mirror of
https://github.com/infiniflow/ragflow.git
synced 2026-02-04 09:35:06 +08:00
Compare commits
12 Commits
pipeline
...
341a7b1473
| Author | SHA1 | Date | |
|---|---|---|---|
| 341a7b1473 | |||
| c29c395390 | |||
| a23a0f230c | |||
| 2a88ce6be1 | |||
| 664b781d62 | |||
| 65571e5254 | |||
| aa30f20730 | |||
| b9b278d441 | |||
| e1d86cfee3 | |||
| 8ebd07337f | |||
| dd584d57b0 | |||
| 3d39b96c6f |
8
.github/workflows/release.yml
vendored
8
.github/workflows/release.yml
vendored
@ -88,7 +88,9 @@ jobs:
|
||||
with:
|
||||
context: .
|
||||
push: true
|
||||
tags: infiniflow/ragflow:${{ env.RELEASE_TAG }}
|
||||
tags: |
|
||||
infiniflow/ragflow:${{ env.RELEASE_TAG }}
|
||||
infiniflow/ragflow:latest-full
|
||||
file: Dockerfile
|
||||
platforms: linux/amd64
|
||||
|
||||
@ -98,7 +100,9 @@ jobs:
|
||||
with:
|
||||
context: .
|
||||
push: true
|
||||
tags: infiniflow/ragflow:${{ env.RELEASE_TAG }}-slim
|
||||
tags: |
|
||||
infiniflow/ragflow:${{ env.RELEASE_TAG }}-slim
|
||||
infiniflow/ragflow:latest-slim
|
||||
file: Dockerfile
|
||||
build-args: LIGHTEN=1
|
||||
platforms: linux/amd64
|
||||
|
||||
@ -219,6 +219,70 @@
|
||||
}
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "TokenPony",
|
||||
"logo": "",
|
||||
"tags": "LLM",
|
||||
"status": "1",
|
||||
"llm": [
|
||||
{
|
||||
"llm_name": "qwen3-8b",
|
||||
"tags": "LLM,CHAT,131k",
|
||||
"max_tokens": 131000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "deepseek-v3-0324",
|
||||
"tags": "LLM,CHAT,128k",
|
||||
"max_tokens": 128000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "qwen3-32b",
|
||||
"tags": "LLM,CHAT,131k",
|
||||
"max_tokens": 131000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "kimi-k2-instruct",
|
||||
"tags": "LLM,CHAT,128K",
|
||||
"max_tokens": 128000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "deepseek-r1-0528",
|
||||
"tags": "LLM,CHAT,164k",
|
||||
"max_tokens": 164000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "qwen3-coder-480b",
|
||||
"tags": "LLM,CHAT,1024k",
|
||||
"max_tokens": 1024000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "glm-4.5",
|
||||
"tags": "LLM,CHAT,131K",
|
||||
"max_tokens": 131000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
},
|
||||
{
|
||||
"llm_name": "deepseek-v3.1",
|
||||
"tags": "LLM,CHAT,128k",
|
||||
"max_tokens": 128000,
|
||||
"model_type": "chat",
|
||||
"is_tools": true
|
||||
}
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "Tongyi-Qianwen",
|
||||
"logo": "",
|
||||
|
||||
@ -13,7 +13,7 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
|
||||
import gc
|
||||
import logging
|
||||
import copy
|
||||
import time
|
||||
@ -348,6 +348,13 @@ class TextRecognizer:
|
||||
|
||||
return img
|
||||
|
||||
def close(self):
|
||||
# close session and release manually
|
||||
logging.info('Close TextRecognizer.')
|
||||
if hasattr(self, "predictor"):
|
||||
del self.predictor
|
||||
gc.collect()
|
||||
|
||||
def __call__(self, img_list):
|
||||
img_num = len(img_list)
|
||||
# Calculate the aspect ratio of all text bars
|
||||
@ -395,6 +402,9 @@ class TextRecognizer:
|
||||
|
||||
return rec_res, time.time() - st
|
||||
|
||||
def __del__(self):
|
||||
self.close()
|
||||
|
||||
|
||||
class TextDetector:
|
||||
def __init__(self, model_dir, device_id: int | None = None):
|
||||
@ -479,6 +489,12 @@ class TextDetector:
|
||||
dt_boxes = np.array(dt_boxes_new)
|
||||
return dt_boxes
|
||||
|
||||
def close(self):
|
||||
logging.info("Close TextDetector.")
|
||||
if hasattr(self, "predictor"):
|
||||
del self.predictor
|
||||
gc.collect()
|
||||
|
||||
def __call__(self, img):
|
||||
ori_im = img.copy()
|
||||
data = {'image': img}
|
||||
@ -508,6 +524,9 @@ class TextDetector:
|
||||
|
||||
return dt_boxes, time.time() - st
|
||||
|
||||
def __del__(self):
|
||||
self.close()
|
||||
|
||||
|
||||
class OCR:
|
||||
def __init__(self, model_dir=None):
|
||||
|
||||
@ -13,7 +13,7 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
|
||||
import gc
|
||||
import logging
|
||||
import os
|
||||
import math
|
||||
@ -406,6 +406,12 @@ class Recognizer:
|
||||
"score": float(scores[i])
|
||||
} for i in indices]
|
||||
|
||||
def close(self):
|
||||
logging.info("Close recognizer.")
|
||||
if hasattr(self, "ort_sess"):
|
||||
del self.ort_sess
|
||||
gc.collect()
|
||||
|
||||
def __call__(self, image_list, thr=0.7, batch_size=16):
|
||||
res = []
|
||||
images = []
|
||||
@ -430,5 +436,7 @@ class Recognizer:
|
||||
|
||||
return res
|
||||
|
||||
def __del__(self):
|
||||
self.close()
|
||||
|
||||
|
||||
|
||||
@ -26,6 +26,84 @@ An **Agent** component is essential when you need the LLM to assist with summari
|
||||
|
||||
2. If your Agent involves dataset retrieval, ensure you [have properly configured your target knowledge base(s)](../../dataset/configure_knowledge_base.md).
|
||||
|
||||
## Quickstart
|
||||
|
||||
### 1. Click on an **Agent** component to show its configuration panel
|
||||
|
||||
The corresponding configuration panel appears to the right of the canvas. Use this panel to define and fine-tune the **Agent** component's behavior.
|
||||
|
||||
### 2. Select your model
|
||||
|
||||
Click **Model**, and select a chat model from the dropdown menu.
|
||||
|
||||
:::tip NOTE
|
||||
If no model appears, check if your have added a chat model on the **Model providers** page.
|
||||
:::
|
||||
|
||||
### 3. Update system prompt (Optional)
|
||||
|
||||
The system prompt typically defines your model's role. You can either keep the system prompt as is or customize it to override the default.
|
||||
|
||||
|
||||
### 4. Update user prompt
|
||||
|
||||
The user prompt typically defines your model's task. You will find the `sys.query` variable auto-populated. Type `/` or click **(x)** to view or add variables.
|
||||
|
||||
In this quickstart, we assume your **Agent** component is used standalone (without tools or sub-Agents below), then you may also need to specify retrieved chunks using the `formalized_content` variable:
|
||||
|
||||
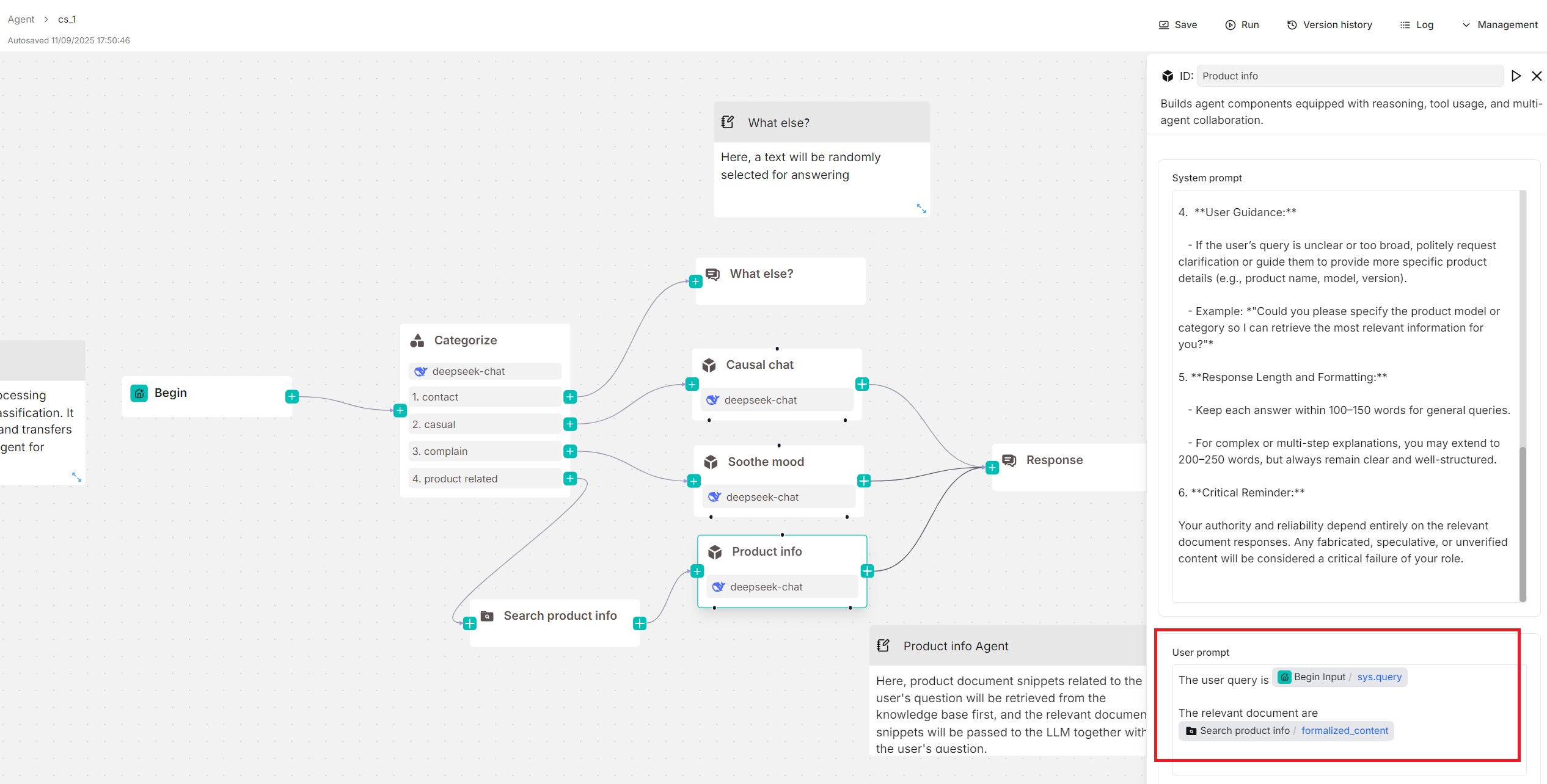
|
||||
|
||||
### 5. Skip Tools and Agent
|
||||
|
||||
The **+ Add tools** and **+ Add agent** sections are used *only* when you need to configure your **Agent** component as a planner (with tools or sub-Agents beneath). In this quickstart, we assume your **Agent** component is used standalone (without tools or sub-Agents beneath).
|
||||
|
||||
### 6. Choose the next component
|
||||
|
||||
When necessary, click the **+** button on the **Agent** component to choose the next component in the worflow from the dropdown list.
|
||||
|
||||
## Connect to an MCP server as a client
|
||||
|
||||
:::danger IMPORTANT
|
||||
In this section, we assume your **Agent** will be configured as a planner, with a Tavily tool beneath it.
|
||||
:::
|
||||
|
||||
### 1. Navigate to the MCP configuration page
|
||||
|
||||

|
||||
|
||||
### 2. Configure your Tavily MCP server
|
||||
|
||||
Update your MCP server's name, URL (including the API key), server type, and other necessary settings. When configured correctly, the available tools will be displayed.
|
||||
|
||||
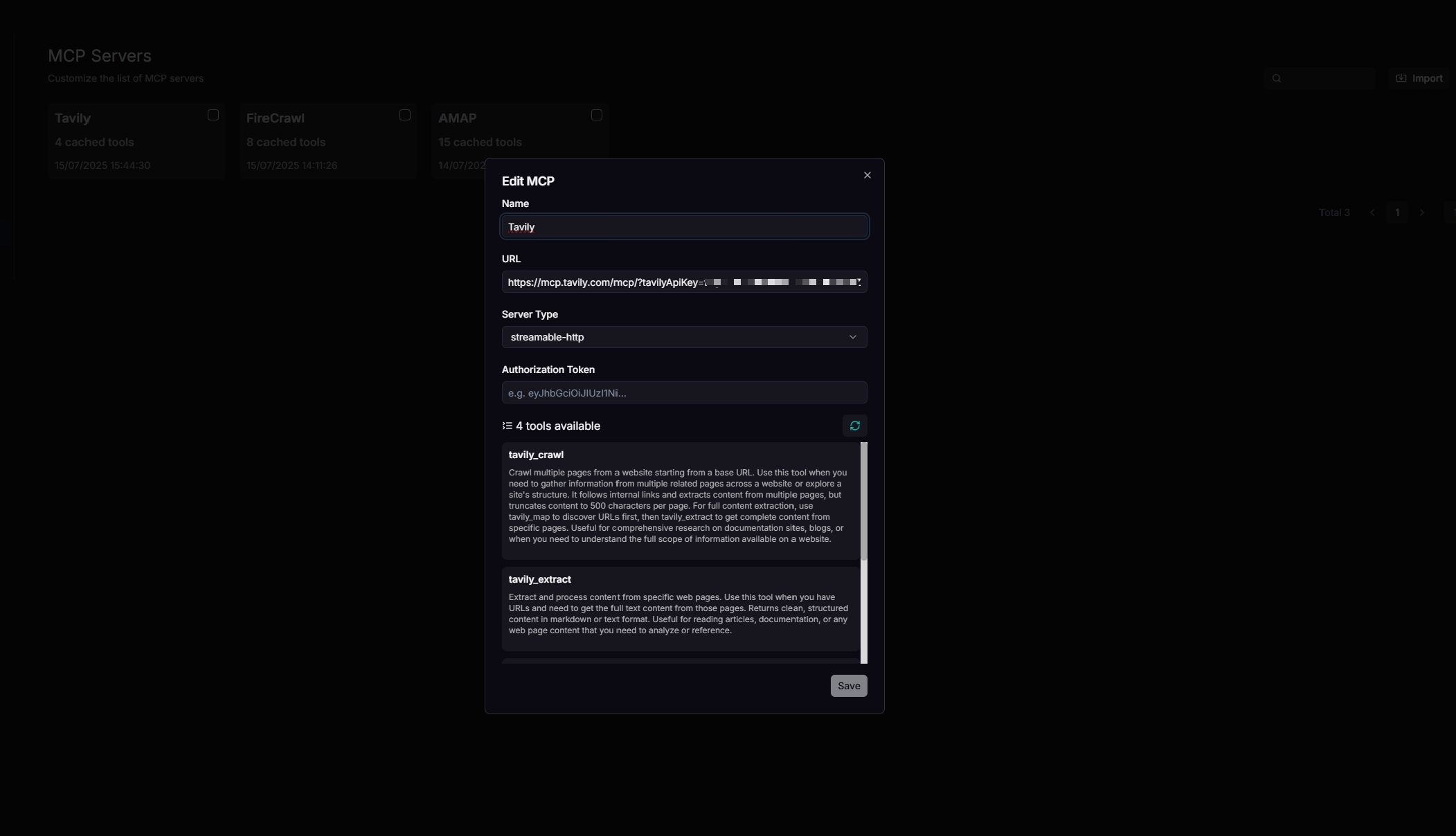
|
||||
|
||||
### 3. Navigate to your Agent's editing page
|
||||
|
||||
### 4. Connect to your MCP server
|
||||
|
||||
1. Click **+ Add tools**:
|
||||
|
||||
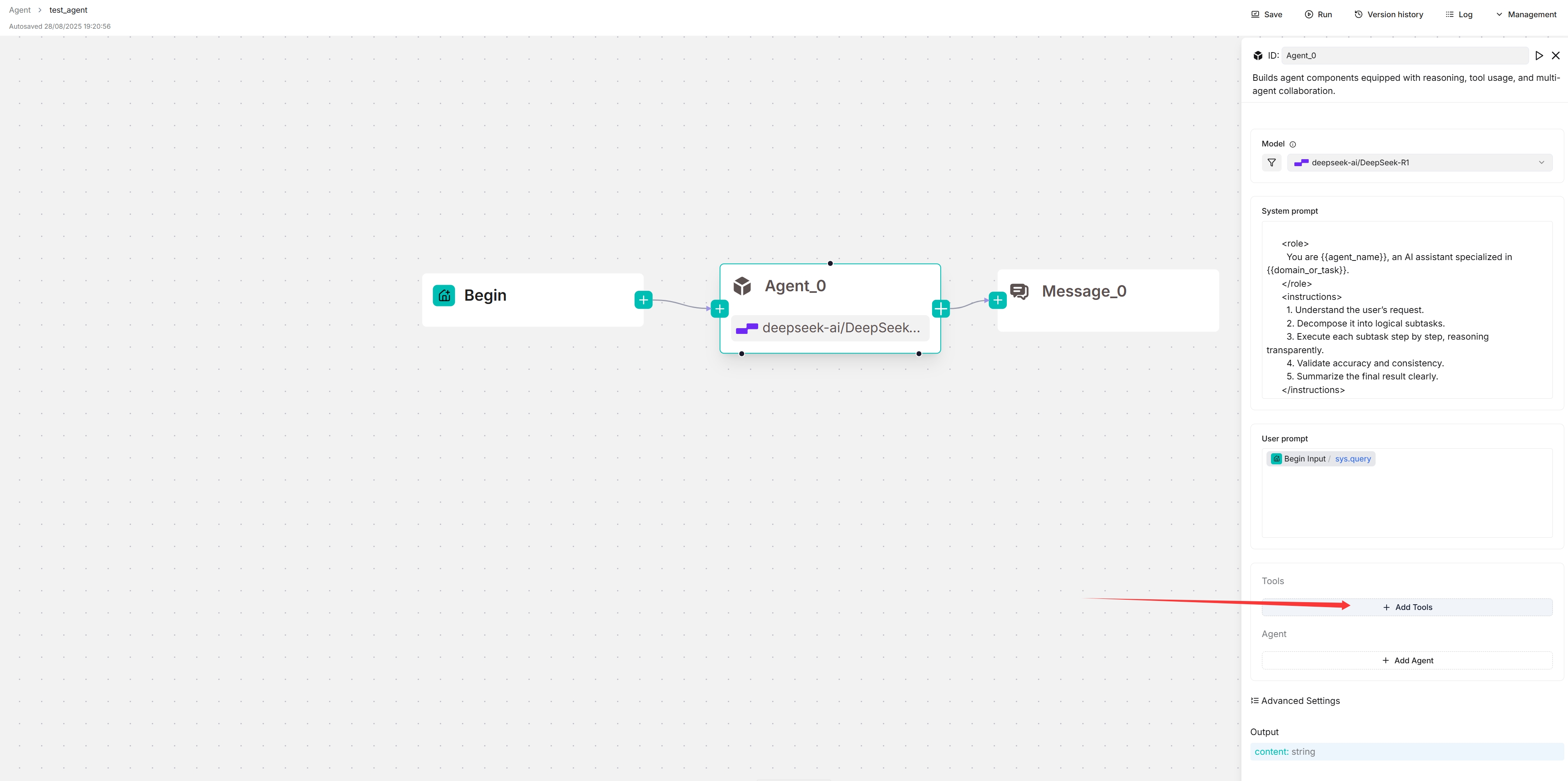
|
||||
|
||||
2. Click **MCP** to show the available MCP servers.
|
||||
|
||||
3. Select your MCP server:
|
||||
|
||||
*The target MCP server appears below your Agent component, and your Agent will autonomously decide when to invoke the available tools it offers.*
|
||||
|
||||
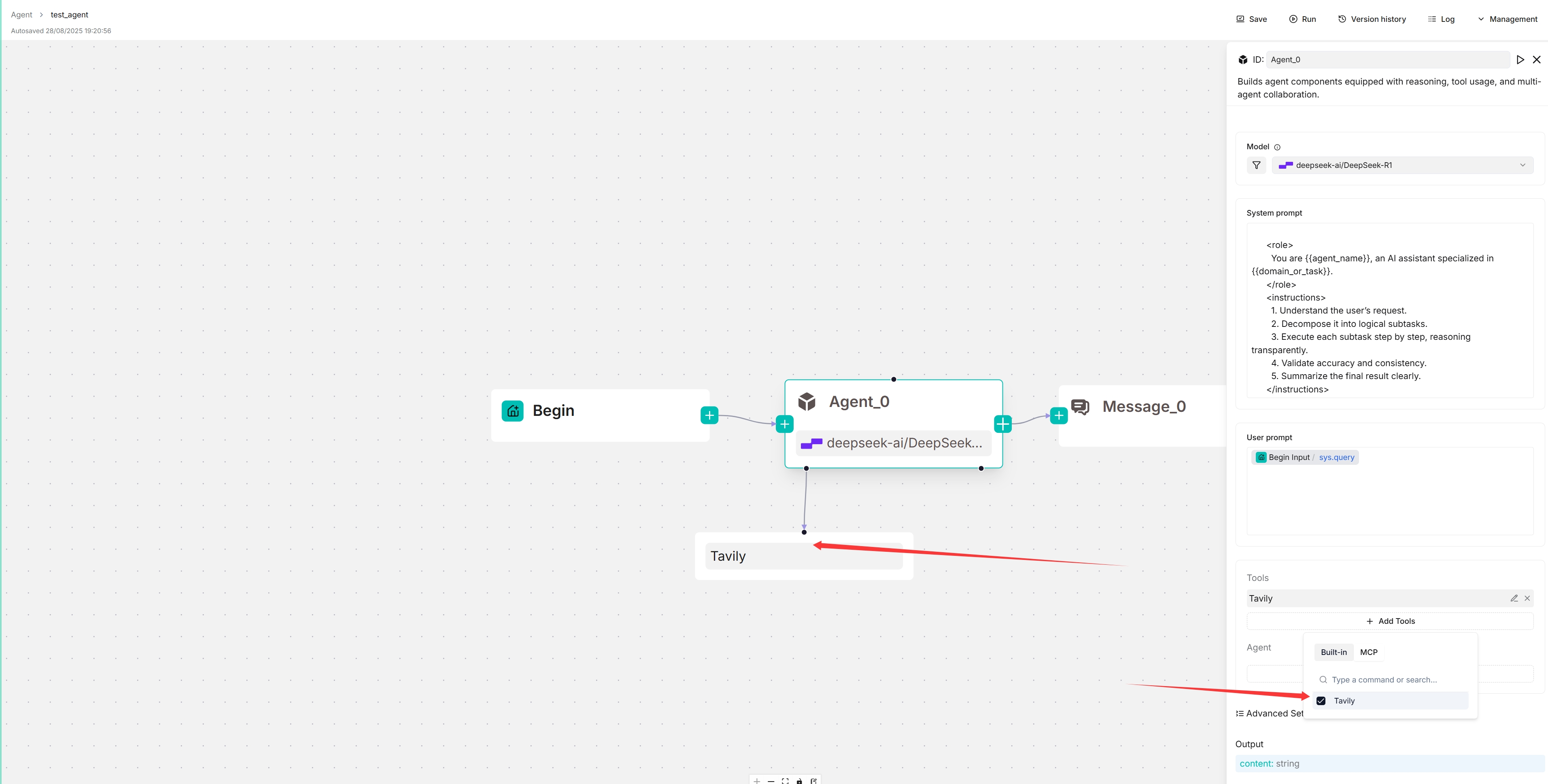
|
||||
|
||||
### 5. Update system prompt to specify trigger conditions (Optional)
|
||||
|
||||
To ensure reliable tool calls, you may specify within the system prompt which tasks should trigger each tool call.
|
||||
|
||||
### 6. View the availabe tools of your MCP server
|
||||
|
||||
On the canvas, click the newly-populated Tavily server to view and select its available tools:
|
||||
|
||||
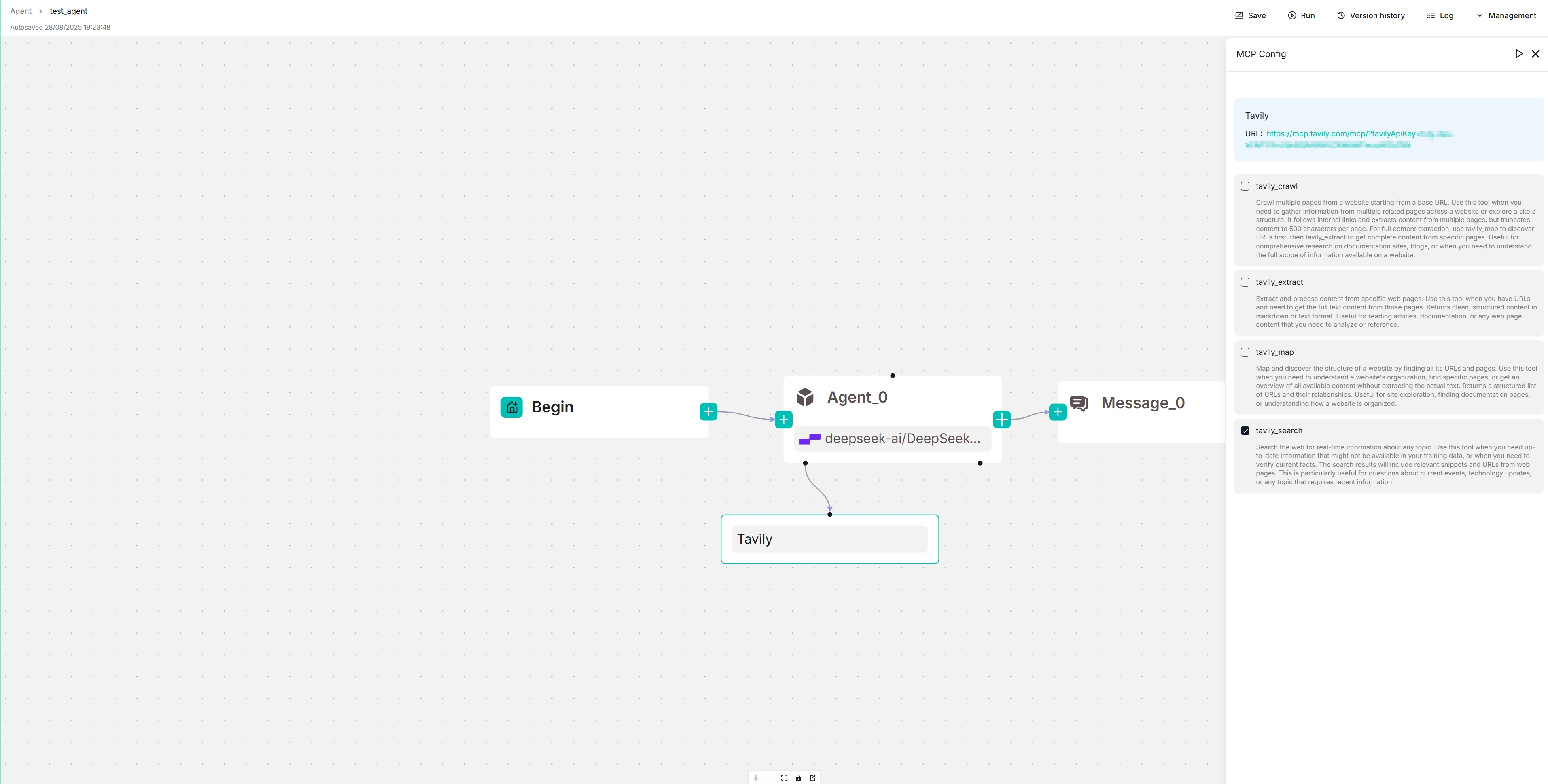
|
||||
|
||||
|
||||
## Configurations
|
||||
|
||||
### Model
|
||||
@ -69,7 +147,7 @@ An **Agent** component relies on keys (variables) to specify its data inputs. It
|
||||
|
||||
#### Advanced usage
|
||||
|
||||
From v0.20.5 onwards, four framework-level prompt blocks are available in the **System prompt** field. Type `/` or click **(x)** to view them; they appear under the **Framework** entry in the dropdown menu.
|
||||
From v0.20.5 onwards, four framework-level prompt blocks are available in the **System prompt** field, enabling you to customize and *override* prompts at the framework level. Type `/` or click **(x)** to view them; they appear under the **Framework** entry in the dropdown menu.
|
||||
|
||||
- `task_analysis` prompt block
|
||||
- This block is responsible for analyzing tasks — either a user task or a task assigned by the lead Agent when the **Agent** component is acting as a Sub-Agent.
|
||||
@ -100,6 +178,12 @@ From v0.20.5 onwards, four framework-level prompt blocks are available in the **
|
||||
- `citation_guidelines` prompt block
|
||||
- Reference design: [citation_prompt.md](https://github.com/infiniflow/ragflow/blob/main/rag/prompts/citation_prompt.md)
|
||||
|
||||
*The screenshots below show the framework prompt blocks available to an **Agent** component, both as a standalone and as a planner (with a Tavily tool below):*
|
||||
|
||||
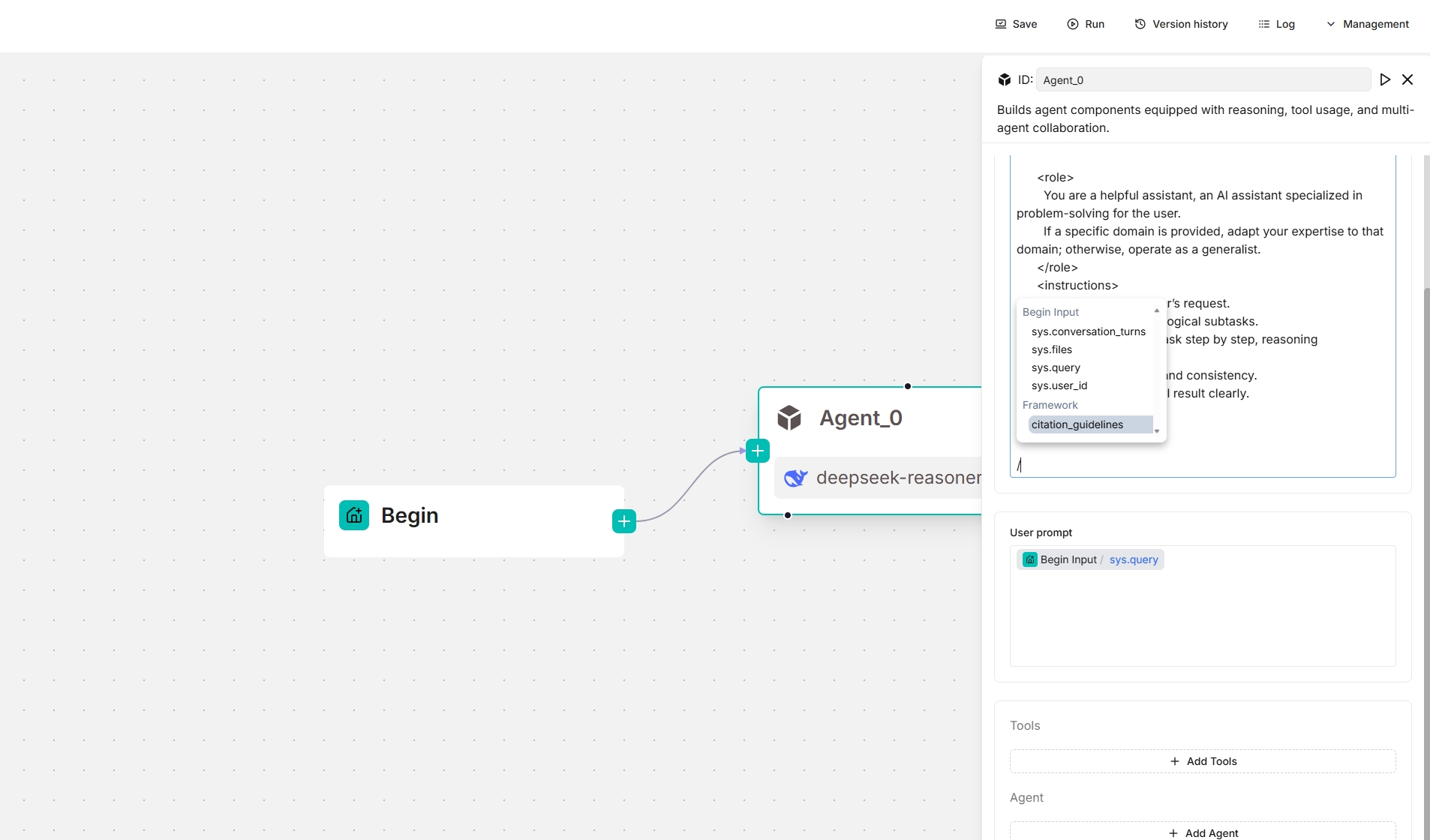
|
||||
|
||||
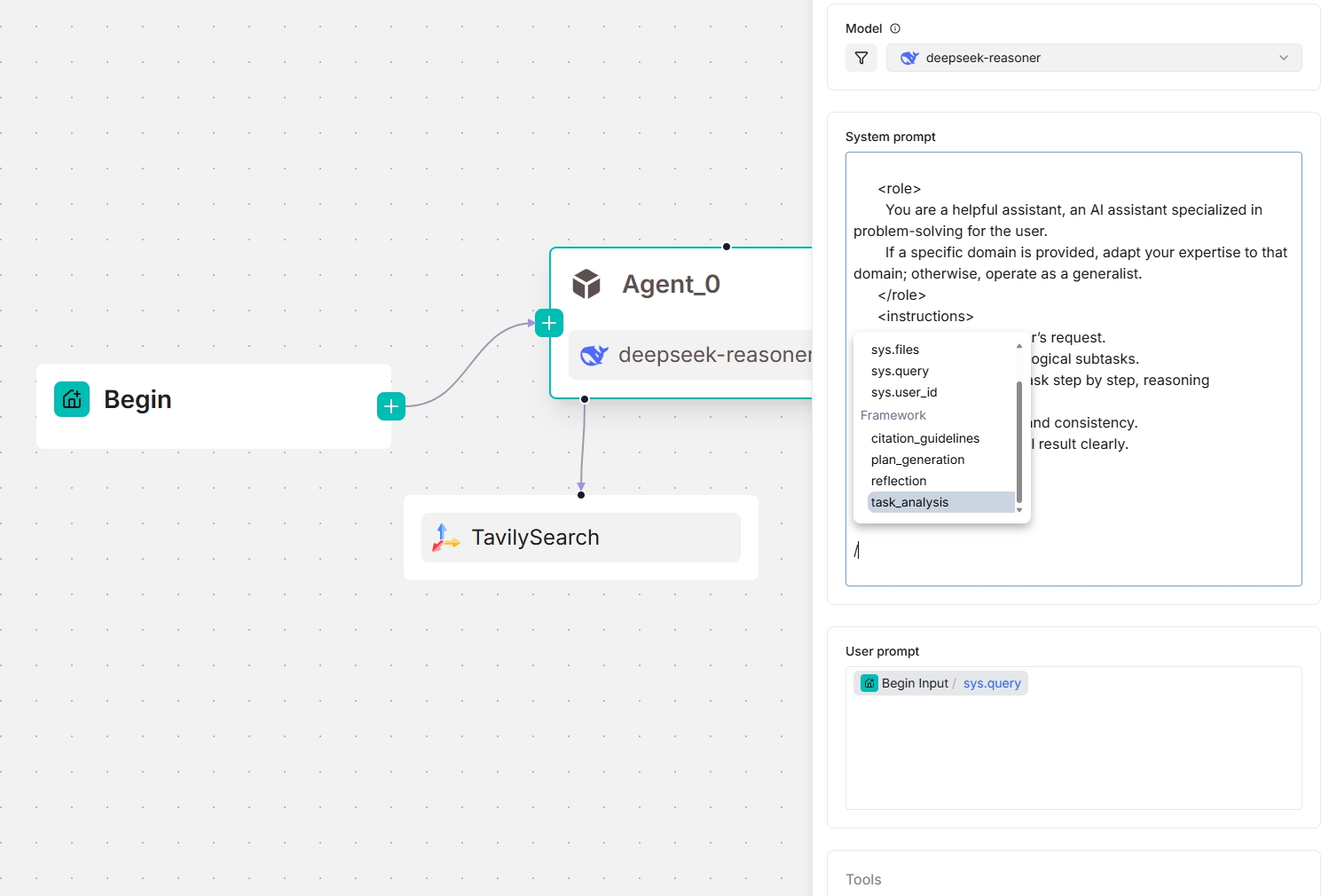
|
||||
|
||||
### User prompt
|
||||
|
||||
The user-defined prompt. Defaults to `sys.query`, the user query. As a general rule, when using the **Agent** component as a standalone module (not as a planner), you usually need to specify the corresponding **Retrieval** component’s output variable (`formalized_content`) here as part of the input to the LLM.
|
||||
@ -129,7 +213,7 @@ Defines the maximum number of attempts the agent will make to retry a failed tas
|
||||
|
||||
The waiting period in seconds that the agent observes before retrying a failed task, helping to prevent immediate repeated attempts and allowing system conditions to improve. Defaults to 1 second.
|
||||
|
||||
### Max rounds
|
||||
### Max reflection rounds
|
||||
|
||||
Defines the maximum number reflection rounds of the selected chat model. Defaults to 1 round.
|
||||
|
||||
|
||||
@ -1856,7 +1856,7 @@ curl --request POST \
|
||||
- `false`: Disable highlighting of matched terms (default).
|
||||
- `"cross_languages"`: (*Body parameter*) `list[string]`
|
||||
The languages that should be translated into, in order to achieve keywords retrievals in different languages.
|
||||
- `"metadata_condition"`: (*Body parameter*), `object`
|
||||
- `"metadata_condition"`: (*Body parameter*), `object`
|
||||
The metadata condition for filtering chunks.
|
||||
#### Response
|
||||
|
||||
|
||||
@ -977,7 +977,7 @@ The languages that should be translated into, in order to achieve keywords retri
|
||||
|
||||
##### metadata_condition: `dict`
|
||||
|
||||
filter condition for meta_fields
|
||||
filter condition for `meta_fields`.
|
||||
|
||||
#### Returns
|
||||
|
||||
|
||||
@ -28,11 +28,11 @@ Released on September 10, 2025.
|
||||
|
||||
### Improvements
|
||||
|
||||
- Agent Performance Optimized: Improved planning and reflection speed for simple tasks; optimized concurrent tool calls for parallelizable scenarios, significantly reducing overall response time.
|
||||
- Agent Prompt Framework exposed: Developers can now customize and override framework-level prompts in the system prompt section, enhancing flexibility and control.
|
||||
- Execute SQL Component Enhanced: Replaced the original variable reference component with a text input field, allowing free-form SQL writing with variable support.
|
||||
- Chat: Re-enabled Reasoning and Cross-language search.
|
||||
- Retrieval API Enhanced: Added metadata filtering support to the [Retrieve chunks](https://ragflow.io/docs/dev/http_api_reference#retrieve-chunks) method.
|
||||
- Agent:
|
||||
- Agent Performance Optimized: Improves planning and reflection speed for simple tasks; optimizes concurrent tool calls for parallelizable scenarios, significantly reducing overall response time.
|
||||
- Four framework-level prompt blocks are available in the **System prompt** section, enabling customization and overriding of prompts at the framework level, thereby enhancing flexibility and control. See [here](./guides/agent/agent_component_reference/agent.mdx#advanced-usage).
|
||||
- **Execute SQL** component enhanced: Replaces the original variable reference component with a text input field, allowing users to write free-form SQL queries and reference variables.
|
||||
- Chat: Re-enables **Reasoning** and **Cross-language search**.
|
||||
|
||||
### Added models
|
||||
|
||||
@ -44,8 +44,22 @@ Released on September 10, 2025.
|
||||
### Fixed issues
|
||||
|
||||
- Dataset: Deleted files remained searchable.
|
||||
- Chat: Unable to chat with an Ollama model.
|
||||
- Agent: Resolved issues including cite toggle failure, task mode requiring dialogue triggers, repeated answers in multi-turn dialogues, and duplicate summarization of parallel execution results.
|
||||
- Chat: Unable to chat with an Ollama model.
|
||||
- Agent:
|
||||
- A **Cite** toggle failure.
|
||||
- An Agent in task mode still required a dialogue to trigger.
|
||||
- Repeated answers in multi-turn dialogues.
|
||||
- Duplicate summarization of parallel execution results.
|
||||
|
||||
### API changes
|
||||
|
||||
#### HTTP APIs
|
||||
|
||||
- Adds a body parameter `"metadata_condition"` to the [Retrieve chunks](./references/http_api_reference.md#retrieve-chunks) method, enabling metadata-based chunk filtering during retrieval. [#9877](https://github.com/infiniflow/ragflow/pull/9877)
|
||||
|
||||
#### Python APIs
|
||||
|
||||
- Adds a parameter `metadata_condition` to the [Retrieve chunks](./references/python_api_reference.md#retrieve-chunks) method, enabling metadata-based chunk filtering during retrieval. [#9877](https://github.com/infiniflow/ragflow/pull/9877)
|
||||
|
||||
## v0.20.4
|
||||
|
||||
|
||||
@ -45,7 +45,10 @@ class ParserParam(ProcessParamBase):
|
||||
"ppt": [],
|
||||
"image": [],
|
||||
"email": [],
|
||||
"text": [],
|
||||
"text": [
|
||||
"text",
|
||||
"json"
|
||||
],
|
||||
"audio": [],
|
||||
"video": [],
|
||||
}
|
||||
@ -84,7 +87,12 @@ class ParserParam(ProcessParamBase):
|
||||
"parse_method": "ocr",
|
||||
},
|
||||
"email": {},
|
||||
"text": {},
|
||||
"text": {
|
||||
"suffix": [
|
||||
"txt"
|
||||
],
|
||||
"output_format": "json",
|
||||
},
|
||||
"audio": {},
|
||||
"video": {},
|
||||
}
|
||||
@ -119,6 +127,11 @@ class ParserParam(ProcessParamBase):
|
||||
image_parse_method = image_config.get("parse_method", "")
|
||||
self.check_valid_value(image_parse_method.lower(), "Parse method abnormal.", ["ocr"])
|
||||
|
||||
text_config = self.setups.get("text", "")
|
||||
if text_config:
|
||||
text_output_format = text_config.get("output_format", "")
|
||||
self.check_valid_value(text_output_format, "Text output format abnormal.", self.allowed_output_format["text"])
|
||||
|
||||
def get_input_form(self) -> dict[str, dict]:
|
||||
return {}
|
||||
|
||||
@ -208,15 +221,13 @@ class Parser(ProcessBase):
|
||||
from rag.app.naive import Markdown as naive_markdown_parser
|
||||
from rag.nlp import concat_img
|
||||
|
||||
self.callback(random.randint(1, 5) / 100.0, "Start to work on a Word Processor Document")
|
||||
self.callback(random.randint(1, 5) / 100.0, "Start to work on a markdown.")
|
||||
|
||||
blob = from_upstream.blob
|
||||
name = from_upstream.name
|
||||
conf = self._param.setups["markdown"]
|
||||
self.set_output("output_format", conf["output_format"])
|
||||
|
||||
print("markdown {conf=}", flush=True)
|
||||
|
||||
markdown_parser = naive_markdown_parser()
|
||||
sections, tables = markdown_parser(name, blob, separate_tables=False)
|
||||
|
||||
@ -240,13 +251,33 @@ class Parser(ProcessBase):
|
||||
|
||||
self.set_output("json", json_results)
|
||||
|
||||
def _text(self, from_upstream: ParserFromUpstream):
|
||||
from deepdoc.parser.utils import get_text
|
||||
|
||||
self.callback(random.randint(1, 5) / 100.0, "Start to work on a text.")
|
||||
|
||||
blob = from_upstream.blob
|
||||
name = from_upstream.name
|
||||
conf = self._param.setups["text"]
|
||||
self.set_output("output_format", conf["output_format"])
|
||||
|
||||
# parse binary to text
|
||||
text_content = get_text(name, binary=blob)
|
||||
|
||||
if conf.get("output_format") == "json":
|
||||
result = [{"text": text_content}]
|
||||
self.set_output("json", result)
|
||||
else:
|
||||
result = text_content
|
||||
self.set_output("text", result)
|
||||
|
||||
async def _invoke(self, **kwargs):
|
||||
function_map = {
|
||||
"pdf": self._pdf,
|
||||
"markdown": self._markdown,
|
||||
"spreadsheet": self._spreadsheet,
|
||||
"word": self._word
|
||||
"word": self._word,
|
||||
"text": self._text,
|
||||
}
|
||||
try:
|
||||
from_upstream = ParserFromUpstream.model_validate(kwargs)
|
||||
|
||||
@ -44,9 +44,12 @@
|
||||
"markdown"
|
||||
],
|
||||
"output_format": "json"
|
||||
},
|
||||
"text": {
|
||||
"suffix": ["txt"],
|
||||
"output_format": "json"
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
},
|
||||
"downstream": ["Chunker:0"],
|
||||
|
||||
@ -1356,6 +1356,14 @@ class Ai302Chat(Base):
|
||||
super().__init__(key, model_name, base_url, **kwargs)
|
||||
|
||||
|
||||
class TokenPonyChat(Base):
|
||||
_FACTORY_NAME = "TokenPony"
|
||||
|
||||
def __init__(self, key, model_name, base_url="https://ragflow.vip-api.tokenpony.cn/v1", **kwargs):
|
||||
if not base_url:
|
||||
base_url = "https://ragflow.vip-api.tokenpony.cn/v1"
|
||||
|
||||
|
||||
class MeituanChat(Base):
|
||||
_FACTORY_NAME = "Meituan"
|
||||
|
||||
|
||||
@ -751,7 +751,11 @@ class SILICONFLOWEmbed(Base):
|
||||
token_count = 0
|
||||
for i in range(0, len(texts), batch_size):
|
||||
texts_batch = texts[i : i + batch_size]
|
||||
texts_batch = [" " if not text.strip() else text for text in texts_batch]
|
||||
if self.model_name in ["BAAI/bge-large-zh-v1.5", "BAAI/bge-large-en-v1.5"]:
|
||||
# limit 512, 340 is almost safe
|
||||
texts_batch = [" " if not text.strip() else truncate(text, 340) for text in texts_batch]
|
||||
else:
|
||||
texts_batch = [" " if not text.strip() else text for text in texts_batch]
|
||||
|
||||
payload = {
|
||||
"model": self.model_name,
|
||||
|
||||
8
web/src/assets/svg/llm/token-pony.svg
Normal file
8
web/src/assets/svg/llm/token-pony.svg
Normal file
{kind=link}
File diff suppressed because one or more lines are too long
|
After Width: | Height: | Size: 16 KiB |
@ -139,7 +139,7 @@ function EmbedDialog({
|
||||
</form>
|
||||
</Form>
|
||||
<div>
|
||||
<span>Embed code</span>
|
||||
<span>{t('embedCode', { keyPrefix: 'search' })}</span>
|
||||
<HightLightMarkdown>{text}</HightLightMarkdown>
|
||||
</div>
|
||||
<div className=" font-medium mt-4 mb-1">
|
||||
|
||||
@ -54,6 +54,7 @@ export enum LLMFactory {
|
||||
DeepInfra = 'DeepInfra',
|
||||
Grok = 'Grok',
|
||||
XAI = 'xAI',
|
||||
TokenPony = 'TokenPony',
|
||||
Meituan = 'Meituan',
|
||||
}
|
||||
|
||||
@ -114,5 +115,6 @@ export const IconMap = {
|
||||
[LLMFactory.DeepInfra]: 'deepinfra',
|
||||
[LLMFactory.Grok]: 'grok',
|
||||
[LLMFactory.XAI]: 'xai',
|
||||
[LLMFactory.TokenPony]: 'token-pony',
|
||||
[LLMFactory.Meituan]: 'longcat',
|
||||
};
|
||||
|
||||
@ -155,7 +155,12 @@ export const useComposeLlmOptionsByModelTypes = (
|
||||
options.forEach((x) => {
|
||||
const item = pre.find((y) => y.label === x.label);
|
||||
if (item) {
|
||||
item.options.push(...x.options);
|
||||
x.options.forEach((y) => {
|
||||
// A model that is both an image2text and speech2text model
|
||||
if (!item.options.some((z) => z.value === y.value)) {
|
||||
item.options.push(y);
|
||||
}
|
||||
});
|
||||
} else {
|
||||
pre.push(x);
|
||||
}
|
||||
|
||||
@ -632,6 +632,8 @@ General:实体和关系提取提示来自 GitHub - microsoft/graphrag:基于
|
||||
},
|
||||
cancel: '取消',
|
||||
chatSetting: '聊天设置',
|
||||
avatarHidden: '隐藏头像',
|
||||
locale: '地区',
|
||||
},
|
||||
setting: {
|
||||
profile: '概要',
|
||||
|
||||
@ -62,7 +62,7 @@ function AgentChatBox() {
|
||||
|
||||
return (
|
||||
<>
|
||||
<section className="flex flex-1 flex-col px-5 h-[90vh]">
|
||||
<section className="flex flex-1 flex-col px-5 min-h-0 pb-4">
|
||||
<div className="flex-1 overflow-auto" ref={messageContainerRef}>
|
||||
<div>
|
||||
{/* <Spin spinning={sendLoading}> */}
|
||||
|
||||
@ -9,7 +9,7 @@ export function ChatSheet({ hideModal }: IModalProps<any>) {
|
||||
return (
|
||||
<Sheet open modal={false} onOpenChange={hideModal}>
|
||||
<SheetContent
|
||||
className={cn('top-20 p-0')}
|
||||
className={cn('top-20 bottom-0 p-0 flex flex-col h-auto')}
|
||||
onInteractOutside={(e) => e.preventDefault()}
|
||||
>
|
||||
<SheetTitle className="hidden"></SheetTitle>
|
||||
|
||||
@ -145,7 +145,7 @@ function AgentForm({ node }: INextOperatorForm) {
|
||||
<PromptEditor
|
||||
{...field}
|
||||
placeholder={t('flow.messagePlaceholder')}
|
||||
showToolbar={false}
|
||||
showToolbar={true}
|
||||
extraOptions={extraOptions}
|
||||
></PromptEditor>
|
||||
</FormControl>
|
||||
@ -166,7 +166,7 @@ function AgentForm({ node }: INextOperatorForm) {
|
||||
<section>
|
||||
<PromptEditor
|
||||
{...field}
|
||||
showToolbar={false}
|
||||
showToolbar={true}
|
||||
></PromptEditor>
|
||||
</section>
|
||||
</FormControl>
|
||||
|
||||
@ -9,13 +9,7 @@ import { cn, formatBytes } from '@/lib/utils';
|
||||
import { Routes } from '@/routes';
|
||||
import { formatPureDate } from '@/utils/date';
|
||||
import { isEmpty } from 'lodash';
|
||||
import {
|
||||
Banknote,
|
||||
Database,
|
||||
DatabaseZap,
|
||||
FileSearch2,
|
||||
GitGraph,
|
||||
} from 'lucide-react';
|
||||
import { Banknote, Database, FileSearch2, GitGraph } from 'lucide-react';
|
||||
import { useMemo } from 'react';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import { useHandleMenuClick } from './hooks';
|
||||
@ -34,11 +28,11 @@ export function SideBar({ refreshCount }: PropType) {
|
||||
|
||||
const items = useMemo(() => {
|
||||
const list = [
|
||||
{
|
||||
icon: DatabaseZap,
|
||||
label: t(`knowledgeDetails.overview`),
|
||||
key: Routes.DataSetOverview,
|
||||
},
|
||||
// {
|
||||
// icon: DatabaseZap,
|
||||
// label: t(`knowledgeDetails.overview`),
|
||||
// key: Routes.DataSetOverview,
|
||||
// },
|
||||
{
|
||||
icon: Database,
|
||||
label: t(`knowledgeDetails.dataset`),
|
||||
|
||||
@ -17,16 +17,9 @@ import {
|
||||
import { Input } from '@/components/ui/input';
|
||||
import { IModalProps } from '@/interfaces/common';
|
||||
import { zodResolver } from '@hookform/resolvers/zod';
|
||||
import { useForm, useWatch } from 'react-hook-form';
|
||||
import { useForm } from 'react-hook-form';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import { z } from 'zod';
|
||||
import {
|
||||
DataExtractKnowledgeItem,
|
||||
DataFlowItem,
|
||||
EmbeddingModelItem,
|
||||
ParseTypeItem,
|
||||
TeamItem,
|
||||
} from '../dataset/dataset-setting/configuration/common-item';
|
||||
|
||||
const FormId = 'dataset-creating-form';
|
||||
|
||||
@ -54,10 +47,6 @@ export function InputForm({ onOk }: IModalProps<any>) {
|
||||
function onSubmit(data: z.infer<typeof FormSchema>) {
|
||||
onOk?.(data.name);
|
||||
}
|
||||
const parseType = useWatch({
|
||||
control: form.control,
|
||||
name: 'parseType',
|
||||
});
|
||||
return (
|
||||
<Form {...form}>
|
||||
<form
|
||||
@ -84,15 +73,6 @@ export function InputForm({ onOk }: IModalProps<any>) {
|
||||
</FormItem>
|
||||
)}
|
||||
/>
|
||||
<EmbeddingModelItem line={2} />
|
||||
<ParseTypeItem />
|
||||
{parseType === 2 && (
|
||||
<>
|
||||
<DataFlowItem />
|
||||
<DataExtractKnowledgeItem />
|
||||
<TeamItem />
|
||||
</>
|
||||
)}
|
||||
</form>
|
||||
</Form>
|
||||
);
|
||||
|
||||
123
web/src/pages/datasets/dataset-dataflow-creating-dialog.tsx
Normal file
123
web/src/pages/datasets/dataset-dataflow-creating-dialog.tsx
Normal file
@ -0,0 +1,123 @@
|
||||
import { ButtonLoading } from '@/components/ui/button';
|
||||
import {
|
||||
Dialog,
|
||||
DialogContent,
|
||||
DialogFooter,
|
||||
DialogHeader,
|
||||
DialogTitle,
|
||||
} from '@/components/ui/dialog';
|
||||
import {
|
||||
Form,
|
||||
FormControl,
|
||||
FormField,
|
||||
FormItem,
|
||||
FormLabel,
|
||||
FormMessage,
|
||||
} from '@/components/ui/form';
|
||||
import { Input } from '@/components/ui/input';
|
||||
import { IModalProps } from '@/interfaces/common';
|
||||
import { zodResolver } from '@hookform/resolvers/zod';
|
||||
import { useForm, useWatch } from 'react-hook-form';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import { z } from 'zod';
|
||||
import {
|
||||
DataExtractKnowledgeItem,
|
||||
DataFlowItem,
|
||||
EmbeddingModelItem,
|
||||
ParseTypeItem,
|
||||
TeamItem,
|
||||
} from '../dataset/dataset-setting/configuration/common-item';
|
||||
|
||||
const FormId = 'dataset-creating-form';
|
||||
|
||||
export function InputForm({ onOk }: IModalProps<any>) {
|
||||
const { t } = useTranslation();
|
||||
|
||||
const FormSchema = z.object({
|
||||
name: z
|
||||
.string()
|
||||
.min(1, {
|
||||
message: t('knowledgeList.namePlaceholder'),
|
||||
})
|
||||
.trim(),
|
||||
parseType: z.number().optional(),
|
||||
});
|
||||
|
||||
const form = useForm<z.infer<typeof FormSchema>>({
|
||||
resolver: zodResolver(FormSchema),
|
||||
defaultValues: {
|
||||
name: '',
|
||||
parseType: 1,
|
||||
},
|
||||
});
|
||||
|
||||
function onSubmit(data: z.infer<typeof FormSchema>) {
|
||||
onOk?.(data.name);
|
||||
}
|
||||
const parseType = useWatch({
|
||||
control: form.control,
|
||||
name: 'parseType',
|
||||
});
|
||||
return (
|
||||
<Form {...form}>
|
||||
<form
|
||||
onSubmit={form.handleSubmit(onSubmit)}
|
||||
className="space-y-6"
|
||||
id={FormId}
|
||||
>
|
||||
<FormField
|
||||
control={form.control}
|
||||
name="name"
|
||||
render={({ field }) => (
|
||||
<FormItem>
|
||||
<FormLabel>
|
||||
<span className="text-destructive mr-1"> *</span>
|
||||
{t('knowledgeList.name')}
|
||||
</FormLabel>
|
||||
<FormControl>
|
||||
<Input
|
||||
placeholder={t('knowledgeList.namePlaceholder')}
|
||||
{...field}
|
||||
/>
|
||||
</FormControl>
|
||||
<FormMessage />
|
||||
</FormItem>
|
||||
)}
|
||||
/>
|
||||
<EmbeddingModelItem line={2} />
|
||||
<ParseTypeItem />
|
||||
{parseType === 2 && (
|
||||
<>
|
||||
<DataFlowItem />
|
||||
<DataExtractKnowledgeItem />
|
||||
<TeamItem />
|
||||
</>
|
||||
)}
|
||||
</form>
|
||||
</Form>
|
||||
);
|
||||
}
|
||||
|
||||
export function DatasetCreatingDialog({
|
||||
hideModal,
|
||||
onOk,
|
||||
loading,
|
||||
}: IModalProps<any>) {
|
||||
const { t } = useTranslation();
|
||||
|
||||
return (
|
||||
<Dialog open onOpenChange={hideModal}>
|
||||
<DialogContent className="sm:max-w-[425px]">
|
||||
<DialogHeader>
|
||||
<DialogTitle>{t('knowledgeList.createKnowledgeBase')}</DialogTitle>
|
||||
</DialogHeader>
|
||||
<InputForm onOk={onOk}></InputForm>
|
||||
<DialogFooter>
|
||||
<ButtonLoading type="submit" form={FormId} loading={loading}>
|
||||
{t('common.save')}
|
||||
</ButtonLoading>
|
||||
</DialogFooter>
|
||||
</DialogContent>
|
||||
</Dialog>
|
||||
);
|
||||
}
|
||||
@ -37,6 +37,7 @@ const llmFactoryToUrlMap = {
|
||||
'https://huggingface.co/docs/text-embeddings-inference/quick_tour',
|
||||
[LLMFactory.GPUStack]: 'https://docs.gpustack.ai/latest/quickstart',
|
||||
[LLMFactory.VLLM]: 'https://docs.vllm.ai/en/latest/',
|
||||
[LLMFactory.TokenPony]: 'https://docs.tokenpony.cn/#/',
|
||||
};
|
||||
type LlmFactory = keyof typeof llmFactoryToUrlMap;
|
||||
|
||||
|
||||
Reference in New Issue
Block a user