mirror of
https://github.com/infiniflow/ragflow.git
synced 2025-12-08 20:42:30 +08:00
Compare commits
241 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
| 887651e5fa | |||
| bb3d3f921a | |||
| 8695d60055 | |||
| 936a91c5fe | |||
| ef5e7d8c44 | |||
| 80f1f2723c | |||
| c4e081d4c6 | |||
| 972fd919b4 | |||
| fa3e90c72e | |||
| 403efe81a1 | |||
| 7e87eb2e23 | |||
| 9077ee8d15 | |||
| 4784aa5b0b | |||
| 8f3fe63d73 | |||
| c8b1790c92 | |||
| d6adcc2d50 | |||
| 1b022116d5 | |||
| 311e20599f | |||
| 35034fed73 | |||
| e470645efd | |||
| e96cf89524 | |||
| 3671d20e43 | |||
| c01237ec0f | |||
| 371f61972d | |||
| 6ce282d462 | |||
| 4a2ff633e0 | |||
| 09b7ac26ad | |||
| 0a13d79b94 | |||
| 64e281b398 | |||
| 307d5299e7 | |||
| a9532cb9e7 | |||
| efc3caf702 | |||
| 12303ff18f | |||
| a3bebeb599 | |||
| bde76d2f55 | |||
| 36ee1d271d | |||
| 601e024d77 | |||
| 6287efde18 | |||
| 8f9bcb1c74 | |||
| b1117a8717 | |||
| 0fa1a1469e | |||
| dabbc852c8 | |||
| 545ea229b6 | |||
| df17294865 | |||
| b8e3852d3b | |||
| 0bde5397d0 | |||
| f7074037ef | |||
| 1aa991d914 | |||
| b2eed8fed1 | |||
| 0c0188b688 | |||
| 6b58b67d12 | |||
| 64af09ce7b | |||
| 8f9e7a6f6f | |||
| 65d5268439 | |||
| 6aa0b0819d | |||
| 3d0b440e9f | |||
| 800e263f64 | |||
| ce65ea1fc1 | |||
| 2341939376 | |||
| a9d9215547 | |||
| 99725444f1 | |||
| 1ab0f52832 | |||
| 24ca4cc6b7 | |||
| d36c8d18b1 | |||
| 86a1411b07 | |||
| 54a465f9e8 | |||
| bf7f7c7027 | |||
| 7fbbc9650d | |||
| d0c5ff04a6 | |||
| d5236b71f4 | |||
| e7c85e569b | |||
| 84b4e32c34 | |||
| 56ee69e9d9 | |||
| 44287fb05f | |||
| cef587abc2 | |||
| 1a5f991d86 | |||
| 713b574c9d | |||
| 60c1bf5a19 | |||
| d331866a12 | |||
| 69e1fc496d | |||
| e87ad8126c | |||
| 5e30426916 | |||
| 6aff3e052a | |||
| f29d9fa3f9 | |||
| 31003cd5f6 | |||
| f0a3d91171 | |||
| e6d36f3a3a | |||
| c8269206d7 | |||
| ab67292aa3 | |||
| 4f92af3cd4 | |||
| a43adafc6b | |||
| c5e4684b44 | |||
| 3a34def55f | |||
| e6f68e1ccf | |||
| 60ab7027c0 | |||
| 08f2223a6a | |||
| 9c6c6c51e0 | |||
| baf32ee461 | |||
| 8fb6b5d945 | |||
| 5cc2eda362 | |||
| 9a69d5f367 | |||
| d9b98cbb18 | |||
| 24625e0695 | |||
| 4649accd54 | |||
| 968ffc7ef3 | |||
| 2337bbf6ca | |||
| ad1f89fea0 | |||
| 2ff911b08c | |||
| 1ed0b25910 | |||
| 5825a24d26 | |||
| 157cd8b1b0 | |||
| 06463135ef | |||
| 7ed9efcd4e | |||
| 0bc1f45634 | |||
| 1885a4a4b8 | |||
| 0e03542db5 | |||
| 2e44c3b743 | |||
| d1ff588d46 | |||
| cc1b2c8f09 | |||
| 100ea574a7 | |||
| 92625e1ca9 | |||
| f007c1c772 | |||
| 841291dda0 | |||
| 6488f22540 | |||
| 6953ae89c4 | |||
| 7c7359a9b2 | |||
| ee52000870 | |||
| 91804f28f1 | |||
| 8b7c424617 | |||
| 640fca7dc9 | |||
| de89b84661 | |||
| f819378fb0 | |||
| c163b799d2 | |||
| 4f3abb855a | |||
| a374816fb2 | |||
| ab5e3ded68 | |||
| ec60b322ab | |||
| 8445143359 | |||
| 9938a4cbb6 | |||
| 73f9c226d3 | |||
| 52c814b89d | |||
| b832372c98 | |||
| 7b268eb134 | |||
| 31d2b3cb5a | |||
| ef899a8859 | |||
| e47186cc42 | |||
| b6f1cd7809 | |||
| f56f7a5f94 | |||
| 4cd0df0567 | |||
| e64da8b2aa | |||
| e702431fcb | |||
| 156290f8d0 | |||
| 37075eab98 | |||
| 37998abef3 | |||
| 09f8dfe456 | |||
| 259a7fc7f1 | |||
| 93f5df716f | |||
| 9f38b22a3f | |||
| bd4678bca6 | |||
| 31f4d44c73 | |||
| 241fdf266a | |||
| 62611809e0 | |||
| a835e97440 | |||
| 62de535ac8 | |||
| f0879563d0 | |||
| 02db995e94 | |||
| a31ad7f960 | |||
| e97fd2b5e6 | |||
| 49ff1ca934 | |||
| 46963ab1ca | |||
| 6ba5a4348a | |||
| f584f5c3d0 | |||
| a0f76b7a4d | |||
| 3f695a542c | |||
| 64f930b1c5 | |||
| 81b306aac9 | |||
| 0c562f0a9f | |||
| 7c098f9fd1 | |||
| b95747be4c | |||
| 1239f5afc8 | |||
| 243ed4bc35 | |||
| 47d40806a4 | |||
| 91df073653 | |||
| 20ab6aad4a | |||
| a71376ad6a | |||
| 4d835b7303 | |||
| b922dd06a5 | |||
| 84f5ae20be | |||
| 273f36cc54 | |||
| 28cb4df127 | |||
| bc578e1e83 | |||
| ff0e82988f | |||
| 13528ec328 | |||
| 590070e47d | |||
| 959793e83c | |||
| aaefc3f44c | |||
| 48294e624c | |||
| add4b13856 | |||
| 5d6bf2224a | |||
| c09bd9fe4a | |||
| c7db0eaca6 | |||
| 78fa37f8ae | |||
| be83074131 | |||
| 1f756947da | |||
| ae171956e8 | |||
| 1f32e6e4f4 | |||
| 2f4d803db1 | |||
| 552023ee4b | |||
| 6c9b8ec860 | |||
| f9e6ad86b7 | |||
| e604634d2a | |||
| 590b9dabab | |||
| c283ea57fd | |||
| 50ff16e7a4 | |||
| 453287b06b | |||
| e166f132b3 | |||
| 42f4d4dbc8 | |||
| 7cb8368e0f | |||
| 0d7cfce6e1 | |||
| 2d7c1368f0 | |||
| db4371c745 | |||
| e6cd799d8a | |||
| ab29b58316 | |||
| 3f037c9786 | |||
| 53b991aa0e | |||
| 9e80f39caa | |||
| bdc2b74e8f | |||
| 1fd92e6bee | |||
| 02fd381072 | |||
| b6f3a6a68a | |||
| ae70512f5d | |||
| d4a123d6dd | |||
| ce816edb5f | |||
| ac2643700b | |||
| 558b252c5a | |||
| 754a5e1cee | |||
| e3e7c7ddaa | |||
| 76b278af8e | |||
| 1c6320828c | |||
| d72468426e | |||
| 796f4032b8 |
22
.github/workflows/tests.yml
vendored
22
.github/workflows/tests.yml
vendored
@ -88,7 +88,12 @@ jobs:
|
|||||||
echo "Waiting for service to be available..."
|
echo "Waiting for service to be available..."
|
||||||
sleep 5
|
sleep 5
|
||||||
done
|
done
|
||||||
cd sdk/python && uv sync --python 3.10 --group test --frozen && uv pip install . && source .venv/bin/activate && cd test/test_sdk_api && pytest -s --tb=short get_email.py t_dataset.py t_chat.py t_session.py t_document.py t_chunk.py
|
if [[ $GITHUB_EVENT_NAME == 'schedule' ]]; then
|
||||||
|
export HTTP_API_TEST_LEVEL=p3
|
||||||
|
else
|
||||||
|
export HTTP_API_TEST_LEVEL=p2
|
||||||
|
fi
|
||||||
|
UV_LINK_MODE=copy uv sync --python 3.10 --only-group test --no-default-groups --frozen && uv pip install sdk/python && uv run --only-group test --no-default-groups pytest -s --tb=short --level=${HTTP_API_TEST_LEVEL} test/testcases/test_sdk_api
|
||||||
|
|
||||||
- name: Run frontend api tests against Elasticsearch
|
- name: Run frontend api tests against Elasticsearch
|
||||||
run: |
|
run: |
|
||||||
@ -98,7 +103,7 @@ jobs:
|
|||||||
echo "Waiting for service to be available..."
|
echo "Waiting for service to be available..."
|
||||||
sleep 5
|
sleep 5
|
||||||
done
|
done
|
||||||
cd sdk/python && uv sync --python 3.10 --group test --frozen && source .venv/bin/activate && cd test/test_frontend_api && pytest -s --tb=short get_email.py test_dataset.py
|
cd sdk/python && UV_LINK_MODE=copy uv sync --python 3.10 --group test --frozen && source .venv/bin/activate && cd test/test_frontend_api && pytest -s --tb=short get_email.py test_dataset.py
|
||||||
|
|
||||||
- name: Run http api tests against Elasticsearch
|
- name: Run http api tests against Elasticsearch
|
||||||
run: |
|
run: |
|
||||||
@ -113,7 +118,7 @@ jobs:
|
|||||||
else
|
else
|
||||||
export HTTP_API_TEST_LEVEL=p2
|
export HTTP_API_TEST_LEVEL=p2
|
||||||
fi
|
fi
|
||||||
cd sdk/python && uv sync --python 3.10 --group test --frozen && source .venv/bin/activate && cd test/test_http_api && pytest -s --tb=short --level=${HTTP_API_TEST_LEVEL}
|
UV_LINK_MODE=copy uv sync --python 3.10 --only-group test --no-default-groups --frozen && uv run --only-group test --no-default-groups pytest -s --tb=short --level=${HTTP_API_TEST_LEVEL} test/testcases/test_http_api
|
||||||
|
|
||||||
- name: Stop ragflow:nightly
|
- name: Stop ragflow:nightly
|
||||||
if: always() # always run this step even if previous steps failed
|
if: always() # always run this step even if previous steps failed
|
||||||
@ -132,7 +137,12 @@ jobs:
|
|||||||
echo "Waiting for service to be available..."
|
echo "Waiting for service to be available..."
|
||||||
sleep 5
|
sleep 5
|
||||||
done
|
done
|
||||||
cd sdk/python && uv sync --python 3.10 --group test --frozen && uv pip install . && source .venv/bin/activate && cd test/test_sdk_api && pytest -s --tb=short get_email.py t_dataset.py t_chat.py t_session.py t_document.py t_chunk.py
|
if [[ $GITHUB_EVENT_NAME == 'schedule' ]]; then
|
||||||
|
export HTTP_API_TEST_LEVEL=p3
|
||||||
|
else
|
||||||
|
export HTTP_API_TEST_LEVEL=p2
|
||||||
|
fi
|
||||||
|
UV_LINK_MODE=copy uv sync --python 3.10 --only-group test --no-default-groups --frozen && uv pip install sdk/python && DOC_ENGINE=infinity uv run --only-group test --no-default-groups pytest -s --tb=short --level=${HTTP_API_TEST_LEVEL} test/testcases/test_sdk_api
|
||||||
|
|
||||||
- name: Run frontend api tests against Infinity
|
- name: Run frontend api tests against Infinity
|
||||||
run: |
|
run: |
|
||||||
@ -142,7 +152,7 @@ jobs:
|
|||||||
echo "Waiting for service to be available..."
|
echo "Waiting for service to be available..."
|
||||||
sleep 5
|
sleep 5
|
||||||
done
|
done
|
||||||
cd sdk/python && uv sync --python 3.10 --group test --frozen && source .venv/bin/activate && cd test/test_frontend_api && pytest -s --tb=short get_email.py test_dataset.py
|
cd sdk/python && UV_LINK_MODE=copy uv sync --python 3.10 --group test --frozen && source .venv/bin/activate && cd test/test_frontend_api && pytest -s --tb=short get_email.py test_dataset.py
|
||||||
|
|
||||||
- name: Run http api tests against Infinity
|
- name: Run http api tests against Infinity
|
||||||
run: |
|
run: |
|
||||||
@ -157,7 +167,7 @@ jobs:
|
|||||||
else
|
else
|
||||||
export HTTP_API_TEST_LEVEL=p2
|
export HTTP_API_TEST_LEVEL=p2
|
||||||
fi
|
fi
|
||||||
cd sdk/python && uv sync --python 3.10 --group test --frozen && source .venv/bin/activate && cd test/test_http_api && DOC_ENGINE=infinity pytest -s --tb=short --level=${HTTP_API_TEST_LEVEL}
|
UV_LINK_MODE=copy uv sync --python 3.10 --only-group test --no-default-groups --frozen && DOC_ENGINE=infinity uv run --only-group test --no-default-groups pytest -s --tb=short --level=${HTTP_API_TEST_LEVEL} test/testcases/test_http_api
|
||||||
|
|
||||||
- name: Stop ragflow:nightly
|
- name: Stop ragflow:nightly
|
||||||
if: always() # always run this step even if previous steps failed
|
if: always() # always run this step even if previous steps failed
|
||||||
|
|||||||
149
.gitignore
vendored
149
.gitignore
vendored
@ -36,6 +36,12 @@ sdk/python/ragflow.egg-info/
|
|||||||
sdk/python/build/
|
sdk/python/build/
|
||||||
sdk/python/dist/
|
sdk/python/dist/
|
||||||
sdk/python/ragflow_sdk.egg-info/
|
sdk/python/ragflow_sdk.egg-info/
|
||||||
|
|
||||||
|
# Exclude dep files
|
||||||
|
libssl*.deb
|
||||||
|
tika-server*.jar*
|
||||||
|
cl100k_base.tiktoken
|
||||||
|
chrome*
|
||||||
huggingface.co/
|
huggingface.co/
|
||||||
nltk_data/
|
nltk_data/
|
||||||
|
|
||||||
@ -44,3 +50,146 @@ nltk_data/
|
|||||||
.lh/
|
.lh/
|
||||||
.venv
|
.venv
|
||||||
docker/data
|
docker/data
|
||||||
|
|
||||||
|
|
||||||
|
#--------------------------------------------------#
|
||||||
|
# The following was generated with gitignore.nvim: #
|
||||||
|
#--------------------------------------------------#
|
||||||
|
# Gitignore for the following technologies: Node
|
||||||
|
|
||||||
|
# Logs
|
||||||
|
logs
|
||||||
|
*.log
|
||||||
|
npm-debug.log*
|
||||||
|
yarn-debug.log*
|
||||||
|
yarn-error.log*
|
||||||
|
lerna-debug.log*
|
||||||
|
.pnpm-debug.log*
|
||||||
|
|
||||||
|
# Diagnostic reports (https://nodejs.org/api/report.html)
|
||||||
|
report.[0-9]*.[0-9]*.[0-9]*.[0-9]*.json
|
||||||
|
|
||||||
|
# Runtime data
|
||||||
|
pids
|
||||||
|
*.pid
|
||||||
|
*.seed
|
||||||
|
*.pid.lock
|
||||||
|
|
||||||
|
# Directory for instrumented libs generated by jscoverage/JSCover
|
||||||
|
lib-cov
|
||||||
|
|
||||||
|
# Coverage directory used by tools like istanbul
|
||||||
|
coverage
|
||||||
|
*.lcov
|
||||||
|
|
||||||
|
# nyc test coverage
|
||||||
|
.nyc_output
|
||||||
|
|
||||||
|
# Grunt intermediate storage (https://gruntjs.com/creating-plugins#storing-task-files)
|
||||||
|
.grunt
|
||||||
|
|
||||||
|
# Bower dependency directory (https://bower.io/)
|
||||||
|
bower_components
|
||||||
|
|
||||||
|
# node-waf configuration
|
||||||
|
.lock-wscript
|
||||||
|
|
||||||
|
# Compiled binary addons (https://nodejs.org/api/addons.html)
|
||||||
|
build/Release
|
||||||
|
|
||||||
|
# Dependency directories
|
||||||
|
node_modules/
|
||||||
|
jspm_packages/
|
||||||
|
|
||||||
|
# Snowpack dependency directory (https://snowpack.dev/)
|
||||||
|
web_modules/
|
||||||
|
|
||||||
|
# TypeScript cache
|
||||||
|
*.tsbuildinfo
|
||||||
|
|
||||||
|
# Optional npm cache directory
|
||||||
|
.npm
|
||||||
|
|
||||||
|
# Optional eslint cache
|
||||||
|
.eslintcache
|
||||||
|
|
||||||
|
# Optional stylelint cache
|
||||||
|
.stylelintcache
|
||||||
|
|
||||||
|
# Microbundle cache
|
||||||
|
.rpt2_cache/
|
||||||
|
.rts2_cache_cjs/
|
||||||
|
.rts2_cache_es/
|
||||||
|
.rts2_cache_umd/
|
||||||
|
|
||||||
|
# Optional REPL history
|
||||||
|
.node_repl_history
|
||||||
|
|
||||||
|
# Output of 'npm pack'
|
||||||
|
*.tgz
|
||||||
|
|
||||||
|
# Yarn Integrity file
|
||||||
|
.yarn-integrity
|
||||||
|
|
||||||
|
# dotenv environment variable files
|
||||||
|
.env
|
||||||
|
.env.development.local
|
||||||
|
.env.test.local
|
||||||
|
.env.production.local
|
||||||
|
.env.local
|
||||||
|
|
||||||
|
# parcel-bundler cache (https://parceljs.org/)
|
||||||
|
.cache
|
||||||
|
.parcel-cache
|
||||||
|
|
||||||
|
# Next.js build output
|
||||||
|
.next
|
||||||
|
out
|
||||||
|
|
||||||
|
# Nuxt.js build / generate output
|
||||||
|
.nuxt
|
||||||
|
dist
|
||||||
|
|
||||||
|
# Gatsby files
|
||||||
|
.cache/
|
||||||
|
# Comment in the public line in if your project uses Gatsby and not Next.js
|
||||||
|
# https://nextjs.org/blog/next-9-1#public-directory-support
|
||||||
|
# public
|
||||||
|
|
||||||
|
# vuepress build output
|
||||||
|
.vuepress/dist
|
||||||
|
|
||||||
|
# vuepress v2.x temp and cache directory
|
||||||
|
.temp
|
||||||
|
|
||||||
|
# Docusaurus cache and generated files
|
||||||
|
.docusaurus
|
||||||
|
|
||||||
|
# Serverless directories
|
||||||
|
.serverless/
|
||||||
|
|
||||||
|
# FuseBox cache
|
||||||
|
.fusebox/
|
||||||
|
|
||||||
|
# DynamoDB Local files
|
||||||
|
.dynamodb/
|
||||||
|
|
||||||
|
# TernJS port file
|
||||||
|
.tern-port
|
||||||
|
|
||||||
|
# Stores VSCode versions used for testing VSCode extensions
|
||||||
|
.vscode-test
|
||||||
|
|
||||||
|
# yarn v2
|
||||||
|
.yarn/cache
|
||||||
|
.yarn/unplugged
|
||||||
|
.yarn/build-state.yml
|
||||||
|
.yarn/install-state.gz
|
||||||
|
.pnp.*
|
||||||
|
|
||||||
|
# Serverless Webpack directories
|
||||||
|
.webpack/
|
||||||
|
|
||||||
|
# SvelteKit build / generate output
|
||||||
|
.svelte-kit
|
||||||
|
|
||||||
|
|||||||
35
README.md
35
README.md
@ -5,13 +5,13 @@
|
|||||||
</div>
|
</div>
|
||||||
|
|
||||||
<p align="center">
|
<p align="center">
|
||||||
<a href="./README.md">English</a> |
|
<a href="./README.md"><img alt="README in English" src="https://img.shields.io/badge/English-DBEDFA"></a>
|
||||||
<a href="./README_zh.md">简体中文</a> |
|
<a href="./README_zh.md"><img alt="简体中文版自述文件" src="https://img.shields.io/badge/简体中文-DFE0E5"></a>
|
||||||
<a href="./README_tzh.md">繁体中文</a> |
|
<a href="./README_tzh.md"><img alt="繁體版中文自述文件" src="https://img.shields.io/badge/繁體中文-DFE0E5"></a>
|
||||||
<a href="./README_ja.md">日本語</a> |
|
<a href="./README_ja.md"><img alt="日本語のREADME" src="https://img.shields.io/badge/日本語-DFE0E5"></a>
|
||||||
<a href="./README_ko.md">한국어</a> |
|
<a href="./README_ko.md"><img alt="한국어" src="https://img.shields.io/badge/한국어-DFE0E5"></a>
|
||||||
<a href="./README_id.md">Bahasa Indonesia</a> |
|
<a href="./README_id.md"><img alt="Bahasa Indonesia" src="https://img.shields.io/badge/Bahasa Indonesia-DFE0E5"></a>
|
||||||
<a href="/README_pt_br.md">Português (Brasil)</a>
|
<a href="./README_pt_br.md"><img alt="Português(Brasil)" src="https://img.shields.io/badge/Português(Brasil)-DFE0E5"></a>
|
||||||
</p>
|
</p>
|
||||||
|
|
||||||
<p align="center">
|
<p align="center">
|
||||||
@ -22,7 +22,7 @@
|
|||||||
<img alt="Static Badge" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
<img alt="Static Badge" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
||||||
</a>
|
</a>
|
||||||
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
||||||
<img src="https://img.shields.io/badge/docker_pull-ragflow:v0.18.0-brightgreen" alt="docker pull infiniflow/ragflow:v0.18.0">
|
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.19.1">
|
||||||
</a>
|
</a>
|
||||||
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
||||||
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Latest%20Release" alt="Latest Release">
|
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Latest%20Release" alt="Latest Release">
|
||||||
@ -30,6 +30,9 @@
|
|||||||
<a href="https://github.com/infiniflow/ragflow/blob/main/LICENSE">
|
<a href="https://github.com/infiniflow/ragflow/blob/main/LICENSE">
|
||||||
<img height="21" src="https://img.shields.io/badge/License-Apache--2.0-ffffff?labelColor=d4eaf7&color=2e6cc4" alt="license">
|
<img height="21" src="https://img.shields.io/badge/License-Apache--2.0-ffffff?labelColor=d4eaf7&color=2e6cc4" alt="license">
|
||||||
</a>
|
</a>
|
||||||
|
<a href="https://deepwiki.com/infiniflow/ragflow">
|
||||||
|
<img alt="Ask DeepWiki" src="https://deepwiki.com/badge.svg">
|
||||||
|
</a>
|
||||||
</p>
|
</p>
|
||||||
|
|
||||||
<h4 align="center">
|
<h4 align="center">
|
||||||
@ -40,6 +43,12 @@
|
|||||||
<a href="https://demo.ragflow.io">Demo</a>
|
<a href="https://demo.ragflow.io">Demo</a>
|
||||||
</h4>
|
</h4>
|
||||||
|
|
||||||
|
#
|
||||||
|
|
||||||
|
<div align="center">
|
||||||
|
<a href="https://trendshift.io/repositories/9064" target="_blank"><img src="https://trendshift.io/api/badge/repositories/9064" alt="infiniflow%2Fragflow | Trendshift" style="width: 250px; height: 55px;" width="250" height="55"/></a>
|
||||||
|
</div>
|
||||||
|
|
||||||
<details open>
|
<details open>
|
||||||
<summary><b>📕 Table of Contents</b></summary>
|
<summary><b>📕 Table of Contents</b></summary>
|
||||||
|
|
||||||
@ -78,11 +87,11 @@ Try our demo at [https://demo.ragflow.io](https://demo.ragflow.io).
|
|||||||
|
|
||||||
## 🔥 Latest Updates
|
## 🔥 Latest Updates
|
||||||
|
|
||||||
|
- 2025-05-23 Adds a Python/JavaScript code executor component to Agent.
|
||||||
|
- 2025-05-05 Supports cross-language query.
|
||||||
- 2025-03-19 Supports using a multi-modal model to make sense of images within PDF or DOCX files.
|
- 2025-03-19 Supports using a multi-modal model to make sense of images within PDF or DOCX files.
|
||||||
- 2025-02-28 Combined with Internet search (Tavily), supports reasoning like Deep Research for any LLMs.
|
- 2025-02-28 Combined with Internet search (Tavily), supports reasoning like Deep Research for any LLMs.
|
||||||
- 2025-01-26 Optimizes knowledge graph extraction and application, offering various configuration options.
|
|
||||||
- 2024-12-18 Upgrades Document Layout Analysis model in DeepDoc.
|
- 2024-12-18 Upgrades Document Layout Analysis model in DeepDoc.
|
||||||
- 2024-11-01 Adds keyword extraction and related question generation to the parsed chunks to improve the accuracy of retrieval.
|
|
||||||
- 2024-08-22 Support text to SQL statements through RAG.
|
- 2024-08-22 Support text to SQL statements through RAG.
|
||||||
|
|
||||||
## 🎉 Stay Tuned
|
## 🎉 Stay Tuned
|
||||||
@ -178,7 +187,7 @@ releases! 🌟
|
|||||||
> All Docker images are built for x86 platforms. We don't currently offer Docker images for ARM64.
|
> All Docker images are built for x86 platforms. We don't currently offer Docker images for ARM64.
|
||||||
> If you are on an ARM64 platform, follow [this guide](https://ragflow.io/docs/dev/build_docker_image) to build a Docker image compatible with your system.
|
> If you are on an ARM64 platform, follow [this guide](https://ragflow.io/docs/dev/build_docker_image) to build a Docker image compatible with your system.
|
||||||
|
|
||||||
> The command below downloads the `v0.18.0-slim` edition of the RAGFlow Docker image. See the following table for descriptions of different RAGFlow editions. To download a RAGFlow edition different from `v0.18.0-slim`, update the `RAGFLOW_IMAGE` variable accordingly in **docker/.env** before using `docker compose` to start the server. For example: set `RAGFLOW_IMAGE=infiniflow/ragflow:v0.18.0` for the full edition `v0.18.0`.
|
> The command below downloads the `v0.19.1-slim` edition of the RAGFlow Docker image. See the following table for descriptions of different RAGFlow editions. To download a RAGFlow edition different from `v0.19.1-slim`, update the `RAGFLOW_IMAGE` variable accordingly in **docker/.env** before using `docker compose` to start the server. For example: set `RAGFLOW_IMAGE=infiniflow/ragflow:v0.19.1` for the full edition `v0.19.1`.
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
$ cd ragflow/docker
|
$ cd ragflow/docker
|
||||||
@ -191,8 +200,8 @@ releases! 🌟
|
|||||||
|
|
||||||
| RAGFlow image tag | Image size (GB) | Has embedding models? | Stable? |
|
| RAGFlow image tag | Image size (GB) | Has embedding models? | Stable? |
|
||||||
|-------------------|-----------------|-----------------------|--------------------------|
|
|-------------------|-----------------|-----------------------|--------------------------|
|
||||||
| v0.18.0 | ≈9 | :heavy_check_mark: | Stable release |
|
| v0.19.1 | ≈9 | :heavy_check_mark: | Stable release |
|
||||||
| v0.18.0-slim | ≈2 | ❌ | Stable release |
|
| v0.19.1-slim | ≈2 | ❌ | Stable release |
|
||||||
| nightly | ≈9 | :heavy_check_mark: | _Unstable_ nightly build |
|
| nightly | ≈9 | :heavy_check_mark: | _Unstable_ nightly build |
|
||||||
| nightly-slim | ≈2 | ❌ | _Unstable_ nightly build |
|
| nightly-slim | ≈2 | ❌ | _Unstable_ nightly build |
|
||||||
|
|
||||||
|
|||||||
31
README_id.md
31
README_id.md
@ -5,13 +5,13 @@
|
|||||||
</div>
|
</div>
|
||||||
|
|
||||||
<p align="center">
|
<p align="center">
|
||||||
<a href="./README.md">English</a> |
|
<a href="./README.md"><img alt="README in English" src="https://img.shields.io/badge/English-DFE0E5"></a>
|
||||||
<a href="./README_zh.md">简体中文</a> |
|
<a href="./README_zh.md"><img alt="简体中文版自述文件" src="https://img.shields.io/badge/简体中文-DFE0E5"></a>
|
||||||
<a href="./README_tzh.md">繁体中文</a> |
|
<a href="./README_tzh.md"><img alt="繁體中文版自述文件" src="https://img.shields.io/badge/繁體中文-DFE0E5"></a>
|
||||||
<a href="./README_ja.md">日本語</a> |
|
<a href="./README_ja.md"><img alt="日本語のREADME" src="https://img.shields.io/badge/日本語-DFE0E5"></a>
|
||||||
<a href="./README_ko.md">한국어</a> |
|
<a href="./README_ko.md"><img alt="한국어" src="https://img.shields.io/badge/한국어-DFE0E5"></a>
|
||||||
<a href="./README_id.md">Bahasa Indonesia</a> |
|
<a href="./README_id.md"><img alt="Bahasa Indonesia" src="https://img.shields.io/badge/Bahasa Indonesia-DBEDFA"></a>
|
||||||
<a href="/README_pt_br.md">Português (Brasil)</a>
|
<a href="./README_pt_br.md"><img alt="Português(Brasil)" src="https://img.shields.io/badge/Português(Brasil)-DFE0E5"></a>
|
||||||
</p>
|
</p>
|
||||||
|
|
||||||
<p align="center">
|
<p align="center">
|
||||||
@ -22,7 +22,7 @@
|
|||||||
<img alt="Lencana Daring" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
<img alt="Lencana Daring" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
||||||
</a>
|
</a>
|
||||||
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
||||||
<img src="https://img.shields.io/badge/docker_pull-ragflow:v0.18.0-brightgreen" alt="docker pull infiniflow/ragflow:v0.18.0">
|
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.19.1">
|
||||||
</a>
|
</a>
|
||||||
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
||||||
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Rilis%20Terbaru" alt="Rilis Terbaru">
|
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Rilis%20Terbaru" alt="Rilis Terbaru">
|
||||||
@ -30,6 +30,9 @@
|
|||||||
<a href="https://github.com/infiniflow/ragflow/blob/main/LICENSE">
|
<a href="https://github.com/infiniflow/ragflow/blob/main/LICENSE">
|
||||||
<img height="21" src="https://img.shields.io/badge/Lisensi-Apache--2.0-ffffff?labelColor=d4eaf7&color=2e6cc4" alt="Lisensi">
|
<img height="21" src="https://img.shields.io/badge/Lisensi-Apache--2.0-ffffff?labelColor=d4eaf7&color=2e6cc4" alt="Lisensi">
|
||||||
</a>
|
</a>
|
||||||
|
<a href="https://deepwiki.com/infiniflow/ragflow">
|
||||||
|
<img alt="Ask DeepWiki" src="https://deepwiki.com/badge.svg">
|
||||||
|
</a>
|
||||||
</p>
|
</p>
|
||||||
|
|
||||||
<h4 align="center">
|
<h4 align="center">
|
||||||
@ -40,6 +43,8 @@
|
|||||||
<a href="https://demo.ragflow.io">Demo</a>
|
<a href="https://demo.ragflow.io">Demo</a>
|
||||||
</h4>
|
</h4>
|
||||||
|
|
||||||
|
#
|
||||||
|
|
||||||
<details open>
|
<details open>
|
||||||
<summary><b>📕 Daftar Isi </b> </summary>
|
<summary><b>📕 Daftar Isi </b> </summary>
|
||||||
|
|
||||||
@ -75,11 +80,11 @@ Coba demo kami di [https://demo.ragflow.io](https://demo.ragflow.io).
|
|||||||
|
|
||||||
## 🔥 Pembaruan Terbaru
|
## 🔥 Pembaruan Terbaru
|
||||||
|
|
||||||
|
- 2025-05-23 Menambahkan komponen pelaksana kode Python/JS ke Agen.
|
||||||
|
- 2025-05-05 Mendukung kueri lintas bahasa.
|
||||||
- 2025-03-19 Mendukung penggunaan model multi-modal untuk memahami gambar di dalam file PDF atau DOCX.
|
- 2025-03-19 Mendukung penggunaan model multi-modal untuk memahami gambar di dalam file PDF atau DOCX.
|
||||||
- 2025-02-28 dikombinasikan dengan pencarian Internet (TAVILY), mendukung penelitian mendalam untuk LLM apa pun.
|
- 2025-02-28 dikombinasikan dengan pencarian Internet (TAVILY), mendukung penelitian mendalam untuk LLM apa pun.
|
||||||
- 2025-01-26 Optimalkan ekstraksi dan penerapan grafik pengetahuan dan sediakan berbagai opsi konfigurasi.
|
|
||||||
- 2024-12-18 Meningkatkan model Analisis Tata Letak Dokumen di DeepDoc.
|
- 2024-12-18 Meningkatkan model Analisis Tata Letak Dokumen di DeepDoc.
|
||||||
- 2024-11-01 Penambahan ekstraksi kata kunci dan pembuatan pertanyaan terkait untuk meningkatkan akurasi pengambilan.
|
|
||||||
- 2024-08-22 Dukungan untuk teks ke pernyataan SQL melalui RAG.
|
- 2024-08-22 Dukungan untuk teks ke pernyataan SQL melalui RAG.
|
||||||
|
|
||||||
## 🎉 Tetap Terkini
|
## 🎉 Tetap Terkini
|
||||||
@ -173,7 +178,7 @@ Coba demo kami di [https://demo.ragflow.io](https://demo.ragflow.io).
|
|||||||
> Semua gambar Docker dibangun untuk platform x86. Saat ini, kami tidak menawarkan gambar Docker untuk ARM64.
|
> Semua gambar Docker dibangun untuk platform x86. Saat ini, kami tidak menawarkan gambar Docker untuk ARM64.
|
||||||
> Jika Anda menggunakan platform ARM64, [silakan gunakan panduan ini untuk membangun gambar Docker yang kompatibel dengan sistem Anda](https://ragflow.io/docs/dev/build_docker_image).
|
> Jika Anda menggunakan platform ARM64, [silakan gunakan panduan ini untuk membangun gambar Docker yang kompatibel dengan sistem Anda](https://ragflow.io/docs/dev/build_docker_image).
|
||||||
|
|
||||||
> Perintah di bawah ini mengunduh edisi v0.18.0-slim dari gambar Docker RAGFlow. Silakan merujuk ke tabel berikut untuk deskripsi berbagai edisi RAGFlow. Untuk mengunduh edisi RAGFlow yang berbeda dari v0.18.0-slim, perbarui variabel RAGFLOW_IMAGE di docker/.env sebelum menggunakan docker compose untuk memulai server. Misalnya, atur RAGFLOW_IMAGE=infiniflow/ragflow:v0.18.0 untuk edisi lengkap v0.18.0.
|
> Perintah di bawah ini mengunduh edisi v0.19.1-slim dari gambar Docker RAGFlow. Silakan merujuk ke tabel berikut untuk deskripsi berbagai edisi RAGFlow. Untuk mengunduh edisi RAGFlow yang berbeda dari v0.19.1-slim, perbarui variabel RAGFLOW_IMAGE di docker/.env sebelum menggunakan docker compose untuk memulai server. Misalnya, atur RAGFLOW_IMAGE=infiniflow/ragflow:v0.19.1 untuk edisi lengkap v0.19.1.
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
$ cd ragflow/docker
|
$ cd ragflow/docker
|
||||||
@ -186,8 +191,8 @@ $ docker compose -f docker-compose.yml up -d
|
|||||||
|
|
||||||
| RAGFlow image tag | Image size (GB) | Has embedding models? | Stable? |
|
| RAGFlow image tag | Image size (GB) | Has embedding models? | Stable? |
|
||||||
| ----------------- | --------------- | --------------------- | ------------------------ |
|
| ----------------- | --------------- | --------------------- | ------------------------ |
|
||||||
| v0.18.0 | ≈9 | :heavy_check_mark: | Stable release |
|
| v0.19.1 | ≈9 | :heavy_check_mark: | Stable release |
|
||||||
| v0.18.0-slim | ≈2 | ❌ | Stable release |
|
| v0.19.1-slim | ≈2 | ❌ | Stable release |
|
||||||
| nightly | ≈9 | :heavy_check_mark: | _Unstable_ nightly build |
|
| nightly | ≈9 | :heavy_check_mark: | _Unstable_ nightly build |
|
||||||
| nightly-slim | ≈2 | ❌ | _Unstable_ nightly build |
|
| nightly-slim | ≈2 | ❌ | _Unstable_ nightly build |
|
||||||
|
|
||||||
|
|||||||
31
README_ja.md
31
README_ja.md
@ -5,13 +5,13 @@
|
|||||||
</div>
|
</div>
|
||||||
|
|
||||||
<p align="center">
|
<p align="center">
|
||||||
<a href="./README.md">English</a> |
|
<a href="./README.md"><img alt="README in English" src="https://img.shields.io/badge/English-DFE0E5"></a>
|
||||||
<a href="./README_zh.md">简体中文</a> |
|
<a href="./README_zh.md"><img alt="简体中文版自述文件" src="https://img.shields.io/badge/简体中文-DFE0E5"></a>
|
||||||
<a href="./README_tzh.md">繁体中文</a> |
|
<a href="./README_tzh.md"><img alt="繁體中文版自述文件" src="https://img.shields.io/badge/繁體中文-DFE0E5"></a>
|
||||||
<a href="./README_ja.md">日本語</a> |
|
<a href="./README_ja.md"><img alt="日本語のREADME" src="https://img.shields.io/badge/日本語-DBEDFA"></a>
|
||||||
<a href="./README_ko.md">한국어</a> |
|
<a href="./README_ko.md"><img alt="한국어" src="https://img.shields.io/badge/한국어-DFE0E5"></a>
|
||||||
<a href="./README_id.md">Bahasa Indonesia</a> |
|
<a href="./README_id.md"><img alt="Bahasa Indonesia" src="https://img.shields.io/badge/Bahasa Indonesia-DFE0E5"></a>
|
||||||
<a href="/README_pt_br.md">Português (Brasil)</a>
|
<a href="./README_pt_br.md"><img alt="Português(Brasil)" src="https://img.shields.io/badge/Português(Brasil)-DFE0E5"></a>
|
||||||
</p>
|
</p>
|
||||||
|
|
||||||
<p align="center">
|
<p align="center">
|
||||||
@ -22,7 +22,7 @@
|
|||||||
<img alt="Static Badge" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
<img alt="Static Badge" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
||||||
</a>
|
</a>
|
||||||
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
||||||
<img src="https://img.shields.io/badge/docker_pull-ragflow:v0.18.0-brightgreen" alt="docker pull infiniflow/ragflow:v0.18.0">
|
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.19.1">
|
||||||
</a>
|
</a>
|
||||||
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
||||||
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Latest%20Release" alt="Latest Release">
|
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Latest%20Release" alt="Latest Release">
|
||||||
@ -30,6 +30,9 @@
|
|||||||
<a href="https://github.com/infiniflow/ragflow/blob/main/LICENSE">
|
<a href="https://github.com/infiniflow/ragflow/blob/main/LICENSE">
|
||||||
<img height="21" src="https://img.shields.io/badge/License-Apache--2.0-ffffff?labelColor=d4eaf7&color=2e6cc4" alt="license">
|
<img height="21" src="https://img.shields.io/badge/License-Apache--2.0-ffffff?labelColor=d4eaf7&color=2e6cc4" alt="license">
|
||||||
</a>
|
</a>
|
||||||
|
<a href="https://deepwiki.com/infiniflow/ragflow">
|
||||||
|
<img alt="Ask DeepWiki" src="https://deepwiki.com/badge.svg">
|
||||||
|
</a>
|
||||||
</p>
|
</p>
|
||||||
|
|
||||||
<h4 align="center">
|
<h4 align="center">
|
||||||
@ -40,6 +43,8 @@
|
|||||||
<a href="https://demo.ragflow.io">Demo</a>
|
<a href="https://demo.ragflow.io">Demo</a>
|
||||||
</h4>
|
</h4>
|
||||||
|
|
||||||
|
#
|
||||||
|
|
||||||
## 💡 RAGFlow とは?
|
## 💡 RAGFlow とは?
|
||||||
|
|
||||||
[RAGFlow](https://ragflow.io/) は、深い文書理解に基づいたオープンソースの RAG (Retrieval-Augmented Generation) エンジンである。LLM(大規模言語モデル)を組み合わせることで、様々な複雑なフォーマットのデータから根拠のある引用に裏打ちされた、信頼できる質問応答機能を実現し、あらゆる規模のビジネスに適した RAG ワークフローを提供します。
|
[RAGFlow](https://ragflow.io/) は、深い文書理解に基づいたオープンソースの RAG (Retrieval-Augmented Generation) エンジンである。LLM(大規模言語モデル)を組み合わせることで、様々な複雑なフォーマットのデータから根拠のある引用に裏打ちされた、信頼できる質問応答機能を実現し、あらゆる規模のビジネスに適した RAG ワークフローを提供します。
|
||||||
@ -55,11 +60,11 @@
|
|||||||
|
|
||||||
## 🔥 最新情報
|
## 🔥 最新情報
|
||||||
|
|
||||||
|
- 2025-05-23 エージェントに Python/JS コードエグゼキュータコンポーネントを追加しました。
|
||||||
|
- 2025-05-05 言語間クエリをサポートしました。
|
||||||
- 2025-03-19 PDFまたはDOCXファイル内の画像を理解するために、多モーダルモデルを使用することをサポートします。
|
- 2025-03-19 PDFまたはDOCXファイル内の画像を理解するために、多モーダルモデルを使用することをサポートします。
|
||||||
- 2025-02-28 インターネット検索 (TAVILY) と組み合わせて、あらゆる LLM の詳細な調査をサポートします。
|
- 2025-02-28 インターネット検索 (TAVILY) と組み合わせて、あらゆる LLM の詳細な調査をサポートします。
|
||||||
- 2025-01-26 ナレッジ グラフの抽出と適用を最適化し、さまざまな構成オプションを提供します。
|
|
||||||
- 2024-12-18 DeepDoc のドキュメント レイアウト分析モデルをアップグレードします。
|
- 2024-12-18 DeepDoc のドキュメント レイアウト分析モデルをアップグレードします。
|
||||||
- 2024-11-01 再現の精度を向上させるために、解析されたチャンクにキーワード抽出と関連質問の生成を追加しました。
|
|
||||||
- 2024-08-22 RAG を介して SQL ステートメントへのテキストをサポートします。
|
- 2024-08-22 RAG を介して SQL ステートメントへのテキストをサポートします。
|
||||||
|
|
||||||
## 🎉 続きを楽しみに
|
## 🎉 続きを楽しみに
|
||||||
@ -152,7 +157,7 @@
|
|||||||
> 現在、公式に提供されているすべての Docker イメージは x86 アーキテクチャ向けにビルドされており、ARM64 用の Docker イメージは提供されていません。
|
> 現在、公式に提供されているすべての Docker イメージは x86 アーキテクチャ向けにビルドされており、ARM64 用の Docker イメージは提供されていません。
|
||||||
> ARM64 アーキテクチャのオペレーティングシステムを使用している場合は、[このドキュメント](https://ragflow.io/docs/dev/build_docker_image)を参照して Docker イメージを自分でビルドしてください。
|
> ARM64 アーキテクチャのオペレーティングシステムを使用している場合は、[このドキュメント](https://ragflow.io/docs/dev/build_docker_image)を参照して Docker イメージを自分でビルドしてください。
|
||||||
|
|
||||||
> 以下のコマンドは、RAGFlow Docker イメージの v0.18.0-slim エディションをダウンロードします。異なる RAGFlow エディションの説明については、以下の表を参照してください。v0.18.0-slim とは異なるエディションをダウンロードするには、docker/.env ファイルの RAGFLOW_IMAGE 変数を適宜更新し、docker compose を使用してサーバーを起動してください。例えば、完全版 v0.18.0 をダウンロードするには、RAGFLOW_IMAGE=infiniflow/ragflow:v0.18.0 と設定します。
|
> 以下のコマンドは、RAGFlow Docker イメージの v0.19.1-slim エディションをダウンロードします。異なる RAGFlow エディションの説明については、以下の表を参照してください。v0.19.1-slim とは異なるエディションをダウンロードするには、docker/.env ファイルの RAGFLOW_IMAGE 変数を適宜更新し、docker compose を使用してサーバーを起動してください。例えば、完全版 v0.19.1 をダウンロードするには、RAGFLOW_IMAGE=infiniflow/ragflow:v0.19.1 と設定します。
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
$ cd ragflow/docker
|
$ cd ragflow/docker
|
||||||
@ -165,8 +170,8 @@
|
|||||||
|
|
||||||
| RAGFlow image tag | Image size (GB) | Has embedding models? | Stable? |
|
| RAGFlow image tag | Image size (GB) | Has embedding models? | Stable? |
|
||||||
| ----------------- | --------------- | --------------------- | ------------------------ |
|
| ----------------- | --------------- | --------------------- | ------------------------ |
|
||||||
| v0.18.0 | ≈9 | :heavy_check_mark: | Stable release |
|
| v0.19.1 | ≈9 | :heavy_check_mark: | Stable release |
|
||||||
| v0.18.0-slim | ≈2 | ❌ | Stable release |
|
| v0.19.1-slim | ≈2 | ❌ | Stable release |
|
||||||
| nightly | ≈9 | :heavy_check_mark: | _Unstable_ nightly build |
|
| nightly | ≈9 | :heavy_check_mark: | _Unstable_ nightly build |
|
||||||
| nightly-slim | ≈2 | ❌ | _Unstable_ nightly build |
|
| nightly-slim | ≈2 | ❌ | _Unstable_ nightly build |
|
||||||
|
|
||||||
|
|||||||
31
README_ko.md
31
README_ko.md
@ -5,13 +5,13 @@
|
|||||||
</div>
|
</div>
|
||||||
|
|
||||||
<p align="center">
|
<p align="center">
|
||||||
<a href="./README.md">English</a> |
|
<a href="./README.md"><img alt="README in English" src="https://img.shields.io/badge/English-DFE0E5"></a>
|
||||||
<a href="./README_zh.md">简体中文</a> |
|
<a href="./README_zh.md"><img alt="简体中文版自述文件" src="https://img.shields.io/badge/简体中文-DFE0E5"></a>
|
||||||
<a href="./README_tzh.md">繁体中文</a> |
|
<a href="./README_tzh.md"><img alt="繁體版中文自述文件" src="https://img.shields.io/badge/繁體中文-DFE0E5"></a>
|
||||||
<a href="./README_ja.md">日本語</a> |
|
<a href="./README_ja.md"><img alt="日本語のREADME" src="https://img.shields.io/badge/日本語-DFE0E5"></a>
|
||||||
<a href="./README_ko.md">한국어</a> |
|
<a href="./README_ko.md"><img alt="한국어" src="https://img.shields.io/badge/한국어-DBEDFA"></a>
|
||||||
<a href="./README_id.md">Bahasa Indonesia</a> |
|
<a href="./README_id.md"><img alt="Bahasa Indonesia" src="https://img.shields.io/badge/Bahasa Indonesia-DFE0E5"></a>
|
||||||
<a href="/README_pt_br.md">Português (Brasil)</a>
|
<a href="./README_pt_br.md"><img alt="Português(Brasil)" src="https://img.shields.io/badge/Português(Brasil)-DFE0E5"></a>
|
||||||
</p>
|
</p>
|
||||||
|
|
||||||
<p align="center">
|
<p align="center">
|
||||||
@ -22,7 +22,7 @@
|
|||||||
<img alt="Static Badge" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
<img alt="Static Badge" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
||||||
</a>
|
</a>
|
||||||
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
||||||
<img src="https://img.shields.io/badge/docker_pull-ragflow:v0.18.0-brightgreen" alt="docker pull infiniflow/ragflow:v0.18.0">
|
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.19.1">
|
||||||
</a>
|
</a>
|
||||||
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
||||||
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Latest%20Release" alt="Latest Release">
|
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Latest%20Release" alt="Latest Release">
|
||||||
@ -30,6 +30,9 @@
|
|||||||
<a href="https://github.com/infiniflow/ragflow/blob/main/LICENSE">
|
<a href="https://github.com/infiniflow/ragflow/blob/main/LICENSE">
|
||||||
<img height="21" src="https://img.shields.io/badge/License-Apache--2.0-ffffff?labelColor=d4eaf7&color=2e6cc4" alt="license">
|
<img height="21" src="https://img.shields.io/badge/License-Apache--2.0-ffffff?labelColor=d4eaf7&color=2e6cc4" alt="license">
|
||||||
</a>
|
</a>
|
||||||
|
<a href="https://deepwiki.com/infiniflow/ragflow">
|
||||||
|
<img alt="Ask DeepWiki" src="https://deepwiki.com/badge.svg">
|
||||||
|
</a>
|
||||||
</p>
|
</p>
|
||||||
|
|
||||||
<h4 align="center">
|
<h4 align="center">
|
||||||
@ -40,6 +43,8 @@
|
|||||||
<a href="https://demo.ragflow.io">Demo</a>
|
<a href="https://demo.ragflow.io">Demo</a>
|
||||||
</h4>
|
</h4>
|
||||||
|
|
||||||
|
#
|
||||||
|
|
||||||
## 💡 RAGFlow란?
|
## 💡 RAGFlow란?
|
||||||
|
|
||||||
[RAGFlow](https://ragflow.io/)는 심층 문서 이해에 기반한 오픈소스 RAG (Retrieval-Augmented Generation) 엔진입니다. 이 엔진은 대규모 언어 모델(LLM)과 결합하여 정확한 질문 응답 기능을 제공하며, 다양한 복잡한 형식의 데이터에서 신뢰할 수 있는 출처를 바탕으로 한 인용을 통해 이를 뒷받침합니다. RAGFlow는 규모에 상관없이 모든 기업에 최적화된 RAG 워크플로우를 제공합니다.
|
[RAGFlow](https://ragflow.io/)는 심층 문서 이해에 기반한 오픈소스 RAG (Retrieval-Augmented Generation) 엔진입니다. 이 엔진은 대규모 언어 모델(LLM)과 결합하여 정확한 질문 응답 기능을 제공하며, 다양한 복잡한 형식의 데이터에서 신뢰할 수 있는 출처를 바탕으로 한 인용을 통해 이를 뒷받침합니다. RAGFlow는 규모에 상관없이 모든 기업에 최적화된 RAG 워크플로우를 제공합니다.
|
||||||
@ -55,11 +60,11 @@
|
|||||||
|
|
||||||
## 🔥 업데이트
|
## 🔥 업데이트
|
||||||
|
|
||||||
|
- 2025-05-23 Agent에 Python/JS 코드 실행기 구성 요소를 추가합니다.
|
||||||
|
- 2025-05-05 언어 간 쿼리를 지원합니다.
|
||||||
- 2025-03-19 PDF 또는 DOCX 파일 내의 이미지를 이해하기 위해 다중 모드 모델을 사용하는 것을 지원합니다.
|
- 2025-03-19 PDF 또는 DOCX 파일 내의 이미지를 이해하기 위해 다중 모드 모델을 사용하는 것을 지원합니다.
|
||||||
- 2025-02-28 인터넷 검색(TAVILY)과 결합되어 모든 LLM에 대한 심층 연구를 지원합니다.
|
- 2025-02-28 인터넷 검색(TAVILY)과 결합되어 모든 LLM에 대한 심층 연구를 지원합니다.
|
||||||
- 2025-01-26 지식 그래프 추출 및 적용을 최적화하고 다양한 구성 옵션을 제공합니다.
|
|
||||||
- 2024-12-18 DeepDoc의 문서 레이아웃 분석 모델 업그레이드.
|
- 2024-12-18 DeepDoc의 문서 레이아웃 분석 모델 업그레이드.
|
||||||
- 2024-11-01 파싱된 청크에 키워드 추출 및 관련 질문 생성을 추가하여 재현율을 향상시킵니다.
|
|
||||||
- 2024-08-22 RAG를 통해 SQL 문에 텍스트를 지원합니다.
|
- 2024-08-22 RAG를 통해 SQL 문에 텍스트를 지원합니다.
|
||||||
|
|
||||||
## 🎉 계속 지켜봐 주세요
|
## 🎉 계속 지켜봐 주세요
|
||||||
@ -152,7 +157,7 @@
|
|||||||
> 모든 Docker 이미지는 x86 플랫폼을 위해 빌드되었습니다. 우리는 현재 ARM64 플랫폼을 위한 Docker 이미지를 제공하지 않습니다.
|
> 모든 Docker 이미지는 x86 플랫폼을 위해 빌드되었습니다. 우리는 현재 ARM64 플랫폼을 위한 Docker 이미지를 제공하지 않습니다.
|
||||||
> ARM64 플랫폼을 사용 중이라면, [시스템과 호환되는 Docker 이미지를 빌드하려면 이 가이드를 사용해 주세요](https://ragflow.io/docs/dev/build_docker_image).
|
> ARM64 플랫폼을 사용 중이라면, [시스템과 호환되는 Docker 이미지를 빌드하려면 이 가이드를 사용해 주세요](https://ragflow.io/docs/dev/build_docker_image).
|
||||||
|
|
||||||
> 아래 명령어는 RAGFlow Docker 이미지의 v0.18.0-slim 버전을 다운로드합니다. 다양한 RAGFlow 버전에 대한 설명은 다음 표를 참조하십시오. v0.18.0-slim과 다른 RAGFlow 버전을 다운로드하려면, docker/.env 파일에서 RAGFLOW_IMAGE 변수를 적절히 업데이트한 후 docker compose를 사용하여 서버를 시작하십시오. 예를 들어, 전체 버전인 v0.18.0을 다운로드하려면 RAGFLOW_IMAGE=infiniflow/ragflow:v0.18.0로 설정합니다.
|
> 아래 명령어는 RAGFlow Docker 이미지의 v0.19.1-slim 버전을 다운로드합니다. 다양한 RAGFlow 버전에 대한 설명은 다음 표를 참조하십시오. v0.19.1-slim과 다른 RAGFlow 버전을 다운로드하려면, docker/.env 파일에서 RAGFLOW_IMAGE 변수를 적절히 업데이트한 후 docker compose를 사용하여 서버를 시작하십시오. 예를 들어, 전체 버전인 v0.19.1을 다운로드하려면 RAGFLOW_IMAGE=infiniflow/ragflow:v0.19.1로 설정합니다.
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
$ cd ragflow/docker
|
$ cd ragflow/docker
|
||||||
@ -165,8 +170,8 @@
|
|||||||
|
|
||||||
| RAGFlow image tag | Image size (GB) | Has embedding models? | Stable? |
|
| RAGFlow image tag | Image size (GB) | Has embedding models? | Stable? |
|
||||||
| ----------------- | --------------- | --------------------- | ------------------------ |
|
| ----------------- | --------------- | --------------------- | ------------------------ |
|
||||||
| v0.18.0 | ≈9 | :heavy_check_mark: | Stable release |
|
| v0.19.1 | ≈9 | :heavy_check_mark: | Stable release |
|
||||||
| v0.18.0-slim | ≈2 | ❌ | Stable release |
|
| v0.19.1-slim | ≈2 | ❌ | Stable release |
|
||||||
| nightly | ≈9 | :heavy_check_mark: | _Unstable_ nightly build |
|
| nightly | ≈9 | :heavy_check_mark: | _Unstable_ nightly build |
|
||||||
| nightly-slim | ≈2 | ❌ | _Unstable_ nightly build |
|
| nightly-slim | ≈2 | ❌ | _Unstable_ nightly build |
|
||||||
|
|
||||||
|
|||||||
@ -5,13 +5,13 @@
|
|||||||
</div>
|
</div>
|
||||||
|
|
||||||
<p align="center">
|
<p align="center">
|
||||||
<a href="./README.md">English</a> |
|
<a href="./README.md"><img alt="README in English" src="https://img.shields.io/badge/English-DFE0E5"></a>
|
||||||
<a href="./README_zh.md">简体中文</a> |
|
<a href="./README_zh.md"><img alt="简体中文版自述文件" src="https://img.shields.io/badge/简体中文-DFE0E5"></a>
|
||||||
<a href="./README_tzh.md">繁体中文</a> |
|
<a href="./README_tzh.md"><img alt="繁體版中文自述文件" src="https://img.shields.io/badge/繁體中文-DFE0E5"></a>
|
||||||
<a href="./README_ja.md">日本語</a> |
|
<a href="./README_ja.md"><img alt="日本語のREADME" src="https://img.shields.io/badge/日本語-DFE0E5"></a>
|
||||||
<a href="./README_ko.md">한국어</a> |
|
<a href="./README_ko.md"><img alt="한국어" src="https://img.shields.io/badge/한국어-DFE0E5"></a>
|
||||||
<a href="./README_id.md">Bahasa Indonesia</a> |
|
<a href="./README_id.md"><img alt="Bahasa Indonesia" src="https://img.shields.io/badge/Bahasa Indonesia-DFE0E5"></a>
|
||||||
<a href="/README_pt_br.md">Português (Brasil)</a>
|
<a href="./README_pt_br.md"><img alt="Português(Brasil)" src="https://img.shields.io/badge/Português(Brasil)-DBEDFA"></a>
|
||||||
</p>
|
</p>
|
||||||
|
|
||||||
<p align="center">
|
<p align="center">
|
||||||
@ -22,7 +22,7 @@
|
|||||||
<img alt="Badge Estático" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
<img alt="Badge Estático" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
||||||
</a>
|
</a>
|
||||||
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
||||||
<img src="https://img.shields.io/badge/docker_pull-ragflow:v0.18.0-brightgreen" alt="docker pull infiniflow/ragflow:v0.18.0">
|
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.19.1">
|
||||||
</a>
|
</a>
|
||||||
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
||||||
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Última%20Relese" alt="Última Versão">
|
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Última%20Relese" alt="Última Versão">
|
||||||
@ -30,6 +30,9 @@
|
|||||||
<a href="https://github.com/infiniflow/ragflow/blob/main/LICENSE">
|
<a href="https://github.com/infiniflow/ragflow/blob/main/LICENSE">
|
||||||
<img height="21" src="https://img.shields.io/badge/License-Apache--2.0-ffffff?labelColor=d4eaf7&color=2e6cc4" alt="licença">
|
<img height="21" src="https://img.shields.io/badge/License-Apache--2.0-ffffff?labelColor=d4eaf7&color=2e6cc4" alt="licença">
|
||||||
</a>
|
</a>
|
||||||
|
<a href="https://deepwiki.com/infiniflow/ragflow">
|
||||||
|
<img alt="Ask DeepWiki" src="https://deepwiki.com/badge.svg">
|
||||||
|
</a>
|
||||||
</p>
|
</p>
|
||||||
|
|
||||||
<h4 align="center">
|
<h4 align="center">
|
||||||
@ -40,6 +43,8 @@
|
|||||||
<a href="https://demo.ragflow.io">Demo</a>
|
<a href="https://demo.ragflow.io">Demo</a>
|
||||||
</h4>
|
</h4>
|
||||||
|
|
||||||
|
#
|
||||||
|
|
||||||
<details open>
|
<details open>
|
||||||
<summary><b>📕 Índice</b></summary>
|
<summary><b>📕 Índice</b></summary>
|
||||||
|
|
||||||
@ -75,11 +80,11 @@ Experimente nossa demo em [https://demo.ragflow.io](https://demo.ragflow.io).
|
|||||||
|
|
||||||
## 🔥 Últimas Atualizações
|
## 🔥 Últimas Atualizações
|
||||||
|
|
||||||
|
- 23-05-2025 Adicione o componente executor de código Python/JS ao Agente.
|
||||||
|
- 05-05-2025 Suporte a consultas entre idiomas.
|
||||||
- 19-03-2025 Suporta o uso de um modelo multi-modal para entender imagens dentro de arquivos PDF ou DOCX.
|
- 19-03-2025 Suporta o uso de um modelo multi-modal para entender imagens dentro de arquivos PDF ou DOCX.
|
||||||
- 28-02-2025 combinado com a pesquisa na Internet (T AVI LY), suporta pesquisas profundas para qualquer LLM.
|
- 28-02-2025 combinado com a pesquisa na Internet (T AVI LY), suporta pesquisas profundas para qualquer LLM.
|
||||||
- 26-01-2025 Otimize a extração e aplicação de gráficos de conhecimento e forneça uma variedade de opções de configuração.
|
|
||||||
- 18-12-2024 Atualiza o modelo de Análise de Layout de Documentos no DeepDoc.
|
- 18-12-2024 Atualiza o modelo de Análise de Layout de Documentos no DeepDoc.
|
||||||
- 01-11-2024 Adiciona extração de palavras-chave e geração de perguntas relacionadas aos blocos analisados para melhorar a precisão da recuperação.
|
|
||||||
- 22-08-2024 Suporta conversão de texto para comandos SQL via RAG.
|
- 22-08-2024 Suporta conversão de texto para comandos SQL via RAG.
|
||||||
|
|
||||||
## 🎉 Fique Ligado
|
## 🎉 Fique Ligado
|
||||||
@ -172,7 +177,7 @@ Experimente nossa demo em [https://demo.ragflow.io](https://demo.ragflow.io).
|
|||||||
> Todas as imagens Docker são construídas para plataformas x86. Atualmente, não oferecemos imagens Docker para ARM64.
|
> Todas as imagens Docker são construídas para plataformas x86. Atualmente, não oferecemos imagens Docker para ARM64.
|
||||||
> Se você estiver usando uma plataforma ARM64, por favor, utilize [este guia](https://ragflow.io/docs/dev/build_docker_image) para construir uma imagem Docker compatível com o seu sistema.
|
> Se você estiver usando uma plataforma ARM64, por favor, utilize [este guia](https://ragflow.io/docs/dev/build_docker_image) para construir uma imagem Docker compatível com o seu sistema.
|
||||||
|
|
||||||
> O comando abaixo baixa a edição `v0.18.0-slim` da imagem Docker do RAGFlow. Consulte a tabela a seguir para descrições de diferentes edições do RAGFlow. Para baixar uma edição do RAGFlow diferente da `v0.18.0-slim`, atualize a variável `RAGFLOW_IMAGE` conforme necessário no **docker/.env** antes de usar `docker compose` para iniciar o servidor. Por exemplo: defina `RAGFLOW_IMAGE=infiniflow/ragflow:v0.18.0` para a edição completa `v0.18.0`.
|
> O comando abaixo baixa a edição `v0.19.1-slim` da imagem Docker do RAGFlow. Consulte a tabela a seguir para descrições de diferentes edições do RAGFlow. Para baixar uma edição do RAGFlow diferente da `v0.19.1-slim`, atualize a variável `RAGFLOW_IMAGE` conforme necessário no **docker/.env** antes de usar `docker compose` para iniciar o servidor. Por exemplo: defina `RAGFLOW_IMAGE=infiniflow/ragflow:v0.19.1` para a edição completa `v0.19.1`.
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
$ cd ragflow/docker
|
$ cd ragflow/docker
|
||||||
@ -185,8 +190,8 @@ Experimente nossa demo em [https://demo.ragflow.io](https://demo.ragflow.io).
|
|||||||
|
|
||||||
| Tag da imagem RAGFlow | Tamanho da imagem (GB) | Possui modelos de incorporação? | Estável? |
|
| Tag da imagem RAGFlow | Tamanho da imagem (GB) | Possui modelos de incorporação? | Estável? |
|
||||||
| --------------------- | ---------------------- | ------------------------------- | ------------------------ |
|
| --------------------- | ---------------------- | ------------------------------- | ------------------------ |
|
||||||
| v0.18.0 | ~9 | :heavy_check_mark: | Lançamento estável |
|
| v0.19.1 | ~9 | :heavy_check_mark: | Lançamento estável |
|
||||||
| v0.18.0-slim | ~2 | ❌ | Lançamento estável |
|
| v0.19.1-slim | ~2 | ❌ | Lançamento estável |
|
||||||
| nightly | ~9 | :heavy_check_mark: | _Instável_ build noturno |
|
| nightly | ~9 | :heavy_check_mark: | _Instável_ build noturno |
|
||||||
| nightly-slim | ~2 | ❌ | _Instável_ build noturno |
|
| nightly-slim | ~2 | ❌ | _Instável_ build noturno |
|
||||||
|
|
||||||
|
|||||||
@ -5,12 +5,13 @@
|
|||||||
</div>
|
</div>
|
||||||
|
|
||||||
<p align="center">
|
<p align="center">
|
||||||
<a href="./README.md">English</a> |
|
<a href="./README.md"><img alt="README in English" src="https://img.shields.io/badge/English-DFE0E5"></a>
|
||||||
<a href="./README_zh.md">简体中文</a> |
|
<a href="./README_zh.md"><img alt="简体中文版自述文件" src="https://img.shields.io/badge/简体中文-DFE0E5"></a>
|
||||||
<a href="./README_ja.md">日本語</a> |
|
<a href="./README_tzh.md"><img alt="繁體版中文自述文件" src="https://img.shields.io/badge/繁體中文-DBEDFA"></a>
|
||||||
<a href="./README_ko.md">한국어</a> |
|
<a href="./README_ja.md"><img alt="日本語のREADME" src="https://img.shields.io/badge/日本語-DFE0E5"></a>
|
||||||
<a href="./README_id.md">Bahasa Indonesia</a> |
|
<a href="./README_ko.md"><img alt="한국어" src="https://img.shields.io/badge/한국어-DFE0E5"></a>
|
||||||
<a href="/README_pt_br.md">Português (Brasil)</a>
|
<a href="./README_id.md"><img alt="Bahasa Indonesia" src="https://img.shields.io/badge/Bahasa Indonesia-DFE0E5"></a>
|
||||||
|
<a href="./README_pt_br.md"><img alt="Português(Brasil)" src="https://img.shields.io/badge/Português(Brasil)-DFE0E5"></a>
|
||||||
</p>
|
</p>
|
||||||
|
|
||||||
<p align="center">
|
<p align="center">
|
||||||
@ -21,7 +22,7 @@
|
|||||||
<img alt="Static Badge" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
<img alt="Static Badge" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
||||||
</a>
|
</a>
|
||||||
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
||||||
<img src="https://img.shields.io/badge/docker_pull-ragflow:v0.18.0-brightgreen" alt="docker pull infiniflow/ragflow:v0.18.0">
|
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.19.1">
|
||||||
</a>
|
</a>
|
||||||
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
||||||
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Latest%20Release" alt="Latest Release">
|
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Latest%20Release" alt="Latest Release">
|
||||||
@ -29,6 +30,9 @@
|
|||||||
<a href="https://github.com/infiniflow/ragflow/blob/main/LICENSE">
|
<a href="https://github.com/infiniflow/ragflow/blob/main/LICENSE">
|
||||||
<img height="21" src="https://img.shields.io/badge/License-Apache--2.0-ffffff?labelColor=d4eaf7&color=2e6cc4" alt="license">
|
<img height="21" src="https://img.shields.io/badge/License-Apache--2.0-ffffff?labelColor=d4eaf7&color=2e6cc4" alt="license">
|
||||||
</a>
|
</a>
|
||||||
|
<a href="https://deepwiki.com/infiniflow/ragflow">
|
||||||
|
<img alt="Ask DeepWiki" src="https://deepwiki.com/badge.svg">
|
||||||
|
</a>
|
||||||
</p>
|
</p>
|
||||||
|
|
||||||
<h4 align="center">
|
<h4 align="center">
|
||||||
@ -39,6 +43,31 @@
|
|||||||
<a href="https://demo.ragflow.io">Demo</a>
|
<a href="https://demo.ragflow.io">Demo</a>
|
||||||
</h4>
|
</h4>
|
||||||
|
|
||||||
|
#
|
||||||
|
|
||||||
|
<div align="center">
|
||||||
|
<a href="https://trendshift.io/repositories/9064" target="_blank"><img src="https://trendshift.io/api/badge/repositories/9064" alt="infiniflow%2Fragflow | Trendshift" style="width: 250px; height: 55px;" width="250" height="55"/></a>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
<details open>
|
||||||
|
<summary><b>📕 目錄</b></summary>
|
||||||
|
|
||||||
|
- 💡 [RAGFlow 是什麼?](#-RAGFlow-是什麼)
|
||||||
|
- 🎮 [Demo-試用](#-demo-試用)
|
||||||
|
- 📌 [近期更新](#-近期更新)
|
||||||
|
- 🌟 [主要功能](#-主要功能)
|
||||||
|
- 🔎 [系統架構](#-系統架構)
|
||||||
|
- 🎬 [快速開始](#-快速開始)
|
||||||
|
- 🔧 [系統配置](#-系統配置)
|
||||||
|
- 🔨 [以原始碼啟動服務](#-以原始碼啟動服務)
|
||||||
|
- 📚 [技術文檔](#-技術文檔)
|
||||||
|
- 📜 [路線圖](#-路線圖)
|
||||||
|
- 🏄 [貢獻指南](#-貢獻指南)
|
||||||
|
- 🙌 [加入社區](#-加入社區)
|
||||||
|
- 🤝 [商務合作](#-商務合作)
|
||||||
|
|
||||||
|
</details>
|
||||||
|
|
||||||
## 💡 RAGFlow 是什麼?
|
## 💡 RAGFlow 是什麼?
|
||||||
|
|
||||||
[RAGFlow](https://ragflow.io/) 是一款基於深度文件理解所建構的開源 RAG(Retrieval-Augmented Generation)引擎。 RAGFlow 可以為各種規模的企業及個人提供一套精簡的 RAG 工作流程,結合大語言模型(LLM)針對用戶各類不同的複雜格式數據提供可靠的問答以及有理有據的引用。
|
[RAGFlow](https://ragflow.io/) 是一款基於深度文件理解所建構的開源 RAG(Retrieval-Augmented Generation)引擎。 RAGFlow 可以為各種規模的企業及個人提供一套精簡的 RAG 工作流程,結合大語言模型(LLM)針對用戶各類不同的複雜格式數據提供可靠的問答以及有理有據的引用。
|
||||||
@ -54,11 +83,11 @@
|
|||||||
|
|
||||||
## 🔥 近期更新
|
## 🔥 近期更新
|
||||||
|
|
||||||
|
- 2025-05-23 為 Agent 新增 Python/JS 程式碼執行器元件。
|
||||||
|
- 2025-05-05 支援跨語言查詢。
|
||||||
- 2025-03-19 PDF和DOCX中的圖支持用多模態大模型去解析得到描述.
|
- 2025-03-19 PDF和DOCX中的圖支持用多模態大模型去解析得到描述.
|
||||||
- 2025-02-28 結合網路搜尋(Tavily),對於任意大模型實現類似 Deep Research 的推理功能.
|
- 2025-02-28 結合網路搜尋(Tavily),對於任意大模型實現類似 Deep Research 的推理功能.
|
||||||
- 2025-01-26 最佳化知識圖譜的擷取與應用,提供了多種配置選擇。
|
|
||||||
- 2024-12-18 升級了 DeepDoc 的文檔佈局分析模型。
|
- 2024-12-18 升級了 DeepDoc 的文檔佈局分析模型。
|
||||||
- 2024-11-01 對解析後的 chunk 加入關鍵字抽取和相關問題產生以提高回想的準確度。
|
|
||||||
- 2024-08-22 支援用 RAG 技術實現從自然語言到 SQL 語句的轉換。
|
- 2024-08-22 支援用 RAG 技術實現從自然語言到 SQL 語句的轉換。
|
||||||
|
|
||||||
## 🎉 關注項目
|
## 🎉 關注項目
|
||||||
@ -151,7 +180,7 @@
|
|||||||
> 所有 Docker 映像檔都是為 x86 平台建置的。目前,我們不提供 ARM64 平台的 Docker 映像檔。
|
> 所有 Docker 映像檔都是為 x86 平台建置的。目前,我們不提供 ARM64 平台的 Docker 映像檔。
|
||||||
> 如果您使用的是 ARM64 平台,請使用 [這份指南](https://ragflow.io/docs/dev/build_docker_image) 來建置適合您系統的 Docker 映像檔。
|
> 如果您使用的是 ARM64 平台,請使用 [這份指南](https://ragflow.io/docs/dev/build_docker_image) 來建置適合您系統的 Docker 映像檔。
|
||||||
|
|
||||||
> 執行以下指令會自動下載 RAGFlow slim Docker 映像 `v0.18.0-slim`。請參考下表查看不同 Docker 發行版的說明。如需下載不同於 `v0.18.0-slim` 的 Docker 映像,請在執行 `docker compose` 啟動服務之前先更新 **docker/.env** 檔案內的 `RAGFLOW_IMAGE` 變數。例如,你可以透過設定 `RAGFLOW_IMAGE=infiniflow/ragflow:v0.18.0` 來下載 RAGFlow 鏡像的 `v0.18.0` 完整發行版。
|
> 執行以下指令會自動下載 RAGFlow slim Docker 映像 `v0.19.1-slim`。請參考下表查看不同 Docker 發行版的說明。如需下載不同於 `v0.19.1-slim` 的 Docker 映像,請在執行 `docker compose` 啟動服務之前先更新 **docker/.env** 檔案內的 `RAGFLOW_IMAGE` 變數。例如,你可以透過設定 `RAGFLOW_IMAGE=infiniflow/ragflow:v0.19.1` 來下載 RAGFlow 鏡像的 `v0.19.1` 完整發行版。
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
$ cd ragflow/docker
|
$ cd ragflow/docker
|
||||||
@ -164,8 +193,8 @@
|
|||||||
|
|
||||||
| RAGFlow image tag | Image size (GB) | Has embedding models? | Stable? |
|
| RAGFlow image tag | Image size (GB) | Has embedding models? | Stable? |
|
||||||
| ----------------- | --------------- | --------------------- | ------------------------ |
|
| ----------------- | --------------- | --------------------- | ------------------------ |
|
||||||
| v0.18.0 | ≈9 | :heavy_check_mark: | Stable release |
|
| v0.19.1 | ≈9 | :heavy_check_mark: | Stable release |
|
||||||
| v0.18.0-slim | ≈2 | ❌ | Stable release |
|
| v0.19.1-slim | ≈2 | ❌ | Stable release |
|
||||||
| nightly | ≈9 | :heavy_check_mark: | _Unstable_ nightly build |
|
| nightly | ≈9 | :heavy_check_mark: | _Unstable_ nightly build |
|
||||||
| nightly-slim | ≈2 | ❌ | _Unstable_ nightly build |
|
| nightly-slim | ≈2 | ❌ | _Unstable_ nightly build |
|
||||||
|
|
||||||
|
|||||||
56
README_zh.md
56
README_zh.md
@ -5,13 +5,13 @@
|
|||||||
</div>
|
</div>
|
||||||
|
|
||||||
<p align="center">
|
<p align="center">
|
||||||
<a href="./README.md">English</a> |
|
<a href="./README.md"><img alt="README in English" src="https://img.shields.io/badge/English-DFE0E5"></a>
|
||||||
<a href="./README_zh.md">简体中文</a> |
|
<a href="./README_zh.md"><img alt="简体中文版自述文件" src="https://img.shields.io/badge/简体中文-DBEDFA"></a>
|
||||||
<a href="./README_tzh.md">繁体中文</a> |
|
<a href="./README_tzh.md"><img alt="繁體版中文自述文件" src="https://img.shields.io/badge/繁體中文-DFE0E5"></a>
|
||||||
<a href="./README_ja.md">日本語</a> |
|
<a href="./README_ja.md"><img alt="日本語のREADME" src="https://img.shields.io/badge/日本語-DFE0E5"></a>
|
||||||
<a href="./README_ko.md">한국어</a> |
|
<a href="./README_ko.md"><img alt="한국어" src="https://img.shields.io/badge/한국어-DFE0E5"></a>
|
||||||
<a href="./README_id.md">Bahasa Indonesia</a> |
|
<a href="./README_id.md"><img alt="Bahasa Indonesia" src="https://img.shields.io/badge/Bahasa Indonesia-DFE0E5"></a>
|
||||||
<a href="/README_pt_br.md">Português (Brasil)</a>
|
<a href="./README_pt_br.md"><img alt="Português(Brasil)" src="https://img.shields.io/badge/Português(Brasil)-DFE0E5"></a>
|
||||||
</p>
|
</p>
|
||||||
|
|
||||||
<p align="center">
|
<p align="center">
|
||||||
@ -22,7 +22,7 @@
|
|||||||
<img alt="Static Badge" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
<img alt="Static Badge" src="https://img.shields.io/badge/Online-Demo-4e6b99">
|
||||||
</a>
|
</a>
|
||||||
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
<a href="https://hub.docker.com/r/infiniflow/ragflow" target="_blank">
|
||||||
<img src="https://img.shields.io/badge/docker_pull-ragflow:v0.18.0-brightgreen" alt="docker pull infiniflow/ragflow:v0.18.0">
|
<img src="https://img.shields.io/docker/pulls/infiniflow/ragflow?label=Docker%20Pulls&color=0db7ed&logo=docker&logoColor=white&style=flat-square" alt="docker pull infiniflow/ragflow:v0.19.1">
|
||||||
</a>
|
</a>
|
||||||
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
<a href="https://github.com/infiniflow/ragflow/releases/latest">
|
||||||
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Latest%20Release" alt="Latest Release">
|
<img src="https://img.shields.io/github/v/release/infiniflow/ragflow?color=blue&label=Latest%20Release" alt="Latest Release">
|
||||||
@ -30,6 +30,9 @@
|
|||||||
<a href="https://github.com/infiniflow/ragflow/blob/main/LICENSE">
|
<a href="https://github.com/infiniflow/ragflow/blob/main/LICENSE">
|
||||||
<img height="21" src="https://img.shields.io/badge/License-Apache--2.0-ffffff?labelColor=d4eaf7&color=2e6cc4" alt="license">
|
<img height="21" src="https://img.shields.io/badge/License-Apache--2.0-ffffff?labelColor=d4eaf7&color=2e6cc4" alt="license">
|
||||||
</a>
|
</a>
|
||||||
|
<a href="https://deepwiki.com/infiniflow/ragflow">
|
||||||
|
<img alt="Ask DeepWiki" src="https://deepwiki.com/badge.svg">
|
||||||
|
</a>
|
||||||
</p>
|
</p>
|
||||||
|
|
||||||
<h4 align="center">
|
<h4 align="center">
|
||||||
@ -40,6 +43,31 @@
|
|||||||
<a href="https://demo.ragflow.io">Demo</a>
|
<a href="https://demo.ragflow.io">Demo</a>
|
||||||
</h4>
|
</h4>
|
||||||
|
|
||||||
|
#
|
||||||
|
|
||||||
|
<div align="center">
|
||||||
|
<a href="https://trendshift.io/repositories/9064" target="_blank"><img src="https://trendshift.io/api/badge/repositories/9064" alt="infiniflow%2Fragflow | Trendshift" style="width: 250px; height: 55px;" width="250" height="55"/></a>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
<details open>
|
||||||
|
<summary><b>📕 目录</b></summary>
|
||||||
|
|
||||||
|
- 💡 [RAGFlow 是什么?](#-RAGFlow-是什么)
|
||||||
|
- 🎮 [Demo](#-demo)
|
||||||
|
- 📌 [近期更新](#-近期更新)
|
||||||
|
- 🌟 [主要功能](#-主要功能)
|
||||||
|
- 🔎 [系统架构](#-系统架构)
|
||||||
|
- 🎬 [快速开始](#-快速开始)
|
||||||
|
- 🔧 [系统配置](#-系统配置)
|
||||||
|
- 🔨 [以源代码启动服务](#-以源代码启动服务)
|
||||||
|
- 📚 [技术文档](#-技术文档)
|
||||||
|
- 📜 [路线图](#-路线图)
|
||||||
|
- 🏄 [贡献指南](#-贡献指南)
|
||||||
|
- 🙌 [加入社区](#-加入社区)
|
||||||
|
- 🤝 [商务合作](#-商务合作)
|
||||||
|
|
||||||
|
</details>
|
||||||
|
|
||||||
## 💡 RAGFlow 是什么?
|
## 💡 RAGFlow 是什么?
|
||||||
|
|
||||||
[RAGFlow](https://ragflow.io/) 是一款基于深度文档理解构建的开源 RAG(Retrieval-Augmented Generation)引擎。RAGFlow 可以为各种规模的企业及个人提供一套精简的 RAG 工作流程,结合大语言模型(LLM)针对用户各类不同的复杂格式数据提供可靠的问答以及有理有据的引用。
|
[RAGFlow](https://ragflow.io/) 是一款基于深度文档理解构建的开源 RAG(Retrieval-Augmented Generation)引擎。RAGFlow 可以为各种规模的企业及个人提供一套精简的 RAG 工作流程,结合大语言模型(LLM)针对用户各类不同的复杂格式数据提供可靠的问答以及有理有据的引用。
|
||||||
@ -55,11 +83,11 @@
|
|||||||
|
|
||||||
## 🔥 近期更新
|
## 🔥 近期更新
|
||||||
|
|
||||||
- 2025-03-19 PDF和DOCX中的图支持用多模态大模型去解析得到描述.
|
- 2025-05-23 Agent 新增 Python/JS 代码执行器组件。
|
||||||
|
- 2025-05-05 支持跨语言查询。
|
||||||
|
- 2025-03-19 PDF 和 DOCX 中的图支持用多模态大模型去解析得到描述.
|
||||||
- 2025-02-28 结合互联网搜索(Tavily),对于任意大模型实现类似 Deep Research 的推理功能.
|
- 2025-02-28 结合互联网搜索(Tavily),对于任意大模型实现类似 Deep Research 的推理功能.
|
||||||
- 2025-01-26 优化知识图谱的提取和应用,提供了多种配置选择。
|
|
||||||
- 2024-12-18 升级了 DeepDoc 的文档布局分析模型。
|
- 2024-12-18 升级了 DeepDoc 的文档布局分析模型。
|
||||||
- 2024-11-01 对解析后的 chunk 加入关键词抽取和相关问题生成以提高召回的准确度。
|
|
||||||
- 2024-08-22 支持用 RAG 技术实现从自然语言到 SQL 语句的转换。
|
- 2024-08-22 支持用 RAG 技术实现从自然语言到 SQL 语句的转换。
|
||||||
|
|
||||||
## 🎉 关注项目
|
## 🎉 关注项目
|
||||||
@ -152,7 +180,7 @@
|
|||||||
> 请注意,目前官方提供的所有 Docker 镜像均基于 x86 架构构建,并不提供基于 ARM64 的 Docker 镜像。
|
> 请注意,目前官方提供的所有 Docker 镜像均基于 x86 架构构建,并不提供基于 ARM64 的 Docker 镜像。
|
||||||
> 如果你的操作系统是 ARM64 架构,请参考[这篇文档](https://ragflow.io/docs/dev/build_docker_image)自行构建 Docker 镜像。
|
> 如果你的操作系统是 ARM64 架构,请参考[这篇文档](https://ragflow.io/docs/dev/build_docker_image)自行构建 Docker 镜像。
|
||||||
|
|
||||||
> 运行以下命令会自动下载 RAGFlow slim Docker 镜像 `v0.18.0-slim`。请参考下表查看不同 Docker 发行版的描述。如需下载不同于 `v0.18.0-slim` 的 Docker 镜像,请在运行 `docker compose` 启动服务之前先更新 **docker/.env** 文件内的 `RAGFLOW_IMAGE` 变量。比如,你可以通过设置 `RAGFLOW_IMAGE=infiniflow/ragflow:v0.18.0` 来下载 RAGFlow 镜像的 `v0.18.0` 完整发行版。
|
> 运行以下命令会自动下载 RAGFlow slim Docker 镜像 `v0.19.1-slim`。请参考下表查看不同 Docker 发行版的描述。如需下载不同于 `v0.19.1-slim` 的 Docker 镜像,请在运行 `docker compose` 启动服务之前先更新 **docker/.env** 文件内的 `RAGFLOW_IMAGE` 变量。比如,你可以通过设置 `RAGFLOW_IMAGE=infiniflow/ragflow:v0.19.1` 来下载 RAGFlow 镜像的 `v0.19.1` 完整发行版。
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
$ cd ragflow/docker
|
$ cd ragflow/docker
|
||||||
@ -165,8 +193,8 @@
|
|||||||
|
|
||||||
| RAGFlow image tag | Image size (GB) | Has embedding models? | Stable? |
|
| RAGFlow image tag | Image size (GB) | Has embedding models? | Stable? |
|
||||||
| ----------------- | --------------- | --------------------- | ------------------------ |
|
| ----------------- | --------------- | --------------------- | ------------------------ |
|
||||||
| v0.18.0 | ≈9 | :heavy_check_mark: | Stable release |
|
| v0.19.1 | ≈9 | :heavy_check_mark: | Stable release |
|
||||||
| v0.18.0-slim | ≈2 | ❌ | Stable release |
|
| v0.19.1-slim | ≈2 | ❌ | Stable release |
|
||||||
| nightly | ≈9 | :heavy_check_mark: | _Unstable_ nightly build |
|
| nightly | ≈9 | :heavy_check_mark: | _Unstable_ nightly build |
|
||||||
| nightly-slim | ≈2 | ❌ | _Unstable_ nightly build |
|
| nightly-slim | ≈2 | ❌ | _Unstable_ nightly build |
|
||||||
|
|
||||||
|
|||||||
@ -169,6 +169,7 @@ class Canvas:
|
|||||||
def run(self, running_hint_text = "is running...🕞", **kwargs):
|
def run(self, running_hint_text = "is running...🕞", **kwargs):
|
||||||
if not running_hint_text or not isinstance(running_hint_text, str):
|
if not running_hint_text or not isinstance(running_hint_text, str):
|
||||||
running_hint_text = "is running...🕞"
|
running_hint_text = "is running...🕞"
|
||||||
|
bypass_begin = bool(kwargs.get("bypass_begin", False))
|
||||||
|
|
||||||
if self.answer:
|
if self.answer:
|
||||||
cpn_id = self.answer[0]
|
cpn_id = self.answer[0]
|
||||||
@ -188,6 +189,12 @@ class Canvas:
|
|||||||
if not self.path:
|
if not self.path:
|
||||||
self.components["begin"]["obj"].run(self.history, **kwargs)
|
self.components["begin"]["obj"].run(self.history, **kwargs)
|
||||||
self.path.append(["begin"])
|
self.path.append(["begin"])
|
||||||
|
if bypass_begin:
|
||||||
|
cpn = self.get_component("begin")
|
||||||
|
downstream = cpn["downstream"]
|
||||||
|
self.path.append(downstream)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
self.path.append([])
|
self.path.append([])
|
||||||
|
|
||||||
@ -304,6 +311,8 @@ class Canvas:
|
|||||||
|
|
||||||
def get_history(self, window_size):
|
def get_history(self, window_size):
|
||||||
convs = []
|
convs = []
|
||||||
|
if window_size <= 0:
|
||||||
|
return convs
|
||||||
for role, obj in self.history[window_size * -1:]:
|
for role, obj in self.history[window_size * -1:]:
|
||||||
if isinstance(obj, list) and obj and all([isinstance(o, dict) for o in obj]):
|
if isinstance(obj, list) and obj and all([isinstance(o, dict) for o in obj]):
|
||||||
convs.append({"role": role, "content": '\n'.join([str(s.get("content", "")) for s in obj])})
|
convs.append({"role": role, "content": '\n'.join([str(s.get("content", "")) for s in obj])})
|
||||||
|
|||||||
@ -64,14 +64,17 @@ class Answer(ComponentBase, ABC):
|
|||||||
for ii, row in stream.iterrows():
|
for ii, row in stream.iterrows():
|
||||||
answer += row.to_dict()["content"]
|
answer += row.to_dict()["content"]
|
||||||
yield {"content": answer}
|
yield {"content": answer}
|
||||||
else:
|
elif stream is not None:
|
||||||
for st in stream():
|
for st in stream():
|
||||||
res = st
|
res = st
|
||||||
yield st
|
yield st
|
||||||
if self._param.post_answers:
|
if self._param.post_answers and res:
|
||||||
res["content"] += random.choice(self._param.post_answers)
|
res["content"] += random.choice(self._param.post_answers)
|
||||||
yield res
|
yield res
|
||||||
|
|
||||||
|
if res is None:
|
||||||
|
res = {"content": ""}
|
||||||
|
|
||||||
self.set_output(res)
|
self.set_output(res)
|
||||||
|
|
||||||
def set_exception(self, e):
|
def set_exception(self, e):
|
||||||
|
|||||||
@ -17,6 +17,7 @@ import logging
|
|||||||
from abc import ABC
|
from abc import ABC
|
||||||
import pandas as pd
|
import pandas as pd
|
||||||
import requests
|
import requests
|
||||||
|
from bs4 import BeautifulSoup
|
||||||
import re
|
import re
|
||||||
from agent.component.base import ComponentBase, ComponentParamBase
|
from agent.component.base import ComponentBase, ComponentParamBase
|
||||||
|
|
||||||
@ -44,17 +45,28 @@ class Baidu(ComponentBase, ABC):
|
|||||||
return Baidu.be_output("")
|
return Baidu.be_output("")
|
||||||
|
|
||||||
try:
|
try:
|
||||||
url = 'http://www.baidu.com/s?wd=' + ans + '&rn=' + str(self._param.top_n)
|
url = 'https://www.baidu.com/s?wd=' + ans + '&rn=' + str(self._param.top_n)
|
||||||
headers = {
|
headers = {
|
||||||
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'}
|
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
|
||||||
|
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
|
||||||
|
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
|
||||||
|
'Connection': 'keep-alive',
|
||||||
|
}
|
||||||
response = requests.get(url=url, headers=headers)
|
response = requests.get(url=url, headers=headers)
|
||||||
|
# check if request success
|
||||||
url_res = re.findall(r"'url': \\\"(.*?)\\\"}", response.text)
|
if response.status_code == 200:
|
||||||
title_res = re.findall(r"'title': \\\"(.*?)\\\",\\n", response.text)
|
soup = BeautifulSoup(response.text, 'html.parser')
|
||||||
body_res = re.findall(r"\"contentText\":\"(.*?)\"", response.text)
|
url_res = []
|
||||||
baidu_res = [{"content": re.sub('<em>|</em>', '', '<a href="' + url + '">' + title + '</a> ' + body)} for
|
title_res = []
|
||||||
url, title, body in zip(url_res, title_res, body_res)]
|
body_res = []
|
||||||
del body_res, url_res, title_res
|
for item in soup.select('.result.c-container'):
|
||||||
|
# extract title
|
||||||
|
title_res.append(item.select_one('h3 a').get_text(strip=True))
|
||||||
|
url_res.append(item.select_one('h3 a')['href'])
|
||||||
|
body_res.append(item.select_one('.c-abstract').get_text(strip=True) if item.select_one('.c-abstract') else '')
|
||||||
|
baidu_res = [{"content": re.sub('<em>|</em>', '', '<a href="' + url + '">' + title + '</a> ' + body)} for
|
||||||
|
url, title, body in zip(url_res, title_res, body_res)]
|
||||||
|
del body_res, url_res, title_res
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
return Baidu.be_output("**ERROR**: " + str(e))
|
return Baidu.be_output("**ERROR**: " + str(e))
|
||||||
|
|
||||||
|
|||||||
@ -13,11 +13,11 @@
|
|||||||
# See the License for the specific language governing permissions and
|
# See the License for the specific language governing permissions and
|
||||||
# limitations under the License.
|
# limitations under the License.
|
||||||
#
|
#
|
||||||
from abc import ABC
|
|
||||||
import builtins
|
import builtins
|
||||||
import json
|
import json
|
||||||
import os
|
|
||||||
import logging
|
import logging
|
||||||
|
import os
|
||||||
|
from abc import ABC
|
||||||
from functools import partial
|
from functools import partial
|
||||||
from typing import Any, Tuple, Union
|
from typing import Any, Tuple, Union
|
||||||
|
|
||||||
@ -110,15 +110,11 @@ class ComponentParamBase(ABC):
|
|||||||
update_from_raw_conf = conf.get(_IS_RAW_CONF, True)
|
update_from_raw_conf = conf.get(_IS_RAW_CONF, True)
|
||||||
if update_from_raw_conf:
|
if update_from_raw_conf:
|
||||||
deprecated_params_set = self._get_or_init_deprecated_params_set()
|
deprecated_params_set = self._get_or_init_deprecated_params_set()
|
||||||
feeded_deprecated_params_set = (
|
feeded_deprecated_params_set = self._get_or_init_feeded_deprecated_params_set()
|
||||||
self._get_or_init_feeded_deprecated_params_set()
|
|
||||||
)
|
|
||||||
user_feeded_params_set = self._get_or_init_user_feeded_params_set()
|
user_feeded_params_set = self._get_or_init_user_feeded_params_set()
|
||||||
setattr(self, _IS_RAW_CONF, False)
|
setattr(self, _IS_RAW_CONF, False)
|
||||||
else:
|
else:
|
||||||
feeded_deprecated_params_set = (
|
feeded_deprecated_params_set = self._get_or_init_feeded_deprecated_params_set(conf)
|
||||||
self._get_or_init_feeded_deprecated_params_set(conf)
|
|
||||||
)
|
|
||||||
user_feeded_params_set = self._get_or_init_user_feeded_params_set(conf)
|
user_feeded_params_set = self._get_or_init_user_feeded_params_set(conf)
|
||||||
|
|
||||||
def _recursive_update_param(param, config, depth, prefix):
|
def _recursive_update_param(param, config, depth, prefix):
|
||||||
@ -154,15 +150,11 @@ class ComponentParamBase(ABC):
|
|||||||
|
|
||||||
else:
|
else:
|
||||||
# recursive set obj attr
|
# recursive set obj attr
|
||||||
sub_params = _recursive_update_param(
|
sub_params = _recursive_update_param(attr, config_value, depth + 1, prefix=f"{prefix}{config_key}.")
|
||||||
attr, config_value, depth + 1, prefix=f"{prefix}{config_key}."
|
|
||||||
)
|
|
||||||
setattr(param, config_key, sub_params)
|
setattr(param, config_key, sub_params)
|
||||||
|
|
||||||
if not allow_redundant and redundant_attrs:
|
if not allow_redundant and redundant_attrs:
|
||||||
raise ValueError(
|
raise ValueError(f"cpn `{getattr(self, '_name', type(self))}` has redundant parameters: `{[redundant_attrs]}`")
|
||||||
f"cpn `{getattr(self, '_name', type(self))}` has redundant parameters: `{[redundant_attrs]}`"
|
|
||||||
)
|
|
||||||
|
|
||||||
return param
|
return param
|
||||||
|
|
||||||
@ -193,9 +185,7 @@ class ComponentParamBase(ABC):
|
|||||||
param_validation_path_prefix = home_dir + "/param_validation/"
|
param_validation_path_prefix = home_dir + "/param_validation/"
|
||||||
|
|
||||||
param_name = type(self).__name__
|
param_name = type(self).__name__
|
||||||
param_validation_path = "/".join(
|
param_validation_path = "/".join([param_validation_path_prefix, param_name + ".json"])
|
||||||
[param_validation_path_prefix, param_name + ".json"]
|
|
||||||
)
|
|
||||||
|
|
||||||
validation_json = None
|
validation_json = None
|
||||||
|
|
||||||
@ -228,11 +218,7 @@ class ComponentParamBase(ABC):
|
|||||||
break
|
break
|
||||||
|
|
||||||
if not value_legal:
|
if not value_legal:
|
||||||
raise ValueError(
|
raise ValueError("Plase check runtime conf, {} = {} does not match user-parameter restriction".format(variable, value))
|
||||||
"Plase check runtime conf, {} = {} does not match user-parameter restriction".format(
|
|
||||||
variable, value
|
|
||||||
)
|
|
||||||
)
|
|
||||||
|
|
||||||
elif variable in validation_json:
|
elif variable in validation_json:
|
||||||
self._validate_param(attr, validation_json)
|
self._validate_param(attr, validation_json)
|
||||||
@ -240,94 +226,63 @@ class ComponentParamBase(ABC):
|
|||||||
@staticmethod
|
@staticmethod
|
||||||
def check_string(param, descr):
|
def check_string(param, descr):
|
||||||
if type(param).__name__ not in ["str"]:
|
if type(param).__name__ not in ["str"]:
|
||||||
raise ValueError(
|
raise ValueError(descr + " {} not supported, should be string type".format(param))
|
||||||
descr + " {} not supported, should be string type".format(param)
|
|
||||||
)
|
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def check_empty(param, descr):
|
def check_empty(param, descr):
|
||||||
if not param:
|
if not param:
|
||||||
raise ValueError(
|
raise ValueError(descr + " does not support empty value.")
|
||||||
descr + " does not support empty value."
|
|
||||||
)
|
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def check_positive_integer(param, descr):
|
def check_positive_integer(param, descr):
|
||||||
if type(param).__name__ not in ["int", "long"] or param <= 0:
|
if type(param).__name__ not in ["int", "long"] or param <= 0:
|
||||||
raise ValueError(
|
raise ValueError(descr + " {} not supported, should be positive integer".format(param))
|
||||||
descr + " {} not supported, should be positive integer".format(param)
|
|
||||||
)
|
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def check_positive_number(param, descr):
|
def check_positive_number(param, descr):
|
||||||
if type(param).__name__ not in ["float", "int", "long"] or param <= 0:
|
if type(param).__name__ not in ["float", "int", "long"] or param <= 0:
|
||||||
raise ValueError(
|
raise ValueError(descr + " {} not supported, should be positive numeric".format(param))
|
||||||
descr + " {} not supported, should be positive numeric".format(param)
|
|
||||||
)
|
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def check_nonnegative_number(param, descr):
|
def check_nonnegative_number(param, descr):
|
||||||
if type(param).__name__ not in ["float", "int", "long"] or param < 0:
|
if type(param).__name__ not in ["float", "int", "long"] or param < 0:
|
||||||
raise ValueError(
|
raise ValueError(descr + " {} not supported, should be non-negative numeric".format(param))
|
||||||
descr
|
|
||||||
+ " {} not supported, should be non-negative numeric".format(param)
|
|
||||||
)
|
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def check_decimal_float(param, descr):
|
def check_decimal_float(param, descr):
|
||||||
if type(param).__name__ not in ["float", "int"] or param < 0 or param > 1:
|
if type(param).__name__ not in ["float", "int"] or param < 0 or param > 1:
|
||||||
raise ValueError(
|
raise ValueError(descr + " {} not supported, should be a float number in range [0, 1]".format(param))
|
||||||
descr
|
|
||||||
+ " {} not supported, should be a float number in range [0, 1]".format(
|
|
||||||
param
|
|
||||||
)
|
|
||||||
)
|
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def check_boolean(param, descr):
|
def check_boolean(param, descr):
|
||||||
if type(param).__name__ != "bool":
|
if type(param).__name__ != "bool":
|
||||||
raise ValueError(
|
raise ValueError(descr + " {} not supported, should be bool type".format(param))
|
||||||
descr + " {} not supported, should be bool type".format(param)
|
|
||||||
)
|
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def check_open_unit_interval(param, descr):
|
def check_open_unit_interval(param, descr):
|
||||||
if type(param).__name__ not in ["float"] or param <= 0 or param >= 1:
|
if type(param).__name__ not in ["float"] or param <= 0 or param >= 1:
|
||||||
raise ValueError(
|
raise ValueError(descr + " should be a numeric number between 0 and 1 exclusively")
|
||||||
descr + " should be a numeric number between 0 and 1 exclusively"
|
|
||||||
)
|
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def check_valid_value(param, descr, valid_values):
|
def check_valid_value(param, descr, valid_values):
|
||||||
if param not in valid_values:
|
if param not in valid_values:
|
||||||
raise ValueError(
|
raise ValueError(descr + " {} is not supported, it should be in {}".format(param, valid_values))
|
||||||
descr
|
|
||||||
+ " {} is not supported, it should be in {}".format(param, valid_values)
|
|
||||||
)
|
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def check_defined_type(param, descr, types):
|
def check_defined_type(param, descr, types):
|
||||||
if type(param).__name__ not in types:
|
if type(param).__name__ not in types:
|
||||||
raise ValueError(
|
raise ValueError(descr + " {} not supported, should be one of {}".format(param, types))
|
||||||
descr + " {} not supported, should be one of {}".format(param, types)
|
|
||||||
)
|
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def check_and_change_lower(param, valid_list, descr=""):
|
def check_and_change_lower(param, valid_list, descr=""):
|
||||||
if type(param).__name__ != "str":
|
if type(param).__name__ != "str":
|
||||||
raise ValueError(
|
raise ValueError(descr + " {} not supported, should be one of {}".format(param, valid_list))
|
||||||
descr
|
|
||||||
+ " {} not supported, should be one of {}".format(param, valid_list)
|
|
||||||
)
|
|
||||||
|
|
||||||
lower_param = param.lower()
|
lower_param = param.lower()
|
||||||
if lower_param in valid_list:
|
if lower_param in valid_list:
|
||||||
return lower_param
|
return lower_param
|
||||||
else:
|
else:
|
||||||
raise ValueError(
|
raise ValueError(descr + " {} not supported, should be one of {}".format(param, valid_list))
|
||||||
descr
|
|
||||||
+ " {} not supported, should be one of {}".format(param, valid_list)
|
|
||||||
)
|
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def _greater_equal_than(value, limit):
|
def _greater_equal_than(value, limit):
|
||||||
@ -341,11 +296,7 @@ class ComponentParamBase(ABC):
|
|||||||
def _range(value, ranges):
|
def _range(value, ranges):
|
||||||
in_range = False
|
in_range = False
|
||||||
for left_limit, right_limit in ranges:
|
for left_limit, right_limit in ranges:
|
||||||
if (
|
if left_limit - settings.FLOAT_ZERO <= value <= right_limit + settings.FLOAT_ZERO:
|
||||||
left_limit - settings.FLOAT_ZERO
|
|
||||||
<= value
|
|
||||||
<= right_limit + settings.FLOAT_ZERO
|
|
||||||
):
|
|
||||||
in_range = True
|
in_range = True
|
||||||
break
|
break
|
||||||
|
|
||||||
@ -361,16 +312,11 @@ class ComponentParamBase(ABC):
|
|||||||
|
|
||||||
def _warn_deprecated_param(self, param_name, descr):
|
def _warn_deprecated_param(self, param_name, descr):
|
||||||
if self._deprecated_params_set.get(param_name):
|
if self._deprecated_params_set.get(param_name):
|
||||||
logging.warning(
|
logging.warning(f"{descr} {param_name} is deprecated and ignored in this version.")
|
||||||
f"{descr} {param_name} is deprecated and ignored in this version."
|
|
||||||
)
|
|
||||||
|
|
||||||
def _warn_to_deprecate_param(self, param_name, descr, new_param):
|
def _warn_to_deprecate_param(self, param_name, descr, new_param):
|
||||||
if self._deprecated_params_set.get(param_name):
|
if self._deprecated_params_set.get(param_name):
|
||||||
logging.warning(
|
logging.warning(f"{descr} {param_name} will be deprecated in future release; please use {new_param} instead.")
|
||||||
f"{descr} {param_name} will be deprecated in future release; "
|
|
||||||
f"please use {new_param} instead."
|
|
||||||
)
|
|
||||||
return True
|
return True
|
||||||
return False
|
return False
|
||||||
|
|
||||||
@ -395,14 +341,16 @@ class ComponentBase(ABC):
|
|||||||
"params": {},
|
"params": {},
|
||||||
"output": {},
|
"output": {},
|
||||||
"inputs": {}
|
"inputs": {}
|
||||||
}}""".format(self.component_name,
|
}}""".format(
|
||||||
self._param,
|
self.component_name,
|
||||||
json.dumps(json.loads(str(self._param)).get("output", {}), ensure_ascii=False),
|
self._param,
|
||||||
json.dumps(json.loads(str(self._param)).get("inputs", []), ensure_ascii=False)
|
json.dumps(json.loads(str(self._param)).get("output", {}), ensure_ascii=False),
|
||||||
|
json.dumps(json.loads(str(self._param)).get("inputs", []), ensure_ascii=False),
|
||||||
)
|
)
|
||||||
|
|
||||||
def __init__(self, canvas, id, param: ComponentParamBase):
|
def __init__(self, canvas, id, param: ComponentParamBase):
|
||||||
from agent.canvas import Canvas # Local import to avoid cyclic dependency
|
from agent.canvas import Canvas # Local import to avoid cyclic dependency
|
||||||
|
|
||||||
assert isinstance(canvas, Canvas), "canvas must be an instance of Canvas"
|
assert isinstance(canvas, Canvas), "canvas must be an instance of Canvas"
|
||||||
self._canvas = canvas
|
self._canvas = canvas
|
||||||
self._id = id
|
self._id = id
|
||||||
@ -410,15 +358,17 @@ class ComponentBase(ABC):
|
|||||||
self._param.check()
|
self._param.check()
|
||||||
|
|
||||||
def get_dependent_components(self):
|
def get_dependent_components(self):
|
||||||
cpnts = set([para["component_id"].split("@")[0] for para in self._param.query \
|
cpnts = set(
|
||||||
if para.get("component_id") \
|
[
|
||||||
and para["component_id"].lower().find("answer") < 0 \
|
para["component_id"].split("@")[0]
|
||||||
and para["component_id"].lower().find("begin") < 0])
|
for para in self._param.query
|
||||||
|
if para.get("component_id") and para["component_id"].lower().find("answer") < 0 and para["component_id"].lower().find("begin") < 0
|
||||||
|
]
|
||||||
|
)
|
||||||
return list(cpnts)
|
return list(cpnts)
|
||||||
|
|
||||||
def run(self, history, **kwargs):
|
def run(self, history, **kwargs):
|
||||||
logging.debug("{}, history: {}, kwargs: {}".format(self, json.dumps(history, ensure_ascii=False),
|
logging.debug("{}, history: {}, kwargs: {}".format(self, json.dumps(history, ensure_ascii=False), json.dumps(kwargs, ensure_ascii=False)))
|
||||||
json.dumps(kwargs, ensure_ascii=False)))
|
|
||||||
self._param.debug_inputs = []
|
self._param.debug_inputs = []
|
||||||
try:
|
try:
|
||||||
res = self._run(history, **kwargs)
|
res = self._run(history, **kwargs)
|
||||||
@ -465,7 +415,7 @@ class ComponentBase(ABC):
|
|||||||
|
|
||||||
def set_infor(self, v):
|
def set_infor(self, v):
|
||||||
setattr(self._param, self._param.infor_var_name, v)
|
setattr(self._param, self._param.infor_var_name, v)
|
||||||
|
|
||||||
def _fetch_outputs_from(self, sources: list[dict[str, Any]]) -> list[pd.DataFrame]:
|
def _fetch_outputs_from(self, sources: list[dict[str, Any]]) -> list[pd.DataFrame]:
|
||||||
outs = []
|
outs = []
|
||||||
for q in sources:
|
for q in sources:
|
||||||
@ -482,7 +432,7 @@ class ComponentBase(ABC):
|
|||||||
|
|
||||||
if q["component_id"].lower().find("answer") == 0:
|
if q["component_id"].lower().find("answer") == 0:
|
||||||
txt = []
|
txt = []
|
||||||
for r, c in self._canvas.history[::-1][:self._param.message_history_window_size][::-1]:
|
for r, c in self._canvas.history[::-1][: self._param.message_history_window_size][::-1]:
|
||||||
txt.append(f"{r.upper()}:{c}")
|
txt.append(f"{r.upper()}:{c}")
|
||||||
txt = "\n".join(txt)
|
txt = "\n".join(txt)
|
||||||
outs.append(pd.DataFrame([{"content": txt}]))
|
outs.append(pd.DataFrame([{"content": txt}]))
|
||||||
@ -512,21 +462,16 @@ class ComponentBase(ABC):
|
|||||||
content: str
|
content: str
|
||||||
|
|
||||||
if len(records) > 1:
|
if len(records) > 1:
|
||||||
content = "\n".join(
|
content = "\n".join([str(d["content"]) for d in records])
|
||||||
[str(d["content"]) for d in records]
|
|
||||||
)
|
|
||||||
else:
|
else:
|
||||||
content = records[0]["content"]
|
content = records[0]["content"]
|
||||||
|
|
||||||
self._param.inputs.append({
|
self._param.inputs.append({"component_id": records[0].get("component_id"), "content": content})
|
||||||
"component_id": records[0].get("component_id"),
|
|
||||||
"content": content
|
|
||||||
})
|
|
||||||
|
|
||||||
if outs:
|
if outs:
|
||||||
df = pd.concat(outs, ignore_index=True)
|
df = pd.concat(outs, ignore_index=True)
|
||||||
if "content" in df:
|
if "content" in df:
|
||||||
df = df.drop_duplicates(subset=['content']).reset_index(drop=True)
|
df = df.drop_duplicates(subset=["content"]).reset_index(drop=True)
|
||||||
return df
|
return df
|
||||||
|
|
||||||
upstream_outs = []
|
upstream_outs = []
|
||||||
@ -540,9 +485,8 @@ class ComponentBase(ABC):
|
|||||||
o["component_id"] = u
|
o["component_id"] = u
|
||||||
upstream_outs.append(o)
|
upstream_outs.append(o)
|
||||||
continue
|
continue
|
||||||
#if self.component_name.lower()!="answer" and u not in self._canvas.get_component(self._id)["upstream"]: continue
|
# if self.component_name.lower()!="answer" and u not in self._canvas.get_component(self._id)["upstream"]: continue
|
||||||
if self.component_name.lower().find("switch") < 0 \
|
if self.component_name.lower().find("switch") < 0 and self.get_component_name(u) in ["relevant", "categorize"]:
|
||||||
and self.get_component_name(u) in ["relevant", "categorize"]:
|
|
||||||
continue
|
continue
|
||||||
if u.lower().find("answer") >= 0:
|
if u.lower().find("answer") >= 0:
|
||||||
for r, c in self._canvas.history[::-1]:
|
for r, c in self._canvas.history[::-1]:
|
||||||
@ -562,7 +506,7 @@ class ComponentBase(ABC):
|
|||||||
|
|
||||||
df = pd.concat(upstream_outs, ignore_index=True)
|
df = pd.concat(upstream_outs, ignore_index=True)
|
||||||
if "content" in df:
|
if "content" in df:
|
||||||
df = df.drop_duplicates(subset=['content']).reset_index(drop=True)
|
df = df.drop_duplicates(subset=["content"]).reset_index(drop=True)
|
||||||
|
|
||||||
self._param.inputs = []
|
self._param.inputs = []
|
||||||
for _, r in df.iterrows():
|
for _, r in df.iterrows():
|
||||||
@ -614,5 +558,5 @@ class ComponentBase(ABC):
|
|||||||
return self._canvas.get_component(pid)["obj"]
|
return self._canvas.get_component(pid)["obj"]
|
||||||
|
|
||||||
def get_upstream(self):
|
def get_upstream(self):
|
||||||
cpn_nms = self._canvas.get_component(self._id)['upstream']
|
cpn_nms = self._canvas.get_component(self._id)["upstream"]
|
||||||
return cpn_nms
|
return cpn_nms
|
||||||
|
|||||||
@ -99,9 +99,13 @@ class Categorize(Generate, ABC):
|
|||||||
# If a category is found, return the category with the highest count.
|
# If a category is found, return the category with the highest count.
|
||||||
if any(category_counts.values()):
|
if any(category_counts.values()):
|
||||||
max_category = max(category_counts.items(), key=lambda x: x[1])
|
max_category = max(category_counts.items(), key=lambda x: x[1])
|
||||||
return Categorize.be_output(self._param.category_description[max_category[0]]["to"])
|
res = Categorize.be_output(self._param.category_description[max_category[0]]["to"])
|
||||||
|
self.set_output(res)
|
||||||
|
return res
|
||||||
|
|
||||||
return Categorize.be_output(list(self._param.category_description.items())[-1][1]["to"])
|
res = Categorize.be_output(list(self._param.category_description.items())[-1][1]["to"])
|
||||||
|
self.set_output(res)
|
||||||
|
return res
|
||||||
|
|
||||||
def debug(self, **kwargs):
|
def debug(self, **kwargs):
|
||||||
df = self._run([], **kwargs)
|
df = self._run([], **kwargs)
|
||||||
|
|||||||
@ -79,15 +79,34 @@ class Code(ComponentBase, ABC):
|
|||||||
def _run(self, history, **kwargs):
|
def _run(self, history, **kwargs):
|
||||||
arguments = {}
|
arguments = {}
|
||||||
for input in self._param.arguments:
|
for input in self._param.arguments:
|
||||||
assert "@" in input["component_id"], "Each code argument should bind to a specific compontent"
|
if "@" in input["component_id"]:
|
||||||
component_id = input["component_id"].split("@")[0]
|
component_id = input["component_id"].split("@")[0]
|
||||||
refered_component_key = input["component_id"].split("@")[1]
|
referred_component_key = input["component_id"].split("@")[1]
|
||||||
refered_component = self._canvas.get_component(component_id)["obj"]
|
referred_component = self._canvas.get_component(component_id)["obj"]
|
||||||
|
|
||||||
for param in refered_component._param.query:
|
for param in referred_component._param.query:
|
||||||
if param["key"] == refered_component_key:
|
if param["key"] == referred_component_key:
|
||||||
if "value" in param:
|
if "value" in param:
|
||||||
arguments[input["name"]] = param["value"]
|
arguments[input["name"]] = param["value"]
|
||||||
|
else:
|
||||||
|
referred_component = self._canvas.get_component(input["component_id"])["obj"]
|
||||||
|
referred_component_name = referred_component.component_name
|
||||||
|
referred_component_id = referred_component._id
|
||||||
|
|
||||||
|
debug_inputs = self._param.debug_inputs
|
||||||
|
if debug_inputs:
|
||||||
|
for param in debug_inputs:
|
||||||
|
if param["key"] == referred_component_id:
|
||||||
|
if "value" in param and param["name"] == input["name"]:
|
||||||
|
arguments[input["name"]] = param["value"]
|
||||||
|
else:
|
||||||
|
if referred_component_name.lower() == "answer":
|
||||||
|
arguments[input["name"]] = self._canvas.get_history(1)[0]["content"]
|
||||||
|
continue
|
||||||
|
|
||||||
|
_, out = referred_component.output(allow_partial=False)
|
||||||
|
if not out.empty:
|
||||||
|
arguments[input["name"]] = "\n".join(out["content"])
|
||||||
|
|
||||||
return self._execute_code(
|
return self._execute_code(
|
||||||
language=self._param.lang,
|
language=self._param.lang,
|
||||||
@ -128,3 +147,6 @@ class Code(ComponentBase, ABC):
|
|||||||
cpn_id = input["component_id"]
|
cpn_id = input["component_id"]
|
||||||
elements.append({"key": cpn_id, "name": input["name"]})
|
elements.append({"key": cpn_id, "name": input["name"]})
|
||||||
return elements
|
return elements
|
||||||
|
|
||||||
|
def debug(self, **kwargs):
|
||||||
|
return self._run([], **kwargs)
|
||||||
|
|||||||
@ -105,6 +105,7 @@ class ExeSQL(Generate, ABC):
|
|||||||
sql_res = []
|
sql_res = []
|
||||||
for i in range(len(input_list)):
|
for i in range(len(input_list)):
|
||||||
single_sql = input_list[i]
|
single_sql = input_list[i]
|
||||||
|
single_sql = single_sql.replace('```','')
|
||||||
while self._loop <= self._param.loop:
|
while self._loop <= self._param.loop:
|
||||||
self._loop += 1
|
self._loop += 1
|
||||||
if not single_sql:
|
if not single_sql:
|
||||||
|
|||||||
@ -40,7 +40,9 @@ class Message(ComponentBase, ABC):
|
|||||||
if kwargs.get("stream"):
|
if kwargs.get("stream"):
|
||||||
return partial(self.stream_output)
|
return partial(self.stream_output)
|
||||||
|
|
||||||
return Message.be_output(random.choice(self._param.messages))
|
res = Message.be_output(random.choice(self._param.messages))
|
||||||
|
self.set_output(res)
|
||||||
|
return res
|
||||||
|
|
||||||
def stream_output(self):
|
def stream_output(self):
|
||||||
res = None
|
res = None
|
||||||
|
|||||||
@ -96,6 +96,7 @@ class Retrieval(ComponentBase, ABC):
|
|||||||
rerank_mdl = LLMBundle(kbs[0].tenant_id, LLMType.RERANK, self._param.rerank_id)
|
rerank_mdl = LLMBundle(kbs[0].tenant_id, LLMType.RERANK, self._param.rerank_id)
|
||||||
|
|
||||||
if kbs:
|
if kbs:
|
||||||
|
query = re.sub(r"^user[::\s]*", "", query, flags=re.IGNORECASE)
|
||||||
kbinfos = settings.retrievaler.retrieval(
|
kbinfos = settings.retrievaler.retrieval(
|
||||||
query,
|
query,
|
||||||
embd_mdl,
|
embd_mdl,
|
||||||
|
|||||||
@ -15,8 +15,11 @@
|
|||||||
#
|
#
|
||||||
import json
|
import json
|
||||||
import re
|
import re
|
||||||
|
|
||||||
|
from jinja2 import StrictUndefined
|
||||||
|
from jinja2.sandbox import SandboxedEnvironment
|
||||||
|
|
||||||
from agent.component.base import ComponentBase, ComponentParamBase
|
from agent.component.base import ComponentBase, ComponentParamBase
|
||||||
from jinja2 import Template as Jinja2Template
|
|
||||||
|
|
||||||
|
|
||||||
class TemplateParam(ComponentParamBase):
|
class TemplateParam(ComponentParamBase):
|
||||||
@ -75,6 +78,11 @@ class Template(ComponentBase):
|
|||||||
if p["key"] == key:
|
if p["key"] == key:
|
||||||
value = p.get("value", "")
|
value = p.get("value", "")
|
||||||
self.make_kwargs(para, kwargs, value)
|
self.make_kwargs(para, kwargs, value)
|
||||||
|
|
||||||
|
origin_pattern = "{begin@" + key + "}"
|
||||||
|
new_pattern = "begin_" + key
|
||||||
|
content = content.replace(origin_pattern, new_pattern)
|
||||||
|
kwargs[new_pattern] = kwargs.pop(origin_pattern, "")
|
||||||
break
|
break
|
||||||
else:
|
else:
|
||||||
assert False, f"Can't find parameter '{key}' for {cpn_id}"
|
assert False, f"Can't find parameter '{key}' for {cpn_id}"
|
||||||
@ -89,19 +97,27 @@ class Template(ComponentBase):
|
|||||||
else:
|
else:
|
||||||
hist = ""
|
hist = ""
|
||||||
self.make_kwargs(para, kwargs, hist)
|
self.make_kwargs(para, kwargs, hist)
|
||||||
|
|
||||||
|
if ":" in component_id:
|
||||||
|
origin_pattern = "{" + component_id + "}"
|
||||||
|
new_pattern = component_id.replace(":", "_")
|
||||||
|
content = content.replace(origin_pattern, new_pattern)
|
||||||
|
kwargs[new_pattern] = kwargs.pop(component_id, "")
|
||||||
continue
|
continue
|
||||||
|
|
||||||
_, out = cpn.output(allow_partial=False)
|
_, out = cpn.output(allow_partial=False)
|
||||||
|
|
||||||
result = ""
|
result = ""
|
||||||
if "content" in out.columns:
|
if "content" in out.columns:
|
||||||
result = "\n".join(
|
result = "\n".join([o if isinstance(o, str) else str(o) for o in out["content"]])
|
||||||
[o if isinstance(o, str) else str(o) for o in out["content"]]
|
|
||||||
)
|
|
||||||
|
|
||||||
self.make_kwargs(para, kwargs, result)
|
self.make_kwargs(para, kwargs, result)
|
||||||
|
|
||||||
template = Jinja2Template(content)
|
env = SandboxedEnvironment(
|
||||||
|
autoescape=True,
|
||||||
|
undefined=StrictUndefined,
|
||||||
|
)
|
||||||
|
template = env.from_string(content)
|
||||||
|
|
||||||
try:
|
try:
|
||||||
content = template.render(kwargs)
|
content = template.render(kwargs)
|
||||||
@ -114,19 +130,16 @@ class Template(ComponentBase):
|
|||||||
v = json.dumps(v, ensure_ascii=False)
|
v = json.dumps(v, ensure_ascii=False)
|
||||||
except Exception:
|
except Exception:
|
||||||
pass
|
pass
|
||||||
content = re.sub(
|
# Process backslashes in strings, Use Lambda function to avoid escape issues
|
||||||
r"\{%s\}" % re.escape(n), v, content
|
if isinstance(v, str):
|
||||||
)
|
v = v.replace("\\", "\\\\")
|
||||||
content = re.sub(
|
content = re.sub(r"\{%s\}" % re.escape(n), lambda match: v, content)
|
||||||
r"(#+)", r" \1 ", content
|
content = re.sub(r"(#+)", r" \1 ", content)
|
||||||
)
|
|
||||||
|
|
||||||
return Template.be_output(content)
|
return Template.be_output(content)
|
||||||
|
|
||||||
def make_kwargs(self, para, kwargs, value):
|
def make_kwargs(self, para, kwargs, value):
|
||||||
self._param.inputs.append(
|
self._param.inputs.append({"component_id": para["key"], "content": value})
|
||||||
{"component_id": para["key"], "content": value}
|
|
||||||
)
|
|
||||||
try:
|
try:
|
||||||
value = json.loads(value)
|
value = json.loads(value)
|
||||||
except Exception:
|
except Exception:
|
||||||
|
|||||||
@ -52,7 +52,10 @@
|
|||||||
"parameters": [],
|
"parameters": [],
|
||||||
"presence_penalty": 0.4,
|
"presence_penalty": 0.4,
|
||||||
"prompt": "",
|
"prompt": "",
|
||||||
"query": [],
|
"query": [{
|
||||||
|
"type": "reference",
|
||||||
|
"component_id": "RewriteQuestion:AllNightsSniff"
|
||||||
|
}],
|
||||||
"temperature": 0.1,
|
"temperature": 0.1,
|
||||||
"top_p": 0.3
|
"top_p": 0.3
|
||||||
}
|
}
|
||||||
@ -195,11 +198,15 @@
|
|||||||
"message_history_window_size": 22,
|
"message_history_window_size": 22,
|
||||||
"output": null,
|
"output": null,
|
||||||
"output_var_name": "output",
|
"output_var_name": "output",
|
||||||
"query": [],
|
|
||||||
"rerank_id": "",
|
"rerank_id": "",
|
||||||
"similarity_threshold": 0.2,
|
"similarity_threshold": 0.2,
|
||||||
"top_k": 1024,
|
"top_k": 1024,
|
||||||
"top_n": 6
|
"top_n": 6,
|
||||||
|
"query": [{
|
||||||
|
"type": "reference",
|
||||||
|
"component_id": "RewriteQuestion:AllNightsSniff"
|
||||||
|
}],
|
||||||
|
"use_kg": false
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"upstream": [
|
"upstream": [
|
||||||
@ -548,7 +555,11 @@
|
|||||||
"temperature": 0.1,
|
"temperature": 0.1,
|
||||||
"temperatureEnabled": true,
|
"temperatureEnabled": true,
|
||||||
"topPEnabled": true,
|
"topPEnabled": true,
|
||||||
"top_p": 0.3
|
"top_p": 0.3,
|
||||||
|
"query": [{
|
||||||
|
"type": "reference",
|
||||||
|
"component_id": "RewriteQuestion:AllNightsSniff"
|
||||||
|
}]
|
||||||
},
|
},
|
||||||
"label": "Categorize",
|
"label": "Categorize",
|
||||||
"name": "Question Categorize"
|
"name": "Question Categorize"
|
||||||
@ -625,7 +636,11 @@
|
|||||||
"keywords_similarity_weight": 0.3,
|
"keywords_similarity_weight": 0.3,
|
||||||
"similarity_threshold": 0.2,
|
"similarity_threshold": 0.2,
|
||||||
"top_k": 1024,
|
"top_k": 1024,
|
||||||
"top_n": 6
|
"top_n": 6,
|
||||||
|
"query": [{
|
||||||
|
"type": "reference",
|
||||||
|
"component_id": "RewriteQuestion:AllNightsSniff"
|
||||||
|
}]
|
||||||
},
|
},
|
||||||
"label": "Retrieval",
|
"label": "Retrieval",
|
||||||
"name": "Search product info"
|
"name": "Search product info"
|
||||||
@ -932,7 +947,7 @@
|
|||||||
"y": 962.5655101584402
|
"y": 962.5655101584402
|
||||||
},
|
},
|
||||||
"resizing": false,
|
"resizing": false,
|
||||||
"selected": true,
|
"selected": false,
|
||||||
"sourcePosition": "right",
|
"sourcePosition": "right",
|
||||||
"style": {
|
"style": {
|
||||||
"height": 163,
|
"height": 163,
|
||||||
|
|||||||
@ -36,17 +36,20 @@ class DeepResearcher:
|
|||||||
self._kb_retrieve = kb_retrieve
|
self._kb_retrieve = kb_retrieve
|
||||||
self._kg_retrieve = kg_retrieve
|
self._kg_retrieve = kg_retrieve
|
||||||
|
|
||||||
@staticmethod
|
def _remove_tags(text: str, start_tag: str, end_tag: str) -> str:
|
||||||
def _remove_query_tags(text):
|
"""General Tag Removal Method"""
|
||||||
"""Remove query tags from text"""
|
pattern = re.escape(start_tag) + r"(.*?)" + re.escape(end_tag)
|
||||||
pattern = re.escape(BEGIN_SEARCH_QUERY) + r"(.*?)" + re.escape(END_SEARCH_QUERY)
|
|
||||||
return re.sub(pattern, "", text)
|
return re.sub(pattern, "", text)
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def _remove_result_tags(text):
|
def _remove_query_tags(text: str) -> str:
|
||||||
"""Remove result tags from text"""
|
"""Remove Query Tags"""
|
||||||
pattern = re.escape(BEGIN_SEARCH_RESULT) + r"(.*?)" + re.escape(END_SEARCH_RESULT)
|
return DeepResearcher._remove_tags(text, BEGIN_SEARCH_QUERY, END_SEARCH_QUERY)
|
||||||
return re.sub(pattern, "", text)
|
|
||||||
|
@staticmethod
|
||||||
|
def _remove_result_tags(text: str) -> str:
|
||||||
|
"""Remove Result Tags"""
|
||||||
|
return DeepResearcher._remove_tags(text, BEGIN_SEARCH_RESULT, END_SEARCH_RESULT)
|
||||||
|
|
||||||
def _generate_reasoning(self, msg_history):
|
def _generate_reasoning(self, msg_history):
|
||||||
"""Generate reasoning steps"""
|
"""Generate reasoning steps"""
|
||||||
@ -95,21 +98,31 @@ class DeepResearcher:
|
|||||||
def _retrieve_information(self, search_query):
|
def _retrieve_information(self, search_query):
|
||||||
"""Retrieve information from different sources"""
|
"""Retrieve information from different sources"""
|
||||||
# 1. Knowledge base retrieval
|
# 1. Knowledge base retrieval
|
||||||
kbinfos = self._kb_retrieve(question=search_query) if self._kb_retrieve else {"chunks": [], "doc_aggs": []}
|
kbinfos = []
|
||||||
|
try:
|
||||||
|
kbinfos = self._kb_retrieve(question=search_query) if self._kb_retrieve else {"chunks": [], "doc_aggs": []}
|
||||||
|
except Exception as e:
|
||||||
|
logging.error(f"Knowledge base retrieval error: {e}")
|
||||||
|
|
||||||
# 2. Web retrieval (if Tavily API is configured)
|
# 2. Web retrieval (if Tavily API is configured)
|
||||||
if self.prompt_config.get("tavily_api_key"):
|
try:
|
||||||
tav = Tavily(self.prompt_config["tavily_api_key"])
|
if self.prompt_config.get("tavily_api_key"):
|
||||||
tav_res = tav.retrieve_chunks(search_query)
|
tav = Tavily(self.prompt_config["tavily_api_key"])
|
||||||
kbinfos["chunks"].extend(tav_res["chunks"])
|
tav_res = tav.retrieve_chunks(search_query)
|
||||||
kbinfos["doc_aggs"].extend(tav_res["doc_aggs"])
|
kbinfos["chunks"].extend(tav_res["chunks"])
|
||||||
|
kbinfos["doc_aggs"].extend(tav_res["doc_aggs"])
|
||||||
|
except Exception as e:
|
||||||
|
logging.error(f"Web retrieval error: {e}")
|
||||||
|
|
||||||
# 3. Knowledge graph retrieval (if configured)
|
# 3. Knowledge graph retrieval (if configured)
|
||||||
if self.prompt_config.get("use_kg") and self._kg_retrieve:
|
try:
|
||||||
ck = self._kg_retrieve(question=search_query)
|
if self.prompt_config.get("use_kg") and self._kg_retrieve:
|
||||||
if ck["content_with_weight"]:
|
ck = self._kg_retrieve(question=search_query)
|
||||||
kbinfos["chunks"].insert(0, ck)
|
if ck["content_with_weight"]:
|
||||||
|
kbinfos["chunks"].insert(0, ck)
|
||||||
|
except Exception as e:
|
||||||
|
logging.error(f"Knowledge graph retrieval error: {e}")
|
||||||
|
|
||||||
return kbinfos
|
return kbinfos
|
||||||
|
|
||||||
def _update_chunk_info(self, chunk_info, kbinfos):
|
def _update_chunk_info(self, chunk_info, kbinfos):
|
||||||
|
|||||||
@ -146,10 +146,23 @@ def load_user(web_request):
|
|||||||
if authorization:
|
if authorization:
|
||||||
try:
|
try:
|
||||||
access_token = str(jwt.loads(authorization))
|
access_token = str(jwt.loads(authorization))
|
||||||
|
|
||||||
|
if not access_token or not access_token.strip():
|
||||||
|
logging.warning("Authentication attempt with empty access token")
|
||||||
|
return None
|
||||||
|
|
||||||
|
# Access tokens should be UUIDs (32 hex characters)
|
||||||
|
if len(access_token.strip()) < 32:
|
||||||
|
logging.warning(f"Authentication attempt with invalid token format: {len(access_token)} chars")
|
||||||
|
return None
|
||||||
|
|
||||||
user = UserService.query(
|
user = UserService.query(
|
||||||
access_token=access_token, status=StatusEnum.VALID.value
|
access_token=access_token, status=StatusEnum.VALID.value
|
||||||
)
|
)
|
||||||
if user:
|
if user:
|
||||||
|
if not user[0].access_token or not user[0].access_token.strip():
|
||||||
|
logging.warning(f"User {user[0].email} has empty access_token in database")
|
||||||
|
return None
|
||||||
return user[0]
|
return user[0]
|
||||||
else:
|
else:
|
||||||
return None
|
return None
|
||||||
|
|||||||
@ -18,7 +18,7 @@ import os
|
|||||||
import re
|
import re
|
||||||
from datetime import datetime, timedelta
|
from datetime import datetime, timedelta
|
||||||
from flask import request, Response
|
from flask import request, Response
|
||||||
from api.db.services.llm_service import TenantLLMService
|
from api.db.services.llm_service import LLMBundle
|
||||||
from flask_login import login_required, current_user
|
from flask_login import login_required, current_user
|
||||||
|
|
||||||
from api.db import VALID_FILE_TYPES, VALID_TASK_STATUS, FileType, LLMType, ParserType, FileSource
|
from api.db import VALID_FILE_TYPES, VALID_TASK_STATUS, FileType, LLMType, ParserType, FileSource
|
||||||
@ -875,14 +875,12 @@ def retrieval():
|
|||||||
data=False, message='Knowledge bases use different embedding models or does not exist."',
|
data=False, message='Knowledge bases use different embedding models or does not exist."',
|
||||||
code=settings.RetCode.AUTHENTICATION_ERROR)
|
code=settings.RetCode.AUTHENTICATION_ERROR)
|
||||||
|
|
||||||
embd_mdl = TenantLLMService.model_instance(
|
embd_mdl = LLMBundle(kbs[0].tenant_id, LLMType.EMBEDDING, llm_name=kbs[0].embd_id)
|
||||||
kbs[0].tenant_id, LLMType.EMBEDDING.value, llm_name=kbs[0].embd_id)
|
|
||||||
rerank_mdl = None
|
rerank_mdl = None
|
||||||
if req.get("rerank_id"):
|
if req.get("rerank_id"):
|
||||||
rerank_mdl = TenantLLMService.model_instance(
|
rerank_mdl = LLMBundle(kbs[0].tenant_id, LLMType.RERANK, llm_name=req["rerank_id"])
|
||||||
kbs[0].tenant_id, LLMType.RERANK.value, llm_name=req["rerank_id"])
|
|
||||||
if req.get("keyword", False):
|
if req.get("keyword", False):
|
||||||
chat_mdl = TenantLLMService.model_instance(kbs[0].tenant_id, LLMType.CHAT)
|
chat_mdl = LLMBundle(kbs[0].tenant_id, LLMType.CHAT)
|
||||||
question += keyword_extraction(chat_mdl, question)
|
question += keyword_extraction(chat_mdl, question)
|
||||||
ranks = settings.retrievaler.retrieval(question, embd_mdl, kbs[0].tenant_id, kb_ids, page, size,
|
ranks = settings.retrievaler.retrieval(question, embd_mdl, kbs[0].tenant_id, kb_ids, page, size,
|
||||||
similarity_threshold, vector_similarity_weight, top,
|
similarity_threshold, vector_similarity_weight, top,
|
||||||
|
|||||||
@ -68,8 +68,7 @@ class OIDCClient(OAuthClient):
|
|||||||
alg = headers.get("alg", "RS256")
|
alg = headers.get("alg", "RS256")
|
||||||
|
|
||||||
# Use PyJWT's PyJWKClient to fetch JWKS and find signing key
|
# Use PyJWT's PyJWKClient to fetch JWKS and find signing key
|
||||||
jwks_url = f"{self.issuer}/.well-known/jwks.json"
|
jwks_cli = jwt.PyJWKClient(self.jwks_uri)
|
||||||
jwks_cli = jwt.PyJWKClient(jwks_url)
|
|
||||||
signing_key = jwks_cli.get_signing_key_from_jwt(id_token).key
|
signing_key = jwks_cli.get_signing_key_from_jwt(id_token).key
|
||||||
|
|
||||||
# Decode and verify signature
|
# Decode and verify signature
|
||||||
|
|||||||
@ -249,7 +249,9 @@ def debug():
|
|||||||
code=RetCode.OPERATING_ERROR)
|
code=RetCode.OPERATING_ERROR)
|
||||||
|
|
||||||
canvas = Canvas(json.dumps(user_canvas.dsl), current_user.id)
|
canvas = Canvas(json.dumps(user_canvas.dsl), current_user.id)
|
||||||
canvas.get_component(req["component_id"])["obj"]._param.debug_inputs = req["params"]
|
componant = canvas.get_component(req["component_id"])["obj"]
|
||||||
|
componant.reset()
|
||||||
|
componant._param.debug_inputs = req["params"]
|
||||||
df = canvas.get_component(req["component_id"])["obj"].debug()
|
df = canvas.get_component(req["component_id"])["obj"].debug()
|
||||||
return get_json_result(data=df.to_dict(orient="records"))
|
return get_json_result(data=df.to_dict(orient="records"))
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
|
|||||||
@ -42,6 +42,7 @@ def set_conversation():
|
|||||||
conv_id = req.get("conversation_id")
|
conv_id = req.get("conversation_id")
|
||||||
is_new = req.get("is_new")
|
is_new = req.get("is_new")
|
||||||
name = req.get("name", "New conversation")
|
name = req.get("name", "New conversation")
|
||||||
|
req["user_id"] = current_user.id
|
||||||
|
|
||||||
if len(name) > 255:
|
if len(name) > 255:
|
||||||
name = name[0:255]
|
name = name[0:255]
|
||||||
@ -64,7 +65,7 @@ def set_conversation():
|
|||||||
e, dia = DialogService.get_by_id(req["dialog_id"])
|
e, dia = DialogService.get_by_id(req["dialog_id"])
|
||||||
if not e:
|
if not e:
|
||||||
return get_data_error_result(message="Dialog not found")
|
return get_data_error_result(message="Dialog not found")
|
||||||
conv = {"id": conv_id, "dialog_id": req["dialog_id"], "name": name, "message": [{"role": "assistant", "content": dia.prompt_config["prologue"]}]}
|
conv = {"id": conv_id, "dialog_id": req["dialog_id"], "name": name, "message": [{"role": "assistant", "content": dia.prompt_config["prologue"]}],"user_id": current_user.id}
|
||||||
ConversationService.save(**conv)
|
ConversationService.save(**conv)
|
||||||
return get_json_result(data=conv)
|
return get_json_result(data=conv)
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
@ -248,7 +249,7 @@ def completion():
|
|||||||
else:
|
else:
|
||||||
answer = None
|
answer = None
|
||||||
for ans in chat(dia, msg, **req):
|
for ans in chat(dia, msg, **req):
|
||||||
answer = structure_answer(conv, ans, message_id, req["conversation_id"])
|
answer = structure_answer(conv, ans, message_id, conv.id)
|
||||||
ConversationService.update_by_id(conv.id, conv.to_dict())
|
ConversationService.update_by_id(conv.id, conv.to_dict())
|
||||||
break
|
break
|
||||||
return get_json_result(data=answer)
|
return get_json_result(data=answer)
|
||||||
|
|||||||
@ -28,6 +28,7 @@ from api.utils.api_utils import get_json_result
|
|||||||
|
|
||||||
|
|
||||||
@manager.route('/set', methods=['POST']) # noqa: F821
|
@manager.route('/set', methods=['POST']) # noqa: F821
|
||||||
|
@validate_request("prompt_config")
|
||||||
@login_required
|
@login_required
|
||||||
def set_dialog():
|
def set_dialog():
|
||||||
req = request.json
|
req = request.json
|
||||||
@ -43,33 +44,10 @@ def set_dialog():
|
|||||||
similarity_threshold = req.get("similarity_threshold", 0.1)
|
similarity_threshold = req.get("similarity_threshold", 0.1)
|
||||||
vector_similarity_weight = req.get("vector_similarity_weight", 0.3)
|
vector_similarity_weight = req.get("vector_similarity_weight", 0.3)
|
||||||
llm_setting = req.get("llm_setting", {})
|
llm_setting = req.get("llm_setting", {})
|
||||||
default_prompt_with_dataset = {
|
prompt_config = req["prompt_config"]
|
||||||
"system": """你是一个智能助手,请总结知识库的内容来回答问题,请列举知识库中的数据详细回答。当所有知识库内容都与问题无关时,你的回答必须包括“知识库中未找到您要的答案!”这句话。回答需要考虑聊天历史。
|
|
||||||
以下是知识库:
|
|
||||||
{knowledge}
|
|
||||||
以上是知识库。""",
|
|
||||||
"prologue": "您好,我是您的助手小樱,长得可爱又善良,can I help you?",
|
|
||||||
"parameters": [
|
|
||||||
{"key": "knowledge", "optional": False}
|
|
||||||
],
|
|
||||||
"empty_response": "Sorry! 知识库中未找到相关内容!"
|
|
||||||
}
|
|
||||||
default_prompt_no_dataset = {
|
|
||||||
"system": """You are a helpful assistant.""",
|
|
||||||
"prologue": "您好,我是您的助手小樱,长得可爱又善良,can I help you?",
|
|
||||||
"parameters": [
|
|
||||||
|
|
||||||
],
|
|
||||||
"empty_response": ""
|
|
||||||
}
|
|
||||||
prompt_config = req.get("prompt_config", default_prompt_with_dataset)
|
|
||||||
|
|
||||||
if not prompt_config["system"]:
|
|
||||||
prompt_config["system"] = default_prompt_with_dataset["system"]
|
|
||||||
|
|
||||||
if not req.get("kb_ids", []):
|
if not req.get("kb_ids", []) and not prompt_config.get("tavily_api_key") and "{knowledge}" in prompt_config['system']:
|
||||||
if prompt_config['system'] == default_prompt_with_dataset['system'] or "{knowledge}" in prompt_config['system']:
|
return get_data_error_result(message="Please remove `{knowledge}` in system prompt since no knowledge base/Tavily used here.")
|
||||||
prompt_config = default_prompt_no_dataset
|
|
||||||
|
|
||||||
for p in prompt_config["parameters"]:
|
for p in prompt_config["parameters"]:
|
||||||
if p["optional"]:
|
if p["optional"]:
|
||||||
|
|||||||
@ -23,7 +23,7 @@ from flask import request
|
|||||||
from flask_login import current_user, login_required
|
from flask_login import current_user, login_required
|
||||||
|
|
||||||
from api import settings
|
from api import settings
|
||||||
from api.constants import IMG_BASE64_PREFIX
|
from api.constants import FILE_NAME_LEN_LIMIT, IMG_BASE64_PREFIX
|
||||||
from api.db import VALID_FILE_TYPES, VALID_TASK_STATUS, FileSource, FileType, ParserType, TaskStatus
|
from api.db import VALID_FILE_TYPES, VALID_TASK_STATUS, FileSource, FileType, ParserType, TaskStatus
|
||||||
from api.db.db_models import File, Task
|
from api.db.db_models import File, Task
|
||||||
from api.db.services import duplicate_name
|
from api.db.services import duplicate_name
|
||||||
@ -61,18 +61,21 @@ def upload():
|
|||||||
for file_obj in file_objs:
|
for file_obj in file_objs:
|
||||||
if file_obj.filename == "":
|
if file_obj.filename == "":
|
||||||
return get_json_result(data=False, message="No file selected!", code=settings.RetCode.ARGUMENT_ERROR)
|
return get_json_result(data=False, message="No file selected!", code=settings.RetCode.ARGUMENT_ERROR)
|
||||||
|
if len(file_obj.filename.encode("utf-8")) > FILE_NAME_LEN_LIMIT:
|
||||||
|
return get_json_result(data=False, message=f"File name must be {FILE_NAME_LEN_LIMIT} bytes or less.", code=settings.RetCode.ARGUMENT_ERROR)
|
||||||
|
|
||||||
e, kb = KnowledgebaseService.get_by_id(kb_id)
|
e, kb = KnowledgebaseService.get_by_id(kb_id)
|
||||||
if not e:
|
if not e:
|
||||||
raise LookupError("Can't find this knowledgebase!")
|
raise LookupError("Can't find this knowledgebase!")
|
||||||
err, files = FileService.upload_document(kb, file_objs, current_user.id)
|
err, files = FileService.upload_document(kb, file_objs, current_user.id)
|
||||||
|
|
||||||
|
if err:
|
||||||
|
return get_json_result(data=files, message="\n".join(err), code=settings.RetCode.SERVER_ERROR)
|
||||||
|
|
||||||
if not files:
|
if not files:
|
||||||
return get_json_result(data=files, message="There seems to be an issue with your file format. Please verify it is correct and not corrupted.", code=settings.RetCode.DATA_ERROR)
|
return get_json_result(data=files, message="There seems to be an issue with your file format. Please verify it is correct and not corrupted.", code=settings.RetCode.DATA_ERROR)
|
||||||
files = [f[0] for f in files] # remove the blob
|
files = [f[0] for f in files] # remove the blob
|
||||||
|
|
||||||
if err:
|
|
||||||
return get_json_result(data=files, message="\n".join(err), code=settings.RetCode.SERVER_ERROR)
|
|
||||||
return get_json_result(data=files)
|
return get_json_result(data=files)
|
||||||
|
|
||||||
|
|
||||||
@ -146,6 +149,12 @@ def create():
|
|||||||
kb_id = req["kb_id"]
|
kb_id = req["kb_id"]
|
||||||
if not kb_id:
|
if not kb_id:
|
||||||
return get_json_result(data=False, message='Lack of "KB ID"', code=settings.RetCode.ARGUMENT_ERROR)
|
return get_json_result(data=False, message='Lack of "KB ID"', code=settings.RetCode.ARGUMENT_ERROR)
|
||||||
|
if len(req["name"].encode("utf-8")) > FILE_NAME_LEN_LIMIT:
|
||||||
|
return get_json_result(data=False, message=f"File name must be {FILE_NAME_LEN_LIMIT} bytes or less.", code=settings.RetCode.ARGUMENT_ERROR)
|
||||||
|
|
||||||
|
if req["name"].strip() == "":
|
||||||
|
return get_json_result(data=False, message="File name can't be empty.", code=settings.RetCode.ARGUMENT_ERROR)
|
||||||
|
req["name"] = req["name"].strip()
|
||||||
|
|
||||||
try:
|
try:
|
||||||
e, kb = KnowledgebaseService.get_by_id(kb_id)
|
e, kb = KnowledgebaseService.get_by_id(kb_id)
|
||||||
@ -190,7 +199,10 @@ def list_docs():
|
|||||||
page_number = int(request.args.get("page", 0))
|
page_number = int(request.args.get("page", 0))
|
||||||
items_per_page = int(request.args.get("page_size", 0))
|
items_per_page = int(request.args.get("page_size", 0))
|
||||||
orderby = request.args.get("orderby", "create_time")
|
orderby = request.args.get("orderby", "create_time")
|
||||||
desc = request.args.get("desc", True)
|
if request.args.get("desc", "true").lower() == "false":
|
||||||
|
desc = False
|
||||||
|
else:
|
||||||
|
desc = True
|
||||||
|
|
||||||
req = request.get_json()
|
req = request.get_json()
|
||||||
|
|
||||||
@ -401,6 +413,9 @@ def rename():
|
|||||||
return get_data_error_result(message="Document not found!")
|
return get_data_error_result(message="Document not found!")
|
||||||
if pathlib.Path(req["name"].lower()).suffix != pathlib.Path(doc.name.lower()).suffix:
|
if pathlib.Path(req["name"].lower()).suffix != pathlib.Path(doc.name.lower()).suffix:
|
||||||
return get_json_result(data=False, message="The extension of file can't be changed", code=settings.RetCode.ARGUMENT_ERROR)
|
return get_json_result(data=False, message="The extension of file can't be changed", code=settings.RetCode.ARGUMENT_ERROR)
|
||||||
|
if len(req["name"].encode("utf-8")) > FILE_NAME_LEN_LIMIT:
|
||||||
|
return get_json_result(data=False, message=f"File name must be {FILE_NAME_LEN_LIMIT} bytes or less.", code=settings.RetCode.ARGUMENT_ERROR)
|
||||||
|
|
||||||
for d in DocumentService.query(name=req["name"], kb_id=doc.kb_id):
|
for d in DocumentService.query(name=req["name"], kb_id=doc.kb_id):
|
||||||
if d.name == req["name"]:
|
if d.name == req["name"]:
|
||||||
return get_data_error_result(message="Duplicated document name in the same knowledgebase.")
|
return get_data_error_result(message="Duplicated document name in the same knowledgebase.")
|
||||||
|
|||||||
@ -34,6 +34,7 @@ from api import settings
|
|||||||
from rag.nlp import search
|
from rag.nlp import search
|
||||||
from api.constants import DATASET_NAME_LIMIT
|
from api.constants import DATASET_NAME_LIMIT
|
||||||
from rag.settings import PAGERANK_FLD
|
from rag.settings import PAGERANK_FLD
|
||||||
|
from rag.utils.storage_factory import STORAGE_IMPL
|
||||||
|
|
||||||
|
|
||||||
@manager.route('/create', methods=['post']) # noqa: F821
|
@manager.route('/create', methods=['post']) # noqa: F821
|
||||||
@ -44,11 +45,11 @@ def create():
|
|||||||
dataset_name = req["name"]
|
dataset_name = req["name"]
|
||||||
if not isinstance(dataset_name, str):
|
if not isinstance(dataset_name, str):
|
||||||
return get_data_error_result(message="Dataset name must be string.")
|
return get_data_error_result(message="Dataset name must be string.")
|
||||||
if dataset_name == "":
|
if dataset_name.strip() == "":
|
||||||
return get_data_error_result(message="Dataset name can't be empty.")
|
return get_data_error_result(message="Dataset name can't be empty.")
|
||||||
if len(dataset_name) >= DATASET_NAME_LIMIT:
|
if len(dataset_name.encode("utf-8")) > DATASET_NAME_LIMIT:
|
||||||
return get_data_error_result(
|
return get_data_error_result(
|
||||||
message=f"Dataset name length is {len(dataset_name)} which is large than {DATASET_NAME_LIMIT}")
|
message=f"Dataset name length is {len(dataset_name)} which is larger than {DATASET_NAME_LIMIT}")
|
||||||
|
|
||||||
dataset_name = dataset_name.strip()
|
dataset_name = dataset_name.strip()
|
||||||
dataset_name = duplicate_name(
|
dataset_name = duplicate_name(
|
||||||
@ -78,7 +79,15 @@ def create():
|
|||||||
@not_allowed_parameters("id", "tenant_id", "created_by", "create_time", "update_time", "create_date", "update_date", "created_by")
|
@not_allowed_parameters("id", "tenant_id", "created_by", "create_time", "update_time", "create_date", "update_date", "created_by")
|
||||||
def update():
|
def update():
|
||||||
req = request.json
|
req = request.json
|
||||||
|
if not isinstance(req["name"], str):
|
||||||
|
return get_data_error_result(message="Dataset name must be string.")
|
||||||
|
if req["name"].strip() == "":
|
||||||
|
return get_data_error_result(message="Dataset name can't be empty.")
|
||||||
|
if len(req["name"].encode("utf-8")) > DATASET_NAME_LIMIT:
|
||||||
|
return get_data_error_result(
|
||||||
|
message=f"Dataset name length is {len(req['name'])} which is large than {DATASET_NAME_LIMIT}")
|
||||||
req["name"] = req["name"].strip()
|
req["name"] = req["name"].strip()
|
||||||
|
|
||||||
if not KnowledgebaseService.accessible4deletion(req["kb_id"], current_user.id):
|
if not KnowledgebaseService.accessible4deletion(req["kb_id"], current_user.id):
|
||||||
return get_json_result(
|
return get_json_result(
|
||||||
data=False,
|
data=False,
|
||||||
@ -106,7 +115,7 @@ def update():
|
|||||||
|
|
||||||
if req["name"].lower() != kb.name.lower() \
|
if req["name"].lower() != kb.name.lower() \
|
||||||
and len(
|
and len(
|
||||||
KnowledgebaseService.query(name=req["name"], tenant_id=current_user.id, status=StatusEnum.VALID.value)) > 1:
|
KnowledgebaseService.query(name=req["name"], tenant_id=current_user.id, status=StatusEnum.VALID.value)) >= 1:
|
||||||
return get_data_error_result(
|
return get_data_error_result(
|
||||||
message="Duplicated knowledgebase name.")
|
message="Duplicated knowledgebase name.")
|
||||||
|
|
||||||
@ -115,6 +124,9 @@ def update():
|
|||||||
return get_data_error_result()
|
return get_data_error_result()
|
||||||
|
|
||||||
if kb.pagerank != req.get("pagerank", 0):
|
if kb.pagerank != req.get("pagerank", 0):
|
||||||
|
if os.environ.get("DOC_ENGINE", "elasticsearch") != "elasticsearch":
|
||||||
|
return get_data_error_result(message="'pagerank' can only be set when doc_engine is elasticsearch")
|
||||||
|
|
||||||
if req.get("pagerank", 0) > 0:
|
if req.get("pagerank", 0) > 0:
|
||||||
settings.docStoreConn.update({"kb_id": kb.id}, {PAGERANK_FLD: req["pagerank"]},
|
settings.docStoreConn.update({"kb_id": kb.id}, {PAGERANK_FLD: req["pagerank"]},
|
||||||
search.index_name(kb.tenant_id), kb.id)
|
search.index_name(kb.tenant_id), kb.id)
|
||||||
@ -167,7 +179,10 @@ def list_kbs():
|
|||||||
items_per_page = int(request.args.get("page_size", 0))
|
items_per_page = int(request.args.get("page_size", 0))
|
||||||
parser_id = request.args.get("parser_id")
|
parser_id = request.args.get("parser_id")
|
||||||
orderby = request.args.get("orderby", "create_time")
|
orderby = request.args.get("orderby", "create_time")
|
||||||
desc = request.args.get("desc", True)
|
if request.args.get("desc", "true").lower() == "false":
|
||||||
|
desc = False
|
||||||
|
else:
|
||||||
|
desc = True
|
||||||
|
|
||||||
req = request.get_json()
|
req = request.get_json()
|
||||||
owner_ids = req.get("owner_ids", [])
|
owner_ids = req.get("owner_ids", [])
|
||||||
@ -184,9 +199,9 @@ def list_kbs():
|
|||||||
tenants, current_user.id, 0,
|
tenants, current_user.id, 0,
|
||||||
0, orderby, desc, keywords, parser_id)
|
0, orderby, desc, keywords, parser_id)
|
||||||
kbs = [kb for kb in kbs if kb["tenant_id"] in tenants]
|
kbs = [kb for kb in kbs if kb["tenant_id"] in tenants]
|
||||||
|
total = len(kbs)
|
||||||
if page_number and items_per_page:
|
if page_number and items_per_page:
|
||||||
kbs = kbs[(page_number-1)*items_per_page:page_number*items_per_page]
|
kbs = kbs[(page_number-1)*items_per_page:page_number*items_per_page]
|
||||||
total = len(kbs)
|
|
||||||
return get_json_result(data={"kbs": kbs, "total": total})
|
return get_json_result(data={"kbs": kbs, "total": total})
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
return server_error_response(e)
|
return server_error_response(e)
|
||||||
@ -226,6 +241,8 @@ def rm():
|
|||||||
for kb in kbs:
|
for kb in kbs:
|
||||||
settings.docStoreConn.delete({"kb_id": kb.id}, search.index_name(kb.tenant_id), kb.id)
|
settings.docStoreConn.delete({"kb_id": kb.id}, search.index_name(kb.tenant_id), kb.id)
|
||||||
settings.docStoreConn.deleteIdx(search.index_name(kb.tenant_id), kb.id)
|
settings.docStoreConn.deleteIdx(search.index_name(kb.tenant_id), kb.id)
|
||||||
|
if hasattr(STORAGE_IMPL, 'remove_bucket'):
|
||||||
|
STORAGE_IMPL.remove_bucket(kb.id)
|
||||||
return get_json_result(data=True)
|
return get_json_result(data=True)
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
return server_error_response(e)
|
return server_error_response(e)
|
||||||
|
|||||||
@ -16,6 +16,7 @@
|
|||||||
import logging
|
import logging
|
||||||
|
|
||||||
from flask import request
|
from flask import request
|
||||||
|
|
||||||
from api import settings
|
from api import settings
|
||||||
from api.db import StatusEnum
|
from api.db import StatusEnum
|
||||||
from api.db.services.dialog_service import DialogService
|
from api.db.services.dialog_service import DialogService
|
||||||
@ -23,15 +24,14 @@ from api.db.services.knowledgebase_service import KnowledgebaseService
|
|||||||
from api.db.services.llm_service import TenantLLMService
|
from api.db.services.llm_service import TenantLLMService
|
||||||
from api.db.services.user_service import TenantService
|
from api.db.services.user_service import TenantService
|
||||||
from api.utils import get_uuid
|
from api.utils import get_uuid
|
||||||
from api.utils.api_utils import get_error_data_result, token_required, get_result, check_duplicate_ids
|
from api.utils.api_utils import check_duplicate_ids, get_error_data_result, get_result, token_required
|
||||||
|
|
||||||
|
|
||||||
|
@manager.route("/chats", methods=["POST"]) # noqa: F821
|
||||||
@manager.route('/chats', methods=['POST']) # noqa: F821
|
|
||||||
@token_required
|
@token_required
|
||||||
def create(tenant_id):
|
def create(tenant_id):
|
||||||
req = request.json
|
req = request.json
|
||||||
ids = [i for i in req.get("dataset_ids", []) if i]
|
ids = [i for i in req.get("dataset_ids", []) if i]
|
||||||
for kb_id in ids:
|
for kb_id in ids:
|
||||||
kbs = KnowledgebaseService.accessible(kb_id=kb_id, user_id=tenant_id)
|
kbs = KnowledgebaseService.accessible(kb_id=kb_id, user_id=tenant_id)
|
||||||
if not kbs:
|
if not kbs:
|
||||||
@ -40,34 +40,30 @@ def create(tenant_id):
|
|||||||
kb = kbs[0]
|
kb = kbs[0]
|
||||||
if kb.chunk_num == 0:
|
if kb.chunk_num == 0:
|
||||||
return get_error_data_result(f"The dataset {kb_id} doesn't own parsed file")
|
return get_error_data_result(f"The dataset {kb_id} doesn't own parsed file")
|
||||||
|
|
||||||
kbs = KnowledgebaseService.get_by_ids(ids) if ids else []
|
kbs = KnowledgebaseService.get_by_ids(ids) if ids else []
|
||||||
embd_ids = [TenantLLMService.split_model_name_and_factory(kb.embd_id)[0] for kb in kbs] # remove vendor suffix for comparison
|
embd_ids = [TenantLLMService.split_model_name_and_factory(kb.embd_id)[0] for kb in kbs] # remove vendor suffix for comparison
|
||||||
embd_count = list(set(embd_ids))
|
embd_count = list(set(embd_ids))
|
||||||
if len(embd_count) > 1:
|
if len(embd_count) > 1:
|
||||||
return get_result(message='Datasets use different embedding models."',
|
return get_result(message='Datasets use different embedding models."', code=settings.RetCode.AUTHENTICATION_ERROR)
|
||||||
code=settings.RetCode.AUTHENTICATION_ERROR)
|
|
||||||
req["kb_ids"] = ids
|
req["kb_ids"] = ids
|
||||||
# llm
|
# llm
|
||||||
llm = req.get("llm")
|
llm = req.get("llm")
|
||||||
if llm:
|
if llm:
|
||||||
if "model_name" in llm:
|
if "model_name" in llm:
|
||||||
req["llm_id"] = llm.pop("model_name")
|
req["llm_id"] = llm.pop("model_name")
|
||||||
if not TenantLLMService.query(tenant_id=tenant_id, llm_name=req["llm_id"], model_type="chat"):
|
if req.get("llm_id") is not None:
|
||||||
return get_error_data_result(f"`model_name` {req.get('llm_id')} doesn't exist")
|
llm_name, llm_factory = TenantLLMService.split_model_name_and_factory(req["llm_id"])
|
||||||
|
if not TenantLLMService.query(tenant_id=tenant_id, llm_name=llm_name, llm_factory=llm_factory, model_type="chat"):
|
||||||
|
return get_error_data_result(f"`model_name` {req.get('llm_id')} doesn't exist")
|
||||||
req["llm_setting"] = req.pop("llm")
|
req["llm_setting"] = req.pop("llm")
|
||||||
e, tenant = TenantService.get_by_id(tenant_id)
|
e, tenant = TenantService.get_by_id(tenant_id)
|
||||||
if not e:
|
if not e:
|
||||||
return get_error_data_result(message="Tenant not found!")
|
return get_error_data_result(message="Tenant not found!")
|
||||||
# prompt
|
# prompt
|
||||||
prompt = req.get("prompt")
|
prompt = req.get("prompt")
|
||||||
key_mapping = {"parameters": "variables",
|
key_mapping = {"parameters": "variables", "prologue": "opener", "quote": "show_quote", "system": "prompt", "rerank_id": "rerank_model", "vector_similarity_weight": "keywords_similarity_weight"}
|
||||||
"prologue": "opener",
|
key_list = ["similarity_threshold", "vector_similarity_weight", "top_n", "rerank_id", "top_k"]
|
||||||
"quote": "show_quote",
|
|
||||||
"system": "prompt",
|
|
||||||
"rerank_id": "rerank_model",
|
|
||||||
"vector_similarity_weight": "keywords_similarity_weight"}
|
|
||||||
key_list = ["similarity_threshold", "vector_similarity_weight", "top_n", "rerank_id","top_k"]
|
|
||||||
if prompt:
|
if prompt:
|
||||||
for new_key, old_key in key_mapping.items():
|
for new_key, old_key in key_mapping.items():
|
||||||
if old_key in prompt:
|
if old_key in prompt:
|
||||||
@ -85,9 +81,7 @@ def create(tenant_id):
|
|||||||
req["rerank_id"] = req.get("rerank_id", "")
|
req["rerank_id"] = req.get("rerank_id", "")
|
||||||
if req.get("rerank_id"):
|
if req.get("rerank_id"):
|
||||||
value_rerank_model = ["BAAI/bge-reranker-v2-m3", "maidalun1020/bce-reranker-base_v1"]
|
value_rerank_model = ["BAAI/bge-reranker-v2-m3", "maidalun1020/bce-reranker-base_v1"]
|
||||||
if req["rerank_id"] not in value_rerank_model and not TenantLLMService.query(tenant_id=tenant_id,
|
if req["rerank_id"] not in value_rerank_model and not TenantLLMService.query(tenant_id=tenant_id, llm_name=req.get("rerank_id"), model_type="rerank"):
|
||||||
llm_name=req.get("rerank_id"),
|
|
||||||
model_type="rerank"):
|
|
||||||
return get_error_data_result(f"`rerank_model` {req.get('rerank_id')} doesn't exist")
|
return get_error_data_result(f"`rerank_model` {req.get('rerank_id')} doesn't exist")
|
||||||
if not req.get("llm_id"):
|
if not req.get("llm_id"):
|
||||||
req["llm_id"] = tenant.llm_id
|
req["llm_id"] = tenant.llm_id
|
||||||
@ -106,27 +100,24 @@ def create(tenant_id):
|
|||||||
{knowledge}
|
{knowledge}
|
||||||
The above is the knowledge base.""",
|
The above is the knowledge base.""",
|
||||||
"prologue": "Hi! I'm your assistant, what can I do for you?",
|
"prologue": "Hi! I'm your assistant, what can I do for you?",
|
||||||
"parameters": [
|
"parameters": [{"key": "knowledge", "optional": False}],
|
||||||
{"key": "knowledge", "optional": False}
|
|
||||||
],
|
|
||||||
"empty_response": "Sorry! No relevant content was found in the knowledge base!",
|
"empty_response": "Sorry! No relevant content was found in the knowledge base!",
|
||||||
"quote": True,
|
"quote": True,
|
||||||
"tts": False,
|
"tts": False,
|
||||||
"refine_multiturn": True
|
"refine_multiturn": True,
|
||||||
}
|
}
|
||||||
key_list_2 = ["system", "prologue", "parameters", "empty_response", "quote", "tts", "refine_multiturn"]
|
key_list_2 = ["system", "prologue", "parameters", "empty_response", "quote", "tts", "refine_multiturn"]
|
||||||
if "prompt_config" not in req:
|
if "prompt_config" not in req:
|
||||||
req['prompt_config'] = {}
|
req["prompt_config"] = {}
|
||||||
for key in key_list_2:
|
for key in key_list_2:
|
||||||
temp = req['prompt_config'].get(key)
|
temp = req["prompt_config"].get(key)
|
||||||
if (not temp and key == 'system') or (key not in req["prompt_config"]):
|
if (not temp and key == "system") or (key not in req["prompt_config"]):
|
||||||
req['prompt_config'][key] = default_prompt[key]
|
req["prompt_config"][key] = default_prompt[key]
|
||||||
for p in req['prompt_config']["parameters"]:
|
for p in req["prompt_config"]["parameters"]:
|
||||||
if p["optional"]:
|
if p["optional"]:
|
||||||
continue
|
continue
|
||||||
if req['prompt_config']["system"].find("{%s}" % p["key"]) < 0:
|
if req["prompt_config"]["system"].find("{%s}" % p["key"]) < 0:
|
||||||
return get_error_data_result(
|
return get_error_data_result(message="Parameter '{}' is not used".format(p["key"]))
|
||||||
message="Parameter '{}' is not used".format(p["key"]))
|
|
||||||
# save
|
# save
|
||||||
if not DialogService.save(**req):
|
if not DialogService.save(**req):
|
||||||
return get_error_data_result(message="Fail to new a chat!")
|
return get_error_data_result(message="Fail to new a chat!")
|
||||||
@ -141,10 +132,7 @@ def create(tenant_id):
|
|||||||
renamed_dict[new_key] = value
|
renamed_dict[new_key] = value
|
||||||
res["prompt"] = renamed_dict
|
res["prompt"] = renamed_dict
|
||||||
del res["prompt_config"]
|
del res["prompt_config"]
|
||||||
new_dict = {"similarity_threshold": res["similarity_threshold"],
|
new_dict = {"similarity_threshold": res["similarity_threshold"], "keywords_similarity_weight": 1 - res["vector_similarity_weight"], "top_n": res["top_n"], "rerank_model": res["rerank_id"]}
|
||||||
"keywords_similarity_weight": 1-res["vector_similarity_weight"],
|
|
||||||
"top_n": res["top_n"],
|
|
||||||
"rerank_model": res['rerank_id']}
|
|
||||||
res["prompt"].update(new_dict)
|
res["prompt"].update(new_dict)
|
||||||
for key in key_list:
|
for key in key_list:
|
||||||
del res[key]
|
del res[key]
|
||||||
@ -156,11 +144,11 @@ def create(tenant_id):
|
|||||||
return get_result(data=res)
|
return get_result(data=res)
|
||||||
|
|
||||||
|
|
||||||
@manager.route('/chats/<chat_id>', methods=['PUT']) # noqa: F821
|
@manager.route("/chats/<chat_id>", methods=["PUT"]) # noqa: F821
|
||||||
@token_required
|
@token_required
|
||||||
def update(tenant_id, chat_id):
|
def update(tenant_id, chat_id):
|
||||||
if not DialogService.query(tenant_id=tenant_id, id=chat_id, status=StatusEnum.VALID.value):
|
if not DialogService.query(tenant_id=tenant_id, id=chat_id, status=StatusEnum.VALID.value):
|
||||||
return get_error_data_result(message='You do not own the chat')
|
return get_error_data_result(message="You do not own the chat")
|
||||||
req = request.json
|
req = request.json
|
||||||
ids = req.get("dataset_ids")
|
ids = req.get("dataset_ids")
|
||||||
if "show_quotation" in req:
|
if "show_quotation" in req:
|
||||||
@ -174,34 +162,29 @@ def update(tenant_id, chat_id):
|
|||||||
kb = kbs[0]
|
kb = kbs[0]
|
||||||
if kb.chunk_num == 0:
|
if kb.chunk_num == 0:
|
||||||
return get_error_data_result(f"The dataset {kb_id} doesn't own parsed file")
|
return get_error_data_result(f"The dataset {kb_id} doesn't own parsed file")
|
||||||
|
|
||||||
kbs = KnowledgebaseService.get_by_ids(ids)
|
kbs = KnowledgebaseService.get_by_ids(ids)
|
||||||
embd_ids = [TenantLLMService.split_model_name_and_factory(kb.embd_id)[0] for kb in kbs] # remove vendor suffix for comparison
|
embd_ids = [TenantLLMService.split_model_name_and_factory(kb.embd_id)[0] for kb in kbs] # remove vendor suffix for comparison
|
||||||
embd_count = list(set(embd_ids))
|
embd_count = list(set(embd_ids))
|
||||||
if len(embd_count) != 1:
|
if len(embd_count) != 1:
|
||||||
return get_result(
|
return get_result(message='Datasets use different embedding models."', code=settings.RetCode.AUTHENTICATION_ERROR)
|
||||||
message='Datasets use different embedding models."',
|
|
||||||
code=settings.RetCode.AUTHENTICATION_ERROR)
|
|
||||||
req["kb_ids"] = ids
|
req["kb_ids"] = ids
|
||||||
llm = req.get("llm")
|
llm = req.get("llm")
|
||||||
if llm:
|
if llm:
|
||||||
if "model_name" in llm:
|
if "model_name" in llm:
|
||||||
req["llm_id"] = llm.pop("model_name")
|
req["llm_id"] = llm.pop("model_name")
|
||||||
if not TenantLLMService.query(tenant_id=tenant_id, llm_name=req["llm_id"], model_type="chat"):
|
if req.get("llm_id") is not None:
|
||||||
return get_error_data_result(f"`model_name` {req.get('llm_id')} doesn't exist")
|
llm_name, llm_factory = TenantLLMService.split_model_name_and_factory(req["llm_id"])
|
||||||
|
if not TenantLLMService.query(tenant_id=tenant_id, llm_name=llm_name, llm_factory=llm_factory, model_type="chat"):
|
||||||
|
return get_error_data_result(f"`model_name` {req.get('llm_id')} doesn't exist")
|
||||||
req["llm_setting"] = req.pop("llm")
|
req["llm_setting"] = req.pop("llm")
|
||||||
e, tenant = TenantService.get_by_id(tenant_id)
|
e, tenant = TenantService.get_by_id(tenant_id)
|
||||||
if not e:
|
if not e:
|
||||||
return get_error_data_result(message="Tenant not found!")
|
return get_error_data_result(message="Tenant not found!")
|
||||||
# prompt
|
# prompt
|
||||||
prompt = req.get("prompt")
|
prompt = req.get("prompt")
|
||||||
key_mapping = {"parameters": "variables",
|
key_mapping = {"parameters": "variables", "prologue": "opener", "quote": "show_quote", "system": "prompt", "rerank_id": "rerank_model", "vector_similarity_weight": "keywords_similarity_weight"}
|
||||||
"prologue": "opener",
|
key_list = ["similarity_threshold", "vector_similarity_weight", "top_n", "rerank_id", "top_k"]
|
||||||
"quote": "show_quote",
|
|
||||||
"system": "prompt",
|
|
||||||
"rerank_id": "rerank_model",
|
|
||||||
"vector_similarity_weight": "keywords_similarity_weight"}
|
|
||||||
key_list = ["similarity_threshold", "vector_similarity_weight", "top_n", "rerank_id","top_k"]
|
|
||||||
if prompt:
|
if prompt:
|
||||||
for new_key, old_key in key_mapping.items():
|
for new_key, old_key in key_mapping.items():
|
||||||
if old_key in prompt:
|
if old_key in prompt:
|
||||||
@ -214,16 +197,12 @@ def update(tenant_id, chat_id):
|
|||||||
res = res.to_json()
|
res = res.to_json()
|
||||||
if req.get("rerank_id"):
|
if req.get("rerank_id"):
|
||||||
value_rerank_model = ["BAAI/bge-reranker-v2-m3", "maidalun1020/bce-reranker-base_v1"]
|
value_rerank_model = ["BAAI/bge-reranker-v2-m3", "maidalun1020/bce-reranker-base_v1"]
|
||||||
if req["rerank_id"] not in value_rerank_model and not TenantLLMService.query(tenant_id=tenant_id,
|
if req["rerank_id"] not in value_rerank_model and not TenantLLMService.query(tenant_id=tenant_id, llm_name=req.get("rerank_id"), model_type="rerank"):
|
||||||
llm_name=req.get("rerank_id"),
|
|
||||||
model_type="rerank"):
|
|
||||||
return get_error_data_result(f"`rerank_model` {req.get('rerank_id')} doesn't exist")
|
return get_error_data_result(f"`rerank_model` {req.get('rerank_id')} doesn't exist")
|
||||||
if "name" in req:
|
if "name" in req:
|
||||||
if not req.get("name"):
|
if not req.get("name"):
|
||||||
return get_error_data_result(message="`name` cannot be empty.")
|
return get_error_data_result(message="`name` cannot be empty.")
|
||||||
if req["name"].lower() != res["name"].lower() \
|
if req["name"].lower() != res["name"].lower() and len(DialogService.query(name=req["name"], tenant_id=tenant_id, status=StatusEnum.VALID.value)) > 0:
|
||||||
and len(
|
|
||||||
DialogService.query(name=req["name"], tenant_id=tenant_id, status=StatusEnum.VALID.value)) > 0:
|
|
||||||
return get_error_data_result(message="Duplicated chat name in updating chat.")
|
return get_error_data_result(message="Duplicated chat name in updating chat.")
|
||||||
if "prompt_config" in req:
|
if "prompt_config" in req:
|
||||||
res["prompt_config"].update(req["prompt_config"])
|
res["prompt_config"].update(req["prompt_config"])
|
||||||
@ -246,7 +225,7 @@ def update(tenant_id, chat_id):
|
|||||||
return get_result()
|
return get_result()
|
||||||
|
|
||||||
|
|
||||||
@manager.route('/chats', methods=['DELETE']) # noqa: F821
|
@manager.route("/chats", methods=["DELETE"]) # noqa: F821
|
||||||
@token_required
|
@token_required
|
||||||
def delete(tenant_id):
|
def delete(tenant_id):
|
||||||
errors = []
|
errors = []
|
||||||
@ -273,30 +252,23 @@ def delete(tenant_id):
|
|||||||
temp_dict = {"status": StatusEnum.INVALID.value}
|
temp_dict = {"status": StatusEnum.INVALID.value}
|
||||||
DialogService.update_by_id(id, temp_dict)
|
DialogService.update_by_id(id, temp_dict)
|
||||||
success_count += 1
|
success_count += 1
|
||||||
|
|
||||||
if errors:
|
if errors:
|
||||||
if success_count > 0:
|
if success_count > 0:
|
||||||
return get_result(
|
return get_result(data={"success_count": success_count, "errors": errors}, message=f"Partially deleted {success_count} chats with {len(errors)} errors")
|
||||||
data={"success_count": success_count, "errors": errors},
|
|
||||||
message=f"Partially deleted {success_count} chats with {len(errors)} errors"
|
|
||||||
)
|
|
||||||
else:
|
else:
|
||||||
return get_error_data_result(message="; ".join(errors))
|
return get_error_data_result(message="; ".join(errors))
|
||||||
|
|
||||||
if duplicate_messages:
|
if duplicate_messages:
|
||||||
if success_count > 0:
|
if success_count > 0:
|
||||||
return get_result(
|
return get_result(message=f"Partially deleted {success_count} chats with {len(duplicate_messages)} errors", data={"success_count": success_count, "errors": duplicate_messages})
|
||||||
message=f"Partially deleted {success_count} chats with {len(duplicate_messages)} errors",
|
|
||||||
data={"success_count": success_count, "errors": duplicate_messages}
|
|
||||||
)
|
|
||||||
else:
|
else:
|
||||||
return get_error_data_result(message=";".join(duplicate_messages))
|
return get_error_data_result(message=";".join(duplicate_messages))
|
||||||
|
|
||||||
return get_result()
|
return get_result()
|
||||||
|
|
||||||
|
|
||||||
|
@manager.route("/chats", methods=["GET"]) # noqa: F821
|
||||||
@manager.route('/chats', methods=['GET']) # noqa: F821
|
|
||||||
@token_required
|
@token_required
|
||||||
def list_chat(tenant_id):
|
def list_chat(tenant_id):
|
||||||
id = request.args.get("id")
|
id = request.args.get("id")
|
||||||
@ -316,13 +288,15 @@ def list_chat(tenant_id):
|
|||||||
if not chats:
|
if not chats:
|
||||||
return get_result(data=[])
|
return get_result(data=[])
|
||||||
list_assts = []
|
list_assts = []
|
||||||
key_mapping = {"parameters": "variables",
|
key_mapping = {
|
||||||
"prologue": "opener",
|
"parameters": "variables",
|
||||||
"quote": "show_quote",
|
"prologue": "opener",
|
||||||
"system": "prompt",
|
"quote": "show_quote",
|
||||||
"rerank_id": "rerank_model",
|
"system": "prompt",
|
||||||
"vector_similarity_weight": "keywords_similarity_weight",
|
"rerank_id": "rerank_model",
|
||||||
"do_refer": "show_quotation"}
|
"vector_similarity_weight": "keywords_similarity_weight",
|
||||||
|
"do_refer": "show_quotation",
|
||||||
|
}
|
||||||
key_list = ["similarity_threshold", "vector_similarity_weight", "top_n", "rerank_id"]
|
key_list = ["similarity_threshold", "vector_similarity_weight", "top_n", "rerank_id"]
|
||||||
for res in chats:
|
for res in chats:
|
||||||
renamed_dict = {}
|
renamed_dict = {}
|
||||||
@ -331,10 +305,7 @@ def list_chat(tenant_id):
|
|||||||
renamed_dict[new_key] = value
|
renamed_dict[new_key] = value
|
||||||
res["prompt"] = renamed_dict
|
res["prompt"] = renamed_dict
|
||||||
del res["prompt_config"]
|
del res["prompt_config"]
|
||||||
new_dict = {"similarity_threshold": res["similarity_threshold"],
|
new_dict = {"similarity_threshold": res["similarity_threshold"], "keywords_similarity_weight": 1 - res["vector_similarity_weight"], "top_n": res["top_n"], "rerank_model": res["rerank_id"]}
|
||||||
"keywords_similarity_weight": 1-res["vector_similarity_weight"],
|
|
||||||
"top_n": res["top_n"],
|
|
||||||
"rerank_model": res['rerank_id']}
|
|
||||||
res["prompt"].update(new_dict)
|
res["prompt"].update(new_dict)
|
||||||
for key in key_list:
|
for key in key_list:
|
||||||
del res[key]
|
del res[key]
|
||||||
|
|||||||
@ -16,10 +16,12 @@
|
|||||||
|
|
||||||
|
|
||||||
import logging
|
import logging
|
||||||
|
import os
|
||||||
|
|
||||||
from flask import request
|
from flask import request
|
||||||
from peewee import OperationalError
|
from peewee import OperationalError
|
||||||
|
|
||||||
|
from api import settings
|
||||||
from api.db import FileSource, StatusEnum
|
from api.db import FileSource, StatusEnum
|
||||||
from api.db.db_models import File
|
from api.db.db_models import File
|
||||||
from api.db.services.document_service import DocumentService
|
from api.db.services.document_service import DocumentService
|
||||||
@ -48,6 +50,8 @@ from api.utils.validation_utils import (
|
|||||||
validate_and_parse_json_request,
|
validate_and_parse_json_request,
|
||||||
validate_and_parse_request_args,
|
validate_and_parse_request_args,
|
||||||
)
|
)
|
||||||
|
from rag.nlp import search
|
||||||
|
from rag.settings import PAGERANK_FLD
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/datasets", methods=["POST"]) # noqa: F821
|
@manager.route("/datasets", methods=["POST"]) # noqa: F821
|
||||||
@ -97,9 +101,6 @@ def create(tenant_id):
|
|||||||
"picture", "presentation", "qa", "table", "tag"
|
"picture", "presentation", "qa", "table", "tag"
|
||||||
]
|
]
|
||||||
description: Chunking method.
|
description: Chunking method.
|
||||||
pagerank:
|
|
||||||
type: integer
|
|
||||||
description: Set page rank.
|
|
||||||
parser_config:
|
parser_config:
|
||||||
type: object
|
type: object
|
||||||
description: Parser configuration.
|
description: Parser configuration.
|
||||||
@ -124,48 +125,36 @@ def create(tenant_id):
|
|||||||
try:
|
try:
|
||||||
if KnowledgebaseService.get_or_none(name=req["name"], tenant_id=tenant_id, status=StatusEnum.VALID.value):
|
if KnowledgebaseService.get_or_none(name=req["name"], tenant_id=tenant_id, status=StatusEnum.VALID.value):
|
||||||
return get_error_operating_result(message=f"Dataset name '{req['name']}' already exists")
|
return get_error_operating_result(message=f"Dataset name '{req['name']}' already exists")
|
||||||
except OperationalError as e:
|
|
||||||
logging.exception(e)
|
|
||||||
return get_error_data_result(message="Database operation failed")
|
|
||||||
|
|
||||||
req["parser_config"] = get_parser_config(req["parser_id"], req["parser_config"])
|
req["parser_config"] = get_parser_config(req["parser_id"], req["parser_config"])
|
||||||
req["id"] = get_uuid()
|
req["id"] = get_uuid()
|
||||||
req["tenant_id"] = tenant_id
|
req["tenant_id"] = tenant_id
|
||||||
req["created_by"] = tenant_id
|
req["created_by"] = tenant_id
|
||||||
|
|
||||||
try:
|
|
||||||
ok, t = TenantService.get_by_id(tenant_id)
|
ok, t = TenantService.get_by_id(tenant_id)
|
||||||
if not ok:
|
if not ok:
|
||||||
return get_error_permission_result(message="Tenant not found")
|
return get_error_permission_result(message="Tenant not found")
|
||||||
except OperationalError as e:
|
|
||||||
logging.exception(e)
|
|
||||||
return get_error_data_result(message="Database operation failed")
|
|
||||||
|
|
||||||
if not req.get("embd_id"):
|
if not req.get("embd_id"):
|
||||||
req["embd_id"] = t.embd_id
|
req["embd_id"] = t.embd_id
|
||||||
else:
|
else:
|
||||||
ok, err = verify_embedding_availability(req["embd_id"], tenant_id)
|
ok, err = verify_embedding_availability(req["embd_id"], tenant_id)
|
||||||
if not ok:
|
if not ok:
|
||||||
return err
|
return err
|
||||||
|
|
||||||
try:
|
|
||||||
if not KnowledgebaseService.save(**req):
|
if not KnowledgebaseService.save(**req):
|
||||||
return get_error_data_result(message="Create dataset error.(Database error)")
|
return get_error_data_result(message="Create dataset error.(Database error)")
|
||||||
except OperationalError as e:
|
|
||||||
logging.exception(e)
|
|
||||||
return get_error_data_result(message="Database operation failed")
|
|
||||||
|
|
||||||
try:
|
|
||||||
ok, k = KnowledgebaseService.get_by_id(req["id"])
|
ok, k = KnowledgebaseService.get_by_id(req["id"])
|
||||||
if not ok:
|
if not ok:
|
||||||
return get_error_data_result(message="Dataset created failed")
|
return get_error_data_result(message="Dataset created failed")
|
||||||
|
|
||||||
|
response_data = remap_dictionary_keys(k.to_dict())
|
||||||
|
return get_result(data=response_data)
|
||||||
except OperationalError as e:
|
except OperationalError as e:
|
||||||
logging.exception(e)
|
logging.exception(e)
|
||||||
return get_error_data_result(message="Database operation failed")
|
return get_error_data_result(message="Database operation failed")
|
||||||
|
|
||||||
response_data = remap_dictionary_keys(k.to_dict())
|
|
||||||
return get_result(data=response_data)
|
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/datasets", methods=["DELETE"]) # noqa: F821
|
@manager.route("/datasets", methods=["DELETE"]) # noqa: F821
|
||||||
@token_required
|
@token_required
|
||||||
@ -211,34 +200,27 @@ def delete(tenant_id):
|
|||||||
if err is not None:
|
if err is not None:
|
||||||
return get_error_argument_result(err)
|
return get_error_argument_result(err)
|
||||||
|
|
||||||
kb_id_instance_pairs = []
|
try:
|
||||||
if req["ids"] is None:
|
kb_id_instance_pairs = []
|
||||||
try:
|
if req["ids"] is None:
|
||||||
kbs = KnowledgebaseService.query(tenant_id=tenant_id)
|
kbs = KnowledgebaseService.query(tenant_id=tenant_id)
|
||||||
for kb in kbs:
|
for kb in kbs:
|
||||||
kb_id_instance_pairs.append((kb.id, kb))
|
kb_id_instance_pairs.append((kb.id, kb))
|
||||||
except OperationalError as e:
|
|
||||||
logging.exception(e)
|
else:
|
||||||
return get_error_data_result(message="Database operation failed")
|
error_kb_ids = []
|
||||||
else:
|
for kb_id in req["ids"]:
|
||||||
error_kb_ids = []
|
|
||||||
for kb_id in req["ids"]:
|
|
||||||
try:
|
|
||||||
kb = KnowledgebaseService.get_or_none(id=kb_id, tenant_id=tenant_id)
|
kb = KnowledgebaseService.get_or_none(id=kb_id, tenant_id=tenant_id)
|
||||||
if kb is None:
|
if kb is None:
|
||||||
error_kb_ids.append(kb_id)
|
error_kb_ids.append(kb_id)
|
||||||
continue
|
continue
|
||||||
kb_id_instance_pairs.append((kb_id, kb))
|
kb_id_instance_pairs.append((kb_id, kb))
|
||||||
except OperationalError as e:
|
if len(error_kb_ids) > 0:
|
||||||
logging.exception(e)
|
return get_error_permission_result(message=f"""User '{tenant_id}' lacks permission for datasets: '{", ".join(error_kb_ids)}'""")
|
||||||
return get_error_data_result(message="Database operation failed")
|
|
||||||
if len(error_kb_ids) > 0:
|
|
||||||
return get_error_permission_result(message=f"""User '{tenant_id}' lacks permission for datasets: '{", ".join(error_kb_ids)}'""")
|
|
||||||
|
|
||||||
errors = []
|
errors = []
|
||||||
success_count = 0
|
success_count = 0
|
||||||
for kb_id, kb in kb_id_instance_pairs:
|
for kb_id, kb in kb_id_instance_pairs:
|
||||||
try:
|
|
||||||
for doc in DocumentService.query(kb_id=kb_id):
|
for doc in DocumentService.query(kb_id=kb_id):
|
||||||
if not DocumentService.remove_document(doc, tenant_id):
|
if not DocumentService.remove_document(doc, tenant_id):
|
||||||
errors.append(f"Remove document '{doc.id}' error for dataset '{kb_id}'")
|
errors.append(f"Remove document '{doc.id}' error for dataset '{kb_id}'")
|
||||||
@ -256,18 +238,18 @@ def delete(tenant_id):
|
|||||||
errors.append(f"Delete dataset error for {kb_id}")
|
errors.append(f"Delete dataset error for {kb_id}")
|
||||||
continue
|
continue
|
||||||
success_count += 1
|
success_count += 1
|
||||||
except OperationalError as e:
|
|
||||||
logging.exception(e)
|
|
||||||
return get_error_data_result(message="Database operation failed")
|
|
||||||
|
|
||||||
if not errors:
|
if not errors:
|
||||||
return get_result()
|
return get_result()
|
||||||
|
|
||||||
error_message = f"Successfully deleted {success_count} datasets, {len(errors)} failed. Details: {'; '.join(errors)[:128]}..."
|
error_message = f"Successfully deleted {success_count} datasets, {len(errors)} failed. Details: {'; '.join(errors)[:128]}..."
|
||||||
if success_count == 0:
|
if success_count == 0:
|
||||||
return get_error_data_result(message=error_message)
|
return get_error_data_result(message=error_message)
|
||||||
|
|
||||||
return get_result(data={"success_count": success_count, "errors": errors[:5]}, message=error_message)
|
return get_result(data={"success_count": success_count, "errors": errors[:5]}, message=error_message)
|
||||||
|
except OperationalError as e:
|
||||||
|
logging.exception(e)
|
||||||
|
return get_error_data_result(message="Database operation failed")
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/datasets/<dataset_id>", methods=["PUT"]) # noqa: F821
|
@manager.route("/datasets/<dataset_id>", methods=["PUT"]) # noqa: F821
|
||||||
@ -349,44 +331,51 @@ def update(tenant_id, dataset_id):
|
|||||||
kb = KnowledgebaseService.get_or_none(id=dataset_id, tenant_id=tenant_id)
|
kb = KnowledgebaseService.get_or_none(id=dataset_id, tenant_id=tenant_id)
|
||||||
if kb is None:
|
if kb is None:
|
||||||
return get_error_permission_result(message=f"User '{tenant_id}' lacks permission for dataset '{dataset_id}'")
|
return get_error_permission_result(message=f"User '{tenant_id}' lacks permission for dataset '{dataset_id}'")
|
||||||
except OperationalError as e:
|
|
||||||
logging.exception(e)
|
|
||||||
return get_error_data_result(message="Database operation failed")
|
|
||||||
|
|
||||||
if req.get("parser_config"):
|
if req.get("parser_config"):
|
||||||
req["parser_config"] = deep_merge(kb.parser_config, req["parser_config"])
|
req["parser_config"] = deep_merge(kb.parser_config, req["parser_config"])
|
||||||
|
|
||||||
if (chunk_method := req.get("parser_id")) and chunk_method != kb.parser_id:
|
if (chunk_method := req.get("parser_id")) and chunk_method != kb.parser_id:
|
||||||
if not req.get("parser_config"):
|
if not req.get("parser_config"):
|
||||||
req["parser_config"] = get_parser_config(chunk_method, None)
|
req["parser_config"] = get_parser_config(chunk_method, None)
|
||||||
elif "parser_config" in req and not req["parser_config"]:
|
elif "parser_config" in req and not req["parser_config"]:
|
||||||
del req["parser_config"]
|
del req["parser_config"]
|
||||||
|
|
||||||
if "name" in req and req["name"].lower() != kb.name.lower():
|
if "name" in req and req["name"].lower() != kb.name.lower():
|
||||||
try:
|
|
||||||
exists = KnowledgebaseService.get_or_none(name=req["name"], tenant_id=tenant_id, status=StatusEnum.VALID.value)
|
exists = KnowledgebaseService.get_or_none(name=req["name"], tenant_id=tenant_id, status=StatusEnum.VALID.value)
|
||||||
if exists:
|
if exists:
|
||||||
return get_error_data_result(message=f"Dataset name '{req['name']}' already exists")
|
return get_error_data_result(message=f"Dataset name '{req['name']}' already exists")
|
||||||
except OperationalError as e:
|
|
||||||
logging.exception(e)
|
|
||||||
return get_error_data_result(message="Database operation failed")
|
|
||||||
|
|
||||||
if "embd_id" in req:
|
if "embd_id" in req:
|
||||||
if kb.chunk_num != 0 and req["embd_id"] != kb.embd_id:
|
if kb.chunk_num != 0 and req["embd_id"] != kb.embd_id:
|
||||||
return get_error_data_result(message=f"When chunk_num ({kb.chunk_num}) > 0, embedding_model must remain {kb.embd_id}")
|
return get_error_data_result(message=f"When chunk_num ({kb.chunk_num}) > 0, embedding_model must remain {kb.embd_id}")
|
||||||
ok, err = verify_embedding_availability(req["embd_id"], tenant_id)
|
ok, err = verify_embedding_availability(req["embd_id"], tenant_id)
|
||||||
if not ok:
|
if not ok:
|
||||||
return err
|
return err
|
||||||
|
|
||||||
|
if "pagerank" in req and req["pagerank"] != kb.pagerank:
|
||||||
|
if os.environ.get("DOC_ENGINE", "elasticsearch") == "infinity":
|
||||||
|
return get_error_argument_result(message="'pagerank' can only be set when doc_engine is elasticsearch")
|
||||||
|
|
||||||
|
if req["pagerank"] > 0:
|
||||||
|
settings.docStoreConn.update({"kb_id": kb.id}, {PAGERANK_FLD: req["pagerank"]}, search.index_name(kb.tenant_id), kb.id)
|
||||||
|
else:
|
||||||
|
# Elasticsearch requires PAGERANK_FLD be non-zero!
|
||||||
|
settings.docStoreConn.update({"exists": PAGERANK_FLD}, {"remove": PAGERANK_FLD}, search.index_name(kb.tenant_id), kb.id)
|
||||||
|
|
||||||
try:
|
|
||||||
if not KnowledgebaseService.update_by_id(kb.id, req):
|
if not KnowledgebaseService.update_by_id(kb.id, req):
|
||||||
return get_error_data_result(message="Update dataset error.(Database error)")
|
return get_error_data_result(message="Update dataset error.(Database error)")
|
||||||
|
|
||||||
|
ok, k = KnowledgebaseService.get_by_id(kb.id)
|
||||||
|
if not ok:
|
||||||
|
return get_error_data_result(message="Dataset created failed")
|
||||||
|
|
||||||
|
response_data = remap_dictionary_keys(k.to_dict())
|
||||||
|
return get_result(data=response_data)
|
||||||
except OperationalError as e:
|
except OperationalError as e:
|
||||||
logging.exception(e)
|
logging.exception(e)
|
||||||
return get_error_data_result(message="Database operation failed")
|
return get_error_data_result(message="Database operation failed")
|
||||||
|
|
||||||
return get_result()
|
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/datasets", methods=["GET"]) # noqa: F821
|
@manager.route("/datasets", methods=["GET"]) # noqa: F821
|
||||||
@token_required
|
@token_required
|
||||||
@ -450,26 +439,19 @@ def list_datasets(tenant_id):
|
|||||||
if err is not None:
|
if err is not None:
|
||||||
return get_error_argument_result(err)
|
return get_error_argument_result(err)
|
||||||
|
|
||||||
kb_id = request.args.get("id")
|
|
||||||
name = args.get("name")
|
|
||||||
if kb_id:
|
|
||||||
try:
|
|
||||||
kbs = KnowledgebaseService.get_kb_by_id(kb_id, tenant_id)
|
|
||||||
except OperationalError as e:
|
|
||||||
logging.exception(e)
|
|
||||||
return get_error_data_result(message="Database operation failed")
|
|
||||||
if not kbs:
|
|
||||||
return get_error_permission_result(message=f"User '{tenant_id}' lacks permission for dataset '{kb_id}'")
|
|
||||||
if name:
|
|
||||||
try:
|
|
||||||
kbs = KnowledgebaseService.get_kb_by_name(name, tenant_id)
|
|
||||||
except OperationalError as e:
|
|
||||||
logging.exception(e)
|
|
||||||
return get_error_data_result(message="Database operation failed")
|
|
||||||
if not kbs:
|
|
||||||
return get_error_permission_result(message=f"User '{tenant_id}' lacks permission for dataset '{name}'")
|
|
||||||
|
|
||||||
try:
|
try:
|
||||||
|
kb_id = request.args.get("id")
|
||||||
|
name = args.get("name")
|
||||||
|
if kb_id:
|
||||||
|
kbs = KnowledgebaseService.get_kb_by_id(kb_id, tenant_id)
|
||||||
|
|
||||||
|
if not kbs:
|
||||||
|
return get_error_permission_result(message=f"User '{tenant_id}' lacks permission for dataset '{kb_id}'")
|
||||||
|
if name:
|
||||||
|
kbs = KnowledgebaseService.get_kb_by_name(name, tenant_id)
|
||||||
|
if not kbs:
|
||||||
|
return get_error_permission_result(message=f"User '{tenant_id}' lacks permission for dataset '{name}'")
|
||||||
|
|
||||||
tenants = TenantService.get_joined_tenants_by_user_id(tenant_id)
|
tenants = TenantService.get_joined_tenants_by_user_id(tenant_id)
|
||||||
kbs = KnowledgebaseService.get_list(
|
kbs = KnowledgebaseService.get_list(
|
||||||
[m["tenant_id"] for m in tenants],
|
[m["tenant_id"] for m in tenants],
|
||||||
@ -481,11 +463,11 @@ def list_datasets(tenant_id):
|
|||||||
kb_id,
|
kb_id,
|
||||||
name,
|
name,
|
||||||
)
|
)
|
||||||
|
|
||||||
|
response_data_list = []
|
||||||
|
for kb in kbs:
|
||||||
|
response_data_list.append(remap_dictionary_keys(kb))
|
||||||
|
return get_result(data=response_data_list)
|
||||||
except OperationalError as e:
|
except OperationalError as e:
|
||||||
logging.exception(e)
|
logging.exception(e)
|
||||||
return get_error_data_result(message="Database operation failed")
|
return get_error_data_result(message="Database operation failed")
|
||||||
|
|
||||||
response_data_list = []
|
|
||||||
for kb in kbs:
|
|
||||||
response_data_list.append(remap_dictionary_keys(kb))
|
|
||||||
return get_result(data=response_data_list)
|
|
||||||
|
|||||||
@ -16,6 +16,7 @@
|
|||||||
from flask import request, jsonify
|
from flask import request, jsonify
|
||||||
|
|
||||||
from api.db import LLMType
|
from api.db import LLMType
|
||||||
|
from api.db.services.document_service import DocumentService
|
||||||
from api.db.services.knowledgebase_service import KnowledgebaseService
|
from api.db.services.knowledgebase_service import KnowledgebaseService
|
||||||
from api.db.services.llm_service import LLMBundle
|
from api.db.services.llm_service import LLMBundle
|
||||||
from api import settings
|
from api import settings
|
||||||
@ -70,12 +71,13 @@ def retrieval(tenant_id):
|
|||||||
|
|
||||||
records = []
|
records = []
|
||||||
for c in ranks["chunks"]:
|
for c in ranks["chunks"]:
|
||||||
|
e, doc = DocumentService.get_by_id( c["doc_id"])
|
||||||
c.pop("vector", None)
|
c.pop("vector", None)
|
||||||
records.append({
|
records.append({
|
||||||
"content": c["content_with_weight"],
|
"content": c["content_with_weight"],
|
||||||
"score": c["similarity"],
|
"score": c["similarity"],
|
||||||
"title": c["docnm_kwd"],
|
"title": c["docnm_kwd"],
|
||||||
"metadata": {}
|
"metadata": doc.meta_fields
|
||||||
})
|
})
|
||||||
|
|
||||||
return jsonify({"records": records})
|
return jsonify({"records": records})
|
||||||
|
|||||||
@ -13,38 +13,35 @@
|
|||||||
# See the License for the specific language governing permissions and
|
# See the License for the specific language governing permissions and
|
||||||
# limitations under the License.
|
# limitations under the License.
|
||||||
#
|
#
|
||||||
import pathlib
|
|
||||||
import datetime
|
import datetime
|
||||||
|
import logging
|
||||||
from rag.app.qa import rmPrefix, beAdoc
|
import pathlib
|
||||||
from rag.nlp import rag_tokenizer
|
|
||||||
from api.db import LLMType, ParserType
|
|
||||||
from api.db.services.llm_service import TenantLLMService, LLMBundle
|
|
||||||
from api import settings
|
|
||||||
import xxhash
|
|
||||||
import re
|
import re
|
||||||
from api.utils.api_utils import token_required
|
|
||||||
from api.db.db_models import Task
|
|
||||||
from api.db.services.task_service import TaskService, queue_tasks
|
|
||||||
from api.utils.api_utils import server_error_response
|
|
||||||
from api.utils.api_utils import get_result, get_error_data_result
|
|
||||||
from io import BytesIO
|
from io import BytesIO
|
||||||
|
|
||||||
|
import xxhash
|
||||||
from flask import request, send_file
|
from flask import request, send_file
|
||||||
from api.db import FileSource, TaskStatus, FileType
|
from peewee import OperationalError
|
||||||
from api.db.db_models import File
|
from pydantic import BaseModel, Field, validator
|
||||||
|
|
||||||
|
from api import settings
|
||||||
|
from api.constants import FILE_NAME_LEN_LIMIT
|
||||||
|
from api.db import FileSource, FileType, LLMType, ParserType, TaskStatus
|
||||||
|
from api.db.db_models import File, Task
|
||||||
from api.db.services.document_service import DocumentService
|
from api.db.services.document_service import DocumentService
|
||||||
from api.db.services.file2document_service import File2DocumentService
|
from api.db.services.file2document_service import File2DocumentService
|
||||||
from api.db.services.file_service import FileService
|
from api.db.services.file_service import FileService
|
||||||
from api.db.services.knowledgebase_service import KnowledgebaseService
|
from api.db.services.knowledgebase_service import KnowledgebaseService
|
||||||
from api.utils.api_utils import construct_json_result, get_parser_config, check_duplicate_ids
|
from api.db.services.llm_service import LLMBundle, TenantLLMService
|
||||||
from rag.nlp import search
|
from api.db.services.task_service import TaskService, queue_tasks
|
||||||
from rag.prompts import keyword_extraction
|
from api.utils.api_utils import check_duplicate_ids, construct_json_result, get_error_data_result, get_parser_config, get_result, server_error_response, token_required
|
||||||
|
from rag.app.qa import beAdoc, rmPrefix
|
||||||
from rag.app.tag import label_question
|
from rag.app.tag import label_question
|
||||||
|
from rag.nlp import rag_tokenizer, search
|
||||||
|
from rag.prompts import keyword_extraction
|
||||||
from rag.utils import rmSpace
|
from rag.utils import rmSpace
|
||||||
from rag.utils.storage_factory import STORAGE_IMPL
|
from rag.utils.storage_factory import STORAGE_IMPL
|
||||||
|
|
||||||
from pydantic import BaseModel, Field, validator
|
|
||||||
|
|
||||||
MAXIMUM_OF_UPLOADING_FILES = 256
|
MAXIMUM_OF_UPLOADING_FILES = 256
|
||||||
|
|
||||||
|
|
||||||
@ -60,7 +57,7 @@ class Chunk(BaseModel):
|
|||||||
available: bool = True
|
available: bool = True
|
||||||
positions: list[list[int]] = Field(default_factory=list)
|
positions: list[list[int]] = Field(default_factory=list)
|
||||||
|
|
||||||
@validator('positions')
|
@validator("positions")
|
||||||
def validate_positions(cls, value):
|
def validate_positions(cls, value):
|
||||||
for sublist in value:
|
for sublist in value:
|
||||||
if len(sublist) != 5:
|
if len(sublist) != 5:
|
||||||
@ -128,20 +125,14 @@ def upload(dataset_id, tenant_id):
|
|||||||
description: Processing status.
|
description: Processing status.
|
||||||
"""
|
"""
|
||||||
if "file" not in request.files:
|
if "file" not in request.files:
|
||||||
return get_error_data_result(
|
return get_error_data_result(message="No file part!", code=settings.RetCode.ARGUMENT_ERROR)
|
||||||
message="No file part!", code=settings.RetCode.ARGUMENT_ERROR
|
|
||||||
)
|
|
||||||
file_objs = request.files.getlist("file")
|
file_objs = request.files.getlist("file")
|
||||||
for file_obj in file_objs:
|
for file_obj in file_objs:
|
||||||
if file_obj.filename == "":
|
if file_obj.filename == "":
|
||||||
return get_result(
|
return get_result(message="No file selected!", code=settings.RetCode.ARGUMENT_ERROR)
|
||||||
message="No file selected!", code=settings.RetCode.ARGUMENT_ERROR
|
if len(file_obj.filename.encode("utf-8")) > FILE_NAME_LEN_LIMIT:
|
||||||
)
|
return get_result(message=f"File name must be {FILE_NAME_LEN_LIMIT} bytes or less.", code=settings.RetCode.ARGUMENT_ERROR)
|
||||||
if len(file_obj.filename.encode("utf-8")) >= 128:
|
"""
|
||||||
return get_result(
|
|
||||||
message="File name should be less than 128 bytes.", code=settings.RetCode.ARGUMENT_ERROR
|
|
||||||
)
|
|
||||||
'''
|
|
||||||
# total size
|
# total size
|
||||||
total_size = 0
|
total_size = 0
|
||||||
for file_obj in file_objs:
|
for file_obj in file_objs:
|
||||||
@ -154,7 +145,7 @@ def upload(dataset_id, tenant_id):
|
|||||||
message=f"Total file size exceeds 10MB limit! ({total_size / (1024 * 1024):.2f} MB)",
|
message=f"Total file size exceeds 10MB limit! ({total_size / (1024 * 1024):.2f} MB)",
|
||||||
code=settings.RetCode.ARGUMENT_ERROR,
|
code=settings.RetCode.ARGUMENT_ERROR,
|
||||||
)
|
)
|
||||||
'''
|
"""
|
||||||
e, kb = KnowledgebaseService.get_by_id(dataset_id)
|
e, kb = KnowledgebaseService.get_by_id(dataset_id)
|
||||||
if not e:
|
if not e:
|
||||||
raise LookupError(f"Can't find the dataset with ID {dataset_id}!")
|
raise LookupError(f"Can't find the dataset with ID {dataset_id}!")
|
||||||
@ -236,8 +227,7 @@ def update_doc(tenant_id, dataset_id, document_id):
|
|||||||
return get_error_data_result(message="You don't own the dataset.")
|
return get_error_data_result(message="You don't own the dataset.")
|
||||||
e, kb = KnowledgebaseService.get_by_id(dataset_id)
|
e, kb = KnowledgebaseService.get_by_id(dataset_id)
|
||||||
if not e:
|
if not e:
|
||||||
return get_error_data_result(
|
return get_error_data_result(message="Can't find this knowledgebase!")
|
||||||
message="Can't find this knowledgebase!")
|
|
||||||
doc = DocumentService.query(kb_id=dataset_id, id=document_id)
|
doc = DocumentService.query(kb_id=dataset_id, id=document_id)
|
||||||
if not doc:
|
if not doc:
|
||||||
return get_error_data_result(message="The dataset doesn't own the document.")
|
return get_error_data_result(message="The dataset doesn't own the document.")
|
||||||
@ -258,24 +248,19 @@ def update_doc(tenant_id, dataset_id, document_id):
|
|||||||
DocumentService.update_meta_fields(document_id, req["meta_fields"])
|
DocumentService.update_meta_fields(document_id, req["meta_fields"])
|
||||||
|
|
||||||
if "name" in req and req["name"] != doc.name:
|
if "name" in req and req["name"] != doc.name:
|
||||||
if len(req["name"].encode("utf-8")) >= 128:
|
if len(req["name"].encode("utf-8")) > FILE_NAME_LEN_LIMIT:
|
||||||
return get_result(
|
return get_result(
|
||||||
message="The name should be less than 128 bytes.",
|
message=f"File name must be {FILE_NAME_LEN_LIMIT} bytes or less.",
|
||||||
code=settings.RetCode.ARGUMENT_ERROR,
|
code=settings.RetCode.ARGUMENT_ERROR,
|
||||||
)
|
)
|
||||||
if (
|
if pathlib.Path(req["name"].lower()).suffix != pathlib.Path(doc.name.lower()).suffix:
|
||||||
pathlib.Path(req["name"].lower()).suffix
|
|
||||||
!= pathlib.Path(doc.name.lower()).suffix
|
|
||||||
):
|
|
||||||
return get_result(
|
return get_result(
|
||||||
message="The extension of file can't be changed",
|
message="The extension of file can't be changed",
|
||||||
code=settings.RetCode.ARGUMENT_ERROR,
|
code=settings.RetCode.ARGUMENT_ERROR,
|
||||||
)
|
)
|
||||||
for d in DocumentService.query(name=req["name"], kb_id=doc.kb_id):
|
for d in DocumentService.query(name=req["name"], kb_id=doc.kb_id):
|
||||||
if d.name == req["name"]:
|
if d.name == req["name"]:
|
||||||
return get_error_data_result(
|
return get_error_data_result(message="Duplicated document name in the same dataset.")
|
||||||
message="Duplicated document name in the same dataset."
|
|
||||||
)
|
|
||||||
if not DocumentService.update_by_id(document_id, {"name": req["name"]}):
|
if not DocumentService.update_by_id(document_id, {"name": req["name"]}):
|
||||||
return get_error_data_result(message="Database error (Document rename)!")
|
return get_error_data_result(message="Database error (Document rename)!")
|
||||||
|
|
||||||
@ -287,46 +272,28 @@ def update_doc(tenant_id, dataset_id, document_id):
|
|||||||
if "parser_config" in req:
|
if "parser_config" in req:
|
||||||
DocumentService.update_parser_config(doc.id, req["parser_config"])
|
DocumentService.update_parser_config(doc.id, req["parser_config"])
|
||||||
if "chunk_method" in req:
|
if "chunk_method" in req:
|
||||||
valid_chunk_method = {
|
valid_chunk_method = {"naive", "manual", "qa", "table", "paper", "book", "laws", "presentation", "picture", "one", "knowledge_graph", "email", "tag"}
|
||||||
"naive",
|
|
||||||
"manual",
|
|
||||||
"qa",
|
|
||||||
"table",
|
|
||||||
"paper",
|
|
||||||
"book",
|
|
||||||
"laws",
|
|
||||||
"presentation",
|
|
||||||
"picture",
|
|
||||||
"one",
|
|
||||||
"knowledge_graph",
|
|
||||||
"email",
|
|
||||||
"tag"
|
|
||||||
}
|
|
||||||
if req.get("chunk_method") not in valid_chunk_method:
|
if req.get("chunk_method") not in valid_chunk_method:
|
||||||
return get_error_data_result(
|
return get_error_data_result(f"`chunk_method` {req['chunk_method']} doesn't exist")
|
||||||
f"`chunk_method` {req['chunk_method']} doesn't exist"
|
|
||||||
)
|
|
||||||
if doc.parser_id.lower() == req["chunk_method"].lower():
|
|
||||||
return get_result()
|
|
||||||
|
|
||||||
if doc.type == FileType.VISUAL or re.search(r"\.(ppt|pptx|pages)$", doc.name):
|
if doc.type == FileType.VISUAL or re.search(r"\.(ppt|pptx|pages)$", doc.name):
|
||||||
return get_error_data_result(message="Not supported yet!")
|
return get_error_data_result(message="Not supported yet!")
|
||||||
|
|
||||||
e = DocumentService.update_by_id(
|
if doc.parser_id.lower() != req["chunk_method"].lower():
|
||||||
doc.id,
|
e = DocumentService.update_by_id(
|
||||||
{
|
doc.id,
|
||||||
"parser_id": req["chunk_method"],
|
{
|
||||||
"progress": 0,
|
"parser_id": req["chunk_method"],
|
||||||
"progress_msg": "",
|
"progress": 0,
|
||||||
"run": TaskStatus.UNSTART.value,
|
"progress_msg": "",
|
||||||
},
|
"run": TaskStatus.UNSTART.value,
|
||||||
)
|
},
|
||||||
if not e:
|
)
|
||||||
return get_error_data_result(message="Document not found!")
|
if not e:
|
||||||
req["parser_config"] = get_parser_config(
|
return get_error_data_result(message="Document not found!")
|
||||||
req["chunk_method"], req.get("parser_config")
|
if not req.get("parser_config"):
|
||||||
)
|
req["parser_config"] = get_parser_config(req["chunk_method"], req.get("parser_config"))
|
||||||
DocumentService.update_parser_config(doc.id, req["parser_config"])
|
DocumentService.update_parser_config(doc.id, req["parser_config"])
|
||||||
if doc.token_num > 0:
|
if doc.token_num > 0:
|
||||||
e = DocumentService.increment_chunk_num(
|
e = DocumentService.increment_chunk_num(
|
||||||
doc.id,
|
doc.id,
|
||||||
@ -343,19 +310,45 @@ def update_doc(tenant_id, dataset_id, document_id):
|
|||||||
status = int(req["enabled"])
|
status = int(req["enabled"])
|
||||||
if doc.status != req["enabled"]:
|
if doc.status != req["enabled"]:
|
||||||
try:
|
try:
|
||||||
if not DocumentService.update_by_id(
|
if not DocumentService.update_by_id(doc.id, {"status": str(status)}):
|
||||||
doc.id, {"status": str(status)}):
|
return get_error_data_result(message="Database error (Document update)!")
|
||||||
return get_error_data_result(
|
|
||||||
message="Database error (Document update)!")
|
|
||||||
|
|
||||||
settings.docStoreConn.update({"doc_id": doc.id}, {"available_int": status},
|
settings.docStoreConn.update({"doc_id": doc.id}, {"available_int": status}, search.index_name(kb.tenant_id), doc.kb_id)
|
||||||
search.index_name(kb.tenant_id), doc.kb_id)
|
|
||||||
return get_result(data=True)
|
return get_result(data=True)
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
return server_error_response(e)
|
return server_error_response(e)
|
||||||
|
|
||||||
return get_result()
|
try:
|
||||||
|
ok, doc = DocumentService.get_by_id(doc.id)
|
||||||
|
if not ok:
|
||||||
|
return get_error_data_result(message="Dataset created failed")
|
||||||
|
except OperationalError as e:
|
||||||
|
logging.exception(e)
|
||||||
|
return get_error_data_result(message="Database operation failed")
|
||||||
|
|
||||||
|
key_mapping = {
|
||||||
|
"chunk_num": "chunk_count",
|
||||||
|
"kb_id": "dataset_id",
|
||||||
|
"token_num": "token_count",
|
||||||
|
"parser_id": "chunk_method",
|
||||||
|
}
|
||||||
|
run_mapping = {
|
||||||
|
"0": "UNSTART",
|
||||||
|
"1": "RUNNING",
|
||||||
|
"2": "CANCEL",
|
||||||
|
"3": "DONE",
|
||||||
|
"4": "FAIL",
|
||||||
|
}
|
||||||
|
renamed_doc = {}
|
||||||
|
for key, value in doc.to_dict().items():
|
||||||
|
if key == "run":
|
||||||
|
renamed_doc["run"] = run_mapping.get(str(value))
|
||||||
|
new_key = key_mapping.get(key, key)
|
||||||
|
renamed_doc[new_key] = value
|
||||||
|
if key == "run":
|
||||||
|
renamed_doc["run"] = run_mapping.get(value)
|
||||||
|
|
||||||
|
return get_result(data=renamed_doc)
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/datasets/<dataset_id>/documents/<document_id>", methods=["GET"]) # noqa: F821
|
@manager.route("/datasets/<dataset_id>/documents/<document_id>", methods=["GET"]) # noqa: F821
|
||||||
@ -397,25 +390,17 @@ def download(tenant_id, dataset_id, document_id):
|
|||||||
type: object
|
type: object
|
||||||
"""
|
"""
|
||||||
if not document_id:
|
if not document_id:
|
||||||
return get_error_data_result(
|
return get_error_data_result(message="Specify document_id please.")
|
||||||
message="Specify document_id please."
|
|
||||||
)
|
|
||||||
if not KnowledgebaseService.query(id=dataset_id, tenant_id=tenant_id):
|
if not KnowledgebaseService.query(id=dataset_id, tenant_id=tenant_id):
|
||||||
return get_error_data_result(message=f"You do not own the dataset {dataset_id}.")
|
return get_error_data_result(message=f"You do not own the dataset {dataset_id}.")
|
||||||
doc = DocumentService.query(kb_id=dataset_id, id=document_id)
|
doc = DocumentService.query(kb_id=dataset_id, id=document_id)
|
||||||
if not doc:
|
if not doc:
|
||||||
return get_error_data_result(
|
return get_error_data_result(message=f"The dataset not own the document {document_id}.")
|
||||||
message=f"The dataset not own the document {document_id}."
|
|
||||||
)
|
|
||||||
# The process of downloading
|
# The process of downloading
|
||||||
doc_id, doc_location = File2DocumentService.get_storage_address(
|
doc_id, doc_location = File2DocumentService.get_storage_address(doc_id=document_id) # minio address
|
||||||
doc_id=document_id
|
|
||||||
) # minio address
|
|
||||||
file_stream = STORAGE_IMPL.get(doc_id, doc_location)
|
file_stream = STORAGE_IMPL.get(doc_id, doc_location)
|
||||||
if not file_stream:
|
if not file_stream:
|
||||||
return construct_json_result(
|
return construct_json_result(message="This file is empty.", code=settings.RetCode.DATA_ERROR)
|
||||||
message="This file is empty.", code=settings.RetCode.DATA_ERROR
|
|
||||||
)
|
|
||||||
file = BytesIO(file_stream)
|
file = BytesIO(file_stream)
|
||||||
# Use send_file with a proper filename and MIME type
|
# Use send_file with a proper filename and MIME type
|
||||||
return send_file(
|
return send_file(
|
||||||
@ -530,9 +515,7 @@ def list_docs(dataset_id, tenant_id):
|
|||||||
desc = False
|
desc = False
|
||||||
else:
|
else:
|
||||||
desc = True
|
desc = True
|
||||||
docs, tol = DocumentService.get_list(
|
docs, tol = DocumentService.get_list(dataset_id, page, page_size, orderby, desc, keywords, id, name)
|
||||||
dataset_id, page, page_size, orderby, desc, keywords, id, name
|
|
||||||
)
|
|
||||||
|
|
||||||
# rename key's name
|
# rename key's name
|
||||||
renamed_doc_list = []
|
renamed_doc_list = []
|
||||||
@ -638,9 +621,7 @@ def delete(tenant_id, dataset_id):
|
|||||||
b, n = File2DocumentService.get_storage_address(doc_id=doc_id)
|
b, n = File2DocumentService.get_storage_address(doc_id=doc_id)
|
||||||
|
|
||||||
if not DocumentService.remove_document(doc, tenant_id):
|
if not DocumentService.remove_document(doc, tenant_id):
|
||||||
return get_error_data_result(
|
return get_error_data_result(message="Database error (Document removal)!")
|
||||||
message="Database error (Document removal)!"
|
|
||||||
)
|
|
||||||
|
|
||||||
f2d = File2DocumentService.get_by_document_id(doc_id)
|
f2d = File2DocumentService.get_by_document_id(doc_id)
|
||||||
FileService.filter_delete(
|
FileService.filter_delete(
|
||||||
@ -664,7 +645,10 @@ def delete(tenant_id, dataset_id):
|
|||||||
|
|
||||||
if duplicate_messages:
|
if duplicate_messages:
|
||||||
if success_count > 0:
|
if success_count > 0:
|
||||||
return get_result(message=f"Partially deleted {success_count} datasets with {len(duplicate_messages)} errors", data={"success_count": success_count, "errors": duplicate_messages},)
|
return get_result(
|
||||||
|
message=f"Partially deleted {success_count} datasets with {len(duplicate_messages)} errors",
|
||||||
|
data={"success_count": success_count, "errors": duplicate_messages},
|
||||||
|
)
|
||||||
else:
|
else:
|
||||||
return get_error_data_result(message=";".join(duplicate_messages))
|
return get_error_data_result(message=";".join(duplicate_messages))
|
||||||
|
|
||||||
@ -729,9 +713,7 @@ def parse(tenant_id, dataset_id):
|
|||||||
if not doc:
|
if not doc:
|
||||||
return get_error_data_result(message=f"You don't own the document {id}.")
|
return get_error_data_result(message=f"You don't own the document {id}.")
|
||||||
if 0.0 < doc[0].progress < 1.0:
|
if 0.0 < doc[0].progress < 1.0:
|
||||||
return get_error_data_result(
|
return get_error_data_result("Can't parse document that is currently being processed")
|
||||||
"Can't parse document that is currently being processed"
|
|
||||||
)
|
|
||||||
info = {"run": "1", "progress": 0, "progress_msg": "", "chunk_num": 0, "token_num": 0}
|
info = {"run": "1", "progress": 0, "progress_msg": "", "chunk_num": 0, "token_num": 0}
|
||||||
DocumentService.update_by_id(id, info)
|
DocumentService.update_by_id(id, info)
|
||||||
settings.docStoreConn.delete({"doc_id": id}, search.index_name(tenant_id), dataset_id)
|
settings.docStoreConn.delete({"doc_id": id}, search.index_name(tenant_id), dataset_id)
|
||||||
@ -746,7 +728,10 @@ def parse(tenant_id, dataset_id):
|
|||||||
return get_result(message=f"Documents not found: {not_found}", code=settings.RetCode.DATA_ERROR)
|
return get_result(message=f"Documents not found: {not_found}", code=settings.RetCode.DATA_ERROR)
|
||||||
if duplicate_messages:
|
if duplicate_messages:
|
||||||
if success_count > 0:
|
if success_count > 0:
|
||||||
return get_result(message=f"Partially parsed {success_count} documents with {len(duplicate_messages)} errors", data={"success_count": success_count, "errors": duplicate_messages},)
|
return get_result(
|
||||||
|
message=f"Partially parsed {success_count} documents with {len(duplicate_messages)} errors",
|
||||||
|
data={"success_count": success_count, "errors": duplicate_messages},
|
||||||
|
)
|
||||||
else:
|
else:
|
||||||
return get_error_data_result(message=";".join(duplicate_messages))
|
return get_error_data_result(message=";".join(duplicate_messages))
|
||||||
|
|
||||||
@ -808,16 +793,17 @@ def stop_parsing(tenant_id, dataset_id):
|
|||||||
if not doc:
|
if not doc:
|
||||||
return get_error_data_result(message=f"You don't own the document {id}.")
|
return get_error_data_result(message=f"You don't own the document {id}.")
|
||||||
if int(doc[0].progress) == 1 or doc[0].progress == 0:
|
if int(doc[0].progress) == 1 or doc[0].progress == 0:
|
||||||
return get_error_data_result(
|
return get_error_data_result("Can't stop parsing document with progress at 0 or 1")
|
||||||
"Can't stop parsing document with progress at 0 or 1"
|
|
||||||
)
|
|
||||||
info = {"run": "2", "progress": 0, "chunk_num": 0}
|
info = {"run": "2", "progress": 0, "chunk_num": 0}
|
||||||
DocumentService.update_by_id(id, info)
|
DocumentService.update_by_id(id, info)
|
||||||
settings.docStoreConn.delete({"doc_id": doc[0].id}, search.index_name(tenant_id), dataset_id)
|
settings.docStoreConn.delete({"doc_id": doc[0].id}, search.index_name(tenant_id), dataset_id)
|
||||||
success_count += 1
|
success_count += 1
|
||||||
if duplicate_messages:
|
if duplicate_messages:
|
||||||
if success_count > 0:
|
if success_count > 0:
|
||||||
return get_result(message=f"Partially stopped {success_count} documents with {len(duplicate_messages)} errors", data={"success_count": success_count, "errors": duplicate_messages},)
|
return get_result(
|
||||||
|
message=f"Partially stopped {success_count} documents with {len(duplicate_messages)} errors",
|
||||||
|
data={"success_count": success_count, "errors": duplicate_messages},
|
||||||
|
)
|
||||||
else:
|
else:
|
||||||
return get_error_data_result(message=";".join(duplicate_messages))
|
return get_error_data_result(message=";".join(duplicate_messages))
|
||||||
return get_result()
|
return get_result()
|
||||||
@ -906,9 +892,7 @@ def list_chunks(tenant_id, dataset_id, document_id):
|
|||||||
return get_error_data_result(message=f"You don't own the dataset {dataset_id}.")
|
return get_error_data_result(message=f"You don't own the dataset {dataset_id}.")
|
||||||
doc = DocumentService.query(id=document_id, kb_id=dataset_id)
|
doc = DocumentService.query(id=document_id, kb_id=dataset_id)
|
||||||
if not doc:
|
if not doc:
|
||||||
return get_error_data_result(
|
return get_error_data_result(message=f"You don't own the document {document_id}.")
|
||||||
message=f"You don't own the document {document_id}."
|
|
||||||
)
|
|
||||||
doc = doc[0]
|
doc = doc[0]
|
||||||
req = request.args
|
req = request.args
|
||||||
doc_id = document_id
|
doc_id = document_id
|
||||||
@ -956,34 +940,29 @@ def list_chunks(tenant_id, dataset_id, document_id):
|
|||||||
del chunk[n]
|
del chunk[n]
|
||||||
if not chunk:
|
if not chunk:
|
||||||
return get_error_data_result(f"Chunk `{req.get('id')}` not found.")
|
return get_error_data_result(f"Chunk `{req.get('id')}` not found.")
|
||||||
res['total'] = 1
|
res["total"] = 1
|
||||||
final_chunk = {
|
final_chunk = {
|
||||||
"id":chunk.get("id",chunk.get("chunk_id")),
|
"id": chunk.get("id", chunk.get("chunk_id")),
|
||||||
"content":chunk["content_with_weight"],
|
"content": chunk["content_with_weight"],
|
||||||
"document_id":chunk.get("doc_id",chunk.get("document_id")),
|
"document_id": chunk.get("doc_id", chunk.get("document_id")),
|
||||||
"docnm_kwd":chunk["docnm_kwd"],
|
"docnm_kwd": chunk["docnm_kwd"],
|
||||||
"important_keywords":chunk.get("important_kwd",[]),
|
"important_keywords": chunk.get("important_kwd", []),
|
||||||
"questions":chunk.get("question_kwd",[]),
|
"questions": chunk.get("question_kwd", []),
|
||||||
"dataset_id":chunk.get("kb_id",chunk.get("dataset_id")),
|
"dataset_id": chunk.get("kb_id", chunk.get("dataset_id")),
|
||||||
"image_id":chunk.get("img_id", ""),
|
"image_id": chunk.get("img_id", ""),
|
||||||
"available":bool(chunk.get("available_int",1)),
|
"available": bool(chunk.get("available_int", 1)),
|
||||||
"positions":chunk.get("position_int",[]),
|
"positions": chunk.get("position_int", []),
|
||||||
}
|
}
|
||||||
res["chunks"].append(final_chunk)
|
res["chunks"].append(final_chunk)
|
||||||
_ = Chunk(**final_chunk)
|
_ = Chunk(**final_chunk)
|
||||||
|
|
||||||
elif settings.docStoreConn.indexExist(search.index_name(tenant_id), dataset_id):
|
elif settings.docStoreConn.indexExist(search.index_name(tenant_id), dataset_id):
|
||||||
sres = settings.retrievaler.search(query, search.index_name(tenant_id), [dataset_id], emb_mdl=None,
|
sres = settings.retrievaler.search(query, search.index_name(tenant_id), [dataset_id], emb_mdl=None, highlight=True)
|
||||||
highlight=True)
|
|
||||||
res["total"] = sres.total
|
res["total"] = sres.total
|
||||||
for id in sres.ids:
|
for id in sres.ids:
|
||||||
d = {
|
d = {
|
||||||
"id": id,
|
"id": id,
|
||||||
"content": (
|
"content": (rmSpace(sres.highlight[id]) if question and id in sres.highlight else sres.field[id].get("content_with_weight", "")),
|
||||||
rmSpace(sres.highlight[id])
|
|
||||||
if question and id in sres.highlight
|
|
||||||
else sres.field[id].get("content_with_weight", "")
|
|
||||||
),
|
|
||||||
"document_id": sres.field[id]["doc_id"],
|
"document_id": sres.field[id]["doc_id"],
|
||||||
"docnm_kwd": sres.field[id]["docnm_kwd"],
|
"docnm_kwd": sres.field[id]["docnm_kwd"],
|
||||||
"important_keywords": sres.field[id].get("important_kwd", []),
|
"important_keywords": sres.field[id].get("important_kwd", []),
|
||||||
@ -991,10 +970,10 @@ def list_chunks(tenant_id, dataset_id, document_id):
|
|||||||
"dataset_id": sres.field[id].get("kb_id", sres.field[id].get("dataset_id")),
|
"dataset_id": sres.field[id].get("kb_id", sres.field[id].get("dataset_id")),
|
||||||
"image_id": sres.field[id].get("img_id", ""),
|
"image_id": sres.field[id].get("img_id", ""),
|
||||||
"available": bool(int(sres.field[id].get("available_int", "1"))),
|
"available": bool(int(sres.field[id].get("available_int", "1"))),
|
||||||
"positions": sres.field[id].get("position_int",[]),
|
"positions": sres.field[id].get("position_int", []),
|
||||||
}
|
}
|
||||||
res["chunks"].append(d)
|
res["chunks"].append(d)
|
||||||
_ = Chunk(**d) # validate the chunk
|
_ = Chunk(**d) # validate the chunk
|
||||||
return get_result(data=res)
|
return get_result(data=res)
|
||||||
|
|
||||||
|
|
||||||
@ -1070,23 +1049,17 @@ def add_chunk(tenant_id, dataset_id, document_id):
|
|||||||
return get_error_data_result(message=f"You don't own the dataset {dataset_id}.")
|
return get_error_data_result(message=f"You don't own the dataset {dataset_id}.")
|
||||||
doc = DocumentService.query(id=document_id, kb_id=dataset_id)
|
doc = DocumentService.query(id=document_id, kb_id=dataset_id)
|
||||||
if not doc:
|
if not doc:
|
||||||
return get_error_data_result(
|
return get_error_data_result(message=f"You don't own the document {document_id}.")
|
||||||
message=f"You don't own the document {document_id}."
|
|
||||||
)
|
|
||||||
doc = doc[0]
|
doc = doc[0]
|
||||||
req = request.json
|
req = request.json
|
||||||
if not str(req.get("content", "")).strip():
|
if not str(req.get("content", "")).strip():
|
||||||
return get_error_data_result(message="`content` is required")
|
return get_error_data_result(message="`content` is required")
|
||||||
if "important_keywords" in req:
|
if "important_keywords" in req:
|
||||||
if not isinstance(req["important_keywords"], list):
|
if not isinstance(req["important_keywords"], list):
|
||||||
return get_error_data_result(
|
return get_error_data_result("`important_keywords` is required to be a list")
|
||||||
"`important_keywords` is required to be a list"
|
|
||||||
)
|
|
||||||
if "questions" in req:
|
if "questions" in req:
|
||||||
if not isinstance(req["questions"], list):
|
if not isinstance(req["questions"], list):
|
||||||
return get_error_data_result(
|
return get_error_data_result("`questions` is required to be a list")
|
||||||
"`questions` is required to be a list"
|
|
||||||
)
|
|
||||||
chunk_id = xxhash.xxh64((req["content"] + document_id).encode("utf-8")).hexdigest()
|
chunk_id = xxhash.xxh64((req["content"] + document_id).encode("utf-8")).hexdigest()
|
||||||
d = {
|
d = {
|
||||||
"id": chunk_id,
|
"id": chunk_id,
|
||||||
@ -1095,22 +1068,16 @@ def add_chunk(tenant_id, dataset_id, document_id):
|
|||||||
}
|
}
|
||||||
d["content_sm_ltks"] = rag_tokenizer.fine_grained_tokenize(d["content_ltks"])
|
d["content_sm_ltks"] = rag_tokenizer.fine_grained_tokenize(d["content_ltks"])
|
||||||
d["important_kwd"] = req.get("important_keywords", [])
|
d["important_kwd"] = req.get("important_keywords", [])
|
||||||
d["important_tks"] = rag_tokenizer.tokenize(
|
d["important_tks"] = rag_tokenizer.tokenize(" ".join(req.get("important_keywords", [])))
|
||||||
" ".join(req.get("important_keywords", []))
|
|
||||||
)
|
|
||||||
d["question_kwd"] = [str(q).strip() for q in req.get("questions", []) if str(q).strip()]
|
d["question_kwd"] = [str(q).strip() for q in req.get("questions", []) if str(q).strip()]
|
||||||
d["question_tks"] = rag_tokenizer.tokenize(
|
d["question_tks"] = rag_tokenizer.tokenize("\n".join(req.get("questions", [])))
|
||||||
"\n".join(req.get("questions", []))
|
|
||||||
)
|
|
||||||
d["create_time"] = str(datetime.datetime.now()).replace("T", " ")[:19]
|
d["create_time"] = str(datetime.datetime.now()).replace("T", " ")[:19]
|
||||||
d["create_timestamp_flt"] = datetime.datetime.now().timestamp()
|
d["create_timestamp_flt"] = datetime.datetime.now().timestamp()
|
||||||
d["kb_id"] = dataset_id
|
d["kb_id"] = dataset_id
|
||||||
d["docnm_kwd"] = doc.name
|
d["docnm_kwd"] = doc.name
|
||||||
d["doc_id"] = document_id
|
d["doc_id"] = document_id
|
||||||
embd_id = DocumentService.get_embd_id(document_id)
|
embd_id = DocumentService.get_embd_id(document_id)
|
||||||
embd_mdl = TenantLLMService.model_instance(
|
embd_mdl = TenantLLMService.model_instance(tenant_id, LLMType.EMBEDDING.value, embd_id)
|
||||||
tenant_id, LLMType.EMBEDDING.value, embd_id
|
|
||||||
)
|
|
||||||
v, c = embd_mdl.encode([doc.name, req["content"] if not d["question_kwd"] else "\n".join(d["question_kwd"])])
|
v, c = embd_mdl.encode([doc.name, req["content"] if not d["question_kwd"] else "\n".join(d["question_kwd"])])
|
||||||
v = 0.1 * v[0] + 0.9 * v[1]
|
v = 0.1 * v[0] + 0.9 * v[1]
|
||||||
d["q_%d_vec" % len(v)] = v.tolist()
|
d["q_%d_vec" % len(v)] = v.tolist()
|
||||||
@ -1203,7 +1170,10 @@ def rm_chunk(tenant_id, dataset_id, document_id):
|
|||||||
return get_result(message=f"deleted {chunk_number} chunks")
|
return get_result(message=f"deleted {chunk_number} chunks")
|
||||||
return get_error_data_result(message=f"rm_chunk deleted chunks {chunk_number}, expect {len(unique_chunk_ids)}")
|
return get_error_data_result(message=f"rm_chunk deleted chunks {chunk_number}, expect {len(unique_chunk_ids)}")
|
||||||
if duplicate_messages:
|
if duplicate_messages:
|
||||||
return get_result(message=f"Partially deleted {chunk_number} chunks with {len(duplicate_messages)} errors", data={"success_count": chunk_number, "errors": duplicate_messages},)
|
return get_result(
|
||||||
|
message=f"Partially deleted {chunk_number} chunks with {len(duplicate_messages)} errors",
|
||||||
|
data={"success_count": chunk_number, "errors": duplicate_messages},
|
||||||
|
)
|
||||||
return get_result(message=f"deleted {chunk_number} chunks")
|
return get_result(message=f"deleted {chunk_number} chunks")
|
||||||
|
|
||||||
|
|
||||||
@ -1271,9 +1241,7 @@ def update_chunk(tenant_id, dataset_id, document_id, chunk_id):
|
|||||||
return get_error_data_result(message=f"You don't own the dataset {dataset_id}.")
|
return get_error_data_result(message=f"You don't own the dataset {dataset_id}.")
|
||||||
doc = DocumentService.query(id=document_id, kb_id=dataset_id)
|
doc = DocumentService.query(id=document_id, kb_id=dataset_id)
|
||||||
if not doc:
|
if not doc:
|
||||||
return get_error_data_result(
|
return get_error_data_result(message=f"You don't own the document {document_id}.")
|
||||||
message=f"You don't own the document {document_id}."
|
|
||||||
)
|
|
||||||
doc = doc[0]
|
doc = doc[0]
|
||||||
req = request.json
|
req = request.json
|
||||||
if "content" in req:
|
if "content" in req:
|
||||||
@ -1296,19 +1264,13 @@ def update_chunk(tenant_id, dataset_id, document_id, chunk_id):
|
|||||||
if "available" in req:
|
if "available" in req:
|
||||||
d["available_int"] = int(req["available"])
|
d["available_int"] = int(req["available"])
|
||||||
embd_id = DocumentService.get_embd_id(document_id)
|
embd_id = DocumentService.get_embd_id(document_id)
|
||||||
embd_mdl = TenantLLMService.model_instance(
|
embd_mdl = TenantLLMService.model_instance(tenant_id, LLMType.EMBEDDING.value, embd_id)
|
||||||
tenant_id, LLMType.EMBEDDING.value, embd_id
|
|
||||||
)
|
|
||||||
if doc.parser_id == ParserType.QA:
|
if doc.parser_id == ParserType.QA:
|
||||||
arr = [t for t in re.split(r"[\n\t]", d["content_with_weight"]) if len(t) > 1]
|
arr = [t for t in re.split(r"[\n\t]", d["content_with_weight"]) if len(t) > 1]
|
||||||
if len(arr) != 2:
|
if len(arr) != 2:
|
||||||
return get_error_data_result(
|
return get_error_data_result(message="Q&A must be separated by TAB/ENTER key.")
|
||||||
message="Q&A must be separated by TAB/ENTER key."
|
|
||||||
)
|
|
||||||
q, a = rmPrefix(arr[0]), rmPrefix(arr[1])
|
q, a = rmPrefix(arr[0]), rmPrefix(arr[1])
|
||||||
d = beAdoc(
|
d = beAdoc(d, arr[0], arr[1], not any([rag_tokenizer.is_chinese(t) for t in q + a]))
|
||||||
d, arr[0], arr[1], not any([rag_tokenizer.is_chinese(t) for t in q + a])
|
|
||||||
)
|
|
||||||
|
|
||||||
v, c = embd_mdl.encode([doc.name, d["content_with_weight"] if not d.get("question_kwd") else "\n".join(d["question_kwd"])])
|
v, c = embd_mdl.encode([doc.name, d["content_with_weight"] if not d.get("question_kwd") else "\n".join(d["question_kwd"])])
|
||||||
v = 0.1 * v[0] + 0.9 * v[1] if doc.parser_id != ParserType.QA else v[1]
|
v = 0.1 * v[0] + 0.9 * v[1] if doc.parser_id != ParserType.QA else v[1]
|
||||||
@ -1425,9 +1387,7 @@ def retrieval_test(tenant_id):
|
|||||||
doc_ids_list = KnowledgebaseService.list_documents_by_ids(kb_ids)
|
doc_ids_list = KnowledgebaseService.list_documents_by_ids(kb_ids)
|
||||||
for doc_id in doc_ids:
|
for doc_id in doc_ids:
|
||||||
if doc_id not in doc_ids_list:
|
if doc_id not in doc_ids_list:
|
||||||
return get_error_data_result(
|
return get_error_data_result(f"The datasets don't own the document {doc_id}")
|
||||||
f"The datasets don't own the document {doc_id}"
|
|
||||||
)
|
|
||||||
similarity_threshold = float(req.get("similarity_threshold", 0.2))
|
similarity_threshold = float(req.get("similarity_threshold", 0.2))
|
||||||
vector_similarity_weight = float(req.get("vector_similarity_weight", 0.3))
|
vector_similarity_weight = float(req.get("vector_similarity_weight", 0.3))
|
||||||
top = int(req.get("top_k", 1024))
|
top = int(req.get("top_k", 1024))
|
||||||
@ -1463,14 +1423,10 @@ def retrieval_test(tenant_id):
|
|||||||
doc_ids,
|
doc_ids,
|
||||||
rerank_mdl=rerank_mdl,
|
rerank_mdl=rerank_mdl,
|
||||||
highlight=highlight,
|
highlight=highlight,
|
||||||
rank_feature=label_question(question, kbs)
|
rank_feature=label_question(question, kbs),
|
||||||
)
|
)
|
||||||
if use_kg:
|
if use_kg:
|
||||||
ck = settings.kg_retrievaler.retrieval(question,
|
ck = settings.kg_retrievaler.retrieval(question, [k.tenant_id for k in kbs], kb_ids, embd_mdl, LLMBundle(kb.tenant_id, LLMType.CHAT))
|
||||||
[k.tenant_id for k in kbs],
|
|
||||||
kb_ids,
|
|
||||||
embd_mdl,
|
|
||||||
LLMBundle(kb.tenant_id, LLMType.CHAT))
|
|
||||||
if ck["content_with_weight"]:
|
if ck["content_with_weight"]:
|
||||||
ranks["chunks"].insert(0, ck)
|
ranks["chunks"].insert(0, ck)
|
||||||
|
|
||||||
@ -1487,7 +1443,7 @@ def retrieval_test(tenant_id):
|
|||||||
"important_kwd": "important_keywords",
|
"important_kwd": "important_keywords",
|
||||||
"question_kwd": "questions",
|
"question_kwd": "questions",
|
||||||
"docnm_kwd": "document_keyword",
|
"docnm_kwd": "document_keyword",
|
||||||
"kb_id":"dataset_id"
|
"kb_id": "dataset_id",
|
||||||
}
|
}
|
||||||
rename_chunk = {}
|
rename_chunk = {}
|
||||||
for key, value in chunk.items():
|
for key, value in chunk.items():
|
||||||
|
|||||||
@ -388,10 +388,10 @@ def agents_completion_openai_compatibility (tenant_id, agent_id):
|
|||||||
question = next((m["content"] for m in reversed(messages) if m["role"] == "user"), "")
|
question = next((m["content"] for m in reversed(messages) if m["role"] == "user"), "")
|
||||||
|
|
||||||
if req.get("stream", True):
|
if req.get("stream", True):
|
||||||
return Response(completionOpenAI(tenant_id, agent_id, question, session_id=req.get("id", ""), stream=True), mimetype="text/event-stream")
|
return Response(completionOpenAI(tenant_id, agent_id, question, session_id=req.get("id", req.get("metadata", {}).get("id","")), stream=True), mimetype="text/event-stream")
|
||||||
else:
|
else:
|
||||||
# For non-streaming, just return the response directly
|
# For non-streaming, just return the response directly
|
||||||
response = next(completionOpenAI(tenant_id, agent_id, question, session_id=req.get("id", ""), stream=False))
|
response = next(completionOpenAI(tenant_id, agent_id, question, session_id=req.get("id", req.get("metadata", {}).get("id","")), stream=False))
|
||||||
return jsonify(response)
|
return jsonify(response)
|
||||||
|
|
||||||
|
|
||||||
@ -464,7 +464,7 @@ def list_session(tenant_id, chat_id):
|
|||||||
if conv["reference"]:
|
if conv["reference"]:
|
||||||
messages = conv["messages"]
|
messages = conv["messages"]
|
||||||
message_num = 0
|
message_num = 0
|
||||||
while message_num < len(messages):
|
while message_num < len(messages) and message_num < len(conv["reference"]):
|
||||||
if message_num != 0 and messages[message_num]["role"] != "user":
|
if message_num != 0 and messages[message_num]["role"] != "user":
|
||||||
chunk_list = []
|
chunk_list = []
|
||||||
if "chunks" in conv["reference"][message_num]:
|
if "chunks" in conv["reference"][message_num]:
|
||||||
|
|||||||
188
api/apps/search_app.py
Normal file
188
api/apps/search_app.py
Normal file
@ -0,0 +1,188 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
|
||||||
|
from flask import request
|
||||||
|
from flask_login import current_user, login_required
|
||||||
|
|
||||||
|
from api import settings
|
||||||
|
from api.constants import DATASET_NAME_LIMIT
|
||||||
|
from api.db import StatusEnum
|
||||||
|
from api.db.db_models import DB
|
||||||
|
from api.db.services import duplicate_name
|
||||||
|
from api.db.services.knowledgebase_service import KnowledgebaseService
|
||||||
|
from api.db.services.search_service import SearchService
|
||||||
|
from api.db.services.user_service import TenantService, UserTenantService
|
||||||
|
from api.utils import get_uuid
|
||||||
|
from api.utils.api_utils import get_data_error_result, get_json_result, not_allowed_parameters, server_error_response, validate_request
|
||||||
|
|
||||||
|
|
||||||
|
@manager.route("/create", methods=["post"]) # noqa: F821
|
||||||
|
@login_required
|
||||||
|
@validate_request("name")
|
||||||
|
def create():
|
||||||
|
req = request.get_json()
|
||||||
|
search_name = req["name"]
|
||||||
|
description = req.get("description", "")
|
||||||
|
if not isinstance(search_name, str):
|
||||||
|
return get_data_error_result(message="Search name must be string.")
|
||||||
|
if search_name.strip() == "":
|
||||||
|
return get_data_error_result(message="Search name can't be empty.")
|
||||||
|
if len(search_name.encode("utf-8")) > DATASET_NAME_LIMIT:
|
||||||
|
return get_data_error_result(message=f"Search name length is {len(search_name)} which is large than {DATASET_NAME_LIMIT}")
|
||||||
|
e, _ = TenantService.get_by_id(current_user.id)
|
||||||
|
if not e:
|
||||||
|
return get_data_error_result(message="Authorizationd identity.")
|
||||||
|
|
||||||
|
search_name = search_name.strip()
|
||||||
|
search_name = duplicate_name(KnowledgebaseService.query, name=search_name, tenant_id=current_user.id, status=StatusEnum.VALID.value)
|
||||||
|
|
||||||
|
req["id"] = get_uuid()
|
||||||
|
req["name"] = search_name
|
||||||
|
req["description"] = description
|
||||||
|
req["tenant_id"] = current_user.id
|
||||||
|
req["created_by"] = current_user.id
|
||||||
|
with DB.atomic():
|
||||||
|
try:
|
||||||
|
if not SearchService.save(**req):
|
||||||
|
return get_data_error_result()
|
||||||
|
return get_json_result(data={"search_id": req["id"]})
|
||||||
|
except Exception as e:
|
||||||
|
return server_error_response(e)
|
||||||
|
|
||||||
|
|
||||||
|
@manager.route("/update", methods=["post"]) # noqa: F821
|
||||||
|
@login_required
|
||||||
|
@validate_request("search_id", "name", "search_config", "tenant_id")
|
||||||
|
@not_allowed_parameters("id", "created_by", "create_time", "update_time", "create_date", "update_date", "created_by")
|
||||||
|
def update():
|
||||||
|
req = request.get_json()
|
||||||
|
if not isinstance(req["name"], str):
|
||||||
|
return get_data_error_result(message="Search name must be string.")
|
||||||
|
if req["name"].strip() == "":
|
||||||
|
return get_data_error_result(message="Search name can't be empty.")
|
||||||
|
if len(req["name"].encode("utf-8")) > DATASET_NAME_LIMIT:
|
||||||
|
return get_data_error_result(message=f"Search name length is {len(req['name'])} which is large than {DATASET_NAME_LIMIT}")
|
||||||
|
req["name"] = req["name"].strip()
|
||||||
|
tenant_id = req["tenant_id"]
|
||||||
|
e, _ = TenantService.get_by_id(tenant_id)
|
||||||
|
if not e:
|
||||||
|
return get_data_error_result(message="Authorizationd identity.")
|
||||||
|
|
||||||
|
search_id = req["search_id"]
|
||||||
|
if not SearchService.accessible4deletion(search_id, current_user.id):
|
||||||
|
return get_json_result(data=False, message="No authorization.", code=settings.RetCode.AUTHENTICATION_ERROR)
|
||||||
|
|
||||||
|
try:
|
||||||
|
search_app = SearchService.query(tenant_id=tenant_id, id=search_id)[0]
|
||||||
|
if not search_app:
|
||||||
|
return get_json_result(data=False, message=f"Cannot find search {search_id}", code=settings.RetCode.DATA_ERROR)
|
||||||
|
|
||||||
|
if req["name"].lower() != search_app.name.lower() and len(SearchService.query(name=req["name"], tenant_id=tenant_id, status=StatusEnum.VALID.value)) >= 1:
|
||||||
|
return get_data_error_result(message="Duplicated search name.")
|
||||||
|
|
||||||
|
if "search_config" in req:
|
||||||
|
current_config = search_app.search_config or {}
|
||||||
|
new_config = req["search_config"]
|
||||||
|
|
||||||
|
if not isinstance(new_config, dict):
|
||||||
|
return get_data_error_result(message="search_config must be a JSON object")
|
||||||
|
|
||||||
|
updated_config = {**current_config, **new_config}
|
||||||
|
req["search_config"] = updated_config
|
||||||
|
|
||||||
|
req.pop("search_id", None)
|
||||||
|
req.pop("tenant_id", None)
|
||||||
|
|
||||||
|
updated = SearchService.update_by_id(search_id, req)
|
||||||
|
if not updated:
|
||||||
|
return get_data_error_result(message="Failed to update search")
|
||||||
|
|
||||||
|
e, updated_search = SearchService.get_by_id(search_id)
|
||||||
|
if not e:
|
||||||
|
return get_data_error_result(message="Failed to fetch updated search")
|
||||||
|
|
||||||
|
return get_json_result(data=updated_search.to_dict())
|
||||||
|
|
||||||
|
except Exception as e:
|
||||||
|
return server_error_response(e)
|
||||||
|
|
||||||
|
|
||||||
|
@manager.route("/detail", methods=["GET"]) # noqa: F821
|
||||||
|
@login_required
|
||||||
|
def detail():
|
||||||
|
search_id = request.args["search_id"]
|
||||||
|
try:
|
||||||
|
tenants = UserTenantService.query(user_id=current_user.id)
|
||||||
|
for tenant in tenants:
|
||||||
|
if SearchService.query(tenant_id=tenant.tenant_id, id=search_id):
|
||||||
|
break
|
||||||
|
else:
|
||||||
|
return get_json_result(data=False, message="Has no permission for this operation.", code=settings.RetCode.OPERATING_ERROR)
|
||||||
|
|
||||||
|
search = SearchService.get_detail(search_id)
|
||||||
|
if not search:
|
||||||
|
return get_data_error_result(message="Can't find this Search App!")
|
||||||
|
return get_json_result(data=search)
|
||||||
|
except Exception as e:
|
||||||
|
return server_error_response(e)
|
||||||
|
|
||||||
|
|
||||||
|
@manager.route("/list", methods=["POST"]) # noqa: F821
|
||||||
|
@login_required
|
||||||
|
def list_search_app():
|
||||||
|
keywords = request.args.get("keywords", "")
|
||||||
|
page_number = int(request.args.get("page", 0))
|
||||||
|
items_per_page = int(request.args.get("page_size", 0))
|
||||||
|
orderby = request.args.get("orderby", "create_time")
|
||||||
|
if request.args.get("desc", "true").lower() == "false":
|
||||||
|
desc = False
|
||||||
|
else:
|
||||||
|
desc = True
|
||||||
|
|
||||||
|
req = request.get_json()
|
||||||
|
owner_ids = req.get("owner_ids", [])
|
||||||
|
try:
|
||||||
|
if not owner_ids:
|
||||||
|
tenants = TenantService.get_joined_tenants_by_user_id(current_user.id)
|
||||||
|
tenants = [m["tenant_id"] for m in tenants]
|
||||||
|
search_apps, total = SearchService.get_by_tenant_ids(tenants, current_user.id, page_number, items_per_page, orderby, desc, keywords)
|
||||||
|
else:
|
||||||
|
tenants = owner_ids
|
||||||
|
search_apps, total = SearchService.get_by_tenant_ids(tenants, current_user.id, 0, 0, orderby, desc, keywords)
|
||||||
|
search_apps = [search_app for search_app in search_apps if search_app["tenant_id"] in tenants]
|
||||||
|
total = len(search_apps)
|
||||||
|
if page_number and items_per_page:
|
||||||
|
search_apps = search_apps[(page_number - 1) * items_per_page : page_number * items_per_page]
|
||||||
|
return get_json_result(data={"search_apps": search_apps, "total": total})
|
||||||
|
except Exception as e:
|
||||||
|
return server_error_response(e)
|
||||||
|
|
||||||
|
|
||||||
|
@manager.route("/rm", methods=["post"]) # noqa: F821
|
||||||
|
@login_required
|
||||||
|
@validate_request("search_id")
|
||||||
|
def rm():
|
||||||
|
req = request.get_json()
|
||||||
|
search_id = req["search_id"]
|
||||||
|
if not SearchService.accessible4deletion(search_id, current_user.id):
|
||||||
|
return get_json_result(data=False, message="No authorization.", code=settings.RetCode.AUTHENTICATION_ERROR)
|
||||||
|
|
||||||
|
try:
|
||||||
|
if not SearchService.delete_by_id(search_id):
|
||||||
|
return get_data_error_result(message=f"Failed to delete search App {search_id}")
|
||||||
|
return get_json_result(data=True)
|
||||||
|
except Exception as e:
|
||||||
|
return server_error_response(e)
|
||||||
@ -13,36 +13,38 @@
|
|||||||
# See the License for the specific language governing permissions and
|
# See the License for the specific language governing permissions and
|
||||||
# limitations under the License.
|
# limitations under the License.
|
||||||
#
|
#
|
||||||
import logging
|
|
||||||
import json
|
import json
|
||||||
|
import logging
|
||||||
import re
|
import re
|
||||||
|
import secrets
|
||||||
from datetime import datetime
|
from datetime import datetime
|
||||||
|
|
||||||
from flask import request, session, redirect
|
from flask import redirect, request, session
|
||||||
from werkzeug.security import generate_password_hash, check_password_hash
|
from flask_login import current_user, login_required, login_user, logout_user
|
||||||
from flask_login import login_required, current_user, login_user, logout_user
|
from werkzeug.security import check_password_hash, generate_password_hash
|
||||||
|
|
||||||
|
from api import settings
|
||||||
|
from api.apps.auth import get_auth_client
|
||||||
|
from api.db import FileType, UserTenantRole
|
||||||
from api.db.db_models import TenantLLM
|
from api.db.db_models import TenantLLM
|
||||||
from api.db.services.llm_service import TenantLLMService, LLMService
|
from api.db.services.file_service import FileService
|
||||||
from api.utils.api_utils import (
|
from api.db.services.llm_service import LLMService, TenantLLMService
|
||||||
server_error_response,
|
from api.db.services.user_service import TenantService, UserService, UserTenantService
|
||||||
validate_request,
|
|
||||||
get_data_error_result,
|
|
||||||
)
|
|
||||||
from api.utils import (
|
from api.utils import (
|
||||||
get_uuid,
|
|
||||||
get_format_time,
|
|
||||||
decrypt,
|
|
||||||
download_img,
|
|
||||||
current_timestamp,
|
current_timestamp,
|
||||||
datetime_format,
|
datetime_format,
|
||||||
|
decrypt,
|
||||||
|
download_img,
|
||||||
|
get_format_time,
|
||||||
|
get_uuid,
|
||||||
|
)
|
||||||
|
from api.utils.api_utils import (
|
||||||
|
construct_response,
|
||||||
|
get_data_error_result,
|
||||||
|
get_json_result,
|
||||||
|
server_error_response,
|
||||||
|
validate_request,
|
||||||
)
|
)
|
||||||
from api.db import UserTenantRole, FileType
|
|
||||||
from api import settings
|
|
||||||
from api.db.services.user_service import UserService, TenantService, UserTenantService
|
|
||||||
from api.db.services.file_service import FileService
|
|
||||||
from api.utils.api_utils import get_json_result, construct_response
|
|
||||||
from api.apps.auth import get_auth_client
|
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/login", methods=["POST", "GET"]) # noqa: F821
|
@manager.route("/login", methods=["POST", "GET"]) # noqa: F821
|
||||||
@ -77,9 +79,7 @@ def login():
|
|||||||
type: object
|
type: object
|
||||||
"""
|
"""
|
||||||
if not request.json:
|
if not request.json:
|
||||||
return get_json_result(
|
return get_json_result(data=False, code=settings.RetCode.AUTHENTICATION_ERROR, message="Unauthorized!")
|
||||||
data=False, code=settings.RetCode.AUTHENTICATION_ERROR, message="Unauthorized!"
|
|
||||||
)
|
|
||||||
|
|
||||||
email = request.json.get("email", "")
|
email = request.json.get("email", "")
|
||||||
users = UserService.query(email=email)
|
users = UserService.query(email=email)
|
||||||
@ -94,9 +94,7 @@ def login():
|
|||||||
try:
|
try:
|
||||||
password = decrypt(password)
|
password = decrypt(password)
|
||||||
except BaseException:
|
except BaseException:
|
||||||
return get_json_result(
|
return get_json_result(data=False, code=settings.RetCode.SERVER_ERROR, message="Fail to crypt password")
|
||||||
data=False, code=settings.RetCode.SERVER_ERROR, message="Fail to crypt password"
|
|
||||||
)
|
|
||||||
|
|
||||||
user = UserService.query_user(email, password)
|
user = UserService.query_user(email, password)
|
||||||
if user:
|
if user:
|
||||||
@ -116,7 +114,7 @@ def login():
|
|||||||
)
|
)
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/login/channels", methods=["GET"]) # noqa: F821
|
@manager.route("/login/channels", methods=["GET"]) # noqa: F821
|
||||||
def get_login_channels():
|
def get_login_channels():
|
||||||
"""
|
"""
|
||||||
Get all supported authentication channels.
|
Get all supported authentication channels.
|
||||||
@ -124,22 +122,20 @@ def get_login_channels():
|
|||||||
try:
|
try:
|
||||||
channels = []
|
channels = []
|
||||||
for channel, config in settings.OAUTH_CONFIG.items():
|
for channel, config in settings.OAUTH_CONFIG.items():
|
||||||
channels.append({
|
channels.append(
|
||||||
"channel": channel,
|
{
|
||||||
"display_name": config.get("display_name", channel.title()),
|
"channel": channel,
|
||||||
"icon": config.get("icon", "sso"),
|
"display_name": config.get("display_name", channel.title()),
|
||||||
})
|
"icon": config.get("icon", "sso"),
|
||||||
|
}
|
||||||
|
)
|
||||||
return get_json_result(data=channels)
|
return get_json_result(data=channels)
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
logging.exception(e)
|
logging.exception(e)
|
||||||
return get_json_result(
|
return get_json_result(data=[], message=f"Load channels failure, error: {str(e)}", code=settings.RetCode.EXCEPTION_ERROR)
|
||||||
data=[],
|
|
||||||
message=f"Load channels failure, error: {str(e)}",
|
|
||||||
code=settings.RetCode.EXCEPTION_ERROR
|
|
||||||
)
|
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/login/<channel>", methods=["GET"]) # noqa: F821
|
@manager.route("/login/<channel>", methods=["GET"]) # noqa: F821
|
||||||
def oauth_login(channel):
|
def oauth_login(channel):
|
||||||
channel_config = settings.OAUTH_CONFIG.get(channel)
|
channel_config = settings.OAUTH_CONFIG.get(channel)
|
||||||
if not channel_config:
|
if not channel_config:
|
||||||
@ -152,7 +148,7 @@ def oauth_login(channel):
|
|||||||
return redirect(auth_url)
|
return redirect(auth_url)
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/oauth/callback/<channel>", methods=["GET"]) # noqa: F821
|
@manager.route("/oauth/callback/<channel>", methods=["GET"]) # noqa: F821
|
||||||
def oauth_callback(channel):
|
def oauth_callback(channel):
|
||||||
"""
|
"""
|
||||||
Handle the OAuth/OIDC callback for various channels dynamically.
|
Handle the OAuth/OIDC callback for various channels dynamically.
|
||||||
@ -190,7 +186,7 @@ def oauth_callback(channel):
|
|||||||
# Login or register
|
# Login or register
|
||||||
users = UserService.query(email=user_info.email)
|
users = UserService.query(email=user_info.email)
|
||||||
user_id = get_uuid()
|
user_id = get_uuid()
|
||||||
|
|
||||||
if not users:
|
if not users:
|
||||||
try:
|
try:
|
||||||
try:
|
try:
|
||||||
@ -434,9 +430,7 @@ def user_info_from_feishu(access_token):
|
|||||||
"Content-Type": "application/json; charset=utf-8",
|
"Content-Type": "application/json; charset=utf-8",
|
||||||
"Authorization": f"Bearer {access_token}",
|
"Authorization": f"Bearer {access_token}",
|
||||||
}
|
}
|
||||||
res = requests.get(
|
res = requests.get("https://open.feishu.cn/open-apis/authen/v1/user_info", headers=headers)
|
||||||
"https://open.feishu.cn/open-apis/authen/v1/user_info", headers=headers
|
|
||||||
)
|
|
||||||
user_info = res.json()["data"]
|
user_info = res.json()["data"]
|
||||||
user_info["email"] = None if user_info.get("email") == "" else user_info["email"]
|
user_info["email"] = None if user_info.get("email") == "" else user_info["email"]
|
||||||
return user_info
|
return user_info
|
||||||
@ -446,17 +440,13 @@ def user_info_from_github(access_token):
|
|||||||
import requests
|
import requests
|
||||||
|
|
||||||
headers = {"Accept": "application/json", "Authorization": f"token {access_token}"}
|
headers = {"Accept": "application/json", "Authorization": f"token {access_token}"}
|
||||||
res = requests.get(
|
res = requests.get(f"https://api.github.com/user?access_token={access_token}", headers=headers)
|
||||||
f"https://api.github.com/user?access_token={access_token}", headers=headers
|
|
||||||
)
|
|
||||||
user_info = res.json()
|
user_info = res.json()
|
||||||
email_info = requests.get(
|
email_info = requests.get(
|
||||||
f"https://api.github.com/user/emails?access_token={access_token}",
|
f"https://api.github.com/user/emails?access_token={access_token}",
|
||||||
headers=headers,
|
headers=headers,
|
||||||
).json()
|
).json()
|
||||||
user_info["email"] = next(
|
user_info["email"] = next((email for email in email_info if email["primary"]), None)["email"]
|
||||||
(email for email in email_info if email["primary"]), None
|
|
||||||
)["email"]
|
|
||||||
return user_info
|
return user_info
|
||||||
|
|
||||||
|
|
||||||
@ -476,7 +466,7 @@ def log_out():
|
|||||||
schema:
|
schema:
|
||||||
type: object
|
type: object
|
||||||
"""
|
"""
|
||||||
current_user.access_token = ""
|
current_user.access_token = f"INVALID_{secrets.token_hex(16)}"
|
||||||
current_user.save()
|
current_user.save()
|
||||||
logout_user()
|
logout_user()
|
||||||
return get_json_result(data=True)
|
return get_json_result(data=True)
|
||||||
@ -516,9 +506,7 @@ def setting_user():
|
|||||||
request_data = request.json
|
request_data = request.json
|
||||||
if request_data.get("password"):
|
if request_data.get("password"):
|
||||||
new_password = request_data.get("new_password")
|
new_password = request_data.get("new_password")
|
||||||
if not check_password_hash(
|
if not check_password_hash(current_user.password, decrypt(request_data["password"])):
|
||||||
current_user.password, decrypt(request_data["password"])
|
|
||||||
):
|
|
||||||
return get_json_result(
|
return get_json_result(
|
||||||
data=False,
|
data=False,
|
||||||
code=settings.RetCode.AUTHENTICATION_ERROR,
|
code=settings.RetCode.AUTHENTICATION_ERROR,
|
||||||
@ -549,9 +537,7 @@ def setting_user():
|
|||||||
return get_json_result(data=True)
|
return get_json_result(data=True)
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
logging.exception(e)
|
logging.exception(e)
|
||||||
return get_json_result(
|
return get_json_result(data=False, message="Update failure!", code=settings.RetCode.EXCEPTION_ERROR)
|
||||||
data=False, message="Update failure!", code=settings.RetCode.EXCEPTION_ERROR
|
|
||||||
)
|
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/info", methods=["GET"]) # noqa: F821
|
@manager.route("/info", methods=["GET"]) # noqa: F821
|
||||||
@ -643,9 +629,23 @@ def user_register(user_id, user):
|
|||||||
"model_type": llm.model_type,
|
"model_type": llm.model_type,
|
||||||
"api_key": settings.API_KEY,
|
"api_key": settings.API_KEY,
|
||||||
"api_base": settings.LLM_BASE_URL,
|
"api_base": settings.LLM_BASE_URL,
|
||||||
"max_tokens": llm.max_tokens if llm.max_tokens else 8192
|
"max_tokens": llm.max_tokens if llm.max_tokens else 8192,
|
||||||
}
|
}
|
||||||
)
|
)
|
||||||
|
if settings.LIGHTEN != 1:
|
||||||
|
for buildin_embedding_model in settings.BUILTIN_EMBEDDING_MODELS:
|
||||||
|
mdlnm, fid = TenantLLMService.split_model_name_and_factory(buildin_embedding_model)
|
||||||
|
tenant_llm.append(
|
||||||
|
{
|
||||||
|
"tenant_id": user_id,
|
||||||
|
"llm_factory": fid,
|
||||||
|
"llm_name": mdlnm,
|
||||||
|
"model_type": "embedding",
|
||||||
|
"api_key": "",
|
||||||
|
"api_base": "",
|
||||||
|
"max_tokens": 1024 if buildin_embedding_model == "BAAI/bge-large-zh-v1.5@BAAI" else 512,
|
||||||
|
}
|
||||||
|
)
|
||||||
|
|
||||||
if not UserService.save(**user):
|
if not UserService.save(**user):
|
||||||
return
|
return
|
||||||
|
|||||||
@ -13,9 +13,9 @@
|
|||||||
# See the License for the specific language governing permissions and
|
# See the License for the specific language governing permissions and
|
||||||
# limitations under the License.
|
# limitations under the License.
|
||||||
|
|
||||||
NAME_LENGTH_LIMIT = 2 ** 10
|
NAME_LENGTH_LIMIT = 2**10
|
||||||
|
|
||||||
IMG_BASE64_PREFIX = 'data:image/png;base64,'
|
IMG_BASE64_PREFIX = "data:image/png;base64,"
|
||||||
|
|
||||||
SERVICE_CONF = "service_conf.yaml"
|
SERVICE_CONF = "service_conf.yaml"
|
||||||
|
|
||||||
@ -25,3 +25,4 @@ REQUEST_WAIT_SEC = 2
|
|||||||
REQUEST_MAX_WAIT_SEC = 300
|
REQUEST_MAX_WAIT_SEC = 300
|
||||||
|
|
||||||
DATASET_NAME_LIMIT = 128
|
DATASET_NAME_LIMIT = 128
|
||||||
|
FILE_NAME_LEN_LIMIT = 255
|
||||||
|
|||||||
@ -13,16 +13,16 @@
|
|||||||
# See the License for the specific language governing permissions and
|
# See the License for the specific language governing permissions and
|
||||||
# limitations under the License.
|
# limitations under the License.
|
||||||
#
|
#
|
||||||
|
import hashlib
|
||||||
import inspect
|
import inspect
|
||||||
import logging
|
import logging
|
||||||
import operator
|
import operator
|
||||||
import os
|
import os
|
||||||
import sys
|
import sys
|
||||||
import typing
|
|
||||||
import time
|
import time
|
||||||
|
import typing
|
||||||
from enum import Enum
|
from enum import Enum
|
||||||
from functools import wraps
|
from functools import wraps
|
||||||
import hashlib
|
|
||||||
|
|
||||||
from flask_login import UserMixin
|
from flask_login import UserMixin
|
||||||
from itsdangerous.url_safe import URLSafeTimedSerializer as Serializer
|
from itsdangerous.url_safe import URLSafeTimedSerializer as Serializer
|
||||||
@ -264,14 +264,15 @@ class BaseDataBase:
|
|||||||
|
|
||||||
def with_retry(max_retries=3, retry_delay=1.0):
|
def with_retry(max_retries=3, retry_delay=1.0):
|
||||||
"""Decorator: Add retry mechanism to database operations
|
"""Decorator: Add retry mechanism to database operations
|
||||||
|
|
||||||
Args:
|
Args:
|
||||||
max_retries (int): maximum number of retries
|
max_retries (int): maximum number of retries
|
||||||
retry_delay (float): initial retry delay (seconds), will increase exponentially
|
retry_delay (float): initial retry delay (seconds), will increase exponentially
|
||||||
|
|
||||||
Returns:
|
Returns:
|
||||||
decorated function
|
decorated function
|
||||||
"""
|
"""
|
||||||
|
|
||||||
def decorator(func):
|
def decorator(func):
|
||||||
@wraps(func)
|
@wraps(func)
|
||||||
def wrapper(*args, **kwargs):
|
def wrapper(*args, **kwargs):
|
||||||
@ -284,26 +285,28 @@ def with_retry(max_retries=3, retry_delay=1.0):
|
|||||||
# get self and method name for logging
|
# get self and method name for logging
|
||||||
self_obj = args[0] if args else None
|
self_obj = args[0] if args else None
|
||||||
func_name = func.__name__
|
func_name = func.__name__
|
||||||
lock_name = getattr(self_obj, 'lock_name', 'unknown') if self_obj else 'unknown'
|
lock_name = getattr(self_obj, "lock_name", "unknown") if self_obj else "unknown"
|
||||||
|
|
||||||
if retry < max_retries - 1:
|
if retry < max_retries - 1:
|
||||||
current_delay = retry_delay * (2 ** retry)
|
current_delay = retry_delay * (2**retry)
|
||||||
logging.warning(f"{func_name} {lock_name} failed: {str(e)}, retrying ({retry+1}/{max_retries})")
|
logging.warning(f"{func_name} {lock_name} failed: {str(e)}, retrying ({retry + 1}/{max_retries})")
|
||||||
time.sleep(current_delay)
|
time.sleep(current_delay)
|
||||||
else:
|
else:
|
||||||
logging.error(f"{func_name} {lock_name} failed after all attempts: {str(e)}")
|
logging.error(f"{func_name} {lock_name} failed after all attempts: {str(e)}")
|
||||||
|
|
||||||
if last_exception:
|
if last_exception:
|
||||||
raise last_exception
|
raise last_exception
|
||||||
return False
|
return False
|
||||||
|
|
||||||
return wrapper
|
return wrapper
|
||||||
|
|
||||||
return decorator
|
return decorator
|
||||||
|
|
||||||
|
|
||||||
class PostgresDatabaseLock:
|
class PostgresDatabaseLock:
|
||||||
def __init__(self, lock_name, timeout=10, db=None):
|
def __init__(self, lock_name, timeout=10, db=None):
|
||||||
self.lock_name = lock_name
|
self.lock_name = lock_name
|
||||||
self.lock_id = int(hashlib.md5(lock_name.encode()).hexdigest(), 16) % (2**31-1)
|
self.lock_id = int(hashlib.md5(lock_name.encode()).hexdigest(), 16) % (2**31 - 1)
|
||||||
self.timeout = int(timeout)
|
self.timeout = int(timeout)
|
||||||
self.db = db if db else DB
|
self.db = db if db else DB
|
||||||
|
|
||||||
@ -542,7 +545,7 @@ class LLM(DataBaseModel):
|
|||||||
max_tokens = IntegerField(default=0)
|
max_tokens = IntegerField(default=0)
|
||||||
|
|
||||||
tags = CharField(max_length=255, null=False, help_text="LLM, Text Embedding, Image2Text, Chat, 32k...", index=True)
|
tags = CharField(max_length=255, null=False, help_text="LLM, Text Embedding, Image2Text, Chat, 32k...", index=True)
|
||||||
is_tools = BooleanField(null=False, help_text="support tools", default=False)
|
is_tools = BooleanField(null=False, help_text="support tools", default=False)
|
||||||
status = CharField(max_length=1, null=True, help_text="is it validate(0: wasted, 1: validate)", default="1", index=True)
|
status = CharField(max_length=1, null=True, help_text="is it validate(0: wasted, 1: validate)", default="1", index=True)
|
||||||
|
|
||||||
def __str__(self):
|
def __str__(self):
|
||||||
@ -796,6 +799,50 @@ class UserCanvasVersion(DataBaseModel):
|
|||||||
db_table = "user_canvas_version"
|
db_table = "user_canvas_version"
|
||||||
|
|
||||||
|
|
||||||
|
class Search(DataBaseModel):
|
||||||
|
id = CharField(max_length=32, primary_key=True)
|
||||||
|
avatar = TextField(null=True, help_text="avatar base64 string")
|
||||||
|
tenant_id = CharField(max_length=32, null=False, index=True)
|
||||||
|
name = CharField(max_length=128, null=False, help_text="Search name", index=True)
|
||||||
|
description = TextField(null=True, help_text="KB description")
|
||||||
|
created_by = CharField(max_length=32, null=False, index=True)
|
||||||
|
search_config = JSONField(
|
||||||
|
null=False,
|
||||||
|
default={
|
||||||
|
"kb_ids": [],
|
||||||
|
"doc_ids": [],
|
||||||
|
"similarity_threshold": 0.0,
|
||||||
|
"vector_similarity_weight": 0.3,
|
||||||
|
"use_kg": False,
|
||||||
|
# rerank settings
|
||||||
|
"rerank_id": "",
|
||||||
|
"top_k": 1024,
|
||||||
|
# chat settings
|
||||||
|
"summary": False,
|
||||||
|
"chat_id": "",
|
||||||
|
"llm_setting": {
|
||||||
|
"temperature": 0.1,
|
||||||
|
"top_p": 0.3,
|
||||||
|
"frequency_penalty": 0.7,
|
||||||
|
"presence_penalty": 0.4,
|
||||||
|
},
|
||||||
|
"chat_settingcross_languages": [],
|
||||||
|
"highlight": False,
|
||||||
|
"keyword": False,
|
||||||
|
"web_search": False,
|
||||||
|
"related_search": False,
|
||||||
|
"query_mindmap": False,
|
||||||
|
},
|
||||||
|
)
|
||||||
|
status = CharField(max_length=1, null=True, help_text="is it validate(0: wasted, 1: validate)", default="1", index=True)
|
||||||
|
|
||||||
|
def __str__(self):
|
||||||
|
return self.name
|
||||||
|
|
||||||
|
class Meta:
|
||||||
|
db_table = "search"
|
||||||
|
|
||||||
|
|
||||||
def migrate_db():
|
def migrate_db():
|
||||||
migrator = DatabaseMigrator[settings.DATABASE_TYPE.upper()].value(DB)
|
migrator = DatabaseMigrator[settings.DATABASE_TYPE.upper()].value(DB)
|
||||||
try:
|
try:
|
||||||
|
|||||||
@ -84,14 +84,14 @@ def init_superuser():
|
|||||||
{"role": "user", "content": "Hello!"}], gen_conf={})
|
{"role": "user", "content": "Hello!"}], gen_conf={})
|
||||||
if msg.find("ERROR: ") == 0:
|
if msg.find("ERROR: ") == 0:
|
||||||
logging.error(
|
logging.error(
|
||||||
"'{}' dosen't work. {}".format(
|
"'{}' doesn't work. {}".format(
|
||||||
tenant["llm_id"],
|
tenant["llm_id"],
|
||||||
msg))
|
msg))
|
||||||
embd_mdl = LLMBundle(tenant["id"], LLMType.EMBEDDING, tenant["embd_id"])
|
embd_mdl = LLMBundle(tenant["id"], LLMType.EMBEDDING, tenant["embd_id"])
|
||||||
v, c = embd_mdl.encode(["Hello!"])
|
v, c = embd_mdl.encode(["Hello!"])
|
||||||
if c == 0:
|
if c == 0:
|
||||||
logging.error(
|
logging.error(
|
||||||
"'{}' dosen't work!".format(
|
"'{}' doesn't work!".format(
|
||||||
tenant["embd_id"]))
|
tenant["embd_id"]))
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
@ -13,27 +13,87 @@
|
|||||||
# See the License for the specific language governing permissions and
|
# See the License for the specific language governing permissions and
|
||||||
# limitations under the License.
|
# limitations under the License.
|
||||||
#
|
#
|
||||||
import pathlib
|
|
||||||
import re
|
import re
|
||||||
|
from pathlib import PurePath
|
||||||
|
|
||||||
from .user_service import UserService as UserService
|
from .user_service import UserService as UserService
|
||||||
|
|
||||||
|
|
||||||
def duplicate_name(query_func, **kwargs):
|
def split_name_counter(filename: str) -> tuple[str, int | None]:
|
||||||
fnm = kwargs["name"]
|
"""
|
||||||
objs = query_func(**kwargs)
|
Splits a filename into main part and counter (if present in parentheses).
|
||||||
if not objs:
|
|
||||||
return fnm
|
|
||||||
ext = pathlib.Path(fnm).suffix #.jpg
|
|
||||||
nm = re.sub(r"%s$"%ext, "", fnm)
|
|
||||||
r = re.search(r"\(([0-9]+)\)$", nm)
|
|
||||||
c = 0
|
|
||||||
if r:
|
|
||||||
c = int(r.group(1))
|
|
||||||
nm = re.sub(r"\([0-9]+\)$", "", nm)
|
|
||||||
c += 1
|
|
||||||
nm = f"{nm}({c})"
|
|
||||||
if ext:
|
|
||||||
nm += f"{ext}"
|
|
||||||
|
|
||||||
kwargs["name"] = nm
|
Args:
|
||||||
return duplicate_name(query_func, **kwargs)
|
filename: Input filename string to be parsed
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
A tuple containing:
|
||||||
|
- The main filename part (string)
|
||||||
|
- The counter from parentheses (integer) or None if no counter exists
|
||||||
|
"""
|
||||||
|
pattern = re.compile(r"^(.*?)\((\d+)\)$")
|
||||||
|
|
||||||
|
match = pattern.search(filename)
|
||||||
|
if match:
|
||||||
|
main_part = match.group(1).rstrip()
|
||||||
|
bracket_part = match.group(2)
|
||||||
|
return main_part, int(bracket_part)
|
||||||
|
|
||||||
|
return filename, None
|
||||||
|
|
||||||
|
|
||||||
|
def duplicate_name(query_func, **kwargs) -> str:
|
||||||
|
"""
|
||||||
|
Generates a unique filename by appending/incrementing a counter when duplicates exist.
|
||||||
|
|
||||||
|
Continuously checks for name availability using the provided query function,
|
||||||
|
automatically appending (1), (2), etc. until finding an available name or
|
||||||
|
reaching maximum retries.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
query_func: Callable that accepts keyword arguments and returns:
|
||||||
|
- True if name exists (should be modified)
|
||||||
|
- False if name is available
|
||||||
|
**kwargs: Must contain 'name' key with original filename to check
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
str: Available filename, either:
|
||||||
|
- Original name (if available)
|
||||||
|
- Modified name with counter (e.g., "file(1).txt")
|
||||||
|
|
||||||
|
Raises:
|
||||||
|
KeyError: If 'name' key not provided in kwargs
|
||||||
|
RuntimeError: If unable to generate unique name after maximum retries
|
||||||
|
|
||||||
|
Example:
|
||||||
|
>>> def name_exists(name): return name in existing_files
|
||||||
|
>>> duplicate_name(name_exists, name="document.pdf")
|
||||||
|
'document(1).pdf' # If original exists
|
||||||
|
"""
|
||||||
|
MAX_RETRIES = 1000
|
||||||
|
|
||||||
|
if "name" not in kwargs:
|
||||||
|
raise KeyError("Arguments must contain 'name' key")
|
||||||
|
|
||||||
|
original_name = kwargs["name"]
|
||||||
|
current_name = original_name
|
||||||
|
retries = 0
|
||||||
|
|
||||||
|
while retries < MAX_RETRIES:
|
||||||
|
if not query_func(**kwargs):
|
||||||
|
return current_name
|
||||||
|
|
||||||
|
path = PurePath(current_name)
|
||||||
|
stem = path.stem
|
||||||
|
suffix = path.suffix
|
||||||
|
|
||||||
|
main_part, counter = split_name_counter(stem)
|
||||||
|
counter = counter + 1 if counter else 1
|
||||||
|
|
||||||
|
new_name = f"{main_part}({counter}){suffix}"
|
||||||
|
|
||||||
|
kwargs["name"] = new_name
|
||||||
|
current_name = new_name
|
||||||
|
retries += 1
|
||||||
|
|
||||||
|
raise RuntimeError(f"Failed to generate unique name within {MAX_RETRIES} attempts. Original: {original_name}")
|
||||||
|
|||||||
@ -73,11 +73,11 @@ class UserCanvasService(CommonService):
|
|||||||
User.nickname,
|
User.nickname,
|
||||||
User.avatar.alias('tenant_avatar'),
|
User.avatar.alias('tenant_avatar'),
|
||||||
]
|
]
|
||||||
angents = cls.model.select(*fields) \
|
agents = cls.model.select(*fields) \
|
||||||
.join(User, on=(cls.model.user_id == User.id)) \
|
.join(User, on=(cls.model.user_id == User.id)) \
|
||||||
.where(cls.model.id == pid)
|
.where(cls.model.id == pid)
|
||||||
# obj = cls.model.query(id=pid)[0]
|
# obj = cls.model.query(id=pid)[0]
|
||||||
return True, angents.dicts()[0]
|
return True, agents.dicts()[0]
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
print(e)
|
print(e)
|
||||||
return False, None
|
return False, None
|
||||||
@ -100,25 +100,25 @@ class UserCanvasService(CommonService):
|
|||||||
cls.model.update_time
|
cls.model.update_time
|
||||||
]
|
]
|
||||||
if keywords:
|
if keywords:
|
||||||
angents = cls.model.select(*fields).join(User, on=(cls.model.user_id == User.id)).where(
|
agents = cls.model.select(*fields).join(User, on=(cls.model.user_id == User.id)).where(
|
||||||
((cls.model.user_id.in_(joined_tenant_ids) & (cls.model.permission ==
|
((cls.model.user_id.in_(joined_tenant_ids) & (cls.model.permission ==
|
||||||
TenantPermission.TEAM.value)) | (
|
TenantPermission.TEAM.value)) | (
|
||||||
cls.model.user_id == user_id)),
|
cls.model.user_id == user_id)),
|
||||||
(fn.LOWER(cls.model.title).contains(keywords.lower()))
|
(fn.LOWER(cls.model.title).contains(keywords.lower()))
|
||||||
)
|
)
|
||||||
else:
|
else:
|
||||||
angents = cls.model.select(*fields).join(User, on=(cls.model.user_id == User.id)).where(
|
agents = cls.model.select(*fields).join(User, on=(cls.model.user_id == User.id)).where(
|
||||||
((cls.model.user_id.in_(joined_tenant_ids) & (cls.model.permission ==
|
((cls.model.user_id.in_(joined_tenant_ids) & (cls.model.permission ==
|
||||||
TenantPermission.TEAM.value)) | (
|
TenantPermission.TEAM.value)) | (
|
||||||
cls.model.user_id == user_id))
|
cls.model.user_id == user_id))
|
||||||
)
|
)
|
||||||
if desc:
|
if desc:
|
||||||
angents = angents.order_by(cls.model.getter_by(orderby).desc())
|
agents = agents.order_by(cls.model.getter_by(orderby).desc())
|
||||||
else:
|
else:
|
||||||
angents = angents.order_by(cls.model.getter_by(orderby).asc())
|
agents = agents.order_by(cls.model.getter_by(orderby).asc())
|
||||||
count = angents.count()
|
count = agents.count()
|
||||||
angents = angents.paginate(page_number, items_per_page)
|
agents = agents.paginate(page_number, items_per_page)
|
||||||
return list(angents.dicts()), count
|
return list(agents.dicts()), count
|
||||||
|
|
||||||
|
|
||||||
def completion(tenant_id, agent_id, question, session_id=None, stream=True, **kwargs):
|
def completion(tenant_id, agent_id, question, session_id=None, stream=True, **kwargs):
|
||||||
@ -173,6 +173,19 @@ def completion(tenant_id, agent_id, question, session_id=None, stream=True, **kw
|
|||||||
conv.reference = []
|
conv.reference = []
|
||||||
conv.reference.append({"chunks": [], "doc_aggs": []})
|
conv.reference.append({"chunks": [], "doc_aggs": []})
|
||||||
|
|
||||||
|
kwargs_changed = False
|
||||||
|
if kwargs:
|
||||||
|
query = canvas.get_preset_param()
|
||||||
|
if query:
|
||||||
|
for ele in query:
|
||||||
|
if ele["key"] in kwargs:
|
||||||
|
if ele["value"] != kwargs[ele["key"]]:
|
||||||
|
ele["value"] = kwargs[ele["key"]]
|
||||||
|
kwargs_changed = True
|
||||||
|
if kwargs_changed:
|
||||||
|
conv.dsl = json.loads(str(canvas))
|
||||||
|
API4ConversationService.update_by_id(session_id, {"dsl": conv.dsl})
|
||||||
|
|
||||||
final_ans = {"reference": [], "content": ""}
|
final_ans = {"reference": [], "content": ""}
|
||||||
if stream:
|
if stream:
|
||||||
try:
|
try:
|
||||||
@ -281,8 +294,22 @@ def completionOpenAI(tenant_id, agent_id, question, session_id=None, stream=True
|
|||||||
"source": "agent",
|
"source": "agent",
|
||||||
"dsl": cvs.dsl
|
"dsl": cvs.dsl
|
||||||
}
|
}
|
||||||
|
canvas.messages.append({"role": "user", "content": question, "id": message_id})
|
||||||
|
canvas.add_user_input(question)
|
||||||
|
|
||||||
API4ConversationService.save(**conv)
|
API4ConversationService.save(**conv)
|
||||||
conv = API4Conversation(**conv)
|
conv = API4Conversation(**conv)
|
||||||
|
if not conv.message:
|
||||||
|
conv.message = []
|
||||||
|
conv.message.append({
|
||||||
|
"role": "user",
|
||||||
|
"content": question,
|
||||||
|
"id": message_id
|
||||||
|
})
|
||||||
|
|
||||||
|
if not conv.reference:
|
||||||
|
conv.reference = []
|
||||||
|
conv.reference.append({"chunks": [], "doc_aggs": []})
|
||||||
|
|
||||||
# Handle existing session
|
# Handle existing session
|
||||||
else:
|
else:
|
||||||
@ -318,7 +345,7 @@ def completionOpenAI(tenant_id, agent_id, question, session_id=None, stream=True
|
|||||||
if stream:
|
if stream:
|
||||||
try:
|
try:
|
||||||
completion_tokens = 0
|
completion_tokens = 0
|
||||||
for ans in canvas.run(stream=True):
|
for ans in canvas.run(stream=True, bypass_begin=True):
|
||||||
if ans.get("running_status"):
|
if ans.get("running_status"):
|
||||||
completion_tokens += len(tiktokenenc.encode(ans.get("content", "")))
|
completion_tokens += len(tiktokenenc.encode(ans.get("content", "")))
|
||||||
yield "data: " + json.dumps(
|
yield "data: " + json.dumps(
|
||||||
@ -381,7 +408,7 @@ def completionOpenAI(tenant_id, agent_id, question, session_id=None, stream=True
|
|||||||
else: # Non-streaming mode
|
else: # Non-streaming mode
|
||||||
try:
|
try:
|
||||||
all_answer_content = ""
|
all_answer_content = ""
|
||||||
for answer in canvas.run(stream=False):
|
for answer in canvas.run(stream=False, bypass_begin=True):
|
||||||
if answer.get("running_status"):
|
if answer.get("running_status"):
|
||||||
continue
|
continue
|
||||||
|
|
||||||
|
|||||||
@ -254,7 +254,7 @@ class CommonService:
|
|||||||
# Returns:
|
# Returns:
|
||||||
# Number of records deleted
|
# Number of records deleted
|
||||||
return cls.model.delete().where(cls.model.id == pid).execute()
|
return cls.model.delete().where(cls.model.id == pid).execute()
|
||||||
|
|
||||||
@classmethod
|
@classmethod
|
||||||
@DB.connection_context()
|
@DB.connection_context()
|
||||||
def delete_by_ids(cls, pids):
|
def delete_by_ids(cls, pids):
|
||||||
|
|||||||
@ -90,17 +90,18 @@ def completion(tenant_id, chat_id, question, name="New session", session_id=None
|
|||||||
"user_id": kwargs.get("user_id", "")
|
"user_id": kwargs.get("user_id", "")
|
||||||
}
|
}
|
||||||
ConversationService.save(**conv)
|
ConversationService.save(**conv)
|
||||||
yield "data:" + json.dumps({"code": 0, "message": "",
|
if stream:
|
||||||
"data": {
|
yield "data:" + json.dumps({"code": 0, "message": "",
|
||||||
"answer": conv["message"][0]["content"],
|
"data": {
|
||||||
"reference": {},
|
"answer": conv["message"][0]["content"],
|
||||||
"audio_binary": None,
|
"reference": {},
|
||||||
"id": None,
|
"audio_binary": None,
|
||||||
"session_id": session_id
|
"id": None,
|
||||||
}},
|
"session_id": session_id
|
||||||
ensure_ascii=False) + "\n\n"
|
}},
|
||||||
yield "data:" + json.dumps({"code": 0, "message": "", "data": True}, ensure_ascii=False) + "\n\n"
|
ensure_ascii=False) + "\n\n"
|
||||||
return
|
yield "data:" + json.dumps({"code": 0, "message": "", "data": True}, ensure_ascii=False) + "\n\n"
|
||||||
|
return
|
||||||
|
|
||||||
conv = ConversationService.query(id=session_id, dialog_id=chat_id)
|
conv = ConversationService.query(id=session_id, dialog_id=chat_id)
|
||||||
if not conv:
|
if not conv:
|
||||||
@ -123,6 +124,8 @@ def completion(tenant_id, chat_id, question, name="New session", session_id=None
|
|||||||
message_id = msg[-1].get("id")
|
message_id = msg[-1].get("id")
|
||||||
e, dia = DialogService.get_by_id(conv.dialog_id)
|
e, dia = DialogService.get_by_id(conv.dialog_id)
|
||||||
|
|
||||||
|
kb_ids = kwargs.get("kb_ids",[])
|
||||||
|
dia.kb_ids = list(set(dia.kb_ids + kb_ids))
|
||||||
if not conv.reference:
|
if not conv.reference:
|
||||||
conv.reference = []
|
conv.reference = []
|
||||||
conv.message.append({"role": "assistant", "content": "", "id": message_id})
|
conv.message.append({"role": "assistant", "content": "", "id": message_id})
|
||||||
|
|||||||
@ -127,9 +127,71 @@ def chat_solo(dialog, messages, stream=True):
|
|||||||
yield {"answer": answer, "reference": {}, "audio_binary": tts(tts_mdl, answer), "prompt": "", "created_at": time.time()}
|
yield {"answer": answer, "reference": {}, "audio_binary": tts(tts_mdl, answer), "prompt": "", "created_at": time.time()}
|
||||||
|
|
||||||
|
|
||||||
|
def get_models(dialog):
|
||||||
|
embd_mdl, chat_mdl, rerank_mdl, tts_mdl = None, None, None, None
|
||||||
|
kbs = KnowledgebaseService.get_by_ids(dialog.kb_ids)
|
||||||
|
embedding_list = list(set([kb.embd_id for kb in kbs]))
|
||||||
|
if len(embedding_list) > 1:
|
||||||
|
raise Exception("**ERROR**: Knowledge bases use different embedding models.")
|
||||||
|
|
||||||
|
if embedding_list:
|
||||||
|
embd_mdl = LLMBundle(dialog.tenant_id, LLMType.EMBEDDING, embedding_list[0])
|
||||||
|
if not embd_mdl:
|
||||||
|
raise LookupError("Embedding model(%s) not found" % embedding_list[0])
|
||||||
|
|
||||||
|
if llm_id2llm_type(dialog.llm_id) == "image2text":
|
||||||
|
chat_mdl = LLMBundle(dialog.tenant_id, LLMType.IMAGE2TEXT, dialog.llm_id)
|
||||||
|
else:
|
||||||
|
chat_mdl = LLMBundle(dialog.tenant_id, LLMType.CHAT, dialog.llm_id)
|
||||||
|
|
||||||
|
if dialog.rerank_id:
|
||||||
|
rerank_mdl = LLMBundle(dialog.tenant_id, LLMType.RERANK, dialog.rerank_id)
|
||||||
|
|
||||||
|
if dialog.prompt_config.get("tts"):
|
||||||
|
tts_mdl = LLMBundle(dialog.tenant_id, LLMType.TTS)
|
||||||
|
return kbs, embd_mdl, rerank_mdl, chat_mdl, tts_mdl
|
||||||
|
|
||||||
|
|
||||||
|
BAD_CITATION_PATTERNS = [
|
||||||
|
re.compile(r"\(\s*ID\s*[: ]*\s*(\d+)\s*\)"), # (ID: 12)
|
||||||
|
re.compile(r"\[\s*ID\s*[: ]*\s*(\d+)\s*\]"), # [ID: 12]
|
||||||
|
re.compile(r"【\s*ID\s*[: ]*\s*(\d+)\s*】"), # 【ID: 12】
|
||||||
|
re.compile(r"ref\s*(\d+)", flags=re.IGNORECASE), # ref12、REF 12
|
||||||
|
]
|
||||||
|
|
||||||
|
|
||||||
|
def repair_bad_citation_formats(answer: str, kbinfos: dict, idx: set):
|
||||||
|
max_index = len(kbinfos["chunks"])
|
||||||
|
|
||||||
|
def safe_add(i):
|
||||||
|
if 0 <= i < max_index:
|
||||||
|
idx.add(i)
|
||||||
|
return True
|
||||||
|
return False
|
||||||
|
|
||||||
|
def find_and_replace(pattern, group_index=1, repl=lambda i: f"ID:{i}", flags=0):
|
||||||
|
nonlocal answer
|
||||||
|
|
||||||
|
def replacement(match):
|
||||||
|
try:
|
||||||
|
i = int(match.group(group_index))
|
||||||
|
if safe_add(i):
|
||||||
|
return f"[{repl(i)}]"
|
||||||
|
except Exception:
|
||||||
|
pass
|
||||||
|
return match.group(0)
|
||||||
|
|
||||||
|
answer = re.sub(pattern, replacement, answer, flags=flags)
|
||||||
|
|
||||||
|
for pattern in BAD_CITATION_PATTERNS:
|
||||||
|
find_and_replace(pattern)
|
||||||
|
|
||||||
|
return answer, idx
|
||||||
|
|
||||||
|
|
||||||
def chat(dialog, messages, stream=True, **kwargs):
|
def chat(dialog, messages, stream=True, **kwargs):
|
||||||
assert messages[-1]["role"] == "user", "The last content of this conversation is not from user."
|
assert messages[-1]["role"] == "user", "The last content of this conversation is not from user."
|
||||||
if not dialog.kb_ids:
|
if not dialog.kb_ids and not dialog.prompt_config.get("tavily_api_key"):
|
||||||
for ans in chat_solo(dialog, messages, stream):
|
for ans in chat_solo(dialog, messages, stream):
|
||||||
yield ans
|
yield ans
|
||||||
return
|
return
|
||||||
@ -154,45 +216,19 @@ def chat(dialog, messages, stream=True, **kwargs):
|
|||||||
langfuse.trace = langfuse_tracer.trace(name=f"{dialog.name}-{llm_model_config['llm_name']}")
|
langfuse.trace = langfuse_tracer.trace(name=f"{dialog.name}-{llm_model_config['llm_name']}")
|
||||||
|
|
||||||
check_langfuse_tracer_ts = timer()
|
check_langfuse_tracer_ts = timer()
|
||||||
|
kbs, embd_mdl, rerank_mdl, chat_mdl, tts_mdl = get_models(dialog)
|
||||||
kbs = KnowledgebaseService.get_by_ids(dialog.kb_ids)
|
toolcall_session, tools = kwargs.get("toolcall_session"), kwargs.get("tools")
|
||||||
embedding_list = list(set([kb.embd_id for kb in kbs]))
|
if toolcall_session and tools:
|
||||||
if len(embedding_list) != 1:
|
chat_mdl.bind_tools(toolcall_session, tools)
|
||||||
yield {"answer": "**ERROR**: Knowledge bases use different embedding models.", "reference": []}
|
bind_models_ts = timer()
|
||||||
return {"answer": "**ERROR**: Knowledge bases use different embedding models.", "reference": []}
|
|
||||||
|
|
||||||
embedding_model_name = embedding_list[0]
|
|
||||||
|
|
||||||
retriever = settings.retrievaler
|
retriever = settings.retrievaler
|
||||||
|
|
||||||
questions = [m["content"] for m in messages if m["role"] == "user"][-3:]
|
questions = [m["content"] for m in messages if m["role"] == "user"][-3:]
|
||||||
attachments = kwargs["doc_ids"].split(",") if "doc_ids" in kwargs else None
|
attachments = kwargs["doc_ids"].split(",") if "doc_ids" in kwargs else None
|
||||||
if "doc_ids" in messages[-1]:
|
if "doc_ids" in messages[-1]:
|
||||||
attachments = messages[-1]["doc_ids"]
|
attachments = messages[-1]["doc_ids"]
|
||||||
|
|
||||||
create_retriever_ts = timer()
|
|
||||||
|
|
||||||
embd_mdl = LLMBundle(dialog.tenant_id, LLMType.EMBEDDING, embedding_model_name)
|
|
||||||
if not embd_mdl:
|
|
||||||
raise LookupError("Embedding model(%s) not found" % embedding_model_name)
|
|
||||||
|
|
||||||
bind_embedding_ts = timer()
|
|
||||||
|
|
||||||
if llm_id2llm_type(dialog.llm_id) == "image2text":
|
|
||||||
chat_mdl = LLMBundle(dialog.tenant_id, LLMType.IMAGE2TEXT, dialog.llm_id)
|
|
||||||
else:
|
|
||||||
chat_mdl = LLMBundle(dialog.tenant_id, LLMType.CHAT, dialog.llm_id)
|
|
||||||
toolcall_session, tools = kwargs.get("toolcall_session"), kwargs.get("tools")
|
|
||||||
if toolcall_session and tools:
|
|
||||||
chat_mdl.bind_tools(toolcall_session, tools)
|
|
||||||
|
|
||||||
bind_llm_ts = timer()
|
|
||||||
|
|
||||||
prompt_config = dialog.prompt_config
|
prompt_config = dialog.prompt_config
|
||||||
field_map = KnowledgebaseService.get_field_map(dialog.kb_ids)
|
field_map = KnowledgebaseService.get_field_map(dialog.kb_ids)
|
||||||
tts_mdl = None
|
|
||||||
if prompt_config.get("tts"):
|
|
||||||
tts_mdl = LLMBundle(dialog.tenant_id, LLMType.TTS)
|
|
||||||
# try to use sql if field mapping is good to go
|
# try to use sql if field mapping is good to go
|
||||||
if field_map:
|
if field_map:
|
||||||
logging.debug("Use SQL to retrieval:{}".format(questions[-1]))
|
logging.debug("Use SQL to retrieval:{}".format(questions[-1]))
|
||||||
@ -217,26 +253,18 @@ def chat(dialog, messages, stream=True, **kwargs):
|
|||||||
if prompt_config.get("cross_languages"):
|
if prompt_config.get("cross_languages"):
|
||||||
questions = [cross_languages(dialog.tenant_id, dialog.llm_id, questions[0], prompt_config["cross_languages"])]
|
questions = [cross_languages(dialog.tenant_id, dialog.llm_id, questions[0], prompt_config["cross_languages"])]
|
||||||
|
|
||||||
|
if prompt_config.get("keyword", False):
|
||||||
|
questions[-1] += keyword_extraction(chat_mdl, questions[-1])
|
||||||
|
|
||||||
refine_question_ts = timer()
|
refine_question_ts = timer()
|
||||||
|
|
||||||
rerank_mdl = None
|
|
||||||
if dialog.rerank_id:
|
|
||||||
rerank_mdl = LLMBundle(dialog.tenant_id, LLMType.RERANK, dialog.rerank_id)
|
|
||||||
|
|
||||||
bind_reranker_ts = timer()
|
|
||||||
generate_keyword_ts = bind_reranker_ts
|
|
||||||
thought = ""
|
thought = ""
|
||||||
kbinfos = {"total": 0, "chunks": [], "doc_aggs": []}
|
kbinfos = {"total": 0, "chunks": [], "doc_aggs": []}
|
||||||
|
|
||||||
if "knowledge" not in [p["key"] for p in prompt_config["parameters"]]:
|
if "knowledge" not in [p["key"] for p in prompt_config["parameters"]]:
|
||||||
knowledges = []
|
knowledges = []
|
||||||
else:
|
else:
|
||||||
if prompt_config.get("keyword", False):
|
|
||||||
questions[-1] += keyword_extraction(chat_mdl, questions[-1])
|
|
||||||
generate_keyword_ts = timer()
|
|
||||||
|
|
||||||
tenant_ids = list(set([kb.tenant_id for kb in kbs]))
|
tenant_ids = list(set([kb.tenant_id for kb in kbs]))
|
||||||
|
|
||||||
knowledges = []
|
knowledges = []
|
||||||
if prompt_config.get("reasoning", False):
|
if prompt_config.get("reasoning", False):
|
||||||
reasoner = DeepResearcher(
|
reasoner = DeepResearcher(
|
||||||
@ -252,21 +280,22 @@ def chat(dialog, messages, stream=True, **kwargs):
|
|||||||
elif stream:
|
elif stream:
|
||||||
yield think
|
yield think
|
||||||
else:
|
else:
|
||||||
kbinfos = retriever.retrieval(
|
if embd_mdl:
|
||||||
" ".join(questions),
|
kbinfos = retriever.retrieval(
|
||||||
embd_mdl,
|
" ".join(questions),
|
||||||
tenant_ids,
|
embd_mdl,
|
||||||
dialog.kb_ids,
|
tenant_ids,
|
||||||
1,
|
dialog.kb_ids,
|
||||||
dialog.top_n,
|
1,
|
||||||
dialog.similarity_threshold,
|
dialog.top_n,
|
||||||
dialog.vector_similarity_weight,
|
dialog.similarity_threshold,
|
||||||
doc_ids=attachments,
|
dialog.vector_similarity_weight,
|
||||||
top=dialog.top_k,
|
doc_ids=attachments,
|
||||||
aggs=False,
|
top=dialog.top_k,
|
||||||
rerank_mdl=rerank_mdl,
|
aggs=False,
|
||||||
rank_feature=label_question(" ".join(questions), kbs),
|
rerank_mdl=rerank_mdl,
|
||||||
)
|
rank_feature=label_question(" ".join(questions), kbs),
|
||||||
|
)
|
||||||
if prompt_config.get("tavily_api_key"):
|
if prompt_config.get("tavily_api_key"):
|
||||||
tav = Tavily(prompt_config["tavily_api_key"])
|
tav = Tavily(prompt_config["tavily_api_key"])
|
||||||
tav_res = tav.retrieve_chunks(" ".join(questions))
|
tav_res = tav.retrieve_chunks(" ".join(questions))
|
||||||
@ -302,41 +331,8 @@ def chat(dialog, messages, stream=True, **kwargs):
|
|||||||
if "max_tokens" in gen_conf:
|
if "max_tokens" in gen_conf:
|
||||||
gen_conf["max_tokens"] = min(gen_conf["max_tokens"], max_tokens - used_token_count)
|
gen_conf["max_tokens"] = min(gen_conf["max_tokens"], max_tokens - used_token_count)
|
||||||
|
|
||||||
def repair_bad_citation_formats(answer: str, kbinfos: dict, idx: dict):
|
|
||||||
max_index = len(kbinfos["chunks"])
|
|
||||||
|
|
||||||
def safe_add(i):
|
|
||||||
if 0 <= i < max_index:
|
|
||||||
idx.add(i)
|
|
||||||
return True
|
|
||||||
return False
|
|
||||||
|
|
||||||
def find_and_replace(pattern, group_index=1, repl=lambda i: f"##{i}$$", flags=0):
|
|
||||||
nonlocal answer
|
|
||||||
for match in re.finditer(pattern, answer, flags=flags):
|
|
||||||
try:
|
|
||||||
i = int(match.group(group_index))
|
|
||||||
if safe_add(i):
|
|
||||||
answer = answer.replace(match.group(0), repl(i))
|
|
||||||
except Exception:
|
|
||||||
continue
|
|
||||||
|
|
||||||
find_and_replace(r"\(\s*ID:\s*(\d+)\s*\)") # (ID: 12)
|
|
||||||
find_and_replace(r"ID[: ]+(\d+)") # ID: 12, ID 12
|
|
||||||
find_and_replace(r"\$\$(\d+)\$\$") # $$12$$
|
|
||||||
find_and_replace(r"\$\[(\d+)\]\$") # $[12]$
|
|
||||||
find_and_replace(r"\$\$(\d+)\${2,}") # $$12$$$$
|
|
||||||
find_and_replace(r"\$(\d+)\$") # $12$
|
|
||||||
find_and_replace(r"#(\d+)\$\$") # #12$$
|
|
||||||
find_and_replace(r"##(\d+)\$") # ##12$
|
|
||||||
find_and_replace(r"##(\d+)#{2,}") # ##12###
|
|
||||||
find_and_replace(r"【(\d+)】") # 【12】
|
|
||||||
find_and_replace(r"ref\s*(\d+)", flags=re.IGNORECASE) # ref12, ref 12, REF 12
|
|
||||||
|
|
||||||
return answer, idx
|
|
||||||
|
|
||||||
def decorate_answer(answer):
|
def decorate_answer(answer):
|
||||||
nonlocal prompt_config, knowledges, kwargs, kbinfos, prompt, retrieval_ts, questions, langfuse_tracer
|
nonlocal embd_mdl, prompt_config, knowledges, kwargs, kbinfos, prompt, retrieval_ts, questions, langfuse_tracer
|
||||||
|
|
||||||
refs = []
|
refs = []
|
||||||
ans = answer.split("</think>")
|
ans = answer.split("</think>")
|
||||||
@ -346,9 +342,8 @@ def chat(dialog, messages, stream=True, **kwargs):
|
|||||||
answer = ans[1]
|
answer = ans[1]
|
||||||
|
|
||||||
if knowledges and (prompt_config.get("quote", True) and kwargs.get("quote", True)):
|
if knowledges and (prompt_config.get("quote", True) and kwargs.get("quote", True)):
|
||||||
answer = re.sub(r"##[ij]\$\$", "", answer, flags=re.DOTALL)
|
|
||||||
idx = set([])
|
idx = set([])
|
||||||
if not re.search(r"##[0-9]+\$\$", answer):
|
if embd_mdl and not re.search(r"\[ID:([0-9]+)\]", answer):
|
||||||
answer, idx = retriever.insert_citations(
|
answer, idx = retriever.insert_citations(
|
||||||
answer,
|
answer,
|
||||||
[ck["content_ltks"] for ck in kbinfos["chunks"]],
|
[ck["content_ltks"] for ck in kbinfos["chunks"]],
|
||||||
@ -358,7 +353,7 @@ def chat(dialog, messages, stream=True, **kwargs):
|
|||||||
vtweight=dialog.vector_similarity_weight,
|
vtweight=dialog.vector_similarity_weight,
|
||||||
)
|
)
|
||||||
else:
|
else:
|
||||||
for match in re.finditer(r"##([0-9]+)\$\$", answer):
|
for match in re.finditer(r"\[ID:([0-9]+)\]", answer):
|
||||||
i = int(match.group(1))
|
i = int(match.group(1))
|
||||||
if i < len(kbinfos["chunks"]):
|
if i < len(kbinfos["chunks"]):
|
||||||
idx.add(i)
|
idx.add(i)
|
||||||
@ -383,13 +378,9 @@ def chat(dialog, messages, stream=True, **kwargs):
|
|||||||
total_time_cost = (finish_chat_ts - chat_start_ts) * 1000
|
total_time_cost = (finish_chat_ts - chat_start_ts) * 1000
|
||||||
check_llm_time_cost = (check_llm_ts - chat_start_ts) * 1000
|
check_llm_time_cost = (check_llm_ts - chat_start_ts) * 1000
|
||||||
check_langfuse_tracer_cost = (check_langfuse_tracer_ts - check_llm_ts) * 1000
|
check_langfuse_tracer_cost = (check_langfuse_tracer_ts - check_llm_ts) * 1000
|
||||||
create_retriever_time_cost = (create_retriever_ts - check_langfuse_tracer_ts) * 1000
|
bind_embedding_time_cost = (bind_models_ts - check_langfuse_tracer_ts) * 1000
|
||||||
bind_embedding_time_cost = (bind_embedding_ts - create_retriever_ts) * 1000
|
refine_question_time_cost = (refine_question_ts - bind_models_ts) * 1000
|
||||||
bind_llm_time_cost = (bind_llm_ts - bind_embedding_ts) * 1000
|
retrieval_time_cost = (retrieval_ts - refine_question_ts) * 1000
|
||||||
refine_question_time_cost = (refine_question_ts - bind_llm_ts) * 1000
|
|
||||||
bind_reranker_time_cost = (bind_reranker_ts - refine_question_ts) * 1000
|
|
||||||
generate_keyword_time_cost = (generate_keyword_ts - bind_reranker_ts) * 1000
|
|
||||||
retrieval_time_cost = (retrieval_ts - generate_keyword_ts) * 1000
|
|
||||||
generate_result_time_cost = (finish_chat_ts - retrieval_ts) * 1000
|
generate_result_time_cost = (finish_chat_ts - retrieval_ts) * 1000
|
||||||
|
|
||||||
tk_num = num_tokens_from_string(think + answer)
|
tk_num = num_tokens_from_string(think + answer)
|
||||||
@ -400,12 +391,8 @@ def chat(dialog, messages, stream=True, **kwargs):
|
|||||||
f" - Total: {total_time_cost:.1f}ms\n"
|
f" - Total: {total_time_cost:.1f}ms\n"
|
||||||
f" - Check LLM: {check_llm_time_cost:.1f}ms\n"
|
f" - Check LLM: {check_llm_time_cost:.1f}ms\n"
|
||||||
f" - Check Langfuse tracer: {check_langfuse_tracer_cost:.1f}ms\n"
|
f" - Check Langfuse tracer: {check_langfuse_tracer_cost:.1f}ms\n"
|
||||||
f" - Create retriever: {create_retriever_time_cost:.1f}ms\n"
|
f" - Bind models: {bind_embedding_time_cost:.1f}ms\n"
|
||||||
f" - Bind embedding: {bind_embedding_time_cost:.1f}ms\n"
|
f" - Query refinement(LLM): {refine_question_time_cost:.1f}ms\n"
|
||||||
f" - Bind LLM: {bind_llm_time_cost:.1f}ms\n"
|
|
||||||
f" - Multi-turn optimization: {refine_question_time_cost:.1f}ms\n"
|
|
||||||
f" - Bind reranker: {bind_reranker_time_cost:.1f}ms\n"
|
|
||||||
f" - Generate keyword: {generate_keyword_time_cost:.1f}ms\n"
|
|
||||||
f" - Retrieval: {retrieval_time_cost:.1f}ms\n"
|
f" - Retrieval: {retrieval_time_cost:.1f}ms\n"
|
||||||
f" - Generate answer: {generate_result_time_cost:.1f}ms\n\n"
|
f" - Generate answer: {generate_result_time_cost:.1f}ms\n\n"
|
||||||
"## Token usage:\n"
|
"## Token usage:\n"
|
||||||
@ -569,7 +556,7 @@ def tts(tts_mdl, text):
|
|||||||
return binascii.hexlify(bin).decode("utf-8")
|
return binascii.hexlify(bin).decode("utf-8")
|
||||||
|
|
||||||
|
|
||||||
def ask(question, kb_ids, tenant_id):
|
def ask(question, kb_ids, tenant_id, chat_llm_name=None):
|
||||||
kbs = KnowledgebaseService.get_by_ids(kb_ids)
|
kbs = KnowledgebaseService.get_by_ids(kb_ids)
|
||||||
embedding_list = list(set([kb.embd_id for kb in kbs]))
|
embedding_list = list(set([kb.embd_id for kb in kbs]))
|
||||||
|
|
||||||
@ -577,7 +564,7 @@ def ask(question, kb_ids, tenant_id):
|
|||||||
retriever = settings.retrievaler if not is_knowledge_graph else settings.kg_retrievaler
|
retriever = settings.retrievaler if not is_knowledge_graph else settings.kg_retrievaler
|
||||||
|
|
||||||
embd_mdl = LLMBundle(tenant_id, LLMType.EMBEDDING, embedding_list[0])
|
embd_mdl = LLMBundle(tenant_id, LLMType.EMBEDDING, embedding_list[0])
|
||||||
chat_mdl = LLMBundle(tenant_id, LLMType.CHAT)
|
chat_mdl = LLMBundle(tenant_id, LLMType.CHAT, chat_llm_name)
|
||||||
max_tokens = chat_mdl.max_length
|
max_tokens = chat_mdl.max_length
|
||||||
tenant_ids = list(set([kb.tenant_id for kb in kbs]))
|
tenant_ids = list(set([kb.tenant_id for kb in kbs]))
|
||||||
kbinfos = retriever.retrieval(question, embd_mdl, tenant_ids, kb_ids, 1, 12, 0.1, 0.3, aggs=False, rank_feature=label_question(question, kbs))
|
kbinfos = retriever.retrieval(question, embd_mdl, tenant_ids, kb_ids, 1, 12, 0.1, 0.3, aggs=False, rank_feature=label_question(question, kbs))
|
||||||
@ -623,4 +610,3 @@ def ask(question, kb_ids, tenant_id):
|
|||||||
answer = ans
|
answer = ans
|
||||||
yield {"answer": answer, "reference": {}}
|
yield {"answer": answer, "reference": {}}
|
||||||
yield decorate_answer(answer)
|
yield decorate_answer(answer)
|
||||||
|
|
||||||
|
|||||||
@ -27,6 +27,7 @@ import xxhash
|
|||||||
from peewee import fn
|
from peewee import fn
|
||||||
|
|
||||||
from api import settings
|
from api import settings
|
||||||
|
from api.constants import IMG_BASE64_PREFIX
|
||||||
from api.db import FileType, LLMType, ParserType, StatusEnum, TaskStatus, UserTenantRole
|
from api.db import FileType, LLMType, ParserType, StatusEnum, TaskStatus, UserTenantRole
|
||||||
from api.db.db_models import DB, Document, Knowledgebase, Task, Tenant, UserTenant
|
from api.db.db_models import DB, Document, Knowledgebase, Task, Tenant, UserTenant
|
||||||
from api.db.db_utils import bulk_insert_into_db
|
from api.db.db_utils import bulk_insert_into_db
|
||||||
@ -34,7 +35,7 @@ from api.db.services.common_service import CommonService
|
|||||||
from api.db.services.knowledgebase_service import KnowledgebaseService
|
from api.db.services.knowledgebase_service import KnowledgebaseService
|
||||||
from api.utils import current_timestamp, get_format_time, get_uuid
|
from api.utils import current_timestamp, get_format_time, get_uuid
|
||||||
from rag.nlp import rag_tokenizer, search
|
from rag.nlp import rag_tokenizer, search
|
||||||
from rag.settings import get_svr_queue_name
|
from rag.settings import get_svr_queue_name, SVR_CONSUMER_GROUP_NAME
|
||||||
from rag.utils.redis_conn import REDIS_CONN
|
from rag.utils.redis_conn import REDIS_CONN
|
||||||
from rag.utils.storage_factory import STORAGE_IMPL
|
from rag.utils.storage_factory import STORAGE_IMPL
|
||||||
from rag.utils.doc_store_conn import OrderByExpr
|
from rag.utils.doc_store_conn import OrderByExpr
|
||||||
@ -147,7 +148,26 @@ class DocumentService(CommonService):
|
|||||||
def remove_document(cls, doc, tenant_id):
|
def remove_document(cls, doc, tenant_id):
|
||||||
cls.clear_chunk_num(doc.id)
|
cls.clear_chunk_num(doc.id)
|
||||||
try:
|
try:
|
||||||
|
page = 0
|
||||||
|
page_size = 1000
|
||||||
|
all_chunk_ids = []
|
||||||
|
while True:
|
||||||
|
chunks = settings.docStoreConn.search(["img_id"], [], {"doc_id": doc.id}, [], OrderByExpr(),
|
||||||
|
page * page_size, page_size, search.index_name(tenant_id),
|
||||||
|
[doc.kb_id])
|
||||||
|
chunk_ids = settings.docStoreConn.getChunkIds(chunks)
|
||||||
|
if not chunk_ids:
|
||||||
|
break
|
||||||
|
all_chunk_ids.extend(chunk_ids)
|
||||||
|
page += 1
|
||||||
|
for cid in all_chunk_ids:
|
||||||
|
if STORAGE_IMPL.obj_exist(doc.kb_id, cid):
|
||||||
|
STORAGE_IMPL.rm(doc.kb_id, cid)
|
||||||
|
if doc.thumbnail and not doc.thumbnail.startswith(IMG_BASE64_PREFIX):
|
||||||
|
if STORAGE_IMPL.obj_exist(doc.kb_id, doc.thumbnail):
|
||||||
|
STORAGE_IMPL.rm(doc.kb_id, doc.thumbnail)
|
||||||
settings.docStoreConn.delete({"doc_id": doc.id}, search.index_name(tenant_id), doc.kb_id)
|
settings.docStoreConn.delete({"doc_id": doc.id}, search.index_name(tenant_id), doc.kb_id)
|
||||||
|
|
||||||
graph_source = settings.docStoreConn.getFields(
|
graph_source = settings.docStoreConn.getFields(
|
||||||
settings.docStoreConn.search(["source_id"], [], {"kb_id": doc.kb_id, "knowledge_graph_kwd": ["graph"]}, [], OrderByExpr(), 0, 1, search.index_name(tenant_id), [doc.kb_id]), ["source_id"]
|
settings.docStoreConn.search(["source_id"], [], {"kb_id": doc.kb_id, "knowledge_graph_kwd": ["graph"]}, [], OrderByExpr(), 0, 1, search.index_name(tenant_id), [doc.kb_id]), ["source_id"]
|
||||||
)
|
)
|
||||||
@ -464,7 +484,8 @@ class DocumentService(CommonService):
|
|||||||
if t.progress == -1:
|
if t.progress == -1:
|
||||||
bad += 1
|
bad += 1
|
||||||
prg += t.progress if t.progress >= 0 else 0
|
prg += t.progress if t.progress >= 0 else 0
|
||||||
msg.append(t.progress_msg)
|
if t.progress_msg.strip():
|
||||||
|
msg.append(t.progress_msg)
|
||||||
if t.task_type == "raptor":
|
if t.task_type == "raptor":
|
||||||
has_raptor = True
|
has_raptor = True
|
||||||
elif t.task_type == "graphrag":
|
elif t.task_type == "graphrag":
|
||||||
@ -494,6 +515,8 @@ class DocumentService(CommonService):
|
|||||||
info["progress"] = prg
|
info["progress"] = prg
|
||||||
if msg:
|
if msg:
|
||||||
info["progress_msg"] = msg
|
info["progress_msg"] = msg
|
||||||
|
else:
|
||||||
|
info["progress_msg"] = "%d tasks are ahead in the queue..."%get_queue_length(priority)
|
||||||
cls.update_by_id(d["id"], info)
|
cls.update_by_id(d["id"], info)
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
if str(e).find("'0'") < 0:
|
if str(e).find("'0'") < 0:
|
||||||
@ -542,6 +565,11 @@ def queue_raptor_o_graphrag_tasks(doc, ty, priority):
|
|||||||
assert REDIS_CONN.queue_product(get_svr_queue_name(priority), message=task), "Can't access Redis. Please check the Redis' status."
|
assert REDIS_CONN.queue_product(get_svr_queue_name(priority), message=task), "Can't access Redis. Please check the Redis' status."
|
||||||
|
|
||||||
|
|
||||||
|
def get_queue_length(priority):
|
||||||
|
group_info = REDIS_CONN.queue_info(get_svr_queue_name(priority), SVR_CONSUMER_GROUP_NAME)
|
||||||
|
return int(group_info.get("lag", 0))
|
||||||
|
|
||||||
|
|
||||||
def doc_upload_and_parse(conversation_id, file_objs, user_id):
|
def doc_upload_and_parse(conversation_id, file_objs, user_id):
|
||||||
from api.db.services.api_service import API4ConversationService
|
from api.db.services.api_service import API4ConversationService
|
||||||
from api.db.services.conversation_service import ConversationService
|
from api.db.services.conversation_service import ConversationService
|
||||||
|
|||||||
@ -21,6 +21,7 @@ from concurrent.futures import ThreadPoolExecutor
|
|||||||
from flask_login import current_user
|
from flask_login import current_user
|
||||||
from peewee import fn
|
from peewee import fn
|
||||||
|
|
||||||
|
from api.constants import FILE_NAME_LEN_LIMIT
|
||||||
from api.db import KNOWLEDGEBASE_FOLDER_NAME, FileSource, FileType, ParserType
|
from api.db import KNOWLEDGEBASE_FOLDER_NAME, FileSource, FileType, ParserType
|
||||||
from api.db.db_models import DB, Document, File, File2Document, Knowledgebase
|
from api.db.db_models import DB, Document, File, File2Document, Knowledgebase
|
||||||
from api.db.services import duplicate_name
|
from api.db.services import duplicate_name
|
||||||
@ -412,8 +413,8 @@ class FileService(CommonService):
|
|||||||
MAX_FILE_NUM_PER_USER = int(os.environ.get("MAX_FILE_NUM_PER_USER", 0))
|
MAX_FILE_NUM_PER_USER = int(os.environ.get("MAX_FILE_NUM_PER_USER", 0))
|
||||||
if MAX_FILE_NUM_PER_USER > 0 and DocumentService.get_doc_count(kb.tenant_id) >= MAX_FILE_NUM_PER_USER:
|
if MAX_FILE_NUM_PER_USER > 0 and DocumentService.get_doc_count(kb.tenant_id) >= MAX_FILE_NUM_PER_USER:
|
||||||
raise RuntimeError("Exceed the maximum file number of a free user!")
|
raise RuntimeError("Exceed the maximum file number of a free user!")
|
||||||
if len(file.filename.encode("utf-8")) >= 128:
|
if len(file.filename.encode("utf-8")) > FILE_NAME_LEN_LIMIT:
|
||||||
raise RuntimeError("Exceed the maximum length of file name!")
|
raise RuntimeError(f"File name must be {FILE_NAME_LEN_LIMIT} bytes or less.")
|
||||||
|
|
||||||
filename = duplicate_name(DocumentService.query, name=file.filename, kb_id=kb.id)
|
filename = duplicate_name(DocumentService.query, name=file.filename, kb_id=kb.id)
|
||||||
filetype = filename_type(filename)
|
filetype = filename_type(filename)
|
||||||
@ -492,4 +493,3 @@ class FileService(CommonService):
|
|||||||
if re.search(r"\.(eml)$", filename):
|
if re.search(r"\.(eml)$", filename):
|
||||||
return ParserType.EMAIL.value
|
return ParserType.EMAIL.value
|
||||||
return default
|
return default
|
||||||
|
|
||||||
|
|||||||
@ -169,7 +169,7 @@ class TenantLLMService(CommonService):
|
|||||||
return 0
|
return 0
|
||||||
|
|
||||||
llm_map = {
|
llm_map = {
|
||||||
LLMType.EMBEDDING.value: tenant.embd_id,
|
LLMType.EMBEDDING.value: tenant.embd_id if not llm_name else llm_name,
|
||||||
LLMType.SPEECH2TEXT.value: tenant.asr_id,
|
LLMType.SPEECH2TEXT.value: tenant.asr_id,
|
||||||
LLMType.IMAGE2TEXT.value: tenant.img2txt_id,
|
LLMType.IMAGE2TEXT.value: tenant.img2txt_id,
|
||||||
LLMType.CHAT.value: tenant.llm_id if not llm_name else llm_name,
|
LLMType.CHAT.value: tenant.llm_id if not llm_name else llm_name,
|
||||||
@ -235,7 +235,8 @@ class LLMBundle:
|
|||||||
generation = self.trace.generation(name="encode", model=self.llm_name, input={"texts": texts})
|
generation = self.trace.generation(name="encode", model=self.llm_name, input={"texts": texts})
|
||||||
|
|
||||||
embeddings, used_tokens = self.mdl.encode(texts)
|
embeddings, used_tokens = self.mdl.encode(texts)
|
||||||
if not TenantLLMService.increase_usage(self.tenant_id, self.llm_type, used_tokens):
|
llm_name = getattr(self, "llm_name", None)
|
||||||
|
if not TenantLLMService.increase_usage(self.tenant_id, self.llm_type, used_tokens, llm_name):
|
||||||
logging.error("LLMBundle.encode can't update token usage for {}/EMBEDDING used_tokens: {}".format(self.tenant_id, used_tokens))
|
logging.error("LLMBundle.encode can't update token usage for {}/EMBEDDING used_tokens: {}".format(self.tenant_id, used_tokens))
|
||||||
|
|
||||||
if self.langfuse:
|
if self.langfuse:
|
||||||
@ -248,7 +249,8 @@ class LLMBundle:
|
|||||||
generation = self.trace.generation(name="encode_queries", model=self.llm_name, input={"query": query})
|
generation = self.trace.generation(name="encode_queries", model=self.llm_name, input={"query": query})
|
||||||
|
|
||||||
emd, used_tokens = self.mdl.encode_queries(query)
|
emd, used_tokens = self.mdl.encode_queries(query)
|
||||||
if not TenantLLMService.increase_usage(self.tenant_id, self.llm_type, used_tokens):
|
llm_name = getattr(self, "llm_name", None)
|
||||||
|
if not TenantLLMService.increase_usage(self.tenant_id, self.llm_type, used_tokens, llm_name):
|
||||||
logging.error("LLMBundle.encode_queries can't update token usage for {}/EMBEDDING used_tokens: {}".format(self.tenant_id, used_tokens))
|
logging.error("LLMBundle.encode_queries can't update token usage for {}/EMBEDDING used_tokens: {}".format(self.tenant_id, used_tokens))
|
||||||
|
|
||||||
if self.langfuse:
|
if self.langfuse:
|
||||||
|
|||||||
110
api/db/services/search_service.py
Normal file
110
api/db/services/search_service.py
Normal file
@ -0,0 +1,110 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2024 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
from datetime import datetime
|
||||||
|
|
||||||
|
from peewee import fn
|
||||||
|
|
||||||
|
from api.db import StatusEnum
|
||||||
|
from api.db.db_models import DB, Search, User
|
||||||
|
from api.db.services.common_service import CommonService
|
||||||
|
from api.utils import current_timestamp, datetime_format
|
||||||
|
|
||||||
|
|
||||||
|
class SearchService(CommonService):
|
||||||
|
model = Search
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def save(cls, **kwargs):
|
||||||
|
kwargs["create_time"] = current_timestamp()
|
||||||
|
kwargs["create_date"] = datetime_format(datetime.now())
|
||||||
|
kwargs["update_time"] = current_timestamp()
|
||||||
|
kwargs["update_date"] = datetime_format(datetime.now())
|
||||||
|
obj = cls.model.create(**kwargs)
|
||||||
|
return obj
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
@DB.connection_context()
|
||||||
|
def accessible4deletion(cls, search_id, user_id) -> bool:
|
||||||
|
search = (
|
||||||
|
cls.model.select(cls.model.id)
|
||||||
|
.where(
|
||||||
|
cls.model.id == search_id,
|
||||||
|
cls.model.created_by == user_id,
|
||||||
|
cls.model.status == StatusEnum.VALID.value,
|
||||||
|
)
|
||||||
|
.first()
|
||||||
|
)
|
||||||
|
return search is not None
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
@DB.connection_context()
|
||||||
|
def get_detail(cls, search_id):
|
||||||
|
fields = [
|
||||||
|
cls.model.id,
|
||||||
|
cls.model.avatar,
|
||||||
|
cls.model.tenant_id,
|
||||||
|
cls.model.name,
|
||||||
|
cls.model.description,
|
||||||
|
cls.model.created_by,
|
||||||
|
cls.model.search_config,
|
||||||
|
cls.model.update_time,
|
||||||
|
User.nickname,
|
||||||
|
User.avatar.alias("tenant_avatar"),
|
||||||
|
]
|
||||||
|
search = (
|
||||||
|
cls.model.select(*fields)
|
||||||
|
.join(User, on=((User.id == cls.model.tenant_id) & (User.status == StatusEnum.VALID.value)))
|
||||||
|
.where((cls.model.id == search_id) & (cls.model.status == StatusEnum.VALID.value))
|
||||||
|
.first()
|
||||||
|
.to_dict()
|
||||||
|
)
|
||||||
|
return search
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
@DB.connection_context()
|
||||||
|
def get_by_tenant_ids(cls, joined_tenant_ids, user_id, page_number, items_per_page, orderby, desc, keywords):
|
||||||
|
fields = [
|
||||||
|
cls.model.id,
|
||||||
|
cls.model.avatar,
|
||||||
|
cls.model.tenant_id,
|
||||||
|
cls.model.name,
|
||||||
|
cls.model.description,
|
||||||
|
cls.model.created_by,
|
||||||
|
cls.model.status,
|
||||||
|
cls.model.update_time,
|
||||||
|
cls.model.create_time,
|
||||||
|
User.nickname,
|
||||||
|
User.avatar.alias("tenant_avatar"),
|
||||||
|
]
|
||||||
|
query = (
|
||||||
|
cls.model.select(*fields)
|
||||||
|
.join(User, on=(cls.model.tenant_id == User.id))
|
||||||
|
.where(((cls.model.tenant_id.in_(joined_tenant_ids)) | (cls.model.tenant_id == user_id)) & (cls.model.status == StatusEnum.VALID.value))
|
||||||
|
)
|
||||||
|
|
||||||
|
if keywords:
|
||||||
|
query = query.where(fn.LOWER(cls.model.name).contains(keywords.lower()))
|
||||||
|
if desc:
|
||||||
|
query = query.order_by(cls.model.getter_by(orderby).desc())
|
||||||
|
else:
|
||||||
|
query = query.order_by(cls.model.getter_by(orderby).asc())
|
||||||
|
|
||||||
|
count = query.count()
|
||||||
|
|
||||||
|
if page_number and items_per_page:
|
||||||
|
query = query.paginate(page_number, items_per_page)
|
||||||
|
|
||||||
|
return list(query.dicts()), count
|
||||||
@ -13,6 +13,7 @@
|
|||||||
# See the License for the specific language governing permissions and
|
# See the License for the specific language governing permissions and
|
||||||
# limitations under the License.
|
# limitations under the License.
|
||||||
#
|
#
|
||||||
|
import logging
|
||||||
import os
|
import os
|
||||||
import random
|
import random
|
||||||
import xxhash
|
import xxhash
|
||||||
@ -256,36 +257,55 @@ class TaskService(CommonService):
|
|||||||
@DB.connection_context()
|
@DB.connection_context()
|
||||||
def update_progress(cls, id, info):
|
def update_progress(cls, id, info):
|
||||||
"""Update the progress information for a task.
|
"""Update the progress information for a task.
|
||||||
|
|
||||||
This method updates both the progress message and completion percentage of a task.
|
This method updates both the progress message and completion percentage of a task.
|
||||||
It handles platform-specific behavior (macOS vs others) and uses database locking
|
It handles platform-specific behavior (macOS vs others) and uses database locking
|
||||||
when necessary to ensure thread safety.
|
when necessary to ensure thread safety.
|
||||||
|
|
||||||
|
Update Rules:
|
||||||
|
- progress_msg: Always appends the new message to the existing one, and trims the result to max 3000 lines.
|
||||||
|
- progress: Only updates if the current progress is not -1 AND
|
||||||
|
(the new progress is -1 OR greater than the existing progress),
|
||||||
|
to avoid overwriting valid progress with invalid or regressive values.
|
||||||
|
|
||||||
Args:
|
Args:
|
||||||
id (str): The unique identifier of the task to update.
|
id (str): The unique identifier of the task to update.
|
||||||
info (dict): Dictionary containing progress information with keys:
|
info (dict): Dictionary containing progress information with keys:
|
||||||
- progress_msg (str, optional): Progress message to append
|
- progress_msg (str, optional): Progress message to append
|
||||||
- progress (float, optional): Progress percentage (0.0 to 1.0)
|
- progress (float, optional): Progress percentage (0.0 to 1.0)
|
||||||
"""
|
"""
|
||||||
|
task = cls.model.get_by_id(id)
|
||||||
|
if not task:
|
||||||
|
logging.warning("Update_progress error: task not found")
|
||||||
|
return
|
||||||
|
|
||||||
if os.environ.get("MACOS"):
|
if os.environ.get("MACOS"):
|
||||||
if info["progress_msg"]:
|
if info["progress_msg"]:
|
||||||
task = cls.model.get_by_id(id)
|
|
||||||
progress_msg = trim_header_by_lines(task.progress_msg + "\n" + info["progress_msg"], 3000)
|
progress_msg = trim_header_by_lines(task.progress_msg + "\n" + info["progress_msg"], 3000)
|
||||||
cls.model.update(progress_msg=progress_msg).where(cls.model.id == id).execute()
|
cls.model.update(progress_msg=progress_msg).where(cls.model.id == id).execute()
|
||||||
if "progress" in info:
|
if "progress" in info:
|
||||||
cls.model.update(progress=info["progress"]).where(
|
prog = info["progress"]
|
||||||
cls.model.id == id
|
cls.model.update(progress=prog).where(
|
||||||
|
(cls.model.id == id) &
|
||||||
|
(
|
||||||
|
(cls.model.progress != -1) &
|
||||||
|
((prog == -1) | (prog > cls.model.progress))
|
||||||
|
)
|
||||||
).execute()
|
).execute()
|
||||||
return
|
return
|
||||||
|
|
||||||
with DB.lock("update_progress", -1):
|
with DB.lock("update_progress", -1):
|
||||||
if info["progress_msg"]:
|
if info["progress_msg"]:
|
||||||
task = cls.model.get_by_id(id)
|
|
||||||
progress_msg = trim_header_by_lines(task.progress_msg + "\n" + info["progress_msg"], 3000)
|
progress_msg = trim_header_by_lines(task.progress_msg + "\n" + info["progress_msg"], 3000)
|
||||||
cls.model.update(progress_msg=progress_msg).where(cls.model.id == id).execute()
|
cls.model.update(progress_msg=progress_msg).where(cls.model.id == id).execute()
|
||||||
if "progress" in info:
|
if "progress" in info:
|
||||||
cls.model.update(progress=info["progress"]).where(
|
prog = info["progress"]
|
||||||
cls.model.id == id
|
cls.model.update(progress=prog).where(
|
||||||
|
(cls.model.id == id) &
|
||||||
|
(
|
||||||
|
(cls.model.progress != -1) &
|
||||||
|
((prog == -1) | (prog > cls.model.progress))
|
||||||
|
)
|
||||||
).execute()
|
).execute()
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
@ -15,6 +15,7 @@
|
|||||||
#
|
#
|
||||||
import hashlib
|
import hashlib
|
||||||
from datetime import datetime
|
from datetime import datetime
|
||||||
|
import logging
|
||||||
|
|
||||||
import peewee
|
import peewee
|
||||||
from werkzeug.security import generate_password_hash, check_password_hash
|
from werkzeug.security import generate_password_hash, check_password_hash
|
||||||
@ -39,6 +40,30 @@ class UserService(CommonService):
|
|||||||
"""
|
"""
|
||||||
model = User
|
model = User
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
@DB.connection_context()
|
||||||
|
def query(cls, cols=None, reverse=None, order_by=None, **kwargs):
|
||||||
|
if 'access_token' in kwargs:
|
||||||
|
access_token = kwargs['access_token']
|
||||||
|
|
||||||
|
# Reject empty, None, or whitespace-only access tokens
|
||||||
|
if not access_token or not str(access_token).strip():
|
||||||
|
logging.warning("UserService.query: Rejecting empty access_token query")
|
||||||
|
return cls.model.select().where(cls.model.id == "INVALID_EMPTY_TOKEN") # Returns empty result
|
||||||
|
|
||||||
|
# Reject tokens that are too short (should be UUID, 32+ chars)
|
||||||
|
if len(str(access_token).strip()) < 32:
|
||||||
|
logging.warning(f"UserService.query: Rejecting short access_token query: {len(str(access_token))} chars")
|
||||||
|
return cls.model.select().where(cls.model.id == "INVALID_SHORT_TOKEN") # Returns empty result
|
||||||
|
|
||||||
|
# Reject tokens that start with "INVALID_" (from logout)
|
||||||
|
if str(access_token).startswith("INVALID_"):
|
||||||
|
logging.warning("UserService.query: Rejecting invalidated access_token")
|
||||||
|
return cls.model.select().where(cls.model.id == "INVALID_LOGOUT_TOKEN") # Returns empty result
|
||||||
|
|
||||||
|
# Call parent query method for valid requests
|
||||||
|
return super().query(cols=cols, reverse=reverse, order_by=order_by, **kwargs)
|
||||||
|
|
||||||
@classmethod
|
@classmethod
|
||||||
@DB.connection_context()
|
@DB.connection_context()
|
||||||
def filter_by_id(cls, user_id):
|
def filter_by_id(cls, user_id):
|
||||||
|
|||||||
@ -18,9 +18,9 @@
|
|||||||
# from beartype.claw import beartype_all # <-- you didn't sign up for this
|
# from beartype.claw import beartype_all # <-- you didn't sign up for this
|
||||||
# beartype_all(conf=BeartypeConf(violation_type=UserWarning)) # <-- emit warnings from all code
|
# beartype_all(conf=BeartypeConf(violation_type=UserWarning)) # <-- emit warnings from all code
|
||||||
|
|
||||||
from api.utils.log_utils import initRootLogger
|
from api.utils.log_utils import init_root_logger
|
||||||
from plugin import GlobalPluginManager
|
from plugin import GlobalPluginManager
|
||||||
initRootLogger("ragflow_server")
|
init_root_logger("ragflow_server")
|
||||||
|
|
||||||
import logging
|
import logging
|
||||||
import os
|
import os
|
||||||
@ -28,7 +28,6 @@ import signal
|
|||||||
import sys
|
import sys
|
||||||
import time
|
import time
|
||||||
import traceback
|
import traceback
|
||||||
from concurrent.futures import ThreadPoolExecutor
|
|
||||||
import threading
|
import threading
|
||||||
import uuid
|
import uuid
|
||||||
|
|
||||||
@ -125,8 +124,16 @@ if __name__ == '__main__':
|
|||||||
signal.signal(signal.SIGINT, signal_handler)
|
signal.signal(signal.SIGINT, signal_handler)
|
||||||
signal.signal(signal.SIGTERM, signal_handler)
|
signal.signal(signal.SIGTERM, signal_handler)
|
||||||
|
|
||||||
thread = ThreadPoolExecutor(max_workers=1)
|
def delayed_start_update_progress():
|
||||||
thread.submit(update_progress)
|
logging.info("Starting update_progress thread (delayed)")
|
||||||
|
t = threading.Thread(target=update_progress, daemon=True)
|
||||||
|
t.start()
|
||||||
|
|
||||||
|
if RuntimeConfig.DEBUG:
|
||||||
|
if os.environ.get("WERKZEUG_RUN_MAIN") == "true":
|
||||||
|
threading.Timer(1.0, delayed_start_update_progress).start()
|
||||||
|
else:
|
||||||
|
threading.Timer(1.0, delayed_start_update_progress).start()
|
||||||
|
|
||||||
# start http server
|
# start http server
|
||||||
try:
|
try:
|
||||||
|
|||||||
@ -15,6 +15,7 @@
|
|||||||
#
|
#
|
||||||
import json
|
import json
|
||||||
import os
|
import os
|
||||||
|
import secrets
|
||||||
from datetime import date
|
from datetime import date
|
||||||
from enum import Enum, IntEnum
|
from enum import Enum, IntEnum
|
||||||
|
|
||||||
@ -73,6 +74,25 @@ SANDBOX_HOST = None
|
|||||||
|
|
||||||
BUILTIN_EMBEDDING_MODELS = ["BAAI/bge-large-zh-v1.5@BAAI", "maidalun1020/bce-embedding-base_v1@Youdao"]
|
BUILTIN_EMBEDDING_MODELS = ["BAAI/bge-large-zh-v1.5@BAAI", "maidalun1020/bce-embedding-base_v1@Youdao"]
|
||||||
|
|
||||||
|
def get_or_create_secret_key():
|
||||||
|
secret_key = os.environ.get("RAGFLOW_SECRET_KEY")
|
||||||
|
if secret_key and len(secret_key) >= 32:
|
||||||
|
return secret_key
|
||||||
|
|
||||||
|
# Check if there's a configured secret key
|
||||||
|
configured_key = get_base_config(RAG_FLOW_SERVICE_NAME, {}).get("secret_key")
|
||||||
|
if configured_key and configured_key != str(date.today()) and len(configured_key) >= 32:
|
||||||
|
return configured_key
|
||||||
|
|
||||||
|
# Generate a new secure key and warn about it
|
||||||
|
import logging
|
||||||
|
new_key = secrets.token_hex(32)
|
||||||
|
logging.warning(
|
||||||
|
"SECURITY WARNING: Using auto-generated SECRET_KEY. "
|
||||||
|
f"Generated key: {new_key}"
|
||||||
|
)
|
||||||
|
return new_key
|
||||||
|
|
||||||
|
|
||||||
def init_settings():
|
def init_settings():
|
||||||
global LLM, LLM_FACTORY, LLM_BASE_URL, LIGHTEN, DATABASE_TYPE, DATABASE, FACTORY_LLM_INFOS, REGISTER_ENABLED
|
global LLM, LLM_FACTORY, LLM_BASE_URL, LIGHTEN, DATABASE_TYPE, DATABASE, FACTORY_LLM_INFOS, REGISTER_ENABLED
|
||||||
@ -81,7 +101,7 @@ def init_settings():
|
|||||||
DATABASE = decrypt_database_config(name=DATABASE_TYPE)
|
DATABASE = decrypt_database_config(name=DATABASE_TYPE)
|
||||||
LLM = get_base_config("user_default_llm", {})
|
LLM = get_base_config("user_default_llm", {})
|
||||||
LLM_DEFAULT_MODELS = LLM.get("default_models", {})
|
LLM_DEFAULT_MODELS = LLM.get("default_models", {})
|
||||||
LLM_FACTORY = LLM.get("factory", "Tongyi-Qianwen")
|
LLM_FACTORY = LLM.get("factory")
|
||||||
LLM_BASE_URL = LLM.get("base_url")
|
LLM_BASE_URL = LLM.get("base_url")
|
||||||
try:
|
try:
|
||||||
REGISTER_ENABLED = int(os.environ.get("REGISTER_ENABLED", "1"))
|
REGISTER_ENABLED = int(os.environ.get("REGISTER_ENABLED", "1"))
|
||||||
@ -121,7 +141,7 @@ def init_settings():
|
|||||||
HOST_IP = get_base_config(RAG_FLOW_SERVICE_NAME, {}).get("host", "127.0.0.1")
|
HOST_IP = get_base_config(RAG_FLOW_SERVICE_NAME, {}).get("host", "127.0.0.1")
|
||||||
HOST_PORT = get_base_config(RAG_FLOW_SERVICE_NAME, {}).get("http_port")
|
HOST_PORT = get_base_config(RAG_FLOW_SERVICE_NAME, {}).get("http_port")
|
||||||
|
|
||||||
SECRET_KEY = get_base_config(RAG_FLOW_SERVICE_NAME, {}).get("secret_key", str(date.today()))
|
SECRET_KEY = get_or_create_secret_key()
|
||||||
|
|
||||||
global AUTHENTICATION_CONF, CLIENT_AUTHENTICATION, HTTP_APP_KEY, GITHUB_OAUTH, FEISHU_OAUTH, OAUTH_CONFIG
|
global AUTHENTICATION_CONF, CLIENT_AUTHENTICATION, HTTP_APP_KEY, GITHUB_OAUTH, FEISHU_OAUTH, OAUTH_CONFIG
|
||||||
# authentication
|
# authentication
|
||||||
|
|||||||
@ -428,11 +428,11 @@ def verify_embedding_availability(embd_id: str, tenant_id: str) -> tuple[bool, R
|
|||||||
"""
|
"""
|
||||||
Verifies availability of an embedding model for a specific tenant.
|
Verifies availability of an embedding model for a specific tenant.
|
||||||
|
|
||||||
Implements a four-stage validation process:
|
Performs comprehensive verification through:
|
||||||
1. Model identifier parsing and validation
|
1. Identifier Parsing: Decomposes embd_id into name and factory components
|
||||||
2. System support verification
|
2. System Verification: Checks model registration in LLMService
|
||||||
3. Tenant authorization check
|
3. Tenant Authorization: Validates tenant-specific model assignments
|
||||||
4. Database operation error handling
|
4. Built-in Model Check: Confirms inclusion in predefined system models
|
||||||
|
|
||||||
Args:
|
Args:
|
||||||
embd_id (str): Unique identifier for the embedding model in format "model_name@factory"
|
embd_id (str): Unique identifier for the embedding model in format "model_name@factory"
|
||||||
@ -460,14 +460,15 @@ def verify_embedding_availability(embd_id: str, tenant_id: str) -> tuple[bool, R
|
|||||||
"""
|
"""
|
||||||
try:
|
try:
|
||||||
llm_name, llm_factory = TenantLLMService.split_model_name_and_factory(embd_id)
|
llm_name, llm_factory = TenantLLMService.split_model_name_and_factory(embd_id)
|
||||||
if not LLMService.query(llm_name=llm_name, fid=llm_factory, model_type="embedding"):
|
in_llm_service = bool(LLMService.query(llm_name=llm_name, fid=llm_factory, model_type="embedding"))
|
||||||
return False, get_error_argument_result(f"Unsupported model: <{embd_id}>")
|
|
||||||
|
|
||||||
# Tongyi-Qianwen is added to TenantLLM by default, but remains unusable with empty api_key
|
|
||||||
tenant_llms = TenantLLMService.get_my_llms(tenant_id=tenant_id)
|
tenant_llms = TenantLLMService.get_my_llms(tenant_id=tenant_id)
|
||||||
is_tenant_model = any(llm["llm_name"] == llm_name and llm["llm_factory"] == llm_factory and llm["model_type"] == "embedding" for llm in tenant_llms)
|
is_tenant_model = any(llm["llm_name"] == llm_name and llm["llm_factory"] == llm_factory and llm["model_type"] == "embedding" for llm in tenant_llms)
|
||||||
|
|
||||||
is_builtin_model = embd_id in settings.BUILTIN_EMBEDDING_MODELS
|
is_builtin_model = embd_id in settings.BUILTIN_EMBEDDING_MODELS
|
||||||
|
if not (is_builtin_model or is_tenant_model or in_llm_service):
|
||||||
|
return False, get_error_argument_result(f"Unsupported model: <{embd_id}>")
|
||||||
|
|
||||||
if not (is_builtin_model or is_tenant_model):
|
if not (is_builtin_model or is_tenant_model):
|
||||||
return False, get_error_argument_result(f"Unauthorized model: <{embd_id}>")
|
return False, get_error_argument_result(f"Unauthorized model: <{embd_id}>")
|
||||||
except OperationalError as e:
|
except OperationalError as e:
|
||||||
|
|||||||
@ -158,7 +158,7 @@ def filename_type(filename):
|
|||||||
if re.match(r".*\.(eml|doc|docx|ppt|pptx|yml|xml|htm|json|csv|txt|ini|xls|xlsx|wps|rtf|hlp|pages|numbers|key|md|py|js|java|c|cpp|h|php|go|ts|sh|cs|kt|html|sql)$", filename):
|
if re.match(r".*\.(eml|doc|docx|ppt|pptx|yml|xml|htm|json|csv|txt|ini|xls|xlsx|wps|rtf|hlp|pages|numbers|key|md|py|js|java|c|cpp|h|php|go|ts|sh|cs|kt|html|sql)$", filename):
|
||||||
return FileType.DOC.value
|
return FileType.DOC.value
|
||||||
|
|
||||||
if re.match(r".*\.(wav|flac|ape|alac|wavpack|wv|mp3|aac|ogg|vorbis|opus|mp3)$", filename):
|
if re.match(r".*\.(wav|flac|ape|alac|wavpack|wv|mp3|aac|ogg|vorbis|opus)$", filename):
|
||||||
return FileType.AURAL.value
|
return FileType.AURAL.value
|
||||||
|
|
||||||
if re.match(r".*\.(jpg|jpeg|png|tif|gif|pcx|tga|exif|fpx|svg|psd|cdr|pcd|dxf|ufo|eps|ai|raw|WMF|webp|avif|apng|icon|ico|mpg|mpeg|avi|rm|rmvb|mov|wmv|asf|dat|asx|wvx|mpe|mpa|mp4)$", filename):
|
if re.match(r".*\.(jpg|jpeg|png|tif|gif|pcx|tga|exif|fpx|svg|psd|cdr|pcd|dxf|ufo|eps|ai|raw|WMF|webp|avif|apng|icon|ico|mpg|mpeg|avi|rm|rmvb|mov|wmv|asf|dat|asx|wvx|mpe|mpa|mp4)$", filename):
|
||||||
|
|||||||
@ -30,7 +30,7 @@ def get_project_base_directory():
|
|||||||
)
|
)
|
||||||
return PROJECT_BASE
|
return PROJECT_BASE
|
||||||
|
|
||||||
def initRootLogger(logfile_basename: str, log_format: str = "%(asctime)-15s %(levelname)-8s %(process)d %(message)s"):
|
def init_root_logger(logfile_basename: str, log_format: str = "%(asctime)-15s %(levelname)-8s %(process)d %(message)s"):
|
||||||
global initialized_root_logger
|
global initialized_root_logger
|
||||||
if initialized_root_logger:
|
if initialized_root_logger:
|
||||||
return
|
return
|
||||||
@ -77,4 +77,11 @@ def initRootLogger(logfile_basename: str, log_format: str = "%(asctime)-15s %(le
|
|||||||
pkg_logger.setLevel(pkg_level)
|
pkg_logger.setLevel(pkg_level)
|
||||||
|
|
||||||
msg = f"{logfile_basename} log path: {log_path}, log levels: {pkg_levels}"
|
msg = f"{logfile_basename} log path: {log_path}, log levels: {pkg_levels}"
|
||||||
logger.info(msg)
|
logger.info(msg)
|
||||||
|
|
||||||
|
|
||||||
|
def log_exception(e, *args):
|
||||||
|
logging.exception(e)
|
||||||
|
for a in args:
|
||||||
|
logging.error(str(a))
|
||||||
|
raise e
|
||||||
@ -35,6 +35,6 @@ def crypt(line):
|
|||||||
|
|
||||||
|
|
||||||
if __name__ == "__main__":
|
if __name__ == "__main__":
|
||||||
pswd = crypt(sys.argv[1])
|
passwd = crypt(sys.argv[1])
|
||||||
print(pswd)
|
print(passwd)
|
||||||
print(decrypt(pswd))
|
print(decrypt(passwd))
|
||||||
|
|||||||
@ -312,7 +312,7 @@ class PermissionEnum(StrEnum):
|
|||||||
team = auto()
|
team = auto()
|
||||||
|
|
||||||
|
|
||||||
class ChunkMethodnEnum(StrEnum):
|
class ChunkMethodEnum(StrEnum):
|
||||||
naive = auto()
|
naive = auto()
|
||||||
book = auto()
|
book = auto()
|
||||||
email = auto()
|
email = auto()
|
||||||
@ -382,8 +382,7 @@ class CreateDatasetReq(Base):
|
|||||||
description: str | None = Field(default=None, max_length=65535)
|
description: str | None = Field(default=None, max_length=65535)
|
||||||
embedding_model: Annotated[str, StringConstraints(strip_whitespace=True, max_length=255), Field(default="", serialization_alias="embd_id")]
|
embedding_model: Annotated[str, StringConstraints(strip_whitespace=True, max_length=255), Field(default="", serialization_alias="embd_id")]
|
||||||
permission: PermissionEnum = Field(default=PermissionEnum.me, min_length=1, max_length=16)
|
permission: PermissionEnum = Field(default=PermissionEnum.me, min_length=1, max_length=16)
|
||||||
chunk_method: ChunkMethodnEnum = Field(default=ChunkMethodnEnum.naive, min_length=1, max_length=32, serialization_alias="parser_id")
|
chunk_method: ChunkMethodEnum = Field(default=ChunkMethodEnum.naive, min_length=1, max_length=32, serialization_alias="parser_id")
|
||||||
pagerank: int = Field(default=0, ge=0, le=100)
|
|
||||||
parser_config: ParserConfig | None = Field(default=None)
|
parser_config: ParserConfig | None = Field(default=None)
|
||||||
|
|
||||||
@field_validator("avatar")
|
@field_validator("avatar")
|
||||||
@ -539,6 +538,7 @@ class CreateDatasetReq(Base):
|
|||||||
class UpdateDatasetReq(CreateDatasetReq):
|
class UpdateDatasetReq(CreateDatasetReq):
|
||||||
dataset_id: str = Field(...)
|
dataset_id: str = Field(...)
|
||||||
name: Annotated[str, StringConstraints(strip_whitespace=True, min_length=1, max_length=DATASET_NAME_LIMIT), Field(default="")]
|
name: Annotated[str, StringConstraints(strip_whitespace=True, min_length=1, max_length=DATASET_NAME_LIMIT), Field(default="")]
|
||||||
|
pagerank: int = Field(default=0, ge=0, le=100)
|
||||||
|
|
||||||
@field_validator("dataset_id", mode="before")
|
@field_validator("dataset_id", mode="before")
|
||||||
@classmethod
|
@classmethod
|
||||||
|
|||||||
@ -360,6 +360,12 @@
|
|||||||
"max_tokens": 8192,
|
"max_tokens": 8192,
|
||||||
"model_type": "embedding"
|
"model_type": "embedding"
|
||||||
},
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "text-embedding-v4",
|
||||||
|
"tags": "TEXT EMBEDDING,8K",
|
||||||
|
"max_tokens": 8192,
|
||||||
|
"model_type": "embedding"
|
||||||
|
},
|
||||||
{
|
{
|
||||||
"llm_name": "qwen-vl-max",
|
"llm_name": "qwen-vl-max",
|
||||||
"tags": "LLM,CHAT,IMAGE2TEXT",
|
"tags": "LLM,CHAT,IMAGE2TEXT",
|
||||||
@ -567,7 +573,7 @@
|
|||||||
{
|
{
|
||||||
"name": "Youdao",
|
"name": "Youdao",
|
||||||
"logo": "",
|
"logo": "",
|
||||||
"tags": "LLM,TEXT EMBEDDING,SPEECH2TEXT,MODERATION",
|
"tags": "TEXT EMBEDDING",
|
||||||
"status": "1",
|
"status": "1",
|
||||||
"llm": [
|
"llm": [
|
||||||
{
|
{
|
||||||
@ -755,7 +761,7 @@
|
|||||||
{
|
{
|
||||||
"name": "BAAI",
|
"name": "BAAI",
|
||||||
"logo": "",
|
"logo": "",
|
||||||
"tags": "TEXT EMBEDDING, TEXT RE-RANK",
|
"tags": "TEXT EMBEDDING",
|
||||||
"status": "1",
|
"status": "1",
|
||||||
"llm": [
|
"llm": [
|
||||||
{
|
{
|
||||||
@ -996,7 +1002,7 @@
|
|||||||
"status": "1",
|
"status": "1",
|
||||||
"llm": [
|
"llm": [
|
||||||
{
|
{
|
||||||
"llm_name": "gemini-2.5-flash-preview-04-17",
|
"llm_name": "gemini-2.5-flash-preview-05-20",
|
||||||
"tags": "LLM,CHAT,1024K,IMAGE2TEXT",
|
"tags": "LLM,CHAT,1024K,IMAGE2TEXT",
|
||||||
"max_tokens": 1048576,
|
"max_tokens": 1048576,
|
||||||
"model_type": "image2text",
|
"model_type": "image2text",
|
||||||
@ -1023,7 +1029,7 @@
|
|||||||
"model_type": "image2text"
|
"model_type": "image2text"
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
"llm_name": "gemini-2.5-pro-exp-03-25",
|
"llm_name": "gemini-2.5-pro-preview-05-06",
|
||||||
"tags": "LLM,IMAGE2TEXT,1024K",
|
"tags": "LLM,IMAGE2TEXT,1024K",
|
||||||
"max_tokens": 1048576,
|
"max_tokens": 1048576,
|
||||||
"model_type": "image2text"
|
"model_type": "image2text"
|
||||||
@ -3133,6 +3139,20 @@
|
|||||||
"tags": "LLM",
|
"tags": "LLM",
|
||||||
"status": "1",
|
"status": "1",
|
||||||
"llm": [
|
"llm": [
|
||||||
|
{
|
||||||
|
"llm_name": "claude-opus-4-20250514",
|
||||||
|
"tags": "LLM,IMAGE2TEXT,200k",
|
||||||
|
"max_tokens": 204800,
|
||||||
|
"model_type": "image2text",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "claude-sonnet-4-20250514",
|
||||||
|
"tags": "LLM,IMAGE2TEXT,200k",
|
||||||
|
"max_tokens": 204800,
|
||||||
|
"model_type": "image2text",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
{
|
{
|
||||||
"llm_name": "claude-3-7-sonnet-20250219",
|
"llm_name": "claude-3-7-sonnet-20250219",
|
||||||
"tags": "LLM,IMAGE2TEXT,200k",
|
"tags": "LLM,IMAGE2TEXT,200k",
|
||||||
@ -3181,6 +3201,12 @@
|
|||||||
"tags": "TEXT EMBEDDING, TEXT RE-RANK",
|
"tags": "TEXT EMBEDDING, TEXT RE-RANK",
|
||||||
"status": "1",
|
"status": "1",
|
||||||
"llm": [
|
"llm": [
|
||||||
|
{
|
||||||
|
"llm_name": "voyage-multimodal-3",
|
||||||
|
"tags": "TEXT EMBEDDING,Chat,IMAGE2TEXT,32000",
|
||||||
|
"max_tokens": 32000,
|
||||||
|
"model_type": "embedding"
|
||||||
|
},
|
||||||
{
|
{
|
||||||
"llm_name": "voyage-large-2-instruct",
|
"llm_name": "voyage-large-2-instruct",
|
||||||
"tags": "TEXT EMBEDDING,16000",
|
"tags": "TEXT EMBEDDING,16000",
|
||||||
@ -3283,4 +3309,4 @@
|
|||||||
"llm": []
|
"llm": []
|
||||||
}
|
}
|
||||||
]
|
]
|
||||||
}
|
}
|
||||||
|
|||||||
@ -9,6 +9,7 @@ mysql:
|
|||||||
port: 5455
|
port: 5455
|
||||||
max_connections: 900
|
max_connections: 900
|
||||||
stale_timeout: 300
|
stale_timeout: 300
|
||||||
|
max_allowed_packet: 1073741824
|
||||||
minio:
|
minio:
|
||||||
user: 'rag_flow'
|
user: 'rag_flow'
|
||||||
password: 'infini_rag_flow'
|
password: 'infini_rag_flow'
|
||||||
@ -28,7 +29,6 @@ redis:
|
|||||||
db: 1
|
db: 1
|
||||||
password: 'infini_rag_flow'
|
password: 'infini_rag_flow'
|
||||||
host: 'localhost:6379'
|
host: 'localhost:6379'
|
||||||
|
|
||||||
# postgres:
|
# postgres:
|
||||||
# name: 'rag_flow'
|
# name: 'rag_flow'
|
||||||
# user: 'rag_flow'
|
# user: 'rag_flow'
|
||||||
@ -58,6 +58,11 @@ redis:
|
|||||||
# secret: 'secret'
|
# secret: 'secret'
|
||||||
# tenant_id: 'tenant_id'
|
# tenant_id: 'tenant_id'
|
||||||
# container_name: 'container_name'
|
# container_name: 'container_name'
|
||||||
|
# The OSS object storage uses the MySQL configuration above by default. If you need to switch to another object storage service, please uncomment and configure the following parameters.
|
||||||
|
# opendal:
|
||||||
|
# scheme: 'mysql' # Storage type, such as s3, oss, azure, etc.
|
||||||
|
# config:
|
||||||
|
# oss_table: 'your_table_name'
|
||||||
# user_default_llm:
|
# user_default_llm:
|
||||||
# factory: 'Tongyi-Qianwen'
|
# factory: 'Tongyi-Qianwen'
|
||||||
# api_key: 'sk-xxxxxxxxxxxxx'
|
# api_key: 'sk-xxxxxxxxxxxxx'
|
||||||
|
|||||||
@ -69,7 +69,7 @@ class RAGFlowDocxParser:
|
|||||||
max_type = max(max_type.items(), key=lambda x: x[1])[0]
|
max_type = max(max_type.items(), key=lambda x: x[1])[0]
|
||||||
|
|
||||||
colnm = len(df.iloc[0, :])
|
colnm = len(df.iloc[0, :])
|
||||||
hdrows = [0] # header is not nessesarily appear in the first line
|
hdrows = [0] # header is not necessarily appear in the first line
|
||||||
if max_type == "Nu":
|
if max_type == "Nu":
|
||||||
for r in range(1, len(df)):
|
for r in range(1, len(df)):
|
||||||
tys = Counter([blockType(str(df.iloc[r, j]))
|
tys = Counter([blockType(str(df.iloc[r, j]))
|
||||||
|
|||||||
@ -21,7 +21,7 @@ from rag.app.picture import vision_llm_chunk as picture_vision_llm_chunk
|
|||||||
from rag.prompts import vision_llm_figure_describe_prompt
|
from rag.prompts import vision_llm_figure_describe_prompt
|
||||||
|
|
||||||
|
|
||||||
def vision_figure_parser_figure_data_wraper(figures_data_without_positions):
|
def vision_figure_parser_figure_data_wrapper(figures_data_without_positions):
|
||||||
return [
|
return [
|
||||||
(
|
(
|
||||||
(figure_data[1], [figure_data[0]]),
|
(figure_data[1], [figure_data[0]]),
|
||||||
|
|||||||
@ -61,7 +61,7 @@ class RAGFlowPdfParser:
|
|||||||
|
|
||||||
self.ocr = OCR()
|
self.ocr = OCR()
|
||||||
self.parallel_limiter = None
|
self.parallel_limiter = None
|
||||||
if PARALLEL_DEVICES is not None and PARALLEL_DEVICES > 1:
|
if PARALLEL_DEVICES > 1:
|
||||||
self.parallel_limiter = [trio.CapacityLimiter(1) for _ in range(PARALLEL_DEVICES)]
|
self.parallel_limiter = [trio.CapacityLimiter(1) for _ in range(PARALLEL_DEVICES)]
|
||||||
|
|
||||||
if hasattr(self, "model_speciess"):
|
if hasattr(self, "model_speciess"):
|
||||||
@ -180,13 +180,13 @@ class RAGFlowPdfParser:
|
|||||||
return fea
|
return fea
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def sort_X_by_page(arr, threashold):
|
def sort_X_by_page(arr, threshold):
|
||||||
# sort using y1 first and then x1
|
# sort using y1 first and then x1
|
||||||
arr = sorted(arr, key=lambda r: (r["page_number"], r["x0"], r["top"]))
|
arr = sorted(arr, key=lambda r: (r["page_number"], r["x0"], r["top"]))
|
||||||
for i in range(len(arr) - 1):
|
for i in range(len(arr) - 1):
|
||||||
for j in range(i, -1, -1):
|
for j in range(i, -1, -1):
|
||||||
# restore the order using th
|
# restore the order using th
|
||||||
if abs(arr[j + 1]["x0"] - arr[j]["x0"]) < threashold \
|
if abs(arr[j + 1]["x0"] - arr[j]["x0"]) < threshold \
|
||||||
and arr[j + 1]["top"] < arr[j]["top"] \
|
and arr[j + 1]["top"] < arr[j]["top"] \
|
||||||
and arr[j + 1]["page_number"] == arr[j]["page_number"]:
|
and arr[j + 1]["page_number"] == arr[j]["page_number"]:
|
||||||
tmp = arr[j]
|
tmp = arr[j]
|
||||||
@ -264,13 +264,13 @@ class RAGFlowPdfParser:
|
|||||||
for b in self.boxes:
|
for b in self.boxes:
|
||||||
if b.get("layout_type", "") != "table":
|
if b.get("layout_type", "") != "table":
|
||||||
continue
|
continue
|
||||||
ii = Recognizer.find_overlapped_with_threashold(b, rows, thr=0.3)
|
ii = Recognizer.find_overlapped_with_threshold(b, rows, thr=0.3)
|
||||||
if ii is not None:
|
if ii is not None:
|
||||||
b["R"] = ii
|
b["R"] = ii
|
||||||
b["R_top"] = rows[ii]["top"]
|
b["R_top"] = rows[ii]["top"]
|
||||||
b["R_bott"] = rows[ii]["bottom"]
|
b["R_bott"] = rows[ii]["bottom"]
|
||||||
|
|
||||||
ii = Recognizer.find_overlapped_with_threashold(
|
ii = Recognizer.find_overlapped_with_threshold(
|
||||||
b, headers, thr=0.3)
|
b, headers, thr=0.3)
|
||||||
if ii is not None:
|
if ii is not None:
|
||||||
b["H_top"] = headers[ii]["top"]
|
b["H_top"] = headers[ii]["top"]
|
||||||
@ -285,7 +285,7 @@ class RAGFlowPdfParser:
|
|||||||
b["C_left"] = clmns[ii]["x0"]
|
b["C_left"] = clmns[ii]["x0"]
|
||||||
b["C_right"] = clmns[ii]["x1"]
|
b["C_right"] = clmns[ii]["x1"]
|
||||||
|
|
||||||
ii = Recognizer.find_overlapped_with_threashold(b, spans, thr=0.3)
|
ii = Recognizer.find_overlapped_with_threshold(b, spans, thr=0.3)
|
||||||
if ii is not None:
|
if ii is not None:
|
||||||
b["H_top"] = spans[ii]["top"]
|
b["H_top"] = spans[ii]["top"]
|
||||||
b["H_bott"] = spans[ii]["bottom"]
|
b["H_bott"] = spans[ii]["bottom"]
|
||||||
|
|||||||
@ -63,7 +63,7 @@ class RAGFlowPptParser:
|
|||||||
if shape_type == 6:
|
if shape_type == 6:
|
||||||
texts = []
|
texts = []
|
||||||
for p in sorted(shape.shapes, key=lambda x: (x.top // 10, x.left)):
|
for p in sorted(shape.shapes, key=lambda x: (x.top // 10, x.left)):
|
||||||
t = self.__extract_texts(p)
|
t = self.__extract(p)
|
||||||
if t:
|
if t:
|
||||||
texts.append(t)
|
texts.append(t)
|
||||||
return "\n".join(texts)
|
return "\n".join(texts)
|
||||||
|
|||||||
@ -53,14 +53,14 @@ def corpNorm(nm, add_region=True):
|
|||||||
nm = re.sub(r"&", "&", nm)
|
nm = re.sub(r"&", "&", nm)
|
||||||
nm = re.sub(r"[\(\)()\+'\"\t \*\\【】-]+", " ", nm)
|
nm = re.sub(r"[\(\)()\+'\"\t \*\\【】-]+", " ", nm)
|
||||||
nm = re.sub(
|
nm = re.sub(
|
||||||
r"([—-]+.*| +co\..*|corp\..*| +inc\..*| +ltd.*)", "", nm, 10000, re.IGNORECASE
|
r"([—-]+.*| +co\..*|corp\..*| +inc\..*| +ltd.*)", "", nm, count=10000, flags=re.IGNORECASE
|
||||||
)
|
)
|
||||||
nm = re.sub(
|
nm = re.sub(
|
||||||
r"(计算机|技术|(技术|科技|网络)*有限公司|公司|有限|研发中心|中国|总部)$",
|
r"(计算机|技术|(技术|科技|网络)*有限公司|公司|有限|研发中心|中国|总部)$",
|
||||||
"",
|
"",
|
||||||
nm,
|
nm,
|
||||||
10000,
|
count=10000,
|
||||||
re.IGNORECASE,
|
flags=re.IGNORECASE,
|
||||||
)
|
)
|
||||||
if not nm or (len(nm) < 5 and not regions.isName(nm[0:2])):
|
if not nm or (len(nm) < 5 and not regions.isName(nm[0:2])):
|
||||||
return nm
|
return nm
|
||||||
|
|||||||
@ -51,7 +51,7 @@ PY = Pinyin()
|
|||||||
|
|
||||||
|
|
||||||
def rmHtmlTag(line):
|
def rmHtmlTag(line):
|
||||||
return re.sub(r"<[a-z0-9.\"=';,:\+_/ -]+>", " ", line, 100000, re.IGNORECASE)
|
return re.sub(r"<[a-z0-9.\"=';,:\+_/ -]+>", " ", line, count=100000, flags=re.IGNORECASE)
|
||||||
|
|
||||||
|
|
||||||
def highest_degree(dg):
|
def highest_degree(dg):
|
||||||
@ -507,7 +507,7 @@ def parse(cv):
|
|||||||
(r".*国有.*", "国企"),
|
(r".*国有.*", "国企"),
|
||||||
(r"[ ()\(\)人/·0-9-]+", ""),
|
(r"[ ()\(\)人/·0-9-]+", ""),
|
||||||
(r".*(元|规模|于|=|北京|上海|至今|中国|工资|州|shanghai|强|餐饮|融资|职).*", "")]:
|
(r".*(元|规模|于|=|北京|上海|至今|中国|工资|州|shanghai|强|餐饮|融资|职).*", "")]:
|
||||||
cv["corporation_type"] = re.sub(p, r, cv["corporation_type"], 1000, re.IGNORECASE)
|
cv["corporation_type"] = re.sub(p, r, cv["corporation_type"], count=1000, flags=re.IGNORECASE)
|
||||||
if len(cv["corporation_type"]) < 2:
|
if len(cv["corporation_type"]) < 2:
|
||||||
del cv["corporation_type"]
|
del cv["corporation_type"]
|
||||||
|
|
||||||
|
|||||||
@ -106,7 +106,7 @@ class LayoutRecognizer(Recognizer):
|
|||||||
bxs.pop(i)
|
bxs.pop(i)
|
||||||
continue
|
continue
|
||||||
|
|
||||||
ii = self.find_overlapped_with_threashold(bxs[i], lts_,
|
ii = self.find_overlapped_with_threshold(bxs[i], lts_,
|
||||||
thr=0.4)
|
thr=0.4)
|
||||||
if ii is None: # belong to nothing
|
if ii is None: # belong to nothing
|
||||||
bxs[i]["layout_type"] = ""
|
bxs[i]["layout_type"] = ""
|
||||||
|
|||||||
@ -529,31 +529,30 @@ class OCR:
|
|||||||
"rag/res/deepdoc")
|
"rag/res/deepdoc")
|
||||||
|
|
||||||
# Append muti-gpus task to the list
|
# Append muti-gpus task to the list
|
||||||
if PARALLEL_DEVICES is not None and PARALLEL_DEVICES > 0:
|
if PARALLEL_DEVICES > 0:
|
||||||
self.text_detector = []
|
self.text_detector = []
|
||||||
self.text_recognizer = []
|
self.text_recognizer = []
|
||||||
for device_id in range(PARALLEL_DEVICES):
|
for device_id in range(PARALLEL_DEVICES):
|
||||||
self.text_detector.append(TextDetector(model_dir, device_id))
|
self.text_detector.append(TextDetector(model_dir, device_id))
|
||||||
self.text_recognizer.append(TextRecognizer(model_dir, device_id))
|
self.text_recognizer.append(TextRecognizer(model_dir, device_id))
|
||||||
else:
|
else:
|
||||||
self.text_detector = [TextDetector(model_dir, 0)]
|
self.text_detector = [TextDetector(model_dir)]
|
||||||
self.text_recognizer = [TextRecognizer(model_dir, 0)]
|
self.text_recognizer = [TextRecognizer(model_dir)]
|
||||||
|
|
||||||
except Exception:
|
except Exception:
|
||||||
model_dir = snapshot_download(repo_id="InfiniFlow/deepdoc",
|
model_dir = snapshot_download(repo_id="InfiniFlow/deepdoc",
|
||||||
local_dir=os.path.join(get_project_base_directory(), "rag/res/deepdoc"),
|
local_dir=os.path.join(get_project_base_directory(), "rag/res/deepdoc"),
|
||||||
local_dir_use_symlinks=False)
|
local_dir_use_symlinks=False)
|
||||||
|
|
||||||
if PARALLEL_DEVICES is not None:
|
if PARALLEL_DEVICES > 0:
|
||||||
assert PARALLEL_DEVICES > 0, "Number of devices must be >= 1"
|
|
||||||
self.text_detector = []
|
self.text_detector = []
|
||||||
self.text_recognizer = []
|
self.text_recognizer = []
|
||||||
for device_id in range(PARALLEL_DEVICES):
|
for device_id in range(PARALLEL_DEVICES):
|
||||||
self.text_detector.append(TextDetector(model_dir, device_id))
|
self.text_detector.append(TextDetector(model_dir, device_id))
|
||||||
self.text_recognizer.append(TextRecognizer(model_dir, device_id))
|
self.text_recognizer.append(TextRecognizer(model_dir, device_id))
|
||||||
else:
|
else:
|
||||||
self.text_detector = [TextDetector(model_dir, 0)]
|
self.text_detector = [TextDetector(model_dir)]
|
||||||
self.text_recognizer = [TextRecognizer(model_dir, 0)]
|
self.text_recognizer = [TextRecognizer(model_dir)]
|
||||||
|
|
||||||
self.drop_score = 0.5
|
self.drop_score = 0.5
|
||||||
self.crop_image_res_index = 0
|
self.crop_image_res_index = 0
|
||||||
@ -589,7 +588,29 @@ class OCR:
|
|||||||
flags=cv2.INTER_CUBIC)
|
flags=cv2.INTER_CUBIC)
|
||||||
dst_img_height, dst_img_width = dst_img.shape[0:2]
|
dst_img_height, dst_img_width = dst_img.shape[0:2]
|
||||||
if dst_img_height * 1.0 / dst_img_width >= 1.5:
|
if dst_img_height * 1.0 / dst_img_width >= 1.5:
|
||||||
dst_img = np.rot90(dst_img)
|
# Try original orientation
|
||||||
|
rec_result = self.text_recognizer[0]([dst_img])
|
||||||
|
text, score = rec_result[0][0]
|
||||||
|
best_score = score
|
||||||
|
best_img = dst_img
|
||||||
|
|
||||||
|
# Try clockwise 90° rotation
|
||||||
|
rotated_cw = np.rot90(dst_img, k=3)
|
||||||
|
rec_result = self.text_recognizer[0]([rotated_cw])
|
||||||
|
rotated_cw_text, rotated_cw_score = rec_result[0][0]
|
||||||
|
if rotated_cw_score > best_score:
|
||||||
|
best_score = rotated_cw_score
|
||||||
|
best_img = rotated_cw
|
||||||
|
|
||||||
|
# Try counter-clockwise 90° rotation
|
||||||
|
rotated_ccw = np.rot90(dst_img, k=1)
|
||||||
|
rec_result = self.text_recognizer[0]([rotated_ccw])
|
||||||
|
rotated_ccw_text, rotated_ccw_score = rec_result[0][0]
|
||||||
|
if rotated_ccw_score > best_score:
|
||||||
|
best_img = rotated_ccw
|
||||||
|
|
||||||
|
# Use the best image
|
||||||
|
dst_img = best_img
|
||||||
return dst_img
|
return dst_img
|
||||||
|
|
||||||
def sorted_boxes(self, dt_boxes):
|
def sorted_boxes(self, dt_boxes):
|
||||||
|
|||||||
@ -52,20 +52,20 @@ class Recognizer:
|
|||||||
self.label_list = label_list
|
self.label_list = label_list
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def sort_Y_firstly(arr, threashold):
|
def sort_Y_firstly(arr, threshold):
|
||||||
def cmp(c1, c2):
|
def cmp(c1, c2):
|
||||||
diff = c1["top"] - c2["top"]
|
diff = c1["top"] - c2["top"]
|
||||||
if abs(diff) < threashold:
|
if abs(diff) < threshold:
|
||||||
diff = c1["x0"] - c2["x0"]
|
diff = c1["x0"] - c2["x0"]
|
||||||
return diff
|
return diff
|
||||||
arr = sorted(arr, key=cmp_to_key(cmp))
|
arr = sorted(arr, key=cmp_to_key(cmp))
|
||||||
return arr
|
return arr
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def sort_X_firstly(arr, threashold):
|
def sort_X_firstly(arr, threshold):
|
||||||
def cmp(c1, c2):
|
def cmp(c1, c2):
|
||||||
diff = c1["x0"] - c2["x0"]
|
diff = c1["x0"] - c2["x0"]
|
||||||
if abs(diff) < threashold:
|
if abs(diff) < threshold:
|
||||||
diff = c1["top"] - c2["top"]
|
diff = c1["top"] - c2["top"]
|
||||||
return diff
|
return diff
|
||||||
arr = sorted(arr, key=cmp_to_key(cmp))
|
arr = sorted(arr, key=cmp_to_key(cmp))
|
||||||
@ -133,7 +133,7 @@ class Recognizer:
|
|||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def layouts_cleanup(boxes, layouts, far=2, thr=0.7):
|
def layouts_cleanup(boxes, layouts, far=2, thr=0.7):
|
||||||
def notOverlapped(a, b):
|
def not_overlapped(a, b):
|
||||||
return any([a["x1"] < b["x0"],
|
return any([a["x1"] < b["x0"],
|
||||||
a["x0"] > b["x1"],
|
a["x0"] > b["x1"],
|
||||||
a["bottom"] < b["top"],
|
a["bottom"] < b["top"],
|
||||||
@ -144,7 +144,7 @@ class Recognizer:
|
|||||||
j = i + 1
|
j = i + 1
|
||||||
while j < min(i + far, len(layouts)) \
|
while j < min(i + far, len(layouts)) \
|
||||||
and (layouts[i].get("type", "") != layouts[j].get("type", "")
|
and (layouts[i].get("type", "") != layouts[j].get("type", "")
|
||||||
or notOverlapped(layouts[i], layouts[j])):
|
or not_overlapped(layouts[i], layouts[j])):
|
||||||
j += 1
|
j += 1
|
||||||
if j >= min(i + far, len(layouts)):
|
if j >= min(i + far, len(layouts)):
|
||||||
i += 1
|
i += 1
|
||||||
@ -163,9 +163,9 @@ class Recognizer:
|
|||||||
|
|
||||||
area_i, area_i_1 = 0, 0
|
area_i, area_i_1 = 0, 0
|
||||||
for b in boxes:
|
for b in boxes:
|
||||||
if not notOverlapped(b, layouts[i]):
|
if not not_overlapped(b, layouts[i]):
|
||||||
area_i += Recognizer.overlapped_area(b, layouts[i], False)
|
area_i += Recognizer.overlapped_area(b, layouts[i], False)
|
||||||
if not notOverlapped(b, layouts[j]):
|
if not not_overlapped(b, layouts[j]):
|
||||||
area_i_1 += Recognizer.overlapped_area(b, layouts[j], False)
|
area_i_1 += Recognizer.overlapped_area(b, layouts[j], False)
|
||||||
|
|
||||||
if area_i > area_i_1:
|
if area_i > area_i_1:
|
||||||
@ -239,15 +239,15 @@ class Recognizer:
|
|||||||
e -= 1
|
e -= 1
|
||||||
break
|
break
|
||||||
|
|
||||||
max_overlaped_i, max_overlaped = None, 0
|
max_overlapped_i, max_overlapped = None, 0
|
||||||
for i in range(s, e):
|
for i in range(s, e):
|
||||||
ov = Recognizer.overlapped_area(bxs[i], box)
|
ov = Recognizer.overlapped_area(bxs[i], box)
|
||||||
if ov <= max_overlaped:
|
if ov <= max_overlapped:
|
||||||
continue
|
continue
|
||||||
max_overlaped_i = i
|
max_overlapped_i = i
|
||||||
max_overlaped = ov
|
max_overlapped = ov
|
||||||
|
|
||||||
return max_overlaped_i
|
return max_overlapped_i
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def find_horizontally_tightest_fit(box, boxes):
|
def find_horizontally_tightest_fit(box, boxes):
|
||||||
@ -264,7 +264,7 @@ class Recognizer:
|
|||||||
return min_i
|
return min_i
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def find_overlapped_with_threashold(box, boxes, thr=0.3):
|
def find_overlapped_with_threshold(box, boxes, thr=0.3):
|
||||||
if not boxes:
|
if not boxes:
|
||||||
return
|
return
|
||||||
max_overlapped_i, max_overlapped, _max_overlapped = None, thr, 0
|
max_overlapped_i, max_overlapped, _max_overlapped = None, thr, 0
|
||||||
@ -408,18 +408,18 @@ class Recognizer:
|
|||||||
|
|
||||||
def __call__(self, image_list, thr=0.7, batch_size=16):
|
def __call__(self, image_list, thr=0.7, batch_size=16):
|
||||||
res = []
|
res = []
|
||||||
imgs = []
|
images = []
|
||||||
for i in range(len(image_list)):
|
for i in range(len(image_list)):
|
||||||
if not isinstance(image_list[i], np.ndarray):
|
if not isinstance(image_list[i], np.ndarray):
|
||||||
imgs.append(np.array(image_list[i]))
|
images.append(np.array(image_list[i]))
|
||||||
else:
|
else:
|
||||||
imgs.append(image_list[i])
|
images.append(image_list[i])
|
||||||
|
|
||||||
batch_loop_cnt = math.ceil(float(len(imgs)) / batch_size)
|
batch_loop_cnt = math.ceil(float(len(images)) / batch_size)
|
||||||
for i in range(batch_loop_cnt):
|
for i in range(batch_loop_cnt):
|
||||||
start_index = i * batch_size
|
start_index = i * batch_size
|
||||||
end_index = min((i + 1) * batch_size, len(imgs))
|
end_index = min((i + 1) * batch_size, len(images))
|
||||||
batch_image_list = imgs[start_index:end_index]
|
batch_image_list = images[start_index:end_index]
|
||||||
inputs = self.preprocess(batch_image_list)
|
inputs = self.preprocess(batch_image_list)
|
||||||
logging.debug("preprocess")
|
logging.debug("preprocess")
|
||||||
for ins in inputs:
|
for ins in inputs:
|
||||||
|
|||||||
@ -84,13 +84,13 @@ def get_table_html(img, tb_cpns, ocr):
|
|||||||
clmns = LayoutRecognizer.layouts_cleanup(boxes, clmns, 5, 0.5)
|
clmns = LayoutRecognizer.layouts_cleanup(boxes, clmns, 5, 0.5)
|
||||||
|
|
||||||
for b in boxes:
|
for b in boxes:
|
||||||
ii = LayoutRecognizer.find_overlapped_with_threashold(b, rows, thr=0.3)
|
ii = LayoutRecognizer.find_overlapped_with_threshold(b, rows, thr=0.3)
|
||||||
if ii is not None:
|
if ii is not None:
|
||||||
b["R"] = ii
|
b["R"] = ii
|
||||||
b["R_top"] = rows[ii]["top"]
|
b["R_top"] = rows[ii]["top"]
|
||||||
b["R_bott"] = rows[ii]["bottom"]
|
b["R_bott"] = rows[ii]["bottom"]
|
||||||
|
|
||||||
ii = LayoutRecognizer.find_overlapped_with_threashold(b, headers, thr=0.3)
|
ii = LayoutRecognizer.find_overlapped_with_threshold(b, headers, thr=0.3)
|
||||||
if ii is not None:
|
if ii is not None:
|
||||||
b["H_top"] = headers[ii]["top"]
|
b["H_top"] = headers[ii]["top"]
|
||||||
b["H_bott"] = headers[ii]["bottom"]
|
b["H_bott"] = headers[ii]["bottom"]
|
||||||
@ -104,7 +104,7 @@ def get_table_html(img, tb_cpns, ocr):
|
|||||||
b["C_left"] = clmns[ii]["x0"]
|
b["C_left"] = clmns[ii]["x0"]
|
||||||
b["C_right"] = clmns[ii]["x1"]
|
b["C_right"] = clmns[ii]["x1"]
|
||||||
|
|
||||||
ii = LayoutRecognizer.find_overlapped_with_threashold(b, spans, thr=0.3)
|
ii = LayoutRecognizer.find_overlapped_with_threshold(b, spans, thr=0.3)
|
||||||
if ii is not None:
|
if ii is not None:
|
||||||
b["H_top"] = spans[ii]["top"]
|
b["H_top"] = spans[ii]["top"]
|
||||||
b["H_bott"] = spans[ii]["bottom"]
|
b["H_bott"] = spans[ii]["bottom"]
|
||||||
|
|||||||
18
docker/.env
18
docker/.env
@ -91,13 +91,13 @@ REDIS_PASSWORD=infini_rag_flow
|
|||||||
SVR_HTTP_PORT=9380
|
SVR_HTTP_PORT=9380
|
||||||
|
|
||||||
# The RAGFlow Docker image to download.
|
# The RAGFlow Docker image to download.
|
||||||
# Defaults to the v0.18.0-slim edition, which is the RAGFlow Docker image without embedding models.
|
# Defaults to the v0.19.0-slim edition, which is the RAGFlow Docker image without embedding models.
|
||||||
RAGFLOW_IMAGE=infiniflow/ragflow:v0.18.0-slim
|
RAGFLOW_IMAGE=infiniflow/ragflow:v0.19.0-slim
|
||||||
#
|
#
|
||||||
# To download the RAGFlow Docker image with embedding models, uncomment the following line instead:
|
# To download the RAGFlow Docker image with embedding models, uncomment the following line instead:
|
||||||
# RAGFLOW_IMAGE=infiniflow/ragflow:v0.18.0
|
# RAGFLOW_IMAGE=infiniflow/ragflow:v0.19.0
|
||||||
#
|
#
|
||||||
# The Docker image of the v0.18.0 edition includes built-in embedding models:
|
# The Docker image of the v0.19.0 edition includes built-in embedding models:
|
||||||
# - BAAI/bge-large-zh-v1.5
|
# - BAAI/bge-large-zh-v1.5
|
||||||
# - maidalun1020/bce-embedding-base_v1
|
# - maidalun1020/bce-embedding-base_v1
|
||||||
#
|
#
|
||||||
@ -129,6 +129,14 @@ TIMEZONE='Asia/Shanghai'
|
|||||||
# Note that neither `MAX_CONTENT_LENGTH` nor `client_max_body_size` sets the maximum size for files uploaded to an agent.
|
# Note that neither `MAX_CONTENT_LENGTH` nor `client_max_body_size` sets the maximum size for files uploaded to an agent.
|
||||||
# See https://ragflow.io/docs/dev/begin_component for details.
|
# See https://ragflow.io/docs/dev/begin_component for details.
|
||||||
|
|
||||||
|
# Controls how many documents are processed in a single batch.
|
||||||
|
# Defaults to 4 if DOC_BULK_SIZE is not explicitly set.
|
||||||
|
DOC_BULK_SIZE=${DOC_BULK_SIZE:-4}
|
||||||
|
|
||||||
|
# Defines the number of items to process per batch when generating embeddings.
|
||||||
|
# Defaults to 16 if EMBEDDING_BATCH_SIZE is not set in the environment.
|
||||||
|
EMBEDDING_BATCH_SIZE=${EMBEDDING_BATCH_SIZE:-16}
|
||||||
|
|
||||||
# Log level for the RAGFlow's own and imported packages.
|
# Log level for the RAGFlow's own and imported packages.
|
||||||
# Available levels:
|
# Available levels:
|
||||||
# - `DEBUG`
|
# - `DEBUG`
|
||||||
@ -169,6 +177,8 @@ REGISTER_ENABLED=1
|
|||||||
# SANDBOX_BASE_NODEJS_IMAGE=infiniflow/sandbox-base-nodejs:latest
|
# SANDBOX_BASE_NODEJS_IMAGE=infiniflow/sandbox-base-nodejs:latest
|
||||||
# SANDBOX_EXECUTOR_MANAGER_PORT=9385
|
# SANDBOX_EXECUTOR_MANAGER_PORT=9385
|
||||||
# SANDBOX_ENABLE_SECCOMP=false
|
# SANDBOX_ENABLE_SECCOMP=false
|
||||||
|
# SANDBOX_MAX_MEMORY=256m # b, k, m, g
|
||||||
|
# SANDBOX_TIMEOUT=10s # s, m, 1m30s
|
||||||
|
|
||||||
# Important: To enable sandbox, you must re-declare the compose profiles.
|
# Important: To enable sandbox, you must re-declare the compose profiles.
|
||||||
# 1. Comment out the COMPOSE_PROFILES line above.
|
# 1. Comment out the COMPOSE_PROFILES line above.
|
||||||
|
|||||||
@ -78,8 +78,8 @@ The [.env](./.env) file contains important environment variables for Docker.
|
|||||||
- `RAGFLOW-IMAGE`
|
- `RAGFLOW-IMAGE`
|
||||||
The Docker image edition. Available editions:
|
The Docker image edition. Available editions:
|
||||||
|
|
||||||
- `infiniflow/ragflow:v0.18.0-slim` (default): The RAGFlow Docker image without embedding models.
|
- `infiniflow/ragflow:v0.19.1-slim` (default): The RAGFlow Docker image without embedding models.
|
||||||
- `infiniflow/ragflow:v0.18.0`: The RAGFlow Docker image with embedding models including:
|
- `infiniflow/ragflow:v0.19.1`: The RAGFlow Docker image with embedding models including:
|
||||||
- Built-in embedding models:
|
- Built-in embedding models:
|
||||||
- `BAAI/bge-large-zh-v1.5`
|
- `BAAI/bge-large-zh-v1.5`
|
||||||
- `maidalun1020/bce-embedding-base_v1`
|
- `maidalun1020/bce-embedding-base_v1`
|
||||||
@ -115,6 +115,16 @@ The [.env](./.env) file contains important environment variables for Docker.
|
|||||||
- `MAX_CONTENT_LENGTH`
|
- `MAX_CONTENT_LENGTH`
|
||||||
The maximum file size for each uploaded file, in bytes. You can uncomment this line if you wish to change the 128M file size limit. After making the change, ensure you update `client_max_body_size` in nginx/nginx.conf correspondingly.
|
The maximum file size for each uploaded file, in bytes. You can uncomment this line if you wish to change the 128M file size limit. After making the change, ensure you update `client_max_body_size` in nginx/nginx.conf correspondingly.
|
||||||
|
|
||||||
|
### Doc bulk size
|
||||||
|
|
||||||
|
- `DOC_BULK_SIZE`
|
||||||
|
The number of document chunks processed in a single batch during document parsing. Defaults to `4`.
|
||||||
|
|
||||||
|
### Embedding batch size
|
||||||
|
|
||||||
|
- `EMBEDDING_BATCH_SIZE`
|
||||||
|
The number of text chunks processed in a single batch during embedding vectorization. Defaults to `16`.
|
||||||
|
|
||||||
## 🐋 Service configuration
|
## 🐋 Service configuration
|
||||||
|
|
||||||
[service_conf.yaml](./service_conf.yaml) specifies the system-level configuration for RAGFlow and is used by its API server and task executor. In a dockerized setup, this file is automatically created based on the [service_conf.yaml.template](./service_conf.yaml.template) file (replacing all environment variables by their values).
|
[service_conf.yaml](./service_conf.yaml) specifies the system-level configuration for RAGFlow and is used by its API server and task executor. In a dockerized setup, this file is automatically created based on the [service_conf.yaml.template](./service_conf.yaml.template) file (replacing all environment variables by their values).
|
||||||
|
|||||||
@ -124,6 +124,8 @@ services:
|
|||||||
- SANDBOX_BASE_PYTHON_IMAGE=${SANDBOX_BASE_PYTHON_IMAGE:-infiniflow/sandbox-base-python:latest}
|
- SANDBOX_BASE_PYTHON_IMAGE=${SANDBOX_BASE_PYTHON_IMAGE:-infiniflow/sandbox-base-python:latest}
|
||||||
- SANDBOX_BASE_NODEJS_IMAGE=${SANDBOX_BASE_NODEJS_IMAGE:-infiniflow/sandbox-base-nodejs:latest}
|
- SANDBOX_BASE_NODEJS_IMAGE=${SANDBOX_BASE_NODEJS_IMAGE:-infiniflow/sandbox-base-nodejs:latest}
|
||||||
- SANDBOX_ENABLE_SECCOMP=${SANDBOX_ENABLE_SECCOMP:-false}
|
- SANDBOX_ENABLE_SECCOMP=${SANDBOX_ENABLE_SECCOMP:-false}
|
||||||
|
- SANDBOX_MAX_MEMORY=${SANDBOX_MAX_MEMORY:-256m}
|
||||||
|
- SANDBOX_TIMEOUT=${SANDBOX_TIMEOUT:-10s}
|
||||||
healthcheck:
|
healthcheck:
|
||||||
test: ["CMD", "curl", "http://localhost:9385/healthz"]
|
test: ["CMD", "curl", "http://localhost:9385/healthz"]
|
||||||
interval: 10s
|
interval: 10s
|
||||||
|
|||||||
@ -1,3 +1,4 @@
|
|||||||
|
|
||||||
include:
|
include:
|
||||||
- ./docker-compose-base.yml
|
- ./docker-compose-base.yml
|
||||||
|
|
||||||
|
|||||||
@ -20,7 +20,7 @@ es:
|
|||||||
os:
|
os:
|
||||||
hosts: 'http://${OS_HOST:-opensearch01}:9201'
|
hosts: 'http://${OS_HOST:-opensearch01}:9201'
|
||||||
username: '${OS_USER:-admin}'
|
username: '${OS_USER:-admin}'
|
||||||
password: '${OPENSEARCHH_PASSWORD:-infini_rag_flow_OS_01}'
|
password: '${OPENSEARCH_PASSWORD:-infini_rag_flow_OS_01}'
|
||||||
infinity:
|
infinity:
|
||||||
uri: '${INFINITY_HOST:-infinity}:23817'
|
uri: '${INFINITY_HOST:-infinity}:23817'
|
||||||
db_name: 'default_db'
|
db_name: 'default_db'
|
||||||
|
|||||||
@ -99,8 +99,8 @@ RAGFlow utilizes MinIO as its object storage solution, leveraging its scalabilit
|
|||||||
- `RAGFLOW-IMAGE`
|
- `RAGFLOW-IMAGE`
|
||||||
The Docker image edition. Available editions:
|
The Docker image edition. Available editions:
|
||||||
|
|
||||||
- `infiniflow/ragflow:v0.18.0-slim` (default): The RAGFlow Docker image without embedding models.
|
- `infiniflow/ragflow:v0.19.1-slim` (default): The RAGFlow Docker image without embedding models.
|
||||||
- `infiniflow/ragflow:v0.18.0`: The RAGFlow Docker image with embedding models including:
|
- `infiniflow/ragflow:v0.19.1`: The RAGFlow Docker image with embedding models including:
|
||||||
- Built-in embedding models:
|
- Built-in embedding models:
|
||||||
- `BAAI/bge-large-zh-v1.5`
|
- `BAAI/bge-large-zh-v1.5`
|
||||||
- `maidalun1020/bce-embedding-base_v1`
|
- `maidalun1020/bce-embedding-base_v1`
|
||||||
|
|||||||
@ -77,7 +77,7 @@ After building the infiniflow/ragflow:nightly-slim image, you are ready to launc
|
|||||||
|
|
||||||
1. Edit Docker Compose Configuration
|
1. Edit Docker Compose Configuration
|
||||||
|
|
||||||
Open the `docker/.env` file. Find the `RAGFLOW_IMAGE` setting and change the image reference from `infiniflow/ragflow:v0.18.0-slim` to `infiniflow/ragflow:nightly-slim` to use the pre-built image.
|
Open the `docker/.env` file. Find the `RAGFLOW_IMAGE` setting and change the image reference from `infiniflow/ragflow:v0.19.1-slim` to `infiniflow/ragflow:nightly-slim` to use the pre-built image.
|
||||||
|
|
||||||
|
|
||||||
2. Launch the Service
|
2. Launch the Service
|
||||||
|
|||||||
@ -23,7 +23,7 @@ Once a connection is established, an MCP server communicates with its client in
|
|||||||
## Prerequisites
|
## Prerequisites
|
||||||
|
|
||||||
1. Ensure RAGFlow is upgraded to v0.18.0 or later.
|
1. Ensure RAGFlow is upgraded to v0.18.0 or later.
|
||||||
2. Have your RAGFlow API key ready. See [Acquire a RAGFlow API key](./acquire_ragflow_api_key.md).
|
2. Have your RAGFlow API key ready. See [Acquire a RAGFlow API key](../acquire_ragflow_api_key.md).
|
||||||
|
|
||||||
:::tip INFO
|
:::tip INFO
|
||||||
If you wish to try out our MCP server without upgrading RAGFlow, community contributor [yiminghub2024](https://github.com/yiminghub2024) 👏 shares their recommended steps [here](#launch-an-mcp-server-without-upgrading-ragflow).
|
If you wish to try out our MCP server without upgrading RAGFlow, community contributor [yiminghub2024](https://github.com/yiminghub2024) 👏 shares their recommended steps [here](#launch-an-mcp-server-without-upgrading-ragflow).
|
||||||
@ -42,10 +42,10 @@ You can start an MCP server either from source code or via Docker.
|
|||||||
```bash
|
```bash
|
||||||
# Launch the MCP server to work in self-host mode, run either of the following
|
# Launch the MCP server to work in self-host mode, run either of the following
|
||||||
uv run mcp/server/server.py --host=127.0.0.1 --port=9382 --base_url=http://127.0.0.1:9380 --api_key=ragflow-xxxxx
|
uv run mcp/server/server.py --host=127.0.0.1 --port=9382 --base_url=http://127.0.0.1:9380 --api_key=ragflow-xxxxx
|
||||||
# uv run mcp/server/server.py --host=127.0.0.1 --port=9382 --base_url=http://127.0.0.1:9380 mode=self-host --api_key=ragflow-xxxxx
|
# uv run mcp/server/server.py --host=127.0.0.1 --port=9382 --base_url=http://127.0.0.1:9380 --mode=self-host --api_key=ragflow-xxxxx
|
||||||
|
|
||||||
# To launch the MCP server to work in host mode, run the following instead:
|
# To launch the MCP server to work in host mode, run the following instead:
|
||||||
# uv run mcp/server/server.py --host=127.0.0.1 --port=9382 --base_url=http://127.0.0.1:9380 mode=host
|
# uv run mcp/server/server.py --host=127.0.0.1 --port=9382 --base_url=http://127.0.0.1:9380 --mode=host
|
||||||
```
|
```
|
||||||
|
|
||||||
Where:
|
Where:
|
||||||
|
|||||||
@ -1,16 +1,240 @@
|
|||||||
---
|
---
|
||||||
sidebar_position: 3
|
sidebar_position: 3
|
||||||
slug: /mcp_client
|
slug: /mcp_client
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
# RAGFlow MCP client example
|
# RAGFlow MCP client examples
|
||||||
|
|
||||||
|
Python and curl MCP client examples.
|
||||||
|
|
||||||
|
------
|
||||||
|
|
||||||
|
## Example MCP Python client
|
||||||
|
|
||||||
We provide a *prototype* MCP client example for testing [here](https://github.com/infiniflow/ragflow/blob/main/mcp/client/client.py).
|
We provide a *prototype* MCP client example for testing [here](https://github.com/infiniflow/ragflow/blob/main/mcp/client/client.py).
|
||||||
|
|
||||||
:::danger IMPORTANT
|
:::danger IMPORTANT
|
||||||
If your MCP server is running in host mode, include your acquired API key in your client's `headers` as shown below:
|
If your MCP server is running in host mode, include your acquired API key in your client's `headers` when connecting asynchronously to it:
|
||||||
|
|
||||||
```python
|
```python
|
||||||
async with sse_client("http://localhost:9382/sse", headers={"api_key": "YOUR_KEY_HERE"}) as streams:
|
async with sse_client("http://localhost:9382/sse", headers={"api_key": "YOUR_KEY_HERE"}) as streams:
|
||||||
# Rest of your code...
|
# Rest of your code...
|
||||||
```
|
```
|
||||||
:::
|
|
||||||
|
Alternatively, to comply with [OAuth 2.1 Section 5](https://datatracker.ietf.org/doc/html/draft-ietf-oauth-v2-1-12#section-5), you can run the following code *instead* to connect to your MCP server:
|
||||||
|
|
||||||
|
```python
|
||||||
|
async with sse_client("http://localhost:9382/sse", headers={"Authorization": "YOUR_KEY_HERE"}) as streams:
|
||||||
|
# Rest of your code...
|
||||||
|
```
|
||||||
|
:::
|
||||||
|
|
||||||
|
## Use curl to interact with the RAGFlow MCP server
|
||||||
|
|
||||||
|
When interacting with the MCP server via HTTP requests, follow this initialization sequence:
|
||||||
|
|
||||||
|
1. **The client sends an `initialize` request** with protocol version and capabilities.
|
||||||
|
2. **The server replies with an `initialize` response**, including the supported protocol and capabilities.
|
||||||
|
3. **The client confirms readiness with an `initialized` notification**.
|
||||||
|
_The connection is established between the client and the server, and further operations (such as tool listing) may proceed._
|
||||||
|
|
||||||
|
:::tip NOTE
|
||||||
|
For more information about this initialization process, see [here](https://modelcontextprotocol.io/docs/concepts/architecture#1-initialization).
|
||||||
|
:::
|
||||||
|
|
||||||
|
In the following sections, we will walk you through a complete tool calling process.
|
||||||
|
|
||||||
|
### 1. Obtain a session ID
|
||||||
|
|
||||||
|
Each curl request with the MCP server must include a session ID:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ curl -N -H "api_key: YOUR_API_KEY" http://127.0.0.1:9382/sse
|
||||||
|
```
|
||||||
|
|
||||||
|
:::tip NOTE
|
||||||
|
See [here](../acquire_ragflow_api_key.md) for information about acquiring an API key.
|
||||||
|
:::
|
||||||
|
|
||||||
|
#### Transport
|
||||||
|
|
||||||
|
The transport will stream messages such as tool results, server responses, and keep-alive pings.
|
||||||
|
|
||||||
|
_The server returns the session ID:_
|
||||||
|
|
||||||
|
```bash
|
||||||
|
event: endpoint
|
||||||
|
data: /messages/?session_id=5c6600ef61b845a788ddf30dceb25c54
|
||||||
|
```
|
||||||
|
|
||||||
|
### 2. Send an `Initialize` request
|
||||||
|
|
||||||
|
The client sends an `initialize` request with protocol version and capabilities:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
session_id="5c6600ef61b845a788ddf30dceb25c54" && \
|
||||||
|
|
||||||
|
curl -X POST "http://127.0.0.1:9382/messages/?session_id=$session_id" \
|
||||||
|
-H "api_key: YOUR_API_KEY" \
|
||||||
|
-H "Content-Type: application/json" \
|
||||||
|
-d '{
|
||||||
|
"jsonrpc": "2.0",
|
||||||
|
"id": 1,
|
||||||
|
"method": "initialize",
|
||||||
|
"params": {
|
||||||
|
"protocolVersion": "1.0",
|
||||||
|
"capabilities": {},
|
||||||
|
"clientInfo": {
|
||||||
|
"name": "ragflow-mcp-client",
|
||||||
|
"version": "0.1"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}' && \
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Transport
|
||||||
|
|
||||||
|
_The server replies with an `initialize` response, including the supported protocol and capabilities:_
|
||||||
|
|
||||||
|
```bash
|
||||||
|
event: message
|
||||||
|
data: {"jsonrpc":"2.0","id":1,"result":{"protocolVersion":"2025-03-26","capabilities":{"experimental":{"headers":{"host":"127.0.0.1:9382","user-agent":"curl/8.7.1","accept":"*/*","api_key":"ragflow-xxxxxxxxxxxx","accept-encoding":"gzip"}},"tools":{"listChanged":false}},"serverInfo":{"name":"ragflow-server","version":"1.9.4"}}}
|
||||||
|
```
|
||||||
|
|
||||||
|
### 3. Acknowledge readiness
|
||||||
|
|
||||||
|
The client confirms readiness with an `initialized` notification:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
curl -X POST "http://127.0.0.1:9382/messages/?session_id=$session_id" \
|
||||||
|
-H "api_key: YOUR_API_KEY" \
|
||||||
|
-H "Content-Type: application/json" \
|
||||||
|
-d '{
|
||||||
|
"jsonrpc": "2.0",
|
||||||
|
"method": "notifications/initialized",
|
||||||
|
"params": {}
|
||||||
|
}' && \
|
||||||
|
```
|
||||||
|
|
||||||
|
_The connection is established between the client and the server, and further operations (such as tool listing) may proceed._
|
||||||
|
|
||||||
|
### 4. Tool listing
|
||||||
|
|
||||||
|
```bash
|
||||||
|
curl -X POST "http://127.0.0.1:9382/messages/?session_id=$session_id" \
|
||||||
|
-H "api_key: YOUR_API_KEY" \
|
||||||
|
-H "Content-Type: application/json" \
|
||||||
|
-d '{
|
||||||
|
"jsonrpc": "2.0",
|
||||||
|
"id": 3,
|
||||||
|
"method": "tools/list",
|
||||||
|
"params": {}
|
||||||
|
}' && \
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Transport
|
||||||
|
|
||||||
|
```bash
|
||||||
|
event: message
|
||||||
|
data: {"jsonrpc":"2.0","id":3,"result":{"tools":[{"name":"ragflow_retrieval","description":"Retrieve relevant chunks from the RAGFlow retrieve interface based on the question, using the specified dataset_ids and optionally document_ids. Below is the list of all available datasets, including their descriptions and IDs. If you're unsure which datasets are relevant to the question, simply pass all dataset IDs to the function.","inputSchema":{"type":"object","properties":{"dataset_ids":{"type":"array","items":{"type":"string"}},"document_ids":{"type":"array","items":{"type":"string"}},"question":{"type":"string"}},"required":["dataset_ids","question"]}}]}}
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
### 5. Tool calling
|
||||||
|
|
||||||
|
```bash
|
||||||
|
curl -X POST "http://127.0.0.1:9382/messages/?session_id=$session_id" \
|
||||||
|
-H "api_key: YOUR_API_KEY" \
|
||||||
|
-H "Content-Type: application/json" \
|
||||||
|
-d '{
|
||||||
|
"jsonrpc": "2.0",
|
||||||
|
"id": 4,
|
||||||
|
"method": "tools/call",
|
||||||
|
"params": {
|
||||||
|
"name": "ragflow_retrieval",
|
||||||
|
"arguments": {
|
||||||
|
"question": "How to install neovim?",
|
||||||
|
"dataset_ids": ["DATASET_ID_HERE"],
|
||||||
|
"document_ids": []
|
||||||
|
}
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Transport
|
||||||
|
|
||||||
|
```bash
|
||||||
|
event: message
|
||||||
|
data: {"jsonrpc":"2.0","id":4,"result":{...}}
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
### A complete curl example
|
||||||
|
|
||||||
|
```bash
|
||||||
|
session_id="YOUR_SESSION_ID" && \
|
||||||
|
|
||||||
|
# Step 1: Initialize request
|
||||||
|
curl -X POST "http://127.0.0.1:9382/messages/?session_id=$session_id" \
|
||||||
|
-H "api_key: YOUR_API_KEY" \
|
||||||
|
-H "Content-Type: application/json" \
|
||||||
|
-d '{
|
||||||
|
"jsonrpc": "2.0",
|
||||||
|
"id": 1,
|
||||||
|
"method": "initialize",
|
||||||
|
"params": {
|
||||||
|
"protocolVersion": "1.0",
|
||||||
|
"capabilities": {},
|
||||||
|
"clientInfo": {
|
||||||
|
"name": "ragflow-mcp-client",
|
||||||
|
"version": "0.1"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}' && \
|
||||||
|
|
||||||
|
sleep 2 && \
|
||||||
|
|
||||||
|
# Step 2: Initialized notification
|
||||||
|
curl -X POST "http://127.0.0.1:9382/messages/?session_id=$session_id" \
|
||||||
|
-H "api_key: YOUR_API_KEY" \
|
||||||
|
-H "Content-Type: application/json" \
|
||||||
|
-d '{
|
||||||
|
"jsonrpc": "2.0",
|
||||||
|
"method": "notifications/initialized",
|
||||||
|
"params": {}
|
||||||
|
}' && \
|
||||||
|
|
||||||
|
sleep 2 && \
|
||||||
|
|
||||||
|
# Step 3: Tool listing
|
||||||
|
curl -X POST "http://127.0.0.1:9382/messages/?session_id=$session_id" \
|
||||||
|
-H "api_key: YOUR_API_KEY" \
|
||||||
|
-H "Content-Type: application/json" \
|
||||||
|
-d '{
|
||||||
|
"jsonrpc": "2.0",
|
||||||
|
"id": 3,
|
||||||
|
"method": "tools/list",
|
||||||
|
"params": {}
|
||||||
|
}' && \
|
||||||
|
|
||||||
|
sleep 2 && \
|
||||||
|
|
||||||
|
# Step 4: Tool call
|
||||||
|
curl -X POST "http://127.0.0.1:9382/messages/?session_id=$session_id" \
|
||||||
|
-H "api_key: YOUR_API_KEY" \
|
||||||
|
-H "Content-Type: application/json" \
|
||||||
|
-d '{
|
||||||
|
"jsonrpc": "2.0",
|
||||||
|
"id": 4,
|
||||||
|
"method": "tools/call",
|
||||||
|
"params": {
|
||||||
|
"name": "ragflow_retrieval",
|
||||||
|
"arguments": {
|
||||||
|
"question": "How to install neovim?",
|
||||||
|
"dataset_ids": ["DATASET_ID_HERE"],
|
||||||
|
"document_ids": []
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}'
|
||||||
|
|
||||||
|
```
|
||||||
|
|||||||
@ -11,7 +11,7 @@ Switch your doc engine from Elasticsearch to Infinity.
|
|||||||
|
|
||||||
RAGFlow uses Elasticsearch by default for storing full text and vectors. To switch to [Infinity](https://github.com/infiniflow/infinity/), follow these steps:
|
RAGFlow uses Elasticsearch by default for storing full text and vectors. To switch to [Infinity](https://github.com/infiniflow/infinity/), follow these steps:
|
||||||
|
|
||||||
:::danger WARNING
|
:::caution WARNING
|
||||||
Switching to Infinity on a Linux/arm64 machine is not yet officially supported.
|
Switching to Infinity on a Linux/arm64 machine is not yet officially supported.
|
||||||
:::
|
:::
|
||||||
|
|
||||||
@ -21,7 +21,7 @@ Switching to Infinity on a Linux/arm64 machine is not yet officially supported.
|
|||||||
$ docker compose -f docker/docker-compose.yml down -v
|
$ docker compose -f docker/docker-compose.yml down -v
|
||||||
```
|
```
|
||||||
|
|
||||||
:::cautiion WARNING
|
:::caution WARNING
|
||||||
`-v` will delete the docker container volumes, and the existing data will be cleared.
|
`-v` will delete the docker container volumes, and the existing data will be cleared.
|
||||||
:::
|
:::
|
||||||
|
|
||||||
|
|||||||
34
docs/faq.mdx
34
docs/faq.mdx
@ -19,7 +19,7 @@ import TOCInline from '@theme/TOCInline';
|
|||||||
|
|
||||||
### What sets RAGFlow apart from other RAG products?
|
### What sets RAGFlow apart from other RAG products?
|
||||||
|
|
||||||
The "garbage in garbage out" status quo remains unchanged despite the fact that LLMs have advanced Natural Language Processing (NLP) significantly. In response, RAGFlow introduces two unique features compared to other Retrieval-Augmented Generation (RAG) products.
|
The "garbage in garbage out" status quo remains unchanged despite the fact that LLMs have advanced Natural Language Processing (NLP) significantly. In its response, RAGFlow introduces two unique features compared to other Retrieval-Augmented Generation (RAG) products.
|
||||||
|
|
||||||
- Fine-grained document parsing: Document parsing involves images and tables, with the flexibility for you to intervene as needed.
|
- Fine-grained document parsing: Document parsing involves images and tables, with the flexibility for you to intervene as needed.
|
||||||
- Traceable answers with reduced hallucinations: You can trust RAGFlow's responses as you can view the citations and references supporting them.
|
- Traceable answers with reduced hallucinations: You can trust RAGFlow's responses as you can view the citations and references supporting them.
|
||||||
@ -30,17 +30,17 @@ The "garbage in garbage out" status quo remains unchanged despite the fact that
|
|||||||
|
|
||||||
Each RAGFlow release is available in two editions:
|
Each RAGFlow release is available in two editions:
|
||||||
|
|
||||||
- **Slim edition**: excludes built-in embedding models and is identified by a **-slim** suffix added to the version name. Example: `infiniflow/ragflow:v0.18.0-slim`
|
- **Slim edition**: excludes built-in embedding models and is identified by a **-slim** suffix added to the version name. Example: `infiniflow/ragflow:v0.19.1-slim`
|
||||||
- **Full edition**: includes built-in embedding models and has no suffix added to the version name. Example: `infiniflow/ragflow:v0.18.0`
|
- **Full edition**: includes built-in embedding models and has no suffix added to the version name. Example: `infiniflow/ragflow:v0.19.1`
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
### Which embedding models can be deployed locally?
|
### Which embedding models can be deployed locally?
|
||||||
|
|
||||||
RAGFlow offers two Docker image editions, `v0.18.0-slim` and `v0.18.0`:
|
RAGFlow offers two Docker image editions, `v0.19.1-slim` and `v0.19.1`:
|
||||||
|
|
||||||
- `infiniflow/ragflow:v0.18.0-slim` (default): The RAGFlow Docker image without embedding models.
|
- `infiniflow/ragflow:v0.19.1-slim` (default): The RAGFlow Docker image without embedding models.
|
||||||
- `infiniflow/ragflow:v0.18.0`: The RAGFlow Docker image with embedding models including:
|
- `infiniflow/ragflow:v0.19.1`: The RAGFlow Docker image with embedding models including:
|
||||||
- Built-in embedding models:
|
- Built-in embedding models:
|
||||||
- `BAAI/bge-large-zh-v1.5`
|
- `BAAI/bge-large-zh-v1.5`
|
||||||
- `maidalun1020/bce-embedding-base_v1`
|
- `maidalun1020/bce-embedding-base_v1`
|
||||||
@ -127,7 +127,19 @@ The corresponding APIs are now available. See the [RAGFlow HTTP API Reference](.
|
|||||||
|
|
||||||
### Do you support stream output?
|
### Do you support stream output?
|
||||||
|
|
||||||
Yes, we do.
|
Yes, we do. Stream output is enabled by default in the chat assistant and agent. Note that you cannot disable stream output via RAGFlow's UI. To disable stream output in responses, use RAGFlow's Python or RESTful APIs:
|
||||||
|
|
||||||
|
Python:
|
||||||
|
|
||||||
|
- [Create chat completion](./references/python_api_reference.md#create-chat-completion)
|
||||||
|
- [Converse with chat assistant](./references/python_api_reference.md#converse-with-chat-assistant)
|
||||||
|
- [Converse with agent](./references/python_api_reference.md#converse-with-agent)
|
||||||
|
|
||||||
|
RESTful:
|
||||||
|
|
||||||
|
- [Create chat completion](./references/http_api_reference.md#create-chat-completion)
|
||||||
|
- [Converse with chat assistant](./references/http_api_reference.md#converse-with-chat-assistant)
|
||||||
|
- [Converse with agent](./references/http_api_reference.md#converse-with-agent)
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
@ -488,4 +500,10 @@ To switch your document engine from Elasticsearch to [Infinity](https://github.c
|
|||||||
|
|
||||||
All uploaded files are stored in Minio, RAGFlow's object storage solution. For instance, if you upload your file directly to a knowledge base, it is located at `<knowledgebase_id>/filename`.
|
All uploaded files are stored in Minio, RAGFlow's object storage solution. For instance, if you upload your file directly to a knowledge base, it is located at `<knowledgebase_id>/filename`.
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
|
### How to tune batch size for document parsing and embedding?
|
||||||
|
|
||||||
|
You can control the batch size for document parsing and embedding by setting the environment variables `DOC_BULK_SIZE` and `EMBEDDING_BATCH_SIZE`. Increasing these values may improve throughput for large-scale data processing, but will also increase memory usage. Adjust them according to your hardware resources.
|
||||||
|
|
||||||
|
---
|
||||||
|
|||||||
@ -21,7 +21,7 @@ Click the component to display its **Configuration** window. Here, you can set a
|
|||||||
|
|
||||||
### ID
|
### ID
|
||||||
|
|
||||||
The ID is the unique identifier for the component within the workflow. Unlike the IDs of other components, the ID of the **Begin** component *cannot* be changed.
|
The ID is the unique identifier for the component within the workflow. Unlike the IDs of other components, the ID of the **Begin** component _cannot_ be changed.
|
||||||
|
|
||||||
### Opening greeting
|
### Opening greeting
|
||||||
|
|
||||||
@ -31,30 +31,36 @@ An opening greeting is the agent's first message to the user. It can be a welcom
|
|||||||
|
|
||||||
You can set global variables within the **Begin** component, which can be either required or optional. Once established, users will need to provide values for these variables when interacting or chatting with the agent. Click **+ Add variable** to add a global variable, each with the following attributes:
|
You can set global variables within the **Begin** component, which can be either required or optional. Once established, users will need to provide values for these variables when interacting or chatting with the agent. Click **+ Add variable** to add a global variable, each with the following attributes:
|
||||||
|
|
||||||
- **Key**: *Required*
|
- **Key**: _Required_
|
||||||
The unique variable name.
|
The unique variable name.
|
||||||
- **Name**: *Required*
|
- **Name**: _Required_
|
||||||
A descriptive name providing additional details about the variable.
|
A descriptive name providing additional details about the variable.
|
||||||
For example, if **Key** is set to `lang`, you can set its **Name** to `Target language`.
|
For example, if **Key** is set to `lang`, you can set its **Name** to `Target language`.
|
||||||
- **Type**: *Required*
|
- **Type**: _Required_
|
||||||
The type of the variable:
|
The type of the variable:
|
||||||
- **line**: Accepts a single line of text without line breaks.
|
- **line**: Accepts a single line of text without line breaks.
|
||||||
- **paragraph**: Accepts multiple lines of text, including line breaks.
|
- **paragraph**: Accepts multiple lines of text, including line breaks.
|
||||||
- **options**: Requires the user to select a value for this variable from a dropdown menu. And you are required to set *at least* one option for the dropdown menu.
|
- **options**: Requires the user to select a value for this variable from a dropdown menu. And you are required to set _at least_ one option for the dropdown menu.
|
||||||
- **file**: Requires the user to upload one or multiple files.
|
- **file**: Requires the user to upload one or multiple files.
|
||||||
- **integer**: Accepts an integer as input.
|
- **integer**: Accepts an integer as input.
|
||||||
- **boolean**: Requires the user to toggle between on and off.
|
- **boolean**: Requires the user to toggle between on and off.
|
||||||
- **Optional**: A toggle indicating whether the variable is optional.
|
- **Optional**: A toggle indicating whether the variable is optional.
|
||||||
|
|
||||||
:::tip NOTE
|
:::tip NOTE
|
||||||
To pass in parameters from a client, call:
|
To pass in parameters from a client, call:
|
||||||
|
|
||||||
- HTTP method [Converse with agent](../../../references/http_api_reference.md#converse-with-agent), or
|
- HTTP method [Converse with agent](../../../references/http_api_reference.md#converse-with-agent), or
|
||||||
- Python method [Converse with agent](../../../references/python_api_reference.md#converse-with-agent).
|
- Python method [Converse with agent](../../../references/python_api_reference.md#converse-with-agent).
|
||||||
:::
|
:::
|
||||||
|
|
||||||
:::danger IMPORTANT
|
:::danger IMPORTANT
|
||||||
|
|
||||||
- If you set the key type as **file**, ensure the token count of the uploaded file does not exceed your model provider's maximum token limit; otherwise, the plain text in your file will be truncated and incomplete.
|
- If you set the key type as **file**, ensure the token count of the uploaded file does not exceed your model provider's maximum token limit; otherwise, the plain text in your file will be truncated and incomplete.
|
||||||
- If your agent's **Begin** component takes a variable, you *cannot* embed it into a webpage.
|
- If your agent's **Begin** component takes a variable, you _cannot_ embed it into a webpage.
|
||||||
|
:::
|
||||||
|
|
||||||
|
:::note
|
||||||
|
You can tune document parsing and embedding efficiency by setting the environment variables `DOC_BULK_SIZE` and `EMBEDDING_BATCH_SIZE`.
|
||||||
:::
|
:::
|
||||||
|
|
||||||
## Examples
|
## Examples
|
||||||
@ -71,7 +77,7 @@ As mentioned earlier, the **Begin** component is indispensable for an agent. Sti
|
|||||||
|
|
||||||
### Is the uploaded file in a knowledge base?
|
### Is the uploaded file in a knowledge base?
|
||||||
|
|
||||||
No. Files uploaded to an agent as input are not stored in a knowledge base and hence will not be processed using RAGFlow's built-in OCR, DLR or TSR models, or chunked using RAGFlow's built-in chunking methods.
|
No. Files uploaded to an agent as input are not stored in a knowledge base and hence will not be processed using RAGFlow's built-in OCR, DLR or TSR models, or chunked using RAGFlow's built-in chunking methods.
|
||||||
|
|
||||||
### How to upload a webpage or file from a URL?
|
### How to upload a webpage or file from a URL?
|
||||||
|
|
||||||
@ -81,8 +87,8 @@ If you set the type of a variable as **file**, your users will be able to upload
|
|||||||
|
|
||||||
### File size limit for an uploaded file
|
### File size limit for an uploaded file
|
||||||
|
|
||||||
There is no *specific* file size limit for a file uploaded to an agent. However, note that model providers typically have a default or explicit maximum token setting, which can range from 8196 to 128k: The plain text part of the uploaded file will be passed in as the key value, but if the file's token count exceeds this limit, the string will be truncated and incomplete.
|
There is no _specific_ file size limit for a file uploaded to an agent. However, note that model providers typically have a default or explicit maximum token setting, which can range from 8196 to 128k: The plain text part of the uploaded file will be passed in as the key value, but if the file's token count exceeds this limit, the string will be truncated and incomplete.
|
||||||
|
|
||||||
:::tip NOTE
|
:::tip NOTE
|
||||||
The variables `MAX_CONTENT_LENGTH` in `/docker/.env` and `client_max_body_size` in `/docker/nginx/nginx.conf` set the file size limit for each upload to a knowledge base or **File Management**. These settings DO NOT apply in this scenario.
|
The variables `MAX_CONTENT_LENGTH` in `/docker/.env` and `client_max_body_size` in `/docker/nginx/nginx.conf` set the file size limit for each upload to a knowledge base or **File Management**. These settings DO NOT apply in this scenario.
|
||||||
:::
|
:::
|
||||||
|
|||||||
52
docs/guides/agent/agent_component_reference/code.mdx
Normal file
52
docs/guides/agent/agent_component_reference/code.mdx
Normal file
@ -0,0 +1,52 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 13
|
||||||
|
slug: /code_component
|
||||||
|
---
|
||||||
|
|
||||||
|
# Code component
|
||||||
|
|
||||||
|
A component that enables users to integrate Python or JavaScript codes into their Agent for dynamic data processing.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## Scenarios
|
||||||
|
|
||||||
|
A **Code** component is essential when you need to integrate complex code logic (Python or JavaScript) into your Agent for dynamic data processing.
|
||||||
|
|
||||||
|
## Input variables
|
||||||
|
|
||||||
|
You can specify multiple input sources for the **Code** component. Click **+ Add variable** in the **Input variables** section to include the desired input variables.
|
||||||
|
|
||||||
|
After defining an input variable, you are required to select from the dropdown menu:
|
||||||
|
- A component ID under **Component Output**, or
|
||||||
|
- A global variable under **Begin input**, which is defined in the **Begin** component.
|
||||||
|
|
||||||
|
## Coding field
|
||||||
|
|
||||||
|
This field allows you to enter and edit your source code.
|
||||||
|
|
||||||
|
### A Python code example
|
||||||
|
|
||||||
|
```Python
|
||||||
|
def main(arg1: str, arg2: str) -> dict:
|
||||||
|
return {
|
||||||
|
"result": arg1 + arg2,
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
### A JavaScript code example
|
||||||
|
|
||||||
|
```JavaScript
|
||||||
|
|
||||||
|
const axios = require('axios');
|
||||||
|
async function main(args) {
|
||||||
|
try {
|
||||||
|
const response = await axios.get('https://github.com/infiniflow/ragflow');
|
||||||
|
console.log('Body:', response.data);
|
||||||
|
} catch (error) {
|
||||||
|
console.error('Error:', error.message);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
@ -1,5 +1,5 @@
|
|||||||
---
|
---
|
||||||
sidebar_position: 13
|
sidebar_position: 18
|
||||||
slug: /note_component
|
slug: /note_component
|
||||||
---
|
---
|
||||||
|
|
||||||
|
|||||||
116
docs/guides/agent/sandbox_quickstart.md
Normal file
116
docs/guides/agent/sandbox_quickstart.md
Normal file
@ -0,0 +1,116 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 20
|
||||||
|
slug: /sandbox_quickstart
|
||||||
|
---
|
||||||
|
|
||||||
|
# Sandbox quickstart
|
||||||
|
|
||||||
|
A secure, pluggable code execution backend designed for RAGFlow and other applications requiring isolated code execution environments.
|
||||||
|
|
||||||
|
## Features:
|
||||||
|
|
||||||
|
- Seamless RAGFlow Integration — Works out-of-the-box with the code component of RAGFlow.
|
||||||
|
- High Security — Uses gVisor for syscall-level sandboxing to isolate execution.
|
||||||
|
- Customisable Sandboxing — Modify seccomp profiles easily to tailor syscall restrictions.
|
||||||
|
- Pluggable Runtime Support — Extendable to support any programming language runtime.
|
||||||
|
- Developer Friendly — Quick setup with a convenient Makefile.
|
||||||
|
|
||||||
|
## Architecture
|
||||||
|
|
||||||
|
The architecture consists of isolated Docker base images for each supported language runtime, managed by the executor manager service. The executor manager orchestrates sandboxed code execution using gVisor for syscall interception and optional seccomp profiles for enhanced syscall filtering.
|
||||||
|
|
||||||
|
## Prerequisites
|
||||||
|
|
||||||
|
- Linux distribution compatible with gVisor.
|
||||||
|
- gVisor installed and configured.
|
||||||
|
- Docker version 24.0.0 or higher.
|
||||||
|
- Docker Compose version 2.26.1 or higher (similar to RAGFlow requirements).
|
||||||
|
- uv package and project manager installed.
|
||||||
|
- (Optional) GNU Make for simplified command-line management.
|
||||||
|
|
||||||
|
## Build Docker base images
|
||||||
|
|
||||||
|
The sandbox uses isolated base images for secure containerised execution environments.
|
||||||
|
|
||||||
|
Build the base images manually:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
docker build -t sandbox-base-python:latest ./sandbox_base_image/python
|
||||||
|
docker build -t sandbox-base-nodejs:latest ./sandbox_base_image/nodejs
|
||||||
|
```
|
||||||
|
|
||||||
|
Alternatively, build all base images at once using the Makefile:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
make build
|
||||||
|
```
|
||||||
|
|
||||||
|
Next, build the executor manager image:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
docker build -t sandbox-executor-manager:latest ./executor_manager
|
||||||
|
```
|
||||||
|
|
||||||
|
## Running with RAGFlow
|
||||||
|
|
||||||
|
1. Verify that gVisor is properly installed and operational.
|
||||||
|
|
||||||
|
2. Configure the .env file located at docker/.env:
|
||||||
|
|
||||||
|
- Uncomment sandbox-related environment variables.
|
||||||
|
- Enable the sandbox profile at the bottom of the file.
|
||||||
|
|
||||||
|
3. Add the following entry to your /etc/hosts file to resolve the executor manager service:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
127.0.0.1 sandbox-executor-manager
|
||||||
|
```
|
||||||
|
|
||||||
|
4. Start the RAGFlow service as usual.
|
||||||
|
|
||||||
|
## Running standalone
|
||||||
|
|
||||||
|
### Manual setup
|
||||||
|
|
||||||
|
1. Initialize the environment variables:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
cp .env.example .env
|
||||||
|
```
|
||||||
|
|
||||||
|
2. Launch the sandbox services with Docker Compose:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
docker compose -f docker-compose.yml up
|
||||||
|
```
|
||||||
|
|
||||||
|
3. Test the sandbox setup:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
source .venv/bin/activate
|
||||||
|
export PYTHONPATH=$(pwd)
|
||||||
|
uv pip install -r executor_manager/requirements.txt
|
||||||
|
uv run tests/sandbox_security_tests_full.py
|
||||||
|
```
|
||||||
|
|
||||||
|
### Using Makefile
|
||||||
|
|
||||||
|
Run all setup, build, launch, and tests with a single command:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
make
|
||||||
|
```
|
||||||
|
|
||||||
|
### Monitoring
|
||||||
|
|
||||||
|
To follow logs of the executor manager container:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
docker logs -f sandbox-executor-manager
|
||||||
|
```
|
||||||
|
|
||||||
|
Or use the Makefile shortcut:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
make logs
|
||||||
|
```
|
||||||
@ -9,7 +9,7 @@ Conduct an AI search.
|
|||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
An AI search is a single-turn AI conversation using a predefined retrieval strategy (a hybrid search of weighted keyword similarity and weighted vector similarity) and the system's default chat model. It does not involve advanced RAG strategies like knowledge graph, auto-keyword, or auto-question. Retrieved chunks will be listed below the chat model's response.
|
An AI search is a single-turn AI conversation using a predefined retrieval strategy (a hybrid search of weighted keyword similarity and weighted vector similarity) and the system's default chat model. It does not involve advanced RAG strategies like knowledge graph, auto-keyword, or auto-question. The related chunks are listed below the chat model's response in descending order based on their similarity scores.
|
||||||
|
|
||||||
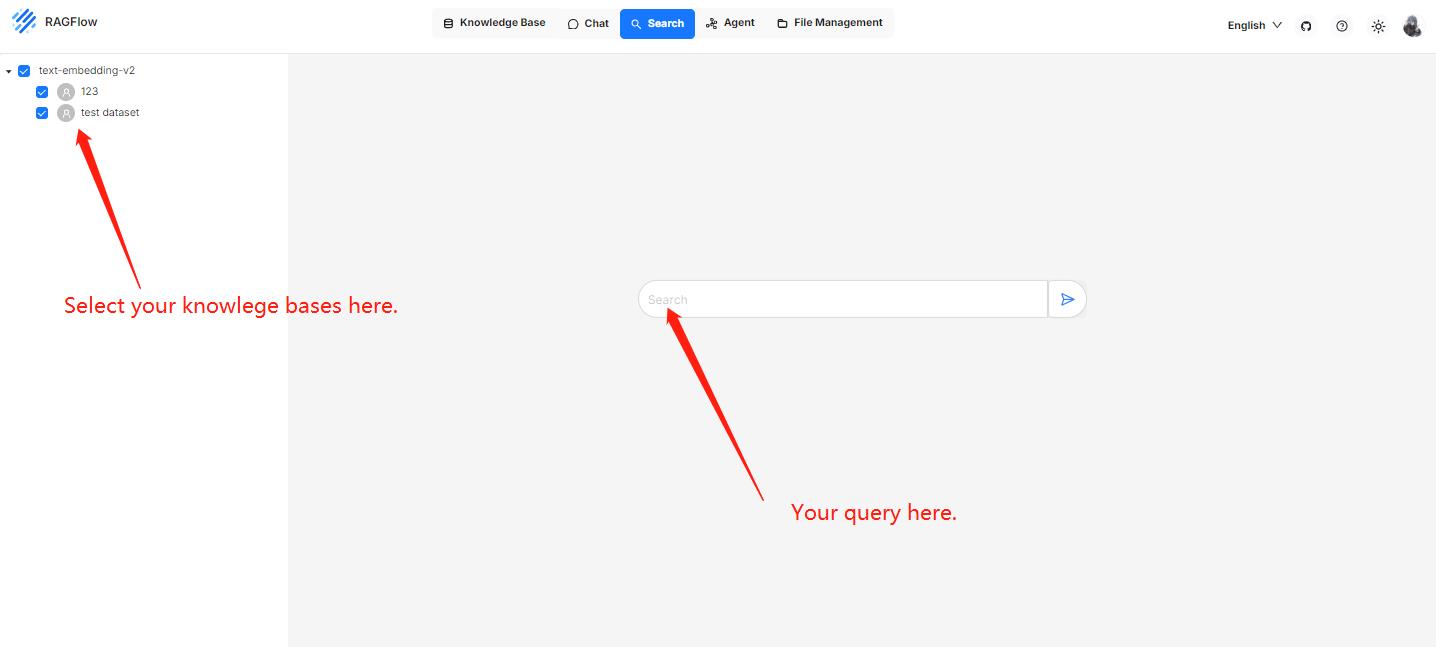
|

|
||||||
|
|
||||||
@ -25,7 +25,7 @@ When debugging your chat assistant, you can use AI search as a reference to veri
|
|||||||
|
|
||||||
## Frequently asked questions
|
## Frequently asked questions
|
||||||
|
|
||||||
### key difference between an AI search and an AI chat?
|
### Key difference between an AI search and an AI chat?
|
||||||
|
|
||||||
A chat is a multi-turn AI conversation where you can define your retrieval strategy (a weighted reranking score can be used to replace the weighted vector similarity in a hybrid search) and choose your chat model. In an AI chat, you can configure advanced RAG strategies, such as knowledge graphs, auto-keyword, and auto-question, for your specific case. Retrieved chunks are not displayed along with the answer.
|
A chat is a multi-turn AI conversation where you can define your retrieval strategy (a weighted reranking score can be used to replace the weighted vector similarity in a hybrid search) and choose your chat model. In an AI chat, you can configure advanced RAG strategies, such as knowledge graphs, auto-keyword, and auto-question, for your specific case. Retrieved chunks are not displayed along with the answer.
|
||||||
|
|
||||||
|
|||||||
@ -30,7 +30,7 @@ In the **Variable** section, you add, remove, or update variables.
|
|||||||
`{knowledge}` is the system's reserved variable, representing the chunks retrieved from the knowledge base(s) specified by **Knowledge bases** under the **Assistant settings** tab. If your chat assistant is associated with certain knowledge bases, you can keep it as is.
|
`{knowledge}` is the system's reserved variable, representing the chunks retrieved from the knowledge base(s) specified by **Knowledge bases** under the **Assistant settings** tab. If your chat assistant is associated with certain knowledge bases, you can keep it as is.
|
||||||
|
|
||||||
:::info NOTE
|
:::info NOTE
|
||||||
It does not currently make a difference whether you set `{knowledge}` to optional or mandatory, but note that this design will be updated at a later point.
|
It currently makes no difference whether `{knowledge}` is set as optional or mandatory, but please note this design will be updated in due course.
|
||||||
:::
|
:::
|
||||||
|
|
||||||
From v0.17.0 onward, you can start an AI chat without specifying knowledge bases. In this case, we recommend removing the `{knowledge}` variable to prevent unnecessary reference and keeping the **Empty response** field empty to avoid errors.
|
From v0.17.0 onward, you can start an AI chat without specifying knowledge bases. In this case, we recommend removing the `{knowledge}` variable to prevent unnecessary reference and keeping the **Empty response** field empty to avoid errors.
|
||||||
|
|||||||
@ -42,9 +42,13 @@ You start an AI conversation by creating an assistant.
|
|||||||
- **Rerank model** sets the reranker model to use. It is left empty by default.
|
- **Rerank model** sets the reranker model to use. It is left empty by default.
|
||||||
- If **Rerank model** is left empty, the hybrid score system uses keyword similarity and vector similarity, and the default weight assigned to the vector similarity component is 1-0.7=0.3.
|
- If **Rerank model** is left empty, the hybrid score system uses keyword similarity and vector similarity, and the default weight assigned to the vector similarity component is 1-0.7=0.3.
|
||||||
- If **Rerank model** is selected, the hybrid score system uses keyword similarity and reranker score, and the default weight assigned to the reranker score is 1-0.7=0.3.
|
- If **Rerank model** is selected, the hybrid score system uses keyword similarity and reranker score, and the default weight assigned to the reranker score is 1-0.7=0.3.
|
||||||
|
- [Cross-language search](../../references/glossary.mdx#cross-language-search): Optional
|
||||||
|
Select one or more target languages from the dropdown menu. The system’s default chat model will then translate your query into the selected target language(s). This translation ensures accurate semantic matching across languages, allowing you to retrieve relevant results regardless of language differences.
|
||||||
|
- When selecting target languages, please ensure that these languages are present in the knowledge base to guarantee an effective search.
|
||||||
|
- If no target language is selected, the system will search only in the language of your query, which may cause relevant information in other languages to be missed.
|
||||||
- **Variable** refers to the variables (keys) to be used in the system prompt. `{knowledge}` is a reserved variable. Click **Add** to add more variables for the system prompt.
|
- **Variable** refers to the variables (keys) to be used in the system prompt. `{knowledge}` is a reserved variable. Click **Add** to add more variables for the system prompt.
|
||||||
- If you are uncertain about the logic behind **Variable**, leave it *as-is*.
|
- If you are uncertain about the logic behind **Variable**, leave it *as-is*.
|
||||||
- As of v0.18.0, if you add custom variables here, the only way you can pass in their values is to call:
|
- As of v0.19.1, if you add custom variables here, the only way you can pass in their values is to call:
|
||||||
- HTTP method [Converse with chat assistant](../../references/http_api_reference.md#converse-with-chat-assistant), or
|
- HTTP method [Converse with chat assistant](../../references/http_api_reference.md#converse-with-chat-assistant), or
|
||||||
- Python method [Converse with chat assistant](../../references/python_api_reference.md#converse-with-chat-assistant).
|
- Python method [Converse with chat assistant](../../references/python_api_reference.md#converse-with-chat-assistant).
|
||||||
|
|
||||||
|
|||||||
72
docs/guides/dataset/autokeyword_autoquestion.mdx
Normal file
72
docs/guides/dataset/autokeyword_autoquestion.mdx
Normal file
@ -0,0 +1,72 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 3
|
||||||
|
slug: /autokeyword_autoquestion
|
||||||
|
---
|
||||||
|
|
||||||
|
# Auto-keyword Auto-question
|
||||||
|
import APITable from '@site/src/components/APITable';
|
||||||
|
|
||||||
|
Use a chat model to generate keywords or questions from each chunk in the knowledge base.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
When selecting a chunking method, you can also enable auto-keyword or auto-question generation to increase retrieval rates. This feature uses a chat model to produce a specified number of keywords and questions from each created chunk, generating an "additional layer of information" from the original content.
|
||||||
|
|
||||||
|
:::caution WARNING
|
||||||
|
Enabling this feature increases document indexing time and uses extra tokens, as all created chunks will be sent to the chat model for keyword or question generation.
|
||||||
|
:::
|
||||||
|
|
||||||
|
## What is Auto-keyword?
|
||||||
|
|
||||||
|
Auto-keyword refers to the auto-keyword generation feature of RAGFlow. It uses a chat model to generate a set of keywords or synonyms from each chunk to correct errors and enhance retrieval accuracy. This feature is implemented as a slider under **Page rank** on the **Configuration** page of your knowledge base.
|
||||||
|
|
||||||
|
**Values**:
|
||||||
|
|
||||||
|
- 0: (Default) Disabled.
|
||||||
|
- Between 3 and 5 (inclusive): Recommended if you have chunks of approximately 1,000 characters.
|
||||||
|
- 30 (maximum)
|
||||||
|
|
||||||
|
:::tip NOTE
|
||||||
|
- If your chunk size increases, you can increase the value accordingly. Please note, as the value increases, the marginal benefit decreases.
|
||||||
|
- An Auto-keyword value must be an integer. If you set it to a non-integer, say 1.7, it will be rounded down to the nearest integer, which in this case is 1.
|
||||||
|
:::
|
||||||
|
|
||||||
|
## What is Auto-question?
|
||||||
|
|
||||||
|
Auto-question is a feature of RAGFlow that automatically generates questions from chunks of data using a chat model. These questions (e.g. who, what, and why) also help correct errors and improve the matching of user queries. The feature usually works with FAQ retrieval scenarios involving product manuals or policy documents. And you can find this feature as a slider under **Page rank** on the **Configuration** page of your knowledge base.
|
||||||
|
|
||||||
|
**Values**:
|
||||||
|
|
||||||
|
- 0: (Default) Disabled.
|
||||||
|
- 1 or 2: Recommended if you have chunks of approximately 1,000 characters.
|
||||||
|
- 10 (maximum)
|
||||||
|
|
||||||
|
:::tip NOTE
|
||||||
|
- If your chunk size increases, you can increase the value accordingly. Please note, as the value increases, the marginal benefit decreases.
|
||||||
|
- An Auto-question value must be an integer. If you set it to a non-integer, say 1.7, it will be rounded down to the nearest integer, which in this case is 1.
|
||||||
|
:::
|
||||||
|
|
||||||
|
## Tips from the community
|
||||||
|
|
||||||
|
The Auto-keyword or Auto-question values relate closely to the chunking size in your knowledge base. However, if you are new to this feature and unsure which value(s) to start with, the following are some value settings we gathered from our community. While they may not be accurate, they provide a starting point at the very least.
|
||||||
|
|
||||||
|
```mdx-code-block
|
||||||
|
<APITable>
|
||||||
|
```
|
||||||
|
|
||||||
|
| Use cases or typical scenarios | Document volume/length | Auto_keyword (0–30) | Auto_question (0–10) |
|
||||||
|
|---------------------------------------------------------------------|---------------------------------|----------------------------|----------------------------|
|
||||||
|
| Internal process guidance for employee handbook | Small, under 10 pages | 0 | 0 |
|
||||||
|
| Customer service FAQs | Medium, 10–100 pages | 3–7 | 1–3 |
|
||||||
|
| Technical whitepapers: Development standards, protocol details | Large, over 100 pages | 2–4 | 1–2 |
|
||||||
|
| Contracts / Regulations / Legal clause retrieval | Large, over 50 pages | 2–5 | 0–1 |
|
||||||
|
| Multi-repository layered new documents + old archive | Many | Adjust as appropriate |Adjust as appropriate |
|
||||||
|
| Social media comment pool: multilingual & mixed spelling | Very large volume of short text | 8–12 | 0 |
|
||||||
|
| Operational logs for troubleshooting | Very large volume of short text | 3–6 | 0 |
|
||||||
|
| Marketing asset library: multilingual product descriptions | Medium | 6–10 | 1–2 |
|
||||||
|
| Training courses / eBooks | Large | 2–5 | 1–2 |
|
||||||
|
| Maintenance manual: equipment diagrams + steps | Medium | 3–7 | 1–2 |
|
||||||
|
|
||||||
|
```mdx-code-block
|
||||||
|
</APITable>
|
||||||
|
```
|
||||||
@ -16,4 +16,4 @@ Please note that some of your settings may consume a significant amount of time.
|
|||||||
- On the configuration page of your knowledge base, switch off **Use RAPTOR to enhance retrieval**.
|
- On the configuration page of your knowledge base, switch off **Use RAPTOR to enhance retrieval**.
|
||||||
- Extracting knowledge graph (GraphRAG) is time-consuming.
|
- Extracting knowledge graph (GraphRAG) is time-consuming.
|
||||||
- Disable **Auto-keyword** and **Auto-question** on the configuration page of your knowledge base, as both depend on the LLM.
|
- Disable **Auto-keyword** and **Auto-question** on the configuration page of your knowledge base, as both depend on the LLM.
|
||||||
- **v0.17.0+:** If your document is plain text PDF and does not require GPU-intensive processes like OCR (Optical Character Recognition), TSR (Table Structure Recognition), or DLA (Document Layout Analysis), you can choose **Naive** over **DeepDoc** or other time-consuming large model options in the **Document parser** dropdown. This will substantially reduce document parsing time.
|
- **v0.17.0+:** If all PDFs in your knowledge base are plain text and do not require GPU-intensive processes like OCR (Optical Character Recognition), TSR (Table Structure Recognition), or DLA (Document Layout Analysis), you can choose **Naive** over **DeepDoc** or other time-consuming large model options in the **Document parser** dropdown. This will substantially reduce document parsing time.
|
||||||
|
|||||||
@ -1,5 +1,5 @@
|
|||||||
---
|
---
|
||||||
sidebar_position: 0
|
sidebar_position: -1
|
||||||
slug: /configure_knowledge_base
|
slug: /configure_knowledge_base
|
||||||
---
|
---
|
||||||
|
|
||||||
@ -41,7 +41,7 @@ RAGFlow offers multiple chunking template to facilitate chunking files of differ
|
|||||||
|
|
||||||
| **Template** | Description | File format |
|
| **Template** | Description | File format |
|
||||||
|--------------|-----------------------------------------------------------------------|-----------------------------------------------------------------------------------------------|
|
|--------------|-----------------------------------------------------------------------|-----------------------------------------------------------------------------------------------|
|
||||||
| General | Files are consecutively chunked based on a preset chunk token number. | DOCX, XLSX, XLS (Excel 97-2003), PPT, PDF, TXT, JPEG, JPG, PNG, TIF, GIF, CSV, JSON, EML, HTML |
|
| General | Files are consecutively chunked based on a preset chunk token number. | MD, MDX, DOCX, XLSX, XLS (Excel 97-2003), PPT, PDF, TXT, JPEG, JPG, PNG, TIF, GIF, CSV, JSON, EML, HTML |
|
||||||
| Q&A | | XLSX, XLS (Excel 97-2003), CSV/TXT |
|
| Q&A | | XLSX, XLS (Excel 97-2003), CSV/TXT |
|
||||||
| Resume | Enterprise edition only. You can also try it out on demo.ragflow.io. | DOCX, PDF, TXT |
|
| Resume | Enterprise edition only. You can also try it out on demo.ragflow.io. | DOCX, PDF, TXT |
|
||||||
| Manual | | PDF |
|
| Manual | | PDF |
|
||||||
@ -67,6 +67,10 @@ The following embedding models can be deployed locally:
|
|||||||
- BAAI/bge-large-zh-v1.5
|
- BAAI/bge-large-zh-v1.5
|
||||||
- maidalun1020/bce-embedding-base_v1
|
- maidalun1020/bce-embedding-base_v1
|
||||||
|
|
||||||
|
:::danger IMPORTANT
|
||||||
|
These two embedding models are optimized specifically for English and Chinese, so performance may be compromised if you use them to embed documents in other languages.
|
||||||
|
:::
|
||||||
|
|
||||||
### Upload file
|
### Upload file
|
||||||
|
|
||||||
- RAGFlow's **File Management** allows you to link a file to multiple knowledge bases, in which case each target knowledge base holds a reference to the file.
|
- RAGFlow's **File Management** allows you to link a file to multiple knowledge bases, in which case each target knowledge base holds a reference to the file.
|
||||||
@ -124,7 +128,7 @@ See [Run retrieval test](./run_retrieval_test.md) for details.
|
|||||||
|
|
||||||
## Search for knowledge base
|
## Search for knowledge base
|
||||||
|
|
||||||
As of RAGFlow v0.18.0, the search feature is still in a rudimentary form, supporting only knowledge base search by name.
|
As of RAGFlow v0.19.1, the search feature is still in a rudimentary form, supporting only knowledge base search by name.
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
|
|||||||
@ -9,7 +9,7 @@ Convert complex Excel spreadsheets into HTML tables.
|
|||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
When using the General chunking method, you can enable the **Excel to HTML** toggle to convert spreadsheet files into HTML tables. If it is disabled, spreadsheet tables will be represented as key-value pairs. For complex tables that cannot be simply represented this way, you must enable this feature.
|
When using the **General** chunking method, you can enable the **Excel to HTML** toggle to convert spreadsheet files into HTML tables. If it is disabled, spreadsheet tables will be represented as key-value pairs. For complex tables that cannot be simply represented this way, you must enable this feature.
|
||||||
|
|
||||||
:::caution WARNING
|
:::caution WARNING
|
||||||
The feature is disabled by default. If your knowledge base contains spreadsheets with complex tables and you do not enable this feature, RAGFlow will not throw an error but your tables are likely to be garbled.
|
The feature is disabled by default. If your knowledge base contains spreadsheets with complex tables and you do not enable this feature, RAGFlow will not throw an error but your tables are likely to be garbled.
|
||||||
@ -22,7 +22,7 @@ Works with complex tables that cannot be represented as key-value pairs. Example
|
|||||||
## Considerations
|
## Considerations
|
||||||
|
|
||||||
- The Excel2HTML feature applies only to spreadsheet files (XLSX or XLS (Excel 97-2003)).
|
- The Excel2HTML feature applies only to spreadsheet files (XLSX or XLS (Excel 97-2003)).
|
||||||
- This feature is associated with the General chunking method. In other words, it is available *only when* you select the General chunking method.
|
- This feature is associated with the **General** chunking method. In other words, it is available *only when* you select the **General** chunking method.
|
||||||
- When this feature is enabled, spreadsheet tables with more than 12 rows will be split into chunks of 12 rows each.
|
- When this feature is enabled, spreadsheet tables with more than 12 rows will be split into chunks of 12 rows each.
|
||||||
|
|
||||||
## Procedure
|
## Procedure
|
||||||
|
|||||||
@ -47,7 +47,7 @@ The RAPTOR feature is disabled by default. To enable it, manually switch on the
|
|||||||
|
|
||||||
### Prompt
|
### Prompt
|
||||||
|
|
||||||
The following prompt will be applied recursively for cluster summarization, with `{cluster_content}` serving as an internal parameter. We recommend that you keep it as-is for now. The design will be updated at a later point.
|
The following prompt will be applied *recursively* for cluster summarization, with `{cluster_content}` serving as an internal parameter. We recommend that you keep it as-is for now. The design will be updated in due course.
|
||||||
|
|
||||||
```
|
```
|
||||||
Please summarize the following paragraphs... Paragraphs as following:
|
Please summarize the following paragraphs... Paragraphs as following:
|
||||||
|
|||||||
@ -60,6 +60,15 @@ The switch is disabled by default. When enabled, RAGFlow performs the following
|
|||||||
Using a knowledge graph in a retrieval test will significantly increase the time to receive a response.
|
Using a knowledge graph in a retrieval test will significantly increase the time to receive a response.
|
||||||
:::
|
:::
|
||||||
|
|
||||||
|
### Cross-language search
|
||||||
|
|
||||||
|
To perform a [cross-language search](../../references/glossary.mdx#cross-language-search), select one or more target languages from the dropdown menu. The system’s default chat model will then translate your query entered in the Test text field into the selected target language(s). This translation ensures accurate semantic matching across languages, allowing you to retrieve relevant results regardless of language differences.
|
||||||
|
|
||||||
|
:::tip NOTE
|
||||||
|
- When selecting target languages, please ensure that these languages are present in the knowledge base to guarantee an effective search.
|
||||||
|
- If no target language is selected, the system will search only in the language of your query, which may cause relevant information in other languages to be missed.
|
||||||
|
:::
|
||||||
|
|
||||||
### Test text
|
### Test text
|
||||||
|
|
||||||
This field is where you put in your testing query.
|
This field is where you put in your testing query.
|
||||||
|
|||||||
53
docs/guides/dataset/select_pdf_parser.md
Normal file
53
docs/guides/dataset/select_pdf_parser.md
Normal file
@ -0,0 +1,53 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 1
|
||||||
|
slug: /select_pdf_parser
|
||||||
|
---
|
||||||
|
|
||||||
|
# Select PDF parser
|
||||||
|
|
||||||
|
Select a visual model for parsing your PDFs.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
RAGFlow isn't one-size-fits-all. It is built for flexibility and supports deeper customization to accommodate more complex use cases. From v0.17.0 onwards, RAGFlow decouples DeepDoc-specific data extraction tasks from chunking methods **for PDF files**. This separation enables you to autonomously select a visual model for OCR (Optical Character Recognition), TSR (Table Structure Recognition), and DLR (Document Layout Recognition) tasks that balances speed and performance to suit your specific use cases. If your PDFs contain only plain text, you can opt to skip these tasks by selecting the **Naive** option, to reduce the overall parsing time.
|
||||||
|
|
||||||
|
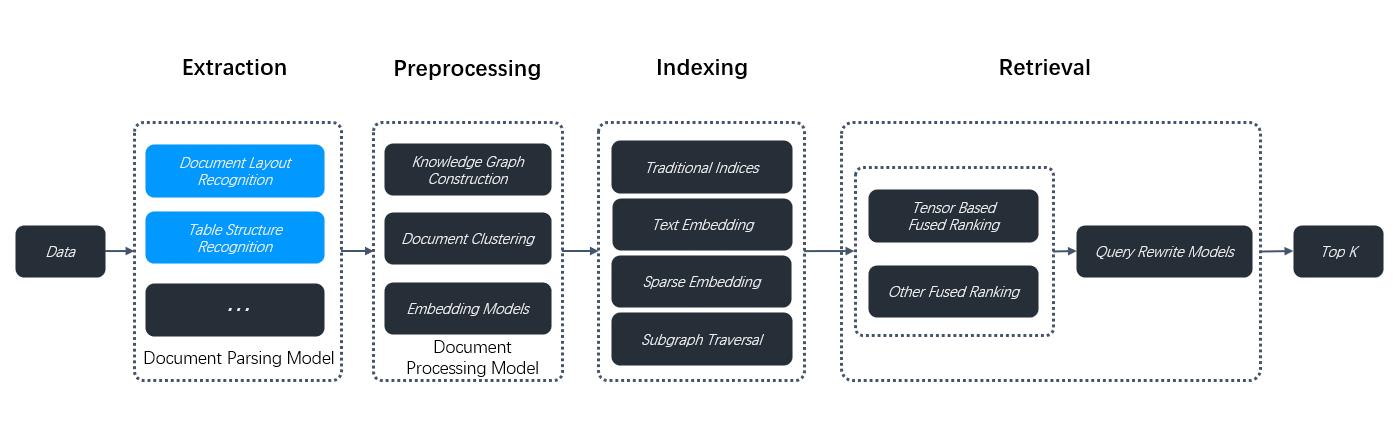
|
||||||
|
|
||||||
|
## Prerequisites
|
||||||
|
|
||||||
|
- The PDF parser dropdown menu appears only when you select a chunking method compatible with PDFs, including:
|
||||||
|
- **General**
|
||||||
|
- **Manual**
|
||||||
|
- **Paper**
|
||||||
|
- **Book**
|
||||||
|
- **Laws**
|
||||||
|
- **Presentation**
|
||||||
|
- **One**
|
||||||
|
- To use a third-party visual model for parsing PDFs, ensure you have set a default img2txt model under **Set default models** on the **Model providers** page.
|
||||||
|
|
||||||
|
## Procedure
|
||||||
|
|
||||||
|
1. On your knowledge base's **Configuration** page, select a chunking method, say **General**.
|
||||||
|
|
||||||
|
_The **PDF parser** dropdown menu appears._
|
||||||
|
|
||||||
|
2. Select the option that works best with your scenario:
|
||||||
|
|
||||||
|
- DeepDoc: (Default) The default visual model performing OCR, TSR, and DLR tasks on PDFs, which can be time-consuming.
|
||||||
|
- Naive: Skip OCR, TSR, and DLR tasks if *all* your PDFs are plain text.
|
||||||
|
- A third-party visual model provided by a specific model provider.
|
||||||
|
|
||||||
|
:::caution WARNING
|
||||||
|
Third-party visual models are marked **Experimental**, because we have not fully tested these models for the aforementioned data extraction tasks.
|
||||||
|
:::
|
||||||
|
|
||||||
|
## Frequently asked questions
|
||||||
|
|
||||||
|
### When should I select DeepDoc or a third-party visual model as the PDF parser?
|
||||||
|
|
||||||
|
Use a visual model to extract data if your PDFs contain formatted or image-based text rather than plain text. DeepDoc is the default visual model but can be time-consuming. You can also choose a lightweight or high-performance img2txt model depending on your needs and hardware capabilities.
|
||||||
|
|
||||||
|
### Can I select a visual model to parse my DOCX files?
|
||||||
|
|
||||||
|
No, you cannot. This dropdown menu is for PDFs only. To use this feature, convert your DOCX files to PDF first.
|
||||||
|
|
||||||
@ -1,5 +1,5 @@
|
|||||||
---
|
---
|
||||||
sidebar_position: 1
|
sidebar_position: 0
|
||||||
slug: /set_metada
|
slug: /set_metada
|
||||||
---
|
---
|
||||||
|
|
||||||
@ -19,4 +19,10 @@ For example, if you have a dataset of HTML files and want the LLM to cite the so
|
|||||||
Ensure that your metadata is in JSON format; otherwise, your updates will not be applied.
|
Ensure that your metadata is in JSON format; otherwise, your updates will not be applied.
|
||||||
:::
|
:::
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
|
## Frequently asked questions
|
||||||
|
|
||||||
|
### Can I set metadata for multiple documents at once?
|
||||||
|
|
||||||
|
No, you must set metadata *individually* for each document, as RAGFlow does not support batch setting of metadata. If you still consider this feature essential, please [raise an issue](https://github.com/infiniflow/ragflow/issues) explaining your use case and its importance.
|
||||||
@ -1,5 +1,5 @@
|
|||||||
---
|
---
|
||||||
sidebar_position: 3
|
sidebar_position: 2
|
||||||
slug: /set_page_rank
|
slug: /set_page_rank
|
||||||
---
|
---
|
||||||
|
|
||||||
|
|||||||
@ -5,7 +5,7 @@ slug: /use_tag_sets
|
|||||||
|
|
||||||
# Use tag set
|
# Use tag set
|
||||||
|
|
||||||
Use a tag set to tag chunks in your datasets.
|
Use a tag set to auto-tag chunks in your datasets.
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
@ -21,7 +21,7 @@ The auto-tagging feature is *unavailable* on the [Infinity](https://github.com/i
|
|||||||
|
|
||||||
Auto-tagging applies in situations where chunks are so similar to each other that the intended chunks cannot be distinguished from the rest. For example, when you have a few chunks about iPhone and a majority about iPhone case or iPhone accessaries, it becomes difficult to retrieve those chunks about iPhone without additional information.
|
Auto-tagging applies in situations where chunks are so similar to each other that the intended chunks cannot be distinguished from the rest. For example, when you have a few chunks about iPhone and a majority about iPhone case or iPhone accessaries, it becomes difficult to retrieve those chunks about iPhone without additional information.
|
||||||
|
|
||||||
## Create tag set
|
## 1. Create tag set
|
||||||
|
|
||||||
You can consider a tag set as a closed set, and the tags to attach to the chunks in your dataset (knowledge base) are *exclusively* from the specified tag set. You use a tag set to "inform" RAGFlow which chunks to tag and which tags to apply.
|
You can consider a tag set as a closed set, and the tags to attach to the chunks in your dataset (knowledge base) are *exclusively* from the specified tag set. You use a tag set to "inform" RAGFlow which chunks to tag and which tags to apply.
|
||||||
|
|
||||||
@ -41,6 +41,10 @@ As a rule of thumb, consider including the following entries in your tag table:
|
|||||||
|
|
||||||
### Create a tag set
|
### Create a tag set
|
||||||
|
|
||||||
|
:::danger IMPORTANT
|
||||||
|
A tag set is *not* involved in document indexing or retrieval. Do not specify a tag set when configuring your chat assistant or agent.
|
||||||
|
:::
|
||||||
|
|
||||||
1. Click **+ Create knowledge base** to create a knowledge base.
|
1. Click **+ Create knowledge base** to create a knowledge base.
|
||||||
2. Navigate to the **Configuration** page of the created knowledge base and choose **Tag** as the default chunking method.
|
2. Navigate to the **Configuration** page of the created knowledge base and choose **Tag** as the default chunking method.
|
||||||
3. Navigate to the **Dataset** page and upload and parse your table file in XLSX, CSV, or TXT formats.
|
3. Navigate to the **Dataset** page and upload and parse your table file in XLSX, CSV, or TXT formats.
|
||||||
@ -49,11 +53,7 @@ As a rule of thumb, consider including the following entries in your tag table:
|
|||||||
4. Click the **Table** tab to view the tag frequency table:
|
4. Click the **Table** tab to view the tag frequency table:
|
||||||

|

|
||||||
|
|
||||||
:::danger IMPORTANT
|
## 2. Tag chunks
|
||||||
A tag set is *not* involved in document indexing or retrieval. Do not specify a tag set when configuring your chat assistant or agent.
|
|
||||||
:::
|
|
||||||
|
|
||||||
## Tag chunks
|
|
||||||
|
|
||||||
Once a tag set is created, you can apply it to your dataset:
|
Once a tag set is created, you can apply it to your dataset:
|
||||||
|
|
||||||
@ -67,7 +67,7 @@ If the tag set is missing from the dropdown, check that it has been created or c
|
|||||||
3. Re-parse your documents to start the auto-tagging process.
|
3. Re-parse your documents to start the auto-tagging process.
|
||||||
_In an AI chat scenario using auto-tagged datasets, each query will be tagged using the corresponding tag set(s) and chunks with these tags will have a higher chance to be retrieved._
|
_In an AI chat scenario using auto-tagged datasets, each query will be tagged using the corresponding tag set(s) and chunks with these tags will have a higher chance to be retrieved._
|
||||||
|
|
||||||
## Update tag set
|
## 3. Update tag set
|
||||||
|
|
||||||
Creating a tag set is *not* for once and for all. Oftentimes, you may find it necessary to update or delete existing tags or add new entries.
|
Creating a tag set is *not* for once and for all. Oftentimes, you may find it necessary to update or delete existing tags or add new entries.
|
||||||
|
|
||||||
|
|||||||
@ -87,4 +87,4 @@ RAGFlow's file management allows you to download an uploaded file:
|
|||||||
|
|
||||||

|

|
||||||
|
|
||||||
> As of RAGFlow v0.18.0, bulk download is not supported, nor can you download an entire folder.
|
> As of RAGFlow v0.19.1, bulk download is not supported, nor can you download an entire folder.
|
||||||
|
|||||||
@ -49,6 +49,6 @@ After logging into RAGFlow, you can *only* configure API Key on the **Model prov
|
|||||||
5. Click **OK** to confirm your changes.
|
5. Click **OK** to confirm your changes.
|
||||||
|
|
||||||
:::note
|
:::note
|
||||||
To update an existing model API key at a later point:
|
To update an existing model API key:
|
||||||

|

|
||||||
:::
|
:::
|
||||||
@ -18,7 +18,7 @@ RAGFlow ships with a built-in [Langfuse](https://langfuse.com) integration so th
|
|||||||
Langfuse stores traces, spans and prompt payloads in a purpose-built observability backend and offers filtering and visualisations on top.
|
Langfuse stores traces, spans and prompt payloads in a purpose-built observability backend and offers filtering and visualisations on top.
|
||||||
|
|
||||||
:::info NOTE
|
:::info NOTE
|
||||||
• RAGFlow **≥ 0.18.0** (contains the Langfuse connector)
|
• RAGFlow **≥ 0.19.1** (contains the Langfuse connector)
|
||||||
• A Langfuse workspace (cloud or self-hosted) with a _Project Public Key_ and _Secret Key_
|
• A Langfuse workspace (cloud or self-hosted) with a _Project Public Key_ and _Secret Key_
|
||||||
:::
|
:::
|
||||||
|
|
||||||
|
|||||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user