Compare commits
18 Commits
v0.21.0
...
b5d6a6e8f2
| Author | SHA1 | Date | |
|---|---|---|---|
| b5d6a6e8f2 | |||
| 5dfdbcce3a | |||
| 4fae40f66a | |||
| a1b947ffd6 | |||
| f9c7404bee | |||
| 5c1791d7f0 | |||
| e82617f6de | |||
| a7abc57f68 | |||
| cf1f523d03 | |||
| ccb255919a | |||
| b68c84b52e | |||
| 93cf0258c3 | |||
| b79fef1ca8 | |||
| 2b50de3186 | |||
| d8ef22db68 | |||
| 592f3b1555 | |||
| 3404469e2a | |||
| 63d7382dc9 |
8
.github/workflows/release.yml
vendored
@ -88,7 +88,9 @@ jobs:
|
|||||||
with:
|
with:
|
||||||
context: .
|
context: .
|
||||||
push: true
|
push: true
|
||||||
tags: infiniflow/ragflow:${{ env.RELEASE_TAG }}
|
tags: |
|
||||||
|
infiniflow/ragflow:${{ env.RELEASE_TAG }}
|
||||||
|
infiniflow/ragflow:latest-full
|
||||||
file: Dockerfile
|
file: Dockerfile
|
||||||
platforms: linux/amd64
|
platforms: linux/amd64
|
||||||
|
|
||||||
@ -98,7 +100,9 @@ jobs:
|
|||||||
with:
|
with:
|
||||||
context: .
|
context: .
|
||||||
push: true
|
push: true
|
||||||
tags: infiniflow/ragflow:${{ env.RELEASE_TAG }}-slim
|
tags: |
|
||||||
|
infiniflow/ragflow:${{ env.RELEASE_TAG }}-slim
|
||||||
|
infiniflow/ragflow:latest-slim
|
||||||
file: Dockerfile
|
file: Dockerfile
|
||||||
build-args: LIGHTEN=1
|
build-args: LIGHTEN=1
|
||||||
platforms: linux/amd64
|
platforms: linux/amd64
|
||||||
|
|||||||
@ -83,7 +83,7 @@
|
|||||||
},
|
},
|
||||||
"password": "20010812Yy!",
|
"password": "20010812Yy!",
|
||||||
"port": 3306,
|
"port": 3306,
|
||||||
"sql": "Agent:WickedGoatsDivide@content",
|
"sql": "{Agent:WickedGoatsDivide@content}",
|
||||||
"username": "13637682833@163.com"
|
"username": "13637682833@163.com"
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
@ -114,9 +114,7 @@
|
|||||||
"params": {
|
"params": {
|
||||||
"cross_languages": [],
|
"cross_languages": [],
|
||||||
"empty_response": "",
|
"empty_response": "",
|
||||||
"kb_ids": [
|
"kb_ids": [],
|
||||||
"ed31364c727211f0bdb2bafe6e7908e6"
|
|
||||||
],
|
|
||||||
"keywords_similarity_weight": 0.7,
|
"keywords_similarity_weight": 0.7,
|
||||||
"outputs": {
|
"outputs": {
|
||||||
"formalized_content": {
|
"formalized_content": {
|
||||||
@ -124,7 +122,7 @@
|
|||||||
"value": ""
|
"value": ""
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"query": "sys.query",
|
"query": "{sys.query}",
|
||||||
"rerank_id": "",
|
"rerank_id": "",
|
||||||
"similarity_threshold": 0.2,
|
"similarity_threshold": 0.2,
|
||||||
"top_k": 1024,
|
"top_k": 1024,
|
||||||
@ -145,9 +143,7 @@
|
|||||||
"params": {
|
"params": {
|
||||||
"cross_languages": [],
|
"cross_languages": [],
|
||||||
"empty_response": "",
|
"empty_response": "",
|
||||||
"kb_ids": [
|
"kb_ids": [],
|
||||||
"0f968106727311f08357bafe6e7908e6"
|
|
||||||
],
|
|
||||||
"keywords_similarity_weight": 0.7,
|
"keywords_similarity_weight": 0.7,
|
||||||
"outputs": {
|
"outputs": {
|
||||||
"formalized_content": {
|
"formalized_content": {
|
||||||
@ -155,7 +151,7 @@
|
|||||||
"value": ""
|
"value": ""
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"query": "sys.query",
|
"query": "{sys.query}",
|
||||||
"rerank_id": "",
|
"rerank_id": "",
|
||||||
"similarity_threshold": 0.2,
|
"similarity_threshold": 0.2,
|
||||||
"top_k": 1024,
|
"top_k": 1024,
|
||||||
@ -176,9 +172,7 @@
|
|||||||
"params": {
|
"params": {
|
||||||
"cross_languages": [],
|
"cross_languages": [],
|
||||||
"empty_response": "",
|
"empty_response": "",
|
||||||
"kb_ids": [
|
"kb_ids": [],
|
||||||
"4ad1f9d0727311f0827dbafe6e7908e6"
|
|
||||||
],
|
|
||||||
"keywords_similarity_weight": 0.7,
|
"keywords_similarity_weight": 0.7,
|
||||||
"outputs": {
|
"outputs": {
|
||||||
"formalized_content": {
|
"formalized_content": {
|
||||||
@ -186,7 +180,7 @@
|
|||||||
"value": ""
|
"value": ""
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"query": "sys.query",
|
"query": "{sys.query}",
|
||||||
"rerank_id": "",
|
"rerank_id": "",
|
||||||
"similarity_threshold": 0.2,
|
"similarity_threshold": 0.2,
|
||||||
"top_k": 1024,
|
"top_k": 1024,
|
||||||
@ -347,9 +341,7 @@
|
|||||||
"form": {
|
"form": {
|
||||||
"cross_languages": [],
|
"cross_languages": [],
|
||||||
"empty_response": "",
|
"empty_response": "",
|
||||||
"kb_ids": [
|
"kb_ids": [],
|
||||||
"ed31364c727211f0bdb2bafe6e7908e6"
|
|
||||||
],
|
|
||||||
"keywords_similarity_weight": 0.7,
|
"keywords_similarity_weight": 0.7,
|
||||||
"outputs": {
|
"outputs": {
|
||||||
"formalized_content": {
|
"formalized_content": {
|
||||||
@ -357,7 +349,7 @@
|
|||||||
"value": ""
|
"value": ""
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"query": "sys.query",
|
"query": "{sys.query}",
|
||||||
"rerank_id": "",
|
"rerank_id": "",
|
||||||
"similarity_threshold": 0.2,
|
"similarity_threshold": 0.2,
|
||||||
"top_k": 1024,
|
"top_k": 1024,
|
||||||
@ -387,9 +379,7 @@
|
|||||||
"form": {
|
"form": {
|
||||||
"cross_languages": [],
|
"cross_languages": [],
|
||||||
"empty_response": "",
|
"empty_response": "",
|
||||||
"kb_ids": [
|
"kb_ids": [],
|
||||||
"0f968106727311f08357bafe6e7908e6"
|
|
||||||
],
|
|
||||||
"keywords_similarity_weight": 0.7,
|
"keywords_similarity_weight": 0.7,
|
||||||
"outputs": {
|
"outputs": {
|
||||||
"formalized_content": {
|
"formalized_content": {
|
||||||
@ -397,7 +387,7 @@
|
|||||||
"value": ""
|
"value": ""
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"query": "sys.query",
|
"query": "{sys.query}",
|
||||||
"rerank_id": "",
|
"rerank_id": "",
|
||||||
"similarity_threshold": 0.2,
|
"similarity_threshold": 0.2,
|
||||||
"top_k": 1024,
|
"top_k": 1024,
|
||||||
@ -427,9 +417,7 @@
|
|||||||
"form": {
|
"form": {
|
||||||
"cross_languages": [],
|
"cross_languages": [],
|
||||||
"empty_response": "",
|
"empty_response": "",
|
||||||
"kb_ids": [
|
"kb_ids": [],
|
||||||
"4ad1f9d0727311f0827dbafe6e7908e6"
|
|
||||||
],
|
|
||||||
"keywords_similarity_weight": 0.7,
|
"keywords_similarity_weight": 0.7,
|
||||||
"outputs": {
|
"outputs": {
|
||||||
"formalized_content": {
|
"formalized_content": {
|
||||||
@ -437,7 +425,7 @@
|
|||||||
"value": ""
|
"value": ""
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"query": "sys.query",
|
"query": "{sys.query}",
|
||||||
"rerank_id": "",
|
"rerank_id": "",
|
||||||
"similarity_threshold": 0.2,
|
"similarity_threshold": 0.2,
|
||||||
"top_k": 1024,
|
"top_k": 1024,
|
||||||
@ -539,7 +527,7 @@
|
|||||||
},
|
},
|
||||||
"password": "20010812Yy!",
|
"password": "20010812Yy!",
|
||||||
"port": 3306,
|
"port": 3306,
|
||||||
"sql": "Agent:WickedGoatsDivide@content",
|
"sql": "{Agent:WickedGoatsDivide@content}",
|
||||||
"username": "13637682833@163.com"
|
"username": "13637682833@163.com"
|
||||||
},
|
},
|
||||||
"label": "ExeSQL",
|
"label": "ExeSQL",
|
||||||
|
|||||||
@ -157,7 +157,7 @@ class CodeExec(ToolBase, ABC):
|
|||||||
|
|
||||||
try:
|
try:
|
||||||
resp = requests.post(url=f"http://{settings.SANDBOX_HOST}:9385/run", json=code_req, timeout=os.environ.get("COMPONENT_EXEC_TIMEOUT", 10*60))
|
resp = requests.post(url=f"http://{settings.SANDBOX_HOST}:9385/run", json=code_req, timeout=os.environ.get("COMPONENT_EXEC_TIMEOUT", 10*60))
|
||||||
logging.info(f"http://{settings.SANDBOX_HOST}:9385/run", code_req, resp.status_code)
|
logging.info(f"http://{settings.SANDBOX_HOST}:9385/run, code_req: {code_req}, resp.status_code {resp.status_code}:")
|
||||||
if resp.status_code != 200:
|
if resp.status_code != 200:
|
||||||
resp.raise_for_status()
|
resp.raise_for_status()
|
||||||
body = resp.json()
|
body = resp.json()
|
||||||
|
|||||||
@ -53,7 +53,7 @@ class ExeSQLParam(ToolParamBase):
|
|||||||
self.max_records = 1024
|
self.max_records = 1024
|
||||||
|
|
||||||
def check(self):
|
def check(self):
|
||||||
self.check_valid_value(self.db_type, "Choose DB type", ['mysql', 'postgresql', 'mariadb', 'mssql'])
|
self.check_valid_value(self.db_type, "Choose DB type", ['mysql', 'postgres', 'mariadb', 'mssql'])
|
||||||
self.check_empty(self.database, "Database name")
|
self.check_empty(self.database, "Database name")
|
||||||
self.check_empty(self.username, "database username")
|
self.check_empty(self.username, "database username")
|
||||||
self.check_empty(self.host, "IP Address")
|
self.check_empty(self.host, "IP Address")
|
||||||
@ -111,7 +111,7 @@ class ExeSQL(ToolBase, ABC):
|
|||||||
if self._param.db_type in ["mysql", "mariadb"]:
|
if self._param.db_type in ["mysql", "mariadb"]:
|
||||||
db = pymysql.connect(db=self._param.database, user=self._param.username, host=self._param.host,
|
db = pymysql.connect(db=self._param.database, user=self._param.username, host=self._param.host,
|
||||||
port=self._param.port, password=self._param.password)
|
port=self._param.port, password=self._param.password)
|
||||||
elif self._param.db_type == 'postgresql':
|
elif self._param.db_type == 'postgres':
|
||||||
db = psycopg2.connect(dbname=self._param.database, user=self._param.username, host=self._param.host,
|
db = psycopg2.connect(dbname=self._param.database, user=self._param.username, host=self._param.host,
|
||||||
port=self._param.port, password=self._param.password)
|
port=self._param.port, password=self._param.password)
|
||||||
elif self._param.db_type == 'mssql':
|
elif self._param.db_type == 'mssql':
|
||||||
|
|||||||
105
api/apps/HEALTHCHECK_TESTING.md
Normal file
@ -0,0 +1,105 @@
|
|||||||
|
# 健康检查与 Kubernetes 探针简明说明
|
||||||
|
|
||||||
|
本文件说明:什么是 K8s 探针、如何用 `/v1/system/healthz` 做健康检查,以及下文用例中的关键词含义。
|
||||||
|
|
||||||
|
## 什么是 K8s 探针(Probe)
|
||||||
|
- 探针是 K8s 用来“探测”容器是否健康/可对外服务的机制。
|
||||||
|
- 常见三类:
|
||||||
|
- livenessProbe:活性探针。失败时 K8s 会重启容器,用于“应用卡死/失去连接时自愈”。
|
||||||
|
- readinessProbe:就绪探针。失败时 Endpoint 不会被加入 Service 负载均衡,用于“应用尚未准备好时不接流量”。
|
||||||
|
- startupProbe:启动探针。给慢启动应用更长的初始化窗口,期间不执行 liveness/readiness。
|
||||||
|
- 这些探针通常通过 HTTP GET 访问一个公开且轻量的健康端点(无需鉴权),以 HTTP 状态码判定结果:200=通过;5xx/超时=失败。
|
||||||
|
|
||||||
|
## 本项目健康端点
|
||||||
|
- 已实现:`GET /v1/system/healthz`(无需认证)。
|
||||||
|
- 语义:
|
||||||
|
- 200:关键依赖正常。
|
||||||
|
- 500:任一关键依赖异常(当前判定为 DB 或 Chat)。
|
||||||
|
- 响应体:JSON,最小字段 `status, db, chat`;并包含 `redis, doc_engine, storage` 等可观测项。失败项会在 `_meta` 中包含 `error/elapsed`。
|
||||||
|
- 示例(DB 故障):
|
||||||
|
```json
|
||||||
|
{"status":"nok","chat":"ok","db":"nok"}
|
||||||
|
```
|
||||||
|
|
||||||
|
## 用例背景(Problem/use case)
|
||||||
|
- 现状:Ragflow 跑在 K8s,数据库是 AWS RDS Postgres,凭证由 Secret Manager 管理并每 7 天轮换。轮换后应用连接失效,需要手动重启 Pod 才能重新建立连接。
|
||||||
|
- 目标:通过 K8s 探针自动化检测并重启异常 Pod,减少人工操作。
|
||||||
|
- 需求:一个“无需鉴权”的公共健康端点,能在依赖异常时返回非 200(如 500)且提供 JSON 详情。
|
||||||
|
- 现已满足:`/v1/system/healthz` 正是为此设计。
|
||||||
|
|
||||||
|
## 关键术语解释(对应你提供的描述)
|
||||||
|
- Ragflow instance:部署在 K8s 的 Ragflow 服务。
|
||||||
|
- AWS RDS Postgres:托管的 PostgreSQL 数据库实例。
|
||||||
|
- Secret Manager rotation:Secrets 定期轮换(每 7 天),会导致旧连接失效。
|
||||||
|
- Probes(K8s 探针):liveness/readiness,用于自动重启或摘除不健康实例。
|
||||||
|
- Public endpoint without API key:无需 Authorization 的 HTTP 路由,便于探针直接访问。
|
||||||
|
- Dependencies statuses:依赖健康状态(db、chat、redis、doc_engine、storage 等)。
|
||||||
|
- HTTP 500 with JSON:当依赖异常时返回 500,并附带 JSON 说明哪个子系统失败。
|
||||||
|
|
||||||
|
## 快速测试
|
||||||
|
- 正常:
|
||||||
|
```bash
|
||||||
|
curl -i http://<host>/v1/system/healthz
|
||||||
|
```
|
||||||
|
- 制造 DB 故障(docker-compose 示例):
|
||||||
|
```bash
|
||||||
|
docker compose stop db && curl -i http://<host>/v1/system/healthz
|
||||||
|
```
|
||||||
|
(预期 500,JSON 中 `db:"nok"`)
|
||||||
|
|
||||||
|
## 更完整的测试清单
|
||||||
|
### 1) 仅查看 HTTP 状态码
|
||||||
|
```bash
|
||||||
|
curl -s -o /dev/null -w "%{http_code}\n" http://<host>/v1/system/healthz
|
||||||
|
```
|
||||||
|
期望:`200` 或 `500`。
|
||||||
|
|
||||||
|
### 2) Windows PowerShell
|
||||||
|
```powershell
|
||||||
|
# 状态码
|
||||||
|
(Invoke-WebRequest -Uri "http://<host>/v1/system/healthz" -Method GET -TimeoutSec 3 -ErrorAction SilentlyContinue).StatusCode
|
||||||
|
# 完整响应
|
||||||
|
Invoke-RestMethod -Uri "http://<host>/v1/system/healthz" -Method GET
|
||||||
|
```
|
||||||
|
|
||||||
|
### 3) 通过 kubectl 端口转发本地测试
|
||||||
|
```bash
|
||||||
|
# 前端/网关暴露端口不同环境自行调整
|
||||||
|
kubectl port-forward deploy/<your-deploy> 8080:80 -n <ns>
|
||||||
|
curl -i http://127.0.0.1:8080/v1/system/healthz
|
||||||
|
```
|
||||||
|
|
||||||
|
### 4) 制造常见失败场景
|
||||||
|
- DB 失败(推荐):
|
||||||
|
```bash
|
||||||
|
docker compose stop db
|
||||||
|
curl -i http://<host>/v1/system/healthz # 预期 500
|
||||||
|
```
|
||||||
|
- Chat 失败(可选):将 `CHAT_CFG` 的 `factory`/`base_url` 设为无效并重启后端,再请求应为 500,且 `chat:"nok"`。
|
||||||
|
- Redis/存储/文档引擎:停用对应服务后再次请求,可在 JSON 中看到相应字段为 `"nok"`(不影响 200/500 判定)。
|
||||||
|
|
||||||
|
### 5) 浏览器验证
|
||||||
|
- 直接打开 `http://<host>/v1/system/healthz`,在 DevTools Network 查看 200/500;页面正文就是 JSON。
|
||||||
|
- 反向代理注意:若有自定义 500 错页,需对 `/healthz` 关闭错误页拦截(如 `proxy_intercept_errors off;`)。
|
||||||
|
|
||||||
|
## K8s 探针示例
|
||||||
|
```yaml
|
||||||
|
readinessProbe:
|
||||||
|
httpGet:
|
||||||
|
path: /v1/system/healthz
|
||||||
|
port: 80
|
||||||
|
initialDelaySeconds: 5
|
||||||
|
periodSeconds: 10
|
||||||
|
timeoutSeconds: 2
|
||||||
|
failureThreshold: 1
|
||||||
|
livenessProbe:
|
||||||
|
httpGet:
|
||||||
|
path: /v1/system/healthz
|
||||||
|
port: 80
|
||||||
|
initialDelaySeconds: 10
|
||||||
|
periodSeconds: 10
|
||||||
|
timeoutSeconds: 2
|
||||||
|
failureThreshold: 3
|
||||||
|
```
|
||||||
|
|
||||||
|
提示:如有反向代理(Nginx)自定义 500 错页,需对 `/healthz` 关闭错误页拦截,以便保留 JSON。
|
||||||
@ -28,6 +28,7 @@ from api.db import CanvasCategory, FileType
|
|||||||
from api.db.services.canvas_service import CanvasTemplateService, UserCanvasService, API4ConversationService
|
from api.db.services.canvas_service import CanvasTemplateService, UserCanvasService, API4ConversationService
|
||||||
from api.db.services.document_service import DocumentService
|
from api.db.services.document_service import DocumentService
|
||||||
from api.db.services.file_service import FileService
|
from api.db.services.file_service import FileService
|
||||||
|
from api.db.services.task_service import queue_dataflow
|
||||||
from api.db.services.user_service import TenantService
|
from api.db.services.user_service import TenantService
|
||||||
from api.db.services.user_canvas_version import UserCanvasVersionService
|
from api.db.services.user_canvas_version import UserCanvasVersionService
|
||||||
from api.settings import RetCode
|
from api.settings import RetCode
|
||||||
@ -48,14 +49,6 @@ def templates():
|
|||||||
return get_json_result(data=[c.to_dict() for c in CanvasTemplateService.query(canvas_category=CanvasCategory.Agent)])
|
return get_json_result(data=[c.to_dict() for c in CanvasTemplateService.query(canvas_category=CanvasCategory.Agent)])
|
||||||
|
|
||||||
|
|
||||||
@manager.route('/list', methods=['GET']) # noqa: F821
|
|
||||||
@login_required
|
|
||||||
def canvas_list():
|
|
||||||
return get_json_result(data=sorted([c.to_dict() for c in \
|
|
||||||
UserCanvasService.query(user_id=current_user.id, canvas_category=CanvasCategory.Agent)], key=lambda x: x["update_time"]*-1)
|
|
||||||
)
|
|
||||||
|
|
||||||
|
|
||||||
@manager.route('/rm', methods=['POST']) # noqa: F821
|
@manager.route('/rm', methods=['POST']) # noqa: F821
|
||||||
@validate_request("canvas_ids")
|
@validate_request("canvas_ids")
|
||||||
@login_required
|
@login_required
|
||||||
@ -77,9 +70,10 @@ def save():
|
|||||||
if not isinstance(req["dsl"], str):
|
if not isinstance(req["dsl"], str):
|
||||||
req["dsl"] = json.dumps(req["dsl"], ensure_ascii=False)
|
req["dsl"] = json.dumps(req["dsl"], ensure_ascii=False)
|
||||||
req["dsl"] = json.loads(req["dsl"])
|
req["dsl"] = json.loads(req["dsl"])
|
||||||
|
cate = req.get("canvas_category", CanvasCategory.Agent)
|
||||||
if "id" not in req:
|
if "id" not in req:
|
||||||
req["user_id"] = current_user.id
|
req["user_id"] = current_user.id
|
||||||
if UserCanvasService.query(user_id=current_user.id, title=req["title"].strip(), canvas_category=CanvasCategory.Agent):
|
if UserCanvasService.query(user_id=current_user.id, title=req["title"].strip(), canvas_category=cate):
|
||||||
return get_data_error_result(message=f"{req['title'].strip()} already exists.")
|
return get_data_error_result(message=f"{req['title'].strip()} already exists.")
|
||||||
req["id"] = get_uuid()
|
req["id"] = get_uuid()
|
||||||
if not UserCanvasService.save(**req):
|
if not UserCanvasService.save(**req):
|
||||||
@ -148,6 +142,14 @@ def run():
|
|||||||
if not isinstance(cvs.dsl, str):
|
if not isinstance(cvs.dsl, str):
|
||||||
cvs.dsl = json.dumps(cvs.dsl, ensure_ascii=False)
|
cvs.dsl = json.dumps(cvs.dsl, ensure_ascii=False)
|
||||||
|
|
||||||
|
if cvs.canvas_category == CanvasCategory.DataFlow:
|
||||||
|
task_id = get_uuid()
|
||||||
|
flow_id = get_uuid()
|
||||||
|
ok, error_message = queue_dataflow(dsl=cvs.dsl, tenant_id=user_id, file=files[0], task_id=task_id, flow_id=flow_id, priority=0)
|
||||||
|
if not ok:
|
||||||
|
return server_error_response(error_message)
|
||||||
|
return get_json_result(data={"task_id": task_id, "message_id": flow_id})
|
||||||
|
|
||||||
try:
|
try:
|
||||||
canvas = Canvas(cvs.dsl, current_user.id, req["id"])
|
canvas = Canvas(cvs.dsl, current_user.id, req["id"])
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
@ -332,7 +334,7 @@ def test_db_connect():
|
|||||||
if req["db_type"] in ["mysql", "mariadb"]:
|
if req["db_type"] in ["mysql", "mariadb"]:
|
||||||
db = MySQLDatabase(req["database"], user=req["username"], host=req["host"], port=req["port"],
|
db = MySQLDatabase(req["database"], user=req["username"], host=req["host"], port=req["port"],
|
||||||
password=req["password"])
|
password=req["password"])
|
||||||
elif req["db_type"] == 'postgresql':
|
elif req["db_type"] == 'postgres':
|
||||||
db = PostgresqlDatabase(req["database"], user=req["username"], host=req["host"], port=req["port"],
|
db = PostgresqlDatabase(req["database"], user=req["username"], host=req["host"], port=req["port"],
|
||||||
password=req["password"])
|
password=req["password"])
|
||||||
elif req["db_type"] == 'mssql':
|
elif req["db_type"] == 'mssql':
|
||||||
@ -383,22 +385,31 @@ def getversion( version_id):
|
|||||||
return get_json_result(data=f"Error getting history file: {e}")
|
return get_json_result(data=f"Error getting history file: {e}")
|
||||||
|
|
||||||
|
|
||||||
@manager.route('/listteam', methods=['GET']) # noqa: F821
|
@manager.route('/list', methods=['GET']) # noqa: F821
|
||||||
@login_required
|
@login_required
|
||||||
def list_canvas():
|
def list_canvas():
|
||||||
keywords = request.args.get("keywords", "")
|
keywords = request.args.get("keywords", "")
|
||||||
page_number = int(request.args.get("page", 1))
|
page_number = int(request.args.get("page", 1))
|
||||||
items_per_page = int(request.args.get("page_size", 150))
|
items_per_page = int(request.args.get("page_size", 150))
|
||||||
orderby = request.args.get("orderby", "create_time")
|
orderby = request.args.get("orderby", "create_time")
|
||||||
desc = request.args.get("desc", True)
|
canvas_category = request.args.get("canvas_category")
|
||||||
try:
|
if request.args.get("desc", "true").lower() == "false":
|
||||||
|
desc = False
|
||||||
|
else:
|
||||||
|
desc = True
|
||||||
|
owner_ids = request.args.get("owner_ids", [])
|
||||||
|
if not owner_ids:
|
||||||
tenants = TenantService.get_joined_tenants_by_user_id(current_user.id)
|
tenants = TenantService.get_joined_tenants_by_user_id(current_user.id)
|
||||||
|
tenants = [m["tenant_id"] for m in tenants]
|
||||||
canvas, total = UserCanvasService.get_by_tenant_ids(
|
canvas, total = UserCanvasService.get_by_tenant_ids(
|
||||||
[m["tenant_id"] for m in tenants], current_user.id, page_number,
|
tenants, current_user.id, page_number,
|
||||||
items_per_page, orderby, desc, keywords, canvas_category=CanvasCategory.Agent)
|
items_per_page, orderby, desc, keywords, canvas_category)
|
||||||
return get_json_result(data={"canvas": canvas, "total": total})
|
else:
|
||||||
except Exception as e:
|
tenants = owner_ids
|
||||||
return server_error_response(e)
|
canvas, total = UserCanvasService.get_by_tenant_ids(
|
||||||
|
tenants, current_user.id, 0,
|
||||||
|
0, orderby, desc, keywords, canvas_category)
|
||||||
|
return get_json_result(data={"canvas": canvas, "total": total})
|
||||||
|
|
||||||
|
|
||||||
@manager.route('/setting', methods=['POST']) # noqa: F821
|
@manager.route('/setting', methods=['POST']) # noqa: F821
|
||||||
|
|||||||
@ -182,6 +182,7 @@ def create():
|
|||||||
"id": get_uuid(),
|
"id": get_uuid(),
|
||||||
"kb_id": kb.id,
|
"kb_id": kb.id,
|
||||||
"parser_id": kb.parser_id,
|
"parser_id": kb.parser_id,
|
||||||
|
"pipeline_id": kb.pipeline_id,
|
||||||
"parser_config": kb.parser_config,
|
"parser_config": kb.parser_config,
|
||||||
"created_by": current_user.id,
|
"created_by": current_user.id,
|
||||||
"type": FileType.VIRTUAL,
|
"type": FileType.VIRTUAL,
|
||||||
@ -546,31 +547,22 @@ def get(doc_id):
|
|||||||
|
|
||||||
@manager.route("/change_parser", methods=["POST"]) # noqa: F821
|
@manager.route("/change_parser", methods=["POST"]) # noqa: F821
|
||||||
@login_required
|
@login_required
|
||||||
@validate_request("doc_id", "parser_id")
|
@validate_request("doc_id")
|
||||||
def change_parser():
|
def change_parser():
|
||||||
req = request.json
|
req = request.json
|
||||||
|
|
||||||
if not DocumentService.accessible(req["doc_id"], current_user.id):
|
if not DocumentService.accessible(req["doc_id"], current_user.id):
|
||||||
return get_json_result(data=False, message="No authorization.", code=settings.RetCode.AUTHENTICATION_ERROR)
|
return get_json_result(data=False, message="No authorization.", code=settings.RetCode.AUTHENTICATION_ERROR)
|
||||||
try:
|
|
||||||
e, doc = DocumentService.get_by_id(req["doc_id"])
|
|
||||||
if not e:
|
|
||||||
return get_data_error_result(message="Document not found!")
|
|
||||||
if doc.parser_id.lower() == req["parser_id"].lower():
|
|
||||||
if "parser_config" in req:
|
|
||||||
if req["parser_config"] == doc.parser_config:
|
|
||||||
return get_json_result(data=True)
|
|
||||||
else:
|
|
||||||
return get_json_result(data=True)
|
|
||||||
|
|
||||||
if (doc.type == FileType.VISUAL and req["parser_id"] != "picture") or (re.search(r"\.(ppt|pptx|pages)$", doc.name) and req["parser_id"] != "presentation"):
|
e, doc = DocumentService.get_by_id(req["doc_id"])
|
||||||
return get_data_error_result(message="Not supported yet!")
|
if not e:
|
||||||
|
return get_data_error_result(message="Document not found!")
|
||||||
|
|
||||||
|
def reset_doc():
|
||||||
|
nonlocal doc
|
||||||
e = DocumentService.update_by_id(doc.id, {"parser_id": req["parser_id"], "progress": 0, "progress_msg": "", "run": TaskStatus.UNSTART.value})
|
e = DocumentService.update_by_id(doc.id, {"parser_id": req["parser_id"], "progress": 0, "progress_msg": "", "run": TaskStatus.UNSTART.value})
|
||||||
if not e:
|
if not e:
|
||||||
return get_data_error_result(message="Document not found!")
|
return get_data_error_result(message="Document not found!")
|
||||||
if "parser_config" in req:
|
|
||||||
DocumentService.update_parser_config(doc.id, req["parser_config"])
|
|
||||||
if doc.token_num > 0:
|
if doc.token_num > 0:
|
||||||
e = DocumentService.increment_chunk_num(doc.id, doc.kb_id, doc.token_num * -1, doc.chunk_num * -1, doc.process_duration * -1)
|
e = DocumentService.increment_chunk_num(doc.id, doc.kb_id, doc.token_num * -1, doc.chunk_num * -1, doc.process_duration * -1)
|
||||||
if not e:
|
if not e:
|
||||||
@ -581,6 +573,26 @@ def change_parser():
|
|||||||
if settings.docStoreConn.indexExist(search.index_name(tenant_id), doc.kb_id):
|
if settings.docStoreConn.indexExist(search.index_name(tenant_id), doc.kb_id):
|
||||||
settings.docStoreConn.delete({"doc_id": doc.id}, search.index_name(tenant_id), doc.kb_id)
|
settings.docStoreConn.delete({"doc_id": doc.id}, search.index_name(tenant_id), doc.kb_id)
|
||||||
|
|
||||||
|
try:
|
||||||
|
if req.get("pipeline_id"):
|
||||||
|
if doc.pipeline_id == req["pipeline_id"]:
|
||||||
|
return get_json_result(data=True)
|
||||||
|
DocumentService.update_by_id(doc.id, {"pipeline_id": req["pipeline_id"]})
|
||||||
|
reset_doc()
|
||||||
|
return get_json_result(data=True)
|
||||||
|
|
||||||
|
if doc.parser_id.lower() == req["parser_id"].lower():
|
||||||
|
if "parser_config" in req:
|
||||||
|
if req["parser_config"] == doc.parser_config:
|
||||||
|
return get_json_result(data=True)
|
||||||
|
else:
|
||||||
|
return get_json_result(data=True)
|
||||||
|
|
||||||
|
if (doc.type == FileType.VISUAL and req["parser_id"] != "picture") or (re.search(r"\.(ppt|pptx|pages)$", doc.name) and req["parser_id"] != "presentation"):
|
||||||
|
return get_data_error_result(message="Not supported yet!")
|
||||||
|
if "parser_config" in req:
|
||||||
|
DocumentService.update_parser_config(doc.id, req["parser_config"])
|
||||||
|
reset_doc()
|
||||||
return get_json_result(data=True)
|
return get_json_result(data=True)
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
return server_error_response(e)
|
return server_error_response(e)
|
||||||
|
|||||||
@ -64,7 +64,7 @@ def create():
|
|||||||
e, t = TenantService.get_by_id(current_user.id)
|
e, t = TenantService.get_by_id(current_user.id)
|
||||||
if not e:
|
if not e:
|
||||||
return get_data_error_result(message="Tenant not found.")
|
return get_data_error_result(message="Tenant not found.")
|
||||||
req["embd_id"] = t.embd_id
|
#req["embd_id"] = t.embd_id
|
||||||
if not KnowledgebaseService.save(**req):
|
if not KnowledgebaseService.save(**req):
|
||||||
return get_data_error_result()
|
return get_data_error_result()
|
||||||
return get_json_result(data={"kb_id": req["id"]})
|
return get_json_result(data={"kb_id": req["id"]})
|
||||||
@ -379,3 +379,19 @@ def get_meta():
|
|||||||
code=settings.RetCode.AUTHENTICATION_ERROR
|
code=settings.RetCode.AUTHENTICATION_ERROR
|
||||||
)
|
)
|
||||||
return get_json_result(data=DocumentService.get_meta_by_kbs(kb_ids))
|
return get_json_result(data=DocumentService.get_meta_by_kbs(kb_ids))
|
||||||
|
|
||||||
|
|
||||||
|
@manager.route("/basic_info", methods=["GET"]) # noqa: F821
|
||||||
|
@login_required
|
||||||
|
def get_basic_info():
|
||||||
|
kb_id = request.args.get("kb_id", "")
|
||||||
|
if not KnowledgebaseService.accessible(kb_id, current_user.id):
|
||||||
|
return get_json_result(
|
||||||
|
data=False,
|
||||||
|
message='No authorization.',
|
||||||
|
code=settings.RetCode.AUTHENTICATION_ERROR
|
||||||
|
)
|
||||||
|
|
||||||
|
basic_info = DocumentService.knowledgebase_basic_info(kb_id)
|
||||||
|
|
||||||
|
return get_json_result(data=basic_info)
|
||||||
|
|||||||
@ -414,7 +414,7 @@ def agents_completion_openai_compatibility(tenant_id, agent_id):
|
|||||||
tenant_id,
|
tenant_id,
|
||||||
agent_id,
|
agent_id,
|
||||||
question,
|
question,
|
||||||
session_id=req.get("session_id", req.get("id", "") or req.get("metadata", {}).get("id", "")),
|
session_id=req.pop("session_id", req.get("id", "")) or req.get("metadata", {}).get("id", ""),
|
||||||
stream=True,
|
stream=True,
|
||||||
**req,
|
**req,
|
||||||
),
|
),
|
||||||
@ -432,7 +432,7 @@ def agents_completion_openai_compatibility(tenant_id, agent_id):
|
|||||||
tenant_id,
|
tenant_id,
|
||||||
agent_id,
|
agent_id,
|
||||||
question,
|
question,
|
||||||
session_id=req.get("session_id", req.get("id", "") or req.get("metadata", {}).get("id", "")),
|
session_id=req.pop("session_id", req.get("id", "")) or req.get("metadata", {}).get("id", ""),
|
||||||
stream=False,
|
stream=False,
|
||||||
**req,
|
**req,
|
||||||
)
|
)
|
||||||
|
|||||||
@ -36,6 +36,8 @@ from rag.utils.storage_factory import STORAGE_IMPL, STORAGE_IMPL_TYPE
|
|||||||
from timeit import default_timer as timer
|
from timeit import default_timer as timer
|
||||||
|
|
||||||
from rag.utils.redis_conn import REDIS_CONN
|
from rag.utils.redis_conn import REDIS_CONN
|
||||||
|
from flask import jsonify
|
||||||
|
from api.utils.health import run_health_checks
|
||||||
|
|
||||||
@manager.route("/version", methods=["GET"]) # noqa: F821
|
@manager.route("/version", methods=["GET"]) # noqa: F821
|
||||||
@login_required
|
@login_required
|
||||||
@ -169,6 +171,12 @@ def status():
|
|||||||
return get_json_result(data=res)
|
return get_json_result(data=res)
|
||||||
|
|
||||||
|
|
||||||
|
@manager.route("/healthz", methods=["GET"]) # noqa: F821
|
||||||
|
def healthz():
|
||||||
|
result, all_ok = run_health_checks()
|
||||||
|
return jsonify(result), (200 if all_ok else 500)
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/new_token", methods=["POST"]) # noqa: F821
|
@manager.route("/new_token", methods=["POST"]) # noqa: F821
|
||||||
@login_required
|
@login_required
|
||||||
def new_token():
|
def new_token():
|
||||||
|
|||||||
@ -646,6 +646,7 @@ class Knowledgebase(DataBaseModel):
|
|||||||
vector_similarity_weight = FloatField(default=0.3, index=True)
|
vector_similarity_weight = FloatField(default=0.3, index=True)
|
||||||
|
|
||||||
parser_id = CharField(max_length=32, null=False, help_text="default parser ID", default=ParserType.NAIVE.value, index=True)
|
parser_id = CharField(max_length=32, null=False, help_text="default parser ID", default=ParserType.NAIVE.value, index=True)
|
||||||
|
pipeline_id = CharField(max_length=32, null=True, help_text="Pipeline ID", index=True)
|
||||||
parser_config = JSONField(null=False, default={"pages": [[1, 1000000]]})
|
parser_config = JSONField(null=False, default={"pages": [[1, 1000000]]})
|
||||||
pagerank = IntegerField(default=0, index=False)
|
pagerank = IntegerField(default=0, index=False)
|
||||||
status = CharField(max_length=1, null=True, help_text="is it validate(0: wasted, 1: validate)", default="1", index=True)
|
status = CharField(max_length=1, null=True, help_text="is it validate(0: wasted, 1: validate)", default="1", index=True)
|
||||||
@ -662,6 +663,7 @@ class Document(DataBaseModel):
|
|||||||
thumbnail = TextField(null=True, help_text="thumbnail base64 string")
|
thumbnail = TextField(null=True, help_text="thumbnail base64 string")
|
||||||
kb_id = CharField(max_length=256, null=False, index=True)
|
kb_id = CharField(max_length=256, null=False, index=True)
|
||||||
parser_id = CharField(max_length=32, null=False, help_text="default parser ID", index=True)
|
parser_id = CharField(max_length=32, null=False, help_text="default parser ID", index=True)
|
||||||
|
pipeline_id = CharField(max_length=32, null=True, help_text="pipleline ID", index=True)
|
||||||
parser_config = JSONField(null=False, default={"pages": [[1, 1000000]]})
|
parser_config = JSONField(null=False, default={"pages": [[1, 1000000]]})
|
||||||
source_type = CharField(max_length=128, null=False, default="local", help_text="where dose this document come from", index=True)
|
source_type = CharField(max_length=128, null=False, default="local", help_text="where dose this document come from", index=True)
|
||||||
type = CharField(max_length=32, null=False, help_text="file extension", index=True)
|
type = CharField(max_length=32, null=False, help_text="file extension", index=True)
|
||||||
@ -1020,7 +1022,6 @@ def migrate_db():
|
|||||||
migrate(migrator.add_column("dialog", "meta_data_filter", JSONField(null=True, default={})))
|
migrate(migrator.add_column("dialog", "meta_data_filter", JSONField(null=True, default={})))
|
||||||
except Exception:
|
except Exception:
|
||||||
pass
|
pass
|
||||||
|
|
||||||
try:
|
try:
|
||||||
migrate(migrator.alter_column_type("canvas_template", "title", JSONField(null=True, default=dict, help_text="Canvas title")))
|
migrate(migrator.alter_column_type("canvas_template", "title", JSONField(null=True, default=dict, help_text="Canvas title")))
|
||||||
except Exception:
|
except Exception:
|
||||||
@ -1037,4 +1038,12 @@ def migrate_db():
|
|||||||
migrate(migrator.add_column("canvas_template", "canvas_category", CharField(max_length=32, null=False, default="agent_canvas", help_text="agent_canvas|dataflow_canvas", index=True)))
|
migrate(migrator.add_column("canvas_template", "canvas_category", CharField(max_length=32, null=False, default="agent_canvas", help_text="agent_canvas|dataflow_canvas", index=True)))
|
||||||
except Exception:
|
except Exception:
|
||||||
pass
|
pass
|
||||||
|
try:
|
||||||
|
migrate(migrator.add_column("knowledgebase", "pipeline_id", CharField(max_length=32, null=True, help_text="default parser ID", index=True)))
|
||||||
|
except Exception:
|
||||||
|
pass
|
||||||
|
try:
|
||||||
|
migrate(migrator.add_column("document", "pipeline_id", CharField(max_length=32, null=True, help_text="default parser ID", index=True)))
|
||||||
|
except Exception:
|
||||||
|
pass
|
||||||
logging.disable(logging.NOTSET)
|
logging.disable(logging.NOTSET)
|
||||||
|
|||||||
@ -95,7 +95,7 @@ class UserCanvasService(CommonService):
|
|||||||
@DB.connection_context()
|
@DB.connection_context()
|
||||||
def get_by_tenant_ids(cls, joined_tenant_ids, user_id,
|
def get_by_tenant_ids(cls, joined_tenant_ids, user_id,
|
||||||
page_number, items_per_page,
|
page_number, items_per_page,
|
||||||
orderby, desc, keywords, canvas_category=CanvasCategory.Agent,
|
orderby, desc, keywords, canvas_category=None
|
||||||
):
|
):
|
||||||
fields = [
|
fields = [
|
||||||
cls.model.id,
|
cls.model.id,
|
||||||
@ -122,7 +122,8 @@ class UserCanvasService(CommonService):
|
|||||||
TenantPermission.TEAM.value)) | (
|
TenantPermission.TEAM.value)) | (
|
||||||
cls.model.user_id == user_id))
|
cls.model.user_id == user_id))
|
||||||
)
|
)
|
||||||
agents = agents.where(cls.model.canvas_category == canvas_category)
|
if canvas_category:
|
||||||
|
agents = agents.where(cls.model.canvas_category == canvas_category)
|
||||||
if desc:
|
if desc:
|
||||||
agents = agents.order_by(cls.model.getter_by(orderby).desc())
|
agents = agents.order_by(cls.model.getter_by(orderby).desc())
|
||||||
else:
|
else:
|
||||||
|
|||||||
@ -24,7 +24,7 @@ from io import BytesIO
|
|||||||
|
|
||||||
import trio
|
import trio
|
||||||
import xxhash
|
import xxhash
|
||||||
from peewee import fn
|
from peewee import fn, Case
|
||||||
|
|
||||||
from api import settings
|
from api import settings
|
||||||
from api.constants import IMG_BASE64_PREFIX, FILE_NAME_LEN_LIMIT
|
from api.constants import IMG_BASE64_PREFIX, FILE_NAME_LEN_LIMIT
|
||||||
@ -674,6 +674,53 @@ class DocumentService(CommonService):
|
|||||||
return False
|
return False
|
||||||
|
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
@DB.connection_context()
|
||||||
|
def knowledgebase_basic_info(cls, kb_id: str) -> dict[str, int]:
|
||||||
|
# cancelled: run == "2" but progress can vary
|
||||||
|
cancelled = (
|
||||||
|
cls.model.select(fn.COUNT(1))
|
||||||
|
.where((cls.model.kb_id == kb_id) & (cls.model.run == TaskStatus.CANCEL))
|
||||||
|
.scalar()
|
||||||
|
)
|
||||||
|
|
||||||
|
row = (
|
||||||
|
cls.model.select(
|
||||||
|
# finished: progress == 1
|
||||||
|
fn.COALESCE(fn.SUM(Case(None, [(cls.model.progress == 1, 1)], 0)), 0).alias("finished"),
|
||||||
|
|
||||||
|
# failed: progress == -1
|
||||||
|
fn.COALESCE(fn.SUM(Case(None, [(cls.model.progress == -1, 1)], 0)), 0).alias("failed"),
|
||||||
|
|
||||||
|
# processing: 0 <= progress < 1
|
||||||
|
fn.COALESCE(
|
||||||
|
fn.SUM(
|
||||||
|
Case(
|
||||||
|
None,
|
||||||
|
[
|
||||||
|
(((cls.model.progress == 0) | ((cls.model.progress > 0) & (cls.model.progress < 1))), 1),
|
||||||
|
],
|
||||||
|
0,
|
||||||
|
)
|
||||||
|
),
|
||||||
|
0,
|
||||||
|
).alias("processing"),
|
||||||
|
)
|
||||||
|
.where(
|
||||||
|
(cls.model.kb_id == kb_id)
|
||||||
|
& ((cls.model.run.is_null(True)) | (cls.model.run != TaskStatus.CANCEL))
|
||||||
|
)
|
||||||
|
.dicts()
|
||||||
|
.get()
|
||||||
|
)
|
||||||
|
|
||||||
|
return {
|
||||||
|
"processing": int(row["processing"]),
|
||||||
|
"finished": int(row["finished"]),
|
||||||
|
"failed": int(row["failed"]),
|
||||||
|
"cancelled": int(cancelled),
|
||||||
|
}
|
||||||
|
|
||||||
def queue_raptor_o_graphrag_tasks(doc, ty, priority):
|
def queue_raptor_o_graphrag_tasks(doc, ty, priority):
|
||||||
chunking_config = DocumentService.get_chunking_config(doc["id"])
|
chunking_config = DocumentService.get_chunking_config(doc["id"])
|
||||||
hasher = xxhash.xxh64()
|
hasher = xxhash.xxh64()
|
||||||
@ -702,6 +749,8 @@ def queue_raptor_o_graphrag_tasks(doc, ty, priority):
|
|||||||
|
|
||||||
def get_queue_length(priority):
|
def get_queue_length(priority):
|
||||||
group_info = REDIS_CONN.queue_info(get_svr_queue_name(priority), SVR_CONSUMER_GROUP_NAME)
|
group_info = REDIS_CONN.queue_info(get_svr_queue_name(priority), SVR_CONSUMER_GROUP_NAME)
|
||||||
|
if not group_info:
|
||||||
|
return 0
|
||||||
return int(group_info.get("lag", 0) or 0)
|
return int(group_info.get("lag", 0) or 0)
|
||||||
|
|
||||||
|
|
||||||
@ -847,3 +896,4 @@ def doc_upload_and_parse(conversation_id, file_objs, user_id):
|
|||||||
doc_id, kb.id, token_counts[doc_id], chunk_counts[doc_id], 0)
|
doc_id, kb.id, token_counts[doc_id], chunk_counts[doc_id], 0)
|
||||||
|
|
||||||
return [d["id"] for d, _ in files]
|
return [d["id"] for d, _ in files]
|
||||||
|
|
||||||
|
|||||||
@ -440,6 +440,7 @@ class FileService(CommonService):
|
|||||||
"id": doc_id,
|
"id": doc_id,
|
||||||
"kb_id": kb.id,
|
"kb_id": kb.id,
|
||||||
"parser_id": self.get_parser(filetype, filename, kb.parser_id),
|
"parser_id": self.get_parser(filetype, filename, kb.parser_id),
|
||||||
|
"pipeline_id": kb.pipeline_id,
|
||||||
"parser_config": kb.parser_config,
|
"parser_config": kb.parser_config,
|
||||||
"created_by": user_id,
|
"created_by": user_id,
|
||||||
"type": filetype,
|
"type": filetype,
|
||||||
|
|||||||
@ -472,19 +472,19 @@ def has_canceled(task_id):
|
|||||||
return False
|
return False
|
||||||
|
|
||||||
|
|
||||||
def queue_dataflow(dsl:str, tenant_id:str, doc_id:str, task_id:str, flow_id:str, priority: int, callback=None) -> tuple[bool, str]:
|
def queue_dataflow(dsl:str, tenant_id:str, task_id:str, flow_id:str=None, doc_id:str=None, file:dict=None, priority: int=0, callback=None) -> tuple[bool, str]:
|
||||||
"""
|
"""
|
||||||
Returns a tuple (success: bool, error_message: str).
|
Returns a tuple (success: bool, error_message: str).
|
||||||
"""
|
"""
|
||||||
_ = callback
|
_ = callback
|
||||||
|
|
||||||
task = dict(
|
task = dict(
|
||||||
id=get_uuid() if not task_id else task_id,
|
id=get_uuid() if not task_id else task_id,
|
||||||
doc_id=doc_id,
|
doc_id=doc_id,
|
||||||
from_page=0,
|
from_page=0,
|
||||||
to_page=100000000,
|
to_page=100000000,
|
||||||
task_type="dataflow",
|
task_type="dataflow",
|
||||||
priority=priority,
|
priority=priority,
|
||||||
)
|
)
|
||||||
|
|
||||||
TaskService.model.delete().where(TaskService.model.id == task["id"]).execute()
|
TaskService.model.delete().where(TaskService.model.id == task["id"]).execute()
|
||||||
@ -499,6 +499,7 @@ def queue_dataflow(dsl:str, tenant_id:str, doc_id:str, task_id:str, flow_id:str,
|
|||||||
task["task_type"] = "dataflow"
|
task["task_type"] = "dataflow"
|
||||||
task["dsl"] = dsl
|
task["dsl"] = dsl
|
||||||
task["dataflow_id"] = get_uuid() if not flow_id else flow_id
|
task["dataflow_id"] = get_uuid() if not flow_id else flow_id
|
||||||
|
task["file"] = file
|
||||||
|
|
||||||
if not REDIS_CONN.queue_product(
|
if not REDIS_CONN.queue_product(
|
||||||
get_svr_queue_name(priority), message=task
|
get_svr_queue_name(priority), message=task
|
||||||
|
|||||||
@ -1,3 +1,51 @@
|
|||||||
import base64
|
import base64
|
||||||
|
from functools import partial
|
||||||
|
from io import BytesIO
|
||||||
|
|
||||||
|
from PIL import Image
|
||||||
|
|
||||||
test_image_base64 = "iVBORw0KGgoAAAANSUhEUgAAAGQAAABkCAIAAAD/gAIDAAAA6ElEQVR4nO3QwQ3AIBDAsIP9d25XIC+EZE8QZc18w5l9O+AlZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBT+IYAHHLHkdEgAAAABJRU5ErkJggg=="
|
test_image_base64 = "iVBORw0KGgoAAAANSUhEUgAAAGQAAABkCAIAAAD/gAIDAAAA6ElEQVR4nO3QwQ3AIBDAsIP9d25XIC+EZE8QZc18w5l9O+AlZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBWYFZgVmBT+IYAHHLHkdEgAAAABJRU5ErkJggg=="
|
||||||
test_image = base64.b64decode(test_image_base64)
|
test_image = base64.b64decode(test_image_base64)
|
||||||
|
|
||||||
|
async def image2id(d: dict, storage_put_func: partial, bucket:str, objname:str):
|
||||||
|
import logging
|
||||||
|
from io import BytesIO
|
||||||
|
import trio
|
||||||
|
from rag.svr.task_executor import minio_limiter
|
||||||
|
if not d.get("image"):
|
||||||
|
return
|
||||||
|
|
||||||
|
with BytesIO() as output_buffer:
|
||||||
|
if isinstance(d["image"], bytes):
|
||||||
|
output_buffer.write(d["image"])
|
||||||
|
output_buffer.seek(0)
|
||||||
|
else:
|
||||||
|
# If the image is in RGBA mode, convert it to RGB mode before saving it in JPEG format.
|
||||||
|
if d["image"].mode in ("RGBA", "P"):
|
||||||
|
converted_image = d["image"].convert("RGB")
|
||||||
|
d["image"] = converted_image
|
||||||
|
try:
|
||||||
|
d["image"].save(output_buffer, format='JPEG')
|
||||||
|
except OSError as e:
|
||||||
|
logging.warning(
|
||||||
|
"Saving image exception, ignore: {}".format(str(e)))
|
||||||
|
|
||||||
|
async with minio_limiter:
|
||||||
|
await trio.to_thread.run_sync(lambda: storage_put_func(bucket=bucket, fnm=objname, binary=output_buffer.getvalue()))
|
||||||
|
d["img_id"] = f"{bucket}-{objname}"
|
||||||
|
if not isinstance(d["image"], bytes):
|
||||||
|
d["image"].close()
|
||||||
|
del d["image"] # Remove image reference
|
||||||
|
|
||||||
|
|
||||||
|
def id2image(image_id:str|None, storage_get_func: partial):
|
||||||
|
if not image_id:
|
||||||
|
return
|
||||||
|
arr = image_id.split("-")
|
||||||
|
if len(arr) != 2:
|
||||||
|
return
|
||||||
|
bkt, nm = image_id.split("-")
|
||||||
|
blob = storage_get_func(bucket=bkt, filename=nm)
|
||||||
|
if not blob:
|
||||||
|
return
|
||||||
|
return Image.open(BytesIO(blob))
|
||||||
104
api/utils/health.py
Normal file
@ -0,0 +1,104 @@
|
|||||||
|
from timeit import default_timer as timer
|
||||||
|
|
||||||
|
from api import settings
|
||||||
|
from api.db.db_models import DB
|
||||||
|
from rag.utils.redis_conn import REDIS_CONN
|
||||||
|
from rag.utils.storage_factory import STORAGE_IMPL
|
||||||
|
|
||||||
|
|
||||||
|
def _ok_nok(ok: bool) -> str:
|
||||||
|
return "ok" if ok else "nok"
|
||||||
|
|
||||||
|
|
||||||
|
def check_db() -> tuple[bool, dict]:
|
||||||
|
st = timer()
|
||||||
|
try:
|
||||||
|
# lightweight probe; works for MySQL/Postgres
|
||||||
|
DB.execute_sql("SELECT 1")
|
||||||
|
return True, {"elapsed": f"{(timer() - st) * 1000.0:.1f}"}
|
||||||
|
except Exception as e:
|
||||||
|
return False, {"elapsed": f"{(timer() - st) * 1000.0:.1f}", "error": str(e)}
|
||||||
|
|
||||||
|
|
||||||
|
def check_redis() -> tuple[bool, dict]:
|
||||||
|
st = timer()
|
||||||
|
try:
|
||||||
|
ok = bool(REDIS_CONN.health())
|
||||||
|
return ok, {"elapsed": f"{(timer() - st) * 1000.0:.1f}"}
|
||||||
|
except Exception as e:
|
||||||
|
return False, {"elapsed": f"{(timer() - st) * 1000.0:.1f}", "error": str(e)}
|
||||||
|
|
||||||
|
|
||||||
|
def check_doc_engine() -> tuple[bool, dict]:
|
||||||
|
st = timer()
|
||||||
|
try:
|
||||||
|
meta = settings.docStoreConn.health()
|
||||||
|
# treat any successful call as ok
|
||||||
|
return True, {"elapsed": f"{(timer() - st) * 1000.0:.1f}", **(meta or {})}
|
||||||
|
except Exception as e:
|
||||||
|
return False, {"elapsed": f"{(timer() - st) * 1000.0:.1f}", "error": str(e)}
|
||||||
|
|
||||||
|
|
||||||
|
def check_storage() -> tuple[bool, dict]:
|
||||||
|
st = timer()
|
||||||
|
try:
|
||||||
|
STORAGE_IMPL.health()
|
||||||
|
return True, {"elapsed": f"{(timer() - st) * 1000.0:.1f}"}
|
||||||
|
except Exception as e:
|
||||||
|
return False, {"elapsed": f"{(timer() - st) * 1000.0:.1f}", "error": str(e)}
|
||||||
|
|
||||||
|
|
||||||
|
def check_chat() -> tuple[bool, dict]:
|
||||||
|
st = timer()
|
||||||
|
try:
|
||||||
|
cfg = getattr(settings, "CHAT_CFG", None)
|
||||||
|
ok = bool(cfg and cfg.get("factory"))
|
||||||
|
return ok, {"elapsed": f"{(timer() - st) * 1000.0:.1f}"}
|
||||||
|
except Exception as e:
|
||||||
|
return False, {"elapsed": f"{(timer() - st) * 1000.0:.1f}", "error": str(e)}
|
||||||
|
|
||||||
|
|
||||||
|
def run_health_checks() -> tuple[dict, bool]:
|
||||||
|
result: dict[str, str | dict] = {}
|
||||||
|
|
||||||
|
db_ok, db_meta = check_db()
|
||||||
|
chat_ok, chat_meta = check_chat()
|
||||||
|
|
||||||
|
result["db"] = _ok_nok(db_ok)
|
||||||
|
if not db_ok:
|
||||||
|
result.setdefault("_meta", {})["db"] = db_meta
|
||||||
|
|
||||||
|
result["chat"] = _ok_nok(chat_ok)
|
||||||
|
if not chat_ok:
|
||||||
|
result.setdefault("_meta", {})["chat"] = chat_meta
|
||||||
|
|
||||||
|
# Optional probes (do not change minimal contract but exposed for observability)
|
||||||
|
try:
|
||||||
|
redis_ok, redis_meta = check_redis()
|
||||||
|
result["redis"] = _ok_nok(redis_ok)
|
||||||
|
if not redis_ok:
|
||||||
|
result.setdefault("_meta", {})["redis"] = redis_meta
|
||||||
|
except Exception:
|
||||||
|
result["redis"] = "nok"
|
||||||
|
|
||||||
|
try:
|
||||||
|
doc_ok, doc_meta = check_doc_engine()
|
||||||
|
result["doc_engine"] = _ok_nok(doc_ok)
|
||||||
|
if not doc_ok:
|
||||||
|
result.setdefault("_meta", {})["doc_engine"] = doc_meta
|
||||||
|
except Exception:
|
||||||
|
result["doc_engine"] = "nok"
|
||||||
|
|
||||||
|
try:
|
||||||
|
sto_ok, sto_meta = check_storage()
|
||||||
|
result["storage"] = _ok_nok(sto_ok)
|
||||||
|
if not sto_ok:
|
||||||
|
result.setdefault("_meta", {})["storage"] = sto_meta
|
||||||
|
except Exception:
|
||||||
|
result["storage"] = "nok"
|
||||||
|
|
||||||
|
all_ok = (result.get("db") == "ok") and (result.get("chat") == "ok")
|
||||||
|
result["status"] = "ok" if all_ok else "nok"
|
||||||
|
return result, all_ok
|
||||||
|
|
||||||
|
|
||||||
@ -219,6 +219,70 @@
|
|||||||
}
|
}
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
|
{
|
||||||
|
"name": "TokenPony",
|
||||||
|
"logo": "",
|
||||||
|
"tags": "LLM",
|
||||||
|
"status": "1",
|
||||||
|
"llm": [
|
||||||
|
{
|
||||||
|
"llm_name": "qwen3-8b",
|
||||||
|
"tags": "LLM,CHAT,131k",
|
||||||
|
"max_tokens": 131000,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "deepseek-v3-0324",
|
||||||
|
"tags": "LLM,CHAT,128k",
|
||||||
|
"max_tokens": 128000,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "qwen3-32b",
|
||||||
|
"tags": "LLM,CHAT,131k",
|
||||||
|
"max_tokens": 131000,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "kimi-k2-instruct",
|
||||||
|
"tags": "LLM,CHAT,128K",
|
||||||
|
"max_tokens": 128000,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "deepseek-r1-0528",
|
||||||
|
"tags": "LLM,CHAT,164k",
|
||||||
|
"max_tokens": 164000,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "qwen3-coder-480b",
|
||||||
|
"tags": "LLM,CHAT,1024k",
|
||||||
|
"max_tokens": 1024000,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "glm-4.5",
|
||||||
|
"tags": "LLM,CHAT,131K",
|
||||||
|
"max_tokens": 131000,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "deepseek-v3.1",
|
||||||
|
"tags": "LLM,CHAT,128k",
|
||||||
|
"max_tokens": 128000,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
}
|
||||||
|
]
|
||||||
|
},
|
||||||
{
|
{
|
||||||
"name": "Tongyi-Qianwen",
|
"name": "Tongyi-Qianwen",
|
||||||
"logo": "",
|
"logo": "",
|
||||||
@ -625,7 +689,7 @@
|
|||||||
},
|
},
|
||||||
{
|
{
|
||||||
"llm_name": "glm-4",
|
"llm_name": "glm-4",
|
||||||
"tags":"LLM,CHAT,128K",
|
"tags": "LLM,CHAT,128K",
|
||||||
"max_tokens": 128000,
|
"max_tokens": 128000,
|
||||||
"model_type": "chat",
|
"model_type": "chat",
|
||||||
"is_tools": true
|
"is_tools": true
|
||||||
@ -4477,6 +4541,273 @@
|
|||||||
}
|
}
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
|
{
|
||||||
|
"name": "CometAPI",
|
||||||
|
"logo": "",
|
||||||
|
"tags": "LLM,TEXT EMBEDDING,IMAGE2TEXT",
|
||||||
|
"status": "1",
|
||||||
|
"llm": [
|
||||||
|
{
|
||||||
|
"llm_name": "gpt-5-chat-latest",
|
||||||
|
"tags": "LLM,CHAT,400k",
|
||||||
|
"max_tokens": 400000,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "chatgpt-4o-latest",
|
||||||
|
"tags": "LLM,CHAT,128k",
|
||||||
|
"max_tokens": 128000,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "gpt-5-mini",
|
||||||
|
"tags": "LLM,CHAT,400k",
|
||||||
|
"max_tokens": 400000,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "gpt-5-nano",
|
||||||
|
"tags": "LLM,CHAT,400k",
|
||||||
|
"max_tokens": 400000,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "gpt-5",
|
||||||
|
"tags": "LLM,CHAT,400k",
|
||||||
|
"max_tokens": 400000,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "gpt-4.1-mini",
|
||||||
|
"tags": "LLM,CHAT,1M",
|
||||||
|
"max_tokens": 1047576,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "gpt-4.1-nano",
|
||||||
|
"tags": "LLM,CHAT,1M",
|
||||||
|
"max_tokens": 1047576,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "gpt-4.1",
|
||||||
|
"tags": "LLM,CHAT,1M",
|
||||||
|
"max_tokens": 1047576,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "gpt-4o-mini",
|
||||||
|
"tags": "LLM,CHAT,128k",
|
||||||
|
"max_tokens": 128000,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "o4-mini-2025-04-16",
|
||||||
|
"tags": "LLM,CHAT,200k",
|
||||||
|
"max_tokens": 200000,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "o3-pro-2025-06-10",
|
||||||
|
"tags": "LLM,CHAT,200k",
|
||||||
|
"max_tokens": 200000,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "claude-opus-4-1-20250805",
|
||||||
|
"tags": "LLM,CHAT,200k,IMAGE2TEXT",
|
||||||
|
"max_tokens": 200000,
|
||||||
|
"model_type": "image2text",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "claude-opus-4-1-20250805-thinking",
|
||||||
|
"tags": "LLM,CHAT,200k,IMAGE2TEXT",
|
||||||
|
"max_tokens": 200000,
|
||||||
|
"model_type": "image2text",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "claude-sonnet-4-20250514",
|
||||||
|
"tags": "LLM,CHAT,200k,IMAGE2TEXT",
|
||||||
|
"max_tokens": 200000,
|
||||||
|
"model_type": "image2text",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "claude-sonnet-4-20250514-thinking",
|
||||||
|
"tags": "LLM,CHAT,200k,IMAGE2TEXT",
|
||||||
|
"max_tokens": 200000,
|
||||||
|
"model_type": "image2text",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "claude-3-7-sonnet-latest",
|
||||||
|
"tags": "LLM,CHAT,200k",
|
||||||
|
"max_tokens": 200000,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "claude-3-5-haiku-latest",
|
||||||
|
"tags": "LLM,CHAT,200k",
|
||||||
|
"max_tokens": 200000,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "gemini-2.5-pro",
|
||||||
|
"tags": "LLM,CHAT,1M,IMAGE2TEXT",
|
||||||
|
"max_tokens": 1000000,
|
||||||
|
"model_type": "image2text",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "gemini-2.5-flash",
|
||||||
|
"tags": "LLM,CHAT,1M,IMAGE2TEXT",
|
||||||
|
"max_tokens": 1000000,
|
||||||
|
"model_type": "image2text",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "gemini-2.5-flash-lite",
|
||||||
|
"tags": "LLM,CHAT,1M,IMAGE2TEXT",
|
||||||
|
"max_tokens": 1000000,
|
||||||
|
"model_type": "image2text",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "gemini-2.0-flash",
|
||||||
|
"tags": "LLM,CHAT,1M,IMAGE2TEXT",
|
||||||
|
"max_tokens": 1000000,
|
||||||
|
"model_type": "image2text",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "grok-4-0709",
|
||||||
|
"tags": "LLM,CHAT,131k",
|
||||||
|
"max_tokens": 131072,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "grok-3",
|
||||||
|
"tags": "LLM,CHAT,131k",
|
||||||
|
"max_tokens": 131072,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "grok-3-mini",
|
||||||
|
"tags": "LLM,CHAT,131k",
|
||||||
|
"max_tokens": 131072,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "grok-2-image-1212",
|
||||||
|
"tags": "LLM,CHAT,32k,IMAGE2TEXT",
|
||||||
|
"max_tokens": 32768,
|
||||||
|
"model_type": "image2text",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "deepseek-v3.1",
|
||||||
|
"tags": "LLM,CHAT,64k",
|
||||||
|
"max_tokens": 64000,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "deepseek-v3",
|
||||||
|
"tags": "LLM,CHAT,64k",
|
||||||
|
"max_tokens": 64000,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "deepseek-r1-0528",
|
||||||
|
"tags": "LLM,CHAT,164k",
|
||||||
|
"max_tokens": 164000,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "deepseek-chat",
|
||||||
|
"tags": "LLM,CHAT,32k",
|
||||||
|
"max_tokens": 32000,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "deepseek-reasoner",
|
||||||
|
"tags": "LLM,CHAT,64k",
|
||||||
|
"max_tokens": 64000,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "qwen3-30b-a3b",
|
||||||
|
"tags": "LLM,CHAT,128k",
|
||||||
|
"max_tokens": 128000,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "qwen3-coder-plus-2025-07-22",
|
||||||
|
"tags": "LLM,CHAT,128k",
|
||||||
|
"max_tokens": 128000,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "text-embedding-ada-002",
|
||||||
|
"tags": "TEXT EMBEDDING,8K",
|
||||||
|
"max_tokens": 8191,
|
||||||
|
"model_type": "embedding",
|
||||||
|
"is_tools": false
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "text-embedding-3-small",
|
||||||
|
"tags": "TEXT EMBEDDING,8K",
|
||||||
|
"max_tokens": 8191,
|
||||||
|
"model_type": "embedding",
|
||||||
|
"is_tools": false
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "text-embedding-3-large",
|
||||||
|
"tags": "TEXT EMBEDDING,8K",
|
||||||
|
"max_tokens": 8191,
|
||||||
|
"model_type": "embedding",
|
||||||
|
"is_tools": false
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "whisper-1",
|
||||||
|
"tags": "SPEECH2TEXT",
|
||||||
|
"max_tokens": 26214400,
|
||||||
|
"model_type": "speech2text",
|
||||||
|
"is_tools": false
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "tts-1",
|
||||||
|
"tags": "TTS",
|
||||||
|
"max_tokens": 2048,
|
||||||
|
"model_type": "tts",
|
||||||
|
"is_tools": false
|
||||||
|
}
|
||||||
|
]
|
||||||
|
},
|
||||||
{
|
{
|
||||||
"name": "Meituan",
|
"name": "Meituan",
|
||||||
"logo": "",
|
"logo": "",
|
||||||
@ -4493,4 +4824,4 @@
|
|||||||
]
|
]
|
||||||
}
|
}
|
||||||
]
|
]
|
||||||
}
|
}
|
||||||
@ -37,7 +37,7 @@ TITLE_TAGS = {"h1": "#", "h2": "##", "h3": "###", "h4": "#####", "h5": "#####",
|
|||||||
|
|
||||||
|
|
||||||
class RAGFlowHtmlParser:
|
class RAGFlowHtmlParser:
|
||||||
def __call__(self, fnm, binary=None, chunk_token_num=None):
|
def __call__(self, fnm, binary=None, chunk_token_num=512):
|
||||||
if binary:
|
if binary:
|
||||||
encoding = find_codec(binary)
|
encoding = find_codec(binary)
|
||||||
txt = binary.decode(encoding, errors="ignore")
|
txt = binary.decode(encoding, errors="ignore")
|
||||||
|
|||||||
@ -34,7 +34,7 @@ from pypdf import PdfReader as pdf2_read
|
|||||||
|
|
||||||
from api import settings
|
from api import settings
|
||||||
from api.utils.file_utils import get_project_base_directory
|
from api.utils.file_utils import get_project_base_directory
|
||||||
from deepdoc.vision import OCR, LayoutRecognizer, Recognizer, TableStructureRecognizer
|
from deepdoc.vision import OCR, AscendLayoutRecognizer, LayoutRecognizer, Recognizer, TableStructureRecognizer
|
||||||
from rag.app.picture import vision_llm_chunk as picture_vision_llm_chunk
|
from rag.app.picture import vision_llm_chunk as picture_vision_llm_chunk
|
||||||
from rag.nlp import rag_tokenizer
|
from rag.nlp import rag_tokenizer
|
||||||
from rag.prompts import vision_llm_describe_prompt
|
from rag.prompts import vision_llm_describe_prompt
|
||||||
@ -64,33 +64,38 @@ class RAGFlowPdfParser:
|
|||||||
if PARALLEL_DEVICES > 1:
|
if PARALLEL_DEVICES > 1:
|
||||||
self.parallel_limiter = [trio.CapacityLimiter(1) for _ in range(PARALLEL_DEVICES)]
|
self.parallel_limiter = [trio.CapacityLimiter(1) for _ in range(PARALLEL_DEVICES)]
|
||||||
|
|
||||||
|
layout_recognizer_type = os.getenv("LAYOUT_RECOGNIZER_TYPE", "onnx").lower()
|
||||||
|
if layout_recognizer_type not in ["onnx", "ascend"]:
|
||||||
|
raise RuntimeError("Unsupported layout recognizer type.")
|
||||||
|
|
||||||
if hasattr(self, "model_speciess"):
|
if hasattr(self, "model_speciess"):
|
||||||
self.layouter = LayoutRecognizer("layout." + self.model_speciess)
|
recognizer_domain = "layout." + self.model_speciess
|
||||||
else:
|
else:
|
||||||
self.layouter = LayoutRecognizer("layout")
|
recognizer_domain = "layout"
|
||||||
|
|
||||||
|
if layout_recognizer_type == "ascend":
|
||||||
|
logging.debug("Using Ascend LayoutRecognizer")
|
||||||
|
self.layouter = AscendLayoutRecognizer(recognizer_domain)
|
||||||
|
else: # onnx
|
||||||
|
logging.debug("Using Onnx LayoutRecognizer")
|
||||||
|
self.layouter = LayoutRecognizer(recognizer_domain)
|
||||||
self.tbl_det = TableStructureRecognizer()
|
self.tbl_det = TableStructureRecognizer()
|
||||||
|
|
||||||
self.updown_cnt_mdl = xgb.Booster()
|
self.updown_cnt_mdl = xgb.Booster()
|
||||||
if not settings.LIGHTEN:
|
if not settings.LIGHTEN:
|
||||||
try:
|
try:
|
||||||
import torch.cuda
|
import torch.cuda
|
||||||
|
|
||||||
if torch.cuda.is_available():
|
if torch.cuda.is_available():
|
||||||
self.updown_cnt_mdl.set_param({"device": "cuda"})
|
self.updown_cnt_mdl.set_param({"device": "cuda"})
|
||||||
except Exception:
|
except Exception:
|
||||||
logging.exception("RAGFlowPdfParser __init__")
|
logging.exception("RAGFlowPdfParser __init__")
|
||||||
try:
|
try:
|
||||||
model_dir = os.path.join(
|
model_dir = os.path.join(get_project_base_directory(), "rag/res/deepdoc")
|
||||||
get_project_base_directory(),
|
self.updown_cnt_mdl.load_model(os.path.join(model_dir, "updown_concat_xgb.model"))
|
||||||
"rag/res/deepdoc")
|
|
||||||
self.updown_cnt_mdl.load_model(os.path.join(
|
|
||||||
model_dir, "updown_concat_xgb.model"))
|
|
||||||
except Exception:
|
except Exception:
|
||||||
model_dir = snapshot_download(
|
model_dir = snapshot_download(repo_id="InfiniFlow/text_concat_xgb_v1.0", local_dir=os.path.join(get_project_base_directory(), "rag/res/deepdoc"), local_dir_use_symlinks=False)
|
||||||
repo_id="InfiniFlow/text_concat_xgb_v1.0",
|
self.updown_cnt_mdl.load_model(os.path.join(model_dir, "updown_concat_xgb.model"))
|
||||||
local_dir=os.path.join(get_project_base_directory(), "rag/res/deepdoc"),
|
|
||||||
local_dir_use_symlinks=False)
|
|
||||||
self.updown_cnt_mdl.load_model(os.path.join(
|
|
||||||
model_dir, "updown_concat_xgb.model"))
|
|
||||||
|
|
||||||
self.page_from = 0
|
self.page_from = 0
|
||||||
self.column_num = 1
|
self.column_num = 1
|
||||||
@ -102,13 +107,10 @@ class RAGFlowPdfParser:
|
|||||||
return c["bottom"] - c["top"]
|
return c["bottom"] - c["top"]
|
||||||
|
|
||||||
def _x_dis(self, a, b):
|
def _x_dis(self, a, b):
|
||||||
return min(abs(a["x1"] - b["x0"]), abs(a["x0"] - b["x1"]),
|
return min(abs(a["x1"] - b["x0"]), abs(a["x0"] - b["x1"]), abs(a["x0"] + a["x1"] - b["x0"] - b["x1"]) / 2)
|
||||||
abs(a["x0"] + a["x1"] - b["x0"] - b["x1"]) / 2)
|
|
||||||
|
|
||||||
def _y_dis(
|
def _y_dis(self, a, b):
|
||||||
self, a, b):
|
return (b["top"] + b["bottom"] - a["top"] - a["bottom"]) / 2
|
||||||
return (
|
|
||||||
b["top"] + b["bottom"] - a["top"] - a["bottom"]) / 2
|
|
||||||
|
|
||||||
def _match_proj(self, b):
|
def _match_proj(self, b):
|
||||||
proj_patt = [
|
proj_patt = [
|
||||||
@ -130,10 +132,7 @@ class RAGFlowPdfParser:
|
|||||||
LEN = 6
|
LEN = 6
|
||||||
tks_down = rag_tokenizer.tokenize(down["text"][:LEN]).split()
|
tks_down = rag_tokenizer.tokenize(down["text"][:LEN]).split()
|
||||||
tks_up = rag_tokenizer.tokenize(up["text"][-LEN:]).split()
|
tks_up = rag_tokenizer.tokenize(up["text"][-LEN:]).split()
|
||||||
tks_all = up["text"][-LEN:].strip() \
|
tks_all = up["text"][-LEN:].strip() + (" " if re.match(r"[a-zA-Z0-9]+", up["text"][-1] + down["text"][0]) else "") + down["text"][:LEN].strip()
|
||||||
+ (" " if re.match(r"[a-zA-Z0-9]+",
|
|
||||||
up["text"][-1] + down["text"][0]) else "") \
|
|
||||||
+ down["text"][:LEN].strip()
|
|
||||||
tks_all = rag_tokenizer.tokenize(tks_all).split()
|
tks_all = rag_tokenizer.tokenize(tks_all).split()
|
||||||
fea = [
|
fea = [
|
||||||
up.get("R", -1) == down.get("R", -1),
|
up.get("R", -1) == down.get("R", -1),
|
||||||
@ -144,39 +143,30 @@ class RAGFlowPdfParser:
|
|||||||
down["layout_type"] == "text",
|
down["layout_type"] == "text",
|
||||||
up["layout_type"] == "table",
|
up["layout_type"] == "table",
|
||||||
down["layout_type"] == "table",
|
down["layout_type"] == "table",
|
||||||
True if re.search(
|
True if re.search(r"([。?!;!?;+))]|[a-z]\.)$", up["text"]) else False,
|
||||||
r"([。?!;!?;+))]|[a-z]\.)$",
|
|
||||||
up["text"]) else False,
|
|
||||||
True if re.search(r"[,:‘“、0-9(+-]$", up["text"]) else False,
|
True if re.search(r"[,:‘“、0-9(+-]$", up["text"]) else False,
|
||||||
True if re.search(
|
True if re.search(r"(^.?[/,?;:\],。;:’”?!》】)-])", down["text"]) else False,
|
||||||
r"(^.?[/,?;:\],。;:’”?!》】)-])",
|
|
||||||
down["text"]) else False,
|
|
||||||
True if re.match(r"[\((][^\(\)()]+[)\)]$", up["text"]) else False,
|
True if re.match(r"[\((][^\(\)()]+[)\)]$", up["text"]) else False,
|
||||||
True if re.search(r"[,,][^。.]+$", up["text"]) else False,
|
True if re.search(r"[,,][^。.]+$", up["text"]) else False,
|
||||||
True if re.search(r"[,,][^。.]+$", up["text"]) else False,
|
True if re.search(r"[,,][^。.]+$", up["text"]) else False,
|
||||||
True if re.search(r"[\((][^\))]+$", up["text"])
|
True if re.search(r"[\((][^\))]+$", up["text"]) and re.search(r"[\))]", down["text"]) else False,
|
||||||
and re.search(r"[\))]", down["text"]) else False,
|
|
||||||
self._match_proj(down),
|
self._match_proj(down),
|
||||||
True if re.match(r"[A-Z]", down["text"]) else False,
|
True if re.match(r"[A-Z]", down["text"]) else False,
|
||||||
True if re.match(r"[A-Z]", up["text"][-1]) else False,
|
True if re.match(r"[A-Z]", up["text"][-1]) else False,
|
||||||
True if re.match(r"[a-z0-9]", up["text"][-1]) else False,
|
True if re.match(r"[a-z0-9]", up["text"][-1]) else False,
|
||||||
True if re.match(r"[0-9.%,-]+$", down["text"]) else False,
|
True if re.match(r"[0-9.%,-]+$", down["text"]) else False,
|
||||||
up["text"].strip()[-2:] == down["text"].strip()[-2:] if len(up["text"].strip()
|
up["text"].strip()[-2:] == down["text"].strip()[-2:] if len(up["text"].strip()) > 1 and len(down["text"].strip()) > 1 else False,
|
||||||
) > 1 and len(
|
|
||||||
down["text"].strip()) > 1 else False,
|
|
||||||
up["x0"] > down["x1"],
|
up["x0"] > down["x1"],
|
||||||
abs(self.__height(up) - self.__height(down)) / min(self.__height(up),
|
abs(self.__height(up) - self.__height(down)) / min(self.__height(up), self.__height(down)),
|
||||||
self.__height(down)),
|
|
||||||
self._x_dis(up, down) / max(w, 0.000001),
|
self._x_dis(up, down) / max(w, 0.000001),
|
||||||
(len(up["text"]) - len(down["text"])) /
|
(len(up["text"]) - len(down["text"])) / max(len(up["text"]), len(down["text"])),
|
||||||
max(len(up["text"]), len(down["text"])),
|
|
||||||
len(tks_all) - len(tks_up) - len(tks_down),
|
len(tks_all) - len(tks_up) - len(tks_down),
|
||||||
len(tks_down) - len(tks_up),
|
len(tks_down) - len(tks_up),
|
||||||
tks_down[-1] == tks_up[-1] if tks_down and tks_up else False,
|
tks_down[-1] == tks_up[-1] if tks_down and tks_up else False,
|
||||||
max(down["in_row"], up["in_row"]),
|
max(down["in_row"], up["in_row"]),
|
||||||
abs(down["in_row"] - up["in_row"]),
|
abs(down["in_row"] - up["in_row"]),
|
||||||
len(tks_down) == 1 and rag_tokenizer.tag(tks_down[0]).find("n") >= 0,
|
len(tks_down) == 1 and rag_tokenizer.tag(tks_down[0]).find("n") >= 0,
|
||||||
len(tks_up) == 1 and rag_tokenizer.tag(tks_up[0]).find("n") >= 0
|
len(tks_up) == 1 and rag_tokenizer.tag(tks_up[0]).find("n") >= 0,
|
||||||
]
|
]
|
||||||
return fea
|
return fea
|
||||||
|
|
||||||
@ -187,9 +177,7 @@ class RAGFlowPdfParser:
|
|||||||
for i in range(len(arr) - 1):
|
for i in range(len(arr) - 1):
|
||||||
for j in range(i, -1, -1):
|
for j in range(i, -1, -1):
|
||||||
# restore the order using th
|
# restore the order using th
|
||||||
if abs(arr[j + 1]["x0"] - arr[j]["x0"]) < threshold \
|
if abs(arr[j + 1]["x0"] - arr[j]["x0"]) < threshold and arr[j + 1]["top"] < arr[j]["top"] and arr[j + 1]["page_number"] == arr[j]["page_number"]:
|
||||||
and arr[j + 1]["top"] < arr[j]["top"] \
|
|
||||||
and arr[j + 1]["page_number"] == arr[j]["page_number"]:
|
|
||||||
tmp = arr[j]
|
tmp = arr[j]
|
||||||
arr[j] = arr[j + 1]
|
arr[j] = arr[j + 1]
|
||||||
arr[j + 1] = tmp
|
arr[j + 1] = tmp
|
||||||
@ -197,8 +185,7 @@ class RAGFlowPdfParser:
|
|||||||
|
|
||||||
def _has_color(self, o):
|
def _has_color(self, o):
|
||||||
if o.get("ncs", "") == "DeviceGray":
|
if o.get("ncs", "") == "DeviceGray":
|
||||||
if o["stroking_color"] and o["stroking_color"][0] == 1 and o["non_stroking_color"] and \
|
if o["stroking_color"] and o["stroking_color"][0] == 1 and o["non_stroking_color"] and o["non_stroking_color"][0] == 1:
|
||||||
o["non_stroking_color"][0] == 1:
|
|
||||||
if re.match(r"[a-zT_\[\]\(\)-]+", o.get("text", "")):
|
if re.match(r"[a-zT_\[\]\(\)-]+", o.get("text", "")):
|
||||||
return False
|
return False
|
||||||
return True
|
return True
|
||||||
@ -216,8 +203,7 @@ class RAGFlowPdfParser:
|
|||||||
if not tbls:
|
if not tbls:
|
||||||
continue
|
continue
|
||||||
for tb in tbls: # for table
|
for tb in tbls: # for table
|
||||||
left, top, right, bott = tb["x0"] - MARGIN, tb["top"] - MARGIN, \
|
left, top, right, bott = tb["x0"] - MARGIN, tb["top"] - MARGIN, tb["x1"] + MARGIN, tb["bottom"] + MARGIN
|
||||||
tb["x1"] + MARGIN, tb["bottom"] + MARGIN
|
|
||||||
left *= ZM
|
left *= ZM
|
||||||
top *= ZM
|
top *= ZM
|
||||||
right *= ZM
|
right *= ZM
|
||||||
@ -232,14 +218,13 @@ class RAGFlowPdfParser:
|
|||||||
tbcnt = np.cumsum(tbcnt)
|
tbcnt = np.cumsum(tbcnt)
|
||||||
for i in range(len(tbcnt) - 1): # for page
|
for i in range(len(tbcnt) - 1): # for page
|
||||||
pg = []
|
pg = []
|
||||||
for j, tb_items in enumerate(
|
for j, tb_items in enumerate(recos[tbcnt[i] : tbcnt[i + 1]]): # for table
|
||||||
recos[tbcnt[i]: tbcnt[i + 1]]): # for table
|
poss = pos[tbcnt[i] : tbcnt[i + 1]]
|
||||||
poss = pos[tbcnt[i]: tbcnt[i + 1]]
|
|
||||||
for it in tb_items: # for table components
|
for it in tb_items: # for table components
|
||||||
it["x0"] = (it["x0"] + poss[j][0])
|
it["x0"] = it["x0"] + poss[j][0]
|
||||||
it["x1"] = (it["x1"] + poss[j][0])
|
it["x1"] = it["x1"] + poss[j][0]
|
||||||
it["top"] = (it["top"] + poss[j][1])
|
it["top"] = it["top"] + poss[j][1]
|
||||||
it["bottom"] = (it["bottom"] + poss[j][1])
|
it["bottom"] = it["bottom"] + poss[j][1]
|
||||||
for n in ["x0", "x1", "top", "bottom"]:
|
for n in ["x0", "x1", "top", "bottom"]:
|
||||||
it[n] /= ZM
|
it[n] /= ZM
|
||||||
it["top"] += self.page_cum_height[i]
|
it["top"] += self.page_cum_height[i]
|
||||||
@ -250,8 +235,7 @@ class RAGFlowPdfParser:
|
|||||||
self.tb_cpns.extend(pg)
|
self.tb_cpns.extend(pg)
|
||||||
|
|
||||||
def gather(kwd, fzy=10, ption=0.6):
|
def gather(kwd, fzy=10, ption=0.6):
|
||||||
eles = Recognizer.sort_Y_firstly(
|
eles = Recognizer.sort_Y_firstly([r for r in self.tb_cpns if re.match(kwd, r["label"])], fzy)
|
||||||
[r for r in self.tb_cpns if re.match(kwd, r["label"])], fzy)
|
|
||||||
eles = Recognizer.layouts_cleanup(self.boxes, eles, 5, ption)
|
eles = Recognizer.layouts_cleanup(self.boxes, eles, 5, ption)
|
||||||
return Recognizer.sort_Y_firstly(eles, 0)
|
return Recognizer.sort_Y_firstly(eles, 0)
|
||||||
|
|
||||||
@ -259,8 +243,7 @@ class RAGFlowPdfParser:
|
|||||||
headers = gather(r".*header$")
|
headers = gather(r".*header$")
|
||||||
rows = gather(r".* (row|header)")
|
rows = gather(r".* (row|header)")
|
||||||
spans = gather(r".*spanning")
|
spans = gather(r".*spanning")
|
||||||
clmns = sorted([r for r in self.tb_cpns if re.match(
|
clmns = sorted([r for r in self.tb_cpns if re.match(r"table column$", r["label"])], key=lambda x: (x["pn"], x["layoutno"], x["x0"]))
|
||||||
r"table column$", r["label"])], key=lambda x: (x["pn"], x["layoutno"], x["x0"]))
|
|
||||||
clmns = Recognizer.layouts_cleanup(self.boxes, clmns, 5, 0.5)
|
clmns = Recognizer.layouts_cleanup(self.boxes, clmns, 5, 0.5)
|
||||||
for b in self.boxes:
|
for b in self.boxes:
|
||||||
if b.get("layout_type", "") != "table":
|
if b.get("layout_type", "") != "table":
|
||||||
@ -271,8 +254,7 @@ class RAGFlowPdfParser:
|
|||||||
b["R_top"] = rows[ii]["top"]
|
b["R_top"] = rows[ii]["top"]
|
||||||
b["R_bott"] = rows[ii]["bottom"]
|
b["R_bott"] = rows[ii]["bottom"]
|
||||||
|
|
||||||
ii = Recognizer.find_overlapped_with_threshold(
|
ii = Recognizer.find_overlapped_with_threshold(b, headers, thr=0.3)
|
||||||
b, headers, thr=0.3)
|
|
||||||
if ii is not None:
|
if ii is not None:
|
||||||
b["H_top"] = headers[ii]["top"]
|
b["H_top"] = headers[ii]["top"]
|
||||||
b["H_bott"] = headers[ii]["bottom"]
|
b["H_bott"] = headers[ii]["bottom"]
|
||||||
@ -305,12 +287,12 @@ class RAGFlowPdfParser:
|
|||||||
return
|
return
|
||||||
bxs = [(line[0], line[1][0]) for line in bxs]
|
bxs = [(line[0], line[1][0]) for line in bxs]
|
||||||
bxs = Recognizer.sort_Y_firstly(
|
bxs = Recognizer.sort_Y_firstly(
|
||||||
[{"x0": b[0][0] / ZM, "x1": b[1][0] / ZM,
|
[
|
||||||
"top": b[0][1] / ZM, "text": "", "txt": t,
|
{"x0": b[0][0] / ZM, "x1": b[1][0] / ZM, "top": b[0][1] / ZM, "text": "", "txt": t, "bottom": b[-1][1] / ZM, "chars": [], "page_number": pagenum}
|
||||||
"bottom": b[-1][1] / ZM,
|
for b, t in bxs
|
||||||
"chars": [],
|
if b[0][0] <= b[1][0] and b[0][1] <= b[-1][1]
|
||||||
"page_number": pagenum} for b, t in bxs if b[0][0] <= b[1][0] and b[0][1] <= b[-1][1]],
|
],
|
||||||
self.mean_height[pagenum-1] / 3
|
self.mean_height[pagenum - 1] / 3,
|
||||||
)
|
)
|
||||||
|
|
||||||
# merge chars in the same rect
|
# merge chars in the same rect
|
||||||
@ -321,7 +303,7 @@ class RAGFlowPdfParser:
|
|||||||
continue
|
continue
|
||||||
ch = c["bottom"] - c["top"]
|
ch = c["bottom"] - c["top"]
|
||||||
bh = bxs[ii]["bottom"] - bxs[ii]["top"]
|
bh = bxs[ii]["bottom"] - bxs[ii]["top"]
|
||||||
if abs(ch - bh) / max(ch, bh) >= 0.7 and c["text"] != ' ':
|
if abs(ch - bh) / max(ch, bh) >= 0.7 and c["text"] != " ":
|
||||||
self.lefted_chars.append(c)
|
self.lefted_chars.append(c)
|
||||||
continue
|
continue
|
||||||
bxs[ii]["chars"].append(c)
|
bxs[ii]["chars"].append(c)
|
||||||
@ -345,8 +327,7 @@ class RAGFlowPdfParser:
|
|||||||
img_np = np.array(img)
|
img_np = np.array(img)
|
||||||
for b in bxs:
|
for b in bxs:
|
||||||
if not b["text"]:
|
if not b["text"]:
|
||||||
left, right, top, bott = b["x0"] * ZM, b["x1"] * \
|
left, right, top, bott = b["x0"] * ZM, b["x1"] * ZM, b["top"] * ZM, b["bottom"] * ZM
|
||||||
ZM, b["top"] * ZM, b["bottom"] * ZM
|
|
||||||
b["box_image"] = self.ocr.get_rotate_crop_image(img_np, np.array([[left, top], [right, top], [right, bott], [left, bott]], dtype=np.float32))
|
b["box_image"] = self.ocr.get_rotate_crop_image(img_np, np.array([[left, top], [right, top], [right, bott], [left, bott]], dtype=np.float32))
|
||||||
boxes_to_reg.append(b)
|
boxes_to_reg.append(b)
|
||||||
del b["txt"]
|
del b["txt"]
|
||||||
@ -356,21 +337,17 @@ class RAGFlowPdfParser:
|
|||||||
del boxes_to_reg[i]["box_image"]
|
del boxes_to_reg[i]["box_image"]
|
||||||
logging.info(f"__ocr recognize {len(bxs)} boxes cost {timer() - start}s")
|
logging.info(f"__ocr recognize {len(bxs)} boxes cost {timer() - start}s")
|
||||||
bxs = [b for b in bxs if b["text"]]
|
bxs = [b for b in bxs if b["text"]]
|
||||||
if self.mean_height[pagenum-1] == 0:
|
if self.mean_height[pagenum - 1] == 0:
|
||||||
self.mean_height[pagenum-1] = np.median([b["bottom"] - b["top"]
|
self.mean_height[pagenum - 1] = np.median([b["bottom"] - b["top"] for b in bxs])
|
||||||
for b in bxs])
|
|
||||||
self.boxes.append(bxs)
|
self.boxes.append(bxs)
|
||||||
|
|
||||||
def _layouts_rec(self, ZM, drop=True):
|
def _layouts_rec(self, ZM, drop=True):
|
||||||
assert len(self.page_images) == len(self.boxes)
|
assert len(self.page_images) == len(self.boxes)
|
||||||
self.boxes, self.page_layout = self.layouter(
|
self.boxes, self.page_layout = self.layouter(self.page_images, self.boxes, ZM, drop=drop)
|
||||||
self.page_images, self.boxes, ZM, drop=drop)
|
|
||||||
# cumlative Y
|
# cumlative Y
|
||||||
for i in range(len(self.boxes)):
|
for i in range(len(self.boxes)):
|
||||||
self.boxes[i]["top"] += \
|
self.boxes[i]["top"] += self.page_cum_height[self.boxes[i]["page_number"] - 1]
|
||||||
self.page_cum_height[self.boxes[i]["page_number"] - 1]
|
self.boxes[i]["bottom"] += self.page_cum_height[self.boxes[i]["page_number"] - 1]
|
||||||
self.boxes[i]["bottom"] += \
|
|
||||||
self.page_cum_height[self.boxes[i]["page_number"] - 1]
|
|
||||||
|
|
||||||
def _text_merge(self):
|
def _text_merge(self):
|
||||||
# merge adjusted boxes
|
# merge adjusted boxes
|
||||||
@ -390,12 +367,10 @@ class RAGFlowPdfParser:
|
|||||||
while i < len(bxs) - 1:
|
while i < len(bxs) - 1:
|
||||||
b = bxs[i]
|
b = bxs[i]
|
||||||
b_ = bxs[i + 1]
|
b_ = bxs[i + 1]
|
||||||
if b.get("layoutno", "0") != b_.get("layoutno", "1") or b.get("layout_type", "") in ["table", "figure",
|
if b.get("layoutno", "0") != b_.get("layoutno", "1") or b.get("layout_type", "") in ["table", "figure", "equation"]:
|
||||||
"equation"]:
|
|
||||||
i += 1
|
i += 1
|
||||||
continue
|
continue
|
||||||
if abs(self._y_dis(b, b_)
|
if abs(self._y_dis(b, b_)) < self.mean_height[bxs[i]["page_number"] - 1] / 3:
|
||||||
) < self.mean_height[bxs[i]["page_number"] - 1] / 3:
|
|
||||||
# merge
|
# merge
|
||||||
bxs[i]["x1"] = b_["x1"]
|
bxs[i]["x1"] = b_["x1"]
|
||||||
bxs[i]["top"] = (b["top"] + b_["top"]) / 2
|
bxs[i]["top"] = (b["top"] + b_["top"]) / 2
|
||||||
@ -408,16 +383,14 @@ class RAGFlowPdfParser:
|
|||||||
|
|
||||||
dis_thr = 1
|
dis_thr = 1
|
||||||
dis = b["x1"] - b_["x0"]
|
dis = b["x1"] - b_["x0"]
|
||||||
if b.get("layout_type", "") != "text" or b_.get(
|
if b.get("layout_type", "") != "text" or b_.get("layout_type", "") != "text":
|
||||||
"layout_type", "") != "text":
|
|
||||||
if end_with(b, ",") or start_with(b_, "(,"):
|
if end_with(b, ",") or start_with(b_, "(,"):
|
||||||
dis_thr = -8
|
dis_thr = -8
|
||||||
else:
|
else:
|
||||||
i += 1
|
i += 1
|
||||||
continue
|
continue
|
||||||
|
|
||||||
if abs(self._y_dis(b, b_)) < self.mean_height[bxs[i]["page_number"] - 1] / 5 \
|
if abs(self._y_dis(b, b_)) < self.mean_height[bxs[i]["page_number"] - 1] / 5 and dis >= dis_thr and b["x1"] < b_["x1"]:
|
||||||
and dis >= dis_thr and b["x1"] < b_["x1"]:
|
|
||||||
# merge
|
# merge
|
||||||
bxs[i]["x1"] = b_["x1"]
|
bxs[i]["x1"] = b_["x1"]
|
||||||
bxs[i]["top"] = (b["top"] + b_["top"]) / 2
|
bxs[i]["top"] = (b["top"] + b_["top"]) / 2
|
||||||
@ -429,23 +402,22 @@ class RAGFlowPdfParser:
|
|||||||
self.boxes = bxs
|
self.boxes = bxs
|
||||||
|
|
||||||
def _naive_vertical_merge(self, zoomin=3):
|
def _naive_vertical_merge(self, zoomin=3):
|
||||||
bxs = Recognizer.sort_Y_firstly(
|
import math
|
||||||
self.boxes, np.median(
|
bxs = Recognizer.sort_Y_firstly(self.boxes, np.median(self.mean_height) / 3)
|
||||||
self.mean_height) / 3)
|
|
||||||
|
|
||||||
column_width = np.median([b["x1"] - b["x0"] for b in self.boxes])
|
column_width = np.median([b["x1"] - b["x0"] for b in self.boxes])
|
||||||
|
if not column_width or math.isnan(column_width):
|
||||||
|
column_width = self.mean_width[0]
|
||||||
self.column_num = int(self.page_images[0].size[0] / zoomin / column_width)
|
self.column_num = int(self.page_images[0].size[0] / zoomin / column_width)
|
||||||
if column_width < self.page_images[0].size[0] / zoomin / self.column_num:
|
if column_width < self.page_images[0].size[0] / zoomin / self.column_num:
|
||||||
logging.info("Multi-column................... {} {}".format(column_width,
|
logging.info("Multi-column................... {} {}".format(column_width, self.page_images[0].size[0] / zoomin / self.column_num))
|
||||||
self.page_images[0].size[0] / zoomin / self.column_num))
|
|
||||||
self.boxes = self.sort_X_by_page(self.boxes, column_width / self.column_num)
|
self.boxes = self.sort_X_by_page(self.boxes, column_width / self.column_num)
|
||||||
|
|
||||||
i = 0
|
i = 0
|
||||||
while i + 1 < len(bxs):
|
while i + 1 < len(bxs):
|
||||||
b = bxs[i]
|
b = bxs[i]
|
||||||
b_ = bxs[i + 1]
|
b_ = bxs[i + 1]
|
||||||
if b["page_number"] < b_["page_number"] and re.match(
|
if b["page_number"] < b_["page_number"] and re.match(r"[0-9 •一—-]+$", b["text"]):
|
||||||
r"[0-9 •一—-]+$", b["text"]):
|
|
||||||
bxs.pop(i)
|
bxs.pop(i)
|
||||||
continue
|
continue
|
||||||
if not b["text"].strip():
|
if not b["text"].strip():
|
||||||
@ -453,8 +425,7 @@ class RAGFlowPdfParser:
|
|||||||
continue
|
continue
|
||||||
concatting_feats = [
|
concatting_feats = [
|
||||||
b["text"].strip()[-1] in ",;:'\",、‘“;:-",
|
b["text"].strip()[-1] in ",;:'\",、‘“;:-",
|
||||||
len(b["text"].strip()) > 1 and b["text"].strip(
|
len(b["text"].strip()) > 1 and b["text"].strip()[-2] in ",;:'\",‘“、;:",
|
||||||
)[-2] in ",;:'\",‘“、;:",
|
|
||||||
b_["text"].strip() and b_["text"].strip()[0] in "。;?!?”)),,、:",
|
b_["text"].strip() and b_["text"].strip()[0] in "。;?!?”)),,、:",
|
||||||
]
|
]
|
||||||
# features for not concating
|
# features for not concating
|
||||||
@ -462,21 +433,20 @@ class RAGFlowPdfParser:
|
|||||||
b.get("layoutno", 0) != b_.get("layoutno", 0),
|
b.get("layoutno", 0) != b_.get("layoutno", 0),
|
||||||
b["text"].strip()[-1] in "。?!?",
|
b["text"].strip()[-1] in "。?!?",
|
||||||
self.is_english and b["text"].strip()[-1] in ".!?",
|
self.is_english and b["text"].strip()[-1] in ".!?",
|
||||||
b["page_number"] == b_["page_number"] and b_["top"] -
|
b["page_number"] == b_["page_number"] and b_["top"] - b["bottom"] > self.mean_height[b["page_number"] - 1] * 1.5,
|
||||||
b["bottom"] > self.mean_height[b["page_number"] - 1] * 1.5,
|
b["page_number"] < b_["page_number"] and abs(b["x0"] - b_["x0"]) > self.mean_width[b["page_number"] - 1] * 4,
|
||||||
b["page_number"] < b_["page_number"] and abs(
|
|
||||||
b["x0"] - b_["x0"]) > self.mean_width[b["page_number"] - 1] * 4,
|
|
||||||
]
|
]
|
||||||
# split features
|
# split features
|
||||||
detach_feats = [b["x1"] < b_["x0"],
|
detach_feats = [b["x1"] < b_["x0"], b["x0"] > b_["x1"]]
|
||||||
b["x0"] > b_["x1"]]
|
|
||||||
if (any(feats) and not any(concatting_feats)) or any(detach_feats):
|
if (any(feats) and not any(concatting_feats)) or any(detach_feats):
|
||||||
logging.debug("{} {} {} {}".format(
|
logging.debug(
|
||||||
b["text"],
|
"{} {} {} {}".format(
|
||||||
b_["text"],
|
b["text"],
|
||||||
any(feats),
|
b_["text"],
|
||||||
any(concatting_feats),
|
any(feats),
|
||||||
))
|
any(concatting_feats),
|
||||||
|
)
|
||||||
|
)
|
||||||
i += 1
|
i += 1
|
||||||
continue
|
continue
|
||||||
# merge up and down
|
# merge up and down
|
||||||
@ -529,14 +499,11 @@ class RAGFlowPdfParser:
|
|||||||
if not concat_between_pages and down["page_number"] > up["page_number"]:
|
if not concat_between_pages and down["page_number"] > up["page_number"]:
|
||||||
break
|
break
|
||||||
|
|
||||||
if up.get("R", "") != down.get(
|
if up.get("R", "") != down.get("R", "") and up["text"][-1] != ",":
|
||||||
"R", "") and up["text"][-1] != ",":
|
|
||||||
i += 1
|
i += 1
|
||||||
continue
|
continue
|
||||||
|
|
||||||
if re.match(r"[0-9]{2,3}/[0-9]{3}$", up["text"]) \
|
if re.match(r"[0-9]{2,3}/[0-9]{3}$", up["text"]) or re.match(r"[0-9]{2,3}/[0-9]{3}$", down["text"]) or not down["text"].strip():
|
||||||
or re.match(r"[0-9]{2,3}/[0-9]{3}$", down["text"]) \
|
|
||||||
or not down["text"].strip():
|
|
||||||
i += 1
|
i += 1
|
||||||
continue
|
continue
|
||||||
|
|
||||||
@ -544,14 +511,12 @@ class RAGFlowPdfParser:
|
|||||||
i += 1
|
i += 1
|
||||||
continue
|
continue
|
||||||
|
|
||||||
if up["x1"] < down["x0"] - 10 * \
|
if up["x1"] < down["x0"] - 10 * mw or up["x0"] > down["x1"] + 10 * mw:
|
||||||
mw or up["x0"] > down["x1"] + 10 * mw:
|
|
||||||
i += 1
|
i += 1
|
||||||
continue
|
continue
|
||||||
|
|
||||||
if i - dp < 5 and up.get("layout_type") == "text":
|
if i - dp < 5 and up.get("layout_type") == "text":
|
||||||
if up.get("layoutno", "1") == down.get(
|
if up.get("layoutno", "1") == down.get("layoutno", "2"):
|
||||||
"layoutno", "2"):
|
|
||||||
dfs(down, i + 1)
|
dfs(down, i + 1)
|
||||||
boxes.pop(i)
|
boxes.pop(i)
|
||||||
return
|
return
|
||||||
@ -559,8 +524,7 @@ class RAGFlowPdfParser:
|
|||||||
continue
|
continue
|
||||||
|
|
||||||
fea = self._updown_concat_features(up, down)
|
fea = self._updown_concat_features(up, down)
|
||||||
if self.updown_cnt_mdl.predict(
|
if self.updown_cnt_mdl.predict(xgb.DMatrix([fea]))[0] <= 0.5:
|
||||||
xgb.DMatrix([fea]))[0] <= 0.5:
|
|
||||||
i += 1
|
i += 1
|
||||||
continue
|
continue
|
||||||
dfs(down, i + 1)
|
dfs(down, i + 1)
|
||||||
@ -584,16 +548,14 @@ class RAGFlowPdfParser:
|
|||||||
c["text"] = c["text"].strip()
|
c["text"] = c["text"].strip()
|
||||||
if not c["text"]:
|
if not c["text"]:
|
||||||
continue
|
continue
|
||||||
if t["text"] and re.match(
|
if t["text"] and re.match(r"[0-9\.a-zA-Z]+$", t["text"][-1] + c["text"][-1]):
|
||||||
r"[0-9\.a-zA-Z]+$", t["text"][-1] + c["text"][-1]):
|
|
||||||
t["text"] += " "
|
t["text"] += " "
|
||||||
t["text"] += c["text"]
|
t["text"] += c["text"]
|
||||||
t["x0"] = min(t["x0"], c["x0"])
|
t["x0"] = min(t["x0"], c["x0"])
|
||||||
t["x1"] = max(t["x1"], c["x1"])
|
t["x1"] = max(t["x1"], c["x1"])
|
||||||
t["page_number"] = min(t["page_number"], c["page_number"])
|
t["page_number"] = min(t["page_number"], c["page_number"])
|
||||||
t["bottom"] = c["bottom"]
|
t["bottom"] = c["bottom"]
|
||||||
if not t["layout_type"] \
|
if not t["layout_type"] and c["layout_type"]:
|
||||||
and c["layout_type"]:
|
|
||||||
t["layout_type"] = c["layout_type"]
|
t["layout_type"] = c["layout_type"]
|
||||||
boxes.append(t)
|
boxes.append(t)
|
||||||
|
|
||||||
@ -605,25 +567,20 @@ class RAGFlowPdfParser:
|
|||||||
findit = False
|
findit = False
|
||||||
i = 0
|
i = 0
|
||||||
while i < len(self.boxes):
|
while i < len(self.boxes):
|
||||||
if not re.match(r"(contents|目录|目次|table of contents|致谢|acknowledge)$",
|
if not re.match(r"(contents|目录|目次|table of contents|致谢|acknowledge)$", re.sub(r"( | |\u3000)+", "", self.boxes[i]["text"].lower())):
|
||||||
re.sub(r"( | |\u3000)+", "", self.boxes[i]["text"].lower())):
|
|
||||||
i += 1
|
i += 1
|
||||||
continue
|
continue
|
||||||
findit = True
|
findit = True
|
||||||
eng = re.match(
|
eng = re.match(r"[0-9a-zA-Z :'.-]{5,}", self.boxes[i]["text"].strip())
|
||||||
r"[0-9a-zA-Z :'.-]{5,}",
|
|
||||||
self.boxes[i]["text"].strip())
|
|
||||||
self.boxes.pop(i)
|
self.boxes.pop(i)
|
||||||
if i >= len(self.boxes):
|
if i >= len(self.boxes):
|
||||||
break
|
break
|
||||||
prefix = self.boxes[i]["text"].strip()[:3] if not eng else " ".join(
|
prefix = self.boxes[i]["text"].strip()[:3] if not eng else " ".join(self.boxes[i]["text"].strip().split()[:2])
|
||||||
self.boxes[i]["text"].strip().split()[:2])
|
|
||||||
while not prefix:
|
while not prefix:
|
||||||
self.boxes.pop(i)
|
self.boxes.pop(i)
|
||||||
if i >= len(self.boxes):
|
if i >= len(self.boxes):
|
||||||
break
|
break
|
||||||
prefix = self.boxes[i]["text"].strip()[:3] if not eng else " ".join(
|
prefix = self.boxes[i]["text"].strip()[:3] if not eng else " ".join(self.boxes[i]["text"].strip().split()[:2])
|
||||||
self.boxes[i]["text"].strip().split()[:2])
|
|
||||||
self.boxes.pop(i)
|
self.boxes.pop(i)
|
||||||
if i >= len(self.boxes) or not prefix:
|
if i >= len(self.boxes) or not prefix:
|
||||||
break
|
break
|
||||||
@ -662,10 +619,12 @@ class RAGFlowPdfParser:
|
|||||||
self.boxes.pop(i + 1)
|
self.boxes.pop(i + 1)
|
||||||
continue
|
continue
|
||||||
|
|
||||||
if b["text"].strip()[0] != b_["text"].strip()[0] \
|
if (
|
||||||
or b["text"].strip()[0].lower() in set("qwertyuopasdfghjklzxcvbnm") \
|
b["text"].strip()[0] != b_["text"].strip()[0]
|
||||||
or rag_tokenizer.is_chinese(b["text"].strip()[0]) \
|
or b["text"].strip()[0].lower() in set("qwertyuopasdfghjklzxcvbnm")
|
||||||
or b["top"] > b_["bottom"]:
|
or rag_tokenizer.is_chinese(b["text"].strip()[0])
|
||||||
|
or b["top"] > b_["bottom"]
|
||||||
|
):
|
||||||
i += 1
|
i += 1
|
||||||
continue
|
continue
|
||||||
b_["text"] = b["text"] + "\n" + b_["text"]
|
b_["text"] = b["text"] + "\n" + b_["text"]
|
||||||
@ -685,12 +644,8 @@ class RAGFlowPdfParser:
|
|||||||
if "layoutno" not in self.boxes[i]:
|
if "layoutno" not in self.boxes[i]:
|
||||||
i += 1
|
i += 1
|
||||||
continue
|
continue
|
||||||
lout_no = str(self.boxes[i]["page_number"]) + \
|
lout_no = str(self.boxes[i]["page_number"]) + "-" + str(self.boxes[i]["layoutno"])
|
||||||
"-" + str(self.boxes[i]["layoutno"])
|
if TableStructureRecognizer.is_caption(self.boxes[i]) or self.boxes[i]["layout_type"] in ["table caption", "title", "figure caption", "reference"]:
|
||||||
if TableStructureRecognizer.is_caption(self.boxes[i]) or self.boxes[i]["layout_type"] in ["table caption",
|
|
||||||
"title",
|
|
||||||
"figure caption",
|
|
||||||
"reference"]:
|
|
||||||
nomerge_lout_no.append(lst_lout_no)
|
nomerge_lout_no.append(lst_lout_no)
|
||||||
if self.boxes[i]["layout_type"] == "table":
|
if self.boxes[i]["layout_type"] == "table":
|
||||||
if re.match(r"(数据|资料|图表)*来源[:: ]", self.boxes[i]["text"]):
|
if re.match(r"(数据|资料|图表)*来源[:: ]", self.boxes[i]["text"]):
|
||||||
@ -716,8 +671,7 @@ class RAGFlowPdfParser:
|
|||||||
|
|
||||||
# merge table on different pages
|
# merge table on different pages
|
||||||
nomerge_lout_no = set(nomerge_lout_no)
|
nomerge_lout_no = set(nomerge_lout_no)
|
||||||
tbls = sorted([(k, bxs) for k, bxs in tables.items()],
|
tbls = sorted([(k, bxs) for k, bxs in tables.items()], key=lambda x: (x[1][0]["top"], x[1][0]["x0"]))
|
||||||
key=lambda x: (x[1][0]["top"], x[1][0]["x0"]))
|
|
||||||
|
|
||||||
i = len(tbls) - 1
|
i = len(tbls) - 1
|
||||||
while i - 1 >= 0:
|
while i - 1 >= 0:
|
||||||
@ -758,9 +712,7 @@ class RAGFlowPdfParser:
|
|||||||
if b.get("layout_type", "").find("caption") >= 0:
|
if b.get("layout_type", "").find("caption") >= 0:
|
||||||
continue
|
continue
|
||||||
y_dis = self._y_dis(c, b)
|
y_dis = self._y_dis(c, b)
|
||||||
x_dis = self._x_dis(
|
x_dis = self._x_dis(c, b) if not x_overlapped(c, b) else 0
|
||||||
c, b) if not x_overlapped(
|
|
||||||
c, b) else 0
|
|
||||||
dis = y_dis * y_dis + x_dis * x_dis
|
dis = y_dis * y_dis + x_dis * x_dis
|
||||||
if dis < minv:
|
if dis < minv:
|
||||||
mink = k
|
mink = k
|
||||||
@ -774,18 +726,10 @@ class RAGFlowPdfParser:
|
|||||||
# continue
|
# continue
|
||||||
if tv < fv and tk:
|
if tv < fv and tk:
|
||||||
tables[tk].insert(0, c)
|
tables[tk].insert(0, c)
|
||||||
logging.debug(
|
logging.debug("TABLE:" + self.boxes[i]["text"] + "; Cap: " + tk)
|
||||||
"TABLE:" +
|
|
||||||
self.boxes[i]["text"] +
|
|
||||||
"; Cap: " +
|
|
||||||
tk)
|
|
||||||
elif fk:
|
elif fk:
|
||||||
figures[fk].insert(0, c)
|
figures[fk].insert(0, c)
|
||||||
logging.debug(
|
logging.debug("FIGURE:" + self.boxes[i]["text"] + "; Cap: " + tk)
|
||||||
"FIGURE:" +
|
|
||||||
self.boxes[i]["text"] +
|
|
||||||
"; Cap: " +
|
|
||||||
tk)
|
|
||||||
self.boxes.pop(i)
|
self.boxes.pop(i)
|
||||||
|
|
||||||
def cropout(bxs, ltype, poss):
|
def cropout(bxs, ltype, poss):
|
||||||
@ -794,29 +738,19 @@ class RAGFlowPdfParser:
|
|||||||
if len(pn) < 2:
|
if len(pn) < 2:
|
||||||
pn = list(pn)[0]
|
pn = list(pn)[0]
|
||||||
ht = self.page_cum_height[pn]
|
ht = self.page_cum_height[pn]
|
||||||
b = {
|
b = {"x0": np.min([b["x0"] for b in bxs]), "top": np.min([b["top"] for b in bxs]) - ht, "x1": np.max([b["x1"] for b in bxs]), "bottom": np.max([b["bottom"] for b in bxs]) - ht}
|
||||||
"x0": np.min([b["x0"] for b in bxs]),
|
|
||||||
"top": np.min([b["top"] for b in bxs]) - ht,
|
|
||||||
"x1": np.max([b["x1"] for b in bxs]),
|
|
||||||
"bottom": np.max([b["bottom"] for b in bxs]) - ht
|
|
||||||
}
|
|
||||||
louts = [layout for layout in self.page_layout[pn] if layout["type"] == ltype]
|
louts = [layout for layout in self.page_layout[pn] if layout["type"] == ltype]
|
||||||
ii = Recognizer.find_overlapped(b, louts, naive=True)
|
ii = Recognizer.find_overlapped(b, louts, naive=True)
|
||||||
if ii is not None:
|
if ii is not None:
|
||||||
b = louts[ii]
|
b = louts[ii]
|
||||||
else:
|
else:
|
||||||
logging.warning(
|
logging.warning(f"Missing layout match: {pn + 1},%s" % (bxs[0].get("layoutno", "")))
|
||||||
f"Missing layout match: {pn + 1},%s" %
|
|
||||||
(bxs[0].get(
|
|
||||||
"layoutno", "")))
|
|
||||||
|
|
||||||
left, top, right, bott = b["x0"], b["top"], b["x1"], b["bottom"]
|
left, top, right, bott = b["x0"], b["top"], b["x1"], b["bottom"]
|
||||||
if right < left:
|
if right < left:
|
||||||
right = left + 1
|
right = left + 1
|
||||||
poss.append((pn + self.page_from, left, right, top, bott))
|
poss.append((pn + self.page_from, left, right, top, bott))
|
||||||
return self.page_images[pn] \
|
return self.page_images[pn].crop((left * ZM, top * ZM, right * ZM, bott * ZM))
|
||||||
.crop((left * ZM, top * ZM,
|
|
||||||
right * ZM, bott * ZM))
|
|
||||||
pn = {}
|
pn = {}
|
||||||
for b in bxs:
|
for b in bxs:
|
||||||
p = b["page_number"] - 1
|
p = b["page_number"] - 1
|
||||||
@ -825,10 +759,7 @@ class RAGFlowPdfParser:
|
|||||||
pn[p].append(b)
|
pn[p].append(b)
|
||||||
pn = sorted(pn.items(), key=lambda x: x[0])
|
pn = sorted(pn.items(), key=lambda x: x[0])
|
||||||
imgs = [cropout(arr, ltype, poss) for p, arr in pn]
|
imgs = [cropout(arr, ltype, poss) for p, arr in pn]
|
||||||
pic = Image.new("RGB",
|
pic = Image.new("RGB", (int(np.max([i.size[0] for i in imgs])), int(np.sum([m.size[1] for m in imgs]))), (245, 245, 245))
|
||||||
(int(np.max([i.size[0] for i in imgs])),
|
|
||||||
int(np.sum([m.size[1] for m in imgs]))),
|
|
||||||
(245, 245, 245))
|
|
||||||
height = 0
|
height = 0
|
||||||
for img in imgs:
|
for img in imgs:
|
||||||
pic.paste(img, (0, int(height)))
|
pic.paste(img, (0, int(height)))
|
||||||
@ -848,30 +779,20 @@ class RAGFlowPdfParser:
|
|||||||
poss = []
|
poss = []
|
||||||
|
|
||||||
if separate_tables_figures:
|
if separate_tables_figures:
|
||||||
figure_results.append(
|
figure_results.append((cropout(bxs, "figure", poss), [txt]))
|
||||||
(cropout(
|
|
||||||
bxs,
|
|
||||||
"figure", poss),
|
|
||||||
[txt]))
|
|
||||||
figure_positions.append(poss)
|
figure_positions.append(poss)
|
||||||
else:
|
else:
|
||||||
res.append(
|
res.append((cropout(bxs, "figure", poss), [txt]))
|
||||||
(cropout(
|
|
||||||
bxs,
|
|
||||||
"figure", poss),
|
|
||||||
[txt]))
|
|
||||||
positions.append(poss)
|
positions.append(poss)
|
||||||
|
|
||||||
for k, bxs in tables.items():
|
for k, bxs in tables.items():
|
||||||
if not bxs:
|
if not bxs:
|
||||||
continue
|
continue
|
||||||
bxs = Recognizer.sort_Y_firstly(bxs, np.mean(
|
bxs = Recognizer.sort_Y_firstly(bxs, np.mean([(b["bottom"] - b["top"]) / 2 for b in bxs]))
|
||||||
[(b["bottom"] - b["top"]) / 2 for b in bxs]))
|
|
||||||
|
|
||||||
poss = []
|
poss = []
|
||||||
|
|
||||||
res.append((cropout(bxs, "table", poss),
|
res.append((cropout(bxs, "table", poss), self.tbl_det.construct_table(bxs, html=return_html, is_english=self.is_english)))
|
||||||
self.tbl_det.construct_table(bxs, html=return_html, is_english=self.is_english)))
|
|
||||||
positions.append(poss)
|
positions.append(poss)
|
||||||
|
|
||||||
if separate_tables_figures:
|
if separate_tables_figures:
|
||||||
@ -905,7 +826,7 @@ class RAGFlowPdfParser:
|
|||||||
(r"[0-9]+)", 10),
|
(r"[0-9]+)", 10),
|
||||||
(r"[\((][0-9]+[)\)]", 11),
|
(r"[\((][0-9]+[)\)]", 11),
|
||||||
(r"[零一二三四五六七八九十百]+是", 12),
|
(r"[零一二三四五六七八九十百]+是", 12),
|
||||||
(r"[⚫•➢✓]", 12)
|
(r"[⚫•➢✓]", 12),
|
||||||
]:
|
]:
|
||||||
if re.match(p, line):
|
if re.match(p, line):
|
||||||
return j
|
return j
|
||||||
@ -924,12 +845,9 @@ class RAGFlowPdfParser:
|
|||||||
if pn[-1] - 1 >= page_images_cnt:
|
if pn[-1] - 1 >= page_images_cnt:
|
||||||
return ""
|
return ""
|
||||||
|
|
||||||
return "@@{}\t{:.1f}\t{:.1f}\t{:.1f}\t{:.1f}##" \
|
return "@@{}\t{:.1f}\t{:.1f}\t{:.1f}\t{:.1f}##".format("-".join([str(p) for p in pn]), bx["x0"], bx["x1"], top, bott)
|
||||||
.format("-".join([str(p) for p in pn]),
|
|
||||||
bx["x0"], bx["x1"], top, bott)
|
|
||||||
|
|
||||||
def __filterout_scraps(self, boxes, ZM):
|
def __filterout_scraps(self, boxes, ZM):
|
||||||
|
|
||||||
def width(b):
|
def width(b):
|
||||||
return b["x1"] - b["x0"]
|
return b["x1"] - b["x0"]
|
||||||
|
|
||||||
@ -939,8 +857,7 @@ class RAGFlowPdfParser:
|
|||||||
def usefull(b):
|
def usefull(b):
|
||||||
if b.get("layout_type"):
|
if b.get("layout_type"):
|
||||||
return True
|
return True
|
||||||
if width(
|
if width(b) > self.page_images[b["page_number"] - 1].size[0] / ZM / 3:
|
||||||
b) > self.page_images[b["page_number"] - 1].size[0] / ZM / 3:
|
|
||||||
return True
|
return True
|
||||||
if b["bottom"] - b["top"] > self.mean_height[b["page_number"] - 1]:
|
if b["bottom"] - b["top"] > self.mean_height[b["page_number"] - 1]:
|
||||||
return True
|
return True
|
||||||
@ -952,31 +869,23 @@ class RAGFlowPdfParser:
|
|||||||
widths = []
|
widths = []
|
||||||
pw = self.page_images[boxes[0]["page_number"] - 1].size[0] / ZM
|
pw = self.page_images[boxes[0]["page_number"] - 1].size[0] / ZM
|
||||||
mh = self.mean_height[boxes[0]["page_number"] - 1]
|
mh = self.mean_height[boxes[0]["page_number"] - 1]
|
||||||
mj = self.proj_match(
|
mj = self.proj_match(boxes[0]["text"]) or boxes[0].get("layout_type", "") == "title"
|
||||||
boxes[0]["text"]) or boxes[0].get(
|
|
||||||
"layout_type",
|
|
||||||
"") == "title"
|
|
||||||
|
|
||||||
def dfs(line, st):
|
def dfs(line, st):
|
||||||
nonlocal mh, pw, lines, widths
|
nonlocal mh, pw, lines, widths
|
||||||
lines.append(line)
|
lines.append(line)
|
||||||
widths.append(width(line))
|
widths.append(width(line))
|
||||||
mmj = self.proj_match(
|
mmj = self.proj_match(line["text"]) or line.get("layout_type", "") == "title"
|
||||||
line["text"]) or line.get(
|
|
||||||
"layout_type",
|
|
||||||
"") == "title"
|
|
||||||
for i in range(st + 1, min(st + 20, len(boxes))):
|
for i in range(st + 1, min(st + 20, len(boxes))):
|
||||||
if (boxes[i]["page_number"] - line["page_number"]) > 0:
|
if (boxes[i]["page_number"] - line["page_number"]) > 0:
|
||||||
break
|
break
|
||||||
if not mmj and self._y_dis(
|
if not mmj and self._y_dis(line, boxes[i]) >= 3 * mh and height(line) < 1.5 * mh:
|
||||||
line, boxes[i]) >= 3 * mh and height(line) < 1.5 * mh:
|
|
||||||
break
|
break
|
||||||
|
|
||||||
if not usefull(boxes[i]):
|
if not usefull(boxes[i]):
|
||||||
continue
|
continue
|
||||||
if mmj or \
|
if mmj or (self._x_dis(boxes[i], line) < pw / 10):
|
||||||
(self._x_dis(boxes[i], line) < pw / 10): \
|
# and abs(width(boxes[i])-width_mean)/max(width(boxes[i]),width_mean)<0.5):
|
||||||
# and abs(width(boxes[i])-width_mean)/max(width(boxes[i]),width_mean)<0.5):
|
|
||||||
# concat following
|
# concat following
|
||||||
dfs(boxes[i], i)
|
dfs(boxes[i], i)
|
||||||
boxes.pop(i)
|
boxes.pop(i)
|
||||||
@ -992,11 +901,9 @@ class RAGFlowPdfParser:
|
|||||||
boxes.pop(0)
|
boxes.pop(0)
|
||||||
mw = np.mean(widths)
|
mw = np.mean(widths)
|
||||||
if mj or mw / pw >= 0.35 or mw > 200:
|
if mj or mw / pw >= 0.35 or mw > 200:
|
||||||
res.append(
|
res.append("\n".join([c["text"] + self._line_tag(c, ZM) for c in lines]))
|
||||||
"\n".join([c["text"] + self._line_tag(c, ZM) for c in lines]))
|
|
||||||
else:
|
else:
|
||||||
logging.debug("REMOVED: " +
|
logging.debug("REMOVED: " + "<<".join([c["text"] for c in lines]))
|
||||||
"<<".join([c["text"] for c in lines]))
|
|
||||||
|
|
||||||
return "\n\n".join(res)
|
return "\n\n".join(res)
|
||||||
|
|
||||||
@ -1004,16 +911,14 @@ class RAGFlowPdfParser:
|
|||||||
def total_page_number(fnm, binary=None):
|
def total_page_number(fnm, binary=None):
|
||||||
try:
|
try:
|
||||||
with sys.modules[LOCK_KEY_pdfplumber]:
|
with sys.modules[LOCK_KEY_pdfplumber]:
|
||||||
pdf = pdfplumber.open(
|
pdf = pdfplumber.open(fnm) if not binary else pdfplumber.open(BytesIO(binary))
|
||||||
fnm) if not binary else pdfplumber.open(BytesIO(binary))
|
|
||||||
total_page = len(pdf.pages)
|
total_page = len(pdf.pages)
|
||||||
pdf.close()
|
pdf.close()
|
||||||
return total_page
|
return total_page
|
||||||
except Exception:
|
except Exception:
|
||||||
logging.exception("total_page_number")
|
logging.exception("total_page_number")
|
||||||
|
|
||||||
def __images__(self, fnm, zoomin=3, page_from=0,
|
def __images__(self, fnm, zoomin=3, page_from=0, page_to=299, callback=None):
|
||||||
page_to=299, callback=None):
|
|
||||||
self.lefted_chars = []
|
self.lefted_chars = []
|
||||||
self.mean_height = []
|
self.mean_height = []
|
||||||
self.mean_width = []
|
self.mean_width = []
|
||||||
@ -1025,10 +930,9 @@ class RAGFlowPdfParser:
|
|||||||
start = timer()
|
start = timer()
|
||||||
try:
|
try:
|
||||||
with sys.modules[LOCK_KEY_pdfplumber]:
|
with sys.modules[LOCK_KEY_pdfplumber]:
|
||||||
with (pdfplumber.open(fnm) if isinstance(fnm, str) else pdfplumber.open(BytesIO(fnm))) as pdf:
|
with pdfplumber.open(fnm) if isinstance(fnm, str) else pdfplumber.open(BytesIO(fnm)) as pdf:
|
||||||
self.pdf = pdf
|
self.pdf = pdf
|
||||||
self.page_images = [p.to_image(resolution=72 * zoomin, antialias=True).annotated for i, p in
|
self.page_images = [p.to_image(resolution=72 * zoomin, antialias=True).annotated for i, p in enumerate(self.pdf.pages[page_from:page_to])]
|
||||||
enumerate(self.pdf.pages[page_from:page_to])]
|
|
||||||
|
|
||||||
try:
|
try:
|
||||||
self.page_chars = [[c for c in page.dedupe_chars().chars if self._has_color(c)] for page in self.pdf.pages[page_from:page_to]]
|
self.page_chars = [[c for c in page.dedupe_chars().chars if self._has_color(c)] for page in self.pdf.pages[page_from:page_to]]
|
||||||
@ -1044,11 +948,11 @@ class RAGFlowPdfParser:
|
|||||||
|
|
||||||
self.outlines = []
|
self.outlines = []
|
||||||
try:
|
try:
|
||||||
with (pdf2_read(fnm if isinstance(fnm, str)
|
with pdf2_read(fnm if isinstance(fnm, str) else BytesIO(fnm)) as pdf:
|
||||||
else BytesIO(fnm))) as pdf:
|
|
||||||
self.pdf = pdf
|
self.pdf = pdf
|
||||||
|
|
||||||
outlines = self.pdf.outline
|
outlines = self.pdf.outline
|
||||||
|
|
||||||
def dfs(arr, depth):
|
def dfs(arr, depth):
|
||||||
for a in arr:
|
for a in arr:
|
||||||
if isinstance(a, dict):
|
if isinstance(a, dict):
|
||||||
@ -1065,11 +969,11 @@ class RAGFlowPdfParser:
|
|||||||
logging.warning("Miss outlines")
|
logging.warning("Miss outlines")
|
||||||
|
|
||||||
logging.debug("Images converted.")
|
logging.debug("Images converted.")
|
||||||
self.is_english = [re.search(r"[a-zA-Z0-9,/¸;:'\[\]\(\)!@#$%^&*\"?<>._-]{30,}", "".join(
|
self.is_english = [
|
||||||
random.choices([c["text"] for c in self.page_chars[i]], k=min(100, len(self.page_chars[i]))))) for i in
|
re.search(r"[a-zA-Z0-9,/¸;:'\[\]\(\)!@#$%^&*\"?<>._-]{30,}", "".join(random.choices([c["text"] for c in self.page_chars[i]], k=min(100, len(self.page_chars[i])))))
|
||||||
range(len(self.page_chars))]
|
for i in range(len(self.page_chars))
|
||||||
if sum([1 if e else 0 for e in self.is_english]) > len(
|
]
|
||||||
self.page_images) / 2:
|
if sum([1 if e else 0 for e in self.is_english]) > len(self.page_images) / 2:
|
||||||
self.is_english = True
|
self.is_english = True
|
||||||
else:
|
else:
|
||||||
self.is_english = False
|
self.is_english = False
|
||||||
@ -1077,10 +981,12 @@ class RAGFlowPdfParser:
|
|||||||
async def __img_ocr(i, id, img, chars, limiter):
|
async def __img_ocr(i, id, img, chars, limiter):
|
||||||
j = 0
|
j = 0
|
||||||
while j + 1 < len(chars):
|
while j + 1 < len(chars):
|
||||||
if chars[j]["text"] and chars[j + 1]["text"] \
|
if (
|
||||||
and re.match(r"[0-9a-zA-Z,.:;!%]+", chars[j]["text"] + chars[j + 1]["text"]) \
|
chars[j]["text"]
|
||||||
and chars[j + 1]["x0"] - chars[j]["x1"] >= min(chars[j + 1]["width"],
|
and chars[j + 1]["text"]
|
||||||
chars[j]["width"]) / 2:
|
and re.match(r"[0-9a-zA-Z,.:;!%]+", chars[j]["text"] + chars[j + 1]["text"])
|
||||||
|
and chars[j + 1]["x0"] - chars[j]["x1"] >= min(chars[j + 1]["width"], chars[j]["width"]) / 2
|
||||||
|
):
|
||||||
chars[j]["text"] += " "
|
chars[j]["text"] += " "
|
||||||
j += 1
|
j += 1
|
||||||
|
|
||||||
@ -1096,12 +1002,8 @@ class RAGFlowPdfParser:
|
|||||||
async def __img_ocr_launcher():
|
async def __img_ocr_launcher():
|
||||||
def __ocr_preprocess():
|
def __ocr_preprocess():
|
||||||
chars = self.page_chars[i] if not self.is_english else []
|
chars = self.page_chars[i] if not self.is_english else []
|
||||||
self.mean_height.append(
|
self.mean_height.append(np.median(sorted([c["height"] for c in chars])) if chars else 0)
|
||||||
np.median(sorted([c["height"] for c in chars])) if chars else 0
|
self.mean_width.append(np.median(sorted([c["width"] for c in chars])) if chars else 8)
|
||||||
)
|
|
||||||
self.mean_width.append(
|
|
||||||
np.median(sorted([c["width"] for c in chars])) if chars else 8
|
|
||||||
)
|
|
||||||
self.page_cum_height.append(img.size[1] / zoomin)
|
self.page_cum_height.append(img.size[1] / zoomin)
|
||||||
return chars
|
return chars
|
||||||
|
|
||||||
@ -1110,8 +1012,7 @@ class RAGFlowPdfParser:
|
|||||||
for i, img in enumerate(self.page_images):
|
for i, img in enumerate(self.page_images):
|
||||||
chars = __ocr_preprocess()
|
chars = __ocr_preprocess()
|
||||||
|
|
||||||
nursery.start_soon(__img_ocr, i, i % PARALLEL_DEVICES, img, chars,
|
nursery.start_soon(__img_ocr, i, i % PARALLEL_DEVICES, img, chars, self.parallel_limiter[i % PARALLEL_DEVICES])
|
||||||
self.parallel_limiter[i % PARALLEL_DEVICES])
|
|
||||||
await trio.sleep(0.1)
|
await trio.sleep(0.1)
|
||||||
else:
|
else:
|
||||||
for i, img in enumerate(self.page_images):
|
for i, img in enumerate(self.page_images):
|
||||||
@ -1124,11 +1025,9 @@ class RAGFlowPdfParser:
|
|||||||
|
|
||||||
logging.info(f"__images__ {len(self.page_images)} pages cost {timer() - start}s")
|
logging.info(f"__images__ {len(self.page_images)} pages cost {timer() - start}s")
|
||||||
|
|
||||||
if not self.is_english and not any(
|
if not self.is_english and not any([c for c in self.page_chars]) and self.boxes:
|
||||||
[c for c in self.page_chars]) and self.boxes:
|
|
||||||
bxes = [b for bxs in self.boxes for b in bxs]
|
bxes = [b for bxs in self.boxes for b in bxs]
|
||||||
self.is_english = re.search(r"[\na-zA-Z0-9,/¸;:'\[\]\(\)!@#$%^&*\"?<>._-]{30,}",
|
self.is_english = re.search(r"[\na-zA-Z0-9,/¸;:'\[\]\(\)!@#$%^&*\"?<>._-]{30,}", "".join([b["text"] for b in random.choices(bxes, k=min(30, len(bxes)))]))
|
||||||
"".join([b["text"] for b in random.choices(bxes, k=min(30, len(bxes)))]))
|
|
||||||
|
|
||||||
logging.debug("Is it English:", self.is_english)
|
logging.debug("Is it English:", self.is_english)
|
||||||
|
|
||||||
@ -1144,8 +1043,7 @@ class RAGFlowPdfParser:
|
|||||||
self._text_merge()
|
self._text_merge()
|
||||||
self._concat_downward()
|
self._concat_downward()
|
||||||
self._filter_forpages()
|
self._filter_forpages()
|
||||||
tbls = self._extract_table_figure(
|
tbls = self._extract_table_figure(need_image, zoomin, return_html, False)
|
||||||
need_image, zoomin, return_html, False)
|
|
||||||
return self.__filterout_scraps(deepcopy(self.boxes), zoomin), tbls
|
return self.__filterout_scraps(deepcopy(self.boxes), zoomin), tbls
|
||||||
|
|
||||||
def parse_into_bboxes(self, fnm, callback=None, zoomin=3):
|
def parse_into_bboxes(self, fnm, callback=None, zoomin=3):
|
||||||
@ -1179,9 +1077,8 @@ class RAGFlowPdfParser:
|
|||||||
import math
|
import math
|
||||||
pn1, left1, right1, top1, bottom1 = rect1
|
pn1, left1, right1, top1, bottom1 = rect1
|
||||||
pn2, left2, right2, top2, bottom2 = rect2
|
pn2, left2, right2, top2, bottom2 = rect2
|
||||||
if (right1 >= left2 and right2 >= left1 and
|
if right1 >= left2 and right2 >= left1 and bottom1 >= top2 and bottom2 >= top1:
|
||||||
bottom1 >= top2 and bottom2 >= top1):
|
return 0
|
||||||
return 0 + (pn1-pn2)*10000
|
|
||||||
if right1 < left2:
|
if right1 < left2:
|
||||||
dx = left2 - right1
|
dx = left2 - right1
|
||||||
elif right2 < left1:
|
elif right2 < left1:
|
||||||
@ -1194,17 +1091,20 @@ class RAGFlowPdfParser:
|
|||||||
dy = top1 - bottom2
|
dy = top1 - bottom2
|
||||||
else:
|
else:
|
||||||
dy = 0
|
dy = 0
|
||||||
return math.sqrt(dx*dx + dy*dy) + (pn1-pn2)*10000
|
return math.sqrt(dx*dx + dy*dy)# + (pn2-pn1)*10000
|
||||||
|
|
||||||
for (img, txt), poss in tbls_or_figs:
|
for (img, txt), poss in tbls_or_figs:
|
||||||
bboxes = [(i, (b["page_number"], b["x0"], b["x1"], b["top"], b["bottom"])) for i, b in enumerate(self.boxes)]
|
bboxes = [(i, (b["page_number"], b["x0"], b["x1"], b["top"], b["bottom"])) for i, b in enumerate(self.boxes)]
|
||||||
dists = [(min_rectangle_distance((pn, left, right, top, bott), rect),i) for i, rect in bboxes for pn, left, right, top, bott in poss]
|
dists = [(min_rectangle_distance((pn, left, right, top+self.page_cum_height[pn], bott+self.page_cum_height[pn]), rect),i) for i, rect in bboxes for pn, left, right, top, bott in poss]
|
||||||
min_i = np.argmin(dists, axis=0)[0]
|
min_i = np.argmin(dists, axis=0)[0]
|
||||||
min_i, rect = bboxes[dists[min_i][-1]]
|
min_i, rect = bboxes[dists[min_i][-1]]
|
||||||
if isinstance(txt, list):
|
if isinstance(txt, list):
|
||||||
txt = "\n".join(txt)
|
txt = "\n".join(txt)
|
||||||
|
pn, left, right, top, bott = poss[0]
|
||||||
|
if self.boxes[min_i]["bottom"] < top+self.page_cum_height[pn]:
|
||||||
|
min_i += 1
|
||||||
self.boxes.insert(min_i, {
|
self.boxes.insert(min_i, {
|
||||||
"page_number": rect[0], "x0": rect[1], "x1": rect[2], "top": rect[3], "bottom": rect[4], "layout_type": layout_type, "text": txt, "image": img
|
"page_number": pn+1, "x0": left, "x1": right, "top": top+self.page_cum_height[pn], "bottom": bott+self.page_cum_height[pn], "layout_type": layout_type, "text": txt, "image": img
|
||||||
})
|
})
|
||||||
|
|
||||||
for b in self.boxes:
|
for b in self.boxes:
|
||||||
@ -1225,12 +1125,9 @@ class RAGFlowPdfParser:
|
|||||||
def extract_positions(txt):
|
def extract_positions(txt):
|
||||||
poss = []
|
poss = []
|
||||||
for tag in re.findall(r"@@[0-9-]+\t[0-9.\t]+##", txt):
|
for tag in re.findall(r"@@[0-9-]+\t[0-9.\t]+##", txt):
|
||||||
pn, left, right, top, bottom = tag.strip(
|
pn, left, right, top, bottom = tag.strip("#").strip("@").split("\t")
|
||||||
"#").strip("@").split("\t")
|
left, right, top, bottom = float(left), float(right), float(top), float(bottom)
|
||||||
left, right, top, bottom = float(left), float(
|
poss.append(([int(p) - 1 for p in pn.split("-")], left, right, top, bottom))
|
||||||
right), float(top), float(bottom)
|
|
||||||
poss.append(([int(p) - 1 for p in pn.split("-")],
|
|
||||||
left, right, top, bottom))
|
|
||||||
return poss
|
return poss
|
||||||
|
|
||||||
def crop(self, text, ZM=3, need_position=False):
|
def crop(self, text, ZM=3, need_position=False):
|
||||||
@ -1241,15 +1138,12 @@ class RAGFlowPdfParser:
|
|||||||
return None, None
|
return None, None
|
||||||
return
|
return
|
||||||
|
|
||||||
max_width = max(
|
max_width = max(np.max([right - left for (_, left, right, _, _) in poss]), 6)
|
||||||
np.max([right - left for (_, left, right, _, _) in poss]), 6)
|
|
||||||
GAP = 6
|
GAP = 6
|
||||||
pos = poss[0]
|
pos = poss[0]
|
||||||
poss.insert(0, ([pos[0][0]], pos[1], pos[2], max(
|
poss.insert(0, ([pos[0][0]], pos[1], pos[2], max(0, pos[3] - 120), max(pos[3] - GAP, 0)))
|
||||||
0, pos[3] - 120), max(pos[3] - GAP, 0)))
|
|
||||||
pos = poss[-1]
|
pos = poss[-1]
|
||||||
poss.append(([pos[0][-1]], pos[1], pos[2], min(self.page_images[pos[0][-1]].size[1] / ZM, pos[4] + GAP),
|
poss.append(([pos[0][-1]], pos[1], pos[2], min(self.page_images[pos[0][-1]].size[1] / ZM, pos[4] + GAP), min(self.page_images[pos[0][-1]].size[1] / ZM, pos[4] + 120)))
|
||||||
min(self.page_images[pos[0][-1]].size[1] / ZM, pos[4] + 120)))
|
|
||||||
|
|
||||||
positions = []
|
positions = []
|
||||||
for ii, (pns, left, right, top, bottom) in enumerate(poss):
|
for ii, (pns, left, right, top, bottom) in enumerate(poss):
|
||||||
@ -1257,28 +1151,14 @@ class RAGFlowPdfParser:
|
|||||||
bottom *= ZM
|
bottom *= ZM
|
||||||
for pn in pns[1:]:
|
for pn in pns[1:]:
|
||||||
bottom += self.page_images[pn - 1].size[1]
|
bottom += self.page_images[pn - 1].size[1]
|
||||||
imgs.append(
|
imgs.append(self.page_images[pns[0]].crop((left * ZM, top * ZM, right * ZM, min(bottom, self.page_images[pns[0]].size[1]))))
|
||||||
self.page_images[pns[0]].crop((left * ZM, top * ZM,
|
|
||||||
right *
|
|
||||||
ZM, min(
|
|
||||||
bottom, self.page_images[pns[0]].size[1])
|
|
||||||
))
|
|
||||||
)
|
|
||||||
if 0 < ii < len(poss) - 1:
|
if 0 < ii < len(poss) - 1:
|
||||||
positions.append((pns[0] + self.page_from, left, right, top, min(
|
positions.append((pns[0] + self.page_from, left, right, top, min(bottom, self.page_images[pns[0]].size[1]) / ZM))
|
||||||
bottom, self.page_images[pns[0]].size[1]) / ZM))
|
|
||||||
bottom -= self.page_images[pns[0]].size[1]
|
bottom -= self.page_images[pns[0]].size[1]
|
||||||
for pn in pns[1:]:
|
for pn in pns[1:]:
|
||||||
imgs.append(
|
imgs.append(self.page_images[pn].crop((left * ZM, 0, right * ZM, min(bottom, self.page_images[pn].size[1]))))
|
||||||
self.page_images[pn].crop((left * ZM, 0,
|
|
||||||
right * ZM,
|
|
||||||
min(bottom,
|
|
||||||
self.page_images[pn].size[1])
|
|
||||||
))
|
|
||||||
)
|
|
||||||
if 0 < ii < len(poss) - 1:
|
if 0 < ii < len(poss) - 1:
|
||||||
positions.append((pn + self.page_from, left, right, 0, min(
|
positions.append((pn + self.page_from, left, right, 0, min(bottom, self.page_images[pn].size[1]) / ZM))
|
||||||
bottom, self.page_images[pn].size[1]) / ZM))
|
|
||||||
bottom -= self.page_images[pn].size[1]
|
bottom -= self.page_images[pn].size[1]
|
||||||
|
|
||||||
if not imgs:
|
if not imgs:
|
||||||
@ -1290,14 +1170,12 @@ class RAGFlowPdfParser:
|
|||||||
height += img.size[1] + GAP
|
height += img.size[1] + GAP
|
||||||
height = int(height)
|
height = int(height)
|
||||||
width = int(np.max([i.size[0] for i in imgs]))
|
width = int(np.max([i.size[0] for i in imgs]))
|
||||||
pic = Image.new("RGB",
|
pic = Image.new("RGB", (width, height), (245, 245, 245))
|
||||||
(width, height),
|
|
||||||
(245, 245, 245))
|
|
||||||
height = 0
|
height = 0
|
||||||
for ii, img in enumerate(imgs):
|
for ii, img in enumerate(imgs):
|
||||||
if ii == 0 or ii + 1 == len(imgs):
|
if ii == 0 or ii + 1 == len(imgs):
|
||||||
img = img.convert('RGBA')
|
img = img.convert("RGBA")
|
||||||
overlay = Image.new('RGBA', img.size, (0, 0, 0, 0))
|
overlay = Image.new("RGBA", img.size, (0, 0, 0, 0))
|
||||||
overlay.putalpha(128)
|
overlay.putalpha(128)
|
||||||
img = Image.alpha_composite(img, overlay).convert("RGB")
|
img = Image.alpha_composite(img, overlay).convert("RGB")
|
||||||
pic.paste(img, (0, int(height)))
|
pic.paste(img, (0, int(height)))
|
||||||
@ -1312,14 +1190,12 @@ class RAGFlowPdfParser:
|
|||||||
pn = bx["page_number"]
|
pn = bx["page_number"]
|
||||||
top = bx["top"] - self.page_cum_height[pn - 1]
|
top = bx["top"] - self.page_cum_height[pn - 1]
|
||||||
bott = bx["bottom"] - self.page_cum_height[pn - 1]
|
bott = bx["bottom"] - self.page_cum_height[pn - 1]
|
||||||
poss.append((pn, bx["x0"], bx["x1"], top, min(
|
poss.append((pn, bx["x0"], bx["x1"], top, min(bott, self.page_images[pn - 1].size[1] / ZM)))
|
||||||
bott, self.page_images[pn - 1].size[1] / ZM)))
|
|
||||||
while bott * ZM > self.page_images[pn - 1].size[1]:
|
while bott * ZM > self.page_images[pn - 1].size[1]:
|
||||||
bott -= self.page_images[pn - 1].size[1] / ZM
|
bott -= self.page_images[pn - 1].size[1] / ZM
|
||||||
top = 0
|
top = 0
|
||||||
pn += 1
|
pn += 1
|
||||||
poss.append((pn, bx["x0"], bx["x1"], top, min(
|
poss.append((pn, bx["x0"], bx["x1"], top, min(bott, self.page_images[pn - 1].size[1] / ZM)))
|
||||||
bott, self.page_images[pn - 1].size[1] / ZM)))
|
|
||||||
return poss
|
return poss
|
||||||
|
|
||||||
|
|
||||||
@ -1328,9 +1204,7 @@ class PlainParser:
|
|||||||
self.outlines = []
|
self.outlines = []
|
||||||
lines = []
|
lines = []
|
||||||
try:
|
try:
|
||||||
self.pdf = pdf2_read(
|
self.pdf = pdf2_read(filename if isinstance(filename, str) else BytesIO(filename))
|
||||||
filename if isinstance(
|
|
||||||
filename, str) else BytesIO(filename))
|
|
||||||
for page in self.pdf.pages[from_page:to_page]:
|
for page in self.pdf.pages[from_page:to_page]:
|
||||||
lines.extend([t for t in page.extract_text().split("\n")])
|
lines.extend([t for t in page.extract_text().split("\n")])
|
||||||
|
|
||||||
@ -1367,10 +1241,8 @@ class VisionParser(RAGFlowPdfParser):
|
|||||||
def __images__(self, fnm, zoomin=3, page_from=0, page_to=299, callback=None):
|
def __images__(self, fnm, zoomin=3, page_from=0, page_to=299, callback=None):
|
||||||
try:
|
try:
|
||||||
with sys.modules[LOCK_KEY_pdfplumber]:
|
with sys.modules[LOCK_KEY_pdfplumber]:
|
||||||
self.pdf = pdfplumber.open(fnm) if isinstance(
|
self.pdf = pdfplumber.open(fnm) if isinstance(fnm, str) else pdfplumber.open(BytesIO(fnm))
|
||||||
fnm, str) else pdfplumber.open(BytesIO(fnm))
|
self.page_images = [p.to_image(resolution=72 * zoomin).annotated for i, p in enumerate(self.pdf.pages[page_from:page_to])]
|
||||||
self.page_images = [p.to_image(resolution=72 * zoomin).annotated for i, p in
|
|
||||||
enumerate(self.pdf.pages[page_from:page_to])]
|
|
||||||
self.total_page = len(self.pdf.pages)
|
self.total_page = len(self.pdf.pages)
|
||||||
except Exception:
|
except Exception:
|
||||||
self.page_images = None
|
self.page_images = None
|
||||||
@ -1397,15 +1269,15 @@ class VisionParser(RAGFlowPdfParser):
|
|||||||
text = picture_vision_llm_chunk(
|
text = picture_vision_llm_chunk(
|
||||||
binary=img_binary,
|
binary=img_binary,
|
||||||
vision_model=self.vision_model,
|
vision_model=self.vision_model,
|
||||||
prompt=vision_llm_describe_prompt(page=pdf_page_num+1),
|
prompt=vision_llm_describe_prompt(page=pdf_page_num + 1),
|
||||||
callback=callback,
|
callback=callback,
|
||||||
)
|
)
|
||||||
if kwargs.get("callback"):
|
if kwargs.get("callback"):
|
||||||
kwargs["callback"](idx*1./len(self.page_images), f"Processed: {idx+1}/{len(self.page_images)}")
|
kwargs["callback"](idx * 1.0 / len(self.page_images), f"Processed: {idx + 1}/{len(self.page_images)}")
|
||||||
|
|
||||||
if text:
|
if text:
|
||||||
width, height = self.page_images[idx].size
|
width, height = self.page_images[idx].size
|
||||||
all_docs.append((text, f"{pdf_page_num+1} 0 {width/zoomin} 0 {height/zoomin}"))
|
all_docs.append((text, f"{pdf_page_num + 1} 0 {width / zoomin} 0 {height / zoomin}"))
|
||||||
return all_docs, []
|
return all_docs, []
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
@ -16,24 +16,28 @@
|
|||||||
import io
|
import io
|
||||||
import sys
|
import sys
|
||||||
import threading
|
import threading
|
||||||
|
|
||||||
import pdfplumber
|
import pdfplumber
|
||||||
|
|
||||||
from .ocr import OCR
|
from .ocr import OCR
|
||||||
from .recognizer import Recognizer
|
from .recognizer import Recognizer
|
||||||
|
from .layout_recognizer import AscendLayoutRecognizer
|
||||||
from .layout_recognizer import LayoutRecognizer4YOLOv10 as LayoutRecognizer
|
from .layout_recognizer import LayoutRecognizer4YOLOv10 as LayoutRecognizer
|
||||||
from .table_structure_recognizer import TableStructureRecognizer
|
from .table_structure_recognizer import TableStructureRecognizer
|
||||||
|
|
||||||
|
|
||||||
LOCK_KEY_pdfplumber = "global_shared_lock_pdfplumber"
|
LOCK_KEY_pdfplumber = "global_shared_lock_pdfplumber"
|
||||||
if LOCK_KEY_pdfplumber not in sys.modules:
|
if LOCK_KEY_pdfplumber not in sys.modules:
|
||||||
sys.modules[LOCK_KEY_pdfplumber] = threading.Lock()
|
sys.modules[LOCK_KEY_pdfplumber] = threading.Lock()
|
||||||
|
|
||||||
|
|
||||||
def init_in_out(args):
|
def init_in_out(args):
|
||||||
from PIL import Image
|
|
||||||
import os
|
import os
|
||||||
import traceback
|
import traceback
|
||||||
|
|
||||||
|
from PIL import Image
|
||||||
|
|
||||||
from api.utils.file_utils import traversal_files
|
from api.utils.file_utils import traversal_files
|
||||||
|
|
||||||
images = []
|
images = []
|
||||||
outputs = []
|
outputs = []
|
||||||
|
|
||||||
@ -44,8 +48,7 @@ def init_in_out(args):
|
|||||||
nonlocal outputs, images
|
nonlocal outputs, images
|
||||||
with sys.modules[LOCK_KEY_pdfplumber]:
|
with sys.modules[LOCK_KEY_pdfplumber]:
|
||||||
pdf = pdfplumber.open(fnm)
|
pdf = pdfplumber.open(fnm)
|
||||||
images = [p.to_image(resolution=72 * zoomin).annotated for i, p in
|
images = [p.to_image(resolution=72 * zoomin).annotated for i, p in enumerate(pdf.pages)]
|
||||||
enumerate(pdf.pages)]
|
|
||||||
|
|
||||||
for i, page in enumerate(images):
|
for i, page in enumerate(images):
|
||||||
outputs.append(os.path.split(fnm)[-1] + f"_{i}.jpg")
|
outputs.append(os.path.split(fnm)[-1] + f"_{i}.jpg")
|
||||||
@ -57,10 +60,10 @@ def init_in_out(args):
|
|||||||
pdf_pages(fnm)
|
pdf_pages(fnm)
|
||||||
return
|
return
|
||||||
try:
|
try:
|
||||||
fp = open(fnm, 'rb')
|
fp = open(fnm, "rb")
|
||||||
binary = fp.read()
|
binary = fp.read()
|
||||||
fp.close()
|
fp.close()
|
||||||
images.append(Image.open(io.BytesIO(binary)).convert('RGB'))
|
images.append(Image.open(io.BytesIO(binary)).convert("RGB"))
|
||||||
outputs.append(os.path.split(fnm)[-1])
|
outputs.append(os.path.split(fnm)[-1])
|
||||||
except Exception:
|
except Exception:
|
||||||
traceback.print_exc()
|
traceback.print_exc()
|
||||||
@ -81,6 +84,7 @@ __all__ = [
|
|||||||
"OCR",
|
"OCR",
|
||||||
"Recognizer",
|
"Recognizer",
|
||||||
"LayoutRecognizer",
|
"LayoutRecognizer",
|
||||||
|
"AscendLayoutRecognizer",
|
||||||
"TableStructureRecognizer",
|
"TableStructureRecognizer",
|
||||||
"init_in_out",
|
"init_in_out",
|
||||||
]
|
]
|
||||||
|
|||||||
@ -14,6 +14,8 @@
|
|||||||
# limitations under the License.
|
# limitations under the License.
|
||||||
#
|
#
|
||||||
|
|
||||||
|
import logging
|
||||||
|
import math
|
||||||
import os
|
import os
|
||||||
import re
|
import re
|
||||||
from collections import Counter
|
from collections import Counter
|
||||||
@ -45,28 +47,22 @@ class LayoutRecognizer(Recognizer):
|
|||||||
|
|
||||||
def __init__(self, domain):
|
def __init__(self, domain):
|
||||||
try:
|
try:
|
||||||
model_dir = os.path.join(
|
model_dir = os.path.join(get_project_base_directory(), "rag/res/deepdoc")
|
||||||
get_project_base_directory(),
|
|
||||||
"rag/res/deepdoc")
|
|
||||||
super().__init__(self.labels, domain, model_dir)
|
super().__init__(self.labels, domain, model_dir)
|
||||||
except Exception:
|
except Exception:
|
||||||
model_dir = snapshot_download(repo_id="InfiniFlow/deepdoc",
|
model_dir = snapshot_download(repo_id="InfiniFlow/deepdoc", local_dir=os.path.join(get_project_base_directory(), "rag/res/deepdoc"), local_dir_use_symlinks=False)
|
||||||
local_dir=os.path.join(get_project_base_directory(), "rag/res/deepdoc"),
|
|
||||||
local_dir_use_symlinks=False)
|
|
||||||
super().__init__(self.labels, domain, model_dir)
|
super().__init__(self.labels, domain, model_dir)
|
||||||
|
|
||||||
self.garbage_layouts = ["footer", "header", "reference"]
|
self.garbage_layouts = ["footer", "header", "reference"]
|
||||||
self.client = None
|
self.client = None
|
||||||
if os.environ.get("TENSORRT_DLA_SVR"):
|
if os.environ.get("TENSORRT_DLA_SVR"):
|
||||||
from deepdoc.vision.dla_cli import DLAClient
|
from deepdoc.vision.dla_cli import DLAClient
|
||||||
|
|
||||||
self.client = DLAClient(os.environ["TENSORRT_DLA_SVR"])
|
self.client = DLAClient(os.environ["TENSORRT_DLA_SVR"])
|
||||||
|
|
||||||
def __call__(self, image_list, ocr_res, scale_factor=3, thr=0.2, batch_size=16, drop=True):
|
def __call__(self, image_list, ocr_res, scale_factor=3, thr=0.2, batch_size=16, drop=True):
|
||||||
def __is_garbage(b):
|
def __is_garbage(b):
|
||||||
patt = [r"^•+$", "^[0-9]{1,2} / ?[0-9]{1,2}$",
|
patt = [r"^•+$", "^[0-9]{1,2} / ?[0-9]{1,2}$", r"^[0-9]{1,2} of [0-9]{1,2}$", "^http://[^ ]{12,}", "\\(cid *: *[0-9]+ *\\)"]
|
||||||
r"^[0-9]{1,2} of [0-9]{1,2}$", "^http://[^ ]{12,}",
|
|
||||||
"\\(cid *: *[0-9]+ *\\)"
|
|
||||||
]
|
|
||||||
return any([re.search(p, b["text"]) for p in patt])
|
return any([re.search(p, b["text"]) for p in patt])
|
||||||
|
|
||||||
if self.client:
|
if self.client:
|
||||||
@ -82,18 +78,23 @@ class LayoutRecognizer(Recognizer):
|
|||||||
page_layout = []
|
page_layout = []
|
||||||
for pn, lts in enumerate(layouts):
|
for pn, lts in enumerate(layouts):
|
||||||
bxs = ocr_res[pn]
|
bxs = ocr_res[pn]
|
||||||
lts = [{"type": b["type"],
|
lts = [
|
||||||
|
{
|
||||||
|
"type": b["type"],
|
||||||
"score": float(b["score"]),
|
"score": float(b["score"]),
|
||||||
"x0": b["bbox"][0] / scale_factor, "x1": b["bbox"][2] / scale_factor,
|
"x0": b["bbox"][0] / scale_factor,
|
||||||
"top": b["bbox"][1] / scale_factor, "bottom": b["bbox"][-1] / scale_factor,
|
"x1": b["bbox"][2] / scale_factor,
|
||||||
|
"top": b["bbox"][1] / scale_factor,
|
||||||
|
"bottom": b["bbox"][-1] / scale_factor,
|
||||||
"page_number": pn,
|
"page_number": pn,
|
||||||
} for b in lts if float(b["score"]) >= 0.4 or b["type"] not in self.garbage_layouts]
|
}
|
||||||
lts = self.sort_Y_firstly(lts, np.mean(
|
for b in lts
|
||||||
[lt["bottom"] - lt["top"] for lt in lts]) / 2)
|
if float(b["score"]) >= 0.4 or b["type"] not in self.garbage_layouts
|
||||||
|
]
|
||||||
|
lts = self.sort_Y_firstly(lts, np.mean([lt["bottom"] - lt["top"] for lt in lts]) / 2)
|
||||||
lts = self.layouts_cleanup(bxs, lts)
|
lts = self.layouts_cleanup(bxs, lts)
|
||||||
page_layout.append(lts)
|
page_layout.append(lts)
|
||||||
|
|
||||||
# Tag layout type, layouts are ready
|
|
||||||
def findLayout(ty):
|
def findLayout(ty):
|
||||||
nonlocal bxs, lts, self
|
nonlocal bxs, lts, self
|
||||||
lts_ = [lt for lt in lts if lt["type"] == ty]
|
lts_ = [lt for lt in lts if lt["type"] == ty]
|
||||||
@ -106,21 +107,17 @@ class LayoutRecognizer(Recognizer):
|
|||||||
bxs.pop(i)
|
bxs.pop(i)
|
||||||
continue
|
continue
|
||||||
|
|
||||||
ii = self.find_overlapped_with_threshold(bxs[i], lts_,
|
ii = self.find_overlapped_with_threshold(bxs[i], lts_, thr=0.4)
|
||||||
thr=0.4)
|
if ii is None:
|
||||||
if ii is None: # belong to nothing
|
|
||||||
bxs[i]["layout_type"] = ""
|
bxs[i]["layout_type"] = ""
|
||||||
i += 1
|
i += 1
|
||||||
continue
|
continue
|
||||||
lts_[ii]["visited"] = True
|
lts_[ii]["visited"] = True
|
||||||
keep_feats = [
|
keep_feats = [
|
||||||
lts_[
|
lts_[ii]["type"] == "footer" and bxs[i]["bottom"] < image_list[pn].size[1] * 0.9 / scale_factor,
|
||||||
ii]["type"] == "footer" and bxs[i]["bottom"] < image_list[pn].size[1] * 0.9 / scale_factor,
|
lts_[ii]["type"] == "header" and bxs[i]["top"] > image_list[pn].size[1] * 0.1 / scale_factor,
|
||||||
lts_[
|
|
||||||
ii]["type"] == "header" and bxs[i]["top"] > image_list[pn].size[1] * 0.1 / scale_factor,
|
|
||||||
]
|
]
|
||||||
if drop and lts_[
|
if drop and lts_[ii]["type"] in self.garbage_layouts and not any(keep_feats):
|
||||||
ii]["type"] in self.garbage_layouts and not any(keep_feats):
|
|
||||||
if lts_[ii]["type"] not in garbages:
|
if lts_[ii]["type"] not in garbages:
|
||||||
garbages[lts_[ii]["type"]] = []
|
garbages[lts_[ii]["type"]] = []
|
||||||
garbages[lts_[ii]["type"]].append(bxs[i]["text"])
|
garbages[lts_[ii]["type"]].append(bxs[i]["text"])
|
||||||
@ -128,17 +125,14 @@ class LayoutRecognizer(Recognizer):
|
|||||||
continue
|
continue
|
||||||
|
|
||||||
bxs[i]["layoutno"] = f"{ty}-{ii}"
|
bxs[i]["layoutno"] = f"{ty}-{ii}"
|
||||||
bxs[i]["layout_type"] = lts_[ii]["type"] if lts_[
|
bxs[i]["layout_type"] = lts_[ii]["type"] if lts_[ii]["type"] != "equation" else "figure"
|
||||||
ii]["type"] != "equation" else "figure"
|
|
||||||
i += 1
|
i += 1
|
||||||
|
|
||||||
for lt in ["footer", "header", "reference", "figure caption",
|
for lt in ["footer", "header", "reference", "figure caption", "table caption", "title", "table", "text", "figure", "equation"]:
|
||||||
"table caption", "title", "table", "text", "figure", "equation"]:
|
|
||||||
findLayout(lt)
|
findLayout(lt)
|
||||||
|
|
||||||
# add box to figure layouts which has not text box
|
# add box to figure layouts which has not text box
|
||||||
for i, lt in enumerate(
|
for i, lt in enumerate([lt for lt in lts if lt["type"] in ["figure", "equation"]]):
|
||||||
[lt for lt in lts if lt["type"] in ["figure", "equation"]]):
|
|
||||||
if lt.get("visited"):
|
if lt.get("visited"):
|
||||||
continue
|
continue
|
||||||
lt = deepcopy(lt)
|
lt = deepcopy(lt)
|
||||||
@ -206,13 +200,11 @@ class LayoutRecognizer4YOLOv10(LayoutRecognizer):
|
|||||||
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
|
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
|
||||||
top, bottom = int(round(dh - 0.1)) if self.center else 0, int(round(dh + 0.1))
|
top, bottom = int(round(dh - 0.1)) if self.center else 0, int(round(dh + 0.1))
|
||||||
left, right = int(round(dw - 0.1)) if self.center else 0, int(round(dw + 0.1))
|
left, right = int(round(dw - 0.1)) if self.center else 0, int(round(dw + 0.1))
|
||||||
img = cv2.copyMakeBorder(
|
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=(114, 114, 114)) # add border
|
||||||
img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=(114, 114, 114)
|
|
||||||
) # add border
|
|
||||||
img /= 255.0
|
img /= 255.0
|
||||||
img = img.transpose(2, 0, 1)
|
img = img.transpose(2, 0, 1)
|
||||||
img = img[np.newaxis, :, :, :].astype(np.float32)
|
img = img[np.newaxis, :, :, :].astype(np.float32)
|
||||||
inputs.append({self.input_names[0]: img, "scale_factor": [shape[1]/ww, shape[0]/hh, dw, dh]})
|
inputs.append({self.input_names[0]: img, "scale_factor": [shape[1] / ww, shape[0] / hh, dw, dh]})
|
||||||
|
|
||||||
return inputs
|
return inputs
|
||||||
|
|
||||||
@ -230,8 +222,7 @@ class LayoutRecognizer4YOLOv10(LayoutRecognizer):
|
|||||||
boxes[:, 2] -= inputs["scale_factor"][2]
|
boxes[:, 2] -= inputs["scale_factor"][2]
|
||||||
boxes[:, 1] -= inputs["scale_factor"][3]
|
boxes[:, 1] -= inputs["scale_factor"][3]
|
||||||
boxes[:, 3] -= inputs["scale_factor"][3]
|
boxes[:, 3] -= inputs["scale_factor"][3]
|
||||||
input_shape = np.array([inputs["scale_factor"][0], inputs["scale_factor"][1], inputs["scale_factor"][0],
|
input_shape = np.array([inputs["scale_factor"][0], inputs["scale_factor"][1], inputs["scale_factor"][0], inputs["scale_factor"][1]])
|
||||||
inputs["scale_factor"][1]])
|
|
||||||
boxes = np.multiply(boxes, input_shape, dtype=np.float32)
|
boxes = np.multiply(boxes, input_shape, dtype=np.float32)
|
||||||
|
|
||||||
unique_class_ids = np.unique(class_ids)
|
unique_class_ids = np.unique(class_ids)
|
||||||
@ -243,8 +234,223 @@ class LayoutRecognizer4YOLOv10(LayoutRecognizer):
|
|||||||
class_keep_boxes = nms(class_boxes, class_scores, 0.45)
|
class_keep_boxes = nms(class_boxes, class_scores, 0.45)
|
||||||
indices.extend(class_indices[class_keep_boxes])
|
indices.extend(class_indices[class_keep_boxes])
|
||||||
|
|
||||||
return [{
|
return [{"type": self.label_list[class_ids[i]].lower(), "bbox": [float(t) for t in boxes[i].tolist()], "score": float(scores[i])} for i in indices]
|
||||||
"type": self.label_list[class_ids[i]].lower(),
|
|
||||||
"bbox": [float(t) for t in boxes[i].tolist()],
|
|
||||||
"score": float(scores[i])
|
class AscendLayoutRecognizer(Recognizer):
|
||||||
} for i in indices]
|
labels = [
|
||||||
|
"title",
|
||||||
|
"Text",
|
||||||
|
"Reference",
|
||||||
|
"Figure",
|
||||||
|
"Figure caption",
|
||||||
|
"Table",
|
||||||
|
"Table caption",
|
||||||
|
"Table caption",
|
||||||
|
"Equation",
|
||||||
|
"Figure caption",
|
||||||
|
]
|
||||||
|
|
||||||
|
def __init__(self, domain):
|
||||||
|
from ais_bench.infer.interface import InferSession
|
||||||
|
|
||||||
|
model_dir = os.path.join(get_project_base_directory(), "rag/res/deepdoc")
|
||||||
|
model_file_path = os.path.join(model_dir, domain + ".om")
|
||||||
|
|
||||||
|
if not os.path.exists(model_file_path):
|
||||||
|
raise ValueError(f"Model file not found: {model_file_path}")
|
||||||
|
|
||||||
|
device_id = int(os.getenv("ASCEND_LAYOUT_RECOGNIZER_DEVICE_ID", 0))
|
||||||
|
self.session = InferSession(device_id=device_id, model_path=model_file_path)
|
||||||
|
self.input_shape = self.session.get_inputs()[0].shape[2:4] # H,W
|
||||||
|
self.garbage_layouts = ["footer", "header", "reference"]
|
||||||
|
|
||||||
|
def preprocess(self, image_list):
|
||||||
|
inputs = []
|
||||||
|
H, W = self.input_shape
|
||||||
|
for img in image_list:
|
||||||
|
h, w = img.shape[:2]
|
||||||
|
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB).astype(np.float32)
|
||||||
|
|
||||||
|
r = min(H / h, W / w)
|
||||||
|
new_unpad = (int(round(w * r)), int(round(h * r)))
|
||||||
|
dw, dh = (W - new_unpad[0]) / 2.0, (H - new_unpad[1]) / 2.0
|
||||||
|
|
||||||
|
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
|
||||||
|
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
|
||||||
|
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
|
||||||
|
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=(114, 114, 114))
|
||||||
|
|
||||||
|
img /= 255.0
|
||||||
|
img = img.transpose(2, 0, 1)[np.newaxis, :, :, :].astype(np.float32)
|
||||||
|
|
||||||
|
inputs.append(
|
||||||
|
{
|
||||||
|
"image": img,
|
||||||
|
"scale_factor": [w / new_unpad[0], h / new_unpad[1]],
|
||||||
|
"pad": [dw, dh],
|
||||||
|
"orig_shape": [h, w],
|
||||||
|
}
|
||||||
|
)
|
||||||
|
return inputs
|
||||||
|
|
||||||
|
def postprocess(self, boxes, inputs, thr=0.25):
|
||||||
|
arr = np.squeeze(boxes)
|
||||||
|
if arr.ndim == 1:
|
||||||
|
arr = arr.reshape(1, -1)
|
||||||
|
|
||||||
|
results = []
|
||||||
|
if arr.shape[1] == 6:
|
||||||
|
# [x1,y1,x2,y2,score,cls]
|
||||||
|
m = arr[:, 4] >= thr
|
||||||
|
arr = arr[m]
|
||||||
|
if arr.size == 0:
|
||||||
|
return []
|
||||||
|
xyxy = arr[:, :4].astype(np.float32)
|
||||||
|
scores = arr[:, 4].astype(np.float32)
|
||||||
|
cls_ids = arr[:, 5].astype(np.int32)
|
||||||
|
|
||||||
|
if "pad" in inputs:
|
||||||
|
dw, dh = inputs["pad"]
|
||||||
|
sx, sy = inputs["scale_factor"]
|
||||||
|
xyxy[:, [0, 2]] -= dw
|
||||||
|
xyxy[:, [1, 3]] -= dh
|
||||||
|
xyxy *= np.array([sx, sy, sx, sy], dtype=np.float32)
|
||||||
|
else:
|
||||||
|
# backup
|
||||||
|
sx, sy = inputs["scale_factor"]
|
||||||
|
xyxy *= np.array([sx, sy, sx, sy], dtype=np.float32)
|
||||||
|
|
||||||
|
keep_indices = []
|
||||||
|
for c in np.unique(cls_ids):
|
||||||
|
idx = np.where(cls_ids == c)[0]
|
||||||
|
k = nms(xyxy[idx], scores[idx], 0.45)
|
||||||
|
keep_indices.extend(idx[k])
|
||||||
|
|
||||||
|
for i in keep_indices:
|
||||||
|
cid = int(cls_ids[i])
|
||||||
|
if 0 <= cid < len(self.labels):
|
||||||
|
results.append({"type": self.labels[cid].lower(), "bbox": [float(t) for t in xyxy[i].tolist()], "score": float(scores[i])})
|
||||||
|
return results
|
||||||
|
|
||||||
|
raise ValueError(f"Unexpected output shape: {arr.shape}")
|
||||||
|
|
||||||
|
def __call__(self, image_list, ocr_res, scale_factor=3, thr=0.2, batch_size=16, drop=True):
|
||||||
|
import re
|
||||||
|
from collections import Counter
|
||||||
|
|
||||||
|
assert len(image_list) == len(ocr_res)
|
||||||
|
|
||||||
|
images = [np.array(im) if not isinstance(im, np.ndarray) else im for im in image_list]
|
||||||
|
layouts_all_pages = [] # list of list[{"type","score","bbox":[x1,y1,x2,y2]}]
|
||||||
|
|
||||||
|
conf_thr = max(thr, 0.08)
|
||||||
|
|
||||||
|
batch_loop_cnt = math.ceil(float(len(images)) / batch_size)
|
||||||
|
for bi in range(batch_loop_cnt):
|
||||||
|
s = bi * batch_size
|
||||||
|
e = min((bi + 1) * batch_size, len(images))
|
||||||
|
batch_images = images[s:e]
|
||||||
|
|
||||||
|
inputs_list = self.preprocess(batch_images)
|
||||||
|
logging.debug("preprocess done")
|
||||||
|
|
||||||
|
for ins in inputs_list:
|
||||||
|
feeds = [ins["image"]]
|
||||||
|
out_list = self.session.infer(feeds=feeds, mode="static")
|
||||||
|
|
||||||
|
for out in out_list:
|
||||||
|
lts = self.postprocess(out, ins, conf_thr)
|
||||||
|
|
||||||
|
page_lts = []
|
||||||
|
for b in lts:
|
||||||
|
if float(b["score"]) >= 0.4 or b["type"] not in self.garbage_layouts:
|
||||||
|
x0, y0, x1, y1 = b["bbox"]
|
||||||
|
page_lts.append(
|
||||||
|
{
|
||||||
|
"type": b["type"],
|
||||||
|
"score": float(b["score"]),
|
||||||
|
"x0": float(x0) / scale_factor,
|
||||||
|
"x1": float(x1) / scale_factor,
|
||||||
|
"top": float(y0) / scale_factor,
|
||||||
|
"bottom": float(y1) / scale_factor,
|
||||||
|
"page_number": len(layouts_all_pages),
|
||||||
|
}
|
||||||
|
)
|
||||||
|
layouts_all_pages.append(page_lts)
|
||||||
|
|
||||||
|
def _is_garbage_text(box):
|
||||||
|
patt = [r"^•+$", r"^[0-9]{1,2} / ?[0-9]{1,2}$", r"^[0-9]{1,2} of [0-9]{1,2}$", r"^http://[^ ]{12,}", r"\(cid *: *[0-9]+ *\)"]
|
||||||
|
return any(re.search(p, box.get("text", "")) for p in patt)
|
||||||
|
|
||||||
|
boxes_out = []
|
||||||
|
page_layout = []
|
||||||
|
garbages = {}
|
||||||
|
|
||||||
|
for pn, lts in enumerate(layouts_all_pages):
|
||||||
|
if lts:
|
||||||
|
avg_h = np.mean([lt["bottom"] - lt["top"] for lt in lts])
|
||||||
|
lts = self.sort_Y_firstly(lts, avg_h / 2 if avg_h > 0 else 0)
|
||||||
|
|
||||||
|
bxs = ocr_res[pn]
|
||||||
|
lts = self.layouts_cleanup(bxs, lts)
|
||||||
|
page_layout.append(lts)
|
||||||
|
|
||||||
|
def _tag_layout(ty):
|
||||||
|
nonlocal bxs, lts
|
||||||
|
lts_of_ty = [lt for lt in lts if lt["type"] == ty]
|
||||||
|
i = 0
|
||||||
|
while i < len(bxs):
|
||||||
|
if bxs[i].get("layout_type"):
|
||||||
|
i += 1
|
||||||
|
continue
|
||||||
|
if _is_garbage_text(bxs[i]):
|
||||||
|
bxs.pop(i)
|
||||||
|
continue
|
||||||
|
|
||||||
|
ii = self.find_overlapped_with_threshold(bxs[i], lts_of_ty, thr=0.4)
|
||||||
|
if ii is None:
|
||||||
|
bxs[i]["layout_type"] = ""
|
||||||
|
i += 1
|
||||||
|
continue
|
||||||
|
|
||||||
|
lts_of_ty[ii]["visited"] = True
|
||||||
|
|
||||||
|
keep_feats = [
|
||||||
|
lts_of_ty[ii]["type"] == "footer" and bxs[i]["bottom"] < image_list[pn].shape[0] * 0.9 / scale_factor,
|
||||||
|
lts_of_ty[ii]["type"] == "header" and bxs[i]["top"] > image_list[pn].shape[0] * 0.1 / scale_factor,
|
||||||
|
]
|
||||||
|
if drop and lts_of_ty[ii]["type"] in self.garbage_layouts and not any(keep_feats):
|
||||||
|
garbages.setdefault(lts_of_ty[ii]["type"], []).append(bxs[i].get("text", ""))
|
||||||
|
bxs.pop(i)
|
||||||
|
continue
|
||||||
|
|
||||||
|
bxs[i]["layoutno"] = f"{ty}-{ii}"
|
||||||
|
bxs[i]["layout_type"] = lts_of_ty[ii]["type"] if lts_of_ty[ii]["type"] != "equation" else "figure"
|
||||||
|
i += 1
|
||||||
|
|
||||||
|
for ty in ["footer", "header", "reference", "figure caption", "table caption", "title", "table", "text", "figure", "equation"]:
|
||||||
|
_tag_layout(ty)
|
||||||
|
|
||||||
|
figs = [lt for lt in lts if lt["type"] in ["figure", "equation"]]
|
||||||
|
for i, lt in enumerate(figs):
|
||||||
|
if lt.get("visited"):
|
||||||
|
continue
|
||||||
|
lt = deepcopy(lt)
|
||||||
|
lt.pop("type", None)
|
||||||
|
lt["text"] = ""
|
||||||
|
lt["layout_type"] = "figure"
|
||||||
|
lt["layoutno"] = f"figure-{i}"
|
||||||
|
bxs.append(lt)
|
||||||
|
|
||||||
|
boxes_out.extend(bxs)
|
||||||
|
|
||||||
|
garbag_set = set()
|
||||||
|
for k, lst in garbages.items():
|
||||||
|
cnt = Counter(lst)
|
||||||
|
for g, c in cnt.items():
|
||||||
|
if c > 1:
|
||||||
|
garbag_set.add(g)
|
||||||
|
|
||||||
|
ocr_res_new = [b for b in boxes_out if b["text"].strip() not in garbag_set]
|
||||||
|
return ocr_res_new, page_layout
|
||||||
|
|||||||
@ -13,7 +13,7 @@
|
|||||||
# See the License for the specific language governing permissions and
|
# See the License for the specific language governing permissions and
|
||||||
# limitations under the License.
|
# limitations under the License.
|
||||||
#
|
#
|
||||||
|
import gc
|
||||||
import logging
|
import logging
|
||||||
import copy
|
import copy
|
||||||
import time
|
import time
|
||||||
@ -348,6 +348,13 @@ class TextRecognizer:
|
|||||||
|
|
||||||
return img
|
return img
|
||||||
|
|
||||||
|
def close(self):
|
||||||
|
# close session and release manually
|
||||||
|
logging.info('Close TextRecognizer.')
|
||||||
|
if hasattr(self, "predictor"):
|
||||||
|
del self.predictor
|
||||||
|
gc.collect()
|
||||||
|
|
||||||
def __call__(self, img_list):
|
def __call__(self, img_list):
|
||||||
img_num = len(img_list)
|
img_num = len(img_list)
|
||||||
# Calculate the aspect ratio of all text bars
|
# Calculate the aspect ratio of all text bars
|
||||||
@ -395,6 +402,9 @@ class TextRecognizer:
|
|||||||
|
|
||||||
return rec_res, time.time() - st
|
return rec_res, time.time() - st
|
||||||
|
|
||||||
|
def __del__(self):
|
||||||
|
self.close()
|
||||||
|
|
||||||
|
|
||||||
class TextDetector:
|
class TextDetector:
|
||||||
def __init__(self, model_dir, device_id: int | None = None):
|
def __init__(self, model_dir, device_id: int | None = None):
|
||||||
@ -479,6 +489,12 @@ class TextDetector:
|
|||||||
dt_boxes = np.array(dt_boxes_new)
|
dt_boxes = np.array(dt_boxes_new)
|
||||||
return dt_boxes
|
return dt_boxes
|
||||||
|
|
||||||
|
def close(self):
|
||||||
|
logging.info("Close TextDetector.")
|
||||||
|
if hasattr(self, "predictor"):
|
||||||
|
del self.predictor
|
||||||
|
gc.collect()
|
||||||
|
|
||||||
def __call__(self, img):
|
def __call__(self, img):
|
||||||
ori_im = img.copy()
|
ori_im = img.copy()
|
||||||
data = {'image': img}
|
data = {'image': img}
|
||||||
@ -508,6 +524,9 @@ class TextDetector:
|
|||||||
|
|
||||||
return dt_boxes, time.time() - st
|
return dt_boxes, time.time() - st
|
||||||
|
|
||||||
|
def __del__(self):
|
||||||
|
self.close()
|
||||||
|
|
||||||
|
|
||||||
class OCR:
|
class OCR:
|
||||||
def __init__(self, model_dir=None):
|
def __init__(self, model_dir=None):
|
||||||
|
|||||||
@ -13,7 +13,7 @@
|
|||||||
# See the License for the specific language governing permissions and
|
# See the License for the specific language governing permissions and
|
||||||
# limitations under the License.
|
# limitations under the License.
|
||||||
#
|
#
|
||||||
|
import gc
|
||||||
import logging
|
import logging
|
||||||
import os
|
import os
|
||||||
import math
|
import math
|
||||||
@ -406,6 +406,12 @@ class Recognizer:
|
|||||||
"score": float(scores[i])
|
"score": float(scores[i])
|
||||||
} for i in indices]
|
} for i in indices]
|
||||||
|
|
||||||
|
def close(self):
|
||||||
|
logging.info("Close recognizer.")
|
||||||
|
if hasattr(self, "ort_sess"):
|
||||||
|
del self.ort_sess
|
||||||
|
gc.collect()
|
||||||
|
|
||||||
def __call__(self, image_list, thr=0.7, batch_size=16):
|
def __call__(self, image_list, thr=0.7, batch_size=16):
|
||||||
res = []
|
res = []
|
||||||
images = []
|
images = []
|
||||||
@ -430,5 +436,7 @@ class Recognizer:
|
|||||||
|
|
||||||
return res
|
return res
|
||||||
|
|
||||||
|
def __del__(self):
|
||||||
|
self.close()
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
@ -23,6 +23,7 @@ from huggingface_hub import snapshot_download
|
|||||||
|
|
||||||
from api.utils.file_utils import get_project_base_directory
|
from api.utils.file_utils import get_project_base_directory
|
||||||
from rag.nlp import rag_tokenizer
|
from rag.nlp import rag_tokenizer
|
||||||
|
|
||||||
from .recognizer import Recognizer
|
from .recognizer import Recognizer
|
||||||
|
|
||||||
|
|
||||||
@ -38,31 +39,49 @@ class TableStructureRecognizer(Recognizer):
|
|||||||
|
|
||||||
def __init__(self):
|
def __init__(self):
|
||||||
try:
|
try:
|
||||||
super().__init__(self.labels, "tsr", os.path.join(
|
super().__init__(self.labels, "tsr", os.path.join(get_project_base_directory(), "rag/res/deepdoc"))
|
||||||
get_project_base_directory(),
|
|
||||||
"rag/res/deepdoc"))
|
|
||||||
except Exception:
|
except Exception:
|
||||||
super().__init__(self.labels, "tsr", snapshot_download(repo_id="InfiniFlow/deepdoc",
|
super().__init__(
|
||||||
local_dir=os.path.join(get_project_base_directory(), "rag/res/deepdoc"),
|
self.labels,
|
||||||
local_dir_use_symlinks=False))
|
"tsr",
|
||||||
|
snapshot_download(
|
||||||
|
repo_id="InfiniFlow/deepdoc",
|
||||||
|
local_dir=os.path.join(get_project_base_directory(), "rag/res/deepdoc"),
|
||||||
|
local_dir_use_symlinks=False,
|
||||||
|
),
|
||||||
|
)
|
||||||
|
|
||||||
def __call__(self, images, thr=0.2):
|
def __call__(self, images, thr=0.2):
|
||||||
tbls = super().__call__(images, thr)
|
table_structure_recognizer_type = os.getenv("TABLE_STRUCTURE_RECOGNIZER_TYPE", "onnx").lower()
|
||||||
|
if table_structure_recognizer_type not in ["onnx", "ascend"]:
|
||||||
|
raise RuntimeError("Unsupported table structure recognizer type.")
|
||||||
|
|
||||||
|
if table_structure_recognizer_type == "onnx":
|
||||||
|
logging.debug("Using Onnx table structure recognizer", flush=True)
|
||||||
|
tbls = super().__call__(images, thr)
|
||||||
|
else: # ascend
|
||||||
|
logging.debug("Using Ascend table structure recognizer", flush=True)
|
||||||
|
tbls = self._run_ascend_tsr(images, thr)
|
||||||
|
|
||||||
res = []
|
res = []
|
||||||
# align left&right for rows, align top&bottom for columns
|
# align left&right for rows, align top&bottom for columns
|
||||||
for tbl in tbls:
|
for tbl in tbls:
|
||||||
lts = [{"label": b["type"],
|
lts = [
|
||||||
|
{
|
||||||
|
"label": b["type"],
|
||||||
"score": b["score"],
|
"score": b["score"],
|
||||||
"x0": b["bbox"][0], "x1": b["bbox"][2],
|
"x0": b["bbox"][0],
|
||||||
"top": b["bbox"][1], "bottom": b["bbox"][-1]
|
"x1": b["bbox"][2],
|
||||||
} for b in tbl]
|
"top": b["bbox"][1],
|
||||||
|
"bottom": b["bbox"][-1],
|
||||||
|
}
|
||||||
|
for b in tbl
|
||||||
|
]
|
||||||
if not lts:
|
if not lts:
|
||||||
continue
|
continue
|
||||||
|
|
||||||
left = [b["x0"] for b in lts if b["label"].find(
|
left = [b["x0"] for b in lts if b["label"].find("row") > 0 or b["label"].find("header") > 0]
|
||||||
"row") > 0 or b["label"].find("header") > 0]
|
right = [b["x1"] for b in lts if b["label"].find("row") > 0 or b["label"].find("header") > 0]
|
||||||
right = [b["x1"] for b in lts if b["label"].find(
|
|
||||||
"row") > 0 or b["label"].find("header") > 0]
|
|
||||||
if not left:
|
if not left:
|
||||||
continue
|
continue
|
||||||
left = np.mean(left) if len(left) > 4 else np.min(left)
|
left = np.mean(left) if len(left) > 4 else np.min(left)
|
||||||
@ -93,11 +112,8 @@ class TableStructureRecognizer(Recognizer):
|
|||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def is_caption(bx):
|
def is_caption(bx):
|
||||||
patt = [
|
patt = [r"[图表]+[ 0-9::]{2,}"]
|
||||||
r"[图表]+[ 0-9::]{2,}"
|
if any([re.match(p, bx["text"].strip()) for p in patt]) or bx.get("layout_type", "").find("caption") >= 0:
|
||||||
]
|
|
||||||
if any([re.match(p, bx["text"].strip()) for p in patt]) \
|
|
||||||
or bx.get("layout_type", "").find("caption") >= 0:
|
|
||||||
return True
|
return True
|
||||||
return False
|
return False
|
||||||
|
|
||||||
@ -115,7 +131,7 @@ class TableStructureRecognizer(Recognizer):
|
|||||||
(r"^[0-9A-Z/\._~-]+$", "Ca"),
|
(r"^[0-9A-Z/\._~-]+$", "Ca"),
|
||||||
(r"^[A-Z]*[a-z' -]+$", "En"),
|
(r"^[A-Z]*[a-z' -]+$", "En"),
|
||||||
(r"^[0-9.,+-]+[0-9A-Za-z/$¥%<>()()' -]+$", "NE"),
|
(r"^[0-9.,+-]+[0-9A-Za-z/$¥%<>()()' -]+$", "NE"),
|
||||||
(r"^.{1}$", "Sg")
|
(r"^.{1}$", "Sg"),
|
||||||
]
|
]
|
||||||
for p, n in patt:
|
for p, n in patt:
|
||||||
if re.search(p, b["text"].strip()):
|
if re.search(p, b["text"].strip()):
|
||||||
@ -156,21 +172,19 @@ class TableStructureRecognizer(Recognizer):
|
|||||||
rowh = [b["R_bott"] - b["R_top"] for b in boxes if "R" in b]
|
rowh = [b["R_bott"] - b["R_top"] for b in boxes if "R" in b]
|
||||||
rowh = np.min(rowh) if rowh else 0
|
rowh = np.min(rowh) if rowh else 0
|
||||||
boxes = Recognizer.sort_R_firstly(boxes, rowh / 2)
|
boxes = Recognizer.sort_R_firstly(boxes, rowh / 2)
|
||||||
#for b in boxes:print(b)
|
# for b in boxes:print(b)
|
||||||
boxes[0]["rn"] = 0
|
boxes[0]["rn"] = 0
|
||||||
rows = [[boxes[0]]]
|
rows = [[boxes[0]]]
|
||||||
btm = boxes[0]["bottom"]
|
btm = boxes[0]["bottom"]
|
||||||
for b in boxes[1:]:
|
for b in boxes[1:]:
|
||||||
b["rn"] = len(rows) - 1
|
b["rn"] = len(rows) - 1
|
||||||
lst_r = rows[-1]
|
lst_r = rows[-1]
|
||||||
if lst_r[-1].get("R", "") != b.get("R", "") \
|
if lst_r[-1].get("R", "") != b.get("R", "") or (b["top"] >= btm - 3 and lst_r[-1].get("R", "-1") != b.get("R", "-2")): # new row
|
||||||
or (b["top"] >= btm - 3 and lst_r[-1].get("R", "-1") != b.get("R", "-2")
|
|
||||||
): # new row
|
|
||||||
btm = b["bottom"]
|
btm = b["bottom"]
|
||||||
b["rn"] += 1
|
b["rn"] += 1
|
||||||
rows.append([b])
|
rows.append([b])
|
||||||
continue
|
continue
|
||||||
btm = (btm + b["bottom"]) / 2.
|
btm = (btm + b["bottom"]) / 2.0
|
||||||
rows[-1].append(b)
|
rows[-1].append(b)
|
||||||
|
|
||||||
colwm = [b["C_right"] - b["C_left"] for b in boxes if "C" in b]
|
colwm = [b["C_right"] - b["C_left"] for b in boxes if "C" in b]
|
||||||
@ -186,14 +200,14 @@ class TableStructureRecognizer(Recognizer):
|
|||||||
for b in boxes[1:]:
|
for b in boxes[1:]:
|
||||||
b["cn"] = len(cols) - 1
|
b["cn"] = len(cols) - 1
|
||||||
lst_c = cols[-1]
|
lst_c = cols[-1]
|
||||||
if (int(b.get("C", "1")) - int(lst_c[-1].get("C", "1")) == 1 and b["page_number"] == lst_c[-1][
|
if (int(b.get("C", "1")) - int(lst_c[-1].get("C", "1")) == 1 and b["page_number"] == lst_c[-1]["page_number"]) or (
|
||||||
"page_number"]) \
|
b["x0"] >= right and lst_c[-1].get("C", "-1") != b.get("C", "-2")
|
||||||
or (b["x0"] >= right and lst_c[-1].get("C", "-1") != b.get("C", "-2")): # new col
|
): # new col
|
||||||
right = b["x1"]
|
right = b["x1"]
|
||||||
b["cn"] += 1
|
b["cn"] += 1
|
||||||
cols.append([b])
|
cols.append([b])
|
||||||
continue
|
continue
|
||||||
right = (right + b["x1"]) / 2.
|
right = (right + b["x1"]) / 2.0
|
||||||
cols[-1].append(b)
|
cols[-1].append(b)
|
||||||
|
|
||||||
tbl = [[[] for _ in range(len(cols))] for _ in range(len(rows))]
|
tbl = [[[] for _ in range(len(cols))] for _ in range(len(rows))]
|
||||||
@ -214,10 +228,8 @@ class TableStructureRecognizer(Recognizer):
|
|||||||
if e > 1:
|
if e > 1:
|
||||||
j += 1
|
j += 1
|
||||||
continue
|
continue
|
||||||
f = (j > 0 and tbl[ii][j - 1] and tbl[ii]
|
f = (j > 0 and tbl[ii][j - 1] and tbl[ii][j - 1][0].get("text")) or j == 0
|
||||||
[j - 1][0].get("text")) or j == 0
|
ff = (j + 1 < len(tbl[ii]) and tbl[ii][j + 1] and tbl[ii][j + 1][0].get("text")) or j + 1 >= len(tbl[ii])
|
||||||
ff = (j + 1 < len(tbl[ii]) and tbl[ii][j + 1] and tbl[ii]
|
|
||||||
[j + 1][0].get("text")) or j + 1 >= len(tbl[ii])
|
|
||||||
if f and ff:
|
if f and ff:
|
||||||
j += 1
|
j += 1
|
||||||
continue
|
continue
|
||||||
@ -228,13 +240,11 @@ class TableStructureRecognizer(Recognizer):
|
|||||||
if j > 0 and not f:
|
if j > 0 and not f:
|
||||||
for i in range(len(tbl)):
|
for i in range(len(tbl)):
|
||||||
if tbl[i][j - 1]:
|
if tbl[i][j - 1]:
|
||||||
left = min(left, np.min(
|
left = min(left, np.min([bx["x0"] - a["x1"] for a in tbl[i][j - 1]]))
|
||||||
[bx["x0"] - a["x1"] for a in tbl[i][j - 1]]))
|
|
||||||
if j + 1 < len(tbl[0]) and not ff:
|
if j + 1 < len(tbl[0]) and not ff:
|
||||||
for i in range(len(tbl)):
|
for i in range(len(tbl)):
|
||||||
if tbl[i][j + 1]:
|
if tbl[i][j + 1]:
|
||||||
right = min(right, np.min(
|
right = min(right, np.min([a["x0"] - bx["x1"] for a in tbl[i][j + 1]]))
|
||||||
[a["x0"] - bx["x1"] for a in tbl[i][j + 1]]))
|
|
||||||
assert left < 100000 or right < 100000
|
assert left < 100000 or right < 100000
|
||||||
if left < right:
|
if left < right:
|
||||||
for jj in range(j, len(tbl[0])):
|
for jj in range(j, len(tbl[0])):
|
||||||
@ -260,8 +270,7 @@ class TableStructureRecognizer(Recognizer):
|
|||||||
for i in range(len(tbl)):
|
for i in range(len(tbl)):
|
||||||
tbl[i].pop(j)
|
tbl[i].pop(j)
|
||||||
cols.pop(j)
|
cols.pop(j)
|
||||||
assert len(cols) == len(tbl[0]), "Column NO. miss matched: %d vs %d" % (
|
assert len(cols) == len(tbl[0]), "Column NO. miss matched: %d vs %d" % (len(cols), len(tbl[0]))
|
||||||
len(cols), len(tbl[0]))
|
|
||||||
|
|
||||||
if len(cols) >= 4:
|
if len(cols) >= 4:
|
||||||
# remove single in row
|
# remove single in row
|
||||||
@ -277,10 +286,8 @@ class TableStructureRecognizer(Recognizer):
|
|||||||
if e > 1:
|
if e > 1:
|
||||||
i += 1
|
i += 1
|
||||||
continue
|
continue
|
||||||
f = (i > 0 and tbl[i - 1][jj] and tbl[i - 1]
|
f = (i > 0 and tbl[i - 1][jj] and tbl[i - 1][jj][0].get("text")) or i == 0
|
||||||
[jj][0].get("text")) or i == 0
|
ff = (i + 1 < len(tbl) and tbl[i + 1][jj] and tbl[i + 1][jj][0].get("text")) or i + 1 >= len(tbl)
|
||||||
ff = (i + 1 < len(tbl) and tbl[i + 1][jj] and tbl[i + 1]
|
|
||||||
[jj][0].get("text")) or i + 1 >= len(tbl)
|
|
||||||
if f and ff:
|
if f and ff:
|
||||||
i += 1
|
i += 1
|
||||||
continue
|
continue
|
||||||
@ -292,13 +299,11 @@ class TableStructureRecognizer(Recognizer):
|
|||||||
if i > 0 and not f:
|
if i > 0 and not f:
|
||||||
for j in range(len(tbl[i - 1])):
|
for j in range(len(tbl[i - 1])):
|
||||||
if tbl[i - 1][j]:
|
if tbl[i - 1][j]:
|
||||||
up = min(up, np.min(
|
up = min(up, np.min([bx["top"] - a["bottom"] for a in tbl[i - 1][j]]))
|
||||||
[bx["top"] - a["bottom"] for a in tbl[i - 1][j]]))
|
|
||||||
if i + 1 < len(tbl) and not ff:
|
if i + 1 < len(tbl) and not ff:
|
||||||
for j in range(len(tbl[i + 1])):
|
for j in range(len(tbl[i + 1])):
|
||||||
if tbl[i + 1][j]:
|
if tbl[i + 1][j]:
|
||||||
down = min(down, np.min(
|
down = min(down, np.min([a["top"] - bx["bottom"] for a in tbl[i + 1][j]]))
|
||||||
[a["top"] - bx["bottom"] for a in tbl[i + 1][j]]))
|
|
||||||
assert up < 100000 or down < 100000
|
assert up < 100000 or down < 100000
|
||||||
if up < down:
|
if up < down:
|
||||||
for ii in range(i, len(tbl)):
|
for ii in range(i, len(tbl)):
|
||||||
@ -333,22 +338,15 @@ class TableStructureRecognizer(Recognizer):
|
|||||||
cnt += 1
|
cnt += 1
|
||||||
if max_type == "Nu" and arr[0]["btype"] == "Nu":
|
if max_type == "Nu" and arr[0]["btype"] == "Nu":
|
||||||
continue
|
continue
|
||||||
if any([a.get("H") for a in arr]) \
|
if any([a.get("H") for a in arr]) or (max_type == "Nu" and arr[0]["btype"] != "Nu"):
|
||||||
or (max_type == "Nu" and arr[0]["btype"] != "Nu"):
|
|
||||||
h += 1
|
h += 1
|
||||||
if h / cnt > 0.5:
|
if h / cnt > 0.5:
|
||||||
hdset.add(i)
|
hdset.add(i)
|
||||||
|
|
||||||
if html:
|
if html:
|
||||||
return TableStructureRecognizer.__html_table(cap, hdset,
|
return TableStructureRecognizer.__html_table(cap, hdset, TableStructureRecognizer.__cal_spans(boxes, rows, cols, tbl, True))
|
||||||
TableStructureRecognizer.__cal_spans(boxes, rows,
|
|
||||||
cols, tbl, True)
|
|
||||||
)
|
|
||||||
|
|
||||||
return TableStructureRecognizer.__desc_table(cap, hdset,
|
return TableStructureRecognizer.__desc_table(cap, hdset, TableStructureRecognizer.__cal_spans(boxes, rows, cols, tbl, False), is_english)
|
||||||
TableStructureRecognizer.__cal_spans(boxes, rows, cols, tbl,
|
|
||||||
False),
|
|
||||||
is_english)
|
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def __html_table(cap, hdset, tbl):
|
def __html_table(cap, hdset, tbl):
|
||||||
@ -367,10 +365,8 @@ class TableStructureRecognizer(Recognizer):
|
|||||||
continue
|
continue
|
||||||
txt = ""
|
txt = ""
|
||||||
if arr:
|
if arr:
|
||||||
h = min(np.min([c["bottom"] - c["top"]
|
h = min(np.min([c["bottom"] - c["top"] for c in arr]) / 2, 10)
|
||||||
for c in arr]) / 2, 10)
|
txt = " ".join([c["text"] for c in Recognizer.sort_Y_firstly(arr, h)])
|
||||||
txt = " ".join([c["text"]
|
|
||||||
for c in Recognizer.sort_Y_firstly(arr, h)])
|
|
||||||
txts.append(txt)
|
txts.append(txt)
|
||||||
sp = ""
|
sp = ""
|
||||||
if arr[0].get("colspan"):
|
if arr[0].get("colspan"):
|
||||||
@ -436,15 +432,11 @@ class TableStructureRecognizer(Recognizer):
|
|||||||
if headers[j][k].find(headers[j - 1][k]) >= 0:
|
if headers[j][k].find(headers[j - 1][k]) >= 0:
|
||||||
continue
|
continue
|
||||||
if len(headers[j][k]) > len(headers[j - 1][k]):
|
if len(headers[j][k]) > len(headers[j - 1][k]):
|
||||||
headers[j][k] += (de if headers[j][k]
|
headers[j][k] += (de if headers[j][k] else "") + headers[j - 1][k]
|
||||||
else "") + headers[j - 1][k]
|
|
||||||
else:
|
else:
|
||||||
headers[j][k] = headers[j - 1][k] \
|
headers[j][k] = headers[j - 1][k] + (de if headers[j - 1][k] else "") + headers[j][k]
|
||||||
+ (de if headers[j - 1][k] else "") \
|
|
||||||
+ headers[j][k]
|
|
||||||
|
|
||||||
logging.debug(
|
logging.debug(f">>>>>>>>>>>>>>>>>{cap}:SIZE:{rowno}X{clmno} Header: {hdr_rowno}")
|
||||||
f">>>>>>>>>>>>>>>>>{cap}:SIZE:{rowno}X{clmno} Header: {hdr_rowno}")
|
|
||||||
row_txt = []
|
row_txt = []
|
||||||
for i in range(rowno):
|
for i in range(rowno):
|
||||||
if i in hdr_rowno:
|
if i in hdr_rowno:
|
||||||
@ -503,14 +495,10 @@ class TableStructureRecognizer(Recognizer):
|
|||||||
@staticmethod
|
@staticmethod
|
||||||
def __cal_spans(boxes, rows, cols, tbl, html=True):
|
def __cal_spans(boxes, rows, cols, tbl, html=True):
|
||||||
# caculate span
|
# caculate span
|
||||||
clft = [np.mean([c.get("C_left", c["x0"]) for c in cln])
|
clft = [np.mean([c.get("C_left", c["x0"]) for c in cln]) for cln in cols]
|
||||||
for cln in cols]
|
crgt = [np.mean([c.get("C_right", c["x1"]) for c in cln]) for cln in cols]
|
||||||
crgt = [np.mean([c.get("C_right", c["x1"]) for c in cln])
|
rtop = [np.mean([c.get("R_top", c["top"]) for c in row]) for row in rows]
|
||||||
for cln in cols]
|
rbtm = [np.mean([c.get("R_btm", c["bottom"]) for c in row]) for row in rows]
|
||||||
rtop = [np.mean([c.get("R_top", c["top"]) for c in row])
|
|
||||||
for row in rows]
|
|
||||||
rbtm = [np.mean([c.get("R_btm", c["bottom"])
|
|
||||||
for c in row]) for row in rows]
|
|
||||||
for b in boxes:
|
for b in boxes:
|
||||||
if "SP" not in b:
|
if "SP" not in b:
|
||||||
continue
|
continue
|
||||||
@ -585,3 +573,40 @@ class TableStructureRecognizer(Recognizer):
|
|||||||
tbl[rowspan[0]][colspan[0]] = arr
|
tbl[rowspan[0]][colspan[0]] = arr
|
||||||
|
|
||||||
return tbl
|
return tbl
|
||||||
|
|
||||||
|
def _run_ascend_tsr(self, image_list, thr=0.2, batch_size=16):
|
||||||
|
import math
|
||||||
|
|
||||||
|
from ais_bench.infer.interface import InferSession
|
||||||
|
|
||||||
|
model_dir = os.path.join(get_project_base_directory(), "rag/res/deepdoc")
|
||||||
|
model_file_path = os.path.join(model_dir, "tsr.om")
|
||||||
|
|
||||||
|
if not os.path.exists(model_file_path):
|
||||||
|
raise ValueError(f"Model file not found: {model_file_path}")
|
||||||
|
|
||||||
|
device_id = int(os.getenv("ASCEND_LAYOUT_RECOGNIZER_DEVICE_ID", 0))
|
||||||
|
session = InferSession(device_id=device_id, model_path=model_file_path)
|
||||||
|
|
||||||
|
images = [np.array(im) if not isinstance(im, np.ndarray) else im for im in image_list]
|
||||||
|
results = []
|
||||||
|
|
||||||
|
conf_thr = max(thr, 0.08)
|
||||||
|
|
||||||
|
batch_loop_cnt = math.ceil(float(len(images)) / batch_size)
|
||||||
|
for bi in range(batch_loop_cnt):
|
||||||
|
s = bi * batch_size
|
||||||
|
e = min((bi + 1) * batch_size, len(images))
|
||||||
|
batch_images = images[s:e]
|
||||||
|
|
||||||
|
inputs_list = self.preprocess(batch_images)
|
||||||
|
for ins in inputs_list:
|
||||||
|
feeds = []
|
||||||
|
if "image" in ins:
|
||||||
|
feeds.append(ins["image"])
|
||||||
|
else:
|
||||||
|
feeds.append(ins[self.input_names[0]])
|
||||||
|
output_list = session.infer(feeds=feeds, mode="static")
|
||||||
|
bb = self.postprocess(output_list, ins, conf_thr)
|
||||||
|
results.append(bb)
|
||||||
|
return results
|
||||||
|
|||||||
@ -26,6 +26,84 @@ An **Agent** component is essential when you need the LLM to assist with summari
|
|||||||
|
|
||||||
2. If your Agent involves dataset retrieval, ensure you [have properly configured your target knowledge base(s)](../../dataset/configure_knowledge_base.md).
|
2. If your Agent involves dataset retrieval, ensure you [have properly configured your target knowledge base(s)](../../dataset/configure_knowledge_base.md).
|
||||||
|
|
||||||
|
## Quickstart
|
||||||
|
|
||||||
|
### 1. Click on an **Agent** component to show its configuration panel
|
||||||
|
|
||||||
|
The corresponding configuration panel appears to the right of the canvas. Use this panel to define and fine-tune the **Agent** component's behavior.
|
||||||
|
|
||||||
|
### 2. Select your model
|
||||||
|
|
||||||
|
Click **Model**, and select a chat model from the dropdown menu.
|
||||||
|
|
||||||
|
:::tip NOTE
|
||||||
|
If no model appears, check if your have added a chat model on the **Model providers** page.
|
||||||
|
:::
|
||||||
|
|
||||||
|
### 3. Update system prompt (Optional)
|
||||||
|
|
||||||
|
The system prompt typically defines your model's role. You can either keep the system prompt as is or customize it to override the default.
|
||||||
|
|
||||||
|
|
||||||
|
### 4. Update user prompt
|
||||||
|
|
||||||
|
The user prompt typically defines your model's task. You will find the `sys.query` variable auto-populated. Type `/` or click **(x)** to view or add variables.
|
||||||
|
|
||||||
|
In this quickstart, we assume your **Agent** component is used standalone (without tools or sub-Agents below), then you may also need to specify retrieved chunks using the `formalized_content` variable:
|
||||||
|
|
||||||
|
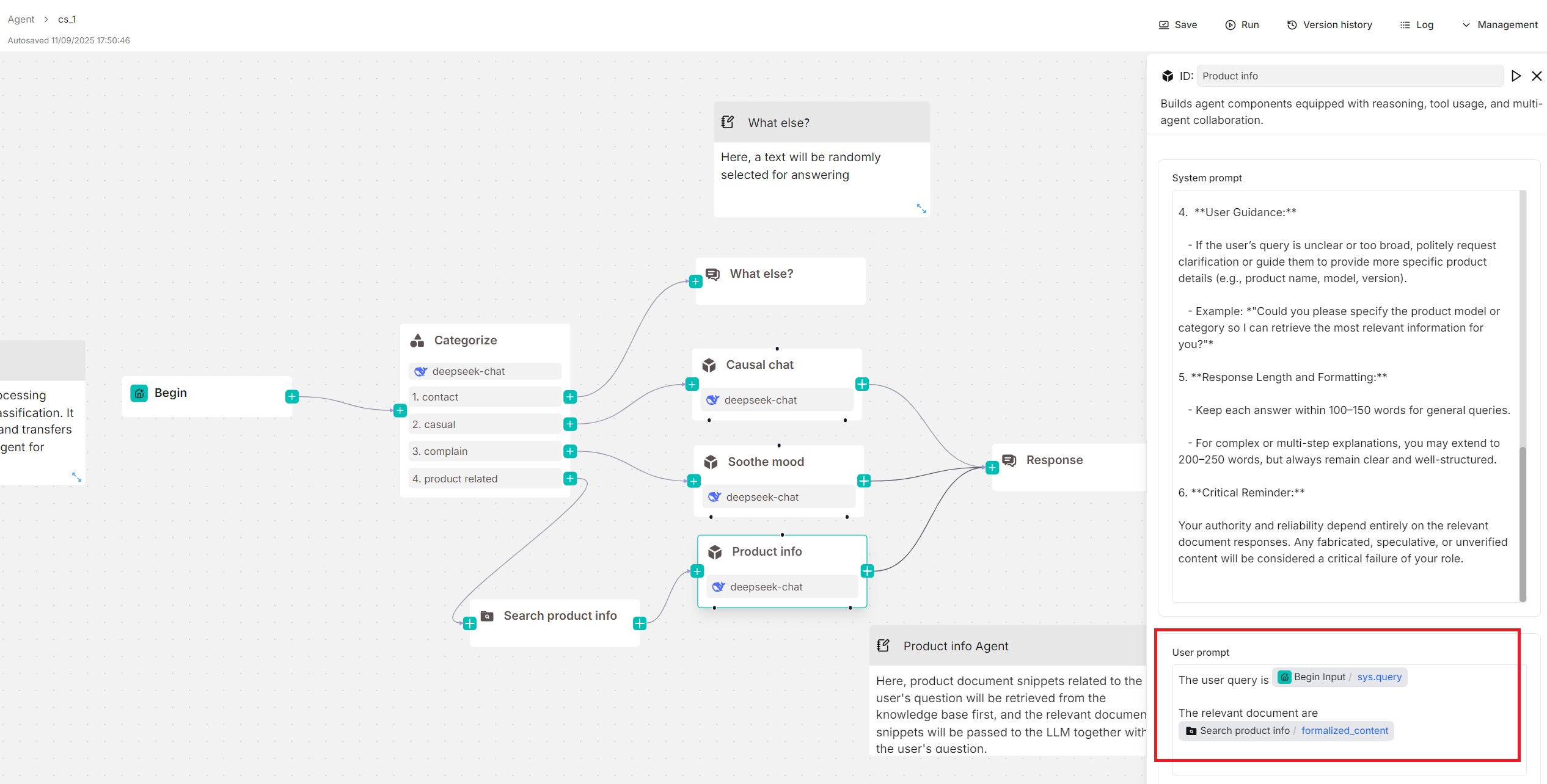
|
||||||
|
|
||||||
|
### 5. Skip Tools and Agent
|
||||||
|
|
||||||
|
The **+ Add tools** and **+ Add agent** sections are used *only* when you need to configure your **Agent** component as a planner (with tools or sub-Agents beneath). In this quickstart, we assume your **Agent** component is used standalone (without tools or sub-Agents beneath).
|
||||||
|
|
||||||
|
### 6. Choose the next component
|
||||||
|
|
||||||
|
When necessary, click the **+** button on the **Agent** component to choose the next component in the worflow from the dropdown list.
|
||||||
|
|
||||||
|
## Connect to an MCP server as a client
|
||||||
|
|
||||||
|
:::danger IMPORTANT
|
||||||
|
In this section, we assume your **Agent** will be configured as a planner, with a Tavily tool beneath it.
|
||||||
|
:::
|
||||||
|
|
||||||
|
### 1. Navigate to the MCP configuration page
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 2. Configure your Tavily MCP server
|
||||||
|
|
||||||
|
Update your MCP server's name, URL (including the API key), server type, and other necessary settings. When configured correctly, the available tools will be displayed.
|
||||||
|
|
||||||
|
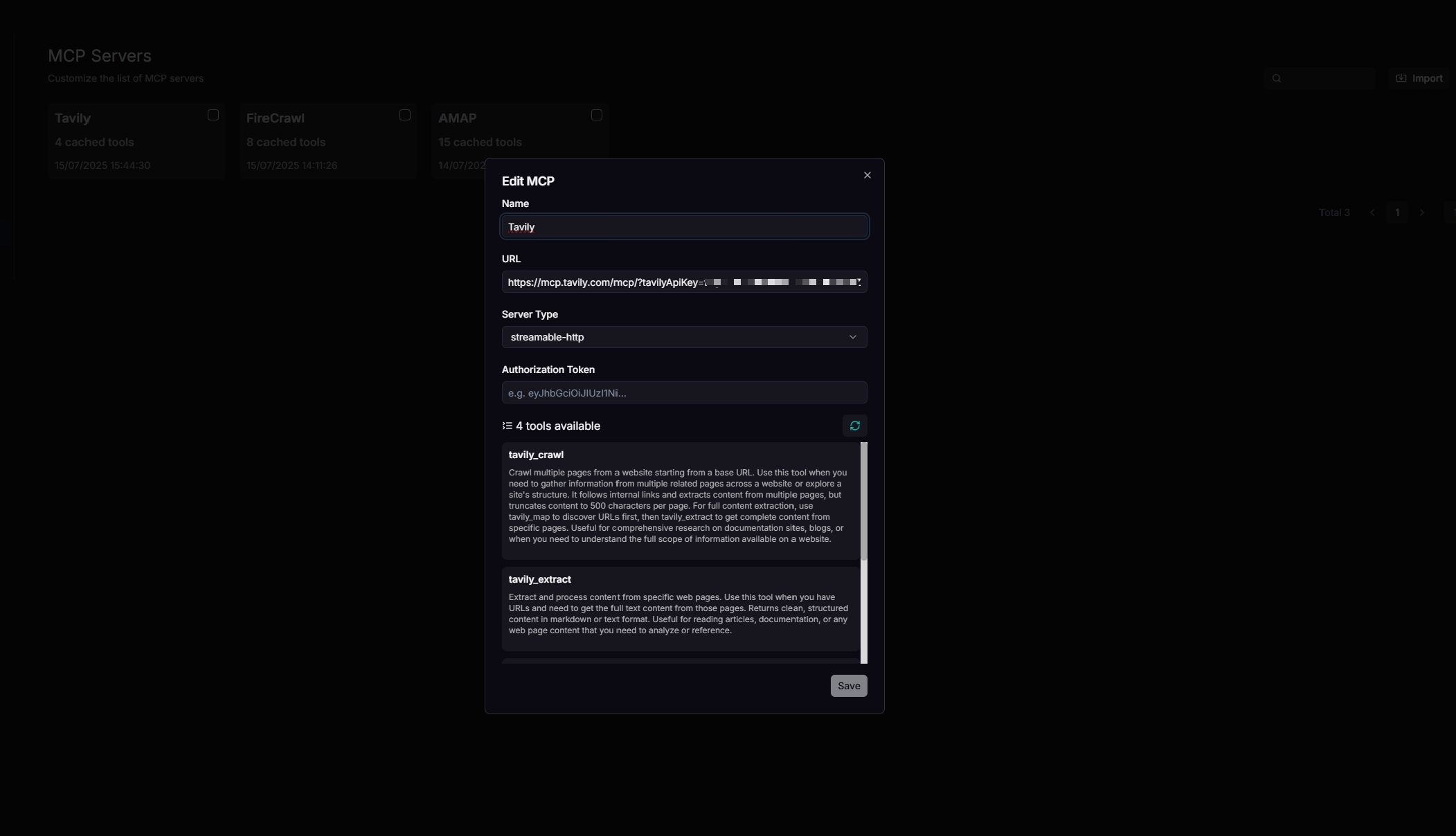
|
||||||
|
|
||||||
|
### 3. Navigate to your Agent's editing page
|
||||||
|
|
||||||
|
### 4. Connect to your MCP server
|
||||||
|
|
||||||
|
1. Click **+ Add tools**:
|
||||||
|
|
||||||
|
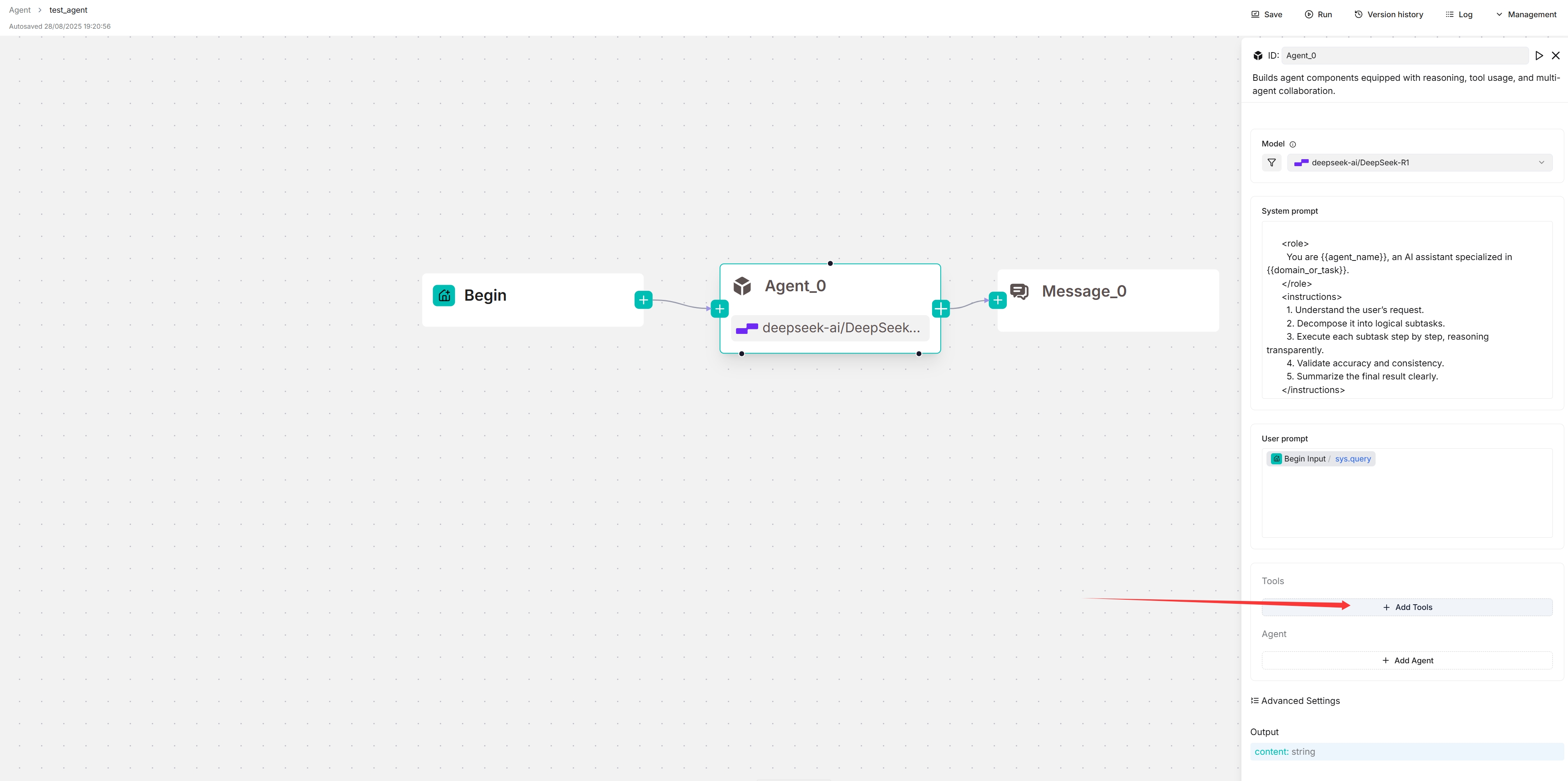
|
||||||
|
|
||||||
|
2. Click **MCP** to show the available MCP servers.
|
||||||
|
|
||||||
|
3. Select your MCP server:
|
||||||
|
|
||||||
|
*The target MCP server appears below your Agent component, and your Agent will autonomously decide when to invoke the available tools it offers.*
|
||||||
|
|
||||||
|
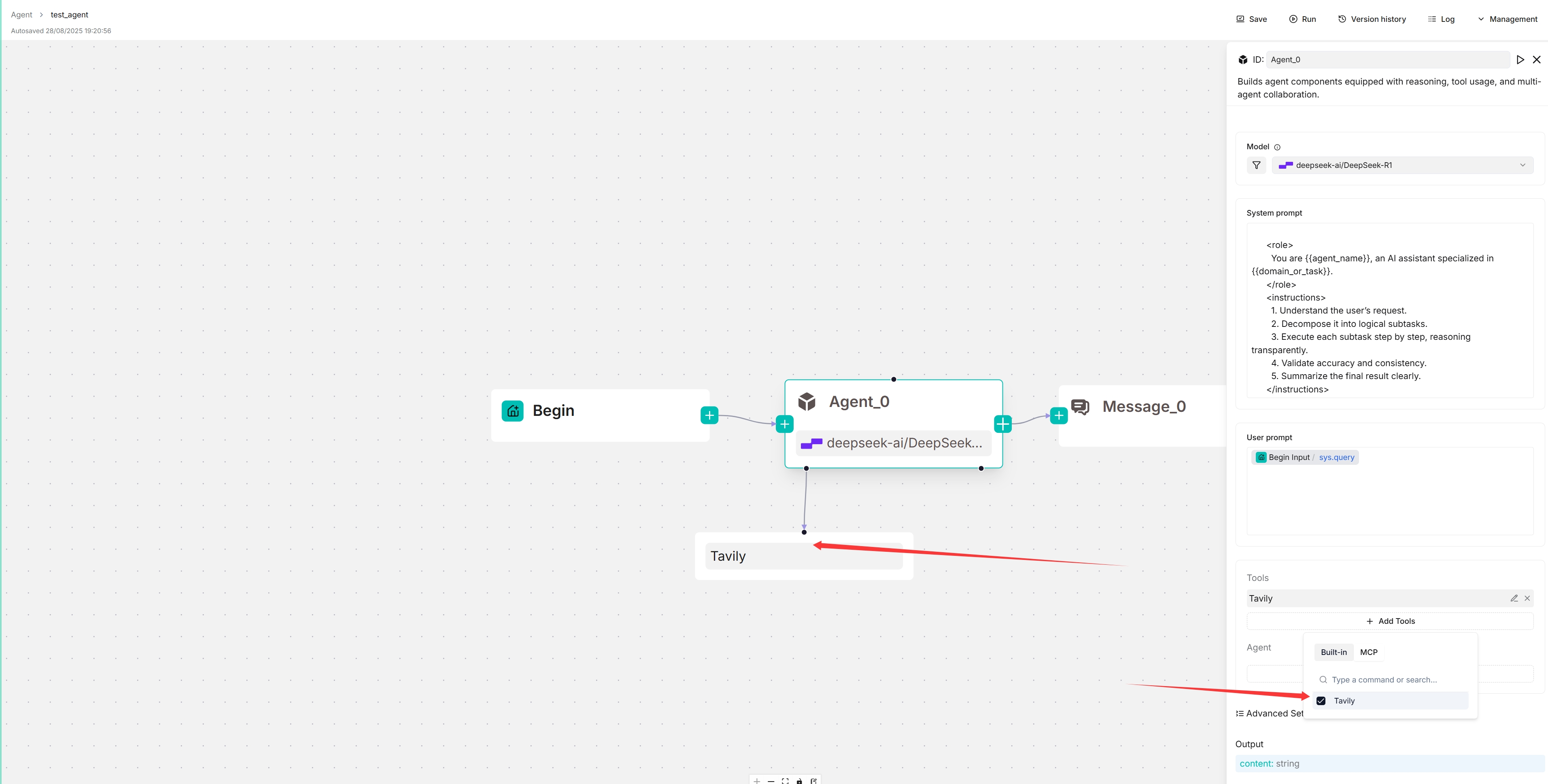
|
||||||
|
|
||||||
|
### 5. Update system prompt to specify trigger conditions (Optional)
|
||||||
|
|
||||||
|
To ensure reliable tool calls, you may specify within the system prompt which tasks should trigger each tool call.
|
||||||
|
|
||||||
|
### 6. View the availabe tools of your MCP server
|
||||||
|
|
||||||
|
On the canvas, click the newly-populated Tavily server to view and select its available tools:
|
||||||
|
|
||||||
|
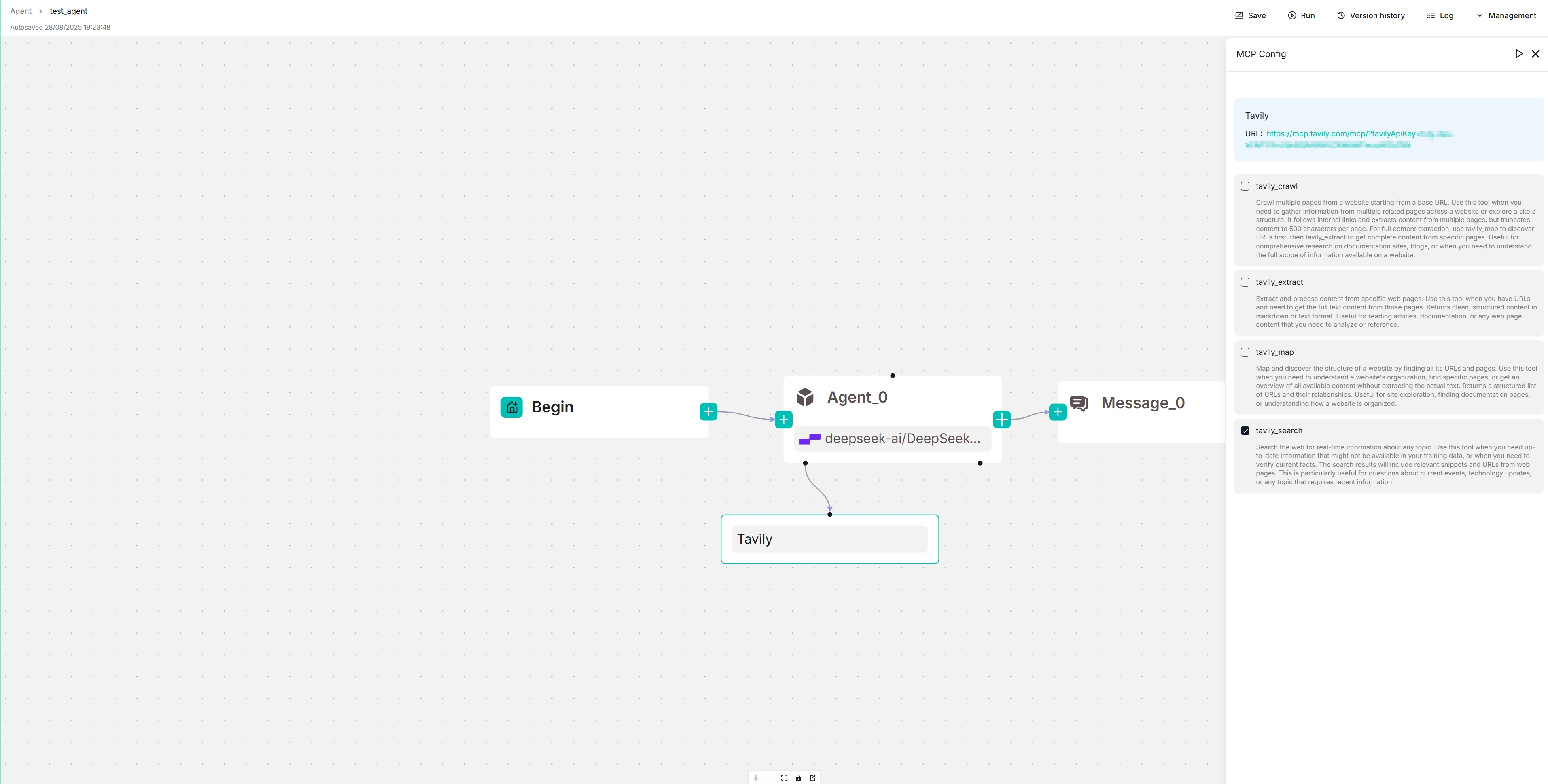
|
||||||
|
|
||||||
|
|
||||||
## Configurations
|
## Configurations
|
||||||
|
|
||||||
### Model
|
### Model
|
||||||
@ -69,7 +147,7 @@ An **Agent** component relies on keys (variables) to specify its data inputs. It
|
|||||||
|
|
||||||
#### Advanced usage
|
#### Advanced usage
|
||||||
|
|
||||||
From v0.20.5 onwards, four framework-level prompt blocks are available in the **System prompt** field. Type `/` or click **(x)** to view them; they appear under the **Framework** entry in the dropdown menu.
|
From v0.20.5 onwards, four framework-level prompt blocks are available in the **System prompt** field, enabling you to customize and *override* prompts at the framework level. Type `/` or click **(x)** to view them; they appear under the **Framework** entry in the dropdown menu.
|
||||||
|
|
||||||
- `task_analysis` prompt block
|
- `task_analysis` prompt block
|
||||||
- This block is responsible for analyzing tasks — either a user task or a task assigned by the lead Agent when the **Agent** component is acting as a Sub-Agent.
|
- This block is responsible for analyzing tasks — either a user task or a task assigned by the lead Agent when the **Agent** component is acting as a Sub-Agent.
|
||||||
@ -100,6 +178,12 @@ From v0.20.5 onwards, four framework-level prompt blocks are available in the **
|
|||||||
- `citation_guidelines` prompt block
|
- `citation_guidelines` prompt block
|
||||||
- Reference design: [citation_prompt.md](https://github.com/infiniflow/ragflow/blob/main/rag/prompts/citation_prompt.md)
|
- Reference design: [citation_prompt.md](https://github.com/infiniflow/ragflow/blob/main/rag/prompts/citation_prompt.md)
|
||||||
|
|
||||||
|
*The screenshots below show the framework prompt blocks available to an **Agent** component, both as a standalone and as a planner (with a Tavily tool below):*
|
||||||
|
|
||||||
|
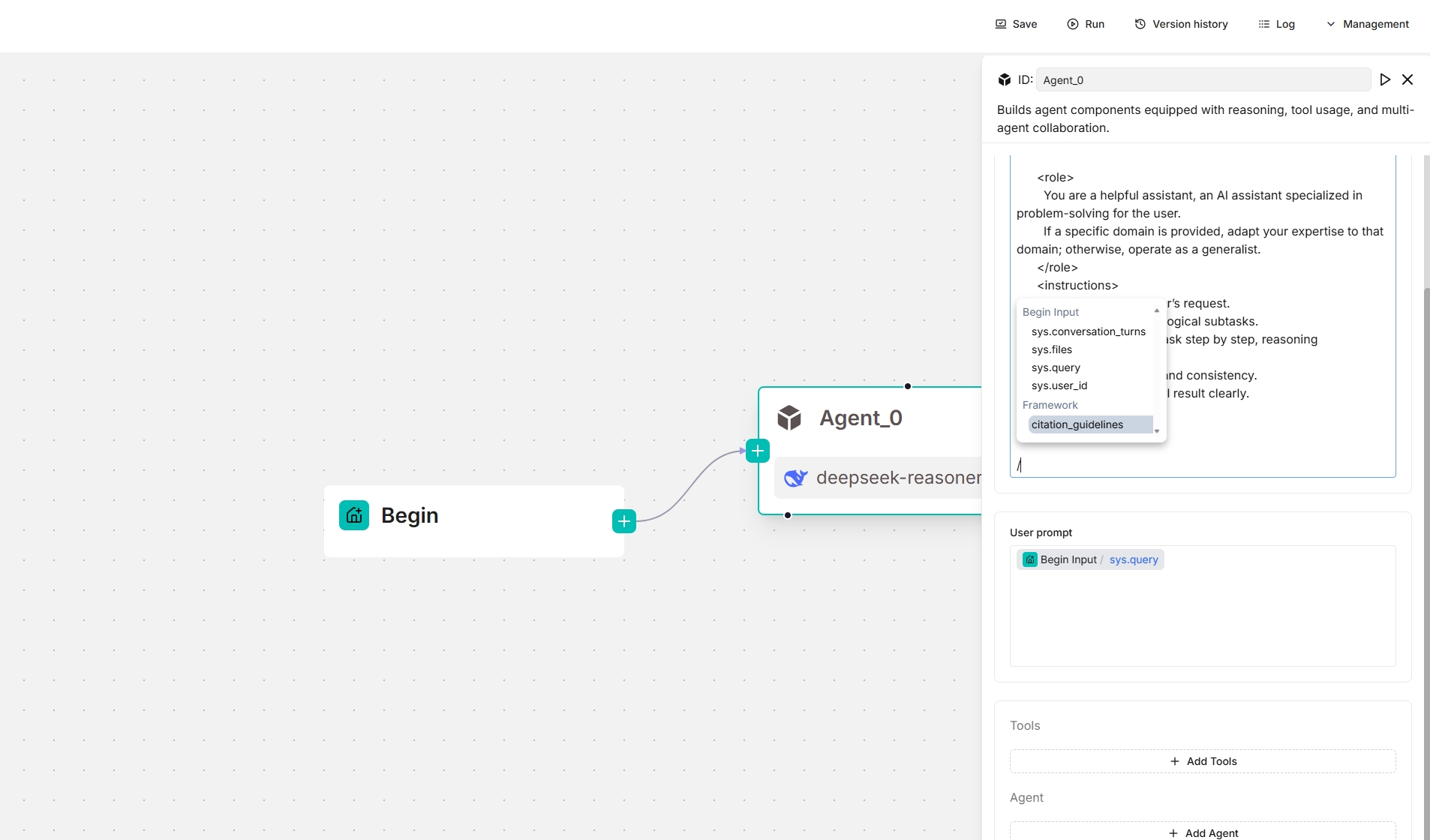
|
||||||
|
|
||||||
|
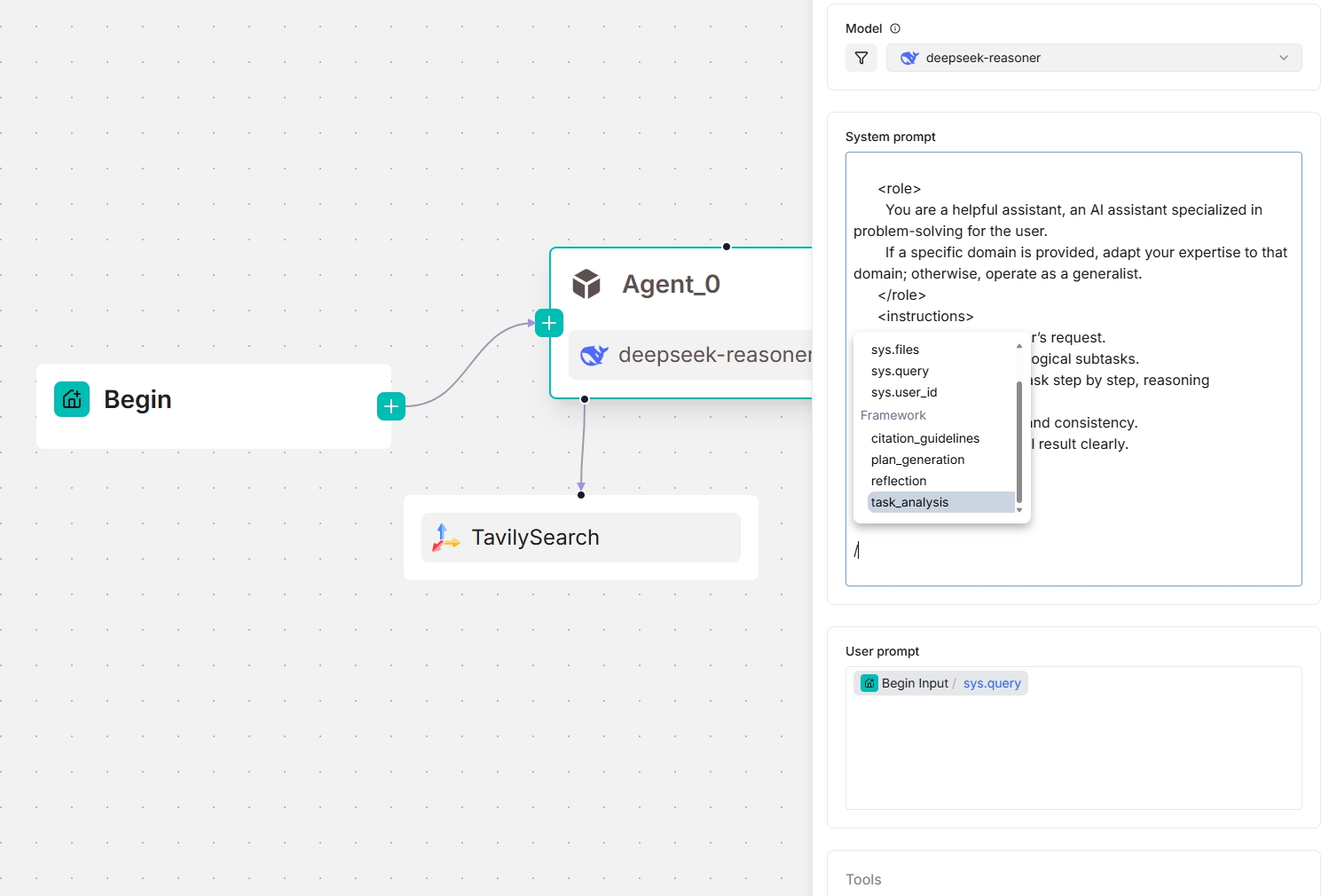
|
||||||
|
|
||||||
### User prompt
|
### User prompt
|
||||||
|
|
||||||
The user-defined prompt. Defaults to `sys.query`, the user query. As a general rule, when using the **Agent** component as a standalone module (not as a planner), you usually need to specify the corresponding **Retrieval** component’s output variable (`formalized_content`) here as part of the input to the LLM.
|
The user-defined prompt. Defaults to `sys.query`, the user query. As a general rule, when using the **Agent** component as a standalone module (not as a planner), you usually need to specify the corresponding **Retrieval** component’s output variable (`formalized_content`) here as part of the input to the LLM.
|
||||||
@ -129,7 +213,7 @@ Defines the maximum number of attempts the agent will make to retry a failed tas
|
|||||||
|
|
||||||
The waiting period in seconds that the agent observes before retrying a failed task, helping to prevent immediate repeated attempts and allowing system conditions to improve. Defaults to 1 second.
|
The waiting period in seconds that the agent observes before retrying a failed task, helping to prevent immediate repeated attempts and allowing system conditions to improve. Defaults to 1 second.
|
||||||
|
|
||||||
### Max rounds
|
### Max reflection rounds
|
||||||
|
|
||||||
Defines the maximum number reflection rounds of the selected chat model. Defaults to 1 round.
|
Defines the maximum number reflection rounds of the selected chat model. Defaults to 1 round.
|
||||||
|
|
||||||
|
|||||||
79
docs/guides/agent/agent_component_reference/execute_sql.md
Normal file
@ -0,0 +1,79 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 25
|
||||||
|
slug: /execute_sql
|
||||||
|
---
|
||||||
|
|
||||||
|
# Execute SQL tool
|
||||||
|
|
||||||
|
A tool that execute SQL queries on a specified relational database.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
The **Execute SQL** tool enables you to connect to a relational database and run SQL queries, whether entered directly or generated by the system’s Text2SQL capability via an **Agent** component.
|
||||||
|
|
||||||
|
## Prerequisites
|
||||||
|
|
||||||
|
- A database instance properly configured and running.
|
||||||
|
- The database must be one of the following types:
|
||||||
|
- MySQL
|
||||||
|
- PostgreSQL
|
||||||
|
- MariaDB
|
||||||
|
- Microsoft SQL Server
|
||||||
|
|
||||||
|
## Examples
|
||||||
|
|
||||||
|
You can pair an **Agent** component with the **Execute SQL** tool, with the **Agent** generating SQL statements and the **Execute SQL** tool handling database connection and query execution. An example of this setup can be found in the **SQL Assistant** Agent template shown below:
|
||||||
|
|
||||||
|
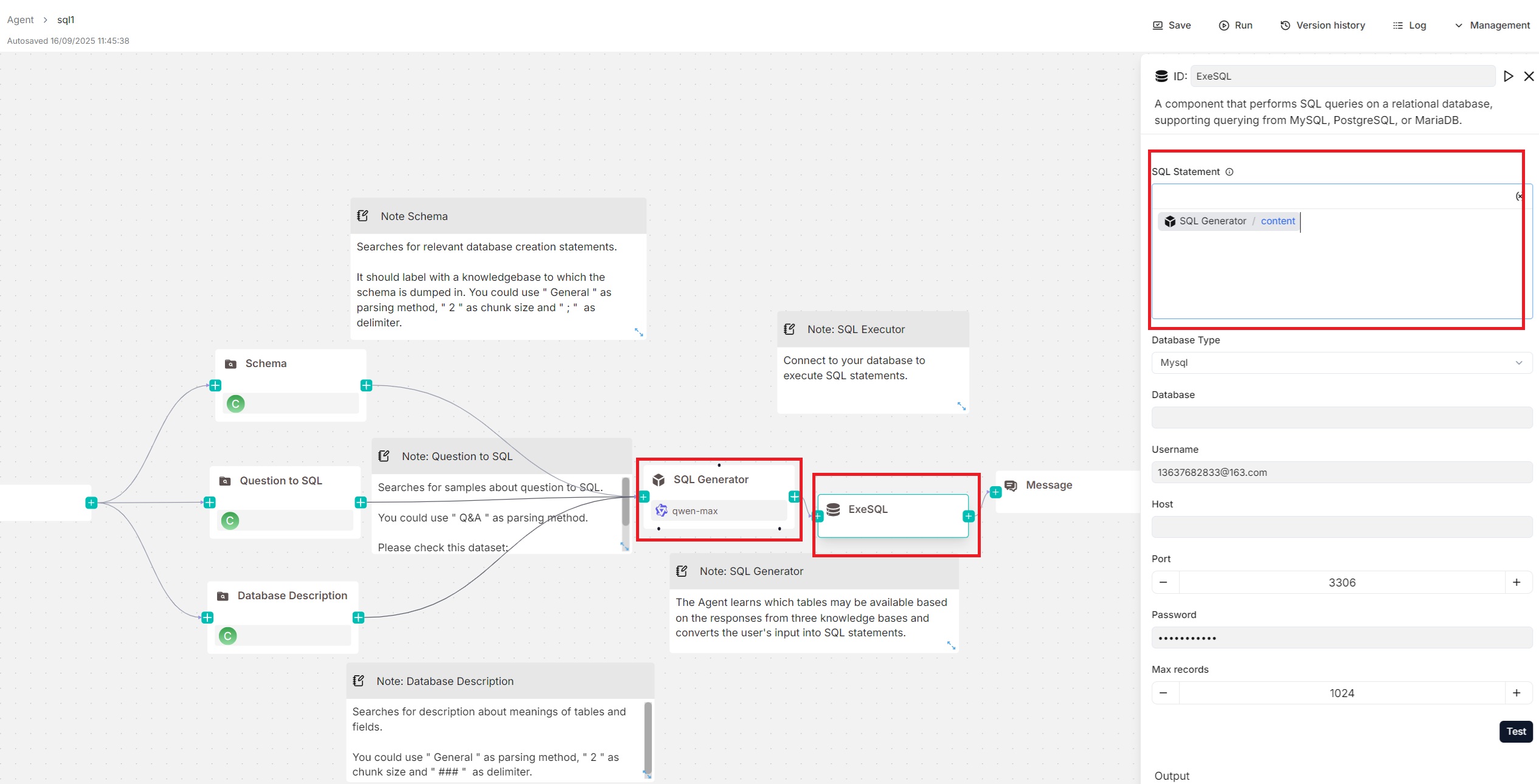
|
||||||
|
|
||||||
|
## Configurations
|
||||||
|
|
||||||
|
### SQL statement
|
||||||
|
|
||||||
|
This text input field allows you to write static SQL queries, such as `SELECT * FROM my_table`, and dynamic SQL queries using variables.
|
||||||
|
|
||||||
|
:::tip NOTE
|
||||||
|
Click **(x)** or type `/` to insert variables.
|
||||||
|
:::
|
||||||
|
|
||||||
|
For dynamic SQL queries, you can include variables in your SQL queries, such as `SELECT * FROM /sys.query`; if an **Agent** component is paired with the **Execute SQL** tool to generate SQL tasks (see the [Examples](#examples) section), you can directly insert that **Agent**'s output, `content`, into this field.
|
||||||
|
|
||||||
|
### Database type
|
||||||
|
|
||||||
|
The supported database type. Currently the following database types are available:
|
||||||
|
|
||||||
|
- MySQL
|
||||||
|
- PostreSQL
|
||||||
|
- MariaDB
|
||||||
|
- Microsoft SQL Server (Myssql)
|
||||||
|
|
||||||
|
### Database
|
||||||
|
|
||||||
|
Appears only when you select **Split** as method.
|
||||||
|
|
||||||
|
### Username
|
||||||
|
|
||||||
|
The username with access privileges to the database.
|
||||||
|
|
||||||
|
### Host
|
||||||
|
|
||||||
|
The IP address of the database server.
|
||||||
|
|
||||||
|
### Port
|
||||||
|
|
||||||
|
The port number on which the database server is listening.
|
||||||
|
|
||||||
|
### Password
|
||||||
|
|
||||||
|
The password for the database user.
|
||||||
|
|
||||||
|
### Max records
|
||||||
|
|
||||||
|
The maximum number of records returned by the SQL query to control response size and improve efficiency. Defaults to `1024`.
|
||||||
|
|
||||||
|
### Output
|
||||||
|
|
||||||
|
The **Execute SQL** tool provides two output variables:
|
||||||
|
|
||||||
|
- `formalized_content`: A string. If you reference this variable in a **Message** component, the returned records are displayed as a table.
|
||||||
|
- `json`: An object array. If you reference this variable in a **Message** component, the returned records will be presented as key-value pairs.
|
||||||
@ -106,7 +106,7 @@ RAGFlow offers HTTP and Python APIs for you to integrate RAGFlow's capabilities
|
|||||||
|
|
||||||
You can use iframe to embed the created chat assistant into a third-party webpage:
|
You can use iframe to embed the created chat assistant into a third-party webpage:
|
||||||
|
|
||||||
1. Before proceeding, you must [acquire an API key](../models/llm_api_key_setup.md); otherwise, an error message would appear.
|
1. Before proceeding, you must [acquire an API key](../../develop/acquire_ragflow_api_key.md); otherwise, an error message would appear.
|
||||||
2. Hover over an intended chat assistant **>** **Edit** to show the **iframe** window:
|
2. Hover over an intended chat assistant **>** **Edit** to show the **iframe** window:
|
||||||
|
|
||||||
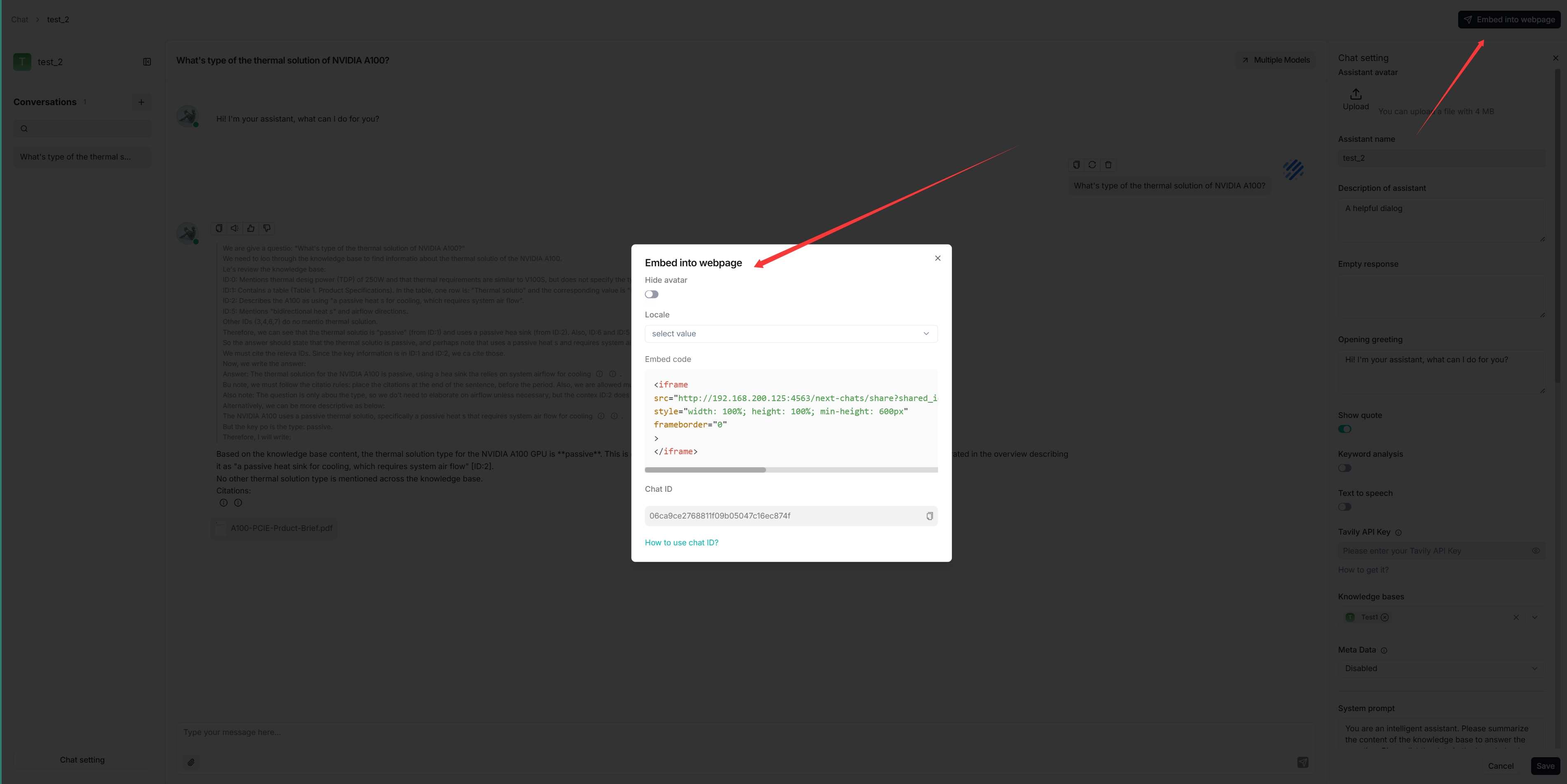
|

|
||||||
|
|||||||
@ -91,7 +91,7 @@ In RAGFlow, click on your logo on the top right of the page **>** **Model provid
|
|||||||
In the popup window, complete basic settings for Ollama:
|
In the popup window, complete basic settings for Ollama:
|
||||||
|
|
||||||
1. Ensure that your model name and type match those been pulled at step 1 (Deploy Ollama using Docker). For example, (`llama3.2` and `chat`) or (`bge-m3` and `embedding`).
|
1. Ensure that your model name and type match those been pulled at step 1 (Deploy Ollama using Docker). For example, (`llama3.2` and `chat`) or (`bge-m3` and `embedding`).
|
||||||
2. In Ollama base URL, put the URL you found in step 2 followed by `/v1`, i.e. `http://host.docker.internal:11434/v1`, `http://localhost:11434/v1` or `http://${IP_OF_OLLAMA_MACHINE}:11434/v1`.
|
2. Put in the Ollama base URL, i.e. `http://host.docker.internal:11434`, `http://localhost:11434` or `http://${IP_OF_OLLAMA_MACHINE}:11434`.
|
||||||
3. OPTIONAL: Switch on the toggle under **Does it support Vision?** if your model includes an image-to-text model.
|
3. OPTIONAL: Switch on the toggle under **Does it support Vision?** if your model includes an image-to-text model.
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
@ -1856,7 +1856,7 @@ curl --request POST \
|
|||||||
- `false`: Disable highlighting of matched terms (default).
|
- `false`: Disable highlighting of matched terms (default).
|
||||||
- `"cross_languages"`: (*Body parameter*) `list[string]`
|
- `"cross_languages"`: (*Body parameter*) `list[string]`
|
||||||
The languages that should be translated into, in order to achieve keywords retrievals in different languages.
|
The languages that should be translated into, in order to achieve keywords retrievals in different languages.
|
||||||
- `"metadata_condition"`: (*Body parameter*), `object`
|
- `"metadata_condition"`: (*Body parameter*), `object`
|
||||||
The metadata condition for filtering chunks.
|
The metadata condition for filtering chunks.
|
||||||
#### Response
|
#### Response
|
||||||
|
|
||||||
|
|||||||
@ -977,7 +977,7 @@ The languages that should be translated into, in order to achieve keywords retri
|
|||||||
|
|
||||||
##### metadata_condition: `dict`
|
##### metadata_condition: `dict`
|
||||||
|
|
||||||
filter condition for meta_fields
|
filter condition for `meta_fields`.
|
||||||
|
|
||||||
#### Returns
|
#### Returns
|
||||||
|
|
||||||
|
|||||||
@ -65,6 +65,7 @@ A complete list of models supported by RAGFlow, which will continue to expand.
|
|||||||
| 01.AI | :heavy_check_mark: | | | | | |
|
| 01.AI | :heavy_check_mark: | | | | | |
|
||||||
| DeepInfra | :heavy_check_mark: | :heavy_check_mark: | | | :heavy_check_mark: | :heavy_check_mark: |
|
| DeepInfra | :heavy_check_mark: | :heavy_check_mark: | | | :heavy_check_mark: | :heavy_check_mark: |
|
||||||
| 302.AI | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | | |
|
| 302.AI | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | | |
|
||||||
|
| CometAPI | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | | |
|
||||||
|
|
||||||
```mdx-code-block
|
```mdx-code-block
|
||||||
</APITable>
|
</APITable>
|
||||||
|
|||||||
@ -28,11 +28,11 @@ Released on September 10, 2025.
|
|||||||
|
|
||||||
### Improvements
|
### Improvements
|
||||||
|
|
||||||
- Agent Performance Optimized: Improved planning and reflection speed for simple tasks; optimized concurrent tool calls for parallelizable scenarios, significantly reducing overall response time.
|
- Agent:
|
||||||
- Agent Prompt Framework exposed: Developers can now customize and override framework-level prompts in the system prompt section, enhancing flexibility and control.
|
- Agent Performance Optimized: Improves planning and reflection speed for simple tasks; optimizes concurrent tool calls for parallelizable scenarios, significantly reducing overall response time.
|
||||||
- Execute SQL Component Enhanced: Replaced the original variable reference component with a text input field, allowing free-form SQL writing with variable support.
|
- Four framework-level prompt blocks are available in the **System prompt** section, enabling customization and overriding of prompts at the framework level, thereby enhancing flexibility and control. See [here](./guides/agent/agent_component_reference/agent.mdx#system-prompt).
|
||||||
- Chat: Re-enabled Reasoning and Cross-language search.
|
- **Execute SQL** component enhanced: Replaces the original variable reference component with a text input field, allowing users to write free-form SQL queries and reference variables.
|
||||||
- Retrieval API Enhanced: Added metadata filtering support to the [Retrieve chunks](https://ragflow.io/docs/dev/http_api_reference#retrieve-chunks) method.
|
- Chat: Re-enables **Reasoning** and **Cross-language search**.
|
||||||
|
|
||||||
### Added models
|
### Added models
|
||||||
|
|
||||||
@ -44,8 +44,22 @@ Released on September 10, 2025.
|
|||||||
### Fixed issues
|
### Fixed issues
|
||||||
|
|
||||||
- Dataset: Deleted files remained searchable.
|
- Dataset: Deleted files remained searchable.
|
||||||
- Chat: Unable to chat with an Ollama model.
|
- Chat: Unable to chat with an Ollama model.
|
||||||
- Agent: Resolved issues including cite toggle failure, task mode requiring dialogue triggers, repeated answers in multi-turn dialogues, and duplicate summarization of parallel execution results.
|
- Agent:
|
||||||
|
- A **Cite** toggle failure.
|
||||||
|
- An Agent in task mode still required a dialogue to trigger.
|
||||||
|
- Repeated answers in multi-turn dialogues.
|
||||||
|
- Duplicate summarization of parallel execution results.
|
||||||
|
|
||||||
|
### API changes
|
||||||
|
|
||||||
|
#### HTTP APIs
|
||||||
|
|
||||||
|
- Adds a body parameter `"metadata_condition"` to the [Retrieve chunks](./references/http_api_reference.md#retrieve-chunks) method, enabling metadata-based chunk filtering during retrieval. [#9877](https://github.com/infiniflow/ragflow/pull/9877)
|
||||||
|
|
||||||
|
#### Python APIs
|
||||||
|
|
||||||
|
- Adds a parameter `metadata_condition` to the [Retrieve chunks](./references/python_api_reference.md#retrieve-chunks) method, enabling metadata-based chunk filtering during retrieval. [#9877](https://github.com/infiniflow/ragflow/pull/9877)
|
||||||
|
|
||||||
## v0.20.4
|
## v0.20.4
|
||||||
|
|
||||||
|
|||||||
@ -507,16 +507,29 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
|||||||
markdown_parser = Markdown(int(parser_config.get("chunk_token_num", 128)))
|
markdown_parser = Markdown(int(parser_config.get("chunk_token_num", 128)))
|
||||||
sections, tables = markdown_parser(filename, binary, separate_tables=False)
|
sections, tables = markdown_parser(filename, binary, separate_tables=False)
|
||||||
|
|
||||||
# Process images for each section
|
try:
|
||||||
section_images = []
|
vision_model = LLMBundle(kwargs["tenant_id"], LLMType.IMAGE2TEXT)
|
||||||
for section_text, _ in sections:
|
callback(0.2, "Visual model detected. Attempting to enhance figure extraction...")
|
||||||
images = markdown_parser.get_pictures(section_text) if section_text else None
|
except Exception:
|
||||||
if images:
|
vision_model = None
|
||||||
# If multiple images found, combine them using concat_img
|
|
||||||
combined_image = reduce(concat_img, images) if len(images) > 1 else images[0]
|
if vision_model:
|
||||||
section_images.append(combined_image)
|
# Process images for each section
|
||||||
else:
|
section_images = []
|
||||||
section_images.append(None)
|
for idx, (section_text, _) in enumerate(sections):
|
||||||
|
images = markdown_parser.get_pictures(section_text) if section_text else None
|
||||||
|
|
||||||
|
if images:
|
||||||
|
# If multiple images found, combine them using concat_img
|
||||||
|
combined_image = reduce(concat_img, images) if len(images) > 1 else images[0]
|
||||||
|
section_images.append(combined_image)
|
||||||
|
markdown_vision_parser = VisionFigureParser(vision_model=vision_model, figures_data= [((combined_image, ["markdown image"]), [(0, 0, 0, 0, 0)])], **kwargs)
|
||||||
|
boosted_figures = markdown_vision_parser(callback=callback)
|
||||||
|
sections[idx] = (section_text + "\n\n" + "\n\n".join([fig[0][1] for fig in boosted_figures]), sections[idx][1])
|
||||||
|
else:
|
||||||
|
section_images.append(None)
|
||||||
|
else:
|
||||||
|
logging.warning("No visual model detected. Skipping figure parsing enhancement.")
|
||||||
|
|
||||||
res = tokenize_table(tables, doc, is_english)
|
res = tokenize_table(tables, doc, is_english)
|
||||||
callback(0.8, "Finish parsing.")
|
callback(0.8, "Finish parsing.")
|
||||||
|
|||||||
@ -13,7 +13,6 @@
|
|||||||
# See the License for the specific language governing permissions and
|
# See the License for the specific language governing permissions and
|
||||||
# limitations under the License.
|
# limitations under the License.
|
||||||
#
|
#
|
||||||
import logging
|
|
||||||
import os
|
import os
|
||||||
import time
|
import time
|
||||||
from functools import partial
|
from functools import partial
|
||||||
@ -44,17 +43,17 @@ class ProcessBase(ComponentBase):
|
|||||||
self.set_output("_created_time", time.perf_counter())
|
self.set_output("_created_time", time.perf_counter())
|
||||||
for k, v in kwargs.items():
|
for k, v in kwargs.items():
|
||||||
self.set_output(k, v)
|
self.set_output(k, v)
|
||||||
try:
|
#try:
|
||||||
with trio.fail_after(self._param.timeout):
|
with trio.fail_after(self._param.timeout):
|
||||||
await self._invoke(**kwargs)
|
await self._invoke(**kwargs)
|
||||||
self.callback(1, "Done")
|
self.callback(1, "Done")
|
||||||
except Exception as e:
|
#except Exception as e:
|
||||||
if self.get_exception_default_value():
|
# if self.get_exception_default_value():
|
||||||
self.set_exception_default_value()
|
# self.set_exception_default_value()
|
||||||
else:
|
# else:
|
||||||
self.set_output("_ERROR", str(e))
|
# self.set_output("_ERROR", str(e))
|
||||||
logging.exception(e)
|
# logging.exception(e)
|
||||||
self.callback(-1, str(e))
|
# self.callback(-1, str(e))
|
||||||
self.set_output("_elapsed_time", time.perf_counter() - self.output("_created_time"))
|
self.set_output("_elapsed_time", time.perf_counter() - self.output("_created_time"))
|
||||||
return self.output()
|
return self.output()
|
||||||
|
|
||||||
|
|||||||
@ -12,18 +12,19 @@
|
|||||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
# See the License for the specific language governing permissions and
|
# See the License for the specific language governing permissions and
|
||||||
# limitations under the License.
|
# limitations under the License.
|
||||||
|
import json
|
||||||
import random
|
import random
|
||||||
|
|
||||||
import trio
|
import trio
|
||||||
|
|
||||||
from api.db import LLMType
|
from api.db import LLMType
|
||||||
from api.db.services.llm_service import LLMBundle
|
from api.db.services.llm_service import LLMBundle
|
||||||
from deepdoc.parser.pdf_parser import RAGFlowPdfParser
|
from deepdoc.parser.pdf_parser import RAGFlowPdfParser
|
||||||
from graphrag.utils import chat_limiter, get_llm_cache, set_llm_cache
|
from graphrag.utils import chat_limiter, get_llm_cache, set_llm_cache
|
||||||
from rag.flow.base import ProcessBase, ProcessParamBase
|
from rag.flow.base import ProcessBase, ProcessParamBase
|
||||||
from rag.flow.chunker.schema import ChunkerFromUpstream
|
from rag.flow.chunker.schema import ChunkerFromUpstream
|
||||||
from rag.nlp import naive_merge, naive_merge_with_images
|
from rag.nlp import naive_merge, naive_merge_with_images, concat_img
|
||||||
from rag.prompts.prompts import keyword_extraction, question_proposal
|
from rag.prompts.prompts import keyword_extraction, question_proposal, detect_table_of_contents, \
|
||||||
|
table_of_contents_index, toc_transformer
|
||||||
|
from rag.utils import num_tokens_from_string
|
||||||
|
|
||||||
|
|
||||||
class ChunkerParam(ProcessParamBase):
|
class ChunkerParam(ProcessParamBase):
|
||||||
@ -43,6 +44,7 @@ class ChunkerParam(ProcessParamBase):
|
|||||||
"paper",
|
"paper",
|
||||||
"laws",
|
"laws",
|
||||||
"presentation",
|
"presentation",
|
||||||
|
"toc" # table of contents
|
||||||
# Other
|
# Other
|
||||||
# "Tag" # TODO: Other method
|
# "Tag" # TODO: Other method
|
||||||
]
|
]
|
||||||
@ -54,7 +56,7 @@ class ChunkerParam(ProcessParamBase):
|
|||||||
self.auto_keywords = 0
|
self.auto_keywords = 0
|
||||||
self.auto_questions = 0
|
self.auto_questions = 0
|
||||||
self.tag_sets = []
|
self.tag_sets = []
|
||||||
self.llm_setting = {"llm_name": "", "lang": "Chinese"}
|
self.llm_setting = {"llm_id": "", "lang": "Chinese"}
|
||||||
|
|
||||||
def check(self):
|
def check(self):
|
||||||
self.check_valid_value(self.method.lower(), "Chunk method abnormal.", self.method_options)
|
self.check_valid_value(self.method.lower(), "Chunk method abnormal.", self.method_options)
|
||||||
@ -142,6 +144,91 @@ class Chunker(ProcessBase):
|
|||||||
def _one(self, from_upstream: ChunkerFromUpstream):
|
def _one(self, from_upstream: ChunkerFromUpstream):
|
||||||
pass
|
pass
|
||||||
|
|
||||||
|
def _toc(self, from_upstream: ChunkerFromUpstream):
|
||||||
|
self.callback(random.randint(1, 5) / 100.0, "Start to chunk via `ToC`.")
|
||||||
|
if from_upstream.output_format in ["markdown", "text", "html"]:
|
||||||
|
return
|
||||||
|
|
||||||
|
# json
|
||||||
|
sections, section_images, page_1024, tc_arr = [], [], [""], [0]
|
||||||
|
for o in from_upstream.json_result or []:
|
||||||
|
txt = o.get("text", "")
|
||||||
|
tc = num_tokens_from_string(txt)
|
||||||
|
page_1024[-1] += "\n" + txt
|
||||||
|
tc_arr[-1] += tc
|
||||||
|
if tc_arr[-1] > 1024:
|
||||||
|
page_1024.append("")
|
||||||
|
tc_arr.append(0)
|
||||||
|
sections.append((o.get("text", ""), o.get("position_tag", "")))
|
||||||
|
section_images.append(o.get("image"))
|
||||||
|
print(len(sections), o)
|
||||||
|
|
||||||
|
llm_setting = self._param.llm_setting
|
||||||
|
chat_mdl = LLMBundle(self._canvas._tenant_id, LLMType.CHAT, llm_name=llm_setting["llm_id"], lang=llm_setting["lang"])
|
||||||
|
self.callback(random.randint(5, 15) / 100.0, "Start to detect table of contents...")
|
||||||
|
toc_secs = detect_table_of_contents(page_1024, chat_mdl)
|
||||||
|
if toc_secs:
|
||||||
|
self.callback(random.randint(25, 35) / 100.0, "Start to extract table of contents...")
|
||||||
|
toc_arr = toc_transformer(toc_secs, chat_mdl)
|
||||||
|
toc_arr = [it for it in toc_arr if it.get("structure")]
|
||||||
|
print(json.dumps(toc_arr, ensure_ascii=False, indent=2), flush=True)
|
||||||
|
self.callback(random.randint(35, 75) / 100.0, "Start to link table of contents...")
|
||||||
|
toc_arr = table_of_contents_index(toc_arr, [t for t,_ in sections], chat_mdl)
|
||||||
|
for i in range(len(toc_arr)-1):
|
||||||
|
if not toc_arr[i].get("indices"):
|
||||||
|
continue
|
||||||
|
|
||||||
|
for j in range(i+1, len(toc_arr)):
|
||||||
|
if toc_arr[j].get("indices"):
|
||||||
|
if toc_arr[j]["indices"][0] - toc_arr[i]["indices"][-1] > 1:
|
||||||
|
toc_arr[i]["indices"].extend([x for x in range(toc_arr[i]["indices"][-1]+1, toc_arr[j]["indices"][0])])
|
||||||
|
break
|
||||||
|
# put all sections ahead of toc_arr[0] into it
|
||||||
|
# for i in range(len(toc_arr)):
|
||||||
|
# if toc_arr[i].get("indices") and toc_arr[i]["indices"][0]:
|
||||||
|
# toc_arr[i]["indices"] = [x for x in range(toc_arr[i]["indices"][-1]+1)]
|
||||||
|
# break
|
||||||
|
# put all sections after toc_arr[-1] into it
|
||||||
|
for i in range(len(toc_arr)-1, -1, -1):
|
||||||
|
if toc_arr[i].get("indices") and toc_arr[i]["indices"][-1]:
|
||||||
|
toc_arr[i]["indices"] = [x for x in range(toc_arr[i]["indices"][0], len(sections))]
|
||||||
|
break
|
||||||
|
print(">>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>\n", json.dumps(toc_arr, ensure_ascii=False, indent=2), flush=True)
|
||||||
|
|
||||||
|
chunks, images = [], []
|
||||||
|
for it in toc_arr:
|
||||||
|
if not it.get("indices"):
|
||||||
|
continue
|
||||||
|
txt = ""
|
||||||
|
img = None
|
||||||
|
for i in it["indices"]:
|
||||||
|
idx = i
|
||||||
|
txt += "\n" + sections[idx][0] + "\t" + sections[idx][1]
|
||||||
|
if img and section_images[idx]:
|
||||||
|
img = concat_img(img, section_images[idx])
|
||||||
|
elif section_images[idx]:
|
||||||
|
img = section_images[idx]
|
||||||
|
|
||||||
|
it["indices"] = []
|
||||||
|
if not txt:
|
||||||
|
continue
|
||||||
|
it["indices"] = [len(chunks)]
|
||||||
|
print(it, "KKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKK\n", txt)
|
||||||
|
chunks.append(txt)
|
||||||
|
images.append(img)
|
||||||
|
self.callback(1, "Done")
|
||||||
|
return [
|
||||||
|
{
|
||||||
|
"text": RAGFlowPdfParser.remove_tag(c),
|
||||||
|
"image": img,
|
||||||
|
"positions": RAGFlowPdfParser.extract_positions(c),
|
||||||
|
}
|
||||||
|
for c, img in zip(chunks, images)
|
||||||
|
]
|
||||||
|
|
||||||
|
self.callback(message="No table of contents detected.")
|
||||||
|
|
||||||
|
|
||||||
async def _invoke(self, **kwargs):
|
async def _invoke(self, **kwargs):
|
||||||
function_map = {
|
function_map = {
|
||||||
"general": self._general,
|
"general": self._general,
|
||||||
@ -154,6 +241,7 @@ class Chunker(ProcessBase):
|
|||||||
"laws": self._laws,
|
"laws": self._laws,
|
||||||
"presentation": self._presentation,
|
"presentation": self._presentation,
|
||||||
"one": self._one,
|
"one": self._one,
|
||||||
|
"toc": self._toc,
|
||||||
}
|
}
|
||||||
|
|
||||||
try:
|
try:
|
||||||
@ -167,7 +255,7 @@ class Chunker(ProcessBase):
|
|||||||
|
|
||||||
async def auto_keywords():
|
async def auto_keywords():
|
||||||
nonlocal chunks, llm_setting
|
nonlocal chunks, llm_setting
|
||||||
chat_mdl = LLMBundle(self._canvas._tenant_id, LLMType.CHAT, llm_name=llm_setting["llm_name"], lang=llm_setting["lang"])
|
chat_mdl = LLMBundle(self._canvas._tenant_id, LLMType.CHAT, llm_name=llm_setting["llm_id"], lang=llm_setting["lang"])
|
||||||
|
|
||||||
async def doc_keyword_extraction(chat_mdl, ck, topn):
|
async def doc_keyword_extraction(chat_mdl, ck, topn):
|
||||||
cached = get_llm_cache(chat_mdl.llm_name, ck["text"], "keywords", {"topn": topn})
|
cached = get_llm_cache(chat_mdl.llm_name, ck["text"], "keywords", {"topn": topn})
|
||||||
@ -184,7 +272,7 @@ class Chunker(ProcessBase):
|
|||||||
|
|
||||||
async def auto_questions():
|
async def auto_questions():
|
||||||
nonlocal chunks, llm_setting
|
nonlocal chunks, llm_setting
|
||||||
chat_mdl = LLMBundle(self._canvas._tenant_id, LLMType.CHAT, llm_name=llm_setting["llm_name"], lang=llm_setting["lang"])
|
chat_mdl = LLMBundle(self._canvas._tenant_id, LLMType.CHAT, llm_name=llm_setting["llm_id"], lang=llm_setting["lang"])
|
||||||
|
|
||||||
async def doc_question_proposal(chat_mdl, d, topn):
|
async def doc_question_proposal(chat_mdl, d, topn):
|
||||||
cached = get_llm_cache(chat_mdl.llm_name, ck["text"], "question", {"topn": topn})
|
cached = get_llm_cache(chat_mdl.llm_name, ck["text"], "question", {"topn": topn})
|
||||||
|
|||||||
@ -22,7 +22,7 @@ class ChunkerFromUpstream(BaseModel):
|
|||||||
elapsed_time: float | None = Field(default=None, alias="_elapsed_time")
|
elapsed_time: float | None = Field(default=None, alias="_elapsed_time")
|
||||||
|
|
||||||
name: str
|
name: str
|
||||||
blob: bytes
|
file: dict | None = Field(default=None)
|
||||||
|
|
||||||
output_format: Literal["json", "markdown", "text", "html"] | None = Field(default=None)
|
output_format: Literal["json", "markdown", "text", "html"] | None = Field(default=None)
|
||||||
|
|
||||||
|
|||||||
@ -14,10 +14,7 @@
|
|||||||
# limitations under the License.
|
# limitations under the License.
|
||||||
#
|
#
|
||||||
from api.db.services.document_service import DocumentService
|
from api.db.services.document_service import DocumentService
|
||||||
from api.db.services.file2document_service import File2DocumentService
|
|
||||||
from api.db.services.file_service import FileService
|
|
||||||
from rag.flow.base import ProcessBase, ProcessParamBase
|
from rag.flow.base import ProcessBase, ProcessParamBase
|
||||||
from rag.utils.storage_factory import STORAGE_IMPL
|
|
||||||
|
|
||||||
|
|
||||||
class FileParam(ProcessParamBase):
|
class FileParam(ProcessParamBase):
|
||||||
@ -41,10 +38,13 @@ class File(ProcessBase):
|
|||||||
self.set_output("_ERROR", f"Document({self._canvas._doc_id}) not found!")
|
self.set_output("_ERROR", f"Document({self._canvas._doc_id}) not found!")
|
||||||
return
|
return
|
||||||
|
|
||||||
b, n = File2DocumentService.get_storage_address(doc_id=self._canvas._doc_id)
|
#b, n = File2DocumentService.get_storage_address(doc_id=self._canvas._doc_id)
|
||||||
self.set_output("blob", STORAGE_IMPL.get(b, n))
|
#self.set_output("blob", STORAGE_IMPL.get(b, n))
|
||||||
self.set_output("name", doc.name)
|
self.set_output("name", doc.name)
|
||||||
else:
|
else:
|
||||||
file = kwargs.get("file")
|
file = kwargs.get("file")
|
||||||
self.set_output("name", file["name"])
|
self.set_output("name", file["name"])
|
||||||
self.set_output("blob", FileService.get_blob(file["created_by"], file["id"]))
|
self.set_output("file", file)
|
||||||
|
#self.set_output("blob", FileService.get_blob(file["created_by"], file["id"]))
|
||||||
|
|
||||||
|
self.callback(1, "File fetched.")
|
||||||
|
|||||||
15
rag/flow/hierarchical_merger/__init__.py
Normal file
@ -0,0 +1,15 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
|
||||||
178
rag/flow/hierarchical_merger/hierarchical_merger.py
Normal file
@ -0,0 +1,178 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
import json
|
||||||
|
import random
|
||||||
|
import re
|
||||||
|
from copy import deepcopy
|
||||||
|
from functools import partial
|
||||||
|
|
||||||
|
import trio
|
||||||
|
|
||||||
|
from api.utils import get_uuid
|
||||||
|
from api.utils.base64_image import id2image, image2id
|
||||||
|
from deepdoc.parser.pdf_parser import RAGFlowPdfParser
|
||||||
|
from rag.flow.base import ProcessBase, ProcessParamBase
|
||||||
|
from rag.flow.hierarchical_merger.schema import HierarchicalMergerFromUpstream
|
||||||
|
from rag.nlp import concat_img
|
||||||
|
from rag.utils.storage_factory import STORAGE_IMPL
|
||||||
|
|
||||||
|
|
||||||
|
class HierarchicalMergerParam(ProcessParamBase):
|
||||||
|
def __init__(self):
|
||||||
|
super().__init__()
|
||||||
|
self.levels = []
|
||||||
|
self.hierarchy = None
|
||||||
|
|
||||||
|
def check(self):
|
||||||
|
self.check_empty(self.levels, "Hierarchical setups.")
|
||||||
|
self.check_empty(self.hierarchy, "Hierarchy number.")
|
||||||
|
|
||||||
|
def get_input_form(self) -> dict[str, dict]:
|
||||||
|
return {}
|
||||||
|
|
||||||
|
|
||||||
|
class HierarchicalMerger(ProcessBase):
|
||||||
|
component_name = "HierarchicalMerger"
|
||||||
|
|
||||||
|
async def _invoke(self, **kwargs):
|
||||||
|
try:
|
||||||
|
from_upstream = HierarchicalMergerFromUpstream.model_validate(kwargs)
|
||||||
|
except Exception as e:
|
||||||
|
self.set_output("_ERROR", f"Input error: {str(e)}")
|
||||||
|
return
|
||||||
|
|
||||||
|
self.callback(random.randint(1, 5) / 100.0, "Start to merge hierarchically.")
|
||||||
|
if from_upstream.output_format in ["markdown", "text", "html"]:
|
||||||
|
if from_upstream.output_format == "markdown":
|
||||||
|
payload = from_upstream.markdown_result
|
||||||
|
elif from_upstream.output_format == "text":
|
||||||
|
payload = from_upstream.text_result
|
||||||
|
else: # == "html"
|
||||||
|
payload = from_upstream.html_result
|
||||||
|
|
||||||
|
if not payload:
|
||||||
|
payload = ""
|
||||||
|
|
||||||
|
lines = [ln for ln in payload.split("\n") if ln]
|
||||||
|
else:
|
||||||
|
lines = [o.get("text", "") for o in from_upstream.json_result]
|
||||||
|
sections, section_images = [], []
|
||||||
|
for o in from_upstream.json_result or []:
|
||||||
|
sections.append((o.get("text", ""), o.get("position_tag", "")))
|
||||||
|
section_images.append(o.get("img_id"))
|
||||||
|
|
||||||
|
matches = []
|
||||||
|
for txt in lines:
|
||||||
|
good = False
|
||||||
|
for lvl, regs in enumerate(self._param.levels):
|
||||||
|
for reg in regs:
|
||||||
|
if re.search(reg, txt):
|
||||||
|
matches.append(lvl)
|
||||||
|
good = True
|
||||||
|
break
|
||||||
|
if good:
|
||||||
|
break
|
||||||
|
if not good:
|
||||||
|
matches.append(len(self._param.levels))
|
||||||
|
assert len(matches) == len(lines), f"{len(matches)} vs. {len(lines)}"
|
||||||
|
|
||||||
|
root = {
|
||||||
|
"level": -1,
|
||||||
|
"index": -1,
|
||||||
|
"texts": [],
|
||||||
|
"children": []
|
||||||
|
}
|
||||||
|
for i, m in enumerate(matches):
|
||||||
|
if m == 0:
|
||||||
|
root["children"].append({
|
||||||
|
"level": m,
|
||||||
|
"index": i,
|
||||||
|
"texts": [],
|
||||||
|
"children": []
|
||||||
|
})
|
||||||
|
elif m == len(self._param.levels):
|
||||||
|
def dfs(b):
|
||||||
|
if not b["children"]:
|
||||||
|
b["texts"].append(i)
|
||||||
|
else:
|
||||||
|
dfs(b["children"][-1])
|
||||||
|
dfs(root)
|
||||||
|
else:
|
||||||
|
def dfs(b):
|
||||||
|
nonlocal m, i
|
||||||
|
if not b["children"] or m == b["level"] + 1:
|
||||||
|
b["children"].append({
|
||||||
|
"level": m,
|
||||||
|
"index": i,
|
||||||
|
"texts": [],
|
||||||
|
"children": []
|
||||||
|
})
|
||||||
|
return
|
||||||
|
dfs(b["children"][-1])
|
||||||
|
|
||||||
|
dfs(root)
|
||||||
|
|
||||||
|
all_pathes = []
|
||||||
|
def dfs(n, path, depth):
|
||||||
|
nonlocal all_pathes
|
||||||
|
if depth < self._param.hierarchy:
|
||||||
|
path = deepcopy(path)
|
||||||
|
|
||||||
|
for nn in n["children"]:
|
||||||
|
path.extend([nn["index"], *nn["texts"]])
|
||||||
|
dfs(nn, path, depth+1)
|
||||||
|
|
||||||
|
if depth == self._param.hierarchy:
|
||||||
|
all_pathes.append(path)
|
||||||
|
|
||||||
|
for i in range(len(lines)):
|
||||||
|
print(i, lines[i])
|
||||||
|
dfs(root, [], 0)
|
||||||
|
print("sSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS", json.dumps(root, ensure_ascii=False, indent=2))
|
||||||
|
|
||||||
|
if from_upstream.output_format in ["markdown", "text", "html"]:
|
||||||
|
cks = []
|
||||||
|
for path in all_pathes:
|
||||||
|
txt = ""
|
||||||
|
for i in path:
|
||||||
|
txt += lines[i] + "\n"
|
||||||
|
cks.append(txt)
|
||||||
|
|
||||||
|
self.set_output("chunks", [{"text": c} for c in cks if c])
|
||||||
|
else:
|
||||||
|
cks = []
|
||||||
|
images = []
|
||||||
|
for path in all_pathes:
|
||||||
|
txt = ""
|
||||||
|
img = None
|
||||||
|
for i in path:
|
||||||
|
txt += lines[i] + "\n"
|
||||||
|
concat_img(img, id2image(section_images[i], partial(STORAGE_IMPL.get)))
|
||||||
|
cks.append(cks)
|
||||||
|
images.append(img)
|
||||||
|
|
||||||
|
cks = [
|
||||||
|
{
|
||||||
|
"text": RAGFlowPdfParser.remove_tag(c),
|
||||||
|
"image": img,
|
||||||
|
"positions": RAGFlowPdfParser.extract_positions(c),
|
||||||
|
}
|
||||||
|
for c, img in zip(cks, images)
|
||||||
|
]
|
||||||
|
async with trio.open_nursery() as nursery:
|
||||||
|
for d in cks:
|
||||||
|
nursery.start_soon(image2id, d, partial(STORAGE_IMPL.put), "_image_temps", get_uuid())
|
||||||
|
|
||||||
|
self.callback(1, "Done.")
|
||||||
37
rag/flow/hierarchical_merger/schema.py
Normal file
@ -0,0 +1,37 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
from typing import Any, Literal
|
||||||
|
|
||||||
|
from pydantic import BaseModel, ConfigDict, Field
|
||||||
|
|
||||||
|
|
||||||
|
class HierarchicalMergerFromUpstream(BaseModel):
|
||||||
|
created_time: float | None = Field(default=None, alias="_created_time")
|
||||||
|
elapsed_time: float | None = Field(default=None, alias="_elapsed_time")
|
||||||
|
|
||||||
|
name: str
|
||||||
|
file: dict | None = Field(default=None)
|
||||||
|
chunks: list[dict[str, Any]] | None = Field(default=None)
|
||||||
|
|
||||||
|
output_format: Literal["json", "markdown", "text", "html"] | None = Field(default=None)
|
||||||
|
json_result: list[dict[str, Any]] | None = Field(default=None, alias="json")
|
||||||
|
markdown_result: str | None = Field(default=None, alias="markdown")
|
||||||
|
text_result: str | None = Field(default=None, alias="text")
|
||||||
|
html_result: list[str] | None = Field(default=None, alias="html")
|
||||||
|
|
||||||
|
model_config = ConfigDict(populate_by_name=True, extra="forbid")
|
||||||
|
|
||||||
|
# def to_dict(self, *, exclude_none: bool = True) -> dict:
|
||||||
|
# return self.model_dump(by_alias=True, exclude_none=exclude_none)
|
||||||
@ -12,18 +12,27 @@
|
|||||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
# See the License for the specific language governing permissions and
|
# See the License for the specific language governing permissions and
|
||||||
# limitations under the License.
|
# limitations under the License.
|
||||||
|
import io
|
||||||
import logging
|
import logging
|
||||||
import random
|
import random
|
||||||
|
from functools import partial
|
||||||
|
|
||||||
import trio
|
import trio
|
||||||
|
import numpy as np
|
||||||
|
from PIL import Image
|
||||||
|
|
||||||
from api.db import LLMType
|
from api.db import LLMType
|
||||||
|
from api.db.services.file2document_service import File2DocumentService
|
||||||
|
from api.db.services.file_service import FileService
|
||||||
from api.db.services.llm_service import LLMBundle
|
from api.db.services.llm_service import LLMBundle
|
||||||
|
from api.utils import get_uuid
|
||||||
|
from api.utils.base64_image import image2id
|
||||||
from deepdoc.parser import ExcelParser
|
from deepdoc.parser import ExcelParser
|
||||||
from deepdoc.parser.pdf_parser import PlainParser, RAGFlowPdfParser, VisionParser
|
from deepdoc.parser.pdf_parser import PlainParser, RAGFlowPdfParser, VisionParser
|
||||||
from rag.flow.base import ProcessBase, ProcessParamBase
|
from rag.flow.base import ProcessBase, ProcessParamBase
|
||||||
from rag.flow.parser.schema import ParserFromUpstream
|
from rag.flow.parser.schema import ParserFromUpstream
|
||||||
from rag.llm.cv_model import Base as VLM
|
from rag.llm.cv_model import Base as VLM
|
||||||
|
from rag.utils.storage_factory import STORAGE_IMPL
|
||||||
|
|
||||||
|
|
||||||
class ParserParam(ProcessParamBase):
|
class ParserParam(ProcessParamBase):
|
||||||
@ -42,18 +51,27 @@ class ParserParam(ProcessParamBase):
|
|||||||
"word": [
|
"word": [
|
||||||
"json",
|
"json",
|
||||||
],
|
],
|
||||||
"ppt": [],
|
"slides": [
|
||||||
"image": [],
|
"json",
|
||||||
|
],
|
||||||
|
"image": [
|
||||||
|
"text"
|
||||||
|
],
|
||||||
"email": [],
|
"email": [],
|
||||||
"text": [],
|
"text": [
|
||||||
"audio": [],
|
"text",
|
||||||
|
"json"
|
||||||
|
],
|
||||||
|
"audio": [
|
||||||
|
"json"
|
||||||
|
],
|
||||||
"video": [],
|
"video": [],
|
||||||
}
|
}
|
||||||
|
|
||||||
self.setups = {
|
self.setups = {
|
||||||
"pdf": {
|
"pdf": {
|
||||||
"parse_method": "deepdoc", # deepdoc/plain_text/vlm
|
"parse_method": "deepdoc", # deepdoc/plain_text/vlm
|
||||||
"vlm_name": "",
|
"llm_id": "",
|
||||||
"lang": "Chinese",
|
"lang": "Chinese",
|
||||||
"suffix": [
|
"suffix": [
|
||||||
"pdf",
|
"pdf",
|
||||||
@ -76,16 +94,52 @@ class ParserParam(ProcessParamBase):
|
|||||||
"output_format": "json",
|
"output_format": "json",
|
||||||
},
|
},
|
||||||
"markdown": {
|
"markdown": {
|
||||||
"suffix": ["md", "markdown"],
|
"suffix": ["md", "markdown", "mdx"],
|
||||||
|
"output_format": "json",
|
||||||
|
},
|
||||||
|
"slides": {
|
||||||
|
"parse_method": "presentation",
|
||||||
|
"suffix": [
|
||||||
|
"pptx",
|
||||||
|
],
|
||||||
"output_format": "json",
|
"output_format": "json",
|
||||||
},
|
},
|
||||||
"ppt": {},
|
|
||||||
"image": {
|
"image": {
|
||||||
"parse_method": "ocr",
|
"parse_method": "ocr",
|
||||||
|
"llm_id": "",
|
||||||
|
"lang": "Chinese",
|
||||||
|
"suffix": ["jpg", "jpeg", "png", "gif"],
|
||||||
|
"output_format": "json",
|
||||||
|
},
|
||||||
|
"email": {
|
||||||
|
"fields": []
|
||||||
|
},
|
||||||
|
"text": {
|
||||||
|
"suffix": [
|
||||||
|
"txt"
|
||||||
|
],
|
||||||
|
"output_format": "json",
|
||||||
|
},
|
||||||
|
"audio": {
|
||||||
|
"suffix":[
|
||||||
|
"da",
|
||||||
|
"wave",
|
||||||
|
"wav",
|
||||||
|
"mp3",
|
||||||
|
"aac",
|
||||||
|
"flac",
|
||||||
|
"ogg",
|
||||||
|
"aiff",
|
||||||
|
"au",
|
||||||
|
"midi",
|
||||||
|
"wma",
|
||||||
|
"realaudio",
|
||||||
|
"vqf",
|
||||||
|
"oggvorbis",
|
||||||
|
"ape"
|
||||||
|
],
|
||||||
|
"output_format": "json",
|
||||||
},
|
},
|
||||||
"email": {},
|
|
||||||
"text": {},
|
|
||||||
"audio": {},
|
|
||||||
"video": {},
|
"video": {},
|
||||||
}
|
}
|
||||||
|
|
||||||
@ -96,7 +150,7 @@ class ParserParam(ProcessParamBase):
|
|||||||
self.check_valid_value(pdf_parse_method.lower(), "Parse method abnormal.", ["deepdoc", "plain_text", "vlm"])
|
self.check_valid_value(pdf_parse_method.lower(), "Parse method abnormal.", ["deepdoc", "plain_text", "vlm"])
|
||||||
|
|
||||||
if pdf_parse_method not in ["deepdoc", "plain_text"]:
|
if pdf_parse_method not in ["deepdoc", "plain_text"]:
|
||||||
self.check_empty(pdf_config.get("vlm_name"), "VLM")
|
self.check_empty(pdf_config.get("llm_id"), "VLM")
|
||||||
|
|
||||||
pdf_language = pdf_config.get("lang", "")
|
pdf_language = pdf_config.get("lang", "")
|
||||||
self.check_empty(pdf_language, "Language")
|
self.check_empty(pdf_language, "Language")
|
||||||
@ -114,10 +168,31 @@ class ParserParam(ProcessParamBase):
|
|||||||
doc_output_format = doc_config.get("output_format", "")
|
doc_output_format = doc_config.get("output_format", "")
|
||||||
self.check_valid_value(doc_output_format, "Word processer document output format abnormal.", self.allowed_output_format["doc"])
|
self.check_valid_value(doc_output_format, "Word processer document output format abnormal.", self.allowed_output_format["doc"])
|
||||||
|
|
||||||
|
slides_config = self.setups.get("slides", "")
|
||||||
|
if slides_config:
|
||||||
|
slides_output_format = slides_config.get("output_format", "")
|
||||||
|
self.check_valid_value(slides_output_format, "Slides output format abnormal.", self.allowed_output_format["slides"])
|
||||||
|
|
||||||
image_config = self.setups.get("image", "")
|
image_config = self.setups.get("image", "")
|
||||||
if image_config:
|
if image_config:
|
||||||
image_parse_method = image_config.get("parse_method", "")
|
image_parse_method = image_config.get("parse_method", "")
|
||||||
self.check_valid_value(image_parse_method.lower(), "Parse method abnormal.", ["ocr"])
|
self.check_valid_value(image_parse_method.lower(), "Parse method abnormal.", ["ocr", "vlm"])
|
||||||
|
if image_parse_method not in ["ocr"]:
|
||||||
|
self.check_empty(image_config.get("llm_id"), "VLM")
|
||||||
|
|
||||||
|
image_language = image_config.get("lang", "")
|
||||||
|
self.check_empty(image_language, "Language")
|
||||||
|
|
||||||
|
text_config = self.setups.get("text", "")
|
||||||
|
if text_config:
|
||||||
|
text_output_format = text_config.get("output_format", "")
|
||||||
|
self.check_valid_value(text_output_format, "Text output format abnormal.", self.allowed_output_format["text"])
|
||||||
|
|
||||||
|
audio_config = self.setups.get("audio", "")
|
||||||
|
if audio_config:
|
||||||
|
self.check_empty(audio_config.get("llm_id"), "VLM")
|
||||||
|
audio_language = audio_config.get("lang", "")
|
||||||
|
self.check_empty(audio_language, "Language")
|
||||||
|
|
||||||
def get_input_form(self) -> dict[str, dict]:
|
def get_input_form(self) -> dict[str, dict]:
|
||||||
return {}
|
return {}
|
||||||
@ -126,10 +201,8 @@ class ParserParam(ProcessParamBase):
|
|||||||
class Parser(ProcessBase):
|
class Parser(ProcessBase):
|
||||||
component_name = "Parser"
|
component_name = "Parser"
|
||||||
|
|
||||||
def _pdf(self, from_upstream: ParserFromUpstream):
|
def _pdf(self, name, blob):
|
||||||
self.callback(random.randint(1, 5) / 100.0, "Start to work on a PDF.")
|
self.callback(random.randint(1, 5) / 100.0, "Start to work on a PDF.")
|
||||||
|
|
||||||
blob = from_upstream.blob
|
|
||||||
conf = self._param.setups["pdf"]
|
conf = self._param.setups["pdf"]
|
||||||
self.set_output("output_format", conf["output_format"])
|
self.set_output("output_format", conf["output_format"])
|
||||||
|
|
||||||
@ -139,8 +212,8 @@ class Parser(ProcessBase):
|
|||||||
lines, _ = PlainParser()(blob)
|
lines, _ = PlainParser()(blob)
|
||||||
bboxes = [{"text": t} for t, _ in lines]
|
bboxes = [{"text": t} for t, _ in lines]
|
||||||
else:
|
else:
|
||||||
assert conf.get("vlm_name")
|
assert conf.get("llm_id")
|
||||||
vision_model = LLMBundle(self._canvas._tenant_id, LLMType.IMAGE2TEXT, llm_name=conf.get("vlm_name"), lang=self._param.setups["pdf"].get("lang"))
|
vision_model = LLMBundle(self._canvas._tenant_id, LLMType.IMAGE2TEXT, llm_name=conf.get("llm_id"), lang=self._param.setups["pdf"].get("lang"))
|
||||||
lines, _ = VisionParser(vision_model=vision_model)(blob, callback=self.callback)
|
lines, _ = VisionParser(vision_model=vision_model)(blob, callback=self.callback)
|
||||||
bboxes = []
|
bboxes = []
|
||||||
for t, poss in lines:
|
for t, poss in lines:
|
||||||
@ -160,14 +233,10 @@ class Parser(ProcessBase):
|
|||||||
mkdn += b.get("text", "") + "\n"
|
mkdn += b.get("text", "") + "\n"
|
||||||
self.set_output("markdown", mkdn)
|
self.set_output("markdown", mkdn)
|
||||||
|
|
||||||
def _spreadsheet(self, from_upstream: ParserFromUpstream):
|
def _spreadsheet(self, name, blob):
|
||||||
self.callback(random.randint(1, 5) / 100.0, "Start to work on a Spreadsheet.")
|
self.callback(random.randint(1, 5) / 100.0, "Start to work on a Spreadsheet.")
|
||||||
|
|
||||||
blob = from_upstream.blob
|
|
||||||
conf = self._param.setups["spreadsheet"]
|
conf = self._param.setups["spreadsheet"]
|
||||||
self.set_output("output_format", conf["output_format"])
|
self.set_output("output_format", conf["output_format"])
|
||||||
|
|
||||||
print("spreadsheet {conf=}", flush=True)
|
|
||||||
spreadsheet_parser = ExcelParser()
|
spreadsheet_parser = ExcelParser()
|
||||||
if conf.get("output_format") == "html":
|
if conf.get("output_format") == "html":
|
||||||
html = spreadsheet_parser.html(blob, 1000000000)
|
html = spreadsheet_parser.html(blob, 1000000000)
|
||||||
@ -177,19 +246,13 @@ class Parser(ProcessBase):
|
|||||||
elif conf.get("output_format") == "markdown":
|
elif conf.get("output_format") == "markdown":
|
||||||
self.set_output("markdown", spreadsheet_parser.markdown(blob))
|
self.set_output("markdown", spreadsheet_parser.markdown(blob))
|
||||||
|
|
||||||
def _word(self, from_upstream: ParserFromUpstream):
|
def _word(self, name, blob):
|
||||||
from tika import parser as word_parser
|
from tika import parser as word_parser
|
||||||
|
|
||||||
self.callback(random.randint(1, 5) / 100.0, "Start to work on a Word Processor Document")
|
self.callback(random.randint(1, 5) / 100.0, "Start to work on a Word Processor Document")
|
||||||
|
|
||||||
blob = from_upstream.blob
|
|
||||||
name = from_upstream.name
|
|
||||||
conf = self._param.setups["word"]
|
conf = self._param.setups["word"]
|
||||||
self.set_output("output_format", conf["output_format"])
|
self.set_output("output_format", conf["output_format"])
|
||||||
|
|
||||||
print("word {conf=}", flush=True)
|
|
||||||
doc_parsed = word_parser.from_buffer(blob)
|
doc_parsed = word_parser.from_buffer(blob)
|
||||||
|
|
||||||
sections = []
|
sections = []
|
||||||
if doc_parsed.get("content"):
|
if doc_parsed.get("content"):
|
||||||
sections = doc_parsed["content"].split("\n")
|
sections = doc_parsed["content"].split("\n")
|
||||||
@ -202,26 +265,37 @@ class Parser(ProcessBase):
|
|||||||
if conf.get("output_format") == "json":
|
if conf.get("output_format") == "json":
|
||||||
self.set_output("json", sections)
|
self.set_output("json", sections)
|
||||||
|
|
||||||
def _markdown(self, from_upstream: ParserFromUpstream):
|
def _slides(self, name, blob):
|
||||||
|
from deepdoc.parser.ppt_parser import RAGFlowPptParser as ppt_parser
|
||||||
|
|
||||||
|
self.callback(random.randint(1, 5) / 100.0, "Start to work on a PowerPoint Document")
|
||||||
|
|
||||||
|
conf = self._param.setups["slides"]
|
||||||
|
self.set_output("output_format", conf["output_format"])
|
||||||
|
|
||||||
|
ppt_parser = ppt_parser()
|
||||||
|
txts = ppt_parser(blob, 0, 100000, None)
|
||||||
|
|
||||||
|
sections = [{"text": section} for section in txts if section.strip()]
|
||||||
|
|
||||||
|
# json
|
||||||
|
assert conf.get("output_format") == "json", "have to be json for ppt"
|
||||||
|
if conf.get("output_format") == "json":
|
||||||
|
self.set_output("json", sections)
|
||||||
|
|
||||||
|
def _markdown(self, name, blob):
|
||||||
from functools import reduce
|
from functools import reduce
|
||||||
|
|
||||||
from rag.app.naive import Markdown as naive_markdown_parser
|
from rag.app.naive import Markdown as naive_markdown_parser
|
||||||
from rag.nlp import concat_img
|
from rag.nlp import concat_img
|
||||||
|
|
||||||
self.callback(random.randint(1, 5) / 100.0, "Start to work on a Word Processor Document")
|
self.callback(random.randint(1, 5) / 100.0, "Start to work on a markdown.")
|
||||||
|
|
||||||
blob = from_upstream.blob
|
|
||||||
name = from_upstream.name
|
|
||||||
conf = self._param.setups["markdown"]
|
conf = self._param.setups["markdown"]
|
||||||
self.set_output("output_format", conf["output_format"])
|
self.set_output("output_format", conf["output_format"])
|
||||||
|
|
||||||
print("markdown {conf=}", flush=True)
|
|
||||||
|
|
||||||
markdown_parser = naive_markdown_parser()
|
markdown_parser = naive_markdown_parser()
|
||||||
sections, tables = markdown_parser(name, blob, separate_tables=False)
|
sections, tables = markdown_parser(name, blob, separate_tables=False)
|
||||||
|
|
||||||
# json
|
|
||||||
assert conf.get("output_format") == "json", "have to be json for doc"
|
|
||||||
if conf.get("output_format") == "json":
|
if conf.get("output_format") == "json":
|
||||||
json_results = []
|
json_results = []
|
||||||
|
|
||||||
@ -239,14 +313,87 @@ class Parser(ProcessBase):
|
|||||||
json_results.append(json_result)
|
json_results.append(json_result)
|
||||||
|
|
||||||
self.set_output("json", json_results)
|
self.set_output("json", json_results)
|
||||||
|
else:
|
||||||
|
self.set_output("text", "\n".join([section_text for section_text, _ in sections]))
|
||||||
|
|
||||||
|
def _text(self, name, blob):
|
||||||
|
from deepdoc.parser.utils import get_text
|
||||||
|
|
||||||
|
self.callback(random.randint(1, 5) / 100.0, "Start to work on a text.")
|
||||||
|
conf = self._param.setups["text"]
|
||||||
|
self.set_output("output_format", conf["output_format"])
|
||||||
|
|
||||||
|
# parse binary to text
|
||||||
|
text_content = get_text(name, binary=blob)
|
||||||
|
|
||||||
|
if conf.get("output_format") == "json":
|
||||||
|
result = [{"text": text_content}]
|
||||||
|
self.set_output("json", result)
|
||||||
|
else:
|
||||||
|
result = text_content
|
||||||
|
self.set_output("text", result)
|
||||||
|
|
||||||
|
def _image(self, from_upstream: ParserFromUpstream):
|
||||||
|
from deepdoc.vision import OCR
|
||||||
|
|
||||||
|
self.callback(random.randint(1, 5) / 100.0, "Start to work on an image.")
|
||||||
|
|
||||||
|
blob = from_upstream.blob
|
||||||
|
conf = self._param.setups["image"]
|
||||||
|
self.set_output("output_format", conf["output_format"])
|
||||||
|
|
||||||
|
img = Image.open(io.BytesIO(blob)).convert("RGB")
|
||||||
|
lang = conf["lang"]
|
||||||
|
|
||||||
|
if conf["parse_method"] == "ocr":
|
||||||
|
# use ocr, recognize chars only
|
||||||
|
ocr = OCR()
|
||||||
|
bxs = ocr(np.array(img)) # return boxes and recognize result
|
||||||
|
txt = "\n".join([t[0] for _, t in bxs if t[0]])
|
||||||
|
|
||||||
|
else:
|
||||||
|
# use VLM to describe the picture
|
||||||
|
cv_model = LLMBundle(self._canvas.get_tenant_id(), LLMType.IMAGE2TEXT, llm_name=conf["llm_id"], lang=lang)
|
||||||
|
img_binary = io.BytesIO()
|
||||||
|
img.save(img_binary, format="JPEG")
|
||||||
|
img_binary.seek(0)
|
||||||
|
txt = cv_model.describe(img_binary.read())
|
||||||
|
|
||||||
|
self.set_output("text", txt)
|
||||||
|
|
||||||
|
def _audio(self, from_upstream: ParserFromUpstream):
|
||||||
|
import os
|
||||||
|
import tempfile
|
||||||
|
|
||||||
|
self.callback(random.randint(1, 5) / 100.0, "Start to work on an audio.")
|
||||||
|
|
||||||
|
blob = from_upstream.blob
|
||||||
|
name = from_upstream.name
|
||||||
|
conf = self._param.setups["audio"]
|
||||||
|
self.set_output("output_format", conf["output_format"])
|
||||||
|
|
||||||
|
lang = conf["lang"]
|
||||||
|
_, ext = os.path.splitext(name)
|
||||||
|
with tempfile.NamedTemporaryFile(suffix=ext) as tmpf:
|
||||||
|
tmpf.write(blob)
|
||||||
|
tmpf.flush()
|
||||||
|
tmp_path = os.path.abspath(tmpf.name)
|
||||||
|
|
||||||
|
seq2txt_mdl = LLMBundle(self._canvas.get_tenant_id(), LLMType.SPEECH2TEXT, lang=lang)
|
||||||
|
txt = seq2txt_mdl.transcription(tmp_path)
|
||||||
|
|
||||||
|
self.set_output("text", txt)
|
||||||
|
|
||||||
async def _invoke(self, **kwargs):
|
async def _invoke(self, **kwargs):
|
||||||
function_map = {
|
function_map = {
|
||||||
"pdf": self._pdf,
|
"pdf": self._pdf,
|
||||||
"markdown": self._markdown,
|
"markdown": self._markdown,
|
||||||
"spreadsheet": self._spreadsheet,
|
"spreadsheet": self._spreadsheet,
|
||||||
"word": self._word
|
"slides": self._slides,
|
||||||
|
"word": self._word,
|
||||||
|
"text": self._text,
|
||||||
|
"image": self._image,
|
||||||
|
"audio": self._audio,
|
||||||
}
|
}
|
||||||
try:
|
try:
|
||||||
from_upstream = ParserFromUpstream.model_validate(kwargs)
|
from_upstream = ParserFromUpstream.model_validate(kwargs)
|
||||||
@ -254,8 +401,20 @@ class Parser(ProcessBase):
|
|||||||
self.set_output("_ERROR", f"Input error: {str(e)}")
|
self.set_output("_ERROR", f"Input error: {str(e)}")
|
||||||
return
|
return
|
||||||
|
|
||||||
|
name = from_upstream.name
|
||||||
|
if self._canvas._doc_id:
|
||||||
|
b, n = File2DocumentService.get_storage_address(doc_id=self._canvas._doc_id)
|
||||||
|
blob = STORAGE_IMPL.get(b, n)
|
||||||
|
else:
|
||||||
|
blob = FileService.get_blob(from_upstream.file["created_by"], from_upstream.file["id"])
|
||||||
|
|
||||||
for p_type, conf in self._param.setups.items():
|
for p_type, conf in self._param.setups.items():
|
||||||
if from_upstream.name.split(".")[-1].lower() not in conf.get("suffix", []):
|
if from_upstream.name.split(".")[-1].lower() not in conf.get("suffix", []):
|
||||||
continue
|
continue
|
||||||
await trio.to_thread.run_sync(function_map[p_type], from_upstream)
|
await trio.to_thread.run_sync(function_map[p_type], name, blob)
|
||||||
break
|
break
|
||||||
|
|
||||||
|
outs = self.output()
|
||||||
|
async with trio.open_nursery() as nursery:
|
||||||
|
for d in outs.get("json", []):
|
||||||
|
nursery.start_soon(image2id, d, partial(STORAGE_IMPL.put), "_image_temps", get_uuid())
|
||||||
|
|||||||
@ -20,6 +20,5 @@ class ParserFromUpstream(BaseModel):
|
|||||||
elapsed_time: float | None = Field(default=None, alias="_elapsed_time")
|
elapsed_time: float | None = Field(default=None, alias="_elapsed_time")
|
||||||
|
|
||||||
name: str
|
name: str
|
||||||
blob: bytes
|
file: dict | None = Field(default=None)
|
||||||
|
|
||||||
model_config = ConfigDict(populate_by_name=True, extra="forbid")
|
model_config = ConfigDict(populate_by_name=True, extra="forbid")
|
||||||
|
|||||||
@ -48,7 +48,24 @@ class Pipeline(Graph):
|
|||||||
obj.append({"component_name": component_name, "trace": [{"progress": progress, "message": message, "datetime": datetime.datetime.now().strftime("%H:%M:%S")}]})
|
obj.append({"component_name": component_name, "trace": [{"progress": progress, "message": message, "datetime": datetime.datetime.now().strftime("%H:%M:%S")}]})
|
||||||
else:
|
else:
|
||||||
obj = [{"component_name": component_name, "trace": [{"progress": progress, "message": message, "datetime": datetime.datetime.now().strftime("%H:%M:%S")}]}]
|
obj = [{"component_name": component_name, "trace": [{"progress": progress, "message": message, "datetime": datetime.datetime.now().strftime("%H:%M:%S")}]}]
|
||||||
REDIS_CONN.set_obj(log_key, obj, 60 * 10)
|
REDIS_CONN.set_obj(log_key, obj, 60 * 30)
|
||||||
|
if self._doc_id:
|
||||||
|
percentage = 1./len(self.components.items())
|
||||||
|
msg = ""
|
||||||
|
finished = 0.
|
||||||
|
for o in obj:
|
||||||
|
if o['component_name'] == "END":
|
||||||
|
continue
|
||||||
|
msg += f"\n[{o['component_name']}]:\n"
|
||||||
|
for t in o["trace"]:
|
||||||
|
msg += "%s: %s\n"%(t["datetime"], t["message"])
|
||||||
|
if t["progress"] < 0:
|
||||||
|
finished = -1
|
||||||
|
break
|
||||||
|
if finished < 0:
|
||||||
|
break
|
||||||
|
finished += o["trace"][-1]["progress"] * percentage
|
||||||
|
DocumentService.update_by_id(self._doc_id, {"progress": finished, "progress_msg": msg})
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
logging.exception(e)
|
logging.exception(e)
|
||||||
|
|
||||||
@ -108,5 +125,11 @@ class Pipeline(Graph):
|
|||||||
idx += 1
|
idx += 1
|
||||||
self.path.extend(cpn_obj.get_downstream())
|
self.path.extend(cpn_obj.get_downstream())
|
||||||
|
|
||||||
|
self.callback("END", 1, json.dumps(self.get_component_obj(self.path[-1]).output(), ensure_ascii=False))
|
||||||
|
|
||||||
if self._doc_id:
|
if self._doc_id:
|
||||||
DocumentService.update_by_id(self._doc_id, {"progress": 1 if not self.error else -1, "progress_msg": "Pipeline finished...\n" + self.error, "process_duration": time.perf_counter() - st})
|
DocumentService.update_by_id(self._doc_id,{
|
||||||
|
"progress": 1 if not self.error else -1,
|
||||||
|
"progress_msg": "Pipeline finished...\n" + self.error,
|
||||||
|
"process_duration": time.perf_counter() - st
|
||||||
|
})
|
||||||
|
|||||||
15
rag/flow/splitter/__init__.py
Normal file
@ -0,0 +1,15 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
|
||||||
38
rag/flow/splitter/schema.py
Normal file
@ -0,0 +1,38 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
from typing import Any, Literal
|
||||||
|
|
||||||
|
from pydantic import BaseModel, ConfigDict, Field
|
||||||
|
|
||||||
|
|
||||||
|
class SplitterFromUpstream(BaseModel):
|
||||||
|
created_time: float | None = Field(default=None, alias="_created_time")
|
||||||
|
elapsed_time: float | None = Field(default=None, alias="_elapsed_time")
|
||||||
|
|
||||||
|
name: str
|
||||||
|
file: dict | None = Field(default=None)
|
||||||
|
chunks: list[dict[str, Any]] | None = Field(default=None)
|
||||||
|
|
||||||
|
output_format: Literal["json", "markdown", "text", "html"] | None = Field(default=None)
|
||||||
|
|
||||||
|
json_result: list[dict[str, Any]] | None = Field(default=None, alias="json")
|
||||||
|
markdown_result: str | None = Field(default=None, alias="markdown")
|
||||||
|
text_result: str | None = Field(default=None, alias="text")
|
||||||
|
html_result: list[str] | None = Field(default=None, alias="html")
|
||||||
|
|
||||||
|
model_config = ConfigDict(populate_by_name=True, extra="forbid")
|
||||||
|
|
||||||
|
# def to_dict(self, *, exclude_none: bool = True) -> dict:
|
||||||
|
# return self.model_dump(by_alias=True, exclude_none=exclude_none)
|
||||||
112
rag/flow/splitter/splitter.py
Normal file
@ -0,0 +1,112 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
import json
|
||||||
|
import random
|
||||||
|
from functools import partial
|
||||||
|
|
||||||
|
import trio
|
||||||
|
|
||||||
|
from api.utils import get_uuid
|
||||||
|
from api.utils.base64_image import id2image, image2id
|
||||||
|
from deepdoc.parser.pdf_parser import RAGFlowPdfParser
|
||||||
|
from rag.flow.base import ProcessBase, ProcessParamBase
|
||||||
|
from rag.flow.splitter.schema import SplitterFromUpstream
|
||||||
|
from rag.nlp import naive_merge, naive_merge_with_images
|
||||||
|
from rag.utils.storage_factory import STORAGE_IMPL
|
||||||
|
|
||||||
|
|
||||||
|
class SplitterParam(ProcessParamBase):
|
||||||
|
def __init__(self):
|
||||||
|
super().__init__()
|
||||||
|
self.chunk_token_size = 512
|
||||||
|
self.delimiters = ["\n"]
|
||||||
|
self.overlapped_percent = 0
|
||||||
|
|
||||||
|
def check(self):
|
||||||
|
self.check_empty(self.delimiters, "Delimiters.")
|
||||||
|
self.check_positive_integer(self.chunk_token_size, "Chunk token size.")
|
||||||
|
self.check_decimal_float(self.overlapped_percent, "Overlapped percentage: [0, 1)")
|
||||||
|
|
||||||
|
def get_input_form(self) -> dict[str, dict]:
|
||||||
|
return {}
|
||||||
|
|
||||||
|
|
||||||
|
class Splitter(ProcessBase):
|
||||||
|
component_name = "Splitter"
|
||||||
|
|
||||||
|
async def _invoke(self, **kwargs):
|
||||||
|
try:
|
||||||
|
from_upstream = SplitterFromUpstream.model_validate(kwargs)
|
||||||
|
except Exception as e:
|
||||||
|
self.set_output("_ERROR", f"Input error: {str(e)}")
|
||||||
|
return
|
||||||
|
|
||||||
|
deli = ""
|
||||||
|
for d in self._param.delimiters:
|
||||||
|
if len(d) > 1:
|
||||||
|
deli += f"`{d}`"
|
||||||
|
else:
|
||||||
|
deli += d
|
||||||
|
|
||||||
|
self.callback(random.randint(1, 5) / 100.0, "Start to split into chunks.")
|
||||||
|
if from_upstream.output_format in ["markdown", "text", "html"]:
|
||||||
|
if from_upstream.output_format == "markdown":
|
||||||
|
payload = from_upstream.markdown_result
|
||||||
|
elif from_upstream.output_format == "text":
|
||||||
|
payload = from_upstream.text_result
|
||||||
|
else: # == "html"
|
||||||
|
payload = from_upstream.html_result
|
||||||
|
|
||||||
|
if not payload:
|
||||||
|
payload = ""
|
||||||
|
|
||||||
|
cks = naive_merge(
|
||||||
|
payload,
|
||||||
|
self._param.chunk_token_size,
|
||||||
|
deli,
|
||||||
|
self._param.overlapped_percent,
|
||||||
|
)
|
||||||
|
self.set_output("chunks", [{"text": c} for c in cks])
|
||||||
|
|
||||||
|
self.callback(1, "Done.")
|
||||||
|
return
|
||||||
|
|
||||||
|
# json
|
||||||
|
sections, section_images = [], []
|
||||||
|
for o in from_upstream.json_result or []:
|
||||||
|
sections.append((o.get("text", ""), o.get("position_tag", "")))
|
||||||
|
section_images.append(id2image(o.get("img_id"), partial(STORAGE_IMPL.get)))
|
||||||
|
|
||||||
|
chunks, images = naive_merge_with_images(
|
||||||
|
sections,
|
||||||
|
section_images,
|
||||||
|
self._param.chunk_token_size,
|
||||||
|
deli,
|
||||||
|
self._param.overlapped_percent,
|
||||||
|
)
|
||||||
|
cks = [
|
||||||
|
{
|
||||||
|
"text": RAGFlowPdfParser.remove_tag(c),
|
||||||
|
"image": img,
|
||||||
|
"positions": RAGFlowPdfParser.extract_positions(c),
|
||||||
|
}
|
||||||
|
for c, img in zip(chunks, images)
|
||||||
|
]
|
||||||
|
async with trio.open_nursery() as nursery:
|
||||||
|
for d in cks:
|
||||||
|
nursery.start_soon(image2id, d, partial(STORAGE_IMPL.put), "_image_temps", get_uuid())
|
||||||
|
print("SSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS\n", json.dumps(cks, ensure_ascii=False, indent=2))
|
||||||
|
self.set_output("chunks", cks)
|
||||||
|
self.callback(1, "Done.")
|
||||||
@ -38,26 +38,71 @@
|
|||||||
],
|
],
|
||||||
"output_format": "json"
|
"output_format": "json"
|
||||||
},
|
},
|
||||||
|
"slides": {
|
||||||
|
"parse_method": "presentation",
|
||||||
|
"suffix": [
|
||||||
|
"pptx"
|
||||||
|
],
|
||||||
|
"output_format": "json"
|
||||||
|
},
|
||||||
"markdown": {
|
"markdown": {
|
||||||
"suffix": [
|
"suffix": [
|
||||||
"md",
|
"md",
|
||||||
"markdown"
|
"markdown"
|
||||||
],
|
],
|
||||||
"output_format": "json"
|
"output_format": "json"
|
||||||
|
},
|
||||||
|
"text": {
|
||||||
|
"suffix": ["txt"],
|
||||||
|
"output_format": "json"
|
||||||
|
},
|
||||||
|
"image": {
|
||||||
|
"parse_method": "vlm",
|
||||||
|
"llm_id":"glm-4.5v",
|
||||||
|
"lang": "Chinese",
|
||||||
|
"suffix": [
|
||||||
|
"jpg",
|
||||||
|
"jpeg",
|
||||||
|
"png",
|
||||||
|
"gif"
|
||||||
|
],
|
||||||
|
"output_format": "text"
|
||||||
|
},
|
||||||
|
"audio": {
|
||||||
|
"suffix": [
|
||||||
|
"da",
|
||||||
|
"wave",
|
||||||
|
"wav",
|
||||||
|
"mp3",
|
||||||
|
"aac",
|
||||||
|
"flac",
|
||||||
|
"ogg",
|
||||||
|
"aiff",
|
||||||
|
"au",
|
||||||
|
"midi",
|
||||||
|
"wma",
|
||||||
|
"realaudio",
|
||||||
|
"vqf",
|
||||||
|
"oggvorbis",
|
||||||
|
"ape"
|
||||||
|
],
|
||||||
|
"lang": "Chinese",
|
||||||
|
"llm_id": "SenseVoiceSmall",
|
||||||
|
"output_format": "json"
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
}
|
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"downstream": ["Chunker:0"],
|
"downstream": ["Splitter:0"],
|
||||||
"upstream": ["Begin"]
|
"upstream": ["Begin"]
|
||||||
},
|
},
|
||||||
"Chunker:0": {
|
"Splitter:0": {
|
||||||
"obj": {
|
"obj": {
|
||||||
"component_name": "Chunker",
|
"component_name": "Splitter",
|
||||||
"params": {
|
"params": {
|
||||||
"method": "general",
|
"chunk_token_size": 512,
|
||||||
"auto_keywords": 5
|
"delimiters": ["\n"],
|
||||||
|
"overlapped_percent": 0
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"downstream": ["Tokenizer:0"],
|
"downstream": ["Tokenizer:0"],
|
||||||
|
|||||||
84
rag/flow/tests/dsl_examples/hierarchical_merger.json
Normal file
@ -0,0 +1,84 @@
|
|||||||
|
{
|
||||||
|
"components": {
|
||||||
|
"File": {
|
||||||
|
"obj":{
|
||||||
|
"component_name": "File",
|
||||||
|
"params": {
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"downstream": ["Parser:0"],
|
||||||
|
"upstream": []
|
||||||
|
},
|
||||||
|
"Parser:0": {
|
||||||
|
"obj": {
|
||||||
|
"component_name": "Parser",
|
||||||
|
"params": {
|
||||||
|
"setups": {
|
||||||
|
"pdf": {
|
||||||
|
"parse_method": "deepdoc",
|
||||||
|
"vlm_name": "",
|
||||||
|
"lang": "Chinese",
|
||||||
|
"suffix": [
|
||||||
|
"pdf"
|
||||||
|
],
|
||||||
|
"output_format": "json"
|
||||||
|
},
|
||||||
|
"spreadsheet": {
|
||||||
|
"suffix": [
|
||||||
|
"xls",
|
||||||
|
"xlsx",
|
||||||
|
"csv"
|
||||||
|
],
|
||||||
|
"output_format": "html"
|
||||||
|
},
|
||||||
|
"word": {
|
||||||
|
"suffix": [
|
||||||
|
"doc",
|
||||||
|
"docx"
|
||||||
|
],
|
||||||
|
"output_format": "json"
|
||||||
|
},
|
||||||
|
"markdown": {
|
||||||
|
"suffix": [
|
||||||
|
"md",
|
||||||
|
"markdown"
|
||||||
|
],
|
||||||
|
"output_format": "text"
|
||||||
|
},
|
||||||
|
"text": {
|
||||||
|
"suffix": ["txt"],
|
||||||
|
"output_format": "json"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"downstream": ["Splitter:0"],
|
||||||
|
"upstream": ["File"]
|
||||||
|
},
|
||||||
|
"Splitter:0": {
|
||||||
|
"obj": {
|
||||||
|
"component_name": "Splitter",
|
||||||
|
"params": {
|
||||||
|
"chunk_token_size": 512,
|
||||||
|
"delimiters": ["\r\n"],
|
||||||
|
"overlapped_percent": 0
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"downstream": ["HierarchicalMerger:0"],
|
||||||
|
"upstream": ["Parser:0"]
|
||||||
|
},
|
||||||
|
"HierarchicalMerger:0": {
|
||||||
|
"obj": {
|
||||||
|
"component_name": "HierarchicalMerger",
|
||||||
|
"params": {
|
||||||
|
"levels": [["^#[^#]"], ["^##[^#]"], ["^###[^#]"], ["^####[^#]"]],
|
||||||
|
"hierarchy": 2
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"downstream": [],
|
||||||
|
"upstream": ["Splitter:0"]
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"path": []
|
||||||
|
}
|
||||||
|
|
||||||
@ -22,7 +22,7 @@ class TokenizerFromUpstream(BaseModel):
|
|||||||
elapsed_time: float | None = Field(default=None, alias="_elapsed_time")
|
elapsed_time: float | None = Field(default=None, alias="_elapsed_time")
|
||||||
|
|
||||||
name: str = ""
|
name: str = ""
|
||||||
blob: bytes
|
file: dict | None = Field(default=None)
|
||||||
|
|
||||||
output_format: Literal["json", "markdown", "text", "html"] | None = Field(default=None)
|
output_format: Literal["json", "markdown", "text", "html"] | None = Field(default=None)
|
||||||
|
|
||||||
|
|||||||
@ -37,6 +37,7 @@ class TokenizerParam(ProcessParamBase):
|
|||||||
super().__init__()
|
super().__init__()
|
||||||
self.search_method = ["full_text", "embedding"]
|
self.search_method = ["full_text", "embedding"]
|
||||||
self.filename_embd_weight = 0.1
|
self.filename_embd_weight = 0.1
|
||||||
|
self.fields = ["text"]
|
||||||
|
|
||||||
def check(self):
|
def check(self):
|
||||||
for v in self.search_method:
|
for v in self.search_method:
|
||||||
@ -61,10 +62,14 @@ class Tokenizer(ProcessBase):
|
|||||||
embedding_model = LLMBundle(self._canvas._tenant_id, LLMType.EMBEDDING, llm_name=embedding_id)
|
embedding_model = LLMBundle(self._canvas._tenant_id, LLMType.EMBEDDING, llm_name=embedding_id)
|
||||||
texts = []
|
texts = []
|
||||||
for c in chunks:
|
for c in chunks:
|
||||||
if c.get("questions"):
|
txt = ""
|
||||||
texts.append("\n".join(c["questions"]))
|
for f in self._param.fields:
|
||||||
else:
|
f = c.get(f)
|
||||||
texts.append(re.sub(r"</?(table|td|caption|tr|th)( [^<>]{0,12})?>", " ", c["text"]))
|
if isinstance(f, str):
|
||||||
|
txt += f
|
||||||
|
elif isinstance(f, list):
|
||||||
|
txt += "\n".join(f)
|
||||||
|
texts.append(re.sub(r"</?(table|td|caption|tr|th)( [^<>]{0,12})?>", " ", txt))
|
||||||
vts, c = embedding_model.encode([name])
|
vts, c = embedding_model.encode([name])
|
||||||
token_count += c
|
token_count += c
|
||||||
tts = np.concatenate([vts[0] for _ in range(len(texts))], axis=0)
|
tts = np.concatenate([vts[0] for _ in range(len(texts))], axis=0)
|
||||||
@ -109,6 +114,9 @@ class Tokenizer(ProcessBase):
|
|||||||
if from_upstream.chunks:
|
if from_upstream.chunks:
|
||||||
chunks = from_upstream.chunks
|
chunks = from_upstream.chunks
|
||||||
for i, ck in enumerate(chunks):
|
for i, ck in enumerate(chunks):
|
||||||
|
if ck.get("docnm_kwd"): # from presentation method
|
||||||
|
ck["title_tks"] = rag_tokenizer.tokenize(re.sub(r"\.[a-zA-Z]+$", "", ck["docnm_kwd"]))
|
||||||
|
ck["title_sm_tks"] = rag_tokenizer.fine_grained_tokenize(ck["title_tks"])
|
||||||
if ck.get("questions"):
|
if ck.get("questions"):
|
||||||
ck["question_tks"] = rag_tokenizer.tokenize("\n".join(ck["questions"]))
|
ck["question_tks"] = rag_tokenizer.tokenize("\n".join(ck["questions"]))
|
||||||
if ck.get("keywords"):
|
if ck.get("keywords"):
|
||||||
@ -130,12 +138,18 @@ class Tokenizer(ProcessBase):
|
|||||||
|
|
||||||
ck = {"text": payload}
|
ck = {"text": payload}
|
||||||
if "full_text" in self._param.search_method:
|
if "full_text" in self._param.search_method:
|
||||||
|
if ck.get("docnm_kwd"): # from presentation method
|
||||||
|
ck["title_tks"] = rag_tokenizer.tokenize(re.sub(r"\.[a-zA-Z]+$", "", ck["docnm_kwd"]))
|
||||||
|
ck["title_sm_tks"] = rag_tokenizer.fine_grained_tokenize(ck["title_tks"])
|
||||||
ck["content_ltks"] = rag_tokenizer.tokenize(kwargs.get(kwargs["output_format"], ""))
|
ck["content_ltks"] = rag_tokenizer.tokenize(kwargs.get(kwargs["output_format"], ""))
|
||||||
ck["content_sm_ltks"] = rag_tokenizer.fine_grained_tokenize(ck["content_ltks"])
|
ck["content_sm_ltks"] = rag_tokenizer.fine_grained_tokenize(ck["content_ltks"])
|
||||||
chunks = [ck]
|
chunks = [ck]
|
||||||
else:
|
else:
|
||||||
chunks = from_upstream.json_result
|
chunks = from_upstream.json_result
|
||||||
for i, ck in enumerate(chunks):
|
for i, ck in enumerate(chunks):
|
||||||
|
if ck.get("docnm_kwd"): # from presentation method
|
||||||
|
ck["title_tks"] = rag_tokenizer.tokenize(re.sub(r"\.[a-zA-Z]+$", "", ck["docnm_kwd"]))
|
||||||
|
ck["title_sm_tks"] = rag_tokenizer.fine_grained_tokenize(ck["title_tks"])
|
||||||
ck["content_ltks"] = rag_tokenizer.tokenize(ck["text"])
|
ck["content_ltks"] = rag_tokenizer.tokenize(ck["text"])
|
||||||
ck["content_sm_ltks"] = rag_tokenizer.fine_grained_tokenize(ck["content_ltks"])
|
ck["content_sm_ltks"] = rag_tokenizer.fine_grained_tokenize(ck["content_ltks"])
|
||||||
if i % 100 == 99:
|
if i % 100 == 99:
|
||||||
|
|||||||
@ -37,6 +37,18 @@ class SupportedLiteLLMProvider(StrEnum):
|
|||||||
TogetherAI = "TogetherAI"
|
TogetherAI = "TogetherAI"
|
||||||
Anthropic = "Anthropic"
|
Anthropic = "Anthropic"
|
||||||
Ollama = "Ollama"
|
Ollama = "Ollama"
|
||||||
|
Meituan = "Meituan"
|
||||||
|
CometAPI = "CometAPI"
|
||||||
|
SILICONFLOW = "SILICONFLOW"
|
||||||
|
OpenRouter = "OpenRouter"
|
||||||
|
StepFun = "StepFun"
|
||||||
|
PPIO = "PPIO"
|
||||||
|
PerfXCloud = "PerfXCloud"
|
||||||
|
Upstage = "Upstage"
|
||||||
|
NovitaAI = "NovitaAI"
|
||||||
|
Lingyi_AI = "01.AI"
|
||||||
|
GiteeAI = "GiteeAI"
|
||||||
|
AI_302 = "302.AI"
|
||||||
|
|
||||||
|
|
||||||
FACTORY_DEFAULT_BASE_URL = {
|
FACTORY_DEFAULT_BASE_URL = {
|
||||||
@ -44,6 +56,18 @@ FACTORY_DEFAULT_BASE_URL = {
|
|||||||
SupportedLiteLLMProvider.Dashscope: "https://dashscope.aliyuncs.com/compatible-mode/v1",
|
SupportedLiteLLMProvider.Dashscope: "https://dashscope.aliyuncs.com/compatible-mode/v1",
|
||||||
SupportedLiteLLMProvider.Moonshot: "https://api.moonshot.cn/v1",
|
SupportedLiteLLMProvider.Moonshot: "https://api.moonshot.cn/v1",
|
||||||
SupportedLiteLLMProvider.Ollama: "",
|
SupportedLiteLLMProvider.Ollama: "",
|
||||||
|
SupportedLiteLLMProvider.Meituan: "https://api.longcat.chat/openai",
|
||||||
|
SupportedLiteLLMProvider.CometAPI: "https://api.cometapi.com/v1",
|
||||||
|
SupportedLiteLLMProvider.SILICONFLOW: "https://api.siliconflow.cn/v1",
|
||||||
|
SupportedLiteLLMProvider.OpenRouter: "https://openrouter.ai/api/v1",
|
||||||
|
SupportedLiteLLMProvider.StepFun: "https://api.stepfun.com/v1",
|
||||||
|
SupportedLiteLLMProvider.PPIO: "https://api.ppinfra.com/v3/openai",
|
||||||
|
SupportedLiteLLMProvider.PerfXCloud: "https://cloud.perfxlab.cn/v1",
|
||||||
|
SupportedLiteLLMProvider.Upstage: "https://api.upstage.ai/v1/solar",
|
||||||
|
SupportedLiteLLMProvider.NovitaAI: "https://api.novita.ai/v3/openai",
|
||||||
|
SupportedLiteLLMProvider.Lingyi_AI: "https://api.lingyiwanwu.com/v1",
|
||||||
|
SupportedLiteLLMProvider.GiteeAI: "https://ai.gitee.com/v1/",
|
||||||
|
SupportedLiteLLMProvider.AI_302: "https://api.302.ai/v1",
|
||||||
}
|
}
|
||||||
|
|
||||||
|
|
||||||
@ -62,6 +86,18 @@ LITELLM_PROVIDER_PREFIX = {
|
|||||||
SupportedLiteLLMProvider.TogetherAI: "together_ai/",
|
SupportedLiteLLMProvider.TogetherAI: "together_ai/",
|
||||||
SupportedLiteLLMProvider.Anthropic: "", # don't need a prefix
|
SupportedLiteLLMProvider.Anthropic: "", # don't need a prefix
|
||||||
SupportedLiteLLMProvider.Ollama: "ollama_chat/",
|
SupportedLiteLLMProvider.Ollama: "ollama_chat/",
|
||||||
|
SupportedLiteLLMProvider.Meituan: "openai/",
|
||||||
|
SupportedLiteLLMProvider.CometAPI: "openai/",
|
||||||
|
SupportedLiteLLMProvider.SILICONFLOW: "openai/",
|
||||||
|
SupportedLiteLLMProvider.OpenRouter: "openai/",
|
||||||
|
SupportedLiteLLMProvider.StepFun: "openai/",
|
||||||
|
SupportedLiteLLMProvider.PPIO: "openai/",
|
||||||
|
SupportedLiteLLMProvider.PerfXCloud: "openai/",
|
||||||
|
SupportedLiteLLMProvider.Upstage: "openai/",
|
||||||
|
SupportedLiteLLMProvider.NovitaAI: "openai/",
|
||||||
|
SupportedLiteLLMProvider.Lingyi_AI: "openai/",
|
||||||
|
SupportedLiteLLMProvider.GiteeAI: "openai/",
|
||||||
|
SupportedLiteLLMProvider.AI_302: "openai/",
|
||||||
}
|
}
|
||||||
|
|
||||||
ChatModel = globals().get("ChatModel", {})
|
ChatModel = globals().get("ChatModel", {})
|
||||||
|
|||||||
@ -895,25 +895,6 @@ class MistralChat(Base):
|
|||||||
yield total_tokens
|
yield total_tokens
|
||||||
|
|
||||||
|
|
||||||
## openrouter
|
|
||||||
class OpenRouterChat(Base):
|
|
||||||
_FACTORY_NAME = "OpenRouter"
|
|
||||||
|
|
||||||
def __init__(self, key, model_name, base_url="https://openrouter.ai/api/v1", **kwargs):
|
|
||||||
if not base_url:
|
|
||||||
base_url = "https://openrouter.ai/api/v1"
|
|
||||||
super().__init__(key, model_name, base_url, **kwargs)
|
|
||||||
|
|
||||||
|
|
||||||
class StepFunChat(Base):
|
|
||||||
_FACTORY_NAME = "StepFun"
|
|
||||||
|
|
||||||
def __init__(self, key, model_name, base_url="https://api.stepfun.com/v1", **kwargs):
|
|
||||||
if not base_url:
|
|
||||||
base_url = "https://api.stepfun.com/v1"
|
|
||||||
super().__init__(key, model_name, base_url, **kwargs)
|
|
||||||
|
|
||||||
|
|
||||||
class LmStudioChat(Base):
|
class LmStudioChat(Base):
|
||||||
_FACTORY_NAME = "LM-Studio"
|
_FACTORY_NAME = "LM-Studio"
|
||||||
|
|
||||||
@ -936,15 +917,6 @@ class OpenAI_APIChat(Base):
|
|||||||
super().__init__(key, model_name, base_url, **kwargs)
|
super().__init__(key, model_name, base_url, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
class PPIOChat(Base):
|
|
||||||
_FACTORY_NAME = "PPIO"
|
|
||||||
|
|
||||||
def __init__(self, key, model_name, base_url="https://api.ppinfra.com/v3/openai", **kwargs):
|
|
||||||
if not base_url:
|
|
||||||
base_url = "https://api.ppinfra.com/v3/openai"
|
|
||||||
super().__init__(key, model_name, base_url, **kwargs)
|
|
||||||
|
|
||||||
|
|
||||||
class LeptonAIChat(Base):
|
class LeptonAIChat(Base):
|
||||||
_FACTORY_NAME = "LeptonAI"
|
_FACTORY_NAME = "LeptonAI"
|
||||||
|
|
||||||
@ -954,60 +926,6 @@ class LeptonAIChat(Base):
|
|||||||
super().__init__(key, model_name, base_url, **kwargs)
|
super().__init__(key, model_name, base_url, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
class PerfXCloudChat(Base):
|
|
||||||
_FACTORY_NAME = "PerfXCloud"
|
|
||||||
|
|
||||||
def __init__(self, key, model_name, base_url="https://cloud.perfxlab.cn/v1", **kwargs):
|
|
||||||
if not base_url:
|
|
||||||
base_url = "https://cloud.perfxlab.cn/v1"
|
|
||||||
super().__init__(key, model_name, base_url, **kwargs)
|
|
||||||
|
|
||||||
|
|
||||||
class UpstageChat(Base):
|
|
||||||
_FACTORY_NAME = "Upstage"
|
|
||||||
|
|
||||||
def __init__(self, key, model_name, base_url="https://api.upstage.ai/v1/solar", **kwargs):
|
|
||||||
if not base_url:
|
|
||||||
base_url = "https://api.upstage.ai/v1/solar"
|
|
||||||
super().__init__(key, model_name, base_url, **kwargs)
|
|
||||||
|
|
||||||
|
|
||||||
class NovitaAIChat(Base):
|
|
||||||
_FACTORY_NAME = "NovitaAI"
|
|
||||||
|
|
||||||
def __init__(self, key, model_name, base_url="https://api.novita.ai/v3/openai", **kwargs):
|
|
||||||
if not base_url:
|
|
||||||
base_url = "https://api.novita.ai/v3/openai"
|
|
||||||
super().__init__(key, model_name, base_url, **kwargs)
|
|
||||||
|
|
||||||
|
|
||||||
class SILICONFLOWChat(Base):
|
|
||||||
_FACTORY_NAME = "SILICONFLOW"
|
|
||||||
|
|
||||||
def __init__(self, key, model_name, base_url="https://api.siliconflow.cn/v1", **kwargs):
|
|
||||||
if not base_url:
|
|
||||||
base_url = "https://api.siliconflow.cn/v1"
|
|
||||||
super().__init__(key, model_name, base_url, **kwargs)
|
|
||||||
|
|
||||||
|
|
||||||
class YiChat(Base):
|
|
||||||
_FACTORY_NAME = "01.AI"
|
|
||||||
|
|
||||||
def __init__(self, key, model_name, base_url="https://api.lingyiwanwu.com/v1", **kwargs):
|
|
||||||
if not base_url:
|
|
||||||
base_url = "https://api.lingyiwanwu.com/v1"
|
|
||||||
super().__init__(key, model_name, base_url, **kwargs)
|
|
||||||
|
|
||||||
|
|
||||||
class GiteeChat(Base):
|
|
||||||
_FACTORY_NAME = "GiteeAI"
|
|
||||||
|
|
||||||
def __init__(self, key, model_name, base_url="https://ai.gitee.com/v1/", **kwargs):
|
|
||||||
if not base_url:
|
|
||||||
base_url = "https://ai.gitee.com/v1/"
|
|
||||||
super().__init__(key, model_name, base_url, **kwargs)
|
|
||||||
|
|
||||||
|
|
||||||
class ReplicateChat(Base):
|
class ReplicateChat(Base):
|
||||||
_FACTORY_NAME = "Replicate"
|
_FACTORY_NAME = "Replicate"
|
||||||
|
|
||||||
@ -1347,26 +1265,46 @@ class GPUStackChat(Base):
|
|||||||
super().__init__(key, model_name, base_url, **kwargs)
|
super().__init__(key, model_name, base_url, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
class Ai302Chat(Base):
|
class TokenPonyChat(Base):
|
||||||
_FACTORY_NAME = "302.AI"
|
_FACTORY_NAME = "TokenPony"
|
||||||
|
|
||||||
def __init__(self, key, model_name, base_url="https://api.302.ai/v1", **kwargs):
|
def __init__(self, key, model_name, base_url="https://ragflow.vip-api.tokenpony.cn/v1", **kwargs):
|
||||||
if not base_url:
|
if not base_url:
|
||||||
base_url = "https://api.302.ai/v1"
|
base_url = "https://ragflow.vip-api.tokenpony.cn/v1"
|
||||||
super().__init__(key, model_name, base_url, **kwargs)
|
|
||||||
|
|
||||||
|
|
||||||
class MeituanChat(Base):
|
|
||||||
_FACTORY_NAME = "Meituan"
|
|
||||||
|
|
||||||
def __init__(self, key, model_name, base_url="https://api.longcat.chat/openai", **kwargs):
|
|
||||||
if not base_url:
|
|
||||||
base_url = "https://api.longcat.chat/openai"
|
|
||||||
super().__init__(key, model_name, base_url, **kwargs)
|
|
||||||
|
|
||||||
|
|
||||||
class LiteLLMBase(ABC):
|
class LiteLLMBase(ABC):
|
||||||
_FACTORY_NAME = ["Tongyi-Qianwen", "Bedrock", "Moonshot", "xAI", "DeepInfra", "Groq", "Cohere", "Gemini", "DeepSeek", "NVIDIA", "TogetherAI", "Anthropic", "Ollama"]
|
_FACTORY_NAME = [
|
||||||
|
"Tongyi-Qianwen",
|
||||||
|
"Bedrock",
|
||||||
|
"Moonshot",
|
||||||
|
"xAI",
|
||||||
|
"DeepInfra",
|
||||||
|
"Groq",
|
||||||
|
"Cohere",
|
||||||
|
"Gemini",
|
||||||
|
"DeepSeek",
|
||||||
|
"NVIDIA",
|
||||||
|
"TogetherAI",
|
||||||
|
"Anthropic",
|
||||||
|
"Ollama",
|
||||||
|
"Meituan",
|
||||||
|
"CometAPI",
|
||||||
|
"SILICONFLOW",
|
||||||
|
"OpenRouter",
|
||||||
|
"StepFun",
|
||||||
|
"PPIO",
|
||||||
|
"PerfXCloud",
|
||||||
|
"Upstage",
|
||||||
|
"NovitaAI",
|
||||||
|
"01.AI",
|
||||||
|
"GiteeAI",
|
||||||
|
"302.AI",
|
||||||
|
]
|
||||||
|
|
||||||
|
import litellm
|
||||||
|
|
||||||
|
litellm._turn_on_debug()
|
||||||
|
|
||||||
def __init__(self, key, model_name, base_url=None, **kwargs):
|
def __init__(self, key, model_name, base_url=None, **kwargs):
|
||||||
self.timeout = int(os.environ.get("LM_TIMEOUT_SECONDS", 600))
|
self.timeout = int(os.environ.get("LM_TIMEOUT_SECONDS", 600))
|
||||||
@ -1374,7 +1312,7 @@ class LiteLLMBase(ABC):
|
|||||||
self.prefix = LITELLM_PROVIDER_PREFIX.get(self.provider, "")
|
self.prefix = LITELLM_PROVIDER_PREFIX.get(self.provider, "")
|
||||||
self.model_name = f"{self.prefix}{model_name}"
|
self.model_name = f"{self.prefix}{model_name}"
|
||||||
self.api_key = key
|
self.api_key = key
|
||||||
self.base_url = (base_url or FACTORY_DEFAULT_BASE_URL.get(self.provider, "")).rstrip('/')
|
self.base_url = (base_url or FACTORY_DEFAULT_BASE_URL.get(self.provider, "")).rstrip("/")
|
||||||
# Configure retry parameters
|
# Configure retry parameters
|
||||||
self.max_retries = kwargs.get("max_retries", int(os.environ.get("LLM_MAX_RETRIES", 5)))
|
self.max_retries = kwargs.get("max_retries", int(os.environ.get("LLM_MAX_RETRIES", 5)))
|
||||||
self.base_delay = kwargs.get("retry_interval", float(os.environ.get("LLM_BASE_DELAY", 2.0)))
|
self.base_delay = kwargs.get("retry_interval", float(os.environ.get("LLM_BASE_DELAY", 2.0)))
|
||||||
|
|||||||
@ -86,9 +86,10 @@ class DefaultEmbedding(Base):
|
|||||||
with DefaultEmbedding._model_lock:
|
with DefaultEmbedding._model_lock:
|
||||||
import torch
|
import torch
|
||||||
from FlagEmbedding import FlagModel
|
from FlagEmbedding import FlagModel
|
||||||
|
|
||||||
if "CUDA_VISIBLE_DEVICES" in os.environ:
|
if "CUDA_VISIBLE_DEVICES" in os.environ:
|
||||||
input_cuda_visible_devices = os.environ["CUDA_VISIBLE_DEVICES"]
|
input_cuda_visible_devices = os.environ["CUDA_VISIBLE_DEVICES"]
|
||||||
os.environ["CUDA_VISIBLE_DEVICES"] = "0" # handle some issues with multiple GPUs when initializing the model
|
os.environ["CUDA_VISIBLE_DEVICES"] = "0" # handle some issues with multiple GPUs when initializing the model
|
||||||
|
|
||||||
if not DefaultEmbedding._model or model_name != DefaultEmbedding._model_name:
|
if not DefaultEmbedding._model or model_name != DefaultEmbedding._model_name:
|
||||||
try:
|
try:
|
||||||
@ -145,7 +146,7 @@ class OpenAIEmbed(Base):
|
|||||||
ress = []
|
ress = []
|
||||||
total_tokens = 0
|
total_tokens = 0
|
||||||
for i in range(0, len(texts), batch_size):
|
for i in range(0, len(texts), batch_size):
|
||||||
res = self.client.embeddings.create(input=texts[i : i + batch_size], model=self.model_name, encoding_format="float")
|
res = self.client.embeddings.create(input=texts[i : i + batch_size], model=self.model_name, encoding_format="float", extra_body={"drop_params": True})
|
||||||
try:
|
try:
|
||||||
ress.extend([d.embedding for d in res.data])
|
ress.extend([d.embedding for d in res.data])
|
||||||
total_tokens += self.total_token_count(res)
|
total_tokens += self.total_token_count(res)
|
||||||
@ -154,7 +155,7 @@ class OpenAIEmbed(Base):
|
|||||||
return np.array(ress), total_tokens
|
return np.array(ress), total_tokens
|
||||||
|
|
||||||
def encode_queries(self, text):
|
def encode_queries(self, text):
|
||||||
res = self.client.embeddings.create(input=[truncate(text, 8191)], model=self.model_name, encoding_format="float")
|
res = self.client.embeddings.create(input=[truncate(text, 8191)], model=self.model_name, encoding_format="float",extra_body={"drop_params": True})
|
||||||
return np.array(res.data[0].embedding), self.total_token_count(res)
|
return np.array(res.data[0].embedding), self.total_token_count(res)
|
||||||
|
|
||||||
|
|
||||||
@ -472,6 +473,7 @@ class MistralEmbed(Base):
|
|||||||
def encode(self, texts: list):
|
def encode(self, texts: list):
|
||||||
import time
|
import time
|
||||||
import random
|
import random
|
||||||
|
|
||||||
texts = [truncate(t, 8196) for t in texts]
|
texts = [truncate(t, 8196) for t in texts]
|
||||||
batch_size = 16
|
batch_size = 16
|
||||||
ress = []
|
ress = []
|
||||||
@ -495,6 +497,7 @@ class MistralEmbed(Base):
|
|||||||
def encode_queries(self, text):
|
def encode_queries(self, text):
|
||||||
import time
|
import time
|
||||||
import random
|
import random
|
||||||
|
|
||||||
retry_max = 5
|
retry_max = 5
|
||||||
while retry_max > 0:
|
while retry_max > 0:
|
||||||
try:
|
try:
|
||||||
@ -659,7 +662,7 @@ class OpenAI_APIEmbed(OpenAIEmbed):
|
|||||||
def __init__(self, key, model_name, base_url):
|
def __init__(self, key, model_name, base_url):
|
||||||
if not base_url:
|
if not base_url:
|
||||||
raise ValueError("url cannot be None")
|
raise ValueError("url cannot be None")
|
||||||
base_url = urljoin(base_url, "v1")
|
#base_url = urljoin(base_url, "v1")
|
||||||
self.client = OpenAI(api_key=key, base_url=base_url)
|
self.client = OpenAI(api_key=key, base_url=base_url)
|
||||||
self.model_name = model_name.split("___")[0]
|
self.model_name = model_name.split("___")[0]
|
||||||
|
|
||||||
@ -751,7 +754,11 @@ class SILICONFLOWEmbed(Base):
|
|||||||
token_count = 0
|
token_count = 0
|
||||||
for i in range(0, len(texts), batch_size):
|
for i in range(0, len(texts), batch_size):
|
||||||
texts_batch = texts[i : i + batch_size]
|
texts_batch = texts[i : i + batch_size]
|
||||||
texts_batch = [" " if not text.strip() else text for text in texts_batch]
|
if self.model_name in ["BAAI/bge-large-zh-v1.5", "BAAI/bge-large-en-v1.5"]:
|
||||||
|
# limit 512, 340 is almost safe
|
||||||
|
texts_batch = [" " if not text.strip() else truncate(text, 340) for text in texts_batch]
|
||||||
|
else:
|
||||||
|
texts_batch = [" " if not text.strip() else text for text in texts_batch]
|
||||||
|
|
||||||
payload = {
|
payload = {
|
||||||
"model": self.model_name,
|
"model": self.model_name,
|
||||||
@ -954,3 +961,12 @@ class Ai302Embed(Base):
|
|||||||
if not base_url:
|
if not base_url:
|
||||||
base_url = "https://api.302.ai/v1/embeddings"
|
base_url = "https://api.302.ai/v1/embeddings"
|
||||||
super().__init__(key, model_name, base_url)
|
super().__init__(key, model_name, base_url)
|
||||||
|
|
||||||
|
|
||||||
|
class CometEmbed(OpenAIEmbed):
|
||||||
|
_FACTORY_NAME = "CometAPI"
|
||||||
|
|
||||||
|
def __init__(self, key, model_name, base_url="https://api.cometapi.com/v1"):
|
||||||
|
if not base_url:
|
||||||
|
base_url = "https://api.cometapi.com/v1"
|
||||||
|
super().__init__(key, model_name, base_url)
|
||||||
|
|||||||
@ -218,7 +218,7 @@ class GPUStackSeq2txt(Base):
|
|||||||
class GiteeSeq2txt(Base):
|
class GiteeSeq2txt(Base):
|
||||||
_FACTORY_NAME = "GiteeAI"
|
_FACTORY_NAME = "GiteeAI"
|
||||||
|
|
||||||
def __init__(self, key, model_name="whisper-1", base_url="https://ai.gitee.com/v1/"):
|
def __init__(self, key, model_name="whisper-1", base_url="https://ai.gitee.com/v1/", **kwargs):
|
||||||
if not base_url:
|
if not base_url:
|
||||||
base_url = "https://ai.gitee.com/v1/"
|
base_url = "https://ai.gitee.com/v1/"
|
||||||
self.client = OpenAI(api_key=key, base_url=base_url)
|
self.client = OpenAI(api_key=key, base_url=base_url)
|
||||||
@ -234,3 +234,13 @@ class DeepInfraSeq2txt(Base):
|
|||||||
|
|
||||||
self.client = OpenAI(api_key=key, base_url=base_url)
|
self.client = OpenAI(api_key=key, base_url=base_url)
|
||||||
self.model_name = model_name
|
self.model_name = model_name
|
||||||
|
|
||||||
|
|
||||||
|
class CometSeq2txt(Base):
|
||||||
|
_FACTORY_NAME = "CometAPI"
|
||||||
|
|
||||||
|
def __init__(self, key, model_name="whisper-1", base_url="https://api.cometapi.com/v1", **kwargs):
|
||||||
|
if not base_url:
|
||||||
|
base_url = "https://api.cometapi.com/v1"
|
||||||
|
self.client = OpenAI(api_key=key, base_url=base_url)
|
||||||
|
self.model_name = model_name
|
||||||
|
|||||||
@ -394,3 +394,11 @@ class DeepInfraTTS(OpenAITTS):
|
|||||||
if not base_url:
|
if not base_url:
|
||||||
base_url = "https://api.deepinfra.com/v1/openai"
|
base_url = "https://api.deepinfra.com/v1/openai"
|
||||||
super().__init__(key, model_name, base_url, **kwargs)
|
super().__init__(key, model_name, base_url, **kwargs)
|
||||||
|
|
||||||
|
class CometAPITTS(OpenAITTS):
|
||||||
|
_FACTORY_NAME = "CometAPI"
|
||||||
|
|
||||||
|
def __init__(self, key, model_name, base_url="https://api.cometapi.com/v1", **kwargs):
|
||||||
|
if not base_url:
|
||||||
|
base_url = "https://api.cometapi.com/v1"
|
||||||
|
super().__init__(key, model_name, base_url, **kwargs)
|
||||||
|
|||||||
@ -436,4 +436,217 @@ def gen_meta_filter(chat_mdl, meta_data:dict, query: str) -> list:
|
|||||||
return ans
|
return ans
|
||||||
except Exception:
|
except Exception:
|
||||||
logging.exception(f"Loading json failure: {ans}")
|
logging.exception(f"Loading json failure: {ans}")
|
||||||
return []
|
return []
|
||||||
|
|
||||||
|
|
||||||
|
def gen_json(system_prompt:str, user_prompt:str, chat_mdl):
|
||||||
|
_, msg = message_fit_in(form_message(system_prompt, user_prompt), chat_mdl.max_length)
|
||||||
|
ans = chat_mdl.chat(msg[0]["content"], msg[1:])
|
||||||
|
ans = re.sub(r"(^.*</think>|```json\n|```\n*$)", "", ans, flags=re.DOTALL)
|
||||||
|
try:
|
||||||
|
return json_repair.loads(ans)
|
||||||
|
except Exception:
|
||||||
|
logging.exception(f"Loading json failure: {ans}")
|
||||||
|
|
||||||
|
|
||||||
|
TOC_DETECTION = load_prompt("toc_detection")
|
||||||
|
def detect_table_of_contents(page_1024:list[str], chat_mdl):
|
||||||
|
toc_secs = []
|
||||||
|
for i, sec in enumerate(page_1024[:22]):
|
||||||
|
ans = gen_json(PROMPT_JINJA_ENV.from_string(TOC_DETECTION).render(page_txt=sec), "Only JSON please.", chat_mdl)
|
||||||
|
if toc_secs and not ans["exists"]:
|
||||||
|
break
|
||||||
|
toc_secs.append(sec)
|
||||||
|
return toc_secs
|
||||||
|
|
||||||
|
|
||||||
|
TOC_EXTRACTION = load_prompt("toc_extraction")
|
||||||
|
TOC_EXTRACTION_CONTINUE = load_prompt("toc_extraction_continue")
|
||||||
|
def extract_table_of_contents(toc_pages, chat_mdl):
|
||||||
|
if not toc_pages:
|
||||||
|
return []
|
||||||
|
|
||||||
|
return gen_json(PROMPT_JINJA_ENV.from_string(TOC_EXTRACTION).render(toc_page="\n".join(toc_pages)), "Only JSON please.", chat_mdl)
|
||||||
|
|
||||||
|
|
||||||
|
def toc_index_extractor(toc:list[dict], content:str, chat_mdl):
|
||||||
|
tob_extractor_prompt = """
|
||||||
|
You are given a table of contents in a json format and several pages of a document, your job is to add the physical_index to the table of contents in the json format.
|
||||||
|
|
||||||
|
The provided pages contains tags like <physical_index_X> and <physical_index_X> to indicate the physical location of the page X.
|
||||||
|
|
||||||
|
The structure variable is the numeric system which represents the index of the hierarchy section in the table of contents. For example, the first section has structure index 1, the first subsection has structure index 1.1, the second subsection has structure index 1.2, etc.
|
||||||
|
|
||||||
|
The response should be in the following JSON format:
|
||||||
|
[
|
||||||
|
{
|
||||||
|
"structure": <structure index, "x.x.x" or None> (string),
|
||||||
|
"title": <title of the section>,
|
||||||
|
"physical_index": "<physical_index_X>" (keep the format)
|
||||||
|
},
|
||||||
|
...
|
||||||
|
]
|
||||||
|
|
||||||
|
Only add the physical_index to the sections that are in the provided pages.
|
||||||
|
If the title of the section are not in the provided pages, do not add the physical_index to it.
|
||||||
|
Directly return the final JSON structure. Do not output anything else."""
|
||||||
|
|
||||||
|
prompt = tob_extractor_prompt + '\nTable of contents:\n' + json.dumps(toc, ensure_ascii=False, indent=2) + '\nDocument pages:\n' + content
|
||||||
|
return gen_json(prompt, "Only JSON please.", chat_mdl)
|
||||||
|
|
||||||
|
|
||||||
|
TOC_INDEX = load_prompt("toc_index")
|
||||||
|
def table_of_contents_index(toc_arr: list[dict], sections: list[str], chat_mdl):
|
||||||
|
if not toc_arr or not sections:
|
||||||
|
return []
|
||||||
|
|
||||||
|
toc_map = {}
|
||||||
|
for i, it in enumerate(toc_arr):
|
||||||
|
k1 = (it["structure"]+it["title"]).replace(" ", "")
|
||||||
|
k2 = it["title"].strip()
|
||||||
|
if k1 not in toc_map:
|
||||||
|
toc_map[k1] = []
|
||||||
|
if k2 not in toc_map:
|
||||||
|
toc_map[k2] = []
|
||||||
|
toc_map[k1].append(i)
|
||||||
|
toc_map[k2].append(i)
|
||||||
|
|
||||||
|
for it in toc_arr:
|
||||||
|
it["indices"] = []
|
||||||
|
for i, sec in enumerate(sections):
|
||||||
|
sec = sec.strip()
|
||||||
|
if sec.replace(" ", "") in toc_map:
|
||||||
|
for j in toc_map[sec.replace(" ", "")]:
|
||||||
|
toc_arr[j]["indices"].append(i)
|
||||||
|
|
||||||
|
all_pathes = []
|
||||||
|
def dfs(start, path):
|
||||||
|
nonlocal all_pathes
|
||||||
|
if start >= len(toc_arr):
|
||||||
|
if path:
|
||||||
|
all_pathes.append(path)
|
||||||
|
return
|
||||||
|
if not toc_arr[start]["indices"]:
|
||||||
|
dfs(start+1, path)
|
||||||
|
return
|
||||||
|
added = False
|
||||||
|
for j in toc_arr[start]["indices"]:
|
||||||
|
if path and j < path[-1][0]:
|
||||||
|
continue
|
||||||
|
_path = deepcopy(path)
|
||||||
|
_path.append((j, start))
|
||||||
|
added = True
|
||||||
|
dfs(start+1, _path)
|
||||||
|
if not added and path:
|
||||||
|
all_pathes.append(path)
|
||||||
|
|
||||||
|
dfs(0, [])
|
||||||
|
path = max(all_pathes, key=lambda x:len(x))
|
||||||
|
for it in toc_arr:
|
||||||
|
it["indices"] = []
|
||||||
|
for j, i in path:
|
||||||
|
toc_arr[i]["indices"] = [j]
|
||||||
|
print(json.dumps(toc_arr, ensure_ascii=False, indent=2))
|
||||||
|
|
||||||
|
i = 0
|
||||||
|
while i < len(toc_arr):
|
||||||
|
it = toc_arr[i]
|
||||||
|
if it["indices"]:
|
||||||
|
i += 1
|
||||||
|
continue
|
||||||
|
|
||||||
|
if i>0 and toc_arr[i-1]["indices"]:
|
||||||
|
st_i = toc_arr[i-1]["indices"][-1]
|
||||||
|
else:
|
||||||
|
st_i = 0
|
||||||
|
e = i + 1
|
||||||
|
while e <len(toc_arr) and not toc_arr[e]["indices"]:
|
||||||
|
e += 1
|
||||||
|
if e >= len(toc_arr):
|
||||||
|
e = len(sections)
|
||||||
|
else:
|
||||||
|
e = toc_arr[e]["indices"][0]
|
||||||
|
|
||||||
|
for j in range(st_i, min(e+1, len(sections))):
|
||||||
|
ans = gen_json(PROMPT_JINJA_ENV.from_string(TOC_INDEX).render(
|
||||||
|
structure=it["structure"],
|
||||||
|
title=it["title"],
|
||||||
|
text=sections[j]), "Only JSON please.", chat_mdl)
|
||||||
|
if ans["exist"] == "yes":
|
||||||
|
it["indices"].append(j)
|
||||||
|
break
|
||||||
|
|
||||||
|
i += 1
|
||||||
|
|
||||||
|
return toc_arr
|
||||||
|
|
||||||
|
|
||||||
|
def check_if_toc_transformation_is_complete(content, toc, chat_mdl):
|
||||||
|
prompt = """
|
||||||
|
You are given a raw table of contents and a table of contents.
|
||||||
|
Your job is to check if the table of contents is complete.
|
||||||
|
|
||||||
|
Reply format:
|
||||||
|
{{
|
||||||
|
"thinking": <why do you think the cleaned table of contents is complete or not>
|
||||||
|
"completed": "yes" or "no"
|
||||||
|
}}
|
||||||
|
Directly return the final JSON structure. Do not output anything else."""
|
||||||
|
|
||||||
|
prompt = prompt + '\n Raw Table of contents:\n' + content + '\n Cleaned Table of contents:\n' + toc
|
||||||
|
response = gen_json(prompt, "Only JSON please.", chat_mdl)
|
||||||
|
return response['completed']
|
||||||
|
|
||||||
|
|
||||||
|
def toc_transformer(toc_pages, chat_mdl):
|
||||||
|
init_prompt = """
|
||||||
|
You are given a table of contents, You job is to transform the whole table of content into a JSON format included table_of_contents.
|
||||||
|
|
||||||
|
The `structure` is the numeric system which represents the index of the hierarchy section in the table of contents. For example, the first section has structure index 1, the first subsection has structure index 1.1, the second subsection has structure index 1.2, etc.
|
||||||
|
The `title` is a short phrase or a several-words term.
|
||||||
|
|
||||||
|
The response should be in the following JSON format:
|
||||||
|
[
|
||||||
|
{
|
||||||
|
"structure": <structure index, "x.x.x" or None> (string),
|
||||||
|
"title": <title of the section>
|
||||||
|
},
|
||||||
|
...
|
||||||
|
],
|
||||||
|
You should transform the full table of contents in one go.
|
||||||
|
Directly return the final JSON structure, do not output anything else. """
|
||||||
|
|
||||||
|
toc_content = "\n".join(toc_pages)
|
||||||
|
prompt = init_prompt + '\n Given table of contents\n:' + toc_content
|
||||||
|
def clean_toc(arr):
|
||||||
|
for a in arr:
|
||||||
|
a["title"] = re.sub(r"[.·….]{2,}", "", a["title"])
|
||||||
|
last_complete = gen_json(prompt, "Only JSON please.", chat_mdl)
|
||||||
|
if_complete = check_if_toc_transformation_is_complete(toc_content, json.dumps(last_complete, ensure_ascii=False, indent=2), chat_mdl)
|
||||||
|
clean_toc(last_complete)
|
||||||
|
if if_complete == "yes":
|
||||||
|
return last_complete
|
||||||
|
|
||||||
|
while not (if_complete == "yes"):
|
||||||
|
prompt = f"""
|
||||||
|
Your task is to continue the table of contents json structure, directly output the remaining part of the json structure.
|
||||||
|
The response should be in the following JSON format:
|
||||||
|
|
||||||
|
The raw table of contents json structure is:
|
||||||
|
{toc_content}
|
||||||
|
|
||||||
|
The incomplete transformed table of contents json structure is:
|
||||||
|
{json.dumps(last_complete[-24:], ensure_ascii=False, indent=2)}
|
||||||
|
|
||||||
|
Please continue the json structure, directly output the remaining part of the json structure."""
|
||||||
|
new_complete = gen_json(prompt, "Only JSON please.", chat_mdl)
|
||||||
|
if not new_complete or str(last_complete).find(str(new_complete)) >= 0:
|
||||||
|
break
|
||||||
|
clean_toc(new_complete)
|
||||||
|
last_complete.extend(new_complete)
|
||||||
|
if_complete = check_if_toc_transformation_is_complete(toc_content, json.dumps(last_complete, ensure_ascii=False, indent=2), chat_mdl)
|
||||||
|
|
||||||
|
return last_complete
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
29
rag/prompts/toc_detection.md
Normal file
@ -0,0 +1,29 @@
|
|||||||
|
You are an AI assistant designed to analyze text content and detect whether a table of contents (TOC) list exists on the given page. Follow these steps:
|
||||||
|
|
||||||
|
1. **Analyze the Input**: Carefully review the provided text content.
|
||||||
|
2. **Identify Key Features**: Look for common indicators of a TOC, such as:
|
||||||
|
- Section titles or headings paired with page numbers.
|
||||||
|
- Patterns like repeated formatting (e.g., bold/italicized text, dots/dashes between titles and numbers).
|
||||||
|
- Phrases like "Table of Contents," "Contents," or similar headings.
|
||||||
|
- Logical grouping of topics/subtopics with sequential page references.
|
||||||
|
3. **Discern Negative Features**:
|
||||||
|
- The text contains no numbers, or the numbers present are clearly not page references (e.g., dates, statistical figures, phone numbers, version numbers).
|
||||||
|
- The text consists of full, descriptive sentences and paragraphs that form a narrative, present arguments, or explain concepts, rather than succinctly listing topics.
|
||||||
|
- Contains citations with authors, publication years, journal titles, and page ranges (e.g., "Smith, J. (2020). Journal Title, 10(2), 45-67.").
|
||||||
|
- Lists keywords or terms followed by multiple page numbers, often in alphabetical order.
|
||||||
|
- Comprises terms followed by their definitions or explanations.
|
||||||
|
- Labeled with headers like "Appendix A," "Appendix B," etc.
|
||||||
|
- Contains expressive language thanking individuals or organizations for their support or contributions.
|
||||||
|
4. **Evaluate Evidence**: Weigh the presence/absence of these features to determine if the content resembles a TOC.
|
||||||
|
5. **Output Format**: Provide your response in the following JSON structure:
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
"reasoning": "Step-by-step explanation of your analysis based on the features identified." ,
|
||||||
|
"exists": true/false
|
||||||
|
}
|
||||||
|
```
|
||||||
|
6. **DO NOT** output anything else except JSON structure.
|
||||||
|
|
||||||
|
**Input text Content ( Text-Only Extraction ):**
|
||||||
|
{{ page_txt }}
|
||||||
|
|
||||||
53
rag/prompts/toc_extraction.md
Normal file
@ -0,0 +1,53 @@
|
|||||||
|
You are an expert parser and data formatter. Your task is to analyze the provided table of contents (TOC) text and convert it into a valid JSON array of objects.
|
||||||
|
|
||||||
|
**Instructions:**
|
||||||
|
1. Analyze each line of the input TOC.
|
||||||
|
2. For each line, extract the following three pieces of information:
|
||||||
|
* `structure`: The hierarchical index/numbering (e.g., "1", "2.1", "3.2.5", "A.1"). If a line has no visible numbering or structure indicator (like a main "Chapter" title), use `null`.
|
||||||
|
* `title`: The textual title of the section or chapter. This should be the main descriptive text, clean and without the page number.
|
||||||
|
3. Output **only** a valid JSON array. Do not include any other text, explanations, or markdown code block fences (like ```json) in your response.
|
||||||
|
|
||||||
|
**JSON Format:**
|
||||||
|
The output must be a list of objects following this exact schema:
|
||||||
|
```json
|
||||||
|
[
|
||||||
|
{
|
||||||
|
"structure": <structure index, "x.x.x" or None> (string),
|
||||||
|
"title": <title of the section>
|
||||||
|
},
|
||||||
|
...
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
**Input Example:**
|
||||||
|
```
|
||||||
|
Contents
|
||||||
|
1 Introduction to the System ... 1
|
||||||
|
1.1 Overview .... 2
|
||||||
|
1.2 Key Features .... 5
|
||||||
|
2 Installation Guide ....8
|
||||||
|
2.1 Prerequisites ........ 9
|
||||||
|
2.2 Step-by-Step Process ........ 12
|
||||||
|
Appendix A: Specifications ..... 45
|
||||||
|
References ... 47
|
||||||
|
```
|
||||||
|
|
||||||
|
**Expected Output For The Example:**
|
||||||
|
```json
|
||||||
|
[
|
||||||
|
{"structure": null, "title": "Contents"},
|
||||||
|
{"structure": "1", "title": "Introduction to the System"},
|
||||||
|
{"structure": "1.1", "title": "Overview"},
|
||||||
|
{"structure": "1.2", "title": "Key Features"},
|
||||||
|
{"structure": "2", "title": "Installation Guide"},
|
||||||
|
{"structure": "2.1", "title": "Prerequisites"},
|
||||||
|
{"structure": "2.2", "title": "Step-by-Step Process"},
|
||||||
|
{"structure": "A", "title": "Specifications"},
|
||||||
|
{"structure": null, "title": "References"}
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
**Now, process the following TOC input:**
|
||||||
|
```
|
||||||
|
{{ toc_page }}
|
||||||
|
```
|
||||||
60
rag/prompts/toc_extraction_continue.md
Normal file
@ -0,0 +1,60 @@
|
|||||||
|
You are an expert parser and data formatter, currently in the process of building a JSON array from a multi-page table of contents (TOC). Your task is to analyze the new page of content and **append** the new entries to the existing JSON array.
|
||||||
|
|
||||||
|
**Instructions:**
|
||||||
|
1. You will be given two inputs:
|
||||||
|
* `current_page_text`: The text content from the new page of the TOC.
|
||||||
|
* `existing_json`: The valid JSON array you have generated from the previous pages.
|
||||||
|
2. Analyze each line of the `current_page_text` input.
|
||||||
|
3. For each new line, extract the following three pieces of information:
|
||||||
|
* `structure`: The hierarchical index/numbering (e.g., "1", "2.1", "3.2.5"). Use `null` if none exists.
|
||||||
|
* `title`: The clean textual title of the section or chapter.
|
||||||
|
* `page`: The page number on which the section starts. Extract only the number. Use `null` if not present.
|
||||||
|
4. **Append these new entries** to the `existing_json` array. Do not modify, reorder, or delete any of the existing entries.
|
||||||
|
5. Output **only** the complete, updated JSON array. Do not include any other text, explanations, or markdown code block fences (like ```json).
|
||||||
|
|
||||||
|
**JSON Format:**
|
||||||
|
The output must be a valid JSON array following this schema:
|
||||||
|
```json
|
||||||
|
[
|
||||||
|
{
|
||||||
|
"structure": <string or null>,
|
||||||
|
"title": <string>,
|
||||||
|
"page": <number or null>
|
||||||
|
},
|
||||||
|
...
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
**Input Example:**
|
||||||
|
`current_page_text`:
|
||||||
|
```
|
||||||
|
3.2 Advanced Configuration ........... 25
|
||||||
|
3.3 Troubleshooting .................. 28
|
||||||
|
4 User Management .................... 30
|
||||||
|
```
|
||||||
|
|
||||||
|
`existing_json`:
|
||||||
|
```json
|
||||||
|
[
|
||||||
|
{"structure": "1", "title": "Introduction", "page": 1},
|
||||||
|
{"structure": "2", "title": "Installation", "page": 5},
|
||||||
|
{"structure": "3", "title": "Configuration", "page": 12},
|
||||||
|
{"structure": "3.1", "title": "Basic Setup", "page": 15}
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
**Expected Output For The Example:**
|
||||||
|
```json
|
||||||
|
[
|
||||||
|
{"structure": "3.2", "title": "Advanced Configuration", "page": 25},
|
||||||
|
{"structure": "3.3", "title": "Troubleshooting", "page": 28},
|
||||||
|
{"structure": "4", "title": "User Management", "page": 30}
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
**Now, process the following inputs:**
|
||||||
|
`current_page_text`:
|
||||||
|
{{ toc_page }}
|
||||||
|
|
||||||
|
`existing_json`:
|
||||||
|
{{ toc_json }}
|
||||||
20
rag/prompts/toc_index.md
Normal file
@ -0,0 +1,20 @@
|
|||||||
|
You are an expert analyst tasked with matching text content to the title.
|
||||||
|
|
||||||
|
**Instructions:**
|
||||||
|
1. Analyze the given title with its numeric structure index and the provided text.
|
||||||
|
2. Determine whether the title is mentioned as a section tile in the given text.
|
||||||
|
3. Provide a concise, step-by-step reasoning for your decision.
|
||||||
|
4. Output **only** the complete JSON object. Do not include any other text, explanations, or markdown code block fences (like ```json).
|
||||||
|
|
||||||
|
**Output Format:**
|
||||||
|
Your output must be a valid JSON object with the following keys:
|
||||||
|
{
|
||||||
|
"reasoning": "Step-by-step explanation of your analysis.",
|
||||||
|
"exist": "<yes or no>",
|
||||||
|
}
|
||||||
|
|
||||||
|
** The title: **
|
||||||
|
{{ structure }} {{ title }}
|
||||||
|
|
||||||
|
** Given text: **
|
||||||
|
{{ text }}
|
||||||
@ -23,6 +23,7 @@ import time
|
|||||||
|
|
||||||
from api.utils import get_uuid
|
from api.utils import get_uuid
|
||||||
from api.utils.api_utils import timeout
|
from api.utils.api_utils import timeout
|
||||||
|
from api.utils.base64_image import image2id
|
||||||
from api.utils.log_utils import init_root_logger, get_project_base_directory
|
from api.utils.log_utils import init_root_logger, get_project_base_directory
|
||||||
from graphrag.general.index import run_graphrag
|
from graphrag.general.index import run_graphrag
|
||||||
from graphrag.utils import get_llm_cache, set_llm_cache, get_tags_from_cache, set_tags_to_cache
|
from graphrag.utils import get_llm_cache, set_llm_cache, get_tags_from_cache, set_tags_to_cache
|
||||||
@ -37,7 +38,6 @@ import xxhash
|
|||||||
import copy
|
import copy
|
||||||
import re
|
import re
|
||||||
from functools import partial
|
from functools import partial
|
||||||
from io import BytesIO
|
|
||||||
from multiprocessing.context import TimeoutError
|
from multiprocessing.context import TimeoutError
|
||||||
from timeit import default_timer as timer
|
from timeit import default_timer as timer
|
||||||
import tracemalloc
|
import tracemalloc
|
||||||
@ -301,30 +301,8 @@ async def build_chunks(task, progress_callback):
|
|||||||
d["img_id"] = ""
|
d["img_id"] = ""
|
||||||
docs.append(d)
|
docs.append(d)
|
||||||
return
|
return
|
||||||
|
await image2id(d, partial(STORAGE_IMPL.put), task["kb_id"], d["id"])
|
||||||
with BytesIO() as output_buffer:
|
docs.append(d)
|
||||||
if isinstance(d["image"], bytes):
|
|
||||||
output_buffer.write(d["image"])
|
|
||||||
output_buffer.seek(0)
|
|
||||||
else:
|
|
||||||
# If the image is in RGBA mode, convert it to RGB mode before saving it in JPEG format.
|
|
||||||
if d["image"].mode in ("RGBA", "P"):
|
|
||||||
converted_image = d["image"].convert("RGB")
|
|
||||||
#d["image"].close() # Close original image
|
|
||||||
d["image"] = converted_image
|
|
||||||
try:
|
|
||||||
d["image"].save(output_buffer, format='JPEG')
|
|
||||||
except OSError as e:
|
|
||||||
logging.warning(
|
|
||||||
"Saving image of chunk {}/{}/{} got exception, ignore: {}".format(task["location"], task["name"], d["id"], str(e)))
|
|
||||||
|
|
||||||
async with minio_limiter:
|
|
||||||
await trio.to_thread.run_sync(lambda: STORAGE_IMPL.put(task["kb_id"], d["id"], output_buffer.getvalue()))
|
|
||||||
d["img_id"] = "{}-{}".format(task["kb_id"], d["id"])
|
|
||||||
if not isinstance(d["image"], bytes):
|
|
||||||
d["image"].close()
|
|
||||||
del d["image"] # Remove image reference
|
|
||||||
docs.append(d)
|
|
||||||
except Exception:
|
except Exception:
|
||||||
logging.exception(
|
logging.exception(
|
||||||
"Saving image of chunk {}/{}/{} got exception".format(task["location"], task["name"], d["id"]))
|
"Saving image of chunk {}/{}/{} got exception".format(task["location"], task["name"], d["id"]))
|
||||||
|
|||||||
53
sandbox/sandbox_base_image/nodejs/package-lock.json
generated
@ -14,24 +14,24 @@
|
|||||||
},
|
},
|
||||||
"node_modules/asynckit": {
|
"node_modules/asynckit": {
|
||||||
"version": "0.4.0",
|
"version": "0.4.0",
|
||||||
"resolved": "https://registry.npmmirror.com/asynckit/-/asynckit-0.4.0.tgz",
|
"resolved": "https://registry.npmjs.org/asynckit/-/asynckit-0.4.0.tgz",
|
||||||
"integrity": "sha512-Oei9OH4tRh0YqU3GxhX79dM/mwVgvbZJaSNaRk+bshkj0S5cfHcgYakreBjrHwatXKbz+IoIdYLxrKim2MjW0Q==",
|
"integrity": "sha512-Oei9OH4tRh0YqU3GxhX79dM/mwVgvbZJaSNaRk+bshkj0S5cfHcgYakreBjrHwatXKbz+IoIdYLxrKim2MjW0Q==",
|
||||||
"license": "MIT"
|
"license": "MIT"
|
||||||
},
|
},
|
||||||
"node_modules/axios": {
|
"node_modules/axios": {
|
||||||
"version": "1.9.0",
|
"version": "1.12.0",
|
||||||
"resolved": "https://registry.npmmirror.com/axios/-/axios-1.9.0.tgz",
|
"resolved": "https://registry.npmjs.org/axios/-/axios-1.12.0.tgz",
|
||||||
"integrity": "sha512-re4CqKTJaURpzbLHtIi6XpDv20/CnpXOtjRY5/CU32L8gU8ek9UIivcfvSWvmKEngmVbrUtPpdDwWDWL7DNHvg==",
|
"integrity": "sha512-oXTDccv8PcfjZmPGlWsPSwtOJCZ/b6W5jAMCNcfwJbCzDckwG0jrYJFaWH1yvivfCXjVzV/SPDEhMB3Q+DSurg==",
|
||||||
"license": "MIT",
|
"license": "MIT",
|
||||||
"dependencies": {
|
"dependencies": {
|
||||||
"follow-redirects": "^1.15.6",
|
"follow-redirects": "^1.15.6",
|
||||||
"form-data": "^4.0.0",
|
"form-data": "^4.0.4",
|
||||||
"proxy-from-env": "^1.1.0"
|
"proxy-from-env": "^1.1.0"
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"node_modules/call-bind-apply-helpers": {
|
"node_modules/call-bind-apply-helpers": {
|
||||||
"version": "1.0.2",
|
"version": "1.0.2",
|
||||||
"resolved": "https://registry.npmmirror.com/call-bind-apply-helpers/-/call-bind-apply-helpers-1.0.2.tgz",
|
"resolved": "https://registry.npmjs.org/call-bind-apply-helpers/-/call-bind-apply-helpers-1.0.2.tgz",
|
||||||
"integrity": "sha512-Sp1ablJ0ivDkSzjcaJdxEunN5/XvksFJ2sMBFfq6x0ryhQV/2b/KwFe21cMpmHtPOSij8K99/wSfoEuTObmuMQ==",
|
"integrity": "sha512-Sp1ablJ0ivDkSzjcaJdxEunN5/XvksFJ2sMBFfq6x0ryhQV/2b/KwFe21cMpmHtPOSij8K99/wSfoEuTObmuMQ==",
|
||||||
"license": "MIT",
|
"license": "MIT",
|
||||||
"dependencies": {
|
"dependencies": {
|
||||||
@ -44,7 +44,7 @@
|
|||||||
},
|
},
|
||||||
"node_modules/combined-stream": {
|
"node_modules/combined-stream": {
|
||||||
"version": "1.0.8",
|
"version": "1.0.8",
|
||||||
"resolved": "https://registry.npmmirror.com/combined-stream/-/combined-stream-1.0.8.tgz",
|
"resolved": "https://registry.npmjs.org/combined-stream/-/combined-stream-1.0.8.tgz",
|
||||||
"integrity": "sha512-FQN4MRfuJeHf7cBbBMJFXhKSDq+2kAArBlmRBvcvFE5BB1HZKXtSFASDhdlz9zOYwxh8lDdnvmMOe/+5cdoEdg==",
|
"integrity": "sha512-FQN4MRfuJeHf7cBbBMJFXhKSDq+2kAArBlmRBvcvFE5BB1HZKXtSFASDhdlz9zOYwxh8lDdnvmMOe/+5cdoEdg==",
|
||||||
"license": "MIT",
|
"license": "MIT",
|
||||||
"dependencies": {
|
"dependencies": {
|
||||||
@ -56,7 +56,7 @@
|
|||||||
},
|
},
|
||||||
"node_modules/delayed-stream": {
|
"node_modules/delayed-stream": {
|
||||||
"version": "1.0.0",
|
"version": "1.0.0",
|
||||||
"resolved": "https://registry.npmmirror.com/delayed-stream/-/delayed-stream-1.0.0.tgz",
|
"resolved": "https://registry.npmjs.org/delayed-stream/-/delayed-stream-1.0.0.tgz",
|
||||||
"integrity": "sha512-ZySD7Nf91aLB0RxL4KGrKHBXl7Eds1DAmEdcoVawXnLD7SDhpNgtuII2aAkg7a7QS41jxPSZ17p4VdGnMHk3MQ==",
|
"integrity": "sha512-ZySD7Nf91aLB0RxL4KGrKHBXl7Eds1DAmEdcoVawXnLD7SDhpNgtuII2aAkg7a7QS41jxPSZ17p4VdGnMHk3MQ==",
|
||||||
"license": "MIT",
|
"license": "MIT",
|
||||||
"engines": {
|
"engines": {
|
||||||
@ -65,7 +65,7 @@
|
|||||||
},
|
},
|
||||||
"node_modules/dunder-proto": {
|
"node_modules/dunder-proto": {
|
||||||
"version": "1.0.1",
|
"version": "1.0.1",
|
||||||
"resolved": "https://registry.npmmirror.com/dunder-proto/-/dunder-proto-1.0.1.tgz",
|
"resolved": "https://registry.npmjs.org/dunder-proto/-/dunder-proto-1.0.1.tgz",
|
||||||
"integrity": "sha512-KIN/nDJBQRcXw0MLVhZE9iQHmG68qAVIBg9CqmUYjmQIhgij9U5MFvrqkUL5FbtyyzZuOeOt0zdeRe4UY7ct+A==",
|
"integrity": "sha512-KIN/nDJBQRcXw0MLVhZE9iQHmG68qAVIBg9CqmUYjmQIhgij9U5MFvrqkUL5FbtyyzZuOeOt0zdeRe4UY7ct+A==",
|
||||||
"license": "MIT",
|
"license": "MIT",
|
||||||
"dependencies": {
|
"dependencies": {
|
||||||
@ -79,7 +79,7 @@
|
|||||||
},
|
},
|
||||||
"node_modules/es-define-property": {
|
"node_modules/es-define-property": {
|
||||||
"version": "1.0.1",
|
"version": "1.0.1",
|
||||||
"resolved": "https://registry.npmmirror.com/es-define-property/-/es-define-property-1.0.1.tgz",
|
"resolved": "https://registry.npmjs.org/es-define-property/-/es-define-property-1.0.1.tgz",
|
||||||
"integrity": "sha512-e3nRfgfUZ4rNGL232gUgX06QNyyez04KdjFrF+LTRoOXmrOgFKDg4BCdsjW8EnT69eqdYGmRpJwiPVYNrCaW3g==",
|
"integrity": "sha512-e3nRfgfUZ4rNGL232gUgX06QNyyez04KdjFrF+LTRoOXmrOgFKDg4BCdsjW8EnT69eqdYGmRpJwiPVYNrCaW3g==",
|
||||||
"license": "MIT",
|
"license": "MIT",
|
||||||
"engines": {
|
"engines": {
|
||||||
@ -88,7 +88,7 @@
|
|||||||
},
|
},
|
||||||
"node_modules/es-errors": {
|
"node_modules/es-errors": {
|
||||||
"version": "1.3.0",
|
"version": "1.3.0",
|
||||||
"resolved": "https://registry.npmmirror.com/es-errors/-/es-errors-1.3.0.tgz",
|
"resolved": "https://registry.npmjs.org/es-errors/-/es-errors-1.3.0.tgz",
|
||||||
"integrity": "sha512-Zf5H2Kxt2xjTvbJvP2ZWLEICxA6j+hAmMzIlypy4xcBg1vKVnx89Wy0GbS+kf5cwCVFFzdCFh2XSCFNULS6csw==",
|
"integrity": "sha512-Zf5H2Kxt2xjTvbJvP2ZWLEICxA6j+hAmMzIlypy4xcBg1vKVnx89Wy0GbS+kf5cwCVFFzdCFh2XSCFNULS6csw==",
|
||||||
"license": "MIT",
|
"license": "MIT",
|
||||||
"engines": {
|
"engines": {
|
||||||
@ -97,7 +97,7 @@
|
|||||||
},
|
},
|
||||||
"node_modules/es-object-atoms": {
|
"node_modules/es-object-atoms": {
|
||||||
"version": "1.1.1",
|
"version": "1.1.1",
|
||||||
"resolved": "https://registry.npmmirror.com/es-object-atoms/-/es-object-atoms-1.1.1.tgz",
|
"resolved": "https://registry.npmjs.org/es-object-atoms/-/es-object-atoms-1.1.1.tgz",
|
||||||
"integrity": "sha512-FGgH2h8zKNim9ljj7dankFPcICIK9Cp5bm+c2gQSYePhpaG5+esrLODihIorn+Pe6FGJzWhXQotPv73jTaldXA==",
|
"integrity": "sha512-FGgH2h8zKNim9ljj7dankFPcICIK9Cp5bm+c2gQSYePhpaG5+esrLODihIorn+Pe6FGJzWhXQotPv73jTaldXA==",
|
||||||
"license": "MIT",
|
"license": "MIT",
|
||||||
"dependencies": {
|
"dependencies": {
|
||||||
@ -109,7 +109,7 @@
|
|||||||
},
|
},
|
||||||
"node_modules/es-set-tostringtag": {
|
"node_modules/es-set-tostringtag": {
|
||||||
"version": "2.1.0",
|
"version": "2.1.0",
|
||||||
"resolved": "https://registry.npmmirror.com/es-set-tostringtag/-/es-set-tostringtag-2.1.0.tgz",
|
"resolved": "https://registry.npmjs.org/es-set-tostringtag/-/es-set-tostringtag-2.1.0.tgz",
|
||||||
"integrity": "sha512-j6vWzfrGVfyXxge+O0x5sh6cvxAog0a/4Rdd2K36zCMV5eJ+/+tOAngRO8cODMNWbVRdVlmGZQL2YS3yR8bIUA==",
|
"integrity": "sha512-j6vWzfrGVfyXxge+O0x5sh6cvxAog0a/4Rdd2K36zCMV5eJ+/+tOAngRO8cODMNWbVRdVlmGZQL2YS3yR8bIUA==",
|
||||||
"license": "MIT",
|
"license": "MIT",
|
||||||
"dependencies": {
|
"dependencies": {
|
||||||
@ -143,14 +143,15 @@
|
|||||||
}
|
}
|
||||||
},
|
},
|
||||||
"node_modules/form-data": {
|
"node_modules/form-data": {
|
||||||
"version": "4.0.2",
|
"version": "4.0.4",
|
||||||
"resolved": "https://registry.npmmirror.com/form-data/-/form-data-4.0.2.tgz",
|
"resolved": "https://registry.npmjs.org/form-data/-/form-data-4.0.4.tgz",
|
||||||
"integrity": "sha512-hGfm/slu0ZabnNt4oaRZ6uREyfCj6P4fT/n6A1rGV+Z0VdGXjfOhVUpkn6qVQONHGIFwmveGXyDs75+nr6FM8w==",
|
"integrity": "sha512-KrGhL9Q4zjj0kiUt5OO4Mr/A/jlI2jDYs5eHBpYHPcBEVSiipAvn2Ko2HnPe20rmcuuvMHNdZFp+4IlGTMF0Ow==",
|
||||||
"license": "MIT",
|
"license": "MIT",
|
||||||
"dependencies": {
|
"dependencies": {
|
||||||
"asynckit": "^0.4.0",
|
"asynckit": "^0.4.0",
|
||||||
"combined-stream": "^1.0.8",
|
"combined-stream": "^1.0.8",
|
||||||
"es-set-tostringtag": "^2.1.0",
|
"es-set-tostringtag": "^2.1.0",
|
||||||
|
"hasown": "^2.0.2",
|
||||||
"mime-types": "^2.1.12"
|
"mime-types": "^2.1.12"
|
||||||
},
|
},
|
||||||
"engines": {
|
"engines": {
|
||||||
@ -159,7 +160,7 @@
|
|||||||
},
|
},
|
||||||
"node_modules/function-bind": {
|
"node_modules/function-bind": {
|
||||||
"version": "1.1.2",
|
"version": "1.1.2",
|
||||||
"resolved": "https://registry.npmmirror.com/function-bind/-/function-bind-1.1.2.tgz",
|
"resolved": "https://registry.npmjs.org/function-bind/-/function-bind-1.1.2.tgz",
|
||||||
"integrity": "sha512-7XHNxH7qX9xG5mIwxkhumTox/MIRNcOgDrxWsMt2pAr23WHp6MrRlN7FBSFpCpr+oVO0F744iUgR82nJMfG2SA==",
|
"integrity": "sha512-7XHNxH7qX9xG5mIwxkhumTox/MIRNcOgDrxWsMt2pAr23WHp6MrRlN7FBSFpCpr+oVO0F744iUgR82nJMfG2SA==",
|
||||||
"license": "MIT",
|
"license": "MIT",
|
||||||
"funding": {
|
"funding": {
|
||||||
@ -168,7 +169,7 @@
|
|||||||
},
|
},
|
||||||
"node_modules/get-intrinsic": {
|
"node_modules/get-intrinsic": {
|
||||||
"version": "1.3.0",
|
"version": "1.3.0",
|
||||||
"resolved": "https://registry.npmmirror.com/get-intrinsic/-/get-intrinsic-1.3.0.tgz",
|
"resolved": "https://registry.npmjs.org/get-intrinsic/-/get-intrinsic-1.3.0.tgz",
|
||||||
"integrity": "sha512-9fSjSaos/fRIVIp+xSJlE6lfwhES7LNtKaCBIamHsjr2na1BiABJPo0mOjjz8GJDURarmCPGqaiVg5mfjb98CQ==",
|
"integrity": "sha512-9fSjSaos/fRIVIp+xSJlE6lfwhES7LNtKaCBIamHsjr2na1BiABJPo0mOjjz8GJDURarmCPGqaiVg5mfjb98CQ==",
|
||||||
"license": "MIT",
|
"license": "MIT",
|
||||||
"dependencies": {
|
"dependencies": {
|
||||||
@ -192,7 +193,7 @@
|
|||||||
},
|
},
|
||||||
"node_modules/get-proto": {
|
"node_modules/get-proto": {
|
||||||
"version": "1.0.1",
|
"version": "1.0.1",
|
||||||
"resolved": "https://registry.npmmirror.com/get-proto/-/get-proto-1.0.1.tgz",
|
"resolved": "https://registry.npmjs.org/get-proto/-/get-proto-1.0.1.tgz",
|
||||||
"integrity": "sha512-sTSfBjoXBp89JvIKIefqw7U2CCebsc74kiY6awiGogKtoSGbgjYE/G/+l9sF3MWFPNc9IcoOC4ODfKHfxFmp0g==",
|
"integrity": "sha512-sTSfBjoXBp89JvIKIefqw7U2CCebsc74kiY6awiGogKtoSGbgjYE/G/+l9sF3MWFPNc9IcoOC4ODfKHfxFmp0g==",
|
||||||
"license": "MIT",
|
"license": "MIT",
|
||||||
"dependencies": {
|
"dependencies": {
|
||||||
@ -205,7 +206,7 @@
|
|||||||
},
|
},
|
||||||
"node_modules/gopd": {
|
"node_modules/gopd": {
|
||||||
"version": "1.2.0",
|
"version": "1.2.0",
|
||||||
"resolved": "https://registry.npmmirror.com/gopd/-/gopd-1.2.0.tgz",
|
"resolved": "https://registry.npmjs.org/gopd/-/gopd-1.2.0.tgz",
|
||||||
"integrity": "sha512-ZUKRh6/kUFoAiTAtTYPZJ3hw9wNxx+BIBOijnlG9PnrJsCcSjs1wyyD6vJpaYtgnzDrKYRSqf3OO6Rfa93xsRg==",
|
"integrity": "sha512-ZUKRh6/kUFoAiTAtTYPZJ3hw9wNxx+BIBOijnlG9PnrJsCcSjs1wyyD6vJpaYtgnzDrKYRSqf3OO6Rfa93xsRg==",
|
||||||
"license": "MIT",
|
"license": "MIT",
|
||||||
"engines": {
|
"engines": {
|
||||||
@ -217,7 +218,7 @@
|
|||||||
},
|
},
|
||||||
"node_modules/has-symbols": {
|
"node_modules/has-symbols": {
|
||||||
"version": "1.1.0",
|
"version": "1.1.0",
|
||||||
"resolved": "https://registry.npmmirror.com/has-symbols/-/has-symbols-1.1.0.tgz",
|
"resolved": "https://registry.npmjs.org/has-symbols/-/has-symbols-1.1.0.tgz",
|
||||||
"integrity": "sha512-1cDNdwJ2Jaohmb3sg4OmKaMBwuC48sYni5HUw2DvsC8LjGTLK9h+eb1X6RyuOHe4hT0ULCW68iomhjUoKUqlPQ==",
|
"integrity": "sha512-1cDNdwJ2Jaohmb3sg4OmKaMBwuC48sYni5HUw2DvsC8LjGTLK9h+eb1X6RyuOHe4hT0ULCW68iomhjUoKUqlPQ==",
|
||||||
"license": "MIT",
|
"license": "MIT",
|
||||||
"engines": {
|
"engines": {
|
||||||
@ -229,7 +230,7 @@
|
|||||||
},
|
},
|
||||||
"node_modules/has-tostringtag": {
|
"node_modules/has-tostringtag": {
|
||||||
"version": "1.0.2",
|
"version": "1.0.2",
|
||||||
"resolved": "https://registry.npmmirror.com/has-tostringtag/-/has-tostringtag-1.0.2.tgz",
|
"resolved": "https://registry.npmjs.org/has-tostringtag/-/has-tostringtag-1.0.2.tgz",
|
||||||
"integrity": "sha512-NqADB8VjPFLM2V0VvHUewwwsw0ZWBaIdgo+ieHtK3hasLz4qeCRjYcqfB6AQrBggRKppKF8L52/VqdVsO47Dlw==",
|
"integrity": "sha512-NqADB8VjPFLM2V0VvHUewwwsw0ZWBaIdgo+ieHtK3hasLz4qeCRjYcqfB6AQrBggRKppKF8L52/VqdVsO47Dlw==",
|
||||||
"license": "MIT",
|
"license": "MIT",
|
||||||
"dependencies": {
|
"dependencies": {
|
||||||
@ -244,7 +245,7 @@
|
|||||||
},
|
},
|
||||||
"node_modules/hasown": {
|
"node_modules/hasown": {
|
||||||
"version": "2.0.2",
|
"version": "2.0.2",
|
||||||
"resolved": "https://registry.npmmirror.com/hasown/-/hasown-2.0.2.tgz",
|
"resolved": "https://registry.npmjs.org/hasown/-/hasown-2.0.2.tgz",
|
||||||
"integrity": "sha512-0hJU9SCPvmMzIBdZFqNPXWa6dqh7WdH0cII9y+CyS8rG3nL48Bclra9HmKhVVUHyPWNH5Y7xDwAB7bfgSjkUMQ==",
|
"integrity": "sha512-0hJU9SCPvmMzIBdZFqNPXWa6dqh7WdH0cII9y+CyS8rG3nL48Bclra9HmKhVVUHyPWNH5Y7xDwAB7bfgSjkUMQ==",
|
||||||
"license": "MIT",
|
"license": "MIT",
|
||||||
"dependencies": {
|
"dependencies": {
|
||||||
@ -256,7 +257,7 @@
|
|||||||
},
|
},
|
||||||
"node_modules/math-intrinsics": {
|
"node_modules/math-intrinsics": {
|
||||||
"version": "1.1.0",
|
"version": "1.1.0",
|
||||||
"resolved": "https://registry.npmmirror.com/math-intrinsics/-/math-intrinsics-1.1.0.tgz",
|
"resolved": "https://registry.npmjs.org/math-intrinsics/-/math-intrinsics-1.1.0.tgz",
|
||||||
"integrity": "sha512-/IXtbwEk5HTPyEwyKX6hGkYXxM9nbj64B+ilVJnC/R6B0pH5G4V3b0pVbL7DBj4tkhBAppbQUlf6F6Xl9LHu1g==",
|
"integrity": "sha512-/IXtbwEk5HTPyEwyKX6hGkYXxM9nbj64B+ilVJnC/R6B0pH5G4V3b0pVbL7DBj4tkhBAppbQUlf6F6Xl9LHu1g==",
|
||||||
"license": "MIT",
|
"license": "MIT",
|
||||||
"engines": {
|
"engines": {
|
||||||
@ -265,7 +266,7 @@
|
|||||||
},
|
},
|
||||||
"node_modules/mime-db": {
|
"node_modules/mime-db": {
|
||||||
"version": "1.52.0",
|
"version": "1.52.0",
|
||||||
"resolved": "https://registry.npmmirror.com/mime-db/-/mime-db-1.52.0.tgz",
|
"resolved": "https://registry.npmjs.org/mime-db/-/mime-db-1.52.0.tgz",
|
||||||
"integrity": "sha512-sPU4uV7dYlvtWJxwwxHD0PuihVNiE7TyAbQ5SWxDCB9mUYvOgroQOwYQQOKPJ8CIbE+1ETVlOoK1UC2nU3gYvg==",
|
"integrity": "sha512-sPU4uV7dYlvtWJxwwxHD0PuihVNiE7TyAbQ5SWxDCB9mUYvOgroQOwYQQOKPJ8CIbE+1ETVlOoK1UC2nU3gYvg==",
|
||||||
"license": "MIT",
|
"license": "MIT",
|
||||||
"engines": {
|
"engines": {
|
||||||
@ -274,7 +275,7 @@
|
|||||||
},
|
},
|
||||||
"node_modules/mime-types": {
|
"node_modules/mime-types": {
|
||||||
"version": "2.1.35",
|
"version": "2.1.35",
|
||||||
"resolved": "https://registry.npmmirror.com/mime-types/-/mime-types-2.1.35.tgz",
|
"resolved": "https://registry.npmjs.org/mime-types/-/mime-types-2.1.35.tgz",
|
||||||
"integrity": "sha512-ZDY+bPm5zTTF+YpCrAU9nK0UgICYPT0QtT1NZWFv4s++TNkcgVaT0g6+4R2uI4MjQjzysHB1zxuWL50hzaeXiw==",
|
"integrity": "sha512-ZDY+bPm5zTTF+YpCrAU9nK0UgICYPT0QtT1NZWFv4s++TNkcgVaT0g6+4R2uI4MjQjzysHB1zxuWL50hzaeXiw==",
|
||||||
"license": "MIT",
|
"license": "MIT",
|
||||||
"dependencies": {
|
"dependencies": {
|
||||||
|
|||||||
15
web/src/assets/svg/data-flow/data-icon-bri.svg
Normal file
{kind=link}
@ -0,0 +1,15 @@
|
|||||||
|
<svg width="40" height="40" viewBox="0 0 40 40" fill="none" xmlns="http://www.w3.org/2000/svg">
|
||||||
|
<path d="M35.3194 10.6367H20.4258C19.4857 10.6367 18.7236 11.3988 18.7236 12.3388V34.892C18.7236 35.8321 19.4857 36.5942 20.4258 36.5942H35.3194C36.2594 36.5942 37.0215 35.8321 37.0215 34.892V12.3388C37.0215 11.3988 36.2594 10.6367 35.3194 10.6367Z" fill="url(#paint0_linear_488_37636)"/>
|
||||||
|
<path d="M31.0639 4.25391H5.10642C4.16637 4.25391 3.4043 5.01597 3.4043 5.95603V18.2965C3.4043 19.2365 4.16637 19.9986 5.10642 19.9986H31.0639C32.0039 19.9986 32.766 19.2365 32.766 18.2965V5.95603C32.766 5.01597 32.0039 4.25391 31.0639 4.25391Z" fill="#00BEB4" fill-opacity="0.1"/>
|
||||||
|
<path d="M31.0639 4.25391C32.0039 4.25391 32.766 5.01597 32.766 5.95603V18.2965C32.766 19.2365 32.0039 19.9986 31.0639 19.9986H5.10642C4.16637 19.9986 3.4043 19.2365 3.4043 18.2965V5.95603C3.4043 5.01597 4.16637 4.25391 5.10642 4.25391H31.0639ZM31.0639 4.67944H5.10642C4.40138 4.67944 3.82983 5.25099 3.82983 5.95603V18.2965C3.82983 19.0015 4.40138 19.5731 5.10642 19.5731H31.0639C31.7689 19.5731 32.3405 19.0015 32.3405 18.2965V5.95603C32.3405 5.25099 31.7689 4.67944 31.0639 4.67944Z" fill="#00BEB4"/>
|
||||||
|
<path d="M31.0639 22.5547H5.10642C4.16637 22.5547 3.4043 23.3168 3.4043 24.2568V34.8951C3.4043 35.8352 4.16637 36.5972 5.10642 36.5972H31.0639C32.0039 36.5972 32.766 35.8352 32.766 34.8951V24.2568C32.766 23.3168 32.0039 22.5547 31.0639 22.5547Z" fill="#00BEB4" fill-opacity="0.1"/>
|
||||||
|
<path d="M31.0639 22.5547C32.0039 22.5547 32.766 23.3168 32.766 24.2568V34.8951C32.766 35.8352 32.0039 36.5972 31.0639 36.5972H5.10642C4.16637 36.5972 3.4043 35.8352 3.4043 34.8951V24.2568C3.4043 23.3168 4.16637 22.5547 5.10642 22.5547H31.0639ZM31.0639 22.9802H5.10642C4.40138 22.9802 3.82983 23.5518 3.82983 24.2568V34.8951C3.82983 35.6002 4.40138 36.1717 5.10642 36.1717H31.0639C31.7689 36.1717 32.3405 35.6002 32.3405 34.8951V24.2568C32.3405 23.5518 31.7689 22.9802 31.0639 22.9802Z" fill="#00BEB4"/>
|
||||||
|
<path d="M10.6384 14.8949C12.2835 14.8949 13.6171 13.5613 13.6171 11.9162C13.6171 10.2711 12.2835 8.9375 10.6384 8.9375C8.99329 8.9375 7.65967 10.2711 7.65967 11.9162C7.65967 13.5613 8.99329 14.8949 10.6384 14.8949Z" fill="#00BEB4"/>
|
||||||
|
<path d="M10.6384 32.766C12.2835 32.766 13.6171 31.4324 13.6171 29.7873C13.6171 28.1422 12.2835 26.8086 10.6384 26.8086C8.99329 26.8086 7.65967 28.1422 7.65967 29.7873C7.65967 31.4324 8.99329 32.766 10.6384 32.766Z" fill="#00BEB4"/>
|
||||||
|
<defs>
|
||||||
|
<linearGradient id="paint0_linear_488_37636" x1="933.617" y1="10.6367" x2="933.617" y2="2606.38" gradientUnits="userSpaceOnUse">
|
||||||
|
<stop stop-color="#C9F1EF"/>
|
||||||
|
<stop offset="1" stop-color="#00BEB4"/>
|
||||||
|
</linearGradient>
|
||||||
|
</defs>
|
||||||
|
</svg>
|
||||||
|
After Width: | Height: | Size: 2.6 KiB |
15
web/src/assets/svg/data-flow/data-icon.svg
Normal file
{kind=link}
@ -0,0 +1,15 @@
|
|||||||
|
<svg width="40" height="40" viewBox="0 0 40 40" fill="none" xmlns="http://www.w3.org/2000/svg">
|
||||||
|
<path d="M35.3194 10.6387H20.4258C19.4857 10.6387 18.7236 11.4007 18.7236 12.3408V34.894C18.7236 35.834 19.4857 36.5961 20.4258 36.5961H35.3194C36.2594 36.5961 37.0215 35.834 37.0215 34.894V12.3408C37.0215 11.4007 36.2594 10.6387 35.3194 10.6387Z" fill="url(#paint0_linear_491_41413)"/>
|
||||||
|
<path d="M31.0639 4.25586H5.10642C4.16637 4.25586 3.4043 5.01793 3.4043 5.95799V18.2984C3.4043 19.2385 4.16637 20.0005 5.10642 20.0005H31.0639C32.0039 20.0005 32.766 19.2385 32.766 18.2984V5.95799C32.766 5.01793 32.0039 4.25586 31.0639 4.25586Z" fill="#00BEB4" fill-opacity="0.2"/>
|
||||||
|
<path d="M31.0639 4.25586C32.0039 4.25586 32.766 5.01793 32.766 5.95799V18.2984C32.766 19.2385 32.0039 20.0005 31.0639 20.0005H5.10642C4.16637 20.0005 3.4043 19.2385 3.4043 18.2984V5.95799C3.4043 5.01793 4.16637 4.25586 5.10642 4.25586H31.0639ZM31.0639 4.68139H5.10642C4.40138 4.68139 3.82983 5.25294 3.82983 5.95799V18.2984C3.82983 19.0035 4.40138 19.575 5.10642 19.575H31.0639C31.7689 19.575 32.3405 19.0035 32.3405 18.2984V5.95799C32.3405 5.25294 31.7689 4.68139 31.0639 4.68139Z" fill="#226365"/>
|
||||||
|
<path d="M31.0639 22.5527H5.10642C4.16637 22.5527 3.4043 23.3148 3.4043 24.2549V34.8932C3.4043 35.8332 4.16637 36.5953 5.10642 36.5953H31.0639C32.0039 36.5953 32.766 35.8332 32.766 34.8932V24.2549C32.766 23.3148 32.0039 22.5527 31.0639 22.5527Z" fill="#3A9093" fill-opacity="0.2"/>
|
||||||
|
<path d="M31.0639 22.5527C32.0039 22.5527 32.766 23.3148 32.766 24.2549V34.8932C32.766 35.8332 32.0039 36.5953 31.0639 36.5953H5.10642C4.16637 36.5953 3.4043 35.8332 3.4043 34.8932V24.2549C3.4043 23.3148 4.16637 22.5527 5.10642 22.5527H31.0639ZM31.0639 22.9783H5.10642C4.40138 22.9783 3.82983 23.5498 3.82983 24.2549V34.8932C3.82983 35.5982 4.40138 36.1698 5.10642 36.1698H31.0639C31.7689 36.1698 32.3405 35.5982 32.3405 34.8932V24.2549C32.3405 23.5498 31.7689 22.9783 31.0639 22.9783Z" fill="#226365"/>
|
||||||
|
<path d="M10.6384 14.893C12.2835 14.893 13.6171 13.5594 13.6171 11.9143C13.6171 10.2692 12.2835 8.93555 10.6384 8.93555C8.99329 8.93555 7.65967 10.2692 7.65967 11.9143C7.65967 13.5594 8.99329 14.893 10.6384 14.893Z" fill="#3A9093"/>
|
||||||
|
<path d="M10.6384 32.766C12.2835 32.766 13.6171 31.4324 13.6171 29.7873C13.6171 28.1422 12.2835 26.8086 10.6384 26.8086C8.99329 26.8086 7.65967 28.1422 7.65967 29.7873C7.65967 31.4324 8.99329 32.766 10.6384 32.766Z" fill="#3A9093"/>
|
||||||
|
<defs>
|
||||||
|
<linearGradient id="paint0_linear_491_41413" x1="933.617" y1="10.6387" x2="933.617" y2="2606.38" gradientUnits="userSpaceOnUse">
|
||||||
|
<stop stop-color="#1B3C3D"/>
|
||||||
|
<stop offset="1" stop-color="#164142"/>
|
||||||
|
</linearGradient>
|
||||||
|
</defs>
|
||||||
|
</svg>
|
||||||
|
After Width: | Height: | Size: 2.6 KiB |
{kind=link}
@ -1 +0,0 @@
|
|||||||
<?xml version="1.0" standalone="no"?><!DOCTYPE svg PUBLIC "-//W3C//DTD SVG 1.1//EN" "http://www.w3.org/Graphics/SVG/1.1/DTD/svg11.dtd"><svg t="1756884949583" class="icon" viewBox="0 0 1024 1024" version="1.1" xmlns="http://www.w3.org/2000/svg" p-id="11332" xmlns:xlink="http://www.w3.org/1999/xlink" width="200" height="200"><path d="M190.464 489.472h327.68v40.96h-327.68z" fill="#C7DCFE" p-id="11333"></path><path d="M482.34496 516.5056l111.26784-308.20352 38.54336 13.9264L520.86784 530.432z" fill="#C7DCFE" p-id="11334"></path><path d="M620.544 196.608m-122.88 0a122.88 122.88 0 1 0 245.76 0 122.88 122.88 0 1 0-245.76 0Z" fill="#8FB8FC" p-id="11335"></path><path d="M182.272 509.952m-122.88 0a122.88 122.88 0 1 0 245.76 0 122.88 122.88 0 1 0-245.76 0Z" fill="#C7DCFE" p-id="11336"></path><path d="M558.65344 520.9088l283.77088 163.84-20.48 35.47136-283.77088-163.84z" fill="#C7DCFE" p-id="11337"></path><path d="M841.728 686.08m-122.88 0a122.88 122.88 0 1 0 245.76 0 122.88 122.88 0 1 0-245.76 0Z" fill="#B3CEFE" p-id="11338"></path><path d="M448.67584 803.77856l49.60256-323.91168 40.48896 6.20544-49.60256 323.91168z" fill="#C7DCFE" p-id="11339"></path><path d="M512 530.432m-143.36 0a143.36 143.36 0 1 0 286.72 0 143.36 143.36 0 1 0-286.72 0Z" fill="#4185FF" p-id="11340"></path><path d="M462.848 843.776m-102.4 0a102.4 102.4 0 1 0 204.8 0 102.4 102.4 0 1 0-204.8 0Z" fill="#8FB8FC" p-id="11341"></path></svg>
|
|
||||||
|
Before Width: | Height: | Size: 1.4 KiB |
6
web/src/assets/svg/data-flow/processing-icon-bri.svg
Normal file
{kind=link}
@ -0,0 +1,6 @@
|
|||||||
|
<svg width="40" height="40" viewBox="0 0 40 40" fill="none" xmlns="http://www.w3.org/2000/svg">
|
||||||
|
<path fill-rule="evenodd" clip-rule="evenodd" d="M21.8074 21.9283L30.4051 33.9033C30.9531 34.667 30.7785 35.7307 30.0148 36.2787C29.7258 36.4865 29.3785 36.5982 29.0223 36.5982H11.8273C10.8871 36.5982 10.125 35.8361 10.125 34.8963C10.125 34.54 10.2367 34.1928 10.4445 33.9033L19.0422 21.9283C19.5902 21.1646 20.6539 20.99 21.4176 21.5385C21.5676 21.6463 21.6996 21.7779 21.8074 21.9283Z" fill="#C6EFED"/>
|
||||||
|
<path fill-rule="evenodd" clip-rule="evenodd" d="M5.94336 3.39844H34.0285C35.9086 3.39844 37.4328 4.92266 37.4328 6.80273V27.2281C37.4328 29.1082 35.9086 30.6324 34.0285 30.6324H5.94336C4.06328 30.6324 2.53906 29.1082 2.53906 27.2281V6.80273C2.53906 4.92266 4.06328 3.39844 5.94336 3.39844Z" fill="#00BEB4" fill-opacity="0.2"/>
|
||||||
|
<path d="M34.0422 3.40625C35.9223 3.40625 37.4465 4.93047 37.4465 6.81055V27.2359C37.4465 29.116 35.9223 30.6402 34.0422 30.6402H5.95703C4.07695 30.6402 2.55273 29.116 2.55273 27.2359V6.81055C2.55273 4.93047 4.07695 3.40625 5.95703 3.40625H34.0422ZM34.0422 3.83164H5.95703C4.31211 3.83164 2.97852 5.16523 2.97852 6.81055V27.2359C2.97852 28.8812 4.31211 30.2148 5.95703 30.2148H34.0422C35.6871 30.2148 37.0207 28.8812 37.0207 27.2359V6.81055C37.0207 5.16523 35.6871 3.83164 34.0422 3.83164Z" fill="#00BEB4"/>
|
||||||
|
<path fill-rule="evenodd" clip-rule="evenodd" d="M19.9785 11.6797C20.6836 11.6797 21.2551 12.2512 21.2551 12.9562V21.0414C21.2551 21.7465 20.6836 22.318 19.9785 22.318C19.2734 22.318 18.702 21.7465 18.702 21.0414V12.9562C18.702 12.2512 19.2734 11.6797 19.9785 11.6797ZM11.0422 11.6797C11.7473 11.6797 12.3187 12.2512 12.3187 12.9562V21.0414C12.3187 21.7465 11.7473 22.318 11.0422 22.318C10.3371 22.318 9.76562 21.7465 9.76562 21.0414V12.9562C9.76562 12.2512 10.3371 11.6797 11.0422 11.6797ZM28.9145 11.6797C29.6195 11.6797 30.191 12.2512 30.191 12.9562V21.0414C30.191 21.7465 29.6195 22.318 28.9145 22.318C28.2094 22.318 27.6379 21.7465 27.6379 21.0414V12.9562C27.6379 12.2512 28.2094 11.6797 28.9145 11.6797Z" fill="#00BEB4"/>
|
||||||
|
</svg>
|
||||||
|
After Width: | Height: | Size: 2.0 KiB |
6
web/src/assets/svg/data-flow/processing-icon.svg
Normal file
{kind=link}
@ -0,0 +1,6 @@
|
|||||||
|
<svg width="40" height="40" viewBox="0 0 40 40" fill="none" xmlns="http://www.w3.org/2000/svg">
|
||||||
|
<path fill-rule="evenodd" clip-rule="evenodd" d="M21.8074 21.9264L30.4051 33.9014C30.9531 34.665 30.7785 35.7287 30.0148 36.2767C29.7258 36.4846 29.3785 36.5963 29.0223 36.5963H11.8273C10.8871 36.5963 10.125 35.8342 10.125 34.8943C10.125 34.5381 10.2367 34.1908 10.4445 33.9014L19.0422 21.9264C19.5902 21.1627 20.6539 20.9881 21.4176 21.5365C21.5676 21.6443 21.6996 21.776 21.8074 21.9264Z" fill="#1C3C3D"/>
|
||||||
|
<path fill-rule="evenodd" clip-rule="evenodd" d="M5.94336 3.39844H34.0285C35.9086 3.39844 37.4328 4.92266 37.4328 6.80273V27.2281C37.4328 29.1082 35.9086 30.6324 34.0285 30.6324H5.94336C4.06328 30.6324 2.53906 29.1082 2.53906 27.2281V6.80273C2.53906 4.92266 4.06328 3.39844 5.94336 3.39844Z" fill="#00BEB4" fill-opacity="0.2"/>
|
||||||
|
<path d="M34.0422 3.4043C35.9223 3.4043 37.4465 4.92852 37.4465 6.80859V27.234C37.4465 29.1141 35.9223 30.6383 34.0422 30.6383H5.95703C4.07695 30.6383 2.55273 29.1141 2.55273 27.234V6.80859C2.55273 4.92852 4.07695 3.4043 5.95703 3.4043H34.0422ZM34.0422 3.82969H5.95703C4.31211 3.82969 2.97852 5.16328 2.97852 6.80859V27.234C2.97852 28.8793 4.31211 30.2129 5.95703 30.2129H34.0422C35.6871 30.2129 37.0207 28.8793 37.0207 27.234V6.80859C37.0207 5.16328 35.6871 3.82969 34.0422 3.82969Z" fill="#1B3B3C"/>
|
||||||
|
<path fill-rule="evenodd" clip-rule="evenodd" d="M19.9785 11.6797C20.6836 11.6797 21.2551 12.2512 21.2551 12.9562V21.0414C21.2551 21.7465 20.6836 22.318 19.9785 22.318C19.2734 22.318 18.702 21.7465 18.702 21.0414V12.9562C18.702 12.2512 19.2734 11.6797 19.9785 11.6797ZM11.0422 11.6797C11.7473 11.6797 12.3187 12.2512 12.3187 12.9562V21.0414C12.3187 21.7465 11.7473 22.318 11.0422 22.318C10.3371 22.318 9.76562 21.7465 9.76562 21.0414V12.9562C9.76562 12.2512 10.3371 11.6797 11.0422 11.6797ZM28.9145 11.6797C29.6195 11.6797 30.191 12.2512 30.191 12.9562V21.0414C30.191 21.7465 29.6195 22.318 28.9145 22.318C28.2094 22.318 27.6379 21.7465 27.6379 21.0414V12.9562C27.6379 12.2512 28.2094 11.6797 28.9145 11.6797Z" fill="#00BEB4"/>
|
||||||
|
</svg>
|
||||||
|
After Width: | Height: | Size: 2.0 KiB |
{kind=link}
|
Before Width: | Height: | Size: 36 KiB |
6
web/src/assets/svg/data-flow/total-files-icon-bri.svg
Normal file
{kind=link}
@ -0,0 +1,6 @@
|
|||||||
|
<svg width="40" height="40" viewBox="0 0 40 40" fill="none" xmlns="http://www.w3.org/2000/svg">
|
||||||
|
<path fill-rule="evenodd" clip-rule="evenodd" d="M11.0291 4.67969C11.8025 4.67969 12.4787 5.20078 12.6752 5.94844L13.3494 8.50937H31.4275C33.1599 8.50937 34.6158 9.81055 34.8103 11.5316L37.0205 31.1062C37.231 32.9746 35.8877 34.6602 34.0193 34.8711C33.8927 34.8852 33.765 34.8926 33.6377 34.8926H6.30289C4.92476 34.8926 3.79547 33.7988 3.75094 32.4215L3.11734 12.7746H3.115L2.90719 6.4375C2.87633 5.49805 3.61304 4.71133 4.5525 4.68047C4.57086 4.68008 4.58961 4.67969 4.60836 4.67969H11.0291Z" fill="#00BEB4" fill-opacity="0.1"/>
|
||||||
|
<path d="M11.0291 4.67969C11.8025 4.67969 12.4787 5.20078 12.6752 5.94844L13.349 8.50937H31.4275C33.1599 8.50937 34.6158 9.81055 34.8103 11.5316L37.0205 31.1062C37.231 32.9746 35.8877 34.6602 34.0193 34.8711C33.8927 34.8852 33.765 34.8926 33.6377 34.8926H6.30289C4.92476 34.8926 3.79547 33.7988 3.75094 32.4215L3.11656 12.7742L2.90719 6.4375C2.87633 5.49805 3.61304 4.71133 4.5525 4.68047L4.58023 4.67969H11.0291ZM11.0291 5.10508H4.59078L4.56656 5.10586C3.86187 5.12891 3.30914 5.71914 3.33219 6.42344L3.54195 12.7605L4.17633 32.4078C4.21344 33.5555 5.15445 34.4668 6.30289 34.4668H33.6377C33.749 34.4668 33.8607 34.4605 33.9716 34.448C35.6064 34.2637 36.7822 32.7887 36.5974 31.1539L34.3873 11.5797C34.2173 10.0734 32.9431 8.93516 31.4275 8.93516H13.0209L12.9377 8.61758L12.2638 6.05703C12.1162 5.49609 11.6091 5.10508 11.0291 5.10508Z" fill="#00BEB4"/>
|
||||||
|
<path fill-rule="evenodd" clip-rule="evenodd" d="M9.72812 12.7656H36.6539C38.0637 12.7656 39.207 13.9086 39.207 15.3188C39.207 15.4328 39.1992 15.5465 39.184 15.6594L36.9922 31.943C36.7648 33.6324 35.323 34.8934 33.6184 34.8934H6.37969C4.96953 34.8934 3.82617 33.75 3.82617 32.3398C3.82617 32.2102 3.83633 32.0801 3.85586 31.952L6.36367 15.6523C6.61914 13.9914 8.04805 12.7656 9.72812 12.7656Z" fill="#CAF2F0"/>
|
||||||
|
<path fill-rule="evenodd" clip-rule="evenodd" d="M8.98438 14.6172H20.4848C20.899 14.6172 21.2348 14.9529 21.2348 15.3672C21.2348 15.7814 20.899 16.1172 20.4848 16.1172H8.98438C8.57013 16.1172 8.23438 15.7814 8.23438 15.3672C8.23438 14.9529 8.57013 14.6172 8.98438 14.6172Z" fill="#00BEB4"/>
|
||||||
|
</svg>
|
||||||
|
After Width: | Height: | Size: 2.1 KiB |
6
web/src/assets/svg/data-flow/total-files-icon.svg
Normal file
{kind=link}
@ -0,0 +1,6 @@
|
|||||||
|
<svg width="40" height="40" viewBox="0 0 40 40" fill="none" xmlns="http://www.w3.org/2000/svg">
|
||||||
|
<path fill-rule="evenodd" clip-rule="evenodd" d="M11.0291 4.68164C11.8025 4.68164 12.4787 5.20273 12.6752 5.95039L13.3494 8.51133H31.4275C33.1599 8.51133 34.6158 9.8125 34.8103 11.5336L37.0205 31.1082C37.231 32.9766 35.8877 34.6621 34.0193 34.873C33.8927 34.8871 33.765 34.8945 33.6377 34.8945H6.30289C4.92476 34.8945 3.79547 33.8008 3.75094 32.4234L3.11734 12.7766H3.115L2.90719 6.43945C2.87633 5.5 3.61304 4.71328 4.5525 4.68242C4.57086 4.68203 4.58961 4.68164 4.60836 4.68164H11.0291Z" fill="#1F3232"/>
|
||||||
|
<path d="M11.0291 4.68164C11.8025 4.68164 12.4787 5.20273 12.6752 5.95039L13.349 8.51133H31.4275C33.1599 8.51133 34.6158 9.8125 34.8103 11.5336L37.0205 31.1082C37.231 32.9766 35.8877 34.6621 34.0193 34.873C33.8927 34.8871 33.765 34.8945 33.6377 34.8945H6.30289C4.92476 34.8945 3.79547 33.8008 3.75094 32.4234L3.11656 12.7762L2.90719 6.43945C2.87633 5.5 3.61304 4.71328 4.5525 4.68242L4.58023 4.68164H11.0291ZM11.0291 5.10703H4.59078L4.56656 5.10781C3.86187 5.13086 3.30914 5.72109 3.33219 6.42539L3.54195 12.7625L4.17633 32.4098C4.21344 33.5574 5.15445 34.4687 6.30289 34.4687H33.6377C33.749 34.4687 33.8607 34.4625 33.9716 34.45C35.6064 34.2656 36.7822 32.7906 36.5974 31.1559L34.3873 11.5816C34.2173 10.0754 32.9431 8.93711 31.4275 8.93711H13.0209L12.9377 8.61953L12.2638 6.05898C12.1162 5.49805 11.6091 5.10703 11.0291 5.10703Z" fill="#1B3B3C"/>
|
||||||
|
<path fill-rule="evenodd" clip-rule="evenodd" d="M9.72812 12.7656H36.6539C38.0637 12.7656 39.207 13.9086 39.207 15.3188C39.207 15.4328 39.1992 15.5465 39.184 15.6594L36.9922 31.943C36.7648 33.6324 35.323 34.8934 33.6184 34.8934H6.37969C4.96953 34.8934 3.82617 33.75 3.82617 32.3398C3.82617 32.2102 3.83633 32.0801 3.85586 31.952L6.36367 15.6523C6.61914 13.9914 8.04805 12.7656 9.72812 12.7656Z" fill="#1B3B3C"/>
|
||||||
|
<path fill-rule="evenodd" clip-rule="evenodd" d="M8.98438 14.6172H20.4848C20.899 14.6172 21.2348 14.9529 21.2348 15.3672C21.2348 15.7814 20.899 16.1172 20.4848 16.1172H8.98438C8.57013 16.1172 8.23438 15.7814 8.23438 15.3672C8.23438 14.9529 8.57013 14.6172 8.98438 14.6172Z" fill="#00BEB4"/>
|
||||||
|
</svg>
|
||||||
|
After Width: | Height: | Size: 2.1 KiB |
6
web/src/assets/svg/llm/cometapi.svg
Normal file
{kind=link}
|
After Width: | Height: | Size: 96 KiB |
8
web/src/assets/svg/llm/token-pony.svg
Normal file
{kind=link}
|
After Width: | Height: | Size: 16 KiB |
@ -1,7 +1,7 @@
|
|||||||
import { IParserConfig } from '@/interfaces/database/document';
|
import { IParserConfig } from '@/interfaces/database/document';
|
||||||
import { useCallback, useMemo } from 'react';
|
import { useCallback, useMemo } from 'react';
|
||||||
import { useTranslation } from 'react-i18next';
|
import { useTranslation } from 'react-i18next';
|
||||||
import { DocumentType } from '../layout-recognize-form-field';
|
import { ParseDocumentType } from '../layout-recognize-form-field';
|
||||||
|
|
||||||
export function useDefaultParserValues() {
|
export function useDefaultParserValues() {
|
||||||
const { t } = useTranslation();
|
const { t } = useTranslation();
|
||||||
@ -9,7 +9,7 @@ export function useDefaultParserValues() {
|
|||||||
const defaultParserValues = useMemo(() => {
|
const defaultParserValues = useMemo(() => {
|
||||||
const defaultParserValues = {
|
const defaultParserValues = {
|
||||||
task_page_size: 12,
|
task_page_size: 12,
|
||||||
layout_recognize: DocumentType.DeepDOC,
|
layout_recognize: ParseDocumentType.DeepDOC,
|
||||||
chunk_token_num: 512,
|
chunk_token_num: 512,
|
||||||
delimiter: '\n',
|
delimiter: '\n',
|
||||||
auto_keywords: 0,
|
auto_keywords: 0,
|
||||||
|
|||||||
@ -22,7 +22,7 @@ const Languages = [
|
|||||||
'Vietnamese',
|
'Vietnamese',
|
||||||
];
|
];
|
||||||
|
|
||||||
const options = Languages.map((x) => ({
|
export const crossLanguageOptions = Languages.map((x) => ({
|
||||||
label: t('language.' + toLower(x)),
|
label: t('language.' + toLower(x)),
|
||||||
value: x,
|
value: x,
|
||||||
}));
|
}));
|
||||||
@ -30,11 +30,13 @@ const options = Languages.map((x) => ({
|
|||||||
type CrossLanguageItemProps = {
|
type CrossLanguageItemProps = {
|
||||||
name?: string;
|
name?: string;
|
||||||
vertical?: boolean;
|
vertical?: boolean;
|
||||||
|
label?: string;
|
||||||
};
|
};
|
||||||
|
|
||||||
export const CrossLanguageFormField = ({
|
export const CrossLanguageFormField = ({
|
||||||
name = 'prompt_config.cross_languages',
|
name = 'prompt_config.cross_languages',
|
||||||
vertical = true,
|
vertical = true,
|
||||||
|
label,
|
||||||
}: CrossLanguageItemProps) => {
|
}: CrossLanguageItemProps) => {
|
||||||
const { t } = useTranslation();
|
const { t } = useTranslation();
|
||||||
const form = useFormContext();
|
const form = useFormContext();
|
||||||
@ -53,11 +55,11 @@ export const CrossLanguageFormField = ({
|
|||||||
})}
|
})}
|
||||||
>
|
>
|
||||||
<FormLabel tooltip={t('chat.crossLanguageTip')}>
|
<FormLabel tooltip={t('chat.crossLanguageTip')}>
|
||||||
{t('chat.crossLanguage')}
|
{label || t('chat.crossLanguage')}
|
||||||
</FormLabel>
|
</FormLabel>
|
||||||
<FormControl>
|
<FormControl>
|
||||||
<MultiSelect
|
<MultiSelect
|
||||||
options={options}
|
options={crossLanguageOptions}
|
||||||
placeholder={t('fileManager.pleaseSelect')}
|
placeholder={t('fileManager.pleaseSelect')}
|
||||||
maxCount={100}
|
maxCount={100}
|
||||||
{...field}
|
{...field}
|
||||||
|
|||||||
100
web/src/components/data-pipeline-select/index.tsx
Normal file
@ -0,0 +1,100 @@
|
|||||||
|
import { useTranslate } from '@/hooks/common-hooks';
|
||||||
|
import { useFetchAgentList } from '@/hooks/use-agent-request';
|
||||||
|
import { buildSelectOptions } from '@/utils/component-util';
|
||||||
|
import { ArrowUpRight } from 'lucide-react';
|
||||||
|
import { useMemo } from 'react';
|
||||||
|
import { useFormContext } from 'react-hook-form';
|
||||||
|
import { SelectWithSearch } from '../originui/select-with-search';
|
||||||
|
import {
|
||||||
|
FormControl,
|
||||||
|
FormField,
|
||||||
|
FormItem,
|
||||||
|
FormLabel,
|
||||||
|
FormMessage,
|
||||||
|
} from '../ui/form';
|
||||||
|
import { MultiSelect } from '../ui/multi-select';
|
||||||
|
|
||||||
|
interface IProps {
|
||||||
|
toDataPipeline?: () => void;
|
||||||
|
formFieldName: string;
|
||||||
|
isMult?: boolean;
|
||||||
|
}
|
||||||
|
|
||||||
|
const data = [
|
||||||
|
{ id: '1', name: 'data-pipeline-1' },
|
||||||
|
{ id: '2', name: 'data-pipeline-2' },
|
||||||
|
{ id: '3', name: 'data-pipeline-3' },
|
||||||
|
{ id: '4', name: 'data-pipeline-4' },
|
||||||
|
];
|
||||||
|
export function DataFlowSelect(props: IProps) {
|
||||||
|
const { toDataPipeline, formFieldName, isMult = true } = props;
|
||||||
|
const { t } = useTranslate('knowledgeConfiguration');
|
||||||
|
const form = useFormContext();
|
||||||
|
console.log('data-pipline form', form);
|
||||||
|
const toDataPipLine = () => {
|
||||||
|
toDataPipeline?.();
|
||||||
|
};
|
||||||
|
const { data: dataPipelineOptions, loading } = useFetchAgentList({
|
||||||
|
canvas_category: 'dataflow_canvas',
|
||||||
|
});
|
||||||
|
const options = useMemo(() => {
|
||||||
|
const option = buildSelectOptions(
|
||||||
|
dataPipelineOptions?.canvas,
|
||||||
|
'id',
|
||||||
|
'title',
|
||||||
|
);
|
||||||
|
return option || [];
|
||||||
|
}, [dataPipelineOptions]);
|
||||||
|
return (
|
||||||
|
<FormField
|
||||||
|
control={form.control}
|
||||||
|
name={formFieldName}
|
||||||
|
render={({ field }) => (
|
||||||
|
<FormItem className=" items-center space-y-0 ">
|
||||||
|
<div className="flex flex-col gap-1">
|
||||||
|
<div className="flex gap-2 justify-between ">
|
||||||
|
<FormLabel
|
||||||
|
tooltip={t('dataFlowTip')}
|
||||||
|
className="text-sm text-text-primary whitespace-wrap "
|
||||||
|
>
|
||||||
|
{t('dataFlow')}
|
||||||
|
</FormLabel>
|
||||||
|
<div
|
||||||
|
className="text-sm flex text-text-primary cursor-pointer"
|
||||||
|
onClick={toDataPipLine}
|
||||||
|
>
|
||||||
|
{t('buildItFromScratch')}
|
||||||
|
<ArrowUpRight size={14} />
|
||||||
|
</div>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
<div className="text-muted-foreground">
|
||||||
|
<FormControl>
|
||||||
|
<>
|
||||||
|
{!isMult && (
|
||||||
|
<SelectWithSearch
|
||||||
|
{...field}
|
||||||
|
placeholder={t('dataFlowPlaceholder')}
|
||||||
|
options={options}
|
||||||
|
/>
|
||||||
|
)}
|
||||||
|
{isMult && (
|
||||||
|
<MultiSelect
|
||||||
|
{...field}
|
||||||
|
onValueChange={field.onChange}
|
||||||
|
placeholder={t('dataFlowPlaceholder')}
|
||||||
|
options={options}
|
||||||
|
/>
|
||||||
|
)}
|
||||||
|
</>
|
||||||
|
</FormControl>
|
||||||
|
</div>
|
||||||
|
</div>
|
||||||
|
<div className="flex pt-1">
|
||||||
|
<FormMessage />
|
||||||
|
</div>
|
||||||
|
</FormItem>
|
||||||
|
)}
|
||||||
|
/>
|
||||||
|
);
|
||||||
|
}
|
||||||
@ -16,7 +16,7 @@ interface IProps {
|
|||||||
}
|
}
|
||||||
|
|
||||||
export const DelimiterInput = forwardRef<HTMLInputElement, InputProps & IProps>(
|
export const DelimiterInput = forwardRef<HTMLInputElement, InputProps & IProps>(
|
||||||
({ value, onChange, maxLength, defaultValue }, ref) => {
|
({ value, onChange, maxLength, defaultValue, ...props }, ref) => {
|
||||||
const nextValue = value?.replaceAll('\n', '\\n');
|
const nextValue = value?.replaceAll('\n', '\\n');
|
||||||
const handleInputChange = (e: React.ChangeEvent<HTMLInputElement>) => {
|
const handleInputChange = (e: React.ChangeEvent<HTMLInputElement>) => {
|
||||||
const val = e.target.value;
|
const val = e.target.value;
|
||||||
@ -30,6 +30,7 @@ export const DelimiterInput = forwardRef<HTMLInputElement, InputProps & IProps>(
|
|||||||
maxLength={maxLength}
|
maxLength={maxLength}
|
||||||
defaultValue={defaultValue}
|
defaultValue={defaultValue}
|
||||||
ref={ref}
|
ref={ref}
|
||||||
|
{...props}
|
||||||
></Input>
|
></Input>
|
||||||
);
|
);
|
||||||
},
|
},
|
||||||
|
|||||||
@ -139,7 +139,7 @@ function EmbedDialog({
|
|||||||
</form>
|
</form>
|
||||||
</Form>
|
</Form>
|
||||||
<div>
|
<div>
|
||||||
<span>Embed code</span>
|
<span>{t('embedCode', { keyPrefix: 'search' })}</span>
|
||||||
<HightLightMarkdown>{text}</HightLightMarkdown>
|
<HightLightMarkdown>{text}</HightLightMarkdown>
|
||||||
</div>
|
</div>
|
||||||
<div className=" font-medium mt-4 mb-1">
|
<div className=" font-medium mt-4 mb-1">
|
||||||
|
|||||||
@ -26,7 +26,7 @@ export function EntityTypesFormField({
|
|||||||
return (
|
return (
|
||||||
<FormItem className=" items-center space-y-0 ">
|
<FormItem className=" items-center space-y-0 ">
|
||||||
<div className="flex items-center">
|
<div className="flex items-center">
|
||||||
<FormLabel className="text-sm text-muted-foreground whitespace-nowrap w-1/4">
|
<FormLabel className="text-sm whitespace-nowrap w-1/4">
|
||||||
<span className="text-red-600">*</span> {t('entityTypes')}
|
<span className="text-red-600">*</span> {t('entityTypes')}
|
||||||
</FormLabel>
|
</FormLabel>
|
||||||
<div className="w-3/4">
|
<div className="w-3/4">
|
||||||
|
|||||||
@ -1,24 +1,28 @@
|
|||||||
// src/pages/dataset/file-logs/file-status-badge.tsx
|
// src/pages/dataset/file-logs/file-status-badge.tsx
|
||||||
import { FC } from 'react';
|
import { FC } from 'react';
|
||||||
|
/**
|
||||||
|
* params: status: 0 not run yet 1 running, 2 cancel, 3 success, 4 fail
|
||||||
|
*/
|
||||||
interface StatusBadgeProps {
|
interface StatusBadgeProps {
|
||||||
status: 'Success' | 'Failed' | 'Running' | 'Pending';
|
// status: 'Success' | 'Failed' | 'Running' | 'Pending';
|
||||||
|
status: 0 | 1 | 2 | 3 | 4;
|
||||||
|
name?: string;
|
||||||
}
|
}
|
||||||
|
|
||||||
const FileStatusBadge: FC<StatusBadgeProps> = ({ status }) => {
|
const FileStatusBadge: FC<StatusBadgeProps> = ({ status, name }) => {
|
||||||
const getStatusColor = () => {
|
const getStatusColor = () => {
|
||||||
// #3ba05c → rgb(59, 160, 92) // state-success
|
// #3ba05c → rgb(59, 160, 92) // state-success
|
||||||
// #d8494b → rgb(216, 73, 75) // state-error
|
// #d8494b → rgb(216, 73, 75) // state-error
|
||||||
// #00beb4 → rgb(0, 190, 180) // accent-primary
|
// #00beb4 → rgb(0, 190, 180) // accent-primary
|
||||||
// #faad14 → rgb(250, 173, 20) // state-warning
|
// #faad14 → rgb(250, 173, 20) // state-warning
|
||||||
switch (status) {
|
switch (status) {
|
||||||
case 'Success':
|
case 3:
|
||||||
return `bg-[rgba(59,160,92,0.1)] text-state-success`;
|
return `bg-[rgba(59,160,92,0.1)] text-state-success`;
|
||||||
case 'Failed':
|
case 4:
|
||||||
return `bg-[rgba(216,73,75,0.1)] text-state-error`;
|
return `bg-[rgba(216,73,75,0.1)] text-state-error`;
|
||||||
case 'Running':
|
case 1:
|
||||||
return `bg-[rgba(0,190,180,0.1)] text-accent-primary`;
|
return `bg-[rgba(0,190,180,0.1)] text-accent-primary`;
|
||||||
case 'Pending':
|
case 0:
|
||||||
return `bg-[rgba(250,173,20,0.1)] text-state-warning`;
|
return `bg-[rgba(250,173,20,0.1)] text-state-warning`;
|
||||||
default:
|
default:
|
||||||
return 'bg-gray-500/10 text-white';
|
return 'bg-gray-500/10 text-white';
|
||||||
@ -31,13 +35,13 @@ const FileStatusBadge: FC<StatusBadgeProps> = ({ status }) => {
|
|||||||
// #00beb4 → rgb(0, 190, 180) // accent-primary
|
// #00beb4 → rgb(0, 190, 180) // accent-primary
|
||||||
// #faad14 → rgb(250, 173, 20) // state-warning
|
// #faad14 → rgb(250, 173, 20) // state-warning
|
||||||
switch (status) {
|
switch (status) {
|
||||||
case 'Success':
|
case 3:
|
||||||
return `bg-[rgba(59,160,92,1)] text-state-success`;
|
return `bg-[rgba(59,160,92,1)] text-state-success`;
|
||||||
case 'Failed':
|
case 4:
|
||||||
return `bg-[rgba(216,73,75,1)] text-state-error`;
|
return `bg-[rgba(216,73,75,1)] text-state-error`;
|
||||||
case 'Running':
|
case 1:
|
||||||
return `bg-[rgba(0,190,180,1)] text-accent-primary`;
|
return `bg-[rgba(0,190,180,1)] text-accent-primary`;
|
||||||
case 'Pending':
|
case 0:
|
||||||
return `bg-[rgba(250,173,20,1)] text-state-warning`;
|
return `bg-[rgba(250,173,20,1)] text-state-warning`;
|
||||||
default:
|
default:
|
||||||
return 'bg-gray-500/10 text-white';
|
return 'bg-gray-500/10 text-white';
|
||||||
@ -46,10 +50,10 @@ const FileStatusBadge: FC<StatusBadgeProps> = ({ status }) => {
|
|||||||
|
|
||||||
return (
|
return (
|
||||||
<span
|
<span
|
||||||
className={`inline-flex items-center w-[75px] px-2 py-1 rounded-full text-xs font-medium ${getStatusColor(0.1)}`}
|
className={`inline-flex items-center w-[75px] px-2 py-1 rounded-full text-xs font-medium ${getStatusColor()}`}
|
||||||
>
|
>
|
||||||
<div className={`w-1 h-1 mr-1 rounded-full ${getBgStatusColor()}`}></div>
|
<div className={`w-1 h-1 mr-1 rounded-full ${getBgStatusColor()}`}></div>
|
||||||
{status}
|
{name || ''}
|
||||||
</span>
|
</span>
|
||||||
);
|
);
|
||||||
};
|
};
|
||||||
|
|||||||
@ -13,8 +13,15 @@ interface IProps {
|
|||||||
onClick?: () => void;
|
onClick?: () => void;
|
||||||
moreDropdown: React.ReactNode;
|
moreDropdown: React.ReactNode;
|
||||||
sharedBadge?: ReactNode;
|
sharedBadge?: ReactNode;
|
||||||
|
icon?: React.ReactNode;
|
||||||
}
|
}
|
||||||
export function HomeCard({ data, onClick, moreDropdown, sharedBadge }: IProps) {
|
export function HomeCard({
|
||||||
|
data,
|
||||||
|
onClick,
|
||||||
|
moreDropdown,
|
||||||
|
sharedBadge,
|
||||||
|
icon,
|
||||||
|
}: IProps) {
|
||||||
return (
|
return (
|
||||||
<Card
|
<Card
|
||||||
className="bg-bg-card border-colors-outline-neutral-standard"
|
className="bg-bg-card border-colors-outline-neutral-standard"
|
||||||
@ -32,10 +39,13 @@ export function HomeCard({ data, onClick, moreDropdown, sharedBadge }: IProps) {
|
|||||||
/>
|
/>
|
||||||
</div>
|
</div>
|
||||||
<div className="flex flex-col justify-between gap-1 flex-1 h-full w-[calc(100%-50px)]">
|
<div className="flex flex-col justify-between gap-1 flex-1 h-full w-[calc(100%-50px)]">
|
||||||
<section className="flex justify-between">
|
<section className="flex justify-between w-full">
|
||||||
<div className="text-[20px] font-bold w-80% leading-5 text-ellipsis overflow-hidden">
|
<section className="flex gap-1 items-center w-full">
|
||||||
{data.name}
|
<div className="text-[20px] font-bold w-80% leading-5 text-ellipsis overflow-hidden">
|
||||||
</div>
|
{data.name}
|
||||||
|
</div>
|
||||||
|
{icon}
|
||||||
|
</section>
|
||||||
{moreDropdown}
|
{moreDropdown}
|
||||||
</section>
|
</section>
|
||||||
|
|
||||||
|
|||||||
@ -4,6 +4,7 @@ import { getExtension } from '@/utils/document-util';
|
|||||||
|
|
||||||
type IconFontType = {
|
type IconFontType = {
|
||||||
name: string;
|
name: string;
|
||||||
|
|
||||||
className?: string;
|
className?: string;
|
||||||
};
|
};
|
||||||
|
|
||||||
@ -13,6 +14,23 @@ export const IconFont = ({ name, className }: IconFontType) => (
|
|||||||
</svg>
|
</svg>
|
||||||
);
|
);
|
||||||
|
|
||||||
|
export function IconFontFill({
|
||||||
|
name,
|
||||||
|
className,
|
||||||
|
isFill = true,
|
||||||
|
}: IconFontType & { isFill?: boolean }) {
|
||||||
|
return (
|
||||||
|
<span className={cn('size-4', className)}>
|
||||||
|
<svg
|
||||||
|
className={cn('size-4', className)}
|
||||||
|
style={{ fill: isFill ? 'currentColor' : '' }}
|
||||||
|
>
|
||||||
|
<use xlinkHref={`#icon-${name}`} />
|
||||||
|
</svg>
|
||||||
|
</span>
|
||||||
|
);
|
||||||
|
}
|
||||||
|
|
||||||
export function FileIcon({
|
export function FileIcon({
|
||||||
name,
|
name,
|
||||||
className,
|
className,
|
||||||
|
|||||||
@ -1,9 +1,11 @@
|
|||||||
import { LlmModelType } from '@/constants/knowledge';
|
import { LlmModelType } from '@/constants/knowledge';
|
||||||
import { useTranslate } from '@/hooks/common-hooks';
|
import { useTranslate } from '@/hooks/common-hooks';
|
||||||
import { useSelectLlmOptionsByModelType } from '@/hooks/llm-hooks';
|
import { useSelectLlmOptionsByModelType } from '@/hooks/llm-hooks';
|
||||||
|
import { cn } from '@/lib/utils';
|
||||||
import { camelCase } from 'lodash';
|
import { camelCase } from 'lodash';
|
||||||
import { useMemo } from 'react';
|
import { useMemo } from 'react';
|
||||||
import { useFormContext } from 'react-hook-form';
|
import { useFormContext } from 'react-hook-form';
|
||||||
|
import { SelectWithSearch } from './originui/select-with-search';
|
||||||
import {
|
import {
|
||||||
FormControl,
|
FormControl,
|
||||||
FormField,
|
FormField,
|
||||||
@ -11,24 +13,34 @@ import {
|
|||||||
FormLabel,
|
FormLabel,
|
||||||
FormMessage,
|
FormMessage,
|
||||||
} from './ui/form';
|
} from './ui/form';
|
||||||
import { RAGFlowSelect } from './ui/select';
|
|
||||||
|
|
||||||
export const enum DocumentType {
|
export const enum ParseDocumentType {
|
||||||
DeepDOC = 'DeepDOC',
|
DeepDOC = 'DeepDOC',
|
||||||
PlainText = 'Plain Text',
|
PlainText = 'Plain Text',
|
||||||
}
|
}
|
||||||
|
|
||||||
export function LayoutRecognizeFormField() {
|
export function LayoutRecognizeFormField({
|
||||||
|
name = 'parser_config.layout_recognize',
|
||||||
|
horizontal = true,
|
||||||
|
optionsWithoutLLM,
|
||||||
|
}: {
|
||||||
|
name?: string;
|
||||||
|
horizontal?: boolean;
|
||||||
|
optionsWithoutLLM?: { value: string; label: string }[];
|
||||||
|
}) {
|
||||||
const form = useFormContext();
|
const form = useFormContext();
|
||||||
|
|
||||||
const { t } = useTranslate('knowledgeDetails');
|
const { t } = useTranslate('knowledgeDetails');
|
||||||
const allOptions = useSelectLlmOptionsByModelType();
|
const allOptions = useSelectLlmOptionsByModelType();
|
||||||
|
|
||||||
const options = useMemo(() => {
|
const options = useMemo(() => {
|
||||||
const list = [DocumentType.DeepDOC, DocumentType.PlainText].map((x) => ({
|
const list = optionsWithoutLLM
|
||||||
label: x === DocumentType.PlainText ? t(camelCase(x)) : 'DeepDoc',
|
? optionsWithoutLLM
|
||||||
value: x,
|
: [ParseDocumentType.DeepDOC, ParseDocumentType.PlainText].map((x) => ({
|
||||||
}));
|
label:
|
||||||
|
x === ParseDocumentType.PlainText ? t(camelCase(x)) : 'DeepDoc',
|
||||||
|
value: x,
|
||||||
|
}));
|
||||||
|
|
||||||
const image2TextList = allOptions[LlmModelType.Image2text].map((x) => {
|
const image2TextList = allOptions[LlmModelType.Image2text].map((x) => {
|
||||||
return {
|
return {
|
||||||
@ -48,38 +60,40 @@ export function LayoutRecognizeFormField() {
|
|||||||
});
|
});
|
||||||
|
|
||||||
return [...list, ...image2TextList];
|
return [...list, ...image2TextList];
|
||||||
}, [allOptions, t]);
|
}, [allOptions, optionsWithoutLLM, t]);
|
||||||
|
|
||||||
return (
|
return (
|
||||||
<FormField
|
<FormField
|
||||||
control={form.control}
|
control={form.control}
|
||||||
name="parser_config.layout_recognize"
|
name={name}
|
||||||
render={({ field }) => {
|
render={({ field }) => {
|
||||||
if (typeof field.value === 'undefined') {
|
|
||||||
// default value set
|
|
||||||
form.setValue(
|
|
||||||
'parser_config.layout_recognize',
|
|
||||||
form.formState.defaultValues?.parser_config?.layout_recognize ??
|
|
||||||
'DeepDOC',
|
|
||||||
);
|
|
||||||
}
|
|
||||||
return (
|
return (
|
||||||
<FormItem className=" items-center space-y-0 ">
|
<FormItem className={'items-center space-y-0 '}>
|
||||||
<div className="flex items-center">
|
<div
|
||||||
|
className={cn('flex', {
|
||||||
|
'flex-col ': !horizontal,
|
||||||
|
'items-center': horizontal,
|
||||||
|
})}
|
||||||
|
>
|
||||||
<FormLabel
|
<FormLabel
|
||||||
tooltip={t('layoutRecognizeTip')}
|
tooltip={t('layoutRecognizeTip')}
|
||||||
className="text-sm text-muted-foreground whitespace-wrap w-1/4"
|
className={cn('text-sm text-muted-foreground whitespace-wrap', {
|
||||||
|
['w-1/4']: horizontal,
|
||||||
|
})}
|
||||||
>
|
>
|
||||||
{t('layoutRecognize')}
|
{t('layoutRecognize')}
|
||||||
</FormLabel>
|
</FormLabel>
|
||||||
<div className="w-3/4">
|
<div className={horizontal ? 'w-3/4' : 'w-full'}>
|
||||||
<FormControl>
|
<FormControl>
|
||||||
<RAGFlowSelect {...field} options={options}></RAGFlowSelect>
|
<SelectWithSearch
|
||||||
|
{...field}
|
||||||
|
options={options}
|
||||||
|
></SelectWithSearch>
|
||||||
</FormControl>
|
</FormControl>
|
||||||
</div>
|
</div>
|
||||||
</div>
|
</div>
|
||||||
<div className="flex pt-1">
|
<div className="flex pt-1">
|
||||||
<div className="w-1/4"></div>
|
<div className={horizontal ? 'w-1/4' : 'w-full'}></div>
|
||||||
<FormMessage />
|
<FormMessage />
|
||||||
</div>
|
</div>
|
||||||
</FormItem>
|
</FormItem>
|
||||||
|
|||||||
25
web/src/components/llm-setting-items/llm-form-field.tsx
Normal file
@ -0,0 +1,25 @@
|
|||||||
|
import { LlmModelType } from '@/constants/knowledge';
|
||||||
|
import { useComposeLlmOptionsByModelTypes } from '@/hooks/llm-hooks';
|
||||||
|
import { useTranslation } from 'react-i18next';
|
||||||
|
import { SelectWithSearch } from '../originui/select-with-search';
|
||||||
|
import { RAGFlowFormItem } from '../ragflow-form';
|
||||||
|
|
||||||
|
type LLMFormFieldProps = {
|
||||||
|
options?: any[];
|
||||||
|
name?: string;
|
||||||
|
};
|
||||||
|
|
||||||
|
export function LLMFormField({ options, name }: LLMFormFieldProps) {
|
||||||
|
const { t } = useTranslation();
|
||||||
|
|
||||||
|
const modelOptions = useComposeLlmOptionsByModelTypes([
|
||||||
|
LlmModelType.Chat,
|
||||||
|
LlmModelType.Image2text,
|
||||||
|
]);
|
||||||
|
|
||||||
|
return (
|
||||||
|
<RAGFlowFormItem name={name || 'llm_id'} label={t('chat.model')}>
|
||||||
|
<SelectWithSearch options={options || modelOptions}></SelectWithSearch>
|
||||||
|
</RAGFlowFormItem>
|
||||||
|
);
|
||||||
|
}
|
||||||
@ -1,11 +1,9 @@
|
|||||||
import { LlmModelType, ModelVariableType } from '@/constants/knowledge';
|
import { ModelVariableType } from '@/constants/knowledge';
|
||||||
import { useTranslate } from '@/hooks/common-hooks';
|
import { useTranslate } from '@/hooks/common-hooks';
|
||||||
import { useComposeLlmOptionsByModelTypes } from '@/hooks/llm-hooks';
|
|
||||||
import { camelCase } from 'lodash';
|
import { camelCase } from 'lodash';
|
||||||
import { useCallback } from 'react';
|
import { useCallback } from 'react';
|
||||||
import { useFormContext } from 'react-hook-form';
|
import { useFormContext } from 'react-hook-form';
|
||||||
import { z } from 'zod';
|
import { z } from 'zod';
|
||||||
import { SelectWithSearch } from '../originui/select-with-search';
|
|
||||||
import {
|
import {
|
||||||
FormControl,
|
FormControl,
|
||||||
FormField,
|
FormField,
|
||||||
@ -20,6 +18,7 @@ import {
|
|||||||
SelectTrigger,
|
SelectTrigger,
|
||||||
SelectValue,
|
SelectValue,
|
||||||
} from '../ui/select';
|
} from '../ui/select';
|
||||||
|
import { LLMFormField } from './llm-form-field';
|
||||||
import { SliderInputSwitchFormField } from './slider';
|
import { SliderInputSwitchFormField } from './slider';
|
||||||
import { useHandleFreedomChange } from './use-watch-change';
|
import { useHandleFreedomChange } from './use-watch-change';
|
||||||
|
|
||||||
@ -61,11 +60,6 @@ export function LlmSettingFieldItems({
|
|||||||
const form = useFormContext();
|
const form = useFormContext();
|
||||||
const { t } = useTranslate('chat');
|
const { t } = useTranslate('chat');
|
||||||
|
|
||||||
const modelOptions = useComposeLlmOptionsByModelTypes([
|
|
||||||
LlmModelType.Chat,
|
|
||||||
LlmModelType.Image2text,
|
|
||||||
]);
|
|
||||||
|
|
||||||
const getFieldWithPrefix = useCallback(
|
const getFieldWithPrefix = useCallback(
|
||||||
(name: string) => {
|
(name: string) => {
|
||||||
return prefix ? `${prefix}.${name}` : name;
|
return prefix ? `${prefix}.${name}` : name;
|
||||||
@ -82,22 +76,7 @@ export function LlmSettingFieldItems({
|
|||||||
|
|
||||||
return (
|
return (
|
||||||
<div className="space-y-5">
|
<div className="space-y-5">
|
||||||
<FormField
|
<LLMFormField options={options}></LLMFormField>
|
||||||
control={form.control}
|
|
||||||
name={'llm_id'}
|
|
||||||
render={({ field }) => (
|
|
||||||
<FormItem>
|
|
||||||
<FormLabel>{t('model')}</FormLabel>
|
|
||||||
<FormControl>
|
|
||||||
<SelectWithSearch
|
|
||||||
options={options || modelOptions}
|
|
||||||
{...field}
|
|
||||||
></SelectWithSearch>
|
|
||||||
</FormControl>
|
|
||||||
<FormMessage />
|
|
||||||
</FormItem>
|
|
||||||
)}
|
|
||||||
/>
|
|
||||||
<FormField
|
<FormField
|
||||||
control={form.control}
|
control={form.control}
|
||||||
name={'parameter'}
|
name={'parameter'}
|
||||||
|
|||||||
@ -45,6 +45,8 @@ export type SelectWithSearchFlagProps = {
|
|||||||
onChange?(value: string): void;
|
onChange?(value: string): void;
|
||||||
triggerClassName?: string;
|
triggerClassName?: string;
|
||||||
allowClear?: boolean;
|
allowClear?: boolean;
|
||||||
|
disabled?: boolean;
|
||||||
|
placeholder?: string;
|
||||||
};
|
};
|
||||||
|
|
||||||
export const SelectWithSearch = forwardRef<
|
export const SelectWithSearch = forwardRef<
|
||||||
@ -58,6 +60,8 @@ export const SelectWithSearch = forwardRef<
|
|||||||
options = [],
|
options = [],
|
||||||
triggerClassName,
|
triggerClassName,
|
||||||
allowClear = false,
|
allowClear = false,
|
||||||
|
disabled = false,
|
||||||
|
placeholder = t('common.selectPlaceholder'),
|
||||||
},
|
},
|
||||||
ref,
|
ref,
|
||||||
) => {
|
) => {
|
||||||
@ -105,6 +109,7 @@ export const SelectWithSearch = forwardRef<
|
|||||||
role="combobox"
|
role="combobox"
|
||||||
aria-expanded={open}
|
aria-expanded={open}
|
||||||
ref={ref}
|
ref={ref}
|
||||||
|
disabled={disabled}
|
||||||
className={cn(
|
className={cn(
|
||||||
'bg-background hover:bg-background border-input w-full justify-between px-3 font-normal outline-offset-0 outline-none focus-visible:outline-[3px] [&_svg]:pointer-events-auto',
|
'bg-background hover:bg-background border-input w-full justify-between px-3 font-normal outline-offset-0 outline-none focus-visible:outline-[3px] [&_svg]:pointer-events-auto',
|
||||||
triggerClassName,
|
triggerClassName,
|
||||||
@ -115,9 +120,7 @@ export const SelectWithSearch = forwardRef<
|
|||||||
<span className="leading-none truncate">{selectLabel}</span>
|
<span className="leading-none truncate">{selectLabel}</span>
|
||||||
</span>
|
</span>
|
||||||
) : (
|
) : (
|
||||||
<span className="text-muted-foreground">
|
<span className="text-muted-foreground">{placeholder}</span>
|
||||||
{t('common.selectPlaceholder')}
|
|
||||||
</span>
|
|
||||||
)}
|
)}
|
||||||
<div className="flex items-center justify-between">
|
<div className="flex items-center justify-between">
|
||||||
{value && allowClear && (
|
{value && allowClear && (
|
||||||
|
|||||||
@ -1,7 +1,7 @@
|
|||||||
'use client';
|
'use client';
|
||||||
|
|
||||||
import { cn } from '@/lib/utils';
|
import { cn } from '@/lib/utils';
|
||||||
import { parseColorToRGBA } from '@/utils/common-util';
|
import { parseColorToRGB } from '@/utils/common-util';
|
||||||
import { Slot } from '@radix-ui/react-slot';
|
import { Slot } from '@radix-ui/react-slot';
|
||||||
import * as React from 'react';
|
import * as React from 'react';
|
||||||
|
|
||||||
@ -251,7 +251,7 @@ const CustomTimeline = ({
|
|||||||
}: CustomTimelineProps) => {
|
}: CustomTimelineProps) => {
|
||||||
const [internalActiveStep, setInternalActiveStep] =
|
const [internalActiveStep, setInternalActiveStep] =
|
||||||
React.useState(defaultValue);
|
React.useState(defaultValue);
|
||||||
const _lineColor = `rgb(${parseColorToRGBA(lineColor)})`;
|
const _lineColor = `rgb(${parseColorToRGB(lineColor)})`;
|
||||||
console.log(lineColor, _lineColor);
|
console.log(lineColor, _lineColor);
|
||||||
const currentActiveStep = activeStep ?? internalActiveStep;
|
const currentActiveStep = activeStep ?? internalActiveStep;
|
||||||
|
|
||||||
@ -261,7 +261,7 @@ const CustomTimeline = ({
|
|||||||
}
|
}
|
||||||
onStepChange?.(step, id);
|
onStepChange?.(step, id);
|
||||||
};
|
};
|
||||||
const [r, g, b] = parseColorToRGBA(indicatorColor);
|
const [r, g, b] = parseColorToRGB(indicatorColor);
|
||||||
return (
|
return (
|
||||||
<Timeline
|
<Timeline
|
||||||
value={currentActiveStep}
|
value={currentActiveStep}
|
||||||
|
|||||||
@ -62,7 +62,7 @@ export function UseGraphRagFormField() {
|
|||||||
<div className="flex items-center gap-1">
|
<div className="flex items-center gap-1">
|
||||||
<FormLabel
|
<FormLabel
|
||||||
tooltip={t('useGraphRagTip')}
|
tooltip={t('useGraphRagTip')}
|
||||||
className="text-sm text-muted-foreground whitespace-break-spaces w-1/4"
|
className="text-sm whitespace-break-spaces w-1/4"
|
||||||
>
|
>
|
||||||
{t('useGraphRag')}
|
{t('useGraphRag')}
|
||||||
</FormLabel>
|
</FormLabel>
|
||||||
@ -125,7 +125,7 @@ const GraphRagItems = ({
|
|||||||
<FormItem className=" items-center space-y-0 ">
|
<FormItem className=" items-center space-y-0 ">
|
||||||
<div className="flex items-center">
|
<div className="flex items-center">
|
||||||
<FormLabel
|
<FormLabel
|
||||||
className="text-sm text-muted-foreground whitespace-nowrap w-1/4"
|
className="text-sm whitespace-nowrap w-1/4"
|
||||||
tooltip={renderWideTooltip(
|
tooltip={renderWideTooltip(
|
||||||
<div
|
<div
|
||||||
dangerouslySetInnerHTML={{
|
dangerouslySetInnerHTML={{
|
||||||
@ -161,7 +161,7 @@ const GraphRagItems = ({
|
|||||||
<div className="flex items-center">
|
<div className="flex items-center">
|
||||||
<FormLabel
|
<FormLabel
|
||||||
tooltip={renderWideTooltip('resolutionTip')}
|
tooltip={renderWideTooltip('resolutionTip')}
|
||||||
className="text-sm text-muted-foreground whitespace-nowrap w-1/4"
|
className="text-sm whitespace-nowrap w-1/4"
|
||||||
>
|
>
|
||||||
{t('resolution')}
|
{t('resolution')}
|
||||||
</FormLabel>
|
</FormLabel>
|
||||||
@ -190,7 +190,7 @@ const GraphRagItems = ({
|
|||||||
<div className="flex items-center">
|
<div className="flex items-center">
|
||||||
<FormLabel
|
<FormLabel
|
||||||
tooltip={renderWideTooltip('communityTip')}
|
tooltip={renderWideTooltip('communityTip')}
|
||||||
className="text-sm text-muted-foreground whitespace-nowrap w-1/4"
|
className="text-sm whitespace-nowrap w-1/4"
|
||||||
>
|
>
|
||||||
{t('community')}
|
{t('community')}
|
||||||
</FormLabel>
|
</FormLabel>
|
||||||
|
|||||||
@ -2,11 +2,10 @@ import { FormLayout } from '@/constants/form';
|
|||||||
import { DocumentParserType } from '@/constants/knowledge';
|
import { DocumentParserType } from '@/constants/knowledge';
|
||||||
import { useTranslate } from '@/hooks/common-hooks';
|
import { useTranslate } from '@/hooks/common-hooks';
|
||||||
import random from 'lodash/random';
|
import random from 'lodash/random';
|
||||||
import { Plus } from 'lucide-react';
|
import { Shuffle } from 'lucide-react';
|
||||||
import { useCallback } from 'react';
|
import { useCallback } from 'react';
|
||||||
import { useFormContext, useWatch } from 'react-hook-form';
|
import { useFormContext, useWatch } from 'react-hook-form';
|
||||||
import { SliderInputFormField } from '../slider-input-form-field';
|
import { SliderInputFormField } from '../slider-input-form-field';
|
||||||
import { Button } from '../ui/button';
|
|
||||||
import {
|
import {
|
||||||
FormControl,
|
FormControl,
|
||||||
FormField,
|
FormField,
|
||||||
@ -14,7 +13,7 @@ import {
|
|||||||
FormLabel,
|
FormLabel,
|
||||||
FormMessage,
|
FormMessage,
|
||||||
} from '../ui/form';
|
} from '../ui/form';
|
||||||
import { Input } from '../ui/input';
|
import { ExpandedInput } from '../ui/input';
|
||||||
import { Switch } from '../ui/switch';
|
import { Switch } from '../ui/switch';
|
||||||
import { Textarea } from '../ui/textarea';
|
import { Textarea } from '../ui/textarea';
|
||||||
|
|
||||||
@ -93,7 +92,7 @@ const RaptorFormFields = () => {
|
|||||||
<div className="flex items-center gap-1">
|
<div className="flex items-center gap-1">
|
||||||
<FormLabel
|
<FormLabel
|
||||||
tooltip={t('useRaptorTip')}
|
tooltip={t('useRaptorTip')}
|
||||||
className="text-sm text-muted-foreground w-1/4 whitespace-break-spaces"
|
className="text-sm w-1/4 whitespace-break-spaces"
|
||||||
>
|
>
|
||||||
<div className="w-auto xl:w-20 2xl:w-24 3xl:w-28 4xl:w-auto ">
|
<div className="w-auto xl:w-20 2xl:w-24 3xl:w-28 4xl:w-auto ">
|
||||||
{t('useRaptor')}
|
{t('useRaptor')}
|
||||||
@ -130,7 +129,7 @@ const RaptorFormFields = () => {
|
|||||||
<div className="flex items-start">
|
<div className="flex items-start">
|
||||||
<FormLabel
|
<FormLabel
|
||||||
tooltip={t('promptTip')}
|
tooltip={t('promptTip')}
|
||||||
className="text-sm text-muted-foreground whitespace-nowrap w-1/4"
|
className="text-sm whitespace-nowrap w-1/4"
|
||||||
>
|
>
|
||||||
{t('prompt')}
|
{t('prompt')}
|
||||||
</FormLabel>
|
</FormLabel>
|
||||||
@ -185,21 +184,23 @@ const RaptorFormFields = () => {
|
|||||||
render={({ field }) => (
|
render={({ field }) => (
|
||||||
<FormItem className=" items-center space-y-0 ">
|
<FormItem className=" items-center space-y-0 ">
|
||||||
<div className="flex items-center">
|
<div className="flex items-center">
|
||||||
<FormLabel className="text-sm text-muted-foreground whitespace-wrap w-1/4">
|
<FormLabel className="text-sm whitespace-wrap w-1/4">
|
||||||
{t('randomSeed')}
|
{t('randomSeed')}
|
||||||
</FormLabel>
|
</FormLabel>
|
||||||
<div className="w-3/4">
|
<div className="w-3/4">
|
||||||
<FormControl defaultValue={0}>
|
<FormControl defaultValue={0}>
|
||||||
<div className="flex gap-4 items-center">
|
<ExpandedInput
|
||||||
<Input {...field} defaultValue={0} type="number" />
|
{...field}
|
||||||
<Button
|
className="w-full"
|
||||||
size={'sm'}
|
defaultValue={0}
|
||||||
onClick={handleGenerate}
|
type="number"
|
||||||
type={'button'}
|
suffix={
|
||||||
>
|
<Shuffle
|
||||||
<Plus />
|
className="size-3.5 cursor-pointer"
|
||||||
</Button>
|
onClick={handleGenerate}
|
||||||
</div>
|
/>
|
||||||
|
}
|
||||||
|
/>
|
||||||
</FormControl>
|
</FormControl>
|
||||||
</div>
|
</div>
|
||||||
</div>
|
</div>
|
||||||
|
|||||||
@ -11,11 +11,12 @@ import { ControllerRenderProps, useFormContext } from 'react-hook-form';
|
|||||||
|
|
||||||
type RAGFlowFormItemProps = {
|
type RAGFlowFormItemProps = {
|
||||||
name: string;
|
name: string;
|
||||||
label: ReactNode;
|
label?: ReactNode;
|
||||||
tooltip?: ReactNode;
|
tooltip?: ReactNode;
|
||||||
children: ReactNode | ((field: ControllerRenderProps) => ReactNode);
|
children: ReactNode | ((field: ControllerRenderProps) => ReactNode);
|
||||||
horizontal?: boolean;
|
horizontal?: boolean;
|
||||||
required?: boolean;
|
required?: boolean;
|
||||||
|
labelClassName?: string;
|
||||||
};
|
};
|
||||||
|
|
||||||
export function RAGFlowFormItem({
|
export function RAGFlowFormItem({
|
||||||
@ -25,6 +26,7 @@ export function RAGFlowFormItem({
|
|||||||
children,
|
children,
|
||||||
horizontal = false,
|
horizontal = false,
|
||||||
required = false,
|
required = false,
|
||||||
|
labelClassName,
|
||||||
}: RAGFlowFormItemProps) {
|
}: RAGFlowFormItemProps) {
|
||||||
const form = useFormContext();
|
const form = useFormContext();
|
||||||
return (
|
return (
|
||||||
@ -37,13 +39,15 @@ export function RAGFlowFormItem({
|
|||||||
'flex items-center': horizontal,
|
'flex items-center': horizontal,
|
||||||
})}
|
})}
|
||||||
>
|
>
|
||||||
<FormLabel
|
{label && (
|
||||||
required={required}
|
<FormLabel
|
||||||
tooltip={tooltip}
|
required={required}
|
||||||
className={cn({ 'w-1/4': horizontal })}
|
tooltip={tooltip}
|
||||||
>
|
className={cn({ 'w-1/4': horizontal }, labelClassName)}
|
||||||
{label}
|
>
|
||||||
</FormLabel>
|
{label}
|
||||||
|
</FormLabel>
|
||||||
|
)}
|
||||||
<FormControl>
|
<FormControl>
|
||||||
{typeof children === 'function'
|
{typeof children === 'function'
|
||||||
? children(field)
|
? children(field)
|
||||||
|
|||||||
@ -54,8 +54,7 @@ export function SliderInputFormField({
|
|||||||
<FormLabel
|
<FormLabel
|
||||||
tooltip={tooltip}
|
tooltip={tooltip}
|
||||||
className={cn({
|
className={cn({
|
||||||
'text-sm text-muted-foreground whitespace-break-spaces w-1/4':
|
'text-sm whitespace-break-spaces w-1/4': isHorizontal,
|
||||||
isHorizontal,
|
|
||||||
})}
|
})}
|
||||||
>
|
>
|
||||||
{label}
|
{label}
|
||||||
|
|||||||
@ -177,7 +177,7 @@ const Modal: ModalType = ({
|
|||||||
<DialogPrimitive.Close asChild>
|
<DialogPrimitive.Close asChild>
|
||||||
<button
|
<button
|
||||||
type="button"
|
type="button"
|
||||||
className="flex h-7 w-7 items-center justify-center rounded-full hover:bg-muted"
|
className="flex h-7 w-7 items-center justify-center rounded-full hover:bg-muted focus-visible:outline-none"
|
||||||
>
|
>
|
||||||
{closeIcon}
|
{closeIcon}
|
||||||
</button>
|
</button>
|
||||||
@ -187,7 +187,7 @@ const Modal: ModalType = ({
|
|||||||
)}
|
)}
|
||||||
|
|
||||||
{/* content */}
|
{/* content */}
|
||||||
<div className="py-2 px-6 overflow-y-auto max-h-[80vh] focus-visible:!outline-none">
|
<div className="py-2 px-6 overflow-y-auto scrollbar-auto max-h-[80vh] focus-visible:!outline-none">
|
||||||
{destroyOnClose && !open ? null : children}
|
{destroyOnClose && !open ? null : children}
|
||||||
</div>
|
</div>
|
||||||
|
|
||||||
|
|||||||
@ -57,6 +57,7 @@ export enum LlmModelType {
|
|||||||
export enum KnowledgeSearchParams {
|
export enum KnowledgeSearchParams {
|
||||||
DocumentId = 'doc_id',
|
DocumentId = 'doc_id',
|
||||||
KnowledgeId = 'id',
|
KnowledgeId = 'id',
|
||||||
|
Type = 'type',
|
||||||
}
|
}
|
||||||
|
|
||||||
export enum DocumentType {
|
export enum DocumentType {
|
||||||
|
|||||||
@ -54,7 +54,9 @@ export enum LLMFactory {
|
|||||||
DeepInfra = 'DeepInfra',
|
DeepInfra = 'DeepInfra',
|
||||||
Grok = 'Grok',
|
Grok = 'Grok',
|
||||||
XAI = 'xAI',
|
XAI = 'xAI',
|
||||||
|
TokenPony = 'TokenPony',
|
||||||
Meituan = 'Meituan',
|
Meituan = 'Meituan',
|
||||||
|
CometAPI = 'CometAPI',
|
||||||
}
|
}
|
||||||
|
|
||||||
// Please lowercase the file name
|
// Please lowercase the file name
|
||||||
@ -114,5 +116,7 @@ export const IconMap = {
|
|||||||
[LLMFactory.DeepInfra]: 'deepinfra',
|
[LLMFactory.DeepInfra]: 'deepinfra',
|
||||||
[LLMFactory.Grok]: 'grok',
|
[LLMFactory.Grok]: 'grok',
|
||||||
[LLMFactory.XAI]: 'xai',
|
[LLMFactory.XAI]: 'xai',
|
||||||
|
[LLMFactory.TokenPony]: 'token-pony',
|
||||||
[LLMFactory.Meituan]: 'longcat',
|
[LLMFactory.Meituan]: 'longcat',
|
||||||
|
[LLMFactory.CometAPI]: 'cometapi',
|
||||||
};
|
};
|
||||||
|
|||||||
@ -136,6 +136,7 @@ export const useSelectLlmOptionsByModelType = () => {
|
|||||||
};
|
};
|
||||||
};
|
};
|
||||||
|
|
||||||
|
// Merge different types of models from the same manufacturer under one manufacturer
|
||||||
export const useComposeLlmOptionsByModelTypes = (
|
export const useComposeLlmOptionsByModelTypes = (
|
||||||
modelTypes: LlmModelType[],
|
modelTypes: LlmModelType[],
|
||||||
) => {
|
) => {
|
||||||
@ -155,7 +156,12 @@ export const useComposeLlmOptionsByModelTypes = (
|
|||||||
options.forEach((x) => {
|
options.forEach((x) => {
|
||||||
const item = pre.find((y) => y.label === x.label);
|
const item = pre.find((y) => y.label === x.label);
|
||||||
if (item) {
|
if (item) {
|
||||||
item.options.push(...x.options);
|
x.options.forEach((y) => {
|
||||||
|
// A model that is both an image2text and speech2text model
|
||||||
|
if (!item.options.some((z) => z.value === y.value)) {
|
||||||
|
item.options.push(y);
|
||||||
|
}
|
||||||
|
});
|
||||||
} else {
|
} else {
|
||||||
pre.push(x);
|
pre.push(x);
|
||||||
}
|
}
|
||||||
|
|||||||
@ -18,7 +18,7 @@ export const useNavigatePage = () => {
|
|||||||
|
|
||||||
const navigateToDataset = useCallback(
|
const navigateToDataset = useCallback(
|
||||||
(id: string) => () => {
|
(id: string) => () => {
|
||||||
navigate(`${Routes.Dataset}/${id}`);
|
navigate(`${Routes.DatasetBase}${Routes.DataSetOverview}/${id}`);
|
||||||
},
|
},
|
||||||
[navigate],
|
[navigate],
|
||||||
);
|
);
|
||||||
@ -61,6 +61,13 @@ export const useNavigatePage = () => {
|
|||||||
[navigate],
|
[navigate],
|
||||||
);
|
);
|
||||||
|
|
||||||
|
const navigateToDataflow = useCallback(
|
||||||
|
(id: string) => () => {
|
||||||
|
navigate(`${Routes.DataFlow}/${id}`);
|
||||||
|
},
|
||||||
|
[navigate],
|
||||||
|
);
|
||||||
|
|
||||||
const navigateToAgentLogs = useCallback(
|
const navigateToAgentLogs = useCallback(
|
||||||
(id: string) => () => {
|
(id: string) => () => {
|
||||||
navigate(`${Routes.AgentLogPage}/${id}`);
|
navigate(`${Routes.AgentLogPage}/${id}`);
|
||||||
@ -87,7 +94,7 @@ export const useNavigatePage = () => {
|
|||||||
(id: string, knowledgeId?: string) => () => {
|
(id: string, knowledgeId?: string) => () => {
|
||||||
navigate(
|
navigate(
|
||||||
// `${Routes.ParsedResult}/${id}?${QueryStringMap.KnowledgeId}=${knowledgeId}`,
|
// `${Routes.ParsedResult}/${id}?${QueryStringMap.KnowledgeId}=${knowledgeId}`,
|
||||||
`${Routes.ParsedResult}/chunks?id=${knowledgeId}&doc_id=${id}`,
|
`${Routes.DataflowResult}?id=${knowledgeId}&doc_id=${id}&type=chunk`,
|
||||||
);
|
);
|
||||||
},
|
},
|
||||||
[navigate],
|
[navigate],
|
||||||
@ -129,7 +136,7 @@ export const useNavigatePage = () => {
|
|||||||
(id: string, knowledgeId?: string) => () => {
|
(id: string, knowledgeId?: string) => () => {
|
||||||
navigate(
|
navigate(
|
||||||
// `${Routes.ParsedResult}/${id}?${QueryStringMap.KnowledgeId}=${knowledgeId}`,
|
// `${Routes.ParsedResult}/${id}?${QueryStringMap.KnowledgeId}=${knowledgeId}`,
|
||||||
`${Routes.DataflowResult}/${id}`,
|
`${Routes.DataflowResult}?id=${knowledgeId}&doc_id=${id}&type=dataflow`,
|
||||||
);
|
);
|
||||||
},
|
},
|
||||||
[navigate],
|
[navigate],
|
||||||
@ -155,5 +162,6 @@ export const useNavigatePage = () => {
|
|||||||
navigateToAgentList,
|
navigateToAgentList,
|
||||||
navigateToOldProfile,
|
navigateToOldProfile,
|
||||||
navigateToDataflowResult,
|
navigateToDataflowResult,
|
||||||
|
navigateToDataflow,
|
||||||
};
|
};
|
||||||
};
|
};
|
||||||
|
|||||||
@ -29,6 +29,7 @@ export const useGetKnowledgeSearchParams = () => {
|
|||||||
const [currentQueryParameters] = useSearchParams();
|
const [currentQueryParameters] = useSearchParams();
|
||||||
|
|
||||||
return {
|
return {
|
||||||
|
type: currentQueryParameters.get(KnowledgeSearchParams.Type) || '',
|
||||||
documentId:
|
documentId:
|
||||||
currentQueryParameters.get(KnowledgeSearchParams.DocumentId) || '',
|
currentQueryParameters.get(KnowledgeSearchParams.DocumentId) || '',
|
||||||
knowledgeId:
|
knowledgeId:
|
||||||
|
|||||||
@ -7,6 +7,7 @@ import {
|
|||||||
IAgentLogsResponse,
|
IAgentLogsResponse,
|
||||||
IFlow,
|
IFlow,
|
||||||
IFlowTemplate,
|
IFlowTemplate,
|
||||||
|
IPipeLineListRequest,
|
||||||
ITraceData,
|
ITraceData,
|
||||||
} from '@/interfaces/database/agent';
|
} from '@/interfaces/database/agent';
|
||||||
import { IDebugSingleRequestBody } from '@/interfaces/request/agent';
|
import { IDebugSingleRequestBody } from '@/interfaces/request/agent';
|
||||||
@ -16,6 +17,7 @@ import { IInputs } from '@/pages/agent/interface';
|
|||||||
import { useGetSharedChatSearchParams } from '@/pages/chat/shared-hooks';
|
import { useGetSharedChatSearchParams } from '@/pages/chat/shared-hooks';
|
||||||
import agentService, {
|
import agentService, {
|
||||||
fetchAgentLogsByCanvasId,
|
fetchAgentLogsByCanvasId,
|
||||||
|
fetchPipeLineList,
|
||||||
fetchTrace,
|
fetchTrace,
|
||||||
} from '@/services/agent-service';
|
} from '@/services/agent-service';
|
||||||
import api from '@/utils/api';
|
import api from '@/utils/api';
|
||||||
@ -123,7 +125,12 @@ export const useFetchAgentListByPage = () => {
|
|||||||
...pagination,
|
...pagination,
|
||||||
},
|
},
|
||||||
],
|
],
|
||||||
initialData: { canvas: [], total: 0 },
|
placeholderData: (previousData) => {
|
||||||
|
if (previousData === undefined) {
|
||||||
|
return { canvas: [], total: 0 };
|
||||||
|
}
|
||||||
|
return previousData;
|
||||||
|
},
|
||||||
gcTime: 0,
|
gcTime: 0,
|
||||||
queryFn: async () => {
|
queryFn: async () => {
|
||||||
const { data } = await agentService.listCanvasTeam(
|
const { data } = await agentService.listCanvasTeam(
|
||||||
@ -150,7 +157,7 @@ export const useFetchAgentListByPage = () => {
|
|||||||
);
|
);
|
||||||
|
|
||||||
return {
|
return {
|
||||||
data: data.canvas,
|
data: data?.canvas ?? [],
|
||||||
loading,
|
loading,
|
||||||
searchString,
|
searchString,
|
||||||
handleInputChange: onInputChange,
|
handleInputChange: onInputChange,
|
||||||
@ -271,6 +278,7 @@ export const useSetAgent = (showMessage: boolean = true) => {
|
|||||||
title?: string;
|
title?: string;
|
||||||
dsl?: DSL;
|
dsl?: DSL;
|
||||||
avatar?: string;
|
avatar?: string;
|
||||||
|
canvas_category?: string;
|
||||||
}) => {
|
}) => {
|
||||||
const { data = {} } = await agentService.setCanvas(params);
|
const { data = {} } = await agentService.setCanvas(params);
|
||||||
if (data.code === 0) {
|
if (data.code === 0) {
|
||||||
@ -647,3 +655,26 @@ export const useFetchPrompt = () => {
|
|||||||
|
|
||||||
return { data, loading, refetch };
|
return { data, loading, refetch };
|
||||||
};
|
};
|
||||||
|
|
||||||
|
export const useFetchAgentList = ({
|
||||||
|
canvas_category = 'agent_canvas',
|
||||||
|
}: IPipeLineListRequest): {
|
||||||
|
data: {
|
||||||
|
canvas: IFlow[];
|
||||||
|
total: number;
|
||||||
|
};
|
||||||
|
loading: boolean;
|
||||||
|
} => {
|
||||||
|
const { data, isFetching: loading } = useQuery({
|
||||||
|
queryKey: ['fetchPipeLineList'],
|
||||||
|
initialData: [],
|
||||||
|
gcTime: 0,
|
||||||
|
queryFn: async () => {
|
||||||
|
const { data } = await fetchPipeLineList({ canvas_category });
|
||||||
|
|
||||||
|
return data?.data ?? [];
|
||||||
|
},
|
||||||
|
});
|
||||||
|
|
||||||
|
return { data, loading };
|
||||||
|
};
|
||||||
|
|||||||
91
web/src/hooks/use-dataflow-request.ts
Normal file
@ -0,0 +1,91 @@
|
|||||||
|
import message from '@/components/ui/message';
|
||||||
|
import { IFlow } from '@/interfaces/database/agent';
|
||||||
|
import dataflowService from '@/services/dataflow-service';
|
||||||
|
import { useMutation, useQuery, useQueryClient } from '@tanstack/react-query';
|
||||||
|
import { useTranslation } from 'react-i18next';
|
||||||
|
import { useParams } from 'umi';
|
||||||
|
|
||||||
|
export const enum DataflowApiAction {
|
||||||
|
ListDataflow = 'listDataflow',
|
||||||
|
RemoveDataflow = 'removeDataflow',
|
||||||
|
FetchDataflow = 'fetchDataflow',
|
||||||
|
RunDataflow = 'runDataflow',
|
||||||
|
SetDataflow = 'setDataflow',
|
||||||
|
}
|
||||||
|
|
||||||
|
export const useRemoveDataflow = () => {
|
||||||
|
const queryClient = useQueryClient();
|
||||||
|
const { t } = useTranslation();
|
||||||
|
|
||||||
|
const {
|
||||||
|
data,
|
||||||
|
isPending: loading,
|
||||||
|
mutateAsync,
|
||||||
|
} = useMutation({
|
||||||
|
mutationKey: [DataflowApiAction.RemoveDataflow],
|
||||||
|
mutationFn: async (ids: string[]) => {
|
||||||
|
const { data } = await dataflowService.removeDataflow({
|
||||||
|
canvas_ids: ids,
|
||||||
|
});
|
||||||
|
if (data.code === 0) {
|
||||||
|
queryClient.invalidateQueries({
|
||||||
|
queryKey: [DataflowApiAction.ListDataflow],
|
||||||
|
});
|
||||||
|
|
||||||
|
message.success(t('message.deleted'));
|
||||||
|
}
|
||||||
|
return data.code;
|
||||||
|
},
|
||||||
|
});
|
||||||
|
|
||||||
|
return { data, loading, removeDataflow: mutateAsync };
|
||||||
|
};
|
||||||
|
|
||||||
|
export const useSetDataflow = () => {
|
||||||
|
const queryClient = useQueryClient();
|
||||||
|
const { t } = useTranslation();
|
||||||
|
|
||||||
|
const {
|
||||||
|
data,
|
||||||
|
isPending: loading,
|
||||||
|
mutateAsync,
|
||||||
|
} = useMutation({
|
||||||
|
mutationKey: [DataflowApiAction.SetDataflow],
|
||||||
|
mutationFn: async (params: Partial<IFlow>) => {
|
||||||
|
const { data } = await dataflowService.setDataflow(params);
|
||||||
|
if (data.code === 0) {
|
||||||
|
queryClient.invalidateQueries({
|
||||||
|
queryKey: [DataflowApiAction.FetchDataflow],
|
||||||
|
});
|
||||||
|
|
||||||
|
message.success(t(`message.${params.id ? 'modified' : 'created'}`));
|
||||||
|
}
|
||||||
|
return data?.code;
|
||||||
|
},
|
||||||
|
});
|
||||||
|
|
||||||
|
return { data, loading, setDataflow: mutateAsync };
|
||||||
|
};
|
||||||
|
|
||||||
|
export const useFetchDataflow = () => {
|
||||||
|
const { id } = useParams();
|
||||||
|
|
||||||
|
const {
|
||||||
|
data,
|
||||||
|
isFetching: loading,
|
||||||
|
refetch,
|
||||||
|
} = useQuery<IFlow>({
|
||||||
|
queryKey: [DataflowApiAction.FetchDataflow, id],
|
||||||
|
gcTime: 0,
|
||||||
|
initialData: {} as IFlow,
|
||||||
|
enabled: !!id,
|
||||||
|
refetchOnWindowFocus: false,
|
||||||
|
queryFn: async () => {
|
||||||
|
const { data } = await dataflowService.fetchDataflow(id);
|
||||||
|
|
||||||
|
return data?.data ?? ({} as IFlow);
|
||||||
|
},
|
||||||
|
});
|
||||||
|
|
||||||
|
return { data, loading, refetch };
|
||||||
|
};
|
||||||