mirror of
https://github.com/infiniflow/ragflow.git
synced 2026-01-04 03:25:30 +08:00
Compare commits
97 Commits
main_backu
...
ff2c70608d
| Author | SHA1 | Date | |
|---|---|---|---|
| ff2c70608d | |||
| 5903d1c8f1 | |||
| f0392e7501 | |||
| 4037788e0c | |||
| 59884ab0fb | |||
| 4a6d37f0e8 | |||
| 731e2d5f26 | |||
| df3cbb9b9e | |||
| 5402666b19 | |||
| 4ec6a4e493 | |||
| 2d5ad42128 | |||
| dccda35f65 | |||
| d142b9095e | |||
| c2c079886f | |||
| c3ae1aaecd | |||
| f099bc1236 | |||
| 0b5d1ebefa | |||
| 082c2ed11c | |||
| a764f0a5b2 | |||
| 651d9fff9f | |||
| fddfce303c | |||
| a24fc8291b | |||
| 37e4485415 | |||
| 8d3f9d61da | |||
| 27c55f6514 | |||
| 9883c572cd | |||
| f9619defcc | |||
| 01f0ced1e6 | |||
| 647fb115a0 | |||
| 2114b9e3ad | |||
| 45b96acf6b | |||
| 3305215144 | |||
| 86b03f399a | |||
| 8dc5b4dc56 | |||
| ef5341b664 | |||
| 050534e743 | |||
| 3fe94d3386 | |||
| 3364cf96cf | |||
| a1ed4430ce | |||
| 7f11a79ad9 | |||
| ddcd9cf2c4 | |||
| c2e9064474 | |||
| bc9e1e3b9a | |||
| 613d2c5790 | |||
| 51bc41b2e8 | |||
| 9de3ecc4a8 | |||
| c4a66204f0 | |||
| 3558a6c170 | |||
| 595fc4ccec | |||
| 3ad147d349 | |||
| d285d8cd97 | |||
| 5714895291 | |||
| a33936e8ff | |||
| 9f8161d13e | |||
| a599a0f4bf | |||
| 7498bc63a3 | |||
| 894bf995bb | |||
| 52dbacc506 | |||
| cbcbbc41af | |||
| 6044314811 | |||
| 5fb38ecc2a | |||
| 73db759558 | |||
| 6e9691a419 | |||
| fd53b83190 | |||
| c7b5bfb809 | |||
| cfd1250615 | |||
| c8eeba5880 | |||
| 1812491679 | |||
| 7b6ab22b78 | |||
| c20d112f60 | |||
| 2817be14d5 | |||
| f6217bb990 | |||
| a3ceb7a944 | |||
| 0f8f35bd5b | |||
| 6373ff898b | |||
| d1c4077a75 | |||
| 059f375d85 | |||
| 8cbfb5aef6 | |||
| 5ebabf5bed | |||
| e23c8a5dcd | |||
| 89ea760e67 | |||
| 02b976ffa4 | |||
| 556b5ad686 | |||
| 884aabd130 | |||
| f0dac1d90e | |||
| 4a2978150c | |||
| df0c092b22 | |||
| 7d4258f50e | |||
| e24fabb03c | |||
| ce08ee399b | |||
| badd5aa101 | |||
| 5ff3be22b4 | |||
| df09cbd271 | |||
| 957bc021eb | |||
| 49dbfdbfb0 | |||
| 9a5c5c46f2 | |||
| 8197f9a873 |
39
.github/workflows/tests.yml
vendored
39
.github/workflows/tests.yml
vendored
@ -197,38 +197,37 @@ jobs:
|
|||||||
echo -e "COMPOSE_PROFILES=\${COMPOSE_PROFILES},tei-cpu" >> docker/.env
|
echo -e "COMPOSE_PROFILES=\${COMPOSE_PROFILES},tei-cpu" >> docker/.env
|
||||||
echo -e "TEI_MODEL=BAAI/bge-small-en-v1.5" >> docker/.env
|
echo -e "TEI_MODEL=BAAI/bge-small-en-v1.5" >> docker/.env
|
||||||
echo -e "RAGFLOW_IMAGE=${RAGFLOW_IMAGE}" >> docker/.env
|
echo -e "RAGFLOW_IMAGE=${RAGFLOW_IMAGE}" >> docker/.env
|
||||||
sed -i '1i DOC_ENGINE=infinity' docker/.env
|
|
||||||
echo "HOST_ADDRESS=http://host.docker.internal:${SVR_HTTP_PORT}" >> ${GITHUB_ENV}
|
echo "HOST_ADDRESS=http://host.docker.internal:${SVR_HTTP_PORT}" >> ${GITHUB_ENV}
|
||||||
|
|
||||||
sudo docker compose -f docker/docker-compose.yml -p ${GITHUB_RUN_ID} up -d
|
sudo docker compose -f docker/docker-compose.yml -p ${GITHUB_RUN_ID} up -d
|
||||||
uv sync --python 3.12 --only-group test --no-default-groups --frozen && uv pip install sdk/python --group test
|
uv sync --python 3.12 --only-group test --no-default-groups --frozen && uv pip install sdk/python --group test
|
||||||
|
|
||||||
- name: Run sdk tests against Infinity
|
- name: Run sdk tests against Elasticsearch
|
||||||
run: |
|
run: |
|
||||||
export http_proxy=""; export https_proxy=""; export no_proxy=""; export HTTP_PROXY=""; export HTTPS_PROXY=""; export NO_PROXY=""
|
export http_proxy=""; export https_proxy=""; export no_proxy=""; export HTTP_PROXY=""; export HTTPS_PROXY=""; export NO_PROXY=""
|
||||||
until sudo docker exec ${RAGFLOW_CONTAINER} curl -s --connect-timeout 5 ${HOST_ADDRESS} > /dev/null; do
|
until sudo docker exec ${RAGFLOW_CONTAINER} curl -s --connect-timeout 5 ${HOST_ADDRESS}/v1/system/ping > /dev/null; do
|
||||||
echo "Waiting for service to be available..."
|
echo "Waiting for service to be available..."
|
||||||
sleep 5
|
sleep 5
|
||||||
done
|
done
|
||||||
source .venv/bin/activate && DOC_ENGINE=infinity pytest -x -s --tb=short --level=${HTTP_API_TEST_LEVEL} test/testcases/test_sdk_api 2>&1 | tee infinity_sdk_test.log
|
source .venv/bin/activate && set -o pipefail; pytest -s --tb=short --level=${HTTP_API_TEST_LEVEL} test/testcases/test_sdk_api 2>&1 | tee es_sdk_test.log
|
||||||
|
|
||||||
- name: Run frontend api tests against Infinity
|
- name: Run frontend api tests against Elasticsearch
|
||||||
run: |
|
run: |
|
||||||
export http_proxy=""; export https_proxy=""; export no_proxy=""; export HTTP_PROXY=""; export HTTPS_PROXY=""; export NO_PROXY=""
|
export http_proxy=""; export https_proxy=""; export no_proxy=""; export HTTP_PROXY=""; export HTTPS_PROXY=""; export NO_PROXY=""
|
||||||
until sudo docker exec ${RAGFLOW_CONTAINER} curl -s --connect-timeout 5 ${HOST_ADDRESS} > /dev/null; do
|
until sudo docker exec ${RAGFLOW_CONTAINER} curl -s --connect-timeout 5 ${HOST_ADDRESS}/v1/system/ping > /dev/null; do
|
||||||
echo "Waiting for service to be available..."
|
echo "Waiting for service to be available..."
|
||||||
sleep 5
|
sleep 5
|
||||||
done
|
done
|
||||||
source .venv/bin/activate && DOC_ENGINE=infinity pytest -x -s --tb=short sdk/python/test/test_frontend_api/get_email.py sdk/python/test/test_frontend_api/test_dataset.py 2>&1 | tee infinity_api_test.log
|
source .venv/bin/activate && set -o pipefail; pytest -s --tb=short sdk/python/test/test_frontend_api/get_email.py sdk/python/test/test_frontend_api/test_dataset.py 2>&1 | tee es_api_test.log
|
||||||
|
|
||||||
- name: Run http api tests against Infinity
|
- name: Run http api tests against Elasticsearch
|
||||||
run: |
|
run: |
|
||||||
export http_proxy=""; export https_proxy=""; export no_proxy=""; export HTTP_PROXY=""; export HTTPS_PROXY=""; export NO_PROXY=""
|
export http_proxy=""; export https_proxy=""; export no_proxy=""; export HTTP_PROXY=""; export HTTPS_PROXY=""; export NO_PROXY=""
|
||||||
until sudo docker exec ${RAGFLOW_CONTAINER} curl -s --connect-timeout 5 ${HOST_ADDRESS} > /dev/null; do
|
until sudo docker exec ${RAGFLOW_CONTAINER} curl -s --connect-timeout 5 ${HOST_ADDRESS}/v1/system/ping > /dev/null; do
|
||||||
echo "Waiting for service to be available..."
|
echo "Waiting for service to be available..."
|
||||||
sleep 5
|
sleep 5
|
||||||
done
|
done
|
||||||
source .venv/bin/activate && DOC_ENGINE=infinity pytest -x -s --tb=short --level=${HTTP_API_TEST_LEVEL} test/testcases/test_http_api 2>&1 | tee infinity_http_api_test.log
|
source .venv/bin/activate && set -o pipefail; pytest -s --tb=short --level=${HTTP_API_TEST_LEVEL} test/testcases/test_http_api 2>&1 | tee es_http_api_test.log
|
||||||
|
|
||||||
- name: Stop ragflow:nightly
|
- name: Stop ragflow:nightly
|
||||||
if: always() # always run this step even if previous steps failed
|
if: always() # always run this step even if previous steps failed
|
||||||
@ -238,35 +237,35 @@ jobs:
|
|||||||
|
|
||||||
- name: Start ragflow:nightly
|
- name: Start ragflow:nightly
|
||||||
run: |
|
run: |
|
||||||
sed -i '1i DOC_ENGINE=elasticsearch' docker/.env
|
sed -i '1i DOC_ENGINE=infinity' docker/.env
|
||||||
sudo docker compose -f docker/docker-compose.yml -p ${GITHUB_RUN_ID} up -d
|
sudo docker compose -f docker/docker-compose.yml -p ${GITHUB_RUN_ID} up -d
|
||||||
|
|
||||||
- name: Run sdk tests against Elasticsearch
|
- name: Run sdk tests against Infinity
|
||||||
run: |
|
run: |
|
||||||
export http_proxy=""; export https_proxy=""; export no_proxy=""; export HTTP_PROXY=""; export HTTPS_PROXY=""; export NO_PROXY=""
|
export http_proxy=""; export https_proxy=""; export no_proxy=""; export HTTP_PROXY=""; export HTTPS_PROXY=""; export NO_PROXY=""
|
||||||
until sudo docker exec ${RAGFLOW_CONTAINER} curl -s --connect-timeout 5 ${HOST_ADDRESS} > /dev/null; do
|
until sudo docker exec ${RAGFLOW_CONTAINER} curl -s --connect-timeout 5 ${HOST_ADDRESS}/v1/system/ping > /dev/null; do
|
||||||
echo "Waiting for service to be available..."
|
echo "Waiting for service to be available..."
|
||||||
sleep 5
|
sleep 5
|
||||||
done
|
done
|
||||||
source .venv/bin/activate && DOC_ENGINE=elasticsearch pytest -x -s --tb=short --level=${HTTP_API_TEST_LEVEL} test/testcases/test_sdk_api 2>&1 | tee es_sdk_test.log
|
source .venv/bin/activate && set -o pipefail; DOC_ENGINE=infinity pytest -s --tb=short --level=${HTTP_API_TEST_LEVEL} test/testcases/test_sdk_api 2>&1 | tee infinity_sdk_test.log
|
||||||
|
|
||||||
- name: Run frontend api tests against Elasticsearch
|
- name: Run frontend api tests against Infinity
|
||||||
run: |
|
run: |
|
||||||
export http_proxy=""; export https_proxy=""; export no_proxy=""; export HTTP_PROXY=""; export HTTPS_PROXY=""; export NO_PROXY=""
|
export http_proxy=""; export https_proxy=""; export no_proxy=""; export HTTP_PROXY=""; export HTTPS_PROXY=""; export NO_PROXY=""
|
||||||
until sudo docker exec ${RAGFLOW_CONTAINER} curl -s --connect-timeout 5 ${HOST_ADDRESS} > /dev/null; do
|
until sudo docker exec ${RAGFLOW_CONTAINER} curl -s --connect-timeout 5 ${HOST_ADDRESS}/v1/system/ping > /dev/null; do
|
||||||
echo "Waiting for service to be available..."
|
echo "Waiting for service to be available..."
|
||||||
sleep 5
|
sleep 5
|
||||||
done
|
done
|
||||||
source .venv/bin/activate && DOC_ENGINE=elasticsearch pytest -x -s --tb=short sdk/python/test/test_frontend_api/get_email.py sdk/python/test/test_frontend_api/test_dataset.py 2>&1 | tee es_api_test.log
|
source .venv/bin/activate && set -o pipefail; DOC_ENGINE=infinity pytest -s --tb=short sdk/python/test/test_frontend_api/get_email.py sdk/python/test/test_frontend_api/test_dataset.py 2>&1 | tee infinity_api_test.log
|
||||||
|
|
||||||
- name: Run http api tests against Elasticsearch
|
- name: Run http api tests against Infinity
|
||||||
run: |
|
run: |
|
||||||
export http_proxy=""; export https_proxy=""; export no_proxy=""; export HTTP_PROXY=""; export HTTPS_PROXY=""; export NO_PROXY=""
|
export http_proxy=""; export https_proxy=""; export no_proxy=""; export HTTP_PROXY=""; export HTTPS_PROXY=""; export NO_PROXY=""
|
||||||
until sudo docker exec ${RAGFLOW_CONTAINER} curl -s --connect-timeout 5 ${HOST_ADDRESS} > /dev/null; do
|
until sudo docker exec ${RAGFLOW_CONTAINER} curl -s --connect-timeout 5 ${HOST_ADDRESS}/v1/system/ping > /dev/null; do
|
||||||
echo "Waiting for service to be available..."
|
echo "Waiting for service to be available..."
|
||||||
sleep 5
|
sleep 5
|
||||||
done
|
done
|
||||||
source .venv/bin/activate && DOC_ENGINE=elasticsearch pytest -x -s --tb=short --level=${HTTP_API_TEST_LEVEL} test/testcases/test_http_api 2>&1 | tee es_http_api_test.log
|
source .venv/bin/activate && set -o pipefail; DOC_ENGINE=infinity pytest -s --tb=short --level=${HTTP_API_TEST_LEVEL} test/testcases/test_http_api 2>&1 | tee infinity_http_api_test.log
|
||||||
|
|
||||||
- name: Stop ragflow:nightly
|
- name: Stop ragflow:nightly
|
||||||
if: always() # always run this step even if previous steps failed
|
if: always() # always run this step even if previous steps failed
|
||||||
|
|||||||
18
README.md
18
README.md
@ -22,7 +22,7 @@
|
|||||||
<img alt="Static Badge" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
<img alt="Static Badge" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
||||||
</a>
|
</a>
|
||||||
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
||||||
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.22.1">
|
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.23.0">
|
||||||
</a>
|
</a>
|
||||||
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
||||||
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Latest%20Release" alt="Latest Release">
|
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Latest%20Release" alt="Latest Release">
|
||||||
@ -85,6 +85,7 @@ Try our demo at [https://demo.ragflow.io](https://demo.ragflow.io).
|
|||||||
|
|
||||||
## 🔥 Latest Updates
|
## 🔥 Latest Updates
|
||||||
|
|
||||||
|
- 2025-12-26 Supports 'Memory' for AI agent.
|
||||||
- 2025-11-19 Supports Gemini 3 Pro.
|
- 2025-11-19 Supports Gemini 3 Pro.
|
||||||
- 2025-11-12 Supports data synchronization from Confluence, S3, Notion, Discord, Google Drive.
|
- 2025-11-12 Supports data synchronization from Confluence, S3, Notion, Discord, Google Drive.
|
||||||
- 2025-10-23 Supports MinerU & Docling as document parsing methods.
|
- 2025-10-23 Supports MinerU & Docling as document parsing methods.
|
||||||
@ -187,12 +188,12 @@ releases! 🌟
|
|||||||
> All Docker images are built for x86 platforms. We don't currently offer Docker images for ARM64.
|
> All Docker images are built for x86 platforms. We don't currently offer Docker images for ARM64.
|
||||||
> If you are on an ARM64 platform, follow [this guide](https://ragflow.io/docs/dev/build_docker_image) to build a Docker image compatible with your system.
|
> If you are on an ARM64 platform, follow [this guide](https://ragflow.io/docs/dev/build_docker_image) to build a Docker image compatible with your system.
|
||||||
|
|
||||||
> The command below downloads the `v0.22.1` edition of the RAGFlow Docker image. See the following table for descriptions of different RAGFlow editions. To download a RAGFlow edition different from `v0.22.1`, update the `RAGFLOW_IMAGE` variable accordingly in **docker/.env** before using `docker compose` to start the server.
|
> The command below downloads the `v0.23.0` edition of the RAGFlow Docker image. See the following table for descriptions of different RAGFlow editions. To download a RAGFlow edition different from `v0.23.0`, update the `RAGFLOW_IMAGE` variable accordingly in **docker/.env** before using `docker compose` to start the server.
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
$ cd ragflow/docker
|
$ cd ragflow/docker
|
||||||
|
|
||||||
# git checkout v0.22.1
|
# git checkout v0.23.0
|
||||||
# Optional: use a stable tag (see releases: https://github.com/infiniflow/ragflow/releases)
|
# Optional: use a stable tag (see releases: https://github.com/infiniflow/ragflow/releases)
|
||||||
# This step ensures the **entrypoint.sh** file in the code matches the Docker image version.
|
# This step ensures the **entrypoint.sh** file in the code matches the Docker image version.
|
||||||
|
|
||||||
@ -232,7 +233,7 @@ releases! 🌟
|
|||||||
* Running on all addresses (0.0.0.0)
|
* Running on all addresses (0.0.0.0)
|
||||||
```
|
```
|
||||||
|
|
||||||
> If you skip this confirmation step and directly log in to RAGFlow, your browser may prompt a `network anormal`
|
> If you skip this confirmation step and directly log in to RAGFlow, your browser may prompt a `network abnormal`
|
||||||
> error because, at that moment, your RAGFlow may not be fully initialized.
|
> error because, at that moment, your RAGFlow may not be fully initialized.
|
||||||
>
|
>
|
||||||
5. In your web browser, enter the IP address of your server and log in to RAGFlow.
|
5. In your web browser, enter the IP address of your server and log in to RAGFlow.
|
||||||
@ -302,6 +303,15 @@ cd ragflow/
|
|||||||
docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly .
|
docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly .
|
||||||
```
|
```
|
||||||
|
|
||||||
|
Or if you are behind a proxy, you can pass proxy arguments:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
docker build --platform linux/amd64 \
|
||||||
|
--build-arg http_proxy=http://YOUR_PROXY:PORT \
|
||||||
|
--build-arg https_proxy=http://YOUR_PROXY:PORT \
|
||||||
|
-f Dockerfile -t infiniflow/ragflow:nightly .
|
||||||
|
```
|
||||||
|
|
||||||
## 🔨 Launch service from source for development
|
## 🔨 Launch service from source for development
|
||||||
|
|
||||||
1. Install `uv` and `pre-commit`, or skip this step if they are already installed:
|
1. Install `uv` and `pre-commit`, or skip this step if they are already installed:
|
||||||
|
|||||||
18
README_id.md
18
README_id.md
@ -22,7 +22,7 @@
|
|||||||
<img alt="Lencana Daring" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
<img alt="Lencana Daring" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
||||||
</a>
|
</a>
|
||||||
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
||||||
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.22.1">
|
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.23.0">
|
||||||
</a>
|
</a>
|
||||||
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
||||||
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Rilis%20Terbaru" alt="Rilis Terbaru">
|
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Rilis%20Terbaru" alt="Rilis Terbaru">
|
||||||
@ -85,6 +85,7 @@ Coba demo kami di [https://demo.ragflow.io](https://demo.ragflow.io).
|
|||||||
|
|
||||||
## 🔥 Pembaruan Terbaru
|
## 🔥 Pembaruan Terbaru
|
||||||
|
|
||||||
|
- 2025-12-26 Mendukung 'Memori' untuk agen AI.
|
||||||
- 2025-11-19 Mendukung Gemini 3 Pro.
|
- 2025-11-19 Mendukung Gemini 3 Pro.
|
||||||
- 2025-11-12 Mendukung sinkronisasi data dari Confluence, S3, Notion, Discord, Google Drive.
|
- 2025-11-12 Mendukung sinkronisasi data dari Confluence, S3, Notion, Discord, Google Drive.
|
||||||
- 2025-10-23 Mendukung MinerU & Docling sebagai metode penguraian dokumen.
|
- 2025-10-23 Mendukung MinerU & Docling sebagai metode penguraian dokumen.
|
||||||
@ -187,12 +188,12 @@ Coba demo kami di [https://demo.ragflow.io](https://demo.ragflow.io).
|
|||||||
> Semua gambar Docker dibangun untuk platform x86. Saat ini, kami tidak menawarkan gambar Docker untuk ARM64.
|
> Semua gambar Docker dibangun untuk platform x86. Saat ini, kami tidak menawarkan gambar Docker untuk ARM64.
|
||||||
> Jika Anda menggunakan platform ARM64, [silakan gunakan panduan ini untuk membangun gambar Docker yang kompatibel dengan sistem Anda](https://ragflow.io/docs/dev/build_docker_image).
|
> Jika Anda menggunakan platform ARM64, [silakan gunakan panduan ini untuk membangun gambar Docker yang kompatibel dengan sistem Anda](https://ragflow.io/docs/dev/build_docker_image).
|
||||||
|
|
||||||
> Perintah di bawah ini mengunduh edisi v0.22.1 dari gambar Docker RAGFlow. Silakan merujuk ke tabel berikut untuk deskripsi berbagai edisi RAGFlow. Untuk mengunduh edisi RAGFlow yang berbeda dari v0.22.1, perbarui variabel RAGFLOW_IMAGE di docker/.env sebelum menggunakan docker compose untuk memulai server.
|
> Perintah di bawah ini mengunduh edisi v0.23.0 dari gambar Docker RAGFlow. Silakan merujuk ke tabel berikut untuk deskripsi berbagai edisi RAGFlow. Untuk mengunduh edisi RAGFlow yang berbeda dari v0.23.0, perbarui variabel RAGFLOW_IMAGE di docker/.env sebelum menggunakan docker compose untuk memulai server.
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
$ cd ragflow/docker
|
$ cd ragflow/docker
|
||||||
|
|
||||||
# git checkout v0.22.1
|
# git checkout v0.23.0
|
||||||
# Opsional: gunakan tag stabil (lihat releases: https://github.com/infiniflow/ragflow/releases)
|
# Opsional: gunakan tag stabil (lihat releases: https://github.com/infiniflow/ragflow/releases)
|
||||||
# This steps ensures the **entrypoint.sh** file in the code matches the Docker image version.
|
# This steps ensures the **entrypoint.sh** file in the code matches the Docker image version.
|
||||||
|
|
||||||
@ -232,7 +233,7 @@ Coba demo kami di [https://demo.ragflow.io](https://demo.ragflow.io).
|
|||||||
* Running on all addresses (0.0.0.0)
|
* Running on all addresses (0.0.0.0)
|
||||||
```
|
```
|
||||||
|
|
||||||
> Jika Anda melewatkan langkah ini dan langsung login ke RAGFlow, browser Anda mungkin menampilkan error `network anormal`
|
> Jika Anda melewatkan langkah ini dan langsung login ke RAGFlow, browser Anda mungkin menampilkan error `network abnormal`
|
||||||
> karena RAGFlow mungkin belum sepenuhnya siap.
|
> karena RAGFlow mungkin belum sepenuhnya siap.
|
||||||
>
|
>
|
||||||
2. Buka browser web Anda, masukkan alamat IP server Anda, dan login ke RAGFlow.
|
2. Buka browser web Anda, masukkan alamat IP server Anda, dan login ke RAGFlow.
|
||||||
@ -276,6 +277,15 @@ cd ragflow/
|
|||||||
docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly .
|
docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly .
|
||||||
```
|
```
|
||||||
|
|
||||||
|
Jika berada di belakang proxy, Anda dapat melewatkan argumen proxy:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
docker build --platform linux/amd64 \
|
||||||
|
--build-arg http_proxy=http://YOUR_PROXY:PORT \
|
||||||
|
--build-arg https_proxy=http://YOUR_PROXY:PORT \
|
||||||
|
-f Dockerfile -t infiniflow/ragflow:nightly .
|
||||||
|
```
|
||||||
|
|
||||||
## 🔨 Menjalankan Aplikasi dari untuk Pengembangan
|
## 🔨 Menjalankan Aplikasi dari untuk Pengembangan
|
||||||
|
|
||||||
1. Instal `uv` dan `pre-commit`, atau lewati langkah ini jika sudah terinstal:
|
1. Instal `uv` dan `pre-commit`, atau lewati langkah ini jika sudah terinstal:
|
||||||
|
|||||||
18
README_ja.md
18
README_ja.md
@ -22,7 +22,7 @@
|
|||||||
<img alt="Static Badge" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
<img alt="Static Badge" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
||||||
</a>
|
</a>
|
||||||
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
||||||
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.22.1">
|
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.23.0">
|
||||||
</a>
|
</a>
|
||||||
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
||||||
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Latest%20Release" alt="Latest Release">
|
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Latest%20Release" alt="Latest Release">
|
||||||
@ -66,7 +66,8 @@
|
|||||||
|
|
||||||
## 🔥 最新情報
|
## 🔥 最新情報
|
||||||
|
|
||||||
- 2025-11-19 Gemini 3 Proをサポートしています
|
- 2025-12-26 AIエージェントの「メモリ」機能をサポート。
|
||||||
|
- 2025-11-19 Gemini 3 Proをサポートしています。
|
||||||
- 2025-11-12 Confluence、S3、Notion、Discord、Google Drive からのデータ同期をサポートします。
|
- 2025-11-12 Confluence、S3、Notion、Discord、Google Drive からのデータ同期をサポートします。
|
||||||
- 2025-10-23 ドキュメント解析方法として MinerU と Docling をサポートします。
|
- 2025-10-23 ドキュメント解析方法として MinerU と Docling をサポートします。
|
||||||
- 2025-10-15 オーケストレーションされたデータパイプラインのサポート。
|
- 2025-10-15 オーケストレーションされたデータパイプラインのサポート。
|
||||||
@ -167,12 +168,12 @@
|
|||||||
> 現在、公式に提供されているすべての Docker イメージは x86 アーキテクチャ向けにビルドされており、ARM64 用の Docker イメージは提供されていません。
|
> 現在、公式に提供されているすべての Docker イメージは x86 アーキテクチャ向けにビルドされており、ARM64 用の Docker イメージは提供されていません。
|
||||||
> ARM64 アーキテクチャのオペレーティングシステムを使用している場合は、[このドキュメント](https://ragflow.io/docs/dev/build_docker_image)を参照して Docker イメージを自分でビルドしてください。
|
> ARM64 アーキテクチャのオペレーティングシステムを使用している場合は、[このドキュメント](https://ragflow.io/docs/dev/build_docker_image)を参照して Docker イメージを自分でビルドしてください。
|
||||||
|
|
||||||
> 以下のコマンドは、RAGFlow Docker イメージの v0.22.1 エディションをダウンロードします。異なる RAGFlow エディションの説明については、以下の表を参照してください。v0.22.1 とは異なるエディションをダウンロードするには、docker/.env ファイルの RAGFLOW_IMAGE 変数を適宜更新し、docker compose を使用してサーバーを起動してください。
|
> 以下のコマンドは、RAGFlow Docker イメージの v0.23.0 エディションをダウンロードします。異なる RAGFlow エディションの説明については、以下の表を参照してください。v0.23.0 とは異なるエディションをダウンロードするには、docker/.env ファイルの RAGFLOW_IMAGE 変数を適宜更新し、docker compose を使用してサーバーを起動してください。
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
$ cd ragflow/docker
|
$ cd ragflow/docker
|
||||||
|
|
||||||
# git checkout v0.22.1
|
# git checkout v0.23.0
|
||||||
# 任意: 安定版タグを利用 (一覧: https://github.com/infiniflow/ragflow/releases)
|
# 任意: 安定版タグを利用 (一覧: https://github.com/infiniflow/ragflow/releases)
|
||||||
# この手順は、コード内の entrypoint.sh ファイルが Docker イメージのバージョンと一致していることを確認します。
|
# この手順は、コード内の entrypoint.sh ファイルが Docker イメージのバージョンと一致していることを確認します。
|
||||||
|
|
||||||
@ -276,6 +277,15 @@ cd ragflow/
|
|||||||
docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly .
|
docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly .
|
||||||
```
|
```
|
||||||
|
|
||||||
|
プロキシ環境下にいる場合は、プロキシ引数を指定できます:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
docker build --platform linux/amd64 \
|
||||||
|
--build-arg http_proxy=http://YOUR_PROXY:PORT \
|
||||||
|
--build-arg https_proxy=http://YOUR_PROXY:PORT \
|
||||||
|
-f Dockerfile -t infiniflow/ragflow:nightly .
|
||||||
|
```
|
||||||
|
|
||||||
## 🔨 ソースコードからサービスを起動する方法
|
## 🔨 ソースコードからサービスを起動する方法
|
||||||
|
|
||||||
1. `uv` と `pre-commit` をインストールする。すでにインストールされている場合は、このステップをスキップしてください:
|
1. `uv` と `pre-commit` をインストールする。すでにインストールされている場合は、このステップをスキップしてください:
|
||||||
|
|||||||
18
README_ko.md
18
README_ko.md
@ -22,7 +22,7 @@
|
|||||||
<img alt="Static Badge" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
<img alt="Static Badge" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
||||||
</a>
|
</a>
|
||||||
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
||||||
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.22.1">
|
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.23.0">
|
||||||
</a>
|
</a>
|
||||||
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
||||||
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Latest%20Release" alt="Latest Release">
|
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Latest%20Release" alt="Latest Release">
|
||||||
@ -67,6 +67,7 @@
|
|||||||
|
|
||||||
## 🔥 업데이트
|
## 🔥 업데이트
|
||||||
|
|
||||||
|
- 2025-12-26 AI 에이전트의 '메모리' 기능 지원.
|
||||||
- 2025-11-19 Gemini 3 Pro를 지원합니다.
|
- 2025-11-19 Gemini 3 Pro를 지원합니다.
|
||||||
- 2025-11-12 Confluence, S3, Notion, Discord, Google Drive에서 데이터 동기화를 지원합니다.
|
- 2025-11-12 Confluence, S3, Notion, Discord, Google Drive에서 데이터 동기화를 지원합니다.
|
||||||
- 2025-10-23 문서 파싱 방법으로 MinerU 및 Docling을 지원합니다.
|
- 2025-10-23 문서 파싱 방법으로 MinerU 및 Docling을 지원합니다.
|
||||||
@ -169,12 +170,12 @@
|
|||||||
> 모든 Docker 이미지는 x86 플랫폼을 위해 빌드되었습니다. 우리는 현재 ARM64 플랫폼을 위한 Docker 이미지를 제공하지 않습니다.
|
> 모든 Docker 이미지는 x86 플랫폼을 위해 빌드되었습니다. 우리는 현재 ARM64 플랫폼을 위한 Docker 이미지를 제공하지 않습니다.
|
||||||
> ARM64 플랫폼을 사용 중이라면, [시스템과 호환되는 Docker 이미지를 빌드하려면 이 가이드를 사용해 주세요](https://ragflow.io/docs/dev/build_docker_image).
|
> ARM64 플랫폼을 사용 중이라면, [시스템과 호환되는 Docker 이미지를 빌드하려면 이 가이드를 사용해 주세요](https://ragflow.io/docs/dev/build_docker_image).
|
||||||
|
|
||||||
> 아래 명령어는 RAGFlow Docker 이미지의 v0.22.1 버전을 다운로드합니다. 다양한 RAGFlow 버전에 대한 설명은 다음 표를 참조하십시오. v0.22.1과 다른 RAGFlow 버전을 다운로드하려면, docker/.env 파일에서 RAGFLOW_IMAGE 변수를 적절히 업데이트한 후 docker compose를 사용하여 서버를 시작하십시오.
|
> 아래 명령어는 RAGFlow Docker 이미지의 v0.23.0 버전을 다운로드합니다. 다양한 RAGFlow 버전에 대한 설명은 다음 표를 참조하십시오. v0.23.0과 다른 RAGFlow 버전을 다운로드하려면, docker/.env 파일에서 RAGFLOW_IMAGE 변수를 적절히 업데이트한 후 docker compose를 사용하여 서버를 시작하십시오.
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
$ cd ragflow/docker
|
$ cd ragflow/docker
|
||||||
|
|
||||||
# git checkout v0.22.1
|
# git checkout v0.23.0
|
||||||
# Optional: use a stable tag (see releases: https://github.com/infiniflow/ragflow/releases)
|
# Optional: use a stable tag (see releases: https://github.com/infiniflow/ragflow/releases)
|
||||||
# 이 단계는 코드의 entrypoint.sh 파일이 Docker 이미지 버전과 일치하도록 보장합니다.
|
# 이 단계는 코드의 entrypoint.sh 파일이 Docker 이미지 버전과 일치하도록 보장합니다.
|
||||||
|
|
||||||
@ -213,7 +214,7 @@
|
|||||||
* Running on all addresses (0.0.0.0)
|
* Running on all addresses (0.0.0.0)
|
||||||
```
|
```
|
||||||
|
|
||||||
> 만약 확인 단계를 건너뛰고 바로 RAGFlow에 로그인하면, RAGFlow가 완전히 초기화되지 않았기 때문에 브라우저에서 `network anormal` 오류가 발생할 수 있습니다.
|
> 만약 확인 단계를 건너뛰고 바로 RAGFlow에 로그인하면, RAGFlow가 완전히 초기화되지 않았기 때문에 브라우저에서 `network abnormal` 오류가 발생할 수 있습니다.
|
||||||
|
|
||||||
2. 웹 브라우저에 서버의 IP 주소를 입력하고 RAGFlow에 로그인하세요.
|
2. 웹 브라우저에 서버의 IP 주소를 입력하고 RAGFlow에 로그인하세요.
|
||||||
> 기본 설정을 사용할 경우, `http://IP_OF_YOUR_MACHINE`만 입력하면 됩니다 (포트 번호는 제외). 기본 HTTP 서비스 포트 `80`은 기본 구성으로 사용할 때 생략할 수 있습니다.
|
> 기본 설정을 사용할 경우, `http://IP_OF_YOUR_MACHINE`만 입력하면 됩니다 (포트 번호는 제외). 기본 HTTP 서비스 포트 `80`은 기본 구성으로 사용할 때 생략할 수 있습니다.
|
||||||
@ -270,6 +271,15 @@ cd ragflow/
|
|||||||
docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly .
|
docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly .
|
||||||
```
|
```
|
||||||
|
|
||||||
|
프록시 환경인 경우, 프록시 인수를 전달할 수 있습니다:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
docker build --platform linux/amd64 \
|
||||||
|
--build-arg http_proxy=http://YOUR_PROXY:PORT \
|
||||||
|
--build-arg https_proxy=http://YOUR_PROXY:PORT \
|
||||||
|
-f Dockerfile -t infiniflow/ragflow:nightly .
|
||||||
|
```
|
||||||
|
|
||||||
## 🔨 소스 코드로 서비스를 시작합니다.
|
## 🔨 소스 코드로 서비스를 시작합니다.
|
||||||
|
|
||||||
1. `uv` 와 `pre-commit` 을 설치하거나, 이미 설치된 경우 이 단계를 건너뜁니다:
|
1. `uv` 와 `pre-commit` 을 설치하거나, 이미 설치된 경우 이 단계를 건너뜁니다:
|
||||||
|
|||||||
@ -22,7 +22,7 @@
|
|||||||
<img alt="Badge Estático" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
<img alt="Badge Estático" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
||||||
</a>
|
</a>
|
||||||
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
||||||
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.22.1">
|
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.23.0">
|
||||||
</a>
|
</a>
|
||||||
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
||||||
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Última%20Relese" alt="Última Versão">
|
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Última%20Relese" alt="Última Versão">
|
||||||
@ -86,6 +86,7 @@ Experimente nossa demo em [https://demo.ragflow.io](https://demo.ragflow.io).
|
|||||||
|
|
||||||
## 🔥 Últimas Atualizações
|
## 🔥 Últimas Atualizações
|
||||||
|
|
||||||
|
- 26-12-2025 Suporte à função 'Memória' para agentes de IA.
|
||||||
- 19-11-2025 Suporta Gemini 3 Pro.
|
- 19-11-2025 Suporta Gemini 3 Pro.
|
||||||
- 12-11-2025 Suporta a sincronização de dados do Confluence, S3, Notion, Discord e Google Drive.
|
- 12-11-2025 Suporta a sincronização de dados do Confluence, S3, Notion, Discord e Google Drive.
|
||||||
- 23-10-2025 Suporta MinerU e Docling como métodos de análise de documentos.
|
- 23-10-2025 Suporta MinerU e Docling como métodos de análise de documentos.
|
||||||
@ -187,12 +188,12 @@ Experimente nossa demo em [https://demo.ragflow.io](https://demo.ragflow.io).
|
|||||||
> Todas as imagens Docker são construídas para plataformas x86. Atualmente, não oferecemos imagens Docker para ARM64.
|
> Todas as imagens Docker são construídas para plataformas x86. Atualmente, não oferecemos imagens Docker para ARM64.
|
||||||
> Se você estiver usando uma plataforma ARM64, por favor, utilize [este guia](https://ragflow.io/docs/dev/build_docker_image) para construir uma imagem Docker compatível com o seu sistema.
|
> Se você estiver usando uma plataforma ARM64, por favor, utilize [este guia](https://ragflow.io/docs/dev/build_docker_image) para construir uma imagem Docker compatível com o seu sistema.
|
||||||
|
|
||||||
> O comando abaixo baixa a edição`v0.22.1` da imagem Docker do RAGFlow. Consulte a tabela a seguir para descrições de diferentes edições do RAGFlow. Para baixar uma edição do RAGFlow diferente da `v0.22.1`, atualize a variável `RAGFLOW_IMAGE` conforme necessário no **docker/.env** antes de usar `docker compose` para iniciar o servidor.
|
> O comando abaixo baixa a edição`v0.23.0` da imagem Docker do RAGFlow. Consulte a tabela a seguir para descrições de diferentes edições do RAGFlow. Para baixar uma edição do RAGFlow diferente da `v0.23.0`, atualize a variável `RAGFLOW_IMAGE` conforme necessário no **docker/.env** antes de usar `docker compose` para iniciar o servidor.
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
$ cd ragflow/docker
|
$ cd ragflow/docker
|
||||||
|
|
||||||
# git checkout v0.22.1
|
# git checkout v0.23.0
|
||||||
# Opcional: use uma tag estável (veja releases: https://github.com/infiniflow/ragflow/releases)
|
# Opcional: use uma tag estável (veja releases: https://github.com/infiniflow/ragflow/releases)
|
||||||
# Esta etapa garante que o arquivo entrypoint.sh no código corresponda à versão da imagem do Docker.
|
# Esta etapa garante que o arquivo entrypoint.sh no código corresponda à versão da imagem do Docker.
|
||||||
|
|
||||||
@ -231,7 +232,7 @@ Experimente nossa demo em [https://demo.ragflow.io](https://demo.ragflow.io).
|
|||||||
* Rodando em todos os endereços (0.0.0.0)
|
* Rodando em todos os endereços (0.0.0.0)
|
||||||
```
|
```
|
||||||
|
|
||||||
> Se você pular essa etapa de confirmação e acessar diretamente o RAGFlow, seu navegador pode exibir um erro `network anormal`, pois, nesse momento, seu RAGFlow pode não estar totalmente inicializado.
|
> Se você pular essa etapa de confirmação e acessar diretamente o RAGFlow, seu navegador pode exibir um erro `network abnormal`, pois, nesse momento, seu RAGFlow pode não estar totalmente inicializado.
|
||||||
>
|
>
|
||||||
5. No seu navegador, insira o endereço IP do seu servidor e faça login no RAGFlow.
|
5. No seu navegador, insira o endereço IP do seu servidor e faça login no RAGFlow.
|
||||||
|
|
||||||
@ -293,6 +294,15 @@ cd ragflow/
|
|||||||
docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly .
|
docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly .
|
||||||
```
|
```
|
||||||
|
|
||||||
|
Se você estiver atrás de um proxy, pode passar argumentos de proxy:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
docker build --platform linux/amd64 \
|
||||||
|
--build-arg http_proxy=http://YOUR_PROXY:PORT \
|
||||||
|
--build-arg https_proxy=http://YOUR_PROXY:PORT \
|
||||||
|
-f Dockerfile -t infiniflow/ragflow:nightly .
|
||||||
|
```
|
||||||
|
|
||||||
## 🔨 Lançar o serviço a partir do código-fonte para desenvolvimento
|
## 🔨 Lançar o serviço a partir do código-fonte para desenvolvimento
|
||||||
|
|
||||||
1. Instale o `uv` e o `pre-commit`, ou pule esta etapa se eles já estiverem instalados:
|
1. Instale o `uv` e o `pre-commit`, ou pule esta etapa se eles já estiverem instalados:
|
||||||
|
|||||||
@ -22,7 +22,7 @@
|
|||||||
<img alt="Static Badge" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
<img alt="Static Badge" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
||||||
</a>
|
</a>
|
||||||
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
||||||
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.22.1">
|
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.23.0">
|
||||||
</a>
|
</a>
|
||||||
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
||||||
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Latest%20Release" alt="Latest Release">
|
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Latest%20Release" alt="Latest Release">
|
||||||
@ -85,15 +85,16 @@
|
|||||||
|
|
||||||
## 🔥 近期更新
|
## 🔥 近期更新
|
||||||
|
|
||||||
- 2025-11-19 支援 Gemini 3 Pro.
|
- 2025-12-26 支援AI代理的「記憶」功能。
|
||||||
|
- 2025-11-19 支援 Gemini 3 Pro。
|
||||||
- 2025-11-12 支援從 Confluence、S3、Notion、Discord、Google Drive 進行資料同步。
|
- 2025-11-12 支援從 Confluence、S3、Notion、Discord、Google Drive 進行資料同步。
|
||||||
- 2025-10-23 支援 MinerU 和 Docling 作為文件解析方法。
|
- 2025-10-23 支援 MinerU 和 Docling 作為文件解析方法。
|
||||||
- 2025-10-15 支援可編排的資料管道。
|
- 2025-10-15 支援可編排的資料管道。
|
||||||
- 2025-08-08 支援 OpenAI 最新的 GPT-5 系列模型。
|
- 2025-08-08 支援 OpenAI 最新的 GPT-5 系列模型。
|
||||||
- 2025-08-01 支援 agentic workflow 和 MCP
|
- 2025-08-01 支援 agentic workflow 和 MCP。
|
||||||
- 2025-05-23 為 Agent 新增 Python/JS 程式碼執行器元件。
|
- 2025-05-23 為 Agent 新增 Python/JS 程式碼執行器元件。
|
||||||
- 2025-05-05 支援跨語言查詢。
|
- 2025-05-05 支援跨語言查詢。
|
||||||
- 2025-03-19 PDF和DOCX中的圖支持用多模態大模型去解析得到描述.
|
- 2025-03-19 PDF和DOCX中的圖支持用多模態大模型去解析得到描述。
|
||||||
- 2024-12-18 升級了 DeepDoc 的文檔佈局分析模型。
|
- 2024-12-18 升級了 DeepDoc 的文檔佈局分析模型。
|
||||||
- 2024-08-22 支援用 RAG 技術實現從自然語言到 SQL 語句的轉換。
|
- 2024-08-22 支援用 RAG 技術實現從自然語言到 SQL 語句的轉換。
|
||||||
|
|
||||||
@ -124,7 +125,7 @@
|
|||||||
|
|
||||||
### 🍔 **相容各類異質資料來源**
|
### 🍔 **相容各類異質資料來源**
|
||||||
|
|
||||||
- 支援豐富的文件類型,包括 Word 文件、PPT、excel 表格、txt 檔案、圖片、PDF、影印件、影印件、結構化資料、網頁等。
|
- 支援豐富的文件類型,包括 Word 文件、PPT、excel 表格、txt 檔案、圖片、PDF、影印件、複印件、結構化資料、網頁等。
|
||||||
|
|
||||||
### 🛀 **全程無憂、自動化的 RAG 工作流程**
|
### 🛀 **全程無憂、自動化的 RAG 工作流程**
|
||||||
|
|
||||||
@ -186,12 +187,12 @@
|
|||||||
> 所有 Docker 映像檔都是為 x86 平台建置的。目前,我們不提供 ARM64 平台的 Docker 映像檔。
|
> 所有 Docker 映像檔都是為 x86 平台建置的。目前,我們不提供 ARM64 平台的 Docker 映像檔。
|
||||||
> 如果您使用的是 ARM64 平台,請使用 [這份指南](https://ragflow.io/docs/dev/build_docker_image) 來建置適合您系統的 Docker 映像檔。
|
> 如果您使用的是 ARM64 平台,請使用 [這份指南](https://ragflow.io/docs/dev/build_docker_image) 來建置適合您系統的 Docker 映像檔。
|
||||||
|
|
||||||
> 執行以下指令會自動下載 RAGFlow Docker 映像 `v0.22.1`。請參考下表查看不同 Docker 發行版的說明。如需下載不同於 `v0.22.1` 的 Docker 映像,請在執行 `docker compose` 啟動服務之前先更新 **docker/.env** 檔案內的 `RAGFLOW_IMAGE` 變數。
|
> 執行以下指令會自動下載 RAGFlow Docker 映像 `v0.23.0`。請參考下表查看不同 Docker 發行版的說明。如需下載不同於 `v0.23.0` 的 Docker 映像,請在執行 `docker compose` 啟動服務之前先更新 **docker/.env** 檔案內的 `RAGFLOW_IMAGE` 變數。
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
$ cd ragflow/docker
|
$ cd ragflow/docker
|
||||||
|
|
||||||
# git checkout v0.22.1
|
# git checkout v0.23.0
|
||||||
# 可選:使用穩定版標籤(查看發佈:https://github.com/infiniflow/ragflow/releases)
|
# 可選:使用穩定版標籤(查看發佈:https://github.com/infiniflow/ragflow/releases)
|
||||||
# 此步驟確保程式碼中的 entrypoint.sh 檔案與 Docker 映像版本一致。
|
# 此步驟確保程式碼中的 entrypoint.sh 檔案與 Docker 映像版本一致。
|
||||||
|
|
||||||
@ -236,7 +237,7 @@
|
|||||||
* Running on all addresses (0.0.0.0)
|
* Running on all addresses (0.0.0.0)
|
||||||
```
|
```
|
||||||
|
|
||||||
> 如果您跳過這一步驟系統確認步驟就登入 RAGFlow,你的瀏覽器有可能會提示 `network anormal` 或 `網路異常`,因為 RAGFlow 可能並未完全啟動成功。
|
> 如果您跳過這一步驟系統確認步驟就登入 RAGFlow,你的瀏覽器有可能會提示 `network abnormal` 或 `網路異常`,因為 RAGFlow 可能並未完全啟動成功。
|
||||||
>
|
>
|
||||||
5. 在你的瀏覽器中輸入你的伺服器對應的 IP 位址並登入 RAGFlow。
|
5. 在你的瀏覽器中輸入你的伺服器對應的 IP 位址並登入 RAGFlow。
|
||||||
|
|
||||||
@ -302,6 +303,15 @@ cd ragflow/
|
|||||||
docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly .
|
docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly .
|
||||||
```
|
```
|
||||||
|
|
||||||
|
若您位於代理環境,可傳遞代理參數:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
docker build --platform linux/amd64 \
|
||||||
|
--build-arg http_proxy=http://YOUR_PROXY:PORT \
|
||||||
|
--build-arg https_proxy=http://YOUR_PROXY:PORT \
|
||||||
|
-f Dockerfile -t infiniflow/ragflow:nightly .
|
||||||
|
```
|
||||||
|
|
||||||
## 🔨 以原始碼啟動服務
|
## 🔨 以原始碼啟動服務
|
||||||
|
|
||||||
1. 安裝 `uv` 和 `pre-commit`。如已安裝,可跳過此步驟:
|
1. 安裝 `uv` 和 `pre-commit`。如已安裝,可跳過此步驟:
|
||||||
|
|||||||
22
README_zh.md
22
README_zh.md
@ -22,7 +22,7 @@
|
|||||||
<img alt="Static Badge" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
<img alt="Static Badge" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
||||||
</a>
|
</a>
|
||||||
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
||||||
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.22.1">
|
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.23.0">
|
||||||
</a>
|
</a>
|
||||||
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
||||||
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Latest%20Release" alt="Latest Release">
|
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Latest%20Release" alt="Latest Release">
|
||||||
@ -85,7 +85,8 @@
|
|||||||
|
|
||||||
## 🔥 近期更新
|
## 🔥 近期更新
|
||||||
|
|
||||||
- 2025-11-19 支持 Gemini 3 Pro.
|
- 2025-12-26 支持AI代理的“记忆”功能。
|
||||||
|
- 2025-11-19 支持 Gemini 3 Pro。
|
||||||
- 2025-11-12 支持从 Confluence、S3、Notion、Discord、Google Drive 进行数据同步。
|
- 2025-11-12 支持从 Confluence、S3、Notion、Discord、Google Drive 进行数据同步。
|
||||||
- 2025-10-23 支持 MinerU 和 Docling 作为文档解析方法。
|
- 2025-10-23 支持 MinerU 和 Docling 作为文档解析方法。
|
||||||
- 2025-10-15 支持可编排的数据管道。
|
- 2025-10-15 支持可编排的数据管道。
|
||||||
@ -93,7 +94,7 @@
|
|||||||
- 2025-08-01 支持 agentic workflow 和 MCP。
|
- 2025-08-01 支持 agentic workflow 和 MCP。
|
||||||
- 2025-05-23 Agent 新增 Python/JS 代码执行器组件。
|
- 2025-05-23 Agent 新增 Python/JS 代码执行器组件。
|
||||||
- 2025-05-05 支持跨语言查询。
|
- 2025-05-05 支持跨语言查询。
|
||||||
- 2025-03-19 PDF 和 DOCX 中的图支持用多模态大模型去解析得到描述.
|
- 2025-03-19 PDF 和 DOCX 中的图支持用多模态大模型去解析得到描述。
|
||||||
- 2024-12-18 升级了 DeepDoc 的文档布局分析模型。
|
- 2024-12-18 升级了 DeepDoc 的文档布局分析模型。
|
||||||
- 2024-08-22 支持用 RAG 技术实现从自然语言到 SQL 语句的转换。
|
- 2024-08-22 支持用 RAG 技术实现从自然语言到 SQL 语句的转换。
|
||||||
|
|
||||||
@ -187,12 +188,12 @@
|
|||||||
> 请注意,目前官方提供的所有 Docker 镜像均基于 x86 架构构建,并不提供基于 ARM64 的 Docker 镜像。
|
> 请注意,目前官方提供的所有 Docker 镜像均基于 x86 架构构建,并不提供基于 ARM64 的 Docker 镜像。
|
||||||
> 如果你的操作系统是 ARM64 架构,请参考[这篇文档](https://ragflow.io/docs/dev/build_docker_image)自行构建 Docker 镜像。
|
> 如果你的操作系统是 ARM64 架构,请参考[这篇文档](https://ragflow.io/docs/dev/build_docker_image)自行构建 Docker 镜像。
|
||||||
|
|
||||||
> 运行以下命令会自动下载 RAGFlow Docker 镜像 `v0.22.1`。请参考下表查看不同 Docker 发行版的描述。如需下载不同于 `v0.22.1` 的 Docker 镜像,请在运行 `docker compose` 启动服务之前先更新 **docker/.env** 文件内的 `RAGFLOW_IMAGE` 变量。
|
> 运行以下命令会自动下载 RAGFlow Docker 镜像 `v0.23.0`。请参考下表查看不同 Docker 发行版的描述。如需下载不同于 `v0.23.0` 的 Docker 镜像,请在运行 `docker compose` 启动服务之前先更新 **docker/.env** 文件内的 `RAGFLOW_IMAGE` 变量。
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
$ cd ragflow/docker
|
$ cd ragflow/docker
|
||||||
|
|
||||||
# git checkout v0.22.1
|
# git checkout v0.23.0
|
||||||
# 可选:使用稳定版本标签(查看发布:https://github.com/infiniflow/ragflow/releases)
|
# 可选:使用稳定版本标签(查看发布:https://github.com/infiniflow/ragflow/releases)
|
||||||
# 这一步确保代码中的 entrypoint.sh 文件与 Docker 镜像的版本保持一致。
|
# 这一步确保代码中的 entrypoint.sh 文件与 Docker 镜像的版本保持一致。
|
||||||
|
|
||||||
@ -237,7 +238,7 @@
|
|||||||
* Running on all addresses (0.0.0.0)
|
* Running on all addresses (0.0.0.0)
|
||||||
```
|
```
|
||||||
|
|
||||||
> 如果您在没有看到上面的提示信息出来之前,就尝试登录 RAGFlow,你的浏览器有可能会提示 `network anormal` 或 `网络异常`。
|
> 如果您在没有看到上面的提示信息出来之前,就尝试登录 RAGFlow,你的浏览器有可能会提示 `network abnormal` 或 `网络异常`。
|
||||||
|
|
||||||
5. 在你的浏览器中输入你的服务器对应的 IP 地址并登录 RAGFlow。
|
5. 在你的浏览器中输入你的服务器对应的 IP 地址并登录 RAGFlow。
|
||||||
> 上面这个例子中,您只需输入 http://IP_OF_YOUR_MACHINE 即可:未改动过配置则无需输入端口(默认的 HTTP 服务端口 80)。
|
> 上面这个例子中,您只需输入 http://IP_OF_YOUR_MACHINE 即可:未改动过配置则无需输入端口(默认的 HTTP 服务端口 80)。
|
||||||
@ -301,6 +302,15 @@ cd ragflow/
|
|||||||
docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly .
|
docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly .
|
||||||
```
|
```
|
||||||
|
|
||||||
|
如果您处在代理环境下,可以传递代理参数:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
docker build --platform linux/amd64 \
|
||||||
|
--build-arg http_proxy=http://YOUR_PROXY:PORT \
|
||||||
|
--build-arg https_proxy=http://YOUR_PROXY:PORT \
|
||||||
|
-f Dockerfile -t infiniflow/ragflow:nightly .
|
||||||
|
```
|
||||||
|
|
||||||
## 🔨 以源代码启动服务
|
## 🔨 以源代码启动服务
|
||||||
|
|
||||||
1. 安装 `uv` 和 `pre-commit`。如已经安装,可跳过本步骤:
|
1. 安装 `uv` 和 `pre-commit`。如已经安装,可跳过本步骤:
|
||||||
|
|||||||
@ -48,7 +48,7 @@ It consists of a server-side Service and a command-line client (CLI), both imple
|
|||||||
1. Ensure the Admin Service is running.
|
1. Ensure the Admin Service is running.
|
||||||
2. Install ragflow-cli.
|
2. Install ragflow-cli.
|
||||||
```bash
|
```bash
|
||||||
pip install ragflow-cli==0.22.1
|
pip install ragflow-cli==0.23.0
|
||||||
```
|
```
|
||||||
3. Launch the CLI client:
|
3. Launch the CLI client:
|
||||||
```bash
|
```bash
|
||||||
|
|||||||
@ -16,14 +16,14 @@
|
|||||||
|
|
||||||
import argparse
|
import argparse
|
||||||
import base64
|
import base64
|
||||||
from cmd import Cmd
|
|
||||||
|
|
||||||
from Cryptodome.PublicKey import RSA
|
|
||||||
from Cryptodome.Cipher import PKCS1_v1_5 as Cipher_pkcs1_v1_5
|
|
||||||
from typing import Dict, List, Any
|
|
||||||
from lark import Lark, Transformer, Tree
|
|
||||||
import requests
|
|
||||||
import getpass
|
import getpass
|
||||||
|
from cmd import Cmd
|
||||||
|
from typing import Any, Dict, List
|
||||||
|
|
||||||
|
import requests
|
||||||
|
from Cryptodome.Cipher import PKCS1_v1_5 as Cipher_pkcs1_v1_5
|
||||||
|
from Cryptodome.PublicKey import RSA
|
||||||
|
from lark import Lark, Transformer, Tree
|
||||||
|
|
||||||
GRAMMAR = r"""
|
GRAMMAR = r"""
|
||||||
start: command
|
start: command
|
||||||
@ -141,7 +141,6 @@ NUMBER: /[0-9]+/
|
|||||||
|
|
||||||
|
|
||||||
class AdminTransformer(Transformer):
|
class AdminTransformer(Transformer):
|
||||||
|
|
||||||
def start(self, items):
|
def start(self, items):
|
||||||
return items[0]
|
return items[0]
|
||||||
|
|
||||||
@ -149,7 +148,7 @@ class AdminTransformer(Transformer):
|
|||||||
return items[0]
|
return items[0]
|
||||||
|
|
||||||
def list_services(self, items):
|
def list_services(self, items):
|
||||||
result = {'type': 'list_services'}
|
result = {"type": "list_services"}
|
||||||
return result
|
return result
|
||||||
|
|
||||||
def show_service(self, items):
|
def show_service(self, items):
|
||||||
@ -236,11 +235,7 @@ class AdminTransformer(Transformer):
|
|||||||
action_list = items[1]
|
action_list = items[1]
|
||||||
resource = items[3]
|
resource = items[3]
|
||||||
role_name = items[6]
|
role_name = items[6]
|
||||||
return {
|
return {"type": "revoke_permission", "role_name": role_name, "resource": resource, "actions": action_list}
|
||||||
"type": "revoke_permission",
|
|
||||||
"role_name": role_name,
|
|
||||||
"resource": resource, "actions": action_list
|
|
||||||
}
|
|
||||||
|
|
||||||
def alter_user_role(self, items):
|
def alter_user_role(self, items):
|
||||||
user_name = items[2]
|
user_name = items[2]
|
||||||
@ -264,12 +259,12 @@ class AdminTransformer(Transformer):
|
|||||||
# handle quoted parameter
|
# handle quoted parameter
|
||||||
parsed_args = []
|
parsed_args = []
|
||||||
for arg in args:
|
for arg in args:
|
||||||
if hasattr(arg, 'value'):
|
if hasattr(arg, "value"):
|
||||||
parsed_args.append(arg.value)
|
parsed_args.append(arg.value)
|
||||||
else:
|
else:
|
||||||
parsed_args.append(str(arg))
|
parsed_args.append(str(arg))
|
||||||
|
|
||||||
return {'type': 'meta', 'command': command_name, 'args': parsed_args}
|
return {"type": "meta", "command": command_name, "args": parsed_args}
|
||||||
|
|
||||||
def meta_command_name(self, items):
|
def meta_command_name(self, items):
|
||||||
return items[0]
|
return items[0]
|
||||||
@ -279,22 +274,22 @@ class AdminTransformer(Transformer):
|
|||||||
|
|
||||||
|
|
||||||
def encrypt(input_string):
|
def encrypt(input_string):
|
||||||
pub = '-----BEGIN PUBLIC KEY-----\nMIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEArq9XTUSeYr2+N1h3Afl/z8Dse/2yD0ZGrKwx+EEEcdsBLca9Ynmx3nIB5obmLlSfmskLpBo0UACBmB5rEjBp2Q2f3AG3Hjd4B+gNCG6BDaawuDlgANIhGnaTLrIqWrrcm4EMzJOnAOI1fgzJRsOOUEfaS318Eq9OVO3apEyCCt0lOQK6PuksduOjVxtltDav+guVAA068NrPYmRNabVKRNLJpL8w4D44sfth5RvZ3q9t+6RTArpEtc5sh5ChzvqPOzKGMXW83C95TxmXqpbK6olN4RevSfVjEAgCydH6HN6OhtOQEcnrU97r9H0iZOWwbw3pVrZiUkuRD1R56Wzs2wIDAQAB\n-----END PUBLIC KEY-----'
|
pub = "-----BEGIN PUBLIC KEY-----\nMIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEArq9XTUSeYr2+N1h3Afl/z8Dse/2yD0ZGrKwx+EEEcdsBLca9Ynmx3nIB5obmLlSfmskLpBo0UACBmB5rEjBp2Q2f3AG3Hjd4B+gNCG6BDaawuDlgANIhGnaTLrIqWrrcm4EMzJOnAOI1fgzJRsOOUEfaS318Eq9OVO3apEyCCt0lOQK6PuksduOjVxtltDav+guVAA068NrPYmRNabVKRNLJpL8w4D44sfth5RvZ3q9t+6RTArpEtc5sh5ChzvqPOzKGMXW83C95TxmXqpbK6olN4RevSfVjEAgCydH6HN6OhtOQEcnrU97r9H0iZOWwbw3pVrZiUkuRD1R56Wzs2wIDAQAB\n-----END PUBLIC KEY-----"
|
||||||
pub_key = RSA.importKey(pub)
|
pub_key = RSA.importKey(pub)
|
||||||
cipher = Cipher_pkcs1_v1_5.new(pub_key)
|
cipher = Cipher_pkcs1_v1_5.new(pub_key)
|
||||||
cipher_text = cipher.encrypt(base64.b64encode(input_string.encode('utf-8')))
|
cipher_text = cipher.encrypt(base64.b64encode(input_string.encode("utf-8")))
|
||||||
return base64.b64encode(cipher_text).decode("utf-8")
|
return base64.b64encode(cipher_text).decode("utf-8")
|
||||||
|
|
||||||
|
|
||||||
def encode_to_base64(input_string):
|
def encode_to_base64(input_string):
|
||||||
base64_encoded = base64.b64encode(input_string.encode('utf-8'))
|
base64_encoded = base64.b64encode(input_string.encode("utf-8"))
|
||||||
return base64_encoded.decode('utf-8')
|
return base64_encoded.decode("utf-8")
|
||||||
|
|
||||||
|
|
||||||
class AdminCLI(Cmd):
|
class AdminCLI(Cmd):
|
||||||
def __init__(self):
|
def __init__(self):
|
||||||
super().__init__()
|
super().__init__()
|
||||||
self.parser = Lark(GRAMMAR, start='start', parser='lalr', transformer=AdminTransformer())
|
self.parser = Lark(GRAMMAR, start="start", parser="lalr", transformer=AdminTransformer())
|
||||||
self.command_history = []
|
self.command_history = []
|
||||||
self.is_interactive = False
|
self.is_interactive = False
|
||||||
self.admin_account = "admin@ragflow.io"
|
self.admin_account = "admin@ragflow.io"
|
||||||
@ -312,7 +307,7 @@ class AdminCLI(Cmd):
|
|||||||
result = self.parse_command(command)
|
result = self.parse_command(command)
|
||||||
|
|
||||||
if isinstance(result, dict):
|
if isinstance(result, dict):
|
||||||
if 'type' in result and result.get('type') == 'empty':
|
if "type" in result and result.get("type") == "empty":
|
||||||
return False
|
return False
|
||||||
|
|
||||||
self.execute_command(result)
|
self.execute_command(result)
|
||||||
@ -320,7 +315,7 @@ class AdminCLI(Cmd):
|
|||||||
if isinstance(result, Tree):
|
if isinstance(result, Tree):
|
||||||
return False
|
return False
|
||||||
|
|
||||||
if result.get('type') == 'meta' and result.get('command') in ['q', 'quit', 'exit']:
|
if result.get("type") == "meta" and result.get("command") in ["q", "quit", "exit"]:
|
||||||
return True
|
return True
|
||||||
|
|
||||||
except KeyboardInterrupt:
|
except KeyboardInterrupt:
|
||||||
@ -338,7 +333,7 @@ class AdminCLI(Cmd):
|
|||||||
|
|
||||||
def parse_command(self, command_str: str) -> dict[str, str]:
|
def parse_command(self, command_str: str) -> dict[str, str]:
|
||||||
if not command_str.strip():
|
if not command_str.strip():
|
||||||
return {'type': 'empty'}
|
return {"type": "empty"}
|
||||||
|
|
||||||
self.command_history.append(command_str)
|
self.command_history.append(command_str)
|
||||||
|
|
||||||
@ -346,11 +341,11 @@ class AdminCLI(Cmd):
|
|||||||
result = self.parser.parse(command_str)
|
result = self.parser.parse(command_str)
|
||||||
return result
|
return result
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
return {'type': 'error', 'message': f'Parse error: {str(e)}'}
|
return {"type": "error", "message": f"Parse error: {str(e)}"}
|
||||||
|
|
||||||
def verify_admin(self, arguments: dict, single_command: bool):
|
def verify_admin(self, arguments: dict, single_command: bool):
|
||||||
self.host = arguments['host']
|
self.host = arguments["host"]
|
||||||
self.port = arguments['port']
|
self.port = arguments["port"]
|
||||||
print("Attempt to access server for admin login")
|
print("Attempt to access server for admin login")
|
||||||
url = f"http://{self.host}:{self.port}/api/v1/admin/login"
|
url = f"http://{self.host}:{self.port}/api/v1/admin/login"
|
||||||
|
|
||||||
@ -365,25 +360,21 @@ class AdminCLI(Cmd):
|
|||||||
return False
|
return False
|
||||||
|
|
||||||
if single_command:
|
if single_command:
|
||||||
admin_passwd = arguments['password']
|
admin_passwd = arguments["password"]
|
||||||
else:
|
else:
|
||||||
admin_passwd = getpass.getpass(f"password for {self.admin_account}: ").strip()
|
admin_passwd = getpass.getpass(f"password for {self.admin_account}: ").strip()
|
||||||
try:
|
try:
|
||||||
self.admin_password = encrypt(admin_passwd)
|
self.admin_password = encrypt(admin_passwd)
|
||||||
response = self.session.post(url, json={'email': self.admin_account, 'password': self.admin_password})
|
response = self.session.post(url, json={"email": self.admin_account, "password": self.admin_password})
|
||||||
if response.status_code == 200:
|
if response.status_code == 200:
|
||||||
res_json = response.json()
|
res_json = response.json()
|
||||||
error_code = res_json.get('code', -1)
|
error_code = res_json.get("code", -1)
|
||||||
if error_code == 0:
|
if error_code == 0:
|
||||||
self.session.headers.update({
|
self.session.headers.update({"Content-Type": "application/json", "Authorization": response.headers["Authorization"], "User-Agent": "RAGFlow-CLI/0.23.0"})
|
||||||
'Content-Type': 'application/json',
|
|
||||||
'Authorization': response.headers['Authorization'],
|
|
||||||
'User-Agent': 'RAGFlow-CLI/0.22.1'
|
|
||||||
})
|
|
||||||
print("Authentication successful.")
|
print("Authentication successful.")
|
||||||
return True
|
return True
|
||||||
else:
|
else:
|
||||||
error_message = res_json.get('message', 'Unknown error')
|
error_message = res_json.get("message", "Unknown error")
|
||||||
print(f"Authentication failed: {error_message}, try again")
|
print(f"Authentication failed: {error_message}, try again")
|
||||||
continue
|
continue
|
||||||
else:
|
else:
|
||||||
@ -403,10 +394,14 @@ class AdminCLI(Cmd):
|
|||||||
for k, v in data.items():
|
for k, v in data.items():
|
||||||
# display latest status
|
# display latest status
|
||||||
heartbeats = sorted(v, key=lambda x: x["now"], reverse=True)
|
heartbeats = sorted(v, key=lambda x: x["now"], reverse=True)
|
||||||
task_executor_list.append({
|
task_executor_list.append(
|
||||||
|
{
|
||||||
"task_executor_name": k,
|
"task_executor_name": k,
|
||||||
**heartbeats[0],
|
**heartbeats[0],
|
||||||
} if heartbeats else {"task_executor_name": k})
|
}
|
||||||
|
if heartbeats
|
||||||
|
else {"task_executor_name": k}
|
||||||
|
)
|
||||||
return task_executor_list
|
return task_executor_list
|
||||||
|
|
||||||
def _print_table_simple(self, data):
|
def _print_table_simple(self, data):
|
||||||
@ -422,12 +417,7 @@ class AdminCLI(Cmd):
|
|||||||
col_widths = {}
|
col_widths = {}
|
||||||
|
|
||||||
def get_string_width(text):
|
def get_string_width(text):
|
||||||
half_width_chars = (
|
half_width_chars = " !\"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\\]^_`abcdefghijklmnopqrstuvwxyz{|}~\t\n\r"
|
||||||
" !\"#$%&'()*+,-./0123456789:;<=>?@"
|
|
||||||
"ABCDEFGHIJKLMNOPQRSTUVWXYZ[\\]^_`"
|
|
||||||
"abcdefghijklmnopqrstuvwxyz{|}~"
|
|
||||||
"\t\n\r"
|
|
||||||
)
|
|
||||||
width = 0
|
width = 0
|
||||||
for char in text:
|
for char in text:
|
||||||
if char in half_width_chars:
|
if char in half_width_chars:
|
||||||
@ -439,7 +429,7 @@ class AdminCLI(Cmd):
|
|||||||
for col in columns:
|
for col in columns:
|
||||||
max_width = get_string_width(str(col))
|
max_width = get_string_width(str(col))
|
||||||
for item in data:
|
for item in data:
|
||||||
value_len = get_string_width(str(item.get(col, '')))
|
value_len = get_string_width(str(item.get(col, "")))
|
||||||
if value_len > max_width:
|
if value_len > max_width:
|
||||||
max_width = value_len
|
max_width = value_len
|
||||||
col_widths[col] = max(2, max_width)
|
col_widths[col] = max(2, max_width)
|
||||||
@ -457,7 +447,7 @@ class AdminCLI(Cmd):
|
|||||||
for item in data:
|
for item in data:
|
||||||
row = "|"
|
row = "|"
|
||||||
for col in columns:
|
for col in columns:
|
||||||
value = str(item.get(col, ''))
|
value = str(item.get(col, ""))
|
||||||
if get_string_width(value) > col_widths[col]:
|
if get_string_width(value) > col_widths[col]:
|
||||||
value = value[: col_widths[col] - 3] + "..."
|
value = value[: col_widths[col] - 3] + "..."
|
||||||
row += f" {value:<{col_widths[col] - (get_string_width(value) - len(value))}} |"
|
row += f" {value:<{col_widths[col] - (get_string_width(value) - len(value))}} |"
|
||||||
@ -466,7 +456,6 @@ class AdminCLI(Cmd):
|
|||||||
print(separator)
|
print(separator)
|
||||||
|
|
||||||
def run_interactive(self):
|
def run_interactive(self):
|
||||||
|
|
||||||
self.is_interactive = True
|
self.is_interactive = True
|
||||||
print("RAGFlow Admin command line interface - Type '\\?' for help, '\\q' to quit")
|
print("RAGFlow Admin command line interface - Type '\\?' for help, '\\q' to quit")
|
||||||
|
|
||||||
@ -483,7 +472,7 @@ class AdminCLI(Cmd):
|
|||||||
if isinstance(result, Tree):
|
if isinstance(result, Tree):
|
||||||
continue
|
continue
|
||||||
|
|
||||||
if result.get('type') == 'meta' and result.get('command') in ['q', 'quit', 'exit']:
|
if result.get("type") == "meta" and result.get("command") in ["q", "quit", "exit"]:
|
||||||
break
|
break
|
||||||
|
|
||||||
except KeyboardInterrupt:
|
except KeyboardInterrupt:
|
||||||
@ -497,36 +486,30 @@ class AdminCLI(Cmd):
|
|||||||
self.execute_command(result)
|
self.execute_command(result)
|
||||||
|
|
||||||
def parse_connection_args(self, args: List[str]) -> Dict[str, Any]:
|
def parse_connection_args(self, args: List[str]) -> Dict[str, Any]:
|
||||||
parser = argparse.ArgumentParser(description='Admin CLI Client', add_help=False)
|
parser = argparse.ArgumentParser(description="Admin CLI Client", add_help=False)
|
||||||
parser.add_argument('-h', '--host', default='localhost', help='Admin service host')
|
parser.add_argument("-h", "--host", default="localhost", help="Admin service host")
|
||||||
parser.add_argument('-p', '--port', type=int, default=9381, help='Admin service port')
|
parser.add_argument("-p", "--port", type=int, default=9381, help="Admin service port")
|
||||||
parser.add_argument('-w', '--password', default='admin', type=str, help='Superuser password')
|
parser.add_argument("-w", "--password", default="admin", type=str, help="Superuser password")
|
||||||
parser.add_argument('command', nargs='?', help='Single command')
|
parser.add_argument("command", nargs="?", help="Single command")
|
||||||
try:
|
try:
|
||||||
parsed_args, remaining_args = parser.parse_known_args(args)
|
parsed_args, remaining_args = parser.parse_known_args(args)
|
||||||
if remaining_args:
|
if remaining_args:
|
||||||
command = remaining_args[0]
|
command = remaining_args[0]
|
||||||
return {
|
return {"host": parsed_args.host, "port": parsed_args.port, "password": parsed_args.password, "command": command}
|
||||||
'host': parsed_args.host,
|
|
||||||
'port': parsed_args.port,
|
|
||||||
'password': parsed_args.password,
|
|
||||||
'command': command
|
|
||||||
}
|
|
||||||
else:
|
else:
|
||||||
return {
|
return {
|
||||||
'host': parsed_args.host,
|
"host": parsed_args.host,
|
||||||
'port': parsed_args.port,
|
"port": parsed_args.port,
|
||||||
}
|
}
|
||||||
except SystemExit:
|
except SystemExit:
|
||||||
return {'error': 'Invalid connection arguments'}
|
return {"error": "Invalid connection arguments"}
|
||||||
|
|
||||||
def execute_command(self, parsed_command: Dict[str, Any]):
|
def execute_command(self, parsed_command: Dict[str, Any]):
|
||||||
|
|
||||||
command_dict: dict
|
command_dict: dict
|
||||||
if isinstance(parsed_command, Tree):
|
if isinstance(parsed_command, Tree):
|
||||||
command_dict = parsed_command.children[0]
|
command_dict = parsed_command.children[0]
|
||||||
else:
|
else:
|
||||||
if parsed_command['type'] == 'error':
|
if parsed_command["type"] == "error":
|
||||||
print(f"Error: {parsed_command['message']}")
|
print(f"Error: {parsed_command['message']}")
|
||||||
return
|
return
|
||||||
else:
|
else:
|
||||||
@ -534,56 +517,56 @@ class AdminCLI(Cmd):
|
|||||||
|
|
||||||
# print(f"Parsed command: {command_dict}")
|
# print(f"Parsed command: {command_dict}")
|
||||||
|
|
||||||
command_type = command_dict['type']
|
command_type = command_dict["type"]
|
||||||
|
|
||||||
match command_type:
|
match command_type:
|
||||||
case 'list_services':
|
case "list_services":
|
||||||
self._handle_list_services(command_dict)
|
self._handle_list_services(command_dict)
|
||||||
case 'show_service':
|
case "show_service":
|
||||||
self._handle_show_service(command_dict)
|
self._handle_show_service(command_dict)
|
||||||
case 'restart_service':
|
case "restart_service":
|
||||||
self._handle_restart_service(command_dict)
|
self._handle_restart_service(command_dict)
|
||||||
case 'shutdown_service':
|
case "shutdown_service":
|
||||||
self._handle_shutdown_service(command_dict)
|
self._handle_shutdown_service(command_dict)
|
||||||
case 'startup_service':
|
case "startup_service":
|
||||||
self._handle_startup_service(command_dict)
|
self._handle_startup_service(command_dict)
|
||||||
case 'list_users':
|
case "list_users":
|
||||||
self._handle_list_users(command_dict)
|
self._handle_list_users(command_dict)
|
||||||
case 'show_user':
|
case "show_user":
|
||||||
self._handle_show_user(command_dict)
|
self._handle_show_user(command_dict)
|
||||||
case 'drop_user':
|
case "drop_user":
|
||||||
self._handle_drop_user(command_dict)
|
self._handle_drop_user(command_dict)
|
||||||
case 'alter_user':
|
case "alter_user":
|
||||||
self._handle_alter_user(command_dict)
|
self._handle_alter_user(command_dict)
|
||||||
case 'create_user':
|
case "create_user":
|
||||||
self._handle_create_user(command_dict)
|
self._handle_create_user(command_dict)
|
||||||
case 'activate_user':
|
case "activate_user":
|
||||||
self._handle_activate_user(command_dict)
|
self._handle_activate_user(command_dict)
|
||||||
case 'list_datasets':
|
case "list_datasets":
|
||||||
self._handle_list_datasets(command_dict)
|
self._handle_list_datasets(command_dict)
|
||||||
case 'list_agents':
|
case "list_agents":
|
||||||
self._handle_list_agents(command_dict)
|
self._handle_list_agents(command_dict)
|
||||||
case 'create_role':
|
case "create_role":
|
||||||
self._create_role(command_dict)
|
self._create_role(command_dict)
|
||||||
case 'drop_role':
|
case "drop_role":
|
||||||
self._drop_role(command_dict)
|
self._drop_role(command_dict)
|
||||||
case 'alter_role':
|
case "alter_role":
|
||||||
self._alter_role(command_dict)
|
self._alter_role(command_dict)
|
||||||
case 'list_roles':
|
case "list_roles":
|
||||||
self._list_roles(command_dict)
|
self._list_roles(command_dict)
|
||||||
case 'show_role':
|
case "show_role":
|
||||||
self._show_role(command_dict)
|
self._show_role(command_dict)
|
||||||
case 'grant_permission':
|
case "grant_permission":
|
||||||
self._grant_permission(command_dict)
|
self._grant_permission(command_dict)
|
||||||
case 'revoke_permission':
|
case "revoke_permission":
|
||||||
self._revoke_permission(command_dict)
|
self._revoke_permission(command_dict)
|
||||||
case 'alter_user_role':
|
case "alter_user_role":
|
||||||
self._alter_user_role(command_dict)
|
self._alter_user_role(command_dict)
|
||||||
case 'show_user_permission':
|
case "show_user_permission":
|
||||||
self._show_user_permission(command_dict)
|
self._show_user_permission(command_dict)
|
||||||
case 'show_version':
|
case "show_version":
|
||||||
self._show_version(command_dict)
|
self._show_version(command_dict)
|
||||||
case 'meta':
|
case "meta":
|
||||||
self._handle_meta_command(command_dict)
|
self._handle_meta_command(command_dict)
|
||||||
case _:
|
case _:
|
||||||
print(f"Command '{command_type}' would be executed with API")
|
print(f"Command '{command_type}' would be executed with API")
|
||||||
@ -591,29 +574,29 @@ class AdminCLI(Cmd):
|
|||||||
def _handle_list_services(self, command):
|
def _handle_list_services(self, command):
|
||||||
print("Listing all services")
|
print("Listing all services")
|
||||||
|
|
||||||
url = f'http://{self.host}:{self.port}/api/v1/admin/services'
|
url = f"http://{self.host}:{self.port}/api/v1/admin/services"
|
||||||
response = self.session.get(url)
|
response = self.session.get(url)
|
||||||
res_json = response.json()
|
res_json = response.json()
|
||||||
if response.status_code == 200:
|
if response.status_code == 200:
|
||||||
self._print_table_simple(res_json['data'])
|
self._print_table_simple(res_json["data"])
|
||||||
else:
|
else:
|
||||||
print(f"Fail to get all services, code: {res_json['code']}, message: {res_json['message']}")
|
print(f"Fail to get all services, code: {res_json['code']}, message: {res_json['message']}")
|
||||||
|
|
||||||
def _handle_show_service(self, command):
|
def _handle_show_service(self, command):
|
||||||
service_id: int = command['number']
|
service_id: int = command["number"]
|
||||||
print(f"Showing service: {service_id}")
|
print(f"Showing service: {service_id}")
|
||||||
|
|
||||||
url = f'http://{self.host}:{self.port}/api/v1/admin/services/{service_id}'
|
url = f"http://{self.host}:{self.port}/api/v1/admin/services/{service_id}"
|
||||||
response = self.session.get(url)
|
response = self.session.get(url)
|
||||||
res_json = response.json()
|
res_json = response.json()
|
||||||
if response.status_code == 200:
|
if response.status_code == 200:
|
||||||
res_data = res_json['data']
|
res_data = res_json["data"]
|
||||||
if 'status' in res_data and res_data['status'] == 'alive':
|
if "status" in res_data and res_data["status"] == "alive":
|
||||||
print(f"Service {res_data['service_name']} is alive, ")
|
print(f"Service {res_data['service_name']} is alive, ")
|
||||||
if isinstance(res_data['message'], str):
|
if isinstance(res_data["message"], str):
|
||||||
print(res_data['message'])
|
print(res_data["message"])
|
||||||
else:
|
else:
|
||||||
data = self._format_service_detail_table(res_data['message'])
|
data = self._format_service_detail_table(res_data["message"])
|
||||||
self._print_table_simple(data)
|
self._print_table_simple(data)
|
||||||
else:
|
else:
|
||||||
print(f"Service {res_data['service_name']} is down, {res_data['message']}")
|
print(f"Service {res_data['service_name']} is down, {res_data['message']}")
|
||||||
@ -621,47 +604,47 @@ class AdminCLI(Cmd):
|
|||||||
print(f"Fail to show service, code: {res_json['code']}, message: {res_json['message']}")
|
print(f"Fail to show service, code: {res_json['code']}, message: {res_json['message']}")
|
||||||
|
|
||||||
def _handle_restart_service(self, command):
|
def _handle_restart_service(self, command):
|
||||||
service_id: int = command['number']
|
service_id: int = command["number"]
|
||||||
print(f"Restart service {service_id}")
|
print(f"Restart service {service_id}")
|
||||||
|
|
||||||
def _handle_shutdown_service(self, command):
|
def _handle_shutdown_service(self, command):
|
||||||
service_id: int = command['number']
|
service_id: int = command["number"]
|
||||||
print(f"Shutdown service {service_id}")
|
print(f"Shutdown service {service_id}")
|
||||||
|
|
||||||
def _handle_startup_service(self, command):
|
def _handle_startup_service(self, command):
|
||||||
service_id: int = command['number']
|
service_id: int = command["number"]
|
||||||
print(f"Startup service {service_id}")
|
print(f"Startup service {service_id}")
|
||||||
|
|
||||||
def _handle_list_users(self, command):
|
def _handle_list_users(self, command):
|
||||||
print("Listing all users")
|
print("Listing all users")
|
||||||
|
|
||||||
url = f'http://{self.host}:{self.port}/api/v1/admin/users'
|
url = f"http://{self.host}:{self.port}/api/v1/admin/users"
|
||||||
response = self.session.get(url)
|
response = self.session.get(url)
|
||||||
res_json = response.json()
|
res_json = response.json()
|
||||||
if response.status_code == 200:
|
if response.status_code == 200:
|
||||||
self._print_table_simple(res_json['data'])
|
self._print_table_simple(res_json["data"])
|
||||||
else:
|
else:
|
||||||
print(f"Fail to get all users, code: {res_json['code']}, message: {res_json['message']}")
|
print(f"Fail to get all users, code: {res_json['code']}, message: {res_json['message']}")
|
||||||
|
|
||||||
def _handle_show_user(self, command):
|
def _handle_show_user(self, command):
|
||||||
username_tree: Tree = command['user_name']
|
username_tree: Tree = command["user_name"]
|
||||||
user_name: str = username_tree.children[0].strip("'\"")
|
user_name: str = username_tree.children[0].strip("'\"")
|
||||||
print(f"Showing user: {user_name}")
|
print(f"Showing user: {user_name}")
|
||||||
url = f'http://{self.host}:{self.port}/api/v1/admin/users/{user_name}'
|
url = f"http://{self.host}:{self.port}/api/v1/admin/users/{user_name}"
|
||||||
response = self.session.get(url)
|
response = self.session.get(url)
|
||||||
res_json = response.json()
|
res_json = response.json()
|
||||||
if response.status_code == 200:
|
if response.status_code == 200:
|
||||||
table_data = res_json['data']
|
table_data = res_json["data"]
|
||||||
table_data.pop('avatar')
|
table_data.pop("avatar")
|
||||||
self._print_table_simple(table_data)
|
self._print_table_simple(table_data)
|
||||||
else:
|
else:
|
||||||
print(f"Fail to get user {user_name}, code: {res_json['code']}, message: {res_json['message']}")
|
print(f"Fail to get user {user_name}, code: {res_json['code']}, message: {res_json['message']}")
|
||||||
|
|
||||||
def _handle_drop_user(self, command):
|
def _handle_drop_user(self, command):
|
||||||
username_tree: Tree = command['user_name']
|
username_tree: Tree = command["user_name"]
|
||||||
user_name: str = username_tree.children[0].strip("'\"")
|
user_name: str = username_tree.children[0].strip("'\"")
|
||||||
print(f"Drop user: {user_name}")
|
print(f"Drop user: {user_name}")
|
||||||
url = f'http://{self.host}:{self.port}/api/v1/admin/users/{user_name}'
|
url = f"http://{self.host}:{self.port}/api/v1/admin/users/{user_name}"
|
||||||
response = self.session.delete(url)
|
response = self.session.delete(url)
|
||||||
res_json = response.json()
|
res_json = response.json()
|
||||||
if response.status_code == 200:
|
if response.status_code == 200:
|
||||||
@ -670,13 +653,13 @@ class AdminCLI(Cmd):
|
|||||||
print(f"Fail to drop user, code: {res_json['code']}, message: {res_json['message']}")
|
print(f"Fail to drop user, code: {res_json['code']}, message: {res_json['message']}")
|
||||||
|
|
||||||
def _handle_alter_user(self, command):
|
def _handle_alter_user(self, command):
|
||||||
user_name_tree: Tree = command['user_name']
|
user_name_tree: Tree = command["user_name"]
|
||||||
user_name: str = user_name_tree.children[0].strip("'\"")
|
user_name: str = user_name_tree.children[0].strip("'\"")
|
||||||
password_tree: Tree = command['password']
|
password_tree: Tree = command["password"]
|
||||||
password: str = password_tree.children[0].strip("'\"")
|
password: str = password_tree.children[0].strip("'\"")
|
||||||
print(f"Alter user: {user_name}, password: ******")
|
print(f"Alter user: {user_name}, password: ******")
|
||||||
url = f'http://{self.host}:{self.port}/api/v1/admin/users/{user_name}/password'
|
url = f"http://{self.host}:{self.port}/api/v1/admin/users/{user_name}/password"
|
||||||
response = self.session.put(url, json={'new_password': encrypt(password)})
|
response = self.session.put(url, json={"new_password": encrypt(password)})
|
||||||
res_json = response.json()
|
res_json = response.json()
|
||||||
if response.status_code == 200:
|
if response.status_code == 200:
|
||||||
print(res_json["message"])
|
print(res_json["message"])
|
||||||
@ -684,32 +667,29 @@ class AdminCLI(Cmd):
|
|||||||
print(f"Fail to alter password, code: {res_json['code']}, message: {res_json['message']}")
|
print(f"Fail to alter password, code: {res_json['code']}, message: {res_json['message']}")
|
||||||
|
|
||||||
def _handle_create_user(self, command):
|
def _handle_create_user(self, command):
|
||||||
user_name_tree: Tree = command['user_name']
|
user_name_tree: Tree = command["user_name"]
|
||||||
user_name: str = user_name_tree.children[0].strip("'\"")
|
user_name: str = user_name_tree.children[0].strip("'\"")
|
||||||
password_tree: Tree = command['password']
|
password_tree: Tree = command["password"]
|
||||||
password: str = password_tree.children[0].strip("'\"")
|
password: str = password_tree.children[0].strip("'\"")
|
||||||
role: str = command['role']
|
role: str = command["role"]
|
||||||
print(f"Create user: {user_name}, password: ******, role: {role}")
|
print(f"Create user: {user_name}, password: ******, role: {role}")
|
||||||
url = f'http://{self.host}:{self.port}/api/v1/admin/users'
|
url = f"http://{self.host}:{self.port}/api/v1/admin/users"
|
||||||
response = self.session.post(
|
response = self.session.post(url, json={"user_name": user_name, "password": encrypt(password), "role": role})
|
||||||
url,
|
|
||||||
json={'user_name': user_name, 'password': encrypt(password), 'role': role}
|
|
||||||
)
|
|
||||||
res_json = response.json()
|
res_json = response.json()
|
||||||
if response.status_code == 200:
|
if response.status_code == 200:
|
||||||
self._print_table_simple(res_json['data'])
|
self._print_table_simple(res_json["data"])
|
||||||
else:
|
else:
|
||||||
print(f"Fail to create user {user_name}, code: {res_json['code']}, message: {res_json['message']}")
|
print(f"Fail to create user {user_name}, code: {res_json['code']}, message: {res_json['message']}")
|
||||||
|
|
||||||
def _handle_activate_user(self, command):
|
def _handle_activate_user(self, command):
|
||||||
user_name_tree: Tree = command['user_name']
|
user_name_tree: Tree = command["user_name"]
|
||||||
user_name: str = user_name_tree.children[0].strip("'\"")
|
user_name: str = user_name_tree.children[0].strip("'\"")
|
||||||
activate_tree: Tree = command['activate_status']
|
activate_tree: Tree = command["activate_status"]
|
||||||
activate_status: str = activate_tree.children[0].strip("'\"")
|
activate_status: str = activate_tree.children[0].strip("'\"")
|
||||||
if activate_status.lower() in ['on', 'off']:
|
if activate_status.lower() in ["on", "off"]:
|
||||||
print(f"Alter user {user_name} activate status, turn {activate_status.lower()}.")
|
print(f"Alter user {user_name} activate status, turn {activate_status.lower()}.")
|
||||||
url = f'http://{self.host}:{self.port}/api/v1/admin/users/{user_name}/activate'
|
url = f"http://{self.host}:{self.port}/api/v1/admin/users/{user_name}/activate"
|
||||||
response = self.session.put(url, json={'activate_status': activate_status})
|
response = self.session.put(url, json={"activate_status": activate_status})
|
||||||
res_json = response.json()
|
res_json = response.json()
|
||||||
if response.status_code == 200:
|
if response.status_code == 200:
|
||||||
print(res_json["message"])
|
print(res_json["message"])
|
||||||
@ -719,202 +699,182 @@ class AdminCLI(Cmd):
|
|||||||
print(f"Unknown activate status: {activate_status}.")
|
print(f"Unknown activate status: {activate_status}.")
|
||||||
|
|
||||||
def _handle_list_datasets(self, command):
|
def _handle_list_datasets(self, command):
|
||||||
username_tree: Tree = command['user_name']
|
username_tree: Tree = command["user_name"]
|
||||||
user_name: str = username_tree.children[0].strip("'\"")
|
user_name: str = username_tree.children[0].strip("'\"")
|
||||||
print(f"Listing all datasets of user: {user_name}")
|
print(f"Listing all datasets of user: {user_name}")
|
||||||
url = f'http://{self.host}:{self.port}/api/v1/admin/users/{user_name}/datasets'
|
url = f"http://{self.host}:{self.port}/api/v1/admin/users/{user_name}/datasets"
|
||||||
response = self.session.get(url)
|
response = self.session.get(url)
|
||||||
res_json = response.json()
|
res_json = response.json()
|
||||||
if response.status_code == 200:
|
if response.status_code == 200:
|
||||||
table_data = res_json['data']
|
table_data = res_json["data"]
|
||||||
for t in table_data:
|
for t in table_data:
|
||||||
t.pop('avatar')
|
t.pop("avatar")
|
||||||
self._print_table_simple(table_data)
|
self._print_table_simple(table_data)
|
||||||
else:
|
else:
|
||||||
print(f"Fail to get all datasets of {user_name}, code: {res_json['code']}, message: {res_json['message']}")
|
print(f"Fail to get all datasets of {user_name}, code: {res_json['code']}, message: {res_json['message']}")
|
||||||
|
|
||||||
def _handle_list_agents(self, command):
|
def _handle_list_agents(self, command):
|
||||||
username_tree: Tree = command['user_name']
|
username_tree: Tree = command["user_name"]
|
||||||
user_name: str = username_tree.children[0].strip("'\"")
|
user_name: str = username_tree.children[0].strip("'\"")
|
||||||
print(f"Listing all agents of user: {user_name}")
|
print(f"Listing all agents of user: {user_name}")
|
||||||
url = f'http://{self.host}:{self.port}/api/v1/admin/users/{user_name}/agents'
|
url = f"http://{self.host}:{self.port}/api/v1/admin/users/{user_name}/agents"
|
||||||
response = self.session.get(url)
|
response = self.session.get(url)
|
||||||
res_json = response.json()
|
res_json = response.json()
|
||||||
if response.status_code == 200:
|
if response.status_code == 200:
|
||||||
table_data = res_json['data']
|
table_data = res_json["data"]
|
||||||
for t in table_data:
|
for t in table_data:
|
||||||
t.pop('avatar')
|
t.pop("avatar")
|
||||||
self._print_table_simple(table_data)
|
self._print_table_simple(table_data)
|
||||||
else:
|
else:
|
||||||
print(f"Fail to get all agents of {user_name}, code: {res_json['code']}, message: {res_json['message']}")
|
print(f"Fail to get all agents of {user_name}, code: {res_json['code']}, message: {res_json['message']}")
|
||||||
|
|
||||||
def _create_role(self, command):
|
def _create_role(self, command):
|
||||||
role_name_tree: Tree = command['role_name']
|
role_name_tree: Tree = command["role_name"]
|
||||||
role_name: str = role_name_tree.children[0].strip("'\"")
|
role_name: str = role_name_tree.children[0].strip("'\"")
|
||||||
desc_str: str = ''
|
desc_str: str = ""
|
||||||
if 'description' in command:
|
if "description" in command:
|
||||||
desc_tree: Tree = command['description']
|
desc_tree: Tree = command["description"]
|
||||||
desc_str = desc_tree.children[0].strip("'\"")
|
desc_str = desc_tree.children[0].strip("'\"")
|
||||||
|
|
||||||
print(f"create role name: {role_name}, description: {desc_str}")
|
print(f"create role name: {role_name}, description: {desc_str}")
|
||||||
url = f'http://{self.host}:{self.port}/api/v1/admin/roles'
|
url = f"http://{self.host}:{self.port}/api/v1/admin/roles"
|
||||||
response = self.session.post(
|
response = self.session.post(url, json={"role_name": role_name, "description": desc_str})
|
||||||
url,
|
|
||||||
json={'role_name': role_name, 'description': desc_str}
|
|
||||||
)
|
|
||||||
res_json = response.json()
|
res_json = response.json()
|
||||||
if response.status_code == 200:
|
if response.status_code == 200:
|
||||||
self._print_table_simple(res_json['data'])
|
self._print_table_simple(res_json["data"])
|
||||||
else:
|
else:
|
||||||
print(f"Fail to create role {role_name}, code: {res_json['code']}, message: {res_json['message']}")
|
print(f"Fail to create role {role_name}, code: {res_json['code']}, message: {res_json['message']}")
|
||||||
|
|
||||||
def _drop_role(self, command):
|
def _drop_role(self, command):
|
||||||
role_name_tree: Tree = command['role_name']
|
role_name_tree: Tree = command["role_name"]
|
||||||
role_name: str = role_name_tree.children[0].strip("'\"")
|
role_name: str = role_name_tree.children[0].strip("'\"")
|
||||||
print(f"drop role name: {role_name}")
|
print(f"drop role name: {role_name}")
|
||||||
url = f'http://{self.host}:{self.port}/api/v1/admin/roles/{role_name}'
|
url = f"http://{self.host}:{self.port}/api/v1/admin/roles/{role_name}"
|
||||||
response = self.session.delete(url)
|
response = self.session.delete(url)
|
||||||
res_json = response.json()
|
res_json = response.json()
|
||||||
if response.status_code == 200:
|
if response.status_code == 200:
|
||||||
self._print_table_simple(res_json['data'])
|
self._print_table_simple(res_json["data"])
|
||||||
else:
|
else:
|
||||||
print(f"Fail to drop role {role_name}, code: {res_json['code']}, message: {res_json['message']}")
|
print(f"Fail to drop role {role_name}, code: {res_json['code']}, message: {res_json['message']}")
|
||||||
|
|
||||||
def _alter_role(self, command):
|
def _alter_role(self, command):
|
||||||
role_name_tree: Tree = command['role_name']
|
role_name_tree: Tree = command["role_name"]
|
||||||
role_name: str = role_name_tree.children[0].strip("'\"")
|
role_name: str = role_name_tree.children[0].strip("'\"")
|
||||||
desc_tree: Tree = command['description']
|
desc_tree: Tree = command["description"]
|
||||||
desc_str: str = desc_tree.children[0].strip("'\"")
|
desc_str: str = desc_tree.children[0].strip("'\"")
|
||||||
|
|
||||||
print(f"alter role name: {role_name}, description: {desc_str}")
|
print(f"alter role name: {role_name}, description: {desc_str}")
|
||||||
url = f'http://{self.host}:{self.port}/api/v1/admin/roles/{role_name}'
|
url = f"http://{self.host}:{self.port}/api/v1/admin/roles/{role_name}"
|
||||||
response = self.session.put(
|
response = self.session.put(url, json={"description": desc_str})
|
||||||
url,
|
|
||||||
json={'description': desc_str}
|
|
||||||
)
|
|
||||||
res_json = response.json()
|
res_json = response.json()
|
||||||
if response.status_code == 200:
|
if response.status_code == 200:
|
||||||
self._print_table_simple(res_json['data'])
|
self._print_table_simple(res_json["data"])
|
||||||
else:
|
else:
|
||||||
print(
|
print(f"Fail to update role {role_name} with description: {desc_str}, code: {res_json['code']}, message: {res_json['message']}")
|
||||||
f"Fail to update role {role_name} with description: {desc_str}, code: {res_json['code']}, message: {res_json['message']}")
|
|
||||||
|
|
||||||
def _list_roles(self, command):
|
def _list_roles(self, command):
|
||||||
print("Listing all roles")
|
print("Listing all roles")
|
||||||
url = f'http://{self.host}:{self.port}/api/v1/admin/roles'
|
url = f"http://{self.host}:{self.port}/api/v1/admin/roles"
|
||||||
response = self.session.get(url)
|
response = self.session.get(url)
|
||||||
res_json = response.json()
|
res_json = response.json()
|
||||||
if response.status_code == 200:
|
if response.status_code == 200:
|
||||||
self._print_table_simple(res_json['data'])
|
self._print_table_simple(res_json["data"])
|
||||||
else:
|
else:
|
||||||
print(f"Fail to list roles, code: {res_json['code']}, message: {res_json['message']}")
|
print(f"Fail to list roles, code: {res_json['code']}, message: {res_json['message']}")
|
||||||
|
|
||||||
def _show_role(self, command):
|
def _show_role(self, command):
|
||||||
role_name_tree: Tree = command['role_name']
|
role_name_tree: Tree = command["role_name"]
|
||||||
role_name: str = role_name_tree.children[0].strip("'\"")
|
role_name: str = role_name_tree.children[0].strip("'\"")
|
||||||
print(f"show role: {role_name}")
|
print(f"show role: {role_name}")
|
||||||
url = f'http://{self.host}:{self.port}/api/v1/admin/roles/{role_name}/permission'
|
url = f"http://{self.host}:{self.port}/api/v1/admin/roles/{role_name}/permission"
|
||||||
response = self.session.get(url)
|
response = self.session.get(url)
|
||||||
res_json = response.json()
|
res_json = response.json()
|
||||||
if response.status_code == 200:
|
if response.status_code == 200:
|
||||||
self._print_table_simple(res_json['data'])
|
self._print_table_simple(res_json["data"])
|
||||||
else:
|
else:
|
||||||
print(f"Fail to list roles, code: {res_json['code']}, message: {res_json['message']}")
|
print(f"Fail to list roles, code: {res_json['code']}, message: {res_json['message']}")
|
||||||
|
|
||||||
def _grant_permission(self, command):
|
def _grant_permission(self, command):
|
||||||
role_name_tree: Tree = command['role_name']
|
role_name_tree: Tree = command["role_name"]
|
||||||
role_name_str: str = role_name_tree.children[0].strip("'\"")
|
role_name_str: str = role_name_tree.children[0].strip("'\"")
|
||||||
resource_tree: Tree = command['resource']
|
resource_tree: Tree = command["resource"]
|
||||||
resource_str: str = resource_tree.children[0].strip("'\"")
|
resource_str: str = resource_tree.children[0].strip("'\"")
|
||||||
action_tree_list: list = command['actions']
|
action_tree_list: list = command["actions"]
|
||||||
actions: list = []
|
actions: list = []
|
||||||
for action_tree in action_tree_list:
|
for action_tree in action_tree_list:
|
||||||
action_str: str = action_tree.children[0].strip("'\"")
|
action_str: str = action_tree.children[0].strip("'\"")
|
||||||
actions.append(action_str)
|
actions.append(action_str)
|
||||||
print(f"grant role_name: {role_name_str}, resource: {resource_str}, actions: {actions}")
|
print(f"grant role_name: {role_name_str}, resource: {resource_str}, actions: {actions}")
|
||||||
url = f'http://{self.host}:{self.port}/api/v1/admin/roles/{role_name_str}/permission'
|
url = f"http://{self.host}:{self.port}/api/v1/admin/roles/{role_name_str}/permission"
|
||||||
response = self.session.post(
|
response = self.session.post(url, json={"actions": actions, "resource": resource_str})
|
||||||
url,
|
|
||||||
json={'actions': actions, 'resource': resource_str}
|
|
||||||
)
|
|
||||||
res_json = response.json()
|
res_json = response.json()
|
||||||
if response.status_code == 200:
|
if response.status_code == 200:
|
||||||
self._print_table_simple(res_json['data'])
|
self._print_table_simple(res_json["data"])
|
||||||
else:
|
else:
|
||||||
print(
|
print(f"Fail to grant role {role_name_str} with {actions} on {resource_str}, code: {res_json['code']}, message: {res_json['message']}")
|
||||||
f"Fail to grant role {role_name_str} with {actions} on {resource_str}, code: {res_json['code']}, message: {res_json['message']}")
|
|
||||||
|
|
||||||
def _revoke_permission(self, command):
|
def _revoke_permission(self, command):
|
||||||
role_name_tree: Tree = command['role_name']
|
role_name_tree: Tree = command["role_name"]
|
||||||
role_name_str: str = role_name_tree.children[0].strip("'\"")
|
role_name_str: str = role_name_tree.children[0].strip("'\"")
|
||||||
resource_tree: Tree = command['resource']
|
resource_tree: Tree = command["resource"]
|
||||||
resource_str: str = resource_tree.children[0].strip("'\"")
|
resource_str: str = resource_tree.children[0].strip("'\"")
|
||||||
action_tree_list: list = command['actions']
|
action_tree_list: list = command["actions"]
|
||||||
actions: list = []
|
actions: list = []
|
||||||
for action_tree in action_tree_list:
|
for action_tree in action_tree_list:
|
||||||
action_str: str = action_tree.children[0].strip("'\"")
|
action_str: str = action_tree.children[0].strip("'\"")
|
||||||
actions.append(action_str)
|
actions.append(action_str)
|
||||||
print(f"revoke role_name: {role_name_str}, resource: {resource_str}, actions: {actions}")
|
print(f"revoke role_name: {role_name_str}, resource: {resource_str}, actions: {actions}")
|
||||||
url = f'http://{self.host}:{self.port}/api/v1/admin/roles/{role_name_str}/permission'
|
url = f"http://{self.host}:{self.port}/api/v1/admin/roles/{role_name_str}/permission"
|
||||||
response = self.session.delete(
|
response = self.session.delete(url, json={"actions": actions, "resource": resource_str})
|
||||||
url,
|
|
||||||
json={'actions': actions, 'resource': resource_str}
|
|
||||||
)
|
|
||||||
res_json = response.json()
|
res_json = response.json()
|
||||||
if response.status_code == 200:
|
if response.status_code == 200:
|
||||||
self._print_table_simple(res_json['data'])
|
self._print_table_simple(res_json["data"])
|
||||||
else:
|
else:
|
||||||
print(
|
print(f"Fail to revoke role {role_name_str} with {actions} on {resource_str}, code: {res_json['code']}, message: {res_json['message']}")
|
||||||
f"Fail to revoke role {role_name_str} with {actions} on {resource_str}, code: {res_json['code']}, message: {res_json['message']}")
|
|
||||||
|
|
||||||
def _alter_user_role(self, command):
|
def _alter_user_role(self, command):
|
||||||
role_name_tree: Tree = command['role_name']
|
role_name_tree: Tree = command["role_name"]
|
||||||
role_name_str: str = role_name_tree.children[0].strip("'\"")
|
role_name_str: str = role_name_tree.children[0].strip("'\"")
|
||||||
user_name_tree: Tree = command['user_name']
|
user_name_tree: Tree = command["user_name"]
|
||||||
user_name_str: str = user_name_tree.children[0].strip("'\"")
|
user_name_str: str = user_name_tree.children[0].strip("'\"")
|
||||||
print(f"alter_user_role user_name: {user_name_str}, role_name: {role_name_str}")
|
print(f"alter_user_role user_name: {user_name_str}, role_name: {role_name_str}")
|
||||||
url = f'http://{self.host}:{self.port}/api/v1/admin/users/{user_name_str}/role'
|
url = f"http://{self.host}:{self.port}/api/v1/admin/users/{user_name_str}/role"
|
||||||
response = self.session.put(
|
response = self.session.put(url, json={"role_name": role_name_str})
|
||||||
url,
|
|
||||||
json={'role_name': role_name_str}
|
|
||||||
)
|
|
||||||
res_json = response.json()
|
res_json = response.json()
|
||||||
if response.status_code == 200:
|
if response.status_code == 200:
|
||||||
self._print_table_simple(res_json['data'])
|
self._print_table_simple(res_json["data"])
|
||||||
else:
|
else:
|
||||||
print(
|
print(f"Fail to alter user: {user_name_str} to role {role_name_str}, code: {res_json['code']}, message: {res_json['message']}")
|
||||||
f"Fail to alter user: {user_name_str} to role {role_name_str}, code: {res_json['code']}, message: {res_json['message']}")
|
|
||||||
|
|
||||||
def _show_user_permission(self, command):
|
def _show_user_permission(self, command):
|
||||||
user_name_tree: Tree = command['user_name']
|
user_name_tree: Tree = command["user_name"]
|
||||||
user_name_str: str = user_name_tree.children[0].strip("'\"")
|
user_name_str: str = user_name_tree.children[0].strip("'\"")
|
||||||
print(f"show_user_permission user_name: {user_name_str}")
|
print(f"show_user_permission user_name: {user_name_str}")
|
||||||
url = f'http://{self.host}:{self.port}/api/v1/admin/users/{user_name_str}/permission'
|
url = f"http://{self.host}:{self.port}/api/v1/admin/users/{user_name_str}/permission"
|
||||||
response = self.session.get(url)
|
response = self.session.get(url)
|
||||||
res_json = response.json()
|
res_json = response.json()
|
||||||
if response.status_code == 200:
|
if response.status_code == 200:
|
||||||
self._print_table_simple(res_json['data'])
|
self._print_table_simple(res_json["data"])
|
||||||
else:
|
else:
|
||||||
print(
|
print(f"Fail to show user: {user_name_str} permission, code: {res_json['code']}, message: {res_json['message']}")
|
||||||
f"Fail to show user: {user_name_str} permission, code: {res_json['code']}, message: {res_json['message']}")
|
|
||||||
|
|
||||||
def _show_version(self, command):
|
def _show_version(self, command):
|
||||||
print("show_version")
|
print("show_version")
|
||||||
url = f'http://{self.host}:{self.port}/api/v1/admin/version'
|
url = f"http://{self.host}:{self.port}/api/v1/admin/version"
|
||||||
response = self.session.get(url)
|
response = self.session.get(url)
|
||||||
res_json = response.json()
|
res_json = response.json()
|
||||||
if response.status_code == 200:
|
if response.status_code == 200:
|
||||||
self._print_table_simple(res_json['data'])
|
self._print_table_simple(res_json["data"])
|
||||||
else:
|
else:
|
||||||
print(f"Fail to show version, code: {res_json['code']}, message: {res_json['message']}")
|
print(f"Fail to show version, code: {res_json['code']}, message: {res_json['message']}")
|
||||||
|
|
||||||
def _handle_meta_command(self, command):
|
def _handle_meta_command(self, command):
|
||||||
meta_command = command['command']
|
meta_command = command["command"]
|
||||||
args = command.get('args', [])
|
args = command.get("args", [])
|
||||||
|
|
||||||
if meta_command in ['?', 'h', 'help']:
|
if meta_command in ["?", "h", "help"]:
|
||||||
self.show_help()
|
self.show_help()
|
||||||
elif meta_command in ['q', 'quit', 'exit']:
|
elif meta_command in ["q", "quit", "exit"]:
|
||||||
print("Goodbye!")
|
print("Goodbye!")
|
||||||
else:
|
else:
|
||||||
print(f"Meta command '{meta_command}' with args {args}")
|
print(f"Meta command '{meta_command}' with args {args}")
|
||||||
@ -950,16 +910,16 @@ def main():
|
|||||||
cli = AdminCLI()
|
cli = AdminCLI()
|
||||||
|
|
||||||
args = cli.parse_connection_args(sys.argv)
|
args = cli.parse_connection_args(sys.argv)
|
||||||
if 'error' in args:
|
if "error" in args:
|
||||||
print("Error: Invalid connection arguments")
|
print("Error: Invalid connection arguments")
|
||||||
return
|
return
|
||||||
|
|
||||||
if 'command' in args:
|
if "command" in args:
|
||||||
if 'password' not in args:
|
if "password" not in args:
|
||||||
print("Error: password is missing")
|
print("Error: password is missing")
|
||||||
return
|
return
|
||||||
if cli.verify_admin(args, single_command=True):
|
if cli.verify_admin(args, single_command=True):
|
||||||
command: str = args['command']
|
command: str = args["command"]
|
||||||
# print(f"Run single command: {command}")
|
# print(f"Run single command: {command}")
|
||||||
cli.run_single_command(command)
|
cli.run_single_command(command)
|
||||||
else:
|
else:
|
||||||
@ -974,5 +934,5 @@ def main():
|
|||||||
cli.cmdloop()
|
cli.cmdloop()
|
||||||
|
|
||||||
|
|
||||||
if __name__ == '__main__':
|
if __name__ == "__main__":
|
||||||
main()
|
main()
|
||||||
|
|||||||
@ -1,6 +1,6 @@
|
|||||||
[project]
|
[project]
|
||||||
name = "ragflow-cli"
|
name = "ragflow-cli"
|
||||||
version = "0.22.1"
|
version = "0.23.0"
|
||||||
description = "Admin Service's client of [RAGFlow](https://github.com/infiniflow/ragflow). The Admin Service provides user management and system monitoring. "
|
description = "Admin Service's client of [RAGFlow](https://github.com/infiniflow/ragflow). The Admin Service provides user management and system monitoring. "
|
||||||
authors = [{ name = "Lynn", email = "lynn_inf@hotmail.com" }]
|
authors = [{ name = "Lynn", email = "lynn_inf@hotmail.com" }]
|
||||||
license = { text = "Apache License, Version 2.0" }
|
license = { text = "Apache License, Version 2.0" }
|
||||||
|
|||||||
2
admin/client/uv.lock
generated
2
admin/client/uv.lock
generated
@ -196,7 +196,7 @@ wheels = [
|
|||||||
|
|
||||||
[[package]]
|
[[package]]
|
||||||
name = "ragflow-cli"
|
name = "ragflow-cli"
|
||||||
version = "0.22.1"
|
version = "0.23.0"
|
||||||
source = { virtual = "." }
|
source = { virtual = "." }
|
||||||
dependencies = [
|
dependencies = [
|
||||||
{ name = "beartype" },
|
{ name = "beartype" },
|
||||||
|
|||||||
@ -278,7 +278,7 @@ class Graph:
|
|||||||
|
|
||||||
class Canvas(Graph):
|
class Canvas(Graph):
|
||||||
|
|
||||||
def __init__(self, dsl: str, tenant_id=None, task_id=None):
|
def __init__(self, dsl: str, tenant_id=None, task_id=None, canvas_id=None):
|
||||||
self.globals = {
|
self.globals = {
|
||||||
"sys.query": "",
|
"sys.query": "",
|
||||||
"sys.user_id": tenant_id,
|
"sys.user_id": tenant_id,
|
||||||
@ -287,6 +287,7 @@ class Canvas(Graph):
|
|||||||
}
|
}
|
||||||
self.variables = {}
|
self.variables = {}
|
||||||
super().__init__(dsl, tenant_id, task_id)
|
super().__init__(dsl, tenant_id, task_id)
|
||||||
|
self._id = canvas_id
|
||||||
|
|
||||||
def load(self):
|
def load(self):
|
||||||
super().load()
|
super().load()
|
||||||
@ -721,6 +722,9 @@ class Canvas(Graph):
|
|||||||
def get_mode(self):
|
def get_mode(self):
|
||||||
return self.components["begin"]["obj"]._param.mode
|
return self.components["begin"]["obj"]._param.mode
|
||||||
|
|
||||||
|
def get_sys_query(self):
|
||||||
|
return self.globals.get("sys.query", "")
|
||||||
|
|
||||||
def set_global_param(self, **kwargs):
|
def set_global_param(self, **kwargs):
|
||||||
self.globals.update(kwargs)
|
self.globals.update(kwargs)
|
||||||
|
|
||||||
|
|||||||
@ -33,6 +33,8 @@ from common.connection_utils import timeout
|
|||||||
from common.misc_utils import get_uuid
|
from common.misc_utils import get_uuid
|
||||||
from common import settings
|
from common import settings
|
||||||
|
|
||||||
|
from api.db.joint_services.memory_message_service import queue_save_to_memory_task
|
||||||
|
|
||||||
|
|
||||||
class MessageParam(ComponentParamBase):
|
class MessageParam(ComponentParamBase):
|
||||||
"""
|
"""
|
||||||
@ -166,6 +168,7 @@ class Message(ComponentBase):
|
|||||||
|
|
||||||
self.set_output("content", all_content)
|
self.set_output("content", all_content)
|
||||||
self._convert_content(all_content)
|
self._convert_content(all_content)
|
||||||
|
await self._save_to_memory(all_content)
|
||||||
|
|
||||||
def _is_jinjia2(self, content:str) -> bool:
|
def _is_jinjia2(self, content:str) -> bool:
|
||||||
patt = [
|
patt = [
|
||||||
@ -198,6 +201,7 @@ class Message(ComponentBase):
|
|||||||
|
|
||||||
self.set_output("content", content)
|
self.set_output("content", content)
|
||||||
self._convert_content(content)
|
self._convert_content(content)
|
||||||
|
self._save_to_memory(content)
|
||||||
|
|
||||||
def thoughts(self) -> str:
|
def thoughts(self) -> str:
|
||||||
return ""
|
return ""
|
||||||
@ -421,3 +425,16 @@ class Message(ComponentBase):
|
|||||||
|
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
logging.error(f"Error converting content to {self._param.output_format}: {e}")
|
logging.error(f"Error converting content to {self._param.output_format}: {e}")
|
||||||
|
|
||||||
|
async def _save_to_memory(self, content):
|
||||||
|
if not hasattr(self._param, "memory_ids") or not self._param.memory_ids:
|
||||||
|
return True, "No memory selected."
|
||||||
|
|
||||||
|
message_dict = {
|
||||||
|
"user_id": self._canvas._tenant_id,
|
||||||
|
"agent_id": self._canvas._id,
|
||||||
|
"session_id": self._canvas.task_id,
|
||||||
|
"user_input": self._canvas.get_sys_query(),
|
||||||
|
"agent_response": content
|
||||||
|
}
|
||||||
|
return await queue_save_to_memory_task(self._param.memory_ids, message_dict)
|
||||||
|
|||||||
@ -26,7 +26,7 @@ from common.metadata_utils import apply_meta_data_filter
|
|||||||
from api.db.services.knowledgebase_service import KnowledgebaseService
|
from api.db.services.knowledgebase_service import KnowledgebaseService
|
||||||
from api.db.services.llm_service import LLMBundle
|
from api.db.services.llm_service import LLMBundle
|
||||||
from api.db.services.memory_service import MemoryService
|
from api.db.services.memory_service import MemoryService
|
||||||
from api.db.joint_services.memory_message_service import query_message
|
from api.db.joint_services import memory_message_service
|
||||||
from common import settings
|
from common import settings
|
||||||
from common.connection_utils import timeout
|
from common.connection_utils import timeout
|
||||||
from rag.app.tag import label_question
|
from rag.app.tag import label_question
|
||||||
@ -259,36 +259,36 @@ class Retrieval(ToolBase, ABC):
|
|||||||
vars = {k: o["value"] for k, o in vars.items()}
|
vars = {k: o["value"] for k, o in vars.items()}
|
||||||
query = self.string_format(query_text, vars)
|
query = self.string_format(query_text, vars)
|
||||||
# query message
|
# query message
|
||||||
message_list = query_message({"memory_id": memory_ids}, {
|
message_list = memory_message_service.query_message({"memory_id": memory_ids}, {
|
||||||
"query": query,
|
"query": query,
|
||||||
"similarity_threshold": self._param.similarity_threshold,
|
"similarity_threshold": self._param.similarity_threshold,
|
||||||
"keywords_similarity_weight": self._param.keywords_similarity_weight,
|
"keywords_similarity_weight": self._param.keywords_similarity_weight,
|
||||||
"top_n": self._param.top_n
|
"top_n": self._param.top_n
|
||||||
})
|
})
|
||||||
print(f"found {len(message_list)} messages.")
|
|
||||||
|
|
||||||
if not message_list:
|
if not message_list:
|
||||||
self.set_output("formalized_content", self._param.empty_response)
|
self.set_output("formalized_content", self._param.empty_response)
|
||||||
return
|
return ""
|
||||||
formated_content = "\n".join(memory_prompt(message_list, 200000))
|
formated_content = "\n".join(memory_prompt(message_list, 200000))
|
||||||
|
|
||||||
# set formalized_content output
|
# set formalized_content output
|
||||||
self.set_output("formalized_content", formated_content)
|
self.set_output("formalized_content", formated_content)
|
||||||
print(f"formated_content {formated_content}")
|
|
||||||
return formated_content
|
return formated_content
|
||||||
|
|
||||||
@timeout(int(os.environ.get("COMPONENT_EXEC_TIMEOUT", 12)))
|
@timeout(int(os.environ.get("COMPONENT_EXEC_TIMEOUT", 12)))
|
||||||
async def _invoke_async(self, **kwargs):
|
async def _invoke_async(self, **kwargs):
|
||||||
if self.check_if_canceled("Retrieval processing"):
|
if self.check_if_canceled("Retrieval processing"):
|
||||||
return
|
return
|
||||||
print(f"debug retrieval, query is {kwargs.get('query')}.", flush=True)
|
|
||||||
if not kwargs.get("query"):
|
if not kwargs.get("query"):
|
||||||
self.set_output("formalized_content", self._param.empty_response)
|
self.set_output("formalized_content", self._param.empty_response)
|
||||||
return
|
return
|
||||||
|
|
||||||
if self._param.kb_ids:
|
if hasattr(self._param, "retrieval_from") and self._param.retrieval_from == "dataset":
|
||||||
return await self._retrieve_kb(kwargs["query"])
|
return await self._retrieve_kb(kwargs["query"])
|
||||||
elif self._param.memory_ids:
|
elif hasattr(self._param, "retrieval_from") and self._param.retrieval_from == "memory":
|
||||||
|
return await self._retrieve_memory(kwargs["query"])
|
||||||
|
elif self._param.kb_ids:
|
||||||
|
return await self._retrieve_kb(kwargs["query"])
|
||||||
|
elif hasattr(self._param, "memory_ids") and self._param.memory_ids:
|
||||||
return await self._retrieve_memory(kwargs["query"])
|
return await self._retrieve_memory(kwargs["query"])
|
||||||
else:
|
else:
|
||||||
self.set_output("formalized_content", self._param.empty_response)
|
self.set_output("formalized_content", self._param.empty_response)
|
||||||
|
|||||||
@ -38,7 +38,6 @@ settings.init_settings()
|
|||||||
|
|
||||||
__all__ = ["app"]
|
__all__ = ["app"]
|
||||||
|
|
||||||
|
|
||||||
app = Quart(__name__)
|
app = Quart(__name__)
|
||||||
app = cors(app, allow_origin="*")
|
app = cors(app, allow_origin="*")
|
||||||
|
|
||||||
@ -103,6 +102,7 @@ from werkzeug.local import LocalProxy
|
|||||||
T = TypeVar("T")
|
T = TypeVar("T")
|
||||||
P = ParamSpec("P")
|
P = ParamSpec("P")
|
||||||
|
|
||||||
|
|
||||||
def _load_user():
|
def _load_user():
|
||||||
jwt = Serializer(secret_key=settings.SECRET_KEY)
|
jwt = Serializer(secret_key=settings.SECRET_KEY)
|
||||||
authorization = request.headers.get("Authorization")
|
authorization = request.headers.get("Authorization")
|
||||||
@ -228,6 +228,7 @@ def logout_user():
|
|||||||
|
|
||||||
return True
|
return True
|
||||||
|
|
||||||
|
|
||||||
def search_pages_path(page_path):
|
def search_pages_path(page_path):
|
||||||
app_path_list = [
|
app_path_list = [
|
||||||
path for path in page_path.glob("*_app.py") if not path.name.startswith(".")
|
path for path in page_path.glob("*_app.py") if not path.name.startswith(".")
|
||||||
@ -274,6 +275,16 @@ client_urls_prefix = [
|
|||||||
]
|
]
|
||||||
|
|
||||||
|
|
||||||
|
@app.errorhandler(404)
|
||||||
|
async def not_found(error):
|
||||||
|
error_msg: str = f"The requested URL {request.path} was not found"
|
||||||
|
logging.error(error_msg)
|
||||||
|
return {
|
||||||
|
"error": "Not Found",
|
||||||
|
"message": error_msg,
|
||||||
|
}, 404
|
||||||
|
|
||||||
|
|
||||||
@app.teardown_request
|
@app.teardown_request
|
||||||
def _db_close(exception):
|
def _db_close(exception):
|
||||||
if exception:
|
if exception:
|
||||||
|
|||||||
@ -153,7 +153,7 @@ async def run():
|
|||||||
return get_json_result(data={"message_id": task_id})
|
return get_json_result(data={"message_id": task_id})
|
||||||
|
|
||||||
try:
|
try:
|
||||||
canvas = Canvas(cvs.dsl, current_user.id)
|
canvas = Canvas(cvs.dsl, current_user.id, canvas_id=cvs.id)
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
return server_error_response(e)
|
return server_error_response(e)
|
||||||
|
|
||||||
@ -232,7 +232,7 @@ async def reset():
|
|||||||
if not e:
|
if not e:
|
||||||
return get_data_error_result(message="canvas not found.")
|
return get_data_error_result(message="canvas not found.")
|
||||||
|
|
||||||
canvas = Canvas(json.dumps(user_canvas.dsl), current_user.id)
|
canvas = Canvas(json.dumps(user_canvas.dsl), current_user.id, canvas_id=user_canvas.id)
|
||||||
canvas.reset()
|
canvas.reset()
|
||||||
req["dsl"] = json.loads(str(canvas))
|
req["dsl"] = json.loads(str(canvas))
|
||||||
UserCanvasService.update_by_id(req["id"], {"dsl": req["dsl"]})
|
UserCanvasService.update_by_id(req["id"], {"dsl": req["dsl"]})
|
||||||
@ -270,7 +270,7 @@ def input_form():
|
|||||||
data=False, message='Only owner of canvas authorized for this operation.',
|
data=False, message='Only owner of canvas authorized for this operation.',
|
||||||
code=RetCode.OPERATING_ERROR)
|
code=RetCode.OPERATING_ERROR)
|
||||||
|
|
||||||
canvas = Canvas(json.dumps(user_canvas.dsl), current_user.id)
|
canvas = Canvas(json.dumps(user_canvas.dsl), current_user.id, canvas_id=user_canvas.id)
|
||||||
return get_json_result(data=canvas.get_component_input_form(cpn_id))
|
return get_json_result(data=canvas.get_component_input_form(cpn_id))
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
return server_error_response(e)
|
return server_error_response(e)
|
||||||
@ -287,7 +287,7 @@ async def debug():
|
|||||||
code=RetCode.OPERATING_ERROR)
|
code=RetCode.OPERATING_ERROR)
|
||||||
try:
|
try:
|
||||||
e, user_canvas = UserCanvasService.get_by_id(req["id"])
|
e, user_canvas = UserCanvasService.get_by_id(req["id"])
|
||||||
canvas = Canvas(json.dumps(user_canvas.dsl), current_user.id)
|
canvas = Canvas(json.dumps(user_canvas.dsl), current_user.id, canvas_id=user_canvas.id)
|
||||||
canvas.reset()
|
canvas.reset()
|
||||||
canvas.message_id = get_uuid()
|
canvas.message_id = get_uuid()
|
||||||
component = canvas.get_component(req["component_id"])["obj"]
|
component = canvas.get_component(req["component_id"])["obj"]
|
||||||
|
|||||||
@ -234,6 +234,10 @@ async def list_docs():
|
|||||||
|
|
||||||
req = await get_request_json()
|
req = await get_request_json()
|
||||||
|
|
||||||
|
return_empty_metadata = req.get("return_empty_metadata", False)
|
||||||
|
if isinstance(return_empty_metadata, str):
|
||||||
|
return_empty_metadata = return_empty_metadata.lower() == "true"
|
||||||
|
|
||||||
run_status = req.get("run_status", [])
|
run_status = req.get("run_status", [])
|
||||||
if run_status:
|
if run_status:
|
||||||
invalid_status = {s for s in run_status if s not in VALID_TASK_STATUS}
|
invalid_status = {s for s in run_status if s not in VALID_TASK_STATUS}
|
||||||
@ -248,9 +252,16 @@ async def list_docs():
|
|||||||
|
|
||||||
suffix = req.get("suffix", [])
|
suffix = req.get("suffix", [])
|
||||||
metadata_condition = req.get("metadata_condition", {}) or {}
|
metadata_condition = req.get("metadata_condition", {}) or {}
|
||||||
|
metadata = req.get("metadata", {}) or {}
|
||||||
|
if isinstance(metadata, dict) and metadata.get("empty_metadata"):
|
||||||
|
return_empty_metadata = True
|
||||||
|
metadata = {k: v for k, v in metadata.items() if k != "empty_metadata"}
|
||||||
|
if return_empty_metadata:
|
||||||
|
metadata_condition = {}
|
||||||
|
metadata = {}
|
||||||
|
else:
|
||||||
if metadata_condition and not isinstance(metadata_condition, dict):
|
if metadata_condition and not isinstance(metadata_condition, dict):
|
||||||
return get_data_error_result(message="metadata_condition must be an object.")
|
return get_data_error_result(message="metadata_condition must be an object.")
|
||||||
metadata = req.get("metadata", {}) or {}
|
|
||||||
if metadata and not isinstance(metadata, dict):
|
if metadata and not isinstance(metadata, dict):
|
||||||
return get_data_error_result(message="metadata must be an object.")
|
return get_data_error_result(message="metadata must be an object.")
|
||||||
|
|
||||||
@ -295,7 +306,19 @@ async def list_docs():
|
|||||||
doc_ids_filter = list(doc_ids_filter)
|
doc_ids_filter = list(doc_ids_filter)
|
||||||
|
|
||||||
try:
|
try:
|
||||||
docs, tol = DocumentService.get_by_kb_id(kb_id, page_number, items_per_page, orderby, desc, keywords, run_status, types, suffix, doc_ids_filter)
|
docs, tol = DocumentService.get_by_kb_id(
|
||||||
|
kb_id,
|
||||||
|
page_number,
|
||||||
|
items_per_page,
|
||||||
|
orderby,
|
||||||
|
desc,
|
||||||
|
keywords,
|
||||||
|
run_status,
|
||||||
|
types,
|
||||||
|
suffix,
|
||||||
|
doc_ids_filter,
|
||||||
|
return_empty_metadata=return_empty_metadata,
|
||||||
|
)
|
||||||
|
|
||||||
if create_time_from or create_time_to:
|
if create_time_from or create_time_to:
|
||||||
filtered_docs = []
|
filtered_docs = []
|
||||||
@ -588,6 +611,13 @@ async def run():
|
|||||||
settings.docStoreConn.delete({"doc_id": id}, search.index_name(tenant_id), doc.kb_id)
|
settings.docStoreConn.delete({"doc_id": id}, search.index_name(tenant_id), doc.kb_id)
|
||||||
|
|
||||||
if str(req["run"]) == TaskStatus.RUNNING.value:
|
if str(req["run"]) == TaskStatus.RUNNING.value:
|
||||||
|
if req.get("apply_kb"):
|
||||||
|
e, kb = KnowledgebaseService.get_by_id(doc.kb_id)
|
||||||
|
if not e:
|
||||||
|
raise LookupError("Can't find this dataset!")
|
||||||
|
doc.parser_config["enable_metadata"] = kb.parser_config.get("enable_metadata", False)
|
||||||
|
doc.parser_config["metadata"] = kb.parser_config.get("metadata", {})
|
||||||
|
DocumentService.update_parser_config(doc.id, doc.parser_config)
|
||||||
doc_dict = doc.to_dict()
|
doc_dict = doc.to_dict()
|
||||||
DocumentService.run(tenant_id, doc_dict, kb_table_num_map)
|
DocumentService.run(tenant_id, doc_dict, kb_table_num_map)
|
||||||
|
|
||||||
@ -716,6 +746,7 @@ async def change_parser():
|
|||||||
tenant_id = DocumentService.get_tenant_id(req["doc_id"])
|
tenant_id = DocumentService.get_tenant_id(req["doc_id"])
|
||||||
if not tenant_id:
|
if not tenant_id:
|
||||||
return get_data_error_result(message="Tenant not found!")
|
return get_data_error_result(message="Tenant not found!")
|
||||||
|
DocumentService.delete_chunk_images(doc, tenant_id)
|
||||||
if settings.docStoreConn.index_exist(search.index_name(tenant_id), doc.kb_id):
|
if settings.docStoreConn.index_exist(search.index_name(tenant_id), doc.kb_id):
|
||||||
settings.docStoreConn.delete({"doc_id": doc.id}, search.index_name(tenant_id), doc.kb_id)
|
settings.docStoreConn.delete({"doc_id": doc.id}, search.index_name(tenant_id), doc.kb_id)
|
||||||
return None
|
return None
|
||||||
|
|||||||
@ -21,11 +21,12 @@ from api.db import TenantPermission
|
|||||||
from api.db.services.memory_service import MemoryService
|
from api.db.services.memory_service import MemoryService
|
||||||
from api.db.services.user_service import UserTenantService
|
from api.db.services.user_service import UserTenantService
|
||||||
from api.db.services.canvas_service import UserCanvasService
|
from api.db.services.canvas_service import UserCanvasService
|
||||||
from api.utils.api_utils import validate_request, get_request_json, get_error_argument_result, get_json_result, \
|
from api.db.joint_services.memory_message_service import get_memory_size_cache, judge_system_prompt_is_default
|
||||||
not_allowed_parameters
|
from api.utils.api_utils import validate_request, get_request_json, get_error_argument_result, get_json_result
|
||||||
from api.utils.memory_utils import format_ret_data_from_memory, get_memory_type_human
|
from api.utils.memory_utils import format_ret_data_from_memory, get_memory_type_human
|
||||||
from api.constants import MEMORY_NAME_LIMIT, MEMORY_SIZE_LIMIT
|
from api.constants import MEMORY_NAME_LIMIT, MEMORY_SIZE_LIMIT
|
||||||
from memory.services.messages import MessageService
|
from memory.services.messages import MessageService
|
||||||
|
from memory.utils.prompt_util import PromptAssembler
|
||||||
from common.constants import MemoryType, RetCode, ForgettingPolicy
|
from common.constants import MemoryType, RetCode, ForgettingPolicy
|
||||||
|
|
||||||
|
|
||||||
@ -68,7 +69,6 @@ async def create_memory():
|
|||||||
|
|
||||||
@manager.route("/<memory_id>", methods=["PUT"]) # noqa: F821
|
@manager.route("/<memory_id>", methods=["PUT"]) # noqa: F821
|
||||||
@login_required
|
@login_required
|
||||||
@not_allowed_parameters("id", "tenant_id", "memory_type", "storage_type", "embd_id")
|
|
||||||
async def update_memory(memory_id):
|
async def update_memory(memory_id):
|
||||||
req = await get_request_json()
|
req = await get_request_json()
|
||||||
update_dict = {}
|
update_dict = {}
|
||||||
@ -88,6 +88,14 @@ async def update_memory(memory_id):
|
|||||||
update_dict["permissions"] = req["permissions"]
|
update_dict["permissions"] = req["permissions"]
|
||||||
if req.get("llm_id"):
|
if req.get("llm_id"):
|
||||||
update_dict["llm_id"] = req["llm_id"]
|
update_dict["llm_id"] = req["llm_id"]
|
||||||
|
if req.get("embd_id"):
|
||||||
|
update_dict["embd_id"] = req["embd_id"]
|
||||||
|
if req.get("memory_type"):
|
||||||
|
memory_type = set(req["memory_type"])
|
||||||
|
invalid_type = memory_type - {e.name.lower() for e in MemoryType}
|
||||||
|
if invalid_type:
|
||||||
|
return get_error_argument_result(f"Memory type '{invalid_type}' is not supported.")
|
||||||
|
update_dict["memory_type"] = list(memory_type)
|
||||||
# check memory_size valid
|
# check memory_size valid
|
||||||
if req.get("memory_size"):
|
if req.get("memory_size"):
|
||||||
if not 0 < int(req["memory_size"]) <= MEMORY_SIZE_LIMIT:
|
if not 0 < int(req["memory_size"]) <= MEMORY_SIZE_LIMIT:
|
||||||
@ -123,6 +131,15 @@ async def update_memory(memory_id):
|
|||||||
|
|
||||||
if not to_update:
|
if not to_update:
|
||||||
return get_json_result(message=True, data=memory_dict)
|
return get_json_result(message=True, data=memory_dict)
|
||||||
|
# check memory empty when update embd_id, memory_type
|
||||||
|
memory_size = get_memory_size_cache(memory_id, current_memory.tenant_id)
|
||||||
|
not_allowed_update = [f for f in ["embd_id", "memory_type"] if f in to_update and memory_size > 0]
|
||||||
|
if not_allowed_update:
|
||||||
|
return get_error_argument_result(f"Can't update {not_allowed_update} when memory isn't empty.")
|
||||||
|
if "memory_type" in to_update:
|
||||||
|
if "system_prompt" not in to_update and judge_system_prompt_is_default(current_memory.system_prompt, current_memory.memory_type):
|
||||||
|
# update old default prompt, assemble a new one
|
||||||
|
to_update["system_prompt"] = PromptAssembler.assemble_system_prompt({"memory_type": to_update["memory_type"]})
|
||||||
|
|
||||||
try:
|
try:
|
||||||
MemoryService.update_memory(current_memory.tenant_id, memory_id, to_update)
|
MemoryService.update_memory(current_memory.tenant_id, memory_id, to_update)
|
||||||
@ -142,6 +159,7 @@ async def delete_memory(memory_id):
|
|||||||
return get_json_result(message=True, code=RetCode.NOT_FOUND)
|
return get_json_result(message=True, code=RetCode.NOT_FOUND)
|
||||||
try:
|
try:
|
||||||
MemoryService.delete_memory(memory_id)
|
MemoryService.delete_memory(memory_id)
|
||||||
|
if MessageService.has_index(memory.tenant_id, memory_id):
|
||||||
MessageService.delete_message({"memory_id": memory_id}, memory.tenant_id, memory_id)
|
MessageService.delete_message({"memory_id": memory_id}, memory.tenant_id, memory_id)
|
||||||
return get_json_result(message=True)
|
return get_json_result(message=True)
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
|
|||||||
@ -20,7 +20,6 @@ from common.time_utils import current_timestamp, timestamp_to_date
|
|||||||
|
|
||||||
from memory.services.messages import MessageService
|
from memory.services.messages import MessageService
|
||||||
from api.db.joint_services import memory_message_service
|
from api.db.joint_services import memory_message_service
|
||||||
from api.db.joint_services.memory_message_service import query_message
|
|
||||||
from api.utils.api_utils import validate_request, get_request_json, get_error_argument_result, get_json_result
|
from api.utils.api_utils import validate_request, get_request_json, get_error_argument_result, get_json_result
|
||||||
from common.constants import RetCode
|
from common.constants import RetCode
|
||||||
|
|
||||||
@ -129,7 +128,7 @@ async def search_message():
|
|||||||
"keywords_similarity_weight": keywords_similarity_weight,
|
"keywords_similarity_weight": keywords_similarity_weight,
|
||||||
"top_n": top_n
|
"top_n": top_n
|
||||||
}
|
}
|
||||||
res = query_message(filter_dict, params)
|
res = memory_message_service.query_message(filter_dict, params)
|
||||||
return get_json_result(message=True, data=res)
|
return get_json_result(message=True, data=res)
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
@ -394,7 +394,7 @@ async def webhook(agent_id: str):
|
|||||||
if not isinstance(cvs.dsl, str):
|
if not isinstance(cvs.dsl, str):
|
||||||
dsl = json.dumps(cvs.dsl, ensure_ascii=False)
|
dsl = json.dumps(cvs.dsl, ensure_ascii=False)
|
||||||
try:
|
try:
|
||||||
canvas = Canvas(dsl, cvs.user_id, agent_id)
|
canvas = Canvas(dsl, cvs.user_id, agent_id, canvas_id=agent_id)
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
resp=get_data_error_result(code=RetCode.BAD_REQUEST,message=str(e))
|
resp=get_data_error_result(code=RetCode.BAD_REQUEST,message=str(e))
|
||||||
resp.status_code = RetCode.BAD_REQUEST
|
resp.status_code = RetCode.BAD_REQUEST
|
||||||
|
|||||||
@ -1286,6 +1286,9 @@ async def rm_chunk(tenant_id, dataset_id, document_id):
|
|||||||
if "chunk_ids" in req:
|
if "chunk_ids" in req:
|
||||||
unique_chunk_ids, duplicate_messages = check_duplicate_ids(req["chunk_ids"], "chunk")
|
unique_chunk_ids, duplicate_messages = check_duplicate_ids(req["chunk_ids"], "chunk")
|
||||||
condition["id"] = unique_chunk_ids
|
condition["id"] = unique_chunk_ids
|
||||||
|
else:
|
||||||
|
unique_chunk_ids = []
|
||||||
|
duplicate_messages = []
|
||||||
chunk_number = settings.docStoreConn.delete(condition, search.index_name(tenant_id), dataset_id)
|
chunk_number = settings.docStoreConn.delete(condition, search.index_name(tenant_id), dataset_id)
|
||||||
if chunk_number != 0:
|
if chunk_number != 0:
|
||||||
DocumentService.decrement_chunk_num(document_id, dataset_id, 1, chunk_number, 0)
|
DocumentService.decrement_chunk_num(document_id, dataset_id, 1, chunk_number, 0)
|
||||||
|
|||||||
@ -88,7 +88,7 @@ async def create_agent_session(tenant_id, agent_id):
|
|||||||
cvs.dsl = json.dumps(cvs.dsl, ensure_ascii=False)
|
cvs.dsl = json.dumps(cvs.dsl, ensure_ascii=False)
|
||||||
|
|
||||||
session_id = get_uuid()
|
session_id = get_uuid()
|
||||||
canvas = Canvas(cvs.dsl, tenant_id, agent_id)
|
canvas = Canvas(cvs.dsl, tenant_id, agent_id, canvas_id=cvs.id)
|
||||||
canvas.reset()
|
canvas.reset()
|
||||||
|
|
||||||
cvs.dsl = json.loads(str(canvas))
|
cvs.dsl = json.loads(str(canvas))
|
||||||
@ -986,7 +986,7 @@ async def begin_inputs(agent_id):
|
|||||||
if not e:
|
if not e:
|
||||||
return get_error_data_result(f"Can't find agent by ID: {agent_id}")
|
return get_error_data_result(f"Can't find agent by ID: {agent_id}")
|
||||||
|
|
||||||
canvas = Canvas(json.dumps(cvs.dsl), objs[0].tenant_id)
|
canvas = Canvas(json.dumps(cvs.dsl), objs[0].tenant_id, canvas_id=cvs.id)
|
||||||
return get_result(
|
return get_result(
|
||||||
data={"title": cvs.title, "avatar": cvs.avatar, "inputs": canvas.get_component_input_form("begin"),
|
data={"title": cvs.title, "avatar": cvs.avatar, "inputs": canvas.get_component_input_form("begin"),
|
||||||
"prologue": canvas.get_prologue(), "mode": canvas.get_mode()})
|
"prologue": canvas.get_prologue(), "mode": canvas.get_mode()})
|
||||||
|
|||||||
@ -213,7 +213,7 @@ def new_token():
|
|||||||
if not tenants:
|
if not tenants:
|
||||||
return get_data_error_result(message="Tenant not found!")
|
return get_data_error_result(message="Tenant not found!")
|
||||||
|
|
||||||
tenant_id = [tenant for tenant in tenants if tenant.role == 'owner'][0].tenant_id
|
tenant_id = [tenant for tenant in tenants if tenant.role == "owner"][0].tenant_id
|
||||||
obj = {
|
obj = {
|
||||||
"tenant_id": tenant_id,
|
"tenant_id": tenant_id,
|
||||||
"token": generate_confirmation_token(),
|
"token": generate_confirmation_token(),
|
||||||
@ -268,13 +268,12 @@ def token_list():
|
|||||||
if not tenants:
|
if not tenants:
|
||||||
return get_data_error_result(message="Tenant not found!")
|
return get_data_error_result(message="Tenant not found!")
|
||||||
|
|
||||||
tenant_id = [tenant for tenant in tenants if tenant.role == 'owner'][0].tenant_id
|
tenant_id = [tenant for tenant in tenants if tenant.role == "owner"][0].tenant_id
|
||||||
objs = APITokenService.query(tenant_id=tenant_id)
|
objs = APITokenService.query(tenant_id=tenant_id)
|
||||||
objs = [o.to_dict() for o in objs]
|
objs = [o.to_dict() for o in objs]
|
||||||
for o in objs:
|
for o in objs:
|
||||||
if not o["beta"]:
|
if not o["beta"]:
|
||||||
o["beta"] = generate_confirmation_token().replace(
|
o["beta"] = generate_confirmation_token().replace("ragflow-", "")[:32]
|
||||||
"ragflow-", "")[:32]
|
|
||||||
APITokenService.filter_update([APIToken.tenant_id == tenant_id, APIToken.token == o["token"]], o)
|
APITokenService.filter_update([APIToken.tenant_id == tenant_id, APIToken.token == o["token"]], o)
|
||||||
return get_json_result(data=objs)
|
return get_json_result(data=objs)
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
@ -307,13 +306,19 @@ def rm(token):
|
|||||||
type: boolean
|
type: boolean
|
||||||
description: Deletion status.
|
description: Deletion status.
|
||||||
"""
|
"""
|
||||||
APITokenService.filter_delete(
|
try:
|
||||||
[APIToken.tenant_id == current_user.id, APIToken.token == token]
|
tenants = UserTenantService.query(user_id=current_user.id)
|
||||||
)
|
if not tenants:
|
||||||
|
return get_data_error_result(message="Tenant not found!")
|
||||||
|
|
||||||
|
tenant_id = tenants[0].tenant_id
|
||||||
|
APITokenService.filter_delete([APIToken.tenant_id == tenant_id, APIToken.token == token])
|
||||||
return get_json_result(data=True)
|
return get_json_result(data=True)
|
||||||
|
except Exception as e:
|
||||||
|
return server_error_response(e)
|
||||||
|
|
||||||
|
|
||||||
@manager.route('/config', methods=['GET']) # noqa: F821
|
@manager.route("/config", methods=["GET"]) # noqa: F821
|
||||||
def get_config():
|
def get_config():
|
||||||
"""
|
"""
|
||||||
Get system configuration.
|
Get system configuration.
|
||||||
@ -330,6 +335,4 @@ def get_config():
|
|||||||
type: integer 0 means disabled, 1 means enabled
|
type: integer 0 means disabled, 1 means enabled
|
||||||
description: Whether user registration is enabled
|
description: Whether user registration is enabled
|
||||||
"""
|
"""
|
||||||
return get_json_result(data={
|
return get_json_result(data={"registerEnabled": settings.REGISTER_ENABLED})
|
||||||
"registerEnabled": settings.REGISTER_ENABLED
|
|
||||||
})
|
|
||||||
|
|||||||
@ -1189,7 +1189,7 @@ class Memory(DataBaseModel):
|
|||||||
permissions = CharField(max_length=16, null=False, index=True, help_text="me|team", default="me")
|
permissions = CharField(max_length=16, null=False, index=True, help_text="me|team", default="me")
|
||||||
description = TextField(null=True, help_text="description")
|
description = TextField(null=True, help_text="description")
|
||||||
memory_size = IntegerField(default=5242880, null=False, index=False)
|
memory_size = IntegerField(default=5242880, null=False, index=False)
|
||||||
forgetting_policy = CharField(max_length=32, null=False, default="fifo", index=False, help_text="lru|fifo")
|
forgetting_policy = CharField(max_length=32, null=False, default="FIFO", index=False, help_text="LRU|FIFO")
|
||||||
temperature = FloatField(default=0.5, index=False)
|
temperature = FloatField(default=0.5, index=False)
|
||||||
system_prompt = TextField(null=True, help_text="system prompt", index=False)
|
system_prompt = TextField(null=True, help_text="system prompt", index=False)
|
||||||
user_prompt = TextField(null=True, help_text="user prompt", index=False)
|
user_prompt = TextField(null=True, help_text="user prompt", index=False)
|
||||||
|
|||||||
@ -16,9 +16,14 @@
|
|||||||
import logging
|
import logging
|
||||||
from typing import List
|
from typing import List
|
||||||
|
|
||||||
|
from api.db.services.task_service import TaskService
|
||||||
|
from common import settings
|
||||||
from common.time_utils import current_timestamp, timestamp_to_date, format_iso_8601_to_ymd_hms
|
from common.time_utils import current_timestamp, timestamp_to_date, format_iso_8601_to_ymd_hms
|
||||||
from common.constants import MemoryType, LLMType
|
from common.constants import MemoryType, LLMType
|
||||||
from common.doc_store.doc_store_base import FusionExpr
|
from common.doc_store.doc_store_base import FusionExpr
|
||||||
|
from common.misc_utils import get_uuid
|
||||||
|
from api.db.db_utils import bulk_insert_into_db
|
||||||
|
from api.db.db_models import Task
|
||||||
from api.db.services.memory_service import MemoryService
|
from api.db.services.memory_service import MemoryService
|
||||||
from api.db.services.tenant_llm_service import TenantLLMService
|
from api.db.services.tenant_llm_service import TenantLLMService
|
||||||
from api.db.services.llm_service import LLMBundle
|
from api.db.services.llm_service import LLMBundle
|
||||||
@ -82,32 +87,44 @@ async def save_to_memory(memory_id: str, message_dict: dict):
|
|||||||
"forget_at": None,
|
"forget_at": None,
|
||||||
"status": True
|
"status": True
|
||||||
} for content in extracted_content]]
|
} for content in extracted_content]]
|
||||||
embedding_model = LLMBundle(tenant_id, llm_type=LLMType.EMBEDDING, llm_name=memory.embd_id)
|
return await embed_and_save(memory, message_list)
|
||||||
vector_list, _ = embedding_model.encode([msg["content"] for msg in message_list])
|
|
||||||
for idx, msg in enumerate(message_list):
|
|
||||||
msg["content_embed"] = vector_list[idx]
|
|
||||||
vector_dimension = len(vector_list[0])
|
|
||||||
if not MessageService.has_index(tenant_id, memory_id):
|
|
||||||
created = MessageService.create_index(tenant_id, memory_id, vector_size=vector_dimension)
|
|
||||||
if not created:
|
|
||||||
return False, "Failed to create message index."
|
|
||||||
|
|
||||||
new_msg_size = sum([MessageService.calculate_message_size(m) for m in message_list])
|
|
||||||
current_memory_size = get_memory_size_cache(memory_id, tenant_id)
|
|
||||||
if new_msg_size + current_memory_size > memory.memory_size:
|
|
||||||
size_to_delete = current_memory_size + new_msg_size - memory.memory_size
|
|
||||||
if memory.forgetting_policy == "fifo":
|
|
||||||
message_ids_to_delete, delete_size = MessageService.pick_messages_to_delete_by_fifo(memory_id, tenant_id, size_to_delete)
|
|
||||||
MessageService.delete_message({"message_id": message_ids_to_delete}, tenant_id, memory_id)
|
|
||||||
decrease_memory_size_cache(memory_id, tenant_id, delete_size)
|
|
||||||
else:
|
|
||||||
return False, "Failed to insert message into memory. Memory size reached limit and cannot decide which to delete."
|
|
||||||
fail_cases = MessageService.insert_message(message_list, tenant_id, memory_id)
|
|
||||||
if fail_cases:
|
|
||||||
return False, "Failed to insert message into memory. Details: " + "; ".join(fail_cases)
|
|
||||||
|
|
||||||
increase_memory_size_cache(memory_id, tenant_id, new_msg_size)
|
async def save_extracted_to_memory_only(memory_id: str, message_dict, source_message_id: int):
|
||||||
return True, "Message saved successfully."
|
memory = MemoryService.get_by_memory_id(memory_id)
|
||||||
|
if not memory:
|
||||||
|
return False, f"Memory '{memory_id}' not found."
|
||||||
|
|
||||||
|
if memory.memory_type == MemoryType.RAW.value:
|
||||||
|
return True, f"Memory '{memory_id}' don't need to extract."
|
||||||
|
|
||||||
|
tenant_id = memory.tenant_id
|
||||||
|
extracted_content = await extract_by_llm(
|
||||||
|
tenant_id,
|
||||||
|
memory.llm_id,
|
||||||
|
{"temperature": memory.temperature},
|
||||||
|
get_memory_type_human(memory.memory_type),
|
||||||
|
message_dict.get("user_input", ""),
|
||||||
|
message_dict.get("agent_response", "")
|
||||||
|
)
|
||||||
|
message_list = [{
|
||||||
|
"message_id": REDIS_CONN.generate_auto_increment_id(namespace="memory"),
|
||||||
|
"message_type": content["message_type"],
|
||||||
|
"source_id": source_message_id,
|
||||||
|
"memory_id": memory_id,
|
||||||
|
"user_id": "",
|
||||||
|
"agent_id": message_dict["agent_id"],
|
||||||
|
"session_id": message_dict["session_id"],
|
||||||
|
"content": content["content"],
|
||||||
|
"valid_at": content["valid_at"],
|
||||||
|
"invalid_at": content["invalid_at"] if content["invalid_at"] else None,
|
||||||
|
"forget_at": None,
|
||||||
|
"status": True
|
||||||
|
} for content in extracted_content]
|
||||||
|
if not message_list:
|
||||||
|
return True, "No memory extracted from raw message."
|
||||||
|
|
||||||
|
return await embed_and_save(memory, message_list)
|
||||||
|
|
||||||
|
|
||||||
async def extract_by_llm(tenant_id: str, llm_id: str, extract_conf: dict, memory_type: List[str], user_input: str,
|
async def extract_by_llm(tenant_id: str, llm_id: str, extract_conf: dict, memory_type: List[str], user_input: str,
|
||||||
@ -136,6 +153,36 @@ async def extract_by_llm(tenant_id: str, llm_id: str, extract_conf: dict, memory
|
|||||||
} for message_type, extracted_content_list in res_json.items() for extracted_content in extracted_content_list]
|
} for message_type, extracted_content_list in res_json.items() for extracted_content in extracted_content_list]
|
||||||
|
|
||||||
|
|
||||||
|
async def embed_and_save(memory, message_list: list[dict]):
|
||||||
|
embedding_model = LLMBundle(memory.tenant_id, llm_type=LLMType.EMBEDDING, llm_name=memory.embd_id)
|
||||||
|
vector_list, _ = embedding_model.encode([msg["content"] for msg in message_list])
|
||||||
|
for idx, msg in enumerate(message_list):
|
||||||
|
msg["content_embed"] = vector_list[idx]
|
||||||
|
vector_dimension = len(vector_list[0])
|
||||||
|
if not MessageService.has_index(memory.tenant_id, memory.id):
|
||||||
|
created = MessageService.create_index(memory.tenant_id, memory.id, vector_size=vector_dimension)
|
||||||
|
if not created:
|
||||||
|
return False, "Failed to create message index."
|
||||||
|
|
||||||
|
new_msg_size = sum([MessageService.calculate_message_size(m) for m in message_list])
|
||||||
|
current_memory_size = get_memory_size_cache(memory.tenant_id, memory.id)
|
||||||
|
if new_msg_size + current_memory_size > memory.memory_size:
|
||||||
|
size_to_delete = current_memory_size + new_msg_size - memory.memory_size
|
||||||
|
if memory.forgetting_policy == "FIFO":
|
||||||
|
message_ids_to_delete, delete_size = MessageService.pick_messages_to_delete_by_fifo(memory.id, memory.tenant_id,
|
||||||
|
size_to_delete)
|
||||||
|
MessageService.delete_message({"message_id": message_ids_to_delete}, memory.tenant_id, memory.id)
|
||||||
|
decrease_memory_size_cache(memory.id, delete_size)
|
||||||
|
else:
|
||||||
|
return False, "Failed to insert message into memory. Memory size reached limit and cannot decide which to delete."
|
||||||
|
fail_cases = MessageService.insert_message(message_list, memory.tenant_id, memory.id)
|
||||||
|
if fail_cases:
|
||||||
|
return False, "Failed to insert message into memory. Details: " + "; ".join(fail_cases)
|
||||||
|
|
||||||
|
increase_memory_size_cache(memory.id, new_msg_size)
|
||||||
|
return True, "Message saved successfully."
|
||||||
|
|
||||||
|
|
||||||
def query_message(filter_dict: dict, params: dict):
|
def query_message(filter_dict: dict, params: dict):
|
||||||
"""
|
"""
|
||||||
:param filter_dict: {
|
:param filter_dict: {
|
||||||
@ -163,9 +210,9 @@ def query_message(filter_dict: dict, params: dict):
|
|||||||
memory = memory_list[0]
|
memory = memory_list[0]
|
||||||
embd_model = LLMBundle(memory.tenant_id, llm_type=LLMType.EMBEDDING, llm_name=memory.embd_id)
|
embd_model = LLMBundle(memory.tenant_id, llm_type=LLMType.EMBEDDING, llm_name=memory.embd_id)
|
||||||
match_dense = get_vector(question, embd_model, similarity=params["similarity_threshold"])
|
match_dense = get_vector(question, embd_model, similarity=params["similarity_threshold"])
|
||||||
match_text, _ = MsgTextQuery().question(question, min_match=0.3)
|
match_text, _ = MsgTextQuery().question(question, min_match=params["similarity_threshold"])
|
||||||
keywords_similarity_weight = params.get("keywords_similarity_weight", 0.7)
|
keywords_similarity_weight = params.get("keywords_similarity_weight", 0.7)
|
||||||
fusion_expr = FusionExpr("weighted_sum", params["top_n"], {"weights": ",".join([str(keywords_similarity_weight), str(1 - keywords_similarity_weight)])})
|
fusion_expr = FusionExpr("weighted_sum", params["top_n"], {"weights": ",".join([str(1 - keywords_similarity_weight), str(keywords_similarity_weight)])})
|
||||||
|
|
||||||
return MessageService.search_message(memory_ids, condition_dict, uids, [match_text, match_dense, fusion_expr], params["top_n"])
|
return MessageService.search_message(memory_ids, condition_dict, uids, [match_text, match_dense, fusion_expr], params["top_n"])
|
||||||
|
|
||||||
@ -191,8 +238,8 @@ def init_message_id_sequence():
|
|||||||
|
|
||||||
def get_memory_size_cache(memory_id: str, uid: str):
|
def get_memory_size_cache(memory_id: str, uid: str):
|
||||||
redis_key = f"memory_{memory_id}"
|
redis_key = f"memory_{memory_id}"
|
||||||
if REDIS_CONN.exists(redis_key):
|
if REDIS_CONN.exist(redis_key):
|
||||||
return REDIS_CONN.get(redis_key)
|
return int(REDIS_CONN.get(redis_key))
|
||||||
else:
|
else:
|
||||||
memory_size_map = MessageService.calculate_memory_size(
|
memory_size_map = MessageService.calculate_memory_size(
|
||||||
[memory_id],
|
[memory_id],
|
||||||
@ -208,14 +255,14 @@ def set_memory_size_cache(memory_id: str, size: int):
|
|||||||
return REDIS_CONN.set(redis_key, size)
|
return REDIS_CONN.set(redis_key, size)
|
||||||
|
|
||||||
|
|
||||||
def increase_memory_size_cache(memory_id: str, uid: str, size: int):
|
def increase_memory_size_cache(memory_id: str, size: int):
|
||||||
current_value = get_memory_size_cache(memory_id, uid)
|
redis_key = f"memory_{memory_id}"
|
||||||
return set_memory_size_cache(memory_id, current_value + size)
|
return REDIS_CONN.incrby(redis_key, size)
|
||||||
|
|
||||||
|
|
||||||
def decrease_memory_size_cache(memory_id: str, uid: str, size: int):
|
def decrease_memory_size_cache(memory_id: str, size: int):
|
||||||
current_value = get_memory_size_cache(memory_id, uid)
|
redis_key = f"memory_{memory_id}"
|
||||||
return set_memory_size_cache(memory_id, max(current_value - size, 0))
|
return REDIS_CONN.decrby(redis_key, size)
|
||||||
|
|
||||||
|
|
||||||
def init_memory_size_cache():
|
def init_memory_size_cache():
|
||||||
@ -223,11 +270,120 @@ def init_memory_size_cache():
|
|||||||
if not memory_list:
|
if not memory_list:
|
||||||
logging.info("No memory found, no need to init memory size.")
|
logging.info("No memory found, no need to init memory size.")
|
||||||
else:
|
else:
|
||||||
memory_size_map = MessageService.calculate_memory_size(
|
for m in memory_list:
|
||||||
memory_ids=[m.id for m in memory_list],
|
get_memory_size_cache(m.id, m.tenant_id)
|
||||||
uid_list=[m.tenant_id for m in memory_list],
|
|
||||||
)
|
|
||||||
for memory in memory_list:
|
|
||||||
memory_size = memory_size_map.get(memory.id, 0)
|
|
||||||
set_memory_size_cache(memory.id, memory_size)
|
|
||||||
logging.info("Memory size cache init done.")
|
logging.info("Memory size cache init done.")
|
||||||
|
|
||||||
|
|
||||||
|
def judge_system_prompt_is_default(system_prompt: str, memory_type: int|list[str]):
|
||||||
|
memory_type_list = memory_type if isinstance(memory_type, list) else get_memory_type_human(memory_type)
|
||||||
|
return system_prompt == PromptAssembler.assemble_system_prompt({"memory_type": memory_type_list})
|
||||||
|
|
||||||
|
|
||||||
|
async def queue_save_to_memory_task(memory_ids: list[str], message_dict: dict):
|
||||||
|
"""
|
||||||
|
:param memory_ids:
|
||||||
|
:param message_dict: {
|
||||||
|
"user_id": str,
|
||||||
|
"agent_id": str,
|
||||||
|
"session_id": str,
|
||||||
|
"user_input": str,
|
||||||
|
"agent_response": str
|
||||||
|
}
|
||||||
|
"""
|
||||||
|
def new_task(_memory_id: str, _source_id: int):
|
||||||
|
return {
|
||||||
|
"id": get_uuid(),
|
||||||
|
"doc_id": _memory_id,
|
||||||
|
"task_type": "memory",
|
||||||
|
"progress": 0.0,
|
||||||
|
"digest": str(_source_id)
|
||||||
|
}
|
||||||
|
|
||||||
|
not_found_memory = []
|
||||||
|
failed_memory = []
|
||||||
|
for memory_id in memory_ids:
|
||||||
|
memory = MemoryService.get_by_memory_id(memory_id)
|
||||||
|
if not memory:
|
||||||
|
not_found_memory.append(memory_id)
|
||||||
|
continue
|
||||||
|
|
||||||
|
raw_message_id = REDIS_CONN.generate_auto_increment_id(namespace="memory")
|
||||||
|
raw_message = {
|
||||||
|
"message_id": raw_message_id,
|
||||||
|
"message_type": MemoryType.RAW.name.lower(),
|
||||||
|
"source_id": 0,
|
||||||
|
"memory_id": memory_id,
|
||||||
|
"user_id": "",
|
||||||
|
"agent_id": message_dict["agent_id"],
|
||||||
|
"session_id": message_dict["session_id"],
|
||||||
|
"content": f"User Input: {message_dict.get('user_input')}\nAgent Response: {message_dict.get('agent_response')}",
|
||||||
|
"valid_at": timestamp_to_date(current_timestamp()),
|
||||||
|
"invalid_at": None,
|
||||||
|
"forget_at": None,
|
||||||
|
"status": True
|
||||||
|
}
|
||||||
|
res, msg = await embed_and_save(memory, [raw_message])
|
||||||
|
if not res:
|
||||||
|
failed_memory.append({"memory_id": memory_id, "fail_msg": msg})
|
||||||
|
continue
|
||||||
|
|
||||||
|
task = new_task(memory_id, raw_message_id)
|
||||||
|
bulk_insert_into_db(Task, [task], replace_on_conflict=True)
|
||||||
|
task_message = {
|
||||||
|
"id": task["id"],
|
||||||
|
"task_id": task["id"],
|
||||||
|
"task_type": task["task_type"],
|
||||||
|
"memory_id": memory_id,
|
||||||
|
"source_id": raw_message_id,
|
||||||
|
"message_dict": message_dict
|
||||||
|
}
|
||||||
|
if not REDIS_CONN.queue_product(settings.get_svr_queue_name(priority=0), message=task_message):
|
||||||
|
failed_memory.append({"memory_id": memory_id, "fail_msg": "Can't access Redis."})
|
||||||
|
|
||||||
|
error_msg = ""
|
||||||
|
if not_found_memory:
|
||||||
|
error_msg = f"Memory {not_found_memory} not found."
|
||||||
|
if failed_memory:
|
||||||
|
error_msg += "".join([f"Memory {fm['memory_id']} failed. Detail: {fm['fail_msg']}" for fm in failed_memory])
|
||||||
|
|
||||||
|
if error_msg:
|
||||||
|
return False, error_msg
|
||||||
|
|
||||||
|
return True, "All add to task."
|
||||||
|
|
||||||
|
|
||||||
|
async def handle_save_to_memory_task(task_param: dict):
|
||||||
|
"""
|
||||||
|
:param task_param: {
|
||||||
|
"id": task_id
|
||||||
|
"memory_id": id
|
||||||
|
"source_id": id
|
||||||
|
"message_dict": {
|
||||||
|
"user_id": str,
|
||||||
|
"agent_id": str,
|
||||||
|
"session_id": str,
|
||||||
|
"user_input": str,
|
||||||
|
"agent_response": str
|
||||||
|
}
|
||||||
|
}
|
||||||
|
"""
|
||||||
|
_, task = TaskService.get_by_id(task_param["id"])
|
||||||
|
if not task:
|
||||||
|
return False, f"Task {task_param['id']} is not found."
|
||||||
|
if task.progress == -1:
|
||||||
|
return False, f"Task {task_param['id']} is already failed."
|
||||||
|
now_time = current_timestamp()
|
||||||
|
TaskService.update_by_id(task_param["id"], {"begin_at": timestamp_to_date(now_time)})
|
||||||
|
|
||||||
|
memory_id = task_param["memory_id"]
|
||||||
|
source_id = task_param["source_id"]
|
||||||
|
message_dict = task_param["message_dict"]
|
||||||
|
success, msg = await save_extracted_to_memory_only(memory_id, message_dict, source_id)
|
||||||
|
if success:
|
||||||
|
TaskService.update_progress(task.id, {"progress": 1.0, "progress_msg": msg})
|
||||||
|
return True, msg
|
||||||
|
|
||||||
|
logging.error(msg)
|
||||||
|
TaskService.update_progress(task.id, {"progress": -1, "progress_msg": None})
|
||||||
|
return False, msg
|
||||||
|
|||||||
@ -211,7 +211,7 @@ async def completion(tenant_id, agent_id, session_id=None, **kwargs):
|
|||||||
if not isinstance(cvs.dsl, str):
|
if not isinstance(cvs.dsl, str):
|
||||||
cvs.dsl = json.dumps(cvs.dsl, ensure_ascii=False)
|
cvs.dsl = json.dumps(cvs.dsl, ensure_ascii=False)
|
||||||
session_id=get_uuid()
|
session_id=get_uuid()
|
||||||
canvas = Canvas(cvs.dsl, tenant_id, agent_id)
|
canvas = Canvas(cvs.dsl, tenant_id, agent_id, canvas_id=cvs.id)
|
||||||
canvas.reset()
|
canvas.reset()
|
||||||
conv = {
|
conv = {
|
||||||
"id": session_id,
|
"id": session_id,
|
||||||
|
|||||||
@ -116,6 +116,16 @@ async def async_completion(tenant_id, chat_id, question, name="New session", ses
|
|||||||
ensure_ascii=False) + "\n\n"
|
ensure_ascii=False) + "\n\n"
|
||||||
yield "data:" + json.dumps({"code": 0, "message": "", "data": True}, ensure_ascii=False) + "\n\n"
|
yield "data:" + json.dumps({"code": 0, "message": "", "data": True}, ensure_ascii=False) + "\n\n"
|
||||||
return
|
return
|
||||||
|
else:
|
||||||
|
answer = {
|
||||||
|
"answer": conv["message"][0]["content"],
|
||||||
|
"reference": {},
|
||||||
|
"audio_binary": None,
|
||||||
|
"id": None,
|
||||||
|
"session_id": session_id
|
||||||
|
}
|
||||||
|
yield answer
|
||||||
|
return
|
||||||
|
|
||||||
conv = ConversationService.query(id=session_id, dialog_id=chat_id)
|
conv = ConversationService.query(id=session_id, dialog_id=chat_id)
|
||||||
if not conv:
|
if not conv:
|
||||||
|
|||||||
@ -125,26 +125,26 @@ class DocumentService(CommonService):
|
|||||||
|
|
||||||
@classmethod
|
@classmethod
|
||||||
@DB.connection_context()
|
@DB.connection_context()
|
||||||
def get_by_kb_id(cls, kb_id, page_number, items_per_page,
|
def get_by_kb_id(cls, kb_id, page_number, items_per_page, orderby, desc, keywords, run_status, types, suffix, doc_ids=None, return_empty_metadata=False):
|
||||||
orderby, desc, keywords, run_status, types, suffix, doc_ids=None):
|
|
||||||
fields = cls.get_cls_model_fields()
|
fields = cls.get_cls_model_fields()
|
||||||
if keywords:
|
if keywords:
|
||||||
docs = cls.model.select(*[*fields, UserCanvas.title.alias("pipeline_name"), User.nickname])\
|
docs = (
|
||||||
.join(File2Document, on=(File2Document.document_id == cls.model.id))\
|
cls.model.select(*[*fields, UserCanvas.title.alias("pipeline_name"), User.nickname])
|
||||||
.join(File, on=(File.id == File2Document.file_id))\
|
.join(File2Document, on=(File2Document.document_id == cls.model.id))
|
||||||
.join(UserCanvas, on=(cls.model.pipeline_id == UserCanvas.id), join_type=JOIN.LEFT_OUTER)\
|
.join(File, on=(File.id == File2Document.file_id))
|
||||||
.join(User, on=(cls.model.created_by == User.id), join_type=JOIN.LEFT_OUTER)\
|
.join(UserCanvas, on=(cls.model.pipeline_id == UserCanvas.id), join_type=JOIN.LEFT_OUTER)
|
||||||
.where(
|
.join(User, on=(cls.model.created_by == User.id), join_type=JOIN.LEFT_OUTER)
|
||||||
(cls.model.kb_id == kb_id),
|
.where((cls.model.kb_id == kb_id), (fn.LOWER(cls.model.name).contains(keywords.lower())))
|
||||||
(fn.LOWER(cls.model.name).contains(keywords.lower()))
|
|
||||||
)
|
)
|
||||||
else:
|
else:
|
||||||
docs = cls.model.select(*[*fields, UserCanvas.title.alias("pipeline_name"), User.nickname])\
|
docs = (
|
||||||
.join(File2Document, on=(File2Document.document_id == cls.model.id))\
|
cls.model.select(*[*fields, UserCanvas.title.alias("pipeline_name"), User.nickname])
|
||||||
.join(UserCanvas, on=(cls.model.pipeline_id == UserCanvas.id), join_type=JOIN.LEFT_OUTER)\
|
.join(File2Document, on=(File2Document.document_id == cls.model.id))
|
||||||
.join(File, on=(File.id == File2Document.file_id))\
|
.join(UserCanvas, on=(cls.model.pipeline_id == UserCanvas.id), join_type=JOIN.LEFT_OUTER)
|
||||||
.join(User, on=(cls.model.created_by == User.id), join_type=JOIN.LEFT_OUTER)\
|
.join(File, on=(File.id == File2Document.file_id))
|
||||||
|
.join(User, on=(cls.model.created_by == User.id), join_type=JOIN.LEFT_OUTER)
|
||||||
.where(cls.model.kb_id == kb_id)
|
.where(cls.model.kb_id == kb_id)
|
||||||
|
)
|
||||||
|
|
||||||
if doc_ids:
|
if doc_ids:
|
||||||
docs = docs.where(cls.model.id.in_(doc_ids))
|
docs = docs.where(cls.model.id.in_(doc_ids))
|
||||||
@ -154,6 +154,8 @@ class DocumentService(CommonService):
|
|||||||
docs = docs.where(cls.model.type.in_(types))
|
docs = docs.where(cls.model.type.in_(types))
|
||||||
if suffix:
|
if suffix:
|
||||||
docs = docs.where(cls.model.suffix.in_(suffix))
|
docs = docs.where(cls.model.suffix.in_(suffix))
|
||||||
|
if return_empty_metadata:
|
||||||
|
docs = docs.where(fn.COALESCE(fn.JSON_LENGTH(cls.model.meta_fields), 0) == 0)
|
||||||
|
|
||||||
count = docs.count()
|
count = docs.count()
|
||||||
if desc:
|
if desc:
|
||||||
@ -161,7 +163,6 @@ class DocumentService(CommonService):
|
|||||||
else:
|
else:
|
||||||
docs = docs.order_by(cls.model.getter_by(orderby).asc())
|
docs = docs.order_by(cls.model.getter_by(orderby).asc())
|
||||||
|
|
||||||
|
|
||||||
if page_number and items_per_page:
|
if page_number and items_per_page:
|
||||||
docs = docs.paginate(page_number, items_per_page)
|
docs = docs.paginate(page_number, items_per_page)
|
||||||
|
|
||||||
@ -217,18 +218,16 @@ class DocumentService(CommonService):
|
|||||||
suffix_counter = {}
|
suffix_counter = {}
|
||||||
run_status_counter = {}
|
run_status_counter = {}
|
||||||
metadata_counter = {}
|
metadata_counter = {}
|
||||||
|
empty_metadata_count = 0
|
||||||
|
|
||||||
for row in rows:
|
for row in rows:
|
||||||
suffix_counter[row.suffix] = suffix_counter.get(row.suffix, 0) + 1
|
suffix_counter[row.suffix] = suffix_counter.get(row.suffix, 0) + 1
|
||||||
run_status_counter[str(row.run)] = run_status_counter.get(str(row.run), 0) + 1
|
run_status_counter[str(row.run)] = run_status_counter.get(str(row.run), 0) + 1
|
||||||
meta_fields = row.meta_fields or {}
|
meta_fields = row.meta_fields or {}
|
||||||
if isinstance(meta_fields, str):
|
if not meta_fields:
|
||||||
try:
|
empty_metadata_count += 1
|
||||||
meta_fields = json.loads(meta_fields)
|
|
||||||
except Exception:
|
|
||||||
meta_fields = {}
|
|
||||||
if not isinstance(meta_fields, dict):
|
|
||||||
continue
|
continue
|
||||||
|
has_valid_meta = False
|
||||||
for key, value in meta_fields.items():
|
for key, value in meta_fields.items():
|
||||||
values = value if isinstance(value, list) else [value]
|
values = value if isinstance(value, list) else [value]
|
||||||
for vv in values:
|
for vv in values:
|
||||||
@ -240,7 +239,11 @@ class DocumentService(CommonService):
|
|||||||
if key not in metadata_counter:
|
if key not in metadata_counter:
|
||||||
metadata_counter[key] = {}
|
metadata_counter[key] = {}
|
||||||
metadata_counter[key][sv] = metadata_counter[key].get(sv, 0) + 1
|
metadata_counter[key][sv] = metadata_counter[key].get(sv, 0) + 1
|
||||||
|
has_valid_meta = True
|
||||||
|
if not has_valid_meta:
|
||||||
|
empty_metadata_count += 1
|
||||||
|
|
||||||
|
metadata_counter["empty_metadata"] = {"true": empty_metadata_count}
|
||||||
return {
|
return {
|
||||||
"suffix": suffix_counter,
|
"suffix": suffix_counter,
|
||||||
"run_status": run_status_counter,
|
"run_status": run_status_counter,
|
||||||
@ -339,21 +342,7 @@ class DocumentService(CommonService):
|
|||||||
cls.clear_chunk_num(doc.id)
|
cls.clear_chunk_num(doc.id)
|
||||||
try:
|
try:
|
||||||
TaskService.filter_delete([Task.doc_id == doc.id])
|
TaskService.filter_delete([Task.doc_id == doc.id])
|
||||||
page = 0
|
cls.delete_chunk_images(doc, tenant_id)
|
||||||
page_size = 1000
|
|
||||||
all_chunk_ids = []
|
|
||||||
while True:
|
|
||||||
chunks = settings.docStoreConn.search(["img_id"], [], {"doc_id": doc.id}, [], OrderByExpr(),
|
|
||||||
page * page_size, page_size, search.index_name(tenant_id),
|
|
||||||
[doc.kb_id])
|
|
||||||
chunk_ids = settings.docStoreConn.get_doc_ids(chunks)
|
|
||||||
if not chunk_ids:
|
|
||||||
break
|
|
||||||
all_chunk_ids.extend(chunk_ids)
|
|
||||||
page += 1
|
|
||||||
for cid in all_chunk_ids:
|
|
||||||
if settings.STORAGE_IMPL.obj_exist(doc.kb_id, cid):
|
|
||||||
settings.STORAGE_IMPL.rm(doc.kb_id, cid)
|
|
||||||
if doc.thumbnail and not doc.thumbnail.startswith(IMG_BASE64_PREFIX):
|
if doc.thumbnail and not doc.thumbnail.startswith(IMG_BASE64_PREFIX):
|
||||||
if settings.STORAGE_IMPL.obj_exist(doc.kb_id, doc.thumbnail):
|
if settings.STORAGE_IMPL.obj_exist(doc.kb_id, doc.thumbnail):
|
||||||
settings.STORAGE_IMPL.rm(doc.kb_id, doc.thumbnail)
|
settings.STORAGE_IMPL.rm(doc.kb_id, doc.thumbnail)
|
||||||
@ -375,6 +364,23 @@ class DocumentService(CommonService):
|
|||||||
pass
|
pass
|
||||||
return cls.delete_by_id(doc.id)
|
return cls.delete_by_id(doc.id)
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
@DB.connection_context()
|
||||||
|
def delete_chunk_images(cls, doc, tenant_id):
|
||||||
|
page = 0
|
||||||
|
page_size = 1000
|
||||||
|
while True:
|
||||||
|
chunks = settings.docStoreConn.search(["img_id"], [], {"doc_id": doc.id}, [], OrderByExpr(),
|
||||||
|
page * page_size, page_size, search.index_name(tenant_id),
|
||||||
|
[doc.kb_id])
|
||||||
|
chunk_ids = settings.docStoreConn.get_doc_ids(chunks)
|
||||||
|
if not chunk_ids:
|
||||||
|
break
|
||||||
|
for cid in chunk_ids:
|
||||||
|
if settings.STORAGE_IMPL.obj_exist(doc.kb_id, cid):
|
||||||
|
settings.STORAGE_IMPL.rm(doc.kb_id, cid)
|
||||||
|
page += 1
|
||||||
|
|
||||||
@classmethod
|
@classmethod
|
||||||
@DB.connection_context()
|
@DB.connection_context()
|
||||||
def get_newly_uploaded(cls):
|
def get_newly_uploaded(cls):
|
||||||
|
|||||||
@ -65,6 +65,7 @@ class EvaluationService(CommonService):
|
|||||||
(success, dataset_id or error_message)
|
(success, dataset_id or error_message)
|
||||||
"""
|
"""
|
||||||
try:
|
try:
|
||||||
|
timestamp= current_timestamp()
|
||||||
dataset_id = get_uuid()
|
dataset_id = get_uuid()
|
||||||
dataset = {
|
dataset = {
|
||||||
"id": dataset_id,
|
"id": dataset_id,
|
||||||
@ -73,8 +74,8 @@ class EvaluationService(CommonService):
|
|||||||
"description": description,
|
"description": description,
|
||||||
"kb_ids": kb_ids,
|
"kb_ids": kb_ids,
|
||||||
"created_by": user_id,
|
"created_by": user_id,
|
||||||
"create_time": current_timestamp(),
|
"create_time": timestamp,
|
||||||
"update_time": current_timestamp(),
|
"update_time": timestamp,
|
||||||
"status": StatusEnum.VALID.value
|
"status": StatusEnum.VALID.value
|
||||||
}
|
}
|
||||||
|
|
||||||
|
|||||||
@ -64,10 +64,13 @@ class TenantLangfuseService(CommonService):
|
|||||||
|
|
||||||
@classmethod
|
@classmethod
|
||||||
def save(cls, **kwargs):
|
def save(cls, **kwargs):
|
||||||
kwargs["create_time"] = current_timestamp()
|
current_ts = current_timestamp()
|
||||||
kwargs["create_date"] = datetime_format(datetime.now())
|
current_date = datetime_format(datetime.now())
|
||||||
kwargs["update_time"] = current_timestamp()
|
|
||||||
kwargs["update_date"] = datetime_format(datetime.now())
|
kwargs["create_time"] = current_ts
|
||||||
|
kwargs["create_date"] = current_date
|
||||||
|
kwargs["update_time"] = current_ts
|
||||||
|
kwargs["update_date"] = current_date
|
||||||
obj = cls.model.create(**kwargs)
|
obj = cls.model.create(**kwargs)
|
||||||
return obj
|
return obj
|
||||||
|
|
||||||
|
|||||||
@ -149,6 +149,8 @@ class MemoryService(CommonService):
|
|||||||
return 0
|
return 0
|
||||||
if "temperature" in update_dict and isinstance(update_dict["temperature"], str):
|
if "temperature" in update_dict and isinstance(update_dict["temperature"], str):
|
||||||
update_dict["temperature"] = float(update_dict["temperature"])
|
update_dict["temperature"] = float(update_dict["temperature"])
|
||||||
|
if "memory_type" in update_dict and isinstance(update_dict["memory_type"], list):
|
||||||
|
update_dict["memory_type"] = calculate_memory_type(update_dict["memory_type"])
|
||||||
if "name" in update_dict:
|
if "name" in update_dict:
|
||||||
update_dict["name"] = duplicate_name(
|
update_dict["name"] = duplicate_name(
|
||||||
cls.query,
|
cls.query,
|
||||||
|
|||||||
@ -169,11 +169,12 @@ class PipelineOperationLogService(CommonService):
|
|||||||
operation_status=operation_status,
|
operation_status=operation_status,
|
||||||
avatar=avatar,
|
avatar=avatar,
|
||||||
)
|
)
|
||||||
log["create_time"] = current_timestamp()
|
timestamp = current_timestamp()
|
||||||
log["create_date"] = datetime_format(datetime.now())
|
datetime_now = datetime_format(datetime.now())
|
||||||
log["update_time"] = current_timestamp()
|
log["create_time"] = timestamp
|
||||||
log["update_date"] = datetime_format(datetime.now())
|
log["create_date"] = datetime_now
|
||||||
|
log["update_time"] = timestamp
|
||||||
|
log["update_date"] = datetime_now
|
||||||
with DB.atomic():
|
with DB.atomic():
|
||||||
obj = cls.save(**log)
|
obj = cls.save(**log)
|
||||||
|
|
||||||
|
|||||||
@ -28,10 +28,13 @@ class SearchService(CommonService):
|
|||||||
|
|
||||||
@classmethod
|
@classmethod
|
||||||
def save(cls, **kwargs):
|
def save(cls, **kwargs):
|
||||||
kwargs["create_time"] = current_timestamp()
|
current_ts = current_timestamp()
|
||||||
kwargs["create_date"] = datetime_format(datetime.now())
|
current_date = datetime_format(datetime.now())
|
||||||
kwargs["update_time"] = current_timestamp()
|
|
||||||
kwargs["update_date"] = datetime_format(datetime.now())
|
kwargs["create_time"] = current_ts
|
||||||
|
kwargs["create_date"] = current_date
|
||||||
|
kwargs["update_time"] = current_ts
|
||||||
|
kwargs["update_date"] = current_date
|
||||||
obj = cls.model.create(**kwargs)
|
obj = cls.model.create(**kwargs)
|
||||||
return obj
|
return obj
|
||||||
|
|
||||||
|
|||||||
@ -116,10 +116,13 @@ class UserService(CommonService):
|
|||||||
kwargs["password"] = generate_password_hash(
|
kwargs["password"] = generate_password_hash(
|
||||||
str(kwargs["password"]))
|
str(kwargs["password"]))
|
||||||
|
|
||||||
kwargs["create_time"] = current_timestamp()
|
current_ts = current_timestamp()
|
||||||
kwargs["create_date"] = datetime_format(datetime.now())
|
current_date = datetime_format(datetime.now())
|
||||||
kwargs["update_time"] = current_timestamp()
|
|
||||||
kwargs["update_date"] = datetime_format(datetime.now())
|
kwargs["create_time"] = current_ts
|
||||||
|
kwargs["create_date"] = current_date
|
||||||
|
kwargs["update_time"] = current_ts
|
||||||
|
kwargs["update_date"] = current_date
|
||||||
obj = cls.model(**kwargs).save(force_insert=True)
|
obj = cls.model(**kwargs).save(force_insert=True)
|
||||||
return obj
|
return obj
|
||||||
|
|
||||||
|
|||||||
@ -42,7 +42,7 @@ def filename_type(filename):
|
|||||||
if re.match(r".*\.pdf$", filename):
|
if re.match(r".*\.pdf$", filename):
|
||||||
return FileType.PDF.value
|
return FileType.PDF.value
|
||||||
|
|
||||||
if re.match(r".*\.(msg|eml|doc|docx|ppt|pptx|yml|xml|htm|json|jsonl|ldjson|csv|txt|ini|xls|xlsx|wps|rtf|hlp|pages|numbers|key|md|py|js|java|c|cpp|h|php|go|ts|sh|cs|kt|html|sql)$", filename):
|
if re.match(r".*\.(msg|eml|doc|docx|ppt|pptx|yml|xml|htm|json|jsonl|ldjson|csv|txt|ini|xls|xlsx|wps|rtf|hlp|pages|numbers|key|md|mdx|py|js|java|c|cpp|h|php|go|ts|sh|cs|kt|html|sql)$", filename):
|
||||||
return FileType.DOC.value
|
return FileType.DOC.value
|
||||||
|
|
||||||
if re.match(r".*\.(wav|flac|ape|alac|wavpack|wv|mp3|aac|ogg|vorbis|opus)$", filename):
|
if re.match(r".*\.(wav|flac|ape|alac|wavpack|wv|mp3|aac|ogg|vorbis|opus)$", filename):
|
||||||
|
|||||||
@ -69,6 +69,7 @@ CONTENT_TYPE_MAP = {
|
|||||||
# Web
|
# Web
|
||||||
"md": "text/markdown",
|
"md": "text/markdown",
|
||||||
"markdown": "text/markdown",
|
"markdown": "text/markdown",
|
||||||
|
"mdx": "text/markdown",
|
||||||
"htm": "text/html",
|
"htm": "text/html",
|
||||||
"html": "text/html",
|
"html": "text/html",
|
||||||
"json": "application/json",
|
"json": "application/json",
|
||||||
|
|||||||
@ -128,7 +128,10 @@ class FileSource(StrEnum):
|
|||||||
R2 = "r2"
|
R2 = "r2"
|
||||||
OCI_STORAGE = "oci_storage"
|
OCI_STORAGE = "oci_storage"
|
||||||
GOOGLE_CLOUD_STORAGE = "google_cloud_storage"
|
GOOGLE_CLOUD_STORAGE = "google_cloud_storage"
|
||||||
|
AIRTABLE = "airtable"
|
||||||
|
ASANA = "asana"
|
||||||
|
GITHUB = "github"
|
||||||
|
GITLAB = "gitlab"
|
||||||
|
|
||||||
class PipelineTaskType(StrEnum):
|
class PipelineTaskType(StrEnum):
|
||||||
PARSE = "Parse"
|
PARSE = "Parse"
|
||||||
@ -136,6 +139,7 @@ class PipelineTaskType(StrEnum):
|
|||||||
RAPTOR = "RAPTOR"
|
RAPTOR = "RAPTOR"
|
||||||
GRAPH_RAG = "GraphRAG"
|
GRAPH_RAG = "GraphRAG"
|
||||||
MINDMAP = "Mindmap"
|
MINDMAP = "Mindmap"
|
||||||
|
MEMORY = "Memory"
|
||||||
|
|
||||||
|
|
||||||
VALID_PIPELINE_TASK_TYPES = {PipelineTaskType.PARSE, PipelineTaskType.DOWNLOAD, PipelineTaskType.RAPTOR,
|
VALID_PIPELINE_TASK_TYPES = {PipelineTaskType.PARSE, PipelineTaskType.DOWNLOAD, PipelineTaskType.RAPTOR,
|
||||||
@ -170,7 +174,7 @@ class MemoryStorageType(StrEnum):
|
|||||||
|
|
||||||
|
|
||||||
class ForgettingPolicy(StrEnum):
|
class ForgettingPolicy(StrEnum):
|
||||||
FIFO = "fifo"
|
FIFO = "FIFO"
|
||||||
|
|
||||||
|
|
||||||
# environment
|
# environment
|
||||||
|
|||||||
@ -36,6 +36,8 @@ from .sharepoint_connector import SharePointConnector
|
|||||||
from .teams_connector import TeamsConnector
|
from .teams_connector import TeamsConnector
|
||||||
from .webdav_connector import WebDAVConnector
|
from .webdav_connector import WebDAVConnector
|
||||||
from .moodle_connector import MoodleConnector
|
from .moodle_connector import MoodleConnector
|
||||||
|
from .airtable_connector import AirtableConnector
|
||||||
|
from .asana_connector import AsanaConnector
|
||||||
from .config import BlobType, DocumentSource
|
from .config import BlobType, DocumentSource
|
||||||
from .models import Document, TextSection, ImageSection, BasicExpertInfo
|
from .models import Document, TextSection, ImageSection, BasicExpertInfo
|
||||||
from .exceptions import (
|
from .exceptions import (
|
||||||
@ -70,5 +72,7 @@ __all__ = [
|
|||||||
"ConnectorValidationError",
|
"ConnectorValidationError",
|
||||||
"CredentialExpiredError",
|
"CredentialExpiredError",
|
||||||
"InsufficientPermissionsError",
|
"InsufficientPermissionsError",
|
||||||
"UnexpectedValidationError"
|
"UnexpectedValidationError",
|
||||||
|
"AirtableConnector",
|
||||||
|
"AsanaConnector",
|
||||||
]
|
]
|
||||||
|
|||||||
149
common/data_source/airtable_connector.py
Normal file
149
common/data_source/airtable_connector.py
Normal file
@ -0,0 +1,149 @@
|
|||||||
|
from datetime import datetime, timezone
|
||||||
|
import logging
|
||||||
|
from typing import Any
|
||||||
|
|
||||||
|
import requests
|
||||||
|
|
||||||
|
from pyairtable import Api as AirtableApi
|
||||||
|
|
||||||
|
from common.data_source.config import AIRTABLE_CONNECTOR_SIZE_THRESHOLD, INDEX_BATCH_SIZE, DocumentSource
|
||||||
|
from common.data_source.exceptions import ConnectorMissingCredentialError
|
||||||
|
from common.data_source.interfaces import LoadConnector
|
||||||
|
from common.data_source.models import Document, GenerateDocumentsOutput
|
||||||
|
from common.data_source.utils import extract_size_bytes, get_file_ext
|
||||||
|
|
||||||
|
class AirtableClientNotSetUpError(PermissionError):
|
||||||
|
def __init__(self) -> None:
|
||||||
|
super().__init__(
|
||||||
|
"Airtable client is not set up. Did you forget to call load_credentials()?"
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
class AirtableConnector(LoadConnector):
|
||||||
|
"""
|
||||||
|
Lightweight Airtable connector.
|
||||||
|
|
||||||
|
This connector ingests Airtable attachments as raw blobs without
|
||||||
|
parsing file content or generating text/image sections.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
base_id: str,
|
||||||
|
table_name_or_id: str,
|
||||||
|
batch_size: int = INDEX_BATCH_SIZE,
|
||||||
|
) -> None:
|
||||||
|
self.base_id = base_id
|
||||||
|
self.table_name_or_id = table_name_or_id
|
||||||
|
self.batch_size = batch_size
|
||||||
|
self._airtable_client: AirtableApi | None = None
|
||||||
|
self.size_threshold = AIRTABLE_CONNECTOR_SIZE_THRESHOLD
|
||||||
|
|
||||||
|
# -------------------------
|
||||||
|
# Credentials
|
||||||
|
# -------------------------
|
||||||
|
def load_credentials(self, credentials: dict[str, Any]) -> dict[str, Any] | None:
|
||||||
|
self._airtable_client = AirtableApi(credentials["airtable_access_token"])
|
||||||
|
return None
|
||||||
|
|
||||||
|
@property
|
||||||
|
def airtable_client(self) -> AirtableApi:
|
||||||
|
if not self._airtable_client:
|
||||||
|
raise AirtableClientNotSetUpError()
|
||||||
|
return self._airtable_client
|
||||||
|
|
||||||
|
# -------------------------
|
||||||
|
# Core logic
|
||||||
|
# -------------------------
|
||||||
|
def load_from_state(self) -> GenerateDocumentsOutput:
|
||||||
|
"""
|
||||||
|
Fetch all Airtable records and ingest attachments as raw blobs.
|
||||||
|
|
||||||
|
Each attachment is converted into a single Document(blob=...).
|
||||||
|
"""
|
||||||
|
if not self._airtable_client:
|
||||||
|
raise ConnectorMissingCredentialError("Airtable credentials not loaded")
|
||||||
|
|
||||||
|
table = self.airtable_client.table(self.base_id, self.table_name_or_id)
|
||||||
|
records = table.all()
|
||||||
|
|
||||||
|
logging.info(
|
||||||
|
f"Starting Airtable blob ingestion for table {self.table_name_or_id}, "
|
||||||
|
f"{len(records)} records found."
|
||||||
|
)
|
||||||
|
|
||||||
|
batch: list[Document] = []
|
||||||
|
|
||||||
|
for record in records:
|
||||||
|
print(record)
|
||||||
|
record_id = record.get("id")
|
||||||
|
fields = record.get("fields", {})
|
||||||
|
created_time = record.get("createdTime")
|
||||||
|
|
||||||
|
for field_value in fields.values():
|
||||||
|
# We only care about attachment fields (lists of dicts with url/filename)
|
||||||
|
if not isinstance(field_value, list):
|
||||||
|
continue
|
||||||
|
|
||||||
|
for attachment in field_value:
|
||||||
|
url = attachment.get("url")
|
||||||
|
filename = attachment.get("filename")
|
||||||
|
attachment_id = attachment.get("id")
|
||||||
|
|
||||||
|
if not url or not filename or not attachment_id:
|
||||||
|
continue
|
||||||
|
|
||||||
|
try:
|
||||||
|
resp = requests.get(url, timeout=30)
|
||||||
|
resp.raise_for_status()
|
||||||
|
content = resp.content
|
||||||
|
except Exception:
|
||||||
|
logging.exception(
|
||||||
|
f"Failed to download attachment {filename} "
|
||||||
|
f"(record={record_id})"
|
||||||
|
)
|
||||||
|
continue
|
||||||
|
size_bytes = extract_size_bytes(attachment)
|
||||||
|
if (
|
||||||
|
self.size_threshold is not None
|
||||||
|
and isinstance(size_bytes, int)
|
||||||
|
and size_bytes > self.size_threshold
|
||||||
|
):
|
||||||
|
logging.warning(
|
||||||
|
f"{filename} exceeds size threshold of {self.size_threshold}. Skipping."
|
||||||
|
)
|
||||||
|
continue
|
||||||
|
batch.append(
|
||||||
|
Document(
|
||||||
|
id=f"airtable:{record_id}:{attachment_id}",
|
||||||
|
blob=content,
|
||||||
|
source=DocumentSource.AIRTABLE,
|
||||||
|
semantic_identifier=filename,
|
||||||
|
extension=get_file_ext(filename),
|
||||||
|
size_bytes=size_bytes if size_bytes else 0,
|
||||||
|
doc_updated_at=datetime.strptime(created_time, "%Y-%m-%dT%H:%M:%S.%fZ").replace(tzinfo=timezone.utc)
|
||||||
|
)
|
||||||
|
)
|
||||||
|
|
||||||
|
if len(batch) >= self.batch_size:
|
||||||
|
yield batch
|
||||||
|
batch = []
|
||||||
|
|
||||||
|
if batch:
|
||||||
|
yield batch
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
import os
|
||||||
|
|
||||||
|
logging.basicConfig(level=logging.DEBUG)
|
||||||
|
connector = AirtableConnector("xxx","xxx")
|
||||||
|
connector.load_credentials({"airtable_access_token": os.environ.get("AIRTABLE_ACCESS_TOKEN")})
|
||||||
|
connector.validate_connector_settings()
|
||||||
|
document_batches = connector.load_from_state()
|
||||||
|
try:
|
||||||
|
first_batch = next(document_batches)
|
||||||
|
print(f"Loaded {len(first_batch)} documents in first batch.")
|
||||||
|
for doc in first_batch:
|
||||||
|
print(f"- {doc.semantic_identifier} ({doc.size_bytes} bytes)")
|
||||||
|
except StopIteration:
|
||||||
|
print("No documents available in Dropbox.")
|
||||||
454
common/data_source/asana_connector.py
Normal file
454
common/data_source/asana_connector.py
Normal file
@ -0,0 +1,454 @@
|
|||||||
|
from collections.abc import Iterator
|
||||||
|
import time
|
||||||
|
from datetime import datetime
|
||||||
|
import logging
|
||||||
|
from typing import Any, Dict
|
||||||
|
import asana
|
||||||
|
import requests
|
||||||
|
from common.data_source.config import CONTINUE_ON_CONNECTOR_FAILURE, INDEX_BATCH_SIZE, DocumentSource
|
||||||
|
from common.data_source.interfaces import LoadConnector, PollConnector
|
||||||
|
from common.data_source.models import Document, GenerateDocumentsOutput, SecondsSinceUnixEpoch
|
||||||
|
from common.data_source.utils import extract_size_bytes, get_file_ext
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
# https://github.com/Asana/python-asana/tree/master?tab=readme-ov-file#documentation-for-api-endpoints
|
||||||
|
class AsanaTask:
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
id: str,
|
||||||
|
title: str,
|
||||||
|
text: str,
|
||||||
|
link: str,
|
||||||
|
last_modified: datetime,
|
||||||
|
project_gid: str,
|
||||||
|
project_name: str,
|
||||||
|
) -> None:
|
||||||
|
self.id = id
|
||||||
|
self.title = title
|
||||||
|
self.text = text
|
||||||
|
self.link = link
|
||||||
|
self.last_modified = last_modified
|
||||||
|
self.project_gid = project_gid
|
||||||
|
self.project_name = project_name
|
||||||
|
|
||||||
|
def __str__(self) -> str:
|
||||||
|
return f"ID: {self.id}\nTitle: {self.title}\nLast modified: {self.last_modified}\nText: {self.text}"
|
||||||
|
|
||||||
|
|
||||||
|
class AsanaAPI:
|
||||||
|
def __init__(
|
||||||
|
self, api_token: str, workspace_gid: str, team_gid: str | None
|
||||||
|
) -> None:
|
||||||
|
self._user = None
|
||||||
|
self.workspace_gid = workspace_gid
|
||||||
|
self.team_gid = team_gid
|
||||||
|
|
||||||
|
self.configuration = asana.Configuration()
|
||||||
|
self.api_client = asana.ApiClient(self.configuration)
|
||||||
|
self.tasks_api = asana.TasksApi(self.api_client)
|
||||||
|
self.attachments_api = asana.AttachmentsApi(self.api_client)
|
||||||
|
self.stories_api = asana.StoriesApi(self.api_client)
|
||||||
|
self.users_api = asana.UsersApi(self.api_client)
|
||||||
|
self.project_api = asana.ProjectsApi(self.api_client)
|
||||||
|
self.project_memberships_api = asana.ProjectMembershipsApi(self.api_client)
|
||||||
|
self.workspaces_api = asana.WorkspacesApi(self.api_client)
|
||||||
|
|
||||||
|
self.api_error_count = 0
|
||||||
|
self.configuration.access_token = api_token
|
||||||
|
self.task_count = 0
|
||||||
|
|
||||||
|
def get_tasks(
|
||||||
|
self, project_gids: list[str] | None, start_date: str
|
||||||
|
) -> Iterator[AsanaTask]:
|
||||||
|
"""Get all tasks from the projects with the given gids that were modified since the given date.
|
||||||
|
If project_gids is None, get all tasks from all projects in the workspace."""
|
||||||
|
logging.info("Starting to fetch Asana projects")
|
||||||
|
projects = self.project_api.get_projects(
|
||||||
|
opts={
|
||||||
|
"workspace": self.workspace_gid,
|
||||||
|
"opt_fields": "gid,name,archived,modified_at",
|
||||||
|
}
|
||||||
|
)
|
||||||
|
start_seconds = int(time.mktime(datetime.now().timetuple()))
|
||||||
|
projects_list = []
|
||||||
|
project_count = 0
|
||||||
|
for project_info in projects:
|
||||||
|
project_gid = project_info["gid"]
|
||||||
|
if project_gids is None or project_gid in project_gids:
|
||||||
|
projects_list.append(project_gid)
|
||||||
|
else:
|
||||||
|
logging.debug(
|
||||||
|
f"Skipping project: {project_gid} - not in accepted project_gids"
|
||||||
|
)
|
||||||
|
project_count += 1
|
||||||
|
if project_count % 100 == 0:
|
||||||
|
logging.info(f"Processed {project_count} projects")
|
||||||
|
logging.info(f"Found {len(projects_list)} projects to process")
|
||||||
|
for project_gid in projects_list:
|
||||||
|
for task in self._get_tasks_for_project(
|
||||||
|
project_gid, start_date, start_seconds
|
||||||
|
):
|
||||||
|
yield task
|
||||||
|
logging.info(f"Completed fetching {self.task_count} tasks from Asana")
|
||||||
|
if self.api_error_count > 0:
|
||||||
|
logging.warning(
|
||||||
|
f"Encountered {self.api_error_count} API errors during task fetching"
|
||||||
|
)
|
||||||
|
|
||||||
|
def _get_tasks_for_project(
|
||||||
|
self, project_gid: str, start_date: str, start_seconds: int
|
||||||
|
) -> Iterator[AsanaTask]:
|
||||||
|
project = self.project_api.get_project(project_gid, opts={})
|
||||||
|
project_name = project.get("name", project_gid)
|
||||||
|
team = project.get("team") or {}
|
||||||
|
team_gid = team.get("gid")
|
||||||
|
|
||||||
|
if project.get("archived"):
|
||||||
|
logging.info(f"Skipping archived project: {project_name} ({project_gid})")
|
||||||
|
return
|
||||||
|
if not team_gid:
|
||||||
|
logging.info(
|
||||||
|
f"Skipping project without a team: {project_name} ({project_gid})"
|
||||||
|
)
|
||||||
|
return
|
||||||
|
if project.get("privacy_setting") == "private":
|
||||||
|
if self.team_gid and team_gid != self.team_gid:
|
||||||
|
logging.info(
|
||||||
|
f"Skipping private project not in configured team: {project_name} ({project_gid})"
|
||||||
|
)
|
||||||
|
return
|
||||||
|
logging.info(
|
||||||
|
f"Processing private project in configured team: {project_name} ({project_gid})"
|
||||||
|
)
|
||||||
|
|
||||||
|
simple_start_date = start_date.split(".")[0].split("+")[0]
|
||||||
|
logging.info(
|
||||||
|
f"Fetching tasks modified since {simple_start_date} for project: {project_name} ({project_gid})"
|
||||||
|
)
|
||||||
|
|
||||||
|
opts = {
|
||||||
|
"opt_fields": "name,memberships,memberships.project,completed_at,completed_by,created_at,"
|
||||||
|
"created_by,custom_fields,dependencies,due_at,due_on,external,html_notes,liked,likes,"
|
||||||
|
"modified_at,notes,num_hearts,parent,projects,resource_subtype,resource_type,start_on,"
|
||||||
|
"workspace,permalink_url",
|
||||||
|
"modified_since": start_date,
|
||||||
|
}
|
||||||
|
tasks_from_api = self.tasks_api.get_tasks_for_project(project_gid, opts)
|
||||||
|
for data in tasks_from_api:
|
||||||
|
self.task_count += 1
|
||||||
|
if self.task_count % 10 == 0:
|
||||||
|
end_seconds = time.mktime(datetime.now().timetuple())
|
||||||
|
runtime_seconds = end_seconds - start_seconds
|
||||||
|
if runtime_seconds > 0:
|
||||||
|
logging.info(
|
||||||
|
f"Processed {self.task_count} tasks in {runtime_seconds:.0f} seconds "
|
||||||
|
f"({self.task_count / runtime_seconds:.2f} tasks/second)"
|
||||||
|
)
|
||||||
|
|
||||||
|
logging.debug(f"Processing Asana task: {data['name']}")
|
||||||
|
|
||||||
|
text = self._construct_task_text(data)
|
||||||
|
|
||||||
|
try:
|
||||||
|
text += self._fetch_and_add_comments(data["gid"])
|
||||||
|
|
||||||
|
last_modified_date = self.format_date(data["modified_at"])
|
||||||
|
text += f"Last modified: {last_modified_date}\n"
|
||||||
|
|
||||||
|
task = AsanaTask(
|
||||||
|
id=data["gid"],
|
||||||
|
title=data["name"],
|
||||||
|
text=text,
|
||||||
|
link=data["permalink_url"],
|
||||||
|
last_modified=datetime.fromisoformat(data["modified_at"]),
|
||||||
|
project_gid=project_gid,
|
||||||
|
project_name=project_name,
|
||||||
|
)
|
||||||
|
yield task
|
||||||
|
except Exception:
|
||||||
|
logging.error(
|
||||||
|
f"Error processing task {data['gid']} in project {project_gid}",
|
||||||
|
exc_info=True,
|
||||||
|
)
|
||||||
|
self.api_error_count += 1
|
||||||
|
|
||||||
|
def _construct_task_text(self, data: Dict) -> str:
|
||||||
|
text = f"{data['name']}\n\n"
|
||||||
|
|
||||||
|
if data["notes"]:
|
||||||
|
text += f"{data['notes']}\n\n"
|
||||||
|
|
||||||
|
if data["created_by"] and data["created_by"]["gid"]:
|
||||||
|
creator = self.get_user(data["created_by"]["gid"])["name"]
|
||||||
|
created_date = self.format_date(data["created_at"])
|
||||||
|
text += f"Created by: {creator} on {created_date}\n"
|
||||||
|
|
||||||
|
if data["due_on"]:
|
||||||
|
due_date = self.format_date(data["due_on"])
|
||||||
|
text += f"Due date: {due_date}\n"
|
||||||
|
|
||||||
|
if data["completed_at"]:
|
||||||
|
completed_date = self.format_date(data["completed_at"])
|
||||||
|
text += f"Completed on: {completed_date}\n"
|
||||||
|
|
||||||
|
text += "\n"
|
||||||
|
return text
|
||||||
|
|
||||||
|
def _fetch_and_add_comments(self, task_gid: str) -> str:
|
||||||
|
text = ""
|
||||||
|
stories_opts: Dict[str, str] = {}
|
||||||
|
story_start = time.time()
|
||||||
|
stories = self.stories_api.get_stories_for_task(task_gid, stories_opts)
|
||||||
|
|
||||||
|
story_count = 0
|
||||||
|
comment_count = 0
|
||||||
|
|
||||||
|
for story in stories:
|
||||||
|
story_count += 1
|
||||||
|
if story["resource_subtype"] == "comment_added":
|
||||||
|
comment = self.stories_api.get_story(
|
||||||
|
story["gid"], opts={"opt_fields": "text,created_by,created_at"}
|
||||||
|
)
|
||||||
|
commenter = self.get_user(comment["created_by"]["gid"])["name"]
|
||||||
|
text += f"Comment by {commenter}: {comment['text']}\n\n"
|
||||||
|
comment_count += 1
|
||||||
|
|
||||||
|
story_duration = time.time() - story_start
|
||||||
|
logging.debug(
|
||||||
|
f"Processed {story_count} stories (including {comment_count} comments) in {story_duration:.2f} seconds"
|
||||||
|
)
|
||||||
|
|
||||||
|
return text
|
||||||
|
|
||||||
|
def get_attachments(self, task_gid: str) -> list[dict]:
|
||||||
|
"""
|
||||||
|
Fetch full attachment info (including download_url) for a task.
|
||||||
|
"""
|
||||||
|
attachments: list[dict] = []
|
||||||
|
|
||||||
|
try:
|
||||||
|
# Step 1: list attachment compact records
|
||||||
|
for att in self.attachments_api.get_attachments_for_object(
|
||||||
|
parent=task_gid,
|
||||||
|
opts={}
|
||||||
|
):
|
||||||
|
gid = att.get("gid")
|
||||||
|
if not gid:
|
||||||
|
continue
|
||||||
|
|
||||||
|
try:
|
||||||
|
# Step 2: expand to full attachment
|
||||||
|
full = self.attachments_api.get_attachment(
|
||||||
|
attachment_gid=gid,
|
||||||
|
opts={
|
||||||
|
"opt_fields": "name,download_url,size,created_at"
|
||||||
|
}
|
||||||
|
)
|
||||||
|
|
||||||
|
if full.get("download_url"):
|
||||||
|
attachments.append(full)
|
||||||
|
|
||||||
|
except Exception:
|
||||||
|
logging.exception(
|
||||||
|
f"Failed to fetch attachment detail {gid} for task {task_gid}"
|
||||||
|
)
|
||||||
|
self.api_error_count += 1
|
||||||
|
|
||||||
|
except Exception:
|
||||||
|
logging.exception(f"Failed to list attachments for task {task_gid}")
|
||||||
|
self.api_error_count += 1
|
||||||
|
|
||||||
|
return attachments
|
||||||
|
|
||||||
|
def get_accessible_emails(
|
||||||
|
self,
|
||||||
|
workspace_id: str,
|
||||||
|
project_ids: list[str] | None,
|
||||||
|
team_id: str | None,
|
||||||
|
):
|
||||||
|
|
||||||
|
ws_users = self.users_api.get_users(
|
||||||
|
opts={
|
||||||
|
"workspace": workspace_id,
|
||||||
|
"opt_fields": "gid,name,email"
|
||||||
|
}
|
||||||
|
)
|
||||||
|
|
||||||
|
workspace_users = {
|
||||||
|
u["gid"]: u.get("email")
|
||||||
|
for u in ws_users
|
||||||
|
if u.get("email")
|
||||||
|
}
|
||||||
|
|
||||||
|
if not project_ids:
|
||||||
|
return set(workspace_users.values())
|
||||||
|
|
||||||
|
|
||||||
|
project_emails = set()
|
||||||
|
|
||||||
|
for pid in project_ids:
|
||||||
|
project = self.project_api.get_project(
|
||||||
|
pid,
|
||||||
|
opts={"opt_fields": "team,privacy_setting"}
|
||||||
|
)
|
||||||
|
|
||||||
|
if project["privacy_setting"] == "private":
|
||||||
|
if team_id and project.get("team", {}).get("gid") != team_id:
|
||||||
|
continue
|
||||||
|
|
||||||
|
memberships = self.project_memberships_api.get_project_membership(
|
||||||
|
pid,
|
||||||
|
opts={"opt_fields": "user.gid,user.email"}
|
||||||
|
)
|
||||||
|
|
||||||
|
for m in memberships:
|
||||||
|
email = m["user"].get("email")
|
||||||
|
if email:
|
||||||
|
project_emails.add(email)
|
||||||
|
|
||||||
|
return project_emails
|
||||||
|
|
||||||
|
def get_user(self, user_gid: str) -> Dict:
|
||||||
|
if self._user is not None:
|
||||||
|
return self._user
|
||||||
|
self._user = self.users_api.get_user(user_gid, {"opt_fields": "name,email"})
|
||||||
|
|
||||||
|
if not self._user:
|
||||||
|
logging.warning(f"Unable to fetch user information for user_gid: {user_gid}")
|
||||||
|
return {"name": "Unknown"}
|
||||||
|
return self._user
|
||||||
|
|
||||||
|
def format_date(self, date_str: str) -> str:
|
||||||
|
date = datetime.fromisoformat(date_str)
|
||||||
|
return time.strftime("%Y-%m-%d", date.timetuple())
|
||||||
|
|
||||||
|
def get_time(self) -> str:
|
||||||
|
return time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
|
||||||
|
|
||||||
|
|
||||||
|
class AsanaConnector(LoadConnector, PollConnector):
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
asana_workspace_id: str,
|
||||||
|
asana_project_ids: str | None = None,
|
||||||
|
asana_team_id: str | None = None,
|
||||||
|
batch_size: int = INDEX_BATCH_SIZE,
|
||||||
|
continue_on_failure: bool = CONTINUE_ON_CONNECTOR_FAILURE,
|
||||||
|
) -> None:
|
||||||
|
self.workspace_id = asana_workspace_id
|
||||||
|
self.project_ids_to_index: list[str] | None = (
|
||||||
|
asana_project_ids.split(",") if asana_project_ids else None
|
||||||
|
)
|
||||||
|
self.asana_team_id = asana_team_id if asana_team_id else None
|
||||||
|
self.batch_size = batch_size
|
||||||
|
self.continue_on_failure = continue_on_failure
|
||||||
|
self.size_threshold = None
|
||||||
|
logging.info(
|
||||||
|
f"AsanaConnector initialized with workspace_id: {asana_workspace_id}"
|
||||||
|
)
|
||||||
|
|
||||||
|
def load_credentials(self, credentials: dict[str, Any]) -> dict[str, Any] | None:
|
||||||
|
self.api_token = credentials["asana_api_token_secret"]
|
||||||
|
self.asana_client = AsanaAPI(
|
||||||
|
api_token=self.api_token,
|
||||||
|
workspace_gid=self.workspace_id,
|
||||||
|
team_gid=self.asana_team_id,
|
||||||
|
)
|
||||||
|
self.workspace_users_email = self.asana_client.get_accessible_emails(self.workspace_id, self.project_ids_to_index, self.asana_team_id)
|
||||||
|
logging.info("Asana credentials loaded and API client initialized")
|
||||||
|
return None
|
||||||
|
|
||||||
|
def poll_source(
|
||||||
|
self, start: SecondsSinceUnixEpoch, end: SecondsSinceUnixEpoch | None
|
||||||
|
) -> GenerateDocumentsOutput:
|
||||||
|
start_time = datetime.fromtimestamp(start).isoformat()
|
||||||
|
logging.info(f"Starting Asana poll from {start_time}")
|
||||||
|
docs_batch: list[Document] = []
|
||||||
|
tasks = self.asana_client.get_tasks(self.project_ids_to_index, start_time)
|
||||||
|
for task in tasks:
|
||||||
|
docs = self._task_to_documents(task)
|
||||||
|
docs_batch.extend(docs)
|
||||||
|
|
||||||
|
if len(docs_batch) >= self.batch_size:
|
||||||
|
logging.info(f"Yielding batch of {len(docs_batch)} documents")
|
||||||
|
yield docs_batch
|
||||||
|
docs_batch = []
|
||||||
|
|
||||||
|
if docs_batch:
|
||||||
|
logging.info(f"Yielding final batch of {len(docs_batch)} documents")
|
||||||
|
yield docs_batch
|
||||||
|
|
||||||
|
logging.info("Asana poll completed")
|
||||||
|
|
||||||
|
def load_from_state(self) -> GenerateDocumentsOutput:
|
||||||
|
logging.info("Starting full index of all Asana tasks")
|
||||||
|
return self.poll_source(start=0, end=None)
|
||||||
|
|
||||||
|
def _task_to_documents(self, task: AsanaTask) -> list[Document]:
|
||||||
|
docs: list[Document] = []
|
||||||
|
|
||||||
|
attachments = self.asana_client.get_attachments(task.id)
|
||||||
|
|
||||||
|
for att in attachments:
|
||||||
|
try:
|
||||||
|
resp = requests.get(att["download_url"], timeout=30)
|
||||||
|
resp.raise_for_status()
|
||||||
|
file_blob = resp.content
|
||||||
|
filename = att.get("name", "attachment")
|
||||||
|
size_bytes = extract_size_bytes(att)
|
||||||
|
if (
|
||||||
|
self.size_threshold is not None
|
||||||
|
and isinstance(size_bytes, int)
|
||||||
|
and size_bytes > self.size_threshold
|
||||||
|
):
|
||||||
|
logging.warning(
|
||||||
|
f"{filename} exceeds size threshold of {self.size_threshold}. Skipping."
|
||||||
|
)
|
||||||
|
continue
|
||||||
|
docs.append(
|
||||||
|
Document(
|
||||||
|
id=f"asana:{task.id}:{att['gid']}",
|
||||||
|
blob=file_blob,
|
||||||
|
extension=get_file_ext(filename) or "",
|
||||||
|
size_bytes=size_bytes,
|
||||||
|
doc_updated_at=task.last_modified,
|
||||||
|
source=DocumentSource.ASANA,
|
||||||
|
semantic_identifier=filename,
|
||||||
|
primary_owners=list(self.workspace_users_email),
|
||||||
|
)
|
||||||
|
)
|
||||||
|
except Exception:
|
||||||
|
logging.exception(
|
||||||
|
f"Failed to download attachment {att.get('gid')} for task {task.id}"
|
||||||
|
)
|
||||||
|
|
||||||
|
return docs
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
import time
|
||||||
|
import os
|
||||||
|
|
||||||
|
logging.info("Starting Asana connector test")
|
||||||
|
connector = AsanaConnector(
|
||||||
|
os.environ["WORKSPACE_ID"],
|
||||||
|
os.environ["PROJECT_IDS"],
|
||||||
|
os.environ["TEAM_ID"],
|
||||||
|
)
|
||||||
|
connector.load_credentials(
|
||||||
|
{
|
||||||
|
"asana_api_token_secret": os.environ["API_TOKEN"],
|
||||||
|
}
|
||||||
|
)
|
||||||
|
logging.info("Loading all documents from Asana")
|
||||||
|
all_docs = connector.load_from_state()
|
||||||
|
current = time.time()
|
||||||
|
one_day_ago = current - 24 * 60 * 60 # 1 day
|
||||||
|
logging.info("Polling for documents updated in the last 24 hours")
|
||||||
|
latest_docs = connector.poll_source(one_day_ago, current)
|
||||||
|
for docs in all_docs:
|
||||||
|
for doc in docs:
|
||||||
|
print(doc.id)
|
||||||
|
logging.info("Asana connector test completed")
|
||||||
@ -53,6 +53,11 @@ class DocumentSource(str, Enum):
|
|||||||
S3_COMPATIBLE = "s3_compatible"
|
S3_COMPATIBLE = "s3_compatible"
|
||||||
DROPBOX = "dropbox"
|
DROPBOX = "dropbox"
|
||||||
BOX = "box"
|
BOX = "box"
|
||||||
|
AIRTABLE = "airtable"
|
||||||
|
ASANA = "asana"
|
||||||
|
GITHUB = "github"
|
||||||
|
GITLAB = "gitlab"
|
||||||
|
|
||||||
|
|
||||||
class FileOrigin(str, Enum):
|
class FileOrigin(str, Enum):
|
||||||
"""File origins"""
|
"""File origins"""
|
||||||
@ -230,6 +235,8 @@ _REPLACEMENT_EXPANSIONS = "body.view.value"
|
|||||||
|
|
||||||
BOX_WEB_OAUTH_REDIRECT_URI = os.environ.get("BOX_WEB_OAUTH_REDIRECT_URI", "http://localhost:9380/v1/connector/box/oauth/web/callback")
|
BOX_WEB_OAUTH_REDIRECT_URI = os.environ.get("BOX_WEB_OAUTH_REDIRECT_URI", "http://localhost:9380/v1/connector/box/oauth/web/callback")
|
||||||
|
|
||||||
|
GITHUB_CONNECTOR_BASE_URL = os.environ.get("GITHUB_CONNECTOR_BASE_URL") or None
|
||||||
|
|
||||||
class HtmlBasedConnectorTransformLinksStrategy(str, Enum):
|
class HtmlBasedConnectorTransformLinksStrategy(str, Enum):
|
||||||
# remove links entirely
|
# remove links entirely
|
||||||
STRIP = "strip"
|
STRIP = "strip"
|
||||||
@ -251,6 +258,14 @@ WEB_CONNECTOR_IGNORED_ELEMENTS = os.environ.get(
|
|||||||
"WEB_CONNECTOR_IGNORED_ELEMENTS", "nav,footer,meta,script,style,symbol,aside"
|
"WEB_CONNECTOR_IGNORED_ELEMENTS", "nav,footer,meta,script,style,symbol,aside"
|
||||||
).split(",")
|
).split(",")
|
||||||
|
|
||||||
|
AIRTABLE_CONNECTOR_SIZE_THRESHOLD = int(
|
||||||
|
os.environ.get("AIRTABLE_CONNECTOR_SIZE_THRESHOLD", 10 * 1024 * 1024)
|
||||||
|
)
|
||||||
|
|
||||||
|
ASANA_CONNECTOR_SIZE_THRESHOLD = int(
|
||||||
|
os.environ.get("ASANA_CONNECTOR_SIZE_THRESHOLD", 10 * 1024 * 1024)
|
||||||
|
)
|
||||||
|
|
||||||
_USER_NOT_FOUND = "Unknown Confluence User"
|
_USER_NOT_FOUND = "Unknown Confluence User"
|
||||||
|
|
||||||
_COMMENT_EXPANSION_FIELDS = ["body.storage.value"]
|
_COMMENT_EXPANSION_FIELDS = ["body.storage.value"]
|
||||||
|
|||||||
217
common/data_source/connector_runner.py
Normal file
217
common/data_source/connector_runner.py
Normal file
@ -0,0 +1,217 @@
|
|||||||
|
import sys
|
||||||
|
import time
|
||||||
|
import logging
|
||||||
|
from collections.abc import Generator
|
||||||
|
from datetime import datetime
|
||||||
|
from typing import Generic
|
||||||
|
from typing import TypeVar
|
||||||
|
from common.data_source.interfaces import (
|
||||||
|
BaseConnector,
|
||||||
|
CheckpointedConnector,
|
||||||
|
CheckpointedConnectorWithPermSync,
|
||||||
|
CheckpointOutput,
|
||||||
|
LoadConnector,
|
||||||
|
PollConnector,
|
||||||
|
)
|
||||||
|
from common.data_source.models import ConnectorCheckpoint, ConnectorFailure, Document
|
||||||
|
|
||||||
|
|
||||||
|
TimeRange = tuple[datetime, datetime]
|
||||||
|
|
||||||
|
CT = TypeVar("CT", bound=ConnectorCheckpoint)
|
||||||
|
|
||||||
|
|
||||||
|
def batched_doc_ids(
|
||||||
|
checkpoint_connector_generator: CheckpointOutput[CT],
|
||||||
|
batch_size: int,
|
||||||
|
) -> Generator[set[str], None, None]:
|
||||||
|
batch: set[str] = set()
|
||||||
|
for document, failure, next_checkpoint in CheckpointOutputWrapper[CT]()(
|
||||||
|
checkpoint_connector_generator
|
||||||
|
):
|
||||||
|
if document is not None:
|
||||||
|
batch.add(document.id)
|
||||||
|
elif (
|
||||||
|
failure and failure.failed_document and failure.failed_document.document_id
|
||||||
|
):
|
||||||
|
batch.add(failure.failed_document.document_id)
|
||||||
|
|
||||||
|
if len(batch) >= batch_size:
|
||||||
|
yield batch
|
||||||
|
batch = set()
|
||||||
|
if len(batch) > 0:
|
||||||
|
yield batch
|
||||||
|
|
||||||
|
|
||||||
|
class CheckpointOutputWrapper(Generic[CT]):
|
||||||
|
"""
|
||||||
|
Wraps a CheckpointOutput generator to give things back in a more digestible format,
|
||||||
|
specifically for Document outputs.
|
||||||
|
The connector format is easier for the connector implementor (e.g. it enforces exactly
|
||||||
|
one new checkpoint is returned AND that the checkpoint is at the end), thus the different
|
||||||
|
formats.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self) -> None:
|
||||||
|
self.next_checkpoint: CT | None = None
|
||||||
|
|
||||||
|
def __call__(
|
||||||
|
self,
|
||||||
|
checkpoint_connector_generator: CheckpointOutput[CT],
|
||||||
|
) -> Generator[
|
||||||
|
tuple[Document | None, ConnectorFailure | None, CT | None],
|
||||||
|
None,
|
||||||
|
None,
|
||||||
|
]:
|
||||||
|
# grabs the final return value and stores it in the `next_checkpoint` variable
|
||||||
|
def _inner_wrapper(
|
||||||
|
checkpoint_connector_generator: CheckpointOutput[CT],
|
||||||
|
) -> CheckpointOutput[CT]:
|
||||||
|
self.next_checkpoint = yield from checkpoint_connector_generator
|
||||||
|
return self.next_checkpoint # not used
|
||||||
|
|
||||||
|
for document_or_failure in _inner_wrapper(checkpoint_connector_generator):
|
||||||
|
if isinstance(document_or_failure, Document):
|
||||||
|
yield document_or_failure, None, None
|
||||||
|
elif isinstance(document_or_failure, ConnectorFailure):
|
||||||
|
yield None, document_or_failure, None
|
||||||
|
else:
|
||||||
|
raise ValueError(
|
||||||
|
f"Invalid document_or_failure type: {type(document_or_failure)}"
|
||||||
|
)
|
||||||
|
|
||||||
|
if self.next_checkpoint is None:
|
||||||
|
raise RuntimeError(
|
||||||
|
"Checkpoint is None. This should never happen - the connector should always return a checkpoint."
|
||||||
|
)
|
||||||
|
|
||||||
|
yield None, None, self.next_checkpoint
|
||||||
|
|
||||||
|
|
||||||
|
class ConnectorRunner(Generic[CT]):
|
||||||
|
"""
|
||||||
|
Handles:
|
||||||
|
- Batching
|
||||||
|
- Additional exception logging
|
||||||
|
- Combining different connector types to a single interface
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
connector: BaseConnector,
|
||||||
|
batch_size: int,
|
||||||
|
# cannot be True for non-checkpointed connectors
|
||||||
|
include_permissions: bool,
|
||||||
|
time_range: TimeRange | None = None,
|
||||||
|
):
|
||||||
|
if not isinstance(connector, CheckpointedConnector) and include_permissions:
|
||||||
|
raise ValueError(
|
||||||
|
"include_permissions cannot be True for non-checkpointed connectors"
|
||||||
|
)
|
||||||
|
|
||||||
|
self.connector = connector
|
||||||
|
self.time_range = time_range
|
||||||
|
self.batch_size = batch_size
|
||||||
|
self.include_permissions = include_permissions
|
||||||
|
|
||||||
|
self.doc_batch: list[Document] = []
|
||||||
|
|
||||||
|
def run(self, checkpoint: CT) -> Generator[
|
||||||
|
tuple[list[Document] | None, ConnectorFailure | None, CT | None],
|
||||||
|
None,
|
||||||
|
None,
|
||||||
|
]:
|
||||||
|
"""Adds additional exception logging to the connector."""
|
||||||
|
try:
|
||||||
|
if isinstance(self.connector, CheckpointedConnector):
|
||||||
|
if self.time_range is None:
|
||||||
|
raise ValueError("time_range is required for CheckpointedConnector")
|
||||||
|
|
||||||
|
start = time.monotonic()
|
||||||
|
if self.include_permissions:
|
||||||
|
if not isinstance(
|
||||||
|
self.connector, CheckpointedConnectorWithPermSync
|
||||||
|
):
|
||||||
|
raise ValueError(
|
||||||
|
"Connector does not support permission syncing"
|
||||||
|
)
|
||||||
|
load_from_checkpoint = (
|
||||||
|
self.connector.load_from_checkpoint_with_perm_sync
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
load_from_checkpoint = self.connector.load_from_checkpoint
|
||||||
|
checkpoint_connector_generator = load_from_checkpoint(
|
||||||
|
start=self.time_range[0].timestamp(),
|
||||||
|
end=self.time_range[1].timestamp(),
|
||||||
|
checkpoint=checkpoint,
|
||||||
|
)
|
||||||
|
next_checkpoint: CT | None = None
|
||||||
|
# this is guaranteed to always run at least once with next_checkpoint being non-None
|
||||||
|
for document, failure, next_checkpoint in CheckpointOutputWrapper[CT]()(
|
||||||
|
checkpoint_connector_generator
|
||||||
|
):
|
||||||
|
if document is not None and isinstance(document, Document):
|
||||||
|
self.doc_batch.append(document)
|
||||||
|
|
||||||
|
if failure is not None:
|
||||||
|
yield None, failure, None
|
||||||
|
|
||||||
|
if len(self.doc_batch) >= self.batch_size:
|
||||||
|
yield self.doc_batch, None, None
|
||||||
|
self.doc_batch = []
|
||||||
|
|
||||||
|
# yield remaining documents
|
||||||
|
if len(self.doc_batch) > 0:
|
||||||
|
yield self.doc_batch, None, None
|
||||||
|
self.doc_batch = []
|
||||||
|
|
||||||
|
yield None, None, next_checkpoint
|
||||||
|
|
||||||
|
logging.debug(
|
||||||
|
f"Connector took {time.monotonic() - start} seconds to get to the next checkpoint."
|
||||||
|
)
|
||||||
|
|
||||||
|
else:
|
||||||
|
finished_checkpoint = self.connector.build_dummy_checkpoint()
|
||||||
|
finished_checkpoint.has_more = False
|
||||||
|
|
||||||
|
if isinstance(self.connector, PollConnector):
|
||||||
|
if self.time_range is None:
|
||||||
|
raise ValueError("time_range is required for PollConnector")
|
||||||
|
|
||||||
|
for document_batch in self.connector.poll_source(
|
||||||
|
start=self.time_range[0].timestamp(),
|
||||||
|
end=self.time_range[1].timestamp(),
|
||||||
|
):
|
||||||
|
yield document_batch, None, None
|
||||||
|
|
||||||
|
yield None, None, finished_checkpoint
|
||||||
|
elif isinstance(self.connector, LoadConnector):
|
||||||
|
for document_batch in self.connector.load_from_state():
|
||||||
|
yield document_batch, None, None
|
||||||
|
|
||||||
|
yield None, None, finished_checkpoint
|
||||||
|
else:
|
||||||
|
raise ValueError(f"Invalid connector. type: {type(self.connector)}")
|
||||||
|
except Exception:
|
||||||
|
exc_type, _, exc_traceback = sys.exc_info()
|
||||||
|
|
||||||
|
# Traverse the traceback to find the last frame where the exception was raised
|
||||||
|
tb = exc_traceback
|
||||||
|
if tb is None:
|
||||||
|
logging.error("No traceback found for exception")
|
||||||
|
raise
|
||||||
|
|
||||||
|
while tb.tb_next:
|
||||||
|
tb = tb.tb_next # Move to the next frame in the traceback
|
||||||
|
|
||||||
|
# Get the local variables from the frame where the exception occurred
|
||||||
|
local_vars = tb.tb_frame.f_locals
|
||||||
|
local_vars_str = "\n".join(
|
||||||
|
f"{key}: {value}" for key, value in local_vars.items()
|
||||||
|
)
|
||||||
|
logging.error(
|
||||||
|
f"Error in connector. type: {exc_type};\n"
|
||||||
|
f"local_vars below -> \n{local_vars_str[:1024]}"
|
||||||
|
)
|
||||||
|
raise
|
||||||
@ -18,6 +18,7 @@ class UploadMimeTypes:
|
|||||||
"text/plain",
|
"text/plain",
|
||||||
"text/markdown",
|
"text/markdown",
|
||||||
"text/x-markdown",
|
"text/x-markdown",
|
||||||
|
"text/mdx",
|
||||||
"text/x-config",
|
"text/x-config",
|
||||||
"text/tab-separated-values",
|
"text/tab-separated-values",
|
||||||
"application/json",
|
"application/json",
|
||||||
|
|||||||
0
common/data_source/github/__init__.py
Normal file
0
common/data_source/github/__init__.py
Normal file
973
common/data_source/github/connector.py
Normal file
973
common/data_source/github/connector.py
Normal file
@ -0,0 +1,973 @@
|
|||||||
|
import copy
|
||||||
|
import logging
|
||||||
|
from collections.abc import Callable
|
||||||
|
from collections.abc import Generator
|
||||||
|
from datetime import datetime
|
||||||
|
from datetime import timedelta
|
||||||
|
from datetime import timezone
|
||||||
|
from enum import Enum
|
||||||
|
from typing import Any
|
||||||
|
from typing import cast
|
||||||
|
|
||||||
|
from github import Github, Auth
|
||||||
|
from github import RateLimitExceededException
|
||||||
|
from github import Repository
|
||||||
|
from github.GithubException import GithubException
|
||||||
|
from github.Issue import Issue
|
||||||
|
from github.NamedUser import NamedUser
|
||||||
|
from github.PaginatedList import PaginatedList
|
||||||
|
from github.PullRequest import PullRequest
|
||||||
|
from pydantic import BaseModel
|
||||||
|
from typing_extensions import override
|
||||||
|
from common.data_source.google_util.util import sanitize_filename
|
||||||
|
from common.data_source.config import DocumentSource, GITHUB_CONNECTOR_BASE_URL
|
||||||
|
from common.data_source.exceptions import (
|
||||||
|
ConnectorMissingCredentialError,
|
||||||
|
ConnectorValidationError,
|
||||||
|
CredentialExpiredError,
|
||||||
|
InsufficientPermissionsError,
|
||||||
|
UnexpectedValidationError,
|
||||||
|
)
|
||||||
|
from common.data_source.interfaces import CheckpointedConnectorWithPermSyncGH, CheckpointOutput
|
||||||
|
from common.data_source.models import (
|
||||||
|
ConnectorCheckpoint,
|
||||||
|
ConnectorFailure,
|
||||||
|
Document,
|
||||||
|
DocumentFailure,
|
||||||
|
ExternalAccess,
|
||||||
|
SecondsSinceUnixEpoch,
|
||||||
|
)
|
||||||
|
from common.data_source.connector_runner import ConnectorRunner
|
||||||
|
from .models import SerializedRepository
|
||||||
|
from .rate_limit_utils import sleep_after_rate_limit_exception
|
||||||
|
from .utils import deserialize_repository
|
||||||
|
from .utils import get_external_access_permission
|
||||||
|
|
||||||
|
ITEMS_PER_PAGE = 100
|
||||||
|
CURSOR_LOG_FREQUENCY = 50
|
||||||
|
|
||||||
|
_MAX_NUM_RATE_LIMIT_RETRIES = 5
|
||||||
|
|
||||||
|
ONE_DAY = timedelta(days=1)
|
||||||
|
SLIM_BATCH_SIZE = 100
|
||||||
|
# Cases
|
||||||
|
# X (from start) standard run, no fallback to cursor-based pagination
|
||||||
|
# X (from start) standard run errors, fallback to cursor-based pagination
|
||||||
|
# X error in the middle of a page
|
||||||
|
# X no errors: run to completion
|
||||||
|
# X (from checkpoint) standard run, no fallback to cursor-based pagination
|
||||||
|
# X (from checkpoint) continue from cursor-based pagination
|
||||||
|
# - retrying
|
||||||
|
# - no retrying
|
||||||
|
|
||||||
|
# things to check:
|
||||||
|
# checkpoint state on return
|
||||||
|
# checkpoint progress (no infinite loop)
|
||||||
|
|
||||||
|
|
||||||
|
class DocMetadata(BaseModel):
|
||||||
|
repo: str
|
||||||
|
|
||||||
|
|
||||||
|
def get_nextUrl_key(pag_list: PaginatedList[PullRequest | Issue]) -> str:
|
||||||
|
if "_PaginatedList__nextUrl" in pag_list.__dict__:
|
||||||
|
return "_PaginatedList__nextUrl"
|
||||||
|
for key in pag_list.__dict__:
|
||||||
|
if "__nextUrl" in key:
|
||||||
|
return key
|
||||||
|
for key in pag_list.__dict__:
|
||||||
|
if "nextUrl" in key:
|
||||||
|
return key
|
||||||
|
return ""
|
||||||
|
|
||||||
|
|
||||||
|
def get_nextUrl(
|
||||||
|
pag_list: PaginatedList[PullRequest | Issue], nextUrl_key: str
|
||||||
|
) -> str | None:
|
||||||
|
return getattr(pag_list, nextUrl_key) if nextUrl_key else None
|
||||||
|
|
||||||
|
|
||||||
|
def set_nextUrl(
|
||||||
|
pag_list: PaginatedList[PullRequest | Issue], nextUrl_key: str, nextUrl: str
|
||||||
|
) -> None:
|
||||||
|
if nextUrl_key:
|
||||||
|
setattr(pag_list, nextUrl_key, nextUrl)
|
||||||
|
elif nextUrl:
|
||||||
|
raise ValueError("Next URL key not found: " + str(pag_list.__dict__))
|
||||||
|
|
||||||
|
|
||||||
|
def _paginate_until_error(
|
||||||
|
git_objs: Callable[[], PaginatedList[PullRequest | Issue]],
|
||||||
|
cursor_url: str | None,
|
||||||
|
prev_num_objs: int,
|
||||||
|
cursor_url_callback: Callable[[str | None, int], None],
|
||||||
|
retrying: bool = False,
|
||||||
|
) -> Generator[PullRequest | Issue, None, None]:
|
||||||
|
num_objs = prev_num_objs
|
||||||
|
pag_list = git_objs()
|
||||||
|
nextUrl_key = get_nextUrl_key(pag_list)
|
||||||
|
if cursor_url:
|
||||||
|
set_nextUrl(pag_list, nextUrl_key, cursor_url)
|
||||||
|
elif retrying:
|
||||||
|
# if we are retrying, we want to skip the objects retrieved
|
||||||
|
# over previous calls. Unfortunately, this WILL retrieve all
|
||||||
|
# pages before the one we are resuming from, so we really
|
||||||
|
# don't want this case to be hit often
|
||||||
|
logging.warning(
|
||||||
|
"Retrying from a previous cursor-based pagination call. "
|
||||||
|
"This will retrieve all pages before the one we are resuming from, "
|
||||||
|
"which may take a while and consume many API calls."
|
||||||
|
)
|
||||||
|
pag_list = cast(PaginatedList[PullRequest | Issue], pag_list[prev_num_objs:])
|
||||||
|
num_objs = 0
|
||||||
|
|
||||||
|
try:
|
||||||
|
# this for loop handles cursor-based pagination
|
||||||
|
for issue_or_pr in pag_list:
|
||||||
|
num_objs += 1
|
||||||
|
yield issue_or_pr
|
||||||
|
# used to store the current cursor url in the checkpoint. This value
|
||||||
|
# is updated during iteration over pag_list.
|
||||||
|
cursor_url_callback(get_nextUrl(pag_list, nextUrl_key), num_objs)
|
||||||
|
|
||||||
|
if num_objs % CURSOR_LOG_FREQUENCY == 0:
|
||||||
|
logging.info(
|
||||||
|
f"Retrieved {num_objs} objects with current cursor url: {get_nextUrl(pag_list, nextUrl_key)}"
|
||||||
|
)
|
||||||
|
|
||||||
|
except Exception as e:
|
||||||
|
logging.exception(f"Error during cursor-based pagination: {e}")
|
||||||
|
if num_objs - prev_num_objs > 0:
|
||||||
|
raise
|
||||||
|
|
||||||
|
if get_nextUrl(pag_list, nextUrl_key) is not None and not retrying:
|
||||||
|
logging.info(
|
||||||
|
"Assuming that this error is due to cursor "
|
||||||
|
"expiration because no objects were retrieved. "
|
||||||
|
"Retrying from the first page."
|
||||||
|
)
|
||||||
|
yield from _paginate_until_error(
|
||||||
|
git_objs, None, prev_num_objs, cursor_url_callback, retrying=True
|
||||||
|
)
|
||||||
|
return
|
||||||
|
|
||||||
|
# for no cursor url or if we reach this point after a retry, raise the error
|
||||||
|
raise
|
||||||
|
|
||||||
|
|
||||||
|
def _get_batch_rate_limited(
|
||||||
|
# We pass in a callable because we want git_objs to produce a fresh
|
||||||
|
# PaginatedList each time it's called to avoid using the same object for cursor-based pagination
|
||||||
|
# from a partial offset-based pagination call.
|
||||||
|
git_objs: Callable[[], PaginatedList],
|
||||||
|
page_num: int,
|
||||||
|
cursor_url: str | None,
|
||||||
|
prev_num_objs: int,
|
||||||
|
cursor_url_callback: Callable[[str | None, int], None],
|
||||||
|
github_client: Github,
|
||||||
|
attempt_num: int = 0,
|
||||||
|
) -> Generator[PullRequest | Issue, None, None]:
|
||||||
|
if attempt_num > _MAX_NUM_RATE_LIMIT_RETRIES:
|
||||||
|
raise RuntimeError(
|
||||||
|
"Re-tried fetching batch too many times. Something is going wrong with fetching objects from Github"
|
||||||
|
)
|
||||||
|
try:
|
||||||
|
if cursor_url:
|
||||||
|
# when this is set, we are resuming from an earlier
|
||||||
|
# cursor-based pagination call.
|
||||||
|
yield from _paginate_until_error(
|
||||||
|
git_objs, cursor_url, prev_num_objs, cursor_url_callback
|
||||||
|
)
|
||||||
|
return
|
||||||
|
objs = list(git_objs().get_page(page_num))
|
||||||
|
# fetch all data here to disable lazy loading later
|
||||||
|
# this is needed to capture the rate limit exception here (if one occurs)
|
||||||
|
for obj in objs:
|
||||||
|
if hasattr(obj, "raw_data"):
|
||||||
|
getattr(obj, "raw_data")
|
||||||
|
yield from objs
|
||||||
|
except RateLimitExceededException:
|
||||||
|
sleep_after_rate_limit_exception(github_client)
|
||||||
|
yield from _get_batch_rate_limited(
|
||||||
|
git_objs,
|
||||||
|
page_num,
|
||||||
|
cursor_url,
|
||||||
|
prev_num_objs,
|
||||||
|
cursor_url_callback,
|
||||||
|
github_client,
|
||||||
|
attempt_num + 1,
|
||||||
|
)
|
||||||
|
except GithubException as e:
|
||||||
|
if not (
|
||||||
|
e.status == 422
|
||||||
|
and (
|
||||||
|
"cursor" in (e.message or "")
|
||||||
|
or "cursor" in (e.data or {}).get("message", "")
|
||||||
|
)
|
||||||
|
):
|
||||||
|
raise
|
||||||
|
# Fallback to a cursor-based pagination strategy
|
||||||
|
# This can happen for "large datasets," but there's no documentation
|
||||||
|
# On the error on the web as far as we can tell.
|
||||||
|
# Error message:
|
||||||
|
# "Pagination with the page parameter is not supported for large datasets,
|
||||||
|
# please use cursor based pagination (after/before)"
|
||||||
|
yield from _paginate_until_error(
|
||||||
|
git_objs, cursor_url, prev_num_objs, cursor_url_callback
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def _get_userinfo(user: NamedUser) -> dict[str, str]:
|
||||||
|
def _safe_get(attr_name: str) -> str | None:
|
||||||
|
try:
|
||||||
|
return cast(str | None, getattr(user, attr_name))
|
||||||
|
except GithubException:
|
||||||
|
logging.debug(f"Error getting {attr_name} for user")
|
||||||
|
return None
|
||||||
|
|
||||||
|
return {
|
||||||
|
k: v
|
||||||
|
for k, v in {
|
||||||
|
"login": _safe_get("login"),
|
||||||
|
"name": _safe_get("name"),
|
||||||
|
"email": _safe_get("email"),
|
||||||
|
}.items()
|
||||||
|
if v is not None
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
def _convert_pr_to_document(
|
||||||
|
pull_request: PullRequest, repo_external_access: ExternalAccess | None
|
||||||
|
) -> Document:
|
||||||
|
repo_name = pull_request.base.repo.full_name if pull_request.base else ""
|
||||||
|
doc_metadata = DocMetadata(repo=repo_name)
|
||||||
|
file_content_byte = pull_request.body.encode('utf-8') if pull_request.body else b""
|
||||||
|
name = sanitize_filename(pull_request.title, "md")
|
||||||
|
|
||||||
|
return Document(
|
||||||
|
id=pull_request.html_url,
|
||||||
|
blob= file_content_byte,
|
||||||
|
source=DocumentSource.GITHUB,
|
||||||
|
external_access=repo_external_access,
|
||||||
|
semantic_identifier=f"{pull_request.number}:{name}",
|
||||||
|
# updated_at is UTC time but is timezone unaware, explicitly add UTC
|
||||||
|
# as there is logic in indexing to prevent wrong timestamped docs
|
||||||
|
# due to local time discrepancies with UTC
|
||||||
|
doc_updated_at=(
|
||||||
|
pull_request.updated_at.replace(tzinfo=timezone.utc)
|
||||||
|
if pull_request.updated_at
|
||||||
|
else None
|
||||||
|
),
|
||||||
|
extension=".md",
|
||||||
|
# this metadata is used in perm sync
|
||||||
|
size_bytes=len(file_content_byte) if file_content_byte else 0,
|
||||||
|
primary_owners=[],
|
||||||
|
doc_metadata=doc_metadata.model_dump(),
|
||||||
|
metadata={
|
||||||
|
k: [str(vi) for vi in v] if isinstance(v, list) else str(v)
|
||||||
|
for k, v in {
|
||||||
|
"object_type": "PullRequest",
|
||||||
|
"id": pull_request.number,
|
||||||
|
"merged": pull_request.merged,
|
||||||
|
"state": pull_request.state,
|
||||||
|
"user": _get_userinfo(pull_request.user) if pull_request.user else None,
|
||||||
|
"assignees": [
|
||||||
|
_get_userinfo(assignee) for assignee in pull_request.assignees
|
||||||
|
],
|
||||||
|
"repo": (
|
||||||
|
pull_request.base.repo.full_name if pull_request.base else None
|
||||||
|
),
|
||||||
|
"num_commits": str(pull_request.commits),
|
||||||
|
"num_files_changed": str(pull_request.changed_files),
|
||||||
|
"labels": [label.name for label in pull_request.labels],
|
||||||
|
"created_at": (
|
||||||
|
pull_request.created_at.replace(tzinfo=timezone.utc)
|
||||||
|
if pull_request.created_at
|
||||||
|
else None
|
||||||
|
),
|
||||||
|
"updated_at": (
|
||||||
|
pull_request.updated_at.replace(tzinfo=timezone.utc)
|
||||||
|
if pull_request.updated_at
|
||||||
|
else None
|
||||||
|
),
|
||||||
|
"closed_at": (
|
||||||
|
pull_request.closed_at.replace(tzinfo=timezone.utc)
|
||||||
|
if pull_request.closed_at
|
||||||
|
else None
|
||||||
|
),
|
||||||
|
"merged_at": (
|
||||||
|
pull_request.merged_at.replace(tzinfo=timezone.utc)
|
||||||
|
if pull_request.merged_at
|
||||||
|
else None
|
||||||
|
),
|
||||||
|
"merged_by": (
|
||||||
|
_get_userinfo(pull_request.merged_by)
|
||||||
|
if pull_request.merged_by
|
||||||
|
else None
|
||||||
|
),
|
||||||
|
}.items()
|
||||||
|
if v is not None
|
||||||
|
},
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def _fetch_issue_comments(issue: Issue) -> str:
|
||||||
|
comments = issue.get_comments()
|
||||||
|
return "\nComment: ".join(comment.body for comment in comments)
|
||||||
|
|
||||||
|
|
||||||
|
def _convert_issue_to_document(
|
||||||
|
issue: Issue, repo_external_access: ExternalAccess | None
|
||||||
|
) -> Document:
|
||||||
|
repo_name = issue.repository.full_name if issue.repository else ""
|
||||||
|
doc_metadata = DocMetadata(repo=repo_name)
|
||||||
|
file_content_byte = issue.body.encode('utf-8') if issue.body else b""
|
||||||
|
name = sanitize_filename(issue.title, "md")
|
||||||
|
|
||||||
|
return Document(
|
||||||
|
id=issue.html_url,
|
||||||
|
blob=file_content_byte,
|
||||||
|
source=DocumentSource.GITHUB,
|
||||||
|
extension=".md",
|
||||||
|
external_access=repo_external_access,
|
||||||
|
semantic_identifier=f"{issue.number}:{name}",
|
||||||
|
# updated_at is UTC time but is timezone unaware
|
||||||
|
doc_updated_at=issue.updated_at.replace(tzinfo=timezone.utc),
|
||||||
|
# this metadata is used in perm sync
|
||||||
|
doc_metadata=doc_metadata.model_dump(),
|
||||||
|
size_bytes=len(file_content_byte) if file_content_byte else 0,
|
||||||
|
primary_owners=[_get_userinfo(issue.user) if issue.user else None],
|
||||||
|
metadata={
|
||||||
|
k: [str(vi) for vi in v] if isinstance(v, list) else str(v)
|
||||||
|
for k, v in {
|
||||||
|
"object_type": "Issue",
|
||||||
|
"id": issue.number,
|
||||||
|
"state": issue.state,
|
||||||
|
"user": _get_userinfo(issue.user) if issue.user else None,
|
||||||
|
"assignees": [_get_userinfo(assignee) for assignee in issue.assignees],
|
||||||
|
"repo": issue.repository.full_name if issue.repository else None,
|
||||||
|
"labels": [label.name for label in issue.labels],
|
||||||
|
"created_at": (
|
||||||
|
issue.created_at.replace(tzinfo=timezone.utc)
|
||||||
|
if issue.created_at
|
||||||
|
else None
|
||||||
|
),
|
||||||
|
"updated_at": (
|
||||||
|
issue.updated_at.replace(tzinfo=timezone.utc)
|
||||||
|
if issue.updated_at
|
||||||
|
else None
|
||||||
|
),
|
||||||
|
"closed_at": (
|
||||||
|
issue.closed_at.replace(tzinfo=timezone.utc)
|
||||||
|
if issue.closed_at
|
||||||
|
else None
|
||||||
|
),
|
||||||
|
"closed_by": (
|
||||||
|
_get_userinfo(issue.closed_by) if issue.closed_by else None
|
||||||
|
),
|
||||||
|
}.items()
|
||||||
|
if v is not None
|
||||||
|
},
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
class GithubConnectorStage(Enum):
|
||||||
|
START = "start"
|
||||||
|
PRS = "prs"
|
||||||
|
ISSUES = "issues"
|
||||||
|
|
||||||
|
|
||||||
|
class GithubConnectorCheckpoint(ConnectorCheckpoint):
|
||||||
|
stage: GithubConnectorStage
|
||||||
|
curr_page: int
|
||||||
|
|
||||||
|
cached_repo_ids: list[int] | None = None
|
||||||
|
cached_repo: SerializedRepository | None = None
|
||||||
|
|
||||||
|
# Used for the fallback cursor-based pagination strategy
|
||||||
|
num_retrieved: int
|
||||||
|
cursor_url: str | None = None
|
||||||
|
|
||||||
|
def reset(self) -> None:
|
||||||
|
"""
|
||||||
|
Resets curr_page, num_retrieved, and cursor_url to their initial values (0, 0, None)
|
||||||
|
"""
|
||||||
|
self.curr_page = 0
|
||||||
|
self.num_retrieved = 0
|
||||||
|
self.cursor_url = None
|
||||||
|
|
||||||
|
|
||||||
|
def make_cursor_url_callback(
|
||||||
|
checkpoint: GithubConnectorCheckpoint,
|
||||||
|
) -> Callable[[str | None, int], None]:
|
||||||
|
def cursor_url_callback(cursor_url: str | None, num_objs: int) -> None:
|
||||||
|
# we want to maintain the old cursor url so code after retrieval
|
||||||
|
# can determine that we are using the fallback cursor-based pagination strategy
|
||||||
|
if cursor_url:
|
||||||
|
checkpoint.cursor_url = cursor_url
|
||||||
|
checkpoint.num_retrieved = num_objs
|
||||||
|
|
||||||
|
return cursor_url_callback
|
||||||
|
|
||||||
|
|
||||||
|
class GithubConnector(CheckpointedConnectorWithPermSyncGH[GithubConnectorCheckpoint]):
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
repo_owner: str,
|
||||||
|
repositories: str | None = None,
|
||||||
|
state_filter: str = "all",
|
||||||
|
include_prs: bool = True,
|
||||||
|
include_issues: bool = False,
|
||||||
|
) -> None:
|
||||||
|
self.repo_owner = repo_owner
|
||||||
|
self.repositories = repositories
|
||||||
|
self.state_filter = state_filter
|
||||||
|
self.include_prs = include_prs
|
||||||
|
self.include_issues = include_issues
|
||||||
|
self.github_client: Github | None = None
|
||||||
|
|
||||||
|
def load_credentials(self, credentials: dict[str, Any]) -> dict[str, Any] | None:
|
||||||
|
# defaults to 30 items per page, can be set to as high as 100
|
||||||
|
token = credentials["github_access_token"]
|
||||||
|
auth = Auth.Token(token)
|
||||||
|
|
||||||
|
if GITHUB_CONNECTOR_BASE_URL:
|
||||||
|
self.github_client = Github(
|
||||||
|
auth=auth,
|
||||||
|
base_url=GITHUB_CONNECTOR_BASE_URL,
|
||||||
|
per_page=ITEMS_PER_PAGE,
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
self.github_client = Github(
|
||||||
|
auth=auth,
|
||||||
|
per_page=ITEMS_PER_PAGE,
|
||||||
|
)
|
||||||
|
|
||||||
|
return None
|
||||||
|
|
||||||
|
def get_github_repo(
|
||||||
|
self, github_client: Github, attempt_num: int = 0
|
||||||
|
) -> Repository.Repository:
|
||||||
|
if attempt_num > _MAX_NUM_RATE_LIMIT_RETRIES:
|
||||||
|
raise RuntimeError(
|
||||||
|
"Re-tried fetching repo too many times. Something is going wrong with fetching objects from Github"
|
||||||
|
)
|
||||||
|
|
||||||
|
try:
|
||||||
|
return github_client.get_repo(f"{self.repo_owner}/{self.repositories}")
|
||||||
|
except RateLimitExceededException:
|
||||||
|
sleep_after_rate_limit_exception(github_client)
|
||||||
|
return self.get_github_repo(github_client, attempt_num + 1)
|
||||||
|
|
||||||
|
def get_github_repos(
|
||||||
|
self, github_client: Github, attempt_num: int = 0
|
||||||
|
) -> list[Repository.Repository]:
|
||||||
|
"""Get specific repositories based on comma-separated repo_name string."""
|
||||||
|
if attempt_num > _MAX_NUM_RATE_LIMIT_RETRIES:
|
||||||
|
raise RuntimeError(
|
||||||
|
"Re-tried fetching repos too many times. Something is going wrong with fetching objects from Github"
|
||||||
|
)
|
||||||
|
|
||||||
|
try:
|
||||||
|
repos = []
|
||||||
|
# Split repo_name by comma and strip whitespace
|
||||||
|
repo_names = [
|
||||||
|
name.strip() for name in (cast(str, self.repositories)).split(",")
|
||||||
|
]
|
||||||
|
|
||||||
|
for repo_name in repo_names:
|
||||||
|
if repo_name: # Skip empty strings
|
||||||
|
try:
|
||||||
|
repo = github_client.get_repo(f"{self.repo_owner}/{repo_name}")
|
||||||
|
repos.append(repo)
|
||||||
|
except GithubException as e:
|
||||||
|
logging.warning(
|
||||||
|
f"Could not fetch repo {self.repo_owner}/{repo_name}: {e}"
|
||||||
|
)
|
||||||
|
|
||||||
|
return repos
|
||||||
|
except RateLimitExceededException:
|
||||||
|
sleep_after_rate_limit_exception(github_client)
|
||||||
|
return self.get_github_repos(github_client, attempt_num + 1)
|
||||||
|
|
||||||
|
def get_all_repos(
|
||||||
|
self, github_client: Github, attempt_num: int = 0
|
||||||
|
) -> list[Repository.Repository]:
|
||||||
|
if attempt_num > _MAX_NUM_RATE_LIMIT_RETRIES:
|
||||||
|
raise RuntimeError(
|
||||||
|
"Re-tried fetching repos too many times. Something is going wrong with fetching objects from Github"
|
||||||
|
)
|
||||||
|
|
||||||
|
try:
|
||||||
|
# Try to get organization first
|
||||||
|
try:
|
||||||
|
org = github_client.get_organization(self.repo_owner)
|
||||||
|
return list(org.get_repos())
|
||||||
|
|
||||||
|
except GithubException:
|
||||||
|
# If not an org, try as a user
|
||||||
|
user = github_client.get_user(self.repo_owner)
|
||||||
|
return list(user.get_repos())
|
||||||
|
except RateLimitExceededException:
|
||||||
|
sleep_after_rate_limit_exception(github_client)
|
||||||
|
return self.get_all_repos(github_client, attempt_num + 1)
|
||||||
|
|
||||||
|
def _pull_requests_func(
|
||||||
|
self, repo: Repository.Repository
|
||||||
|
) -> Callable[[], PaginatedList[PullRequest]]:
|
||||||
|
return lambda: repo.get_pulls(
|
||||||
|
state=self.state_filter, sort="updated", direction="desc"
|
||||||
|
)
|
||||||
|
|
||||||
|
def _issues_func(
|
||||||
|
self, repo: Repository.Repository
|
||||||
|
) -> Callable[[], PaginatedList[Issue]]:
|
||||||
|
return lambda: repo.get_issues(
|
||||||
|
state=self.state_filter, sort="updated", direction="desc"
|
||||||
|
)
|
||||||
|
|
||||||
|
def _fetch_from_github(
|
||||||
|
self,
|
||||||
|
checkpoint: GithubConnectorCheckpoint,
|
||||||
|
start: datetime | None = None,
|
||||||
|
end: datetime | None = None,
|
||||||
|
include_permissions: bool = False,
|
||||||
|
) -> Generator[Document | ConnectorFailure, None, GithubConnectorCheckpoint]:
|
||||||
|
if self.github_client is None:
|
||||||
|
raise ConnectorMissingCredentialError("GitHub")
|
||||||
|
|
||||||
|
checkpoint = copy.deepcopy(checkpoint)
|
||||||
|
|
||||||
|
# First run of the connector, fetch all repos and store in checkpoint
|
||||||
|
if checkpoint.cached_repo_ids is None:
|
||||||
|
repos = []
|
||||||
|
if self.repositories:
|
||||||
|
if "," in self.repositories:
|
||||||
|
# Multiple repositories specified
|
||||||
|
repos = self.get_github_repos(self.github_client)
|
||||||
|
else:
|
||||||
|
# Single repository (backward compatibility)
|
||||||
|
repos = [self.get_github_repo(self.github_client)]
|
||||||
|
else:
|
||||||
|
# All repositories
|
||||||
|
repos = self.get_all_repos(self.github_client)
|
||||||
|
if not repos:
|
||||||
|
checkpoint.has_more = False
|
||||||
|
return checkpoint
|
||||||
|
|
||||||
|
curr_repo = repos.pop()
|
||||||
|
checkpoint.cached_repo_ids = [repo.id for repo in repos]
|
||||||
|
checkpoint.cached_repo = SerializedRepository(
|
||||||
|
id=curr_repo.id,
|
||||||
|
headers=curr_repo.raw_headers,
|
||||||
|
raw_data=curr_repo.raw_data,
|
||||||
|
)
|
||||||
|
checkpoint.stage = GithubConnectorStage.PRS
|
||||||
|
checkpoint.curr_page = 0
|
||||||
|
# save checkpoint with repo ids retrieved
|
||||||
|
return checkpoint
|
||||||
|
|
||||||
|
if checkpoint.cached_repo is None:
|
||||||
|
raise ValueError("No repo saved in checkpoint")
|
||||||
|
|
||||||
|
# Deserialize the repository from the checkpoint
|
||||||
|
repo = deserialize_repository(checkpoint.cached_repo, self.github_client)
|
||||||
|
|
||||||
|
cursor_url_callback = make_cursor_url_callback(checkpoint)
|
||||||
|
repo_external_access: ExternalAccess | None = None
|
||||||
|
if include_permissions:
|
||||||
|
repo_external_access = get_external_access_permission(
|
||||||
|
repo, self.github_client
|
||||||
|
)
|
||||||
|
if self.include_prs and checkpoint.stage == GithubConnectorStage.PRS:
|
||||||
|
logging.info(f"Fetching PRs for repo: {repo.name}")
|
||||||
|
|
||||||
|
pr_batch = _get_batch_rate_limited(
|
||||||
|
self._pull_requests_func(repo),
|
||||||
|
checkpoint.curr_page,
|
||||||
|
checkpoint.cursor_url,
|
||||||
|
checkpoint.num_retrieved,
|
||||||
|
cursor_url_callback,
|
||||||
|
self.github_client,
|
||||||
|
)
|
||||||
|
checkpoint.curr_page += 1 # NOTE: not used for cursor-based fallback
|
||||||
|
done_with_prs = False
|
||||||
|
num_prs = 0
|
||||||
|
pr = None
|
||||||
|
print("start: ", start)
|
||||||
|
for pr in pr_batch:
|
||||||
|
num_prs += 1
|
||||||
|
print("-"*40)
|
||||||
|
print("PR name", pr.title)
|
||||||
|
print("updated at", pr.updated_at)
|
||||||
|
print("-"*40)
|
||||||
|
print("\n")
|
||||||
|
# we iterate backwards in time, so at this point we stop processing prs
|
||||||
|
if (
|
||||||
|
start is not None
|
||||||
|
and pr.updated_at
|
||||||
|
and pr.updated_at.replace(tzinfo=timezone.utc) <= start
|
||||||
|
):
|
||||||
|
done_with_prs = True
|
||||||
|
break
|
||||||
|
# Skip PRs updated after the end date
|
||||||
|
if (
|
||||||
|
end is not None
|
||||||
|
and pr.updated_at
|
||||||
|
and pr.updated_at.replace(tzinfo=timezone.utc) > end
|
||||||
|
):
|
||||||
|
continue
|
||||||
|
try:
|
||||||
|
yield _convert_pr_to_document(
|
||||||
|
cast(PullRequest, pr), repo_external_access
|
||||||
|
)
|
||||||
|
except Exception as e:
|
||||||
|
error_msg = f"Error converting PR to document: {e}"
|
||||||
|
logging.exception(error_msg)
|
||||||
|
yield ConnectorFailure(
|
||||||
|
failed_document=DocumentFailure(
|
||||||
|
document_id=str(pr.id), document_link=pr.html_url
|
||||||
|
),
|
||||||
|
failure_message=error_msg,
|
||||||
|
exception=e,
|
||||||
|
)
|
||||||
|
continue
|
||||||
|
|
||||||
|
# If we reach this point with a cursor url in the checkpoint, we were using
|
||||||
|
# the fallback cursor-based pagination strategy. That strategy tries to get all
|
||||||
|
# PRs, so having curosr_url set means we are done with prs. However, we need to
|
||||||
|
# return AFTER the checkpoint reset to avoid infinite loops.
|
||||||
|
|
||||||
|
# if we found any PRs on the page and there are more PRs to get, return the checkpoint.
|
||||||
|
# In offset mode, while indexing without time constraints, the pr batch
|
||||||
|
# will be empty when we're done.
|
||||||
|
used_cursor = checkpoint.cursor_url is not None
|
||||||
|
if num_prs > 0 and not done_with_prs and not used_cursor:
|
||||||
|
return checkpoint
|
||||||
|
|
||||||
|
# if we went past the start date during the loop or there are no more
|
||||||
|
# prs to get, we move on to issues
|
||||||
|
checkpoint.stage = GithubConnectorStage.ISSUES
|
||||||
|
checkpoint.reset()
|
||||||
|
|
||||||
|
if used_cursor:
|
||||||
|
# save the checkpoint after changing stage; next run will continue from issues
|
||||||
|
return checkpoint
|
||||||
|
|
||||||
|
checkpoint.stage = GithubConnectorStage.ISSUES
|
||||||
|
|
||||||
|
if self.include_issues and checkpoint.stage == GithubConnectorStage.ISSUES:
|
||||||
|
logging.info(f"Fetching issues for repo: {repo.name}")
|
||||||
|
|
||||||
|
issue_batch = list(
|
||||||
|
_get_batch_rate_limited(
|
||||||
|
self._issues_func(repo),
|
||||||
|
checkpoint.curr_page,
|
||||||
|
checkpoint.cursor_url,
|
||||||
|
checkpoint.num_retrieved,
|
||||||
|
cursor_url_callback,
|
||||||
|
self.github_client,
|
||||||
|
)
|
||||||
|
)
|
||||||
|
checkpoint.curr_page += 1
|
||||||
|
done_with_issues = False
|
||||||
|
num_issues = 0
|
||||||
|
for issue in issue_batch:
|
||||||
|
num_issues += 1
|
||||||
|
issue = cast(Issue, issue)
|
||||||
|
# we iterate backwards in time, so at this point we stop processing prs
|
||||||
|
if (
|
||||||
|
start is not None
|
||||||
|
and issue.updated_at.replace(tzinfo=timezone.utc) <= start
|
||||||
|
):
|
||||||
|
done_with_issues = True
|
||||||
|
break
|
||||||
|
# Skip PRs updated after the end date
|
||||||
|
if (
|
||||||
|
end is not None
|
||||||
|
and issue.updated_at.replace(tzinfo=timezone.utc) > end
|
||||||
|
):
|
||||||
|
continue
|
||||||
|
|
||||||
|
if issue.pull_request is not None:
|
||||||
|
# PRs are handled separately
|
||||||
|
continue
|
||||||
|
|
||||||
|
try:
|
||||||
|
yield _convert_issue_to_document(issue, repo_external_access)
|
||||||
|
except Exception as e:
|
||||||
|
error_msg = f"Error converting issue to document: {e}"
|
||||||
|
logging.exception(error_msg)
|
||||||
|
yield ConnectorFailure(
|
||||||
|
failed_document=DocumentFailure(
|
||||||
|
document_id=str(issue.id),
|
||||||
|
document_link=issue.html_url,
|
||||||
|
),
|
||||||
|
failure_message=error_msg,
|
||||||
|
exception=e,
|
||||||
|
)
|
||||||
|
continue
|
||||||
|
|
||||||
|
# if we found any issues on the page, and we're not done, return the checkpoint.
|
||||||
|
# don't return if we're using cursor-based pagination to avoid infinite loops
|
||||||
|
if num_issues > 0 and not done_with_issues and not checkpoint.cursor_url:
|
||||||
|
return checkpoint
|
||||||
|
|
||||||
|
# if we went past the start date during the loop or there are no more
|
||||||
|
# issues to get, we move on to the next repo
|
||||||
|
checkpoint.stage = GithubConnectorStage.PRS
|
||||||
|
checkpoint.reset()
|
||||||
|
|
||||||
|
checkpoint.has_more = len(checkpoint.cached_repo_ids) > 0
|
||||||
|
if checkpoint.cached_repo_ids:
|
||||||
|
next_id = checkpoint.cached_repo_ids.pop()
|
||||||
|
next_repo = self.github_client.get_repo(next_id)
|
||||||
|
checkpoint.cached_repo = SerializedRepository(
|
||||||
|
id=next_id,
|
||||||
|
headers=next_repo.raw_headers,
|
||||||
|
raw_data=next_repo.raw_data,
|
||||||
|
)
|
||||||
|
checkpoint.stage = GithubConnectorStage.PRS
|
||||||
|
checkpoint.reset()
|
||||||
|
|
||||||
|
if checkpoint.cached_repo_ids:
|
||||||
|
logging.info(
|
||||||
|
f"{len(checkpoint.cached_repo_ids)} repos remaining (IDs: {checkpoint.cached_repo_ids})"
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
logging.info("No more repos remaining")
|
||||||
|
|
||||||
|
return checkpoint
|
||||||
|
|
||||||
|
def _load_from_checkpoint(
|
||||||
|
self,
|
||||||
|
start: SecondsSinceUnixEpoch,
|
||||||
|
end: SecondsSinceUnixEpoch,
|
||||||
|
checkpoint: GithubConnectorCheckpoint,
|
||||||
|
include_permissions: bool = False,
|
||||||
|
) -> CheckpointOutput[GithubConnectorCheckpoint]:
|
||||||
|
start_datetime = datetime.fromtimestamp(start, tz=timezone.utc)
|
||||||
|
# add a day for timezone safety
|
||||||
|
end_datetime = datetime.fromtimestamp(end, tz=timezone.utc) + ONE_DAY
|
||||||
|
|
||||||
|
# Move start time back by 3 hours, since some Issues/PRs are getting dropped
|
||||||
|
# Could be due to delayed processing on GitHub side
|
||||||
|
# The non-updated issues since last poll will be shortcut-ed and not embedded
|
||||||
|
# adjusted_start_datetime = start_datetime - timedelta(hours=3)
|
||||||
|
|
||||||
|
adjusted_start_datetime = start_datetime
|
||||||
|
|
||||||
|
epoch = datetime.fromtimestamp(0, tz=timezone.utc)
|
||||||
|
if adjusted_start_datetime < epoch:
|
||||||
|
adjusted_start_datetime = epoch
|
||||||
|
|
||||||
|
return self._fetch_from_github(
|
||||||
|
checkpoint,
|
||||||
|
start=adjusted_start_datetime,
|
||||||
|
end=end_datetime,
|
||||||
|
include_permissions=include_permissions,
|
||||||
|
)
|
||||||
|
|
||||||
|
@override
|
||||||
|
def load_from_checkpoint(
|
||||||
|
self,
|
||||||
|
start: SecondsSinceUnixEpoch,
|
||||||
|
end: SecondsSinceUnixEpoch,
|
||||||
|
checkpoint: GithubConnectorCheckpoint,
|
||||||
|
) -> CheckpointOutput[GithubConnectorCheckpoint]:
|
||||||
|
return self._load_from_checkpoint(
|
||||||
|
start, end, checkpoint, include_permissions=False
|
||||||
|
)
|
||||||
|
|
||||||
|
@override
|
||||||
|
def load_from_checkpoint_with_perm_sync(
|
||||||
|
self,
|
||||||
|
start: SecondsSinceUnixEpoch,
|
||||||
|
end: SecondsSinceUnixEpoch,
|
||||||
|
checkpoint: GithubConnectorCheckpoint,
|
||||||
|
) -> CheckpointOutput[GithubConnectorCheckpoint]:
|
||||||
|
return self._load_from_checkpoint(
|
||||||
|
start, end, checkpoint, include_permissions=True
|
||||||
|
)
|
||||||
|
|
||||||
|
def validate_connector_settings(self) -> None:
|
||||||
|
if self.github_client is None:
|
||||||
|
raise ConnectorMissingCredentialError("GitHub credentials not loaded.")
|
||||||
|
|
||||||
|
if not self.repo_owner:
|
||||||
|
raise ConnectorValidationError(
|
||||||
|
"Invalid connector settings: 'repo_owner' must be provided."
|
||||||
|
)
|
||||||
|
|
||||||
|
try:
|
||||||
|
if self.repositories:
|
||||||
|
if "," in self.repositories:
|
||||||
|
# Multiple repositories specified
|
||||||
|
repo_names = [name.strip() for name in self.repositories.split(",")]
|
||||||
|
if not repo_names:
|
||||||
|
raise ConnectorValidationError(
|
||||||
|
"Invalid connector settings: No valid repository names provided."
|
||||||
|
)
|
||||||
|
|
||||||
|
# Validate at least one repository exists and is accessible
|
||||||
|
valid_repos = False
|
||||||
|
validation_errors = []
|
||||||
|
|
||||||
|
for repo_name in repo_names:
|
||||||
|
if not repo_name:
|
||||||
|
continue
|
||||||
|
|
||||||
|
try:
|
||||||
|
test_repo = self.github_client.get_repo(
|
||||||
|
f"{self.repo_owner}/{repo_name}"
|
||||||
|
)
|
||||||
|
logging.info(
|
||||||
|
f"Successfully accessed repository: {self.repo_owner}/{repo_name}"
|
||||||
|
)
|
||||||
|
test_repo.get_contents("")
|
||||||
|
valid_repos = True
|
||||||
|
# If at least one repo is valid, we can proceed
|
||||||
|
break
|
||||||
|
except GithubException as e:
|
||||||
|
validation_errors.append(
|
||||||
|
f"Repository '{repo_name}': {e.data.get('message', str(e))}"
|
||||||
|
)
|
||||||
|
|
||||||
|
if not valid_repos:
|
||||||
|
error_msg = (
|
||||||
|
"None of the specified repositories could be accessed: "
|
||||||
|
)
|
||||||
|
error_msg += ", ".join(validation_errors)
|
||||||
|
raise ConnectorValidationError(error_msg)
|
||||||
|
else:
|
||||||
|
# Single repository (backward compatibility)
|
||||||
|
test_repo = self.github_client.get_repo(
|
||||||
|
f"{self.repo_owner}/{self.repositories}"
|
||||||
|
)
|
||||||
|
test_repo.get_contents("")
|
||||||
|
else:
|
||||||
|
# Try to get organization first
|
||||||
|
try:
|
||||||
|
org = self.github_client.get_organization(self.repo_owner)
|
||||||
|
total_count = org.get_repos().totalCount
|
||||||
|
if total_count == 0:
|
||||||
|
raise ConnectorValidationError(
|
||||||
|
f"Found no repos for organization: {self.repo_owner}. "
|
||||||
|
"Does the credential have the right scopes?"
|
||||||
|
)
|
||||||
|
except GithubException as e:
|
||||||
|
# Check for missing SSO
|
||||||
|
MISSING_SSO_ERROR_MESSAGE = "You must grant your Personal Access token access to this organization".lower()
|
||||||
|
if MISSING_SSO_ERROR_MESSAGE in str(e).lower():
|
||||||
|
SSO_GUIDE_LINK = (
|
||||||
|
"https://docs.github.com/en/enterprise-cloud@latest/authentication/"
|
||||||
|
"authenticating-with-saml-single-sign-on/"
|
||||||
|
"authorizing-a-personal-access-token-for-use-with-saml-single-sign-on"
|
||||||
|
)
|
||||||
|
raise ConnectorValidationError(
|
||||||
|
f"Your GitHub token is missing authorization to access the "
|
||||||
|
f"`{self.repo_owner}` organization. Please follow the guide to "
|
||||||
|
f"authorize your token: {SSO_GUIDE_LINK}"
|
||||||
|
)
|
||||||
|
# If not an org, try as a user
|
||||||
|
user = self.github_client.get_user(self.repo_owner)
|
||||||
|
|
||||||
|
# Check if we can access any repos
|
||||||
|
total_count = user.get_repos().totalCount
|
||||||
|
if total_count == 0:
|
||||||
|
raise ConnectorValidationError(
|
||||||
|
f"Found no repos for user: {self.repo_owner}. "
|
||||||
|
"Does the credential have the right scopes?"
|
||||||
|
)
|
||||||
|
|
||||||
|
except RateLimitExceededException:
|
||||||
|
raise UnexpectedValidationError(
|
||||||
|
"Validation failed due to GitHub rate-limits being exceeded. Please try again later."
|
||||||
|
)
|
||||||
|
|
||||||
|
except GithubException as e:
|
||||||
|
if e.status == 401:
|
||||||
|
raise CredentialExpiredError(
|
||||||
|
"GitHub credential appears to be invalid or expired (HTTP 401)."
|
||||||
|
)
|
||||||
|
elif e.status == 403:
|
||||||
|
raise InsufficientPermissionsError(
|
||||||
|
"Your GitHub token does not have sufficient permissions for this repository (HTTP 403)."
|
||||||
|
)
|
||||||
|
elif e.status == 404:
|
||||||
|
if self.repositories:
|
||||||
|
if "," in self.repositories:
|
||||||
|
raise ConnectorValidationError(
|
||||||
|
f"None of the specified GitHub repositories could be found for owner: {self.repo_owner}"
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
raise ConnectorValidationError(
|
||||||
|
f"GitHub repository not found with name: {self.repo_owner}/{self.repositories}"
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
raise ConnectorValidationError(
|
||||||
|
f"GitHub user or organization not found: {self.repo_owner}"
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
raise ConnectorValidationError(
|
||||||
|
f"Unexpected GitHub error (status={e.status}): {e.data}"
|
||||||
|
)
|
||||||
|
|
||||||
|
except Exception as exc:
|
||||||
|
raise Exception(
|
||||||
|
f"Unexpected error during GitHub settings validation: {exc}"
|
||||||
|
)
|
||||||
|
|
||||||
|
def validate_checkpoint_json(
|
||||||
|
self, checkpoint_json: str
|
||||||
|
) -> GithubConnectorCheckpoint:
|
||||||
|
return GithubConnectorCheckpoint.model_validate_json(checkpoint_json)
|
||||||
|
|
||||||
|
def build_dummy_checkpoint(self) -> GithubConnectorCheckpoint:
|
||||||
|
return GithubConnectorCheckpoint(
|
||||||
|
stage=GithubConnectorStage.PRS, curr_page=0, has_more=True, num_retrieved=0
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
# Initialize the connector
|
||||||
|
connector = GithubConnector(
|
||||||
|
repo_owner="EvoAgentX",
|
||||||
|
repositories="EvoAgentX",
|
||||||
|
include_issues=True,
|
||||||
|
include_prs=False,
|
||||||
|
)
|
||||||
|
connector.load_credentials(
|
||||||
|
{"github_access_token": "<Your_GitHub_Access_Token>"}
|
||||||
|
)
|
||||||
|
|
||||||
|
if connector.github_client:
|
||||||
|
get_external_access_permission(
|
||||||
|
connector.get_github_repos(connector.github_client).pop(),
|
||||||
|
connector.github_client,
|
||||||
|
)
|
||||||
|
|
||||||
|
# Create a time range from epoch to now
|
||||||
|
end_time = datetime.now(timezone.utc)
|
||||||
|
start_time = datetime.fromtimestamp(0, tz=timezone.utc)
|
||||||
|
time_range = (start_time, end_time)
|
||||||
|
|
||||||
|
# Initialize the runner with a batch size of 10
|
||||||
|
runner: ConnectorRunner[GithubConnectorCheckpoint] = ConnectorRunner(
|
||||||
|
connector, batch_size=10, include_permissions=False, time_range=time_range
|
||||||
|
)
|
||||||
|
|
||||||
|
# Get initial checkpoint
|
||||||
|
checkpoint = connector.build_dummy_checkpoint()
|
||||||
|
|
||||||
|
# Run the connector
|
||||||
|
while checkpoint.has_more:
|
||||||
|
for doc_batch, failure, next_checkpoint in runner.run(checkpoint):
|
||||||
|
if doc_batch:
|
||||||
|
print(f"Retrieved batch of {len(doc_batch)} documents")
|
||||||
|
for doc in doc_batch:
|
||||||
|
print(f"Document: {doc.semantic_identifier}")
|
||||||
|
if failure:
|
||||||
|
print(f"Failure: {failure.failure_message}")
|
||||||
|
if next_checkpoint:
|
||||||
|
checkpoint = next_checkpoint
|
||||||
17
common/data_source/github/models.py
Normal file
17
common/data_source/github/models.py
Normal file
@ -0,0 +1,17 @@
|
|||||||
|
from typing import Any
|
||||||
|
|
||||||
|
from github import Repository
|
||||||
|
from github.Requester import Requester
|
||||||
|
from pydantic import BaseModel
|
||||||
|
|
||||||
|
|
||||||
|
class SerializedRepository(BaseModel):
|
||||||
|
# id is part of the raw_data as well, just pulled out for convenience
|
||||||
|
id: int
|
||||||
|
headers: dict[str, str | int]
|
||||||
|
raw_data: dict[str, Any]
|
||||||
|
|
||||||
|
def to_Repository(self, requester: Requester) -> Repository.Repository:
|
||||||
|
return Repository.Repository(
|
||||||
|
requester, self.headers, self.raw_data, completed=True
|
||||||
|
)
|
||||||
24
common/data_source/github/rate_limit_utils.py
Normal file
24
common/data_source/github/rate_limit_utils.py
Normal file
@ -0,0 +1,24 @@
|
|||||||
|
import time
|
||||||
|
import logging
|
||||||
|
from datetime import datetime
|
||||||
|
from datetime import timedelta
|
||||||
|
from datetime import timezone
|
||||||
|
|
||||||
|
from github import Github
|
||||||
|
|
||||||
|
|
||||||
|
def sleep_after_rate_limit_exception(github_client: Github) -> None:
|
||||||
|
"""
|
||||||
|
Sleep until the GitHub rate limit resets.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
github_client: The GitHub client that hit the rate limit
|
||||||
|
"""
|
||||||
|
sleep_time = github_client.get_rate_limit().core.reset.replace(
|
||||||
|
tzinfo=timezone.utc
|
||||||
|
) - datetime.now(tz=timezone.utc)
|
||||||
|
sleep_time += timedelta(minutes=1) # add an extra minute just to be safe
|
||||||
|
logging.info(
|
||||||
|
"Ran into Github rate-limit. Sleeping %s seconds.", sleep_time.seconds
|
||||||
|
)
|
||||||
|
time.sleep(sleep_time.total_seconds())
|
||||||
44
common/data_source/github/utils.py
Normal file
44
common/data_source/github/utils.py
Normal file
@ -0,0 +1,44 @@
|
|||||||
|
import logging
|
||||||
|
|
||||||
|
from github import Github
|
||||||
|
from github.Repository import Repository
|
||||||
|
|
||||||
|
from common.data_source.models import ExternalAccess
|
||||||
|
|
||||||
|
from .models import SerializedRepository
|
||||||
|
|
||||||
|
|
||||||
|
def get_external_access_permission(
|
||||||
|
repo: Repository, github_client: Github
|
||||||
|
) -> ExternalAccess:
|
||||||
|
"""
|
||||||
|
Get the external access permission for a repository.
|
||||||
|
This functionality requires Enterprise Edition.
|
||||||
|
"""
|
||||||
|
# RAGFlow doesn't implement the Onyx EE external-permissions system.
|
||||||
|
# Default to private/unknown permissions.
|
||||||
|
return ExternalAccess.empty()
|
||||||
|
|
||||||
|
|
||||||
|
def deserialize_repository(
|
||||||
|
cached_repo: SerializedRepository, github_client: Github
|
||||||
|
) -> Repository:
|
||||||
|
"""
|
||||||
|
Deserialize a SerializedRepository back into a Repository object.
|
||||||
|
"""
|
||||||
|
# Try to access the requester - different PyGithub versions may use different attribute names
|
||||||
|
try:
|
||||||
|
# Try to get the requester using getattr to avoid linter errors
|
||||||
|
requester = getattr(github_client, "_requester", None)
|
||||||
|
if requester is None:
|
||||||
|
requester = getattr(github_client, "_Github__requester", None)
|
||||||
|
if requester is None:
|
||||||
|
# If we can't find the requester attribute, we need to fall back to recreating the repo
|
||||||
|
raise AttributeError("Could not find requester attribute")
|
||||||
|
|
||||||
|
return cached_repo.to_Repository(requester)
|
||||||
|
except Exception as e:
|
||||||
|
# If all else fails, re-fetch the repo directly
|
||||||
|
logging.warning("Failed to deserialize repository: %s. Attempting to re-fetch.", e)
|
||||||
|
repo_id = cached_repo.id
|
||||||
|
return github_client.get_repo(repo_id)
|
||||||
340
common/data_source/gitlab_connector.py
Normal file
340
common/data_source/gitlab_connector.py
Normal file
@ -0,0 +1,340 @@
|
|||||||
|
import fnmatch
|
||||||
|
import itertools
|
||||||
|
from collections import deque
|
||||||
|
from collections.abc import Iterable
|
||||||
|
from collections.abc import Iterator
|
||||||
|
from datetime import datetime
|
||||||
|
from datetime import timezone
|
||||||
|
from typing import Any
|
||||||
|
from typing import TypeVar
|
||||||
|
import gitlab
|
||||||
|
from gitlab.v4.objects import Project
|
||||||
|
|
||||||
|
from common.data_source.config import DocumentSource, INDEX_BATCH_SIZE
|
||||||
|
from common.data_source.exceptions import ConnectorMissingCredentialError
|
||||||
|
from common.data_source.exceptions import ConnectorValidationError
|
||||||
|
from common.data_source.exceptions import CredentialExpiredError
|
||||||
|
from common.data_source.exceptions import InsufficientPermissionsError
|
||||||
|
from common.data_source.exceptions import UnexpectedValidationError
|
||||||
|
from common.data_source.interfaces import GenerateDocumentsOutput
|
||||||
|
from common.data_source.interfaces import LoadConnector
|
||||||
|
from common.data_source.interfaces import PollConnector
|
||||||
|
from common.data_source.interfaces import SecondsSinceUnixEpoch
|
||||||
|
from common.data_source.models import BasicExpertInfo
|
||||||
|
from common.data_source.models import Document
|
||||||
|
from common.data_source.utils import get_file_ext
|
||||||
|
|
||||||
|
T = TypeVar("T")
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
# List of directories/Files to exclude
|
||||||
|
exclude_patterns = [
|
||||||
|
"logs",
|
||||||
|
".github/",
|
||||||
|
".gitlab/",
|
||||||
|
".pre-commit-config.yaml",
|
||||||
|
]
|
||||||
|
|
||||||
|
|
||||||
|
def _batch_gitlab_objects(git_objs: Iterable[T], batch_size: int) -> Iterator[list[T]]:
|
||||||
|
it = iter(git_objs)
|
||||||
|
while True:
|
||||||
|
batch = list(itertools.islice(it, batch_size))
|
||||||
|
if not batch:
|
||||||
|
break
|
||||||
|
yield batch
|
||||||
|
|
||||||
|
|
||||||
|
def get_author(author: Any) -> BasicExpertInfo:
|
||||||
|
return BasicExpertInfo(
|
||||||
|
display_name=author.get("name"),
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def _convert_merge_request_to_document(mr: Any) -> Document:
|
||||||
|
mr_text = mr.description or ""
|
||||||
|
doc = Document(
|
||||||
|
id=mr.web_url,
|
||||||
|
blob=mr_text,
|
||||||
|
source=DocumentSource.GITLAB,
|
||||||
|
semantic_identifier=mr.title,
|
||||||
|
extension=".md",
|
||||||
|
# updated_at is UTC time but is timezone unaware, explicitly add UTC
|
||||||
|
# as there is logic in indexing to prevent wrong timestamped docs
|
||||||
|
# due to local time discrepancies with UTC
|
||||||
|
doc_updated_at=mr.updated_at.replace(tzinfo=timezone.utc),
|
||||||
|
size_bytes=len(mr_text.encode("utf-8")),
|
||||||
|
primary_owners=[get_author(mr.author)],
|
||||||
|
metadata={"state": mr.state, "type": "MergeRequest", "web_url": mr.web_url},
|
||||||
|
)
|
||||||
|
return doc
|
||||||
|
|
||||||
|
|
||||||
|
def _convert_issue_to_document(issue: Any) -> Document:
|
||||||
|
issue_text = issue.description or ""
|
||||||
|
doc = Document(
|
||||||
|
id=issue.web_url,
|
||||||
|
blob=issue_text,
|
||||||
|
source=DocumentSource.GITLAB,
|
||||||
|
semantic_identifier=issue.title,
|
||||||
|
extension=".md",
|
||||||
|
# updated_at is UTC time but is timezone unaware, explicitly add UTC
|
||||||
|
# as there is logic in indexing to prevent wrong timestamped docs
|
||||||
|
# due to local time discrepancies with UTC
|
||||||
|
doc_updated_at=issue.updated_at.replace(tzinfo=timezone.utc),
|
||||||
|
size_bytes=len(issue_text.encode("utf-8")),
|
||||||
|
primary_owners=[get_author(issue.author)],
|
||||||
|
metadata={
|
||||||
|
"state": issue.state,
|
||||||
|
"type": issue.type if issue.type else "Issue",
|
||||||
|
"web_url": issue.web_url,
|
||||||
|
},
|
||||||
|
)
|
||||||
|
return doc
|
||||||
|
|
||||||
|
|
||||||
|
def _convert_code_to_document(
|
||||||
|
project: Project, file: Any, url: str, projectName: str, projectOwner: str
|
||||||
|
) -> Document:
|
||||||
|
|
||||||
|
# Dynamically get the default branch from the project object
|
||||||
|
default_branch = project.default_branch
|
||||||
|
|
||||||
|
# Fetch the file content using the correct branch
|
||||||
|
file_content_obj = project.files.get(
|
||||||
|
file_path=file["path"], ref=default_branch # Use the default branch
|
||||||
|
)
|
||||||
|
# BoxConnector uses raw bytes for blob. Keep the same here.
|
||||||
|
file_content_bytes = file_content_obj.decode()
|
||||||
|
file_url = f"{url}/{projectOwner}/{projectName}/-/blob/{default_branch}/{file['path']}"
|
||||||
|
|
||||||
|
# Try to use the last commit timestamp for incremental sync.
|
||||||
|
# Falls back to "now" if the commit lookup fails.
|
||||||
|
last_commit_at = None
|
||||||
|
try:
|
||||||
|
# Query commit history for this file on the default branch.
|
||||||
|
commits = project.commits.list(
|
||||||
|
ref_name=default_branch,
|
||||||
|
path=file["path"],
|
||||||
|
per_page=1,
|
||||||
|
)
|
||||||
|
if commits:
|
||||||
|
# committed_date is ISO string like "2024-01-01T00:00:00.000+00:00"
|
||||||
|
committed_date = commits[0].committed_date
|
||||||
|
if isinstance(committed_date, str):
|
||||||
|
last_commit_at = datetime.strptime(
|
||||||
|
committed_date, "%Y-%m-%dT%H:%M:%S.%f%z"
|
||||||
|
).astimezone(timezone.utc)
|
||||||
|
elif isinstance(committed_date, datetime):
|
||||||
|
last_commit_at = committed_date.astimezone(timezone.utc)
|
||||||
|
except Exception:
|
||||||
|
last_commit_at = None
|
||||||
|
|
||||||
|
# Create and return a Document object
|
||||||
|
doc = Document(
|
||||||
|
# Use a stable ID so reruns don't create duplicates.
|
||||||
|
id=file_url,
|
||||||
|
blob=file_content_bytes,
|
||||||
|
source=DocumentSource.GITLAB,
|
||||||
|
semantic_identifier=file.get("name"),
|
||||||
|
extension=get_file_ext(file.get("name")),
|
||||||
|
doc_updated_at=last_commit_at or datetime.now(tz=timezone.utc),
|
||||||
|
size_bytes=len(file_content_bytes) if file_content_bytes is not None else 0,
|
||||||
|
primary_owners=[], # Add owners if needed
|
||||||
|
metadata={
|
||||||
|
"type": "CodeFile",
|
||||||
|
"path": file.get("path"),
|
||||||
|
"ref": default_branch,
|
||||||
|
"project": f"{projectOwner}/{projectName}",
|
||||||
|
"web_url": file_url,
|
||||||
|
},
|
||||||
|
)
|
||||||
|
return doc
|
||||||
|
|
||||||
|
|
||||||
|
def _should_exclude(path: str) -> bool:
|
||||||
|
"""Check if a path matches any of the exclude patterns."""
|
||||||
|
return any(fnmatch.fnmatch(path, pattern) for pattern in exclude_patterns)
|
||||||
|
|
||||||
|
|
||||||
|
class GitlabConnector(LoadConnector, PollConnector):
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
project_owner: str,
|
||||||
|
project_name: str,
|
||||||
|
batch_size: int = INDEX_BATCH_SIZE,
|
||||||
|
state_filter: str = "all",
|
||||||
|
include_mrs: bool = True,
|
||||||
|
include_issues: bool = True,
|
||||||
|
include_code_files: bool = False,
|
||||||
|
) -> None:
|
||||||
|
self.project_owner = project_owner
|
||||||
|
self.project_name = project_name
|
||||||
|
self.batch_size = batch_size
|
||||||
|
self.state_filter = state_filter
|
||||||
|
self.include_mrs = include_mrs
|
||||||
|
self.include_issues = include_issues
|
||||||
|
self.include_code_files = include_code_files
|
||||||
|
self.gitlab_client: gitlab.Gitlab | None = None
|
||||||
|
|
||||||
|
def load_credentials(self, credentials: dict[str, Any]) -> dict[str, Any] | None:
|
||||||
|
self.gitlab_client = gitlab.Gitlab(
|
||||||
|
credentials["gitlab_url"], private_token=credentials["gitlab_access_token"]
|
||||||
|
)
|
||||||
|
return None
|
||||||
|
|
||||||
|
def validate_connector_settings(self) -> None:
|
||||||
|
if self.gitlab_client is None:
|
||||||
|
raise ConnectorMissingCredentialError("GitLab")
|
||||||
|
|
||||||
|
try:
|
||||||
|
self.gitlab_client.auth()
|
||||||
|
self.gitlab_client.projects.get(
|
||||||
|
f"{self.project_owner}/{self.project_name}",
|
||||||
|
lazy=True,
|
||||||
|
)
|
||||||
|
|
||||||
|
except gitlab.exceptions.GitlabAuthenticationError as e:
|
||||||
|
raise CredentialExpiredError(
|
||||||
|
"Invalid or expired GitLab credentials."
|
||||||
|
) from e
|
||||||
|
|
||||||
|
except gitlab.exceptions.GitlabAuthorizationError as e:
|
||||||
|
raise InsufficientPermissionsError(
|
||||||
|
"Insufficient permissions to access GitLab resources."
|
||||||
|
) from e
|
||||||
|
|
||||||
|
except gitlab.exceptions.GitlabGetError as e:
|
||||||
|
raise ConnectorValidationError(
|
||||||
|
"GitLab project not found or not accessible."
|
||||||
|
) from e
|
||||||
|
|
||||||
|
except Exception as e:
|
||||||
|
raise UnexpectedValidationError(
|
||||||
|
f"Unexpected error while validating GitLab settings: {e}"
|
||||||
|
) from e
|
||||||
|
|
||||||
|
def _fetch_from_gitlab(
|
||||||
|
self, start: datetime | None = None, end: datetime | None = None
|
||||||
|
) -> GenerateDocumentsOutput:
|
||||||
|
if self.gitlab_client is None:
|
||||||
|
raise ConnectorMissingCredentialError("Gitlab")
|
||||||
|
project: Project = self.gitlab_client.projects.get(
|
||||||
|
f"{self.project_owner}/{self.project_name}"
|
||||||
|
)
|
||||||
|
|
||||||
|
start_utc = start.astimezone(timezone.utc) if start else None
|
||||||
|
end_utc = end.astimezone(timezone.utc) if end else None
|
||||||
|
|
||||||
|
# Fetch code files
|
||||||
|
if self.include_code_files:
|
||||||
|
# Fetching using BFS as project.report_tree with recursion causing slow load
|
||||||
|
queue = deque([""]) # Start with the root directory
|
||||||
|
while queue:
|
||||||
|
current_path = queue.popleft()
|
||||||
|
files = project.repository_tree(path=current_path, all=True)
|
||||||
|
for file_batch in _batch_gitlab_objects(files, self.batch_size):
|
||||||
|
code_doc_batch: list[Document] = []
|
||||||
|
for file in file_batch:
|
||||||
|
if _should_exclude(file["path"]):
|
||||||
|
continue
|
||||||
|
|
||||||
|
if file["type"] == "blob":
|
||||||
|
|
||||||
|
doc = _convert_code_to_document(
|
||||||
|
project,
|
||||||
|
file,
|
||||||
|
self.gitlab_client.url,
|
||||||
|
self.project_name,
|
||||||
|
self.project_owner,
|
||||||
|
)
|
||||||
|
|
||||||
|
# Apply incremental window filtering for code files too.
|
||||||
|
if start_utc is not None and doc.doc_updated_at <= start_utc:
|
||||||
|
continue
|
||||||
|
if end_utc is not None and doc.doc_updated_at > end_utc:
|
||||||
|
continue
|
||||||
|
|
||||||
|
code_doc_batch.append(doc)
|
||||||
|
elif file["type"] == "tree":
|
||||||
|
queue.append(file["path"])
|
||||||
|
|
||||||
|
if code_doc_batch:
|
||||||
|
yield code_doc_batch
|
||||||
|
|
||||||
|
if self.include_mrs:
|
||||||
|
merge_requests = project.mergerequests.list(
|
||||||
|
state=self.state_filter,
|
||||||
|
order_by="updated_at",
|
||||||
|
sort="desc",
|
||||||
|
iterator=True,
|
||||||
|
)
|
||||||
|
|
||||||
|
for mr_batch in _batch_gitlab_objects(merge_requests, self.batch_size):
|
||||||
|
mr_doc_batch: list[Document] = []
|
||||||
|
for mr in mr_batch:
|
||||||
|
mr.updated_at = datetime.strptime(
|
||||||
|
mr.updated_at, "%Y-%m-%dT%H:%M:%S.%f%z"
|
||||||
|
)
|
||||||
|
if start_utc is not None and mr.updated_at <= start_utc:
|
||||||
|
yield mr_doc_batch
|
||||||
|
return
|
||||||
|
if end_utc is not None and mr.updated_at > end_utc:
|
||||||
|
continue
|
||||||
|
mr_doc_batch.append(_convert_merge_request_to_document(mr))
|
||||||
|
yield mr_doc_batch
|
||||||
|
|
||||||
|
if self.include_issues:
|
||||||
|
issues = project.issues.list(state=self.state_filter, iterator=True)
|
||||||
|
|
||||||
|
for issue_batch in _batch_gitlab_objects(issues, self.batch_size):
|
||||||
|
issue_doc_batch: list[Document] = []
|
||||||
|
for issue in issue_batch:
|
||||||
|
issue.updated_at = datetime.strptime(
|
||||||
|
issue.updated_at, "%Y-%m-%dT%H:%M:%S.%f%z"
|
||||||
|
)
|
||||||
|
# Avoid re-syncing the last-seen item.
|
||||||
|
if start_utc is not None and issue.updated_at <= start_utc:
|
||||||
|
yield issue_doc_batch
|
||||||
|
return
|
||||||
|
if end_utc is not None and issue.updated_at > end_utc:
|
||||||
|
continue
|
||||||
|
issue_doc_batch.append(_convert_issue_to_document(issue))
|
||||||
|
yield issue_doc_batch
|
||||||
|
|
||||||
|
def load_from_state(self) -> GenerateDocumentsOutput:
|
||||||
|
return self._fetch_from_gitlab()
|
||||||
|
|
||||||
|
def poll_source(
|
||||||
|
self, start: SecondsSinceUnixEpoch, end: SecondsSinceUnixEpoch
|
||||||
|
) -> GenerateDocumentsOutput:
|
||||||
|
start_datetime = datetime.fromtimestamp(start, tz=timezone.utc)
|
||||||
|
end_datetime = datetime.fromtimestamp(end, tz=timezone.utc)
|
||||||
|
return self._fetch_from_gitlab(start_datetime, end_datetime)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
import os
|
||||||
|
|
||||||
|
connector = GitlabConnector(
|
||||||
|
# gitlab_url="https://gitlab.com/api/v4",
|
||||||
|
project_owner=os.environ["PROJECT_OWNER"],
|
||||||
|
project_name=os.environ["PROJECT_NAME"],
|
||||||
|
batch_size=INDEX_BATCH_SIZE,
|
||||||
|
state_filter="all",
|
||||||
|
include_mrs=True,
|
||||||
|
include_issues=True,
|
||||||
|
include_code_files=True,
|
||||||
|
)
|
||||||
|
|
||||||
|
connector.load_credentials(
|
||||||
|
{
|
||||||
|
"gitlab_access_token": os.environ["GITLAB_ACCESS_TOKEN"],
|
||||||
|
"gitlab_url": os.environ["GITLAB_URL"],
|
||||||
|
}
|
||||||
|
)
|
||||||
|
document_batches = connector.load_from_state()
|
||||||
|
for f in document_batches:
|
||||||
|
print("Batch:", f)
|
||||||
|
print("Finished loading from state.")
|
||||||
@ -191,7 +191,7 @@ def get_credentials_from_env(email: str, oauth: bool = False, source="drive") ->
|
|||||||
DB_CREDENTIALS_AUTHENTICATION_METHOD: "uploaded",
|
DB_CREDENTIALS_AUTHENTICATION_METHOD: "uploaded",
|
||||||
}
|
}
|
||||||
|
|
||||||
def sanitize_filename(name: str) -> str:
|
def sanitize_filename(name: str, extension: str = "txt") -> str:
|
||||||
"""
|
"""
|
||||||
Soft sanitize for MinIO/S3:
|
Soft sanitize for MinIO/S3:
|
||||||
- Replace only prohibited characters with a space.
|
- Replace only prohibited characters with a space.
|
||||||
@ -199,7 +199,7 @@ def sanitize_filename(name: str) -> str:
|
|||||||
- Collapse multiple spaces.
|
- Collapse multiple spaces.
|
||||||
"""
|
"""
|
||||||
if name is None:
|
if name is None:
|
||||||
return "file.txt"
|
return f"file.{extension}"
|
||||||
|
|
||||||
name = str(name).strip()
|
name = str(name).strip()
|
||||||
|
|
||||||
@ -222,9 +222,8 @@ def sanitize_filename(name: str) -> str:
|
|||||||
base, ext = os.path.splitext(name)
|
base, ext = os.path.splitext(name)
|
||||||
name = base[:180].rstrip() + ext
|
name = base[:180].rstrip() + ext
|
||||||
|
|
||||||
# Ensure there is an extension (your original logic)
|
|
||||||
if not os.path.splitext(name)[1]:
|
if not os.path.splitext(name)[1]:
|
||||||
name += ".txt"
|
name += f".{extension}"
|
||||||
|
|
||||||
return name
|
return name
|
||||||
|
|
||||||
|
|||||||
@ -5,7 +5,7 @@ from abc import ABC, abstractmethod
|
|||||||
from enum import IntFlag, auto
|
from enum import IntFlag, auto
|
||||||
from types import TracebackType
|
from types import TracebackType
|
||||||
from typing import Any, Dict, Generator, TypeVar, Generic, Callable, TypeAlias
|
from typing import Any, Dict, Generator, TypeVar, Generic, Callable, TypeAlias
|
||||||
|
from collections.abc import Iterator
|
||||||
from anthropic import BaseModel
|
from anthropic import BaseModel
|
||||||
|
|
||||||
from common.data_source.models import (
|
from common.data_source.models import (
|
||||||
@ -16,6 +16,7 @@ from common.data_source.models import (
|
|||||||
SecondsSinceUnixEpoch, GenerateSlimDocumentOutput
|
SecondsSinceUnixEpoch, GenerateSlimDocumentOutput
|
||||||
)
|
)
|
||||||
|
|
||||||
|
GenerateDocumentsOutput = Iterator[list[Document]]
|
||||||
|
|
||||||
class LoadConnector(ABC):
|
class LoadConnector(ABC):
|
||||||
"""Load connector interface"""
|
"""Load connector interface"""
|
||||||
@ -236,16 +237,13 @@ class BaseConnector(abc.ABC, Generic[CT]):
|
|||||||
|
|
||||||
def validate_perm_sync(self) -> None:
|
def validate_perm_sync(self) -> None:
|
||||||
"""
|
"""
|
||||||
Don't override this; add a function to perm_sync_valid.py in the ee package
|
Permission-sync validation hook.
|
||||||
to do permission sync validation
|
|
||||||
|
RAGFlow doesn't ship the Onyx EE permission-sync validation package.
|
||||||
|
Connectors that support permission sync should override
|
||||||
|
`validate_connector_settings()` as needed.
|
||||||
"""
|
"""
|
||||||
"""
|
return None
|
||||||
validate_connector_settings_fn = fetch_ee_implementation_or_noop(
|
|
||||||
"onyx.connectors.perm_sync_valid",
|
|
||||||
"validate_perm_sync",
|
|
||||||
noop_return_value=None,
|
|
||||||
)
|
|
||||||
validate_connector_settings_fn(self)"""
|
|
||||||
|
|
||||||
def set_allow_images(self, value: bool) -> None:
|
def set_allow_images(self, value: bool) -> None:
|
||||||
"""Implement if the underlying connector wants to skip/allow image downloading
|
"""Implement if the underlying connector wants to skip/allow image downloading
|
||||||
@ -344,6 +342,17 @@ class CheckpointOutputWrapper(Generic[CT]):
|
|||||||
yield None, None, self.next_checkpoint
|
yield None, None, self.next_checkpoint
|
||||||
|
|
||||||
|
|
||||||
|
class CheckpointedConnectorWithPermSyncGH(CheckpointedConnector[CT]):
|
||||||
|
@abc.abstractmethod
|
||||||
|
def load_from_checkpoint_with_perm_sync(
|
||||||
|
self,
|
||||||
|
start: SecondsSinceUnixEpoch,
|
||||||
|
end: SecondsSinceUnixEpoch,
|
||||||
|
checkpoint: CT,
|
||||||
|
) -> CheckpointOutput[CT]:
|
||||||
|
raise NotImplementedError
|
||||||
|
|
||||||
|
|
||||||
# Slim connectors retrieve just the ids of documents
|
# Slim connectors retrieve just the ids of documents
|
||||||
class SlimConnector(BaseConnector):
|
class SlimConnector(BaseConnector):
|
||||||
@abc.abstractmethod
|
@abc.abstractmethod
|
||||||
|
|||||||
@ -94,8 +94,10 @@ class Document(BaseModel):
|
|||||||
blob: bytes
|
blob: bytes
|
||||||
doc_updated_at: datetime
|
doc_updated_at: datetime
|
||||||
size_bytes: int
|
size_bytes: int
|
||||||
primary_owners: list
|
externale_access: Optional[ExternalAccess] = None
|
||||||
|
primary_owners: Optional[list] = None
|
||||||
metadata: Optional[dict[str, Any]] = None
|
metadata: Optional[dict[str, Any]] = None
|
||||||
|
doc_metadata: Optional[dict[str, Any]] = None
|
||||||
|
|
||||||
|
|
||||||
class BasicExpertInfo(BaseModel):
|
class BasicExpertInfo(BaseModel):
|
||||||
|
|||||||
@ -21,7 +21,7 @@ import time
|
|||||||
import os
|
import os
|
||||||
from abc import abstractmethod
|
from abc import abstractmethod
|
||||||
|
|
||||||
from elasticsearch import Elasticsearch, NotFoundError
|
from elasticsearch import NotFoundError
|
||||||
from elasticsearch_dsl import Index
|
from elasticsearch_dsl import Index
|
||||||
from elastic_transport import ConnectionTimeout
|
from elastic_transport import ConnectionTimeout
|
||||||
from common.file_utils import get_project_base_directory
|
from common.file_utils import get_project_base_directory
|
||||||
@ -35,28 +35,13 @@ ATTEMPT_TIME = 2
|
|||||||
|
|
||||||
class ESConnectionBase(DocStoreConnection):
|
class ESConnectionBase(DocStoreConnection):
|
||||||
def __init__(self, mapping_file_name: str="mapping.json", logger_name: str='ragflow.es_conn'):
|
def __init__(self, mapping_file_name: str="mapping.json", logger_name: str='ragflow.es_conn'):
|
||||||
|
from common.doc_store.es_conn_pool import ES_CONN
|
||||||
|
|
||||||
self.logger = logging.getLogger(logger_name)
|
self.logger = logging.getLogger(logger_name)
|
||||||
|
|
||||||
self.info = {}
|
self.info = {}
|
||||||
self.logger.info(f"Use Elasticsearch {settings.ES['hosts']} as the doc engine.")
|
self.logger.info(f"Use Elasticsearch {settings.ES['hosts']} as the doc engine.")
|
||||||
for _ in range(ATTEMPT_TIME):
|
self.es = ES_CONN.get_conn()
|
||||||
try:
|
|
||||||
if self._connect():
|
|
||||||
break
|
|
||||||
except Exception as e:
|
|
||||||
self.logger.warning(f"{str(e)}. Waiting Elasticsearch {settings.ES['hosts']} to be healthy.")
|
|
||||||
time.sleep(5)
|
|
||||||
|
|
||||||
if not self.es.ping():
|
|
||||||
msg = f"Elasticsearch {settings.ES['hosts']} is unhealthy in 120s."
|
|
||||||
self.logger.error(msg)
|
|
||||||
raise Exception(msg)
|
|
||||||
v = self.info.get("version", {"number": "8.11.3"})
|
|
||||||
v = v["number"].split(".")[0]
|
|
||||||
if int(v) < 8:
|
|
||||||
msg = f"Elasticsearch version must be greater than or equal to 8, current version: {v}"
|
|
||||||
self.logger.error(msg)
|
|
||||||
raise Exception(msg)
|
|
||||||
fp_mapping = os.path.join(get_project_base_directory(), "conf", mapping_file_name)
|
fp_mapping = os.path.join(get_project_base_directory(), "conf", mapping_file_name)
|
||||||
if not os.path.exists(fp_mapping):
|
if not os.path.exists(fp_mapping):
|
||||||
msg = f"Elasticsearch mapping file not found at {fp_mapping}"
|
msg = f"Elasticsearch mapping file not found at {fp_mapping}"
|
||||||
@ -66,16 +51,12 @@ class ESConnectionBase(DocStoreConnection):
|
|||||||
self.logger.info(f"Elasticsearch {settings.ES['hosts']} is healthy.")
|
self.logger.info(f"Elasticsearch {settings.ES['hosts']} is healthy.")
|
||||||
|
|
||||||
def _connect(self):
|
def _connect(self):
|
||||||
self.es = Elasticsearch(
|
from common.doc_store.es_conn_pool import ES_CONN
|
||||||
settings.ES["hosts"].split(","),
|
|
||||||
basic_auth=(settings.ES["username"], settings.ES[
|
if self.es.ping():
|
||||||
"password"]) if "username" in settings.ES and "password" in settings.ES else None,
|
return True
|
||||||
verify_certs= settings.ES.get("verify_certs", False),
|
self.es = ES_CONN.refresh_conn()
|
||||||
timeout=600 )
|
|
||||||
if self.es:
|
|
||||||
self.info = self.es.info()
|
|
||||||
return True
|
return True
|
||||||
return False
|
|
||||||
|
|
||||||
"""
|
"""
|
||||||
Database operations
|
Database operations
|
||||||
|
|||||||
84
common/doc_store/es_conn_pool.py
Normal file
84
common/doc_store/es_conn_pool.py
Normal file
@ -0,0 +1,84 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
import logging
|
||||||
|
import time
|
||||||
|
from elasticsearch import Elasticsearch
|
||||||
|
|
||||||
|
from common import settings
|
||||||
|
from common.decorator import singleton
|
||||||
|
|
||||||
|
ATTEMPT_TIME = 2
|
||||||
|
|
||||||
|
|
||||||
|
@singleton
|
||||||
|
class ElasticSearchConnectionPool:
|
||||||
|
|
||||||
|
def __init__(self):
|
||||||
|
if hasattr(settings, "ES"):
|
||||||
|
self.ES_CONFIG = settings.ES
|
||||||
|
else:
|
||||||
|
self.ES_CONFIG = settings.get_base_config("es", {})
|
||||||
|
|
||||||
|
for _ in range(ATTEMPT_TIME):
|
||||||
|
try:
|
||||||
|
if self._connect():
|
||||||
|
break
|
||||||
|
except Exception as e:
|
||||||
|
logging.warning(f"{str(e)}. Waiting Elasticsearch {self.ES_CONFIG['hosts']} to be healthy.")
|
||||||
|
time.sleep(5)
|
||||||
|
|
||||||
|
if not hasattr(self, "es_conn") or not self.es_conn or not self.es_conn.ping():
|
||||||
|
msg = f"Elasticsearch {self.ES_CONFIG['hosts']} is unhealthy in 10s."
|
||||||
|
logging.error(msg)
|
||||||
|
raise Exception(msg)
|
||||||
|
v = self.info.get("version", {"number": "8.11.3"})
|
||||||
|
v = v["number"].split(".")[0]
|
||||||
|
if int(v) < 8:
|
||||||
|
msg = f"Elasticsearch version must be greater than or equal to 8, current version: {v}"
|
||||||
|
logging.error(msg)
|
||||||
|
raise Exception(msg)
|
||||||
|
|
||||||
|
def _connect(self):
|
||||||
|
self.es_conn = Elasticsearch(
|
||||||
|
self.ES_CONFIG["hosts"].split(","),
|
||||||
|
basic_auth=(self.ES_CONFIG["username"], self.ES_CONFIG[
|
||||||
|
"password"]) if "username" in self.ES_CONFIG and "password" in self.ES_CONFIG else None,
|
||||||
|
verify_certs= self.ES_CONFIG.get("verify_certs", False),
|
||||||
|
timeout=600 )
|
||||||
|
if self.es_conn:
|
||||||
|
self.info = self.es_conn.info()
|
||||||
|
return True
|
||||||
|
return False
|
||||||
|
|
||||||
|
def get_conn(self):
|
||||||
|
return self.es_conn
|
||||||
|
|
||||||
|
def refresh_conn(self):
|
||||||
|
if self.es_conn.ping():
|
||||||
|
return self.es_conn
|
||||||
|
else:
|
||||||
|
# close current if exist
|
||||||
|
if self.es_conn:
|
||||||
|
self.es_conn.close()
|
||||||
|
self._connect()
|
||||||
|
return self.es_conn
|
||||||
|
|
||||||
|
def __del__(self):
|
||||||
|
if hasattr(self, "es_conn") and self.es_conn:
|
||||||
|
self.es_conn.close()
|
||||||
|
|
||||||
|
|
||||||
|
ES_CONN = ElasticSearchConnectionPool()
|
||||||
@ -24,7 +24,6 @@ from abc import abstractmethod
|
|||||||
import infinity
|
import infinity
|
||||||
from infinity.common import ConflictType
|
from infinity.common import ConflictType
|
||||||
from infinity.index import IndexInfo, IndexType
|
from infinity.index import IndexInfo, IndexType
|
||||||
from infinity.connection_pool import ConnectionPool
|
|
||||||
from infinity.errors import ErrorCode
|
from infinity.errors import ErrorCode
|
||||||
import pandas as pd
|
import pandas as pd
|
||||||
from common.file_utils import get_project_base_directory
|
from common.file_utils import get_project_base_directory
|
||||||
@ -35,6 +34,8 @@ from common.doc_store.doc_store_base import DocStoreConnection, MatchExpr, Order
|
|||||||
|
|
||||||
class InfinityConnectionBase(DocStoreConnection):
|
class InfinityConnectionBase(DocStoreConnection):
|
||||||
def __init__(self, mapping_file_name: str="infinity_mapping.json", logger_name: str="ragflow.infinity_conn"):
|
def __init__(self, mapping_file_name: str="infinity_mapping.json", logger_name: str="ragflow.infinity_conn"):
|
||||||
|
from common.doc_store.infinity_conn_pool import INFINITY_CONN
|
||||||
|
|
||||||
self.dbName = settings.INFINITY.get("db_name", "default_db")
|
self.dbName = settings.INFINITY.get("db_name", "default_db")
|
||||||
self.mapping_file_name = mapping_file_name
|
self.mapping_file_name = mapping_file_name
|
||||||
self.logger = logging.getLogger(logger_name)
|
self.logger = logging.getLogger(logger_name)
|
||||||
@ -44,9 +45,9 @@ class InfinityConnectionBase(DocStoreConnection):
|
|||||||
infinity_uri = infinity.common.NetworkAddress(host, int(port))
|
infinity_uri = infinity.common.NetworkAddress(host, int(port))
|
||||||
self.connPool = None
|
self.connPool = None
|
||||||
self.logger.info(f"Use Infinity {infinity_uri} as the doc engine.")
|
self.logger.info(f"Use Infinity {infinity_uri} as the doc engine.")
|
||||||
|
conn_pool = INFINITY_CONN.get_conn_pool()
|
||||||
for _ in range(24):
|
for _ in range(24):
|
||||||
try:
|
try:
|
||||||
conn_pool = ConnectionPool(infinity_uri, max_size=4)
|
|
||||||
inf_conn = conn_pool.get_conn()
|
inf_conn = conn_pool.get_conn()
|
||||||
res = inf_conn.show_current_node()
|
res = inf_conn.show_current_node()
|
||||||
if res.error_code == ErrorCode.OK and res.server_status in ["started", "alive"]:
|
if res.error_code == ErrorCode.OK and res.server_status in ["started", "alive"]:
|
||||||
@ -58,6 +59,7 @@ class InfinityConnectionBase(DocStoreConnection):
|
|||||||
self.logger.warning(f"Infinity status: {res.server_status}. Waiting Infinity {infinity_uri} to be healthy.")
|
self.logger.warning(f"Infinity status: {res.server_status}. Waiting Infinity {infinity_uri} to be healthy.")
|
||||||
time.sleep(5)
|
time.sleep(5)
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
|
conn_pool = INFINITY_CONN.refresh_conn_pool()
|
||||||
self.logger.warning(f"{str(e)}. Waiting Infinity {infinity_uri} to be healthy.")
|
self.logger.warning(f"{str(e)}. Waiting Infinity {infinity_uri} to be healthy.")
|
||||||
time.sleep(5)
|
time.sleep(5)
|
||||||
if self.connPool is None:
|
if self.connPool is None:
|
||||||
|
|||||||
85
common/doc_store/infinity_conn_pool.py
Normal file
85
common/doc_store/infinity_conn_pool.py
Normal file
@ -0,0 +1,85 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
import logging
|
||||||
|
import time
|
||||||
|
|
||||||
|
import infinity
|
||||||
|
from infinity.connection_pool import ConnectionPool
|
||||||
|
from infinity.errors import ErrorCode
|
||||||
|
|
||||||
|
from common import settings
|
||||||
|
from common.decorator import singleton
|
||||||
|
|
||||||
|
|
||||||
|
@singleton
|
||||||
|
class InfinityConnectionPool:
|
||||||
|
|
||||||
|
def __init__(self):
|
||||||
|
if hasattr(settings, "INFINITY"):
|
||||||
|
self.INFINITY_CONFIG = settings.INFINITY
|
||||||
|
else:
|
||||||
|
self.INFINITY_CONFIG = settings.get_base_config("infinity", {"uri": "infinity:23817"})
|
||||||
|
|
||||||
|
infinity_uri = self.INFINITY_CONFIG["uri"]
|
||||||
|
if ":" in infinity_uri:
|
||||||
|
host, port = infinity_uri.split(":")
|
||||||
|
self.infinity_uri = infinity.common.NetworkAddress(host, int(port))
|
||||||
|
|
||||||
|
for _ in range(24):
|
||||||
|
try:
|
||||||
|
conn_pool = ConnectionPool(self.infinity_uri, max_size=4)
|
||||||
|
inf_conn = conn_pool.get_conn()
|
||||||
|
res = inf_conn.show_current_node()
|
||||||
|
if res.error_code == ErrorCode.OK and res.server_status in ["started", "alive"]:
|
||||||
|
self.conn_pool = conn_pool
|
||||||
|
conn_pool.release_conn(inf_conn)
|
||||||
|
break
|
||||||
|
except Exception as e:
|
||||||
|
logging.warning(f"{str(e)}. Waiting Infinity {infinity_uri} to be healthy.")
|
||||||
|
time.sleep(5)
|
||||||
|
|
||||||
|
if self.conn_pool is None:
|
||||||
|
msg = f"Infinity {infinity_uri} is unhealthy in 120s."
|
||||||
|
logging.error(msg)
|
||||||
|
raise Exception(msg)
|
||||||
|
|
||||||
|
logging.info(f"Infinity {infinity_uri} is healthy.")
|
||||||
|
|
||||||
|
def get_conn_pool(self):
|
||||||
|
return self.conn_pool
|
||||||
|
|
||||||
|
def refresh_conn_pool(self):
|
||||||
|
try:
|
||||||
|
inf_conn = self.conn_pool.get_conn()
|
||||||
|
res = inf_conn.show_current_node()
|
||||||
|
if res.error_code == ErrorCode.OK and res.server_status in ["started", "alive"]:
|
||||||
|
return self.conn_pool
|
||||||
|
else:
|
||||||
|
raise Exception(f"{res.error_code}: {res.server_status}")
|
||||||
|
|
||||||
|
except Exception as e:
|
||||||
|
logging.error(str(e))
|
||||||
|
if hasattr(self, "conn_pool") and self.conn_pool:
|
||||||
|
self.conn_pool.destroy()
|
||||||
|
self.conn_pool = ConnectionPool(self.infinity_uri, max_size=32)
|
||||||
|
return self.conn_pool
|
||||||
|
|
||||||
|
def __del__(self):
|
||||||
|
if hasattr(self, "conn_pool") and self.conn_pool:
|
||||||
|
self.conn_pool.destroy()
|
||||||
|
|
||||||
|
|
||||||
|
INFINITY_CONN = InfinityConnectionPool()
|
||||||
@ -13,6 +13,7 @@
|
|||||||
# See the License for the specific language governing permissions and
|
# See the License for the specific language governing permissions and
|
||||||
# limitations under the License.
|
# limitations under the License.
|
||||||
#
|
#
|
||||||
|
import ast
|
||||||
import logging
|
import logging
|
||||||
from typing import Any, Callable, Dict
|
from typing import Any, Callable, Dict
|
||||||
|
|
||||||
@ -49,8 +50,8 @@ def meta_filter(metas: dict, filters: list[dict], logic: str = "and"):
|
|||||||
try:
|
try:
|
||||||
if isinstance(input, list):
|
if isinstance(input, list):
|
||||||
input = input[0]
|
input = input[0]
|
||||||
input = float(input)
|
input = ast.literal_eval(input)
|
||||||
value = float(value)
|
value = ast.literal_eval(value)
|
||||||
except Exception:
|
except Exception:
|
||||||
pass
|
pass
|
||||||
if isinstance(input, str):
|
if isinstance(input, str):
|
||||||
@ -58,28 +59,41 @@ def meta_filter(metas: dict, filters: list[dict], logic: str = "and"):
|
|||||||
if isinstance(value, str):
|
if isinstance(value, str):
|
||||||
value = value.lower()
|
value = value.lower()
|
||||||
|
|
||||||
for conds in [
|
matched = False
|
||||||
(operator == "contains", input in value if not isinstance(input, list) else all([i in value for i in input])),
|
|
||||||
(operator == "not contains", input not in value if not isinstance(input, list) else all([i not in value for i in input])),
|
|
||||||
(operator == "in", input in value if not isinstance(input, list) else all([i in value for i in input])),
|
|
||||||
(operator == "not in", input not in value if not isinstance(input, list) else all([i not in value for i in input])),
|
|
||||||
(operator == "start with", str(input).lower().startswith(str(value).lower()) if not isinstance(input, list) else "".join([str(i).lower() for i in input]).startswith(str(value).lower())),
|
|
||||||
(operator == "end with", str(input).lower().endswith(str(value).lower()) if not isinstance(input, list) else "".join([str(i).lower() for i in input]).endswith(str(value).lower())),
|
|
||||||
(operator == "empty", not input),
|
|
||||||
(operator == "not empty", input),
|
|
||||||
(operator == "=", input == value),
|
|
||||||
(operator == "≠", input != value),
|
|
||||||
(operator == ">", input > value),
|
|
||||||
(operator == "<", input < value),
|
|
||||||
(operator == "≥", input >= value),
|
|
||||||
(operator == "≤", input <= value),
|
|
||||||
]:
|
|
||||||
try:
|
try:
|
||||||
if all(conds):
|
if operator == "contains":
|
||||||
ids.extend(docids)
|
matched = input in value if not isinstance(input, list) else all(i in value for i in input)
|
||||||
break
|
elif operator == "not contains":
|
||||||
|
matched = input not in value if not isinstance(input, list) else all(i not in value for i in input)
|
||||||
|
elif operator == "in":
|
||||||
|
matched = input in value if not isinstance(input, list) else all(i in value for i in input)
|
||||||
|
elif operator == "not in":
|
||||||
|
matched = input not in value if not isinstance(input, list) else all(i not in value for i in input)
|
||||||
|
elif operator == "start with":
|
||||||
|
matched = str(input).lower().startswith(str(value).lower()) if not isinstance(input, list) else "".join([str(i).lower() for i in input]).startswith(str(value).lower())
|
||||||
|
elif operator == "end with":
|
||||||
|
matched = str(input).lower().endswith(str(value).lower()) if not isinstance(input, list) else "".join([str(i).lower() for i in input]).endswith(str(value).lower())
|
||||||
|
elif operator == "empty":
|
||||||
|
matched = not input
|
||||||
|
elif operator == "not empty":
|
||||||
|
matched = bool(input)
|
||||||
|
elif operator == "=":
|
||||||
|
matched = input == value
|
||||||
|
elif operator == "≠":
|
||||||
|
matched = input != value
|
||||||
|
elif operator == ">":
|
||||||
|
matched = input > value
|
||||||
|
elif operator == "<":
|
||||||
|
matched = input < value
|
||||||
|
elif operator == "≥":
|
||||||
|
matched = input >= value
|
||||||
|
elif operator == "≤":
|
||||||
|
matched = input <= value
|
||||||
except Exception:
|
except Exception:
|
||||||
pass
|
pass
|
||||||
|
|
||||||
|
if matched:
|
||||||
|
ids.extend(docids)
|
||||||
return ids
|
return ids
|
||||||
|
|
||||||
for k, v2docs in metas.items():
|
for k, v2docs in metas.items():
|
||||||
|
|||||||
@ -79,7 +79,6 @@ FEISHU_OAUTH = None
|
|||||||
OAUTH_CONFIG = None
|
OAUTH_CONFIG = None
|
||||||
DOC_ENGINE = os.getenv('DOC_ENGINE', 'elasticsearch')
|
DOC_ENGINE = os.getenv('DOC_ENGINE', 'elasticsearch')
|
||||||
DOC_ENGINE_INFINITY = (DOC_ENGINE.lower() == "infinity")
|
DOC_ENGINE_INFINITY = (DOC_ENGINE.lower() == "infinity")
|
||||||
MSG_ENGINE = DOC_ENGINE
|
|
||||||
|
|
||||||
|
|
||||||
docStoreConn = None
|
docStoreConn = None
|
||||||
@ -261,12 +260,12 @@ def init_settings():
|
|||||||
else:
|
else:
|
||||||
raise Exception(f"Not supported doc engine: {DOC_ENGINE}")
|
raise Exception(f"Not supported doc engine: {DOC_ENGINE}")
|
||||||
|
|
||||||
global MSG_ENGINE, msgStoreConn
|
global msgStoreConn
|
||||||
MSG_ENGINE = DOC_ENGINE # use the same engine for message store
|
# use the same engine for message store
|
||||||
if MSG_ENGINE == "elasticsearch":
|
if DOC_ENGINE == "elasticsearch":
|
||||||
ES = get_base_config("es", {})
|
ES = get_base_config("es", {})
|
||||||
msgStoreConn = memory_es_conn.ESConnection()
|
msgStoreConn = memory_es_conn.ESConnection()
|
||||||
elif MSG_ENGINE == "infinity":
|
elif DOC_ENGINE == "infinity":
|
||||||
INFINITY = get_base_config("infinity", {"uri": "infinity:23817"})
|
INFINITY = get_base_config("infinity", {"uri": "infinity:23817"})
|
||||||
msgStoreConn = memory_infinity_conn.InfinityConnection()
|
msgStoreConn = memory_infinity_conn.InfinityConnection()
|
||||||
|
|
||||||
@ -335,6 +334,9 @@ def init_settings():
|
|||||||
DOC_BULK_SIZE = int(os.environ.get("DOC_BULK_SIZE", 4))
|
DOC_BULK_SIZE = int(os.environ.get("DOC_BULK_SIZE", 4))
|
||||||
EMBEDDING_BATCH_SIZE = int(os.environ.get("EMBEDDING_BATCH_SIZE", 16))
|
EMBEDDING_BATCH_SIZE = int(os.environ.get("EMBEDDING_BATCH_SIZE", 16))
|
||||||
|
|
||||||
|
os.environ["DOTNET_SYSTEM_GLOBALIZATION_INVARIANT"] = "1"
|
||||||
|
|
||||||
|
|
||||||
def check_and_install_torch():
|
def check_and_install_torch():
|
||||||
global PARALLEL_DEVICES
|
global PARALLEL_DEVICES
|
||||||
try:
|
try:
|
||||||
|
|||||||
@ -78,14 +78,21 @@ class DoclingParser(RAGFlowPdfParser):
|
|||||||
def __images__(self, fnm, zoomin: int = 1, page_from=0, page_to=600, callback=None):
|
def __images__(self, fnm, zoomin: int = 1, page_from=0, page_to=600, callback=None):
|
||||||
self.page_from = page_from
|
self.page_from = page_from
|
||||||
self.page_to = page_to
|
self.page_to = page_to
|
||||||
|
bytes_io = None
|
||||||
try:
|
try:
|
||||||
opener = pdfplumber.open(fnm) if isinstance(fnm, (str, PathLike)) else pdfplumber.open(BytesIO(fnm))
|
if not isinstance(fnm, (str, PathLike)):
|
||||||
|
bytes_io = BytesIO(fnm)
|
||||||
|
|
||||||
|
opener = pdfplumber.open(fnm) if isinstance(fnm, (str, PathLike)) else pdfplumber.open(bytes_io)
|
||||||
with opener as pdf:
|
with opener as pdf:
|
||||||
pages = pdf.pages[page_from:page_to]
|
pages = pdf.pages[page_from:page_to]
|
||||||
self.page_images = [p.to_image(resolution=72 * zoomin, antialias=True).original for p in pages]
|
self.page_images = [p.to_image(resolution=72 * zoomin, antialias=True).original for p in pages]
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
self.page_images = []
|
self.page_images = []
|
||||||
self.logger.exception(e)
|
self.logger.exception(e)
|
||||||
|
finally:
|
||||||
|
if bytes_io:
|
||||||
|
bytes_io.close()
|
||||||
|
|
||||||
def _make_line_tag(self,bbox: _BBox) -> str:
|
def _make_line_tag(self,bbox: _BBox) -> str:
|
||||||
if bbox is None:
|
if bbox is None:
|
||||||
|
|||||||
@ -1061,8 +1061,8 @@ class RAGFlowPdfParser:
|
|||||||
|
|
||||||
self.total_page = len(self.pdf.pages)
|
self.total_page = len(self.pdf.pages)
|
||||||
|
|
||||||
except Exception:
|
except Exception as e:
|
||||||
logging.exception("RAGFlowPdfParser __images__")
|
logging.exception(f"RAGFlowPdfParser __images__, exception: {e}")
|
||||||
logging.info(f"__images__ dedupe_chars cost {timer() - start}s")
|
logging.info(f"__images__ dedupe_chars cost {timer() - start}s")
|
||||||
|
|
||||||
self.outlines = []
|
self.outlines = []
|
||||||
@ -1206,7 +1206,7 @@ class RAGFlowPdfParser:
|
|||||||
start = timer()
|
start = timer()
|
||||||
self._text_merge()
|
self._text_merge()
|
||||||
self._concat_downward()
|
self._concat_downward()
|
||||||
self._naive_vertical_merge(zoomin)
|
#self._naive_vertical_merge(zoomin)
|
||||||
if callback:
|
if callback:
|
||||||
callback(0.92, "Text merged ({:.2f}s)".format(timer() - start))
|
callback(0.92, "Text merged ({:.2f}s)".format(timer() - start))
|
||||||
|
|
||||||
|
|||||||
@ -16,6 +16,7 @@
|
|||||||
|
|
||||||
import logging
|
import logging
|
||||||
import sys
|
import sys
|
||||||
|
import ast
|
||||||
import six
|
import six
|
||||||
import cv2
|
import cv2
|
||||||
import numpy as np
|
import numpy as np
|
||||||
@ -108,7 +109,14 @@ class NormalizeImage:
|
|||||||
|
|
||||||
def __init__(self, scale=None, mean=None, std=None, order='chw', **kwargs):
|
def __init__(self, scale=None, mean=None, std=None, order='chw', **kwargs):
|
||||||
if isinstance(scale, str):
|
if isinstance(scale, str):
|
||||||
scale = eval(scale)
|
try:
|
||||||
|
scale = float(scale)
|
||||||
|
except ValueError:
|
||||||
|
if '/' in scale:
|
||||||
|
parts = scale.split('/')
|
||||||
|
scale = ast.literal_eval(parts[0]) / ast.literal_eval(parts[1])
|
||||||
|
else:
|
||||||
|
scale = ast.literal_eval(scale)
|
||||||
self.scale = np.float32(scale if scale is not None else 1.0 / 255.0)
|
self.scale = np.float32(scale if scale is not None else 1.0 / 255.0)
|
||||||
mean = mean if mean is not None else [0.485, 0.456, 0.406]
|
mean = mean if mean is not None else [0.485, 0.456, 0.406]
|
||||||
std = std if std is not None else [0.229, 0.224, 0.225]
|
std = std if std is not None else [0.229, 0.224, 0.225]
|
||||||
|
|||||||
18
docker/.env
18
docker/.env
@ -1,3 +1,10 @@
|
|||||||
|
# -----------------------------------------------------------------------------
|
||||||
|
# SECURITY WARNING: DO NOT DEPLOY WITH DEFAULT PASSWORDS
|
||||||
|
# For non-local deployments, please change all passwords (ELASTIC_PASSWORD,
|
||||||
|
# MYSQL_PASSWORD, MINIO_PASSWORD, etc.) to strong, unique values.
|
||||||
|
# You can generate a random string using: openssl rand -hex 32
|
||||||
|
# -----------------------------------------------------------------------------
|
||||||
|
|
||||||
# ------------------------------
|
# ------------------------------
|
||||||
# docker env var for specifying vector db type at startup
|
# docker env var for specifying vector db type at startup
|
||||||
# (based on the vector db type, the corresponding docker
|
# (based on the vector db type, the corresponding docker
|
||||||
@ -30,6 +37,7 @@ ES_HOST=es01
|
|||||||
ES_PORT=1200
|
ES_PORT=1200
|
||||||
|
|
||||||
# The password for Elasticsearch.
|
# The password for Elasticsearch.
|
||||||
|
# WARNING: Change this for production!
|
||||||
ELASTIC_PASSWORD=infini_rag_flow
|
ELASTIC_PASSWORD=infini_rag_flow
|
||||||
|
|
||||||
# the hostname where OpenSearch service is exposed, set it not the same as elasticsearch
|
# the hostname where OpenSearch service is exposed, set it not the same as elasticsearch
|
||||||
@ -85,6 +93,7 @@ OB_DATAFILE_SIZE=${OB_DATAFILE_SIZE:-20G}
|
|||||||
OB_LOG_DISK_SIZE=${OB_LOG_DISK_SIZE:-20G}
|
OB_LOG_DISK_SIZE=${OB_LOG_DISK_SIZE:-20G}
|
||||||
|
|
||||||
# The password for MySQL.
|
# The password for MySQL.
|
||||||
|
# WARNING: Change this for production!
|
||||||
MYSQL_PASSWORD=infini_rag_flow
|
MYSQL_PASSWORD=infini_rag_flow
|
||||||
# The hostname where the MySQL service is exposed
|
# The hostname where the MySQL service is exposed
|
||||||
MYSQL_HOST=mysql
|
MYSQL_HOST=mysql
|
||||||
@ -128,11 +137,11 @@ ADMIN_SVR_HTTP_PORT=9381
|
|||||||
SVR_MCP_PORT=9382
|
SVR_MCP_PORT=9382
|
||||||
|
|
||||||
# The RAGFlow Docker image to download. v0.22+ doesn't include embedding models.
|
# The RAGFlow Docker image to download. v0.22+ doesn't include embedding models.
|
||||||
RAGFLOW_IMAGE=infiniflow/ragflow:v0.22.1
|
RAGFLOW_IMAGE=infiniflow/ragflow:v0.23.0
|
||||||
|
|
||||||
# If you cannot download the RAGFlow Docker image:
|
# If you cannot download the RAGFlow Docker image:
|
||||||
# RAGFLOW_IMAGE=swr.cn-north-4.myhuaweicloud.com/infiniflow/ragflow:v0.22.1
|
# RAGFLOW_IMAGE=swr.cn-north-4.myhuaweicloud.com/infiniflow/ragflow:v0.23.0
|
||||||
# RAGFLOW_IMAGE=registry.cn-hangzhou.aliyuncs.com/infiniflow/ragflow:v0.22.1
|
# RAGFLOW_IMAGE=registry.cn-hangzhou.aliyuncs.com/infiniflow/ragflow:v0.23.0
|
||||||
#
|
#
|
||||||
# - For the `nightly` edition, uncomment either of the following:
|
# - For the `nightly` edition, uncomment either of the following:
|
||||||
# RAGFLOW_IMAGE=swr.cn-north-4.myhuaweicloud.com/infiniflow/ragflow:nightly
|
# RAGFLOW_IMAGE=swr.cn-north-4.myhuaweicloud.com/infiniflow/ragflow:nightly
|
||||||
@ -234,9 +243,8 @@ REGISTER_ENABLED=1
|
|||||||
USE_DOCLING=false
|
USE_DOCLING=false
|
||||||
|
|
||||||
# Enable Mineru
|
# Enable Mineru
|
||||||
USE_MINERU=false
|
|
||||||
MINERU_EXECUTABLE="$HOME/uv_tools/.venv/bin/mineru"
|
|
||||||
# Uncommenting these lines will automatically add MinerU to the model provider whenever possible.
|
# Uncommenting these lines will automatically add MinerU to the model provider whenever possible.
|
||||||
|
# More details see https://ragflow.io/docs/faq#how-to-use-mineru-to-parse-pdf-documents.
|
||||||
# MINERU_DELETE_OUTPUT=0 # keep output directory
|
# MINERU_DELETE_OUTPUT=0 # keep output directory
|
||||||
# MINERU_BACKEND=pipeline # or another backend you prefer
|
# MINERU_BACKEND=pipeline # or another backend you prefer
|
||||||
|
|
||||||
|
|||||||
@ -77,7 +77,7 @@ The [.env](./.env) file contains important environment variables for Docker.
|
|||||||
- `SVR_HTTP_PORT`
|
- `SVR_HTTP_PORT`
|
||||||
The port used to expose RAGFlow's HTTP API service to the host machine, allowing **external** access to the service running inside the Docker container. Defaults to `9380`.
|
The port used to expose RAGFlow's HTTP API service to the host machine, allowing **external** access to the service running inside the Docker container. Defaults to `9380`.
|
||||||
- `RAGFLOW-IMAGE`
|
- `RAGFLOW-IMAGE`
|
||||||
The Docker image edition. Defaults to `infiniflow/ragflow:v0.22.1`. The RAGFlow Docker image does not include embedding models.
|
The Docker image edition. Defaults to `infiniflow/ragflow:v0.23.0`. The RAGFlow Docker image does not include embedding models.
|
||||||
|
|
||||||
|
|
||||||
> [!TIP]
|
> [!TIP]
|
||||||
|
|||||||
@ -72,7 +72,7 @@ services:
|
|||||||
infinity:
|
infinity:
|
||||||
profiles:
|
profiles:
|
||||||
- infinity
|
- infinity
|
||||||
image: infiniflow/infinity:v0.6.13
|
image: infiniflow/infinity:v0.6.15
|
||||||
volumes:
|
volumes:
|
||||||
- infinity_data:/var/infinity
|
- infinity_data:/var/infinity
|
||||||
- ./infinity_conf.toml:/infinity_conf.toml
|
- ./infinity_conf.toml:/infinity_conf.toml
|
||||||
|
|||||||
@ -1,5 +1,5 @@
|
|||||||
[general]
|
[general]
|
||||||
version = "0.6.13"
|
version = "0.6.15"
|
||||||
time_zone = "utc-8"
|
time_zone = "utc-8"
|
||||||
|
|
||||||
[network]
|
[network]
|
||||||
|
|||||||
@ -99,7 +99,7 @@ RAGFlow utilizes MinIO as its object storage solution, leveraging its scalabilit
|
|||||||
- `SVR_HTTP_PORT`
|
- `SVR_HTTP_PORT`
|
||||||
The port used to expose RAGFlow's HTTP API service to the host machine, allowing **external** access to the service running inside the Docker container. Defaults to `9380`.
|
The port used to expose RAGFlow's HTTP API service to the host machine, allowing **external** access to the service running inside the Docker container. Defaults to `9380`.
|
||||||
- `RAGFLOW-IMAGE`
|
- `RAGFLOW-IMAGE`
|
||||||
The Docker image edition. Defaults to `infiniflow/ragflow:v0.22.1` (the RAGFlow Docker image without embedding models).
|
The Docker image edition. Defaults to `infiniflow/ragflow:v0.23.0` (the RAGFlow Docker image without embedding models).
|
||||||
|
|
||||||
:::tip NOTE
|
:::tip NOTE
|
||||||
If you cannot download the RAGFlow Docker image, try the following mirrors.
|
If you cannot download the RAGFlow Docker image, try the following mirrors.
|
||||||
|
|||||||
@ -47,7 +47,7 @@ After building the infiniflow/ragflow:nightly image, you are ready to launch a f
|
|||||||
|
|
||||||
1. Edit Docker Compose Configuration
|
1. Edit Docker Compose Configuration
|
||||||
|
|
||||||
Open the `docker/.env` file. Find the `RAGFLOW_IMAGE` setting and change the image reference from `infiniflow/ragflow:v0.22.1` to `infiniflow/ragflow:nightly` to use the pre-built image.
|
Open the `docker/.env` file. Find the `RAGFLOW_IMAGE` setting and change the image reference from `infiniflow/ragflow:v0.23.0` to `infiniflow/ragflow:nightly` to use the pre-built image.
|
||||||
|
|
||||||
|
|
||||||
2. Launch the Service
|
2. Launch the Service
|
||||||
|
|||||||
48
docs/guides/dataset/auto_metadata.md
Normal file
48
docs/guides/dataset/auto_metadata.md
Normal file
@ -0,0 +1,48 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: -6
|
||||||
|
slug: /auto_metadata
|
||||||
|
---
|
||||||
|
|
||||||
|
# Auto-extract metadata
|
||||||
|
|
||||||
|
Automatically extract metadata from uploaded files.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
RAGFlow v0.23.0 introduces the Auto-metadata feature, which uses large language models to automatically extract and generate metadata for files—eliminating the need for manual entry. In a typical RAG pipeline, metadata serves two key purposes:
|
||||||
|
|
||||||
|
- During the retrieval stage: Filters out irrelevant documents, narrowing the search scope to improve retrieval accuracy.
|
||||||
|
- During the generation stage: If a text chunk is retrieved, its associated metadata is also passed to the LLM, providing richer contextual information about the source document to aid answer generation.
|
||||||
|
|
||||||
|
|
||||||
|
:::danger WARNING
|
||||||
|
Enabling TOC extraction requires significant memory, computational resources, and tokens.
|
||||||
|
:::
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
## Procedure
|
||||||
|
|
||||||
|
1. On your dataset's **Configuration** page, select an indexing model, which will be used to generate the knowledge graph, RAPTOR, auto-metadata, auto-keyword, and auto-question features for this dataset.
|
||||||
|
|
||||||
|
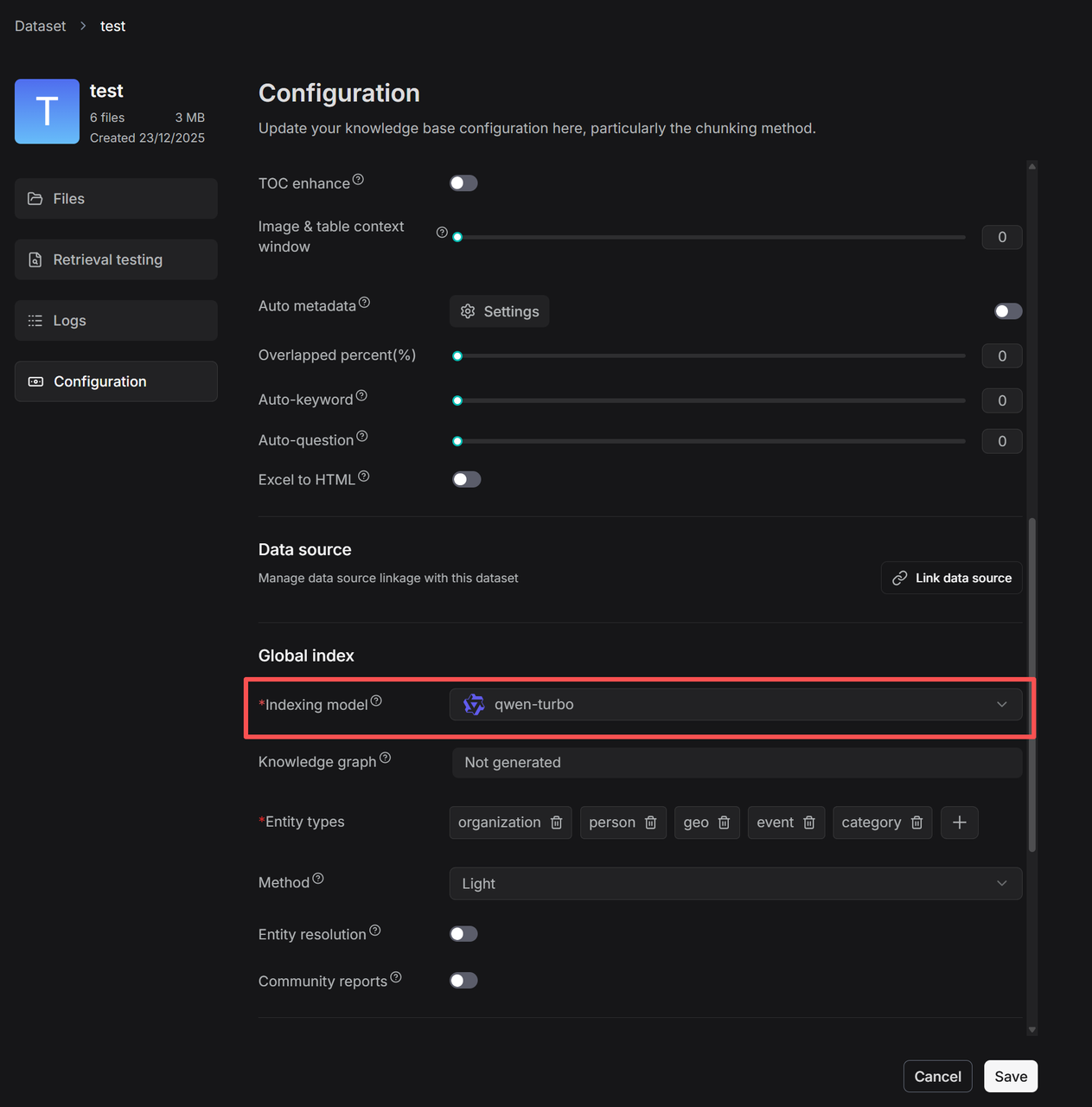
|
||||||
|
|
||||||
|
|
||||||
|
2. Click **Auto metadata** **>** **Settings** to go to the configuration page for automatic metadata generation rules.
|
||||||
|
|
||||||
|
_The configuration page for rules on automatically generating metadata appears._
|
||||||
|
|
||||||
|
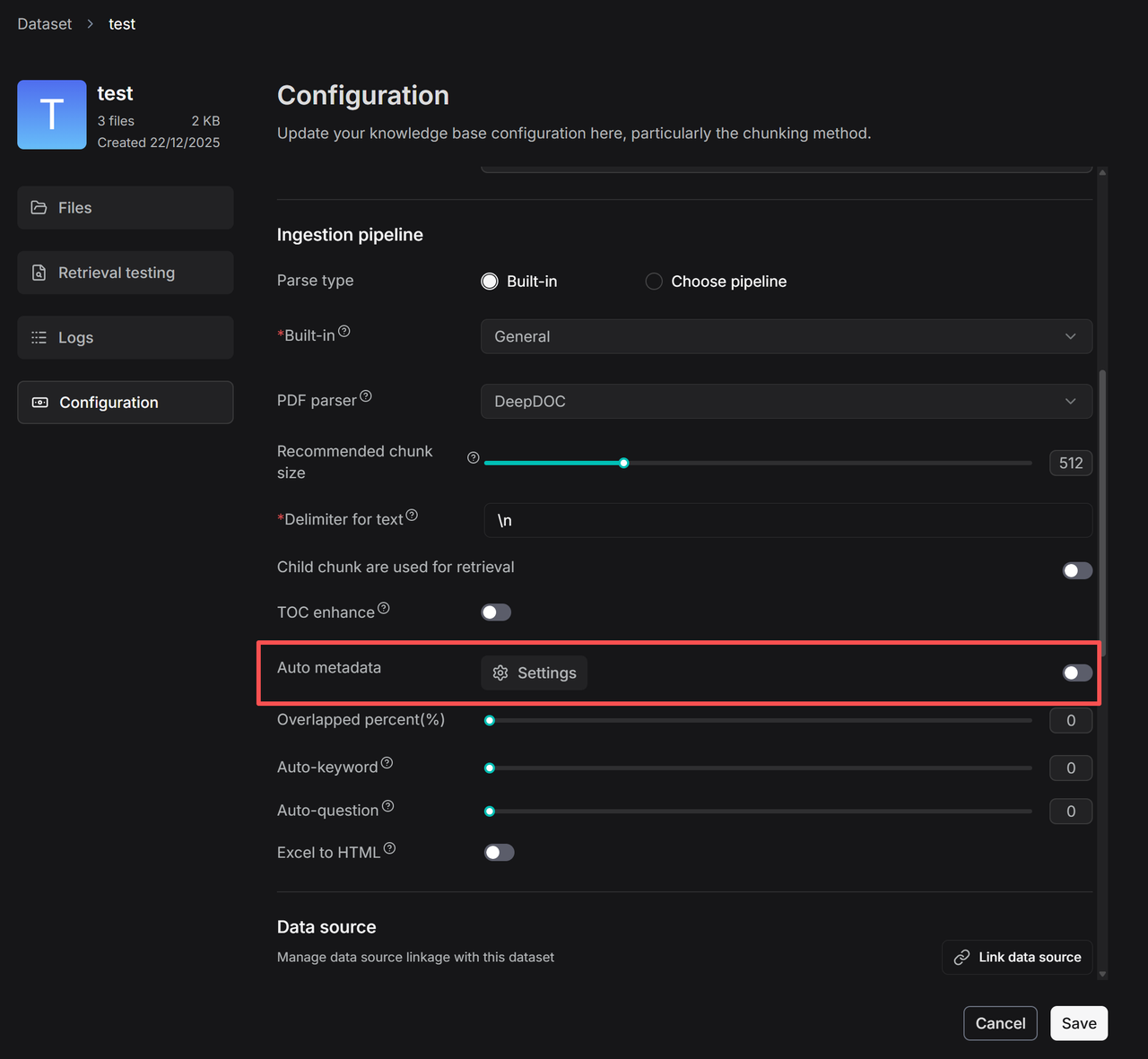
|
||||||
|
|
||||||
|
3. Click **+** to add new fields and enter the configuration page.
|
||||||
|
|
||||||
|
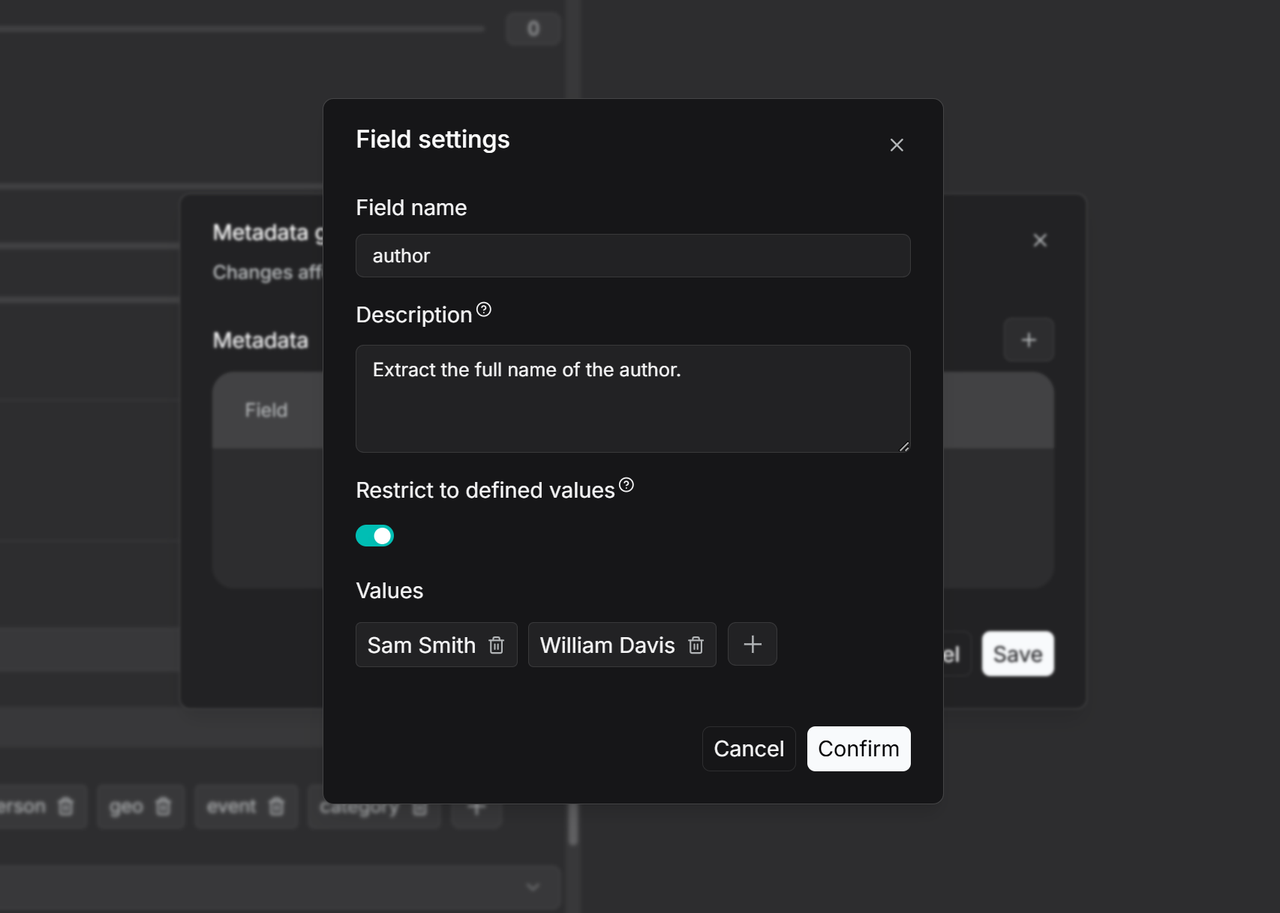
|
||||||
|
|
||||||
|
4. Enter a field name, such as Author, and add a description and examples in the Description section. This provides context to the large language model (LLM) for more accurate value extraction. If left blank, the LLM will extract values based only on the field name.
|
||||||
|
|
||||||
|
5. To restrict the LLM to generating metadata from a predefined list, enable the Restrict to defined values mode and manually add the allowed values. The LLM will then only generate results from this preset range.
|
||||||
|
|
||||||
|
6. Once configured, turn on the Auto-metadata switch on the Configuration page. All newly uploaded files will have these rules applied during parsing. For files that have already been processed, you must re-parse them to trigger metadata generation. You can then use the filter function to check the metadata generation status of your files.
|
||||||
|
|
||||||
|
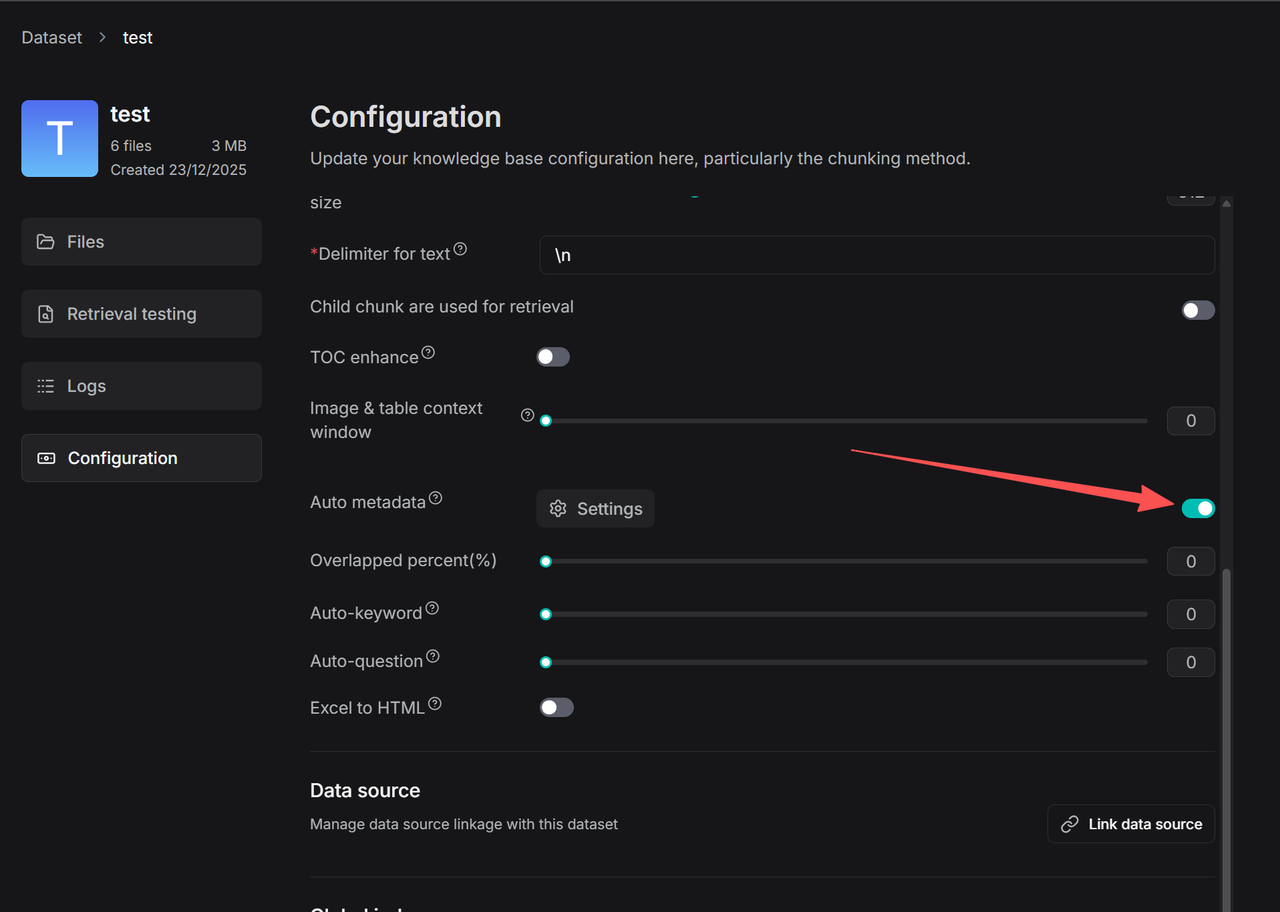
|
||||||
|
|
||||||
34
docs/guides/dataset/configure_child_chunking_strategy.md
Normal file
34
docs/guides/dataset/configure_child_chunking_strategy.md
Normal file
@ -0,0 +1,34 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: -4
|
||||||
|
slug: /configure_child_chunking_strategy
|
||||||
|
---
|
||||||
|
|
||||||
|
# Configure child chunking strategy
|
||||||
|
|
||||||
|
Set parent-child chunking strategy to improve retrieval.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
A persistent challenge in practical RAG applications lies in a structural tension within the traditional "chunk-embed-retrieve" pipeline: a single text chunk is tasked with both semantic matching (recall) and contextual understanding (utilization)—two inherently conflicting objectives. Recall demands fine-grained, precise chunks, while answer generation requires coherent, informationally complete context.
|
||||||
|
|
||||||
|
To resolve this tension, RAGFlow previously introduced the Table of Contents (TOC) enhancement feature, which uses a large language model (LLM) to generate document structure and automatically supplements missing context during retrieval based on that TOC. In version 0.23.0, this capability has been systematically integrated into the Ingestion Pipeline, and a novel parent-child chunking mechanism has been introduced.
|
||||||
|
|
||||||
|
Under this mechanism, a document is first segmented into larger parent chunks, each maintaining a relatively complete semantic unit to ensure logical and background integrity. Each parent chunk can then be further subdivided into multiple child chunks for precise recall. During retrieval, the system first locates the most relevant text segments based on the child chunks while automatically associating and recalling their parent chunk. This approach maintains high recall relevance while providing ample semantic background for the generation phase.
|
||||||
|
|
||||||
|
For instance, when processing a *Compliance Handbook*, a user query about "liability for breach" might precisely retrieve a child chunk stating, "The penalty for breach is 20% of the total contract value," but without context, it cannot clarify whether this clause applies to "minor breach" or "material breach." Leveraging the parent-child chunking mechanism, the system returns this child chunk along with its parent chunk, which contains the complete section of the clause. This allows the LLM to make accurate judgments based on broader context, avoiding misinterpretation.
|
||||||
|
|
||||||
|
Through this dual-layer structure of "precise localization + contextual supplementation," RAGFlow ensures retrieval accuracy while significantly enhancing the reliability and completeness of generated answers.
|
||||||
|
|
||||||
|
|
||||||
|
## Procedure
|
||||||
|
|
||||||
|
1. On your dataset's **Configuration** page, find the **Child chunk are used for retrieval** toggle:
|
||||||
|
|
||||||
|
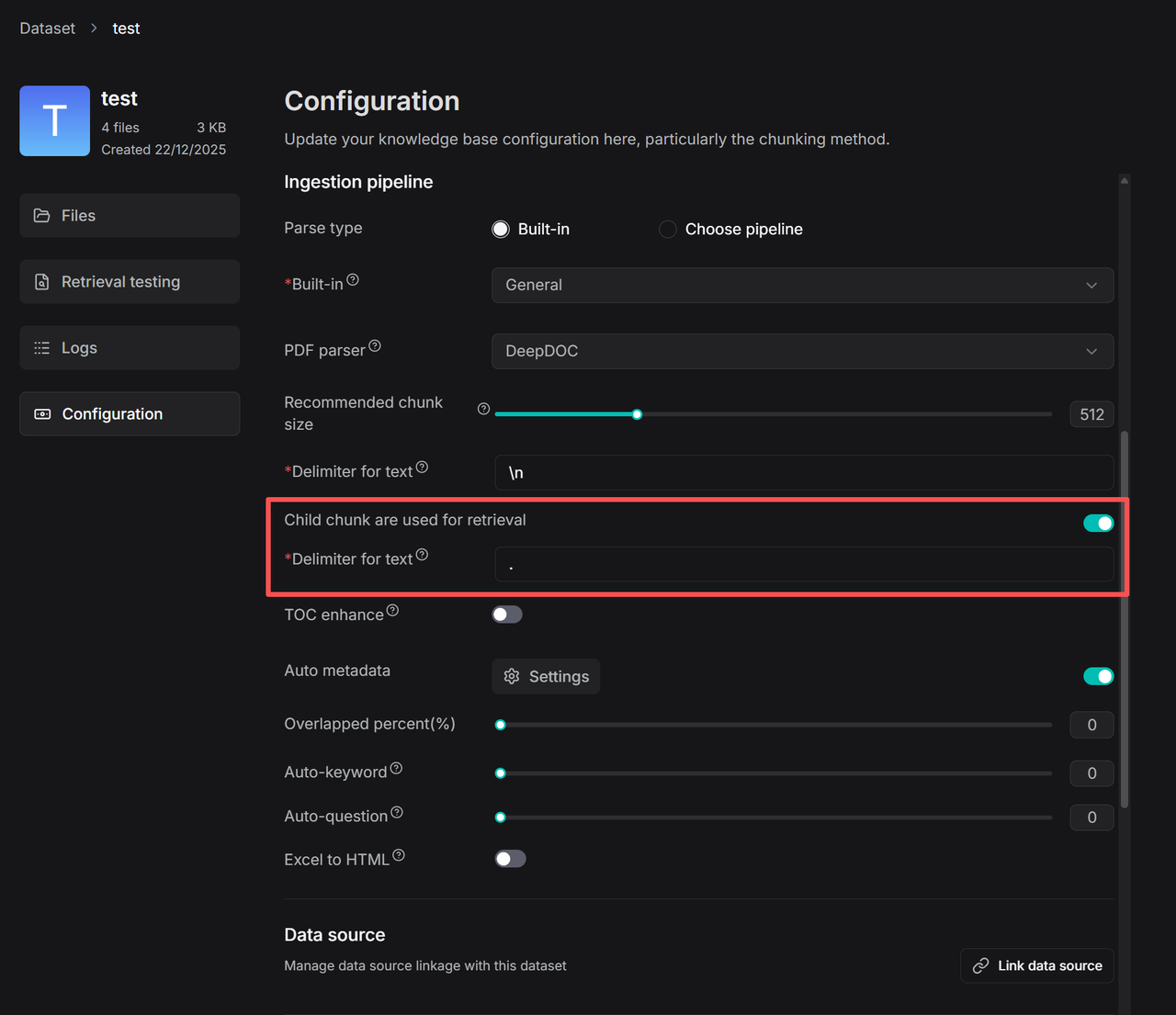
|
||||||
|
|
||||||
|
|
||||||
|
2. Set the delimiter for child chunks.
|
||||||
|
|
||||||
|
3. This configuration applies to the **Chunker** component when it comes to ingestion pipeline settings:
|
||||||
|
|
||||||
|

|
||||||
@ -133,7 +133,7 @@ See [Run retrieval test](./run_retrieval_test.md) for details.
|
|||||||
|
|
||||||
## Search for dataset
|
## Search for dataset
|
||||||
|
|
||||||
As of RAGFlow v0.22.1, the search feature is still in a rudimentary form, supporting only dataset search by name.
|
As of RAGFlow v0.23.0, the search feature is still in a rudimentary form, supporting only dataset search by name.
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
|
|||||||
47
docs/guides/dataset/manage_metadata.md
Normal file
47
docs/guides/dataset/manage_metadata.md
Normal file
@ -0,0 +1,47 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: -5
|
||||||
|
slug: /manage_metadata
|
||||||
|
---
|
||||||
|
|
||||||
|
# Manage metadata
|
||||||
|
|
||||||
|
Manage metadata for your dataset and for your individual documents.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
From v0.23.0 onwards, RAGFlow allows you to manage metadata both at the dataset level and for individual files.
|
||||||
|
|
||||||
|
|
||||||
|
## Procedure
|
||||||
|
|
||||||
|
1. Click on **Metadata** within your dataset to access the **Manage Metadata** page.
|
||||||
|
|
||||||
|
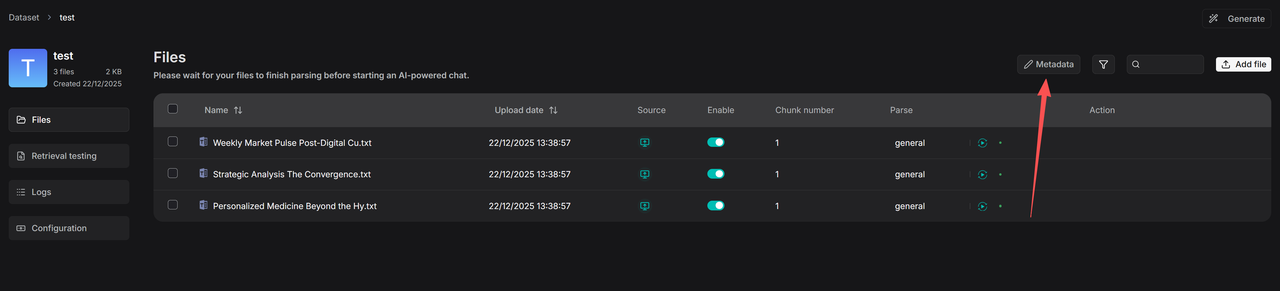
|
||||||
|
|
||||||
|
|
||||||
|
2. On the **Manage Metadata** page, you can do either of the following:
|
||||||
|
- Edit Values: You can modify existing values. If you rename two values to be identical, they will be automatically merged.
|
||||||
|
- Delete: You can delete specific values or entire fields. These changes will apply to all associated files.
|
||||||
|
|
||||||
|
_The configuration page for rules on automatically generating metadata appears._
|
||||||
|
|
||||||
|
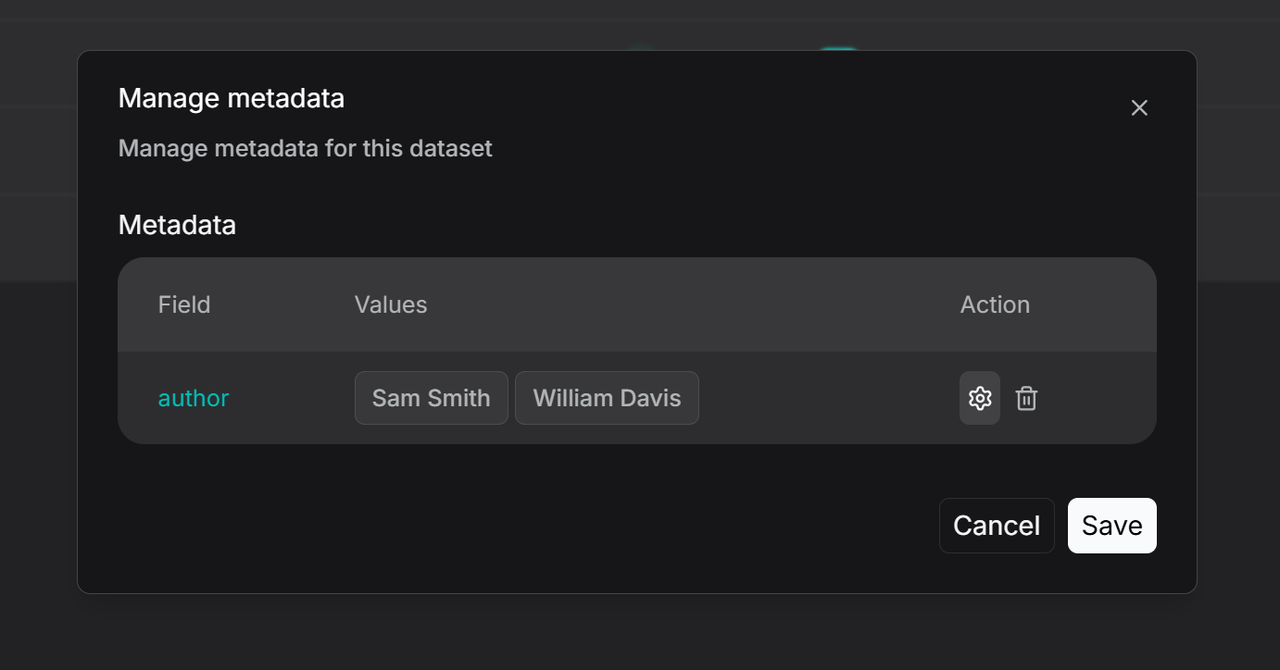
|
||||||
|
|
||||||
|
3. To manage metadata for a single file, navigate to the file's details page as shown below. Click on the parsing method (e.g., **General**), then select **Set Metadata** to view or edit the file's metadata. Here, you can add, delete, or modify metadata fields for this specific file. Any edits made here will be reflected in the global statistics on the main Metadata management page for the knowledge base.
|
||||||
|
|
||||||
|
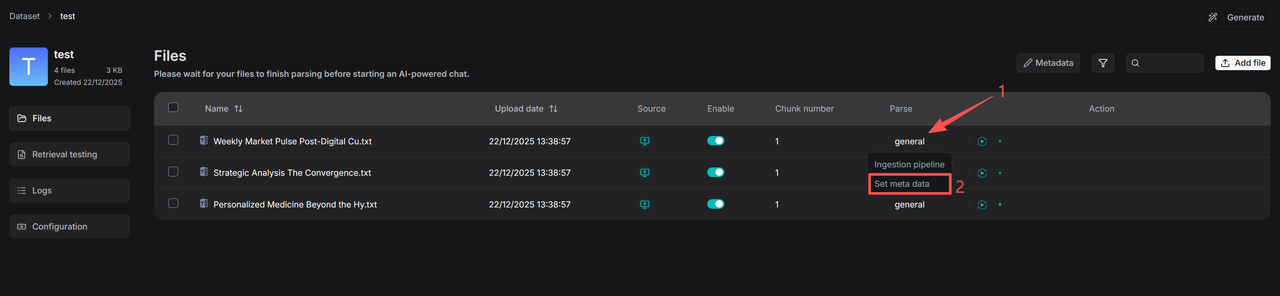
|
||||||
|
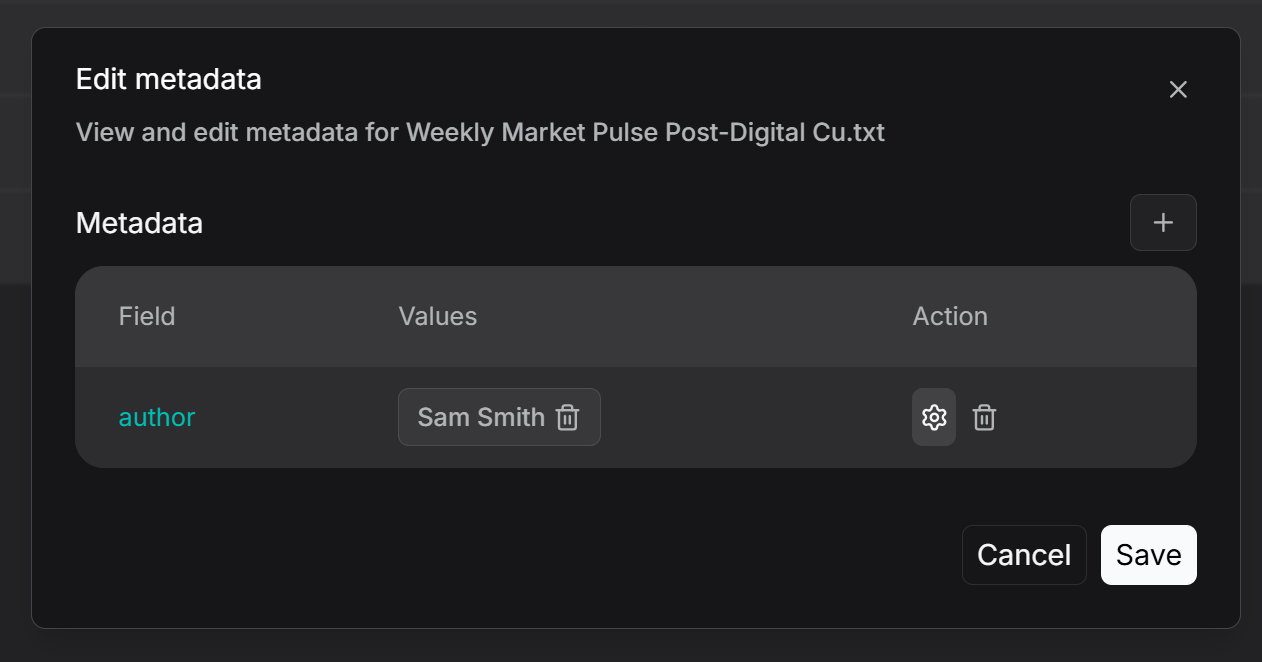
|
||||||
|
|
||||||
|
4. The filtering function operates at two levels: knowledge base management and retrieval. Within the dataset, click the Filter button to view the number of files associated with each value under existing metadata fields. By selecting specific values, you can display all linked files.
|
||||||
|
|
||||||
|
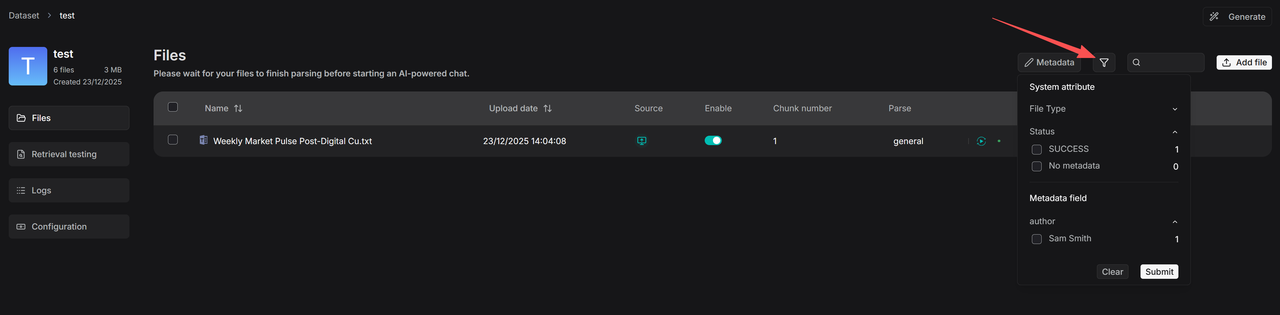
|
||||||
|
|
||||||
|
5. Metadata filtering is also supported during the retrieval stage. In Chat, for example, you can set metadata filtering rules after configuring a knowledge base:
|
||||||
|
|
||||||
|
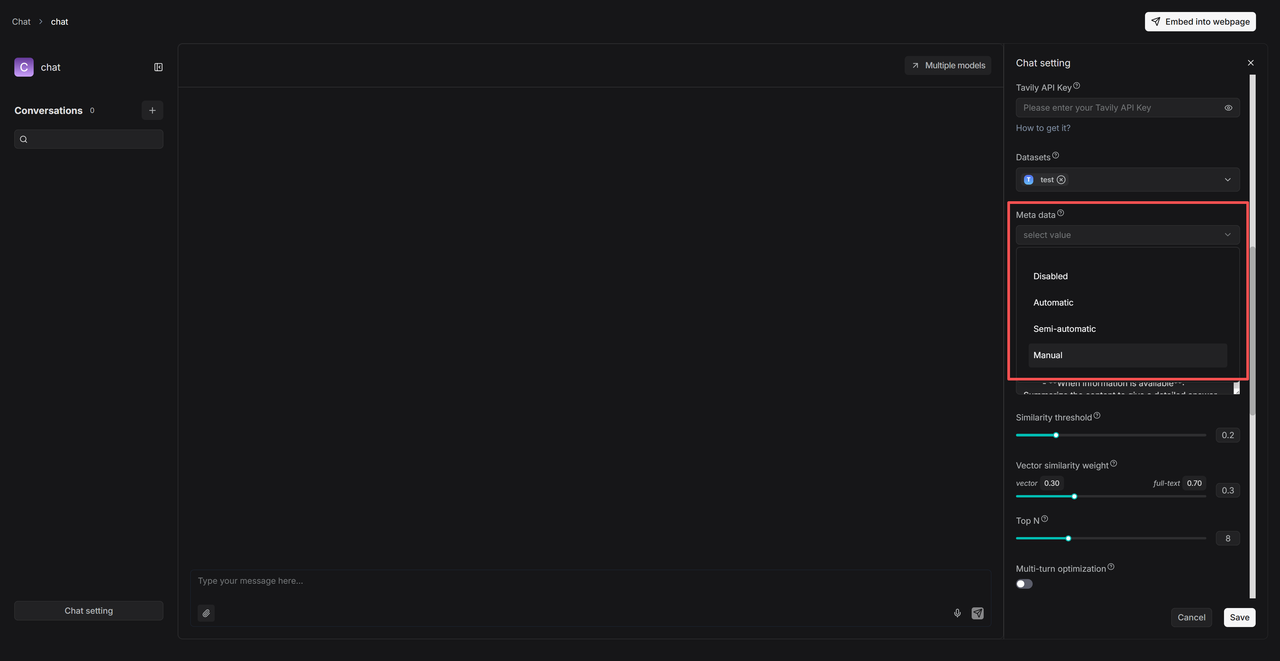
|
||||||
|
|
||||||
|
- **Automatic** Mode: The system automatically filters documents based on the user's query and the existing metadata in the knowledge base.
|
||||||
|
- **Semi-automatic** Mode: Users first define the filtering scope at the field level (e.g., for **Author**), and then the system automatically filters within that preset range.
|
||||||
|
- **Manual** Mode: Users manually set precise, value-specific filter conditions, supported by operators such as **Equals**, **Not equals**, **In**, **Not in**, and more.
|
||||||
|
|
||||||
|
|
||||||
@ -1,5 +1,5 @@
|
|||||||
---
|
---
|
||||||
sidebar_position: -4
|
sidebar_position: -3
|
||||||
slug: /select_pdf_parser
|
slug: /select_pdf_parser
|
||||||
---
|
---
|
||||||
|
|
||||||
|
|||||||
25
docs/guides/dataset/set_context_window.md
Normal file
25
docs/guides/dataset/set_context_window.md
Normal file
@ -0,0 +1,25 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: -8
|
||||||
|
slug: /set_context_window
|
||||||
|
---
|
||||||
|
|
||||||
|
# Set context window size
|
||||||
|
|
||||||
|
Set context window size for images and tables to improve long-context RAG performances.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
RAGFlow leverages built-in DeepDoc, along with external document models like MinerU and Docling, to parse document layouts. In previous versions, images and tables extracted based on document layout were treated as independent chunks. Consequently, if a search query did not directly match the content of an image or table, these elements would not be retrieved. However, real-world documents frequently interweave charts and tables with surrounding text, which often describes them. Therefore, recalling charts based on this contextual text is an essential capability.
|
||||||
|
|
||||||
|
To address this, RAGFlow 0.23.0 introduces the **Image & table context window** feature. Inspired by key principles of the research-focused, open-source multimodal RAG project RAG-Anything, this functionality allows surrounding text and adjacent visuals to be grouped into a single chunk based on a user-configurable window size. This ensures they are retrieved together, significantly improving the recall accuracy for charts and tables.
|
||||||
|
|
||||||
|
## Procedure
|
||||||
|
|
||||||
|
1. On your dataset's **Configuration** page, find the **Image & table context window** slider:
|
||||||
|
|
||||||
|
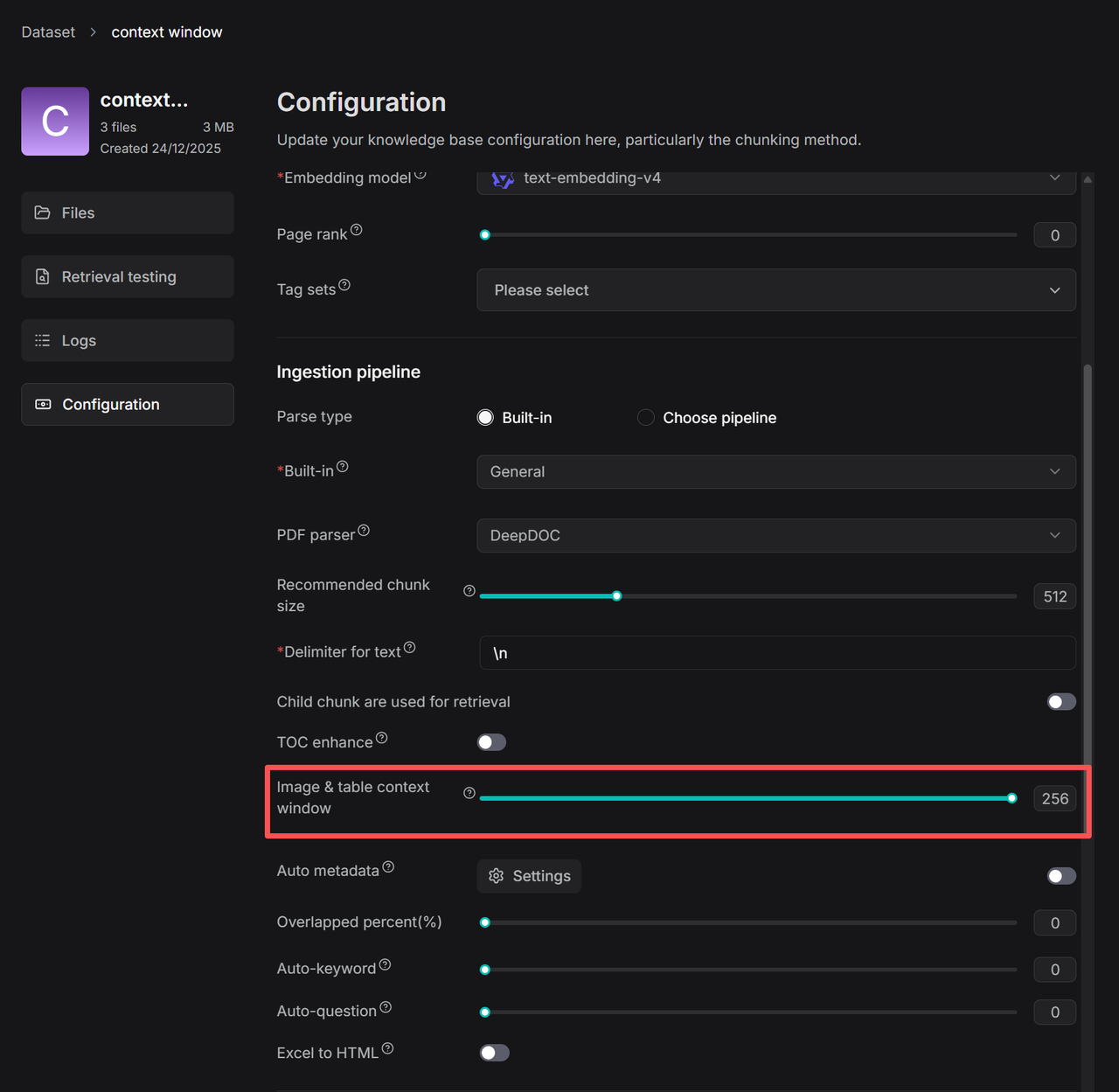
|
||||||
|
|
||||||
|
|
||||||
|
2. Adjust the number of context tokens according to your needs.
|
||||||
|
|
||||||
|
*The number in the red box indicates that approximately **N tokens** of text from above and below the image/table will be captured and inserted into the image or table chunk as contextual information. The capture process intelligently optimizes boundaries at punctuation marks to preserve semantic integrity. *
|
||||||
@ -5,7 +5,7 @@ slug: /set_metadata
|
|||||||
|
|
||||||
# Set metadata
|
# Set metadata
|
||||||
|
|
||||||
Add metadata to an uploaded file
|
Manually add metadata to an uploaded file
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
@ -29,4 +29,4 @@ Ensure that your metadata is in JSON format; otherwise, your updates will not be
|
|||||||
|
|
||||||
### Can I set metadata for multiple documents at once?
|
### Can I set metadata for multiple documents at once?
|
||||||
|
|
||||||
No, you must set metadata *individually* for each document, as RAGFlow does not support batch setting of metadata. If you still consider this feature essential, please [raise an issue](https://github.com/infiniflow/ragflow/issues) explaining your use case and its importance.
|
From v0.23.0 onwards, you can set metadata for each document individually or have the LLM auto-generate metadata for multiple files. See [Extract metadata](./auto_metadata.md) for details.
|
||||||
@ -87,4 +87,4 @@ RAGFlow's file management allows you to download an uploaded file:
|
|||||||
|
|
||||||

|

|
||||||
|
|
||||||
> As of RAGFlow v0.22.1, bulk download is not supported, nor can you download an entire folder.
|
> As of RAGFlow v0.23.0, bulk download is not supported, nor can you download an entire folder.
|
||||||
|
|||||||
@ -46,7 +46,7 @@ The Admin CLI and Admin Service form a client-server architectural suite for RAG
|
|||||||
2. Install ragflow-cli.
|
2. Install ragflow-cli.
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
pip install ragflow-cli==0.22.1
|
pip install ragflow-cli==0.23.0
|
||||||
```
|
```
|
||||||
|
|
||||||
3. Launch the CLI client:
|
3. Launch the CLI client:
|
||||||
|
|||||||
@ -7,7 +7,7 @@ slug: /deploy_local_llm
|
|||||||
import Tabs from '@theme/Tabs';
|
import Tabs from '@theme/Tabs';
|
||||||
import TabItem from '@theme/TabItem';
|
import TabItem from '@theme/TabItem';
|
||||||
|
|
||||||
Deploy and run local models using Ollama, Xinference, or other frameworks.
|
Deploy and run local models using Ollama, Xinference, VLLM ,SGLANG or other frameworks.
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
@ -314,3 +314,41 @@ To enable IPEX-LLM accelerated Ollama in RAGFlow, you must also complete the con
|
|||||||
3. [Update System Model Settings](#6-update-system-model-settings)
|
3. [Update System Model Settings](#6-update-system-model-settings)
|
||||||
4. [Update Chat Configuration](#7-update-chat-configuration)
|
4. [Update Chat Configuration](#7-update-chat-configuration)
|
||||||
|
|
||||||
|
### 5. Deploy VLLM
|
||||||
|
|
||||||
|
ubuntu 22.04/24.04
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install vllm
|
||||||
|
```
|
||||||
|
### 5.1 RUN VLLM WITH BEST PRACTISE
|
||||||
|
|
||||||
|
```bash
|
||||||
|
nohup vllm serve /data/Qwen3-8B --served-model-name Qwen3-8B-FP8 --dtype auto --port 1025 --gpu-memory-utilization 0.90 --tool-call-parser hermes --enable-auto-tool-choice > /var/log/vllm_startup1.log 2>&1 &
|
||||||
|
```
|
||||||
|
you can get log info
|
||||||
|
```bash
|
||||||
|
tail -f -n 100 /var/log/vllm_startup1.log
|
||||||
|
```
|
||||||
|
when see the follow ,it means vllm engine is ready for access
|
||||||
|
```bash
|
||||||
|
Starting vLLM API server 0 on http://0.0.0.0:1025
|
||||||
|
Started server process [19177]
|
||||||
|
Application startup complete.
|
||||||
|
```
|
||||||
|
### 5.2 INTERGRATEING RAGFLOW WITH VLLM CHAT/EM/RERANK LLM WITH WEBUI
|
||||||
|
|
||||||
|
setting->model providers->search->vllm->add ,configure as follow:
|
||||||
|
|
||||||
|
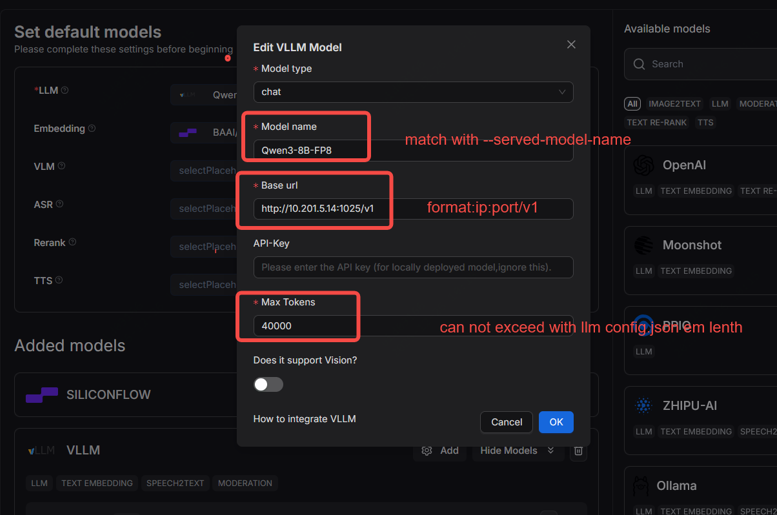
|
||||||
|
|
||||||
|
select vllm chat model as default llm model as follow:
|
||||||
|
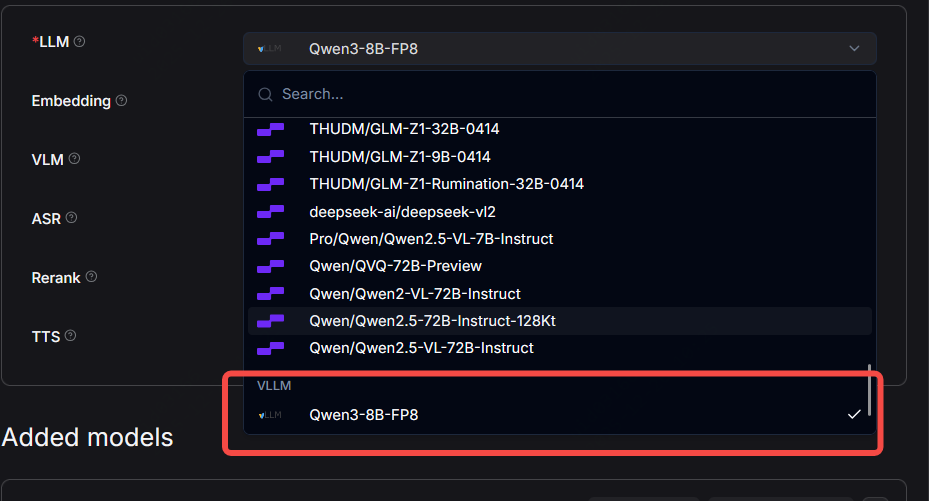
|
||||||
|
### 5.3 chat with vllm chat model
|
||||||
|
create chat->create conversations-chat as follow:
|
||||||
|
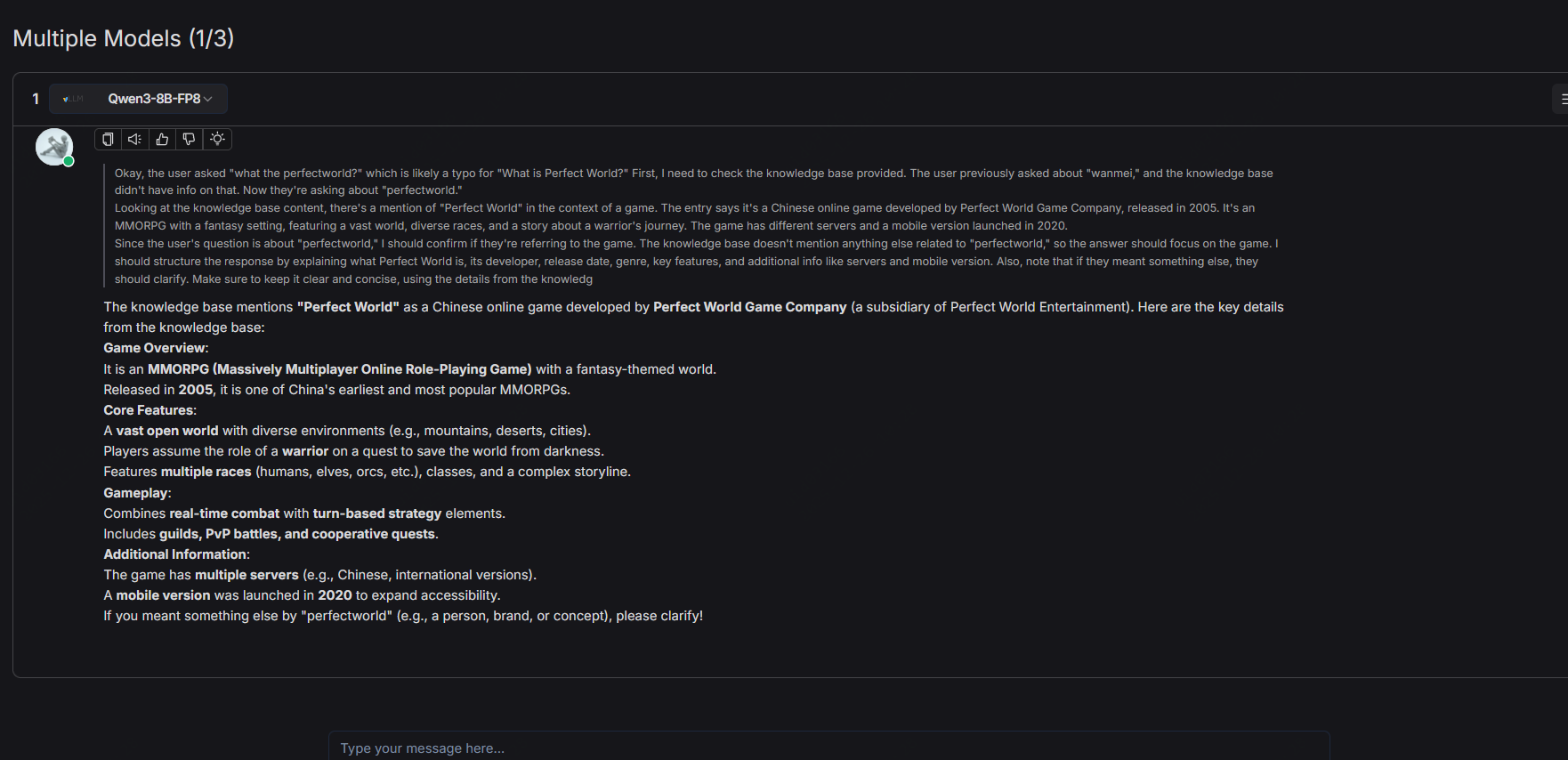
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
@ -60,16 +60,16 @@ To upgrade RAGFlow, you must upgrade **both** your code **and** your Docker imag
|
|||||||
git pull
|
git pull
|
||||||
```
|
```
|
||||||
|
|
||||||
3. Switch to the latest, officially published release, e.g., `v0.22.1`:
|
3. Switch to the latest, officially published release, e.g., `v0.23.0`:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
git checkout -f v0.22.1
|
git checkout -f v0.23.0
|
||||||
```
|
```
|
||||||
|
|
||||||
4. Update **ragflow/docker/.env**:
|
4. Update **ragflow/docker/.env**:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
RAGFLOW_IMAGE=infiniflow/ragflow:v0.22.1
|
RAGFLOW_IMAGE=infiniflow/ragflow:v0.23.0
|
||||||
```
|
```
|
||||||
|
|
||||||
5. Update the RAGFlow image and restart RAGFlow:
|
5. Update the RAGFlow image and restart RAGFlow:
|
||||||
@ -90,10 +90,10 @@ No, you do not need to. Upgrading RAGFlow in itself will *not* remove your uploa
|
|||||||
1. From an environment with Internet access, pull the required Docker image.
|
1. From an environment with Internet access, pull the required Docker image.
|
||||||
2. Save the Docker image to a **.tar** file.
|
2. Save the Docker image to a **.tar** file.
|
||||||
```bash
|
```bash
|
||||||
docker save -o ragflow.v0.22.1.tar infiniflow/ragflow:v0.22.1
|
docker save -o ragflow.v0.23.0.tar infiniflow/ragflow:v0.23.0
|
||||||
```
|
```
|
||||||
3. Copy the **.tar** file to the target server.
|
3. Copy the **.tar** file to the target server.
|
||||||
4. Load the **.tar** file into Docker:
|
4. Load the **.tar** file into Docker:
|
||||||
```bash
|
```bash
|
||||||
docker load -i ragflow.v0.22.1.tar
|
docker load -i ragflow.v0.23.0.tar
|
||||||
```
|
```
|
||||||
|
|||||||
@ -46,7 +46,7 @@ This section provides instructions on setting up the RAGFlow server on Linux. If
|
|||||||
|
|
||||||
`vm.max_map_count`. This value sets the maximum number of memory map areas a process may have. Its default value is 65530. While most applications require fewer than a thousand maps, reducing this value can result in abnormal behaviors, and the system will throw out-of-memory errors when a process reaches the limitation.
|
`vm.max_map_count`. This value sets the maximum number of memory map areas a process may have. Its default value is 65530. While most applications require fewer than a thousand maps, reducing this value can result in abnormal behaviors, and the system will throw out-of-memory errors when a process reaches the limitation.
|
||||||
|
|
||||||
RAGFlow v0.22.1 uses Elasticsearch or [Infinity](https://github.com/infiniflow/infinity) for multiple recall. Setting the value of `vm.max_map_count` correctly is crucial to the proper functioning of the Elasticsearch component.
|
RAGFlow v0.23.0 uses Elasticsearch or [Infinity](https://github.com/infiniflow/infinity) for multiple recall. Setting the value of `vm.max_map_count` correctly is crucial to the proper functioning of the Elasticsearch component.
|
||||||
|
|
||||||
<Tabs
|
<Tabs
|
||||||
defaultValue="linux"
|
defaultValue="linux"
|
||||||
@ -186,7 +186,7 @@ This section provides instructions on setting up the RAGFlow server on Linux. If
|
|||||||
```bash
|
```bash
|
||||||
$ git clone https://github.com/infiniflow/ragflow.git
|
$ git clone https://github.com/infiniflow/ragflow.git
|
||||||
$ cd ragflow/docker
|
$ cd ragflow/docker
|
||||||
$ git checkout -f v0.22.1
|
$ git checkout -f v0.23.0
|
||||||
```
|
```
|
||||||
|
|
||||||
3. Use the pre-built Docker images and start up the server:
|
3. Use the pre-built Docker images and start up the server:
|
||||||
@ -202,7 +202,7 @@ This section provides instructions on setting up the RAGFlow server on Linux. If
|
|||||||
|
|
||||||
| RAGFlow image tag | Image size (GB) | Stable? |
|
| RAGFlow image tag | Image size (GB) | Stable? |
|
||||||
| ------------------- | --------------- | ------------------------ |
|
| ------------------- | --------------- | ------------------------ |
|
||||||
| v0.22.1 | ≈2 | Stable release |
|
| v0.23.0 | ≈2 | Stable release |
|
||||||
| nightly | ≈2 | _Unstable_ nightly build |
|
| nightly | ≈2 | _Unstable_ nightly build |
|
||||||
|
|
||||||
```mdx-code-block
|
```mdx-code-block
|
||||||
|
|||||||
@ -7,6 +7,61 @@ slug: /release_notes
|
|||||||
|
|
||||||
Key features, improvements and bug fixes in the latest releases.
|
Key features, improvements and bug fixes in the latest releases.
|
||||||
|
|
||||||
|
## v0.23.0
|
||||||
|
|
||||||
|
Released on December 27, 2025.
|
||||||
|
|
||||||
|
### New features
|
||||||
|
|
||||||
|
- Memory
|
||||||
|
- Implements a **Memory** interface for managing memory.
|
||||||
|
- Supports configuring context via the **Retrieval** or **Message** component.
|
||||||
|
- Agent
|
||||||
|
- Improves the **Agent** component's performance by refactoring the underlying architecture.
|
||||||
|
- The **Agent** component can now output structured data for use in downstream components.
|
||||||
|
- Supports using webhook to trigger agent execution.
|
||||||
|
- Supports voice input/output.
|
||||||
|
- Supports configuring multiple **Retrieval** components per **Agent** component.
|
||||||
|
- Ingestion pipeline
|
||||||
|
- Supports extracting table of contents in the **Transformer** component to improve long-context RAG performance.
|
||||||
|
- Dataset
|
||||||
|
- Supports configuring context window for images and tables.
|
||||||
|
- Introduces parent-child chunking strategy.
|
||||||
|
- Supports auto-generation of metadata during file parsing.
|
||||||
|
- Chat: Supports voice input.
|
||||||
|
|
||||||
|
### Improvements
|
||||||
|
|
||||||
|
- Bumps RAGFlow's document engine, [Infinity](https://github.com/infiniflow/infinity) to v0.6.15 (backward compatible).
|
||||||
|
|
||||||
|
### Data sources
|
||||||
|
|
||||||
|
- Google Cloud Storage
|
||||||
|
- Gmail
|
||||||
|
- Dropbox
|
||||||
|
- WebDAV
|
||||||
|
- Airtable
|
||||||
|
|
||||||
|
### Model support
|
||||||
|
|
||||||
|
- GPT-5.2
|
||||||
|
- GPT-5.2 Pro
|
||||||
|
- GPT-5.1
|
||||||
|
- GPT-5.1 Instant
|
||||||
|
- Claude Opus 4.5
|
||||||
|
- MiniMax M2
|
||||||
|
- GLM-4.7.
|
||||||
|
- A MinerU configuration interface.
|
||||||
|
- AI Badgr (model provider).
|
||||||
|
|
||||||
|
### API changes
|
||||||
|
|
||||||
|
#### HTTP API
|
||||||
|
|
||||||
|
- [Converse with Agent](./references/http_api_reference.md#converse-with-agent) returns complete execution trace logs.
|
||||||
|
- [Create chat completion](./references/http_api_reference.md#create-chat-completion) supports metadata-based filtering.
|
||||||
|
- [Converse with chat assistant](./references/http_api_reference.md#converse-with-chat-assistant) supports metadata-based filtering.
|
||||||
|
|
||||||
## v0.22.1
|
## v0.22.1
|
||||||
|
|
||||||
Released on November 19, 2025.
|
Released on November 19, 2025.
|
||||||
|
|||||||
133
helm/README.md
Normal file
133
helm/README.md
Normal file
@ -0,0 +1,133 @@
|
|||||||
|
# RAGFlow Helm Chart
|
||||||
|
|
||||||
|
A Helm chart to deploy RAGFlow and its dependencies on Kubernetes.
|
||||||
|
|
||||||
|
- Components: RAGFlow (web/api) and optional dependencies (Infinity/Elasticsearch/OpenSearch, MySQL, MinIO, Redis)
|
||||||
|
- Requirements: Kubernetes >= 1.24, Helm >= 3.10
|
||||||
|
|
||||||
|
## Install
|
||||||
|
|
||||||
|
```bash
|
||||||
|
helm upgrade --install ragflow ./ \
|
||||||
|
--namespace ragflow --create-namespace
|
||||||
|
```
|
||||||
|
|
||||||
|
Uninstall:
|
||||||
|
```bash
|
||||||
|
helm uninstall ragflow -n ragflow
|
||||||
|
```
|
||||||
|
|
||||||
|
## Global Settings
|
||||||
|
|
||||||
|
- `global.repo`: Prepend a global image registry prefix for all images.
|
||||||
|
- Behavior: Replaces the registry part and keeps the image path (e.g., `quay.io/minio/minio` -> `registry.example.com/myproj/minio/minio`).
|
||||||
|
- Example: `global.repo: "registry.example.com/myproj"`
|
||||||
|
- `global.imagePullSecrets`: List of image pull secrets applied to all Pods.
|
||||||
|
- Example:
|
||||||
|
```yaml
|
||||||
|
global:
|
||||||
|
imagePullSecrets:
|
||||||
|
- name: regcred
|
||||||
|
```
|
||||||
|
|
||||||
|
## External Services (MySQL / MinIO / Redis)
|
||||||
|
|
||||||
|
The chart can deploy in-cluster services or connect to external ones. Toggle with `*.enabled`. When disabled, provide host/port via `env.*`.
|
||||||
|
|
||||||
|
- MySQL
|
||||||
|
- `mysql.enabled`: default `true`
|
||||||
|
- If `false`, set:
|
||||||
|
- `env.MYSQL_HOST` (required), `env.MYSQL_PORT` (default `3306`)
|
||||||
|
- `env.MYSQL_DBNAME` (default `rag_flow`), `env.MYSQL_PASSWORD` (required)
|
||||||
|
- `env.MYSQL_USER` (default `root` if omitted)
|
||||||
|
- MinIO
|
||||||
|
- `minio.enabled`: default `true`
|
||||||
|
- Configure:
|
||||||
|
- `env.MINIO_HOST` (optional external host), `env.MINIO_PORT` (default `9000`)
|
||||||
|
- `env.MINIO_ROOT_USER` (default `rag_flow`), `env.MINIO_PASSWORD` (optional)
|
||||||
|
- Redis (Valkey)
|
||||||
|
- `redis.enabled`: default `true`
|
||||||
|
- If `false`, set:
|
||||||
|
- `env.REDIS_HOST` (required), `env.REDIS_PORT` (default `6379`)
|
||||||
|
- `env.REDIS_PASSWORD` (optional; empty disables auth if server allows)
|
||||||
|
|
||||||
|
Notes:
|
||||||
|
- When `*.enabled=true`, the chart renders in-cluster resources and injects corresponding `*_HOST`/`*_PORT` automatically.
|
||||||
|
- Sensitive variables like `MYSQL_PASSWORD` are required; `MINIO_PASSWORD` and `REDIS_PASSWORD` are optional. All secrets are stored in a Secret.
|
||||||
|
|
||||||
|
### Example: use external MySQL, MinIO, and Redis
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
# values.override.yaml
|
||||||
|
mysql:
|
||||||
|
enabled: false # use external MySQL
|
||||||
|
minio:
|
||||||
|
enabled: false # use external MinIO (S3 compatible)
|
||||||
|
redis:
|
||||||
|
enabled: false # use external Redis/Valkey
|
||||||
|
|
||||||
|
env:
|
||||||
|
# MySQL
|
||||||
|
MYSQL_HOST: mydb.example.com
|
||||||
|
MYSQL_PORT: "3306"
|
||||||
|
MYSQL_USER: root
|
||||||
|
MYSQL_DBNAME: rag_flow
|
||||||
|
MYSQL_PASSWORD: "<your-mysql-password>"
|
||||||
|
|
||||||
|
# MinIO
|
||||||
|
MINIO_HOST: s3.example.com
|
||||||
|
MINIO_PORT: "9000"
|
||||||
|
MINIO_ROOT_USER: rag_flow
|
||||||
|
MINIO_PASSWORD: "<your-minio-secret>"
|
||||||
|
|
||||||
|
# Redis
|
||||||
|
REDIS_HOST: redis.example.com
|
||||||
|
REDIS_PORT: "6379"
|
||||||
|
REDIS_PASSWORD: "<your-redis-pass>"
|
||||||
|
```
|
||||||
|
|
||||||
|
Apply:
|
||||||
|
```bash
|
||||||
|
helm upgrade --install ragflow ./helm -n ragflow -f values.override.yaml
|
||||||
|
```
|
||||||
|
|
||||||
|
## Document Engine Selection
|
||||||
|
|
||||||
|
Choose one of `infinity` (default), `elasticsearch`, or `opensearch` via `env.DOC_ENGINE`. The chart renders only the selected engine and sets the appropriate host variables.
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
env:
|
||||||
|
DOC_ENGINE: infinity # or: elasticsearch | opensearch
|
||||||
|
# For elasticsearch
|
||||||
|
ELASTIC_PASSWORD: "<es-pass>"
|
||||||
|
# For opensearch
|
||||||
|
OPENSEARCH_PASSWORD: "<os-pass>"
|
||||||
|
```
|
||||||
|
|
||||||
|
## Ingress
|
||||||
|
|
||||||
|
Expose the web UI via Ingress:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
ingress:
|
||||||
|
enabled: true
|
||||||
|
className: nginx
|
||||||
|
hosts:
|
||||||
|
- host: ragflow.example.com
|
||||||
|
paths:
|
||||||
|
- path: /
|
||||||
|
pathType: Prefix
|
||||||
|
```
|
||||||
|
|
||||||
|
## Validate the Chart
|
||||||
|
|
||||||
|
```bash
|
||||||
|
helm lint ./helm
|
||||||
|
helm template ragflow ./helm > rendered.yaml
|
||||||
|
```
|
||||||
|
|
||||||
|
## Notes
|
||||||
|
|
||||||
|
- By default, the chart uses `DOC_ENGINE: infinity` and deploys in-cluster MySQL, MinIO, and Redis.
|
||||||
|
- The chart injects derived `*_HOST`/`*_PORT` and required secrets into a single Secret (`<release>-ragflow-env-config`).
|
||||||
|
- `global.repo` and `global.imagePullSecrets` apply to all Pods; per-component `*.image.pullSecrets` still work and are merged with global settings.
|
||||||
@ -42,6 +42,31 @@ app.kubernetes.io/version: {{ .Chart.AppVersion | quote }}
|
|||||||
app.kubernetes.io/managed-by: {{ .Release.Service }}
|
app.kubernetes.io/managed-by: {{ .Release.Service }}
|
||||||
{{- end }}
|
{{- end }}
|
||||||
|
|
||||||
|
{{/*
|
||||||
|
Resolve image repository with optional global repo prefix.
|
||||||
|
If .Values.global.repo is set, replace registry part and keep image path.
|
||||||
|
Detect existing registry by first segment containing '.' or ':' or being 'localhost'.
|
||||||
|
Usage: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.foo.image.repository) }}
|
||||||
|
*/}}
|
||||||
|
{{- define "ragflow.imageRepo" -}}
|
||||||
|
{{- $root := .root -}}
|
||||||
|
{{- $repo := .repo -}}
|
||||||
|
{{- $global := $root.Values.global -}}
|
||||||
|
{{- if and $global $global.repo }}
|
||||||
|
{{- $parts := splitList "/" $repo -}}
|
||||||
|
{{- $first := index $parts 0 -}}
|
||||||
|
{{- $hasRegistry := or (regexMatch "\\." $first) (regexMatch ":" $first) (eq $first "localhost") -}}
|
||||||
|
{{- if $hasRegistry -}}
|
||||||
|
{{- $path := join "/" (rest $parts) -}}
|
||||||
|
{{- printf "%s/%s" $global.repo $path -}}
|
||||||
|
{{- else -}}
|
||||||
|
{{- printf "%s/%s" $global.repo $repo -}}
|
||||||
|
{{- end -}}
|
||||||
|
{{- else -}}
|
||||||
|
{{- $repo -}}
|
||||||
|
{{- end -}}
|
||||||
|
{{- end }}
|
||||||
|
|
||||||
{{/*
|
{{/*
|
||||||
Selector labels
|
Selector labels
|
||||||
*/}}
|
*/}}
|
||||||
|
|||||||
@ -32,7 +32,7 @@ spec:
|
|||||||
{{- include "ragflow.selectorLabels" . | nindent 6 }}
|
{{- include "ragflow.selectorLabels" . | nindent 6 }}
|
||||||
app.kubernetes.io/component: elasticsearch
|
app.kubernetes.io/component: elasticsearch
|
||||||
{{- with .Values.elasticsearch.deployment.strategy }}
|
{{- with .Values.elasticsearch.deployment.strategy }}
|
||||||
strategy:
|
updateStrategy:
|
||||||
{{- . | toYaml | nindent 4 }}
|
{{- . | toYaml | nindent 4 }}
|
||||||
{{- end }}
|
{{- end }}
|
||||||
template:
|
template:
|
||||||
@ -44,9 +44,9 @@ spec:
|
|||||||
checksum/config-es: {{ include (print $.Template.BasePath "/elasticsearch-config.yaml") . | sha256sum }}
|
checksum/config-es: {{ include (print $.Template.BasePath "/elasticsearch-config.yaml") . | sha256sum }}
|
||||||
checksum/config-env: {{ include (print $.Template.BasePath "/env.yaml") . | sha256sum }}
|
checksum/config-env: {{ include (print $.Template.BasePath "/env.yaml") . | sha256sum }}
|
||||||
spec:
|
spec:
|
||||||
{{- if or .Values.imagePullSecrets .Values.elasticsearch.image.pullSecrets }}
|
{{- if or .Values.global.imagePullSecrets .Values.elasticsearch.image.pullSecrets }}
|
||||||
imagePullSecrets:
|
imagePullSecrets:
|
||||||
{{- with .Values.imagePullSecrets }}
|
{{- with .Values.global.imagePullSecrets }}
|
||||||
{{- toYaml . | nindent 8 }}
|
{{- toYaml . | nindent 8 }}
|
||||||
{{- end }}
|
{{- end }}
|
||||||
{{- with .Values.elasticsearch.image.pullSecrets }}
|
{{- with .Values.elasticsearch.image.pullSecrets }}
|
||||||
@ -55,7 +55,7 @@ spec:
|
|||||||
{{- end }}
|
{{- end }}
|
||||||
initContainers:
|
initContainers:
|
||||||
- name: fix-data-volume-permissions
|
- name: fix-data-volume-permissions
|
||||||
image: {{ .Values.elasticsearch.initContainers.alpine.repository }}:{{ .Values.elasticsearch.initContainers.alpine.tag }}
|
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.elasticsearch.initContainers.alpine.repository) }}:{{ .Values.elasticsearch.initContainers.alpine.tag }}
|
||||||
{{- with .Values.elasticsearch.initContainers.alpine.pullPolicy }}
|
{{- with .Values.elasticsearch.initContainers.alpine.pullPolicy }}
|
||||||
imagePullPolicy: {{ . }}
|
imagePullPolicy: {{ . }}
|
||||||
{{- end }}
|
{{- end }}
|
||||||
@ -67,7 +67,7 @@ spec:
|
|||||||
- mountPath: /usr/share/elasticsearch/data
|
- mountPath: /usr/share/elasticsearch/data
|
||||||
name: es-data
|
name: es-data
|
||||||
- name: sysctl
|
- name: sysctl
|
||||||
image: {{ .Values.elasticsearch.initContainers.busybox.repository }}:{{ .Values.elasticsearch.initContainers.busybox.tag }}
|
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.elasticsearch.initContainers.busybox.repository) }}:{{ .Values.elasticsearch.initContainers.busybox.tag }}
|
||||||
{{- with .Values.elasticsearch.initContainers.busybox.pullPolicy }}
|
{{- with .Values.elasticsearch.initContainers.busybox.pullPolicy }}
|
||||||
imagePullPolicy: {{ . }}
|
imagePullPolicy: {{ . }}
|
||||||
{{- end }}
|
{{- end }}
|
||||||
@ -77,7 +77,7 @@ spec:
|
|||||||
command: ["sysctl", "-w", "vm.max_map_count=262144"]
|
command: ["sysctl", "-w", "vm.max_map_count=262144"]
|
||||||
containers:
|
containers:
|
||||||
- name: elasticsearch
|
- name: elasticsearch
|
||||||
image: {{ .Values.elasticsearch.image.repository }}:{{ .Values.elasticsearch.image.tag }}
|
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.elasticsearch.image.repository) }}:{{ .Values.elasticsearch.image.tag }}
|
||||||
{{- with .Values.elasticsearch.image.pullPolicy }}
|
{{- with .Values.elasticsearch.image.pullPolicy }}
|
||||||
imagePullPolicy: {{ . }}
|
imagePullPolicy: {{ . }}
|
||||||
{{- end }}
|
{{- end }}
|
||||||
|
|||||||
@ -9,20 +9,39 @@ metadata:
|
|||||||
type: Opaque
|
type: Opaque
|
||||||
stringData:
|
stringData:
|
||||||
{{- range $key, $val := .Values.env }}
|
{{- range $key, $val := .Values.env }}
|
||||||
{{- if $val }}
|
{{- if and $val (ne $key "MYSQL_HOST") (ne $key "MYSQL_PORT") (ne $key "MYSQL_USER") (ne $key "MINIO_HOST") (ne $key "MINIO_PORT") (ne $key "REDIS_HOST") (ne $key "REDIS_PORT") }}
|
||||||
{{ $key }}: {{ quote $val }}
|
{{ $key }}: {{ quote $val }}
|
||||||
{{- end }}
|
{{- end }}
|
||||||
{{- end }}
|
{{- end }}
|
||||||
{{- /*
|
{{- /*
|
||||||
Use host names derived from internal cluster DNS
|
Use host names derived from internal cluster DNS
|
||||||
*/}}
|
*/}}
|
||||||
|
{{- if .Values.redis.enabled }}
|
||||||
REDIS_HOST: {{ printf "%s-redis.%s.svc" (include "ragflow.fullname" .) .Release.Namespace }}
|
REDIS_HOST: {{ printf "%s-redis.%s.svc" (include "ragflow.fullname" .) .Release.Namespace }}
|
||||||
|
REDIS_PORT: "6379"
|
||||||
|
{{- else }}
|
||||||
|
REDIS_HOST: {{ required "env.REDIS_HOST is required when redis.enabled=false" .Values.env.REDIS_HOST | quote }}
|
||||||
|
REDIS_PORT: {{ default "6379" .Values.env.REDIS_PORT | quote }}
|
||||||
|
{{- end }}
|
||||||
|
{{- if .Values.mysql.enabled }}
|
||||||
MYSQL_HOST: {{ printf "%s-mysql.%s.svc" (include "ragflow.fullname" .) .Release.Namespace }}
|
MYSQL_HOST: {{ printf "%s-mysql.%s.svc" (include "ragflow.fullname" .) .Release.Namespace }}
|
||||||
|
MYSQL_PORT: "3306"
|
||||||
|
{{- else }}
|
||||||
|
MYSQL_HOST: {{ required "env.MYSQL_HOST is required when mysql.enabled=false" .Values.env.MYSQL_HOST | quote }}
|
||||||
|
MYSQL_PORT: {{ default "3306" .Values.env.MYSQL_PORT | quote }}
|
||||||
|
MYSQL_USER: {{ default "root" .Values.env.MYSQL_USER | quote }}
|
||||||
|
{{- end }}
|
||||||
|
{{- if .Values.minio.enabled }}
|
||||||
MINIO_HOST: {{ printf "%s-minio.%s.svc" (include "ragflow.fullname" .) .Release.Namespace }}
|
MINIO_HOST: {{ printf "%s-minio.%s.svc" (include "ragflow.fullname" .) .Release.Namespace }}
|
||||||
|
MINIO_PORT: "9000"
|
||||||
|
{{- else }}
|
||||||
|
MINIO_HOST: {{ default "" .Values.env.MINIO_HOST | quote }}
|
||||||
|
MINIO_PORT: {{ default "9000" .Values.env.MINIO_PORT | quote }}
|
||||||
|
{{- end }}
|
||||||
{{- /*
|
{{- /*
|
||||||
Fail if passwords are not provided in release values
|
Fail if passwords are not provided in release values
|
||||||
*/}}
|
*/}}
|
||||||
REDIS_PASSWORD: {{ .Values.env.REDIS_PASSWORD | required "REDIS_PASSWORD is required" }}
|
REDIS_PASSWORD: {{ default "" .Values.env.REDIS_PASSWORD }}
|
||||||
{{- /*
|
{{- /*
|
||||||
NOTE: MySQL uses MYSQL_ROOT_PASSWORD env var but Ragflow container expects
|
NOTE: MySQL uses MYSQL_ROOT_PASSWORD env var but Ragflow container expects
|
||||||
MYSQL_PASSWORD so we need to define both as the same value here.
|
MYSQL_PASSWORD so we need to define both as the same value here.
|
||||||
@ -31,10 +50,9 @@ stringData:
|
|||||||
MYSQL_PASSWORD: {{ . }}
|
MYSQL_PASSWORD: {{ . }}
|
||||||
MYSQL_ROOT_PASSWORD: {{ . }}
|
MYSQL_ROOT_PASSWORD: {{ . }}
|
||||||
{{- end }}
|
{{- end }}
|
||||||
{{- with .Values.env.MINIO_PASSWORD | required "MINIO_PASSWORD is required" }}
|
{{- $minioPass := default "" .Values.env.MINIO_PASSWORD }}
|
||||||
MINIO_PASSWORD: {{ . }}
|
MINIO_PASSWORD: {{ $minioPass }}
|
||||||
MINIO_ROOT_PASSWORD: {{ . }}
|
MINIO_ROOT_PASSWORD: {{ $minioPass }}
|
||||||
{{- end }}
|
|
||||||
{{- /*
|
{{- /*
|
||||||
Only provide env vars for enabled doc engine
|
Only provide env vars for enabled doc engine
|
||||||
*/}}
|
*/}}
|
||||||
|
|||||||
@ -32,7 +32,7 @@ spec:
|
|||||||
{{- include "ragflow.selectorLabels" . | nindent 6 }}
|
{{- include "ragflow.selectorLabels" . | nindent 6 }}
|
||||||
app.kubernetes.io/component: infinity
|
app.kubernetes.io/component: infinity
|
||||||
{{- with .Values.infinity.deployment.strategy }}
|
{{- with .Values.infinity.deployment.strategy }}
|
||||||
strategy:
|
updateStrategy:
|
||||||
{{- . | toYaml | nindent 4 }}
|
{{- . | toYaml | nindent 4 }}
|
||||||
{{- end }}
|
{{- end }}
|
||||||
template:
|
template:
|
||||||
@ -43,9 +43,9 @@ spec:
|
|||||||
annotations:
|
annotations:
|
||||||
checksum/config: {{ include (print $.Template.BasePath "/env.yaml") . | sha256sum }}
|
checksum/config: {{ include (print $.Template.BasePath "/env.yaml") . | sha256sum }}
|
||||||
spec:
|
spec:
|
||||||
{{- if or .Values.imagePullSecrets .Values.infinity.image.pullSecrets }}
|
{{- if or .Values.global.imagePullSecrets .Values.infinity.image.pullSecrets }}
|
||||||
imagePullSecrets:
|
imagePullSecrets:
|
||||||
{{- with .Values.imagePullSecrets }}
|
{{- with .Values.global.imagePullSecrets }}
|
||||||
{{- toYaml . | nindent 8 }}
|
{{- toYaml . | nindent 8 }}
|
||||||
{{- end }}
|
{{- end }}
|
||||||
{{- with .Values.infinity.image.pullSecrets }}
|
{{- with .Values.infinity.image.pullSecrets }}
|
||||||
@ -54,7 +54,7 @@ spec:
|
|||||||
{{- end }}
|
{{- end }}
|
||||||
containers:
|
containers:
|
||||||
- name: infinity
|
- name: infinity
|
||||||
image: {{ .Values.infinity.image.repository }}:{{ .Values.infinity.image.tag }}
|
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.infinity.image.repository) }}:{{ .Values.infinity.image.tag }}
|
||||||
{{- with .Values.infinity.image.pullPolicy }}
|
{{- with .Values.infinity.image.pullPolicy }}
|
||||||
imagePullPolicy: {{ . }}
|
imagePullPolicy: {{ . }}
|
||||||
{{- end }}
|
{{- end }}
|
||||||
|
|||||||
@ -35,7 +35,7 @@ spec:
|
|||||||
{{- end }}
|
{{- end }}
|
||||||
backend:
|
backend:
|
||||||
service:
|
service:
|
||||||
name: {{ $.Release.Name }}
|
name: {{ include "ragflow.fullname" $ }}
|
||||||
port:
|
port:
|
||||||
name: http
|
name: http
|
||||||
{{- end }}
|
{{- end }}
|
||||||
|
|||||||
@ -1,3 +1,4 @@
|
|||||||
|
{{- if .Values.minio.enabled }}
|
||||||
---
|
---
|
||||||
apiVersion: v1
|
apiVersion: v1
|
||||||
kind: PersistentVolumeClaim
|
kind: PersistentVolumeClaim
|
||||||
@ -43,9 +44,9 @@ spec:
|
|||||||
{{- include "ragflow.labels" . | nindent 8 }}
|
{{- include "ragflow.labels" . | nindent 8 }}
|
||||||
app.kubernetes.io/component: minio
|
app.kubernetes.io/component: minio
|
||||||
spec:
|
spec:
|
||||||
{{- if or .Values.imagePullSecrets .Values.minio.image.pullSecrets }}
|
{{- if or .Values.global.imagePullSecrets .Values.minio.image.pullSecrets }}
|
||||||
imagePullSecrets:
|
imagePullSecrets:
|
||||||
{{- with .Values.imagePullSecrets }}
|
{{- with .Values.global.imagePullSecrets }}
|
||||||
{{- toYaml . | nindent 8 }}
|
{{- toYaml . | nindent 8 }}
|
||||||
{{- end }}
|
{{- end }}
|
||||||
{{- with .Values.minio.image.pullSecrets }}
|
{{- with .Values.minio.image.pullSecrets }}
|
||||||
@ -54,7 +55,7 @@ spec:
|
|||||||
{{- end }}
|
{{- end }}
|
||||||
containers:
|
containers:
|
||||||
- name: minio
|
- name: minio
|
||||||
image: {{ .Values.minio.image.repository }}:{{ .Values.minio.image.tag }}
|
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.minio.image.repository) }}:{{ .Values.minio.image.tag }}
|
||||||
{{- with .Values.minio.image.pullPolicy }}
|
{{- with .Values.minio.image.pullPolicy }}
|
||||||
imagePullPolicy: {{ . }}
|
imagePullPolicy: {{ . }}
|
||||||
{{- end }}
|
{{- end }}
|
||||||
@ -103,3 +104,4 @@ spec:
|
|||||||
port: 9001
|
port: 9001
|
||||||
targetPort: console
|
targetPort: console
|
||||||
type: {{ .Values.minio.service.type }}
|
type: {{ .Values.minio.service.type }}
|
||||||
|
{{- end }}
|
||||||
|
|||||||
@ -1,3 +1,4 @@
|
|||||||
|
{{- if .Values.mysql.enabled }}
|
||||||
---
|
---
|
||||||
apiVersion: v1
|
apiVersion: v1
|
||||||
kind: ConfigMap
|
kind: ConfigMap
|
||||||
@ -7,3 +8,4 @@ data:
|
|||||||
init.sql: |-
|
init.sql: |-
|
||||||
CREATE DATABASE IF NOT EXISTS rag_flow;
|
CREATE DATABASE IF NOT EXISTS rag_flow;
|
||||||
USE rag_flow;
|
USE rag_flow;
|
||||||
|
{{- end }}
|
||||||
|
|||||||
@ -1,3 +1,4 @@
|
|||||||
|
{{- if .Values.mysql.enabled }}
|
||||||
---
|
---
|
||||||
apiVersion: v1
|
apiVersion: v1
|
||||||
kind: PersistentVolumeClaim
|
kind: PersistentVolumeClaim
|
||||||
@ -32,7 +33,7 @@ spec:
|
|||||||
{{- include "ragflow.selectorLabels" . | nindent 6 }}
|
{{- include "ragflow.selectorLabels" . | nindent 6 }}
|
||||||
app.kubernetes.io/component: mysql
|
app.kubernetes.io/component: mysql
|
||||||
{{- with .Values.mysql.deployment.strategy }}
|
{{- with .Values.mysql.deployment.strategy }}
|
||||||
strategy:
|
updateStrategy:
|
||||||
{{- . | toYaml | nindent 4 }}
|
{{- . | toYaml | nindent 4 }}
|
||||||
{{- end }}
|
{{- end }}
|
||||||
template:
|
template:
|
||||||
@ -44,9 +45,9 @@ spec:
|
|||||||
checksum/config-mysql: {{ include (print $.Template.BasePath "/mysql-config.yaml") . | sha256sum }}
|
checksum/config-mysql: {{ include (print $.Template.BasePath "/mysql-config.yaml") . | sha256sum }}
|
||||||
checksum/config-env: {{ include (print $.Template.BasePath "/env.yaml") . | sha256sum }}
|
checksum/config-env: {{ include (print $.Template.BasePath "/env.yaml") . | sha256sum }}
|
||||||
spec:
|
spec:
|
||||||
{{- if or .Values.imagePullSecrets .Values.mysql.image.pullSecrets }}
|
{{- if or .Values.global.imagePullSecrets .Values.mysql.image.pullSecrets }}
|
||||||
imagePullSecrets:
|
imagePullSecrets:
|
||||||
{{- with .Values.imagePullSecrets }}
|
{{- with .Values.global.imagePullSecrets }}
|
||||||
{{- toYaml . | nindent 8 }}
|
{{- toYaml . | nindent 8 }}
|
||||||
{{- end }}
|
{{- end }}
|
||||||
{{- with .Values.mysql.image.pullSecrets }}
|
{{- with .Values.mysql.image.pullSecrets }}
|
||||||
@ -55,7 +56,7 @@ spec:
|
|||||||
{{- end }}
|
{{- end }}
|
||||||
containers:
|
containers:
|
||||||
- name: mysql
|
- name: mysql
|
||||||
image: {{ .Values.mysql.image.repository }}:{{ .Values.mysql.image.tag }}
|
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.mysql.image.repository) }}:{{ .Values.mysql.image.tag }}
|
||||||
{{- with .Values.mysql.image.pullPolicy }}
|
{{- with .Values.mysql.image.pullPolicy }}
|
||||||
imagePullPolicy: {{ . }}
|
imagePullPolicy: {{ . }}
|
||||||
{{- end }}
|
{{- end }}
|
||||||
@ -108,3 +109,4 @@ spec:
|
|||||||
port: 3306
|
port: 3306
|
||||||
targetPort: mysql
|
targetPort: mysql
|
||||||
type: {{ .Values.mysql.service.type }}
|
type: {{ .Values.mysql.service.type }}
|
||||||
|
{{- end }}
|
||||||
|
|||||||
@ -32,7 +32,7 @@ spec:
|
|||||||
{{- include "ragflow.selectorLabels" . | nindent 6 }}
|
{{- include "ragflow.selectorLabels" . | nindent 6 }}
|
||||||
app.kubernetes.io/component: opensearch
|
app.kubernetes.io/component: opensearch
|
||||||
{{- with .Values.opensearch.deployment.strategy }}
|
{{- with .Values.opensearch.deployment.strategy }}
|
||||||
strategy:
|
updateStrategy:
|
||||||
{{- . | toYaml | nindent 4 }}
|
{{- . | toYaml | nindent 4 }}
|
||||||
{{- end }}
|
{{- end }}
|
||||||
template:
|
template:
|
||||||
@ -44,9 +44,9 @@ spec:
|
|||||||
checksum/config-opensearch: {{ include (print $.Template.BasePath "/opensearch-config.yaml") . | sha256sum }}
|
checksum/config-opensearch: {{ include (print $.Template.BasePath "/opensearch-config.yaml") . | sha256sum }}
|
||||||
checksum/config-env: {{ include (print $.Template.BasePath "/env.yaml") . | sha256sum }}
|
checksum/config-env: {{ include (print $.Template.BasePath "/env.yaml") . | sha256sum }}
|
||||||
spec:
|
spec:
|
||||||
{{- if or .Values.imagePullSecrets .Values.opensearch.image.pullSecrets }}
|
{{- if or .Values.global.imagePullSecrets .Values.opensearch.image.pullSecrets }}
|
||||||
imagePullSecrets:
|
imagePullSecrets:
|
||||||
{{- with .Values.imagePullSecrets }}
|
{{- with .Values.global.imagePullSecrets }}
|
||||||
{{- toYaml . | nindent 8 }}
|
{{- toYaml . | nindent 8 }}
|
||||||
{{- end }}
|
{{- end }}
|
||||||
{{- with .Values.opensearch.image.pullSecrets }}
|
{{- with .Values.opensearch.image.pullSecrets }}
|
||||||
@ -55,7 +55,7 @@ spec:
|
|||||||
{{- end }}
|
{{- end }}
|
||||||
initContainers:
|
initContainers:
|
||||||
- name: fix-data-volume-permissions
|
- name: fix-data-volume-permissions
|
||||||
image: {{ .Values.opensearch.initContainers.alpine.repository }}:{{ .Values.opensearch.initContainers.alpine.tag }}
|
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.opensearch.initContainers.alpine.repository) }}:{{ .Values.opensearch.initContainers.alpine.tag }}
|
||||||
{{- with .Values.opensearch.initContainers.alpine.pullPolicy }}
|
{{- with .Values.opensearch.initContainers.alpine.pullPolicy }}
|
||||||
imagePullPolicy: {{ . }}
|
imagePullPolicy: {{ . }}
|
||||||
{{- end }}
|
{{- end }}
|
||||||
@ -67,7 +67,7 @@ spec:
|
|||||||
- mountPath: /usr/share/opensearch/data
|
- mountPath: /usr/share/opensearch/data
|
||||||
name: opensearch-data
|
name: opensearch-data
|
||||||
- name: sysctl
|
- name: sysctl
|
||||||
image: {{ .Values.opensearch.initContainers.busybox.repository }}:{{ .Values.opensearch.initContainers.busybox.tag }}
|
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.opensearch.initContainers.busybox.repository) }}:{{ .Values.opensearch.initContainers.busybox.tag }}
|
||||||
{{- with .Values.opensearch.initContainers.busybox.pullPolicy }}
|
{{- with .Values.opensearch.initContainers.busybox.pullPolicy }}
|
||||||
imagePullPolicy: {{ . }}
|
imagePullPolicy: {{ . }}
|
||||||
{{- end }}
|
{{- end }}
|
||||||
@ -77,7 +77,7 @@ spec:
|
|||||||
command: ["sysctl", "-w", "vm.max_map_count=262144"]
|
command: ["sysctl", "-w", "vm.max_map_count=262144"]
|
||||||
containers:
|
containers:
|
||||||
- name: opensearch
|
- name: opensearch
|
||||||
image: {{ .Values.opensearch.image.repository }}:{{ .Values.opensearch.image.tag }}
|
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.opensearch.image.repository) }}:{{ .Values.opensearch.image.tag }}
|
||||||
{{- with .Values.opensearch.image.pullPolicy }}
|
{{- with .Values.opensearch.image.pullPolicy }}
|
||||||
imagePullPolicy: {{ . }}
|
imagePullPolicy: {{ . }}
|
||||||
{{- end }}
|
{{- end }}
|
||||||
|
|||||||
@ -25,9 +25,9 @@ spec:
|
|||||||
checksum/config-env: {{ include (print $.Template.BasePath "/env.yaml") . | sha256sum }}
|
checksum/config-env: {{ include (print $.Template.BasePath "/env.yaml") . | sha256sum }}
|
||||||
checksum/config-ragflow: {{ include (print $.Template.BasePath "/ragflow_config.yaml") . | sha256sum }}
|
checksum/config-ragflow: {{ include (print $.Template.BasePath "/ragflow_config.yaml") . | sha256sum }}
|
||||||
spec:
|
spec:
|
||||||
{{- if or .Values.imagePullSecrets .Values.ragflow.image.pullSecrets }}
|
{{- if or .Values.global.imagePullSecrets .Values.ragflow.image.pullSecrets }}
|
||||||
imagePullSecrets:
|
imagePullSecrets:
|
||||||
{{- with .Values.imagePullSecrets }}
|
{{- with .Values.global.imagePullSecrets }}
|
||||||
{{- toYaml . | nindent 8 }}
|
{{- toYaml . | nindent 8 }}
|
||||||
{{- end }}
|
{{- end }}
|
||||||
{{- with .Values.ragflow.image.pullSecrets }}
|
{{- with .Values.ragflow.image.pullSecrets }}
|
||||||
@ -36,7 +36,7 @@ spec:
|
|||||||
{{- end }}
|
{{- end }}
|
||||||
containers:
|
containers:
|
||||||
- name: ragflow
|
- name: ragflow
|
||||||
image: {{ .Values.ragflow.image.repository }}:{{ .Values.ragflow.image.tag }}
|
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.ragflow.image.repository) }}:{{ .Values.ragflow.image.tag }}
|
||||||
{{- with .Values.ragflow.image.pullPolicy }}
|
{{- with .Values.ragflow.image.pullPolicy }}
|
||||||
imagePullPolicy: {{ . }}
|
imagePullPolicy: {{ . }}
|
||||||
{{- end }}
|
{{- end }}
|
||||||
|
|||||||
@ -1,3 +1,4 @@
|
|||||||
|
{{- if .Values.redis.enabled }}
|
||||||
---
|
---
|
||||||
apiVersion: v1
|
apiVersion: v1
|
||||||
kind: Service
|
kind: Service
|
||||||
@ -40,9 +41,9 @@ spec:
|
|||||||
annotations:
|
annotations:
|
||||||
checksum/config-env: {{ include (print $.Template.BasePath "/env.yaml") . | sha256sum }}
|
checksum/config-env: {{ include (print $.Template.BasePath "/env.yaml") . | sha256sum }}
|
||||||
spec:
|
spec:
|
||||||
{{- if or .Values.imagePullSecrets .Values.redis.image.pullSecrets }}
|
{{- if or .Values.global.imagePullSecrets .Values.redis.image.pullSecrets }}
|
||||||
imagePullSecrets:
|
imagePullSecrets:
|
||||||
{{- with .Values.imagePullSecrets }}
|
{{- with .Values.global.imagePullSecrets }}
|
||||||
{{- toYaml . | nindent 8 }}
|
{{- toYaml . | nindent 8 }}
|
||||||
{{- end }}
|
{{- end }}
|
||||||
{{- with .Values.redis.image.pullSecrets }}
|
{{- with .Values.redis.image.pullSecrets }}
|
||||||
@ -52,7 +53,7 @@ spec:
|
|||||||
terminationGracePeriodSeconds: 60
|
terminationGracePeriodSeconds: 60
|
||||||
containers:
|
containers:
|
||||||
- name: redis
|
- name: redis
|
||||||
image: {{ .Values.redis.image.repository }}:{{ .Values.redis.image.tag }}
|
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" .Values.redis.image.repository) }}:{{ .Values.redis.image.tag }}
|
||||||
{{- with .Values.redis.image.pullPolicy }}
|
{{- with .Values.redis.image.pullPolicy }}
|
||||||
imagePullPolicy: {{ . }}
|
imagePullPolicy: {{ . }}
|
||||||
{{- end }}
|
{{- end }}
|
||||||
@ -131,3 +132,4 @@ spec:
|
|||||||
matchLabels:
|
matchLabels:
|
||||||
{{- include "ragflow.selectorLabels" . | nindent 6 }}
|
{{- include "ragflow.selectorLabels" . | nindent 6 }}
|
||||||
app.kubernetes.io/component: redis
|
app.kubernetes.io/component: redis
|
||||||
|
{{- end }}
|
||||||
|
|||||||
@ -9,7 +9,7 @@ metadata:
|
|||||||
spec:
|
spec:
|
||||||
containers:
|
containers:
|
||||||
- name: wget
|
- name: wget
|
||||||
image: busybox
|
image: {{ include "ragflow.imageRepo" (dict "root" . "repo" "busybox") }}
|
||||||
command:
|
command:
|
||||||
- 'wget'
|
- 'wget'
|
||||||
args:
|
args:
|
||||||
|
|||||||
@ -1,6 +1,13 @@
|
|||||||
# Based on docker compose .env file
|
# Based on docker compose .env file
|
||||||
|
|
||||||
# Global image pull secrets configuration
|
# Global image pull secrets configuration
|
||||||
|
global:
|
||||||
|
# Global image repo prefix to render all images from a mirror/registry.
|
||||||
|
# Example: "registry.example.com/myproj"
|
||||||
|
# When set, template will replace the registry part of each image and keep the path.
|
||||||
|
# Leave empty to use per-image repositories as-is.
|
||||||
|
repo: ""
|
||||||
|
# Global image pull secrets for all pods
|
||||||
imagePullSecrets: []
|
imagePullSecrets: []
|
||||||
|
|
||||||
env:
|
env:
|
||||||
@ -27,14 +34,28 @@ env:
|
|||||||
MYSQL_PASSWORD: infini_rag_flow_helm
|
MYSQL_PASSWORD: infini_rag_flow_helm
|
||||||
# The database of the MySQL service to use
|
# The database of the MySQL service to use
|
||||||
MYSQL_DBNAME: rag_flow
|
MYSQL_DBNAME: rag_flow
|
||||||
|
# External MySQL host (only required when mysql.enabled=false)
|
||||||
|
# MYSQL_HOST: ""
|
||||||
|
# External MySQL port (defaults to 3306 if not set)
|
||||||
|
# MYSQL_PORT: "3306"
|
||||||
|
# External MySQL user (only when mysql.enabled=false), default is root if omitted
|
||||||
|
# MYSQL_USER: "root"
|
||||||
|
|
||||||
# The username for MinIO.
|
# The username for MinIO.
|
||||||
MINIO_ROOT_USER: rag_flow
|
MINIO_ROOT_USER: rag_flow
|
||||||
# The password for MinIO
|
# The password for MinIO
|
||||||
MINIO_PASSWORD: infini_rag_flow_helm
|
MINIO_PASSWORD: infini_rag_flow_helm
|
||||||
|
# External MinIO host
|
||||||
|
# MINIO_HOST: ""
|
||||||
|
# External MinIO port (defaults to 9000 if not set)
|
||||||
|
# MINIO_PORT: "9000"
|
||||||
|
|
||||||
# The password for Redis
|
# The password for Redis
|
||||||
REDIS_PASSWORD: infini_rag_flow_helm
|
REDIS_PASSWORD: infini_rag_flow_helm
|
||||||
|
# External Redis host (only required when redis.enabled=false)
|
||||||
|
# REDIS_HOST: ""
|
||||||
|
# External Redis port (defaults to 6379 if not set)
|
||||||
|
# REDIS_PORT: "6379"
|
||||||
|
|
||||||
# The local time zone.
|
# The local time zone.
|
||||||
TZ: "Asia/Shanghai"
|
TZ: "Asia/Shanghai"
|
||||||
@ -56,7 +77,7 @@ env:
|
|||||||
ragflow:
|
ragflow:
|
||||||
image:
|
image:
|
||||||
repository: infiniflow/ragflow
|
repository: infiniflow/ragflow
|
||||||
tag: v0.22.1
|
tag: v0.23.0
|
||||||
pullPolicy: IfNotPresent
|
pullPolicy: IfNotPresent
|
||||||
pullSecrets: []
|
pullSecrets: []
|
||||||
# Optional service configuration overrides
|
# Optional service configuration overrides
|
||||||
@ -96,7 +117,7 @@ ragflow:
|
|||||||
infinity:
|
infinity:
|
||||||
image:
|
image:
|
||||||
repository: infiniflow/infinity
|
repository: infiniflow/infinity
|
||||||
tag: v0.6.13
|
tag: v0.6.15
|
||||||
pullPolicy: IfNotPresent
|
pullPolicy: IfNotPresent
|
||||||
pullSecrets: []
|
pullSecrets: []
|
||||||
storage:
|
storage:
|
||||||
@ -163,6 +184,7 @@ opensearch:
|
|||||||
type: ClusterIP
|
type: ClusterIP
|
||||||
|
|
||||||
minio:
|
minio:
|
||||||
|
enabled: true
|
||||||
image:
|
image:
|
||||||
repository: quay.io/minio/minio
|
repository: quay.io/minio/minio
|
||||||
tag: RELEASE.2023-12-20T01-00-02Z
|
tag: RELEASE.2023-12-20T01-00-02Z
|
||||||
@ -178,6 +200,7 @@ minio:
|
|||||||
type: ClusterIP
|
type: ClusterIP
|
||||||
|
|
||||||
mysql:
|
mysql:
|
||||||
|
enabled: true
|
||||||
image:
|
image:
|
||||||
repository: mysql
|
repository: mysql
|
||||||
tag: 8.0.39
|
tag: 8.0.39
|
||||||
@ -193,6 +216,7 @@ mysql:
|
|||||||
type: ClusterIP
|
type: ClusterIP
|
||||||
|
|
||||||
redis:
|
redis:
|
||||||
|
enabled: true
|
||||||
image:
|
image:
|
||||||
repository: valkey/valkey
|
repository: valkey/valkey
|
||||||
tag: 8
|
tag: 8
|
||||||
|
|||||||
@ -71,7 +71,7 @@ class MessageService:
|
|||||||
filter_dict["session_id"] = keywords
|
filter_dict["session_id"] = keywords
|
||||||
order_by = OrderByExpr()
|
order_by = OrderByExpr()
|
||||||
order_by.desc("valid_at")
|
order_by.desc("valid_at")
|
||||||
res = settings.msgStoreConn.search(
|
res, total_count = settings.msgStoreConn.search(
|
||||||
select_fields=[
|
select_fields=[
|
||||||
"message_id", "message_type", "source_id", "memory_id", "user_id", "agent_id", "session_id", "valid_at",
|
"message_id", "message_type", "source_id", "memory_id", "user_id", "agent_id", "session_id", "valid_at",
|
||||||
"invalid_at", "forget_at", "status"
|
"invalid_at", "forget_at", "status"
|
||||||
@ -82,7 +82,12 @@ class MessageService:
|
|||||||
offset=(page-1)*page_size, limit=page_size,
|
offset=(page-1)*page_size, limit=page_size,
|
||||||
index_names=index, memory_ids=[memory_id], agg_fields=[], hide_forgotten=False
|
index_names=index, memory_ids=[memory_id], agg_fields=[], hide_forgotten=False
|
||||||
)
|
)
|
||||||
total_count = settings.msgStoreConn.get_total(res)
|
if not total_count:
|
||||||
|
return {
|
||||||
|
"message_list": [],
|
||||||
|
"total_count": 0
|
||||||
|
}
|
||||||
|
|
||||||
doc_mapping = settings.msgStoreConn.get_fields(res, [
|
doc_mapping = settings.msgStoreConn.get_fields(res, [
|
||||||
"message_id", "message_type", "source_id", "memory_id", "user_id", "agent_id", "session_id",
|
"message_id", "message_type", "source_id", "memory_id", "user_id", "agent_id", "session_id",
|
||||||
"valid_at", "invalid_at", "forget_at", "status"
|
"valid_at", "invalid_at", "forget_at", "status"
|
||||||
@ -101,7 +106,7 @@ class MessageService:
|
|||||||
}
|
}
|
||||||
order_by = OrderByExpr()
|
order_by = OrderByExpr()
|
||||||
order_by.desc("valid_at")
|
order_by.desc("valid_at")
|
||||||
res = settings.msgStoreConn.search(
|
res, total_count = settings.msgStoreConn.search(
|
||||||
select_fields=[
|
select_fields=[
|
||||||
"message_id", "message_type", "source_id", "memory_id", "user_id", "agent_id", "session_id", "valid_at",
|
"message_id", "message_type", "source_id", "memory_id", "user_id", "agent_id", "session_id", "valid_at",
|
||||||
"invalid_at", "forget_at", "status", "content"
|
"invalid_at", "forget_at", "status", "content"
|
||||||
@ -112,6 +117,9 @@ class MessageService:
|
|||||||
offset=0, limit=limit,
|
offset=0, limit=limit,
|
||||||
index_names=index_names, memory_ids=memory_ids, agg_fields=[]
|
index_names=index_names, memory_ids=memory_ids, agg_fields=[]
|
||||||
)
|
)
|
||||||
|
if not total_count:
|
||||||
|
return []
|
||||||
|
|
||||||
doc_mapping = settings.msgStoreConn.get_fields(res, [
|
doc_mapping = settings.msgStoreConn.get_fields(res, [
|
||||||
"message_id", "message_type", "source_id", "memory_id","user_id", "agent_id", "session_id",
|
"message_id", "message_type", "source_id", "memory_id","user_id", "agent_id", "session_id",
|
||||||
"valid_at", "invalid_at", "forget_at", "status", "content"
|
"valid_at", "invalid_at", "forget_at", "status", "content"
|
||||||
@ -127,7 +135,7 @@ class MessageService:
|
|||||||
|
|
||||||
order_by = OrderByExpr()
|
order_by = OrderByExpr()
|
||||||
order_by.desc("valid_at")
|
order_by.desc("valid_at")
|
||||||
res = settings.msgStoreConn.search(
|
res, total_count = settings.msgStoreConn.search(
|
||||||
select_fields=[
|
select_fields=[
|
||||||
"message_id", "message_type", "source_id", "memory_id", "user_id", "agent_id", "session_id",
|
"message_id", "message_type", "source_id", "memory_id", "user_id", "agent_id", "session_id",
|
||||||
"valid_at",
|
"valid_at",
|
||||||
@ -140,6 +148,9 @@ class MessageService:
|
|||||||
offset=0, limit=top_n,
|
offset=0, limit=top_n,
|
||||||
index_names=index_names, memory_ids=memory_ids, agg_fields=[]
|
index_names=index_names, memory_ids=memory_ids, agg_fields=[]
|
||||||
)
|
)
|
||||||
|
if not total_count:
|
||||||
|
return []
|
||||||
|
|
||||||
docs = settings.msgStoreConn.get_fields(res, [
|
docs = settings.msgStoreConn.get_fields(res, [
|
||||||
"message_id", "message_type", "source_id", "memory_id", "user_id", "agent_id", "session_id", "valid_at",
|
"message_id", "message_type", "source_id", "memory_id", "user_id", "agent_id", "session_id", "valid_at",
|
||||||
"invalid_at", "forget_at", "status", "content"
|
"invalid_at", "forget_at", "status", "content"
|
||||||
@ -156,15 +167,19 @@ class MessageService:
|
|||||||
order_by = OrderByExpr()
|
order_by = OrderByExpr()
|
||||||
order_by.desc("valid_at")
|
order_by.desc("valid_at")
|
||||||
|
|
||||||
res = settings.msgStoreConn.search(
|
res, count = settings.msgStoreConn.search(
|
||||||
select_fields=["memory_id", "content", "content_embed"],
|
select_fields=["memory_id", "content", "content_embed"],
|
||||||
highlight_fields=[],
|
highlight_fields=[],
|
||||||
condition={},
|
condition={},
|
||||||
match_expressions=[],
|
match_expressions=[],
|
||||||
order_by=order_by,
|
order_by=order_by,
|
||||||
offset=0, limit=2000*len(memory_ids),
|
offset=0, limit=2048*len(memory_ids),
|
||||||
index_names=index_names, memory_ids=memory_ids, agg_fields=[], hide_forgotten=False
|
index_names=index_names, memory_ids=memory_ids, agg_fields=[], hide_forgotten=False
|
||||||
)
|
)
|
||||||
|
|
||||||
|
if count == 0:
|
||||||
|
return {}
|
||||||
|
|
||||||
docs = settings.msgStoreConn.get_fields(res, ["memory_id", "content", "content_embed"])
|
docs = settings.msgStoreConn.get_fields(res, ["memory_id", "content", "content_embed"])
|
||||||
size_dict = {}
|
size_dict = {}
|
||||||
for doc in docs.values():
|
for doc in docs.values():
|
||||||
@ -179,10 +194,11 @@ class MessageService:
|
|||||||
select_fields = ["message_id", "content", "content_embed"]
|
select_fields = ["message_id", "content", "content_embed"]
|
||||||
_index_name = index_name(uid)
|
_index_name = index_name(uid)
|
||||||
res = settings.msgStoreConn.get_forgotten_messages(select_fields, _index_name, memory_id)
|
res = settings.msgStoreConn.get_forgotten_messages(select_fields, _index_name, memory_id)
|
||||||
message_list = settings.msgStoreConn.get_fields(res, select_fields)
|
|
||||||
current_size = 0
|
current_size = 0
|
||||||
ids_to_remove = []
|
ids_to_remove = []
|
||||||
for message in message_list:
|
if res:
|
||||||
|
message_list = settings.msgStoreConn.get_fields(res, select_fields)
|
||||||
|
for message in message_list.values():
|
||||||
if current_size < size_to_delete:
|
if current_size < size_to_delete:
|
||||||
current_size += cls.calculate_message_size(message)
|
current_size += cls.calculate_message_size(message)
|
||||||
ids_to_remove.append(message["message_id"])
|
ids_to_remove.append(message["message_id"])
|
||||||
@ -193,20 +209,20 @@ class MessageService:
|
|||||||
|
|
||||||
order_by = OrderByExpr()
|
order_by = OrderByExpr()
|
||||||
order_by.asc("valid_at")
|
order_by.asc("valid_at")
|
||||||
res = settings.msgStoreConn.search(
|
res, total_count = settings.msgStoreConn.search(
|
||||||
select_fields=["memory_id", "content", "content_embed"],
|
select_fields=select_fields,
|
||||||
highlight_fields=[],
|
highlight_fields=[],
|
||||||
condition={},
|
condition={},
|
||||||
match_expressions=[],
|
match_expressions=[],
|
||||||
order_by=order_by,
|
order_by=order_by,
|
||||||
offset=0, limit=2000,
|
offset=0, limit=512,
|
||||||
index_names=[_index_name], memory_ids=[memory_id], agg_fields=[]
|
index_names=[_index_name], memory_ids=[memory_id], agg_fields=[]
|
||||||
)
|
)
|
||||||
docs = settings.msgStoreConn.get_fields(res, select_fields)
|
docs = settings.msgStoreConn.get_fields(res, select_fields)
|
||||||
for doc in docs.values():
|
for doc in docs.values():
|
||||||
if current_size < size_to_delete:
|
if current_size < size_to_delete:
|
||||||
current_size += cls.calculate_message_size(doc)
|
current_size += cls.calculate_message_size(doc)
|
||||||
ids_to_remove.append(doc["memory_id"])
|
ids_to_remove.append(doc["message_id"])
|
||||||
else:
|
else:
|
||||||
return ids_to_remove, current_size
|
return ids_to_remove, current_size
|
||||||
return ids_to_remove, current_size
|
return ids_to_remove, current_size
|
||||||
@ -222,7 +238,7 @@ class MessageService:
|
|||||||
order_by = OrderByExpr()
|
order_by = OrderByExpr()
|
||||||
order_by.desc("message_id")
|
order_by.desc("message_id")
|
||||||
index_names = [index_name(uid) for uid in uid_list]
|
index_names = [index_name(uid) for uid in uid_list]
|
||||||
res = settings.msgStoreConn.search(
|
res, total_count = settings.msgStoreConn.search(
|
||||||
select_fields=["message_id"],
|
select_fields=["message_id"],
|
||||||
highlight_fields=[],
|
highlight_fields=[],
|
||||||
condition={},
|
condition={},
|
||||||
@ -232,6 +248,9 @@ class MessageService:
|
|||||||
index_names=index_names, memory_ids=memory_ids,
|
index_names=index_names, memory_ids=memory_ids,
|
||||||
agg_fields=[], hide_forgotten=False
|
agg_fields=[], hide_forgotten=False
|
||||||
)
|
)
|
||||||
|
if not total_count:
|
||||||
|
return 1
|
||||||
|
|
||||||
docs = settings.msgStoreConn.get_fields(res, ["message_id"])
|
docs = settings.msgStoreConn.get_fields(res, ["message_id"])
|
||||||
if not docs:
|
if not docs:
|
||||||
return 1
|
return 1
|
||||||
|
|||||||
@ -127,6 +127,11 @@ class ESConnection(ESConnectionBase):
|
|||||||
index_names = index_names.split(",")
|
index_names = index_names.split(",")
|
||||||
assert isinstance(index_names, list) and len(index_names) > 0
|
assert isinstance(index_names, list) and len(index_names) > 0
|
||||||
assert "_id" not in condition
|
assert "_id" not in condition
|
||||||
|
|
||||||
|
exist_index_list = [idx for idx in index_names if self.index_exist(idx)]
|
||||||
|
if not exist_index_list:
|
||||||
|
return None, 0
|
||||||
|
|
||||||
bool_query = Q("bool", must=[], must_not=[])
|
bool_query = Q("bool", must=[], must_not=[])
|
||||||
if hide_forgotten:
|
if hide_forgotten:
|
||||||
# filter not forget
|
# filter not forget
|
||||||
@ -134,15 +139,16 @@ class ESConnection(ESConnectionBase):
|
|||||||
|
|
||||||
condition["memory_id"] = memory_ids
|
condition["memory_id"] = memory_ids
|
||||||
for k, v in condition.items():
|
for k, v in condition.items():
|
||||||
if k == "session_id" and v:
|
field_name = self.convert_field_name(k)
|
||||||
|
if field_name == "session_id" and v:
|
||||||
bool_query.filter.append(Q("query_string", **{"query": f"*{v}*", "fields": ["session_id"], "analyze_wildcard": True}))
|
bool_query.filter.append(Q("query_string", **{"query": f"*{v}*", "fields": ["session_id"], "analyze_wildcard": True}))
|
||||||
continue
|
continue
|
||||||
if not v:
|
if not v:
|
||||||
continue
|
continue
|
||||||
if isinstance(v, list):
|
if isinstance(v, list):
|
||||||
bool_query.filter.append(Q("terms", **{k: v}))
|
bool_query.filter.append(Q("terms", **{field_name: v}))
|
||||||
elif isinstance(v, str) or isinstance(v, int):
|
elif isinstance(v, str) or isinstance(v, int):
|
||||||
bool_query.filter.append(Q("term", **{k: v}))
|
bool_query.filter.append(Q("term", **{field_name: v}))
|
||||||
else:
|
else:
|
||||||
raise Exception(
|
raise Exception(
|
||||||
f"Condition `{str(k)}={str(v)}` value type is {str(type(v))}, expected to be int, str or list.")
|
f"Condition `{str(k)}={str(v)}` value type is {str(type(v))}, expected to be int, str or list.")
|
||||||
@ -213,7 +219,7 @@ class ESConnection(ESConnectionBase):
|
|||||||
for i in range(ATTEMPT_TIME):
|
for i in range(ATTEMPT_TIME):
|
||||||
try:
|
try:
|
||||||
#print(json.dumps(q, ensure_ascii=False))
|
#print(json.dumps(q, ensure_ascii=False))
|
||||||
res = self.es.search(index=index_names,
|
res = self.es.search(index=exist_index_list,
|
||||||
body=q,
|
body=q,
|
||||||
timeout="600s",
|
timeout="600s",
|
||||||
# search_type="dfs_query_then_fetch",
|
# search_type="dfs_query_then_fetch",
|
||||||
@ -222,11 +228,14 @@ class ESConnection(ESConnectionBase):
|
|||||||
if str(res.get("timed_out", "")).lower() == "true":
|
if str(res.get("timed_out", "")).lower() == "true":
|
||||||
raise Exception("Es Timeout.")
|
raise Exception("Es Timeout.")
|
||||||
self.logger.debug(f"ESConnection.search {str(index_names)} res: " + str(res))
|
self.logger.debug(f"ESConnection.search {str(index_names)} res: " + str(res))
|
||||||
return res
|
return res, self.get_total(res)
|
||||||
except ConnectionTimeout:
|
except ConnectionTimeout:
|
||||||
self.logger.exception("ES request timeout")
|
self.logger.exception("ES request timeout")
|
||||||
self._connect()
|
self._connect()
|
||||||
continue
|
continue
|
||||||
|
except NotFoundError as e:
|
||||||
|
self.logger.debug(f"ESConnection.search {str(index_names)} query: " + str(q) + str(e))
|
||||||
|
return None, 0
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
self.logger.exception(f"ESConnection.search {str(index_names)} query: " + str(q) + str(e))
|
self.logger.exception(f"ESConnection.search {str(index_names)} query: " + str(q) + str(e))
|
||||||
raise e
|
raise e
|
||||||
@ -234,9 +243,9 @@ class ESConnection(ESConnectionBase):
|
|||||||
self.logger.error(f"ESConnection.search timeout for {ATTEMPT_TIME} times!")
|
self.logger.error(f"ESConnection.search timeout for {ATTEMPT_TIME} times!")
|
||||||
raise Exception("ESConnection.search timeout.")
|
raise Exception("ESConnection.search timeout.")
|
||||||
|
|
||||||
def get_forgotten_messages(self, select_fields: list[str], index_name: str, memory_id: str, limit: int=2000):
|
def get_forgotten_messages(self, select_fields: list[str], index_name: str, memory_id: str, limit: int=512):
|
||||||
bool_query = Q("bool", must_not=[])
|
bool_query = Q("bool", must=[])
|
||||||
bool_query.must_not.append(Q("term", forget_at=None))
|
bool_query.must.append(Q("exists", field="forget_at"))
|
||||||
bool_query.filter.append(Q("term", memory_id=memory_id))
|
bool_query.filter.append(Q("term", memory_id=memory_id))
|
||||||
# from old to new
|
# from old to new
|
||||||
order_by = OrderByExpr()
|
order_by = OrderByExpr()
|
||||||
@ -244,7 +253,15 @@ class ESConnection(ESConnectionBase):
|
|||||||
# build search
|
# build search
|
||||||
s = Search()
|
s = Search()
|
||||||
s = s.query(bool_query)
|
s = s.query(bool_query)
|
||||||
s = s.sort(order_by)
|
orders = list()
|
||||||
|
for field, order in order_by.fields:
|
||||||
|
order = "asc" if order == 0 else "desc"
|
||||||
|
if field.endswith("_int") or field.endswith("_flt"):
|
||||||
|
order_info = {"order": order, "unmapped_type": "float"}
|
||||||
|
else:
|
||||||
|
order_info = {"order": order, "unmapped_type": "text"}
|
||||||
|
orders.append({field: order_info})
|
||||||
|
s = s.sort(*orders)
|
||||||
s = s[:limit]
|
s = s[:limit]
|
||||||
q = s.to_dict()
|
q = s.to_dict()
|
||||||
# search
|
# search
|
||||||
@ -259,6 +276,9 @@ class ESConnection(ESConnectionBase):
|
|||||||
self.logger.exception("ES request timeout")
|
self.logger.exception("ES request timeout")
|
||||||
self._connect()
|
self._connect()
|
||||||
continue
|
continue
|
||||||
|
except NotFoundError as e:
|
||||||
|
self.logger.debug(f"ESConnection.search {str(index_name)} query: " + str(q) + str(e))
|
||||||
|
return None
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
self.logger.exception(f"ESConnection.search {str(index_name)} query: " + str(q) + str(e))
|
self.logger.exception(f"ESConnection.search {str(index_name)} query: " + str(q) + str(e))
|
||||||
raise e
|
raise e
|
||||||
|
|||||||
@ -22,7 +22,6 @@ from infinity.errors import ErrorCode
|
|||||||
|
|
||||||
from common.decorator import singleton
|
from common.decorator import singleton
|
||||||
import pandas as pd
|
import pandas as pd
|
||||||
from common.constants import PAGERANK_FLD, TAG_FLD
|
|
||||||
from common.doc_store.doc_store_base import MatchExpr, MatchTextExpr, MatchDenseExpr, FusionExpr, OrderByExpr
|
from common.doc_store.doc_store_base import MatchExpr, MatchTextExpr, MatchDenseExpr, FusionExpr, OrderByExpr
|
||||||
from common.doc_store.infinity_conn_base import InfinityConnectionBase
|
from common.doc_store.infinity_conn_base import InfinityConnectionBase
|
||||||
from common.time_utils import date_string_to_timestamp
|
from common.time_utils import date_string_to_timestamp
|
||||||
@ -31,8 +30,7 @@ from common.time_utils import date_string_to_timestamp
|
|||||||
@singleton
|
@singleton
|
||||||
class InfinityConnection(InfinityConnectionBase):
|
class InfinityConnection(InfinityConnectionBase):
|
||||||
def __init__(self):
|
def __init__(self):
|
||||||
super().__init__()
|
super().__init__(mapping_file_name="message_infinity_mapping.json")
|
||||||
self.mapping_file_name = "message_infinity_mapping.json"
|
|
||||||
|
|
||||||
"""
|
"""
|
||||||
Dataframe and fields convert
|
Dataframe and fields convert
|
||||||
@ -44,12 +42,19 @@ class InfinityConnection(InfinityConnectionBase):
|
|||||||
return False
|
return False
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def convert_message_field_to_infinity(field_name: str):
|
def convert_message_field_to_infinity(field_name: str, table_fields: list[str]=None):
|
||||||
match field_name:
|
match field_name:
|
||||||
case "message_type":
|
case "message_type":
|
||||||
return "message_type_kwd"
|
return "message_type_kwd"
|
||||||
case "status":
|
case "status":
|
||||||
return "status_int"
|
return "status_int"
|
||||||
|
case "content_embed":
|
||||||
|
if not table_fields:
|
||||||
|
raise Exception("Can't convert 'content_embed' to vector field name with empty table fields.")
|
||||||
|
vector_field = [tf for tf in table_fields if re.match(r"q_\d+_vec", tf)]
|
||||||
|
if not vector_field:
|
||||||
|
raise Exception("Can't convert 'content_embed' to vector field name. No match field name found.")
|
||||||
|
return vector_field[0]
|
||||||
case _:
|
case _:
|
||||||
return field_name
|
return field_name
|
||||||
|
|
||||||
@ -63,15 +68,15 @@ class InfinityConnection(InfinityConnectionBase):
|
|||||||
return "content_embed"
|
return "content_embed"
|
||||||
return field_name
|
return field_name
|
||||||
|
|
||||||
def convert_select_fields(self, output_fields: list[str]) -> list[str]:
|
def convert_select_fields(self, output_fields: list[str], table_fields: list[str]=None) -> list[str]:
|
||||||
return list({self.convert_message_field_to_infinity(f) for f in output_fields})
|
return list({self.convert_message_field_to_infinity(f, table_fields) for f in output_fields})
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def convert_matching_field(field_weight_str: str) -> str:
|
def convert_matching_field(field_weight_str: str) -> str:
|
||||||
tokens = field_weight_str.split("^")
|
tokens = field_weight_str.split("^")
|
||||||
field = tokens[0]
|
field = tokens[0]
|
||||||
if field == "content":
|
if field == "content":
|
||||||
field = "content@ft_contentm_rag_fine"
|
field = "content@ft_content_rag_fine"
|
||||||
tokens[0] = field
|
tokens[0] = field
|
||||||
return "^".join(tokens)
|
return "^".join(tokens)
|
||||||
|
|
||||||
@ -123,7 +128,6 @@ class InfinityConnection(InfinityConnectionBase):
|
|||||||
if hide_forgotten:
|
if hide_forgotten:
|
||||||
condition.update({"must_not": {"exists": "forget_at_flt"}})
|
condition.update({"must_not": {"exists": "forget_at_flt"}})
|
||||||
output = select_fields.copy()
|
output = select_fields.copy()
|
||||||
output = self.convert_select_fields(output)
|
|
||||||
if agg_fields is None:
|
if agg_fields is None:
|
||||||
agg_fields = []
|
agg_fields = []
|
||||||
for essential_field in ["id"] + agg_fields:
|
for essential_field in ["id"] + agg_fields:
|
||||||
@ -145,8 +149,6 @@ class InfinityConnection(InfinityConnectionBase):
|
|||||||
if match_expressions:
|
if match_expressions:
|
||||||
if score_func not in output:
|
if score_func not in output:
|
||||||
output.append(score_func)
|
output.append(score_func)
|
||||||
if PAGERANK_FLD not in output:
|
|
||||||
output.append(PAGERANK_FLD)
|
|
||||||
output = [f for f in output if f != "_score"]
|
output = [f for f in output if f != "_score"]
|
||||||
if limit <= 0:
|
if limit <= 0:
|
||||||
# ElasticSearch default limit is 10000
|
# ElasticSearch default limit is 10000
|
||||||
@ -187,17 +189,6 @@ class InfinityConnection(InfinityConnectionBase):
|
|||||||
str_minimum_should_match = str(int(minimum_should_match * 100)) + "%"
|
str_minimum_should_match = str(int(minimum_should_match * 100)) + "%"
|
||||||
matchExpr.extra_options["minimum_should_match"] = str_minimum_should_match
|
matchExpr.extra_options["minimum_should_match"] = str_minimum_should_match
|
||||||
|
|
||||||
# Add rank_feature support
|
|
||||||
if rank_feature and "rank_features" not in matchExpr.extra_options:
|
|
||||||
# Convert rank_feature dict to Infinity's rank_features string format
|
|
||||||
# Format: "field^feature_name^weight,field^feature_name^weight"
|
|
||||||
rank_features_list = []
|
|
||||||
for feature_name, weight in rank_feature.items():
|
|
||||||
# Use TAG_FLD as the field containing rank features
|
|
||||||
rank_features_list.append(f"{TAG_FLD}^{feature_name}^{weight}")
|
|
||||||
if rank_features_list:
|
|
||||||
matchExpr.extra_options["rank_features"] = ",".join(rank_features_list)
|
|
||||||
|
|
||||||
for k, v in matchExpr.extra_options.items():
|
for k, v in matchExpr.extra_options.items():
|
||||||
if not isinstance(v, str):
|
if not isinstance(v, str):
|
||||||
matchExpr.extra_options[k] = str(v)
|
matchExpr.extra_options[k] = str(v)
|
||||||
@ -214,6 +205,9 @@ class InfinityConnection(InfinityConnectionBase):
|
|||||||
del matchExpr.extra_options["similarity"]
|
del matchExpr.extra_options["similarity"]
|
||||||
self.logger.debug(f"INFINITY search MatchDenseExpr: {json.dumps(matchExpr.__dict__)}")
|
self.logger.debug(f"INFINITY search MatchDenseExpr: {json.dumps(matchExpr.__dict__)}")
|
||||||
elif isinstance(matchExpr, FusionExpr):
|
elif isinstance(matchExpr, FusionExpr):
|
||||||
|
if matchExpr.method == "weighted_sum":
|
||||||
|
# The default is "minmax" which gives a zero score for the last doc.
|
||||||
|
matchExpr.fusion_params["normalize"] = "atan"
|
||||||
self.logger.debug(f"INFINITY search FusionExpr: {json.dumps(matchExpr.__dict__)}")
|
self.logger.debug(f"INFINITY search FusionExpr: {json.dumps(matchExpr.__dict__)}")
|
||||||
|
|
||||||
order_by_expr_list = list()
|
order_by_expr_list = list()
|
||||||
@ -227,6 +221,7 @@ class InfinityConnection(InfinityConnectionBase):
|
|||||||
|
|
||||||
total_hits_count = 0
|
total_hits_count = 0
|
||||||
# Scatter search tables and gather the results
|
# Scatter search tables and gather the results
|
||||||
|
column_name_list = []
|
||||||
for indexName in index_names:
|
for indexName in index_names:
|
||||||
for memory_id in memory_ids:
|
for memory_id in memory_ids:
|
||||||
table_name = f"{indexName}_{memory_id}"
|
table_name = f"{indexName}_{memory_id}"
|
||||||
@ -235,6 +230,9 @@ class InfinityConnection(InfinityConnectionBase):
|
|||||||
except Exception:
|
except Exception:
|
||||||
continue
|
continue
|
||||||
table_list.append(table_name)
|
table_list.append(table_name)
|
||||||
|
if not column_name_list:
|
||||||
|
column_name_list = [r[0] for r in table_instance.show_columns().rows()]
|
||||||
|
output = self.convert_select_fields(output, column_name_list)
|
||||||
builder = table_instance.output(output)
|
builder = table_instance.output(output)
|
||||||
if len(match_expressions) > 0:
|
if len(match_expressions) > 0:
|
||||||
for matchExpr in match_expressions:
|
for matchExpr in match_expressions:
|
||||||
@ -271,13 +269,13 @@ class InfinityConnection(InfinityConnectionBase):
|
|||||||
self.connPool.release_conn(inf_conn)
|
self.connPool.release_conn(inf_conn)
|
||||||
res = self.concat_dataframes(df_list, output)
|
res = self.concat_dataframes(df_list, output)
|
||||||
if match_expressions:
|
if match_expressions:
|
||||||
res["_score"] = res[score_column] + res[PAGERANK_FLD]
|
res["_score"] = res[score_column]
|
||||||
res = res.sort_values(by="_score", ascending=False).reset_index(drop=True)
|
res = res.sort_values(by="_score", ascending=False).reset_index(drop=True)
|
||||||
res = res.head(limit)
|
res = res.head(limit)
|
||||||
self.logger.debug(f"INFINITY search final result: {str(res)}")
|
self.logger.debug(f"INFINITY search final result: {str(res)}")
|
||||||
return res, total_hits_count
|
return res, total_hits_count
|
||||||
|
|
||||||
def get_forgotten_messages(self, select_fields: list[str], index_name: str, memory_id: str, limit: int=2000):
|
def get_forgotten_messages(self, select_fields: list[str], index_name: str, memory_id: str, limit: int=512):
|
||||||
condition = {"memory_id": memory_id, "exists": "forget_at_flt"}
|
condition = {"memory_id": memory_id, "exists": "forget_at_flt"}
|
||||||
order_by = OrderByExpr()
|
order_by = OrderByExpr()
|
||||||
order_by.asc("forget_at_flt")
|
order_by.asc("forget_at_flt")
|
||||||
@ -286,7 +284,8 @@ class InfinityConnection(InfinityConnectionBase):
|
|||||||
db_instance = inf_conn.get_database(self.dbName)
|
db_instance = inf_conn.get_database(self.dbName)
|
||||||
table_name = f"{index_name}_{memory_id}"
|
table_name = f"{index_name}_{memory_id}"
|
||||||
table_instance = db_instance.get_table(table_name)
|
table_instance = db_instance.get_table(table_name)
|
||||||
output_fields = [self.convert_message_field_to_infinity(f) for f in select_fields]
|
column_name_list = [r[0] for r in table_instance.show_columns().rows()]
|
||||||
|
output_fields = [self.convert_message_field_to_infinity(f, column_name_list) for f in select_fields]
|
||||||
builder = table_instance.output(output_fields)
|
builder = table_instance.output(output_fields)
|
||||||
filter_cond = self.equivalent_condition_to_str(condition, db_instance.get_table(table_name))
|
filter_cond = self.equivalent_condition_to_str(condition, db_instance.get_table(table_name))
|
||||||
builder.filter(filter_cond)
|
builder.filter(filter_cond)
|
||||||
@ -327,7 +326,7 @@ class InfinityConnection(InfinityConnectionBase):
|
|||||||
res = self.concat_dataframes(df_list, ["id"])
|
res = self.concat_dataframes(df_list, ["id"])
|
||||||
fields = set(res.columns.tolist())
|
fields = set(res.columns.tolist())
|
||||||
res_fields = self.get_fields(res, list(fields))
|
res_fields = self.get_fields(res, list(fields))
|
||||||
return res_fields.get(message_id, None)
|
return {self.convert_infinity_field_to_message(k): v for k, v in res_fields[message_id].items()} if res_fields.get(message_id) else {}
|
||||||
|
|
||||||
def insert(self, documents: list[dict], index_name: str, memory_id: str = None) -> list[str]:
|
def insert(self, documents: list[dict], index_name: str, memory_id: str = None) -> list[str]:
|
||||||
if not documents:
|
if not documents:
|
||||||
@ -361,6 +360,10 @@ class InfinityConnection(InfinityConnectionBase):
|
|||||||
assert "_id" not in d
|
assert "_id" not in d
|
||||||
assert "id" in d
|
assert "id" in d
|
||||||
for k, v in list(d.items()):
|
for k, v in list(d.items()):
|
||||||
|
if k == "content_embed":
|
||||||
|
d[f"q_{vector_size}_vec"] = d["content_embed"]
|
||||||
|
d.pop("content_embed")
|
||||||
|
continue
|
||||||
field_name = self.convert_message_field_to_infinity(k)
|
field_name = self.convert_message_field_to_infinity(k)
|
||||||
if field_name in ["valid_at", "invalid_at", "forget_at"]:
|
if field_name in ["valid_at", "invalid_at", "forget_at"]:
|
||||||
d[f"{field_name}_flt"] = date_string_to_timestamp(v) if v else 0
|
d[f"{field_name}_flt"] = date_string_to_timestamp(v) if v else 0
|
||||||
@ -374,9 +377,6 @@ class InfinityConnection(InfinityConnectionBase):
|
|||||||
elif k == "memory_id":
|
elif k == "memory_id":
|
||||||
if isinstance(d[k], list):
|
if isinstance(d[k], list):
|
||||||
d[k] = d[k][0] # since d[k] is a list, but we need a str
|
d[k] = d[k][0] # since d[k] is a list, but we need a str
|
||||||
elif field_name == "content_embed":
|
|
||||||
d[f"q_{vector_size}_vec"] = d["content_embed"]
|
|
||||||
d.pop("content_embed")
|
|
||||||
else:
|
else:
|
||||||
d[field_name] = v
|
d[field_name] = v
|
||||||
if k != field_name:
|
if k != field_name:
|
||||||
@ -436,32 +436,32 @@ class InfinityConnection(InfinityConnectionBase):
|
|||||||
|
|
||||||
def get_fields(self, res: tuple[pd.DataFrame, int] | pd.DataFrame, fields: list[str]) -> dict[str, dict]:
|
def get_fields(self, res: tuple[pd.DataFrame, int] | pd.DataFrame, fields: list[str]) -> dict[str, dict]:
|
||||||
if isinstance(res, tuple):
|
if isinstance(res, tuple):
|
||||||
res = res[0]
|
res_df = res[0]
|
||||||
|
else:
|
||||||
|
res_df = res
|
||||||
if not fields:
|
if not fields:
|
||||||
return {}
|
return {}
|
||||||
fields_all = fields.copy()
|
fields_all = fields.copy()
|
||||||
fields_all.append("id")
|
fields_all.append("id")
|
||||||
fields_all = {self.convert_message_field_to_infinity(f) for f in fields_all}
|
fields_all = self.convert_select_fields(fields_all, res_df.columns.tolist())
|
||||||
|
|
||||||
column_map = {col.lower(): col for col in res.columns}
|
column_map = {col.lower(): col for col in res_df.columns}
|
||||||
matched_columns = {column_map[col.lower()]: col for col in fields_all if col.lower() in column_map}
|
matched_columns = {column_map[col.lower()]: col for col in fields_all if col.lower() in column_map}
|
||||||
none_columns = [col for col in fields_all if col.lower() not in column_map]
|
none_columns = [col for col in fields_all if col.lower() not in column_map]
|
||||||
|
|
||||||
res2 = res[matched_columns.keys()]
|
selected_res = res_df[matched_columns.keys()]
|
||||||
res2 = res2.rename(columns=matched_columns)
|
selected_res = selected_res.rename(columns=matched_columns)
|
||||||
res2.drop_duplicates(subset=["id"], inplace=True)
|
selected_res.drop_duplicates(subset=["id"], inplace=True)
|
||||||
|
|
||||||
for column in list(res2.columns):
|
for column in list(selected_res.columns):
|
||||||
k = column.lower()
|
k = column.lower()
|
||||||
if self.field_keyword(k):
|
if self.field_keyword(k):
|
||||||
res2[column] = res2[column].apply(lambda v: [kwd for kwd in v.split("###") if kwd])
|
selected_res[column] = selected_res[column].apply(lambda v: [kwd for kwd in v.split("###") if kwd])
|
||||||
else:
|
else:
|
||||||
pass
|
pass
|
||||||
for column in ["content"]:
|
|
||||||
if column in res2:
|
|
||||||
del res2[column]
|
|
||||||
for column in none_columns:
|
|
||||||
res2[column] = None
|
|
||||||
|
|
||||||
res_dict = res2.set_index("id").to_dict(orient="index")
|
for column in none_columns:
|
||||||
|
selected_res[column] = None
|
||||||
|
|
||||||
|
res_dict = selected_res.set_index("id").to_dict(orient="index")
|
||||||
return {_id: {self.convert_infinity_field_to_message(k): v for k, v in doc.items()} for _id, doc in res_dict.items()}
|
return {_id: {self.convert_infinity_field_to_message(k): v for k, v in doc.items()} for _id, doc in res_dict.items()}
|
||||||
|
|||||||
@ -1,6 +1,6 @@
|
|||||||
[project]
|
[project]
|
||||||
name = "ragflow"
|
name = "ragflow"
|
||||||
version = "0.22.1"
|
version = "0.23.0"
|
||||||
description = "[RAGFlow](https://ragflow.io/) is an open-source RAG (Retrieval-Augmented Generation) engine based on deep document understanding. It offers a streamlined RAG workflow for businesses of any scale, combining LLM (Large Language Models) to provide truthful question-answering capabilities, backed by well-founded citations from various complex formatted data."
|
description = "[RAGFlow](https://ragflow.io/) is an open-source RAG (Retrieval-Augmented Generation) engine based on deep document understanding. It offers a streamlined RAG workflow for businesses of any scale, combining LLM (Large Language Models) to provide truthful question-answering capabilities, backed by well-founded citations from various complex formatted data."
|
||||||
authors = [{ name = "Zhichang Yu", email = "yuzhichang@gmail.com" }]
|
authors = [{ name = "Zhichang Yu", email = "yuzhichang@gmail.com" }]
|
||||||
license-files = ["LICENSE"]
|
license-files = ["LICENSE"]
|
||||||
@ -46,7 +46,7 @@ dependencies = [
|
|||||||
"groq==0.9.0",
|
"groq==0.9.0",
|
||||||
"grpcio-status==1.67.1",
|
"grpcio-status==1.67.1",
|
||||||
"html-text==0.6.2",
|
"html-text==0.6.2",
|
||||||
"infinity-sdk==0.6.13",
|
"infinity-sdk==0.6.15",
|
||||||
"infinity-emb>=0.0.66,<0.0.67",
|
"infinity-emb>=0.0.66,<0.0.67",
|
||||||
"jira==3.10.5",
|
"jira==3.10.5",
|
||||||
"json-repair==0.35.0",
|
"json-repair==0.35.0",
|
||||||
@ -148,6 +148,10 @@ dependencies = [
|
|||||||
# "imageio-ffmpeg>=0.6.0",
|
# "imageio-ffmpeg>=0.6.0",
|
||||||
# "cryptography==46.0.3",
|
# "cryptography==46.0.3",
|
||||||
# "jinja2>=3.1.0",
|
# "jinja2>=3.1.0",
|
||||||
|
"pyairtable>=3.3.0",
|
||||||
|
"pygithub>=2.8.1",
|
||||||
|
"asana>=5.2.2",
|
||||||
|
"python-gitlab>=7.0.0",
|
||||||
]
|
]
|
||||||
|
|
||||||
[dependency-groups]
|
[dependency-groups]
|
||||||
|
|||||||
@ -13,7 +13,7 @@
|
|||||||
# See the License for the specific language governing permissions and
|
# See the License for the specific language governing permissions and
|
||||||
# limitations under the License.
|
# limitations under the License.
|
||||||
#
|
#
|
||||||
|
import logging
|
||||||
import os
|
import os
|
||||||
import re
|
import re
|
||||||
import tempfile
|
import tempfile
|
||||||
@ -28,13 +28,14 @@ def chunk(filename, binary, tenant_id, lang, callback=None, **kwargs):
|
|||||||
doc["title_sm_tks"] = rag_tokenizer.fine_grained_tokenize(doc["title_tks"])
|
doc["title_sm_tks"] = rag_tokenizer.fine_grained_tokenize(doc["title_tks"])
|
||||||
|
|
||||||
# is it English
|
# is it English
|
||||||
eng = lang.lower() == "english" # is_english(sections)
|
is_english = lang.lower() == "english" # is_english(sections)
|
||||||
try:
|
try:
|
||||||
_, ext = os.path.splitext(filename)
|
_, ext = os.path.splitext(filename)
|
||||||
if not ext:
|
if not ext:
|
||||||
raise RuntimeError("No extension detected.")
|
raise RuntimeError("No extension detected.")
|
||||||
|
|
||||||
if ext not in [".da", ".wave", ".wav", ".mp3", ".wav", ".aac", ".flac", ".ogg", ".aiff", ".au", ".midi", ".wma", ".realaudio", ".vqf", ".oggvorbis", ".aac", ".ape"]:
|
if ext not in [".da", ".wave", ".wav", ".mp3", ".wav", ".aac", ".flac", ".ogg", ".aiff", ".au", ".midi", ".wma",
|
||||||
|
".realaudio", ".vqf", ".oggvorbis", ".aac", ".ape"]:
|
||||||
raise RuntimeError(f"Extension {ext} is not supported yet.")
|
raise RuntimeError(f"Extension {ext} is not supported yet.")
|
||||||
|
|
||||||
tmp_path = ""
|
tmp_path = ""
|
||||||
@ -48,7 +49,7 @@ def chunk(filename, binary, tenant_id, lang, callback=None, **kwargs):
|
|||||||
ans = seq2txt_mdl.transcription(tmp_path)
|
ans = seq2txt_mdl.transcription(tmp_path)
|
||||||
callback(0.8, "Sequence2Txt LLM respond: %s ..." % ans[:32])
|
callback(0.8, "Sequence2Txt LLM respond: %s ..." % ans[:32])
|
||||||
|
|
||||||
tokenize(doc, ans, eng)
|
tokenize(doc, ans, is_english)
|
||||||
return [doc]
|
return [doc]
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
callback(prog=-1, msg=str(e))
|
callback(prog=-1, msg=str(e))
|
||||||
@ -56,6 +57,7 @@ def chunk(filename, binary, tenant_id, lang, callback=None, **kwargs):
|
|||||||
if tmp_path and os.path.exists(tmp_path):
|
if tmp_path and os.path.exists(tmp_path):
|
||||||
try:
|
try:
|
||||||
os.unlink(tmp_path)
|
os.unlink(tmp_path)
|
||||||
except Exception:
|
except Exception as e:
|
||||||
|
logging.exception(f"Failed to remove temporary file: {tmp_path}, exception: {e}")
|
||||||
pass
|
pass
|
||||||
return []
|
return []
|
||||||
|
|||||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user