mirror of
https://github.com/infiniflow/ragflow.git
synced 2026-01-04 03:25:30 +08:00
Compare commits
133 Commits
672958a192
...
v0.23.0
| Author | SHA1 | Date | |
|---|---|---|---|
| 8dc5b4dc56 | |||
| ef5341b664 | |||
| 050534e743 | |||
| 3fe94d3386 | |||
| 3364cf96cf | |||
| a1ed4430ce | |||
| 7f11a79ad9 | |||
| ddcd9cf2c4 | |||
| c2e9064474 | |||
| bc9e1e3b9a | |||
| 613d2c5790 | |||
| 51bc41b2e8 | |||
| 9de3ecc4a8 | |||
| c4a66204f0 | |||
| 3558a6c170 | |||
| 595fc4ccec | |||
| 3ad147d349 | |||
| d285d8cd97 | |||
| 5714895291 | |||
| a33936e8ff | |||
| 9f8161d13e | |||
| a599a0f4bf | |||
| 7498bc63a3 | |||
| 894bf995bb | |||
| 52dbacc506 | |||
| cbcbbc41af | |||
| 6044314811 | |||
| 5fb38ecc2a | |||
| 73db759558 | |||
| 6e9691a419 | |||
| fd53b83190 | |||
| c7b5bfb809 | |||
| cfd1250615 | |||
| c8eeba5880 | |||
| 1812491679 | |||
| 7b6ab22b78 | |||
| c20d112f60 | |||
| 2817be14d5 | |||
| f6217bb990 | |||
| a3ceb7a944 | |||
| 0f8f35bd5b | |||
| 6373ff898b | |||
| d1c4077a75 | |||
| 059f375d85 | |||
| 8cbfb5aef6 | |||
| 5ebabf5bed | |||
| e23c8a5dcd | |||
| 89ea760e67 | |||
| 02b976ffa4 | |||
| 556b5ad686 | |||
| 884aabd130 | |||
| f0dac1d90e | |||
| 4a2978150c | |||
| df0c092b22 | |||
| 7d4258f50e | |||
| e24fabb03c | |||
| ce08ee399b | |||
| badd5aa101 | |||
| 5ff3be22b4 | |||
| df09cbd271 | |||
| 957bc021eb | |||
| 49dbfdbfb0 | |||
| 9a5c5c46f2 | |||
| 8197f9a873 | |||
| bab6a4a219 | |||
| 6c93157b14 | |||
| 033029eaa1 | |||
| a958ddb27a | |||
| f63f007326 | |||
| b47f1afa35 | |||
| 2369be7244 | |||
| 00bb6fbd28 | |||
| 063b06494a | |||
| b824185a3a | |||
| 8e6ddd7c1b | |||
| d1bc7ad2ee | |||
| 321474fb97 | |||
| ea89e4e0c6 | |||
| 9e31631d8f | |||
| 712d537d66 | |||
| bd4eb19393 | |||
| 02efab7c11 | |||
| 8ce129bc51 | |||
| d5a44e913d | |||
| 1444de981c | |||
| bd76b8ff1a | |||
| a95f22fa88 | |||
| 38ac6a7c27 | |||
| e5f3d5ae26 | |||
| 4cbc91f2fa | |||
| 6d3d3a40ab | |||
| 51b12841d6 | |||
| 993bf7c2c8 | |||
| b42b5fcf65 | |||
| 5d391fb1f9 | |||
| 2ddfcc7cf6 | |||
| 5ba51b21c9 | |||
| 3ea84ad9c8 | |||
| 0a5dce50fb | |||
| 6c9afd1ffb | |||
| bfef96d56e | |||
| 74adf3d59c | |||
| ba7e087aef | |||
| f911aa2997 | |||
| 42f9ac997f | |||
| c7cf7aad4e | |||
| 2118bc2556 | |||
| b49eb6826b | |||
| 8dd2394e93 | |||
| 5aea82d9c4 | |||
| 47005ebe10 | |||
| 3ee47e4af7 | |||
| 55c0468ac9 | |||
| eeb36a5ce7 | |||
| aceca266ff | |||
| d82e502a71 | |||
| 0494b92371 | |||
| 8683a5b1b7 | |||
| 4cbe470089 | |||
| 6cd1824a77 | |||
| 2844700dc4 | |||
| f8fd1ea7e1 | |||
| 57edc215d7 | |||
| 7a4044b05f | |||
| e84d5412bc | |||
| 151480dc85 | |||
| 2331b3a270 | |||
| 5cd1a678c8 | |||
| cc9546b761 | |||
| a63dcfed6f | |||
| 4dd8cdc38b | |||
| 1a4822d6be | |||
| ce161f09cc |
24
.github/workflows/tests.yml
vendored
24
.github/workflows/tests.yml
vendored
@ -205,29 +205,29 @@ jobs:
|
||||
- name: Run sdk tests against Elasticsearch
|
||||
run: |
|
||||
export http_proxy=""; export https_proxy=""; export no_proxy=""; export HTTP_PROXY=""; export HTTPS_PROXY=""; export NO_PROXY=""
|
||||
until sudo docker exec ${RAGFLOW_CONTAINER} curl -s --connect-timeout 5 ${HOST_ADDRESS} > /dev/null; do
|
||||
until sudo docker exec ${RAGFLOW_CONTAINER} curl -s --connect-timeout 5 ${HOST_ADDRESS}/v1/system/ping > /dev/null; do
|
||||
echo "Waiting for service to be available..."
|
||||
sleep 5
|
||||
done
|
||||
source .venv/bin/activate && pytest -s --tb=short --level=${HTTP_API_TEST_LEVEL} test/testcases/test_sdk_api
|
||||
source .venv/bin/activate && set -o pipefail; pytest -s --tb=short --level=${HTTP_API_TEST_LEVEL} test/testcases/test_sdk_api 2>&1 | tee es_sdk_test.log
|
||||
|
||||
- name: Run frontend api tests against Elasticsearch
|
||||
run: |
|
||||
export http_proxy=""; export https_proxy=""; export no_proxy=""; export HTTP_PROXY=""; export HTTPS_PROXY=""; export NO_PROXY=""
|
||||
until sudo docker exec ${RAGFLOW_CONTAINER} curl -s --connect-timeout 5 ${HOST_ADDRESS} > /dev/null; do
|
||||
until sudo docker exec ${RAGFLOW_CONTAINER} curl -s --connect-timeout 5 ${HOST_ADDRESS}/v1/system/ping > /dev/null; do
|
||||
echo "Waiting for service to be available..."
|
||||
sleep 5
|
||||
done
|
||||
source .venv/bin/activate && pytest -s --tb=short sdk/python/test/test_frontend_api/get_email.py sdk/python/test/test_frontend_api/test_dataset.py
|
||||
source .venv/bin/activate && set -o pipefail; pytest -s --tb=short sdk/python/test/test_frontend_api/get_email.py sdk/python/test/test_frontend_api/test_dataset.py 2>&1 | tee es_api_test.log
|
||||
|
||||
- name: Run http api tests against Elasticsearch
|
||||
run: |
|
||||
export http_proxy=""; export https_proxy=""; export no_proxy=""; export HTTP_PROXY=""; export HTTPS_PROXY=""; export NO_PROXY=""
|
||||
until sudo docker exec ${RAGFLOW_CONTAINER} curl -s --connect-timeout 5 ${HOST_ADDRESS} > /dev/null; do
|
||||
until sudo docker exec ${RAGFLOW_CONTAINER} curl -s --connect-timeout 5 ${HOST_ADDRESS}/v1/system/ping > /dev/null; do
|
||||
echo "Waiting for service to be available..."
|
||||
sleep 5
|
||||
done
|
||||
source .venv/bin/activate && pytest -s --tb=short --level=${HTTP_API_TEST_LEVEL} test/testcases/test_http_api
|
||||
source .venv/bin/activate && set -o pipefail; pytest -s --tb=short --level=${HTTP_API_TEST_LEVEL} test/testcases/test_http_api 2>&1 | tee es_http_api_test.log
|
||||
|
||||
- name: Stop ragflow:nightly
|
||||
if: always() # always run this step even if previous steps failed
|
||||
@ -243,29 +243,29 @@ jobs:
|
||||
- name: Run sdk tests against Infinity
|
||||
run: |
|
||||
export http_proxy=""; export https_proxy=""; export no_proxy=""; export HTTP_PROXY=""; export HTTPS_PROXY=""; export NO_PROXY=""
|
||||
until sudo docker exec ${RAGFLOW_CONTAINER} curl -s --connect-timeout 5 ${HOST_ADDRESS} > /dev/null; do
|
||||
until sudo docker exec ${RAGFLOW_CONTAINER} curl -s --connect-timeout 5 ${HOST_ADDRESS}/v1/system/ping > /dev/null; do
|
||||
echo "Waiting for service to be available..."
|
||||
sleep 5
|
||||
done
|
||||
source .venv/bin/activate && DOC_ENGINE=infinity pytest -s --tb=short --level=${HTTP_API_TEST_LEVEL} test/testcases/test_sdk_api
|
||||
source .venv/bin/activate && set -o pipefail; DOC_ENGINE=infinity pytest -s --tb=short --level=${HTTP_API_TEST_LEVEL} test/testcases/test_sdk_api 2>&1 | tee infinity_sdk_test.log
|
||||
|
||||
- name: Run frontend api tests against Infinity
|
||||
run: |
|
||||
export http_proxy=""; export https_proxy=""; export no_proxy=""; export HTTP_PROXY=""; export HTTPS_PROXY=""; export NO_PROXY=""
|
||||
until sudo docker exec ${RAGFLOW_CONTAINER} curl -s --connect-timeout 5 ${HOST_ADDRESS} > /dev/null; do
|
||||
until sudo docker exec ${RAGFLOW_CONTAINER} curl -s --connect-timeout 5 ${HOST_ADDRESS}/v1/system/ping > /dev/null; do
|
||||
echo "Waiting for service to be available..."
|
||||
sleep 5
|
||||
done
|
||||
source .venv/bin/activate && DOC_ENGINE=infinity pytest -s --tb=short sdk/python/test/test_frontend_api/get_email.py sdk/python/test/test_frontend_api/test_dataset.py
|
||||
source .venv/bin/activate && set -o pipefail; DOC_ENGINE=infinity pytest -s --tb=short sdk/python/test/test_frontend_api/get_email.py sdk/python/test/test_frontend_api/test_dataset.py 2>&1 | tee infinity_api_test.log
|
||||
|
||||
- name: Run http api tests against Infinity
|
||||
run: |
|
||||
export http_proxy=""; export https_proxy=""; export no_proxy=""; export HTTP_PROXY=""; export HTTPS_PROXY=""; export NO_PROXY=""
|
||||
until sudo docker exec ${RAGFLOW_CONTAINER} curl -s --connect-timeout 5 ${HOST_ADDRESS} > /dev/null; do
|
||||
until sudo docker exec ${RAGFLOW_CONTAINER} curl -s --connect-timeout 5 ${HOST_ADDRESS}/v1/system/ping > /dev/null; do
|
||||
echo "Waiting for service to be available..."
|
||||
sleep 5
|
||||
done
|
||||
source .venv/bin/activate && DOC_ENGINE=infinity pytest -s --tb=short --level=${HTTP_API_TEST_LEVEL} test/testcases/test_http_api
|
||||
source .venv/bin/activate && set -o pipefail; DOC_ENGINE=infinity pytest -s --tb=short --level=${HTTP_API_TEST_LEVEL} test/testcases/test_http_api 2>&1 | tee infinity_http_api_test.log
|
||||
|
||||
- name: Stop ragflow:nightly
|
||||
if: always() # always run this step even if previous steps failed
|
||||
|
||||
@ -192,6 +192,7 @@ COPY pyproject.toml uv.lock ./
|
||||
COPY mcp mcp
|
||||
COPY plugin plugin
|
||||
COPY common common
|
||||
COPY memory memory
|
||||
|
||||
COPY docker/service_conf.yaml.template ./conf/service_conf.yaml.template
|
||||
COPY docker/entrypoint.sh ./
|
||||
|
||||
@ -22,7 +22,7 @@
|
||||
<img alt="Static Badge" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
||||
</a>
|
||||
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
||||
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.22.1">
|
||||
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.23.0">
|
||||
</a>
|
||||
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
||||
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Latest%20Release" alt="Latest Release">
|
||||
@ -85,6 +85,7 @@ Try our demo at [https://demo.ragflow.io](https://demo.ragflow.io).
|
||||
|
||||
## 🔥 Latest Updates
|
||||
|
||||
- 2025-12-26 Supports 'Memory' for AI agent.
|
||||
- 2025-11-19 Supports Gemini 3 Pro.
|
||||
- 2025-11-12 Supports data synchronization from Confluence, S3, Notion, Discord, Google Drive.
|
||||
- 2025-10-23 Supports MinerU & Docling as document parsing methods.
|
||||
@ -187,12 +188,12 @@ releases! 🌟
|
||||
> All Docker images are built for x86 platforms. We don't currently offer Docker images for ARM64.
|
||||
> If you are on an ARM64 platform, follow [this guide](https://ragflow.io/docs/dev/build_docker_image) to build a Docker image compatible with your system.
|
||||
|
||||
> The command below downloads the `v0.22.1` edition of the RAGFlow Docker image. See the following table for descriptions of different RAGFlow editions. To download a RAGFlow edition different from `v0.22.1`, update the `RAGFLOW_IMAGE` variable accordingly in **docker/.env** before using `docker compose` to start the server.
|
||||
> The command below downloads the `v0.23.0` edition of the RAGFlow Docker image. See the following table for descriptions of different RAGFlow editions. To download a RAGFlow edition different from `v0.23.0`, update the `RAGFLOW_IMAGE` variable accordingly in **docker/.env** before using `docker compose` to start the server.
|
||||
|
||||
```bash
|
||||
$ cd ragflow/docker
|
||||
|
||||
# git checkout v0.22.1
|
||||
# git checkout v0.23.0
|
||||
# Optional: use a stable tag (see releases: https://github.com/infiniflow/ragflow/releases)
|
||||
# This step ensures the **entrypoint.sh** file in the code matches the Docker image version.
|
||||
|
||||
|
||||
@ -22,7 +22,7 @@
|
||||
<img alt="Lencana Daring" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
||||
</a>
|
||||
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
||||
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.22.1">
|
||||
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.23.0">
|
||||
</a>
|
||||
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
||||
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Rilis%20Terbaru" alt="Rilis Terbaru">
|
||||
@ -85,6 +85,7 @@ Coba demo kami di [https://demo.ragflow.io](https://demo.ragflow.io).
|
||||
|
||||
## 🔥 Pembaruan Terbaru
|
||||
|
||||
- 2025-12-26 Mendukung 'Memori' untuk agen AI.
|
||||
- 2025-11-19 Mendukung Gemini 3 Pro.
|
||||
- 2025-11-12 Mendukung sinkronisasi data dari Confluence, S3, Notion, Discord, Google Drive.
|
||||
- 2025-10-23 Mendukung MinerU & Docling sebagai metode penguraian dokumen.
|
||||
@ -187,12 +188,12 @@ Coba demo kami di [https://demo.ragflow.io](https://demo.ragflow.io).
|
||||
> Semua gambar Docker dibangun untuk platform x86. Saat ini, kami tidak menawarkan gambar Docker untuk ARM64.
|
||||
> Jika Anda menggunakan platform ARM64, [silakan gunakan panduan ini untuk membangun gambar Docker yang kompatibel dengan sistem Anda](https://ragflow.io/docs/dev/build_docker_image).
|
||||
|
||||
> Perintah di bawah ini mengunduh edisi v0.22.1 dari gambar Docker RAGFlow. Silakan merujuk ke tabel berikut untuk deskripsi berbagai edisi RAGFlow. Untuk mengunduh edisi RAGFlow yang berbeda dari v0.22.1, perbarui variabel RAGFLOW_IMAGE di docker/.env sebelum menggunakan docker compose untuk memulai server.
|
||||
> Perintah di bawah ini mengunduh edisi v0.23.0 dari gambar Docker RAGFlow. Silakan merujuk ke tabel berikut untuk deskripsi berbagai edisi RAGFlow. Untuk mengunduh edisi RAGFlow yang berbeda dari v0.23.0, perbarui variabel RAGFLOW_IMAGE di docker/.env sebelum menggunakan docker compose untuk memulai server.
|
||||
|
||||
```bash
|
||||
$ cd ragflow/docker
|
||||
|
||||
# git checkout v0.22.1
|
||||
# git checkout v0.23.0
|
||||
# Opsional: gunakan tag stabil (lihat releases: https://github.com/infiniflow/ragflow/releases)
|
||||
# This steps ensures the **entrypoint.sh** file in the code matches the Docker image version.
|
||||
|
||||
|
||||
@ -22,7 +22,7 @@
|
||||
<img alt="Static Badge" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
||||
</a>
|
||||
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
||||
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.22.1">
|
||||
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.23.0">
|
||||
</a>
|
||||
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
||||
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Latest%20Release" alt="Latest Release">
|
||||
@ -66,7 +66,8 @@
|
||||
|
||||
## 🔥 最新情報
|
||||
|
||||
- 2025-11-19 Gemini 3 Proをサポートしています
|
||||
- 2025-12-26 AIエージェントの「メモリ」機能をサポート。
|
||||
- 2025-11-19 Gemini 3 Proをサポートしています。
|
||||
- 2025-11-12 Confluence、S3、Notion、Discord、Google Drive からのデータ同期をサポートします。
|
||||
- 2025-10-23 ドキュメント解析方法として MinerU と Docling をサポートします。
|
||||
- 2025-10-15 オーケストレーションされたデータパイプラインのサポート。
|
||||
@ -167,12 +168,12 @@
|
||||
> 現在、公式に提供されているすべての Docker イメージは x86 アーキテクチャ向けにビルドされており、ARM64 用の Docker イメージは提供されていません。
|
||||
> ARM64 アーキテクチャのオペレーティングシステムを使用している場合は、[このドキュメント](https://ragflow.io/docs/dev/build_docker_image)を参照して Docker イメージを自分でビルドしてください。
|
||||
|
||||
> 以下のコマンドは、RAGFlow Docker イメージの v0.22.1 エディションをダウンロードします。異なる RAGFlow エディションの説明については、以下の表を参照してください。v0.22.1 とは異なるエディションをダウンロードするには、docker/.env ファイルの RAGFLOW_IMAGE 変数を適宜更新し、docker compose を使用してサーバーを起動してください。
|
||||
> 以下のコマンドは、RAGFlow Docker イメージの v0.23.0 エディションをダウンロードします。異なる RAGFlow エディションの説明については、以下の表を参照してください。v0.23.0 とは異なるエディションをダウンロードするには、docker/.env ファイルの RAGFLOW_IMAGE 変数を適宜更新し、docker compose を使用してサーバーを起動してください。
|
||||
|
||||
```bash
|
||||
$ cd ragflow/docker
|
||||
|
||||
# git checkout v0.22.1
|
||||
# git checkout v0.23.0
|
||||
# 任意: 安定版タグを利用 (一覧: https://github.com/infiniflow/ragflow/releases)
|
||||
# この手順は、コード内の entrypoint.sh ファイルが Docker イメージのバージョンと一致していることを確認します。
|
||||
|
||||
|
||||
@ -22,7 +22,7 @@
|
||||
<img alt="Static Badge" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
||||
</a>
|
||||
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
||||
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.22.1">
|
||||
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.23.0">
|
||||
</a>
|
||||
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
||||
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Latest%20Release" alt="Latest Release">
|
||||
@ -67,6 +67,7 @@
|
||||
|
||||
## 🔥 업데이트
|
||||
|
||||
- 2025-12-26 AI 에이전트의 '메모리' 기능 지원.
|
||||
- 2025-11-19 Gemini 3 Pro를 지원합니다.
|
||||
- 2025-11-12 Confluence, S3, Notion, Discord, Google Drive에서 데이터 동기화를 지원합니다.
|
||||
- 2025-10-23 문서 파싱 방법으로 MinerU 및 Docling을 지원합니다.
|
||||
@ -169,12 +170,12 @@
|
||||
> 모든 Docker 이미지는 x86 플랫폼을 위해 빌드되었습니다. 우리는 현재 ARM64 플랫폼을 위한 Docker 이미지를 제공하지 않습니다.
|
||||
> ARM64 플랫폼을 사용 중이라면, [시스템과 호환되는 Docker 이미지를 빌드하려면 이 가이드를 사용해 주세요](https://ragflow.io/docs/dev/build_docker_image).
|
||||
|
||||
> 아래 명령어는 RAGFlow Docker 이미지의 v0.22.1 버전을 다운로드합니다. 다양한 RAGFlow 버전에 대한 설명은 다음 표를 참조하십시오. v0.22.1과 다른 RAGFlow 버전을 다운로드하려면, docker/.env 파일에서 RAGFLOW_IMAGE 변수를 적절히 업데이트한 후 docker compose를 사용하여 서버를 시작하십시오.
|
||||
> 아래 명령어는 RAGFlow Docker 이미지의 v0.23.0 버전을 다운로드합니다. 다양한 RAGFlow 버전에 대한 설명은 다음 표를 참조하십시오. v0.23.0과 다른 RAGFlow 버전을 다운로드하려면, docker/.env 파일에서 RAGFLOW_IMAGE 변수를 적절히 업데이트한 후 docker compose를 사용하여 서버를 시작하십시오.
|
||||
|
||||
```bash
|
||||
$ cd ragflow/docker
|
||||
|
||||
# git checkout v0.22.1
|
||||
# git checkout v0.23.0
|
||||
# Optional: use a stable tag (see releases: https://github.com/infiniflow/ragflow/releases)
|
||||
# 이 단계는 코드의 entrypoint.sh 파일이 Docker 이미지 버전과 일치하도록 보장합니다.
|
||||
|
||||
|
||||
@ -22,7 +22,7 @@
|
||||
<img alt="Badge Estático" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
||||
</a>
|
||||
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
||||
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.22.1">
|
||||
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.23.0">
|
||||
</a>
|
||||
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
||||
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Última%20Relese" alt="Última Versão">
|
||||
@ -86,6 +86,7 @@ Experimente nossa demo em [https://demo.ragflow.io](https://demo.ragflow.io).
|
||||
|
||||
## 🔥 Últimas Atualizações
|
||||
|
||||
- 26-12-2025 Suporte à função 'Memória' para agentes de IA.
|
||||
- 19-11-2025 Suporta Gemini 3 Pro.
|
||||
- 12-11-2025 Suporta a sincronização de dados do Confluence, S3, Notion, Discord e Google Drive.
|
||||
- 23-10-2025 Suporta MinerU e Docling como métodos de análise de documentos.
|
||||
@ -187,12 +188,12 @@ Experimente nossa demo em [https://demo.ragflow.io](https://demo.ragflow.io).
|
||||
> Todas as imagens Docker são construídas para plataformas x86. Atualmente, não oferecemos imagens Docker para ARM64.
|
||||
> Se você estiver usando uma plataforma ARM64, por favor, utilize [este guia](https://ragflow.io/docs/dev/build_docker_image) para construir uma imagem Docker compatível com o seu sistema.
|
||||
|
||||
> O comando abaixo baixa a edição`v0.22.1` da imagem Docker do RAGFlow. Consulte a tabela a seguir para descrições de diferentes edições do RAGFlow. Para baixar uma edição do RAGFlow diferente da `v0.22.1`, atualize a variável `RAGFLOW_IMAGE` conforme necessário no **docker/.env** antes de usar `docker compose` para iniciar o servidor.
|
||||
> O comando abaixo baixa a edição`v0.23.0` da imagem Docker do RAGFlow. Consulte a tabela a seguir para descrições de diferentes edições do RAGFlow. Para baixar uma edição do RAGFlow diferente da `v0.23.0`, atualize a variável `RAGFLOW_IMAGE` conforme necessário no **docker/.env** antes de usar `docker compose` para iniciar o servidor.
|
||||
|
||||
```bash
|
||||
$ cd ragflow/docker
|
||||
|
||||
# git checkout v0.22.1
|
||||
# git checkout v0.23.0
|
||||
# Opcional: use uma tag estável (veja releases: https://github.com/infiniflow/ragflow/releases)
|
||||
# Esta etapa garante que o arquivo entrypoint.sh no código corresponda à versão da imagem do Docker.
|
||||
|
||||
|
||||
@ -22,7 +22,7 @@
|
||||
<img alt="Static Badge" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
||||
</a>
|
||||
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
||||
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.22.1">
|
||||
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.23.0">
|
||||
</a>
|
||||
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
||||
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Latest%20Release" alt="Latest Release">
|
||||
@ -85,15 +85,16 @@
|
||||
|
||||
## 🔥 近期更新
|
||||
|
||||
- 2025-11-19 支援 Gemini 3 Pro.
|
||||
- 2025-12-26 支援AI代理的「記憶」功能。
|
||||
- 2025-11-19 支援 Gemini 3 Pro。
|
||||
- 2025-11-12 支援從 Confluence、S3、Notion、Discord、Google Drive 進行資料同步。
|
||||
- 2025-10-23 支援 MinerU 和 Docling 作為文件解析方法。
|
||||
- 2025-10-15 支援可編排的資料管道。
|
||||
- 2025-08-08 支援 OpenAI 最新的 GPT-5 系列模型。
|
||||
- 2025-08-01 支援 agentic workflow 和 MCP
|
||||
- 2025-08-01 支援 agentic workflow 和 MCP。
|
||||
- 2025-05-23 為 Agent 新增 Python/JS 程式碼執行器元件。
|
||||
- 2025-05-05 支援跨語言查詢。
|
||||
- 2025-03-19 PDF和DOCX中的圖支持用多模態大模型去解析得到描述.
|
||||
- 2025-03-19 PDF和DOCX中的圖支持用多模態大模型去解析得到描述。
|
||||
- 2024-12-18 升級了 DeepDoc 的文檔佈局分析模型。
|
||||
- 2024-08-22 支援用 RAG 技術實現從自然語言到 SQL 語句的轉換。
|
||||
|
||||
@ -186,12 +187,12 @@
|
||||
> 所有 Docker 映像檔都是為 x86 平台建置的。目前,我們不提供 ARM64 平台的 Docker 映像檔。
|
||||
> 如果您使用的是 ARM64 平台,請使用 [這份指南](https://ragflow.io/docs/dev/build_docker_image) 來建置適合您系統的 Docker 映像檔。
|
||||
|
||||
> 執行以下指令會自動下載 RAGFlow Docker 映像 `v0.22.1`。請參考下表查看不同 Docker 發行版的說明。如需下載不同於 `v0.22.1` 的 Docker 映像,請在執行 `docker compose` 啟動服務之前先更新 **docker/.env** 檔案內的 `RAGFLOW_IMAGE` 變數。
|
||||
> 執行以下指令會自動下載 RAGFlow Docker 映像 `v0.23.0`。請參考下表查看不同 Docker 發行版的說明。如需下載不同於 `v0.23.0` 的 Docker 映像,請在執行 `docker compose` 啟動服務之前先更新 **docker/.env** 檔案內的 `RAGFLOW_IMAGE` 變數。
|
||||
|
||||
```bash
|
||||
$ cd ragflow/docker
|
||||
|
||||
# git checkout v0.22.1
|
||||
# git checkout v0.23.0
|
||||
# 可選:使用穩定版標籤(查看發佈:https://github.com/infiniflow/ragflow/releases)
|
||||
# 此步驟確保程式碼中的 entrypoint.sh 檔案與 Docker 映像版本一致。
|
||||
|
||||
|
||||
11
README_zh.md
11
README_zh.md
@ -22,7 +22,7 @@
|
||||
<img alt="Static Badge" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
||||
</a>
|
||||
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
||||
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.22.1">
|
||||
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.23.0">
|
||||
</a>
|
||||
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
||||
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Latest%20Release" alt="Latest Release">
|
||||
@ -85,7 +85,8 @@
|
||||
|
||||
## 🔥 近期更新
|
||||
|
||||
- 2025-11-19 支持 Gemini 3 Pro.
|
||||
- 2025-12-26 支持AI代理的“记忆”功能。
|
||||
- 2025-11-19 支持 Gemini 3 Pro。
|
||||
- 2025-11-12 支持从 Confluence、S3、Notion、Discord、Google Drive 进行数据同步。
|
||||
- 2025-10-23 支持 MinerU 和 Docling 作为文档解析方法。
|
||||
- 2025-10-15 支持可编排的数据管道。
|
||||
@ -93,7 +94,7 @@
|
||||
- 2025-08-01 支持 agentic workflow 和 MCP。
|
||||
- 2025-05-23 Agent 新增 Python/JS 代码执行器组件。
|
||||
- 2025-05-05 支持跨语言查询。
|
||||
- 2025-03-19 PDF 和 DOCX 中的图支持用多模态大模型去解析得到描述.
|
||||
- 2025-03-19 PDF 和 DOCX 中的图支持用多模态大模型去解析得到描述。
|
||||
- 2024-12-18 升级了 DeepDoc 的文档布局分析模型。
|
||||
- 2024-08-22 支持用 RAG 技术实现从自然语言到 SQL 语句的转换。
|
||||
|
||||
@ -187,12 +188,12 @@
|
||||
> 请注意,目前官方提供的所有 Docker 镜像均基于 x86 架构构建,并不提供基于 ARM64 的 Docker 镜像。
|
||||
> 如果你的操作系统是 ARM64 架构,请参考[这篇文档](https://ragflow.io/docs/dev/build_docker_image)自行构建 Docker 镜像。
|
||||
|
||||
> 运行以下命令会自动下载 RAGFlow Docker 镜像 `v0.22.1`。请参考下表查看不同 Docker 发行版的描述。如需下载不同于 `v0.22.1` 的 Docker 镜像,请在运行 `docker compose` 启动服务之前先更新 **docker/.env** 文件内的 `RAGFLOW_IMAGE` 变量。
|
||||
> 运行以下命令会自动下载 RAGFlow Docker 镜像 `v0.23.0`。请参考下表查看不同 Docker 发行版的描述。如需下载不同于 `v0.23.0` 的 Docker 镜像,请在运行 `docker compose` 启动服务之前先更新 **docker/.env** 文件内的 `RAGFLOW_IMAGE` 变量。
|
||||
|
||||
```bash
|
||||
$ cd ragflow/docker
|
||||
|
||||
# git checkout v0.22.1
|
||||
# git checkout v0.23.0
|
||||
# 可选:使用稳定版本标签(查看发布:https://github.com/infiniflow/ragflow/releases)
|
||||
# 这一步确保代码中的 entrypoint.sh 文件与 Docker 镜像的版本保持一致。
|
||||
|
||||
|
||||
@ -48,7 +48,7 @@ It consists of a server-side Service and a command-line client (CLI), both imple
|
||||
1. Ensure the Admin Service is running.
|
||||
2. Install ragflow-cli.
|
||||
```bash
|
||||
pip install ragflow-cli==0.22.1
|
||||
pip install ragflow-cli==0.23.0
|
||||
```
|
||||
3. Launch the CLI client:
|
||||
```bash
|
||||
|
||||
@ -16,14 +16,14 @@
|
||||
|
||||
import argparse
|
||||
import base64
|
||||
from cmd import Cmd
|
||||
|
||||
from Cryptodome.PublicKey import RSA
|
||||
from Cryptodome.Cipher import PKCS1_v1_5 as Cipher_pkcs1_v1_5
|
||||
from typing import Dict, List, Any
|
||||
from lark import Lark, Transformer, Tree
|
||||
import requests
|
||||
import getpass
|
||||
from cmd import Cmd
|
||||
from typing import Any, Dict, List
|
||||
|
||||
import requests
|
||||
from Cryptodome.Cipher import PKCS1_v1_5 as Cipher_pkcs1_v1_5
|
||||
from Cryptodome.PublicKey import RSA
|
||||
from lark import Lark, Transformer, Tree
|
||||
|
||||
GRAMMAR = r"""
|
||||
start: command
|
||||
@ -141,7 +141,6 @@ NUMBER: /[0-9]+/
|
||||
|
||||
|
||||
class AdminTransformer(Transformer):
|
||||
|
||||
def start(self, items):
|
||||
return items[0]
|
||||
|
||||
@ -149,7 +148,7 @@ class AdminTransformer(Transformer):
|
||||
return items[0]
|
||||
|
||||
def list_services(self, items):
|
||||
result = {'type': 'list_services'}
|
||||
result = {"type": "list_services"}
|
||||
return result
|
||||
|
||||
def show_service(self, items):
|
||||
@ -236,11 +235,7 @@ class AdminTransformer(Transformer):
|
||||
action_list = items[1]
|
||||
resource = items[3]
|
||||
role_name = items[6]
|
||||
return {
|
||||
"type": "revoke_permission",
|
||||
"role_name": role_name,
|
||||
"resource": resource, "actions": action_list
|
||||
}
|
||||
return {"type": "revoke_permission", "role_name": role_name, "resource": resource, "actions": action_list}
|
||||
|
||||
def alter_user_role(self, items):
|
||||
user_name = items[2]
|
||||
@ -264,12 +259,12 @@ class AdminTransformer(Transformer):
|
||||
# handle quoted parameter
|
||||
parsed_args = []
|
||||
for arg in args:
|
||||
if hasattr(arg, 'value'):
|
||||
if hasattr(arg, "value"):
|
||||
parsed_args.append(arg.value)
|
||||
else:
|
||||
parsed_args.append(str(arg))
|
||||
|
||||
return {'type': 'meta', 'command': command_name, 'args': parsed_args}
|
||||
return {"type": "meta", "command": command_name, "args": parsed_args}
|
||||
|
||||
def meta_command_name(self, items):
|
||||
return items[0]
|
||||
@ -279,22 +274,22 @@ class AdminTransformer(Transformer):
|
||||
|
||||
|
||||
def encrypt(input_string):
|
||||
pub = '-----BEGIN PUBLIC KEY-----\nMIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEArq9XTUSeYr2+N1h3Afl/z8Dse/2yD0ZGrKwx+EEEcdsBLca9Ynmx3nIB5obmLlSfmskLpBo0UACBmB5rEjBp2Q2f3AG3Hjd4B+gNCG6BDaawuDlgANIhGnaTLrIqWrrcm4EMzJOnAOI1fgzJRsOOUEfaS318Eq9OVO3apEyCCt0lOQK6PuksduOjVxtltDav+guVAA068NrPYmRNabVKRNLJpL8w4D44sfth5RvZ3q9t+6RTArpEtc5sh5ChzvqPOzKGMXW83C95TxmXqpbK6olN4RevSfVjEAgCydH6HN6OhtOQEcnrU97r9H0iZOWwbw3pVrZiUkuRD1R56Wzs2wIDAQAB\n-----END PUBLIC KEY-----'
|
||||
pub = "-----BEGIN PUBLIC KEY-----\nMIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEArq9XTUSeYr2+N1h3Afl/z8Dse/2yD0ZGrKwx+EEEcdsBLca9Ynmx3nIB5obmLlSfmskLpBo0UACBmB5rEjBp2Q2f3AG3Hjd4B+gNCG6BDaawuDlgANIhGnaTLrIqWrrcm4EMzJOnAOI1fgzJRsOOUEfaS318Eq9OVO3apEyCCt0lOQK6PuksduOjVxtltDav+guVAA068NrPYmRNabVKRNLJpL8w4D44sfth5RvZ3q9t+6RTArpEtc5sh5ChzvqPOzKGMXW83C95TxmXqpbK6olN4RevSfVjEAgCydH6HN6OhtOQEcnrU97r9H0iZOWwbw3pVrZiUkuRD1R56Wzs2wIDAQAB\n-----END PUBLIC KEY-----"
|
||||
pub_key = RSA.importKey(pub)
|
||||
cipher = Cipher_pkcs1_v1_5.new(pub_key)
|
||||
cipher_text = cipher.encrypt(base64.b64encode(input_string.encode('utf-8')))
|
||||
cipher_text = cipher.encrypt(base64.b64encode(input_string.encode("utf-8")))
|
||||
return base64.b64encode(cipher_text).decode("utf-8")
|
||||
|
||||
|
||||
def encode_to_base64(input_string):
|
||||
base64_encoded = base64.b64encode(input_string.encode('utf-8'))
|
||||
return base64_encoded.decode('utf-8')
|
||||
base64_encoded = base64.b64encode(input_string.encode("utf-8"))
|
||||
return base64_encoded.decode("utf-8")
|
||||
|
||||
|
||||
class AdminCLI(Cmd):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.parser = Lark(GRAMMAR, start='start', parser='lalr', transformer=AdminTransformer())
|
||||
self.parser = Lark(GRAMMAR, start="start", parser="lalr", transformer=AdminTransformer())
|
||||
self.command_history = []
|
||||
self.is_interactive = False
|
||||
self.admin_account = "admin@ragflow.io"
|
||||
@ -312,7 +307,7 @@ class AdminCLI(Cmd):
|
||||
result = self.parse_command(command)
|
||||
|
||||
if isinstance(result, dict):
|
||||
if 'type' in result and result.get('type') == 'empty':
|
||||
if "type" in result and result.get("type") == "empty":
|
||||
return False
|
||||
|
||||
self.execute_command(result)
|
||||
@ -320,7 +315,7 @@ class AdminCLI(Cmd):
|
||||
if isinstance(result, Tree):
|
||||
return False
|
||||
|
||||
if result.get('type') == 'meta' and result.get('command') in ['q', 'quit', 'exit']:
|
||||
if result.get("type") == "meta" and result.get("command") in ["q", "quit", "exit"]:
|
||||
return True
|
||||
|
||||
except KeyboardInterrupt:
|
||||
@ -338,7 +333,7 @@ class AdminCLI(Cmd):
|
||||
|
||||
def parse_command(self, command_str: str) -> dict[str, str]:
|
||||
if not command_str.strip():
|
||||
return {'type': 'empty'}
|
||||
return {"type": "empty"}
|
||||
|
||||
self.command_history.append(command_str)
|
||||
|
||||
@ -346,11 +341,11 @@ class AdminCLI(Cmd):
|
||||
result = self.parser.parse(command_str)
|
||||
return result
|
||||
except Exception as e:
|
||||
return {'type': 'error', 'message': f'Parse error: {str(e)}'}
|
||||
return {"type": "error", "message": f"Parse error: {str(e)}"}
|
||||
|
||||
def verify_admin(self, arguments: dict, single_command: bool):
|
||||
self.host = arguments['host']
|
||||
self.port = arguments['port']
|
||||
self.host = arguments["host"]
|
||||
self.port = arguments["port"]
|
||||
print("Attempt to access server for admin login")
|
||||
url = f"http://{self.host}:{self.port}/api/v1/admin/login"
|
||||
|
||||
@ -365,25 +360,21 @@ class AdminCLI(Cmd):
|
||||
return False
|
||||
|
||||
if single_command:
|
||||
admin_passwd = arguments['password']
|
||||
admin_passwd = arguments["password"]
|
||||
else:
|
||||
admin_passwd = getpass.getpass(f"password for {self.admin_account}: ").strip()
|
||||
try:
|
||||
self.admin_password = encrypt(admin_passwd)
|
||||
response = self.session.post(url, json={'email': self.admin_account, 'password': self.admin_password})
|
||||
response = self.session.post(url, json={"email": self.admin_account, "password": self.admin_password})
|
||||
if response.status_code == 200:
|
||||
res_json = response.json()
|
||||
error_code = res_json.get('code', -1)
|
||||
error_code = res_json.get("code", -1)
|
||||
if error_code == 0:
|
||||
self.session.headers.update({
|
||||
'Content-Type': 'application/json',
|
||||
'Authorization': response.headers['Authorization'],
|
||||
'User-Agent': 'RAGFlow-CLI/0.22.1'
|
||||
})
|
||||
self.session.headers.update({"Content-Type": "application/json", "Authorization": response.headers["Authorization"], "User-Agent": "RAGFlow-CLI/0.23.0"})
|
||||
print("Authentication successful.")
|
||||
return True
|
||||
else:
|
||||
error_message = res_json.get('message', 'Unknown error')
|
||||
error_message = res_json.get("message", "Unknown error")
|
||||
print(f"Authentication failed: {error_message}, try again")
|
||||
continue
|
||||
else:
|
||||
@ -403,10 +394,14 @@ class AdminCLI(Cmd):
|
||||
for k, v in data.items():
|
||||
# display latest status
|
||||
heartbeats = sorted(v, key=lambda x: x["now"], reverse=True)
|
||||
task_executor_list.append({
|
||||
"task_executor_name": k,
|
||||
**heartbeats[0],
|
||||
} if heartbeats else {"task_executor_name": k})
|
||||
task_executor_list.append(
|
||||
{
|
||||
"task_executor_name": k,
|
||||
**heartbeats[0],
|
||||
}
|
||||
if heartbeats
|
||||
else {"task_executor_name": k}
|
||||
)
|
||||
return task_executor_list
|
||||
|
||||
def _print_table_simple(self, data):
|
||||
@ -422,12 +417,7 @@ class AdminCLI(Cmd):
|
||||
col_widths = {}
|
||||
|
||||
def get_string_width(text):
|
||||
half_width_chars = (
|
||||
" !\"#$%&'()*+,-./0123456789:;<=>?@"
|
||||
"ABCDEFGHIJKLMNOPQRSTUVWXYZ[\\]^_`"
|
||||
"abcdefghijklmnopqrstuvwxyz{|}~"
|
||||
"\t\n\r"
|
||||
)
|
||||
half_width_chars = " !\"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\\]^_`abcdefghijklmnopqrstuvwxyz{|}~\t\n\r"
|
||||
width = 0
|
||||
for char in text:
|
||||
if char in half_width_chars:
|
||||
@ -439,7 +429,7 @@ class AdminCLI(Cmd):
|
||||
for col in columns:
|
||||
max_width = get_string_width(str(col))
|
||||
for item in data:
|
||||
value_len = get_string_width(str(item.get(col, '')))
|
||||
value_len = get_string_width(str(item.get(col, "")))
|
||||
if value_len > max_width:
|
||||
max_width = value_len
|
||||
col_widths[col] = max(2, max_width)
|
||||
@ -457,16 +447,15 @@ class AdminCLI(Cmd):
|
||||
for item in data:
|
||||
row = "|"
|
||||
for col in columns:
|
||||
value = str(item.get(col, ''))
|
||||
value = str(item.get(col, ""))
|
||||
if get_string_width(value) > col_widths[col]:
|
||||
value = value[:col_widths[col] - 3] + "..."
|
||||
value = value[: col_widths[col] - 3] + "..."
|
||||
row += f" {value:<{col_widths[col] - (get_string_width(value) - len(value))}} |"
|
||||
print(row)
|
||||
|
||||
print(separator)
|
||||
|
||||
def run_interactive(self):
|
||||
|
||||
self.is_interactive = True
|
||||
print("RAGFlow Admin command line interface - Type '\\?' for help, '\\q' to quit")
|
||||
|
||||
@ -483,7 +472,7 @@ class AdminCLI(Cmd):
|
||||
if isinstance(result, Tree):
|
||||
continue
|
||||
|
||||
if result.get('type') == 'meta' and result.get('command') in ['q', 'quit', 'exit']:
|
||||
if result.get("type") == "meta" and result.get("command") in ["q", "quit", "exit"]:
|
||||
break
|
||||
|
||||
except KeyboardInterrupt:
|
||||
@ -497,36 +486,30 @@ class AdminCLI(Cmd):
|
||||
self.execute_command(result)
|
||||
|
||||
def parse_connection_args(self, args: List[str]) -> Dict[str, Any]:
|
||||
parser = argparse.ArgumentParser(description='Admin CLI Client', add_help=False)
|
||||
parser.add_argument('-h', '--host', default='localhost', help='Admin service host')
|
||||
parser.add_argument('-p', '--port', type=int, default=9381, help='Admin service port')
|
||||
parser.add_argument('-w', '--password', default='admin', type=str, help='Superuser password')
|
||||
parser.add_argument('command', nargs='?', help='Single command')
|
||||
parser = argparse.ArgumentParser(description="Admin CLI Client", add_help=False)
|
||||
parser.add_argument("-h", "--host", default="localhost", help="Admin service host")
|
||||
parser.add_argument("-p", "--port", type=int, default=9381, help="Admin service port")
|
||||
parser.add_argument("-w", "--password", default="admin", type=str, help="Superuser password")
|
||||
parser.add_argument("command", nargs="?", help="Single command")
|
||||
try:
|
||||
parsed_args, remaining_args = parser.parse_known_args(args)
|
||||
if remaining_args:
|
||||
command = remaining_args[0]
|
||||
return {
|
||||
'host': parsed_args.host,
|
||||
'port': parsed_args.port,
|
||||
'password': parsed_args.password,
|
||||
'command': command
|
||||
}
|
||||
return {"host": parsed_args.host, "port": parsed_args.port, "password": parsed_args.password, "command": command}
|
||||
else:
|
||||
return {
|
||||
'host': parsed_args.host,
|
||||
'port': parsed_args.port,
|
||||
"host": parsed_args.host,
|
||||
"port": parsed_args.port,
|
||||
}
|
||||
except SystemExit:
|
||||
return {'error': 'Invalid connection arguments'}
|
||||
return {"error": "Invalid connection arguments"}
|
||||
|
||||
def execute_command(self, parsed_command: Dict[str, Any]):
|
||||
|
||||
command_dict: dict
|
||||
if isinstance(parsed_command, Tree):
|
||||
command_dict = parsed_command.children[0]
|
||||
else:
|
||||
if parsed_command['type'] == 'error':
|
||||
if parsed_command["type"] == "error":
|
||||
print(f"Error: {parsed_command['message']}")
|
||||
return
|
||||
else:
|
||||
@ -534,56 +517,56 @@ class AdminCLI(Cmd):
|
||||
|
||||
# print(f"Parsed command: {command_dict}")
|
||||
|
||||
command_type = command_dict['type']
|
||||
command_type = command_dict["type"]
|
||||
|
||||
match command_type:
|
||||
case 'list_services':
|
||||
case "list_services":
|
||||
self._handle_list_services(command_dict)
|
||||
case 'show_service':
|
||||
case "show_service":
|
||||
self._handle_show_service(command_dict)
|
||||
case 'restart_service':
|
||||
case "restart_service":
|
||||
self._handle_restart_service(command_dict)
|
||||
case 'shutdown_service':
|
||||
case "shutdown_service":
|
||||
self._handle_shutdown_service(command_dict)
|
||||
case 'startup_service':
|
||||
case "startup_service":
|
||||
self._handle_startup_service(command_dict)
|
||||
case 'list_users':
|
||||
case "list_users":
|
||||
self._handle_list_users(command_dict)
|
||||
case 'show_user':
|
||||
case "show_user":
|
||||
self._handle_show_user(command_dict)
|
||||
case 'drop_user':
|
||||
case "drop_user":
|
||||
self._handle_drop_user(command_dict)
|
||||
case 'alter_user':
|
||||
case "alter_user":
|
||||
self._handle_alter_user(command_dict)
|
||||
case 'create_user':
|
||||
case "create_user":
|
||||
self._handle_create_user(command_dict)
|
||||
case 'activate_user':
|
||||
case "activate_user":
|
||||
self._handle_activate_user(command_dict)
|
||||
case 'list_datasets':
|
||||
case "list_datasets":
|
||||
self._handle_list_datasets(command_dict)
|
||||
case 'list_agents':
|
||||
case "list_agents":
|
||||
self._handle_list_agents(command_dict)
|
||||
case 'create_role':
|
||||
case "create_role":
|
||||
self._create_role(command_dict)
|
||||
case 'drop_role':
|
||||
case "drop_role":
|
||||
self._drop_role(command_dict)
|
||||
case 'alter_role':
|
||||
case "alter_role":
|
||||
self._alter_role(command_dict)
|
||||
case 'list_roles':
|
||||
case "list_roles":
|
||||
self._list_roles(command_dict)
|
||||
case 'show_role':
|
||||
case "show_role":
|
||||
self._show_role(command_dict)
|
||||
case 'grant_permission':
|
||||
case "grant_permission":
|
||||
self._grant_permission(command_dict)
|
||||
case 'revoke_permission':
|
||||
case "revoke_permission":
|
||||
self._revoke_permission(command_dict)
|
||||
case 'alter_user_role':
|
||||
case "alter_user_role":
|
||||
self._alter_user_role(command_dict)
|
||||
case 'show_user_permission':
|
||||
case "show_user_permission":
|
||||
self._show_user_permission(command_dict)
|
||||
case 'show_version':
|
||||
case "show_version":
|
||||
self._show_version(command_dict)
|
||||
case 'meta':
|
||||
case "meta":
|
||||
self._handle_meta_command(command_dict)
|
||||
case _:
|
||||
print(f"Command '{command_type}' would be executed with API")
|
||||
@ -591,29 +574,29 @@ class AdminCLI(Cmd):
|
||||
def _handle_list_services(self, command):
|
||||
print("Listing all services")
|
||||
|
||||
url = f'http://{self.host}:{self.port}/api/v1/admin/services'
|
||||
url = f"http://{self.host}:{self.port}/api/v1/admin/services"
|
||||
response = self.session.get(url)
|
||||
res_json = response.json()
|
||||
if response.status_code == 200:
|
||||
self._print_table_simple(res_json['data'])
|
||||
self._print_table_simple(res_json["data"])
|
||||
else:
|
||||
print(f"Fail to get all services, code: {res_json['code']}, message: {res_json['message']}")
|
||||
|
||||
def _handle_show_service(self, command):
|
||||
service_id: int = command['number']
|
||||
service_id: int = command["number"]
|
||||
print(f"Showing service: {service_id}")
|
||||
|
||||
url = f'http://{self.host}:{self.port}/api/v1/admin/services/{service_id}'
|
||||
url = f"http://{self.host}:{self.port}/api/v1/admin/services/{service_id}"
|
||||
response = self.session.get(url)
|
||||
res_json = response.json()
|
||||
if response.status_code == 200:
|
||||
res_data = res_json['data']
|
||||
if 'status' in res_data and res_data['status'] == 'alive':
|
||||
res_data = res_json["data"]
|
||||
if "status" in res_data and res_data["status"] == "alive":
|
||||
print(f"Service {res_data['service_name']} is alive, ")
|
||||
if isinstance(res_data['message'], str):
|
||||
print(res_data['message'])
|
||||
if isinstance(res_data["message"], str):
|
||||
print(res_data["message"])
|
||||
else:
|
||||
data = self._format_service_detail_table(res_data['message'])
|
||||
data = self._format_service_detail_table(res_data["message"])
|
||||
self._print_table_simple(data)
|
||||
else:
|
||||
print(f"Service {res_data['service_name']} is down, {res_data['message']}")
|
||||
@ -621,47 +604,47 @@ class AdminCLI(Cmd):
|
||||
print(f"Fail to show service, code: {res_json['code']}, message: {res_json['message']}")
|
||||
|
||||
def _handle_restart_service(self, command):
|
||||
service_id: int = command['number']
|
||||
service_id: int = command["number"]
|
||||
print(f"Restart service {service_id}")
|
||||
|
||||
def _handle_shutdown_service(self, command):
|
||||
service_id: int = command['number']
|
||||
service_id: int = command["number"]
|
||||
print(f"Shutdown service {service_id}")
|
||||
|
||||
def _handle_startup_service(self, command):
|
||||
service_id: int = command['number']
|
||||
service_id: int = command["number"]
|
||||
print(f"Startup service {service_id}")
|
||||
|
||||
def _handle_list_users(self, command):
|
||||
print("Listing all users")
|
||||
|
||||
url = f'http://{self.host}:{self.port}/api/v1/admin/users'
|
||||
url = f"http://{self.host}:{self.port}/api/v1/admin/users"
|
||||
response = self.session.get(url)
|
||||
res_json = response.json()
|
||||
if response.status_code == 200:
|
||||
self._print_table_simple(res_json['data'])
|
||||
self._print_table_simple(res_json["data"])
|
||||
else:
|
||||
print(f"Fail to get all users, code: {res_json['code']}, message: {res_json['message']}")
|
||||
|
||||
def _handle_show_user(self, command):
|
||||
username_tree: Tree = command['user_name']
|
||||
username_tree: Tree = command["user_name"]
|
||||
user_name: str = username_tree.children[0].strip("'\"")
|
||||
print(f"Showing user: {user_name}")
|
||||
url = f'http://{self.host}:{self.port}/api/v1/admin/users/{user_name}'
|
||||
url = f"http://{self.host}:{self.port}/api/v1/admin/users/{user_name}"
|
||||
response = self.session.get(url)
|
||||
res_json = response.json()
|
||||
if response.status_code == 200:
|
||||
table_data = res_json['data']
|
||||
table_data.pop('avatar')
|
||||
table_data = res_json["data"]
|
||||
table_data.pop("avatar")
|
||||
self._print_table_simple(table_data)
|
||||
else:
|
||||
print(f"Fail to get user {user_name}, code: {res_json['code']}, message: {res_json['message']}")
|
||||
|
||||
def _handle_drop_user(self, command):
|
||||
username_tree: Tree = command['user_name']
|
||||
username_tree: Tree = command["user_name"]
|
||||
user_name: str = username_tree.children[0].strip("'\"")
|
||||
print(f"Drop user: {user_name}")
|
||||
url = f'http://{self.host}:{self.port}/api/v1/admin/users/{user_name}'
|
||||
url = f"http://{self.host}:{self.port}/api/v1/admin/users/{user_name}"
|
||||
response = self.session.delete(url)
|
||||
res_json = response.json()
|
||||
if response.status_code == 200:
|
||||
@ -670,13 +653,13 @@ class AdminCLI(Cmd):
|
||||
print(f"Fail to drop user, code: {res_json['code']}, message: {res_json['message']}")
|
||||
|
||||
def _handle_alter_user(self, command):
|
||||
user_name_tree: Tree = command['user_name']
|
||||
user_name_tree: Tree = command["user_name"]
|
||||
user_name: str = user_name_tree.children[0].strip("'\"")
|
||||
password_tree: Tree = command['password']
|
||||
password_tree: Tree = command["password"]
|
||||
password: str = password_tree.children[0].strip("'\"")
|
||||
print(f"Alter user: {user_name}, password: ******")
|
||||
url = f'http://{self.host}:{self.port}/api/v1/admin/users/{user_name}/password'
|
||||
response = self.session.put(url, json={'new_password': encrypt(password)})
|
||||
url = f"http://{self.host}:{self.port}/api/v1/admin/users/{user_name}/password"
|
||||
response = self.session.put(url, json={"new_password": encrypt(password)})
|
||||
res_json = response.json()
|
||||
if response.status_code == 200:
|
||||
print(res_json["message"])
|
||||
@ -684,32 +667,29 @@ class AdminCLI(Cmd):
|
||||
print(f"Fail to alter password, code: {res_json['code']}, message: {res_json['message']}")
|
||||
|
||||
def _handle_create_user(self, command):
|
||||
user_name_tree: Tree = command['user_name']
|
||||
user_name_tree: Tree = command["user_name"]
|
||||
user_name: str = user_name_tree.children[0].strip("'\"")
|
||||
password_tree: Tree = command['password']
|
||||
password_tree: Tree = command["password"]
|
||||
password: str = password_tree.children[0].strip("'\"")
|
||||
role: str = command['role']
|
||||
role: str = command["role"]
|
||||
print(f"Create user: {user_name}, password: ******, role: {role}")
|
||||
url = f'http://{self.host}:{self.port}/api/v1/admin/users'
|
||||
response = self.session.post(
|
||||
url,
|
||||
json={'user_name': user_name, 'password': encrypt(password), 'role': role}
|
||||
)
|
||||
url = f"http://{self.host}:{self.port}/api/v1/admin/users"
|
||||
response = self.session.post(url, json={"user_name": user_name, "password": encrypt(password), "role": role})
|
||||
res_json = response.json()
|
||||
if response.status_code == 200:
|
||||
self._print_table_simple(res_json['data'])
|
||||
self._print_table_simple(res_json["data"])
|
||||
else:
|
||||
print(f"Fail to create user {user_name}, code: {res_json['code']}, message: {res_json['message']}")
|
||||
|
||||
def _handle_activate_user(self, command):
|
||||
user_name_tree: Tree = command['user_name']
|
||||
user_name_tree: Tree = command["user_name"]
|
||||
user_name: str = user_name_tree.children[0].strip("'\"")
|
||||
activate_tree: Tree = command['activate_status']
|
||||
activate_tree: Tree = command["activate_status"]
|
||||
activate_status: str = activate_tree.children[0].strip("'\"")
|
||||
if activate_status.lower() in ['on', 'off']:
|
||||
if activate_status.lower() in ["on", "off"]:
|
||||
print(f"Alter user {user_name} activate status, turn {activate_status.lower()}.")
|
||||
url = f'http://{self.host}:{self.port}/api/v1/admin/users/{user_name}/activate'
|
||||
response = self.session.put(url, json={'activate_status': activate_status})
|
||||
url = f"http://{self.host}:{self.port}/api/v1/admin/users/{user_name}/activate"
|
||||
response = self.session.put(url, json={"activate_status": activate_status})
|
||||
res_json = response.json()
|
||||
if response.status_code == 200:
|
||||
print(res_json["message"])
|
||||
@ -719,202 +699,182 @@ class AdminCLI(Cmd):
|
||||
print(f"Unknown activate status: {activate_status}.")
|
||||
|
||||
def _handle_list_datasets(self, command):
|
||||
username_tree: Tree = command['user_name']
|
||||
username_tree: Tree = command["user_name"]
|
||||
user_name: str = username_tree.children[0].strip("'\"")
|
||||
print(f"Listing all datasets of user: {user_name}")
|
||||
url = f'http://{self.host}:{self.port}/api/v1/admin/users/{user_name}/datasets'
|
||||
url = f"http://{self.host}:{self.port}/api/v1/admin/users/{user_name}/datasets"
|
||||
response = self.session.get(url)
|
||||
res_json = response.json()
|
||||
if response.status_code == 200:
|
||||
table_data = res_json['data']
|
||||
table_data = res_json["data"]
|
||||
for t in table_data:
|
||||
t.pop('avatar')
|
||||
t.pop("avatar")
|
||||
self._print_table_simple(table_data)
|
||||
else:
|
||||
print(f"Fail to get all datasets of {user_name}, code: {res_json['code']}, message: {res_json['message']}")
|
||||
|
||||
def _handle_list_agents(self, command):
|
||||
username_tree: Tree = command['user_name']
|
||||
username_tree: Tree = command["user_name"]
|
||||
user_name: str = username_tree.children[0].strip("'\"")
|
||||
print(f"Listing all agents of user: {user_name}")
|
||||
url = f'http://{self.host}:{self.port}/api/v1/admin/users/{user_name}/agents'
|
||||
url = f"http://{self.host}:{self.port}/api/v1/admin/users/{user_name}/agents"
|
||||
response = self.session.get(url)
|
||||
res_json = response.json()
|
||||
if response.status_code == 200:
|
||||
table_data = res_json['data']
|
||||
table_data = res_json["data"]
|
||||
for t in table_data:
|
||||
t.pop('avatar')
|
||||
t.pop("avatar")
|
||||
self._print_table_simple(table_data)
|
||||
else:
|
||||
print(f"Fail to get all agents of {user_name}, code: {res_json['code']}, message: {res_json['message']}")
|
||||
|
||||
def _create_role(self, command):
|
||||
role_name_tree: Tree = command['role_name']
|
||||
role_name_tree: Tree = command["role_name"]
|
||||
role_name: str = role_name_tree.children[0].strip("'\"")
|
||||
desc_str: str = ''
|
||||
if 'description' in command:
|
||||
desc_tree: Tree = command['description']
|
||||
desc_str: str = ""
|
||||
if "description" in command:
|
||||
desc_tree: Tree = command["description"]
|
||||
desc_str = desc_tree.children[0].strip("'\"")
|
||||
|
||||
print(f"create role name: {role_name}, description: {desc_str}")
|
||||
url = f'http://{self.host}:{self.port}/api/v1/admin/roles'
|
||||
response = self.session.post(
|
||||
url,
|
||||
json={'role_name': role_name, 'description': desc_str}
|
||||
)
|
||||
url = f"http://{self.host}:{self.port}/api/v1/admin/roles"
|
||||
response = self.session.post(url, json={"role_name": role_name, "description": desc_str})
|
||||
res_json = response.json()
|
||||
if response.status_code == 200:
|
||||
self._print_table_simple(res_json['data'])
|
||||
self._print_table_simple(res_json["data"])
|
||||
else:
|
||||
print(f"Fail to create role {role_name}, code: {res_json['code']}, message: {res_json['message']}")
|
||||
|
||||
def _drop_role(self, command):
|
||||
role_name_tree: Tree = command['role_name']
|
||||
role_name_tree: Tree = command["role_name"]
|
||||
role_name: str = role_name_tree.children[0].strip("'\"")
|
||||
print(f"drop role name: {role_name}")
|
||||
url = f'http://{self.host}:{self.port}/api/v1/admin/roles/{role_name}'
|
||||
url = f"http://{self.host}:{self.port}/api/v1/admin/roles/{role_name}"
|
||||
response = self.session.delete(url)
|
||||
res_json = response.json()
|
||||
if response.status_code == 200:
|
||||
self._print_table_simple(res_json['data'])
|
||||
self._print_table_simple(res_json["data"])
|
||||
else:
|
||||
print(f"Fail to drop role {role_name}, code: {res_json['code']}, message: {res_json['message']}")
|
||||
|
||||
def _alter_role(self, command):
|
||||
role_name_tree: Tree = command['role_name']
|
||||
role_name_tree: Tree = command["role_name"]
|
||||
role_name: str = role_name_tree.children[0].strip("'\"")
|
||||
desc_tree: Tree = command['description']
|
||||
desc_tree: Tree = command["description"]
|
||||
desc_str: str = desc_tree.children[0].strip("'\"")
|
||||
|
||||
print(f"alter role name: {role_name}, description: {desc_str}")
|
||||
url = f'http://{self.host}:{self.port}/api/v1/admin/roles/{role_name}'
|
||||
response = self.session.put(
|
||||
url,
|
||||
json={'description': desc_str}
|
||||
)
|
||||
url = f"http://{self.host}:{self.port}/api/v1/admin/roles/{role_name}"
|
||||
response = self.session.put(url, json={"description": desc_str})
|
||||
res_json = response.json()
|
||||
if response.status_code == 200:
|
||||
self._print_table_simple(res_json['data'])
|
||||
self._print_table_simple(res_json["data"])
|
||||
else:
|
||||
print(
|
||||
f"Fail to update role {role_name} with description: {desc_str}, code: {res_json['code']}, message: {res_json['message']}")
|
||||
print(f"Fail to update role {role_name} with description: {desc_str}, code: {res_json['code']}, message: {res_json['message']}")
|
||||
|
||||
def _list_roles(self, command):
|
||||
print("Listing all roles")
|
||||
url = f'http://{self.host}:{self.port}/api/v1/admin/roles'
|
||||
url = f"http://{self.host}:{self.port}/api/v1/admin/roles"
|
||||
response = self.session.get(url)
|
||||
res_json = response.json()
|
||||
if response.status_code == 200:
|
||||
self._print_table_simple(res_json['data'])
|
||||
self._print_table_simple(res_json["data"])
|
||||
else:
|
||||
print(f"Fail to list roles, code: {res_json['code']}, message: {res_json['message']}")
|
||||
|
||||
def _show_role(self, command):
|
||||
role_name_tree: Tree = command['role_name']
|
||||
role_name_tree: Tree = command["role_name"]
|
||||
role_name: str = role_name_tree.children[0].strip("'\"")
|
||||
print(f"show role: {role_name}")
|
||||
url = f'http://{self.host}:{self.port}/api/v1/admin/roles/{role_name}/permission'
|
||||
url = f"http://{self.host}:{self.port}/api/v1/admin/roles/{role_name}/permission"
|
||||
response = self.session.get(url)
|
||||
res_json = response.json()
|
||||
if response.status_code == 200:
|
||||
self._print_table_simple(res_json['data'])
|
||||
self._print_table_simple(res_json["data"])
|
||||
else:
|
||||
print(f"Fail to list roles, code: {res_json['code']}, message: {res_json['message']}")
|
||||
|
||||
def _grant_permission(self, command):
|
||||
role_name_tree: Tree = command['role_name']
|
||||
role_name_tree: Tree = command["role_name"]
|
||||
role_name_str: str = role_name_tree.children[0].strip("'\"")
|
||||
resource_tree: Tree = command['resource']
|
||||
resource_tree: Tree = command["resource"]
|
||||
resource_str: str = resource_tree.children[0].strip("'\"")
|
||||
action_tree_list: list = command['actions']
|
||||
action_tree_list: list = command["actions"]
|
||||
actions: list = []
|
||||
for action_tree in action_tree_list:
|
||||
action_str: str = action_tree.children[0].strip("'\"")
|
||||
actions.append(action_str)
|
||||
print(f"grant role_name: {role_name_str}, resource: {resource_str}, actions: {actions}")
|
||||
url = f'http://{self.host}:{self.port}/api/v1/admin/roles/{role_name_str}/permission'
|
||||
response = self.session.post(
|
||||
url,
|
||||
json={'actions': actions, 'resource': resource_str}
|
||||
)
|
||||
url = f"http://{self.host}:{self.port}/api/v1/admin/roles/{role_name_str}/permission"
|
||||
response = self.session.post(url, json={"actions": actions, "resource": resource_str})
|
||||
res_json = response.json()
|
||||
if response.status_code == 200:
|
||||
self._print_table_simple(res_json['data'])
|
||||
self._print_table_simple(res_json["data"])
|
||||
else:
|
||||
print(
|
||||
f"Fail to grant role {role_name_str} with {actions} on {resource_str}, code: {res_json['code']}, message: {res_json['message']}")
|
||||
print(f"Fail to grant role {role_name_str} with {actions} on {resource_str}, code: {res_json['code']}, message: {res_json['message']}")
|
||||
|
||||
def _revoke_permission(self, command):
|
||||
role_name_tree: Tree = command['role_name']
|
||||
role_name_tree: Tree = command["role_name"]
|
||||
role_name_str: str = role_name_tree.children[0].strip("'\"")
|
||||
resource_tree: Tree = command['resource']
|
||||
resource_tree: Tree = command["resource"]
|
||||
resource_str: str = resource_tree.children[0].strip("'\"")
|
||||
action_tree_list: list = command['actions']
|
||||
action_tree_list: list = command["actions"]
|
||||
actions: list = []
|
||||
for action_tree in action_tree_list:
|
||||
action_str: str = action_tree.children[0].strip("'\"")
|
||||
actions.append(action_str)
|
||||
print(f"revoke role_name: {role_name_str}, resource: {resource_str}, actions: {actions}")
|
||||
url = f'http://{self.host}:{self.port}/api/v1/admin/roles/{role_name_str}/permission'
|
||||
response = self.session.delete(
|
||||
url,
|
||||
json={'actions': actions, 'resource': resource_str}
|
||||
)
|
||||
url = f"http://{self.host}:{self.port}/api/v1/admin/roles/{role_name_str}/permission"
|
||||
response = self.session.delete(url, json={"actions": actions, "resource": resource_str})
|
||||
res_json = response.json()
|
||||
if response.status_code == 200:
|
||||
self._print_table_simple(res_json['data'])
|
||||
self._print_table_simple(res_json["data"])
|
||||
else:
|
||||
print(
|
||||
f"Fail to revoke role {role_name_str} with {actions} on {resource_str}, code: {res_json['code']}, message: {res_json['message']}")
|
||||
print(f"Fail to revoke role {role_name_str} with {actions} on {resource_str}, code: {res_json['code']}, message: {res_json['message']}")
|
||||
|
||||
def _alter_user_role(self, command):
|
||||
role_name_tree: Tree = command['role_name']
|
||||
role_name_tree: Tree = command["role_name"]
|
||||
role_name_str: str = role_name_tree.children[0].strip("'\"")
|
||||
user_name_tree: Tree = command['user_name']
|
||||
user_name_tree: Tree = command["user_name"]
|
||||
user_name_str: str = user_name_tree.children[0].strip("'\"")
|
||||
print(f"alter_user_role user_name: {user_name_str}, role_name: {role_name_str}")
|
||||
url = f'http://{self.host}:{self.port}/api/v1/admin/users/{user_name_str}/role'
|
||||
response = self.session.put(
|
||||
url,
|
||||
json={'role_name': role_name_str}
|
||||
)
|
||||
url = f"http://{self.host}:{self.port}/api/v1/admin/users/{user_name_str}/role"
|
||||
response = self.session.put(url, json={"role_name": role_name_str})
|
||||
res_json = response.json()
|
||||
if response.status_code == 200:
|
||||
self._print_table_simple(res_json['data'])
|
||||
self._print_table_simple(res_json["data"])
|
||||
else:
|
||||
print(
|
||||
f"Fail to alter user: {user_name_str} to role {role_name_str}, code: {res_json['code']}, message: {res_json['message']}")
|
||||
print(f"Fail to alter user: {user_name_str} to role {role_name_str}, code: {res_json['code']}, message: {res_json['message']}")
|
||||
|
||||
def _show_user_permission(self, command):
|
||||
user_name_tree: Tree = command['user_name']
|
||||
user_name_tree: Tree = command["user_name"]
|
||||
user_name_str: str = user_name_tree.children[0].strip("'\"")
|
||||
print(f"show_user_permission user_name: {user_name_str}")
|
||||
url = f'http://{self.host}:{self.port}/api/v1/admin/users/{user_name_str}/permission'
|
||||
url = f"http://{self.host}:{self.port}/api/v1/admin/users/{user_name_str}/permission"
|
||||
response = self.session.get(url)
|
||||
res_json = response.json()
|
||||
if response.status_code == 200:
|
||||
self._print_table_simple(res_json['data'])
|
||||
self._print_table_simple(res_json["data"])
|
||||
else:
|
||||
print(
|
||||
f"Fail to show user: {user_name_str} permission, code: {res_json['code']}, message: {res_json['message']}")
|
||||
print(f"Fail to show user: {user_name_str} permission, code: {res_json['code']}, message: {res_json['message']}")
|
||||
|
||||
def _show_version(self, command):
|
||||
print("show_version")
|
||||
url = f'http://{self.host}:{self.port}/api/v1/admin/version'
|
||||
url = f"http://{self.host}:{self.port}/api/v1/admin/version"
|
||||
response = self.session.get(url)
|
||||
res_json = response.json()
|
||||
if response.status_code == 200:
|
||||
self._print_table_simple(res_json['data'])
|
||||
self._print_table_simple(res_json["data"])
|
||||
else:
|
||||
print(f"Fail to show version, code: {res_json['code']}, message: {res_json['message']}")
|
||||
|
||||
def _handle_meta_command(self, command):
|
||||
meta_command = command['command']
|
||||
args = command.get('args', [])
|
||||
meta_command = command["command"]
|
||||
args = command.get("args", [])
|
||||
|
||||
if meta_command in ['?', 'h', 'help']:
|
||||
if meta_command in ["?", "h", "help"]:
|
||||
self.show_help()
|
||||
elif meta_command in ['q', 'quit', 'exit']:
|
||||
elif meta_command in ["q", "quit", "exit"]:
|
||||
print("Goodbye!")
|
||||
else:
|
||||
print(f"Meta command '{meta_command}' with args {args}")
|
||||
@ -950,16 +910,16 @@ def main():
|
||||
cli = AdminCLI()
|
||||
|
||||
args = cli.parse_connection_args(sys.argv)
|
||||
if 'error' in args:
|
||||
if "error" in args:
|
||||
print("Error: Invalid connection arguments")
|
||||
return
|
||||
|
||||
if 'command' in args:
|
||||
if 'password' not in args:
|
||||
if "command" in args:
|
||||
if "password" not in args:
|
||||
print("Error: password is missing")
|
||||
return
|
||||
if cli.verify_admin(args, single_command=True):
|
||||
command: str = args['command']
|
||||
command: str = args["command"]
|
||||
# print(f"Run single command: {command}")
|
||||
cli.run_single_command(command)
|
||||
else:
|
||||
@ -974,5 +934,5 @@ def main():
|
||||
cli.cmdloop()
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
[project]
|
||||
name = "ragflow-cli"
|
||||
version = "0.22.1"
|
||||
version = "0.23.0"
|
||||
description = "Admin Service's client of [RAGFlow](https://github.com/infiniflow/ragflow). The Admin Service provides user management and system monitoring. "
|
||||
authors = [{ name = "Lynn", email = "lynn_inf@hotmail.com" }]
|
||||
license = { text = "Apache License, Version 2.0" }
|
||||
|
||||
2
admin/client/uv.lock
generated
2
admin/client/uv.lock
generated
@ -196,7 +196,7 @@ wheels = [
|
||||
|
||||
[[package]]
|
||||
name = "ragflow-cli"
|
||||
version = "0.22.1"
|
||||
version = "0.23.0"
|
||||
source = { virtual = "." }
|
||||
dependencies = [
|
||||
{ name = "beartype" },
|
||||
|
||||
@ -29,6 +29,11 @@ from common.versions import get_ragflow_version
|
||||
admin_bp = Blueprint('admin', __name__, url_prefix='/api/v1/admin')
|
||||
|
||||
|
||||
@admin_bp.route('/ping', methods=['GET'])
|
||||
def ping():
|
||||
return success_response('PONG')
|
||||
|
||||
|
||||
@admin_bp.route('/login', methods=['POST'])
|
||||
def login():
|
||||
if not request.json:
|
||||
|
||||
@ -160,7 +160,7 @@ class Graph:
|
||||
return self._tenant_id
|
||||
|
||||
def get_value_with_variable(self,value: str) -> Any:
|
||||
pat = re.compile(r"\{* *\{([a-zA-Z:0-9]+@[A-Za-z0-9_.]+|sys\.[A-Za-z0-9_.]+|env\.[A-Za-z0-9_.]+)\} *\}*")
|
||||
pat = re.compile(r"\{* *\{([a-zA-Z:0-9]+@[A-Za-z0-9_.-]+|sys\.[A-Za-z0-9_.]+|env\.[A-Za-z0-9_.]+)\} *\}*")
|
||||
out_parts = []
|
||||
last = 0
|
||||
|
||||
@ -278,7 +278,7 @@ class Graph:
|
||||
|
||||
class Canvas(Graph):
|
||||
|
||||
def __init__(self, dsl: str, tenant_id=None, task_id=None):
|
||||
def __init__(self, dsl: str, tenant_id=None, task_id=None, canvas_id=None):
|
||||
self.globals = {
|
||||
"sys.query": "",
|
||||
"sys.user_id": tenant_id,
|
||||
@ -287,6 +287,7 @@ class Canvas(Graph):
|
||||
}
|
||||
self.variables = {}
|
||||
super().__init__(dsl, tenant_id, task_id)
|
||||
self._id = canvas_id
|
||||
|
||||
def load(self):
|
||||
super().load()
|
||||
@ -368,8 +369,13 @@ class Canvas(Graph):
|
||||
|
||||
if kwargs.get("webhook_payload"):
|
||||
for k, cpn in self.components.items():
|
||||
if self.components[k]["obj"].component_name.lower() == "webhook":
|
||||
for kk, vv in kwargs["webhook_payload"].items():
|
||||
if self.components[k]["obj"].component_name.lower() == "begin" and self.components[k]["obj"]._param.mode == "Webhook":
|
||||
payload = kwargs.get("webhook_payload", {})
|
||||
if "input" in payload:
|
||||
self.components[k]["obj"].set_input_value("request", payload["input"])
|
||||
for kk, vv in payload.items():
|
||||
if kk == "input":
|
||||
continue
|
||||
self.components[k]["obj"].set_output(kk, vv)
|
||||
|
||||
for k in kwargs.keys():
|
||||
@ -535,6 +541,8 @@ class Canvas(Graph):
|
||||
cite = re.search(r"\[ID:[ 0-9]+\]", cpn_obj.output("content"))
|
||||
|
||||
message_end = {}
|
||||
if cpn_obj.get_param("status"):
|
||||
message_end["status"] = cpn_obj.get_param("status")
|
||||
if isinstance(cpn_obj.output("attachment"), dict):
|
||||
message_end["attachment"] = cpn_obj.output("attachment")
|
||||
if cite:
|
||||
@ -714,6 +722,9 @@ class Canvas(Graph):
|
||||
def get_mode(self):
|
||||
return self.components["begin"]["obj"]._param.mode
|
||||
|
||||
def get_sys_query(self):
|
||||
return self.globals.get("sys.query", "")
|
||||
|
||||
def set_global_param(self, **kwargs):
|
||||
self.globals.update(kwargs)
|
||||
|
||||
|
||||
@ -29,8 +29,8 @@ from api.db.services.llm_service import LLMBundle
|
||||
from api.db.services.tenant_llm_service import TenantLLMService
|
||||
from api.db.services.mcp_server_service import MCPServerService
|
||||
from common.connection_utils import timeout
|
||||
from rag.prompts.generator import next_step_async, COMPLETE_TASK, analyze_task_async, \
|
||||
citation_prompt, reflect_async, kb_prompt, citation_plus, full_question, message_fit_in, structured_output_prompt
|
||||
from rag.prompts.generator import next_step_async, COMPLETE_TASK, \
|
||||
citation_prompt, kb_prompt, citation_plus, full_question, message_fit_in, structured_output_prompt
|
||||
from common.mcp_tool_call_conn import MCPToolCallSession, mcp_tool_metadata_to_openai_tool
|
||||
from agent.component.llm import LLMParam, LLM
|
||||
|
||||
@ -84,9 +84,11 @@ class Agent(LLM, ToolBase):
|
||||
def __init__(self, canvas, id, param: LLMParam):
|
||||
LLM.__init__(self, canvas, id, param)
|
||||
self.tools = {}
|
||||
for cpn in self._param.tools:
|
||||
for idx, cpn in enumerate(self._param.tools):
|
||||
cpn = self._load_tool_obj(cpn)
|
||||
self.tools[cpn.get_meta()["function"]["name"]] = cpn
|
||||
original_name = cpn.get_meta()["function"]["name"]
|
||||
indexed_name = f"{original_name}_{idx}"
|
||||
self.tools[indexed_name] = cpn
|
||||
|
||||
self.chat_mdl = LLMBundle(self._canvas.get_tenant_id(), TenantLLMService.llm_id2llm_type(self._param.llm_id), self._param.llm_id,
|
||||
max_retries=self._param.max_retries,
|
||||
@ -94,7 +96,12 @@ class Agent(LLM, ToolBase):
|
||||
max_rounds=self._param.max_rounds,
|
||||
verbose_tool_use=True
|
||||
)
|
||||
self.tool_meta = [v.get_meta() for _,v in self.tools.items()]
|
||||
self.tool_meta = []
|
||||
for indexed_name, tool_obj in self.tools.items():
|
||||
original_meta = tool_obj.get_meta()
|
||||
indexed_meta = deepcopy(original_meta)
|
||||
indexed_meta["function"]["name"] = indexed_name
|
||||
self.tool_meta.append(indexed_meta)
|
||||
|
||||
for mcp in self._param.mcp:
|
||||
_, mcp_server = MCPServerService.get_by_id(mcp["mcp_id"])
|
||||
@ -108,7 +115,8 @@ class Agent(LLM, ToolBase):
|
||||
|
||||
def _load_tool_obj(self, cpn: dict) -> object:
|
||||
from agent.component import component_class
|
||||
param = component_class(cpn["component_name"] + "Param")()
|
||||
tool_name = cpn["component_name"]
|
||||
param = component_class(tool_name + "Param")()
|
||||
param.update(cpn["params"])
|
||||
try:
|
||||
param.check()
|
||||
@ -202,7 +210,7 @@ class Agent(LLM, ToolBase):
|
||||
_, msg = message_fit_in([{"role": "system", "content": prompt}, *msg], int(self.chat_mdl.max_length * 0.97))
|
||||
use_tools = []
|
||||
ans = ""
|
||||
async for delta_ans, _tk in self._react_with_tools_streamly_async(prompt, msg, use_tools, user_defined_prompt,schema_prompt=schema_prompt):
|
||||
async for delta_ans, _tk in self._react_with_tools_streamly_async_simple(prompt, msg, use_tools, user_defined_prompt,schema_prompt=schema_prompt):
|
||||
if self.check_if_canceled("Agent processing"):
|
||||
return
|
||||
ans += delta_ans
|
||||
@ -246,7 +254,7 @@ class Agent(LLM, ToolBase):
|
||||
_, msg = message_fit_in([{"role": "system", "content": prompt}, *msg], int(self.chat_mdl.max_length * 0.97))
|
||||
answer_without_toolcall = ""
|
||||
use_tools = []
|
||||
async for delta_ans, _ in self._react_with_tools_streamly_async(prompt, msg, use_tools, user_defined_prompt):
|
||||
async for delta_ans, _ in self._react_with_tools_streamly_async_simple(prompt, msg, use_tools, user_defined_prompt):
|
||||
if self.check_if_canceled("Agent streaming"):
|
||||
return
|
||||
|
||||
@ -264,7 +272,7 @@ class Agent(LLM, ToolBase):
|
||||
if use_tools:
|
||||
self.set_output("use_tools", use_tools)
|
||||
|
||||
async def _react_with_tools_streamly_async(self, prompt, history: list[dict], use_tools, user_defined_prompt={}, schema_prompt: str = ""):
|
||||
async def _react_with_tools_streamly_async_simple(self, prompt, history: list[dict], use_tools, user_defined_prompt={}, schema_prompt: str = ""):
|
||||
token_count = 0
|
||||
tool_metas = self.tool_meta
|
||||
hist = deepcopy(history)
|
||||
@ -276,6 +284,24 @@ class Agent(LLM, ToolBase):
|
||||
else:
|
||||
user_request = history[-1]["content"]
|
||||
|
||||
def build_task_desc(prompt: str, user_request: str, user_defined_prompt: dict | None = None) -> str:
|
||||
"""Build a minimal task_desc by concatenating prompt, query, and tool schemas."""
|
||||
user_defined_prompt = user_defined_prompt or {}
|
||||
|
||||
task_desc = (
|
||||
"### Agent Prompt\n"
|
||||
f"{prompt}\n\n"
|
||||
"### User Request\n"
|
||||
f"{user_request}\n\n"
|
||||
)
|
||||
|
||||
if user_defined_prompt:
|
||||
udp_json = json.dumps(user_defined_prompt, ensure_ascii=False, indent=2)
|
||||
task_desc += "\n### User Defined Prompts\n" + udp_json + "\n"
|
||||
|
||||
return task_desc
|
||||
|
||||
|
||||
async def use_tool_async(name, args):
|
||||
nonlocal hist, use_tools, last_calling
|
||||
logging.info(f"{last_calling=} == {name=}")
|
||||
@ -286,9 +312,6 @@ class Agent(LLM, ToolBase):
|
||||
"arguments": args,
|
||||
"results": tool_response
|
||||
})
|
||||
# self.callback("add_memory", {}, "...")
|
||||
#self.add_memory(hist[-2]["content"], hist[-1]["content"], name, args, str(tool_response), user_defined_prompt)
|
||||
|
||||
return name, tool_response
|
||||
|
||||
async def complete():
|
||||
@ -326,6 +349,21 @@ class Agent(LLM, ToolBase):
|
||||
|
||||
self.callback("gen_citations", {}, txt, elapsed_time=timer()-st)
|
||||
|
||||
def build_observation(tool_call_res: list[tuple]) -> str:
|
||||
"""
|
||||
Build a Observation from tool call results.
|
||||
No LLM involved.
|
||||
"""
|
||||
if not tool_call_res:
|
||||
return ""
|
||||
|
||||
lines = ["Observation:"]
|
||||
for name, result in tool_call_res:
|
||||
lines.append(f"[{name} result]")
|
||||
lines.append(str(result))
|
||||
|
||||
return "\n".join(lines)
|
||||
|
||||
def append_user_content(hist, content):
|
||||
if hist[-1]["role"] == "user":
|
||||
hist[-1]["content"] += content
|
||||
@ -333,7 +371,7 @@ class Agent(LLM, ToolBase):
|
||||
hist.append({"role": "user", "content": content})
|
||||
|
||||
st = timer()
|
||||
task_desc = await analyze_task_async(self.chat_mdl, prompt, user_request, tool_metas, user_defined_prompt)
|
||||
task_desc = build_task_desc(prompt, user_request, user_defined_prompt)
|
||||
self.callback("analyze_task", {}, task_desc, elapsed_time=timer()-st)
|
||||
for _ in range(self._param.max_rounds + 1):
|
||||
if self.check_if_canceled("Agent streaming"):
|
||||
@ -364,7 +402,7 @@ class Agent(LLM, ToolBase):
|
||||
|
||||
results = await asyncio.gather(*tool_tasks) if tool_tasks else []
|
||||
st = timer()
|
||||
reflection = await reflect_async(self.chat_mdl, hist, results, user_defined_prompt)
|
||||
reflection = build_observation(results)
|
||||
append_user_content(hist, reflection)
|
||||
self.callback("reflection", {}, str(reflection), elapsed_time=timer()-st)
|
||||
|
||||
@ -393,6 +431,135 @@ Respond immediately with your final comprehensive answer.
|
||||
async for txt, tkcnt in complete():
|
||||
yield txt, tkcnt
|
||||
|
||||
# async def _react_with_tools_streamly_async(self, prompt, history: list[dict], use_tools, user_defined_prompt={}, schema_prompt: str = ""):
|
||||
# token_count = 0
|
||||
# tool_metas = self.tool_meta
|
||||
# hist = deepcopy(history)
|
||||
# last_calling = ""
|
||||
# if len(hist) > 3:
|
||||
# st = timer()
|
||||
# user_request = await full_question(messages=history, chat_mdl=self.chat_mdl)
|
||||
# self.callback("Multi-turn conversation optimization", {}, user_request, elapsed_time=timer()-st)
|
||||
# else:
|
||||
# user_request = history[-1]["content"]
|
||||
|
||||
# async def use_tool_async(name, args):
|
||||
# nonlocal hist, use_tools, last_calling
|
||||
# logging.info(f"{last_calling=} == {name=}")
|
||||
# last_calling = name
|
||||
# tool_response = await self.toolcall_session.tool_call_async(name, args)
|
||||
# use_tools.append({
|
||||
# "name": name,
|
||||
# "arguments": args,
|
||||
# "results": tool_response
|
||||
# })
|
||||
# # self.callback("add_memory", {}, "...")
|
||||
# #self.add_memory(hist[-2]["content"], hist[-1]["content"], name, args, str(tool_response), user_defined_prompt)
|
||||
|
||||
# return name, tool_response
|
||||
|
||||
# async def complete():
|
||||
# nonlocal hist
|
||||
# need2cite = self._param.cite and self._canvas.get_reference()["chunks"] and self._id.find("-->") < 0
|
||||
# if schema_prompt:
|
||||
# need2cite = False
|
||||
# cited = False
|
||||
# if hist and hist[0]["role"] == "system":
|
||||
# if schema_prompt:
|
||||
# hist[0]["content"] += "\n" + schema_prompt
|
||||
# if need2cite and len(hist) < 7:
|
||||
# hist[0]["content"] += citation_prompt()
|
||||
# cited = True
|
||||
# yield "", token_count
|
||||
|
||||
# _hist = hist
|
||||
# if len(hist) > 12:
|
||||
# _hist = [hist[0], hist[1], *hist[-10:]]
|
||||
# entire_txt = ""
|
||||
# async for delta_ans in self._generate_streamly(_hist):
|
||||
# if not need2cite or cited:
|
||||
# yield delta_ans, 0
|
||||
# entire_txt += delta_ans
|
||||
# if not need2cite or cited:
|
||||
# return
|
||||
|
||||
# st = timer()
|
||||
# txt = ""
|
||||
# async for delta_ans in self._gen_citations_async(entire_txt):
|
||||
# if self.check_if_canceled("Agent streaming"):
|
||||
# return
|
||||
# yield delta_ans, 0
|
||||
# txt += delta_ans
|
||||
|
||||
# self.callback("gen_citations", {}, txt, elapsed_time=timer()-st)
|
||||
|
||||
# def append_user_content(hist, content):
|
||||
# if hist[-1]["role"] == "user":
|
||||
# hist[-1]["content"] += content
|
||||
# else:
|
||||
# hist.append({"role": "user", "content": content})
|
||||
|
||||
# st = timer()
|
||||
# task_desc = await analyze_task_async(self.chat_mdl, prompt, user_request, tool_metas, user_defined_prompt)
|
||||
# self.callback("analyze_task", {}, task_desc, elapsed_time=timer()-st)
|
||||
# for _ in range(self._param.max_rounds + 1):
|
||||
# if self.check_if_canceled("Agent streaming"):
|
||||
# return
|
||||
# response, tk = await next_step_async(self.chat_mdl, hist, tool_metas, task_desc, user_defined_prompt)
|
||||
# # self.callback("next_step", {}, str(response)[:256]+"...")
|
||||
# token_count += tk or 0
|
||||
# hist.append({"role": "assistant", "content": response})
|
||||
# try:
|
||||
# functions = json_repair.loads(re.sub(r"```.*", "", response))
|
||||
# if not isinstance(functions, list):
|
||||
# raise TypeError(f"List should be returned, but `{functions}`")
|
||||
# for f in functions:
|
||||
# if not isinstance(f, dict):
|
||||
# raise TypeError(f"An object type should be returned, but `{f}`")
|
||||
|
||||
# tool_tasks = []
|
||||
# for func in functions:
|
||||
# name = func["name"]
|
||||
# args = func["arguments"]
|
||||
# if name == COMPLETE_TASK:
|
||||
# append_user_content(hist, f"Respond with a formal answer. FORGET(DO NOT mention) about `{COMPLETE_TASK}`. The language for the response MUST be as the same as the first user request.\n")
|
||||
# async for txt, tkcnt in complete():
|
||||
# yield txt, tkcnt
|
||||
# return
|
||||
|
||||
# tool_tasks.append(asyncio.create_task(use_tool_async(name, args)))
|
||||
|
||||
# results = await asyncio.gather(*tool_tasks) if tool_tasks else []
|
||||
# st = timer()
|
||||
# reflection = await reflect_async(self.chat_mdl, hist, results, user_defined_prompt)
|
||||
# append_user_content(hist, reflection)
|
||||
# self.callback("reflection", {}, str(reflection), elapsed_time=timer()-st)
|
||||
|
||||
# except Exception as e:
|
||||
# logging.exception(msg=f"Wrong JSON argument format in LLM ReAct response: {e}")
|
||||
# e = f"\nTool call error, please correct the input parameter of response format and call it again.\n *** Exception ***\n{e}"
|
||||
# append_user_content(hist, str(e))
|
||||
|
||||
# logging.warning( f"Exceed max rounds: {self._param.max_rounds}")
|
||||
# final_instruction = f"""
|
||||
# {user_request}
|
||||
# IMPORTANT: You have reached the conversation limit. Based on ALL the information and research you have gathered so far, please provide a DIRECT and COMPREHENSIVE final answer to the original request.
|
||||
# Instructions:
|
||||
# 1. SYNTHESIZE all information collected during this conversation
|
||||
# 2. Provide a COMPLETE response using existing data - do not suggest additional research
|
||||
# 3. Structure your response as a FINAL DELIVERABLE, not a plan
|
||||
# 4. If information is incomplete, state what you found and provide the best analysis possible with available data
|
||||
# 5. DO NOT mention conversation limits or suggest further steps
|
||||
# 6. Focus on delivering VALUE with the information already gathered
|
||||
# Respond immediately with your final comprehensive answer.
|
||||
# """
|
||||
# if self.check_if_canceled("Agent final instruction"):
|
||||
# return
|
||||
# append_user_content(hist, final_instruction)
|
||||
|
||||
# async for txt, tkcnt in complete():
|
||||
# yield txt, tkcnt
|
||||
|
||||
async def _gen_citations_async(self, text):
|
||||
retrievals = self._canvas.get_reference()
|
||||
retrievals = {"chunks": list(retrievals["chunks"].values()), "doc_aggs": list(retrievals["doc_aggs"].values())}
|
||||
|
||||
@ -361,7 +361,7 @@ class ComponentParamBase(ABC):
|
||||
class ComponentBase(ABC):
|
||||
component_name: str
|
||||
thread_limiter = asyncio.Semaphore(int(os.environ.get("MAX_CONCURRENT_CHATS", 10)))
|
||||
variable_ref_patt = r"\{* *\{([a-zA-Z_:0-9]+@[A-Za-z0-9_.]+|sys\.[A-Za-z0-9_.]+|env\.[A-Za-z0-9_.]+)\} *\}*"
|
||||
variable_ref_patt = r"\{* *\{([a-zA-Z:0-9]+@[A-Za-z0-9_.-]+|sys\.[A-Za-z0-9_.]+|env\.[A-Za-z0-9_.]+)\} *\}*"
|
||||
|
||||
def __str__(self):
|
||||
"""
|
||||
|
||||
@ -28,7 +28,7 @@ class BeginParam(UserFillUpParam):
|
||||
self.prologue = "Hi! I'm your smart assistant. What can I do for you?"
|
||||
|
||||
def check(self):
|
||||
self.check_valid_value(self.mode, "The 'mode' should be either `conversational` or `task`", ["conversational", "task"])
|
||||
self.check_valid_value(self.mode, "The 'mode' should be either `conversational` or `task`", ["conversational", "task","Webhook"])
|
||||
|
||||
def get_input_form(self) -> dict[str, dict]:
|
||||
return getattr(self, "inputs")
|
||||
|
||||
@ -56,7 +56,6 @@ class LLMParam(ComponentParamBase):
|
||||
self.check_nonnegative_number(int(self.max_tokens), "[Agent] Max tokens")
|
||||
self.check_decimal_float(float(self.top_p), "[Agent] Top P")
|
||||
self.check_empty(self.llm_id, "[Agent] LLM")
|
||||
self.check_empty(self.sys_prompt, "[Agent] System prompt")
|
||||
self.check_empty(self.prompts, "[Agent] User prompt")
|
||||
|
||||
def gen_conf(self):
|
||||
|
||||
@ -113,6 +113,10 @@ class LoopItem(ComponentBase, ABC):
|
||||
return len(var) == 0
|
||||
elif operator == "not empty":
|
||||
return len(var) > 0
|
||||
elif var is None:
|
||||
if operator == "empty":
|
||||
return True
|
||||
return False
|
||||
|
||||
raise Exception(f"Invalid operator: {operator}")
|
||||
|
||||
|
||||
@ -33,6 +33,8 @@ from common.connection_utils import timeout
|
||||
from common.misc_utils import get_uuid
|
||||
from common import settings
|
||||
|
||||
from api.db.joint_services.memory_message_service import save_to_memory
|
||||
|
||||
|
||||
class MessageParam(ComponentParamBase):
|
||||
"""
|
||||
@ -166,6 +168,7 @@ class Message(ComponentBase):
|
||||
|
||||
self.set_output("content", all_content)
|
||||
self._convert_content(all_content)
|
||||
await self._save_to_memory(all_content)
|
||||
|
||||
def _is_jinjia2(self, content:str) -> bool:
|
||||
patt = [
|
||||
@ -198,6 +201,7 @@ class Message(ComponentBase):
|
||||
|
||||
self.set_output("content", content)
|
||||
self._convert_content(content)
|
||||
self._save_to_memory(content)
|
||||
|
||||
def thoughts(self) -> str:
|
||||
return ""
|
||||
@ -421,3 +425,29 @@ class Message(ComponentBase):
|
||||
|
||||
except Exception as e:
|
||||
logging.error(f"Error converting content to {self._param.output_format}: {e}")
|
||||
|
||||
async def _save_to_memory(self, content):
|
||||
if not hasattr(self._param, "memory_ids") or not self._param.memory_ids:
|
||||
return True, "No memory selected."
|
||||
|
||||
message_dict = {
|
||||
"user_id": self._canvas._tenant_id,
|
||||
"agent_id": self._canvas._id,
|
||||
"session_id": self._canvas.task_id,
|
||||
"user_input": self._canvas.get_sys_query(),
|
||||
"agent_response": content
|
||||
}
|
||||
res = []
|
||||
for memory_id in self._param.memory_ids:
|
||||
success, msg = await save_to_memory(memory_id, message_dict)
|
||||
res.append({
|
||||
"memory_id": memory_id,
|
||||
"success": success,
|
||||
"msg": msg
|
||||
})
|
||||
if all([r["success"] for r in res]):
|
||||
return True, "Successfully added to memories."
|
||||
|
||||
error_text = "Some messages failed to add. " + " ".join([f"Add to memory {r['memory_id']} failed, detail: {r['msg']}" for r in res if not r["success"]])
|
||||
logging.error(error_text)
|
||||
return False, error_text
|
||||
|
||||
@ -1,38 +0,0 @@
|
||||
#
|
||||
# Copyright 2024 The InfiniFlow Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
from agent.component.base import ComponentParamBase, ComponentBase
|
||||
|
||||
|
||||
class WebhookParam(ComponentParamBase):
|
||||
|
||||
"""
|
||||
Define the Begin component parameters.
|
||||
"""
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
|
||||
def get_input_form(self) -> dict[str, dict]:
|
||||
return getattr(self, "inputs")
|
||||
|
||||
|
||||
class Webhook(ComponentBase):
|
||||
component_name = "Webhook"
|
||||
|
||||
def _invoke(self, **kwargs):
|
||||
pass
|
||||
|
||||
def thoughts(self) -> str:
|
||||
return ""
|
||||
@ -25,10 +25,12 @@ from api.db.services.document_service import DocumentService
|
||||
from common.metadata_utils import apply_meta_data_filter
|
||||
from api.db.services.knowledgebase_service import KnowledgebaseService
|
||||
from api.db.services.llm_service import LLMBundle
|
||||
from api.db.services.memory_service import MemoryService
|
||||
from api.db.joint_services import memory_message_service
|
||||
from common import settings
|
||||
from common.connection_utils import timeout
|
||||
from rag.app.tag import label_question
|
||||
from rag.prompts.generator import cross_languages, kb_prompt
|
||||
from rag.prompts.generator import cross_languages, kb_prompt, memory_prompt
|
||||
|
||||
|
||||
class RetrievalParam(ToolParamBase):
|
||||
@ -57,6 +59,7 @@ class RetrievalParam(ToolParamBase):
|
||||
self.top_n = 8
|
||||
self.top_k = 1024
|
||||
self.kb_ids = []
|
||||
self.memory_ids = []
|
||||
self.kb_vars = []
|
||||
self.rerank_id = ""
|
||||
self.empty_response = ""
|
||||
@ -81,15 +84,7 @@ class RetrievalParam(ToolParamBase):
|
||||
class Retrieval(ToolBase, ABC):
|
||||
component_name = "Retrieval"
|
||||
|
||||
@timeout(int(os.environ.get("COMPONENT_EXEC_TIMEOUT", 12)))
|
||||
async def _invoke_async(self, **kwargs):
|
||||
if self.check_if_canceled("Retrieval processing"):
|
||||
return
|
||||
|
||||
if not kwargs.get("query"):
|
||||
self.set_output("formalized_content", self._param.empty_response)
|
||||
return
|
||||
|
||||
async def _retrieve_kb(self, query_text: str):
|
||||
kb_ids: list[str] = []
|
||||
for id in self._param.kb_ids:
|
||||
if id.find("@") < 0:
|
||||
@ -124,12 +119,12 @@ class Retrieval(ToolBase, ABC):
|
||||
if self._param.rerank_id:
|
||||
rerank_mdl = LLMBundle(kbs[0].tenant_id, LLMType.RERANK, self._param.rerank_id)
|
||||
|
||||
vars = self.get_input_elements_from_text(kwargs["query"])
|
||||
vars = {k:o["value"] for k,o in vars.items()}
|
||||
query = self.string_format(kwargs["query"], vars)
|
||||
vars = self.get_input_elements_from_text(query_text)
|
||||
vars = {k: o["value"] for k, o in vars.items()}
|
||||
query = self.string_format(query_text, vars)
|
||||
|
||||
doc_ids=[]
|
||||
if self._param.meta_data_filter!={}:
|
||||
doc_ids = []
|
||||
if self._param.meta_data_filter != {}:
|
||||
metas = DocumentService.get_meta_by_kbs(kb_ids)
|
||||
|
||||
def _resolve_manual_filter(flt: dict) -> dict:
|
||||
@ -198,18 +193,20 @@ class Retrieval(ToolBase, ABC):
|
||||
|
||||
if self._param.toc_enhance:
|
||||
chat_mdl = LLMBundle(self._canvas._tenant_id, LLMType.CHAT)
|
||||
cks = settings.retriever.retrieval_by_toc(query, kbinfos["chunks"], [kb.tenant_id for kb in kbs], chat_mdl, self._param.top_n)
|
||||
cks = settings.retriever.retrieval_by_toc(query, kbinfos["chunks"], [kb.tenant_id for kb in kbs],
|
||||
chat_mdl, self._param.top_n)
|
||||
if self.check_if_canceled("Retrieval processing"):
|
||||
return
|
||||
if cks:
|
||||
kbinfos["chunks"] = cks
|
||||
kbinfos["chunks"] = settings.retriever.retrieval_by_children(kbinfos["chunks"], [kb.tenant_id for kb in kbs])
|
||||
kbinfos["chunks"] = settings.retriever.retrieval_by_children(kbinfos["chunks"],
|
||||
[kb.tenant_id for kb in kbs])
|
||||
if self._param.use_kg:
|
||||
ck = settings.kg_retriever.retrieval(query,
|
||||
[kb.tenant_id for kb in kbs],
|
||||
kb_ids,
|
||||
embd_mdl,
|
||||
LLMBundle(self._canvas.get_tenant_id(), LLMType.CHAT))
|
||||
[kb.tenant_id for kb in kbs],
|
||||
kb_ids,
|
||||
embd_mdl,
|
||||
LLMBundle(self._canvas.get_tenant_id(), LLMType.CHAT))
|
||||
if self.check_if_canceled("Retrieval processing"):
|
||||
return
|
||||
if ck["content_with_weight"]:
|
||||
@ -218,7 +215,8 @@ class Retrieval(ToolBase, ABC):
|
||||
kbinfos = {"chunks": [], "doc_aggs": []}
|
||||
|
||||
if self._param.use_kg and kbs:
|
||||
ck = settings.kg_retriever.retrieval(query, [kb.tenant_id for kb in kbs], filtered_kb_ids, embd_mdl, LLMBundle(kbs[0].tenant_id, LLMType.CHAT))
|
||||
ck = settings.kg_retriever.retrieval(query, [kb.tenant_id for kb in kbs], filtered_kb_ids, embd_mdl,
|
||||
LLMBundle(kbs[0].tenant_id, LLMType.CHAT))
|
||||
if self.check_if_canceled("Retrieval processing"):
|
||||
return
|
||||
if ck["content_with_weight"]:
|
||||
@ -248,6 +246,54 @@ class Retrieval(ToolBase, ABC):
|
||||
|
||||
return form_cnt
|
||||
|
||||
async def _retrieve_memory(self, query_text: str):
|
||||
memory_ids: list[str] = [memory_id for memory_id in self._param.memory_ids]
|
||||
memory_list = MemoryService.get_by_ids(memory_ids)
|
||||
if not memory_list:
|
||||
raise Exception("No memory is selected.")
|
||||
|
||||
embd_names = list({memory.embd_id for memory in memory_list})
|
||||
assert len(embd_names) == 1, "Memory use different embedding models."
|
||||
|
||||
vars = self.get_input_elements_from_text(query_text)
|
||||
vars = {k: o["value"] for k, o in vars.items()}
|
||||
query = self.string_format(query_text, vars)
|
||||
# query message
|
||||
message_list = memory_message_service.query_message({"memory_id": memory_ids}, {
|
||||
"query": query,
|
||||
"similarity_threshold": self._param.similarity_threshold,
|
||||
"keywords_similarity_weight": self._param.keywords_similarity_weight,
|
||||
"top_n": self._param.top_n
|
||||
})
|
||||
if not message_list:
|
||||
self.set_output("formalized_content", self._param.empty_response)
|
||||
return ""
|
||||
formated_content = "\n".join(memory_prompt(message_list, 200000))
|
||||
# set formalized_content output
|
||||
self.set_output("formalized_content", formated_content)
|
||||
|
||||
return formated_content
|
||||
|
||||
@timeout(int(os.environ.get("COMPONENT_EXEC_TIMEOUT", 12)))
|
||||
async def _invoke_async(self, **kwargs):
|
||||
if self.check_if_canceled("Retrieval processing"):
|
||||
return
|
||||
if not kwargs.get("query"):
|
||||
self.set_output("formalized_content", self._param.empty_response)
|
||||
return
|
||||
|
||||
if hasattr(self._param, "retrieval_from") and self._param.retrieval_from == "dataset":
|
||||
return await self._retrieve_kb(kwargs["query"])
|
||||
elif hasattr(self._param, "retrieval_from") and self._param.retrieval_from == "memory":
|
||||
return await self._retrieve_memory(kwargs["query"])
|
||||
elif self._param.kb_ids:
|
||||
return await self._retrieve_kb(kwargs["query"])
|
||||
elif hasattr(self._param, "memory_ids") and self._param.memory_ids:
|
||||
return await self._retrieve_memory(kwargs["query"])
|
||||
else:
|
||||
self.set_output("formalized_content", self._param.empty_response)
|
||||
return
|
||||
|
||||
@timeout(int(os.environ.get("COMPONENT_EXEC_TIMEOUT", 12)))
|
||||
def _invoke(self, **kwargs):
|
||||
return asyncio.run(self._invoke_async(**kwargs))
|
||||
|
||||
@ -38,7 +38,6 @@ settings.init_settings()
|
||||
|
||||
__all__ = ["app"]
|
||||
|
||||
|
||||
app = Quart(__name__)
|
||||
app = cors(app, allow_origin="*")
|
||||
|
||||
@ -103,12 +102,13 @@ from werkzeug.local import LocalProxy
|
||||
T = TypeVar("T")
|
||||
P = ParamSpec("P")
|
||||
|
||||
|
||||
def _load_user():
|
||||
jwt = Serializer(secret_key=settings.SECRET_KEY)
|
||||
authorization = request.headers.get("Authorization")
|
||||
g.user = None
|
||||
if not authorization:
|
||||
return
|
||||
return None
|
||||
|
||||
try:
|
||||
access_token = str(jwt.loads(authorization))
|
||||
@ -164,7 +164,7 @@ def login_required(func: Callable[P, Awaitable[T]]) -> Callable[P, Awaitable[T]]
|
||||
|
||||
@wraps(func)
|
||||
async def wrapper(*args: P.args, **kwargs: P.kwargs) -> T:
|
||||
if not current_user:# or not session.get("_user_id"):
|
||||
if not current_user: # or not session.get("_user_id"):
|
||||
raise Unauthorized()
|
||||
else:
|
||||
return await current_app.ensure_async(func)(*args, **kwargs)
|
||||
@ -228,6 +228,7 @@ def logout_user():
|
||||
|
||||
return True
|
||||
|
||||
|
||||
def search_pages_path(page_path):
|
||||
app_path_list = [
|
||||
path for path in page_path.glob("*_app.py") if not path.name.startswith(".")
|
||||
@ -274,6 +275,16 @@ client_urls_prefix = [
|
||||
]
|
||||
|
||||
|
||||
@app.errorhandler(404)
|
||||
async def not_found(error):
|
||||
error_msg: str = f"The requested URL {request.path} was not found"
|
||||
logging.error(error_msg)
|
||||
return {
|
||||
"error": "Not Found",
|
||||
"message": error_msg,
|
||||
}, 404
|
||||
|
||||
|
||||
@app.teardown_request
|
||||
def _db_close(exception):
|
||||
if exception:
|
||||
|
||||
@ -153,7 +153,7 @@ async def run():
|
||||
return get_json_result(data={"message_id": task_id})
|
||||
|
||||
try:
|
||||
canvas = Canvas(cvs.dsl, current_user.id)
|
||||
canvas = Canvas(cvs.dsl, current_user.id, canvas_id=cvs.id)
|
||||
except Exception as e:
|
||||
return server_error_response(e)
|
||||
|
||||
@ -192,7 +192,7 @@ async def rerun():
|
||||
if 0 < doc["progress"] < 1:
|
||||
return get_data_error_result(message=f"`{doc['name']}` is processing...")
|
||||
|
||||
if settings.docStoreConn.indexExist(search.index_name(current_user.id), doc["kb_id"]):
|
||||
if settings.docStoreConn.index_exist(search.index_name(current_user.id), doc["kb_id"]):
|
||||
settings.docStoreConn.delete({"doc_id": doc["id"]}, search.index_name(current_user.id), doc["kb_id"])
|
||||
doc["progress_msg"] = ""
|
||||
doc["chunk_num"] = 0
|
||||
@ -232,7 +232,7 @@ async def reset():
|
||||
if not e:
|
||||
return get_data_error_result(message="canvas not found.")
|
||||
|
||||
canvas = Canvas(json.dumps(user_canvas.dsl), current_user.id)
|
||||
canvas = Canvas(json.dumps(user_canvas.dsl), current_user.id, canvas_id=user_canvas.id)
|
||||
canvas.reset()
|
||||
req["dsl"] = json.loads(str(canvas))
|
||||
UserCanvasService.update_by_id(req["id"], {"dsl": req["dsl"]})
|
||||
@ -270,7 +270,7 @@ def input_form():
|
||||
data=False, message='Only owner of canvas authorized for this operation.',
|
||||
code=RetCode.OPERATING_ERROR)
|
||||
|
||||
canvas = Canvas(json.dumps(user_canvas.dsl), current_user.id)
|
||||
canvas = Canvas(json.dumps(user_canvas.dsl), current_user.id, canvas_id=user_canvas.id)
|
||||
return get_json_result(data=canvas.get_component_input_form(cpn_id))
|
||||
except Exception as e:
|
||||
return server_error_response(e)
|
||||
@ -287,7 +287,7 @@ async def debug():
|
||||
code=RetCode.OPERATING_ERROR)
|
||||
try:
|
||||
e, user_canvas = UserCanvasService.get_by_id(req["id"])
|
||||
canvas = Canvas(json.dumps(user_canvas.dsl), current_user.id)
|
||||
canvas = Canvas(json.dumps(user_canvas.dsl), current_user.id, canvas_id=user_canvas.id)
|
||||
canvas.reset()
|
||||
canvas.message_id = get_uuid()
|
||||
component = canvas.get_component(req["component_id"])["obj"]
|
||||
|
||||
@ -76,6 +76,7 @@ async def list_chunk():
|
||||
"image_id": sres.field[id].get("img_id", ""),
|
||||
"available_int": int(sres.field[id].get("available_int", 1)),
|
||||
"positions": sres.field[id].get("position_int", []),
|
||||
"doc_type_kwd": sres.field[id].get("doc_type_kwd")
|
||||
}
|
||||
assert isinstance(d["positions"], list)
|
||||
assert len(d["positions"]) == 0 or (isinstance(d["positions"][0], list) and len(d["positions"][0]) == 5)
|
||||
@ -178,8 +179,9 @@ async def set():
|
||||
# update image
|
||||
image_base64 = req.get("image_base64", None)
|
||||
if image_base64:
|
||||
bkt, name = req.get("img_id", "-").split("-")
|
||||
image_binary = base64.b64decode(image_base64)
|
||||
settings.STORAGE_IMPL.put(req["doc_id"], req["chunk_id"], image_binary)
|
||||
settings.STORAGE_IMPL.put(bkt, name, image_binary)
|
||||
return get_json_result(data=True)
|
||||
|
||||
return await asyncio.to_thread(_set_sync)
|
||||
|
||||
@ -234,6 +234,10 @@ async def list_docs():
|
||||
|
||||
req = await get_request_json()
|
||||
|
||||
return_empty_metadata = req.get("return_empty_metadata", False)
|
||||
if isinstance(return_empty_metadata, str):
|
||||
return_empty_metadata = return_empty_metadata.lower() == "true"
|
||||
|
||||
run_status = req.get("run_status", [])
|
||||
if run_status:
|
||||
invalid_status = {s for s in run_status if s not in VALID_TASK_STATUS}
|
||||
@ -248,18 +252,73 @@ async def list_docs():
|
||||
|
||||
suffix = req.get("suffix", [])
|
||||
metadata_condition = req.get("metadata_condition", {}) or {}
|
||||
if metadata_condition and not isinstance(metadata_condition, dict):
|
||||
return get_data_error_result(message="metadata_condition must be an object.")
|
||||
metadata = req.get("metadata", {}) or {}
|
||||
if isinstance(metadata, dict) and metadata.get("empty_metadata"):
|
||||
return_empty_metadata = True
|
||||
metadata = {k: v for k, v in metadata.items() if k != "empty_metadata"}
|
||||
if return_empty_metadata:
|
||||
metadata_condition = {}
|
||||
metadata = {}
|
||||
else:
|
||||
if metadata_condition and not isinstance(metadata_condition, dict):
|
||||
return get_data_error_result(message="metadata_condition must be an object.")
|
||||
if metadata and not isinstance(metadata, dict):
|
||||
return get_data_error_result(message="metadata must be an object.")
|
||||
|
||||
doc_ids_filter = None
|
||||
if metadata_condition:
|
||||
metas = None
|
||||
if metadata_condition or metadata:
|
||||
metas = DocumentService.get_flatted_meta_by_kbs([kb_id])
|
||||
doc_ids_filter = meta_filter(metas, convert_conditions(metadata_condition), metadata_condition.get("logic", "and"))
|
||||
|
||||
if metadata_condition:
|
||||
doc_ids_filter = set(meta_filter(metas, convert_conditions(metadata_condition), metadata_condition.get("logic", "and")))
|
||||
if metadata_condition.get("conditions") and not doc_ids_filter:
|
||||
return get_json_result(data={"total": 0, "docs": []})
|
||||
|
||||
if metadata:
|
||||
metadata_doc_ids = None
|
||||
for key, values in metadata.items():
|
||||
if not values:
|
||||
continue
|
||||
if not isinstance(values, list):
|
||||
values = [values]
|
||||
values = [str(v) for v in values if v is not None and str(v).strip()]
|
||||
if not values:
|
||||
continue
|
||||
key_doc_ids = set()
|
||||
for value in values:
|
||||
key_doc_ids.update(metas.get(key, {}).get(value, []))
|
||||
if metadata_doc_ids is None:
|
||||
metadata_doc_ids = key_doc_ids
|
||||
else:
|
||||
metadata_doc_ids &= key_doc_ids
|
||||
if not metadata_doc_ids:
|
||||
return get_json_result(data={"total": 0, "docs": []})
|
||||
if metadata_doc_ids is not None:
|
||||
if doc_ids_filter is None:
|
||||
doc_ids_filter = metadata_doc_ids
|
||||
else:
|
||||
doc_ids_filter &= metadata_doc_ids
|
||||
if not doc_ids_filter:
|
||||
return get_json_result(data={"total": 0, "docs": []})
|
||||
|
||||
if doc_ids_filter is not None:
|
||||
doc_ids_filter = list(doc_ids_filter)
|
||||
|
||||
try:
|
||||
docs, tol = DocumentService.get_by_kb_id(kb_id, page_number, items_per_page, orderby, desc, keywords, run_status, types, suffix, doc_ids_filter)
|
||||
docs, tol = DocumentService.get_by_kb_id(
|
||||
kb_id,
|
||||
page_number,
|
||||
items_per_page,
|
||||
orderby,
|
||||
desc,
|
||||
keywords,
|
||||
run_status,
|
||||
types,
|
||||
suffix,
|
||||
doc_ids_filter,
|
||||
return_empty_metadata=return_empty_metadata,
|
||||
)
|
||||
|
||||
if create_time_from or create_time_to:
|
||||
filtered_docs = []
|
||||
@ -411,6 +470,26 @@ async def metadata_update():
|
||||
return get_json_result(data={"updated": updated, "matched_docs": len(target_doc_ids)})
|
||||
|
||||
|
||||
@manager.route("/update_metadata_setting", methods=["POST"]) # noqa: F821
|
||||
@login_required
|
||||
@validate_request("doc_id", "metadata")
|
||||
async def update_metadata_setting():
|
||||
req = await get_request_json()
|
||||
if not DocumentService.accessible(req["doc_id"], current_user.id):
|
||||
return get_json_result(data=False, message="No authorization.", code=RetCode.AUTHENTICATION_ERROR)
|
||||
|
||||
e, doc = DocumentService.get_by_id(req["doc_id"])
|
||||
if not e:
|
||||
return get_data_error_result(message="Document not found!")
|
||||
|
||||
DocumentService.update_parser_config(doc.id, {"metadata": req["metadata"]})
|
||||
e, doc = DocumentService.get_by_id(doc.id)
|
||||
if not e:
|
||||
return get_data_error_result(message="Document not found!")
|
||||
|
||||
return get_json_result(data=doc.to_dict())
|
||||
|
||||
|
||||
@manager.route("/thumbnails", methods=["GET"]) # noqa: F821
|
||||
# @login_required
|
||||
def thumbnails():
|
||||
@ -528,10 +607,17 @@ async def run():
|
||||
DocumentService.update_by_id(id, info)
|
||||
if req.get("delete", False):
|
||||
TaskService.filter_delete([Task.doc_id == id])
|
||||
if settings.docStoreConn.indexExist(search.index_name(tenant_id), doc.kb_id):
|
||||
if settings.docStoreConn.index_exist(search.index_name(tenant_id), doc.kb_id):
|
||||
settings.docStoreConn.delete({"doc_id": id}, search.index_name(tenant_id), doc.kb_id)
|
||||
|
||||
if str(req["run"]) == TaskStatus.RUNNING.value:
|
||||
if req.get("apply_kb"):
|
||||
e, kb = KnowledgebaseService.get_by_id(doc.kb_id)
|
||||
if not e:
|
||||
raise LookupError("Can't find this dataset!")
|
||||
doc.parser_config["enable_metadata"] = kb.parser_config.get("enable_metadata", False)
|
||||
doc.parser_config["metadata"] = kb.parser_config.get("metadata", {})
|
||||
DocumentService.update_parser_config(doc.id, doc.parser_config)
|
||||
doc_dict = doc.to_dict()
|
||||
DocumentService.run(tenant_id, doc_dict, kb_table_num_map)
|
||||
|
||||
@ -579,7 +665,7 @@ async def rename():
|
||||
"title_tks": title_tks,
|
||||
"title_sm_tks": rag_tokenizer.fine_grained_tokenize(title_tks),
|
||||
}
|
||||
if settings.docStoreConn.indexExist(search.index_name(tenant_id), doc.kb_id):
|
||||
if settings.docStoreConn.index_exist(search.index_name(tenant_id), doc.kb_id):
|
||||
settings.docStoreConn.update(
|
||||
{"doc_id": req["doc_id"]},
|
||||
es_body,
|
||||
@ -660,7 +746,7 @@ async def change_parser():
|
||||
tenant_id = DocumentService.get_tenant_id(req["doc_id"])
|
||||
if not tenant_id:
|
||||
return get_data_error_result(message="Tenant not found!")
|
||||
if settings.docStoreConn.indexExist(search.index_name(tenant_id), doc.kb_id):
|
||||
if settings.docStoreConn.index_exist(search.index_name(tenant_id), doc.kb_id):
|
||||
settings.docStoreConn.delete({"doc_id": doc.id}, search.index_name(tenant_id), doc.kb_id)
|
||||
return None
|
||||
|
||||
|
||||
@ -39,9 +39,9 @@ from api.utils.api_utils import get_json_result
|
||||
from rag.nlp import search
|
||||
from api.constants import DATASET_NAME_LIMIT
|
||||
from rag.utils.redis_conn import REDIS_CONN
|
||||
from rag.utils.doc_store_conn import OrderByExpr
|
||||
from common.constants import RetCode, PipelineTaskType, StatusEnum, VALID_TASK_STATUS, FileSource, LLMType, PAGERANK_FLD
|
||||
from common import settings
|
||||
from common.doc_store.doc_store_base import OrderByExpr
|
||||
from api.apps import login_required, current_user
|
||||
|
||||
|
||||
@ -97,6 +97,19 @@ async def update():
|
||||
code=RetCode.OPERATING_ERROR)
|
||||
|
||||
e, kb = KnowledgebaseService.get_by_id(req["kb_id"])
|
||||
|
||||
# Rename folder in FileService
|
||||
if e and req["name"].lower() != kb.name.lower():
|
||||
FileService.filter_update(
|
||||
[
|
||||
File.tenant_id == kb.tenant_id,
|
||||
File.source_type == FileSource.KNOWLEDGEBASE,
|
||||
File.type == "folder",
|
||||
File.name == kb.name,
|
||||
],
|
||||
{"name": req["name"]},
|
||||
)
|
||||
|
||||
if not e:
|
||||
return get_data_error_result(
|
||||
message="Can't find this dataset!")
|
||||
@ -150,6 +163,21 @@ async def update():
|
||||
return server_error_response(e)
|
||||
|
||||
|
||||
@manager.route('/update_metadata_setting', methods=['post']) # noqa: F821
|
||||
@login_required
|
||||
@validate_request("kb_id", "metadata")
|
||||
async def update_metadata_setting():
|
||||
req = await get_request_json()
|
||||
e, kb = KnowledgebaseService.get_by_id(req["kb_id"])
|
||||
if not e:
|
||||
return get_data_error_result(
|
||||
message="Database error (Knowledgebase rename)!")
|
||||
kb = kb.to_dict()
|
||||
kb["parser_config"]["metadata"] = req["metadata"]
|
||||
KnowledgebaseService.update_by_id(kb["id"], kb)
|
||||
return get_json_result(data=kb)
|
||||
|
||||
|
||||
@manager.route('/detail', methods=['GET']) # noqa: F821
|
||||
@login_required
|
||||
def detail():
|
||||
@ -245,13 +273,19 @@ async def rm():
|
||||
FileService.filter_delete([File.source_type == FileSource.KNOWLEDGEBASE, File.id == f2d[0].file_id])
|
||||
File2DocumentService.delete_by_document_id(doc.id)
|
||||
FileService.filter_delete(
|
||||
[File.source_type == FileSource.KNOWLEDGEBASE, File.type == "folder", File.name == kbs[0].name])
|
||||
[
|
||||
File.tenant_id == kbs[0].tenant_id,
|
||||
File.source_type == FileSource.KNOWLEDGEBASE,
|
||||
File.type == "folder",
|
||||
File.name == kbs[0].name,
|
||||
]
|
||||
)
|
||||
if not KnowledgebaseService.delete_by_id(req["kb_id"]):
|
||||
return get_data_error_result(
|
||||
message="Database error (Knowledgebase removal)!")
|
||||
for kb in kbs:
|
||||
settings.docStoreConn.delete({"kb_id": kb.id}, search.index_name(kb.tenant_id), kb.id)
|
||||
settings.docStoreConn.deleteIdx(search.index_name(kb.tenant_id), kb.id)
|
||||
settings.docStoreConn.delete_idx(search.index_name(kb.tenant_id), kb.id)
|
||||
if hasattr(settings.STORAGE_IMPL, 'remove_bucket'):
|
||||
settings.STORAGE_IMPL.remove_bucket(kb.id)
|
||||
return get_json_result(data=True)
|
||||
@ -352,7 +386,7 @@ def knowledge_graph(kb_id):
|
||||
}
|
||||
|
||||
obj = {"graph": {}, "mind_map": {}}
|
||||
if not settings.docStoreConn.indexExist(search.index_name(kb.tenant_id), kb_id):
|
||||
if not settings.docStoreConn.index_exist(search.index_name(kb.tenant_id), kb_id):
|
||||
return get_json_result(data=obj)
|
||||
sres = settings.retriever.search(req, search.index_name(kb.tenant_id), [kb_id])
|
||||
if not len(sres.ids):
|
||||
@ -824,11 +858,11 @@ async def check_embedding():
|
||||
index_nm = search.index_name(tenant_id)
|
||||
|
||||
res0 = docStoreConn.search(
|
||||
selectFields=[], highlightFields=[],
|
||||
select_fields=[], highlight_fields=[],
|
||||
condition={"kb_id": kb_id, "available_int": 1},
|
||||
matchExprs=[], orderBy=OrderByExpr(),
|
||||
match_expressions=[], order_by=OrderByExpr(),
|
||||
offset=0, limit=1,
|
||||
indexNames=index_nm, knowledgebaseIds=[kb_id]
|
||||
index_names=index_nm, knowledgebase_ids=[kb_id]
|
||||
)
|
||||
total = docStoreConn.get_total(res0)
|
||||
if total <= 0:
|
||||
@ -840,14 +874,14 @@ async def check_embedding():
|
||||
|
||||
for off in offsets:
|
||||
res1 = docStoreConn.search(
|
||||
selectFields=list(base_fields),
|
||||
highlightFields=[],
|
||||
select_fields=list(base_fields),
|
||||
highlight_fields=[],
|
||||
condition={"kb_id": kb_id, "available_int": 1},
|
||||
matchExprs=[], orderBy=OrderByExpr(),
|
||||
match_expressions=[], order_by=OrderByExpr(),
|
||||
offset=off, limit=1,
|
||||
indexNames=index_nm, knowledgebaseIds=[kb_id]
|
||||
index_names=index_nm, knowledgebase_ids=[kb_id]
|
||||
)
|
||||
ids = docStoreConn.get_chunk_ids(res1)
|
||||
ids = docStoreConn.get_doc_ids(res1)
|
||||
if not ids:
|
||||
continue
|
||||
|
||||
|
||||
@ -25,7 +25,7 @@ from api.utils.api_utils import get_allowed_llm_factories, get_data_error_result
|
||||
from common.constants import StatusEnum, LLMType
|
||||
from api.db.db_models import TenantLLM
|
||||
from rag.utils.base64_image import test_image
|
||||
from rag.llm import EmbeddingModel, ChatModel, RerankModel, CvModel, TTSModel, OcrModel
|
||||
from rag.llm import EmbeddingModel, ChatModel, RerankModel, CvModel, TTSModel, OcrModel, Seq2txtModel
|
||||
|
||||
|
||||
@manager.route("/factories", methods=["GET"]) # noqa: F821
|
||||
@ -157,7 +157,7 @@ async def add_llm():
|
||||
elif factory == "Bedrock":
|
||||
# For Bedrock, due to its special authentication method
|
||||
# Assemble bedrock_ak, bedrock_sk, bedrock_region
|
||||
api_key = apikey_json(["bedrock_ak", "bedrock_sk", "bedrock_region"])
|
||||
api_key = apikey_json(["auth_mode", "bedrock_ak", "bedrock_sk", "bedrock_region", "aws_role_arn"])
|
||||
|
||||
elif factory == "LocalAI":
|
||||
llm_name += "___LocalAI"
|
||||
@ -208,70 +208,83 @@ async def add_llm():
|
||||
msg = ""
|
||||
mdl_nm = llm["llm_name"].split("___")[0]
|
||||
extra = {"provider": factory}
|
||||
if llm["model_type"] == LLMType.EMBEDDING.value:
|
||||
assert factory in EmbeddingModel, f"Embedding model from {factory} is not supported yet."
|
||||
mdl = EmbeddingModel[factory](key=llm["api_key"], model_name=mdl_nm, base_url=llm["api_base"])
|
||||
try:
|
||||
arr, tc = mdl.encode(["Test if the api key is available"])
|
||||
if len(arr[0]) == 0:
|
||||
raise Exception("Fail")
|
||||
except Exception as e:
|
||||
msg += f"\nFail to access embedding model({mdl_nm})." + str(e)
|
||||
elif llm["model_type"] == LLMType.CHAT.value:
|
||||
assert factory in ChatModel, f"Chat model from {factory} is not supported yet."
|
||||
mdl = ChatModel[factory](
|
||||
key=llm["api_key"],
|
||||
model_name=mdl_nm,
|
||||
base_url=llm["api_base"],
|
||||
**extra,
|
||||
)
|
||||
try:
|
||||
m, tc = await mdl.async_chat(None, [{"role": "user", "content": "Hello! How are you doing!"}], {"temperature": 0.9})
|
||||
if not tc and m.find("**ERROR**:") >= 0:
|
||||
raise Exception(m)
|
||||
except Exception as e:
|
||||
msg += f"\nFail to access model({factory}/{mdl_nm})." + str(e)
|
||||
elif llm["model_type"] == LLMType.RERANK:
|
||||
assert factory in RerankModel, f"RE-rank model from {factory} is not supported yet."
|
||||
try:
|
||||
mdl = RerankModel[factory](key=llm["api_key"], model_name=mdl_nm, base_url=llm["api_base"])
|
||||
arr, tc = mdl.similarity("Hello~ RAGFlower!", ["Hi, there!", "Ohh, my friend!"])
|
||||
if len(arr) == 0:
|
||||
raise Exception("Not known.")
|
||||
except KeyError:
|
||||
msg += f"{factory} dose not support this model({factory}/{mdl_nm})"
|
||||
except Exception as e:
|
||||
msg += f"\nFail to access model({factory}/{mdl_nm})." + str(e)
|
||||
elif llm["model_type"] == LLMType.IMAGE2TEXT.value:
|
||||
assert factory in CvModel, f"Image to text model from {factory} is not supported yet."
|
||||
mdl = CvModel[factory](key=llm["api_key"], model_name=mdl_nm, base_url=llm["api_base"])
|
||||
try:
|
||||
image_data = test_image
|
||||
m, tc = mdl.describe(image_data)
|
||||
if not tc and m.find("**ERROR**:") >= 0:
|
||||
raise Exception(m)
|
||||
except Exception as e:
|
||||
msg += f"\nFail to access model({factory}/{mdl_nm})." + str(e)
|
||||
elif llm["model_type"] == LLMType.TTS:
|
||||
assert factory in TTSModel, f"TTS model from {factory} is not supported yet."
|
||||
mdl = TTSModel[factory](key=llm["api_key"], model_name=mdl_nm, base_url=llm["api_base"])
|
||||
try:
|
||||
for resp in mdl.tts("Hello~ RAGFlower!"):
|
||||
pass
|
||||
except RuntimeError as e:
|
||||
msg += f"\nFail to access model({factory}/{mdl_nm})." + str(e)
|
||||
elif llm["model_type"] == LLMType.OCR.value:
|
||||
assert factory in OcrModel, f"OCR model from {factory} is not supported yet."
|
||||
try:
|
||||
mdl = OcrModel[factory](key=llm["api_key"], model_name=mdl_nm, base_url=llm.get("api_base", ""))
|
||||
ok, reason = mdl.check_available()
|
||||
if not ok:
|
||||
raise RuntimeError(reason or "Model not available")
|
||||
except Exception as e:
|
||||
msg += f"\nFail to access model({factory}/{mdl_nm})." + str(e)
|
||||
else:
|
||||
# TODO: check other type of models
|
||||
pass
|
||||
model_type = llm["model_type"]
|
||||
model_api_key = llm["api_key"]
|
||||
model_base_url = llm.get("api_base", "")
|
||||
match model_type:
|
||||
case LLMType.EMBEDDING.value:
|
||||
assert factory in EmbeddingModel, f"Embedding model from {factory} is not supported yet."
|
||||
mdl = EmbeddingModel[factory](key=model_api_key, model_name=mdl_nm, base_url=model_base_url)
|
||||
try:
|
||||
arr, tc = mdl.encode(["Test if the api key is available"])
|
||||
if len(arr[0]) == 0:
|
||||
raise Exception("Fail")
|
||||
except Exception as e:
|
||||
msg += f"\nFail to access embedding model({mdl_nm})." + str(e)
|
||||
case LLMType.CHAT.value:
|
||||
assert factory in ChatModel, f"Chat model from {factory} is not supported yet."
|
||||
mdl = ChatModel[factory](
|
||||
key=model_api_key,
|
||||
model_name=mdl_nm,
|
||||
base_url=model_base_url,
|
||||
**extra,
|
||||
)
|
||||
try:
|
||||
m, tc = await mdl.async_chat(None, [{"role": "user", "content": "Hello! How are you doing!"}],
|
||||
{"temperature": 0.9})
|
||||
if not tc and m.find("**ERROR**:") >= 0:
|
||||
raise Exception(m)
|
||||
except Exception as e:
|
||||
msg += f"\nFail to access model({factory}/{mdl_nm})." + str(e)
|
||||
|
||||
case LLMType.RERANK.value:
|
||||
assert factory in RerankModel, f"RE-rank model from {factory} is not supported yet."
|
||||
try:
|
||||
mdl = RerankModel[factory](key=model_api_key, model_name=mdl_nm, base_url=model_base_url)
|
||||
arr, tc = mdl.similarity("Hello~ RAGFlower!", ["Hi, there!", "Ohh, my friend!"])
|
||||
if len(arr) == 0:
|
||||
raise Exception("Not known.")
|
||||
except KeyError:
|
||||
msg += f"{factory} dose not support this model({factory}/{mdl_nm})"
|
||||
except Exception as e:
|
||||
msg += f"\nFail to access model({factory}/{mdl_nm})." + str(e)
|
||||
|
||||
case LLMType.IMAGE2TEXT.value:
|
||||
assert factory in CvModel, f"Image to text model from {factory} is not supported yet."
|
||||
mdl = CvModel[factory](key=model_api_key, model_name=mdl_nm, base_url=model_base_url)
|
||||
try:
|
||||
image_data = test_image
|
||||
m, tc = mdl.describe(image_data)
|
||||
if not tc and m.find("**ERROR**:") >= 0:
|
||||
raise Exception(m)
|
||||
except Exception as e:
|
||||
msg += f"\nFail to access model({factory}/{mdl_nm})." + str(e)
|
||||
case LLMType.TTS.value:
|
||||
assert factory in TTSModel, f"TTS model from {factory} is not supported yet."
|
||||
mdl = TTSModel[factory](key=model_api_key, model_name=mdl_nm, base_url=model_base_url)
|
||||
try:
|
||||
for resp in mdl.tts("Hello~ RAGFlower!"):
|
||||
pass
|
||||
except RuntimeError as e:
|
||||
msg += f"\nFail to access model({factory}/{mdl_nm})." + str(e)
|
||||
case LLMType.OCR.value:
|
||||
assert factory in OcrModel, f"OCR model from {factory} is not supported yet."
|
||||
try:
|
||||
mdl = OcrModel[factory](key=model_api_key, model_name=mdl_nm, base_url=model_base_url)
|
||||
ok, reason = mdl.check_available()
|
||||
if not ok:
|
||||
raise RuntimeError(reason or "Model not available")
|
||||
except Exception as e:
|
||||
msg += f"\nFail to access model({factory}/{mdl_nm})." + str(e)
|
||||
case LLMType.SPEECH2TEXT:
|
||||
assert factory in Seq2txtModel, f"Speech model from {factory} is not supported yet."
|
||||
try:
|
||||
mdl = Seq2txtModel[factory](key=model_api_key, model_name=mdl_nm, base_url=model_base_url)
|
||||
# TODO: check the availability
|
||||
except Exception as e:
|
||||
msg += f"\nFail to access model({factory}/{mdl_nm})." + str(e)
|
||||
case _:
|
||||
raise RuntimeError(f"Unknown model type: {model_type}")
|
||||
|
||||
if msg:
|
||||
return get_data_error_result(message=msg)
|
||||
|
||||
@ -13,6 +13,8 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
import asyncio
|
||||
|
||||
from quart import Response, request
|
||||
from api.apps import current_user, login_required
|
||||
|
||||
@ -106,7 +108,7 @@ async def create() -> Response:
|
||||
return get_data_error_result(message="Tenant not found.")
|
||||
|
||||
mcp_server = MCPServer(id=server_name, name=server_name, url=url, server_type=server_type, variables=variables, headers=headers)
|
||||
server_tools, err_message = get_mcp_tools([mcp_server], timeout)
|
||||
server_tools, err_message = await asyncio.to_thread(get_mcp_tools, [mcp_server], timeout)
|
||||
if err_message:
|
||||
return get_data_error_result(err_message)
|
||||
|
||||
@ -158,7 +160,7 @@ async def update() -> Response:
|
||||
req["id"] = mcp_id
|
||||
|
||||
mcp_server = MCPServer(id=server_name, name=server_name, url=url, server_type=server_type, variables=variables, headers=headers)
|
||||
server_tools, err_message = get_mcp_tools([mcp_server], timeout)
|
||||
server_tools, err_message = await asyncio.to_thread(get_mcp_tools, [mcp_server], timeout)
|
||||
if err_message:
|
||||
return get_data_error_result(err_message)
|
||||
|
||||
@ -242,7 +244,7 @@ async def import_multiple() -> Response:
|
||||
headers = {"authorization_token": config["authorization_token"]} if "authorization_token" in config else {}
|
||||
variables = {k: v for k, v in config.items() if k not in {"type", "url", "headers"}}
|
||||
mcp_server = MCPServer(id=new_name, name=new_name, url=config["url"], server_type=config["type"], variables=variables, headers=headers)
|
||||
server_tools, err_message = get_mcp_tools([mcp_server], timeout)
|
||||
server_tools, err_message = await asyncio.to_thread(get_mcp_tools, [mcp_server], timeout)
|
||||
if err_message:
|
||||
results.append({"server": base_name, "success": False, "message": err_message})
|
||||
continue
|
||||
@ -322,9 +324,8 @@ async def list_tools() -> Response:
|
||||
tool_call_sessions.append(tool_call_session)
|
||||
|
||||
try:
|
||||
tools = tool_call_session.get_tools(timeout)
|
||||
tools = await asyncio.to_thread(tool_call_session.get_tools, timeout)
|
||||
except Exception as e:
|
||||
tools = []
|
||||
return get_data_error_result(message=f"MCP list tools error: {e}")
|
||||
|
||||
results[server_key] = []
|
||||
@ -340,7 +341,7 @@ async def list_tools() -> Response:
|
||||
return server_error_response(e)
|
||||
finally:
|
||||
# PERF: blocking call to close sessions — consider moving to background thread or task queue
|
||||
close_multiple_mcp_toolcall_sessions(tool_call_sessions)
|
||||
await asyncio.to_thread(close_multiple_mcp_toolcall_sessions, tool_call_sessions)
|
||||
|
||||
|
||||
@manager.route("/test_tool", methods=["POST"]) # noqa: F821
|
||||
@ -367,10 +368,10 @@ async def test_tool() -> Response:
|
||||
|
||||
tool_call_session = MCPToolCallSession(mcp_server, mcp_server.variables)
|
||||
tool_call_sessions.append(tool_call_session)
|
||||
result = tool_call_session.tool_call(tool_name, arguments, timeout)
|
||||
result = await asyncio.to_thread(tool_call_session.tool_call, tool_name, arguments, timeout)
|
||||
|
||||
# PERF: blocking call to close sessions — consider moving to background thread or task queue
|
||||
close_multiple_mcp_toolcall_sessions(tool_call_sessions)
|
||||
await asyncio.to_thread(close_multiple_mcp_toolcall_sessions, tool_call_sessions)
|
||||
return get_json_result(data=result)
|
||||
except Exception as e:
|
||||
return server_error_response(e)
|
||||
@ -424,13 +425,12 @@ async def test_mcp() -> Response:
|
||||
tool_call_session = MCPToolCallSession(mcp_server, mcp_server.variables)
|
||||
|
||||
try:
|
||||
tools = tool_call_session.get_tools(timeout)
|
||||
tools = await asyncio.to_thread(tool_call_session.get_tools, timeout)
|
||||
except Exception as e:
|
||||
tools = []
|
||||
return get_data_error_result(message=f"Test MCP error: {e}")
|
||||
finally:
|
||||
# PERF: blocking call to close sessions — consider moving to background thread or task queue
|
||||
close_multiple_mcp_toolcall_sessions([tool_call_session])
|
||||
await asyncio.to_thread(close_multiple_mcp_toolcall_sessions, [tool_call_session])
|
||||
|
||||
for tool in tools:
|
||||
tool_dict = tool.model_dump()
|
||||
|
||||
@ -20,10 +20,13 @@ from api.apps import login_required, current_user
|
||||
from api.db import TenantPermission
|
||||
from api.db.services.memory_service import MemoryService
|
||||
from api.db.services.user_service import UserTenantService
|
||||
from api.utils.api_utils import validate_request, get_request_json, get_error_argument_result, get_json_result, \
|
||||
not_allowed_parameters
|
||||
from api.db.services.canvas_service import UserCanvasService
|
||||
from api.db.joint_services.memory_message_service import get_memory_size_cache, judge_system_prompt_is_default
|
||||
from api.utils.api_utils import validate_request, get_request_json, get_error_argument_result, get_json_result
|
||||
from api.utils.memory_utils import format_ret_data_from_memory, get_memory_type_human
|
||||
from api.constants import MEMORY_NAME_LIMIT, MEMORY_SIZE_LIMIT
|
||||
from memory.services.messages import MessageService
|
||||
from memory.utils.prompt_util import PromptAssembler
|
||||
from common.constants import MemoryType, RetCode, ForgettingPolicy
|
||||
|
||||
|
||||
@ -57,7 +60,6 @@ async def create_memory():
|
||||
|
||||
if res:
|
||||
return get_json_result(message=True, data=format_ret_data_from_memory(memory))
|
||||
|
||||
else:
|
||||
return get_json_result(message=memory, code=RetCode.SERVER_ERROR)
|
||||
|
||||
@ -67,7 +69,6 @@ async def create_memory():
|
||||
|
||||
@manager.route("/<memory_id>", methods=["PUT"]) # noqa: F821
|
||||
@login_required
|
||||
@not_allowed_parameters("id", "tenant_id", "memory_type", "storage_type", "embd_id")
|
||||
async def update_memory(memory_id):
|
||||
req = await get_request_json()
|
||||
update_dict = {}
|
||||
@ -87,6 +88,14 @@ async def update_memory(memory_id):
|
||||
update_dict["permissions"] = req["permissions"]
|
||||
if req.get("llm_id"):
|
||||
update_dict["llm_id"] = req["llm_id"]
|
||||
if req.get("embd_id"):
|
||||
update_dict["embd_id"] = req["embd_id"]
|
||||
if req.get("memory_type"):
|
||||
memory_type = set(req["memory_type"])
|
||||
invalid_type = memory_type - {e.name.lower() for e in MemoryType}
|
||||
if invalid_type:
|
||||
return get_error_argument_result(f"Memory type '{invalid_type}' is not supported.")
|
||||
update_dict["memory_type"] = list(memory_type)
|
||||
# check memory_size valid
|
||||
if req.get("memory_size"):
|
||||
if not 0 < int(req["memory_size"]) <= MEMORY_SIZE_LIMIT:
|
||||
@ -122,9 +131,18 @@ async def update_memory(memory_id):
|
||||
|
||||
if not to_update:
|
||||
return get_json_result(message=True, data=memory_dict)
|
||||
# check memory empty when update embd_id, memory_type
|
||||
memory_size = get_memory_size_cache(memory_id, current_memory.tenant_id)
|
||||
not_allowed_update = [f for f in ["embd_id", "memory_type"] if f in to_update and memory_size > 0]
|
||||
if not_allowed_update:
|
||||
return get_error_argument_result(f"Can't update {not_allowed_update} when memory isn't empty.")
|
||||
if "memory_type" in to_update:
|
||||
if "system_prompt" not in to_update and judge_system_prompt_is_default(current_memory.system_prompt, current_memory.memory_type):
|
||||
# update old default prompt, assemble a new one
|
||||
to_update["system_prompt"] = PromptAssembler.assemble_system_prompt({"memory_type": to_update["memory_type"]})
|
||||
|
||||
try:
|
||||
MemoryService.update_memory(memory_id, to_update)
|
||||
MemoryService.update_memory(current_memory.tenant_id, memory_id, to_update)
|
||||
updated_memory = MemoryService.get_by_memory_id(memory_id)
|
||||
return get_json_result(message=True, data=format_ret_data_from_memory(updated_memory))
|
||||
|
||||
@ -133,7 +151,7 @@ async def update_memory(memory_id):
|
||||
return get_json_result(message=str(e), code=RetCode.SERVER_ERROR)
|
||||
|
||||
|
||||
@manager.route("/<memory_id>", methods=["DELETE"]) # noqa: F821
|
||||
@manager.route("/<memory_id>", methods=["DELETE"]) # noqa: F821
|
||||
@login_required
|
||||
async def delete_memory(memory_id):
|
||||
memory = MemoryService.get_by_memory_id(memory_id)
|
||||
@ -141,13 +159,14 @@ async def delete_memory(memory_id):
|
||||
return get_json_result(message=True, code=RetCode.NOT_FOUND)
|
||||
try:
|
||||
MemoryService.delete_memory(memory_id)
|
||||
MessageService.delete_message({"memory_id": memory_id}, memory.tenant_id, memory_id)
|
||||
return get_json_result(message=True)
|
||||
except Exception as e:
|
||||
logging.error(e)
|
||||
return get_json_result(message=str(e), code=RetCode.SERVER_ERROR)
|
||||
|
||||
|
||||
@manager.route("", methods=["GET"]) # noqa: F821
|
||||
@manager.route("", methods=["GET"]) # noqa: F821
|
||||
@login_required
|
||||
async def list_memory():
|
||||
args = request.args
|
||||
@ -183,3 +202,26 @@ async def get_memory_config(memory_id):
|
||||
if not memory:
|
||||
return get_json_result(code=RetCode.NOT_FOUND, message=f"Memory '{memory_id}' not found.")
|
||||
return get_json_result(message=True, data=format_ret_data_from_memory(memory))
|
||||
|
||||
|
||||
@manager.route("/<memory_id>", methods=["GET"]) # noqa: F821
|
||||
@login_required
|
||||
async def get_memory_detail(memory_id):
|
||||
args = request.args
|
||||
agent_ids = args.getlist("agent_id")
|
||||
keywords = args.get("keywords", "")
|
||||
keywords = keywords.strip()
|
||||
page = int(args.get("page", 1))
|
||||
page_size = int(args.get("page_size", 50))
|
||||
memory = MemoryService.get_by_memory_id(memory_id)
|
||||
if not memory:
|
||||
return get_json_result(code=RetCode.NOT_FOUND, message=f"Memory '{memory_id}' not found.")
|
||||
messages = MessageService.list_message(
|
||||
memory.tenant_id, memory_id, agent_ids, keywords, page, page_size)
|
||||
agent_name_mapping = {}
|
||||
if messages["message_list"]:
|
||||
agent_list = UserCanvasService.get_basic_info_by_canvas_ids([message["agent_id"] for message in messages["message_list"]])
|
||||
agent_name_mapping = {agent["id"]: agent["title"] for agent in agent_list}
|
||||
for message in messages["message_list"]:
|
||||
message["agent_name"] = agent_name_mapping.get(message["agent_id"], "Unknown")
|
||||
return get_json_result(data={"messages": messages, "storage_type": memory.storage_type}, message=True)
|
||||
|
||||
168
api/apps/messages_app.py
Normal file
168
api/apps/messages_app.py
Normal file
@ -0,0 +1,168 @@
|
||||
#
|
||||
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
from quart import request
|
||||
from api.apps import login_required
|
||||
from api.db.services.memory_service import MemoryService
|
||||
from common.time_utils import current_timestamp, timestamp_to_date
|
||||
|
||||
from memory.services.messages import MessageService
|
||||
from api.db.joint_services import memory_message_service
|
||||
from api.utils.api_utils import validate_request, get_request_json, get_error_argument_result, get_json_result
|
||||
from common.constants import RetCode
|
||||
|
||||
|
||||
@manager.route("", methods=["POST"]) # noqa: F821
|
||||
@login_required
|
||||
@validate_request("memory_id", "agent_id", "session_id", "user_input", "agent_response")
|
||||
async def add_message():
|
||||
|
||||
req = await get_request_json()
|
||||
memory_ids = req["memory_id"]
|
||||
agent_id = req["agent_id"]
|
||||
session_id = req["session_id"]
|
||||
user_id = req["user_id"] if req.get("user_id") else ""
|
||||
user_input = req["user_input"]
|
||||
agent_response = req["agent_response"]
|
||||
|
||||
res = []
|
||||
for memory_id in memory_ids:
|
||||
success, msg = await memory_message_service.save_to_memory(
|
||||
memory_id,
|
||||
{
|
||||
"user_id": user_id,
|
||||
"agent_id": agent_id,
|
||||
"session_id": session_id,
|
||||
"user_input": user_input,
|
||||
"agent_response": agent_response
|
||||
}
|
||||
)
|
||||
res.append({
|
||||
"memory_id": memory_id,
|
||||
"success": success,
|
||||
"message": msg
|
||||
})
|
||||
|
||||
if all([r["success"] for r in res]):
|
||||
return get_json_result(message="Successfully added to memories.")
|
||||
|
||||
return get_json_result(code=RetCode.SERVER_ERROR, message="Some messages failed to add.", data=res)
|
||||
|
||||
|
||||
@manager.route("/<memory_id>:<message_id>", methods=["DELETE"]) # noqa: F821
|
||||
@login_required
|
||||
async def forget_message(memory_id: str, message_id: int):
|
||||
|
||||
memory = MemoryService.get_by_memory_id(memory_id)
|
||||
if not memory:
|
||||
return get_json_result(code=RetCode.NOT_FOUND, message=f"Memory '{memory_id}' not found.")
|
||||
|
||||
forget_time = timestamp_to_date(current_timestamp())
|
||||
update_succeed = MessageService.update_message(
|
||||
{"memory_id": memory_id, "message_id": int(message_id)},
|
||||
{"forget_at": forget_time},
|
||||
memory.tenant_id, memory_id)
|
||||
if update_succeed:
|
||||
return get_json_result(message=update_succeed)
|
||||
else:
|
||||
return get_json_result(code=RetCode.SERVER_ERROR, message=f"Failed to forget message '{message_id}' in memory '{memory_id}'.")
|
||||
|
||||
|
||||
@manager.route("/<memory_id>:<message_id>", methods=["PUT"]) # noqa: F821
|
||||
@login_required
|
||||
@validate_request("status")
|
||||
async def update_message(memory_id: str, message_id: int):
|
||||
req = await get_request_json()
|
||||
status = req["status"]
|
||||
if not isinstance(status, bool):
|
||||
return get_error_argument_result("Status must be a boolean.")
|
||||
|
||||
memory = MemoryService.get_by_memory_id(memory_id)
|
||||
if not memory:
|
||||
return get_json_result(code=RetCode.NOT_FOUND, message=f"Memory '{memory_id}' not found.")
|
||||
|
||||
update_succeed = MessageService.update_message({"memory_id": memory_id, "message_id": int(message_id)}, {"status": status}, memory.tenant_id, memory_id)
|
||||
if update_succeed:
|
||||
return get_json_result(message=update_succeed)
|
||||
else:
|
||||
return get_json_result(code=RetCode.SERVER_ERROR, message=f"Failed to set status for message '{message_id}' in memory '{memory_id}'.")
|
||||
|
||||
|
||||
@manager.route("/search", methods=["GET"]) # noqa: F821
|
||||
@login_required
|
||||
async def search_message():
|
||||
args = request.args
|
||||
print(args, flush=True)
|
||||
empty_fields = [f for f in ["memory_id", "query"] if not args.get(f)]
|
||||
if empty_fields:
|
||||
return get_error_argument_result(f"{', '.join(empty_fields)} can't be empty.")
|
||||
|
||||
memory_ids = args.getlist("memory_id")
|
||||
query = args.get("query")
|
||||
similarity_threshold = float(args.get("similarity_threshold", 0.2))
|
||||
keywords_similarity_weight = float(args.get("keywords_similarity_weight", 0.7))
|
||||
top_n = int(args.get("top_n", 5))
|
||||
agent_id = args.get("agent_id", "")
|
||||
session_id = args.get("session_id", "")
|
||||
|
||||
filter_dict = {
|
||||
"memory_id": memory_ids,
|
||||
"agent_id": agent_id,
|
||||
"session_id": session_id
|
||||
}
|
||||
params = {
|
||||
"query": query,
|
||||
"similarity_threshold": similarity_threshold,
|
||||
"keywords_similarity_weight": keywords_similarity_weight,
|
||||
"top_n": top_n
|
||||
}
|
||||
res = memory_message_service.query_message(filter_dict, params)
|
||||
return get_json_result(message=True, data=res)
|
||||
|
||||
|
||||
@manager.route("", methods=["GET"]) # noqa: F821
|
||||
@login_required
|
||||
async def get_messages():
|
||||
args = request.args
|
||||
memory_ids = args.getlist("memory_id")
|
||||
agent_id = args.get("agent_id", "")
|
||||
session_id = args.get("session_id", "")
|
||||
limit = int(args.get("limit", 10))
|
||||
if not memory_ids:
|
||||
return get_error_argument_result("memory_ids is required.")
|
||||
memory_list = MemoryService.get_by_ids(memory_ids)
|
||||
uids = [memory.tenant_id for memory in memory_list]
|
||||
res = MessageService.get_recent_messages(
|
||||
uids,
|
||||
memory_ids,
|
||||
agent_id,
|
||||
session_id,
|
||||
limit
|
||||
)
|
||||
return get_json_result(message=True, data=res)
|
||||
|
||||
|
||||
@manager.route("/<memory_id>:<message_id>/content", methods=["GET"]) # noqa: F821
|
||||
@login_required
|
||||
async def get_message_content(memory_id:str, message_id: int):
|
||||
memory = MemoryService.get_by_memory_id(memory_id)
|
||||
if not memory:
|
||||
return get_json_result(code=RetCode.NOT_FOUND, message=f"Memory '{memory_id}' not found.")
|
||||
|
||||
res = MessageService.get_by_message_id(memory_id, message_id, memory.tenant_id)
|
||||
if res:
|
||||
return get_json_result(message=True, data=res)
|
||||
else:
|
||||
return get_json_result(code=RetCode.NOT_FOUND, message=f"Message '{message_id}' in memory '{memory_id}' not found.")
|
||||
@ -14,20 +14,29 @@
|
||||
# limitations under the License.
|
||||
#
|
||||
|
||||
import asyncio
|
||||
import base64
|
||||
import hashlib
|
||||
import hmac
|
||||
import ipaddress
|
||||
import json
|
||||
import logging
|
||||
import time
|
||||
from typing import Any, cast
|
||||
|
||||
import jwt
|
||||
|
||||
from agent.canvas import Canvas
|
||||
from api.db import CanvasCategory
|
||||
from api.db.services.canvas_service import UserCanvasService
|
||||
from api.db.services.file_service import FileService
|
||||
from api.db.services.user_canvas_version import UserCanvasVersionService
|
||||
from common.constants import RetCode
|
||||
from common.misc_utils import get_uuid
|
||||
from api.utils.api_utils import get_data_error_result, get_error_data_result, get_json_result, get_request_json, token_required
|
||||
from api.utils.api_utils import get_result
|
||||
from quart import request, Response
|
||||
from rag.utils.redis_conn import REDIS_CONN
|
||||
|
||||
|
||||
@manager.route('/agents', methods=['GET']) # noqa: F821
|
||||
@ -132,48 +141,785 @@ def delete_agent(tenant_id: str, agent_id: str):
|
||||
UserCanvasService.delete_by_id(agent_id)
|
||||
return get_json_result(data=True)
|
||||
|
||||
@manager.route("/webhook/<agent_id>", methods=["POST", "GET", "PUT", "PATCH", "DELETE", "HEAD"]) # noqa: F821
|
||||
@manager.route("/webhook_test/<agent_id>",methods=["POST", "GET", "PUT", "PATCH", "DELETE", "HEAD"],) # noqa: F821
|
||||
async def webhook(agent_id: str):
|
||||
is_test = request.path.startswith("/api/v1/webhook_test")
|
||||
start_ts = time.time()
|
||||
|
||||
@manager.route('/webhook/<agent_id>', methods=['POST']) # noqa: F821
|
||||
@token_required
|
||||
async def webhook(tenant_id: str, agent_id: str):
|
||||
req = await get_request_json()
|
||||
if not UserCanvasService.accessible(req["id"], tenant_id):
|
||||
return get_json_result(
|
||||
data=False, message='Only owner of canvas authorized for this operation.',
|
||||
code=RetCode.OPERATING_ERROR)
|
||||
|
||||
e, cvs = UserCanvasService.get_by_id(req["id"])
|
||||
if not e:
|
||||
return get_data_error_result(message="canvas not found.")
|
||||
|
||||
if not isinstance(cvs.dsl, str):
|
||||
cvs.dsl = json.dumps(cvs.dsl, ensure_ascii=False)
|
||||
# 1. Fetch canvas by agent_id
|
||||
exists, cvs = UserCanvasService.get_by_id(agent_id)
|
||||
if not exists:
|
||||
return get_data_error_result(code=RetCode.BAD_REQUEST,message="Canvas not found."),RetCode.BAD_REQUEST
|
||||
|
||||
# 2. Check canvas category
|
||||
if cvs.canvas_category == CanvasCategory.DataFlow:
|
||||
return get_data_error_result(message="Dataflow can not be triggered by webhook.")
|
||||
return get_data_error_result(code=RetCode.BAD_REQUEST,message="Dataflow can not be triggered by webhook."),RetCode.BAD_REQUEST
|
||||
|
||||
# 3. Load DSL from canvas
|
||||
dsl = getattr(cvs, "dsl", None)
|
||||
if not isinstance(dsl, dict):
|
||||
return get_data_error_result(code=RetCode.BAD_REQUEST,message="Invalid DSL format."),RetCode.BAD_REQUEST
|
||||
|
||||
# 4. Check webhook configuration in DSL
|
||||
components = dsl.get("components", {})
|
||||
for k, _ in components.items():
|
||||
cpn_obj = components[k]["obj"]
|
||||
if cpn_obj["component_name"].lower() == "begin" and cpn_obj["params"]["mode"] == "Webhook":
|
||||
webhook_cfg = cpn_obj["params"]
|
||||
|
||||
if not webhook_cfg:
|
||||
return get_data_error_result(code=RetCode.BAD_REQUEST,message="Webhook not configured for this agent."),RetCode.BAD_REQUEST
|
||||
|
||||
# 5. Validate request method against webhook_cfg.methods
|
||||
allowed_methods = webhook_cfg.get("methods", [])
|
||||
request_method = request.method.upper()
|
||||
if allowed_methods and request_method not in allowed_methods:
|
||||
return get_data_error_result(
|
||||
code=RetCode.BAD_REQUEST,message=f"HTTP method '{request_method}' not allowed for this webhook."
|
||||
),RetCode.BAD_REQUEST
|
||||
|
||||
# 6. Validate webhook security
|
||||
async def validate_webhook_security(security_cfg: dict):
|
||||
"""Validate webhook security rules based on security configuration."""
|
||||
|
||||
if not security_cfg:
|
||||
return # No security config → allowed by default
|
||||
|
||||
# 1. Validate max body size
|
||||
await _validate_max_body_size(security_cfg)
|
||||
|
||||
# 2. Validate IP whitelist
|
||||
_validate_ip_whitelist(security_cfg)
|
||||
|
||||
# # 3. Validate rate limiting
|
||||
_validate_rate_limit(security_cfg)
|
||||
|
||||
# 4. Validate authentication
|
||||
auth_type = security_cfg.get("auth_type", "none")
|
||||
|
||||
if auth_type == "none":
|
||||
return
|
||||
|
||||
if auth_type == "token":
|
||||
_validate_token_auth(security_cfg)
|
||||
|
||||
elif auth_type == "basic":
|
||||
_validate_basic_auth(security_cfg)
|
||||
|
||||
elif auth_type == "jwt":
|
||||
_validate_jwt_auth(security_cfg)
|
||||
|
||||
else:
|
||||
raise Exception(f"Unsupported auth_type: {auth_type}")
|
||||
|
||||
async def _validate_max_body_size(security_cfg):
|
||||
"""Check request size does not exceed max_body_size."""
|
||||
max_size = security_cfg.get("max_body_size")
|
||||
if not max_size:
|
||||
return
|
||||
|
||||
# Convert "10MB" → bytes
|
||||
units = {"kb": 1024, "mb": 1024**2}
|
||||
size_str = max_size.lower()
|
||||
|
||||
for suffix, factor in units.items():
|
||||
if size_str.endswith(suffix):
|
||||
limit = int(size_str.replace(suffix, "")) * factor
|
||||
break
|
||||
else:
|
||||
raise Exception("Invalid max_body_size format")
|
||||
MAX_LIMIT = 10 * 1024 * 1024 # 10MB
|
||||
if limit > MAX_LIMIT:
|
||||
raise Exception("max_body_size exceeds maximum allowed size (10MB)")
|
||||
|
||||
content_length = request.content_length or 0
|
||||
if content_length > limit:
|
||||
raise Exception(f"Request body too large: {content_length} > {limit}")
|
||||
|
||||
def _validate_ip_whitelist(security_cfg):
|
||||
"""Allow only IPs listed in ip_whitelist."""
|
||||
whitelist = security_cfg.get("ip_whitelist", [])
|
||||
if not whitelist:
|
||||
return
|
||||
|
||||
client_ip = request.remote_addr
|
||||
|
||||
|
||||
for rule in whitelist:
|
||||
if "/" in rule:
|
||||
# CIDR notation
|
||||
if ipaddress.ip_address(client_ip) in ipaddress.ip_network(rule, strict=False):
|
||||
return
|
||||
else:
|
||||
# Single IP
|
||||
if client_ip == rule:
|
||||
return
|
||||
|
||||
raise Exception(f"IP {client_ip} is not allowed by whitelist")
|
||||
|
||||
def _validate_rate_limit(security_cfg):
|
||||
"""Simple in-memory rate limiting."""
|
||||
rl = security_cfg.get("rate_limit")
|
||||
if not rl:
|
||||
return
|
||||
|
||||
limit = int(rl.get("limit", 60))
|
||||
if limit <= 0:
|
||||
raise Exception("rate_limit.limit must be > 0")
|
||||
per = rl.get("per", "minute")
|
||||
|
||||
window = {
|
||||
"second": 1,
|
||||
"minute": 60,
|
||||
"hour": 3600,
|
||||
"day": 86400,
|
||||
}.get(per)
|
||||
|
||||
if not window:
|
||||
raise Exception(f"Invalid rate_limit.per: {per}")
|
||||
|
||||
capacity = limit
|
||||
rate = limit / window
|
||||
cost = 1
|
||||
|
||||
key = f"rl:tb:{agent_id}"
|
||||
now = time.time()
|
||||
|
||||
try:
|
||||
res = REDIS_CONN.lua_token_bucket(
|
||||
keys=[key],
|
||||
args=[capacity, rate, now, cost],
|
||||
client=REDIS_CONN.REDIS,
|
||||
)
|
||||
|
||||
allowed = int(res[0])
|
||||
if allowed != 1:
|
||||
raise Exception("Too many requests (rate limit exceeded)")
|
||||
|
||||
except Exception as e:
|
||||
raise Exception(f"Rate limit error: {e}")
|
||||
|
||||
def _validate_token_auth(security_cfg):
|
||||
"""Validate header-based token authentication."""
|
||||
token_cfg = security_cfg.get("token",{})
|
||||
header = token_cfg.get("token_header")
|
||||
token_value = token_cfg.get("token_value")
|
||||
|
||||
provided = request.headers.get(header)
|
||||
if provided != token_value:
|
||||
raise Exception("Invalid token authentication")
|
||||
|
||||
def _validate_basic_auth(security_cfg):
|
||||
"""Validate HTTP Basic Auth credentials."""
|
||||
auth_cfg = security_cfg.get("basic_auth", {})
|
||||
username = auth_cfg.get("username")
|
||||
password = auth_cfg.get("password")
|
||||
|
||||
auth = request.authorization
|
||||
if not auth or auth.username != username or auth.password != password:
|
||||
raise Exception("Invalid Basic Auth credentials")
|
||||
|
||||
def _validate_jwt_auth(security_cfg):
|
||||
"""Validate JWT token in Authorization header."""
|
||||
jwt_cfg = security_cfg.get("jwt", {})
|
||||
secret = jwt_cfg.get("secret")
|
||||
if not secret:
|
||||
raise Exception("JWT secret not configured")
|
||||
|
||||
auth_header = request.headers.get("Authorization", "")
|
||||
if not auth_header.startswith("Bearer "):
|
||||
raise Exception("Missing Bearer token")
|
||||
|
||||
token = auth_header[len("Bearer "):].strip()
|
||||
if not token:
|
||||
raise Exception("Empty Bearer token")
|
||||
|
||||
alg = (jwt_cfg.get("algorithm") or "HS256").upper()
|
||||
|
||||
decode_kwargs = {
|
||||
"key": secret,
|
||||
"algorithms": [alg],
|
||||
}
|
||||
options = {}
|
||||
if jwt_cfg.get("audience"):
|
||||
decode_kwargs["audience"] = jwt_cfg["audience"]
|
||||
options["verify_aud"] = True
|
||||
else:
|
||||
options["verify_aud"] = False
|
||||
|
||||
if jwt_cfg.get("issuer"):
|
||||
decode_kwargs["issuer"] = jwt_cfg["issuer"]
|
||||
options["verify_iss"] = True
|
||||
else:
|
||||
options["verify_iss"] = False
|
||||
try:
|
||||
decoded = jwt.decode(
|
||||
token,
|
||||
options=options,
|
||||
**decode_kwargs,
|
||||
)
|
||||
except Exception as e:
|
||||
raise Exception(f"Invalid JWT: {str(e)}")
|
||||
|
||||
raw_required_claims = jwt_cfg.get("required_claims", [])
|
||||
if isinstance(raw_required_claims, str):
|
||||
required_claims = [raw_required_claims]
|
||||
elif isinstance(raw_required_claims, (list, tuple, set)):
|
||||
required_claims = list(raw_required_claims)
|
||||
else:
|
||||
required_claims = []
|
||||
|
||||
required_claims = [
|
||||
c for c in required_claims
|
||||
if isinstance(c, str) and c.strip()
|
||||
]
|
||||
|
||||
RESERVED_CLAIMS = {"exp", "sub", "aud", "iss", "nbf", "iat"}
|
||||
for claim in required_claims:
|
||||
if claim in RESERVED_CLAIMS:
|
||||
raise Exception(f"Reserved JWT claim cannot be required: {claim}")
|
||||
|
||||
for claim in required_claims:
|
||||
if claim not in decoded:
|
||||
raise Exception(f"Missing JWT claim: {claim}")
|
||||
|
||||
return decoded
|
||||
|
||||
try:
|
||||
canvas = Canvas(cvs.dsl, tenant_id, agent_id)
|
||||
security_config=webhook_cfg.get("security", {})
|
||||
await validate_webhook_security(security_config)
|
||||
except Exception as e:
|
||||
return get_json_result(
|
||||
data=False, message=str(e),
|
||||
code=RetCode.EXCEPTION_ERROR)
|
||||
return get_data_error_result(code=RetCode.BAD_REQUEST,message=str(e)),RetCode.BAD_REQUEST
|
||||
if not isinstance(cvs.dsl, str):
|
||||
dsl = json.dumps(cvs.dsl, ensure_ascii=False)
|
||||
try:
|
||||
canvas = Canvas(dsl, cvs.user_id, agent_id, canvas_id=agent_id)
|
||||
except Exception as e:
|
||||
resp=get_data_error_result(code=RetCode.BAD_REQUEST,message=str(e))
|
||||
resp.status_code = RetCode.BAD_REQUEST
|
||||
return resp
|
||||
|
||||
# 7. Parse request body
|
||||
async def parse_webhook_request(content_type):
|
||||
"""Parse request based on content-type and return structured data."""
|
||||
|
||||
# 1. Query
|
||||
query_data = {k: v for k, v in request.args.items()}
|
||||
|
||||
# 2. Headers
|
||||
header_data = {k: v for k, v in request.headers.items()}
|
||||
|
||||
# 3. Body
|
||||
ctype = request.headers.get("Content-Type", "").split(";")[0].strip()
|
||||
if ctype and ctype != content_type:
|
||||
raise ValueError(
|
||||
f"Invalid Content-Type: expect '{content_type}', got '{ctype}'"
|
||||
)
|
||||
|
||||
body_data: dict = {}
|
||||
|
||||
async def sse():
|
||||
nonlocal canvas
|
||||
try:
|
||||
async for ans in canvas.run(query=req.get("query", ""), files=req.get("files", []), user_id=req.get("user_id", tenant_id), webhook_payload=req):
|
||||
yield "data:" + json.dumps(ans, ensure_ascii=False) + "\n\n"
|
||||
if ctype == "application/json":
|
||||
body_data = await request.get_json() or {}
|
||||
|
||||
cvs.dsl = json.loads(str(canvas))
|
||||
UserCanvasService.update_by_id(req["id"], cvs.to_dict())
|
||||
except Exception as e:
|
||||
logging.exception(e)
|
||||
yield "data:" + json.dumps({"code": 500, "message": str(e), "data": False}, ensure_ascii=False) + "\n\n"
|
||||
elif ctype == "multipart/form-data":
|
||||
nonlocal canvas
|
||||
form = await request.form
|
||||
files = await request.files
|
||||
|
||||
resp = Response(sse(), mimetype="text/event-stream")
|
||||
resp.headers.add_header("Cache-control", "no-cache")
|
||||
resp.headers.add_header("Connection", "keep-alive")
|
||||
resp.headers.add_header("X-Accel-Buffering", "no")
|
||||
resp.headers.add_header("Content-Type", "text/event-stream; charset=utf-8")
|
||||
return resp
|
||||
body_data = {}
|
||||
|
||||
for key, value in form.items():
|
||||
body_data[key] = value
|
||||
|
||||
if len(files) > 10:
|
||||
raise Exception("Too many uploaded files")
|
||||
for key, file in files.items():
|
||||
desc = FileService.upload_info(
|
||||
cvs.user_id, # user
|
||||
file, # FileStorage
|
||||
None # url (None for webhook)
|
||||
)
|
||||
file_parsed= await canvas.get_files_async([desc])
|
||||
body_data[key] = file_parsed
|
||||
|
||||
elif ctype == "application/x-www-form-urlencoded":
|
||||
form = await request.form
|
||||
body_data = dict(form)
|
||||
|
||||
else:
|
||||
# text/plain / octet-stream / empty / unknown
|
||||
raw = await request.get_data()
|
||||
if raw:
|
||||
try:
|
||||
body_data = json.loads(raw.decode("utf-8"))
|
||||
except Exception:
|
||||
body_data = {}
|
||||
else:
|
||||
body_data = {}
|
||||
|
||||
except Exception:
|
||||
body_data = {}
|
||||
|
||||
return {
|
||||
"query": query_data,
|
||||
"headers": header_data,
|
||||
"body": body_data,
|
||||
"content_type": ctype,
|
||||
}
|
||||
|
||||
def extract_by_schema(data, schema, name="section"):
|
||||
"""
|
||||
Extract only fields defined in schema.
|
||||
Required fields must exist.
|
||||
Optional fields default to type-based default values.
|
||||
Type validation included.
|
||||
"""
|
||||
props = schema.get("properties", {})
|
||||
required = schema.get("required", [])
|
||||
|
||||
extracted = {}
|
||||
|
||||
for field, field_schema in props.items():
|
||||
field_type = field_schema.get("type")
|
||||
|
||||
# 1. Required field missing
|
||||
if field in required and field not in data:
|
||||
raise Exception(f"{name} missing required field: {field}")
|
||||
|
||||
# 2. Optional → default value
|
||||
if field not in data:
|
||||
extracted[field] = default_for_type(field_type)
|
||||
continue
|
||||
|
||||
raw_value = data[field]
|
||||
|
||||
# 3. Auto convert value
|
||||
try:
|
||||
value = auto_cast_value(raw_value, field_type)
|
||||
except Exception as e:
|
||||
raise Exception(f"{name}.{field} auto-cast failed: {str(e)}")
|
||||
|
||||
# 4. Type validation
|
||||
if not validate_type(value, field_type):
|
||||
raise Exception(
|
||||
f"{name}.{field} type mismatch: expected {field_type}, got {type(value).__name__}"
|
||||
)
|
||||
|
||||
extracted[field] = value
|
||||
|
||||
return extracted
|
||||
|
||||
|
||||
def default_for_type(t):
|
||||
"""Return default value for the given schema type."""
|
||||
if t == "file":
|
||||
return []
|
||||
if t == "object":
|
||||
return {}
|
||||
if t == "boolean":
|
||||
return False
|
||||
if t == "number":
|
||||
return 0
|
||||
if t == "string":
|
||||
return ""
|
||||
if t and t.startswith("array"):
|
||||
return []
|
||||
if t == "null":
|
||||
return None
|
||||
return None
|
||||
|
||||
def auto_cast_value(value, expected_type):
|
||||
"""Convert string values into schema type when possible."""
|
||||
|
||||
# Non-string values already good
|
||||
if not isinstance(value, str):
|
||||
return value
|
||||
|
||||
v = value.strip()
|
||||
|
||||
# Boolean
|
||||
if expected_type == "boolean":
|
||||
if v.lower() in ["true", "1"]:
|
||||
return True
|
||||
if v.lower() in ["false", "0"]:
|
||||
return False
|
||||
raise Exception(f"Cannot convert '{value}' to boolean")
|
||||
|
||||
# Number
|
||||
if expected_type == "number":
|
||||
# integer
|
||||
if v.isdigit() or (v.startswith("-") and v[1:].isdigit()):
|
||||
return int(v)
|
||||
|
||||
# float
|
||||
try:
|
||||
return float(v)
|
||||
except Exception:
|
||||
raise Exception(f"Cannot convert '{value}' to number")
|
||||
|
||||
# Object
|
||||
if expected_type == "object":
|
||||
try:
|
||||
parsed = json.loads(v)
|
||||
if isinstance(parsed, dict):
|
||||
return parsed
|
||||
else:
|
||||
raise Exception("JSON is not an object")
|
||||
except Exception:
|
||||
raise Exception(f"Cannot convert '{value}' to object")
|
||||
|
||||
# Array <T>
|
||||
if expected_type.startswith("array"):
|
||||
try:
|
||||
parsed = json.loads(v)
|
||||
if isinstance(parsed, list):
|
||||
return parsed
|
||||
else:
|
||||
raise Exception("JSON is not an array")
|
||||
except Exception:
|
||||
raise Exception(f"Cannot convert '{value}' to array")
|
||||
|
||||
# String (accept original)
|
||||
if expected_type == "string":
|
||||
return value
|
||||
|
||||
# File
|
||||
if expected_type == "file":
|
||||
return value
|
||||
# Default: do nothing
|
||||
return value
|
||||
|
||||
|
||||
def validate_type(value, t):
|
||||
"""Validate value type against schema type t."""
|
||||
if t == "file":
|
||||
return isinstance(value, list)
|
||||
|
||||
if t == "string":
|
||||
return isinstance(value, str)
|
||||
|
||||
if t == "number":
|
||||
return isinstance(value, (int, float))
|
||||
|
||||
if t == "boolean":
|
||||
return isinstance(value, bool)
|
||||
|
||||
if t == "object":
|
||||
return isinstance(value, dict)
|
||||
|
||||
# array<string> / array<number> / array<object>
|
||||
if t.startswith("array"):
|
||||
if not isinstance(value, list):
|
||||
return False
|
||||
|
||||
if "<" in t and ">" in t:
|
||||
inner = t[t.find("<") + 1 : t.find(">")]
|
||||
|
||||
# Check each element type
|
||||
for item in value:
|
||||
if not validate_type(item, inner):
|
||||
return False
|
||||
|
||||
return True
|
||||
|
||||
return True
|
||||
parsed = await parse_webhook_request(webhook_cfg.get("content_types"))
|
||||
SCHEMA = webhook_cfg.get("schema", {"query": {}, "headers": {}, "body": {}})
|
||||
|
||||
# Extract strictly by schema
|
||||
try:
|
||||
query_clean = extract_by_schema(parsed["query"], SCHEMA.get("query", {}), name="query")
|
||||
header_clean = extract_by_schema(parsed["headers"], SCHEMA.get("headers", {}), name="headers")
|
||||
body_clean = extract_by_schema(parsed["body"], SCHEMA.get("body", {}), name="body")
|
||||
except Exception as e:
|
||||
return get_data_error_result(code=RetCode.BAD_REQUEST,message=str(e)),RetCode.BAD_REQUEST
|
||||
|
||||
clean_request = {
|
||||
"query": query_clean,
|
||||
"headers": header_clean,
|
||||
"body": body_clean,
|
||||
"input": parsed
|
||||
}
|
||||
|
||||
execution_mode = webhook_cfg.get("execution_mode", "Immediately")
|
||||
response_cfg = webhook_cfg.get("response", {})
|
||||
|
||||
def append_webhook_trace(agent_id: str, start_ts: float,event: dict, ttl=600):
|
||||
key = f"webhook-trace-{agent_id}-logs"
|
||||
|
||||
raw = REDIS_CONN.get(key)
|
||||
obj = json.loads(raw) if raw else {"webhooks": {}}
|
||||
|
||||
ws = obj["webhooks"].setdefault(
|
||||
str(start_ts),
|
||||
{"start_ts": start_ts, "events": []}
|
||||
)
|
||||
|
||||
ws["events"].append({
|
||||
"ts": time.time(),
|
||||
**event
|
||||
})
|
||||
|
||||
REDIS_CONN.set_obj(key, obj, ttl)
|
||||
|
||||
if execution_mode == "Immediately":
|
||||
status = response_cfg.get("status", 200)
|
||||
try:
|
||||
status = int(status)
|
||||
except (TypeError, ValueError):
|
||||
return get_data_error_result(code=RetCode.BAD_REQUEST,message=str(f"Invalid response status code: {status}")),RetCode.BAD_REQUEST
|
||||
|
||||
if not (200 <= status <= 399):
|
||||
return get_data_error_result(code=RetCode.BAD_REQUEST,message=str(f"Invalid response status code: {status}, must be between 200 and 399")),RetCode.BAD_REQUEST
|
||||
|
||||
body_tpl = response_cfg.get("body_template", "")
|
||||
|
||||
def parse_body(body: str):
|
||||
if not body:
|
||||
return None, "application/json"
|
||||
|
||||
try:
|
||||
parsed = json.loads(body)
|
||||
return parsed, "application/json"
|
||||
except (json.JSONDecodeError, TypeError):
|
||||
return body, "text/plain"
|
||||
|
||||
|
||||
body, content_type = parse_body(body_tpl)
|
||||
resp = Response(
|
||||
json.dumps(body, ensure_ascii=False) if content_type == "application/json" else body,
|
||||
status=status,
|
||||
content_type=content_type,
|
||||
)
|
||||
|
||||
async def background_run():
|
||||
try:
|
||||
async for ans in canvas.run(
|
||||
query="",
|
||||
user_id=cvs.user_id,
|
||||
webhook_payload=clean_request
|
||||
):
|
||||
if is_test:
|
||||
append_webhook_trace(agent_id, start_ts, ans)
|
||||
|
||||
if is_test:
|
||||
append_webhook_trace(
|
||||
agent_id,
|
||||
start_ts,
|
||||
{
|
||||
"event": "finished",
|
||||
"elapsed_time": time.time() - start_ts,
|
||||
"success": True,
|
||||
}
|
||||
)
|
||||
|
||||
cvs.dsl = json.loads(str(canvas))
|
||||
UserCanvasService.update_by_id(cvs.user_id, cvs.to_dict())
|
||||
|
||||
except Exception as e:
|
||||
logging.exception("Webhook background run failed")
|
||||
if is_test:
|
||||
try:
|
||||
append_webhook_trace(
|
||||
agent_id,
|
||||
start_ts,
|
||||
{
|
||||
"event": "error",
|
||||
"message": str(e),
|
||||
"error_type": type(e).__name__,
|
||||
}
|
||||
)
|
||||
append_webhook_trace(
|
||||
agent_id,
|
||||
start_ts,
|
||||
{
|
||||
"event": "finished",
|
||||
"elapsed_time": time.time() - start_ts,
|
||||
"success": False,
|
||||
}
|
||||
)
|
||||
except Exception:
|
||||
logging.exception("Failed to append webhook trace")
|
||||
|
||||
asyncio.create_task(background_run())
|
||||
return resp
|
||||
else:
|
||||
async def sse():
|
||||
nonlocal canvas
|
||||
contents: list[str] = []
|
||||
status = 200
|
||||
try:
|
||||
async for ans in canvas.run(
|
||||
query="",
|
||||
user_id=cvs.user_id,
|
||||
webhook_payload=clean_request,
|
||||
):
|
||||
if ans["event"] == "message":
|
||||
content = ans["data"]["content"]
|
||||
if ans["data"].get("start_to_think", False):
|
||||
content = "<think>"
|
||||
elif ans["data"].get("end_to_think", False):
|
||||
content = "</think>"
|
||||
if content:
|
||||
contents.append(content)
|
||||
if ans["event"] == "message_end":
|
||||
status = int(ans["data"].get("status", status))
|
||||
if is_test:
|
||||
append_webhook_trace(
|
||||
agent_id,
|
||||
start_ts,
|
||||
ans
|
||||
)
|
||||
if is_test:
|
||||
append_webhook_trace(
|
||||
agent_id,
|
||||
start_ts,
|
||||
{
|
||||
"event": "finished",
|
||||
"elapsed_time": time.time() - start_ts,
|
||||
"success": True,
|
||||
}
|
||||
)
|
||||
final_content = "".join(contents)
|
||||
return {
|
||||
"message": final_content,
|
||||
"success": True,
|
||||
"code": status,
|
||||
}
|
||||
|
||||
except Exception as e:
|
||||
if is_test:
|
||||
append_webhook_trace(
|
||||
agent_id,
|
||||
start_ts,
|
||||
{
|
||||
"event": "error",
|
||||
"message": str(e),
|
||||
"error_type": type(e).__name__,
|
||||
}
|
||||
)
|
||||
append_webhook_trace(
|
||||
agent_id,
|
||||
start_ts,
|
||||
{
|
||||
"event": "finished",
|
||||
"elapsed_time": time.time() - start_ts,
|
||||
"success": False,
|
||||
}
|
||||
)
|
||||
return {"code": 400, "message": str(e),"success":False}
|
||||
|
||||
result = await sse()
|
||||
return Response(
|
||||
json.dumps(result),
|
||||
status=result["code"],
|
||||
mimetype="application/json",
|
||||
)
|
||||
|
||||
|
||||
@manager.route("/webhook_trace/<agent_id>", methods=["GET"]) # noqa: F821
|
||||
async def webhook_trace(agent_id: str):
|
||||
def encode_webhook_id(start_ts: str) -> str:
|
||||
WEBHOOK_ID_SECRET = "webhook_id_secret"
|
||||
sig = hmac.new(
|
||||
WEBHOOK_ID_SECRET.encode("utf-8"),
|
||||
start_ts.encode("utf-8"),
|
||||
hashlib.sha256,
|
||||
).digest()
|
||||
return base64.urlsafe_b64encode(sig).decode("utf-8").rstrip("=")
|
||||
|
||||
def decode_webhook_id(enc_id: str, webhooks: dict) -> str | None:
|
||||
for ts in webhooks.keys():
|
||||
if encode_webhook_id(ts) == enc_id:
|
||||
return ts
|
||||
return None
|
||||
since_ts = request.args.get("since_ts", type=float)
|
||||
webhook_id = request.args.get("webhook_id")
|
||||
|
||||
key = f"webhook-trace-{agent_id}-logs"
|
||||
raw = REDIS_CONN.get(key)
|
||||
|
||||
if since_ts is None:
|
||||
now = time.time()
|
||||
return get_json_result(
|
||||
data={
|
||||
"webhook_id": None,
|
||||
"events": [],
|
||||
"next_since_ts": now,
|
||||
"finished": False,
|
||||
}
|
||||
)
|
||||
|
||||
if not raw:
|
||||
return get_json_result(
|
||||
data={
|
||||
"webhook_id": None,
|
||||
"events": [],
|
||||
"next_since_ts": since_ts,
|
||||
"finished": False,
|
||||
}
|
||||
)
|
||||
|
||||
obj = json.loads(raw)
|
||||
webhooks = obj.get("webhooks", {})
|
||||
|
||||
if webhook_id is None:
|
||||
candidates = [
|
||||
float(k) for k in webhooks.keys() if float(k) > since_ts
|
||||
]
|
||||
|
||||
if not candidates:
|
||||
return get_json_result(
|
||||
data={
|
||||
"webhook_id": None,
|
||||
"events": [],
|
||||
"next_since_ts": since_ts,
|
||||
"finished": False,
|
||||
}
|
||||
)
|
||||
|
||||
start_ts = min(candidates)
|
||||
real_id = str(start_ts)
|
||||
webhook_id = encode_webhook_id(real_id)
|
||||
|
||||
return get_json_result(
|
||||
data={
|
||||
"webhook_id": webhook_id,
|
||||
"events": [],
|
||||
"next_since_ts": start_ts,
|
||||
"finished": False,
|
||||
}
|
||||
)
|
||||
|
||||
real_id = decode_webhook_id(webhook_id, webhooks)
|
||||
|
||||
if not real_id:
|
||||
return get_json_result(
|
||||
data={
|
||||
"webhook_id": webhook_id,
|
||||
"events": [],
|
||||
"next_since_ts": since_ts,
|
||||
"finished": True,
|
||||
}
|
||||
)
|
||||
|
||||
ws = webhooks.get(str(real_id))
|
||||
events = ws.get("events", [])
|
||||
new_events = [e for e in events if e.get("ts", 0) > since_ts]
|
||||
|
||||
next_ts = since_ts
|
||||
for e in new_events:
|
||||
next_ts = max(next_ts, e["ts"])
|
||||
|
||||
finished = any(e.get("event") == "finished" for e in new_events)
|
||||
|
||||
return get_json_result(
|
||||
data={
|
||||
"webhook_id": webhook_id,
|
||||
"events": new_events,
|
||||
"next_since_ts": next_ts,
|
||||
"finished": finished,
|
||||
}
|
||||
)
|
||||
|
||||
@ -287,7 +287,7 @@ def list_chat(tenant_id):
|
||||
chats = DialogService.get_list(tenant_id, page_number, items_per_page, orderby, desc, id, name)
|
||||
if not chats:
|
||||
return get_result(data=[])
|
||||
list_assts = []
|
||||
list_assistants = []
|
||||
key_mapping = {
|
||||
"parameters": "variables",
|
||||
"prologue": "opener",
|
||||
@ -321,5 +321,5 @@ def list_chat(tenant_id):
|
||||
del res["kb_ids"]
|
||||
res["datasets"] = kb_list
|
||||
res["avatar"] = res.pop("icon")
|
||||
list_assts.append(res)
|
||||
return get_result(data=list_assts)
|
||||
list_assistants.append(res)
|
||||
return get_result(data=list_assistants)
|
||||
|
||||
@ -495,7 +495,7 @@ def knowledge_graph(tenant_id, dataset_id):
|
||||
}
|
||||
|
||||
obj = {"graph": {}, "mind_map": {}}
|
||||
if not settings.docStoreConn.indexExist(search.index_name(kb.tenant_id), dataset_id):
|
||||
if not settings.docStoreConn.index_exist(search.index_name(kb.tenant_id), dataset_id):
|
||||
return get_result(data=obj)
|
||||
sres = settings.retriever.search(req, search.index_name(kb.tenant_id), [dataset_id])
|
||||
if not len(sres.ids):
|
||||
|
||||
@ -1080,7 +1080,7 @@ def list_chunks(tenant_id, dataset_id, document_id):
|
||||
res["chunks"].append(final_chunk)
|
||||
_ = Chunk(**final_chunk)
|
||||
|
||||
elif settings.docStoreConn.indexExist(search.index_name(tenant_id), dataset_id):
|
||||
elif settings.docStoreConn.index_exist(search.index_name(tenant_id), dataset_id):
|
||||
sres = settings.retriever.search(query, search.index_name(tenant_id), [dataset_id], emb_mdl=None, highlight=True)
|
||||
res["total"] = sres.total
|
||||
for id in sres.ids:
|
||||
|
||||
@ -205,7 +205,8 @@ async def create(tenant_id):
|
||||
if not FileService.is_parent_folder_exist(pf_id):
|
||||
return get_json_result(data=False, message="Parent Folder Doesn't Exist!", code=RetCode.BAD_REQUEST)
|
||||
if FileService.query(name=req["name"], parent_id=pf_id):
|
||||
return get_json_result(data=False, message="Duplicated folder name in the same folder.", code=409)
|
||||
return get_json_result(data=False, message="Duplicated folder name in the same folder.",
|
||||
code=RetCode.CONFLICT)
|
||||
|
||||
if input_file_type == FileType.FOLDER.value:
|
||||
file_type = FileType.FOLDER.value
|
||||
@ -565,11 +566,13 @@ async def rename(tenant_id):
|
||||
|
||||
if file.type != FileType.FOLDER.value and pathlib.Path(req["name"].lower()).suffix != pathlib.Path(
|
||||
file.name.lower()).suffix:
|
||||
return get_json_result(data=False, message="The extension of file can't be changed", code=RetCode.BAD_REQUEST)
|
||||
return get_json_result(data=False, message="The extension of file can't be changed",
|
||||
code=RetCode.BAD_REQUEST)
|
||||
|
||||
for existing_file in FileService.query(name=req["name"], pf_id=file.parent_id):
|
||||
if existing_file.name == req["name"]:
|
||||
return get_json_result(data=False, message="Duplicated file name in the same folder.", code=409)
|
||||
return get_json_result(data=False, message="Duplicated file name in the same folder.",
|
||||
code=RetCode.CONFLICT)
|
||||
|
||||
if not FileService.update_by_id(req["file_id"], {"name": req["name"]}):
|
||||
return get_json_result(message="Database error (File rename)!", code=RetCode.SERVER_ERROR)
|
||||
@ -631,9 +634,10 @@ async def get(tenant_id, file_id):
|
||||
except Exception as e:
|
||||
return server_error_response(e)
|
||||
|
||||
|
||||
@manager.route("/file/download/<attachment_id>", methods=["GET"]) # noqa: F821
|
||||
@token_required
|
||||
async def download_attachment(tenant_id,attachment_id):
|
||||
async def download_attachment(tenant_id, attachment_id):
|
||||
try:
|
||||
ext = request.args.get("ext", "markdown")
|
||||
data = await asyncio.to_thread(settings.STORAGE_IMPL.get, tenant_id, attachment_id)
|
||||
@ -645,6 +649,7 @@ async def download_attachment(tenant_id,attachment_id):
|
||||
except Exception as e:
|
||||
return server_error_response(e)
|
||||
|
||||
|
||||
@manager.route('/file/mv', methods=['POST']) # noqa: F821
|
||||
@token_required
|
||||
async def move(tenant_id):
|
||||
|
||||
@ -14,6 +14,7 @@
|
||||
# limitations under the License.
|
||||
#
|
||||
import json
|
||||
import copy
|
||||
import re
|
||||
import time
|
||||
|
||||
@ -32,7 +33,7 @@ from api.db.services.dialog_service import DialogService, async_ask, async_chat,
|
||||
from api.db.services.document_service import DocumentService
|
||||
from api.db.services.knowledgebase_service import KnowledgebaseService
|
||||
from api.db.services.llm_service import LLMBundle
|
||||
from common.metadata_utils import apply_meta_data_filter
|
||||
from common.metadata_utils import apply_meta_data_filter, convert_conditions, meta_filter
|
||||
from api.db.services.search_service import SearchService
|
||||
from api.db.services.user_service import UserTenantService
|
||||
from common.misc_utils import get_uuid
|
||||
@ -87,7 +88,7 @@ async def create_agent_session(tenant_id, agent_id):
|
||||
cvs.dsl = json.dumps(cvs.dsl, ensure_ascii=False)
|
||||
|
||||
session_id = get_uuid()
|
||||
canvas = Canvas(cvs.dsl, tenant_id, agent_id)
|
||||
canvas = Canvas(cvs.dsl, tenant_id, agent_id, canvas_id=cvs.id)
|
||||
canvas.reset()
|
||||
|
||||
cvs.dsl = json.loads(str(canvas))
|
||||
@ -128,11 +129,33 @@ async def chat_completion(tenant_id, chat_id):
|
||||
req = {"question": ""}
|
||||
if not req.get("session_id"):
|
||||
req["question"] = ""
|
||||
if not DialogService.query(tenant_id=tenant_id, id=chat_id, status=StatusEnum.VALID.value):
|
||||
dia = DialogService.query(tenant_id=tenant_id, id=chat_id, status=StatusEnum.VALID.value)
|
||||
if not dia:
|
||||
return get_error_data_result(f"You don't own the chat {chat_id}")
|
||||
dia = dia[0]
|
||||
if req.get("session_id"):
|
||||
if not ConversationService.query(id=req["session_id"], dialog_id=chat_id):
|
||||
return get_error_data_result(f"You don't own the session {req['session_id']}")
|
||||
|
||||
metadata_condition = req.get("metadata_condition") or {}
|
||||
if metadata_condition and not isinstance(metadata_condition, dict):
|
||||
return get_error_data_result(message="metadata_condition must be an object.")
|
||||
|
||||
if metadata_condition and req.get("question"):
|
||||
metas = DocumentService.get_meta_by_kbs(dia.kb_ids or [])
|
||||
filtered_doc_ids = meta_filter(
|
||||
metas,
|
||||
convert_conditions(metadata_condition),
|
||||
metadata_condition.get("logic", "and"),
|
||||
)
|
||||
if metadata_condition.get("conditions") and not filtered_doc_ids:
|
||||
filtered_doc_ids = ["-999"]
|
||||
|
||||
if filtered_doc_ids:
|
||||
req["doc_ids"] = ",".join(filtered_doc_ids)
|
||||
else:
|
||||
req.pop("doc_ids", None)
|
||||
|
||||
if req.get("stream", True):
|
||||
resp = Response(rag_completion(tenant_id, chat_id, **req), mimetype="text/event-stream")
|
||||
resp.headers.add_header("Cache-control", "no-cache")
|
||||
@ -195,7 +218,19 @@ async def chat_completion_openai_like(tenant_id, chat_id):
|
||||
{"role": "user", "content": "Can you tell me how to install neovim"},
|
||||
],
|
||||
stream=stream,
|
||||
extra_body={"reference": reference}
|
||||
extra_body={
|
||||
"reference": reference,
|
||||
"metadata_condition": {
|
||||
"logic": "and",
|
||||
"conditions": [
|
||||
{
|
||||
"name": "author",
|
||||
"comparison_operator": "is",
|
||||
"value": "bob"
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
)
|
||||
|
||||
if stream:
|
||||
@ -211,7 +246,11 @@ async def chat_completion_openai_like(tenant_id, chat_id):
|
||||
"""
|
||||
req = await get_request_json()
|
||||
|
||||
need_reference = bool(req.get("reference", False))
|
||||
extra_body = req.get("extra_body") or {}
|
||||
if extra_body and not isinstance(extra_body, dict):
|
||||
return get_error_data_result("extra_body must be an object.")
|
||||
|
||||
need_reference = bool(extra_body.get("reference", False))
|
||||
|
||||
messages = req.get("messages", [])
|
||||
# To prevent empty [] input
|
||||
@ -229,6 +268,22 @@ async def chat_completion_openai_like(tenant_id, chat_id):
|
||||
return get_error_data_result(f"You don't own the chat {chat_id}")
|
||||
dia = dia[0]
|
||||
|
||||
metadata_condition = extra_body.get("metadata_condition") or {}
|
||||
if metadata_condition and not isinstance(metadata_condition, dict):
|
||||
return get_error_data_result(message="metadata_condition must be an object.")
|
||||
|
||||
doc_ids_str = None
|
||||
if metadata_condition:
|
||||
metas = DocumentService.get_meta_by_kbs(dia.kb_ids or [])
|
||||
filtered_doc_ids = meta_filter(
|
||||
metas,
|
||||
convert_conditions(metadata_condition),
|
||||
metadata_condition.get("logic", "and"),
|
||||
)
|
||||
if metadata_condition.get("conditions") and not filtered_doc_ids:
|
||||
filtered_doc_ids = ["-999"]
|
||||
doc_ids_str = ",".join(filtered_doc_ids) if filtered_doc_ids else None
|
||||
|
||||
# Filter system and non-sense assistant messages
|
||||
msg = []
|
||||
for m in messages:
|
||||
@ -276,14 +331,17 @@ async def chat_completion_openai_like(tenant_id, chat_id):
|
||||
}
|
||||
|
||||
try:
|
||||
async for ans in async_chat(dia, msg, True, toolcall_session=toolcall_session, tools=tools, quote=need_reference):
|
||||
chat_kwargs = {"toolcall_session": toolcall_session, "tools": tools, "quote": need_reference}
|
||||
if doc_ids_str:
|
||||
chat_kwargs["doc_ids"] = doc_ids_str
|
||||
async for ans in async_chat(dia, msg, True, **chat_kwargs):
|
||||
last_ans = ans
|
||||
answer = ans["answer"]
|
||||
|
||||
reasoning_match = re.search(r"<think>(.*?)</think>", answer, flags=re.DOTALL)
|
||||
if reasoning_match:
|
||||
reasoning_part = reasoning_match.group(1)
|
||||
content_part = answer[reasoning_match.end():]
|
||||
content_part = answer[reasoning_match.end() :]
|
||||
else:
|
||||
reasoning_part = ""
|
||||
content_part = answer
|
||||
@ -328,8 +386,7 @@ async def chat_completion_openai_like(tenant_id, chat_id):
|
||||
response["choices"][0]["delta"]["content"] = None
|
||||
response["choices"][0]["delta"]["reasoning_content"] = None
|
||||
response["choices"][0]["finish_reason"] = "stop"
|
||||
response["usage"] = {"prompt_tokens": len(prompt), "completion_tokens": token_used,
|
||||
"total_tokens": len(prompt) + token_used}
|
||||
response["usage"] = {"prompt_tokens": len(prompt), "completion_tokens": token_used, "total_tokens": len(prompt) + token_used}
|
||||
if need_reference:
|
||||
response["choices"][0]["delta"]["reference"] = chunks_format(last_ans.get("reference", []))
|
||||
response["choices"][0]["delta"]["final_content"] = last_ans.get("answer", "")
|
||||
@ -344,7 +401,10 @@ async def chat_completion_openai_like(tenant_id, chat_id):
|
||||
return resp
|
||||
else:
|
||||
answer = None
|
||||
async for ans in async_chat(dia, msg, False, toolcall_session=toolcall_session, tools=tools, quote=need_reference):
|
||||
chat_kwargs = {"toolcall_session": toolcall_session, "tools": tools, "quote": need_reference}
|
||||
if doc_ids_str:
|
||||
chat_kwargs["doc_ids"] = doc_ids_str
|
||||
async for ans in async_chat(dia, msg, False, **chat_kwargs):
|
||||
# focus answer content only
|
||||
answer = ans
|
||||
break
|
||||
@ -388,7 +448,7 @@ async def chat_completion_openai_like(tenant_id, chat_id):
|
||||
@token_required
|
||||
async def agents_completion_openai_compatibility(tenant_id, agent_id):
|
||||
req = await get_request_json()
|
||||
tiktokenenc = tiktoken.get_encoding("cl100k_base")
|
||||
tiktoken_encode = tiktoken.get_encoding("cl100k_base")
|
||||
messages = req.get("messages", [])
|
||||
if not messages:
|
||||
return get_error_data_result("You must provide at least one message.")
|
||||
@ -396,7 +456,7 @@ async def agents_completion_openai_compatibility(tenant_id, agent_id):
|
||||
return get_error_data_result(f"You don't own the agent {agent_id}")
|
||||
|
||||
filtered_messages = [m for m in messages if m["role"] in ["user", "assistant"]]
|
||||
prompt_tokens = sum(len(tiktokenenc.encode(m["content"])) for m in filtered_messages)
|
||||
prompt_tokens = sum(len(tiktoken_encode.encode(m["content"])) for m in filtered_messages)
|
||||
if not filtered_messages:
|
||||
return jsonify(
|
||||
get_data_openai(
|
||||
@ -404,7 +464,7 @@ async def agents_completion_openai_compatibility(tenant_id, agent_id):
|
||||
content="No valid messages found (user or assistant).",
|
||||
finish_reason="stop",
|
||||
model=req.get("model", ""),
|
||||
completion_tokens=len(tiktokenenc.encode("No valid messages found (user or assistant).")),
|
||||
completion_tokens=len(tiktoken_encode.encode("No valid messages found (user or assistant).")),
|
||||
prompt_tokens=prompt_tokens,
|
||||
)
|
||||
)
|
||||
@ -441,15 +501,19 @@ async def agents_completion_openai_compatibility(tenant_id, agent_id):
|
||||
):
|
||||
return jsonify(response)
|
||||
|
||||
return None
|
||||
|
||||
|
||||
@manager.route("/agents/<agent_id>/completions", methods=["POST"]) # noqa: F821
|
||||
@token_required
|
||||
async def agent_completions(tenant_id, agent_id):
|
||||
req = await get_request_json()
|
||||
return_trace = bool(req.get("return_trace", False))
|
||||
|
||||
if req.get("stream", True):
|
||||
|
||||
async def generate():
|
||||
trace_items = []
|
||||
async for answer in agent_completion(tenant_id=tenant_id, agent_id=agent_id, **req):
|
||||
if isinstance(answer, str):
|
||||
try:
|
||||
@ -457,7 +521,21 @@ async def agent_completions(tenant_id, agent_id):
|
||||
except Exception:
|
||||
continue
|
||||
|
||||
if ans.get("event") not in ["message", "message_end"]:
|
||||
event = ans.get("event")
|
||||
if event == "node_finished":
|
||||
if return_trace:
|
||||
data = ans.get("data", {})
|
||||
trace_items.append(
|
||||
{
|
||||
"component_id": data.get("component_id"),
|
||||
"trace": [copy.deepcopy(data)],
|
||||
}
|
||||
)
|
||||
ans.setdefault("data", {})["trace"] = trace_items
|
||||
answer = "data:" + json.dumps(ans, ensure_ascii=False) + "\n\n"
|
||||
yield answer
|
||||
|
||||
if event not in ["message", "message_end"]:
|
||||
continue
|
||||
|
||||
yield answer
|
||||
@ -474,6 +552,7 @@ async def agent_completions(tenant_id, agent_id):
|
||||
full_content = ""
|
||||
reference = {}
|
||||
final_ans = ""
|
||||
trace_items = []
|
||||
async for answer in agent_completion(tenant_id=tenant_id, agent_id=agent_id, **req):
|
||||
try:
|
||||
ans = json.loads(answer[5:])
|
||||
@ -484,11 +563,22 @@ async def agent_completions(tenant_id, agent_id):
|
||||
if ans.get("data", {}).get("reference", None):
|
||||
reference.update(ans["data"]["reference"])
|
||||
|
||||
if return_trace and ans.get("event") == "node_finished":
|
||||
data = ans.get("data", {})
|
||||
trace_items.append(
|
||||
{
|
||||
"component_id": data.get("component_id"),
|
||||
"trace": [copy.deepcopy(data)],
|
||||
}
|
||||
)
|
||||
|
||||
final_ans = ans
|
||||
except Exception as e:
|
||||
return get_result(data=f"**ERROR**: {str(e)}")
|
||||
final_ans["data"]["content"] = full_content
|
||||
final_ans["data"]["reference"] = reference
|
||||
if return_trace and final_ans:
|
||||
final_ans["data"]["trace"] = trace_items
|
||||
return get_result(data=final_ans)
|
||||
|
||||
|
||||
@ -832,6 +922,7 @@ async def chatbot_completions(dialog_id):
|
||||
async for answer in iframe_completion(dialog_id, **req):
|
||||
return get_result(data=answer)
|
||||
|
||||
return None
|
||||
|
||||
@manager.route("/chatbots/<dialog_id>/info", methods=["GET"]) # noqa: F821
|
||||
async def chatbots_inputs(dialog_id):
|
||||
@ -879,6 +970,7 @@ async def agent_bot_completions(agent_id):
|
||||
async for answer in agent_completion(objs[0].tenant_id, agent_id, **req):
|
||||
return get_result(data=answer)
|
||||
|
||||
return None
|
||||
|
||||
@manager.route("/agentbots/<agent_id>/inputs", methods=["GET"]) # noqa: F821
|
||||
async def begin_inputs(agent_id):
|
||||
@ -894,7 +986,7 @@ async def begin_inputs(agent_id):
|
||||
if not e:
|
||||
return get_error_data_result(f"Can't find agent by ID: {agent_id}")
|
||||
|
||||
canvas = Canvas(json.dumps(cvs.dsl), objs[0].tenant_id)
|
||||
canvas = Canvas(json.dumps(cvs.dsl), objs[0].tenant_id, canvas_id=cvs.id)
|
||||
return get_result(
|
||||
data={"title": cvs.title, "avatar": cvs.avatar, "inputs": canvas.get_component_input_form("begin"),
|
||||
"prologue": canvas.get_prologue(), "mode": canvas.get_mode()})
|
||||
|
||||
@ -660,7 +660,7 @@ def user_register(user_id, user):
|
||||
tenant_llm = get_init_tenant_llm(user_id)
|
||||
|
||||
if not UserService.save(**user):
|
||||
return
|
||||
return None
|
||||
TenantService.insert(**tenant)
|
||||
UserTenantService.insert(**usr_tenant)
|
||||
TenantLLMService.insert_many(tenant_llm)
|
||||
|
||||
@ -1189,7 +1189,7 @@ class Memory(DataBaseModel):
|
||||
permissions = CharField(max_length=16, null=False, index=True, help_text="me|team", default="me")
|
||||
description = TextField(null=True, help_text="description")
|
||||
memory_size = IntegerField(default=5242880, null=False, index=False)
|
||||
forgetting_policy = CharField(max_length=32, null=False, default="fifo", index=False, help_text="lru|fifo")
|
||||
forgetting_policy = CharField(max_length=32, null=False, default="FIFO", index=False, help_text="LRU|FIFO")
|
||||
temperature = FloatField(default=0.5, index=False)
|
||||
system_prompt = TextField(null=True, help_text="system prompt", index=False)
|
||||
user_prompt = TextField(null=True, help_text="user prompt", index=False)
|
||||
|
||||
@ -30,6 +30,7 @@ from api.db.services.knowledgebase_service import KnowledgebaseService
|
||||
from api.db.services.tenant_llm_service import LLMFactoriesService, TenantLLMService
|
||||
from api.db.services.llm_service import LLMService, LLMBundle, get_init_tenant_llm
|
||||
from api.db.services.user_service import TenantService, UserTenantService
|
||||
from api.db.joint_services.memory_message_service import init_message_id_sequence, init_memory_size_cache
|
||||
from common.constants import LLMType
|
||||
from common.file_utils import get_project_base_directory
|
||||
from common import settings
|
||||
@ -169,6 +170,8 @@ def init_web_data():
|
||||
# init_superuser()
|
||||
|
||||
add_graph_templates()
|
||||
init_message_id_sequence()
|
||||
init_memory_size_cache()
|
||||
logging.info("init web data success:{}".format(time.time() - start_time))
|
||||
|
||||
|
||||
|
||||
233
api/db/joint_services/memory_message_service.py
Normal file
233
api/db/joint_services/memory_message_service.py
Normal file
@ -0,0 +1,233 @@
|
||||
#
|
||||
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
import logging
|
||||
from typing import List
|
||||
|
||||
from common.time_utils import current_timestamp, timestamp_to_date, format_iso_8601_to_ymd_hms
|
||||
from common.constants import MemoryType, LLMType
|
||||
from common.doc_store.doc_store_base import FusionExpr
|
||||
from api.db.services.memory_service import MemoryService
|
||||
from api.db.services.tenant_llm_service import TenantLLMService
|
||||
from api.db.services.llm_service import LLMBundle
|
||||
from api.utils.memory_utils import get_memory_type_human
|
||||
from memory.services.messages import MessageService
|
||||
from memory.services.query import MsgTextQuery, get_vector
|
||||
from memory.utils.prompt_util import PromptAssembler
|
||||
from memory.utils.msg_util import get_json_result_from_llm_response
|
||||
from rag.utils.redis_conn import REDIS_CONN
|
||||
|
||||
|
||||
async def save_to_memory(memory_id: str, message_dict: dict):
|
||||
"""
|
||||
:param memory_id:
|
||||
:param message_dict: {
|
||||
"user_id": str,
|
||||
"agent_id": str,
|
||||
"session_id": str,
|
||||
"user_input": str,
|
||||
"agent_response": str
|
||||
}
|
||||
"""
|
||||
memory = MemoryService.get_by_memory_id(memory_id)
|
||||
if not memory:
|
||||
return False, f"Memory '{memory_id}' not found."
|
||||
|
||||
tenant_id = memory.tenant_id
|
||||
extracted_content = await extract_by_llm(
|
||||
tenant_id,
|
||||
memory.llm_id,
|
||||
{"temperature": memory.temperature},
|
||||
get_memory_type_human(memory.memory_type),
|
||||
message_dict.get("user_input", ""),
|
||||
message_dict.get("agent_response", "")
|
||||
) if memory.memory_type != MemoryType.RAW.value else [] # if only RAW, no need to extract
|
||||
raw_message_id = REDIS_CONN.generate_auto_increment_id(namespace="memory")
|
||||
message_list = [{
|
||||
"message_id": raw_message_id,
|
||||
"message_type": MemoryType.RAW.name.lower(),
|
||||
"source_id": 0,
|
||||
"memory_id": memory_id,
|
||||
"user_id": "",
|
||||
"agent_id": message_dict["agent_id"],
|
||||
"session_id": message_dict["session_id"],
|
||||
"content": f"User Input: {message_dict.get('user_input')}\nAgent Response: {message_dict.get('agent_response')}",
|
||||
"valid_at": timestamp_to_date(current_timestamp()),
|
||||
"invalid_at": None,
|
||||
"forget_at": None,
|
||||
"status": True
|
||||
}, *[{
|
||||
"message_id": REDIS_CONN.generate_auto_increment_id(namespace="memory"),
|
||||
"message_type": content["message_type"],
|
||||
"source_id": raw_message_id,
|
||||
"memory_id": memory_id,
|
||||
"user_id": "",
|
||||
"agent_id": message_dict["agent_id"],
|
||||
"session_id": message_dict["session_id"],
|
||||
"content": content["content"],
|
||||
"valid_at": content["valid_at"],
|
||||
"invalid_at": content["invalid_at"] if content["invalid_at"] else None,
|
||||
"forget_at": None,
|
||||
"status": True
|
||||
} for content in extracted_content]]
|
||||
embedding_model = LLMBundle(tenant_id, llm_type=LLMType.EMBEDDING, llm_name=memory.embd_id)
|
||||
vector_list, _ = embedding_model.encode([msg["content"] for msg in message_list])
|
||||
for idx, msg in enumerate(message_list):
|
||||
msg["content_embed"] = vector_list[idx]
|
||||
vector_dimension = len(vector_list[0])
|
||||
if not MessageService.has_index(tenant_id, memory_id):
|
||||
created = MessageService.create_index(tenant_id, memory_id, vector_size=vector_dimension)
|
||||
if not created:
|
||||
return False, "Failed to create message index."
|
||||
|
||||
new_msg_size = sum([MessageService.calculate_message_size(m) for m in message_list])
|
||||
current_memory_size = get_memory_size_cache(memory_id, tenant_id)
|
||||
if new_msg_size + current_memory_size > memory.memory_size:
|
||||
size_to_delete = current_memory_size + new_msg_size - memory.memory_size
|
||||
if memory.forgetting_policy == "FIFO":
|
||||
message_ids_to_delete, delete_size = MessageService.pick_messages_to_delete_by_fifo(memory_id, tenant_id, size_to_delete)
|
||||
MessageService.delete_message({"message_id": message_ids_to_delete}, tenant_id, memory_id)
|
||||
decrease_memory_size_cache(memory_id, delete_size)
|
||||
else:
|
||||
return False, "Failed to insert message into memory. Memory size reached limit and cannot decide which to delete."
|
||||
fail_cases = MessageService.insert_message(message_list, tenant_id, memory_id)
|
||||
if fail_cases:
|
||||
return False, "Failed to insert message into memory. Details: " + "; ".join(fail_cases)
|
||||
|
||||
increase_memory_size_cache(memory_id, new_msg_size)
|
||||
return True, "Message saved successfully."
|
||||
|
||||
|
||||
async def extract_by_llm(tenant_id: str, llm_id: str, extract_conf: dict, memory_type: List[str], user_input: str,
|
||||
agent_response: str, system_prompt: str = "", user_prompt: str="") -> List[dict]:
|
||||
llm_type = TenantLLMService.llm_id2llm_type(llm_id)
|
||||
if not llm_type:
|
||||
raise RuntimeError(f"Unknown type of LLM '{llm_id}'")
|
||||
if not system_prompt:
|
||||
system_prompt = PromptAssembler.assemble_system_prompt({"memory_type": memory_type})
|
||||
conversation_content = f"User Input: {user_input}\nAgent Response: {agent_response}"
|
||||
conversation_time = timestamp_to_date(current_timestamp())
|
||||
user_prompts = []
|
||||
if user_prompt:
|
||||
user_prompts.append({"role": "user", "content": user_prompt})
|
||||
user_prompts.append({"role": "user", "content": f"Conversation: {conversation_content}\nConversation Time: {conversation_time}\nCurrent Time: {conversation_time}"})
|
||||
else:
|
||||
user_prompts.append({"role": "user", "content": PromptAssembler.assemble_user_prompt(conversation_content, conversation_time, conversation_time)})
|
||||
llm = LLMBundle(tenant_id, llm_type, llm_id)
|
||||
res = await llm.async_chat(system_prompt, user_prompts, extract_conf)
|
||||
res_json = get_json_result_from_llm_response(res)
|
||||
return [{
|
||||
"content": extracted_content["content"],
|
||||
"valid_at": format_iso_8601_to_ymd_hms(extracted_content["valid_at"]),
|
||||
"invalid_at": format_iso_8601_to_ymd_hms(extracted_content["invalid_at"]) if extracted_content.get("invalid_at") else "",
|
||||
"message_type": message_type
|
||||
} for message_type, extracted_content_list in res_json.items() for extracted_content in extracted_content_list]
|
||||
|
||||
|
||||
def query_message(filter_dict: dict, params: dict):
|
||||
"""
|
||||
:param filter_dict: {
|
||||
"memory_id": List[str],
|
||||
"agent_id": optional
|
||||
"session_id": optional
|
||||
}
|
||||
:param params: {
|
||||
"query": question str,
|
||||
"similarity_threshold": float,
|
||||
"keywords_similarity_weight": float,
|
||||
"top_n": int
|
||||
}
|
||||
"""
|
||||
memory_ids = filter_dict["memory_id"]
|
||||
memory_list = MemoryService.get_by_ids(memory_ids)
|
||||
if not memory_list:
|
||||
return []
|
||||
|
||||
condition_dict = {k: v for k, v in filter_dict.items() if v}
|
||||
uids = [memory.tenant_id for memory in memory_list]
|
||||
|
||||
question = params["query"]
|
||||
question = question.strip()
|
||||
memory = memory_list[0]
|
||||
embd_model = LLMBundle(memory.tenant_id, llm_type=LLMType.EMBEDDING, llm_name=memory.embd_id)
|
||||
match_dense = get_vector(question, embd_model, similarity=params["similarity_threshold"])
|
||||
match_text, _ = MsgTextQuery().question(question, min_match=params["similarity_threshold"])
|
||||
keywords_similarity_weight = params.get("keywords_similarity_weight", 0.7)
|
||||
fusion_expr = FusionExpr("weighted_sum", params["top_n"], {"weights": ",".join([str(1 - keywords_similarity_weight), str(keywords_similarity_weight)])})
|
||||
|
||||
return MessageService.search_message(memory_ids, condition_dict, uids, [match_text, match_dense, fusion_expr], params["top_n"])
|
||||
|
||||
|
||||
def init_message_id_sequence():
|
||||
message_id_redis_key = "id_generator:memory"
|
||||
if REDIS_CONN.exist(message_id_redis_key):
|
||||
current_max_id = REDIS_CONN.get(message_id_redis_key)
|
||||
logging.info(f"No need to init message_id sequence, current max id is {current_max_id}.")
|
||||
else:
|
||||
max_id = 1
|
||||
exist_memory_list = MemoryService.get_all_memory()
|
||||
if not exist_memory_list:
|
||||
REDIS_CONN.set(message_id_redis_key, max_id)
|
||||
else:
|
||||
max_id = MessageService.get_max_message_id(
|
||||
uid_list=[m.tenant_id for m in exist_memory_list],
|
||||
memory_ids=[m.id for m in exist_memory_list]
|
||||
)
|
||||
REDIS_CONN.set(message_id_redis_key, max_id)
|
||||
logging.info(f"Init message_id sequence done, current max id is {max_id}.")
|
||||
|
||||
|
||||
def get_memory_size_cache(memory_id: str, uid: str):
|
||||
redis_key = f"memory_{memory_id}"
|
||||
if REDIS_CONN.exist(redis_key):
|
||||
return int(REDIS_CONN.get(redis_key))
|
||||
else:
|
||||
memory_size_map = MessageService.calculate_memory_size(
|
||||
[memory_id],
|
||||
[uid]
|
||||
)
|
||||
memory_size = memory_size_map.get(memory_id, 0)
|
||||
set_memory_size_cache(memory_id, memory_size)
|
||||
return memory_size
|
||||
|
||||
|
||||
def set_memory_size_cache(memory_id: str, size: int):
|
||||
redis_key = f"memory_{memory_id}"
|
||||
return REDIS_CONN.set(redis_key, size)
|
||||
|
||||
|
||||
def increase_memory_size_cache(memory_id: str, size: int):
|
||||
redis_key = f"memory_{memory_id}"
|
||||
return REDIS_CONN.incrby(redis_key, size)
|
||||
|
||||
|
||||
def decrease_memory_size_cache(memory_id: str, size: int):
|
||||
redis_key = f"memory_{memory_id}"
|
||||
return REDIS_CONN.decrby(redis_key, size)
|
||||
|
||||
|
||||
def init_memory_size_cache():
|
||||
memory_list = MemoryService.get_all_memory()
|
||||
if not memory_list:
|
||||
logging.info("No memory found, no need to init memory size.")
|
||||
else:
|
||||
for m in memory_list:
|
||||
get_memory_size_cache(m.id, m.tenant_id)
|
||||
logging.info("Memory size cache init done.")
|
||||
|
||||
|
||||
def judge_system_prompt_is_default(system_prompt: str, memory_type: int|list[str]):
|
||||
memory_type_list = memory_type if isinstance(memory_type, list) else get_memory_type_human(memory_type)
|
||||
return system_prompt == PromptAssembler.assemble_system_prompt({"memory_type": memory_type_list})
|
||||
@ -34,6 +34,8 @@ from api.db.services.task_service import TaskService
|
||||
from api.db.services.tenant_llm_service import TenantLLMService
|
||||
from api.db.services.user_canvas_version import UserCanvasVersionService
|
||||
from api.db.services.user_service import TenantService, UserService, UserTenantService
|
||||
from api.db.services.memory_service import MemoryService
|
||||
from memory.services.messages import MessageService
|
||||
from rag.nlp import search
|
||||
from common.constants import ActiveEnum
|
||||
from common import settings
|
||||
@ -200,7 +202,16 @@ def delete_user_data(user_id: str) -> dict:
|
||||
done_msg += f"- Deleted {llm_delete_res} tenant-LLM records.\n"
|
||||
langfuse_delete_res = TenantLangfuseService.delete_ty_tenant_id(tenant_id)
|
||||
done_msg += f"- Deleted {langfuse_delete_res} langfuse records.\n"
|
||||
# step1.3 delete own tenant
|
||||
# step1.3 delete memory and messages
|
||||
user_memory = MemoryService.get_by_tenant_id(tenant_id)
|
||||
if user_memory:
|
||||
for memory in user_memory:
|
||||
if MessageService.has_index(tenant_id, memory.id):
|
||||
MessageService.delete_index(tenant_id, memory.id)
|
||||
done_msg += " Deleted memory index."
|
||||
memory_delete_res = MemoryService.delete_by_ids([m.id for m in user_memory])
|
||||
done_msg += f"Deleted {memory_delete_res} memory datasets."
|
||||
# step1.4 delete own tenant
|
||||
tenant_delete_res = TenantService.delete_by_id(tenant_id)
|
||||
done_msg += f"- Deleted {tenant_delete_res} tenant.\n"
|
||||
# step2 delete user-tenant relation
|
||||
|
||||
@ -123,6 +123,19 @@ class UserCanvasService(CommonService):
|
||||
logging.exception(e)
|
||||
return False, None
|
||||
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
def get_basic_info_by_canvas_ids(cls, canvas_id):
|
||||
fields = [
|
||||
cls.model.id,
|
||||
cls.model.avatar,
|
||||
cls.model.user_id,
|
||||
cls.model.title,
|
||||
cls.model.permission,
|
||||
cls.model.canvas_category
|
||||
]
|
||||
return cls.model.select(*fields).where(cls.model.id.in_(canvas_id)).dicts()
|
||||
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
def get_by_tenant_ids(cls, joined_tenant_ids, user_id,
|
||||
@ -198,7 +211,7 @@ async def completion(tenant_id, agent_id, session_id=None, **kwargs):
|
||||
if not isinstance(cvs.dsl, str):
|
||||
cvs.dsl = json.dumps(cvs.dsl, ensure_ascii=False)
|
||||
session_id=get_uuid()
|
||||
canvas = Canvas(cvs.dsl, tenant_id, agent_id)
|
||||
canvas = Canvas(cvs.dsl, tenant_id, agent_id, canvas_id=cvs.id)
|
||||
canvas.reset()
|
||||
conv = {
|
||||
"id": session_id,
|
||||
|
||||
@ -169,10 +169,12 @@ class CommonService:
|
||||
"""
|
||||
if "id" not in kwargs:
|
||||
kwargs["id"] = get_uuid()
|
||||
kwargs["create_time"] = current_timestamp()
|
||||
kwargs["create_date"] = datetime_format(datetime.now())
|
||||
kwargs["update_time"] = current_timestamp()
|
||||
kwargs["update_date"] = datetime_format(datetime.now())
|
||||
timestamp = current_timestamp()
|
||||
cur_datetime = datetime_format(datetime.now())
|
||||
kwargs["create_time"] = timestamp
|
||||
kwargs["create_date"] = cur_datetime
|
||||
kwargs["update_time"] = timestamp
|
||||
kwargs["update_date"] = cur_datetime
|
||||
sample_obj = cls.model(**kwargs).save(force_insert=True)
|
||||
return sample_obj
|
||||
|
||||
@ -207,10 +209,14 @@ class CommonService:
|
||||
data_list (list): List of dictionaries containing record data to update.
|
||||
Each dictionary must include an 'id' field.
|
||||
"""
|
||||
|
||||
timestamp = current_timestamp()
|
||||
cur_datetime = datetime_format(datetime.now())
|
||||
for data in data_list:
|
||||
data["update_time"] = timestamp
|
||||
data["update_date"] = cur_datetime
|
||||
with DB.atomic():
|
||||
for data in data_list:
|
||||
data["update_time"] = current_timestamp()
|
||||
data["update_date"] = datetime_format(datetime.now())
|
||||
cls.model.update(data).where(cls.model.id == data["id"]).execute()
|
||||
|
||||
@classmethod
|
||||
|
||||
@ -116,6 +116,16 @@ async def async_completion(tenant_id, chat_id, question, name="New session", ses
|
||||
ensure_ascii=False) + "\n\n"
|
||||
yield "data:" + json.dumps({"code": 0, "message": "", "data": True}, ensure_ascii=False) + "\n\n"
|
||||
return
|
||||
else:
|
||||
answer = {
|
||||
"answer": conv["message"][0]["content"],
|
||||
"reference": {},
|
||||
"audio_binary": None,
|
||||
"id": None,
|
||||
"session_id": session_id
|
||||
}
|
||||
yield answer
|
||||
return
|
||||
|
||||
conv = ConversationService.query(id=session_id, dialog_id=chat_id)
|
||||
if not conv:
|
||||
|
||||
@ -406,7 +406,7 @@ async def async_chat(dialog, messages, stream=True, **kwargs):
|
||||
dialog.vector_similarity_weight,
|
||||
doc_ids=attachments,
|
||||
top=dialog.top_k,
|
||||
aggs=False,
|
||||
aggs=True,
|
||||
rerank_mdl=rerank_mdl,
|
||||
rank_feature=label_question(" ".join(questions), kbs),
|
||||
)
|
||||
@ -769,7 +769,7 @@ async def async_ask(question, kb_ids, tenant_id, chat_llm_name=None, search_conf
|
||||
vector_similarity_weight=search_config.get("vector_similarity_weight", 0.3),
|
||||
top=search_config.get("top_k", 1024),
|
||||
doc_ids=doc_ids,
|
||||
aggs=False,
|
||||
aggs=True,
|
||||
rerank_mdl=rerank_mdl,
|
||||
rank_feature=label_question(question, kbs)
|
||||
)
|
||||
|
||||
@ -33,12 +33,13 @@ from api.db.db_models import DB, Document, Knowledgebase, Task, Tenant, UserTena
|
||||
from api.db.db_utils import bulk_insert_into_db
|
||||
from api.db.services.common_service import CommonService
|
||||
from api.db.services.knowledgebase_service import KnowledgebaseService
|
||||
from common.metadata_utils import dedupe_list
|
||||
from common.misc_utils import get_uuid
|
||||
from common.time_utils import current_timestamp, get_format_time
|
||||
from common.constants import LLMType, ParserType, StatusEnum, TaskStatus, SVR_CONSUMER_GROUP_NAME
|
||||
from rag.nlp import rag_tokenizer, search
|
||||
from rag.utils.redis_conn import REDIS_CONN
|
||||
from rag.utils.doc_store_conn import OrderByExpr
|
||||
from common.doc_store.doc_store_base import OrderByExpr
|
||||
from common import settings
|
||||
|
||||
|
||||
@ -124,26 +125,26 @@ class DocumentService(CommonService):
|
||||
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
def get_by_kb_id(cls, kb_id, page_number, items_per_page,
|
||||
orderby, desc, keywords, run_status, types, suffix, doc_ids=None):
|
||||
def get_by_kb_id(cls, kb_id, page_number, items_per_page, orderby, desc, keywords, run_status, types, suffix, doc_ids=None, return_empty_metadata=False):
|
||||
fields = cls.get_cls_model_fields()
|
||||
if keywords:
|
||||
docs = cls.model.select(*[*fields, UserCanvas.title.alias("pipeline_name"), User.nickname])\
|
||||
.join(File2Document, on=(File2Document.document_id == cls.model.id))\
|
||||
.join(File, on=(File.id == File2Document.file_id))\
|
||||
.join(UserCanvas, on=(cls.model.pipeline_id == UserCanvas.id), join_type=JOIN.LEFT_OUTER)\
|
||||
.join(User, on=(cls.model.created_by == User.id), join_type=JOIN.LEFT_OUTER)\
|
||||
.where(
|
||||
(cls.model.kb_id == kb_id),
|
||||
(fn.LOWER(cls.model.name).contains(keywords.lower()))
|
||||
)
|
||||
docs = (
|
||||
cls.model.select(*[*fields, UserCanvas.title.alias("pipeline_name"), User.nickname])
|
||||
.join(File2Document, on=(File2Document.document_id == cls.model.id))
|
||||
.join(File, on=(File.id == File2Document.file_id))
|
||||
.join(UserCanvas, on=(cls.model.pipeline_id == UserCanvas.id), join_type=JOIN.LEFT_OUTER)
|
||||
.join(User, on=(cls.model.created_by == User.id), join_type=JOIN.LEFT_OUTER)
|
||||
.where((cls.model.kb_id == kb_id), (fn.LOWER(cls.model.name).contains(keywords.lower())))
|
||||
)
|
||||
else:
|
||||
docs = cls.model.select(*[*fields, UserCanvas.title.alias("pipeline_name"), User.nickname])\
|
||||
.join(File2Document, on=(File2Document.document_id == cls.model.id))\
|
||||
.join(UserCanvas, on=(cls.model.pipeline_id == UserCanvas.id), join_type=JOIN.LEFT_OUTER)\
|
||||
.join(File, on=(File.id == File2Document.file_id))\
|
||||
.join(User, on=(cls.model.created_by == User.id), join_type=JOIN.LEFT_OUTER)\
|
||||
docs = (
|
||||
cls.model.select(*[*fields, UserCanvas.title.alias("pipeline_name"), User.nickname])
|
||||
.join(File2Document, on=(File2Document.document_id == cls.model.id))
|
||||
.join(UserCanvas, on=(cls.model.pipeline_id == UserCanvas.id), join_type=JOIN.LEFT_OUTER)
|
||||
.join(File, on=(File.id == File2Document.file_id))
|
||||
.join(User, on=(cls.model.created_by == User.id), join_type=JOIN.LEFT_OUTER)
|
||||
.where(cls.model.kb_id == kb_id)
|
||||
)
|
||||
|
||||
if doc_ids:
|
||||
docs = docs.where(cls.model.id.in_(doc_ids))
|
||||
@ -153,6 +154,8 @@ class DocumentService(CommonService):
|
||||
docs = docs.where(cls.model.type.in_(types))
|
||||
if suffix:
|
||||
docs = docs.where(cls.model.suffix.in_(suffix))
|
||||
if return_empty_metadata:
|
||||
docs = docs.where(fn.COALESCE(fn.JSON_LENGTH(cls.model.meta_fields), 0) == 0)
|
||||
|
||||
count = docs.count()
|
||||
if desc:
|
||||
@ -160,7 +163,6 @@ class DocumentService(CommonService):
|
||||
else:
|
||||
docs = docs.order_by(cls.model.getter_by(orderby).asc())
|
||||
|
||||
|
||||
if page_number and items_per_page:
|
||||
docs = docs.paginate(page_number, items_per_page)
|
||||
|
||||
@ -180,6 +182,16 @@ class DocumentService(CommonService):
|
||||
"1": 2,
|
||||
"2": 2
|
||||
}
|
||||
"metadata": {
|
||||
"key1": {
|
||||
"key1_value1": 1,
|
||||
"key1_value2": 2,
|
||||
},
|
||||
"key2": {
|
||||
"key2_value1": 2,
|
||||
"key2_value2": 1,
|
||||
},
|
||||
}
|
||||
}, total
|
||||
where "1" => RUNNING, "2" => CANCEL
|
||||
"""
|
||||
@ -200,19 +212,42 @@ class DocumentService(CommonService):
|
||||
if suffix:
|
||||
query = query.where(cls.model.suffix.in_(suffix))
|
||||
|
||||
rows = query.select(cls.model.run, cls.model.suffix)
|
||||
rows = query.select(cls.model.run, cls.model.suffix, cls.model.meta_fields)
|
||||
total = rows.count()
|
||||
|
||||
suffix_counter = {}
|
||||
run_status_counter = {}
|
||||
metadata_counter = {}
|
||||
empty_metadata_count = 0
|
||||
|
||||
for row in rows:
|
||||
suffix_counter[row.suffix] = suffix_counter.get(row.suffix, 0) + 1
|
||||
run_status_counter[str(row.run)] = run_status_counter.get(str(row.run), 0) + 1
|
||||
meta_fields = row.meta_fields or {}
|
||||
if not meta_fields:
|
||||
empty_metadata_count += 1
|
||||
continue
|
||||
has_valid_meta = False
|
||||
for key, value in meta_fields.items():
|
||||
values = value if isinstance(value, list) else [value]
|
||||
for vv in values:
|
||||
if vv is None:
|
||||
continue
|
||||
if isinstance(vv, str) and not vv.strip():
|
||||
continue
|
||||
sv = str(vv)
|
||||
if key not in metadata_counter:
|
||||
metadata_counter[key] = {}
|
||||
metadata_counter[key][sv] = metadata_counter[key].get(sv, 0) + 1
|
||||
has_valid_meta = True
|
||||
if not has_valid_meta:
|
||||
empty_metadata_count += 1
|
||||
|
||||
metadata_counter["empty_metadata"] = {"true": empty_metadata_count}
|
||||
return {
|
||||
"suffix": suffix_counter,
|
||||
"run_status": run_status_counter
|
||||
"run_status": run_status_counter,
|
||||
"metadata": metadata_counter,
|
||||
}, total
|
||||
|
||||
@classmethod
|
||||
@ -314,7 +349,7 @@ class DocumentService(CommonService):
|
||||
chunks = settings.docStoreConn.search(["img_id"], [], {"doc_id": doc.id}, [], OrderByExpr(),
|
||||
page * page_size, page_size, search.index_name(tenant_id),
|
||||
[doc.kb_id])
|
||||
chunk_ids = settings.docStoreConn.get_chunk_ids(chunks)
|
||||
chunk_ids = settings.docStoreConn.get_doc_ids(chunks)
|
||||
if not chunk_ids:
|
||||
break
|
||||
all_chunk_ids.extend(chunk_ids)
|
||||
@ -665,10 +700,14 @@ class DocumentService(CommonService):
|
||||
for k,v in r.meta_fields.items():
|
||||
if k not in meta:
|
||||
meta[k] = {}
|
||||
v = str(v)
|
||||
if v not in meta[k]:
|
||||
meta[k][v] = []
|
||||
meta[k][v].append(doc_id)
|
||||
if not isinstance(v, list):
|
||||
v = [v]
|
||||
for vv in v:
|
||||
if vv not in meta[k]:
|
||||
if isinstance(vv, list) or isinstance(vv, dict):
|
||||
continue
|
||||
meta[k][vv] = []
|
||||
meta[k][vv].append(doc_id)
|
||||
return meta
|
||||
|
||||
@classmethod
|
||||
@ -766,7 +805,10 @@ class DocumentService(CommonService):
|
||||
match_provided = "match" in upd
|
||||
if isinstance(meta[key], list):
|
||||
if not match_provided:
|
||||
meta[key] = new_value
|
||||
if isinstance(new_value, list):
|
||||
meta[key] = dedupe_list(new_value)
|
||||
else:
|
||||
meta[key] = new_value
|
||||
changed = True
|
||||
else:
|
||||
match_value = upd.get("match")
|
||||
@ -779,7 +821,7 @@ class DocumentService(CommonService):
|
||||
else:
|
||||
new_list.append(item)
|
||||
if replaced:
|
||||
meta[key] = new_list
|
||||
meta[key] = dedupe_list(new_list)
|
||||
changed = True
|
||||
else:
|
||||
if not match_provided:
|
||||
@ -1199,8 +1241,8 @@ def doc_upload_and_parse(conversation_id, file_objs, user_id):
|
||||
d["q_%d_vec" % len(v)] = v
|
||||
for b in range(0, len(cks), es_bulk_size):
|
||||
if try_create_idx:
|
||||
if not settings.docStoreConn.indexExist(idxnm, kb_id):
|
||||
settings.docStoreConn.createIdx(idxnm, kb_id, len(vectors[0]))
|
||||
if not settings.docStoreConn.index_exist(idxnm, kb_id):
|
||||
settings.docStoreConn.create_idx(idxnm, kb_id, len(vectors[0]))
|
||||
try_create_idx = False
|
||||
settings.docStoreConn.insert(cks[b:b + es_bulk_size], idxnm, kb_id)
|
||||
|
||||
|
||||
@ -100,7 +100,7 @@ class FileService(CommonService):
|
||||
# Returns:
|
||||
# List of dictionaries containing dataset IDs and names
|
||||
kbs = (
|
||||
cls.model.select(*[Knowledgebase.id, Knowledgebase.name])
|
||||
cls.model.select(*[Knowledgebase.id, Knowledgebase.name, File2Document.document_id])
|
||||
.join(File2Document, on=(File2Document.file_id == file_id))
|
||||
.join(Document, on=(File2Document.document_id == Document.id))
|
||||
.join(Knowledgebase, on=(Knowledgebase.id == Document.kb_id))
|
||||
@ -110,7 +110,7 @@ class FileService(CommonService):
|
||||
return []
|
||||
kbs_info_list = []
|
||||
for kb in list(kbs.dicts()):
|
||||
kbs_info_list.append({"kb_id": kb["id"], "kb_name": kb["name"]})
|
||||
kbs_info_list.append({"kb_id": kb["id"], "kb_name": kb["name"], "document_id": kb["document_id"]})
|
||||
return kbs_info_list
|
||||
|
||||
@classmethod
|
||||
|
||||
@ -425,6 +425,7 @@ class KnowledgebaseService(CommonService):
|
||||
|
||||
# Update parser_config (always override with validated default/merged config)
|
||||
payload["parser_config"] = get_parser_config(parser_id, kwargs.get("parser_config"))
|
||||
payload["parser_config"]["llm_id"] = _t.llm_id
|
||||
|
||||
return True, payload
|
||||
|
||||
|
||||
@ -15,7 +15,6 @@
|
||||
#
|
||||
from typing import List
|
||||
|
||||
from api.apps import current_user
|
||||
from api.db.db_models import DB, Memory, User
|
||||
from api.db.services import duplicate_name
|
||||
from api.db.services.common_service import CommonService
|
||||
@ -23,6 +22,7 @@ from api.utils.memory_utils import calculate_memory_type
|
||||
from api.constants import MEMORY_NAME_LIMIT
|
||||
from common.misc_utils import get_uuid
|
||||
from common.time_utils import get_format_time, current_timestamp
|
||||
from memory.utils.prompt_util import PromptAssembler
|
||||
|
||||
|
||||
class MemoryService(CommonService):
|
||||
@ -34,6 +34,17 @@ class MemoryService(CommonService):
|
||||
def get_by_memory_id(cls, memory_id: str):
|
||||
return cls.model.select().where(cls.model.id == memory_id).first()
|
||||
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
def get_by_tenant_id(cls, tenant_id: str):
|
||||
return cls.model.select().where(cls.model.tenant_id == tenant_id)
|
||||
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
def get_all_memory(cls):
|
||||
memory_list = cls.model.select()
|
||||
return list(memory_list)
|
||||
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
def get_with_owner_name_by_id(cls, memory_id: str):
|
||||
@ -53,7 +64,9 @@ class MemoryService(CommonService):
|
||||
cls.model.forgetting_policy,
|
||||
cls.model.temperature,
|
||||
cls.model.system_prompt,
|
||||
cls.model.user_prompt
|
||||
cls.model.user_prompt,
|
||||
cls.model.create_date,
|
||||
cls.model.create_time
|
||||
]
|
||||
memory = cls.model.select(*fields).join(User, on=(cls.model.tenant_id == User.id)).where(
|
||||
cls.model.id == memory_id
|
||||
@ -72,7 +85,9 @@ class MemoryService(CommonService):
|
||||
cls.model.memory_type,
|
||||
cls.model.storage_type,
|
||||
cls.model.permissions,
|
||||
cls.model.description
|
||||
cls.model.description,
|
||||
cls.model.create_time,
|
||||
cls.model.create_date
|
||||
]
|
||||
memories = cls.model.select(*fields).join(User, on=(cls.model.tenant_id == User.id))
|
||||
if filter_dict.get("tenant_id"):
|
||||
@ -102,6 +117,8 @@ class MemoryService(CommonService):
|
||||
if len(memory_name) > MEMORY_NAME_LIMIT:
|
||||
return False, f"Memory name {memory_name} exceeds limit of {MEMORY_NAME_LIMIT}."
|
||||
|
||||
timestamp = current_timestamp()
|
||||
format_time = get_format_time()
|
||||
# build create dict
|
||||
memory_info = {
|
||||
"id": get_uuid(),
|
||||
@ -110,10 +127,11 @@ class MemoryService(CommonService):
|
||||
"tenant_id": tenant_id,
|
||||
"embd_id": embd_id,
|
||||
"llm_id": llm_id,
|
||||
"create_time": current_timestamp(),
|
||||
"create_date": get_format_time(),
|
||||
"update_time": current_timestamp(),
|
||||
"update_date": get_format_time(),
|
||||
"system_prompt": PromptAssembler.assemble_system_prompt({"memory_type": memory_type}),
|
||||
"create_time": timestamp,
|
||||
"create_date": format_time,
|
||||
"update_time": timestamp,
|
||||
"update_date": format_time,
|
||||
}
|
||||
obj = cls.model(**memory_info).save(force_insert=True)
|
||||
|
||||
@ -126,16 +144,18 @@ class MemoryService(CommonService):
|
||||
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
def update_memory(cls, memory_id: str, update_dict: dict):
|
||||
def update_memory(cls, tenant_id: str, memory_id: str, update_dict: dict):
|
||||
if not update_dict:
|
||||
return 0
|
||||
if "temperature" in update_dict and isinstance(update_dict["temperature"], str):
|
||||
update_dict["temperature"] = float(update_dict["temperature"])
|
||||
if "memory_type" in update_dict and isinstance(update_dict["memory_type"], list):
|
||||
update_dict["memory_type"] = calculate_memory_type(update_dict["memory_type"])
|
||||
if "name" in update_dict:
|
||||
update_dict["name"] = duplicate_name(
|
||||
cls.query,
|
||||
name=update_dict["name"],
|
||||
tenant_id=current_user.id
|
||||
tenant_id=tenant_id
|
||||
)
|
||||
update_dict.update({
|
||||
"update_time": current_timestamp(),
|
||||
|
||||
@ -97,7 +97,7 @@ class TenantLLMService(CommonService):
|
||||
if llm_type == LLMType.EMBEDDING.value:
|
||||
mdlnm = tenant.embd_id if not llm_name else llm_name
|
||||
elif llm_type == LLMType.SPEECH2TEXT.value:
|
||||
mdlnm = tenant.asr_id
|
||||
mdlnm = tenant.asr_id if not llm_name else llm_name
|
||||
elif llm_type == LLMType.IMAGE2TEXT.value:
|
||||
mdlnm = tenant.img2txt_id if not llm_name else llm_name
|
||||
elif llm_type == LLMType.CHAT.value:
|
||||
|
||||
@ -163,6 +163,7 @@ def validate_request(*args, **kwargs):
|
||||
if error_arguments:
|
||||
error_string += "required argument values: {}".format(",".join(["{}={}".format(a[0], a[1]) for a in error_arguments]))
|
||||
return error_string
|
||||
return None
|
||||
|
||||
def wrapper(func):
|
||||
@wraps(func)
|
||||
@ -409,7 +410,7 @@ def get_parser_config(chunk_method, parser_config):
|
||||
if default_config is None:
|
||||
return deep_merge(base_defaults, parser_config)
|
||||
|
||||
# Ensure raptor and graphrag fields have default values if not provided
|
||||
# Ensure raptor and graph_rag fields have default values if not provided
|
||||
merged_config = deep_merge(base_defaults, default_config)
|
||||
merged_config = deep_merge(merged_config, parser_config)
|
||||
|
||||
|
||||
@ -54,6 +54,7 @@ class RetCode(IntEnum, CustomEnum):
|
||||
SERVER_ERROR = 500
|
||||
FORBIDDEN = 403
|
||||
NOT_FOUND = 404
|
||||
CONFLICT = 409
|
||||
|
||||
|
||||
class StatusEnum(Enum):
|
||||
@ -124,7 +125,12 @@ class FileSource(StrEnum):
|
||||
MOODLE = "moodle"
|
||||
DROPBOX = "dropbox"
|
||||
BOX = "box"
|
||||
R2 = "r2"
|
||||
OCI_STORAGE = "oci_storage"
|
||||
GOOGLE_CLOUD_STORAGE = "google_cloud_storage"
|
||||
AIRTABLE = "airtable"
|
||||
|
||||
|
||||
class PipelineTaskType(StrEnum):
|
||||
PARSE = "Parse"
|
||||
DOWNLOAD = "Download"
|
||||
@ -165,7 +171,7 @@ class MemoryStorageType(StrEnum):
|
||||
|
||||
|
||||
class ForgettingPolicy(StrEnum):
|
||||
FIFO = "fifo"
|
||||
FIFO = "FIFO"
|
||||
|
||||
|
||||
# environment
|
||||
|
||||
@ -36,6 +36,7 @@ from .sharepoint_connector import SharePointConnector
|
||||
from .teams_connector import TeamsConnector
|
||||
from .webdav_connector import WebDAVConnector
|
||||
from .moodle_connector import MoodleConnector
|
||||
from .airtable_connector import AirtableConnector
|
||||
from .config import BlobType, DocumentSource
|
||||
from .models import Document, TextSection, ImageSection, BasicExpertInfo
|
||||
from .exceptions import (
|
||||
@ -70,5 +71,6 @@ __all__ = [
|
||||
"ConnectorValidationError",
|
||||
"CredentialExpiredError",
|
||||
"InsufficientPermissionsError",
|
||||
"UnexpectedValidationError"
|
||||
"UnexpectedValidationError",
|
||||
"AirtableConnector",
|
||||
]
|
||||
|
||||
149
common/data_source/airtable_connector.py
Normal file
149
common/data_source/airtable_connector.py
Normal file
@ -0,0 +1,149 @@
|
||||
from datetime import datetime, timezone
|
||||
import logging
|
||||
from typing import Any
|
||||
|
||||
import requests
|
||||
|
||||
from pyairtable import Api as AirtableApi
|
||||
|
||||
from common.data_source.config import AIRTABLE_CONNECTOR_SIZE_THRESHOLD, INDEX_BATCH_SIZE, DocumentSource
|
||||
from common.data_source.exceptions import ConnectorMissingCredentialError
|
||||
from common.data_source.interfaces import LoadConnector
|
||||
from common.data_source.models import Document, GenerateDocumentsOutput
|
||||
from common.data_source.utils import extract_size_bytes, get_file_ext
|
||||
|
||||
class AirtableClientNotSetUpError(PermissionError):
|
||||
def __init__(self) -> None:
|
||||
super().__init__(
|
||||
"Airtable client is not set up. Did you forget to call load_credentials()?"
|
||||
)
|
||||
|
||||
|
||||
class AirtableConnector(LoadConnector):
|
||||
"""
|
||||
Lightweight Airtable connector.
|
||||
|
||||
This connector ingests Airtable attachments as raw blobs without
|
||||
parsing file content or generating text/image sections.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
base_id: str,
|
||||
table_name_or_id: str,
|
||||
batch_size: int = INDEX_BATCH_SIZE,
|
||||
) -> None:
|
||||
self.base_id = base_id
|
||||
self.table_name_or_id = table_name_or_id
|
||||
self.batch_size = batch_size
|
||||
self._airtable_client: AirtableApi | None = None
|
||||
self.size_threshold = AIRTABLE_CONNECTOR_SIZE_THRESHOLD
|
||||
|
||||
# -------------------------
|
||||
# Credentials
|
||||
# -------------------------
|
||||
def load_credentials(self, credentials: dict[str, Any]) -> dict[str, Any] | None:
|
||||
self._airtable_client = AirtableApi(credentials["airtable_access_token"])
|
||||
return None
|
||||
|
||||
@property
|
||||
def airtable_client(self) -> AirtableApi:
|
||||
if not self._airtable_client:
|
||||
raise AirtableClientNotSetUpError()
|
||||
return self._airtable_client
|
||||
|
||||
# -------------------------
|
||||
# Core logic
|
||||
# -------------------------
|
||||
def load_from_state(self) -> GenerateDocumentsOutput:
|
||||
"""
|
||||
Fetch all Airtable records and ingest attachments as raw blobs.
|
||||
|
||||
Each attachment is converted into a single Document(blob=...).
|
||||
"""
|
||||
if not self._airtable_client:
|
||||
raise ConnectorMissingCredentialError("Airtable credentials not loaded")
|
||||
|
||||
table = self.airtable_client.table(self.base_id, self.table_name_or_id)
|
||||
records = table.all()
|
||||
|
||||
logging.info(
|
||||
f"Starting Airtable blob ingestion for table {self.table_name_or_id}, "
|
||||
f"{len(records)} records found."
|
||||
)
|
||||
|
||||
batch: list[Document] = []
|
||||
|
||||
for record in records:
|
||||
print(record)
|
||||
record_id = record.get("id")
|
||||
fields = record.get("fields", {})
|
||||
created_time = record.get("createdTime")
|
||||
|
||||
for field_value in fields.values():
|
||||
# We only care about attachment fields (lists of dicts with url/filename)
|
||||
if not isinstance(field_value, list):
|
||||
continue
|
||||
|
||||
for attachment in field_value:
|
||||
url = attachment.get("url")
|
||||
filename = attachment.get("filename")
|
||||
attachment_id = attachment.get("id")
|
||||
|
||||
if not url or not filename or not attachment_id:
|
||||
continue
|
||||
|
||||
try:
|
||||
resp = requests.get(url, timeout=30)
|
||||
resp.raise_for_status()
|
||||
content = resp.content
|
||||
except Exception:
|
||||
logging.exception(
|
||||
f"Failed to download attachment {filename} "
|
||||
f"(record={record_id})"
|
||||
)
|
||||
continue
|
||||
size_bytes = extract_size_bytes(attachment)
|
||||
if (
|
||||
self.size_threshold is not None
|
||||
and isinstance(size_bytes, int)
|
||||
and size_bytes > self.size_threshold
|
||||
):
|
||||
logging.warning(
|
||||
f"{filename} exceeds size threshold of {self.size_threshold}. Skipping."
|
||||
)
|
||||
continue
|
||||
batch.append(
|
||||
Document(
|
||||
id=f"airtable:{record_id}:{attachment_id}",
|
||||
blob=content,
|
||||
source=DocumentSource.AIRTABLE,
|
||||
semantic_identifier=filename,
|
||||
extension=get_file_ext(filename),
|
||||
size_bytes=size_bytes if size_bytes else 0,
|
||||
doc_updated_at=datetime.strptime(created_time, "%Y-%m-%dT%H:%M:%S.%fZ").replace(tzinfo=timezone.utc)
|
||||
)
|
||||
)
|
||||
|
||||
if len(batch) >= self.batch_size:
|
||||
yield batch
|
||||
batch = []
|
||||
|
||||
if batch:
|
||||
yield batch
|
||||
|
||||
if __name__ == "__main__":
|
||||
import os
|
||||
|
||||
logging.basicConfig(level=logging.DEBUG)
|
||||
connector = AirtableConnector("xxx","xxx")
|
||||
connector.load_credentials({"airtable_access_token": os.environ.get("AIRTABLE_ACCESS_TOKEN")})
|
||||
connector.validate_connector_settings()
|
||||
document_batches = connector.load_from_state()
|
||||
try:
|
||||
first_batch = next(document_batches)
|
||||
print(f"Loaded {len(first_batch)} documents in first batch.")
|
||||
for doc in first_batch:
|
||||
print(f"- {doc.semantic_identifier} ({doc.size_bytes} bytes)")
|
||||
except StopIteration:
|
||||
print("No documents available in Dropbox.")
|
||||
@ -56,7 +56,7 @@ class BlobStorageConnector(LoadConnector, PollConnector):
|
||||
|
||||
# Validate credentials
|
||||
if self.bucket_type == BlobType.R2:
|
||||
if not all(
|
||||
if not all(
|
||||
credentials.get(key)
|
||||
for key in ["r2_access_key_id", "r2_secret_access_key", "account_id"]
|
||||
):
|
||||
@ -64,15 +64,23 @@ class BlobStorageConnector(LoadConnector, PollConnector):
|
||||
|
||||
elif self.bucket_type == BlobType.S3:
|
||||
authentication_method = credentials.get("authentication_method", "access_key")
|
||||
|
||||
if authentication_method == "access_key":
|
||||
if not all(
|
||||
credentials.get(key)
|
||||
for key in ["aws_access_key_id", "aws_secret_access_key"]
|
||||
):
|
||||
raise ConnectorMissingCredentialError("Amazon S3")
|
||||
|
||||
elif authentication_method == "iam_role":
|
||||
if not credentials.get("aws_role_arn"):
|
||||
raise ConnectorMissingCredentialError("Amazon S3 IAM role ARN is required")
|
||||
|
||||
elif authentication_method == "assume_role":
|
||||
pass
|
||||
|
||||
else:
|
||||
raise ConnectorMissingCredentialError("Unsupported S3 authentication method")
|
||||
|
||||
elif self.bucket_type == BlobType.GOOGLE_CLOUD_STORAGE:
|
||||
if not all(
|
||||
@ -120,55 +128,72 @@ class BlobStorageConnector(LoadConnector, PollConnector):
|
||||
paginator = self.s3_client.get_paginator("list_objects_v2")
|
||||
pages = paginator.paginate(Bucket=self.bucket_name, Prefix=self.prefix)
|
||||
|
||||
batch: list[Document] = []
|
||||
# Collect all objects first to count filename occurrences
|
||||
all_objects = []
|
||||
for page in pages:
|
||||
if "Contents" not in page:
|
||||
continue
|
||||
|
||||
for obj in page["Contents"]:
|
||||
if obj["Key"].endswith("/"):
|
||||
continue
|
||||
|
||||
last_modified = obj["LastModified"].replace(tzinfo=timezone.utc)
|
||||
if start < last_modified <= end:
|
||||
all_objects.append(obj)
|
||||
|
||||
# Count filename occurrences to determine which need full paths
|
||||
filename_counts: dict[str, int] = {}
|
||||
for obj in all_objects:
|
||||
file_name = os.path.basename(obj["Key"])
|
||||
filename_counts[file_name] = filename_counts.get(file_name, 0) + 1
|
||||
|
||||
if not (start < last_modified <= end):
|
||||
batch: list[Document] = []
|
||||
for obj in all_objects:
|
||||
last_modified = obj["LastModified"].replace(tzinfo=timezone.utc)
|
||||
file_name = os.path.basename(obj["Key"])
|
||||
key = obj["Key"]
|
||||
|
||||
size_bytes = extract_size_bytes(obj)
|
||||
if (
|
||||
self.size_threshold is not None
|
||||
and isinstance(size_bytes, int)
|
||||
and size_bytes > self.size_threshold
|
||||
):
|
||||
logging.warning(
|
||||
f"{file_name} exceeds size threshold of {self.size_threshold}. Skipping."
|
||||
)
|
||||
continue
|
||||
|
||||
try:
|
||||
blob = download_object(self.s3_client, self.bucket_name, key, self.size_threshold)
|
||||
if blob is None:
|
||||
continue
|
||||
|
||||
file_name = os.path.basename(obj["Key"])
|
||||
key = obj["Key"]
|
||||
# Use full path only if filename appears multiple times
|
||||
if filename_counts.get(file_name, 0) > 1:
|
||||
relative_path = key
|
||||
if self.prefix and key.startswith(self.prefix):
|
||||
relative_path = key[len(self.prefix):]
|
||||
semantic_id = relative_path.replace('/', ' / ') if relative_path else file_name
|
||||
else:
|
||||
semantic_id = file_name
|
||||
|
||||
size_bytes = extract_size_bytes(obj)
|
||||
if (
|
||||
self.size_threshold is not None
|
||||
and isinstance(size_bytes, int)
|
||||
and size_bytes > self.size_threshold
|
||||
):
|
||||
logging.warning(
|
||||
f"{file_name} exceeds size threshold of {self.size_threshold}. Skipping."
|
||||
batch.append(
|
||||
Document(
|
||||
id=f"{self.bucket_type}:{self.bucket_name}:{key}",
|
||||
blob=blob,
|
||||
source=DocumentSource(self.bucket_type.value),
|
||||
semantic_identifier=semantic_id,
|
||||
extension=get_file_ext(file_name),
|
||||
doc_updated_at=last_modified,
|
||||
size_bytes=size_bytes if size_bytes else 0
|
||||
)
|
||||
continue
|
||||
try:
|
||||
blob = download_object(self.s3_client, self.bucket_name, key, self.size_threshold)
|
||||
if blob is None:
|
||||
continue
|
||||
)
|
||||
if len(batch) == self.batch_size:
|
||||
yield batch
|
||||
batch = []
|
||||
|
||||
batch.append(
|
||||
Document(
|
||||
id=f"{self.bucket_type}:{self.bucket_name}:{key}",
|
||||
blob=blob,
|
||||
source=DocumentSource(self.bucket_type.value),
|
||||
semantic_identifier=file_name,
|
||||
extension=get_file_ext(file_name),
|
||||
doc_updated_at=last_modified,
|
||||
size_bytes=size_bytes if size_bytes else 0
|
||||
)
|
||||
)
|
||||
if len(batch) == self.batch_size:
|
||||
yield batch
|
||||
batch = []
|
||||
|
||||
except Exception:
|
||||
logging.exception(f"Error decoding object {key}")
|
||||
except Exception:
|
||||
logging.exception(f"Error decoding object {key}")
|
||||
|
||||
if batch:
|
||||
yield batch
|
||||
@ -276,4 +301,4 @@ if __name__ == "__main__":
|
||||
except ConnectorMissingCredentialError as e:
|
||||
print(f"Error: {e}")
|
||||
except Exception as e:
|
||||
print(f"An unexpected error occurred: {e}")
|
||||
print(f"An unexpected error occurred: {e}")
|
||||
|
||||
@ -53,6 +53,7 @@ class DocumentSource(str, Enum):
|
||||
S3_COMPATIBLE = "s3_compatible"
|
||||
DROPBOX = "dropbox"
|
||||
BOX = "box"
|
||||
AIRTABLE = "airtable"
|
||||
|
||||
class FileOrigin(str, Enum):
|
||||
"""File origins"""
|
||||
@ -83,6 +84,7 @@ _PAGE_EXPANSION_FIELDS = [
|
||||
"space",
|
||||
"metadata.labels",
|
||||
"history.lastUpdated",
|
||||
"ancestors",
|
||||
]
|
||||
|
||||
|
||||
@ -250,6 +252,10 @@ WEB_CONNECTOR_IGNORED_ELEMENTS = os.environ.get(
|
||||
"WEB_CONNECTOR_IGNORED_ELEMENTS", "nav,footer,meta,script,style,symbol,aside"
|
||||
).split(",")
|
||||
|
||||
AIRTABLE_CONNECTOR_SIZE_THRESHOLD = int(
|
||||
os.environ.get("AIRTABLE_CONNECTOR_SIZE_THRESHOLD", 10 * 1024 * 1024)
|
||||
)
|
||||
|
||||
_USER_NOT_FOUND = "Unknown Confluence User"
|
||||
|
||||
_COMMENT_EXPANSION_FIELDS = ["body.storage.value"]
|
||||
|
||||
@ -186,7 +186,7 @@ class OnyxConfluence:
|
||||
# between the db and redis everywhere the credentials might be updated
|
||||
new_credential_str = json.dumps(new_credentials)
|
||||
self.redis_client.set(
|
||||
self.credential_key, new_credential_str, nx=True, ex=self.CREDENTIAL_TTL
|
||||
self.credential_key, new_credential_str, exp=self.CREDENTIAL_TTL
|
||||
)
|
||||
self._credentials_provider.set_credentials(new_credentials)
|
||||
|
||||
@ -1311,6 +1311,9 @@ class ConfluenceConnector(
|
||||
self._low_timeout_confluence_client: OnyxConfluence | None = None
|
||||
self._fetched_titles: set[str] = set()
|
||||
self.allow_images = False
|
||||
# Track document names to detect duplicates
|
||||
self._document_name_counts: dict[str, int] = {}
|
||||
self._document_name_paths: dict[str, list[str]] = {}
|
||||
|
||||
# Remove trailing slash from wiki_base if present
|
||||
self.wiki_base = wiki_base.rstrip("/")
|
||||
@ -1513,6 +1516,40 @@ class ConfluenceConnector(
|
||||
self.wiki_base, page["_links"]["webui"], self.is_cloud
|
||||
)
|
||||
|
||||
# Build hierarchical path for semantic identifier
|
||||
space_name = page.get("space", {}).get("name", "")
|
||||
|
||||
# Build path from ancestors
|
||||
path_parts = []
|
||||
if space_name:
|
||||
path_parts.append(space_name)
|
||||
|
||||
# Add ancestor pages to path if available
|
||||
if "ancestors" in page and page["ancestors"]:
|
||||
for ancestor in page["ancestors"]:
|
||||
ancestor_title = ancestor.get("title", "")
|
||||
if ancestor_title:
|
||||
path_parts.append(ancestor_title)
|
||||
|
||||
# Add current page title
|
||||
path_parts.append(page_title)
|
||||
|
||||
# Track page names for duplicate detection
|
||||
full_path = " / ".join(path_parts) if len(path_parts) > 1 else page_title
|
||||
|
||||
# Count occurrences of this page title
|
||||
if page_title not in self._document_name_counts:
|
||||
self._document_name_counts[page_title] = 0
|
||||
self._document_name_paths[page_title] = []
|
||||
self._document_name_counts[page_title] += 1
|
||||
self._document_name_paths[page_title].append(full_path)
|
||||
|
||||
# Use simple name if no duplicates, otherwise use full path
|
||||
if self._document_name_counts[page_title] == 1:
|
||||
semantic_identifier = page_title
|
||||
else:
|
||||
semantic_identifier = full_path
|
||||
|
||||
# Get the page content
|
||||
page_content = extract_text_from_confluence_html(
|
||||
self.confluence_client, page, self._fetched_titles
|
||||
@ -1559,11 +1596,11 @@ class ConfluenceConnector(
|
||||
return Document(
|
||||
id=page_url,
|
||||
source=DocumentSource.CONFLUENCE,
|
||||
semantic_identifier=page_title,
|
||||
semantic_identifier=semantic_identifier,
|
||||
extension=".html", # Confluence pages are HTML
|
||||
blob=page_content.encode("utf-8"), # Encode page content as bytes
|
||||
size_bytes=len(page_content.encode("utf-8")), # Calculate size in bytes
|
||||
doc_updated_at=datetime_from_string(page["version"]["when"]),
|
||||
size_bytes=len(page_content.encode("utf-8")), # Calculate size in bytes
|
||||
primary_owners=primary_owners if primary_owners else None,
|
||||
metadata=metadata if metadata else None,
|
||||
)
|
||||
@ -1601,7 +1638,6 @@ class ConfluenceConnector(
|
||||
expand=",".join(_ATTACHMENT_EXPANSION_FIELDS),
|
||||
):
|
||||
media_type: str = attachment.get("metadata", {}).get("mediaType", "")
|
||||
|
||||
# TODO(rkuo): this check is partially redundant with validate_attachment_filetype
|
||||
# and checks in convert_attachment_to_content/process_attachment
|
||||
# but doing the check here avoids an unnecessary download. Due for refactoring.
|
||||
@ -1669,6 +1705,34 @@ class ConfluenceConnector(
|
||||
self.wiki_base, attachment["_links"]["webui"], self.is_cloud
|
||||
)
|
||||
|
||||
# Build semantic identifier with space and page context
|
||||
attachment_title = attachment.get("title", object_url)
|
||||
space_name = page.get("space", {}).get("name", "")
|
||||
page_title = page.get("title", "")
|
||||
|
||||
# Create hierarchical name: Space / Page / Attachment
|
||||
attachment_path_parts = []
|
||||
if space_name:
|
||||
attachment_path_parts.append(space_name)
|
||||
if page_title:
|
||||
attachment_path_parts.append(page_title)
|
||||
attachment_path_parts.append(attachment_title)
|
||||
|
||||
full_attachment_path = " / ".join(attachment_path_parts) if len(attachment_path_parts) > 1 else attachment_title
|
||||
|
||||
# Track attachment names for duplicate detection
|
||||
if attachment_title not in self._document_name_counts:
|
||||
self._document_name_counts[attachment_title] = 0
|
||||
self._document_name_paths[attachment_title] = []
|
||||
self._document_name_counts[attachment_title] += 1
|
||||
self._document_name_paths[attachment_title].append(full_attachment_path)
|
||||
|
||||
# Use simple name if no duplicates, otherwise use full path
|
||||
if self._document_name_counts[attachment_title] == 1:
|
||||
attachment_semantic_identifier = attachment_title
|
||||
else:
|
||||
attachment_semantic_identifier = full_attachment_path
|
||||
|
||||
primary_owners: list[BasicExpertInfo] | None = None
|
||||
if "version" in attachment and "by" in attachment["version"]:
|
||||
author = attachment["version"]["by"]
|
||||
@ -1680,11 +1744,12 @@ class ConfluenceConnector(
|
||||
|
||||
extension = Path(attachment.get("title", "")).suffix or ".unknown"
|
||||
|
||||
|
||||
attachment_doc = Document(
|
||||
id=attachment_id,
|
||||
# sections=sections,
|
||||
source=DocumentSource.CONFLUENCE,
|
||||
semantic_identifier=attachment.get("title", object_url),
|
||||
semantic_identifier=attachment_semantic_identifier,
|
||||
extension=extension,
|
||||
blob=file_blob,
|
||||
size_bytes=len(file_blob),
|
||||
@ -1741,7 +1806,7 @@ class ConfluenceConnector(
|
||||
start_ts, end, self.batch_size
|
||||
)
|
||||
logging.debug(f"page_query_url: {page_query_url}")
|
||||
|
||||
|
||||
# store the next page start for confluence server, cursor for confluence cloud
|
||||
def store_next_page_url(next_page_url: str) -> None:
|
||||
checkpoint.next_page_url = next_page_url
|
||||
|
||||
@ -87,15 +87,69 @@ class DropboxConnector(LoadConnector, PollConnector):
|
||||
if self.dropbox_client is None:
|
||||
raise ConnectorMissingCredentialError("Dropbox")
|
||||
|
||||
# Collect all files first to count filename occurrences
|
||||
all_files = []
|
||||
self._collect_files_recursive(path, start, end, all_files)
|
||||
|
||||
# Count filename occurrences
|
||||
filename_counts: dict[str, int] = {}
|
||||
for entry, _ in all_files:
|
||||
filename_counts[entry.name] = filename_counts.get(entry.name, 0) + 1
|
||||
|
||||
# Process files in batches
|
||||
batch: list[Document] = []
|
||||
for entry, downloaded_file in all_files:
|
||||
modified_time = entry.client_modified
|
||||
if modified_time.tzinfo is None:
|
||||
modified_time = modified_time.replace(tzinfo=timezone.utc)
|
||||
else:
|
||||
modified_time = modified_time.astimezone(timezone.utc)
|
||||
|
||||
# Use full path only if filename appears multiple times
|
||||
if filename_counts.get(entry.name, 0) > 1:
|
||||
# Remove leading slash and replace slashes with ' / '
|
||||
relative_path = entry.path_display.lstrip('/')
|
||||
semantic_id = relative_path.replace('/', ' / ') if relative_path else entry.name
|
||||
else:
|
||||
semantic_id = entry.name
|
||||
|
||||
batch.append(
|
||||
Document(
|
||||
id=f"dropbox:{entry.id}",
|
||||
blob=downloaded_file,
|
||||
source=DocumentSource.DROPBOX,
|
||||
semantic_identifier=semantic_id,
|
||||
extension=get_file_ext(entry.name),
|
||||
doc_updated_at=modified_time,
|
||||
size_bytes=entry.size if getattr(entry, "size", None) is not None else len(downloaded_file),
|
||||
)
|
||||
)
|
||||
|
||||
if len(batch) == self.batch_size:
|
||||
yield batch
|
||||
batch = []
|
||||
|
||||
if batch:
|
||||
yield batch
|
||||
|
||||
def _collect_files_recursive(
|
||||
self,
|
||||
path: str,
|
||||
start: SecondsSinceUnixEpoch | None,
|
||||
end: SecondsSinceUnixEpoch | None,
|
||||
all_files: list,
|
||||
) -> None:
|
||||
"""Recursively collect all files matching time criteria."""
|
||||
if self.dropbox_client is None:
|
||||
raise ConnectorMissingCredentialError("Dropbox")
|
||||
|
||||
result = self.dropbox_client.files_list_folder(
|
||||
path,
|
||||
limit=self.batch_size,
|
||||
recursive=False,
|
||||
include_non_downloadable_files=False,
|
||||
)
|
||||
|
||||
while True:
|
||||
batch: list[Document] = []
|
||||
for entry in result.entries:
|
||||
if isinstance(entry, FileMetadata):
|
||||
modified_time = entry.client_modified
|
||||
@ -112,27 +166,13 @@ class DropboxConnector(LoadConnector, PollConnector):
|
||||
|
||||
try:
|
||||
downloaded_file = self._download_file(entry.path_display)
|
||||
all_files.append((entry, downloaded_file))
|
||||
except Exception:
|
||||
logger.exception(f"[Dropbox]: Error downloading file {entry.path_display}")
|
||||
continue
|
||||
|
||||
batch.append(
|
||||
Document(
|
||||
id=f"dropbox:{entry.id}",
|
||||
blob=downloaded_file,
|
||||
source=DocumentSource.DROPBOX,
|
||||
semantic_identifier=entry.name,
|
||||
extension=get_file_ext(entry.name),
|
||||
doc_updated_at=modified_time,
|
||||
size_bytes=entry.size if getattr(entry, "size", None) is not None else len(downloaded_file),
|
||||
)
|
||||
)
|
||||
|
||||
elif isinstance(entry, FolderMetadata):
|
||||
yield from self._yield_files_recursive(entry.path_lower, start, end)
|
||||
|
||||
if batch:
|
||||
yield batch
|
||||
self._collect_files_recursive(entry.path_lower, start, end, all_files)
|
||||
|
||||
if not result.has_more:
|
||||
break
|
||||
|
||||
@ -94,6 +94,7 @@ class Document(BaseModel):
|
||||
blob: bytes
|
||||
doc_updated_at: datetime
|
||||
size_bytes: int
|
||||
primary_owners: Optional[list] = None
|
||||
metadata: Optional[dict[str, Any]] = None
|
||||
|
||||
|
||||
@ -180,6 +181,7 @@ class NotionPage(BaseModel):
|
||||
archived: bool
|
||||
properties: dict[str, Any]
|
||||
url: str
|
||||
parent: Optional[dict[str, Any]] = None # Parent reference for path reconstruction
|
||||
database_name: Optional[str] = None # Only applicable to database type pages
|
||||
|
||||
|
||||
|
||||
@ -66,6 +66,7 @@ class NotionConnector(LoadConnector, PollConnector):
|
||||
self.indexed_pages: set[str] = set()
|
||||
self.root_page_id = root_page_id
|
||||
self.recursive_index_enabled = recursive_index_enabled or bool(root_page_id)
|
||||
self.page_path_cache: dict[str, str] = {}
|
||||
|
||||
@retry(tries=3, delay=1, backoff=2)
|
||||
def _fetch_child_blocks(self, block_id: str, cursor: Optional[str] = None) -> dict[str, Any] | None:
|
||||
@ -242,6 +243,20 @@ class NotionConnector(LoadConnector, PollConnector):
|
||||
logging.warning(f"[Notion]: Failed to download Notion file from {url}: {exc}")
|
||||
return None
|
||||
|
||||
def _append_block_id_to_name(self, name: str, block_id: Optional[str]) -> str:
|
||||
"""Append the Notion block ID to the filename while keeping the extension."""
|
||||
if not block_id:
|
||||
return name
|
||||
|
||||
path = Path(name)
|
||||
stem = path.stem or name
|
||||
suffix = path.suffix
|
||||
|
||||
if not stem:
|
||||
return name
|
||||
|
||||
return f"{stem}_{block_id}{suffix}" if suffix else f"{stem}_{block_id}"
|
||||
|
||||
def _extract_file_metadata(self, result_obj: dict[str, Any], block_id: str) -> tuple[str | None, str, str | None]:
|
||||
file_source_type = result_obj.get("type")
|
||||
file_source = result_obj.get(file_source_type, {}) if file_source_type else {}
|
||||
@ -254,6 +269,8 @@ class NotionConnector(LoadConnector, PollConnector):
|
||||
elif not name:
|
||||
name = f"notion_file_{block_id}"
|
||||
|
||||
name = self._append_block_id_to_name(name, block_id)
|
||||
|
||||
caption = self._extract_rich_text(result_obj.get("caption", [])) if "caption" in result_obj else None
|
||||
|
||||
return url, name, caption
|
||||
@ -265,6 +282,7 @@ class NotionConnector(LoadConnector, PollConnector):
|
||||
name: str,
|
||||
caption: Optional[str],
|
||||
page_last_edited_time: Optional[str],
|
||||
page_path: Optional[str],
|
||||
) -> Document | None:
|
||||
file_bytes = self._download_file(url)
|
||||
if file_bytes is None:
|
||||
@ -277,7 +295,8 @@ class NotionConnector(LoadConnector, PollConnector):
|
||||
extension = ".bin"
|
||||
|
||||
updated_at = datetime_from_string(page_last_edited_time) if page_last_edited_time else datetime.now(timezone.utc)
|
||||
semantic_identifier = caption or name or f"Notion file {block_id}"
|
||||
base_identifier = name or caption or (f"Notion file {block_id}" if block_id else "Notion file")
|
||||
semantic_identifier = f"{page_path} / {base_identifier}" if page_path else base_identifier
|
||||
|
||||
return Document(
|
||||
id=block_id,
|
||||
@ -289,7 +308,7 @@ class NotionConnector(LoadConnector, PollConnector):
|
||||
doc_updated_at=updated_at,
|
||||
)
|
||||
|
||||
def _read_blocks(self, base_block_id: str, page_last_edited_time: Optional[str] = None) -> tuple[list[NotionBlock], list[str], list[Document]]:
|
||||
def _read_blocks(self, base_block_id: str, page_last_edited_time: Optional[str] = None, page_path: Optional[str] = None) -> tuple[list[NotionBlock], list[str], list[Document]]:
|
||||
result_blocks: list[NotionBlock] = []
|
||||
child_pages: list[str] = []
|
||||
attachments: list[Document] = []
|
||||
@ -370,11 +389,14 @@ class NotionConnector(LoadConnector, PollConnector):
|
||||
name=file_name,
|
||||
caption=caption,
|
||||
page_last_edited_time=page_last_edited_time,
|
||||
page_path=page_path,
|
||||
)
|
||||
if attachment_doc:
|
||||
attachments.append(attachment_doc)
|
||||
|
||||
attachment_label = caption or file_name
|
||||
attachment_label = file_name
|
||||
if caption:
|
||||
attachment_label = f"{file_name} ({caption})"
|
||||
if attachment_label:
|
||||
cur_result_text_arr.append(f"{result_type.capitalize()}: {attachment_label}")
|
||||
|
||||
@ -383,7 +405,7 @@ class NotionConnector(LoadConnector, PollConnector):
|
||||
child_pages.append(result_block_id)
|
||||
else:
|
||||
logging.debug(f"[Notion]: Entering sub-block: {result_block_id}")
|
||||
subblocks, subblock_child_pages, subblock_attachments = self._read_blocks(result_block_id, page_last_edited_time)
|
||||
subblocks, subblock_child_pages, subblock_attachments = self._read_blocks(result_block_id, page_last_edited_time, page_path)
|
||||
logging.debug(f"[Notion]: Finished sub-block: {result_block_id}")
|
||||
result_blocks.extend(subblocks)
|
||||
child_pages.extend(subblock_child_pages)
|
||||
@ -423,6 +445,35 @@ class NotionConnector(LoadConnector, PollConnector):
|
||||
|
||||
return None
|
||||
|
||||
def _build_page_path(self, page: NotionPage, visited: Optional[set[str]] = None) -> Optional[str]:
|
||||
"""Construct a hierarchical path for a page based on its parent chain."""
|
||||
if page.id in self.page_path_cache:
|
||||
return self.page_path_cache[page.id]
|
||||
|
||||
visited = visited or set()
|
||||
if page.id in visited:
|
||||
logging.warning(f"[Notion]: Detected cycle while building path for page {page.id}")
|
||||
return self._read_page_title(page)
|
||||
visited.add(page.id)
|
||||
|
||||
current_title = self._read_page_title(page) or f"Untitled Page {page.id}"
|
||||
|
||||
parent_info = getattr(page, "parent", None) or {}
|
||||
parent_type = parent_info.get("type")
|
||||
parent_id = parent_info.get(parent_type) if parent_type else None
|
||||
|
||||
parent_path = None
|
||||
if parent_type in {"page_id", "database_id"} and isinstance(parent_id, str):
|
||||
try:
|
||||
parent_page = self._fetch_page(parent_id)
|
||||
parent_path = self._build_page_path(parent_page, visited)
|
||||
except Exception as exc:
|
||||
logging.warning(f"[Notion]: Failed to resolve parent {parent_id} for page {page.id}: {exc}")
|
||||
|
||||
full_path = f"{parent_path} / {current_title}" if parent_path else current_title
|
||||
self.page_path_cache[page.id] = full_path
|
||||
return full_path
|
||||
|
||||
def _read_pages(self, pages: list[NotionPage], start: SecondsSinceUnixEpoch | None = None, end: SecondsSinceUnixEpoch | None = None) -> Generator[Document, None, None]:
|
||||
"""Reads pages for rich text content and generates Documents."""
|
||||
all_child_page_ids: list[str] = []
|
||||
@ -441,13 +492,18 @@ class NotionConnector(LoadConnector, PollConnector):
|
||||
continue
|
||||
|
||||
logging.info(f"[Notion]: Reading page with ID {page.id}, with url {page.url}")
|
||||
page_blocks, child_page_ids, attachment_docs = self._read_blocks(page.id, page.last_edited_time)
|
||||
page_path = self._build_page_path(page)
|
||||
page_blocks, child_page_ids, attachment_docs = self._read_blocks(page.id, page.last_edited_time, page_path)
|
||||
all_child_page_ids.extend(child_page_ids)
|
||||
self.indexed_pages.add(page.id)
|
||||
|
||||
raw_page_title = self._read_page_title(page)
|
||||
page_title = raw_page_title or f"Untitled Page with ID {page.id}"
|
||||
|
||||
# Append the page id to help disambiguate duplicate names
|
||||
base_identifier = page_path or page_title
|
||||
semantic_identifier = f"{base_identifier}_{page.id}" if base_identifier else page.id
|
||||
|
||||
if not page_blocks:
|
||||
if not raw_page_title:
|
||||
logging.warning(f"[Notion]: No blocks OR title found for page with ID {page.id}. Skipping.")
|
||||
@ -469,7 +525,7 @@ class NotionConnector(LoadConnector, PollConnector):
|
||||
joined_text = "\n".join(sec.text for sec in sections)
|
||||
blob = joined_text.encode("utf-8")
|
||||
yield Document(
|
||||
id=page.id, blob=blob, source=DocumentSource.NOTION, semantic_identifier=page_title, extension=".txt", size_bytes=len(blob), doc_updated_at=datetime_from_string(page.last_edited_time)
|
||||
id=page.id, blob=blob, source=DocumentSource.NOTION, semantic_identifier=semantic_identifier, extension=".txt", size_bytes=len(blob), doc_updated_at=datetime_from_string(page.last_edited_time)
|
||||
)
|
||||
|
||||
for attachment_doc in attachment_docs:
|
||||
@ -597,4 +653,4 @@ if __name__ == "__main__":
|
||||
document_batches = connector.load_from_state()
|
||||
for doc_batch in document_batches:
|
||||
for doc in doc_batch:
|
||||
print(doc)
|
||||
print(doc)
|
||||
@ -167,7 +167,6 @@ def get_latest_message_time(thread: ThreadType) -> datetime:
|
||||
|
||||
|
||||
def _build_doc_id(channel_id: str, thread_ts: str) -> str:
|
||||
"""构建文档ID"""
|
||||
return f"{channel_id}__{thread_ts}"
|
||||
|
||||
|
||||
@ -179,7 +178,6 @@ def thread_to_doc(
|
||||
user_cache: dict[str, BasicExpertInfo | None],
|
||||
channel_access: Any | None,
|
||||
) -> Document:
|
||||
"""将线程转换为文档"""
|
||||
channel_id = channel["id"]
|
||||
|
||||
initial_sender_expert_info = expert_info_from_slack_id(
|
||||
@ -237,7 +235,6 @@ def filter_channels(
|
||||
channels_to_connect: list[str] | None,
|
||||
regex_enabled: bool,
|
||||
) -> list[ChannelType]:
|
||||
"""过滤频道"""
|
||||
if not channels_to_connect:
|
||||
return all_channels
|
||||
|
||||
@ -381,7 +378,6 @@ def _process_message(
|
||||
[MessageType], SlackMessageFilterReason | None
|
||||
] = default_msg_filter,
|
||||
) -> ProcessedSlackMessage:
|
||||
"""处理消息"""
|
||||
thread_ts = message.get("thread_ts")
|
||||
thread_or_message_ts = thread_ts or message["ts"]
|
||||
try:
|
||||
@ -536,7 +532,6 @@ class SlackConnector(
|
||||
end: SecondsSinceUnixEpoch | None = None,
|
||||
callback: Any = None,
|
||||
) -> GenerateSlimDocumentOutput:
|
||||
"""获取所有简化文档(带权限同步)"""
|
||||
if self.client is None:
|
||||
raise ConnectorMissingCredentialError("Slack")
|
||||
|
||||
|
||||
@ -254,18 +254,21 @@ def create_s3_client(bucket_type: BlobType, credentials: dict[str, Any], europea
|
||||
elif bucket_type == BlobType.S3:
|
||||
authentication_method = credentials.get("authentication_method", "access_key")
|
||||
|
||||
region_name = credentials.get("region") or None
|
||||
|
||||
if authentication_method == "access_key":
|
||||
session = boto3.Session(
|
||||
aws_access_key_id=credentials["aws_access_key_id"],
|
||||
aws_secret_access_key=credentials["aws_secret_access_key"],
|
||||
region_name=region_name,
|
||||
)
|
||||
return session.client("s3")
|
||||
return session.client("s3", region_name=region_name)
|
||||
|
||||
elif authentication_method == "iam_role":
|
||||
role_arn = credentials["aws_role_arn"]
|
||||
|
||||
def _refresh_credentials() -> dict[str, str]:
|
||||
sts_client = boto3.client("sts")
|
||||
sts_client = boto3.client("sts", region_name=credentials.get("region") or None)
|
||||
assumed_role_object = sts_client.assume_role(
|
||||
RoleArn=role_arn,
|
||||
RoleSessionName=f"onyx_blob_storage_{int(datetime.now().timestamp())}",
|
||||
@ -285,11 +288,11 @@ def create_s3_client(bucket_type: BlobType, credentials: dict[str, Any], europea
|
||||
)
|
||||
botocore_session = get_session()
|
||||
botocore_session._credentials = refreshable
|
||||
session = boto3.Session(botocore_session=botocore_session)
|
||||
return session.client("s3")
|
||||
session = boto3.Session(botocore_session=botocore_session, region_name=region_name)
|
||||
return session.client("s3", region_name=region_name)
|
||||
|
||||
elif authentication_method == "assume_role":
|
||||
return boto3.client("s3")
|
||||
return boto3.client("s3", region_name=region_name)
|
||||
|
||||
else:
|
||||
raise ValueError("Invalid authentication method for S3.")
|
||||
|
||||
0
common/doc_store/__init__.py
Normal file
0
common/doc_store/__init__.py
Normal file
@ -13,7 +13,6 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
|
||||
from abc import ABC, abstractmethod
|
||||
from dataclasses import dataclass
|
||||
import numpy as np
|
||||
@ -22,7 +21,6 @@ DEFAULT_MATCH_VECTOR_TOPN = 10
|
||||
DEFAULT_MATCH_SPARSE_TOPN = 10
|
||||
VEC = list | np.ndarray
|
||||
|
||||
|
||||
@dataclass
|
||||
class SparseVector:
|
||||
indices: list[int]
|
||||
@ -55,14 +53,13 @@ class SparseVector:
|
||||
def __repr__(self):
|
||||
return str(self)
|
||||
|
||||
|
||||
class MatchTextExpr(ABC):
|
||||
class MatchTextExpr:
|
||||
def __init__(
|
||||
self,
|
||||
fields: list[str],
|
||||
matching_text: str,
|
||||
topn: int,
|
||||
extra_options: dict = dict(),
|
||||
extra_options: dict | None = None,
|
||||
):
|
||||
self.fields = fields
|
||||
self.matching_text = matching_text
|
||||
@ -70,7 +67,7 @@ class MatchTextExpr(ABC):
|
||||
self.extra_options = extra_options
|
||||
|
||||
|
||||
class MatchDenseExpr(ABC):
|
||||
class MatchDenseExpr:
|
||||
def __init__(
|
||||
self,
|
||||
vector_column_name: str,
|
||||
@ -78,7 +75,7 @@ class MatchDenseExpr(ABC):
|
||||
embedding_data_type: str,
|
||||
distance_type: str,
|
||||
topn: int = DEFAULT_MATCH_VECTOR_TOPN,
|
||||
extra_options: dict = dict(),
|
||||
extra_options: dict | None = None,
|
||||
):
|
||||
self.vector_column_name = vector_column_name
|
||||
self.embedding_data = embedding_data
|
||||
@ -88,7 +85,7 @@ class MatchDenseExpr(ABC):
|
||||
self.extra_options = extra_options
|
||||
|
||||
|
||||
class MatchSparseExpr(ABC):
|
||||
class MatchSparseExpr:
|
||||
def __init__(
|
||||
self,
|
||||
vector_column_name: str,
|
||||
@ -104,7 +101,7 @@ class MatchSparseExpr(ABC):
|
||||
self.opt_params = opt_params
|
||||
|
||||
|
||||
class MatchTensorExpr(ABC):
|
||||
class MatchTensorExpr:
|
||||
def __init__(
|
||||
self,
|
||||
column_name: str,
|
||||
@ -120,7 +117,7 @@ class MatchTensorExpr(ABC):
|
||||
self.extra_option = extra_option
|
||||
|
||||
|
||||
class FusionExpr(ABC):
|
||||
class FusionExpr:
|
||||
def __init__(self, method: str, topn: int, fusion_params: dict | None = None):
|
||||
self.method = method
|
||||
self.topn = topn
|
||||
@ -129,7 +126,8 @@ class FusionExpr(ABC):
|
||||
|
||||
MatchExpr = MatchTextExpr | MatchDenseExpr | MatchSparseExpr | MatchTensorExpr | FusionExpr
|
||||
|
||||
class OrderByExpr(ABC):
|
||||
|
||||
class OrderByExpr:
|
||||
def __init__(self):
|
||||
self.fields = list()
|
||||
def asc(self, field: str):
|
||||
@ -141,13 +139,14 @@ class OrderByExpr(ABC):
|
||||
def fields(self):
|
||||
return self.fields
|
||||
|
||||
|
||||
class DocStoreConnection(ABC):
|
||||
"""
|
||||
Database operations
|
||||
"""
|
||||
|
||||
@abstractmethod
|
||||
def dbType(self) -> str:
|
||||
def db_type(self) -> str:
|
||||
"""
|
||||
Return the type of the database.
|
||||
"""
|
||||
@ -165,21 +164,21 @@ class DocStoreConnection(ABC):
|
||||
"""
|
||||
|
||||
@abstractmethod
|
||||
def createIdx(self, indexName: str, knowledgebaseId: str, vectorSize: int):
|
||||
def create_idx(self, index_name: str, dataset_id: str, vector_size: int):
|
||||
"""
|
||||
Create an index with given name
|
||||
"""
|
||||
raise NotImplementedError("Not implemented")
|
||||
|
||||
@abstractmethod
|
||||
def deleteIdx(self, indexName: str, knowledgebaseId: str):
|
||||
def delete_idx(self, index_name: str, dataset_id: str):
|
||||
"""
|
||||
Delete an index with given name
|
||||
"""
|
||||
raise NotImplementedError("Not implemented")
|
||||
|
||||
@abstractmethod
|
||||
def indexExist(self, indexName: str, knowledgebaseId: str) -> bool:
|
||||
def index_exist(self, index_name: str, dataset_id: str) -> bool:
|
||||
"""
|
||||
Check if an index with given name exists
|
||||
"""
|
||||
@ -191,16 +190,16 @@ class DocStoreConnection(ABC):
|
||||
|
||||
@abstractmethod
|
||||
def search(
|
||||
self, selectFields: list[str],
|
||||
highlightFields: list[str],
|
||||
self, select_fields: list[str],
|
||||
highlight_fields: list[str],
|
||||
condition: dict,
|
||||
matchExprs: list[MatchExpr],
|
||||
orderBy: OrderByExpr,
|
||||
match_expressions: list[MatchExpr],
|
||||
order_by: OrderByExpr,
|
||||
offset: int,
|
||||
limit: int,
|
||||
indexNames: str|list[str],
|
||||
knowledgebaseIds: list[str],
|
||||
aggFields: list[str] = [],
|
||||
index_names: str|list[str],
|
||||
dataset_ids: list[str],
|
||||
agg_fields: list[str] | None = None,
|
||||
rank_feature: dict | None = None
|
||||
):
|
||||
"""
|
||||
@ -209,28 +208,28 @@ class DocStoreConnection(ABC):
|
||||
raise NotImplementedError("Not implemented")
|
||||
|
||||
@abstractmethod
|
||||
def get(self, chunkId: str, indexName: str, knowledgebaseIds: list[str]) -> dict | None:
|
||||
def get(self, data_id: str, index_name: str, dataset_ids: list[str]) -> dict | None:
|
||||
"""
|
||||
Get single chunk with given id
|
||||
"""
|
||||
raise NotImplementedError("Not implemented")
|
||||
|
||||
@abstractmethod
|
||||
def insert(self, rows: list[dict], indexName: str, knowledgebaseId: str = None) -> list[str]:
|
||||
def insert(self, rows: list[dict], index_name: str, dataset_id: str = None) -> list[str]:
|
||||
"""
|
||||
Update or insert a bulk of rows
|
||||
"""
|
||||
raise NotImplementedError("Not implemented")
|
||||
|
||||
@abstractmethod
|
||||
def update(self, condition: dict, newValue: dict, indexName: str, knowledgebaseId: str) -> bool:
|
||||
def update(self, condition: dict, new_value: dict, index_name: str, dataset_id: str) -> bool:
|
||||
"""
|
||||
Update rows with given conjunctive equivalent filtering condition
|
||||
"""
|
||||
raise NotImplementedError("Not implemented")
|
||||
|
||||
@abstractmethod
|
||||
def delete(self, condition: dict, indexName: str, knowledgebaseId: str) -> int:
|
||||
def delete(self, condition: dict, index_name: str, dataset_id: str) -> int:
|
||||
"""
|
||||
Delete rows with given conjunctive equivalent filtering condition
|
||||
"""
|
||||
@ -245,7 +244,7 @@ class DocStoreConnection(ABC):
|
||||
raise NotImplementedError("Not implemented")
|
||||
|
||||
@abstractmethod
|
||||
def get_chunk_ids(self, res):
|
||||
def get_doc_ids(self, res):
|
||||
raise NotImplementedError("Not implemented")
|
||||
|
||||
@abstractmethod
|
||||
@ -253,18 +252,18 @@ class DocStoreConnection(ABC):
|
||||
raise NotImplementedError("Not implemented")
|
||||
|
||||
@abstractmethod
|
||||
def get_highlight(self, res, keywords: list[str], fieldnm: str):
|
||||
def get_highlight(self, res, keywords: list[str], field_name: str):
|
||||
raise NotImplementedError("Not implemented")
|
||||
|
||||
@abstractmethod
|
||||
def get_aggregation(self, res, fieldnm: str):
|
||||
def get_aggregation(self, res, field_name: str):
|
||||
raise NotImplementedError("Not implemented")
|
||||
|
||||
"""
|
||||
SQL
|
||||
"""
|
||||
@abstractmethod
|
||||
def sql(sql: str, fetch_size: int, format: str):
|
||||
def sql(self, sql: str, fetch_size: int, format: str):
|
||||
"""
|
||||
Run the sql generated by text-to-sql
|
||||
"""
|
||||
307
common/doc_store/es_conn_base.py
Normal file
307
common/doc_store/es_conn_base.py
Normal file
@ -0,0 +1,307 @@
|
||||
#
|
||||
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
|
||||
import logging
|
||||
import re
|
||||
import json
|
||||
import time
|
||||
import os
|
||||
from abc import abstractmethod
|
||||
|
||||
from elasticsearch import NotFoundError
|
||||
from elasticsearch_dsl import Index
|
||||
from elastic_transport import ConnectionTimeout
|
||||
from common.file_utils import get_project_base_directory
|
||||
from common.misc_utils import convert_bytes
|
||||
from common.doc_store.doc_store_base import DocStoreConnection, OrderByExpr, MatchExpr
|
||||
from rag.nlp import is_english, rag_tokenizer
|
||||
from common import settings
|
||||
|
||||
ATTEMPT_TIME = 2
|
||||
|
||||
|
||||
class ESConnectionBase(DocStoreConnection):
|
||||
def __init__(self, mapping_file_name: str="mapping.json", logger_name: str='ragflow.es_conn'):
|
||||
from common.doc_store.es_conn_pool import ES_CONN
|
||||
|
||||
self.logger = logging.getLogger(logger_name)
|
||||
|
||||
self.info = {}
|
||||
self.logger.info(f"Use Elasticsearch {settings.ES['hosts']} as the doc engine.")
|
||||
self.es = ES_CONN.get_conn()
|
||||
fp_mapping = os.path.join(get_project_base_directory(), "conf", mapping_file_name)
|
||||
if not os.path.exists(fp_mapping):
|
||||
msg = f"Elasticsearch mapping file not found at {fp_mapping}"
|
||||
self.logger.error(msg)
|
||||
raise Exception(msg)
|
||||
self.mapping = json.load(open(fp_mapping, "r"))
|
||||
self.logger.info(f"Elasticsearch {settings.ES['hosts']} is healthy.")
|
||||
|
||||
def _connect(self):
|
||||
from common.doc_store.es_conn_pool import ES_CONN
|
||||
|
||||
if self.es.ping():
|
||||
return True
|
||||
self.es = ES_CONN.refresh_conn()
|
||||
return True
|
||||
|
||||
"""
|
||||
Database operations
|
||||
"""
|
||||
|
||||
def db_type(self) -> str:
|
||||
return "elasticsearch"
|
||||
|
||||
def health(self) -> dict:
|
||||
health_dict = dict(self.es.cluster.health())
|
||||
health_dict["type"] = "elasticsearch"
|
||||
return health_dict
|
||||
|
||||
def get_cluster_stats(self):
|
||||
"""
|
||||
curl -XGET "http://{es_host}/_cluster/stats" -H "kbn-xsrf: reporting" to view raw stats.
|
||||
"""
|
||||
raw_stats = self.es.cluster.stats()
|
||||
self.logger.debug(f"ESConnection.get_cluster_stats: {raw_stats}")
|
||||
try:
|
||||
res = {
|
||||
'cluster_name': raw_stats['cluster_name'],
|
||||
'status': raw_stats['status']
|
||||
}
|
||||
indices_status = raw_stats['indices']
|
||||
res.update({
|
||||
'indices': indices_status['count'],
|
||||
'indices_shards': indices_status['shards']['total']
|
||||
})
|
||||
doc_info = indices_status['docs']
|
||||
res.update({
|
||||
'docs': doc_info['count'],
|
||||
'docs_deleted': doc_info['deleted']
|
||||
})
|
||||
store_info = indices_status['store']
|
||||
res.update({
|
||||
'store_size': convert_bytes(store_info['size_in_bytes']),
|
||||
'total_dataset_size': convert_bytes(store_info['total_data_set_size_in_bytes'])
|
||||
})
|
||||
mappings_info = indices_status['mappings']
|
||||
res.update({
|
||||
'mappings_fields': mappings_info['total_field_count'],
|
||||
'mappings_deduplicated_fields': mappings_info['total_deduplicated_field_count'],
|
||||
'mappings_deduplicated_size': convert_bytes(mappings_info['total_deduplicated_mapping_size_in_bytes'])
|
||||
})
|
||||
node_info = raw_stats['nodes']
|
||||
res.update({
|
||||
'nodes': node_info['count']['total'],
|
||||
'nodes_version': node_info['versions'],
|
||||
'os_mem': convert_bytes(node_info['os']['mem']['total_in_bytes']),
|
||||
'os_mem_used': convert_bytes(node_info['os']['mem']['used_in_bytes']),
|
||||
'os_mem_used_percent': node_info['os']['mem']['used_percent'],
|
||||
'jvm_versions': node_info['jvm']['versions'][0]['vm_version'],
|
||||
'jvm_heap_used': convert_bytes(node_info['jvm']['mem']['heap_used_in_bytes']),
|
||||
'jvm_heap_max': convert_bytes(node_info['jvm']['mem']['heap_max_in_bytes'])
|
||||
})
|
||||
return res
|
||||
|
||||
except Exception as e:
|
||||
self.logger.exception(f"ESConnection.get_cluster_stats: {e}")
|
||||
return None
|
||||
|
||||
"""
|
||||
Table operations
|
||||
"""
|
||||
|
||||
def create_idx(self, index_name: str, dataset_id: str, vector_size: int):
|
||||
if self.index_exist(index_name, dataset_id):
|
||||
return True
|
||||
try:
|
||||
from elasticsearch.client import IndicesClient
|
||||
return IndicesClient(self.es).create(index=index_name,
|
||||
settings=self.mapping["settings"],
|
||||
mappings=self.mapping["mappings"])
|
||||
except Exception:
|
||||
self.logger.exception("ESConnection.createIndex error %s" % index_name)
|
||||
|
||||
def delete_idx(self, index_name: str, dataset_id: str):
|
||||
if len(dataset_id) > 0:
|
||||
# The index need to be alive after any kb deletion since all kb under this tenant are in one index.
|
||||
return
|
||||
try:
|
||||
self.es.indices.delete(index=index_name, allow_no_indices=True)
|
||||
except NotFoundError:
|
||||
pass
|
||||
except Exception:
|
||||
self.logger.exception("ESConnection.deleteIdx error %s" % index_name)
|
||||
|
||||
def index_exist(self, index_name: str, dataset_id: str = None) -> bool:
|
||||
s = Index(index_name, self.es)
|
||||
for i in range(ATTEMPT_TIME):
|
||||
try:
|
||||
return s.exists()
|
||||
except ConnectionTimeout:
|
||||
self.logger.exception("ES request timeout")
|
||||
time.sleep(3)
|
||||
self._connect()
|
||||
continue
|
||||
except Exception as e:
|
||||
self.logger.exception(e)
|
||||
break
|
||||
return False
|
||||
|
||||
"""
|
||||
CRUD operations
|
||||
"""
|
||||
|
||||
def get(self, doc_id: str, index_name: str, dataset_ids: list[str]) -> dict | None:
|
||||
for i in range(ATTEMPT_TIME):
|
||||
try:
|
||||
res = self.es.get(index=index_name,
|
||||
id=doc_id, source=True, )
|
||||
if str(res.get("timed_out", "")).lower() == "true":
|
||||
raise Exception("Es Timeout.")
|
||||
doc = res["_source"]
|
||||
doc["id"] = doc_id
|
||||
return doc
|
||||
except NotFoundError:
|
||||
return None
|
||||
except Exception as e:
|
||||
self.logger.exception(f"ESConnection.get({doc_id}) got exception")
|
||||
raise e
|
||||
self.logger.error(f"ESConnection.get timeout for {ATTEMPT_TIME} times!")
|
||||
raise Exception("ESConnection.get timeout.")
|
||||
|
||||
@abstractmethod
|
||||
def search(
|
||||
self, select_fields: list[str],
|
||||
highlight_fields: list[str],
|
||||
condition: dict,
|
||||
match_expressions: list[MatchExpr],
|
||||
order_by: OrderByExpr,
|
||||
offset: int,
|
||||
limit: int,
|
||||
index_names: str | list[str],
|
||||
dataset_ids: list[str],
|
||||
agg_fields: list[str] | None = None,
|
||||
rank_feature: dict | None = None
|
||||
):
|
||||
raise NotImplementedError("Not implemented")
|
||||
|
||||
@abstractmethod
|
||||
def insert(self, documents: list[dict], index_name: str, dataset_id: str = None) -> list[str]:
|
||||
raise NotImplementedError("Not implemented")
|
||||
|
||||
@abstractmethod
|
||||
def update(self, condition: dict, new_value: dict, index_name: str, dataset_id: str) -> bool:
|
||||
raise NotImplementedError("Not implemented")
|
||||
|
||||
@abstractmethod
|
||||
def delete(self, condition: dict, index_name: str, dataset_id: str) -> int:
|
||||
raise NotImplementedError("Not implemented")
|
||||
|
||||
"""
|
||||
Helper functions for search result
|
||||
"""
|
||||
|
||||
def get_total(self, res):
|
||||
if isinstance(res["hits"]["total"], type({})):
|
||||
return res["hits"]["total"]["value"]
|
||||
return res["hits"]["total"]
|
||||
|
||||
def get_doc_ids(self, res):
|
||||
return [d["_id"] for d in res["hits"]["hits"]]
|
||||
|
||||
def _get_source(self, res):
|
||||
rr = []
|
||||
for d in res["hits"]["hits"]:
|
||||
d["_source"]["id"] = d["_id"]
|
||||
d["_source"]["_score"] = d["_score"]
|
||||
rr.append(d["_source"])
|
||||
return rr
|
||||
|
||||
@abstractmethod
|
||||
def get_fields(self, res, fields: list[str]) -> dict[str, dict]:
|
||||
raise NotImplementedError("Not implemented")
|
||||
|
||||
def get_highlight(self, res, keywords: list[str], field_name: str):
|
||||
ans = {}
|
||||
for d in res["hits"]["hits"]:
|
||||
highlights = d.get("highlight")
|
||||
if not highlights:
|
||||
continue
|
||||
txt = "...".join([a for a in list(highlights.items())[0][1]])
|
||||
if not is_english(txt.split()):
|
||||
ans[d["_id"]] = txt
|
||||
continue
|
||||
|
||||
txt = d["_source"][field_name]
|
||||
txt = re.sub(r"[\r\n]", " ", txt, flags=re.IGNORECASE | re.MULTILINE)
|
||||
txt_list = []
|
||||
for t in re.split(r"[.?!;\n]", txt):
|
||||
for w in keywords:
|
||||
t = re.sub(r"(^|[ .?/'\"\(\)!,:;-])(%s)([ .?/'\"\(\)!,:;-])" % re.escape(w), r"\1<em>\2</em>\3", t,
|
||||
flags=re.IGNORECASE | re.MULTILINE)
|
||||
if not re.search(r"<em>[^<>]+</em>", t, flags=re.IGNORECASE | re.MULTILINE):
|
||||
continue
|
||||
txt_list.append(t)
|
||||
ans[d["_id"]] = "...".join(txt_list) if txt_list else "...".join([a for a in list(highlights.items())[0][1]])
|
||||
|
||||
return ans
|
||||
|
||||
def get_aggregation(self, res, field_name: str):
|
||||
agg_field = "aggs_" + field_name
|
||||
if "aggregations" not in res or agg_field not in res["aggregations"]:
|
||||
return list()
|
||||
buckets = res["aggregations"][agg_field]["buckets"]
|
||||
return [(b["key"], b["doc_count"]) for b in buckets]
|
||||
|
||||
"""
|
||||
SQL
|
||||
"""
|
||||
|
||||
def sql(self, sql: str, fetch_size: int, format: str):
|
||||
self.logger.debug(f"ESConnection.sql get sql: {sql}")
|
||||
sql = re.sub(r"[ `]+", " ", sql)
|
||||
sql = sql.replace("%", "")
|
||||
replaces = []
|
||||
for r in re.finditer(r" ([a-z_]+_l?tks)( like | ?= ?)'([^']+)'", sql):
|
||||
fld, v = r.group(1), r.group(3)
|
||||
match = " MATCH({}, '{}', 'operator=OR;minimum_should_match=30%') ".format(
|
||||
fld, rag_tokenizer.fine_grained_tokenize(rag_tokenizer.tokenize(v)))
|
||||
replaces.append(
|
||||
("{}{}'{}'".format(
|
||||
r.group(1),
|
||||
r.group(2),
|
||||
r.group(3)),
|
||||
match))
|
||||
|
||||
for p, r in replaces:
|
||||
sql = sql.replace(p, r, 1)
|
||||
self.logger.debug(f"ESConnection.sql to es: {sql}")
|
||||
|
||||
for i in range(ATTEMPT_TIME):
|
||||
try:
|
||||
res = self.es.sql.query(body={"query": sql, "fetch_size": fetch_size}, format=format,
|
||||
request_timeout="2s")
|
||||
return res
|
||||
except ConnectionTimeout:
|
||||
self.logger.exception("ES request timeout")
|
||||
time.sleep(3)
|
||||
self._connect()
|
||||
continue
|
||||
except Exception as e:
|
||||
self.logger.exception(f"ESConnection.sql got exception. SQL:\n{sql}")
|
||||
raise Exception(f"SQL error: {e}\n\nSQL: {sql}")
|
||||
self.logger.error(f"ESConnection.sql timeout for {ATTEMPT_TIME} times!")
|
||||
return None
|
||||
84
common/doc_store/es_conn_pool.py
Normal file
84
common/doc_store/es_conn_pool.py
Normal file
@ -0,0 +1,84 @@
|
||||
#
|
||||
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
import logging
|
||||
import time
|
||||
from elasticsearch import Elasticsearch
|
||||
|
||||
from common import settings
|
||||
from common.decorator import singleton
|
||||
|
||||
ATTEMPT_TIME = 2
|
||||
|
||||
|
||||
@singleton
|
||||
class ElasticSearchConnectionPool:
|
||||
|
||||
def __init__(self):
|
||||
if hasattr(settings, "ES"):
|
||||
self.ES_CONFIG = settings.ES
|
||||
else:
|
||||
self.ES_CONFIG = settings.get_base_config("es", {})
|
||||
|
||||
for _ in range(ATTEMPT_TIME):
|
||||
try:
|
||||
if self._connect():
|
||||
break
|
||||
except Exception as e:
|
||||
logging.warning(f"{str(e)}. Waiting Elasticsearch {self.ES_CONFIG['hosts']} to be healthy.")
|
||||
time.sleep(5)
|
||||
|
||||
if not hasattr(self, "es_conn") or not self.es_conn or not self.es_conn.ping():
|
||||
msg = f"Elasticsearch {self.ES_CONFIG['hosts']} is unhealthy in 10s."
|
||||
logging.error(msg)
|
||||
raise Exception(msg)
|
||||
v = self.info.get("version", {"number": "8.11.3"})
|
||||
v = v["number"].split(".")[0]
|
||||
if int(v) < 8:
|
||||
msg = f"Elasticsearch version must be greater than or equal to 8, current version: {v}"
|
||||
logging.error(msg)
|
||||
raise Exception(msg)
|
||||
|
||||
def _connect(self):
|
||||
self.es_conn = Elasticsearch(
|
||||
self.ES_CONFIG["hosts"].split(","),
|
||||
basic_auth=(self.ES_CONFIG["username"], self.ES_CONFIG[
|
||||
"password"]) if "username" in self.ES_CONFIG and "password" in self.ES_CONFIG else None,
|
||||
verify_certs= self.ES_CONFIG.get("verify_certs", False),
|
||||
timeout=600 )
|
||||
if self.es_conn:
|
||||
self.info = self.es_conn.info()
|
||||
return True
|
||||
return False
|
||||
|
||||
def get_conn(self):
|
||||
return self.es_conn
|
||||
|
||||
def refresh_conn(self):
|
||||
if self.es_conn.ping():
|
||||
return self.es_conn
|
||||
else:
|
||||
# close current if exist
|
||||
if self.es_conn:
|
||||
self.es_conn.close()
|
||||
self._connect()
|
||||
return self.es_conn
|
||||
|
||||
def __del__(self):
|
||||
if hasattr(self, "es_conn") and self.es_conn:
|
||||
self.es_conn.close()
|
||||
|
||||
|
||||
ES_CONN = ElasticSearchConnectionPool()
|
||||
453
common/doc_store/infinity_conn_base.py
Normal file
453
common/doc_store/infinity_conn_base.py
Normal file
@ -0,0 +1,453 @@
|
||||
#
|
||||
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
|
||||
import logging
|
||||
import os
|
||||
import re
|
||||
import json
|
||||
import time
|
||||
from abc import abstractmethod
|
||||
|
||||
import infinity
|
||||
from infinity.common import ConflictType
|
||||
from infinity.index import IndexInfo, IndexType
|
||||
from infinity.errors import ErrorCode
|
||||
import pandas as pd
|
||||
from common.file_utils import get_project_base_directory
|
||||
from rag.nlp import is_english
|
||||
from common import settings
|
||||
from common.doc_store.doc_store_base import DocStoreConnection, MatchExpr, OrderByExpr
|
||||
|
||||
|
||||
class InfinityConnectionBase(DocStoreConnection):
|
||||
def __init__(self, mapping_file_name: str="infinity_mapping.json", logger_name: str="ragflow.infinity_conn"):
|
||||
from common.doc_store.infinity_conn_pool import INFINITY_CONN
|
||||
|
||||
self.dbName = settings.INFINITY.get("db_name", "default_db")
|
||||
self.mapping_file_name = mapping_file_name
|
||||
self.logger = logging.getLogger(logger_name)
|
||||
infinity_uri = settings.INFINITY["uri"]
|
||||
if ":" in infinity_uri:
|
||||
host, port = infinity_uri.split(":")
|
||||
infinity_uri = infinity.common.NetworkAddress(host, int(port))
|
||||
self.connPool = None
|
||||
self.logger.info(f"Use Infinity {infinity_uri} as the doc engine.")
|
||||
conn_pool = INFINITY_CONN.get_conn_pool()
|
||||
for _ in range(24):
|
||||
try:
|
||||
inf_conn = conn_pool.get_conn()
|
||||
res = inf_conn.show_current_node()
|
||||
if res.error_code == ErrorCode.OK and res.server_status in ["started", "alive"]:
|
||||
self._migrate_db(inf_conn)
|
||||
self.connPool = conn_pool
|
||||
conn_pool.release_conn(inf_conn)
|
||||
break
|
||||
conn_pool.release_conn(inf_conn)
|
||||
self.logger.warning(f"Infinity status: {res.server_status}. Waiting Infinity {infinity_uri} to be healthy.")
|
||||
time.sleep(5)
|
||||
except Exception as e:
|
||||
conn_pool = INFINITY_CONN.refresh_conn_pool()
|
||||
self.logger.warning(f"{str(e)}. Waiting Infinity {infinity_uri} to be healthy.")
|
||||
time.sleep(5)
|
||||
if self.connPool is None:
|
||||
msg = f"Infinity {infinity_uri} is unhealthy in 120s."
|
||||
self.logger.error(msg)
|
||||
raise Exception(msg)
|
||||
self.logger.info(f"Infinity {infinity_uri} is healthy.")
|
||||
|
||||
def _migrate_db(self, inf_conn):
|
||||
inf_db = inf_conn.create_database(self.dbName, ConflictType.Ignore)
|
||||
fp_mapping = os.path.join(get_project_base_directory(), "conf", self.mapping_file_name)
|
||||
if not os.path.exists(fp_mapping):
|
||||
raise Exception(f"Mapping file not found at {fp_mapping}")
|
||||
schema = json.load(open(fp_mapping))
|
||||
table_names = inf_db.list_tables().table_names
|
||||
for table_name in table_names:
|
||||
inf_table = inf_db.get_table(table_name)
|
||||
index_names = inf_table.list_indexes().index_names
|
||||
if "q_vec_idx" not in index_names:
|
||||
# Skip tables not created by me
|
||||
continue
|
||||
column_names = inf_table.show_columns()["name"]
|
||||
column_names = set(column_names)
|
||||
for field_name, field_info in schema.items():
|
||||
if field_name in column_names:
|
||||
continue
|
||||
res = inf_table.add_columns({field_name: field_info})
|
||||
assert res.error_code == infinity.ErrorCode.OK
|
||||
self.logger.info(f"INFINITY added following column to table {table_name}: {field_name} {field_info}")
|
||||
if field_info["type"] != "varchar" or "analyzer" not in field_info:
|
||||
continue
|
||||
analyzers = field_info["analyzer"]
|
||||
if isinstance(analyzers, str):
|
||||
analyzers = [analyzers]
|
||||
for analyzer in analyzers:
|
||||
inf_table.create_index(
|
||||
f"ft_{re.sub(r'[^a-zA-Z0-9]', '_', field_name)}_{re.sub(r'[^a-zA-Z0-9]', '_', analyzer)}",
|
||||
IndexInfo(field_name, IndexType.FullText, {"ANALYZER": analyzer}),
|
||||
ConflictType.Ignore,
|
||||
)
|
||||
|
||||
"""
|
||||
Dataframe and fields convert
|
||||
"""
|
||||
|
||||
@staticmethod
|
||||
@abstractmethod
|
||||
def field_keyword(field_name: str):
|
||||
# judge keyword or not, such as "*_kwd" tag-like columns.
|
||||
raise NotImplementedError("Not implemented")
|
||||
|
||||
@abstractmethod
|
||||
def convert_select_fields(self, output_fields: list[str]) -> list[str]:
|
||||
# rm _kwd, _tks, _sm_tks, _with_weight suffix in field name.
|
||||
raise NotImplementedError("Not implemented")
|
||||
|
||||
@staticmethod
|
||||
@abstractmethod
|
||||
def convert_matching_field(field_weight_str: str) -> str:
|
||||
# convert matching field to
|
||||
raise NotImplementedError("Not implemented")
|
||||
|
||||
@staticmethod
|
||||
def list2str(lst: str | list, sep: str = " ") -> str:
|
||||
if isinstance(lst, str):
|
||||
return lst
|
||||
return sep.join(lst)
|
||||
|
||||
def equivalent_condition_to_str(self, condition: dict, table_instance=None) -> str | None:
|
||||
assert "_id" not in condition
|
||||
columns = {}
|
||||
if table_instance:
|
||||
for n, ty, de, _ in table_instance.show_columns().rows():
|
||||
columns[n] = (ty, de)
|
||||
|
||||
def exists(cln):
|
||||
nonlocal columns
|
||||
assert cln in columns, f"'{cln}' should be in '{columns}'."
|
||||
ty, de = columns[cln]
|
||||
if ty.lower().find("cha"):
|
||||
if not de:
|
||||
de = ""
|
||||
return f" {cln}!='{de}' "
|
||||
return f"{cln}!={de}"
|
||||
|
||||
cond = list()
|
||||
for k, v in condition.items():
|
||||
if not isinstance(k, str) or not v:
|
||||
continue
|
||||
if self.field_keyword(k):
|
||||
if isinstance(v, list):
|
||||
inCond = list()
|
||||
for item in v:
|
||||
if isinstance(item, str):
|
||||
item = item.replace("'", "''")
|
||||
inCond.append(f"filter_fulltext('{self.convert_matching_field(k)}', '{item}')")
|
||||
if inCond:
|
||||
strInCond = " or ".join(inCond)
|
||||
strInCond = f"({strInCond})"
|
||||
cond.append(strInCond)
|
||||
else:
|
||||
cond.append(f"filter_fulltext('{self.convert_matching_field(k)}', '{v}')")
|
||||
elif isinstance(v, list):
|
||||
inCond = list()
|
||||
for item in v:
|
||||
if isinstance(item, str):
|
||||
item = item.replace("'", "''")
|
||||
inCond.append(f"'{item}'")
|
||||
else:
|
||||
inCond.append(str(item))
|
||||
if inCond:
|
||||
strInCond = ", ".join(inCond)
|
||||
strInCond = f"{k} IN ({strInCond})"
|
||||
cond.append(strInCond)
|
||||
elif k == "must_not":
|
||||
if isinstance(v, dict):
|
||||
for kk, vv in v.items():
|
||||
if kk == "exists":
|
||||
cond.append("NOT (%s)" % exists(vv))
|
||||
elif isinstance(v, str):
|
||||
cond.append(f"{k}='{v}'")
|
||||
elif k == "exists":
|
||||
cond.append(exists(v))
|
||||
else:
|
||||
cond.append(f"{k}={str(v)}")
|
||||
return " AND ".join(cond) if cond else "1=1"
|
||||
|
||||
@staticmethod
|
||||
def concat_dataframes(df_list: list[pd.DataFrame], select_fields: list[str]) -> pd.DataFrame:
|
||||
df_list2 = [df for df in df_list if not df.empty]
|
||||
if df_list2:
|
||||
return pd.concat(df_list2, axis=0).reset_index(drop=True)
|
||||
|
||||
schema = []
|
||||
for field_name in select_fields:
|
||||
if field_name == "score()": # Workaround: fix schema is changed to score()
|
||||
schema.append("SCORE")
|
||||
elif field_name == "similarity()": # Workaround: fix schema is changed to similarity()
|
||||
schema.append("SIMILARITY")
|
||||
else:
|
||||
schema.append(field_name)
|
||||
return pd.DataFrame(columns=schema)
|
||||
|
||||
"""
|
||||
Database operations
|
||||
"""
|
||||
|
||||
def db_type(self) -> str:
|
||||
return "infinity"
|
||||
|
||||
def health(self) -> dict:
|
||||
"""
|
||||
Return the health status of the database.
|
||||
"""
|
||||
inf_conn = self.connPool.get_conn()
|
||||
res = inf_conn.show_current_node()
|
||||
self.connPool.release_conn(inf_conn)
|
||||
res2 = {
|
||||
"type": "infinity",
|
||||
"status": "green" if res.error_code == 0 and res.server_status in ["started", "alive"] else "red",
|
||||
"error": res.error_msg,
|
||||
}
|
||||
return res2
|
||||
|
||||
"""
|
||||
Table operations
|
||||
"""
|
||||
|
||||
def create_idx(self, index_name: str, dataset_id: str, vector_size: int):
|
||||
table_name = f"{index_name}_{dataset_id}"
|
||||
inf_conn = self.connPool.get_conn()
|
||||
inf_db = inf_conn.create_database(self.dbName, ConflictType.Ignore)
|
||||
|
||||
fp_mapping = os.path.join(get_project_base_directory(), "conf", self.mapping_file_name)
|
||||
if not os.path.exists(fp_mapping):
|
||||
raise Exception(f"Mapping file not found at {fp_mapping}")
|
||||
schema = json.load(open(fp_mapping))
|
||||
vector_name = f"q_{vector_size}_vec"
|
||||
schema[vector_name] = {"type": f"vector,{vector_size},float"}
|
||||
inf_table = inf_db.create_table(
|
||||
table_name,
|
||||
schema,
|
||||
ConflictType.Ignore,
|
||||
)
|
||||
inf_table.create_index(
|
||||
"q_vec_idx",
|
||||
IndexInfo(
|
||||
vector_name,
|
||||
IndexType.Hnsw,
|
||||
{
|
||||
"M": "16",
|
||||
"ef_construction": "50",
|
||||
"metric": "cosine",
|
||||
"encode": "lvq",
|
||||
},
|
||||
),
|
||||
ConflictType.Ignore,
|
||||
)
|
||||
for field_name, field_info in schema.items():
|
||||
if field_info["type"] != "varchar" or "analyzer" not in field_info:
|
||||
continue
|
||||
analyzers = field_info["analyzer"]
|
||||
if isinstance(analyzers, str):
|
||||
analyzers = [analyzers]
|
||||
for analyzer in analyzers:
|
||||
inf_table.create_index(
|
||||
f"ft_{re.sub(r'[^a-zA-Z0-9]', '_', field_name)}_{re.sub(r'[^a-zA-Z0-9]', '_', analyzer)}",
|
||||
IndexInfo(field_name, IndexType.FullText, {"ANALYZER": analyzer}),
|
||||
ConflictType.Ignore,
|
||||
)
|
||||
self.connPool.release_conn(inf_conn)
|
||||
self.logger.info(f"INFINITY created table {table_name}, vector size {vector_size}")
|
||||
return True
|
||||
|
||||
def delete_idx(self, index_name: str, dataset_id: str):
|
||||
table_name = f"{index_name}_{dataset_id}"
|
||||
inf_conn = self.connPool.get_conn()
|
||||
db_instance = inf_conn.get_database(self.dbName)
|
||||
db_instance.drop_table(table_name, ConflictType.Ignore)
|
||||
self.connPool.release_conn(inf_conn)
|
||||
self.logger.info(f"INFINITY dropped table {table_name}")
|
||||
|
||||
def index_exist(self, index_name: str, dataset_id: str) -> bool:
|
||||
table_name = f"{index_name}_{dataset_id}"
|
||||
try:
|
||||
inf_conn = self.connPool.get_conn()
|
||||
db_instance = inf_conn.get_database(self.dbName)
|
||||
_ = db_instance.get_table(table_name)
|
||||
self.connPool.release_conn(inf_conn)
|
||||
return True
|
||||
except Exception as e:
|
||||
self.logger.warning(f"INFINITY indexExist {str(e)}")
|
||||
return False
|
||||
|
||||
"""
|
||||
CRUD operations
|
||||
"""
|
||||
|
||||
@abstractmethod
|
||||
def search(
|
||||
self,
|
||||
select_fields: list[str],
|
||||
highlight_fields: list[str],
|
||||
condition: dict,
|
||||
match_expressions: list[MatchExpr],
|
||||
order_by: OrderByExpr,
|
||||
offset: int,
|
||||
limit: int,
|
||||
index_names: str | list[str],
|
||||
dataset_ids: list[str],
|
||||
agg_fields: list[str] | None = None,
|
||||
rank_feature: dict | None = None,
|
||||
) -> tuple[pd.DataFrame, int]:
|
||||
raise NotImplementedError("Not implemented")
|
||||
|
||||
@abstractmethod
|
||||
def get(self, doc_id: str, index_name: str, knowledgebase_ids: list[str]) -> dict | None:
|
||||
raise NotImplementedError("Not implemented")
|
||||
|
||||
@abstractmethod
|
||||
def insert(self, documents: list[dict], index_name: str, dataset_ids: str = None) -> list[str]:
|
||||
raise NotImplementedError("Not implemented")
|
||||
|
||||
@abstractmethod
|
||||
def update(self, condition: dict, new_value: dict, index_name: str, dataset_id: str) -> bool:
|
||||
raise NotImplementedError("Not implemented")
|
||||
|
||||
def delete(self, condition: dict, index_name: str, dataset_id: str) -> int:
|
||||
inf_conn = self.connPool.get_conn()
|
||||
db_instance = inf_conn.get_database(self.dbName)
|
||||
table_name = f"{index_name}_{dataset_id}"
|
||||
try:
|
||||
table_instance = db_instance.get_table(table_name)
|
||||
except Exception:
|
||||
self.logger.warning(f"Skipped deleting from table {table_name} since the table doesn't exist.")
|
||||
return 0
|
||||
filter = self.equivalent_condition_to_str(condition, table_instance)
|
||||
self.logger.debug(f"INFINITY delete table {table_name}, filter {filter}.")
|
||||
res = table_instance.delete(filter)
|
||||
self.connPool.release_conn(inf_conn)
|
||||
return res.deleted_rows
|
||||
|
||||
"""
|
||||
Helper functions for search result
|
||||
"""
|
||||
|
||||
def get_total(self, res: tuple[pd.DataFrame, int] | pd.DataFrame) -> int:
|
||||
if isinstance(res, tuple):
|
||||
return res[1]
|
||||
return len(res)
|
||||
|
||||
def get_doc_ids(self, res: tuple[pd.DataFrame, int] | pd.DataFrame) -> list[str]:
|
||||
if isinstance(res, tuple):
|
||||
res = res[0]
|
||||
return list(res["id"])
|
||||
|
||||
@abstractmethod
|
||||
def get_fields(self, res: tuple[pd.DataFrame, int] | pd.DataFrame, fields: list[str]) -> dict[str, dict]:
|
||||
raise NotImplementedError("Not implemented")
|
||||
|
||||
def get_highlight(self, res: tuple[pd.DataFrame, int] | pd.DataFrame, keywords: list[str], field_name: str):
|
||||
if isinstance(res, tuple):
|
||||
res = res[0]
|
||||
ans = {}
|
||||
num_rows = len(res)
|
||||
column_id = res["id"]
|
||||
if field_name not in res:
|
||||
return {}
|
||||
for i in range(num_rows):
|
||||
id = column_id[i]
|
||||
txt = res[field_name][i]
|
||||
if re.search(r"<em>[^<>]+</em>", txt, flags=re.IGNORECASE | re.MULTILINE):
|
||||
ans[id] = txt
|
||||
continue
|
||||
txt = re.sub(r"[\r\n]", " ", txt, flags=re.IGNORECASE | re.MULTILINE)
|
||||
txt_list = []
|
||||
for t in re.split(r"[.?!;\n]", txt):
|
||||
if is_english([t]):
|
||||
for w in keywords:
|
||||
t = re.sub(
|
||||
r"(^|[ .?/'\"\(\)!,:;-])(%s)([ .?/'\"\(\)!,:;-])" % re.escape(w),
|
||||
r"\1<em>\2</em>\3",
|
||||
t,
|
||||
flags=re.IGNORECASE | re.MULTILINE,
|
||||
)
|
||||
else:
|
||||
for w in sorted(keywords, key=len, reverse=True):
|
||||
t = re.sub(
|
||||
re.escape(w),
|
||||
f"<em>{w}</em>",
|
||||
t,
|
||||
flags=re.IGNORECASE | re.MULTILINE,
|
||||
)
|
||||
if not re.search(r"<em>[^<>]+</em>", t, flags=re.IGNORECASE | re.MULTILINE):
|
||||
continue
|
||||
txt_list.append(t)
|
||||
if txt_list:
|
||||
ans[id] = "...".join(txt_list)
|
||||
else:
|
||||
ans[id] = txt
|
||||
return ans
|
||||
|
||||
def get_aggregation(self, res: tuple[pd.DataFrame, int] | pd.DataFrame, field_name: str):
|
||||
"""
|
||||
Manual aggregation for tag fields since Infinity doesn't provide native aggregation
|
||||
"""
|
||||
from collections import Counter
|
||||
|
||||
# Extract DataFrame from result
|
||||
if isinstance(res, tuple):
|
||||
df, _ = res
|
||||
else:
|
||||
df = res
|
||||
|
||||
if df.empty or field_name not in df.columns:
|
||||
return []
|
||||
|
||||
# Aggregate tag counts
|
||||
tag_counter = Counter()
|
||||
|
||||
for value in df[field_name]:
|
||||
if pd.isna(value) or not value:
|
||||
continue
|
||||
|
||||
# Handle different tag formats
|
||||
if isinstance(value, str):
|
||||
# Split by ### for tag_kwd field or comma for other formats
|
||||
if field_name == "tag_kwd" and "###" in value:
|
||||
tags = [tag.strip() for tag in value.split("###") if tag.strip()]
|
||||
else:
|
||||
# Try comma separation as fallback
|
||||
tags = [tag.strip() for tag in value.split(",") if tag.strip()]
|
||||
|
||||
for tag in tags:
|
||||
if tag: # Only count non-empty tags
|
||||
tag_counter[tag] += 1
|
||||
elif isinstance(value, list):
|
||||
# Handle list format
|
||||
for tag in value:
|
||||
if tag and isinstance(tag, str):
|
||||
tag_counter[tag.strip()] += 1
|
||||
|
||||
# Return as list of [tag, count] pairs, sorted by count descending
|
||||
return [[tag, count] for tag, count in tag_counter.most_common()]
|
||||
|
||||
"""
|
||||
SQL
|
||||
"""
|
||||
|
||||
def sql(self, sql: str, fetch_size: int, format: str):
|
||||
raise NotImplementedError("Not implemented")
|
||||
85
common/doc_store/infinity_conn_pool.py
Normal file
85
common/doc_store/infinity_conn_pool.py
Normal file
@ -0,0 +1,85 @@
|
||||
#
|
||||
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
import logging
|
||||
import time
|
||||
|
||||
import infinity
|
||||
from infinity.connection_pool import ConnectionPool
|
||||
from infinity.errors import ErrorCode
|
||||
|
||||
from common import settings
|
||||
from common.decorator import singleton
|
||||
|
||||
|
||||
@singleton
|
||||
class InfinityConnectionPool:
|
||||
|
||||
def __init__(self):
|
||||
if hasattr(settings, "INFINITY"):
|
||||
self.INFINITY_CONFIG = settings.INFINITY
|
||||
else:
|
||||
self.INFINITY_CONFIG = settings.get_base_config("infinity", {"uri": "infinity:23817"})
|
||||
|
||||
infinity_uri = self.INFINITY_CONFIG["uri"]
|
||||
if ":" in infinity_uri:
|
||||
host, port = infinity_uri.split(":")
|
||||
self.infinity_uri = infinity.common.NetworkAddress(host, int(port))
|
||||
|
||||
for _ in range(24):
|
||||
try:
|
||||
conn_pool = ConnectionPool(self.infinity_uri, max_size=4)
|
||||
inf_conn = conn_pool.get_conn()
|
||||
res = inf_conn.show_current_node()
|
||||
if res.error_code == ErrorCode.OK and res.server_status in ["started", "alive"]:
|
||||
self.conn_pool = conn_pool
|
||||
conn_pool.release_conn(inf_conn)
|
||||
break
|
||||
except Exception as e:
|
||||
logging.warning(f"{str(e)}. Waiting Infinity {infinity_uri} to be healthy.")
|
||||
time.sleep(5)
|
||||
|
||||
if self.conn_pool is None:
|
||||
msg = f"Infinity {infinity_uri} is unhealthy in 120s."
|
||||
logging.error(msg)
|
||||
raise Exception(msg)
|
||||
|
||||
logging.info(f"Infinity {infinity_uri} is healthy.")
|
||||
|
||||
def get_conn_pool(self):
|
||||
return self.conn_pool
|
||||
|
||||
def refresh_conn_pool(self):
|
||||
try:
|
||||
inf_conn = self.conn_pool.get_conn()
|
||||
res = inf_conn.show_current_node()
|
||||
if res.error_code == ErrorCode.OK and res.server_status in ["started", "alive"]:
|
||||
return self.conn_pool
|
||||
else:
|
||||
raise Exception(f"{res.error_code}: {res.server_status}")
|
||||
|
||||
except Exception as e:
|
||||
logging.error(str(e))
|
||||
if hasattr(self, "conn_pool") and self.conn_pool:
|
||||
self.conn_pool.destroy()
|
||||
self.conn_pool = ConnectionPool(self.infinity_uri, max_size=32)
|
||||
return self.conn_pool
|
||||
|
||||
def __del__(self):
|
||||
if hasattr(self, "conn_pool") and self.conn_pool:
|
||||
self.conn_pool.destroy()
|
||||
|
||||
|
||||
INFINITY_CONN = InfinityConnectionPool()
|
||||
@ -16,7 +16,7 @@ import logging
|
||||
import os
|
||||
import time
|
||||
from typing import Any, Dict, Optional
|
||||
from urllib.parse import parse_qsl, urlencode, urlparse, urlunparse
|
||||
from urllib.parse import urlparse, urlunparse
|
||||
|
||||
from common import settings
|
||||
import httpx
|
||||
@ -58,21 +58,34 @@ def _get_delay(backoff_factor: float, attempt: int) -> float:
|
||||
_SENSITIVE_QUERY_KEYS = {"client_secret", "secret", "code", "access_token", "refresh_token", "password", "token", "app_secret"}
|
||||
|
||||
def _redact_sensitive_url_params(url: str) -> str:
|
||||
"""
|
||||
Return a version of the URL that is safe to log.
|
||||
|
||||
We intentionally drop query parameters and userinfo to avoid leaking
|
||||
credentials or tokens via logs. Only scheme, host, port and path
|
||||
are preserved.
|
||||
"""
|
||||
try:
|
||||
parsed = urlparse(url)
|
||||
if not parsed.query:
|
||||
return url
|
||||
clean_query = []
|
||||
for k, v in parse_qsl(parsed.query, keep_blank_values=True):
|
||||
if k.lower() in _SENSITIVE_QUERY_KEYS:
|
||||
clean_query.append((k, "***REDACTED***"))
|
||||
else:
|
||||
clean_query.append((k, v))
|
||||
new_query = urlencode(clean_query, doseq=True)
|
||||
redacted_url = urlunparse(parsed._replace(query=new_query))
|
||||
return redacted_url
|
||||
# Remove any potential userinfo (username:password@)
|
||||
netloc = parsed.hostname or ""
|
||||
if parsed.port:
|
||||
netloc = f"{netloc}:{parsed.port}"
|
||||
# Reconstruct URL without query, params, fragment, or userinfo.
|
||||
safe_url = urlunparse(
|
||||
(
|
||||
parsed.scheme,
|
||||
netloc,
|
||||
parsed.path,
|
||||
"", # params
|
||||
"", # query
|
||||
"", # fragment
|
||||
)
|
||||
)
|
||||
return safe_url
|
||||
except Exception:
|
||||
return url
|
||||
# If parsing fails, fall back to omitting the URL entirely.
|
||||
return "<redacted-url>"
|
||||
|
||||
def _is_sensitive_url(url: str) -> bool:
|
||||
"""Return True if URL is one of the configured OAuth endpoints."""
|
||||
@ -144,23 +157,28 @@ async def async_request(
|
||||
method=method, url=url, headers=headers, **kwargs
|
||||
)
|
||||
duration = time.monotonic() - start
|
||||
log_url = "<SENSITIVE ENDPOINT>" if _is_sensitive_url(url) else _redact_sensitive_url_params(url)
|
||||
logger.debug(
|
||||
f"async_request {method} {log_url} -> {response.status_code} in {duration:.3f}s"
|
||||
)
|
||||
if not _is_sensitive_url(url):
|
||||
log_url = _redact_sensitive_url_params(url)
|
||||
logger.debug(f"async_request {method} {log_url} -> {response.status_code} in {duration:.3f}s")
|
||||
return response
|
||||
except httpx.RequestError as exc:
|
||||
last_exc = exc
|
||||
if attempt >= retries:
|
||||
log_url = "<SENSITIVE ENDPOINT>" if _is_sensitive_url(url) else _redact_sensitive_url_params(url)
|
||||
if not _is_sensitive_url(url):
|
||||
log_url = _redact_sensitive_url_params(url)
|
||||
logger.warning(f"async_request exhausted retries for {method}")
|
||||
raise
|
||||
delay = _get_delay(backoff_factor, attempt)
|
||||
if not _is_sensitive_url(url):
|
||||
log_url = _redact_sensitive_url_params(url)
|
||||
logger.warning(
|
||||
f"async_request exhausted retries for {method} {log_url}"
|
||||
f"async_request attempt {attempt + 1}/{retries + 1} failed for {method}; retrying in {delay:.2f}s"
|
||||
)
|
||||
raise
|
||||
delay = _get_delay(backoff_factor, attempt)
|
||||
log_url = "<SENSITIVE ENDPOINT>" if _is_sensitive_url(url) else _redact_sensitive_url_params(url)
|
||||
# Avoid including the (potentially sensitive) URL in retry logs.
|
||||
logger.warning(
|
||||
f"async_request attempt {attempt + 1}/{retries + 1} failed for {method} {log_url}; retrying in {delay:.2f}s"
|
||||
f"async_request attempt {attempt + 1}/{retries + 1} failed for {method}; retrying in {delay:.2f}s"
|
||||
)
|
||||
await asyncio.sleep(delay)
|
||||
raise last_exc # pragma: no cover
|
||||
|
||||
@ -75,9 +75,12 @@ def init_root_logger(logfile_basename: str, log_format: str = "%(asctime)-15s %(
|
||||
def log_exception(e, *args):
|
||||
logging.exception(e)
|
||||
for a in args:
|
||||
if hasattr(a, "text"):
|
||||
logging.error(a.text)
|
||||
raise Exception(a.text)
|
||||
else:
|
||||
logging.error(str(a))
|
||||
try:
|
||||
text = getattr(a, "text")
|
||||
except Exception:
|
||||
text = None
|
||||
if text is not None:
|
||||
logging.error(text)
|
||||
raise Exception(text)
|
||||
logging.error(str(a))
|
||||
raise e
|
||||
|
||||
@ -44,21 +44,27 @@ def meta_filter(metas: dict, filters: list[dict], logic: str = "and"):
|
||||
def filter_out(v2docs, operator, value):
|
||||
ids = []
|
||||
for input, docids in v2docs.items():
|
||||
|
||||
if operator in ["=", "≠", ">", "<", "≥", "≤"]:
|
||||
try:
|
||||
if isinstance(input, list):
|
||||
input = input[0]
|
||||
input = float(input)
|
||||
value = float(value)
|
||||
except Exception:
|
||||
input = str(input)
|
||||
value = str(value)
|
||||
pass
|
||||
if isinstance(input, str):
|
||||
input = input.lower()
|
||||
if isinstance(value, str):
|
||||
value = value.lower()
|
||||
|
||||
for conds in [
|
||||
(operator == "contains", str(value).lower() in str(input).lower()),
|
||||
(operator == "not contains", str(value).lower() not in str(input).lower()),
|
||||
(operator == "in", str(input).lower() in str(value).lower()),
|
||||
(operator == "not in", str(input).lower() not in str(value).lower()),
|
||||
(operator == "start with", str(input).lower().startswith(str(value).lower())),
|
||||
(operator == "end with", str(input).lower().endswith(str(value).lower())),
|
||||
(operator == "contains", input in value if not isinstance(input, list) else all([i in value for i in input])),
|
||||
(operator == "not contains", input not in value if not isinstance(input, list) else all([i not in value for i in input])),
|
||||
(operator == "in", input in value if not isinstance(input, list) else all([i in value for i in input])),
|
||||
(operator == "not in", input not in value if not isinstance(input, list) else all([i not in value for i in input])),
|
||||
(operator == "start with", str(input).lower().startswith(str(value).lower()) if not isinstance(input, list) else "".join([str(i).lower() for i in input]).startswith(str(value).lower())),
|
||||
(operator == "end with", str(input).lower().endswith(str(value).lower()) if not isinstance(input, list) else "".join([str(i).lower() for i in input]).endswith(str(value).lower())),
|
||||
(operator == "empty", not input),
|
||||
(operator == "not empty", input),
|
||||
(operator == "=", input == value),
|
||||
@ -145,6 +151,18 @@ async def apply_meta_data_filter(
|
||||
return doc_ids
|
||||
|
||||
|
||||
def dedupe_list(values: list) -> list:
|
||||
seen = set()
|
||||
deduped = []
|
||||
for item in values:
|
||||
key = str(item)
|
||||
if key in seen:
|
||||
continue
|
||||
seen.add(key)
|
||||
deduped.append(item)
|
||||
return deduped
|
||||
|
||||
|
||||
def update_metadata_to(metadata, meta):
|
||||
if not meta:
|
||||
return metadata
|
||||
@ -156,11 +174,13 @@ def update_metadata_to(metadata, meta):
|
||||
return metadata
|
||||
if not isinstance(meta, dict):
|
||||
return metadata
|
||||
|
||||
for k, v in meta.items():
|
||||
if isinstance(v, list):
|
||||
v = [vv for vv in v if isinstance(vv, str)]
|
||||
if not v:
|
||||
continue
|
||||
v = dedupe_list(v)
|
||||
if not isinstance(v, list) and not isinstance(v, str):
|
||||
continue
|
||||
if k not in metadata:
|
||||
@ -171,6 +191,7 @@ def update_metadata_to(metadata, meta):
|
||||
metadata[k].extend(v)
|
||||
else:
|
||||
metadata[k].append(v)
|
||||
metadata[k] = dedupe_list(metadata[k])
|
||||
else:
|
||||
metadata[k] = v
|
||||
|
||||
@ -202,4 +223,4 @@ def metadata_schema(metadata: list|None) -> Dict[str, Any]:
|
||||
}
|
||||
|
||||
json_schema["additionalProperties"] = False
|
||||
return json_schema
|
||||
return json_schema
|
||||
|
||||
72
common/query_base.py
Normal file
72
common/query_base.py
Normal file
@ -0,0 +1,72 @@
|
||||
#
|
||||
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
import re
|
||||
from abc import ABC, abstractmethod
|
||||
|
||||
|
||||
class QueryBase(ABC):
|
||||
|
||||
@staticmethod
|
||||
def is_chinese(line):
|
||||
arr = re.split(r"[ \t]+", line)
|
||||
if len(arr) <= 3:
|
||||
return True
|
||||
e = 0
|
||||
for t in arr:
|
||||
if not re.match(r"[a-zA-Z]+$", t):
|
||||
e += 1
|
||||
return e * 1.0 / len(arr) >= 0.7
|
||||
|
||||
@staticmethod
|
||||
def sub_special_char(line):
|
||||
return re.sub(r"([:\{\}/\[\]\-\*\"\(\)\|\+~\^])", r"\\\1", line).strip()
|
||||
|
||||
@staticmethod
|
||||
def rmWWW(txt):
|
||||
patts = [
|
||||
(
|
||||
r"是*(怎么办|什么样的|哪家|一下|那家|请问|啥样|咋样了|什么时候|何时|何地|何人|是否|是不是|多少|哪里|怎么|哪儿|怎么样|如何|哪些|是啥|啥是|啊|吗|呢|吧|咋|什么|有没有|呀|谁|哪位|哪个)是*",
|
||||
"",
|
||||
),
|
||||
(r"(^| )(what|who|how|which|where|why)('re|'s)? ", " "),
|
||||
(
|
||||
r"(^| )('s|'re|is|are|were|was|do|does|did|don't|doesn't|didn't|has|have|be|there|you|me|your|my|mine|just|please|may|i|should|would|wouldn't|will|won't|done|go|for|with|so|the|a|an|by|i'm|it's|he's|she's|they|they're|you're|as|by|on|in|at|up|out|down|of|to|or|and|if) ",
|
||||
" ")
|
||||
]
|
||||
otxt = txt
|
||||
for r, p in patts:
|
||||
txt = re.sub(r, p, txt, flags=re.IGNORECASE)
|
||||
if not txt:
|
||||
txt = otxt
|
||||
return txt
|
||||
|
||||
@staticmethod
|
||||
def add_space_between_eng_zh(txt):
|
||||
# (ENG/ENG+NUM) + ZH
|
||||
txt = re.sub(r'([A-Za-z]+[0-9]+)([\u4e00-\u9fa5]+)', r'\1 \2', txt)
|
||||
# ENG + ZH
|
||||
txt = re.sub(r'([A-Za-z])([\u4e00-\u9fa5]+)', r'\1 \2', txt)
|
||||
# ZH + (ENG/ENG+NUM)
|
||||
txt = re.sub(r'([\u4e00-\u9fa5]+)([A-Za-z]+[0-9]+)', r'\1 \2', txt)
|
||||
txt = re.sub(r'([\u4e00-\u9fa5]+)([A-Za-z])', r'\1 \2', txt)
|
||||
return txt
|
||||
|
||||
@abstractmethod
|
||||
def question(self, text, tbl, min_match):
|
||||
"""
|
||||
Returns a query object based on the input text, table, and minimum match criteria.
|
||||
"""
|
||||
raise NotImplementedError("Not implemented")
|
||||
@ -39,6 +39,9 @@ from rag.utils.oss_conn import RAGFlowOSS
|
||||
|
||||
from rag.nlp import search
|
||||
|
||||
import memory.utils.es_conn as memory_es_conn
|
||||
import memory.utils.infinity_conn as memory_infinity_conn
|
||||
|
||||
LLM = None
|
||||
LLM_FACTORY = None
|
||||
LLM_BASE_URL = None
|
||||
@ -79,6 +82,7 @@ DOC_ENGINE_INFINITY = (DOC_ENGINE.lower() == "infinity")
|
||||
|
||||
|
||||
docStoreConn = None
|
||||
msgStoreConn = None
|
||||
|
||||
retriever = None
|
||||
kg_retriever = None
|
||||
@ -256,6 +260,15 @@ def init_settings():
|
||||
else:
|
||||
raise Exception(f"Not supported doc engine: {DOC_ENGINE}")
|
||||
|
||||
global msgStoreConn
|
||||
# use the same engine for message store
|
||||
if DOC_ENGINE == "elasticsearch":
|
||||
ES = get_base_config("es", {})
|
||||
msgStoreConn = memory_es_conn.ESConnection()
|
||||
elif DOC_ENGINE == "infinity":
|
||||
INFINITY = get_base_config("infinity", {"uri": "infinity:23817"})
|
||||
msgStoreConn = memory_infinity_conn.InfinityConnection()
|
||||
|
||||
global AZURE, S3, MINIO, OSS, GCS
|
||||
if STORAGE_IMPL_TYPE in ['AZURE_SPN', 'AZURE_SAS']:
|
||||
AZURE = get_base_config("azure", {})
|
||||
|
||||
@ -14,6 +14,7 @@
|
||||
# limitations under the License.
|
||||
|
||||
import datetime
|
||||
import logging
|
||||
import time
|
||||
|
||||
def current_timestamp():
|
||||
@ -123,4 +124,31 @@ def delta_seconds(date_string: str):
|
||||
3600.0 # If current time is 2024-01-01 13:00:00
|
||||
"""
|
||||
dt = datetime.datetime.strptime(date_string, "%Y-%m-%d %H:%M:%S")
|
||||
return (datetime.datetime.now() - dt).total_seconds()
|
||||
return (datetime.datetime.now() - dt).total_seconds()
|
||||
|
||||
|
||||
def format_iso_8601_to_ymd_hms(time_str: str) -> str:
|
||||
"""
|
||||
Convert ISO 8601 formatted string to "YYYY-MM-DD HH:MM:SS" format.
|
||||
|
||||
Args:
|
||||
time_str: ISO 8601 date string (e.g. "2024-01-01T12:00:00Z")
|
||||
|
||||
Returns:
|
||||
str: Date string in "YYYY-MM-DD HH:MM:SS" format
|
||||
|
||||
Example:
|
||||
>>> format_iso_8601_to_ymd_hms("2024-01-01T12:00:00Z")
|
||||
'2024-01-01 12:00:00'
|
||||
"""
|
||||
from dateutil import parser
|
||||
|
||||
try:
|
||||
if parser.isoparse(time_str):
|
||||
dt = datetime.datetime.fromisoformat(time_str.replace("Z", "+00:00"))
|
||||
return dt.strftime("%Y-%m-%d %H:%M:%S")
|
||||
else:
|
||||
return time_str
|
||||
except Exception as e:
|
||||
logging.error(str(e))
|
||||
return time_str
|
||||
|
||||
@ -44,17 +44,23 @@ def total_token_count_from_response(resp):
|
||||
if resp is None:
|
||||
return 0
|
||||
|
||||
if hasattr(resp, "usage") and hasattr(resp.usage, "total_tokens"):
|
||||
try:
|
||||
try:
|
||||
if hasattr(resp, "usage") and hasattr(resp.usage, "total_tokens"):
|
||||
return resp.usage.total_tokens
|
||||
except Exception:
|
||||
pass
|
||||
except Exception:
|
||||
pass
|
||||
|
||||
if hasattr(resp, "usage_metadata") and hasattr(resp.usage_metadata, "total_tokens"):
|
||||
try:
|
||||
try:
|
||||
if hasattr(resp, "usage_metadata") and hasattr(resp.usage_metadata, "total_tokens"):
|
||||
return resp.usage_metadata.total_tokens
|
||||
except Exception:
|
||||
pass
|
||||
except Exception:
|
||||
pass
|
||||
|
||||
try:
|
||||
if hasattr(resp, "meta") and hasattr(resp.meta, "billed_units") and hasattr(resp.meta.billed_units, "input_tokens"):
|
||||
return resp.meta.billed_units.input_tokens
|
||||
except Exception:
|
||||
pass
|
||||
|
||||
if isinstance(resp, dict) and 'usage' in resp and 'total_tokens' in resp['usage']:
|
||||
try:
|
||||
@ -79,4 +85,3 @@ def total_token_count_from_response(resp):
|
||||
def truncate(string: str, max_len: int) -> str:
|
||||
"""Returns truncated text if the length of text exceed max_len."""
|
||||
return encoder.decode(encoder.encode(string)[:max_len])
|
||||
|
||||
|
||||
@ -31,6 +31,7 @@
|
||||
"entity_type_kwd": {"type": "varchar", "default": "", "analyzer": "whitespace-#"},
|
||||
"source_id": {"type": "varchar", "default": "", "analyzer": "whitespace-#"},
|
||||
"n_hop_with_weight": {"type": "varchar", "default": ""},
|
||||
"mom_with_weight": {"type": "varchar", "default": ""},
|
||||
"removed_kwd": {"type": "varchar", "default": "", "analyzer": "whitespace-#"},
|
||||
"doc_type_kwd": {"type": "varchar", "default": "", "analyzer": "whitespace-#"},
|
||||
"toc_kwd": {"type": "varchar", "default": "", "analyzer": "whitespace-#"},
|
||||
|
||||
@ -762,6 +762,13 @@
|
||||
"status": "1",
|
||||
"rank": "940",
|
||||
"llm": [
|
||||
{
|
||||
"llm_name": "glm-4.7",
|
||||
"tags": "LLM,CHAT,128K",
|
||||
"max_tokens": 128000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "glm-4.5",
|
||||
"tags": "LLM,CHAT,128K",
|
||||
@ -1251,6 +1258,12 @@
|
||||
"status": "1",
|
||||
"rank": "810",
|
||||
"llm": [
|
||||
{
|
||||
"llm_name": "MiniMax-M2.1",
|
||||
"tags": "LLM,CHAT,200k",
|
||||
"max_tokens": 200000,
|
||||
"model_type": "chat"
|
||||
},
|
||||
{
|
||||
"llm_name": "MiniMax-M2",
|
||||
"tags": "LLM,CHAT,200k",
|
||||
|
||||
19
conf/message_infinity_mapping.json
Normal file
19
conf/message_infinity_mapping.json
Normal file
@ -0,0 +1,19 @@
|
||||
{
|
||||
"id": {"type": "varchar", "default": ""},
|
||||
"message_id": {"type": "integer", "default": 0},
|
||||
"message_type_kwd": {"type": "varchar", "default": ""},
|
||||
"source_id": {"type": "integer", "default": 0},
|
||||
"memory_id": {"type": "varchar", "default": ""},
|
||||
"user_id": {"type": "varchar", "default": ""},
|
||||
"agent_id": {"type": "varchar", "default": ""},
|
||||
"session_id": {"type": "varchar", "default": ""},
|
||||
"valid_at": {"type": "varchar", "default": ""},
|
||||
"valid_at_flt": {"type": "float", "default": 0.0},
|
||||
"invalid_at": {"type": "varchar", "default": ""},
|
||||
"invalid_at_flt": {"type": "float", "default": 0.0},
|
||||
"forget_at": {"type": "varchar", "default": ""},
|
||||
"forget_at_flt": {"type": "float", "default": 0.0},
|
||||
"status_int": {"type": "integer", "default": 1},
|
||||
"zone_id": {"type": "integer", "default": 0},
|
||||
"content": {"type": "varchar", "default": "", "analyzer": ["rag-coarse", "rag-fine"], "comment": "content_ltks"}
|
||||
}
|
||||
@ -18,6 +18,7 @@ from io import BytesIO
|
||||
|
||||
import pandas as pd
|
||||
from openpyxl import Workbook, load_workbook
|
||||
from PIL import Image
|
||||
|
||||
from rag.nlp import find_codec
|
||||
|
||||
@ -109,6 +110,52 @@ class RAGFlowExcelParser:
|
||||
ws.cell(row=row_num, column=col_num, value=value)
|
||||
return wb
|
||||
|
||||
@staticmethod
|
||||
def _extract_images_from_worksheet(ws, sheetname=None):
|
||||
"""
|
||||
Extract images from a worksheet and enrich them with vision-based descriptions.
|
||||
|
||||
Returns: List[dict]
|
||||
"""
|
||||
images = getattr(ws, "_images", [])
|
||||
if not images:
|
||||
return []
|
||||
|
||||
raw_items = []
|
||||
|
||||
for img in images:
|
||||
try:
|
||||
img_bytes = img._data()
|
||||
pil_img = Image.open(BytesIO(img_bytes)).convert("RGB")
|
||||
|
||||
anchor = img.anchor
|
||||
if hasattr(anchor, "_from") and hasattr(anchor, "_to"):
|
||||
r1, c1 = anchor._from.row + 1, anchor._from.col + 1
|
||||
r2, c2 = anchor._to.row + 1, anchor._to.col + 1
|
||||
if r1 == r2 and c1 == c2:
|
||||
span = "single_cell"
|
||||
else:
|
||||
span = "multi_cell"
|
||||
else:
|
||||
r1, c1 = anchor._from.row + 1, anchor._from.col + 1
|
||||
r2, c2 = r1, c1
|
||||
span = "single_cell"
|
||||
|
||||
item = {
|
||||
"sheet": sheetname or ws.title,
|
||||
"image": pil_img,
|
||||
"image_description": "",
|
||||
"row_from": r1,
|
||||
"col_from": c1,
|
||||
"row_to": r2,
|
||||
"col_to": c2,
|
||||
"span_type": span,
|
||||
}
|
||||
raw_items.append(item)
|
||||
except Exception:
|
||||
continue
|
||||
return raw_items
|
||||
|
||||
def html(self, fnm, chunk_rows=256):
|
||||
from html import escape
|
||||
|
||||
|
||||
@ -38,8 +38,8 @@ def vision_figure_parser_figure_data_wrapper(figures_data_without_positions):
|
||||
|
||||
|
||||
def vision_figure_parser_docx_wrapper(sections, tbls, callback=None,**kwargs):
|
||||
if not tbls:
|
||||
return []
|
||||
if not sections:
|
||||
return tbls
|
||||
try:
|
||||
vision_model = LLMBundle(kwargs["tenant_id"], LLMType.IMAGE2TEXT)
|
||||
callback(0.7, "Visual model detected. Attempting to enhance figure extraction...")
|
||||
@ -55,6 +55,31 @@ def vision_figure_parser_docx_wrapper(sections, tbls, callback=None,**kwargs):
|
||||
callback(0.8, f"Visual model error: {e}. Skipping figure parsing enhancement.")
|
||||
return tbls
|
||||
|
||||
def vision_figure_parser_figure_xlsx_wrapper(images,callback=None, **kwargs):
|
||||
tbls = []
|
||||
if not images:
|
||||
return []
|
||||
try:
|
||||
vision_model = LLMBundle(kwargs["tenant_id"], LLMType.IMAGE2TEXT)
|
||||
callback(0.2, "Visual model detected. Attempting to enhance Excel image extraction...")
|
||||
except Exception:
|
||||
vision_model = None
|
||||
if vision_model:
|
||||
figures_data = [((
|
||||
img["image"], # Image.Image
|
||||
[img["image_description"]] # description list (must be list)
|
||||
),
|
||||
[
|
||||
(0, 0, 0, 0, 0) # dummy position
|
||||
]) for img in images]
|
||||
try:
|
||||
parser = VisionFigureParser(vision_model=vision_model, figures_data=figures_data, **kwargs)
|
||||
callback(0.22, "Parsing images...")
|
||||
boosted_figures = parser(callback=callback)
|
||||
tbls.extend(boosted_figures)
|
||||
except Exception as e:
|
||||
callback(0.25, f"Excel visual model error: {e}. Skipping vision enhancement.")
|
||||
return tbls
|
||||
|
||||
def vision_figure_parser_pdf_wrapper(tbls, callback=None, **kwargs):
|
||||
if not tbls:
|
||||
|
||||
@ -511,7 +511,7 @@ class MinerUParser(RAGFlowPdfParser):
|
||||
for output in outputs:
|
||||
match output["type"]:
|
||||
case MinerUContentType.TEXT:
|
||||
section = output["text"]
|
||||
section = output.get("text", "")
|
||||
case MinerUContentType.TABLE:
|
||||
section = output.get("table_body", "") + "\n".join(output.get("table_caption", [])) + "\n".join(
|
||||
output.get("table_footnote", []))
|
||||
@ -521,13 +521,13 @@ class MinerUParser(RAGFlowPdfParser):
|
||||
section = "".join(output.get("image_caption", [])) + "\n" + "".join(
|
||||
output.get("image_footnote", []))
|
||||
case MinerUContentType.EQUATION:
|
||||
section = output["text"]
|
||||
section = output.get("text", "")
|
||||
case MinerUContentType.CODE:
|
||||
section = output["code_body"] + "\n".join(output.get("code_caption", []))
|
||||
section = output.get("code_body", "") + "\n".join(output.get("code_caption", []))
|
||||
case MinerUContentType.LIST:
|
||||
section = "\n".join(output.get("list_items", []))
|
||||
case MinerUContentType.DISCARDED:
|
||||
pass
|
||||
continue # Skip discarded blocks entirely
|
||||
|
||||
if section and parse_method == "manual":
|
||||
sections.append((section, output["type"], self._line_tag(output)))
|
||||
|
||||
@ -1206,7 +1206,7 @@ class RAGFlowPdfParser:
|
||||
start = timer()
|
||||
self._text_merge()
|
||||
self._concat_downward()
|
||||
self._naive_vertical_merge(zoomin)
|
||||
#self._naive_vertical_merge(zoomin)
|
||||
if callback:
|
||||
callback(0.92, "Text merged ({:.2f}s)".format(timer() - start))
|
||||
|
||||
@ -1447,6 +1447,7 @@ class VisionParser(RAGFlowPdfParser):
|
||||
def __init__(self, vision_model, *args, **kwargs):
|
||||
super().__init__(*args, **kwargs)
|
||||
self.vision_model = vision_model
|
||||
self.outlines = []
|
||||
|
||||
def __images__(self, fnm, zoomin=3, page_from=0, page_to=299, callback=None):
|
||||
try:
|
||||
|
||||
@ -88,12 +88,9 @@ class RAGFlowPptParser:
|
||||
texts = []
|
||||
for shape in sorted(
|
||||
slide.shapes, key=lambda x: ((x.top if x.top is not None else 0) // 10, x.left if x.left is not None else 0)):
|
||||
try:
|
||||
txt = self.__extract(shape)
|
||||
if txt:
|
||||
texts.append(txt)
|
||||
except Exception as e:
|
||||
logging.exception(e)
|
||||
txt = self.__extract(shape)
|
||||
if txt:
|
||||
texts.append(txt)
|
||||
txts.append("\n".join(texts))
|
||||
|
||||
return txts
|
||||
|
||||
@ -128,11 +128,11 @@ ADMIN_SVR_HTTP_PORT=9381
|
||||
SVR_MCP_PORT=9382
|
||||
|
||||
# The RAGFlow Docker image to download. v0.22+ doesn't include embedding models.
|
||||
RAGFLOW_IMAGE=infiniflow/ragflow:v0.22.1
|
||||
RAGFLOW_IMAGE=infiniflow/ragflow:v0.23.0
|
||||
|
||||
# If you cannot download the RAGFlow Docker image:
|
||||
# RAGFLOW_IMAGE=swr.cn-north-4.myhuaweicloud.com/infiniflow/ragflow:v0.22.1
|
||||
# RAGFLOW_IMAGE=registry.cn-hangzhou.aliyuncs.com/infiniflow/ragflow:v0.22.1
|
||||
# RAGFLOW_IMAGE=swr.cn-north-4.myhuaweicloud.com/infiniflow/ragflow:v0.23.0
|
||||
# RAGFLOW_IMAGE=registry.cn-hangzhou.aliyuncs.com/infiniflow/ragflow:v0.23.0
|
||||
#
|
||||
# - For the `nightly` edition, uncomment either of the following:
|
||||
# RAGFLOW_IMAGE=swr.cn-north-4.myhuaweicloud.com/infiniflow/ragflow:nightly
|
||||
@ -234,9 +234,8 @@ REGISTER_ENABLED=1
|
||||
USE_DOCLING=false
|
||||
|
||||
# Enable Mineru
|
||||
USE_MINERU=false
|
||||
MINERU_EXECUTABLE="$HOME/uv_tools/.venv/bin/mineru"
|
||||
# Uncommenting these lines will automatically add MinerU to the model provider whenever possible.
|
||||
# More details see https://ragflow.io/docs/faq#how-to-use-mineru-to-parse-pdf-documents.
|
||||
# MINERU_DELETE_OUTPUT=0 # keep output directory
|
||||
# MINERU_BACKEND=pipeline # or another backend you prefer
|
||||
|
||||
|
||||
@ -77,7 +77,7 @@ The [.env](./.env) file contains important environment variables for Docker.
|
||||
- `SVR_HTTP_PORT`
|
||||
The port used to expose RAGFlow's HTTP API service to the host machine, allowing **external** access to the service running inside the Docker container. Defaults to `9380`.
|
||||
- `RAGFLOW-IMAGE`
|
||||
The Docker image edition. Defaults to `infiniflow/ragflow:v0.22.1`. The RAGFlow Docker image does not include embedding models.
|
||||
The Docker image edition. Defaults to `infiniflow/ragflow:v0.23.0`. The RAGFlow Docker image does not include embedding models.
|
||||
|
||||
|
||||
> [!TIP]
|
||||
|
||||
@ -72,7 +72,7 @@ services:
|
||||
infinity:
|
||||
profiles:
|
||||
- infinity
|
||||
image: infiniflow/infinity:v0.6.11
|
||||
image: infiniflow/infinity:v0.6.15
|
||||
volumes:
|
||||
- infinity_data:/var/infinity
|
||||
- ./infinity_conf.toml:/infinity_conf.toml
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
[general]
|
||||
version = "0.6.11"
|
||||
version = "0.6.15"
|
||||
time_zone = "utc-8"
|
||||
|
||||
[network]
|
||||
|
||||
0
docker/launch_backend_service.sh
Normal file → Executable file
0
docker/launch_backend_service.sh
Normal file → Executable file
@ -99,7 +99,7 @@ RAGFlow utilizes MinIO as its object storage solution, leveraging its scalabilit
|
||||
- `SVR_HTTP_PORT`
|
||||
The port used to expose RAGFlow's HTTP API service to the host machine, allowing **external** access to the service running inside the Docker container. Defaults to `9380`.
|
||||
- `RAGFLOW-IMAGE`
|
||||
The Docker image edition. Defaults to `infiniflow/ragflow:v0.22.1` (the RAGFlow Docker image without embedding models).
|
||||
The Docker image edition. Defaults to `infiniflow/ragflow:v0.23.0` (the RAGFlow Docker image without embedding models).
|
||||
|
||||
:::tip NOTE
|
||||
If you cannot download the RAGFlow Docker image, try the following mirrors.
|
||||
|
||||
@ -47,7 +47,7 @@ After building the infiniflow/ragflow:nightly image, you are ready to launch a f
|
||||
|
||||
1. Edit Docker Compose Configuration
|
||||
|
||||
Open the `docker/.env` file. Find the `RAGFLOW_IMAGE` setting and change the image reference from `infiniflow/ragflow:v0.22.1` to `infiniflow/ragflow:nightly` to use the pre-built image.
|
||||
Open the `docker/.env` file. Find the `RAGFLOW_IMAGE` setting and change the image reference from `infiniflow/ragflow:v0.23.0` to `infiniflow/ragflow:nightly` to use the pre-built image.
|
||||
|
||||
|
||||
2. Launch the Service
|
||||
|
||||
37
docs/faq.mdx
37
docs/faq.mdx
@ -493,18 +493,35 @@ See [here](./guides/agent/best_practices/accelerate_agent_question_answering.md)
|
||||
|
||||
### How to use MinerU to parse PDF documents?
|
||||
|
||||
MinerU PDF document parsing is available starting from v0.22.0. RAGFlow works only as a remote client to MinerU (>= 2.6.3) and does not install or execute MinerU locally. To use this feature:
|
||||
From v0.22.0 onwards, RAGFlow includes MinerU (≥ 2.6.3) as an optional PDF parser of multiple backends. Please note that RAGFlow acts only as a *remote client* for MinerU, calling the MinerU API to parse PDFs and reading the returned files. To use this feature:
|
||||
|
||||
1. Prepare a reachable MinerU API service (for example, the FastAPI server provided by MinerU).
|
||||
2. Configure RAGFlow with remote MinerU settings (environment variables or UI model provider):
|
||||
- `MINERU_APISERVER`: MinerU API endpoint, for example `http://mineru-host:8886`.
|
||||
- `MINERU_BACKEND`: MinerU backend, defaults to `pipeline` (supports `vlm-http-client`, `vlm-transformers`, `vlm-vllm-engine`, `vlm-mlx-engine`, `vlm-vllm-async-engine`, `vlm-lmdeploy-engine`).
|
||||
- `MINERU_SERVER_URL`: (optional) For `vlm-http-client`, the downstream vLLM HTTP server, for example `http://vllm-host:30000`.
|
||||
- `MINERU_OUTPUT_DIR`: (optional) Local directory to store MinerU API outputs (zip/JSON) before ingestion.
|
||||
- `MINERU_DELETE_OUTPUT`: Whether to delete temporary output when a temp dir is used (`1` deletes temp outputs; set `0` to keep).
|
||||
3. In the web UI, navigate to the **Configuration** page of your dataset. Click **Built-in** in the **Ingestion pipeline** section, select a chunking method from the **Built-in** dropdown (which supports PDF parsing), and select **MinerU** in **PDF parser**.
|
||||
4. If you use a custom ingestion pipeline instead, provide the same MinerU settings and select **MinerU** in the **Parsing method** section of the **Parser** component.
|
||||
1. Prepare a reachable MinerU API service (FastAPI server).
|
||||
2. In the **.env** file or from the **Model providers** page in the UI, configure RAGFlow as a remote client to MinerU:
|
||||
- `MINERU_APISERVER`: The MinerU API endpoint (e.g., `http://mineru-host:8886`).
|
||||
- `MINERU_BACKEND`: The MinerU backend:
|
||||
- `"pipeline"` (default)
|
||||
- `"vlm-http-client"`
|
||||
- `"vlm-transformers"`
|
||||
- `"vlm-vllm-engine"`
|
||||
- `"vlm-mlx-engine"`
|
||||
- `"vlm-vllm-async-engine"`
|
||||
- `"vlm-lmdeploy-engine"`.
|
||||
- `MINERU_SERVER_URL`: (optional) The downstream vLLM HTTP server (e.g., `http://vllm-host:30000`). Applicable when `MINERU_BACKEND` is set to `"vlm-http-client"`.
|
||||
- `MINERU_OUTPUT_DIR`: (optional) The local directory for holding the outputs of the MinerU API service (zip/JSON) before ingestion.
|
||||
- `MINERU_DELETE_OUTPUT`: Whether to delete temporary output when a temporary directory is used:
|
||||
- `1`: Delete.
|
||||
- `0`: Retain.
|
||||
3. In the web UI, navigate to your dataset's **Configuration** page and find the **Ingestion pipeline** section:
|
||||
- If you decide to use a chunking method from the **Built-in** dropdown, ensure it supports PDF parsing, then select **MinerU** from the **PDF parser** dropdown.
|
||||
- If you use a custom ingestion pipeline instead, select **MinerU** in the **PDF parser** section of the **Parser** component.
|
||||
|
||||
:::note
|
||||
All MinerU environment variables are optional. When set, these values are used to auto-provision a MinerU OCR model for the tenant on first use. To avoid auto-provisioning, skip the environment variable settings and only configure MinerU from the **Model providers** page in the UI.
|
||||
:::
|
||||
|
||||
:::caution WARNING
|
||||
Third-party visual models are marked **Experimental**, because we have not fully tested these models for the aforementioned data extraction tasks.
|
||||
:::
|
||||
---
|
||||
|
||||
### How to configure MinerU-specific settings?
|
||||
|
||||
@ -24,7 +24,7 @@ We use gVisor to isolate code execution from the host system. Please follow [the
|
||||
RAGFlow Sandbox is a secure, pluggable code execution backend. It serves as the code executor for the **Code** component. Please follow the [instructions here](https://github.com/infiniflow/ragflow/tree/main/sandbox) to install RAGFlow Sandbox.
|
||||
|
||||
:::note Docker client version
|
||||
The executor manager image now bundles Docker CLI `29.1.0` (API 1.44+). Older images shipped Docker 24.x and will fail against newer Docker daemons with `client version 1.43 is too old`. Pull the latest `infiniflow/sandbox-executor-manager:latest` or rebuild `./sandbox/executor_manager` if you encounter this error.
|
||||
The executor manager image now bundles Docker CLI `29.1.0` (API 1.44+). Older images shipped Docker 24.x and will fail against newer Docker daemons with `client version 1.43 is too old`. Pull the latest `infiniflow/sandbox-executor-manager:latest` or rebuild it in `./sandbox/executor_manager` if you encounter this error.
|
||||
:::
|
||||
|
||||
:::tip NOTE
|
||||
@ -134,7 +134,7 @@ Your executor manager image includes Docker CLI 24.x (API 1.43), but the host Do
|
||||
|
||||
**Solution**
|
||||
|
||||
Pull the latest executor manager image or rebuild it locally to upgrade the built-in Docker client:
|
||||
Pull the latest executor manager image or rebuild it in `./sandbox/executor_manager` to upgrade the built-in Docker client:
|
||||
|
||||
```bash
|
||||
docker pull infiniflow/sandbox-executor-manager:latest
|
||||
|
||||
90
docs/guides/agent/agent_component_reference/http.md
Normal file
90
docs/guides/agent/agent_component_reference/http.md
Normal file
@ -0,0 +1,90 @@
|
||||
---
|
||||
sidebar_position: 30
|
||||
slug: /http_request_component
|
||||
---
|
||||
|
||||
# HTTP request component
|
||||
|
||||
A component that calls remote services.
|
||||
|
||||
---
|
||||
|
||||
An **HTTP request** component lets you access remote APIs or services by providing a URL and an HTTP method, and then receive the response. You can customize headers, parameters, proxies, and timeout settings, and use common methods like GET and POST. It’s useful for exchanging data with external systems in a workflow.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- An accessible remote API or service.
|
||||
- Add a Token or credentials to the request header, if the target service requires authentication.
|
||||
|
||||
## Configurations
|
||||
|
||||
### Url
|
||||
|
||||
*Required*. The complete request address, for example: http://api.example.com/data.
|
||||
|
||||
### Method
|
||||
|
||||
The HTTP request method to select. Available options:
|
||||
|
||||
- GET
|
||||
- POST
|
||||
- PUT
|
||||
|
||||
### Timeout
|
||||
|
||||
The maximum waiting time for the request, in seconds. Defaults to `60`.
|
||||
|
||||
### Headers
|
||||
|
||||
Custom HTTP headers can be set here, for example:
|
||||
|
||||
```http
|
||||
{
|
||||
"Accept": "application/json",
|
||||
"Cache-Control": "no-cache",
|
||||
"Connection": "keep-alive"
|
||||
}
|
||||
```
|
||||
|
||||
### Proxy
|
||||
|
||||
Optional. The proxy server address to use for this request.
|
||||
|
||||
### Clean HTML
|
||||
|
||||
`Boolean`: Whether to remove HTML tags from the returned results and keep plain text only.
|
||||
|
||||
### Parameter
|
||||
|
||||
*Optional*. Parameters to send with the HTTP request. Supports key-value pairs:
|
||||
|
||||
- To assign a value using a dynamic system variable, set it as Variable.
|
||||
- To override these dynamic values under certain conditions and use a fixed static value instead, Value is the appropriate choice.
|
||||
|
||||
|
||||
:::tip NOTE
|
||||
- For GET requests, these parameters are appended to the end of the URL.
|
||||
- For POST/PUT requests, they are sent as the request body.
|
||||
:::
|
||||
|
||||
#### Example setting
|
||||
|
||||
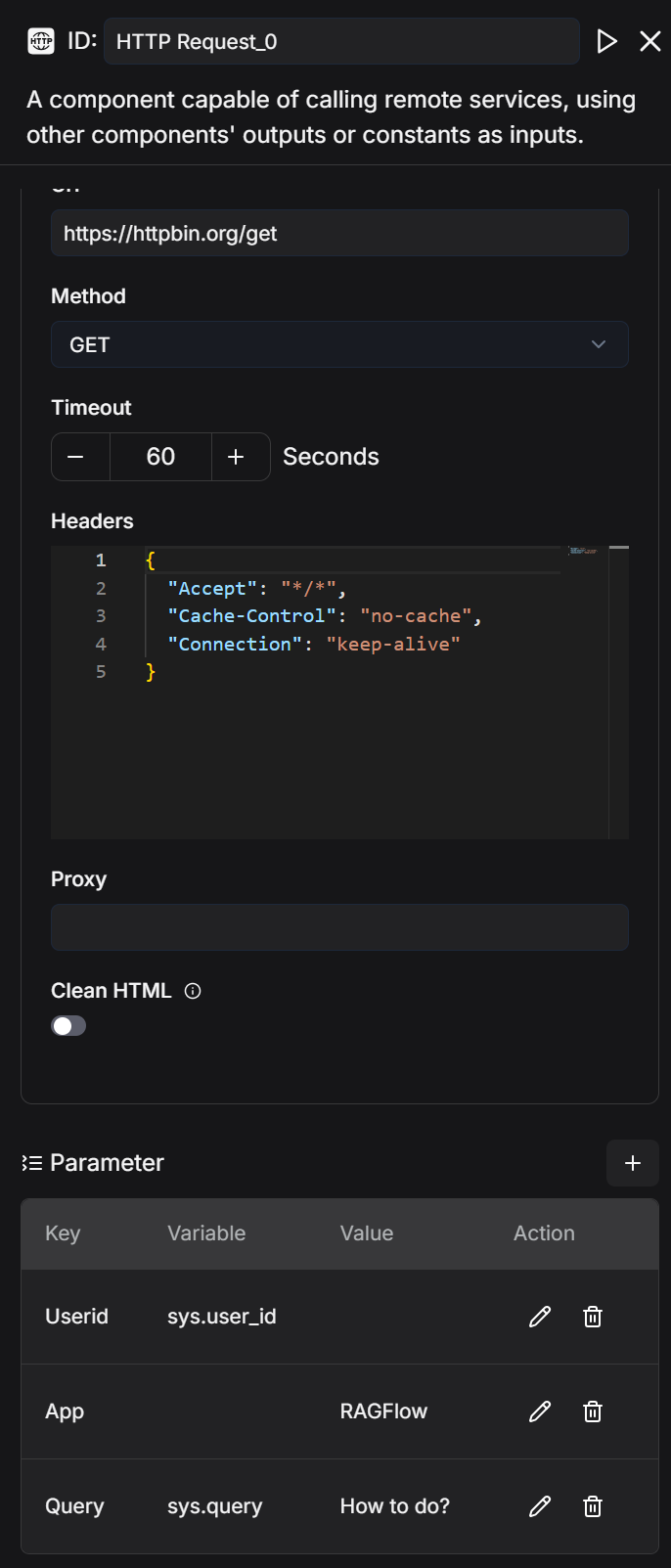
|
||||
|
||||
#### Example response
|
||||
|
||||
```html
|
||||
{ "args": { "App": "RAGFlow", "Query": "How to do?", "Userid": "241ed25a8e1011f0b979424ebc5b108b" }, "headers": { "Accept": "/", "Accept-Encoding": "gzip, deflate, br, zstd", "Cache-Control": "no-cache", "Host": "httpbin.org", "User-Agent": "python-requests/2.32.2", "X-Amzn-Trace-Id": "Root=1-68c9210c-5aab9088580c130a2f065523" }, "origin": "185.36.193.38", "url": "https://httpbin.org/get?Userid=241ed25a8e1011f0b979424ebc5b108b&App=RAGFlow&Query=How+to+do%3F" }
|
||||
```
|
||||
|
||||
### Output
|
||||
|
||||
The global variable name for the output of the HTTP request component, which can be referenced by other components in the workflow.
|
||||
|
||||
- `Result`: `string` The response returned by the remote service.
|
||||
|
||||
## Example
|
||||
|
||||
This is a usage example: a workflow sends a GET request from the **Begin** component to `https://httpbin.org/get` via the **HTTP Request_0** component, passes parameters to the server, and finally outputs the result through the **Message_0** component.
|
||||
|
||||
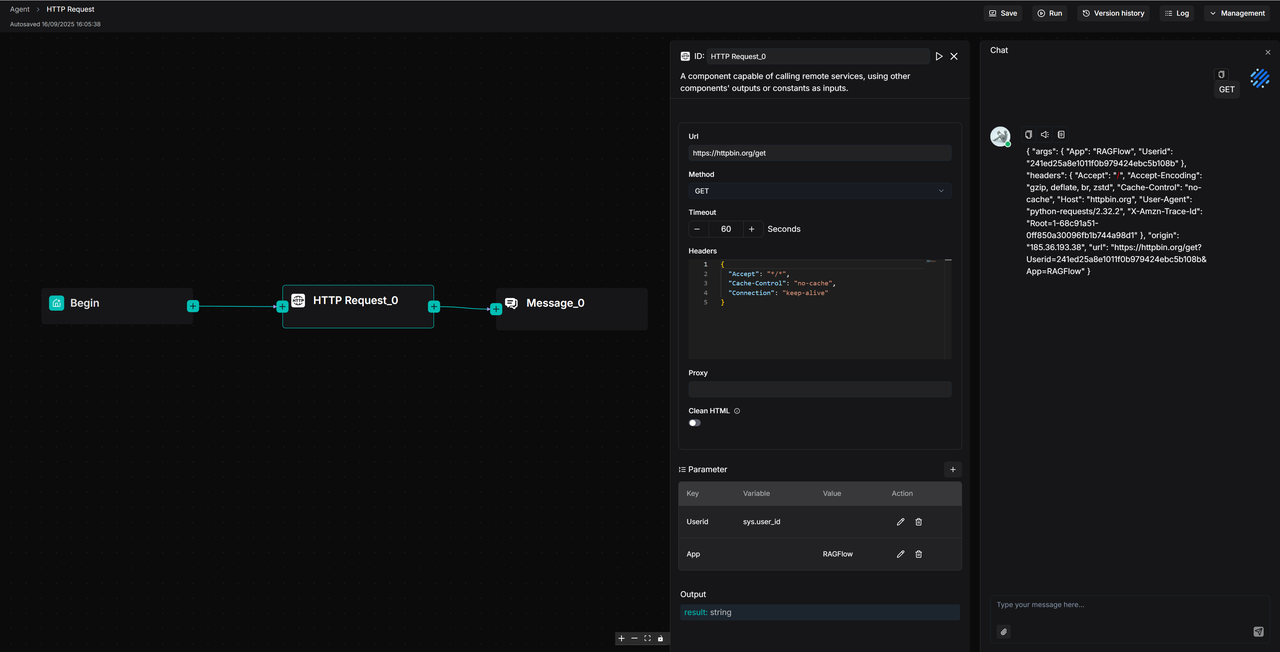
|
||||
@ -40,21 +40,31 @@ The output of a PDF parser is `json`. In the PDF parser, you select the parsing
|
||||
- A third-party visual model from a specific model provider.
|
||||
|
||||
:::danger IMPORTANT
|
||||
MinerU PDF document parsing is available starting from v0.22.0. RAGFlow supports MinerU (>= 2.6.3) as an optional PDF parser with multiple backends. RAGFlow acts only as a **remote client** for MinerU, calling the MinerU API to parse documents, reading the returned output files, and ingesting the parsed content. To use this feature:
|
||||
Starting from v0.22.0, RAGFlow includes MinerU (≥ 2.6.3) as an optional PDF parser of multiple backends. Please note that RAGFlow acts only as a *remote client* for MinerU, calling the MinerU API to parse documents and reading the returned files. To use this feature:
|
||||
:::
|
||||
|
||||
1. Prepare a reachable MinerU API service (FastAPI server).
|
||||
2. Configure RAGFlow with the remote MinerU settings (env or UI model provider):
|
||||
- `MINERU_APISERVER`: MinerU API endpoint, for example `http://mineru-host:8886`.
|
||||
- `MINERU_BACKEND`: MinerU backend, defaults to `pipeline` (supports `vlm-http-client`, `vlm-transformers`, `vlm-vllm-engine`, `vlm-mlx-engine`, `vlm-vllm-async-engine`, `vlm-lmdeploy-engine`).
|
||||
- `MINERU_SERVER_URL`: (optional) For `vlm-http-client`, the downstream vLLM HTTP server, for example `http://vllm-host:30000`.
|
||||
- `MINERU_OUTPUT_DIR`: (optional) Local directory to store MinerU API outputs (zip/JSON) before ingestion.
|
||||
- `MINERU_DELETE_OUTPUT`: Whether to delete temporary output when a temp dir is used (`1` deletes temp outputs; set `0` to keep).
|
||||
3. In the web UI, navigate to the **Configuration** page of your dataset. Click **Built-in** in the **Ingestion pipeline** section, select a chunking method from the **Built-in** dropdown, which supports PDF parsing, and select **MinerU** in **PDF parser**.
|
||||
4. If you use a custom ingestion pipeline instead, provide the same MinerU settings and select **MinerU** in the **Parsing method** section of the **Parser** component.
|
||||
2. In the **.env** file or from the **Model providers** page in the UI, configure RAGFlow as a remote client to MinerU:
|
||||
- `MINERU_APISERVER`: The MinerU API endpoint (e.g., `http://mineru-host:8886`).
|
||||
- `MINERU_BACKEND`: The MinerU backend:
|
||||
- `"pipeline"` (default)
|
||||
- `"vlm-http-client"`
|
||||
- `"vlm-transformers"`
|
||||
- `"vlm-vllm-engine"`
|
||||
- `"vlm-mlx-engine"`
|
||||
- `"vlm-vllm-async-engine"`
|
||||
- `"vlm-lmdeploy-engine"`.
|
||||
- `MINERU_SERVER_URL`: (optional) The downstream vLLM HTTP server (e.g., `http://vllm-host:30000`). Applicable when `MINERU_BACKEND` is set to `"vlm-http-client"`.
|
||||
- `MINERU_OUTPUT_DIR`: (optional) The local directory for holding the outputs of the MinerU API service (zip/JSON) before ingestion.
|
||||
- `MINERU_DELETE_OUTPUT`: Whether to delete temporary output when a temporary directory is used:
|
||||
- `1`: Delete.
|
||||
- `0`: Retain.
|
||||
3. In the web UI, navigate to your dataset's **Configuration** page and find the **Ingestion pipeline** section:
|
||||
- If you decide to use a chunking method from the **Built-in** dropdown, ensure it supports PDF parsing, then select **MinerU** from the **PDF parser** dropdown.
|
||||
- If you use a custom ingestion pipeline instead, select **MinerU** in the **PDF parser** section of the **Parser** component.
|
||||
|
||||
:::note
|
||||
All MinerU environment variables are optional. If set, RAGFlow will auto-provision a MinerU OCR model for the tenant on first use with these values. To avoid auto-provisioning, configure MinerU solely through the UI and leave the env vars unset.
|
||||
All MinerU environment variables are optional. When set, these values are used to auto-provision a MinerU OCR model for the tenant on first use. To avoid auto-provisioning, skip the environment variable settings and only configure MinerU from the **Model providers** page in the UI.
|
||||
:::
|
||||
|
||||
:::caution WARNING
|
||||
|
||||
@ -29,7 +29,7 @@ The architecture consists of isolated Docker base images for each supported lang
|
||||
- (Optional) GNU Make for simplified command-line management.
|
||||
|
||||
:::tip NOTE
|
||||
The error message `client version 1.43 is too old. Minimum supported API version is 1.44` indicates that your executor manager image's built-in Docker CLI version is lower than `29.1.0` required by the Docker daemon in use. To solve this issue, pull the latest `infiniflow/sandbox-executor-manager:latest` from Docker Hub (or rebuild `./sandbox/executor_manager`).
|
||||
The error message `client version 1.43 is too old. Minimum supported API version is 1.44` indicates that your executor manager image's built-in Docker CLI version is lower than `29.1.0` required by the Docker daemon in use. To solve this issue, pull the latest `infiniflow/sandbox-executor-manager:latest` from Docker Hub or rebuild it in `./sandbox/executor_manager`.
|
||||
:::
|
||||
|
||||
## Build Docker base images
|
||||
|
||||
@ -45,7 +45,7 @@ Google Cloud external project.
|
||||
http://localhost:9380/v1/connector/google-drive/oauth/web/callback
|
||||
```
|
||||
|
||||
### If using Docker deployment:
|
||||
- If using Docker deployment:
|
||||
|
||||
**Authorized JavaScript origin:**
|
||||
```
|
||||
@ -53,15 +53,16 @@ http://localhost:80
|
||||
```
|
||||
|
||||

|
||||
### If running from source:
|
||||
|
||||
- If running from source:
|
||||
**Authorized JavaScript origin:**
|
||||
```
|
||||
http://localhost:9222
|
||||
```
|
||||
|
||||

|
||||
5. After saving, click **Download JSON**. This file will later be
|
||||
uploaded into RAGFlow.
|
||||
|
||||
5. After saving, click **Download JSON**. This file will later be uploaded into RAGFlow.
|
||||
|
||||

|
||||
|
||||
|
||||
48
docs/guides/dataset/auto_metadata.md
Normal file
48
docs/guides/dataset/auto_metadata.md
Normal file
@ -0,0 +1,48 @@
|
||||
---
|
||||
sidebar_position: -6
|
||||
slug: /auto_metadata
|
||||
---
|
||||
|
||||
# Auto-extract metadata
|
||||
|
||||
Automatically extract metadata from uploaded files.
|
||||
|
||||
---
|
||||
|
||||
RAGFlow v0.23.0 introduces the Auto-metadata feature, which uses large language models to automatically extract and generate metadata for files—eliminating the need for manual entry. In a typical RAG pipeline, metadata serves two key purposes:
|
||||
|
||||
- During the retrieval stage: Filters out irrelevant documents, narrowing the search scope to improve retrieval accuracy.
|
||||
- During the generation stage: If a text chunk is retrieved, its associated metadata is also passed to the LLM, providing richer contextual information about the source document to aid answer generation.
|
||||
|
||||
|
||||
:::danger WARNING
|
||||
Enabling TOC extraction requires significant memory, computational resources, and tokens.
|
||||
:::
|
||||
|
||||
|
||||
|
||||
## Procedure
|
||||
|
||||
1. On your dataset's **Configuration** page, select an indexing model, which will be used to generate the knowledge graph, RAPTOR, auto-metadata, auto-keyword, and auto-question features for this dataset.
|
||||
|
||||
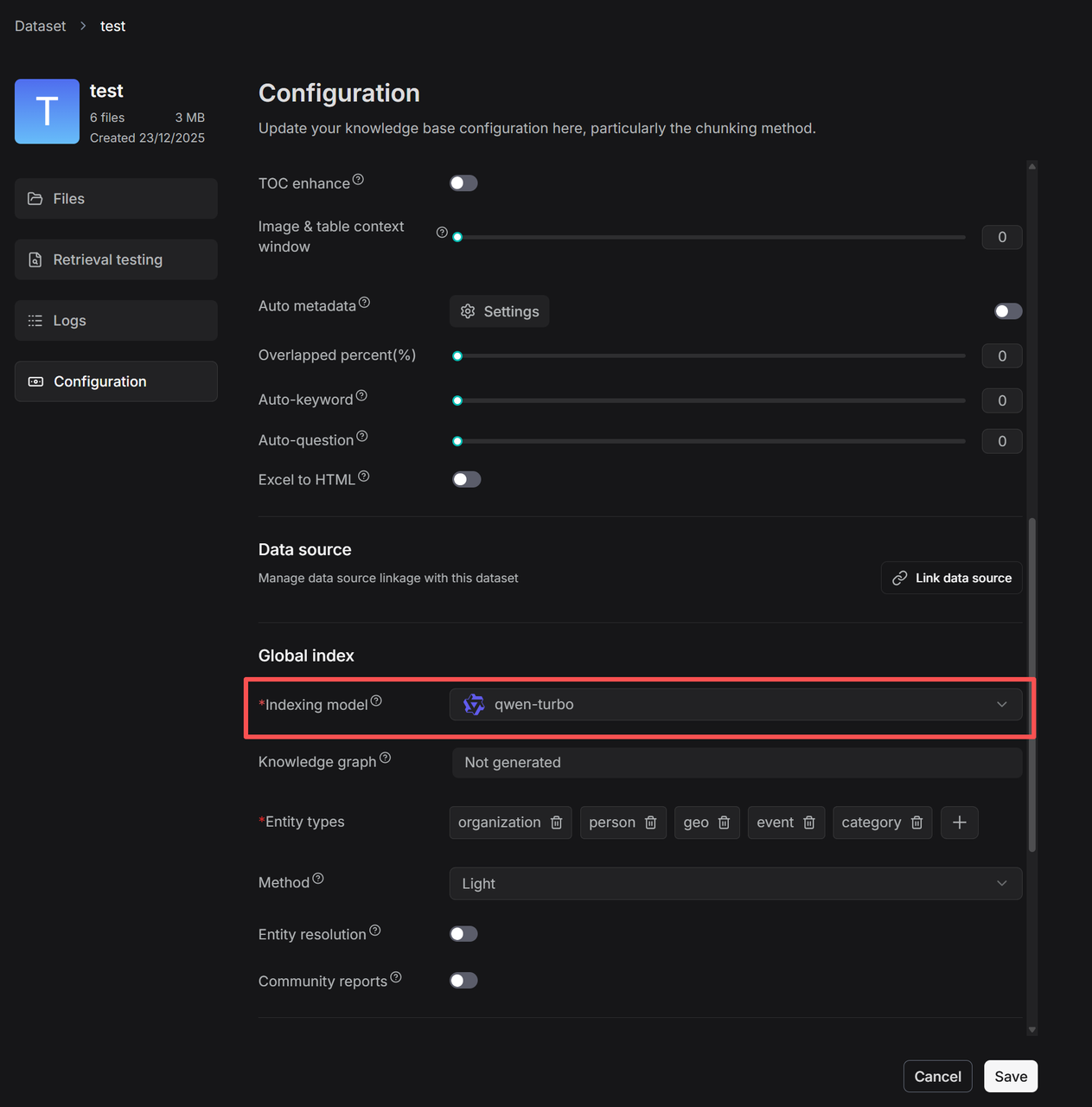
|
||||
|
||||
|
||||
2. Click **Auto metadata** **>** **Settings** to go to the configuration page for automatic metadata generation rules.
|
||||
|
||||
_The configuration page for rules on automatically generating metadata appears._
|
||||
|
||||
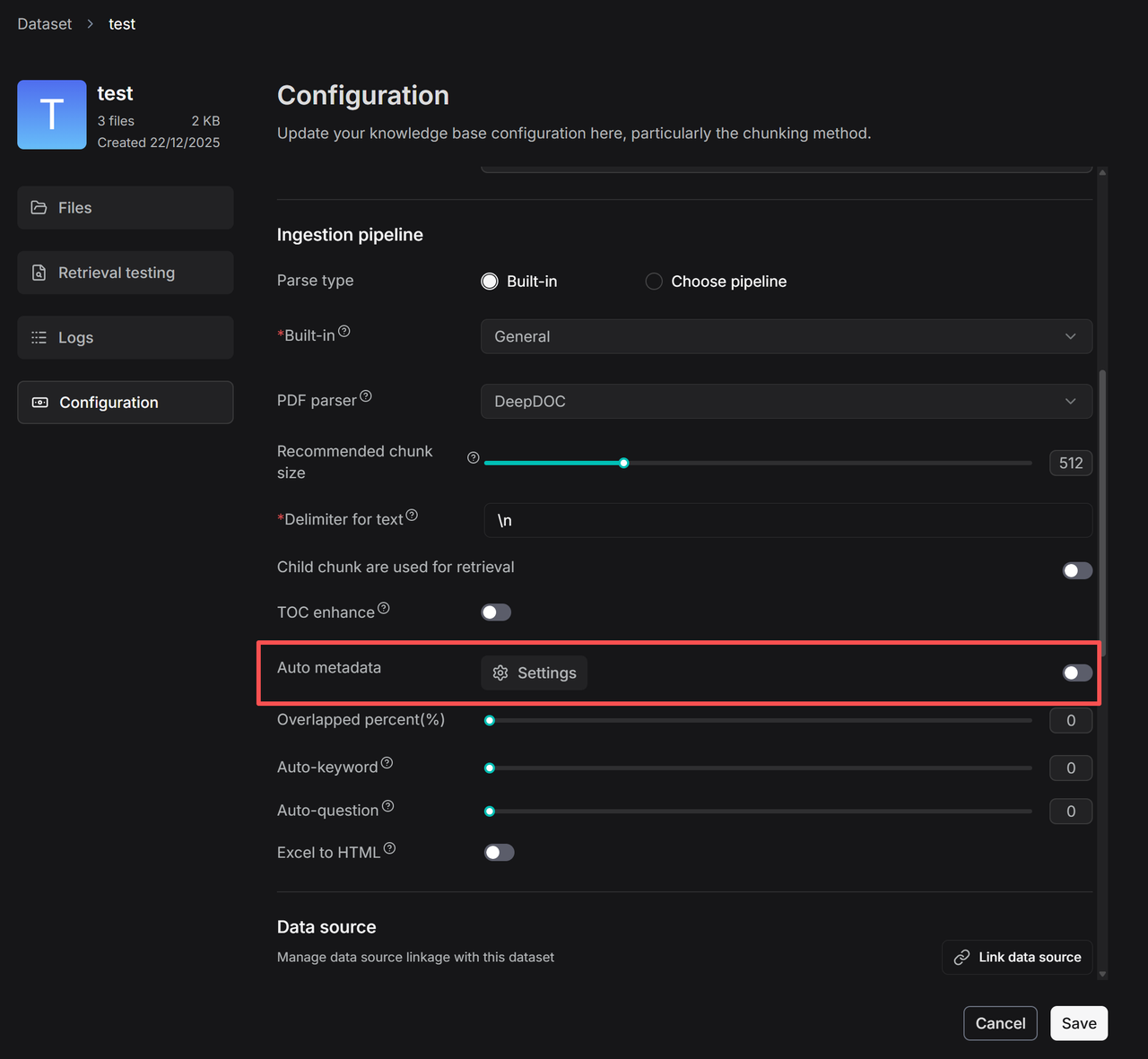
|
||||
|
||||
3. Click **+** to add new fields and enter the congiruation page.
|
||||
|
||||
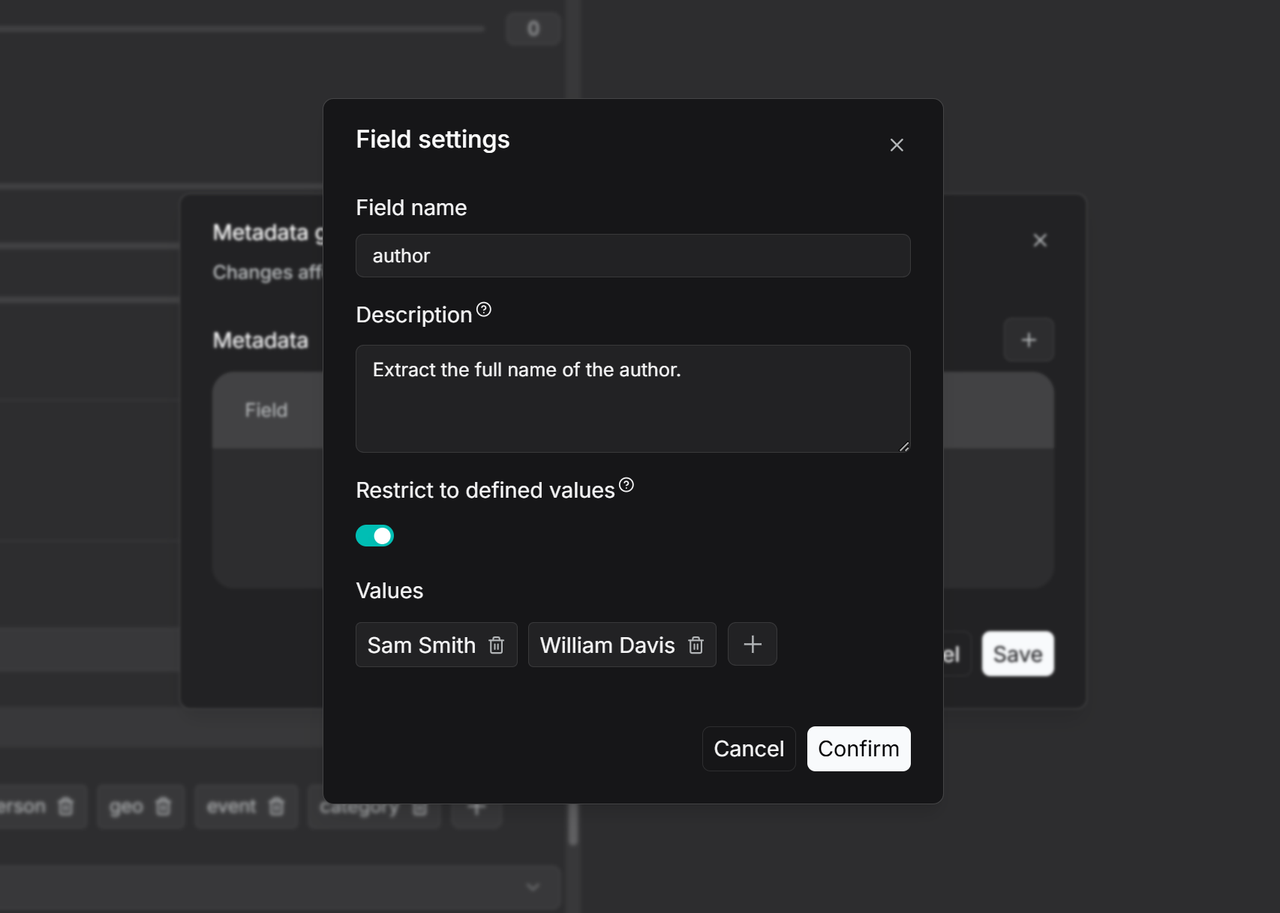
|
||||
|
||||
4. Enter a field name, such as Author, and add a description and examples in the Description section. This provides context to the large language model (LLM) for more accurate value extraction. If left blank, the LLM will extract values based only on the field name.
|
||||
|
||||
5. To restrict the LLM to generating metadata from a predefined list, enable the Restrict to defined values mode and manually add the allowed values. The LLM will then only generate results from this preset range.
|
||||
|
||||
6. Once configured, turn on the Auto-metadata switch on the Configuration page. All newly uploaded files will have these rules applied during parsing. For files that have already been processed, you must re-parse them to trigger metadata generation. You can then use the filter function to check the metadata generation status of your files.
|
||||
|
||||
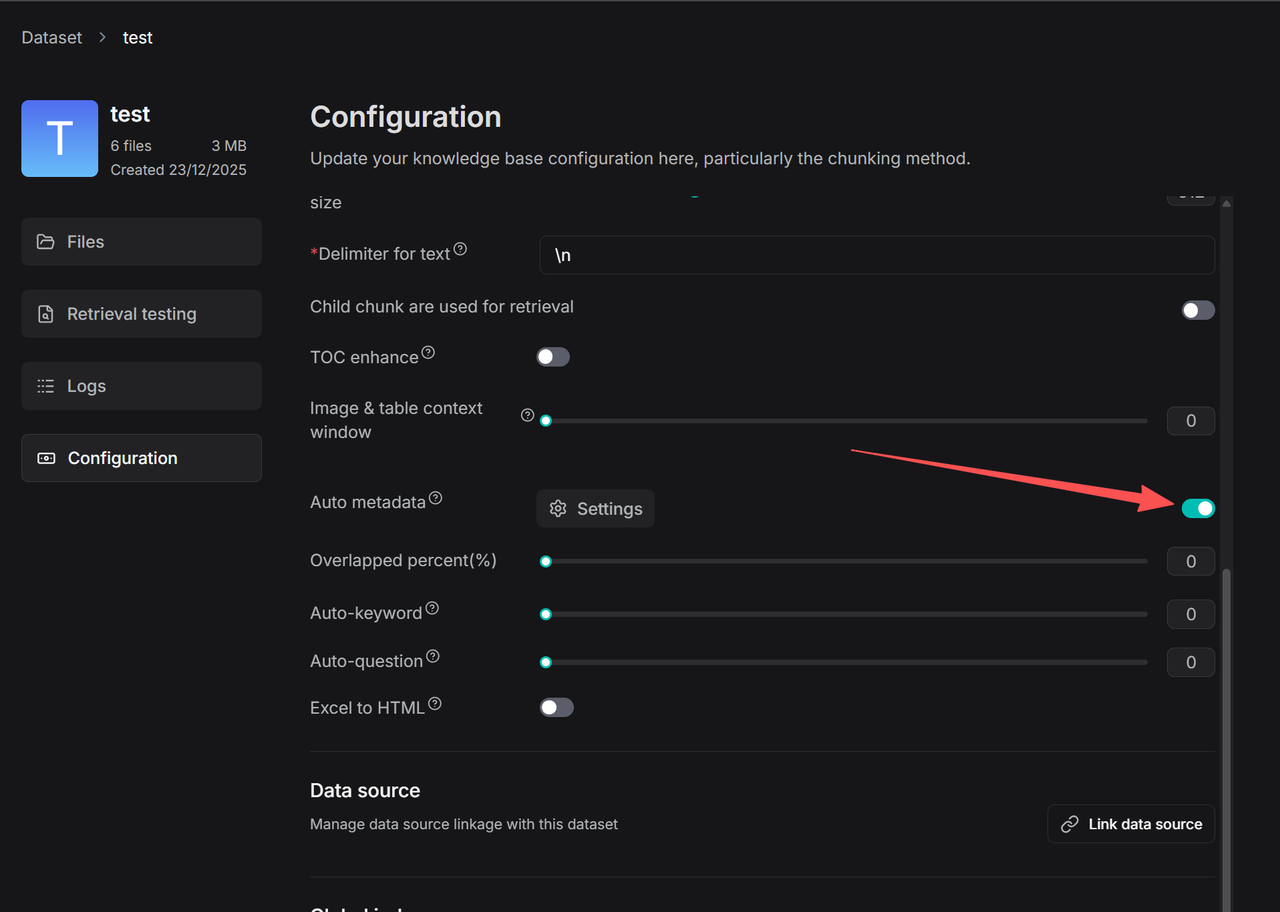
|
||||
|
||||
34
docs/guides/dataset/configure_child_chunking_strategy.md
Normal file
34
docs/guides/dataset/configure_child_chunking_strategy.md
Normal file
@ -0,0 +1,34 @@
|
||||
---
|
||||
sidebar_position: -4
|
||||
slug: /configure_child_chunking_strategy
|
||||
---
|
||||
|
||||
# Configure child chunking strategy
|
||||
|
||||
Set parent-child chunking strategy to improve retrieval.
|
||||
|
||||
---
|
||||
|
||||
A persistent challenge in practical RAG applications lies in a structural tension within the traditional "chunk-embed-retrieve" pipeline: a single text chunk is tasked with both semantic matching (recall) and contextual understanding (utilization)—two inherently conflicting objectives. Recall demands fine-grained, precise chunks, while answer generation requires coherent, informationally complete context.
|
||||
|
||||
To resolve this tension, RAGFlow previously introduced the Table of Contents (TOC) enhancement feature, which uses a large language model (LLM) to generate document structure and automatically supplements missing context during retrieval based on that TOC. In version 0.23.0, this capability has been systematically integrated into the Ingestion Pipeline, and a novel parent-child chunking mechanism has been introduced.
|
||||
|
||||
Under this mechanism, a document is first segmented into larger parent chunks, each maintaining a relatively complete semantic unit to ensure logical and background integrity. Each parent chunk can then be further subdivided into multiple child chunks for precise recall. During retrieval, the system first locates the most relevant text segments based on the child chunks while automatically associating and recalling their parent chunk. This approach maintains high recall relevance while providing ample semantic background for the generation phase.
|
||||
|
||||
For instance, when processing a *Compliance Handbook*, a user query about "liability for breach" might precisely retrieve a child chunk stating, "The penalty for breach is 20% of the total contract value," but without context, it cannot clarify whether this clause applies to "minor breach" or "material breach." Leveraging the parent-child chunking mechanism, the system returns this child chunk along with its parent chunk, which contains the complete section of the clause. This allows the LLM to make accurate judgments based on broader context, avoiding misinterpretation.
|
||||
|
||||
Through this dual-layer structure of "precise localization + contextual supplementation," RAGFlow ensures retrieval accuracy while significantly enhancing the reliability and completeness of generated answers.
|
||||
|
||||
|
||||
## Procedure
|
||||
|
||||
1. On your dataset's **Configuration** page, find the **Child chunk are used for retrieval** toggle:
|
||||
|
||||
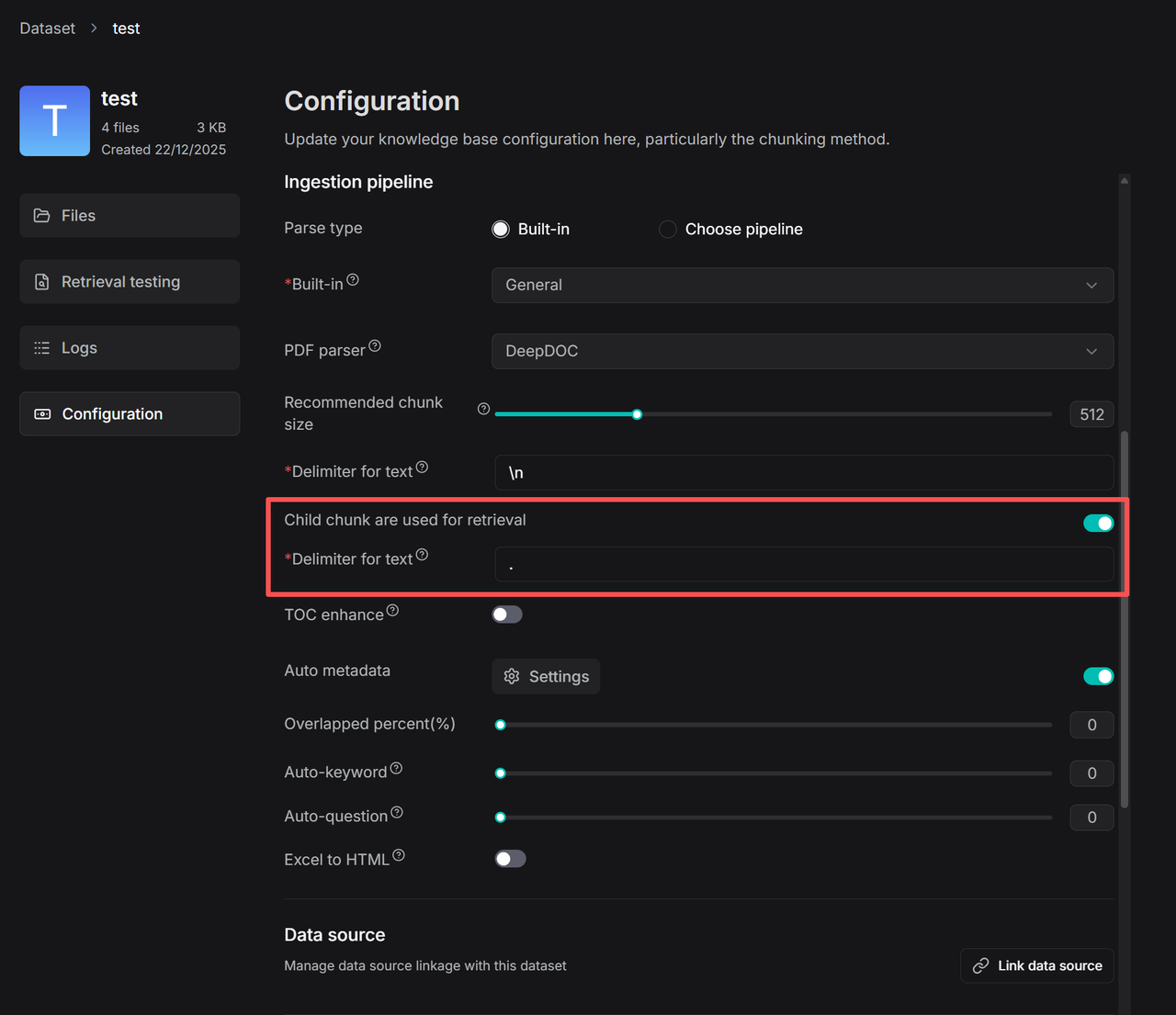
|
||||
|
||||
|
||||
2. Set the delimiter for child chunks.
|
||||
|
||||
3. This configuration applies to the **Chunker** component when it comes to ingestion pipeline settings:
|
||||
|
||||

|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user