mirror of
https://github.com/infiniflow/ragflow.git
synced 2026-02-04 17:45:07 +08:00
Compare commits
27 Commits
v0.20.5
...
86f6da2f74
| Author | SHA1 | Date | |
|---|---|---|---|
| 86f6da2f74 | |||
| 8c00cbc87a | |||
| 41e808f4e6 | |||
| bc0281040b | |||
| 341a7b1473 | |||
| c29c395390 | |||
| a23a0f230c | |||
| 2a88ce6be1 | |||
| 664b781d62 | |||
| 65571e5254 | |||
| aa30f20730 | |||
| b9b278d441 | |||
| e1d86cfee3 | |||
| 8ebd07337f | |||
| dd584d57b0 | |||
| 3d39b96c6f | |||
| 179091b1a4 | |||
| d14d92a900 | |||
| 1936ad82d2 | |||
| 8a09f07186 | |||
| df8d31451b | |||
| fc95d113c3 | |||
| 7d14455fbe | |||
| bbe6ed3b90 | |||
| 127af4e45c | |||
| 41cdba19ba | |||
| 0d9c1f1c3c |
8
.github/workflows/release.yml
vendored
8
.github/workflows/release.yml
vendored
@ -88,7 +88,9 @@ jobs:
|
||||
with:
|
||||
context: .
|
||||
push: true
|
||||
tags: infiniflow/ragflow:${{ env.RELEASE_TAG }}
|
||||
tags: |
|
||||
infiniflow/ragflow:${{ env.RELEASE_TAG }}
|
||||
infiniflow/ragflow:latest-full
|
||||
file: Dockerfile
|
||||
platforms: linux/amd64
|
||||
|
||||
@ -98,7 +100,9 @@ jobs:
|
||||
with:
|
||||
context: .
|
||||
push: true
|
||||
tags: infiniflow/ragflow:${{ env.RELEASE_TAG }}-slim
|
||||
tags: |
|
||||
infiniflow/ragflow:${{ env.RELEASE_TAG }}-slim
|
||||
infiniflow/ragflow:latest-slim
|
||||
file: Dockerfile
|
||||
build-args: LIGHTEN=1
|
||||
platforms: linux/amd64
|
||||
|
||||
@ -83,7 +83,7 @@
|
||||
},
|
||||
"password": "20010812Yy!",
|
||||
"port": 3306,
|
||||
"sql": "Agent:WickedGoatsDivide@content",
|
||||
"sql": "{Agent:WickedGoatsDivide@content}",
|
||||
"username": "13637682833@163.com"
|
||||
}
|
||||
},
|
||||
@ -114,9 +114,7 @@
|
||||
"params": {
|
||||
"cross_languages": [],
|
||||
"empty_response": "",
|
||||
"kb_ids": [
|
||||
"ed31364c727211f0bdb2bafe6e7908e6"
|
||||
],
|
||||
"kb_ids": [],
|
||||
"keywords_similarity_weight": 0.7,
|
||||
"outputs": {
|
||||
"formalized_content": {
|
||||
@ -124,7 +122,7 @@
|
||||
"value": ""
|
||||
}
|
||||
},
|
||||
"query": "sys.query",
|
||||
"query": "{sys.query}",
|
||||
"rerank_id": "",
|
||||
"similarity_threshold": 0.2,
|
||||
"top_k": 1024,
|
||||
@ -145,9 +143,7 @@
|
||||
"params": {
|
||||
"cross_languages": [],
|
||||
"empty_response": "",
|
||||
"kb_ids": [
|
||||
"0f968106727311f08357bafe6e7908e6"
|
||||
],
|
||||
"kb_ids": [],
|
||||
"keywords_similarity_weight": 0.7,
|
||||
"outputs": {
|
||||
"formalized_content": {
|
||||
@ -155,7 +151,7 @@
|
||||
"value": ""
|
||||
}
|
||||
},
|
||||
"query": "sys.query",
|
||||
"query": "{sys.query}",
|
||||
"rerank_id": "",
|
||||
"similarity_threshold": 0.2,
|
||||
"top_k": 1024,
|
||||
@ -176,9 +172,7 @@
|
||||
"params": {
|
||||
"cross_languages": [],
|
||||
"empty_response": "",
|
||||
"kb_ids": [
|
||||
"4ad1f9d0727311f0827dbafe6e7908e6"
|
||||
],
|
||||
"kb_ids": [],
|
||||
"keywords_similarity_weight": 0.7,
|
||||
"outputs": {
|
||||
"formalized_content": {
|
||||
@ -186,7 +180,7 @@
|
||||
"value": ""
|
||||
}
|
||||
},
|
||||
"query": "sys.query",
|
||||
"query": "{sys.query}",
|
||||
"rerank_id": "",
|
||||
"similarity_threshold": 0.2,
|
||||
"top_k": 1024,
|
||||
@ -347,9 +341,7 @@
|
||||
"form": {
|
||||
"cross_languages": [],
|
||||
"empty_response": "",
|
||||
"kb_ids": [
|
||||
"ed31364c727211f0bdb2bafe6e7908e6"
|
||||
],
|
||||
"kb_ids": [],
|
||||
"keywords_similarity_weight": 0.7,
|
||||
"outputs": {
|
||||
"formalized_content": {
|
||||
@ -357,7 +349,7 @@
|
||||
"value": ""
|
||||
}
|
||||
},
|
||||
"query": "sys.query",
|
||||
"query": "{sys.query}",
|
||||
"rerank_id": "",
|
||||
"similarity_threshold": 0.2,
|
||||
"top_k": 1024,
|
||||
@ -387,9 +379,7 @@
|
||||
"form": {
|
||||
"cross_languages": [],
|
||||
"empty_response": "",
|
||||
"kb_ids": [
|
||||
"0f968106727311f08357bafe6e7908e6"
|
||||
],
|
||||
"kb_ids": [],
|
||||
"keywords_similarity_weight": 0.7,
|
||||
"outputs": {
|
||||
"formalized_content": {
|
||||
@ -397,7 +387,7 @@
|
||||
"value": ""
|
||||
}
|
||||
},
|
||||
"query": "sys.query",
|
||||
"query": "{sys.query}",
|
||||
"rerank_id": "",
|
||||
"similarity_threshold": 0.2,
|
||||
"top_k": 1024,
|
||||
@ -427,9 +417,7 @@
|
||||
"form": {
|
||||
"cross_languages": [],
|
||||
"empty_response": "",
|
||||
"kb_ids": [
|
||||
"4ad1f9d0727311f0827dbafe6e7908e6"
|
||||
],
|
||||
"kb_ids": [],
|
||||
"keywords_similarity_weight": 0.7,
|
||||
"outputs": {
|
||||
"formalized_content": {
|
||||
@ -437,7 +425,7 @@
|
||||
"value": ""
|
||||
}
|
||||
},
|
||||
"query": "sys.query",
|
||||
"query": "{sys.query}",
|
||||
"rerank_id": "",
|
||||
"similarity_threshold": 0.2,
|
||||
"top_k": 1024,
|
||||
@ -539,7 +527,7 @@
|
||||
},
|
||||
"password": "20010812Yy!",
|
||||
"port": 3306,
|
||||
"sql": "Agent:WickedGoatsDivide@content",
|
||||
"sql": "{Agent:WickedGoatsDivide@content}",
|
||||
"username": "13637682833@163.com"
|
||||
},
|
||||
"label": "ExeSQL",
|
||||
|
||||
@ -219,6 +219,70 @@
|
||||
}
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "TokenPony",
|
||||
"logo": "",
|
||||
"tags": "LLM",
|
||||
"status": "1",
|
||||
"llm": [
|
||||
{
|
||||
"llm_name": "qwen3-8b",
|
||||
"tags": "LLM,CHAT,131k",
|
||||
"max_tokens": 131000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "deepseek-v3-0324",
|
||||
"tags": "LLM,CHAT,128k",
|
||||
"max_tokens": 128000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "qwen3-32b",
|
||||
"tags": "LLM,CHAT,131k",
|
||||
"max_tokens": 131000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "kimi-k2-instruct",
|
||||
"tags": "LLM,CHAT,128K",
|
||||
"max_tokens": 128000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "deepseek-r1-0528",
|
||||
"tags": "LLM,CHAT,164k",
|
||||
"max_tokens": 164000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "qwen3-coder-480b",
|
||||
"tags": "LLM,CHAT,1024k",
|
||||
"max_tokens": 1024000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "glm-4.5",
|
||||
"tags": "LLM,CHAT,131K",
|
||||
"max_tokens": 131000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "deepseek-v3.1",
|
||||
"tags": "LLM,CHAT,128k",
|
||||
"max_tokens": 128000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
}
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "Tongyi-Qianwen",
|
||||
"logo": "",
|
||||
|
||||
@ -22,10 +22,10 @@ from openpyxl import Workbook, load_workbook
|
||||
from rag.nlp import find_codec
|
||||
|
||||
# copied from `/openpyxl/cell/cell.py`
|
||||
ILLEGAL_CHARACTERS_RE = re.compile(r'[\000-\010]|[\013-\014]|[\016-\037]')
|
||||
ILLEGAL_CHARACTERS_RE = re.compile(r"[\000-\010]|[\013-\014]|[\016-\037]")
|
||||
|
||||
|
||||
class RAGFlowExcelParser:
|
||||
|
||||
@staticmethod
|
||||
def _load_excel_to_workbook(file_like_object):
|
||||
if isinstance(file_like_object, bytes):
|
||||
@ -36,7 +36,7 @@ class RAGFlowExcelParser:
|
||||
file_head = file_like_object.read(4)
|
||||
file_like_object.seek(0)
|
||||
|
||||
if not (file_head.startswith(b'PK\x03\x04') or file_head.startswith(b'\xD0\xCF\x11\xE0')):
|
||||
if not (file_head.startswith(b"PK\x03\x04") or file_head.startswith(b"\xd0\xcf\x11\xe0")):
|
||||
logging.info("Not an Excel file, converting CSV to Excel Workbook")
|
||||
|
||||
try:
|
||||
@ -48,7 +48,7 @@ class RAGFlowExcelParser:
|
||||
raise Exception(f"Failed to parse CSV and convert to Excel Workbook: {e_csv}")
|
||||
|
||||
try:
|
||||
return load_workbook(file_like_object,data_only= True)
|
||||
return load_workbook(file_like_object, data_only=True)
|
||||
except Exception as e:
|
||||
logging.info(f"openpyxl load error: {e}, try pandas instead")
|
||||
try:
|
||||
@ -59,7 +59,7 @@ class RAGFlowExcelParser:
|
||||
except Exception as ex:
|
||||
logging.info(f"pandas with default engine load error: {ex}, try calamine instead")
|
||||
file_like_object.seek(0)
|
||||
df = pd.read_excel(file_like_object, engine='calamine')
|
||||
df = pd.read_excel(file_like_object, engine="calamine")
|
||||
return RAGFlowExcelParser._dataframe_to_workbook(df)
|
||||
except Exception as e_pandas:
|
||||
raise Exception(f"pandas.read_excel error: {e_pandas}, original openpyxl error: {e}")
|
||||
@ -116,9 +116,7 @@ class RAGFlowExcelParser:
|
||||
tb = ""
|
||||
tb += f"<table><caption>{sheetname}</caption>"
|
||||
tb += tb_rows_0
|
||||
for r in list(
|
||||
rows[1 + chunk_i * chunk_rows: min(1 + (chunk_i + 1) * chunk_rows, len(rows))]
|
||||
):
|
||||
for r in list(rows[1 + chunk_i * chunk_rows : min(1 + (chunk_i + 1) * chunk_rows, len(rows))]):
|
||||
tb += "<tr>"
|
||||
for i, c in enumerate(r):
|
||||
if c.value is None:
|
||||
@ -133,8 +131,16 @@ class RAGFlowExcelParser:
|
||||
|
||||
def markdown(self, fnm):
|
||||
import pandas as pd
|
||||
|
||||
file_like_object = BytesIO(fnm) if not isinstance(fnm, str) else fnm
|
||||
df = pd.read_excel(file_like_object)
|
||||
try:
|
||||
file_like_object.seek(0)
|
||||
df = pd.read_excel(file_like_object)
|
||||
except Exception as e:
|
||||
logging.warning(f"Parse spreadsheet error: {e}, trying to interpret as CSV file")
|
||||
file_like_object.seek(0)
|
||||
df = pd.read_csv(file_like_object)
|
||||
df = df.replace(r"^\s*$", "", regex=True)
|
||||
return df.to_markdown(index=False)
|
||||
|
||||
def __call__(self, fnm):
|
||||
|
||||
@ -34,7 +34,7 @@ from pypdf import PdfReader as pdf2_read
|
||||
|
||||
from api import settings
|
||||
from api.utils.file_utils import get_project_base_directory
|
||||
from deepdoc.vision import OCR, LayoutRecognizer, Recognizer, TableStructureRecognizer
|
||||
from deepdoc.vision import OCR, AscendLayoutRecognizer, LayoutRecognizer, Recognizer, TableStructureRecognizer
|
||||
from rag.app.picture import vision_llm_chunk as picture_vision_llm_chunk
|
||||
from rag.nlp import rag_tokenizer
|
||||
from rag.prompts import vision_llm_describe_prompt
|
||||
@ -64,33 +64,38 @@ class RAGFlowPdfParser:
|
||||
if PARALLEL_DEVICES > 1:
|
||||
self.parallel_limiter = [trio.CapacityLimiter(1) for _ in range(PARALLEL_DEVICES)]
|
||||
|
||||
layout_recognizer_type = os.getenv("LAYOUT_RECOGNIZER_TYPE", "onnx").lower()
|
||||
if layout_recognizer_type not in ["onnx", "ascend"]:
|
||||
raise RuntimeError("Unsupported layout recognizer type.")
|
||||
|
||||
if hasattr(self, "model_speciess"):
|
||||
self.layouter = LayoutRecognizer("layout." + self.model_speciess)
|
||||
recognizer_domain = "layout." + self.model_speciess
|
||||
else:
|
||||
self.layouter = LayoutRecognizer("layout")
|
||||
recognizer_domain = "layout"
|
||||
|
||||
if layout_recognizer_type == "ascend":
|
||||
logging.debug("Using Ascend LayoutRecognizer", flush=True)
|
||||
self.layouter = AscendLayoutRecognizer(recognizer_domain)
|
||||
else: # onnx
|
||||
logging.debug("Using Onnx LayoutRecognizer", flush=True)
|
||||
self.layouter = LayoutRecognizer(recognizer_domain)
|
||||
self.tbl_det = TableStructureRecognizer()
|
||||
|
||||
self.updown_cnt_mdl = xgb.Booster()
|
||||
if not settings.LIGHTEN:
|
||||
try:
|
||||
import torch.cuda
|
||||
|
||||
if torch.cuda.is_available():
|
||||
self.updown_cnt_mdl.set_param({"device": "cuda"})
|
||||
except Exception:
|
||||
logging.exception("RAGFlowPdfParser __init__")
|
||||
try:
|
||||
model_dir = os.path.join(
|
||||
get_project_base_directory(),
|
||||
"rag/res/deepdoc")
|
||||
self.updown_cnt_mdl.load_model(os.path.join(
|
||||
model_dir, "updown_concat_xgb.model"))
|
||||
model_dir = os.path.join(get_project_base_directory(), "rag/res/deepdoc")
|
||||
self.updown_cnt_mdl.load_model(os.path.join(model_dir, "updown_concat_xgb.model"))
|
||||
except Exception:
|
||||
model_dir = snapshot_download(
|
||||
repo_id="InfiniFlow/text_concat_xgb_v1.0",
|
||||
local_dir=os.path.join(get_project_base_directory(), "rag/res/deepdoc"),
|
||||
local_dir_use_symlinks=False)
|
||||
self.updown_cnt_mdl.load_model(os.path.join(
|
||||
model_dir, "updown_concat_xgb.model"))
|
||||
model_dir = snapshot_download(repo_id="InfiniFlow/text_concat_xgb_v1.0", local_dir=os.path.join(get_project_base_directory(), "rag/res/deepdoc"), local_dir_use_symlinks=False)
|
||||
self.updown_cnt_mdl.load_model(os.path.join(model_dir, "updown_concat_xgb.model"))
|
||||
|
||||
self.page_from = 0
|
||||
self.column_num = 1
|
||||
@ -102,13 +107,10 @@ class RAGFlowPdfParser:
|
||||
return c["bottom"] - c["top"]
|
||||
|
||||
def _x_dis(self, a, b):
|
||||
return min(abs(a["x1"] - b["x0"]), abs(a["x0"] - b["x1"]),
|
||||
abs(a["x0"] + a["x1"] - b["x0"] - b["x1"]) / 2)
|
||||
return min(abs(a["x1"] - b["x0"]), abs(a["x0"] - b["x1"]), abs(a["x0"] + a["x1"] - b["x0"] - b["x1"]) / 2)
|
||||
|
||||
def _y_dis(
|
||||
self, a, b):
|
||||
return (
|
||||
b["top"] + b["bottom"] - a["top"] - a["bottom"]) / 2
|
||||
def _y_dis(self, a, b):
|
||||
return (b["top"] + b["bottom"] - a["top"] - a["bottom"]) / 2
|
||||
|
||||
def _match_proj(self, b):
|
||||
proj_patt = [
|
||||
@ -130,10 +132,7 @@ class RAGFlowPdfParser:
|
||||
LEN = 6
|
||||
tks_down = rag_tokenizer.tokenize(down["text"][:LEN]).split()
|
||||
tks_up = rag_tokenizer.tokenize(up["text"][-LEN:]).split()
|
||||
tks_all = up["text"][-LEN:].strip() \
|
||||
+ (" " if re.match(r"[a-zA-Z0-9]+",
|
||||
up["text"][-1] + down["text"][0]) else "") \
|
||||
+ down["text"][:LEN].strip()
|
||||
tks_all = up["text"][-LEN:].strip() + (" " if re.match(r"[a-zA-Z0-9]+", up["text"][-1] + down["text"][0]) else "") + down["text"][:LEN].strip()
|
||||
tks_all = rag_tokenizer.tokenize(tks_all).split()
|
||||
fea = [
|
||||
up.get("R", -1) == down.get("R", -1),
|
||||
@ -144,39 +143,30 @@ class RAGFlowPdfParser:
|
||||
down["layout_type"] == "text",
|
||||
up["layout_type"] == "table",
|
||||
down["layout_type"] == "table",
|
||||
True if re.search(
|
||||
r"([。?!;!?;+))]|[a-z]\.)$",
|
||||
up["text"]) else False,
|
||||
True if re.search(r"([。?!;!?;+))]|[a-z]\.)$", up["text"]) else False,
|
||||
True if re.search(r"[,:‘“、0-9(+-]$", up["text"]) else False,
|
||||
True if re.search(
|
||||
r"(^.?[/,?;:\],。;:’”?!》】)-])",
|
||||
down["text"]) else False,
|
||||
True if re.search(r"(^.?[/,?;:\],。;:’”?!》】)-])", down["text"]) else False,
|
||||
True if re.match(r"[\((][^\(\)()]+[)\)]$", up["text"]) else False,
|
||||
True if re.search(r"[,,][^。.]+$", up["text"]) else False,
|
||||
True if re.search(r"[,,][^。.]+$", up["text"]) else False,
|
||||
True if re.search(r"[\((][^\))]+$", up["text"])
|
||||
and re.search(r"[\))]", down["text"]) else False,
|
||||
True if re.search(r"[\((][^\))]+$", up["text"]) and re.search(r"[\))]", down["text"]) else False,
|
||||
self._match_proj(down),
|
||||
True if re.match(r"[A-Z]", down["text"]) else False,
|
||||
True if re.match(r"[A-Z]", up["text"][-1]) else False,
|
||||
True if re.match(r"[a-z0-9]", up["text"][-1]) else False,
|
||||
True if re.match(r"[0-9.%,-]+$", down["text"]) else False,
|
||||
up["text"].strip()[-2:] == down["text"].strip()[-2:] if len(up["text"].strip()
|
||||
) > 1 and len(
|
||||
down["text"].strip()) > 1 else False,
|
||||
up["text"].strip()[-2:] == down["text"].strip()[-2:] if len(up["text"].strip()) > 1 and len(down["text"].strip()) > 1 else False,
|
||||
up["x0"] > down["x1"],
|
||||
abs(self.__height(up) - self.__height(down)) / min(self.__height(up),
|
||||
self.__height(down)),
|
||||
abs(self.__height(up) - self.__height(down)) / min(self.__height(up), self.__height(down)),
|
||||
self._x_dis(up, down) / max(w, 0.000001),
|
||||
(len(up["text"]) - len(down["text"])) /
|
||||
max(len(up["text"]), len(down["text"])),
|
||||
(len(up["text"]) - len(down["text"])) / max(len(up["text"]), len(down["text"])),
|
||||
len(tks_all) - len(tks_up) - len(tks_down),
|
||||
len(tks_down) - len(tks_up),
|
||||
tks_down[-1] == tks_up[-1] if tks_down and tks_up else False,
|
||||
max(down["in_row"], up["in_row"]),
|
||||
abs(down["in_row"] - up["in_row"]),
|
||||
len(tks_down) == 1 and rag_tokenizer.tag(tks_down[0]).find("n") >= 0,
|
||||
len(tks_up) == 1 and rag_tokenizer.tag(tks_up[0]).find("n") >= 0
|
||||
len(tks_up) == 1 and rag_tokenizer.tag(tks_up[0]).find("n") >= 0,
|
||||
]
|
||||
return fea
|
||||
|
||||
@ -187,9 +177,7 @@ class RAGFlowPdfParser:
|
||||
for i in range(len(arr) - 1):
|
||||
for j in range(i, -1, -1):
|
||||
# restore the order using th
|
||||
if abs(arr[j + 1]["x0"] - arr[j]["x0"]) < threshold \
|
||||
and arr[j + 1]["top"] < arr[j]["top"] \
|
||||
and arr[j + 1]["page_number"] == arr[j]["page_number"]:
|
||||
if abs(arr[j + 1]["x0"] - arr[j]["x0"]) < threshold and arr[j + 1]["top"] < arr[j]["top"] and arr[j + 1]["page_number"] == arr[j]["page_number"]:
|
||||
tmp = arr[j]
|
||||
arr[j] = arr[j + 1]
|
||||
arr[j + 1] = tmp
|
||||
@ -197,8 +185,7 @@ class RAGFlowPdfParser:
|
||||
|
||||
def _has_color(self, o):
|
||||
if o.get("ncs", "") == "DeviceGray":
|
||||
if o["stroking_color"] and o["stroking_color"][0] == 1 and o["non_stroking_color"] and \
|
||||
o["non_stroking_color"][0] == 1:
|
||||
if o["stroking_color"] and o["stroking_color"][0] == 1 and o["non_stroking_color"] and o["non_stroking_color"][0] == 1:
|
||||
if re.match(r"[a-zT_\[\]\(\)-]+", o.get("text", "")):
|
||||
return False
|
||||
return True
|
||||
@ -216,8 +203,7 @@ class RAGFlowPdfParser:
|
||||
if not tbls:
|
||||
continue
|
||||
for tb in tbls: # for table
|
||||
left, top, right, bott = tb["x0"] - MARGIN, tb["top"] - MARGIN, \
|
||||
tb["x1"] + MARGIN, tb["bottom"] + MARGIN
|
||||
left, top, right, bott = tb["x0"] - MARGIN, tb["top"] - MARGIN, tb["x1"] + MARGIN, tb["bottom"] + MARGIN
|
||||
left *= ZM
|
||||
top *= ZM
|
||||
right *= ZM
|
||||
@ -232,14 +218,13 @@ class RAGFlowPdfParser:
|
||||
tbcnt = np.cumsum(tbcnt)
|
||||
for i in range(len(tbcnt) - 1): # for page
|
||||
pg = []
|
||||
for j, tb_items in enumerate(
|
||||
recos[tbcnt[i]: tbcnt[i + 1]]): # for table
|
||||
poss = pos[tbcnt[i]: tbcnt[i + 1]]
|
||||
for j, tb_items in enumerate(recos[tbcnt[i] : tbcnt[i + 1]]): # for table
|
||||
poss = pos[tbcnt[i] : tbcnt[i + 1]]
|
||||
for it in tb_items: # for table components
|
||||
it["x0"] = (it["x0"] + poss[j][0])
|
||||
it["x1"] = (it["x1"] + poss[j][0])
|
||||
it["top"] = (it["top"] + poss[j][1])
|
||||
it["bottom"] = (it["bottom"] + poss[j][1])
|
||||
it["x0"] = it["x0"] + poss[j][0]
|
||||
it["x1"] = it["x1"] + poss[j][0]
|
||||
it["top"] = it["top"] + poss[j][1]
|
||||
it["bottom"] = it["bottom"] + poss[j][1]
|
||||
for n in ["x0", "x1", "top", "bottom"]:
|
||||
it[n] /= ZM
|
||||
it["top"] += self.page_cum_height[i]
|
||||
@ -250,8 +235,7 @@ class RAGFlowPdfParser:
|
||||
self.tb_cpns.extend(pg)
|
||||
|
||||
def gather(kwd, fzy=10, ption=0.6):
|
||||
eles = Recognizer.sort_Y_firstly(
|
||||
[r for r in self.tb_cpns if re.match(kwd, r["label"])], fzy)
|
||||
eles = Recognizer.sort_Y_firstly([r for r in self.tb_cpns if re.match(kwd, r["label"])], fzy)
|
||||
eles = Recognizer.layouts_cleanup(self.boxes, eles, 5, ption)
|
||||
return Recognizer.sort_Y_firstly(eles, 0)
|
||||
|
||||
@ -259,8 +243,7 @@ class RAGFlowPdfParser:
|
||||
headers = gather(r".*header$")
|
||||
rows = gather(r".* (row|header)")
|
||||
spans = gather(r".*spanning")
|
||||
clmns = sorted([r for r in self.tb_cpns if re.match(
|
||||
r"table column$", r["label"])], key=lambda x: (x["pn"], x["layoutno"], x["x0"]))
|
||||
clmns = sorted([r for r in self.tb_cpns if re.match(r"table column$", r["label"])], key=lambda x: (x["pn"], x["layoutno"], x["x0"]))
|
||||
clmns = Recognizer.layouts_cleanup(self.boxes, clmns, 5, 0.5)
|
||||
for b in self.boxes:
|
||||
if b.get("layout_type", "") != "table":
|
||||
@ -271,8 +254,7 @@ class RAGFlowPdfParser:
|
||||
b["R_top"] = rows[ii]["top"]
|
||||
b["R_bott"] = rows[ii]["bottom"]
|
||||
|
||||
ii = Recognizer.find_overlapped_with_threshold(
|
||||
b, headers, thr=0.3)
|
||||
ii = Recognizer.find_overlapped_with_threshold(b, headers, thr=0.3)
|
||||
if ii is not None:
|
||||
b["H_top"] = headers[ii]["top"]
|
||||
b["H_bott"] = headers[ii]["bottom"]
|
||||
@ -305,12 +287,12 @@ class RAGFlowPdfParser:
|
||||
return
|
||||
bxs = [(line[0], line[1][0]) for line in bxs]
|
||||
bxs = Recognizer.sort_Y_firstly(
|
||||
[{"x0": b[0][0] / ZM, "x1": b[1][0] / ZM,
|
||||
"top": b[0][1] / ZM, "text": "", "txt": t,
|
||||
"bottom": b[-1][1] / ZM,
|
||||
"chars": [],
|
||||
"page_number": pagenum} for b, t in bxs if b[0][0] <= b[1][0] and b[0][1] <= b[-1][1]],
|
||||
self.mean_height[pagenum-1] / 3
|
||||
[
|
||||
{"x0": b[0][0] / ZM, "x1": b[1][0] / ZM, "top": b[0][1] / ZM, "text": "", "txt": t, "bottom": b[-1][1] / ZM, "chars": [], "page_number": pagenum}
|
||||
for b, t in bxs
|
||||
if b[0][0] <= b[1][0] and b[0][1] <= b[-1][1]
|
||||
],
|
||||
self.mean_height[pagenum - 1] / 3,
|
||||
)
|
||||
|
||||
# merge chars in the same rect
|
||||
@ -321,7 +303,7 @@ class RAGFlowPdfParser:
|
||||
continue
|
||||
ch = c["bottom"] - c["top"]
|
||||
bh = bxs[ii]["bottom"] - bxs[ii]["top"]
|
||||
if abs(ch - bh) / max(ch, bh) >= 0.7 and c["text"] != ' ':
|
||||
if abs(ch - bh) / max(ch, bh) >= 0.7 and c["text"] != " ":
|
||||
self.lefted_chars.append(c)
|
||||
continue
|
||||
bxs[ii]["chars"].append(c)
|
||||
@ -345,8 +327,7 @@ class RAGFlowPdfParser:
|
||||
img_np = np.array(img)
|
||||
for b in bxs:
|
||||
if not b["text"]:
|
||||
left, right, top, bott = b["x0"] * ZM, b["x1"] * \
|
||||
ZM, b["top"] * ZM, b["bottom"] * ZM
|
||||
left, right, top, bott = b["x0"] * ZM, b["x1"] * ZM, b["top"] * ZM, b["bottom"] * ZM
|
||||
b["box_image"] = self.ocr.get_rotate_crop_image(img_np, np.array([[left, top], [right, top], [right, bott], [left, bott]], dtype=np.float32))
|
||||
boxes_to_reg.append(b)
|
||||
del b["txt"]
|
||||
@ -356,21 +337,17 @@ class RAGFlowPdfParser:
|
||||
del boxes_to_reg[i]["box_image"]
|
||||
logging.info(f"__ocr recognize {len(bxs)} boxes cost {timer() - start}s")
|
||||
bxs = [b for b in bxs if b["text"]]
|
||||
if self.mean_height[pagenum-1] == 0:
|
||||
self.mean_height[pagenum-1] = np.median([b["bottom"] - b["top"]
|
||||
for b in bxs])
|
||||
if self.mean_height[pagenum - 1] == 0:
|
||||
self.mean_height[pagenum - 1] = np.median([b["bottom"] - b["top"] for b in bxs])
|
||||
self.boxes.append(bxs)
|
||||
|
||||
def _layouts_rec(self, ZM, drop=True):
|
||||
assert len(self.page_images) == len(self.boxes)
|
||||
self.boxes, self.page_layout = self.layouter(
|
||||
self.page_images, self.boxes, ZM, drop=drop)
|
||||
self.boxes, self.page_layout = self.layouter(self.page_images, self.boxes, ZM, drop=drop)
|
||||
# cumlative Y
|
||||
for i in range(len(self.boxes)):
|
||||
self.boxes[i]["top"] += \
|
||||
self.page_cum_height[self.boxes[i]["page_number"] - 1]
|
||||
self.boxes[i]["bottom"] += \
|
||||
self.page_cum_height[self.boxes[i]["page_number"] - 1]
|
||||
self.boxes[i]["top"] += self.page_cum_height[self.boxes[i]["page_number"] - 1]
|
||||
self.boxes[i]["bottom"] += self.page_cum_height[self.boxes[i]["page_number"] - 1]
|
||||
|
||||
def _text_merge(self):
|
||||
# merge adjusted boxes
|
||||
@ -390,12 +367,10 @@ class RAGFlowPdfParser:
|
||||
while i < len(bxs) - 1:
|
||||
b = bxs[i]
|
||||
b_ = bxs[i + 1]
|
||||
if b.get("layoutno", "0") != b_.get("layoutno", "1") or b.get("layout_type", "") in ["table", "figure",
|
||||
"equation"]:
|
||||
if b.get("layoutno", "0") != b_.get("layoutno", "1") or b.get("layout_type", "") in ["table", "figure", "equation"]:
|
||||
i += 1
|
||||
continue
|
||||
if abs(self._y_dis(b, b_)
|
||||
) < self.mean_height[bxs[i]["page_number"] - 1] / 3:
|
||||
if abs(self._y_dis(b, b_)) < self.mean_height[bxs[i]["page_number"] - 1] / 3:
|
||||
# merge
|
||||
bxs[i]["x1"] = b_["x1"]
|
||||
bxs[i]["top"] = (b["top"] + b_["top"]) / 2
|
||||
@ -408,16 +383,14 @@ class RAGFlowPdfParser:
|
||||
|
||||
dis_thr = 1
|
||||
dis = b["x1"] - b_["x0"]
|
||||
if b.get("layout_type", "") != "text" or b_.get(
|
||||
"layout_type", "") != "text":
|
||||
if b.get("layout_type", "") != "text" or b_.get("layout_type", "") != "text":
|
||||
if end_with(b, ",") or start_with(b_, "(,"):
|
||||
dis_thr = -8
|
||||
else:
|
||||
i += 1
|
||||
continue
|
||||
|
||||
if abs(self._y_dis(b, b_)) < self.mean_height[bxs[i]["page_number"] - 1] / 5 \
|
||||
and dis >= dis_thr and b["x1"] < b_["x1"]:
|
||||
if abs(self._y_dis(b, b_)) < self.mean_height[bxs[i]["page_number"] - 1] / 5 and dis >= dis_thr and b["x1"] < b_["x1"]:
|
||||
# merge
|
||||
bxs[i]["x1"] = b_["x1"]
|
||||
bxs[i]["top"] = (b["top"] + b_["top"]) / 2
|
||||
@ -429,23 +402,19 @@ class RAGFlowPdfParser:
|
||||
self.boxes = bxs
|
||||
|
||||
def _naive_vertical_merge(self, zoomin=3):
|
||||
bxs = Recognizer.sort_Y_firstly(
|
||||
self.boxes, np.median(
|
||||
self.mean_height) / 3)
|
||||
bxs = Recognizer.sort_Y_firstly(self.boxes, np.median(self.mean_height) / 3)
|
||||
|
||||
column_width = np.median([b["x1"] - b["x0"] for b in self.boxes])
|
||||
self.column_num = int(self.page_images[0].size[0] / zoomin / column_width)
|
||||
if column_width < self.page_images[0].size[0] / zoomin / self.column_num:
|
||||
logging.info("Multi-column................... {} {}".format(column_width,
|
||||
self.page_images[0].size[0] / zoomin / self.column_num))
|
||||
logging.info("Multi-column................... {} {}".format(column_width, self.page_images[0].size[0] / zoomin / self.column_num))
|
||||
self.boxes = self.sort_X_by_page(self.boxes, column_width / self.column_num)
|
||||
|
||||
i = 0
|
||||
while i + 1 < len(bxs):
|
||||
b = bxs[i]
|
||||
b_ = bxs[i + 1]
|
||||
if b["page_number"] < b_["page_number"] and re.match(
|
||||
r"[0-9 •一—-]+$", b["text"]):
|
||||
if b["page_number"] < b_["page_number"] and re.match(r"[0-9 •一—-]+$", b["text"]):
|
||||
bxs.pop(i)
|
||||
continue
|
||||
if not b["text"].strip():
|
||||
@ -453,8 +422,7 @@ class RAGFlowPdfParser:
|
||||
continue
|
||||
concatting_feats = [
|
||||
b["text"].strip()[-1] in ",;:'\",、‘“;:-",
|
||||
len(b["text"].strip()) > 1 and b["text"].strip(
|
||||
)[-2] in ",;:'\",‘“、;:",
|
||||
len(b["text"].strip()) > 1 and b["text"].strip()[-2] in ",;:'\",‘“、;:",
|
||||
b_["text"].strip() and b_["text"].strip()[0] in "。;?!?”)),,、:",
|
||||
]
|
||||
# features for not concating
|
||||
@ -462,21 +430,20 @@ class RAGFlowPdfParser:
|
||||
b.get("layoutno", 0) != b_.get("layoutno", 0),
|
||||
b["text"].strip()[-1] in "。?!?",
|
||||
self.is_english and b["text"].strip()[-1] in ".!?",
|
||||
b["page_number"] == b_["page_number"] and b_["top"] -
|
||||
b["bottom"] > self.mean_height[b["page_number"] - 1] * 1.5,
|
||||
b["page_number"] < b_["page_number"] and abs(
|
||||
b["x0"] - b_["x0"]) > self.mean_width[b["page_number"] - 1] * 4,
|
||||
b["page_number"] == b_["page_number"] and b_["top"] - b["bottom"] > self.mean_height[b["page_number"] - 1] * 1.5,
|
||||
b["page_number"] < b_["page_number"] and abs(b["x0"] - b_["x0"]) > self.mean_width[b["page_number"] - 1] * 4,
|
||||
]
|
||||
# split features
|
||||
detach_feats = [b["x1"] < b_["x0"],
|
||||
b["x0"] > b_["x1"]]
|
||||
detach_feats = [b["x1"] < b_["x0"], b["x0"] > b_["x1"]]
|
||||
if (any(feats) and not any(concatting_feats)) or any(detach_feats):
|
||||
logging.debug("{} {} {} {}".format(
|
||||
b["text"],
|
||||
b_["text"],
|
||||
any(feats),
|
||||
any(concatting_feats),
|
||||
))
|
||||
logging.debug(
|
||||
"{} {} {} {}".format(
|
||||
b["text"],
|
||||
b_["text"],
|
||||
any(feats),
|
||||
any(concatting_feats),
|
||||
)
|
||||
)
|
||||
i += 1
|
||||
continue
|
||||
# merge up and down
|
||||
@ -529,14 +496,11 @@ class RAGFlowPdfParser:
|
||||
if not concat_between_pages and down["page_number"] > up["page_number"]:
|
||||
break
|
||||
|
||||
if up.get("R", "") != down.get(
|
||||
"R", "") and up["text"][-1] != ",":
|
||||
if up.get("R", "") != down.get("R", "") and up["text"][-1] != ",":
|
||||
i += 1
|
||||
continue
|
||||
|
||||
if re.match(r"[0-9]{2,3}/[0-9]{3}$", up["text"]) \
|
||||
or re.match(r"[0-9]{2,3}/[0-9]{3}$", down["text"]) \
|
||||
or not down["text"].strip():
|
||||
if re.match(r"[0-9]{2,3}/[0-9]{3}$", up["text"]) or re.match(r"[0-9]{2,3}/[0-9]{3}$", down["text"]) or not down["text"].strip():
|
||||
i += 1
|
||||
continue
|
||||
|
||||
@ -544,14 +508,12 @@ class RAGFlowPdfParser:
|
||||
i += 1
|
||||
continue
|
||||
|
||||
if up["x1"] < down["x0"] - 10 * \
|
||||
mw or up["x0"] > down["x1"] + 10 * mw:
|
||||
if up["x1"] < down["x0"] - 10 * mw or up["x0"] > down["x1"] + 10 * mw:
|
||||
i += 1
|
||||
continue
|
||||
|
||||
if i - dp < 5 and up.get("layout_type") == "text":
|
||||
if up.get("layoutno", "1") == down.get(
|
||||
"layoutno", "2"):
|
||||
if up.get("layoutno", "1") == down.get("layoutno", "2"):
|
||||
dfs(down, i + 1)
|
||||
boxes.pop(i)
|
||||
return
|
||||
@ -559,8 +521,7 @@ class RAGFlowPdfParser:
|
||||
continue
|
||||
|
||||
fea = self._updown_concat_features(up, down)
|
||||
if self.updown_cnt_mdl.predict(
|
||||
xgb.DMatrix([fea]))[0] <= 0.5:
|
||||
if self.updown_cnt_mdl.predict(xgb.DMatrix([fea]))[0] <= 0.5:
|
||||
i += 1
|
||||
continue
|
||||
dfs(down, i + 1)
|
||||
@ -584,16 +545,14 @@ class RAGFlowPdfParser:
|
||||
c["text"] = c["text"].strip()
|
||||
if not c["text"]:
|
||||
continue
|
||||
if t["text"] and re.match(
|
||||
r"[0-9\.a-zA-Z]+$", t["text"][-1] + c["text"][-1]):
|
||||
if t["text"] and re.match(r"[0-9\.a-zA-Z]+$", t["text"][-1] + c["text"][-1]):
|
||||
t["text"] += " "
|
||||
t["text"] += c["text"]
|
||||
t["x0"] = min(t["x0"], c["x0"])
|
||||
t["x1"] = max(t["x1"], c["x1"])
|
||||
t["page_number"] = min(t["page_number"], c["page_number"])
|
||||
t["bottom"] = c["bottom"]
|
||||
if not t["layout_type"] \
|
||||
and c["layout_type"]:
|
||||
if not t["layout_type"] and c["layout_type"]:
|
||||
t["layout_type"] = c["layout_type"]
|
||||
boxes.append(t)
|
||||
|
||||
@ -605,25 +564,20 @@ class RAGFlowPdfParser:
|
||||
findit = False
|
||||
i = 0
|
||||
while i < len(self.boxes):
|
||||
if not re.match(r"(contents|目录|目次|table of contents|致谢|acknowledge)$",
|
||||
re.sub(r"( | |\u3000)+", "", self.boxes[i]["text"].lower())):
|
||||
if not re.match(r"(contents|目录|目次|table of contents|致谢|acknowledge)$", re.sub(r"( | |\u3000)+", "", self.boxes[i]["text"].lower())):
|
||||
i += 1
|
||||
continue
|
||||
findit = True
|
||||
eng = re.match(
|
||||
r"[0-9a-zA-Z :'.-]{5,}",
|
||||
self.boxes[i]["text"].strip())
|
||||
eng = re.match(r"[0-9a-zA-Z :'.-]{5,}", self.boxes[i]["text"].strip())
|
||||
self.boxes.pop(i)
|
||||
if i >= len(self.boxes):
|
||||
break
|
||||
prefix = self.boxes[i]["text"].strip()[:3] if not eng else " ".join(
|
||||
self.boxes[i]["text"].strip().split()[:2])
|
||||
prefix = self.boxes[i]["text"].strip()[:3] if not eng else " ".join(self.boxes[i]["text"].strip().split()[:2])
|
||||
while not prefix:
|
||||
self.boxes.pop(i)
|
||||
if i >= len(self.boxes):
|
||||
break
|
||||
prefix = self.boxes[i]["text"].strip()[:3] if not eng else " ".join(
|
||||
self.boxes[i]["text"].strip().split()[:2])
|
||||
prefix = self.boxes[i]["text"].strip()[:3] if not eng else " ".join(self.boxes[i]["text"].strip().split()[:2])
|
||||
self.boxes.pop(i)
|
||||
if i >= len(self.boxes) or not prefix:
|
||||
break
|
||||
@ -662,10 +616,12 @@ class RAGFlowPdfParser:
|
||||
self.boxes.pop(i + 1)
|
||||
continue
|
||||
|
||||
if b["text"].strip()[0] != b_["text"].strip()[0] \
|
||||
or b["text"].strip()[0].lower() in set("qwertyuopasdfghjklzxcvbnm") \
|
||||
or rag_tokenizer.is_chinese(b["text"].strip()[0]) \
|
||||
or b["top"] > b_["bottom"]:
|
||||
if (
|
||||
b["text"].strip()[0] != b_["text"].strip()[0]
|
||||
or b["text"].strip()[0].lower() in set("qwertyuopasdfghjklzxcvbnm")
|
||||
or rag_tokenizer.is_chinese(b["text"].strip()[0])
|
||||
or b["top"] > b_["bottom"]
|
||||
):
|
||||
i += 1
|
||||
continue
|
||||
b_["text"] = b["text"] + "\n" + b_["text"]
|
||||
@ -685,12 +641,8 @@ class RAGFlowPdfParser:
|
||||
if "layoutno" not in self.boxes[i]:
|
||||
i += 1
|
||||
continue
|
||||
lout_no = str(self.boxes[i]["page_number"]) + \
|
||||
"-" + str(self.boxes[i]["layoutno"])
|
||||
if TableStructureRecognizer.is_caption(self.boxes[i]) or self.boxes[i]["layout_type"] in ["table caption",
|
||||
"title",
|
||||
"figure caption",
|
||||
"reference"]:
|
||||
lout_no = str(self.boxes[i]["page_number"]) + "-" + str(self.boxes[i]["layoutno"])
|
||||
if TableStructureRecognizer.is_caption(self.boxes[i]) or self.boxes[i]["layout_type"] in ["table caption", "title", "figure caption", "reference"]:
|
||||
nomerge_lout_no.append(lst_lout_no)
|
||||
if self.boxes[i]["layout_type"] == "table":
|
||||
if re.match(r"(数据|资料|图表)*来源[:: ]", self.boxes[i]["text"]):
|
||||
@ -716,8 +668,7 @@ class RAGFlowPdfParser:
|
||||
|
||||
# merge table on different pages
|
||||
nomerge_lout_no = set(nomerge_lout_no)
|
||||
tbls = sorted([(k, bxs) for k, bxs in tables.items()],
|
||||
key=lambda x: (x[1][0]["top"], x[1][0]["x0"]))
|
||||
tbls = sorted([(k, bxs) for k, bxs in tables.items()], key=lambda x: (x[1][0]["top"], x[1][0]["x0"]))
|
||||
|
||||
i = len(tbls) - 1
|
||||
while i - 1 >= 0:
|
||||
@ -758,9 +709,7 @@ class RAGFlowPdfParser:
|
||||
if b.get("layout_type", "").find("caption") >= 0:
|
||||
continue
|
||||
y_dis = self._y_dis(c, b)
|
||||
x_dis = self._x_dis(
|
||||
c, b) if not x_overlapped(
|
||||
c, b) else 0
|
||||
x_dis = self._x_dis(c, b) if not x_overlapped(c, b) else 0
|
||||
dis = y_dis * y_dis + x_dis * x_dis
|
||||
if dis < minv:
|
||||
mink = k
|
||||
@ -774,18 +723,10 @@ class RAGFlowPdfParser:
|
||||
# continue
|
||||
if tv < fv and tk:
|
||||
tables[tk].insert(0, c)
|
||||
logging.debug(
|
||||
"TABLE:" +
|
||||
self.boxes[i]["text"] +
|
||||
"; Cap: " +
|
||||
tk)
|
||||
logging.debug("TABLE:" + self.boxes[i]["text"] + "; Cap: " + tk)
|
||||
elif fk:
|
||||
figures[fk].insert(0, c)
|
||||
logging.debug(
|
||||
"FIGURE:" +
|
||||
self.boxes[i]["text"] +
|
||||
"; Cap: " +
|
||||
tk)
|
||||
logging.debug("FIGURE:" + self.boxes[i]["text"] + "; Cap: " + tk)
|
||||
self.boxes.pop(i)
|
||||
|
||||
def cropout(bxs, ltype, poss):
|
||||
@ -794,29 +735,19 @@ class RAGFlowPdfParser:
|
||||
if len(pn) < 2:
|
||||
pn = list(pn)[0]
|
||||
ht = self.page_cum_height[pn]
|
||||
b = {
|
||||
"x0": np.min([b["x0"] for b in bxs]),
|
||||
"top": np.min([b["top"] for b in bxs]) - ht,
|
||||
"x1": np.max([b["x1"] for b in bxs]),
|
||||
"bottom": np.max([b["bottom"] for b in bxs]) - ht
|
||||
}
|
||||
b = {"x0": np.min([b["x0"] for b in bxs]), "top": np.min([b["top"] for b in bxs]) - ht, "x1": np.max([b["x1"] for b in bxs]), "bottom": np.max([b["bottom"] for b in bxs]) - ht}
|
||||
louts = [layout for layout in self.page_layout[pn] if layout["type"] == ltype]
|
||||
ii = Recognizer.find_overlapped(b, louts, naive=True)
|
||||
if ii is not None:
|
||||
b = louts[ii]
|
||||
else:
|
||||
logging.warning(
|
||||
f"Missing layout match: {pn + 1},%s" %
|
||||
(bxs[0].get(
|
||||
"layoutno", "")))
|
||||
logging.warning(f"Missing layout match: {pn + 1},%s" % (bxs[0].get("layoutno", "")))
|
||||
|
||||
left, top, right, bott = b["x0"], b["top"], b["x1"], b["bottom"]
|
||||
if right < left:
|
||||
right = left + 1
|
||||
poss.append((pn + self.page_from, left, right, top, bott))
|
||||
return self.page_images[pn] \
|
||||
.crop((left * ZM, top * ZM,
|
||||
right * ZM, bott * ZM))
|
||||
return self.page_images[pn].crop((left * ZM, top * ZM, right * ZM, bott * ZM))
|
||||
pn = {}
|
||||
for b in bxs:
|
||||
p = b["page_number"] - 1
|
||||
@ -825,10 +756,7 @@ class RAGFlowPdfParser:
|
||||
pn[p].append(b)
|
||||
pn = sorted(pn.items(), key=lambda x: x[0])
|
||||
imgs = [cropout(arr, ltype, poss) for p, arr in pn]
|
||||
pic = Image.new("RGB",
|
||||
(int(np.max([i.size[0] for i in imgs])),
|
||||
int(np.sum([m.size[1] for m in imgs]))),
|
||||
(245, 245, 245))
|
||||
pic = Image.new("RGB", (int(np.max([i.size[0] for i in imgs])), int(np.sum([m.size[1] for m in imgs]))), (245, 245, 245))
|
||||
height = 0
|
||||
for img in imgs:
|
||||
pic.paste(img, (0, int(height)))
|
||||
@ -848,30 +776,20 @@ class RAGFlowPdfParser:
|
||||
poss = []
|
||||
|
||||
if separate_tables_figures:
|
||||
figure_results.append(
|
||||
(cropout(
|
||||
bxs,
|
||||
"figure", poss),
|
||||
[txt]))
|
||||
figure_results.append((cropout(bxs, "figure", poss), [txt]))
|
||||
figure_positions.append(poss)
|
||||
else:
|
||||
res.append(
|
||||
(cropout(
|
||||
bxs,
|
||||
"figure", poss),
|
||||
[txt]))
|
||||
res.append((cropout(bxs, "figure", poss), [txt]))
|
||||
positions.append(poss)
|
||||
|
||||
for k, bxs in tables.items():
|
||||
if not bxs:
|
||||
continue
|
||||
bxs = Recognizer.sort_Y_firstly(bxs, np.mean(
|
||||
[(b["bottom"] - b["top"]) / 2 for b in bxs]))
|
||||
bxs = Recognizer.sort_Y_firstly(bxs, np.mean([(b["bottom"] - b["top"]) / 2 for b in bxs]))
|
||||
|
||||
poss = []
|
||||
|
||||
res.append((cropout(bxs, "table", poss),
|
||||
self.tbl_det.construct_table(bxs, html=return_html, is_english=self.is_english)))
|
||||
res.append((cropout(bxs, "table", poss), self.tbl_det.construct_table(bxs, html=return_html, is_english=self.is_english)))
|
||||
positions.append(poss)
|
||||
|
||||
if separate_tables_figures:
|
||||
@ -905,7 +823,7 @@ class RAGFlowPdfParser:
|
||||
(r"[0-9]+)", 10),
|
||||
(r"[\((][0-9]+[)\)]", 11),
|
||||
(r"[零一二三四五六七八九十百]+是", 12),
|
||||
(r"[⚫•➢✓]", 12)
|
||||
(r"[⚫•➢✓]", 12),
|
||||
]:
|
||||
if re.match(p, line):
|
||||
return j
|
||||
@ -924,12 +842,9 @@ class RAGFlowPdfParser:
|
||||
if pn[-1] - 1 >= page_images_cnt:
|
||||
return ""
|
||||
|
||||
return "@@{}\t{:.1f}\t{:.1f}\t{:.1f}\t{:.1f}##" \
|
||||
.format("-".join([str(p) for p in pn]),
|
||||
bx["x0"], bx["x1"], top, bott)
|
||||
return "@@{}\t{:.1f}\t{:.1f}\t{:.1f}\t{:.1f}##".format("-".join([str(p) for p in pn]), bx["x0"], bx["x1"], top, bott)
|
||||
|
||||
def __filterout_scraps(self, boxes, ZM):
|
||||
|
||||
def width(b):
|
||||
return b["x1"] - b["x0"]
|
||||
|
||||
@ -939,8 +854,7 @@ class RAGFlowPdfParser:
|
||||
def usefull(b):
|
||||
if b.get("layout_type"):
|
||||
return True
|
||||
if width(
|
||||
b) > self.page_images[b["page_number"] - 1].size[0] / ZM / 3:
|
||||
if width(b) > self.page_images[b["page_number"] - 1].size[0] / ZM / 3:
|
||||
return True
|
||||
if b["bottom"] - b["top"] > self.mean_height[b["page_number"] - 1]:
|
||||
return True
|
||||
@ -952,31 +866,23 @@ class RAGFlowPdfParser:
|
||||
widths = []
|
||||
pw = self.page_images[boxes[0]["page_number"] - 1].size[0] / ZM
|
||||
mh = self.mean_height[boxes[0]["page_number"] - 1]
|
||||
mj = self.proj_match(
|
||||
boxes[0]["text"]) or boxes[0].get(
|
||||
"layout_type",
|
||||
"") == "title"
|
||||
mj = self.proj_match(boxes[0]["text"]) or boxes[0].get("layout_type", "") == "title"
|
||||
|
||||
def dfs(line, st):
|
||||
nonlocal mh, pw, lines, widths
|
||||
lines.append(line)
|
||||
widths.append(width(line))
|
||||
mmj = self.proj_match(
|
||||
line["text"]) or line.get(
|
||||
"layout_type",
|
||||
"") == "title"
|
||||
mmj = self.proj_match(line["text"]) or line.get("layout_type", "") == "title"
|
||||
for i in range(st + 1, min(st + 20, len(boxes))):
|
||||
if (boxes[i]["page_number"] - line["page_number"]) > 0:
|
||||
break
|
||||
if not mmj and self._y_dis(
|
||||
line, boxes[i]) >= 3 * mh and height(line) < 1.5 * mh:
|
||||
if not mmj and self._y_dis(line, boxes[i]) >= 3 * mh and height(line) < 1.5 * mh:
|
||||
break
|
||||
|
||||
if not usefull(boxes[i]):
|
||||
continue
|
||||
if mmj or \
|
||||
(self._x_dis(boxes[i], line) < pw / 10): \
|
||||
# and abs(width(boxes[i])-width_mean)/max(width(boxes[i]),width_mean)<0.5):
|
||||
if mmj or (self._x_dis(boxes[i], line) < pw / 10):
|
||||
# and abs(width(boxes[i])-width_mean)/max(width(boxes[i]),width_mean)<0.5):
|
||||
# concat following
|
||||
dfs(boxes[i], i)
|
||||
boxes.pop(i)
|
||||
@ -992,11 +898,9 @@ class RAGFlowPdfParser:
|
||||
boxes.pop(0)
|
||||
mw = np.mean(widths)
|
||||
if mj or mw / pw >= 0.35 or mw > 200:
|
||||
res.append(
|
||||
"\n".join([c["text"] + self._line_tag(c, ZM) for c in lines]))
|
||||
res.append("\n".join([c["text"] + self._line_tag(c, ZM) for c in lines]))
|
||||
else:
|
||||
logging.debug("REMOVED: " +
|
||||
"<<".join([c["text"] for c in lines]))
|
||||
logging.debug("REMOVED: " + "<<".join([c["text"] for c in lines]))
|
||||
|
||||
return "\n\n".join(res)
|
||||
|
||||
@ -1004,16 +908,14 @@ class RAGFlowPdfParser:
|
||||
def total_page_number(fnm, binary=None):
|
||||
try:
|
||||
with sys.modules[LOCK_KEY_pdfplumber]:
|
||||
pdf = pdfplumber.open(
|
||||
fnm) if not binary else pdfplumber.open(BytesIO(binary))
|
||||
pdf = pdfplumber.open(fnm) if not binary else pdfplumber.open(BytesIO(binary))
|
||||
total_page = len(pdf.pages)
|
||||
pdf.close()
|
||||
return total_page
|
||||
except Exception:
|
||||
logging.exception("total_page_number")
|
||||
|
||||
def __images__(self, fnm, zoomin=3, page_from=0,
|
||||
page_to=299, callback=None):
|
||||
def __images__(self, fnm, zoomin=3, page_from=0, page_to=299, callback=None):
|
||||
self.lefted_chars = []
|
||||
self.mean_height = []
|
||||
self.mean_width = []
|
||||
@ -1025,10 +927,9 @@ class RAGFlowPdfParser:
|
||||
start = timer()
|
||||
try:
|
||||
with sys.modules[LOCK_KEY_pdfplumber]:
|
||||
with (pdfplumber.open(fnm) if isinstance(fnm, str) else pdfplumber.open(BytesIO(fnm))) as pdf:
|
||||
with pdfplumber.open(fnm) if isinstance(fnm, str) else pdfplumber.open(BytesIO(fnm)) as pdf:
|
||||
self.pdf = pdf
|
||||
self.page_images = [p.to_image(resolution=72 * zoomin, antialias=True).annotated for i, p in
|
||||
enumerate(self.pdf.pages[page_from:page_to])]
|
||||
self.page_images = [p.to_image(resolution=72 * zoomin, antialias=True).annotated for i, p in enumerate(self.pdf.pages[page_from:page_to])]
|
||||
|
||||
try:
|
||||
self.page_chars = [[c for c in page.dedupe_chars().chars if self._has_color(c)] for page in self.pdf.pages[page_from:page_to]]
|
||||
@ -1044,11 +945,11 @@ class RAGFlowPdfParser:
|
||||
|
||||
self.outlines = []
|
||||
try:
|
||||
with (pdf2_read(fnm if isinstance(fnm, str)
|
||||
else BytesIO(fnm))) as pdf:
|
||||
with pdf2_read(fnm if isinstance(fnm, str) else BytesIO(fnm)) as pdf:
|
||||
self.pdf = pdf
|
||||
|
||||
outlines = self.pdf.outline
|
||||
|
||||
def dfs(arr, depth):
|
||||
for a in arr:
|
||||
if isinstance(a, dict):
|
||||
@ -1065,11 +966,11 @@ class RAGFlowPdfParser:
|
||||
logging.warning("Miss outlines")
|
||||
|
||||
logging.debug("Images converted.")
|
||||
self.is_english = [re.search(r"[a-zA-Z0-9,/¸;:'\[\]\(\)!@#$%^&*\"?<>._-]{30,}", "".join(
|
||||
random.choices([c["text"] for c in self.page_chars[i]], k=min(100, len(self.page_chars[i]))))) for i in
|
||||
range(len(self.page_chars))]
|
||||
if sum([1 if e else 0 for e in self.is_english]) > len(
|
||||
self.page_images) / 2:
|
||||
self.is_english = [
|
||||
re.search(r"[a-zA-Z0-9,/¸;:'\[\]\(\)!@#$%^&*\"?<>._-]{30,}", "".join(random.choices([c["text"] for c in self.page_chars[i]], k=min(100, len(self.page_chars[i])))))
|
||||
for i in range(len(self.page_chars))
|
||||
]
|
||||
if sum([1 if e else 0 for e in self.is_english]) > len(self.page_images) / 2:
|
||||
self.is_english = True
|
||||
else:
|
||||
self.is_english = False
|
||||
@ -1077,10 +978,12 @@ class RAGFlowPdfParser:
|
||||
async def __img_ocr(i, id, img, chars, limiter):
|
||||
j = 0
|
||||
while j + 1 < len(chars):
|
||||
if chars[j]["text"] and chars[j + 1]["text"] \
|
||||
and re.match(r"[0-9a-zA-Z,.:;!%]+", chars[j]["text"] + chars[j + 1]["text"]) \
|
||||
and chars[j + 1]["x0"] - chars[j]["x1"] >= min(chars[j + 1]["width"],
|
||||
chars[j]["width"]) / 2:
|
||||
if (
|
||||
chars[j]["text"]
|
||||
and chars[j + 1]["text"]
|
||||
and re.match(r"[0-9a-zA-Z,.:;!%]+", chars[j]["text"] + chars[j + 1]["text"])
|
||||
and chars[j + 1]["x0"] - chars[j]["x1"] >= min(chars[j + 1]["width"], chars[j]["width"]) / 2
|
||||
):
|
||||
chars[j]["text"] += " "
|
||||
j += 1
|
||||
|
||||
@ -1096,12 +999,8 @@ class RAGFlowPdfParser:
|
||||
async def __img_ocr_launcher():
|
||||
def __ocr_preprocess():
|
||||
chars = self.page_chars[i] if not self.is_english else []
|
||||
self.mean_height.append(
|
||||
np.median(sorted([c["height"] for c in chars])) if chars else 0
|
||||
)
|
||||
self.mean_width.append(
|
||||
np.median(sorted([c["width"] for c in chars])) if chars else 8
|
||||
)
|
||||
self.mean_height.append(np.median(sorted([c["height"] for c in chars])) if chars else 0)
|
||||
self.mean_width.append(np.median(sorted([c["width"] for c in chars])) if chars else 8)
|
||||
self.page_cum_height.append(img.size[1] / zoomin)
|
||||
return chars
|
||||
|
||||
@ -1110,8 +1009,7 @@ class RAGFlowPdfParser:
|
||||
for i, img in enumerate(self.page_images):
|
||||
chars = __ocr_preprocess()
|
||||
|
||||
nursery.start_soon(__img_ocr, i, i % PARALLEL_DEVICES, img, chars,
|
||||
self.parallel_limiter[i % PARALLEL_DEVICES])
|
||||
nursery.start_soon(__img_ocr, i, i % PARALLEL_DEVICES, img, chars, self.parallel_limiter[i % PARALLEL_DEVICES])
|
||||
await trio.sleep(0.1)
|
||||
else:
|
||||
for i, img in enumerate(self.page_images):
|
||||
@ -1124,11 +1022,9 @@ class RAGFlowPdfParser:
|
||||
|
||||
logging.info(f"__images__ {len(self.page_images)} pages cost {timer() - start}s")
|
||||
|
||||
if not self.is_english and not any(
|
||||
[c for c in self.page_chars]) and self.boxes:
|
||||
if not self.is_english and not any([c for c in self.page_chars]) and self.boxes:
|
||||
bxes = [b for bxs in self.boxes for b in bxs]
|
||||
self.is_english = re.search(r"[\na-zA-Z0-9,/¸;:'\[\]\(\)!@#$%^&*\"?<>._-]{30,}",
|
||||
"".join([b["text"] for b in random.choices(bxes, k=min(30, len(bxes)))]))
|
||||
self.is_english = re.search(r"[\na-zA-Z0-9,/¸;:'\[\]\(\)!@#$%^&*\"?<>._-]{30,}", "".join([b["text"] for b in random.choices(bxes, k=min(30, len(bxes)))]))
|
||||
|
||||
logging.debug("Is it English:", self.is_english)
|
||||
|
||||
@ -1144,8 +1040,7 @@ class RAGFlowPdfParser:
|
||||
self._text_merge()
|
||||
self._concat_downward()
|
||||
self._filter_forpages()
|
||||
tbls = self._extract_table_figure(
|
||||
need_image, zoomin, return_html, False)
|
||||
tbls = self._extract_table_figure(need_image, zoomin, return_html, False)
|
||||
return self.__filterout_scraps(deepcopy(self.boxes), zoomin), tbls
|
||||
|
||||
def parse_into_bboxes(self, fnm, callback=None, zoomin=3):
|
||||
@ -1177,11 +1072,11 @@ class RAGFlowPdfParser:
|
||||
def insert_table_figures(tbls_or_figs, layout_type):
|
||||
def min_rectangle_distance(rect1, rect2):
|
||||
import math
|
||||
|
||||
pn1, left1, right1, top1, bottom1 = rect1
|
||||
pn2, left2, right2, top2, bottom2 = rect2
|
||||
if (right1 >= left2 and right2 >= left1 and
|
||||
bottom1 >= top2 and bottom2 >= top1):
|
||||
return 0 + (pn1-pn2)*10000
|
||||
if right1 >= left2 and right2 >= left1 and bottom1 >= top2 and bottom2 >= top1:
|
||||
return 0 + (pn1 - pn2) * 10000
|
||||
if right1 < left2:
|
||||
dx = left2 - right1
|
||||
elif right2 < left1:
|
||||
@ -1194,18 +1089,16 @@ class RAGFlowPdfParser:
|
||||
dy = top1 - bottom2
|
||||
else:
|
||||
dy = 0
|
||||
return math.sqrt(dx*dx + dy*dy) + (pn1-pn2)*10000
|
||||
return math.sqrt(dx * dx + dy * dy) + (pn1 - pn2) * 10000
|
||||
|
||||
for (img, txt), poss in tbls_or_figs:
|
||||
bboxes = [(i, (b["page_number"], b["x0"], b["x1"], b["top"], b["bottom"])) for i, b in enumerate(self.boxes)]
|
||||
dists = [(min_rectangle_distance((pn, left, right, top, bott), rect),i) for i, rect in bboxes for pn, left, right, top, bott in poss]
|
||||
dists = [(min_rectangle_distance((pn, left, right, top, bott), rect), i) for i, rect in bboxes for pn, left, right, top, bott in poss]
|
||||
min_i = np.argmin(dists, axis=0)[0]
|
||||
min_i, rect = bboxes[dists[min_i][-1]]
|
||||
if isinstance(txt, list):
|
||||
txt = "\n".join(txt)
|
||||
self.boxes.insert(min_i, {
|
||||
"page_number": rect[0], "x0": rect[1], "x1": rect[2], "top": rect[3], "bottom": rect[4], "layout_type": layout_type, "text": txt, "image": img
|
||||
})
|
||||
self.boxes.insert(min_i, {"page_number": rect[0], "x0": rect[1], "x1": rect[2], "top": rect[3], "bottom": rect[4], "layout_type": layout_type, "text": txt, "image": img})
|
||||
|
||||
for b in self.boxes:
|
||||
b["position_tag"] = self._line_tag(b, zoomin)
|
||||
@ -1225,12 +1118,9 @@ class RAGFlowPdfParser:
|
||||
def extract_positions(txt):
|
||||
poss = []
|
||||
for tag in re.findall(r"@@[0-9-]+\t[0-9.\t]+##", txt):
|
||||
pn, left, right, top, bottom = tag.strip(
|
||||
"#").strip("@").split("\t")
|
||||
left, right, top, bottom = float(left), float(
|
||||
right), float(top), float(bottom)
|
||||
poss.append(([int(p) - 1 for p in pn.split("-")],
|
||||
left, right, top, bottom))
|
||||
pn, left, right, top, bottom = tag.strip("#").strip("@").split("\t")
|
||||
left, right, top, bottom = float(left), float(right), float(top), float(bottom)
|
||||
poss.append(([int(p) - 1 for p in pn.split("-")], left, right, top, bottom))
|
||||
return poss
|
||||
|
||||
def crop(self, text, ZM=3, need_position=False):
|
||||
@ -1241,15 +1131,12 @@ class RAGFlowPdfParser:
|
||||
return None, None
|
||||
return
|
||||
|
||||
max_width = max(
|
||||
np.max([right - left for (_, left, right, _, _) in poss]), 6)
|
||||
max_width = max(np.max([right - left for (_, left, right, _, _) in poss]), 6)
|
||||
GAP = 6
|
||||
pos = poss[0]
|
||||
poss.insert(0, ([pos[0][0]], pos[1], pos[2], max(
|
||||
0, pos[3] - 120), max(pos[3] - GAP, 0)))
|
||||
poss.insert(0, ([pos[0][0]], pos[1], pos[2], max(0, pos[3] - 120), max(pos[3] - GAP, 0)))
|
||||
pos = poss[-1]
|
||||
poss.append(([pos[0][-1]], pos[1], pos[2], min(self.page_images[pos[0][-1]].size[1] / ZM, pos[4] + GAP),
|
||||
min(self.page_images[pos[0][-1]].size[1] / ZM, pos[4] + 120)))
|
||||
poss.append(([pos[0][-1]], pos[1], pos[2], min(self.page_images[pos[0][-1]].size[1] / ZM, pos[4] + GAP), min(self.page_images[pos[0][-1]].size[1] / ZM, pos[4] + 120)))
|
||||
|
||||
positions = []
|
||||
for ii, (pns, left, right, top, bottom) in enumerate(poss):
|
||||
@ -1257,28 +1144,14 @@ class RAGFlowPdfParser:
|
||||
bottom *= ZM
|
||||
for pn in pns[1:]:
|
||||
bottom += self.page_images[pn - 1].size[1]
|
||||
imgs.append(
|
||||
self.page_images[pns[0]].crop((left * ZM, top * ZM,
|
||||
right *
|
||||
ZM, min(
|
||||
bottom, self.page_images[pns[0]].size[1])
|
||||
))
|
||||
)
|
||||
imgs.append(self.page_images[pns[0]].crop((left * ZM, top * ZM, right * ZM, min(bottom, self.page_images[pns[0]].size[1]))))
|
||||
if 0 < ii < len(poss) - 1:
|
||||
positions.append((pns[0] + self.page_from, left, right, top, min(
|
||||
bottom, self.page_images[pns[0]].size[1]) / ZM))
|
||||
positions.append((pns[0] + self.page_from, left, right, top, min(bottom, self.page_images[pns[0]].size[1]) / ZM))
|
||||
bottom -= self.page_images[pns[0]].size[1]
|
||||
for pn in pns[1:]:
|
||||
imgs.append(
|
||||
self.page_images[pn].crop((left * ZM, 0,
|
||||
right * ZM,
|
||||
min(bottom,
|
||||
self.page_images[pn].size[1])
|
||||
))
|
||||
)
|
||||
imgs.append(self.page_images[pn].crop((left * ZM, 0, right * ZM, min(bottom, self.page_images[pn].size[1]))))
|
||||
if 0 < ii < len(poss) - 1:
|
||||
positions.append((pn + self.page_from, left, right, 0, min(
|
||||
bottom, self.page_images[pn].size[1]) / ZM))
|
||||
positions.append((pn + self.page_from, left, right, 0, min(bottom, self.page_images[pn].size[1]) / ZM))
|
||||
bottom -= self.page_images[pn].size[1]
|
||||
|
||||
if not imgs:
|
||||
@ -1290,14 +1163,12 @@ class RAGFlowPdfParser:
|
||||
height += img.size[1] + GAP
|
||||
height = int(height)
|
||||
width = int(np.max([i.size[0] for i in imgs]))
|
||||
pic = Image.new("RGB",
|
||||
(width, height),
|
||||
(245, 245, 245))
|
||||
pic = Image.new("RGB", (width, height), (245, 245, 245))
|
||||
height = 0
|
||||
for ii, img in enumerate(imgs):
|
||||
if ii == 0 or ii + 1 == len(imgs):
|
||||
img = img.convert('RGBA')
|
||||
overlay = Image.new('RGBA', img.size, (0, 0, 0, 0))
|
||||
img = img.convert("RGBA")
|
||||
overlay = Image.new("RGBA", img.size, (0, 0, 0, 0))
|
||||
overlay.putalpha(128)
|
||||
img = Image.alpha_composite(img, overlay).convert("RGB")
|
||||
pic.paste(img, (0, int(height)))
|
||||
@ -1312,14 +1183,12 @@ class RAGFlowPdfParser:
|
||||
pn = bx["page_number"]
|
||||
top = bx["top"] - self.page_cum_height[pn - 1]
|
||||
bott = bx["bottom"] - self.page_cum_height[pn - 1]
|
||||
poss.append((pn, bx["x0"], bx["x1"], top, min(
|
||||
bott, self.page_images[pn - 1].size[1] / ZM)))
|
||||
poss.append((pn, bx["x0"], bx["x1"], top, min(bott, self.page_images[pn - 1].size[1] / ZM)))
|
||||
while bott * ZM > self.page_images[pn - 1].size[1]:
|
||||
bott -= self.page_images[pn - 1].size[1] / ZM
|
||||
top = 0
|
||||
pn += 1
|
||||
poss.append((pn, bx["x0"], bx["x1"], top, min(
|
||||
bott, self.page_images[pn - 1].size[1] / ZM)))
|
||||
poss.append((pn, bx["x0"], bx["x1"], top, min(bott, self.page_images[pn - 1].size[1] / ZM)))
|
||||
return poss
|
||||
|
||||
|
||||
@ -1328,9 +1197,7 @@ class PlainParser:
|
||||
self.outlines = []
|
||||
lines = []
|
||||
try:
|
||||
self.pdf = pdf2_read(
|
||||
filename if isinstance(
|
||||
filename, str) else BytesIO(filename))
|
||||
self.pdf = pdf2_read(filename if isinstance(filename, str) else BytesIO(filename))
|
||||
for page in self.pdf.pages[from_page:to_page]:
|
||||
lines.extend([t for t in page.extract_text().split("\n")])
|
||||
|
||||
@ -1367,10 +1234,8 @@ class VisionParser(RAGFlowPdfParser):
|
||||
def __images__(self, fnm, zoomin=3, page_from=0, page_to=299, callback=None):
|
||||
try:
|
||||
with sys.modules[LOCK_KEY_pdfplumber]:
|
||||
self.pdf = pdfplumber.open(fnm) if isinstance(
|
||||
fnm, str) else pdfplumber.open(BytesIO(fnm))
|
||||
self.page_images = [p.to_image(resolution=72 * zoomin).annotated for i, p in
|
||||
enumerate(self.pdf.pages[page_from:page_to])]
|
||||
self.pdf = pdfplumber.open(fnm) if isinstance(fnm, str) else pdfplumber.open(BytesIO(fnm))
|
||||
self.page_images = [p.to_image(resolution=72 * zoomin).annotated for i, p in enumerate(self.pdf.pages[page_from:page_to])]
|
||||
self.total_page = len(self.pdf.pages)
|
||||
except Exception:
|
||||
self.page_images = None
|
||||
@ -1397,15 +1262,15 @@ class VisionParser(RAGFlowPdfParser):
|
||||
text = picture_vision_llm_chunk(
|
||||
binary=img_binary,
|
||||
vision_model=self.vision_model,
|
||||
prompt=vision_llm_describe_prompt(page=pdf_page_num+1),
|
||||
prompt=vision_llm_describe_prompt(page=pdf_page_num + 1),
|
||||
callback=callback,
|
||||
)
|
||||
if kwargs.get("callback"):
|
||||
kwargs["callback"](idx*1./len(self.page_images), f"Processed: {idx+1}/{len(self.page_images)}")
|
||||
kwargs["callback"](idx * 1.0 / len(self.page_images), f"Processed: {idx + 1}/{len(self.page_images)}")
|
||||
|
||||
if text:
|
||||
width, height = self.page_images[idx].size
|
||||
all_docs.append((text, f"{pdf_page_num+1} 0 {width/zoomin} 0 {height/zoomin}"))
|
||||
all_docs.append((text, f"{pdf_page_num + 1} 0 {width / zoomin} 0 {height / zoomin}"))
|
||||
return all_docs, []
|
||||
|
||||
|
||||
|
||||
@ -16,24 +16,28 @@
|
||||
import io
|
||||
import sys
|
||||
import threading
|
||||
|
||||
import pdfplumber
|
||||
|
||||
from .ocr import OCR
|
||||
from .recognizer import Recognizer
|
||||
from .layout_recognizer import AscendLayoutRecognizer
|
||||
from .layout_recognizer import LayoutRecognizer4YOLOv10 as LayoutRecognizer
|
||||
from .table_structure_recognizer import TableStructureRecognizer
|
||||
|
||||
|
||||
LOCK_KEY_pdfplumber = "global_shared_lock_pdfplumber"
|
||||
if LOCK_KEY_pdfplumber not in sys.modules:
|
||||
sys.modules[LOCK_KEY_pdfplumber] = threading.Lock()
|
||||
|
||||
|
||||
def init_in_out(args):
|
||||
from PIL import Image
|
||||
import os
|
||||
import traceback
|
||||
|
||||
from PIL import Image
|
||||
|
||||
from api.utils.file_utils import traversal_files
|
||||
|
||||
images = []
|
||||
outputs = []
|
||||
|
||||
@ -44,8 +48,7 @@ def init_in_out(args):
|
||||
nonlocal outputs, images
|
||||
with sys.modules[LOCK_KEY_pdfplumber]:
|
||||
pdf = pdfplumber.open(fnm)
|
||||
images = [p.to_image(resolution=72 * zoomin).annotated for i, p in
|
||||
enumerate(pdf.pages)]
|
||||
images = [p.to_image(resolution=72 * zoomin).annotated for i, p in enumerate(pdf.pages)]
|
||||
|
||||
for i, page in enumerate(images):
|
||||
outputs.append(os.path.split(fnm)[-1] + f"_{i}.jpg")
|
||||
@ -57,10 +60,10 @@ def init_in_out(args):
|
||||
pdf_pages(fnm)
|
||||
return
|
||||
try:
|
||||
fp = open(fnm, 'rb')
|
||||
fp = open(fnm, "rb")
|
||||
binary = fp.read()
|
||||
fp.close()
|
||||
images.append(Image.open(io.BytesIO(binary)).convert('RGB'))
|
||||
images.append(Image.open(io.BytesIO(binary)).convert("RGB"))
|
||||
outputs.append(os.path.split(fnm)[-1])
|
||||
except Exception:
|
||||
traceback.print_exc()
|
||||
@ -81,6 +84,7 @@ __all__ = [
|
||||
"OCR",
|
||||
"Recognizer",
|
||||
"LayoutRecognizer",
|
||||
"AscendLayoutRecognizer",
|
||||
"TableStructureRecognizer",
|
||||
"init_in_out",
|
||||
]
|
||||
|
||||
@ -14,6 +14,8 @@
|
||||
# limitations under the License.
|
||||
#
|
||||
|
||||
import logging
|
||||
import math
|
||||
import os
|
||||
import re
|
||||
from collections import Counter
|
||||
@ -45,28 +47,22 @@ class LayoutRecognizer(Recognizer):
|
||||
|
||||
def __init__(self, domain):
|
||||
try:
|
||||
model_dir = os.path.join(
|
||||
get_project_base_directory(),
|
||||
"rag/res/deepdoc")
|
||||
model_dir = os.path.join(get_project_base_directory(), "rag/res/deepdoc")
|
||||
super().__init__(self.labels, domain, model_dir)
|
||||
except Exception:
|
||||
model_dir = snapshot_download(repo_id="InfiniFlow/deepdoc",
|
||||
local_dir=os.path.join(get_project_base_directory(), "rag/res/deepdoc"),
|
||||
local_dir_use_symlinks=False)
|
||||
model_dir = snapshot_download(repo_id="InfiniFlow/deepdoc", local_dir=os.path.join(get_project_base_directory(), "rag/res/deepdoc"), local_dir_use_symlinks=False)
|
||||
super().__init__(self.labels, domain, model_dir)
|
||||
|
||||
self.garbage_layouts = ["footer", "header", "reference"]
|
||||
self.client = None
|
||||
if os.environ.get("TENSORRT_DLA_SVR"):
|
||||
from deepdoc.vision.dla_cli import DLAClient
|
||||
|
||||
self.client = DLAClient(os.environ["TENSORRT_DLA_SVR"])
|
||||
|
||||
def __call__(self, image_list, ocr_res, scale_factor=3, thr=0.2, batch_size=16, drop=True):
|
||||
def __is_garbage(b):
|
||||
patt = [r"^•+$", "^[0-9]{1,2} / ?[0-9]{1,2}$",
|
||||
r"^[0-9]{1,2} of [0-9]{1,2}$", "^http://[^ ]{12,}",
|
||||
"\\(cid *: *[0-9]+ *\\)"
|
||||
]
|
||||
patt = [r"^•+$", "^[0-9]{1,2} / ?[0-9]{1,2}$", r"^[0-9]{1,2} of [0-9]{1,2}$", "^http://[^ ]{12,}", "\\(cid *: *[0-9]+ *\\)"]
|
||||
return any([re.search(p, b["text"]) for p in patt])
|
||||
|
||||
if self.client:
|
||||
@ -82,18 +78,23 @@ class LayoutRecognizer(Recognizer):
|
||||
page_layout = []
|
||||
for pn, lts in enumerate(layouts):
|
||||
bxs = ocr_res[pn]
|
||||
lts = [{"type": b["type"],
|
||||
lts = [
|
||||
{
|
||||
"type": b["type"],
|
||||
"score": float(b["score"]),
|
||||
"x0": b["bbox"][0] / scale_factor, "x1": b["bbox"][2] / scale_factor,
|
||||
"top": b["bbox"][1] / scale_factor, "bottom": b["bbox"][-1] / scale_factor,
|
||||
"x0": b["bbox"][0] / scale_factor,
|
||||
"x1": b["bbox"][2] / scale_factor,
|
||||
"top": b["bbox"][1] / scale_factor,
|
||||
"bottom": b["bbox"][-1] / scale_factor,
|
||||
"page_number": pn,
|
||||
} for b in lts if float(b["score"]) >= 0.4 or b["type"] not in self.garbage_layouts]
|
||||
lts = self.sort_Y_firstly(lts, np.mean(
|
||||
[lt["bottom"] - lt["top"] for lt in lts]) / 2)
|
||||
}
|
||||
for b in lts
|
||||
if float(b["score"]) >= 0.4 or b["type"] not in self.garbage_layouts
|
||||
]
|
||||
lts = self.sort_Y_firstly(lts, np.mean([lt["bottom"] - lt["top"] for lt in lts]) / 2)
|
||||
lts = self.layouts_cleanup(bxs, lts)
|
||||
page_layout.append(lts)
|
||||
|
||||
# Tag layout type, layouts are ready
|
||||
def findLayout(ty):
|
||||
nonlocal bxs, lts, self
|
||||
lts_ = [lt for lt in lts if lt["type"] == ty]
|
||||
@ -106,21 +107,17 @@ class LayoutRecognizer(Recognizer):
|
||||
bxs.pop(i)
|
||||
continue
|
||||
|
||||
ii = self.find_overlapped_with_threshold(bxs[i], lts_,
|
||||
thr=0.4)
|
||||
if ii is None: # belong to nothing
|
||||
ii = self.find_overlapped_with_threshold(bxs[i], lts_, thr=0.4)
|
||||
if ii is None:
|
||||
bxs[i]["layout_type"] = ""
|
||||
i += 1
|
||||
continue
|
||||
lts_[ii]["visited"] = True
|
||||
keep_feats = [
|
||||
lts_[
|
||||
ii]["type"] == "footer" and bxs[i]["bottom"] < image_list[pn].size[1] * 0.9 / scale_factor,
|
||||
lts_[
|
||||
ii]["type"] == "header" and bxs[i]["top"] > image_list[pn].size[1] * 0.1 / scale_factor,
|
||||
lts_[ii]["type"] == "footer" and bxs[i]["bottom"] < image_list[pn].size[1] * 0.9 / scale_factor,
|
||||
lts_[ii]["type"] == "header" and bxs[i]["top"] > image_list[pn].size[1] * 0.1 / scale_factor,
|
||||
]
|
||||
if drop and lts_[
|
||||
ii]["type"] in self.garbage_layouts and not any(keep_feats):
|
||||
if drop and lts_[ii]["type"] in self.garbage_layouts and not any(keep_feats):
|
||||
if lts_[ii]["type"] not in garbages:
|
||||
garbages[lts_[ii]["type"]] = []
|
||||
garbages[lts_[ii]["type"]].append(bxs[i]["text"])
|
||||
@ -128,17 +125,14 @@ class LayoutRecognizer(Recognizer):
|
||||
continue
|
||||
|
||||
bxs[i]["layoutno"] = f"{ty}-{ii}"
|
||||
bxs[i]["layout_type"] = lts_[ii]["type"] if lts_[
|
||||
ii]["type"] != "equation" else "figure"
|
||||
bxs[i]["layout_type"] = lts_[ii]["type"] if lts_[ii]["type"] != "equation" else "figure"
|
||||
i += 1
|
||||
|
||||
for lt in ["footer", "header", "reference", "figure caption",
|
||||
"table caption", "title", "table", "text", "figure", "equation"]:
|
||||
for lt in ["footer", "header", "reference", "figure caption", "table caption", "title", "table", "text", "figure", "equation"]:
|
||||
findLayout(lt)
|
||||
|
||||
# add box to figure layouts which has not text box
|
||||
for i, lt in enumerate(
|
||||
[lt for lt in lts if lt["type"] in ["figure", "equation"]]):
|
||||
for i, lt in enumerate([lt for lt in lts if lt["type"] in ["figure", "equation"]]):
|
||||
if lt.get("visited"):
|
||||
continue
|
||||
lt = deepcopy(lt)
|
||||
@ -206,13 +200,11 @@ class LayoutRecognizer4YOLOv10(LayoutRecognizer):
|
||||
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
|
||||
top, bottom = int(round(dh - 0.1)) if self.center else 0, int(round(dh + 0.1))
|
||||
left, right = int(round(dw - 0.1)) if self.center else 0, int(round(dw + 0.1))
|
||||
img = cv2.copyMakeBorder(
|
||||
img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=(114, 114, 114)
|
||||
) # add border
|
||||
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=(114, 114, 114)) # add border
|
||||
img /= 255.0
|
||||
img = img.transpose(2, 0, 1)
|
||||
img = img[np.newaxis, :, :, :].astype(np.float32)
|
||||
inputs.append({self.input_names[0]: img, "scale_factor": [shape[1]/ww, shape[0]/hh, dw, dh]})
|
||||
inputs.append({self.input_names[0]: img, "scale_factor": [shape[1] / ww, shape[0] / hh, dw, dh]})
|
||||
|
||||
return inputs
|
||||
|
||||
@ -230,8 +222,7 @@ class LayoutRecognizer4YOLOv10(LayoutRecognizer):
|
||||
boxes[:, 2] -= inputs["scale_factor"][2]
|
||||
boxes[:, 1] -= inputs["scale_factor"][3]
|
||||
boxes[:, 3] -= inputs["scale_factor"][3]
|
||||
input_shape = np.array([inputs["scale_factor"][0], inputs["scale_factor"][1], inputs["scale_factor"][0],
|
||||
inputs["scale_factor"][1]])
|
||||
input_shape = np.array([inputs["scale_factor"][0], inputs["scale_factor"][1], inputs["scale_factor"][0], inputs["scale_factor"][1]])
|
||||
boxes = np.multiply(boxes, input_shape, dtype=np.float32)
|
||||
|
||||
unique_class_ids = np.unique(class_ids)
|
||||
@ -243,8 +234,223 @@ class LayoutRecognizer4YOLOv10(LayoutRecognizer):
|
||||
class_keep_boxes = nms(class_boxes, class_scores, 0.45)
|
||||
indices.extend(class_indices[class_keep_boxes])
|
||||
|
||||
return [{
|
||||
"type": self.label_list[class_ids[i]].lower(),
|
||||
"bbox": [float(t) for t in boxes[i].tolist()],
|
||||
"score": float(scores[i])
|
||||
} for i in indices]
|
||||
return [{"type": self.label_list[class_ids[i]].lower(), "bbox": [float(t) for t in boxes[i].tolist()], "score": float(scores[i])} for i in indices]
|
||||
|
||||
|
||||
class AscendLayoutRecognizer(Recognizer):
|
||||
labels = [
|
||||
"title",
|
||||
"Text",
|
||||
"Reference",
|
||||
"Figure",
|
||||
"Figure caption",
|
||||
"Table",
|
||||
"Table caption",
|
||||
"Table caption",
|
||||
"Equation",
|
||||
"Figure caption",
|
||||
]
|
||||
|
||||
def __init__(self, domain):
|
||||
from ais_bench.infer.interface import InferSession
|
||||
|
||||
model_dir = os.path.join(get_project_base_directory(), "rag/res/deepdoc")
|
||||
model_file_path = os.path.join(model_dir, domain + ".om")
|
||||
|
||||
if not os.path.exists(model_file_path):
|
||||
raise ValueError(f"Model file not found: {model_file_path}")
|
||||
|
||||
device_id = int(os.getenv("ASCEND_LAYOUT_RECOGNIZER_DEVICE_ID", 0))
|
||||
self.session = InferSession(device_id=device_id, model_path=model_file_path)
|
||||
self.input_shape = self.session.get_inputs()[0].shape[2:4] # H,W
|
||||
self.garbage_layouts = ["footer", "header", "reference"]
|
||||
|
||||
def preprocess(self, image_list):
|
||||
inputs = []
|
||||
H, W = self.input_shape
|
||||
for img in image_list:
|
||||
h, w = img.shape[:2]
|
||||
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB).astype(np.float32)
|
||||
|
||||
r = min(H / h, W / w)
|
||||
new_unpad = (int(round(w * r)), int(round(h * r)))
|
||||
dw, dh = (W - new_unpad[0]) / 2.0, (H - new_unpad[1]) / 2.0
|
||||
|
||||
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
|
||||
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
|
||||
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
|
||||
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=(114, 114, 114))
|
||||
|
||||
img /= 255.0
|
||||
img = img.transpose(2, 0, 1)[np.newaxis, :, :, :].astype(np.float32)
|
||||
|
||||
inputs.append(
|
||||
{
|
||||
"image": img,
|
||||
"scale_factor": [w / new_unpad[0], h / new_unpad[1]],
|
||||
"pad": [dw, dh],
|
||||
"orig_shape": [h, w],
|
||||
}
|
||||
)
|
||||
return inputs
|
||||
|
||||
def postprocess(self, boxes, inputs, thr=0.25):
|
||||
arr = np.squeeze(boxes)
|
||||
if arr.ndim == 1:
|
||||
arr = arr.reshape(1, -1)
|
||||
|
||||
results = []
|
||||
if arr.shape[1] == 6:
|
||||
# [x1,y1,x2,y2,score,cls]
|
||||
m = arr[:, 4] >= thr
|
||||
arr = arr[m]
|
||||
if arr.size == 0:
|
||||
return []
|
||||
xyxy = arr[:, :4].astype(np.float32)
|
||||
scores = arr[:, 4].astype(np.float32)
|
||||
cls_ids = arr[:, 5].astype(np.int32)
|
||||
|
||||
if "pad" in inputs:
|
||||
dw, dh = inputs["pad"]
|
||||
sx, sy = inputs["scale_factor"]
|
||||
xyxy[:, [0, 2]] -= dw
|
||||
xyxy[:, [1, 3]] -= dh
|
||||
xyxy *= np.array([sx, sy, sx, sy], dtype=np.float32)
|
||||
else:
|
||||
# backup
|
||||
sx, sy = inputs["scale_factor"]
|
||||
xyxy *= np.array([sx, sy, sx, sy], dtype=np.float32)
|
||||
|
||||
keep_indices = []
|
||||
for c in np.unique(cls_ids):
|
||||
idx = np.where(cls_ids == c)[0]
|
||||
k = nms(xyxy[idx], scores[idx], 0.45)
|
||||
keep_indices.extend(idx[k])
|
||||
|
||||
for i in keep_indices:
|
||||
cid = int(cls_ids[i])
|
||||
if 0 <= cid < len(self.labels):
|
||||
results.append({"type": self.labels[cid].lower(), "bbox": [float(t) for t in xyxy[i].tolist()], "score": float(scores[i])})
|
||||
return results
|
||||
|
||||
raise ValueError(f"Unexpected output shape: {arr.shape}")
|
||||
|
||||
def __call__(self, image_list, ocr_res, scale_factor=3, thr=0.2, batch_size=16, drop=True):
|
||||
import re
|
||||
from collections import Counter
|
||||
|
||||
assert len(image_list) == len(ocr_res)
|
||||
|
||||
images = [np.array(im) if not isinstance(im, np.ndarray) else im for im in image_list]
|
||||
layouts_all_pages = [] # list of list[{"type","score","bbox":[x1,y1,x2,y2]}]
|
||||
|
||||
conf_thr = max(thr, 0.08)
|
||||
|
||||
batch_loop_cnt = math.ceil(float(len(images)) / batch_size)
|
||||
for bi in range(batch_loop_cnt):
|
||||
s = bi * batch_size
|
||||
e = min((bi + 1) * batch_size, len(images))
|
||||
batch_images = images[s:e]
|
||||
|
||||
inputs_list = self.preprocess(batch_images)
|
||||
logging.debug("preprocess done")
|
||||
|
||||
for ins in inputs_list:
|
||||
feeds = [ins["image"]]
|
||||
out_list = self.session.infer(feeds=feeds, mode="static")
|
||||
|
||||
for out in out_list:
|
||||
lts = self.postprocess(out, ins, conf_thr)
|
||||
|
||||
page_lts = []
|
||||
for b in lts:
|
||||
if float(b["score"]) >= 0.4 or b["type"] not in self.garbage_layouts:
|
||||
x0, y0, x1, y1 = b["bbox"]
|
||||
page_lts.append(
|
||||
{
|
||||
"type": b["type"],
|
||||
"score": float(b["score"]),
|
||||
"x0": float(x0) / scale_factor,
|
||||
"x1": float(x1) / scale_factor,
|
||||
"top": float(y0) / scale_factor,
|
||||
"bottom": float(y1) / scale_factor,
|
||||
"page_number": len(layouts_all_pages),
|
||||
}
|
||||
)
|
||||
layouts_all_pages.append(page_lts)
|
||||
|
||||
def _is_garbage_text(box):
|
||||
patt = [r"^•+$", r"^[0-9]{1,2} / ?[0-9]{1,2}$", r"^[0-9]{1,2} of [0-9]{1,2}$", r"^http://[^ ]{12,}", r"\(cid *: *[0-9]+ *\)"]
|
||||
return any(re.search(p, box.get("text", "")) for p in patt)
|
||||
|
||||
boxes_out = []
|
||||
page_layout = []
|
||||
garbages = {}
|
||||
|
||||
for pn, lts in enumerate(layouts_all_pages):
|
||||
if lts:
|
||||
avg_h = np.mean([lt["bottom"] - lt["top"] for lt in lts])
|
||||
lts = self.sort_Y_firstly(lts, avg_h / 2 if avg_h > 0 else 0)
|
||||
|
||||
bxs = ocr_res[pn]
|
||||
lts = self.layouts_cleanup(bxs, lts)
|
||||
page_layout.append(lts)
|
||||
|
||||
def _tag_layout(ty):
|
||||
nonlocal bxs, lts
|
||||
lts_of_ty = [lt for lt in lts if lt["type"] == ty]
|
||||
i = 0
|
||||
while i < len(bxs):
|
||||
if bxs[i].get("layout_type"):
|
||||
i += 1
|
||||
continue
|
||||
if _is_garbage_text(bxs[i]):
|
||||
bxs.pop(i)
|
||||
continue
|
||||
|
||||
ii = self.find_overlapped_with_threshold(bxs[i], lts_of_ty, thr=0.4)
|
||||
if ii is None:
|
||||
bxs[i]["layout_type"] = ""
|
||||
i += 1
|
||||
continue
|
||||
|
||||
lts_of_ty[ii]["visited"] = True
|
||||
|
||||
keep_feats = [
|
||||
lts_of_ty[ii]["type"] == "footer" and bxs[i]["bottom"] < image_list[pn].shape[0] * 0.9 / scale_factor,
|
||||
lts_of_ty[ii]["type"] == "header" and bxs[i]["top"] > image_list[pn].shape[0] * 0.1 / scale_factor,
|
||||
]
|
||||
if drop and lts_of_ty[ii]["type"] in self.garbage_layouts and not any(keep_feats):
|
||||
garbages.setdefault(lts_of_ty[ii]["type"], []).append(bxs[i].get("text", ""))
|
||||
bxs.pop(i)
|
||||
continue
|
||||
|
||||
bxs[i]["layoutno"] = f"{ty}-{ii}"
|
||||
bxs[i]["layout_type"] = lts_of_ty[ii]["type"] if lts_of_ty[ii]["type"] != "equation" else "figure"
|
||||
i += 1
|
||||
|
||||
for ty in ["footer", "header", "reference", "figure caption", "table caption", "title", "table", "text", "figure", "equation"]:
|
||||
_tag_layout(ty)
|
||||
|
||||
figs = [lt for lt in lts if lt["type"] in ["figure", "equation"]]
|
||||
for i, lt in enumerate(figs):
|
||||
if lt.get("visited"):
|
||||
continue
|
||||
lt = deepcopy(lt)
|
||||
lt.pop("type", None)
|
||||
lt["text"] = ""
|
||||
lt["layout_type"] = "figure"
|
||||
lt["layoutno"] = f"figure-{i}"
|
||||
bxs.append(lt)
|
||||
|
||||
boxes_out.extend(bxs)
|
||||
|
||||
garbag_set = set()
|
||||
for k, lst in garbages.items():
|
||||
cnt = Counter(lst)
|
||||
for g, c in cnt.items():
|
||||
if c > 1:
|
||||
garbag_set.add(g)
|
||||
|
||||
ocr_res_new = [b for b in boxes_out if b["text"].strip() not in garbag_set]
|
||||
return ocr_res_new, page_layout
|
||||
|
||||
@ -13,7 +13,7 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
|
||||
import gc
|
||||
import logging
|
||||
import copy
|
||||
import time
|
||||
@ -348,6 +348,13 @@ class TextRecognizer:
|
||||
|
||||
return img
|
||||
|
||||
def close(self):
|
||||
# close session and release manually
|
||||
logging.info('Close TextRecognizer.')
|
||||
if hasattr(self, "predictor"):
|
||||
del self.predictor
|
||||
gc.collect()
|
||||
|
||||
def __call__(self, img_list):
|
||||
img_num = len(img_list)
|
||||
# Calculate the aspect ratio of all text bars
|
||||
@ -395,6 +402,9 @@ class TextRecognizer:
|
||||
|
||||
return rec_res, time.time() - st
|
||||
|
||||
def __del__(self):
|
||||
self.close()
|
||||
|
||||
|
||||
class TextDetector:
|
||||
def __init__(self, model_dir, device_id: int | None = None):
|
||||
@ -479,6 +489,12 @@ class TextDetector:
|
||||
dt_boxes = np.array(dt_boxes_new)
|
||||
return dt_boxes
|
||||
|
||||
def close(self):
|
||||
logging.info("Close TextDetector.")
|
||||
if hasattr(self, "predictor"):
|
||||
del self.predictor
|
||||
gc.collect()
|
||||
|
||||
def __call__(self, img):
|
||||
ori_im = img.copy()
|
||||
data = {'image': img}
|
||||
@ -508,6 +524,9 @@ class TextDetector:
|
||||
|
||||
return dt_boxes, time.time() - st
|
||||
|
||||
def __del__(self):
|
||||
self.close()
|
||||
|
||||
|
||||
class OCR:
|
||||
def __init__(self, model_dir=None):
|
||||
|
||||
@ -13,7 +13,7 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
|
||||
import gc
|
||||
import logging
|
||||
import os
|
||||
import math
|
||||
@ -406,6 +406,12 @@ class Recognizer:
|
||||
"score": float(scores[i])
|
||||
} for i in indices]
|
||||
|
||||
def close(self):
|
||||
logging.info("Close recognizer.")
|
||||
if hasattr(self, "ort_sess"):
|
||||
del self.ort_sess
|
||||
gc.collect()
|
||||
|
||||
def __call__(self, image_list, thr=0.7, batch_size=16):
|
||||
res = []
|
||||
images = []
|
||||
@ -430,5 +436,7 @@ class Recognizer:
|
||||
|
||||
return res
|
||||
|
||||
def __del__(self):
|
||||
self.close()
|
||||
|
||||
|
||||
|
||||
@ -23,6 +23,7 @@ from huggingface_hub import snapshot_download
|
||||
|
||||
from api.utils.file_utils import get_project_base_directory
|
||||
from rag.nlp import rag_tokenizer
|
||||
|
||||
from .recognizer import Recognizer
|
||||
|
||||
|
||||
@ -38,31 +39,49 @@ class TableStructureRecognizer(Recognizer):
|
||||
|
||||
def __init__(self):
|
||||
try:
|
||||
super().__init__(self.labels, "tsr", os.path.join(
|
||||
get_project_base_directory(),
|
||||
"rag/res/deepdoc"))
|
||||
super().__init__(self.labels, "tsr", os.path.join(get_project_base_directory(), "rag/res/deepdoc"))
|
||||
except Exception:
|
||||
super().__init__(self.labels, "tsr", snapshot_download(repo_id="InfiniFlow/deepdoc",
|
||||
local_dir=os.path.join(get_project_base_directory(), "rag/res/deepdoc"),
|
||||
local_dir_use_symlinks=False))
|
||||
super().__init__(
|
||||
self.labels,
|
||||
"tsr",
|
||||
snapshot_download(
|
||||
repo_id="InfiniFlow/deepdoc",
|
||||
local_dir=os.path.join(get_project_base_directory(), "rag/res/deepdoc"),
|
||||
local_dir_use_symlinks=False,
|
||||
),
|
||||
)
|
||||
|
||||
def __call__(self, images, thr=0.2):
|
||||
tbls = super().__call__(images, thr)
|
||||
table_structure_recognizer_type = os.getenv("TABLE_STRUCTURE_RECOGNIZER_TYPE", "onnx").lower()
|
||||
if table_structure_recognizer_type not in ["onnx", "ascend"]:
|
||||
raise RuntimeError("Unsupported table structure recognizer type.")
|
||||
|
||||
if table_structure_recognizer_type == "onnx":
|
||||
logging.debug("Using Onnx table structure recognizer", flush=True)
|
||||
tbls = super().__call__(images, thr)
|
||||
else: # ascend
|
||||
logging.debug("Using Ascend table structure recognizer", flush=True)
|
||||
tbls = self._run_ascend_tsr(images, thr)
|
||||
|
||||
res = []
|
||||
# align left&right for rows, align top&bottom for columns
|
||||
for tbl in tbls:
|
||||
lts = [{"label": b["type"],
|
||||
lts = [
|
||||
{
|
||||
"label": b["type"],
|
||||
"score": b["score"],
|
||||
"x0": b["bbox"][0], "x1": b["bbox"][2],
|
||||
"top": b["bbox"][1], "bottom": b["bbox"][-1]
|
||||
} for b in tbl]
|
||||
"x0": b["bbox"][0],
|
||||
"x1": b["bbox"][2],
|
||||
"top": b["bbox"][1],
|
||||
"bottom": b["bbox"][-1],
|
||||
}
|
||||
for b in tbl
|
||||
]
|
||||
if not lts:
|
||||
continue
|
||||
|
||||
left = [b["x0"] for b in lts if b["label"].find(
|
||||
"row") > 0 or b["label"].find("header") > 0]
|
||||
right = [b["x1"] for b in lts if b["label"].find(
|
||||
"row") > 0 or b["label"].find("header") > 0]
|
||||
left = [b["x0"] for b in lts if b["label"].find("row") > 0 or b["label"].find("header") > 0]
|
||||
right = [b["x1"] for b in lts if b["label"].find("row") > 0 or b["label"].find("header") > 0]
|
||||
if not left:
|
||||
continue
|
||||
left = np.mean(left) if len(left) > 4 else np.min(left)
|
||||
@ -93,11 +112,8 @@ class TableStructureRecognizer(Recognizer):
|
||||
|
||||
@staticmethod
|
||||
def is_caption(bx):
|
||||
patt = [
|
||||
r"[图表]+[ 0-9::]{2,}"
|
||||
]
|
||||
if any([re.match(p, bx["text"].strip()) for p in patt]) \
|
||||
or bx.get("layout_type", "").find("caption") >= 0:
|
||||
patt = [r"[图表]+[ 0-9::]{2,}"]
|
||||
if any([re.match(p, bx["text"].strip()) for p in patt]) or bx.get("layout_type", "").find("caption") >= 0:
|
||||
return True
|
||||
return False
|
||||
|
||||
@ -115,7 +131,7 @@ class TableStructureRecognizer(Recognizer):
|
||||
(r"^[0-9A-Z/\._~-]+$", "Ca"),
|
||||
(r"^[A-Z]*[a-z' -]+$", "En"),
|
||||
(r"^[0-9.,+-]+[0-9A-Za-z/$¥%<>()()' -]+$", "NE"),
|
||||
(r"^.{1}$", "Sg")
|
||||
(r"^.{1}$", "Sg"),
|
||||
]
|
||||
for p, n in patt:
|
||||
if re.search(p, b["text"].strip()):
|
||||
@ -156,21 +172,19 @@ class TableStructureRecognizer(Recognizer):
|
||||
rowh = [b["R_bott"] - b["R_top"] for b in boxes if "R" in b]
|
||||
rowh = np.min(rowh) if rowh else 0
|
||||
boxes = Recognizer.sort_R_firstly(boxes, rowh / 2)
|
||||
#for b in boxes:print(b)
|
||||
# for b in boxes:print(b)
|
||||
boxes[0]["rn"] = 0
|
||||
rows = [[boxes[0]]]
|
||||
btm = boxes[0]["bottom"]
|
||||
for b in boxes[1:]:
|
||||
b["rn"] = len(rows) - 1
|
||||
lst_r = rows[-1]
|
||||
if lst_r[-1].get("R", "") != b.get("R", "") \
|
||||
or (b["top"] >= btm - 3 and lst_r[-1].get("R", "-1") != b.get("R", "-2")
|
||||
): # new row
|
||||
if lst_r[-1].get("R", "") != b.get("R", "") or (b["top"] >= btm - 3 and lst_r[-1].get("R", "-1") != b.get("R", "-2")): # new row
|
||||
btm = b["bottom"]
|
||||
b["rn"] += 1
|
||||
rows.append([b])
|
||||
continue
|
||||
btm = (btm + b["bottom"]) / 2.
|
||||
btm = (btm + b["bottom"]) / 2.0
|
||||
rows[-1].append(b)
|
||||
|
||||
colwm = [b["C_right"] - b["C_left"] for b in boxes if "C" in b]
|
||||
@ -186,14 +200,14 @@ class TableStructureRecognizer(Recognizer):
|
||||
for b in boxes[1:]:
|
||||
b["cn"] = len(cols) - 1
|
||||
lst_c = cols[-1]
|
||||
if (int(b.get("C", "1")) - int(lst_c[-1].get("C", "1")) == 1 and b["page_number"] == lst_c[-1][
|
||||
"page_number"]) \
|
||||
or (b["x0"] >= right and lst_c[-1].get("C", "-1") != b.get("C", "-2")): # new col
|
||||
if (int(b.get("C", "1")) - int(lst_c[-1].get("C", "1")) == 1 and b["page_number"] == lst_c[-1]["page_number"]) or (
|
||||
b["x0"] >= right and lst_c[-1].get("C", "-1") != b.get("C", "-2")
|
||||
): # new col
|
||||
right = b["x1"]
|
||||
b["cn"] += 1
|
||||
cols.append([b])
|
||||
continue
|
||||
right = (right + b["x1"]) / 2.
|
||||
right = (right + b["x1"]) / 2.0
|
||||
cols[-1].append(b)
|
||||
|
||||
tbl = [[[] for _ in range(len(cols))] for _ in range(len(rows))]
|
||||
@ -214,10 +228,8 @@ class TableStructureRecognizer(Recognizer):
|
||||
if e > 1:
|
||||
j += 1
|
||||
continue
|
||||
f = (j > 0 and tbl[ii][j - 1] and tbl[ii]
|
||||
[j - 1][0].get("text")) or j == 0
|
||||
ff = (j + 1 < len(tbl[ii]) and tbl[ii][j + 1] and tbl[ii]
|
||||
[j + 1][0].get("text")) or j + 1 >= len(tbl[ii])
|
||||
f = (j > 0 and tbl[ii][j - 1] and tbl[ii][j - 1][0].get("text")) or j == 0
|
||||
ff = (j + 1 < len(tbl[ii]) and tbl[ii][j + 1] and tbl[ii][j + 1][0].get("text")) or j + 1 >= len(tbl[ii])
|
||||
if f and ff:
|
||||
j += 1
|
||||
continue
|
||||
@ -228,13 +240,11 @@ class TableStructureRecognizer(Recognizer):
|
||||
if j > 0 and not f:
|
||||
for i in range(len(tbl)):
|
||||
if tbl[i][j - 1]:
|
||||
left = min(left, np.min(
|
||||
[bx["x0"] - a["x1"] for a in tbl[i][j - 1]]))
|
||||
left = min(left, np.min([bx["x0"] - a["x1"] for a in tbl[i][j - 1]]))
|
||||
if j + 1 < len(tbl[0]) and not ff:
|
||||
for i in range(len(tbl)):
|
||||
if tbl[i][j + 1]:
|
||||
right = min(right, np.min(
|
||||
[a["x0"] - bx["x1"] for a in tbl[i][j + 1]]))
|
||||
right = min(right, np.min([a["x0"] - bx["x1"] for a in tbl[i][j + 1]]))
|
||||
assert left < 100000 or right < 100000
|
||||
if left < right:
|
||||
for jj in range(j, len(tbl[0])):
|
||||
@ -260,8 +270,7 @@ class TableStructureRecognizer(Recognizer):
|
||||
for i in range(len(tbl)):
|
||||
tbl[i].pop(j)
|
||||
cols.pop(j)
|
||||
assert len(cols) == len(tbl[0]), "Column NO. miss matched: %d vs %d" % (
|
||||
len(cols), len(tbl[0]))
|
||||
assert len(cols) == len(tbl[0]), "Column NO. miss matched: %d vs %d" % (len(cols), len(tbl[0]))
|
||||
|
||||
if len(cols) >= 4:
|
||||
# remove single in row
|
||||
@ -277,10 +286,8 @@ class TableStructureRecognizer(Recognizer):
|
||||
if e > 1:
|
||||
i += 1
|
||||
continue
|
||||
f = (i > 0 and tbl[i - 1][jj] and tbl[i - 1]
|
||||
[jj][0].get("text")) or i == 0
|
||||
ff = (i + 1 < len(tbl) and tbl[i + 1][jj] and tbl[i + 1]
|
||||
[jj][0].get("text")) or i + 1 >= len(tbl)
|
||||
f = (i > 0 and tbl[i - 1][jj] and tbl[i - 1][jj][0].get("text")) or i == 0
|
||||
ff = (i + 1 < len(tbl) and tbl[i + 1][jj] and tbl[i + 1][jj][0].get("text")) or i + 1 >= len(tbl)
|
||||
if f and ff:
|
||||
i += 1
|
||||
continue
|
||||
@ -292,13 +299,11 @@ class TableStructureRecognizer(Recognizer):
|
||||
if i > 0 and not f:
|
||||
for j in range(len(tbl[i - 1])):
|
||||
if tbl[i - 1][j]:
|
||||
up = min(up, np.min(
|
||||
[bx["top"] - a["bottom"] for a in tbl[i - 1][j]]))
|
||||
up = min(up, np.min([bx["top"] - a["bottom"] for a in tbl[i - 1][j]]))
|
||||
if i + 1 < len(tbl) and not ff:
|
||||
for j in range(len(tbl[i + 1])):
|
||||
if tbl[i + 1][j]:
|
||||
down = min(down, np.min(
|
||||
[a["top"] - bx["bottom"] for a in tbl[i + 1][j]]))
|
||||
down = min(down, np.min([a["top"] - bx["bottom"] for a in tbl[i + 1][j]]))
|
||||
assert up < 100000 or down < 100000
|
||||
if up < down:
|
||||
for ii in range(i, len(tbl)):
|
||||
@ -333,22 +338,15 @@ class TableStructureRecognizer(Recognizer):
|
||||
cnt += 1
|
||||
if max_type == "Nu" and arr[0]["btype"] == "Nu":
|
||||
continue
|
||||
if any([a.get("H") for a in arr]) \
|
||||
or (max_type == "Nu" and arr[0]["btype"] != "Nu"):
|
||||
if any([a.get("H") for a in arr]) or (max_type == "Nu" and arr[0]["btype"] != "Nu"):
|
||||
h += 1
|
||||
if h / cnt > 0.5:
|
||||
hdset.add(i)
|
||||
|
||||
if html:
|
||||
return TableStructureRecognizer.__html_table(cap, hdset,
|
||||
TableStructureRecognizer.__cal_spans(boxes, rows,
|
||||
cols, tbl, True)
|
||||
)
|
||||
return TableStructureRecognizer.__html_table(cap, hdset, TableStructureRecognizer.__cal_spans(boxes, rows, cols, tbl, True))
|
||||
|
||||
return TableStructureRecognizer.__desc_table(cap, hdset,
|
||||
TableStructureRecognizer.__cal_spans(boxes, rows, cols, tbl,
|
||||
False),
|
||||
is_english)
|
||||
return TableStructureRecognizer.__desc_table(cap, hdset, TableStructureRecognizer.__cal_spans(boxes, rows, cols, tbl, False), is_english)
|
||||
|
||||
@staticmethod
|
||||
def __html_table(cap, hdset, tbl):
|
||||
@ -367,10 +365,8 @@ class TableStructureRecognizer(Recognizer):
|
||||
continue
|
||||
txt = ""
|
||||
if arr:
|
||||
h = min(np.min([c["bottom"] - c["top"]
|
||||
for c in arr]) / 2, 10)
|
||||
txt = " ".join([c["text"]
|
||||
for c in Recognizer.sort_Y_firstly(arr, h)])
|
||||
h = min(np.min([c["bottom"] - c["top"] for c in arr]) / 2, 10)
|
||||
txt = " ".join([c["text"] for c in Recognizer.sort_Y_firstly(arr, h)])
|
||||
txts.append(txt)
|
||||
sp = ""
|
||||
if arr[0].get("colspan"):
|
||||
@ -436,15 +432,11 @@ class TableStructureRecognizer(Recognizer):
|
||||
if headers[j][k].find(headers[j - 1][k]) >= 0:
|
||||
continue
|
||||
if len(headers[j][k]) > len(headers[j - 1][k]):
|
||||
headers[j][k] += (de if headers[j][k]
|
||||
else "") + headers[j - 1][k]
|
||||
headers[j][k] += (de if headers[j][k] else "") + headers[j - 1][k]
|
||||
else:
|
||||
headers[j][k] = headers[j - 1][k] \
|
||||
+ (de if headers[j - 1][k] else "") \
|
||||
+ headers[j][k]
|
||||
headers[j][k] = headers[j - 1][k] + (de if headers[j - 1][k] else "") + headers[j][k]
|
||||
|
||||
logging.debug(
|
||||
f">>>>>>>>>>>>>>>>>{cap}:SIZE:{rowno}X{clmno} Header: {hdr_rowno}")
|
||||
logging.debug(f">>>>>>>>>>>>>>>>>{cap}:SIZE:{rowno}X{clmno} Header: {hdr_rowno}")
|
||||
row_txt = []
|
||||
for i in range(rowno):
|
||||
if i in hdr_rowno:
|
||||
@ -503,14 +495,10 @@ class TableStructureRecognizer(Recognizer):
|
||||
@staticmethod
|
||||
def __cal_spans(boxes, rows, cols, tbl, html=True):
|
||||
# caculate span
|
||||
clft = [np.mean([c.get("C_left", c["x0"]) for c in cln])
|
||||
for cln in cols]
|
||||
crgt = [np.mean([c.get("C_right", c["x1"]) for c in cln])
|
||||
for cln in cols]
|
||||
rtop = [np.mean([c.get("R_top", c["top"]) for c in row])
|
||||
for row in rows]
|
||||
rbtm = [np.mean([c.get("R_btm", c["bottom"])
|
||||
for c in row]) for row in rows]
|
||||
clft = [np.mean([c.get("C_left", c["x0"]) for c in cln]) for cln in cols]
|
||||
crgt = [np.mean([c.get("C_right", c["x1"]) for c in cln]) for cln in cols]
|
||||
rtop = [np.mean([c.get("R_top", c["top"]) for c in row]) for row in rows]
|
||||
rbtm = [np.mean([c.get("R_btm", c["bottom"]) for c in row]) for row in rows]
|
||||
for b in boxes:
|
||||
if "SP" not in b:
|
||||
continue
|
||||
@ -585,3 +573,40 @@ class TableStructureRecognizer(Recognizer):
|
||||
tbl[rowspan[0]][colspan[0]] = arr
|
||||
|
||||
return tbl
|
||||
|
||||
def _run_ascend_tsr(self, image_list, thr=0.2, batch_size=16):
|
||||
import math
|
||||
|
||||
from ais_bench.infer.interface import InferSession
|
||||
|
||||
model_dir = os.path.join(get_project_base_directory(), "rag/res/deepdoc")
|
||||
model_file_path = os.path.join(model_dir, "tsr.om")
|
||||
|
||||
if not os.path.exists(model_file_path):
|
||||
raise ValueError(f"Model file not found: {model_file_path}")
|
||||
|
||||
device_id = int(os.getenv("ASCEND_LAYOUT_RECOGNIZER_DEVICE_ID", 0))
|
||||
session = InferSession(device_id=device_id, model_path=model_file_path)
|
||||
|
||||
images = [np.array(im) if not isinstance(im, np.ndarray) else im for im in image_list]
|
||||
results = []
|
||||
|
||||
conf_thr = max(thr, 0.08)
|
||||
|
||||
batch_loop_cnt = math.ceil(float(len(images)) / batch_size)
|
||||
for bi in range(batch_loop_cnt):
|
||||
s = bi * batch_size
|
||||
e = min((bi + 1) * batch_size, len(images))
|
||||
batch_images = images[s:e]
|
||||
|
||||
inputs_list = self.preprocess(batch_images)
|
||||
for ins in inputs_list:
|
||||
feeds = []
|
||||
if "image" in ins:
|
||||
feeds.append(ins["image"])
|
||||
else:
|
||||
feeds.append(ins[self.input_names[0]])
|
||||
output_list = session.infer(feeds=feeds, mode="static")
|
||||
bb = self.postprocess(output_list, ins, conf_thr)
|
||||
results.append(bb)
|
||||
return results
|
||||
|
||||
@ -29,7 +29,6 @@ redis:
|
||||
db: 1
|
||||
password: '${REDIS_PASSWORD:-infini_rag_flow}'
|
||||
host: '${REDIS_HOST:-redis}:6379'
|
||||
|
||||
# postgres:
|
||||
# name: '${POSTGRES_DBNAME:-rag_flow}'
|
||||
# user: '${POSTGRES_USER:-rag_flow}'
|
||||
@ -65,15 +64,26 @@ redis:
|
||||
# secret: 'secret'
|
||||
# tenant_id: 'tenant_id'
|
||||
# container_name: 'container_name'
|
||||
# The OSS object storage uses the MySQL configuration above by default. If you need to switch to another object storage service, please uncomment and configure the following parameters.
|
||||
# opendal:
|
||||
# scheme: 'mysql' # Storage type, such as s3, oss, azure, etc.
|
||||
# config:
|
||||
# oss_table: 'opendal_storage'
|
||||
# user_default_llm:
|
||||
# factory: 'Tongyi-Qianwen'
|
||||
# api_key: 'sk-xxxxxxxxxxxxx'
|
||||
# base_url: ''
|
||||
# factory: 'BAAI'
|
||||
# api_key: 'backup'
|
||||
# base_url: 'backup_base_url'
|
||||
# default_models:
|
||||
# chat_model: 'qwen-plus'
|
||||
# embedding_model: 'BAAI/bge-large-zh-v1.5@BAAI'
|
||||
# rerank_model: ''
|
||||
# asr_model: ''
|
||||
# chat_model:
|
||||
# name: 'qwen2.5-7b-instruct'
|
||||
# factory: 'xxxx'
|
||||
# api_key: 'xxxx'
|
||||
# base_url: 'https://api.xx.com'
|
||||
# embedding_model:
|
||||
# name: 'bge-m3'
|
||||
# rerank_model: 'bge-reranker-v2'
|
||||
# asr_model:
|
||||
# model: 'whisper-large-v3' # alias of name
|
||||
# image2text_model: ''
|
||||
# oauth:
|
||||
# oauth2:
|
||||
@ -109,3 +119,14 @@ redis:
|
||||
# switch: false
|
||||
# component: false
|
||||
# dataset: false
|
||||
# smtp:
|
||||
# mail_server: ""
|
||||
# mail_port: 465
|
||||
# mail_use_ssl: true
|
||||
# mail_use_tls: false
|
||||
# mail_username: ""
|
||||
# mail_password: ""
|
||||
# mail_default_sender:
|
||||
# - "RAGFlow" # display name
|
||||
# - "" # sender email address
|
||||
# mail_frontend_url: "https://your-frontend.example.com"
|
||||
|
||||
@ -26,6 +26,84 @@ An **Agent** component is essential when you need the LLM to assist with summari
|
||||
|
||||
2. If your Agent involves dataset retrieval, ensure you [have properly configured your target knowledge base(s)](../../dataset/configure_knowledge_base.md).
|
||||
|
||||
## Quickstart
|
||||
|
||||
### 1. Click on an **Agent** component to show its configuration panel
|
||||
|
||||
The corresponding configuration panel appears to the right of the canvas. Use this panel to define and fine-tune the **Agent** component's behavior.
|
||||
|
||||
### 2. Select your model
|
||||
|
||||
Click **Model**, and select a chat model from the dropdown menu.
|
||||
|
||||
:::tip NOTE
|
||||
If no model appears, check if your have added a chat model on the **Model providers** page.
|
||||
:::
|
||||
|
||||
### 3. Update system prompt (Optional)
|
||||
|
||||
The system prompt typically defines your model's role. You can either keep the system prompt as is or customize it to override the default.
|
||||
|
||||
|
||||
### 4. Update user prompt
|
||||
|
||||
The user prompt typically defines your model's task. You will find the `sys.query` variable auto-populated. Type `/` or click **(x)** to view or add variables.
|
||||
|
||||
In this quickstart, we assume your **Agent** component is used standalone (without tools or sub-Agents below), then you may also need to specify retrieved chunks using the `formalized_content` variable:
|
||||
|
||||
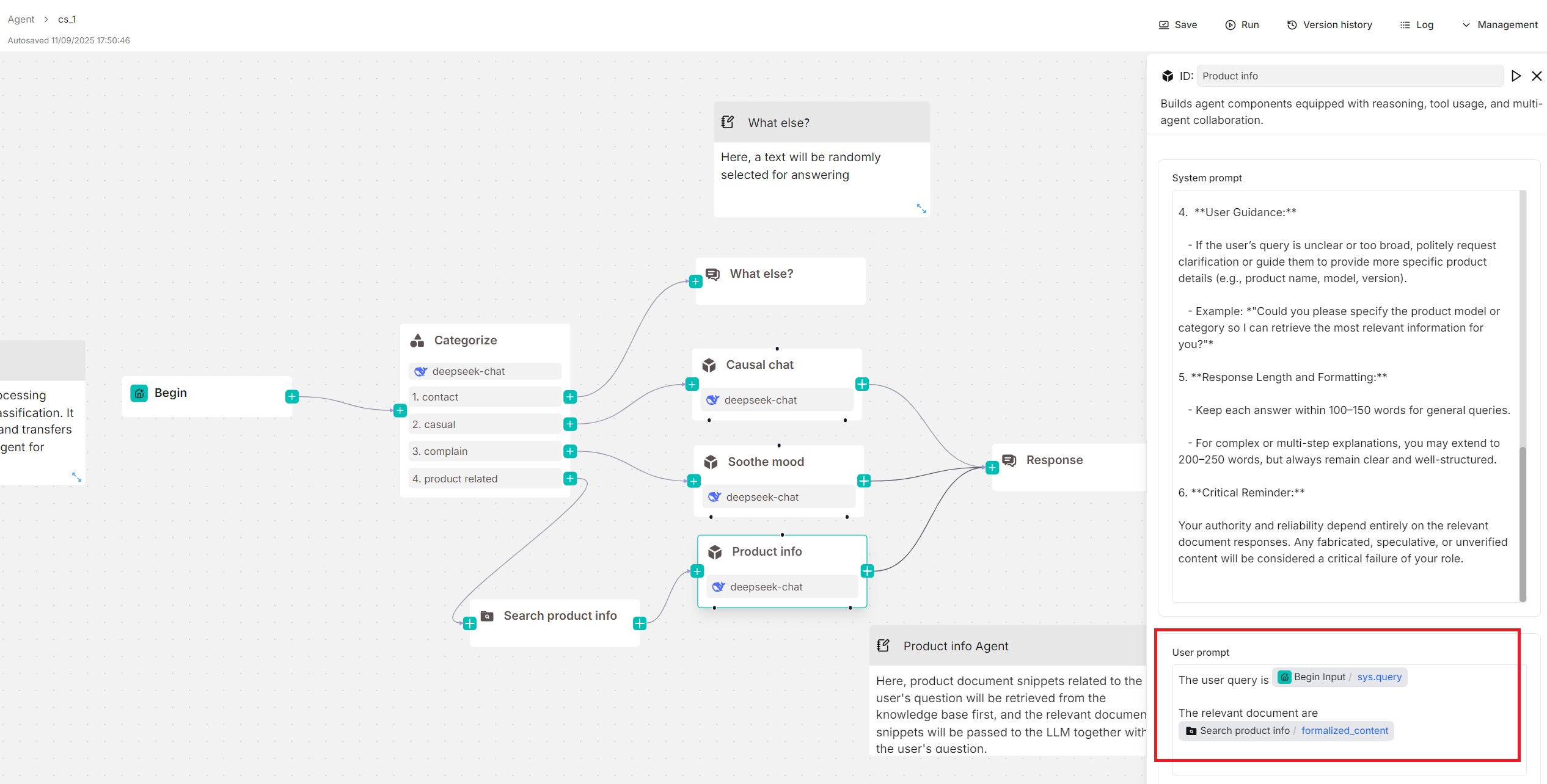
|
||||
|
||||
### 5. Skip Tools and Agent
|
||||
|
||||
The **+ Add tools** and **+ Add agent** sections are used *only* when you need to configure your **Agent** component as a planner (with tools or sub-Agents beneath). In this quickstart, we assume your **Agent** component is used standalone (without tools or sub-Agents beneath).
|
||||
|
||||
### 6. Choose the next component
|
||||
|
||||
When necessary, click the **+** button on the **Agent** component to choose the next component in the worflow from the dropdown list.
|
||||
|
||||
## Connect to an MCP server as a client
|
||||
|
||||
:::danger IMPORTANT
|
||||
In this section, we assume your **Agent** will be configured as a planner, with a Tavily tool beneath it.
|
||||
:::
|
||||
|
||||
### 1. Navigate to the MCP configuration page
|
||||
|
||||

|
||||
|
||||
### 2. Configure your Tavily MCP server
|
||||
|
||||
Update your MCP server's name, URL (including the API key), server type, and other necessary settings. When configured correctly, the available tools will be displayed.
|
||||
|
||||
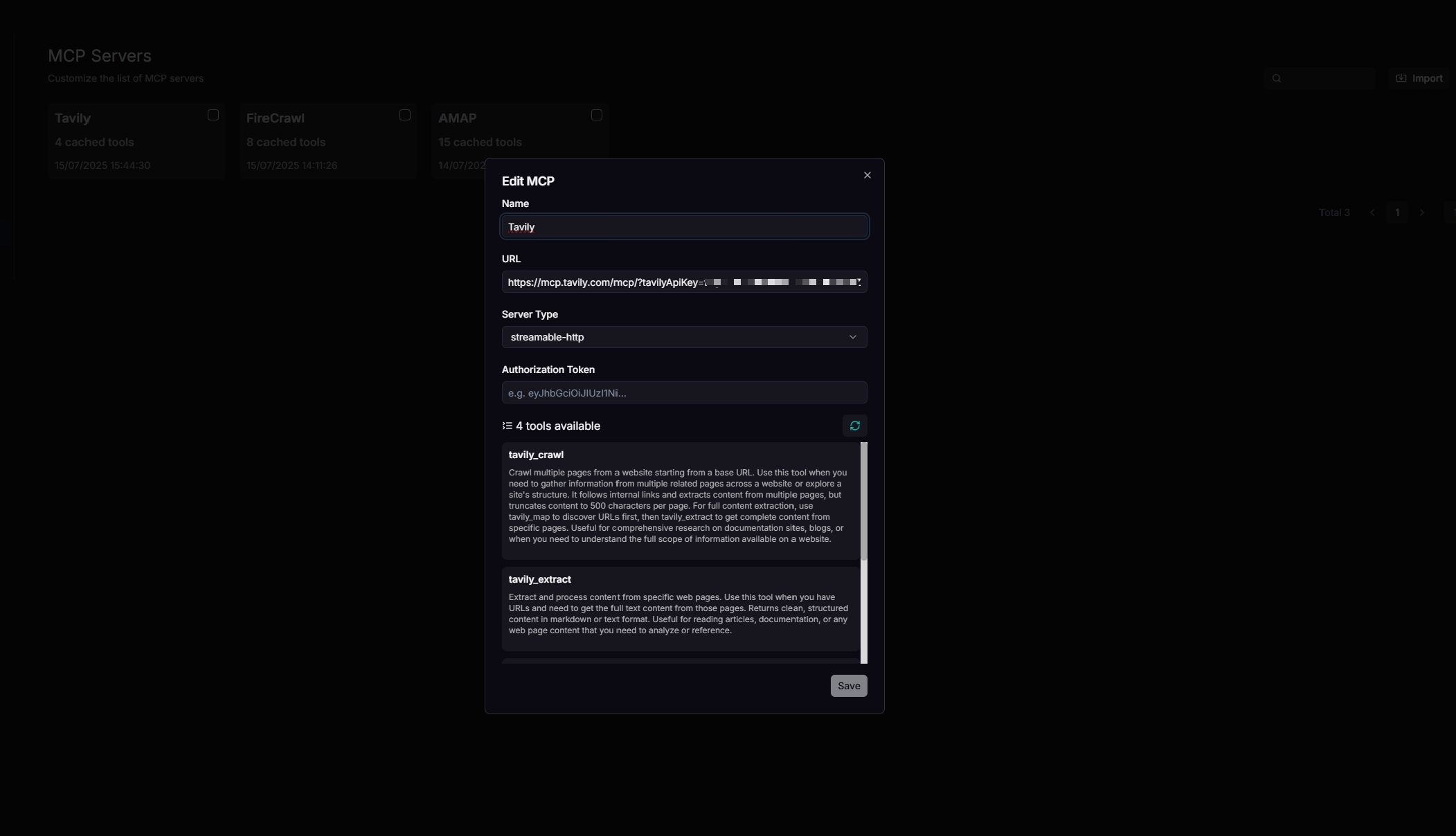
|
||||
|
||||
### 3. Navigate to your Agent's editing page
|
||||
|
||||
### 4. Connect to your MCP server
|
||||
|
||||
1. Click **+ Add tools**:
|
||||
|
||||
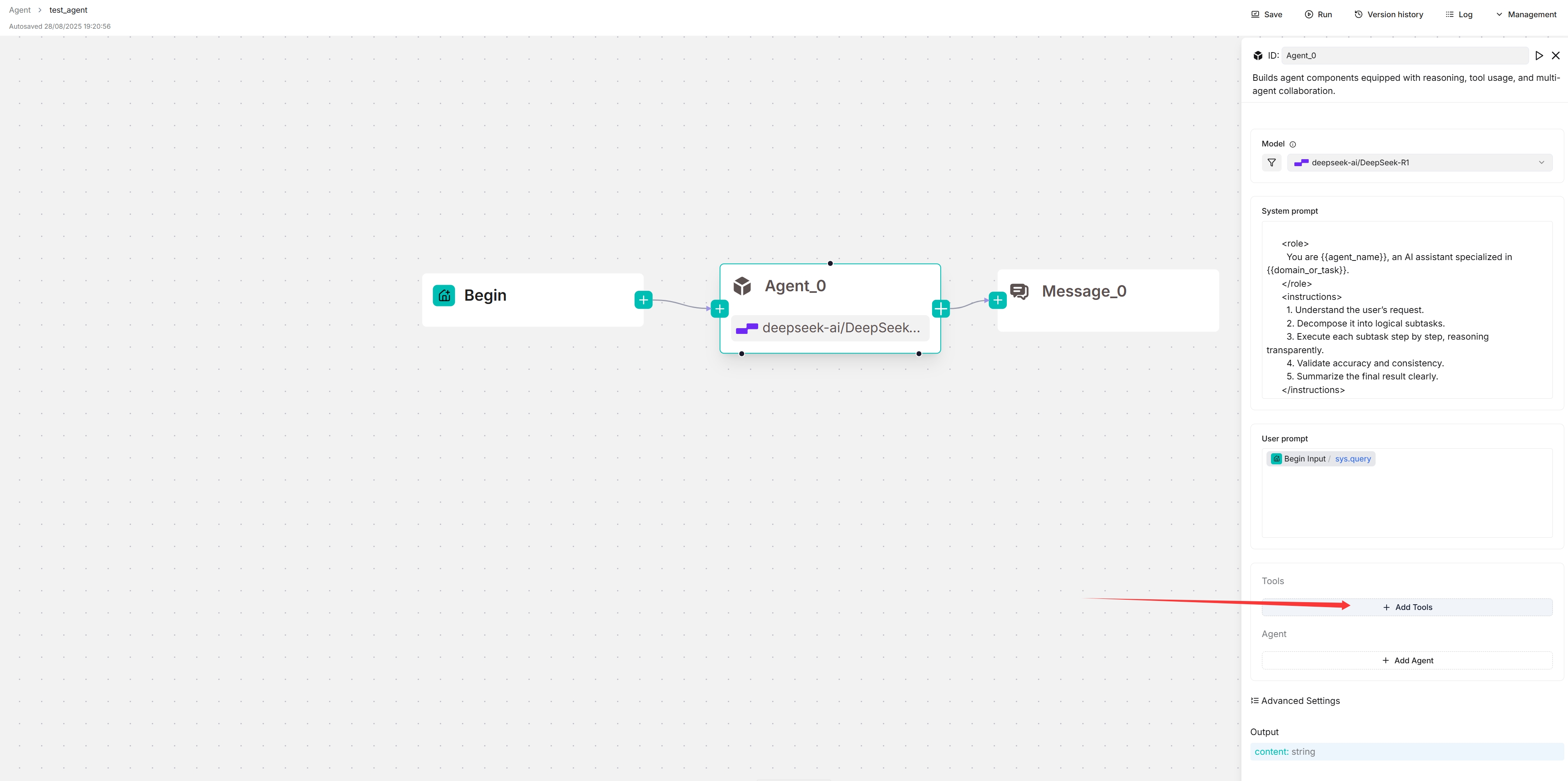
|
||||
|
||||
2. Click **MCP** to show the available MCP servers.
|
||||
|
||||
3. Select your MCP server:
|
||||
|
||||
*The target MCP server appears below your Agent component, and your Agent will autonomously decide when to invoke the available tools it offers.*
|
||||
|
||||
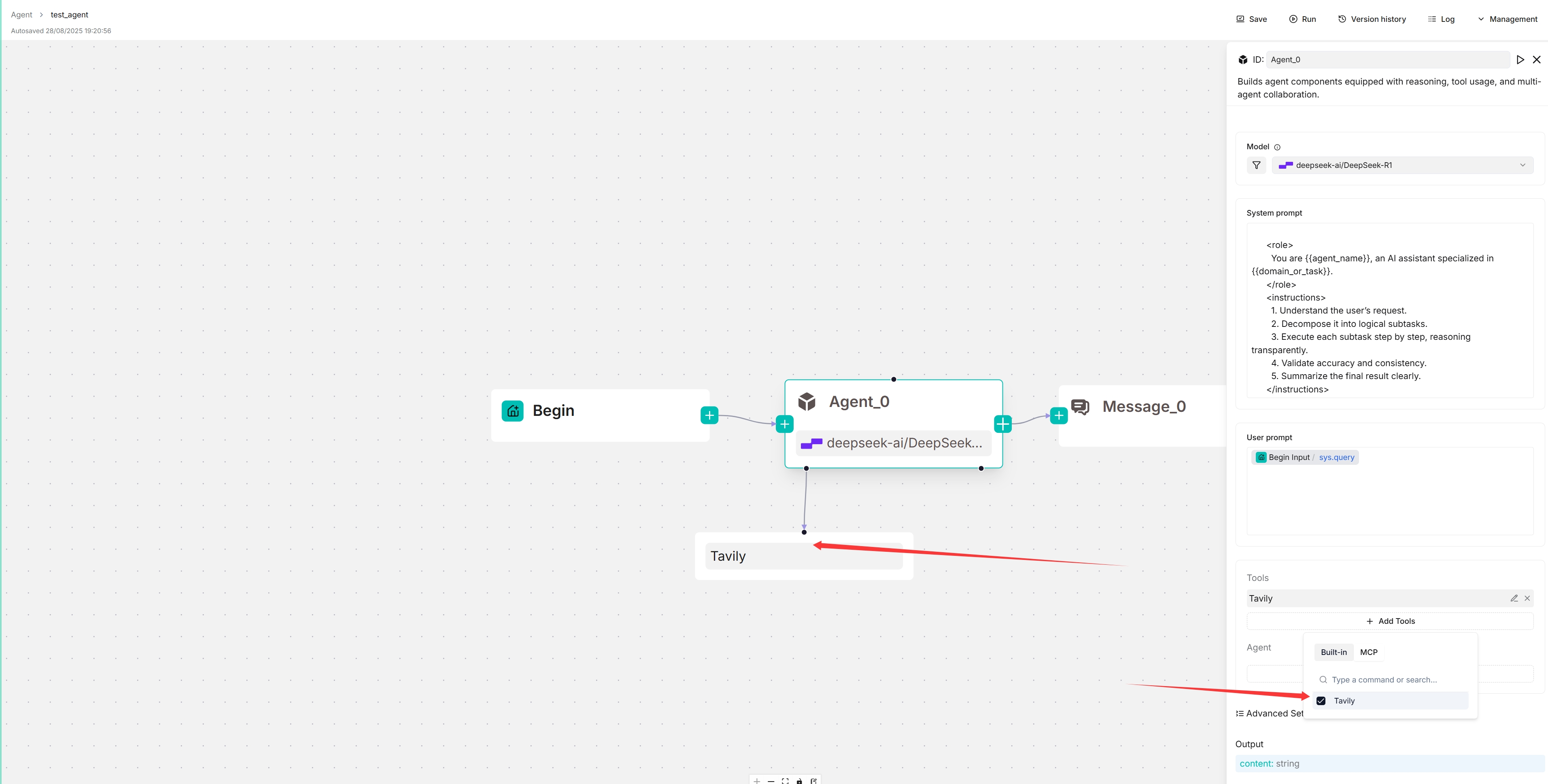
|
||||
|
||||
### 5. Update system prompt to specify trigger conditions (Optional)
|
||||
|
||||
To ensure reliable tool calls, you may specify within the system prompt which tasks should trigger each tool call.
|
||||
|
||||
### 6. View the availabe tools of your MCP server
|
||||
|
||||
On the canvas, click the newly-populated Tavily server to view and select its available tools:
|
||||
|
||||
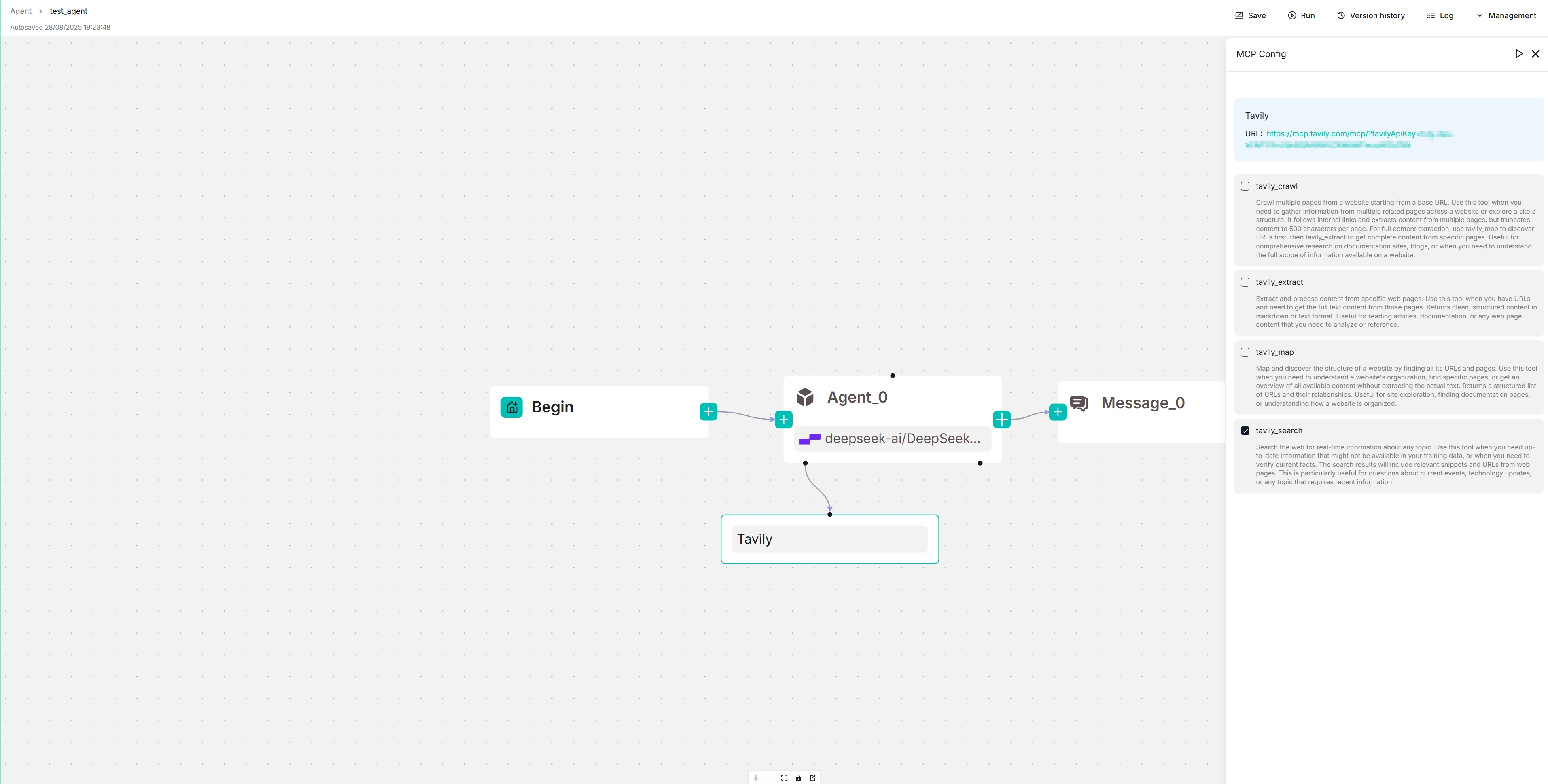
|
||||
|
||||
|
||||
## Configurations
|
||||
|
||||
### Model
|
||||
@ -69,7 +147,7 @@ An **Agent** component relies on keys (variables) to specify its data inputs. It
|
||||
|
||||
#### Advanced usage
|
||||
|
||||
From v0.20.5 onwards, four framework-level prompt blocks are available in the **System prompt** field. Type `/` or click **(x)** to view them; they appear under the **Framework** entry in the dropdown menu.
|
||||
From v0.20.5 onwards, four framework-level prompt blocks are available in the **System prompt** field, enabling you to customize and *override* prompts at the framework level. Type `/` or click **(x)** to view them; they appear under the **Framework** entry in the dropdown menu.
|
||||
|
||||
- `task_analysis` prompt block
|
||||
- This block is responsible for analyzing tasks — either a user task or a task assigned by the lead Agent when the **Agent** component is acting as a Sub-Agent.
|
||||
@ -100,6 +178,12 @@ From v0.20.5 onwards, four framework-level prompt blocks are available in the **
|
||||
- `citation_guidelines` prompt block
|
||||
- Reference design: [citation_prompt.md](https://github.com/infiniflow/ragflow/blob/main/rag/prompts/citation_prompt.md)
|
||||
|
||||
*The screenshots below show the framework prompt blocks available to an **Agent** component, both as a standalone and as a planner (with a Tavily tool below):*
|
||||
|
||||
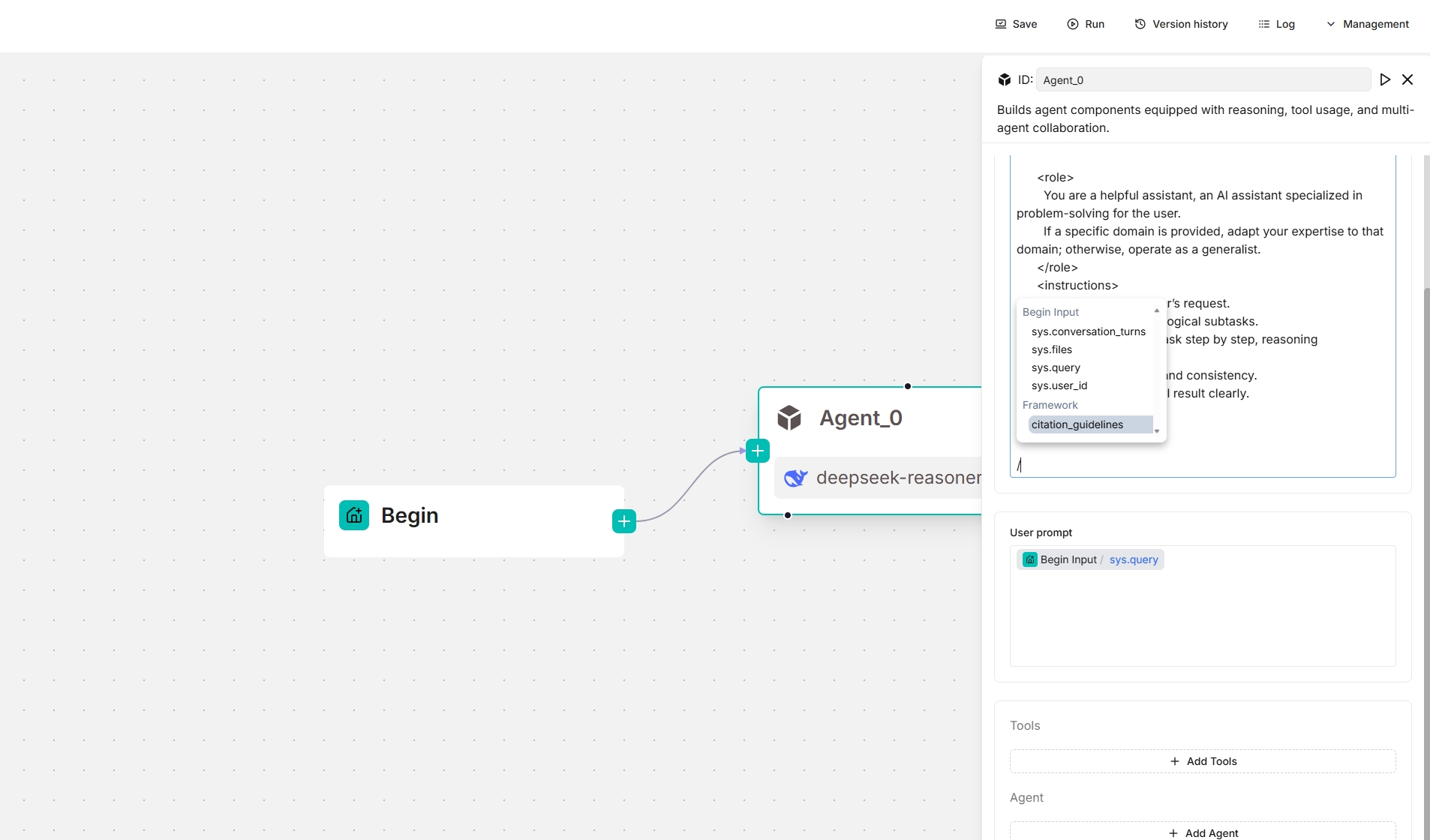
|
||||
|
||||
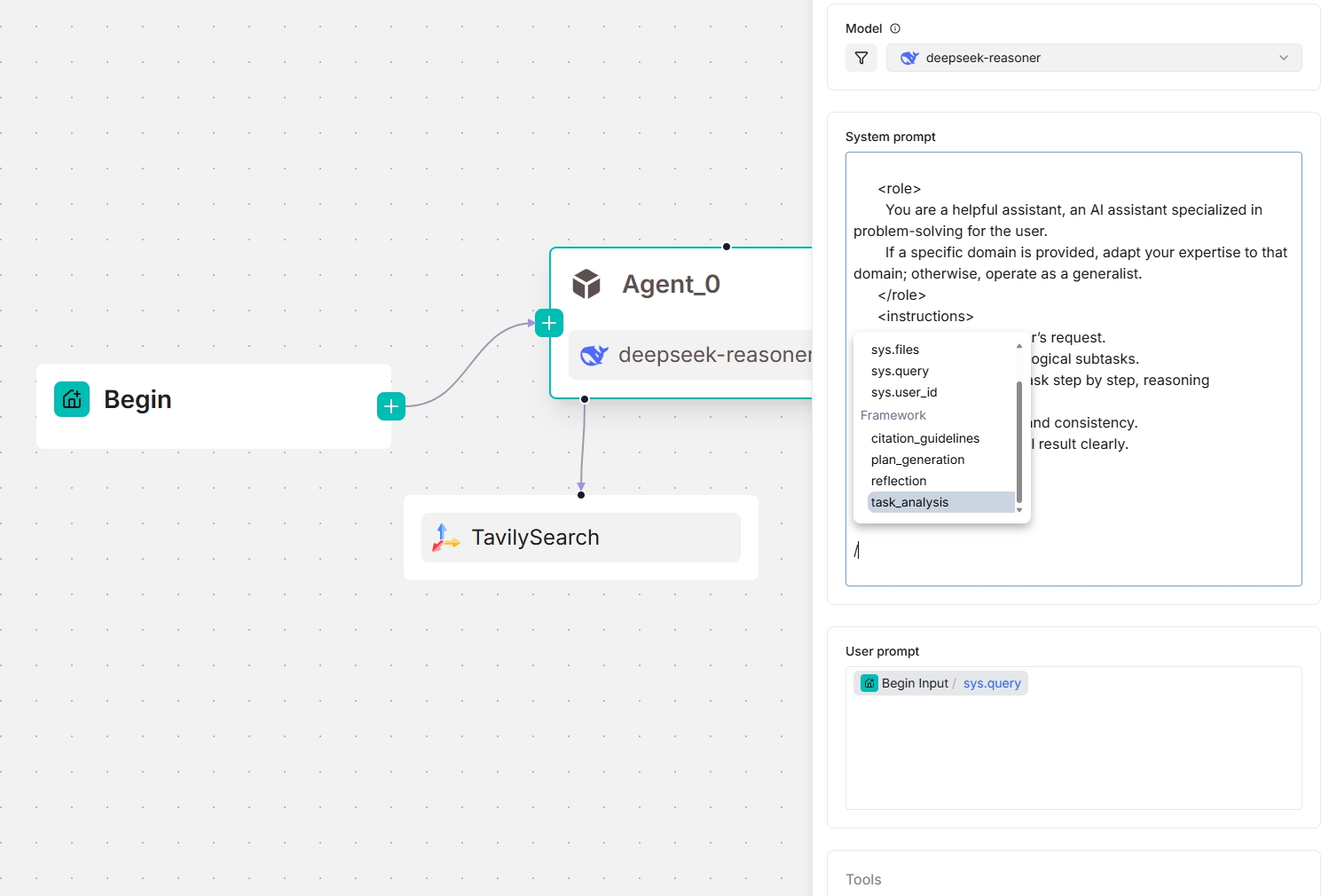
|
||||
|
||||
### User prompt
|
||||
|
||||
The user-defined prompt. Defaults to `sys.query`, the user query. As a general rule, when using the **Agent** component as a standalone module (not as a planner), you usually need to specify the corresponding **Retrieval** component’s output variable (`formalized_content`) here as part of the input to the LLM.
|
||||
@ -129,7 +213,7 @@ Defines the maximum number of attempts the agent will make to retry a failed tas
|
||||
|
||||
The waiting period in seconds that the agent observes before retrying a failed task, helping to prevent immediate repeated attempts and allowing system conditions to improve. Defaults to 1 second.
|
||||
|
||||
### Max rounds
|
||||
### Max reflection rounds
|
||||
|
||||
Defines the maximum number reflection rounds of the selected chat model. Defaults to 1 round.
|
||||
|
||||
|
||||
77
docs/guides/agent/agent_component_reference/execute_sql.md
Normal file
77
docs/guides/agent/agent_component_reference/execute_sql.md
Normal file
@ -0,0 +1,77 @@
|
||||
---
|
||||
sidebar_position: 25
|
||||
slug: /execute_sql
|
||||
---
|
||||
|
||||
# Execute SQL tool
|
||||
|
||||
A tool that execute SQL queries on a specified relational database.
|
||||
|
||||
---
|
||||
|
||||
The **Execute SQL** tool enables you to connect to a relational database and run SQL queries, whether entered directly or generated by the system’s Text2SQL capability via an **Agent** component. It currently supports three popular databases: MySQL, PostgreSQL, and MariaDB.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- A database instance properly configured and running.
|
||||
- The database must be one of the following types:
|
||||
- MySQL
|
||||
- PostgreSQL
|
||||
- MariaDB
|
||||
|
||||
## Examples
|
||||
|
||||
You can pair an **Agent** component with the **Execute SQL** tool, with the **Agent** generating SQL statements and the **Execute SQL** tool handling database connection and query execution. An example of this setup can be found in the **SQL Assistant** Agent template shown below:
|
||||
|
||||
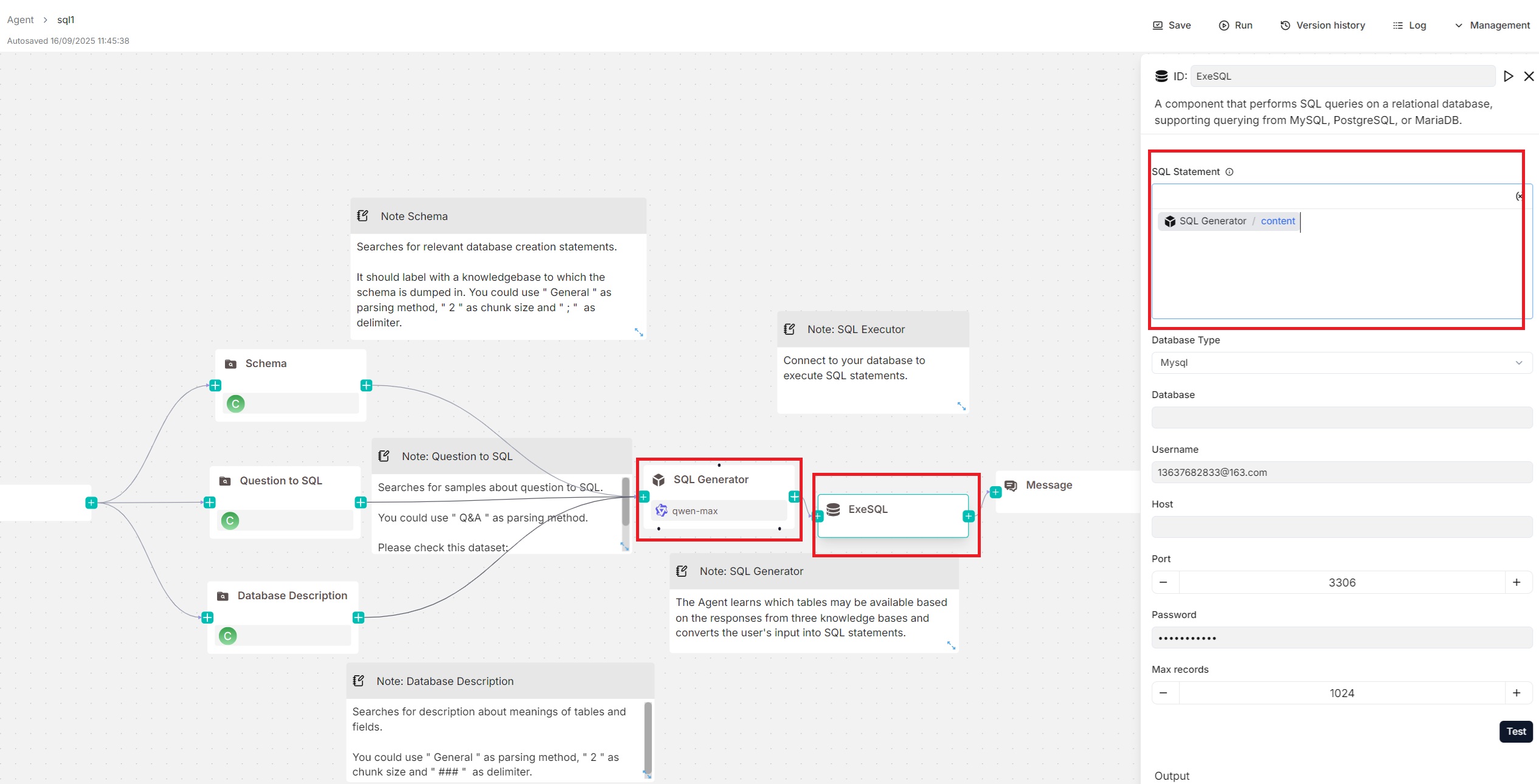
|
||||
|
||||
## Configurations
|
||||
|
||||
### SQL statement
|
||||
|
||||
This text input field allows you to write static SQL queries, such as `SELECT * FROM Table1`, and dynamic SQL queries using variables.
|
||||
|
||||
:::tip NOTE
|
||||
Click **(x)** or type `/` to insert variables.
|
||||
:::
|
||||
|
||||
For dynamic SQL queries, you can include variables in your SQL queries, such as `SELECT * FROM /sys.query`; if an **Agent** component is paired with the **Execute SQL** tool to generate SQL tasks (see the [Examples](#examples) section), you can directly insert that **Agent**'s output, `content`, into this field.
|
||||
|
||||
### Database type
|
||||
|
||||
The supported database type. Currently the following database types are available:
|
||||
|
||||
- MySQL
|
||||
- PostreSQL
|
||||
- MariaDB
|
||||
|
||||
### Database
|
||||
|
||||
Appears only when you select **Split** as method.
|
||||
|
||||
### Username
|
||||
|
||||
The username with access privileges to the database.
|
||||
|
||||
### Host
|
||||
|
||||
The IP address of the database server.
|
||||
|
||||
### Port
|
||||
|
||||
The port number on which the database server is listening.
|
||||
|
||||
### Password
|
||||
|
||||
The password for the database user.
|
||||
|
||||
### Max records
|
||||
|
||||
The maximum number of records returned by the SQL query to control response size and improve efficiency. Defaults to `1024`.
|
||||
|
||||
### Output
|
||||
|
||||
The **Execute SQL** tool provides two output variables:
|
||||
|
||||
- `formalized_content`: A string. If you reference this variable in a **Message** component, the returned records are displayed as a table.
|
||||
- `json`: An object array. If you reference this variable in a **Message** component, the returned records will be presented as key-value pairs.
|
||||
@ -1856,7 +1856,7 @@ curl --request POST \
|
||||
- `false`: Disable highlighting of matched terms (default).
|
||||
- `"cross_languages"`: (*Body parameter*) `list[string]`
|
||||
The languages that should be translated into, in order to achieve keywords retrievals in different languages.
|
||||
- `"metadata_condition"`: (*Body parameter*), `object`
|
||||
- `"metadata_condition"`: (*Body parameter*), `object`
|
||||
The metadata condition for filtering chunks.
|
||||
#### Response
|
||||
|
||||
|
||||
@ -977,7 +977,7 @@ The languages that should be translated into, in order to achieve keywords retri
|
||||
|
||||
##### metadata_condition: `dict`
|
||||
|
||||
filter condition for meta_fields
|
||||
filter condition for `meta_fields`.
|
||||
|
||||
#### Returns
|
||||
|
||||
|
||||
@ -28,11 +28,11 @@ Released on September 10, 2025.
|
||||
|
||||
### Improvements
|
||||
|
||||
- Agent Performance Optimized: Improved planning and reflection speed for simple tasks; optimized concurrent tool calls for parallelizable scenarios, significantly reducing overall response time.
|
||||
- Agent Prompt Framework exposed: Developers can now customize and override framework-level prompts in the system prompt section, enhancing flexibility and control.
|
||||
- Execute SQL Component Enhanced: Replaced the original variable reference component with a text input field, allowing free-form SQL writing with variable support.
|
||||
- Chat: Re-enabled Reasoning and Cross-language search.
|
||||
- Retrieval API Enhanced: Added metadata filtering support to the [Retrieve chunks](https://ragflow.io/docs/dev/http_api_reference#retrieve-chunks) method.
|
||||
- Agent:
|
||||
- Agent Performance Optimized: Improves planning and reflection speed for simple tasks; optimizes concurrent tool calls for parallelizable scenarios, significantly reducing overall response time.
|
||||
- Four framework-level prompt blocks are available in the **System prompt** section, enabling customization and overriding of prompts at the framework level, thereby enhancing flexibility and control. See [here](./guides/agent/agent_component_reference/agent.mdx#system-prompt).
|
||||
- **Execute SQL** component enhanced: Replaces the original variable reference component with a text input field, allowing users to write free-form SQL queries and reference variables.
|
||||
- Chat: Re-enables **Reasoning** and **Cross-language search**.
|
||||
|
||||
### Added models
|
||||
|
||||
@ -44,8 +44,22 @@ Released on September 10, 2025.
|
||||
### Fixed issues
|
||||
|
||||
- Dataset: Deleted files remained searchable.
|
||||
- Chat: Unable to chat with an Ollama model.
|
||||
- Agent: Resolved issues including cite toggle failure, task mode requiring dialogue triggers, repeated answers in multi-turn dialogues, and duplicate summarization of parallel execution results.
|
||||
- Chat: Unable to chat with an Ollama model.
|
||||
- Agent:
|
||||
- A **Cite** toggle failure.
|
||||
- An Agent in task mode still required a dialogue to trigger.
|
||||
- Repeated answers in multi-turn dialogues.
|
||||
- Duplicate summarization of parallel execution results.
|
||||
|
||||
### API changes
|
||||
|
||||
#### HTTP APIs
|
||||
|
||||
- Adds a body parameter `"metadata_condition"` to the [Retrieve chunks](./references/http_api_reference.md#retrieve-chunks) method, enabling metadata-based chunk filtering during retrieval. [#9877](https://github.com/infiniflow/ragflow/pull/9877)
|
||||
|
||||
#### Python APIs
|
||||
|
||||
- Adds a parameter `metadata_condition` to the [Retrieve chunks](./references/python_api_reference.md#retrieve-chunks) method, enabling metadata-based chunk filtering during retrieval. [#9877](https://github.com/infiniflow/ragflow/pull/9877)
|
||||
|
||||
## v0.20.4
|
||||
|
||||
|
||||
@ -41,37 +41,43 @@ class Docx(DocxParser):
|
||||
pass
|
||||
|
||||
def get_picture(self, document, paragraph):
|
||||
img = paragraph._element.xpath('.//pic:pic')
|
||||
if not img:
|
||||
return None
|
||||
img = img[0]
|
||||
embed = img.xpath('.//a:blip/@r:embed')
|
||||
if not embed:
|
||||
return None
|
||||
embed = embed[0]
|
||||
try:
|
||||
related_part = document.part.related_parts[embed]
|
||||
image_blob = related_part.image.blob
|
||||
except UnrecognizedImageError:
|
||||
logging.info("Unrecognized image format. Skipping image.")
|
||||
return None
|
||||
except UnexpectedEndOfFileError:
|
||||
logging.info("EOF was unexpectedly encountered while reading an image stream. Skipping image.")
|
||||
return None
|
||||
except InvalidImageStreamError:
|
||||
logging.info("The recognized image stream appears to be corrupted. Skipping image.")
|
||||
return None
|
||||
except UnicodeDecodeError:
|
||||
logging.info("The recognized image stream appears to be corrupted. Skipping image.")
|
||||
return None
|
||||
except Exception:
|
||||
logging.info("The recognized image stream appears to be corrupted. Skipping image.")
|
||||
return None
|
||||
try:
|
||||
image = Image.open(BytesIO(image_blob)).convert('RGB')
|
||||
return image
|
||||
except Exception:
|
||||
imgs = paragraph._element.xpath('.//pic:pic')
|
||||
if not imgs:
|
||||
return None
|
||||
res_img = None
|
||||
for img in imgs:
|
||||
embed = img.xpath('.//a:blip/@r:embed')
|
||||
if not embed:
|
||||
continue
|
||||
embed = embed[0]
|
||||
try:
|
||||
related_part = document.part.related_parts[embed]
|
||||
image_blob = related_part.image.blob
|
||||
except UnrecognizedImageError:
|
||||
logging.info("Unrecognized image format. Skipping image.")
|
||||
continue
|
||||
except UnexpectedEndOfFileError:
|
||||
logging.info("EOF was unexpectedly encountered while reading an image stream. Skipping image.")
|
||||
continue
|
||||
except InvalidImageStreamError:
|
||||
logging.info("The recognized image stream appears to be corrupted. Skipping image.")
|
||||
continue
|
||||
except UnicodeDecodeError:
|
||||
logging.info("The recognized image stream appears to be corrupted. Skipping image.")
|
||||
continue
|
||||
except Exception:
|
||||
logging.info("The recognized image stream appears to be corrupted. Skipping image.")
|
||||
continue
|
||||
try:
|
||||
image = Image.open(BytesIO(image_blob)).convert('RGB')
|
||||
if res_img is None:
|
||||
res_img = image
|
||||
else:
|
||||
res_img = concat_img(res_img, image)
|
||||
except Exception:
|
||||
continue
|
||||
|
||||
return res_img
|
||||
|
||||
def __clean(self, line):
|
||||
line = re.sub(r"\u3000", " ", line).strip()
|
||||
|
||||
@ -73,11 +73,13 @@ class Chunker(ProcessBase):
|
||||
|
||||
def _general(self, from_upstream: ChunkerFromUpstream):
|
||||
self.callback(random.randint(1, 5) / 100.0, "Start to chunk via `General`.")
|
||||
if from_upstream.output_format in ["markdown", "text"]:
|
||||
if from_upstream.output_format in ["markdown", "text", "html"]:
|
||||
if from_upstream.output_format == "markdown":
|
||||
payload = from_upstream.markdown_result
|
||||
else: # == "text"
|
||||
elif from_upstream.output_format == "text":
|
||||
payload = from_upstream.text_result
|
||||
else: # == "html"
|
||||
payload = from_upstream.html_result
|
||||
|
||||
if not payload:
|
||||
payload = ""
|
||||
@ -90,6 +92,7 @@ class Chunker(ProcessBase):
|
||||
)
|
||||
return [{"text": c} for c in cks]
|
||||
|
||||
# json
|
||||
sections, section_images = [], []
|
||||
for o in from_upstream.json_result or []:
|
||||
sections.append((o.get("text", ""), o.get("position_tag", "")))
|
||||
|
||||
@ -29,7 +29,7 @@ class ChunkerFromUpstream(BaseModel):
|
||||
json_result: list[dict[str, Any]] | None = Field(default=None, alias="json")
|
||||
markdown_result: str | None = Field(default=None, alias="markdown")
|
||||
text_result: str | None = Field(default=None, alias="text")
|
||||
html_result: str | None = Field(default=None, alias="html")
|
||||
html_result: list[str] | None = Field(default=None, alias="html")
|
||||
|
||||
model_config = ConfigDict(populate_by_name=True, extra="forbid")
|
||||
|
||||
|
||||
@ -12,6 +12,7 @@
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import logging
|
||||
import random
|
||||
|
||||
import trio
|
||||
@ -29,12 +30,25 @@ class ParserParam(ProcessParamBase):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.allowed_output_format = {
|
||||
"pdf": ["json", "markdown"],
|
||||
"excel": ["json", "markdown", "html"],
|
||||
"pdf": [
|
||||
"json",
|
||||
"markdown",
|
||||
],
|
||||
"spreadsheet": [
|
||||
"json",
|
||||
"markdown",
|
||||
"html",
|
||||
],
|
||||
"word": [
|
||||
"json",
|
||||
],
|
||||
"ppt": [],
|
||||
"image": [],
|
||||
"email": [],
|
||||
"text": [],
|
||||
"text": [
|
||||
"text",
|
||||
"json"
|
||||
],
|
||||
"audio": [],
|
||||
"video": [],
|
||||
}
|
||||
@ -44,19 +58,41 @@ class ParserParam(ProcessParamBase):
|
||||
"parse_method": "deepdoc", # deepdoc/plain_text/vlm
|
||||
"vlm_name": "",
|
||||
"lang": "Chinese",
|
||||
"suffix": ["pdf"],
|
||||
"suffix": [
|
||||
"pdf",
|
||||
],
|
||||
"output_format": "json",
|
||||
},
|
||||
"excel": {
|
||||
"spreadsheet": {
|
||||
"output_format": "html",
|
||||
"suffix": ["xls", "xlsx", "csv"],
|
||||
"suffix": [
|
||||
"xls",
|
||||
"xlsx",
|
||||
"csv",
|
||||
],
|
||||
},
|
||||
"word": {
|
||||
"suffix": [
|
||||
"doc",
|
||||
"docx",
|
||||
],
|
||||
"output_format": "json",
|
||||
},
|
||||
"markdown": {
|
||||
"suffix": ["md", "markdown"],
|
||||
"output_format": "json",
|
||||
},
|
||||
"ppt": {},
|
||||
"image": {
|
||||
"parse_method": "ocr",
|
||||
},
|
||||
"email": {},
|
||||
"text": {},
|
||||
"text": {
|
||||
"suffix": [
|
||||
"txt"
|
||||
],
|
||||
"output_format": "json",
|
||||
},
|
||||
"audio": {},
|
||||
"video": {},
|
||||
}
|
||||
@ -76,16 +112,26 @@ class ParserParam(ProcessParamBase):
|
||||
pdf_output_format = pdf_config.get("output_format", "")
|
||||
self.check_valid_value(pdf_output_format, "PDF output format abnormal.", self.allowed_output_format["pdf"])
|
||||
|
||||
excel_config = self.setups.get("excel", "")
|
||||
if excel_config:
|
||||
excel_output_format = excel_config.get("output_format", "")
|
||||
self.check_valid_value(excel_output_format, "Excel output format abnormal.", self.allowed_output_format["excel"])
|
||||
spreadsheet_config = self.setups.get("spreadsheet", "")
|
||||
if spreadsheet_config:
|
||||
spreadsheet_output_format = spreadsheet_config.get("output_format", "")
|
||||
self.check_valid_value(spreadsheet_output_format, "Spreadsheet output format abnormal.", self.allowed_output_format["spreadsheet"])
|
||||
|
||||
doc_config = self.setups.get("doc", "")
|
||||
if doc_config:
|
||||
doc_output_format = doc_config.get("output_format", "")
|
||||
self.check_valid_value(doc_output_format, "Word processer document output format abnormal.", self.allowed_output_format["doc"])
|
||||
|
||||
image_config = self.setups.get("image", "")
|
||||
if image_config:
|
||||
image_parse_method = image_config.get("parse_method", "")
|
||||
self.check_valid_value(image_parse_method.lower(), "Parse method abnormal.", ["ocr"])
|
||||
|
||||
text_config = self.setups.get("text", "")
|
||||
if text_config:
|
||||
text_output_format = text_config.get("output_format", "")
|
||||
self.check_valid_value(text_output_format, "Text output format abnormal.", self.allowed_output_format["text"])
|
||||
|
||||
def get_input_form(self) -> dict[str, dict]:
|
||||
return {}
|
||||
|
||||
@ -93,10 +139,13 @@ class ParserParam(ProcessParamBase):
|
||||
class Parser(ProcessBase):
|
||||
component_name = "Parser"
|
||||
|
||||
def _pdf(self, blob):
|
||||
def _pdf(self, from_upstream: ParserFromUpstream):
|
||||
self.callback(random.randint(1, 5) / 100.0, "Start to work on a PDF.")
|
||||
|
||||
blob = from_upstream.blob
|
||||
conf = self._param.setups["pdf"]
|
||||
self.set_output("output_format", conf["output_format"])
|
||||
|
||||
if conf.get("parse_method") == "deepdoc":
|
||||
bboxes = RAGFlowPdfParser().parse_into_bboxes(blob, callback=self.callback)
|
||||
elif conf.get("parse_method") == "plain_text":
|
||||
@ -110,6 +159,7 @@ class Parser(ProcessBase):
|
||||
for t, poss in lines:
|
||||
pn, x0, x1, top, bott = poss.split(" ")
|
||||
bboxes.append({"page_number": int(pn), "x0": float(x0), "x1": float(x1), "top": float(top), "bottom": float(bott), "text": t})
|
||||
|
||||
if conf.get("output_format") == "json":
|
||||
self.set_output("json", bboxes)
|
||||
if conf.get("output_format") == "markdown":
|
||||
@ -123,23 +173,111 @@ class Parser(ProcessBase):
|
||||
mkdn += b.get("text", "") + "\n"
|
||||
self.set_output("markdown", mkdn)
|
||||
|
||||
def _excel(self, blob):
|
||||
self.callback(random.randint(1, 5) / 100.0, "Start to work on a Excel.")
|
||||
conf = self._param.setups["excel"]
|
||||
def _spreadsheet(self, from_upstream: ParserFromUpstream):
|
||||
self.callback(random.randint(1, 5) / 100.0, "Start to work on a Spreadsheet.")
|
||||
|
||||
blob = from_upstream.blob
|
||||
conf = self._param.setups["spreadsheet"]
|
||||
self.set_output("output_format", conf["output_format"])
|
||||
excel_parser = ExcelParser()
|
||||
|
||||
print("spreadsheet {conf=}", flush=True)
|
||||
spreadsheet_parser = ExcelParser()
|
||||
if conf.get("output_format") == "html":
|
||||
html = excel_parser.html(blob, 1000000000)
|
||||
html = spreadsheet_parser.html(blob, 1000000000)
|
||||
self.set_output("html", html)
|
||||
elif conf.get("output_format") == "json":
|
||||
self.set_output("json", [{"text": txt} for txt in excel_parser(blob) if txt])
|
||||
self.set_output("json", [{"text": txt} for txt in spreadsheet_parser(blob) if txt])
|
||||
elif conf.get("output_format") == "markdown":
|
||||
self.set_output("markdown", excel_parser.markdown(blob))
|
||||
self.set_output("markdown", spreadsheet_parser.markdown(blob))
|
||||
|
||||
def _word(self, from_upstream: ParserFromUpstream):
|
||||
from tika import parser as word_parser
|
||||
|
||||
self.callback(random.randint(1, 5) / 100.0, "Start to work on a Word Processor Document")
|
||||
|
||||
blob = from_upstream.blob
|
||||
name = from_upstream.name
|
||||
conf = self._param.setups["word"]
|
||||
self.set_output("output_format", conf["output_format"])
|
||||
|
||||
print("word {conf=}", flush=True)
|
||||
doc_parsed = word_parser.from_buffer(blob)
|
||||
|
||||
sections = []
|
||||
if doc_parsed.get("content"):
|
||||
sections = doc_parsed["content"].split("\n")
|
||||
sections = [{"text": section} for section in sections if section]
|
||||
else:
|
||||
logging.warning(f"tika.parser got empty content from {name}.")
|
||||
|
||||
# json
|
||||
assert conf.get("output_format") == "json", "have to be json for doc"
|
||||
if conf.get("output_format") == "json":
|
||||
self.set_output("json", sections)
|
||||
|
||||
def _markdown(self, from_upstream: ParserFromUpstream):
|
||||
from functools import reduce
|
||||
|
||||
from rag.app.naive import Markdown as naive_markdown_parser
|
||||
from rag.nlp import concat_img
|
||||
|
||||
self.callback(random.randint(1, 5) / 100.0, "Start to work on a markdown.")
|
||||
|
||||
blob = from_upstream.blob
|
||||
name = from_upstream.name
|
||||
conf = self._param.setups["markdown"]
|
||||
self.set_output("output_format", conf["output_format"])
|
||||
|
||||
markdown_parser = naive_markdown_parser()
|
||||
sections, tables = markdown_parser(name, blob, separate_tables=False)
|
||||
|
||||
# json
|
||||
assert conf.get("output_format") == "json", "have to be json for doc"
|
||||
if conf.get("output_format") == "json":
|
||||
json_results = []
|
||||
|
||||
for section_text, _ in sections:
|
||||
json_result = {
|
||||
"text": section_text,
|
||||
}
|
||||
|
||||
images = markdown_parser.get_pictures(section_text) if section_text else None
|
||||
if images:
|
||||
# If multiple images found, combine them using concat_img
|
||||
combined_image = reduce(concat_img, images) if len(images) > 1 else images[0]
|
||||
json_result["image"] = combined_image
|
||||
|
||||
json_results.append(json_result)
|
||||
|
||||
self.set_output("json", json_results)
|
||||
|
||||
def _text(self, from_upstream: ParserFromUpstream):
|
||||
from deepdoc.parser.utils import get_text
|
||||
|
||||
self.callback(random.randint(1, 5) / 100.0, "Start to work on a text.")
|
||||
|
||||
blob = from_upstream.blob
|
||||
name = from_upstream.name
|
||||
conf = self._param.setups["text"]
|
||||
self.set_output("output_format", conf["output_format"])
|
||||
|
||||
# parse binary to text
|
||||
text_content = get_text(name, binary=blob)
|
||||
|
||||
if conf.get("output_format") == "json":
|
||||
result = [{"text": text_content}]
|
||||
self.set_output("json", result)
|
||||
else:
|
||||
result = text_content
|
||||
self.set_output("text", result)
|
||||
|
||||
async def _invoke(self, **kwargs):
|
||||
function_map = {
|
||||
"pdf": self._pdf,
|
||||
"excel": self._excel,
|
||||
"markdown": self._markdown,
|
||||
"spreadsheet": self._spreadsheet,
|
||||
"word": self._word,
|
||||
"text": self._text,
|
||||
}
|
||||
try:
|
||||
from_upstream = ParserFromUpstream.model_validate(kwargs)
|
||||
@ -150,5 +288,5 @@ class Parser(ProcessBase):
|
||||
for p_type, conf in self._param.setups.items():
|
||||
if from_upstream.name.split(".")[-1].lower() not in conf.get("suffix", []):
|
||||
continue
|
||||
await trio.to_thread.run_sync(function_map[p_type], from_upstream.blob)
|
||||
await trio.to_thread.run_sync(function_map[p_type], from_upstream)
|
||||
break
|
||||
|
||||
@ -23,16 +23,34 @@
|
||||
],
|
||||
"output_format": "json"
|
||||
},
|
||||
"excel": {
|
||||
"output_format": "html",
|
||||
"spreadsheet": {
|
||||
"suffix": [
|
||||
"xls",
|
||||
"xlsx",
|
||||
"csv"
|
||||
]
|
||||
],
|
||||
"output_format": "html"
|
||||
},
|
||||
"word": {
|
||||
"suffix": [
|
||||
"doc",
|
||||
"docx"
|
||||
],
|
||||
"output_format": "json"
|
||||
},
|
||||
"markdown": {
|
||||
"suffix": [
|
||||
"md",
|
||||
"markdown"
|
||||
],
|
||||
"output_format": "json"
|
||||
},
|
||||
"text": {
|
||||
"suffix": ["txt"],
|
||||
"output_format": "json"
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
},
|
||||
"downstream": ["Chunker:0"],
|
||||
"upstream": ["Begin"]
|
||||
|
||||
@ -31,7 +31,7 @@ class TokenizerFromUpstream(BaseModel):
|
||||
json_result: list[dict[str, Any]] | None = Field(default=None, alias="json")
|
||||
markdown_result: str | None = Field(default=None, alias="markdown")
|
||||
text_result: str | None = Field(default=None, alias="text")
|
||||
html_result: str | None = Field(default=None, alias="html")
|
||||
html_result: list[str] | None = Field(default=None, alias="html")
|
||||
|
||||
model_config = ConfigDict(populate_by_name=True, extra="forbid")
|
||||
|
||||
|
||||
@ -117,11 +117,13 @@ class Tokenizer(ProcessBase):
|
||||
ck["content_sm_ltks"] = rag_tokenizer.fine_grained_tokenize(ck["content_ltks"])
|
||||
if i % 100 == 99:
|
||||
self.callback(i * 1.0 / len(chunks) / parts)
|
||||
elif from_upstream.output_format in ["markdown", "text"]:
|
||||
elif from_upstream.output_format in ["markdown", "text", "html"]:
|
||||
if from_upstream.output_format == "markdown":
|
||||
payload = from_upstream.markdown_result
|
||||
else: # == "text"
|
||||
elif from_upstream.output_format == "text":
|
||||
payload = from_upstream.text_result
|
||||
else: # == "html"
|
||||
payload = from_upstream.html_result
|
||||
|
||||
if not payload:
|
||||
return ""
|
||||
|
||||
@ -1356,6 +1356,14 @@ class Ai302Chat(Base):
|
||||
super().__init__(key, model_name, base_url, **kwargs)
|
||||
|
||||
|
||||
class TokenPonyChat(Base):
|
||||
_FACTORY_NAME = "TokenPony"
|
||||
|
||||
def __init__(self, key, model_name, base_url="https://ragflow.vip-api.tokenpony.cn/v1", **kwargs):
|
||||
if not base_url:
|
||||
base_url = "https://ragflow.vip-api.tokenpony.cn/v1"
|
||||
|
||||
|
||||
class MeituanChat(Base):
|
||||
_FACTORY_NAME = "Meituan"
|
||||
|
||||
|
||||
@ -124,17 +124,19 @@ class Base(ABC):
|
||||
mime = "image/jpeg"
|
||||
b64 = base64.b64encode(data).decode("utf-8")
|
||||
return f"data:{mime};base64,{b64}"
|
||||
buffered = BytesIO()
|
||||
fmt = "JPEG"
|
||||
try:
|
||||
image.save(buffered, format="JPEG")
|
||||
except Exception:
|
||||
buffered = BytesIO() # reset buffer before saving PNG
|
||||
image.save(buffered, format="PNG")
|
||||
fmt = "PNG"
|
||||
data = buffered.getvalue()
|
||||
b64 = base64.b64encode(data).decode("utf-8")
|
||||
mime = f"image/{fmt.lower()}"
|
||||
with BytesIO() as buffered:
|
||||
fmt = "JPEG"
|
||||
try:
|
||||
image.save(buffered, format="JPEG")
|
||||
except Exception:
|
||||
# reset buffer before saving PNG
|
||||
buffered.seek(0)
|
||||
buffered.truncate()
|
||||
image.save(buffered, format="PNG")
|
||||
fmt = "PNG"
|
||||
data = buffered.getvalue()
|
||||
b64 = base64.b64encode(data).decode("utf-8")
|
||||
mime = f"image/{fmt.lower()}"
|
||||
return f"data:{mime};base64,{b64}"
|
||||
|
||||
def prompt(self, b64):
|
||||
@ -519,24 +521,24 @@ class GeminiCV(Base):
|
||||
else "Please describe the content of this picture, like where, when, who, what happen. If it has number data, please extract them out."
|
||||
)
|
||||
b64 = self.image2base64(image)
|
||||
img = open(BytesIO(base64.b64decode(b64)))
|
||||
input = [prompt, img]
|
||||
res = self.model.generate_content(input)
|
||||
img.close()
|
||||
return res.text, res.usage_metadata.total_token_count
|
||||
with BytesIO(base64.b64decode(b64)) as bio:
|
||||
img = open(bio)
|
||||
input = [prompt, img]
|
||||
res = self.model.generate_content(input)
|
||||
img.close()
|
||||
return res.text, res.usage_metadata.total_token_count
|
||||
|
||||
def describe_with_prompt(self, image, prompt=None):
|
||||
from PIL.Image import open
|
||||
|
||||
b64 = self.image2base64(image)
|
||||
vision_prompt = prompt if prompt else vision_llm_describe_prompt()
|
||||
img = open(BytesIO(base64.b64decode(b64)))
|
||||
input = [vision_prompt, img]
|
||||
res = self.model.generate_content(
|
||||
input,
|
||||
)
|
||||
img.close()
|
||||
return res.text, res.usage_metadata.total_token_count
|
||||
with BytesIO(base64.b64decode(b64)) as bio:
|
||||
img = open(bio)
|
||||
input = [vision_prompt, img]
|
||||
res = self.model.generate_content(input)
|
||||
img.close()
|
||||
return res.text, res.usage_metadata.total_token_count
|
||||
|
||||
def chat(self, system, history, gen_conf, images=[]):
|
||||
generation_config = dict(temperature=gen_conf.get("temperature", 0.3), top_p=gen_conf.get("top_p", 0.7))
|
||||
|
||||
@ -751,6 +751,12 @@ class SILICONFLOWEmbed(Base):
|
||||
token_count = 0
|
||||
for i in range(0, len(texts), batch_size):
|
||||
texts_batch = texts[i : i + batch_size]
|
||||
if self.model_name in ["BAAI/bge-large-zh-v1.5", "BAAI/bge-large-en-v1.5"]:
|
||||
# limit 512, 340 is almost safe
|
||||
texts_batch = [" " if not text.strip() else truncate(text, 340) for text in texts_batch]
|
||||
else:
|
||||
texts_batch = [" " if not text.strip() else text for text in texts_batch]
|
||||
|
||||
payload = {
|
||||
"model": self.model_name,
|
||||
"input": texts_batch,
|
||||
@ -935,7 +941,7 @@ class GiteeEmbed(SILICONFLOWEmbed):
|
||||
if not base_url:
|
||||
base_url = "https://ai.gitee.com/v1/embeddings"
|
||||
super().__init__(key, model_name, base_url)
|
||||
|
||||
|
||||
class DeepInfraEmbed(OpenAIEmbed):
|
||||
_FACTORY_NAME = "DeepInfra"
|
||||
|
||||
@ -951,4 +957,4 @@ class Ai302Embed(Base):
|
||||
def __init__(self, key, model_name, base_url="https://api.302.ai/v1/embeddings"):
|
||||
if not base_url:
|
||||
base_url = "https://api.302.ai/v1/embeddings"
|
||||
super().__init__(key, model_name, base_url)
|
||||
super().__init__(key, model_name, base_url)
|
||||
|
||||
@ -518,7 +518,7 @@ def hierarchical_merge(bull, sections, depth):
|
||||
return res
|
||||
|
||||
|
||||
def naive_merge(sections, chunk_token_num=128, delimiter="\n。;!?", overlapped_percent=0):
|
||||
def naive_merge(sections: str | list, chunk_token_num=128, delimiter="\n。;!?", overlapped_percent=0):
|
||||
from deepdoc.parser.pdf_parser import RAGFlowPdfParser
|
||||
if not sections:
|
||||
return []
|
||||
@ -534,7 +534,7 @@ def naive_merge(sections, chunk_token_num=128, delimiter="\n。;!?", overl
|
||||
pos = ""
|
||||
if tnum < 8:
|
||||
pos = ""
|
||||
# Ensure that the length of the merged chunk does not exceed chunk_token_num
|
||||
# Ensure that the length of the merged chunk does not exceed chunk_token_num
|
||||
if cks[-1] == "" or tk_nums[-1] > chunk_token_num * (100 - overlapped_percent)/100.:
|
||||
if cks:
|
||||
overlapped = RAGFlowPdfParser.remove_tag(cks[-1])
|
||||
@ -638,10 +638,10 @@ def concat_img(img1, img2):
|
||||
return img2
|
||||
if not img1 and not img2:
|
||||
return None
|
||||
|
||||
|
||||
if img1 is img2:
|
||||
return img1
|
||||
|
||||
|
||||
if isinstance(img1, Image.Image) and isinstance(img2, Image.Image):
|
||||
pixel_data1 = img1.tobytes()
|
||||
pixel_data2 = img2.tobytes()
|
||||
|
||||
8
web/package-lock.json
generated
8
web/package-lock.json
generated
@ -66,7 +66,7 @@
|
||||
"jsencrypt": "^3.3.2",
|
||||
"lexical": "^0.23.1",
|
||||
"lodash": "^4.17.21",
|
||||
"lucide-react": "^0.508.0",
|
||||
"lucide-react": "^0.542.0",
|
||||
"mammoth": "^1.7.2",
|
||||
"next-themes": "^0.4.6",
|
||||
"openai-speech-stream-player": "^1.0.8",
|
||||
@ -25113,9 +25113,9 @@
|
||||
}
|
||||
},
|
||||
"node_modules/lucide-react": {
|
||||
"version": "0.508.0",
|
||||
"resolved": "https://registry.npmmirror.com/lucide-react/-/lucide-react-0.508.0.tgz",
|
||||
"integrity": "sha512-gcP16PnexqtOFrTtv98kVsGzTfnbPekzZiQfByi2S89xfk7E/4uKE1USZqccIp58v42LqkO7MuwpCqshwSrJCg==",
|
||||
"version": "0.542.0",
|
||||
"resolved": "https://registry.npmmirror.com/lucide-react/-/lucide-react-0.542.0.tgz",
|
||||
"integrity": "sha512-w3hD8/SQB7+lzU2r4VdFyzzOzKnUjTZIF/MQJGSSvni7Llewni4vuViRppfRAa2guOsY5k4jZyxw/i9DQHv+dw==",
|
||||
"license": "ISC",
|
||||
"peerDependencies": {
|
||||
"react": "^16.5.1 || ^17.0.0 || ^18.0.0 || ^19.0.0"
|
||||
|
||||
@ -79,7 +79,7 @@
|
||||
"jsencrypt": "^3.3.2",
|
||||
"lexical": "^0.23.1",
|
||||
"lodash": "^4.17.21",
|
||||
"lucide-react": "^0.508.0",
|
||||
"lucide-react": "^0.542.0",
|
||||
"mammoth": "^1.7.2",
|
||||
"next-themes": "^0.4.6",
|
||||
"openai-speech-stream-player": "^1.0.8",
|
||||
|
||||
1
web/src/assets/svg/data-flow/knowledgegraph.svg
Normal file
1
web/src/assets/svg/data-flow/knowledgegraph.svg
Normal file
{kind=link}
@ -0,0 +1 @@
|
||||
<?xml version="1.0" standalone="no"?><!DOCTYPE svg PUBLIC "-//W3C//DTD SVG 1.1//EN" "http://www.w3.org/Graphics/SVG/1.1/DTD/svg11.dtd"><svg t="1756884949583" class="icon" viewBox="0 0 1024 1024" version="1.1" xmlns="http://www.w3.org/2000/svg" p-id="11332" xmlns:xlink="http://www.w3.org/1999/xlink" width="200" height="200"><path d="M190.464 489.472h327.68v40.96h-327.68z" fill="#C7DCFE" p-id="11333"></path><path d="M482.34496 516.5056l111.26784-308.20352 38.54336 13.9264L520.86784 530.432z" fill="#C7DCFE" p-id="11334"></path><path d="M620.544 196.608m-122.88 0a122.88 122.88 0 1 0 245.76 0 122.88 122.88 0 1 0-245.76 0Z" fill="#8FB8FC" p-id="11335"></path><path d="M182.272 509.952m-122.88 0a122.88 122.88 0 1 0 245.76 0 122.88 122.88 0 1 0-245.76 0Z" fill="#C7DCFE" p-id="11336"></path><path d="M558.65344 520.9088l283.77088 163.84-20.48 35.47136-283.77088-163.84z" fill="#C7DCFE" p-id="11337"></path><path d="M841.728 686.08m-122.88 0a122.88 122.88 0 1 0 245.76 0 122.88 122.88 0 1 0-245.76 0Z" fill="#B3CEFE" p-id="11338"></path><path d="M448.67584 803.77856l49.60256-323.91168 40.48896 6.20544-49.60256 323.91168z" fill="#C7DCFE" p-id="11339"></path><path d="M512 530.432m-143.36 0a143.36 143.36 0 1 0 286.72 0 143.36 143.36 0 1 0-286.72 0Z" fill="#4185FF" p-id="11340"></path><path d="M462.848 843.776m-102.4 0a102.4 102.4 0 1 0 204.8 0 102.4 102.4 0 1 0-204.8 0Z" fill="#8FB8FC" p-id="11341"></path></svg>
|
||||
|
After Width: | Height: | Size: 1.4 KiB |
1
web/src/assets/svg/data-flow/raptor.svg
Normal file
1
web/src/assets/svg/data-flow/raptor.svg
Normal file
{kind=link}
File diff suppressed because one or more lines are too long
|
After Width: | Height: | Size: 36 KiB |
8
web/src/assets/svg/llm/token-pony.svg
Normal file
8
web/src/assets/svg/llm/token-pony.svg
Normal file
{kind=link}
File diff suppressed because one or more lines are too long
|
After Width: | Height: | Size: 16 KiB |
1
web/src/assets/svg/rerun.svg
Normal file
1
web/src/assets/svg/rerun.svg
Normal file
{kind=link}
@ -0,0 +1 @@
|
||||
<?xml version="1.0" standalone="no"?><!DOCTYPE svg PUBLIC "-//W3C//DTD SVG 1.1//EN" "http://www.w3.org/Graphics/SVG/1.1/DTD/svg11.dtd"><svg t="1757483419289" class="icon" viewBox="0 0 1024 1024" version="1.1" xmlns="http://www.w3.org/2000/svg" p-id="22299" xmlns:xlink="http://www.w3.org/1999/xlink" width="200" height="200"><path d="M998.765714 523.629714c13.824 0 25.014857 11.190857 25.014857 25.014857a475.282286 475.282286 0 0 1-875.593142 256.219429l-27.574858 55.149714a25.014857 25.014857 0 1 1-44.763428-22.454857l44.178286-88.283428a24.868571 24.868571 0 0 1 26.550857-25.526858 25.014857 25.014857 0 0 1 8.265143 0.804572l99.474285 24.868571a25.014857 25.014857 0 0 1-12.068571 48.566857l-46.372572-11.556571A425.252571 425.252571 0 0 0 973.750857 548.571429c0-13.897143 11.190857-25.014857 25.014857-25.014858zM430.957714 365.714286l6.729143 0.658285c2.633143 0.438857 285.549714 160.109714 285.549714 160.109715 20.114286 17.846857 7.314286 34.523429-6.582857 45.933714-1.828571 1.462857-194.779429 113.078857-249.929143 144.969143l-10.678857 6.217143-3.876571 2.194285c-16.676571 8.923429-39.497143 8.923429-47.250286-11.995428-0.877714-2.194286-2.267429-250.221714-2.56-303.396572L402.285714 400.457143l0.731429-0.512c0.731429-18.651429 8.265143-38.034286 34.669714-33.645714z m-15.945143-273.408a475.282286 475.282286 0 0 1 533.869715 200.045714l27.501714-55.149714a25.014857 25.014857 0 1 1 44.690286 22.454857l-44.105143 88.283428a24.868571 24.868571 0 0 1-26.624 25.526858 24.868571 24.868571 0 0 1-8.192-0.804572l-99.547429-24.868571a25.014857 25.014857 0 0 1 12.068572-48.566857l46.445714 11.629714A425.252571 425.252571 0 0 0 123.245714 548.571429a25.014857 25.014857 0 0 1-50.029714 0 475.282286 475.282286 0 0 1 341.796571-456.265143z" fill="#3BA05C" p-id="22300"></path></svg>
|
||||
|
After Width: | Height: | Size: 1.8 KiB |
@ -139,7 +139,7 @@ function EmbedDialog({
|
||||
</form>
|
||||
</Form>
|
||||
<div>
|
||||
<span>Embed code</span>
|
||||
<span>{t('embedCode', { keyPrefix: 'search' })}</span>
|
||||
<HightLightMarkdown>{text}</HightLightMarkdown>
|
||||
</div>
|
||||
<div className=" font-medium mt-4 mb-1">
|
||||
|
||||
57
web/src/components/file-status-badge.tsx
Normal file
57
web/src/components/file-status-badge.tsx
Normal file
@ -0,0 +1,57 @@
|
||||
// src/pages/dataset/file-logs/file-status-badge.tsx
|
||||
import { FC } from 'react';
|
||||
|
||||
interface StatusBadgeProps {
|
||||
status: 'Success' | 'Failed' | 'Running' | 'Pending';
|
||||
}
|
||||
|
||||
const FileStatusBadge: FC<StatusBadgeProps> = ({ status }) => {
|
||||
const getStatusColor = () => {
|
||||
// #3ba05c → rgb(59, 160, 92) // state-success
|
||||
// #d8494b → rgb(216, 73, 75) // state-error
|
||||
// #00beb4 → rgb(0, 190, 180) // accent-primary
|
||||
// #faad14 → rgb(250, 173, 20) // state-warning
|
||||
switch (status) {
|
||||
case 'Success':
|
||||
return `bg-[rgba(59,160,92,0.1)] text-state-success`;
|
||||
case 'Failed':
|
||||
return `bg-[rgba(216,73,75,0.1)] text-state-error`;
|
||||
case 'Running':
|
||||
return `bg-[rgba(0,190,180,0.1)] text-accent-primary`;
|
||||
case 'Pending':
|
||||
return `bg-[rgba(250,173,20,0.1)] text-state-warning`;
|
||||
default:
|
||||
return 'bg-gray-500/10 text-white';
|
||||
}
|
||||
};
|
||||
|
||||
const getBgStatusColor = () => {
|
||||
// #3ba05c → rgb(59, 160, 92) // state-success
|
||||
// #d8494b → rgb(216, 73, 75) // state-error
|
||||
// #00beb4 → rgb(0, 190, 180) // accent-primary
|
||||
// #faad14 → rgb(250, 173, 20) // state-warning
|
||||
switch (status) {
|
||||
case 'Success':
|
||||
return `bg-[rgba(59,160,92,1)] text-state-success`;
|
||||
case 'Failed':
|
||||
return `bg-[rgba(216,73,75,1)] text-state-error`;
|
||||
case 'Running':
|
||||
return `bg-[rgba(0,190,180,1)] text-accent-primary`;
|
||||
case 'Pending':
|
||||
return `bg-[rgba(250,173,20,1)] text-state-warning`;
|
||||
default:
|
||||
return 'bg-gray-500/10 text-white';
|
||||
}
|
||||
};
|
||||
|
||||
return (
|
||||
<span
|
||||
className={`inline-flex items-center w-[75px] px-2 py-1 rounded-full text-xs font-medium ${getStatusColor(0.1)}`}
|
||||
>
|
||||
<div className={`w-1 h-1 mr-1 rounded-full ${getBgStatusColor()}`}></div>
|
||||
{status}
|
||||
</span>
|
||||
);
|
||||
};
|
||||
|
||||
export default FileStatusBadge;
|
||||
@ -1,6 +1,7 @@
|
||||
'use client';
|
||||
|
||||
import { cn } from '@/lib/utils';
|
||||
import { parseColorToRGBA } from '@/utils/common-util';
|
||||
import { Slot } from '@radix-ui/react-slot';
|
||||
import * as React from 'react';
|
||||
|
||||
@ -197,7 +198,208 @@ function TimelineTitle({
|
||||
);
|
||||
}
|
||||
|
||||
interface TimelineIndicatorNodeProps {
|
||||
nodeSize?: string | number;
|
||||
iconColor?: string;
|
||||
lineColor?: string;
|
||||
textColor?: string;
|
||||
indicatorBgColor?: string;
|
||||
indicatorBorderColor?: string;
|
||||
}
|
||||
interface TimelineNode
|
||||
extends Omit<
|
||||
React.HTMLAttributes<HTMLDivElement>,
|
||||
'id' | 'title' | 'content'
|
||||
>,
|
||||
TimelineIndicatorNodeProps {
|
||||
id: string | number;
|
||||
title?: React.ReactNode;
|
||||
content?: React.ReactNode;
|
||||
date?: React.ReactNode;
|
||||
icon?: React.ReactNode;
|
||||
completed?: boolean;
|
||||
clickable?: boolean;
|
||||
activeStyle?: TimelineIndicatorNodeProps;
|
||||
}
|
||||
|
||||
interface CustomTimelineProps extends React.HTMLAttributes<HTMLDivElement> {
|
||||
nodes: TimelineNode[];
|
||||
activeStep?: number;
|
||||
nodeSize?: string | number;
|
||||
onStepChange?: (step: number, id: string | number) => void;
|
||||
orientation?: 'horizontal' | 'vertical';
|
||||
lineStyle?: 'solid' | 'dashed';
|
||||
lineColor?: string;
|
||||
indicatorColor?: string;
|
||||
defaultValue?: number;
|
||||
activeStyle?: TimelineIndicatorNodeProps;
|
||||
}
|
||||
|
||||
const CustomTimeline = ({
|
||||
nodes,
|
||||
activeStep,
|
||||
nodeSize = 12,
|
||||
onStepChange,
|
||||
orientation = 'horizontal',
|
||||
lineStyle = 'solid',
|
||||
lineColor = 'var(--text-secondary)',
|
||||
indicatorColor = 'var(--accent-primary)',
|
||||
defaultValue = 1,
|
||||
className,
|
||||
activeStyle,
|
||||
...props
|
||||
}: CustomTimelineProps) => {
|
||||
const [internalActiveStep, setInternalActiveStep] =
|
||||
React.useState(defaultValue);
|
||||
const _lineColor = `rgb(${parseColorToRGBA(lineColor)})`;
|
||||
console.log(lineColor, _lineColor);
|
||||
const currentActiveStep = activeStep ?? internalActiveStep;
|
||||
|
||||
const handleStepChange = (step: number, id: string | number) => {
|
||||
if (activeStep === undefined) {
|
||||
setInternalActiveStep(step);
|
||||
}
|
||||
onStepChange?.(step, id);
|
||||
};
|
||||
const [r, g, b] = parseColorToRGBA(indicatorColor);
|
||||
return (
|
||||
<Timeline
|
||||
value={currentActiveStep}
|
||||
onValueChange={(step) => handleStepChange(step, nodes[step - 1]?.id)}
|
||||
orientation={orientation}
|
||||
className={className}
|
||||
{...props}
|
||||
>
|
||||
{nodes.map((node, index) => {
|
||||
const step = index + 1;
|
||||
const isCompleted = node.completed ?? step <= currentActiveStep;
|
||||
const isActive = step === currentActiveStep;
|
||||
const isClickable = node.clickable ?? true;
|
||||
const _activeStyle = node.activeStyle ?? (activeStyle || {});
|
||||
const _nodeSizeTemp =
|
||||
isActive && _activeStyle?.nodeSize
|
||||
? _activeStyle?.nodeSize
|
||||
: node.nodeSize ?? nodeSize;
|
||||
const _nodeSize =
|
||||
typeof _nodeSizeTemp === 'number'
|
||||
? `${_nodeSizeTemp}px`
|
||||
: _nodeSizeTemp;
|
||||
console.log('icon-size', nodeSize, node.nodeSize, _nodeSize);
|
||||
// const activeStyle = _activeStyle || {};
|
||||
|
||||
return (
|
||||
<TimelineItem
|
||||
key={node.id}
|
||||
step={step}
|
||||
className={cn(
|
||||
node.className,
|
||||
isClickable &&
|
||||
'cursor-pointer hover:opacity-80 transition-opacity',
|
||||
isCompleted && 'data-[completed]:data-completed/timeline-item',
|
||||
isActive && 'relative z-10',
|
||||
)}
|
||||
onClick={() => isClickable && handleStepChange(step, node.id)}
|
||||
>
|
||||
<TimelineSeparator
|
||||
className={cn(
|
||||
'group-data-[orientation=horizontal]/timeline:-top-6 group-data-[orientation=horizontal]/timeline:h-0.1 group-data-[orientation=horizontal]/timeline:-translate-y-1/2',
|
||||
'group-data-[orientation=vertical]/timeline:-left-6 group-data-[orientation=vertical]/timeline:w-0.1 group-data-[orientation=vertical]/timeline:-translate-x-1/2 ',
|
||||
// `group-data-[orientation=horizontal]/timeline:w-[calc(100%-0.5rem-1rem)] group-data-[orientation=vertical]/timeline:h-[calc(100%-1rem-1rem)] group-data-[orientation=vertical]/timeline:translate-y-7 group-data-[orientation=horizontal]/timeline:translate-x-7`,
|
||||
)}
|
||||
style={{
|
||||
border:
|
||||
lineStyle === 'dashed'
|
||||
? `1px dashed ${isActive ? _activeStyle.lineColor || _lineColor : _lineColor}`
|
||||
: lineStyle === 'solid'
|
||||
? `1px solid ${isActive ? _activeStyle.lineColor || _lineColor : _lineColor}`
|
||||
: 'none',
|
||||
backgroundColor: 'transparent',
|
||||
width:
|
||||
orientation === 'horizontal'
|
||||
? `calc(100% - ${_nodeSize} - 2px - 0.1rem)`
|
||||
: '1px',
|
||||
height:
|
||||
orientation === 'vertical'
|
||||
? `calc(100% - ${_nodeSize} - 2px - 0.1rem)`
|
||||
: '1px',
|
||||
transform: `translate(${
|
||||
orientation === 'horizontal' ? `${_nodeSize}` : '0'
|
||||
}, ${orientation === 'vertical' ? `${_nodeSize}` : '0'})`,
|
||||
}}
|
||||
/>
|
||||
|
||||
<TimelineIndicator
|
||||
className={cn(
|
||||
'flex items-center justify-center p-1',
|
||||
isCompleted && 'bg-primary border-primary',
|
||||
!isCompleted && 'border-text-secondary bg-bg-base',
|
||||
)}
|
||||
style={{
|
||||
width: _nodeSize,
|
||||
height: _nodeSize,
|
||||
borderColor: isActive
|
||||
? _activeStyle.indicatorBorderColor || indicatorColor
|
||||
: isCompleted
|
||||
? indicatorColor
|
||||
: '',
|
||||
// backgroundColor: isActive
|
||||
// ? _activeStyle.indicatorBgColor || indicatorColor
|
||||
// : isCompleted
|
||||
// ? indicatorColor
|
||||
// : '',
|
||||
backgroundColor: isActive
|
||||
? _activeStyle.indicatorBgColor ||
|
||||
`rgba(${r}, ${g}, ${b}, 0.1)`
|
||||
: isCompleted
|
||||
? `rgba(${r}, ${g}, ${b}, 0.1)`
|
||||
: '',
|
||||
}}
|
||||
>
|
||||
{node.icon && (
|
||||
<div
|
||||
className={cn(
|
||||
'text-current',
|
||||
`w-[${_nodeSize}] h-[${_nodeSize}]`,
|
||||
isActive &&
|
||||
`text-primary w-[${_activeStyle.nodeSize || _nodeSize}] h-[${_activeStyle.nodeSize || _nodeSize}]`,
|
||||
)}
|
||||
style={{
|
||||
color: isActive ? _activeStyle.iconColor : undefined,
|
||||
}}
|
||||
>
|
||||
{node.icon}
|
||||
</div>
|
||||
)}
|
||||
</TimelineIndicator>
|
||||
|
||||
<TimelineHeader>
|
||||
{node.date && <TimelineDate>{node.date}</TimelineDate>}
|
||||
<TimelineTitle
|
||||
className={cn(
|
||||
'text-sm font-medium',
|
||||
isActive && _activeStyle.textColor
|
||||
? `text-${_activeStyle.textColor}`
|
||||
: '',
|
||||
)}
|
||||
style={{
|
||||
color: isActive ? _activeStyle.textColor : undefined,
|
||||
}}
|
||||
>
|
||||
{node.title}
|
||||
</TimelineTitle>
|
||||
</TimelineHeader>
|
||||
{node.content && <TimelineContent>{node.content}</TimelineContent>}
|
||||
</TimelineItem>
|
||||
);
|
||||
})}
|
||||
</Timeline>
|
||||
);
|
||||
};
|
||||
|
||||
CustomTimeline.displayName = 'CustomTimeline';
|
||||
|
||||
export {
|
||||
CustomTimeline,
|
||||
Timeline,
|
||||
TimelineContent,
|
||||
TimelineDate,
|
||||
@ -206,4 +408,5 @@ export {
|
||||
TimelineItem,
|
||||
TimelineSeparator,
|
||||
TimelineTitle,
|
||||
type TimelineNode,
|
||||
};
|
||||
|
||||
@ -15,6 +15,7 @@ type RAGFlowFormItemProps = {
|
||||
tooltip?: ReactNode;
|
||||
children: ReactNode | ((field: ControllerRenderProps) => ReactNode);
|
||||
horizontal?: boolean;
|
||||
required?: boolean;
|
||||
};
|
||||
|
||||
export function RAGFlowFormItem({
|
||||
@ -23,6 +24,7 @@ export function RAGFlowFormItem({
|
||||
tooltip,
|
||||
children,
|
||||
horizontal = false,
|
||||
required = false,
|
||||
}: RAGFlowFormItemProps) {
|
||||
const form = useFormContext();
|
||||
return (
|
||||
@ -35,7 +37,11 @@ export function RAGFlowFormItem({
|
||||
'flex items-center': horizontal,
|
||||
})}
|
||||
>
|
||||
<FormLabel tooltip={tooltip} className={cn({ 'w-1/4': horizontal })}>
|
||||
<FormLabel
|
||||
required={required}
|
||||
tooltip={tooltip}
|
||||
className={cn({ 'w-1/4': horizontal })}
|
||||
>
|
||||
{label}
|
||||
</FormLabel>
|
||||
<FormControl>
|
||||
|
||||
@ -3,10 +3,22 @@ import React from 'react';
|
||||
|
||||
interface SpotlightProps {
|
||||
className?: string;
|
||||
opcity?: number;
|
||||
coverage?: number;
|
||||
}
|
||||
|
||||
const Spotlight: React.FC<SpotlightProps> = ({ className }) => {
|
||||
/**
|
||||
*
|
||||
* @param opcity 0~1 default 0.5
|
||||
* @param coverage 0~100 default 60
|
||||
* @returns
|
||||
*/
|
||||
const Spotlight: React.FC<SpotlightProps> = ({
|
||||
className,
|
||||
opcity = 0.5,
|
||||
coverage = 60,
|
||||
}) => {
|
||||
const isDark = useIsDarkTheme();
|
||||
const rgb = isDark ? '255, 255, 255' : '194, 221, 243';
|
||||
return (
|
||||
<div
|
||||
className={`absolute inset-0 opacity-80 ${className} rounded-lg`}
|
||||
@ -18,9 +30,7 @@ const Spotlight: React.FC<SpotlightProps> = ({ className }) => {
|
||||
<div
|
||||
className="absolute inset-0"
|
||||
style={{
|
||||
background: isDark
|
||||
? 'radial-gradient(circle at 50% 190%, #fff4 0%, #fff0 60%)'
|
||||
: 'radial-gradient(circle at 50% 190%, #E4F3FF 0%, #E4F3FF00 60%)',
|
||||
background: `radial-gradient(circle at 50% 190%, rgba(${rgb},${opcity}) 0%, rgba(${rgb},0) ${coverage}%)`,
|
||||
pointerEvents: 'none',
|
||||
}}
|
||||
></div>
|
||||
@ -38,7 +38,7 @@ const DialogContent = React.forwardRef<
|
||||
<DialogPrimitive.Content
|
||||
ref={ref}
|
||||
className={cn(
|
||||
'fixed left-[50%] top-[50%] z-50 grid w-full max-w-xl translate-x-[-50%] translate-y-[-50%] gap-4 border bg-colors-background-neutral-standard p-6 shadow-lg duration-200 data-[state=open]:animate-in data-[state=closed]:animate-out data-[state=closed]:fade-out-0 data-[state=open]:fade-in-0 data-[state=closed]:zoom-out-95 data-[state=open]:zoom-in-95 data-[state=closed]:slide-out-to-left-1/2 data-[state=closed]:slide-out-to-top-[48%] data-[state=open]:slide-in-from-left-1/2 data-[state=open]:slide-in-from-top-[48%] sm:rounded-lg',
|
||||
'fixed left-[50%] top-[50%] z-50 grid w-full max-w-xl translate-x-[-50%] translate-y-[-50%] gap-4 border bg-bg-base p-6 shadow-lg duration-200 data-[state=open]:animate-in data-[state=closed]:animate-out data-[state=closed]:fade-out-0 data-[state=open]:fade-in-0 data-[state=closed]:zoom-out-95 data-[state=open]:zoom-in-95 data-[state=closed]:slide-out-to-left-1/2 data-[state=closed]:slide-out-to-top-[48%] data-[state=open]:slide-in-from-left-1/2 data-[state=open]:slide-in-from-top-[48%] sm:rounded-lg',
|
||||
className,
|
||||
)}
|
||||
{...props}
|
||||
|
||||
@ -54,6 +54,7 @@ export enum LLMFactory {
|
||||
DeepInfra = 'DeepInfra',
|
||||
Grok = 'Grok',
|
||||
XAI = 'xAI',
|
||||
TokenPony = 'TokenPony',
|
||||
Meituan = 'Meituan',
|
||||
}
|
||||
|
||||
@ -114,5 +115,6 @@ export const IconMap = {
|
||||
[LLMFactory.DeepInfra]: 'deepinfra',
|
||||
[LLMFactory.Grok]: 'grok',
|
||||
[LLMFactory.XAI]: 'xai',
|
||||
[LLMFactory.TokenPony]: 'token-pony',
|
||||
[LLMFactory.Meituan]: 'longcat',
|
||||
};
|
||||
|
||||
@ -155,7 +155,12 @@ export const useComposeLlmOptionsByModelTypes = (
|
||||
options.forEach((x) => {
|
||||
const item = pre.find((y) => y.label === x.label);
|
||||
if (item) {
|
||||
item.options.push(...x.options);
|
||||
x.options.forEach((y) => {
|
||||
// A model that is both an image2text and speech2text model
|
||||
if (!item.options.some((z) => z.value === y.value)) {
|
||||
item.options.push(y);
|
||||
}
|
||||
});
|
||||
} else {
|
||||
pre.push(x);
|
||||
}
|
||||
|
||||
@ -125,6 +125,16 @@ export const useNavigatePage = () => {
|
||||
[navigate],
|
||||
);
|
||||
|
||||
const navigateToDataflowResult = useCallback(
|
||||
(id: string, knowledgeId?: string) => () => {
|
||||
navigate(
|
||||
// `${Routes.ParsedResult}/${id}?${QueryStringMap.KnowledgeId}=${knowledgeId}`,
|
||||
`${Routes.DataflowResult}/${id}`,
|
||||
);
|
||||
},
|
||||
[navigate],
|
||||
);
|
||||
|
||||
return {
|
||||
navigateToDatasetList,
|
||||
navigateToDataset,
|
||||
@ -144,5 +154,6 @@ export const useNavigatePage = () => {
|
||||
navigateToFiles,
|
||||
navigateToAgentList,
|
||||
navigateToOldProfile,
|
||||
navigateToDataflowResult,
|
||||
};
|
||||
};
|
||||
|
||||
@ -24,9 +24,7 @@ import { useMutation, useQuery, useQueryClient } from '@tanstack/react-query';
|
||||
import { useDebounce } from 'ahooks';
|
||||
import { get, set } from 'lodash';
|
||||
import { useCallback, useState } from 'react';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import { useParams, useSearchParams } from 'umi';
|
||||
import { v4 as uuid } from 'uuid';
|
||||
import {
|
||||
useGetPaginationWithRouter,
|
||||
useHandleSearchChange,
|
||||
@ -80,7 +78,7 @@ export const EmptyDsl = {
|
||||
component_name: 'Begin',
|
||||
params: {},
|
||||
},
|
||||
downstream: ['Answer:China'], // other edge target is downstream, edge source is current node id
|
||||
downstream: [], // other edge target is downstream, edge source is current node id
|
||||
upstream: [], // edge source is upstream, edge target is current node id
|
||||
},
|
||||
},
|
||||
@ -96,21 +94,11 @@ export const EmptyDsl = {
|
||||
};
|
||||
|
||||
export const useFetchAgentTemplates = () => {
|
||||
const { t } = useTranslation();
|
||||
|
||||
const { data } = useQuery<IFlowTemplate[]>({
|
||||
queryKey: [AgentApiAction.FetchAgentTemplates],
|
||||
initialData: [],
|
||||
queryFn: async () => {
|
||||
const { data } = await agentService.listTemplates();
|
||||
if (Array.isArray(data?.data)) {
|
||||
data.data.unshift({
|
||||
id: uuid(),
|
||||
title: t('flow.blank'),
|
||||
description: t('flow.createFromNothing'),
|
||||
dsl: EmptyDsl,
|
||||
});
|
||||
}
|
||||
|
||||
return data.data;
|
||||
},
|
||||
|
||||
@ -41,8 +41,8 @@ export interface DSL {
|
||||
path?: string[];
|
||||
answer?: any[];
|
||||
graph?: IGraph;
|
||||
messages: Message[];
|
||||
reference: IReference[];
|
||||
messages?: Message[];
|
||||
reference?: IReference[];
|
||||
globals: Record<string, any>;
|
||||
retrieval: IReference[];
|
||||
}
|
||||
|
||||
@ -102,6 +102,28 @@ export default {
|
||||
noMoreData: `That's all. Nothing more.`,
|
||||
},
|
||||
knowledgeDetails: {
|
||||
generateKnowledgeGraph:
|
||||
'This will extract entities and relationships from all your documents in this dataset. The process may take a while to complete.',
|
||||
generateRaptor:
|
||||
'This will extract entities and relationships from all your documents in this dataset. The process may take a while to complete.',
|
||||
generate: 'Generate',
|
||||
raptor: 'Raptor',
|
||||
knowledgeGraph: 'Knowledge Graph',
|
||||
processingType: 'Processing Type',
|
||||
dataPipeline: 'Data Pipeline',
|
||||
operations: 'Operations',
|
||||
status: 'Status',
|
||||
task: 'Task',
|
||||
startDate: 'Start Date',
|
||||
source: 'Source',
|
||||
fileName: 'File Name',
|
||||
datasetLogs: 'Dataset Logs',
|
||||
fileLogs: 'File Logs',
|
||||
overview: 'Overview',
|
||||
success: 'Success',
|
||||
failed: 'Failed',
|
||||
completed: 'Completed',
|
||||
processLog: 'Process Log',
|
||||
created: 'Created',
|
||||
learnMore: 'Learn More',
|
||||
general: 'General',
|
||||
@ -195,6 +217,7 @@ export default {
|
||||
chunk: 'Chunk',
|
||||
bulk: 'Bulk',
|
||||
cancel: 'Cancel',
|
||||
close: 'Close',
|
||||
rerankModel: 'Rerank model',
|
||||
rerankPlaceholder: 'Please select',
|
||||
rerankTip: `Optional. If left empty, RAGFlow will use a combination of weighted keyword similarity and weighted vector cosine similarity; if a rerank model is selected, a weighted reranking score will replace the weighted vector cosine similarity. Please be aware that using a rerank model will significantly increase the system's response time. If you wish to use a rerank model, ensure you use a SaaS reranker; if you prefer a locally deployed rerank model, ensure you start RAGFlow with docker-compose-gpu.yml.`,
|
||||
@ -238,6 +261,16 @@ export default {
|
||||
reRankModelWaring: 'Re-rank model is very time consuming.',
|
||||
},
|
||||
knowledgeConfiguration: {
|
||||
enableAutoGenerate: 'Enable Auto Generate',
|
||||
teamPlaceholder: 'Please select a team.',
|
||||
dataFlowPlaceholder: 'Please select a data flow.',
|
||||
buildItFromScratch: 'Build it from scratch',
|
||||
useRAPTORToEnhanceRetrieval: 'Use RAPTOR to Enhance Retrieval',
|
||||
extractKnowledgeGraph: 'Extract Knowledge Graph',
|
||||
dataFlow: 'Data Flow',
|
||||
parseType: 'Parse Type',
|
||||
manualSetup: 'Manual Setup',
|
||||
builtIn: 'Built-in',
|
||||
titleDescription:
|
||||
'Update your knowledge base configuration here, particularly the chunking method.',
|
||||
name: 'Knowledge base name',
|
||||
@ -934,7 +967,7 @@ This auto-tagging feature enhances retrieval by adding another layer of domain-s
|
||||
exceptionMethod: 'Exception method',
|
||||
maxRounds: 'Max reflection rounds',
|
||||
delayEfterError: 'Delay after error',
|
||||
maxRetries: 'Max retries',
|
||||
maxRetries: 'Max reflection rounds',
|
||||
advancedSettings: 'Advanced Settings',
|
||||
addTools: 'Add Tools',
|
||||
sysPromptDefultValue: `
|
||||
@ -1589,5 +1622,19 @@ This delimiter is used to split the input text into several text pieces echo of
|
||||
total: 'Total {{total}}',
|
||||
page: '{{page}} /Page',
|
||||
},
|
||||
dataflowParser: {
|
||||
parseSummary: 'Parse Summary',
|
||||
parseSummaryTip: 'Parser:deepdoc',
|
||||
rerunFromCurrentStep: 'Rerun From Current Step',
|
||||
rerunFromCurrentStepTip: 'Changes detected. Click to re-run.',
|
||||
},
|
||||
dataflow: {
|
||||
parser: 'Parser',
|
||||
parserDescription: 'Parser',
|
||||
chunker: 'Chunker',
|
||||
chunkerDescription: 'Chunker',
|
||||
tokenizer: 'Tokenizer',
|
||||
tokenizerDescription: 'Tokenizer',
|
||||
},
|
||||
},
|
||||
};
|
||||
|
||||
@ -94,6 +94,24 @@ export default {
|
||||
noMoreData: '没有更多数据了',
|
||||
},
|
||||
knowledgeDetails: {
|
||||
generate: '生成',
|
||||
raptor: 'Raptor',
|
||||
knowledgeGraph: '知识图谱',
|
||||
processingType: '处理类型',
|
||||
dataPipeline: '数据管道',
|
||||
operations: '操作',
|
||||
status: '状态',
|
||||
task: '任务',
|
||||
startDate: '开始时间',
|
||||
source: '来源',
|
||||
fileName: '文件名',
|
||||
datasetLogs: '数据集日志',
|
||||
fileLogs: '文件日志',
|
||||
overview: '概览',
|
||||
success: '成功',
|
||||
failed: '失败',
|
||||
completed: '已完成',
|
||||
processLog: '处理进度日志',
|
||||
created: '创建于',
|
||||
learnMore: '了解更多',
|
||||
general: '通用',
|
||||
@ -183,6 +201,7 @@ export default {
|
||||
chunk: '解析块',
|
||||
bulk: '批量',
|
||||
cancel: '取消',
|
||||
close: '关闭',
|
||||
rerankModel: 'Rerank模型',
|
||||
rerankPlaceholder: '请选择',
|
||||
rerankTip: `非必选项:若不选择 rerank 模型,系统将默认采用关键词相似度与向量余弦相似度相结合的混合查询方式;如果设置了 rerank 模型,则混合查询中的向量相似度部分将被 rerank 打分替代。请注意:采用 rerank 模型会非常耗时。如需选用 rerank 模型,建议使用 SaaS 的 rerank 模型服务;如果你倾向使用本地部署的 rerank 模型,请务必确保你使用 docker-compose-gpu.yml 启动 RAGFlow。`,
|
||||
@ -227,6 +246,16 @@ export default {
|
||||
theDocumentBeingParsedCannotBeDeleted: '正在解析的文档不能被删除',
|
||||
},
|
||||
knowledgeConfiguration: {
|
||||
enableAutoGenerate: '是否启用自动生成',
|
||||
teamPlaceholder: '请选择团队',
|
||||
dataFlowPlaceholder: '请选择数据流',
|
||||
buildItFromScratch: '去Scratch构建',
|
||||
useRAPTORToEnhanceRetrieval: '使用 RAPTOR 提升检索效果',
|
||||
extractKnowledgeGraph: '知识图谱提取',
|
||||
dataFlow: '数据流',
|
||||
parseType: '切片方法',
|
||||
manualSetup: '手动设置',
|
||||
builtIn: '内置',
|
||||
titleDescription: '在这里更新您的知识库详细信息,尤其是切片方法。',
|
||||
name: '知识库名称',
|
||||
photo: '知识库图片',
|
||||
@ -603,6 +632,8 @@ General:实体和关系提取提示来自 GitHub - microsoft/graphrag:基于
|
||||
},
|
||||
cancel: '取消',
|
||||
chatSetting: '聊天设置',
|
||||
avatarHidden: '隐藏头像',
|
||||
locale: '地区',
|
||||
},
|
||||
setting: {
|
||||
profile: '概要',
|
||||
@ -892,7 +923,7 @@ General:实体和关系提取提示来自 GitHub - microsoft/graphrag:基于
|
||||
exceptionMethod: '异常处理方法',
|
||||
maxRounds: '最大反思轮数',
|
||||
delayEfterError: '错误后延迟',
|
||||
maxRetries: '最大重试次数',
|
||||
maxRetries: '最大反思轮数',
|
||||
advancedSettings: '高级设置',
|
||||
addTools: '添加工具',
|
||||
sysPromptDefultValue: `
|
||||
@ -1501,5 +1532,19 @@ General:实体和关系提取提示来自 GitHub - microsoft/graphrag:基于
|
||||
total: '总共 {{total}} 条',
|
||||
page: '{{page}}条/页',
|
||||
},
|
||||
dataflowParser: {
|
||||
parseSummary: '解析摘要',
|
||||
parseSummaryTip: '解析器: deepdoc',
|
||||
rerunFromCurrentStep: '从当前步骤重新运行',
|
||||
rerunFromCurrentStepTip: '已修改,点击重新运行。',
|
||||
},
|
||||
dataflow: {
|
||||
parser: '解析器',
|
||||
parserDescription: '解析器',
|
||||
chunker: '分块器',
|
||||
chunkerDescription: '分块器',
|
||||
tokenizer: '分词器',
|
||||
tokenizerDescription: '分词器',
|
||||
},
|
||||
},
|
||||
};
|
||||
|
||||
@ -40,6 +40,7 @@ import { useCacheChatLog } from '../hooks/use-cache-chat-log';
|
||||
import { useMoveNote } from '../hooks/use-move-note';
|
||||
import { useDropdownManager } from './context';
|
||||
|
||||
import Spotlight from '@/components/spotlight';
|
||||
import {
|
||||
useHideFormSheetOnNodeDeletion,
|
||||
useShowDrawer,
|
||||
@ -309,6 +310,7 @@ function AgentCanvas({ drawerVisible, hideDrawer }: IProps) {
|
||||
onBeforeDelete={handleBeforeDelete}
|
||||
>
|
||||
<AgentBackground></AgentBackground>
|
||||
<Spotlight className="z-0" opcity={0.7} coverage={70} />
|
||||
<Controls position={'bottom-center'} orientation="horizontal">
|
||||
<ControlButton>
|
||||
<Tooltip>
|
||||
|
||||
@ -62,7 +62,7 @@ function AgentChatBox() {
|
||||
|
||||
return (
|
||||
<>
|
||||
<section className="flex flex-1 flex-col px-5 h-[90vh]">
|
||||
<section className="flex flex-1 flex-col px-5 min-h-0 pb-4">
|
||||
<div className="flex-1 overflow-auto" ref={messageContainerRef}>
|
||||
<div>
|
||||
{/* <Spin spinning={sendLoading}> */}
|
||||
|
||||
@ -9,7 +9,7 @@ export function ChatSheet({ hideModal }: IModalProps<any>) {
|
||||
return (
|
||||
<Sheet open modal={false} onOpenChange={hideModal}>
|
||||
<SheetContent
|
||||
className={cn('top-20 p-0')}
|
||||
className={cn('top-20 bottom-0 p-0 flex flex-col h-auto')}
|
||||
onInteractOutside={(e) => e.preventDefault()}
|
||||
>
|
||||
<SheetTitle className="hidden"></SheetTitle>
|
||||
|
||||
@ -57,13 +57,6 @@ const FormSchema = z.object({
|
||||
// )
|
||||
// .optional(),
|
||||
message_history_window_size: z.coerce.number(),
|
||||
tools: z
|
||||
.array(
|
||||
z.object({
|
||||
component_name: z.string(),
|
||||
}),
|
||||
)
|
||||
.optional(),
|
||||
...LlmSettingSchema,
|
||||
max_retries: z.coerce.number(),
|
||||
delay_after_error: z.coerce.number().optional(),
|
||||
@ -152,7 +145,7 @@ function AgentForm({ node }: INextOperatorForm) {
|
||||
<PromptEditor
|
||||
{...field}
|
||||
placeholder={t('flow.messagePlaceholder')}
|
||||
showToolbar={false}
|
||||
showToolbar={true}
|
||||
extraOptions={extraOptions}
|
||||
></PromptEditor>
|
||||
</FormControl>
|
||||
@ -173,7 +166,7 @@ function AgentForm({ node }: INextOperatorForm) {
|
||||
<section>
|
||||
<PromptEditor
|
||||
{...field}
|
||||
showToolbar={false}
|
||||
showToolbar={true}
|
||||
></PromptEditor>
|
||||
</section>
|
||||
</FormControl>
|
||||
|
||||
@ -1,15 +1,21 @@
|
||||
import { useFetchModelId } from '@/hooks/logic-hooks';
|
||||
import { RAGFlowNodeType } from '@/interfaces/database/flow';
|
||||
import { get, isEmpty } from 'lodash';
|
||||
import { get, isEmpty, omit } from 'lodash';
|
||||
import { useMemo } from 'react';
|
||||
import { initialAgentValues } from '../../constant';
|
||||
|
||||
// You need to exclude the mcp and tools fields that are not in the form,
|
||||
// otherwise the form data update will reset the tools or mcp data to an array
|
||||
function omitToolsAndMcp(values: Record<string, any>) {
|
||||
return omit(values, ['mcp', 'tools']);
|
||||
}
|
||||
|
||||
export function useValues(node?: RAGFlowNodeType) {
|
||||
const llmId = useFetchModelId();
|
||||
|
||||
const defaultValues = useMemo(
|
||||
() => ({
|
||||
...initialAgentValues,
|
||||
...omitToolsAndMcp(initialAgentValues),
|
||||
llm_id: llmId,
|
||||
prompts: '',
|
||||
}),
|
||||
@ -24,7 +30,7 @@ export function useValues(node?: RAGFlowNodeType) {
|
||||
}
|
||||
|
||||
return {
|
||||
...formData,
|
||||
...omitToolsAndMcp(formData),
|
||||
prompts: get(formData, 'prompts.0.content', ''),
|
||||
};
|
||||
}, [defaultValues, node?.data?.form]);
|
||||
|
||||
@ -1,71 +1,17 @@
|
||||
import { useToast } from '@/components/hooks/use-toast';
|
||||
import { FileMimeType, Platform } from '@/constants/common';
|
||||
import { useSetModalState } from '@/hooks/common-hooks';
|
||||
import { useFetchAgent } from '@/hooks/use-agent-request';
|
||||
import { IGraph } from '@/interfaces/database/flow';
|
||||
import { downloadJsonFile } from '@/utils/file-util';
|
||||
import { message } from 'antd';
|
||||
import isEmpty from 'lodash/isEmpty';
|
||||
import { useCallback } from 'react';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import { useBuildDslData } from './use-build-dsl';
|
||||
import { useSetGraphInfo } from './use-set-graph';
|
||||
|
||||
export const useHandleExportOrImportJsonFile = () => {
|
||||
export const useHandleExportJsonFile = () => {
|
||||
const { buildDslData } = useBuildDslData();
|
||||
const {
|
||||
visible: fileUploadVisible,
|
||||
hideModal: hideFileUploadModal,
|
||||
showModal: showFileUploadModal,
|
||||
} = useSetModalState();
|
||||
const setGraphInfo = useSetGraphInfo();
|
||||
const { data } = useFetchAgent();
|
||||
const { t } = useTranslation();
|
||||
const { toast } = useToast();
|
||||
|
||||
const onFileUploadOk = useCallback(
|
||||
async ({
|
||||
fileList,
|
||||
platform,
|
||||
}: {
|
||||
fileList: File[];
|
||||
platform: Platform;
|
||||
}) => {
|
||||
console.log('🚀 ~ useHandleExportOrImportJsonFile ~ platform:', platform);
|
||||
if (fileList.length > 0) {
|
||||
const file = fileList[0];
|
||||
if (file.type !== FileMimeType.Json) {
|
||||
toast({ title: t('flow.jsonUploadTypeErrorMessage') });
|
||||
return;
|
||||
}
|
||||
|
||||
const graphStr = await file.text();
|
||||
const errorMessage = t('flow.jsonUploadContentErrorMessage');
|
||||
try {
|
||||
const graph = JSON.parse(graphStr);
|
||||
if (graphStr && !isEmpty(graph) && Array.isArray(graph?.nodes)) {
|
||||
setGraphInfo(graph ?? ({} as IGraph));
|
||||
hideFileUploadModal();
|
||||
} else {
|
||||
message.error(errorMessage);
|
||||
}
|
||||
} catch (error) {
|
||||
message.error(errorMessage);
|
||||
}
|
||||
}
|
||||
},
|
||||
[hideFileUploadModal, setGraphInfo, t, toast],
|
||||
);
|
||||
|
||||
const handleExportJson = useCallback(() => {
|
||||
downloadJsonFile(buildDslData().graph, `${data.title}.json`);
|
||||
}, [buildDslData, data.title]);
|
||||
|
||||
return {
|
||||
fileUploadVisible,
|
||||
handleExportJson,
|
||||
handleImportJson: showFileUploadModal,
|
||||
hideFileUploadModal,
|
||||
onFileUploadOk,
|
||||
};
|
||||
};
|
||||
|
||||
@ -24,7 +24,6 @@ import { ReactFlowProvider } from '@xyflow/react';
|
||||
import {
|
||||
ChevronDown,
|
||||
CirclePlay,
|
||||
Download,
|
||||
History,
|
||||
LaptopMinimalCheck,
|
||||
Logs,
|
||||
@ -37,7 +36,7 @@ import { useTranslation } from 'react-i18next';
|
||||
import { useParams } from 'umi';
|
||||
import AgentCanvas from './canvas';
|
||||
import { DropdownProvider } from './canvas/context';
|
||||
import { useHandleExportOrImportJsonFile } from './hooks/use-export-json';
|
||||
import { useHandleExportJsonFile } from './hooks/use-export-json';
|
||||
import { useFetchDataOnMount } from './hooks/use-fetch-data';
|
||||
import { useGetBeginNodeDataInputs } from './hooks/use-get-begin-query';
|
||||
import {
|
||||
@ -46,7 +45,6 @@ import {
|
||||
useWatchAgentChange,
|
||||
} from './hooks/use-save-graph';
|
||||
import { SettingDialog } from './setting-dialog';
|
||||
import { UploadAgentDialog } from './upload-agent-dialog';
|
||||
import { useAgentHistoryManager } from './use-agent-history-manager';
|
||||
import { VersionDialog } from './version-dialog';
|
||||
|
||||
@ -71,13 +69,8 @@ export default function Agent() {
|
||||
} = useSetModalState();
|
||||
const { t } = useTranslation();
|
||||
useAgentHistoryManager();
|
||||
const {
|
||||
handleExportJson,
|
||||
handleImportJson,
|
||||
fileUploadVisible,
|
||||
onFileUploadOk,
|
||||
hideFileUploadModal,
|
||||
} = useHandleExportOrImportJsonFile();
|
||||
|
||||
const { handleExportJson } = useHandleExportJsonFile();
|
||||
const { saveGraph, loading } = useSaveGraph();
|
||||
const { flowDetail: agentDetail } = useFetchDataOnMount();
|
||||
const inputs = useGetBeginNodeDataInputs();
|
||||
@ -158,11 +151,6 @@ export default function Agent() {
|
||||
</Button>
|
||||
</DropdownMenuTrigger>
|
||||
<DropdownMenuContent>
|
||||
<AgentDropdownMenuItem onClick={handleImportJson}>
|
||||
<Download />
|
||||
{t('flow.import')}
|
||||
</AgentDropdownMenuItem>
|
||||
<DropdownMenuSeparator />
|
||||
<AgentDropdownMenuItem onClick={handleExportJson}>
|
||||
<Upload />
|
||||
{t('flow.export')}
|
||||
@ -193,12 +181,6 @@ export default function Agent() {
|
||||
></AgentCanvas>
|
||||
</DropdownProvider>
|
||||
</ReactFlowProvider>
|
||||
{fileUploadVisible && (
|
||||
<UploadAgentDialog
|
||||
hideModal={hideFileUploadModal}
|
||||
onOk={onFileUploadOk}
|
||||
></UploadAgentDialog>
|
||||
)}
|
||||
{embedVisible && (
|
||||
<EmbedDialog
|
||||
visible={embedVisible}
|
||||
|
||||
@ -27,9 +27,11 @@ export default function AgentTemplates() {
|
||||
const [selectMenuItem, setSelectMenuItem] = useState<string>(
|
||||
MenuItemKey.Recommended,
|
||||
);
|
||||
|
||||
useEffect(() => {
|
||||
setTemplateList(list);
|
||||
}, [list]);
|
||||
|
||||
const {
|
||||
visible: creatingVisible,
|
||||
hideModal: hideCreatingModal,
|
||||
@ -110,10 +112,9 @@ export default function AgentTemplates() {
|
||||
|
||||
<main className="flex-1 bg-text-title-invert/50 h-dvh">
|
||||
<div className="grid gap-6 sm:grid-cols-1 md:grid-cols-2 lg:grid-cols-3 xl:grid-cols-4 2xl:grid-cols-5 max-h-[94vh] overflow-auto px-8 pt-8">
|
||||
{tempListFilter?.map((x, index) => {
|
||||
{tempListFilter?.map((x) => {
|
||||
return (
|
||||
<TemplateCard
|
||||
isCreate={index === 0}
|
||||
key={x.id}
|
||||
data={x}
|
||||
showModal={showModal}
|
||||
|
||||
4
web/src/pages/agents/constant.ts
Normal file
4
web/src/pages/agents/constant.ts
Normal file
@ -0,0 +1,4 @@
|
||||
export enum FlowType {
|
||||
Agent = 'agent',
|
||||
Flow = 'flow',
|
||||
}
|
||||
@ -6,16 +6,18 @@ import {
|
||||
DialogHeader,
|
||||
DialogTitle,
|
||||
} from '@/components/ui/dialog';
|
||||
import { IModalProps } from '@/interfaces/common';
|
||||
import { TagRenameId } from '@/pages/add-knowledge/constant';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import { CreateAgentForm } from './create-agent-form';
|
||||
import { CreateAgentForm, CreateAgentFormProps } from './create-agent-form';
|
||||
|
||||
type CreateAgentDialogProps = CreateAgentFormProps;
|
||||
|
||||
export function CreateAgentDialog({
|
||||
hideModal,
|
||||
onOk,
|
||||
loading,
|
||||
}: IModalProps<any>) {
|
||||
shouldChooseAgent,
|
||||
}: CreateAgentDialogProps) {
|
||||
const { t } = useTranslation();
|
||||
|
||||
return (
|
||||
@ -24,7 +26,11 @@ export function CreateAgentDialog({
|
||||
<DialogHeader>
|
||||
<DialogTitle>{t('flow.createGraph')}</DialogTitle>
|
||||
</DialogHeader>
|
||||
<CreateAgentForm hideModal={hideModal} onOk={onOk}></CreateAgentForm>
|
||||
<CreateAgentForm
|
||||
hideModal={hideModal}
|
||||
onOk={onOk}
|
||||
shouldChooseAgent={shouldChooseAgent}
|
||||
></CreateAgentForm>
|
||||
<DialogFooter>
|
||||
<ButtonLoading type="submit" form={TagRenameId} loading={loading}>
|
||||
{t('common.save')}
|
||||
|
||||
@ -4,38 +4,94 @@ import { zodResolver } from '@hookform/resolvers/zod';
|
||||
import { useForm } from 'react-hook-form';
|
||||
import { z } from 'zod';
|
||||
|
||||
import {
|
||||
Form,
|
||||
FormControl,
|
||||
FormField,
|
||||
FormItem,
|
||||
FormLabel,
|
||||
FormMessage,
|
||||
} from '@/components/ui/form';
|
||||
import { Input } from '@/components/ui/input';
|
||||
import { RAGFlowFormItem } from '@/components/ragflow-form';
|
||||
import { Card, CardContent } from '@/components/ui/card';
|
||||
import { Form } from '@/components/ui/form';
|
||||
import { IModalProps } from '@/interfaces/common';
|
||||
import { cn } from '@/lib/utils';
|
||||
import { TagRenameId } from '@/pages/add-knowledge/constant';
|
||||
import { BrainCircuit, Check, Route } from 'lucide-react';
|
||||
import { useCallback } from 'react';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import { FlowType } from './constant';
|
||||
import { NameFormField, NameFormSchema } from './name-form-field';
|
||||
|
||||
export function CreateAgentForm({ hideModal, onOk }: IModalProps<any>) {
|
||||
export type CreateAgentFormProps = IModalProps<any> & {
|
||||
shouldChooseAgent?: boolean;
|
||||
};
|
||||
|
||||
type FlowTypeCardProps = {
|
||||
value?: FlowType;
|
||||
onChange?: (value: FlowType) => void;
|
||||
};
|
||||
function FlowTypeCards({ value, onChange }: FlowTypeCardProps) {
|
||||
const handleChange = useCallback(
|
||||
(value: FlowType) => () => {
|
||||
onChange?.(value);
|
||||
},
|
||||
[onChange],
|
||||
);
|
||||
|
||||
return (
|
||||
<section className="flex gap-10">
|
||||
{Object.values(FlowType).map((val) => {
|
||||
const isActive = value === val;
|
||||
return (
|
||||
<Card
|
||||
key={val}
|
||||
className={cn('flex-1 rounded-lg border bg-transparent', {
|
||||
'border-text-primary': isActive,
|
||||
'border-border-default': !isActive,
|
||||
})}
|
||||
>
|
||||
<CardContent
|
||||
onClick={handleChange(val)}
|
||||
className={cn(
|
||||
'cursor-pointer p-5 text-text-secondary flex justify-between items-center',
|
||||
{
|
||||
'text-text-primary': isActive,
|
||||
},
|
||||
)}
|
||||
>
|
||||
<div className="flex gap-2">
|
||||
{val === FlowType.Agent ? (
|
||||
<BrainCircuit className="size-6" />
|
||||
) : (
|
||||
<Route className="size-6" />
|
||||
)}
|
||||
<p>{val}</p>
|
||||
</div>
|
||||
{isActive && <Check />}
|
||||
</CardContent>
|
||||
</Card>
|
||||
);
|
||||
})}
|
||||
</section>
|
||||
);
|
||||
}
|
||||
|
||||
export const FormSchema = z.object({
|
||||
...NameFormSchema,
|
||||
tag: z.string().trim().optional(),
|
||||
description: z.string().trim().optional(),
|
||||
type: z.nativeEnum(FlowType).optional(),
|
||||
});
|
||||
|
||||
export type FormSchemaType = z.infer<typeof FormSchema>;
|
||||
|
||||
export function CreateAgentForm({
|
||||
hideModal,
|
||||
onOk,
|
||||
shouldChooseAgent = false,
|
||||
}: CreateAgentFormProps) {
|
||||
const { t } = useTranslation();
|
||||
const FormSchema = z.object({
|
||||
name: z
|
||||
.string()
|
||||
.min(1, {
|
||||
message: t('common.namePlaceholder'),
|
||||
})
|
||||
.trim(),
|
||||
tag: z.string().trim().optional(),
|
||||
description: z.string().trim().optional(),
|
||||
});
|
||||
|
||||
const form = useForm<z.infer<typeof FormSchema>>({
|
||||
const form = useForm<FormSchemaType>({
|
||||
resolver: zodResolver(FormSchema),
|
||||
defaultValues: { name: '' },
|
||||
defaultValues: { name: '', type: FlowType.Agent },
|
||||
});
|
||||
|
||||
async function onSubmit(data: z.infer<typeof FormSchema>) {
|
||||
async function onSubmit(data: FormSchemaType) {
|
||||
const ret = await onOk?.(data);
|
||||
if (ret) {
|
||||
hideModal?.();
|
||||
@ -49,57 +105,12 @@ export function CreateAgentForm({ hideModal, onOk }: IModalProps<any>) {
|
||||
className="space-y-6"
|
||||
id={TagRenameId}
|
||||
>
|
||||
<FormField
|
||||
control={form.control}
|
||||
name="name"
|
||||
render={({ field }) => (
|
||||
<FormItem>
|
||||
<FormLabel>{t('common.name')}</FormLabel>
|
||||
<FormControl>
|
||||
<Input
|
||||
placeholder={t('common.namePlaceholder')}
|
||||
{...field}
|
||||
autoComplete="off"
|
||||
/>
|
||||
</FormControl>
|
||||
<FormMessage />
|
||||
</FormItem>
|
||||
)}
|
||||
/>
|
||||
{/* <FormField
|
||||
control={form.control}
|
||||
name="tag"
|
||||
render={({ field }) => (
|
||||
<FormItem>
|
||||
<FormLabel>{t('flow.tag')}</FormLabel>
|
||||
<FormControl>
|
||||
<Input
|
||||
placeholder={t('flow.tagPlaceholder')}
|
||||
{...field}
|
||||
autoComplete="off"
|
||||
/>
|
||||
</FormControl>
|
||||
<FormMessage />
|
||||
</FormItem>
|
||||
)}
|
||||
/>
|
||||
<FormField
|
||||
control={form.control}
|
||||
name="description"
|
||||
render={({ field }) => (
|
||||
<FormItem>
|
||||
<FormLabel>{t('flow.description')}</FormLabel>
|
||||
<FormControl>
|
||||
<Input
|
||||
placeholder={t('flow.descriptionPlaceholder')}
|
||||
{...field}
|
||||
autoComplete="off"
|
||||
/>
|
||||
</FormControl>
|
||||
<FormMessage />
|
||||
</FormItem>
|
||||
)}
|
||||
/> */}
|
||||
{shouldChooseAgent && (
|
||||
<RAGFlowFormItem required name="type" label={t('common.type')}>
|
||||
<FlowTypeCards></FlowTypeCards>
|
||||
</RAGFlowFormItem>
|
||||
)}
|
||||
<NameFormField></NameFormField>
|
||||
</form>
|
||||
</Form>
|
||||
);
|
||||
|
||||
42
web/src/pages/agents/hooks/use-create-agent.ts
Normal file
42
web/src/pages/agents/hooks/use-create-agent.ts
Normal file
@ -0,0 +1,42 @@
|
||||
import { useSetModalState } from '@/hooks/common-hooks';
|
||||
import { EmptyDsl, useSetAgent } from '@/hooks/use-agent-request';
|
||||
import { DSL } from '@/interfaces/database/agent';
|
||||
import { useCallback } from 'react';
|
||||
import { FlowType } from '../constant';
|
||||
import { FormSchemaType } from '../create-agent-form';
|
||||
|
||||
export function useCreateAgentOrPipeline() {
|
||||
const { loading, setAgent } = useSetAgent();
|
||||
const {
|
||||
visible: creatingVisible,
|
||||
hideModal: hideCreatingModal,
|
||||
showModal: showCreatingModal,
|
||||
} = useSetModalState();
|
||||
|
||||
const createAgent = useCallback(
|
||||
async (name: string) => {
|
||||
return setAgent({ title: name, dsl: EmptyDsl as DSL });
|
||||
},
|
||||
[setAgent],
|
||||
);
|
||||
|
||||
const handleCreateAgentOrPipeline = useCallback(
|
||||
async (data: FormSchemaType) => {
|
||||
if (data.type === FlowType.Agent) {
|
||||
const ret = await createAgent(data.name);
|
||||
if (ret.code === 0) {
|
||||
hideCreatingModal();
|
||||
}
|
||||
}
|
||||
},
|
||||
[createAgent, hideCreatingModal],
|
||||
);
|
||||
|
||||
return {
|
||||
loading,
|
||||
creatingVisible,
|
||||
hideCreatingModal,
|
||||
showCreatingModal,
|
||||
handleCreateAgentOrPipeline,
|
||||
};
|
||||
}
|
||||
@ -1,14 +1,24 @@
|
||||
import ListFilterBar from '@/components/list-filter-bar';
|
||||
import { RenameDialog } from '@/components/rename-dialog';
|
||||
import { Button } from '@/components/ui/button';
|
||||
import {
|
||||
DropdownMenu,
|
||||
DropdownMenuContent,
|
||||
DropdownMenuItem,
|
||||
DropdownMenuTrigger,
|
||||
} from '@/components/ui/dropdown-menu';
|
||||
import { RAGFlowPagination } from '@/components/ui/ragflow-pagination';
|
||||
import { useNavigatePage } from '@/hooks/logic-hooks/navigate-hooks';
|
||||
import { useFetchAgentListByPage } from '@/hooks/use-agent-request';
|
||||
import { t } from 'i18next';
|
||||
import { pick } from 'lodash';
|
||||
import { Plus } from 'lucide-react';
|
||||
import { Clipboard, ClipboardPlus, FileInput, Plus } from 'lucide-react';
|
||||
import { useCallback } from 'react';
|
||||
import { AgentCard } from './agent-card';
|
||||
import { CreateAgentDialog } from './create-agent-dialog';
|
||||
import { useCreateAgentOrPipeline } from './hooks/use-create-agent';
|
||||
import { UploadAgentDialog } from './upload-agent-dialog';
|
||||
import { useHandleImportJsonFile } from './use-import-json';
|
||||
import { useRenameAgent } from './use-rename-agent';
|
||||
|
||||
export default function Agents() {
|
||||
@ -25,6 +35,21 @@ export default function Agents() {
|
||||
showAgentRenameModal,
|
||||
} = useRenameAgent();
|
||||
|
||||
const {
|
||||
creatingVisible,
|
||||
hideCreatingModal,
|
||||
showCreatingModal,
|
||||
loading,
|
||||
handleCreateAgentOrPipeline,
|
||||
} = useCreateAgentOrPipeline();
|
||||
|
||||
const {
|
||||
handleImportJson,
|
||||
fileUploadVisible,
|
||||
onFileUploadOk,
|
||||
hideFileUploadModal,
|
||||
} = useHandleImportJsonFile();
|
||||
|
||||
const handlePageChange = useCallback(
|
||||
(page: number, pageSize?: number) => {
|
||||
setPagination({ page, pageSize });
|
||||
@ -41,10 +66,37 @@ export default function Agents() {
|
||||
onSearchChange={handleInputChange}
|
||||
icon="agent"
|
||||
>
|
||||
<Button onClick={navigateToAgentTemplates}>
|
||||
<Plus className="mr-2 h-4 w-4" />
|
||||
{t('flow.createGraph')}
|
||||
</Button>
|
||||
<DropdownMenu>
|
||||
<DropdownMenuTrigger>
|
||||
<Button>
|
||||
<Plus className="mr-2 h-4 w-4" />
|
||||
{t('flow.createGraph')}
|
||||
</Button>
|
||||
</DropdownMenuTrigger>
|
||||
<DropdownMenuContent>
|
||||
<DropdownMenuItem
|
||||
justifyBetween={false}
|
||||
onClick={showCreatingModal}
|
||||
>
|
||||
<Clipboard />
|
||||
Create from Blank
|
||||
</DropdownMenuItem>
|
||||
<DropdownMenuItem
|
||||
justifyBetween={false}
|
||||
onClick={navigateToAgentTemplates}
|
||||
>
|
||||
<ClipboardPlus />
|
||||
Create from Template
|
||||
</DropdownMenuItem>
|
||||
<DropdownMenuItem
|
||||
justifyBetween={false}
|
||||
onClick={handleImportJson}
|
||||
>
|
||||
<FileInput />
|
||||
Import json file
|
||||
</DropdownMenuItem>
|
||||
</DropdownMenuContent>
|
||||
</DropdownMenu>
|
||||
</ListFilterBar>
|
||||
</div>
|
||||
<div className="flex-1 overflow-auto">
|
||||
@ -75,6 +127,21 @@ export default function Agents() {
|
||||
loading={agentRenameLoading}
|
||||
></RenameDialog>
|
||||
)}
|
||||
{creatingVisible && (
|
||||
<CreateAgentDialog
|
||||
loading={loading}
|
||||
visible={creatingVisible}
|
||||
hideModal={hideCreatingModal}
|
||||
shouldChooseAgent
|
||||
onOk={handleCreateAgentOrPipeline}
|
||||
></CreateAgentDialog>
|
||||
)}
|
||||
{fileUploadVisible && (
|
||||
<UploadAgentDialog
|
||||
hideModal={hideFileUploadModal}
|
||||
onOk={onFileUploadOk}
|
||||
></UploadAgentDialog>
|
||||
)}
|
||||
</section>
|
||||
);
|
||||
}
|
||||
|
||||
28
web/src/pages/agents/name-form-field.tsx
Normal file
28
web/src/pages/agents/name-form-field.tsx
Normal file
@ -0,0 +1,28 @@
|
||||
import { RAGFlowFormItem } from '@/components/ragflow-form';
|
||||
import { Input } from '@/components/ui/input';
|
||||
import i18n from '@/locales/config';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import { z } from 'zod';
|
||||
|
||||
export const NameFormSchema = {
|
||||
name: z
|
||||
.string()
|
||||
.min(1, {
|
||||
message: i18n.t('common.namePlaceholder'),
|
||||
})
|
||||
.trim(),
|
||||
};
|
||||
|
||||
export function NameFormField() {
|
||||
const { t } = useTranslation();
|
||||
return (
|
||||
<RAGFlowFormItem
|
||||
name="name"
|
||||
required
|
||||
label={t('common.name')}
|
||||
tooltip={t('flow.sqlStatementTip')}
|
||||
>
|
||||
<Input placeholder={t('common.namePlaceholder')} autoComplete="off" />
|
||||
</RAGFlowFormItem>
|
||||
);
|
||||
}
|
||||
@ -3,7 +3,6 @@ import { Button } from '@/components/ui/button';
|
||||
import { Card, CardContent } from '@/components/ui/card';
|
||||
import { IFlowTemplate } from '@/interfaces/database/flow';
|
||||
import i18n from '@/locales/config';
|
||||
import { Plus } from 'lucide-react';
|
||||
import { useCallback, useMemo } from 'react';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
interface IProps {
|
||||
@ -12,7 +11,7 @@ interface IProps {
|
||||
showModal(record: IFlowTemplate): void;
|
||||
}
|
||||
|
||||
export function TemplateCard({ data, showModal, isCreate = false }: IProps) {
|
||||
export function TemplateCard({ data, showModal }: IProps) {
|
||||
const { t } = useTranslation();
|
||||
|
||||
const handleClick = useCallback(() => {
|
||||
@ -26,41 +25,24 @@ export function TemplateCard({ data, showModal, isCreate = false }: IProps) {
|
||||
return (
|
||||
<Card className="border-colors-outline-neutral-standard group relative min-h-40">
|
||||
<CardContent className="p-4 ">
|
||||
{isCreate && (
|
||||
<div
|
||||
className="flex flex-col justify-center items-center gap-4 mb-4 absolute top-0 right-0 left-0 bottom-0 cursor-pointer "
|
||||
<div className="flex justify-start items-center gap-4 mb-4">
|
||||
<RAGFlowAvatar
|
||||
className="w-7 h-7"
|
||||
avatar={data.avatar ? data.avatar : 'https://github.com/shadcn.png'}
|
||||
name={data?.title[language] || 'CN'}
|
||||
></RAGFlowAvatar>
|
||||
<div className="text-[18px] font-bold ">{data?.title[language]}</div>
|
||||
</div>
|
||||
<p className="break-words">{data?.description[language]}</p>
|
||||
<div className="group-hover:bg-gradient-to-t from-black/70 from-10% via-black/0 via-50% to-black/0 w-full h-full group-hover:block absolute top-0 left-0 hidden rounded-xl">
|
||||
<Button
|
||||
variant="default"
|
||||
className="w-1/3 absolute bottom-4 right-4 left-4 justify-center text-center m-auto"
|
||||
onClick={handleClick}
|
||||
>
|
||||
<Plus size={50} fontWeight={700} />
|
||||
<div>{t('flow.createAgent')}</div>
|
||||
</div>
|
||||
)}
|
||||
{!isCreate && (
|
||||
<>
|
||||
<div className="flex justify-start items-center gap-4 mb-4">
|
||||
<RAGFlowAvatar
|
||||
className="w-7 h-7"
|
||||
avatar={
|
||||
data.avatar ? data.avatar : 'https://github.com/shadcn.png'
|
||||
}
|
||||
name={data?.title[language] || 'CN'}
|
||||
></RAGFlowAvatar>
|
||||
<div className="text-[18px] font-bold ">
|
||||
{data?.title[language]}
|
||||
</div>
|
||||
</div>
|
||||
<p className="break-words">{data?.description[language]}</p>
|
||||
<div className="group-hover:bg-gradient-to-t from-black/70 from-10% via-black/0 via-50% to-black/0 w-full h-full group-hover:block absolute top-0 left-0 hidden rounded-xl">
|
||||
<Button
|
||||
variant="default"
|
||||
className="w-1/3 absolute bottom-4 right-4 left-4 justify-center text-center m-auto"
|
||||
onClick={handleClick}
|
||||
>
|
||||
{t('flow.useTemplate')}
|
||||
</Button>
|
||||
</div>
|
||||
</>
|
||||
)}
|
||||
{t('flow.useTemplate')}
|
||||
</Button>
|
||||
</div>
|
||||
</CardContent>
|
||||
</Card>
|
||||
);
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
import { ButtonLoading } from '@/components/ui/button';
|
||||
import {
|
||||
Dialog,
|
||||
DialogContent,
|
||||
@ -5,7 +6,6 @@ import {
|
||||
DialogHeader,
|
||||
DialogTitle,
|
||||
} from '@/components/ui/dialog';
|
||||
import { LoadingButton } from '@/components/ui/loading-button';
|
||||
import { IModalProps } from '@/interfaces/common';
|
||||
import { TagRenameId } from '@/pages/add-knowledge/constant';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
@ -26,9 +26,9 @@ export function UploadAgentDialog({
|
||||
</DialogHeader>
|
||||
<UploadAgentForm hideModal={hideModal} onOk={onOk}></UploadAgentForm>
|
||||
<DialogFooter>
|
||||
<LoadingButton type="submit" form={TagRenameId} loading={loading}>
|
||||
<ButtonLoading type="submit" form={TagRenameId} loading={loading}>
|
||||
{t('common.save')}
|
||||
</LoadingButton>
|
||||
</ButtonLoading>
|
||||
</DialogFooter>
|
||||
</DialogContent>
|
||||
</Dialog>
|
||||
@ -13,32 +13,24 @@ import {
|
||||
FormLabel,
|
||||
FormMessage,
|
||||
} from '@/components/ui/form';
|
||||
import { FileMimeType, Platform } from '@/constants/common';
|
||||
import { FileMimeType } from '@/constants/common';
|
||||
import { IModalProps } from '@/interfaces/common';
|
||||
import { TagRenameId } from '@/pages/add-knowledge/constant';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import { NameFormField, NameFormSchema } from '../name-form-field';
|
||||
|
||||
// const options = Object.values(Platform).map((x) => ({ label: x, value: x }));
|
||||
export const FormSchema = z.object({
|
||||
fileList: z.array(z.instanceof(File)),
|
||||
...NameFormSchema,
|
||||
});
|
||||
|
||||
export type FormSchemaType = z.infer<typeof FormSchema>;
|
||||
export function UploadAgentForm({ hideModal, onOk }: IModalProps<any>) {
|
||||
const { t } = useTranslation();
|
||||
const FormSchema = z.object({
|
||||
platform: z
|
||||
.string()
|
||||
.min(1, {
|
||||
message: t('common.namePlaceholder'),
|
||||
})
|
||||
.trim(),
|
||||
fileList: z.array(z.instanceof(File)),
|
||||
});
|
||||
|
||||
const form = useForm<z.infer<typeof FormSchema>>({
|
||||
resolver: zodResolver(FormSchema),
|
||||
defaultValues: { platform: Platform.RAGFlow },
|
||||
defaultValues: { name: '' },
|
||||
});
|
||||
|
||||
async function onSubmit(data: z.infer<typeof FormSchema>) {
|
||||
console.log('🚀 ~ onSubmit ~ data:', data);
|
||||
async function onSubmit(data: FormSchemaType) {
|
||||
const ret = await onOk?.(data);
|
||||
if (ret) {
|
||||
hideModal?.();
|
||||
@ -52,12 +44,13 @@ export function UploadAgentForm({ hideModal, onOk }: IModalProps<any>) {
|
||||
className="space-y-6"
|
||||
id={TagRenameId}
|
||||
>
|
||||
<NameFormField></NameFormField>
|
||||
<FormField
|
||||
control={form.control}
|
||||
name="fileList"
|
||||
render={({ field }) => (
|
||||
<FormItem>
|
||||
<FormLabel>{t('common.name')}</FormLabel>
|
||||
<FormLabel required>DSL</FormLabel>
|
||||
<FormControl>
|
||||
<FileUploader
|
||||
value={field.value}
|
||||
@ -70,19 +63,6 @@ export function UploadAgentForm({ hideModal, onOk }: IModalProps<any>) {
|
||||
</FormItem>
|
||||
)}
|
||||
/>
|
||||
{/* <FormField
|
||||
control={form.control}
|
||||
name="platform"
|
||||
render={({ field }) => (
|
||||
<FormItem>
|
||||
<FormLabel>{t('common.name')}</FormLabel>
|
||||
<FormControl>
|
||||
<RAGFlowSelect {...field} options={options} />
|
||||
</FormControl>
|
||||
<FormMessage />
|
||||
</FormItem>
|
||||
)}
|
||||
/> */}
|
||||
</form>
|
||||
</Form>
|
||||
);
|
||||
56
web/src/pages/agents/use-import-json.ts
Normal file
56
web/src/pages/agents/use-import-json.ts
Normal file
@ -0,0 +1,56 @@
|
||||
import { useToast } from '@/components/hooks/use-toast';
|
||||
import { FileMimeType } from '@/constants/common';
|
||||
import { useSetModalState } from '@/hooks/common-hooks';
|
||||
import { EmptyDsl, useSetAgent } from '@/hooks/use-agent-request';
|
||||
import { message } from 'antd';
|
||||
import isEmpty from 'lodash/isEmpty';
|
||||
import { useCallback } from 'react';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import { FormSchemaType } from './upload-agent-dialog/upload-agent-form';
|
||||
|
||||
export const useHandleImportJsonFile = () => {
|
||||
const {
|
||||
visible: fileUploadVisible,
|
||||
hideModal: hideFileUploadModal,
|
||||
showModal: showFileUploadModal,
|
||||
} = useSetModalState();
|
||||
const { t } = useTranslation();
|
||||
const { toast } = useToast();
|
||||
const { loading, setAgent } = useSetAgent();
|
||||
|
||||
const onFileUploadOk = useCallback(
|
||||
async ({ fileList, name }: FormSchemaType) => {
|
||||
if (fileList.length > 0) {
|
||||
const file = fileList[0];
|
||||
if (file.type !== FileMimeType.Json) {
|
||||
toast({ title: t('flow.jsonUploadTypeErrorMessage') });
|
||||
return;
|
||||
}
|
||||
|
||||
const graphStr = await file.text();
|
||||
const errorMessage = t('flow.jsonUploadContentErrorMessage');
|
||||
try {
|
||||
const graph = JSON.parse(graphStr);
|
||||
if (graphStr && !isEmpty(graph) && Array.isArray(graph?.nodes)) {
|
||||
const dsl = { ...EmptyDsl, graph };
|
||||
setAgent({ title: name, dsl });
|
||||
hideFileUploadModal();
|
||||
} else {
|
||||
message.error(errorMessage);
|
||||
}
|
||||
} catch (error) {
|
||||
message.error(errorMessage);
|
||||
}
|
||||
}
|
||||
},
|
||||
[hideFileUploadModal, setAgent, t, toast],
|
||||
);
|
||||
|
||||
return {
|
||||
fileUploadVisible,
|
||||
handleImportJson: showFileUploadModal,
|
||||
hideFileUploadModal,
|
||||
onFileUploadOk,
|
||||
loading,
|
||||
};
|
||||
};
|
||||
@ -17,9 +17,9 @@ import {
|
||||
TooltipTrigger,
|
||||
} from '@/components/ui/tooltip';
|
||||
import { IModalProps } from '@/interfaces/common';
|
||||
import { useGetNodeDescription, useGetNodeName } from '@/pages/data-flow/hooks';
|
||||
import { Position } from '@xyflow/react';
|
||||
import { t } from 'i18next';
|
||||
import { lowerFirst } from 'lodash';
|
||||
import {
|
||||
PropsWithChildren,
|
||||
createContext,
|
||||
@ -28,7 +28,6 @@ import {
|
||||
useEffect,
|
||||
useRef,
|
||||
} from 'react';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import { Operator } from '../../../constant';
|
||||
import { AgentInstanceContext, HandleContext } from '../../../context';
|
||||
import OperatorIcon from '../../../operator-icon';
|
||||
@ -53,7 +52,9 @@ function OperatorItemList({
|
||||
const handleContext = useContext(HandleContext);
|
||||
const hideModal = useContext(HideModalContext);
|
||||
const onNodeCreated = useContext(OnNodeCreatedContext);
|
||||
const { t } = useTranslation();
|
||||
|
||||
const getNodeName = useGetNodeName();
|
||||
const getNodeDescription = useGetNodeDescription();
|
||||
|
||||
const handleClick = (operator: Operator) => {
|
||||
const contextData = handleContext || {
|
||||
@ -84,7 +85,7 @@ function OperatorItemList({
|
||||
const commonContent = (
|
||||
<div className="hover:bg-background-card py-1 px-3 cursor-pointer rounded-sm flex gap-2 items-center justify-start">
|
||||
<OperatorIcon name={operator} />
|
||||
{t(`flow.${lowerFirst(operator)}`)}
|
||||
{getNodeName(operator)}
|
||||
</div>
|
||||
);
|
||||
|
||||
@ -101,12 +102,12 @@ function OperatorItemList({
|
||||
onSelect={() => hideModal?.()}
|
||||
>
|
||||
<OperatorIcon name={operator} />
|
||||
{t(`flow.${lowerFirst(operator)}`)}
|
||||
{getNodeName(operator)}
|
||||
</DropdownMenuItem>
|
||||
)}
|
||||
</TooltipTrigger>
|
||||
<TooltipContent side="right">
|
||||
<p>{t(`flow.${lowerFirst(operator)}Description`)}</p>
|
||||
<p>{getNodeDescription(operator)}</p>
|
||||
</TooltipContent>
|
||||
</Tooltip>
|
||||
);
|
||||
|
||||
@ -5,13 +5,13 @@ import {
|
||||
SheetHeader,
|
||||
SheetTitle,
|
||||
} from '@/components/ui/sheet';
|
||||
import { useTranslate } from '@/hooks/common-hooks';
|
||||
import { IModalProps } from '@/interfaces/common';
|
||||
import { RAGFlowNodeType } from '@/interfaces/database/flow';
|
||||
import { cn } from '@/lib/utils';
|
||||
import { lowerFirst } from 'lodash';
|
||||
import { Play, X } from 'lucide-react';
|
||||
import { useMemo } from 'react';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import { BeginId, Operator } from '../constant';
|
||||
import { AgentFormContext } from '../context';
|
||||
import { RunTooltip } from '../flow-tooltip';
|
||||
@ -60,7 +60,7 @@ const FormSheet = ({
|
||||
);
|
||||
}, [clickedToolId, operatorName]);
|
||||
|
||||
const { t } = useTranslate('flow');
|
||||
const { t } = useTranslation();
|
||||
|
||||
return (
|
||||
<Sheet open={visible} modal={false}>
|
||||
@ -80,7 +80,7 @@ const FormSheet = ({
|
||||
<div className="flex-1">MCP Config</div>
|
||||
) : (
|
||||
<div className="flex items-center gap-1 flex-1">
|
||||
<label htmlFor="">{t('title')}</label>
|
||||
<label htmlFor="">{t('flow.title')}</label>
|
||||
{node?.id === BeginId ? (
|
||||
<span>{t(BeginId)}</span>
|
||||
) : (
|
||||
@ -106,7 +106,7 @@ const FormSheet = ({
|
||||
{isMcp || (
|
||||
<span>
|
||||
{t(
|
||||
`${lowerFirst(operatorName === Operator.Tool ? clickedToolId : operatorName)}Description`,
|
||||
`dataflow.${lowerFirst(operatorName === Operator.Tool ? clickedToolId : operatorName)}Description`,
|
||||
)}
|
||||
</span>
|
||||
)}
|
||||
|
||||
@ -30,7 +30,16 @@ export const useGetNodeName = () => {
|
||||
const { t } = useTranslation();
|
||||
|
||||
return (type: string) => {
|
||||
const name = t(`flow.${lowerFirst(type)}`);
|
||||
const name = t(`dataflow.${lowerFirst(type)}`);
|
||||
return name;
|
||||
};
|
||||
};
|
||||
|
||||
export const useGetNodeDescription = () => {
|
||||
const { t } = useTranslation();
|
||||
|
||||
return (type: string) => {
|
||||
const name = t(`dataflow.${lowerFirst(type)}Description`);
|
||||
return name;
|
||||
};
|
||||
};
|
||||
|
||||
@ -108,7 +108,7 @@ export const useGetNodeName = () => {
|
||||
const { t } = useTranslation();
|
||||
|
||||
return (type: string) => {
|
||||
const name = t(`flow.${lowerFirst(type)}`);
|
||||
const name = t(`dataflow.${lowerFirst(type)}`);
|
||||
return name;
|
||||
};
|
||||
};
|
||||
|
||||
234
web/src/pages/dataflow-result/chunker.tsx
Normal file
234
web/src/pages/dataflow-result/chunker.tsx
Normal file
@ -0,0 +1,234 @@
|
||||
import message from '@/components/ui/message';
|
||||
import {
|
||||
RAGFlowPagination,
|
||||
RAGFlowPaginationType,
|
||||
} from '@/components/ui/ragflow-pagination';
|
||||
import { Spin } from '@/components/ui/spin';
|
||||
import {
|
||||
useFetchNextChunkList,
|
||||
useSwitchChunk,
|
||||
} from '@/hooks/use-chunk-request';
|
||||
import classNames from 'classnames';
|
||||
import { useCallback, useEffect, useState } from 'react';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import ChunkCard from './components/chunk-card';
|
||||
import CreatingModal from './components/chunk-creating-modal';
|
||||
import ChunkResultBar from './components/chunk-result-bar';
|
||||
import CheckboxSets from './components/chunk-result-bar/checkbox-sets';
|
||||
import RerunButton from './components/rerun-button';
|
||||
import {
|
||||
useChangeChunkTextMode,
|
||||
useDeleteChunkByIds,
|
||||
useHandleChunkCardClick,
|
||||
useUpdateChunk,
|
||||
} from './hooks';
|
||||
import styles from './index.less';
|
||||
const ChunkerContainer = () => {
|
||||
const [selectedChunkIds, setSelectedChunkIds] = useState<string[]>([]);
|
||||
const [isChange, setIsChange] = useState(false);
|
||||
const { t } = useTranslation();
|
||||
const {
|
||||
data: { documentInfo, data = [], total },
|
||||
pagination,
|
||||
loading,
|
||||
searchString,
|
||||
handleInputChange,
|
||||
available,
|
||||
handleSetAvailable,
|
||||
} = useFetchNextChunkList();
|
||||
const { handleChunkCardClick, selectedChunkId } = useHandleChunkCardClick();
|
||||
const isPdf = documentInfo?.type === 'pdf';
|
||||
const {
|
||||
chunkUpdatingLoading,
|
||||
onChunkUpdatingOk,
|
||||
showChunkUpdatingModal,
|
||||
hideChunkUpdatingModal,
|
||||
chunkId,
|
||||
chunkUpdatingVisible,
|
||||
documentId,
|
||||
} = useUpdateChunk();
|
||||
const { removeChunk } = useDeleteChunkByIds();
|
||||
const { changeChunkTextMode, textMode } = useChangeChunkTextMode();
|
||||
const selectAllChunk = useCallback(
|
||||
(checked: boolean) => {
|
||||
setSelectedChunkIds(checked ? data.map((x) => x.chunk_id) : []);
|
||||
},
|
||||
[data],
|
||||
);
|
||||
const showSelectedChunkWarning = useCallback(() => {
|
||||
message.warning(t('message.pleaseSelectChunk'));
|
||||
}, [t]);
|
||||
const { switchChunk } = useSwitchChunk();
|
||||
|
||||
const [chunkList, setChunkList] = useState(data);
|
||||
useEffect(() => {
|
||||
setChunkList(data);
|
||||
}, [data]);
|
||||
const onPaginationChange: RAGFlowPaginationType['onChange'] = (
|
||||
page,
|
||||
size,
|
||||
) => {
|
||||
setSelectedChunkIds([]);
|
||||
pagination.onChange?.(page, size);
|
||||
};
|
||||
|
||||
const handleSwitchChunk = useCallback(
|
||||
async (available?: number, chunkIds?: string[]) => {
|
||||
let ids = chunkIds;
|
||||
if (!chunkIds) {
|
||||
ids = selectedChunkIds;
|
||||
if (selectedChunkIds.length === 0) {
|
||||
showSelectedChunkWarning();
|
||||
return;
|
||||
}
|
||||
}
|
||||
|
||||
const resCode: number = await switchChunk({
|
||||
chunk_ids: ids,
|
||||
available_int: available,
|
||||
doc_id: documentId,
|
||||
});
|
||||
if (ids?.length && resCode === 0) {
|
||||
chunkList.forEach((x: any) => {
|
||||
if (ids.indexOf(x['chunk_id']) > -1) {
|
||||
x['available_int'] = available;
|
||||
}
|
||||
});
|
||||
setChunkList(chunkList);
|
||||
}
|
||||
},
|
||||
[
|
||||
switchChunk,
|
||||
documentId,
|
||||
selectedChunkIds,
|
||||
showSelectedChunkWarning,
|
||||
chunkList,
|
||||
],
|
||||
);
|
||||
const handleSingleCheckboxClick = useCallback(
|
||||
(chunkId: string, checked: boolean) => {
|
||||
setSelectedChunkIds((previousIds) => {
|
||||
const idx = previousIds.findIndex((x) => x === chunkId);
|
||||
const nextIds = [...previousIds];
|
||||
if (checked && idx === -1) {
|
||||
nextIds.push(chunkId);
|
||||
} else if (!checked && idx !== -1) {
|
||||
nextIds.splice(idx, 1);
|
||||
}
|
||||
return nextIds;
|
||||
});
|
||||
},
|
||||
[],
|
||||
);
|
||||
const handleRemoveChunk = useCallback(async () => {
|
||||
if (selectedChunkIds.length > 0) {
|
||||
const resCode: number = await removeChunk(selectedChunkIds, documentId);
|
||||
if (resCode === 0) {
|
||||
setSelectedChunkIds([]);
|
||||
}
|
||||
} else {
|
||||
showSelectedChunkWarning();
|
||||
}
|
||||
}, [selectedChunkIds, documentId, removeChunk, showSelectedChunkWarning]);
|
||||
|
||||
const handleChunkEditSave = (e: any) => {
|
||||
setIsChange(true);
|
||||
onChunkUpdatingOk(e);
|
||||
};
|
||||
return (
|
||||
<>
|
||||
{isChange && (
|
||||
<div className=" absolute top-2 right-6">
|
||||
<RerunButton />
|
||||
</div>
|
||||
)}
|
||||
<div
|
||||
className={classNames(
|
||||
{ [styles.pagePdfWrapper]: isPdf },
|
||||
'flex flex-col w-3/5',
|
||||
)}
|
||||
>
|
||||
<Spin spinning={loading} className={styles.spin} size="large">
|
||||
<div className="h-[50px] flex flex-row justify-between items-end pb-[5px]">
|
||||
<div>
|
||||
<h2 className="text-[16px]">{t('chunk.chunkResult')}</h2>
|
||||
<div className="text-[12px] text-text-secondary italic">
|
||||
{t('chunk.chunkResultTip')}
|
||||
</div>
|
||||
</div>
|
||||
<ChunkResultBar
|
||||
handleInputChange={handleInputChange}
|
||||
searchString={searchString}
|
||||
changeChunkTextMode={changeChunkTextMode}
|
||||
createChunk={showChunkUpdatingModal}
|
||||
available={available}
|
||||
selectAllChunk={selectAllChunk}
|
||||
handleSetAvailable={handleSetAvailable}
|
||||
/>
|
||||
</div>
|
||||
<div className=" rounded-[16px] box-border mb-2">
|
||||
<div className="pt-[5px] pb-[5px]">
|
||||
<CheckboxSets
|
||||
selectAllChunk={selectAllChunk}
|
||||
switchChunk={handleSwitchChunk}
|
||||
removeChunk={handleRemoveChunk}
|
||||
checked={selectedChunkIds.length === data.length}
|
||||
selectedChunkIds={selectedChunkIds}
|
||||
/>
|
||||
</div>
|
||||
<div className="h-[calc(100vh-280px)] overflow-y-auto pr-2 scrollbar-thin">
|
||||
<div
|
||||
className={classNames(
|
||||
styles.chunkContainer,
|
||||
{
|
||||
[styles.chunkOtherContainer]: !isPdf,
|
||||
},
|
||||
'flex flex-col gap-4',
|
||||
)}
|
||||
>
|
||||
{chunkList.map((item) => (
|
||||
<ChunkCard
|
||||
item={item}
|
||||
key={item.chunk_id}
|
||||
editChunk={showChunkUpdatingModal}
|
||||
checked={selectedChunkIds.some((x) => x === item.chunk_id)}
|
||||
handleCheckboxClick={handleSingleCheckboxClick}
|
||||
switchChunk={handleSwitchChunk}
|
||||
clickChunkCard={handleChunkCardClick}
|
||||
selected={item.chunk_id === selectedChunkId}
|
||||
textMode={textMode}
|
||||
></ChunkCard>
|
||||
))}
|
||||
</div>
|
||||
</div>
|
||||
<div className={styles.pageFooter}>
|
||||
<RAGFlowPagination
|
||||
pageSize={pagination.pageSize}
|
||||
current={pagination.current}
|
||||
total={total}
|
||||
onChange={(page, pageSize) => {
|
||||
onPaginationChange(page, pageSize);
|
||||
}}
|
||||
></RAGFlowPagination>
|
||||
</div>
|
||||
</div>
|
||||
</Spin>
|
||||
</div>
|
||||
{chunkUpdatingVisible && (
|
||||
<CreatingModal
|
||||
doc_id={documentId}
|
||||
chunkId={chunkId}
|
||||
hideModal={hideChunkUpdatingModal}
|
||||
visible={chunkUpdatingVisible}
|
||||
loading={chunkUpdatingLoading}
|
||||
onOk={(e) => {
|
||||
handleChunkEditSave(e);
|
||||
}}
|
||||
parserId={documentInfo.parser_id}
|
||||
/>
|
||||
)}
|
||||
</>
|
||||
);
|
||||
};
|
||||
|
||||
export { ChunkerContainer };
|
||||
@ -0,0 +1,36 @@
|
||||
.image {
|
||||
width: 100px !important;
|
||||
object-fit: contain;
|
||||
}
|
||||
|
||||
.imagePreview {
|
||||
max-width: 50vw;
|
||||
max-height: 50vh;
|
||||
object-fit: contain;
|
||||
}
|
||||
|
||||
.content {
|
||||
flex: 1;
|
||||
.chunkText;
|
||||
}
|
||||
|
||||
.contentEllipsis {
|
||||
.multipleLineEllipsis(3);
|
||||
}
|
||||
|
||||
.contentText {
|
||||
word-break: break-all !important;
|
||||
}
|
||||
|
||||
.chunkCard {
|
||||
width: 100%;
|
||||
padding: 18px 10px;
|
||||
}
|
||||
|
||||
.cardSelected {
|
||||
background-color: @selectedBackgroundColor;
|
||||
}
|
||||
|
||||
.cardSelectedDark {
|
||||
background-color: #ffffff2f;
|
||||
}
|
||||
127
web/src/pages/dataflow-result/components/chunk-card/index.tsx
Normal file
127
web/src/pages/dataflow-result/components/chunk-card/index.tsx
Normal file
@ -0,0 +1,127 @@
|
||||
import Image from '@/components/image';
|
||||
import { useTheme } from '@/components/theme-provider';
|
||||
import { Card } from '@/components/ui/card';
|
||||
import { Checkbox } from '@/components/ui/checkbox';
|
||||
import {
|
||||
Popover,
|
||||
PopoverContent,
|
||||
PopoverTrigger,
|
||||
} from '@/components/ui/popover';
|
||||
import { Switch } from '@/components/ui/switch';
|
||||
import { IChunk } from '@/interfaces/database/knowledge';
|
||||
import { CheckedState } from '@radix-ui/react-checkbox';
|
||||
import classNames from 'classnames';
|
||||
import DOMPurify from 'dompurify';
|
||||
import { useEffect, useState } from 'react';
|
||||
import { ChunkTextMode } from '../../constant';
|
||||
import styles from './index.less';
|
||||
|
||||
interface IProps {
|
||||
item: IChunk;
|
||||
checked: boolean;
|
||||
switchChunk: (available?: number, chunkIds?: string[]) => void;
|
||||
editChunk: (chunkId: string) => void;
|
||||
handleCheckboxClick: (chunkId: string, checked: boolean) => void;
|
||||
selected: boolean;
|
||||
clickChunkCard: (chunkId: string) => void;
|
||||
textMode: ChunkTextMode;
|
||||
}
|
||||
|
||||
const ChunkCard = ({
|
||||
item,
|
||||
checked,
|
||||
handleCheckboxClick,
|
||||
editChunk,
|
||||
switchChunk,
|
||||
selected,
|
||||
clickChunkCard,
|
||||
textMode,
|
||||
}: IProps) => {
|
||||
const available = Number(item.available_int);
|
||||
const [enabled, setEnabled] = useState(false);
|
||||
const { theme } = useTheme();
|
||||
|
||||
const onChange = (checked: boolean) => {
|
||||
setEnabled(checked);
|
||||
switchChunk(available === 0 ? 1 : 0, [item.chunk_id]);
|
||||
};
|
||||
|
||||
const handleCheck = (e: CheckedState) => {
|
||||
handleCheckboxClick(item.chunk_id, e === 'indeterminate' ? false : e);
|
||||
};
|
||||
|
||||
const handleContentDoubleClick = () => {
|
||||
editChunk(item.chunk_id);
|
||||
};
|
||||
|
||||
const handleContentClick = () => {
|
||||
clickChunkCard(item.chunk_id);
|
||||
};
|
||||
|
||||
useEffect(() => {
|
||||
setEnabled(available === 1);
|
||||
}, [available]);
|
||||
const [open, setOpen] = useState<boolean>(false);
|
||||
return (
|
||||
<Card
|
||||
className={classNames('rounded-lg w-full py-3 px-3', {
|
||||
'bg-bg-title': selected,
|
||||
'bg-bg-input': !selected,
|
||||
})}
|
||||
>
|
||||
<div className="flex items-start justify-between gap-2">
|
||||
<Checkbox onCheckedChange={handleCheck} checked={checked}></Checkbox>
|
||||
{item.image_id && (
|
||||
<Popover open={open}>
|
||||
<PopoverTrigger
|
||||
asChild
|
||||
onMouseEnter={() => setOpen(true)}
|
||||
onMouseLeave={() => setOpen(false)}
|
||||
>
|
||||
<div>
|
||||
<Image id={item.image_id} className={styles.image}></Image>
|
||||
</div>
|
||||
</PopoverTrigger>
|
||||
<PopoverContent
|
||||
className="p-0"
|
||||
align={'start'}
|
||||
side={'right'}
|
||||
sideOffset={-20}
|
||||
>
|
||||
<div>
|
||||
<Image
|
||||
id={item.image_id}
|
||||
className={styles.imagePreview}
|
||||
></Image>
|
||||
</div>
|
||||
</PopoverContent>
|
||||
</Popover>
|
||||
)}
|
||||
<section
|
||||
onDoubleClick={handleContentDoubleClick}
|
||||
onClick={handleContentClick}
|
||||
className={styles.content}
|
||||
>
|
||||
<div
|
||||
dangerouslySetInnerHTML={{
|
||||
__html: DOMPurify.sanitize(item.content_with_weight),
|
||||
}}
|
||||
className={classNames(styles.contentText, {
|
||||
[styles.contentEllipsis]: textMode === ChunkTextMode.Ellipse,
|
||||
})}
|
||||
></div>
|
||||
</section>
|
||||
<div>
|
||||
<Switch
|
||||
checked={enabled}
|
||||
onCheckedChange={onChange}
|
||||
aria-readonly
|
||||
className="!m-0"
|
||||
/>
|
||||
</div>
|
||||
</div>
|
||||
</Card>
|
||||
);
|
||||
};
|
||||
|
||||
export default ChunkCard;
|
||||
@ -0,0 +1,206 @@
|
||||
import EditTag from '@/components/edit-tag';
|
||||
import Divider from '@/components/ui/divider';
|
||||
import {
|
||||
Form,
|
||||
FormControl,
|
||||
FormField,
|
||||
FormItem,
|
||||
FormLabel,
|
||||
FormMessage,
|
||||
} from '@/components/ui/form';
|
||||
import {
|
||||
HoverCard,
|
||||
HoverCardContent,
|
||||
HoverCardTrigger,
|
||||
} from '@/components/ui/hover-card';
|
||||
import { Modal } from '@/components/ui/modal/modal';
|
||||
import Space from '@/components/ui/space';
|
||||
import { Switch } from '@/components/ui/switch';
|
||||
import { Textarea } from '@/components/ui/textarea';
|
||||
import { useFetchChunk } from '@/hooks/chunk-hooks';
|
||||
import { IModalProps } from '@/interfaces/common';
|
||||
import { Trash2 } from 'lucide-react';
|
||||
import React, { useCallback, useEffect, useState } from 'react';
|
||||
import { FieldValues, FormProvider, useForm } from 'react-hook-form';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import { useDeleteChunkByIds } from '../../hooks';
|
||||
import {
|
||||
transformTagFeaturesArrayToObject,
|
||||
transformTagFeaturesObjectToArray,
|
||||
} from '../../utils';
|
||||
import { TagFeatureItem } from './tag-feature-item';
|
||||
|
||||
interface kFProps {
|
||||
doc_id: string;
|
||||
chunkId: string | undefined;
|
||||
parserId: string;
|
||||
}
|
||||
|
||||
const ChunkCreatingModal: React.FC<IModalProps<any> & kFProps> = ({
|
||||
doc_id,
|
||||
chunkId,
|
||||
hideModal,
|
||||
onOk,
|
||||
loading,
|
||||
parserId,
|
||||
}) => {
|
||||
// const [form] = Form.useForm();
|
||||
// const form = useFormContext();
|
||||
const form = useForm<FieldValues>({
|
||||
defaultValues: {
|
||||
content_with_weight: '',
|
||||
tag_kwd: [],
|
||||
question_kwd: [],
|
||||
important_kwd: [],
|
||||
tag_feas: [],
|
||||
},
|
||||
});
|
||||
const [checked, setChecked] = useState(false);
|
||||
const { removeChunk } = useDeleteChunkByIds();
|
||||
const { data } = useFetchChunk(chunkId);
|
||||
const { t } = useTranslation();
|
||||
|
||||
const isTagParser = parserId === 'tag';
|
||||
const onSubmit = useCallback(
|
||||
(values: FieldValues) => {
|
||||
onOk?.({
|
||||
...values,
|
||||
tag_feas: transformTagFeaturesArrayToObject(values.tag_feas),
|
||||
available_int: checked ? 1 : 0,
|
||||
});
|
||||
},
|
||||
[checked, onOk],
|
||||
);
|
||||
|
||||
const handleOk = form.handleSubmit(onSubmit);
|
||||
|
||||
const handleRemove = useCallback(() => {
|
||||
if (chunkId) {
|
||||
return removeChunk([chunkId], doc_id);
|
||||
}
|
||||
}, [chunkId, doc_id, removeChunk]);
|
||||
|
||||
const handleCheck = useCallback(() => {
|
||||
setChecked(!checked);
|
||||
}, [checked]);
|
||||
|
||||
useEffect(() => {
|
||||
if (data?.code === 0) {
|
||||
const { available_int, tag_feas } = data.data;
|
||||
form.reset({
|
||||
...data.data,
|
||||
tag_feas: transformTagFeaturesObjectToArray(tag_feas),
|
||||
});
|
||||
|
||||
setChecked(available_int !== 0);
|
||||
}
|
||||
}, [data, form, chunkId]);
|
||||
|
||||
return (
|
||||
<Modal
|
||||
title={`${chunkId ? t('common.edit') : t('common.create')} ${t('chunk.chunk')}`}
|
||||
open={true}
|
||||
onOk={handleOk}
|
||||
onCancel={hideModal}
|
||||
confirmLoading={loading}
|
||||
destroyOnClose
|
||||
>
|
||||
<Form {...form}>
|
||||
<div className="flex flex-col gap-4">
|
||||
<FormField
|
||||
control={form.control}
|
||||
name="content_with_weight"
|
||||
render={({ field }) => (
|
||||
<FormItem>
|
||||
<FormLabel>{t('chunk.chunk')}</FormLabel>
|
||||
<FormControl>
|
||||
<Textarea {...field} autoSize={{ minRows: 4, maxRows: 10 }} />
|
||||
</FormControl>
|
||||
<FormMessage />
|
||||
</FormItem>
|
||||
)}
|
||||
/>
|
||||
<FormField
|
||||
control={form.control}
|
||||
name="important_kwd"
|
||||
render={({ field }) => (
|
||||
<FormItem>
|
||||
<FormLabel>{t('chunk.keyword')}</FormLabel>
|
||||
<FormControl>
|
||||
<EditTag {...field} />
|
||||
</FormControl>
|
||||
<FormMessage />
|
||||
</FormItem>
|
||||
)}
|
||||
/>
|
||||
|
||||
<FormField
|
||||
control={form.control}
|
||||
name="question_kwd"
|
||||
render={({ field }) => (
|
||||
<FormItem>
|
||||
<FormLabel className="flex justify-start items-start">
|
||||
<div className="flex items-center gap-0">
|
||||
<span>{t('chunk.question')}</span>
|
||||
<HoverCard>
|
||||
<HoverCardTrigger asChild>
|
||||
<span className="text-xs mt-[-3px] text-center scale-[90%] font-thin text-primary cursor-pointer rounded-full w-[16px] h-[16px] border-muted-foreground/50 border">
|
||||
?
|
||||
</span>
|
||||
</HoverCardTrigger>
|
||||
<HoverCardContent className="w-80" side="top">
|
||||
{t('chunk.questionTip')}
|
||||
</HoverCardContent>
|
||||
</HoverCard>
|
||||
</div>
|
||||
</FormLabel>
|
||||
<FormControl>
|
||||
<EditTag {...field} />
|
||||
</FormControl>
|
||||
<FormMessage />
|
||||
</FormItem>
|
||||
)}
|
||||
/>
|
||||
|
||||
{isTagParser && (
|
||||
<FormField
|
||||
control={form.control}
|
||||
name="tag_kwd"
|
||||
render={({ field }) => (
|
||||
<FormItem>
|
||||
<FormLabel>{t('knowledgeConfiguration.tagName')}</FormLabel>
|
||||
<FormControl>
|
||||
<EditTag {...field} />
|
||||
</FormControl>
|
||||
<FormMessage />
|
||||
</FormItem>
|
||||
)}
|
||||
/>
|
||||
)}
|
||||
|
||||
{!isTagParser && (
|
||||
<FormProvider {...form}>
|
||||
<TagFeatureItem />
|
||||
</FormProvider>
|
||||
)}
|
||||
</div>
|
||||
</Form>
|
||||
|
||||
{chunkId && (
|
||||
<section>
|
||||
<Divider />
|
||||
<Space size={'large'}>
|
||||
<div className="flex items-center gap-2">
|
||||
{t('chunk.enabled')}
|
||||
<Switch checked={checked} onCheckedChange={handleCheck} />
|
||||
</div>
|
||||
<div className="flex items-center gap-1" onClick={handleRemove}>
|
||||
<Trash2 size={16} /> {t('common.delete')}
|
||||
</div>
|
||||
</Space>
|
||||
</section>
|
||||
)}
|
||||
</Modal>
|
||||
);
|
||||
};
|
||||
export default ChunkCreatingModal;
|
||||
@ -0,0 +1,136 @@
|
||||
import { SelectWithSearch } from '@/components/originui/select-with-search';
|
||||
import { Button } from '@/components/ui/button';
|
||||
import {
|
||||
FormControl,
|
||||
FormField,
|
||||
FormItem,
|
||||
FormLabel,
|
||||
FormMessage,
|
||||
} from '@/components/ui/form';
|
||||
import { NumberInput } from '@/components/ui/input';
|
||||
import { useFetchTagListByKnowledgeIds } from '@/hooks/knowledge-hooks';
|
||||
import { useFetchKnowledgeBaseConfiguration } from '@/hooks/use-knowledge-request';
|
||||
import { CircleMinus, Plus } from 'lucide-react';
|
||||
import { useCallback, useEffect, useMemo } from 'react';
|
||||
import { useFieldArray, useFormContext } from 'react-hook-form';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import { FormListItem } from '../../utils';
|
||||
|
||||
const FieldKey = 'tag_feas';
|
||||
|
||||
export const TagFeatureItem = () => {
|
||||
const { t } = useTranslation();
|
||||
const { setKnowledgeIds, list } = useFetchTagListByKnowledgeIds();
|
||||
const { data: knowledgeConfiguration } = useFetchKnowledgeBaseConfiguration();
|
||||
const form = useFormContext();
|
||||
const tagKnowledgeIds = useMemo(() => {
|
||||
return knowledgeConfiguration?.parser_config?.tag_kb_ids ?? [];
|
||||
}, [knowledgeConfiguration?.parser_config?.tag_kb_ids]);
|
||||
|
||||
const options = useMemo(() => {
|
||||
return list.map((x) => ({
|
||||
value: x[0],
|
||||
label: x[0],
|
||||
}));
|
||||
}, [list]);
|
||||
|
||||
const filterOptions = useCallback(
|
||||
(index: number) => {
|
||||
const tags: FormListItem[] = form.getValues(FieldKey) ?? [];
|
||||
|
||||
// Exclude it's own current data
|
||||
const list = tags
|
||||
.filter((x, idx) => x && index !== idx)
|
||||
.map((x) => x.tag);
|
||||
// Exclude the selected data from other options from one's own options.
|
||||
const resultList = options.filter(
|
||||
(x) => !list.some((y) => x.value === y),
|
||||
);
|
||||
return resultList;
|
||||
},
|
||||
[form, options],
|
||||
);
|
||||
|
||||
useEffect(() => {
|
||||
setKnowledgeIds(tagKnowledgeIds);
|
||||
}, [setKnowledgeIds, tagKnowledgeIds]);
|
||||
|
||||
const { fields, append, remove } = useFieldArray({
|
||||
control: form.control,
|
||||
name: FieldKey,
|
||||
});
|
||||
return (
|
||||
<FormField
|
||||
control={form.control}
|
||||
name={FieldKey as any}
|
||||
render={() => (
|
||||
<FormItem>
|
||||
<FormLabel>{t('knowledgeConfiguration.tags')}</FormLabel>
|
||||
<div>
|
||||
{fields.map((item, name) => {
|
||||
return (
|
||||
<div key={item.id} className="flex gap-3 items-center mb-4">
|
||||
<div className="flex flex-1 gap-8">
|
||||
<FormField
|
||||
control={form.control}
|
||||
name={`${FieldKey}.${name}.tag` as any}
|
||||
render={({ field }) => (
|
||||
<FormItem className="w-2/3">
|
||||
<FormControl className="w-full">
|
||||
<div>
|
||||
<SelectWithSearch
|
||||
options={filterOptions(name)}
|
||||
placeholder={t(
|
||||
'knowledgeConfiguration.tagName',
|
||||
)}
|
||||
value={field.value}
|
||||
onChange={field.onChange}
|
||||
/>
|
||||
</div>
|
||||
</FormControl>
|
||||
<FormMessage />
|
||||
</FormItem>
|
||||
)}
|
||||
/>
|
||||
<FormField
|
||||
control={form.control}
|
||||
name={`${FieldKey}.${name}.frequency`}
|
||||
render={({ field }) => (
|
||||
<FormItem>
|
||||
<FormControl>
|
||||
<NumberInput
|
||||
value={field.value}
|
||||
onChange={field.onChange}
|
||||
placeholder={t(
|
||||
'knowledgeConfiguration.frequency',
|
||||
)}
|
||||
max={10}
|
||||
min={0}
|
||||
/>
|
||||
</FormControl>
|
||||
<FormMessage />
|
||||
</FormItem>
|
||||
)}
|
||||
/>
|
||||
</div>
|
||||
<CircleMinus
|
||||
onClick={() => remove(name)}
|
||||
className="text-red-500"
|
||||
/>
|
||||
</div>
|
||||
);
|
||||
})}
|
||||
<Button
|
||||
variant="dashed"
|
||||
className="w-full flex items-center justify-center gap-2"
|
||||
onClick={() => append({ tag: '', frequency: 0 })}
|
||||
>
|
||||
<Plus size={16} />
|
||||
{t('knowledgeConfiguration.addTag')}
|
||||
</Button>
|
||||
</div>
|
||||
</FormItem>
|
||||
)}
|
||||
/>
|
||||
);
|
||||
};
|
||||
@ -0,0 +1,85 @@
|
||||
import { Checkbox } from '@/components/ui/checkbox';
|
||||
import { Label } from '@/components/ui/label';
|
||||
import { Ban, CircleCheck, Trash2 } from 'lucide-react';
|
||||
import { useCallback, useMemo } from 'react';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
|
||||
type ICheckboxSetProps = {
|
||||
selectAllChunk: (e: any) => void;
|
||||
removeChunk: (e?: any) => void;
|
||||
switchChunk: (available: number) => void;
|
||||
checked: boolean;
|
||||
selectedChunkIds: string[];
|
||||
};
|
||||
export default (props: ICheckboxSetProps) => {
|
||||
const {
|
||||
selectAllChunk,
|
||||
removeChunk,
|
||||
switchChunk,
|
||||
checked,
|
||||
selectedChunkIds,
|
||||
} = props;
|
||||
const { t } = useTranslation();
|
||||
const handleSelectAllCheck = useCallback(
|
||||
(e: any) => {
|
||||
console.log('eee=', e);
|
||||
selectAllChunk(e);
|
||||
},
|
||||
[selectAllChunk],
|
||||
);
|
||||
|
||||
const handleDeleteClick = useCallback(() => {
|
||||
removeChunk();
|
||||
}, [removeChunk]);
|
||||
|
||||
const handleEnabledClick = useCallback(() => {
|
||||
switchChunk(1);
|
||||
}, [switchChunk]);
|
||||
|
||||
const handleDisabledClick = useCallback(() => {
|
||||
switchChunk(0);
|
||||
}, [switchChunk]);
|
||||
|
||||
const isSelected = useMemo(() => {
|
||||
return selectedChunkIds?.length > 0;
|
||||
}, [selectedChunkIds]);
|
||||
|
||||
return (
|
||||
<div className="flex gap-[40px] py-4 px-2">
|
||||
<div className="flex items-center gap-3 cursor-pointer text-muted-foreground hover:text-text-primary">
|
||||
<Checkbox
|
||||
id="all_chunks_checkbox"
|
||||
onCheckedChange={handleSelectAllCheck}
|
||||
checked={checked}
|
||||
className=" data-[state=checked]:bg-text-primary data-[state=checked]:border-text-primary data-[state=checked]:text-bg-base border-muted-foreground text-muted-foreground hover:text-bg-base hover:border-text-primary "
|
||||
/>
|
||||
<Label htmlFor="all_chunks_checkbox">{t('chunk.selectAll')}</Label>
|
||||
</div>
|
||||
{isSelected && (
|
||||
<>
|
||||
<div
|
||||
className="flex items-center cursor-pointer text-muted-foreground hover:text-text-primary"
|
||||
onClick={handleEnabledClick}
|
||||
>
|
||||
<CircleCheck size={16} />
|
||||
<span className="block ml-1">{t('chunk.enable')}</span>
|
||||
</div>
|
||||
<div
|
||||
className="flex items-center cursor-pointer text-muted-foreground hover:text-text-primary"
|
||||
onClick={handleDisabledClick}
|
||||
>
|
||||
<Ban size={16} />
|
||||
<span className="block ml-1">{t('chunk.disable')}</span>
|
||||
</div>
|
||||
<div
|
||||
className="flex items-center cursor-pointer text-red-400 hover:text-red-500"
|
||||
onClick={handleDeleteClick}
|
||||
>
|
||||
<Trash2 size={16} />
|
||||
<span className="block ml-1">{t('chunk.delete')}</span>
|
||||
</div>
|
||||
</>
|
||||
)}
|
||||
</div>
|
||||
);
|
||||
};
|
||||
@ -0,0 +1,108 @@
|
||||
import { Input } from '@/components/originui/input';
|
||||
import { Button } from '@/components/ui/button';
|
||||
import {
|
||||
Popover,
|
||||
PopoverContent,
|
||||
PopoverTrigger,
|
||||
} from '@/components/ui/popover';
|
||||
import { Radio } from '@/components/ui/radio';
|
||||
import { useTranslate } from '@/hooks/common-hooks';
|
||||
import { cn } from '@/lib/utils';
|
||||
import { SearchOutlined } from '@ant-design/icons';
|
||||
import { ListFilter, Plus } from 'lucide-react';
|
||||
import { useState } from 'react';
|
||||
import { ChunkTextMode } from '../../constant';
|
||||
interface ChunkResultBarProps {
|
||||
changeChunkTextMode: React.Dispatch<React.SetStateAction<string | number>>;
|
||||
available: number | undefined;
|
||||
selectAllChunk: (value: boolean) => void;
|
||||
handleSetAvailable: (value: number | undefined) => void;
|
||||
createChunk: () => void;
|
||||
handleInputChange: (e: React.ChangeEvent<HTMLInputElement>) => void;
|
||||
searchString: string;
|
||||
}
|
||||
export default ({
|
||||
changeChunkTextMode,
|
||||
available,
|
||||
selectAllChunk,
|
||||
handleSetAvailable,
|
||||
createChunk,
|
||||
handleInputChange,
|
||||
searchString,
|
||||
}: ChunkResultBarProps) => {
|
||||
const { t } = useTranslate('chunk');
|
||||
const [textSelectValue, setTextSelectValue] = useState<string | number>(
|
||||
ChunkTextMode.Full,
|
||||
);
|
||||
const handleFilterChange = (e: string | number) => {
|
||||
const value = e === -1 ? undefined : (e as number);
|
||||
selectAllChunk(false);
|
||||
handleSetAvailable(value);
|
||||
};
|
||||
const filterContent = (
|
||||
<div className="w-[200px]">
|
||||
<Radio.Group onChange={handleFilterChange} value={available}>
|
||||
<div className="flex flex-col gap-2 p-4">
|
||||
<Radio value={-1}>{t('all')}</Radio>
|
||||
<Radio value={1}>{t('enabled')}</Radio>
|
||||
<Radio value={0}>{t('disabled')}</Radio>
|
||||
</div>
|
||||
</Radio.Group>
|
||||
</div>
|
||||
);
|
||||
const textSelectOptions = [
|
||||
{ label: t(ChunkTextMode.Full), value: ChunkTextMode.Full },
|
||||
{ label: t(ChunkTextMode.Ellipse), value: ChunkTextMode.Ellipse },
|
||||
];
|
||||
|
||||
const changeTextSelectValue = (value: string | number) => {
|
||||
setTextSelectValue(value);
|
||||
changeChunkTextMode(value);
|
||||
};
|
||||
return (
|
||||
<div className="flex gap-2">
|
||||
<div className="flex items-center gap-1 bg-bg-card text-muted-foreground w-fit h-[35px] rounded-md p-1">
|
||||
{textSelectOptions.map((option) => (
|
||||
<div
|
||||
key={option.value}
|
||||
className={cn(
|
||||
'flex items-center cursor-pointer px-4 py-1 rounded-md',
|
||||
{
|
||||
'text-primary bg-bg-base': option.value === textSelectValue,
|
||||
'text-text-primary': option.value !== textSelectValue,
|
||||
},
|
||||
)}
|
||||
onClick={() => changeTextSelectValue(option.value)}
|
||||
>
|
||||
{option.label}
|
||||
</div>
|
||||
))}
|
||||
</div>
|
||||
<Input
|
||||
className="bg-bg-card text-muted-foreground"
|
||||
style={{ width: 200 }}
|
||||
placeholder={t('search')}
|
||||
icon={<SearchOutlined />}
|
||||
onChange={handleInputChange}
|
||||
value={searchString}
|
||||
/>
|
||||
<Popover>
|
||||
<PopoverTrigger asChild>
|
||||
<Button className="bg-bg-card text-muted-foreground hover:bg-card">
|
||||
<ListFilter />
|
||||
</Button>
|
||||
</PopoverTrigger>
|
||||
<PopoverContent className="p-0 w-[200px]">
|
||||
{filterContent}
|
||||
</PopoverContent>
|
||||
</Popover>
|
||||
<Button
|
||||
onClick={() => createChunk()}
|
||||
variant={'secondary'}
|
||||
className="bg-bg-card text-muted-foreground hover:bg-card"
|
||||
>
|
||||
<Plus size={44} />
|
||||
</Button>
|
||||
</div>
|
||||
);
|
||||
};
|
||||
221
web/src/pages/dataflow-result/components/chunk-toolbar/index.tsx
Normal file
221
web/src/pages/dataflow-result/components/chunk-toolbar/index.tsx
Normal file
@ -0,0 +1,221 @@
|
||||
import { ReactComponent as FilterIcon } from '@/assets/filter.svg';
|
||||
import { KnowledgeRouteKey } from '@/constants/knowledge';
|
||||
import { IChunkListResult, useSelectChunkList } from '@/hooks/chunk-hooks';
|
||||
import { useTranslate } from '@/hooks/common-hooks';
|
||||
import { useKnowledgeBaseId } from '@/hooks/knowledge-hooks';
|
||||
import {
|
||||
ArrowLeftOutlined,
|
||||
CheckCircleOutlined,
|
||||
CloseCircleOutlined,
|
||||
DeleteOutlined,
|
||||
DownOutlined,
|
||||
FilePdfOutlined,
|
||||
PlusOutlined,
|
||||
SearchOutlined,
|
||||
} from '@ant-design/icons';
|
||||
import {
|
||||
Button,
|
||||
Checkbox,
|
||||
Flex,
|
||||
Input,
|
||||
Menu,
|
||||
MenuProps,
|
||||
Popover,
|
||||
Radio,
|
||||
RadioChangeEvent,
|
||||
Segmented,
|
||||
SegmentedProps,
|
||||
Space,
|
||||
Typography,
|
||||
} from 'antd';
|
||||
import { useCallback, useMemo, useState } from 'react';
|
||||
import { Link } from 'umi';
|
||||
import { ChunkTextMode } from '../../constant';
|
||||
|
||||
const { Text } = Typography;
|
||||
|
||||
interface IProps
|
||||
extends Pick<
|
||||
IChunkListResult,
|
||||
'searchString' | 'handleInputChange' | 'available' | 'handleSetAvailable'
|
||||
> {
|
||||
checked: boolean;
|
||||
selectAllChunk: (checked: boolean) => void;
|
||||
createChunk: () => void;
|
||||
removeChunk: () => void;
|
||||
switchChunk: (available: number) => void;
|
||||
changeChunkTextMode(mode: ChunkTextMode): void;
|
||||
}
|
||||
|
||||
const ChunkToolBar = ({
|
||||
selectAllChunk,
|
||||
checked,
|
||||
createChunk,
|
||||
removeChunk,
|
||||
switchChunk,
|
||||
changeChunkTextMode,
|
||||
available,
|
||||
handleSetAvailable,
|
||||
searchString,
|
||||
handleInputChange,
|
||||
}: IProps) => {
|
||||
const data = useSelectChunkList();
|
||||
const documentInfo = data?.documentInfo;
|
||||
const knowledgeBaseId = useKnowledgeBaseId();
|
||||
const [isShowSearchBox, setIsShowSearchBox] = useState(false);
|
||||
const { t } = useTranslate('chunk');
|
||||
|
||||
const handleSelectAllCheck = useCallback(
|
||||
(e: any) => {
|
||||
selectAllChunk(e.target.checked);
|
||||
},
|
||||
[selectAllChunk],
|
||||
);
|
||||
|
||||
const handleSearchIconClick = () => {
|
||||
setIsShowSearchBox(true);
|
||||
};
|
||||
|
||||
const handleSearchBlur = () => {
|
||||
if (!searchString?.trim()) {
|
||||
setIsShowSearchBox(false);
|
||||
}
|
||||
};
|
||||
|
||||
const handleDelete = useCallback(() => {
|
||||
removeChunk();
|
||||
}, [removeChunk]);
|
||||
|
||||
const handleEnabledClick = useCallback(() => {
|
||||
switchChunk(1);
|
||||
}, [switchChunk]);
|
||||
|
||||
const handleDisabledClick = useCallback(() => {
|
||||
switchChunk(0);
|
||||
}, [switchChunk]);
|
||||
|
||||
const items: MenuProps['items'] = useMemo(() => {
|
||||
return [
|
||||
{
|
||||
key: '1',
|
||||
label: (
|
||||
<>
|
||||
<Checkbox onChange={handleSelectAllCheck} checked={checked}>
|
||||
<b>{t('selectAll')}</b>
|
||||
</Checkbox>
|
||||
</>
|
||||
),
|
||||
},
|
||||
{ type: 'divider' },
|
||||
{
|
||||
key: '2',
|
||||
label: (
|
||||
<Space onClick={handleEnabledClick}>
|
||||
<CheckCircleOutlined />
|
||||
<b>{t('enabledSelected')}</b>
|
||||
</Space>
|
||||
),
|
||||
},
|
||||
{
|
||||
key: '3',
|
||||
label: (
|
||||
<Space onClick={handleDisabledClick}>
|
||||
<CloseCircleOutlined />
|
||||
<b>{t('disabledSelected')}</b>
|
||||
</Space>
|
||||
),
|
||||
},
|
||||
{ type: 'divider' },
|
||||
{
|
||||
key: '4',
|
||||
label: (
|
||||
<Space onClick={handleDelete}>
|
||||
<DeleteOutlined />
|
||||
<b>{t('deleteSelected')}</b>
|
||||
</Space>
|
||||
),
|
||||
},
|
||||
];
|
||||
}, [
|
||||
checked,
|
||||
handleSelectAllCheck,
|
||||
handleDelete,
|
||||
handleEnabledClick,
|
||||
handleDisabledClick,
|
||||
t,
|
||||
]);
|
||||
|
||||
const content = (
|
||||
<Menu style={{ width: 200 }} items={items} selectable={false} />
|
||||
);
|
||||
|
||||
const handleFilterChange = (e: RadioChangeEvent) => {
|
||||
selectAllChunk(false);
|
||||
handleSetAvailable(e.target.value);
|
||||
};
|
||||
|
||||
const filterContent = (
|
||||
<Radio.Group onChange={handleFilterChange} value={available}>
|
||||
<Space direction="vertical">
|
||||
<Radio value={undefined}>{t('all')}</Radio>
|
||||
<Radio value={1}>{t('enabled')}</Radio>
|
||||
<Radio value={0}>{t('disabled')}</Radio>
|
||||
</Space>
|
||||
</Radio.Group>
|
||||
);
|
||||
|
||||
return (
|
||||
<Flex justify="space-between" align="center">
|
||||
<Space size={'middle'}>
|
||||
<Link
|
||||
to={`/knowledge/${KnowledgeRouteKey.Dataset}?id=${knowledgeBaseId}`}
|
||||
>
|
||||
<ArrowLeftOutlined />
|
||||
</Link>
|
||||
<FilePdfOutlined />
|
||||
<Text ellipsis={{ tooltip: documentInfo?.name }} style={{ width: 150 }}>
|
||||
{documentInfo?.name}
|
||||
</Text>
|
||||
</Space>
|
||||
<Space>
|
||||
<Segmented
|
||||
options={[
|
||||
{ label: t(ChunkTextMode.Full), value: ChunkTextMode.Full },
|
||||
{ label: t(ChunkTextMode.Ellipse), value: ChunkTextMode.Ellipse },
|
||||
]}
|
||||
onChange={changeChunkTextMode as SegmentedProps['onChange']}
|
||||
/>
|
||||
<Popover content={content} placement="bottom" arrow={false}>
|
||||
<Button>
|
||||
{t('bulk')}
|
||||
<DownOutlined />
|
||||
</Button>
|
||||
</Popover>
|
||||
{isShowSearchBox ? (
|
||||
<Input
|
||||
size="middle"
|
||||
placeholder={t('search')}
|
||||
prefix={<SearchOutlined />}
|
||||
allowClear
|
||||
onChange={handleInputChange}
|
||||
onBlur={handleSearchBlur}
|
||||
value={searchString}
|
||||
/>
|
||||
) : (
|
||||
<Button icon={<SearchOutlined />} onClick={handleSearchIconClick} />
|
||||
)}
|
||||
|
||||
<Popover content={filterContent} placement="bottom" arrow={false}>
|
||||
<Button icon={<FilterIcon />} />
|
||||
</Popover>
|
||||
<Button
|
||||
icon={<PlusOutlined />}
|
||||
type="primary"
|
||||
onClick={() => createChunk()}
|
||||
/>
|
||||
</Space>
|
||||
</Flex>
|
||||
);
|
||||
};
|
||||
|
||||
export default ChunkToolBar;
|
||||
@ -0,0 +1,114 @@
|
||||
import message from '@/components/ui/message';
|
||||
import { Spin } from '@/components/ui/spin';
|
||||
import request from '@/utils/request';
|
||||
import classNames from 'classnames';
|
||||
import React, { useEffect, useRef, useState } from 'react';
|
||||
|
||||
interface CSVData {
|
||||
rows: string[][];
|
||||
headers: string[];
|
||||
}
|
||||
|
||||
interface FileViewerProps {
|
||||
className?: string;
|
||||
url: string;
|
||||
}
|
||||
|
||||
const CSVFileViewer: React.FC<FileViewerProps> = ({ url }) => {
|
||||
const [data, setData] = useState<CSVData | null>(null);
|
||||
const [isLoading, setIsLoading] = useState<boolean>(true);
|
||||
const containerRef = useRef<HTMLDivElement>(null);
|
||||
// const url = useGetDocumentUrl();
|
||||
const parseCSV = (csvText: string): CSVData => {
|
||||
console.log('Parsing CSV data:', csvText);
|
||||
const lines = csvText.split('\n');
|
||||
const headers = lines[0].split(',').map((header) => header.trim());
|
||||
const rows = lines
|
||||
.slice(1)
|
||||
.map((line) => line.split(',').map((cell) => cell.trim()));
|
||||
|
||||
return { headers, rows };
|
||||
};
|
||||
|
||||
useEffect(() => {
|
||||
const loadCSV = async () => {
|
||||
try {
|
||||
const res = await request(url, {
|
||||
method: 'GET',
|
||||
responseType: 'blob',
|
||||
onError: () => {
|
||||
message.error('file load failed');
|
||||
setIsLoading(false);
|
||||
},
|
||||
});
|
||||
|
||||
// parse CSV file
|
||||
const reader = new FileReader();
|
||||
reader.readAsText(res.data);
|
||||
reader.onload = () => {
|
||||
const parsedData = parseCSV(reader.result as string);
|
||||
console.log('file loaded successfully', reader.result);
|
||||
setData(parsedData);
|
||||
};
|
||||
} catch (error) {
|
||||
message.error('CSV file parse failed');
|
||||
console.error('Error loading CSV file:', error);
|
||||
} finally {
|
||||
setIsLoading(false);
|
||||
}
|
||||
};
|
||||
|
||||
loadCSV();
|
||||
|
||||
return () => {
|
||||
setData(null);
|
||||
};
|
||||
}, [url]);
|
||||
|
||||
return (
|
||||
<div
|
||||
ref={containerRef}
|
||||
className={classNames(
|
||||
'relative w-full h-full p-4 bg-background-paper border border-border-normal rounded-md',
|
||||
'overflow-auto max-h-[80vh] p-2',
|
||||
)}
|
||||
>
|
||||
{isLoading ? (
|
||||
<div className="absolute inset-0 flex items-center justify-center">
|
||||
<Spin />
|
||||
</div>
|
||||
) : data ? (
|
||||
<table className="min-w-full divide-y divide-border-normal">
|
||||
<thead className="bg-background-header-bar">
|
||||
<tr>
|
||||
{data.headers.map((header, index) => (
|
||||
<th
|
||||
key={`header-${index}`}
|
||||
className="px-6 py-3 text-left text-sm font-medium text-text-primary"
|
||||
>
|
||||
{header}
|
||||
</th>
|
||||
))}
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody className="bg-background-paper divide-y divide-border-normal">
|
||||
{data.rows.map((row, rowIndex) => (
|
||||
<tr key={`row-${rowIndex}`}>
|
||||
{row.map((cell, cellIndex) => (
|
||||
<td
|
||||
key={`cell-${rowIndex}-${cellIndex}`}
|
||||
className="px-6 py-4 whitespace-nowrap text-sm text-text-secondary"
|
||||
>
|
||||
{cell || '-'}
|
||||
</td>
|
||||
))}
|
||||
</tr>
|
||||
))}
|
||||
</tbody>
|
||||
</table>
|
||||
) : null}
|
||||
</div>
|
||||
);
|
||||
};
|
||||
|
||||
export default CSVFileViewer;
|
||||
@ -0,0 +1,70 @@
|
||||
import message from '@/components/ui/message';
|
||||
import { Spin } from '@/components/ui/spin';
|
||||
import request from '@/utils/request';
|
||||
import classNames from 'classnames';
|
||||
import mammoth from 'mammoth';
|
||||
import { useEffect, useState } from 'react';
|
||||
|
||||
interface DocPreviewerProps {
|
||||
className?: string;
|
||||
url: string;
|
||||
}
|
||||
|
||||
export const DocPreviewer: React.FC<DocPreviewerProps> = ({
|
||||
className,
|
||||
url,
|
||||
}) => {
|
||||
// const url = useGetDocumentUrl();
|
||||
const [htmlContent, setHtmlContent] = useState<string>('');
|
||||
const [loading, setLoading] = useState(false);
|
||||
const fetchDocument = async () => {
|
||||
setLoading(true);
|
||||
const res = await request(url, {
|
||||
method: 'GET',
|
||||
responseType: 'blob',
|
||||
onError: () => {
|
||||
message.error('Document parsing failed');
|
||||
console.error('Error loading document:', url);
|
||||
},
|
||||
});
|
||||
try {
|
||||
const arrayBuffer = await res.data.arrayBuffer();
|
||||
const result = await mammoth.convertToHtml(
|
||||
{ arrayBuffer },
|
||||
{ includeDefaultStyleMap: true },
|
||||
);
|
||||
|
||||
const styledContent = result.value
|
||||
.replace(/<p>/g, '<p class="mb-2">')
|
||||
.replace(/<h(\d)>/g, '<h$1 class="font-semibold mt-4 mb-2">');
|
||||
|
||||
setHtmlContent(styledContent);
|
||||
} catch (err) {
|
||||
message.error('Document parsing failed');
|
||||
console.error('Error parsing document:', err);
|
||||
}
|
||||
setLoading(false);
|
||||
};
|
||||
|
||||
useEffect(() => {
|
||||
if (url) {
|
||||
fetchDocument();
|
||||
}
|
||||
}, [url]);
|
||||
return (
|
||||
<div
|
||||
className={classNames(
|
||||
'relative w-full h-full p-4 bg-background-paper border border-border-normal rounded-md',
|
||||
className,
|
||||
)}
|
||||
>
|
||||
{loading && (
|
||||
<div className="absolute inset-0 flex items-center justify-center">
|
||||
<Spin />
|
||||
</div>
|
||||
)}
|
||||
|
||||
{!loading && <div dangerouslySetInnerHTML={{ __html: htmlContent }} />}
|
||||
</div>
|
||||
);
|
||||
};
|
||||
@ -0,0 +1,21 @@
|
||||
import { formatDate } from '@/utils/date';
|
||||
import { formatBytes } from '@/utils/file-util';
|
||||
|
||||
type Props = {
|
||||
size: number;
|
||||
name: string;
|
||||
create_date: string;
|
||||
};
|
||||
|
||||
export default ({ size, name, create_date }: Props) => {
|
||||
const sizeName = formatBytes(size);
|
||||
const dateStr = formatDate(create_date);
|
||||
return (
|
||||
<div>
|
||||
<h2 className="text-[16px]">{name}</h2>
|
||||
<div className="text-text-secondary text-[12px] pt-[5px]">
|
||||
Size:{sizeName} Uploaded Time:{dateStr}
|
||||
</div>
|
||||
</div>
|
||||
);
|
||||
};
|
||||
@ -0,0 +1,25 @@
|
||||
import { useFetchExcel } from '@/pages/document-viewer/hooks';
|
||||
import classNames from 'classnames';
|
||||
|
||||
interface ExcelCsvPreviewerProps {
|
||||
className?: string;
|
||||
url: string;
|
||||
}
|
||||
|
||||
export const ExcelCsvPreviewer: React.FC<ExcelCsvPreviewerProps> = ({
|
||||
className,
|
||||
url,
|
||||
}) => {
|
||||
// const url = useGetDocumentUrl();
|
||||
const { containerRef } = useFetchExcel(url);
|
||||
|
||||
return (
|
||||
<div
|
||||
ref={containerRef}
|
||||
className={classNames(
|
||||
'relative w-full h-full p-4 bg-background-paper border border-border-normal rounded-md excel-csv-previewer',
|
||||
className,
|
||||
)}
|
||||
></div>
|
||||
);
|
||||
};
|
||||
@ -0,0 +1,55 @@
|
||||
import { useGetKnowledgeSearchParams } from '@/hooks/route-hook';
|
||||
import { api_host } from '@/utils/api';
|
||||
import { useSize } from 'ahooks';
|
||||
import { CustomTextRenderer } from 'node_modules/react-pdf/dist/esm/shared/types';
|
||||
import { useCallback, useEffect, useMemo, useState } from 'react';
|
||||
|
||||
export const useDocumentResizeObserver = () => {
|
||||
const [containerWidth, setContainerWidth] = useState<number>();
|
||||
const [containerRef, setContainerRef] = useState<HTMLElement | null>(null);
|
||||
const size = useSize(containerRef);
|
||||
|
||||
const onResize = useCallback((width?: number) => {
|
||||
if (width) {
|
||||
setContainerWidth(width);
|
||||
}
|
||||
}, []);
|
||||
|
||||
useEffect(() => {
|
||||
onResize(size?.width);
|
||||
}, [size?.width, onResize]);
|
||||
|
||||
return { containerWidth, setContainerRef };
|
||||
};
|
||||
|
||||
function highlightPattern(text: string, pattern: string, pageNumber: number) {
|
||||
if (pageNumber === 2) {
|
||||
return `<mark>${text}</mark>`;
|
||||
}
|
||||
if (text.trim() !== '' && pattern.match(text)) {
|
||||
// return pattern.replace(text, (value) => `<mark>${value}</mark>`);
|
||||
return `<mark>${text}</mark>`;
|
||||
}
|
||||
return text.replace(pattern, (value) => `<mark>${value}</mark>`);
|
||||
}
|
||||
|
||||
export const useHighlightText = (searchText: string = '') => {
|
||||
const textRenderer: CustomTextRenderer = useCallback(
|
||||
(textItem) => {
|
||||
return highlightPattern(textItem.str, searchText, textItem.pageNumber);
|
||||
},
|
||||
[searchText],
|
||||
);
|
||||
|
||||
return textRenderer;
|
||||
};
|
||||
|
||||
export const useGetDocumentUrl = () => {
|
||||
const { documentId } = useGetKnowledgeSearchParams();
|
||||
|
||||
const url = useMemo(() => {
|
||||
return `${api_host}/document/get/${documentId}`;
|
||||
}, [documentId]);
|
||||
|
||||
return url;
|
||||
};
|
||||
@ -0,0 +1,73 @@
|
||||
import message from '@/components/ui/message';
|
||||
import { Spin } from '@/components/ui/spin';
|
||||
import request from '@/utils/request';
|
||||
import classNames from 'classnames';
|
||||
import { useEffect, useState } from 'react';
|
||||
|
||||
interface ImagePreviewerProps {
|
||||
className?: string;
|
||||
url: string;
|
||||
}
|
||||
|
||||
export const ImagePreviewer: React.FC<ImagePreviewerProps> = ({
|
||||
className,
|
||||
url,
|
||||
}) => {
|
||||
// const url = useGetDocumentUrl();
|
||||
const [imageSrc, setImageSrc] = useState<string | null>(null);
|
||||
const [isLoading, setIsLoading] = useState<boolean>(true);
|
||||
|
||||
const fetchImage = async () => {
|
||||
setIsLoading(true);
|
||||
const res = await request(url, {
|
||||
method: 'GET',
|
||||
responseType: 'blob',
|
||||
onError: () => {
|
||||
message.error('Failed to load image');
|
||||
setIsLoading(false);
|
||||
},
|
||||
});
|
||||
const objectUrl = URL.createObjectURL(res.data);
|
||||
setImageSrc(objectUrl);
|
||||
setIsLoading(false);
|
||||
};
|
||||
useEffect(() => {
|
||||
if (url) {
|
||||
fetchImage();
|
||||
}
|
||||
}, [url]);
|
||||
|
||||
useEffect(() => {
|
||||
return () => {
|
||||
if (imageSrc) {
|
||||
URL.revokeObjectURL(imageSrc);
|
||||
}
|
||||
};
|
||||
}, [imageSrc]);
|
||||
|
||||
return (
|
||||
<div
|
||||
className={classNames(
|
||||
'relative w-full h-full p-4 bg-background-paper border border-border-normal rounded-md image-previewer',
|
||||
className,
|
||||
)}
|
||||
>
|
||||
{isLoading && (
|
||||
<div className="absolute inset-0 flex items-center justify-center">
|
||||
<Spin />
|
||||
</div>
|
||||
)}
|
||||
|
||||
{!isLoading && imageSrc && (
|
||||
<div className="max-h-[80vh] overflow-auto p-2">
|
||||
<img
|
||||
src={imageSrc}
|
||||
alt={'image'}
|
||||
className="w-full h-auto max-w-full object-contain"
|
||||
onLoad={() => URL.revokeObjectURL(imageSrc!)}
|
||||
/>
|
||||
</div>
|
||||
)}
|
||||
</div>
|
||||
);
|
||||
};
|
||||
@ -0,0 +1,13 @@
|
||||
.documentContainer {
|
||||
width: 100%;
|
||||
// height: calc(100vh - 284px);
|
||||
height: calc(100vh - 170px);
|
||||
position: relative;
|
||||
:global(.PdfHighlighter) {
|
||||
overflow-x: hidden;
|
||||
}
|
||||
:global(.Highlight--scrolledTo .Highlight__part) {
|
||||
overflow-x: hidden;
|
||||
background-color: rgba(255, 226, 143, 1);
|
||||
}
|
||||
}
|
||||
@ -0,0 +1,68 @@
|
||||
import { memo } from 'react';
|
||||
|
||||
import CSVFileViewer from './csv-preview';
|
||||
import { DocPreviewer } from './doc-preview';
|
||||
import { ExcelCsvPreviewer } from './excel-preview';
|
||||
import { ImagePreviewer } from './image-preview';
|
||||
import styles from './index.less';
|
||||
import PdfPreviewer, { IProps } from './pdf-preview';
|
||||
import { PptPreviewer } from './ppt-preview';
|
||||
import { TxtPreviewer } from './txt-preview';
|
||||
|
||||
type PreviewProps = {
|
||||
fileType: string;
|
||||
className?: string;
|
||||
url: string;
|
||||
};
|
||||
const Preview = ({
|
||||
fileType,
|
||||
className,
|
||||
highlights,
|
||||
setWidthAndHeight,
|
||||
url,
|
||||
}: PreviewProps & Partial<IProps>) => {
|
||||
return (
|
||||
<>
|
||||
{fileType === 'pdf' && highlights && setWidthAndHeight && (
|
||||
<section className={styles.documentPreview}>
|
||||
<PdfPreviewer
|
||||
highlights={highlights}
|
||||
setWidthAndHeight={setWidthAndHeight}
|
||||
url={url}
|
||||
></PdfPreviewer>
|
||||
</section>
|
||||
)}
|
||||
{['doc', 'docx'].indexOf(fileType) > -1 && (
|
||||
<section>
|
||||
<DocPreviewer className={className} url={url} />
|
||||
</section>
|
||||
)}
|
||||
{['txt', 'md'].indexOf(fileType) > -1 && (
|
||||
<section>
|
||||
<TxtPreviewer className={className} url={url} />
|
||||
</section>
|
||||
)}
|
||||
{['visual'].indexOf(fileType) > -1 && (
|
||||
<section>
|
||||
<ImagePreviewer className={className} url={url} />
|
||||
</section>
|
||||
)}
|
||||
{['pptx'].indexOf(fileType) > -1 && (
|
||||
<section>
|
||||
<PptPreviewer className={className} url={url} />
|
||||
</section>
|
||||
)}
|
||||
{['xlsx'].indexOf(fileType) > -1 && (
|
||||
<section>
|
||||
<ExcelCsvPreviewer className={className} url={url} />
|
||||
</section>
|
||||
)}
|
||||
{['csv'].indexOf(fileType) > -1 && (
|
||||
<section>
|
||||
<CSVFileViewer className={className} url={url} />
|
||||
</section>
|
||||
)}
|
||||
</>
|
||||
);
|
||||
};
|
||||
export default memo(Preview);
|
||||
@ -0,0 +1,127 @@
|
||||
import { memo, useEffect, useRef } from 'react';
|
||||
import {
|
||||
AreaHighlight,
|
||||
Highlight,
|
||||
IHighlight,
|
||||
PdfHighlighter,
|
||||
PdfLoader,
|
||||
Popup,
|
||||
} from 'react-pdf-highlighter';
|
||||
|
||||
import { useCatchDocumentError } from '@/components/pdf-previewer/hooks';
|
||||
import { Spin } from '@/components/ui/spin';
|
||||
import FileError from '@/pages/document-viewer/file-error';
|
||||
import styles from './index.less';
|
||||
|
||||
export interface IProps {
|
||||
highlights: IHighlight[];
|
||||
setWidthAndHeight: (width: number, height: number) => void;
|
||||
url: string;
|
||||
}
|
||||
const HighlightPopup = ({
|
||||
comment,
|
||||
}: {
|
||||
comment: { text: string; emoji: string };
|
||||
}) =>
|
||||
comment.text ? (
|
||||
<div className="Highlight__popup">
|
||||
{comment.emoji} {comment.text}
|
||||
</div>
|
||||
) : null;
|
||||
|
||||
// TODO: merge with DocumentPreviewer
|
||||
const PdfPreview = ({ highlights: state, setWidthAndHeight, url }: IProps) => {
|
||||
// const url = useGetDocumentUrl();
|
||||
|
||||
const ref = useRef<(highlight: IHighlight) => void>(() => {});
|
||||
const error = useCatchDocumentError(url);
|
||||
|
||||
const resetHash = () => {};
|
||||
|
||||
useEffect(() => {
|
||||
if (state.length > 0) {
|
||||
ref?.current(state[0]);
|
||||
}
|
||||
}, [state]);
|
||||
|
||||
return (
|
||||
<div
|
||||
className={`${styles.documentContainer} rounded-[10px] overflow-hidden `}
|
||||
>
|
||||
<PdfLoader
|
||||
url={url}
|
||||
beforeLoad={
|
||||
<div className="absolute inset-0 flex items-center justify-center">
|
||||
<Spin />
|
||||
</div>
|
||||
}
|
||||
workerSrc="/pdfjs-dist/pdf.worker.min.js"
|
||||
errorMessage={<FileError>{error}</FileError>}
|
||||
>
|
||||
{(pdfDocument) => {
|
||||
pdfDocument.getPage(1).then((page) => {
|
||||
const viewport = page.getViewport({ scale: 1 });
|
||||
const width = viewport.width;
|
||||
const height = viewport.height;
|
||||
setWidthAndHeight(width, height);
|
||||
});
|
||||
|
||||
return (
|
||||
<PdfHighlighter
|
||||
pdfDocument={pdfDocument}
|
||||
enableAreaSelection={(event) => event.altKey}
|
||||
onScrollChange={resetHash}
|
||||
scrollRef={(scrollTo) => {
|
||||
ref.current = scrollTo;
|
||||
}}
|
||||
onSelectionFinished={() => null}
|
||||
highlightTransform={(
|
||||
highlight,
|
||||
index,
|
||||
setTip,
|
||||
hideTip,
|
||||
viewportToScaled,
|
||||
screenshot,
|
||||
isScrolledTo,
|
||||
) => {
|
||||
const isTextHighlight = !Boolean(
|
||||
highlight.content && highlight.content.image,
|
||||
);
|
||||
|
||||
const component = isTextHighlight ? (
|
||||
<Highlight
|
||||
isScrolledTo={isScrolledTo}
|
||||
position={highlight.position}
|
||||
comment={highlight.comment}
|
||||
/>
|
||||
) : (
|
||||
<AreaHighlight
|
||||
isScrolledTo={isScrolledTo}
|
||||
highlight={highlight}
|
||||
onChange={() => {}}
|
||||
/>
|
||||
);
|
||||
|
||||
return (
|
||||
<Popup
|
||||
popupContent={<HighlightPopup {...highlight} />}
|
||||
onMouseOver={(popupContent) =>
|
||||
setTip(highlight, () => popupContent)
|
||||
}
|
||||
onMouseOut={hideTip}
|
||||
key={index}
|
||||
>
|
||||
{component}
|
||||
</Popup>
|
||||
);
|
||||
}}
|
||||
highlights={state}
|
||||
/>
|
||||
);
|
||||
}}
|
||||
</PdfLoader>
|
||||
</div>
|
||||
);
|
||||
};
|
||||
|
||||
export default memo(PdfPreview);
|
||||
@ -0,0 +1,70 @@
|
||||
import message from '@/components/ui/message';
|
||||
import request from '@/utils/request';
|
||||
import classNames from 'classnames';
|
||||
import { init } from 'pptx-preview';
|
||||
import { useEffect, useRef } from 'react';
|
||||
interface PptPreviewerProps {
|
||||
className?: string;
|
||||
url: string;
|
||||
}
|
||||
|
||||
export const PptPreviewer: React.FC<PptPreviewerProps> = ({
|
||||
className,
|
||||
url,
|
||||
}) => {
|
||||
// const url = useGetDocumentUrl();
|
||||
const wrapper = useRef<HTMLDivElement>(null);
|
||||
const containerRef = useRef<HTMLDivElement>(null);
|
||||
const fetchDocument = async () => {
|
||||
const res = await request(url, {
|
||||
method: 'GET',
|
||||
responseType: 'blob',
|
||||
onError: () => {
|
||||
message.error('Document parsing failed');
|
||||
console.error('Error loading document:', url);
|
||||
},
|
||||
});
|
||||
console.log(res);
|
||||
try {
|
||||
const arrayBuffer = await res.data.arrayBuffer();
|
||||
|
||||
if (containerRef.current) {
|
||||
let width = 500;
|
||||
let height = 900;
|
||||
if (containerRef.current) {
|
||||
width = containerRef.current.clientWidth - 50;
|
||||
height = containerRef.current.clientHeight - 50;
|
||||
}
|
||||
let pptxPrviewer = init(containerRef.current, {
|
||||
width: width,
|
||||
height: height,
|
||||
});
|
||||
pptxPrviewer.preview(arrayBuffer);
|
||||
}
|
||||
} catch (err) {
|
||||
message.error('ppt parse failed');
|
||||
}
|
||||
};
|
||||
|
||||
useEffect(() => {
|
||||
if (url) {
|
||||
fetchDocument();
|
||||
}
|
||||
}, [url]);
|
||||
|
||||
return (
|
||||
<div
|
||||
ref={containerRef}
|
||||
className={classNames(
|
||||
'relative w-full h-full p-4 bg-background-paper border border-border-normal rounded-md ppt-previewer',
|
||||
className,
|
||||
)}
|
||||
>
|
||||
<div className="overflow-auto p-2">
|
||||
<div className="flex flex-col gap-4">
|
||||
<div ref={wrapper} />
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
);
|
||||
};
|
||||
@ -0,0 +1,56 @@
|
||||
import message from '@/components/ui/message';
|
||||
import { Spin } from '@/components/ui/spin';
|
||||
import request from '@/utils/request';
|
||||
import classNames from 'classnames';
|
||||
import { useEffect, useState } from 'react';
|
||||
|
||||
type TxtPreviewerProps = { className?: string; url: string };
|
||||
export const TxtPreviewer = ({ className, url }: TxtPreviewerProps) => {
|
||||
// const url = useGetDocumentUrl();
|
||||
const [loading, setLoading] = useState(false);
|
||||
const [data, setData] = useState<string>('');
|
||||
const fetchTxt = async () => {
|
||||
setLoading(true);
|
||||
const res = await request(url, {
|
||||
method: 'GET',
|
||||
responseType: 'blob',
|
||||
onError: (err: any) => {
|
||||
message.error('Failed to load file');
|
||||
console.error('Error loading file:', err);
|
||||
},
|
||||
});
|
||||
// blob to string
|
||||
const reader = new FileReader();
|
||||
reader.readAsText(res.data);
|
||||
reader.onload = () => {
|
||||
setData(reader.result as string);
|
||||
setLoading(false);
|
||||
console.log('file loaded successfully', reader.result);
|
||||
};
|
||||
console.log('file data:', res);
|
||||
};
|
||||
useEffect(() => {
|
||||
if (url) {
|
||||
fetchTxt();
|
||||
} else {
|
||||
setLoading(false);
|
||||
setData('');
|
||||
}
|
||||
}, [url]);
|
||||
return (
|
||||
<div
|
||||
className={classNames(
|
||||
'relative w-full h-full p-4 bg-background-paper border border-border-normal rounded-md',
|
||||
className,
|
||||
)}
|
||||
>
|
||||
{loading && (
|
||||
<div className="absolute inset-0 flex items-center justify-center">
|
||||
<Spin />
|
||||
</div>
|
||||
)}
|
||||
|
||||
{!loading && <pre className="whitespace-pre-wrap p-2 ">{data}</pre>}
|
||||
</div>
|
||||
);
|
||||
};
|
||||
@ -0,0 +1,48 @@
|
||||
import { Textarea } from '@/components/ui/textarea';
|
||||
import { cn } from '@/lib/utils';
|
||||
import { useState } from 'react';
|
||||
|
||||
interface FormatPreserveEditorProps {
|
||||
initialValue: string;
|
||||
onSave: (value: string) => void;
|
||||
className?: string;
|
||||
}
|
||||
const FormatPreserveEditor = ({
|
||||
initialValue,
|
||||
onSave,
|
||||
className,
|
||||
}: FormatPreserveEditorProps) => {
|
||||
const [content, setContent] = useState(initialValue);
|
||||
const [isEditing, setIsEditing] = useState(false);
|
||||
|
||||
const handleEdit = () => setIsEditing(true);
|
||||
|
||||
const handleSave = () => {
|
||||
onSave(content);
|
||||
setIsEditing(false);
|
||||
};
|
||||
|
||||
return (
|
||||
<div className="editor-container">
|
||||
{isEditing ? (
|
||||
<Textarea
|
||||
className={cn(
|
||||
'w-full h-full bg-transparent text-text-secondary',
|
||||
className,
|
||||
)}
|
||||
value={content}
|
||||
onChange={(e) => setContent(e.target.value)}
|
||||
onBlur={handleSave}
|
||||
autoSize={{ maxRows: 100 }}
|
||||
autoFocus
|
||||
/>
|
||||
) : (
|
||||
<pre className="text-text-secondary" onClick={handleEdit}>
|
||||
{content}
|
||||
</pre>
|
||||
)}
|
||||
</div>
|
||||
);
|
||||
};
|
||||
|
||||
export default FormatPreserveEditor;
|
||||
@ -0,0 +1,29 @@
|
||||
import SvgIcon from '@/components/svg-icon';
|
||||
import { Button } from '@/components/ui/button';
|
||||
import { CircleAlert } from 'lucide-react';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import { useRerunDataflow } from '../../hooks';
|
||||
interface RerunButtonProps {
|
||||
className?: string;
|
||||
}
|
||||
const RerunButton = (props: RerunButtonProps) => {
|
||||
const { t } = useTranslation();
|
||||
const { loading } = useRerunDataflow();
|
||||
const clickFunc = () => {
|
||||
console.log('click rerun button');
|
||||
};
|
||||
return (
|
||||
<div className="flex flex-col gap-2">
|
||||
<div className="text-xs text-text-primary flex items-center gap-1">
|
||||
<CircleAlert color="#d29e2d" strokeWidth={1} size={12} />
|
||||
{t('dataflowParser.rerunFromCurrentStepTip')}
|
||||
</div>
|
||||
<Button onClick={clickFunc} disabled={loading}>
|
||||
<SvgIcon name="rerun" width={16} />
|
||||
{t('dataflowParser.rerunFromCurrentStep')}
|
||||
</Button>
|
||||
</div>
|
||||
);
|
||||
};
|
||||
|
||||
export default RerunButton;
|
||||
82
web/src/pages/dataflow-result/components/time-line/index.tsx
Normal file
82
web/src/pages/dataflow-result/components/time-line/index.tsx
Normal file
@ -0,0 +1,82 @@
|
||||
import { CustomTimeline, TimelineNode } from '@/components/originui/timeline';
|
||||
import {
|
||||
CheckLine,
|
||||
FilePlayIcon,
|
||||
Grid3x2,
|
||||
ListPlus,
|
||||
PlayIcon,
|
||||
} from 'lucide-react';
|
||||
import { useMemo } from 'react';
|
||||
export const TimelineNodeObj = {
|
||||
begin: {
|
||||
id: 1,
|
||||
title: 'Begin',
|
||||
icon: <PlayIcon size={13} />,
|
||||
clickable: false,
|
||||
},
|
||||
parser: { id: 2, title: 'Parser', icon: <FilePlayIcon size={13} /> },
|
||||
chunker: { id: 3, title: 'Chunker', icon: <Grid3x2 size={13} /> },
|
||||
indexer: {
|
||||
id: 4,
|
||||
title: 'Indexer',
|
||||
icon: <ListPlus size={13} />,
|
||||
clickable: false,
|
||||
},
|
||||
complete: {
|
||||
id: 5,
|
||||
title: 'Complete',
|
||||
icon: <CheckLine size={13} />,
|
||||
clickable: false,
|
||||
},
|
||||
};
|
||||
|
||||
export interface TimelineDataFlowProps {
|
||||
activeId: number | string;
|
||||
activeFunc: (id: number | string) => void;
|
||||
}
|
||||
const TimelineDataFlow = ({ activeFunc, activeId }: TimelineDataFlowProps) => {
|
||||
// const [activeStep, setActiveStep] = useState(2);
|
||||
const timelineNodes: TimelineNode[] = useMemo(() => {
|
||||
const nodes: TimelineNode[] = [];
|
||||
Object.keys(TimelineNodeObj).forEach((key) => {
|
||||
nodes.push({
|
||||
...TimelineNodeObj[key as keyof typeof TimelineNodeObj],
|
||||
className: 'w-32',
|
||||
completed: false,
|
||||
});
|
||||
});
|
||||
return nodes;
|
||||
}, []);
|
||||
|
||||
const activeStep = useMemo(() => {
|
||||
const index = timelineNodes.findIndex((node) => node.id === activeId);
|
||||
return index > -1 ? index + 1 : 0;
|
||||
}, [activeId, timelineNodes]);
|
||||
const handleStepChange = (step: number, id: string | number) => {
|
||||
// setActiveStep(step);
|
||||
activeFunc?.(id);
|
||||
console.log(step, id);
|
||||
};
|
||||
|
||||
return (
|
||||
<div className="">
|
||||
<div>
|
||||
<CustomTimeline
|
||||
nodes={timelineNodes as TimelineNode[]}
|
||||
activeStep={activeStep}
|
||||
onStepChange={handleStepChange}
|
||||
orientation="horizontal"
|
||||
lineStyle="solid"
|
||||
nodeSize={24}
|
||||
activeStyle={{
|
||||
nodeSize: 30,
|
||||
iconColor: 'var(--accent-primary)',
|
||||
textColor: 'var(--accent-primary)',
|
||||
}}
|
||||
/>
|
||||
</div>
|
||||
</div>
|
||||
);
|
||||
};
|
||||
|
||||
export default TimelineDataFlow;
|
||||
4
web/src/pages/dataflow-result/constant.ts
Normal file
4
web/src/pages/dataflow-result/constant.ts
Normal file
@ -0,0 +1,4 @@
|
||||
export enum ChunkTextMode {
|
||||
Full = 'full',
|
||||
Ellipse = 'ellipse',
|
||||
}
|
||||
185
web/src/pages/dataflow-result/hooks.ts
Normal file
185
web/src/pages/dataflow-result/hooks.ts
Normal file
@ -0,0 +1,185 @@
|
||||
import message from '@/components/ui/message';
|
||||
import {
|
||||
useCreateChunk,
|
||||
useDeleteChunk,
|
||||
useSelectChunkList,
|
||||
} from '@/hooks/chunk-hooks';
|
||||
import { useSetModalState, useShowDeleteConfirm } from '@/hooks/common-hooks';
|
||||
import { useGetKnowledgeSearchParams } from '@/hooks/route-hook';
|
||||
import { IChunk } from '@/interfaces/database/knowledge';
|
||||
import { buildChunkHighlights } from '@/utils/document-util';
|
||||
import { useMutation, useQueryClient } from '@tanstack/react-query';
|
||||
import { useCallback, useMemo, useState } from 'react';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import { IHighlight } from 'react-pdf-highlighter';
|
||||
import { ChunkTextMode } from './constant';
|
||||
|
||||
export const useHandleChunkCardClick = () => {
|
||||
const [selectedChunkId, setSelectedChunkId] = useState<string>('');
|
||||
|
||||
const handleChunkCardClick = useCallback((chunkId: string) => {
|
||||
setSelectedChunkId(chunkId);
|
||||
}, []);
|
||||
|
||||
return { handleChunkCardClick, selectedChunkId };
|
||||
};
|
||||
|
||||
export const useGetSelectedChunk = (selectedChunkId: string) => {
|
||||
const data = useSelectChunkList();
|
||||
return (
|
||||
data?.data?.find((x) => x.chunk_id === selectedChunkId) ?? ({} as IChunk)
|
||||
);
|
||||
};
|
||||
|
||||
export const useGetChunkHighlights = (selectedChunkId: string) => {
|
||||
const [size, setSize] = useState({ width: 849, height: 1200 });
|
||||
const selectedChunk: IChunk = useGetSelectedChunk(selectedChunkId);
|
||||
|
||||
const highlights: IHighlight[] = useMemo(() => {
|
||||
return buildChunkHighlights(selectedChunk, size);
|
||||
}, [selectedChunk, size]);
|
||||
|
||||
const setWidthAndHeight = useCallback((width: number, height: number) => {
|
||||
setSize((pre) => {
|
||||
if (pre.height !== height || pre.width !== width) {
|
||||
return { height, width };
|
||||
}
|
||||
return pre;
|
||||
});
|
||||
}, []);
|
||||
|
||||
return { highlights, setWidthAndHeight };
|
||||
};
|
||||
|
||||
// Switch chunk text to be fully displayed or ellipse
|
||||
export const useChangeChunkTextMode = () => {
|
||||
const [textMode, setTextMode] = useState<ChunkTextMode>(ChunkTextMode.Full);
|
||||
|
||||
const changeChunkTextMode = useCallback((mode: ChunkTextMode) => {
|
||||
setTextMode(mode);
|
||||
}, []);
|
||||
|
||||
return { textMode, changeChunkTextMode };
|
||||
};
|
||||
|
||||
export const useDeleteChunkByIds = (): {
|
||||
removeChunk: (chunkIds: string[], documentId: string) => Promise<number>;
|
||||
} => {
|
||||
const { deleteChunk } = useDeleteChunk();
|
||||
const showDeleteConfirm = useShowDeleteConfirm();
|
||||
|
||||
const removeChunk = useCallback(
|
||||
(chunkIds: string[], documentId: string) => () => {
|
||||
return deleteChunk({ chunkIds, doc_id: documentId });
|
||||
},
|
||||
[deleteChunk],
|
||||
);
|
||||
|
||||
const onRemoveChunk = useCallback(
|
||||
(chunkIds: string[], documentId: string): Promise<number> => {
|
||||
return showDeleteConfirm({ onOk: removeChunk(chunkIds, documentId) });
|
||||
},
|
||||
[removeChunk, showDeleteConfirm],
|
||||
);
|
||||
|
||||
return {
|
||||
removeChunk: onRemoveChunk,
|
||||
};
|
||||
};
|
||||
|
||||
export const useUpdateChunk = () => {
|
||||
const [chunkId, setChunkId] = useState<string | undefined>('');
|
||||
const {
|
||||
visible: chunkUpdatingVisible,
|
||||
hideModal: hideChunkUpdatingModal,
|
||||
showModal,
|
||||
} = useSetModalState();
|
||||
const { createChunk, loading } = useCreateChunk();
|
||||
const { documentId } = useGetKnowledgeSearchParams();
|
||||
|
||||
const onChunkUpdatingOk = useCallback(
|
||||
async (params: IChunk) => {
|
||||
const code = await createChunk({
|
||||
...params,
|
||||
doc_id: documentId,
|
||||
chunk_id: chunkId,
|
||||
});
|
||||
|
||||
if (code === 0) {
|
||||
hideChunkUpdatingModal();
|
||||
}
|
||||
},
|
||||
[createChunk, hideChunkUpdatingModal, chunkId, documentId],
|
||||
);
|
||||
|
||||
const handleShowChunkUpdatingModal = useCallback(
|
||||
async (id?: string) => {
|
||||
setChunkId(id);
|
||||
showModal();
|
||||
},
|
||||
[showModal],
|
||||
);
|
||||
|
||||
return {
|
||||
chunkUpdatingLoading: loading,
|
||||
onChunkUpdatingOk,
|
||||
chunkUpdatingVisible,
|
||||
hideChunkUpdatingModal,
|
||||
showChunkUpdatingModal: handleShowChunkUpdatingModal,
|
||||
chunkId,
|
||||
documentId,
|
||||
};
|
||||
};
|
||||
|
||||
export const useFetchParserList = () => {
|
||||
const [loading, setLoading] = useState(false);
|
||||
return {
|
||||
loading,
|
||||
};
|
||||
};
|
||||
|
||||
export const useRerunDataflow = () => {
|
||||
const [loading, setLoading] = useState(false);
|
||||
return {
|
||||
loading,
|
||||
};
|
||||
};
|
||||
|
||||
export const useFetchPaserText = () => {
|
||||
const initialText =
|
||||
'第一行文本\n\t第二行缩进文本\n第三行 多个空格 第一行文本\n\t第二行缩进文本\n第三行 ' +
|
||||
'多个空格第一行文本\n\t第二行缩进文本\n第三行 多个空格第一行文本\n\t第二行缩进文本\n第三行 ' +
|
||||
'多个空格第一行文本\n\t第二行缩进文本\n第三行 多个空格第一行文本\n\t第二行缩进文本\n第三行 ' +
|
||||
'多个空格第一行文本\n\t第二行缩进文本\n第三行 多个空格第一行文本\n\t第二行缩进文本\n第三行 ' +
|
||||
'多个空格第一行文本\n\t第二行缩进文本\n第三行 多个空格第一行文本\n\t第二行缩进文本\n第三行 ' +
|
||||
'多个空格第一行文本\n\t第二行缩进文本\n第三行 多个空格第一行文本\n\t第二行缩进文本\n第三行 ' +
|
||||
'多个空格第一行文本\n\t第二行缩进文本\n第三行 多个空格第一行文本\n\t第二行缩进文本\n第三行 多个空格';
|
||||
const [loading, setLoading] = useState(false);
|
||||
const [data, setData] = useState<string>(initialText);
|
||||
const { t } = useTranslation();
|
||||
const queryClient = useQueryClient();
|
||||
|
||||
const {
|
||||
// data,
|
||||
// isPending: loading,
|
||||
mutateAsync,
|
||||
} = useMutation({
|
||||
mutationKey: ['createChunk'],
|
||||
mutationFn: async (payload: any) => {
|
||||
// let service = kbService.create_chunk;
|
||||
// if (payload.chunk_id) {
|
||||
// service = kbService.set_chunk;
|
||||
// }
|
||||
// const { data } = await service(payload);
|
||||
// if (data.code === 0) {
|
||||
message.success(t('message.created'));
|
||||
setTimeout(() => {
|
||||
queryClient.invalidateQueries({ queryKey: ['fetchChunkList'] });
|
||||
}, 1000); // Delay to ensure the list is updated
|
||||
// }
|
||||
// return data?.code;
|
||||
},
|
||||
});
|
||||
|
||||
return { data, loading, rerun: mutateAsync };
|
||||
};
|
||||
96
web/src/pages/dataflow-result/index.less
Normal file
96
web/src/pages/dataflow-result/index.less
Normal file
@ -0,0 +1,96 @@
|
||||
.chunkPage {
|
||||
padding: 24px;
|
||||
padding-top: 2px;
|
||||
|
||||
display: flex;
|
||||
// height: calc(100vh - 112px);
|
||||
height: 100vh;
|
||||
flex-direction: column;
|
||||
|
||||
.filter {
|
||||
margin: 10px 0;
|
||||
display: flex;
|
||||
height: 32px;
|
||||
justify-content: space-between;
|
||||
}
|
||||
|
||||
.pagePdfWrapper {
|
||||
width: 60%;
|
||||
}
|
||||
|
||||
.pageWrapper {
|
||||
width: 100%;
|
||||
}
|
||||
|
||||
.pageContent {
|
||||
flex: 1;
|
||||
width: 100%;
|
||||
padding-right: 12px;
|
||||
overflow-y: auto;
|
||||
|
||||
.spin {
|
||||
min-height: 400px;
|
||||
}
|
||||
}
|
||||
|
||||
.documentPreview {
|
||||
// width: 40%;
|
||||
height: calc(100vh - 180px);
|
||||
overflow: auto;
|
||||
}
|
||||
|
||||
.chunkContainer {
|
||||
display: flex;
|
||||
height: calc(100vh - 332px);
|
||||
}
|
||||
|
||||
.chunkOtherContainer {
|
||||
width: 100%;
|
||||
}
|
||||
|
||||
.pageFooter {
|
||||
padding-top: 10px;
|
||||
padding-right: 10px;
|
||||
height: 32px;
|
||||
}
|
||||
}
|
||||
|
||||
.container {
|
||||
height: 100px;
|
||||
display: flex;
|
||||
flex-direction: column;
|
||||
justify-content: space-between;
|
||||
|
||||
.content {
|
||||
display: flex;
|
||||
justify-content: space-between;
|
||||
|
||||
.context {
|
||||
flex: 1;
|
||||
// width: 207px;
|
||||
height: 88px;
|
||||
overflow: hidden;
|
||||
}
|
||||
}
|
||||
|
||||
.footer {
|
||||
height: 20px;
|
||||
|
||||
.text {
|
||||
margin-left: 10px;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
.card {
|
||||
:global {
|
||||
.ant-card-body {
|
||||
padding: 10px;
|
||||
margin: 0;
|
||||
}
|
||||
|
||||
margin-bottom: 10px;
|
||||
}
|
||||
|
||||
cursor: pointer;
|
||||
}
|
||||
121
web/src/pages/dataflow-result/index.tsx
Normal file
121
web/src/pages/dataflow-result/index.tsx
Normal file
@ -0,0 +1,121 @@
|
||||
import { useFetchNextChunkList } from '@/hooks/use-chunk-request';
|
||||
import { useMemo, useState } from 'react';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import DocumentPreview from './components/document-preview';
|
||||
import { useGetChunkHighlights, useHandleChunkCardClick } from './hooks';
|
||||
|
||||
import DocumentHeader from './components/document-preview/document-header';
|
||||
|
||||
import { PageHeader } from '@/components/page-header';
|
||||
import {
|
||||
Breadcrumb,
|
||||
BreadcrumbItem,
|
||||
BreadcrumbLink,
|
||||
BreadcrumbList,
|
||||
BreadcrumbPage,
|
||||
BreadcrumbSeparator,
|
||||
} from '@/components/ui/breadcrumb';
|
||||
import {
|
||||
QueryStringMap,
|
||||
useNavigatePage,
|
||||
} from '@/hooks/logic-hooks/navigate-hooks';
|
||||
import { useFetchKnowledgeBaseConfiguration } from '@/hooks/use-knowledge-request';
|
||||
import { ChunkerContainer } from './chunker';
|
||||
import { useGetDocumentUrl } from './components/document-preview/hooks';
|
||||
import TimelineDataFlow, { TimelineNodeObj } from './components/time-line';
|
||||
import styles from './index.less';
|
||||
import ParserContainer from './parser';
|
||||
|
||||
const Chunk = () => {
|
||||
const {
|
||||
data: { documentInfo },
|
||||
} = useFetchNextChunkList();
|
||||
const { selectedChunkId } = useHandleChunkCardClick();
|
||||
const [activeStepId, setActiveStepId] = useState<number | string>(0);
|
||||
const { data: dataset } = useFetchKnowledgeBaseConfiguration();
|
||||
|
||||
const { t } = useTranslation();
|
||||
|
||||
const { navigateToDataset, getQueryString, navigateToDatasetList } =
|
||||
useNavigatePage();
|
||||
const fileUrl = useGetDocumentUrl();
|
||||
|
||||
const { highlights, setWidthAndHeight } =
|
||||
useGetChunkHighlights(selectedChunkId);
|
||||
|
||||
const fileType = useMemo(() => {
|
||||
switch (documentInfo?.type) {
|
||||
case 'doc':
|
||||
return documentInfo?.name.split('.').pop() || 'doc';
|
||||
case 'visual':
|
||||
case 'docx':
|
||||
case 'txt':
|
||||
case 'md':
|
||||
case 'pdf':
|
||||
return documentInfo?.type;
|
||||
}
|
||||
return 'unknown';
|
||||
}, [documentInfo]);
|
||||
|
||||
const handleStepChange = (id: number | string) => {
|
||||
setActiveStepId(id);
|
||||
};
|
||||
return (
|
||||
<>
|
||||
<PageHeader>
|
||||
<Breadcrumb>
|
||||
<BreadcrumbList>
|
||||
<BreadcrumbItem>
|
||||
<BreadcrumbLink onClick={navigateToDatasetList}>
|
||||
{t('knowledgeDetails.dataset')}
|
||||
</BreadcrumbLink>
|
||||
</BreadcrumbItem>
|
||||
<BreadcrumbSeparator />
|
||||
<BreadcrumbItem>
|
||||
<BreadcrumbLink
|
||||
onClick={navigateToDataset(
|
||||
getQueryString(QueryStringMap.id) as string,
|
||||
)}
|
||||
>
|
||||
{dataset.name}
|
||||
</BreadcrumbLink>
|
||||
</BreadcrumbItem>
|
||||
<BreadcrumbSeparator />
|
||||
<BreadcrumbItem>
|
||||
<BreadcrumbPage>{documentInfo?.name}</BreadcrumbPage>
|
||||
</BreadcrumbItem>
|
||||
</BreadcrumbList>
|
||||
</Breadcrumb>
|
||||
</PageHeader>
|
||||
<div className=" absolute ml-[50%] translate-x-[-50%] top-4 flex justify-center">
|
||||
<TimelineDataFlow
|
||||
activeFunc={handleStepChange}
|
||||
activeId={activeStepId}
|
||||
/>
|
||||
</div>
|
||||
<div className={styles.chunkPage}>
|
||||
<div className="flex flex-none gap-8 border border-border mt-[26px] p-3 rounded-lg h-[calc(100vh-100px)]">
|
||||
<div className="w-2/5">
|
||||
<div className="h-[50px] flex flex-col justify-end pb-[5px]">
|
||||
<DocumentHeader {...documentInfo} />
|
||||
</div>
|
||||
<section className={styles.documentPreview}>
|
||||
<DocumentPreview
|
||||
className={styles.documentPreview}
|
||||
fileType={fileType}
|
||||
highlights={highlights}
|
||||
setWidthAndHeight={setWidthAndHeight}
|
||||
url={fileUrl}
|
||||
></DocumentPreview>
|
||||
</section>
|
||||
</div>
|
||||
<div className="h-dvh border-r -mt-3"></div>
|
||||
{activeStepId === TimelineNodeObj.chunker.id && <ChunkerContainer />}
|
||||
{activeStepId === TimelineNodeObj.parser.id && <ParserContainer />}
|
||||
</div>
|
||||
</div>
|
||||
</>
|
||||
);
|
||||
};
|
||||
|
||||
export default Chunk;
|
||||
58
web/src/pages/dataflow-result/parser.tsx
Normal file
58
web/src/pages/dataflow-result/parser.tsx
Normal file
@ -0,0 +1,58 @@
|
||||
import Spotlight from '@/components/spotlight';
|
||||
import { Spin } from '@/components/ui/spin';
|
||||
import classNames from 'classnames';
|
||||
import { useState } from 'react';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import FormatPreserveEditor from './components/parse-editer';
|
||||
import RerunButton from './components/rerun-button';
|
||||
import { useFetchParserList, useFetchPaserText } from './hooks';
|
||||
const ParserContainer = () => {
|
||||
const { data: initialValue, rerun: onSave } = useFetchPaserText();
|
||||
const { t } = useTranslation();
|
||||
const { loading } = useFetchParserList();
|
||||
|
||||
const [initialText, setInitialText] = useState(initialValue);
|
||||
const [isChange, setIsChange] = useState(false);
|
||||
const handleSave = (newContent: string) => {
|
||||
console.log('保存内容:', newContent);
|
||||
if (newContent !== initialText) {
|
||||
setIsChange(true);
|
||||
onSave(newContent);
|
||||
} else {
|
||||
setIsChange(false);
|
||||
}
|
||||
// Here, the API is called to send newContent to the backend
|
||||
};
|
||||
return (
|
||||
<>
|
||||
{isChange && (
|
||||
<div className=" absolute top-2 right-6">
|
||||
<RerunButton />
|
||||
</div>
|
||||
)}
|
||||
<div className={classNames('flex flex-col w-3/5')}>
|
||||
<Spin spinning={loading} className="" size="large">
|
||||
<div className="h-[50px] flex flex-col justify-end pb-[5px]">
|
||||
<div>
|
||||
<h2 className="text-[16px]">
|
||||
{t('dataflowParser.parseSummary')}
|
||||
</h2>
|
||||
<div className="text-[12px] text-text-secondary italic ">
|
||||
{t('dataflowParser.parseSummaryTip')}
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
<div className=" border rounded-lg p-[20px] box-border h-[calc(100vh-180px)] overflow-auto scrollbar-none">
|
||||
<FormatPreserveEditor
|
||||
initialValue={initialText}
|
||||
onSave={handleSave}
|
||||
className="!h-[calc(100vh-220px)]"
|
||||
/>
|
||||
<Spotlight opcity={0.6} coverage={60} />
|
||||
</div>
|
||||
</Spin>
|
||||
</div>
|
||||
</>
|
||||
);
|
||||
};
|
||||
export default ParserContainer;
|
||||
24
web/src/pages/dataflow-result/utils.ts
Normal file
24
web/src/pages/dataflow-result/utils.ts
Normal file
@ -0,0 +1,24 @@
|
||||
export type FormListItem = {
|
||||
frequency: number;
|
||||
tag: string;
|
||||
};
|
||||
|
||||
export function transformTagFeaturesArrayToObject(
|
||||
list: Array<FormListItem> = [],
|
||||
) {
|
||||
return list.reduce<Record<string, number>>((pre, cur) => {
|
||||
pre[cur.tag] = cur.frequency;
|
||||
|
||||
return pre;
|
||||
}, {});
|
||||
}
|
||||
|
||||
export function transformTagFeaturesObjectToArray(
|
||||
object: Record<string, number> = {},
|
||||
) {
|
||||
return Object.keys(object).reduce<Array<FormListItem>>((pre, key) => {
|
||||
pre.push({ frequency: object[key], tag: key });
|
||||
|
||||
return pre;
|
||||
}, []);
|
||||
}
|
||||
9
web/src/pages/dataset/dataset-overview/dataset-common.ts
Normal file
9
web/src/pages/dataset/dataset-overview/dataset-common.ts
Normal file
@ -0,0 +1,9 @@
|
||||
export enum LogTabs {
|
||||
FILE_LOGS = 'fileLogs',
|
||||
DATASET_LOGS = 'datasetLogs',
|
||||
}
|
||||
|
||||
export enum processingType {
|
||||
knowledgeGraph = 'knowledgeGraph',
|
||||
raptor = 'raptor',
|
||||
}
|
||||
91
web/src/pages/dataset/dataset-overview/dataset-filter.tsx
Normal file
91
web/src/pages/dataset/dataset-overview/dataset-filter.tsx
Normal file
@ -0,0 +1,91 @@
|
||||
import { FilterButton } from '@/components/list-filter-bar';
|
||||
import {
|
||||
CheckboxFormMultipleProps,
|
||||
FilterPopover,
|
||||
} from '@/components/list-filter-bar/filter-popover';
|
||||
import { Button } from '@/components/ui/button';
|
||||
import { SearchInput } from '@/components/ui/input';
|
||||
import { cn } from '@/lib/utils';
|
||||
import { ChangeEventHandler, useMemo } from 'react';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import { LogTabs } from './dataset-common';
|
||||
|
||||
interface IProps {
|
||||
searchString?: string;
|
||||
onSearchChange?: ChangeEventHandler<HTMLInputElement>;
|
||||
active?: (typeof LogTabs)[keyof typeof LogTabs];
|
||||
setActive?: (active: (typeof LogTabs)[keyof typeof LogTabs]) => void;
|
||||
}
|
||||
const DatasetFilter = (
|
||||
props: IProps & Omit<CheckboxFormMultipleProps, 'setOpen'>,
|
||||
) => {
|
||||
const {
|
||||
searchString,
|
||||
onSearchChange,
|
||||
value,
|
||||
onChange,
|
||||
filters,
|
||||
onOpenChange,
|
||||
active = LogTabs.FILE_LOGS,
|
||||
setActive,
|
||||
...rest
|
||||
} = props;
|
||||
const { t } = useTranslation();
|
||||
const filterCount = useMemo(() => {
|
||||
return typeof value === 'object' && value !== null
|
||||
? Object.values(value).reduce((pre, cur) => {
|
||||
return pre + cur.length;
|
||||
}, 0)
|
||||
: 0;
|
||||
}, [value]);
|
||||
return (
|
||||
<div className="flex items-center justify-between mb-4">
|
||||
<div className="flex space-x-2 bg-bg-card p-1 rounded-md">
|
||||
<Button
|
||||
className={cn(
|
||||
'px-4 py-2 rounded-md hover:text-text-primary hover:bg-bg-base',
|
||||
{
|
||||
'bg-bg-base text-text-primary': active === LogTabs.FILE_LOGS,
|
||||
'bg-transparent text-text-secondary ':
|
||||
active !== LogTabs.FILE_LOGS,
|
||||
},
|
||||
)}
|
||||
onClick={() => setActive?.(LogTabs.FILE_LOGS)}
|
||||
>
|
||||
{t('knowledgeDetails.fileLogs')}
|
||||
</Button>
|
||||
<Button
|
||||
className={cn(
|
||||
'px-4 py-2 rounded-md hover:text-text-primary hover:bg-bg-base',
|
||||
{
|
||||
'bg-bg-base text-text-primary': active === LogTabs.DATASET_LOGS,
|
||||
'bg-transparent text-text-secondary ':
|
||||
active !== LogTabs.DATASET_LOGS,
|
||||
},
|
||||
)}
|
||||
onClick={() => setActive?.(LogTabs.DATASET_LOGS)}
|
||||
>
|
||||
{t('knowledgeDetails.datasetLogs')}
|
||||
</Button>
|
||||
</div>
|
||||
<div className="flex items-center space-x-2">
|
||||
<FilterPopover
|
||||
value={value}
|
||||
onChange={onChange}
|
||||
filters={filters}
|
||||
onOpenChange={onOpenChange}
|
||||
>
|
||||
<FilterButton count={filterCount}></FilterButton>
|
||||
</FilterPopover>
|
||||
|
||||
<SearchInput
|
||||
value={searchString}
|
||||
onChange={onSearchChange}
|
||||
className="w-32"
|
||||
></SearchInput>
|
||||
</div>
|
||||
</div>
|
||||
);
|
||||
};
|
||||
|
||||
export { DatasetFilter };
|
||||
156
web/src/pages/dataset/dataset-overview/index.tsx
Normal file
156
web/src/pages/dataset/dataset-overview/index.tsx
Normal file
@ -0,0 +1,156 @@
|
||||
import {
|
||||
CircleQuestionMark,
|
||||
Cpu,
|
||||
FileChartLine,
|
||||
HardDriveDownload,
|
||||
} from 'lucide-react';
|
||||
import { FC, useState } from 'react';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import { LogTabs } from './dataset-common';
|
||||
import { DatasetFilter } from './dataset-filter';
|
||||
import FileLogsTable from './overview-table';
|
||||
|
||||
interface StatCardProps {
|
||||
title: string;
|
||||
value: number;
|
||||
icon: JSX.Element;
|
||||
children?: JSX.Element;
|
||||
}
|
||||
|
||||
const StatCard: FC<StatCardProps> = ({ title, value, children, icon }) => {
|
||||
return (
|
||||
<div className="bg-bg-card p-4 rounded-lg border border-border flex flex-col gap-2">
|
||||
<div className="flex items-center justify-between">
|
||||
<h3 className="flex items-center gap-1 text-sm font-medium text-text-secondary">
|
||||
{title}
|
||||
<CircleQuestionMark size={12} />
|
||||
</h3>
|
||||
{icon}
|
||||
</div>
|
||||
<div className="text-2xl font-bold text-text-primary">{value}</div>
|
||||
<div className="h-12 w-full flex items-center">
|
||||
<div className="flex-1">{children}</div>
|
||||
</div>
|
||||
</div>
|
||||
);
|
||||
};
|
||||
|
||||
interface CardFooterProcessProps {
|
||||
total: number;
|
||||
completed: number;
|
||||
success: number;
|
||||
failed: number;
|
||||
}
|
||||
const CardFooterProcess: FC<CardFooterProcessProps> = ({
|
||||
total,
|
||||
completed,
|
||||
success,
|
||||
failed,
|
||||
}) => {
|
||||
const { t } = useTranslation();
|
||||
const successPrecentage = (success / total) * 100;
|
||||
const failedPrecentage = (failed / total) * 100;
|
||||
return (
|
||||
<div className="flex items-center flex-col gap-2">
|
||||
<div className="flex justify-between w-full text-sm text-text-secondary">
|
||||
<div className="flex items-center gap-2">
|
||||
<div className="flex items-center gap-1">
|
||||
{success}
|
||||
<span>{t('knowledgeDetails.success')}</span>
|
||||
</div>
|
||||
<div className="flex items-center gap-1">
|
||||
{failed}
|
||||
<span>{t('knowledgeDetails.failed')}</span>
|
||||
</div>
|
||||
</div>
|
||||
<div className="flex items-center gap-1">
|
||||
{completed}
|
||||
<span>{t('knowledgeDetails.completed')}</span>
|
||||
</div>
|
||||
</div>
|
||||
<div className="w-full flex rounded-full h-3 bg-bg-card text-sm font-bold text-text-primary">
|
||||
<div
|
||||
className=" rounded-full h-3 bg-accent-primary"
|
||||
style={{ width: successPrecentage + '%' }}
|
||||
></div>
|
||||
<div
|
||||
className=" rounded-full h-3 bg-state-error"
|
||||
style={{ width: failedPrecentage + '%' }}
|
||||
></div>
|
||||
</div>
|
||||
</div>
|
||||
);
|
||||
};
|
||||
const FileLogsPage: FC = () => {
|
||||
const { t } = useTranslation();
|
||||
const [active, setActive] = useState<(typeof LogTabs)[keyof typeof LogTabs]>(
|
||||
LogTabs.FILE_LOGS,
|
||||
);
|
||||
const mockData = Array(30)
|
||||
.fill(0)
|
||||
.map((_, i) => ({
|
||||
id: i === 0 ? '#952734' : `14`,
|
||||
fileName: 'PRD for DealBees 1.2 (1).txt',
|
||||
source: 'GitHub',
|
||||
pipeline: i === 0 ? 'data demo for...' : i === 1 ? 'test' : 'kiki’s demo',
|
||||
startDate: '14/03/2025 14:53:39',
|
||||
task: i === 0 ? 'Parse' : 'Parser',
|
||||
status:
|
||||
i === 0
|
||||
? 'Success'
|
||||
: i === 1
|
||||
? 'Failed'
|
||||
: i === 2
|
||||
? 'Running'
|
||||
: 'Pending',
|
||||
}));
|
||||
|
||||
const pagination = {
|
||||
current: 1,
|
||||
pageSize: 30,
|
||||
total: 100,
|
||||
};
|
||||
|
||||
const changeActiveLogs = (active: (typeof LogTabs)[keyof typeof LogTabs]) => {
|
||||
setActive(active);
|
||||
};
|
||||
const handlePaginationChange = (page: number, pageSize: number) => {
|
||||
console.log('Pagination changed:', { page, pageSize });
|
||||
};
|
||||
|
||||
return (
|
||||
<div className="p-5 min-w-[880px] border-border border rounded-lg mr-5">
|
||||
{/* Stats Cards */}
|
||||
<div className="grid grid-cols-3 md:grid-cols-3 gap-4 mb-6">
|
||||
<StatCard title="Total Files" value={2827} icon={<FileChartLine />}>
|
||||
<div>+7% from last week</div>
|
||||
</StatCard>
|
||||
<StatCard title="Downloading" value={28} icon={<HardDriveDownload />}>
|
||||
<CardFooterProcess
|
||||
total={100}
|
||||
success={8}
|
||||
failed={2}
|
||||
completed={15}
|
||||
/>
|
||||
</StatCard>
|
||||
<StatCard title="Processing" value={156} icon={<Cpu />}>
|
||||
<CardFooterProcess total={20} success={8} failed={2} completed={15} />
|
||||
</StatCard>
|
||||
</div>
|
||||
|
||||
{/* Tabs & Search */}
|
||||
<DatasetFilter active={active} setActive={changeActiveLogs} />
|
||||
|
||||
{/* Table */}
|
||||
<FileLogsTable
|
||||
data={mockData}
|
||||
pagination={pagination}
|
||||
setPagination={handlePaginationChange}
|
||||
pageCount={10}
|
||||
active={active}
|
||||
/>
|
||||
</div>
|
||||
);
|
||||
};
|
||||
|
||||
export default FileLogsPage;
|
||||
384
web/src/pages/dataset/dataset-overview/overview-table.tsx
Normal file
384
web/src/pages/dataset/dataset-overview/overview-table.tsx
Normal file
@ -0,0 +1,384 @@
|
||||
import FileStatusBadge from '@/components/file-status-badge';
|
||||
import { FileIcon } from '@/components/icon-font';
|
||||
import { RAGFlowAvatar } from '@/components/ragflow-avatar';
|
||||
import SvgIcon from '@/components/svg-icon';
|
||||
import { Button } from '@/components/ui/button';
|
||||
import { RAGFlowPagination } from '@/components/ui/ragflow-pagination';
|
||||
import {
|
||||
Table,
|
||||
TableBody,
|
||||
TableCell,
|
||||
TableHead,
|
||||
TableHeader,
|
||||
TableRow,
|
||||
} from '@/components/ui/table';
|
||||
import { useTranslate } from '@/hooks/common-hooks';
|
||||
import { useNavigatePage } from '@/hooks/logic-hooks/navigate-hooks';
|
||||
import ProcessLogModal from '@/pages/datasets/process-log-modal';
|
||||
import {
|
||||
ColumnDef,
|
||||
ColumnFiltersState,
|
||||
SortingState,
|
||||
flexRender,
|
||||
getCoreRowModel,
|
||||
getFilteredRowModel,
|
||||
getPaginationRowModel,
|
||||
getSortedRowModel,
|
||||
useReactTable,
|
||||
} from '@tanstack/react-table';
|
||||
import { TFunction } from 'i18next';
|
||||
import { ClipboardList, Eye } from 'lucide-react';
|
||||
import { Dispatch, FC, SetStateAction, useMemo, useState } from 'react';
|
||||
import { LogTabs, processingType } from './dataset-common';
|
||||
|
||||
interface DocumentLog {
|
||||
id: string;
|
||||
fileName: string;
|
||||
source: string;
|
||||
pipeline: string;
|
||||
startDate: string;
|
||||
task: string;
|
||||
status: 'Success' | 'Failed' | 'Running' | 'Pending';
|
||||
}
|
||||
|
||||
interface FileLogsTableProps {
|
||||
data: DocumentLog[];
|
||||
pageCount: number;
|
||||
pagination: {
|
||||
current: number;
|
||||
pageSize: number;
|
||||
total: number;
|
||||
};
|
||||
setPagination: (pagination: { page: number; pageSize: number }) => void;
|
||||
loading?: boolean;
|
||||
active: (typeof LogTabs)[keyof typeof LogTabs];
|
||||
}
|
||||
|
||||
export const getFileLogsTableColumns = (
|
||||
t: TFunction<'translation', string>,
|
||||
setIsModalVisible: Dispatch<SetStateAction<boolean>>,
|
||||
navigateToDataflowResult: (
|
||||
id: string,
|
||||
knowledgeId?: string | undefined,
|
||||
) => () => void,
|
||||
) => {
|
||||
// const { t } = useTranslate('knowledgeDetails');
|
||||
const columns: ColumnDef<DocumentLog>[] = [
|
||||
{
|
||||
id: 'select',
|
||||
header: ({ table }) => (
|
||||
<input
|
||||
type="checkbox"
|
||||
checked={table.getIsAllRowsSelected()}
|
||||
onChange={table.getToggleAllRowsSelectedHandler()}
|
||||
className="rounded bg-gray-900 text-blue-500 focus:ring-blue-500"
|
||||
/>
|
||||
),
|
||||
cell: ({ row }) => (
|
||||
<input
|
||||
type="checkbox"
|
||||
checked={row.getIsSelected()}
|
||||
onChange={row.getToggleSelectedHandler()}
|
||||
className="rounded border-gray-600 bg-gray-900 text-blue-500 focus:ring-blue-500"
|
||||
/>
|
||||
),
|
||||
},
|
||||
{
|
||||
accessorKey: 'id',
|
||||
header: 'ID',
|
||||
cell: ({ row }) => (
|
||||
<div className="text-text-primary">{row.original.id}</div>
|
||||
),
|
||||
},
|
||||
{
|
||||
accessorKey: 'fileName',
|
||||
header: t('fileName'),
|
||||
cell: ({ row }) => (
|
||||
<div
|
||||
className="flex items-center gap-2 text-text-primary"
|
||||
onClick={navigateToDataflowResult(
|
||||
row.original.id,
|
||||
row.original.kb_id,
|
||||
)}
|
||||
>
|
||||
<FileIcon name={row.original.fileName}></FileIcon>
|
||||
{row.original.fileName}
|
||||
</div>
|
||||
),
|
||||
},
|
||||
{
|
||||
accessorKey: 'source',
|
||||
header: t('source'),
|
||||
cell: ({ row }) => (
|
||||
<div className="text-text-primary">{row.original.source}</div>
|
||||
),
|
||||
},
|
||||
{
|
||||
accessorKey: 'pipeline',
|
||||
header: t('dataPipeline'),
|
||||
cell: ({ row }) => (
|
||||
<div className="flex items-center gap-2 text-text-primary">
|
||||
<RAGFlowAvatar
|
||||
avatar={null}
|
||||
name={row.original.pipeline}
|
||||
className="size-4"
|
||||
/>
|
||||
{row.original.pipeline}
|
||||
</div>
|
||||
),
|
||||
},
|
||||
{
|
||||
accessorKey: 'startDate',
|
||||
header: t('startDate'),
|
||||
cell: ({ row }) => (
|
||||
<div className="text-text-primary">{row.original.startDate}</div>
|
||||
),
|
||||
},
|
||||
{
|
||||
accessorKey: 'task',
|
||||
header: t('task'),
|
||||
cell: ({ row }) => (
|
||||
<div className="text-text-primary">{row.original.task}</div>
|
||||
),
|
||||
},
|
||||
{
|
||||
accessorKey: 'status',
|
||||
header: t('status'),
|
||||
cell: ({ row }) => <FileStatusBadge status={row.original.status} />,
|
||||
},
|
||||
{
|
||||
id: 'operations',
|
||||
header: t('operations'),
|
||||
cell: ({ row }) => (
|
||||
<div className="flex justify-start space-x-2">
|
||||
<Button
|
||||
variant="ghost"
|
||||
size="sm"
|
||||
className="p-1"
|
||||
onClick={() => {
|
||||
setIsModalVisible(true);
|
||||
}}
|
||||
>
|
||||
<Eye />
|
||||
</Button>
|
||||
<Button
|
||||
variant="ghost"
|
||||
size="sm"
|
||||
className="p-1"
|
||||
onClick={navigateToDataflowResult(row.original.id)}
|
||||
>
|
||||
<ClipboardList />
|
||||
</Button>
|
||||
</div>
|
||||
),
|
||||
},
|
||||
];
|
||||
|
||||
return columns;
|
||||
};
|
||||
|
||||
export const getDatasetLogsTableColumns = (
|
||||
t: TFunction<'translation', string>,
|
||||
setIsModalVisible: Dispatch<SetStateAction<boolean>>,
|
||||
) => {
|
||||
// const { t } = useTranslate('knowledgeDetails');
|
||||
const columns: ColumnDef<DocumentLog>[] = [
|
||||
{
|
||||
id: 'select',
|
||||
header: ({ table }) => (
|
||||
<input
|
||||
type="checkbox"
|
||||
checked={table.getIsAllRowsSelected()}
|
||||
onChange={table.getToggleAllRowsSelectedHandler()}
|
||||
className="rounded bg-gray-900 text-blue-500 focus:ring-blue-500"
|
||||
/>
|
||||
),
|
||||
cell: ({ row }) => (
|
||||
<input
|
||||
type="checkbox"
|
||||
checked={row.getIsSelected()}
|
||||
onChange={row.getToggleSelectedHandler()}
|
||||
className="rounded border-gray-600 bg-gray-900 text-blue-500 focus:ring-blue-500"
|
||||
/>
|
||||
),
|
||||
},
|
||||
{
|
||||
accessorKey: 'id',
|
||||
header: 'ID',
|
||||
cell: ({ row }) => (
|
||||
<div className="text-text-primary">{row.original.id}</div>
|
||||
),
|
||||
},
|
||||
{
|
||||
accessorKey: 'startDate',
|
||||
header: t('startDate'),
|
||||
cell: ({ row }) => (
|
||||
<div className="text-text-primary">{row.original.startDate}</div>
|
||||
),
|
||||
},
|
||||
{
|
||||
accessorKey: 'processingType',
|
||||
header: t('processingType'),
|
||||
cell: ({ row }) => (
|
||||
<div className="flex items-center gap-2 text-text-primary">
|
||||
{processingType.knowledgeGraph === row.original.processingType && (
|
||||
<SvgIcon name={`data-flow/knowledgegraph`} width={24}></SvgIcon>
|
||||
)}
|
||||
{processingType.raptor === row.original.processingType && (
|
||||
<SvgIcon name={`data-flow/raptor`} width={24}></SvgIcon>
|
||||
)}
|
||||
{row.original.processingType}
|
||||
</div>
|
||||
),
|
||||
},
|
||||
{
|
||||
accessorKey: 'status',
|
||||
header: t('status'),
|
||||
cell: ({ row }) => <FileStatusBadge status={row.original.status} />,
|
||||
},
|
||||
{
|
||||
id: 'operations',
|
||||
header: t('operations'),
|
||||
cell: ({ row }) => (
|
||||
<div className="flex justify-start space-x-2">
|
||||
<Button
|
||||
variant="ghost"
|
||||
size="sm"
|
||||
className="p-1"
|
||||
onClick={() => {
|
||||
setIsModalVisible(true);
|
||||
}}
|
||||
>
|
||||
<Eye />
|
||||
</Button>
|
||||
</div>
|
||||
),
|
||||
},
|
||||
];
|
||||
|
||||
return columns;
|
||||
};
|
||||
|
||||
const FileLogsTable: FC<FileLogsTableProps> = ({
|
||||
data,
|
||||
pagination,
|
||||
setPagination,
|
||||
loading,
|
||||
active = LogTabs.FILE_LOGS,
|
||||
}) => {
|
||||
const [sorting, setSorting] = useState<SortingState>([]);
|
||||
const [columnFilters, setColumnFilters] = useState<ColumnFiltersState>([]);
|
||||
const [rowSelection, setRowSelection] = useState({});
|
||||
const { t } = useTranslate('knowledgeDetails');
|
||||
const [isModalVisible, setIsModalVisible] = useState(false);
|
||||
const { navigateToDataflowResult } = useNavigatePage();
|
||||
const columns = useMemo(() => {
|
||||
console.log('columns', active);
|
||||
return active === LogTabs.FILE_LOGS
|
||||
? getFileLogsTableColumns(t, setIsModalVisible, navigateToDataflowResult)
|
||||
: getDatasetLogsTableColumns(t, setIsModalVisible);
|
||||
}, [active, t]);
|
||||
|
||||
const currentPagination = useMemo(
|
||||
() => ({
|
||||
pageIndex: (pagination.current || 1) - 1,
|
||||
pageSize: pagination.pageSize || 10,
|
||||
}),
|
||||
[pagination],
|
||||
);
|
||||
|
||||
const table = useReactTable({
|
||||
data,
|
||||
columns,
|
||||
manualPagination: true,
|
||||
getCoreRowModel: getCoreRowModel(),
|
||||
getPaginationRowModel: getPaginationRowModel(),
|
||||
getSortedRowModel: getSortedRowModel(),
|
||||
getFilteredRowModel: getFilteredRowModel(),
|
||||
onSortingChange: setSorting,
|
||||
onColumnFiltersChange: setColumnFilters,
|
||||
onRowSelectionChange: setRowSelection,
|
||||
state: {
|
||||
sorting,
|
||||
columnFilters,
|
||||
rowSelection,
|
||||
pagination: currentPagination,
|
||||
},
|
||||
pageCount: pagination.total
|
||||
? Math.ceil(pagination.total / pagination.pageSize)
|
||||
: 0,
|
||||
});
|
||||
const taskInfo = {
|
||||
taskId: '#9527',
|
||||
fileName: 'PRD for DealBees 1.2 (1).text',
|
||||
fileSize: '2.4G',
|
||||
source: 'Github',
|
||||
task: 'Parse',
|
||||
state: 'Running',
|
||||
startTime: '14/03/2025 14:53:39',
|
||||
duration: '800',
|
||||
details: 'PRD for DealBees 1.2 (1).text',
|
||||
};
|
||||
return (
|
||||
<div className="w-full h-[calc(100vh-350px)]">
|
||||
<Table rootClassName="max-h-[calc(100vh-380px)]">
|
||||
<TableHeader>
|
||||
{table.getHeaderGroups().map((headerGroup) => (
|
||||
<TableRow key={headerGroup.id}>
|
||||
{headerGroup.headers.map((header) => (
|
||||
<TableHead key={header.id}>
|
||||
{flexRender(
|
||||
header.column.columnDef.header,
|
||||
header.getContext(),
|
||||
)}
|
||||
</TableHead>
|
||||
))}
|
||||
</TableRow>
|
||||
))}
|
||||
</TableHeader>
|
||||
<TableBody className="relative">
|
||||
{table.getRowModel().rows.length ? (
|
||||
table.getRowModel().rows.map((row) => (
|
||||
<TableRow
|
||||
key={row.id}
|
||||
data-state={row.getIsSelected() && 'selected'}
|
||||
className="group"
|
||||
>
|
||||
{row.getVisibleCells().map((cell) => (
|
||||
<TableCell
|
||||
key={cell.id}
|
||||
className={cell.column.columnDef.meta?.cellClassName}
|
||||
>
|
||||
{flexRender(cell.column.columnDef.cell, cell.getContext())}
|
||||
</TableCell>
|
||||
))}
|
||||
</TableRow>
|
||||
))
|
||||
) : (
|
||||
<TableRow>
|
||||
<TableCell colSpan={columns.length} className="h-24 text-center">
|
||||
No results.
|
||||
</TableCell>
|
||||
</TableRow>
|
||||
)}
|
||||
</TableBody>
|
||||
</Table>
|
||||
<div className="flex items-center justify-end py-4 absolute bottom-3 right-12">
|
||||
<div className="space-x-2">
|
||||
<RAGFlowPagination
|
||||
{...{ current: pagination.current, pageSize: pagination.pageSize }}
|
||||
total={pagination.total}
|
||||
onChange={(page, pageSize) => setPagination({ page, pageSize })}
|
||||
/>
|
||||
</div>
|
||||
</div>
|
||||
<ProcessLogModal
|
||||
visible={isModalVisible}
|
||||
onCancel={() => setIsModalVisible(false)}
|
||||
taskInfo={taskInfo}
|
||||
/>
|
||||
</div>
|
||||
);
|
||||
};
|
||||
|
||||
export default FileLogsTable;
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user