) during retrieval for multi-hop question answering. When enabled, this would involve iterative searches across entity, relationship, and community report chunks, greatly increasing retrieval time.
|
||||
|
||||
### Output
|
||||
|
||||
The global variable name for the output of the **Retrieval** component, which can be referenced by other components in the workflow.
|
||||
|
||||
|
||||
## Frequently asked questions
|
||||
|
||||
### How to reduce response time?
|
||||
|
||||
Go through the checklist below for best performance:
|
||||
|
||||
- Leave the **Rerank model** field empty.
|
||||
- If you must use a rerank model, ensure you use a SaaS reranker; if you prefer a locally deployed rerank model, ensure you start RAGFlow with **docker-compose-gpu.yml**.
|
||||
- Disable **Use knowledge graph**.
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user