mirror of
https://github.com/infiniflow/ragflow.git
synced 2025-12-18 03:26:42 +08:00
### What problem does this PR solve? Only support MinerU-API now, still need to complete frontend for pipeline to allow the configuration of MinerU options. ### Type of change - [x] Refactoring
73 lines
4.5 KiB
Markdown
73 lines
4.5 KiB
Markdown
---
|
|
sidebar_position: -4
|
|
slug: /select_pdf_parser
|
|
---
|
|
|
|
# Select PDF parser
|
|
|
|
Select a visual model for parsing your PDFs.
|
|
|
|
---
|
|
|
|
RAGFlow isn't one-size-fits-all. It is built for flexibility and supports deeper customization to accommodate more complex use cases. From v0.17.0 onwards, RAGFlow decouples DeepDoc-specific data extraction tasks from chunking methods **for PDF files**. This separation enables you to autonomously select a visual model for OCR (Optical Character Recognition), TSR (Table Structure Recognition), and DLR (Document Layout Recognition) tasks that balances speed and performance to suit your specific use cases. If your PDFs contain only plain text, you can opt to skip these tasks by selecting the **Naive** option, to reduce the overall parsing time.
|
|
|
|
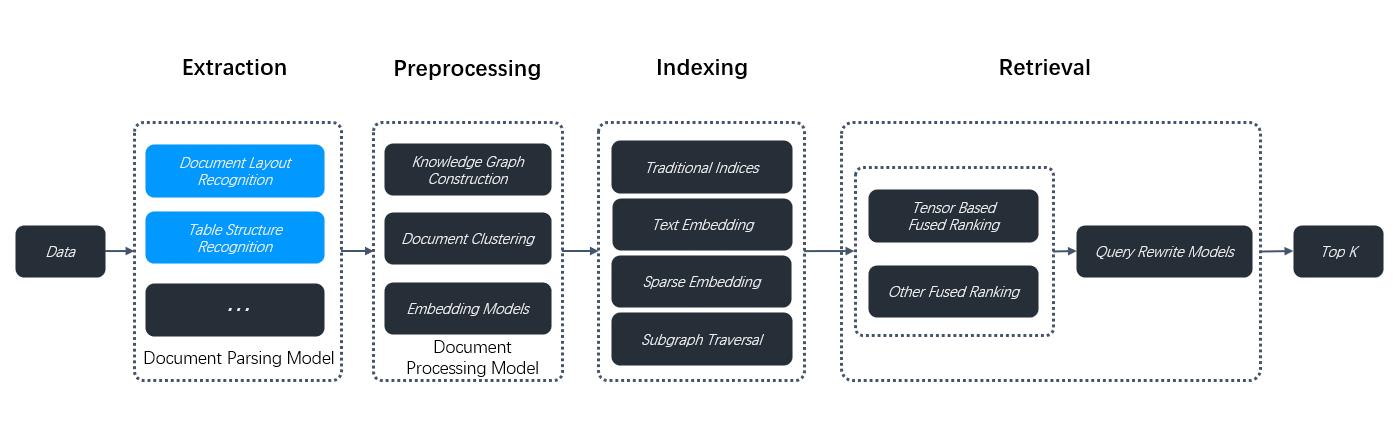
|
|
|
|
## Prerequisites
|
|
|
|
- The PDF parser dropdown menu appears only when you select a chunking method compatible with PDFs, including:
|
|
- **General**
|
|
- **Manual**
|
|
- **Paper**
|
|
- **Book**
|
|
- **Laws**
|
|
- **Presentation**
|
|
- **One**
|
|
- To use a third-party visual model for parsing PDFs, ensure you have set a default VLM under **Set default models** on the **Model providers** page.
|
|
|
|
## Quickstart
|
|
|
|
1. On your dataset's **Configuration** page, select a chunking method, say **General**.
|
|
|
|
_The **PDF parser** dropdown menu appears._
|
|
|
|
2. Select the option that works best with your scenario:
|
|
|
|
- DeepDoc: (Default) The default visual model performing OCR, TSR, and DLR tasks on PDFs, but can be time-consuming.
|
|
- Naive: Skip OCR, TSR, and DLR tasks if _all_ your PDFs are plain text.
|
|
- [MinerU](https://github.com/opendatalab/MinerU): (Experimental) An open-source tool that converts PDF into machine-readable formats.
|
|
- [Docling](https://github.com/docling-project/docling): (Experimental) An open-source document processing tool for gen AI.
|
|
- A third-party visual model from a specific model provider.
|
|
|
|
:::danger IMPORTANT
|
|
MinerU PDF document parsing is available starting from v0.22.0. RAGFlow supports MinerU (>= 2.6.3) as an optional PDF parser with multiple backends. RAGFlow acts only as a **remote client** for MinerU, calling the MinerU API to parse documents, reading the returned output files, and ingesting the parsed content. To use this feature:
|
|
|
|
1. Prepare a reachable MinerU API service (FastAPI server).
|
|
2. Configure RAGFlow with the remote MinerU settings (env or UI model provider):
|
|
- `MINERU_APISERVER`: MinerU API endpoint, for example `http://mineru-host:8886`.
|
|
- `MINERU_BACKEND`: MinerU backend, defaults to `pipeline` (supports `vlm-http-client`, `vlm-transformers`, `vlm-vllm-engine`, `vlm-mlx-engine`, `vlm-vllm-async-engine`).
|
|
- `MINERU_SERVER_URL`: (optional) For `vlm-http-client`, the downstream vLLM HTTP server, for example `http://vllm-host:30000`.
|
|
- `MINERU_OUTPUT_DIR`: (optional) Local directory to store MinerU API outputs (zip/JSON) before ingestion.
|
|
- `MINERU_DELETE_OUTPUT`: Whether to delete temporary output when a temp dir is used (`1` deletes temp outputs; set `0` to keep).
|
|
3. In the web UI, navigate to the **Configuration** page of your dataset. Click **Built-in** in the **Ingestion pipeline** section, select a chunking method from the **Built-in** dropdown, which supports PDF parsing, and select **MinerU** in **PDF parser**.
|
|
4. If you use a custom ingestion pipeline instead, provide the same MinerU settings and select **MinerU** in the **Parsing method** section of the **Parser** component.
|
|
:::
|
|
|
|
:::note
|
|
All MinerU environment variables are optional. When they are set, RAGFlow will auto-create a MinerU OCR model for a tenant on first use using these values. If you do not want this auto-provisioning, configure MinerU only through the UI and leave the env vars unset.
|
|
:::
|
|
|
|
:::caution WARNING
|
|
Third-party visual models are marked **Experimental**, because we have not fully tested these models for the aforementioned data extraction tasks.
|
|
:::
|
|
|
|
## Frequently asked questions
|
|
|
|
### When should I select DeepDoc or a third-party visual model as the PDF parser?
|
|
|
|
Use a visual model to extract data if your PDFs contain formatted or image-based text rather than plain text. DeepDoc is the default visual model but can be time-consuming. You can also choose a lightweight or high-performance VLM depending on your needs and hardware capabilities.
|
|
|
|
### Can I select a visual model to parse my DOCX files?
|
|
|
|
No, you cannot. This dropdown menu is for PDFs only. To use this feature, convert your DOCX files to PDF first.
|