mirror of
https://github.com/infiniflow/ragflow.git
synced 2025-12-08 20:42:30 +08:00
Compare commits
185 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
| 6ca1aef52e | |||
| d285a12b85 | |||
| cbb90e171d | |||
| 59934b63aa | |||
| 31e229ff78 | |||
| f21d023260 | |||
| 40423878eb | |||
| db8a3f3480 | |||
| 0cf8c5bedb | |||
| 47c5cdccf6 | |||
| 0c2b8182e4 | |||
| 4a7ed9afef | |||
| 1ae7b942d9 | |||
| fed1221302 | |||
| 6ed81d6774 | |||
| 115850945e | |||
| 8e87436725 | |||
| e8e2a95165 | |||
| b908c33464 | |||
| 0ebf05440e | |||
| 7df1bd4b4a | |||
| 5d21cc3660 | |||
| b0275b8483 | |||
| 86c6fee320 | |||
| c0bee906d2 | |||
| bfaa469b9a | |||
| d73a08b9eb | |||
| a1f06a4fdc | |||
| cb26564d50 | |||
| 59705a1c1d | |||
| 205974c359 | |||
| 04edf9729f | |||
| bb1268ef4b | |||
| c5826d4720 | |||
| deb2faf7aa | |||
| 2777941b4e | |||
| ae8b628f0a | |||
| 0e9ff8c1f7 | |||
| d373c46976 | |||
| 008e55a65e | |||
| 772992812a | |||
| a8542508b7 | |||
| 0b4d366514 | |||
| e7a84bdac2 | |||
| d2b346cf9e | |||
| 1d0dcddf61 | |||
| d49025b501 | |||
| dd0fd13ea8 | |||
| 36e32dde1a | |||
| 53a2c8e452 | |||
| 5218ff775c | |||
| 5d5dbb3bcb | |||
| 5a0273e3ea | |||
| ce81e470e3 | |||
| 4ac61fc470 | |||
| bfe97d896d | |||
| e7a6a9e47e | |||
| d06431f670 | |||
| 2fa8e3309f | |||
| fe3b2acde0 | |||
| 01330fa428 | |||
| b4cc37f3c1 | |||
| a8dbb5d3b0 | |||
| 321a280031 | |||
| 5c9025918a | |||
| 573d46a4ef | |||
| 4ae8f87754 | |||
| 63af158086 | |||
| 3877bcfc21 | |||
| f8cc557892 | |||
| e39ceb2bd1 | |||
| 992398bca3 | |||
| baa108f5cc | |||
| 4a891f2d67 | |||
| 514c08a932 | |||
| d05e8a173d | |||
| ad412380cb | |||
| af35e84655 | |||
| 29f45a85e4 | |||
| ea5e8caa69 | |||
| 473aa28422 | |||
| ef0c4b134d | |||
| 35e36cb945 | |||
| 31718581b5 | |||
| 6bd7d572ec | |||
| 5b626870d0 | |||
| 2ccec93d71 | |||
| 2fe332d01d | |||
| a14865e6bb | |||
| d66c17ab5c | |||
| b781207752 | |||
| 34ec550014 | |||
| c2c63b07c3 | |||
| 332e6ffbd4 | |||
| 5352bdf4da | |||
| 138778b51b | |||
| 17e7571639 | |||
| 0fbca63e9d | |||
| 1657755b5d | |||
| 9d3dd13fef | |||
| 3827c47515 | |||
| e9053b6ed4 | |||
| e349635a3d | |||
| 014a1535f2 | |||
| 7b57ab5dea | |||
| e300d90c00 | |||
| 87317bcfc4 | |||
| 9849230a04 | |||
| fa32a2d0fd | |||
| 27ffc0ed74 | |||
| 539876af11 | |||
| b1c8746984 | |||
| bc3160f75a | |||
| 75b24ba02a | |||
| 953b3e1b3f | |||
| c98933499a | |||
| 2f768b96e8 | |||
| d6cc6453d1 | |||
| 45dfaf230c | |||
| 65537b8200 | |||
| 60787f8d5d | |||
| c4b3d3af95 | |||
| f29a5de9f5 | |||
| cb37f00a8f | |||
| fc379e90d1 | |||
| fea9d970ec | |||
| 6e7dd54a50 | |||
| f56b651acb | |||
| 2dbcc0a1bf | |||
| 1f82889001 | |||
| e6c824e606 | |||
| e2b0bceb1b | |||
| 713c055e04 | |||
| 1fc52033ba | |||
| ab27609a64 | |||
| 538a408608 | |||
| 093d280528 | |||
| de166d0ff2 | |||
| 942b94fc3c | |||
| 77bb7750e9 | |||
| 78380fa181 | |||
| c88e4b3fc0 | |||
| 552475dd5c | |||
| c69fbca24f | |||
| 5bb1c383ac | |||
| c7310f7fb2 | |||
| 3a43043c8a | |||
| dbfa859ca3 | |||
| 53c59c47a1 | |||
| af393b0003 | |||
| 1a5608d0f8 | |||
| 23dcbc94ef | |||
| af770c5ced | |||
| 8ce5e69b2f | |||
| 1aa97600df | |||
| 969c596d4c | |||
| 67b087019c | |||
| 6a45d93005 | |||
| 43e507d554 | |||
| a4be6c50cf | |||
| 5043143bc5 | |||
| bdebd1b2e3 | |||
| dadd8d9f94 | |||
| 3da8776a3c | |||
| 3052006ba8 | |||
| 1662c7eda3 | |||
| fef44a71c5 | |||
| b271cc34b3 | |||
| eead838353 | |||
| 02cc867c06 | |||
| 6e98cd311c | |||
| 97a13ef1ab | |||
| 7e1464a950 | |||
| e6a4d6bcf0 | |||
| c8c3b756b0 | |||
| 9a8dda8fc7 | |||
| ff442c48b5 | |||
| 216cd7474b | |||
| 2c62652ea8 | |||
| 4e8fd73a20 | |||
| 19931cd9ed | |||
| 0b460a9a12 | |||
| 4e31eea55f | |||
| 1366712560 | |||
| 51d9bde5a3 |
3
.gitattributes
vendored
3
.gitattributes
vendored
@ -1 +1,2 @@
|
||||
*.sh text eol=lf
|
||||
*.sh text eol=lf
|
||||
docker/entrypoint.sh text eol=lf executable
|
||||
|
||||
28
.github/workflows/tests.yml
vendored
28
.github/workflows/tests.yml
vendored
@ -15,6 +15,8 @@ on:
|
||||
- 'docs/**'
|
||||
- '*.md'
|
||||
- '*.mdx'
|
||||
schedule:
|
||||
- cron: '0 16 * * *' # This schedule runs every 16:00:00Z(00:00:00+08:00)
|
||||
|
||||
# https://docs.github.com/en/actions/using-jobs/using-concurrency
|
||||
concurrency:
|
||||
@ -48,9 +50,9 @@ jobs:
|
||||
|
||||
# https://github.com/astral-sh/ruff-action
|
||||
- name: Static check with Ruff
|
||||
uses: astral-sh/ruff-action@v2
|
||||
uses: astral-sh/ruff-action@v3
|
||||
with:
|
||||
version: ">=0.8.2"
|
||||
version: ">=0.11.x"
|
||||
args: "check"
|
||||
|
||||
- name: Build ragflow:nightly-slim
|
||||
@ -86,7 +88,7 @@ jobs:
|
||||
echo "Waiting for service to be available..."
|
||||
sleep 5
|
||||
done
|
||||
cd sdk/python && uv sync --python 3.10 --frozen && uv pip install . && source .venv/bin/activate && cd test/test_sdk_api && pytest -s --tb=short get_email.py t_dataset.py t_chat.py t_session.py t_document.py t_chunk.py
|
||||
cd sdk/python && uv sync --python 3.10 --group test --frozen && uv pip install . && source .venv/bin/activate && cd test/test_sdk_api && pytest -s --tb=short get_email.py t_dataset.py t_chat.py t_session.py t_document.py t_chunk.py
|
||||
|
||||
- name: Run frontend api tests against Elasticsearch
|
||||
run: |
|
||||
@ -96,7 +98,7 @@ jobs:
|
||||
echo "Waiting for service to be available..."
|
||||
sleep 5
|
||||
done
|
||||
cd sdk/python && uv sync --python 3.10 --frozen && uv pip install . && source .venv/bin/activate && cd test/test_frontend_api && pytest -s --tb=short get_email.py test_dataset.py
|
||||
cd sdk/python && uv sync --python 3.10 --group test --frozen && source .venv/bin/activate && cd test/test_frontend_api && pytest -s --tb=short get_email.py test_dataset.py
|
||||
|
||||
- name: Run http api tests against Elasticsearch
|
||||
run: |
|
||||
@ -106,7 +108,12 @@ jobs:
|
||||
echo "Waiting for service to be available..."
|
||||
sleep 5
|
||||
done
|
||||
cd sdk/python && uv sync --python 3.10 --frozen && uv pip install . && source .venv/bin/activate && cd test/test_http_api && pytest -s --tb=short -m "not slow"
|
||||
if [[ $GITHUB_EVENT_NAME == 'schedule' ]]; then
|
||||
export HTTP_API_TEST_LEVEL=p3
|
||||
else
|
||||
export HTTP_API_TEST_LEVEL=p2
|
||||
fi
|
||||
cd sdk/python && uv sync --python 3.10 --group test --frozen && source .venv/bin/activate && cd test/test_http_api && pytest -s --tb=short --level=${HTTP_API_TEST_LEVEL}
|
||||
|
||||
- name: Stop ragflow:nightly
|
||||
if: always() # always run this step even if previous steps failed
|
||||
@ -125,7 +132,7 @@ jobs:
|
||||
echo "Waiting for service to be available..."
|
||||
sleep 5
|
||||
done
|
||||
cd sdk/python && uv sync --python 3.10 --frozen && uv pip install . && source .venv/bin/activate && cd test/test_sdk_api && pytest -s --tb=short get_email.py t_dataset.py t_chat.py t_session.py t_document.py t_chunk.py
|
||||
cd sdk/python && uv sync --python 3.10 --group test --frozen && uv pip install . && source .venv/bin/activate && cd test/test_sdk_api && pytest -s --tb=short get_email.py t_dataset.py t_chat.py t_session.py t_document.py t_chunk.py
|
||||
|
||||
- name: Run frontend api tests against Infinity
|
||||
run: |
|
||||
@ -135,7 +142,7 @@ jobs:
|
||||
echo "Waiting for service to be available..."
|
||||
sleep 5
|
||||
done
|
||||
cd sdk/python && uv sync --python 3.10 --frozen && uv pip install . && source .venv/bin/activate && cd test/test_frontend_api && pytest -s --tb=short get_email.py test_dataset.py
|
||||
cd sdk/python && uv sync --python 3.10 --group test --frozen && source .venv/bin/activate && cd test/test_frontend_api && pytest -s --tb=short get_email.py test_dataset.py
|
||||
|
||||
- name: Run http api tests against Infinity
|
||||
run: |
|
||||
@ -145,7 +152,12 @@ jobs:
|
||||
echo "Waiting for service to be available..."
|
||||
sleep 5
|
||||
done
|
||||
cd sdk/python && uv sync --python 3.10 --frozen && uv pip install . && source .venv/bin/activate && cd test/test_http_api && DOC_ENGINE=infinity pytest -s --tb=short -m "not slow"
|
||||
if [[ $GITHUB_EVENT_NAME == 'schedule' ]]; then
|
||||
export HTTP_API_TEST_LEVEL=p3
|
||||
else
|
||||
export HTTP_API_TEST_LEVEL=p2
|
||||
fi
|
||||
cd sdk/python && uv sync --python 3.10 --group test --frozen && source .venv/bin/activate && cd test/test_http_api && DOC_ENGINE=infinity pytest -s --tb=short --level=${HTTP_API_TEST_LEVEL}
|
||||
|
||||
- name: Stop ragflow:nightly
|
||||
if: always() # always run this step even if previous steps failed
|
||||
|
||||
2
.gitignore
vendored
2
.gitignore
vendored
@ -42,3 +42,5 @@ nltk_data/
|
||||
# Exclude hash-like temporary files like 9b5ad71b2ce5302211f9c61530b329a4922fc6a4
|
||||
*[0-9a-f][0-9a-f][0-9a-f][0-9a-f][0-9a-f][0-9a-f][0-9a-f][0-9a-f][0-9a-f][0-9a-f]*
|
||||
.lh/
|
||||
.venv
|
||||
docker/data
|
||||
|
||||
19
.pre-commit-config.yaml
Normal file
19
.pre-commit-config.yaml
Normal file
@ -0,0 +1,19 @@
|
||||
repos:
|
||||
- repo: https://github.com/pre-commit/pre-commit-hooks
|
||||
rev: v4.6.0
|
||||
hooks:
|
||||
- id: check-yaml
|
||||
- id: check-json
|
||||
- id: end-of-file-fixer
|
||||
- id: trailing-whitespace
|
||||
- id: check-case-conflict
|
||||
- id: check-merge-conflict
|
||||
- id: mixed-line-ending
|
||||
- id: check-symlinks
|
||||
|
||||
- repo: https://github.com/astral-sh/ruff-pre-commit
|
||||
rev: v0.11.6
|
||||
hooks:
|
||||
- id: ruff
|
||||
args: [ --fix ]
|
||||
- id: ruff-format
|
||||
@ -59,7 +59,8 @@ RUN --mount=type=cache,id=ragflow_apt,target=/var/cache/apt,sharing=locked \
|
||||
apt install -y libatk-bridge2.0-0 && \
|
||||
apt install -y libpython3-dev libgtk-4-1 libnss3 xdg-utils libgbm-dev && \
|
||||
apt install -y libjemalloc-dev && \
|
||||
apt install -y python3-pip pipx nginx unzip curl wget git vim less
|
||||
apt install -y python3-pip pipx nginx unzip curl wget git vim less && \
|
||||
apt install -y ghostscript
|
||||
|
||||
RUN if [ "$NEED_MIRROR" == "1" ]; then \
|
||||
pip3 config set global.index-url https://mirrors.aliyun.com/pypi/simple && \
|
||||
@ -199,6 +200,7 @@ COPY graphrag graphrag
|
||||
COPY agentic_reasoning agentic_reasoning
|
||||
COPY pyproject.toml uv.lock ./
|
||||
COPY mcp mcp
|
||||
COPY plugin plugin
|
||||
|
||||
COPY docker/service_conf.yaml.template ./conf/service_conf.yaml.template
|
||||
COPY docker/entrypoint.sh ./
|
||||
|
||||
@ -33,6 +33,7 @@ ADD ./rag ./rag
|
||||
ADD ./requirements.txt ./requirements.txt
|
||||
ADD ./agent ./agent
|
||||
ADD ./graphrag ./graphrag
|
||||
ADD ./plugin ./plugin
|
||||
|
||||
RUN dnf install -y openmpi openmpi-devel python3-openmpi
|
||||
ENV C_INCLUDE_PATH /usr/include/openmpi-x86_64:$C_INCLUDE_PATH
|
||||
|
||||
46
README.md
46
README.md
@ -22,7 +22,7 @@
|
||||
<img alt="Static Badge" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
||||
</a>
|
||||
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
||||
<img src="https://img.shields.io/badge/docker_pull-ragflow:v0.18.0-brightgreen" alt="docker pull infiniflow/ragflow:v0.18.0">
|
||||
<img src="https://img.shields.io/badge/docker_pull-ragflow:v0.19.0-brightgreen" alt="docker pull infiniflow/ragflow:v0.19.0">
|
||||
</a>
|
||||
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
||||
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Latest%20Release" alt="Latest Release">
|
||||
@ -137,8 +137,10 @@ releases! 🌟
|
||||
- RAM >= 16 GB
|
||||
- Disk >= 50 GB
|
||||
- Docker >= 24.0.0 & Docker Compose >= v2.26.1
|
||||
> If you have not installed Docker on your local machine (Windows, Mac, or Linux),
|
||||
> see [Install Docker Engine](https://docs.docker.com/engine/install/).
|
||||
- [gVisor](https://gvisor.dev/docs/user_guide/install/): Required only if you intend to use the code executor (sandbox) feature of RAGFlow.
|
||||
|
||||
> [!TIP]
|
||||
> If you have not installed Docker on your local machine (Windows, Mac, or Linux), see [Install Docker Engine](https://docs.docker.com/engine/install/).
|
||||
|
||||
### 🚀 Start up the server
|
||||
|
||||
@ -176,7 +178,7 @@ releases! 🌟
|
||||
> All Docker images are built for x86 platforms. We don't currently offer Docker images for ARM64.
|
||||
> If you are on an ARM64 platform, follow [this guide](https://ragflow.io/docs/dev/build_docker_image) to build a Docker image compatible with your system.
|
||||
|
||||
> The command below downloads the `v0.18.0-slim` edition of the RAGFlow Docker image. See the following table for descriptions of different RAGFlow editions. To download a RAGFlow edition different from `v0.18.0-slim`, update the `RAGFLOW_IMAGE` variable accordingly in **docker/.env** before using `docker compose` to start the server. For example: set `RAGFLOW_IMAGE=infiniflow/ragflow:v0.18.0` for the full edition `v0.18.0`.
|
||||
> The command below downloads the `v0.19.0-slim` edition of the RAGFlow Docker image. See the following table for descriptions of different RAGFlow editions. To download a RAGFlow edition different from `v0.19.0-slim`, update the `RAGFLOW_IMAGE` variable accordingly in **docker/.env** before using `docker compose` to start the server. For example: set `RAGFLOW_IMAGE=infiniflow/ragflow:v0.19.0` for the full edition `v0.19.0`.
|
||||
|
||||
```bash
|
||||
$ cd ragflow/docker
|
||||
@ -189,8 +191,8 @@ releases! 🌟
|
||||
|
||||
| RAGFlow image tag | Image size (GB) | Has embedding models? | Stable? |
|
||||
|-------------------|-----------------|-----------------------|--------------------------|
|
||||
| v0.18.0 | ≈9 | :heavy_check_mark: | Stable release |
|
||||
| v0.18.0-slim | ≈2 | ❌ | Stable release |
|
||||
| v0.19.0 | ≈9 | :heavy_check_mark: | Stable release |
|
||||
| v0.19.0-slim | ≈2 | ❌ | Stable release |
|
||||
| nightly | ≈9 | :heavy_check_mark: | _Unstable_ nightly build |
|
||||
| nightly-slim | ≈2 | ❌ | _Unstable_ nightly build |
|
||||
|
||||
@ -296,7 +298,7 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
1. Install uv, or skip this step if it is already installed:
|
||||
|
||||
```bash
|
||||
pipx install uv
|
||||
pipx install uv pre-commit
|
||||
```
|
||||
|
||||
2. Clone the source code and install Python dependencies:
|
||||
@ -305,6 +307,8 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
git clone https://github.com/infiniflow/ragflow.git
|
||||
cd ragflow/
|
||||
uv sync --python 3.10 --all-extras # install RAGFlow dependent python modules
|
||||
uv run download_deps.py
|
||||
pre-commit install
|
||||
```
|
||||
|
||||
3. Launch the dependent services (MinIO, Elasticsearch, Redis, and MySQL) using Docker Compose:
|
||||
@ -316,7 +320,7 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
Add the following line to `/etc/hosts` to resolve all hosts specified in **docker/.env** to `127.0.0.1`:
|
||||
|
||||
```
|
||||
127.0.0.1 es01 infinity mysql minio redis
|
||||
127.0.0.1 es01 infinity mysql minio redis sandbox-executor-manager
|
||||
```
|
||||
|
||||
4. If you cannot access HuggingFace, set the `HF_ENDPOINT` environment variable to use a mirror site:
|
||||
@ -325,7 +329,16 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
export HF_ENDPOINT=https://hf-mirror.com
|
||||
```
|
||||
|
||||
5. Launch backend service:
|
||||
5. If your operating system does not have jemalloc, please install it as follows:
|
||||
|
||||
```bash
|
||||
# ubuntu
|
||||
sudo apt-get install libjemalloc-dev
|
||||
# centos
|
||||
sudo yum install jemalloc
|
||||
```
|
||||
|
||||
6. Launch backend service:
|
||||
|
||||
```bash
|
||||
source .venv/bin/activate
|
||||
@ -333,12 +346,14 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
bash docker/launch_backend_service.sh
|
||||
```
|
||||
|
||||
6. Install frontend dependencies:
|
||||
7. Install frontend dependencies:
|
||||
|
||||
```bash
|
||||
cd web
|
||||
npm install
|
||||
```
|
||||
7. Launch frontend service:
|
||||
|
||||
8. Launch frontend service:
|
||||
|
||||
```bash
|
||||
npm run dev
|
||||
@ -348,6 +363,13 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
|
||||

|
||||
|
||||
9. Stop RAGFlow front-end and back-end service after development is complete:
|
||||
|
||||
```bash
|
||||
pkill -f "ragflow_server.py|task_executor.py"
|
||||
```
|
||||
|
||||
|
||||
## 📚 Documentation
|
||||
|
||||
- [Quickstart](https://ragflow.io/docs/dev/)
|
||||
@ -371,4 +393,4 @@ See the [RAGFlow Roadmap 2025](https://github.com/infiniflow/ragflow/issues/4214
|
||||
## 🙌 Contributing
|
||||
|
||||
RAGFlow flourishes via open-source collaboration. In this spirit, we embrace diverse contributions from the community.
|
||||
If you would like to be a part, review our [Contribution Guidelines](./CONTRIBUTING.md) first.
|
||||
If you would like to be a part, review our [Contribution Guidelines](https://ragflow.io/docs/dev/contributing) first.
|
||||
|
||||
45
README_id.md
45
README_id.md
@ -22,7 +22,7 @@
|
||||
<img alt="Lencana Daring" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
||||
</a>
|
||||
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
||||
<img src="https://img.shields.io/badge/docker_pull-ragflow:v0.18.0-brightgreen" alt="docker pull infiniflow/ragflow:v0.18.0">
|
||||
<img src="https://img.shields.io/badge/docker_pull-ragflow:v0.19.0-brightgreen" alt="docker pull infiniflow/ragflow:v0.19.0">
|
||||
</a>
|
||||
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
||||
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Rilis%20Terbaru" alt="Rilis Terbaru">
|
||||
@ -132,6 +132,10 @@ Coba demo kami di [https://demo.ragflow.io](https://demo.ragflow.io).
|
||||
- RAM >= 16 GB
|
||||
- Disk >= 50 GB
|
||||
- Docker >= 24.0.0 & Docker Compose >= v2.26.1
|
||||
- [gVisor](https://gvisor.dev/docs/user_guide/install/): Hanya diperlukan jika Anda ingin menggunakan fitur eksekutor kode (sandbox) dari RAGFlow.
|
||||
|
||||
> [!TIP]
|
||||
> Jika Anda belum menginstal Docker di komputer lokal Anda (Windows, Mac, atau Linux), lihat [Install Docker Engine](https://docs.docker.com/engine/install/).
|
||||
|
||||
### 🚀 Menjalankan Server
|
||||
|
||||
@ -169,7 +173,7 @@ Coba demo kami di [https://demo.ragflow.io](https://demo.ragflow.io).
|
||||
> Semua gambar Docker dibangun untuk platform x86. Saat ini, kami tidak menawarkan gambar Docker untuk ARM64.
|
||||
> Jika Anda menggunakan platform ARM64, [silakan gunakan panduan ini untuk membangun gambar Docker yang kompatibel dengan sistem Anda](https://ragflow.io/docs/dev/build_docker_image).
|
||||
|
||||
> Perintah di bawah ini mengunduh edisi v0.18.0-slim dari gambar Docker RAGFlow. Silakan merujuk ke tabel berikut untuk deskripsi berbagai edisi RAGFlow. Untuk mengunduh edisi RAGFlow yang berbeda dari v0.18.0-slim, perbarui variabel RAGFLOW_IMAGE di docker/.env sebelum menggunakan docker compose untuk memulai server. Misalnya, atur RAGFLOW_IMAGE=infiniflow/ragflow:v0.18.0 untuk edisi lengkap v0.18.0.
|
||||
> Perintah di bawah ini mengunduh edisi v0.19.0-slim dari gambar Docker RAGFlow. Silakan merujuk ke tabel berikut untuk deskripsi berbagai edisi RAGFlow. Untuk mengunduh edisi RAGFlow yang berbeda dari v0.19.0-slim, perbarui variabel RAGFLOW_IMAGE di docker/.env sebelum menggunakan docker compose untuk memulai server. Misalnya, atur RAGFLOW_IMAGE=infiniflow/ragflow:v0.19.0 untuk edisi lengkap v0.19.0.
|
||||
|
||||
```bash
|
||||
$ cd ragflow/docker
|
||||
@ -182,8 +186,8 @@ $ docker compose -f docker-compose.yml up -d
|
||||
|
||||
| RAGFlow image tag | Image size (GB) | Has embedding models? | Stable? |
|
||||
| ----------------- | --------------- | --------------------- | ------------------------ |
|
||||
| v0.18.0 | ≈9 | :heavy_check_mark: | Stable release |
|
||||
| v0.18.0-slim | ≈2 | ❌ | Stable release |
|
||||
| v0.19.0 | ≈9 | :heavy_check_mark: | Stable release |
|
||||
| v0.19.0-slim | ≈2 | ❌ | Stable release |
|
||||
| nightly | ≈9 | :heavy_check_mark: | _Unstable_ nightly build |
|
||||
| nightly-slim | ≈2 | ❌ | _Unstable_ nightly build |
|
||||
|
||||
@ -262,7 +266,7 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
1. Instal uv, atau lewati langkah ini jika sudah terinstal:
|
||||
|
||||
```bash
|
||||
pipx install uv
|
||||
pipx install uv pre-commit
|
||||
```
|
||||
|
||||
2. Clone kode sumber dan instal dependensi Python:
|
||||
@ -271,6 +275,8 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
git clone https://github.com/infiniflow/ragflow.git
|
||||
cd ragflow/
|
||||
uv sync --python 3.10 --all-extras # install RAGFlow dependent python modules
|
||||
uv run download_deps.py
|
||||
pre-commit install
|
||||
```
|
||||
|
||||
3. Jalankan aplikasi yang diperlukan (MinIO, Elasticsearch, Redis, dan MySQL) menggunakan Docker Compose:
|
||||
@ -282,7 +288,7 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
Tambahkan baris berikut ke `/etc/hosts` untuk memetakan semua host yang ditentukan di **conf/service_conf.yaml** ke `127.0.0.1`:
|
||||
|
||||
```
|
||||
127.0.0.1 es01 infinity mysql minio redis
|
||||
127.0.0.1 es01 infinity mysql minio redis sandbox-executor-manager
|
||||
```
|
||||
|
||||
4. Jika Anda tidak dapat mengakses HuggingFace, atur variabel lingkungan `HF_ENDPOINT` untuk menggunakan situs mirror:
|
||||
@ -291,7 +297,16 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
export HF_ENDPOINT=https://hf-mirror.com
|
||||
```
|
||||
|
||||
5. Jalankan aplikasi backend:
|
||||
5. Jika sistem operasi Anda tidak memiliki jemalloc, instal sebagai berikut:
|
||||
|
||||
```bash
|
||||
# ubuntu
|
||||
sudo apt-get install libjemalloc-dev
|
||||
# centos
|
||||
sudo yum install jemalloc
|
||||
```
|
||||
|
||||
6. Jalankan aplikasi backend:
|
||||
|
||||
```bash
|
||||
source .venv/bin/activate
|
||||
@ -299,12 +314,14 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
bash docker/launch_backend_service.sh
|
||||
```
|
||||
|
||||
6. Instal dependensi frontend:
|
||||
7. Instal dependensi frontend:
|
||||
|
||||
```bash
|
||||
cd web
|
||||
npm install
|
||||
```
|
||||
7. Jalankan aplikasi frontend:
|
||||
|
||||
8. Jalankan aplikasi frontend:
|
||||
|
||||
```bash
|
||||
npm run dev
|
||||
@ -314,6 +331,14 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
|
||||

|
||||
|
||||
|
||||
9. Hentikan layanan front-end dan back-end RAGFlow setelah pengembangan selesai:
|
||||
|
||||
```bash
|
||||
pkill -f "ragflow_server.py|task_executor.py"
|
||||
```
|
||||
|
||||
|
||||
## 📚 Dokumentasi
|
||||
|
||||
- [Quickstart](https://ragflow.io/docs/dev/)
|
||||
@ -337,4 +362,4 @@ Lihat [Roadmap RAGFlow 2025](https://github.com/infiniflow/ragflow/issues/4214)
|
||||
## 🙌 Kontribusi
|
||||
|
||||
RAGFlow berkembang melalui kolaborasi open-source. Dalam semangat ini, kami menerima kontribusi dari komunitas.
|
||||
Jika Anda ingin berpartisipasi, tinjau terlebih dahulu [Panduan Kontribusi](./CONTRIBUTING.md).
|
||||
Jika Anda ingin berpartisipasi, tinjau terlebih dahulu [Panduan Kontribusi](https://ragflow.io/docs/dev/contributing).
|
||||
|
||||
45
README_ja.md
45
README_ja.md
@ -22,7 +22,7 @@
|
||||
<img alt="Static Badge" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
||||
</a>
|
||||
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
||||
<img src="https://img.shields.io/badge/docker_pull-ragflow:v0.18.0-brightgreen" alt="docker pull infiniflow/ragflow:v0.18.0">
|
||||
<img src="https://img.shields.io/badge/docker_pull-ragflow:v0.19.0-brightgreen" alt="docker pull infiniflow/ragflow:v0.19.0">
|
||||
</a>
|
||||
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
||||
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Latest%20Release" alt="Latest Release">
|
||||
@ -112,7 +112,10 @@
|
||||
- RAM >= 16 GB
|
||||
- Disk >= 50 GB
|
||||
- Docker >= 24.0.0 & Docker Compose >= v2.26.1
|
||||
> ローカルマシン(Windows、Mac、または Linux)に Docker をインストールしていない場合は、[Docker Engine のインストール](https://docs.docker.com/engine/install/) を参照してください。
|
||||
- [gVisor](https://gvisor.dev/docs/user_guide/install/): RAGFlowのコード実行(サンドボックス)機能を利用する場合のみ必要です。
|
||||
|
||||
> [!TIP]
|
||||
> ローカルマシン(Windows、Mac、または Linux)に Docker をインストールしていない場合は、[Docker Engine のインストール](https://docs.docker.com/engine/install/) を参照してください。
|
||||
|
||||
### 🚀 サーバーを起動
|
||||
|
||||
@ -149,7 +152,7 @@
|
||||
> 現在、公式に提供されているすべての Docker イメージは x86 アーキテクチャ向けにビルドされており、ARM64 用の Docker イメージは提供されていません。
|
||||
> ARM64 アーキテクチャのオペレーティングシステムを使用している場合は、[このドキュメント](https://ragflow.io/docs/dev/build_docker_image)を参照して Docker イメージを自分でビルドしてください。
|
||||
|
||||
> 以下のコマンドは、RAGFlow Docker イメージの v0.18.0-slim エディションをダウンロードします。異なる RAGFlow エディションの説明については、以下の表を参照してください。v0.18.0-slim とは異なるエディションをダウンロードするには、docker/.env ファイルの RAGFLOW_IMAGE 変数を適宜更新し、docker compose を使用してサーバーを起動してください。例えば、完全版 v0.18.0 をダウンロードするには、RAGFLOW_IMAGE=infiniflow/ragflow:v0.18.0 と設定します。
|
||||
> 以下のコマンドは、RAGFlow Docker イメージの v0.19.0-slim エディションをダウンロードします。異なる RAGFlow エディションの説明については、以下の表を参照してください。v0.19.0-slim とは異なるエディションをダウンロードするには、docker/.env ファイルの RAGFLOW_IMAGE 変数を適宜更新し、docker compose を使用してサーバーを起動してください。例えば、完全版 v0.19.0 をダウンロードするには、RAGFLOW_IMAGE=infiniflow/ragflow:v0.19.0 と設定します。
|
||||
|
||||
```bash
|
||||
$ cd ragflow/docker
|
||||
@ -162,8 +165,8 @@
|
||||
|
||||
| RAGFlow image tag | Image size (GB) | Has embedding models? | Stable? |
|
||||
| ----------------- | --------------- | --------------------- | ------------------------ |
|
||||
| v0.18.0 | ≈9 | :heavy_check_mark: | Stable release |
|
||||
| v0.18.0-slim | ≈2 | ❌ | Stable release |
|
||||
| v0.19.0 | ≈9 | :heavy_check_mark: | Stable release |
|
||||
| v0.19.0-slim | ≈2 | ❌ | Stable release |
|
||||
| nightly | ≈9 | :heavy_check_mark: | _Unstable_ nightly build |
|
||||
| nightly-slim | ≈2 | ❌ | _Unstable_ nightly build |
|
||||
|
||||
@ -258,7 +261,7 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
1. uv をインストールする。すでにインストールされている場合は、このステップをスキップしてください:
|
||||
|
||||
```bash
|
||||
pipx install uv
|
||||
pipx install uv pre-commit
|
||||
```
|
||||
|
||||
2. ソースコードをクローンし、Python の依存関係をインストールする:
|
||||
@ -267,6 +270,8 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
git clone https://github.com/infiniflow/ragflow.git
|
||||
cd ragflow/
|
||||
uv sync --python 3.10 --all-extras # install RAGFlow dependent python modules
|
||||
uv run download_deps.py
|
||||
pre-commit install
|
||||
```
|
||||
|
||||
3. Docker Compose を使用して依存サービス(MinIO、Elasticsearch、Redis、MySQL)を起動する:
|
||||
@ -278,7 +283,7 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
`/etc/hosts` に以下の行を追加して、**conf/service_conf.yaml** に指定されたすべてのホストを `127.0.0.1` に解決します:
|
||||
|
||||
```
|
||||
127.0.0.1 es01 infinity mysql minio redis
|
||||
127.0.0.1 es01 infinity mysql minio redis sandbox-executor-manager
|
||||
```
|
||||
|
||||
4. HuggingFace にアクセスできない場合は、`HF_ENDPOINT` 環境変数を設定してミラーサイトを使用してください:
|
||||
@ -287,7 +292,16 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
export HF_ENDPOINT=https://hf-mirror.com
|
||||
```
|
||||
|
||||
5. バックエンドサービスを起動する:
|
||||
5. オペレーティングシステムにjemallocがない場合は、次のようにインストールします:
|
||||
|
||||
```bash
|
||||
# ubuntu
|
||||
sudo apt-get install libjemalloc-dev
|
||||
# centos
|
||||
sudo yum install jemalloc
|
||||
```
|
||||
|
||||
6. バックエンドサービスを起動する:
|
||||
|
||||
```bash
|
||||
source .venv/bin/activate
|
||||
@ -295,12 +309,14 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
bash docker/launch_backend_service.sh
|
||||
```
|
||||
|
||||
6. フロントエンドの依存関係をインストールする:
|
||||
7. フロントエンドの依存関係をインストールする:
|
||||
|
||||
```bash
|
||||
cd web
|
||||
npm install
|
||||
```
|
||||
7. フロントエンドサービスを起動する:
|
||||
|
||||
8. フロントエンドサービスを起動する:
|
||||
|
||||
```bash
|
||||
npm run dev
|
||||
@ -310,6 +326,13 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
|
||||

|
||||
|
||||
9. 開発が完了したら、RAGFlow のフロントエンド サービスとバックエンド サービスを停止します:
|
||||
|
||||
```bash
|
||||
pkill -f "ragflow_server.py|task_executor.py"
|
||||
```
|
||||
|
||||
|
||||
## 📚 ドキュメンテーション
|
||||
|
||||
- [Quickstart](https://ragflow.io/docs/dev/)
|
||||
@ -332,4 +355,4 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
|
||||
## 🙌 コントリビュート
|
||||
|
||||
RAGFlow はオープンソースのコラボレーションによって発展してきました。この精神に基づき、私たちはコミュニティからの多様なコントリビュートを受け入れています。 参加を希望される方は、まず [コントリビューションガイド](./CONTRIBUTING.md)をご覧ください。
|
||||
RAGFlow はオープンソースのコラボレーションによって発展してきました。この精神に基づき、私たちはコミュニティからの多様なコントリビュートを受け入れています。 参加を希望される方は、まず [コントリビューションガイド](https://ragflow.io/docs/dev/contributing)をご覧ください。
|
||||
|
||||
46
README_ko.md
46
README_ko.md
@ -22,7 +22,7 @@
|
||||
<img alt="Static Badge" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
||||
</a>
|
||||
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
||||
<img src="https://img.shields.io/badge/docker_pull-ragflow:v0.18.0-brightgreen" alt="docker pull infiniflow/ragflow:v0.18.0">
|
||||
<img src="https://img.shields.io/badge/docker_pull-ragflow:v0.19.0-brightgreen" alt="docker pull infiniflow/ragflow:v0.19.0">
|
||||
</a>
|
||||
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
||||
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Latest%20Release" alt="Latest Release">
|
||||
@ -112,7 +112,10 @@
|
||||
- RAM >= 16 GB
|
||||
- Disk >= 50 GB
|
||||
- Docker >= 24.0.0 & Docker Compose >= v2.26.1
|
||||
> 로컬 머신(Windows, Mac, Linux)에 Docker가 설치되지 않은 경우, [Docker 엔진 설치](<(https://docs.docker.com/engine/install/)>)를 참조하세요.
|
||||
- [gVisor](https://gvisor.dev/docs/user_guide/install/): RAGFlow의 코드 실행기(샌드박스) 기능을 사용하려는 경우에만 필요합니다.
|
||||
|
||||
> [!TIP]
|
||||
> 로컬 머신(Windows, Mac, Linux)에 Docker가 설치되지 않은 경우, [Docker 엔진 설치](<(https://docs.docker.com/engine/install/)>)를 참조하세요.
|
||||
|
||||
### 🚀 서버 시작하기
|
||||
|
||||
@ -149,7 +152,7 @@
|
||||
> 모든 Docker 이미지는 x86 플랫폼을 위해 빌드되었습니다. 우리는 현재 ARM64 플랫폼을 위한 Docker 이미지를 제공하지 않습니다.
|
||||
> ARM64 플랫폼을 사용 중이라면, [시스템과 호환되는 Docker 이미지를 빌드하려면 이 가이드를 사용해 주세요](https://ragflow.io/docs/dev/build_docker_image).
|
||||
|
||||
> 아래 명령어는 RAGFlow Docker 이미지의 v0.18.0-slim 버전을 다운로드합니다. 다양한 RAGFlow 버전에 대한 설명은 다음 표를 참조하십시오. v0.18.0-slim과 다른 RAGFlow 버전을 다운로드하려면, docker/.env 파일에서 RAGFLOW_IMAGE 변수를 적절히 업데이트한 후 docker compose를 사용하여 서버를 시작하십시오. 예를 들어, 전체 버전인 v0.18.0을 다운로드하려면 RAGFLOW_IMAGE=infiniflow/ragflow:v0.18.0로 설정합니다.
|
||||
> 아래 명령어는 RAGFlow Docker 이미지의 v0.19.0-slim 버전을 다운로드합니다. 다양한 RAGFlow 버전에 대한 설명은 다음 표를 참조하십시오. v0.19.0-slim과 다른 RAGFlow 버전을 다운로드하려면, docker/.env 파일에서 RAGFLOW_IMAGE 변수를 적절히 업데이트한 후 docker compose를 사용하여 서버를 시작하십시오. 예를 들어, 전체 버전인 v0.19.0을 다운로드하려면 RAGFLOW_IMAGE=infiniflow/ragflow:v0.19.0로 설정합니다.
|
||||
|
||||
```bash
|
||||
$ cd ragflow/docker
|
||||
@ -162,8 +165,8 @@
|
||||
|
||||
| RAGFlow image tag | Image size (GB) | Has embedding models? | Stable? |
|
||||
| ----------------- | --------------- | --------------------- | ------------------------ |
|
||||
| v0.18.0 | ≈9 | :heavy_check_mark: | Stable release |
|
||||
| v0.18.0-slim | ≈2 | ❌ | Stable release |
|
||||
| v0.19.0 | ≈9 | :heavy_check_mark: | Stable release |
|
||||
| v0.19.0-slim | ≈2 | ❌ | Stable release |
|
||||
| nightly | ≈9 | :heavy_check_mark: | _Unstable_ nightly build |
|
||||
| nightly-slim | ≈2 | ❌ | _Unstable_ nightly build |
|
||||
|
||||
@ -257,7 +260,7 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
1. uv를 설치하거나 이미 설치된 경우 이 단계를 건너뜁니다:
|
||||
|
||||
```bash
|
||||
pipx install uv
|
||||
pipx install uv pre-commit
|
||||
```
|
||||
|
||||
2. 소스 코드를 클론하고 Python 의존성을 설치합니다:
|
||||
@ -266,6 +269,8 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
git clone https://github.com/infiniflow/ragflow.git
|
||||
cd ragflow/
|
||||
uv sync --python 3.10 --all-extras # install RAGFlow dependent python modules
|
||||
uv run download_deps.py
|
||||
pre-commit install
|
||||
```
|
||||
|
||||
3. Docker Compose를 사용하여 의존 서비스(MinIO, Elasticsearch, Redis 및 MySQL)를 시작합니다:
|
||||
@ -277,7 +282,7 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
`/etc/hosts` 에 다음 줄을 추가하여 **conf/service_conf.yaml** 에 지정된 모든 호스트를 `127.0.0.1` 로 해결합니다:
|
||||
|
||||
```
|
||||
127.0.0.1 es01 infinity mysql minio redis
|
||||
127.0.0.1 es01 infinity mysql minio redis sandbox-executor-manager
|
||||
```
|
||||
|
||||
4. HuggingFace에 접근할 수 없는 경우, `HF_ENDPOINT` 환경 변수를 설정하여 미러 사이트를 사용하세요:
|
||||
@ -286,7 +291,16 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
export HF_ENDPOINT=https://hf-mirror.com
|
||||
```
|
||||
|
||||
5. 백엔드 서비스를 시작합니다:
|
||||
5. 만약 운영 체제에 jemalloc이 없으면 다음 방식으로 설치하세요:
|
||||
|
||||
```bash
|
||||
# ubuntu
|
||||
sudo apt-get install libjemalloc-dev
|
||||
# centos
|
||||
sudo yum install jemalloc
|
||||
```
|
||||
|
||||
6. 백엔드 서비스를 시작합니다:
|
||||
|
||||
```bash
|
||||
source .venv/bin/activate
|
||||
@ -294,12 +308,14 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
bash docker/launch_backend_service.sh
|
||||
```
|
||||
|
||||
6. 프론트엔드 의존성을 설치합니다:
|
||||
7. 프론트엔드 의존성을 설치합니다:
|
||||
|
||||
```bash
|
||||
cd web
|
||||
npm install
|
||||
```
|
||||
7. 프론트엔드 서비스를 시작합니다:
|
||||
|
||||
8. 프론트엔드 서비스를 시작합니다:
|
||||
|
||||
```bash
|
||||
npm run dev
|
||||
@ -309,6 +325,14 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
|
||||

|
||||
|
||||
|
||||
9. 개발이 완료된 후 RAGFlow 프론트엔드 및 백엔드 서비스를 중지합니다.
|
||||
|
||||
```bash
|
||||
pkill -f "ragflow_server.py|task_executor.py"
|
||||
```
|
||||
|
||||
|
||||
## 📚 문서
|
||||
|
||||
- [Quickstart](https://ragflow.io/docs/dev/)
|
||||
@ -331,4 +355,4 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
|
||||
## 🙌 컨트리뷰션
|
||||
|
||||
RAGFlow는 오픈소스 협업을 통해 발전합니다. 이러한 정신을 바탕으로, 우리는 커뮤니티의 다양한 기여를 환영합니다. 참여하고 싶으시다면, 먼저 [가이드라인](./CONTRIBUTING.md)을 검토해 주세요.
|
||||
RAGFlow는 오픈소스 협업을 통해 발전합니다. 이러한 정신을 바탕으로, 우리는 커뮤니티의 다양한 기여를 환영합니다. 참여하고 싶으시다면, 먼저 [가이드라인](https://ragflow.io/docs/dev/contributing)을 검토해 주세요.
|
||||
|
||||
@ -22,7 +22,7 @@
|
||||
<img alt="Badge Estático" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
||||
</a>
|
||||
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
||||
<img src="https://img.shields.io/badge/docker_pull-ragflow:v0.18.0-brightgreen" alt="docker pull infiniflow/ragflow:v0.18.0">
|
||||
<img src="https://img.shields.io/badge/docker_pull-ragflow:v0.19.0-brightgreen" alt="docker pull infiniflow/ragflow:v0.19.0">
|
||||
</a>
|
||||
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
||||
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Última%20Relese" alt="Última Versão">
|
||||
@ -132,7 +132,10 @@ Experimente nossa demo em [https://demo.ragflow.io](https://demo.ragflow.io).
|
||||
- RAM >= 16 GB
|
||||
- Disco >= 50 GB
|
||||
- Docker >= 24.0.0 & Docker Compose >= v2.26.1
|
||||
> Se você não instalou o Docker na sua máquina local (Windows, Mac ou Linux), veja [Instalar Docker Engine](https://docs.docker.com/engine/install/).
|
||||
- [gVisor](https://gvisor.dev/docs/user_guide/install/): Necessário apenas se você pretende usar o recurso de executor de código (sandbox) do RAGFlow.
|
||||
|
||||
> [!TIP]
|
||||
> Se você não instalou o Docker na sua máquina local (Windows, Mac ou Linux), veja [Instalar Docker Engine](https://docs.docker.com/engine/install/).
|
||||
|
||||
### 🚀 Iniciar o servidor
|
||||
|
||||
@ -169,7 +172,7 @@ Experimente nossa demo em [https://demo.ragflow.io](https://demo.ragflow.io).
|
||||
> Todas as imagens Docker são construídas para plataformas x86. Atualmente, não oferecemos imagens Docker para ARM64.
|
||||
> Se você estiver usando uma plataforma ARM64, por favor, utilize [este guia](https://ragflow.io/docs/dev/build_docker_image) para construir uma imagem Docker compatível com o seu sistema.
|
||||
|
||||
> O comando abaixo baixa a edição `v0.18.0-slim` da imagem Docker do RAGFlow. Consulte a tabela a seguir para descrições de diferentes edições do RAGFlow. Para baixar uma edição do RAGFlow diferente da `v0.18.0-slim`, atualize a variável `RAGFLOW_IMAGE` conforme necessário no **docker/.env** antes de usar `docker compose` para iniciar o servidor. Por exemplo: defina `RAGFLOW_IMAGE=infiniflow/ragflow:v0.18.0` para a edição completa `v0.18.0`.
|
||||
> O comando abaixo baixa a edição `v0.19.0-slim` da imagem Docker do RAGFlow. Consulte a tabela a seguir para descrições de diferentes edições do RAGFlow. Para baixar uma edição do RAGFlow diferente da `v0.19.0-slim`, atualize a variável `RAGFLOW_IMAGE` conforme necessário no **docker/.env** antes de usar `docker compose` para iniciar o servidor. Por exemplo: defina `RAGFLOW_IMAGE=infiniflow/ragflow:v0.19.0` para a edição completa `v0.19.0`.
|
||||
|
||||
```bash
|
||||
$ cd ragflow/docker
|
||||
@ -182,8 +185,8 @@ Experimente nossa demo em [https://demo.ragflow.io](https://demo.ragflow.io).
|
||||
|
||||
| Tag da imagem RAGFlow | Tamanho da imagem (GB) | Possui modelos de incorporação? | Estável? |
|
||||
| --------------------- | ---------------------- | ------------------------------- | ------------------------ |
|
||||
| v0.18.0 | ~9 | :heavy_check_mark: | Lançamento estável |
|
||||
| v0.18.0-slim | ~2 | ❌ | Lançamento estável |
|
||||
| v0.19.0 | ~9 | :heavy_check_mark: | Lançamento estável |
|
||||
| v0.19.0-slim | ~2 | ❌ | Lançamento estável |
|
||||
| nightly | ~9 | :heavy_check_mark: | _Instável_ build noturno |
|
||||
| nightly-slim | ~2 | ❌ | _Instável_ build noturno |
|
||||
|
||||
@ -281,7 +284,7 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
1. Instale o `uv`, ou pule esta etapa se ele já estiver instalado:
|
||||
|
||||
```bash
|
||||
pipx install uv
|
||||
pipx install uv pre-commit
|
||||
```
|
||||
|
||||
2. Clone o código-fonte e instale as dependências Python:
|
||||
@ -290,6 +293,8 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
git clone https://github.com/infiniflow/ragflow.git
|
||||
cd ragflow/
|
||||
uv sync --python 3.10 --all-extras # instala os módulos Python dependentes do RAGFlow
|
||||
uv run download_deps.py
|
||||
pre-commit install
|
||||
```
|
||||
|
||||
3. Inicie os serviços dependentes (MinIO, Elasticsearch, Redis e MySQL) usando Docker Compose:
|
||||
@ -301,7 +306,7 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
Adicione a seguinte linha ao arquivo `/etc/hosts` para resolver todos os hosts especificados em **docker/.env** para `127.0.0.1`:
|
||||
|
||||
```
|
||||
127.0.0.1 es01 infinity mysql minio redis
|
||||
127.0.0.1 es01 infinity mysql minio redis sandbox-executor-manager
|
||||
```
|
||||
|
||||
4. Se não conseguir acessar o HuggingFace, defina a variável de ambiente `HF_ENDPOINT` para usar um site espelho:
|
||||
@ -310,7 +315,16 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
export HF_ENDPOINT=https://hf-mirror.com
|
||||
```
|
||||
|
||||
5. Lance o serviço de back-end:
|
||||
5. Se o seu sistema operacional não tiver jemalloc, instale-o da seguinte maneira:
|
||||
|
||||
```bash
|
||||
# ubuntu
|
||||
sudo apt-get install libjemalloc-dev
|
||||
# centos
|
||||
sudo yum instalar jemalloc
|
||||
```
|
||||
|
||||
6. Lance o serviço de back-end:
|
||||
|
||||
```bash
|
||||
source .venv/bin/activate
|
||||
@ -318,14 +332,14 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
bash docker/launch_backend_service.sh
|
||||
```
|
||||
|
||||
6. Instale as dependências do front-end:
|
||||
7. Instale as dependências do front-end:
|
||||
|
||||
```bash
|
||||
cd web
|
||||
npm install
|
||||
```
|
||||
|
||||
7. Lance o serviço de front-end:
|
||||
8. Lance o serviço de front-end:
|
||||
|
||||
```bash
|
||||
npm run dev
|
||||
@ -335,6 +349,13 @@ docker build --platform linux/amd64 -f Dockerfile -t infiniflow/ragflow:nightly
|
||||
|
||||

|
||||
|
||||
9. Pare os serviços de front-end e back-end do RAGFlow após a conclusão do desenvolvimento:
|
||||
|
||||
```bash
|
||||
pkill -f "ragflow_server.py|task_executor.py"
|
||||
```
|
||||
|
||||
|
||||
## 📚 Documentação
|
||||
|
||||
- [Quickstart](https://ragflow.io/docs/dev/)
|
||||
@ -358,4 +379,4 @@ Veja o [RAGFlow Roadmap 2025](https://github.com/infiniflow/ragflow/issues/4214)
|
||||
## 🙌 Contribuindo
|
||||
|
||||
O RAGFlow prospera por meio da colaboração de código aberto. Com esse espírito, abraçamos contribuições diversas da comunidade.
|
||||
Se você deseja fazer parte, primeiro revise nossas [Diretrizes de Contribuição](./CONTRIBUTING.md).
|
||||
Se você deseja fazer parte, primeiro revise nossas [Diretrizes de Contribuição](https://ragflow.io/docs/dev/contributing).
|
||||
|
||||
@ -21,7 +21,7 @@
|
||||
<img alt="Static Badge" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
||||
</a>
|
||||
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
||||
<img src="https://img.shields.io/badge/docker_pull-ragflow:v0.18.0-brightgreen" alt="docker pull infiniflow/ragflow:v0.18.0">
|
||||
<img src="https://img.shields.io/badge/docker_pull-ragflow:v0.19.0-brightgreen" alt="docker pull infiniflow/ragflow:v0.19.0">
|
||||
</a>
|
||||
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
||||
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Latest%20Release" alt="Latest Release">
|
||||
@ -111,7 +111,10 @@
|
||||
- RAM >= 16 GB
|
||||
- Disk >= 50 GB
|
||||
- Docker >= 24.0.0 & Docker Compose >= v2.26.1
|
||||
> 如果你並沒有在本機安裝 Docker(Windows、Mac,或 Linux), 可以參考文件 [Install Docker Engine](https://docs.docker.com/engine/install/) 自行安裝。
|
||||
- [gVisor](https://gvisor.dev/docs/user_guide/install/): 僅在您打算使用 RAGFlow 的代碼執行器(沙箱)功能時才需要安裝。
|
||||
|
||||
> [!TIP]
|
||||
> 如果你並沒有在本機安裝 Docker(Windows、Mac,或 Linux), 可以參考文件 [Install Docker Engine](https://docs.docker.com/engine/install/) 自行安裝。
|
||||
|
||||
### 🚀 啟動伺服器
|
||||
|
||||
@ -148,7 +151,7 @@
|
||||
> 所有 Docker 映像檔都是為 x86 平台建置的。目前,我們不提供 ARM64 平台的 Docker 映像檔。
|
||||
> 如果您使用的是 ARM64 平台,請使用 [這份指南](https://ragflow.io/docs/dev/build_docker_image) 來建置適合您系統的 Docker 映像檔。
|
||||
|
||||
> 執行以下指令會自動下載 RAGFlow slim Docker 映像 `v0.18.0-slim`。請參考下表查看不同 Docker 發行版的說明。如需下載不同於 `v0.18.0-slim` 的 Docker 映像,請在執行 `docker compose` 啟動服務之前先更新 **docker/.env** 檔案內的 `RAGFLOW_IMAGE` 變數。例如,你可以透過設定 `RAGFLOW_IMAGE=infiniflow/ragflow:v0.18.0` 來下載 RAGFlow 鏡像的 `v0.18.0` 完整發行版。
|
||||
> 執行以下指令會自動下載 RAGFlow slim Docker 映像 `v0.19.0-slim`。請參考下表查看不同 Docker 發行版的說明。如需下載不同於 `v0.19.0-slim` 的 Docker 映像,請在執行 `docker compose` 啟動服務之前先更新 **docker/.env** 檔案內的 `RAGFLOW_IMAGE` 變數。例如,你可以透過設定 `RAGFLOW_IMAGE=infiniflow/ragflow:v0.19.0` 來下載 RAGFlow 鏡像的 `v0.19.0` 完整發行版。
|
||||
|
||||
```bash
|
||||
$ cd ragflow/docker
|
||||
@ -161,8 +164,8 @@
|
||||
|
||||
| RAGFlow image tag | Image size (GB) | Has embedding models? | Stable? |
|
||||
| ----------------- | --------------- | --------------------- | ------------------------ |
|
||||
| v0.18.0 | ≈9 | :heavy_check_mark: | Stable release |
|
||||
| v0.18.0-slim | ≈2 | ❌ | Stable release |
|
||||
| v0.19.0 | ≈9 | :heavy_check_mark: | Stable release |
|
||||
| v0.19.0-slim | ≈2 | ❌ | Stable release |
|
||||
| nightly | ≈9 | :heavy_check_mark: | _Unstable_ nightly build |
|
||||
| nightly-slim | ≈2 | ❌ | _Unstable_ nightly build |
|
||||
|
||||
@ -269,7 +272,7 @@ docker build --platform linux/amd64 --build-arg NEED_MIRROR=1 -f Dockerfile -t i
|
||||
1. 安裝 uv。如已安裝,可跳過此步驟:
|
||||
|
||||
```bash
|
||||
pipx install uv
|
||||
pipx install uv pre-commit
|
||||
export UV_INDEX=https://mirrors.aliyun.com/pypi/simple
|
||||
```
|
||||
|
||||
@ -279,6 +282,8 @@ docker build --platform linux/amd64 --build-arg NEED_MIRROR=1 -f Dockerfile -t i
|
||||
git clone https://github.com/infiniflow/ragflow.git
|
||||
cd ragflow/
|
||||
uv sync --python 3.10 --all-extras # install RAGFlow dependent python modules
|
||||
uv run download_deps.py
|
||||
pre-commit install
|
||||
```
|
||||
|
||||
3. 透過 Docker Compose 啟動依賴的服務(MinIO, Elasticsearch, Redis, and MySQL):
|
||||
@ -290,7 +295,7 @@ docker build --platform linux/amd64 --build-arg NEED_MIRROR=1 -f Dockerfile -t i
|
||||
在 `/etc/hosts` 中加入以下程式碼,將 **conf/service_conf.yaml** 檔案中的所有 host 位址都解析為 `127.0.0.1`:
|
||||
|
||||
```
|
||||
127.0.0.1 es01 infinity mysql minio redis
|
||||
127.0.0.1 es01 infinity mysql minio redis sandbox-executor-manager
|
||||
```
|
||||
|
||||
4. 如果無法存取 HuggingFace,可以把環境變數 `HF_ENDPOINT` 設為對應的鏡像網站:
|
||||
@ -299,24 +304,34 @@ docker build --platform linux/amd64 --build-arg NEED_MIRROR=1 -f Dockerfile -t i
|
||||
export HF_ENDPOINT=https://hf-mirror.com
|
||||
```
|
||||
|
||||
5.啟動後端服務:
|
||||
『`bash
|
||||
source .venv/bin/activate
|
||||
export PYTHONPATH=$(pwd)
|
||||
bash docker/launch_backend_service.sh
|
||||
5. 如果你的操作系统没有 jemalloc,请按照如下方式安装:
|
||||
|
||||
```
|
||||
```bash
|
||||
# ubuntu
|
||||
sudo apt-get install libjemalloc-dev
|
||||
# centos
|
||||
sudo yum install jemalloc
|
||||
```
|
||||
|
||||
6. 安裝前端依賴:
|
||||
『`bash
|
||||
cd web
|
||||
npm install
|
||||
```
|
||||
6. 啟動後端服務:
|
||||
|
||||
7. 啟動前端服務:
|
||||
『`bash
|
||||
```bash
|
||||
source .venv/bin/activate
|
||||
export PYTHONPATH=$(pwd)
|
||||
bash docker/launch_backend_service.sh
|
||||
```
|
||||
|
||||
7. 安裝前端依賴:
|
||||
|
||||
```bash
|
||||
cd web
|
||||
npm install
|
||||
```
|
||||
|
||||
8. 啟動前端服務:
|
||||
|
||||
```bash
|
||||
npm run dev
|
||||
|
||||
```
|
||||
|
||||
以下界面說明系統已成功啟動:_
|
||||
@ -324,6 +339,13 @@ npm install
|
||||

|
||||
```
|
||||
|
||||
9. 開發完成後停止 RAGFlow 前端和後端服務:
|
||||
|
||||
```bash
|
||||
pkill -f "ragflow_server.py|task_executor.py"
|
||||
```
|
||||
|
||||
|
||||
## 📚 技術文檔
|
||||
|
||||
- [Quickstart](https://ragflow.io/docs/dev/)
|
||||
@ -346,7 +368,7 @@ npm install
|
||||
|
||||
## 🙌 貢獻指南
|
||||
|
||||
RAGFlow 只有透過開源協作才能蓬勃發展。秉持這項精神,我們歡迎來自社區的各種貢獻。如果您有意參與其中,請查閱我們的 [貢獻者指南](./CONTRIBUTING.md) 。
|
||||
RAGFlow 只有透過開源協作才能蓬勃發展。秉持這項精神,我們歡迎來自社區的各種貢獻。如果您有意參與其中,請查閱我們的 [貢獻者指南](https://ragflow.io/docs/dev/contributing) 。
|
||||
|
||||
## 🤝 商務合作
|
||||
|
||||
|
||||
44
README_zh.md
44
README_zh.md
@ -22,7 +22,7 @@
|
||||
<img alt="Static Badge" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
||||
</a>
|
||||
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
||||
<img src="https://img.shields.io/badge/docker_pull-ragflow:v0.18.0-brightgreen" alt="docker pull infiniflow/ragflow:v0.18.0">
|
||||
<img src="https://img.shields.io/badge/docker_pull-ragflow:v0.19.0-brightgreen" alt="docker pull infiniflow/ragflow:v0.19.0">
|
||||
</a>
|
||||
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
||||
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Latest%20Release" alt="Latest Release">
|
||||
@ -112,7 +112,10 @@
|
||||
- RAM >= 16 GB
|
||||
- Disk >= 50 GB
|
||||
- Docker >= 24.0.0 & Docker Compose >= v2.26.1
|
||||
> 如果你并没有在本机安装 Docker(Windows、Mac,或者 Linux), 可以参考文档 [Install Docker Engine](https://docs.docker.com/engine/install/) 自行安装。
|
||||
- [gVisor](https://gvisor.dev/docs/user_guide/install/): 仅在你打算使用 RAGFlow 的代码执行器(沙箱)功能时才需要安装。
|
||||
|
||||
> [!TIP]
|
||||
> 如果你并没有在本机安装 Docker(Windows、Mac,或者 Linux), 可以参考文档 [Install Docker Engine](https://docs.docker.com/engine/install/) 自行安装。
|
||||
|
||||
### 🚀 启动服务器
|
||||
|
||||
@ -149,7 +152,7 @@
|
||||
> 请注意,目前官方提供的所有 Docker 镜像均基于 x86 架构构建,并不提供基于 ARM64 的 Docker 镜像。
|
||||
> 如果你的操作系统是 ARM64 架构,请参考[这篇文档](https://ragflow.io/docs/dev/build_docker_image)自行构建 Docker 镜像。
|
||||
|
||||
> 运行以下命令会自动下载 RAGFlow slim Docker 镜像 `v0.18.0-slim`。请参考下表查看不同 Docker 发行版的描述。如需下载不同于 `v0.18.0-slim` 的 Docker 镜像,请在运行 `docker compose` 启动服务之前先更新 **docker/.env** 文件内的 `RAGFLOW_IMAGE` 变量。比如,你可以通过设置 `RAGFLOW_IMAGE=infiniflow/ragflow:v0.18.0` 来下载 RAGFlow 镜像的 `v0.18.0` 完整发行版。
|
||||
> 运行以下命令会自动下载 RAGFlow slim Docker 镜像 `v0.19.0-slim`。请参考下表查看不同 Docker 发行版的描述。如需下载不同于 `v0.19.0-slim` 的 Docker 镜像,请在运行 `docker compose` 启动服务之前先更新 **docker/.env** 文件内的 `RAGFLOW_IMAGE` 变量。比如,你可以通过设置 `RAGFLOW_IMAGE=infiniflow/ragflow:v0.19.0` 来下载 RAGFlow 镜像的 `v0.19.0` 完整发行版。
|
||||
|
||||
```bash
|
||||
$ cd ragflow/docker
|
||||
@ -162,8 +165,8 @@
|
||||
|
||||
| RAGFlow image tag | Image size (GB) | Has embedding models? | Stable? |
|
||||
| ----------------- | --------------- | --------------------- | ------------------------ |
|
||||
| v0.18.0 | ≈9 | :heavy_check_mark: | Stable release |
|
||||
| v0.18.0-slim | ≈2 | ❌ | Stable release |
|
||||
| v0.19.0 | ≈9 | :heavy_check_mark: | Stable release |
|
||||
| v0.19.0-slim | ≈2 | ❌ | Stable release |
|
||||
| nightly | ≈9 | :heavy_check_mark: | _Unstable_ nightly build |
|
||||
| nightly-slim | ≈2 | ❌ | _Unstable_ nightly build |
|
||||
|
||||
@ -270,7 +273,7 @@ docker build --platform linux/amd64 --build-arg NEED_MIRROR=1 -f Dockerfile -t i
|
||||
1. 安装 uv。如已经安装,可跳过本步骤:
|
||||
|
||||
```bash
|
||||
pipx install uv
|
||||
pipx install uv pre-commit
|
||||
export UV_INDEX=https://mirrors.aliyun.com/pypi/simple
|
||||
```
|
||||
|
||||
@ -280,6 +283,8 @@ docker build --platform linux/amd64 --build-arg NEED_MIRROR=1 -f Dockerfile -t i
|
||||
git clone https://github.com/infiniflow/ragflow.git
|
||||
cd ragflow/
|
||||
uv sync --python 3.10 --all-extras # install RAGFlow dependent python modules
|
||||
uv run download_deps.py
|
||||
pre-commit install
|
||||
```
|
||||
|
||||
3. 通过 Docker Compose 启动依赖的服务(MinIO, Elasticsearch, Redis, and MySQL):
|
||||
@ -291,7 +296,7 @@ docker build --platform linux/amd64 --build-arg NEED_MIRROR=1 -f Dockerfile -t i
|
||||
在 `/etc/hosts` 中添加以下代码,目的是将 **conf/service_conf.yaml** 文件中的所有 host 地址都解析为 `127.0.0.1`:
|
||||
|
||||
```
|
||||
127.0.0.1 es01 infinity mysql minio redis
|
||||
127.0.0.1 es01 infinity mysql minio redis sandbox-executor-manager
|
||||
```
|
||||
4. 如果无法访问 HuggingFace,可以把环境变量 `HF_ENDPOINT` 设成相应的镜像站点:
|
||||
|
||||
@ -299,7 +304,16 @@ docker build --platform linux/amd64 --build-arg NEED_MIRROR=1 -f Dockerfile -t i
|
||||
export HF_ENDPOINT=https://hf-mirror.com
|
||||
```
|
||||
|
||||
5. 启动后端服务:
|
||||
5. 如果你的操作系统没有 jemalloc,请按照如下方式安装:
|
||||
|
||||
```bash
|
||||
# ubuntu
|
||||
sudo apt-get install libjemalloc-dev
|
||||
# centos
|
||||
sudo yum install jemalloc
|
||||
```
|
||||
|
||||
6. 启动后端服务:
|
||||
|
||||
```bash
|
||||
source .venv/bin/activate
|
||||
@ -307,12 +321,14 @@ docker build --platform linux/amd64 --build-arg NEED_MIRROR=1 -f Dockerfile -t i
|
||||
bash docker/launch_backend_service.sh
|
||||
```
|
||||
|
||||
6. 安装前端依赖:
|
||||
7. 安装前端依赖:
|
||||
|
||||
```bash
|
||||
cd web
|
||||
npm install
|
||||
```
|
||||
7. 启动前端服务:
|
||||
|
||||
8. 启动前端服务:
|
||||
|
||||
```bash
|
||||
npm run dev
|
||||
@ -321,12 +337,14 @@ docker build --platform linux/amd64 --build-arg NEED_MIRROR=1 -f Dockerfile -t i
|
||||
_以下界面说明系统已经成功启动:_
|
||||
|
||||

|
||||
8. 开发完成后停止 RAGFlow 服务
|
||||
停止 RAGFlow 前端和后端服务:
|
||||
|
||||
9. 开发完成后停止 RAGFlow 前端和后端服务:
|
||||
|
||||
```bash
|
||||
pkill -f "ragflow_server.py|task_executor.py"
|
||||
```
|
||||
|
||||
|
||||
## 📚 技术文档
|
||||
|
||||
- [Quickstart](https://ragflow.io/docs/dev/)
|
||||
@ -349,7 +367,7 @@ docker build --platform linux/amd64 --build-arg NEED_MIRROR=1 -f Dockerfile -t i
|
||||
|
||||
## 🙌 贡献指南
|
||||
|
||||
RAGFlow 只有通过开源协作才能蓬勃发展。秉持这一精神,我们欢迎来自社区的各种贡献。如果您有意参与其中,请查阅我们的 [贡献者指南](./CONTRIBUTING.md) 。
|
||||
RAGFlow 只有通过开源协作才能蓬勃发展。秉持这一精神,我们欢迎来自社区的各种贡献。如果您有意参与其中,请查阅我们的 [贡献者指南](https://ragflow.io/docs/dev/contributing) 。
|
||||
|
||||
## 🤝 商务合作
|
||||
|
||||
|
||||
@ -17,7 +17,6 @@ import logging
|
||||
import json
|
||||
from copy import deepcopy
|
||||
from functools import partial
|
||||
|
||||
import pandas as pd
|
||||
|
||||
from agent.component import component_class
|
||||
@ -167,7 +166,10 @@ class Canvas:
|
||||
return n["data"]["name"]
|
||||
return ""
|
||||
|
||||
def run(self, **kwargs):
|
||||
def run(self, running_hint_text = "is running...🕞", **kwargs):
|
||||
if not running_hint_text or not isinstance(running_hint_text, str):
|
||||
running_hint_text = "is running...🕞"
|
||||
|
||||
if self.answer:
|
||||
cpn_id = self.answer[0]
|
||||
self.answer.pop(0)
|
||||
@ -209,7 +211,7 @@ class Canvas:
|
||||
if c not in waiting:
|
||||
waiting.append(c)
|
||||
continue
|
||||
yield "*'{}'* is running...🕞".format(self.get_component_name(c))
|
||||
yield "*'{}'* {}".format(self.get_component_name(c), running_hint_text)
|
||||
|
||||
if cpn.component_name.lower() == "iteration":
|
||||
st_cpn = cpn.get_start()
|
||||
@ -362,4 +364,7 @@ class Canvas:
|
||||
return self.components["begin"]["obj"]._param.query
|
||||
|
||||
def get_component_input_elements(self, cpnnm):
|
||||
return self.components[cpnnm]["obj"].get_input_elements()
|
||||
return self.components[cpnnm]["obj"].get_input_elements()
|
||||
|
||||
def set_component_infor(self, cpn_id, infor):
|
||||
self.components[cpn_id]["obj"].set_infor(infor)
|
||||
|
||||
@ -50,6 +50,7 @@ from .template import Template, TemplateParam
|
||||
from .email import Email, EmailParam
|
||||
from .iteration import Iteration, IterationParam
|
||||
from .iterationitem import IterationItem, IterationItemParam
|
||||
from .code import Code, CodeParam
|
||||
|
||||
|
||||
def component_class(class_name):
|
||||
@ -129,5 +130,7 @@ __all__ = [
|
||||
"TemplateParam",
|
||||
"Email",
|
||||
"EmailParam",
|
||||
"Code",
|
||||
"CodeParam",
|
||||
"component_class"
|
||||
]
|
||||
|
||||
@ -19,7 +19,7 @@ import json
|
||||
import os
|
||||
import logging
|
||||
from functools import partial
|
||||
from typing import Tuple, Union
|
||||
from typing import Any, Tuple, Union
|
||||
|
||||
import pandas as pd
|
||||
|
||||
@ -34,6 +34,7 @@ _IS_RAW_CONF = "_is_raw_conf"
|
||||
class ComponentParamBase(ABC):
|
||||
def __init__(self):
|
||||
self.output_var_name = "output"
|
||||
self.infor_var_name = "infor"
|
||||
self.message_history_window_size = 22
|
||||
self.query = []
|
||||
self.inputs = []
|
||||
@ -462,6 +463,35 @@ class ComponentBase(ABC):
|
||||
def set_output(self, v):
|
||||
setattr(self._param, self._param.output_var_name, v)
|
||||
|
||||
def set_infor(self, v):
|
||||
setattr(self._param, self._param.infor_var_name, v)
|
||||
|
||||
def _fetch_outputs_from(self, sources: list[dict[str, Any]]) -> list[pd.DataFrame]:
|
||||
outs = []
|
||||
for q in sources:
|
||||
if q.get("component_id"):
|
||||
if "@" in q["component_id"] and q["component_id"].split("@")[0].lower().find("begin") >= 0:
|
||||
cpn_id, key = q["component_id"].split("@")
|
||||
for p in self._canvas.get_component(cpn_id)["obj"]._param.query:
|
||||
if p["key"] == key:
|
||||
outs.append(pd.DataFrame([{"content": p.get("value", "")}]))
|
||||
break
|
||||
else:
|
||||
assert False, f"Can't find parameter '{key}' for {cpn_id}"
|
||||
continue
|
||||
|
||||
if q["component_id"].lower().find("answer") == 0:
|
||||
txt = []
|
||||
for r, c in self._canvas.history[::-1][:self._param.message_history_window_size][::-1]:
|
||||
txt.append(f"{r.upper()}:{c}")
|
||||
txt = "\n".join(txt)
|
||||
outs.append(pd.DataFrame([{"content": txt}]))
|
||||
continue
|
||||
|
||||
outs.append(self._canvas.get_component(q["component_id"])["obj"].output(allow_partial=False)[1])
|
||||
elif q.get("value"):
|
||||
outs.append(pd.DataFrame([{"content": q["value"]}]))
|
||||
return outs
|
||||
def get_input(self):
|
||||
if self._param.debug_inputs:
|
||||
return pd.DataFrame([{"content": v["value"]} for v in self._param.debug_inputs if v.get("value")])
|
||||
@ -475,37 +505,24 @@ class ComponentBase(ABC):
|
||||
|
||||
if self._param.query:
|
||||
self._param.inputs = []
|
||||
outs = []
|
||||
for q in self._param.query:
|
||||
if q.get("component_id"):
|
||||
if q["component_id"].split("@")[0].lower().find("begin") >= 0:
|
||||
cpn_id, key = q["component_id"].split("@")
|
||||
for p in self._canvas.get_component(cpn_id)["obj"]._param.query:
|
||||
if p["key"] == key:
|
||||
outs.append(pd.DataFrame([{"content": p.get("value", "")}]))
|
||||
self._param.inputs.append({"component_id": q["component_id"],
|
||||
"content": p.get("value", "")})
|
||||
break
|
||||
else:
|
||||
assert False, f"Can't find parameter '{key}' for {cpn_id}"
|
||||
continue
|
||||
outs = self._fetch_outputs_from(self._param.query)
|
||||
|
||||
if q["component_id"].lower().find("answer") == 0:
|
||||
txt = []
|
||||
for r, c in self._canvas.history[::-1][:self._param.message_history_window_size][::-1]:
|
||||
txt.append(f"{r.upper()}:{c}")
|
||||
txt = "\n".join(txt)
|
||||
self._param.inputs.append({"content": txt, "component_id": q["component_id"]})
|
||||
outs.append(pd.DataFrame([{"content": txt}]))
|
||||
continue
|
||||
for out in outs:
|
||||
records = out.to_dict("records")
|
||||
content: str
|
||||
|
||||
if len(records) > 1:
|
||||
content = "\n".join(
|
||||
[str(d["content"]) for d in records]
|
||||
)
|
||||
else:
|
||||
content = records[0]["content"]
|
||||
|
||||
self._param.inputs.append({
|
||||
"component_id": records[0].get("component_id"),
|
||||
"content": content
|
||||
})
|
||||
|
||||
outs.append(self._canvas.get_component(q["component_id"])["obj"].output(allow_partial=False)[1])
|
||||
self._param.inputs.append({"component_id": q["component_id"],
|
||||
"content": "\n".join(
|
||||
[str(d["content"]) for d in outs[-1].to_dict('records')])})
|
||||
elif q.get("value"):
|
||||
self._param.inputs.append({"component_id": None, "content": q["value"]})
|
||||
outs.append(pd.DataFrame([{"content": q["value"]}]))
|
||||
if outs:
|
||||
df = pd.concat(outs, ignore_index=True)
|
||||
if "content" in df:
|
||||
|
||||
@ -85,6 +85,8 @@ class Categorize(Generate, ABC):
|
||||
input = self.get_input()
|
||||
input = " - ".join(input["content"]) if "content" in input else ""
|
||||
chat_mdl = LLMBundle(self._canvas.get_tenant_id(), LLMType.CHAT, self._param.llm_id)
|
||||
self._canvas.set_component_infor(self._id, {"prompt":self._param.get_prompt(input),"messages": [{"role": "user", "content": "\nCategory: "}],"conf": self._param.gen_conf()})
|
||||
|
||||
ans = chat_mdl.chat(self._param.get_prompt(input), [{"role": "user", "content": "\nCategory: "}],
|
||||
self._param.gen_conf())
|
||||
logging.debug(f"input: {input}, answer: {str(ans)}")
|
||||
|
||||
138
agent/component/code.py
Normal file
138
agent/component/code.py
Normal file
@ -0,0 +1,138 @@
|
||||
#
|
||||
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
import base64
|
||||
from abc import ABC
|
||||
from enum import Enum
|
||||
from typing import Optional
|
||||
|
||||
from pydantic import BaseModel, Field, field_validator
|
||||
|
||||
from agent.component.base import ComponentBase, ComponentParamBase
|
||||
from api import settings
|
||||
|
||||
|
||||
class Language(str, Enum):
|
||||
PYTHON = "python"
|
||||
NODEJS = "nodejs"
|
||||
|
||||
|
||||
class CodeExecutionRequest(BaseModel):
|
||||
code_b64: str = Field(..., description="Base64 encoded code string")
|
||||
language: Language = Field(default=Language.PYTHON, description="Programming language")
|
||||
arguments: Optional[dict] = Field(default={}, description="Arguments")
|
||||
|
||||
@field_validator("code_b64")
|
||||
@classmethod
|
||||
def validate_base64(cls, v: str) -> str:
|
||||
try:
|
||||
base64.b64decode(v, validate=True)
|
||||
return v
|
||||
except Exception as e:
|
||||
raise ValueError(f"Invalid base64 encoding: {str(e)}")
|
||||
|
||||
@field_validator("language", mode="before")
|
||||
@classmethod
|
||||
def normalize_language(cls, v) -> str:
|
||||
if isinstance(v, str):
|
||||
low = v.lower()
|
||||
if low in ("python", "python3"):
|
||||
return "python"
|
||||
elif low in ("javascript", "nodejs"):
|
||||
return "nodejs"
|
||||
raise ValueError(f"Unsupported language: {v}")
|
||||
|
||||
|
||||
class CodeParam(ComponentParamBase):
|
||||
"""
|
||||
Define the code sandbox component parameters.
|
||||
"""
|
||||
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.lang = "python"
|
||||
self.script = ""
|
||||
self.arguments = []
|
||||
self.address = f"http://{settings.SANDBOX_HOST}:9385/run"
|
||||
self.enable_network = True
|
||||
|
||||
def check(self):
|
||||
self.check_valid_value(self.lang, "Support languages", ["python", "python3", "nodejs", "javascript"])
|
||||
self.check_defined_type(self.enable_network, "Enable network", ["bool"])
|
||||
|
||||
|
||||
class Code(ComponentBase, ABC):
|
||||
component_name = "Code"
|
||||
|
||||
def _run(self, history, **kwargs):
|
||||
arguments = {}
|
||||
for input in self._param.arguments:
|
||||
if "@" in input["component_id"]:
|
||||
component_id = input["component_id"].split("@")[0]
|
||||
refered_component_key = input["component_id"].split("@")[1]
|
||||
refered_component = self._canvas.get_component(component_id)["obj"]
|
||||
|
||||
for param in refered_component._param.query:
|
||||
if param["key"] == refered_component_key:
|
||||
if "value" in param:
|
||||
arguments[input["name"]] = param["value"]
|
||||
else:
|
||||
cpn = self._canvas.get_component(input["component_id"])["obj"]
|
||||
if cpn.component_name.lower() == "answer":
|
||||
arguments[input["name"]] = self._canvas.get_history(1)[0]["content"]
|
||||
continue
|
||||
_, out = cpn.output(allow_partial=False)
|
||||
if not out.empty:
|
||||
arguments[input["name"]] = "\n".join(out["content"])
|
||||
|
||||
return self._execute_code(
|
||||
language=self._param.lang,
|
||||
code=self._param.script,
|
||||
arguments=arguments,
|
||||
address=self._param.address,
|
||||
enable_network=self._param.enable_network,
|
||||
)
|
||||
|
||||
def _execute_code(self, language: str, code: str, arguments: dict, address: str, enable_network: bool):
|
||||
import requests
|
||||
|
||||
try:
|
||||
code_b64 = self._encode_code(code)
|
||||
code_req = CodeExecutionRequest(code_b64=code_b64, language=language, arguments=arguments).model_dump()
|
||||
except Exception as e:
|
||||
return Code.be_output("**Error**: construct code request error: " + str(e))
|
||||
|
||||
try:
|
||||
resp = requests.post(url=address, json=code_req, timeout=10)
|
||||
body = resp.json()
|
||||
if body:
|
||||
stdout = body.get("stdout")
|
||||
stderr = body.get("stderr")
|
||||
return Code.be_output(stdout or stderr)
|
||||
else:
|
||||
return Code.be_output("**Error**: There is no response from sanbox")
|
||||
|
||||
except Exception as e:
|
||||
return Code.be_output("**Error**: Internal error in sanbox: " + str(e))
|
||||
|
||||
def _encode_code(self, code: str) -> str:
|
||||
return base64.b64encode(code.encode("utf-8")).decode("utf-8")
|
||||
|
||||
def get_input_elements(self):
|
||||
elements = []
|
||||
for input in self._param.arguments:
|
||||
cpn_id = input["component_id"]
|
||||
elements.append({"key": cpn_id, "name": input["name"]})
|
||||
return elements
|
||||
@ -61,7 +61,7 @@ class ExeSQL(Generate, ABC):
|
||||
component_name = "ExeSQL"
|
||||
|
||||
def _refactor(self, ans):
|
||||
ans = re.sub(r"<think>.*</think>", "", ans, flags=re.DOTALL)
|
||||
ans = re.sub(r"^.*</think>", "", ans, flags=re.DOTALL)
|
||||
match = re.search(r"```sql\s*(.*?)\s*```", ans, re.DOTALL)
|
||||
if match:
|
||||
ans = match.group(1) # Query content
|
||||
|
||||
@ -16,15 +16,29 @@
|
||||
import json
|
||||
import re
|
||||
from functools import partial
|
||||
from typing import Any
|
||||
import pandas as pd
|
||||
from api.db import LLMType
|
||||
from api.db.services.conversation_service import structure_answer
|
||||
from api.db.services.llm_service import LLMBundle
|
||||
from api import settings
|
||||
from agent.component.base import ComponentBase, ComponentParamBase
|
||||
from plugin import GlobalPluginManager
|
||||
from plugin.llm_tool_plugin import llm_tool_metadata_to_openai_tool
|
||||
from rag.llm.chat_model import ToolCallSession
|
||||
from rag.prompts import message_fit_in
|
||||
|
||||
|
||||
class LLMToolPluginCallSession(ToolCallSession):
|
||||
def tool_call(self, name: str, arguments: dict[str, Any]) -> str:
|
||||
tool = GlobalPluginManager.get_llm_tool_by_name(name)
|
||||
|
||||
if tool is None:
|
||||
raise ValueError(f"LLM tool {name} does not exist")
|
||||
|
||||
return tool().invoke(**arguments)
|
||||
|
||||
|
||||
class GenerateParam(ComponentParamBase):
|
||||
"""
|
||||
Define the Generate component parameters.
|
||||
@ -41,6 +55,7 @@ class GenerateParam(ComponentParamBase):
|
||||
self.frequency_penalty = 0
|
||||
self.cite = True
|
||||
self.parameters = []
|
||||
self.llm_enabled_tools = []
|
||||
|
||||
def check(self):
|
||||
self.check_decimal_float(self.temperature, "[Generate] Temperature")
|
||||
@ -133,6 +148,15 @@ class Generate(ComponentBase):
|
||||
|
||||
def _run(self, history, **kwargs):
|
||||
chat_mdl = LLMBundle(self._canvas.get_tenant_id(), LLMType.CHAT, self._param.llm_id)
|
||||
|
||||
if len(self._param.llm_enabled_tools) > 0:
|
||||
tools = GlobalPluginManager.get_llm_tools_by_names(self._param.llm_enabled_tools)
|
||||
|
||||
chat_mdl.bind_tools(
|
||||
LLMToolPluginCallSession(),
|
||||
[llm_tool_metadata_to_openai_tool(t.get_metadata()) for t in tools]
|
||||
)
|
||||
|
||||
prompt = self._param.prompt
|
||||
|
||||
retrieval_res = []
|
||||
@ -200,8 +224,8 @@ class Generate(ComponentBase):
|
||||
if len(msg) < 2:
|
||||
msg.append({"role": "user", "content": "Output: "})
|
||||
ans = chat_mdl.chat(msg[0]["content"], msg[1:], self._param.gen_conf())
|
||||
ans = re.sub(r"<think>.*</think>", "", ans, flags=re.DOTALL)
|
||||
|
||||
ans = re.sub(r"^.*</think>", "", ans, flags=re.DOTALL)
|
||||
self._canvas.set_component_infor(self._id, {"prompt":msg[0]["content"],"messages": msg[1:],"conf": self._param.gen_conf()})
|
||||
if self._param.cite and "chunks" in retrieval_res.columns:
|
||||
res = self.set_cite(retrieval_res, ans)
|
||||
return pd.DataFrame([res])
|
||||
@ -234,7 +258,7 @@ class Generate(ComponentBase):
|
||||
if self._param.cite and "chunks" in retrieval_res.columns:
|
||||
res = self.set_cite(retrieval_res, answer)
|
||||
yield res
|
||||
|
||||
self._canvas.set_component_infor(self._id, {"prompt":msg[0]["content"],"messages": msg[1:],"conf": self._param.gen_conf()})
|
||||
self.set_output(Generate.be_output(res))
|
||||
|
||||
def debug(self, **kwargs):
|
||||
|
||||
@ -51,13 +51,19 @@ class KeywordExtract(Generate, ABC):
|
||||
|
||||
def _run(self, history, **kwargs):
|
||||
query = self.get_input()
|
||||
query = str(query["content"][0]) if "content" in query else ""
|
||||
if hasattr(query, "to_dict") and "content" in query:
|
||||
query = ", ".join(map(str, query["content"].dropna()))
|
||||
else:
|
||||
query = str(query)
|
||||
|
||||
|
||||
chat_mdl = LLMBundle(self._canvas.get_tenant_id(), LLMType.CHAT, self._param.llm_id)
|
||||
self._canvas.set_component_infor(self._id, {"prompt":self._param.get_prompt(),"messages": [{"role": "user", "content": query}],"conf": self._param.gen_conf()})
|
||||
|
||||
ans = chat_mdl.chat(self._param.get_prompt(), [{"role": "user", "content": query}],
|
||||
self._param.gen_conf())
|
||||
|
||||
ans = re.sub(r"<think>.*</think>", "", ans, flags=re.DOTALL)
|
||||
ans = re.sub(r"^.*</think>", "", ans, flags=re.DOTALL)
|
||||
ans = re.sub(r".*keyword:", "", ans).strip()
|
||||
logging.debug(f"ans: {ans}")
|
||||
return KeywordExtract.be_output(ans)
|
||||
|
||||
@ -15,6 +15,7 @@
|
||||
#
|
||||
import json
|
||||
import logging
|
||||
import re
|
||||
from abc import ABC
|
||||
|
||||
import pandas as pd
|
||||
@ -30,10 +31,10 @@ from rag.utils.tavily_conn import Tavily
|
||||
|
||||
|
||||
class RetrievalParam(ComponentParamBase):
|
||||
|
||||
"""
|
||||
Define the Retrieval component parameters.
|
||||
"""
|
||||
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.similarity_threshold = 0.2
|
||||
@ -41,6 +42,7 @@ class RetrievalParam(ComponentParamBase):
|
||||
self.top_n = 8
|
||||
self.top_k = 1024
|
||||
self.kb_ids = []
|
||||
self.kb_vars = []
|
||||
self.rerank_id = ""
|
||||
self.empty_response = ""
|
||||
self.tavily_api_key = ""
|
||||
@ -58,7 +60,26 @@ class Retrieval(ComponentBase, ABC):
|
||||
def _run(self, history, **kwargs):
|
||||
query = self.get_input()
|
||||
query = str(query["content"][0]) if "content" in query else ""
|
||||
kbs = KnowledgebaseService.get_by_ids(self._param.kb_ids)
|
||||
query = re.split(r"(USER:|ASSISTANT:)", query)[-1]
|
||||
|
||||
kb_ids: list[str] = self._param.kb_ids or []
|
||||
|
||||
kb_vars = self._fetch_outputs_from(self._param.kb_vars)
|
||||
|
||||
if len(kb_vars) > 0:
|
||||
for kb_var in kb_vars:
|
||||
if len(kb_var) == 1:
|
||||
kb_var_value = str(kb_var["content"][0])
|
||||
|
||||
for v in kb_var_value.split(","):
|
||||
kb_ids.append(v)
|
||||
else:
|
||||
for v in kb_var.to_dict("records"):
|
||||
kb_ids.append(v["content"])
|
||||
|
||||
filtered_kb_ids: list[str] = [kb_id for kb_id in kb_ids if kb_id]
|
||||
|
||||
kbs = KnowledgebaseService.get_by_ids(filtered_kb_ids)
|
||||
if not kbs:
|
||||
return Retrieval.be_output("")
|
||||
|
||||
@ -75,20 +96,24 @@ class Retrieval(ComponentBase, ABC):
|
||||
rerank_mdl = LLMBundle(kbs[0].tenant_id, LLMType.RERANK, self._param.rerank_id)
|
||||
|
||||
if kbs:
|
||||
kbinfos = settings.retrievaler.retrieval(query, embd_mdl, kbs[0].tenant_id, self._param.kb_ids,
|
||||
1, self._param.top_n,
|
||||
self._param.similarity_threshold, 1 - self._param.keywords_similarity_weight,
|
||||
aggs=False, rerank_mdl=rerank_mdl,
|
||||
rank_feature=label_question(query, kbs))
|
||||
kbinfos = settings.retrievaler.retrieval(
|
||||
query,
|
||||
embd_mdl,
|
||||
[kb.tenant_id for kb in kbs],
|
||||
filtered_kb_ids,
|
||||
1,
|
||||
self._param.top_n,
|
||||
self._param.similarity_threshold,
|
||||
1 - self._param.keywords_similarity_weight,
|
||||
aggs=False,
|
||||
rerank_mdl=rerank_mdl,
|
||||
rank_feature=label_question(query, kbs),
|
||||
)
|
||||
else:
|
||||
kbinfos = {"chunks": [], "doc_aggs": []}
|
||||
|
||||
if self._param.use_kg and kbs:
|
||||
ck = settings.kg_retrievaler.retrieval(query,
|
||||
[kbs[0].tenant_id],
|
||||
self._param.kb_ids,
|
||||
embd_mdl,
|
||||
LLMBundle(kbs[0].tenant_id, LLMType.CHAT))
|
||||
ck = settings.kg_retrievaler.retrieval(query, [kb.tenant_id for kb in kbs], filtered_kb_ids, embd_mdl, LLMBundle(kbs[0].tenant_id, LLMType.CHAT))
|
||||
if ck["content_with_weight"]:
|
||||
kbinfos["chunks"].insert(0, ck)
|
||||
|
||||
@ -107,5 +132,3 @@ class Retrieval(ComponentBase, ABC):
|
||||
df = pd.DataFrame({"content": kb_prompt(kbinfos, 200000), "chunks": json.dumps(kbinfos["chunks"])})
|
||||
logging.debug("{} {}".format(query, df))
|
||||
return df.dropna()
|
||||
|
||||
|
||||
|
||||
@ -57,7 +57,7 @@ class DeepResearcher:
|
||||
msg_history[-1]["content"] += "\n\nContinues reasoning with the new information.\n"
|
||||
|
||||
for ans in self.chat_mdl.chat_streamly(REASON_PROMPT, msg_history, {"temperature": 0.7}):
|
||||
ans = re.sub(r"<think>.*</think>", "", ans, flags=re.DOTALL)
|
||||
ans = re.sub(r"^.*</think>", "", ans, flags=re.DOTALL)
|
||||
if not ans:
|
||||
continue
|
||||
query_think = ans
|
||||
@ -142,7 +142,7 @@ class DeepResearcher:
|
||||
[{"role": "user",
|
||||
"content": f'Now you should analyze each web page and find helpful information based on the current search query "{search_query}" and previous reasoning steps.'}],
|
||||
{"temperature": 0.7}):
|
||||
ans = re.sub(r"<think>.*</think>", "", ans, flags=re.DOTALL)
|
||||
ans = re.sub(r"^.*</think>", "", ans, flags=re.DOTALL)
|
||||
if not ans:
|
||||
continue
|
||||
summary_think = ans
|
||||
|
||||
@ -107,7 +107,7 @@ def search_pages_path(pages_dir):
|
||||
def register_page(page_path):
|
||||
path = f"{page_path}"
|
||||
|
||||
page_name = page_path.stem.rstrip("_app")
|
||||
page_name = page_path.stem.removesuffix("_app")
|
||||
module_name = ".".join(
|
||||
page_path.parts[page_path.parts.index("api"): -1] + (page_name,)
|
||||
)
|
||||
|
||||
@ -21,7 +21,7 @@ from flask import request, Response
|
||||
from api.db.services.llm_service import TenantLLMService
|
||||
from flask_login import login_required, current_user
|
||||
|
||||
from api.db import FileType, LLMType, ParserType, FileSource
|
||||
from api.db import VALID_FILE_TYPES, VALID_TASK_STATUS, FileType, LLMType, ParserType, FileSource
|
||||
from api.db.db_models import APIToken, Task, File
|
||||
from api.db.services import duplicate_name
|
||||
from api.db.services.api_service import APITokenService, API4ConversationService
|
||||
@ -345,7 +345,7 @@ def completion():
|
||||
|
||||
@manager.route('/conversation/<conversation_id>', methods=['GET']) # noqa: F821
|
||||
# @login_required
|
||||
def get(conversation_id):
|
||||
def get_conversation(conversation_id):
|
||||
token = request.headers.get('Authorization').split()[1]
|
||||
objs = APIToken.query(token=token)
|
||||
if not objs:
|
||||
@ -548,6 +548,31 @@ def list_chunks():
|
||||
|
||||
return get_json_result(data=res)
|
||||
|
||||
@manager.route('/get_chunk/<chunk_id>', methods=['GET']) # noqa: F821
|
||||
# @login_required
|
||||
def get_chunk(chunk_id):
|
||||
from rag.nlp import search
|
||||
token = request.headers.get('Authorization').split()[1]
|
||||
objs = APIToken.query(token=token)
|
||||
if not objs:
|
||||
return get_json_result(
|
||||
data=False, message='Authentication error: API key is invalid!"', code=settings.RetCode.AUTHENTICATION_ERROR)
|
||||
try:
|
||||
tenant_id = objs[0].tenant_id
|
||||
kb_ids = KnowledgebaseService.get_kb_ids(tenant_id)
|
||||
chunk = settings.docStoreConn.get(chunk_id, search.index_name(tenant_id), kb_ids)
|
||||
if chunk is None:
|
||||
return server_error_response(Exception("Chunk not found"))
|
||||
k = []
|
||||
for n in chunk.keys():
|
||||
if re.search(r"(_vec$|_sm_|_tks|_ltks)", n):
|
||||
k.append(n)
|
||||
for n in k:
|
||||
del chunk[n]
|
||||
|
||||
return get_json_result(data=chunk)
|
||||
except Exception as e:
|
||||
return server_error_response(e)
|
||||
|
||||
@manager.route('/list_kb_docs', methods=['POST']) # noqa: F821
|
||||
# @login_required
|
||||
@ -577,10 +602,23 @@ def list_kb_docs():
|
||||
orderby = req.get("orderby", "create_time")
|
||||
desc = req.get("desc", True)
|
||||
keywords = req.get("keywords", "")
|
||||
|
||||
status = req.get("status", [])
|
||||
if status:
|
||||
invalid_status = {s for s in status if s not in VALID_TASK_STATUS}
|
||||
if invalid_status:
|
||||
return get_data_error_result(
|
||||
message=f"Invalid filter status conditions: {', '.join(invalid_status)}"
|
||||
)
|
||||
types = req.get("types", [])
|
||||
if types:
|
||||
invalid_types = {t for t in types if t not in VALID_FILE_TYPES}
|
||||
if invalid_types:
|
||||
return get_data_error_result(
|
||||
message=f"Invalid filter conditions: {', '.join(invalid_types)} type{'s' if len(invalid_types) > 1 else ''}"
|
||||
)
|
||||
try:
|
||||
docs, tol = DocumentService.get_by_kb_id(
|
||||
kb_id, page_number, items_per_page, orderby, desc, keywords)
|
||||
kb_id, page_number, items_per_page, orderby, desc, keywords, status, types)
|
||||
docs = [{"doc_id": doc['id'], "doc_name": doc['name']} for doc in docs]
|
||||
|
||||
return get_json_result(data={"total": tol, "docs": docs})
|
||||
@ -615,7 +653,7 @@ def document_rm():
|
||||
tenant_id = objs[0].tenant_id
|
||||
req = request.json
|
||||
try:
|
||||
doc_ids = [DocumentService.get_doc_id_by_doc_name(doc_name) for doc_name in req.get("doc_names", [])]
|
||||
doc_ids = DocumentService.get_doc_ids_by_doc_names(req.get("doc_names", []))
|
||||
for doc_id in req.get("doc_ids", []):
|
||||
if doc_id not in doc_ids:
|
||||
doc_ids.append(doc_id)
|
||||
@ -633,11 +671,16 @@ def document_rm():
|
||||
FileService.init_knowledgebase_docs(pf_id, tenant_id)
|
||||
|
||||
errors = ""
|
||||
docs = DocumentService.get_by_ids(doc_ids)
|
||||
doc_dic = {}
|
||||
for doc in docs:
|
||||
doc_dic[doc.id] = doc
|
||||
|
||||
for doc_id in doc_ids:
|
||||
try:
|
||||
e, doc = DocumentService.get_by_id(doc_id)
|
||||
if not e:
|
||||
if doc_id not in doc_dic:
|
||||
return get_data_error_result(message="Document not found!")
|
||||
doc = doc_dic[doc_id]
|
||||
tenant_id = DocumentService.get_tenant_id(doc_id)
|
||||
if not tenant_id:
|
||||
return get_data_error_result(message="Tenant not found!")
|
||||
@ -818,10 +861,11 @@ def retrieval():
|
||||
doc_ids = req.get("doc_ids", [])
|
||||
question = req.get("question")
|
||||
page = int(req.get("page", 1))
|
||||
size = int(req.get("size", 30))
|
||||
size = int(req.get("page_size", 30))
|
||||
similarity_threshold = float(req.get("similarity_threshold", 0.2))
|
||||
vector_similarity_weight = float(req.get("vector_similarity_weight", 0.3))
|
||||
top = int(req.get("top_k", 1024))
|
||||
highlight = bool(req.get("highlight", False))
|
||||
|
||||
try:
|
||||
kbs = KnowledgebaseService.get_by_ids(kb_ids)
|
||||
@ -842,7 +886,7 @@ def retrieval():
|
||||
question += keyword_extraction(chat_mdl, question)
|
||||
ranks = settings.retrievaler.retrieval(question, embd_mdl, kbs[0].tenant_id, kb_ids, page, size,
|
||||
similarity_threshold, vector_similarity_weight, top,
|
||||
doc_ids, rerank_mdl=rerank_mdl,
|
||||
doc_ids, rerank_mdl=rerank_mdl, highlight= highlight,
|
||||
rank_feature=label_question(question, kbs))
|
||||
for c in ranks["chunks"]:
|
||||
c.pop("vector", None)
|
||||
|
||||
76
api/apps/auth/README.md
Normal file
76
api/apps/auth/README.md
Normal file
@ -0,0 +1,76 @@
|
||||
# Auth
|
||||
|
||||
The Auth module provides implementations of OAuth2 and OpenID Connect (OIDC) authentication for integration with third-party identity providers.
|
||||
|
||||
**Features**
|
||||
|
||||
- Supports both OAuth2 and OIDC authentication protocols
|
||||
- Automatic OIDC configuration discovery (via `/.well-known/openid-configuration`)
|
||||
- JWT token validation
|
||||
- Unified user information handling
|
||||
|
||||
## Usage
|
||||
|
||||
```python
|
||||
# OAuth2 configuration
|
||||
oauth_config = {
|
||||
"type": "oauth2",
|
||||
"client_id": "your_client_id",
|
||||
"client_secret": "your_client_secret",
|
||||
"authorization_url": "https://your-oauth-provider.com/oauth/authorize",
|
||||
"token_url": "https://your-oauth-provider.com/oauth/token",
|
||||
"userinfo_url": "https://your-oauth-provider.com/oauth/userinfo",
|
||||
"redirect_uri": "https://your-app.com/v1/user/oauth/callback/<channel>"
|
||||
}
|
||||
|
||||
# OIDC configuration
|
||||
oidc_config = {
|
||||
"type": "oidc",
|
||||
"issuer": "https://your-oauth-provider.com/oidc",
|
||||
"client_id": "your_client_id",
|
||||
"client_secret": "your_client_secret",
|
||||
"redirect_uri": "https://your-app.com/v1/user/oauth/callback/<channel>"
|
||||
}
|
||||
|
||||
# Github OAuth configuration
|
||||
github_config = {
|
||||
"type": "github"
|
||||
"client_id": "your_client_id",
|
||||
"client_secret": "your_client_secret",
|
||||
"redirect_uri": "https://your-app.com/v1/user/oauth/callback/<channel>"
|
||||
}
|
||||
|
||||
# Get client instance
|
||||
client = get_auth_client(oauth_config)
|
||||
```
|
||||
|
||||
### Authentication Flow
|
||||
|
||||
1. Get authorization URL:
|
||||
```python
|
||||
auth_url = client.get_authorization_url()
|
||||
```
|
||||
|
||||
2. After user authorization, exchange authorization code for token:
|
||||
```python
|
||||
token_response = client.exchange_code_for_token(authorization_code)
|
||||
access_token = token_response["access_token"]
|
||||
```
|
||||
|
||||
3. Fetch user information:
|
||||
```python
|
||||
user_info = client.fetch_user_info(access_token)
|
||||
```
|
||||
|
||||
## User Information Structure
|
||||
|
||||
All authentication methods return user information following this structure:
|
||||
|
||||
```python
|
||||
{
|
||||
"email": "user@example.com",
|
||||
"username": "username",
|
||||
"nickname": "User Name",
|
||||
"avatar_url": "https://example.com/avatar.jpg"
|
||||
}
|
||||
```
|
||||
40
api/apps/auth/__init__.py
Normal file
40
api/apps/auth/__init__.py
Normal file
@ -0,0 +1,40 @@
|
||||
#
|
||||
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
|
||||
from .oauth import OAuthClient
|
||||
from .oidc import OIDCClient
|
||||
from .github import GithubOAuthClient
|
||||
|
||||
|
||||
CLIENT_TYPES = {
|
||||
"oauth2": OAuthClient,
|
||||
"oidc": OIDCClient,
|
||||
"github": GithubOAuthClient
|
||||
}
|
||||
|
||||
|
||||
def get_auth_client(config)->OAuthClient:
|
||||
channel_type = str(config.get("type", "")).lower()
|
||||
if channel_type == "":
|
||||
if config.get("issuer"):
|
||||
channel_type = "oidc"
|
||||
else:
|
||||
channel_type = "oauth2"
|
||||
client_class = CLIENT_TYPES.get(channel_type)
|
||||
if not client_class:
|
||||
raise ValueError(f"Unsupported type: {channel_type}")
|
||||
|
||||
return client_class(config)
|
||||
63
api/apps/auth/github.py
Normal file
63
api/apps/auth/github.py
Normal file
@ -0,0 +1,63 @@
|
||||
#
|
||||
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
|
||||
import requests
|
||||
from .oauth import OAuthClient, UserInfo
|
||||
|
||||
|
||||
class GithubOAuthClient(OAuthClient):
|
||||
def __init__(self, config):
|
||||
"""
|
||||
Initialize the GithubOAuthClient with the provider's configuration.
|
||||
"""
|
||||
config.update({
|
||||
"authorization_url": "https://github.com/login/oauth/authorize",
|
||||
"token_url": "https://github.com/login/oauth/access_token",
|
||||
"userinfo_url": "https://api.github.com/user",
|
||||
"scope": "user:email"
|
||||
})
|
||||
super().__init__(config)
|
||||
|
||||
|
||||
def fetch_user_info(self, access_token, **kwargs):
|
||||
"""
|
||||
Fetch github user info.
|
||||
"""
|
||||
user_info = {}
|
||||
try:
|
||||
headers = {"Authorization": f"Bearer {access_token}"}
|
||||
# user info
|
||||
response = requests.get(self.userinfo_url, headers=headers, timeout=self.http_request_timeout)
|
||||
response.raise_for_status()
|
||||
user_info.update(response.json())
|
||||
# email info
|
||||
response = requests.get(self.userinfo_url+"/emails", headers=headers, timeout=self.http_request_timeout)
|
||||
response.raise_for_status()
|
||||
email_info = response.json()
|
||||
user_info["email"] = next(
|
||||
(email for email in email_info if email["primary"]), None
|
||||
)["email"]
|
||||
return self.normalize_user_info(user_info)
|
||||
except requests.exceptions.RequestException as e:
|
||||
raise ValueError(f"Failed to fetch github user info: {e}")
|
||||
|
||||
|
||||
def normalize_user_info(self, user_info):
|
||||
email = user_info.get("email")
|
||||
username = user_info.get("login", str(email).split("@")[0])
|
||||
nickname = user_info.get("name", username)
|
||||
avatar_url = user_info.get("avatar_url", "")
|
||||
return UserInfo(email=email, username=username, nickname=nickname, avatar_url=avatar_url)
|
||||
110
api/apps/auth/oauth.py
Normal file
110
api/apps/auth/oauth.py
Normal file
@ -0,0 +1,110 @@
|
||||
#
|
||||
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
|
||||
import requests
|
||||
import urllib.parse
|
||||
|
||||
|
||||
class UserInfo:
|
||||
def __init__(self, email, username, nickname, avatar_url):
|
||||
self.email = email
|
||||
self.username = username
|
||||
self.nickname = nickname
|
||||
self.avatar_url = avatar_url
|
||||
|
||||
def to_dict(self):
|
||||
return {key: value for key, value in self.__dict__.items()}
|
||||
|
||||
|
||||
class OAuthClient:
|
||||
def __init__(self, config):
|
||||
"""
|
||||
Initialize the OAuthClient with the provider's configuration.
|
||||
"""
|
||||
self.client_id = config["client_id"]
|
||||
self.client_secret = config["client_secret"]
|
||||
self.authorization_url = config["authorization_url"]
|
||||
self.token_url = config["token_url"]
|
||||
self.userinfo_url = config["userinfo_url"]
|
||||
self.redirect_uri = config["redirect_uri"]
|
||||
self.scope = config.get("scope", None)
|
||||
|
||||
self.http_request_timeout = 7
|
||||
|
||||
|
||||
def get_authorization_url(self, state=None):
|
||||
"""
|
||||
Generate the authorization URL for user login.
|
||||
"""
|
||||
params = {
|
||||
"client_id": self.client_id,
|
||||
"redirect_uri": self.redirect_uri,
|
||||
"response_type": "code",
|
||||
}
|
||||
if self.scope:
|
||||
params["scope"] = self.scope
|
||||
if state:
|
||||
params["state"] = state
|
||||
authorization_url = f"{self.authorization_url}?{urllib.parse.urlencode(params)}"
|
||||
return authorization_url
|
||||
|
||||
|
||||
def exchange_code_for_token(self, code):
|
||||
"""
|
||||
Exchange authorization code for access token.
|
||||
"""
|
||||
try:
|
||||
payload = {
|
||||
"client_id": self.client_id,
|
||||
"client_secret": self.client_secret,
|
||||
"code": code,
|
||||
"redirect_uri": self.redirect_uri,
|
||||
"grant_type": "authorization_code"
|
||||
}
|
||||
response = requests.post(
|
||||
self.token_url,
|
||||
data=payload,
|
||||
headers={"Accept": "application/json"},
|
||||
timeout=self.http_request_timeout
|
||||
)
|
||||
response.raise_for_status()
|
||||
return response.json()
|
||||
except requests.exceptions.RequestException as e:
|
||||
raise ValueError(f"Failed to exchange authorization code for token: {e}")
|
||||
|
||||
|
||||
def fetch_user_info(self, access_token, **kwargs):
|
||||
"""
|
||||
Fetch user information using access token.
|
||||
"""
|
||||
try:
|
||||
headers = {"Authorization": f"Bearer {access_token}"}
|
||||
response = requests.get(self.userinfo_url, headers=headers, timeout=self.http_request_timeout)
|
||||
response.raise_for_status()
|
||||
user_info = response.json()
|
||||
return self.normalize_user_info(user_info)
|
||||
except requests.exceptions.RequestException as e:
|
||||
raise ValueError(f"Failed to fetch user info: {e}")
|
||||
|
||||
|
||||
def normalize_user_info(self, user_info):
|
||||
email = user_info.get("email")
|
||||
username = user_info.get("username", str(email).split("@")[0])
|
||||
nickname = user_info.get("nickname", username)
|
||||
avatar_url = user_info.get("avatar_url", None)
|
||||
if avatar_url is None:
|
||||
avatar_url = user_info.get("picture", "")
|
||||
return UserInfo(email=email, username=username, nickname=nickname, avatar_url=avatar_url)
|
||||
100
api/apps/auth/oidc.py
Normal file
100
api/apps/auth/oidc.py
Normal file
@ -0,0 +1,100 @@
|
||||
#
|
||||
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
|
||||
import jwt
|
||||
import requests
|
||||
from .oauth import OAuthClient
|
||||
|
||||
|
||||
class OIDCClient(OAuthClient):
|
||||
def __init__(self, config):
|
||||
"""
|
||||
Initialize the OIDCClient with the provider's configuration.
|
||||
Use `issuer` as the single source of truth for configuration discovery.
|
||||
"""
|
||||
self.issuer = config.get("issuer")
|
||||
if not self.issuer:
|
||||
raise ValueError("Missing issuer in configuration.")
|
||||
|
||||
oidc_metadata = self._load_oidc_metadata(self.issuer)
|
||||
config.update({
|
||||
'issuer': oidc_metadata['issuer'],
|
||||
'jwks_uri': oidc_metadata['jwks_uri'],
|
||||
'authorization_url': oidc_metadata['authorization_endpoint'],
|
||||
'token_url': oidc_metadata['token_endpoint'],
|
||||
'userinfo_url': oidc_metadata['userinfo_endpoint']
|
||||
})
|
||||
|
||||
super().__init__(config)
|
||||
self.issuer = config['issuer']
|
||||
self.jwks_uri = config['jwks_uri']
|
||||
|
||||
|
||||
def _load_oidc_metadata(self, issuer):
|
||||
"""
|
||||
Load OIDC metadata from `/.well-known/openid-configuration`.
|
||||
"""
|
||||
try:
|
||||
metadata_url = f"{issuer}/.well-known/openid-configuration"
|
||||
response = requests.get(metadata_url, timeout=7)
|
||||
response.raise_for_status()
|
||||
return response.json()
|
||||
except requests.exceptions.RequestException as e:
|
||||
raise ValueError(f"Failed to fetch OIDC metadata: {e}")
|
||||
|
||||
|
||||
def parse_id_token(self, id_token):
|
||||
"""
|
||||
Parse and validate OIDC ID Token (JWT format) with signature verification.
|
||||
"""
|
||||
try:
|
||||
# Decode JWT header without verifying signature
|
||||
headers = jwt.get_unverified_header(id_token)
|
||||
|
||||
# OIDC usually uses `RS256` for signing
|
||||
alg = headers.get("alg", "RS256")
|
||||
|
||||
# Use PyJWT's PyJWKClient to fetch JWKS and find signing key
|
||||
jwks_url = f"{self.issuer}/.well-known/jwks.json"
|
||||
jwks_cli = jwt.PyJWKClient(jwks_url)
|
||||
signing_key = jwks_cli.get_signing_key_from_jwt(id_token).key
|
||||
|
||||
# Decode and verify signature
|
||||
decoded_token = jwt.decode(
|
||||
id_token,
|
||||
key=signing_key,
|
||||
algorithms=[alg],
|
||||
audience=str(self.client_id),
|
||||
issuer=self.issuer,
|
||||
)
|
||||
return decoded_token
|
||||
except Exception as e:
|
||||
raise ValueError(f"Error parsing ID Token: {e}")
|
||||
|
||||
|
||||
def fetch_user_info(self, access_token, id_token=None, **kwargs):
|
||||
"""
|
||||
Fetch user info.
|
||||
"""
|
||||
user_info = {}
|
||||
if id_token:
|
||||
user_info = self.parse_id_token(id_token)
|
||||
user_info.update(super().fetch_user_info(access_token).to_dict())
|
||||
return self.normalize_user_info(user_info)
|
||||
|
||||
|
||||
def normalize_user_info(self, user_info):
|
||||
return super().normalize_user_info(user_info)
|
||||
@ -26,7 +26,6 @@ from api.utils.api_utils import get_json_result, server_error_response, validate
|
||||
from agent.canvas import Canvas
|
||||
from peewee import MySQLDatabase, PostgresqlDatabase
|
||||
from api.db.db_models import APIToken
|
||||
import logging
|
||||
import time
|
||||
|
||||
@manager.route('/templates', methods=['GET']) # noqa: F821
|
||||
@ -89,7 +88,6 @@ def save():
|
||||
@login_required
|
||||
def get(canvas_id):
|
||||
e, c = UserCanvasService.get_by_tenant_id(canvas_id)
|
||||
logging.info(f"get canvas_id: {canvas_id} c: {c}")
|
||||
if not e:
|
||||
return get_data_error_result(message="canvas not found.")
|
||||
return get_json_result(data=c)
|
||||
@ -115,6 +113,7 @@ def getsse(canvas_id):
|
||||
def run():
|
||||
req = request.json
|
||||
stream = req.get("stream", True)
|
||||
running_hint_text = req.get("running_hint_text", "")
|
||||
e, cvs = UserCanvasService.get_by_id(req["id"])
|
||||
if not e:
|
||||
return get_data_error_result(message="canvas not found.")
|
||||
@ -140,7 +139,7 @@ def run():
|
||||
def sse():
|
||||
nonlocal answer, cvs
|
||||
try:
|
||||
for ans in canvas.run(stream=True):
|
||||
for ans in canvas.run(running_hint_text = running_hint_text, stream=True):
|
||||
if ans.get("running_status"):
|
||||
yield "data:" + json.dumps({"code": 0, "message": "",
|
||||
"data": {"answer": ans["content"],
|
||||
@ -178,7 +177,7 @@ def run():
|
||||
resp.headers.add_header("Content-Type", "text/event-stream; charset=utf-8")
|
||||
return resp
|
||||
|
||||
for answer in canvas.run(stream=False):
|
||||
for answer in canvas.run(running_hint_text = running_hint_text, stream=False):
|
||||
if answer.get("running_status"):
|
||||
continue
|
||||
final_ans["content"] = "\n".join(answer["content"]) if "content" in answer else ""
|
||||
|
||||
@ -22,7 +22,7 @@ from flask_login import login_required, current_user
|
||||
from rag.app.qa import rmPrefix, beAdoc
|
||||
from rag.app.tag import label_question
|
||||
from rag.nlp import search, rag_tokenizer
|
||||
from rag.prompts import keyword_extraction
|
||||
from rag.prompts import keyword_extraction, cross_languages
|
||||
from rag.settings import PAGERANK_FLD
|
||||
from rag.utils import rmSpace
|
||||
from api.db import LLMType, ParserType
|
||||
@ -37,6 +37,7 @@ import xxhash
|
||||
import re
|
||||
|
||||
|
||||
|
||||
@manager.route('/list', methods=['POST']) # noqa: F821
|
||||
@login_required
|
||||
@validate_request("doc_id")
|
||||
@ -194,6 +195,7 @@ def switch():
|
||||
@login_required
|
||||
@validate_request("chunk_ids", "doc_id")
|
||||
def rm():
|
||||
from rag.utils.storage_factory import STORAGE_IMPL
|
||||
req = request.json
|
||||
try:
|
||||
e, doc = DocumentService.get_by_id(req["doc_id"])
|
||||
@ -204,6 +206,9 @@ def rm():
|
||||
deleted_chunk_ids = req["chunk_ids"]
|
||||
chunk_number = len(deleted_chunk_ids)
|
||||
DocumentService.decrement_chunk_num(doc.id, doc.kb_id, 1, chunk_number, 0)
|
||||
for cid in deleted_chunk_ids:
|
||||
if STORAGE_IMPL.obj_exist(doc.kb_id, cid):
|
||||
STORAGE_IMPL.rm(doc.kb_id, cid)
|
||||
return get_json_result(data=True)
|
||||
except Exception as e:
|
||||
return server_error_response(e)
|
||||
@ -275,6 +280,7 @@ def retrieval_test():
|
||||
vector_similarity_weight = float(req.get("vector_similarity_weight", 0.3))
|
||||
use_kg = req.get("use_kg", False)
|
||||
top = int(req.get("top_k", 1024))
|
||||
langs = req.get("cross_languages", [])
|
||||
tenant_ids = []
|
||||
|
||||
try:
|
||||
@ -294,6 +300,9 @@ def retrieval_test():
|
||||
if not e:
|
||||
return get_data_error_result(message="Knowledgebase not found!")
|
||||
|
||||
if langs:
|
||||
question = cross_languages(kb.tenant_id, None, question, langs)
|
||||
|
||||
embd_mdl = LLMBundle(kb.tenant_id, LLMType.EMBEDDING.value, llm_name=kb.embd_id)
|
||||
|
||||
rerank_mdl = None
|
||||
|
||||
@ -41,6 +41,11 @@ def set_conversation():
|
||||
req = request.json
|
||||
conv_id = req.get("conversation_id")
|
||||
is_new = req.get("is_new")
|
||||
name = req.get("name", "New conversation")
|
||||
|
||||
if len(name) > 255:
|
||||
name = name[0:255]
|
||||
|
||||
del req["is_new"]
|
||||
if not is_new:
|
||||
del req["conversation_id"]
|
||||
@ -59,7 +64,7 @@ def set_conversation():
|
||||
e, dia = DialogService.get_by_id(req["dialog_id"])
|
||||
if not e:
|
||||
return get_data_error_result(message="Dialog not found")
|
||||
conv = {"id": conv_id, "dialog_id": req["dialog_id"], "name": req.get("name", "New conversation"), "message": [{"role": "assistant", "content": dia.prompt_config["prologue"]}]}
|
||||
conv = {"id": conv_id, "dialog_id": req["dialog_id"], "name": name, "message": [{"role": "assistant", "content": dia.prompt_config["prologue"]}]}
|
||||
ConversationService.save(**conv)
|
||||
return get_json_result(data=conv)
|
||||
except Exception as e:
|
||||
@ -99,6 +104,7 @@ def get():
|
||||
"dataset_id": get_value(ck, "kb_id", "dataset_id"),
|
||||
"image_id": get_value(ck, "image_id", "img_id"),
|
||||
"positions": get_value(ck, "positions", "position_int"),
|
||||
"doc_type": get_value(ck, "doc_type", "doc_type_kwd"),
|
||||
}
|
||||
for ck in ref.get("chunks", [])
|
||||
]
|
||||
@ -210,6 +216,7 @@ def completion():
|
||||
"dataset_id": get_value(ck, "kb_id", "dataset_id"),
|
||||
"image_id": get_value(ck, "image_id", "img_id"),
|
||||
"positions": get_value(ck, "positions", "position_int"),
|
||||
"doc_type": get_value(ck, "doc_type_kwd", "doc_type_kwd"),
|
||||
}
|
||||
for ck in ref.get("chunks", [])
|
||||
]
|
||||
|
||||
@ -43,7 +43,7 @@ def set_dialog():
|
||||
similarity_threshold = req.get("similarity_threshold", 0.1)
|
||||
vector_similarity_weight = req.get("vector_similarity_weight", 0.3)
|
||||
llm_setting = req.get("llm_setting", {})
|
||||
default_prompt = {
|
||||
default_prompt_with_dataset = {
|
||||
"system": """你是一个智能助手,请总结知识库的内容来回答问题,请列举知识库中的数据详细回答。当所有知识库内容都与问题无关时,你的回答必须包括“知识库中未找到您要的答案!”这句话。回答需要考虑聊天历史。
|
||||
以下是知识库:
|
||||
{knowledge}
|
||||
@ -54,10 +54,22 @@ def set_dialog():
|
||||
],
|
||||
"empty_response": "Sorry! 知识库中未找到相关内容!"
|
||||
}
|
||||
prompt_config = req.get("prompt_config", default_prompt)
|
||||
default_prompt_no_dataset = {
|
||||
"system": """You are a helpful assistant.""",
|
||||
"prologue": "您好,我是您的助手小樱,长得可爱又善良,can I help you?",
|
||||
"parameters": [
|
||||
|
||||
],
|
||||
"empty_response": ""
|
||||
}
|
||||
prompt_config = req.get("prompt_config", default_prompt_with_dataset)
|
||||
|
||||
if not prompt_config["system"]:
|
||||
prompt_config["system"] = default_prompt["system"]
|
||||
prompt_config["system"] = default_prompt_with_dataset["system"]
|
||||
|
||||
if not req.get("kb_ids", []):
|
||||
if prompt_config['system'] == default_prompt_with_dataset['system'] or "{knowledge}" in prompt_config['system']:
|
||||
prompt_config = default_prompt_no_dataset
|
||||
|
||||
for p in prompt_config["parameters"]:
|
||||
if p["optional"]:
|
||||
|
||||
@ -20,79 +20,73 @@ import re
|
||||
|
||||
import flask
|
||||
from flask import request
|
||||
from flask_login import login_required, current_user
|
||||
from flask_login import current_user, login_required
|
||||
|
||||
from deepdoc.parser.html_parser import RAGFlowHtmlParser
|
||||
from rag.nlp import search
|
||||
|
||||
from api.db import FileType, TaskStatus, ParserType, FileSource
|
||||
from api import settings
|
||||
from api.constants import IMG_BASE64_PREFIX
|
||||
from api.db import VALID_FILE_TYPES, VALID_TASK_STATUS, FileSource, FileType, ParserType, TaskStatus
|
||||
from api.db.db_models import File, Task
|
||||
from api.db.services import duplicate_name
|
||||
from api.db.services.document_service import DocumentService, doc_upload_and_parse
|
||||
from api.db.services.file2document_service import File2DocumentService
|
||||
from api.db.services.file_service import FileService
|
||||
from api.db.services.task_service import queue_tasks
|
||||
from api.db.services.user_service import UserTenantService
|
||||
from api.db.services import duplicate_name
|
||||
from api.db.services.knowledgebase_service import KnowledgebaseService
|
||||
from api.db.services.task_service import TaskService
|
||||
from api.db.services.document_service import DocumentService, doc_upload_and_parse
|
||||
from api.db.services.task_service import TaskService, queue_tasks
|
||||
from api.db.services.user_service import UserTenantService
|
||||
from api.utils import get_uuid
|
||||
from api.utils.api_utils import (
|
||||
server_error_response,
|
||||
get_data_error_result,
|
||||
get_json_result,
|
||||
server_error_response,
|
||||
validate_request,
|
||||
)
|
||||
from api.utils import get_uuid
|
||||
from api import settings
|
||||
from api.utils.api_utils import get_json_result
|
||||
from rag.utils.storage_factory import STORAGE_IMPL
|
||||
from api.utils.file_utils import filename_type, thumbnail, get_project_base_directory
|
||||
from api.utils.file_utils import filename_type, get_project_base_directory, thumbnail
|
||||
from api.utils.web_utils import html2pdf, is_valid_url
|
||||
from api.constants import IMG_BASE64_PREFIX
|
||||
from deepdoc.parser.html_parser import RAGFlowHtmlParser
|
||||
from rag.nlp import search
|
||||
from rag.utils.storage_factory import STORAGE_IMPL
|
||||
|
||||
|
||||
@manager.route('/upload', methods=['POST']) # noqa: F821
|
||||
@manager.route("/upload", methods=["POST"]) # noqa: F821
|
||||
@login_required
|
||||
@validate_request("kb_id")
|
||||
def upload():
|
||||
kb_id = request.form.get("kb_id")
|
||||
if not kb_id:
|
||||
return get_json_result(
|
||||
data=False, message='Lack of "KB ID"', code=settings.RetCode.ARGUMENT_ERROR)
|
||||
if 'file' not in request.files:
|
||||
return get_json_result(
|
||||
data=False, message='No file part!', code=settings.RetCode.ARGUMENT_ERROR)
|
||||
return get_json_result(data=False, message='Lack of "KB ID"', code=settings.RetCode.ARGUMENT_ERROR)
|
||||
if "file" not in request.files:
|
||||
return get_json_result(data=False, message="No file part!", code=settings.RetCode.ARGUMENT_ERROR)
|
||||
|
||||
file_objs = request.files.getlist('file')
|
||||
file_objs = request.files.getlist("file")
|
||||
for file_obj in file_objs:
|
||||
if file_obj.filename == '':
|
||||
return get_json_result(
|
||||
data=False, message='No file selected!', code=settings.RetCode.ARGUMENT_ERROR)
|
||||
if file_obj.filename == "":
|
||||
return get_json_result(data=False, message="No file selected!", code=settings.RetCode.ARGUMENT_ERROR)
|
||||
|
||||
e, kb = KnowledgebaseService.get_by_id(kb_id)
|
||||
if not e:
|
||||
raise LookupError("Can't find this knowledgebase!")
|
||||
|
||||
err, files = FileService.upload_document(kb, file_objs, current_user.id)
|
||||
files = [f[0] for f in files] # remove the blob
|
||||
|
||||
|
||||
if not files:
|
||||
return get_json_result(data=files, message="There seems to be an issue with your file format. Please verify it is correct and not corrupted.", code=settings.RetCode.DATA_ERROR)
|
||||
files = [f[0] for f in files] # remove the blob
|
||||
|
||||
if err:
|
||||
return get_json_result(
|
||||
data=files, message="\n".join(err), code=settings.RetCode.SERVER_ERROR)
|
||||
return get_json_result(data=files, message="\n".join(err), code=settings.RetCode.SERVER_ERROR)
|
||||
return get_json_result(data=files)
|
||||
|
||||
|
||||
@manager.route('/web_crawl', methods=['POST']) # noqa: F821
|
||||
@manager.route("/web_crawl", methods=["POST"]) # noqa: F821
|
||||
@login_required
|
||||
@validate_request("kb_id", "name", "url")
|
||||
def web_crawl():
|
||||
kb_id = request.form.get("kb_id")
|
||||
if not kb_id:
|
||||
return get_json_result(
|
||||
data=False, message='Lack of "KB ID"', code=settings.RetCode.ARGUMENT_ERROR)
|
||||
return get_json_result(data=False, message='Lack of "KB ID"', code=settings.RetCode.ARGUMENT_ERROR)
|
||||
name = request.form.get("name")
|
||||
url = request.form.get("url")
|
||||
if not is_valid_url(url):
|
||||
return get_json_result(
|
||||
data=False, message='The URL format is invalid', code=settings.RetCode.ARGUMENT_ERROR)
|
||||
return get_json_result(data=False, message="The URL format is invalid", code=settings.RetCode.ARGUMENT_ERROR)
|
||||
e, kb = KnowledgebaseService.get_by_id(kb_id)
|
||||
if not e:
|
||||
raise LookupError("Can't find this knowledgebase!")
|
||||
@ -108,10 +102,7 @@ def web_crawl():
|
||||
kb_folder = FileService.new_a_file_from_kb(kb.tenant_id, kb.name, kb_root_folder["id"])
|
||||
|
||||
try:
|
||||
filename = duplicate_name(
|
||||
DocumentService.query,
|
||||
name=name + ".pdf",
|
||||
kb_id=kb.id)
|
||||
filename = duplicate_name(DocumentService.query, name=name + ".pdf", kb_id=kb.id)
|
||||
filetype = filename_type(filename)
|
||||
if filetype == FileType.OTHER.value:
|
||||
raise RuntimeError("This type of file has not been supported yet!")
|
||||
@ -130,7 +121,7 @@ def web_crawl():
|
||||
"name": filename,
|
||||
"location": location,
|
||||
"size": len(blob),
|
||||
"thumbnail": thumbnail(filename, blob)
|
||||
"thumbnail": thumbnail(filename, blob),
|
||||
}
|
||||
if doc["type"] == FileType.VISUAL:
|
||||
doc["parser_id"] = ParserType.PICTURE.value
|
||||
@ -147,129 +138,127 @@ def web_crawl():
|
||||
return get_json_result(data=True)
|
||||
|
||||
|
||||
@manager.route('/create', methods=['POST']) # noqa: F821
|
||||
@manager.route("/create", methods=["POST"]) # noqa: F821
|
||||
@login_required
|
||||
@validate_request("name", "kb_id")
|
||||
def create():
|
||||
req = request.json
|
||||
kb_id = req["kb_id"]
|
||||
if not kb_id:
|
||||
return get_json_result(
|
||||
data=False, message='Lack of "KB ID"', code=settings.RetCode.ARGUMENT_ERROR)
|
||||
return get_json_result(data=False, message='Lack of "KB ID"', code=settings.RetCode.ARGUMENT_ERROR)
|
||||
|
||||
try:
|
||||
e, kb = KnowledgebaseService.get_by_id(kb_id)
|
||||
if not e:
|
||||
return get_data_error_result(
|
||||
message="Can't find this knowledgebase!")
|
||||
return get_data_error_result(message="Can't find this knowledgebase!")
|
||||
|
||||
if DocumentService.query(name=req["name"], kb_id=kb_id):
|
||||
return get_data_error_result(
|
||||
message="Duplicated document name in the same knowledgebase.")
|
||||
return get_data_error_result(message="Duplicated document name in the same knowledgebase.")
|
||||
|
||||
doc = DocumentService.insert({
|
||||
"id": get_uuid(),
|
||||
"kb_id": kb.id,
|
||||
"parser_id": kb.parser_id,
|
||||
"parser_config": kb.parser_config,
|
||||
"created_by": current_user.id,
|
||||
"type": FileType.VIRTUAL,
|
||||
"name": req["name"],
|
||||
"location": "",
|
||||
"size": 0
|
||||
})
|
||||
doc = DocumentService.insert(
|
||||
{
|
||||
"id": get_uuid(),
|
||||
"kb_id": kb.id,
|
||||
"parser_id": kb.parser_id,
|
||||
"parser_config": kb.parser_config,
|
||||
"created_by": current_user.id,
|
||||
"type": FileType.VIRTUAL,
|
||||
"name": req["name"],
|
||||
"location": "",
|
||||
"size": 0,
|
||||
}
|
||||
)
|
||||
return get_json_result(data=doc.to_json())
|
||||
except Exception as e:
|
||||
return server_error_response(e)
|
||||
|
||||
|
||||
@manager.route('/list', methods=['GET']) # noqa: F821
|
||||
@manager.route("/list", methods=["POST"]) # noqa: F821
|
||||
@login_required
|
||||
def list_docs():
|
||||
kb_id = request.args.get("kb_id")
|
||||
if not kb_id:
|
||||
return get_json_result(
|
||||
data=False, message='Lack of "KB ID"', code=settings.RetCode.ARGUMENT_ERROR)
|
||||
return get_json_result(data=False, message='Lack of "KB ID"', code=settings.RetCode.ARGUMENT_ERROR)
|
||||
tenants = UserTenantService.query(user_id=current_user.id)
|
||||
for tenant in tenants:
|
||||
if KnowledgebaseService.query(
|
||||
tenant_id=tenant.tenant_id, id=kb_id):
|
||||
if KnowledgebaseService.query(tenant_id=tenant.tenant_id, id=kb_id):
|
||||
break
|
||||
else:
|
||||
return get_json_result(
|
||||
data=False, message='Only owner of knowledgebase authorized for this operation.',
|
||||
code=settings.RetCode.OPERATING_ERROR)
|
||||
return get_json_result(data=False, message="Only owner of knowledgebase authorized for this operation.", code=settings.RetCode.OPERATING_ERROR)
|
||||
keywords = request.args.get("keywords", "")
|
||||
|
||||
page_number = int(request.args.get("page", 1))
|
||||
items_per_page = int(request.args.get("page_size", 15))
|
||||
page_number = int(request.args.get("page", 0))
|
||||
items_per_page = int(request.args.get("page_size", 0))
|
||||
orderby = request.args.get("orderby", "create_time")
|
||||
desc = request.args.get("desc", True)
|
||||
|
||||
req = request.get_json()
|
||||
|
||||
run_status = req.get("run_status", [])
|
||||
if run_status:
|
||||
invalid_status = {s for s in run_status if s not in VALID_TASK_STATUS}
|
||||
if invalid_status:
|
||||
return get_data_error_result(message=f"Invalid filter run status conditions: {', '.join(invalid_status)}")
|
||||
|
||||
types = req.get("types", [])
|
||||
if types:
|
||||
invalid_types = {t for t in types if t not in VALID_FILE_TYPES}
|
||||
if invalid_types:
|
||||
return get_data_error_result(message=f"Invalid filter conditions: {', '.join(invalid_types)} type{'s' if len(invalid_types) > 1 else ''}")
|
||||
|
||||
try:
|
||||
docs, tol = DocumentService.get_by_kb_id(
|
||||
kb_id, page_number, items_per_page, orderby, desc, keywords)
|
||||
docs, tol = DocumentService.get_by_kb_id(kb_id, page_number, items_per_page, orderby, desc, keywords, run_status, types)
|
||||
|
||||
for doc_item in docs:
|
||||
if doc_item['thumbnail'] and not doc_item['thumbnail'].startswith(IMG_BASE64_PREFIX):
|
||||
doc_item['thumbnail'] = f"/v1/document/image/{kb_id}-{doc_item['thumbnail']}"
|
||||
if doc_item["thumbnail"] and not doc_item["thumbnail"].startswith(IMG_BASE64_PREFIX):
|
||||
doc_item["thumbnail"] = f"/v1/document/image/{kb_id}-{doc_item['thumbnail']}"
|
||||
|
||||
return get_json_result(data={"total": tol, "docs": docs})
|
||||
except Exception as e:
|
||||
return server_error_response(e)
|
||||
|
||||
|
||||
@manager.route('/infos', methods=['POST']) # noqa: F821
|
||||
@manager.route("/infos", methods=["POST"]) # noqa: F821
|
||||
@login_required
|
||||
def docinfos():
|
||||
req = request.json
|
||||
doc_ids = req["doc_ids"]
|
||||
for doc_id in doc_ids:
|
||||
if not DocumentService.accessible(doc_id, current_user.id):
|
||||
return get_json_result(
|
||||
data=False,
|
||||
message='No authorization.',
|
||||
code=settings.RetCode.AUTHENTICATION_ERROR
|
||||
)
|
||||
return get_json_result(data=False, message="No authorization.", code=settings.RetCode.AUTHENTICATION_ERROR)
|
||||
docs = DocumentService.get_by_ids(doc_ids)
|
||||
return get_json_result(data=list(docs.dicts()))
|
||||
|
||||
|
||||
@manager.route('/thumbnails', methods=['GET']) # noqa: F821
|
||||
@manager.route("/thumbnails", methods=["GET"]) # noqa: F821
|
||||
# @login_required
|
||||
def thumbnails():
|
||||
doc_ids = request.args.get("doc_ids").split(",")
|
||||
if not doc_ids:
|
||||
return get_json_result(
|
||||
data=False, message='Lack of "Document ID"', code=settings.RetCode.ARGUMENT_ERROR)
|
||||
return get_json_result(data=False, message='Lack of "Document ID"', code=settings.RetCode.ARGUMENT_ERROR)
|
||||
|
||||
try:
|
||||
docs = DocumentService.get_thumbnails(doc_ids)
|
||||
|
||||
for doc_item in docs:
|
||||
if doc_item['thumbnail'] and not doc_item['thumbnail'].startswith(IMG_BASE64_PREFIX):
|
||||
doc_item['thumbnail'] = f"/v1/document/image/{doc_item['kb_id']}-{doc_item['thumbnail']}"
|
||||
if doc_item["thumbnail"] and not doc_item["thumbnail"].startswith(IMG_BASE64_PREFIX):
|
||||
doc_item["thumbnail"] = f"/v1/document/image/{doc_item['kb_id']}-{doc_item['thumbnail']}"
|
||||
|
||||
return get_json_result(data={d["id"]: d["thumbnail"] for d in docs})
|
||||
except Exception as e:
|
||||
return server_error_response(e)
|
||||
|
||||
|
||||
@manager.route('/change_status', methods=['POST']) # noqa: F821
|
||||
@manager.route("/change_status", methods=["POST"]) # noqa: F821
|
||||
@login_required
|
||||
@validate_request("doc_id", "status")
|
||||
def change_status():
|
||||
req = request.json
|
||||
if str(req["status"]) not in ["0", "1"]:
|
||||
return get_json_result(
|
||||
data=False,
|
||||
message='"Status" must be either 0 or 1!',
|
||||
code=settings.RetCode.ARGUMENT_ERROR)
|
||||
return get_json_result(data=False, message='"Status" must be either 0 or 1!', code=settings.RetCode.ARGUMENT_ERROR)
|
||||
|
||||
if not DocumentService.accessible(req["doc_id"], current_user.id):
|
||||
return get_json_result(
|
||||
data=False,
|
||||
message='No authorization.',
|
||||
code=settings.RetCode.AUTHENTICATION_ERROR)
|
||||
return get_json_result(data=False, message="No authorization.", code=settings.RetCode.AUTHENTICATION_ERROR)
|
||||
|
||||
try:
|
||||
e, doc = DocumentService.get_by_id(req["doc_id"])
|
||||
@ -277,23 +266,19 @@ def change_status():
|
||||
return get_data_error_result(message="Document not found!")
|
||||
e, kb = KnowledgebaseService.get_by_id(doc.kb_id)
|
||||
if not e:
|
||||
return get_data_error_result(
|
||||
message="Can't find this knowledgebase!")
|
||||
return get_data_error_result(message="Can't find this knowledgebase!")
|
||||
|
||||
if not DocumentService.update_by_id(
|
||||
req["doc_id"], {"status": str(req["status"])}):
|
||||
return get_data_error_result(
|
||||
message="Database error (Document update)!")
|
||||
if not DocumentService.update_by_id(req["doc_id"], {"status": str(req["status"])}):
|
||||
return get_data_error_result(message="Database error (Document update)!")
|
||||
|
||||
status = int(req["status"])
|
||||
settings.docStoreConn.update({"doc_id": req["doc_id"]}, {"available_int": status},
|
||||
search.index_name(kb.tenant_id), doc.kb_id)
|
||||
settings.docStoreConn.update({"doc_id": req["doc_id"]}, {"available_int": status}, search.index_name(kb.tenant_id), doc.kb_id)
|
||||
return get_json_result(data=True)
|
||||
except Exception as e:
|
||||
return server_error_response(e)
|
||||
|
||||
|
||||
@manager.route('/rm', methods=['POST']) # noqa: F821
|
||||
@manager.route("/rm", methods=["POST"]) # noqa: F821
|
||||
@login_required
|
||||
@validate_request("doc_id")
|
||||
def rm():
|
||||
@ -304,16 +289,13 @@ def rm():
|
||||
|
||||
for doc_id in doc_ids:
|
||||
if not DocumentService.accessible4deletion(doc_id, current_user.id):
|
||||
return get_json_result(
|
||||
data=False,
|
||||
message='No authorization.',
|
||||
code=settings.RetCode.AUTHENTICATION_ERROR
|
||||
)
|
||||
return get_json_result(data=False, message="No authorization.", code=settings.RetCode.AUTHENTICATION_ERROR)
|
||||
|
||||
root_folder = FileService.get_root_folder(current_user.id)
|
||||
pf_id = root_folder["id"]
|
||||
FileService.init_knowledgebase_docs(pf_id, current_user.id)
|
||||
errors = ""
|
||||
kb_table_num_map = {}
|
||||
for doc_id in doc_ids:
|
||||
try:
|
||||
e, doc = DocumentService.get_by_id(doc_id)
|
||||
@ -327,14 +309,25 @@ def rm():
|
||||
|
||||
TaskService.filter_delete([Task.doc_id == doc_id])
|
||||
if not DocumentService.remove_document(doc, tenant_id):
|
||||
return get_data_error_result(
|
||||
message="Database error (Document removal)!")
|
||||
return get_data_error_result(message="Database error (Document removal)!")
|
||||
|
||||
f2d = File2DocumentService.get_by_document_id(doc_id)
|
||||
deleted_file_count = FileService.filter_delete([File.source_type == FileSource.KNOWLEDGEBASE, File.id == f2d[0].file_id])
|
||||
deleted_file_count = 0
|
||||
if f2d:
|
||||
deleted_file_count = FileService.filter_delete([File.source_type == FileSource.KNOWLEDGEBASE, File.id == f2d[0].file_id])
|
||||
File2DocumentService.delete_by_document_id(doc_id)
|
||||
if deleted_file_count > 0:
|
||||
STORAGE_IMPL.rm(b, n)
|
||||
|
||||
doc_parser = doc.parser_id
|
||||
if doc_parser == ParserType.TABLE:
|
||||
kb_id = doc.kb_id
|
||||
if kb_id not in kb_table_num_map:
|
||||
counts = DocumentService.count_by_kb_id(kb_id=kb_id, keywords="", run_status=[TaskStatus.DONE], types=[])
|
||||
kb_table_num_map[kb_id] = counts
|
||||
kb_table_num_map[kb_id] -= 1
|
||||
if kb_table_num_map[kb_id] <= 0:
|
||||
KnowledgebaseService.delete_field_map(kb_id)
|
||||
except Exception as e:
|
||||
errors += str(e)
|
||||
|
||||
@ -344,19 +337,16 @@ def rm():
|
||||
return get_json_result(data=True)
|
||||
|
||||
|
||||
@manager.route('/run', methods=['POST']) # noqa: F821
|
||||
@manager.route("/run", methods=["POST"]) # noqa: F821
|
||||
@login_required
|
||||
@validate_request("doc_ids", "run")
|
||||
def run():
|
||||
def run():
|
||||
req = request.json
|
||||
for doc_id in req["doc_ids"]:
|
||||
if not DocumentService.accessible(doc_id, current_user.id):
|
||||
return get_json_result(
|
||||
data=False,
|
||||
message='No authorization.',
|
||||
code=settings.RetCode.AUTHENTICATION_ERROR
|
||||
)
|
||||
return get_json_result(data=False, message="No authorization.", code=settings.RetCode.AUTHENTICATION_ERROR)
|
||||
try:
|
||||
kb_table_num_map = {}
|
||||
for id in req["doc_ids"]:
|
||||
info = {"run": str(req["run"]), "progress": 0}
|
||||
if str(req["run"]) == TaskStatus.RUNNING.value and req.get("delete", False):
|
||||
@ -379,6 +369,17 @@ def run():
|
||||
e, doc = DocumentService.get_by_id(id)
|
||||
doc = doc.to_dict()
|
||||
doc["tenant_id"] = tenant_id
|
||||
|
||||
doc_parser = doc.get("parser_id", ParserType.NAIVE)
|
||||
if doc_parser == ParserType.TABLE:
|
||||
kb_id = doc.get("kb_id")
|
||||
if not kb_id:
|
||||
continue
|
||||
if kb_id not in kb_table_num_map:
|
||||
count = DocumentService.count_by_kb_id(kb_id=kb_id, keywords="", run_status=[TaskStatus.DONE], types=[])
|
||||
kb_table_num_map[kb_id] = count
|
||||
if kb_table_num_map[kb_id] <= 0:
|
||||
KnowledgebaseService.delete_field_map(kb_id)
|
||||
bucket, name = File2DocumentService.get_storage_address(doc_id=doc["id"])
|
||||
queue_tasks(doc, bucket, name, 0)
|
||||
|
||||
@ -387,36 +388,25 @@ def run():
|
||||
return server_error_response(e)
|
||||
|
||||
|
||||
@manager.route('/rename', methods=['POST']) # noqa: F821
|
||||
@manager.route("/rename", methods=["POST"]) # noqa: F821
|
||||
@login_required
|
||||
@validate_request("doc_id", "name")
|
||||
def rename():
|
||||
req = request.json
|
||||
if not DocumentService.accessible(req["doc_id"], current_user.id):
|
||||
return get_json_result(
|
||||
data=False,
|
||||
message='No authorization.',
|
||||
code=settings.RetCode.AUTHENTICATION_ERROR
|
||||
)
|
||||
return get_json_result(data=False, message="No authorization.", code=settings.RetCode.AUTHENTICATION_ERROR)
|
||||
try:
|
||||
e, doc = DocumentService.get_by_id(req["doc_id"])
|
||||
if not e:
|
||||
return get_data_error_result(message="Document not found!")
|
||||
if pathlib.Path(req["name"].lower()).suffix != pathlib.Path(
|
||||
doc.name.lower()).suffix:
|
||||
return get_json_result(
|
||||
data=False,
|
||||
message="The extension of file can't be changed",
|
||||
code=settings.RetCode.ARGUMENT_ERROR)
|
||||
if pathlib.Path(req["name"].lower()).suffix != pathlib.Path(doc.name.lower()).suffix:
|
||||
return get_json_result(data=False, message="The extension of file can't be changed", code=settings.RetCode.ARGUMENT_ERROR)
|
||||
for d in DocumentService.query(name=req["name"], kb_id=doc.kb_id):
|
||||
if d.name == req["name"]:
|
||||
return get_data_error_result(
|
||||
message="Duplicated document name in the same knowledgebase.")
|
||||
return get_data_error_result(message="Duplicated document name in the same knowledgebase.")
|
||||
|
||||
if not DocumentService.update_by_id(
|
||||
req["doc_id"], {"name": req["name"]}):
|
||||
return get_data_error_result(
|
||||
message="Database error (Document rename)!")
|
||||
if not DocumentService.update_by_id(req["doc_id"], {"name": req["name"]}):
|
||||
return get_data_error_result(message="Database error (Document rename)!")
|
||||
|
||||
informs = File2DocumentService.get_by_document_id(req["doc_id"])
|
||||
if informs:
|
||||
@ -428,7 +418,7 @@ def rename():
|
||||
return server_error_response(e)
|
||||
|
||||
|
||||
@manager.route('/get/<doc_id>', methods=['GET']) # noqa: F821
|
||||
@manager.route("/get/<doc_id>", methods=["GET"]) # noqa: F821
|
||||
# @login_required
|
||||
def get(doc_id):
|
||||
try:
|
||||
@ -442,29 +432,22 @@ def get(doc_id):
|
||||
ext = re.search(r"\.([^.]+)$", doc.name)
|
||||
if ext:
|
||||
if doc.type == FileType.VISUAL.value:
|
||||
response.headers.set('Content-Type', 'image/%s' % ext.group(1))
|
||||
response.headers.set("Content-Type", "image/%s" % ext.group(1))
|
||||
else:
|
||||
response.headers.set(
|
||||
'Content-Type',
|
||||
'application/%s' %
|
||||
ext.group(1))
|
||||
response.headers.set("Content-Type", "application/%s" % ext.group(1))
|
||||
return response
|
||||
except Exception as e:
|
||||
return server_error_response(e)
|
||||
|
||||
|
||||
@manager.route('/change_parser', methods=['POST']) # noqa: F821
|
||||
@manager.route("/change_parser", methods=["POST"]) # noqa: F821
|
||||
@login_required
|
||||
@validate_request("doc_id", "parser_id")
|
||||
def change_parser():
|
||||
req = request.json
|
||||
|
||||
if not DocumentService.accessible(req["doc_id"], current_user.id):
|
||||
return get_json_result(
|
||||
data=False,
|
||||
message='No authorization.',
|
||||
code=settings.RetCode.AUTHENTICATION_ERROR
|
||||
)
|
||||
return get_json_result(data=False, message="No authorization.", code=settings.RetCode.AUTHENTICATION_ERROR)
|
||||
try:
|
||||
e, doc = DocumentService.get_by_id(req["doc_id"])
|
||||
if not e:
|
||||
@ -476,21 +459,16 @@ def change_parser():
|
||||
else:
|
||||
return get_json_result(data=True)
|
||||
|
||||
if ((doc.type == FileType.VISUAL and req["parser_id"] != "picture")
|
||||
or (re.search(
|
||||
r"\.(ppt|pptx|pages)$", doc.name) and req["parser_id"] != "presentation")):
|
||||
if (doc.type == FileType.VISUAL and req["parser_id"] != "picture") or (re.search(r"\.(ppt|pptx|pages)$", doc.name) and req["parser_id"] != "presentation"):
|
||||
return get_data_error_result(message="Not supported yet!")
|
||||
|
||||
e = DocumentService.update_by_id(doc.id,
|
||||
{"parser_id": req["parser_id"], "progress": 0, "progress_msg": "",
|
||||
"run": TaskStatus.UNSTART.value})
|
||||
e = DocumentService.update_by_id(doc.id, {"parser_id": req["parser_id"], "progress": 0, "progress_msg": "", "run": TaskStatus.UNSTART.value})
|
||||
if not e:
|
||||
return get_data_error_result(message="Document not found!")
|
||||
if "parser_config" in req:
|
||||
DocumentService.update_parser_config(doc.id, req["parser_config"])
|
||||
if doc.token_num > 0:
|
||||
e = DocumentService.increment_chunk_num(doc.id, doc.kb_id, doc.token_num * -1, doc.chunk_num * -1,
|
||||
doc.process_duation * -1)
|
||||
e = DocumentService.increment_chunk_num(doc.id, doc.kb_id, doc.token_num * -1, doc.chunk_num * -1, doc.process_duation * -1)
|
||||
if not e:
|
||||
return get_data_error_result(message="Document not found!")
|
||||
tenant_id = DocumentService.get_tenant_id(req["doc_id"])
|
||||
@ -504,7 +482,7 @@ def change_parser():
|
||||
return server_error_response(e)
|
||||
|
||||
|
||||
@manager.route('/image/<image_id>', methods=['GET']) # noqa: F821
|
||||
@manager.route("/image/<image_id>", methods=["GET"]) # noqa: F821
|
||||
# @login_required
|
||||
def get_image(image_id):
|
||||
try:
|
||||
@ -513,53 +491,46 @@ def get_image(image_id):
|
||||
return get_data_error_result(message="Image not found.")
|
||||
bkt, nm = image_id.split("-")
|
||||
response = flask.make_response(STORAGE_IMPL.get(bkt, nm))
|
||||
response.headers.set('Content-Type', 'image/JPEG')
|
||||
response.headers.set("Content-Type", "image/JPEG")
|
||||
return response
|
||||
except Exception as e:
|
||||
return server_error_response(e)
|
||||
|
||||
|
||||
@manager.route('/upload_and_parse', methods=['POST']) # noqa: F821
|
||||
@manager.route("/upload_and_parse", methods=["POST"]) # noqa: F821
|
||||
@login_required
|
||||
@validate_request("conversation_id")
|
||||
def upload_and_parse():
|
||||
if 'file' not in request.files:
|
||||
return get_json_result(
|
||||
data=False, message='No file part!', code=settings.RetCode.ARGUMENT_ERROR)
|
||||
if "file" not in request.files:
|
||||
return get_json_result(data=False, message="No file part!", code=settings.RetCode.ARGUMENT_ERROR)
|
||||
|
||||
file_objs = request.files.getlist('file')
|
||||
file_objs = request.files.getlist("file")
|
||||
for file_obj in file_objs:
|
||||
if file_obj.filename == '':
|
||||
return get_json_result(
|
||||
data=False, message='No file selected!', code=settings.RetCode.ARGUMENT_ERROR)
|
||||
if file_obj.filename == "":
|
||||
return get_json_result(data=False, message="No file selected!", code=settings.RetCode.ARGUMENT_ERROR)
|
||||
|
||||
doc_ids = doc_upload_and_parse(request.form.get("conversation_id"), file_objs, current_user.id)
|
||||
|
||||
return get_json_result(data=doc_ids)
|
||||
|
||||
|
||||
@manager.route('/parse', methods=['POST']) # noqa: F821
|
||||
@manager.route("/parse", methods=["POST"]) # noqa: F821
|
||||
@login_required
|
||||
def parse():
|
||||
url = request.json.get("url") if request.json else ""
|
||||
if url:
|
||||
if not is_valid_url(url):
|
||||
return get_json_result(
|
||||
data=False, message='The URL format is invalid', code=settings.RetCode.ARGUMENT_ERROR)
|
||||
return get_json_result(data=False, message="The URL format is invalid", code=settings.RetCode.ARGUMENT_ERROR)
|
||||
download_path = os.path.join(get_project_base_directory(), "logs/downloads")
|
||||
os.makedirs(download_path, exist_ok=True)
|
||||
from seleniumwire.webdriver import Chrome, ChromeOptions
|
||||
|
||||
options = ChromeOptions()
|
||||
options.add_argument('--headless')
|
||||
options.add_argument('--disable-gpu')
|
||||
options.add_argument('--no-sandbox')
|
||||
options.add_argument('--disable-dev-shm-usage')
|
||||
options.add_experimental_option('prefs', {
|
||||
'download.default_directory': download_path,
|
||||
'download.prompt_for_download': False,
|
||||
'download.directory_upgrade': True,
|
||||
'safebrowsing.enabled': True
|
||||
})
|
||||
options.add_argument("--headless")
|
||||
options.add_argument("--disable-gpu")
|
||||
options.add_argument("--no-sandbox")
|
||||
options.add_argument("--disable-dev-shm-usage")
|
||||
options.add_experimental_option("prefs", {"download.default_directory": download_path, "download.prompt_for_download": False, "download.directory_upgrade": True, "safebrowsing.enabled": True})
|
||||
driver = Chrome(options=options)
|
||||
driver.get(url)
|
||||
res_headers = [r.response.headers for r in driver.requests if r and r.response]
|
||||
@ -582,51 +553,41 @@ def parse():
|
||||
|
||||
r = re.search(r"filename=\"([^\"]+)\"", str(res_headers))
|
||||
if not r or not r.group(1):
|
||||
return get_json_result(
|
||||
data=False, message="Can't not identify downloaded file", code=settings.RetCode.ARGUMENT_ERROR)
|
||||
return get_json_result(data=False, message="Can't not identify downloaded file", code=settings.RetCode.ARGUMENT_ERROR)
|
||||
f = File(r.group(1), os.path.join(download_path, r.group(1)))
|
||||
txt = FileService.parse_docs([f], current_user.id)
|
||||
return get_json_result(data=txt)
|
||||
|
||||
if 'file' not in request.files:
|
||||
return get_json_result(
|
||||
data=False, message='No file part!', code=settings.RetCode.ARGUMENT_ERROR)
|
||||
if "file" not in request.files:
|
||||
return get_json_result(data=False, message="No file part!", code=settings.RetCode.ARGUMENT_ERROR)
|
||||
|
||||
file_objs = request.files.getlist('file')
|
||||
file_objs = request.files.getlist("file")
|
||||
txt = FileService.parse_docs(file_objs, current_user.id)
|
||||
|
||||
return get_json_result(data=txt)
|
||||
|
||||
|
||||
@manager.route('/set_meta', methods=['POST']) # noqa: F821
|
||||
@manager.route("/set_meta", methods=["POST"]) # noqa: F821
|
||||
@login_required
|
||||
@validate_request("doc_id", "meta")
|
||||
def set_meta():
|
||||
req = request.json
|
||||
if not DocumentService.accessible(req["doc_id"], current_user.id):
|
||||
return get_json_result(
|
||||
data=False,
|
||||
message='No authorization.',
|
||||
code=settings.RetCode.AUTHENTICATION_ERROR
|
||||
)
|
||||
return get_json_result(data=False, message="No authorization.", code=settings.RetCode.AUTHENTICATION_ERROR)
|
||||
try:
|
||||
meta = json.loads(req["meta"])
|
||||
except Exception as e:
|
||||
return get_json_result(
|
||||
data=False, message=f'Json syntax error: {e}', code=settings.RetCode.ARGUMENT_ERROR)
|
||||
return get_json_result(data=False, message=f"Json syntax error: {e}", code=settings.RetCode.ARGUMENT_ERROR)
|
||||
if not isinstance(meta, dict):
|
||||
return get_json_result(
|
||||
data=False, message='Meta data should be in Json map format, like {"key": "value"}', code=settings.RetCode.ARGUMENT_ERROR)
|
||||
return get_json_result(data=False, message='Meta data should be in Json map format, like {"key": "value"}', code=settings.RetCode.ARGUMENT_ERROR)
|
||||
|
||||
try:
|
||||
e, doc = DocumentService.get_by_id(req["doc_id"])
|
||||
if not e:
|
||||
return get_data_error_result(message="Document not found!")
|
||||
|
||||
if not DocumentService.update_by_id(
|
||||
req["doc_id"], {"meta_fields": meta}):
|
||||
return get_data_error_result(
|
||||
message="Database error (meta updates)!")
|
||||
if not DocumentService.update_by_id(req["doc_id"], {"meta_fields": meta}):
|
||||
return get_data_error_result(message="Database error (meta updates)!")
|
||||
|
||||
return get_json_result(data=True)
|
||||
except Exception as e:
|
||||
|
||||
@ -257,6 +257,7 @@ def rm():
|
||||
STORAGE_IMPL.rm(file.parent_id, file.location)
|
||||
FileService.delete_folder_by_pf_id(current_user.id, file_id)
|
||||
else:
|
||||
STORAGE_IMPL.rm(file.parent_id, file.location)
|
||||
if not FileService.delete(file):
|
||||
return get_data_error_result(
|
||||
message="Database error (File removal)!")
|
||||
|
||||
@ -58,6 +58,7 @@ def create():
|
||||
status=StatusEnum.VALID.value)
|
||||
try:
|
||||
req["id"] = get_uuid()
|
||||
req["name"] = dataset_name
|
||||
req["tenant_id"] = current_user.id
|
||||
req["created_by"] = current_user.id
|
||||
e, t = TenantService.get_by_id(current_user.id)
|
||||
@ -99,7 +100,7 @@ def update():
|
||||
if req.get("parser_id", "") == "tag" and os.environ.get('DOC_ENGINE', "elasticsearch") == "infinity":
|
||||
return get_json_result(
|
||||
data=False,
|
||||
message='The chunk method Tag has not been supported by Infinity yet.',
|
||||
message='The chunking method Tag has not been supported by Infinity yet.',
|
||||
code=settings.RetCode.OPERATING_ERROR
|
||||
)
|
||||
|
||||
@ -152,6 +153,7 @@ def detail():
|
||||
if not kb:
|
||||
return get_data_error_result(
|
||||
message="Can't find this knowledgebase!")
|
||||
kb["size"] = DocumentService.get_total_size_by_kb_id(kb_id=kb["id"],keywords="", run_status=[], types=[])
|
||||
return get_json_result(data=kb)
|
||||
except Exception as e:
|
||||
return server_error_response(e)
|
||||
|
||||
12
api/apps/plugin_app.py
Normal file
12
api/apps/plugin_app.py
Normal file
@ -0,0 +1,12 @@
|
||||
from flask import Response
|
||||
from flask_login import login_required
|
||||
from api.utils.api_utils import get_json_result
|
||||
from plugin import GlobalPluginManager
|
||||
|
||||
@manager.route('/llm_tools', methods=['GET']) # noqa: F821
|
||||
@login_required
|
||||
def llm_tools() -> Response:
|
||||
tools = GlobalPluginManager.get_llm_tools()
|
||||
tools_metadata = [t.get_metadata() for t in tools]
|
||||
|
||||
return get_json_result(data=tools_metadata)
|
||||
@ -14,8 +14,14 @@
|
||||
# limitations under the License.
|
||||
#
|
||||
|
||||
import json
|
||||
import time
|
||||
from typing import Any, cast
|
||||
from api.db.services.canvas_service import UserCanvasService
|
||||
from api.utils.api_utils import get_error_data_result, token_required
|
||||
from api.db.services.user_canvas_version import UserCanvasVersionService
|
||||
from api.settings import RetCode
|
||||
from api.utils import get_uuid
|
||||
from api.utils.api_utils import get_data_error_result, get_error_data_result, get_json_result, token_required
|
||||
from api.utils.api_utils import get_result
|
||||
from flask import request
|
||||
|
||||
@ -37,3 +43,86 @@ def list_agents(tenant_id):
|
||||
desc = True
|
||||
canvas = UserCanvasService.get_list(tenant_id,page_number,items_per_page,orderby,desc,id,title)
|
||||
return get_result(data=canvas)
|
||||
|
||||
|
||||
@manager.route("/agents", methods=["POST"]) # noqa: F821
|
||||
@token_required
|
||||
def create_agent(tenant_id: str):
|
||||
req: dict[str, Any] = cast(dict[str, Any], request.json)
|
||||
req["user_id"] = tenant_id
|
||||
|
||||
if req.get("dsl") is not None:
|
||||
if not isinstance(req["dsl"], str):
|
||||
req["dsl"] = json.dumps(req["dsl"], ensure_ascii=False)
|
||||
|
||||
req["dsl"] = json.loads(req["dsl"])
|
||||
else:
|
||||
return get_json_result(data=False, message="No DSL data in request.", code=RetCode.ARGUMENT_ERROR)
|
||||
|
||||
if req.get("title") is not None:
|
||||
req["title"] = req["title"].strip()
|
||||
else:
|
||||
return get_json_result(data=False, message="No title in request.", code=RetCode.ARGUMENT_ERROR)
|
||||
|
||||
if UserCanvasService.query(user_id=tenant_id, title=req["title"]):
|
||||
return get_data_error_result(message=f"Agent with title {req['title']} already exists.")
|
||||
|
||||
agent_id = get_uuid()
|
||||
req["id"] = agent_id
|
||||
|
||||
if not UserCanvasService.save(**req):
|
||||
return get_data_error_result(message="Fail to create agent.")
|
||||
|
||||
UserCanvasVersionService.insert(
|
||||
user_canvas_id=agent_id,
|
||||
title="{0}_{1}".format(req["title"], time.strftime("%Y_%m_%d_%H_%M_%S")),
|
||||
dsl=req["dsl"]
|
||||
)
|
||||
|
||||
return get_json_result(data=True)
|
||||
|
||||
|
||||
@manager.route("/agents/<agent_id>", methods=["PUT"]) # noqa: F821
|
||||
@token_required
|
||||
def update_agent(tenant_id: str, agent_id: str):
|
||||
req: dict[str, Any] = {k: v for k, v in cast(dict[str, Any], request.json).items() if v is not None}
|
||||
req["user_id"] = tenant_id
|
||||
|
||||
if req.get("dsl") is not None:
|
||||
if not isinstance(req["dsl"], str):
|
||||
req["dsl"] = json.dumps(req["dsl"], ensure_ascii=False)
|
||||
|
||||
req["dsl"] = json.loads(req["dsl"])
|
||||
|
||||
if req.get("title") is not None:
|
||||
req["title"] = req["title"].strip()
|
||||
|
||||
if not UserCanvasService.query(user_id=tenant_id, id=agent_id):
|
||||
return get_json_result(
|
||||
data=False, message="Only owner of canvas authorized for this operation.",
|
||||
code=RetCode.OPERATING_ERROR)
|
||||
|
||||
UserCanvasService.update_by_id(agent_id, req)
|
||||
|
||||
if req.get("dsl") is not None:
|
||||
UserCanvasVersionService.insert(
|
||||
user_canvas_id=agent_id,
|
||||
title="{0}_{1}".format(req["title"], time.strftime("%Y_%m_%d_%H_%M_%S")),
|
||||
dsl=req["dsl"]
|
||||
)
|
||||
|
||||
UserCanvasVersionService.delete_all_versions(agent_id)
|
||||
|
||||
return get_json_result(data=True)
|
||||
|
||||
|
||||
@manager.route("/agents/<agent_id>", methods=["DELETE"]) # noqa: F821
|
||||
@token_required
|
||||
def delete_agent(tenant_id: str, agent_id: str):
|
||||
if not UserCanvasService.query(user_id=tenant_id, id=agent_id):
|
||||
return get_json_result(
|
||||
data=False, message="Only owner of canvas authorized for this operation.",
|
||||
code=RetCode.OPERATING_ERROR)
|
||||
|
||||
UserCanvasService.delete_by_id(agent_id)
|
||||
return get_json_result(data=True)
|
||||
|
||||
@ -16,6 +16,7 @@
|
||||
import logging
|
||||
|
||||
from flask import request
|
||||
|
||||
from api import settings
|
||||
from api.db import StatusEnum
|
||||
from api.db.services.dialog_service import DialogService
|
||||
@ -23,15 +24,14 @@ from api.db.services.knowledgebase_service import KnowledgebaseService
|
||||
from api.db.services.llm_service import TenantLLMService
|
||||
from api.db.services.user_service import TenantService
|
||||
from api.utils import get_uuid
|
||||
from api.utils.api_utils import get_error_data_result, token_required, get_result, check_duplicate_ids
|
||||
from api.utils.api_utils import check_duplicate_ids, get_error_data_result, get_result, token_required
|
||||
|
||||
|
||||
|
||||
@manager.route('/chats', methods=['POST']) # noqa: F821
|
||||
@manager.route("/chats", methods=["POST"]) # noqa: F821
|
||||
@token_required
|
||||
def create(tenant_id):
|
||||
req = request.json
|
||||
ids = [i for i in req.get("dataset_ids", []) if i]
|
||||
ids = [i for i in req.get("dataset_ids", []) if i]
|
||||
for kb_id in ids:
|
||||
kbs = KnowledgebaseService.accessible(kb_id=kb_id, user_id=tenant_id)
|
||||
if not kbs:
|
||||
@ -40,34 +40,30 @@ def create(tenant_id):
|
||||
kb = kbs[0]
|
||||
if kb.chunk_num == 0:
|
||||
return get_error_data_result(f"The dataset {kb_id} doesn't own parsed file")
|
||||
|
||||
|
||||
kbs = KnowledgebaseService.get_by_ids(ids) if ids else []
|
||||
embd_ids = [TenantLLMService.split_model_name_and_factory(kb.embd_id)[0] for kb in kbs] # remove vendor suffix for comparison
|
||||
embd_count = list(set(embd_ids))
|
||||
if len(embd_count) > 1:
|
||||
return get_result(message='Datasets use different embedding models."',
|
||||
code=settings.RetCode.AUTHENTICATION_ERROR)
|
||||
return get_result(message='Datasets use different embedding models."', code=settings.RetCode.AUTHENTICATION_ERROR)
|
||||
req["kb_ids"] = ids
|
||||
# llm
|
||||
llm = req.get("llm")
|
||||
if llm:
|
||||
if "model_name" in llm:
|
||||
req["llm_id"] = llm.pop("model_name")
|
||||
if not TenantLLMService.query(tenant_id=tenant_id, llm_name=req["llm_id"], model_type="chat"):
|
||||
return get_error_data_result(f"`model_name` {req.get('llm_id')} doesn't exist")
|
||||
if req.get("llm_id") is not None:
|
||||
llm_name, llm_factory = TenantLLMService.split_model_name_and_factory(req["llm_id"])
|
||||
if not TenantLLMService.query(tenant_id=tenant_id, llm_name=llm_name, llm_factory=llm_factory, model_type="chat"):
|
||||
return get_error_data_result(f"`model_name` {req.get('llm_id')} doesn't exist")
|
||||
req["llm_setting"] = req.pop("llm")
|
||||
e, tenant = TenantService.get_by_id(tenant_id)
|
||||
if not e:
|
||||
return get_error_data_result(message="Tenant not found!")
|
||||
# prompt
|
||||
prompt = req.get("prompt")
|
||||
key_mapping = {"parameters": "variables",
|
||||
"prologue": "opener",
|
||||
"quote": "show_quote",
|
||||
"system": "prompt",
|
||||
"rerank_id": "rerank_model",
|
||||
"vector_similarity_weight": "keywords_similarity_weight"}
|
||||
key_list = ["similarity_threshold", "vector_similarity_weight", "top_n", "rerank_id","top_k"]
|
||||
key_mapping = {"parameters": "variables", "prologue": "opener", "quote": "show_quote", "system": "prompt", "rerank_id": "rerank_model", "vector_similarity_weight": "keywords_similarity_weight"}
|
||||
key_list = ["similarity_threshold", "vector_similarity_weight", "top_n", "rerank_id", "top_k"]
|
||||
if prompt:
|
||||
for new_key, old_key in key_mapping.items():
|
||||
if old_key in prompt:
|
||||
@ -85,9 +81,7 @@ def create(tenant_id):
|
||||
req["rerank_id"] = req.get("rerank_id", "")
|
||||
if req.get("rerank_id"):
|
||||
value_rerank_model = ["BAAI/bge-reranker-v2-m3", "maidalun1020/bce-reranker-base_v1"]
|
||||
if req["rerank_id"] not in value_rerank_model and not TenantLLMService.query(tenant_id=tenant_id,
|
||||
llm_name=req.get("rerank_id"),
|
||||
model_type="rerank"):
|
||||
if req["rerank_id"] not in value_rerank_model and not TenantLLMService.query(tenant_id=tenant_id, llm_name=req.get("rerank_id"), model_type="rerank"):
|
||||
return get_error_data_result(f"`rerank_model` {req.get('rerank_id')} doesn't exist")
|
||||
if not req.get("llm_id"):
|
||||
req["llm_id"] = tenant.llm_id
|
||||
@ -106,27 +100,24 @@ def create(tenant_id):
|
||||
{knowledge}
|
||||
The above is the knowledge base.""",
|
||||
"prologue": "Hi! I'm your assistant, what can I do for you?",
|
||||
"parameters": [
|
||||
{"key": "knowledge", "optional": False}
|
||||
],
|
||||
"parameters": [{"key": "knowledge", "optional": False}],
|
||||
"empty_response": "Sorry! No relevant content was found in the knowledge base!",
|
||||
"quote": True,
|
||||
"tts": False,
|
||||
"refine_multiturn": True
|
||||
"refine_multiturn": True,
|
||||
}
|
||||
key_list_2 = ["system", "prologue", "parameters", "empty_response", "quote", "tts", "refine_multiturn"]
|
||||
if "prompt_config" not in req:
|
||||
req['prompt_config'] = {}
|
||||
req["prompt_config"] = {}
|
||||
for key in key_list_2:
|
||||
temp = req['prompt_config'].get(key)
|
||||
if (not temp and key == 'system') or (key not in req["prompt_config"]):
|
||||
req['prompt_config'][key] = default_prompt[key]
|
||||
for p in req['prompt_config']["parameters"]:
|
||||
temp = req["prompt_config"].get(key)
|
||||
if (not temp and key == "system") or (key not in req["prompt_config"]):
|
||||
req["prompt_config"][key] = default_prompt[key]
|
||||
for p in req["prompt_config"]["parameters"]:
|
||||
if p["optional"]:
|
||||
continue
|
||||
if req['prompt_config']["system"].find("{%s}" % p["key"]) < 0:
|
||||
return get_error_data_result(
|
||||
message="Parameter '{}' is not used".format(p["key"]))
|
||||
if req["prompt_config"]["system"].find("{%s}" % p["key"]) < 0:
|
||||
return get_error_data_result(message="Parameter '{}' is not used".format(p["key"]))
|
||||
# save
|
||||
if not DialogService.save(**req):
|
||||
return get_error_data_result(message="Fail to new a chat!")
|
||||
@ -141,10 +132,7 @@ def create(tenant_id):
|
||||
renamed_dict[new_key] = value
|
||||
res["prompt"] = renamed_dict
|
||||
del res["prompt_config"]
|
||||
new_dict = {"similarity_threshold": res["similarity_threshold"],
|
||||
"keywords_similarity_weight": 1-res["vector_similarity_weight"],
|
||||
"top_n": res["top_n"],
|
||||
"rerank_model": res['rerank_id']}
|
||||
new_dict = {"similarity_threshold": res["similarity_threshold"], "keywords_similarity_weight": 1 - res["vector_similarity_weight"], "top_n": res["top_n"], "rerank_model": res["rerank_id"]}
|
||||
res["prompt"].update(new_dict)
|
||||
for key in key_list:
|
||||
del res[key]
|
||||
@ -156,36 +144,31 @@ def create(tenant_id):
|
||||
return get_result(data=res)
|
||||
|
||||
|
||||
@manager.route('/chats/<chat_id>', methods=['PUT']) # noqa: F821
|
||||
@manager.route("/chats/<chat_id>", methods=["PUT"]) # noqa: F821
|
||||
@token_required
|
||||
def update(tenant_id, chat_id):
|
||||
if not DialogService.query(tenant_id=tenant_id, id=chat_id, status=StatusEnum.VALID.value):
|
||||
return get_error_data_result(message='You do not own the chat')
|
||||
return get_error_data_result(message="You do not own the chat")
|
||||
req = request.json
|
||||
ids = req.get("dataset_ids")
|
||||
if "show_quotation" in req:
|
||||
req["do_refer"] = req.pop("show_quotation")
|
||||
if "dataset_ids" in req:
|
||||
if not ids:
|
||||
return get_error_data_result("`dataset_ids` can't be empty")
|
||||
if ids:
|
||||
for kb_id in ids:
|
||||
kbs = KnowledgebaseService.accessible(kb_id=kb_id, user_id=tenant_id)
|
||||
if not kbs:
|
||||
return get_error_data_result(f"You don't own the dataset {kb_id}")
|
||||
kbs = KnowledgebaseService.query(id=kb_id)
|
||||
kb = kbs[0]
|
||||
if kb.chunk_num == 0:
|
||||
return get_error_data_result(f"The dataset {kb_id} doesn't own parsed file")
|
||||
|
||||
kbs = KnowledgebaseService.get_by_ids(ids)
|
||||
embd_ids = [TenantLLMService.split_model_name_and_factory(kb.embd_id)[0] for kb in kbs] # remove vendor suffix for comparison
|
||||
embd_count = list(set(embd_ids))
|
||||
if len(embd_count) != 1:
|
||||
return get_result(
|
||||
message='Datasets use different embedding models."',
|
||||
code=settings.RetCode.AUTHENTICATION_ERROR)
|
||||
req["kb_ids"] = ids
|
||||
if ids is not None:
|
||||
for kb_id in ids:
|
||||
kbs = KnowledgebaseService.accessible(kb_id=kb_id, user_id=tenant_id)
|
||||
if not kbs:
|
||||
return get_error_data_result(f"You don't own the dataset {kb_id}")
|
||||
kbs = KnowledgebaseService.query(id=kb_id)
|
||||
kb = kbs[0]
|
||||
if kb.chunk_num == 0:
|
||||
return get_error_data_result(f"The dataset {kb_id} doesn't own parsed file")
|
||||
|
||||
kbs = KnowledgebaseService.get_by_ids(ids)
|
||||
embd_ids = [TenantLLMService.split_model_name_and_factory(kb.embd_id)[0] for kb in kbs] # remove vendor suffix for comparison
|
||||
embd_count = list(set(embd_ids))
|
||||
if len(embd_count) != 1:
|
||||
return get_result(message='Datasets use different embedding models."', code=settings.RetCode.AUTHENTICATION_ERROR)
|
||||
req["kb_ids"] = ids
|
||||
llm = req.get("llm")
|
||||
if llm:
|
||||
if "model_name" in llm:
|
||||
@ -198,13 +181,8 @@ def update(tenant_id, chat_id):
|
||||
return get_error_data_result(message="Tenant not found!")
|
||||
# prompt
|
||||
prompt = req.get("prompt")
|
||||
key_mapping = {"parameters": "variables",
|
||||
"prologue": "opener",
|
||||
"quote": "show_quote",
|
||||
"system": "prompt",
|
||||
"rerank_id": "rerank_model",
|
||||
"vector_similarity_weight": "keywords_similarity_weight"}
|
||||
key_list = ["similarity_threshold", "vector_similarity_weight", "top_n", "rerank_id","top_k"]
|
||||
key_mapping = {"parameters": "variables", "prologue": "opener", "quote": "show_quote", "system": "prompt", "rerank_id": "rerank_model", "vector_similarity_weight": "keywords_similarity_weight"}
|
||||
key_list = ["similarity_threshold", "vector_similarity_weight", "top_n", "rerank_id", "top_k"]
|
||||
if prompt:
|
||||
for new_key, old_key in key_mapping.items():
|
||||
if old_key in prompt:
|
||||
@ -217,16 +195,12 @@ def update(tenant_id, chat_id):
|
||||
res = res.to_json()
|
||||
if req.get("rerank_id"):
|
||||
value_rerank_model = ["BAAI/bge-reranker-v2-m3", "maidalun1020/bce-reranker-base_v1"]
|
||||
if req["rerank_id"] not in value_rerank_model and not TenantLLMService.query(tenant_id=tenant_id,
|
||||
llm_name=req.get("rerank_id"),
|
||||
model_type="rerank"):
|
||||
if req["rerank_id"] not in value_rerank_model and not TenantLLMService.query(tenant_id=tenant_id, llm_name=req.get("rerank_id"), model_type="rerank"):
|
||||
return get_error_data_result(f"`rerank_model` {req.get('rerank_id')} doesn't exist")
|
||||
if "name" in req:
|
||||
if not req.get("name"):
|
||||
return get_error_data_result(message="`name` cannot be empty.")
|
||||
if req["name"].lower() != res["name"].lower() \
|
||||
and len(
|
||||
DialogService.query(name=req["name"], tenant_id=tenant_id, status=StatusEnum.VALID.value)) > 0:
|
||||
if req["name"].lower() != res["name"].lower() and len(DialogService.query(name=req["name"], tenant_id=tenant_id, status=StatusEnum.VALID.value)) > 0:
|
||||
return get_error_data_result(message="Duplicated chat name in updating chat.")
|
||||
if "prompt_config" in req:
|
||||
res["prompt_config"].update(req["prompt_config"])
|
||||
@ -249,7 +223,7 @@ def update(tenant_id, chat_id):
|
||||
return get_result()
|
||||
|
||||
|
||||
@manager.route('/chats', methods=['DELETE']) # noqa: F821
|
||||
@manager.route("/chats", methods=["DELETE"]) # noqa: F821
|
||||
@token_required
|
||||
def delete(tenant_id):
|
||||
errors = []
|
||||
@ -276,30 +250,23 @@ def delete(tenant_id):
|
||||
temp_dict = {"status": StatusEnum.INVALID.value}
|
||||
DialogService.update_by_id(id, temp_dict)
|
||||
success_count += 1
|
||||
|
||||
|
||||
if errors:
|
||||
if success_count > 0:
|
||||
return get_result(
|
||||
data={"success_count": success_count, "errors": errors},
|
||||
message=f"Partially deleted {success_count} chats with {len(errors)} errors"
|
||||
)
|
||||
return get_result(data={"success_count": success_count, "errors": errors}, message=f"Partially deleted {success_count} chats with {len(errors)} errors")
|
||||
else:
|
||||
return get_error_data_result(message="; ".join(errors))
|
||||
|
||||
|
||||
if duplicate_messages:
|
||||
if success_count > 0:
|
||||
return get_result(
|
||||
message=f"Partially deleted {success_count} chats with {len(duplicate_messages)} errors",
|
||||
data={"success_count": success_count, "errors": duplicate_messages}
|
||||
)
|
||||
return get_result(message=f"Partially deleted {success_count} chats with {len(duplicate_messages)} errors", data={"success_count": success_count, "errors": duplicate_messages})
|
||||
else:
|
||||
return get_error_data_result(message=";".join(duplicate_messages))
|
||||
|
||||
|
||||
return get_result()
|
||||
|
||||
|
||||
|
||||
@manager.route('/chats', methods=['GET']) # noqa: F821
|
||||
@manager.route("/chats", methods=["GET"]) # noqa: F821
|
||||
@token_required
|
||||
def list_chat(tenant_id):
|
||||
id = request.args.get("id")
|
||||
@ -319,13 +286,15 @@ def list_chat(tenant_id):
|
||||
if not chats:
|
||||
return get_result(data=[])
|
||||
list_assts = []
|
||||
key_mapping = {"parameters": "variables",
|
||||
"prologue": "opener",
|
||||
"quote": "show_quote",
|
||||
"system": "prompt",
|
||||
"rerank_id": "rerank_model",
|
||||
"vector_similarity_weight": "keywords_similarity_weight",
|
||||
"do_refer": "show_quotation"}
|
||||
key_mapping = {
|
||||
"parameters": "variables",
|
||||
"prologue": "opener",
|
||||
"quote": "show_quote",
|
||||
"system": "prompt",
|
||||
"rerank_id": "rerank_model",
|
||||
"vector_similarity_weight": "keywords_similarity_weight",
|
||||
"do_refer": "show_quotation",
|
||||
}
|
||||
key_list = ["similarity_threshold", "vector_similarity_weight", "top_n", "rerank_id"]
|
||||
for res in chats:
|
||||
renamed_dict = {}
|
||||
@ -334,10 +303,7 @@ def list_chat(tenant_id):
|
||||
renamed_dict[new_key] = value
|
||||
res["prompt"] = renamed_dict
|
||||
del res["prompt_config"]
|
||||
new_dict = {"similarity_threshold": res["similarity_threshold"],
|
||||
"keywords_similarity_weight": 1-res["vector_similarity_weight"],
|
||||
"top_n": res["top_n"],
|
||||
"rerank_model": res['rerank_id']}
|
||||
new_dict = {"similarity_threshold": res["similarity_threshold"], "keywords_similarity_weight": 1 - res["vector_similarity_weight"], "top_n": res["top_n"], "rerank_model": res["rerank_id"]}
|
||||
res["prompt"].update(new_dict)
|
||||
for key in key_list:
|
||||
del res[key]
|
||||
|
||||
@ -14,23 +14,39 @@
|
||||
# limitations under the License.
|
||||
#
|
||||
|
||||
|
||||
import logging
|
||||
|
||||
from flask import request
|
||||
from api.db import StatusEnum, FileSource
|
||||
from peewee import OperationalError
|
||||
|
||||
from api.db import FileSource, StatusEnum
|
||||
from api.db.db_models import File
|
||||
from api.db.services.document_service import DocumentService
|
||||
from api.db.services.file2document_service import File2DocumentService
|
||||
from api.db.services.file_service import FileService
|
||||
from api.db.services.knowledgebase_service import KnowledgebaseService
|
||||
from api.db.services.llm_service import TenantLLMService, LLMService
|
||||
from api.db.services.user_service import TenantService
|
||||
from api import settings
|
||||
from api.utils import get_uuid
|
||||
from api.utils.api_utils import (
|
||||
get_result,
|
||||
token_required,
|
||||
deep_merge,
|
||||
get_error_argument_result,
|
||||
get_error_data_result,
|
||||
valid,
|
||||
get_parser_config, valid_parser_config, dataset_readonly_fields,check_duplicate_ids
|
||||
get_error_operating_result,
|
||||
get_error_permission_result,
|
||||
get_parser_config,
|
||||
get_result,
|
||||
remap_dictionary_keys,
|
||||
token_required,
|
||||
verify_embedding_availability,
|
||||
)
|
||||
from api.utils.validation_utils import (
|
||||
CreateDatasetReq,
|
||||
DeleteDatasetReq,
|
||||
ListDatasetReq,
|
||||
UpdateDatasetReq,
|
||||
validate_and_parse_json_request,
|
||||
validate_and_parse_request_args,
|
||||
)
|
||||
|
||||
|
||||
@ -62,16 +78,28 @@ def create(tenant_id):
|
||||
name:
|
||||
type: string
|
||||
description: Name of the dataset.
|
||||
avatar:
|
||||
type: string
|
||||
description: Base64 encoding of the avatar.
|
||||
description:
|
||||
type: string
|
||||
description: Description of the dataset.
|
||||
embedding_model:
|
||||
type: string
|
||||
description: Embedding model Name.
|
||||
permission:
|
||||
type: string
|
||||
enum: ['me', 'team']
|
||||
description: Dataset permission.
|
||||
chunk_method:
|
||||
type: string
|
||||
enum: ["naive", "manual", "qa", "table", "paper", "book", "laws",
|
||||
"presentation", "picture", "one", "email", "tag"
|
||||
enum: ["naive", "book", "email", "laws", "manual", "one", "paper",
|
||||
"picture", "presentation", "qa", "table", "tag"
|
||||
]
|
||||
description: Chunking method.
|
||||
pagerank:
|
||||
type: integer
|
||||
description: Set page rank.
|
||||
parser_config:
|
||||
type: object
|
||||
description: Parser configuration.
|
||||
@ -84,106 +112,59 @@ def create(tenant_id):
|
||||
data:
|
||||
type: object
|
||||
"""
|
||||
req = request.json
|
||||
for k in req.keys():
|
||||
if dataset_readonly_fields(k):
|
||||
return get_result(code=settings.RetCode.ARGUMENT_ERROR, message=f"'{k}' is readonly.")
|
||||
e, t = TenantService.get_by_id(tenant_id)
|
||||
permission = req.get("permission")
|
||||
chunk_method = req.get("chunk_method")
|
||||
parser_config = req.get("parser_config")
|
||||
valid_parser_config(parser_config)
|
||||
valid_permission = ["me", "team"]
|
||||
valid_chunk_method = [
|
||||
"naive",
|
||||
"manual",
|
||||
"qa",
|
||||
"table",
|
||||
"paper",
|
||||
"book",
|
||||
"laws",
|
||||
"presentation",
|
||||
"picture",
|
||||
"one",
|
||||
"email",
|
||||
"tag"
|
||||
]
|
||||
check_validation = valid(
|
||||
permission,
|
||||
valid_permission,
|
||||
chunk_method,
|
||||
valid_chunk_method,
|
||||
)
|
||||
if check_validation:
|
||||
return check_validation
|
||||
req["parser_config"] = get_parser_config(chunk_method, parser_config)
|
||||
if "tenant_id" in req:
|
||||
return get_error_data_result(message="`tenant_id` must not be provided")
|
||||
if "chunk_count" in req or "document_count" in req:
|
||||
return get_error_data_result(
|
||||
message="`chunk_count` or `document_count` must not be provided"
|
||||
)
|
||||
if "name" not in req:
|
||||
return get_error_data_result(message="`name` is not empty!")
|
||||
# Field name transformations during model dump:
|
||||
# | Original | Dump Output |
|
||||
# |----------------|-------------|
|
||||
# | embedding_model| embd_id |
|
||||
# | chunk_method | parser_id |
|
||||
req, err = validate_and_parse_json_request(request, CreateDatasetReq)
|
||||
if err is not None:
|
||||
return get_error_argument_result(err)
|
||||
|
||||
try:
|
||||
if KnowledgebaseService.get_or_none(name=req["name"], tenant_id=tenant_id, status=StatusEnum.VALID.value):
|
||||
return get_error_operating_result(message=f"Dataset name '{req['name']}' already exists")
|
||||
except OperationalError as e:
|
||||
logging.exception(e)
|
||||
return get_error_data_result(message="Database operation failed")
|
||||
|
||||
req["parser_config"] = get_parser_config(req["parser_id"], req["parser_config"])
|
||||
req["id"] = get_uuid()
|
||||
req["name"] = req["name"].strip()
|
||||
if req["name"] == "":
|
||||
return get_error_data_result(message="`name` is not empty string!")
|
||||
if len(req["name"]) >= 128:
|
||||
return get_error_data_result(
|
||||
message="Dataset name should not be longer than 128 characters."
|
||||
)
|
||||
if KnowledgebaseService.query(
|
||||
name=req["name"], tenant_id=tenant_id, status=StatusEnum.VALID.value
|
||||
):
|
||||
return get_error_data_result(
|
||||
message="Duplicated dataset name in creating dataset."
|
||||
)
|
||||
req["tenant_id"] = tenant_id
|
||||
req["created_by"] = tenant_id
|
||||
if not req.get("embedding_model"):
|
||||
req["embedding_model"] = t.embd_id
|
||||
|
||||
try:
|
||||
ok, t = TenantService.get_by_id(tenant_id)
|
||||
if not ok:
|
||||
return get_error_permission_result(message="Tenant not found")
|
||||
except OperationalError as e:
|
||||
logging.exception(e)
|
||||
return get_error_data_result(message="Database operation failed")
|
||||
|
||||
if not req.get("embd_id"):
|
||||
req["embd_id"] = t.embd_id
|
||||
else:
|
||||
valid_embedding_models = [
|
||||
"BAAI/bge-large-zh-v1.5",
|
||||
"maidalun1020/bce-embedding-base_v1",
|
||||
]
|
||||
embd_model = LLMService.query(
|
||||
llm_name=req["embedding_model"], model_type="embedding"
|
||||
)
|
||||
if embd_model:
|
||||
if req["embedding_model"] not in valid_embedding_models and not TenantLLMService.query(tenant_id=tenant_id,model_type="embedding",llm_name=req.get("embedding_model"),):
|
||||
return get_error_data_result(f"`embedding_model` {req.get('embedding_model')} doesn't exist")
|
||||
if not embd_model:
|
||||
embd_model=TenantLLMService.query(tenant_id=tenant_id,model_type="embedding", llm_name=req.get("embedding_model"))
|
||||
if not embd_model:
|
||||
return get_error_data_result(
|
||||
f"`embedding_model` {req.get('embedding_model')} doesn't exist"
|
||||
)
|
||||
key_mapping = {
|
||||
"chunk_num": "chunk_count",
|
||||
"doc_num": "document_count",
|
||||
"parser_id": "chunk_method",
|
||||
"embd_id": "embedding_model",
|
||||
}
|
||||
mapped_keys = {
|
||||
new_key: req[old_key]
|
||||
for new_key, old_key in key_mapping.items()
|
||||
if old_key in req
|
||||
}
|
||||
req.update(mapped_keys)
|
||||
flds = list(req.keys())
|
||||
for f in flds:
|
||||
if req[f] == "" and f in ["permission", "parser_id", "chunk_method"]:
|
||||
del req[f]
|
||||
if not KnowledgebaseService.save(**req):
|
||||
return get_error_data_result(message="Create dataset error.(Database error)")
|
||||
renamed_data = {}
|
||||
e, k = KnowledgebaseService.get_by_id(req["id"])
|
||||
for key, value in k.to_dict().items():
|
||||
new_key = key_mapping.get(key, key)
|
||||
renamed_data[new_key] = value
|
||||
return get_result(data=renamed_data)
|
||||
ok, err = verify_embedding_availability(req["embd_id"], tenant_id)
|
||||
if not ok:
|
||||
return err
|
||||
|
||||
try:
|
||||
if not KnowledgebaseService.save(**req):
|
||||
return get_error_data_result(message="Create dataset error.(Database error)")
|
||||
except OperationalError as e:
|
||||
logging.exception(e)
|
||||
return get_error_data_result(message="Database operation failed")
|
||||
|
||||
try:
|
||||
ok, k = KnowledgebaseService.get_by_id(req["id"])
|
||||
if not ok:
|
||||
return get_error_data_result(message="Dataset created failed")
|
||||
except OperationalError as e:
|
||||
logging.exception(e)
|
||||
return get_error_data_result(message="Database operation failed")
|
||||
|
||||
response_data = remap_dictionary_keys(k.to_dict())
|
||||
return get_result(data=response_data)
|
||||
|
||||
|
||||
@manager.route("/datasets", methods=["DELETE"]) # noqa: F821
|
||||
@ -208,75 +189,88 @@ def delete(tenant_id):
|
||||
required: true
|
||||
schema:
|
||||
type: object
|
||||
required:
|
||||
- ids
|
||||
properties:
|
||||
ids:
|
||||
type: array
|
||||
type: array or null
|
||||
items:
|
||||
type: string
|
||||
description: List of dataset IDs to delete.
|
||||
description: |
|
||||
Specifies the datasets to delete:
|
||||
- If `null`, all datasets will be deleted.
|
||||
- If an array of IDs, only the specified datasets will be deleted.
|
||||
- If an empty array, no datasets will be deleted.
|
||||
responses:
|
||||
200:
|
||||
description: Successful operation.
|
||||
schema:
|
||||
type: object
|
||||
"""
|
||||
req, err = validate_and_parse_json_request(request, DeleteDatasetReq)
|
||||
if err is not None:
|
||||
return get_error_argument_result(err)
|
||||
|
||||
kb_id_instance_pairs = []
|
||||
if req["ids"] is None:
|
||||
try:
|
||||
kbs = KnowledgebaseService.query(tenant_id=tenant_id)
|
||||
for kb in kbs:
|
||||
kb_id_instance_pairs.append((kb.id, kb))
|
||||
except OperationalError as e:
|
||||
logging.exception(e)
|
||||
return get_error_data_result(message="Database operation failed")
|
||||
else:
|
||||
error_kb_ids = []
|
||||
for kb_id in req["ids"]:
|
||||
try:
|
||||
kb = KnowledgebaseService.get_or_none(id=kb_id, tenant_id=tenant_id)
|
||||
if kb is None:
|
||||
error_kb_ids.append(kb_id)
|
||||
continue
|
||||
kb_id_instance_pairs.append((kb_id, kb))
|
||||
except OperationalError as e:
|
||||
logging.exception(e)
|
||||
return get_error_data_result(message="Database operation failed")
|
||||
if len(error_kb_ids) > 0:
|
||||
return get_error_permission_result(message=f"""User '{tenant_id}' lacks permission for datasets: '{", ".join(error_kb_ids)}'""")
|
||||
|
||||
errors = []
|
||||
success_count = 0
|
||||
req = request.json
|
||||
if not req:
|
||||
ids = None
|
||||
else:
|
||||
ids = req.get("ids")
|
||||
if not ids:
|
||||
id_list = []
|
||||
kbs = KnowledgebaseService.query(tenant_id=tenant_id)
|
||||
for kb in kbs:
|
||||
id_list.append(kb.id)
|
||||
else:
|
||||
id_list = ids
|
||||
unique_id_list, duplicate_messages = check_duplicate_ids(id_list, "dataset")
|
||||
id_list = unique_id_list
|
||||
|
||||
for id in id_list:
|
||||
kbs = KnowledgebaseService.query(id=id, tenant_id=tenant_id)
|
||||
if not kbs:
|
||||
errors.append(f"You don't own the dataset {id}")
|
||||
continue
|
||||
for doc in DocumentService.query(kb_id=id):
|
||||
if not DocumentService.remove_document(doc, tenant_id):
|
||||
errors.append(f"Remove document error for dataset {id}")
|
||||
for kb_id, kb in kb_id_instance_pairs:
|
||||
try:
|
||||
for doc in DocumentService.query(kb_id=kb_id):
|
||||
if not DocumentService.remove_document(doc, tenant_id):
|
||||
errors.append(f"Remove document '{doc.id}' error for dataset '{kb_id}'")
|
||||
continue
|
||||
f2d = File2DocumentService.get_by_document_id(doc.id)
|
||||
FileService.filter_delete(
|
||||
[
|
||||
File.source_type == FileSource.KNOWLEDGEBASE,
|
||||
File.id == f2d[0].file_id,
|
||||
]
|
||||
)
|
||||
File2DocumentService.delete_by_document_id(doc.id)
|
||||
FileService.filter_delete([File.source_type == FileSource.KNOWLEDGEBASE, File.type == "folder", File.name == kb.name])
|
||||
if not KnowledgebaseService.delete_by_id(kb_id):
|
||||
errors.append(f"Delete dataset error for {kb_id}")
|
||||
continue
|
||||
f2d = File2DocumentService.get_by_document_id(doc.id)
|
||||
FileService.filter_delete(
|
||||
[
|
||||
File.source_type == FileSource.KNOWLEDGEBASE,
|
||||
File.id == f2d[0].file_id,
|
||||
]
|
||||
)
|
||||
File2DocumentService.delete_by_document_id(doc.id)
|
||||
FileService.filter_delete(
|
||||
[File.source_type == FileSource.KNOWLEDGEBASE, File.type == "folder", File.name == kbs[0].name])
|
||||
if not KnowledgebaseService.delete_by_id(id):
|
||||
errors.append(f"Delete dataset error for {id}")
|
||||
continue
|
||||
success_count += 1
|
||||
if errors:
|
||||
if success_count > 0:
|
||||
return get_result(
|
||||
data={"success_count": success_count, "errors": errors},
|
||||
message=f"Partially deleted {success_count} datasets with {len(errors)} errors"
|
||||
)
|
||||
else:
|
||||
return get_error_data_result(message="; ".join(errors))
|
||||
if duplicate_messages:
|
||||
if success_count > 0:
|
||||
return get_result(message=f"Partially deleted {success_count} datasets with {len(duplicate_messages)} errors", data={"success_count": success_count, "errors": duplicate_messages},)
|
||||
else:
|
||||
return get_error_data_result(message=";".join(duplicate_messages))
|
||||
return get_result(code=settings.RetCode.SUCCESS)
|
||||
success_count += 1
|
||||
except OperationalError as e:
|
||||
logging.exception(e)
|
||||
return get_error_data_result(message="Database operation failed")
|
||||
|
||||
if not errors:
|
||||
return get_result()
|
||||
|
||||
error_message = f"Successfully deleted {success_count} datasets, {len(errors)} failed. Details: {'; '.join(errors)[:128]}..."
|
||||
if success_count == 0:
|
||||
return get_error_data_result(message=error_message)
|
||||
|
||||
return get_result(data={"success_count": success_count, "errors": errors[:5]}, message=error_message)
|
||||
|
||||
|
||||
@manager.route("/datasets/<dataset_id>", methods=["PUT"]) # noqa: F821
|
||||
@manager.route("/datasets/<dataset_id>", methods=["PUT"]) # noqa: F821
|
||||
@token_required
|
||||
def update(tenant_id, dataset_id):
|
||||
"""
|
||||
@ -307,16 +301,28 @@ def update(tenant_id, dataset_id):
|
||||
name:
|
||||
type: string
|
||||
description: New name of the dataset.
|
||||
avatar:
|
||||
type: string
|
||||
description: Updated base64 encoding of the avatar.
|
||||
description:
|
||||
type: string
|
||||
description: Updated description of the dataset.
|
||||
embedding_model:
|
||||
type: string
|
||||
description: Updated embedding model Name.
|
||||
permission:
|
||||
type: string
|
||||
enum: ['me', 'team']
|
||||
description: Updated permission.
|
||||
description: Updated dataset permission.
|
||||
chunk_method:
|
||||
type: string
|
||||
enum: ["naive", "manual", "qa", "table", "paper", "book", "laws",
|
||||
"presentation", "picture", "one", "email", "tag"
|
||||
enum: ["naive", "book", "email", "laws", "manual", "one", "paper",
|
||||
"picture", "presentation", "qa", "table", "tag"
|
||||
]
|
||||
description: Updated chunking method.
|
||||
pagerank:
|
||||
type: integer
|
||||
description: Updated page rank.
|
||||
parser_config:
|
||||
type: object
|
||||
description: Updated parser configuration.
|
||||
@ -326,128 +332,60 @@ def update(tenant_id, dataset_id):
|
||||
schema:
|
||||
type: object
|
||||
"""
|
||||
if not KnowledgebaseService.query(id=dataset_id, tenant_id=tenant_id):
|
||||
return get_error_data_result(message="You don't own the dataset")
|
||||
req = request.json
|
||||
for k in req.keys():
|
||||
if dataset_readonly_fields(k):
|
||||
return get_result(code=settings.RetCode.ARGUMENT_ERROR, message=f"'{k}' is readonly.")
|
||||
e, t = TenantService.get_by_id(tenant_id)
|
||||
invalid_keys = {"id", "embd_id", "chunk_num", "doc_num", "parser_id", "create_date", "create_time", "created_by", "status","token_num","update_date","update_time"}
|
||||
if any(key in req for key in invalid_keys):
|
||||
return get_error_data_result(message="The input parameters are invalid.")
|
||||
permission = req.get("permission")
|
||||
chunk_method = req.get("chunk_method")
|
||||
parser_config = req.get("parser_config")
|
||||
valid_parser_config(parser_config)
|
||||
valid_permission = ["me", "team"]
|
||||
valid_chunk_method = [
|
||||
"naive",
|
||||
"manual",
|
||||
"qa",
|
||||
"table",
|
||||
"paper",
|
||||
"book",
|
||||
"laws",
|
||||
"presentation",
|
||||
"picture",
|
||||
"one",
|
||||
"email",
|
||||
"tag"
|
||||
]
|
||||
check_validation = valid(
|
||||
permission,
|
||||
valid_permission,
|
||||
chunk_method,
|
||||
valid_chunk_method,
|
||||
)
|
||||
if check_validation:
|
||||
return check_validation
|
||||
if "tenant_id" in req:
|
||||
if req["tenant_id"] != tenant_id:
|
||||
return get_error_data_result(message="Can't change `tenant_id`.")
|
||||
e, kb = KnowledgebaseService.get_by_id(dataset_id)
|
||||
if "parser_config" in req:
|
||||
temp_dict = kb.parser_config
|
||||
temp_dict.update(req["parser_config"])
|
||||
req["parser_config"] = temp_dict
|
||||
if "chunk_count" in req:
|
||||
if req["chunk_count"] != kb.chunk_num:
|
||||
return get_error_data_result(message="Can't change `chunk_count`.")
|
||||
req.pop("chunk_count")
|
||||
if "document_count" in req:
|
||||
if req["document_count"] != kb.doc_num:
|
||||
return get_error_data_result(message="Can't change `document_count`.")
|
||||
req.pop("document_count")
|
||||
if req.get("chunk_method"):
|
||||
if kb.chunk_num != 0 and req["chunk_method"] != kb.parser_id:
|
||||
return get_error_data_result(
|
||||
message="If `chunk_count` is not 0, `chunk_method` is not changeable."
|
||||
)
|
||||
req["parser_id"] = req.pop("chunk_method")
|
||||
if req["parser_id"] != kb.parser_id:
|
||||
if not req.get("parser_config"):
|
||||
req["parser_config"] = get_parser_config(chunk_method, parser_config)
|
||||
if "embedding_model" in req:
|
||||
if kb.chunk_num != 0 and req["embedding_model"] != kb.embd_id:
|
||||
return get_error_data_result(
|
||||
message="If `chunk_count` is not 0, `embedding_model` is not changeable."
|
||||
)
|
||||
if not req.get("embedding_model"):
|
||||
return get_error_data_result("`embedding_model` can't be empty")
|
||||
valid_embedding_models = [
|
||||
"BAAI/bge-large-zh-v1.5",
|
||||
"BAAI/bge-base-en-v1.5",
|
||||
"BAAI/bge-large-en-v1.5",
|
||||
"BAAI/bge-small-en-v1.5",
|
||||
"BAAI/bge-small-zh-v1.5",
|
||||
"jinaai/jina-embeddings-v2-base-en",
|
||||
"jinaai/jina-embeddings-v2-small-en",
|
||||
"nomic-ai/nomic-embed-text-v1.5",
|
||||
"sentence-transformers/all-MiniLM-L6-v2",
|
||||
"text-embedding-v2",
|
||||
"text-embedding-v3",
|
||||
"maidalun1020/bce-embedding-base_v1",
|
||||
]
|
||||
embd_model = LLMService.query(
|
||||
llm_name=req["embedding_model"], model_type="embedding"
|
||||
)
|
||||
if embd_model:
|
||||
if req["embedding_model"] not in valid_embedding_models and not TenantLLMService.query(tenant_id=tenant_id,model_type="embedding",llm_name=req.get("embedding_model"),):
|
||||
return get_error_data_result(f"`embedding_model` {req.get('embedding_model')} doesn't exist")
|
||||
if not embd_model:
|
||||
embd_model=TenantLLMService.query(tenant_id=tenant_id,model_type="embedding", llm_name=req.get("embedding_model"))
|
||||
# Field name transformations during model dump:
|
||||
# | Original | Dump Output |
|
||||
# |----------------|-------------|
|
||||
# | embedding_model| embd_id |
|
||||
# | chunk_method | parser_id |
|
||||
extras = {"dataset_id": dataset_id}
|
||||
req, err = validate_and_parse_json_request(request, UpdateDatasetReq, extras=extras, exclude_unset=True)
|
||||
if err is not None:
|
||||
return get_error_argument_result(err)
|
||||
|
||||
if not embd_model:
|
||||
return get_error_data_result(
|
||||
f"`embedding_model` {req.get('embedding_model')} doesn't exist"
|
||||
)
|
||||
req["embd_id"] = req.pop("embedding_model")
|
||||
if "name" in req:
|
||||
req["name"] = req["name"].strip()
|
||||
if len(req["name"]) >= 128:
|
||||
return get_error_data_result(
|
||||
message="Dataset name should not be longer than 128 characters."
|
||||
)
|
||||
if (
|
||||
req["name"].lower() != kb.name.lower()
|
||||
and len(
|
||||
KnowledgebaseService.query(
|
||||
name=req["name"], tenant_id=tenant_id, status=StatusEnum.VALID.value
|
||||
)
|
||||
)
|
||||
> 0
|
||||
):
|
||||
return get_error_data_result(
|
||||
message="Duplicated dataset name in updating dataset."
|
||||
)
|
||||
flds = list(req.keys())
|
||||
for f in flds:
|
||||
if req[f] == "" and f in ["permission", "parser_id", "chunk_method"]:
|
||||
del req[f]
|
||||
if not KnowledgebaseService.update_by_id(kb.id, req):
|
||||
return get_error_data_result(message="Update dataset error.(Database error)")
|
||||
return get_result(code=settings.RetCode.SUCCESS)
|
||||
if not req:
|
||||
return get_error_argument_result(message="No properties were modified")
|
||||
|
||||
try:
|
||||
kb = KnowledgebaseService.get_or_none(id=dataset_id, tenant_id=tenant_id)
|
||||
if kb is None:
|
||||
return get_error_permission_result(message=f"User '{tenant_id}' lacks permission for dataset '{dataset_id}'")
|
||||
except OperationalError as e:
|
||||
logging.exception(e)
|
||||
return get_error_data_result(message="Database operation failed")
|
||||
|
||||
if req.get("parser_config"):
|
||||
req["parser_config"] = deep_merge(kb.parser_config, req["parser_config"])
|
||||
|
||||
if (chunk_method := req.get("parser_id")) and chunk_method != kb.parser_id:
|
||||
if not req.get("parser_config"):
|
||||
req["parser_config"] = get_parser_config(chunk_method, None)
|
||||
elif "parser_config" in req and not req["parser_config"]:
|
||||
del req["parser_config"]
|
||||
|
||||
if "name" in req and req["name"].lower() != kb.name.lower():
|
||||
try:
|
||||
exists = KnowledgebaseService.get_or_none(name=req["name"], tenant_id=tenant_id, status=StatusEnum.VALID.value)
|
||||
if exists:
|
||||
return get_error_data_result(message=f"Dataset name '{req['name']}' already exists")
|
||||
except OperationalError as e:
|
||||
logging.exception(e)
|
||||
return get_error_data_result(message="Database operation failed")
|
||||
|
||||
if "embd_id" in req:
|
||||
if kb.chunk_num != 0 and req["embd_id"] != kb.embd_id:
|
||||
return get_error_data_result(message=f"When chunk_num ({kb.chunk_num}) > 0, embedding_model must remain {kb.embd_id}")
|
||||
ok, err = verify_embedding_availability(req["embd_id"], tenant_id)
|
||||
if not ok:
|
||||
return err
|
||||
|
||||
try:
|
||||
if not KnowledgebaseService.update_by_id(kb.id, req):
|
||||
return get_error_data_result(message="Update dataset error.(Database error)")
|
||||
except OperationalError as e:
|
||||
logging.exception(e)
|
||||
return get_error_data_result(message="Database operation failed")
|
||||
|
||||
return get_result()
|
||||
|
||||
|
||||
@manager.route("/datasets", methods=["GET"]) # noqa: F821
|
||||
@ -481,7 +419,7 @@ def list_datasets(tenant_id):
|
||||
name: page_size
|
||||
type: integer
|
||||
required: false
|
||||
default: 1024
|
||||
default: 30
|
||||
description: Number of items per page.
|
||||
- in: query
|
||||
name: orderby
|
||||
@ -508,47 +446,46 @@ def list_datasets(tenant_id):
|
||||
items:
|
||||
type: object
|
||||
"""
|
||||
id = request.args.get("id")
|
||||
name = request.args.get("name")
|
||||
if id:
|
||||
kbs = KnowledgebaseService.get_kb_by_id(id,tenant_id)
|
||||
args, err = validate_and_parse_request_args(request, ListDatasetReq)
|
||||
if err is not None:
|
||||
return get_error_argument_result(err)
|
||||
|
||||
kb_id = request.args.get("id")
|
||||
name = args.get("name")
|
||||
if kb_id:
|
||||
try:
|
||||
kbs = KnowledgebaseService.get_kb_by_id(kb_id, tenant_id)
|
||||
except OperationalError as e:
|
||||
logging.exception(e)
|
||||
return get_error_data_result(message="Database operation failed")
|
||||
if not kbs:
|
||||
return get_error_data_result(f"You don't own the dataset {id}")
|
||||
return get_error_permission_result(message=f"User '{tenant_id}' lacks permission for dataset '{kb_id}'")
|
||||
if name:
|
||||
kbs = KnowledgebaseService.get_kb_by_name(name,tenant_id)
|
||||
try:
|
||||
kbs = KnowledgebaseService.get_kb_by_name(name, tenant_id)
|
||||
except OperationalError as e:
|
||||
logging.exception(e)
|
||||
return get_error_data_result(message="Database operation failed")
|
||||
if not kbs:
|
||||
return get_error_data_result(f"You don't own the dataset {name}")
|
||||
page_number = int(request.args.get("page", 1))
|
||||
items_per_page = int(request.args.get("page_size", 30))
|
||||
orderby = request.args.get("orderby", "create_time")
|
||||
if request.args.get("desc", "false").lower() not in ["true", "false"]:
|
||||
return get_error_data_result("desc should be true or false")
|
||||
if request.args.get("desc", "true").lower() == "false":
|
||||
desc = False
|
||||
else:
|
||||
desc = True
|
||||
tenants = TenantService.get_joined_tenants_by_user_id(tenant_id)
|
||||
kbs = KnowledgebaseService.get_list(
|
||||
[m["tenant_id"] for m in tenants],
|
||||
tenant_id,
|
||||
page_number,
|
||||
items_per_page,
|
||||
orderby,
|
||||
desc,
|
||||
id,
|
||||
name,
|
||||
)
|
||||
renamed_list = []
|
||||
return get_error_permission_result(message=f"User '{tenant_id}' lacks permission for dataset '{name}'")
|
||||
|
||||
try:
|
||||
tenants = TenantService.get_joined_tenants_by_user_id(tenant_id)
|
||||
kbs = KnowledgebaseService.get_list(
|
||||
[m["tenant_id"] for m in tenants],
|
||||
tenant_id,
|
||||
args["page"],
|
||||
args["page_size"],
|
||||
args["orderby"],
|
||||
args["desc"],
|
||||
kb_id,
|
||||
name,
|
||||
)
|
||||
except OperationalError as e:
|
||||
logging.exception(e)
|
||||
return get_error_data_result(message="Database operation failed")
|
||||
|
||||
response_data_list = []
|
||||
for kb in kbs:
|
||||
key_mapping = {
|
||||
"chunk_num": "chunk_count",
|
||||
"doc_num": "document_count",
|
||||
"parser_id": "chunk_method",
|
||||
"embd_id": "embedding_model",
|
||||
}
|
||||
renamed_data = {}
|
||||
for key, value in kb.items():
|
||||
new_key = key_mapping.get(key, key)
|
||||
renamed_data[new_key] = value
|
||||
renamed_list.append(renamed_data)
|
||||
return get_result(data=renamed_list)
|
||||
response_data_list.append(remap_dictionary_keys(kb))
|
||||
return get_result(data=response_data_list)
|
||||
|
||||
@ -222,6 +222,9 @@ def update_doc(tenant_id, dataset_id, document_id):
|
||||
chunk_method:
|
||||
type: string
|
||||
description: Chunking method.
|
||||
enabled:
|
||||
type: boolean
|
||||
description: Document status.
|
||||
responses:
|
||||
200:
|
||||
description: Document updated successfully.
|
||||
@ -231,6 +234,10 @@ def update_doc(tenant_id, dataset_id, document_id):
|
||||
req = request.json
|
||||
if not KnowledgebaseService.query(id=dataset_id, tenant_id=tenant_id):
|
||||
return get_error_data_result(message="You don't own the dataset.")
|
||||
e, kb = KnowledgebaseService.get_by_id(dataset_id)
|
||||
if not e:
|
||||
return get_error_data_result(
|
||||
message="Can't find this knowledgebase!")
|
||||
doc = DocumentService.query(kb_id=dataset_id, id=document_id)
|
||||
if not doc:
|
||||
return get_error_data_result(message="The dataset doesn't own the document.")
|
||||
@ -332,9 +339,25 @@ def update_doc(tenant_id, dataset_id, document_id):
|
||||
return get_error_data_result(message="Document not found!")
|
||||
settings.docStoreConn.delete({"doc_id": doc.id}, search.index_name(tenant_id), dataset_id)
|
||||
|
||||
if "enabled" in req:
|
||||
status = int(req["enabled"])
|
||||
if doc.status != req["enabled"]:
|
||||
try:
|
||||
if not DocumentService.update_by_id(
|
||||
doc.id, {"status": str(status)}):
|
||||
return get_error_data_result(
|
||||
message="Database error (Document update)!")
|
||||
|
||||
settings.docStoreConn.update({"doc_id": doc.id}, {"available_int": status},
|
||||
search.index_name(kb.tenant_id), doc.kb_id)
|
||||
return get_result(data=True)
|
||||
except Exception as e:
|
||||
return server_error_response(e)
|
||||
|
||||
return get_result()
|
||||
|
||||
|
||||
|
||||
@manager.route("/datasets/<dataset_id>/documents/<document_id>", methods=["GET"]) # noqa: F821
|
||||
@token_required
|
||||
def download(tenant_id, dataset_id, document_id):
|
||||
@ -833,6 +856,12 @@ def list_chunks(tenant_id, dataset_id, document_id):
|
||||
required: false
|
||||
default: 30
|
||||
description: Number of items per page.
|
||||
- in: query
|
||||
name: id
|
||||
type: string
|
||||
required: false
|
||||
default: ""
|
||||
description: Chunk Id.
|
||||
- in: header
|
||||
name: Authorization
|
||||
type: string
|
||||
@ -1407,6 +1436,7 @@ def retrieval_test(tenant_id):
|
||||
else:
|
||||
highlight = True
|
||||
try:
|
||||
tenant_ids = list(set([kb.tenant_id for kb in kbs]))
|
||||
e, kb = KnowledgebaseService.get_by_id(kb_ids[0])
|
||||
if not e:
|
||||
return get_error_data_result(message="Dataset not found!")
|
||||
@ -1423,7 +1453,7 @@ def retrieval_test(tenant_id):
|
||||
ranks = settings.retrievaler.retrieval(
|
||||
question,
|
||||
embd_mdl,
|
||||
kb.tenant_id,
|
||||
tenant_ids,
|
||||
kb_ids,
|
||||
page,
|
||||
size,
|
||||
|
||||
@ -464,12 +464,11 @@ def list_session(tenant_id, chat_id):
|
||||
if conv["reference"]:
|
||||
messages = conv["messages"]
|
||||
message_num = 0
|
||||
chunk_num = 0
|
||||
while message_num < len(messages):
|
||||
if message_num != 0 and messages[message_num]["role"] != "user":
|
||||
chunk_list = []
|
||||
if "chunks" in conv["reference"][chunk_num]:
|
||||
chunks = conv["reference"][chunk_num]["chunks"]
|
||||
if "chunks" in conv["reference"][message_num]:
|
||||
chunks = conv["reference"][message_num]["chunks"]
|
||||
for chunk in chunks:
|
||||
new_chunk = {
|
||||
"id": chunk.get("chunk_id", chunk.get("id")),
|
||||
@ -482,7 +481,6 @@ def list_session(tenant_id, chat_id):
|
||||
}
|
||||
|
||||
chunk_list.append(new_chunk)
|
||||
chunk_num += 1
|
||||
messages[message_num]["reference"] = chunk_list
|
||||
message_num += 1
|
||||
del conv["reference"]
|
||||
|
||||
@ -13,35 +13,37 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
import logging
|
||||
import json
|
||||
import logging
|
||||
import re
|
||||
from datetime import datetime
|
||||
|
||||
from flask import request, session, redirect
|
||||
from werkzeug.security import generate_password_hash, check_password_hash
|
||||
from flask_login import login_required, current_user, login_user, logout_user
|
||||
from flask import redirect, request, session
|
||||
from flask_login import current_user, login_required, login_user, logout_user
|
||||
from werkzeug.security import check_password_hash, generate_password_hash
|
||||
|
||||
from api import settings
|
||||
from api.apps.auth import get_auth_client
|
||||
from api.db import FileType, UserTenantRole
|
||||
from api.db.db_models import TenantLLM
|
||||
from api.db.services.llm_service import TenantLLMService, LLMService
|
||||
from api.utils.api_utils import (
|
||||
server_error_response,
|
||||
validate_request,
|
||||
get_data_error_result,
|
||||
)
|
||||
from api.db.services.file_service import FileService
|
||||
from api.db.services.llm_service import LLMService, TenantLLMService
|
||||
from api.db.services.user_service import TenantService, UserService, UserTenantService
|
||||
from api.utils import (
|
||||
get_uuid,
|
||||
get_format_time,
|
||||
decrypt,
|
||||
download_img,
|
||||
current_timestamp,
|
||||
datetime_format,
|
||||
decrypt,
|
||||
download_img,
|
||||
get_format_time,
|
||||
get_uuid,
|
||||
)
|
||||
from api.utils.api_utils import (
|
||||
construct_response,
|
||||
get_data_error_result,
|
||||
get_json_result,
|
||||
server_error_response,
|
||||
validate_request,
|
||||
)
|
||||
from api.db import UserTenantRole, FileType
|
||||
from api import settings
|
||||
from api.db.services.user_service import UserService, TenantService, UserTenantService
|
||||
from api.db.services.file_service import FileService
|
||||
from api.utils.api_utils import get_json_result, construct_response
|
||||
|
||||
|
||||
@manager.route("/login", methods=["POST", "GET"]) # noqa: F821
|
||||
@ -76,9 +78,7 @@ def login():
|
||||
type: object
|
||||
"""
|
||||
if not request.json:
|
||||
return get_json_result(
|
||||
data=False, code=settings.RetCode.AUTHENTICATION_ERROR, message="Unauthorized!"
|
||||
)
|
||||
return get_json_result(data=False, code=settings.RetCode.AUTHENTICATION_ERROR, message="Unauthorized!")
|
||||
|
||||
email = request.json.get("email", "")
|
||||
users = UserService.query(email=email)
|
||||
@ -93,9 +93,7 @@ def login():
|
||||
try:
|
||||
password = decrypt(password)
|
||||
except BaseException:
|
||||
return get_json_result(
|
||||
data=False, code=settings.RetCode.SERVER_ERROR, message="Fail to crypt password"
|
||||
)
|
||||
return get_json_result(data=False, code=settings.RetCode.SERVER_ERROR, message="Fail to crypt password")
|
||||
|
||||
user = UserService.query_user(email, password)
|
||||
if user:
|
||||
@ -115,9 +113,131 @@ def login():
|
||||
)
|
||||
|
||||
|
||||
@manager.route("/login/channels", methods=["GET"]) # noqa: F821
|
||||
def get_login_channels():
|
||||
"""
|
||||
Get all supported authentication channels.
|
||||
"""
|
||||
try:
|
||||
channels = []
|
||||
for channel, config in settings.OAUTH_CONFIG.items():
|
||||
channels.append(
|
||||
{
|
||||
"channel": channel,
|
||||
"display_name": config.get("display_name", channel.title()),
|
||||
"icon": config.get("icon", "sso"),
|
||||
}
|
||||
)
|
||||
return get_json_result(data=channels)
|
||||
except Exception as e:
|
||||
logging.exception(e)
|
||||
return get_json_result(data=[], message=f"Load channels failure, error: {str(e)}", code=settings.RetCode.EXCEPTION_ERROR)
|
||||
|
||||
|
||||
@manager.route("/login/<channel>", methods=["GET"]) # noqa: F821
|
||||
def oauth_login(channel):
|
||||
channel_config = settings.OAUTH_CONFIG.get(channel)
|
||||
if not channel_config:
|
||||
raise ValueError(f"Invalid channel name: {channel}")
|
||||
auth_cli = get_auth_client(channel_config)
|
||||
|
||||
state = get_uuid()
|
||||
session["oauth_state"] = state
|
||||
auth_url = auth_cli.get_authorization_url(state)
|
||||
return redirect(auth_url)
|
||||
|
||||
|
||||
@manager.route("/oauth/callback/<channel>", methods=["GET"]) # noqa: F821
|
||||
def oauth_callback(channel):
|
||||
"""
|
||||
Handle the OAuth/OIDC callback for various channels dynamically.
|
||||
"""
|
||||
try:
|
||||
channel_config = settings.OAUTH_CONFIG.get(channel)
|
||||
if not channel_config:
|
||||
raise ValueError(f"Invalid channel name: {channel}")
|
||||
auth_cli = get_auth_client(channel_config)
|
||||
|
||||
# Check the state
|
||||
state = request.args.get("state")
|
||||
if not state or state != session.get("oauth_state"):
|
||||
return redirect("/?error=invalid_state")
|
||||
session.pop("oauth_state", None)
|
||||
|
||||
# Obtain the authorization code
|
||||
code = request.args.get("code")
|
||||
if not code:
|
||||
return redirect("/?error=missing_code")
|
||||
|
||||
# Exchange authorization code for access token
|
||||
token_info = auth_cli.exchange_code_for_token(code)
|
||||
access_token = token_info.get("access_token")
|
||||
if not access_token:
|
||||
return redirect("/?error=token_failed")
|
||||
|
||||
id_token = token_info.get("id_token")
|
||||
|
||||
# Fetch user info
|
||||
user_info = auth_cli.fetch_user_info(access_token, id_token=id_token)
|
||||
if not user_info.email:
|
||||
return redirect("/?error=email_missing")
|
||||
|
||||
# Login or register
|
||||
users = UserService.query(email=user_info.email)
|
||||
user_id = get_uuid()
|
||||
|
||||
if not users:
|
||||
try:
|
||||
try:
|
||||
avatar = download_img(user_info.avatar_url)
|
||||
except Exception as e:
|
||||
logging.exception(e)
|
||||
avatar = ""
|
||||
|
||||
users = user_register(
|
||||
user_id,
|
||||
{
|
||||
"access_token": get_uuid(),
|
||||
"email": user_info.email,
|
||||
"avatar": avatar,
|
||||
"nickname": user_info.nickname,
|
||||
"login_channel": channel,
|
||||
"last_login_time": get_format_time(),
|
||||
"is_superuser": False,
|
||||
},
|
||||
)
|
||||
|
||||
if not users:
|
||||
raise Exception(f"Failed to register {user_info.email}")
|
||||
if len(users) > 1:
|
||||
raise Exception(f"Same email: {user_info.email} exists!")
|
||||
|
||||
# Try to log in
|
||||
user = users[0]
|
||||
login_user(user)
|
||||
return redirect(f"/?auth={user.get_id()}")
|
||||
|
||||
except Exception as e:
|
||||
rollback_user_registration(user_id)
|
||||
logging.exception(e)
|
||||
return redirect(f"/?error={str(e)}")
|
||||
|
||||
# User exists, try to log in
|
||||
user = users[0]
|
||||
user.access_token = get_uuid()
|
||||
login_user(user)
|
||||
user.save()
|
||||
return redirect(f"/?auth={user.get_id()}")
|
||||
except Exception as e:
|
||||
logging.exception(e)
|
||||
return redirect(f"/?error={str(e)}")
|
||||
|
||||
|
||||
@manager.route("/github_callback", methods=["GET"]) # noqa: F821
|
||||
def github_callback():
|
||||
"""
|
||||
**Deprecated**, Use `/oauth/callback/<channel>` instead.
|
||||
|
||||
GitHub OAuth callback endpoint.
|
||||
---
|
||||
tags:
|
||||
@ -309,9 +429,7 @@ def user_info_from_feishu(access_token):
|
||||
"Content-Type": "application/json; charset=utf-8",
|
||||
"Authorization": f"Bearer {access_token}",
|
||||
}
|
||||
res = requests.get(
|
||||
"https://open.feishu.cn/open-apis/authen/v1/user_info", headers=headers
|
||||
)
|
||||
res = requests.get("https://open.feishu.cn/open-apis/authen/v1/user_info", headers=headers)
|
||||
user_info = res.json()["data"]
|
||||
user_info["email"] = None if user_info.get("email") == "" else user_info["email"]
|
||||
return user_info
|
||||
@ -321,17 +439,13 @@ def user_info_from_github(access_token):
|
||||
import requests
|
||||
|
||||
headers = {"Accept": "application/json", "Authorization": f"token {access_token}"}
|
||||
res = requests.get(
|
||||
f"https://api.github.com/user?access_token={access_token}", headers=headers
|
||||
)
|
||||
res = requests.get(f"https://api.github.com/user?access_token={access_token}", headers=headers)
|
||||
user_info = res.json()
|
||||
email_info = requests.get(
|
||||
f"https://api.github.com/user/emails?access_token={access_token}",
|
||||
headers=headers,
|
||||
).json()
|
||||
user_info["email"] = next(
|
||||
(email for email in email_info if email["primary"]), None
|
||||
)["email"]
|
||||
user_info["email"] = next((email for email in email_info if email["primary"]), None)["email"]
|
||||
return user_info
|
||||
|
||||
|
||||
@ -391,9 +505,7 @@ def setting_user():
|
||||
request_data = request.json
|
||||
if request_data.get("password"):
|
||||
new_password = request_data.get("new_password")
|
||||
if not check_password_hash(
|
||||
current_user.password, decrypt(request_data["password"])
|
||||
):
|
||||
if not check_password_hash(current_user.password, decrypt(request_data["password"])):
|
||||
return get_json_result(
|
||||
data=False,
|
||||
code=settings.RetCode.AUTHENTICATION_ERROR,
|
||||
@ -424,9 +536,7 @@ def setting_user():
|
||||
return get_json_result(data=True)
|
||||
except Exception as e:
|
||||
logging.exception(e)
|
||||
return get_json_result(
|
||||
data=False, message="Update failure!", code=settings.RetCode.EXCEPTION_ERROR
|
||||
)
|
||||
return get_json_result(data=False, message="Update failure!", code=settings.RetCode.EXCEPTION_ERROR)
|
||||
|
||||
|
||||
@manager.route("/info", methods=["GET"]) # noqa: F821
|
||||
@ -518,9 +628,23 @@ def user_register(user_id, user):
|
||||
"model_type": llm.model_type,
|
||||
"api_key": settings.API_KEY,
|
||||
"api_base": settings.LLM_BASE_URL,
|
||||
"max_tokens": llm.max_tokens if llm.max_tokens else 8192
|
||||
"max_tokens": llm.max_tokens if llm.max_tokens else 8192,
|
||||
}
|
||||
)
|
||||
if settings.LIGHTEN != 1:
|
||||
for buildin_embedding_model in settings.BUILTIN_EMBEDDING_MODELS:
|
||||
mdlnm, fid = TenantLLMService.split_model_name_and_factory(buildin_embedding_model)
|
||||
tenant_llm.append(
|
||||
{
|
||||
"tenant_id": user_id,
|
||||
"llm_factory": fid,
|
||||
"llm_name": mdlnm,
|
||||
"model_type": "embedding",
|
||||
"api_key": "",
|
||||
"api_base": "",
|
||||
"max_tokens": 1024 if buildin_embedding_model == "BAAI/bge-large-zh-v1.5@BAAI" else 512,
|
||||
}
|
||||
)
|
||||
|
||||
if not UserService.save(**user):
|
||||
return
|
||||
|
||||
@ -49,6 +49,7 @@ class FileType(StrEnum):
|
||||
FOLDER = 'folder'
|
||||
OTHER = "other"
|
||||
|
||||
VALID_FILE_TYPES = {FileType.PDF, FileType.DOC, FileType.VISUAL, FileType.AURAL, FileType.VIRTUAL, FileType.FOLDER, FileType.OTHER}
|
||||
|
||||
class LLMType(StrEnum):
|
||||
CHAT = 'chat'
|
||||
@ -73,6 +74,7 @@ class TaskStatus(StrEnum):
|
||||
DONE = "3"
|
||||
FAIL = "4"
|
||||
|
||||
VALID_TASK_STATUS = {TaskStatus.UNSTART, TaskStatus.RUNNING, TaskStatus.CANCEL, TaskStatus.DONE, TaskStatus.FAIL}
|
||||
|
||||
class ParserType(StrEnum):
|
||||
PRESENTATION = "presentation"
|
||||
|
||||
@ -119,7 +119,7 @@ def init_llm_factory():
|
||||
except Exception:
|
||||
pass
|
||||
|
||||
LLMFactoriesService.filter_delete([LLMFactories.name == "Local"])
|
||||
LLMFactoriesService.filter_delete([(LLMFactories.name == "Local") | (LLMFactories.name == "novita.ai")])
|
||||
LLMService.filter_delete([LLM.fid == "Local"])
|
||||
LLMService.filter_delete([LLM.llm_name == "qwen-vl-max"])
|
||||
LLMService.filter_delete([LLM.fid == "Moonshot", LLM.llm_name == "flag-embedding"])
|
||||
|
||||
@ -18,57 +18,57 @@ from datetime import datetime
|
||||
import peewee
|
||||
|
||||
from api.db.db_models import DB
|
||||
from api.utils import datetime_format, current_timestamp, get_uuid
|
||||
from api.utils import current_timestamp, datetime_format, get_uuid
|
||||
|
||||
|
||||
class CommonService:
|
||||
"""Base service class that provides common database operations.
|
||||
|
||||
|
||||
This class serves as a foundation for all service classes in the application,
|
||||
implementing standard CRUD operations and common database query patterns.
|
||||
It uses the Peewee ORM for database interactions and provides a consistent
|
||||
interface for database operations across all derived service classes.
|
||||
|
||||
|
||||
Attributes:
|
||||
model: The Peewee model class that this service operates on. Must be set by subclasses.
|
||||
"""
|
||||
|
||||
model = None
|
||||
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
def query(cls, cols=None, reverse=None, order_by=None, **kwargs):
|
||||
"""Execute a database query with optional column selection and ordering.
|
||||
|
||||
|
||||
This method provides a flexible way to query the database with various filters
|
||||
and sorting options. It supports column selection, sort order control, and
|
||||
additional filter conditions.
|
||||
|
||||
|
||||
Args:
|
||||
cols (list, optional): List of column names to select. If None, selects all columns.
|
||||
reverse (bool, optional): If True, sorts in descending order. If False, sorts in ascending order.
|
||||
order_by (str, optional): Column name to sort results by.
|
||||
**kwargs: Additional filter conditions passed as keyword arguments.
|
||||
|
||||
|
||||
Returns:
|
||||
peewee.ModelSelect: A query result containing matching records.
|
||||
"""
|
||||
return cls.model.query(cols=cols, reverse=reverse,
|
||||
order_by=order_by, **kwargs)
|
||||
return cls.model.query(cols=cols, reverse=reverse, order_by=order_by, **kwargs)
|
||||
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
def get_all(cls, cols=None, reverse=None, order_by=None):
|
||||
"""Retrieve all records from the database with optional column selection and ordering.
|
||||
|
||||
|
||||
This method fetches all records from the model's table with support for
|
||||
column selection and result ordering. If no order_by is specified and reverse
|
||||
is True, it defaults to ordering by create_time.
|
||||
|
||||
|
||||
Args:
|
||||
cols (list, optional): List of column names to select. If None, selects all columns.
|
||||
reverse (bool, optional): If True, sorts in descending order. If False, sorts in ascending order.
|
||||
order_by (str, optional): Column name to sort results by. Defaults to 'create_time' if reverse is specified.
|
||||
|
||||
|
||||
Returns:
|
||||
peewee.ModelSelect: A query containing all matching records.
|
||||
"""
|
||||
@ -80,27 +80,25 @@ class CommonService:
|
||||
if not order_by or not hasattr(cls, order_by):
|
||||
order_by = "create_time"
|
||||
if reverse is True:
|
||||
query_records = query_records.order_by(
|
||||
cls.model.getter_by(order_by).desc())
|
||||
query_records = query_records.order_by(cls.model.getter_by(order_by).desc())
|
||||
elif reverse is False:
|
||||
query_records = query_records.order_by(
|
||||
cls.model.getter_by(order_by).asc())
|
||||
query_records = query_records.order_by(cls.model.getter_by(order_by).asc())
|
||||
return query_records
|
||||
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
def get(cls, **kwargs):
|
||||
"""Get a single record matching the given criteria.
|
||||
|
||||
|
||||
This method retrieves a single record from the database that matches
|
||||
the specified filter conditions.
|
||||
|
||||
|
||||
Args:
|
||||
**kwargs: Filter conditions as keyword arguments.
|
||||
|
||||
|
||||
Returns:
|
||||
Model instance: Single matching record.
|
||||
|
||||
|
||||
Raises:
|
||||
peewee.DoesNotExist: If no matching record is found.
|
||||
"""
|
||||
@ -110,13 +108,13 @@ class CommonService:
|
||||
@DB.connection_context()
|
||||
def get_or_none(cls, **kwargs):
|
||||
"""Get a single record or None if not found.
|
||||
|
||||
|
||||
This method attempts to retrieve a single record matching the given criteria,
|
||||
returning None if no match is found instead of raising an exception.
|
||||
|
||||
|
||||
Args:
|
||||
**kwargs: Filter conditions as keyword arguments.
|
||||
|
||||
|
||||
Returns:
|
||||
Model instance or None: Matching record if found, None otherwise.
|
||||
"""
|
||||
@ -129,13 +127,13 @@ class CommonService:
|
||||
@DB.connection_context()
|
||||
def save(cls, **kwargs):
|
||||
"""Save a new record to database.
|
||||
|
||||
|
||||
This method creates a new record in the database with the provided field values,
|
||||
forcing an insert operation rather than an update.
|
||||
|
||||
|
||||
Args:
|
||||
**kwargs: Record field values as keyword arguments.
|
||||
|
||||
|
||||
Returns:
|
||||
Model instance: The created record object.
|
||||
"""
|
||||
@ -146,13 +144,13 @@ class CommonService:
|
||||
@DB.connection_context()
|
||||
def insert(cls, **kwargs):
|
||||
"""Insert a new record with automatic ID and timestamps.
|
||||
|
||||
|
||||
This method creates a new record with automatically generated ID and timestamp fields.
|
||||
It handles the creation of create_time, create_date, update_time, and update_date fields.
|
||||
|
||||
|
||||
Args:
|
||||
**kwargs: Record field values as keyword arguments.
|
||||
|
||||
|
||||
Returns:
|
||||
Model instance: The newly created record object.
|
||||
"""
|
||||
@ -169,10 +167,10 @@ class CommonService:
|
||||
@DB.connection_context()
|
||||
def insert_many(cls, data_list, batch_size=100):
|
||||
"""Insert multiple records in batches.
|
||||
|
||||
|
||||
This method efficiently inserts multiple records into the database using batch processing.
|
||||
It automatically sets creation timestamps for all records.
|
||||
|
||||
|
||||
Args:
|
||||
data_list (list): List of dictionaries containing record data to insert.
|
||||
batch_size (int, optional): Number of records to insert in each batch. Defaults to 100.
|
||||
@ -182,16 +180,16 @@ class CommonService:
|
||||
d["create_time"] = current_timestamp()
|
||||
d["create_date"] = datetime_format(datetime.now())
|
||||
for i in range(0, len(data_list), batch_size):
|
||||
cls.model.insert_many(data_list[i:i + batch_size]).execute()
|
||||
cls.model.insert_many(data_list[i : i + batch_size]).execute()
|
||||
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
def update_many_by_id(cls, data_list):
|
||||
"""Update multiple records by their IDs.
|
||||
|
||||
|
||||
This method updates multiple records in the database, identified by their IDs.
|
||||
It automatically updates the update_time and update_date fields for each record.
|
||||
|
||||
|
||||
Args:
|
||||
data_list (list): List of dictionaries containing record data to update.
|
||||
Each dictionary must include an 'id' field.
|
||||
@ -200,8 +198,7 @@ class CommonService:
|
||||
for data in data_list:
|
||||
data["update_time"] = current_timestamp()
|
||||
data["update_date"] = datetime_format(datetime.now())
|
||||
cls.model.update(data).where(
|
||||
cls.model.id == data["id"]).execute()
|
||||
cls.model.update(data).where(cls.model.id == data["id"]).execute()
|
||||
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
@ -258,6 +255,18 @@ class CommonService:
|
||||
# Number of records deleted
|
||||
return cls.model.delete().where(cls.model.id == pid).execute()
|
||||
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
def delete_by_ids(cls, pids):
|
||||
# Delete multiple records by their IDs
|
||||
# Args:
|
||||
# pids: List of record IDs
|
||||
# Returns:
|
||||
# Number of records deleted
|
||||
with DB.atomic():
|
||||
res = cls.model.delete().where(cls.model.id.in_(pids)).execute()
|
||||
return res
|
||||
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
def filter_delete(cls, filters):
|
||||
@ -292,13 +301,12 @@ class CommonService:
|
||||
# List of tuples containing chunks
|
||||
length = len(tar_list)
|
||||
arr = range(length)
|
||||
result = [tuple(tar_list[x:(x + n)]) for x in arr[::n]]
|
||||
result = [tuple(tar_list[x : (x + n)]) for x in arr[::n]]
|
||||
return result
|
||||
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
def filter_scope_list(cls, in_key, in_filters_list,
|
||||
filters=None, cols=None):
|
||||
def filter_scope_list(cls, in_key, in_filters_list, filters=None, cols=None):
|
||||
# Get records matching IN clause filters with optional column selection
|
||||
# Args:
|
||||
# in_key: Field name for IN clause
|
||||
@ -313,22 +321,12 @@ class CommonService:
|
||||
res_list = []
|
||||
if cols:
|
||||
for i in in_filters_tuple_list:
|
||||
query_records = cls.model.select(
|
||||
*
|
||||
cols).where(
|
||||
getattr(
|
||||
cls.model,
|
||||
in_key).in_(i),
|
||||
*
|
||||
filters)
|
||||
query_records = cls.model.select(*cols).where(getattr(cls.model, in_key).in_(i), *filters)
|
||||
if query_records:
|
||||
res_list.extend(
|
||||
[query_record for query_record in query_records])
|
||||
res_list.extend([query_record for query_record in query_records])
|
||||
else:
|
||||
for i in in_filters_tuple_list:
|
||||
query_records = cls.model.select().where(
|
||||
getattr(cls.model, in_key).in_(i), *filters)
|
||||
query_records = cls.model.select().where(getattr(cls.model, in_key).in_(i), *filters)
|
||||
if query_records:
|
||||
res_list.extend(
|
||||
[query_record for query_record in query_records])
|
||||
res_list.extend([query_record for query_record in query_records])
|
||||
return res_list
|
||||
|
||||
@ -14,11 +14,11 @@
|
||||
# limitations under the License.
|
||||
#
|
||||
import binascii
|
||||
from datetime import datetime
|
||||
import logging
|
||||
import re
|
||||
import time
|
||||
from copy import deepcopy
|
||||
from datetime import datetime
|
||||
from functools import partial
|
||||
from timeit import default_timer as timer
|
||||
|
||||
@ -36,7 +36,7 @@ from api.utils import current_timestamp, datetime_format
|
||||
from rag.app.resume import forbidden_select_fields4resume
|
||||
from rag.app.tag import label_question
|
||||
from rag.nlp.search import index_name
|
||||
from rag.prompts import chunks_format, citation_prompt, full_question, kb_prompt, keyword_extraction, llm_id2llm_type, message_fit_in
|
||||
from rag.prompts import chunks_format, citation_prompt, cross_languages, full_question, kb_prompt, keyword_extraction, llm_id2llm_type, message_fit_in
|
||||
from rag.utils import num_tokens_from_string, rmSpace
|
||||
from rag.utils.tavily_conn import Tavily
|
||||
|
||||
@ -109,6 +109,7 @@ def chat_solo(dialog, messages, stream=True):
|
||||
msg = [{"role": m["role"], "content": re.sub(r"##\d+\$\$", "", m["content"])} for m in messages if m["role"] != "system"]
|
||||
if stream:
|
||||
last_ans = ""
|
||||
delta_ans = ""
|
||||
for ans in chat_mdl.chat_streamly(prompt_config.get("system", ""), msg, dialog.llm_setting):
|
||||
answer = ans
|
||||
delta_ans = ans[len(last_ans) :]
|
||||
@ -116,6 +117,7 @@ def chat_solo(dialog, messages, stream=True):
|
||||
continue
|
||||
last_ans = answer
|
||||
yield {"answer": answer, "reference": {}, "audio_binary": tts(tts_mdl, delta_ans), "prompt": "", "created_at": time.time()}
|
||||
delta_ans = ""
|
||||
if delta_ans:
|
||||
yield {"answer": answer, "reference": {}, "audio_binary": tts(tts_mdl, delta_ans), "prompt": "", "created_at": time.time()}
|
||||
else:
|
||||
@ -212,6 +214,9 @@ def chat(dialog, messages, stream=True, **kwargs):
|
||||
else:
|
||||
questions = questions[-1:]
|
||||
|
||||
if prompt_config.get("cross_languages"):
|
||||
questions = [cross_languages(dialog.tenant_id, dialog.llm_id, questions[0], prompt_config["cross_languages"])]
|
||||
|
||||
refine_question_ts = timer()
|
||||
|
||||
rerank_mdl = None
|
||||
@ -297,6 +302,39 @@ def chat(dialog, messages, stream=True, **kwargs):
|
||||
if "max_tokens" in gen_conf:
|
||||
gen_conf["max_tokens"] = min(gen_conf["max_tokens"], max_tokens - used_token_count)
|
||||
|
||||
def repair_bad_citation_formats(answer: str, kbinfos: dict, idx: set):
|
||||
max_index = len(kbinfos["chunks"])
|
||||
|
||||
def safe_add(i):
|
||||
if 0 <= i < max_index:
|
||||
idx.add(i)
|
||||
return True
|
||||
return False
|
||||
|
||||
def find_and_replace(pattern, group_index=1, repl=lambda i: f"##{i}$$", flags=0):
|
||||
nonlocal answer
|
||||
for match in re.finditer(pattern, answer, flags=flags):
|
||||
try:
|
||||
i = int(match.group(group_index))
|
||||
if safe_add(i):
|
||||
answer = answer.replace(match.group(0), repl(i))
|
||||
except Exception:
|
||||
continue
|
||||
|
||||
find_and_replace(r"\(\s*ID:\s*(\d+)\s*\)") # (ID: 12)
|
||||
find_and_replace(r"ID[: ]+(\d+)") # ID: 12, ID 12
|
||||
find_and_replace(r"\$\$(\d+)\$\$") # $$12$$
|
||||
find_and_replace(r"\$\[(\d+)\]\$") # $[12]$
|
||||
find_and_replace(r"\$\$(\d+)\${2,}") # $$12$$$$
|
||||
find_and_replace(r"\$(\d+)\$") # $12$
|
||||
find_and_replace(r"(#{2,})(\d+)(\${2,})", group_index=2) # 2+ # and 2+ $
|
||||
find_and_replace(r"(#{2,})(\d+)(#{1,})", group_index=2) # 2+ # and 1+ #
|
||||
find_and_replace(r"##(\d+)#{2,}") # ##12###
|
||||
find_and_replace(r"【(\d+)】") # 【12】
|
||||
find_and_replace(r"ref\s*(\d+)", flags=re.IGNORECASE) # ref12, ref 12, REF 12
|
||||
|
||||
return answer, idx
|
||||
|
||||
def decorate_answer(answer):
|
||||
nonlocal prompt_config, knowledges, kwargs, kbinfos, prompt, retrieval_ts, questions, langfuse_tracer
|
||||
|
||||
@ -325,15 +363,7 @@ def chat(dialog, messages, stream=True, **kwargs):
|
||||
if i < len(kbinfos["chunks"]):
|
||||
idx.add(i)
|
||||
|
||||
# handle (ID: 1), ID: 2 etc.
|
||||
for match in re.finditer(r"\(\s*ID:\s*(\d+)\s*\)|ID[: ]+\s*(\d+)", answer):
|
||||
full_match = match.group(0)
|
||||
id = match.group(1) or match.group(2)
|
||||
if id:
|
||||
i = int(id)
|
||||
if i < len(kbinfos["chunks"]):
|
||||
idx.add(i)
|
||||
answer = answer.replace(full_match, f"##{i}$$")
|
||||
answer, idx = repair_bad_citation_formats(answer, kbinfos, idx)
|
||||
|
||||
idx = set([kbinfos["chunks"][int(i)]["doc_id"] for i in idx])
|
||||
recall_docs = [d for d in kbinfos["doc_aggs"] if d["doc_id"] in idx]
|
||||
@ -400,7 +430,7 @@ def chat(dialog, messages, stream=True, **kwargs):
|
||||
answer = ""
|
||||
for ans in chat_mdl.chat_streamly(prompt + prompt4citation, msg[1:], gen_conf):
|
||||
if thought:
|
||||
ans = re.sub(r"<think>.*</think>", "", ans, flags=re.DOTALL)
|
||||
ans = re.sub(r"^.*</think>", "", ans, flags=re.DOTALL)
|
||||
answer = ans
|
||||
delta_ans = ans[len(last_ans) :]
|
||||
if num_tokens_from_string(delta_ans) < 16:
|
||||
@ -436,7 +466,7 @@ Please write the SQL, only SQL, without any other explanations or text.
|
||||
def get_table():
|
||||
nonlocal sys_prompt, user_prompt, question, tried_times
|
||||
sql = chat_mdl.chat(sys_prompt, [{"role": "user", "content": user_prompt}], {"temperature": 0.06})
|
||||
sql = re.sub(r"<think>.*</think>", "", sql, flags=re.DOTALL)
|
||||
sql = re.sub(r"^.*</think>", "", sql, flags=re.DOTALL)
|
||||
logging.debug(f"{question} ==> {user_prompt} get SQL: {sql}")
|
||||
sql = re.sub(r"[\r\n]+", " ", sql.lower())
|
||||
sql = re.sub(r".*select ", "select ", sql.lower())
|
||||
@ -496,7 +526,7 @@ Please write the SQL, only SQL, without any other explanations or text.
|
||||
|
||||
# compose Markdown table
|
||||
columns = (
|
||||
"|" + "|".join([re.sub(r"(/.*|([^()]+))", "", field_map.get(tbl["columns"][i]["name"], tbl["columns"][i]["name"])) for i in column_idx]) + ("|Source|" if docid_idx and docid_idx else "|")
|
||||
"|" + "|".join([re.sub(r"(/.*|([^()]+))", "", field_map.get(tbl["columns"][i]["name"], tbl["columns"][i]["name"])) for i in column_idx]) + ("|Source|" if docid_idx and docid_idx else "|")
|
||||
)
|
||||
|
||||
line = "|" + "|".join(["------" for _ in range(len(column_idx))]) + ("|------|" if docid_idx and docid_idx else "")
|
||||
@ -592,4 +622,4 @@ def ask(question, kb_ids, tenant_id):
|
||||
for ans in chat_mdl.chat_streamly(prompt, msg, {"temperature": 0.1}):
|
||||
answer = ans
|
||||
yield {"answer": answer, "reference": {}}
|
||||
yield decorate_answer(answer)
|
||||
yield decorate_answer(answer)
|
||||
|
||||
@ -37,6 +37,7 @@ from rag.nlp import rag_tokenizer, search
|
||||
from rag.settings import get_svr_queue_name
|
||||
from rag.utils.redis_conn import REDIS_CONN
|
||||
from rag.utils.storage_factory import STORAGE_IMPL
|
||||
from rag.utils.doc_store_conn import OrderByExpr
|
||||
|
||||
|
||||
class DocumentService(CommonService):
|
||||
@ -70,7 +71,7 @@ class DocumentService(CommonService):
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
def get_by_kb_id(cls, kb_id, page_number, items_per_page,
|
||||
orderby, desc, keywords):
|
||||
orderby, desc, keywords, run_status, types):
|
||||
if keywords:
|
||||
docs = cls.model.select().where(
|
||||
(cls.model.kb_id == kb_id),
|
||||
@ -78,16 +79,60 @@ class DocumentService(CommonService):
|
||||
)
|
||||
else:
|
||||
docs = cls.model.select().where(cls.model.kb_id == kb_id)
|
||||
|
||||
if run_status:
|
||||
docs = docs.where(cls.model.run.in_(run_status))
|
||||
if types:
|
||||
docs = docs.where(cls.model.type.in_(types))
|
||||
|
||||
count = docs.count()
|
||||
if desc:
|
||||
docs = docs.order_by(cls.model.getter_by(orderby).desc())
|
||||
else:
|
||||
docs = docs.order_by(cls.model.getter_by(orderby).asc())
|
||||
|
||||
docs = docs.paginate(page_number, items_per_page)
|
||||
|
||||
if page_number and items_per_page:
|
||||
docs = docs.paginate(page_number, items_per_page)
|
||||
|
||||
return list(docs.dicts()), count
|
||||
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
def count_by_kb_id(cls, kb_id, keywords, run_status, types):
|
||||
if keywords:
|
||||
docs = cls.model.select().where(
|
||||
(cls.model.kb_id == kb_id),
|
||||
(fn.LOWER(cls.model.name).contains(keywords.lower()))
|
||||
)
|
||||
else:
|
||||
docs = cls.model.select().where(cls.model.kb_id == kb_id)
|
||||
|
||||
if run_status:
|
||||
docs = docs.where(cls.model.run.in_(run_status))
|
||||
if types:
|
||||
docs = docs.where(cls.model.type.in_(types))
|
||||
|
||||
count = docs.count()
|
||||
|
||||
return count
|
||||
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
def get_total_size_by_kb_id(cls, kb_id, keywords="", run_status=[], types=[]):
|
||||
query = cls.model.select(fn.COALESCE(fn.SUM(cls.model.size), 0)).where(
|
||||
cls.model.kb_id == kb_id
|
||||
)
|
||||
|
||||
if keywords:
|
||||
query = query.where(fn.LOWER(cls.model.name).contains(keywords.lower()))
|
||||
if run_status:
|
||||
query = query.where(cls.model.run.in_(run_status))
|
||||
if types:
|
||||
query = query.where(cls.model.type.in_(types))
|
||||
|
||||
return int(query.scalar()) or 0
|
||||
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
def insert(cls, doc):
|
||||
@ -103,14 +148,18 @@ class DocumentService(CommonService):
|
||||
cls.clear_chunk_num(doc.id)
|
||||
try:
|
||||
settings.docStoreConn.delete({"doc_id": doc.id}, search.index_name(tenant_id), doc.kb_id)
|
||||
settings.docStoreConn.update({"kb_id": doc.kb_id, "knowledge_graph_kwd": ["entity", "relation", "graph", "subgraph", "community_report"], "source_id": doc.id},
|
||||
{"remove": {"source_id": doc.id}},
|
||||
search.index_name(tenant_id), doc.kb_id)
|
||||
settings.docStoreConn.update({"kb_id": doc.kb_id, "knowledge_graph_kwd": ["graph"]},
|
||||
{"removed_kwd": "Y"},
|
||||
search.index_name(tenant_id), doc.kb_id)
|
||||
settings.docStoreConn.delete({"kb_id": doc.kb_id, "knowledge_graph_kwd": ["entity", "relation", "graph", "subgraph", "community_report"], "must_not": {"exists": "source_id"}},
|
||||
search.index_name(tenant_id), doc.kb_id)
|
||||
graph_source = settings.docStoreConn.getFields(
|
||||
settings.docStoreConn.search(["source_id"], [], {"kb_id": doc.kb_id, "knowledge_graph_kwd": ["graph"]}, [], OrderByExpr(), 0, 1, search.index_name(tenant_id), [doc.kb_id]), ["source_id"]
|
||||
)
|
||||
if len(graph_source) > 0 and doc.id in list(graph_source.values())[0]["source_id"]:
|
||||
settings.docStoreConn.update({"kb_id": doc.kb_id, "knowledge_graph_kwd": ["entity", "relation", "graph", "subgraph", "community_report"], "source_id": doc.id},
|
||||
{"remove": {"source_id": doc.id}},
|
||||
search.index_name(tenant_id), doc.kb_id)
|
||||
settings.docStoreConn.update({"kb_id": doc.kb_id, "knowledge_graph_kwd": ["graph"]},
|
||||
{"removed_kwd": "Y"},
|
||||
search.index_name(tenant_id), doc.kb_id)
|
||||
settings.docStoreConn.delete({"kb_id": doc.kb_id, "knowledge_graph_kwd": ["entity", "relation", "graph", "subgraph", "community_report"], "must_not": {"exists": "source_id"}},
|
||||
search.index_name(tenant_id), doc.kb_id)
|
||||
except Exception:
|
||||
pass
|
||||
return cls.delete_by_id(doc.id)
|
||||
@ -327,6 +376,15 @@ class DocumentService(CommonService):
|
||||
if not doc_id:
|
||||
return
|
||||
return doc_id[0]["id"]
|
||||
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
def get_doc_ids_by_doc_names(cls, doc_names):
|
||||
if not doc_names:
|
||||
return []
|
||||
|
||||
query = cls.model.select(cls.model.id).where(cls.model.name.in_(doc_names))
|
||||
return list(query.scalars().iterator())
|
||||
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
|
||||
@ -14,22 +14,21 @@
|
||||
# limitations under the License.
|
||||
#
|
||||
import logging
|
||||
import re
|
||||
import os
|
||||
import re
|
||||
from concurrent.futures import ThreadPoolExecutor
|
||||
|
||||
from flask_login import current_user
|
||||
from peewee import fn
|
||||
|
||||
from api.db import FileType, KNOWLEDGEBASE_FOLDER_NAME, FileSource, ParserType
|
||||
from api.db.db_models import DB, File2Document, Knowledgebase
|
||||
from api.db.db_models import File, Document
|
||||
from api.db import KNOWLEDGEBASE_FOLDER_NAME, FileSource, FileType, ParserType
|
||||
from api.db.db_models import DB, Document, File, File2Document, Knowledgebase
|
||||
from api.db.services import duplicate_name
|
||||
from api.db.services.common_service import CommonService
|
||||
from api.db.services.document_service import DocumentService
|
||||
from api.db.services.file2document_service import File2DocumentService
|
||||
from api.utils import get_uuid
|
||||
from api.utils.file_utils import filename_type, thumbnail_img
|
||||
from api.utils.file_utils import filename_type, read_potential_broken_pdf, thumbnail_img
|
||||
from rag.utils.storage_factory import STORAGE_IMPL
|
||||
|
||||
|
||||
@ -39,8 +38,7 @@ class FileService(CommonService):
|
||||
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
def get_by_pf_id(cls, tenant_id, pf_id, page_number, items_per_page,
|
||||
orderby, desc, keywords):
|
||||
def get_by_pf_id(cls, tenant_id, pf_id, page_number, items_per_page, orderby, desc, keywords):
|
||||
# Get files by parent folder ID with pagination and filtering
|
||||
# Args:
|
||||
# tenant_id: ID of the tenant
|
||||
@ -53,17 +51,9 @@ class FileService(CommonService):
|
||||
# Returns:
|
||||
# Tuple of (file_list, total_count)
|
||||
if keywords:
|
||||
files = cls.model.select().where(
|
||||
(cls.model.tenant_id == tenant_id),
|
||||
(cls.model.parent_id == pf_id),
|
||||
(fn.LOWER(cls.model.name).contains(keywords.lower())),
|
||||
~(cls.model.id == pf_id)
|
||||
)
|
||||
files = cls.model.select().where((cls.model.tenant_id == tenant_id), (cls.model.parent_id == pf_id), (fn.LOWER(cls.model.name).contains(keywords.lower())), ~(cls.model.id == pf_id))
|
||||
else:
|
||||
files = cls.model.select().where((cls.model.tenant_id == tenant_id),
|
||||
(cls.model.parent_id == pf_id),
|
||||
~(cls.model.id == pf_id)
|
||||
)
|
||||
files = cls.model.select().where((cls.model.tenant_id == tenant_id), (cls.model.parent_id == pf_id), ~(cls.model.id == pf_id))
|
||||
count = files.count()
|
||||
if desc:
|
||||
files = files.order_by(cls.model.getter_by(orderby).desc())
|
||||
@ -76,16 +66,20 @@ class FileService(CommonService):
|
||||
for file in res_files:
|
||||
if file["type"] == FileType.FOLDER.value:
|
||||
file["size"] = cls.get_folder_size(file["id"])
|
||||
file['kbs_info'] = []
|
||||
children = list(cls.model.select().where(
|
||||
(cls.model.tenant_id == tenant_id),
|
||||
(cls.model.parent_id == file["id"]),
|
||||
~(cls.model.id == file["id"]),
|
||||
).dicts())
|
||||
file["has_child_folder"] = any(value["type"] == FileType.FOLDER.value for value in children)
|
||||
file["kbs_info"] = []
|
||||
children = list(
|
||||
cls.model.select()
|
||||
.where(
|
||||
(cls.model.tenant_id == tenant_id),
|
||||
(cls.model.parent_id == file["id"]),
|
||||
~(cls.model.id == file["id"]),
|
||||
)
|
||||
.dicts()
|
||||
)
|
||||
file["has_child_folder"] = any(value["type"] == FileType.FOLDER.value for value in children)
|
||||
continue
|
||||
kbs_info = cls.get_kb_id_by_file_id(file['id'])
|
||||
file['kbs_info'] = kbs_info
|
||||
kbs_info = cls.get_kb_id_by_file_id(file["id"])
|
||||
file["kbs_info"] = kbs_info
|
||||
|
||||
return res_files, count
|
||||
|
||||
@ -97,16 +91,18 @@ class FileService(CommonService):
|
||||
# file_id: File ID
|
||||
# Returns:
|
||||
# List of dictionaries containing knowledge base IDs and names
|
||||
kbs = (cls.model.select(*[Knowledgebase.id, Knowledgebase.name])
|
||||
.join(File2Document, on=(File2Document.file_id == file_id))
|
||||
.join(Document, on=(File2Document.document_id == Document.id))
|
||||
.join(Knowledgebase, on=(Knowledgebase.id == Document.kb_id))
|
||||
.where(cls.model.id == file_id))
|
||||
kbs = (
|
||||
cls.model.select(*[Knowledgebase.id, Knowledgebase.name])
|
||||
.join(File2Document, on=(File2Document.file_id == file_id))
|
||||
.join(Document, on=(File2Document.document_id == Document.id))
|
||||
.join(Knowledgebase, on=(Knowledgebase.id == Document.kb_id))
|
||||
.where(cls.model.id == file_id)
|
||||
)
|
||||
if not kbs:
|
||||
return []
|
||||
kbs_info_list = []
|
||||
for kb in list(kbs.dicts()):
|
||||
kbs_info_list.append({"kb_id": kb['id'], "kb_name": kb['name']})
|
||||
kbs_info_list.append({"kb_id": kb["id"], "kb_name": kb["name"]})
|
||||
return kbs_info_list
|
||||
|
||||
@classmethod
|
||||
@ -178,16 +174,9 @@ class FileService(CommonService):
|
||||
if count > len(name) - 2:
|
||||
return file
|
||||
else:
|
||||
file = cls.insert({
|
||||
"id": get_uuid(),
|
||||
"parent_id": parent_id,
|
||||
"tenant_id": current_user.id,
|
||||
"created_by": current_user.id,
|
||||
"name": name[count],
|
||||
"location": "",
|
||||
"size": 0,
|
||||
"type": FileType.FOLDER.value
|
||||
})
|
||||
file = cls.insert(
|
||||
{"id": get_uuid(), "parent_id": parent_id, "tenant_id": current_user.id, "created_by": current_user.id, "name": name[count], "location": "", "size": 0, "type": FileType.FOLDER.value}
|
||||
)
|
||||
return cls.create_folder(file, file.id, name, count + 1)
|
||||
|
||||
@classmethod
|
||||
@ -212,9 +201,7 @@ class FileService(CommonService):
|
||||
# tenant_id: Tenant ID
|
||||
# Returns:
|
||||
# Root folder dictionary
|
||||
for file in cls.model.select().where((cls.model.tenant_id == tenant_id),
|
||||
(cls.model.parent_id == cls.model.id)
|
||||
):
|
||||
for file in cls.model.select().where((cls.model.tenant_id == tenant_id), (cls.model.parent_id == cls.model.id)):
|
||||
return file.to_dict()
|
||||
|
||||
file_id = get_uuid()
|
||||
@ -239,11 +226,8 @@ class FileService(CommonService):
|
||||
# tenant_id: Tenant ID
|
||||
# Returns:
|
||||
# Knowledge base folder dictionary
|
||||
for root in cls.model.select().where(
|
||||
(cls.model.tenant_id == tenant_id), (cls.model.parent_id == cls.model.id)):
|
||||
for folder in cls.model.select().where(
|
||||
(cls.model.tenant_id == tenant_id), (cls.model.parent_id == root.id),
|
||||
(cls.model.name == KNOWLEDGEBASE_FOLDER_NAME)):
|
||||
for root in cls.model.select().where((cls.model.tenant_id == tenant_id), (cls.model.parent_id == cls.model.id)):
|
||||
for folder in cls.model.select().where((cls.model.tenant_id == tenant_id), (cls.model.parent_id == root.id), (cls.model.name == KNOWLEDGEBASE_FOLDER_NAME)):
|
||||
return folder.to_dict()
|
||||
assert False, "Can't find the KB folder. Database init error."
|
||||
|
||||
@ -271,7 +255,7 @@ class FileService(CommonService):
|
||||
"type": ty,
|
||||
"size": size,
|
||||
"location": location,
|
||||
"source_type": FileSource.KNOWLEDGEBASE
|
||||
"source_type": FileSource.KNOWLEDGEBASE,
|
||||
}
|
||||
cls.save(**file)
|
||||
return file
|
||||
@ -283,12 +267,11 @@ class FileService(CommonService):
|
||||
# Args:
|
||||
# root_id: Root folder ID
|
||||
# tenant_id: Tenant ID
|
||||
for _ in cls.model.select().where((cls.model.name == KNOWLEDGEBASE_FOLDER_NAME)\
|
||||
& (cls.model.parent_id == root_id)):
|
||||
for _ in cls.model.select().where((cls.model.name == KNOWLEDGEBASE_FOLDER_NAME) & (cls.model.parent_id == root_id)):
|
||||
return
|
||||
folder = cls.new_a_file_from_kb(tenant_id, KNOWLEDGEBASE_FOLDER_NAME, root_id)
|
||||
|
||||
for kb in Knowledgebase.select(*[Knowledgebase.id, Knowledgebase.name]).where(Knowledgebase.tenant_id==tenant_id):
|
||||
for kb in Knowledgebase.select(*[Knowledgebase.id, Knowledgebase.name]).where(Knowledgebase.tenant_id == tenant_id):
|
||||
kb_folder = cls.new_a_file_from_kb(tenant_id, kb.name, folder["id"])
|
||||
for doc in DocumentService.query(kb_id=kb.id):
|
||||
FileService.add_file_from_kb(doc.to_dict(), kb_folder["id"], tenant_id)
|
||||
@ -357,12 +340,10 @@ class FileService(CommonService):
|
||||
@DB.connection_context()
|
||||
def delete_folder_by_pf_id(cls, user_id, folder_id):
|
||||
try:
|
||||
files = cls.model.select().where((cls.model.tenant_id == user_id)
|
||||
& (cls.model.parent_id == folder_id))
|
||||
files = cls.model.select().where((cls.model.tenant_id == user_id) & (cls.model.parent_id == folder_id))
|
||||
for file in files:
|
||||
cls.delete_folder_by_pf_id(user_id, file.id)
|
||||
return cls.model.delete().where((cls.model.tenant_id == user_id)
|
||||
& (cls.model.id == folder_id)).execute(),
|
||||
return (cls.model.delete().where((cls.model.tenant_id == user_id) & (cls.model.id == folder_id)).execute(),)
|
||||
except Exception:
|
||||
logging.exception("delete_folder_by_pf_id")
|
||||
raise RuntimeError("Database error (File retrieval)!")
|
||||
@ -380,8 +361,7 @@ class FileService(CommonService):
|
||||
|
||||
def dfs(parent_id):
|
||||
nonlocal size
|
||||
for f in cls.model.select(*[cls.model.id, cls.model.size, cls.model.type]).where(
|
||||
cls.model.parent_id == parent_id, cls.model.id != parent_id):
|
||||
for f in cls.model.select(*[cls.model.id, cls.model.size, cls.model.type]).where(cls.model.parent_id == parent_id, cls.model.id != parent_id):
|
||||
size += f.size
|
||||
if f.type == FileType.FOLDER.value:
|
||||
dfs(f.id)
|
||||
@ -403,16 +383,16 @@ class FileService(CommonService):
|
||||
"type": doc["type"],
|
||||
"size": doc["size"],
|
||||
"location": doc["location"],
|
||||
"source_type": FileSource.KNOWLEDGEBASE
|
||||
"source_type": FileSource.KNOWLEDGEBASE,
|
||||
}
|
||||
cls.save(**file)
|
||||
File2DocumentService.save(**{"id": get_uuid(), "file_id": file["id"], "document_id": doc["id"]})
|
||||
|
||||
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
def move_file(cls, file_ids, folder_id):
|
||||
try:
|
||||
cls.filter_update((cls.model.id << file_ids, ), { 'parent_id': folder_id })
|
||||
cls.filter_update((cls.model.id << file_ids,), {"parent_id": folder_id})
|
||||
except Exception:
|
||||
logging.exception("move_file")
|
||||
raise RuntimeError("Database error (File move)!")
|
||||
@ -429,16 +409,13 @@ class FileService(CommonService):
|
||||
err, files = [], []
|
||||
for file in file_objs:
|
||||
try:
|
||||
MAX_FILE_NUM_PER_USER = int(os.environ.get('MAX_FILE_NUM_PER_USER', 0))
|
||||
MAX_FILE_NUM_PER_USER = int(os.environ.get("MAX_FILE_NUM_PER_USER", 0))
|
||||
if MAX_FILE_NUM_PER_USER > 0 and DocumentService.get_doc_count(kb.tenant_id) >= MAX_FILE_NUM_PER_USER:
|
||||
raise RuntimeError("Exceed the maximum file number of a free user!")
|
||||
if len(file.filename) >= 128:
|
||||
if len(file.filename.encode("utf-8")) >= 128:
|
||||
raise RuntimeError("Exceed the maximum length of file name!")
|
||||
|
||||
filename = duplicate_name(
|
||||
DocumentService.query,
|
||||
name=file.filename,
|
||||
kb_id=kb.id)
|
||||
filename = duplicate_name(DocumentService.query, name=file.filename, kb_id=kb.id)
|
||||
filetype = filename_type(filename)
|
||||
if filetype == FileType.OTHER.value:
|
||||
raise RuntimeError("This type of file has not been supported yet!")
|
||||
@ -446,15 +423,18 @@ class FileService(CommonService):
|
||||
location = filename
|
||||
while STORAGE_IMPL.obj_exist(kb.id, location):
|
||||
location += "_"
|
||||
|
||||
blob = file.read()
|
||||
if filetype == FileType.PDF.value:
|
||||
blob = read_potential_broken_pdf(blob)
|
||||
STORAGE_IMPL.put(kb.id, location, blob)
|
||||
|
||||
doc_id = get_uuid()
|
||||
|
||||
img = thumbnail_img(filename, blob)
|
||||
thumbnail_location = ''
|
||||
thumbnail_location = ""
|
||||
if img is not None:
|
||||
thumbnail_location = f'thumbnail_{doc_id}.png'
|
||||
thumbnail_location = f"thumbnail_{doc_id}.png"
|
||||
STORAGE_IMPL.put(kb.id, thumbnail_location, img)
|
||||
|
||||
doc = {
|
||||
@ -467,7 +447,7 @@ class FileService(CommonService):
|
||||
"name": filename,
|
||||
"location": location,
|
||||
"size": len(blob),
|
||||
"thumbnail": thumbnail_location
|
||||
"thumbnail": thumbnail_location,
|
||||
}
|
||||
DocumentService.insert(doc)
|
||||
|
||||
@ -480,29 +460,17 @@ class FileService(CommonService):
|
||||
|
||||
@staticmethod
|
||||
def parse_docs(file_objs, user_id):
|
||||
from rag.app import presentation, picture, naive, audio, email
|
||||
from rag.app import audio, email, naive, picture, presentation
|
||||
|
||||
def dummy(prog=None, msg=""):
|
||||
pass
|
||||
|
||||
FACTORY = {
|
||||
ParserType.PRESENTATION.value: presentation,
|
||||
ParserType.PICTURE.value: picture,
|
||||
ParserType.AUDIO.value: audio,
|
||||
ParserType.EMAIL.value: email
|
||||
}
|
||||
FACTORY = {ParserType.PRESENTATION.value: presentation, ParserType.PICTURE.value: picture, ParserType.AUDIO.value: audio, ParserType.EMAIL.value: email}
|
||||
parser_config = {"chunk_token_num": 16096, "delimiter": "\n!?;。;!?", "layout_recognize": "Plain Text"}
|
||||
exe = ThreadPoolExecutor(max_workers=12)
|
||||
threads = []
|
||||
for file in file_objs:
|
||||
kwargs = {
|
||||
"lang": "English",
|
||||
"callback": dummy,
|
||||
"parser_config": parser_config,
|
||||
"from_page": 0,
|
||||
"to_page": 100000,
|
||||
"tenant_id": user_id
|
||||
}
|
||||
kwargs = {"lang": "English", "callback": dummy, "parser_config": parser_config, "from_page": 0, "to_page": 100000, "tenant_id": user_id}
|
||||
filetype = filename_type(file.filename)
|
||||
blob = file.read()
|
||||
threads.append(exe.submit(FACTORY.get(FileService.get_parser(filetype, file.filename, ""), naive).chunk, file.filename, blob, **kwargs))
|
||||
@ -523,4 +491,5 @@ class FileService(CommonService):
|
||||
return ParserType.PRESENTATION.value
|
||||
if re.search(r"\.(eml)$", filename):
|
||||
return ParserType.EMAIL.value
|
||||
return default
|
||||
return default
|
||||
|
||||
|
||||
@ -97,7 +97,7 @@ class KnowledgebaseService(CommonService):
|
||||
kb = kbs[0]
|
||||
|
||||
# Get all documents in the knowledge base
|
||||
docs, _ = DocumentService.get_by_kb_id(kb_id, 1, 1000, "create_time", True, "")
|
||||
docs, _ = DocumentService.get_by_kb_id(kb_id, 1, 1000, "create_time", True, "", [], [])
|
||||
|
||||
# Check parsing status of each document
|
||||
for doc in docs:
|
||||
@ -226,7 +226,10 @@ class KnowledgebaseService(CommonService):
|
||||
cls.model.chunk_num,
|
||||
cls.model.parser_id,
|
||||
cls.model.parser_config,
|
||||
cls.model.pagerank]
|
||||
cls.model.pagerank,
|
||||
cls.model.create_time,
|
||||
cls.model.update_time
|
||||
]
|
||||
kbs = cls.model.select(*fields).join(Tenant, on=(
|
||||
(Tenant.id == cls.model.tenant_id) & (Tenant.status == StatusEnum.VALID.value))).where(
|
||||
(cls.model.id == kb_id),
|
||||
@ -266,6 +269,16 @@ class KnowledgebaseService(CommonService):
|
||||
dfs_update(m.parser_config, config)
|
||||
cls.update_by_id(id, {"parser_config": m.parser_config})
|
||||
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
def delete_field_map(cls, id):
|
||||
e, m = cls.get_by_id(id)
|
||||
if not e:
|
||||
raise LookupError(f"knowledgebase({id}) not found.")
|
||||
|
||||
m.parser_config.pop("field_map", None)
|
||||
cls.update_by_id(id, {"parser_config": m.parser_config})
|
||||
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
def get_field_map(cls, ids):
|
||||
|
||||
@ -100,9 +100,13 @@ class TenantLLMService(CommonService):
|
||||
|
||||
model_config = cls.get_api_key(tenant_id, mdlnm)
|
||||
mdlnm, fid = TenantLLMService.split_model_name_and_factory(mdlnm)
|
||||
if not model_config: # for some cases seems fid mismatch
|
||||
model_config = cls.get_api_key(tenant_id, mdlnm)
|
||||
if model_config:
|
||||
model_config = model_config.to_dict()
|
||||
llm = LLMService.query(llm_name=mdlnm) if not fid else LLMService.query(llm_name=mdlnm, fid=fid)
|
||||
if not llm and fid: # for some cases seems fid mismatch
|
||||
llm = LLMService.query(llm_name=mdlnm)
|
||||
if llm:
|
||||
model_config["is_tools"] = llm[0].is_tools
|
||||
if not model_config:
|
||||
@ -159,12 +163,6 @@ class TenantLLMService(CommonService):
|
||||
@classmethod
|
||||
@DB.connection_context()
|
||||
def increase_usage(cls, tenant_id, llm_type, used_tokens, llm_name=None):
|
||||
try:
|
||||
if not DB.is_connection_usable():
|
||||
DB.connect()
|
||||
except Exception:
|
||||
DB.close()
|
||||
DB.connect()
|
||||
e, tenant = TenantService.get_by_id(tenant_id)
|
||||
if not e:
|
||||
logging.error(f"Tenant not found: {tenant_id}")
|
||||
@ -228,6 +226,7 @@ class LLMBundle:
|
||||
|
||||
def bind_tools(self, toolcall_session, tools):
|
||||
if not self.is_tools:
|
||||
logging.warning(f"Model {self.llm_name} does not support tool call, but you have assigned one or more tools to it!")
|
||||
return
|
||||
self.mdl.bind_tools(toolcall_session, tools)
|
||||
|
||||
@ -362,7 +361,7 @@ class LLMBundle:
|
||||
|
||||
ans = ""
|
||||
chat_streamly = self.mdl.chat_streamly
|
||||
total_tokens = 0
|
||||
total_tokens = 0
|
||||
if self.is_tools and self.mdl.is_tools:
|
||||
chat_streamly = self.mdl.chat_streamly_with_tools
|
||||
|
||||
|
||||
@ -31,8 +31,11 @@ class UserCanvasVersionService(CommonService):
|
||||
try:
|
||||
user_canvas_version = cls.model.select().where(cls.model.user_canvas_id == user_canvas_id).order_by(cls.model.create_time.desc())
|
||||
if user_canvas_version.count() > 20:
|
||||
delete_ids = []
|
||||
for i in range(20, user_canvas_version.count()):
|
||||
cls.delete(user_canvas_version[i].id)
|
||||
delete_ids.append(user_canvas_version[i].id)
|
||||
|
||||
cls.delete_by_ids(delete_ids)
|
||||
return True
|
||||
except DoesNotExist:
|
||||
return None
|
||||
|
||||
@ -19,6 +19,7 @@
|
||||
# beartype_all(conf=BeartypeConf(violation_type=UserWarning)) # <-- emit warnings from all code
|
||||
|
||||
from api.utils.log_utils import initRootLogger
|
||||
from plugin import GlobalPluginManager
|
||||
initRootLogger("ragflow_server")
|
||||
|
||||
import logging
|
||||
@ -119,6 +120,8 @@ if __name__ == '__main__':
|
||||
RuntimeConfig.init_env()
|
||||
RuntimeConfig.init_config(JOB_SERVER_HOST=settings.HOST_IP, HTTP_PORT=settings.HOST_PORT)
|
||||
|
||||
GlobalPluginManager.load_plugins()
|
||||
|
||||
signal.signal(signal.SIGINT, signal_handler)
|
||||
signal.signal(signal.SIGTERM, signal_handler)
|
||||
|
||||
|
||||
@ -13,21 +13,22 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
import json
|
||||
import os
|
||||
from datetime import date
|
||||
from enum import IntEnum, Enum
|
||||
import json
|
||||
import rag.utils.es_conn
|
||||
import rag.utils.infinity_conn
|
||||
from enum import Enum, IntEnum
|
||||
|
||||
import rag.utils
|
||||
from rag.nlp import search
|
||||
from graphrag import search as kg_search
|
||||
from api.utils import get_base_config, decrypt_database_config
|
||||
import rag.utils.es_conn
|
||||
import rag.utils.infinity_conn
|
||||
import rag.utils.opensearch_coon
|
||||
from api.constants import RAG_FLOW_SERVICE_NAME
|
||||
from api.utils import decrypt_database_config, get_base_config
|
||||
from api.utils.file_utils import get_project_base_directory
|
||||
from graphrag import search as kg_search
|
||||
from rag.nlp import search
|
||||
|
||||
LIGHTEN = int(os.environ.get('LIGHTEN', "0"))
|
||||
LIGHTEN = int(os.environ.get("LIGHTEN", "0"))
|
||||
|
||||
LLM = None
|
||||
LLM_FACTORY = None
|
||||
@ -44,7 +45,7 @@ HOST_PORT = None
|
||||
SECRET_KEY = None
|
||||
FACTORY_LLM_INFOS = None
|
||||
|
||||
DATABASE_TYPE = os.getenv("DB_TYPE", 'mysql')
|
||||
DATABASE_TYPE = os.getenv("DB_TYPE", "mysql")
|
||||
DATABASE = decrypt_database_config(name=DATABASE_TYPE)
|
||||
|
||||
# authentication
|
||||
@ -55,7 +56,7 @@ CLIENT_AUTHENTICATION = None
|
||||
HTTP_APP_KEY = None
|
||||
GITHUB_OAUTH = None
|
||||
FEISHU_OAUTH = None
|
||||
|
||||
OAUTH_CONFIG = None
|
||||
DOC_ENGINE = None
|
||||
docStoreConn = None
|
||||
|
||||
@ -66,20 +67,27 @@ kg_retrievaler = None
|
||||
REGISTER_ENABLED = 1
|
||||
|
||||
|
||||
# sandbox-executor-manager
|
||||
SANDBOX_ENABLED = 0
|
||||
SANDBOX_HOST = None
|
||||
|
||||
BUILTIN_EMBEDDING_MODELS = ["BAAI/bge-large-zh-v1.5@BAAI", "maidalun1020/bce-embedding-base_v1@Youdao"]
|
||||
|
||||
|
||||
def init_settings():
|
||||
global LLM, LLM_FACTORY, LLM_BASE_URL, LIGHTEN, DATABASE_TYPE, DATABASE, FACTORY_LLM_INFOS, REGISTER_ENABLED
|
||||
LIGHTEN = int(os.environ.get('LIGHTEN', "0"))
|
||||
DATABASE_TYPE = os.getenv("DB_TYPE", 'mysql')
|
||||
LIGHTEN = int(os.environ.get("LIGHTEN", "0"))
|
||||
DATABASE_TYPE = os.getenv("DB_TYPE", "mysql")
|
||||
DATABASE = decrypt_database_config(name=DATABASE_TYPE)
|
||||
LLM = get_base_config("user_default_llm", {})
|
||||
LLM_DEFAULT_MODELS = LLM.get("default_models", {})
|
||||
LLM_FACTORY = LLM.get("factory", "Tongyi-Qianwen")
|
||||
LLM_FACTORY = LLM.get("factory")
|
||||
LLM_BASE_URL = LLM.get("base_url")
|
||||
try:
|
||||
REGISTER_ENABLED = int(os.environ.get("REGISTER_ENABLED", "1"))
|
||||
except Exception:
|
||||
pass
|
||||
|
||||
pass
|
||||
|
||||
try:
|
||||
with open(os.path.join(get_project_base_directory(), "conf", "llm_factories.json"), "r") as f:
|
||||
FACTORY_LLM_INFOS = json.load(f)["factory_llm_infos"]
|
||||
@ -88,7 +96,7 @@ def init_settings():
|
||||
|
||||
global CHAT_MDL, EMBEDDING_MDL, RERANK_MDL, ASR_MDL, IMAGE2TEXT_MDL
|
||||
if not LIGHTEN:
|
||||
EMBEDDING_MDL = "BAAI/bge-large-zh-v1.5@BAAI"
|
||||
EMBEDDING_MDL = BUILTIN_EMBEDDING_MODELS[0]
|
||||
|
||||
if LLM_DEFAULT_MODELS:
|
||||
CHAT_MDL = LLM_DEFAULT_MODELS.get("chat_model", CHAT_MDL)
|
||||
@ -102,47 +110,51 @@ def init_settings():
|
||||
EMBEDDING_MDL = EMBEDDING_MDL + (f"@{LLM_FACTORY}" if "@" not in EMBEDDING_MDL and EMBEDDING_MDL != "" else "")
|
||||
RERANK_MDL = RERANK_MDL + (f"@{LLM_FACTORY}" if "@" not in RERANK_MDL and RERANK_MDL != "" else "")
|
||||
ASR_MDL = ASR_MDL + (f"@{LLM_FACTORY}" if "@" not in ASR_MDL and ASR_MDL != "" else "")
|
||||
IMAGE2TEXT_MDL = IMAGE2TEXT_MDL + (
|
||||
f"@{LLM_FACTORY}" if "@" not in IMAGE2TEXT_MDL and IMAGE2TEXT_MDL != "" else "")
|
||||
IMAGE2TEXT_MDL = IMAGE2TEXT_MDL + (f"@{LLM_FACTORY}" if "@" not in IMAGE2TEXT_MDL and IMAGE2TEXT_MDL != "" else "")
|
||||
|
||||
global API_KEY, PARSERS, HOST_IP, HOST_PORT, SECRET_KEY
|
||||
API_KEY = LLM.get("api_key", "")
|
||||
API_KEY = LLM.get("api_key")
|
||||
PARSERS = LLM.get(
|
||||
"parsers",
|
||||
"naive:General,qa:Q&A,resume:Resume,manual:Manual,table:Table,paper:Paper,book:Book,laws:Laws,presentation:Presentation,picture:Picture,one:One,audio:Audio,email:Email,tag:Tag")
|
||||
"parsers", "naive:General,qa:Q&A,resume:Resume,manual:Manual,table:Table,paper:Paper,book:Book,laws:Laws,presentation:Presentation,picture:Picture,one:One,audio:Audio,email:Email,tag:Tag"
|
||||
)
|
||||
|
||||
HOST_IP = get_base_config(RAG_FLOW_SERVICE_NAME, {}).get("host", "127.0.0.1")
|
||||
HOST_PORT = get_base_config(RAG_FLOW_SERVICE_NAME, {}).get("http_port")
|
||||
|
||||
SECRET_KEY = get_base_config(
|
||||
RAG_FLOW_SERVICE_NAME,
|
||||
{}).get("secret_key", str(date.today()))
|
||||
SECRET_KEY = get_base_config(RAG_FLOW_SERVICE_NAME, {}).get("secret_key", str(date.today()))
|
||||
|
||||
global AUTHENTICATION_CONF, CLIENT_AUTHENTICATION, HTTP_APP_KEY, GITHUB_OAUTH, FEISHU_OAUTH
|
||||
global AUTHENTICATION_CONF, CLIENT_AUTHENTICATION, HTTP_APP_KEY, GITHUB_OAUTH, FEISHU_OAUTH, OAUTH_CONFIG
|
||||
# authentication
|
||||
AUTHENTICATION_CONF = get_base_config("authentication", {})
|
||||
|
||||
# client
|
||||
CLIENT_AUTHENTICATION = AUTHENTICATION_CONF.get(
|
||||
"client", {}).get(
|
||||
"switch", False)
|
||||
CLIENT_AUTHENTICATION = AUTHENTICATION_CONF.get("client", {}).get("switch", False)
|
||||
HTTP_APP_KEY = AUTHENTICATION_CONF.get("client", {}).get("http_app_key")
|
||||
GITHUB_OAUTH = get_base_config("oauth", {}).get("github")
|
||||
FEISHU_OAUTH = get_base_config("oauth", {}).get("feishu")
|
||||
|
||||
OAUTH_CONFIG = get_base_config("oauth", {})
|
||||
|
||||
global DOC_ENGINE, docStoreConn, retrievaler, kg_retrievaler
|
||||
DOC_ENGINE = os.environ.get('DOC_ENGINE', "elasticsearch")
|
||||
DOC_ENGINE = os.environ.get("DOC_ENGINE", "elasticsearch")
|
||||
# DOC_ENGINE = os.environ.get('DOC_ENGINE', "opensearch")
|
||||
lower_case_doc_engine = DOC_ENGINE.lower()
|
||||
if lower_case_doc_engine == "elasticsearch":
|
||||
docStoreConn = rag.utils.es_conn.ESConnection()
|
||||
elif lower_case_doc_engine == "infinity":
|
||||
docStoreConn = rag.utils.infinity_conn.InfinityConnection()
|
||||
elif lower_case_doc_engine == "opensearch":
|
||||
docStoreConn = rag.utils.opensearch_coon.OSConnection()
|
||||
else:
|
||||
raise Exception(f"Not supported doc engine: {DOC_ENGINE}")
|
||||
|
||||
retrievaler = search.Dealer(docStoreConn)
|
||||
kg_retrievaler = kg_search.KGSearch(docStoreConn)
|
||||
|
||||
if int(os.environ.get("SANDBOX_ENABLED", "0")):
|
||||
global SANDBOX_HOST
|
||||
SANDBOX_HOST = os.environ.get("SANDBOX_HOST", "sandbox-executor-manager")
|
||||
|
||||
|
||||
class CustomEnum(Enum):
|
||||
@classmethod
|
||||
|
||||
@ -19,6 +19,7 @@ import logging
|
||||
import random
|
||||
import time
|
||||
from base64 import b64encode
|
||||
from copy import deepcopy
|
||||
from functools import wraps
|
||||
from hmac import HMAC
|
||||
from io import BytesIO
|
||||
@ -36,11 +37,13 @@ from flask import (
|
||||
request as flask_request,
|
||||
)
|
||||
from itsdangerous import URLSafeTimedSerializer
|
||||
from peewee import OperationalError
|
||||
from werkzeug.http import HTTP_STATUS_CODES
|
||||
|
||||
from api import settings
|
||||
from api.constants import REQUEST_MAX_WAIT_SEC, REQUEST_WAIT_SEC
|
||||
from api.db.db_models import APIToken
|
||||
from api.db.services.llm_service import LLMService, TenantLLMService
|
||||
from api.utils import CustomJSONEncoder, get_uuid, json_dumps
|
||||
|
||||
requests.models.complexjson.dumps = functools.partial(json.dumps, cls=CustomJSONEncoder)
|
||||
@ -322,25 +325,21 @@ def get_error_data_result(
|
||||
return jsonify(response)
|
||||
|
||||
|
||||
def generate_confirmation_token(tenent_id):
|
||||
serializer = URLSafeTimedSerializer(tenent_id)
|
||||
return "ragflow-" + serializer.dumps(get_uuid(), salt=tenent_id)[2:34]
|
||||
def get_error_argument_result(message="Invalid arguments"):
|
||||
return get_result(code=settings.RetCode.ARGUMENT_ERROR, message=message)
|
||||
|
||||
|
||||
def valid(permission, valid_permission, chunk_method, valid_chunk_method):
|
||||
if valid_parameter(permission, valid_permission):
|
||||
return valid_parameter(permission, valid_permission)
|
||||
if valid_parameter(chunk_method, valid_chunk_method):
|
||||
return valid_parameter(chunk_method, valid_chunk_method)
|
||||
def get_error_permission_result(message="Permission error"):
|
||||
return get_result(code=settings.RetCode.PERMISSION_ERROR, message=message)
|
||||
|
||||
|
||||
def valid_parameter(parameter, valid_values):
|
||||
if parameter and parameter not in valid_values:
|
||||
return get_error_data_result(f"'{parameter}' is not in {valid_values}")
|
||||
def get_error_operating_result(message="Operating error"):
|
||||
return get_result(code=settings.RetCode.OPERATING_ERROR, message=message)
|
||||
|
||||
|
||||
def dataset_readonly_fields(field_name):
|
||||
return field_name in ["chunk_count", "create_date", "create_time", "update_date", "update_time", "created_by", "document_count", "token_num", "status", "tenant_id", "id"]
|
||||
def generate_confirmation_token(tenant_id):
|
||||
serializer = URLSafeTimedSerializer(tenant_id)
|
||||
return "ragflow-" + serializer.dumps(get_uuid(), salt=tenant_id)[2:34]
|
||||
|
||||
|
||||
def get_parser_config(chunk_method, parser_config):
|
||||
@ -349,7 +348,7 @@ def get_parser_config(chunk_method, parser_config):
|
||||
if not chunk_method:
|
||||
chunk_method = "naive"
|
||||
key_mapping = {
|
||||
"naive": {"chunk_token_num": 128, "delimiter": "\\n!?;。;!?", "html4excel": False, "layout_recognize": "DeepDOC", "raptor": {"use_raptor": False}},
|
||||
"naive": {"chunk_token_num": 128, "delimiter": r"\n", "html4excel": False, "layout_recognize": "DeepDOC", "raptor": {"use_raptor": False}},
|
||||
"qa": {"raptor": {"use_raptor": False}},
|
||||
"tag": None,
|
||||
"resume": None,
|
||||
@ -360,7 +359,7 @@ def get_parser_config(chunk_method, parser_config):
|
||||
"laws": {"raptor": {"use_raptor": False}},
|
||||
"presentation": {"raptor": {"use_raptor": False}},
|
||||
"one": None,
|
||||
"knowledge_graph": {"chunk_token_num": 8192, "delimiter": "\\n!?;。;!?", "entity_types": ["organization", "person", "location", "event", "time"]},
|
||||
"knowledge_graph": {"chunk_token_num": 8192, "delimiter": r"\n", "entity_types": ["organization", "person", "location", "event", "time"]},
|
||||
"email": None,
|
||||
"picture": None,
|
||||
}
|
||||
@ -368,81 +367,32 @@ def get_parser_config(chunk_method, parser_config):
|
||||
return parser_config
|
||||
|
||||
|
||||
def get_data_openai(id=None,
|
||||
created=None,
|
||||
model=None,
|
||||
prompt_tokens= 0,
|
||||
completion_tokens=0,
|
||||
content = None,
|
||||
finish_reason= None,
|
||||
object="chat.completion",
|
||||
param=None,
|
||||
def get_data_openai(
|
||||
id=None,
|
||||
created=None,
|
||||
model=None,
|
||||
prompt_tokens=0,
|
||||
completion_tokens=0,
|
||||
content=None,
|
||||
finish_reason=None,
|
||||
object="chat.completion",
|
||||
param=None,
|
||||
):
|
||||
|
||||
total_tokens= prompt_tokens + completion_tokens
|
||||
total_tokens = prompt_tokens + completion_tokens
|
||||
return {
|
||||
"id":f"{id}",
|
||||
"id": f"{id}",
|
||||
"object": object,
|
||||
"created": int(time.time()) if created else None,
|
||||
"model": model,
|
||||
"param":param,
|
||||
"param": param,
|
||||
"usage": {
|
||||
"prompt_tokens": prompt_tokens,
|
||||
"completion_tokens": completion_tokens,
|
||||
"total_tokens": total_tokens,
|
||||
"completion_tokens_details": {
|
||||
"reasoning_tokens": 0,
|
||||
"accepted_prediction_tokens": 0,
|
||||
"rejected_prediction_tokens": 0
|
||||
}
|
||||
"completion_tokens_details": {"reasoning_tokens": 0, "accepted_prediction_tokens": 0, "rejected_prediction_tokens": 0},
|
||||
},
|
||||
"choices": [
|
||||
{
|
||||
"message": {
|
||||
"role": "assistant",
|
||||
"content": content
|
||||
},
|
||||
"logprobs": None,
|
||||
"finish_reason": finish_reason,
|
||||
"index": 0
|
||||
}
|
||||
]
|
||||
}
|
||||
def valid_parser_config(parser_config):
|
||||
if not parser_config:
|
||||
return
|
||||
scopes = set(
|
||||
[
|
||||
"chunk_token_num",
|
||||
"delimiter",
|
||||
"raptor",
|
||||
"graphrag",
|
||||
"layout_recognize",
|
||||
"task_page_size",
|
||||
"pages",
|
||||
"html4excel",
|
||||
"auto_keywords",
|
||||
"auto_questions",
|
||||
"tag_kb_ids",
|
||||
"topn_tags",
|
||||
"filename_embd_weight",
|
||||
]
|
||||
)
|
||||
for k in parser_config.keys():
|
||||
assert k in scopes, f"Abnormal 'parser_config'. Invalid key: {k}"
|
||||
|
||||
assert isinstance(parser_config.get("chunk_token_num", 1), int), "chunk_token_num should be int"
|
||||
assert 1 <= parser_config.get("chunk_token_num", 1) < 100000000, "chunk_token_num should be in range from 1 to 100000000"
|
||||
assert isinstance(parser_config.get("task_page_size", 1), int), "task_page_size should be int"
|
||||
assert 1 <= parser_config.get("task_page_size", 1) < 100000000, "task_page_size should be in range from 1 to 100000000"
|
||||
assert isinstance(parser_config.get("auto_keywords", 1), int), "auto_keywords should be int"
|
||||
assert 0 <= parser_config.get("auto_keywords", 0) < 32, "auto_keywords should be in range from 0 to 32"
|
||||
assert isinstance(parser_config.get("auto_questions", 1), int), "auto_questions should be int"
|
||||
assert 0 <= parser_config.get("auto_questions", 0) < 10, "auto_questions should be in range from 0 to 10"
|
||||
assert isinstance(parser_config.get("topn_tags", 1), int), "topn_tags should be int"
|
||||
assert 0 <= parser_config.get("topn_tags", 0) < 10, "topn_tags should be in range from 0 to 10"
|
||||
assert isinstance(parser_config.get("html4excel", False), bool), "html4excel should be True or False"
|
||||
assert isinstance(parser_config.get("delimiter", ""), str), "delimiter should be str"
|
||||
"choices": [{"message": {"role": "assistant", "content": content}, "logprobs": None, "finish_reason": finish_reason, "index": 0}],
|
||||
}
|
||||
|
||||
|
||||
def check_duplicate_ids(ids, id_type="item"):
|
||||
@ -472,3 +422,138 @@ def check_duplicate_ids(ids, id_type="item"):
|
||||
|
||||
# Return unique IDs and error messages
|
||||
return list(set(ids)), duplicate_messages
|
||||
|
||||
|
||||
def verify_embedding_availability(embd_id: str, tenant_id: str) -> tuple[bool, Response | None]:
|
||||
"""
|
||||
Verifies availability of an embedding model for a specific tenant.
|
||||
|
||||
Implements a four-stage validation process:
|
||||
1. Model identifier parsing and validation
|
||||
2. System support verification
|
||||
3. Tenant authorization check
|
||||
4. Database operation error handling
|
||||
|
||||
Args:
|
||||
embd_id (str): Unique identifier for the embedding model in format "model_name@factory"
|
||||
tenant_id (str): Tenant identifier for access control
|
||||
|
||||
Returns:
|
||||
tuple[bool, Response | None]:
|
||||
- First element (bool):
|
||||
- True: Model is available and authorized
|
||||
- False: Validation failed
|
||||
- Second element contains:
|
||||
- None on success
|
||||
- Error detail dict on failure
|
||||
|
||||
Raises:
|
||||
ValueError: When model identifier format is invalid
|
||||
OperationalError: When database connection fails (auto-handled)
|
||||
|
||||
Examples:
|
||||
>>> verify_embedding_availability("text-embedding@openai", "tenant_123")
|
||||
(True, None)
|
||||
|
||||
>>> verify_embedding_availability("invalid_model", "tenant_123")
|
||||
(False, {'code': 101, 'message': "Unsupported model: <invalid_model>"})
|
||||
"""
|
||||
try:
|
||||
llm_name, llm_factory = TenantLLMService.split_model_name_and_factory(embd_id)
|
||||
if not LLMService.query(llm_name=llm_name, fid=llm_factory, model_type="embedding"):
|
||||
return False, get_error_argument_result(f"Unsupported model: <{embd_id}>")
|
||||
|
||||
# Tongyi-Qianwen is added to TenantLLM by default, but remains unusable with empty api_key
|
||||
tenant_llms = TenantLLMService.get_my_llms(tenant_id=tenant_id)
|
||||
is_tenant_model = any(llm["llm_name"] == llm_name and llm["llm_factory"] == llm_factory and llm["model_type"] == "embedding" for llm in tenant_llms)
|
||||
|
||||
is_builtin_model = embd_id in settings.BUILTIN_EMBEDDING_MODELS
|
||||
if not (is_builtin_model or is_tenant_model):
|
||||
return False, get_error_argument_result(f"Unauthorized model: <{embd_id}>")
|
||||
except OperationalError as e:
|
||||
logging.exception(e)
|
||||
return False, get_error_data_result(message="Database operation failed")
|
||||
|
||||
return True, None
|
||||
|
||||
|
||||
def deep_merge(default: dict, custom: dict) -> dict:
|
||||
"""
|
||||
Recursively merges two dictionaries with priority given to `custom` values.
|
||||
|
||||
Creates a deep copy of the `default` dictionary and iteratively merges nested
|
||||
dictionaries using a stack-based approach. Non-dict values in `custom` will
|
||||
completely override corresponding entries in `default`.
|
||||
|
||||
Args:
|
||||
default (dict): Base dictionary containing default values.
|
||||
custom (dict): Dictionary containing overriding values.
|
||||
|
||||
Returns:
|
||||
dict: New merged dictionary combining values from both inputs.
|
||||
|
||||
Example:
|
||||
>>> from copy import deepcopy
|
||||
>>> default = {"a": 1, "nested": {"x": 10, "y": 20}}
|
||||
>>> custom = {"b": 2, "nested": {"y": 99, "z": 30}}
|
||||
>>> deep_merge(default, custom)
|
||||
{'a': 1, 'b': 2, 'nested': {'x': 10, 'y': 99, 'z': 30}}
|
||||
|
||||
>>> deep_merge({"config": {"mode": "auto"}}, {"config": "manual"})
|
||||
{'config': 'manual'}
|
||||
|
||||
Notes:
|
||||
1. Merge priority is always given to `custom` values at all nesting levels
|
||||
2. Non-dict values (e.g. list, str) in `custom` will replace entire values
|
||||
in `default`, even if the original value was a dictionary
|
||||
3. Time complexity: O(N) where N is total key-value pairs in `custom`
|
||||
4. Recommended for configuration merging and nested data updates
|
||||
"""
|
||||
merged = deepcopy(default)
|
||||
stack = [(merged, custom)]
|
||||
|
||||
while stack:
|
||||
base_dict, override_dict = stack.pop()
|
||||
|
||||
for key, val in override_dict.items():
|
||||
if key in base_dict and isinstance(val, dict) and isinstance(base_dict[key], dict):
|
||||
stack.append((base_dict[key], val))
|
||||
else:
|
||||
base_dict[key] = val
|
||||
|
||||
return merged
|
||||
|
||||
|
||||
def remap_dictionary_keys(source_data: dict, key_aliases: dict = None) -> dict:
|
||||
"""
|
||||
Transform dictionary keys using a configurable mapping schema.
|
||||
|
||||
Args:
|
||||
source_data: Original dictionary to process
|
||||
key_aliases: Custom key transformation rules (Optional)
|
||||
When provided, overrides default key mapping
|
||||
Format: {<original_key>: <new_key>, ...}
|
||||
|
||||
Returns:
|
||||
dict: New dictionary with transformed keys preserving original values
|
||||
|
||||
Example:
|
||||
>>> input_data = {"old_key": "value", "another_field": 42}
|
||||
>>> remap_dictionary_keys(input_data, {"old_key": "new_key"})
|
||||
{'new_key': 'value', 'another_field': 42}
|
||||
"""
|
||||
DEFAULT_KEY_MAP = {
|
||||
"chunk_num": "chunk_count",
|
||||
"doc_num": "document_count",
|
||||
"parser_id": "chunk_method",
|
||||
"embd_id": "embedding_model",
|
||||
}
|
||||
|
||||
transformed_data = {}
|
||||
mapping = key_aliases or DEFAULT_KEY_MAP
|
||||
|
||||
for original_key, value in source_data.items():
|
||||
mapped_key = mapping.get(original_key, original_key)
|
||||
transformed_data[mapped_key] = value
|
||||
|
||||
return transformed_data
|
||||
|
||||
@ -17,17 +17,20 @@ import base64
|
||||
import json
|
||||
import os
|
||||
import re
|
||||
import shutil
|
||||
import subprocess
|
||||
import sys
|
||||
import tempfile
|
||||
import threading
|
||||
from io import BytesIO
|
||||
|
||||
import pdfplumber
|
||||
from PIL import Image
|
||||
from cachetools import LRUCache, cached
|
||||
from PIL import Image
|
||||
from ruamel.yaml import YAML
|
||||
|
||||
from api.db import FileType
|
||||
from api.constants import IMG_BASE64_PREFIX
|
||||
from api.db import FileType
|
||||
|
||||
PROJECT_BASE = os.getenv("RAG_PROJECT_BASE") or os.getenv("RAG_DEPLOY_BASE")
|
||||
RAG_BASE = os.getenv("RAG_BASE")
|
||||
@ -74,7 +77,7 @@ def get_rag_python_directory(*args):
|
||||
|
||||
|
||||
def get_home_cache_dir():
|
||||
dir = os.path.join(os.path.expanduser('~'), ".ragflow")
|
||||
dir = os.path.join(os.path.expanduser("~"), ".ragflow")
|
||||
try:
|
||||
os.mkdir(dir)
|
||||
except OSError:
|
||||
@ -92,9 +95,7 @@ def load_json_conf(conf_path):
|
||||
with open(json_conf_path) as f:
|
||||
return json.load(f)
|
||||
except BaseException:
|
||||
raise EnvironmentError(
|
||||
"loading json file config from '{}' failed!".format(json_conf_path)
|
||||
)
|
||||
raise EnvironmentError("loading json file config from '{}' failed!".format(json_conf_path))
|
||||
|
||||
|
||||
def dump_json_conf(config_data, conf_path):
|
||||
@ -106,9 +107,7 @@ def dump_json_conf(config_data, conf_path):
|
||||
with open(json_conf_path, "w") as f:
|
||||
json.dump(config_data, f, indent=4)
|
||||
except BaseException:
|
||||
raise EnvironmentError(
|
||||
"loading json file config from '{}' failed!".format(json_conf_path)
|
||||
)
|
||||
raise EnvironmentError("loading json file config from '{}' failed!".format(json_conf_path))
|
||||
|
||||
|
||||
def load_json_conf_real_time(conf_path):
|
||||
@ -120,9 +119,7 @@ def load_json_conf_real_time(conf_path):
|
||||
with open(json_conf_path) as f:
|
||||
return json.load(f)
|
||||
except BaseException:
|
||||
raise EnvironmentError(
|
||||
"loading json file config from '{}' failed!".format(json_conf_path)
|
||||
)
|
||||
raise EnvironmentError("loading json file config from '{}' failed!".format(json_conf_path))
|
||||
|
||||
|
||||
def load_yaml_conf(conf_path):
|
||||
@ -130,12 +127,10 @@ def load_yaml_conf(conf_path):
|
||||
conf_path = os.path.join(get_project_base_directory(), conf_path)
|
||||
try:
|
||||
with open(conf_path) as f:
|
||||
yaml = YAML(typ='safe', pure=True)
|
||||
yaml = YAML(typ="safe", pure=True)
|
||||
return yaml.load(f)
|
||||
except Exception as e:
|
||||
raise EnvironmentError(
|
||||
"loading yaml file config from {} failed:".format(conf_path), e
|
||||
)
|
||||
raise EnvironmentError("loading yaml file config from {} failed:".format(conf_path), e)
|
||||
|
||||
|
||||
def rewrite_yaml_conf(conf_path, config):
|
||||
@ -146,13 +141,11 @@ def rewrite_yaml_conf(conf_path, config):
|
||||
yaml = YAML(typ="safe")
|
||||
yaml.dump(config, f)
|
||||
except Exception as e:
|
||||
raise EnvironmentError(
|
||||
"rewrite yaml file config {} failed:".format(conf_path), e
|
||||
)
|
||||
raise EnvironmentError("rewrite yaml file config {} failed:".format(conf_path), e)
|
||||
|
||||
|
||||
def rewrite_json_file(filepath, json_data):
|
||||
with open(filepath, "w", encoding='utf-8') as f:
|
||||
with open(filepath, "w", encoding="utf-8") as f:
|
||||
json.dump(json_data, f, indent=4, separators=(",", ": "))
|
||||
f.close()
|
||||
|
||||
@ -162,12 +155,10 @@ def filename_type(filename):
|
||||
if re.match(r".*\.pdf$", filename):
|
||||
return FileType.PDF.value
|
||||
|
||||
if re.match(
|
||||
r".*\.(eml|doc|docx|ppt|pptx|yml|xml|htm|json|csv|txt|ini|xls|xlsx|wps|rtf|hlp|pages|numbers|key|md|py|js|java|c|cpp|h|php|go|ts|sh|cs|kt|html|sql)$", filename):
|
||||
if re.match(r".*\.(eml|doc|docx|ppt|pptx|yml|xml|htm|json|csv|txt|ini|xls|xlsx|wps|rtf|hlp|pages|numbers|key|md|py|js|java|c|cpp|h|php|go|ts|sh|cs|kt|html|sql)$", filename):
|
||||
return FileType.DOC.value
|
||||
|
||||
if re.match(
|
||||
r".*\.(wav|flac|ape|alac|wavpack|wv|mp3|aac|ogg|vorbis|opus|mp3)$", filename):
|
||||
if re.match(r".*\.(wav|flac|ape|alac|wavpack|wv|mp3|aac|ogg|vorbis|opus|mp3)$", filename):
|
||||
return FileType.AURAL.value
|
||||
|
||||
if re.match(r".*\.(jpg|jpeg|png|tif|gif|pcx|tga|exif|fpx|svg|psd|cdr|pcd|dxf|ufo|eps|ai|raw|WMF|webp|avif|apng|icon|ico|mpg|mpeg|avi|rm|rmvb|mov|wmv|asf|dat|asx|wvx|mpe|mpa|mp4)$", filename):
|
||||
@ -175,6 +166,7 @@ def filename_type(filename):
|
||||
|
||||
return FileType.OTHER.value
|
||||
|
||||
|
||||
def thumbnail_img(filename, blob):
|
||||
"""
|
||||
MySQL LongText max length is 65535
|
||||
@ -183,6 +175,7 @@ def thumbnail_img(filename, blob):
|
||||
if re.match(r".*\.pdf$", filename):
|
||||
with sys.modules[LOCK_KEY_pdfplumber]:
|
||||
pdf = pdfplumber.open(BytesIO(blob))
|
||||
|
||||
buffered = BytesIO()
|
||||
resolution = 32
|
||||
img = None
|
||||
@ -206,8 +199,9 @@ def thumbnail_img(filename, blob):
|
||||
return buffered.getvalue()
|
||||
|
||||
elif re.match(r".*\.(ppt|pptx)$", filename):
|
||||
import aspose.slides as slides
|
||||
import aspose.pydrawing as drawing
|
||||
import aspose.slides as slides
|
||||
|
||||
try:
|
||||
with slides.Presentation(BytesIO(blob)) as presentation:
|
||||
buffered = BytesIO()
|
||||
@ -215,8 +209,7 @@ def thumbnail_img(filename, blob):
|
||||
img = None
|
||||
for _ in range(10):
|
||||
# https://reference.aspose.com/slides/python-net/aspose.slides/slide/get_thumbnail/#float-float
|
||||
presentation.slides[0].get_thumbnail(scale, scale).save(
|
||||
buffered, drawing.imaging.ImageFormat.png)
|
||||
presentation.slides[0].get_thumbnail(scale, scale).save(buffered, drawing.imaging.ImageFormat.png)
|
||||
img = buffered.getvalue()
|
||||
if len(img) >= 64000:
|
||||
scale = scale / 2.0
|
||||
@ -232,10 +225,9 @@ def thumbnail_img(filename, blob):
|
||||
def thumbnail(filename, blob):
|
||||
img = thumbnail_img(filename, blob)
|
||||
if img is not None:
|
||||
return IMG_BASE64_PREFIX + \
|
||||
base64.b64encode(img).decode("utf-8")
|
||||
return IMG_BASE64_PREFIX + base64.b64encode(img).decode("utf-8")
|
||||
else:
|
||||
return ''
|
||||
return ""
|
||||
|
||||
|
||||
def traversal_files(base):
|
||||
@ -243,3 +235,52 @@ def traversal_files(base):
|
||||
for f in fs:
|
||||
fullname = os.path.join(root, f)
|
||||
yield fullname
|
||||
|
||||
|
||||
def repair_pdf_with_ghostscript(input_bytes):
|
||||
if shutil.which("gs") is None:
|
||||
return input_bytes
|
||||
|
||||
with tempfile.NamedTemporaryFile(suffix=".pdf") as temp_in, tempfile.NamedTemporaryFile(suffix=".pdf") as temp_out:
|
||||
temp_in.write(input_bytes)
|
||||
temp_in.flush()
|
||||
|
||||
cmd = [
|
||||
"gs",
|
||||
"-o",
|
||||
temp_out.name,
|
||||
"-sDEVICE=pdfwrite",
|
||||
"-dPDFSETTINGS=/prepress",
|
||||
temp_in.name,
|
||||
]
|
||||
try:
|
||||
proc = subprocess.run(cmd, capture_output=True, text=True)
|
||||
if proc.returncode != 0:
|
||||
return input_bytes
|
||||
except Exception:
|
||||
return input_bytes
|
||||
|
||||
temp_out.seek(0)
|
||||
repaired_bytes = temp_out.read()
|
||||
|
||||
return repaired_bytes
|
||||
|
||||
|
||||
def read_potential_broken_pdf(blob):
|
||||
def try_open(blob):
|
||||
try:
|
||||
with pdfplumber.open(BytesIO(blob)) as pdf:
|
||||
if pdf.pages:
|
||||
return True
|
||||
except Exception:
|
||||
return False
|
||||
return False
|
||||
|
||||
if try_open(blob):
|
||||
return blob
|
||||
|
||||
repaired = repair_pdf_with_ghostscript(blob)
|
||||
if try_open(repaired):
|
||||
return repaired
|
||||
|
||||
return blob
|
||||
|
||||
653
api/utils/validation_utils.py
Normal file
653
api/utils/validation_utils.py
Normal file
@ -0,0 +1,653 @@
|
||||
#
|
||||
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
from collections import Counter
|
||||
from enum import auto
|
||||
from typing import Annotated, Any
|
||||
from uuid import UUID
|
||||
|
||||
from flask import Request
|
||||
from pydantic import BaseModel, Field, StringConstraints, ValidationError, field_validator
|
||||
from pydantic_core import PydanticCustomError
|
||||
from strenum import StrEnum
|
||||
from werkzeug.exceptions import BadRequest, UnsupportedMediaType
|
||||
|
||||
from api.constants import DATASET_NAME_LIMIT
|
||||
|
||||
|
||||
def validate_and_parse_json_request(request: Request, validator: type[BaseModel], *, extras: dict[str, Any] | None = None, exclude_unset: bool = False) -> tuple[dict[str, Any] | None, str | None]:
|
||||
"""
|
||||
Validates and parses JSON requests through a multi-stage validation pipeline.
|
||||
|
||||
Implements a four-stage validation process:
|
||||
1. Content-Type verification (must be application/json)
|
||||
2. JSON syntax validation
|
||||
3. Payload structure type checking
|
||||
4. Pydantic model validation with error formatting
|
||||
|
||||
Args:
|
||||
request (Request): Flask request object containing HTTP payload
|
||||
validator (type[BaseModel]): Pydantic model class for data validation
|
||||
extras (dict[str, Any] | None): Additional fields to merge into payload
|
||||
before validation. These fields will be removed from the final output
|
||||
exclude_unset (bool): Whether to exclude fields that have not been explicitly set
|
||||
|
||||
Returns:
|
||||
tuple[Dict[str, Any] | None, str | None]:
|
||||
- First element:
|
||||
- Validated dictionary on success
|
||||
- None on validation failure
|
||||
- Second element:
|
||||
- None on success
|
||||
- Diagnostic error message on failure
|
||||
|
||||
Raises:
|
||||
UnsupportedMediaType: When Content-Type header is not application/json
|
||||
BadRequest: For structural JSON syntax errors
|
||||
ValidationError: When payload violates Pydantic schema rules
|
||||
|
||||
Examples:
|
||||
>>> validate_and_parse_json_request(valid_request, DatasetSchema)
|
||||
({"name": "Dataset1", "format": "csv"}, None)
|
||||
|
||||
>>> validate_and_parse_json_request(xml_request, DatasetSchema)
|
||||
(None, "Unsupported content type: Expected application/json, got text/xml")
|
||||
|
||||
>>> validate_and_parse_json_request(bad_json_request, DatasetSchema)
|
||||
(None, "Malformed JSON syntax: Missing commas/brackets or invalid encoding")
|
||||
|
||||
Notes:
|
||||
1. Validation Priority:
|
||||
- Content-Type verification precedes JSON parsing
|
||||
- Structural validation occurs before schema validation
|
||||
2. Extra fields added via `extras` parameter are automatically removed
|
||||
from the final output after validation
|
||||
"""
|
||||
try:
|
||||
payload = request.get_json() or {}
|
||||
except UnsupportedMediaType:
|
||||
return None, f"Unsupported content type: Expected application/json, got {request.content_type}"
|
||||
except BadRequest:
|
||||
return None, "Malformed JSON syntax: Missing commas/brackets or invalid encoding"
|
||||
|
||||
if not isinstance(payload, dict):
|
||||
return None, f"Invalid request payload: expected object, got {type(payload).__name__}"
|
||||
|
||||
try:
|
||||
if extras is not None:
|
||||
payload.update(extras)
|
||||
validated_request = validator(**payload)
|
||||
except ValidationError as e:
|
||||
return None, format_validation_error_message(e)
|
||||
|
||||
parsed_payload = validated_request.model_dump(by_alias=True, exclude_unset=exclude_unset)
|
||||
|
||||
if extras is not None:
|
||||
for key in list(parsed_payload.keys()):
|
||||
if key in extras:
|
||||
del parsed_payload[key]
|
||||
|
||||
return parsed_payload, None
|
||||
|
||||
|
||||
def validate_and_parse_request_args(request: Request, validator: type[BaseModel], *, extras: dict[str, Any] | None = None) -> tuple[dict[str, Any] | None, str | None]:
|
||||
"""
|
||||
Validates and parses request arguments against a Pydantic model.
|
||||
|
||||
This function performs a complete request validation workflow:
|
||||
1. Extracts query parameters from the request
|
||||
2. Merges with optional extra values (if provided)
|
||||
3. Validates against the specified Pydantic model
|
||||
4. Cleans the output by removing extra values
|
||||
5. Returns either parsed data or an error message
|
||||
|
||||
Args:
|
||||
request (Request): Web framework request object containing query parameters
|
||||
validator (type[BaseModel]): Pydantic model class for validation
|
||||
extras (dict[str, Any] | None): Optional additional values to include in validation
|
||||
but exclude from final output. Defaults to None.
|
||||
|
||||
Returns:
|
||||
tuple[dict[str, Any] | None, str | None]:
|
||||
- First element: Validated/parsed arguments as dict if successful, None otherwise
|
||||
- Second element: Formatted error message if validation failed, None otherwise
|
||||
|
||||
Behavior:
|
||||
- Query parameters are merged with extras before validation
|
||||
- Extras are automatically removed from the final output
|
||||
- All validation errors are formatted into a human-readable string
|
||||
|
||||
Raises:
|
||||
TypeError: If validator is not a Pydantic BaseModel subclass
|
||||
|
||||
Examples:
|
||||
Successful validation:
|
||||
>>> validate_and_parse_request_args(request, MyValidator)
|
||||
({'param1': 'value'}, None)
|
||||
|
||||
Failed validation:
|
||||
>>> validate_and_parse_request_args(request, MyValidator)
|
||||
(None, "param1: Field required")
|
||||
|
||||
With extras:
|
||||
>>> validate_and_parse_request_args(request, MyValidator, extras={'internal_id': 123})
|
||||
({'param1': 'value'}, None) # internal_id removed from output
|
||||
|
||||
Notes:
|
||||
- Uses request.args.to_dict() for Flask-compatible parameter extraction
|
||||
- Maintains immutability of original request arguments
|
||||
- Preserves type conversion from Pydantic validation
|
||||
"""
|
||||
args = request.args.to_dict(flat=True)
|
||||
try:
|
||||
if extras is not None:
|
||||
args.update(extras)
|
||||
validated_args = validator(**args)
|
||||
except ValidationError as e:
|
||||
return None, format_validation_error_message(e)
|
||||
|
||||
parsed_args = validated_args.model_dump()
|
||||
if extras is not None:
|
||||
for key in list(parsed_args.keys()):
|
||||
if key in extras:
|
||||
del parsed_args[key]
|
||||
|
||||
return parsed_args, None
|
||||
|
||||
|
||||
def format_validation_error_message(e: ValidationError) -> str:
|
||||
"""
|
||||
Formats validation errors into a standardized string format.
|
||||
|
||||
Processes pydantic ValidationError objects to create human-readable error messages
|
||||
containing field locations, error descriptions, and input values.
|
||||
|
||||
Args:
|
||||
e (ValidationError): The validation error instance containing error details
|
||||
|
||||
Returns:
|
||||
str: Formatted error messages joined by newlines. Each line contains:
|
||||
- Field path (dot-separated)
|
||||
- Error message
|
||||
- Truncated input value (max 128 chars)
|
||||
|
||||
Example:
|
||||
>>> try:
|
||||
... UserModel(name=123, email="invalid")
|
||||
... except ValidationError as e:
|
||||
... print(format_validation_error_message(e))
|
||||
Field: <name> - Message: <Input should be a valid string> - Value: <123>
|
||||
Field: <email> - Message: <value is not a valid email address> - Value: <invalid>
|
||||
"""
|
||||
error_messages = []
|
||||
|
||||
for error in e.errors():
|
||||
field = ".".join(map(str, error["loc"]))
|
||||
msg = error["msg"]
|
||||
input_val = error["input"]
|
||||
input_str = str(input_val)
|
||||
|
||||
if len(input_str) > 128:
|
||||
input_str = input_str[:125] + "..."
|
||||
|
||||
error_msg = f"Field: <{field}> - Message: <{msg}> - Value: <{input_str}>"
|
||||
error_messages.append(error_msg)
|
||||
|
||||
return "\n".join(error_messages)
|
||||
|
||||
|
||||
def normalize_str(v: Any) -> Any:
|
||||
"""
|
||||
Normalizes string values to a standard format while preserving non-string inputs.
|
||||
|
||||
Performs the following transformations when input is a string:
|
||||
1. Trims leading/trailing whitespace (str.strip())
|
||||
2. Converts to lowercase (str.lower())
|
||||
|
||||
Non-string inputs are returned unchanged, making this function safe for mixed-type
|
||||
processing pipelines.
|
||||
|
||||
Args:
|
||||
v (Any): Input value to normalize. Accepts any Python object.
|
||||
|
||||
Returns:
|
||||
Any: Normalized string if input was string-type, original value otherwise.
|
||||
|
||||
Behavior Examples:
|
||||
String Input: " Admin " → "admin"
|
||||
Empty String: " " → "" (empty string)
|
||||
Non-String:
|
||||
- 123 → 123
|
||||
- None → None
|
||||
- ["User"] → ["User"]
|
||||
|
||||
Typical Use Cases:
|
||||
- Standardizing user input
|
||||
- Preparing data for case-insensitive comparison
|
||||
- Cleaning API parameters
|
||||
- Normalizing configuration values
|
||||
|
||||
Edge Cases:
|
||||
- Unicode whitespace is handled by str.strip()
|
||||
- Locale-independent lowercasing (str.lower())
|
||||
- Preserves falsy values (0, False, etc.)
|
||||
|
||||
Example:
|
||||
>>> normalize_str(" ReadOnly ")
|
||||
'readonly'
|
||||
>>> normalize_str(42)
|
||||
42
|
||||
"""
|
||||
if isinstance(v, str):
|
||||
stripped = v.strip()
|
||||
normalized = stripped.lower()
|
||||
return normalized
|
||||
return v
|
||||
|
||||
|
||||
def validate_uuid1_hex(v: Any) -> str:
|
||||
"""
|
||||
Validates and converts input to a UUID version 1 hexadecimal string.
|
||||
|
||||
This function performs strict validation and normalization:
|
||||
1. Accepts either UUID objects or UUID-formatted strings
|
||||
2. Verifies the UUID is version 1 (time-based)
|
||||
3. Returns the 32-character hexadecimal representation
|
||||
|
||||
Args:
|
||||
v (Any): Input value to validate. Can be:
|
||||
- UUID object (must be version 1)
|
||||
- String in UUID format (e.g. "550e8400-e29b-41d4-a716-446655440000")
|
||||
|
||||
Returns:
|
||||
str: 32-character lowercase hexadecimal string without hyphens
|
||||
Example: "550e8400e29b41d4a716446655440000"
|
||||
|
||||
Raises:
|
||||
PydanticCustomError: With code "invalid_UUID1_format" when:
|
||||
- Input is not a UUID object or valid UUID string
|
||||
- UUID version is not 1
|
||||
- String doesn't match UUID format
|
||||
|
||||
Examples:
|
||||
Valid cases:
|
||||
>>> validate_uuid1_hex("550e8400-e29b-41d4-a716-446655440000")
|
||||
'550e8400e29b41d4a716446655440000'
|
||||
>>> validate_uuid1_hex(UUID('550e8400-e29b-41d4-a716-446655440000'))
|
||||
'550e8400e29b41d4a716446655440000'
|
||||
|
||||
Invalid cases:
|
||||
>>> validate_uuid1_hex("not-a-uuid") # raises PydanticCustomError
|
||||
>>> validate_uuid1_hex(12345) # raises PydanticCustomError
|
||||
>>> validate_uuid1_hex(UUID(int=0)) # v4, raises PydanticCustomError
|
||||
|
||||
Notes:
|
||||
- Uses Python's built-in UUID parser for format validation
|
||||
- Version check prevents accidental use of other UUID versions
|
||||
- Hyphens in input strings are automatically removed in output
|
||||
"""
|
||||
try:
|
||||
uuid_obj = UUID(v) if isinstance(v, str) else v
|
||||
if uuid_obj.version != 1:
|
||||
raise PydanticCustomError("invalid_UUID1_format", "Must be a UUID1 format")
|
||||
return uuid_obj.hex
|
||||
except (AttributeError, ValueError, TypeError):
|
||||
raise PydanticCustomError("invalid_UUID1_format", "Invalid UUID1 format")
|
||||
|
||||
|
||||
class PermissionEnum(StrEnum):
|
||||
me = auto()
|
||||
team = auto()
|
||||
|
||||
|
||||
class ChunkMethodnEnum(StrEnum):
|
||||
naive = auto()
|
||||
book = auto()
|
||||
email = auto()
|
||||
laws = auto()
|
||||
manual = auto()
|
||||
one = auto()
|
||||
paper = auto()
|
||||
picture = auto()
|
||||
presentation = auto()
|
||||
qa = auto()
|
||||
table = auto()
|
||||
tag = auto()
|
||||
|
||||
|
||||
class GraphragMethodEnum(StrEnum):
|
||||
light = auto()
|
||||
general = auto()
|
||||
|
||||
|
||||
class Base(BaseModel):
|
||||
class Config:
|
||||
extra = "forbid"
|
||||
|
||||
|
||||
class RaptorConfig(Base):
|
||||
use_raptor: bool = Field(default=False)
|
||||
prompt: Annotated[
|
||||
str,
|
||||
StringConstraints(strip_whitespace=True, min_length=1),
|
||||
Field(
|
||||
default="Please summarize the following paragraphs. Be careful with the numbers, do not make things up. Paragraphs as following:\n {cluster_content}\nThe above is the content you need to summarize."
|
||||
),
|
||||
]
|
||||
max_token: int = Field(default=256, ge=1, le=2048)
|
||||
threshold: float = Field(default=0.1, ge=0.0, le=1.0)
|
||||
max_cluster: int = Field(default=64, ge=1, le=1024)
|
||||
random_seed: int = Field(default=0, ge=0)
|
||||
|
||||
|
||||
class GraphragConfig(Base):
|
||||
use_graphrag: bool = Field(default=False)
|
||||
entity_types: list[str] = Field(default_factory=lambda: ["organization", "person", "geo", "event", "category"])
|
||||
method: GraphragMethodEnum = Field(default=GraphragMethodEnum.light)
|
||||
community: bool = Field(default=False)
|
||||
resolution: bool = Field(default=False)
|
||||
|
||||
|
||||
class ParserConfig(Base):
|
||||
auto_keywords: int = Field(default=0, ge=0, le=32)
|
||||
auto_questions: int = Field(default=0, ge=0, le=10)
|
||||
chunk_token_num: int = Field(default=128, ge=1, le=2048)
|
||||
delimiter: str = Field(default=r"\n", min_length=1)
|
||||
graphrag: GraphragConfig | None = None
|
||||
html4excel: bool = False
|
||||
layout_recognize: str = "DeepDOC"
|
||||
raptor: RaptorConfig | None = None
|
||||
tag_kb_ids: list[str] = Field(default_factory=list)
|
||||
topn_tags: int = Field(default=1, ge=1, le=10)
|
||||
filename_embd_weight: float | None = Field(default=None, ge=0.0, le=1.0)
|
||||
task_page_size: int | None = Field(default=None, ge=1)
|
||||
pages: list[list[int]] | None = None
|
||||
|
||||
|
||||
class CreateDatasetReq(Base):
|
||||
name: Annotated[str, StringConstraints(strip_whitespace=True, min_length=1, max_length=DATASET_NAME_LIMIT), Field(...)]
|
||||
avatar: str | None = Field(default=None, max_length=65535)
|
||||
description: str | None = Field(default=None, max_length=65535)
|
||||
embedding_model: Annotated[str, StringConstraints(strip_whitespace=True, max_length=255), Field(default="", serialization_alias="embd_id")]
|
||||
permission: PermissionEnum = Field(default=PermissionEnum.me, min_length=1, max_length=16)
|
||||
chunk_method: ChunkMethodnEnum = Field(default=ChunkMethodnEnum.naive, min_length=1, max_length=32, serialization_alias="parser_id")
|
||||
pagerank: int = Field(default=0, ge=0, le=100)
|
||||
parser_config: ParserConfig | None = Field(default=None)
|
||||
|
||||
@field_validator("avatar")
|
||||
@classmethod
|
||||
def validate_avatar_base64(cls, v: str | None) -> str | None:
|
||||
"""
|
||||
Validates Base64-encoded avatar string format and MIME type compliance.
|
||||
|
||||
Implements a three-stage validation workflow:
|
||||
1. MIME prefix existence check
|
||||
2. MIME type format validation
|
||||
3. Supported type verification
|
||||
|
||||
Args:
|
||||
v (str): Raw avatar field value
|
||||
|
||||
Returns:
|
||||
str: Validated Base64 string
|
||||
|
||||
Raises:
|
||||
PydanticCustomError: For structural errors in these cases:
|
||||
- Missing MIME prefix header
|
||||
- Invalid MIME prefix format
|
||||
- Unsupported image MIME type
|
||||
|
||||
Example:
|
||||
```python
|
||||
# Valid case
|
||||
CreateDatasetReq(avatar="data:image/png;base64,iVBORw0KGg...")
|
||||
|
||||
# Invalid cases
|
||||
CreateDatasetReq(avatar="image/jpeg;base64,...") # Missing 'data:' prefix
|
||||
CreateDatasetReq(avatar="data:video/mp4;base64,...") # Unsupported MIME type
|
||||
```
|
||||
"""
|
||||
if v is None:
|
||||
return v
|
||||
|
||||
if "," in v:
|
||||
prefix, _ = v.split(",", 1)
|
||||
if not prefix.startswith("data:"):
|
||||
raise PydanticCustomError("format_invalid", "Invalid MIME prefix format. Must start with 'data:'")
|
||||
|
||||
mime_type = prefix[5:].split(";")[0]
|
||||
supported_mime_types = ["image/jpeg", "image/png"]
|
||||
if mime_type not in supported_mime_types:
|
||||
raise PydanticCustomError("format_invalid", "Unsupported MIME type. Allowed: {supported_mime_types}", {"supported_mime_types": supported_mime_types})
|
||||
|
||||
return v
|
||||
else:
|
||||
raise PydanticCustomError("format_invalid", "Missing MIME prefix. Expected format: data:<mime>;base64,<data>")
|
||||
|
||||
@field_validator("embedding_model", mode="after")
|
||||
@classmethod
|
||||
def validate_embedding_model(cls, v: str) -> str:
|
||||
"""
|
||||
Validates embedding model identifier format compliance.
|
||||
|
||||
Validation pipeline:
|
||||
1. Structural format verification
|
||||
2. Component non-empty check
|
||||
3. Value normalization
|
||||
|
||||
Args:
|
||||
v (str): Raw model identifier
|
||||
|
||||
Returns:
|
||||
str: Validated <model_name>@<provider> format
|
||||
|
||||
Raises:
|
||||
PydanticCustomError: For these violations:
|
||||
- Missing @ separator
|
||||
- Empty model_name/provider
|
||||
- Invalid component structure
|
||||
|
||||
Examples:
|
||||
Valid: "text-embedding-3-large@openai"
|
||||
Invalid: "invalid_model" (no @)
|
||||
Invalid: "@openai" (empty model_name)
|
||||
Invalid: "text-embedding-3-large@" (empty provider)
|
||||
"""
|
||||
if "@" not in v:
|
||||
raise PydanticCustomError("format_invalid", "Embedding model identifier must follow <model_name>@<provider> format")
|
||||
|
||||
components = v.split("@", 1)
|
||||
if len(components) != 2 or not all(components):
|
||||
raise PydanticCustomError("format_invalid", "Both model_name and provider must be non-empty strings")
|
||||
|
||||
model_name, provider = components
|
||||
if not model_name.strip() or not provider.strip():
|
||||
raise PydanticCustomError("format_invalid", "Model name and provider cannot be whitespace-only strings")
|
||||
return v
|
||||
|
||||
@field_validator("permission", mode="before")
|
||||
@classmethod
|
||||
def normalize_permission(cls, v: Any) -> Any:
|
||||
return normalize_str(v)
|
||||
|
||||
@field_validator("parser_config", mode="before")
|
||||
@classmethod
|
||||
def normalize_empty_parser_config(cls, v: Any) -> Any:
|
||||
"""
|
||||
Normalizes empty parser configuration by converting empty dictionaries to None.
|
||||
|
||||
This validator ensures consistent handling of empty parser configurations across
|
||||
the application by converting empty dicts to None values.
|
||||
|
||||
Args:
|
||||
v (Any): Raw input value for the parser config field
|
||||
|
||||
Returns:
|
||||
Any: Returns None if input is an empty dict, otherwise returns the original value
|
||||
|
||||
Example:
|
||||
>>> normalize_empty_parser_config({})
|
||||
None
|
||||
|
||||
>>> normalize_empty_parser_config({"key": "value"})
|
||||
{"key": "value"}
|
||||
"""
|
||||
if v == {}:
|
||||
return None
|
||||
return v
|
||||
|
||||
@field_validator("parser_config", mode="after")
|
||||
@classmethod
|
||||
def validate_parser_config_json_length(cls, v: ParserConfig | None) -> ParserConfig | None:
|
||||
"""
|
||||
Validates serialized JSON length constraints for parser configuration.
|
||||
|
||||
Implements a two-stage validation workflow:
|
||||
1. Null check - bypass validation for empty configurations
|
||||
2. Model serialization - convert Pydantic model to JSON string
|
||||
3. Size verification - enforce maximum allowed payload size
|
||||
|
||||
Args:
|
||||
v (ParserConfig | None): Raw parser configuration object
|
||||
|
||||
Returns:
|
||||
ParserConfig | None: Validated configuration object
|
||||
|
||||
Raises:
|
||||
PydanticCustomError: When serialized JSON exceeds 65,535 characters
|
||||
"""
|
||||
if v is None:
|
||||
return None
|
||||
|
||||
if (json_str := v.model_dump_json()) and len(json_str) > 65535:
|
||||
raise PydanticCustomError("string_too_long", "Parser config exceeds size limit (max 65,535 characters). Current size: {actual}", {"actual": len(json_str)})
|
||||
return v
|
||||
|
||||
|
||||
class UpdateDatasetReq(CreateDatasetReq):
|
||||
dataset_id: str = Field(...)
|
||||
name: Annotated[str, StringConstraints(strip_whitespace=True, min_length=1, max_length=DATASET_NAME_LIMIT), Field(default="")]
|
||||
|
||||
@field_validator("dataset_id", mode="before")
|
||||
@classmethod
|
||||
def validate_dataset_id(cls, v: Any) -> str:
|
||||
return validate_uuid1_hex(v)
|
||||
|
||||
|
||||
class DeleteReq(Base):
|
||||
ids: list[str] | None = Field(...)
|
||||
|
||||
@field_validator("ids", mode="after")
|
||||
@classmethod
|
||||
def validate_ids(cls, v_list: list[str] | None) -> list[str] | None:
|
||||
"""
|
||||
Validates and normalizes a list of UUID strings with None handling.
|
||||
|
||||
This post-processing validator performs:
|
||||
1. None input handling (pass-through)
|
||||
2. UUID version 1 validation for each list item
|
||||
3. Duplicate value detection
|
||||
4. Returns normalized UUID hex strings or None
|
||||
|
||||
Args:
|
||||
v_list (list[str] | None): Input list that has passed initial validation.
|
||||
Either a list of UUID strings or None.
|
||||
|
||||
Returns:
|
||||
list[str] | None:
|
||||
- None if input was None
|
||||
- List of normalized UUID hex strings otherwise:
|
||||
* 32-character lowercase
|
||||
* Valid UUID version 1
|
||||
* Unique within list
|
||||
|
||||
Raises:
|
||||
PydanticCustomError: With structured error details when:
|
||||
- "invalid_UUID1_format": Any string fails UUIDv1 validation
|
||||
- "duplicate_uuids": If duplicate IDs are detected
|
||||
|
||||
Validation Rules:
|
||||
- None input returns None
|
||||
- Empty list returns empty list
|
||||
- All non-None items must be valid UUIDv1
|
||||
- No duplicates permitted
|
||||
- Original order preserved
|
||||
|
||||
Examples:
|
||||
Valid cases:
|
||||
>>> validate_ids(None)
|
||||
None
|
||||
>>> validate_ids([])
|
||||
[]
|
||||
>>> validate_ids(["550e8400-e29b-41d4-a716-446655440000"])
|
||||
["550e8400e29b41d4a716446655440000"]
|
||||
|
||||
Invalid cases:
|
||||
>>> validate_ids(["invalid"])
|
||||
# raises PydanticCustomError(invalid_UUID1_format)
|
||||
>>> validate_ids(["550e...", "550e..."])
|
||||
# raises PydanticCustomError(duplicate_uuids)
|
||||
|
||||
Security Notes:
|
||||
- Validates UUID version to prevent version spoofing
|
||||
- Duplicate check prevents data injection
|
||||
- None handling maintains pipeline integrity
|
||||
"""
|
||||
if v_list is None:
|
||||
return None
|
||||
|
||||
ids_list = []
|
||||
for v in v_list:
|
||||
try:
|
||||
ids_list.append(validate_uuid1_hex(v))
|
||||
except PydanticCustomError as e:
|
||||
raise e
|
||||
|
||||
duplicates = [item for item, count in Counter(ids_list).items() if count > 1]
|
||||
if duplicates:
|
||||
duplicates_str = ", ".join(duplicates)
|
||||
raise PydanticCustomError("duplicate_uuids", "Duplicate ids: '{duplicate_ids}'", {"duplicate_ids": duplicates_str})
|
||||
|
||||
return ids_list
|
||||
|
||||
|
||||
class DeleteDatasetReq(DeleteReq): ...
|
||||
|
||||
|
||||
class OrderByEnum(StrEnum):
|
||||
create_time = auto()
|
||||
update_time = auto()
|
||||
|
||||
|
||||
class BaseListReq(Base):
|
||||
id: str | None = None
|
||||
name: str | None = None
|
||||
page: int = Field(default=1, ge=1)
|
||||
page_size: int = Field(default=30, ge=1)
|
||||
orderby: OrderByEnum = Field(default=OrderByEnum.create_time)
|
||||
desc: bool = Field(default=True)
|
||||
|
||||
@field_validator("id", mode="before")
|
||||
@classmethod
|
||||
def validate_id(cls, v: Any) -> str:
|
||||
return validate_uuid1_hex(v)
|
||||
|
||||
@field_validator("orderby", mode="before")
|
||||
@classmethod
|
||||
def normalize_orderby(cls, v: Any) -> Any:
|
||||
return normalize_str(v)
|
||||
|
||||
|
||||
class ListDatasetReq(BaseListReq): ...
|
||||
@ -38,5 +38,7 @@
|
||||
"entity_type_kwd": {"type": "varchar", "default": "", "analyzer": "whitespace-#"},
|
||||
"source_id": {"type": "varchar", "default": "", "analyzer": "whitespace-#"},
|
||||
"n_hop_with_weight": {"type": "varchar", "default": ""},
|
||||
"removed_kwd": {"type": "varchar", "default": "", "analyzer": "whitespace-#"}
|
||||
"removed_kwd": {"type": "varchar", "default": "", "analyzer": "whitespace-#"},
|
||||
|
||||
"doc_type_kwd": {"type": "varchar", "default": "", "analyzer": "whitespace-#"}
|
||||
}
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
213
conf/os_mapping.json
Normal file
213
conf/os_mapping.json
Normal file
@ -0,0 +1,213 @@
|
||||
{
|
||||
"settings": {
|
||||
"index": {
|
||||
"number_of_shards": 2,
|
||||
"number_of_replicas": 0,
|
||||
"refresh_interval": "1000ms",
|
||||
"knn": true,
|
||||
"similarity": {
|
||||
"scripted_sim": {
|
||||
"type": "scripted",
|
||||
"script": {
|
||||
"source": "double idf = Math.log(1+(field.docCount-term.docFreq+0.5)/(term.docFreq + 0.5))/Math.log(1+((field.docCount-0.5)/1.5)); return query.boost * idf * Math.min(doc.freq, 1);"
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
},
|
||||
"mappings": {
|
||||
"properties": {
|
||||
"lat_lon": {
|
||||
"type": "geo_point",
|
||||
"store": "true"
|
||||
}
|
||||
},
|
||||
"date_detection": "true",
|
||||
"dynamic_templates": [
|
||||
{
|
||||
"int": {
|
||||
"match": "*_int",
|
||||
"mapping": {
|
||||
"type": "integer",
|
||||
"store": "true"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"ulong": {
|
||||
"match": "*_ulong",
|
||||
"mapping": {
|
||||
"type": "unsigned_long",
|
||||
"store": "true"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"long": {
|
||||
"match": "*_long",
|
||||
"mapping": {
|
||||
"type": "long",
|
||||
"store": "true"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"short": {
|
||||
"match": "*_short",
|
||||
"mapping": {
|
||||
"type": "short",
|
||||
"store": "true"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"numeric": {
|
||||
"match": "*_flt",
|
||||
"mapping": {
|
||||
"type": "float",
|
||||
"store": true
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"tks": {
|
||||
"match": "*_tks",
|
||||
"mapping": {
|
||||
"type": "text",
|
||||
"similarity": "scripted_sim",
|
||||
"analyzer": "whitespace",
|
||||
"store": true
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"ltks": {
|
||||
"match": "*_ltks",
|
||||
"mapping": {
|
||||
"type": "text",
|
||||
"analyzer": "whitespace",
|
||||
"store": true
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"kwd": {
|
||||
"match_pattern": "regex",
|
||||
"match": "^(.*_(kwd|id|ids|uid|uids)|uid)$",
|
||||
"mapping": {
|
||||
"type": "keyword",
|
||||
"similarity": "boolean",
|
||||
"store": true
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"dt": {
|
||||
"match_pattern": "regex",
|
||||
"match": "^.*(_dt|_time|_at)$",
|
||||
"mapping": {
|
||||
"type": "date",
|
||||
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||yyyy-MM-dd_HH:mm:ss",
|
||||
"store": true
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"nested": {
|
||||
"match": "*_nst",
|
||||
"mapping": {
|
||||
"type": "nested"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"object": {
|
||||
"match": "*_obj",
|
||||
"mapping": {
|
||||
"type": "object",
|
||||
"dynamic": "true"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"string": {
|
||||
"match_pattern": "regex",
|
||||
"match": "^.*_(with_weight|list)$",
|
||||
"mapping": {
|
||||
"type": "text",
|
||||
"index": "false",
|
||||
"store": true
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"rank_feature": {
|
||||
"match": "*_fea",
|
||||
"mapping": {
|
||||
"type": "rank_feature"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"rank_features": {
|
||||
"match": "*_feas",
|
||||
"mapping": {
|
||||
"type": "rank_features"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"knn_vector": {
|
||||
"match": "*_512_vec",
|
||||
"mapping": {
|
||||
"type": "knn_vector",
|
||||
"index": true,
|
||||
"space_type": "cosinesimil",
|
||||
"dimension": 512
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"knn_vector": {
|
||||
"match": "*_768_vec",
|
||||
"mapping": {
|
||||
"type": "knn_vector",
|
||||
"index": true,
|
||||
"space_type": "cosinesimil",
|
||||
"dimension": 768
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"knn_vector": {
|
||||
"match": "*_1024_vec",
|
||||
"mapping": {
|
||||
"type": "knn_vector",
|
||||
"index": true,
|
||||
"space_type": "cosinesimil",
|
||||
"dimension": 1024
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"knn_vector": {
|
||||
"match": "*_1536_vec",
|
||||
"mapping": {
|
||||
"type": "knn_vector",
|
||||
"index": true,
|
||||
"space_type": "cosinesimil",
|
||||
"dimension": 1536
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"binary": {
|
||||
"match": "*_bin",
|
||||
"mapping": {
|
||||
"type": "binary"
|
||||
}
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
@ -7,8 +7,8 @@ mysql:
|
||||
password: 'infini_rag_flow'
|
||||
host: 'localhost'
|
||||
port: 5455
|
||||
max_connections: 100
|
||||
stale_timeout: 30
|
||||
max_connections: 900
|
||||
stale_timeout: 300
|
||||
minio:
|
||||
user: 'rag_flow'
|
||||
password: 'infini_rag_flow'
|
||||
@ -17,6 +17,10 @@ es:
|
||||
hosts: 'http://localhost:1200'
|
||||
username: 'elastic'
|
||||
password: 'infini_rag_flow'
|
||||
os:
|
||||
hosts: 'http://localhost:1201'
|
||||
username: 'admin'
|
||||
password: 'infini_rag_flow_OS_01'
|
||||
infinity:
|
||||
uri: 'localhost:23817'
|
||||
db_name: 'default_db'
|
||||
@ -59,16 +63,28 @@ redis:
|
||||
# api_key: 'sk-xxxxxxxxxxxxx'
|
||||
# base_url: ''
|
||||
# oauth:
|
||||
# oauth2:
|
||||
# display_name: "OAuth2"
|
||||
# client_id: "your_client_id"
|
||||
# client_secret: "your_client_secret"
|
||||
# authorization_url: "https://your-oauth-provider.com/oauth/authorize"
|
||||
# token_url: "https://your-oauth-provider.com/oauth/token"
|
||||
# userinfo_url: "https://your-oauth-provider.com/oauth/userinfo"
|
||||
# redirect_uri: "https://your-app.com/v1/user/oauth/callback/oauth2"
|
||||
# oidc:
|
||||
# display_name: "OIDC"
|
||||
# client_id: "your_client_id"
|
||||
# client_secret: "your_client_secret"
|
||||
# issuer: "https://your-oauth-provider.com/oidc"
|
||||
# scope: "openid email profile"
|
||||
# redirect_uri: "https://your-app.com/v1/user/oauth/callback/oidc"
|
||||
# github:
|
||||
# client_id: xxxxxxxxxxxxxxxxxxxxxxxxx
|
||||
# secret_key: xxxxxxxxxxxxxxxxxxxxxxxxxxxx
|
||||
# url: https://github.com/login/oauth/access_token
|
||||
# feishu:
|
||||
# app_id: cli_xxxxxxxxxxxxxxxxxxx
|
||||
# app_secret: xxxxxxxxxxxxxxxxxxxxxxxxxxxx
|
||||
# app_access_token_url: https://open.feishu.cn/open-apis/auth/v3/app_access_token/internal
|
||||
# user_access_token_url: https://open.feishu.cn/open-apis/authen/v1/oidc/access_token
|
||||
# grant_type: 'authorization_code'
|
||||
# type: "github"
|
||||
# icon: "github"
|
||||
# display_name: "Github"
|
||||
# client_id: "your_client_id"
|
||||
# client_secret: "your_client_secret"
|
||||
# redirect_uri: "https://your-app.com/v1/user/oauth/callback/github"
|
||||
# authentication:
|
||||
# client:
|
||||
# switch: false
|
||||
|
||||
@ -13,7 +13,7 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
|
||||
from concurrent.futures import ThreadPoolExecutor, as_completed
|
||||
|
||||
from PIL import Image
|
||||
|
||||
@ -22,10 +22,17 @@ from rag.prompts import vision_llm_figure_describe_prompt
|
||||
|
||||
|
||||
def vision_figure_parser_figure_data_wraper(figures_data_without_positions):
|
||||
return [(
|
||||
(figure_data[1], [figure_data[0]]),
|
||||
[(0, 0, 0, 0, 0)]
|
||||
) for figure_data in figures_data_without_positions if isinstance(figure_data[1], Image.Image)]
|
||||
return [
|
||||
(
|
||||
(figure_data[1], [figure_data[0]]),
|
||||
[(0, 0, 0, 0, 0)],
|
||||
)
|
||||
for figure_data in figures_data_without_positions
|
||||
if isinstance(figure_data[1], Image.Image)
|
||||
]
|
||||
|
||||
|
||||
shared_executor = ThreadPoolExecutor(max_workers=10)
|
||||
|
||||
|
||||
class VisionFigureParser:
|
||||
@ -42,14 +49,14 @@ class VisionFigureParser:
|
||||
|
||||
for item in figures_data:
|
||||
# position
|
||||
if len(item) == 2 and isinstance(item[1], list) and len(item[1]) == 1 and isinstance(item[1][0], tuple) and len(item[1][0]) == 5:
|
||||
if len(item) == 2 and isinstance(item[0], tuple) and len(item[0]) == 2 and isinstance(item[1], list) and isinstance(item[1][0], tuple) and len(item[1][0]) == 5:
|
||||
img_desc = item[0]
|
||||
assert len(img_desc) == 2 and isinstance(img_desc[0], Image.Image) and isinstance(img_desc[1], list), "Should be (figure, [description])"
|
||||
self.figures.append(img_desc[0])
|
||||
self.descriptions.append(img_desc[1])
|
||||
self.positions.append(item[1])
|
||||
else:
|
||||
assert len(item) == 2 and isinstance(item, tuple) and isinstance(item[1], list), f"get {len(item)=}, {item=}"
|
||||
assert len(item) == 2 and isinstance(item[0], Image.Image) and isinstance(item[1], list), f"Unexpected form of figure data: get {len(item)=}, {item=}"
|
||||
self.figures.append(item[0])
|
||||
self.descriptions.append(item[1])
|
||||
|
||||
@ -73,16 +80,21 @@ class VisionFigureParser:
|
||||
def __call__(self, **kwargs):
|
||||
callback = kwargs.get("callback", lambda prog, msg: None)
|
||||
|
||||
for idx, img_binary in enumerate(self.figures or []):
|
||||
figure_num = idx # 0-based
|
||||
|
||||
txt = picture_vision_llm_chunk(
|
||||
binary=img_binary,
|
||||
def process(figure_idx, figure_binary):
|
||||
description_text = picture_vision_llm_chunk(
|
||||
binary=figure_binary,
|
||||
vision_model=self.vision_model,
|
||||
prompt=vision_llm_figure_describe_prompt(),
|
||||
callback=callback,
|
||||
)
|
||||
return figure_idx, description_text
|
||||
|
||||
futures = []
|
||||
for idx, img_binary in enumerate(self.figures or []):
|
||||
futures.append(shared_executor.submit(process, idx, img_binary))
|
||||
|
||||
for future in as_completed(futures):
|
||||
figure_num, txt = future.result()
|
||||
if txt:
|
||||
self.descriptions[figure_num] = txt + "\n".join(self.descriptions[figure_num])
|
||||
|
||||
|
||||
@ -307,13 +307,13 @@ class RAGFlowPdfParser:
|
||||
[{"x0": b[0][0] / ZM, "x1": b[1][0] / ZM,
|
||||
"top": b[0][1] / ZM, "text": "", "txt": t,
|
||||
"bottom": b[-1][1] / ZM,
|
||||
"chars": [],
|
||||
"page_number": pagenum} for b, t in bxs if b[0][0] <= b[1][0] and b[0][1] <= b[-1][1]],
|
||||
self.mean_height[-1] / 3
|
||||
self.mean_height[pagenum-1] / 3
|
||||
)
|
||||
|
||||
# merge chars in the same rect
|
||||
for c in Recognizer.sort_Y_firstly(
|
||||
chars, self.mean_height[pagenum - 1] // 4):
|
||||
for c in chars:
|
||||
ii = Recognizer.find_overlapped(c, bxs)
|
||||
if ii is None:
|
||||
self.lefted_chars.append(c)
|
||||
@ -323,11 +323,20 @@ class RAGFlowPdfParser:
|
||||
if abs(ch - bh) / max(ch, bh) >= 0.7 and c["text"] != ' ':
|
||||
self.lefted_chars.append(c)
|
||||
continue
|
||||
if c["text"] == " " and bxs[ii]["text"]:
|
||||
if re.match(r"[0-9a-zA-Zа-яА-Я,.?;:!%%]", bxs[ii]["text"][-1]):
|
||||
bxs[ii]["text"] += " "
|
||||
else:
|
||||
bxs[ii]["text"] += c["text"]
|
||||
bxs[ii]["chars"].append(c)
|
||||
|
||||
for b in bxs:
|
||||
if not b["chars"]:
|
||||
del b["chars"]
|
||||
continue
|
||||
m_ht = np.mean([c["height"] for c in b["chars"]])
|
||||
for c in Recognizer.sort_Y_firstly(b["chars"], m_ht):
|
||||
if c["text"] == " " and b["text"]:
|
||||
if re.match(r"[0-9a-zA-Zа-яА-Я,.?;:!%%]", b["text"][-1]):
|
||||
b["text"] += " "
|
||||
else:
|
||||
b["text"] += c["text"]
|
||||
del b["chars"]
|
||||
|
||||
logging.info(f"__ocr sorting {len(chars)} chars cost {timer() - start}s")
|
||||
start = timer()
|
||||
@ -346,8 +355,8 @@ class RAGFlowPdfParser:
|
||||
del boxes_to_reg[i]["box_image"]
|
||||
logging.info(f"__ocr recognize {len(bxs)} boxes cost {timer() - start}s")
|
||||
bxs = [b for b in bxs if b["text"]]
|
||||
if self.mean_height[-1] == 0:
|
||||
self.mean_height[-1] = np.median([b["bottom"] - b["top"]
|
||||
if self.mean_height[pagenum-1] == 0:
|
||||
self.mean_height[pagenum-1] = np.median([b["bottom"] - b["top"]
|
||||
for b in bxs])
|
||||
self.boxes.append(bxs)
|
||||
|
||||
@ -1006,7 +1015,7 @@ class RAGFlowPdfParser:
|
||||
with sys.modules[LOCK_KEY_pdfplumber]:
|
||||
with (pdfplumber.open(fnm) if isinstance(fnm, str) else pdfplumber.open(BytesIO(fnm))) as pdf:
|
||||
self.pdf = pdf
|
||||
self.page_images = [p.to_image(resolution=72 * zoomin).annotated for i, p in
|
||||
self.page_images = [p.to_image(resolution=72 * zoomin, antialias=True).annotated for i, p in
|
||||
enumerate(self.pdf.pages[page_from:page_to])]
|
||||
|
||||
try:
|
||||
|
||||
96
docker/.env
96
docker/.env
@ -1,7 +1,8 @@
|
||||
# The type of doc engine to use.
|
||||
# Available options:
|
||||
# - `elasticsearch` (default)
|
||||
# - `elasticsearch` (default)
|
||||
# - `infinity` (https://github.com/infiniflow/infinity)
|
||||
# - `opensearch` (https://github.com/opensearch-project/OpenSearch)
|
||||
DOC_ENGINE=${DOC_ENGINE:-elasticsearch}
|
||||
|
||||
# ------------------------------
|
||||
@ -17,14 +18,24 @@ STACK_VERSION=8.11.3
|
||||
# The hostname where the Elasticsearch service is exposed
|
||||
ES_HOST=es01
|
||||
|
||||
# The port used to expose the Elasticsearch service to the host machine,
|
||||
# The port used to expose the Elasticsearch service to the host machine,
|
||||
# allowing EXTERNAL access to the service running inside the Docker container.
|
||||
ES_PORT=1200
|
||||
|
||||
# The password for Elasticsearch.
|
||||
# The password for Elasticsearch.
|
||||
ELASTIC_PASSWORD=infini_rag_flow
|
||||
|
||||
# The port used to expose the Kibana service to the host machine,
|
||||
# the hostname where OpenSearch service is exposed, set it not the same as elasticsearch
|
||||
OS_PORT=1201
|
||||
|
||||
# The hostname where the OpenSearch service is exposed
|
||||
OS_HOST=opensearch01
|
||||
|
||||
# The password for OpenSearch.
|
||||
# At least one uppercase letter, one lowercase letter, one digit, and one special character
|
||||
OPENSEARCH_PASSWORD=infini_rag_flow_OS_01
|
||||
|
||||
# The port used to expose the Kibana service to the host machine,
|
||||
# allowing EXTERNAL access to the service running inside the Docker container.
|
||||
KIBANA_PORT=6601
|
||||
KIBANA_USER=rag_flow
|
||||
@ -42,56 +53,54 @@ INFINITY_THRIFT_PORT=23817
|
||||
INFINITY_HTTP_PORT=23820
|
||||
INFINITY_PSQL_PORT=5432
|
||||
|
||||
# The password for MySQL.
|
||||
# The password for MySQL.
|
||||
MYSQL_PASSWORD=infini_rag_flow
|
||||
# The hostname where the MySQL service is exposed
|
||||
MYSQL_HOST=mysql
|
||||
# The database of the MySQL service to use
|
||||
MYSQL_DBNAME=rag_flow
|
||||
# The port used to expose the MySQL service to the host machine,
|
||||
# allowing EXTERNAL access to the MySQL database running inside the Docker container.
|
||||
# The port used to expose the MySQL service to the host machine,
|
||||
# allowing EXTERNAL access to the MySQL database running inside the Docker container.
|
||||
MYSQL_PORT=5455
|
||||
|
||||
# The hostname where the MinIO service is exposed
|
||||
MINIO_HOST=minio
|
||||
# The port used to expose the MinIO console interface to the host machine,
|
||||
# allowing EXTERNAL access to the web-based console running inside the Docker container.
|
||||
# The port used to expose the MinIO console interface to the host machine,
|
||||
# allowing EXTERNAL access to the web-based console running inside the Docker container.
|
||||
MINIO_CONSOLE_PORT=9001
|
||||
# The port used to expose the MinIO API service to the host machine,
|
||||
# allowing EXTERNAL access to the MinIO object storage service running inside the Docker container.
|
||||
# The port used to expose the MinIO API service to the host machine,
|
||||
# allowing EXTERNAL access to the MinIO object storage service running inside the Docker container.
|
||||
MINIO_PORT=9000
|
||||
# The username for MinIO.
|
||||
# The username for MinIO.
|
||||
# When updated, you must revise the `minio.user` entry in service_conf.yaml accordingly.
|
||||
MINIO_USER=rag_flow
|
||||
# The password for MinIO.
|
||||
# The password for MinIO.
|
||||
# When updated, you must revise the `minio.password` entry in service_conf.yaml accordingly.
|
||||
MINIO_PASSWORD=infini_rag_flow
|
||||
|
||||
# The hostname where the Redis service is exposed
|
||||
REDIS_HOST=redis
|
||||
# The port used to expose the Redis service to the host machine,
|
||||
# The port used to expose the Redis service to the host machine,
|
||||
# allowing EXTERNAL access to the Redis service running inside the Docker container.
|
||||
REDIS_PORT=6379
|
||||
# The password for Redis.
|
||||
REDIS_PASSWORD=infini_rag_flow
|
||||
|
||||
# The port used to expose RAGFlow's HTTP API service to the host machine,
|
||||
# The port used to expose RAGFlow's HTTP API service to the host machine,
|
||||
# allowing EXTERNAL access to the service running inside the Docker container.
|
||||
SVR_HTTP_PORT=9380
|
||||
|
||||
# The RAGFlow Docker image to download.
|
||||
# Defaults to the v0.18.0-slim edition, which is the RAGFlow Docker image without embedding models.
|
||||
RAGFLOW_IMAGE=infiniflow/ragflow:v0.18.0-slim
|
||||
# Defaults to the v0.19.0-slim edition, which is the RAGFlow Docker image without embedding models.
|
||||
RAGFLOW_IMAGE=infiniflow/ragflow:v0.19.0-slim
|
||||
#
|
||||
# To download the RAGFlow Docker image with embedding models, uncomment the following line instead:
|
||||
# RAGFLOW_IMAGE=infiniflow/ragflow:v0.18.0
|
||||
#
|
||||
# The Docker image of the v0.18.0 edition includes built-in embedding models:
|
||||
# RAGFLOW_IMAGE=infiniflow/ragflow:v0.19.0
|
||||
#
|
||||
# The Docker image of the v0.19.0 edition includes built-in embedding models:
|
||||
# - BAAI/bge-large-zh-v1.5
|
||||
# - maidalun1020/bce-embedding-base_v1
|
||||
|
||||
#
|
||||
|
||||
#
|
||||
|
||||
# If you cannot download the RAGFlow Docker image:
|
||||
#
|
||||
@ -120,13 +129,13 @@ TIMEZONE='Asia/Shanghai'
|
||||
# Note that neither `MAX_CONTENT_LENGTH` nor `client_max_body_size` sets the maximum size for files uploaded to an agent.
|
||||
# See https://ragflow.io/docs/dev/begin_component for details.
|
||||
|
||||
# The log level for the RAGFlow's owned packages and imported packages.
|
||||
# Available level:
|
||||
# Log level for the RAGFlow's own and imported packages.
|
||||
# Available levels:
|
||||
# - `DEBUG`
|
||||
# - `INFO` (default)
|
||||
# - `WARNING`
|
||||
# - `ERROR`
|
||||
# For example, following line changes the log level of `ragflow.es_conn` to `DEBUG`:
|
||||
# For example, the following line changes the log level of `ragflow.es_conn` to `DEBUG`:
|
||||
# LOG_LEVELS=ragflow.es_conn=DEBUG
|
||||
|
||||
# aliyun OSS configuration
|
||||
@ -137,5 +146,38 @@ TIMEZONE='Asia/Shanghai'
|
||||
# REGION=cn-hangzhou
|
||||
# BUCKET=ragflow65536
|
||||
|
||||
# user registration switch
|
||||
# A user registration switch:
|
||||
# - Enable registration: 1
|
||||
# - Disable registration: 0
|
||||
REGISTER_ENABLED=1
|
||||
|
||||
# Sandbox settings
|
||||
# Important: To enable sandbox, you must re-declare the compose profiles. See hints at the end of file.
|
||||
# Double check if you add `sandbox-executor-manager` to your `/etc/hosts`
|
||||
# Pull the required base images before running:
|
||||
# docker pull infiniflow/sandbox-base-nodejs:latest
|
||||
# docker pull infiniflow/sandbox-base-python:latest
|
||||
# Our default sandbox environments include:
|
||||
# - Node.js base image: includes axios
|
||||
# - Python base image: includes requests, numpy, and pandas
|
||||
# Specify custom executor images below if you're using non-default environments.
|
||||
# SANDBOX_ENABLED=1
|
||||
# SANDBOX_HOST=sandbox-executor-manager
|
||||
# SANDBOX_EXECUTOR_MANAGER_IMAGE=infiniflow/sandbox-executor-manager:latest
|
||||
# SANDBOX_EXECUTOR_MANAGER_POOL_SIZE=3
|
||||
# SANDBOX_BASE_PYTHON_IMAGE=infiniflow/sandbox-base-python:latest
|
||||
# SANDBOX_BASE_NODEJS_IMAGE=infiniflow/sandbox-base-nodejs:latest
|
||||
# SANDBOX_EXECUTOR_MANAGER_PORT=9385
|
||||
# SANDBOX_ENABLE_SECCOMP=false
|
||||
# SANDBOX_MAX_MEMORY=256m # b, k, m, g
|
||||
# SANDBOX_TIMEOUT=10s # s, m, 1m30s
|
||||
|
||||
# Important: To enable sandbox, you must re-declare the compose profiles.
|
||||
# 1. Comment out the COMPOSE_PROFILES line above.
|
||||
# 2. Uncomment one of the following based on your chosen document engine:
|
||||
# - For Elasticsearch:
|
||||
# COMPOSE_PROFILES=elasticsearch,sandbox
|
||||
# - For Infinity:
|
||||
# COMPOSE_PROFILES=infinity,sandbox
|
||||
# - For OpenSearch:
|
||||
# COMPOSE_PROFILES=opensearch,sandbox
|
||||
|
||||
@ -78,8 +78,8 @@ The [.env](./.env) file contains important environment variables for Docker.
|
||||
- `RAGFLOW-IMAGE`
|
||||
The Docker image edition. Available editions:
|
||||
|
||||
- `infiniflow/ragflow:v0.18.0-slim` (default): The RAGFlow Docker image without embedding models.
|
||||
- `infiniflow/ragflow:v0.18.0`: The RAGFlow Docker image with embedding models including:
|
||||
- `infiniflow/ragflow:v0.19.0-slim` (default): The RAGFlow Docker image without embedding models.
|
||||
- `infiniflow/ragflow:v0.19.0`: The RAGFlow Docker image with embedding models including:
|
||||
- Built-in embedding models:
|
||||
- `BAAI/bge-large-zh-v1.5`
|
||||
- `maidalun1020/bce-embedding-base_v1`
|
||||
@ -154,9 +154,20 @@ The [.env](./.env) file contains important environment variables for Docker.
|
||||
- `addressing_style`: Optional. The style of addressing to use for the S3 endpoint. This can be `path` or `virtual`.
|
||||
- `prefix_path`: Optional. A prefix path to prepend to file names in the S3 bucket, which can help organize files within the bucket.
|
||||
|
||||
- `oauth`
|
||||
The OAuth configuration for signing up or signing in to RAGFlow using a third-party account. It is disabled by default. To enable this feature, uncomment the corresponding lines in **service_conf.yaml.template**.
|
||||
- `github`: The GitHub authentication settings for your application. Visit the [Github Developer Settings page](https://github.com/settings/developers) to obtain your client_id and secret_key.
|
||||
- `oauth`
|
||||
The OAuth configuration for signing up or signing in to RAGFlow using a third-party account.
|
||||
- `<channel>`: Custom channel ID.
|
||||
- `type`: Authentication type, options include `oauth2`, `oidc`, `github`. Default is `oauth2`, when `issuer` parameter is provided, defaults to `oidc`.
|
||||
- `icon`: Icon ID, options include `github`, `sso`, default is `sso`.
|
||||
- `display_name`: Channel name, defaults to the Title Case format of the channel ID.
|
||||
- `client_id`: Required, unique identifier assigned to the client application.
|
||||
- `client_secret`: Required, secret key for the client application, used for communication with the authentication server.
|
||||
- `authorization_url`: Base URL for obtaining user authorization.
|
||||
- `token_url`: URL for exchanging authorization code and obtaining access token.
|
||||
- `userinfo_url`: URL for obtaining user information (username, email, etc.).
|
||||
- `issuer`: Base URL of the identity provider. OIDC clients can dynamically obtain the identity provider's metadata (`authorization_url`, `token_url`, `userinfo_url`) through `issuer`.
|
||||
- `scope`: Requested permission scope, a space-separated string. For example, `openid profile email`.
|
||||
- `redirect_uri`: Required, URI to which the authorization server redirects during the authentication flow to return results. Must match the callback URI registered with the authentication server. Format: `https://your-app.com/v1/user/oauth/callback/<channel>`. For local configuration, you can directly use `http://127.0.0.1:80/v1/user/oauth/callback/<channel>`.
|
||||
|
||||
- `user_default_llm`
|
||||
The default LLM to use for a new RAGFlow user. It is disabled by default. To enable this feature, uncomment the corresponding lines in **service_conf.yaml.template**.
|
||||
|
||||
@ -35,6 +35,44 @@ services:
|
||||
- ragflow
|
||||
restart: on-failure
|
||||
|
||||
opensearch01:
|
||||
container_name: ragflow-opensearch-01
|
||||
profiles:
|
||||
- opensearch
|
||||
image: hub.icert.top/opensearchproject/opensearch:2.19.1
|
||||
volumes:
|
||||
- osdata01:/usr/share/opensearch/data
|
||||
ports:
|
||||
- ${OS_PORT}:9201
|
||||
env_file: .env
|
||||
environment:
|
||||
- node.name=opensearch01
|
||||
- OPENSEARCH_PASSWORD=${OPENSEARCH_PASSWORD}
|
||||
- OPENSEARCH_INITIAL_ADMIN_PASSWORD=${OPENSEARCH_PASSWORD}
|
||||
- bootstrap.memory_lock=false
|
||||
- discovery.type=single-node
|
||||
- plugins.security.disabled=false
|
||||
- plugins.security.ssl.http.enabled=false
|
||||
- plugins.security.ssl.transport.enabled=true
|
||||
- cluster.routing.allocation.disk.watermark.low=5gb
|
||||
- cluster.routing.allocation.disk.watermark.high=3gb
|
||||
- cluster.routing.allocation.disk.watermark.flood_stage=2gb
|
||||
- TZ=${TIMEZONE}
|
||||
- http.port=9201
|
||||
mem_limit: ${MEM_LIMIT}
|
||||
ulimits:
|
||||
memlock:
|
||||
soft: -1
|
||||
hard: -1
|
||||
healthcheck:
|
||||
test: ["CMD-SHELL", "curl http://localhost:9201"]
|
||||
interval: 10s
|
||||
timeout: 10s
|
||||
retries: 120
|
||||
networks:
|
||||
- ragflow
|
||||
restart: on-failure
|
||||
|
||||
infinity:
|
||||
container_name: ragflow-infinity
|
||||
profiles:
|
||||
@ -65,6 +103,35 @@ services:
|
||||
retries: 120
|
||||
restart: on-failure
|
||||
|
||||
sandbox-executor-manager:
|
||||
container_name: ragflow-sandbox-executor-manager
|
||||
profiles:
|
||||
- sandbox
|
||||
image: ${SANDBOX_EXECUTOR_MANAGER_IMAGE}
|
||||
privileged: true
|
||||
ports:
|
||||
- ${SANDBOX_EXECUTOR_MANAGER_PORT}:9385
|
||||
env_file: .env
|
||||
volumes:
|
||||
- /var/run/docker.sock:/var/run/docker.sock
|
||||
networks:
|
||||
- ragflow
|
||||
security_opt:
|
||||
- no-new-privileges:true
|
||||
environment:
|
||||
- TZ=${TIMEZONE}
|
||||
- SANDBOX_EXECUTOR_MANAGER_POOL_SIZE=${SANDBOX_EXECUTOR_MANAGER_POOL_SIZE:-3}
|
||||
- SANDBOX_BASE_PYTHON_IMAGE=${SANDBOX_BASE_PYTHON_IMAGE:-infiniflow/sandbox-base-python:latest}
|
||||
- SANDBOX_BASE_NODEJS_IMAGE=${SANDBOX_BASE_NODEJS_IMAGE:-infiniflow/sandbox-base-nodejs:latest}
|
||||
- SANDBOX_ENABLE_SECCOMP=${SANDBOX_ENABLE_SECCOMP:-false}
|
||||
- SANDBOX_MAX_MEMORY=${SANDBOX_MAX_MEMORY:-256m}
|
||||
- SANDBOX_TIMEOUT=${SANDBOX_TIMEOUT:-10s}
|
||||
healthcheck:
|
||||
test: ["CMD", "curl", "http://localhost:9385/healthz"]
|
||||
interval: 10s
|
||||
timeout: 5s
|
||||
retries: 5
|
||||
restart: on-failure
|
||||
|
||||
mysql:
|
||||
# mysql:5.7 linux/arm64 image is unavailable.
|
||||
@ -133,6 +200,8 @@ services:
|
||||
volumes:
|
||||
esdata01:
|
||||
driver: local
|
||||
osdata01:
|
||||
driver: local
|
||||
infinity_data:
|
||||
driver: local
|
||||
mysql_data:
|
||||
|
||||
@ -8,7 +8,7 @@ services:
|
||||
mysql:
|
||||
condition: service_healthy
|
||||
image: ${RAGFLOW_IMAGE}
|
||||
# example to setup MCP server
|
||||
# Example configuration to set up an MCP server:
|
||||
# command:
|
||||
# - --enable-mcpserver
|
||||
# - --mcp-host=0.0.0.0
|
||||
@ -16,7 +16,7 @@ services:
|
||||
# - --mcp-base-url=http://127.0.0.1:9380
|
||||
# - --mcp-script-path=/ragflow/mcp/server/server.py
|
||||
# - --mcp-mode=self-host
|
||||
# - --mcp--host-api-key="ragflow-xxxxxxx"
|
||||
# - --mcp-host-api-key=ragflow-xxxxxxx
|
||||
container_name: ragflow-server
|
||||
ports:
|
||||
- ${SVR_HTTP_PORT}:9380
|
||||
@ -24,7 +24,7 @@ services:
|
||||
- 443:443
|
||||
- 5678:5678
|
||||
- 5679:5679
|
||||
- 9382:9382 # entry for MCP (host_port:docker_port). The docker_port should match with the value you set for `mcp-port` above
|
||||
- 9382:9382 # entry for MCP (host_port:docker_port). The docker_port must match the value you set for `mcp-port` above.
|
||||
volumes:
|
||||
- ./ragflow-logs:/ragflow/logs
|
||||
- ./nginx/ragflow.conf:/etc/nginx/conf.d/ragflow.conf
|
||||
@ -32,6 +32,7 @@ services:
|
||||
- ./nginx/nginx.conf:/etc/nginx/nginx.conf
|
||||
- ../history_data_agent:/ragflow/history_data_agent
|
||||
- ./service_conf.yaml.template:/ragflow/conf/service_conf.yaml.template
|
||||
- ./entrypoint.sh:/ragflow/entrypoint.sh
|
||||
|
||||
env_file: .env
|
||||
environment:
|
||||
@ -42,7 +43,7 @@ services:
|
||||
- ragflow
|
||||
restart: on-failure
|
||||
# https://docs.docker.com/engine/daemon/prometheus/#create-a-prometheus-configuration
|
||||
# If you're using Docker Desktop, the --add-host flag is optional. This flag makes sure that the host's internal IP gets exposed to the Prometheus container.
|
||||
# If you use Docker Desktop, the --add-host flag is optional. This flag ensures that the host's internal IP is exposed to the Prometheus container.
|
||||
extra_hosts:
|
||||
- "host.docker.internal:host-gateway"
|
||||
# executor:
|
||||
|
||||
2
docker/entrypoint.sh
Normal file → Executable file
2
docker/entrypoint.sh
Normal file → Executable file
@ -150,7 +150,7 @@ function start_mcp_server() {
|
||||
--port="${MCP_PORT}" \
|
||||
--base_url="${MCP_BASE_URL}" \
|
||||
--mode="${MCP_MODE}" \
|
||||
--api_key="${MCP_HOST_API_KEY}" \ &
|
||||
--api_key="${MCP_HOST_API_KEY}" &
|
||||
}
|
||||
|
||||
# -----------------------------------------------------------------------------
|
||||
|
||||
@ -47,6 +47,9 @@ STOP=false
|
||||
# Array to keep track of child PIDs
|
||||
PIDS=()
|
||||
|
||||
# Set the path to the NLTK data directory
|
||||
export NLTK_DATA="./nltk_data"
|
||||
|
||||
# Function to handle termination signals
|
||||
cleanup() {
|
||||
echo "Termination signal received. Shutting down..."
|
||||
|
||||
@ -7,8 +7,8 @@ mysql:
|
||||
password: '${MYSQL_PASSWORD:-infini_rag_flow}'
|
||||
host: '${MYSQL_HOST:-mysql}'
|
||||
port: 3306
|
||||
max_connections: 100
|
||||
stale_timeout: 30
|
||||
max_connections: 900
|
||||
stale_timeout: 300
|
||||
minio:
|
||||
user: '${MINIO_USER:-rag_flow}'
|
||||
password: '${MINIO_PASSWORD:-infini_rag_flow}'
|
||||
@ -17,6 +17,10 @@ es:
|
||||
hosts: 'http://${ES_HOST:-es01}:9200'
|
||||
username: '${ES_USER:-elastic}'
|
||||
password: '${ELASTIC_PASSWORD:-infini_rag_flow}'
|
||||
os:
|
||||
hosts: 'http://${OS_HOST:-opensearch01}:9201'
|
||||
username: '${OS_USER:-admin}'
|
||||
password: '${OPENSEARCHH_PASSWORD:-infini_rag_flow_OS_01}'
|
||||
infinity:
|
||||
uri: '${INFINITY_HOST:-infinity}:23817'
|
||||
db_name: 'default_db'
|
||||
@ -71,16 +75,28 @@ redis:
|
||||
# asr_model: ''
|
||||
# image2text_model: ''
|
||||
# oauth:
|
||||
# oauth2:
|
||||
# display_name: "OAuth2"
|
||||
# client_id: "your_client_id"
|
||||
# client_secret: "your_client_secret"
|
||||
# authorization_url: "https://your-oauth-provider.com/oauth/authorize"
|
||||
# token_url: "https://your-oauth-provider.com/oauth/token"
|
||||
# userinfo_url: "https://your-oauth-provider.com/oauth/userinfo"
|
||||
# redirect_uri: "https://your-app.com/v1/user/oauth/callback/oauth2"
|
||||
# oidc:
|
||||
# display_name: "OIDC"
|
||||
# client_id: "your_client_id"
|
||||
# client_secret: "your_client_secret"
|
||||
# issuer: "https://your-oauth-provider.com/oidc"
|
||||
# scope: "openid email profile"
|
||||
# redirect_uri: "https://your-app.com/v1/user/oauth/callback/oidc"
|
||||
# github:
|
||||
# client_id: xxxxxxxxxxxxxxxxxxxxxxxxx
|
||||
# secret_key: xxxxxxxxxxxxxxxxxxxxxxxxxxxx
|
||||
# url: https://github.com/login/oauth/access_token
|
||||
# feishu:
|
||||
# app_id: cli_xxxxxxxxxxxxxxxxxxx
|
||||
# app_secret: xxxxxxxxxxxxxxxxxxxxxxxxxxxx
|
||||
# app_access_token_url: https://open.feishu.cn/open-apis/auth/v3/app_access_token/internal
|
||||
# user_access_token_url: https://open.feishu.cn/open-apis/authen/v1/oidc/access_token
|
||||
# grant_type: 'authorization_code'
|
||||
# type: "github"
|
||||
# icon: "github"
|
||||
# display_name: "Github"
|
||||
# client_id: "your_client_id"
|
||||
# client_secret: "your_client_secret"
|
||||
# redirect_uri: "https://your-app.com/v1/user/oauth/callback/github"
|
||||
# authentication:
|
||||
# client:
|
||||
# switch: false
|
||||
|
||||
@ -99,8 +99,8 @@ RAGFlow utilizes MinIO as its object storage solution, leveraging its scalabilit
|
||||
- `RAGFLOW-IMAGE`
|
||||
The Docker image edition. Available editions:
|
||||
|
||||
- `infiniflow/ragflow:v0.18.0-slim` (default): The RAGFlow Docker image without embedding models.
|
||||
- `infiniflow/ragflow:v0.18.0`: The RAGFlow Docker image with embedding models including:
|
||||
- `infiniflow/ragflow:v0.19.0-slim` (default): The RAGFlow Docker image without embedding models.
|
||||
- `infiniflow/ragflow:v0.19.0`: The RAGFlow Docker image with embedding models including:
|
||||
- Built-in embedding models:
|
||||
- `BAAI/bge-large-zh-v1.5`
|
||||
- `maidalun1020/bce-embedding-base_v1`
|
||||
@ -132,6 +132,12 @@ If you cannot download the RAGFlow Docker image, try the following mirrors.
|
||||
- `MACOS`
|
||||
Optimizations for macOS. It is disabled by default. You can uncomment this line if your OS is macOS.
|
||||
|
||||
### User registration
|
||||
|
||||
- `REGISTER_ENABLED`
|
||||
- `1`: (Default) Enable user registration.
|
||||
- `0`: Disable user registration.
|
||||
|
||||
## Service configuration
|
||||
|
||||
[service_conf.yaml.template](https://github.com/infiniflow/ragflow/blob/main/docker/service_conf.yaml.template) specifies the system-level configuration for RAGFlow and is used by its API server and task executor.
|
||||
@ -158,9 +164,52 @@ If you cannot download the RAGFlow Docker image, try the following mirrors.
|
||||
|
||||
### `oauth`
|
||||
|
||||
The OAuth configuration for signing up or signing in to RAGFlow using a third-party account. It is disabled by default. To enable this feature, uncomment the corresponding lines in **service_conf.yaml.template**.
|
||||
The OAuth configuration for signing up or signing in to RAGFlow using a third-party account.
|
||||
|
||||
- `github`: The GitHub authentication settings for your application. Visit the [GitHub Developer Settings](https://github.com/settings/developers) page to obtain your client_id and secret_key.
|
||||
- `<channel>`: Custom channel ID.
|
||||
- `type`: Authentication type, options include `oauth2`, `oidc`, `github`. Default is `oauth2`, when `issuer` parameter is provided, defaults to `oidc`.
|
||||
- `icon`: Icon ID, options include `github`, `sso`, default is `sso`.
|
||||
- `display_name`: Channel name, defaults to the Title Case format of the channel ID.
|
||||
- `client_id`: Required, unique identifier assigned to the client application.
|
||||
- `client_secret`: Required, secret key for the client application, used for communication with the authentication server.
|
||||
- `authorization_url`: Base URL for obtaining user authorization.
|
||||
- `token_url`: URL for exchanging authorization code and obtaining access token.
|
||||
- `userinfo_url`: URL for obtaining user information (username, email, etc.).
|
||||
- `issuer`: Base URL of the identity provider. OIDC clients can dynamically obtain the identity provider's metadata (`authorization_url`, `token_url`, `userinfo_url`) through `issuer`.
|
||||
- `scope`: Requested permission scope, a space-separated string. For example, `openid profile email`.
|
||||
- `redirect_uri`: Required, URI to which the authorization server redirects during the authentication flow to return results. Must match the callback URI registered with the authentication server. Format: `https://your-app.com/v1/user/oauth/callback/<channel>`. For local configuration, you can directly use `http://127.0.0.1:80/v1/user/oauth/callback/<channel>`.
|
||||
|
||||
:::tip NOTE
|
||||
The following are best practices for configuring various third-party authentication methods. You can configure one or multiple third-party authentication methods for Ragflow:
|
||||
```yaml
|
||||
oauth:
|
||||
oauth2:
|
||||
display_name: "OAuth2"
|
||||
client_id: "your_client_id"
|
||||
client_secret: "your_client_secret"
|
||||
authorization_url: "https://your-oauth-provider.com/oauth/authorize"
|
||||
token_url: "https://your-oauth-provider.com/oauth/token"
|
||||
userinfo_url: "https://your-oauth-provider.com/oauth/userinfo"
|
||||
redirect_uri: "https://your-app.com/v1/user/oauth/callback/oauth2"
|
||||
|
||||
oidc:
|
||||
display_name: "OIDC"
|
||||
client_id: "your_client_id"
|
||||
client_secret: "your_client_secret"
|
||||
issuer: "https://your-oauth-provider.com/oidc"
|
||||
scope: "openid email profile"
|
||||
redirect_uri: "https://your-app.com/v1/user/oauth/callback/oidc"
|
||||
|
||||
github:
|
||||
# https://docs.github.com/en/apps/oauth-apps/building-oauth-apps/creating-an-oauth-app
|
||||
type: "github"
|
||||
icon: "github"
|
||||
display_name: "Github"
|
||||
client_id: "your_client_id"
|
||||
client_secret: "your_client_secret"
|
||||
redirect_uri: "https://your-app.com/v1/user/oauth/callback/github"
|
||||
```
|
||||
:::
|
||||
|
||||
### `user_default_llm`
|
||||
|
||||
|
||||
8
docs/contribution/_category_.json
Normal file
8
docs/contribution/_category_.json
Normal file
@ -0,0 +1,8 @@
|
||||
{
|
||||
"label": "Contribution",
|
||||
"position": 8,
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "Miscellaneous contribution guides."
|
||||
}
|
||||
}
|
||||
@ -1,5 +1,14 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
slug: /contributing
|
||||
---
|
||||
|
||||
# Contribution guidelines
|
||||
|
||||
General guidelines for RAGFlow's community contributors.
|
||||
|
||||
---
|
||||
|
||||
This document offers guidelines and major considerations for submitting your contributions to RAGFlow.
|
||||
|
||||
- To report a bug, file a [GitHub issue](https://github.com/infiniflow/ragflow/issues/new/choose) with us.
|
||||
@ -1,11 +1,11 @@
|
||||
---
|
||||
sidebar_position: 3
|
||||
sidebar_position: 4
|
||||
slug: /acquire_ragflow_api_key
|
||||
---
|
||||
|
||||
# Acquire RAGFlow API key
|
||||
|
||||
A key is required for the RAGFlow server to authenticate your requests via HTTP or a Python API. This documents provides instructions on obtaining a RAGFlow API key.
|
||||
An API key is required for the RAGFlow server to authenticate your HTTP/Python or MCP requests. This documents provides instructions on obtaining a RAGFlow API key.
|
||||
|
||||
1. Click your avatar in the top right corner of the RAGFlow UI to access the configuration page.
|
||||
2. Click **API** to switch to the **API** page.
|
||||
|
||||
@ -77,7 +77,7 @@ After building the infiniflow/ragflow:nightly-slim image, you are ready to launc
|
||||
|
||||
1. Edit Docker Compose Configuration
|
||||
|
||||
Open the `docker/.env` file. Find the `RAGFLOW_IMAGE` setting and change the image reference from `infiniflow/ragflow:v0.18.0-slim` to `infiniflow/ragflow:nightly-slim` to use the pre-built image.
|
||||
Open the `docker/.env` file. Find the `RAGFLOW_IMAGE` setting and change the image reference from `infiniflow/ragflow:v0.19.0-slim` to `infiniflow/ragflow:nightly-slim` to use the pre-built image.
|
||||
|
||||
|
||||
2. Launch the Service
|
||||
|
||||
@ -1,195 +0,0 @@
|
||||
---
|
||||
sidebar_position: 4
|
||||
slug: /mcp_server
|
||||
---
|
||||
|
||||
# RAGFlow MCP server overview
|
||||
|
||||
The RAGFlow Model Context Protocol (MCP) server operates as an independent component that complements the RAGFlow server. However, it requires a RAGFlow server to work functionally well, meaning, the MCP client and server communicate with each other in MCP HTTP+SSE mode (once the connection is established, server pushes messages to client only), and responses are expected from RAGFlow server.
|
||||
|
||||
The MCP server currently offers a specific tool to assist users in searching for relevant information powered by RAGFlow DeepDoc technology:
|
||||
|
||||
- **retrieve**: Fetches relevant chunks from specified `dataset_ids` and optional `document_ids` using the RAGFlow retrieve interface, based on a given question. Details of all available datasets, namely, `id` and `description`, are provided within the tool description for each individual dataset.
|
||||
|
||||
## Launching the MCP Server
|
||||
|
||||
Similar to launching the RAGFlow server, the MCP server can be started either from source code or via Docker.
|
||||
|
||||
### Launch Modes
|
||||
|
||||
The MCP server supports two launch modes:
|
||||
|
||||
1. **Self-Host Mode**:
|
||||
|
||||
- In this mode, the MCP server is launched to access a specific tenant's datasets.
|
||||
- This is the default mode.
|
||||
- The `--api_key` argument is **required** to authenticate the server with the RAGFlow server.
|
||||
- Example:
|
||||
```bash
|
||||
uv run mcp/server/server.py --host=127.0.0.1 --port=9382 --base_url=http://127.0.0.1:9380 --mode=self-host --api_key=ragflow-xxxxx
|
||||
```
|
||||
|
||||
1. **Host Mode**:
|
||||
|
||||
- In this mode, the MCP server allows each user to access their own datasets.
|
||||
- To ensure secure access, a valid API key must be included in the request headers to identify the user.
|
||||
- The `--api_key` argument is **not required** during server launch but must be provided in the headers on each client request for user authentication.
|
||||
- Example:
|
||||
```bash
|
||||
uv run mcp/server/server.py --host=127.0.0.1 --port=9382 --base_url=http://127.0.0.1:9380 --mode=host
|
||||
```
|
||||
|
||||
### Launching from Source Code
|
||||
|
||||
All you need to do is stand on the right place and strike out command, assuming you are on the project working directory.
|
||||
|
||||
```bash
|
||||
uv run mcp/server/server.py --host=127.0.0.1 --port=9382 --base_url=http://127.0.0.1:9380 --api_key=ragflow-xxxxx
|
||||
```
|
||||
|
||||
For testing purposes, there is an [MCP client example](#example_mcp_client) provided, free to take!
|
||||
|
||||
#### Required Arguments
|
||||
|
||||
- **`host`**: Specifies the server's host address.
|
||||
- **`port`**: Defines the server's listening port.
|
||||
- **`base_url`**: The address of the RAGFlow server that is already running and ready to handle tasks.
|
||||
- **`mode`**: Launch mode, only accept `self-host` or `host`.
|
||||
- **`api_key`**: Required when `mode` is `self-host` to authenticate the MCP server with the RAGFlow server.
|
||||
|
||||
Here are three augments required, the first two,`host` and `port`, are self-explained. The`base_url` is the address of the ready-to-serve RAGFlow server to actually perform the task.
|
||||
|
||||
### Launching from Docker
|
||||
|
||||
Building a standalone MCP server image is straightforward and easy, so we just proposed a way to launch it with RAGFlow server here.
|
||||
|
||||
#### Alongside RAGFlow
|
||||
|
||||
As MCP server is an extra and optional component of RAGFlow server, we consume that not everybody going to use it. Thus, it is disable by default.
|
||||
To enable it, simply find `docker/docker-compose.yml` to uncomment `services.ragflow.command` section.
|
||||
|
||||
```yaml
|
||||
services:
|
||||
ragflow:
|
||||
...
|
||||
image: ${RAGFLOW_IMAGE}
|
||||
# example to setup MCP server
|
||||
command:
|
||||
- --enable-mcpserver
|
||||
- --mcp-host=0.0.0.0
|
||||
- --mcp-port=9382
|
||||
- --mcp-base-url=http://127.0.0.1:9380
|
||||
- --mcp-script-path=/ragflow/mcp/server/server.py
|
||||
- --mcp-mode=self-host # `self-host` or `host`
|
||||
- --mcp--host-api-key="ragflow-xxxxxxx" # only need to privide when mode is `self-host`
|
||||
```
|
||||
|
||||
Then launch it normally `docker compose -f docker-compose.yml`.
|
||||
|
||||
```bash
|
||||
ragflow-server | Starting MCP Server on 0.0.0.0:9382 with base URL http://127.0.0.1:9380...
|
||||
ragflow-server | Starting 1 task executor(s) on host 'dd0b5e07e76f'...
|
||||
ragflow-server | 2025-04-18 15:41:18,816 INFO 27 ragflow_server log path: /ragflow/logs/ragflow_server.log, log levels: {'peewee': 'WARNING', 'pdfminer': 'WARNING', 'root': 'INFO'}
|
||||
ragflow-server |
|
||||
ragflow-server | __ __ ____ ____ ____ _____ ______ _______ ____
|
||||
ragflow-server | | \/ |/ ___| _ \ / ___|| ____| _ \ \ / / ____| _ \
|
||||
ragflow-server | | |\/| | | | |_) | \___ \| _| | |_) \ \ / /| _| | |_) |
|
||||
ragflow-server | | | | | |___| __/ ___) | |___| _ < \ V / | |___| _ <
|
||||
ragflow-server | |_| |_|\____|_| |____/|_____|_| \_\ \_/ |_____|_| \_\
|
||||
ragflow-server |
|
||||
ragflow-server | MCP launch mode: self-host
|
||||
ragflow-server | MCP host: 0.0.0.0
|
||||
ragflow-server | MCP port: 9382
|
||||
ragflow-server | MCP base_url: http://127.0.0.1:9380
|
||||
ragflow-server | INFO: Started server process [26]
|
||||
ragflow-server | INFO: Waiting for application startup.
|
||||
ragflow-server | INFO: Application startup complete.
|
||||
ragflow-server | INFO: Uvicorn running on http://0.0.0.0:9382 (Press CTRL+C to quit)
|
||||
ragflow-server | 2025-04-18 15:41:20,469 INFO 27 found 0 gpus
|
||||
ragflow-server | 2025-04-18 15:41:23,263 INFO 27 init database on cluster mode successfully
|
||||
ragflow-server | 2025-04-18 15:41:25,318 INFO 27 load_model /ragflow/rag/res/deepdoc/det.onnx uses CPU
|
||||
ragflow-server | 2025-04-18 15:41:25,367 INFO 27 load_model /ragflow/rag/res/deepdoc/rec.onnx uses CPU
|
||||
ragflow-server | ____ ___ ______ ______ __
|
||||
ragflow-server | / __ \ / | / ____// ____// /____ _ __
|
||||
ragflow-server | / /_/ // /| | / / __ / /_ / // __ \| | /| / /
|
||||
ragflow-server | / _, _// ___ |/ /_/ // __/ / // /_/ /| |/ |/ /
|
||||
ragflow-server | /_/ |_|/_/ |_|\____//_/ /_/ \____/ |__/|__/
|
||||
ragflow-server |
|
||||
ragflow-server |
|
||||
ragflow-server | 2025-04-18 15:41:29,088 INFO 27 RAGFlow version: v0.18.0-285-gb2c299fa full
|
||||
ragflow-server | 2025-04-18 15:41:29,088 INFO 27 project base: /ragflow
|
||||
ragflow-server | 2025-04-18 15:41:29,088 INFO 27 Current configs, from /ragflow/conf/service_conf.yaml:
|
||||
ragflow-server | ragflow: {'host': '0.0.0.0', 'http_port': 9380}
|
||||
...
|
||||
ragflow-server | * Running on all addresses (0.0.0.0)
|
||||
ragflow-server | * Running on http://127.0.0.1:9380
|
||||
ragflow-server | * Running on http://172.19.0.6:9380
|
||||
ragflow-server | ______ __ ______ __
|
||||
ragflow-server | /_ __/___ ______/ /__ / ____/ _____ _______ __/ /_____ _____
|
||||
ragflow-server | / / / __ `/ ___/ //_/ / __/ | |/_/ _ \/ ___/ / / / __/ __ \/ ___/
|
||||
ragflow-server | / / / /_/ (__ ) ,< / /____> </ __/ /__/ /_/ / /_/ /_/ / /
|
||||
ragflow-server | /_/ \__,_/____/_/|_| /_____/_/|_|\___/\___/\__,_/\__/\____/_/
|
||||
ragflow-server |
|
||||
ragflow-server | 2025-04-18 15:41:34,501 INFO 32 TaskExecutor: RAGFlow version: v0.18.0-285-gb2c299fa full
|
||||
ragflow-server | 2025-04-18 15:41:34,501 INFO 32 Use Elasticsearch http://es01:9200 as the doc engine.
|
||||
...
|
||||
```
|
||||
|
||||
You are ready to brew🍺!
|
||||
|
||||
## Testing and Usage
|
||||
|
||||
Typically, there are various ways to utilize an MCP server. You can integrate it with LLMs or use it as a standalone tool. You find the way.
|
||||
|
||||
### Example MCP Client {#example_mcp_client}
|
||||
|
||||
```python
|
||||
#
|
||||
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
|
||||
|
||||
from mcp.client.session import ClientSession
|
||||
from mcp.client.sse import sse_client
|
||||
|
||||
|
||||
async def main():
|
||||
try:
|
||||
# To access RAGFlow server in `host` mode, you need to attach `api_key` for each request to indicate identification.
|
||||
# async with sse_client("http://localhost:9382/sse", headers={"api_key": "ragflow-IyMGI1ZDhjMTA2ZTExZjBiYTMyMGQ4Zm"}) as streams:
|
||||
async with sse_client("http://localhost:9382/sse") as streams:
|
||||
async with ClientSession(
|
||||
streams[0],
|
||||
streams[1],
|
||||
) as session:
|
||||
await session.initialize()
|
||||
tools = await session.list_tools()
|
||||
print(f"{tools.tools=}")
|
||||
response = await session.call_tool(name="ragflow_retrieval", arguments={"dataset_ids": ["ce3bb17cf27a11efa69751e139332ced"], "document_ids": [], "question": "How to install neovim?"})
|
||||
print(f"Tool response: {response.model_dump()}")
|
||||
|
||||
except Exception as e:
|
||||
print(e)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
from anyio import run
|
||||
|
||||
run(main)
|
||||
```
|
||||
|
||||
## Security and Concerns
|
||||
|
||||
Since MCP technology is still in booming age and there are still no official Authentication and Authorization best practices to follow, RAGFlow uses `api_key` to validate the identification, and it is required to perform any operations mentioned in the preview section. Obviously, this is not a premium solution to do so, thus this RAGFlow MCP server is not expected to exposed to public use as it could be highly venerable to be attacked. For local SSE server, bind only to localhost (127.0.0.1) instead of all interfaces (0.0.0.0). For additional guidance, you can refer to [MCP official website](https://modelcontextprotocol.io/docs/concepts/transports#security-considerations).
|
||||
8
docs/develop/mcp/_category_.json
Normal file
8
docs/develop/mcp/_category_.json
Normal file
@ -0,0 +1,8 @@
|
||||
{
|
||||
"label": "MCP",
|
||||
"position": 40,
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "Guides and references on accessing RAGFlow's knowledge bases via MCP."
|
||||
}
|
||||
}
|
||||
197
docs/develop/mcp/launch_mcp_server.md
Normal file
197
docs/develop/mcp/launch_mcp_server.md
Normal file
@ -0,0 +1,197 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
slug: /launch_mcp_server
|
||||
---
|
||||
|
||||
# Launch RAGFlow MCP server
|
||||
|
||||
Launch an MCP server from source or via Docker.
|
||||
|
||||
---
|
||||
|
||||
A RAGFlow Model Context Protocol (MCP) server is designed as an independent component to complement the RAGFlow server. Note that an MCP server must operate alongside a properly functioning RAGFlow server.
|
||||
|
||||
An MCP server can start up in either self-host mode (default) or host mode:
|
||||
|
||||
- **Self-host mode**:
|
||||
When launching an MCP server in self-host mode, you must provide an API key to authenticate the MCP server with the RAGFlow server. In this mode, the MCP server can access *only* the datasets (knowledge bases) of a specified tenant on the RAGFlow server.
|
||||
- **Host mode**:
|
||||
In host mode, each MCP client can access their own knowledge bases on the RAGFlow server. However, each client request must include a valid API key to authenticate the client with the RAGFlow server.
|
||||
|
||||
Once a connection is established, an MCP server communicates with its client in MCP HTTP+SSE (Server-Sent Events) mode, unidirectionally pushing responses from the RAGFlow server to its client in real time.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
1. Ensure RAGFlow is upgraded to v0.18.0 or later.
|
||||
2. Have your RAGFlow API key ready. See [Acquire a RAGFlow API key](./acquire_ragflow_api_key.md).
|
||||
|
||||
:::tip INFO
|
||||
If you wish to try out our MCP server without upgrading RAGFlow, community contributor [yiminghub2024](https://github.com/yiminghub2024) 👏 shares their recommended steps [here](#launch-an-mcp-server-without-upgrading-ragflow).
|
||||
:::
|
||||
|
||||
## Launch an MCP server
|
||||
|
||||
You can start an MCP server either from source code or via Docker.
|
||||
|
||||
### Launch from source code
|
||||
|
||||
1. Ensure that a RAGFlow server v0.18.0+ is properly running.
|
||||
2. Launch the MCP server:
|
||||
|
||||
|
||||
```bash
|
||||
# Launch the MCP server to work in self-host mode, run either of the following
|
||||
uv run mcp/server/server.py --host=127.0.0.1 --port=9382 --base_url=http://127.0.0.1:9380 --api_key=ragflow-xxxxx
|
||||
# uv run mcp/server/server.py --host=127.0.0.1 --port=9382 --base_url=http://127.0.0.1:9380 mode=self-host --api_key=ragflow-xxxxx
|
||||
|
||||
# To launch the MCP server to work in host mode, run the following instead:
|
||||
# uv run mcp/server/server.py --host=127.0.0.1 --port=9382 --base_url=http://127.0.0.1:9380 mode=host
|
||||
```
|
||||
|
||||
Where:
|
||||
|
||||
- `host`: The MCP server's host address.
|
||||
- `port`: The MCP server's listening port.
|
||||
- `base_url`: The address of the running RAGFlow server.
|
||||
- `mode`: The launch mode.
|
||||
- `self-host`: (default) self-host mode.
|
||||
- `host`: host mode.
|
||||
- `api_key`: Required in self-host mode to authenticate the MCP server with the RAGFlow server.
|
||||
|
||||
### Launch from Docker
|
||||
|
||||
#### 1. Enable MCP server
|
||||
|
||||
The MCP server is designed as an optional component that complements the RAGFlow server and disabled by default. To enable MCP server:
|
||||
|
||||
1. Navigate to **docker/docker-compose.yml**.
|
||||
2. Uncomment the `services.ragflow.command` section as shown below:
|
||||
|
||||
```yaml {6-13}
|
||||
services:
|
||||
ragflow:
|
||||
...
|
||||
image: ${RAGFLOW_IMAGE}
|
||||
# Example configuration to set up an MCP server:
|
||||
command:
|
||||
- --enable-mcpserver
|
||||
- --mcp-host=0.0.0.0
|
||||
- --mcp-port=9382
|
||||
- --mcp-base-url=http://127.0.0.1:9380
|
||||
- --mcp-script-path=/ragflow/mcp/server/server.py
|
||||
- --mcp-mode=self-host
|
||||
- --mcp-host-api-key=ragflow-xxxxxxx
|
||||
```
|
||||
|
||||
Where:
|
||||
|
||||
- `mcp-host`: The MCP server's host address.
|
||||
- `mcp-port`: The MCP server's listening port.
|
||||
- `mcp-base_url`: The address of the running RAGFlow server.
|
||||
- `mcp-script-path`: The file path to the MCP server’s main script.
|
||||
- `mcp-mode`: The launch mode.
|
||||
- `self-host`: (default) self-host mode.
|
||||
- `host`: host mode.
|
||||
- `mcp-host-api_key`: Required in self-host mode to authenticate the MCP server with the RAGFlow server.
|
||||
|
||||
#### 2. Launch a RAGFlow server with an MCP server
|
||||
|
||||
Run `docker compose -f docker-compose.yml` to launch the RAGFlow server together with the MCP server.
|
||||
|
||||
*The following ASCII art confirms a successful launch:*
|
||||
|
||||
```bash
|
||||
ragflow-server | Starting MCP Server on 0.0.0.0:9382 with base URL http://127.0.0.1:9380...
|
||||
ragflow-server | Starting 1 task executor(s) on host 'dd0b5e07e76f'...
|
||||
ragflow-server | 2025-04-18 15:41:18,816 INFO 27 ragflow_server log path: /ragflow/logs/ragflow_server.log, log levels: {'peewee': 'WARNING', 'pdfminer': 'WARNING', 'root': 'INFO'}
|
||||
ragflow-server |
|
||||
ragflow-server | __ __ ____ ____ ____ _____ ______ _______ ____
|
||||
ragflow-server | | \/ |/ ___| _ \ / ___|| ____| _ \ \ / / ____| _ \
|
||||
ragflow-server | | |\/| | | | |_) | \___ \| _| | |_) \ \ / /| _| | |_) |
|
||||
ragflow-server | | | | | |___| __/ ___) | |___| _ < \ V / | |___| _ <
|
||||
ragflow-server | |_| |_|\____|_| |____/|_____|_| \_\ \_/ |_____|_| \_\
|
||||
ragflow-server |
|
||||
ragflow-server | MCP launch mode: self-host
|
||||
ragflow-server | MCP host: 0.0.0.0
|
||||
ragflow-server | MCP port: 9382
|
||||
ragflow-server | MCP base_url: http://127.0.0.1:9380
|
||||
ragflow-server | INFO: Started server process [26]
|
||||
ragflow-server | INFO: Waiting for application startup.
|
||||
ragflow-server | INFO: Application startup complete.
|
||||
ragflow-server | INFO: Uvicorn running on http://0.0.0.0:9382 (Press CTRL+C to quit)
|
||||
ragflow-server | 2025-04-18 15:41:20,469 INFO 27 found 0 gpus
|
||||
ragflow-server | 2025-04-18 15:41:23,263 INFO 27 init database on cluster mode successfully
|
||||
ragflow-server | 2025-04-18 15:41:25,318 INFO 27 load_model /ragflow/rag/res/deepdoc/det.onnx uses CPU
|
||||
ragflow-server | 2025-04-18 15:41:25,367 INFO 27 load_model /ragflow/rag/res/deepdoc/rec.onnx uses CPU
|
||||
ragflow-server | ____ ___ ______ ______ __
|
||||
ragflow-server | / __ \ / | / ____// ____// /____ _ __
|
||||
ragflow-server | / /_/ // /| | / / __ / /_ / // __ \| | /| / /
|
||||
ragflow-server | / _, _// ___ |/ /_/ // __/ / // /_/ /| |/ |/ /
|
||||
ragflow-server | /_/ |_|/_/ |_|\____//_/ /_/ \____/ |__/|__/
|
||||
ragflow-server |
|
||||
ragflow-server |
|
||||
ragflow-server | 2025-04-18 15:41:29,088 INFO 27 RAGFlow version: v0.18.0-285-gb2c299fa full
|
||||
ragflow-server | 2025-04-18 15:41:29,088 INFO 27 project base: /ragflow
|
||||
ragflow-server | 2025-04-18 15:41:29,088 INFO 27 Current configs, from /ragflow/conf/service_conf.yaml:
|
||||
ragflow-server | ragflow: {'host': '0.0.0.0', 'http_port': 9380}
|
||||
...
|
||||
ragflow-server | * Running on all addresses (0.0.0.0)
|
||||
ragflow-server | * Running on http://127.0.0.1:9380
|
||||
ragflow-server | * Running on http://172.19.0.6:9380
|
||||
ragflow-server | ______ __ ______ __
|
||||
ragflow-server | /_ __/___ ______/ /__ / ____/ _____ _______ __/ /_____ _____
|
||||
ragflow-server | / / / __ `/ ___/ //_/ / __/ | |/_/ _ \/ ___/ / / / __/ __ \/ ___/
|
||||
ragflow-server | / / / /_/ (__ ) ,< / /____> </ __/ /__/ /_/ / /_/ /_/ / /
|
||||
ragflow-server | /_/ \__,_/____/_/|_| /_____/_/|_|\___/\___/\__,_/\__/\____/_/
|
||||
ragflow-server |
|
||||
ragflow-server | 2025-04-18 15:41:34,501 INFO 32 TaskExecutor: RAGFlow version: v0.18.0-285-gb2c299fa full
|
||||
ragflow-server | 2025-04-18 15:41:34,501 INFO 32 Use Elasticsearch http://es01:9200 as the doc engine.
|
||||
...
|
||||
```
|
||||
|
||||
#### Launch an MCP server without upgrading RAGFlow
|
||||
|
||||
:::info KUDOS
|
||||
This section is contributed by our community contributor [yiminghub2024](https://github.com/yiminghub2024). 👏
|
||||
:::
|
||||
|
||||
1. Prepare all MCP-specific files and directories.
|
||||
i. Copy the [mcp/](https://github.com/infiniflow/ragflow/tree/main/mcp) directory to your local working directory.
|
||||
ii. Copy [docker/docker-compose.yml](https://github.com/infiniflow/ragflow/blob/main/docker/docker-compose.yml) locally.
|
||||
iii. Copy [docker/entrypoint.sh](https://github.com/infiniflow/ragflow/blob/main/docker/entrypoint.sh) locally.
|
||||
iv. Install the required dependencies using `uv`:
|
||||
- Run `uv add mcp` or
|
||||
- Copy [pyproject.toml](https://github.com/infiniflow/ragflow/blob/main/pyproject.toml) locally and run `uv sync --python 3.10 --all-extras`.
|
||||
2. Edit **docker-compose.yml** to enable MCP (disabled by default).
|
||||
3. Launch the MCP server:
|
||||
|
||||
```bash
|
||||
docker compose -f docker-compose.yml up -d`
|
||||
```
|
||||
|
||||
### Check MCP server status
|
||||
|
||||
Run the following to check the logs the RAGFlow server and the MCP server:
|
||||
|
||||
```bash
|
||||
docker logs ragflow-server
|
||||
```
|
||||
|
||||
## Security considerations
|
||||
|
||||
As MCP technology is still at early stage and no official best practices for authentication or authorization have been established, RAGFlow currently uses [API key](./acquire_ragflow_api_key.md) to validate identity for the operations described earlier. However, in public environments, this makeshift solution could expose your MCP server to potential network attacks. Therefore, when running a local SSE server, it is recommended to bind only to localhost (`127.0.0.1`) rather than to all interfaces (`0.0.0.0`).
|
||||
|
||||
For further guidance, see the [official MCP documentation](https://modelcontextprotocol.io/docs/concepts/transports#security-considerations).
|
||||
|
||||
## Frequently asked questions
|
||||
|
||||
### When to use an API key for authentication?
|
||||
|
||||
The use of an API key depends on the operating mode of your MCP server.
|
||||
|
||||
- **Self-host mode** (default):
|
||||
When starting the MCP server in self-host mode, you should provide an API key when launching it to authenticate it with the RAGFlow server:
|
||||
- If launching from source, include the API key in the command.
|
||||
- If launching from Docker, update the API key in **docker/docker-compose.yml**.
|
||||
- **Host mode**:
|
||||
If your RAGFlow MCP server is working in host mode, include the API key in the `headers` of your client requests to authenticate your client with the RAGFlow server. An example is available [here](https://github.com/infiniflow/ragflow/blob/main/mcp/client/client.py).
|
||||
16
docs/develop/mcp/mcp_client_example.md
Normal file
16
docs/develop/mcp/mcp_client_example.md
Normal file
@ -0,0 +1,16 @@
|
||||
---
|
||||
sidebar_position: 3
|
||||
slug: /mcp_client
|
||||
---
|
||||
|
||||
# RAGFlow MCP client example
|
||||
|
||||
We provide a *prototype* MCP client example for testing [here](https://github.com/infiniflow/ragflow/blob/main/mcp/client/client.py).
|
||||
|
||||
:::danger IMPORTANT
|
||||
If your MCP server is running in host mode, include your acquired API key in your client's `headers` as shown below:
|
||||
```python
|
||||
async with sse_client("http://localhost:9382/sse", headers={"api_key": "YOUR_KEY_HERE"}) as streams:
|
||||
# Rest of your code...
|
||||
```
|
||||
:::
|
||||
12
docs/develop/mcp/mcp_tools.md
Normal file
12
docs/develop/mcp/mcp_tools.md
Normal file
@ -0,0 +1,12 @@
|
||||
---
|
||||
sidebar_position: 2
|
||||
slug: /mcp_tools
|
||||
---
|
||||
|
||||
# RAGFlow MCP tools
|
||||
|
||||
The MCP server currently offers a specialized tool to assist users in searching for relevant information powered by RAGFlow DeepDoc technology:
|
||||
|
||||
- **retrieve**: Fetches relevant chunks from specified `dataset_ids` and optional `document_ids` using the RAGFlow retrieve interface, based on a given question. Details of all available datasets, namely, `id` and `description`, are provided within the tool description for each individual dataset.
|
||||
|
||||
For more information, see our Python implementation of the [MCP server](https://github.com/infiniflow/ragflow/blob/main/mcp/server/server.py).
|
||||
34
docs/develop/switch_doc_engine.md
Normal file
34
docs/develop/switch_doc_engine.md
Normal file
@ -0,0 +1,34 @@
|
||||
---
|
||||
sidebar_position: 3
|
||||
slug: /switch_doc_engine
|
||||
---
|
||||
|
||||
# Switch document engine
|
||||
|
||||
Switch your doc engine from Elasticsearch to Infinity.
|
||||
|
||||
---
|
||||
|
||||
RAGFlow uses Elasticsearch by default for storing full text and vectors. To switch to [Infinity](https://github.com/infiniflow/infinity/), follow these steps:
|
||||
|
||||
:::danger WARNING
|
||||
Switching to Infinity on a Linux/arm64 machine is not yet officially supported.
|
||||
:::
|
||||
|
||||
1. Stop all running containers:
|
||||
|
||||
```bash
|
||||
$ docker compose -f docker/docker-compose.yml down -v
|
||||
```
|
||||
|
||||
:::cautiion WARNING
|
||||
`-v` will delete the docker container volumes, and the existing data will be cleared.
|
||||
:::
|
||||
|
||||
2. Set `DOC_ENGINE` in **docker/.env** to `infinity`.
|
||||
|
||||
3. Start the containers:
|
||||
|
||||
```bash
|
||||
$ docker compose -f docker-compose.yml up -d
|
||||
```
|
||||
69
docs/faq.mdx
69
docs/faq.mdx
@ -26,6 +26,36 @@ The "garbage in garbage out" status quo remains unchanged despite the fact that
|
||||
|
||||
---
|
||||
|
||||
### Differences between RAGFlow full edition and RAGFlow slim edition?
|
||||
|
||||
Each RAGFlow release is available in two editions:
|
||||
|
||||
- **Slim edition**: excludes built-in embedding models and is identified by a **-slim** suffix added to the version name. Example: `infiniflow/ragflow:v0.19.0-slim`
|
||||
- **Full edition**: includes built-in embedding models and has no suffix added to the version name. Example: `infiniflow/ragflow:v0.19.0`
|
||||
|
||||
---
|
||||
|
||||
### Which embedding models can be deployed locally?
|
||||
|
||||
RAGFlow offers two Docker image editions, `v0.19.0-slim` and `v0.19.0`:
|
||||
|
||||
- `infiniflow/ragflow:v0.19.0-slim` (default): The RAGFlow Docker image without embedding models.
|
||||
- `infiniflow/ragflow:v0.19.0`: The RAGFlow Docker image with embedding models including:
|
||||
- Built-in embedding models:
|
||||
- `BAAI/bge-large-zh-v1.5`
|
||||
- `maidalun1020/bce-embedding-base_v1`
|
||||
- Embedding models that will be downloaded once you select them in the RAGFlow UI:
|
||||
- `BAAI/bge-base-en-v1.5`
|
||||
- `BAAI/bge-large-en-v1.5`
|
||||
- `BAAI/bge-small-en-v1.5`
|
||||
- `BAAI/bge-small-zh-v1.5`
|
||||
- `jinaai/jina-embeddings-v2-base-en`
|
||||
- `jinaai/jina-embeddings-v2-small-en`
|
||||
- `nomic-ai/nomic-embed-text-v1.5`
|
||||
- `sentence-transformers/all-MiniLM-L6-v2`
|
||||
|
||||
---
|
||||
|
||||
### Where to find the version of RAGFlow? How to interpret it?
|
||||
|
||||
You can find the RAGFlow version number on the **System** page of the UI:
|
||||
@ -55,6 +85,22 @@ Where:
|
||||
|
||||
---
|
||||
|
||||
### Why not use other open-source vector databases as the document engine?
|
||||
|
||||
Currently, only Elasticsearch and [Infinity](https://github.com/infiniflow/infinity) meet the hybrid search requirements of RAGFlow. Most open-source vector databases have limited support for full-text search, and sparse embedding is not an alternative to full-text search. Additionally, these vector databases lack critical features essential to RAGFlow, such as phrase search and advanced ranking capabilities.
|
||||
|
||||
These limitations led us to develop [Infinity](https://github.com/infiniflow/infinity), the AI-native database, from the ground up.
|
||||
|
||||
---
|
||||
|
||||
### Differences between demo.ragflow.io and a locally deployed open-source RAGFlow service?
|
||||
|
||||
demo.ragflow.io demonstrates the capabilities of RAGFlow Enterprise. Its DeepDoc models are pre-trained using proprietary data and it offers much more sophisticated team permission controls. Essentially, demo.ragflow.io serves as a preview of RAGFlow's forthcoming SaaS (Software as a Service) offering.
|
||||
|
||||
You can deploy an open-source RAGFlow service and call it from a Python client or through RESTful APIs. However, this is not supported on demo.ragflow.io.
|
||||
|
||||
---
|
||||
|
||||
### Why does it take longer for RAGFlow to parse a document than LangChain?
|
||||
|
||||
We put painstaking effort into document pre-processing tasks like layout analysis, table structure recognition, and OCR (Optical Character Recognition) using our vision models. This contributes to the additional time required.
|
||||
@ -73,29 +119,6 @@ We officially support x86 CPU and nvidia GPU. While we also test RAGFlow on ARM6
|
||||
|
||||
---
|
||||
|
||||
### Which embedding models can be deployed locally?
|
||||
|
||||
RAGFlow offers two Docker image editions, `v0.18.0-slim` and `v0.18.0`:
|
||||
|
||||
- `infiniflow/ragflow:v0.18.0-slim` (default): The RAGFlow Docker image without embedding models.
|
||||
- `infiniflow/ragflow:v0.18.0`: The RAGFlow Docker image with embedding models including:
|
||||
- Built-in embedding models:
|
||||
- `BAAI/bge-large-zh-v1.5`
|
||||
- `BAAI/bge-reranker-v2-m3`
|
||||
- `maidalun1020/bce-embedding-base_v1`
|
||||
- `maidalun1020/bce-reranker-base_v1`
|
||||
- Embedding models that will be downloaded once you select them in the RAGFlow UI:
|
||||
- `BAAI/bge-base-en-v1.5`
|
||||
- `BAAI/bge-large-en-v1.5`
|
||||
- `BAAI/bge-small-en-v1.5`
|
||||
- `BAAI/bge-small-zh-v1.5`
|
||||
- `jinaai/jina-embeddings-v2-base-en`
|
||||
- `jinaai/jina-embeddings-v2-small-en`
|
||||
- `nomic-ai/nomic-embed-text-v1.5`
|
||||
- `sentence-transformers/all-MiniLM-L6-v2`
|
||||
|
||||
---
|
||||
|
||||
### Do you offer an API for integration with third-party applications?
|
||||
|
||||
The corresponding APIs are now available. See the [RAGFlow HTTP API Reference](./references/http_api_reference.md) or the [RAGFlow Python API Reference](./references/python_api_reference.md) for more information.
|
||||
|
||||
@ -71,7 +71,7 @@ As mentioned earlier, the **Begin** component is indispensable for an agent. Sti
|
||||
|
||||
### Is the uploaded file in a knowledge base?
|
||||
|
||||
No. Files uploaded to an agent as input are not stored in a knowledge base and hence will not be processed using RAGFlow's built-in OCR, DLR or TSR models, or chunked using RAGFlow's built-in chunk methods.
|
||||
No. Files uploaded to an agent as input are not stored in a knowledge base and hence will not be processed using RAGFlow's built-in OCR, DLR or TSR models, or chunked using RAGFlow's built-in chunking methods.
|
||||
|
||||
### How to upload a webpage or file from a URL?
|
||||
|
||||
|
||||
50
docs/guides/agent/agent_component_reference/code.mdx
Normal file
50
docs/guides/agent/agent_component_reference/code.mdx
Normal file
@ -0,0 +1,50 @@
|
||||
---
|
||||
sidebar_position: 13
|
||||
slug: /code_component
|
||||
---
|
||||
|
||||
# Code component
|
||||
|
||||
A component that enables users to integrate Python or JavaScript codes into their Agent for dynamic data processing.
|
||||
|
||||
---
|
||||
|
||||
## Scenarios
|
||||
|
||||
A **Code** component is essential when you need to integrate complex code logic (Python or JavaScript) into your Agent for dynamic data processing.
|
||||
|
||||
## Input variables
|
||||
|
||||
You can specify multiple input sources for the **Code** component. Click **+ Add variable** in the **Input variables** section to include the desired input variables.
|
||||
|
||||
After defining an input variable, you are required to select from the dropdown menu:
|
||||
- A component ID under **Component Output**, or
|
||||
- A global variable under **Begin input**, which is defined in the **Begin** component.
|
||||
|
||||
## Coding field
|
||||
|
||||
### A Python code example
|
||||
|
||||
```Python
|
||||
def main(arg1: str, arg2: str) -> dict:
|
||||
return {
|
||||
"result": arg1 + arg2,
|
||||
}
|
||||
```
|
||||
|
||||
### A JavaScript code example
|
||||
|
||||
```JavaScript
|
||||
|
||||
const axios = require('axios');
|
||||
async function main(args) {
|
||||
try {
|
||||
const response = await axios.get('https://github.com/infiniflow/ragflow');
|
||||
console.log('Body:', response.data);
|
||||
} catch (error) {
|
||||
console.error('Error:', error.message);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
@ -83,10 +83,9 @@ This toggle sets whether to cite the original text as reference.
|
||||
|
||||
|
||||
:::tip NOTE
|
||||
This feature is used for multi-turn dialogue *only* and is applicable *only* when the original documents are uploaded to a knowledge base and have finished file parsing.
|
||||
This feature applies *only* after the original documents have been uploaded to the corresponding knowledge base(s) and file parsing is complete.
|
||||
:::
|
||||
|
||||
|
||||
### Message window size
|
||||
|
||||
An integer specifying the number of previous dialogue rounds to input into the LLM. For example, if it is set to 12, the tokens from the last 12 dialogue rounds will be fed to the LLM. This feature consumes additional tokens.
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
---
|
||||
sidebar_position: 13
|
||||
sidebar_position: 18
|
||||
slug: /note_component
|
||||
---
|
||||
|
||||
|
||||
@ -5,7 +5,11 @@ slug: /text2sql_agent
|
||||
|
||||
# Create a Text2SQL agent
|
||||
|
||||
Build a Text2SQL agent leveraging RAGFlow's RAG capabilities. Contributed by @TeslaZY.
|
||||
Build a Text2SQL agent leveraging RAGFlow's RAG capabilities.
|
||||
|
||||
:::info KUDOS
|
||||
This document is contributed by our community contributor [TeslaZY](https://github.com/TeslaZY). 👏
|
||||
:::
|
||||
|
||||
## Scenario
|
||||
|
||||
|
||||
31
docs/guides/ai_search.md
Normal file
31
docs/guides/ai_search.md
Normal file
@ -0,0 +1,31 @@
|
||||
---
|
||||
sidebar_position: 2
|
||||
slug: /ai_search
|
||||
---
|
||||
|
||||
# Search
|
||||
|
||||
Conduct an AI search.
|
||||
|
||||
---
|
||||
|
||||
An AI search is a single-turn AI conversation using a predefined retrieval strategy (a hybrid search of weighted keyword similarity and weighted vector similarity) and the system's default chat model. It does not involve advanced RAG strategies like knowledge graph, auto-keyword, or auto-question. Retrieved chunks will be listed below the chat model's response.
|
||||
|
||||
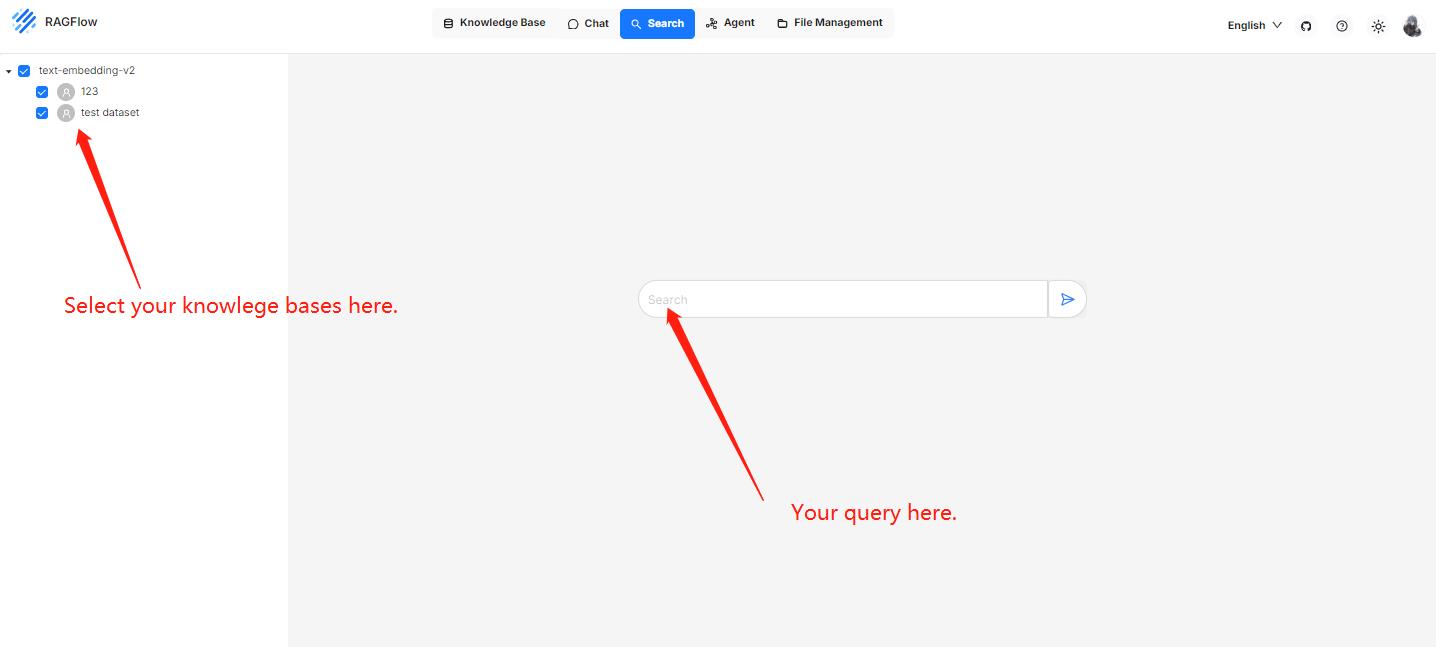
|
||||
|
||||
:::tip NOTE
|
||||
When debugging your chat assistant, you can use AI search as a reference to verify your model settings and retrieval strategy.
|
||||
:::
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- Ensure that you have configured the system's default models on the **Model providers** page.
|
||||
- Ensure that the intended knowledge bases are properly configured and the intended documents have finished file parsing.
|
||||
|
||||
|
||||
## Frequently asked questions
|
||||
|
||||
### key difference between an AI search and an AI chat?
|
||||
|
||||
A chat is a multi-turn AI conversation where you can define your retrieval strategy (a weighted reranking score can be used to replace the weighted vector similarity in a hybrid search) and choose your chat model. In an AI chat, you can configure advanced RAG strategies, such as knowledge graphs, auto-keyword, and auto-question, for your specific case. Retrieved chunks are not displayed along with the answer.
|
||||
|
||||
8
docs/guides/chat/best_practices/_category_.json
Normal file
8
docs/guides/chat/best_practices/_category_.json
Normal file
@ -0,0 +1,8 @@
|
||||
{
|
||||
"label": "Best practices",
|
||||
"position": 7,
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "Best practices on chat assistant configuration."
|
||||
}
|
||||
}
|
||||
@ -1,5 +1,5 @@
|
||||
---
|
||||
sidebar_position: 2
|
||||
sidebar_position: 1
|
||||
slug: /accelerate_question_answering
|
||||
---
|
||||
|
||||
@ -42,9 +42,13 @@ You start an AI conversation by creating an assistant.
|
||||
- **Rerank model** sets the reranker model to use. It is left empty by default.
|
||||
- If **Rerank model** is left empty, the hybrid score system uses keyword similarity and vector similarity, and the default weight assigned to the vector similarity component is 1-0.7=0.3.
|
||||
- If **Rerank model** is selected, the hybrid score system uses keyword similarity and reranker score, and the default weight assigned to the reranker score is 1-0.7=0.3.
|
||||
- **Cross-language search**: Optional
|
||||
Select one or more target languages from the dropdown menu. The system’s default chat model will then translate your query into the selected target language(s). This translation ensures accurate semantic matching across languages, allowing you to retrieve relevant results regardless of language differences.
|
||||
- When selecting target languages, please ensure that these languages are present in the knowledge base to guarantee an effective search.
|
||||
- If no target language is selected, the system will search only in the language of your query, which may cause relevant information in other languages to be missed.
|
||||
- **Variable** refers to the variables (keys) to be used in the system prompt. `{knowledge}` is a reserved variable. Click **Add** to add more variables for the system prompt.
|
||||
- If you are uncertain about the logic behind **Variable**, leave it *as-is*.
|
||||
- As of v0.18.0, if you add custom variables here, the only way you can pass in their values is to call:
|
||||
- As of v0.19.0, if you add custom variables here, the only way you can pass in their values is to call:
|
||||
- HTTP method [Converse with chat assistant](../../references/http_api_reference.md#converse-with-chat-assistant), or
|
||||
- Python method [Converse with chat assistant](../../references/python_api_reference.md#converse-with-chat-assistant).
|
||||
|
||||
|
||||
8
docs/guides/dataset/best_practices/_category_.json
Normal file
8
docs/guides/dataset/best_practices/_category_.json
Normal file
@ -0,0 +1,8 @@
|
||||
{
|
||||
"label": "Best practices",
|
||||
"position": 11,
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "Best practices on configuring a knowledge base."
|
||||
}
|
||||
}
|
||||
@ -1,5 +1,5 @@
|
||||
---
|
||||
sidebar_position: 9
|
||||
sidebar_position: 1
|
||||
slug: /accelerate_doc_indexing
|
||||
---
|
||||
|
||||
@ -22,41 +22,41 @@ _Each time a knowledge base is created, a folder with the same name is generated
|
||||
|
||||
## Configure knowledge base
|
||||
|
||||
The following screenshot shows the configuration page of a knowledge base. A proper configuration of your knowledge base is crucial for future AI chats. For example, choosing the wrong embedding model or chunk method would cause unexpected semantic loss or mismatched answers in chats.
|
||||
The following screenshot shows the configuration page of a knowledge base. A proper configuration of your knowledge base is crucial for future AI chats. For example, choosing the wrong embedding model or chunking method would cause unexpected semantic loss or mismatched answers in chats.
|
||||
|
||||

|
||||
|
||||
This section covers the following topics:
|
||||
|
||||
- Select chunk method
|
||||
- Select chunking method
|
||||
- Select embedding model
|
||||
- Upload file
|
||||
- Parse file
|
||||
- Intervene with file parsing results
|
||||
- Run retrieval testing
|
||||
|
||||
### Select chunk method
|
||||
### Select chunking method
|
||||
|
||||
RAGFlow offers multiple chunking template to facilitate chunking files of different layouts and ensure semantic integrity. In **Chunk method**, you can choose the default template that suits the layouts and formats of your files. The following table shows the descriptions and the compatible file formats of each supported chunk template:
|
||||
RAGFlow offers multiple chunking template to facilitate chunking files of different layouts and ensure semantic integrity. In **Chunking method**, you can choose the default template that suits the layouts and formats of your files. The following table shows the descriptions and the compatible file formats of each supported chunk template:
|
||||
|
||||
| **Template** | Description | File format |
|
||||
|--------------|-----------------------------------------------------------------------|-----------------------------------------------------------------------------------------------|
|
||||
| General | Files are consecutively chunked based on a preset chunk token number. | DOCX, XLSX, XLS (Excel97~2003), PPT, PDF, TXT, JPEG, JPG, PNG, TIF, GIF, CSV, JSON, EML, HTML |
|
||||
| Q&A | | XLSX, XLS (Excel97~2003), CSV/TXT |
|
||||
| General | Files are consecutively chunked based on a preset chunk token number. | DOCX, XLSX, XLS (Excel 97-2003), PPT, PDF, TXT, JPEG, JPG, PNG, TIF, GIF, CSV, JSON, EML, HTML |
|
||||
| Q&A | | XLSX, XLS (Excel 97-2003), CSV/TXT |
|
||||
| Resume | Enterprise edition only. You can also try it out on demo.ragflow.io. | DOCX, PDF, TXT |
|
||||
| Manual | | PDF |
|
||||
| Table | | XLSX, XLS (Excel97~2003), CSV/TXT |
|
||||
| Table | | XLSX, XLS (Excel 97-2003), CSV/TXT |
|
||||
| Paper | | PDF |
|
||||
| Book | | DOCX, PDF, TXT |
|
||||
| Laws | | DOCX, PDF, TXT |
|
||||
| Presentation | | PDF, PPTX |
|
||||
| Picture | | JPEG, JPG, PNG, TIF, GIF |
|
||||
| One | Each document is chunked in its entirety (as one). | DOCX, XLSX, XLS (Excel97~2003), PDF, TXT |
|
||||
| One | Each document is chunked in its entirety (as one). | DOCX, XLSX, XLS (Excel 97-2003), PDF, TXT |
|
||||
| Tag | The knowledge base functions as a tag set for the others. | XLSX, CSV/TXT |
|
||||
|
||||
You can also change a file's chunk method on the **Datasets** page.
|
||||
You can also change a file's chunking method on the **Datasets** page.
|
||||
|
||||

|
||||

|
||||
|
||||
### Select embedding model
|
||||
|
||||
@ -67,6 +67,10 @@ The following embedding models can be deployed locally:
|
||||
- BAAI/bge-large-zh-v1.5
|
||||
- maidalun1020/bce-embedding-base_v1
|
||||
|
||||
:::danger IMPORTANT
|
||||
Please note these two embedding models support both English and Chinese. If your knowledge base contains other languages, the performance may be COMPROMISED.
|
||||
:::
|
||||
|
||||
### Upload file
|
||||
|
||||
- RAGFlow's **File Management** allows you to link a file to multiple knowledge bases, in which case each target knowledge base holds a reference to the file.
|
||||
@ -76,13 +80,13 @@ While uploading files directly to a knowledge base seems more convenient, we *hi
|
||||
|
||||
### Parse file
|
||||
|
||||
File parsing is a crucial topic in knowledge base configuration. The meaning of file parsing in RAGFlow is twofold: chunking files based on file layout and building embedding and full-text (keyword) indexes on these chunks. After having selected the chunk method and embedding model, you can start parsing a file:
|
||||
File parsing is a crucial topic in knowledge base configuration. The meaning of file parsing in RAGFlow is twofold: chunking files based on file layout and building embedding and full-text (keyword) indexes on these chunks. After having selected the chunking method and embedding model, you can start parsing a file:
|
||||
|
||||

|
||||
|
||||
- Click the play button next to **UNSTART** to start file parsing.
|
||||
- Click the red-cross icon and then refresh, if your file parsing stalls for a long time.
|
||||
- As shown above, RAGFlow allows you to use a different chunk method for a particular file, offering flexibility beyond the default method.
|
||||
- As shown above, RAGFlow allows you to use a different chunking method for a particular file, offering flexibility beyond the default method.
|
||||
- As shown above, RAGFlow allows you to enable or disable individual files, offering finer control over knowledge base-based AI chats.
|
||||
|
||||
### Intervene with file parsing results
|
||||
@ -124,7 +128,7 @@ See [Run retrieval test](./run_retrieval_test.md) for details.
|
||||
|
||||
## Search for knowledge base
|
||||
|
||||
As of RAGFlow v0.18.0, the search feature is still in a rudimentary form, supporting only knowledge base search by name.
|
||||
As of RAGFlow v0.19.0, the search feature is still in a rudimentary form, supporting only knowledge base search by name.
|
||||
|
||||

|
||||
|
||||
|
||||
@ -9,7 +9,7 @@ Generate a knowledge graph for your knowledge base.
|
||||
|
||||
---
|
||||
|
||||
To enhance multi-hop question-answering, RAGFlow adds a knowledge graph construction step between data extraction and indexing, as illustrated below. This step creates additional chunks from existing ones generated by your specified chunk method.
|
||||
To enhance multi-hop question-answering, RAGFlow adds a knowledge graph construction step between data extraction and indexing, as illustrated below. This step creates additional chunks from existing ones generated by your specified chunking method.
|
||||
|
||||

|
||||
|
||||
@ -85,8 +85,12 @@ Yes, you can. Just one graph is generated per knowledge base. The smaller graphs
|
||||
|
||||
### Does the knowledge graph automatically update when I remove a related file?
|
||||
|
||||
Nope. The knowledge graph does *not* automatically update *until* a newly uploaded graph is parsed.
|
||||
Nope. The knowledge graph does *not* automatically update *until* a newly uploaded document is parsed.
|
||||
|
||||
### How to remove a generated knowledge graph?
|
||||
|
||||
To remove the generated knowledge graph, delete all related files in your knowledge base. Although the **Knowledge graph** entry will still be visible, the graph has actually been deleted.
|
||||
To remove the generated knowledge graph, delete all related files in your knowledge base. Although the **Knowledge graph** entry will still be visible, the graph has actually been deleted.
|
||||
|
||||
### Where is the created knowledge graph stored?
|
||||
|
||||
All chunks of the created knowledge graph are stored in RAGFlow's document engine: either Elasticsearch or [Infinity](https://github.com/infiniflow/infinity).
|
||||
42
docs/guides/dataset/enable_excel2html.md
Normal file
42
docs/guides/dataset/enable_excel2html.md
Normal file
@ -0,0 +1,42 @@
|
||||
---
|
||||
sidebar_position: 4
|
||||
slug: /enable_excel2html
|
||||
---
|
||||
|
||||
# Enable Excel2HTML
|
||||
|
||||
Convert complex Excel spreadsheets into HTML tables.
|
||||
|
||||
---
|
||||
|
||||
When using the General chunking method, you can enable the **Excel to HTML** toggle to convert spreadsheet files into HTML tables. If it is disabled, spreadsheet tables will be represented as key-value pairs. For complex tables that cannot be simply represented this way, you must enable this feature.
|
||||
|
||||
:::caution WARNING
|
||||
The feature is disabled by default. If your knowledge base contains spreadsheets with complex tables and you do not enable this feature, RAGFlow will not throw an error but your tables are likely to be garbled.
|
||||
:::
|
||||
|
||||
## Scenarios
|
||||
|
||||
Works with complex tables that cannot be represented as key-value pairs. Examples include spreadsheet tables with multiple columns, tables with merged cells, or multiple tables within one sheet. In such cases, consider converting these spreadsheet tables into HTML tables.
|
||||
|
||||
## Considerations
|
||||
|
||||
- The Excel2HTML feature applies only to spreadsheet files (XLSX or XLS (Excel 97-2003)).
|
||||
- This feature is associated with the General chunking method. In other words, it is available *only when* you select the General chunking method.
|
||||
- When this feature is enabled, spreadsheet tables with more than 12 rows will be split into chunks of 12 rows each.
|
||||
|
||||
## Procedure
|
||||
|
||||
1. On your knowledge base's **Configuration** page, select **General** as the chunking method.
|
||||
|
||||
_The **Excel to HTML** toggle appears._
|
||||
|
||||
2. Enable **Excel to HTML** if your knowledge base contains complex spreadsheet tables that cannot be represented as key-value pairs.
|
||||
3. Leave **Excel to HTML** disabled if your knowledge base has no spreadsheet tables or if its spreadsheet tables can be represented as key-value pairs.
|
||||
4. If question-answering regarding complex tables is unsatisfactory, check if **Excel to HTML** is enabled.
|
||||
|
||||
## Frequently asked questions
|
||||
|
||||
### Should I enable this feature for PDFs with complex tables?
|
||||
|
||||
Nope. This feature applies to spreadsheet files only. Enabling **Excel to HTML** does not affect your PDFs.
|
||||
@ -21,7 +21,7 @@ Enabling RAPTOR requires significant memory, computational resources, and tokens
|
||||
|
||||
## Basic principles
|
||||
|
||||
After the original documents are divided into chunks, the chunks are clustered by semantic similarity rather than by their original order in the text. Clusters are then summarized into higher-level chunks by your system's default chat model. This process is applied recursively, forming a tree structure with various levels of summarization from the bottom up. As illustrated in the figure below, the initial chunks form the leaf nodes (shown in blue) and are progressively summarized into a root node (shown in orange).
|
||||
After the original documents are divided into chunks, the chunks are clustered by semantic similarity rather than by their original order in the text. Clusters are then summarized into higher-level chunks by your system's default chat model. This process is applied recursively, forming a tree structure with various levels of summarization from the bottom up. As illustrated in the figure below, the initial chunks form the leaf nodes (shown in blue) and are recursively summarized into a root node (shown in orange).
|
||||
|
||||
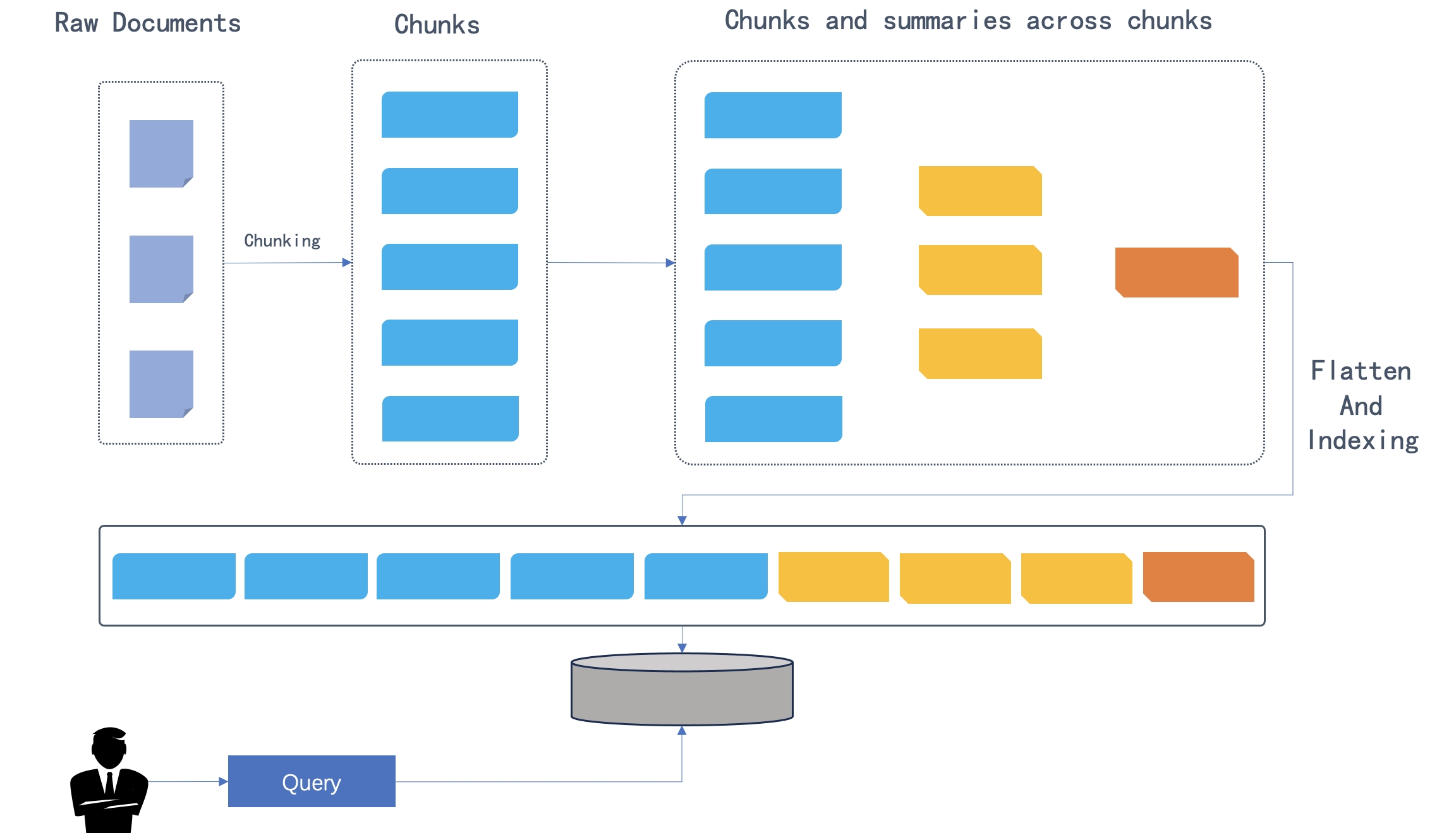
|
||||
|
||||
@ -67,8 +67,8 @@ It defaults to 0.1, with a maximum limit of 1. A higher **Threshold** means fewe
|
||||
|
||||
### Max cluster
|
||||
|
||||
The maximum number of clusters to create. Defaults to 108, with a maximum limit of 1024.
|
||||
The maximum number of clusters to create. Defaults to 64, with a maximum limit of 1024.
|
||||
|
||||
### Random seed
|
||||
|
||||
A random seed. Click the **+** button to change the seed value.
|
||||
A random seed. Click **+** to change the seed value.
|
||||
|
||||
@ -11,7 +11,7 @@ Conduct a retrieval test on your knowledge base to check whether the intended ch
|
||||
|
||||
After your files are uploaded and parsed, it is recommended that you run a retrieval test before proceeding with the chat assistant configuration. Running a retrieval test is *not* an unnecessary or superfluous step at all! Just like fine-tuning a precision instrument, RAGFlow requires careful tuning to deliver optimal question answering performance. Your knowledge base settings, chat assistant configurations, and the specified large and small models can all significantly impact the final results. Running a retrieval test verifies whether the intended chunks can be recovered, allowing you to quickly identify areas for improvement or pinpoint any issue that needs addressing. For instance, when debugging your question answering system, if you know that the correct chunks can be retrieved, you can focus your efforts elsewhere. For example, in issue [#5627](https://github.com/infiniflow/ragflow/issues/5627), the problem was found to be due to the LLM's limitations.
|
||||
|
||||
During a retrieval test, chunks created from your specified chunk method are retrieved using a hybrid search. This search combines weighted keyword similarity with either weighted vector cosine similarity or a weighted reranking score, depending on your settings:
|
||||
During a retrieval test, chunks created from your specified chunking method are retrieved using a hybrid search. This search combines weighted keyword similarity with either weighted vector cosine similarity or a weighted reranking score, depending on your settings:
|
||||
|
||||
- If no rerank model is selected, weighted keyword similarity will be combined with weighted vector cosine similarity.
|
||||
- If a rerank model is selected, weighted keyword similarity will be combined with weighted vector reranking score.
|
||||
@ -60,6 +60,15 @@ The switch is disabled by default. When enabled, RAGFlow performs the following
|
||||
Using a knowledge graph in a retrieval test will significantly increase the time to receive a response.
|
||||
:::
|
||||
|
||||
### Cross-language search
|
||||
|
||||
To perform a cross-language search, select one or more target languages from the dropdown menu. The system’s default chat model will then translate your query entered in the Test text field into the selected target language(s). This translation ensures accurate semantic matching across languages, allowing you to retrieve relevant results regardless of language differences.
|
||||
|
||||
:::tip NOTE
|
||||
- When selecting target languages, please ensure that these languages are present in the knowledge base to guarantee an effective search.
|
||||
- If no target language is selected, the system will search only in the language of your query, which may cause relevant information in other languages to be missed.
|
||||
:::
|
||||
|
||||
### Test text
|
||||
|
||||
This field is where you put in your testing query.
|
||||
|
||||
@ -32,7 +32,7 @@ The page rank value must be an integer. Range: [0,100]
|
||||
If you set the page rank value to a non-integer, say 1.7, it will be rounded down to the nearest integer, which in this case is 1.
|
||||
:::
|
||||
|
||||
## Mechanism
|
||||
## Scoring mechanism
|
||||
|
||||
If you configure a chat assistant's **similarity threshold** to 0.2, only chunks with a hybrid score greater than 0.2 x 100 = 20 will be retrieved and sent to the chat model for content generation. This initial filtering step is crucial for narrowing down relevant information.
|
||||
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user