mirror of
https://github.com/infiniflow/ragflow.git
synced 2025-12-08 20:42:30 +08:00
Compare commits
77 Commits
f0a14f5fce
...
revert-116
| Author | SHA1 | Date | |
|---|---|---|---|
| cd0216cce3 | |||
| 962bd5f5df | |||
| 627c11c429 | |||
| 4ba17361e9 | |||
| c946858328 | |||
| ba6e2af5fd | |||
| 2ffe6f7439 | |||
| e3987e21b9 | |||
| a713f54732 | |||
| 519f03097e | |||
| 299c655e39 | |||
| b8c0fb4572 | |||
| d1e172171f | |||
| 81ae6cf78d | |||
| 1120575021 | |||
| 221947acc4 | |||
| 21d8ffca56 | |||
| 41cff3e09e | |||
| b6c4722687 | |||
| 6ea4248bdc | |||
| 88a28212b3 | |||
| 9d0309aedc | |||
| 9a8ce9d3e2 | |||
| 7499608a8b | |||
| 0ebbb60102 | |||
| 80f6d22d2a | |||
| 088b049b4c | |||
| fa9b7b259c | |||
| 14616cf845 | |||
| d2915f6984 | |||
| ccce8beeeb | |||
| 3d2e0f1a1b | |||
| 918d5a9ff8 | |||
| 7d05d4ced7 | |||
| dbdda0fbab | |||
| cf7fdd274b | |||
| 982ed233a2 | |||
| 1f96c95b42 | |||
| 8604c4f57c | |||
| a674338c21 | |||
| 89d82ff031 | |||
| c71d25f744 | |||
| f57f32cf3a | |||
| b6314164c5 | |||
| 856201c0f2 | |||
| 9d8b96c1d0 | |||
| 7c3c185038 | |||
| a9259917c6 | |||
| 8c28587821 | |||
| 12979a3f21 | |||
| 376eb15c63 | |||
| 89ba7abe30 | |||
| 2fd5ac1031 | |||
| 40e84ca41a | |||
| a28c672695 | |||
| 74e0b58d89 | |||
| 7c20c964b4 | |||
| 5d0981d046 | |||
| a793dd2ea8 | |||
| 915e385244 | |||
| 7a344a32f9 | |||
| 8c1ee3845a | |||
| 8c751d5afc | |||
| f5faf0c94f | |||
| af72e8dc33 | |||
| bcd70affb5 | |||
| 6987e9f23b | |||
| 41665b0865 | |||
| d1744aaaf3 | |||
| d5f8548200 | |||
| 4d8698624c | |||
| 1009819801 | |||
| 8fe782f4ea | |||
| 7140950e93 | |||
| 0181747881 | |||
| 3c41159d26 | |||
| e0e1d04da5 |
12
.github/workflows/tests.yml
vendored
12
.github/workflows/tests.yml
vendored
@ -12,7 +12,7 @@ on:
|
||||
# The only difference between pull_request and pull_request_target is the context in which the workflow runs:
|
||||
# — pull_request_target workflows use the workflow files from the default branch, and secrets are available.
|
||||
# — pull_request workflows use the workflow files from the pull request branch, and secrets are unavailable.
|
||||
pull_request_target:
|
||||
pull_request:
|
||||
types: [ synchronize, ready_for_review ]
|
||||
paths-ignore:
|
||||
- 'docs/**'
|
||||
@ -31,7 +31,7 @@ jobs:
|
||||
name: ragflow_tests
|
||||
# https://docs.github.com/en/actions/using-jobs/using-conditions-to-control-job-execution
|
||||
# https://github.com/orgs/community/discussions/26261
|
||||
if: ${{ github.event_name != 'pull_request_target' || contains(github.event.pull_request.labels.*.name, 'ci') }}
|
||||
if: ${{ github.event_name != 'pull_request' || (github.event.pull_request.draft == false && contains(github.event.pull_request.labels.*.name, 'ci')) }}
|
||||
runs-on: [ "self-hosted", "ragflow-test" ]
|
||||
steps:
|
||||
# https://github.com/hmarr/debug-action
|
||||
@ -53,7 +53,7 @@ jobs:
|
||||
- name: Check workflow duplication
|
||||
if: ${{ !cancelled() && !failure() }}
|
||||
run: |
|
||||
if [[ ${GITHUB_EVENT_NAME} != "pull_request_target" && ${GITHUB_EVENT_NAME} != "schedule" ]]; then
|
||||
if [[ ${GITHUB_EVENT_NAME} != "pull_request" && ${GITHUB_EVENT_NAME} != "schedule" ]]; then
|
||||
HEAD=$(git rev-parse HEAD)
|
||||
# Find a PR that introduced a given commit
|
||||
gh auth login --with-token <<< "${{ secrets.GITHUB_TOKEN }}"
|
||||
@ -78,7 +78,7 @@ jobs:
|
||||
fi
|
||||
fi
|
||||
fi
|
||||
elif [[ ${GITHUB_EVENT_NAME} == "pull_request_target" ]]; then
|
||||
elif [[ ${GITHUB_EVENT_NAME} == "pull_request" ]]; then
|
||||
PR_NUMBER=${{ github.event.pull_request.number }}
|
||||
PR_SHA_FP=${RUNNER_WORKSPACE_PREFIX}/artifacts/${GITHUB_REPOSITORY}/PR_${PR_NUMBER}
|
||||
# Calculate the hash of the current workspace content
|
||||
@ -98,7 +98,7 @@ jobs:
|
||||
- name: Check comments of changed Python files
|
||||
if: ${{ false }}
|
||||
run: |
|
||||
if [[ ${{ github.event_name }} == 'pull_request_target' ]]; then
|
||||
if [[ ${{ github.event_name }} == 'pull_request' || ${{ github.event_name }} == 'pull_request_target' ]]; then
|
||||
CHANGED_FILES=$(git diff --name-only ${{ github.event.pull_request.base.sha }}...${{ github.event.pull_request.head.sha }} \
|
||||
| grep -E '\.(py)$' || true)
|
||||
|
||||
@ -193,7 +193,7 @@ jobs:
|
||||
echo "HOST_ADDRESS=http://host.docker.internal:${SVR_HTTP_PORT}" >> ${GITHUB_ENV}
|
||||
|
||||
sudo docker compose -f docker/docker-compose.yml -p ${GITHUB_RUN_ID} up -d
|
||||
uv sync --python 3.10 --only-group test --no-default-groups --frozen && uv pip install sdk/python
|
||||
uv sync --python 3.10 --only-group test --no-default-groups --frozen && uv pip install sdk/python --group test
|
||||
|
||||
- name: Run sdk tests against Elasticsearch
|
||||
run: |
|
||||
|
||||
@ -194,7 +194,7 @@ releases! 🌟
|
||||
|
||||
# git checkout v0.22.1
|
||||
# Optional: use a stable tag (see releases: https://github.com/infiniflow/ragflow/releases)
|
||||
# This steps ensures the **entrypoint.sh** file in the code matches the Docker image version.
|
||||
# This step ensures the **entrypoint.sh** file in the code matches the Docker image version.
|
||||
|
||||
# Use CPU for DeepDoc tasks:
|
||||
$ docker compose -f docker-compose.yml up -d
|
||||
|
||||
@ -8,7 +8,7 @@ readme = "README.md"
|
||||
requires-python = ">=3.10,<3.13"
|
||||
dependencies = [
|
||||
"requests>=2.30.0,<3.0.0",
|
||||
"beartype>=0.18.5,<0.19.0",
|
||||
"beartype>=0.20.0,<1.0.0",
|
||||
"pycryptodomex>=3.10.0",
|
||||
"lark>=1.1.0",
|
||||
]
|
||||
|
||||
298
admin/client/uv.lock
generated
Normal file
298
admin/client/uv.lock
generated
Normal file
@ -0,0 +1,298 @@
|
||||
version = 1
|
||||
revision = 3
|
||||
requires-python = ">=3.10, <3.13"
|
||||
|
||||
[[package]]
|
||||
name = "beartype"
|
||||
version = "0.22.6"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/88/e2/105ceb1704cb80fe4ab3872529ab7b6f365cf7c74f725e6132d0efcf1560/beartype-0.22.6.tar.gz", hash = "sha256:97fbda69c20b48c5780ac2ca60ce3c1bb9af29b3a1a0216898ffabdd523e48f4", size = 1588975, upload-time = "2025-11-20T04:47:14.736Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/98/c9/ceecc71fe2c9495a1d8e08d44f5f31f5bca1350d5b2e27a4b6265424f59e/beartype-0.22.6-py3-none-any.whl", hash = "sha256:0584bc46a2ea2a871509679278cda992eadde676c01356ab0ac77421f3c9a093", size = 1324807, upload-time = "2025-11-20T04:47:11.837Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "certifi"
|
||||
version = "2025.11.12"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/a2/8c/58f469717fa48465e4a50c014a0400602d3c437d7c0c468e17ada824da3a/certifi-2025.11.12.tar.gz", hash = "sha256:d8ab5478f2ecd78af242878415affce761ca6bc54a22a27e026d7c25357c3316", size = 160538, upload-time = "2025-11-12T02:54:51.517Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/70/7d/9bc192684cea499815ff478dfcdc13835ddf401365057044fb721ec6bddb/certifi-2025.11.12-py3-none-any.whl", hash = "sha256:97de8790030bbd5c2d96b7ec782fc2f7820ef8dba6db909ccf95449f2d062d4b", size = 159438, upload-time = "2025-11-12T02:54:49.735Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "charset-normalizer"
|
||||
version = "3.4.4"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/13/69/33ddede1939fdd074bce5434295f38fae7136463422fe4fd3e0e89b98062/charset_normalizer-3.4.4.tar.gz", hash = "sha256:94537985111c35f28720e43603b8e7b43a6ecfb2ce1d3058bbe955b73404e21a", size = 129418, upload-time = "2025-10-14T04:42:32.879Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/1f/b8/6d51fc1d52cbd52cd4ccedd5b5b2f0f6a11bbf6765c782298b0f3e808541/charset_normalizer-3.4.4-cp310-cp310-macosx_10_9_universal2.whl", hash = "sha256:e824f1492727fa856dd6eda4f7cee25f8518a12f3c4a56a74e8095695089cf6d", size = 209709, upload-time = "2025-10-14T04:40:11.385Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/5c/af/1f9d7f7faafe2ddfb6f72a2e07a548a629c61ad510fe60f9630309908fef/charset_normalizer-3.4.4-cp310-cp310-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:4bd5d4137d500351a30687c2d3971758aac9a19208fc110ccb9d7188fbe709e8", size = 148814, upload-time = "2025-10-14T04:40:13.135Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/79/3d/f2e3ac2bbc056ca0c204298ea4e3d9db9b4afe437812638759db2c976b5f/charset_normalizer-3.4.4-cp310-cp310-manylinux2014_armv7l.manylinux_2_17_armv7l.manylinux_2_31_armv7l.whl", hash = "sha256:027f6de494925c0ab2a55eab46ae5129951638a49a34d87f4c3eda90f696b4ad", size = 144467, upload-time = "2025-10-14T04:40:14.728Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/ec/85/1bf997003815e60d57de7bd972c57dc6950446a3e4ccac43bc3070721856/charset_normalizer-3.4.4-cp310-cp310-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:f820802628d2694cb7e56db99213f930856014862f3fd943d290ea8438d07ca8", size = 162280, upload-time = "2025-10-14T04:40:16.14Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/3e/8e/6aa1952f56b192f54921c436b87f2aaf7c7a7c3d0d1a765547d64fd83c13/charset_normalizer-3.4.4-cp310-cp310-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:798d75d81754988d2565bff1b97ba5a44411867c0cf32b77a7e8f8d84796b10d", size = 159454, upload-time = "2025-10-14T04:40:17.567Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/36/3b/60cbd1f8e93aa25d1c669c649b7a655b0b5fb4c571858910ea9332678558/charset_normalizer-3.4.4-cp310-cp310-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:9d1bb833febdff5c8927f922386db610b49db6e0d4f4ee29601d71e7c2694313", size = 153609, upload-time = "2025-10-14T04:40:19.08Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/64/91/6a13396948b8fd3c4b4fd5bc74d045f5637d78c9675585e8e9fbe5636554/charset_normalizer-3.4.4-cp310-cp310-manylinux_2_31_riscv64.manylinux_2_39_riscv64.whl", hash = "sha256:9cd98cdc06614a2f768d2b7286d66805f94c48cde050acdbbb7db2600ab3197e", size = 151849, upload-time = "2025-10-14T04:40:20.607Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/b7/7a/59482e28b9981d105691e968c544cc0df3b7d6133152fb3dcdc8f135da7a/charset_normalizer-3.4.4-cp310-cp310-musllinux_1_2_aarch64.whl", hash = "sha256:077fbb858e903c73f6c9db43374fd213b0b6a778106bc7032446a8e8b5b38b93", size = 151586, upload-time = "2025-10-14T04:40:21.719Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/92/59/f64ef6a1c4bdd2baf892b04cd78792ed8684fbc48d4c2afe467d96b4df57/charset_normalizer-3.4.4-cp310-cp310-musllinux_1_2_armv7l.whl", hash = "sha256:244bfb999c71b35de57821b8ea746b24e863398194a4014e4c76adc2bbdfeff0", size = 145290, upload-time = "2025-10-14T04:40:23.069Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/6b/63/3bf9f279ddfa641ffa1962b0db6a57a9c294361cc2f5fcac997049a00e9c/charset_normalizer-3.4.4-cp310-cp310-musllinux_1_2_ppc64le.whl", hash = "sha256:64b55f9dce520635f018f907ff1b0df1fdc31f2795a922fb49dd14fbcdf48c84", size = 163663, upload-time = "2025-10-14T04:40:24.17Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/ed/09/c9e38fc8fa9e0849b172b581fd9803bdf6e694041127933934184e19f8c3/charset_normalizer-3.4.4-cp310-cp310-musllinux_1_2_riscv64.whl", hash = "sha256:faa3a41b2b66b6e50f84ae4a68c64fcd0c44355741c6374813a800cd6695db9e", size = 151964, upload-time = "2025-10-14T04:40:25.368Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/d2/d1/d28b747e512d0da79d8b6a1ac18b7ab2ecfd81b2944c4c710e166d8dd09c/charset_normalizer-3.4.4-cp310-cp310-musllinux_1_2_s390x.whl", hash = "sha256:6515f3182dbe4ea06ced2d9e8666d97b46ef4c75e326b79bb624110f122551db", size = 161064, upload-time = "2025-10-14T04:40:26.806Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/bb/9a/31d62b611d901c3b9e5500c36aab0ff5eb442043fb3a1c254200d3d397d9/charset_normalizer-3.4.4-cp310-cp310-musllinux_1_2_x86_64.whl", hash = "sha256:cc00f04ed596e9dc0da42ed17ac5e596c6ccba999ba6bd92b0e0aef2f170f2d6", size = 155015, upload-time = "2025-10-14T04:40:28.284Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/1f/f3/107e008fa2bff0c8b9319584174418e5e5285fef32f79d8ee6a430d0039c/charset_normalizer-3.4.4-cp310-cp310-win32.whl", hash = "sha256:f34be2938726fc13801220747472850852fe6b1ea75869a048d6f896838c896f", size = 99792, upload-time = "2025-10-14T04:40:29.613Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/eb/66/e396e8a408843337d7315bab30dbf106c38966f1819f123257f5520f8a96/charset_normalizer-3.4.4-cp310-cp310-win_amd64.whl", hash = "sha256:a61900df84c667873b292c3de315a786dd8dac506704dea57bc957bd31e22c7d", size = 107198, upload-time = "2025-10-14T04:40:30.644Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/b5/58/01b4f815bf0312704c267f2ccb6e5d42bcc7752340cd487bc9f8c3710597/charset_normalizer-3.4.4-cp310-cp310-win_arm64.whl", hash = "sha256:cead0978fc57397645f12578bfd2d5ea9138ea0fac82b2f63f7f7c6877986a69", size = 100262, upload-time = "2025-10-14T04:40:32.108Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/ed/27/c6491ff4954e58a10f69ad90aca8a1b6fe9c5d3c6f380907af3c37435b59/charset_normalizer-3.4.4-cp311-cp311-macosx_10_9_universal2.whl", hash = "sha256:6e1fcf0720908f200cd21aa4e6750a48ff6ce4afe7ff5a79a90d5ed8a08296f8", size = 206988, upload-time = "2025-10-14T04:40:33.79Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/94/59/2e87300fe67ab820b5428580a53cad894272dbb97f38a7a814a2a1ac1011/charset_normalizer-3.4.4-cp311-cp311-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:5f819d5fe9234f9f82d75bdfa9aef3a3d72c4d24a6e57aeaebba32a704553aa0", size = 147324, upload-time = "2025-10-14T04:40:34.961Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/07/fb/0cf61dc84b2b088391830f6274cb57c82e4da8bbc2efeac8c025edb88772/charset_normalizer-3.4.4-cp311-cp311-manylinux2014_armv7l.manylinux_2_17_armv7l.manylinux_2_31_armv7l.whl", hash = "sha256:a59cb51917aa591b1c4e6a43c132f0cdc3c76dbad6155df4e28ee626cc77a0a3", size = 142742, upload-time = "2025-10-14T04:40:36.105Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/62/8b/171935adf2312cd745d290ed93cf16cf0dfe320863ab7cbeeae1dcd6535f/charset_normalizer-3.4.4-cp311-cp311-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:8ef3c867360f88ac904fd3f5e1f902f13307af9052646963ee08ff4f131adafc", size = 160863, upload-time = "2025-10-14T04:40:37.188Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/09/73/ad875b192bda14f2173bfc1bc9a55e009808484a4b256748d931b6948442/charset_normalizer-3.4.4-cp311-cp311-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:d9e45d7faa48ee908174d8fe84854479ef838fc6a705c9315372eacbc2f02897", size = 157837, upload-time = "2025-10-14T04:40:38.435Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/6d/fc/de9cce525b2c5b94b47c70a4b4fb19f871b24995c728e957ee68ab1671ea/charset_normalizer-3.4.4-cp311-cp311-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:840c25fb618a231545cbab0564a799f101b63b9901f2569faecd6b222ac72381", size = 151550, upload-time = "2025-10-14T04:40:40.053Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/55/c2/43edd615fdfba8c6f2dfbd459b25a6b3b551f24ea21981e23fb768503ce1/charset_normalizer-3.4.4-cp311-cp311-manylinux_2_31_riscv64.manylinux_2_39_riscv64.whl", hash = "sha256:ca5862d5b3928c4940729dacc329aa9102900382fea192fc5e52eb69d6093815", size = 149162, upload-time = "2025-10-14T04:40:41.163Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/03/86/bde4ad8b4d0e9429a4e82c1e8f5c659993a9a863ad62c7df05cf7b678d75/charset_normalizer-3.4.4-cp311-cp311-musllinux_1_2_aarch64.whl", hash = "sha256:d9c7f57c3d666a53421049053eaacdd14bbd0a528e2186fcb2e672effd053bb0", size = 150019, upload-time = "2025-10-14T04:40:42.276Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/1f/86/a151eb2af293a7e7bac3a739b81072585ce36ccfb4493039f49f1d3cae8c/charset_normalizer-3.4.4-cp311-cp311-musllinux_1_2_armv7l.whl", hash = "sha256:277e970e750505ed74c832b4bf75dac7476262ee2a013f5574dd49075879e161", size = 143310, upload-time = "2025-10-14T04:40:43.439Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/b5/fe/43dae6144a7e07b87478fdfc4dbe9efd5defb0e7ec29f5f58a55aeef7bf7/charset_normalizer-3.4.4-cp311-cp311-musllinux_1_2_ppc64le.whl", hash = "sha256:31fd66405eaf47bb62e8cd575dc621c56c668f27d46a61d975a249930dd5e2a4", size = 162022, upload-time = "2025-10-14T04:40:44.547Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/80/e6/7aab83774f5d2bca81f42ac58d04caf44f0cc2b65fc6db2b3b2e8a05f3b3/charset_normalizer-3.4.4-cp311-cp311-musllinux_1_2_riscv64.whl", hash = "sha256:0d3d8f15c07f86e9ff82319b3d9ef6f4bf907608f53fe9d92b28ea9ae3d1fd89", size = 149383, upload-time = "2025-10-14T04:40:46.018Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/4f/e8/b289173b4edae05c0dde07f69f8db476a0b511eac556dfe0d6bda3c43384/charset_normalizer-3.4.4-cp311-cp311-musllinux_1_2_s390x.whl", hash = "sha256:9f7fcd74d410a36883701fafa2482a6af2ff5ba96b9a620e9e0721e28ead5569", size = 159098, upload-time = "2025-10-14T04:40:47.081Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/d8/df/fe699727754cae3f8478493c7f45f777b17c3ef0600e28abfec8619eb49c/charset_normalizer-3.4.4-cp311-cp311-musllinux_1_2_x86_64.whl", hash = "sha256:ebf3e58c7ec8a8bed6d66a75d7fb37b55e5015b03ceae72a8e7c74495551e224", size = 152991, upload-time = "2025-10-14T04:40:48.246Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/1a/86/584869fe4ddb6ffa3bd9f491b87a01568797fb9bd8933f557dba9771beaf/charset_normalizer-3.4.4-cp311-cp311-win32.whl", hash = "sha256:eecbc200c7fd5ddb9a7f16c7decb07b566c29fa2161a16cf67b8d068bd21690a", size = 99456, upload-time = "2025-10-14T04:40:49.376Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/65/f6/62fdd5feb60530f50f7e38b4f6a1d5203f4d16ff4f9f0952962c044e919a/charset_normalizer-3.4.4-cp311-cp311-win_amd64.whl", hash = "sha256:5ae497466c7901d54b639cf42d5b8c1b6a4fead55215500d2f486d34db48d016", size = 106978, upload-time = "2025-10-14T04:40:50.844Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/7a/9d/0710916e6c82948b3be62d9d398cb4fcf4e97b56d6a6aeccd66c4b2f2bd5/charset_normalizer-3.4.4-cp311-cp311-win_arm64.whl", hash = "sha256:65e2befcd84bc6f37095f5961e68a6f077bf44946771354a28ad434c2cce0ae1", size = 99969, upload-time = "2025-10-14T04:40:52.272Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/f3/85/1637cd4af66fa687396e757dec650f28025f2a2f5a5531a3208dc0ec43f2/charset_normalizer-3.4.4-cp312-cp312-macosx_10_13_universal2.whl", hash = "sha256:0a98e6759f854bd25a58a73fa88833fba3b7c491169f86ce1180c948ab3fd394", size = 208425, upload-time = "2025-10-14T04:40:53.353Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/9d/6a/04130023fef2a0d9c62d0bae2649b69f7b7d8d24ea5536feef50551029df/charset_normalizer-3.4.4-cp312-cp312-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:b5b290ccc2a263e8d185130284f8501e3e36c5e02750fc6b6bdeb2e9e96f1e25", size = 148162, upload-time = "2025-10-14T04:40:54.558Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/78/29/62328d79aa60da22c9e0b9a66539feae06ca0f5a4171ac4f7dc285b83688/charset_normalizer-3.4.4-cp312-cp312-manylinux2014_armv7l.manylinux_2_17_armv7l.manylinux_2_31_armv7l.whl", hash = "sha256:74bb723680f9f7a6234dcf67aea57e708ec1fbdf5699fb91dfd6f511b0a320ef", size = 144558, upload-time = "2025-10-14T04:40:55.677Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/86/bb/b32194a4bf15b88403537c2e120b817c61cd4ecffa9b6876e941c3ee38fe/charset_normalizer-3.4.4-cp312-cp312-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:f1e34719c6ed0b92f418c7c780480b26b5d9c50349e9a9af7d76bf757530350d", size = 161497, upload-time = "2025-10-14T04:40:57.217Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/19/89/a54c82b253d5b9b111dc74aca196ba5ccfcca8242d0fb64146d4d3183ff1/charset_normalizer-3.4.4-cp312-cp312-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:2437418e20515acec67d86e12bf70056a33abdacb5cb1655042f6538d6b085a8", size = 159240, upload-time = "2025-10-14T04:40:58.358Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/c0/10/d20b513afe03acc89ec33948320a5544d31f21b05368436d580dec4e234d/charset_normalizer-3.4.4-cp312-cp312-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:11d694519d7f29d6cd09f6ac70028dba10f92f6cdd059096db198c283794ac86", size = 153471, upload-time = "2025-10-14T04:40:59.468Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/61/fa/fbf177b55bdd727010f9c0a3c49eefa1d10f960e5f09d1d887bf93c2e698/charset_normalizer-3.4.4-cp312-cp312-manylinux_2_31_riscv64.manylinux_2_39_riscv64.whl", hash = "sha256:ac1c4a689edcc530fc9d9aa11f5774b9e2f33f9a0c6a57864e90908f5208d30a", size = 150864, upload-time = "2025-10-14T04:41:00.623Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/05/12/9fbc6a4d39c0198adeebbde20b619790e9236557ca59fc40e0e3cebe6f40/charset_normalizer-3.4.4-cp312-cp312-musllinux_1_2_aarch64.whl", hash = "sha256:21d142cc6c0ec30d2efee5068ca36c128a30b0f2c53c1c07bd78cb6bc1d3be5f", size = 150647, upload-time = "2025-10-14T04:41:01.754Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/ad/1f/6a9a593d52e3e8c5d2b167daf8c6b968808efb57ef4c210acb907c365bc4/charset_normalizer-3.4.4-cp312-cp312-musllinux_1_2_armv7l.whl", hash = "sha256:5dbe56a36425d26d6cfb40ce79c314a2e4dd6211d51d6d2191c00bed34f354cc", size = 145110, upload-time = "2025-10-14T04:41:03.231Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/30/42/9a52c609e72471b0fc54386dc63c3781a387bb4fe61c20231a4ebcd58bdd/charset_normalizer-3.4.4-cp312-cp312-musllinux_1_2_ppc64le.whl", hash = "sha256:5bfbb1b9acf3334612667b61bd3002196fe2a1eb4dd74d247e0f2a4d50ec9bbf", size = 162839, upload-time = "2025-10-14T04:41:04.715Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/c4/5b/c0682bbf9f11597073052628ddd38344a3d673fda35a36773f7d19344b23/charset_normalizer-3.4.4-cp312-cp312-musllinux_1_2_riscv64.whl", hash = "sha256:d055ec1e26e441f6187acf818b73564e6e6282709e9bcb5b63f5b23068356a15", size = 150667, upload-time = "2025-10-14T04:41:05.827Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/e4/24/a41afeab6f990cf2daf6cb8c67419b63b48cf518e4f56022230840c9bfb2/charset_normalizer-3.4.4-cp312-cp312-musllinux_1_2_s390x.whl", hash = "sha256:af2d8c67d8e573d6de5bc30cdb27e9b95e49115cd9baad5ddbd1a6207aaa82a9", size = 160535, upload-time = "2025-10-14T04:41:06.938Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/2a/e5/6a4ce77ed243c4a50a1fecca6aaaab419628c818a49434be428fe24c9957/charset_normalizer-3.4.4-cp312-cp312-musllinux_1_2_x86_64.whl", hash = "sha256:780236ac706e66881f3b7f2f32dfe90507a09e67d1d454c762cf642e6e1586e0", size = 154816, upload-time = "2025-10-14T04:41:08.101Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/a8/ef/89297262b8092b312d29cdb2517cb1237e51db8ecef2e9af5edbe7b683b1/charset_normalizer-3.4.4-cp312-cp312-win32.whl", hash = "sha256:5833d2c39d8896e4e19b689ffc198f08ea58116bee26dea51e362ecc7cd3ed26", size = 99694, upload-time = "2025-10-14T04:41:09.23Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/3d/2d/1e5ed9dd3b3803994c155cd9aacb60c82c331bad84daf75bcb9c91b3295e/charset_normalizer-3.4.4-cp312-cp312-win_amd64.whl", hash = "sha256:a79cfe37875f822425b89a82333404539ae63dbdddf97f84dcbc3d339aae9525", size = 107131, upload-time = "2025-10-14T04:41:10.467Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/d0/d9/0ed4c7098a861482a7b6a95603edce4c0d9db2311af23da1fb2b75ec26fc/charset_normalizer-3.4.4-cp312-cp312-win_arm64.whl", hash = "sha256:376bec83a63b8021bb5c8ea75e21c4ccb86e7e45ca4eb81146091b56599b80c3", size = 100390, upload-time = "2025-10-14T04:41:11.915Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/0a/4c/925909008ed5a988ccbb72dcc897407e5d6d3bd72410d69e051fc0c14647/charset_normalizer-3.4.4-py3-none-any.whl", hash = "sha256:7a32c560861a02ff789ad905a2fe94e3f840803362c84fecf1851cb4cf3dc37f", size = 53402, upload-time = "2025-10-14T04:42:31.76Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "colorama"
|
||||
version = "0.4.6"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/d8/53/6f443c9a4a8358a93a6792e2acffb9d9d5cb0a5cfd8802644b7b1c9a02e4/colorama-0.4.6.tar.gz", hash = "sha256:08695f5cb7ed6e0531a20572697297273c47b8cae5a63ffc6d6ed5c201be6e44", size = 27697, upload-time = "2022-10-25T02:36:22.414Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/d1/d6/3965ed04c63042e047cb6a3e6ed1a63a35087b6a609aa3a15ed8ac56c221/colorama-0.4.6-py2.py3-none-any.whl", hash = "sha256:4f1d9991f5acc0ca119f9d443620b77f9d6b33703e51011c16baf57afb285fc6", size = 25335, upload-time = "2022-10-25T02:36:20.889Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "exceptiongroup"
|
||||
version = "1.3.1"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
dependencies = [
|
||||
{ name = "typing-extensions" },
|
||||
]
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/50/79/66800aadf48771f6b62f7eb014e352e5d06856655206165d775e675a02c9/exceptiongroup-1.3.1.tar.gz", hash = "sha256:8b412432c6055b0b7d14c310000ae93352ed6754f70fa8f7c34141f91c4e3219", size = 30371, upload-time = "2025-11-21T23:01:54.787Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/8a/0e/97c33bf5009bdbac74fd2beace167cab3f978feb69cc36f1ef79360d6c4e/exceptiongroup-1.3.1-py3-none-any.whl", hash = "sha256:a7a39a3bd276781e98394987d3a5701d0c4edffb633bb7a5144577f82c773598", size = 16740, upload-time = "2025-11-21T23:01:53.443Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "idna"
|
||||
version = "3.11"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/6f/6d/0703ccc57f3a7233505399edb88de3cbd678da106337b9fcde432b65ed60/idna-3.11.tar.gz", hash = "sha256:795dafcc9c04ed0c1fb032c2aa73654d8e8c5023a7df64a53f39190ada629902", size = 194582, upload-time = "2025-10-12T14:55:20.501Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/0e/61/66938bbb5fc52dbdf84594873d5b51fb1f7c7794e9c0f5bd885f30bc507b/idna-3.11-py3-none-any.whl", hash = "sha256:771a87f49d9defaf64091e6e6fe9c18d4833f140bd19464795bc32d966ca37ea", size = 71008, upload-time = "2025-10-12T14:55:18.883Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "iniconfig"
|
||||
version = "2.3.0"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/72/34/14ca021ce8e5dfedc35312d08ba8bf51fdd999c576889fc2c24cb97f4f10/iniconfig-2.3.0.tar.gz", hash = "sha256:c76315c77db068650d49c5b56314774a7804df16fee4402c1f19d6d15d8c4730", size = 20503, upload-time = "2025-10-18T21:55:43.219Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/cb/b1/3846dd7f199d53cb17f49cba7e651e9ce294d8497c8c150530ed11865bb8/iniconfig-2.3.0-py3-none-any.whl", hash = "sha256:f631c04d2c48c52b84d0d0549c99ff3859c98df65b3101406327ecc7d53fbf12", size = 7484, upload-time = "2025-10-18T21:55:41.639Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "lark"
|
||||
version = "1.3.1"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/da/34/28fff3ab31ccff1fd4f6c7c7b0ceb2b6968d8ea4950663eadcb5720591a0/lark-1.3.1.tar.gz", hash = "sha256:b426a7a6d6d53189d318f2b6236ab5d6429eaf09259f1ca33eb716eed10d2905", size = 382732, upload-time = "2025-10-27T18:25:56.653Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/82/3d/14ce75ef66813643812f3093ab17e46d3a206942ce7376d31ec2d36229e7/lark-1.3.1-py3-none-any.whl", hash = "sha256:c629b661023a014c37da873b4ff58a817398d12635d3bbb2c5a03be7fe5d1e12", size = 113151, upload-time = "2025-10-27T18:25:54.882Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "packaging"
|
||||
version = "25.0"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/a1/d4/1fc4078c65507b51b96ca8f8c3ba19e6a61c8253c72794544580a7b6c24d/packaging-25.0.tar.gz", hash = "sha256:d443872c98d677bf60f6a1f2f8c1cb748e8fe762d2bf9d3148b5599295b0fc4f", size = 165727, upload-time = "2025-04-19T11:48:59.673Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/20/12/38679034af332785aac8774540895e234f4d07f7545804097de4b666afd8/packaging-25.0-py3-none-any.whl", hash = "sha256:29572ef2b1f17581046b3a2227d5c611fb25ec70ca1ba8554b24b0e69331a484", size = 66469, upload-time = "2025-04-19T11:48:57.875Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "pluggy"
|
||||
version = "1.6.0"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/f9/e2/3e91f31a7d2b083fe6ef3fa267035b518369d9511ffab804f839851d2779/pluggy-1.6.0.tar.gz", hash = "sha256:7dcc130b76258d33b90f61b658791dede3486c3e6bfb003ee5c9bfb396dd22f3", size = 69412, upload-time = "2025-05-15T12:30:07.975Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/54/20/4d324d65cc6d9205fabedc306948156824eb9f0ee1633355a8f7ec5c66bf/pluggy-1.6.0-py3-none-any.whl", hash = "sha256:e920276dd6813095e9377c0bc5566d94c932c33b27a3e3945d8389c374dd4746", size = 20538, upload-time = "2025-05-15T12:30:06.134Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "pycryptodomex"
|
||||
version = "3.23.0"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/c9/85/e24bf90972a30b0fcd16c73009add1d7d7cd9140c2498a68252028899e41/pycryptodomex-3.23.0.tar.gz", hash = "sha256:71909758f010c82bc99b0abf4ea12012c98962fbf0583c2164f8b84533c2e4da", size = 4922157, upload-time = "2025-05-17T17:23:41.434Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/dd/9c/1a8f35daa39784ed8adf93a694e7e5dc15c23c741bbda06e1d45f8979e9e/pycryptodomex-3.23.0-cp37-abi3-macosx_10_9_universal2.whl", hash = "sha256:06698f957fe1ab229a99ba2defeeae1c09af185baa909a31a5d1f9d42b1aaed6", size = 2499240, upload-time = "2025-05-17T17:22:46.953Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/7a/62/f5221a191a97157d240cf6643747558759126c76ee92f29a3f4aee3197a5/pycryptodomex-3.23.0-cp37-abi3-macosx_10_9_x86_64.whl", hash = "sha256:b2c2537863eccef2d41061e82a881dcabb04944c5c06c5aa7110b577cc487545", size = 1644042, upload-time = "2025-05-17T17:22:49.098Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/8c/fd/5a054543c8988d4ed7b612721d7e78a4b9bf36bc3c5ad45ef45c22d0060e/pycryptodomex-3.23.0-cp37-abi3-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:43c446e2ba8df8889e0e16f02211c25b4934898384c1ec1ec04d7889c0333587", size = 2186227, upload-time = "2025-05-17T17:22:51.139Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/c8/a9/8862616a85cf450d2822dbd4fff1fcaba90877907a6ff5bc2672cafe42f8/pycryptodomex-3.23.0-cp37-abi3-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:f489c4765093fb60e2edafdf223397bc716491b2b69fe74367b70d6999257a5c", size = 2272578, upload-time = "2025-05-17T17:22:53.676Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/46/9f/bda9c49a7c1842820de674ab36c79f4fbeeee03f8ff0e4f3546c3889076b/pycryptodomex-3.23.0-cp37-abi3-manylinux_2_5_i686.manylinux1_i686.manylinux_2_17_i686.manylinux2014_i686.whl", hash = "sha256:bdc69d0d3d989a1029df0eed67cc5e8e5d968f3724f4519bd03e0ec68df7543c", size = 2312166, upload-time = "2025-05-17T17:22:56.585Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/03/cc/870b9bf8ca92866ca0186534801cf8d20554ad2a76ca959538041b7a7cf4/pycryptodomex-3.23.0-cp37-abi3-musllinux_1_2_aarch64.whl", hash = "sha256:6bbcb1dd0f646484939e142462d9e532482bc74475cecf9c4903d4e1cd21f003", size = 2185467, upload-time = "2025-05-17T17:22:59.237Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/96/e3/ce9348236d8e669fea5dd82a90e86be48b9c341210f44e25443162aba187/pycryptodomex-3.23.0-cp37-abi3-musllinux_1_2_i686.whl", hash = "sha256:8a4fcd42ccb04c31268d1efeecfccfd1249612b4de6374205376b8f280321744", size = 2346104, upload-time = "2025-05-17T17:23:02.112Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/a5/e9/e869bcee87beb89040263c416a8a50204f7f7a83ac11897646c9e71e0daf/pycryptodomex-3.23.0-cp37-abi3-musllinux_1_2_x86_64.whl", hash = "sha256:55ccbe27f049743a4caf4f4221b166560d3438d0b1e5ab929e07ae1702a4d6fd", size = 2271038, upload-time = "2025-05-17T17:23:04.872Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/8d/67/09ee8500dd22614af5fbaa51a4aee6e342b5fa8aecf0a6cb9cbf52fa6d45/pycryptodomex-3.23.0-cp37-abi3-win32.whl", hash = "sha256:189afbc87f0b9f158386bf051f720e20fa6145975f1e76369303d0f31d1a8d7c", size = 1771969, upload-time = "2025-05-17T17:23:07.115Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/69/96/11f36f71a865dd6df03716d33bd07a67e9d20f6b8d39820470b766af323c/pycryptodomex-3.23.0-cp37-abi3-win_amd64.whl", hash = "sha256:52e5ca58c3a0b0bd5e100a9fbc8015059b05cffc6c66ce9d98b4b45e023443b9", size = 1803124, upload-time = "2025-05-17T17:23:09.267Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/f9/93/45c1cdcbeb182ccd2e144c693eaa097763b08b38cded279f0053ed53c553/pycryptodomex-3.23.0-cp37-abi3-win_arm64.whl", hash = "sha256:02d87b80778c171445d67e23d1caef279bf4b25c3597050ccd2e13970b57fd51", size = 1707161, upload-time = "2025-05-17T17:23:11.414Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/f3/b8/3e76d948c3c4ac71335bbe75dac53e154b40b0f8f1f022dfa295257a0c96/pycryptodomex-3.23.0-pp310-pypy310_pp73-macosx_10_15_x86_64.whl", hash = "sha256:ebfff755c360d674306e5891c564a274a47953562b42fb74a5c25b8fc1fb1cb5", size = 1627695, upload-time = "2025-05-17T17:23:17.38Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/6a/cf/80f4297a4820dfdfd1c88cf6c4666a200f204b3488103d027b5edd9176ec/pycryptodomex-3.23.0-pp310-pypy310_pp73-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:eca54f4bb349d45afc17e3011ed4264ef1cc9e266699874cdd1349c504e64798", size = 1675772, upload-time = "2025-05-17T17:23:19.202Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/d1/42/1e969ee0ad19fe3134b0e1b856c39bd0b70d47a4d0e81c2a8b05727394c9/pycryptodomex-3.23.0-pp310-pypy310_pp73-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:4f2596e643d4365e14d0879dc5aafe6355616c61c2176009270f3048f6d9a61f", size = 1668083, upload-time = "2025-05-17T17:23:21.867Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/6e/c3/1de4f7631fea8a992a44ba632aa40e0008764c0fb9bf2854b0acf78c2cf2/pycryptodomex-3.23.0-pp310-pypy310_pp73-manylinux_2_5_i686.manylinux1_i686.manylinux_2_17_i686.manylinux2014_i686.whl", hash = "sha256:fdfac7cda115bca3a5abb2f9e43bc2fb66c2b65ab074913643803ca7083a79ea", size = 1706056, upload-time = "2025-05-17T17:23:24.031Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/f2/5f/af7da8e6f1e42b52f44a24d08b8e4c726207434e2593732d39e7af5e7256/pycryptodomex-3.23.0-pp310-pypy310_pp73-win_amd64.whl", hash = "sha256:14c37aaece158d0ace436f76a7bb19093db3b4deade9797abfc39ec6cd6cc2fe", size = 1806478, upload-time = "2025-05-17T17:23:26.066Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "pygments"
|
||||
version = "2.19.2"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/b0/77/a5b8c569bf593b0140bde72ea885a803b82086995367bf2037de0159d924/pygments-2.19.2.tar.gz", hash = "sha256:636cb2477cec7f8952536970bc533bc43743542f70392ae026374600add5b887", size = 4968631, upload-time = "2025-06-21T13:39:12.283Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/c7/21/705964c7812476f378728bdf590ca4b771ec72385c533964653c68e86bdc/pygments-2.19.2-py3-none-any.whl", hash = "sha256:86540386c03d588bb81d44bc3928634ff26449851e99741617ecb9037ee5ec0b", size = 1225217, upload-time = "2025-06-21T13:39:07.939Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "pytest"
|
||||
version = "9.0.1"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
dependencies = [
|
||||
{ name = "colorama", marker = "sys_platform == 'win32'" },
|
||||
{ name = "exceptiongroup", marker = "python_full_version < '3.11'" },
|
||||
{ name = "iniconfig" },
|
||||
{ name = "packaging" },
|
||||
{ name = "pluggy" },
|
||||
{ name = "pygments" },
|
||||
{ name = "tomli", marker = "python_full_version < '3.11'" },
|
||||
]
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/07/56/f013048ac4bc4c1d9be45afd4ab209ea62822fb1598f40687e6bf45dcea4/pytest-9.0.1.tar.gz", hash = "sha256:3e9c069ea73583e255c3b21cf46b8d3c56f6e3a1a8f6da94ccb0fcf57b9d73c8", size = 1564125, upload-time = "2025-11-12T13:05:09.333Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/0b/8b/6300fb80f858cda1c51ffa17075df5d846757081d11ab4aa35cef9e6258b/pytest-9.0.1-py3-none-any.whl", hash = "sha256:67be0030d194df2dfa7b556f2e56fb3c3315bd5c8822c6951162b92b32ce7dad", size = 373668, upload-time = "2025-11-12T13:05:07.379Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "ragflow-cli"
|
||||
version = "0.22.1"
|
||||
source = { virtual = "." }
|
||||
dependencies = [
|
||||
{ name = "beartype" },
|
||||
{ name = "lark" },
|
||||
{ name = "pycryptodomex" },
|
||||
{ name = "requests" },
|
||||
]
|
||||
|
||||
[package.dev-dependencies]
|
||||
test = [
|
||||
{ name = "pytest" },
|
||||
{ name = "requests" },
|
||||
{ name = "requests-toolbelt" },
|
||||
]
|
||||
|
||||
[package.metadata]
|
||||
requires-dist = [
|
||||
{ name = "beartype", specifier = ">=0.20.0,<1.0.0" },
|
||||
{ name = "lark", specifier = ">=1.1.0" },
|
||||
{ name = "pycryptodomex", specifier = ">=3.10.0" },
|
||||
{ name = "requests", specifier = ">=2.30.0,<3.0.0" },
|
||||
]
|
||||
|
||||
[package.metadata.requires-dev]
|
||||
test = [
|
||||
{ name = "pytest", specifier = ">=8.3.5" },
|
||||
{ name = "requests", specifier = ">=2.32.3" },
|
||||
{ name = "requests-toolbelt", specifier = ">=1.0.0" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "requests"
|
||||
version = "2.32.5"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
dependencies = [
|
||||
{ name = "certifi" },
|
||||
{ name = "charset-normalizer" },
|
||||
{ name = "idna" },
|
||||
{ name = "urllib3" },
|
||||
]
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/c9/74/b3ff8e6c8446842c3f5c837e9c3dfcfe2018ea6ecef224c710c85ef728f4/requests-2.32.5.tar.gz", hash = "sha256:dbba0bac56e100853db0ea71b82b4dfd5fe2bf6d3754a8893c3af500cec7d7cf", size = 134517, upload-time = "2025-08-18T20:46:02.573Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/1e/db/4254e3eabe8020b458f1a747140d32277ec7a271daf1d235b70dc0b4e6e3/requests-2.32.5-py3-none-any.whl", hash = "sha256:2462f94637a34fd532264295e186976db0f5d453d1cdd31473c85a6a161affb6", size = 64738, upload-time = "2025-08-18T20:46:00.542Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "requests-toolbelt"
|
||||
version = "1.0.0"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
dependencies = [
|
||||
{ name = "requests" },
|
||||
]
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/f3/61/d7545dafb7ac2230c70d38d31cbfe4cc64f7144dc41f6e4e4b78ecd9f5bb/requests-toolbelt-1.0.0.tar.gz", hash = "sha256:7681a0a3d047012b5bdc0ee37d7f8f07ebe76ab08caeccfc3921ce23c88d5bc6", size = 206888, upload-time = "2023-05-01T04:11:33.229Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/3f/51/d4db610ef29373b879047326cbf6fa98b6c1969d6f6dc423279de2b1be2c/requests_toolbelt-1.0.0-py2.py3-none-any.whl", hash = "sha256:cccfdd665f0a24fcf4726e690f65639d272bb0637b9b92dfd91a5568ccf6bd06", size = 54481, upload-time = "2023-05-01T04:11:28.427Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "tomli"
|
||||
version = "2.3.0"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/52/ed/3f73f72945444548f33eba9a87fc7a6e969915e7b1acc8260b30e1f76a2f/tomli-2.3.0.tar.gz", hash = "sha256:64be704a875d2a59753d80ee8a533c3fe183e3f06807ff7dc2232938ccb01549", size = 17392, upload-time = "2025-10-08T22:01:47.119Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/b3/2e/299f62b401438d5fe1624119c723f5d877acc86a4c2492da405626665f12/tomli-2.3.0-cp311-cp311-macosx_10_9_x86_64.whl", hash = "sha256:88bd15eb972f3664f5ed4b57c1634a97153b4bac4479dcb6a495f41921eb7f45", size = 153236, upload-time = "2025-10-08T22:01:00.137Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/86/7f/d8fffe6a7aefdb61bced88fcb5e280cfd71e08939da5894161bd71bea022/tomli-2.3.0-cp311-cp311-macosx_11_0_arm64.whl", hash = "sha256:883b1c0d6398a6a9d29b508c331fa56adbcdff647f6ace4dfca0f50e90dfd0ba", size = 148084, upload-time = "2025-10-08T22:01:01.63Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/47/5c/24935fb6a2ee63e86d80e4d3b58b222dafaf438c416752c8b58537c8b89a/tomli-2.3.0-cp311-cp311-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:d1381caf13ab9f300e30dd8feadb3de072aeb86f1d34a8569453ff32a7dea4bf", size = 234832, upload-time = "2025-10-08T22:01:02.543Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/89/da/75dfd804fc11e6612846758a23f13271b76d577e299592b4371a4ca4cd09/tomli-2.3.0-cp311-cp311-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:a0e285d2649b78c0d9027570d4da3425bdb49830a6156121360b3f8511ea3441", size = 242052, upload-time = "2025-10-08T22:01:03.836Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/70/8c/f48ac899f7b3ca7eb13af73bacbc93aec37f9c954df3c08ad96991c8c373/tomli-2.3.0-cp311-cp311-musllinux_1_2_aarch64.whl", hash = "sha256:0a154a9ae14bfcf5d8917a59b51ffd5a3ac1fd149b71b47a3a104ca4edcfa845", size = 239555, upload-time = "2025-10-08T22:01:04.834Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/ba/28/72f8afd73f1d0e7829bfc093f4cb98ce0a40ffc0cc997009ee1ed94ba705/tomli-2.3.0-cp311-cp311-musllinux_1_2_x86_64.whl", hash = "sha256:74bf8464ff93e413514fefd2be591c3b0b23231a77f901db1eb30d6f712fc42c", size = 245128, upload-time = "2025-10-08T22:01:05.84Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/b6/eb/a7679c8ac85208706d27436e8d421dfa39d4c914dcf5fa8083a9305f58d9/tomli-2.3.0-cp311-cp311-win32.whl", hash = "sha256:00b5f5d95bbfc7d12f91ad8c593a1659b6387b43f054104cda404be6bda62456", size = 96445, upload-time = "2025-10-08T22:01:06.896Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/0a/fe/3d3420c4cb1ad9cb462fb52967080575f15898da97e21cb6f1361d505383/tomli-2.3.0-cp311-cp311-win_amd64.whl", hash = "sha256:4dc4ce8483a5d429ab602f111a93a6ab1ed425eae3122032db7e9acf449451be", size = 107165, upload-time = "2025-10-08T22:01:08.107Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/ff/b7/40f36368fcabc518bb11c8f06379a0fd631985046c038aca08c6d6a43c6e/tomli-2.3.0-cp312-cp312-macosx_10_13_x86_64.whl", hash = "sha256:d7d86942e56ded512a594786a5ba0a5e521d02529b3826e7761a05138341a2ac", size = 154891, upload-time = "2025-10-08T22:01:09.082Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/f9/3f/d9dd692199e3b3aab2e4e4dd948abd0f790d9ded8cd10cbaae276a898434/tomli-2.3.0-cp312-cp312-macosx_11_0_arm64.whl", hash = "sha256:73ee0b47d4dad1c5e996e3cd33b8a76a50167ae5f96a2607cbe8cc773506ab22", size = 148796, upload-time = "2025-10-08T22:01:10.266Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/60/83/59bff4996c2cf9f9387a0f5a3394629c7efa5ef16142076a23a90f1955fa/tomli-2.3.0-cp312-cp312-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:792262b94d5d0a466afb5bc63c7daa9d75520110971ee269152083270998316f", size = 242121, upload-time = "2025-10-08T22:01:11.332Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/45/e5/7c5119ff39de8693d6baab6c0b6dcb556d192c165596e9fc231ea1052041/tomli-2.3.0-cp312-cp312-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:4f195fe57ecceac95a66a75ac24d9d5fbc98ef0962e09b2eddec5d39375aae52", size = 250070, upload-time = "2025-10-08T22:01:12.498Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/45/12/ad5126d3a278f27e6701abde51d342aa78d06e27ce2bb596a01f7709a5a2/tomli-2.3.0-cp312-cp312-musllinux_1_2_aarch64.whl", hash = "sha256:e31d432427dcbf4d86958c184b9bfd1e96b5b71f8eb17e6d02531f434fd335b8", size = 245859, upload-time = "2025-10-08T22:01:13.551Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/fb/a1/4d6865da6a71c603cfe6ad0e6556c73c76548557a8d658f9e3b142df245f/tomli-2.3.0-cp312-cp312-musllinux_1_2_x86_64.whl", hash = "sha256:7b0882799624980785240ab732537fcfc372601015c00f7fc367c55308c186f6", size = 250296, upload-time = "2025-10-08T22:01:14.614Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/a0/b7/a7a7042715d55c9ba6e8b196d65d2cb662578b4d8cd17d882d45322b0d78/tomli-2.3.0-cp312-cp312-win32.whl", hash = "sha256:ff72b71b5d10d22ecb084d345fc26f42b5143c5533db5e2eaba7d2d335358876", size = 97124, upload-time = "2025-10-08T22:01:15.629Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/06/1e/f22f100db15a68b520664eb3328fb0ae4e90530887928558112c8d1f4515/tomli-2.3.0-cp312-cp312-win_amd64.whl", hash = "sha256:1cb4ed918939151a03f33d4242ccd0aa5f11b3547d0cf30f7c74a408a5b99878", size = 107698, upload-time = "2025-10-08T22:01:16.51Z" },
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/77/b8/0135fadc89e73be292b473cb820b4f5a08197779206b33191e801feeae40/tomli-2.3.0-py3-none-any.whl", hash = "sha256:e95b1af3c5b07d9e643909b5abbec77cd9f1217e6d0bca72b0234736b9fb1f1b", size = 14408, upload-time = "2025-10-08T22:01:46.04Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "typing-extensions"
|
||||
version = "4.15.0"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/72/94/1a15dd82efb362ac84269196e94cf00f187f7ed21c242792a923cdb1c61f/typing_extensions-4.15.0.tar.gz", hash = "sha256:0cea48d173cc12fa28ecabc3b837ea3cf6f38c6d1136f85cbaaf598984861466", size = 109391, upload-time = "2025-08-25T13:49:26.313Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/18/67/36e9267722cc04a6b9f15c7f3441c2363321a3ea07da7ae0c0707beb2a9c/typing_extensions-4.15.0-py3-none-any.whl", hash = "sha256:f0fa19c6845758ab08074a0cfa8b7aecb71c999ca73d62883bc25cc018c4e548", size = 44614, upload-time = "2025-08-25T13:49:24.86Z" },
|
||||
]
|
||||
|
||||
[[package]]
|
||||
name = "urllib3"
|
||||
version = "2.5.0"
|
||||
source = { registry = "https://pypi.tuna.tsinghua.edu.cn/simple" }
|
||||
sdist = { url = "https://pypi.tuna.tsinghua.edu.cn/packages/15/22/9ee70a2574a4f4599c47dd506532914ce044817c7752a79b6a51286319bc/urllib3-2.5.0.tar.gz", hash = "sha256:3fc47733c7e419d4bc3f6b3dc2b4f890bb743906a30d56ba4a5bfa4bbff92760", size = 393185, upload-time = "2025-06-18T14:07:41.644Z" }
|
||||
wheels = [
|
||||
{ url = "https://pypi.tuna.tsinghua.edu.cn/packages/a7/c2/fe1e52489ae3122415c51f387e221dd0773709bad6c6cdaa599e8a2c5185/urllib3-2.5.0-py3-none-any.whl", hash = "sha256:e6b01673c0fa6a13e374b50871808eb3bf7046c4b125b216f6bf1cc604cff0dc", size = 129795, upload-time = "2025-06-18T14:07:40.39Z" },
|
||||
]
|
||||
@ -20,6 +20,7 @@ import logging
|
||||
import time
|
||||
import threading
|
||||
import traceback
|
||||
import faulthandler
|
||||
|
||||
from flask import Flask
|
||||
from flask_login import LoginManager
|
||||
@ -37,6 +38,7 @@ from common.versions import get_ragflow_version
|
||||
stop_event = threading.Event()
|
||||
|
||||
if __name__ == '__main__':
|
||||
faulthandler.enable()
|
||||
init_root_logger("admin_service")
|
||||
logging.info(r"""
|
||||
____ ___ ______________ ___ __ _
|
||||
|
||||
170
agent/canvas.py
170
agent/canvas.py
@ -13,7 +13,9 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
import asyncio
|
||||
import base64
|
||||
import inspect
|
||||
import json
|
||||
import logging
|
||||
import re
|
||||
@ -25,6 +27,7 @@ from typing import Any, Union, Tuple
|
||||
|
||||
from agent.component import component_class
|
||||
from agent.component.base import ComponentBase
|
||||
from api.db.services.file_service import FileService
|
||||
from api.db.services.task_service import has_canceled
|
||||
from common.misc_utils import get_uuid, hash_str2int
|
||||
from common.exceptions import TaskCanceledException
|
||||
@ -79,6 +82,7 @@ class Graph:
|
||||
self.dsl = json.loads(dsl)
|
||||
self._tenant_id = tenant_id
|
||||
self.task_id = task_id if task_id else get_uuid()
|
||||
self._thread_pool = ThreadPoolExecutor(max_workers=5)
|
||||
self.load()
|
||||
|
||||
def load(self):
|
||||
@ -206,17 +210,28 @@ class Graph:
|
||||
for key in path.split('.'):
|
||||
if cur is None:
|
||||
return None
|
||||
|
||||
if isinstance(cur, str):
|
||||
try:
|
||||
cur = json.loads(cur)
|
||||
except Exception:
|
||||
return None
|
||||
|
||||
if isinstance(cur, dict):
|
||||
cur = cur.get(key)
|
||||
else:
|
||||
cur = getattr(cur, key, None)
|
||||
continue
|
||||
|
||||
if isinstance(cur, (list, tuple)):
|
||||
try:
|
||||
idx = int(key)
|
||||
cur = cur[idx]
|
||||
except Exception:
|
||||
return None
|
||||
continue
|
||||
|
||||
cur = getattr(cur, key, None)
|
||||
return cur
|
||||
|
||||
|
||||
def set_variable_value(self, exp: str,value):
|
||||
exp = exp.strip("{").strip("}").strip(" ").strip("{").strip("}")
|
||||
if exp.find("@") < 0:
|
||||
@ -270,6 +285,7 @@ class Canvas(Graph):
|
||||
"sys.conversation_turns": 0,
|
||||
"sys.files": []
|
||||
}
|
||||
self.variables = {}
|
||||
super().__init__(dsl, tenant_id, task_id)
|
||||
|
||||
def load(self):
|
||||
@ -284,6 +300,10 @@ class Canvas(Graph):
|
||||
"sys.conversation_turns": 0,
|
||||
"sys.files": []
|
||||
}
|
||||
if "variables" in self.dsl:
|
||||
self.variables = self.dsl["variables"]
|
||||
else:
|
||||
self.variables = {}
|
||||
|
||||
self.retrieval = self.dsl["retrieval"]
|
||||
self.memory = self.dsl.get("memory", [])
|
||||
@ -300,8 +320,9 @@ class Canvas(Graph):
|
||||
self.history = []
|
||||
self.retrieval = []
|
||||
self.memory = []
|
||||
print(self.variables)
|
||||
for k in self.globals.keys():
|
||||
if k.startswith("sys.") or k.startswith("env."):
|
||||
if k.startswith("sys."):
|
||||
if isinstance(self.globals[k], str):
|
||||
self.globals[k] = ""
|
||||
elif isinstance(self.globals[k], int):
|
||||
@ -314,9 +335,33 @@ class Canvas(Graph):
|
||||
self.globals[k] = {}
|
||||
else:
|
||||
self.globals[k] = None
|
||||
if k.startswith("env."):
|
||||
key = k[4:]
|
||||
if key in self.variables:
|
||||
variable = self.variables[key]
|
||||
if variable["value"]:
|
||||
self.globals[k] = variable["value"]
|
||||
else:
|
||||
if variable["type"] == "string":
|
||||
self.globals[k] = ""
|
||||
elif variable["type"] == "number":
|
||||
self.globals[k] = 0
|
||||
elif variable["type"] == "boolean":
|
||||
self.globals[k] = False
|
||||
elif variable["type"] == "object":
|
||||
self.globals[k] = {}
|
||||
elif variable["type"].startswith("array"):
|
||||
self.globals[k] = []
|
||||
else:
|
||||
self.globals[k] = ""
|
||||
else:
|
||||
self.globals[k] = ""
|
||||
print(self.globals)
|
||||
|
||||
|
||||
async def run(self, **kwargs):
|
||||
st = time.perf_counter()
|
||||
self._loop = asyncio.get_running_loop()
|
||||
self.message_id = get_uuid()
|
||||
created_at = int(time.time())
|
||||
self.add_user_input(kwargs.get("query"))
|
||||
@ -332,7 +377,7 @@ class Canvas(Graph):
|
||||
for k in kwargs.keys():
|
||||
if k in ["query", "user_id", "files"] and kwargs[k]:
|
||||
if k == "files":
|
||||
self.globals[f"sys.{k}"] = self.get_files(kwargs[k])
|
||||
self.globals[f"sys.{k}"] = await self.get_files_async(kwargs[k])
|
||||
else:
|
||||
self.globals[f"sys.{k}"] = kwargs[k]
|
||||
if not self.globals["sys.conversation_turns"] :
|
||||
@ -362,31 +407,39 @@ class Canvas(Graph):
|
||||
yield decorate("workflow_started", {"inputs": kwargs.get("inputs")})
|
||||
self.retrieval.append({"chunks": {}, "doc_aggs": {}})
|
||||
|
||||
def _run_batch(f, t):
|
||||
async def _run_batch(f, t):
|
||||
if self.is_canceled():
|
||||
msg = f"Task {self.task_id} has been canceled during batch execution."
|
||||
logging.info(msg)
|
||||
raise TaskCanceledException(msg)
|
||||
|
||||
with ThreadPoolExecutor(max_workers=5) as executor:
|
||||
thr = []
|
||||
i = f
|
||||
while i < t:
|
||||
cpn = self.get_component_obj(self.path[i])
|
||||
if cpn.component_name.lower() in ["begin", "userfillup"]:
|
||||
thr.append(executor.submit(cpn.invoke, inputs=kwargs.get("inputs", {})))
|
||||
i += 1
|
||||
loop = asyncio.get_running_loop()
|
||||
tasks = []
|
||||
i = f
|
||||
while i < t:
|
||||
cpn = self.get_component_obj(self.path[i])
|
||||
task_fn = None
|
||||
|
||||
if cpn.component_name.lower() in ["begin", "userfillup"]:
|
||||
task_fn = partial(cpn.invoke, inputs=kwargs.get("inputs", {}))
|
||||
i += 1
|
||||
else:
|
||||
for _, ele in cpn.get_input_elements().items():
|
||||
if isinstance(ele, dict) and ele.get("_cpn_id") and ele.get("_cpn_id") not in self.path[:i] and self.path[0].lower().find("userfillup") < 0:
|
||||
self.path.pop(i)
|
||||
t -= 1
|
||||
break
|
||||
else:
|
||||
for _, ele in cpn.get_input_elements().items():
|
||||
if isinstance(ele, dict) and ele.get("_cpn_id") and ele.get("_cpn_id") not in self.path[:i] and self.path[0].lower().find("userfillup") < 0:
|
||||
self.path.pop(i)
|
||||
t -= 1
|
||||
break
|
||||
else:
|
||||
thr.append(executor.submit(cpn.invoke, **cpn.get_input()))
|
||||
i += 1
|
||||
for t in thr:
|
||||
t.result()
|
||||
task_fn = partial(cpn.invoke, **cpn.get_input())
|
||||
i += 1
|
||||
|
||||
if task_fn is None:
|
||||
continue
|
||||
|
||||
tasks.append(loop.run_in_executor(self._thread_pool, task_fn))
|
||||
|
||||
if tasks:
|
||||
await asyncio.gather(*tasks)
|
||||
|
||||
def _node_finished(cpn_obj):
|
||||
return decorate("node_finished",{
|
||||
@ -413,7 +466,7 @@ class Canvas(Graph):
|
||||
"component_type": self.get_component_type(self.path[i]),
|
||||
"thoughts": self.get_component_thoughts(self.path[i])
|
||||
})
|
||||
_run_batch(idx, to)
|
||||
await _run_batch(idx, to)
|
||||
to = len(self.path)
|
||||
# post processing of components invocation
|
||||
for i in range(idx, to):
|
||||
@ -422,16 +475,29 @@ class Canvas(Graph):
|
||||
if cpn_obj.component_name.lower() == "message":
|
||||
if isinstance(cpn_obj.output("content"), partial):
|
||||
_m = ""
|
||||
for m in cpn_obj.output("content")():
|
||||
if not m:
|
||||
continue
|
||||
if m == "<think>":
|
||||
yield decorate("message", {"content": "", "start_to_think": True})
|
||||
elif m == "</think>":
|
||||
yield decorate("message", {"content": "", "end_to_think": True})
|
||||
else:
|
||||
yield decorate("message", {"content": m})
|
||||
_m += m
|
||||
stream = cpn_obj.output("content")()
|
||||
if inspect.isasyncgen(stream):
|
||||
async for m in stream:
|
||||
if not m:
|
||||
continue
|
||||
if m == "<think>":
|
||||
yield decorate("message", {"content": "", "start_to_think": True})
|
||||
elif m == "</think>":
|
||||
yield decorate("message", {"content": "", "end_to_think": True})
|
||||
else:
|
||||
yield decorate("message", {"content": m})
|
||||
_m += m
|
||||
else:
|
||||
for m in stream:
|
||||
if not m:
|
||||
continue
|
||||
if m == "<think>":
|
||||
yield decorate("message", {"content": "", "start_to_think": True})
|
||||
elif m == "</think>":
|
||||
yield decorate("message", {"content": "", "end_to_think": True})
|
||||
else:
|
||||
yield decorate("message", {"content": m})
|
||||
_m += m
|
||||
cpn_obj.set_output("content", _m)
|
||||
cite = re.search(r"\[ID:[ 0-9]+\]", _m)
|
||||
else:
|
||||
@ -440,7 +506,7 @@ class Canvas(Graph):
|
||||
|
||||
if isinstance(cpn_obj.output("attachment"), tuple):
|
||||
yield decorate("message", {"attachment": cpn_obj.output("attachment")})
|
||||
|
||||
|
||||
yield decorate("message_end", {"reference": self.get_reference() if cite else None})
|
||||
|
||||
while partials:
|
||||
@ -462,7 +528,7 @@ class Canvas(Graph):
|
||||
else:
|
||||
self.error = cpn_obj.error()
|
||||
|
||||
if cpn_obj.component_name.lower() != "iteration":
|
||||
if cpn_obj.component_name.lower() not in ("iteration","loop"):
|
||||
if isinstance(cpn_obj.output("content"), partial):
|
||||
if self.error:
|
||||
cpn_obj.set_output("content", None)
|
||||
@ -487,14 +553,16 @@ class Canvas(Graph):
|
||||
for cpn_id in cpn_ids:
|
||||
_append_path(cpn_id)
|
||||
|
||||
if cpn_obj.component_name.lower() == "iterationitem" and cpn_obj.end():
|
||||
if cpn_obj.component_name.lower() in ("iterationitem","loopitem") and cpn_obj.end():
|
||||
iter = cpn_obj.get_parent()
|
||||
yield _node_finished(iter)
|
||||
_extend_path(self.get_component(cpn["parent_id"])["downstream"])
|
||||
elif cpn_obj.component_name.lower() in ["categorize", "switch"]:
|
||||
_extend_path(cpn_obj.output("_next"))
|
||||
elif cpn_obj.component_name.lower() == "iteration":
|
||||
elif cpn_obj.component_name.lower() in ("iteration", "loop"):
|
||||
_append_path(cpn_obj.get_start())
|
||||
elif cpn_obj.component_name.lower() == "exitloop" and cpn_obj.get_parent().component_name.lower() == "loop":
|
||||
_extend_path(self.get_component(cpn["parent_id"])["downstream"])
|
||||
elif not cpn["downstream"] and cpn_obj.get_parent():
|
||||
_append_path(cpn_obj.get_parent().get_start())
|
||||
else:
|
||||
@ -579,21 +647,30 @@ class Canvas(Graph):
|
||||
def get_component_input_elements(self, cpnnm):
|
||||
return self.components[cpnnm]["obj"].get_input_elements()
|
||||
|
||||
def get_files(self, files: Union[None, list[dict]]) -> list[str]:
|
||||
from api.db.services.file_service import FileService
|
||||
async def get_files_async(self, files: Union[None, list[dict]]) -> list[str]:
|
||||
if not files:
|
||||
return []
|
||||
def image_to_base64(file):
|
||||
return "data:{};base64,{}".format(file["mime_type"],
|
||||
base64.b64encode(FileService.get_blob(file["created_by"], file["id"])).decode("utf-8"))
|
||||
exe = ThreadPoolExecutor(max_workers=5)
|
||||
threads = []
|
||||
loop = asyncio.get_running_loop()
|
||||
tasks = []
|
||||
for file in files:
|
||||
if file["mime_type"].find("image") >=0:
|
||||
threads.append(exe.submit(image_to_base64, file))
|
||||
tasks.append(loop.run_in_executor(self._thread_pool, image_to_base64, file))
|
||||
continue
|
||||
threads.append(exe.submit(FileService.parse, file["name"], FileService.get_blob(file["created_by"], file["id"]), True, file["created_by"]))
|
||||
return [th.result() for th in threads]
|
||||
tasks.append(loop.run_in_executor(self._thread_pool, FileService.parse, file["name"], FileService.get_blob(file["created_by"], file["id"]), True, file["created_by"]))
|
||||
return await asyncio.gather(*tasks)
|
||||
|
||||
def get_files(self, files: Union[None, list[dict]]) -> list[str]:
|
||||
"""
|
||||
Synchronous wrapper for get_files_async, used by sync component invoke paths.
|
||||
"""
|
||||
loop = getattr(self, "_loop", None)
|
||||
if loop and loop.is_running():
|
||||
return asyncio.run_coroutine_threadsafe(self.get_files_async(files), loop).result()
|
||||
|
||||
return asyncio.run(self.get_files_async(files))
|
||||
|
||||
def tool_use_callback(self, agent_id: str, func_name: str, params: dict, result: Any, elapsed_time=None):
|
||||
agent_ids = agent_id.split("-->")
|
||||
@ -647,4 +724,3 @@ class Canvas(Graph):
|
||||
|
||||
def get_component_thoughts(self, cpn_id) -> str:
|
||||
return self.components.get(cpn_id)["obj"].thoughts()
|
||||
|
||||
|
||||
@ -13,6 +13,7 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
import json
|
||||
import logging
|
||||
import os
|
||||
import re
|
||||
@ -29,7 +30,7 @@ from api.db.services.tenant_llm_service import TenantLLMService
|
||||
from api.db.services.mcp_server_service import MCPServerService
|
||||
from common.connection_utils import timeout
|
||||
from rag.prompts.generator import next_step, COMPLETE_TASK, analyze_task, \
|
||||
citation_prompt, reflect, rank_memories, kb_prompt, citation_plus, full_question, message_fit_in
|
||||
citation_prompt, reflect, rank_memories, kb_prompt, citation_plus, full_question, message_fit_in, structured_output_prompt
|
||||
from common.mcp_tool_call_conn import MCPToolCallSession, mcp_tool_metadata_to_openai_tool
|
||||
from agent.component.llm import LLMParam, LLM
|
||||
|
||||
@ -137,6 +138,29 @@ class Agent(LLM, ToolBase):
|
||||
res.update(cpn.get_input_form())
|
||||
return res
|
||||
|
||||
def _get_output_schema(self):
|
||||
try:
|
||||
cand = self._param.outputs.get("structured")
|
||||
except Exception:
|
||||
return None
|
||||
|
||||
if isinstance(cand, dict):
|
||||
if isinstance(cand.get("properties"), dict) and len(cand["properties"]) > 0:
|
||||
return cand
|
||||
for k in ("schema", "structured"):
|
||||
if isinstance(cand.get(k), dict) and isinstance(cand[k].get("properties"), dict) and len(cand[k]["properties"]) > 0:
|
||||
return cand[k]
|
||||
|
||||
return None
|
||||
|
||||
def _force_format_to_schema(self, text: str, schema_prompt: str) -> str:
|
||||
fmt_msgs = [
|
||||
{"role": "system", "content": schema_prompt + "\nIMPORTANT: Output ONLY valid JSON. No markdown, no extra text."},
|
||||
{"role": "user", "content": text},
|
||||
]
|
||||
_, fmt_msgs = message_fit_in(fmt_msgs, int(self.chat_mdl.max_length * 0.97))
|
||||
return self._generate(fmt_msgs)
|
||||
|
||||
@timeout(int(os.environ.get("COMPONENT_EXEC_TIMEOUT", 20*60)))
|
||||
def _invoke(self, **kwargs):
|
||||
if self.check_if_canceled("Agent processing"):
|
||||
@ -160,17 +184,22 @@ class Agent(LLM, ToolBase):
|
||||
return LLM._invoke(self, **kwargs)
|
||||
|
||||
prompt, msg, user_defined_prompt = self._prepare_prompt_variables()
|
||||
output_schema = self._get_output_schema()
|
||||
schema_prompt = ""
|
||||
if output_schema:
|
||||
schema = json.dumps(output_schema, ensure_ascii=False, indent=2)
|
||||
schema_prompt = structured_output_prompt(schema)
|
||||
|
||||
downstreams = self._canvas.get_component(self._id)["downstream"] if self._canvas.get_component(self._id) else []
|
||||
ex = self.exception_handler()
|
||||
if any([self._canvas.get_component_obj(cid).component_name.lower()=="message" for cid in downstreams]) and not (ex and ex["goto"]):
|
||||
if any([self._canvas.get_component_obj(cid).component_name.lower()=="message" for cid in downstreams]) and not (ex and ex["goto"]) and not output_schema:
|
||||
self.set_output("content", partial(self.stream_output_with_tools, prompt, msg, user_defined_prompt))
|
||||
return
|
||||
|
||||
_, msg = message_fit_in([{"role": "system", "content": prompt}, *msg], int(self.chat_mdl.max_length * 0.97))
|
||||
use_tools = []
|
||||
ans = ""
|
||||
for delta_ans, tk in self._react_with_tools_streamly(prompt, msg, use_tools, user_defined_prompt):
|
||||
for delta_ans, tk in self._react_with_tools_streamly(prompt, msg, use_tools, user_defined_prompt,schema_prompt=schema_prompt):
|
||||
if self.check_if_canceled("Agent processing"):
|
||||
return
|
||||
ans += delta_ans
|
||||
@ -183,6 +212,28 @@ class Agent(LLM, ToolBase):
|
||||
self.set_output("_ERROR", ans)
|
||||
return
|
||||
|
||||
if output_schema:
|
||||
error = ""
|
||||
for _ in range(self._param.max_retries + 1):
|
||||
try:
|
||||
def clean_formated_answer(ans: str) -> str:
|
||||
ans = re.sub(r"^.*</think>", "", ans, flags=re.DOTALL)
|
||||
ans = re.sub(r"^.*```json", "", ans, flags=re.DOTALL)
|
||||
return re.sub(r"```\n*$", "", ans, flags=re.DOTALL)
|
||||
obj = json_repair.loads(clean_formated_answer(ans))
|
||||
self.set_output("structured", obj)
|
||||
if use_tools:
|
||||
self.set_output("use_tools", use_tools)
|
||||
return obj
|
||||
except Exception:
|
||||
error = "The answer cannot be parsed as JSON"
|
||||
ans = self._force_format_to_schema(ans, schema_prompt)
|
||||
if ans.find("**ERROR**") >= 0:
|
||||
continue
|
||||
|
||||
self.set_output("_ERROR", error)
|
||||
return
|
||||
|
||||
self.set_output("content", ans)
|
||||
if use_tools:
|
||||
self.set_output("use_tools", use_tools)
|
||||
@ -219,7 +270,7 @@ class Agent(LLM, ToolBase):
|
||||
]):
|
||||
yield delta_ans
|
||||
|
||||
def _react_with_tools_streamly(self, prompt, history: list[dict], use_tools, user_defined_prompt={}):
|
||||
def _react_with_tools_streamly(self, prompt, history: list[dict], use_tools, user_defined_prompt={}, schema_prompt: str = ""):
|
||||
token_count = 0
|
||||
tool_metas = self.tool_meta
|
||||
hist = deepcopy(history)
|
||||
@ -256,9 +307,13 @@ class Agent(LLM, ToolBase):
|
||||
def complete():
|
||||
nonlocal hist
|
||||
need2cite = self._param.cite and self._canvas.get_reference()["chunks"] and self._id.find("-->") < 0
|
||||
if schema_prompt:
|
||||
need2cite = False
|
||||
cited = False
|
||||
if hist[0]["role"] == "system" and need2cite:
|
||||
if len(hist) < 7:
|
||||
if hist and hist[0]["role"] == "system":
|
||||
if schema_prompt:
|
||||
hist[0]["content"] += "\n" + schema_prompt
|
||||
if need2cite and len(hist) < 7:
|
||||
hist[0]["content"] += citation_prompt()
|
||||
cited = True
|
||||
yield "", token_count
|
||||
@ -369,7 +424,7 @@ Respond immediately with your final comprehensive answer.
|
||||
"""
|
||||
for k in self._param.outputs.keys():
|
||||
self._param.outputs[k]["value"] = None
|
||||
|
||||
|
||||
for k, cpn in self.tools.items():
|
||||
if hasattr(cpn, "reset") and callable(cpn.reset):
|
||||
cpn.reset()
|
||||
|
||||
@ -14,6 +14,7 @@
|
||||
# limitations under the License.
|
||||
#
|
||||
from agent.component.fillup import UserFillUpParam, UserFillUp
|
||||
from api.db.services.file_service import FileService
|
||||
|
||||
|
||||
class BeginParam(UserFillUpParam):
|
||||
@ -48,7 +49,7 @@ class Begin(UserFillUp):
|
||||
if v.get("optional") and v.get("value", None) is None:
|
||||
v = None
|
||||
else:
|
||||
v = self._canvas.get_files([v["value"]])
|
||||
v = FileService.get_files([v["value"]])
|
||||
else:
|
||||
v = v.get("value")
|
||||
self.set_output(k, v)
|
||||
|
||||
32
agent/component/exit_loop.py
Normal file
32
agent/component/exit_loop.py
Normal file
@ -0,0 +1,32 @@
|
||||
#
|
||||
# Copyright 2024 The InfiniFlow Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
from abc import ABC
|
||||
from agent.component.base import ComponentBase, ComponentParamBase
|
||||
|
||||
|
||||
class ExitLoopParam(ComponentParamBase, ABC):
|
||||
def check(self):
|
||||
return True
|
||||
|
||||
|
||||
class ExitLoop(ComponentBase, ABC):
|
||||
component_name = "ExitLoop"
|
||||
|
||||
def _invoke(self, **kwargs):
|
||||
pass
|
||||
|
||||
def thoughts(self) -> str:
|
||||
return ""
|
||||
@ -205,6 +205,55 @@ class LLM(ComponentBase):
|
||||
for txt in self.chat_mdl.chat_streamly(msg[0]["content"], msg[1:], self._param.gen_conf(), images=self.imgs, **kwargs):
|
||||
yield delta(txt)
|
||||
|
||||
async def _stream_output_async(self, prompt, msg):
|
||||
_, msg = message_fit_in([{"role": "system", "content": prompt}, *msg], int(self.chat_mdl.max_length * 0.97))
|
||||
answer = ""
|
||||
last_idx = 0
|
||||
endswith_think = False
|
||||
|
||||
def delta(txt):
|
||||
nonlocal answer, last_idx, endswith_think
|
||||
delta_ans = txt[last_idx:]
|
||||
answer = txt
|
||||
|
||||
if delta_ans.find("<think>") == 0:
|
||||
last_idx += len("<think>")
|
||||
return "<think>"
|
||||
elif delta_ans.find("<think>") > 0:
|
||||
delta_ans = txt[last_idx:last_idx + delta_ans.find("<think>")]
|
||||
last_idx += delta_ans.find("<think>")
|
||||
return delta_ans
|
||||
elif delta_ans.endswith("</think>"):
|
||||
endswith_think = True
|
||||
elif endswith_think:
|
||||
endswith_think = False
|
||||
return "</think>"
|
||||
|
||||
last_idx = len(answer)
|
||||
if answer.endswith("</think>"):
|
||||
last_idx -= len("</think>")
|
||||
return re.sub(r"(<think>|</think>)", "", delta_ans)
|
||||
|
||||
stream_kwargs = {"images": self.imgs} if self.imgs else {}
|
||||
async for ans in self.chat_mdl.async_chat_streamly(msg[0]["content"], msg[1:], self._param.gen_conf(), **stream_kwargs):
|
||||
if self.check_if_canceled("LLM streaming"):
|
||||
return
|
||||
|
||||
if isinstance(ans, int):
|
||||
continue
|
||||
|
||||
if ans.find("**ERROR**") >= 0:
|
||||
if self.get_exception_default_value():
|
||||
self.set_output("content", self.get_exception_default_value())
|
||||
yield self.get_exception_default_value()
|
||||
else:
|
||||
self.set_output("_ERROR", ans)
|
||||
return
|
||||
|
||||
yield delta(ans)
|
||||
|
||||
self.set_output("content", answer)
|
||||
|
||||
@timeout(int(os.environ.get("COMPONENT_EXEC_TIMEOUT", 10*60)))
|
||||
def _invoke(self, **kwargs):
|
||||
if self.check_if_canceled("LLM processing"):
|
||||
@ -222,7 +271,7 @@ class LLM(ComponentBase):
|
||||
output_structure = self._param.outputs['structured']
|
||||
except Exception:
|
||||
pass
|
||||
if output_structure and isinstance(output_structure, dict) and output_structure.get("properties"):
|
||||
if output_structure and isinstance(output_structure, dict) and output_structure.get("properties") and len(output_structure["properties"]) > 0:
|
||||
schema=json.dumps(output_structure, ensure_ascii=False, indent=2)
|
||||
prompt += structured_output_prompt(schema)
|
||||
for _ in range(self._param.max_retries+1):
|
||||
@ -250,7 +299,7 @@ class LLM(ComponentBase):
|
||||
downstreams = self._canvas.get_component(self._id)["downstream"] if self._canvas.get_component(self._id) else []
|
||||
ex = self.exception_handler()
|
||||
if any([self._canvas.get_component_obj(cid).component_name.lower()=="message" for cid in downstreams]) and not (ex and ex["goto"]):
|
||||
self.set_output("content", partial(self._stream_output, prompt, msg))
|
||||
self.set_output("content", partial(self._stream_output_async, prompt, msg))
|
||||
return
|
||||
|
||||
for _ in range(self._param.max_retries+1):
|
||||
|
||||
80
agent/component/loop.py
Normal file
80
agent/component/loop.py
Normal file
@ -0,0 +1,80 @@
|
||||
#
|
||||
# Copyright 2024 The InfiniFlow Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
from abc import ABC
|
||||
from agent.component.base import ComponentBase, ComponentParamBase
|
||||
|
||||
|
||||
class LoopParam(ComponentParamBase):
|
||||
"""
|
||||
Define the Loop component parameters.
|
||||
"""
|
||||
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.loop_variables = []
|
||||
self.loop_termination_condition=[]
|
||||
self.maximum_loop_count = 0
|
||||
|
||||
def get_input_form(self) -> dict[str, dict]:
|
||||
return {
|
||||
"items": {
|
||||
"type": "json",
|
||||
"name": "Items"
|
||||
}
|
||||
}
|
||||
|
||||
def check(self):
|
||||
return True
|
||||
|
||||
|
||||
class Loop(ComponentBase, ABC):
|
||||
component_name = "Loop"
|
||||
|
||||
def get_start(self):
|
||||
for cid in self._canvas.components.keys():
|
||||
if self._canvas.get_component(cid)["obj"].component_name.lower() != "loopitem":
|
||||
continue
|
||||
if self._canvas.get_component(cid)["parent_id"] == self._id:
|
||||
return cid
|
||||
|
||||
def _invoke(self, **kwargs):
|
||||
if self.check_if_canceled("Loop processing"):
|
||||
return
|
||||
|
||||
for item in self._param.loop_variables:
|
||||
if any([not item.get("variable"), not item.get("input_mode"), not item.get("value"),not item.get("type")]):
|
||||
assert "Loop Variable is not complete."
|
||||
if item["input_mode"]=="variable":
|
||||
self.set_output(item["variable"],self._canvas.get_variable_value(item["value"]))
|
||||
elif item["input_mode"]=="constant":
|
||||
self.set_output(item["variable"],item["value"])
|
||||
else:
|
||||
if item["type"] == "number":
|
||||
self.set_output(item["variable"], 0)
|
||||
elif item["type"] == "string":
|
||||
self.set_output(item["variable"], "")
|
||||
elif item["type"] == "boolean":
|
||||
self.set_output(item["variable"], False)
|
||||
elif item["type"].startswith("object"):
|
||||
self.set_output(item["variable"], {})
|
||||
elif item["type"].startswith("array"):
|
||||
self.set_output(item["variable"], [])
|
||||
else:
|
||||
self.set_output(item["variable"], "")
|
||||
|
||||
|
||||
def thoughts(self) -> str:
|
||||
return "Loop from canvas."
|
||||
163
agent/component/loopitem.py
Normal file
163
agent/component/loopitem.py
Normal file
@ -0,0 +1,163 @@
|
||||
#
|
||||
# Copyright 2024 The InfiniFlow Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
from abc import ABC
|
||||
from agent.component.base import ComponentBase, ComponentParamBase
|
||||
|
||||
|
||||
class LoopItemParam(ComponentParamBase):
|
||||
"""
|
||||
Define the LoopItem component parameters.
|
||||
"""
|
||||
def check(self):
|
||||
return True
|
||||
|
||||
class LoopItem(ComponentBase, ABC):
|
||||
component_name = "LoopItem"
|
||||
|
||||
def __init__(self, canvas, id, param: ComponentParamBase):
|
||||
super().__init__(canvas, id, param)
|
||||
self._idx = 0
|
||||
|
||||
|
||||
def _invoke(self, **kwargs):
|
||||
if self.check_if_canceled("LoopItem processing"):
|
||||
return
|
||||
parent = self.get_parent()
|
||||
maximum_loop_count = parent._param.maximum_loop_count
|
||||
if self._idx >= maximum_loop_count:
|
||||
self._idx = -1
|
||||
return
|
||||
if self._idx > 0:
|
||||
if self.check_if_canceled("LoopItem processing"):
|
||||
return
|
||||
self._idx += 1
|
||||
|
||||
def evaluate_condition(self,var, operator, value):
|
||||
if isinstance(var, str):
|
||||
if operator == "contains":
|
||||
return value in var
|
||||
elif operator == "not contains":
|
||||
return value not in var
|
||||
elif operator == "start with":
|
||||
return var.startswith(value)
|
||||
elif operator == "end with":
|
||||
return var.endswith(value)
|
||||
elif operator == "is":
|
||||
return var == value
|
||||
elif operator == "is not":
|
||||
return var != value
|
||||
elif operator == "empty":
|
||||
return var == ""
|
||||
elif operator == "not empty":
|
||||
return var != ""
|
||||
|
||||
elif isinstance(var, (int, float)):
|
||||
if operator == "=":
|
||||
return var == value
|
||||
elif operator == "≠":
|
||||
return var != value
|
||||
elif operator == ">":
|
||||
return var > value
|
||||
elif operator == "<":
|
||||
return var < value
|
||||
elif operator == "≥":
|
||||
return var >= value
|
||||
elif operator == "≤":
|
||||
return var <= value
|
||||
elif operator == "empty":
|
||||
return var is None
|
||||
elif operator == "not empty":
|
||||
return var is not None
|
||||
|
||||
elif isinstance(var, bool):
|
||||
if operator == "is":
|
||||
return var is value
|
||||
elif operator == "is not":
|
||||
return var is not value
|
||||
elif operator == "empty":
|
||||
return var is None
|
||||
elif operator == "not empty":
|
||||
return var is not None
|
||||
|
||||
elif isinstance(var, dict):
|
||||
if operator == "empty":
|
||||
return len(var) == 0
|
||||
elif operator == "not empty":
|
||||
return len(var) > 0
|
||||
|
||||
elif isinstance(var, list):
|
||||
if operator == "contains":
|
||||
return value in var
|
||||
elif operator == "not contains":
|
||||
return value not in var
|
||||
|
||||
elif operator == "is":
|
||||
return var == value
|
||||
elif operator == "is not":
|
||||
return var != value
|
||||
|
||||
elif operator == "empty":
|
||||
return len(var) == 0
|
||||
elif operator == "not empty":
|
||||
return len(var) > 0
|
||||
|
||||
raise Exception(f"Invalid operator: {operator}")
|
||||
|
||||
def end(self):
|
||||
if self._idx == -1:
|
||||
return True
|
||||
parent = self.get_parent()
|
||||
logical_operator = parent._param.logical_operator if hasattr(parent._param, "logical_operator") else "and"
|
||||
conditions = []
|
||||
for item in parent._param.loop_termination_condition:
|
||||
if not item.get("variable") or not item.get("operator"):
|
||||
raise ValueError("Loop condition is incomplete.")
|
||||
var = self._canvas.get_variable_value(item["variable"])
|
||||
operator = item["operator"]
|
||||
input_mode = item.get("input_mode", "constant")
|
||||
|
||||
if input_mode == "variable":
|
||||
value = self._canvas.get_variable_value(item.get("value", ""))
|
||||
elif input_mode == "constant":
|
||||
value = item.get("value", "")
|
||||
else:
|
||||
raise ValueError("Invalid input mode.")
|
||||
conditions.append(self.evaluate_condition(var, operator, value))
|
||||
should_end = (
|
||||
all(conditions) if logical_operator == "and"
|
||||
else any(conditions) if logical_operator == "or"
|
||||
else None
|
||||
)
|
||||
if should_end is None:
|
||||
raise ValueError("Invalid logical operator,should be 'and' or 'or'.")
|
||||
|
||||
if should_end:
|
||||
self._idx = -1
|
||||
return True
|
||||
|
||||
return False
|
||||
|
||||
def next(self):
|
||||
if self._idx == -1:
|
||||
self._idx = 0
|
||||
else:
|
||||
self._idx += 1
|
||||
if self._idx >= len(self._items):
|
||||
self._idx = -1
|
||||
return False
|
||||
|
||||
def thoughts(self) -> str:
|
||||
return "Next turn..."
|
||||
@ -13,6 +13,8 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
import asyncio
|
||||
import inspect
|
||||
import json
|
||||
import os
|
||||
import random
|
||||
@ -39,6 +41,7 @@ class MessageParam(ComponentParamBase):
|
||||
self.content = []
|
||||
self.stream = True
|
||||
self.output_format = None # default output format
|
||||
self.auto_play = False
|
||||
self.outputs = {
|
||||
"content": {
|
||||
"type": "str"
|
||||
@ -66,8 +69,12 @@ class Message(ComponentBase):
|
||||
v = ""
|
||||
ans = ""
|
||||
if isinstance(v, partial):
|
||||
for t in v():
|
||||
ans += t
|
||||
iter_obj = v()
|
||||
if inspect.isasyncgen(iter_obj):
|
||||
ans = asyncio.run(self._consume_async_gen(iter_obj))
|
||||
else:
|
||||
for t in iter_obj:
|
||||
ans += t
|
||||
elif isinstance(v, list) and delimiter:
|
||||
ans = delimiter.join([str(vv) for vv in v])
|
||||
elif not isinstance(v, str):
|
||||
@ -89,7 +96,13 @@ class Message(ComponentBase):
|
||||
_kwargs[_n] = v
|
||||
return script, _kwargs
|
||||
|
||||
def _stream(self, rand_cnt:str):
|
||||
async def _consume_async_gen(self, agen):
|
||||
buf = ""
|
||||
async for t in agen:
|
||||
buf += t
|
||||
return buf
|
||||
|
||||
async def _stream(self, rand_cnt:str):
|
||||
s = 0
|
||||
all_content = ""
|
||||
cache = {}
|
||||
@ -111,15 +124,27 @@ class Message(ComponentBase):
|
||||
v = ""
|
||||
if isinstance(v, partial):
|
||||
cnt = ""
|
||||
for t in v():
|
||||
if self.check_if_canceled("Message streaming"):
|
||||
return
|
||||
iter_obj = v()
|
||||
if inspect.isasyncgen(iter_obj):
|
||||
async for t in iter_obj:
|
||||
if self.check_if_canceled("Message streaming"):
|
||||
return
|
||||
|
||||
all_content += t
|
||||
cnt += t
|
||||
yield t
|
||||
all_content += t
|
||||
cnt += t
|
||||
yield t
|
||||
else:
|
||||
for t in iter_obj:
|
||||
if self.check_if_canceled("Message streaming"):
|
||||
return
|
||||
|
||||
all_content += t
|
||||
cnt += t
|
||||
yield t
|
||||
self.set_input_value(exp, cnt)
|
||||
continue
|
||||
elif inspect.isawaitable(v):
|
||||
v = await v
|
||||
elif not isinstance(v, str):
|
||||
try:
|
||||
v = json.dumps(v, ensure_ascii=False)
|
||||
@ -181,7 +206,7 @@ class Message(ComponentBase):
|
||||
|
||||
import pypandoc
|
||||
doc_id = get_uuid()
|
||||
|
||||
|
||||
if self._param.output_format.lower() not in {"markdown", "html", "pdf", "docx"}:
|
||||
self._param.output_format = "markdown"
|
||||
|
||||
@ -231,11 +256,11 @@ class Message(ComponentBase):
|
||||
|
||||
settings.STORAGE_IMPL.put(self._canvas._tenant_id, doc_id, binary_content)
|
||||
self.set_output("attachment", {
|
||||
"doc_id":doc_id,
|
||||
"format":self._param.output_format,
|
||||
"doc_id":doc_id,
|
||||
"format":self._param.output_format,
|
||||
"file_name":f"{doc_id[:8]}.{self._param.output_format}"})
|
||||
|
||||
logging.info(f"Converted content uploaded as {doc_id} (format={self._param.output_format})")
|
||||
|
||||
except Exception as e:
|
||||
logging.error(f"Error converting content to {self._param.output_format}: {e}")
|
||||
logging.error(f"Error converting content to {self._param.output_format}: {e}")
|
||||
|
||||
@ -13,16 +13,20 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
import ast
|
||||
import base64
|
||||
import json
|
||||
import logging
|
||||
import os
|
||||
from abc import ABC
|
||||
from strenum import StrEnum
|
||||
from typing import Optional
|
||||
|
||||
from pydantic import BaseModel, Field, field_validator
|
||||
from agent.tools.base import ToolParamBase, ToolBase, ToolMeta
|
||||
from common.connection_utils import timeout
|
||||
from strenum import StrEnum
|
||||
|
||||
from agent.tools.base import ToolBase, ToolMeta, ToolParamBase
|
||||
from common import settings
|
||||
from common.connection_utils import timeout
|
||||
|
||||
|
||||
class Language(StrEnum):
|
||||
@ -62,10 +66,10 @@ class CodeExecParam(ToolParamBase):
|
||||
"""
|
||||
|
||||
def __init__(self):
|
||||
self.meta:ToolMeta = {
|
||||
self.meta: ToolMeta = {
|
||||
"name": "execute_code",
|
||||
"description": """
|
||||
This tool has a sandbox that can execute code written in 'Python'/'Javascript'. It recieves a piece of code and return a Json string.
|
||||
This tool has a sandbox that can execute code written in 'Python'/'Javascript'. It receives a piece of code and return a Json string.
|
||||
Here's a code example for Python(`main` function MUST be included):
|
||||
def main() -> dict:
|
||||
\"\"\"
|
||||
@ -99,16 +103,12 @@ module.exports = { main };
|
||||
"enum": ["python", "javascript"],
|
||||
"required": True,
|
||||
},
|
||||
"script": {
|
||||
"type": "string",
|
||||
"description": "A piece of code in right format. There MUST be main function.",
|
||||
"required": True
|
||||
}
|
||||
}
|
||||
"script": {"type": "string", "description": "A piece of code in right format. There MUST be main function.", "required": True},
|
||||
},
|
||||
}
|
||||
super().__init__()
|
||||
self.lang = Language.PYTHON.value
|
||||
self.script = "def main(arg1: str, arg2: str) -> dict: return {\"result\": arg1 + arg2}"
|
||||
self.script = 'def main(arg1: str, arg2: str) -> dict: return {"result": arg1 + arg2}'
|
||||
self.arguments = {}
|
||||
self.outputs = {"result": {"value": "", "type": "string"}}
|
||||
|
||||
@ -119,17 +119,14 @@ module.exports = { main };
|
||||
def get_input_form(self) -> dict[str, dict]:
|
||||
res = {}
|
||||
for k, v in self.arguments.items():
|
||||
res[k] = {
|
||||
"type": "line",
|
||||
"name": k
|
||||
}
|
||||
res[k] = {"type": "line", "name": k}
|
||||
return res
|
||||
|
||||
|
||||
class CodeExec(ToolBase, ABC):
|
||||
component_name = "CodeExec"
|
||||
|
||||
@timeout(int(os.environ.get("COMPONENT_EXEC_TIMEOUT", 10*60)))
|
||||
@timeout(int(os.environ.get("COMPONENT_EXEC_TIMEOUT", 10 * 60)))
|
||||
def _invoke(self, **kwargs):
|
||||
if self.check_if_canceled("CodeExec processing"):
|
||||
return
|
||||
@ -138,17 +135,12 @@ class CodeExec(ToolBase, ABC):
|
||||
script = kwargs.get("script", self._param.script)
|
||||
arguments = {}
|
||||
for k, v in self._param.arguments.items():
|
||||
|
||||
if kwargs.get(k):
|
||||
arguments[k] = kwargs[k]
|
||||
continue
|
||||
arguments[k] = self._canvas.get_variable_value(v) if v else None
|
||||
|
||||
self._execute_code(
|
||||
language=lang,
|
||||
code=script,
|
||||
arguments=arguments
|
||||
)
|
||||
self._execute_code(language=lang, code=script, arguments=arguments)
|
||||
|
||||
def _execute_code(self, language: str, code: str, arguments: dict):
|
||||
import requests
|
||||
@ -169,7 +161,7 @@ class CodeExec(ToolBase, ABC):
|
||||
if self.check_if_canceled("CodeExec execution"):
|
||||
return "Task has been canceled"
|
||||
|
||||
resp = requests.post(url=f"http://{settings.SANDBOX_HOST}:9385/run", json=code_req, timeout=int(os.environ.get("COMPONENT_EXEC_TIMEOUT", 10*60)))
|
||||
resp = requests.post(url=f"http://{settings.SANDBOX_HOST}:9385/run", json=code_req, timeout=int(os.environ.get("COMPONENT_EXEC_TIMEOUT", 10 * 60)))
|
||||
logging.info(f"http://{settings.SANDBOX_HOST}:9385/run, code_req: {code_req}, resp.status_code {resp.status_code}:")
|
||||
|
||||
if self.check_if_canceled("CodeExec execution"):
|
||||
@ -183,35 +175,10 @@ class CodeExec(ToolBase, ABC):
|
||||
if stderr:
|
||||
self.set_output("_ERROR", stderr)
|
||||
return
|
||||
try:
|
||||
rt = eval(body.get("stdout", ""))
|
||||
except Exception:
|
||||
rt = body.get("stdout", "")
|
||||
logging.info(f"http://{settings.SANDBOX_HOST}:9385/run -> {rt}")
|
||||
if isinstance(rt, tuple):
|
||||
for i, (k, o) in enumerate(self._param.outputs.items()):
|
||||
if self.check_if_canceled("CodeExec execution"):
|
||||
return
|
||||
|
||||
if k.find("_") == 0:
|
||||
continue
|
||||
o["value"] = rt[i]
|
||||
elif isinstance(rt, dict):
|
||||
for i, (k, o) in enumerate(self._param.outputs.items()):
|
||||
if self.check_if_canceled("CodeExec execution"):
|
||||
return
|
||||
|
||||
if k not in rt or k.find("_") == 0:
|
||||
continue
|
||||
o["value"] = rt[k]
|
||||
else:
|
||||
for i, (k, o) in enumerate(self._param.outputs.items()):
|
||||
if self.check_if_canceled("CodeExec execution"):
|
||||
return
|
||||
|
||||
if k.find("_") == 0:
|
||||
continue
|
||||
o["value"] = rt
|
||||
raw_stdout = body.get("stdout", "")
|
||||
parsed_stdout = self._deserialize_stdout(raw_stdout)
|
||||
logging.info(f"[CodeExec]: http://{settings.SANDBOX_HOST}:9385/run -> {parsed_stdout}")
|
||||
self._populate_outputs(parsed_stdout, raw_stdout)
|
||||
else:
|
||||
self.set_output("_ERROR", "There is no response from sandbox")
|
||||
|
||||
@ -228,3 +195,149 @@ class CodeExec(ToolBase, ABC):
|
||||
|
||||
def thoughts(self) -> str:
|
||||
return "Running a short script to process data."
|
||||
|
||||
def _deserialize_stdout(self, stdout: str):
|
||||
text = str(stdout).strip()
|
||||
if not text:
|
||||
return ""
|
||||
for loader in (json.loads, ast.literal_eval):
|
||||
try:
|
||||
return loader(text)
|
||||
except Exception:
|
||||
continue
|
||||
return text
|
||||
|
||||
def _coerce_output_value(self, value, expected_type: Optional[str]):
|
||||
if expected_type is None:
|
||||
return value
|
||||
|
||||
etype = expected_type.strip().lower()
|
||||
inner_type = None
|
||||
if etype.startswith("array<") and etype.endswith(">"):
|
||||
inner_type = etype[6:-1].strip()
|
||||
etype = "array"
|
||||
|
||||
try:
|
||||
if etype == "string":
|
||||
return "" if value is None else str(value)
|
||||
|
||||
if etype == "number":
|
||||
if value is None or value == "":
|
||||
return None
|
||||
if isinstance(value, (int, float)):
|
||||
return value
|
||||
if isinstance(value, str):
|
||||
try:
|
||||
return float(value)
|
||||
except Exception:
|
||||
return value
|
||||
return float(value)
|
||||
|
||||
if etype == "boolean":
|
||||
if isinstance(value, bool):
|
||||
return value
|
||||
if isinstance(value, str):
|
||||
lv = value.lower()
|
||||
if lv in ("true", "1", "yes", "y", "on"):
|
||||
return True
|
||||
if lv in ("false", "0", "no", "n", "off"):
|
||||
return False
|
||||
return bool(value)
|
||||
|
||||
if etype == "array":
|
||||
candidate = value
|
||||
if isinstance(candidate, str):
|
||||
parsed = self._deserialize_stdout(candidate)
|
||||
candidate = parsed
|
||||
if isinstance(candidate, tuple):
|
||||
candidate = list(candidate)
|
||||
if not isinstance(candidate, list):
|
||||
candidate = [] if candidate is None else [candidate]
|
||||
|
||||
if inner_type == "string":
|
||||
return ["" if v is None else str(v) for v in candidate]
|
||||
if inner_type == "number":
|
||||
coerced = []
|
||||
for v in candidate:
|
||||
try:
|
||||
if v is None or v == "":
|
||||
coerced.append(None)
|
||||
elif isinstance(v, (int, float)):
|
||||
coerced.append(v)
|
||||
else:
|
||||
coerced.append(float(v))
|
||||
except Exception:
|
||||
coerced.append(v)
|
||||
return coerced
|
||||
return candidate
|
||||
|
||||
if etype == "object":
|
||||
if isinstance(value, dict):
|
||||
return value
|
||||
if isinstance(value, str):
|
||||
parsed = self._deserialize_stdout(value)
|
||||
if isinstance(parsed, dict):
|
||||
return parsed
|
||||
return value
|
||||
except Exception:
|
||||
return value
|
||||
|
||||
return value
|
||||
|
||||
def _populate_outputs(self, parsed_stdout, raw_stdout: str):
|
||||
outputs_items = list(self._param.outputs.items())
|
||||
logging.info(f"[CodeExec]: outputs schema keys: {[k for k, _ in outputs_items]}")
|
||||
if not outputs_items:
|
||||
return
|
||||
|
||||
if isinstance(parsed_stdout, dict):
|
||||
for key, meta in outputs_items:
|
||||
if key.startswith("_"):
|
||||
continue
|
||||
val = self._get_by_path(parsed_stdout, key)
|
||||
coerced = self._coerce_output_value(val, meta.get("type"))
|
||||
logging.info(f"[CodeExec]: populate dict key='{key}' raw='{val}' coerced='{coerced}'")
|
||||
self.set_output(key, coerced)
|
||||
return
|
||||
|
||||
if isinstance(parsed_stdout, (list, tuple)):
|
||||
for idx, (key, meta) in enumerate(outputs_items):
|
||||
if key.startswith("_"):
|
||||
continue
|
||||
val = parsed_stdout[idx] if idx < len(parsed_stdout) else None
|
||||
coerced = self._coerce_output_value(val, meta.get("type"))
|
||||
logging.info(f"[CodeExec]: populate list key='{key}' raw='{val}' coerced='{coerced}'")
|
||||
self.set_output(key, coerced)
|
||||
return
|
||||
|
||||
default_val = parsed_stdout if parsed_stdout is not None else raw_stdout
|
||||
for idx, (key, meta) in enumerate(outputs_items):
|
||||
if key.startswith("_"):
|
||||
continue
|
||||
val = default_val if idx == 0 else None
|
||||
coerced = self._coerce_output_value(val, meta.get("type"))
|
||||
logging.info(f"[CodeExec]: populate scalar key='{key}' raw='{val}' coerced='{coerced}'")
|
||||
self.set_output(key, coerced)
|
||||
|
||||
def _get_by_path(self, data, path: str):
|
||||
if not path:
|
||||
return None
|
||||
cur = data
|
||||
for part in path.split("."):
|
||||
part = part.strip()
|
||||
if not part:
|
||||
return None
|
||||
if isinstance(cur, dict):
|
||||
cur = cur.get(part)
|
||||
elif isinstance(cur, list):
|
||||
try:
|
||||
idx = int(part)
|
||||
cur = cur[idx]
|
||||
except Exception:
|
||||
return None
|
||||
else:
|
||||
return None
|
||||
if cur is None:
|
||||
return None
|
||||
logging.info(f"[CodeExec]: resolve path '{path}' -> {cur}")
|
||||
return cur
|
||||
|
||||
@ -13,13 +13,12 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
import logging
|
||||
import os
|
||||
import sys
|
||||
import logging
|
||||
from importlib.util import module_from_spec, spec_from_file_location
|
||||
from pathlib import Path
|
||||
from quart import Blueprint, Quart, request, g, current_app, session
|
||||
from werkzeug.wrappers.request import Request
|
||||
from flasgger import Swagger
|
||||
from itsdangerous.url_safe import URLSafeTimedSerializer as Serializer
|
||||
from quart_cors import cors
|
||||
@ -40,7 +39,6 @@ settings.init_settings()
|
||||
|
||||
__all__ = ["app"]
|
||||
|
||||
Request.json = property(lambda self: self.get_json(force=True, silent=True))
|
||||
|
||||
app = Quart(__name__)
|
||||
app = cors(app, allow_origin="*")
|
||||
@ -82,6 +80,11 @@ app.url_map.strict_slashes = False
|
||||
app.json_encoder = CustomJSONEncoder
|
||||
app.errorhandler(Exception)(server_error_response)
|
||||
|
||||
# Configure Quart timeouts for slow LLM responses (e.g., local Ollama on CPU)
|
||||
# Default Quart timeouts are 60 seconds which is too short for many LLM backends
|
||||
app.config["RESPONSE_TIMEOUT"] = int(os.environ.get("QUART_RESPONSE_TIMEOUT", 600))
|
||||
app.config["BODY_TIMEOUT"] = int(os.environ.get("QUART_BODY_TIMEOUT", 600))
|
||||
|
||||
## convince for dev and debug
|
||||
# app.config["LOGIN_DISABLED"] = True
|
||||
app.config["SESSION_PERMANENT"] = False
|
||||
|
||||
@ -18,8 +18,7 @@ from quart import request
|
||||
from api.db.db_models import APIToken
|
||||
from api.db.services.api_service import APITokenService, API4ConversationService
|
||||
from api.db.services.user_service import UserTenantService
|
||||
from api.utils.api_utils import server_error_response, get_data_error_result, get_json_result, validate_request, \
|
||||
generate_confirmation_token
|
||||
from api.utils.api_utils import generate_confirmation_token, get_data_error_result, get_json_result, get_request_json, server_error_response, validate_request
|
||||
from common.time_utils import current_timestamp, datetime_format
|
||||
from api.apps import login_required, current_user
|
||||
|
||||
@ -27,7 +26,7 @@ from api.apps import login_required, current_user
|
||||
@manager.route('/new_token', methods=['POST']) # noqa: F821
|
||||
@login_required
|
||||
async def new_token():
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
try:
|
||||
tenants = UserTenantService.query(user_id=current_user.id)
|
||||
if not tenants:
|
||||
@ -73,7 +72,7 @@ def token_list():
|
||||
@validate_request("tokens", "tenant_id")
|
||||
@login_required
|
||||
async def rm():
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
try:
|
||||
for token in req["tokens"]:
|
||||
APITokenService.filter_delete(
|
||||
@ -116,4 +115,3 @@ def stats():
|
||||
return get_json_result(data=res)
|
||||
except Exception as e:
|
||||
return server_error_response(e)
|
||||
|
||||
|
||||
@ -14,7 +14,7 @@
|
||||
# limitations under the License.
|
||||
#
|
||||
|
||||
import requests
|
||||
from common.http_client import async_request, sync_request
|
||||
from .oauth import OAuthClient, UserInfo
|
||||
|
||||
|
||||
@ -34,24 +34,49 @@ class GithubOAuthClient(OAuthClient):
|
||||
|
||||
def fetch_user_info(self, access_token, **kwargs):
|
||||
"""
|
||||
Fetch GitHub user info.
|
||||
Fetch GitHub user info (synchronous).
|
||||
"""
|
||||
user_info = {}
|
||||
try:
|
||||
headers = {"Authorization": f"Bearer {access_token}"}
|
||||
# user info
|
||||
response = requests.get(self.userinfo_url, headers=headers, timeout=self.http_request_timeout)
|
||||
response = sync_request("GET", self.userinfo_url, headers=headers, timeout=self.http_request_timeout)
|
||||
response.raise_for_status()
|
||||
user_info.update(response.json())
|
||||
# email info
|
||||
response = requests.get(self.userinfo_url+"/emails", headers=headers, timeout=self.http_request_timeout)
|
||||
response.raise_for_status()
|
||||
email_info = response.json()
|
||||
user_info["email"] = next(
|
||||
(email for email in email_info if email["primary"]), None
|
||||
)["email"]
|
||||
email_response = sync_request(
|
||||
"GET", self.userinfo_url + "/emails", headers=headers, timeout=self.http_request_timeout
|
||||
)
|
||||
email_response.raise_for_status()
|
||||
email_info = email_response.json()
|
||||
user_info["email"] = next((email for email in email_info if email["primary"]), None)["email"]
|
||||
return self.normalize_user_info(user_info)
|
||||
except requests.exceptions.RequestException as e:
|
||||
except Exception as e:
|
||||
raise ValueError(f"Failed to fetch github user info: {e}")
|
||||
|
||||
async def async_fetch_user_info(self, access_token, **kwargs):
|
||||
"""Async variant of fetch_user_info using httpx."""
|
||||
user_info = {}
|
||||
headers = {"Authorization": f"Bearer {access_token}"}
|
||||
try:
|
||||
response = await async_request(
|
||||
"GET",
|
||||
self.userinfo_url,
|
||||
headers=headers,
|
||||
timeout=self.http_request_timeout,
|
||||
)
|
||||
response.raise_for_status()
|
||||
user_info.update(response.json())
|
||||
|
||||
email_response = await async_request(
|
||||
"GET",
|
||||
self.userinfo_url + "/emails",
|
||||
headers=headers,
|
||||
timeout=self.http_request_timeout,
|
||||
)
|
||||
email_response.raise_for_status()
|
||||
email_info = email_response.json()
|
||||
user_info["email"] = next((email for email in email_info if email["primary"]), None)["email"]
|
||||
return self.normalize_user_info(user_info)
|
||||
except Exception as e:
|
||||
raise ValueError(f"Failed to fetch github user info: {e}")
|
||||
|
||||
|
||||
|
||||
@ -14,8 +14,8 @@
|
||||
# limitations under the License.
|
||||
#
|
||||
|
||||
import requests
|
||||
import urllib.parse
|
||||
from common.http_client import async_request, sync_request
|
||||
|
||||
|
||||
class UserInfo:
|
||||
@ -74,15 +74,40 @@ class OAuthClient:
|
||||
"redirect_uri": self.redirect_uri,
|
||||
"grant_type": "authorization_code"
|
||||
}
|
||||
response = requests.post(
|
||||
response = sync_request(
|
||||
"POST",
|
||||
self.token_url,
|
||||
data=payload,
|
||||
headers={"Accept": "application/json"},
|
||||
timeout=self.http_request_timeout
|
||||
timeout=self.http_request_timeout,
|
||||
)
|
||||
response.raise_for_status()
|
||||
return response.json()
|
||||
except requests.exceptions.RequestException as e:
|
||||
except Exception as e:
|
||||
raise ValueError(f"Failed to exchange authorization code for token: {e}")
|
||||
|
||||
async def async_exchange_code_for_token(self, code):
|
||||
"""
|
||||
Async variant of exchange_code_for_token using httpx.
|
||||
"""
|
||||
payload = {
|
||||
"client_id": self.client_id,
|
||||
"client_secret": self.client_secret,
|
||||
"code": code,
|
||||
"redirect_uri": self.redirect_uri,
|
||||
"grant_type": "authorization_code",
|
||||
}
|
||||
try:
|
||||
response = await async_request(
|
||||
"POST",
|
||||
self.token_url,
|
||||
data=payload,
|
||||
headers={"Accept": "application/json"},
|
||||
timeout=self.http_request_timeout,
|
||||
)
|
||||
response.raise_for_status()
|
||||
return response.json()
|
||||
except Exception as e:
|
||||
raise ValueError(f"Failed to exchange authorization code for token: {e}")
|
||||
|
||||
|
||||
@ -92,11 +117,27 @@ class OAuthClient:
|
||||
"""
|
||||
try:
|
||||
headers = {"Authorization": f"Bearer {access_token}"}
|
||||
response = requests.get(self.userinfo_url, headers=headers, timeout=self.http_request_timeout)
|
||||
response = sync_request("GET", self.userinfo_url, headers=headers, timeout=self.http_request_timeout)
|
||||
response.raise_for_status()
|
||||
user_info = response.json()
|
||||
return self.normalize_user_info(user_info)
|
||||
except requests.exceptions.RequestException as e:
|
||||
except Exception as e:
|
||||
raise ValueError(f"Failed to fetch user info: {e}")
|
||||
|
||||
async def async_fetch_user_info(self, access_token, **kwargs):
|
||||
"""Async variant of fetch_user_info using httpx."""
|
||||
headers = {"Authorization": f"Bearer {access_token}"}
|
||||
try:
|
||||
response = await async_request(
|
||||
"GET",
|
||||
self.userinfo_url,
|
||||
headers=headers,
|
||||
timeout=self.http_request_timeout,
|
||||
)
|
||||
response.raise_for_status()
|
||||
user_info = response.json()
|
||||
return self.normalize_user_info(user_info)
|
||||
except Exception as e:
|
||||
raise ValueError(f"Failed to fetch user info: {e}")
|
||||
|
||||
|
||||
|
||||
@ -15,7 +15,7 @@
|
||||
#
|
||||
|
||||
import jwt
|
||||
import requests
|
||||
from common.http_client import sync_request
|
||||
from .oauth import OAuthClient
|
||||
|
||||
|
||||
@ -50,10 +50,10 @@ class OIDCClient(OAuthClient):
|
||||
"""
|
||||
try:
|
||||
metadata_url = f"{issuer}/.well-known/openid-configuration"
|
||||
response = requests.get(metadata_url, timeout=7)
|
||||
response = sync_request("GET", metadata_url, timeout=7)
|
||||
response.raise_for_status()
|
||||
return response.json()
|
||||
except requests.exceptions.RequestException as e:
|
||||
except Exception as e:
|
||||
raise ValueError(f"Failed to fetch OIDC metadata: {e}")
|
||||
|
||||
|
||||
@ -95,6 +95,13 @@ class OIDCClient(OAuthClient):
|
||||
user_info.update(super().fetch_user_info(access_token).to_dict())
|
||||
return self.normalize_user_info(user_info)
|
||||
|
||||
async def async_fetch_user_info(self, access_token, id_token=None, **kwargs):
|
||||
user_info = {}
|
||||
if id_token:
|
||||
user_info = self.parse_id_token(id_token)
|
||||
user_info.update((await super().async_fetch_user_info(access_token)).to_dict())
|
||||
return self.normalize_user_info(user_info)
|
||||
|
||||
|
||||
def normalize_user_info(self, user_info):
|
||||
return super().normalize_user_info(user_info)
|
||||
|
||||
@ -13,15 +13,13 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
import asyncio
|
||||
import json
|
||||
import logging
|
||||
import re
|
||||
import sys
|
||||
from functools import partial
|
||||
import trio
|
||||
from quart import request, Response, make_response
|
||||
from agent.component import LLM
|
||||
from api.db import CanvasCategory, FileType
|
||||
from api.db import CanvasCategory
|
||||
from api.db.services.canvas_service import CanvasTemplateService, UserCanvasService, API4ConversationService
|
||||
from api.db.services.document_service import DocumentService
|
||||
from api.db.services.file_service import FileService
|
||||
@ -32,13 +30,12 @@ from api.db.services.user_canvas_version import UserCanvasVersionService
|
||||
from common.constants import RetCode
|
||||
from common.misc_utils import get_uuid
|
||||
from api.utils.api_utils import get_json_result, server_error_response, validate_request, get_data_error_result, \
|
||||
request_json
|
||||
get_request_json
|
||||
from agent.canvas import Canvas
|
||||
from peewee import MySQLDatabase, PostgresqlDatabase
|
||||
from api.db.db_models import APIToken, Task
|
||||
import time
|
||||
|
||||
from api.utils.file_utils import filename_type, read_potential_broken_pdf
|
||||
from rag.flow.pipeline import Pipeline
|
||||
from rag.nlp import search
|
||||
from rag.utils.redis_conn import REDIS_CONN
|
||||
@ -56,7 +53,7 @@ def templates():
|
||||
@validate_request("canvas_ids")
|
||||
@login_required
|
||||
async def rm():
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
for i in req["canvas_ids"]:
|
||||
if not UserCanvasService.accessible(i, current_user.id):
|
||||
return get_json_result(
|
||||
@ -70,7 +67,7 @@ async def rm():
|
||||
@validate_request("dsl", "title")
|
||||
@login_required
|
||||
async def save():
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
if not isinstance(req["dsl"], str):
|
||||
req["dsl"] = json.dumps(req["dsl"], ensure_ascii=False)
|
||||
req["dsl"] = json.loads(req["dsl"])
|
||||
@ -129,17 +126,17 @@ def getsse(canvas_id):
|
||||
@validate_request("id")
|
||||
@login_required
|
||||
async def run():
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
query = req.get("query", "")
|
||||
files = req.get("files", [])
|
||||
inputs = req.get("inputs", {})
|
||||
user_id = req.get("user_id", current_user.id)
|
||||
if not UserCanvasService.accessible(req["id"], current_user.id):
|
||||
if not await asyncio.to_thread(UserCanvasService.accessible, req["id"], current_user.id):
|
||||
return get_json_result(
|
||||
data=False, message='Only owner of canvas authorized for this operation.',
|
||||
code=RetCode.OPERATING_ERROR)
|
||||
|
||||
e, cvs = UserCanvasService.get_by_id(req["id"])
|
||||
e, cvs = await asyncio.to_thread(UserCanvasService.get_by_id, req["id"])
|
||||
if not e:
|
||||
return get_data_error_result(message="canvas not found.")
|
||||
|
||||
@ -149,7 +146,7 @@ async def run():
|
||||
if cvs.canvas_category == CanvasCategory.DataFlow:
|
||||
task_id = get_uuid()
|
||||
Pipeline(cvs.dsl, tenant_id=current_user.id, doc_id=CANVAS_DEBUG_DOC_ID, task_id=task_id, flow_id=req["id"])
|
||||
ok, error_message = queue_dataflow(tenant_id=user_id, flow_id=req["id"], task_id=task_id, file=files[0], priority=0)
|
||||
ok, error_message = await asyncio.to_thread(queue_dataflow, user_id, req["id"], task_id, files[0], 0)
|
||||
if not ok:
|
||||
return get_data_error_result(message=error_message)
|
||||
return get_json_result(data={"message_id": task_id})
|
||||
@ -186,7 +183,7 @@ async def run():
|
||||
@validate_request("id", "dsl", "component_id")
|
||||
@login_required
|
||||
async def rerun():
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
doc = PipelineOperationLogService.get_documents_info(req["id"])
|
||||
if not doc:
|
||||
return get_data_error_result(message="Document not found.")
|
||||
@ -224,7 +221,7 @@ def cancel(task_id):
|
||||
@validate_request("id")
|
||||
@login_required
|
||||
async def reset():
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
if not UserCanvasService.accessible(req["id"], current_user.id):
|
||||
return get_json_result(
|
||||
data=False, message='Only owner of canvas authorized for this operation.',
|
||||
@ -250,71 +247,10 @@ async def upload(canvas_id):
|
||||
return get_data_error_result(message="canvas not found.")
|
||||
|
||||
user_id = cvs["user_id"]
|
||||
def structured(filename, filetype, blob, content_type):
|
||||
nonlocal user_id
|
||||
if filetype == FileType.PDF.value:
|
||||
blob = read_potential_broken_pdf(blob)
|
||||
|
||||
location = get_uuid()
|
||||
FileService.put_blob(user_id, location, blob)
|
||||
|
||||
return {
|
||||
"id": location,
|
||||
"name": filename,
|
||||
"size": sys.getsizeof(blob),
|
||||
"extension": filename.split(".")[-1].lower(),
|
||||
"mime_type": content_type,
|
||||
"created_by": user_id,
|
||||
"created_at": time.time(),
|
||||
"preview_url": None
|
||||
}
|
||||
|
||||
if request.args.get("url"):
|
||||
from crawl4ai import (
|
||||
AsyncWebCrawler,
|
||||
BrowserConfig,
|
||||
CrawlerRunConfig,
|
||||
DefaultMarkdownGenerator,
|
||||
PruningContentFilter,
|
||||
CrawlResult
|
||||
)
|
||||
try:
|
||||
url = request.args.get("url")
|
||||
filename = re.sub(r"\?.*", "", url.split("/")[-1])
|
||||
async def adownload():
|
||||
browser_config = BrowserConfig(
|
||||
headless=True,
|
||||
verbose=False,
|
||||
)
|
||||
async with AsyncWebCrawler(config=browser_config) as crawler:
|
||||
crawler_config = CrawlerRunConfig(
|
||||
markdown_generator=DefaultMarkdownGenerator(
|
||||
content_filter=PruningContentFilter()
|
||||
),
|
||||
pdf=True,
|
||||
screenshot=False
|
||||
)
|
||||
result: CrawlResult = await crawler.arun(
|
||||
url=url,
|
||||
config=crawler_config
|
||||
)
|
||||
return result
|
||||
page = trio.run(adownload())
|
||||
if page.pdf:
|
||||
if filename.split(".")[-1].lower() != "pdf":
|
||||
filename += ".pdf"
|
||||
return get_json_result(data=structured(filename, "pdf", page.pdf, page.response_headers["content-type"]))
|
||||
|
||||
return get_json_result(data=structured(filename, "html", str(page.markdown).encode("utf-8"), page.response_headers["content-type"], user_id))
|
||||
|
||||
except Exception as e:
|
||||
return server_error_response(e)
|
||||
|
||||
files = await request.files
|
||||
file = files['file']
|
||||
file = files['file'] if files and files.get("file") else None
|
||||
try:
|
||||
DocumentService.check_doc_health(user_id, file.filename)
|
||||
return get_json_result(data=structured(file.filename, filename_type(file.filename), file.read(), file.content_type))
|
||||
return get_json_result(data=FileService.upload_info(user_id, file, request.args.get("url")))
|
||||
except Exception as e:
|
||||
return server_error_response(e)
|
||||
|
||||
@ -343,7 +279,7 @@ def input_form():
|
||||
@validate_request("id", "component_id", "params")
|
||||
@login_required
|
||||
async def debug():
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
if not UserCanvasService.accessible(req["id"], current_user.id):
|
||||
return get_json_result(
|
||||
data=False, message='Only owner of canvas authorized for this operation.',
|
||||
@ -375,7 +311,7 @@ async def debug():
|
||||
@validate_request("db_type", "database", "username", "host", "port", "password")
|
||||
@login_required
|
||||
async def test_db_connect():
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
try:
|
||||
if req["db_type"] in ["mysql", "mariadb"]:
|
||||
db = MySQLDatabase(req["database"], user=req["username"], host=req["host"], port=req["port"],
|
||||
@ -520,7 +456,7 @@ def list_canvas():
|
||||
@validate_request("id", "title", "permission")
|
||||
@login_required
|
||||
async def setting():
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
req["user_id"] = current_user.id
|
||||
|
||||
if not UserCanvasService.accessible(req["id"], current_user.id):
|
||||
|
||||
@ -27,7 +27,7 @@ from api.db.services.llm_service import LLMBundle
|
||||
from api.db.services.search_service import SearchService
|
||||
from api.db.services.user_service import UserTenantService
|
||||
from api.utils.api_utils import get_data_error_result, get_json_result, server_error_response, validate_request, \
|
||||
request_json
|
||||
get_request_json
|
||||
from rag.app.qa import beAdoc, rmPrefix
|
||||
from rag.app.tag import label_question
|
||||
from rag.nlp import rag_tokenizer, search
|
||||
@ -42,7 +42,7 @@ from api.apps import login_required, current_user
|
||||
@login_required
|
||||
@validate_request("doc_id")
|
||||
async def list_chunk():
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
doc_id = req["doc_id"]
|
||||
page = int(req.get("page", 1))
|
||||
size = int(req.get("size", 30))
|
||||
@ -123,7 +123,7 @@ def get():
|
||||
@login_required
|
||||
@validate_request("doc_id", "chunk_id", "content_with_weight")
|
||||
async def set():
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
d = {
|
||||
"id": req["chunk_id"],
|
||||
"content_with_weight": req["content_with_weight"]}
|
||||
@ -180,7 +180,7 @@ async def set():
|
||||
@login_required
|
||||
@validate_request("chunk_ids", "available_int", "doc_id")
|
||||
async def switch():
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
try:
|
||||
e, doc = DocumentService.get_by_id(req["doc_id"])
|
||||
if not e:
|
||||
@ -200,7 +200,7 @@ async def switch():
|
||||
@login_required
|
||||
@validate_request("chunk_ids", "doc_id")
|
||||
async def rm():
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
try:
|
||||
e, doc = DocumentService.get_by_id(req["doc_id"])
|
||||
if not e:
|
||||
@ -224,7 +224,7 @@ async def rm():
|
||||
@login_required
|
||||
@validate_request("doc_id", "content_with_weight")
|
||||
async def create():
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
chunck_id = xxhash.xxh64((req["content_with_weight"] + req["doc_id"]).encode("utf-8")).hexdigest()
|
||||
d = {"id": chunck_id, "content_ltks": rag_tokenizer.tokenize(req["content_with_weight"]),
|
||||
"content_with_weight": req["content_with_weight"]}
|
||||
@ -282,7 +282,7 @@ async def create():
|
||||
@login_required
|
||||
@validate_request("kb_id", "question")
|
||||
async def retrieval_test():
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
page = int(req.get("page", 1))
|
||||
size = int(req.get("size", 30))
|
||||
question = req["question"]
|
||||
|
||||
@ -26,10 +26,10 @@ from google_auth_oauthlib.flow import Flow
|
||||
|
||||
from api.db import InputType
|
||||
from api.db.services.connector_service import ConnectorService, SyncLogsService
|
||||
from api.utils.api_utils import get_data_error_result, get_json_result, validate_request
|
||||
from api.utils.api_utils import get_data_error_result, get_json_result, get_request_json, validate_request
|
||||
from common.constants import RetCode, TaskStatus
|
||||
from common.data_source.config import GOOGLE_DRIVE_WEB_OAUTH_REDIRECT_URI, DocumentSource
|
||||
from common.data_source.google_util.constant import GOOGLE_DRIVE_WEB_OAUTH_POPUP_TEMPLATE, GOOGLE_SCOPES
|
||||
from common.data_source.config import GOOGLE_DRIVE_WEB_OAUTH_REDIRECT_URI, GMAIL_WEB_OAUTH_REDIRECT_URI, DocumentSource
|
||||
from common.data_source.google_util.constant import GOOGLE_WEB_OAUTH_POPUP_TEMPLATE, GOOGLE_SCOPES
|
||||
from common.misc_utils import get_uuid
|
||||
from rag.utils.redis_conn import REDIS_CONN
|
||||
from api.apps import login_required, current_user
|
||||
@ -38,7 +38,7 @@ from api.apps import login_required, current_user
|
||||
@manager.route("/set", methods=["POST"]) # noqa: F821
|
||||
@login_required
|
||||
async def set_connector():
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
if req.get("id"):
|
||||
conn = {fld: req[fld] for fld in ["prune_freq", "refresh_freq", "config", "timeout_secs"] if fld in req}
|
||||
ConnectorService.update_by_id(req["id"], conn)
|
||||
@ -90,7 +90,7 @@ def list_logs(connector_id):
|
||||
@manager.route("/<connector_id>/resume", methods=["PUT"]) # noqa: F821
|
||||
@login_required
|
||||
async def resume(connector_id):
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
if req.get("resume"):
|
||||
ConnectorService.resume(connector_id, TaskStatus.SCHEDULE)
|
||||
else:
|
||||
@ -102,7 +102,7 @@ async def resume(connector_id):
|
||||
@login_required
|
||||
@validate_request("kb_id")
|
||||
async def rebuild(connector_id):
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
err = ConnectorService.rebuild(req["kb_id"], connector_id, current_user.id)
|
||||
if err:
|
||||
return get_json_result(data=False, message=err, code=RetCode.SERVER_ERROR)
|
||||
@ -122,12 +122,30 @@ GOOGLE_WEB_FLOW_RESULT_PREFIX = "google_drive_web_flow_result"
|
||||
WEB_FLOW_TTL_SECS = 15 * 60
|
||||
|
||||
|
||||
def _web_state_cache_key(flow_id: str) -> str:
|
||||
return f"{GOOGLE_WEB_FLOW_STATE_PREFIX}:{flow_id}"
|
||||
def _web_state_cache_key(flow_id: str, source_type: str | None = None) -> str:
|
||||
"""Return Redis key for web OAuth state.
|
||||
|
||||
The default prefix keeps backward compatibility for Google Drive.
|
||||
When source_type == "gmail", a different prefix is used so that
|
||||
Drive/Gmail flows don't clash in Redis.
|
||||
"""
|
||||
if source_type == "gmail":
|
||||
prefix = "gmail_web_flow_state"
|
||||
else:
|
||||
prefix = GOOGLE_WEB_FLOW_STATE_PREFIX
|
||||
return f"{prefix}:{flow_id}"
|
||||
|
||||
|
||||
def _web_result_cache_key(flow_id: str) -> str:
|
||||
return f"{GOOGLE_WEB_FLOW_RESULT_PREFIX}:{flow_id}"
|
||||
def _web_result_cache_key(flow_id: str, source_type: str | None = None) -> str:
|
||||
"""Return Redis key for web OAuth result.
|
||||
|
||||
Mirrors _web_state_cache_key logic for result storage.
|
||||
"""
|
||||
if source_type == "gmail":
|
||||
prefix = "gmail_web_flow_result"
|
||||
else:
|
||||
prefix = GOOGLE_WEB_FLOW_RESULT_PREFIX
|
||||
return f"{prefix}:{flow_id}"
|
||||
|
||||
|
||||
def _load_credentials(payload: str | dict[str, Any]) -> dict[str, Any]:
|
||||
@ -146,19 +164,22 @@ def _get_web_client_config(credentials: dict[str, Any]) -> dict[str, Any]:
|
||||
return {"web": web_section}
|
||||
|
||||
|
||||
async def _render_web_oauth_popup(flow_id: str, success: bool, message: str):
|
||||
async def _render_web_oauth_popup(flow_id: str, success: bool, message: str, source="drive"):
|
||||
status = "success" if success else "error"
|
||||
auto_close = "window.close();" if success else ""
|
||||
escaped_message = escape(message)
|
||||
payload_json = json.dumps(
|
||||
{
|
||||
"type": "ragflow-google-drive-oauth",
|
||||
# TODO(google-oauth): include connector type (drive/gmail) in payload type if needed
|
||||
"type": f"ragflow-google-{source}-oauth",
|
||||
"status": status,
|
||||
"flowId": flow_id or "",
|
||||
"message": message,
|
||||
}
|
||||
)
|
||||
html = GOOGLE_DRIVE_WEB_OAUTH_POPUP_TEMPLATE.format(
|
||||
# TODO(google-oauth): title/heading/message may need to reflect drive/gmail based on cached type
|
||||
html = GOOGLE_WEB_OAUTH_POPUP_TEMPLATE.format(
|
||||
title=f"Google {source.capitalize()} Authorization",
|
||||
heading="Authorization complete" if success else "Authorization failed",
|
||||
message=escaped_message,
|
||||
payload_json=payload_json,
|
||||
@ -169,20 +190,33 @@ async def _render_web_oauth_popup(flow_id: str, success: bool, message: str):
|
||||
return response
|
||||
|
||||
|
||||
@manager.route("/google-drive/oauth/web/start", methods=["POST"]) # noqa: F821
|
||||
@manager.route("/google/oauth/web/start", methods=["POST"]) # noqa: F821
|
||||
@login_required
|
||||
@validate_request("credentials")
|
||||
async def start_google_drive_web_oauth():
|
||||
if not GOOGLE_DRIVE_WEB_OAUTH_REDIRECT_URI:
|
||||
async def start_google_web_oauth():
|
||||
source = request.args.get("type", "google-drive")
|
||||
if source not in ("google-drive", "gmail"):
|
||||
return get_json_result(code=RetCode.ARGUMENT_ERROR, message="Invalid Google OAuth type.")
|
||||
|
||||
if source == "gmail":
|
||||
redirect_uri = GMAIL_WEB_OAUTH_REDIRECT_URI
|
||||
scopes = GOOGLE_SCOPES[DocumentSource.GMAIL]
|
||||
else:
|
||||
redirect_uri = GOOGLE_DRIVE_WEB_OAUTH_REDIRECT_URI if source == "google-drive" else GMAIL_WEB_OAUTH_REDIRECT_URI
|
||||
scopes = GOOGLE_SCOPES[DocumentSource.GOOGLE_DRIVE if source == "google-drive" else DocumentSource.GMAIL]
|
||||
|
||||
if not redirect_uri:
|
||||
return get_json_result(
|
||||
code=RetCode.SERVER_ERROR,
|
||||
message="Google Drive OAuth redirect URI is not configured on the server.",
|
||||
message="Google OAuth redirect URI is not configured on the server.",
|
||||
)
|
||||
|
||||
req = await request.json or {}
|
||||
req = await get_request_json()
|
||||
raw_credentials = req.get("credentials", "")
|
||||
|
||||
try:
|
||||
credentials = _load_credentials(raw_credentials)
|
||||
print(credentials)
|
||||
except ValueError as exc:
|
||||
return get_json_result(code=RetCode.ARGUMENT_ERROR, message=str(exc))
|
||||
|
||||
@ -199,8 +233,8 @@ async def start_google_drive_web_oauth():
|
||||
|
||||
flow_id = str(uuid.uuid4())
|
||||
try:
|
||||
flow = Flow.from_client_config(client_config, scopes=GOOGLE_SCOPES[DocumentSource.GOOGLE_DRIVE])
|
||||
flow.redirect_uri = GOOGLE_DRIVE_WEB_OAUTH_REDIRECT_URI
|
||||
flow = Flow.from_client_config(client_config, scopes=scopes)
|
||||
flow.redirect_uri = redirect_uri
|
||||
authorization_url, _ = flow.authorization_url(
|
||||
access_type="offline",
|
||||
include_granted_scopes="true",
|
||||
@ -219,7 +253,7 @@ async def start_google_drive_web_oauth():
|
||||
"client_config": client_config,
|
||||
"created_at": int(time.time()),
|
||||
}
|
||||
REDIS_CONN.set_obj(_web_state_cache_key(flow_id), cache_payload, WEB_FLOW_TTL_SECS)
|
||||
REDIS_CONN.set_obj(_web_state_cache_key(flow_id, source), cache_payload, WEB_FLOW_TTL_SECS)
|
||||
|
||||
return get_json_result(
|
||||
data={
|
||||
@ -230,60 +264,122 @@ async def start_google_drive_web_oauth():
|
||||
)
|
||||
|
||||
|
||||
@manager.route("/google-drive/oauth/web/callback", methods=["GET"]) # noqa: F821
|
||||
async def google_drive_web_oauth_callback():
|
||||
@manager.route("/gmail/oauth/web/callback", methods=["GET"]) # noqa: F821
|
||||
async def google_gmail_web_oauth_callback():
|
||||
state_id = request.args.get("state")
|
||||
error = request.args.get("error")
|
||||
source = "gmail"
|
||||
if source != 'gmail':
|
||||
return await _render_web_oauth_popup("", False, "Invalid Google OAuth type.", source)
|
||||
|
||||
error_description = request.args.get("error_description") or error
|
||||
|
||||
if not state_id:
|
||||
return await _render_web_oauth_popup("", False, "Missing OAuth state parameter.")
|
||||
return await _render_web_oauth_popup("", False, "Missing OAuth state parameter.", source)
|
||||
|
||||
state_cache = REDIS_CONN.get(_web_state_cache_key(state_id))
|
||||
state_cache = REDIS_CONN.get(_web_state_cache_key(state_id, source))
|
||||
if not state_cache:
|
||||
return await _render_web_oauth_popup(state_id, False, "Authorization session expired. Please restart from the main window.")
|
||||
return await _render_web_oauth_popup(state_id, False, "Authorization session expired. Please restart from the main window.", source)
|
||||
|
||||
state_obj = json.loads(state_cache)
|
||||
client_config = state_obj.get("client_config")
|
||||
if not client_config:
|
||||
REDIS_CONN.delete(_web_state_cache_key(state_id))
|
||||
return await _render_web_oauth_popup(state_id, False, "Authorization session was invalid. Please retry.")
|
||||
REDIS_CONN.delete(_web_state_cache_key(state_id, source))
|
||||
return await _render_web_oauth_popup(state_id, False, "Authorization session was invalid. Please retry.", source)
|
||||
|
||||
if error:
|
||||
REDIS_CONN.delete(_web_state_cache_key(state_id))
|
||||
return await _render_web_oauth_popup(state_id, False, error_description or "Authorization was cancelled.")
|
||||
REDIS_CONN.delete(_web_state_cache_key(state_id, source))
|
||||
return await _render_web_oauth_popup(state_id, False, error_description or "Authorization was cancelled.", source)
|
||||
|
||||
code = request.args.get("code")
|
||||
if not code:
|
||||
return await _render_web_oauth_popup(state_id, False, "Missing authorization code from Google.")
|
||||
return await _render_web_oauth_popup(state_id, False, "Missing authorization code from Google.", source)
|
||||
|
||||
try:
|
||||
flow = Flow.from_client_config(client_config, scopes=GOOGLE_SCOPES[DocumentSource.GOOGLE_DRIVE])
|
||||
flow.redirect_uri = GOOGLE_DRIVE_WEB_OAUTH_REDIRECT_URI
|
||||
# TODO(google-oauth): branch scopes/redirect_uri based on source_type (drive vs gmail)
|
||||
flow = Flow.from_client_config(client_config, scopes=GOOGLE_SCOPES[DocumentSource.GMAIL])
|
||||
flow.redirect_uri = GMAIL_WEB_OAUTH_REDIRECT_URI
|
||||
flow.fetch_token(code=code)
|
||||
except Exception as exc: # pragma: no cover - defensive
|
||||
logging.exception("Failed to exchange Google OAuth code: %s", exc)
|
||||
REDIS_CONN.delete(_web_state_cache_key(state_id))
|
||||
return await _render_web_oauth_popup(state_id, False, "Failed to exchange tokens with Google. Please retry.")
|
||||
REDIS_CONN.delete(_web_state_cache_key(state_id, source))
|
||||
return await _render_web_oauth_popup(state_id, False, "Failed to exchange tokens with Google. Please retry.", source)
|
||||
|
||||
creds_json = flow.credentials.to_json()
|
||||
result_payload = {
|
||||
"user_id": state_obj.get("user_id"),
|
||||
"credentials": creds_json,
|
||||
}
|
||||
REDIS_CONN.set_obj(_web_result_cache_key(state_id), result_payload, WEB_FLOW_TTL_SECS)
|
||||
REDIS_CONN.delete(_web_state_cache_key(state_id))
|
||||
REDIS_CONN.set_obj(_web_result_cache_key(state_id, source), result_payload, WEB_FLOW_TTL_SECS)
|
||||
|
||||
return await _render_web_oauth_popup(state_id, True, "Authorization completed successfully.")
|
||||
print("\n\n", _web_result_cache_key(state_id, source), "\n\n")
|
||||
|
||||
REDIS_CONN.delete(_web_state_cache_key(state_id, source))
|
||||
|
||||
return await _render_web_oauth_popup(state_id, True, "Authorization completed successfully.", source)
|
||||
|
||||
|
||||
@manager.route("/google-drive/oauth/web/result", methods=["POST"]) # noqa: F821
|
||||
@manager.route("/google-drive/oauth/web/callback", methods=["GET"]) # noqa: F821
|
||||
async def google_drive_web_oauth_callback():
|
||||
state_id = request.args.get("state")
|
||||
error = request.args.get("error")
|
||||
source = "google-drive"
|
||||
if source not in ("google-drive", "gmail"):
|
||||
return await _render_web_oauth_popup("", False, "Invalid Google OAuth type.", source)
|
||||
|
||||
error_description = request.args.get("error_description") or error
|
||||
|
||||
if not state_id:
|
||||
return await _render_web_oauth_popup("", False, "Missing OAuth state parameter.", source)
|
||||
|
||||
state_cache = REDIS_CONN.get(_web_state_cache_key(state_id, source))
|
||||
if not state_cache:
|
||||
return await _render_web_oauth_popup(state_id, False, "Authorization session expired. Please restart from the main window.", source)
|
||||
|
||||
state_obj = json.loads(state_cache)
|
||||
client_config = state_obj.get("client_config")
|
||||
if not client_config:
|
||||
REDIS_CONN.delete(_web_state_cache_key(state_id, source))
|
||||
return await _render_web_oauth_popup(state_id, False, "Authorization session was invalid. Please retry.", source)
|
||||
|
||||
if error:
|
||||
REDIS_CONN.delete(_web_state_cache_key(state_id, source))
|
||||
return await _render_web_oauth_popup(state_id, False, error_description or "Authorization was cancelled.", source)
|
||||
|
||||
code = request.args.get("code")
|
||||
if not code:
|
||||
return await _render_web_oauth_popup(state_id, False, "Missing authorization code from Google.", source)
|
||||
|
||||
try:
|
||||
# TODO(google-oauth): branch scopes/redirect_uri based on source_type (drive vs gmail)
|
||||
flow = Flow.from_client_config(client_config, scopes=GOOGLE_SCOPES[DocumentSource.GOOGLE_DRIVE])
|
||||
flow.redirect_uri = GOOGLE_DRIVE_WEB_OAUTH_REDIRECT_URI
|
||||
flow.fetch_token(code=code)
|
||||
except Exception as exc: # pragma: no cover - defensive
|
||||
logging.exception("Failed to exchange Google OAuth code: %s", exc)
|
||||
REDIS_CONN.delete(_web_state_cache_key(state_id, source))
|
||||
return await _render_web_oauth_popup(state_id, False, "Failed to exchange tokens with Google. Please retry.", source)
|
||||
|
||||
creds_json = flow.credentials.to_json()
|
||||
result_payload = {
|
||||
"user_id": state_obj.get("user_id"),
|
||||
"credentials": creds_json,
|
||||
}
|
||||
REDIS_CONN.set_obj(_web_result_cache_key(state_id, source), result_payload, WEB_FLOW_TTL_SECS)
|
||||
REDIS_CONN.delete(_web_state_cache_key(state_id, source))
|
||||
|
||||
return await _render_web_oauth_popup(state_id, True, "Authorization completed successfully.", source)
|
||||
|
||||
@manager.route("/google/oauth/web/result", methods=["POST"]) # noqa: F821
|
||||
@login_required
|
||||
@validate_request("flow_id")
|
||||
async def poll_google_drive_web_result():
|
||||
async def poll_google_web_result():
|
||||
req = await request.json or {}
|
||||
source = request.args.get("type")
|
||||
if source not in ("google-drive", "gmail"):
|
||||
return get_json_result(code=RetCode.ARGUMENT_ERROR, message="Invalid Google OAuth type.")
|
||||
flow_id = req.get("flow_id")
|
||||
cache_raw = REDIS_CONN.get(_web_result_cache_key(flow_id))
|
||||
cache_raw = REDIS_CONN.get(_web_result_cache_key(flow_id, source))
|
||||
if not cache_raw:
|
||||
return get_json_result(code=RetCode.RUNNING, message="Authorization is still pending.")
|
||||
|
||||
@ -291,5 +387,5 @@ async def poll_google_drive_web_result():
|
||||
if result.get("user_id") != current_user.id:
|
||||
return get_json_result(code=RetCode.PERMISSION_ERROR, message="You are not allowed to access this authorization result.")
|
||||
|
||||
REDIS_CONN.delete(_web_result_cache_key(flow_id))
|
||||
REDIS_CONN.delete(_web_result_cache_key(flow_id, source))
|
||||
return get_json_result(data={"credentials": result.get("credentials")})
|
||||
|
||||
@ -14,9 +14,11 @@
|
||||
# limitations under the License.
|
||||
#
|
||||
import json
|
||||
import os
|
||||
import re
|
||||
import logging
|
||||
from copy import deepcopy
|
||||
import tempfile
|
||||
from quart import Response, request
|
||||
from api.apps import current_user, login_required
|
||||
from api.db.db_models import APIToken
|
||||
@ -26,7 +28,7 @@ from api.db.services.llm_service import LLMBundle
|
||||
from api.db.services.search_service import SearchService
|
||||
from api.db.services.tenant_llm_service import TenantLLMService
|
||||
from api.db.services.user_service import TenantService, UserTenantService
|
||||
from api.utils.api_utils import get_data_error_result, get_json_result, server_error_response, validate_request
|
||||
from api.utils.api_utils import get_data_error_result, get_json_result, get_request_json, server_error_response, validate_request
|
||||
from rag.prompts.template import load_prompt
|
||||
from rag.prompts.generator import chunks_format
|
||||
from common.constants import RetCode, LLMType
|
||||
@ -35,7 +37,7 @@ from common.constants import RetCode, LLMType
|
||||
@manager.route("/set", methods=["POST"]) # noqa: F821
|
||||
@login_required
|
||||
async def set_conversation():
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
conv_id = req.get("conversation_id")
|
||||
is_new = req.get("is_new")
|
||||
name = req.get("name", "New conversation")
|
||||
@ -78,7 +80,7 @@ async def set_conversation():
|
||||
|
||||
@manager.route("/get", methods=["GET"]) # noqa: F821
|
||||
@login_required
|
||||
def get():
|
||||
async def get():
|
||||
conv_id = request.args["conversation_id"]
|
||||
try:
|
||||
e, conv = ConversationService.get_by_id(conv_id)
|
||||
@ -129,7 +131,7 @@ def getsse(dialog_id):
|
||||
@manager.route("/rm", methods=["POST"]) # noqa: F821
|
||||
@login_required
|
||||
async def rm():
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
conv_ids = req["conversation_ids"]
|
||||
try:
|
||||
for cid in conv_ids:
|
||||
@ -150,7 +152,7 @@ async def rm():
|
||||
|
||||
@manager.route("/list", methods=["GET"]) # noqa: F821
|
||||
@login_required
|
||||
def list_conversation():
|
||||
async def list_conversation():
|
||||
dialog_id = request.args["dialog_id"]
|
||||
try:
|
||||
if not DialogService.query(tenant_id=current_user.id, id=dialog_id):
|
||||
@ -167,7 +169,7 @@ def list_conversation():
|
||||
@login_required
|
||||
@validate_request("conversation_id", "messages")
|
||||
async def completion():
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
msg = []
|
||||
for m in req["messages"]:
|
||||
if m["role"] == "system":
|
||||
@ -248,11 +250,69 @@ async def completion():
|
||||
except Exception as e:
|
||||
return server_error_response(e)
|
||||
|
||||
@manager.route("/sequence2txt", methods=["POST"]) # noqa: F821
|
||||
@login_required
|
||||
async def sequence2txt():
|
||||
req = await request.form
|
||||
stream_mode = req.get("stream", "false").lower() == "true"
|
||||
files = await request.files
|
||||
if "file" not in files:
|
||||
return get_data_error_result(message="Missing 'file' in multipart form-data")
|
||||
|
||||
uploaded = files["file"]
|
||||
|
||||
ALLOWED_EXTS = {
|
||||
".wav", ".mp3", ".m4a", ".aac",
|
||||
".flac", ".ogg", ".webm",
|
||||
".opus", ".wma"
|
||||
}
|
||||
|
||||
filename = uploaded.filename or ""
|
||||
suffix = os.path.splitext(filename)[-1].lower()
|
||||
if suffix not in ALLOWED_EXTS:
|
||||
return get_data_error_result(message=
|
||||
f"Unsupported audio format: {suffix}. "
|
||||
f"Allowed: {', '.join(sorted(ALLOWED_EXTS))}"
|
||||
)
|
||||
fd, temp_audio_path = tempfile.mkstemp(suffix=suffix)
|
||||
os.close(fd)
|
||||
await uploaded.save(temp_audio_path)
|
||||
|
||||
tenants = TenantService.get_info_by(current_user.id)
|
||||
if not tenants:
|
||||
return get_data_error_result(message="Tenant not found!")
|
||||
|
||||
asr_id = tenants[0]["asr_id"]
|
||||
if not asr_id:
|
||||
return get_data_error_result(message="No default ASR model is set")
|
||||
|
||||
asr_mdl=LLMBundle(tenants[0]["tenant_id"], LLMType.SPEECH2TEXT, asr_id)
|
||||
if not stream_mode:
|
||||
text = asr_mdl.transcription(temp_audio_path)
|
||||
try:
|
||||
os.remove(temp_audio_path)
|
||||
except Exception as e:
|
||||
logging.error(f"Failed to remove temp audio file: {str(e)}")
|
||||
return get_json_result(data={"text": text})
|
||||
async def event_stream():
|
||||
try:
|
||||
for evt in asr_mdl.stream_transcription(temp_audio_path):
|
||||
yield f"data: {json.dumps(evt, ensure_ascii=False)}\n\n"
|
||||
except Exception as e:
|
||||
err = {"event": "error", "text": str(e)}
|
||||
yield f"data: {json.dumps(err, ensure_ascii=False)}\n\n"
|
||||
finally:
|
||||
try:
|
||||
os.remove(temp_audio_path)
|
||||
except Exception as e:
|
||||
logging.error(f"Failed to remove temp audio file: {str(e)}")
|
||||
|
||||
return Response(event_stream(), content_type="text/event-stream")
|
||||
|
||||
@manager.route("/tts", methods=["POST"]) # noqa: F821
|
||||
@login_required
|
||||
async def tts():
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
text = req["text"]
|
||||
|
||||
tenants = TenantService.get_info_by(current_user.id)
|
||||
@ -285,7 +345,7 @@ async def tts():
|
||||
@login_required
|
||||
@validate_request("conversation_id", "message_id")
|
||||
async def delete_msg():
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
e, conv = ConversationService.get_by_id(req["conversation_id"])
|
||||
if not e:
|
||||
return get_data_error_result(message="Conversation not found!")
|
||||
@ -308,7 +368,7 @@ async def delete_msg():
|
||||
@login_required
|
||||
@validate_request("conversation_id", "message_id")
|
||||
async def thumbup():
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
e, conv = ConversationService.get_by_id(req["conversation_id"])
|
||||
if not e:
|
||||
return get_data_error_result(message="Conversation not found!")
|
||||
@ -335,7 +395,7 @@ async def thumbup():
|
||||
@login_required
|
||||
@validate_request("question", "kb_ids")
|
||||
async def ask_about():
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
uid = current_user.id
|
||||
|
||||
search_id = req.get("search_id", "")
|
||||
@ -367,7 +427,7 @@ async def ask_about():
|
||||
@login_required
|
||||
@validate_request("question", "kb_ids")
|
||||
async def mindmap():
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
search_id = req.get("search_id", "")
|
||||
search_app = SearchService.get_detail(search_id) if search_id else {}
|
||||
search_config = search_app.get("search_config", {}) if search_app else {}
|
||||
@ -385,7 +445,7 @@ async def mindmap():
|
||||
@login_required
|
||||
@validate_request("question")
|
||||
async def related_questions():
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
|
||||
search_id = req.get("search_id", "")
|
||||
search_config = {}
|
||||
|
||||
@ -21,10 +21,9 @@ from common.constants import StatusEnum
|
||||
from api.db.services.tenant_llm_service import TenantLLMService
|
||||
from api.db.services.knowledgebase_service import KnowledgebaseService
|
||||
from api.db.services.user_service import TenantService, UserTenantService
|
||||
from api.utils.api_utils import server_error_response, get_data_error_result, validate_request
|
||||
from api.utils.api_utils import get_data_error_result, get_json_result, get_request_json, server_error_response, validate_request
|
||||
from common.misc_utils import get_uuid
|
||||
from common.constants import RetCode
|
||||
from api.utils.api_utils import get_json_result
|
||||
from api.apps import login_required, current_user
|
||||
|
||||
|
||||
@ -32,7 +31,7 @@ from api.apps import login_required, current_user
|
||||
@validate_request("prompt_config")
|
||||
@login_required
|
||||
async def set_dialog():
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
dialog_id = req.get("dialog_id", "")
|
||||
is_create = not dialog_id
|
||||
name = req.get("name", "New Dialog")
|
||||
@ -181,7 +180,7 @@ async def list_dialogs_next():
|
||||
else:
|
||||
desc = True
|
||||
|
||||
req = await request.get_json()
|
||||
req = await get_request_json()
|
||||
owner_ids = req.get("owner_ids", [])
|
||||
try:
|
||||
if not owner_ids:
|
||||
@ -209,7 +208,7 @@ async def list_dialogs_next():
|
||||
@login_required
|
||||
@validate_request("dialog_ids")
|
||||
async def rm():
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
dialog_list=[]
|
||||
tenants = UserTenantService.query(user_id=current_user.id)
|
||||
try:
|
||||
|
||||
@ -36,7 +36,7 @@ from api.utils.api_utils import (
|
||||
get_data_error_result,
|
||||
get_json_result,
|
||||
server_error_response,
|
||||
validate_request, request_json,
|
||||
validate_request, get_request_json,
|
||||
)
|
||||
from api.utils.file_utils import filename_type, thumbnail
|
||||
from common.file_utils import get_project_base_directory
|
||||
@ -153,7 +153,7 @@ async def web_crawl():
|
||||
@login_required
|
||||
@validate_request("name", "kb_id")
|
||||
async def create():
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
kb_id = req["kb_id"]
|
||||
if not kb_id:
|
||||
return get_json_result(data=False, message='Lack of "KB ID"', code=RetCode.ARGUMENT_ERROR)
|
||||
@ -230,7 +230,7 @@ async def list_docs():
|
||||
create_time_from = int(request.args.get("create_time_from", 0))
|
||||
create_time_to = int(request.args.get("create_time_to", 0))
|
||||
|
||||
req = await request.get_json()
|
||||
req = await get_request_json()
|
||||
|
||||
run_status = req.get("run_status", [])
|
||||
if run_status:
|
||||
@ -271,7 +271,7 @@ async def list_docs():
|
||||
@manager.route("/filter", methods=["POST"]) # noqa: F821
|
||||
@login_required
|
||||
async def get_filter():
|
||||
req = await request.get_json()
|
||||
req = await get_request_json()
|
||||
|
||||
kb_id = req.get("kb_id")
|
||||
if not kb_id:
|
||||
@ -309,7 +309,7 @@ async def get_filter():
|
||||
@manager.route("/infos", methods=["POST"]) # noqa: F821
|
||||
@login_required
|
||||
async def doc_infos():
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
doc_ids = req["doc_ids"]
|
||||
for doc_id in doc_ids:
|
||||
if not DocumentService.accessible(doc_id, current_user.id):
|
||||
@ -341,7 +341,7 @@ def thumbnails():
|
||||
@login_required
|
||||
@validate_request("doc_ids", "status")
|
||||
async def change_status():
|
||||
req = await request.get_json()
|
||||
req = await get_request_json()
|
||||
doc_ids = req.get("doc_ids", [])
|
||||
status = str(req.get("status", ""))
|
||||
|
||||
@ -381,7 +381,7 @@ async def change_status():
|
||||
@login_required
|
||||
@validate_request("doc_id")
|
||||
async def rm():
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
doc_ids = req["doc_id"]
|
||||
if isinstance(doc_ids, str):
|
||||
doc_ids = [doc_ids]
|
||||
@ -402,7 +402,7 @@ async def rm():
|
||||
@login_required
|
||||
@validate_request("doc_ids", "run")
|
||||
async def run():
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
for doc_id in req["doc_ids"]:
|
||||
if not DocumentService.accessible(doc_id, current_user.id):
|
||||
return get_json_result(data=False, message="No authorization.", code=RetCode.AUTHENTICATION_ERROR)
|
||||
@ -449,7 +449,7 @@ async def run():
|
||||
@login_required
|
||||
@validate_request("doc_id", "name")
|
||||
async def rename():
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
if not DocumentService.accessible(req["doc_id"], current_user.id):
|
||||
return get_json_result(data=False, message="No authorization.", code=RetCode.AUTHENTICATION_ERROR)
|
||||
try:
|
||||
@ -539,7 +539,7 @@ async def download_attachment(attachment_id):
|
||||
@validate_request("doc_id")
|
||||
async def change_parser():
|
||||
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
if not DocumentService.accessible(req["doc_id"], current_user.id):
|
||||
return get_json_result(data=False, message="No authorization.", code=RetCode.AUTHENTICATION_ERROR)
|
||||
|
||||
@ -607,7 +607,7 @@ async def get_image(image_id):
|
||||
@login_required
|
||||
@validate_request("conversation_id")
|
||||
async def upload_and_parse():
|
||||
files = await request.file
|
||||
files = await request.files
|
||||
if "file" not in files:
|
||||
return get_json_result(data=False, message="No file part!", code=RetCode.ARGUMENT_ERROR)
|
||||
|
||||
@ -624,7 +624,8 @@ async def upload_and_parse():
|
||||
@manager.route("/parse", methods=["POST"]) # noqa: F821
|
||||
@login_required
|
||||
async def parse():
|
||||
url = await request.json.get("url") if await request.json else ""
|
||||
req = await get_request_json()
|
||||
url = req.get("url", "")
|
||||
if url:
|
||||
if not is_valid_url(url):
|
||||
return get_json_result(data=False, message="The URL format is invalid", code=RetCode.ARGUMENT_ERROR)
|
||||
@ -679,7 +680,7 @@ async def parse():
|
||||
@login_required
|
||||
@validate_request("doc_id", "meta")
|
||||
async def set_meta():
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
if not DocumentService.accessible(req["doc_id"], current_user.id):
|
||||
return get_json_result(data=False, message="No authorization.", code=RetCode.AUTHENTICATION_ERROR)
|
||||
try:
|
||||
@ -705,3 +706,13 @@ async def set_meta():
|
||||
return get_json_result(data=True)
|
||||
except Exception as e:
|
||||
return server_error_response(e)
|
||||
|
||||
|
||||
@manager.route("/upload_info", methods=["POST"]) # noqa: F821
|
||||
async def upload_info():
|
||||
files = await request.files
|
||||
file = files['file'] if files and files.get("file") else None
|
||||
try:
|
||||
return get_json_result(data=FileService.upload_info(current_user.id, file, request.args.get("url")))
|
||||
except Exception as e:
|
||||
return server_error_response(e)
|
||||
|
||||
@ -19,22 +19,20 @@ from pathlib import Path
|
||||
from api.db.services.file2document_service import File2DocumentService
|
||||
from api.db.services.file_service import FileService
|
||||
|
||||
from quart import request
|
||||
from api.apps import login_required, current_user
|
||||
from api.db.services.knowledgebase_service import KnowledgebaseService
|
||||
from api.utils.api_utils import server_error_response, get_data_error_result, validate_request
|
||||
from api.utils.api_utils import get_data_error_result, get_json_result, get_request_json, server_error_response, validate_request
|
||||
from common.misc_utils import get_uuid
|
||||
from common.constants import RetCode
|
||||
from api.db import FileType
|
||||
from api.db.services.document_service import DocumentService
|
||||
from api.utils.api_utils import get_json_result
|
||||
|
||||
|
||||
@manager.route('/convert', methods=['POST']) # noqa: F821
|
||||
@login_required
|
||||
@validate_request("file_ids", "kb_ids")
|
||||
async def convert():
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
kb_ids = req["kb_ids"]
|
||||
file_ids = req["file_ids"]
|
||||
file2documents = []
|
||||
@ -79,7 +77,8 @@ async def convert():
|
||||
doc = DocumentService.insert({
|
||||
"id": get_uuid(),
|
||||
"kb_id": kb.id,
|
||||
"parser_id": FileService.get_parser(file.type, file.name, kb.parser_id),
|
||||
"parser_id": kb.parser_id,
|
||||
"pipeline_id": kb.pipeline_id,
|
||||
"parser_config": kb.parser_config,
|
||||
"created_by": current_user.id,
|
||||
"type": file.type,
|
||||
@ -104,7 +103,7 @@ async def convert():
|
||||
@login_required
|
||||
@validate_request("file_ids")
|
||||
async def rm():
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
file_ids = req["file_ids"]
|
||||
if not file_ids:
|
||||
return get_json_result(
|
||||
|
||||
@ -29,7 +29,7 @@ from common.constants import RetCode, FileSource
|
||||
from api.db import FileType
|
||||
from api.db.services import duplicate_name
|
||||
from api.db.services.file_service import FileService
|
||||
from api.utils.api_utils import get_json_result
|
||||
from api.utils.api_utils import get_json_result, get_request_json
|
||||
from api.utils.file_utils import filename_type
|
||||
from api.utils.web_utils import CONTENT_TYPE_MAP
|
||||
from common import settings
|
||||
@ -124,9 +124,9 @@ async def upload():
|
||||
@login_required
|
||||
@validate_request("name")
|
||||
async def create():
|
||||
req = await request.json
|
||||
pf_id = await request.json.get("parent_id")
|
||||
input_file_type = await request.json.get("type")
|
||||
req = await get_request_json()
|
||||
pf_id = req.get("parent_id")
|
||||
input_file_type = req.get("type")
|
||||
if not pf_id:
|
||||
root_folder = FileService.get_root_folder(current_user.id)
|
||||
pf_id = root_folder["id"]
|
||||
@ -239,7 +239,7 @@ def get_all_parent_folders():
|
||||
@login_required
|
||||
@validate_request("file_ids")
|
||||
async def rm():
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
file_ids = req["file_ids"]
|
||||
|
||||
def _delete_single_file(file):
|
||||
@ -300,7 +300,7 @@ async def rm():
|
||||
@login_required
|
||||
@validate_request("file_id", "name")
|
||||
async def rename():
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
try:
|
||||
e, file = FileService.get_by_id(req["file_id"])
|
||||
if not e:
|
||||
@ -369,7 +369,7 @@ async def get(file_id):
|
||||
@login_required
|
||||
@validate_request("src_file_ids", "dest_file_id")
|
||||
async def move():
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
try:
|
||||
file_ids = req["src_file_ids"]
|
||||
dest_parent_id = req["dest_file_id"]
|
||||
|
||||
@ -30,7 +30,7 @@ from api.db.services.pipeline_operation_log_service import PipelineOperationLogS
|
||||
from api.db.services.task_service import TaskService, GRAPH_RAPTOR_FAKE_DOC_ID
|
||||
from api.db.services.user_service import TenantService, UserTenantService
|
||||
from api.utils.api_utils import get_error_data_result, server_error_response, get_data_error_result, validate_request, not_allowed_parameters, \
|
||||
request_json
|
||||
get_request_json
|
||||
from api.db import VALID_FILE_TYPES
|
||||
from api.db.services.knowledgebase_service import KnowledgebaseService
|
||||
from api.db.db_models import File
|
||||
@ -48,7 +48,7 @@ from api.apps import login_required, current_user
|
||||
@login_required
|
||||
@validate_request("name")
|
||||
async def create():
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
e, res = KnowledgebaseService.create_with_name(
|
||||
name = req.pop("name", None),
|
||||
tenant_id = current_user.id,
|
||||
@ -72,7 +72,7 @@ async def create():
|
||||
@validate_request("kb_id", "name", "description", "parser_id")
|
||||
@not_allowed_parameters("id", "tenant_id", "created_by", "create_time", "update_time", "create_date", "update_date", "created_by")
|
||||
async def update():
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
if not isinstance(req["name"], str):
|
||||
return get_data_error_result(message="Dataset name must be string.")
|
||||
if req["name"].strip() == "":
|
||||
@ -182,7 +182,7 @@ async def list_kbs():
|
||||
else:
|
||||
desc = True
|
||||
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
owner_ids = req.get("owner_ids", [])
|
||||
try:
|
||||
if not owner_ids:
|
||||
@ -209,7 +209,7 @@ async def list_kbs():
|
||||
@login_required
|
||||
@validate_request("kb_id")
|
||||
async def rm():
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
if not KnowledgebaseService.accessible4deletion(req["kb_id"], current_user.id):
|
||||
return get_json_result(
|
||||
data=False,
|
||||
@ -286,7 +286,7 @@ def list_tags_from_kbs():
|
||||
@manager.route('/<kb_id>/rm_tags', methods=['POST']) # noqa: F821
|
||||
@login_required
|
||||
async def rm_tags(kb_id):
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
if not KnowledgebaseService.accessible(kb_id, current_user.id):
|
||||
return get_json_result(
|
||||
data=False,
|
||||
@ -306,7 +306,7 @@ async def rm_tags(kb_id):
|
||||
@manager.route('/<kb_id>/rename_tag', methods=['POST']) # noqa: F821
|
||||
@login_required
|
||||
async def rename_tags(kb_id):
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
if not KnowledgebaseService.accessible(kb_id, current_user.id):
|
||||
return get_json_result(
|
||||
data=False,
|
||||
@ -428,7 +428,7 @@ async def list_pipeline_logs():
|
||||
if create_date_to > create_date_from:
|
||||
return get_data_error_result(message="Create data filter is abnormal.")
|
||||
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
|
||||
operation_status = req.get("operation_status", [])
|
||||
if operation_status:
|
||||
@ -470,7 +470,7 @@ async def list_pipeline_dataset_logs():
|
||||
if create_date_to > create_date_from:
|
||||
return get_data_error_result(message="Create data filter is abnormal.")
|
||||
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
|
||||
operation_status = req.get("operation_status", [])
|
||||
if operation_status:
|
||||
@ -492,7 +492,7 @@ async def delete_pipeline_logs():
|
||||
if not kb_id:
|
||||
return get_json_result(data=False, message='Lack of "KB ID"', code=RetCode.ARGUMENT_ERROR)
|
||||
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
log_ids = req.get("log_ids", [])
|
||||
|
||||
PipelineOperationLogService.delete_by_ids(log_ids)
|
||||
@ -517,7 +517,7 @@ def pipeline_log_detail():
|
||||
@manager.route("/run_graphrag", methods=["POST"]) # noqa: F821
|
||||
@login_required
|
||||
async def run_graphrag():
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
|
||||
kb_id = req.get("kb_id", "")
|
||||
if not kb_id:
|
||||
@ -586,7 +586,7 @@ def trace_graphrag():
|
||||
@manager.route("/run_raptor", methods=["POST"]) # noqa: F821
|
||||
@login_required
|
||||
async def run_raptor():
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
|
||||
kb_id = req.get("kb_id", "")
|
||||
if not kb_id:
|
||||
@ -655,7 +655,7 @@ def trace_raptor():
|
||||
@manager.route("/run_mindmap", methods=["POST"]) # noqa: F821
|
||||
@login_required
|
||||
async def run_mindmap():
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
|
||||
kb_id = req.get("kb_id", "")
|
||||
if not kb_id:
|
||||
@ -857,11 +857,11 @@ async def check_embedding():
|
||||
"question_kwd": full_doc.get("question_kwd") or []
|
||||
})
|
||||
return out
|
||||
|
||||
|
||||
def _clean(s: str) -> str:
|
||||
s = re.sub(r"</?(table|td|caption|tr|th)( [^<>]{0,12})?>", " ", s or "")
|
||||
return s if s else "None"
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
kb_id = req.get("kb_id", "")
|
||||
embd_id = req.get("embd_id", "")
|
||||
n = int(req.get("check_num", 5))
|
||||
|
||||
@ -15,20 +15,19 @@
|
||||
#
|
||||
|
||||
|
||||
from quart import request
|
||||
from api.apps import current_user, login_required
|
||||
from langfuse import Langfuse
|
||||
|
||||
from api.db.db_models import DB
|
||||
from api.db.services.langfuse_service import TenantLangfuseService
|
||||
from api.utils.api_utils import get_error_data_result, get_json_result, server_error_response, validate_request
|
||||
from api.utils.api_utils import get_error_data_result, get_json_result, get_request_json, server_error_response, validate_request
|
||||
|
||||
|
||||
@manager.route("/api_key", methods=["POST", "PUT"]) # noqa: F821
|
||||
@login_required
|
||||
@validate_request("secret_key", "public_key", "host")
|
||||
async def set_api_key():
|
||||
req = await request.get_json()
|
||||
req = await get_request_json()
|
||||
secret_key = req.get("secret_key", "")
|
||||
public_key = req.get("public_key", "")
|
||||
host = req.get("host", "")
|
||||
|
||||
@ -21,10 +21,9 @@ from quart import request
|
||||
from api.apps import login_required, current_user
|
||||
from api.db.services.tenant_llm_service import LLMFactoriesService, TenantLLMService
|
||||
from api.db.services.llm_service import LLMService
|
||||
from api.utils.api_utils import server_error_response, get_data_error_result, validate_request
|
||||
from api.utils.api_utils import get_allowed_llm_factories, get_data_error_result, get_json_result, get_request_json, server_error_response, validate_request
|
||||
from common.constants import StatusEnum, LLMType
|
||||
from api.db.db_models import TenantLLM
|
||||
from api.utils.api_utils import get_json_result, get_allowed_llm_factories
|
||||
from rag.utils.base64_image import test_image
|
||||
from rag.llm import EmbeddingModel, ChatModel, RerankModel, CvModel, TTSModel
|
||||
|
||||
@ -54,7 +53,7 @@ def factories():
|
||||
@login_required
|
||||
@validate_request("llm_factory", "api_key")
|
||||
async def set_api_key():
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
# test if api key works
|
||||
chat_passed, embd_passed, rerank_passed = False, False, False
|
||||
factory = req["llm_factory"]
|
||||
@ -124,7 +123,7 @@ async def set_api_key():
|
||||
@login_required
|
||||
@validate_request("llm_factory")
|
||||
async def add_llm():
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
factory = req["llm_factory"]
|
||||
api_key = req.get("api_key", "x")
|
||||
llm_name = req.get("llm_name")
|
||||
@ -269,7 +268,7 @@ async def add_llm():
|
||||
@login_required
|
||||
@validate_request("llm_factory", "llm_name")
|
||||
async def delete_llm():
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
TenantLLMService.filter_delete([TenantLLM.tenant_id == current_user.id, TenantLLM.llm_factory == req["llm_factory"], TenantLLM.llm_name == req["llm_name"]])
|
||||
return get_json_result(data=True)
|
||||
|
||||
@ -278,7 +277,7 @@ async def delete_llm():
|
||||
@login_required
|
||||
@validate_request("llm_factory", "llm_name")
|
||||
async def enable_llm():
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
TenantLLMService.filter_update(
|
||||
[TenantLLM.tenant_id == current_user.id, TenantLLM.llm_factory == req["llm_factory"], TenantLLM.llm_name == req["llm_name"]], {"status": str(req.get("status", "1"))}
|
||||
)
|
||||
@ -289,7 +288,7 @@ async def enable_llm():
|
||||
@login_required
|
||||
@validate_request("llm_factory")
|
||||
async def delete_factory():
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
TenantLLMService.filter_delete([TenantLLM.tenant_id == current_user.id, TenantLLM.llm_factory == req["llm_factory"]])
|
||||
return get_json_result(data=True)
|
||||
|
||||
|
||||
@ -22,8 +22,7 @@ from api.db.services.user_service import TenantService
|
||||
from common.constants import RetCode, VALID_MCP_SERVER_TYPES
|
||||
|
||||
from common.misc_utils import get_uuid
|
||||
from api.utils.api_utils import get_data_error_result, get_json_result, server_error_response, validate_request, \
|
||||
get_mcp_tools
|
||||
from api.utils.api_utils import get_data_error_result, get_json_result, get_mcp_tools, get_request_json, server_error_response, validate_request
|
||||
from api.utils.web_utils import get_float, safe_json_parse
|
||||
from common.mcp_tool_call_conn import MCPToolCallSession, close_multiple_mcp_toolcall_sessions
|
||||
|
||||
@ -40,7 +39,7 @@ async def list_mcp() -> Response:
|
||||
else:
|
||||
desc = True
|
||||
|
||||
req = await request.get_json()
|
||||
req = await get_request_json()
|
||||
mcp_ids = req.get("mcp_ids", [])
|
||||
try:
|
||||
servers = MCPServerService.get_servers(current_user.id, mcp_ids, 0, 0, orderby, desc, keywords) or []
|
||||
@ -73,7 +72,7 @@ def detail() -> Response:
|
||||
@login_required
|
||||
@validate_request("name", "url", "server_type")
|
||||
async def create() -> Response:
|
||||
req = await request.get_json()
|
||||
req = await get_request_json()
|
||||
|
||||
server_type = req.get("server_type", "")
|
||||
if server_type not in VALID_MCP_SERVER_TYPES:
|
||||
@ -128,7 +127,7 @@ async def create() -> Response:
|
||||
@login_required
|
||||
@validate_request("mcp_id")
|
||||
async def update() -> Response:
|
||||
req = await request.get_json()
|
||||
req = await get_request_json()
|
||||
|
||||
mcp_id = req.get("mcp_id", "")
|
||||
e, mcp_server = MCPServerService.get_by_id(mcp_id)
|
||||
@ -184,7 +183,7 @@ async def update() -> Response:
|
||||
@login_required
|
||||
@validate_request("mcp_ids")
|
||||
async def rm() -> Response:
|
||||
req = await request.get_json()
|
||||
req = await get_request_json()
|
||||
mcp_ids = req.get("mcp_ids", [])
|
||||
|
||||
try:
|
||||
@ -202,7 +201,7 @@ async def rm() -> Response:
|
||||
@login_required
|
||||
@validate_request("mcpServers")
|
||||
async def import_multiple() -> Response:
|
||||
req = await request.get_json()
|
||||
req = await get_request_json()
|
||||
servers = req.get("mcpServers", {})
|
||||
if not servers:
|
||||
return get_data_error_result(message="No MCP servers provided.")
|
||||
@ -269,7 +268,7 @@ async def import_multiple() -> Response:
|
||||
@login_required
|
||||
@validate_request("mcp_ids")
|
||||
async def export_multiple() -> Response:
|
||||
req = await request.get_json()
|
||||
req = await get_request_json()
|
||||
mcp_ids = req.get("mcp_ids", [])
|
||||
|
||||
if not mcp_ids:
|
||||
@ -301,7 +300,7 @@ async def export_multiple() -> Response:
|
||||
@login_required
|
||||
@validate_request("mcp_ids")
|
||||
async def list_tools() -> Response:
|
||||
req = await request.get_json()
|
||||
req = await get_request_json()
|
||||
mcp_ids = req.get("mcp_ids", [])
|
||||
if not mcp_ids:
|
||||
return get_data_error_result(message="No MCP server IDs provided.")
|
||||
@ -348,7 +347,7 @@ async def list_tools() -> Response:
|
||||
@login_required
|
||||
@validate_request("mcp_id", "tool_name", "arguments")
|
||||
async def test_tool() -> Response:
|
||||
req = await request.get_json()
|
||||
req = await get_request_json()
|
||||
mcp_id = req.get("mcp_id", "")
|
||||
if not mcp_id:
|
||||
return get_data_error_result(message="No MCP server ID provided.")
|
||||
@ -381,7 +380,7 @@ async def test_tool() -> Response:
|
||||
@login_required
|
||||
@validate_request("mcp_id", "tools")
|
||||
async def cache_tool() -> Response:
|
||||
req = await request.get_json()
|
||||
req = await get_request_json()
|
||||
mcp_id = req.get("mcp_id", "")
|
||||
if not mcp_id:
|
||||
return get_data_error_result(message="No MCP server ID provided.")
|
||||
@ -404,7 +403,7 @@ async def cache_tool() -> Response:
|
||||
@manager.route("/test_mcp", methods=["POST"]) # noqa: F821
|
||||
@validate_request("url", "server_type")
|
||||
async def test_mcp() -> Response:
|
||||
req = await request.get_json()
|
||||
req = await get_request_json()
|
||||
|
||||
url = req.get("url", "")
|
||||
if not url:
|
||||
|
||||
@ -25,7 +25,7 @@ from api.db.services.canvas_service import UserCanvasService
|
||||
from api.db.services.user_canvas_version import UserCanvasVersionService
|
||||
from common.constants import RetCode
|
||||
from common.misc_utils import get_uuid
|
||||
from api.utils.api_utils import get_data_error_result, get_error_data_result, get_json_result, token_required
|
||||
from api.utils.api_utils import get_data_error_result, get_error_data_result, get_json_result, get_request_json, token_required
|
||||
from api.utils.api_utils import get_result
|
||||
from quart import request, Response
|
||||
|
||||
@ -53,7 +53,7 @@ def list_agents(tenant_id):
|
||||
@manager.route("/agents", methods=["POST"]) # noqa: F821
|
||||
@token_required
|
||||
async def create_agent(tenant_id: str):
|
||||
req: dict[str, Any] = cast(dict[str, Any], await request.json)
|
||||
req: dict[str, Any] = cast(dict[str, Any], await get_request_json())
|
||||
req["user_id"] = tenant_id
|
||||
|
||||
if req.get("dsl") is not None:
|
||||
@ -90,7 +90,7 @@ async def create_agent(tenant_id: str):
|
||||
@manager.route("/agents/<agent_id>", methods=["PUT"]) # noqa: F821
|
||||
@token_required
|
||||
async def update_agent(tenant_id: str, agent_id: str):
|
||||
req: dict[str, Any] = {k: v for k, v in cast(dict[str, Any], (await request.json)).items() if v is not None}
|
||||
req: dict[str, Any] = {k: v for k, v in cast(dict[str, Any], (await get_request_json())).items() if v is not None}
|
||||
req["user_id"] = tenant_id
|
||||
|
||||
if req.get("dsl") is not None:
|
||||
@ -136,7 +136,7 @@ def delete_agent(tenant_id: str, agent_id: str):
|
||||
@manager.route('/webhook/<agent_id>', methods=['POST']) # noqa: F821
|
||||
@token_required
|
||||
async def webhook(tenant_id: str, agent_id: str):
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
if not UserCanvasService.accessible(req["id"], tenant_id):
|
||||
return get_json_result(
|
||||
data=False, message='Only owner of canvas authorized for this operation.',
|
||||
|
||||
@ -21,13 +21,13 @@ from api.db.services.tenant_llm_service import TenantLLMService
|
||||
from api.db.services.user_service import TenantService
|
||||
from common.misc_utils import get_uuid
|
||||
from common.constants import RetCode, StatusEnum
|
||||
from api.utils.api_utils import check_duplicate_ids, get_error_data_result, get_result, token_required, request_json
|
||||
from api.utils.api_utils import check_duplicate_ids, get_error_data_result, get_result, token_required, get_request_json
|
||||
|
||||
|
||||
@manager.route("/chats", methods=["POST"]) # noqa: F821
|
||||
@token_required
|
||||
async def create(tenant_id):
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
ids = [i for i in req.get("dataset_ids", []) if i]
|
||||
for kb_id in ids:
|
||||
kbs = KnowledgebaseService.accessible(kb_id=kb_id, user_id=tenant_id)
|
||||
@ -146,7 +146,7 @@ async def create(tenant_id):
|
||||
async def update(tenant_id, chat_id):
|
||||
if not DialogService.query(tenant_id=tenant_id, id=chat_id, status=StatusEnum.VALID.value):
|
||||
return get_error_data_result(message="You do not own the chat")
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
ids = req.get("dataset_ids", [])
|
||||
if "show_quotation" in req:
|
||||
req["do_refer"] = req.pop("show_quotation")
|
||||
@ -229,7 +229,7 @@ async def update(tenant_id, chat_id):
|
||||
async def delete_chats(tenant_id):
|
||||
errors = []
|
||||
success_count = 0
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
if not req:
|
||||
ids = None
|
||||
else:
|
||||
|
||||
@ -15,12 +15,12 @@
|
||||
#
|
||||
import logging
|
||||
|
||||
from quart import request, jsonify
|
||||
from quart import jsonify
|
||||
|
||||
from api.db.services.document_service import DocumentService
|
||||
from api.db.services.knowledgebase_service import KnowledgebaseService
|
||||
from api.db.services.llm_service import LLMBundle
|
||||
from api.utils.api_utils import validate_request, build_error_result, apikey_required
|
||||
from api.utils.api_utils import apikey_required, build_error_result, get_request_json, validate_request
|
||||
from rag.app.tag import label_question
|
||||
from api.db.services.dialog_service import meta_filter, convert_conditions
|
||||
from common.constants import RetCode, LLMType
|
||||
@ -113,7 +113,7 @@ async def retrieval(tenant_id):
|
||||
404:
|
||||
description: Knowledge base or document not found
|
||||
"""
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
question = req["query"]
|
||||
kb_id = req["knowledge_id"]
|
||||
use_kg = req.get("use_kg", False)
|
||||
|
||||
@ -36,7 +36,7 @@ from api.db.services.tenant_llm_service import TenantLLMService
|
||||
from api.db.services.task_service import TaskService, queue_tasks
|
||||
from api.db.services.dialog_service import meta_filter, convert_conditions
|
||||
from api.utils.api_utils import check_duplicate_ids, construct_json_result, get_error_data_result, get_parser_config, get_result, server_error_response, token_required, \
|
||||
request_json
|
||||
get_request_json
|
||||
from rag.app.qa import beAdoc, rmPrefix
|
||||
from rag.app.tag import label_question
|
||||
from rag.nlp import rag_tokenizer, search
|
||||
@ -231,7 +231,7 @@ async def update_doc(tenant_id, dataset_id, document_id):
|
||||
schema:
|
||||
type: object
|
||||
"""
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
if not KnowledgebaseService.query(id=dataset_id, tenant_id=tenant_id):
|
||||
return get_error_data_result(message="You don't own the dataset.")
|
||||
e, kb = KnowledgebaseService.get_by_id(dataset_id)
|
||||
@ -536,7 +536,7 @@ def list_docs(dataset_id, tenant_id):
|
||||
return get_error_data_result(message=f"You don't own the dataset {dataset_id}. ")
|
||||
|
||||
q = request.args
|
||||
document_id = q.get("id")
|
||||
document_id = q.get("id")
|
||||
name = q.get("name")
|
||||
|
||||
if document_id and not DocumentService.query(id=document_id, kb_id=dataset_id):
|
||||
@ -545,16 +545,16 @@ def list_docs(dataset_id, tenant_id):
|
||||
return get_error_data_result(message=f"You don't own the document {name}.")
|
||||
|
||||
page = int(q.get("page", 1))
|
||||
page_size = int(q.get("page_size", 30))
|
||||
page_size = int(q.get("page_size", 30))
|
||||
orderby = q.get("orderby", "create_time")
|
||||
desc = str(q.get("desc", "true")).strip().lower() != "false"
|
||||
keywords = q.get("keywords", "")
|
||||
|
||||
# filters - align with OpenAPI parameter names
|
||||
suffix = q.getlist("suffix")
|
||||
run_status = q.getlist("run")
|
||||
create_time_from = int(q.get("create_time_from", 0))
|
||||
create_time_to = int(q.get("create_time_to", 0))
|
||||
suffix = q.getlist("suffix")
|
||||
run_status = q.getlist("run")
|
||||
create_time_from = int(q.get("create_time_from", 0))
|
||||
create_time_to = int(q.get("create_time_to", 0))
|
||||
|
||||
# map run status (accept text or numeric) - align with API parameter
|
||||
run_status_text_to_numeric = {"UNSTART": "0", "RUNNING": "1", "CANCEL": "2", "DONE": "3", "FAIL": "4"}
|
||||
@ -575,7 +575,7 @@ def list_docs(dataset_id, tenant_id):
|
||||
# rename keys + map run status back to text for output
|
||||
key_mapping = {
|
||||
"chunk_num": "chunk_count",
|
||||
"kb_id": "dataset_id",
|
||||
"kb_id": "dataset_id",
|
||||
"token_num": "token_count",
|
||||
"parser_id": "chunk_method",
|
||||
}
|
||||
@ -631,7 +631,7 @@ async def delete(tenant_id, dataset_id):
|
||||
"""
|
||||
if not KnowledgebaseService.accessible(kb_id=dataset_id, user_id=tenant_id):
|
||||
return get_error_data_result(message=f"You don't own the dataset {dataset_id}. ")
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
if not req:
|
||||
doc_ids = None
|
||||
else:
|
||||
@ -741,7 +741,7 @@ async def parse(tenant_id, dataset_id):
|
||||
"""
|
||||
if not KnowledgebaseService.accessible(kb_id=dataset_id, user_id=tenant_id):
|
||||
return get_error_data_result(message=f"You don't own the dataset {dataset_id}.")
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
if not req.get("document_ids"):
|
||||
return get_error_data_result("`document_ids` is required")
|
||||
doc_list = req.get("document_ids")
|
||||
@ -824,7 +824,7 @@ async def stop_parsing(tenant_id, dataset_id):
|
||||
"""
|
||||
if not KnowledgebaseService.accessible(kb_id=dataset_id, user_id=tenant_id):
|
||||
return get_error_data_result(message=f"You don't own the dataset {dataset_id}.")
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
|
||||
if not req.get("document_ids"):
|
||||
return get_error_data_result("`document_ids` is required")
|
||||
@ -1096,7 +1096,7 @@ async def add_chunk(tenant_id, dataset_id, document_id):
|
||||
if not doc:
|
||||
return get_error_data_result(message=f"You don't own the document {document_id}.")
|
||||
doc = doc[0]
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
if not str(req.get("content", "")).strip():
|
||||
return get_error_data_result(message="`content` is required")
|
||||
if "important_keywords" in req:
|
||||
@ -1202,7 +1202,7 @@ async def rm_chunk(tenant_id, dataset_id, document_id):
|
||||
docs = DocumentService.get_by_ids([document_id])
|
||||
if not docs:
|
||||
raise LookupError(f"Can't find the document with ID {document_id}!")
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
condition = {"doc_id": document_id}
|
||||
if "chunk_ids" in req:
|
||||
unique_chunk_ids, duplicate_messages = check_duplicate_ids(req["chunk_ids"], "chunk")
|
||||
@ -1288,8 +1288,8 @@ async def update_chunk(tenant_id, dataset_id, document_id, chunk_id):
|
||||
if not doc:
|
||||
return get_error_data_result(message=f"You don't own the document {document_id}.")
|
||||
doc = doc[0]
|
||||
req = await request_json()
|
||||
if "content" in req:
|
||||
req = await get_request_json()
|
||||
if "content" in req and req["content"] is not None:
|
||||
content = req["content"]
|
||||
else:
|
||||
content = chunk.get("content_with_weight", "")
|
||||
@ -1411,7 +1411,7 @@ async def retrieval_test(tenant_id):
|
||||
format: float
|
||||
description: Similarity score.
|
||||
"""
|
||||
req = await request_json()
|
||||
req = await get_request_json()
|
||||
if not req.get("dataset_ids"):
|
||||
return get_error_data_result("`dataset_ids` is required.")
|
||||
kb_ids = req["dataset_ids"]
|
||||
@ -1446,6 +1446,9 @@ async def retrieval_test(tenant_id):
|
||||
metadata_condition = req.get("metadata_condition", {}) or {}
|
||||
metas = DocumentService.get_meta_by_kbs(kb_ids)
|
||||
doc_ids = meta_filter(metas, convert_conditions(metadata_condition), metadata_condition.get("logic", "and"))
|
||||
# If metadata_condition has conditions but no docs match, return empty result
|
||||
if not doc_ids and metadata_condition.get("conditions"):
|
||||
return get_result(data={"total": 0, "chunks": [], "doc_aggs": {}})
|
||||
if metadata_condition and not doc_ids:
|
||||
doc_ids = ["-999"]
|
||||
similarity_threshold = float(req.get("similarity_threshold", 0.2))
|
||||
|
||||
@ -23,15 +23,14 @@ from pathlib import Path
|
||||
from api.db.services.document_service import DocumentService
|
||||
from api.db.services.file2document_service import File2DocumentService
|
||||
from api.db.services.knowledgebase_service import KnowledgebaseService
|
||||
from api.utils.api_utils import server_error_response, token_required
|
||||
from api.utils.api_utils import get_json_result, get_request_json, server_error_response, token_required
|
||||
from common.misc_utils import get_uuid
|
||||
from api.db import FileType
|
||||
from api.db.services import duplicate_name
|
||||
from api.db.services.file_service import FileService
|
||||
from api.utils.api_utils import get_json_result
|
||||
from api.utils.file_utils import filename_type
|
||||
from common import settings
|
||||
|
||||
from common.constants import RetCode
|
||||
|
||||
@manager.route('/file/upload', methods=['POST']) # noqa: F821
|
||||
@token_required
|
||||
@ -86,19 +85,19 @@ async def upload(tenant_id):
|
||||
pf_id = root_folder["id"]
|
||||
|
||||
if 'file' not in files:
|
||||
return get_json_result(data=False, message='No file part!', code=400)
|
||||
return get_json_result(data=False, message='No file part!', code=RetCode.BAD_REQUEST)
|
||||
file_objs = files.getlist('file')
|
||||
|
||||
for file_obj in file_objs:
|
||||
if file_obj.filename == '':
|
||||
return get_json_result(data=False, message='No selected file!', code=400)
|
||||
return get_json_result(data=False, message='No selected file!', code=RetCode.BAD_REQUEST)
|
||||
|
||||
file_res = []
|
||||
|
||||
try:
|
||||
e, pf_folder = FileService.get_by_id(pf_id)
|
||||
if not e:
|
||||
return get_json_result(data=False, message="Can't find this folder!", code=404)
|
||||
return get_json_result(data=False, message="Can't find this folder!", code=RetCode.NOT_FOUND)
|
||||
|
||||
for file_obj in file_objs:
|
||||
# Handle file path
|
||||
@ -114,13 +113,13 @@ async def upload(tenant_id):
|
||||
if file_len != len_id_list:
|
||||
e, file = FileService.get_by_id(file_id_list[len_id_list - 1])
|
||||
if not e:
|
||||
return get_json_result(data=False, message="Folder not found!", code=404)
|
||||
return get_json_result(data=False, message="Folder not found!", code=RetCode.NOT_FOUND)
|
||||
last_folder = FileService.create_folder(file, file_id_list[len_id_list - 1], file_obj_names,
|
||||
len_id_list)
|
||||
else:
|
||||
e, file = FileService.get_by_id(file_id_list[len_id_list - 2])
|
||||
if not e:
|
||||
return get_json_result(data=False, message="Folder not found!", code=404)
|
||||
return get_json_result(data=False, message="Folder not found!", code=RetCode.NOT_FOUND)
|
||||
last_folder = FileService.create_folder(file, file_id_list[len_id_list - 2], file_obj_names,
|
||||
len_id_list)
|
||||
|
||||
@ -193,16 +192,16 @@ async def create(tenant_id):
|
||||
type:
|
||||
type: string
|
||||
"""
|
||||
req = await request.json
|
||||
pf_id = await request.json.get("parent_id")
|
||||
input_file_type = await request.json.get("type")
|
||||
req = await get_request_json()
|
||||
pf_id = req.get("parent_id")
|
||||
input_file_type = req.get("type")
|
||||
if not pf_id:
|
||||
root_folder = FileService.get_root_folder(tenant_id)
|
||||
pf_id = root_folder["id"]
|
||||
|
||||
try:
|
||||
if not FileService.is_parent_folder_exist(pf_id):
|
||||
return get_json_result(data=False, message="Parent Folder Doesn't Exist!", code=400)
|
||||
return get_json_result(data=False, message="Parent Folder Doesn't Exist!", code=RetCode.BAD_REQUEST)
|
||||
if FileService.query(name=req["name"], parent_id=pf_id):
|
||||
return get_json_result(data=False, message="Duplicated folder name in the same folder.", code=409)
|
||||
|
||||
@ -229,7 +228,7 @@ async def create(tenant_id):
|
||||
|
||||
@manager.route('/file/list', methods=['GET']) # noqa: F821
|
||||
@token_required
|
||||
def list_files(tenant_id):
|
||||
async def list_files(tenant_id):
|
||||
"""
|
||||
List files under a specific folder.
|
||||
---
|
||||
@ -306,13 +305,13 @@ def list_files(tenant_id):
|
||||
try:
|
||||
e, file = FileService.get_by_id(pf_id)
|
||||
if not e:
|
||||
return get_json_result(message="Folder not found!", code=404)
|
||||
return get_json_result(message="Folder not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
files, total = FileService.get_by_pf_id(tenant_id, pf_id, page_number, items_per_page, orderby, desc, keywords)
|
||||
|
||||
parent_folder = FileService.get_parent_folder(pf_id)
|
||||
if not parent_folder:
|
||||
return get_json_result(message="File not found!", code=404)
|
||||
return get_json_result(message="File not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
return get_json_result(data={"total": total, "files": files, "parent_folder": parent_folder.to_json()})
|
||||
except Exception as e:
|
||||
@ -321,7 +320,7 @@ def list_files(tenant_id):
|
||||
|
||||
@manager.route('/file/root_folder', methods=['GET']) # noqa: F821
|
||||
@token_required
|
||||
def get_root_folder(tenant_id):
|
||||
async def get_root_folder(tenant_id):
|
||||
"""
|
||||
Get user's root folder.
|
||||
---
|
||||
@ -357,7 +356,7 @@ def get_root_folder(tenant_id):
|
||||
|
||||
@manager.route('/file/parent_folder', methods=['GET']) # noqa: F821
|
||||
@token_required
|
||||
def get_parent_folder():
|
||||
async def get_parent_folder():
|
||||
"""
|
||||
Get parent folder info of a file.
|
||||
---
|
||||
@ -392,7 +391,7 @@ def get_parent_folder():
|
||||
try:
|
||||
e, file = FileService.get_by_id(file_id)
|
||||
if not e:
|
||||
return get_json_result(message="Folder not found!", code=404)
|
||||
return get_json_result(message="Folder not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
parent_folder = FileService.get_parent_folder(file_id)
|
||||
return get_json_result(data={"parent_folder": parent_folder.to_json()})
|
||||
@ -402,7 +401,7 @@ def get_parent_folder():
|
||||
|
||||
@manager.route('/file/all_parent_folder', methods=['GET']) # noqa: F821
|
||||
@token_required
|
||||
def get_all_parent_folders(tenant_id):
|
||||
async def get_all_parent_folders(tenant_id):
|
||||
"""
|
||||
Get all parent folders of a file.
|
||||
---
|
||||
@ -439,7 +438,7 @@ def get_all_parent_folders(tenant_id):
|
||||
try:
|
||||
e, file = FileService.get_by_id(file_id)
|
||||
if not e:
|
||||
return get_json_result(message="Folder not found!", code=404)
|
||||
return get_json_result(message="Folder not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
parent_folders = FileService.get_all_parent_folders(file_id)
|
||||
parent_folders_res = [folder.to_json() for folder in parent_folders]
|
||||
@ -481,40 +480,40 @@ async def rm(tenant_id):
|
||||
type: boolean
|
||||
example: true
|
||||
"""
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
file_ids = req["file_ids"]
|
||||
try:
|
||||
for file_id in file_ids:
|
||||
e, file = FileService.get_by_id(file_id)
|
||||
if not e:
|
||||
return get_json_result(message="File or Folder not found!", code=404)
|
||||
return get_json_result(message="File or Folder not found!", code=RetCode.NOT_FOUND)
|
||||
if not file.tenant_id:
|
||||
return get_json_result(message="Tenant not found!", code=404)
|
||||
return get_json_result(message="Tenant not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
if file.type == FileType.FOLDER.value:
|
||||
file_id_list = FileService.get_all_innermost_file_ids(file_id, [])
|
||||
for inner_file_id in file_id_list:
|
||||
e, file = FileService.get_by_id(inner_file_id)
|
||||
if not e:
|
||||
return get_json_result(message="File not found!", code=404)
|
||||
return get_json_result(message="File not found!", code=RetCode.NOT_FOUND)
|
||||
settings.STORAGE_IMPL.rm(file.parent_id, file.location)
|
||||
FileService.delete_folder_by_pf_id(tenant_id, file_id)
|
||||
else:
|
||||
settings.STORAGE_IMPL.rm(file.parent_id, file.location)
|
||||
if not FileService.delete(file):
|
||||
return get_json_result(message="Database error (File removal)!", code=500)
|
||||
return get_json_result(message="Database error (File removal)!", code=RetCode.SERVER_ERROR)
|
||||
|
||||
informs = File2DocumentService.get_by_file_id(file_id)
|
||||
for inform in informs:
|
||||
doc_id = inform.document_id
|
||||
e, doc = DocumentService.get_by_id(doc_id)
|
||||
if not e:
|
||||
return get_json_result(message="Document not found!", code=404)
|
||||
return get_json_result(message="Document not found!", code=RetCode.NOT_FOUND)
|
||||
tenant_id = DocumentService.get_tenant_id(doc_id)
|
||||
if not tenant_id:
|
||||
return get_json_result(message="Tenant not found!", code=404)
|
||||
return get_json_result(message="Tenant not found!", code=RetCode.NOT_FOUND)
|
||||
if not DocumentService.remove_document(doc, tenant_id):
|
||||
return get_json_result(message="Database error (Document removal)!", code=500)
|
||||
return get_json_result(message="Database error (Document removal)!", code=RetCode.SERVER_ERROR)
|
||||
File2DocumentService.delete_by_file_id(file_id)
|
||||
|
||||
return get_json_result(data=True)
|
||||
@ -556,27 +555,27 @@ async def rename(tenant_id):
|
||||
type: boolean
|
||||
example: true
|
||||
"""
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
try:
|
||||
e, file = FileService.get_by_id(req["file_id"])
|
||||
if not e:
|
||||
return get_json_result(message="File not found!", code=404)
|
||||
return get_json_result(message="File not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
if file.type != FileType.FOLDER.value and pathlib.Path(req["name"].lower()).suffix != pathlib.Path(
|
||||
file.name.lower()).suffix:
|
||||
return get_json_result(data=False, message="The extension of file can't be changed", code=400)
|
||||
return get_json_result(data=False, message="The extension of file can't be changed", code=RetCode.BAD_REQUEST)
|
||||
|
||||
for existing_file in FileService.query(name=req["name"], pf_id=file.parent_id):
|
||||
if existing_file.name == req["name"]:
|
||||
return get_json_result(data=False, message="Duplicated file name in the same folder.", code=409)
|
||||
|
||||
if not FileService.update_by_id(req["file_id"], {"name": req["name"]}):
|
||||
return get_json_result(message="Database error (File rename)!", code=500)
|
||||
return get_json_result(message="Database error (File rename)!", code=RetCode.SERVER_ERROR)
|
||||
|
||||
informs = File2DocumentService.get_by_file_id(req["file_id"])
|
||||
if informs:
|
||||
if not DocumentService.update_by_id(informs[0].document_id, {"name": req["name"]}):
|
||||
return get_json_result(message="Database error (Document rename)!", code=500)
|
||||
return get_json_result(message="Database error (Document rename)!", code=RetCode.SERVER_ERROR)
|
||||
|
||||
return get_json_result(data=True)
|
||||
except Exception as e:
|
||||
@ -606,13 +605,13 @@ async def get(tenant_id, file_id):
|
||||
description: File stream
|
||||
schema:
|
||||
type: file
|
||||
404:
|
||||
RetCode.NOT_FOUND:
|
||||
description: File not found
|
||||
"""
|
||||
try:
|
||||
e, file = FileService.get_by_id(file_id)
|
||||
if not e:
|
||||
return get_json_result(message="Document not found!", code=404)
|
||||
return get_json_result(message="Document not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
blob = settings.STORAGE_IMPL.get(file.parent_id, file.location)
|
||||
if not blob:
|
||||
@ -667,7 +666,7 @@ async def move(tenant_id):
|
||||
type: boolean
|
||||
example: true
|
||||
"""
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
try:
|
||||
file_ids = req["src_file_ids"]
|
||||
parent_id = req["dest_file_id"]
|
||||
@ -677,13 +676,13 @@ async def move(tenant_id):
|
||||
for file_id in file_ids:
|
||||
file = files_dict[file_id]
|
||||
if not file:
|
||||
return get_json_result(message="File or Folder not found!", code=404)
|
||||
return get_json_result(message="File or Folder not found!", code=RetCode.NOT_FOUND)
|
||||
if not file.tenant_id:
|
||||
return get_json_result(message="Tenant not found!", code=404)
|
||||
return get_json_result(message="Tenant not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
fe, _ = FileService.get_by_id(parent_id)
|
||||
if not fe:
|
||||
return get_json_result(message="Parent Folder not found!", code=404)
|
||||
return get_json_result(message="Parent Folder not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
FileService.move_file(file_ids, parent_id)
|
||||
return get_json_result(data=True)
|
||||
@ -694,7 +693,7 @@ async def move(tenant_id):
|
||||
@manager.route('/file/convert', methods=['POST']) # noqa: F821
|
||||
@token_required
|
||||
async def convert(tenant_id):
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
kb_ids = req["kb_ids"]
|
||||
file_ids = req["file_ids"]
|
||||
file2documents = []
|
||||
@ -705,7 +704,7 @@ async def convert(tenant_id):
|
||||
for file_id in file_ids:
|
||||
file = files_set[file_id]
|
||||
if not file:
|
||||
return get_json_result(message="File not found!", code=404)
|
||||
return get_json_result(message="File not found!", code=RetCode.NOT_FOUND)
|
||||
file_ids_list = [file_id]
|
||||
if file.type == FileType.FOLDER.value:
|
||||
file_ids_list = FileService.get_all_innermost_file_ids(file_id, [])
|
||||
@ -716,13 +715,13 @@ async def convert(tenant_id):
|
||||
doc_id = inform.document_id
|
||||
e, doc = DocumentService.get_by_id(doc_id)
|
||||
if not e:
|
||||
return get_json_result(message="Document not found!", code=404)
|
||||
return get_json_result(message="Document not found!", code=RetCode.NOT_FOUND)
|
||||
tenant_id = DocumentService.get_tenant_id(doc_id)
|
||||
if not tenant_id:
|
||||
return get_json_result(message="Tenant not found!", code=404)
|
||||
return get_json_result(message="Tenant not found!", code=RetCode.NOT_FOUND)
|
||||
if not DocumentService.remove_document(doc, tenant_id):
|
||||
return get_json_result(
|
||||
message="Database error (Document removal)!", code=404)
|
||||
message="Database error (Document removal)!", code=RetCode.NOT_FOUND)
|
||||
File2DocumentService.delete_by_file_id(id)
|
||||
|
||||
# insert
|
||||
@ -730,11 +729,11 @@ async def convert(tenant_id):
|
||||
e, kb = KnowledgebaseService.get_by_id(kb_id)
|
||||
if not e:
|
||||
return get_json_result(
|
||||
message="Can't find this knowledgebase!", code=404)
|
||||
message="Can't find this knowledgebase!", code=RetCode.NOT_FOUND)
|
||||
e, file = FileService.get_by_id(id)
|
||||
if not e:
|
||||
return get_json_result(
|
||||
message="Can't find this file!", code=404)
|
||||
message="Can't find this file!", code=RetCode.NOT_FOUND)
|
||||
|
||||
doc = DocumentService.insert({
|
||||
"id": get_uuid(),
|
||||
|
||||
@ -35,7 +35,7 @@ from api.db.services.search_service import SearchService
|
||||
from api.db.services.user_service import UserTenantService
|
||||
from common.misc_utils import get_uuid
|
||||
from api.utils.api_utils import check_duplicate_ids, get_data_openai, get_error_data_result, get_json_result, \
|
||||
get_result, server_error_response, token_required, validate_request
|
||||
get_result, get_request_json, server_error_response, token_required, validate_request
|
||||
from rag.app.tag import label_question
|
||||
from rag.prompts.template import load_prompt
|
||||
from rag.prompts.generator import cross_languages, gen_meta_filter, keyword_extraction, chunks_format
|
||||
@ -45,7 +45,7 @@ from common import settings
|
||||
@manager.route("/chats/<chat_id>/sessions", methods=["POST"]) # noqa: F821
|
||||
@token_required
|
||||
async def create(tenant_id, chat_id):
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
req["dialog_id"] = chat_id
|
||||
dia = DialogService.query(tenant_id=tenant_id, id=req["dialog_id"], status=StatusEnum.VALID.value)
|
||||
if not dia:
|
||||
@ -73,7 +73,7 @@ async def create(tenant_id, chat_id):
|
||||
|
||||
@manager.route("/agents/<agent_id>/sessions", methods=["POST"]) # noqa: F821
|
||||
@token_required
|
||||
def create_agent_session(tenant_id, agent_id):
|
||||
async def create_agent_session(tenant_id, agent_id):
|
||||
user_id = request.args.get("user_id", tenant_id)
|
||||
e, cvs = UserCanvasService.get_by_id(agent_id)
|
||||
if not e:
|
||||
@ -98,7 +98,7 @@ def create_agent_session(tenant_id, agent_id):
|
||||
@manager.route("/chats/<chat_id>/sessions/<session_id>", methods=["PUT"]) # noqa: F821
|
||||
@token_required
|
||||
async def update(tenant_id, chat_id, session_id):
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
req["dialog_id"] = chat_id
|
||||
conv_id = session_id
|
||||
conv = ConversationService.query(id=conv_id, dialog_id=chat_id)
|
||||
@ -120,7 +120,7 @@ async def update(tenant_id, chat_id, session_id):
|
||||
@manager.route("/chats/<chat_id>/completions", methods=["POST"]) # noqa: F821
|
||||
@token_required
|
||||
async def chat_completion(tenant_id, chat_id):
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
if not req:
|
||||
req = {"question": ""}
|
||||
if not req.get("session_id"):
|
||||
@ -206,7 +206,7 @@ async def chat_completion_openai_like(tenant_id, chat_id):
|
||||
if reference:
|
||||
print(completion.choices[0].message.reference)
|
||||
"""
|
||||
req = await request.get_json()
|
||||
req = await get_request_json()
|
||||
|
||||
need_reference = bool(req.get("reference", False))
|
||||
|
||||
@ -384,7 +384,7 @@ async def chat_completion_openai_like(tenant_id, chat_id):
|
||||
@validate_request("model", "messages") # noqa: F821
|
||||
@token_required
|
||||
async def agents_completion_openai_compatibility(tenant_id, agent_id):
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
tiktokenenc = tiktoken.get_encoding("cl100k_base")
|
||||
messages = req.get("messages", [])
|
||||
if not messages:
|
||||
@ -442,7 +442,7 @@ async def agents_completion_openai_compatibility(tenant_id, agent_id):
|
||||
@manager.route("/agents/<agent_id>/completions", methods=["POST"]) # noqa: F821
|
||||
@token_required
|
||||
async def agent_completions(tenant_id, agent_id):
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
|
||||
if req.get("stream", True):
|
||||
|
||||
@ -491,7 +491,7 @@ async def agent_completions(tenant_id, agent_id):
|
||||
|
||||
@manager.route("/chats/<chat_id>/sessions", methods=["GET"]) # noqa: F821
|
||||
@token_required
|
||||
def list_session(tenant_id, chat_id):
|
||||
async def list_session(tenant_id, chat_id):
|
||||
if not DialogService.query(tenant_id=tenant_id, id=chat_id, status=StatusEnum.VALID.value):
|
||||
return get_error_data_result(message=f"You don't own the assistant {chat_id}.")
|
||||
id = request.args.get("id")
|
||||
@ -545,7 +545,7 @@ def list_session(tenant_id, chat_id):
|
||||
|
||||
@manager.route("/agents/<agent_id>/sessions", methods=["GET"]) # noqa: F821
|
||||
@token_required
|
||||
def list_agent_session(tenant_id, agent_id):
|
||||
async def list_agent_session(tenant_id, agent_id):
|
||||
if not UserCanvasService.query(user_id=tenant_id, id=agent_id):
|
||||
return get_error_data_result(message=f"You don't own the agent {agent_id}.")
|
||||
id = request.args.get("id")
|
||||
@ -614,7 +614,7 @@ async def delete(tenant_id, chat_id):
|
||||
|
||||
errors = []
|
||||
success_count = 0
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
convs = ConversationService.query(dialog_id=chat_id)
|
||||
if not req:
|
||||
ids = None
|
||||
@ -662,7 +662,7 @@ async def delete(tenant_id, chat_id):
|
||||
async def delete_agent_session(tenant_id, agent_id):
|
||||
errors = []
|
||||
success_count = 0
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
cvs = UserCanvasService.query(user_id=tenant_id, id=agent_id)
|
||||
if not cvs:
|
||||
return get_error_data_result(f"You don't own the agent {agent_id}")
|
||||
@ -715,7 +715,7 @@ async def delete_agent_session(tenant_id, agent_id):
|
||||
@manager.route("/sessions/ask", methods=["POST"]) # noqa: F821
|
||||
@token_required
|
||||
async def ask_about(tenant_id):
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
if not req.get("question"):
|
||||
return get_error_data_result("`question` is required.")
|
||||
if not req.get("dataset_ids"):
|
||||
@ -754,7 +754,7 @@ async def ask_about(tenant_id):
|
||||
@manager.route("/sessions/related_questions", methods=["POST"]) # noqa: F821
|
||||
@token_required
|
||||
async def related_questions(tenant_id):
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
if not req.get("question"):
|
||||
return get_error_data_result("`question` is required.")
|
||||
question = req["question"]
|
||||
@ -805,7 +805,7 @@ Related search terms:
|
||||
|
||||
@manager.route("/chatbots/<dialog_id>/completions", methods=["POST"]) # noqa: F821
|
||||
async def chatbot_completions(dialog_id):
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
|
||||
token = request.headers.get("Authorization").split()
|
||||
if len(token) != 2:
|
||||
@ -831,7 +831,7 @@ async def chatbot_completions(dialog_id):
|
||||
|
||||
|
||||
@manager.route("/chatbots/<dialog_id>/info", methods=["GET"]) # noqa: F821
|
||||
def chatbots_inputs(dialog_id):
|
||||
async def chatbots_inputs(dialog_id):
|
||||
token = request.headers.get("Authorization").split()
|
||||
if len(token) != 2:
|
||||
return get_error_data_result(message='Authorization is not valid!"')
|
||||
@ -855,7 +855,7 @@ def chatbots_inputs(dialog_id):
|
||||
|
||||
@manager.route("/agentbots/<agent_id>/completions", methods=["POST"]) # noqa: F821
|
||||
async def agent_bot_completions(agent_id):
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
|
||||
token = request.headers.get("Authorization").split()
|
||||
if len(token) != 2:
|
||||
@ -878,7 +878,7 @@ async def agent_bot_completions(agent_id):
|
||||
|
||||
|
||||
@manager.route("/agentbots/<agent_id>/inputs", methods=["GET"]) # noqa: F821
|
||||
def begin_inputs(agent_id):
|
||||
async def begin_inputs(agent_id):
|
||||
token = request.headers.get("Authorization").split()
|
||||
if len(token) != 2:
|
||||
return get_error_data_result(message='Authorization is not valid!"')
|
||||
@ -908,7 +908,7 @@ async def ask_about_embedded():
|
||||
if not objs:
|
||||
return get_error_data_result(message='Authentication error: API key is invalid!"')
|
||||
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
uid = objs[0].tenant_id
|
||||
|
||||
search_id = req.get("search_id", "")
|
||||
@ -947,7 +947,7 @@ async def retrieval_test_embedded():
|
||||
if not objs:
|
||||
return get_error_data_result(message='Authentication error: API key is invalid!"')
|
||||
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
page = int(req.get("page", 1))
|
||||
size = int(req.get("size", 30))
|
||||
question = req["question"]
|
||||
@ -1046,7 +1046,7 @@ async def related_questions_embedded():
|
||||
if not objs:
|
||||
return get_error_data_result(message='Authentication error: API key is invalid!"')
|
||||
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
tenant_id = objs[0].tenant_id
|
||||
if not tenant_id:
|
||||
return get_error_data_result(message="permission denined.")
|
||||
@ -1081,7 +1081,7 @@ Related search terms:
|
||||
|
||||
|
||||
@manager.route("/searchbots/detail", methods=["GET"]) # noqa: F821
|
||||
def detail_share_embedded():
|
||||
async def detail_share_embedded():
|
||||
token = request.headers.get("Authorization").split()
|
||||
if len(token) != 2:
|
||||
return get_error_data_result(message='Authorization is not valid!"')
|
||||
@ -1123,7 +1123,7 @@ async def mindmap():
|
||||
return get_error_data_result(message='Authentication error: API key is invalid!"')
|
||||
|
||||
tenant_id = objs[0].tenant_id
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
|
||||
search_id = req.get("search_id", "")
|
||||
search_app = SearchService.get_detail(search_id) if search_id else {}
|
||||
|
||||
@ -24,14 +24,14 @@ from api.db.services.search_service import SearchService
|
||||
from api.db.services.user_service import TenantService, UserTenantService
|
||||
from common.misc_utils import get_uuid
|
||||
from common.constants import RetCode, StatusEnum
|
||||
from api.utils.api_utils import get_data_error_result, get_json_result, not_allowed_parameters, server_error_response, validate_request
|
||||
from api.utils.api_utils import get_data_error_result, get_json_result, not_allowed_parameters, get_request_json, server_error_response, validate_request
|
||||
|
||||
|
||||
@manager.route("/create", methods=["post"]) # noqa: F821
|
||||
@login_required
|
||||
@validate_request("name")
|
||||
async def create():
|
||||
req = await request.get_json()
|
||||
req = await get_request_json()
|
||||
search_name = req["name"]
|
||||
description = req.get("description", "")
|
||||
if not isinstance(search_name, str):
|
||||
@ -66,7 +66,7 @@ async def create():
|
||||
@validate_request("search_id", "name", "search_config", "tenant_id")
|
||||
@not_allowed_parameters("id", "created_by", "create_time", "update_time", "create_date", "update_date", "created_by")
|
||||
async def update():
|
||||
req = await request.get_json()
|
||||
req = await get_request_json()
|
||||
if not isinstance(req["name"], str):
|
||||
return get_data_error_result(message="Search name must be string.")
|
||||
if req["name"].strip() == "":
|
||||
@ -150,7 +150,7 @@ async def list_search_app():
|
||||
else:
|
||||
desc = True
|
||||
|
||||
req = await request.get_json()
|
||||
req = await get_request_json()
|
||||
owner_ids = req.get("owner_ids", [])
|
||||
try:
|
||||
if not owner_ids:
|
||||
@ -174,7 +174,7 @@ async def list_search_app():
|
||||
@login_required
|
||||
@validate_request("search_id")
|
||||
async def rm():
|
||||
req = await request.get_json()
|
||||
req = await get_request_json()
|
||||
search_id = req["search_id"]
|
||||
if not SearchService.accessible4deletion(search_id, current_user.id):
|
||||
return get_json_result(data=False, message="No authorization.", code=RetCode.AUTHENTICATION_ERROR)
|
||||
|
||||
@ -14,7 +14,6 @@
|
||||
# limitations under the License.
|
||||
#
|
||||
|
||||
from quart import request
|
||||
from api.db import UserTenantRole
|
||||
from api.db.db_models import UserTenant
|
||||
from api.db.services.user_service import UserTenantService, UserService
|
||||
@ -22,7 +21,7 @@ from api.db.services.user_service import UserTenantService, UserService
|
||||
from common.constants import RetCode, StatusEnum
|
||||
from common.misc_utils import get_uuid
|
||||
from common.time_utils import delta_seconds
|
||||
from api.utils.api_utils import get_json_result, validate_request, server_error_response, get_data_error_result
|
||||
from api.utils.api_utils import get_data_error_result, get_json_result, get_request_json, server_error_response, validate_request
|
||||
from api.utils.web_utils import send_invite_email
|
||||
from common import settings
|
||||
from api.apps import smtp_mail_server, login_required, current_user
|
||||
@ -56,7 +55,7 @@ async def create(tenant_id):
|
||||
message='No authorization.',
|
||||
code=RetCode.AUTHENTICATION_ERROR)
|
||||
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
invite_user_email = req["email"]
|
||||
invite_users = UserService.query(email=invite_user_email)
|
||||
if not invite_users:
|
||||
|
||||
@ -39,6 +39,7 @@ from common.connection_utils import construct_response
|
||||
from api.utils.api_utils import (
|
||||
get_data_error_result,
|
||||
get_json_result,
|
||||
get_request_json,
|
||||
server_error_response,
|
||||
validate_request,
|
||||
)
|
||||
@ -57,6 +58,7 @@ from api.utils.web_utils import (
|
||||
captcha_key,
|
||||
)
|
||||
from common import settings
|
||||
from common.http_client import async_request
|
||||
|
||||
|
||||
@manager.route("/login", methods=["POST", "GET"]) # noqa: F821
|
||||
@ -90,7 +92,7 @@ async def login():
|
||||
schema:
|
||||
type: object
|
||||
"""
|
||||
json_body = await request.json
|
||||
json_body = await get_request_json()
|
||||
if not json_body:
|
||||
return get_json_result(data=False, code=RetCode.AUTHENTICATION_ERROR, message="Unauthorized!")
|
||||
|
||||
@ -121,8 +123,8 @@ async def login():
|
||||
response_data = user.to_json()
|
||||
user.access_token = get_uuid()
|
||||
login_user(user)
|
||||
user.update_time = (current_timestamp(),)
|
||||
user.update_date = (datetime_format(datetime.now()),)
|
||||
user.update_time = current_timestamp()
|
||||
user.update_date = datetime_format(datetime.now())
|
||||
user.save()
|
||||
msg = "Welcome back!"
|
||||
|
||||
@ -136,7 +138,7 @@ async def login():
|
||||
|
||||
|
||||
@manager.route("/login/channels", methods=["GET"]) # noqa: F821
|
||||
def get_login_channels():
|
||||
async def get_login_channels():
|
||||
"""
|
||||
Get all supported authentication channels.
|
||||
"""
|
||||
@ -157,7 +159,7 @@ def get_login_channels():
|
||||
|
||||
|
||||
@manager.route("/login/<channel>", methods=["GET"]) # noqa: F821
|
||||
def oauth_login(channel):
|
||||
async def oauth_login(channel):
|
||||
channel_config = settings.OAUTH_CONFIG.get(channel)
|
||||
if not channel_config:
|
||||
raise ValueError(f"Invalid channel name: {channel}")
|
||||
@ -170,7 +172,7 @@ def oauth_login(channel):
|
||||
|
||||
|
||||
@manager.route("/oauth/callback/<channel>", methods=["GET"]) # noqa: F821
|
||||
def oauth_callback(channel):
|
||||
async def oauth_callback(channel):
|
||||
"""
|
||||
Handle the OAuth/OIDC callback for various channels dynamically.
|
||||
"""
|
||||
@ -192,7 +194,10 @@ def oauth_callback(channel):
|
||||
return redirect("/?error=missing_code")
|
||||
|
||||
# Exchange authorization code for access token
|
||||
token_info = auth_cli.exchange_code_for_token(code)
|
||||
if hasattr(auth_cli, "async_exchange_code_for_token"):
|
||||
token_info = await auth_cli.async_exchange_code_for_token(code)
|
||||
else:
|
||||
token_info = auth_cli.exchange_code_for_token(code)
|
||||
access_token = token_info.get("access_token")
|
||||
if not access_token:
|
||||
return redirect("/?error=token_failed")
|
||||
@ -200,7 +205,10 @@ def oauth_callback(channel):
|
||||
id_token = token_info.get("id_token")
|
||||
|
||||
# Fetch user info
|
||||
user_info = auth_cli.fetch_user_info(access_token, id_token=id_token)
|
||||
if hasattr(auth_cli, "async_fetch_user_info"):
|
||||
user_info = await auth_cli.async_fetch_user_info(access_token, id_token=id_token)
|
||||
else:
|
||||
user_info = auth_cli.fetch_user_info(access_token, id_token=id_token)
|
||||
if not user_info.email:
|
||||
return redirect("/?error=email_missing")
|
||||
|
||||
@ -259,7 +267,7 @@ def oauth_callback(channel):
|
||||
|
||||
|
||||
@manager.route("/github_callback", methods=["GET"]) # noqa: F821
|
||||
def github_callback():
|
||||
async def github_callback():
|
||||
"""
|
||||
**Deprecated**, Use `/oauth/callback/<channel>` instead.
|
||||
|
||||
@ -279,9 +287,8 @@ def github_callback():
|
||||
schema:
|
||||
type: object
|
||||
"""
|
||||
import requests
|
||||
|
||||
res = requests.post(
|
||||
res = await async_request(
|
||||
"POST",
|
||||
settings.GITHUB_OAUTH.get("url"),
|
||||
data={
|
||||
"client_id": settings.GITHUB_OAUTH.get("client_id"),
|
||||
@ -299,7 +306,7 @@ def github_callback():
|
||||
|
||||
session["access_token"] = res["access_token"]
|
||||
session["access_token_from"] = "github"
|
||||
user_info = user_info_from_github(session["access_token"])
|
||||
user_info = await user_info_from_github(session["access_token"])
|
||||
email_address = user_info["email"]
|
||||
users = UserService.query(email=email_address)
|
||||
user_id = get_uuid()
|
||||
@ -348,7 +355,7 @@ def github_callback():
|
||||
|
||||
|
||||
@manager.route("/feishu_callback", methods=["GET"]) # noqa: F821
|
||||
def feishu_callback():
|
||||
async def feishu_callback():
|
||||
"""
|
||||
Feishu OAuth callback endpoint.
|
||||
---
|
||||
@ -366,9 +373,8 @@ def feishu_callback():
|
||||
schema:
|
||||
type: object
|
||||
"""
|
||||
import requests
|
||||
|
||||
app_access_token_res = requests.post(
|
||||
app_access_token_res = await async_request(
|
||||
"POST",
|
||||
settings.FEISHU_OAUTH.get("app_access_token_url"),
|
||||
data=json.dumps(
|
||||
{
|
||||
@ -382,7 +388,8 @@ def feishu_callback():
|
||||
if app_access_token_res["code"] != 0:
|
||||
return redirect("/?error=%s" % app_access_token_res)
|
||||
|
||||
res = requests.post(
|
||||
res = await async_request(
|
||||
"POST",
|
||||
settings.FEISHU_OAUTH.get("user_access_token_url"),
|
||||
data=json.dumps(
|
||||
{
|
||||
@ -403,7 +410,7 @@ def feishu_callback():
|
||||
return redirect("/?error=contact:user.email:readonly not in scope")
|
||||
session["access_token"] = res["data"]["access_token"]
|
||||
session["access_token_from"] = "feishu"
|
||||
user_info = user_info_from_feishu(session["access_token"])
|
||||
user_info = await user_info_from_feishu(session["access_token"])
|
||||
email_address = user_info["email"]
|
||||
users = UserService.query(email=email_address)
|
||||
user_id = get_uuid()
|
||||
@ -451,36 +458,34 @@ def feishu_callback():
|
||||
return redirect("/?auth=%s" % user.get_id())
|
||||
|
||||
|
||||
def user_info_from_feishu(access_token):
|
||||
import requests
|
||||
|
||||
async def user_info_from_feishu(access_token):
|
||||
headers = {
|
||||
"Content-Type": "application/json; charset=utf-8",
|
||||
"Authorization": f"Bearer {access_token}",
|
||||
}
|
||||
res = requests.get("https://open.feishu.cn/open-apis/authen/v1/user_info", headers=headers)
|
||||
res = await async_request("GET", "https://open.feishu.cn/open-apis/authen/v1/user_info", headers=headers)
|
||||
user_info = res.json()["data"]
|
||||
user_info["email"] = None if user_info.get("email") == "" else user_info["email"]
|
||||
return user_info
|
||||
|
||||
|
||||
def user_info_from_github(access_token):
|
||||
import requests
|
||||
|
||||
async def user_info_from_github(access_token):
|
||||
headers = {"Accept": "application/json", "Authorization": f"token {access_token}"}
|
||||
res = requests.get(f"https://api.github.com/user?access_token={access_token}", headers=headers)
|
||||
res = await async_request("GET", f"https://api.github.com/user?access_token={access_token}", headers=headers)
|
||||
user_info = res.json()
|
||||
email_info = requests.get(
|
||||
email_info_response = await async_request(
|
||||
"GET",
|
||||
f"https://api.github.com/user/emails?access_token={access_token}",
|
||||
headers=headers,
|
||||
).json()
|
||||
)
|
||||
email_info = email_info_response.json()
|
||||
user_info["email"] = next((email for email in email_info if email["primary"]), None)["email"]
|
||||
return user_info
|
||||
|
||||
|
||||
@manager.route("/logout", methods=["GET"]) # noqa: F821
|
||||
@login_required
|
||||
def log_out():
|
||||
async def log_out():
|
||||
"""
|
||||
User logout endpoint.
|
||||
---
|
||||
@ -531,7 +536,7 @@ async def setting_user():
|
||||
type: object
|
||||
"""
|
||||
update_dict = {}
|
||||
request_data = await request.json
|
||||
request_data = await get_request_json()
|
||||
if request_data.get("password"):
|
||||
new_password = request_data.get("new_password")
|
||||
if not check_password_hash(current_user.password, decrypt(request_data["password"])):
|
||||
@ -570,7 +575,7 @@ async def setting_user():
|
||||
|
||||
@manager.route("/info", methods=["GET"]) # noqa: F821
|
||||
@login_required
|
||||
def user_profile():
|
||||
async def user_profile():
|
||||
"""
|
||||
Get user profile information.
|
||||
---
|
||||
@ -698,7 +703,7 @@ async def user_add():
|
||||
code=RetCode.OPERATING_ERROR,
|
||||
)
|
||||
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
email_address = req["email"]
|
||||
|
||||
# Validate the email address
|
||||
@ -755,7 +760,7 @@ async def user_add():
|
||||
|
||||
@manager.route("/tenant_info", methods=["GET"]) # noqa: F821
|
||||
@login_required
|
||||
def tenant_info():
|
||||
async def tenant_info():
|
||||
"""
|
||||
Get tenant information.
|
||||
---
|
||||
@ -831,14 +836,14 @@ async def set_tenant_info():
|
||||
schema:
|
||||
type: object
|
||||
"""
|
||||
req = await request.json
|
||||
req = await get_request_json()
|
||||
try:
|
||||
tid = req.pop("tenant_id")
|
||||
TenantService.update_by_id(tid, req)
|
||||
return get_json_result(data=True)
|
||||
except Exception as e:
|
||||
return server_error_response(e)
|
||||
|
||||
|
||||
|
||||
@manager.route("/forget/captcha", methods=["GET"]) # noqa: F821
|
||||
async def forget_get_captcha():
|
||||
@ -875,7 +880,7 @@ async def forget_send_otp():
|
||||
- Verify the image captcha stored at captcha:{email} (case-insensitive).
|
||||
- On success, generate an email OTP (A–Z with length = OTP_LENGTH), store hash + salt (and timestamp) in Redis with TTL, reset attempts and cooldown, and send the OTP via email.
|
||||
"""
|
||||
req = await request.get_json()
|
||||
req = await get_request_json()
|
||||
email = req.get("email") or ""
|
||||
captcha = (req.get("captcha") or "").strip()
|
||||
|
||||
@ -931,7 +936,7 @@ async def forget_send_otp():
|
||||
)
|
||||
except Exception:
|
||||
return get_json_result(data=False, code=RetCode.SERVER_ERROR, message="failed to send email")
|
||||
|
||||
|
||||
return get_json_result(data=True, code=RetCode.SUCCESS, message="verification passed, email sent")
|
||||
|
||||
|
||||
@ -941,7 +946,7 @@ async def forget():
|
||||
POST: Verify email + OTP and reset password, then log the user in.
|
||||
Request JSON: { email, otp, new_password, confirm_new_password }
|
||||
"""
|
||||
req = await request.get_json()
|
||||
req = await get_request_json()
|
||||
email = req.get("email") or ""
|
||||
otp = (req.get("otp") or "").strip()
|
||||
new_pwd = req.get("new_password")
|
||||
@ -1002,8 +1007,8 @@ async def forget():
|
||||
# Auto login (reuse login flow)
|
||||
user.access_token = get_uuid()
|
||||
login_user(user)
|
||||
user.update_time = (current_timestamp(),)
|
||||
user.update_date = (datetime_format(datetime.now()),)
|
||||
user.update_time = current_timestamp()
|
||||
user.update_date = datetime_format(datetime.now())
|
||||
user.save()
|
||||
msg = "Password reset successful. Logged in."
|
||||
return construct_response(data=user.to_json(), auth=user.get_id(), message=msg)
|
||||
return await construct_response(data=user.to_json(), auth=user.get_id(), message=msg)
|
||||
|
||||
@ -749,7 +749,7 @@ class Knowledgebase(DataBaseModel):
|
||||
|
||||
parser_id = CharField(max_length=32, null=False, help_text="default parser ID", default=ParserType.NAIVE.value, index=True)
|
||||
pipeline_id = CharField(max_length=32, null=True, help_text="Pipeline ID", index=True)
|
||||
parser_config = JSONField(null=False, default={"pages": [[1, 1000000]]})
|
||||
parser_config = JSONField(null=False, default={"pages": [[1, 1000000]], "table_context_size": 0, "image_context_size": 0})
|
||||
pagerank = IntegerField(default=0, index=False)
|
||||
|
||||
graphrag_task_id = CharField(max_length=32, null=True, help_text="Graph RAG task ID", index=True)
|
||||
@ -774,7 +774,7 @@ class Document(DataBaseModel):
|
||||
kb_id = CharField(max_length=256, null=False, index=True)
|
||||
parser_id = CharField(max_length=32, null=False, help_text="default parser ID", index=True)
|
||||
pipeline_id = CharField(max_length=32, null=True, help_text="pipeline ID", index=True)
|
||||
parser_config = JSONField(null=False, default={"pages": [[1, 1000000]]})
|
||||
parser_config = JSONField(null=False, default={"pages": [[1, 1000000]], "table_context_size": 0, "image_context_size": 0})
|
||||
source_type = CharField(max_length=128, null=False, default="local", help_text="where dose this document come from", index=True)
|
||||
type = CharField(max_length=32, null=False, help_text="file extension", index=True)
|
||||
created_by = CharField(max_length=32, null=False, help_text="who created it", index=True)
|
||||
|
||||
@ -34,14 +34,17 @@ from common.file_utils import get_project_base_directory
|
||||
from common import settings
|
||||
from api.common.base64 import encode_to_base64
|
||||
|
||||
DEFAULT_SUPERUSER_NICKNAME = os.getenv("DEFAULT_SUPERUSER_NICKNAME", "admin")
|
||||
DEFAULT_SUPERUSER_EMAIL = os.getenv("DEFAULT_SUPERUSER_EMAIL", "admin@ragflow.io")
|
||||
DEFAULT_SUPERUSER_PASSWORD = os.getenv("DEFAULT_SUPERUSER_PASSWORD", "admin")
|
||||
|
||||
def init_superuser():
|
||||
def init_superuser(nickname=DEFAULT_SUPERUSER_NICKNAME, email=DEFAULT_SUPERUSER_EMAIL, password=DEFAULT_SUPERUSER_PASSWORD, role=UserTenantRole.OWNER):
|
||||
user_info = {
|
||||
"id": uuid.uuid1().hex,
|
||||
"password": encode_to_base64("admin"),
|
||||
"nickname": "admin",
|
||||
"password": encode_to_base64(password),
|
||||
"nickname": nickname,
|
||||
"is_superuser": True,
|
||||
"email": "admin@ragflow.io",
|
||||
"email": email,
|
||||
"creator": "system",
|
||||
"status": "1",
|
||||
}
|
||||
@ -58,7 +61,7 @@ def init_superuser():
|
||||
"tenant_id": user_info["id"],
|
||||
"user_id": user_info["id"],
|
||||
"invited_by": user_info["id"],
|
||||
"role": UserTenantRole.OWNER
|
||||
"role": role
|
||||
}
|
||||
|
||||
tenant_llm = get_init_tenant_llm(user_info["id"])
|
||||
@ -70,7 +73,7 @@ def init_superuser():
|
||||
UserTenantService.insert(**usr_tenant)
|
||||
TenantLLMService.insert_many(tenant_llm)
|
||||
logging.info(
|
||||
"Super user initialized. email: admin@ragflow.io, password: admin. Changing the password after login is strongly recommended.")
|
||||
f"Super user initialized. email: {email}, password: {password}. Changing the password after login is strongly recommended.")
|
||||
|
||||
chat_mdl = LLMBundle(tenant["id"], LLMType.CHAT, tenant["llm_id"])
|
||||
msg = chat_mdl.chat(system="", history=[
|
||||
|
||||
@ -214,9 +214,21 @@ class SyncLogsService(CommonService):
|
||||
err, doc_blob_pairs = FileService.upload_document(kb, files, tenant_id, src)
|
||||
errs.extend(err)
|
||||
|
||||
# Create a mapping from filename to metadata for later use
|
||||
metadata_map = {}
|
||||
for d in docs:
|
||||
if d.get("metadata"):
|
||||
filename = d["semantic_identifier"]+(f"{d['extension']}" if d["semantic_identifier"][::-1].find(d['extension'][::-1])<0 else "")
|
||||
metadata_map[filename] = d["metadata"]
|
||||
|
||||
kb_table_num_map = {}
|
||||
for doc, _ in doc_blob_pairs:
|
||||
doc_ids.append(doc["id"])
|
||||
|
||||
# Set metadata if available for this document
|
||||
if doc["name"] in metadata_map:
|
||||
DocumentService.update_by_id(doc["id"], {"meta_fields": metadata_map[doc["name"]]})
|
||||
|
||||
if not auto_parse or auto_parse == "0":
|
||||
continue
|
||||
DocumentService.run(tenant_id, doc, kb_table_num_map)
|
||||
|
||||
@ -25,6 +25,7 @@ import trio
|
||||
from langfuse import Langfuse
|
||||
from peewee import fn
|
||||
from agentic_reasoning import DeepResearcher
|
||||
from api.db.services.file_service import FileService
|
||||
from common.constants import LLMType, ParserType, StatusEnum
|
||||
from api.db.db_models import DB, Dialog
|
||||
from api.db.services.common_service import CommonService
|
||||
@ -178,6 +179,9 @@ class DialogService(CommonService):
|
||||
return res
|
||||
|
||||
def chat_solo(dialog, messages, stream=True):
|
||||
attachments = ""
|
||||
if "files" in messages[-1]:
|
||||
attachments = "\n\n".join(FileService.get_files(messages[-1]["files"]))
|
||||
if TenantLLMService.llm_id2llm_type(dialog.llm_id) == "image2text":
|
||||
chat_mdl = LLMBundle(dialog.tenant_id, LLMType.IMAGE2TEXT, dialog.llm_id)
|
||||
else:
|
||||
@ -188,6 +192,8 @@ def chat_solo(dialog, messages, stream=True):
|
||||
if prompt_config.get("tts"):
|
||||
tts_mdl = LLMBundle(dialog.tenant_id, LLMType.TTS)
|
||||
msg = [{"role": m["role"], "content": re.sub(r"##\d+\$\$", "", m["content"])} for m in messages if m["role"] != "system"]
|
||||
if attachments and msg:
|
||||
msg[-1]["content"] += attachments
|
||||
if stream:
|
||||
last_ans = ""
|
||||
delta_ans = ""
|
||||
@ -304,6 +310,8 @@ def meta_filter(metas: dict, filters: list[dict], logic: str = "and"):
|
||||
for conds in [
|
||||
(operator == "contains", str(value).lower() in str(input).lower()),
|
||||
(operator == "not contains", str(value).lower() not in str(input).lower()),
|
||||
(operator == "in", str(input).lower() in str(value).lower()),
|
||||
(operator == "not in", str(input).lower() not in str(value).lower()),
|
||||
(operator == "start with", str(input).lower().startswith(str(value).lower())),
|
||||
(operator == "end with", str(input).lower().endswith(str(value).lower())),
|
||||
(operator == "empty", not input),
|
||||
@ -378,8 +386,11 @@ def chat(dialog, messages, stream=True, **kwargs):
|
||||
retriever = settings.retriever
|
||||
questions = [m["content"] for m in messages if m["role"] == "user"][-3:]
|
||||
attachments = kwargs["doc_ids"].split(",") if "doc_ids" in kwargs else []
|
||||
attachments_= ""
|
||||
if "doc_ids" in messages[-1]:
|
||||
attachments = messages[-1]["doc_ids"]
|
||||
if "files" in messages[-1]:
|
||||
attachments_ = "\n\n".join(FileService.get_files(messages[-1]["files"]))
|
||||
|
||||
prompt_config = dialog.prompt_config
|
||||
field_map = KnowledgebaseService.get_field_map(dialog.kb_ids)
|
||||
@ -449,7 +460,7 @@ def chat(dialog, messages, stream=True, **kwargs):
|
||||
),
|
||||
)
|
||||
|
||||
for think in reasoner.thinking(kbinfos, " ".join(questions)):
|
||||
for think in reasoner.thinking(kbinfos, attachments_ + " ".join(questions)):
|
||||
if isinstance(think, str):
|
||||
thought = think
|
||||
knowledges = [t for t in think.split("\n") if t]
|
||||
@ -476,6 +487,7 @@ def chat(dialog, messages, stream=True, **kwargs):
|
||||
cks = retriever.retrieval_by_toc(" ".join(questions), kbinfos["chunks"], tenant_ids, chat_mdl, dialog.top_n)
|
||||
if cks:
|
||||
kbinfos["chunks"] = cks
|
||||
kbinfos["chunks"] = retriever.retrieval_by_children(kbinfos["chunks"], tenant_ids)
|
||||
if prompt_config.get("tavily_api_key"):
|
||||
tav = Tavily(prompt_config["tavily_api_key"])
|
||||
tav_res = tav.retrieve_chunks(" ".join(questions))
|
||||
@ -501,7 +513,7 @@ def chat(dialog, messages, stream=True, **kwargs):
|
||||
kwargs["knowledge"] = "\n------\n" + "\n\n------\n\n".join(knowledges)
|
||||
gen_conf = dialog.llm_setting
|
||||
|
||||
msg = [{"role": "system", "content": prompt_config["system"].format(**kwargs)}]
|
||||
msg = [{"role": "system", "content": prompt_config["system"].format(**kwargs)+attachments_}]
|
||||
prompt4citation = ""
|
||||
if knowledges and (prompt_config.get("quote", True) and kwargs.get("quote", True)):
|
||||
prompt4citation = citation_prompt()
|
||||
@ -670,7 +682,11 @@ Please write the SQL, only SQL, without any other explanations or text.
|
||||
if kb_ids:
|
||||
kb_filter = "(" + " OR ".join([f"kb_id = '{kb_id}'" for kb_id in kb_ids]) + ")"
|
||||
if "where" not in sql.lower():
|
||||
sql += f" WHERE {kb_filter}"
|
||||
o = sql.lower().split("order by")
|
||||
if len(o) > 1:
|
||||
sql = o[0] + f" WHERE {kb_filter} order by " + o[1]
|
||||
else:
|
||||
sql += f" WHERE {kb_filter}"
|
||||
else:
|
||||
sql += f" AND {kb_filter}"
|
||||
|
||||
@ -678,10 +694,9 @@ Please write the SQL, only SQL, without any other explanations or text.
|
||||
tried_times += 1
|
||||
return settings.retriever.sql_retrieval(sql, format="json"), sql
|
||||
|
||||
tbl, sql = get_table()
|
||||
if tbl is None:
|
||||
return None
|
||||
if tbl.get("error") and tried_times <= 2:
|
||||
try:
|
||||
tbl, sql = get_table()
|
||||
except Exception as e:
|
||||
user_prompt = """
|
||||
Table name: {};
|
||||
Table of database fields are as follows:
|
||||
@ -695,16 +710,14 @@ Please write the SQL, only SQL, without any other explanations or text.
|
||||
The SQL error you provided last time is as follows:
|
||||
{}
|
||||
|
||||
Error issued by database as follows:
|
||||
{}
|
||||
|
||||
Please correct the error and write SQL again, only SQL, without any other explanations or text.
|
||||
""".format(index_name(tenant_id), "\n".join([f"{k}: {v}" for k, v in field_map.items()]), question, sql, tbl["error"])
|
||||
tbl, sql = get_table()
|
||||
logging.debug("TRY it again: {}".format(sql))
|
||||
""".format(index_name(tenant_id), "\n".join([f"{k}: {v}" for k, v in field_map.items()]), question, e)
|
||||
try:
|
||||
tbl, sql = get_table()
|
||||
except Exception:
|
||||
return
|
||||
|
||||
logging.debug("GET table: {}".format(tbl))
|
||||
if tbl.get("error") or len(tbl["rows"]) == 0:
|
||||
if len(tbl["rows"]) == 0:
|
||||
return None
|
||||
|
||||
docid_idx = set([ii for ii, c in enumerate(tbl["columns"]) if c["name"] == "doc_id"])
|
||||
|
||||
@ -923,7 +923,7 @@ def doc_upload_and_parse(conversation_id, file_objs, user_id):
|
||||
ParserType.AUDIO.value: audio,
|
||||
ParserType.EMAIL.value: email
|
||||
}
|
||||
parser_config = {"chunk_token_num": 4096, "delimiter": "\n!?;。;!?", "layout_recognize": "Plain Text"}
|
||||
parser_config = {"chunk_token_num": 4096, "delimiter": "\n!?;。;!?", "layout_recognize": "Plain Text", "table_context_size": 0, "image_context_size": 0}
|
||||
exe = ThreadPoolExecutor(max_workers=12)
|
||||
threads = []
|
||||
doc_nm = {}
|
||||
|
||||
@ -13,10 +13,15 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
import asyncio
|
||||
import base64
|
||||
import logging
|
||||
import re
|
||||
import sys
|
||||
import time
|
||||
from concurrent.futures import ThreadPoolExecutor
|
||||
from pathlib import Path
|
||||
from typing import Union
|
||||
|
||||
from peewee import fn
|
||||
|
||||
@ -520,7 +525,7 @@ class FileService(CommonService):
|
||||
if img_base64 and file_type == FileType.VISUAL.value:
|
||||
return GptV4.image2base64(blob)
|
||||
cks = FACTORY.get(FileService.get_parser(filename_type(filename), filename, ""), naive).chunk(filename, blob, **kwargs)
|
||||
return "\n".join([ck["content_with_weight"] for ck in cks])
|
||||
return f"\n -----------------\nFile: {filename}\nContent as following: \n" + "\n".join([ck["content_with_weight"] for ck in cks])
|
||||
|
||||
@staticmethod
|
||||
def get_parser(doc_type, filename, default):
|
||||
@ -588,3 +593,80 @@ class FileService(CommonService):
|
||||
errors += str(e)
|
||||
|
||||
return errors
|
||||
|
||||
@staticmethod
|
||||
def upload_info(user_id, file, url: str|None=None):
|
||||
def structured(filename, filetype, blob, content_type):
|
||||
nonlocal user_id
|
||||
if filetype == FileType.PDF.value:
|
||||
blob = read_potential_broken_pdf(blob)
|
||||
|
||||
location = get_uuid()
|
||||
FileService.put_blob(user_id, location, blob)
|
||||
|
||||
return {
|
||||
"id": location,
|
||||
"name": filename,
|
||||
"size": sys.getsizeof(blob),
|
||||
"extension": filename.split(".")[-1].lower(),
|
||||
"mime_type": content_type,
|
||||
"created_by": user_id,
|
||||
"created_at": time.time(),
|
||||
"preview_url": None
|
||||
}
|
||||
|
||||
if url:
|
||||
from crawl4ai import (
|
||||
AsyncWebCrawler,
|
||||
BrowserConfig,
|
||||
CrawlerRunConfig,
|
||||
DefaultMarkdownGenerator,
|
||||
PruningContentFilter,
|
||||
CrawlResult
|
||||
)
|
||||
filename = re.sub(r"\?.*", "", url.split("/")[-1])
|
||||
async def adownload():
|
||||
browser_config = BrowserConfig(
|
||||
headless=True,
|
||||
verbose=False,
|
||||
)
|
||||
async with AsyncWebCrawler(config=browser_config) as crawler:
|
||||
crawler_config = CrawlerRunConfig(
|
||||
markdown_generator=DefaultMarkdownGenerator(
|
||||
content_filter=PruningContentFilter()
|
||||
),
|
||||
pdf=True,
|
||||
screenshot=False
|
||||
)
|
||||
result: CrawlResult = await crawler.arun(
|
||||
url=url,
|
||||
config=crawler_config
|
||||
)
|
||||
return result
|
||||
page = asyncio.run(adownload())
|
||||
if page.pdf:
|
||||
if filename.split(".")[-1].lower() != "pdf":
|
||||
filename += ".pdf"
|
||||
return structured(filename, "pdf", page.pdf, page.response_headers["content-type"])
|
||||
|
||||
return structured(filename, "html", str(page.markdown).encode("utf-8"), page.response_headers["content-type"], user_id)
|
||||
|
||||
DocumentService.check_doc_health(user_id, file.filename)
|
||||
return structured(file.filename, filename_type(file.filename), file.read(), file.content_type)
|
||||
|
||||
@staticmethod
|
||||
def get_files(files: Union[None, list[dict]]) -> list[str]:
|
||||
if not files:
|
||||
return []
|
||||
def image_to_base64(file):
|
||||
return "data:{};base64,{}".format(file["mime_type"],
|
||||
base64.b64encode(FileService.get_blob(file["created_by"], file["id"])).decode("utf-8"))
|
||||
exe = ThreadPoolExecutor(max_workers=5)
|
||||
threads = []
|
||||
for file in files:
|
||||
if file["mime_type"].find("image") >=0:
|
||||
threads.append(exe.submit(image_to_base64, file))
|
||||
continue
|
||||
threads.append(exe.submit(FileService.parse, file["name"], FileService.get_blob(file["created_by"], file["id"]), True, file["created_by"]))
|
||||
return [th.result() for th in threads]
|
||||
|
||||
|
||||
@ -13,9 +13,11 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
import asyncio
|
||||
import inspect
|
||||
import logging
|
||||
import re
|
||||
import threading
|
||||
from common.token_utils import num_tokens_from_string
|
||||
from functools import partial
|
||||
from typing import Generator
|
||||
@ -183,6 +185,66 @@ class LLMBundle(LLM4Tenant):
|
||||
|
||||
return txt
|
||||
|
||||
def stream_transcription(self, audio):
|
||||
mdl = self.mdl
|
||||
supports_stream = hasattr(mdl, "stream_transcription") and callable(getattr(mdl, "stream_transcription"))
|
||||
if supports_stream:
|
||||
if self.langfuse:
|
||||
generation = self.langfuse.start_generation(
|
||||
trace_context=self.trace_context,
|
||||
name="stream_transcription",
|
||||
metadata={"model": self.llm_name}
|
||||
)
|
||||
final_text = ""
|
||||
used_tokens = 0
|
||||
|
||||
try:
|
||||
for evt in mdl.stream_transcription(audio):
|
||||
if evt.get("event") == "final":
|
||||
final_text = evt.get("text", "")
|
||||
|
||||
yield evt
|
||||
|
||||
except Exception as e:
|
||||
err = {"event": "error", "text": str(e)}
|
||||
yield err
|
||||
final_text = final_text or ""
|
||||
finally:
|
||||
if final_text:
|
||||
used_tokens = num_tokens_from_string(final_text)
|
||||
TenantLLMService.increase_usage(self.tenant_id, self.llm_type, used_tokens)
|
||||
|
||||
if self.langfuse:
|
||||
generation.update(
|
||||
output={"output": final_text},
|
||||
usage_details={"total_tokens": used_tokens}
|
||||
)
|
||||
generation.end()
|
||||
|
||||
return
|
||||
|
||||
if self.langfuse:
|
||||
generation = self.langfuse.start_generation(trace_context=self.trace_context, name="stream_transcription", metadata={"model": self.llm_name})
|
||||
full_text, used_tokens = mdl.transcription(audio)
|
||||
if not TenantLLMService.increase_usage(
|
||||
self.tenant_id, self.llm_type, used_tokens
|
||||
):
|
||||
logging.error(
|
||||
f"LLMBundle.stream_transcription can't update token usage for {self.tenant_id}/SEQUENCE2TXT used_tokens: {used_tokens}"
|
||||
)
|
||||
if self.langfuse:
|
||||
generation.update(
|
||||
output={"output": full_text},
|
||||
usage_details={"total_tokens": used_tokens}
|
||||
)
|
||||
generation.end()
|
||||
|
||||
yield {
|
||||
"event": "final",
|
||||
"text": full_text,
|
||||
"streaming": False
|
||||
}
|
||||
|
||||
def tts(self, text: str) -> Generator[bytes, None, None]:
|
||||
if self.langfuse:
|
||||
generation = self.langfuse.start_generation(trace_context=self.trace_context, name="tts", input={"text": text})
|
||||
@ -242,7 +304,7 @@ class LLMBundle(LLM4Tenant):
|
||||
if not self.verbose_tool_use:
|
||||
txt = re.sub(r"<tool_call>.*?</tool_call>", "", txt, flags=re.DOTALL)
|
||||
|
||||
if isinstance(txt, int) and not TenantLLMService.increase_usage(self.tenant_id, self.llm_type, used_tokens, self.llm_name):
|
||||
if used_tokens and not TenantLLMService.increase_usage(self.tenant_id, self.llm_type, used_tokens, self.llm_name):
|
||||
logging.error("LLMBundle.chat can't update token usage for {}/CHAT llm_name: {}, used_tokens: {}".format(self.tenant_id, self.llm_name, used_tokens))
|
||||
|
||||
if self.langfuse:
|
||||
@ -279,5 +341,80 @@ class LLMBundle(LLM4Tenant):
|
||||
yield ans
|
||||
|
||||
if total_tokens > 0:
|
||||
if not TenantLLMService.increase_usage(self.tenant_id, self.llm_type, txt, self.llm_name):
|
||||
logging.error("LLMBundle.chat_streamly can't update token usage for {}/CHAT llm_name: {}, content: {}".format(self.tenant_id, self.llm_name, txt))
|
||||
if not TenantLLMService.increase_usage(self.tenant_id, self.llm_type, total_tokens, self.llm_name):
|
||||
logging.error("LLMBundle.chat_streamly can't update token usage for {}/CHAT llm_name: {}, used_tokens: {}".format(self.tenant_id, self.llm_name, total_tokens))
|
||||
|
||||
def _bridge_sync_stream(self, gen):
|
||||
loop = asyncio.get_running_loop()
|
||||
queue: asyncio.Queue = asyncio.Queue()
|
||||
|
||||
def worker():
|
||||
try:
|
||||
for item in gen:
|
||||
loop.call_soon_threadsafe(queue.put_nowait, item)
|
||||
except Exception as e: # pragma: no cover
|
||||
loop.call_soon_threadsafe(queue.put_nowait, e)
|
||||
finally:
|
||||
loop.call_soon_threadsafe(queue.put_nowait, StopAsyncIteration)
|
||||
|
||||
threading.Thread(target=worker, daemon=True).start()
|
||||
return queue
|
||||
|
||||
async def async_chat(self, system: str, history: list, gen_conf: dict = {}, **kwargs):
|
||||
chat_partial = partial(self.mdl.chat, system, history, gen_conf, **kwargs)
|
||||
if self.is_tools and self.mdl.is_tools and hasattr(self.mdl, "chat_with_tools"):
|
||||
chat_partial = partial(self.mdl.chat_with_tools, system, history, gen_conf, **kwargs)
|
||||
|
||||
use_kwargs = self._clean_param(chat_partial, **kwargs)
|
||||
|
||||
if hasattr(self.mdl, "async_chat_with_tools") and self.is_tools and self.mdl.is_tools:
|
||||
txt, used_tokens = await self.mdl.async_chat_with_tools(system, history, gen_conf, **use_kwargs)
|
||||
elif hasattr(self.mdl, "async_chat"):
|
||||
txt, used_tokens = await self.mdl.async_chat(system, history, gen_conf, **use_kwargs)
|
||||
else:
|
||||
txt, used_tokens = await asyncio.to_thread(chat_partial, **use_kwargs)
|
||||
|
||||
txt = self._remove_reasoning_content(txt)
|
||||
if not self.verbose_tool_use:
|
||||
txt = re.sub(r"<tool_call>.*?</tool_call>", "", txt, flags=re.DOTALL)
|
||||
|
||||
if used_tokens and not TenantLLMService.increase_usage(self.tenant_id, self.llm_type, used_tokens, self.llm_name):
|
||||
logging.error("LLMBundle.async_chat can't update token usage for {}/CHAT llm_name: {}, used_tokens: {}".format(self.tenant_id, self.llm_name, used_tokens))
|
||||
|
||||
return txt
|
||||
|
||||
async def async_chat_streamly(self, system: str, history: list, gen_conf: dict = {}, **kwargs):
|
||||
total_tokens = 0
|
||||
if self.is_tools and self.mdl.is_tools:
|
||||
stream_fn = getattr(self.mdl, "async_chat_streamly_with_tools", None)
|
||||
else:
|
||||
stream_fn = getattr(self.mdl, "async_chat_streamly", None)
|
||||
|
||||
if stream_fn:
|
||||
chat_partial = partial(stream_fn, system, history, gen_conf)
|
||||
use_kwargs = self._clean_param(chat_partial, **kwargs)
|
||||
async for txt in chat_partial(**use_kwargs):
|
||||
if isinstance(txt, int):
|
||||
total_tokens = txt
|
||||
break
|
||||
yield txt
|
||||
if total_tokens and not TenantLLMService.increase_usage(self.tenant_id, self.llm_type, total_tokens, self.llm_name):
|
||||
logging.error("LLMBundle.async_chat_streamly can't update token usage for {}/CHAT llm_name: {}, used_tokens: {}".format(self.tenant_id, self.llm_name, total_tokens))
|
||||
return
|
||||
|
||||
chat_partial = partial(self.mdl.chat_streamly_with_tools if (self.is_tools and self.mdl.is_tools) else self.mdl.chat_streamly, system, history, gen_conf)
|
||||
use_kwargs = self._clean_param(chat_partial, **kwargs)
|
||||
queue = self._bridge_sync_stream(chat_partial(**use_kwargs))
|
||||
while True:
|
||||
item = await queue.get()
|
||||
if item is StopAsyncIteration:
|
||||
break
|
||||
if isinstance(item, Exception):
|
||||
raise item
|
||||
if isinstance(item, int):
|
||||
total_tokens = item
|
||||
break
|
||||
yield item
|
||||
|
||||
if total_tokens and not TenantLLMService.increase_usage(self.tenant_id, self.llm_type, total_tokens, self.llm_name):
|
||||
logging.error("LLMBundle.async_chat_streamly can't update token usage for {}/CHAT llm_name: {}, used_tokens: {}".format(self.tenant_id, self.llm_name, total_tokens))
|
||||
|
||||
@ -20,16 +20,15 @@
|
||||
|
||||
from common.log_utils import init_root_logger
|
||||
from plugin import GlobalPluginManager
|
||||
init_root_logger("ragflow_server")
|
||||
|
||||
import logging
|
||||
import os
|
||||
import signal
|
||||
import sys
|
||||
import time
|
||||
import traceback
|
||||
import threading
|
||||
import uuid
|
||||
import faulthandler
|
||||
|
||||
from api.apps import app, smtp_mail_server
|
||||
from api.db.runtime_config import RuntimeConfig
|
||||
@ -37,7 +36,7 @@ from api.db.services.document_service import DocumentService
|
||||
from common.file_utils import get_project_base_directory
|
||||
from common import settings
|
||||
from api.db.db_models import init_database_tables as init_web_db
|
||||
from api.db.init_data import init_web_data
|
||||
from api.db.init_data import init_web_data, init_superuser
|
||||
from common.versions import get_ragflow_version
|
||||
from common.config_utils import show_configs
|
||||
from common.mcp_tool_call_conn import shutdown_all_mcp_sessions
|
||||
@ -69,10 +68,12 @@ def signal_handler(sig, frame):
|
||||
logging.info("Received interrupt signal, shutting down...")
|
||||
shutdown_all_mcp_sessions()
|
||||
stop_event.set()
|
||||
time.sleep(1)
|
||||
stop_event.wait(1)
|
||||
sys.exit(0)
|
||||
|
||||
if __name__ == '__main__':
|
||||
faulthandler.enable()
|
||||
init_root_logger("ragflow_server")
|
||||
logging.info(r"""
|
||||
____ ___ ______ ______ __
|
||||
/ __ \ / | / ____// ____// /____ _ __
|
||||
@ -109,11 +110,16 @@ if __name__ == '__main__':
|
||||
parser.add_argument(
|
||||
"--debug", default=False, help="debug mode", action="store_true"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--init-superuser", default=False, help="init superuser", action="store_true"
|
||||
)
|
||||
args = parser.parse_args()
|
||||
if args.version:
|
||||
print(get_ragflow_version())
|
||||
sys.exit(0)
|
||||
|
||||
if args.init_superuser:
|
||||
init_superuser()
|
||||
RuntimeConfig.DEBUG = args.debug
|
||||
if RuntimeConfig.DEBUG:
|
||||
logging.info("run on debug mode")
|
||||
@ -156,5 +162,5 @@ if __name__ == '__main__':
|
||||
except Exception:
|
||||
traceback.print_exc()
|
||||
stop_event.set()
|
||||
time.sleep(1)
|
||||
stop_event.wait(1)
|
||||
os.kill(os.getpid(), signal.SIGKILL)
|
||||
|
||||
@ -22,6 +22,7 @@ import os
|
||||
import time
|
||||
from copy import deepcopy
|
||||
from functools import wraps
|
||||
from typing import Any
|
||||
|
||||
import requests
|
||||
import trio
|
||||
@ -45,11 +46,40 @@ from common import settings
|
||||
requests.models.complexjson.dumps = functools.partial(json.dumps, cls=CustomJSONEncoder)
|
||||
|
||||
|
||||
async def request_json():
|
||||
async def _coerce_request_data() -> dict:
|
||||
"""Fetch JSON body with sane defaults; fallback to form data."""
|
||||
payload: Any = None
|
||||
last_error: Exception | None = None
|
||||
|
||||
try:
|
||||
return await request.json
|
||||
except Exception:
|
||||
return {}
|
||||
payload = await request.get_json(force=True, silent=True)
|
||||
except Exception as e:
|
||||
last_error = e
|
||||
payload = None
|
||||
|
||||
if payload is None:
|
||||
try:
|
||||
form = await request.form
|
||||
payload = form.to_dict()
|
||||
except Exception as e:
|
||||
last_error = e
|
||||
payload = None
|
||||
|
||||
if payload is None:
|
||||
if last_error is not None:
|
||||
raise last_error
|
||||
raise ValueError("No JSON body or form data found in request.")
|
||||
|
||||
if isinstance(payload, dict):
|
||||
return payload or {}
|
||||
|
||||
if isinstance(payload, str):
|
||||
raise AttributeError("'str' object has no attribute 'get'")
|
||||
|
||||
raise TypeError(f"Unsupported request payload type: {type(payload)!r}")
|
||||
|
||||
async def get_request_json():
|
||||
return await _coerce_request_data()
|
||||
|
||||
def serialize_for_json(obj):
|
||||
"""
|
||||
@ -89,7 +119,8 @@ def get_data_error_result(code=RetCode.DATA_ERROR, message="Sorry! Data missing!
|
||||
|
||||
|
||||
def server_error_response(e):
|
||||
logging.exception(e)
|
||||
# Quart invokes this handler outside the original except block, so we must pass exc_info manually.
|
||||
logging.error("Unhandled exception during request", exc_info=(type(e), e, e.__traceback__))
|
||||
try:
|
||||
msg = repr(e).lower()
|
||||
if getattr(e, "code", None) == 401 or ("unauthorized" in msg) or ("401" in msg):
|
||||
@ -136,7 +167,7 @@ def validate_request(*args, **kwargs):
|
||||
def wrapper(func):
|
||||
@wraps(func)
|
||||
async def decorated_function(*_args, **_kwargs):
|
||||
errs = process_args(await request.json or (await request.form).to_dict())
|
||||
errs = process_args(await _coerce_request_data())
|
||||
if errs:
|
||||
return get_json_result(code=RetCode.ARGUMENT_ERROR, message=errs)
|
||||
if inspect.iscoroutinefunction(func):
|
||||
@ -151,7 +182,7 @@ def validate_request(*args, **kwargs):
|
||||
def not_allowed_parameters(*params):
|
||||
def decorator(func):
|
||||
async def wrapper(*args, **kwargs):
|
||||
input_arguments = await request.json or (await request.form).to_dict()
|
||||
input_arguments = await _coerce_request_data()
|
||||
for param in params:
|
||||
if param in input_arguments:
|
||||
return get_json_result(code=RetCode.ARGUMENT_ERROR, message=f"Parameter {param} isn't allowed")
|
||||
@ -312,6 +343,10 @@ def get_parser_config(chunk_method, parser_config):
|
||||
chunk_method = "naive"
|
||||
|
||||
# Define default configurations for each chunking method
|
||||
base_defaults = {
|
||||
"table_context_size": 0,
|
||||
"image_context_size": 0,
|
||||
}
|
||||
key_mapping = {
|
||||
"naive": {
|
||||
"layout_recognize": "DeepDOC",
|
||||
@ -364,16 +399,19 @@ def get_parser_config(chunk_method, parser_config):
|
||||
|
||||
default_config = key_mapping[chunk_method]
|
||||
|
||||
# If no parser_config provided, return default
|
||||
# If no parser_config provided, return default merged with base defaults
|
||||
if not parser_config:
|
||||
return default_config
|
||||
if default_config is None:
|
||||
return deep_merge(base_defaults, {})
|
||||
return deep_merge(base_defaults, default_config)
|
||||
|
||||
# If parser_config is provided, merge with defaults to ensure required fields exist
|
||||
if default_config is None:
|
||||
return parser_config
|
||||
return deep_merge(base_defaults, parser_config)
|
||||
|
||||
# Ensure raptor and graphrag fields have default values if not provided
|
||||
merged_config = deep_merge(default_config, parser_config)
|
||||
merged_config = deep_merge(base_defaults, default_config)
|
||||
merged_config = deep_merge(merged_config, parser_config)
|
||||
|
||||
return merged_config
|
||||
|
||||
|
||||
@ -14,6 +14,7 @@
|
||||
# limitations under the License.
|
||||
#
|
||||
from collections import Counter
|
||||
import string
|
||||
from typing import Annotated, Any, Literal
|
||||
from uuid import UUID
|
||||
|
||||
@ -25,6 +26,7 @@ from pydantic import (
|
||||
StringConstraints,
|
||||
ValidationError,
|
||||
field_validator,
|
||||
model_validator,
|
||||
)
|
||||
from pydantic_core import PydanticCustomError
|
||||
from werkzeug.exceptions import BadRequest, UnsupportedMediaType
|
||||
@ -361,10 +363,9 @@ class CreateDatasetReq(Base):
|
||||
description: Annotated[str | None, Field(default=None, max_length=65535)]
|
||||
embedding_model: Annotated[str | None, Field(default=None, max_length=255, serialization_alias="embd_id")]
|
||||
permission: Annotated[Literal["me", "team"], Field(default="me", min_length=1, max_length=16)]
|
||||
chunk_method: Annotated[
|
||||
Literal["naive", "book", "email", "laws", "manual", "one", "paper", "picture", "presentation", "qa", "table", "tag"],
|
||||
Field(default="naive", min_length=1, max_length=32, serialization_alias="parser_id"),
|
||||
]
|
||||
chunk_method: Annotated[str | None, Field(default=None, serialization_alias="parser_id")]
|
||||
parse_type: Annotated[int | None, Field(default=None, ge=0, le=64)]
|
||||
pipeline_id: Annotated[str | None, Field(default=None, min_length=32, max_length=32, serialization_alias="pipeline_id")]
|
||||
parser_config: Annotated[ParserConfig | None, Field(default=None)]
|
||||
|
||||
@field_validator("avatar", mode="after")
|
||||
@ -525,6 +526,93 @@ class CreateDatasetReq(Base):
|
||||
raise PydanticCustomError("string_too_long", "Parser config exceeds size limit (max 65,535 characters). Current size: {actual}", {"actual": len(json_str)})
|
||||
return v
|
||||
|
||||
@field_validator("pipeline_id", mode="after")
|
||||
@classmethod
|
||||
def validate_pipeline_id(cls, v: str | None) -> str | None:
|
||||
"""Validate pipeline_id as 32-char lowercase hex string if provided.
|
||||
|
||||
Rules:
|
||||
- None or empty string: treat as None (not set)
|
||||
- Must be exactly length 32
|
||||
- Must contain only hex digits (0-9a-fA-F); normalized to lowercase
|
||||
"""
|
||||
if v is None:
|
||||
return None
|
||||
if v == "":
|
||||
return None
|
||||
if len(v) != 32:
|
||||
raise PydanticCustomError("format_invalid", "pipeline_id must be 32 hex characters")
|
||||
if any(ch not in string.hexdigits for ch in v):
|
||||
raise PydanticCustomError("format_invalid", "pipeline_id must be hexadecimal")
|
||||
return v.lower()
|
||||
|
||||
@model_validator(mode="after")
|
||||
def validate_parser_dependency(self) -> "CreateDatasetReq":
|
||||
"""
|
||||
Mixed conditional validation:
|
||||
- If parser_id is omitted (field not set):
|
||||
* If both parse_type and pipeline_id are omitted → default chunk_method = "naive"
|
||||
* If both parse_type and pipeline_id are provided → allow ingestion pipeline mode
|
||||
- If parser_id is provided (valid enum) → parse_type and pipeline_id must be None (disallow mixed usage)
|
||||
|
||||
Raises:
|
||||
PydanticCustomError with code 'dependency_error' on violation.
|
||||
"""
|
||||
# Omitted chunk_method (not in fields) logic
|
||||
if self.chunk_method is None and "chunk_method" not in self.model_fields_set:
|
||||
# All three absent → default naive
|
||||
if self.parse_type is None and self.pipeline_id is None:
|
||||
object.__setattr__(self, "chunk_method", "naive")
|
||||
return self
|
||||
# parser_id omitted: require BOTH parse_type & pipeline_id present (no partial allowed)
|
||||
if self.parse_type is None or self.pipeline_id is None:
|
||||
missing = []
|
||||
if self.parse_type is None:
|
||||
missing.append("parse_type")
|
||||
if self.pipeline_id is None:
|
||||
missing.append("pipeline_id")
|
||||
raise PydanticCustomError(
|
||||
"dependency_error",
|
||||
"parser_id omitted → required fields missing: {fields}",
|
||||
{"fields": ", ".join(missing)},
|
||||
)
|
||||
# Both provided → allow pipeline mode
|
||||
return self
|
||||
|
||||
# parser_id provided (valid): MUST NOT have parse_type or pipeline_id
|
||||
if isinstance(self.chunk_method, str):
|
||||
if self.parse_type is not None or self.pipeline_id is not None:
|
||||
invalid = []
|
||||
if self.parse_type is not None:
|
||||
invalid.append("parse_type")
|
||||
if self.pipeline_id is not None:
|
||||
invalid.append("pipeline_id")
|
||||
raise PydanticCustomError(
|
||||
"dependency_error",
|
||||
"parser_id provided → disallowed fields present: {fields}",
|
||||
{"fields": ", ".join(invalid)},
|
||||
)
|
||||
return self
|
||||
|
||||
@field_validator("chunk_method", mode="wrap")
|
||||
@classmethod
|
||||
def validate_chunk_method(cls, v: Any, handler) -> Any:
|
||||
"""Wrap validation to unify error messages, including type errors (e.g. list)."""
|
||||
allowed = {"naive", "book", "email", "laws", "manual", "one", "paper", "picture", "presentation", "qa", "table", "tag"}
|
||||
error_msg = "Input should be 'naive', 'book', 'email', 'laws', 'manual', 'one', 'paper', 'picture', 'presentation', 'qa', 'table' or 'tag'"
|
||||
# Omitted field: handler won't be invoked (wrap still gets value); None treated as explicit invalid
|
||||
if v is None:
|
||||
raise PydanticCustomError("literal_error", error_msg)
|
||||
try:
|
||||
# Run inner validation (type checking)
|
||||
result = handler(v)
|
||||
except Exception:
|
||||
raise PydanticCustomError("literal_error", error_msg)
|
||||
# After handler, enforce enumeration
|
||||
if not isinstance(result, str) or result == "" or result not in allowed:
|
||||
raise PydanticCustomError("literal_error", error_msg)
|
||||
return result
|
||||
|
||||
|
||||
class UpdateDatasetReq(CreateDatasetReq):
|
||||
dataset_id: Annotated[str, Field(...)]
|
||||
|
||||
@ -49,6 +49,7 @@ class RetCode(IntEnum, CustomEnum):
|
||||
RUNNING = 106
|
||||
PERMISSION_ERROR = 108
|
||||
AUTHENTICATION_ERROR = 109
|
||||
BAD_REQUEST = 400
|
||||
UNAUTHORIZED = 401
|
||||
SERVER_ERROR = 500
|
||||
FORBIDDEN = 403
|
||||
@ -118,7 +119,9 @@ class FileSource(StrEnum):
|
||||
SHAREPOINT = "sharepoint"
|
||||
SLACK = "slack"
|
||||
TEAMS = "teams"
|
||||
WEBDAV = "webdav"
|
||||
MOODLE = "moodle"
|
||||
DROPBOX = "dropbox"
|
||||
|
||||
|
||||
class PipelineTaskType(StrEnum):
|
||||
|
||||
@ -14,6 +14,7 @@ from .google_drive.connector import GoogleDriveConnector
|
||||
from .jira.connector import JiraConnector
|
||||
from .sharepoint_connector import SharePointConnector
|
||||
from .teams_connector import TeamsConnector
|
||||
from .webdav_connector import WebDAVConnector
|
||||
from .moodle_connector import MoodleConnector
|
||||
from .config import BlobType, DocumentSource
|
||||
from .models import Document, TextSection, ImageSection, BasicExpertInfo
|
||||
@ -37,6 +38,7 @@ __all__ = [
|
||||
"JiraConnector",
|
||||
"SharePointConnector",
|
||||
"TeamsConnector",
|
||||
"WebDAVConnector",
|
||||
"MoodleConnector",
|
||||
"BlobType",
|
||||
"DocumentSource",
|
||||
|
||||
@ -90,7 +90,7 @@ class BlobStorageConnector(LoadConnector, PollConnector):
|
||||
elif self.bucket_type == BlobType.S3_COMPATIBLE:
|
||||
if not all(
|
||||
credentials.get(key)
|
||||
for key in ["endpoint_url", "aws_access_key_id", "aws_secret_access_key"]
|
||||
for key in ["endpoint_url", "aws_access_key_id", "aws_secret_access_key", "addressing_style"]
|
||||
):
|
||||
raise ConnectorMissingCredentialError("S3 Compatible Storage")
|
||||
|
||||
|
||||
@ -48,8 +48,10 @@ class DocumentSource(str, Enum):
|
||||
GOOGLE_DRIVE = "google_drive"
|
||||
GMAIL = "gmail"
|
||||
DISCORD = "discord"
|
||||
WEBDAV = "webdav"
|
||||
MOODLE = "moodle"
|
||||
S3_COMPATIBLE = "s3_compatible"
|
||||
DROPBOX = "dropbox"
|
||||
|
||||
|
||||
class FileOrigin(str, Enum):
|
||||
@ -215,6 +217,7 @@ OAUTH_GOOGLE_DRIVE_CLIENT_SECRET = os.environ.get(
|
||||
"OAUTH_GOOGLE_DRIVE_CLIENT_SECRET", ""
|
||||
)
|
||||
GOOGLE_DRIVE_WEB_OAUTH_REDIRECT_URI = os.environ.get("GOOGLE_DRIVE_WEB_OAUTH_REDIRECT_URI", "http://localhost:9380/v1/connector/google-drive/oauth/web/callback")
|
||||
GMAIL_WEB_OAUTH_REDIRECT_URI = os.environ.get("GMAIL_WEB_OAUTH_REDIRECT_URI", "http://localhost:9380/v1/connector/gmail/oauth/web/callback")
|
||||
|
||||
CONFLUENCE_OAUTH_TOKEN_URL = "https://auth.atlassian.com/oauth/token"
|
||||
RATE_LIMIT_MESSAGE_LOWERCASE = "Rate limit exceeded".lower()
|
||||
|
||||
@ -1562,6 +1562,7 @@ class ConfluenceConnector(
|
||||
size_bytes=len(page_content.encode("utf-8")), # Calculate size in bytes
|
||||
doc_updated_at=datetime_from_string(page["version"]["when"]),
|
||||
primary_owners=primary_owners if primary_owners else None,
|
||||
metadata=metadata if metadata else None,
|
||||
)
|
||||
except Exception as e:
|
||||
logging.error(f"Error converting page {page.get('id', 'unknown')}: {e}")
|
||||
|
||||
@ -65,6 +65,7 @@ def _convert_message_to_document(
|
||||
blob=message.content.encode("utf-8"),
|
||||
extension=".txt",
|
||||
size_bytes=len(message.content.encode("utf-8")),
|
||||
metadata=metadata if metadata else None,
|
||||
)
|
||||
|
||||
|
||||
|
||||
@ -1,13 +1,24 @@
|
||||
"""Dropbox connector"""
|
||||
|
||||
import logging
|
||||
from datetime import timezone
|
||||
from typing import Any
|
||||
|
||||
from dropbox import Dropbox
|
||||
from dropbox.exceptions import ApiError, AuthError
|
||||
from dropbox.files import FileMetadata, FolderMetadata
|
||||
|
||||
from common.data_source.config import INDEX_BATCH_SIZE
|
||||
from common.data_source.exceptions import ConnectorValidationError, InsufficientPermissionsError, ConnectorMissingCredentialError
|
||||
from common.data_source.config import INDEX_BATCH_SIZE, DocumentSource
|
||||
from common.data_source.exceptions import (
|
||||
ConnectorMissingCredentialError,
|
||||
ConnectorValidationError,
|
||||
InsufficientPermissionsError,
|
||||
)
|
||||
from common.data_source.interfaces import LoadConnector, PollConnector, SecondsSinceUnixEpoch
|
||||
from common.data_source.models import Document, GenerateDocumentsOutput
|
||||
from common.data_source.utils import get_file_ext
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
class DropboxConnector(LoadConnector, PollConnector):
|
||||
@ -19,29 +30,29 @@ class DropboxConnector(LoadConnector, PollConnector):
|
||||
|
||||
def load_credentials(self, credentials: dict[str, Any]) -> dict[str, Any] | None:
|
||||
"""Load Dropbox credentials"""
|
||||
try:
|
||||
access_token = credentials.get("dropbox_access_token")
|
||||
if not access_token:
|
||||
raise ConnectorMissingCredentialError("Dropbox access token is required")
|
||||
|
||||
self.dropbox_client = Dropbox(access_token)
|
||||
return None
|
||||
except Exception as e:
|
||||
raise ConnectorMissingCredentialError(f"Dropbox: {e}")
|
||||
access_token = credentials.get("dropbox_access_token")
|
||||
if not access_token:
|
||||
raise ConnectorMissingCredentialError("Dropbox access token is required")
|
||||
|
||||
self.dropbox_client = Dropbox(access_token)
|
||||
return None
|
||||
|
||||
def validate_connector_settings(self) -> None:
|
||||
"""Validate Dropbox connector settings"""
|
||||
if not self.dropbox_client:
|
||||
if self.dropbox_client is None:
|
||||
raise ConnectorMissingCredentialError("Dropbox")
|
||||
|
||||
|
||||
try:
|
||||
# Test connection by getting current account info
|
||||
self.dropbox_client.users_get_current_account()
|
||||
except (AuthError, ApiError) as e:
|
||||
if "invalid_access_token" in str(e).lower():
|
||||
raise InsufficientPermissionsError("Invalid Dropbox access token")
|
||||
else:
|
||||
raise ConnectorValidationError(f"Dropbox validation error: {e}")
|
||||
self.dropbox_client.files_list_folder(path="", limit=1)
|
||||
except AuthError as e:
|
||||
logger.exception("[Dropbox]: Failed to validate Dropbox credentials")
|
||||
raise ConnectorValidationError(f"Dropbox credential is invalid: {e}")
|
||||
except ApiError as e:
|
||||
if e.error is not None and "insufficient_permissions" in str(e.error).lower():
|
||||
raise InsufficientPermissionsError("Your Dropbox token does not have sufficient permissions.")
|
||||
raise ConnectorValidationError(f"Unexpected Dropbox error during validation: {e.user_message_text or e}")
|
||||
except Exception as e:
|
||||
raise ConnectorValidationError(f"Unexpected error during Dropbox settings validation: {e}")
|
||||
|
||||
def _download_file(self, path: str) -> bytes:
|
||||
"""Download a single file from Dropbox."""
|
||||
@ -54,26 +65,105 @@ class DropboxConnector(LoadConnector, PollConnector):
|
||||
"""Create a shared link for a file in Dropbox."""
|
||||
if self.dropbox_client is None:
|
||||
raise ConnectorMissingCredentialError("Dropbox")
|
||||
|
||||
|
||||
try:
|
||||
# Try to get existing shared links first
|
||||
shared_links = self.dropbox_client.sharing_list_shared_links(path=path)
|
||||
if shared_links.links:
|
||||
return shared_links.links[0].url
|
||||
|
||||
# Create a new shared link
|
||||
link_settings = self.dropbox_client.sharing_create_shared_link_with_settings(path)
|
||||
return link_settings.url
|
||||
except Exception:
|
||||
# Fallback to basic link format
|
||||
return f"https://www.dropbox.com/home{path}"
|
||||
|
||||
def poll_source(self, start: SecondsSinceUnixEpoch, end: SecondsSinceUnixEpoch) -> Any:
|
||||
link_metadata = self.dropbox_client.sharing_create_shared_link_with_settings(path)
|
||||
return link_metadata.url
|
||||
except ApiError as err:
|
||||
logger.exception(f"[Dropbox]: Failed to create a shared link for {path}: {err}")
|
||||
return ""
|
||||
|
||||
def _yield_files_recursive(
|
||||
self,
|
||||
path: str,
|
||||
start: SecondsSinceUnixEpoch | None,
|
||||
end: SecondsSinceUnixEpoch | None,
|
||||
) -> GenerateDocumentsOutput:
|
||||
"""Yield files in batches from a specified Dropbox folder, including subfolders."""
|
||||
if self.dropbox_client is None:
|
||||
raise ConnectorMissingCredentialError("Dropbox")
|
||||
|
||||
result = self.dropbox_client.files_list_folder(
|
||||
path,
|
||||
limit=self.batch_size,
|
||||
recursive=False,
|
||||
include_non_downloadable_files=False,
|
||||
)
|
||||
|
||||
while True:
|
||||
batch: list[Document] = []
|
||||
for entry in result.entries:
|
||||
if isinstance(entry, FileMetadata):
|
||||
modified_time = entry.client_modified
|
||||
if modified_time.tzinfo is None:
|
||||
modified_time = modified_time.replace(tzinfo=timezone.utc)
|
||||
else:
|
||||
modified_time = modified_time.astimezone(timezone.utc)
|
||||
|
||||
time_as_seconds = modified_time.timestamp()
|
||||
if start is not None and time_as_seconds <= start:
|
||||
continue
|
||||
if end is not None and time_as_seconds > end:
|
||||
continue
|
||||
|
||||
try:
|
||||
downloaded_file = self._download_file(entry.path_display)
|
||||
except Exception:
|
||||
logger.exception(f"[Dropbox]: Error downloading file {entry.path_display}")
|
||||
continue
|
||||
|
||||
batch.append(
|
||||
Document(
|
||||
id=f"dropbox:{entry.id}",
|
||||
blob=downloaded_file,
|
||||
source=DocumentSource.DROPBOX,
|
||||
semantic_identifier=entry.name,
|
||||
extension=get_file_ext(entry.name),
|
||||
doc_updated_at=modified_time,
|
||||
size_bytes=entry.size if getattr(entry, "size", None) is not None else len(downloaded_file),
|
||||
)
|
||||
)
|
||||
|
||||
elif isinstance(entry, FolderMetadata):
|
||||
yield from self._yield_files_recursive(entry.path_lower, start, end)
|
||||
|
||||
if batch:
|
||||
yield batch
|
||||
|
||||
if not result.has_more:
|
||||
break
|
||||
|
||||
result = self.dropbox_client.files_list_folder_continue(result.cursor)
|
||||
|
||||
def poll_source(self, start: SecondsSinceUnixEpoch, end: SecondsSinceUnixEpoch) -> GenerateDocumentsOutput:
|
||||
"""Poll Dropbox for recent file changes"""
|
||||
# Simplified implementation - in production this would handle actual polling
|
||||
return []
|
||||
if self.dropbox_client is None:
|
||||
raise ConnectorMissingCredentialError("Dropbox")
|
||||
|
||||
def load_from_state(self) -> Any:
|
||||
for batch in self._yield_files_recursive("", start, end):
|
||||
yield batch
|
||||
|
||||
def load_from_state(self) -> GenerateDocumentsOutput:
|
||||
"""Load files from Dropbox state"""
|
||||
# Simplified implementation
|
||||
return []
|
||||
return self._yield_files_recursive("", None, None)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
import os
|
||||
|
||||
logging.basicConfig(level=logging.DEBUG)
|
||||
connector = DropboxConnector()
|
||||
connector.load_credentials({"dropbox_access_token": os.environ.get("DROPBOX_ACCESS_TOKEN")})
|
||||
connector.validate_connector_settings()
|
||||
document_batches = connector.load_from_state()
|
||||
try:
|
||||
first_batch = next(document_batches)
|
||||
print(f"Loaded {len(first_batch)} documents in first batch.")
|
||||
for doc in first_batch:
|
||||
print(f"- {doc.semantic_identifier} ({doc.size_bytes} bytes)")
|
||||
except StopIteration:
|
||||
print("No documents available in Dropbox.")
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
import logging
|
||||
import os
|
||||
from typing import Any
|
||||
|
||||
from google.oauth2.credentials import Credentials as OAuthCredentials
|
||||
from google.oauth2.service_account import Credentials as ServiceAccountCredentials
|
||||
from googleapiclient.errors import HttpError
|
||||
@ -9,10 +9,10 @@ from common.data_source.config import INDEX_BATCH_SIZE, SLIM_BATCH_SIZE, Documen
|
||||
from common.data_source.google_util.auth import get_google_creds
|
||||
from common.data_source.google_util.constant import DB_CREDENTIALS_PRIMARY_ADMIN_KEY, MISSING_SCOPES_ERROR_STR, SCOPE_INSTRUCTIONS, USER_FIELDS
|
||||
from common.data_source.google_util.resource import get_admin_service, get_gmail_service
|
||||
from common.data_source.google_util.util import _execute_single_retrieval, execute_paginated_retrieval
|
||||
from common.data_source.google_util.util import _execute_single_retrieval, execute_paginated_retrieval, sanitize_filename, clean_string
|
||||
from common.data_source.interfaces import LoadConnector, PollConnector, SecondsSinceUnixEpoch, SlimConnectorWithPermSync
|
||||
from common.data_source.models import BasicExpertInfo, Document, ExternalAccess, GenerateDocumentsOutput, GenerateSlimDocumentOutput, SlimDocument, TextSection
|
||||
from common.data_source.utils import build_time_range_query, clean_email_and_extract_name, get_message_body, is_mail_service_disabled_error, time_str_to_utc
|
||||
from common.data_source.utils import build_time_range_query, clean_email_and_extract_name, get_message_body, is_mail_service_disabled_error, gmail_time_str_to_utc
|
||||
|
||||
# Constants for Gmail API fields
|
||||
THREAD_LIST_FIELDS = "nextPageToken, threads(id)"
|
||||
@ -67,7 +67,6 @@ def message_to_section(message: dict[str, Any]) -> tuple[TextSection, dict[str,
|
||||
message_data += f"{name}: {value}\n"
|
||||
|
||||
message_body_text: str = get_message_body(payload)
|
||||
|
||||
return TextSection(link=link, text=message_body_text + message_data), metadata
|
||||
|
||||
|
||||
@ -97,13 +96,15 @@ def thread_to_document(full_thread: dict[str, Any], email_used_to_fetch_thread:
|
||||
|
||||
if not semantic_identifier:
|
||||
semantic_identifier = message_metadata.get("subject", "")
|
||||
semantic_identifier = clean_string(semantic_identifier)
|
||||
semantic_identifier = sanitize_filename(semantic_identifier)
|
||||
|
||||
if message_metadata.get("updated_at"):
|
||||
updated_at = message_metadata.get("updated_at")
|
||||
|
||||
|
||||
updated_at_datetime = None
|
||||
if updated_at:
|
||||
updated_at_datetime = time_str_to_utc(updated_at)
|
||||
updated_at_datetime = gmail_time_str_to_utc(updated_at)
|
||||
|
||||
thread_id = full_thread.get("id")
|
||||
if not thread_id:
|
||||
@ -115,15 +116,24 @@ def thread_to_document(full_thread: dict[str, Any], email_used_to_fetch_thread:
|
||||
if not semantic_identifier:
|
||||
semantic_identifier = "(no subject)"
|
||||
|
||||
combined_sections = "\n\n".join(
|
||||
sec.text for sec in sections if hasattr(sec, "text")
|
||||
)
|
||||
blob = combined_sections
|
||||
size_bytes = len(blob)
|
||||
extension = '.txt'
|
||||
|
||||
return Document(
|
||||
id=thread_id,
|
||||
semantic_identifier=semantic_identifier,
|
||||
sections=sections,
|
||||
blob=blob,
|
||||
size_bytes=size_bytes,
|
||||
extension=extension,
|
||||
source=DocumentSource.GMAIL,
|
||||
primary_owners=primary_owners,
|
||||
secondary_owners=secondary_owners,
|
||||
doc_updated_at=updated_at_datetime,
|
||||
metadata={},
|
||||
metadata=message_metadata,
|
||||
external_access=ExternalAccess(
|
||||
external_user_emails={email_used_to_fetch_thread},
|
||||
external_user_group_ids=set(),
|
||||
@ -214,15 +224,13 @@ class GmailConnector(LoadConnector, PollConnector, SlimConnectorWithPermSync):
|
||||
q=query,
|
||||
continue_on_404_or_403=True,
|
||||
):
|
||||
full_threads = _execute_single_retrieval(
|
||||
full_thread = _execute_single_retrieval(
|
||||
retrieval_function=gmail_service.users().threads().get,
|
||||
list_key=None,
|
||||
userId=user_email,
|
||||
fields=THREAD_FIELDS,
|
||||
id=thread["id"],
|
||||
continue_on_404_or_403=True,
|
||||
)
|
||||
full_thread = list(full_threads)[0]
|
||||
doc = thread_to_document(full_thread, user_email)
|
||||
if doc is None:
|
||||
continue
|
||||
@ -310,4 +318,30 @@ class GmailConnector(LoadConnector, PollConnector, SlimConnectorWithPermSync):
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
pass
|
||||
import time
|
||||
import os
|
||||
from common.data_source.google_util.util import get_credentials_from_env
|
||||
logging.basicConfig(level=logging.INFO)
|
||||
try:
|
||||
email = os.environ.get("GMAIL_TEST_EMAIL", "newyorkupperbay@gmail.com")
|
||||
creds = get_credentials_from_env(email, oauth=True, source="gmail")
|
||||
print("Credentials loaded successfully")
|
||||
print(f"{creds=}")
|
||||
|
||||
connector = GmailConnector(batch_size=2)
|
||||
print("GmailConnector initialized")
|
||||
connector.load_credentials(creds)
|
||||
print("Credentials loaded into connector")
|
||||
|
||||
print("Gmail is ready to use")
|
||||
|
||||
for file in connector._fetch_threads(
|
||||
int(time.time()) - 1 * 24 * 60 * 60,
|
||||
int(time.time()),
|
||||
):
|
||||
print("new batch","-"*80)
|
||||
for f in file:
|
||||
print(f)
|
||||
print("\n\n")
|
||||
except Exception as e:
|
||||
logging.exception(f"Error loading credentials: {e}")
|
||||
@ -1,7 +1,6 @@
|
||||
"""Google Drive connector"""
|
||||
|
||||
import copy
|
||||
import json
|
||||
import logging
|
||||
import os
|
||||
import sys
|
||||
@ -32,7 +31,6 @@ from common.data_source.google_drive.file_retrieval import (
|
||||
from common.data_source.google_drive.model import DriveRetrievalStage, GoogleDriveCheckpoint, GoogleDriveFileType, RetrievedDriveFile, StageCompletion
|
||||
from common.data_source.google_util.auth import get_google_creds
|
||||
from common.data_source.google_util.constant import DB_CREDENTIALS_PRIMARY_ADMIN_KEY, MISSING_SCOPES_ERROR_STR, USER_FIELDS
|
||||
from common.data_source.google_util.oauth_flow import ensure_oauth_token_dict
|
||||
from common.data_source.google_util.resource import GoogleDriveService, get_admin_service, get_drive_service
|
||||
from common.data_source.google_util.util import GoogleFields, execute_paginated_retrieval, get_file_owners
|
||||
from common.data_source.google_util.util_threadpool_concurrency import ThreadSafeDict
|
||||
@ -1138,39 +1136,6 @@ class GoogleDriveConnector(SlimConnectorWithPermSync, CheckpointedConnectorWithP
|
||||
return GoogleDriveCheckpoint.model_validate_json(checkpoint_json)
|
||||
|
||||
|
||||
def get_credentials_from_env(email: str, oauth: bool = False) -> dict:
|
||||
try:
|
||||
if oauth:
|
||||
raw_credential_string = os.environ["GOOGLE_DRIVE_OAUTH_CREDENTIALS_JSON_STR"]
|
||||
else:
|
||||
raw_credential_string = os.environ["GOOGLE_DRIVE_SERVICE_ACCOUNT_JSON_STR"]
|
||||
except KeyError:
|
||||
raise ValueError("Missing Google Drive credentials in environment variables")
|
||||
|
||||
try:
|
||||
credential_dict = json.loads(raw_credential_string)
|
||||
except json.JSONDecodeError:
|
||||
raise ValueError("Invalid JSON in Google Drive credentials")
|
||||
|
||||
if oauth:
|
||||
credential_dict = ensure_oauth_token_dict(credential_dict, DocumentSource.GOOGLE_DRIVE)
|
||||
|
||||
refried_credential_string = json.dumps(credential_dict)
|
||||
|
||||
DB_CREDENTIALS_DICT_TOKEN_KEY = "google_tokens"
|
||||
DB_CREDENTIALS_DICT_SERVICE_ACCOUNT_KEY = "google_service_account_key"
|
||||
DB_CREDENTIALS_PRIMARY_ADMIN_KEY = "google_primary_admin"
|
||||
DB_CREDENTIALS_AUTHENTICATION_METHOD = "authentication_method"
|
||||
|
||||
cred_key = DB_CREDENTIALS_DICT_TOKEN_KEY if oauth else DB_CREDENTIALS_DICT_SERVICE_ACCOUNT_KEY
|
||||
|
||||
return {
|
||||
cred_key: refried_credential_string,
|
||||
DB_CREDENTIALS_PRIMARY_ADMIN_KEY: email,
|
||||
DB_CREDENTIALS_AUTHENTICATION_METHOD: "uploaded",
|
||||
}
|
||||
|
||||
|
||||
class CheckpointOutputWrapper:
|
||||
"""
|
||||
Wraps a CheckpointOutput generator to give things back in a more digestible format.
|
||||
@ -1236,7 +1201,7 @@ def yield_all_docs_from_checkpoint_connector(
|
||||
|
||||
if __name__ == "__main__":
|
||||
import time
|
||||
|
||||
from common.data_source.google_util.util import get_credentials_from_env
|
||||
logging.basicConfig(level=logging.DEBUG)
|
||||
|
||||
try:
|
||||
@ -1245,7 +1210,7 @@ if __name__ == "__main__":
|
||||
creds = get_credentials_from_env(email, oauth=True)
|
||||
print("Credentials loaded successfully")
|
||||
print(f"{creds=}")
|
||||
|
||||
sys.exit(0)
|
||||
connector = GoogleDriveConnector(
|
||||
include_shared_drives=False,
|
||||
shared_drive_urls=None,
|
||||
|
||||
@ -49,11 +49,11 @@ MISSING_SCOPES_ERROR_STR = "client not authorized for any of the scopes requeste
|
||||
SCOPE_INSTRUCTIONS = ""
|
||||
|
||||
|
||||
GOOGLE_DRIVE_WEB_OAUTH_POPUP_TEMPLATE = """<!DOCTYPE html>
|
||||
GOOGLE_WEB_OAUTH_POPUP_TEMPLATE = """<!DOCTYPE html>
|
||||
<html lang="en">
|
||||
<head>
|
||||
<meta charset="utf-8" />
|
||||
<title>Google Drive Authorization</title>
|
||||
<title>{title}</title>
|
||||
<style>
|
||||
body {{
|
||||
font-family: Arial, sans-serif;
|
||||
|
||||
@ -1,12 +1,17 @@
|
||||
import json
|
||||
import logging
|
||||
import os
|
||||
import re
|
||||
import socket
|
||||
from collections.abc import Callable, Iterator
|
||||
from enum import Enum
|
||||
from typing import Any
|
||||
|
||||
import unicodedata
|
||||
from googleapiclient.errors import HttpError # type: ignore # type: ignore
|
||||
|
||||
from common.data_source.config import DocumentSource
|
||||
from common.data_source.google_drive.model import GoogleDriveFileType
|
||||
from common.data_source.google_util.oauth_flow import ensure_oauth_token_dict
|
||||
|
||||
|
||||
# See https://developers.google.com/drive/api/reference/rest/v3/files/list for more
|
||||
@ -117,6 +122,7 @@ def _execute_single_retrieval(
|
||||
"""Execute a single retrieval from Google Drive API"""
|
||||
try:
|
||||
results = retrieval_function(**request_kwargs).execute()
|
||||
|
||||
except HttpError as e:
|
||||
if e.resp.status >= 500:
|
||||
results = retrieval_function()
|
||||
@ -148,5 +154,110 @@ def _execute_single_retrieval(
|
||||
error,
|
||||
)
|
||||
results = retrieval_function()
|
||||
|
||||
return results
|
||||
|
||||
|
||||
def get_credentials_from_env(email: str, oauth: bool = False, source="drive") -> dict:
|
||||
try:
|
||||
if oauth:
|
||||
raw_credential_string = os.environ["GOOGLE_OAUTH_CREDENTIALS_JSON_STR"]
|
||||
else:
|
||||
raw_credential_string = os.environ["GOOGLE_SERVICE_ACCOUNT_JSON_STR"]
|
||||
except KeyError:
|
||||
raise ValueError("Missing Google Drive credentials in environment variables")
|
||||
|
||||
try:
|
||||
credential_dict = json.loads(raw_credential_string)
|
||||
except json.JSONDecodeError:
|
||||
raise ValueError("Invalid JSON in Google Drive credentials")
|
||||
|
||||
if oauth and source == "drive":
|
||||
credential_dict = ensure_oauth_token_dict(credential_dict, DocumentSource.GOOGLE_DRIVE)
|
||||
else:
|
||||
credential_dict = ensure_oauth_token_dict(credential_dict, DocumentSource.GMAIL)
|
||||
|
||||
refried_credential_string = json.dumps(credential_dict)
|
||||
|
||||
DB_CREDENTIALS_DICT_TOKEN_KEY = "google_tokens"
|
||||
DB_CREDENTIALS_DICT_SERVICE_ACCOUNT_KEY = "google_service_account_key"
|
||||
DB_CREDENTIALS_PRIMARY_ADMIN_KEY = "google_primary_admin"
|
||||
DB_CREDENTIALS_AUTHENTICATION_METHOD = "authentication_method"
|
||||
|
||||
cred_key = DB_CREDENTIALS_DICT_TOKEN_KEY if oauth else DB_CREDENTIALS_DICT_SERVICE_ACCOUNT_KEY
|
||||
|
||||
return {
|
||||
cred_key: refried_credential_string,
|
||||
DB_CREDENTIALS_PRIMARY_ADMIN_KEY: email,
|
||||
DB_CREDENTIALS_AUTHENTICATION_METHOD: "uploaded",
|
||||
}
|
||||
|
||||
def sanitize_filename(name: str) -> str:
|
||||
"""
|
||||
Soft sanitize for MinIO/S3:
|
||||
- Replace only prohibited characters with a space.
|
||||
- Preserve readability (no ugly underscores).
|
||||
- Collapse multiple spaces.
|
||||
"""
|
||||
if name is None:
|
||||
return "file.txt"
|
||||
|
||||
name = str(name).strip()
|
||||
|
||||
# Characters that MUST NOT appear in S3/MinIO object keys
|
||||
# Replace them with a space (not underscore)
|
||||
forbidden = r'[\\\?\#\%\*\:\|\<\>"]'
|
||||
name = re.sub(forbidden, " ", name)
|
||||
|
||||
# Replace slashes "/" (S3 interprets as folder) with space
|
||||
name = name.replace("/", " ")
|
||||
|
||||
# Collapse multiple spaces into one
|
||||
name = re.sub(r"\s+", " ", name)
|
||||
|
||||
# Trim both ends
|
||||
name = name.strip()
|
||||
|
||||
# Enforce reasonable max length
|
||||
if len(name) > 200:
|
||||
base, ext = os.path.splitext(name)
|
||||
name = base[:180].rstrip() + ext
|
||||
|
||||
# Ensure there is an extension (your original logic)
|
||||
if not os.path.splitext(name)[1]:
|
||||
name += ".txt"
|
||||
|
||||
return name
|
||||
|
||||
|
||||
def clean_string(text: str | None) -> str | None:
|
||||
"""
|
||||
Clean a string to make it safe for insertion into MySQL (utf8mb4).
|
||||
- Normalize Unicode
|
||||
- Remove control characters / zero-width characters
|
||||
- Optionally remove high-plane emoji and symbols
|
||||
"""
|
||||
if text is None:
|
||||
return None
|
||||
|
||||
# 0. Ensure the value is a string
|
||||
text = str(text)
|
||||
|
||||
# 1. Normalize Unicode (NFC)
|
||||
text = unicodedata.normalize("NFC", text)
|
||||
|
||||
# 2. Remove ASCII control characters (except tab, newline, carriage return)
|
||||
text = re.sub(r"[\x00-\x08\x0b\x0c\x0e-\x1f\x7f]", "", text)
|
||||
|
||||
# 3. Remove zero-width characters / BOM
|
||||
text = re.sub(r"[\u200b-\u200d\uFEFF]", "", text)
|
||||
|
||||
# 4. Remove high Unicode characters (emoji, special symbols)
|
||||
text = re.sub(r"[\U00010000-\U0010FFFF]", "", text)
|
||||
|
||||
# 5. Final fallback: strip any invalid UTF-8 sequences
|
||||
try:
|
||||
text.encode("utf-8")
|
||||
except UnicodeEncodeError:
|
||||
text = text.encode("utf-8", errors="ignore").decode("utf-8")
|
||||
|
||||
return text
|
||||
@ -30,7 +30,6 @@ class LoadConnector(ABC):
|
||||
"""Load documents from state"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def validate_connector_settings(self) -> None:
|
||||
"""Validate connector settings"""
|
||||
pass
|
||||
|
||||
@ -94,6 +94,7 @@ class Document(BaseModel):
|
||||
blob: bytes
|
||||
doc_updated_at: datetime
|
||||
size_bytes: int
|
||||
metadata: Optional[dict[str, Any]] = None
|
||||
|
||||
|
||||
class BasicExpertInfo(BaseModel):
|
||||
|
||||
@ -17,7 +17,11 @@ from common.data_source.exceptions import (
|
||||
InsufficientPermissionsError,
|
||||
ConnectorValidationError,
|
||||
)
|
||||
from common.data_source.interfaces import LoadConnector, PollConnector, SecondsSinceUnixEpoch
|
||||
from common.data_source.interfaces import (
|
||||
LoadConnector,
|
||||
PollConnector,
|
||||
SecondsSinceUnixEpoch,
|
||||
)
|
||||
from common.data_source.models import Document
|
||||
from common.data_source.utils import batch_generator, rl_requests
|
||||
|
||||
@ -42,7 +46,9 @@ class MoodleConnector(LoadConnector, PollConnector):
|
||||
delimiter = "&" if "?" in file_url else "?"
|
||||
return f"{file_url}{delimiter}token={token}"
|
||||
|
||||
def _log_error(self, context: str, error: Exception, level: str = "warning") -> None:
|
||||
def _log_error(
|
||||
self, context: str, error: Exception, level: str = "warning"
|
||||
) -> None:
|
||||
"""Simplified logging wrapper"""
|
||||
msg = f"{context}: {error}"
|
||||
if level == "error":
|
||||
@ -73,7 +79,9 @@ class MoodleConnector(LoadConnector, PollConnector):
|
||||
except MoodleException as e:
|
||||
if "invalidtoken" in str(e).lower():
|
||||
raise CredentialExpiredError("Moodle token is invalid or expired")
|
||||
raise ConnectorMissingCredentialError(f"Failed to initialize Moodle client: {e}")
|
||||
raise ConnectorMissingCredentialError(
|
||||
f"Failed to initialize Moodle client: {e}"
|
||||
)
|
||||
|
||||
def validate_connector_settings(self) -> None:
|
||||
if not self.moodle_client:
|
||||
@ -125,7 +133,9 @@ class MoodleConnector(LoadConnector, PollConnector):
|
||||
logger.warning("No courses found to poll")
|
||||
return
|
||||
|
||||
yield from self._yield_in_batches(self._get_updated_content(courses, start, end))
|
||||
yield from self._yield_in_batches(
|
||||
self._get_updated_content(courses, start, end)
|
||||
)
|
||||
|
||||
@retry(tries=3, delay=1, backoff=2)
|
||||
def _get_enrolled_courses(self) -> list:
|
||||
@ -187,9 +197,7 @@ class MoodleConnector(LoadConnector, PollConnector):
|
||||
except Exception as e:
|
||||
self._log_error(f"polling course {course.fullname}", e)
|
||||
|
||||
def _process_module(
|
||||
self, course, section, module
|
||||
) -> Optional[Document]:
|
||||
def _process_module(self, course, section, module) -> Optional[Document]:
|
||||
try:
|
||||
mtype = module.modname
|
||||
if mtype in ["label", "url"]:
|
||||
@ -224,11 +232,37 @@ class MoodleConnector(LoadConnector, PollConnector):
|
||||
)
|
||||
|
||||
try:
|
||||
resp = rl_requests.get(self._add_token_to_url(file_info.fileurl), timeout=60)
|
||||
resp = rl_requests.get(
|
||||
self._add_token_to_url(file_info.fileurl), timeout=60
|
||||
)
|
||||
resp.raise_for_status()
|
||||
blob = resp.content
|
||||
ext = os.path.splitext(file_name)[1] or ".bin"
|
||||
semantic_id = f"{course.fullname} / {section.name} / {file_name}"
|
||||
|
||||
# Create metadata dictionary with relevant information
|
||||
metadata = {
|
||||
"moodle_url": self.moodle_url,
|
||||
"course_id": getattr(course, "id", None),
|
||||
"course_name": getattr(course, "fullname", None),
|
||||
"course_shortname": getattr(course, "shortname", None),
|
||||
"section_id": getattr(section, "id", None),
|
||||
"section_name": getattr(section, "name", None),
|
||||
"section_number": getattr(section, "section", None),
|
||||
"module_id": getattr(module, "id", None),
|
||||
"module_name": getattr(module, "name", None),
|
||||
"module_type": getattr(module, "modname", None),
|
||||
"module_instance": getattr(module, "instance", None),
|
||||
"file_url": getattr(file_info, "fileurl", None),
|
||||
"file_name": file_name,
|
||||
"file_size": getattr(file_info, "filesize", len(blob)),
|
||||
"file_type": getattr(file_info, "mimetype", None),
|
||||
"time_created": getattr(module, "timecreated", None),
|
||||
"time_modified": getattr(module, "timemodified", None),
|
||||
"visible": getattr(module, "visible", None),
|
||||
"groupmode": getattr(module, "groupmode", None),
|
||||
}
|
||||
|
||||
return Document(
|
||||
id=f"moodle_resource_{module.id}",
|
||||
source="moodle",
|
||||
@ -237,6 +271,7 @@ class MoodleConnector(LoadConnector, PollConnector):
|
||||
blob=blob,
|
||||
doc_updated_at=datetime.fromtimestamp(ts or 0, tz=timezone.utc),
|
||||
size_bytes=len(blob),
|
||||
metadata=metadata,
|
||||
)
|
||||
except Exception as e:
|
||||
self._log_error(f"downloading resource {file_name}", e, "error")
|
||||
@ -247,7 +282,9 @@ class MoodleConnector(LoadConnector, PollConnector):
|
||||
return None
|
||||
|
||||
try:
|
||||
result = self.moodle_client.mod.forum.get_forum_discussions(forumid=module.instance)
|
||||
result = self.moodle_client.mod.forum.get_forum_discussions(
|
||||
forumid=module.instance
|
||||
)
|
||||
disc_list = getattr(result, "discussions", [])
|
||||
if not disc_list:
|
||||
return None
|
||||
@ -264,6 +301,38 @@ class MoodleConnector(LoadConnector, PollConnector):
|
||||
|
||||
blob = "\n".join(markdown).encode("utf-8")
|
||||
semantic_id = f"{course.fullname} / {section.name} / {module.name}"
|
||||
|
||||
# Create metadata dictionary with relevant information
|
||||
metadata = {
|
||||
"moodle_url": self.moodle_url,
|
||||
"course_id": getattr(course, "id", None),
|
||||
"course_name": getattr(course, "fullname", None),
|
||||
"course_shortname": getattr(course, "shortname", None),
|
||||
"section_id": getattr(section, "id", None),
|
||||
"section_name": getattr(section, "name", None),
|
||||
"section_number": getattr(section, "section", None),
|
||||
"module_id": getattr(module, "id", None),
|
||||
"module_name": getattr(module, "name", None),
|
||||
"module_type": getattr(module, "modname", None),
|
||||
"forum_id": getattr(module, "instance", None),
|
||||
"discussion_count": len(disc_list),
|
||||
"time_created": getattr(module, "timecreated", None),
|
||||
"time_modified": getattr(module, "timemodified", None),
|
||||
"visible": getattr(module, "visible", None),
|
||||
"groupmode": getattr(module, "groupmode", None),
|
||||
"discussions": [
|
||||
{
|
||||
"id": getattr(d, "id", None),
|
||||
"name": getattr(d, "name", None),
|
||||
"user_id": getattr(d, "userid", None),
|
||||
"user_fullname": getattr(d, "userfullname", None),
|
||||
"time_created": getattr(d, "timecreated", None),
|
||||
"time_modified": getattr(d, "timemodified", None),
|
||||
}
|
||||
for d in disc_list
|
||||
],
|
||||
}
|
||||
|
||||
return Document(
|
||||
id=f"moodle_forum_{module.id}",
|
||||
source="moodle",
|
||||
@ -272,6 +341,7 @@ class MoodleConnector(LoadConnector, PollConnector):
|
||||
blob=blob,
|
||||
doc_updated_at=datetime.fromtimestamp(latest_ts or 0, tz=timezone.utc),
|
||||
size_bytes=len(blob),
|
||||
metadata=metadata,
|
||||
)
|
||||
except Exception as e:
|
||||
self._log_error(f"processing forum {module.name}", e)
|
||||
@ -293,11 +363,37 @@ class MoodleConnector(LoadConnector, PollConnector):
|
||||
)
|
||||
|
||||
try:
|
||||
resp = rl_requests.get(self._add_token_to_url(file_info.fileurl), timeout=60)
|
||||
resp = rl_requests.get(
|
||||
self._add_token_to_url(file_info.fileurl), timeout=60
|
||||
)
|
||||
resp.raise_for_status()
|
||||
blob = resp.content
|
||||
ext = os.path.splitext(file_name)[1] or ".html"
|
||||
semantic_id = f"{course.fullname} / {section.name} / {module.name}"
|
||||
|
||||
# Create metadata dictionary with relevant information
|
||||
metadata = {
|
||||
"moodle_url": self.moodle_url,
|
||||
"course_id": getattr(course, "id", None),
|
||||
"course_name": getattr(course, "fullname", None),
|
||||
"course_shortname": getattr(course, "shortname", None),
|
||||
"section_id": getattr(section, "id", None),
|
||||
"section_name": getattr(section, "name", None),
|
||||
"section_number": getattr(section, "section", None),
|
||||
"module_id": getattr(module, "id", None),
|
||||
"module_name": getattr(module, "name", None),
|
||||
"module_type": getattr(module, "modname", None),
|
||||
"module_instance": getattr(module, "instance", None),
|
||||
"page_url": getattr(file_info, "fileurl", None),
|
||||
"file_name": file_name,
|
||||
"file_size": getattr(file_info, "filesize", len(blob)),
|
||||
"file_type": getattr(file_info, "mimetype", None),
|
||||
"time_created": getattr(module, "timecreated", None),
|
||||
"time_modified": getattr(module, "timemodified", None),
|
||||
"visible": getattr(module, "visible", None),
|
||||
"groupmode": getattr(module, "groupmode", None),
|
||||
}
|
||||
|
||||
return Document(
|
||||
id=f"moodle_page_{module.id}",
|
||||
source="moodle",
|
||||
@ -306,6 +402,7 @@ class MoodleConnector(LoadConnector, PollConnector):
|
||||
blob=blob,
|
||||
doc_updated_at=datetime.fromtimestamp(ts or 0, tz=timezone.utc),
|
||||
size_bytes=len(blob),
|
||||
metadata=metadata,
|
||||
)
|
||||
except Exception as e:
|
||||
self._log_error(f"processing page {file_name}", e, "error")
|
||||
@ -326,6 +423,29 @@ class MoodleConnector(LoadConnector, PollConnector):
|
||||
|
||||
semantic_id = f"{course.fullname} / {section.name} / {mname}"
|
||||
blob = markdown.encode("utf-8")
|
||||
|
||||
# Create metadata dictionary with relevant information
|
||||
metadata = {
|
||||
"moodle_url": self.moodle_url,
|
||||
"course_id": getattr(course, "id", None),
|
||||
"course_name": getattr(course, "fullname", None),
|
||||
"course_shortname": getattr(course, "shortname", None),
|
||||
"section_id": getattr(section, "id", None),
|
||||
"section_name": getattr(section, "name", None),
|
||||
"section_number": getattr(section, "section", None),
|
||||
"module_id": getattr(module, "id", None),
|
||||
"module_name": getattr(module, "name", None),
|
||||
"module_type": getattr(module, "modname", None),
|
||||
"activity_type": mtype,
|
||||
"activity_instance": getattr(module, "instance", None),
|
||||
"description": desc,
|
||||
"time_created": getattr(module, "timecreated", None),
|
||||
"time_modified": getattr(module, "timemodified", None),
|
||||
"added": getattr(module, "added", None),
|
||||
"visible": getattr(module, "visible", None),
|
||||
"groupmode": getattr(module, "groupmode", None),
|
||||
}
|
||||
|
||||
return Document(
|
||||
id=f"moodle_{mtype}_{module.id}",
|
||||
source="moodle",
|
||||
@ -334,6 +454,7 @@ class MoodleConnector(LoadConnector, PollConnector):
|
||||
blob=blob,
|
||||
doc_updated_at=datetime.fromtimestamp(ts or 0, tz=timezone.utc),
|
||||
size_bytes=len(blob),
|
||||
metadata=metadata,
|
||||
)
|
||||
|
||||
def _process_book(self, course, section, module) -> Optional[Document]:
|
||||
@ -342,8 +463,10 @@ class MoodleConnector(LoadConnector, PollConnector):
|
||||
|
||||
contents = module.contents
|
||||
chapters = [
|
||||
c for c in contents
|
||||
if getattr(c, "fileurl", None) and os.path.basename(c.filename) == "index.html"
|
||||
c
|
||||
for c in contents
|
||||
if getattr(c, "fileurl", None)
|
||||
and os.path.basename(c.filename) == "index.html"
|
||||
]
|
||||
if not chapters:
|
||||
return None
|
||||
@ -356,17 +479,54 @@ class MoodleConnector(LoadConnector, PollConnector):
|
||||
)
|
||||
|
||||
markdown_parts = [f"# {module.name}\n"]
|
||||
chapter_info = []
|
||||
|
||||
for ch in chapters:
|
||||
try:
|
||||
resp = rl_requests.get(self._add_token_to_url(ch.fileurl), timeout=60)
|
||||
resp.raise_for_status()
|
||||
html = resp.content.decode("utf-8", errors="ignore")
|
||||
markdown_parts.append(md(html) + "\n\n---\n")
|
||||
|
||||
# Collect chapter information for metadata
|
||||
chapter_info.append(
|
||||
{
|
||||
"chapter_id": getattr(ch, "chapterid", None),
|
||||
"title": getattr(ch, "title", None),
|
||||
"filename": getattr(ch, "filename", None),
|
||||
"fileurl": getattr(ch, "fileurl", None),
|
||||
"time_created": getattr(ch, "timecreated", None),
|
||||
"time_modified": getattr(ch, "timemodified", None),
|
||||
"size": getattr(ch, "filesize", None),
|
||||
}
|
||||
)
|
||||
except Exception as e:
|
||||
self._log_error(f"processing book chapter {ch.filename}", e)
|
||||
|
||||
blob = "\n".join(markdown_parts).encode("utf-8")
|
||||
semantic_id = f"{course.fullname} / {section.name} / {module.name}"
|
||||
|
||||
# Create metadata dictionary with relevant information
|
||||
metadata = {
|
||||
"moodle_url": self.moodle_url,
|
||||
"course_id": getattr(course, "id", None),
|
||||
"course_name": getattr(course, "fullname", None),
|
||||
"course_shortname": getattr(course, "shortname", None),
|
||||
"section_id": getattr(section, "id", None),
|
||||
"section_name": getattr(section, "name", None),
|
||||
"section_number": getattr(section, "section", None),
|
||||
"module_id": getattr(module, "id", None),
|
||||
"module_name": getattr(module, "name", None),
|
||||
"module_type": getattr(module, "modname", None),
|
||||
"book_id": getattr(module, "instance", None),
|
||||
"chapter_count": len(chapters),
|
||||
"chapters": chapter_info,
|
||||
"time_created": getattr(module, "timecreated", None),
|
||||
"time_modified": getattr(module, "timemodified", None),
|
||||
"visible": getattr(module, "visible", None),
|
||||
"groupmode": getattr(module, "groupmode", None),
|
||||
}
|
||||
|
||||
return Document(
|
||||
id=f"moodle_book_{module.id}",
|
||||
source="moodle",
|
||||
@ -375,4 +535,5 @@ class MoodleConnector(LoadConnector, PollConnector):
|
||||
blob=blob,
|
||||
doc_updated_at=datetime.fromtimestamp(latest_ts or 0, tz=timezone.utc),
|
||||
size_bytes=len(blob),
|
||||
metadata=metadata,
|
||||
)
|
||||
|
||||
@ -312,12 +312,15 @@ def create_s3_client(bucket_type: BlobType, credentials: dict[str, Any], europea
|
||||
region_name=credentials["region"],
|
||||
)
|
||||
elif bucket_type == BlobType.S3_COMPATIBLE:
|
||||
addressing_style = credentials.get("addressing_style", "virtual")
|
||||
|
||||
return boto3.client(
|
||||
"s3",
|
||||
endpoint_url=credentials["endpoint_url"],
|
||||
aws_access_key_id=credentials["aws_access_key_id"],
|
||||
aws_secret_access_key=credentials["aws_secret_access_key"],
|
||||
)
|
||||
config=Config(s3={'addressing_style': addressing_style}),
|
||||
)
|
||||
|
||||
else:
|
||||
raise ValueError(f"Unsupported bucket type: {bucket_type}")
|
||||
@ -730,7 +733,7 @@ def build_time_range_query(
|
||||
"""Build time range query for Gmail API"""
|
||||
query = ""
|
||||
if time_range_start is not None and time_range_start != 0:
|
||||
query += f"after:{int(time_range_start)}"
|
||||
query += f"after:{int(time_range_start) + 1}"
|
||||
if time_range_end is not None and time_range_end != 0:
|
||||
query += f" before:{int(time_range_end)}"
|
||||
query = query.strip()
|
||||
@ -775,6 +778,15 @@ def time_str_to_utc(time_str: str):
|
||||
return datetime.fromisoformat(time_str.replace("Z", "+00:00"))
|
||||
|
||||
|
||||
def gmail_time_str_to_utc(time_str: str):
|
||||
"""Convert Gmail RFC 2822 time string to UTC."""
|
||||
from email.utils import parsedate_to_datetime
|
||||
from datetime import timezone
|
||||
|
||||
dt = parsedate_to_datetime(time_str)
|
||||
return dt.astimezone(timezone.utc)
|
||||
|
||||
|
||||
# Notion Utilities
|
||||
T = TypeVar("T")
|
||||
|
||||
|
||||
370
common/data_source/webdav_connector.py
Normal file
370
common/data_source/webdav_connector.py
Normal file
@ -0,0 +1,370 @@
|
||||
"""WebDAV connector"""
|
||||
import logging
|
||||
import os
|
||||
from datetime import datetime, timezone
|
||||
from typing import Any, Optional
|
||||
|
||||
from webdav4.client import Client as WebDAVClient
|
||||
|
||||
from common.data_source.utils import (
|
||||
get_file_ext,
|
||||
)
|
||||
from common.data_source.config import DocumentSource, INDEX_BATCH_SIZE, BLOB_STORAGE_SIZE_THRESHOLD
|
||||
from common.data_source.exceptions import (
|
||||
ConnectorMissingCredentialError,
|
||||
ConnectorValidationError,
|
||||
CredentialExpiredError,
|
||||
InsufficientPermissionsError
|
||||
)
|
||||
from common.data_source.interfaces import LoadConnector, PollConnector
|
||||
from common.data_source.models import Document, SecondsSinceUnixEpoch, GenerateDocumentsOutput
|
||||
|
||||
|
||||
class WebDAVConnector(LoadConnector, PollConnector):
|
||||
"""WebDAV connector for syncing files from WebDAV servers"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
base_url: str,
|
||||
remote_path: str = "/",
|
||||
batch_size: int = INDEX_BATCH_SIZE,
|
||||
) -> None:
|
||||
"""Initialize WebDAV connector
|
||||
|
||||
Args:
|
||||
base_url: Base URL of the WebDAV server (e.g., "https://webdav.example.com")
|
||||
remote_path: Remote path to sync from (default: "/")
|
||||
batch_size: Number of documents per batch
|
||||
"""
|
||||
self.base_url = base_url.rstrip("/")
|
||||
if not remote_path:
|
||||
remote_path = "/"
|
||||
if not remote_path.startswith("/"):
|
||||
remote_path = f"/{remote_path}"
|
||||
if remote_path.endswith("/") and remote_path != "/":
|
||||
remote_path = remote_path.rstrip("/")
|
||||
self.remote_path = remote_path
|
||||
self.batch_size = batch_size
|
||||
self.client: Optional[WebDAVClient] = None
|
||||
self._allow_images: bool | None = None
|
||||
self.size_threshold: int | None = BLOB_STORAGE_SIZE_THRESHOLD
|
||||
|
||||
def set_allow_images(self, allow_images: bool) -> None:
|
||||
"""Set whether to process images"""
|
||||
logging.info(f"Setting allow_images to {allow_images}.")
|
||||
self._allow_images = allow_images
|
||||
|
||||
def load_credentials(self, credentials: dict[str, Any]) -> dict[str, Any] | None:
|
||||
"""Load credentials and initialize WebDAV client
|
||||
|
||||
Args:
|
||||
credentials: Dictionary containing 'username' and 'password'
|
||||
|
||||
Returns:
|
||||
None
|
||||
|
||||
Raises:
|
||||
ConnectorMissingCredentialError: If required credentials are missing
|
||||
"""
|
||||
logging.debug(f"Loading credentials for WebDAV server {self.base_url}")
|
||||
|
||||
username = credentials.get("username")
|
||||
password = credentials.get("password")
|
||||
|
||||
if not username or not password:
|
||||
raise ConnectorMissingCredentialError(
|
||||
"WebDAV requires 'username' and 'password' credentials"
|
||||
)
|
||||
|
||||
try:
|
||||
# Initialize WebDAV client
|
||||
self.client = WebDAVClient(
|
||||
base_url=self.base_url,
|
||||
auth=(username, password)
|
||||
)
|
||||
|
||||
# Test connection
|
||||
self.client.exists(self.remote_path)
|
||||
|
||||
except Exception as e:
|
||||
logging.error(f"Failed to connect to WebDAV server: {e}")
|
||||
raise ConnectorMissingCredentialError(
|
||||
f"Failed to authenticate with WebDAV server: {e}"
|
||||
)
|
||||
|
||||
return None
|
||||
|
||||
def _list_files_recursive(
|
||||
self,
|
||||
path: str,
|
||||
start: datetime,
|
||||
end: datetime,
|
||||
) -> list[tuple[str, dict]]:
|
||||
"""Recursively list all files in the given path
|
||||
|
||||
Args:
|
||||
path: Path to list files from
|
||||
start: Start datetime for filtering
|
||||
end: End datetime for filtering
|
||||
|
||||
Returns:
|
||||
List of tuples containing (file_path, file_info)
|
||||
"""
|
||||
if self.client is None:
|
||||
raise ConnectorMissingCredentialError("WebDAV client not initialized")
|
||||
|
||||
files = []
|
||||
|
||||
try:
|
||||
logging.debug(f"Listing directory: {path}")
|
||||
for item in self.client.ls(path, detail=True):
|
||||
item_path = item['name']
|
||||
|
||||
if item_path == path or item_path == path + '/':
|
||||
continue
|
||||
|
||||
logging.debug(f"Found item: {item_path}, type: {item.get('type')}")
|
||||
|
||||
if item.get('type') == 'directory':
|
||||
try:
|
||||
files.extend(self._list_files_recursive(item_path, start, end))
|
||||
except Exception as e:
|
||||
logging.error(f"Error recursing into directory {item_path}: {e}")
|
||||
continue
|
||||
else:
|
||||
try:
|
||||
modified_time = item.get('modified')
|
||||
if modified_time:
|
||||
if isinstance(modified_time, datetime):
|
||||
modified = modified_time
|
||||
if modified.tzinfo is None:
|
||||
modified = modified.replace(tzinfo=timezone.utc)
|
||||
elif isinstance(modified_time, str):
|
||||
try:
|
||||
modified = datetime.strptime(modified_time, '%a, %d %b %Y %H:%M:%S %Z')
|
||||
modified = modified.replace(tzinfo=timezone.utc)
|
||||
except (ValueError, TypeError):
|
||||
try:
|
||||
modified = datetime.fromisoformat(modified_time.replace('Z', '+00:00'))
|
||||
except (ValueError, TypeError):
|
||||
logging.warning(f"Could not parse modified time for {item_path}: {modified_time}")
|
||||
modified = datetime.now(timezone.utc)
|
||||
else:
|
||||
modified = datetime.now(timezone.utc)
|
||||
else:
|
||||
modified = datetime.now(timezone.utc)
|
||||
|
||||
|
||||
logging.debug(f"File {item_path}: modified={modified}, start={start}, end={end}, include={start < modified <= end}")
|
||||
if start < modified <= end:
|
||||
files.append((item_path, item))
|
||||
else:
|
||||
logging.debug(f"File {item_path} filtered out by time range")
|
||||
except Exception as e:
|
||||
logging.error(f"Error processing file {item_path}: {e}")
|
||||
continue
|
||||
|
||||
except Exception as e:
|
||||
logging.error(f"Error listing directory {path}: {e}")
|
||||
|
||||
return files
|
||||
|
||||
def _yield_webdav_documents(
|
||||
self,
|
||||
start: datetime,
|
||||
end: datetime,
|
||||
) -> GenerateDocumentsOutput:
|
||||
"""Generate documents from WebDAV server
|
||||
|
||||
Args:
|
||||
start: Start datetime for filtering
|
||||
end: End datetime for filtering
|
||||
|
||||
Yields:
|
||||
Batches of documents
|
||||
"""
|
||||
if self.client is None:
|
||||
raise ConnectorMissingCredentialError("WebDAV client not initialized")
|
||||
|
||||
logging.info(f"Searching for files in {self.remote_path} between {start} and {end}")
|
||||
files = self._list_files_recursive(self.remote_path, start, end)
|
||||
logging.info(f"Found {len(files)} files matching time criteria")
|
||||
|
||||
batch: list[Document] = []
|
||||
for file_path, file_info in files:
|
||||
file_name = os.path.basename(file_path)
|
||||
|
||||
size_bytes = file_info.get('size', 0)
|
||||
if (
|
||||
self.size_threshold is not None
|
||||
and isinstance(size_bytes, int)
|
||||
and size_bytes > self.size_threshold
|
||||
):
|
||||
logging.warning(
|
||||
f"{file_name} exceeds size threshold of {self.size_threshold}. Skipping."
|
||||
)
|
||||
continue
|
||||
|
||||
try:
|
||||
logging.debug(f"Downloading file: {file_path}")
|
||||
from io import BytesIO
|
||||
buffer = BytesIO()
|
||||
self.client.download_fileobj(file_path, buffer)
|
||||
blob = buffer.getvalue()
|
||||
|
||||
if blob is None or len(blob) == 0:
|
||||
logging.warning(f"Downloaded content is empty for {file_path}")
|
||||
continue
|
||||
|
||||
modified_time = file_info.get('modified')
|
||||
if modified_time:
|
||||
if isinstance(modified_time, datetime):
|
||||
modified = modified_time
|
||||
if modified.tzinfo is None:
|
||||
modified = modified.replace(tzinfo=timezone.utc)
|
||||
elif isinstance(modified_time, str):
|
||||
try:
|
||||
modified = datetime.strptime(modified_time, '%a, %d %b %Y %H:%M:%S %Z')
|
||||
modified = modified.replace(tzinfo=timezone.utc)
|
||||
except (ValueError, TypeError):
|
||||
try:
|
||||
modified = datetime.fromisoformat(modified_time.replace('Z', '+00:00'))
|
||||
except (ValueError, TypeError):
|
||||
logging.warning(f"Could not parse modified time for {file_path}: {modified_time}")
|
||||
modified = datetime.now(timezone.utc)
|
||||
else:
|
||||
modified = datetime.now(timezone.utc)
|
||||
else:
|
||||
modified = datetime.now(timezone.utc)
|
||||
|
||||
batch.append(
|
||||
Document(
|
||||
id=f"webdav:{self.base_url}:{file_path}",
|
||||
blob=blob,
|
||||
source=DocumentSource.WEBDAV,
|
||||
semantic_identifier=file_name,
|
||||
extension=get_file_ext(file_name),
|
||||
doc_updated_at=modified,
|
||||
size_bytes=size_bytes if size_bytes else 0
|
||||
)
|
||||
)
|
||||
|
||||
if len(batch) == self.batch_size:
|
||||
yield batch
|
||||
batch = []
|
||||
|
||||
except Exception as e:
|
||||
logging.exception(f"Error downloading file {file_path}: {e}")
|
||||
|
||||
if batch:
|
||||
yield batch
|
||||
|
||||
def load_from_state(self) -> GenerateDocumentsOutput:
|
||||
"""Load all documents from WebDAV server
|
||||
|
||||
Yields:
|
||||
Batches of documents
|
||||
"""
|
||||
logging.debug(f"Loading documents from WebDAV server {self.base_url}")
|
||||
return self._yield_webdav_documents(
|
||||
start=datetime(1970, 1, 1, tzinfo=timezone.utc),
|
||||
end=datetime.now(timezone.utc),
|
||||
)
|
||||
|
||||
def poll_source(
|
||||
self, start: SecondsSinceUnixEpoch, end: SecondsSinceUnixEpoch
|
||||
) -> GenerateDocumentsOutput:
|
||||
"""Poll WebDAV server for updated documents
|
||||
|
||||
Args:
|
||||
start: Start timestamp (seconds since Unix epoch)
|
||||
end: End timestamp (seconds since Unix epoch)
|
||||
|
||||
Yields:
|
||||
Batches of documents
|
||||
"""
|
||||
if self.client is None:
|
||||
raise ConnectorMissingCredentialError("WebDAV client not initialized")
|
||||
|
||||
start_datetime = datetime.fromtimestamp(start, tz=timezone.utc)
|
||||
end_datetime = datetime.fromtimestamp(end, tz=timezone.utc)
|
||||
|
||||
for batch in self._yield_webdav_documents(start_datetime, end_datetime):
|
||||
yield batch
|
||||
|
||||
def validate_connector_settings(self) -> None:
|
||||
"""Validate WebDAV connector settings
|
||||
|
||||
Raises:
|
||||
ConnectorMissingCredentialError: If credentials are not loaded
|
||||
ConnectorValidationError: If settings are invalid
|
||||
"""
|
||||
if self.client is None:
|
||||
raise ConnectorMissingCredentialError(
|
||||
"WebDAV credentials not loaded."
|
||||
)
|
||||
|
||||
if not self.base_url:
|
||||
raise ConnectorValidationError(
|
||||
"No base URL was provided in connector settings."
|
||||
)
|
||||
|
||||
try:
|
||||
if not self.client.exists(self.remote_path):
|
||||
raise ConnectorValidationError(
|
||||
f"Remote path '{self.remote_path}' does not exist on WebDAV server."
|
||||
)
|
||||
|
||||
except Exception as e:
|
||||
error_message = str(e)
|
||||
|
||||
if "401" in error_message or "unauthorized" in error_message.lower():
|
||||
raise CredentialExpiredError(
|
||||
"WebDAV credentials appear invalid or expired."
|
||||
)
|
||||
|
||||
if "403" in error_message or "forbidden" in error_message.lower():
|
||||
raise InsufficientPermissionsError(
|
||||
f"Insufficient permissions to access path '{self.remote_path}' on WebDAV server."
|
||||
)
|
||||
|
||||
if "404" in error_message or "not found" in error_message.lower():
|
||||
raise ConnectorValidationError(
|
||||
f"Remote path '{self.remote_path}' does not exist on WebDAV server."
|
||||
)
|
||||
|
||||
raise ConnectorValidationError(
|
||||
f"Unexpected WebDAV client error: {e}"
|
||||
)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
credentials_dict = {
|
||||
"username": os.environ.get("WEBDAV_USERNAME"),
|
||||
"password": os.environ.get("WEBDAV_PASSWORD"),
|
||||
}
|
||||
|
||||
connector = WebDAVConnector(
|
||||
base_url=os.environ.get("WEBDAV_URL") or "https://webdav.example.com",
|
||||
remote_path=os.environ.get("WEBDAV_PATH") or "/",
|
||||
)
|
||||
|
||||
try:
|
||||
connector.load_credentials(credentials_dict)
|
||||
connector.validate_connector_settings()
|
||||
|
||||
document_batch_generator = connector.load_from_state()
|
||||
for document_batch in document_batch_generator:
|
||||
print("First batch of documents:")
|
||||
for doc in document_batch:
|
||||
print(f"Document ID: {doc.id}")
|
||||
print(f"Semantic Identifier: {doc.semantic_identifier}")
|
||||
print(f"Source: {doc.source}")
|
||||
print(f"Updated At: {doc.doc_updated_at}")
|
||||
print("---")
|
||||
break
|
||||
|
||||
except ConnectorMissingCredentialError as e:
|
||||
print(f"Error: {e}")
|
||||
except Exception as e:
|
||||
print(f"An unexpected error occurred: {e}")
|
||||
157
common/http_client.py
Normal file
157
common/http_client.py
Normal file
@ -0,0 +1,157 @@
|
||||
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import asyncio
|
||||
import logging
|
||||
import os
|
||||
import time
|
||||
from typing import Any, Dict, Optional
|
||||
|
||||
import httpx
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
# Default knobs; keep conservative to avoid unexpected behavioural changes.
|
||||
DEFAULT_TIMEOUT = float(os.environ.get("HTTP_CLIENT_TIMEOUT", "15"))
|
||||
# Align with requests default: follow redirects with a max of 30 unless overridden.
|
||||
DEFAULT_FOLLOW_REDIRECTS = bool(int(os.environ.get("HTTP_CLIENT_FOLLOW_REDIRECTS", "1")))
|
||||
DEFAULT_MAX_REDIRECTS = int(os.environ.get("HTTP_CLIENT_MAX_REDIRECTS", "30"))
|
||||
DEFAULT_MAX_RETRIES = int(os.environ.get("HTTP_CLIENT_MAX_RETRIES", "2"))
|
||||
DEFAULT_BACKOFF_FACTOR = float(os.environ.get("HTTP_CLIENT_BACKOFF_FACTOR", "0.5"))
|
||||
DEFAULT_PROXY = os.environ.get("HTTP_CLIENT_PROXY")
|
||||
DEFAULT_USER_AGENT = os.environ.get("HTTP_CLIENT_USER_AGENT", "ragflow-http-client")
|
||||
|
||||
|
||||
def _clean_headers(headers: Optional[Dict[str, str]], auth_token: Optional[str] = None) -> Optional[Dict[str, str]]:
|
||||
merged_headers: Dict[str, str] = {}
|
||||
if DEFAULT_USER_AGENT:
|
||||
merged_headers["User-Agent"] = DEFAULT_USER_AGENT
|
||||
if auth_token:
|
||||
merged_headers["Authorization"] = auth_token
|
||||
if headers is None:
|
||||
return merged_headers or None
|
||||
merged_headers.update({str(k): str(v) for k, v in headers.items() if v is not None})
|
||||
return merged_headers or None
|
||||
|
||||
|
||||
def _get_delay(backoff_factor: float, attempt: int) -> float:
|
||||
return backoff_factor * (2**attempt)
|
||||
|
||||
|
||||
async def async_request(
|
||||
method: str,
|
||||
url: str,
|
||||
*,
|
||||
timeout: float | httpx.Timeout | None = None,
|
||||
follow_redirects: bool | None = None,
|
||||
max_redirects: Optional[int] = None,
|
||||
headers: Optional[Dict[str, str]] = None,
|
||||
auth_token: Optional[str] = None,
|
||||
retries: Optional[int] = None,
|
||||
backoff_factor: Optional[float] = None,
|
||||
proxies: Any = None,
|
||||
**kwargs: Any,
|
||||
) -> httpx.Response:
|
||||
"""Lightweight async HTTP wrapper using httpx.AsyncClient with safe defaults."""
|
||||
timeout = timeout if timeout is not None else DEFAULT_TIMEOUT
|
||||
follow_redirects = DEFAULT_FOLLOW_REDIRECTS if follow_redirects is None else follow_redirects
|
||||
max_redirects = DEFAULT_MAX_REDIRECTS if max_redirects is None else max_redirects
|
||||
retries = DEFAULT_MAX_RETRIES if retries is None else max(retries, 0)
|
||||
backoff_factor = DEFAULT_BACKOFF_FACTOR if backoff_factor is None else backoff_factor
|
||||
headers = _clean_headers(headers, auth_token=auth_token)
|
||||
proxies = DEFAULT_PROXY if proxies is None else proxies
|
||||
|
||||
async with httpx.AsyncClient(
|
||||
timeout=timeout,
|
||||
follow_redirects=follow_redirects,
|
||||
max_redirects=max_redirects,
|
||||
proxies=proxies,
|
||||
) as client:
|
||||
last_exc: Exception | None = None
|
||||
for attempt in range(retries + 1):
|
||||
try:
|
||||
start = time.monotonic()
|
||||
response = await client.request(method=method, url=url, headers=headers, **kwargs)
|
||||
duration = time.monotonic() - start
|
||||
logger.debug(f"async_request {method} {url} -> {response.status_code} in {duration:.3f}s")
|
||||
return response
|
||||
except httpx.RequestError as exc:
|
||||
last_exc = exc
|
||||
if attempt >= retries:
|
||||
logger.warning(f"async_request exhausted retries for {method} {url}: {exc}")
|
||||
raise
|
||||
delay = _get_delay(backoff_factor, attempt)
|
||||
logger.warning(f"async_request attempt {attempt + 1}/{retries + 1} failed for {method} {url}: {exc}; retrying in {delay:.2f}s")
|
||||
await asyncio.sleep(delay)
|
||||
raise last_exc # pragma: no cover
|
||||
|
||||
|
||||
def sync_request(
|
||||
method: str,
|
||||
url: str,
|
||||
*,
|
||||
timeout: float | httpx.Timeout | None = None,
|
||||
follow_redirects: bool | None = None,
|
||||
max_redirects: Optional[int] = None,
|
||||
headers: Optional[Dict[str, str]] = None,
|
||||
auth_token: Optional[str] = None,
|
||||
retries: Optional[int] = None,
|
||||
backoff_factor: Optional[float] = None,
|
||||
proxies: Any = None,
|
||||
**kwargs: Any,
|
||||
) -> httpx.Response:
|
||||
"""Synchronous counterpart to async_request, for CLI/tests or sync contexts."""
|
||||
timeout = timeout if timeout is not None else DEFAULT_TIMEOUT
|
||||
follow_redirects = DEFAULT_FOLLOW_REDIRECTS if follow_redirects is None else follow_redirects
|
||||
max_redirects = DEFAULT_MAX_REDIRECTS if max_redirects is None else max_redirects
|
||||
retries = DEFAULT_MAX_RETRIES if retries is None else max(retries, 0)
|
||||
backoff_factor = DEFAULT_BACKOFF_FACTOR if backoff_factor is None else backoff_factor
|
||||
headers = _clean_headers(headers, auth_token=auth_token)
|
||||
proxies = DEFAULT_PROXY if proxies is None else proxies
|
||||
|
||||
with httpx.Client(
|
||||
timeout=timeout,
|
||||
follow_redirects=follow_redirects,
|
||||
max_redirects=max_redirects,
|
||||
proxies=proxies,
|
||||
) as client:
|
||||
last_exc: Exception | None = None
|
||||
for attempt in range(retries + 1):
|
||||
try:
|
||||
start = time.monotonic()
|
||||
response = client.request(method=method, url=url, headers=headers, **kwargs)
|
||||
duration = time.monotonic() - start
|
||||
logger.debug(f"sync_request {method} {url} -> {response.status_code} in {duration:.3f}s")
|
||||
return response
|
||||
except httpx.RequestError as exc:
|
||||
last_exc = exc
|
||||
if attempt >= retries:
|
||||
logger.warning(f"sync_request exhausted retries for {method} {url}: {exc}")
|
||||
raise
|
||||
delay = _get_delay(backoff_factor, attempt)
|
||||
logger.warning(f"sync_request attempt {attempt + 1}/{retries + 1} failed for {method} {url}: {exc}; retrying in {delay:.2f}s")
|
||||
time.sleep(delay)
|
||||
raise last_exc # pragma: no cover
|
||||
|
||||
|
||||
__all__ = [
|
||||
"async_request",
|
||||
"sync_request",
|
||||
"DEFAULT_TIMEOUT",
|
||||
"DEFAULT_FOLLOW_REDIRECTS",
|
||||
"DEFAULT_MAX_REDIRECTS",
|
||||
"DEFAULT_MAX_RETRIES",
|
||||
"DEFAULT_BACKOFF_FACTOR",
|
||||
"DEFAULT_PROXY",
|
||||
"DEFAULT_USER_AGENT",
|
||||
]
|
||||
@ -23,6 +23,8 @@ import subprocess
|
||||
import sys
|
||||
import os
|
||||
import logging
|
||||
from pathlib import Path
|
||||
from typing import Dict
|
||||
|
||||
def get_uuid():
|
||||
return uuid.uuid1().hex
|
||||
@ -106,3 +108,152 @@ def pip_install_torch():
|
||||
logging.info("Installing pytorch")
|
||||
pkg_names = ["torch>=2.5.0,<3.0.0"]
|
||||
subprocess.check_call([sys.executable, "-m", "pip", "install", *pkg_names])
|
||||
|
||||
|
||||
def parse_mineru_paths() -> Dict[str, Path]:
|
||||
"""
|
||||
Parse MinerU-related paths based on the MINERU_EXECUTABLE environment variable.
|
||||
|
||||
Expected layout (default convention):
|
||||
MINERU_EXECUTABLE = /home/user/uv_tools/.venv/bin/mineru
|
||||
|
||||
From this path we derive:
|
||||
- mineru_exec : full path to the mineru executable
|
||||
- venv_dir : the virtual environment directory (.venv)
|
||||
- tools_dir : the parent tools directory (e.g. uv_tools)
|
||||
|
||||
If MINERU_EXECUTABLE is not set, we fall back to the default layout:
|
||||
$HOME/uv_tools/.venv/bin/mineru
|
||||
|
||||
Returns:
|
||||
A dict with keys:
|
||||
- "mineru_exec": Path
|
||||
- "venv_dir": Path
|
||||
- "tools_dir": Path
|
||||
"""
|
||||
mineru_exec_env = os.getenv("MINERU_EXECUTABLE")
|
||||
|
||||
if mineru_exec_env:
|
||||
# Use the path from the environment variable
|
||||
mineru_exec = Path(mineru_exec_env).expanduser().resolve()
|
||||
venv_dir = mineru_exec.parent.parent
|
||||
tools_dir = venv_dir.parent
|
||||
else:
|
||||
# Fall back to default convention: $HOME/uv_tools/.venv/bin/mineru
|
||||
home = Path(os.path.expanduser("~"))
|
||||
tools_dir = home / "uv_tools"
|
||||
venv_dir = tools_dir / ".venv"
|
||||
mineru_exec = venv_dir / "bin" / "mineru"
|
||||
|
||||
return {
|
||||
"mineru_exec": mineru_exec,
|
||||
"venv_dir": venv_dir,
|
||||
"tools_dir": tools_dir,
|
||||
}
|
||||
|
||||
|
||||
@once
|
||||
def install_mineru() -> None:
|
||||
"""
|
||||
Ensure MinerU is installed.
|
||||
|
||||
Behavior:
|
||||
1. MinerU is enabled only when USE_MINERU is true/yes/1/y.
|
||||
2. Resolve mineru_exec / venv_dir / tools_dir.
|
||||
3. If mineru exists and works, log success and exit.
|
||||
4. Otherwise:
|
||||
- Create tools_dir
|
||||
- Create venv if missing
|
||||
- Install mineru[core], fallback to mineru[all]
|
||||
- Validate with `--help`
|
||||
5. Log installation success.
|
||||
|
||||
NOTE:
|
||||
This function intentionally does NOT return the path.
|
||||
Logging is used to indicate status.
|
||||
"""
|
||||
# Check if MinerU is enabled
|
||||
use_mineru = os.getenv("USE_MINERU", "").strip().lower()
|
||||
if use_mineru == "false":
|
||||
logging.info("USE_MINERU=%r. Skipping MinerU installation.", use_mineru)
|
||||
return
|
||||
|
||||
# Resolve expected paths
|
||||
paths = parse_mineru_paths()
|
||||
mineru_exec: Path = paths["mineru_exec"]
|
||||
venv_dir: Path = paths["venv_dir"]
|
||||
tools_dir: Path = paths["tools_dir"]
|
||||
|
||||
# Construct environment variables for installation/execution
|
||||
env = os.environ.copy()
|
||||
env["VIRTUAL_ENV"] = str(venv_dir)
|
||||
env["PATH"] = str(venv_dir / "bin") + os.pathsep + env.get("PATH", "")
|
||||
|
||||
# Configure HuggingFace endpoint
|
||||
env.setdefault("HUGGINGFACE_HUB_ENDPOINT", os.getenv("HF_ENDPOINT") or "https://hf-mirror.com")
|
||||
|
||||
# Helper: check whether mineru works
|
||||
def mineru_works() -> bool:
|
||||
try:
|
||||
subprocess.check_call(
|
||||
[str(mineru_exec), "--help"],
|
||||
stdout=subprocess.DEVNULL,
|
||||
stderr=subprocess.PIPE,
|
||||
env=env,
|
||||
)
|
||||
return True
|
||||
except Exception:
|
||||
return False
|
||||
|
||||
# If MinerU is already installed and functional
|
||||
if mineru_exec.is_file() and os.access(mineru_exec, os.X_OK) and mineru_works():
|
||||
logging.info("MinerU already installed.")
|
||||
os.environ["MINERU_EXECUTABLE"] = str(mineru_exec)
|
||||
return
|
||||
|
||||
logging.info("MinerU not found. Installing into virtualenv: %s", venv_dir)
|
||||
|
||||
# Ensure parent directory exists
|
||||
tools_dir.mkdir(parents=True, exist_ok=True)
|
||||
|
||||
# Create venv if missing
|
||||
if not venv_dir.exists():
|
||||
subprocess.check_call(
|
||||
["uv", "venv", str(venv_dir)],
|
||||
cwd=str(tools_dir),
|
||||
env=env,
|
||||
# stdout=subprocess.DEVNULL,
|
||||
# stderr=subprocess.PIPE,
|
||||
)
|
||||
else:
|
||||
logging.info("Virtual environment exists at %s. Reusing it.", venv_dir)
|
||||
|
||||
# Helper for pip install
|
||||
def pip_install(pkg: str) -> None:
|
||||
subprocess.check_call(
|
||||
[
|
||||
"uv", "pip", "install", "-U", pkg,
|
||||
"-i", "https://mirrors.aliyun.com/pypi/simple",
|
||||
"--extra-index-url", "https://pypi.org/simple",
|
||||
],
|
||||
cwd=str(tools_dir),
|
||||
# stdout=subprocess.DEVNULL,
|
||||
# stderr=subprocess.PIPE,
|
||||
env=env,
|
||||
)
|
||||
|
||||
# Install core version first; fallback to all
|
||||
try:
|
||||
logging.info("Installing mineru[core] ...")
|
||||
pip_install("mineru[core]")
|
||||
except subprocess.CalledProcessError:
|
||||
logging.warning("mineru[core] installation failed. Installing mineru[all] ...")
|
||||
pip_install("mineru[all]")
|
||||
|
||||
# Validate installation
|
||||
if not mineru_works():
|
||||
logging.error("MinerU installation failed: %s does not work.", mineru_exec)
|
||||
raise RuntimeError(f"MinerU installation failed: {mineru_exec} is not functional")
|
||||
|
||||
os.environ["MINERU_EXECUTABLE"] = str(mineru_exec)
|
||||
logging.info("MinerU installation completed successfully. Executable: %s", mineru_exec)
|
||||
|
||||
@ -74,6 +74,8 @@ GITHUB_OAUTH = None
|
||||
FEISHU_OAUTH = None
|
||||
OAUTH_CONFIG = None
|
||||
DOC_ENGINE = os.getenv('DOC_ENGINE', 'elasticsearch')
|
||||
DOC_ENGINE_INFINITY = (DOC_ENGINE.lower() == "infinity")
|
||||
|
||||
|
||||
docStoreConn = None
|
||||
|
||||
@ -139,7 +141,7 @@ def _get_or_create_secret_key():
|
||||
import logging
|
||||
|
||||
new_key = secrets.token_hex(32)
|
||||
logging.warning(f"SECURITY WARNING: Using auto-generated SECRET_KEY. Generated key: {new_key}")
|
||||
logging.warning("SECURITY WARNING: Using auto-generated SECRET_KEY.")
|
||||
return new_key
|
||||
|
||||
class StorageFactory:
|
||||
@ -229,9 +231,9 @@ def init_settings():
|
||||
FEISHU_OAUTH = get_base_config("oauth", {}).get("feishu")
|
||||
OAUTH_CONFIG = get_base_config("oauth", {})
|
||||
|
||||
global DOC_ENGINE, docStoreConn, ES, OB, OS, INFINITY
|
||||
global DOC_ENGINE, DOC_ENGINE_INFINITY, docStoreConn, ES, OB, OS, INFINITY
|
||||
DOC_ENGINE = os.environ.get("DOC_ENGINE", "elasticsearch")
|
||||
# DOC_ENGINE = os.environ.get('DOC_ENGINE', "opensearch")
|
||||
DOC_ENGINE_INFINITY = (DOC_ENGINE.lower() == "infinity")
|
||||
lower_case_doc_engine = DOC_ENGINE.lower()
|
||||
if lower_case_doc_engine == "elasticsearch":
|
||||
ES = get_base_config("es", {})
|
||||
|
||||
@ -5,20 +5,13 @@
|
||||
"create_time": {"type": "varchar", "default": ""},
|
||||
"create_timestamp_flt": {"type": "float", "default": 0.0},
|
||||
"img_id": {"type": "varchar", "default": ""},
|
||||
"docnm_kwd": {"type": "varchar", "default": ""},
|
||||
"title_tks": {"type": "varchar", "default": "", "analyzer": "whitespace"},
|
||||
"title_sm_tks": {"type": "varchar", "default": "", "analyzer": "whitespace"},
|
||||
"docnm": {"type": "varchar", "default": "", "analyzer": ["rag-coarse", "rag-fine"], "comment": "docnm_kwd, title_tks, title_sm_tks"},
|
||||
"name_kwd": {"type": "varchar", "default": "", "analyzer": "whitespace-#"},
|
||||
"important_kwd": {"type": "varchar", "default": "", "analyzer": "whitespace-#"},
|
||||
"tag_kwd": {"type": "varchar", "default": "", "analyzer": "whitespace-#"},
|
||||
"important_tks": {"type": "varchar", "default": "", "analyzer": "whitespace"},
|
||||
"question_kwd": {"type": "varchar", "default": "", "analyzer": "whitespace-#"},
|
||||
"question_tks": {"type": "varchar", "default": "", "analyzer": "whitespace"},
|
||||
"content_with_weight": {"type": "varchar", "default": ""},
|
||||
"content_ltks": {"type": "varchar", "default": "", "analyzer": "whitespace"},
|
||||
"content_sm_ltks": {"type": "varchar", "default": "", "analyzer": "whitespace"},
|
||||
"authors_tks": {"type": "varchar", "default": "", "analyzer": "whitespace"},
|
||||
"authors_sm_tks": {"type": "varchar", "default": "", "analyzer": "whitespace"},
|
||||
"important_keywords": {"type": "varchar", "default": "", "analyzer": ["rag-coarse", "rag-fine"], "comment": "important_kwd, important_tks"},
|
||||
"questions": {"type": "varchar", "default": "", "analyzer": ["rag-coarse", "rag-fine"], "comment": "question_kwd, question_tks"},
|
||||
"content": {"type": "varchar", "default": "", "analyzer": ["rag-coarse", "rag-fine"], "comment": "content_with_weight, content_ltks, content_sm_ltks"},
|
||||
"authors": {"type": "varchar", "default": "", "analyzer": ["rag-coarse", "rag-fine"], "comment": "authors_tks, authors_sm_tks"},
|
||||
"page_num_int": {"type": "varchar", "default": ""},
|
||||
"top_int": {"type": "varchar", "default": ""},
|
||||
"position_int": {"type": "varchar", "default": ""},
|
||||
|
||||
@ -7,6 +7,20 @@
|
||||
"status": "1",
|
||||
"rank": "999",
|
||||
"llm": [
|
||||
{
|
||||
"llm_name": "gpt-5.1",
|
||||
"tags": "LLM,CHAT,400k,IMAGE2TEXT",
|
||||
"max_tokens": 400000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "gpt-5.1-chat-latest",
|
||||
"tags": "LLM,CHAT,400k,IMAGE2TEXT",
|
||||
"max_tokens": 400000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "gpt-5",
|
||||
"tags": "LLM,CHAT,400k,IMAGE2TEXT",
|
||||
@ -269,20 +283,6 @@
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "glm-4.5",
|
||||
"tags": "LLM,CHAT,131K",
|
||||
"max_tokens": 131000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "deepseek-v3.1",
|
||||
"tags": "LLM,CHAT,128k",
|
||||
"max_tokens": 128000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "hunyuan-a13b-instruct",
|
||||
"tags": "LLM,CHAT,256k",
|
||||
@ -324,6 +324,34 @@
|
||||
"max_tokens": 262000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "deepseek-ocr",
|
||||
"tags": "LLM,8k",
|
||||
"max_tokens": 8000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "qwen3-235b-a22b-instruct-2507",
|
||||
"tags": "LLM,CHAT,256k",
|
||||
"max_tokens": 256000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "glm-4.6",
|
||||
"tags": "LLM,CHAT,200k",
|
||||
"max_tokens": 200000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "minimax-m2",
|
||||
"tags": "LLM,CHAT,200k",
|
||||
"max_tokens": 200000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
}
|
||||
]
|
||||
},
|
||||
@ -686,19 +714,13 @@
|
||||
"model_type": "rerank"
|
||||
},
|
||||
{
|
||||
"llm_name": "qwen-audio-asr",
|
||||
"llm_name": "qwen3-asr-flash",
|
||||
"tags": "SPEECH2TEXT,8k",
|
||||
"max_tokens": 8000,
|
||||
"model_type": "speech2text"
|
||||
},
|
||||
{
|
||||
"llm_name": "qwen-audio-asr-latest",
|
||||
"tags": "SPEECH2TEXT,8k",
|
||||
"max_tokens": 8000,
|
||||
"model_type": "speech2text"
|
||||
},
|
||||
{
|
||||
"llm_name": "qwen-audio-asr-1204",
|
||||
"llm_name": "qwen3-asr-flash-2025-09-08",
|
||||
"tags": "SPEECH2TEXT,8k",
|
||||
"max_tokens": 8000,
|
||||
"model_type": "speech2text"
|
||||
@ -1166,6 +1188,12 @@
|
||||
"tags": "TEXT EMBEDDING",
|
||||
"max_tokens": 8196,
|
||||
"model_type": "embedding"
|
||||
},
|
||||
{
|
||||
"llm_name": "jina-embeddings-v4",
|
||||
"tags": "TEXT EMBEDDING",
|
||||
"max_tokens": 32768,
|
||||
"model_type": "embedding"
|
||||
}
|
||||
]
|
||||
},
|
||||
@ -1198,39 +1226,14 @@
|
||||
{
|
||||
"name": "MiniMax",
|
||||
"logo": "",
|
||||
"tags": "LLM,TEXT EMBEDDING",
|
||||
"tags": "LLM",
|
||||
"status": "1",
|
||||
"rank": "810",
|
||||
"llm": [
|
||||
{
|
||||
"llm_name": "abab6.5-chat",
|
||||
"tags": "LLM,CHAT,8k",
|
||||
"max_tokens": 8192,
|
||||
"model_type": "chat"
|
||||
},
|
||||
{
|
||||
"llm_name": "abab6.5s-chat",
|
||||
"tags": "LLM,CHAT,245k",
|
||||
"max_tokens": 245760,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "abab6.5t-chat",
|
||||
"tags": "LLM,CHAT,8k",
|
||||
"max_tokens": 8192,
|
||||
"model_type": "chat"
|
||||
},
|
||||
{
|
||||
"llm_name": "abab6.5g-chat",
|
||||
"tags": "LLM,CHAT,8k",
|
||||
"max_tokens": 8192,
|
||||
"model_type": "chat"
|
||||
},
|
||||
{
|
||||
"llm_name": "abab5.5s-chat",
|
||||
"tags": "LLM,CHAT,8k",
|
||||
"max_tokens": 8192,
|
||||
"llm_name": "MiniMax-M2",
|
||||
"tags": "LLM,CHAT,200k",
|
||||
"max_tokens": 200000,
|
||||
"model_type": "chat"
|
||||
}
|
||||
]
|
||||
@ -3218,6 +3221,13 @@
|
||||
"status": "1",
|
||||
"rank": "990",
|
||||
"llm": [
|
||||
{
|
||||
"llm_name": "claude-opus-4-5-20251101",
|
||||
"tags": "LLM,CHAT,IMAGE2TEXT,200k",
|
||||
"max_tokens": 204800,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "claude-opus-4-1-20250805",
|
||||
"tags": "LLM,CHAT,IMAGE2TEXT,200k",
|
||||
|
||||
@ -38,6 +38,7 @@ oceanbase:
|
||||
port: 2881
|
||||
redis:
|
||||
db: 1
|
||||
username: ''
|
||||
password: 'infini_rag_flow'
|
||||
host: 'localhost:6379'
|
||||
task_executor:
|
||||
|
||||
@ -138,7 +138,6 @@ class RAGFlowHtmlParser:
|
||||
"metadata": {"table_id": table_id, "index": table_list.index(t)}})
|
||||
return table_info_list
|
||||
else:
|
||||
block_id = None
|
||||
if str.lower(element.name) in BLOCK_TAGS:
|
||||
block_id = str(uuid.uuid1())
|
||||
for child in element.children:
|
||||
@ -172,7 +171,7 @@ class RAGFlowHtmlParser:
|
||||
if tag_name == "table":
|
||||
table_info_list.append(item)
|
||||
else:
|
||||
current_content += (" " if current_content else "" + content)
|
||||
current_content += (" " if current_content else "") + content
|
||||
if current_content:
|
||||
block_content.append(current_content)
|
||||
return block_content, table_info_list
|
||||
|
||||
@ -72,9 +72,8 @@ class RAGFlowMarkdownParser:
|
||||
|
||||
# Replace any TAGS e.g. <table ...> to <table>
|
||||
TAGS = ["table", "td", "tr", "th", "tbody", "thead", "div"]
|
||||
table_with_attributes_pattern = re.compile(
|
||||
rf"<(?:{'|'.join(TAGS)})[^>]*>", re.IGNORECASE
|
||||
)
|
||||
table_with_attributes_pattern = re.compile(rf"<(?:{'|'.join(TAGS)})[^>]*>", re.IGNORECASE)
|
||||
|
||||
def replace_tag(m):
|
||||
tag_name = re.match(r"<(\w+)", m.group()).group(1)
|
||||
return "<{}>".format(tag_name)
|
||||
@ -128,23 +127,48 @@ class MarkdownElementExtractor:
|
||||
self.markdown_content = markdown_content
|
||||
self.lines = markdown_content.split("\n")
|
||||
|
||||
def get_delimiters(self,delimiters):
|
||||
def get_delimiters(self, delimiters):
|
||||
toks = re.findall(r"`([^`]+)`", delimiters)
|
||||
toks = sorted(set(toks), key=lambda x: -len(x))
|
||||
return "|".join(re.escape(t) for t in toks if t)
|
||||
|
||||
def extract_elements(self,delimiter=None):
|
||||
|
||||
def extract_elements(self, delimiter=None, include_meta=False):
|
||||
"""Extract individual elements (headers, code blocks, lists, etc.)"""
|
||||
sections = []
|
||||
|
||||
i = 0
|
||||
dels=""
|
||||
dels = ""
|
||||
if delimiter:
|
||||
dels = self.get_delimiters(delimiter)
|
||||
if len(dels) > 0:
|
||||
text = "\n".join(self.lines)
|
||||
parts = re.split(dels, text)
|
||||
sections = [p.strip() for p in parts if p and p.strip()]
|
||||
if include_meta:
|
||||
pattern = re.compile(dels)
|
||||
last_end = 0
|
||||
for m in pattern.finditer(text):
|
||||
part = text[last_end : m.start()]
|
||||
if part and part.strip():
|
||||
sections.append(
|
||||
{
|
||||
"content": part.strip(),
|
||||
"start_line": text.count("\n", 0, last_end),
|
||||
"end_line": text.count("\n", 0, m.start()),
|
||||
}
|
||||
)
|
||||
last_end = m.end()
|
||||
|
||||
part = text[last_end:]
|
||||
if part and part.strip():
|
||||
sections.append(
|
||||
{
|
||||
"content": part.strip(),
|
||||
"start_line": text.count("\n", 0, last_end),
|
||||
"end_line": text.count("\n", 0, len(text)),
|
||||
}
|
||||
)
|
||||
else:
|
||||
parts = re.split(dels, text)
|
||||
sections = [p.strip() for p in parts if p and p.strip()]
|
||||
return sections
|
||||
while i < len(self.lines):
|
||||
line = self.lines[i]
|
||||
@ -152,32 +176,35 @@ class MarkdownElementExtractor:
|
||||
if re.match(r"^#{1,6}\s+.*$", line):
|
||||
# header
|
||||
element = self._extract_header(i)
|
||||
sections.append(element["content"])
|
||||
sections.append(element if include_meta else element["content"])
|
||||
i = element["end_line"] + 1
|
||||
elif line.strip().startswith("```"):
|
||||
# code block
|
||||
element = self._extract_code_block(i)
|
||||
sections.append(element["content"])
|
||||
sections.append(element if include_meta else element["content"])
|
||||
i = element["end_line"] + 1
|
||||
elif re.match(r"^\s*[-*+]\s+.*$", line) or re.match(r"^\s*\d+\.\s+.*$", line):
|
||||
# list block
|
||||
element = self._extract_list_block(i)
|
||||
sections.append(element["content"])
|
||||
sections.append(element if include_meta else element["content"])
|
||||
i = element["end_line"] + 1
|
||||
elif line.strip().startswith(">"):
|
||||
# blockquote
|
||||
element = self._extract_blockquote(i)
|
||||
sections.append(element["content"])
|
||||
sections.append(element if include_meta else element["content"])
|
||||
i = element["end_line"] + 1
|
||||
elif line.strip():
|
||||
# text block (paragraphs and inline elements until next block element)
|
||||
element = self._extract_text_block(i)
|
||||
sections.append(element["content"])
|
||||
sections.append(element if include_meta else element["content"])
|
||||
i = element["end_line"] + 1
|
||||
else:
|
||||
i += 1
|
||||
|
||||
sections = [section for section in sections if section.strip()]
|
||||
if include_meta:
|
||||
sections = [section for section in sections if section["content"].strip()]
|
||||
else:
|
||||
sections = [section for section in sections if section.strip()]
|
||||
return sections
|
||||
|
||||
def _extract_header(self, start_pos):
|
||||
|
||||
@ -190,7 +190,7 @@ class MinerUParser(RAGFlowPdfParser):
|
||||
self._run_mineru_executable(input_path, output_dir, method, backend, lang, server_url, callback)
|
||||
|
||||
def _run_mineru_api(self, input_path: Path, output_dir: Path, method: str = "auto", backend: str = "pipeline", lang: Optional[str] = None, callback: Optional[Callable] = None):
|
||||
OUTPUT_ZIP_PATH = os.path.join(str(output_dir), "output.zip")
|
||||
output_zip_path = os.path.join(str(output_dir), "output.zip")
|
||||
|
||||
pdf_file_path = str(input_path)
|
||||
|
||||
@ -230,16 +230,16 @@ class MinerUParser(RAGFlowPdfParser):
|
||||
|
||||
response.raise_for_status()
|
||||
if response.headers.get("Content-Type") == "application/zip":
|
||||
self.logger.info(f"[MinerU] zip file returned, saving to {OUTPUT_ZIP_PATH}...")
|
||||
self.logger.info(f"[MinerU] zip file returned, saving to {output_zip_path}...")
|
||||
|
||||
if callback:
|
||||
callback(0.30, f"[MinerU] zip file returned, saving to {OUTPUT_ZIP_PATH}...")
|
||||
callback(0.30, f"[MinerU] zip file returned, saving to {output_zip_path}...")
|
||||
|
||||
with open(OUTPUT_ZIP_PATH, "wb") as f:
|
||||
with open(output_zip_path, "wb") as f:
|
||||
f.write(response.content)
|
||||
|
||||
self.logger.info(f"[MinerU] Unzip to {output_path}...")
|
||||
self._extract_zip_no_root(OUTPUT_ZIP_PATH, output_path, pdf_file_name + "/")
|
||||
self._extract_zip_no_root(output_zip_path, output_path, pdf_file_name + "/")
|
||||
|
||||
if callback:
|
||||
callback(0.40, f"[MinerU] Unzip to {output_path}...")
|
||||
@ -459,13 +459,36 @@ class MinerUParser(RAGFlowPdfParser):
|
||||
return poss
|
||||
|
||||
def _read_output(self, output_dir: Path, file_stem: str, method: str = "auto", backend: str = "pipeline") -> list[dict[str, Any]]:
|
||||
subdir = output_dir / file_stem / method
|
||||
if backend.startswith("vlm-"):
|
||||
subdir = output_dir / file_stem / "vlm"
|
||||
json_file = subdir / f"{file_stem}_content_list.json"
|
||||
candidates = []
|
||||
seen = set()
|
||||
|
||||
if not json_file.exists():
|
||||
raise FileNotFoundError(f"[MinerU] Missing output file: {json_file}")
|
||||
def add_candidate_path(p: Path):
|
||||
if p not in seen:
|
||||
seen.add(p)
|
||||
candidates.append(p)
|
||||
|
||||
if backend.startswith("vlm-"):
|
||||
add_candidate_path(output_dir / file_stem / "vlm")
|
||||
if method:
|
||||
add_candidate_path(output_dir / file_stem / method)
|
||||
add_candidate_path(output_dir / file_stem / "auto")
|
||||
else:
|
||||
if method:
|
||||
add_candidate_path(output_dir / file_stem / method)
|
||||
add_candidate_path(output_dir / file_stem / "vlm")
|
||||
add_candidate_path(output_dir / file_stem / "auto")
|
||||
|
||||
json_file = None
|
||||
subdir = None
|
||||
for sub in candidates:
|
||||
jf = sub / f"{file_stem}_content_list.json"
|
||||
if jf.exists():
|
||||
subdir = sub
|
||||
json_file = jf
|
||||
break
|
||||
|
||||
if not json_file:
|
||||
raise FileNotFoundError(f"[MinerU] Missing output file, tried: {', '.join(str(c / (file_stem + '_content_list.json')) for c in candidates)}")
|
||||
|
||||
with open(json_file, "r", encoding="utf-8") as f:
|
||||
data = json.load(f)
|
||||
@ -520,7 +543,7 @@ class MinerUParser(RAGFlowPdfParser):
|
||||
method: str = "auto",
|
||||
server_url: Optional[str] = None,
|
||||
delete_output: bool = True,
|
||||
parse_method: str = "raw"
|
||||
parse_method: str = "raw",
|
||||
) -> tuple:
|
||||
import shutil
|
||||
|
||||
@ -570,7 +593,7 @@ class MinerUParser(RAGFlowPdfParser):
|
||||
self.logger.info(f"[MinerU] Parsed {len(outputs)} blocks from PDF.")
|
||||
if callback:
|
||||
callback(0.75, f"[MinerU] Parsed {len(outputs)} blocks from PDF.")
|
||||
|
||||
|
||||
return self._transfer_to_sections(outputs, parse_method), self._transfer_to_tables(outputs)
|
||||
finally:
|
||||
if temp_pdf and temp_pdf.exists():
|
||||
|
||||
@ -402,7 +402,6 @@ class RAGFlowPdfParser:
|
||||
continue
|
||||
else:
|
||||
score = 0
|
||||
print(f"{k=},{score=}",flush=True)
|
||||
if score > best_score:
|
||||
best_score = score
|
||||
best_k = k
|
||||
|
||||
@ -17,7 +17,7 @@
|
||||
import logging
|
||||
import math
|
||||
import os
|
||||
import re
|
||||
# import re
|
||||
from collections import Counter
|
||||
from copy import deepcopy
|
||||
|
||||
@ -62,8 +62,9 @@ class LayoutRecognizer(Recognizer):
|
||||
|
||||
def __call__(self, image_list, ocr_res, scale_factor=3, thr=0.2, batch_size=16, drop=True):
|
||||
def __is_garbage(b):
|
||||
patt = [r"^•+$", "^[0-9]{1,2} / ?[0-9]{1,2}$", r"^[0-9]{1,2} of [0-9]{1,2}$", "^http://[^ ]{12,}", "\\(cid *: *[0-9]+ *\\)"]
|
||||
return any([re.search(p, b["text"]) for p in patt])
|
||||
return False
|
||||
# patt = [r"^•+$", "^[0-9]{1,2} / ?[0-9]{1,2}$", r"^[0-9]{1,2} of [0-9]{1,2}$", "^http://[^ ]{12,}", "\\(cid *: *[0-9]+ *\\)"]
|
||||
# return any([re.search(p, b["text"]) for p in patt])
|
||||
|
||||
if self.client:
|
||||
layouts = self.client.predict(image_list)
|
||||
|
||||
@ -72,7 +72,7 @@ services:
|
||||
infinity:
|
||||
profiles:
|
||||
- infinity
|
||||
image: infiniflow/infinity:v0.6.6
|
||||
image: infiniflow/infinity:v0.6.8
|
||||
volumes:
|
||||
- infinity_data:/var/infinity
|
||||
- ./infinity_conf.toml:/infinity_conf.toml
|
||||
|
||||
@ -13,6 +13,7 @@ function usage() {
|
||||
echo " --disable-datasync Disables synchronization of datasource workers."
|
||||
echo " --enable-mcpserver Enables the MCP server."
|
||||
echo " --enable-adminserver Enables the Admin server."
|
||||
echo " --init-superuser Initializes the superuser."
|
||||
echo " --consumer-no-beg=<num> Start range for consumers (if using range-based)."
|
||||
echo " --consumer-no-end=<num> End range for consumers (if using range-based)."
|
||||
echo " --workers=<num> Number of task executors to run (if range is not used)."
|
||||
@ -24,6 +25,7 @@ function usage() {
|
||||
echo " $0 --disable-webserver --workers=2 --host-id=myhost123"
|
||||
echo " $0 --enable-mcpserver"
|
||||
echo " $0 --enable-adminserver"
|
||||
echo " $0 --init-superuser"
|
||||
exit 1
|
||||
}
|
||||
|
||||
@ -32,6 +34,7 @@ ENABLE_TASKEXECUTOR=1 # Default to enable task executor
|
||||
ENABLE_DATASYNC=1
|
||||
ENABLE_MCP_SERVER=0
|
||||
ENABLE_ADMIN_SERVER=0 # Default close admin server
|
||||
INIT_SUPERUSER_ARGS="" # Default to not initialize superuser
|
||||
CONSUMER_NO_BEG=0
|
||||
CONSUMER_NO_END=0
|
||||
WORKERS=1
|
||||
@ -83,6 +86,10 @@ for arg in "$@"; do
|
||||
ENABLE_ADMIN_SERVER=1
|
||||
shift
|
||||
;;
|
||||
--init-superuser)
|
||||
INIT_SUPERUSER_ARGS="--init-superuser"
|
||||
shift
|
||||
;;
|
||||
--mcp-host=*)
|
||||
MCP_HOST="${arg#*=}"
|
||||
shift
|
||||
@ -240,7 +247,7 @@ if [[ "${ENABLE_WEBSERVER}" -eq 1 ]]; then
|
||||
|
||||
echo "Starting ragflow_server..."
|
||||
while true; do
|
||||
"$PY" api/ragflow_server.py &
|
||||
"$PY" api/ragflow_server.py ${INIT_SUPERUSER_ARGS} &
|
||||
wait;
|
||||
sleep 1;
|
||||
done &
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
[general]
|
||||
version = "0.6.6"
|
||||
version = "0.6.8"
|
||||
time_zone = "utc-8"
|
||||
|
||||
[network]
|
||||
@ -54,4 +54,3 @@ memindex_memory_quota = "1GB"
|
||||
wal_dir = "/var/infinity/wal"
|
||||
|
||||
[resource]
|
||||
resource_dir = "/var/infinity/resource"
|
||||
|
||||
@ -23,12 +23,12 @@ server {
|
||||
gzip_disable "MSIE [1-6]\.";
|
||||
|
||||
location ~ ^/api/v1/admin {
|
||||
proxy_pass http://ragflow:9381;
|
||||
proxy_pass http://localhost:9381;
|
||||
include proxy.conf;
|
||||
}
|
||||
|
||||
location ~ ^/(v1|api) {
|
||||
proxy_pass http://ragflow:9380;
|
||||
proxy_pass http://localhost:9380;
|
||||
include proxy.conf;
|
||||
}
|
||||
|
||||
|
||||
@ -38,6 +38,7 @@ oceanbase:
|
||||
port: ${OCEANBASE_PORT:-2881}
|
||||
redis:
|
||||
db: 1
|
||||
username: '${REDIS_USERNAME:-}'
|
||||
password: '${REDIS_PASSWORD:-infini_rag_flow}'
|
||||
host: '${REDIS_HOST:-redis}:6379'
|
||||
user_default_llm:
|
||||
|
||||
@ -89,6 +89,8 @@ RAGFlow utilizes MinIO as its object storage solution, leveraging its scalabilit
|
||||
|
||||
- `REDIS_PORT`
|
||||
The port used to expose the Redis service to the host machine, allowing **external** access to the Redis service running inside the Docker container. Defaults to `6379`.
|
||||
- `REDIS_USERNAME`
|
||||
Optional Redis ACL username when using Redis 6+ authentication.
|
||||
- `REDIS_PASSWORD`
|
||||
The password for Redis.
|
||||
|
||||
@ -160,6 +162,13 @@ If you cannot download the RAGFlow Docker image, try the following mirrors.
|
||||
- `password`: The password for MinIO.
|
||||
- `host`: The MinIO serving IP *and* port inside the Docker container. Defaults to `minio:9000`.
|
||||
|
||||
### `redis`
|
||||
|
||||
- `host`: The Redis serving IP *and* port inside the Docker container. Defaults to `redis:6379`.
|
||||
- `db`: The Redis database index to use. Defaults to `1`.
|
||||
- `username`: Optional Redis ACL username (Redis 6+).
|
||||
- `password`: The password for the specified Redis user.
|
||||
|
||||
### `oauth`
|
||||
|
||||
The OAuth configuration for signing up or signing in to RAGFlow using a third-party account.
|
||||
|
||||
37
docs/faq.mdx
37
docs/faq.mdx
@ -323,9 +323,9 @@ The status of a Docker container status does not necessarily reflect the status
|
||||
|
||||
2. Follow [this document](./guides/run_health_check.md) to check the health status of the Elasticsearch service.
|
||||
|
||||
:::danger IMPORTANT
|
||||
The status of a Docker container status does not necessarily reflect the status of the service. You may find that your services are unhealthy even when the corresponding Docker containers are up running. Possible reasons for this include network failures, incorrect port numbers, or DNS issues.
|
||||
:::
|
||||
:::danger IMPORTANT
|
||||
The status of a Docker container status does not necessarily reflect the status of the service. You may find that your services are unhealthy even when the corresponding Docker containers are up running. Possible reasons for this include network failures, incorrect port numbers, or DNS issues.
|
||||
:::
|
||||
|
||||
3. If your container keeps restarting, ensure `vm.max_map_count` >= 262144 as per [this README](https://github.com/infiniflow/ragflow?tab=readme-ov-file#-start-up-the-server). Updating the `vm.max_map_count` value in **/etc/sysctl.conf** is required, if you wish to keep your change permanent. Note that this configuration works only for Linux.
|
||||
|
||||
@ -456,9 +456,9 @@ To switch your document engine from Elasticsearch to [Infinity](https://github.c
|
||||
```bash
|
||||
$ docker compose -f docker/docker-compose.yml down -v
|
||||
```
|
||||
:::caution WARNING
|
||||
`-v` will delete all Docker container volumes, and the existing data will be cleared.
|
||||
:::
|
||||
:::caution WARNING
|
||||
`-v` will delete all Docker container volumes, and the existing data will be cleared.
|
||||
:::
|
||||
|
||||
2. In **docker/.env**, set `DOC_ENGINE=${DOC_ENGINE:-infinity}`
|
||||
3. Restart your Docker image:
|
||||
@ -497,20 +497,6 @@ MinerU PDF document parsing is available starting from v0.22.0. RAGFlow supports
|
||||
|
||||
1. Prepare MinerU
|
||||
|
||||
- **If you deploy RAGFlow from source**, install MinerU into an isolated virtual environment (recommended path: `$HOME/uv_tools`):
|
||||
|
||||
```bash
|
||||
mkdir -p "$HOME/uv_tools"
|
||||
cd "$HOME/uv_tools"
|
||||
uv venv .venv
|
||||
source .venv/bin/activate
|
||||
uv pip install -U "mineru[core]" -i https://mirrors.aliyun.com/pypi/simple
|
||||
# or
|
||||
# uv pip install -U "mineru[all]" -i https://mirrors.aliyun.com/pypi/simple
|
||||
```
|
||||
|
||||
- **If you deploy RAGFlow with Docker**, you usually only need to turn on MinerU support in `docker/.env`:
|
||||
|
||||
```bash
|
||||
# docker/.env
|
||||
...
|
||||
@ -518,18 +504,15 @@ MinerU PDF document parsing is available starting from v0.22.0. RAGFlow supports
|
||||
...
|
||||
```
|
||||
|
||||
Enabling `USE_MINERU=true` will internally perform the same setup as the manual configuration (including setting the MinerU executable path and related environment variables). You only need the manual installation above if you are running from source or want full control over the MinerU installation.
|
||||
Enabling `USE_MINERU=true` will internally perform the same setup as the manual configuration (including setting the MinerU executable path and related environment variables).
|
||||
|
||||
|
||||
2. Start RAGFlow with MinerU enabled:
|
||||
|
||||
- **Source deployment** – in the RAGFlow repo, export the key MinerU-related variables and start the backend service:
|
||||
- **Source deployment** – in the RAGFlow repo, continue to start the backend service:
|
||||
|
||||
```bash
|
||||
# in RAGFlow repo
|
||||
export MINERU_EXECUTABLE="$HOME/uv_tools/.venv/bin/mineru"
|
||||
export MINERU_DELETE_OUTPUT=0 # keep output directory
|
||||
export MINERU_BACKEND=pipeline # or another backend you prefer
|
||||
|
||||
...
|
||||
source .venv/bin/activate
|
||||
export PYTHONPATH=$(pwd)
|
||||
bash docker/launch_backend_service.sh
|
||||
|
||||
@ -22,7 +22,7 @@ An **Agent** component is essential when you need the LLM to assist with summari
|
||||
|
||||
1. Ensure you have a chat model properly configured:
|
||||
|
||||

|
||||

|
||||
|
||||
2. If your Agent involves dataset retrieval, ensure you [have properly configured your target dataset(s)](../../dataset/configure_knowledge_base.md).
|
||||
|
||||
@ -91,7 +91,7 @@ Update your MCP server's name, URL (including the API key), server type, and oth
|
||||
|
||||
*The target MCP server appears below your Agent component, and your Agent will autonomously decide when to invoke the available tools it offers.*
|
||||
|
||||
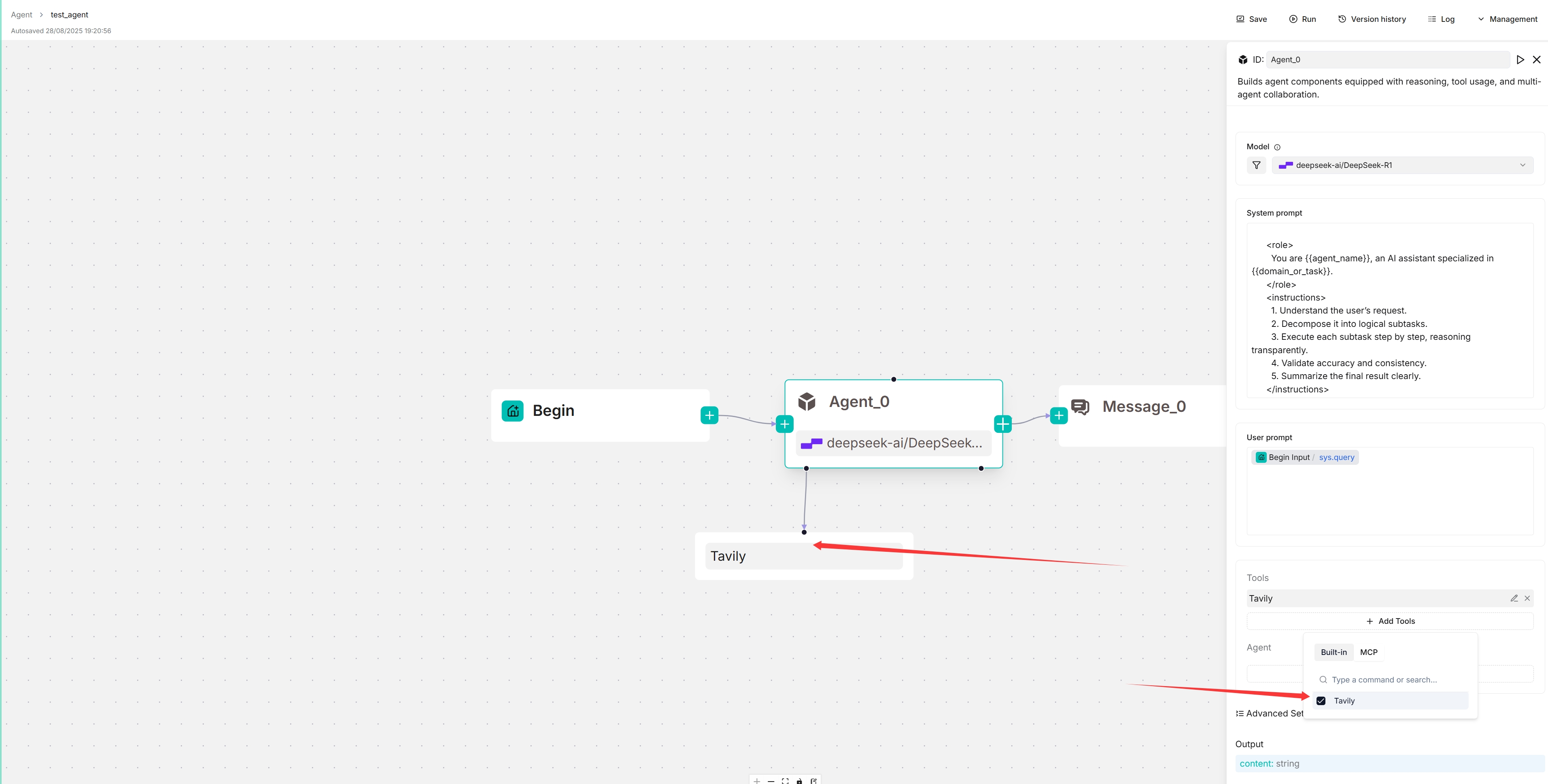
|
||||

|
||||
|
||||
### 5. Update system prompt to specify trigger conditions (Optional)
|
||||
|
||||
|
||||
@ -62,9 +62,9 @@ docker build -t sandbox-executor-manager:latest ./executor_manager
|
||||
|
||||
3. Add the following entry to your /etc/hosts file to resolve the executor manager service:
|
||||
|
||||
```bash
|
||||
127.0.0.1 es01 infinity mysql minio redis sandbox-executor-manager
|
||||
```
|
||||
```bash
|
||||
127.0.0.1 es01 infinity mysql minio redis sandbox-executor-manager
|
||||
```
|
||||
|
||||
4. Start the RAGFlow service as usual.
|
||||
|
||||
@ -74,24 +74,24 @@ docker build -t sandbox-executor-manager:latest ./executor_manager
|
||||
|
||||
1. Initialize the environment variables:
|
||||
|
||||
```bash
|
||||
cp .env.example .env
|
||||
```
|
||||
```bash
|
||||
cp .env.example .env
|
||||
```
|
||||
|
||||
2. Launch the sandbox services with Docker Compose:
|
||||
|
||||
```bash
|
||||
docker compose -f docker-compose.yml up
|
||||
```
|
||||
```bash
|
||||
docker compose -f docker-compose.yml up
|
||||
```
|
||||
|
||||
3. Test the sandbox setup:
|
||||
|
||||
```bash
|
||||
source .venv/bin/activate
|
||||
export PYTHONPATH=$(pwd)
|
||||
uv pip install -r executor_manager/requirements.txt
|
||||
uv run tests/sandbox_security_tests_full.py
|
||||
```
|
||||
```bash
|
||||
source .venv/bin/activate
|
||||
export PYTHONPATH=$(pwd)
|
||||
uv pip install -r executor_manager/requirements.txt
|
||||
uv run tests/sandbox_security_tests_full.py
|
||||
```
|
||||
|
||||
### Using Makefile
|
||||
|
||||
|
||||
@ -83,13 +83,13 @@ You start an AI conversation by creating an assistant.
|
||||
|
||||
1. Click the light bulb icon above the answer to view the expanded system prompt:
|
||||
|
||||
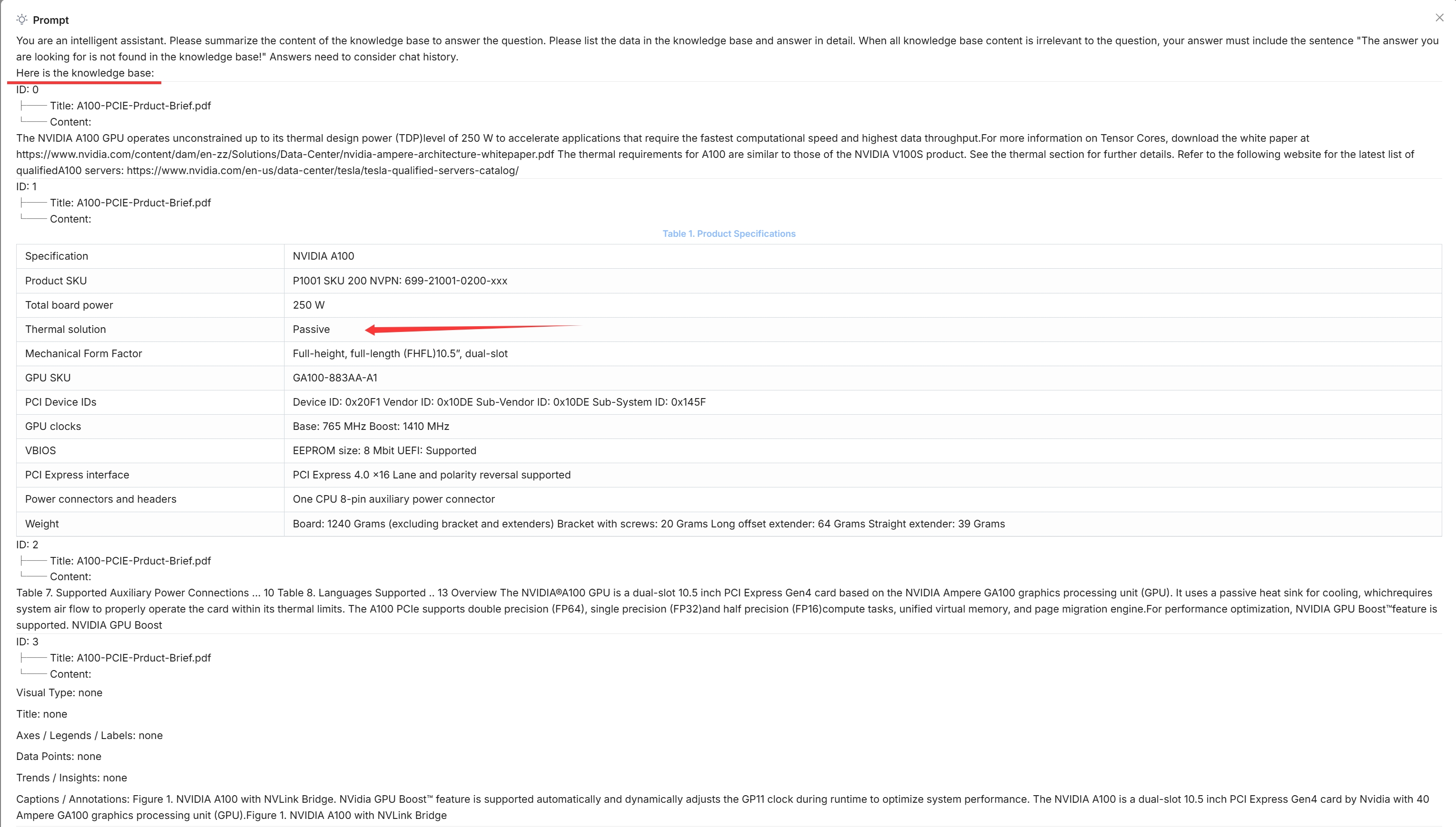
|
||||

|
||||
|
||||
*The light bulb icon is available only for the current dialogue.*
|
||||
|
||||
2. Scroll down the expanded prompt to view the time consumed for each task:
|
||||
|
||||

|
||||

|
||||
:::
|
||||
|
||||
## Update settings of an existing chat assistant
|
||||
|
||||
@ -56,9 +56,9 @@ Once a tag set is created, you can apply it to your dataset:
|
||||
1. Navigate to the **Configuration** page of your dataset.
|
||||
2. Select the tag set from the **Tag sets** dropdown and click **Save** to confirm.
|
||||
|
||||
:::tip NOTE
|
||||
If the tag set is missing from the dropdown, check that it has been created or configured correctly.
|
||||
:::
|
||||
:::tip NOTE
|
||||
If the tag set is missing from the dropdown, check that it has been created or configured correctly.
|
||||
:::
|
||||
|
||||
3. Re-parse your documents to start the auto-tagging process.
|
||||
_In an AI chat scenario using auto-tagged datasets, each query will be tagged using the corresponding tag set(s) and chunks with these tags will have a higher chance to be retrieved._
|
||||
|
||||
@ -314,35 +314,3 @@ To enable IPEX-LLM accelerated Ollama in RAGFlow, you must also complete the con
|
||||
3. [Update System Model Settings](#6-update-system-model-settings)
|
||||
4. [Update Chat Configuration](#7-update-chat-configuration)
|
||||
|
||||
## Deploy a local model using jina
|
||||
|
||||
To deploy a local model, e.g., **gpt2**, using jina:
|
||||
|
||||
### 1. Check firewall settings
|
||||
|
||||
Ensure that your host machine's firewall allows inbound connections on port 12345.
|
||||
|
||||
```bash
|
||||
sudo ufw allow 12345/tcp
|
||||
```
|
||||
|
||||
### 2. Install jina package
|
||||
|
||||
```bash
|
||||
pip install jina
|
||||
```
|
||||
|
||||
### 3. Deploy a local model
|
||||
|
||||
Step 1: Navigate to the **rag/svr** directory.
|
||||
|
||||
```bash
|
||||
cd rag/svr
|
||||
```
|
||||
|
||||
Step 2: Run **jina_server.py**, specifying either the model's name or its local directory:
|
||||
|
||||
```bash
|
||||
python jina_server.py --model_name gpt2
|
||||
```
|
||||
> The script only supports models downloaded from Hugging Face.
|
||||
|
||||
@ -19,48 +19,60 @@ Upgrading RAGFlow in itself will *not* remove your uploaded/historical data. How
|
||||
|
||||
To upgrade RAGFlow, you must upgrade **both** your code **and** your Docker image:
|
||||
|
||||
1. Clone the repo
|
||||
1. Stop the server
|
||||
|
||||
```bash
|
||||
git clone https://github.com/infiniflow/ragflow.git
|
||||
docker compose -f docker/docker-compose.yml down
|
||||
```
|
||||
|
||||
2. Update **ragflow/docker/.env**:
|
||||
2. Update the local code
|
||||
|
||||
```bash
|
||||
git pull
|
||||
```
|
||||
|
||||
3. Update **ragflow/docker/.env**:
|
||||
|
||||
```bash
|
||||
RAGFLOW_IMAGE=infiniflow/ragflow:nightly
|
||||
```
|
||||
|
||||
3. Update RAGFlow image and restart RAGFlow:
|
||||
4. Update RAGFlow image and restart RAGFlow:
|
||||
|
||||
```bash
|
||||
docker compose -f docker/docker-compose.yml pull
|
||||
docker compose -f docker/docker-compose.yml up -d
|
||||
```
|
||||
|
||||
## Upgrade RAGFlow to the most recent, officially published release
|
||||
## Upgrade RAGFlow to given release
|
||||
|
||||
To upgrade RAGFlow, you must upgrade **both** your code **and** your Docker image:
|
||||
|
||||
1. Clone the repo
|
||||
1. Stop the server
|
||||
|
||||
```bash
|
||||
git clone https://github.com/infiniflow/ragflow.git
|
||||
docker compose -f docker/docker-compose.yml down
|
||||
```
|
||||
|
||||
2. Switch to the latest, officially published release, e.g., `v0.22.1`:
|
||||
2. Update the local code
|
||||
|
||||
```bash
|
||||
git pull
|
||||
```
|
||||
|
||||
3. Switch to the latest, officially published release, e.g., `v0.22.1`:
|
||||
|
||||
```bash
|
||||
git checkout -f v0.22.1
|
||||
```
|
||||
|
||||
3. Update **ragflow/docker/.env**:
|
||||
4. Update **ragflow/docker/.env**:
|
||||
|
||||
```bash
|
||||
RAGFLOW_IMAGE=infiniflow/ragflow:v0.22.1
|
||||
```
|
||||
|
||||
4. Update the RAGFlow image and restart RAGFlow:
|
||||
5. Update the RAGFlow image and restart RAGFlow:
|
||||
|
||||
```bash
|
||||
docker compose -f docker/docker-compose.yml pull
|
||||
|
||||
@ -39,8 +39,10 @@ If you have not installed Docker on your local machine (Windows, Mac, or Linux),
|
||||
|
||||
This section provides instructions on setting up the RAGFlow server on Linux. If you are on a different operating system, no worries. Most steps are alike.
|
||||
|
||||
1. Ensure `vm.max_map_count` ≥ 262144.
|
||||
|
||||
<details>
|
||||
<summary>1. Ensure <code>vm.max_map_count</code> ≥ 262144:</summary>
|
||||
<summary>Expand to show details:</summary>
|
||||
|
||||
`vm.max_map_count`. This value sets the maximum number of memory map areas a process may have. Its default value is 65530. While most applications require fewer than a thousand maps, reducing this value can result in abnormal behaviors, and the system will throw out-of-memory errors when a process reaches the limitation.
|
||||
|
||||
@ -194,22 +196,22 @@ This section provides instructions on setting up the RAGFlow server on Linux. If
|
||||
$ docker compose -f docker-compose.yml up -d
|
||||
```
|
||||
|
||||
```mdx-code-block
|
||||
<APITable>
|
||||
```
|
||||
```mdx-code-block
|
||||
<APITable>
|
||||
```
|
||||
|
||||
| RAGFlow image tag | Image size (GB) | Stable? |
|
||||
| ------------------- | --------------- | ------------------------ |
|
||||
| v0.22.1 | ≈2 | Stable release |
|
||||
| nightly | ≈2 | _Unstable_ nightly build |
|
||||
| RAGFlow image tag | Image size (GB) | Stable? |
|
||||
| ------------------- | --------------- | ------------------------ |
|
||||
| v0.22.1 | ≈2 | Stable release |
|
||||
| nightly | ≈2 | _Unstable_ nightly build |
|
||||
|
||||
```mdx-code-block
|
||||
</APITable>
|
||||
```
|
||||
```mdx-code-block
|
||||
</APITable>
|
||||
```
|
||||
|
||||
:::tip NOTE
|
||||
The image size shown refers to the size of the *downloaded* Docker image, which is compressed. When Docker runs the image, it unpacks it, resulting in significantly greater disk usage. A Docker image will expand to around 7 GB once unpacked.
|
||||
:::
|
||||
:::tip NOTE
|
||||
The image size shown refers to the size of the *downloaded* Docker image, which is compressed. When Docker runs the image, it unpacks it, resulting in significantly greater disk usage. A Docker image will expand to around 7 GB once unpacked.
|
||||
:::
|
||||
|
||||
4. Check the server status after having the server up and running:
|
||||
|
||||
@ -229,15 +231,15 @@ The image size shown refers to the size of the *downloaded* Docker image, which
|
||||
* Running on all addresses (0.0.0.0)
|
||||
```
|
||||
|
||||
:::danger IMPORTANT
|
||||
If you skip this confirmation step and directly log in to RAGFlow, your browser may prompt a `network anomaly` error because, at that moment, your RAGFlow may not be fully initialized.
|
||||
:::
|
||||
:::danger IMPORTANT
|
||||
If you skip this confirmation step and directly log in to RAGFlow, your browser may prompt a `network anomaly` error because, at that moment, your RAGFlow may not be fully initialized.
|
||||
:::
|
||||
|
||||
5. In your web browser, enter the IP address of your server and log in to RAGFlow.
|
||||
|
||||
:::caution WARNING
|
||||
With the default settings, you only need to enter `http://IP_OF_YOUR_MACHINE` (**sans** port number) as the default HTTP serving port `80` can be omitted when using the default configurations.
|
||||
:::
|
||||
:::caution WARNING
|
||||
With the default settings, you only need to enter `http://IP_OF_YOUR_MACHINE` (**sans** port number) as the default HTTP serving port `80` can be omitted when using the default configurations.
|
||||
:::
|
||||
|
||||
## Configure LLMs
|
||||
|
||||
@ -278,9 +280,9 @@ To create your first dataset:
|
||||
|
||||
3. RAGFlow offers multiple chunk templates that cater to different document layouts and file formats. Select the embedding model and chunking method (template) for your dataset.
|
||||
|
||||
:::danger IMPORTANT
|
||||
Once you have selected an embedding model and used it to parse a file, you are no longer allowed to change it. The obvious reason is that we must ensure that all files in a specific dataset are parsed using the *same* embedding model (ensure that they are being compared in the same embedding space).
|
||||
:::
|
||||
:::danger IMPORTANT
|
||||
Once you have selected an embedding model and used it to parse a file, you are no longer allowed to change it. The obvious reason is that we must ensure that all files in a specific dataset are parsed using the *same* embedding model (ensure that they are being compared in the same embedding space).
|
||||
:::
|
||||
|
||||
_You are taken to the **Dataset** page of your dataset._
|
||||
|
||||
@ -290,10 +292,10 @@ Once you have selected an embedding model and used it to parse a file, you are n
|
||||
|
||||
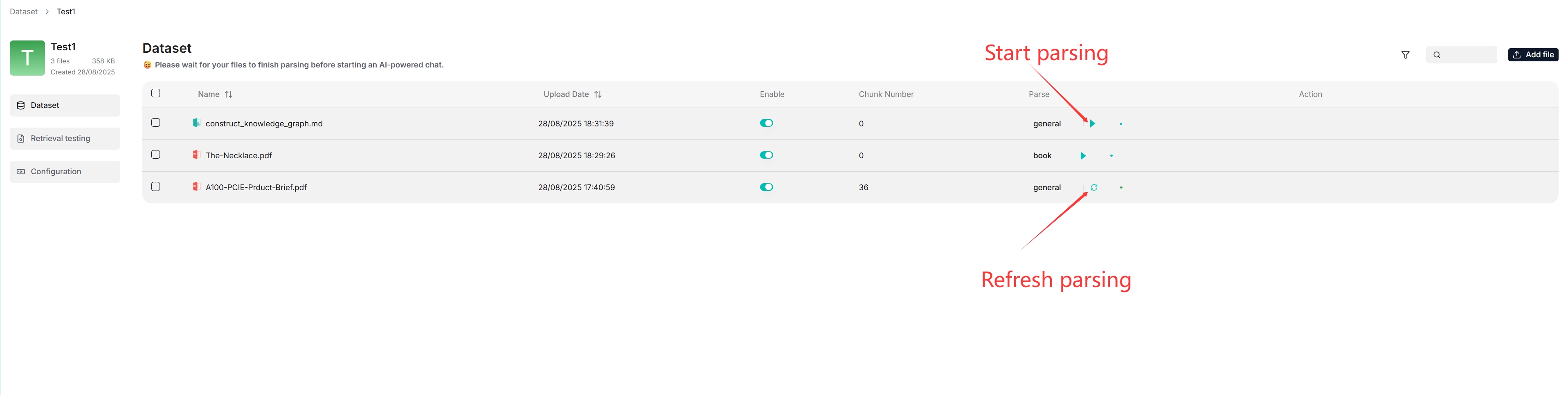
|
||||
|
||||
:::caution NOTE
|
||||
- If your file parsing gets stuck at below 1%, see [this FAQ](./faq.mdx#why-does-my-document-parsing-stall-at-under-one-percent).
|
||||
- If your file parsing gets stuck at near completion, see [this FAQ](./faq.mdx#why-does-my-pdf-parsing-stall-near-completion-while-the-log-does-not-show-any-error)
|
||||
:::
|
||||
:::caution NOTE
|
||||
- If your file parsing gets stuck at below 1%, see [this FAQ](./faq.mdx#why-does-my-document-parsing-stall-at-under-one-percent).
|
||||
- If your file parsing gets stuck at near completion, see [this FAQ](./faq.mdx#why-does-my-pdf-parsing-stall-near-completion-while-the-log-does-not-show-any-error)
|
||||
:::
|
||||
|
||||
## Intervene with file parsing
|
||||
|
||||
@ -311,9 +313,9 @@ RAGFlow features visibility and explainability, allowing you to view the chunkin
|
||||
|
||||
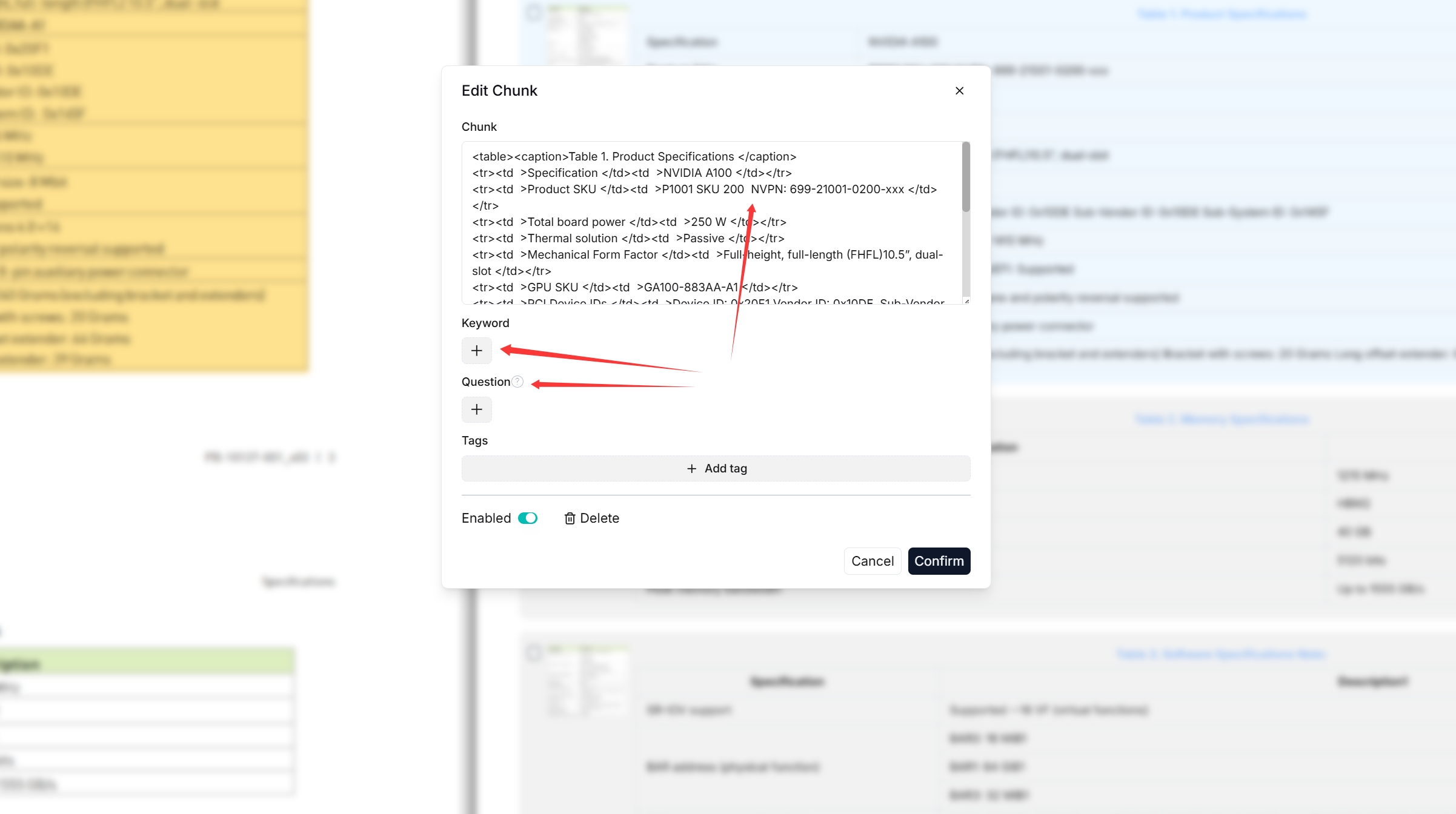
|
||||
|
||||
:::caution NOTE
|
||||
You can add keywords or questions to a file chunk to improve its ranking for queries containing those keywords. This action increases its keyword weight and can improve its position in search list.
|
||||
:::
|
||||
:::caution NOTE
|
||||
You can add keywords or questions to a file chunk to improve its ranking for queries containing those keywords. This action increases its keyword weight and can improve its position in search list.
|
||||
:::
|
||||
|
||||
4. In Retrieval testing, ask a quick question in **Test text** to double check if your configurations work:
|
||||
|
||||
|
||||
@ -419,7 +419,15 @@ Creates a dataset.
|
||||
- `"embedding_model"`: `string`
|
||||
- `"permission"`: `string`
|
||||
- `"chunk_method"`: `string`
|
||||
- `"parser_config"`: `object`
|
||||
- "parser_config": `object`
|
||||
- "parse_type": `int`
|
||||
- "pipeline_id": `string`
|
||||
|
||||
Note: Choose exactly one ingestion mode when creating a dataset.
|
||||
- Chunking method: provide `"chunk_method"` (optionally with `"parser_config"`).
|
||||
- Ingestion pipeline: provide both `"parse_type"` and `"pipeline_id"` and do not provide `"chunk_method"`.
|
||||
|
||||
These options are mutually exclusive. If all three of `chunk_method`, `parse_type`, and `pipeline_id` are omitted, the system defaults to `chunk_method = "naive"`.
|
||||
|
||||
##### Request example
|
||||
|
||||
@ -433,6 +441,26 @@ curl --request POST \
|
||||
}'
|
||||
```
|
||||
|
||||
##### Request example (ingestion pipeline)
|
||||
|
||||
Use this form when specifying an ingestion pipeline (do not include `chunk_method`).
|
||||
|
||||
```bash
|
||||
curl --request POST \
|
||||
--url http://{address}/api/v1/datasets \
|
||||
--header 'Content-Type: application/json' \
|
||||
--header 'Authorization: Bearer <YOUR_API_KEY>' \
|
||||
--data '{
|
||||
"name": "test-sdk",
|
||||
"parse_type": <NUMBER_OF_FORMATS_IN_PARSE>,
|
||||
"pipeline_id": "<PIPELINE_ID_32_HEX>"
|
||||
}'
|
||||
```
|
||||
|
||||
Notes:
|
||||
- `parse_type` is an integer. Replace `<NUMBER_OF_FORMATS_IN_PARSE>` with your pipeline's parse-type value.
|
||||
- `pipeline_id` must be a 32-character lowercase hexadecimal string.
|
||||
|
||||
##### Request parameters
|
||||
|
||||
- `"name"`: (*Body parameter*), `string`, *Required*
|
||||
@ -473,6 +501,7 @@ curl --request POST \
|
||||
- `"qa"`: Q&A
|
||||
- `"table"`: Table
|
||||
- `"tag"`: Tag
|
||||
- Mutually exclusive with `parse_type` and `pipeline_id`. If you set `chunk_method`, do not include `parse_type` or `pipeline_id`.
|
||||
|
||||
- `"parser_config"`: (*Body parameter*), `object`
|
||||
The configuration settings for the dataset parser. The attributes in this JSON object vary with the selected `"chunk_method"`:
|
||||
@ -509,6 +538,15 @@ curl --request POST \
|
||||
- Defaults to: `{"use_raptor": false}`.
|
||||
- If `"chunk_method"` is `"table"`, `"picture"`, `"one"`, or `"email"`, `"parser_config"` is an empty JSON object.
|
||||
|
||||
- "parse_type": (*Body parameter*), `int`
|
||||
The ingestion pipeline parse type identifier. Required if and only if you are using an ingestion pipeline (together with `"pipeline_id"`). Must not be provided when `"chunk_method"` is set.
|
||||
|
||||
- "pipeline_id": (*Body parameter*), `string`
|
||||
The ingestion pipeline ID. Required if and only if you are using an ingestion pipeline (together with `"parse_type"`).
|
||||
- Must not be provided when `"chunk_method"` is set.
|
||||
|
||||
Note: If none of `chunk_method`, `parse_type`, and `pipeline_id` are provided, the system will default to `chunk_method = "naive"`.
|
||||
|
||||
#### Response
|
||||
|
||||
Success:
|
||||
@ -2122,9 +2160,9 @@ curl --request POST \
|
||||
- `"top_k"`: (*Body parameter*), `integer`
|
||||
The number of chunks engaged in vector cosine computation. Defaults to `1024`.
|
||||
- `"use_kg"`: (*Body parameter*), `boolean`
|
||||
The search includes text chunks related to the knowledge graph of the selected dataset to handle complex multi-hop queries. Defaults to `False`.
|
||||
Whether to search chunks related to the generated knowledge graph for multi-hop queries. Defaults to `False`. Before enabling this, ensure you have successfully constructed a knowledge graph for the specified datasets. See [here](https://ragflow.io/docs/dev/construct_knowledge_graph) for details.
|
||||
- `"toc_enhance"`: (*Body parameter*), `boolean`
|
||||
The search includes table of content enhancement in order to boost rank of relevant chunks. Files parsed with `TOC Enhance` enabled is prerequisite. Defaults to `False`.
|
||||
Whether to search chunks with extracted table of content. Defaults to `False`. Before enabling this, ensure you have enabled `TOC_Enhance` and successfully extracted table of contents for the specified datasets. See [here](https://ragflow.io/docs/dev/enable_table_of_contents) for details.
|
||||
- `"rerank_id"`: (*Body parameter*), `integer`
|
||||
The ID of the rerank model.
|
||||
- `"keyword"`: (*Body parameter*), `boolean`
|
||||
@ -2140,8 +2178,8 @@ curl --request POST \
|
||||
- `"metadata_condition"`: (*Body parameter*), `object`
|
||||
The metadata condition used for filtering chunks:
|
||||
- `"logic"`: (*Body parameter*), `string`
|
||||
- `"and"` Intersection of the result from each condition (default).
|
||||
- `"or"` union of the result from each condition.
|
||||
- `"and"`: Return only results that satisfy *every* condition (default).
|
||||
- `"or"`: Return results that satisfy *any* condition.
|
||||
- `"conditions"`: (*Body parameter*), `array`
|
||||
A list of metadata filter conditions.
|
||||
- `"name"`: `string` - The metadata field name to filter by, e.g., `"author"`, `"company"`, `"url"`. Ensure this parameter before use. See [Set metadata](../guides/dataset/set_metadata.md) for details.
|
||||
|
||||
@ -96,7 +96,7 @@ ragflow:
|
||||
infinity:
|
||||
image:
|
||||
repository: infiniflow/infinity
|
||||
tag: v0.6.6
|
||||
tag: v0.6.8
|
||||
pullPolicy: IfNotPresent
|
||||
pullSecrets: []
|
||||
storage:
|
||||
|
||||
@ -16,7 +16,7 @@ dependencies = [
|
||||
"arxiv==2.1.3",
|
||||
"aspose-slides>=25.10.0,<26.0.0; platform_machine == 'x86_64' or (sys_platform == 'darwin' and platform_machine == 'arm64')",
|
||||
"atlassian-python-api==4.0.7",
|
||||
"beartype>=0.18.5,<0.19.0",
|
||||
"beartype>=0.20.0,<1.0.0",
|
||||
"bio==1.7.1",
|
||||
"blinker==1.7.0",
|
||||
"boto3==1.34.140",
|
||||
@ -49,7 +49,7 @@ dependencies = [
|
||||
"html-text==0.6.2",
|
||||
"httpx[socks]>=0.28.1,<0.29.0",
|
||||
"huggingface-hub>=0.25.0,<0.26.0",
|
||||
"infinity-sdk==0.6.6",
|
||||
"infinity-sdk==0.6.8",
|
||||
"infinity-emb>=0.0.66,<0.0.67",
|
||||
"itsdangerous==2.1.2",
|
||||
"json-repair==0.35.0",
|
||||
@ -80,7 +80,7 @@ dependencies = [
|
||||
"pyclipper==1.3.0.post5",
|
||||
"pycryptodomex==3.20.0",
|
||||
"pymysql>=1.1.1,<2.0.0",
|
||||
"pypdf==6.0.0",
|
||||
"pypdf==6.4.0",
|
||||
"python-dotenv==1.0.1",
|
||||
"python-dateutil==2.8.2",
|
||||
"python-pptx>=1.0.2,<2.0.0",
|
||||
@ -116,6 +116,7 @@ dependencies = [
|
||||
"google-genai>=1.41.0,<2.0.0",
|
||||
"volcengine==1.0.194",
|
||||
"voyageai==0.2.3",
|
||||
"webdav4>=0.10.0,<0.11.0",
|
||||
"webdriver-manager==4.0.1",
|
||||
"werkzeug==3.0.6",
|
||||
"wikipedia==1.4.0",
|
||||
@ -127,7 +128,7 @@ dependencies = [
|
||||
"google-generativeai>=0.8.1,<0.9.0", # Needed for cv_model and embedding_model
|
||||
"python-docx>=1.1.2,<2.0.0",
|
||||
"pypdf2>=3.0.1,<4.0.0",
|
||||
"graspologic>=3.4.1,<4.0.0",
|
||||
"graspologic @ git+https://github.com/yuzhichang/graspologic.git@38e680cab72bc9fb68a7992c3bcc2d53b24e42fd",
|
||||
"mini-racer>=0.12.4,<0.13.0",
|
||||
"pyodbc>=5.2.0,<6.0.0",
|
||||
"pyicu>=2.15.3,<3.0.0",
|
||||
@ -151,6 +152,9 @@ dependencies = [
|
||||
"moodlepy>=0.23.0",
|
||||
"pypandoc>=1.16",
|
||||
"pyobvector==0.2.18",
|
||||
"exceptiongroup>=1.3.0,<2.0.0",
|
||||
"ffmpeg-python>=0.2.0",
|
||||
"imageio-ffmpeg>=0.6.0",
|
||||
]
|
||||
|
||||
[dependency-groups]
|
||||
|
||||
@ -23,7 +23,7 @@ from rag.app import naive
|
||||
from rag.app.naive import by_plaintext, PARSERS
|
||||
from rag.nlp import bullets_category, is_english,remove_contents_table, \
|
||||
hierarchical_merge, make_colon_as_title, naive_merge, random_choices, tokenize_table, \
|
||||
tokenize_chunks
|
||||
tokenize_chunks, attach_media_context
|
||||
from rag.nlp import rag_tokenizer
|
||||
from deepdoc.parser import PdfParser, HtmlParser
|
||||
from deepdoc.parser.figure_parser import vision_figure_parser_docx_wrapper
|
||||
@ -175,6 +175,10 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
|
||||
res = tokenize_table(tbls, doc, eng)
|
||||
res.extend(tokenize_chunks(chunks, doc, eng, pdf_parser))
|
||||
table_ctx = max(0, int(parser_config.get("table_context_size", 0) or 0))
|
||||
image_ctx = max(0, int(parser_config.get("image_context_size", 0) or 0))
|
||||
if table_ctx or image_ctx:
|
||||
attach_media_context(res, table_ctx, image_ctx)
|
||||
|
||||
return res
|
||||
|
||||
|
||||
@ -51,9 +51,11 @@ def chunk(
|
||||
attachment_res = []
|
||||
|
||||
if binary:
|
||||
msg = BytesParser(policy=policy.default).parse(io.BytesIO(binary))
|
||||
with io.BytesIO(binary) as buffer:
|
||||
msg = BytesParser(policy=policy.default).parse(buffer)
|
||||
else:
|
||||
msg = BytesParser(policy=policy.default).parse(open(filename, "rb"))
|
||||
with open(filename, "rb") as buffer:
|
||||
msg = BytesParser(policy=policy.default).parse(buffer)
|
||||
|
||||
text_txt, html_txt = [], []
|
||||
# get the email header info
|
||||
|
||||
@ -20,7 +20,7 @@ import re
|
||||
|
||||
from common.constants import ParserType
|
||||
from io import BytesIO
|
||||
from rag.nlp import rag_tokenizer, tokenize, tokenize_table, bullets_category, title_frequency, tokenize_chunks, docx_question_level
|
||||
from rag.nlp import rag_tokenizer, tokenize, tokenize_table, bullets_category, title_frequency, tokenize_chunks, docx_question_level, attach_media_context
|
||||
from common.token_utils import num_tokens_from_string
|
||||
from deepdoc.parser import PdfParser, DocxParser
|
||||
from deepdoc.parser.figure_parser import vision_figure_parser_pdf_wrapper,vision_figure_parser_docx_wrapper
|
||||
@ -155,7 +155,7 @@ class Docx(DocxParser):
|
||||
sum_question = '\n'.join(question_stack)
|
||||
if sum_question:
|
||||
ti_list.append((f'{sum_question}\n{last_answer}', last_image))
|
||||
|
||||
|
||||
tbls = []
|
||||
for tb in self.doc.tables:
|
||||
html= "<table>"
|
||||
@ -231,14 +231,14 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
if isinstance(poss, str):
|
||||
poss = pdf_parser.extract_positions(poss)
|
||||
first = poss[0] # tuple: ([pn], x1, x2, y1, y2)
|
||||
pn = first[0]
|
||||
pn = first[0]
|
||||
|
||||
if isinstance(pn, list):
|
||||
pn = pn[0] # [pn] -> pn
|
||||
poss[0] = (pn, *first[1:])
|
||||
|
||||
return (txt, layoutno, poss)
|
||||
|
||||
|
||||
|
||||
sections = [_normalize_section(sec) for sec in sections]
|
||||
|
||||
@ -247,7 +247,7 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
|
||||
if name in ["tcadp", "docling", "mineru"]:
|
||||
parser_config["chunk_token_num"] = 0
|
||||
|
||||
|
||||
callback(0.8, "Finish parsing.")
|
||||
|
||||
if len(sections) > 0 and len(pdf_parser.outlines) / len(sections) > 0.03:
|
||||
@ -310,6 +310,10 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
tbls=vision_figure_parser_pdf_wrapper(tbls=tbls,callback=callback,**kwargs)
|
||||
res = tokenize_table(tbls, doc, eng)
|
||||
res.extend(tokenize_chunks(chunks, doc, eng, pdf_parser))
|
||||
table_ctx = max(0, int(parser_config.get("table_context_size", 0) or 0))
|
||||
image_ctx = max(0, int(parser_config.get("image_context_size", 0) or 0))
|
||||
if table_ctx or image_ctx:
|
||||
attach_media_context(res, table_ctx, image_ctx)
|
||||
return res
|
||||
|
||||
elif re.search(r"\.docx?$", filename, re.IGNORECASE):
|
||||
@ -325,10 +329,14 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
d["doc_type_kwd"] = "image"
|
||||
tokenize(d, text, eng)
|
||||
res.append(d)
|
||||
table_ctx = max(0, int(parser_config.get("table_context_size", 0) or 0))
|
||||
image_ctx = max(0, int(parser_config.get("image_context_size", 0) or 0))
|
||||
if table_ctx or image_ctx:
|
||||
attach_media_context(res, table_ctx, image_ctx)
|
||||
return res
|
||||
else:
|
||||
raise NotImplementedError("file type not supported yet(pdf and docx supported)")
|
||||
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
import sys
|
||||
|
||||
258
rag/app/naive.py
258
rag/app/naive.py
@ -26,6 +26,7 @@ from docx.opc.pkgreader import _SerializedRelationships, _SerializedRelationship
|
||||
from docx.opc.oxml import parse_xml
|
||||
from markdown import markdown
|
||||
from PIL import Image
|
||||
from common.token_utils import num_tokens_from_string
|
||||
|
||||
from common.constants import LLMType
|
||||
from api.db.services.llm_service import LLMBundle
|
||||
@ -36,7 +37,8 @@ from deepdoc.parser.pdf_parser import PlainParser, VisionParser
|
||||
from deepdoc.parser.mineru_parser import MinerUParser
|
||||
from deepdoc.parser.docling_parser import DoclingParser
|
||||
from deepdoc.parser.tcadp_parser import TCADPParser
|
||||
from rag.nlp import concat_img, find_codec, naive_merge, naive_merge_with_images, naive_merge_docx, rag_tokenizer, tokenize_chunks, tokenize_chunks_with_images, tokenize_table
|
||||
from rag.nlp import concat_img, find_codec, naive_merge, naive_merge_with_images, naive_merge_docx, rag_tokenizer, tokenize_chunks, tokenize_chunks_with_images, tokenize_table, attach_media_context
|
||||
|
||||
|
||||
def by_deepdoc(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", callback=None, pdf_cls = None ,**kwargs):
|
||||
callback = callback
|
||||
@ -464,51 +466,88 @@ class Markdown(MarkdownParser):
|
||||
html_content = markdown(text)
|
||||
soup = BeautifulSoup(html_content, 'html.parser')
|
||||
return soup
|
||||
|
||||
def get_picture_urls(self, soup):
|
||||
if soup:
|
||||
return [img.get('src') for img in soup.find_all('img') if img.get('src')]
|
||||
return []
|
||||
|
||||
def get_hyperlink_urls(self, soup):
|
||||
if soup:
|
||||
return set([a.get('href') for a in soup.find_all('a') if a.get('href')])
|
||||
return []
|
||||
|
||||
def get_pictures(self, text):
|
||||
"""Download and open all images from markdown text."""
|
||||
|
||||
def extract_image_urls_with_lines(self, text):
|
||||
md_img_re = re.compile(r"!\[[^\]]*\]\(([^)\s]+)")
|
||||
html_img_re = re.compile(r'src=["\\\']([^"\\\'>\\s]+)', re.IGNORECASE)
|
||||
urls = []
|
||||
seen = set()
|
||||
lines = text.splitlines()
|
||||
for idx, line in enumerate(lines):
|
||||
for url in md_img_re.findall(line):
|
||||
if (url, idx) not in seen:
|
||||
urls.append({"url": url, "line": idx})
|
||||
seen.add((url, idx))
|
||||
for url in html_img_re.findall(line):
|
||||
if (url, idx) not in seen:
|
||||
urls.append({"url": url, "line": idx})
|
||||
seen.add((url, idx))
|
||||
|
||||
# cross-line
|
||||
try:
|
||||
from bs4 import BeautifulSoup
|
||||
|
||||
soup = BeautifulSoup(text, 'html.parser')
|
||||
newline_offsets = [m.start() for m in re.finditer(r"\n", text)] + [len(text)]
|
||||
for img_tag in soup.find_all('img'):
|
||||
src = img_tag.get('src')
|
||||
if not src:
|
||||
continue
|
||||
|
||||
tag_str = str(img_tag)
|
||||
pos = text.find(tag_str)
|
||||
if pos == -1:
|
||||
# fallback
|
||||
pos = max(text.find(src), 0)
|
||||
line_no = 0
|
||||
for i, off in enumerate(newline_offsets):
|
||||
if pos <= off:
|
||||
line_no = i
|
||||
break
|
||||
if (src, line_no) not in seen:
|
||||
urls.append({"url": src, "line": line_no})
|
||||
seen.add((src, line_no))
|
||||
except Exception:
|
||||
pass
|
||||
|
||||
return urls
|
||||
|
||||
def load_images_from_urls(self, urls, cache=None):
|
||||
import requests
|
||||
soup = self.md_to_html(text)
|
||||
image_urls = self.get_picture_urls(soup)
|
||||
from pathlib import Path
|
||||
|
||||
cache = cache or {}
|
||||
images = []
|
||||
# Find all image URLs in text
|
||||
for url in image_urls:
|
||||
if not url:
|
||||
for url in urls:
|
||||
if url in cache:
|
||||
if cache[url]:
|
||||
images.append(cache[url])
|
||||
continue
|
||||
img_obj = None
|
||||
try:
|
||||
# check if the url is a local file or a remote URL
|
||||
if url.startswith(('http://', 'https://')):
|
||||
# For remote URLs, download the image
|
||||
response = requests.get(url, stream=True, timeout=30)
|
||||
if response.status_code == 200 and response.headers['Content-Type'] and response.headers['Content-Type'].startswith('image/'):
|
||||
img = Image.open(BytesIO(response.content)).convert('RGB')
|
||||
images.append(img)
|
||||
if response.status_code == 200 and response.headers.get('Content-Type', '').startswith('image/'):
|
||||
img_obj = Image.open(BytesIO(response.content)).convert('RGB')
|
||||
else:
|
||||
# For local file paths, open the image directly
|
||||
from pathlib import Path
|
||||
local_path = Path(url)
|
||||
if not local_path.exists():
|
||||
if local_path.exists():
|
||||
img_obj = Image.open(url).convert('RGB')
|
||||
else:
|
||||
logging.warning(f"Local image file not found: {url}")
|
||||
continue
|
||||
img = Image.open(url).convert('RGB')
|
||||
images.append(img)
|
||||
except Exception as e:
|
||||
logging.error(f"Failed to download/open image from {url}: {e}")
|
||||
continue
|
||||
cache[url] = img_obj
|
||||
if img_obj:
|
||||
images.append(img_obj)
|
||||
return images, cache
|
||||
|
||||
return images if images else None
|
||||
|
||||
def __call__(self, filename, binary=None, separate_tables=True, delimiter=None):
|
||||
def __call__(self, filename, binary=None, separate_tables=True, delimiter=None, return_section_images=False):
|
||||
if binary:
|
||||
encoding = find_codec(binary)
|
||||
txt = binary.decode(encoding, errors="ignore")
|
||||
@ -520,11 +559,31 @@ class Markdown(MarkdownParser):
|
||||
# To eliminate duplicate tables in chunking result, uncomment code below and set separate_tables to True in line 410.
|
||||
# extractor = MarkdownElementExtractor(remainder)
|
||||
extractor = MarkdownElementExtractor(txt)
|
||||
element_sections = extractor.extract_elements(delimiter)
|
||||
sections = [(element, "") for element in element_sections]
|
||||
image_refs = self.extract_image_urls_with_lines(txt)
|
||||
element_sections = extractor.extract_elements(delimiter, include_meta=True)
|
||||
|
||||
sections = []
|
||||
section_images = []
|
||||
image_cache = {}
|
||||
for element in element_sections:
|
||||
content = element["content"]
|
||||
start_line = element["start_line"]
|
||||
end_line = element["end_line"]
|
||||
urls_in_section = [ref["url"] for ref in image_refs if start_line <= ref["line"] <= end_line]
|
||||
imgs = []
|
||||
if urls_in_section:
|
||||
imgs, image_cache = self.load_images_from_urls(urls_in_section, image_cache)
|
||||
combined_image = None
|
||||
if imgs:
|
||||
combined_image = reduce(concat_img, imgs) if len(imgs) > 1 else imgs[0]
|
||||
sections.append((content, ""))
|
||||
section_images.append(combined_image)
|
||||
|
||||
tbls = []
|
||||
for table in tables:
|
||||
tbls.append(((None, markdown(table, extensions=['markdown.extensions.tables'])), ""))
|
||||
if return_section_images:
|
||||
return sections, tbls, section_images
|
||||
return sections, tbls
|
||||
|
||||
def load_from_xml_v2(baseURI, rels_item_xml):
|
||||
@ -542,8 +601,7 @@ def load_from_xml_v2(baseURI, rels_item_xml):
|
||||
srels._srels.append(_SerializedRelationship(baseURI, rel_elm))
|
||||
return srels
|
||||
|
||||
def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
lang="Chinese", callback=None, **kwargs):
|
||||
def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", callback=None, **kwargs):
|
||||
"""
|
||||
Supported file formats are docx, pdf, excel, txt.
|
||||
This method apply the naive ways to chunk files.
|
||||
@ -553,11 +611,18 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
urls = set()
|
||||
url_res = []
|
||||
|
||||
|
||||
is_english = lang.lower() == "english" # is_english(cks)
|
||||
parser_config = kwargs.get(
|
||||
"parser_config", {
|
||||
"chunk_token_num": 512, "delimiter": "\n!?。;!?", "layout_recognize": "DeepDOC", "analyze_hyperlink": True})
|
||||
|
||||
child_deli = re.findall(r"`([^`]+)`", parser_config.get("children_delimiter", ""))
|
||||
child_deli = sorted(set(child_deli), key=lambda x: -len(x))
|
||||
child_deli = "|".join(re.escape(t) for t in child_deli if t)
|
||||
is_markdown = False
|
||||
table_context_size = max(0, int(parser_config.get("table_context_size", 0) or 0))
|
||||
image_context_size = max(0, int(parser_config.get("image_context_size", 0) or 0))
|
||||
|
||||
doc = {
|
||||
"docnm_kwd": filename,
|
||||
"title_tks": rag_tokenizer.tokenize(re.sub(r"\.[a-zA-Z]+$", "", filename))
|
||||
@ -618,15 +683,12 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
"chunk_token_num", 128)), parser_config.get(
|
||||
"delimiter", "\n!?。;!?"))
|
||||
|
||||
if kwargs.get("section_only", False):
|
||||
chunks.extend(embed_res)
|
||||
chunks.extend(url_res)
|
||||
return chunks
|
||||
|
||||
res.extend(tokenize_chunks_with_images(chunks, doc, is_english, images))
|
||||
res.extend(tokenize_chunks_with_images(chunks, doc, is_english, images, child_delimiters_pattern=child_deli))
|
||||
logging.info("naive_merge({}): {}".format(filename, timer() - st))
|
||||
res.extend(embed_res)
|
||||
res.extend(url_res)
|
||||
if table_context_size or image_context_size:
|
||||
attach_media_context(res, table_context_size, image_context_size)
|
||||
return res
|
||||
|
||||
elif re.search(r"\.pdf$", filename, re.IGNORECASE):
|
||||
@ -695,9 +757,9 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
excel_parser = ExcelParser()
|
||||
if parser_config.get("html4excel"):
|
||||
sections = [(_, "") for _ in excel_parser.html(binary, 12) if _]
|
||||
parser_config["chunk_token_num"] = 0
|
||||
else:
|
||||
sections = [(_, "") for _ in excel_parser(binary) if _]
|
||||
parser_config["chunk_token_num"] = 12800
|
||||
|
||||
elif re.search(r"\.(txt|py|js|java|c|cpp|h|php|go|ts|sh|cs|kt|sql)$", filename, re.IGNORECASE):
|
||||
callback(0.1, "Start to parse.")
|
||||
@ -709,7 +771,15 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
elif re.search(r"\.(md|markdown)$", filename, re.IGNORECASE):
|
||||
callback(0.1, "Start to parse.")
|
||||
markdown_parser = Markdown(int(parser_config.get("chunk_token_num", 128)))
|
||||
sections, tables = markdown_parser(filename, binary, separate_tables=False, delimiter=parser_config.get("delimiter", "\n!?;。;!?"))
|
||||
sections, tables, section_images = markdown_parser(
|
||||
filename,
|
||||
binary,
|
||||
separate_tables=False,
|
||||
delimiter=parser_config.get("delimiter", "\n!?;。;!?"),
|
||||
return_section_images=True,
|
||||
)
|
||||
|
||||
is_markdown = True
|
||||
|
||||
try:
|
||||
vision_model = LLMBundle(kwargs["tenant_id"], LLMType.IMAGE2TEXT)
|
||||
@ -719,19 +789,22 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
|
||||
if vision_model:
|
||||
# Process images for each section
|
||||
section_images = []
|
||||
for idx, (section_text, _) in enumerate(sections):
|
||||
images = markdown_parser.get_pictures(section_text) if section_text else None
|
||||
images = []
|
||||
if section_images and len(section_images) > idx and section_images[idx] is not None:
|
||||
images.append(section_images[idx])
|
||||
|
||||
if images:
|
||||
if images and len(images) > 0:
|
||||
# If multiple images found, combine them using concat_img
|
||||
combined_image = reduce(concat_img, images) if len(images) > 1 else images[0]
|
||||
section_images.append(combined_image)
|
||||
if section_images:
|
||||
section_images[idx] = combined_image
|
||||
else:
|
||||
section_images = [None] * len(sections)
|
||||
section_images[idx] = combined_image
|
||||
markdown_vision_parser = VisionFigureParser(vision_model=vision_model, figures_data= [((combined_image, ["markdown image"]), [(0, 0, 0, 0, 0)])], **kwargs)
|
||||
boosted_figures = markdown_vision_parser(callback=callback)
|
||||
sections[idx] = (section_text + "\n\n" + "\n\n".join([fig[0][1] for fig in boosted_figures]), sections[idx][1])
|
||||
else:
|
||||
section_images.append(None)
|
||||
|
||||
else:
|
||||
logging.warning("No visual model detected. Skipping figure parsing enhancement.")
|
||||
@ -783,31 +856,72 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
"file type not supported yet(pdf, xlsx, doc, docx, txt supported)")
|
||||
|
||||
st = timer()
|
||||
if section_images:
|
||||
# if all images are None, set section_images to None
|
||||
if all(image is None for image in section_images):
|
||||
section_images = None
|
||||
if is_markdown:
|
||||
merged_chunks = []
|
||||
merged_images = []
|
||||
chunk_limit = max(0, int(parser_config.get("chunk_token_num", 128)))
|
||||
overlapped_percent = int(parser_config.get("overlapped_percent", 0))
|
||||
overlapped_percent = max(0, min(overlapped_percent, 90))
|
||||
|
||||
if section_images:
|
||||
chunks, images = naive_merge_with_images(sections, section_images,
|
||||
int(parser_config.get(
|
||||
"chunk_token_num", 128)), parser_config.get(
|
||||
"delimiter", "\n!?。;!?"))
|
||||
if kwargs.get("section_only", False):
|
||||
chunks.extend(embed_res)
|
||||
return chunks
|
||||
current_text = ""
|
||||
current_tokens = 0
|
||||
current_image = None
|
||||
|
||||
res.extend(tokenize_chunks_with_images(chunks, doc, is_english, images))
|
||||
for idx, sec in enumerate(sections):
|
||||
text = sec[0] if isinstance(sec, tuple) else sec
|
||||
sec_tokens = num_tokens_from_string(text)
|
||||
sec_image = section_images[idx] if section_images and idx < len(section_images) else None
|
||||
|
||||
if current_text and current_tokens + sec_tokens > chunk_limit:
|
||||
merged_chunks.append(current_text)
|
||||
merged_images.append(current_image)
|
||||
overlap_part = ""
|
||||
if overlapped_percent > 0:
|
||||
overlap_len = int(len(current_text) * overlapped_percent / 100)
|
||||
if overlap_len > 0:
|
||||
overlap_part = current_text[-overlap_len:]
|
||||
current_text = overlap_part
|
||||
current_tokens = num_tokens_from_string(current_text)
|
||||
current_image = current_image if overlap_part else None
|
||||
|
||||
if current_text:
|
||||
current_text += "\n" + text
|
||||
else:
|
||||
current_text = text
|
||||
current_tokens += sec_tokens
|
||||
|
||||
if sec_image:
|
||||
current_image = concat_img(current_image, sec_image) if current_image else sec_image
|
||||
|
||||
if current_text:
|
||||
merged_chunks.append(current_text)
|
||||
merged_images.append(current_image)
|
||||
|
||||
chunks = merged_chunks
|
||||
has_images = merged_images and any(img is not None for img in merged_images)
|
||||
|
||||
if has_images:
|
||||
res.extend(tokenize_chunks_with_images(chunks, doc, is_english, merged_images, child_delimiters_pattern=child_deli))
|
||||
else:
|
||||
res.extend(tokenize_chunks(chunks, doc, is_english, pdf_parser, child_delimiters_pattern=child_deli))
|
||||
else:
|
||||
chunks = naive_merge(
|
||||
sections, int(parser_config.get(
|
||||
"chunk_token_num", 128)), parser_config.get(
|
||||
"delimiter", "\n!?。;!?"))
|
||||
if kwargs.get("section_only", False):
|
||||
chunks.extend(embed_res)
|
||||
return chunks
|
||||
if section_images:
|
||||
if all(image is None for image in section_images):
|
||||
section_images = None
|
||||
|
||||
res.extend(tokenize_chunks(chunks, doc, is_english, pdf_parser))
|
||||
if section_images:
|
||||
chunks, images = naive_merge_with_images(sections, section_images,
|
||||
int(parser_config.get(
|
||||
"chunk_token_num", 128)), parser_config.get(
|
||||
"delimiter", "\n!?。;!?"))
|
||||
res.extend(tokenize_chunks_with_images(chunks, doc, is_english, images, child_delimiters_pattern=child_deli))
|
||||
else:
|
||||
chunks = naive_merge(
|
||||
sections, int(parser_config.get(
|
||||
"chunk_token_num", 128)), parser_config.get(
|
||||
"delimiter", "\n!?。;!?"))
|
||||
|
||||
res.extend(tokenize_chunks(chunks, doc, is_english, pdf_parser, child_delimiters_pattern=child_deli))
|
||||
|
||||
if urls and parser_config.get("analyze_hyperlink", False) and is_root:
|
||||
for index, url in enumerate(urls):
|
||||
@ -820,13 +934,15 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
logging.info(f"Failed to chunk url in registered file type {url}: {e}")
|
||||
sub_url_res = chunk(f"{index}.html", html_bytes, callback=callback, lang=lang, is_root=False, **kwargs)
|
||||
url_res.extend(sub_url_res)
|
||||
|
||||
|
||||
logging.info("naive_merge({}): {}".format(filename, timer() - st))
|
||||
|
||||
|
||||
if embed_res:
|
||||
res.extend(embed_res)
|
||||
if url_res:
|
||||
res.extend(url_res)
|
||||
if table_context_size or image_context_size:
|
||||
attach_media_context(res, table_context_size, image_context_size)
|
||||
return res
|
||||
|
||||
|
||||
|
||||
@ -20,7 +20,7 @@ import re
|
||||
|
||||
from deepdoc.parser.figure_parser import vision_figure_parser_pdf_wrapper
|
||||
from common.constants import ParserType
|
||||
from rag.nlp import rag_tokenizer, tokenize, tokenize_table, add_positions, bullets_category, title_frequency, tokenize_chunks
|
||||
from rag.nlp import rag_tokenizer, tokenize, tokenize_table, add_positions, bullets_category, title_frequency, tokenize_chunks, attach_media_context
|
||||
from deepdoc.parser import PdfParser
|
||||
import numpy as np
|
||||
from rag.app.naive import by_plaintext, PARSERS
|
||||
@ -150,7 +150,7 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
"chunk_token_num": 512, "delimiter": "\n!?。;!?", "layout_recognize": "DeepDOC"})
|
||||
if re.search(r"\.pdf$", filename, re.IGNORECASE):
|
||||
layout_recognizer = parser_config.get("layout_recognize", "DeepDOC")
|
||||
|
||||
|
||||
if isinstance(layout_recognizer, bool):
|
||||
layout_recognizer = "DeepDOC" if layout_recognizer else "Plain Text"
|
||||
|
||||
@ -234,6 +234,10 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
chunks.append(txt)
|
||||
last_sid = sec_id
|
||||
res.extend(tokenize_chunks(chunks, doc, eng, pdf_parser))
|
||||
table_ctx = max(0, int(parser_config.get("table_context_size", 0) or 0))
|
||||
image_ctx = max(0, int(parser_config.get("image_context_size", 0) or 0))
|
||||
if table_ctx or image_ctx:
|
||||
attach_media_context(res, table_ctx, image_ctx)
|
||||
return res
|
||||
|
||||
|
||||
|
||||
@ -20,11 +20,11 @@ import re
|
||||
import numpy as np
|
||||
from PIL import Image
|
||||
|
||||
from common.constants import LLMType
|
||||
from api.db.services.llm_service import LLMBundle
|
||||
from deepdoc.vision import OCR
|
||||
from rag.nlp import rag_tokenizer, tokenize
|
||||
from common.constants import LLMType
|
||||
from common.string_utils import clean_markdown_block
|
||||
from deepdoc.vision import OCR
|
||||
from rag.nlp import attach_media_context, rag_tokenizer, tokenize
|
||||
|
||||
ocr = OCR()
|
||||
|
||||
@ -39,9 +39,16 @@ def chunk(filename, binary, tenant_id, lang, callback=None, **kwargs):
|
||||
}
|
||||
eng = lang.lower() == "english"
|
||||
|
||||
parser_config = kwargs.get("parser_config", {}) or {}
|
||||
image_ctx = max(0, int(parser_config.get("image_context_size", 0) or 0))
|
||||
|
||||
if any(filename.lower().endswith(ext) for ext in VIDEO_EXTS):
|
||||
try:
|
||||
doc.update({"doc_type_kwd": "video"})
|
||||
doc.update(
|
||||
{
|
||||
"doc_type_kwd": "video",
|
||||
}
|
||||
)
|
||||
cv_mdl = LLMBundle(tenant_id, llm_type=LLMType.IMAGE2TEXT, lang=lang)
|
||||
ans = cv_mdl.chat(system="", history=[], gen_conf={}, video_bytes=binary, filename=filename)
|
||||
callback(0.8, "CV LLM respond: %s ..." % ans[:32])
|
||||
@ -64,7 +71,7 @@ def chunk(filename, binary, tenant_id, lang, callback=None, **kwargs):
|
||||
if (eng and len(txt.split()) > 32) or len(txt) > 32:
|
||||
tokenize(doc, txt, eng)
|
||||
callback(0.8, "OCR results is too long to use CV LLM.")
|
||||
return [doc]
|
||||
return attach_media_context([doc], 0, image_ctx)
|
||||
|
||||
try:
|
||||
callback(0.4, "Use CV LLM to describe the picture.")
|
||||
@ -76,7 +83,7 @@ def chunk(filename, binary, tenant_id, lang, callback=None, **kwargs):
|
||||
callback(0.8, "CV LLM respond: %s ..." % ans[:32])
|
||||
txt += "\n" + ans
|
||||
tokenize(doc, txt, eng)
|
||||
return [doc]
|
||||
return attach_media_context([doc], 0, image_ctx)
|
||||
except Exception as e:
|
||||
callback(prog=-1, msg=str(e))
|
||||
|
||||
@ -103,7 +110,7 @@ def vision_llm_chunk(binary, vision_model, prompt=None, callback=None):
|
||||
img_binary.seek(0)
|
||||
img_binary.truncate()
|
||||
img.save(img_binary, format="PNG")
|
||||
|
||||
|
||||
img_binary.seek(0)
|
||||
ans = clean_markdown_block(vision_model.describe_with_prompt(img_binary.read(), prompt))
|
||||
txt += "\n" + ans
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user