mirror of
https://github.com/infiniflow/ragflow.git
synced 2026-02-04 09:35:06 +08:00
Compare commits
16 Commits
pipeline
...
86f6da2f74
| Author | SHA1 | Date | |
|---|---|---|---|
| 86f6da2f74 | |||
| 8c00cbc87a | |||
| 41e808f4e6 | |||
| bc0281040b | |||
| 341a7b1473 | |||
| c29c395390 | |||
| a23a0f230c | |||
| 2a88ce6be1 | |||
| 664b781d62 | |||
| 65571e5254 | |||
| aa30f20730 | |||
| b9b278d441 | |||
| e1d86cfee3 | |||
| 8ebd07337f | |||
| dd584d57b0 | |||
| 3d39b96c6f |
8
.github/workflows/release.yml
vendored
8
.github/workflows/release.yml
vendored
@ -88,7 +88,9 @@ jobs:
|
|||||||
with:
|
with:
|
||||||
context: .
|
context: .
|
||||||
push: true
|
push: true
|
||||||
tags: infiniflow/ragflow:${{ env.RELEASE_TAG }}
|
tags: |
|
||||||
|
infiniflow/ragflow:${{ env.RELEASE_TAG }}
|
||||||
|
infiniflow/ragflow:latest-full
|
||||||
file: Dockerfile
|
file: Dockerfile
|
||||||
platforms: linux/amd64
|
platforms: linux/amd64
|
||||||
|
|
||||||
@ -98,7 +100,9 @@ jobs:
|
|||||||
with:
|
with:
|
||||||
context: .
|
context: .
|
||||||
push: true
|
push: true
|
||||||
tags: infiniflow/ragflow:${{ env.RELEASE_TAG }}-slim
|
tags: |
|
||||||
|
infiniflow/ragflow:${{ env.RELEASE_TAG }}-slim
|
||||||
|
infiniflow/ragflow:latest-slim
|
||||||
file: Dockerfile
|
file: Dockerfile
|
||||||
build-args: LIGHTEN=1
|
build-args: LIGHTEN=1
|
||||||
platforms: linux/amd64
|
platforms: linux/amd64
|
||||||
|
|||||||
@ -83,7 +83,7 @@
|
|||||||
},
|
},
|
||||||
"password": "20010812Yy!",
|
"password": "20010812Yy!",
|
||||||
"port": 3306,
|
"port": 3306,
|
||||||
"sql": "Agent:WickedGoatsDivide@content",
|
"sql": "{Agent:WickedGoatsDivide@content}",
|
||||||
"username": "13637682833@163.com"
|
"username": "13637682833@163.com"
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
@ -114,9 +114,7 @@
|
|||||||
"params": {
|
"params": {
|
||||||
"cross_languages": [],
|
"cross_languages": [],
|
||||||
"empty_response": "",
|
"empty_response": "",
|
||||||
"kb_ids": [
|
"kb_ids": [],
|
||||||
"ed31364c727211f0bdb2bafe6e7908e6"
|
|
||||||
],
|
|
||||||
"keywords_similarity_weight": 0.7,
|
"keywords_similarity_weight": 0.7,
|
||||||
"outputs": {
|
"outputs": {
|
||||||
"formalized_content": {
|
"formalized_content": {
|
||||||
@ -124,7 +122,7 @@
|
|||||||
"value": ""
|
"value": ""
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"query": "sys.query",
|
"query": "{sys.query}",
|
||||||
"rerank_id": "",
|
"rerank_id": "",
|
||||||
"similarity_threshold": 0.2,
|
"similarity_threshold": 0.2,
|
||||||
"top_k": 1024,
|
"top_k": 1024,
|
||||||
@ -145,9 +143,7 @@
|
|||||||
"params": {
|
"params": {
|
||||||
"cross_languages": [],
|
"cross_languages": [],
|
||||||
"empty_response": "",
|
"empty_response": "",
|
||||||
"kb_ids": [
|
"kb_ids": [],
|
||||||
"0f968106727311f08357bafe6e7908e6"
|
|
||||||
],
|
|
||||||
"keywords_similarity_weight": 0.7,
|
"keywords_similarity_weight": 0.7,
|
||||||
"outputs": {
|
"outputs": {
|
||||||
"formalized_content": {
|
"formalized_content": {
|
||||||
@ -155,7 +151,7 @@
|
|||||||
"value": ""
|
"value": ""
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"query": "sys.query",
|
"query": "{sys.query}",
|
||||||
"rerank_id": "",
|
"rerank_id": "",
|
||||||
"similarity_threshold": 0.2,
|
"similarity_threshold": 0.2,
|
||||||
"top_k": 1024,
|
"top_k": 1024,
|
||||||
@ -176,9 +172,7 @@
|
|||||||
"params": {
|
"params": {
|
||||||
"cross_languages": [],
|
"cross_languages": [],
|
||||||
"empty_response": "",
|
"empty_response": "",
|
||||||
"kb_ids": [
|
"kb_ids": [],
|
||||||
"4ad1f9d0727311f0827dbafe6e7908e6"
|
|
||||||
],
|
|
||||||
"keywords_similarity_weight": 0.7,
|
"keywords_similarity_weight": 0.7,
|
||||||
"outputs": {
|
"outputs": {
|
||||||
"formalized_content": {
|
"formalized_content": {
|
||||||
@ -186,7 +180,7 @@
|
|||||||
"value": ""
|
"value": ""
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"query": "sys.query",
|
"query": "{sys.query}",
|
||||||
"rerank_id": "",
|
"rerank_id": "",
|
||||||
"similarity_threshold": 0.2,
|
"similarity_threshold": 0.2,
|
||||||
"top_k": 1024,
|
"top_k": 1024,
|
||||||
@ -347,9 +341,7 @@
|
|||||||
"form": {
|
"form": {
|
||||||
"cross_languages": [],
|
"cross_languages": [],
|
||||||
"empty_response": "",
|
"empty_response": "",
|
||||||
"kb_ids": [
|
"kb_ids": [],
|
||||||
"ed31364c727211f0bdb2bafe6e7908e6"
|
|
||||||
],
|
|
||||||
"keywords_similarity_weight": 0.7,
|
"keywords_similarity_weight": 0.7,
|
||||||
"outputs": {
|
"outputs": {
|
||||||
"formalized_content": {
|
"formalized_content": {
|
||||||
@ -357,7 +349,7 @@
|
|||||||
"value": ""
|
"value": ""
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"query": "sys.query",
|
"query": "{sys.query}",
|
||||||
"rerank_id": "",
|
"rerank_id": "",
|
||||||
"similarity_threshold": 0.2,
|
"similarity_threshold": 0.2,
|
||||||
"top_k": 1024,
|
"top_k": 1024,
|
||||||
@ -387,9 +379,7 @@
|
|||||||
"form": {
|
"form": {
|
||||||
"cross_languages": [],
|
"cross_languages": [],
|
||||||
"empty_response": "",
|
"empty_response": "",
|
||||||
"kb_ids": [
|
"kb_ids": [],
|
||||||
"0f968106727311f08357bafe6e7908e6"
|
|
||||||
],
|
|
||||||
"keywords_similarity_weight": 0.7,
|
"keywords_similarity_weight": 0.7,
|
||||||
"outputs": {
|
"outputs": {
|
||||||
"formalized_content": {
|
"formalized_content": {
|
||||||
@ -397,7 +387,7 @@
|
|||||||
"value": ""
|
"value": ""
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"query": "sys.query",
|
"query": "{sys.query}",
|
||||||
"rerank_id": "",
|
"rerank_id": "",
|
||||||
"similarity_threshold": 0.2,
|
"similarity_threshold": 0.2,
|
||||||
"top_k": 1024,
|
"top_k": 1024,
|
||||||
@ -427,9 +417,7 @@
|
|||||||
"form": {
|
"form": {
|
||||||
"cross_languages": [],
|
"cross_languages": [],
|
||||||
"empty_response": "",
|
"empty_response": "",
|
||||||
"kb_ids": [
|
"kb_ids": [],
|
||||||
"4ad1f9d0727311f0827dbafe6e7908e6"
|
|
||||||
],
|
|
||||||
"keywords_similarity_weight": 0.7,
|
"keywords_similarity_weight": 0.7,
|
||||||
"outputs": {
|
"outputs": {
|
||||||
"formalized_content": {
|
"formalized_content": {
|
||||||
@ -437,7 +425,7 @@
|
|||||||
"value": ""
|
"value": ""
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"query": "sys.query",
|
"query": "{sys.query}",
|
||||||
"rerank_id": "",
|
"rerank_id": "",
|
||||||
"similarity_threshold": 0.2,
|
"similarity_threshold": 0.2,
|
||||||
"top_k": 1024,
|
"top_k": 1024,
|
||||||
@ -539,7 +527,7 @@
|
|||||||
},
|
},
|
||||||
"password": "20010812Yy!",
|
"password": "20010812Yy!",
|
||||||
"port": 3306,
|
"port": 3306,
|
||||||
"sql": "Agent:WickedGoatsDivide@content",
|
"sql": "{Agent:WickedGoatsDivide@content}",
|
||||||
"username": "13637682833@163.com"
|
"username": "13637682833@163.com"
|
||||||
},
|
},
|
||||||
"label": "ExeSQL",
|
"label": "ExeSQL",
|
||||||
|
|||||||
@ -219,6 +219,70 @@
|
|||||||
}
|
}
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
|
{
|
||||||
|
"name": "TokenPony",
|
||||||
|
"logo": "",
|
||||||
|
"tags": "LLM",
|
||||||
|
"status": "1",
|
||||||
|
"llm": [
|
||||||
|
{
|
||||||
|
"llm_name": "qwen3-8b",
|
||||||
|
"tags": "LLM,CHAT,131k",
|
||||||
|
"max_tokens": 131000,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "deepseek-v3-0324",
|
||||||
|
"tags": "LLM,CHAT,128k",
|
||||||
|
"max_tokens": 128000,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "qwen3-32b",
|
||||||
|
"tags": "LLM,CHAT,131k",
|
||||||
|
"max_tokens": 131000,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "kimi-k2-instruct",
|
||||||
|
"tags": "LLM,CHAT,128K",
|
||||||
|
"max_tokens": 128000,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "deepseek-r1-0528",
|
||||||
|
"tags": "LLM,CHAT,164k",
|
||||||
|
"max_tokens": 164000,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "qwen3-coder-480b",
|
||||||
|
"tags": "LLM,CHAT,1024k",
|
||||||
|
"max_tokens": 1024000,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "glm-4.5",
|
||||||
|
"tags": "LLM,CHAT,131K",
|
||||||
|
"max_tokens": 131000,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"llm_name": "deepseek-v3.1",
|
||||||
|
"tags": "LLM,CHAT,128k",
|
||||||
|
"max_tokens": 128000,
|
||||||
|
"model_type": "chat",
|
||||||
|
"is_tools": true
|
||||||
|
}
|
||||||
|
]
|
||||||
|
},
|
||||||
{
|
{
|
||||||
"name": "Tongyi-Qianwen",
|
"name": "Tongyi-Qianwen",
|
||||||
"logo": "",
|
"logo": "",
|
||||||
|
|||||||
@ -34,7 +34,7 @@ from pypdf import PdfReader as pdf2_read
|
|||||||
|
|
||||||
from api import settings
|
from api import settings
|
||||||
from api.utils.file_utils import get_project_base_directory
|
from api.utils.file_utils import get_project_base_directory
|
||||||
from deepdoc.vision import OCR, LayoutRecognizer, Recognizer, TableStructureRecognizer
|
from deepdoc.vision import OCR, AscendLayoutRecognizer, LayoutRecognizer, Recognizer, TableStructureRecognizer
|
||||||
from rag.app.picture import vision_llm_chunk as picture_vision_llm_chunk
|
from rag.app.picture import vision_llm_chunk as picture_vision_llm_chunk
|
||||||
from rag.nlp import rag_tokenizer
|
from rag.nlp import rag_tokenizer
|
||||||
from rag.prompts import vision_llm_describe_prompt
|
from rag.prompts import vision_llm_describe_prompt
|
||||||
@ -64,33 +64,38 @@ class RAGFlowPdfParser:
|
|||||||
if PARALLEL_DEVICES > 1:
|
if PARALLEL_DEVICES > 1:
|
||||||
self.parallel_limiter = [trio.CapacityLimiter(1) for _ in range(PARALLEL_DEVICES)]
|
self.parallel_limiter = [trio.CapacityLimiter(1) for _ in range(PARALLEL_DEVICES)]
|
||||||
|
|
||||||
|
layout_recognizer_type = os.getenv("LAYOUT_RECOGNIZER_TYPE", "onnx").lower()
|
||||||
|
if layout_recognizer_type not in ["onnx", "ascend"]:
|
||||||
|
raise RuntimeError("Unsupported layout recognizer type.")
|
||||||
|
|
||||||
if hasattr(self, "model_speciess"):
|
if hasattr(self, "model_speciess"):
|
||||||
self.layouter = LayoutRecognizer("layout." + self.model_speciess)
|
recognizer_domain = "layout." + self.model_speciess
|
||||||
else:
|
else:
|
||||||
self.layouter = LayoutRecognizer("layout")
|
recognizer_domain = "layout"
|
||||||
|
|
||||||
|
if layout_recognizer_type == "ascend":
|
||||||
|
logging.debug("Using Ascend LayoutRecognizer", flush=True)
|
||||||
|
self.layouter = AscendLayoutRecognizer(recognizer_domain)
|
||||||
|
else: # onnx
|
||||||
|
logging.debug("Using Onnx LayoutRecognizer", flush=True)
|
||||||
|
self.layouter = LayoutRecognizer(recognizer_domain)
|
||||||
self.tbl_det = TableStructureRecognizer()
|
self.tbl_det = TableStructureRecognizer()
|
||||||
|
|
||||||
self.updown_cnt_mdl = xgb.Booster()
|
self.updown_cnt_mdl = xgb.Booster()
|
||||||
if not settings.LIGHTEN:
|
if not settings.LIGHTEN:
|
||||||
try:
|
try:
|
||||||
import torch.cuda
|
import torch.cuda
|
||||||
|
|
||||||
if torch.cuda.is_available():
|
if torch.cuda.is_available():
|
||||||
self.updown_cnt_mdl.set_param({"device": "cuda"})
|
self.updown_cnt_mdl.set_param({"device": "cuda"})
|
||||||
except Exception:
|
except Exception:
|
||||||
logging.exception("RAGFlowPdfParser __init__")
|
logging.exception("RAGFlowPdfParser __init__")
|
||||||
try:
|
try:
|
||||||
model_dir = os.path.join(
|
model_dir = os.path.join(get_project_base_directory(), "rag/res/deepdoc")
|
||||||
get_project_base_directory(),
|
self.updown_cnt_mdl.load_model(os.path.join(model_dir, "updown_concat_xgb.model"))
|
||||||
"rag/res/deepdoc")
|
|
||||||
self.updown_cnt_mdl.load_model(os.path.join(
|
|
||||||
model_dir, "updown_concat_xgb.model"))
|
|
||||||
except Exception:
|
except Exception:
|
||||||
model_dir = snapshot_download(
|
model_dir = snapshot_download(repo_id="InfiniFlow/text_concat_xgb_v1.0", local_dir=os.path.join(get_project_base_directory(), "rag/res/deepdoc"), local_dir_use_symlinks=False)
|
||||||
repo_id="InfiniFlow/text_concat_xgb_v1.0",
|
self.updown_cnt_mdl.load_model(os.path.join(model_dir, "updown_concat_xgb.model"))
|
||||||
local_dir=os.path.join(get_project_base_directory(), "rag/res/deepdoc"),
|
|
||||||
local_dir_use_symlinks=False)
|
|
||||||
self.updown_cnt_mdl.load_model(os.path.join(
|
|
||||||
model_dir, "updown_concat_xgb.model"))
|
|
||||||
|
|
||||||
self.page_from = 0
|
self.page_from = 0
|
||||||
self.column_num = 1
|
self.column_num = 1
|
||||||
@ -102,13 +107,10 @@ class RAGFlowPdfParser:
|
|||||||
return c["bottom"] - c["top"]
|
return c["bottom"] - c["top"]
|
||||||
|
|
||||||
def _x_dis(self, a, b):
|
def _x_dis(self, a, b):
|
||||||
return min(abs(a["x1"] - b["x0"]), abs(a["x0"] - b["x1"]),
|
return min(abs(a["x1"] - b["x0"]), abs(a["x0"] - b["x1"]), abs(a["x0"] + a["x1"] - b["x0"] - b["x1"]) / 2)
|
||||||
abs(a["x0"] + a["x1"] - b["x0"] - b["x1"]) / 2)
|
|
||||||
|
|
||||||
def _y_dis(
|
def _y_dis(self, a, b):
|
||||||
self, a, b):
|
return (b["top"] + b["bottom"] - a["top"] - a["bottom"]) / 2
|
||||||
return (
|
|
||||||
b["top"] + b["bottom"] - a["top"] - a["bottom"]) / 2
|
|
||||||
|
|
||||||
def _match_proj(self, b):
|
def _match_proj(self, b):
|
||||||
proj_patt = [
|
proj_patt = [
|
||||||
@ -130,10 +132,7 @@ class RAGFlowPdfParser:
|
|||||||
LEN = 6
|
LEN = 6
|
||||||
tks_down = rag_tokenizer.tokenize(down["text"][:LEN]).split()
|
tks_down = rag_tokenizer.tokenize(down["text"][:LEN]).split()
|
||||||
tks_up = rag_tokenizer.tokenize(up["text"][-LEN:]).split()
|
tks_up = rag_tokenizer.tokenize(up["text"][-LEN:]).split()
|
||||||
tks_all = up["text"][-LEN:].strip() \
|
tks_all = up["text"][-LEN:].strip() + (" " if re.match(r"[a-zA-Z0-9]+", up["text"][-1] + down["text"][0]) else "") + down["text"][:LEN].strip()
|
||||||
+ (" " if re.match(r"[a-zA-Z0-9]+",
|
|
||||||
up["text"][-1] + down["text"][0]) else "") \
|
|
||||||
+ down["text"][:LEN].strip()
|
|
||||||
tks_all = rag_tokenizer.tokenize(tks_all).split()
|
tks_all = rag_tokenizer.tokenize(tks_all).split()
|
||||||
fea = [
|
fea = [
|
||||||
up.get("R", -1) == down.get("R", -1),
|
up.get("R", -1) == down.get("R", -1),
|
||||||
@ -144,39 +143,30 @@ class RAGFlowPdfParser:
|
|||||||
down["layout_type"] == "text",
|
down["layout_type"] == "text",
|
||||||
up["layout_type"] == "table",
|
up["layout_type"] == "table",
|
||||||
down["layout_type"] == "table",
|
down["layout_type"] == "table",
|
||||||
True if re.search(
|
True if re.search(r"([。?!;!?;+))]|[a-z]\.)$", up["text"]) else False,
|
||||||
r"([。?!;!?;+))]|[a-z]\.)$",
|
|
||||||
up["text"]) else False,
|
|
||||||
True if re.search(r"[,:‘“、0-9(+-]$", up["text"]) else False,
|
True if re.search(r"[,:‘“、0-9(+-]$", up["text"]) else False,
|
||||||
True if re.search(
|
True if re.search(r"(^.?[/,?;:\],。;:’”?!》】)-])", down["text"]) else False,
|
||||||
r"(^.?[/,?;:\],。;:’”?!》】)-])",
|
|
||||||
down["text"]) else False,
|
|
||||||
True if re.match(r"[\((][^\(\)()]+[)\)]$", up["text"]) else False,
|
True if re.match(r"[\((][^\(\)()]+[)\)]$", up["text"]) else False,
|
||||||
True if re.search(r"[,,][^。.]+$", up["text"]) else False,
|
True if re.search(r"[,,][^。.]+$", up["text"]) else False,
|
||||||
True if re.search(r"[,,][^。.]+$", up["text"]) else False,
|
True if re.search(r"[,,][^。.]+$", up["text"]) else False,
|
||||||
True if re.search(r"[\((][^\))]+$", up["text"])
|
True if re.search(r"[\((][^\))]+$", up["text"]) and re.search(r"[\))]", down["text"]) else False,
|
||||||
and re.search(r"[\))]", down["text"]) else False,
|
|
||||||
self._match_proj(down),
|
self._match_proj(down),
|
||||||
True if re.match(r"[A-Z]", down["text"]) else False,
|
True if re.match(r"[A-Z]", down["text"]) else False,
|
||||||
True if re.match(r"[A-Z]", up["text"][-1]) else False,
|
True if re.match(r"[A-Z]", up["text"][-1]) else False,
|
||||||
True if re.match(r"[a-z0-9]", up["text"][-1]) else False,
|
True if re.match(r"[a-z0-9]", up["text"][-1]) else False,
|
||||||
True if re.match(r"[0-9.%,-]+$", down["text"]) else False,
|
True if re.match(r"[0-9.%,-]+$", down["text"]) else False,
|
||||||
up["text"].strip()[-2:] == down["text"].strip()[-2:] if len(up["text"].strip()
|
up["text"].strip()[-2:] == down["text"].strip()[-2:] if len(up["text"].strip()) > 1 and len(down["text"].strip()) > 1 else False,
|
||||||
) > 1 and len(
|
|
||||||
down["text"].strip()) > 1 else False,
|
|
||||||
up["x0"] > down["x1"],
|
up["x0"] > down["x1"],
|
||||||
abs(self.__height(up) - self.__height(down)) / min(self.__height(up),
|
abs(self.__height(up) - self.__height(down)) / min(self.__height(up), self.__height(down)),
|
||||||
self.__height(down)),
|
|
||||||
self._x_dis(up, down) / max(w, 0.000001),
|
self._x_dis(up, down) / max(w, 0.000001),
|
||||||
(len(up["text"]) - len(down["text"])) /
|
(len(up["text"]) - len(down["text"])) / max(len(up["text"]), len(down["text"])),
|
||||||
max(len(up["text"]), len(down["text"])),
|
|
||||||
len(tks_all) - len(tks_up) - len(tks_down),
|
len(tks_all) - len(tks_up) - len(tks_down),
|
||||||
len(tks_down) - len(tks_up),
|
len(tks_down) - len(tks_up),
|
||||||
tks_down[-1] == tks_up[-1] if tks_down and tks_up else False,
|
tks_down[-1] == tks_up[-1] if tks_down and tks_up else False,
|
||||||
max(down["in_row"], up["in_row"]),
|
max(down["in_row"], up["in_row"]),
|
||||||
abs(down["in_row"] - up["in_row"]),
|
abs(down["in_row"] - up["in_row"]),
|
||||||
len(tks_down) == 1 and rag_tokenizer.tag(tks_down[0]).find("n") >= 0,
|
len(tks_down) == 1 and rag_tokenizer.tag(tks_down[0]).find("n") >= 0,
|
||||||
len(tks_up) == 1 and rag_tokenizer.tag(tks_up[0]).find("n") >= 0
|
len(tks_up) == 1 and rag_tokenizer.tag(tks_up[0]).find("n") >= 0,
|
||||||
]
|
]
|
||||||
return fea
|
return fea
|
||||||
|
|
||||||
@ -187,9 +177,7 @@ class RAGFlowPdfParser:
|
|||||||
for i in range(len(arr) - 1):
|
for i in range(len(arr) - 1):
|
||||||
for j in range(i, -1, -1):
|
for j in range(i, -1, -1):
|
||||||
# restore the order using th
|
# restore the order using th
|
||||||
if abs(arr[j + 1]["x0"] - arr[j]["x0"]) < threshold \
|
if abs(arr[j + 1]["x0"] - arr[j]["x0"]) < threshold and arr[j + 1]["top"] < arr[j]["top"] and arr[j + 1]["page_number"] == arr[j]["page_number"]:
|
||||||
and arr[j + 1]["top"] < arr[j]["top"] \
|
|
||||||
and arr[j + 1]["page_number"] == arr[j]["page_number"]:
|
|
||||||
tmp = arr[j]
|
tmp = arr[j]
|
||||||
arr[j] = arr[j + 1]
|
arr[j] = arr[j + 1]
|
||||||
arr[j + 1] = tmp
|
arr[j + 1] = tmp
|
||||||
@ -197,8 +185,7 @@ class RAGFlowPdfParser:
|
|||||||
|
|
||||||
def _has_color(self, o):
|
def _has_color(self, o):
|
||||||
if o.get("ncs", "") == "DeviceGray":
|
if o.get("ncs", "") == "DeviceGray":
|
||||||
if o["stroking_color"] and o["stroking_color"][0] == 1 and o["non_stroking_color"] and \
|
if o["stroking_color"] and o["stroking_color"][0] == 1 and o["non_stroking_color"] and o["non_stroking_color"][0] == 1:
|
||||||
o["non_stroking_color"][0] == 1:
|
|
||||||
if re.match(r"[a-zT_\[\]\(\)-]+", o.get("text", "")):
|
if re.match(r"[a-zT_\[\]\(\)-]+", o.get("text", "")):
|
||||||
return False
|
return False
|
||||||
return True
|
return True
|
||||||
@ -216,8 +203,7 @@ class RAGFlowPdfParser:
|
|||||||
if not tbls:
|
if not tbls:
|
||||||
continue
|
continue
|
||||||
for tb in tbls: # for table
|
for tb in tbls: # for table
|
||||||
left, top, right, bott = tb["x0"] - MARGIN, tb["top"] - MARGIN, \
|
left, top, right, bott = tb["x0"] - MARGIN, tb["top"] - MARGIN, tb["x1"] + MARGIN, tb["bottom"] + MARGIN
|
||||||
tb["x1"] + MARGIN, tb["bottom"] + MARGIN
|
|
||||||
left *= ZM
|
left *= ZM
|
||||||
top *= ZM
|
top *= ZM
|
||||||
right *= ZM
|
right *= ZM
|
||||||
@ -232,14 +218,13 @@ class RAGFlowPdfParser:
|
|||||||
tbcnt = np.cumsum(tbcnt)
|
tbcnt = np.cumsum(tbcnt)
|
||||||
for i in range(len(tbcnt) - 1): # for page
|
for i in range(len(tbcnt) - 1): # for page
|
||||||
pg = []
|
pg = []
|
||||||
for j, tb_items in enumerate(
|
for j, tb_items in enumerate(recos[tbcnt[i] : tbcnt[i + 1]]): # for table
|
||||||
recos[tbcnt[i]: tbcnt[i + 1]]): # for table
|
poss = pos[tbcnt[i] : tbcnt[i + 1]]
|
||||||
poss = pos[tbcnt[i]: tbcnt[i + 1]]
|
|
||||||
for it in tb_items: # for table components
|
for it in tb_items: # for table components
|
||||||
it["x0"] = (it["x0"] + poss[j][0])
|
it["x0"] = it["x0"] + poss[j][0]
|
||||||
it["x1"] = (it["x1"] + poss[j][0])
|
it["x1"] = it["x1"] + poss[j][0]
|
||||||
it["top"] = (it["top"] + poss[j][1])
|
it["top"] = it["top"] + poss[j][1]
|
||||||
it["bottom"] = (it["bottom"] + poss[j][1])
|
it["bottom"] = it["bottom"] + poss[j][1]
|
||||||
for n in ["x0", "x1", "top", "bottom"]:
|
for n in ["x0", "x1", "top", "bottom"]:
|
||||||
it[n] /= ZM
|
it[n] /= ZM
|
||||||
it["top"] += self.page_cum_height[i]
|
it["top"] += self.page_cum_height[i]
|
||||||
@ -250,8 +235,7 @@ class RAGFlowPdfParser:
|
|||||||
self.tb_cpns.extend(pg)
|
self.tb_cpns.extend(pg)
|
||||||
|
|
||||||
def gather(kwd, fzy=10, ption=0.6):
|
def gather(kwd, fzy=10, ption=0.6):
|
||||||
eles = Recognizer.sort_Y_firstly(
|
eles = Recognizer.sort_Y_firstly([r for r in self.tb_cpns if re.match(kwd, r["label"])], fzy)
|
||||||
[r for r in self.tb_cpns if re.match(kwd, r["label"])], fzy)
|
|
||||||
eles = Recognizer.layouts_cleanup(self.boxes, eles, 5, ption)
|
eles = Recognizer.layouts_cleanup(self.boxes, eles, 5, ption)
|
||||||
return Recognizer.sort_Y_firstly(eles, 0)
|
return Recognizer.sort_Y_firstly(eles, 0)
|
||||||
|
|
||||||
@ -259,8 +243,7 @@ class RAGFlowPdfParser:
|
|||||||
headers = gather(r".*header$")
|
headers = gather(r".*header$")
|
||||||
rows = gather(r".* (row|header)")
|
rows = gather(r".* (row|header)")
|
||||||
spans = gather(r".*spanning")
|
spans = gather(r".*spanning")
|
||||||
clmns = sorted([r for r in self.tb_cpns if re.match(
|
clmns = sorted([r for r in self.tb_cpns if re.match(r"table column$", r["label"])], key=lambda x: (x["pn"], x["layoutno"], x["x0"]))
|
||||||
r"table column$", r["label"])], key=lambda x: (x["pn"], x["layoutno"], x["x0"]))
|
|
||||||
clmns = Recognizer.layouts_cleanup(self.boxes, clmns, 5, 0.5)
|
clmns = Recognizer.layouts_cleanup(self.boxes, clmns, 5, 0.5)
|
||||||
for b in self.boxes:
|
for b in self.boxes:
|
||||||
if b.get("layout_type", "") != "table":
|
if b.get("layout_type", "") != "table":
|
||||||
@ -271,8 +254,7 @@ class RAGFlowPdfParser:
|
|||||||
b["R_top"] = rows[ii]["top"]
|
b["R_top"] = rows[ii]["top"]
|
||||||
b["R_bott"] = rows[ii]["bottom"]
|
b["R_bott"] = rows[ii]["bottom"]
|
||||||
|
|
||||||
ii = Recognizer.find_overlapped_with_threshold(
|
ii = Recognizer.find_overlapped_with_threshold(b, headers, thr=0.3)
|
||||||
b, headers, thr=0.3)
|
|
||||||
if ii is not None:
|
if ii is not None:
|
||||||
b["H_top"] = headers[ii]["top"]
|
b["H_top"] = headers[ii]["top"]
|
||||||
b["H_bott"] = headers[ii]["bottom"]
|
b["H_bott"] = headers[ii]["bottom"]
|
||||||
@ -305,12 +287,12 @@ class RAGFlowPdfParser:
|
|||||||
return
|
return
|
||||||
bxs = [(line[0], line[1][0]) for line in bxs]
|
bxs = [(line[0], line[1][0]) for line in bxs]
|
||||||
bxs = Recognizer.sort_Y_firstly(
|
bxs = Recognizer.sort_Y_firstly(
|
||||||
[{"x0": b[0][0] / ZM, "x1": b[1][0] / ZM,
|
[
|
||||||
"top": b[0][1] / ZM, "text": "", "txt": t,
|
{"x0": b[0][0] / ZM, "x1": b[1][0] / ZM, "top": b[0][1] / ZM, "text": "", "txt": t, "bottom": b[-1][1] / ZM, "chars": [], "page_number": pagenum}
|
||||||
"bottom": b[-1][1] / ZM,
|
for b, t in bxs
|
||||||
"chars": [],
|
if b[0][0] <= b[1][0] and b[0][1] <= b[-1][1]
|
||||||
"page_number": pagenum} for b, t in bxs if b[0][0] <= b[1][0] and b[0][1] <= b[-1][1]],
|
],
|
||||||
self.mean_height[pagenum-1] / 3
|
self.mean_height[pagenum - 1] / 3,
|
||||||
)
|
)
|
||||||
|
|
||||||
# merge chars in the same rect
|
# merge chars in the same rect
|
||||||
@ -321,7 +303,7 @@ class RAGFlowPdfParser:
|
|||||||
continue
|
continue
|
||||||
ch = c["bottom"] - c["top"]
|
ch = c["bottom"] - c["top"]
|
||||||
bh = bxs[ii]["bottom"] - bxs[ii]["top"]
|
bh = bxs[ii]["bottom"] - bxs[ii]["top"]
|
||||||
if abs(ch - bh) / max(ch, bh) >= 0.7 and c["text"] != ' ':
|
if abs(ch - bh) / max(ch, bh) >= 0.7 and c["text"] != " ":
|
||||||
self.lefted_chars.append(c)
|
self.lefted_chars.append(c)
|
||||||
continue
|
continue
|
||||||
bxs[ii]["chars"].append(c)
|
bxs[ii]["chars"].append(c)
|
||||||
@ -345,8 +327,7 @@ class RAGFlowPdfParser:
|
|||||||
img_np = np.array(img)
|
img_np = np.array(img)
|
||||||
for b in bxs:
|
for b in bxs:
|
||||||
if not b["text"]:
|
if not b["text"]:
|
||||||
left, right, top, bott = b["x0"] * ZM, b["x1"] * \
|
left, right, top, bott = b["x0"] * ZM, b["x1"] * ZM, b["top"] * ZM, b["bottom"] * ZM
|
||||||
ZM, b["top"] * ZM, b["bottom"] * ZM
|
|
||||||
b["box_image"] = self.ocr.get_rotate_crop_image(img_np, np.array([[left, top], [right, top], [right, bott], [left, bott]], dtype=np.float32))
|
b["box_image"] = self.ocr.get_rotate_crop_image(img_np, np.array([[left, top], [right, top], [right, bott], [left, bott]], dtype=np.float32))
|
||||||
boxes_to_reg.append(b)
|
boxes_to_reg.append(b)
|
||||||
del b["txt"]
|
del b["txt"]
|
||||||
@ -356,21 +337,17 @@ class RAGFlowPdfParser:
|
|||||||
del boxes_to_reg[i]["box_image"]
|
del boxes_to_reg[i]["box_image"]
|
||||||
logging.info(f"__ocr recognize {len(bxs)} boxes cost {timer() - start}s")
|
logging.info(f"__ocr recognize {len(bxs)} boxes cost {timer() - start}s")
|
||||||
bxs = [b for b in bxs if b["text"]]
|
bxs = [b for b in bxs if b["text"]]
|
||||||
if self.mean_height[pagenum-1] == 0:
|
if self.mean_height[pagenum - 1] == 0:
|
||||||
self.mean_height[pagenum-1] = np.median([b["bottom"] - b["top"]
|
self.mean_height[pagenum - 1] = np.median([b["bottom"] - b["top"] for b in bxs])
|
||||||
for b in bxs])
|
|
||||||
self.boxes.append(bxs)
|
self.boxes.append(bxs)
|
||||||
|
|
||||||
def _layouts_rec(self, ZM, drop=True):
|
def _layouts_rec(self, ZM, drop=True):
|
||||||
assert len(self.page_images) == len(self.boxes)
|
assert len(self.page_images) == len(self.boxes)
|
||||||
self.boxes, self.page_layout = self.layouter(
|
self.boxes, self.page_layout = self.layouter(self.page_images, self.boxes, ZM, drop=drop)
|
||||||
self.page_images, self.boxes, ZM, drop=drop)
|
|
||||||
# cumlative Y
|
# cumlative Y
|
||||||
for i in range(len(self.boxes)):
|
for i in range(len(self.boxes)):
|
||||||
self.boxes[i]["top"] += \
|
self.boxes[i]["top"] += self.page_cum_height[self.boxes[i]["page_number"] - 1]
|
||||||
self.page_cum_height[self.boxes[i]["page_number"] - 1]
|
self.boxes[i]["bottom"] += self.page_cum_height[self.boxes[i]["page_number"] - 1]
|
||||||
self.boxes[i]["bottom"] += \
|
|
||||||
self.page_cum_height[self.boxes[i]["page_number"] - 1]
|
|
||||||
|
|
||||||
def _text_merge(self):
|
def _text_merge(self):
|
||||||
# merge adjusted boxes
|
# merge adjusted boxes
|
||||||
@ -390,12 +367,10 @@ class RAGFlowPdfParser:
|
|||||||
while i < len(bxs) - 1:
|
while i < len(bxs) - 1:
|
||||||
b = bxs[i]
|
b = bxs[i]
|
||||||
b_ = bxs[i + 1]
|
b_ = bxs[i + 1]
|
||||||
if b.get("layoutno", "0") != b_.get("layoutno", "1") or b.get("layout_type", "") in ["table", "figure",
|
if b.get("layoutno", "0") != b_.get("layoutno", "1") or b.get("layout_type", "") in ["table", "figure", "equation"]:
|
||||||
"equation"]:
|
|
||||||
i += 1
|
i += 1
|
||||||
continue
|
continue
|
||||||
if abs(self._y_dis(b, b_)
|
if abs(self._y_dis(b, b_)) < self.mean_height[bxs[i]["page_number"] - 1] / 3:
|
||||||
) < self.mean_height[bxs[i]["page_number"] - 1] / 3:
|
|
||||||
# merge
|
# merge
|
||||||
bxs[i]["x1"] = b_["x1"]
|
bxs[i]["x1"] = b_["x1"]
|
||||||
bxs[i]["top"] = (b["top"] + b_["top"]) / 2
|
bxs[i]["top"] = (b["top"] + b_["top"]) / 2
|
||||||
@ -408,16 +383,14 @@ class RAGFlowPdfParser:
|
|||||||
|
|
||||||
dis_thr = 1
|
dis_thr = 1
|
||||||
dis = b["x1"] - b_["x0"]
|
dis = b["x1"] - b_["x0"]
|
||||||
if b.get("layout_type", "") != "text" or b_.get(
|
if b.get("layout_type", "") != "text" or b_.get("layout_type", "") != "text":
|
||||||
"layout_type", "") != "text":
|
|
||||||
if end_with(b, ",") or start_with(b_, "(,"):
|
if end_with(b, ",") or start_with(b_, "(,"):
|
||||||
dis_thr = -8
|
dis_thr = -8
|
||||||
else:
|
else:
|
||||||
i += 1
|
i += 1
|
||||||
continue
|
continue
|
||||||
|
|
||||||
if abs(self._y_dis(b, b_)) < self.mean_height[bxs[i]["page_number"] - 1] / 5 \
|
if abs(self._y_dis(b, b_)) < self.mean_height[bxs[i]["page_number"] - 1] / 5 and dis >= dis_thr and b["x1"] < b_["x1"]:
|
||||||
and dis >= dis_thr and b["x1"] < b_["x1"]:
|
|
||||||
# merge
|
# merge
|
||||||
bxs[i]["x1"] = b_["x1"]
|
bxs[i]["x1"] = b_["x1"]
|
||||||
bxs[i]["top"] = (b["top"] + b_["top"]) / 2
|
bxs[i]["top"] = (b["top"] + b_["top"]) / 2
|
||||||
@ -429,23 +402,19 @@ class RAGFlowPdfParser:
|
|||||||
self.boxes = bxs
|
self.boxes = bxs
|
||||||
|
|
||||||
def _naive_vertical_merge(self, zoomin=3):
|
def _naive_vertical_merge(self, zoomin=3):
|
||||||
bxs = Recognizer.sort_Y_firstly(
|
bxs = Recognizer.sort_Y_firstly(self.boxes, np.median(self.mean_height) / 3)
|
||||||
self.boxes, np.median(
|
|
||||||
self.mean_height) / 3)
|
|
||||||
|
|
||||||
column_width = np.median([b["x1"] - b["x0"] for b in self.boxes])
|
column_width = np.median([b["x1"] - b["x0"] for b in self.boxes])
|
||||||
self.column_num = int(self.page_images[0].size[0] / zoomin / column_width)
|
self.column_num = int(self.page_images[0].size[0] / zoomin / column_width)
|
||||||
if column_width < self.page_images[0].size[0] / zoomin / self.column_num:
|
if column_width < self.page_images[0].size[0] / zoomin / self.column_num:
|
||||||
logging.info("Multi-column................... {} {}".format(column_width,
|
logging.info("Multi-column................... {} {}".format(column_width, self.page_images[0].size[0] / zoomin / self.column_num))
|
||||||
self.page_images[0].size[0] / zoomin / self.column_num))
|
|
||||||
self.boxes = self.sort_X_by_page(self.boxes, column_width / self.column_num)
|
self.boxes = self.sort_X_by_page(self.boxes, column_width / self.column_num)
|
||||||
|
|
||||||
i = 0
|
i = 0
|
||||||
while i + 1 < len(bxs):
|
while i + 1 < len(bxs):
|
||||||
b = bxs[i]
|
b = bxs[i]
|
||||||
b_ = bxs[i + 1]
|
b_ = bxs[i + 1]
|
||||||
if b["page_number"] < b_["page_number"] and re.match(
|
if b["page_number"] < b_["page_number"] and re.match(r"[0-9 •一—-]+$", b["text"]):
|
||||||
r"[0-9 •一—-]+$", b["text"]):
|
|
||||||
bxs.pop(i)
|
bxs.pop(i)
|
||||||
continue
|
continue
|
||||||
if not b["text"].strip():
|
if not b["text"].strip():
|
||||||
@ -453,8 +422,7 @@ class RAGFlowPdfParser:
|
|||||||
continue
|
continue
|
||||||
concatting_feats = [
|
concatting_feats = [
|
||||||
b["text"].strip()[-1] in ",;:'\",、‘“;:-",
|
b["text"].strip()[-1] in ",;:'\",、‘“;:-",
|
||||||
len(b["text"].strip()) > 1 and b["text"].strip(
|
len(b["text"].strip()) > 1 and b["text"].strip()[-2] in ",;:'\",‘“、;:",
|
||||||
)[-2] in ",;:'\",‘“、;:",
|
|
||||||
b_["text"].strip() and b_["text"].strip()[0] in "。;?!?”)),,、:",
|
b_["text"].strip() and b_["text"].strip()[0] in "。;?!?”)),,、:",
|
||||||
]
|
]
|
||||||
# features for not concating
|
# features for not concating
|
||||||
@ -462,21 +430,20 @@ class RAGFlowPdfParser:
|
|||||||
b.get("layoutno", 0) != b_.get("layoutno", 0),
|
b.get("layoutno", 0) != b_.get("layoutno", 0),
|
||||||
b["text"].strip()[-1] in "。?!?",
|
b["text"].strip()[-1] in "。?!?",
|
||||||
self.is_english and b["text"].strip()[-1] in ".!?",
|
self.is_english and b["text"].strip()[-1] in ".!?",
|
||||||
b["page_number"] == b_["page_number"] and b_["top"] -
|
b["page_number"] == b_["page_number"] and b_["top"] - b["bottom"] > self.mean_height[b["page_number"] - 1] * 1.5,
|
||||||
b["bottom"] > self.mean_height[b["page_number"] - 1] * 1.5,
|
b["page_number"] < b_["page_number"] and abs(b["x0"] - b_["x0"]) > self.mean_width[b["page_number"] - 1] * 4,
|
||||||
b["page_number"] < b_["page_number"] and abs(
|
|
||||||
b["x0"] - b_["x0"]) > self.mean_width[b["page_number"] - 1] * 4,
|
|
||||||
]
|
]
|
||||||
# split features
|
# split features
|
||||||
detach_feats = [b["x1"] < b_["x0"],
|
detach_feats = [b["x1"] < b_["x0"], b["x0"] > b_["x1"]]
|
||||||
b["x0"] > b_["x1"]]
|
|
||||||
if (any(feats) and not any(concatting_feats)) or any(detach_feats):
|
if (any(feats) and not any(concatting_feats)) or any(detach_feats):
|
||||||
logging.debug("{} {} {} {}".format(
|
logging.debug(
|
||||||
b["text"],
|
"{} {} {} {}".format(
|
||||||
b_["text"],
|
b["text"],
|
||||||
any(feats),
|
b_["text"],
|
||||||
any(concatting_feats),
|
any(feats),
|
||||||
))
|
any(concatting_feats),
|
||||||
|
)
|
||||||
|
)
|
||||||
i += 1
|
i += 1
|
||||||
continue
|
continue
|
||||||
# merge up and down
|
# merge up and down
|
||||||
@ -529,14 +496,11 @@ class RAGFlowPdfParser:
|
|||||||
if not concat_between_pages and down["page_number"] > up["page_number"]:
|
if not concat_between_pages and down["page_number"] > up["page_number"]:
|
||||||
break
|
break
|
||||||
|
|
||||||
if up.get("R", "") != down.get(
|
if up.get("R", "") != down.get("R", "") and up["text"][-1] != ",":
|
||||||
"R", "") and up["text"][-1] != ",":
|
|
||||||
i += 1
|
i += 1
|
||||||
continue
|
continue
|
||||||
|
|
||||||
if re.match(r"[0-9]{2,3}/[0-9]{3}$", up["text"]) \
|
if re.match(r"[0-9]{2,3}/[0-9]{3}$", up["text"]) or re.match(r"[0-9]{2,3}/[0-9]{3}$", down["text"]) or not down["text"].strip():
|
||||||
or re.match(r"[0-9]{2,3}/[0-9]{3}$", down["text"]) \
|
|
||||||
or not down["text"].strip():
|
|
||||||
i += 1
|
i += 1
|
||||||
continue
|
continue
|
||||||
|
|
||||||
@ -544,14 +508,12 @@ class RAGFlowPdfParser:
|
|||||||
i += 1
|
i += 1
|
||||||
continue
|
continue
|
||||||
|
|
||||||
if up["x1"] < down["x0"] - 10 * \
|
if up["x1"] < down["x0"] - 10 * mw or up["x0"] > down["x1"] + 10 * mw:
|
||||||
mw or up["x0"] > down["x1"] + 10 * mw:
|
|
||||||
i += 1
|
i += 1
|
||||||
continue
|
continue
|
||||||
|
|
||||||
if i - dp < 5 and up.get("layout_type") == "text":
|
if i - dp < 5 and up.get("layout_type") == "text":
|
||||||
if up.get("layoutno", "1") == down.get(
|
if up.get("layoutno", "1") == down.get("layoutno", "2"):
|
||||||
"layoutno", "2"):
|
|
||||||
dfs(down, i + 1)
|
dfs(down, i + 1)
|
||||||
boxes.pop(i)
|
boxes.pop(i)
|
||||||
return
|
return
|
||||||
@ -559,8 +521,7 @@ class RAGFlowPdfParser:
|
|||||||
continue
|
continue
|
||||||
|
|
||||||
fea = self._updown_concat_features(up, down)
|
fea = self._updown_concat_features(up, down)
|
||||||
if self.updown_cnt_mdl.predict(
|
if self.updown_cnt_mdl.predict(xgb.DMatrix([fea]))[0] <= 0.5:
|
||||||
xgb.DMatrix([fea]))[0] <= 0.5:
|
|
||||||
i += 1
|
i += 1
|
||||||
continue
|
continue
|
||||||
dfs(down, i + 1)
|
dfs(down, i + 1)
|
||||||
@ -584,16 +545,14 @@ class RAGFlowPdfParser:
|
|||||||
c["text"] = c["text"].strip()
|
c["text"] = c["text"].strip()
|
||||||
if not c["text"]:
|
if not c["text"]:
|
||||||
continue
|
continue
|
||||||
if t["text"] and re.match(
|
if t["text"] and re.match(r"[0-9\.a-zA-Z]+$", t["text"][-1] + c["text"][-1]):
|
||||||
r"[0-9\.a-zA-Z]+$", t["text"][-1] + c["text"][-1]):
|
|
||||||
t["text"] += " "
|
t["text"] += " "
|
||||||
t["text"] += c["text"]
|
t["text"] += c["text"]
|
||||||
t["x0"] = min(t["x0"], c["x0"])
|
t["x0"] = min(t["x0"], c["x0"])
|
||||||
t["x1"] = max(t["x1"], c["x1"])
|
t["x1"] = max(t["x1"], c["x1"])
|
||||||
t["page_number"] = min(t["page_number"], c["page_number"])
|
t["page_number"] = min(t["page_number"], c["page_number"])
|
||||||
t["bottom"] = c["bottom"]
|
t["bottom"] = c["bottom"]
|
||||||
if not t["layout_type"] \
|
if not t["layout_type"] and c["layout_type"]:
|
||||||
and c["layout_type"]:
|
|
||||||
t["layout_type"] = c["layout_type"]
|
t["layout_type"] = c["layout_type"]
|
||||||
boxes.append(t)
|
boxes.append(t)
|
||||||
|
|
||||||
@ -605,25 +564,20 @@ class RAGFlowPdfParser:
|
|||||||
findit = False
|
findit = False
|
||||||
i = 0
|
i = 0
|
||||||
while i < len(self.boxes):
|
while i < len(self.boxes):
|
||||||
if not re.match(r"(contents|目录|目次|table of contents|致谢|acknowledge)$",
|
if not re.match(r"(contents|目录|目次|table of contents|致谢|acknowledge)$", re.sub(r"( | |\u3000)+", "", self.boxes[i]["text"].lower())):
|
||||||
re.sub(r"( | |\u3000)+", "", self.boxes[i]["text"].lower())):
|
|
||||||
i += 1
|
i += 1
|
||||||
continue
|
continue
|
||||||
findit = True
|
findit = True
|
||||||
eng = re.match(
|
eng = re.match(r"[0-9a-zA-Z :'.-]{5,}", self.boxes[i]["text"].strip())
|
||||||
r"[0-9a-zA-Z :'.-]{5,}",
|
|
||||||
self.boxes[i]["text"].strip())
|
|
||||||
self.boxes.pop(i)
|
self.boxes.pop(i)
|
||||||
if i >= len(self.boxes):
|
if i >= len(self.boxes):
|
||||||
break
|
break
|
||||||
prefix = self.boxes[i]["text"].strip()[:3] if not eng else " ".join(
|
prefix = self.boxes[i]["text"].strip()[:3] if not eng else " ".join(self.boxes[i]["text"].strip().split()[:2])
|
||||||
self.boxes[i]["text"].strip().split()[:2])
|
|
||||||
while not prefix:
|
while not prefix:
|
||||||
self.boxes.pop(i)
|
self.boxes.pop(i)
|
||||||
if i >= len(self.boxes):
|
if i >= len(self.boxes):
|
||||||
break
|
break
|
||||||
prefix = self.boxes[i]["text"].strip()[:3] if not eng else " ".join(
|
prefix = self.boxes[i]["text"].strip()[:3] if not eng else " ".join(self.boxes[i]["text"].strip().split()[:2])
|
||||||
self.boxes[i]["text"].strip().split()[:2])
|
|
||||||
self.boxes.pop(i)
|
self.boxes.pop(i)
|
||||||
if i >= len(self.boxes) or not prefix:
|
if i >= len(self.boxes) or not prefix:
|
||||||
break
|
break
|
||||||
@ -662,10 +616,12 @@ class RAGFlowPdfParser:
|
|||||||
self.boxes.pop(i + 1)
|
self.boxes.pop(i + 1)
|
||||||
continue
|
continue
|
||||||
|
|
||||||
if b["text"].strip()[0] != b_["text"].strip()[0] \
|
if (
|
||||||
or b["text"].strip()[0].lower() in set("qwertyuopasdfghjklzxcvbnm") \
|
b["text"].strip()[0] != b_["text"].strip()[0]
|
||||||
or rag_tokenizer.is_chinese(b["text"].strip()[0]) \
|
or b["text"].strip()[0].lower() in set("qwertyuopasdfghjklzxcvbnm")
|
||||||
or b["top"] > b_["bottom"]:
|
or rag_tokenizer.is_chinese(b["text"].strip()[0])
|
||||||
|
or b["top"] > b_["bottom"]
|
||||||
|
):
|
||||||
i += 1
|
i += 1
|
||||||
continue
|
continue
|
||||||
b_["text"] = b["text"] + "\n" + b_["text"]
|
b_["text"] = b["text"] + "\n" + b_["text"]
|
||||||
@ -685,12 +641,8 @@ class RAGFlowPdfParser:
|
|||||||
if "layoutno" not in self.boxes[i]:
|
if "layoutno" not in self.boxes[i]:
|
||||||
i += 1
|
i += 1
|
||||||
continue
|
continue
|
||||||
lout_no = str(self.boxes[i]["page_number"]) + \
|
lout_no = str(self.boxes[i]["page_number"]) + "-" + str(self.boxes[i]["layoutno"])
|
||||||
"-" + str(self.boxes[i]["layoutno"])
|
if TableStructureRecognizer.is_caption(self.boxes[i]) or self.boxes[i]["layout_type"] in ["table caption", "title", "figure caption", "reference"]:
|
||||||
if TableStructureRecognizer.is_caption(self.boxes[i]) or self.boxes[i]["layout_type"] in ["table caption",
|
|
||||||
"title",
|
|
||||||
"figure caption",
|
|
||||||
"reference"]:
|
|
||||||
nomerge_lout_no.append(lst_lout_no)
|
nomerge_lout_no.append(lst_lout_no)
|
||||||
if self.boxes[i]["layout_type"] == "table":
|
if self.boxes[i]["layout_type"] == "table":
|
||||||
if re.match(r"(数据|资料|图表)*来源[:: ]", self.boxes[i]["text"]):
|
if re.match(r"(数据|资料|图表)*来源[:: ]", self.boxes[i]["text"]):
|
||||||
@ -716,8 +668,7 @@ class RAGFlowPdfParser:
|
|||||||
|
|
||||||
# merge table on different pages
|
# merge table on different pages
|
||||||
nomerge_lout_no = set(nomerge_lout_no)
|
nomerge_lout_no = set(nomerge_lout_no)
|
||||||
tbls = sorted([(k, bxs) for k, bxs in tables.items()],
|
tbls = sorted([(k, bxs) for k, bxs in tables.items()], key=lambda x: (x[1][0]["top"], x[1][0]["x0"]))
|
||||||
key=lambda x: (x[1][0]["top"], x[1][0]["x0"]))
|
|
||||||
|
|
||||||
i = len(tbls) - 1
|
i = len(tbls) - 1
|
||||||
while i - 1 >= 0:
|
while i - 1 >= 0:
|
||||||
@ -758,9 +709,7 @@ class RAGFlowPdfParser:
|
|||||||
if b.get("layout_type", "").find("caption") >= 0:
|
if b.get("layout_type", "").find("caption") >= 0:
|
||||||
continue
|
continue
|
||||||
y_dis = self._y_dis(c, b)
|
y_dis = self._y_dis(c, b)
|
||||||
x_dis = self._x_dis(
|
x_dis = self._x_dis(c, b) if not x_overlapped(c, b) else 0
|
||||||
c, b) if not x_overlapped(
|
|
||||||
c, b) else 0
|
|
||||||
dis = y_dis * y_dis + x_dis * x_dis
|
dis = y_dis * y_dis + x_dis * x_dis
|
||||||
if dis < minv:
|
if dis < minv:
|
||||||
mink = k
|
mink = k
|
||||||
@ -774,18 +723,10 @@ class RAGFlowPdfParser:
|
|||||||
# continue
|
# continue
|
||||||
if tv < fv and tk:
|
if tv < fv and tk:
|
||||||
tables[tk].insert(0, c)
|
tables[tk].insert(0, c)
|
||||||
logging.debug(
|
logging.debug("TABLE:" + self.boxes[i]["text"] + "; Cap: " + tk)
|
||||||
"TABLE:" +
|
|
||||||
self.boxes[i]["text"] +
|
|
||||||
"; Cap: " +
|
|
||||||
tk)
|
|
||||||
elif fk:
|
elif fk:
|
||||||
figures[fk].insert(0, c)
|
figures[fk].insert(0, c)
|
||||||
logging.debug(
|
logging.debug("FIGURE:" + self.boxes[i]["text"] + "; Cap: " + tk)
|
||||||
"FIGURE:" +
|
|
||||||
self.boxes[i]["text"] +
|
|
||||||
"; Cap: " +
|
|
||||||
tk)
|
|
||||||
self.boxes.pop(i)
|
self.boxes.pop(i)
|
||||||
|
|
||||||
def cropout(bxs, ltype, poss):
|
def cropout(bxs, ltype, poss):
|
||||||
@ -794,29 +735,19 @@ class RAGFlowPdfParser:
|
|||||||
if len(pn) < 2:
|
if len(pn) < 2:
|
||||||
pn = list(pn)[0]
|
pn = list(pn)[0]
|
||||||
ht = self.page_cum_height[pn]
|
ht = self.page_cum_height[pn]
|
||||||
b = {
|
b = {"x0": np.min([b["x0"] for b in bxs]), "top": np.min([b["top"] for b in bxs]) - ht, "x1": np.max([b["x1"] for b in bxs]), "bottom": np.max([b["bottom"] for b in bxs]) - ht}
|
||||||
"x0": np.min([b["x0"] for b in bxs]),
|
|
||||||
"top": np.min([b["top"] for b in bxs]) - ht,
|
|
||||||
"x1": np.max([b["x1"] for b in bxs]),
|
|
||||||
"bottom": np.max([b["bottom"] for b in bxs]) - ht
|
|
||||||
}
|
|
||||||
louts = [layout for layout in self.page_layout[pn] if layout["type"] == ltype]
|
louts = [layout for layout in self.page_layout[pn] if layout["type"] == ltype]
|
||||||
ii = Recognizer.find_overlapped(b, louts, naive=True)
|
ii = Recognizer.find_overlapped(b, louts, naive=True)
|
||||||
if ii is not None:
|
if ii is not None:
|
||||||
b = louts[ii]
|
b = louts[ii]
|
||||||
else:
|
else:
|
||||||
logging.warning(
|
logging.warning(f"Missing layout match: {pn + 1},%s" % (bxs[0].get("layoutno", "")))
|
||||||
f"Missing layout match: {pn + 1},%s" %
|
|
||||||
(bxs[0].get(
|
|
||||||
"layoutno", "")))
|
|
||||||
|
|
||||||
left, top, right, bott = b["x0"], b["top"], b["x1"], b["bottom"]
|
left, top, right, bott = b["x0"], b["top"], b["x1"], b["bottom"]
|
||||||
if right < left:
|
if right < left:
|
||||||
right = left + 1
|
right = left + 1
|
||||||
poss.append((pn + self.page_from, left, right, top, bott))
|
poss.append((pn + self.page_from, left, right, top, bott))
|
||||||
return self.page_images[pn] \
|
return self.page_images[pn].crop((left * ZM, top * ZM, right * ZM, bott * ZM))
|
||||||
.crop((left * ZM, top * ZM,
|
|
||||||
right * ZM, bott * ZM))
|
|
||||||
pn = {}
|
pn = {}
|
||||||
for b in bxs:
|
for b in bxs:
|
||||||
p = b["page_number"] - 1
|
p = b["page_number"] - 1
|
||||||
@ -825,10 +756,7 @@ class RAGFlowPdfParser:
|
|||||||
pn[p].append(b)
|
pn[p].append(b)
|
||||||
pn = sorted(pn.items(), key=lambda x: x[0])
|
pn = sorted(pn.items(), key=lambda x: x[0])
|
||||||
imgs = [cropout(arr, ltype, poss) for p, arr in pn]
|
imgs = [cropout(arr, ltype, poss) for p, arr in pn]
|
||||||
pic = Image.new("RGB",
|
pic = Image.new("RGB", (int(np.max([i.size[0] for i in imgs])), int(np.sum([m.size[1] for m in imgs]))), (245, 245, 245))
|
||||||
(int(np.max([i.size[0] for i in imgs])),
|
|
||||||
int(np.sum([m.size[1] for m in imgs]))),
|
|
||||||
(245, 245, 245))
|
|
||||||
height = 0
|
height = 0
|
||||||
for img in imgs:
|
for img in imgs:
|
||||||
pic.paste(img, (0, int(height)))
|
pic.paste(img, (0, int(height)))
|
||||||
@ -848,30 +776,20 @@ class RAGFlowPdfParser:
|
|||||||
poss = []
|
poss = []
|
||||||
|
|
||||||
if separate_tables_figures:
|
if separate_tables_figures:
|
||||||
figure_results.append(
|
figure_results.append((cropout(bxs, "figure", poss), [txt]))
|
||||||
(cropout(
|
|
||||||
bxs,
|
|
||||||
"figure", poss),
|
|
||||||
[txt]))
|
|
||||||
figure_positions.append(poss)
|
figure_positions.append(poss)
|
||||||
else:
|
else:
|
||||||
res.append(
|
res.append((cropout(bxs, "figure", poss), [txt]))
|
||||||
(cropout(
|
|
||||||
bxs,
|
|
||||||
"figure", poss),
|
|
||||||
[txt]))
|
|
||||||
positions.append(poss)
|
positions.append(poss)
|
||||||
|
|
||||||
for k, bxs in tables.items():
|
for k, bxs in tables.items():
|
||||||
if not bxs:
|
if not bxs:
|
||||||
continue
|
continue
|
||||||
bxs = Recognizer.sort_Y_firstly(bxs, np.mean(
|
bxs = Recognizer.sort_Y_firstly(bxs, np.mean([(b["bottom"] - b["top"]) / 2 for b in bxs]))
|
||||||
[(b["bottom"] - b["top"]) / 2 for b in bxs]))
|
|
||||||
|
|
||||||
poss = []
|
poss = []
|
||||||
|
|
||||||
res.append((cropout(bxs, "table", poss),
|
res.append((cropout(bxs, "table", poss), self.tbl_det.construct_table(bxs, html=return_html, is_english=self.is_english)))
|
||||||
self.tbl_det.construct_table(bxs, html=return_html, is_english=self.is_english)))
|
|
||||||
positions.append(poss)
|
positions.append(poss)
|
||||||
|
|
||||||
if separate_tables_figures:
|
if separate_tables_figures:
|
||||||
@ -905,7 +823,7 @@ class RAGFlowPdfParser:
|
|||||||
(r"[0-9]+)", 10),
|
(r"[0-9]+)", 10),
|
||||||
(r"[\((][0-9]+[)\)]", 11),
|
(r"[\((][0-9]+[)\)]", 11),
|
||||||
(r"[零一二三四五六七八九十百]+是", 12),
|
(r"[零一二三四五六七八九十百]+是", 12),
|
||||||
(r"[⚫•➢✓]", 12)
|
(r"[⚫•➢✓]", 12),
|
||||||
]:
|
]:
|
||||||
if re.match(p, line):
|
if re.match(p, line):
|
||||||
return j
|
return j
|
||||||
@ -924,12 +842,9 @@ class RAGFlowPdfParser:
|
|||||||
if pn[-1] - 1 >= page_images_cnt:
|
if pn[-1] - 1 >= page_images_cnt:
|
||||||
return ""
|
return ""
|
||||||
|
|
||||||
return "@@{}\t{:.1f}\t{:.1f}\t{:.1f}\t{:.1f}##" \
|
return "@@{}\t{:.1f}\t{:.1f}\t{:.1f}\t{:.1f}##".format("-".join([str(p) for p in pn]), bx["x0"], bx["x1"], top, bott)
|
||||||
.format("-".join([str(p) for p in pn]),
|
|
||||||
bx["x0"], bx["x1"], top, bott)
|
|
||||||
|
|
||||||
def __filterout_scraps(self, boxes, ZM):
|
def __filterout_scraps(self, boxes, ZM):
|
||||||
|
|
||||||
def width(b):
|
def width(b):
|
||||||
return b["x1"] - b["x0"]
|
return b["x1"] - b["x0"]
|
||||||
|
|
||||||
@ -939,8 +854,7 @@ class RAGFlowPdfParser:
|
|||||||
def usefull(b):
|
def usefull(b):
|
||||||
if b.get("layout_type"):
|
if b.get("layout_type"):
|
||||||
return True
|
return True
|
||||||
if width(
|
if width(b) > self.page_images[b["page_number"] - 1].size[0] / ZM / 3:
|
||||||
b) > self.page_images[b["page_number"] - 1].size[0] / ZM / 3:
|
|
||||||
return True
|
return True
|
||||||
if b["bottom"] - b["top"] > self.mean_height[b["page_number"] - 1]:
|
if b["bottom"] - b["top"] > self.mean_height[b["page_number"] - 1]:
|
||||||
return True
|
return True
|
||||||
@ -952,31 +866,23 @@ class RAGFlowPdfParser:
|
|||||||
widths = []
|
widths = []
|
||||||
pw = self.page_images[boxes[0]["page_number"] - 1].size[0] / ZM
|
pw = self.page_images[boxes[0]["page_number"] - 1].size[0] / ZM
|
||||||
mh = self.mean_height[boxes[0]["page_number"] - 1]
|
mh = self.mean_height[boxes[0]["page_number"] - 1]
|
||||||
mj = self.proj_match(
|
mj = self.proj_match(boxes[0]["text"]) or boxes[0].get("layout_type", "") == "title"
|
||||||
boxes[0]["text"]) or boxes[0].get(
|
|
||||||
"layout_type",
|
|
||||||
"") == "title"
|
|
||||||
|
|
||||||
def dfs(line, st):
|
def dfs(line, st):
|
||||||
nonlocal mh, pw, lines, widths
|
nonlocal mh, pw, lines, widths
|
||||||
lines.append(line)
|
lines.append(line)
|
||||||
widths.append(width(line))
|
widths.append(width(line))
|
||||||
mmj = self.proj_match(
|
mmj = self.proj_match(line["text"]) or line.get("layout_type", "") == "title"
|
||||||
line["text"]) or line.get(
|
|
||||||
"layout_type",
|
|
||||||
"") == "title"
|
|
||||||
for i in range(st + 1, min(st + 20, len(boxes))):
|
for i in range(st + 1, min(st + 20, len(boxes))):
|
||||||
if (boxes[i]["page_number"] - line["page_number"]) > 0:
|
if (boxes[i]["page_number"] - line["page_number"]) > 0:
|
||||||
break
|
break
|
||||||
if not mmj and self._y_dis(
|
if not mmj and self._y_dis(line, boxes[i]) >= 3 * mh and height(line) < 1.5 * mh:
|
||||||
line, boxes[i]) >= 3 * mh and height(line) < 1.5 * mh:
|
|
||||||
break
|
break
|
||||||
|
|
||||||
if not usefull(boxes[i]):
|
if not usefull(boxes[i]):
|
||||||
continue
|
continue
|
||||||
if mmj or \
|
if mmj or (self._x_dis(boxes[i], line) < pw / 10):
|
||||||
(self._x_dis(boxes[i], line) < pw / 10): \
|
# and abs(width(boxes[i])-width_mean)/max(width(boxes[i]),width_mean)<0.5):
|
||||||
# and abs(width(boxes[i])-width_mean)/max(width(boxes[i]),width_mean)<0.5):
|
|
||||||
# concat following
|
# concat following
|
||||||
dfs(boxes[i], i)
|
dfs(boxes[i], i)
|
||||||
boxes.pop(i)
|
boxes.pop(i)
|
||||||
@ -992,11 +898,9 @@ class RAGFlowPdfParser:
|
|||||||
boxes.pop(0)
|
boxes.pop(0)
|
||||||
mw = np.mean(widths)
|
mw = np.mean(widths)
|
||||||
if mj or mw / pw >= 0.35 or mw > 200:
|
if mj or mw / pw >= 0.35 or mw > 200:
|
||||||
res.append(
|
res.append("\n".join([c["text"] + self._line_tag(c, ZM) for c in lines]))
|
||||||
"\n".join([c["text"] + self._line_tag(c, ZM) for c in lines]))
|
|
||||||
else:
|
else:
|
||||||
logging.debug("REMOVED: " +
|
logging.debug("REMOVED: " + "<<".join([c["text"] for c in lines]))
|
||||||
"<<".join([c["text"] for c in lines]))
|
|
||||||
|
|
||||||
return "\n\n".join(res)
|
return "\n\n".join(res)
|
||||||
|
|
||||||
@ -1004,16 +908,14 @@ class RAGFlowPdfParser:
|
|||||||
def total_page_number(fnm, binary=None):
|
def total_page_number(fnm, binary=None):
|
||||||
try:
|
try:
|
||||||
with sys.modules[LOCK_KEY_pdfplumber]:
|
with sys.modules[LOCK_KEY_pdfplumber]:
|
||||||
pdf = pdfplumber.open(
|
pdf = pdfplumber.open(fnm) if not binary else pdfplumber.open(BytesIO(binary))
|
||||||
fnm) if not binary else pdfplumber.open(BytesIO(binary))
|
|
||||||
total_page = len(pdf.pages)
|
total_page = len(pdf.pages)
|
||||||
pdf.close()
|
pdf.close()
|
||||||
return total_page
|
return total_page
|
||||||
except Exception:
|
except Exception:
|
||||||
logging.exception("total_page_number")
|
logging.exception("total_page_number")
|
||||||
|
|
||||||
def __images__(self, fnm, zoomin=3, page_from=0,
|
def __images__(self, fnm, zoomin=3, page_from=0, page_to=299, callback=None):
|
||||||
page_to=299, callback=None):
|
|
||||||
self.lefted_chars = []
|
self.lefted_chars = []
|
||||||
self.mean_height = []
|
self.mean_height = []
|
||||||
self.mean_width = []
|
self.mean_width = []
|
||||||
@ -1025,10 +927,9 @@ class RAGFlowPdfParser:
|
|||||||
start = timer()
|
start = timer()
|
||||||
try:
|
try:
|
||||||
with sys.modules[LOCK_KEY_pdfplumber]:
|
with sys.modules[LOCK_KEY_pdfplumber]:
|
||||||
with (pdfplumber.open(fnm) if isinstance(fnm, str) else pdfplumber.open(BytesIO(fnm))) as pdf:
|
with pdfplumber.open(fnm) if isinstance(fnm, str) else pdfplumber.open(BytesIO(fnm)) as pdf:
|
||||||
self.pdf = pdf
|
self.pdf = pdf
|
||||||
self.page_images = [p.to_image(resolution=72 * zoomin, antialias=True).annotated for i, p in
|
self.page_images = [p.to_image(resolution=72 * zoomin, antialias=True).annotated for i, p in enumerate(self.pdf.pages[page_from:page_to])]
|
||||||
enumerate(self.pdf.pages[page_from:page_to])]
|
|
||||||
|
|
||||||
try:
|
try:
|
||||||
self.page_chars = [[c for c in page.dedupe_chars().chars if self._has_color(c)] for page in self.pdf.pages[page_from:page_to]]
|
self.page_chars = [[c for c in page.dedupe_chars().chars if self._has_color(c)] for page in self.pdf.pages[page_from:page_to]]
|
||||||
@ -1044,11 +945,11 @@ class RAGFlowPdfParser:
|
|||||||
|
|
||||||
self.outlines = []
|
self.outlines = []
|
||||||
try:
|
try:
|
||||||
with (pdf2_read(fnm if isinstance(fnm, str)
|
with pdf2_read(fnm if isinstance(fnm, str) else BytesIO(fnm)) as pdf:
|
||||||
else BytesIO(fnm))) as pdf:
|
|
||||||
self.pdf = pdf
|
self.pdf = pdf
|
||||||
|
|
||||||
outlines = self.pdf.outline
|
outlines = self.pdf.outline
|
||||||
|
|
||||||
def dfs(arr, depth):
|
def dfs(arr, depth):
|
||||||
for a in arr:
|
for a in arr:
|
||||||
if isinstance(a, dict):
|
if isinstance(a, dict):
|
||||||
@ -1065,11 +966,11 @@ class RAGFlowPdfParser:
|
|||||||
logging.warning("Miss outlines")
|
logging.warning("Miss outlines")
|
||||||
|
|
||||||
logging.debug("Images converted.")
|
logging.debug("Images converted.")
|
||||||
self.is_english = [re.search(r"[a-zA-Z0-9,/¸;:'\[\]\(\)!@#$%^&*\"?<>._-]{30,}", "".join(
|
self.is_english = [
|
||||||
random.choices([c["text"] for c in self.page_chars[i]], k=min(100, len(self.page_chars[i]))))) for i in
|
re.search(r"[a-zA-Z0-9,/¸;:'\[\]\(\)!@#$%^&*\"?<>._-]{30,}", "".join(random.choices([c["text"] for c in self.page_chars[i]], k=min(100, len(self.page_chars[i])))))
|
||||||
range(len(self.page_chars))]
|
for i in range(len(self.page_chars))
|
||||||
if sum([1 if e else 0 for e in self.is_english]) > len(
|
]
|
||||||
self.page_images) / 2:
|
if sum([1 if e else 0 for e in self.is_english]) > len(self.page_images) / 2:
|
||||||
self.is_english = True
|
self.is_english = True
|
||||||
else:
|
else:
|
||||||
self.is_english = False
|
self.is_english = False
|
||||||
@ -1077,10 +978,12 @@ class RAGFlowPdfParser:
|
|||||||
async def __img_ocr(i, id, img, chars, limiter):
|
async def __img_ocr(i, id, img, chars, limiter):
|
||||||
j = 0
|
j = 0
|
||||||
while j + 1 < len(chars):
|
while j + 1 < len(chars):
|
||||||
if chars[j]["text"] and chars[j + 1]["text"] \
|
if (
|
||||||
and re.match(r"[0-9a-zA-Z,.:;!%]+", chars[j]["text"] + chars[j + 1]["text"]) \
|
chars[j]["text"]
|
||||||
and chars[j + 1]["x0"] - chars[j]["x1"] >= min(chars[j + 1]["width"],
|
and chars[j + 1]["text"]
|
||||||
chars[j]["width"]) / 2:
|
and re.match(r"[0-9a-zA-Z,.:;!%]+", chars[j]["text"] + chars[j + 1]["text"])
|
||||||
|
and chars[j + 1]["x0"] - chars[j]["x1"] >= min(chars[j + 1]["width"], chars[j]["width"]) / 2
|
||||||
|
):
|
||||||
chars[j]["text"] += " "
|
chars[j]["text"] += " "
|
||||||
j += 1
|
j += 1
|
||||||
|
|
||||||
@ -1096,12 +999,8 @@ class RAGFlowPdfParser:
|
|||||||
async def __img_ocr_launcher():
|
async def __img_ocr_launcher():
|
||||||
def __ocr_preprocess():
|
def __ocr_preprocess():
|
||||||
chars = self.page_chars[i] if not self.is_english else []
|
chars = self.page_chars[i] if not self.is_english else []
|
||||||
self.mean_height.append(
|
self.mean_height.append(np.median(sorted([c["height"] for c in chars])) if chars else 0)
|
||||||
np.median(sorted([c["height"] for c in chars])) if chars else 0
|
self.mean_width.append(np.median(sorted([c["width"] for c in chars])) if chars else 8)
|
||||||
)
|
|
||||||
self.mean_width.append(
|
|
||||||
np.median(sorted([c["width"] for c in chars])) if chars else 8
|
|
||||||
)
|
|
||||||
self.page_cum_height.append(img.size[1] / zoomin)
|
self.page_cum_height.append(img.size[1] / zoomin)
|
||||||
return chars
|
return chars
|
||||||
|
|
||||||
@ -1110,8 +1009,7 @@ class RAGFlowPdfParser:
|
|||||||
for i, img in enumerate(self.page_images):
|
for i, img in enumerate(self.page_images):
|
||||||
chars = __ocr_preprocess()
|
chars = __ocr_preprocess()
|
||||||
|
|
||||||
nursery.start_soon(__img_ocr, i, i % PARALLEL_DEVICES, img, chars,
|
nursery.start_soon(__img_ocr, i, i % PARALLEL_DEVICES, img, chars, self.parallel_limiter[i % PARALLEL_DEVICES])
|
||||||
self.parallel_limiter[i % PARALLEL_DEVICES])
|
|
||||||
await trio.sleep(0.1)
|
await trio.sleep(0.1)
|
||||||
else:
|
else:
|
||||||
for i, img in enumerate(self.page_images):
|
for i, img in enumerate(self.page_images):
|
||||||
@ -1124,11 +1022,9 @@ class RAGFlowPdfParser:
|
|||||||
|
|
||||||
logging.info(f"__images__ {len(self.page_images)} pages cost {timer() - start}s")
|
logging.info(f"__images__ {len(self.page_images)} pages cost {timer() - start}s")
|
||||||
|
|
||||||
if not self.is_english and not any(
|
if not self.is_english and not any([c for c in self.page_chars]) and self.boxes:
|
||||||
[c for c in self.page_chars]) and self.boxes:
|
|
||||||
bxes = [b for bxs in self.boxes for b in bxs]
|
bxes = [b for bxs in self.boxes for b in bxs]
|
||||||
self.is_english = re.search(r"[\na-zA-Z0-9,/¸;:'\[\]\(\)!@#$%^&*\"?<>._-]{30,}",
|
self.is_english = re.search(r"[\na-zA-Z0-9,/¸;:'\[\]\(\)!@#$%^&*\"?<>._-]{30,}", "".join([b["text"] for b in random.choices(bxes, k=min(30, len(bxes)))]))
|
||||||
"".join([b["text"] for b in random.choices(bxes, k=min(30, len(bxes)))]))
|
|
||||||
|
|
||||||
logging.debug("Is it English:", self.is_english)
|
logging.debug("Is it English:", self.is_english)
|
||||||
|
|
||||||
@ -1144,8 +1040,7 @@ class RAGFlowPdfParser:
|
|||||||
self._text_merge()
|
self._text_merge()
|
||||||
self._concat_downward()
|
self._concat_downward()
|
||||||
self._filter_forpages()
|
self._filter_forpages()
|
||||||
tbls = self._extract_table_figure(
|
tbls = self._extract_table_figure(need_image, zoomin, return_html, False)
|
||||||
need_image, zoomin, return_html, False)
|
|
||||||
return self.__filterout_scraps(deepcopy(self.boxes), zoomin), tbls
|
return self.__filterout_scraps(deepcopy(self.boxes), zoomin), tbls
|
||||||
|
|
||||||
def parse_into_bboxes(self, fnm, callback=None, zoomin=3):
|
def parse_into_bboxes(self, fnm, callback=None, zoomin=3):
|
||||||
@ -1177,11 +1072,11 @@ class RAGFlowPdfParser:
|
|||||||
def insert_table_figures(tbls_or_figs, layout_type):
|
def insert_table_figures(tbls_or_figs, layout_type):
|
||||||
def min_rectangle_distance(rect1, rect2):
|
def min_rectangle_distance(rect1, rect2):
|
||||||
import math
|
import math
|
||||||
|
|
||||||
pn1, left1, right1, top1, bottom1 = rect1
|
pn1, left1, right1, top1, bottom1 = rect1
|
||||||
pn2, left2, right2, top2, bottom2 = rect2
|
pn2, left2, right2, top2, bottom2 = rect2
|
||||||
if (right1 >= left2 and right2 >= left1 and
|
if right1 >= left2 and right2 >= left1 and bottom1 >= top2 and bottom2 >= top1:
|
||||||
bottom1 >= top2 and bottom2 >= top1):
|
return 0 + (pn1 - pn2) * 10000
|
||||||
return 0 + (pn1-pn2)*10000
|
|
||||||
if right1 < left2:
|
if right1 < left2:
|
||||||
dx = left2 - right1
|
dx = left2 - right1
|
||||||
elif right2 < left1:
|
elif right2 < left1:
|
||||||
@ -1194,18 +1089,16 @@ class RAGFlowPdfParser:
|
|||||||
dy = top1 - bottom2
|
dy = top1 - bottom2
|
||||||
else:
|
else:
|
||||||
dy = 0
|
dy = 0
|
||||||
return math.sqrt(dx*dx + dy*dy) + (pn1-pn2)*10000
|
return math.sqrt(dx * dx + dy * dy) + (pn1 - pn2) * 10000
|
||||||
|
|
||||||
for (img, txt), poss in tbls_or_figs:
|
for (img, txt), poss in tbls_or_figs:
|
||||||
bboxes = [(i, (b["page_number"], b["x0"], b["x1"], b["top"], b["bottom"])) for i, b in enumerate(self.boxes)]
|
bboxes = [(i, (b["page_number"], b["x0"], b["x1"], b["top"], b["bottom"])) for i, b in enumerate(self.boxes)]
|
||||||
dists = [(min_rectangle_distance((pn, left, right, top, bott), rect),i) for i, rect in bboxes for pn, left, right, top, bott in poss]
|
dists = [(min_rectangle_distance((pn, left, right, top, bott), rect), i) for i, rect in bboxes for pn, left, right, top, bott in poss]
|
||||||
min_i = np.argmin(dists, axis=0)[0]
|
min_i = np.argmin(dists, axis=0)[0]
|
||||||
min_i, rect = bboxes[dists[min_i][-1]]
|
min_i, rect = bboxes[dists[min_i][-1]]
|
||||||
if isinstance(txt, list):
|
if isinstance(txt, list):
|
||||||
txt = "\n".join(txt)
|
txt = "\n".join(txt)
|
||||||
self.boxes.insert(min_i, {
|
self.boxes.insert(min_i, {"page_number": rect[0], "x0": rect[1], "x1": rect[2], "top": rect[3], "bottom": rect[4], "layout_type": layout_type, "text": txt, "image": img})
|
||||||
"page_number": rect[0], "x0": rect[1], "x1": rect[2], "top": rect[3], "bottom": rect[4], "layout_type": layout_type, "text": txt, "image": img
|
|
||||||
})
|
|
||||||
|
|
||||||
for b in self.boxes:
|
for b in self.boxes:
|
||||||
b["position_tag"] = self._line_tag(b, zoomin)
|
b["position_tag"] = self._line_tag(b, zoomin)
|
||||||
@ -1225,12 +1118,9 @@ class RAGFlowPdfParser:
|
|||||||
def extract_positions(txt):
|
def extract_positions(txt):
|
||||||
poss = []
|
poss = []
|
||||||
for tag in re.findall(r"@@[0-9-]+\t[0-9.\t]+##", txt):
|
for tag in re.findall(r"@@[0-9-]+\t[0-9.\t]+##", txt):
|
||||||
pn, left, right, top, bottom = tag.strip(
|
pn, left, right, top, bottom = tag.strip("#").strip("@").split("\t")
|
||||||
"#").strip("@").split("\t")
|
left, right, top, bottom = float(left), float(right), float(top), float(bottom)
|
||||||
left, right, top, bottom = float(left), float(
|
poss.append(([int(p) - 1 for p in pn.split("-")], left, right, top, bottom))
|
||||||
right), float(top), float(bottom)
|
|
||||||
poss.append(([int(p) - 1 for p in pn.split("-")],
|
|
||||||
left, right, top, bottom))
|
|
||||||
return poss
|
return poss
|
||||||
|
|
||||||
def crop(self, text, ZM=3, need_position=False):
|
def crop(self, text, ZM=3, need_position=False):
|
||||||
@ -1241,15 +1131,12 @@ class RAGFlowPdfParser:
|
|||||||
return None, None
|
return None, None
|
||||||
return
|
return
|
||||||
|
|
||||||
max_width = max(
|
max_width = max(np.max([right - left for (_, left, right, _, _) in poss]), 6)
|
||||||
np.max([right - left for (_, left, right, _, _) in poss]), 6)
|
|
||||||
GAP = 6
|
GAP = 6
|
||||||
pos = poss[0]
|
pos = poss[0]
|
||||||
poss.insert(0, ([pos[0][0]], pos[1], pos[2], max(
|
poss.insert(0, ([pos[0][0]], pos[1], pos[2], max(0, pos[3] - 120), max(pos[3] - GAP, 0)))
|
||||||
0, pos[3] - 120), max(pos[3] - GAP, 0)))
|
|
||||||
pos = poss[-1]
|
pos = poss[-1]
|
||||||
poss.append(([pos[0][-1]], pos[1], pos[2], min(self.page_images[pos[0][-1]].size[1] / ZM, pos[4] + GAP),
|
poss.append(([pos[0][-1]], pos[1], pos[2], min(self.page_images[pos[0][-1]].size[1] / ZM, pos[4] + GAP), min(self.page_images[pos[0][-1]].size[1] / ZM, pos[4] + 120)))
|
||||||
min(self.page_images[pos[0][-1]].size[1] / ZM, pos[4] + 120)))
|
|
||||||
|
|
||||||
positions = []
|
positions = []
|
||||||
for ii, (pns, left, right, top, bottom) in enumerate(poss):
|
for ii, (pns, left, right, top, bottom) in enumerate(poss):
|
||||||
@ -1257,28 +1144,14 @@ class RAGFlowPdfParser:
|
|||||||
bottom *= ZM
|
bottom *= ZM
|
||||||
for pn in pns[1:]:
|
for pn in pns[1:]:
|
||||||
bottom += self.page_images[pn - 1].size[1]
|
bottom += self.page_images[pn - 1].size[1]
|
||||||
imgs.append(
|
imgs.append(self.page_images[pns[0]].crop((left * ZM, top * ZM, right * ZM, min(bottom, self.page_images[pns[0]].size[1]))))
|
||||||
self.page_images[pns[0]].crop((left * ZM, top * ZM,
|
|
||||||
right *
|
|
||||||
ZM, min(
|
|
||||||
bottom, self.page_images[pns[0]].size[1])
|
|
||||||
))
|
|
||||||
)
|
|
||||||
if 0 < ii < len(poss) - 1:
|
if 0 < ii < len(poss) - 1:
|
||||||
positions.append((pns[0] + self.page_from, left, right, top, min(
|
positions.append((pns[0] + self.page_from, left, right, top, min(bottom, self.page_images[pns[0]].size[1]) / ZM))
|
||||||
bottom, self.page_images[pns[0]].size[1]) / ZM))
|
|
||||||
bottom -= self.page_images[pns[0]].size[1]
|
bottom -= self.page_images[pns[0]].size[1]
|
||||||
for pn in pns[1:]:
|
for pn in pns[1:]:
|
||||||
imgs.append(
|
imgs.append(self.page_images[pn].crop((left * ZM, 0, right * ZM, min(bottom, self.page_images[pn].size[1]))))
|
||||||
self.page_images[pn].crop((left * ZM, 0,
|
|
||||||
right * ZM,
|
|
||||||
min(bottom,
|
|
||||||
self.page_images[pn].size[1])
|
|
||||||
))
|
|
||||||
)
|
|
||||||
if 0 < ii < len(poss) - 1:
|
if 0 < ii < len(poss) - 1:
|
||||||
positions.append((pn + self.page_from, left, right, 0, min(
|
positions.append((pn + self.page_from, left, right, 0, min(bottom, self.page_images[pn].size[1]) / ZM))
|
||||||
bottom, self.page_images[pn].size[1]) / ZM))
|
|
||||||
bottom -= self.page_images[pn].size[1]
|
bottom -= self.page_images[pn].size[1]
|
||||||
|
|
||||||
if not imgs:
|
if not imgs:
|
||||||
@ -1290,14 +1163,12 @@ class RAGFlowPdfParser:
|
|||||||
height += img.size[1] + GAP
|
height += img.size[1] + GAP
|
||||||
height = int(height)
|
height = int(height)
|
||||||
width = int(np.max([i.size[0] for i in imgs]))
|
width = int(np.max([i.size[0] for i in imgs]))
|
||||||
pic = Image.new("RGB",
|
pic = Image.new("RGB", (width, height), (245, 245, 245))
|
||||||
(width, height),
|
|
||||||
(245, 245, 245))
|
|
||||||
height = 0
|
height = 0
|
||||||
for ii, img in enumerate(imgs):
|
for ii, img in enumerate(imgs):
|
||||||
if ii == 0 or ii + 1 == len(imgs):
|
if ii == 0 or ii + 1 == len(imgs):
|
||||||
img = img.convert('RGBA')
|
img = img.convert("RGBA")
|
||||||
overlay = Image.new('RGBA', img.size, (0, 0, 0, 0))
|
overlay = Image.new("RGBA", img.size, (0, 0, 0, 0))
|
||||||
overlay.putalpha(128)
|
overlay.putalpha(128)
|
||||||
img = Image.alpha_composite(img, overlay).convert("RGB")
|
img = Image.alpha_composite(img, overlay).convert("RGB")
|
||||||
pic.paste(img, (0, int(height)))
|
pic.paste(img, (0, int(height)))
|
||||||
@ -1312,14 +1183,12 @@ class RAGFlowPdfParser:
|
|||||||
pn = bx["page_number"]
|
pn = bx["page_number"]
|
||||||
top = bx["top"] - self.page_cum_height[pn - 1]
|
top = bx["top"] - self.page_cum_height[pn - 1]
|
||||||
bott = bx["bottom"] - self.page_cum_height[pn - 1]
|
bott = bx["bottom"] - self.page_cum_height[pn - 1]
|
||||||
poss.append((pn, bx["x0"], bx["x1"], top, min(
|
poss.append((pn, bx["x0"], bx["x1"], top, min(bott, self.page_images[pn - 1].size[1] / ZM)))
|
||||||
bott, self.page_images[pn - 1].size[1] / ZM)))
|
|
||||||
while bott * ZM > self.page_images[pn - 1].size[1]:
|
while bott * ZM > self.page_images[pn - 1].size[1]:
|
||||||
bott -= self.page_images[pn - 1].size[1] / ZM
|
bott -= self.page_images[pn - 1].size[1] / ZM
|
||||||
top = 0
|
top = 0
|
||||||
pn += 1
|
pn += 1
|
||||||
poss.append((pn, bx["x0"], bx["x1"], top, min(
|
poss.append((pn, bx["x0"], bx["x1"], top, min(bott, self.page_images[pn - 1].size[1] / ZM)))
|
||||||
bott, self.page_images[pn - 1].size[1] / ZM)))
|
|
||||||
return poss
|
return poss
|
||||||
|
|
||||||
|
|
||||||
@ -1328,9 +1197,7 @@ class PlainParser:
|
|||||||
self.outlines = []
|
self.outlines = []
|
||||||
lines = []
|
lines = []
|
||||||
try:
|
try:
|
||||||
self.pdf = pdf2_read(
|
self.pdf = pdf2_read(filename if isinstance(filename, str) else BytesIO(filename))
|
||||||
filename if isinstance(
|
|
||||||
filename, str) else BytesIO(filename))
|
|
||||||
for page in self.pdf.pages[from_page:to_page]:
|
for page in self.pdf.pages[from_page:to_page]:
|
||||||
lines.extend([t for t in page.extract_text().split("\n")])
|
lines.extend([t for t in page.extract_text().split("\n")])
|
||||||
|
|
||||||
@ -1367,10 +1234,8 @@ class VisionParser(RAGFlowPdfParser):
|
|||||||
def __images__(self, fnm, zoomin=3, page_from=0, page_to=299, callback=None):
|
def __images__(self, fnm, zoomin=3, page_from=0, page_to=299, callback=None):
|
||||||
try:
|
try:
|
||||||
with sys.modules[LOCK_KEY_pdfplumber]:
|
with sys.modules[LOCK_KEY_pdfplumber]:
|
||||||
self.pdf = pdfplumber.open(fnm) if isinstance(
|
self.pdf = pdfplumber.open(fnm) if isinstance(fnm, str) else pdfplumber.open(BytesIO(fnm))
|
||||||
fnm, str) else pdfplumber.open(BytesIO(fnm))
|
self.page_images = [p.to_image(resolution=72 * zoomin).annotated for i, p in enumerate(self.pdf.pages[page_from:page_to])]
|
||||||
self.page_images = [p.to_image(resolution=72 * zoomin).annotated for i, p in
|
|
||||||
enumerate(self.pdf.pages[page_from:page_to])]
|
|
||||||
self.total_page = len(self.pdf.pages)
|
self.total_page = len(self.pdf.pages)
|
||||||
except Exception:
|
except Exception:
|
||||||
self.page_images = None
|
self.page_images = None
|
||||||
@ -1397,15 +1262,15 @@ class VisionParser(RAGFlowPdfParser):
|
|||||||
text = picture_vision_llm_chunk(
|
text = picture_vision_llm_chunk(
|
||||||
binary=img_binary,
|
binary=img_binary,
|
||||||
vision_model=self.vision_model,
|
vision_model=self.vision_model,
|
||||||
prompt=vision_llm_describe_prompt(page=pdf_page_num+1),
|
prompt=vision_llm_describe_prompt(page=pdf_page_num + 1),
|
||||||
callback=callback,
|
callback=callback,
|
||||||
)
|
)
|
||||||
if kwargs.get("callback"):
|
if kwargs.get("callback"):
|
||||||
kwargs["callback"](idx*1./len(self.page_images), f"Processed: {idx+1}/{len(self.page_images)}")
|
kwargs["callback"](idx * 1.0 / len(self.page_images), f"Processed: {idx + 1}/{len(self.page_images)}")
|
||||||
|
|
||||||
if text:
|
if text:
|
||||||
width, height = self.page_images[idx].size
|
width, height = self.page_images[idx].size
|
||||||
all_docs.append((text, f"{pdf_page_num+1} 0 {width/zoomin} 0 {height/zoomin}"))
|
all_docs.append((text, f"{pdf_page_num + 1} 0 {width / zoomin} 0 {height / zoomin}"))
|
||||||
return all_docs, []
|
return all_docs, []
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
@ -16,24 +16,28 @@
|
|||||||
import io
|
import io
|
||||||
import sys
|
import sys
|
||||||
import threading
|
import threading
|
||||||
|
|
||||||
import pdfplumber
|
import pdfplumber
|
||||||
|
|
||||||
from .ocr import OCR
|
from .ocr import OCR
|
||||||
from .recognizer import Recognizer
|
from .recognizer import Recognizer
|
||||||
|
from .layout_recognizer import AscendLayoutRecognizer
|
||||||
from .layout_recognizer import LayoutRecognizer4YOLOv10 as LayoutRecognizer
|
from .layout_recognizer import LayoutRecognizer4YOLOv10 as LayoutRecognizer
|
||||||
from .table_structure_recognizer import TableStructureRecognizer
|
from .table_structure_recognizer import TableStructureRecognizer
|
||||||
|
|
||||||
|
|
||||||
LOCK_KEY_pdfplumber = "global_shared_lock_pdfplumber"
|
LOCK_KEY_pdfplumber = "global_shared_lock_pdfplumber"
|
||||||
if LOCK_KEY_pdfplumber not in sys.modules:
|
if LOCK_KEY_pdfplumber not in sys.modules:
|
||||||
sys.modules[LOCK_KEY_pdfplumber] = threading.Lock()
|
sys.modules[LOCK_KEY_pdfplumber] = threading.Lock()
|
||||||
|
|
||||||
|
|
||||||
def init_in_out(args):
|
def init_in_out(args):
|
||||||
from PIL import Image
|
|
||||||
import os
|
import os
|
||||||
import traceback
|
import traceback
|
||||||
|
|
||||||
|
from PIL import Image
|
||||||
|
|
||||||
from api.utils.file_utils import traversal_files
|
from api.utils.file_utils import traversal_files
|
||||||
|
|
||||||
images = []
|
images = []
|
||||||
outputs = []
|
outputs = []
|
||||||
|
|
||||||
@ -44,8 +48,7 @@ def init_in_out(args):
|
|||||||
nonlocal outputs, images
|
nonlocal outputs, images
|
||||||
with sys.modules[LOCK_KEY_pdfplumber]:
|
with sys.modules[LOCK_KEY_pdfplumber]:
|
||||||
pdf = pdfplumber.open(fnm)
|
pdf = pdfplumber.open(fnm)
|
||||||
images = [p.to_image(resolution=72 * zoomin).annotated for i, p in
|
images = [p.to_image(resolution=72 * zoomin).annotated for i, p in enumerate(pdf.pages)]
|
||||||
enumerate(pdf.pages)]
|
|
||||||
|
|
||||||
for i, page in enumerate(images):
|
for i, page in enumerate(images):
|
||||||
outputs.append(os.path.split(fnm)[-1] + f"_{i}.jpg")
|
outputs.append(os.path.split(fnm)[-1] + f"_{i}.jpg")
|
||||||
@ -57,10 +60,10 @@ def init_in_out(args):
|
|||||||
pdf_pages(fnm)
|
pdf_pages(fnm)
|
||||||
return
|
return
|
||||||
try:
|
try:
|
||||||
fp = open(fnm, 'rb')
|
fp = open(fnm, "rb")
|
||||||
binary = fp.read()
|
binary = fp.read()
|
||||||
fp.close()
|
fp.close()
|
||||||
images.append(Image.open(io.BytesIO(binary)).convert('RGB'))
|
images.append(Image.open(io.BytesIO(binary)).convert("RGB"))
|
||||||
outputs.append(os.path.split(fnm)[-1])
|
outputs.append(os.path.split(fnm)[-1])
|
||||||
except Exception:
|
except Exception:
|
||||||
traceback.print_exc()
|
traceback.print_exc()
|
||||||
@ -81,6 +84,7 @@ __all__ = [
|
|||||||
"OCR",
|
"OCR",
|
||||||
"Recognizer",
|
"Recognizer",
|
||||||
"LayoutRecognizer",
|
"LayoutRecognizer",
|
||||||
|
"AscendLayoutRecognizer",
|
||||||
"TableStructureRecognizer",
|
"TableStructureRecognizer",
|
||||||
"init_in_out",
|
"init_in_out",
|
||||||
]
|
]
|
||||||
|
|||||||
@ -14,6 +14,8 @@
|
|||||||
# limitations under the License.
|
# limitations under the License.
|
||||||
#
|
#
|
||||||
|
|
||||||
|
import logging
|
||||||
|
import math
|
||||||
import os
|
import os
|
||||||
import re
|
import re
|
||||||
from collections import Counter
|
from collections import Counter
|
||||||
@ -45,28 +47,22 @@ class LayoutRecognizer(Recognizer):
|
|||||||
|
|
||||||
def __init__(self, domain):
|
def __init__(self, domain):
|
||||||
try:
|
try:
|
||||||
model_dir = os.path.join(
|
model_dir = os.path.join(get_project_base_directory(), "rag/res/deepdoc")
|
||||||
get_project_base_directory(),
|
|
||||||
"rag/res/deepdoc")
|
|
||||||
super().__init__(self.labels, domain, model_dir)
|
super().__init__(self.labels, domain, model_dir)
|
||||||
except Exception:
|
except Exception:
|
||||||
model_dir = snapshot_download(repo_id="InfiniFlow/deepdoc",
|
model_dir = snapshot_download(repo_id="InfiniFlow/deepdoc", local_dir=os.path.join(get_project_base_directory(), "rag/res/deepdoc"), local_dir_use_symlinks=False)
|
||||||
local_dir=os.path.join(get_project_base_directory(), "rag/res/deepdoc"),
|
|
||||||
local_dir_use_symlinks=False)
|
|
||||||
super().__init__(self.labels, domain, model_dir)
|
super().__init__(self.labels, domain, model_dir)
|
||||||
|
|
||||||
self.garbage_layouts = ["footer", "header", "reference"]
|
self.garbage_layouts = ["footer", "header", "reference"]
|
||||||
self.client = None
|
self.client = None
|
||||||
if os.environ.get("TENSORRT_DLA_SVR"):
|
if os.environ.get("TENSORRT_DLA_SVR"):
|
||||||
from deepdoc.vision.dla_cli import DLAClient
|
from deepdoc.vision.dla_cli import DLAClient
|
||||||
|
|
||||||
self.client = DLAClient(os.environ["TENSORRT_DLA_SVR"])
|
self.client = DLAClient(os.environ["TENSORRT_DLA_SVR"])
|
||||||
|
|
||||||
def __call__(self, image_list, ocr_res, scale_factor=3, thr=0.2, batch_size=16, drop=True):
|
def __call__(self, image_list, ocr_res, scale_factor=3, thr=0.2, batch_size=16, drop=True):
|
||||||
def __is_garbage(b):
|
def __is_garbage(b):
|
||||||
patt = [r"^•+$", "^[0-9]{1,2} / ?[0-9]{1,2}$",
|
patt = [r"^•+$", "^[0-9]{1,2} / ?[0-9]{1,2}$", r"^[0-9]{1,2} of [0-9]{1,2}$", "^http://[^ ]{12,}", "\\(cid *: *[0-9]+ *\\)"]
|
||||||
r"^[0-9]{1,2} of [0-9]{1,2}$", "^http://[^ ]{12,}",
|
|
||||||
"\\(cid *: *[0-9]+ *\\)"
|
|
||||||
]
|
|
||||||
return any([re.search(p, b["text"]) for p in patt])
|
return any([re.search(p, b["text"]) for p in patt])
|
||||||
|
|
||||||
if self.client:
|
if self.client:
|
||||||
@ -82,18 +78,23 @@ class LayoutRecognizer(Recognizer):
|
|||||||
page_layout = []
|
page_layout = []
|
||||||
for pn, lts in enumerate(layouts):
|
for pn, lts in enumerate(layouts):
|
||||||
bxs = ocr_res[pn]
|
bxs = ocr_res[pn]
|
||||||
lts = [{"type": b["type"],
|
lts = [
|
||||||
|
{
|
||||||
|
"type": b["type"],
|
||||||
"score": float(b["score"]),
|
"score": float(b["score"]),
|
||||||
"x0": b["bbox"][0] / scale_factor, "x1": b["bbox"][2] / scale_factor,
|
"x0": b["bbox"][0] / scale_factor,
|
||||||
"top": b["bbox"][1] / scale_factor, "bottom": b["bbox"][-1] / scale_factor,
|
"x1": b["bbox"][2] / scale_factor,
|
||||||
|
"top": b["bbox"][1] / scale_factor,
|
||||||
|
"bottom": b["bbox"][-1] / scale_factor,
|
||||||
"page_number": pn,
|
"page_number": pn,
|
||||||
} for b in lts if float(b["score"]) >= 0.4 or b["type"] not in self.garbage_layouts]
|
}
|
||||||
lts = self.sort_Y_firstly(lts, np.mean(
|
for b in lts
|
||||||
[lt["bottom"] - lt["top"] for lt in lts]) / 2)
|
if float(b["score"]) >= 0.4 or b["type"] not in self.garbage_layouts
|
||||||
|
]
|
||||||
|
lts = self.sort_Y_firstly(lts, np.mean([lt["bottom"] - lt["top"] for lt in lts]) / 2)
|
||||||
lts = self.layouts_cleanup(bxs, lts)
|
lts = self.layouts_cleanup(bxs, lts)
|
||||||
page_layout.append(lts)
|
page_layout.append(lts)
|
||||||
|
|
||||||
# Tag layout type, layouts are ready
|
|
||||||
def findLayout(ty):
|
def findLayout(ty):
|
||||||
nonlocal bxs, lts, self
|
nonlocal bxs, lts, self
|
||||||
lts_ = [lt for lt in lts if lt["type"] == ty]
|
lts_ = [lt for lt in lts if lt["type"] == ty]
|
||||||
@ -106,21 +107,17 @@ class LayoutRecognizer(Recognizer):
|
|||||||
bxs.pop(i)
|
bxs.pop(i)
|
||||||
continue
|
continue
|
||||||
|
|
||||||
ii = self.find_overlapped_with_threshold(bxs[i], lts_,
|
ii = self.find_overlapped_with_threshold(bxs[i], lts_, thr=0.4)
|
||||||
thr=0.4)
|
if ii is None:
|
||||||
if ii is None: # belong to nothing
|
|
||||||
bxs[i]["layout_type"] = ""
|
bxs[i]["layout_type"] = ""
|
||||||
i += 1
|
i += 1
|
||||||
continue
|
continue
|
||||||
lts_[ii]["visited"] = True
|
lts_[ii]["visited"] = True
|
||||||
keep_feats = [
|
keep_feats = [
|
||||||
lts_[
|
lts_[ii]["type"] == "footer" and bxs[i]["bottom"] < image_list[pn].size[1] * 0.9 / scale_factor,
|
||||||
ii]["type"] == "footer" and bxs[i]["bottom"] < image_list[pn].size[1] * 0.9 / scale_factor,
|
lts_[ii]["type"] == "header" and bxs[i]["top"] > image_list[pn].size[1] * 0.1 / scale_factor,
|
||||||
lts_[
|
|
||||||
ii]["type"] == "header" and bxs[i]["top"] > image_list[pn].size[1] * 0.1 / scale_factor,
|
|
||||||
]
|
]
|
||||||
if drop and lts_[
|
if drop and lts_[ii]["type"] in self.garbage_layouts and not any(keep_feats):
|
||||||
ii]["type"] in self.garbage_layouts and not any(keep_feats):
|
|
||||||
if lts_[ii]["type"] not in garbages:
|
if lts_[ii]["type"] not in garbages:
|
||||||
garbages[lts_[ii]["type"]] = []
|
garbages[lts_[ii]["type"]] = []
|
||||||
garbages[lts_[ii]["type"]].append(bxs[i]["text"])
|
garbages[lts_[ii]["type"]].append(bxs[i]["text"])
|
||||||
@ -128,17 +125,14 @@ class LayoutRecognizer(Recognizer):
|
|||||||
continue
|
continue
|
||||||
|
|
||||||
bxs[i]["layoutno"] = f"{ty}-{ii}"
|
bxs[i]["layoutno"] = f"{ty}-{ii}"
|
||||||
bxs[i]["layout_type"] = lts_[ii]["type"] if lts_[
|
bxs[i]["layout_type"] = lts_[ii]["type"] if lts_[ii]["type"] != "equation" else "figure"
|
||||||
ii]["type"] != "equation" else "figure"
|
|
||||||
i += 1
|
i += 1
|
||||||
|
|
||||||
for lt in ["footer", "header", "reference", "figure caption",
|
for lt in ["footer", "header", "reference", "figure caption", "table caption", "title", "table", "text", "figure", "equation"]:
|
||||||
"table caption", "title", "table", "text", "figure", "equation"]:
|
|
||||||
findLayout(lt)
|
findLayout(lt)
|
||||||
|
|
||||||
# add box to figure layouts which has not text box
|
# add box to figure layouts which has not text box
|
||||||
for i, lt in enumerate(
|
for i, lt in enumerate([lt for lt in lts if lt["type"] in ["figure", "equation"]]):
|
||||||
[lt for lt in lts if lt["type"] in ["figure", "equation"]]):
|
|
||||||
if lt.get("visited"):
|
if lt.get("visited"):
|
||||||
continue
|
continue
|
||||||
lt = deepcopy(lt)
|
lt = deepcopy(lt)
|
||||||
@ -206,13 +200,11 @@ class LayoutRecognizer4YOLOv10(LayoutRecognizer):
|
|||||||
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
|
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
|
||||||
top, bottom = int(round(dh - 0.1)) if self.center else 0, int(round(dh + 0.1))
|
top, bottom = int(round(dh - 0.1)) if self.center else 0, int(round(dh + 0.1))
|
||||||
left, right = int(round(dw - 0.1)) if self.center else 0, int(round(dw + 0.1))
|
left, right = int(round(dw - 0.1)) if self.center else 0, int(round(dw + 0.1))
|
||||||
img = cv2.copyMakeBorder(
|
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=(114, 114, 114)) # add border
|
||||||
img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=(114, 114, 114)
|
|
||||||
) # add border
|
|
||||||
img /= 255.0
|
img /= 255.0
|
||||||
img = img.transpose(2, 0, 1)
|
img = img.transpose(2, 0, 1)
|
||||||
img = img[np.newaxis, :, :, :].astype(np.float32)
|
img = img[np.newaxis, :, :, :].astype(np.float32)
|
||||||
inputs.append({self.input_names[0]: img, "scale_factor": [shape[1]/ww, shape[0]/hh, dw, dh]})
|
inputs.append({self.input_names[0]: img, "scale_factor": [shape[1] / ww, shape[0] / hh, dw, dh]})
|
||||||
|
|
||||||
return inputs
|
return inputs
|
||||||
|
|
||||||
@ -230,8 +222,7 @@ class LayoutRecognizer4YOLOv10(LayoutRecognizer):
|
|||||||
boxes[:, 2] -= inputs["scale_factor"][2]
|
boxes[:, 2] -= inputs["scale_factor"][2]
|
||||||
boxes[:, 1] -= inputs["scale_factor"][3]
|
boxes[:, 1] -= inputs["scale_factor"][3]
|
||||||
boxes[:, 3] -= inputs["scale_factor"][3]
|
boxes[:, 3] -= inputs["scale_factor"][3]
|
||||||
input_shape = np.array([inputs["scale_factor"][0], inputs["scale_factor"][1], inputs["scale_factor"][0],
|
input_shape = np.array([inputs["scale_factor"][0], inputs["scale_factor"][1], inputs["scale_factor"][0], inputs["scale_factor"][1]])
|
||||||
inputs["scale_factor"][1]])
|
|
||||||
boxes = np.multiply(boxes, input_shape, dtype=np.float32)
|
boxes = np.multiply(boxes, input_shape, dtype=np.float32)
|
||||||
|
|
||||||
unique_class_ids = np.unique(class_ids)
|
unique_class_ids = np.unique(class_ids)
|
||||||
@ -243,8 +234,223 @@ class LayoutRecognizer4YOLOv10(LayoutRecognizer):
|
|||||||
class_keep_boxes = nms(class_boxes, class_scores, 0.45)
|
class_keep_boxes = nms(class_boxes, class_scores, 0.45)
|
||||||
indices.extend(class_indices[class_keep_boxes])
|
indices.extend(class_indices[class_keep_boxes])
|
||||||
|
|
||||||
return [{
|
return [{"type": self.label_list[class_ids[i]].lower(), "bbox": [float(t) for t in boxes[i].tolist()], "score": float(scores[i])} for i in indices]
|
||||||
"type": self.label_list[class_ids[i]].lower(),
|
|
||||||
"bbox": [float(t) for t in boxes[i].tolist()],
|
|
||||||
"score": float(scores[i])
|
class AscendLayoutRecognizer(Recognizer):
|
||||||
} for i in indices]
|
labels = [
|
||||||
|
"title",
|
||||||
|
"Text",
|
||||||
|
"Reference",
|
||||||
|
"Figure",
|
||||||
|
"Figure caption",
|
||||||
|
"Table",
|
||||||
|
"Table caption",
|
||||||
|
"Table caption",
|
||||||
|
"Equation",
|
||||||
|
"Figure caption",
|
||||||
|
]
|
||||||
|
|
||||||
|
def __init__(self, domain):
|
||||||
|
from ais_bench.infer.interface import InferSession
|
||||||
|
|
||||||
|
model_dir = os.path.join(get_project_base_directory(), "rag/res/deepdoc")
|
||||||
|
model_file_path = os.path.join(model_dir, domain + ".om")
|
||||||
|
|
||||||
|
if not os.path.exists(model_file_path):
|
||||||
|
raise ValueError(f"Model file not found: {model_file_path}")
|
||||||
|
|
||||||
|
device_id = int(os.getenv("ASCEND_LAYOUT_RECOGNIZER_DEVICE_ID", 0))
|
||||||
|
self.session = InferSession(device_id=device_id, model_path=model_file_path)
|
||||||
|
self.input_shape = self.session.get_inputs()[0].shape[2:4] # H,W
|
||||||
|
self.garbage_layouts = ["footer", "header", "reference"]
|
||||||
|
|
||||||
|
def preprocess(self, image_list):
|
||||||
|
inputs = []
|
||||||
|
H, W = self.input_shape
|
||||||
|
for img in image_list:
|
||||||
|
h, w = img.shape[:2]
|
||||||
|
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB).astype(np.float32)
|
||||||
|
|
||||||
|
r = min(H / h, W / w)
|
||||||
|
new_unpad = (int(round(w * r)), int(round(h * r)))
|
||||||
|
dw, dh = (W - new_unpad[0]) / 2.0, (H - new_unpad[1]) / 2.0
|
||||||
|
|
||||||
|
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
|
||||||
|
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
|
||||||
|
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
|
||||||
|
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=(114, 114, 114))
|
||||||
|
|
||||||
|
img /= 255.0
|
||||||
|
img = img.transpose(2, 0, 1)[np.newaxis, :, :, :].astype(np.float32)
|
||||||
|
|
||||||
|
inputs.append(
|
||||||
|
{
|
||||||
|
"image": img,
|
||||||
|
"scale_factor": [w / new_unpad[0], h / new_unpad[1]],
|
||||||
|
"pad": [dw, dh],
|
||||||
|
"orig_shape": [h, w],
|
||||||
|
}
|
||||||
|
)
|
||||||
|
return inputs
|
||||||
|
|
||||||
|
def postprocess(self, boxes, inputs, thr=0.25):
|
||||||
|
arr = np.squeeze(boxes)
|
||||||
|
if arr.ndim == 1:
|
||||||
|
arr = arr.reshape(1, -1)
|
||||||
|
|
||||||
|
results = []
|
||||||
|
if arr.shape[1] == 6:
|
||||||
|
# [x1,y1,x2,y2,score,cls]
|
||||||
|
m = arr[:, 4] >= thr
|
||||||
|
arr = arr[m]
|
||||||
|
if arr.size == 0:
|
||||||
|
return []
|
||||||
|
xyxy = arr[:, :4].astype(np.float32)
|
||||||
|
scores = arr[:, 4].astype(np.float32)
|
||||||
|
cls_ids = arr[:, 5].astype(np.int32)
|
||||||
|
|
||||||
|
if "pad" in inputs:
|
||||||
|
dw, dh = inputs["pad"]
|
||||||
|
sx, sy = inputs["scale_factor"]
|
||||||
|
xyxy[:, [0, 2]] -= dw
|
||||||
|
xyxy[:, [1, 3]] -= dh
|
||||||
|
xyxy *= np.array([sx, sy, sx, sy], dtype=np.float32)
|
||||||
|
else:
|
||||||
|
# backup
|
||||||
|
sx, sy = inputs["scale_factor"]
|
||||||
|
xyxy *= np.array([sx, sy, sx, sy], dtype=np.float32)
|
||||||
|
|
||||||
|
keep_indices = []
|
||||||
|
for c in np.unique(cls_ids):
|
||||||
|
idx = np.where(cls_ids == c)[0]
|
||||||
|
k = nms(xyxy[idx], scores[idx], 0.45)
|
||||||
|
keep_indices.extend(idx[k])
|
||||||
|
|
||||||
|
for i in keep_indices:
|
||||||
|
cid = int(cls_ids[i])
|
||||||
|
if 0 <= cid < len(self.labels):
|
||||||
|
results.append({"type": self.labels[cid].lower(), "bbox": [float(t) for t in xyxy[i].tolist()], "score": float(scores[i])})
|
||||||
|
return results
|
||||||
|
|
||||||
|
raise ValueError(f"Unexpected output shape: {arr.shape}")
|
||||||
|
|
||||||
|
def __call__(self, image_list, ocr_res, scale_factor=3, thr=0.2, batch_size=16, drop=True):
|
||||||
|
import re
|
||||||
|
from collections import Counter
|
||||||
|
|
||||||
|
assert len(image_list) == len(ocr_res)
|
||||||
|
|
||||||
|
images = [np.array(im) if not isinstance(im, np.ndarray) else im for im in image_list]
|
||||||
|
layouts_all_pages = [] # list of list[{"type","score","bbox":[x1,y1,x2,y2]}]
|
||||||
|
|
||||||
|
conf_thr = max(thr, 0.08)
|
||||||
|
|
||||||
|
batch_loop_cnt = math.ceil(float(len(images)) / batch_size)
|
||||||
|
for bi in range(batch_loop_cnt):
|
||||||
|
s = bi * batch_size
|
||||||
|
e = min((bi + 1) * batch_size, len(images))
|
||||||
|
batch_images = images[s:e]
|
||||||
|
|
||||||
|
inputs_list = self.preprocess(batch_images)
|
||||||
|
logging.debug("preprocess done")
|
||||||
|
|
||||||
|
for ins in inputs_list:
|
||||||
|
feeds = [ins["image"]]
|
||||||
|
out_list = self.session.infer(feeds=feeds, mode="static")
|
||||||
|
|
||||||
|
for out in out_list:
|
||||||
|
lts = self.postprocess(out, ins, conf_thr)
|
||||||
|
|
||||||
|
page_lts = []
|
||||||
|
for b in lts:
|
||||||
|
if float(b["score"]) >= 0.4 or b["type"] not in self.garbage_layouts:
|
||||||
|
x0, y0, x1, y1 = b["bbox"]
|
||||||
|
page_lts.append(
|
||||||
|
{
|
||||||
|
"type": b["type"],
|
||||||
|
"score": float(b["score"]),
|
||||||
|
"x0": float(x0) / scale_factor,
|
||||||
|
"x1": float(x1) / scale_factor,
|
||||||
|
"top": float(y0) / scale_factor,
|
||||||
|
"bottom": float(y1) / scale_factor,
|
||||||
|
"page_number": len(layouts_all_pages),
|
||||||
|
}
|
||||||
|
)
|
||||||
|
layouts_all_pages.append(page_lts)
|
||||||
|
|
||||||
|
def _is_garbage_text(box):
|
||||||
|
patt = [r"^•+$", r"^[0-9]{1,2} / ?[0-9]{1,2}$", r"^[0-9]{1,2} of [0-9]{1,2}$", r"^http://[^ ]{12,}", r"\(cid *: *[0-9]+ *\)"]
|
||||||
|
return any(re.search(p, box.get("text", "")) for p in patt)
|
||||||
|
|
||||||
|
boxes_out = []
|
||||||
|
page_layout = []
|
||||||
|
garbages = {}
|
||||||
|
|
||||||
|
for pn, lts in enumerate(layouts_all_pages):
|
||||||
|
if lts:
|
||||||
|
avg_h = np.mean([lt["bottom"] - lt["top"] for lt in lts])
|
||||||
|
lts = self.sort_Y_firstly(lts, avg_h / 2 if avg_h > 0 else 0)
|
||||||
|
|
||||||
|
bxs = ocr_res[pn]
|
||||||
|
lts = self.layouts_cleanup(bxs, lts)
|
||||||
|
page_layout.append(lts)
|
||||||
|
|
||||||
|
def _tag_layout(ty):
|
||||||
|
nonlocal bxs, lts
|
||||||
|
lts_of_ty = [lt for lt in lts if lt["type"] == ty]
|
||||||
|
i = 0
|
||||||
|
while i < len(bxs):
|
||||||
|
if bxs[i].get("layout_type"):
|
||||||
|
i += 1
|
||||||
|
continue
|
||||||
|
if _is_garbage_text(bxs[i]):
|
||||||
|
bxs.pop(i)
|
||||||
|
continue
|
||||||
|
|
||||||
|
ii = self.find_overlapped_with_threshold(bxs[i], lts_of_ty, thr=0.4)
|
||||||
|
if ii is None:
|
||||||
|
bxs[i]["layout_type"] = ""
|
||||||
|
i += 1
|
||||||
|
continue
|
||||||
|
|
||||||
|
lts_of_ty[ii]["visited"] = True
|
||||||
|
|
||||||
|
keep_feats = [
|
||||||
|
lts_of_ty[ii]["type"] == "footer" and bxs[i]["bottom"] < image_list[pn].shape[0] * 0.9 / scale_factor,
|
||||||
|
lts_of_ty[ii]["type"] == "header" and bxs[i]["top"] > image_list[pn].shape[0] * 0.1 / scale_factor,
|
||||||
|
]
|
||||||
|
if drop and lts_of_ty[ii]["type"] in self.garbage_layouts and not any(keep_feats):
|
||||||
|
garbages.setdefault(lts_of_ty[ii]["type"], []).append(bxs[i].get("text", ""))
|
||||||
|
bxs.pop(i)
|
||||||
|
continue
|
||||||
|
|
||||||
|
bxs[i]["layoutno"] = f"{ty}-{ii}"
|
||||||
|
bxs[i]["layout_type"] = lts_of_ty[ii]["type"] if lts_of_ty[ii]["type"] != "equation" else "figure"
|
||||||
|
i += 1
|
||||||
|
|
||||||
|
for ty in ["footer", "header", "reference", "figure caption", "table caption", "title", "table", "text", "figure", "equation"]:
|
||||||
|
_tag_layout(ty)
|
||||||
|
|
||||||
|
figs = [lt for lt in lts if lt["type"] in ["figure", "equation"]]
|
||||||
|
for i, lt in enumerate(figs):
|
||||||
|
if lt.get("visited"):
|
||||||
|
continue
|
||||||
|
lt = deepcopy(lt)
|
||||||
|
lt.pop("type", None)
|
||||||
|
lt["text"] = ""
|
||||||
|
lt["layout_type"] = "figure"
|
||||||
|
lt["layoutno"] = f"figure-{i}"
|
||||||
|
bxs.append(lt)
|
||||||
|
|
||||||
|
boxes_out.extend(bxs)
|
||||||
|
|
||||||
|
garbag_set = set()
|
||||||
|
for k, lst in garbages.items():
|
||||||
|
cnt = Counter(lst)
|
||||||
|
for g, c in cnt.items():
|
||||||
|
if c > 1:
|
||||||
|
garbag_set.add(g)
|
||||||
|
|
||||||
|
ocr_res_new = [b for b in boxes_out if b["text"].strip() not in garbag_set]
|
||||||
|
return ocr_res_new, page_layout
|
||||||
|
|||||||
@ -13,7 +13,7 @@
|
|||||||
# See the License for the specific language governing permissions and
|
# See the License for the specific language governing permissions and
|
||||||
# limitations under the License.
|
# limitations under the License.
|
||||||
#
|
#
|
||||||
|
import gc
|
||||||
import logging
|
import logging
|
||||||
import copy
|
import copy
|
||||||
import time
|
import time
|
||||||
@ -348,6 +348,13 @@ class TextRecognizer:
|
|||||||
|
|
||||||
return img
|
return img
|
||||||
|
|
||||||
|
def close(self):
|
||||||
|
# close session and release manually
|
||||||
|
logging.info('Close TextRecognizer.')
|
||||||
|
if hasattr(self, "predictor"):
|
||||||
|
del self.predictor
|
||||||
|
gc.collect()
|
||||||
|
|
||||||
def __call__(self, img_list):
|
def __call__(self, img_list):
|
||||||
img_num = len(img_list)
|
img_num = len(img_list)
|
||||||
# Calculate the aspect ratio of all text bars
|
# Calculate the aspect ratio of all text bars
|
||||||
@ -395,6 +402,9 @@ class TextRecognizer:
|
|||||||
|
|
||||||
return rec_res, time.time() - st
|
return rec_res, time.time() - st
|
||||||
|
|
||||||
|
def __del__(self):
|
||||||
|
self.close()
|
||||||
|
|
||||||
|
|
||||||
class TextDetector:
|
class TextDetector:
|
||||||
def __init__(self, model_dir, device_id: int | None = None):
|
def __init__(self, model_dir, device_id: int | None = None):
|
||||||
@ -479,6 +489,12 @@ class TextDetector:
|
|||||||
dt_boxes = np.array(dt_boxes_new)
|
dt_boxes = np.array(dt_boxes_new)
|
||||||
return dt_boxes
|
return dt_boxes
|
||||||
|
|
||||||
|
def close(self):
|
||||||
|
logging.info("Close TextDetector.")
|
||||||
|
if hasattr(self, "predictor"):
|
||||||
|
del self.predictor
|
||||||
|
gc.collect()
|
||||||
|
|
||||||
def __call__(self, img):
|
def __call__(self, img):
|
||||||
ori_im = img.copy()
|
ori_im = img.copy()
|
||||||
data = {'image': img}
|
data = {'image': img}
|
||||||
@ -508,6 +524,9 @@ class TextDetector:
|
|||||||
|
|
||||||
return dt_boxes, time.time() - st
|
return dt_boxes, time.time() - st
|
||||||
|
|
||||||
|
def __del__(self):
|
||||||
|
self.close()
|
||||||
|
|
||||||
|
|
||||||
class OCR:
|
class OCR:
|
||||||
def __init__(self, model_dir=None):
|
def __init__(self, model_dir=None):
|
||||||
|
|||||||
@ -13,7 +13,7 @@
|
|||||||
# See the License for the specific language governing permissions and
|
# See the License for the specific language governing permissions and
|
||||||
# limitations under the License.
|
# limitations under the License.
|
||||||
#
|
#
|
||||||
|
import gc
|
||||||
import logging
|
import logging
|
||||||
import os
|
import os
|
||||||
import math
|
import math
|
||||||
@ -406,6 +406,12 @@ class Recognizer:
|
|||||||
"score": float(scores[i])
|
"score": float(scores[i])
|
||||||
} for i in indices]
|
} for i in indices]
|
||||||
|
|
||||||
|
def close(self):
|
||||||
|
logging.info("Close recognizer.")
|
||||||
|
if hasattr(self, "ort_sess"):
|
||||||
|
del self.ort_sess
|
||||||
|
gc.collect()
|
||||||
|
|
||||||
def __call__(self, image_list, thr=0.7, batch_size=16):
|
def __call__(self, image_list, thr=0.7, batch_size=16):
|
||||||
res = []
|
res = []
|
||||||
images = []
|
images = []
|
||||||
@ -430,5 +436,7 @@ class Recognizer:
|
|||||||
|
|
||||||
return res
|
return res
|
||||||
|
|
||||||
|
def __del__(self):
|
||||||
|
self.close()
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
@ -23,6 +23,7 @@ from huggingface_hub import snapshot_download
|
|||||||
|
|
||||||
from api.utils.file_utils import get_project_base_directory
|
from api.utils.file_utils import get_project_base_directory
|
||||||
from rag.nlp import rag_tokenizer
|
from rag.nlp import rag_tokenizer
|
||||||
|
|
||||||
from .recognizer import Recognizer
|
from .recognizer import Recognizer
|
||||||
|
|
||||||
|
|
||||||
@ -38,31 +39,49 @@ class TableStructureRecognizer(Recognizer):
|
|||||||
|
|
||||||
def __init__(self):
|
def __init__(self):
|
||||||
try:
|
try:
|
||||||
super().__init__(self.labels, "tsr", os.path.join(
|
super().__init__(self.labels, "tsr", os.path.join(get_project_base_directory(), "rag/res/deepdoc"))
|
||||||
get_project_base_directory(),
|
|
||||||
"rag/res/deepdoc"))
|
|
||||||
except Exception:
|
except Exception:
|
||||||
super().__init__(self.labels, "tsr", snapshot_download(repo_id="InfiniFlow/deepdoc",
|
super().__init__(
|
||||||
local_dir=os.path.join(get_project_base_directory(), "rag/res/deepdoc"),
|
self.labels,
|
||||||
local_dir_use_symlinks=False))
|
"tsr",
|
||||||
|
snapshot_download(
|
||||||
|
repo_id="InfiniFlow/deepdoc",
|
||||||
|
local_dir=os.path.join(get_project_base_directory(), "rag/res/deepdoc"),
|
||||||
|
local_dir_use_symlinks=False,
|
||||||
|
),
|
||||||
|
)
|
||||||
|
|
||||||
def __call__(self, images, thr=0.2):
|
def __call__(self, images, thr=0.2):
|
||||||
tbls = super().__call__(images, thr)
|
table_structure_recognizer_type = os.getenv("TABLE_STRUCTURE_RECOGNIZER_TYPE", "onnx").lower()
|
||||||
|
if table_structure_recognizer_type not in ["onnx", "ascend"]:
|
||||||
|
raise RuntimeError("Unsupported table structure recognizer type.")
|
||||||
|
|
||||||
|
if table_structure_recognizer_type == "onnx":
|
||||||
|
logging.debug("Using Onnx table structure recognizer", flush=True)
|
||||||
|
tbls = super().__call__(images, thr)
|
||||||
|
else: # ascend
|
||||||
|
logging.debug("Using Ascend table structure recognizer", flush=True)
|
||||||
|
tbls = self._run_ascend_tsr(images, thr)
|
||||||
|
|
||||||
res = []
|
res = []
|
||||||
# align left&right for rows, align top&bottom for columns
|
# align left&right for rows, align top&bottom for columns
|
||||||
for tbl in tbls:
|
for tbl in tbls:
|
||||||
lts = [{"label": b["type"],
|
lts = [
|
||||||
|
{
|
||||||
|
"label": b["type"],
|
||||||
"score": b["score"],
|
"score": b["score"],
|
||||||
"x0": b["bbox"][0], "x1": b["bbox"][2],
|
"x0": b["bbox"][0],
|
||||||
"top": b["bbox"][1], "bottom": b["bbox"][-1]
|
"x1": b["bbox"][2],
|
||||||
} for b in tbl]
|
"top": b["bbox"][1],
|
||||||
|
"bottom": b["bbox"][-1],
|
||||||
|
}
|
||||||
|
for b in tbl
|
||||||
|
]
|
||||||
if not lts:
|
if not lts:
|
||||||
continue
|
continue
|
||||||
|
|
||||||
left = [b["x0"] for b in lts if b["label"].find(
|
left = [b["x0"] for b in lts if b["label"].find("row") > 0 or b["label"].find("header") > 0]
|
||||||
"row") > 0 or b["label"].find("header") > 0]
|
right = [b["x1"] for b in lts if b["label"].find("row") > 0 or b["label"].find("header") > 0]
|
||||||
right = [b["x1"] for b in lts if b["label"].find(
|
|
||||||
"row") > 0 or b["label"].find("header") > 0]
|
|
||||||
if not left:
|
if not left:
|
||||||
continue
|
continue
|
||||||
left = np.mean(left) if len(left) > 4 else np.min(left)
|
left = np.mean(left) if len(left) > 4 else np.min(left)
|
||||||
@ -93,11 +112,8 @@ class TableStructureRecognizer(Recognizer):
|
|||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def is_caption(bx):
|
def is_caption(bx):
|
||||||
patt = [
|
patt = [r"[图表]+[ 0-9::]{2,}"]
|
||||||
r"[图表]+[ 0-9::]{2,}"
|
if any([re.match(p, bx["text"].strip()) for p in patt]) or bx.get("layout_type", "").find("caption") >= 0:
|
||||||
]
|
|
||||||
if any([re.match(p, bx["text"].strip()) for p in patt]) \
|
|
||||||
or bx.get("layout_type", "").find("caption") >= 0:
|
|
||||||
return True
|
return True
|
||||||
return False
|
return False
|
||||||
|
|
||||||
@ -115,7 +131,7 @@ class TableStructureRecognizer(Recognizer):
|
|||||||
(r"^[0-9A-Z/\._~-]+$", "Ca"),
|
(r"^[0-9A-Z/\._~-]+$", "Ca"),
|
||||||
(r"^[A-Z]*[a-z' -]+$", "En"),
|
(r"^[A-Z]*[a-z' -]+$", "En"),
|
||||||
(r"^[0-9.,+-]+[0-9A-Za-z/$¥%<>()()' -]+$", "NE"),
|
(r"^[0-9.,+-]+[0-9A-Za-z/$¥%<>()()' -]+$", "NE"),
|
||||||
(r"^.{1}$", "Sg")
|
(r"^.{1}$", "Sg"),
|
||||||
]
|
]
|
||||||
for p, n in patt:
|
for p, n in patt:
|
||||||
if re.search(p, b["text"].strip()):
|
if re.search(p, b["text"].strip()):
|
||||||
@ -156,21 +172,19 @@ class TableStructureRecognizer(Recognizer):
|
|||||||
rowh = [b["R_bott"] - b["R_top"] for b in boxes if "R" in b]
|
rowh = [b["R_bott"] - b["R_top"] for b in boxes if "R" in b]
|
||||||
rowh = np.min(rowh) if rowh else 0
|
rowh = np.min(rowh) if rowh else 0
|
||||||
boxes = Recognizer.sort_R_firstly(boxes, rowh / 2)
|
boxes = Recognizer.sort_R_firstly(boxes, rowh / 2)
|
||||||
#for b in boxes:print(b)
|
# for b in boxes:print(b)
|
||||||
boxes[0]["rn"] = 0
|
boxes[0]["rn"] = 0
|
||||||
rows = [[boxes[0]]]
|
rows = [[boxes[0]]]
|
||||||
btm = boxes[0]["bottom"]
|
btm = boxes[0]["bottom"]
|
||||||
for b in boxes[1:]:
|
for b in boxes[1:]:
|
||||||
b["rn"] = len(rows) - 1
|
b["rn"] = len(rows) - 1
|
||||||
lst_r = rows[-1]
|
lst_r = rows[-1]
|
||||||
if lst_r[-1].get("R", "") != b.get("R", "") \
|
if lst_r[-1].get("R", "") != b.get("R", "") or (b["top"] >= btm - 3 and lst_r[-1].get("R", "-1") != b.get("R", "-2")): # new row
|
||||||
or (b["top"] >= btm - 3 and lst_r[-1].get("R", "-1") != b.get("R", "-2")
|
|
||||||
): # new row
|
|
||||||
btm = b["bottom"]
|
btm = b["bottom"]
|
||||||
b["rn"] += 1
|
b["rn"] += 1
|
||||||
rows.append([b])
|
rows.append([b])
|
||||||
continue
|
continue
|
||||||
btm = (btm + b["bottom"]) / 2.
|
btm = (btm + b["bottom"]) / 2.0
|
||||||
rows[-1].append(b)
|
rows[-1].append(b)
|
||||||
|
|
||||||
colwm = [b["C_right"] - b["C_left"] for b in boxes if "C" in b]
|
colwm = [b["C_right"] - b["C_left"] for b in boxes if "C" in b]
|
||||||
@ -186,14 +200,14 @@ class TableStructureRecognizer(Recognizer):
|
|||||||
for b in boxes[1:]:
|
for b in boxes[1:]:
|
||||||
b["cn"] = len(cols) - 1
|
b["cn"] = len(cols) - 1
|
||||||
lst_c = cols[-1]
|
lst_c = cols[-1]
|
||||||
if (int(b.get("C", "1")) - int(lst_c[-1].get("C", "1")) == 1 and b["page_number"] == lst_c[-1][
|
if (int(b.get("C", "1")) - int(lst_c[-1].get("C", "1")) == 1 and b["page_number"] == lst_c[-1]["page_number"]) or (
|
||||||
"page_number"]) \
|
b["x0"] >= right and lst_c[-1].get("C", "-1") != b.get("C", "-2")
|
||||||
or (b["x0"] >= right and lst_c[-1].get("C", "-1") != b.get("C", "-2")): # new col
|
): # new col
|
||||||
right = b["x1"]
|
right = b["x1"]
|
||||||
b["cn"] += 1
|
b["cn"] += 1
|
||||||
cols.append([b])
|
cols.append([b])
|
||||||
continue
|
continue
|
||||||
right = (right + b["x1"]) / 2.
|
right = (right + b["x1"]) / 2.0
|
||||||
cols[-1].append(b)
|
cols[-1].append(b)
|
||||||
|
|
||||||
tbl = [[[] for _ in range(len(cols))] for _ in range(len(rows))]
|
tbl = [[[] for _ in range(len(cols))] for _ in range(len(rows))]
|
||||||
@ -214,10 +228,8 @@ class TableStructureRecognizer(Recognizer):
|
|||||||
if e > 1:
|
if e > 1:
|
||||||
j += 1
|
j += 1
|
||||||
continue
|
continue
|
||||||
f = (j > 0 and tbl[ii][j - 1] and tbl[ii]
|
f = (j > 0 and tbl[ii][j - 1] and tbl[ii][j - 1][0].get("text")) or j == 0
|
||||||
[j - 1][0].get("text")) or j == 0
|
ff = (j + 1 < len(tbl[ii]) and tbl[ii][j + 1] and tbl[ii][j + 1][0].get("text")) or j + 1 >= len(tbl[ii])
|
||||||
ff = (j + 1 < len(tbl[ii]) and tbl[ii][j + 1] and tbl[ii]
|
|
||||||
[j + 1][0].get("text")) or j + 1 >= len(tbl[ii])
|
|
||||||
if f and ff:
|
if f and ff:
|
||||||
j += 1
|
j += 1
|
||||||
continue
|
continue
|
||||||
@ -228,13 +240,11 @@ class TableStructureRecognizer(Recognizer):
|
|||||||
if j > 0 and not f:
|
if j > 0 and not f:
|
||||||
for i in range(len(tbl)):
|
for i in range(len(tbl)):
|
||||||
if tbl[i][j - 1]:
|
if tbl[i][j - 1]:
|
||||||
left = min(left, np.min(
|
left = min(left, np.min([bx["x0"] - a["x1"] for a in tbl[i][j - 1]]))
|
||||||
[bx["x0"] - a["x1"] for a in tbl[i][j - 1]]))
|
|
||||||
if j + 1 < len(tbl[0]) and not ff:
|
if j + 1 < len(tbl[0]) and not ff:
|
||||||
for i in range(len(tbl)):
|
for i in range(len(tbl)):
|
||||||
if tbl[i][j + 1]:
|
if tbl[i][j + 1]:
|
||||||
right = min(right, np.min(
|
right = min(right, np.min([a["x0"] - bx["x1"] for a in tbl[i][j + 1]]))
|
||||||
[a["x0"] - bx["x1"] for a in tbl[i][j + 1]]))
|
|
||||||
assert left < 100000 or right < 100000
|
assert left < 100000 or right < 100000
|
||||||
if left < right:
|
if left < right:
|
||||||
for jj in range(j, len(tbl[0])):
|
for jj in range(j, len(tbl[0])):
|
||||||
@ -260,8 +270,7 @@ class TableStructureRecognizer(Recognizer):
|
|||||||
for i in range(len(tbl)):
|
for i in range(len(tbl)):
|
||||||
tbl[i].pop(j)
|
tbl[i].pop(j)
|
||||||
cols.pop(j)
|
cols.pop(j)
|
||||||
assert len(cols) == len(tbl[0]), "Column NO. miss matched: %d vs %d" % (
|
assert len(cols) == len(tbl[0]), "Column NO. miss matched: %d vs %d" % (len(cols), len(tbl[0]))
|
||||||
len(cols), len(tbl[0]))
|
|
||||||
|
|
||||||
if len(cols) >= 4:
|
if len(cols) >= 4:
|
||||||
# remove single in row
|
# remove single in row
|
||||||
@ -277,10 +286,8 @@ class TableStructureRecognizer(Recognizer):
|
|||||||
if e > 1:
|
if e > 1:
|
||||||
i += 1
|
i += 1
|
||||||
continue
|
continue
|
||||||
f = (i > 0 and tbl[i - 1][jj] and tbl[i - 1]
|
f = (i > 0 and tbl[i - 1][jj] and tbl[i - 1][jj][0].get("text")) or i == 0
|
||||||
[jj][0].get("text")) or i == 0
|
ff = (i + 1 < len(tbl) and tbl[i + 1][jj] and tbl[i + 1][jj][0].get("text")) or i + 1 >= len(tbl)
|
||||||
ff = (i + 1 < len(tbl) and tbl[i + 1][jj] and tbl[i + 1]
|
|
||||||
[jj][0].get("text")) or i + 1 >= len(tbl)
|
|
||||||
if f and ff:
|
if f and ff:
|
||||||
i += 1
|
i += 1
|
||||||
continue
|
continue
|
||||||
@ -292,13 +299,11 @@ class TableStructureRecognizer(Recognizer):
|
|||||||
if i > 0 and not f:
|
if i > 0 and not f:
|
||||||
for j in range(len(tbl[i - 1])):
|
for j in range(len(tbl[i - 1])):
|
||||||
if tbl[i - 1][j]:
|
if tbl[i - 1][j]:
|
||||||
up = min(up, np.min(
|
up = min(up, np.min([bx["top"] - a["bottom"] for a in tbl[i - 1][j]]))
|
||||||
[bx["top"] - a["bottom"] for a in tbl[i - 1][j]]))
|
|
||||||
if i + 1 < len(tbl) and not ff:
|
if i + 1 < len(tbl) and not ff:
|
||||||
for j in range(len(tbl[i + 1])):
|
for j in range(len(tbl[i + 1])):
|
||||||
if tbl[i + 1][j]:
|
if tbl[i + 1][j]:
|
||||||
down = min(down, np.min(
|
down = min(down, np.min([a["top"] - bx["bottom"] for a in tbl[i + 1][j]]))
|
||||||
[a["top"] - bx["bottom"] for a in tbl[i + 1][j]]))
|
|
||||||
assert up < 100000 or down < 100000
|
assert up < 100000 or down < 100000
|
||||||
if up < down:
|
if up < down:
|
||||||
for ii in range(i, len(tbl)):
|
for ii in range(i, len(tbl)):
|
||||||
@ -333,22 +338,15 @@ class TableStructureRecognizer(Recognizer):
|
|||||||
cnt += 1
|
cnt += 1
|
||||||
if max_type == "Nu" and arr[0]["btype"] == "Nu":
|
if max_type == "Nu" and arr[0]["btype"] == "Nu":
|
||||||
continue
|
continue
|
||||||
if any([a.get("H") for a in arr]) \
|
if any([a.get("H") for a in arr]) or (max_type == "Nu" and arr[0]["btype"] != "Nu"):
|
||||||
or (max_type == "Nu" and arr[0]["btype"] != "Nu"):
|
|
||||||
h += 1
|
h += 1
|
||||||
if h / cnt > 0.5:
|
if h / cnt > 0.5:
|
||||||
hdset.add(i)
|
hdset.add(i)
|
||||||
|
|
||||||
if html:
|
if html:
|
||||||
return TableStructureRecognizer.__html_table(cap, hdset,
|
return TableStructureRecognizer.__html_table(cap, hdset, TableStructureRecognizer.__cal_spans(boxes, rows, cols, tbl, True))
|
||||||
TableStructureRecognizer.__cal_spans(boxes, rows,
|
|
||||||
cols, tbl, True)
|
|
||||||
)
|
|
||||||
|
|
||||||
return TableStructureRecognizer.__desc_table(cap, hdset,
|
return TableStructureRecognizer.__desc_table(cap, hdset, TableStructureRecognizer.__cal_spans(boxes, rows, cols, tbl, False), is_english)
|
||||||
TableStructureRecognizer.__cal_spans(boxes, rows, cols, tbl,
|
|
||||||
False),
|
|
||||||
is_english)
|
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def __html_table(cap, hdset, tbl):
|
def __html_table(cap, hdset, tbl):
|
||||||
@ -367,10 +365,8 @@ class TableStructureRecognizer(Recognizer):
|
|||||||
continue
|
continue
|
||||||
txt = ""
|
txt = ""
|
||||||
if arr:
|
if arr:
|
||||||
h = min(np.min([c["bottom"] - c["top"]
|
h = min(np.min([c["bottom"] - c["top"] for c in arr]) / 2, 10)
|
||||||
for c in arr]) / 2, 10)
|
txt = " ".join([c["text"] for c in Recognizer.sort_Y_firstly(arr, h)])
|
||||||
txt = " ".join([c["text"]
|
|
||||||
for c in Recognizer.sort_Y_firstly(arr, h)])
|
|
||||||
txts.append(txt)
|
txts.append(txt)
|
||||||
sp = ""
|
sp = ""
|
||||||
if arr[0].get("colspan"):
|
if arr[0].get("colspan"):
|
||||||
@ -436,15 +432,11 @@ class TableStructureRecognizer(Recognizer):
|
|||||||
if headers[j][k].find(headers[j - 1][k]) >= 0:
|
if headers[j][k].find(headers[j - 1][k]) >= 0:
|
||||||
continue
|
continue
|
||||||
if len(headers[j][k]) > len(headers[j - 1][k]):
|
if len(headers[j][k]) > len(headers[j - 1][k]):
|
||||||
headers[j][k] += (de if headers[j][k]
|
headers[j][k] += (de if headers[j][k] else "") + headers[j - 1][k]
|
||||||
else "") + headers[j - 1][k]
|
|
||||||
else:
|
else:
|
||||||
headers[j][k] = headers[j - 1][k] \
|
headers[j][k] = headers[j - 1][k] + (de if headers[j - 1][k] else "") + headers[j][k]
|
||||||
+ (de if headers[j - 1][k] else "") \
|
|
||||||
+ headers[j][k]
|
|
||||||
|
|
||||||
logging.debug(
|
logging.debug(f">>>>>>>>>>>>>>>>>{cap}:SIZE:{rowno}X{clmno} Header: {hdr_rowno}")
|
||||||
f">>>>>>>>>>>>>>>>>{cap}:SIZE:{rowno}X{clmno} Header: {hdr_rowno}")
|
|
||||||
row_txt = []
|
row_txt = []
|
||||||
for i in range(rowno):
|
for i in range(rowno):
|
||||||
if i in hdr_rowno:
|
if i in hdr_rowno:
|
||||||
@ -503,14 +495,10 @@ class TableStructureRecognizer(Recognizer):
|
|||||||
@staticmethod
|
@staticmethod
|
||||||
def __cal_spans(boxes, rows, cols, tbl, html=True):
|
def __cal_spans(boxes, rows, cols, tbl, html=True):
|
||||||
# caculate span
|
# caculate span
|
||||||
clft = [np.mean([c.get("C_left", c["x0"]) for c in cln])
|
clft = [np.mean([c.get("C_left", c["x0"]) for c in cln]) for cln in cols]
|
||||||
for cln in cols]
|
crgt = [np.mean([c.get("C_right", c["x1"]) for c in cln]) for cln in cols]
|
||||||
crgt = [np.mean([c.get("C_right", c["x1"]) for c in cln])
|
rtop = [np.mean([c.get("R_top", c["top"]) for c in row]) for row in rows]
|
||||||
for cln in cols]
|
rbtm = [np.mean([c.get("R_btm", c["bottom"]) for c in row]) for row in rows]
|
||||||
rtop = [np.mean([c.get("R_top", c["top"]) for c in row])
|
|
||||||
for row in rows]
|
|
||||||
rbtm = [np.mean([c.get("R_btm", c["bottom"])
|
|
||||||
for c in row]) for row in rows]
|
|
||||||
for b in boxes:
|
for b in boxes:
|
||||||
if "SP" not in b:
|
if "SP" not in b:
|
||||||
continue
|
continue
|
||||||
@ -585,3 +573,40 @@ class TableStructureRecognizer(Recognizer):
|
|||||||
tbl[rowspan[0]][colspan[0]] = arr
|
tbl[rowspan[0]][colspan[0]] = arr
|
||||||
|
|
||||||
return tbl
|
return tbl
|
||||||
|
|
||||||
|
def _run_ascend_tsr(self, image_list, thr=0.2, batch_size=16):
|
||||||
|
import math
|
||||||
|
|
||||||
|
from ais_bench.infer.interface import InferSession
|
||||||
|
|
||||||
|
model_dir = os.path.join(get_project_base_directory(), "rag/res/deepdoc")
|
||||||
|
model_file_path = os.path.join(model_dir, "tsr.om")
|
||||||
|
|
||||||
|
if not os.path.exists(model_file_path):
|
||||||
|
raise ValueError(f"Model file not found: {model_file_path}")
|
||||||
|
|
||||||
|
device_id = int(os.getenv("ASCEND_LAYOUT_RECOGNIZER_DEVICE_ID", 0))
|
||||||
|
session = InferSession(device_id=device_id, model_path=model_file_path)
|
||||||
|
|
||||||
|
images = [np.array(im) if not isinstance(im, np.ndarray) else im for im in image_list]
|
||||||
|
results = []
|
||||||
|
|
||||||
|
conf_thr = max(thr, 0.08)
|
||||||
|
|
||||||
|
batch_loop_cnt = math.ceil(float(len(images)) / batch_size)
|
||||||
|
for bi in range(batch_loop_cnt):
|
||||||
|
s = bi * batch_size
|
||||||
|
e = min((bi + 1) * batch_size, len(images))
|
||||||
|
batch_images = images[s:e]
|
||||||
|
|
||||||
|
inputs_list = self.preprocess(batch_images)
|
||||||
|
for ins in inputs_list:
|
||||||
|
feeds = []
|
||||||
|
if "image" in ins:
|
||||||
|
feeds.append(ins["image"])
|
||||||
|
else:
|
||||||
|
feeds.append(ins[self.input_names[0]])
|
||||||
|
output_list = session.infer(feeds=feeds, mode="static")
|
||||||
|
bb = self.postprocess(output_list, ins, conf_thr)
|
||||||
|
results.append(bb)
|
||||||
|
return results
|
||||||
|
|||||||
@ -26,6 +26,84 @@ An **Agent** component is essential when you need the LLM to assist with summari
|
|||||||
|
|
||||||
2. If your Agent involves dataset retrieval, ensure you [have properly configured your target knowledge base(s)](../../dataset/configure_knowledge_base.md).
|
2. If your Agent involves dataset retrieval, ensure you [have properly configured your target knowledge base(s)](../../dataset/configure_knowledge_base.md).
|
||||||
|
|
||||||
|
## Quickstart
|
||||||
|
|
||||||
|
### 1. Click on an **Agent** component to show its configuration panel
|
||||||
|
|
||||||
|
The corresponding configuration panel appears to the right of the canvas. Use this panel to define and fine-tune the **Agent** component's behavior.
|
||||||
|
|
||||||
|
### 2. Select your model
|
||||||
|
|
||||||
|
Click **Model**, and select a chat model from the dropdown menu.
|
||||||
|
|
||||||
|
:::tip NOTE
|
||||||
|
If no model appears, check if your have added a chat model on the **Model providers** page.
|
||||||
|
:::
|
||||||
|
|
||||||
|
### 3. Update system prompt (Optional)
|
||||||
|
|
||||||
|
The system prompt typically defines your model's role. You can either keep the system prompt as is or customize it to override the default.
|
||||||
|
|
||||||
|
|
||||||
|
### 4. Update user prompt
|
||||||
|
|
||||||
|
The user prompt typically defines your model's task. You will find the `sys.query` variable auto-populated. Type `/` or click **(x)** to view or add variables.
|
||||||
|
|
||||||
|
In this quickstart, we assume your **Agent** component is used standalone (without tools or sub-Agents below), then you may also need to specify retrieved chunks using the `formalized_content` variable:
|
||||||
|
|
||||||
|
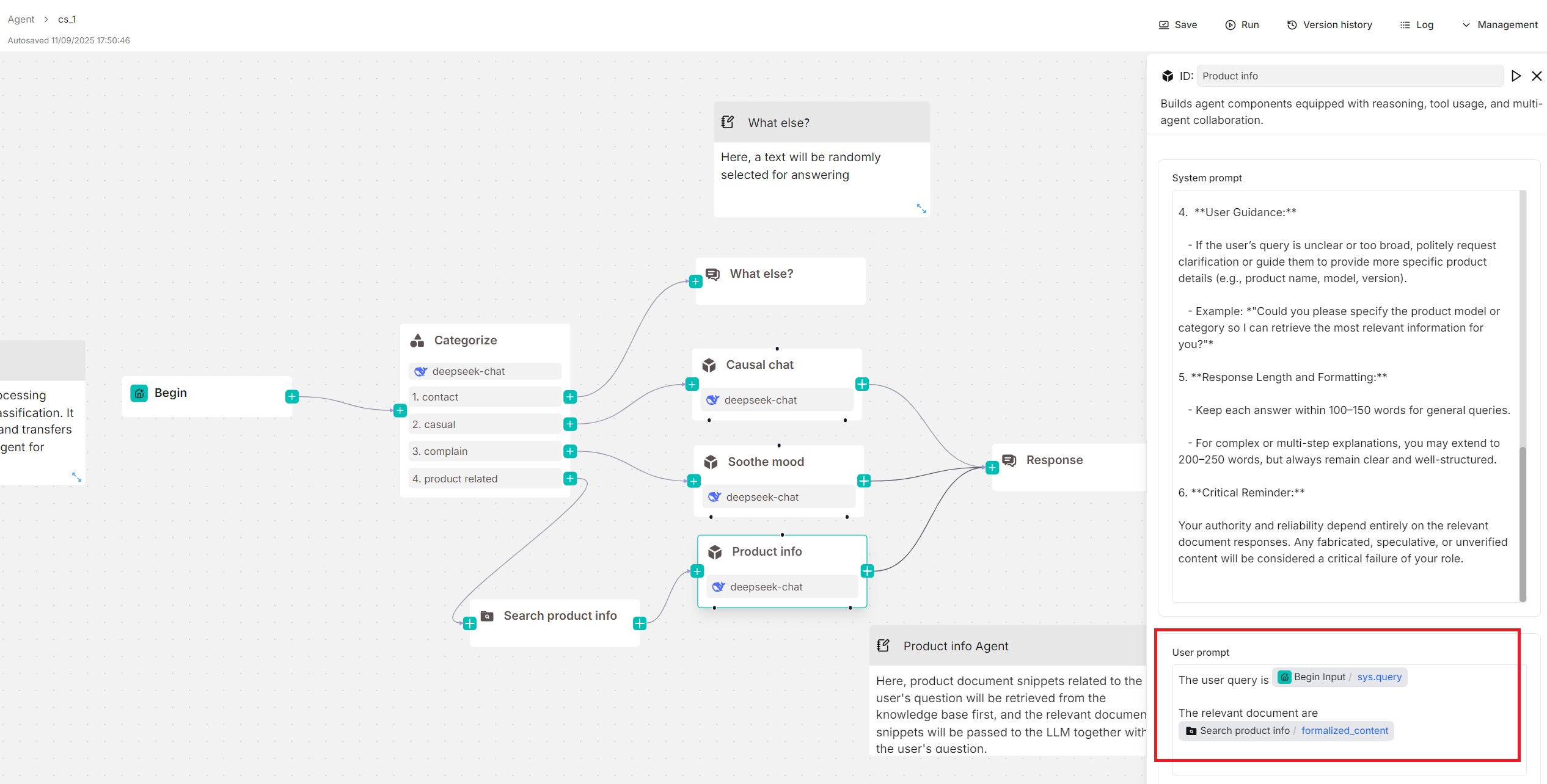
|
||||||
|
|
||||||
|
### 5. Skip Tools and Agent
|
||||||
|
|
||||||
|
The **+ Add tools** and **+ Add agent** sections are used *only* when you need to configure your **Agent** component as a planner (with tools or sub-Agents beneath). In this quickstart, we assume your **Agent** component is used standalone (without tools or sub-Agents beneath).
|
||||||
|
|
||||||
|
### 6. Choose the next component
|
||||||
|
|
||||||
|
When necessary, click the **+** button on the **Agent** component to choose the next component in the worflow from the dropdown list.
|
||||||
|
|
||||||
|
## Connect to an MCP server as a client
|
||||||
|
|
||||||
|
:::danger IMPORTANT
|
||||||
|
In this section, we assume your **Agent** will be configured as a planner, with a Tavily tool beneath it.
|
||||||
|
:::
|
||||||
|
|
||||||
|
### 1. Navigate to the MCP configuration page
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 2. Configure your Tavily MCP server
|
||||||
|
|
||||||
|
Update your MCP server's name, URL (including the API key), server type, and other necessary settings. When configured correctly, the available tools will be displayed.
|
||||||
|
|
||||||
|
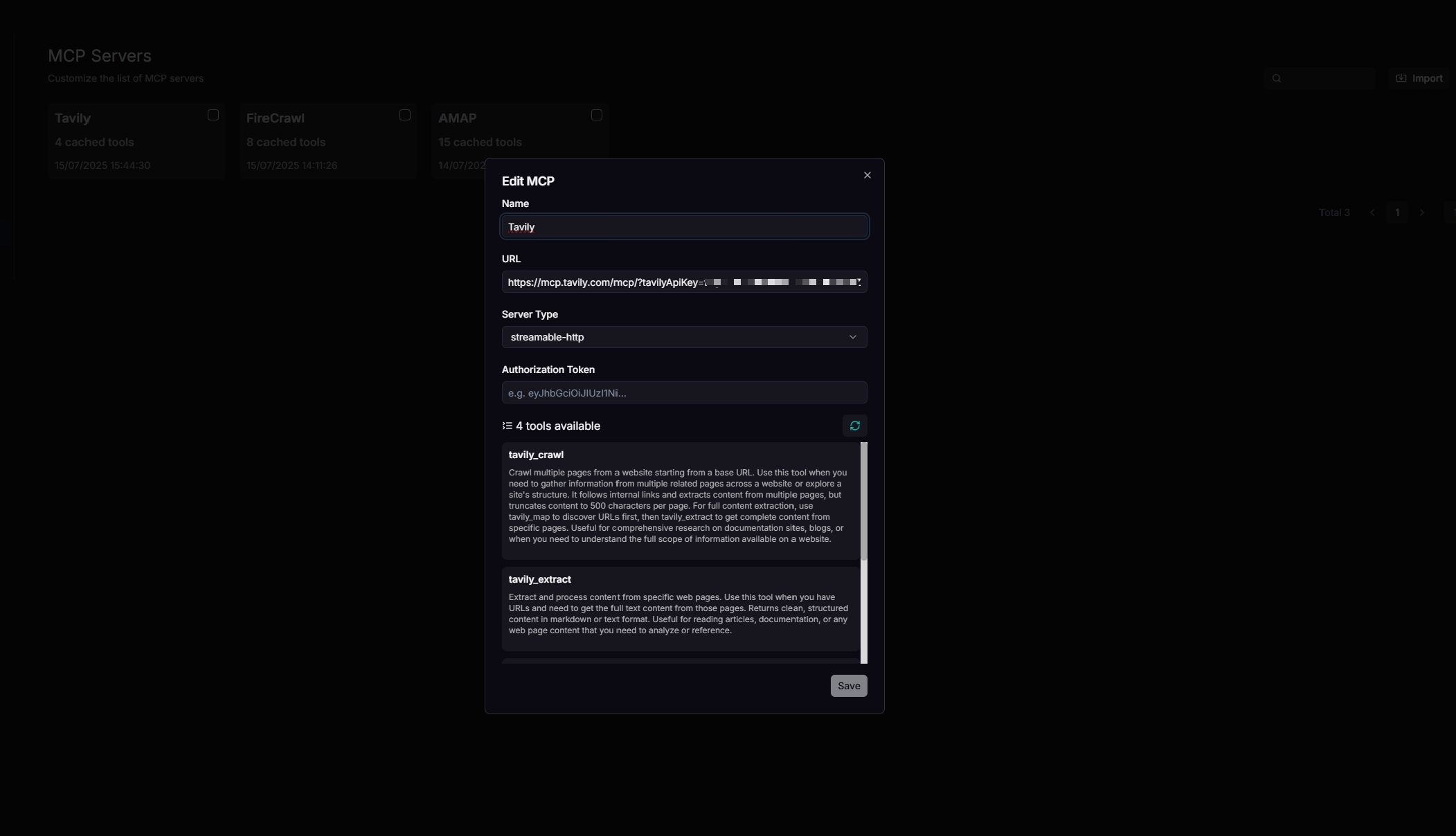
|
||||||
|
|
||||||
|
### 3. Navigate to your Agent's editing page
|
||||||
|
|
||||||
|
### 4. Connect to your MCP server
|
||||||
|
|
||||||
|
1. Click **+ Add tools**:
|
||||||
|
|
||||||
|
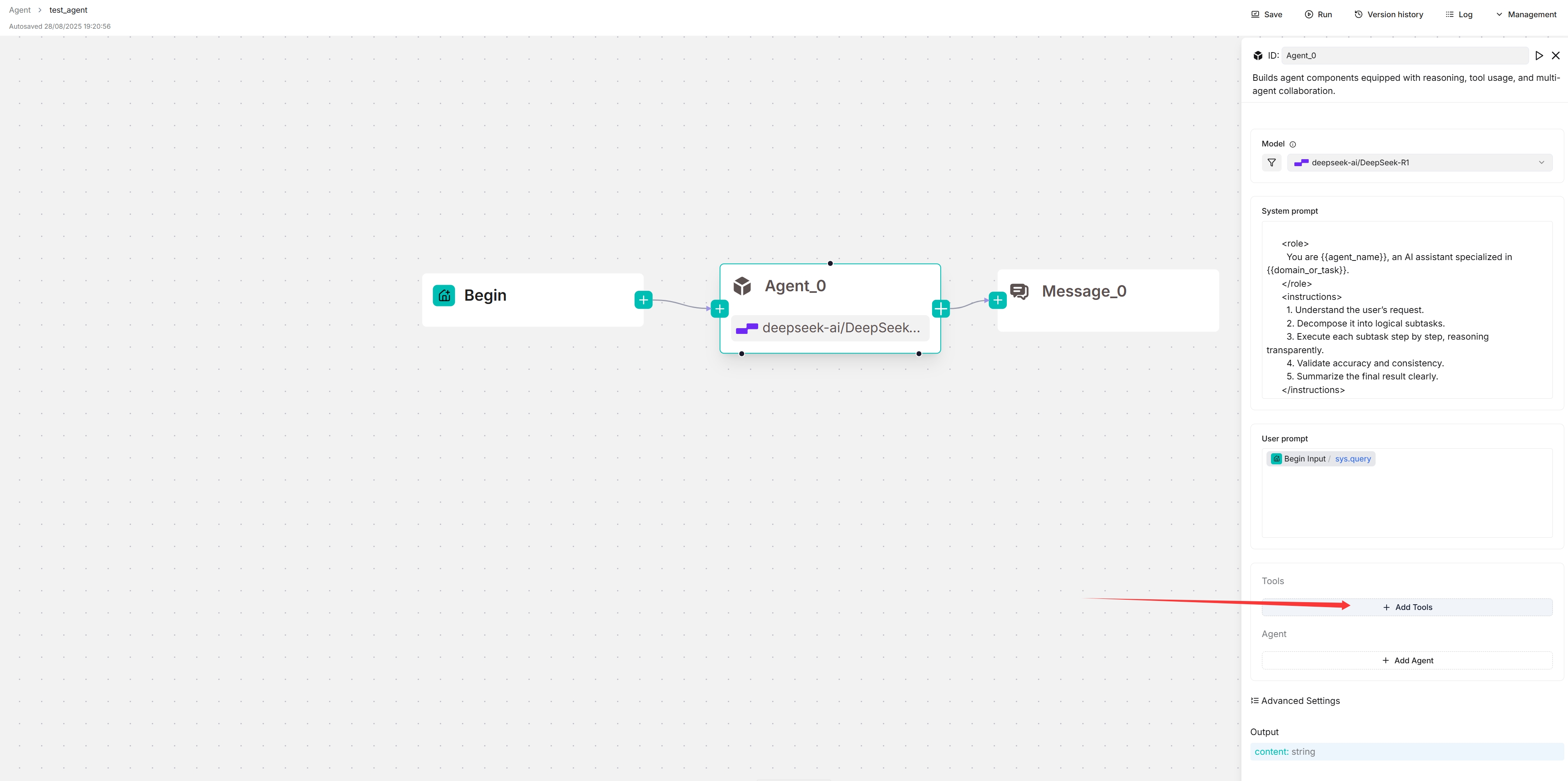
|
||||||
|
|
||||||
|
2. Click **MCP** to show the available MCP servers.
|
||||||
|
|
||||||
|
3. Select your MCP server:
|
||||||
|
|
||||||
|
*The target MCP server appears below your Agent component, and your Agent will autonomously decide when to invoke the available tools it offers.*
|
||||||
|
|
||||||
|
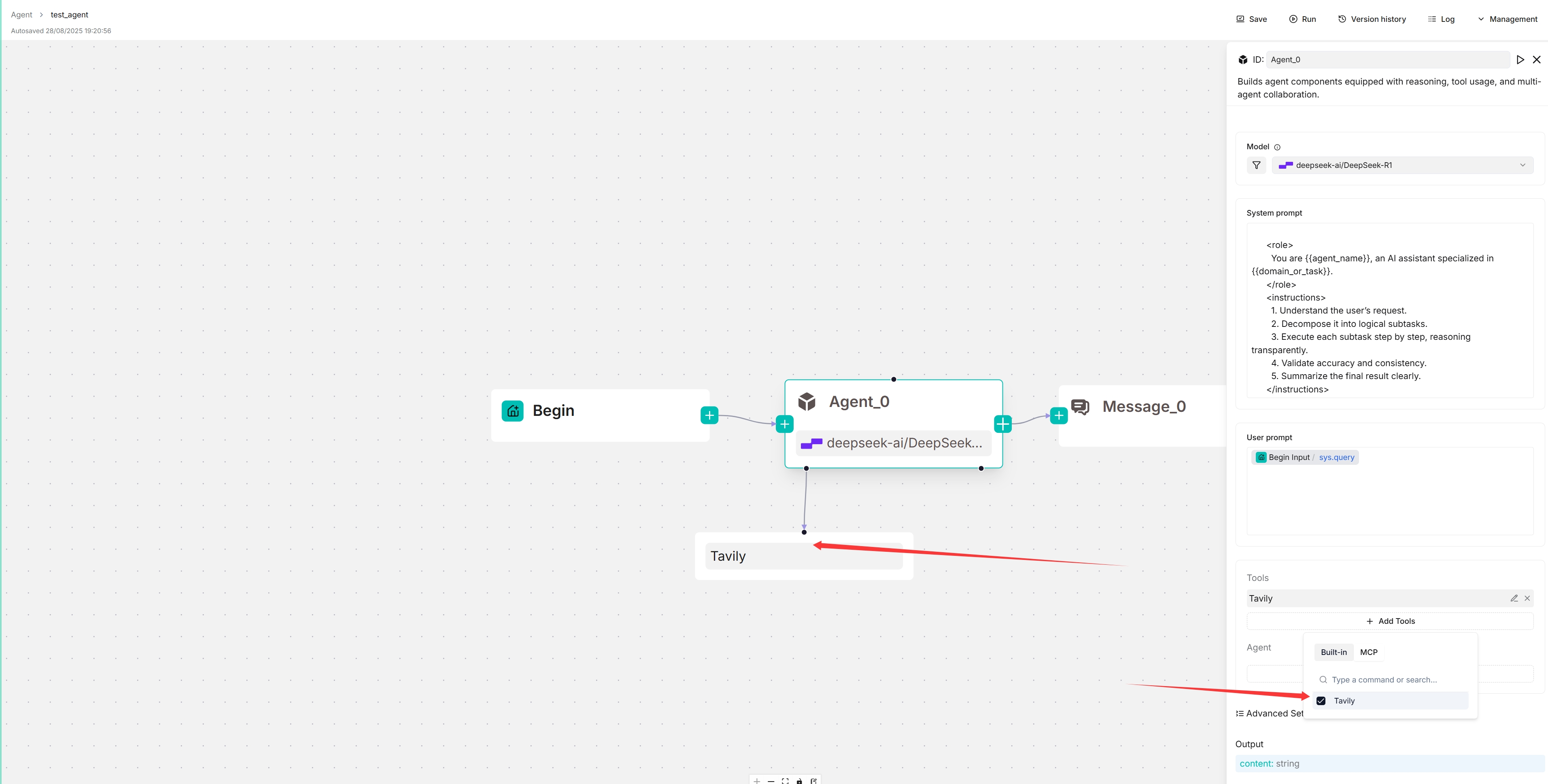
|
||||||
|
|
||||||
|
### 5. Update system prompt to specify trigger conditions (Optional)
|
||||||
|
|
||||||
|
To ensure reliable tool calls, you may specify within the system prompt which tasks should trigger each tool call.
|
||||||
|
|
||||||
|
### 6. View the availabe tools of your MCP server
|
||||||
|
|
||||||
|
On the canvas, click the newly-populated Tavily server to view and select its available tools:
|
||||||
|
|
||||||
|
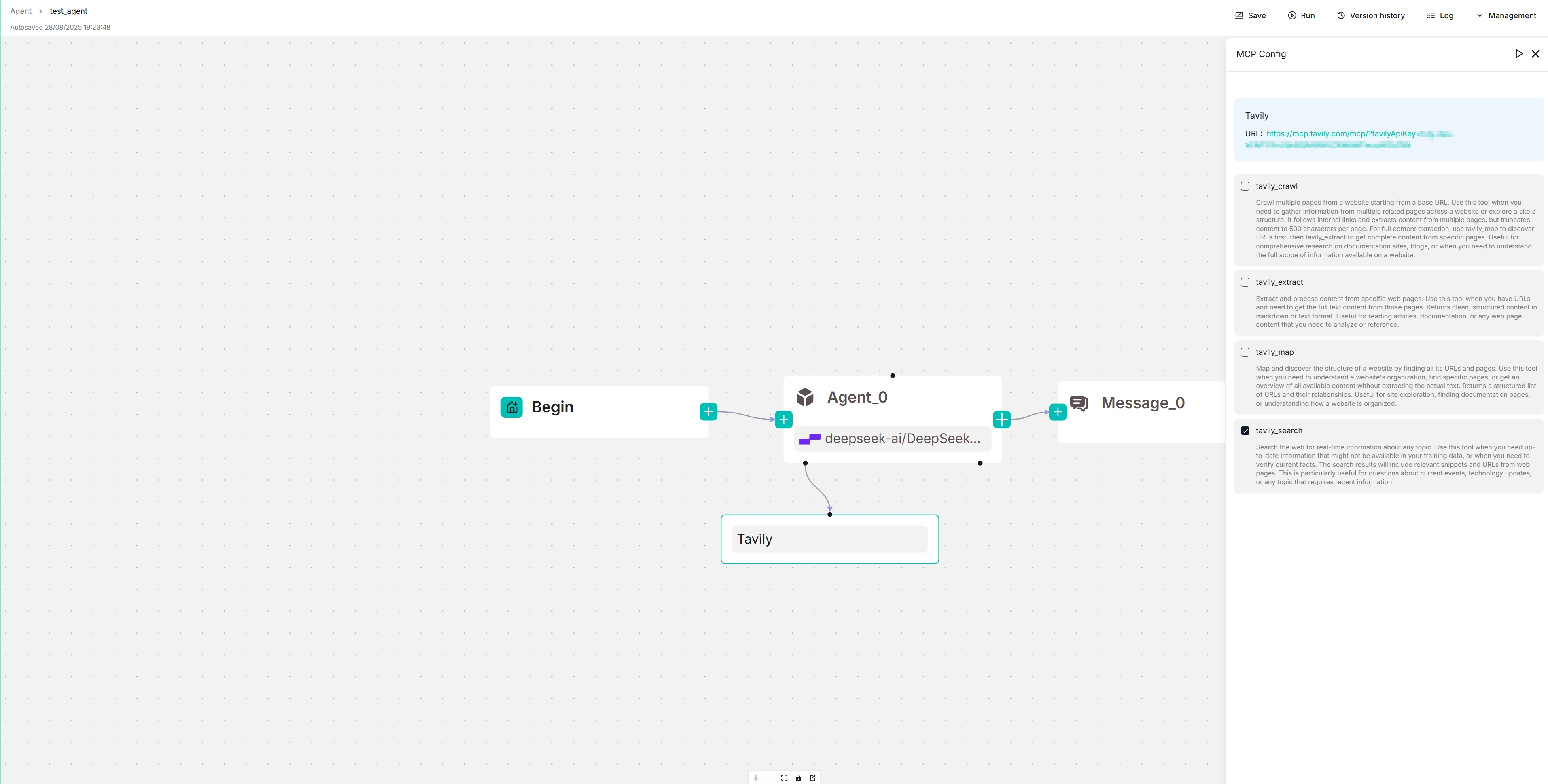
|
||||||
|
|
||||||
|
|
||||||
## Configurations
|
## Configurations
|
||||||
|
|
||||||
### Model
|
### Model
|
||||||
@ -69,7 +147,7 @@ An **Agent** component relies on keys (variables) to specify its data inputs. It
|
|||||||
|
|
||||||
#### Advanced usage
|
#### Advanced usage
|
||||||
|
|
||||||
From v0.20.5 onwards, four framework-level prompt blocks are available in the **System prompt** field. Type `/` or click **(x)** to view them; they appear under the **Framework** entry in the dropdown menu.
|
From v0.20.5 onwards, four framework-level prompt blocks are available in the **System prompt** field, enabling you to customize and *override* prompts at the framework level. Type `/` or click **(x)** to view them; they appear under the **Framework** entry in the dropdown menu.
|
||||||
|
|
||||||
- `task_analysis` prompt block
|
- `task_analysis` prompt block
|
||||||
- This block is responsible for analyzing tasks — either a user task or a task assigned by the lead Agent when the **Agent** component is acting as a Sub-Agent.
|
- This block is responsible for analyzing tasks — either a user task or a task assigned by the lead Agent when the **Agent** component is acting as a Sub-Agent.
|
||||||
@ -100,6 +178,12 @@ From v0.20.5 onwards, four framework-level prompt blocks are available in the **
|
|||||||
- `citation_guidelines` prompt block
|
- `citation_guidelines` prompt block
|
||||||
- Reference design: [citation_prompt.md](https://github.com/infiniflow/ragflow/blob/main/rag/prompts/citation_prompt.md)
|
- Reference design: [citation_prompt.md](https://github.com/infiniflow/ragflow/blob/main/rag/prompts/citation_prompt.md)
|
||||||
|
|
||||||
|
*The screenshots below show the framework prompt blocks available to an **Agent** component, both as a standalone and as a planner (with a Tavily tool below):*
|
||||||
|
|
||||||
|
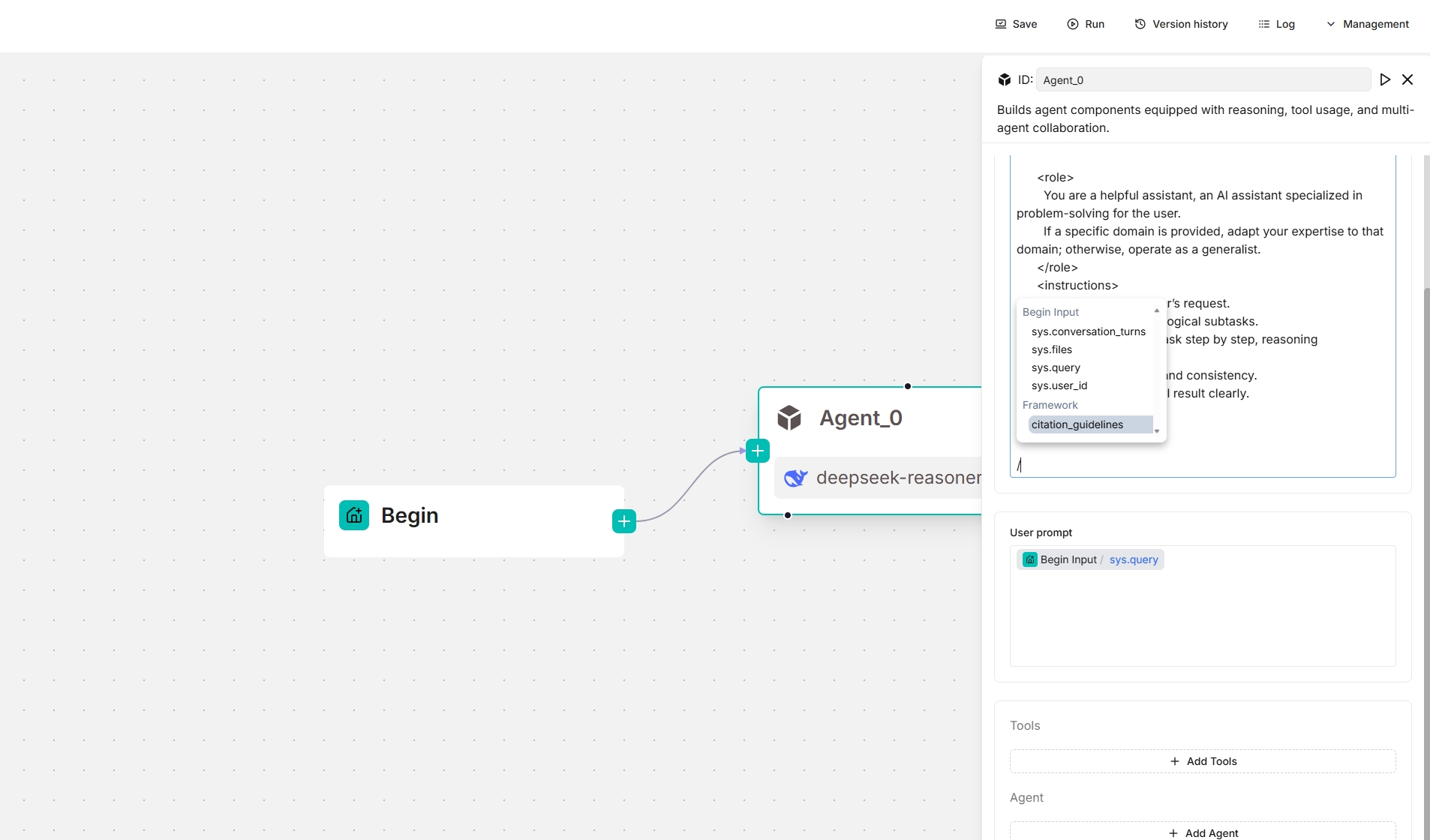
|
||||||
|
|
||||||
|
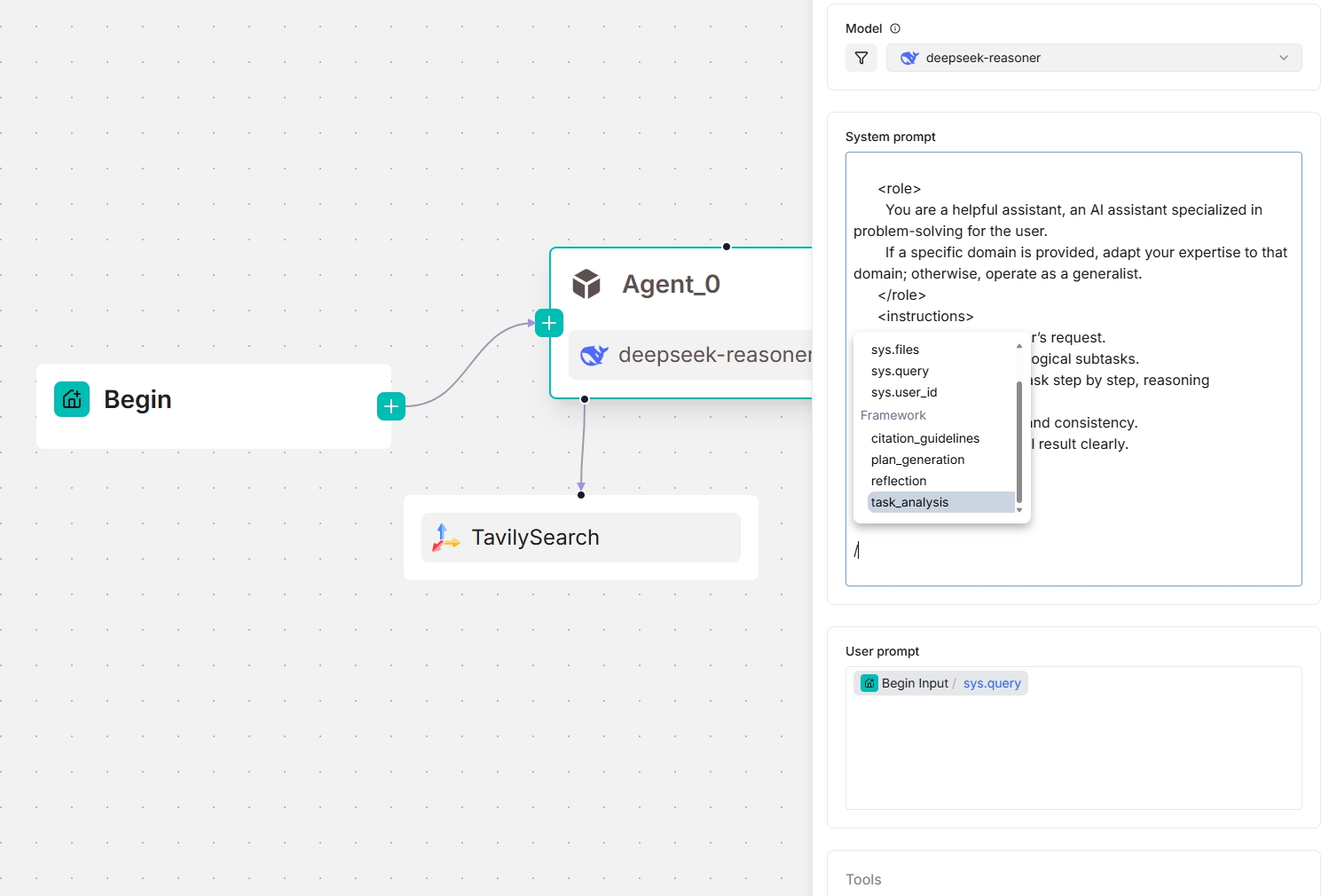
|
||||||
|
|
||||||
### User prompt
|
### User prompt
|
||||||
|
|
||||||
The user-defined prompt. Defaults to `sys.query`, the user query. As a general rule, when using the **Agent** component as a standalone module (not as a planner), you usually need to specify the corresponding **Retrieval** component’s output variable (`formalized_content`) here as part of the input to the LLM.
|
The user-defined prompt. Defaults to `sys.query`, the user query. As a general rule, when using the **Agent** component as a standalone module (not as a planner), you usually need to specify the corresponding **Retrieval** component’s output variable (`formalized_content`) here as part of the input to the LLM.
|
||||||
@ -129,7 +213,7 @@ Defines the maximum number of attempts the agent will make to retry a failed tas
|
|||||||
|
|
||||||
The waiting period in seconds that the agent observes before retrying a failed task, helping to prevent immediate repeated attempts and allowing system conditions to improve. Defaults to 1 second.
|
The waiting period in seconds that the agent observes before retrying a failed task, helping to prevent immediate repeated attempts and allowing system conditions to improve. Defaults to 1 second.
|
||||||
|
|
||||||
### Max rounds
|
### Max reflection rounds
|
||||||
|
|
||||||
Defines the maximum number reflection rounds of the selected chat model. Defaults to 1 round.
|
Defines the maximum number reflection rounds of the selected chat model. Defaults to 1 round.
|
||||||
|
|
||||||
|
|||||||
77
docs/guides/agent/agent_component_reference/execute_sql.md
Normal file
77
docs/guides/agent/agent_component_reference/execute_sql.md
Normal file
@ -0,0 +1,77 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 25
|
||||||
|
slug: /execute_sql
|
||||||
|
---
|
||||||
|
|
||||||
|
# Execute SQL tool
|
||||||
|
|
||||||
|
A tool that execute SQL queries on a specified relational database.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
The **Execute SQL** tool enables you to connect to a relational database and run SQL queries, whether entered directly or generated by the system’s Text2SQL capability via an **Agent** component. It currently supports three popular databases: MySQL, PostgreSQL, and MariaDB.
|
||||||
|
|
||||||
|
## Prerequisites
|
||||||
|
|
||||||
|
- A database instance properly configured and running.
|
||||||
|
- The database must be one of the following types:
|
||||||
|
- MySQL
|
||||||
|
- PostgreSQL
|
||||||
|
- MariaDB
|
||||||
|
|
||||||
|
## Examples
|
||||||
|
|
||||||
|
You can pair an **Agent** component with the **Execute SQL** tool, with the **Agent** generating SQL statements and the **Execute SQL** tool handling database connection and query execution. An example of this setup can be found in the **SQL Assistant** Agent template shown below:
|
||||||
|
|
||||||
|
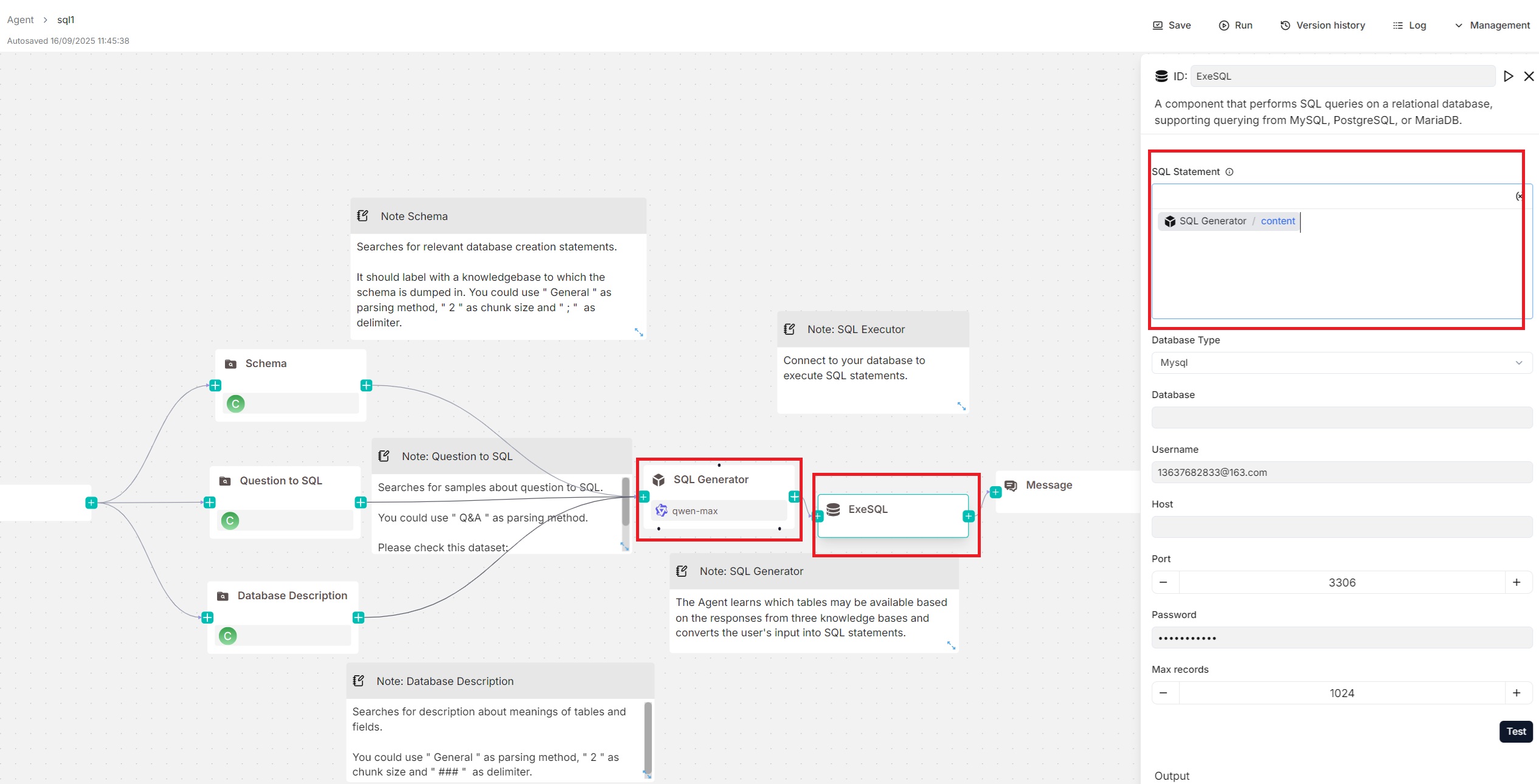
|
||||||
|
|
||||||
|
## Configurations
|
||||||
|
|
||||||
|
### SQL statement
|
||||||
|
|
||||||
|
This text input field allows you to write static SQL queries, such as `SELECT * FROM Table1`, and dynamic SQL queries using variables.
|
||||||
|
|
||||||
|
:::tip NOTE
|
||||||
|
Click **(x)** or type `/` to insert variables.
|
||||||
|
:::
|
||||||
|
|
||||||
|
For dynamic SQL queries, you can include variables in your SQL queries, such as `SELECT * FROM /sys.query`; if an **Agent** component is paired with the **Execute SQL** tool to generate SQL tasks (see the [Examples](#examples) section), you can directly insert that **Agent**'s output, `content`, into this field.
|
||||||
|
|
||||||
|
### Database type
|
||||||
|
|
||||||
|
The supported database type. Currently the following database types are available:
|
||||||
|
|
||||||
|
- MySQL
|
||||||
|
- PostreSQL
|
||||||
|
- MariaDB
|
||||||
|
|
||||||
|
### Database
|
||||||
|
|
||||||
|
Appears only when you select **Split** as method.
|
||||||
|
|
||||||
|
### Username
|
||||||
|
|
||||||
|
The username with access privileges to the database.
|
||||||
|
|
||||||
|
### Host
|
||||||
|
|
||||||
|
The IP address of the database server.
|
||||||
|
|
||||||
|
### Port
|
||||||
|
|
||||||
|
The port number on which the database server is listening.
|
||||||
|
|
||||||
|
### Password
|
||||||
|
|
||||||
|
The password for the database user.
|
||||||
|
|
||||||
|
### Max records
|
||||||
|
|
||||||
|
The maximum number of records returned by the SQL query to control response size and improve efficiency. Defaults to `1024`.
|
||||||
|
|
||||||
|
### Output
|
||||||
|
|
||||||
|
The **Execute SQL** tool provides two output variables:
|
||||||
|
|
||||||
|
- `formalized_content`: A string. If you reference this variable in a **Message** component, the returned records are displayed as a table.
|
||||||
|
- `json`: An object array. If you reference this variable in a **Message** component, the returned records will be presented as key-value pairs.
|
||||||
@ -1856,7 +1856,7 @@ curl --request POST \
|
|||||||
- `false`: Disable highlighting of matched terms (default).
|
- `false`: Disable highlighting of matched terms (default).
|
||||||
- `"cross_languages"`: (*Body parameter*) `list[string]`
|
- `"cross_languages"`: (*Body parameter*) `list[string]`
|
||||||
The languages that should be translated into, in order to achieve keywords retrievals in different languages.
|
The languages that should be translated into, in order to achieve keywords retrievals in different languages.
|
||||||
- `"metadata_condition"`: (*Body parameter*), `object`
|
- `"metadata_condition"`: (*Body parameter*), `object`
|
||||||
The metadata condition for filtering chunks.
|
The metadata condition for filtering chunks.
|
||||||
#### Response
|
#### Response
|
||||||
|
|
||||||
|
|||||||
@ -977,7 +977,7 @@ The languages that should be translated into, in order to achieve keywords retri
|
|||||||
|
|
||||||
##### metadata_condition: `dict`
|
##### metadata_condition: `dict`
|
||||||
|
|
||||||
filter condition for meta_fields
|
filter condition for `meta_fields`.
|
||||||
|
|
||||||
#### Returns
|
#### Returns
|
||||||
|
|
||||||
|
|||||||
@ -28,11 +28,11 @@ Released on September 10, 2025.
|
|||||||
|
|
||||||
### Improvements
|
### Improvements
|
||||||
|
|
||||||
- Agent Performance Optimized: Improved planning and reflection speed for simple tasks; optimized concurrent tool calls for parallelizable scenarios, significantly reducing overall response time.
|
- Agent:
|
||||||
- Agent Prompt Framework exposed: Developers can now customize and override framework-level prompts in the system prompt section, enhancing flexibility and control.
|
- Agent Performance Optimized: Improves planning and reflection speed for simple tasks; optimizes concurrent tool calls for parallelizable scenarios, significantly reducing overall response time.
|
||||||
- Execute SQL Component Enhanced: Replaced the original variable reference component with a text input field, allowing free-form SQL writing with variable support.
|
- Four framework-level prompt blocks are available in the **System prompt** section, enabling customization and overriding of prompts at the framework level, thereby enhancing flexibility and control. See [here](./guides/agent/agent_component_reference/agent.mdx#system-prompt).
|
||||||
- Chat: Re-enabled Reasoning and Cross-language search.
|
- **Execute SQL** component enhanced: Replaces the original variable reference component with a text input field, allowing users to write free-form SQL queries and reference variables.
|
||||||
- Retrieval API Enhanced: Added metadata filtering support to the [Retrieve chunks](https://ragflow.io/docs/dev/http_api_reference#retrieve-chunks) method.
|
- Chat: Re-enables **Reasoning** and **Cross-language search**.
|
||||||
|
|
||||||
### Added models
|
### Added models
|
||||||
|
|
||||||
@ -44,8 +44,22 @@ Released on September 10, 2025.
|
|||||||
### Fixed issues
|
### Fixed issues
|
||||||
|
|
||||||
- Dataset: Deleted files remained searchable.
|
- Dataset: Deleted files remained searchable.
|
||||||
- Chat: Unable to chat with an Ollama model.
|
- Chat: Unable to chat with an Ollama model.
|
||||||
- Agent: Resolved issues including cite toggle failure, task mode requiring dialogue triggers, repeated answers in multi-turn dialogues, and duplicate summarization of parallel execution results.
|
- Agent:
|
||||||
|
- A **Cite** toggle failure.
|
||||||
|
- An Agent in task mode still required a dialogue to trigger.
|
||||||
|
- Repeated answers in multi-turn dialogues.
|
||||||
|
- Duplicate summarization of parallel execution results.
|
||||||
|
|
||||||
|
### API changes
|
||||||
|
|
||||||
|
#### HTTP APIs
|
||||||
|
|
||||||
|
- Adds a body parameter `"metadata_condition"` to the [Retrieve chunks](./references/http_api_reference.md#retrieve-chunks) method, enabling metadata-based chunk filtering during retrieval. [#9877](https://github.com/infiniflow/ragflow/pull/9877)
|
||||||
|
|
||||||
|
#### Python APIs
|
||||||
|
|
||||||
|
- Adds a parameter `metadata_condition` to the [Retrieve chunks](./references/python_api_reference.md#retrieve-chunks) method, enabling metadata-based chunk filtering during retrieval. [#9877](https://github.com/infiniflow/ragflow/pull/9877)
|
||||||
|
|
||||||
## v0.20.4
|
## v0.20.4
|
||||||
|
|
||||||
|
|||||||
@ -45,7 +45,10 @@ class ParserParam(ProcessParamBase):
|
|||||||
"ppt": [],
|
"ppt": [],
|
||||||
"image": [],
|
"image": [],
|
||||||
"email": [],
|
"email": [],
|
||||||
"text": [],
|
"text": [
|
||||||
|
"text",
|
||||||
|
"json"
|
||||||
|
],
|
||||||
"audio": [],
|
"audio": [],
|
||||||
"video": [],
|
"video": [],
|
||||||
}
|
}
|
||||||
@ -84,7 +87,12 @@ class ParserParam(ProcessParamBase):
|
|||||||
"parse_method": "ocr",
|
"parse_method": "ocr",
|
||||||
},
|
},
|
||||||
"email": {},
|
"email": {},
|
||||||
"text": {},
|
"text": {
|
||||||
|
"suffix": [
|
||||||
|
"txt"
|
||||||
|
],
|
||||||
|
"output_format": "json",
|
||||||
|
},
|
||||||
"audio": {},
|
"audio": {},
|
||||||
"video": {},
|
"video": {},
|
||||||
}
|
}
|
||||||
@ -119,6 +127,11 @@ class ParserParam(ProcessParamBase):
|
|||||||
image_parse_method = image_config.get("parse_method", "")
|
image_parse_method = image_config.get("parse_method", "")
|
||||||
self.check_valid_value(image_parse_method.lower(), "Parse method abnormal.", ["ocr"])
|
self.check_valid_value(image_parse_method.lower(), "Parse method abnormal.", ["ocr"])
|
||||||
|
|
||||||
|
text_config = self.setups.get("text", "")
|
||||||
|
if text_config:
|
||||||
|
text_output_format = text_config.get("output_format", "")
|
||||||
|
self.check_valid_value(text_output_format, "Text output format abnormal.", self.allowed_output_format["text"])
|
||||||
|
|
||||||
def get_input_form(self) -> dict[str, dict]:
|
def get_input_form(self) -> dict[str, dict]:
|
||||||
return {}
|
return {}
|
||||||
|
|
||||||
@ -208,15 +221,13 @@ class Parser(ProcessBase):
|
|||||||
from rag.app.naive import Markdown as naive_markdown_parser
|
from rag.app.naive import Markdown as naive_markdown_parser
|
||||||
from rag.nlp import concat_img
|
from rag.nlp import concat_img
|
||||||
|
|
||||||
self.callback(random.randint(1, 5) / 100.0, "Start to work on a Word Processor Document")
|
self.callback(random.randint(1, 5) / 100.0, "Start to work on a markdown.")
|
||||||
|
|
||||||
blob = from_upstream.blob
|
blob = from_upstream.blob
|
||||||
name = from_upstream.name
|
name = from_upstream.name
|
||||||
conf = self._param.setups["markdown"]
|
conf = self._param.setups["markdown"]
|
||||||
self.set_output("output_format", conf["output_format"])
|
self.set_output("output_format", conf["output_format"])
|
||||||
|
|
||||||
print("markdown {conf=}", flush=True)
|
|
||||||
|
|
||||||
markdown_parser = naive_markdown_parser()
|
markdown_parser = naive_markdown_parser()
|
||||||
sections, tables = markdown_parser(name, blob, separate_tables=False)
|
sections, tables = markdown_parser(name, blob, separate_tables=False)
|
||||||
|
|
||||||
@ -240,13 +251,33 @@ class Parser(ProcessBase):
|
|||||||
|
|
||||||
self.set_output("json", json_results)
|
self.set_output("json", json_results)
|
||||||
|
|
||||||
|
def _text(self, from_upstream: ParserFromUpstream):
|
||||||
|
from deepdoc.parser.utils import get_text
|
||||||
|
|
||||||
|
self.callback(random.randint(1, 5) / 100.0, "Start to work on a text.")
|
||||||
|
|
||||||
|
blob = from_upstream.blob
|
||||||
|
name = from_upstream.name
|
||||||
|
conf = self._param.setups["text"]
|
||||||
|
self.set_output("output_format", conf["output_format"])
|
||||||
|
|
||||||
|
# parse binary to text
|
||||||
|
text_content = get_text(name, binary=blob)
|
||||||
|
|
||||||
|
if conf.get("output_format") == "json":
|
||||||
|
result = [{"text": text_content}]
|
||||||
|
self.set_output("json", result)
|
||||||
|
else:
|
||||||
|
result = text_content
|
||||||
|
self.set_output("text", result)
|
||||||
|
|
||||||
async def _invoke(self, **kwargs):
|
async def _invoke(self, **kwargs):
|
||||||
function_map = {
|
function_map = {
|
||||||
"pdf": self._pdf,
|
"pdf": self._pdf,
|
||||||
"markdown": self._markdown,
|
"markdown": self._markdown,
|
||||||
"spreadsheet": self._spreadsheet,
|
"spreadsheet": self._spreadsheet,
|
||||||
"word": self._word
|
"word": self._word,
|
||||||
|
"text": self._text,
|
||||||
}
|
}
|
||||||
try:
|
try:
|
||||||
from_upstream = ParserFromUpstream.model_validate(kwargs)
|
from_upstream = ParserFromUpstream.model_validate(kwargs)
|
||||||
|
|||||||
@ -44,9 +44,12 @@
|
|||||||
"markdown"
|
"markdown"
|
||||||
],
|
],
|
||||||
"output_format": "json"
|
"output_format": "json"
|
||||||
|
},
|
||||||
|
"text": {
|
||||||
|
"suffix": ["txt"],
|
||||||
|
"output_format": "json"
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
}
|
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"downstream": ["Chunker:0"],
|
"downstream": ["Chunker:0"],
|
||||||
|
|||||||
@ -1356,6 +1356,14 @@ class Ai302Chat(Base):
|
|||||||
super().__init__(key, model_name, base_url, **kwargs)
|
super().__init__(key, model_name, base_url, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
|
class TokenPonyChat(Base):
|
||||||
|
_FACTORY_NAME = "TokenPony"
|
||||||
|
|
||||||
|
def __init__(self, key, model_name, base_url="https://ragflow.vip-api.tokenpony.cn/v1", **kwargs):
|
||||||
|
if not base_url:
|
||||||
|
base_url = "https://ragflow.vip-api.tokenpony.cn/v1"
|
||||||
|
|
||||||
|
|
||||||
class MeituanChat(Base):
|
class MeituanChat(Base):
|
||||||
_FACTORY_NAME = "Meituan"
|
_FACTORY_NAME = "Meituan"
|
||||||
|
|
||||||
|
|||||||
@ -751,7 +751,11 @@ class SILICONFLOWEmbed(Base):
|
|||||||
token_count = 0
|
token_count = 0
|
||||||
for i in range(0, len(texts), batch_size):
|
for i in range(0, len(texts), batch_size):
|
||||||
texts_batch = texts[i : i + batch_size]
|
texts_batch = texts[i : i + batch_size]
|
||||||
texts_batch = [" " if not text.strip() else text for text in texts_batch]
|
if self.model_name in ["BAAI/bge-large-zh-v1.5", "BAAI/bge-large-en-v1.5"]:
|
||||||
|
# limit 512, 340 is almost safe
|
||||||
|
texts_batch = [" " if not text.strip() else truncate(text, 340) for text in texts_batch]
|
||||||
|
else:
|
||||||
|
texts_batch = [" " if not text.strip() else text for text in texts_batch]
|
||||||
|
|
||||||
payload = {
|
payload = {
|
||||||
"model": self.model_name,
|
"model": self.model_name,
|
||||||
|
|||||||
8
web/src/assets/svg/llm/token-pony.svg
Normal file
8
web/src/assets/svg/llm/token-pony.svg
Normal file
{kind=link}
File diff suppressed because one or more lines are too long
|
After Width: | Height: | Size: 16 KiB |
@ -139,7 +139,7 @@ function EmbedDialog({
|
|||||||
</form>
|
</form>
|
||||||
</Form>
|
</Form>
|
||||||
<div>
|
<div>
|
||||||
<span>Embed code</span>
|
<span>{t('embedCode', { keyPrefix: 'search' })}</span>
|
||||||
<HightLightMarkdown>{text}</HightLightMarkdown>
|
<HightLightMarkdown>{text}</HightLightMarkdown>
|
||||||
</div>
|
</div>
|
||||||
<div className=" font-medium mt-4 mb-1">
|
<div className=" font-medium mt-4 mb-1">
|
||||||
|
|||||||
@ -54,6 +54,7 @@ export enum LLMFactory {
|
|||||||
DeepInfra = 'DeepInfra',
|
DeepInfra = 'DeepInfra',
|
||||||
Grok = 'Grok',
|
Grok = 'Grok',
|
||||||
XAI = 'xAI',
|
XAI = 'xAI',
|
||||||
|
TokenPony = 'TokenPony',
|
||||||
Meituan = 'Meituan',
|
Meituan = 'Meituan',
|
||||||
}
|
}
|
||||||
|
|
||||||
@ -114,5 +115,6 @@ export const IconMap = {
|
|||||||
[LLMFactory.DeepInfra]: 'deepinfra',
|
[LLMFactory.DeepInfra]: 'deepinfra',
|
||||||
[LLMFactory.Grok]: 'grok',
|
[LLMFactory.Grok]: 'grok',
|
||||||
[LLMFactory.XAI]: 'xai',
|
[LLMFactory.XAI]: 'xai',
|
||||||
|
[LLMFactory.TokenPony]: 'token-pony',
|
||||||
[LLMFactory.Meituan]: 'longcat',
|
[LLMFactory.Meituan]: 'longcat',
|
||||||
};
|
};
|
||||||
|
|||||||
@ -155,7 +155,12 @@ export const useComposeLlmOptionsByModelTypes = (
|
|||||||
options.forEach((x) => {
|
options.forEach((x) => {
|
||||||
const item = pre.find((y) => y.label === x.label);
|
const item = pre.find((y) => y.label === x.label);
|
||||||
if (item) {
|
if (item) {
|
||||||
item.options.push(...x.options);
|
x.options.forEach((y) => {
|
||||||
|
// A model that is both an image2text and speech2text model
|
||||||
|
if (!item.options.some((z) => z.value === y.value)) {
|
||||||
|
item.options.push(y);
|
||||||
|
}
|
||||||
|
});
|
||||||
} else {
|
} else {
|
||||||
pre.push(x);
|
pre.push(x);
|
||||||
}
|
}
|
||||||
|
|||||||
@ -632,6 +632,8 @@ General:实体和关系提取提示来自 GitHub - microsoft/graphrag:基于
|
|||||||
},
|
},
|
||||||
cancel: '取消',
|
cancel: '取消',
|
||||||
chatSetting: '聊天设置',
|
chatSetting: '聊天设置',
|
||||||
|
avatarHidden: '隐藏头像',
|
||||||
|
locale: '地区',
|
||||||
},
|
},
|
||||||
setting: {
|
setting: {
|
||||||
profile: '概要',
|
profile: '概要',
|
||||||
|
|||||||
@ -62,7 +62,7 @@ function AgentChatBox() {
|
|||||||
|
|
||||||
return (
|
return (
|
||||||
<>
|
<>
|
||||||
<section className="flex flex-1 flex-col px-5 h-[90vh]">
|
<section className="flex flex-1 flex-col px-5 min-h-0 pb-4">
|
||||||
<div className="flex-1 overflow-auto" ref={messageContainerRef}>
|
<div className="flex-1 overflow-auto" ref={messageContainerRef}>
|
||||||
<div>
|
<div>
|
||||||
{/* <Spin spinning={sendLoading}> */}
|
{/* <Spin spinning={sendLoading}> */}
|
||||||
|
|||||||
@ -9,7 +9,7 @@ export function ChatSheet({ hideModal }: IModalProps<any>) {
|
|||||||
return (
|
return (
|
||||||
<Sheet open modal={false} onOpenChange={hideModal}>
|
<Sheet open modal={false} onOpenChange={hideModal}>
|
||||||
<SheetContent
|
<SheetContent
|
||||||
className={cn('top-20 p-0')}
|
className={cn('top-20 bottom-0 p-0 flex flex-col h-auto')}
|
||||||
onInteractOutside={(e) => e.preventDefault()}
|
onInteractOutside={(e) => e.preventDefault()}
|
||||||
>
|
>
|
||||||
<SheetTitle className="hidden"></SheetTitle>
|
<SheetTitle className="hidden"></SheetTitle>
|
||||||
|
|||||||
@ -145,7 +145,7 @@ function AgentForm({ node }: INextOperatorForm) {
|
|||||||
<PromptEditor
|
<PromptEditor
|
||||||
{...field}
|
{...field}
|
||||||
placeholder={t('flow.messagePlaceholder')}
|
placeholder={t('flow.messagePlaceholder')}
|
||||||
showToolbar={false}
|
showToolbar={true}
|
||||||
extraOptions={extraOptions}
|
extraOptions={extraOptions}
|
||||||
></PromptEditor>
|
></PromptEditor>
|
||||||
</FormControl>
|
</FormControl>
|
||||||
@ -166,7 +166,7 @@ function AgentForm({ node }: INextOperatorForm) {
|
|||||||
<section>
|
<section>
|
||||||
<PromptEditor
|
<PromptEditor
|
||||||
{...field}
|
{...field}
|
||||||
showToolbar={false}
|
showToolbar={true}
|
||||||
></PromptEditor>
|
></PromptEditor>
|
||||||
</section>
|
</section>
|
||||||
</FormControl>
|
</FormControl>
|
||||||
|
|||||||
@ -9,13 +9,7 @@ import { cn, formatBytes } from '@/lib/utils';
|
|||||||
import { Routes } from '@/routes';
|
import { Routes } from '@/routes';
|
||||||
import { formatPureDate } from '@/utils/date';
|
import { formatPureDate } from '@/utils/date';
|
||||||
import { isEmpty } from 'lodash';
|
import { isEmpty } from 'lodash';
|
||||||
import {
|
import { Banknote, Database, FileSearch2, GitGraph } from 'lucide-react';
|
||||||
Banknote,
|
|
||||||
Database,
|
|
||||||
DatabaseZap,
|
|
||||||
FileSearch2,
|
|
||||||
GitGraph,
|
|
||||||
} from 'lucide-react';
|
|
||||||
import { useMemo } from 'react';
|
import { useMemo } from 'react';
|
||||||
import { useTranslation } from 'react-i18next';
|
import { useTranslation } from 'react-i18next';
|
||||||
import { useHandleMenuClick } from './hooks';
|
import { useHandleMenuClick } from './hooks';
|
||||||
@ -34,11 +28,11 @@ export function SideBar({ refreshCount }: PropType) {
|
|||||||
|
|
||||||
const items = useMemo(() => {
|
const items = useMemo(() => {
|
||||||
const list = [
|
const list = [
|
||||||
{
|
// {
|
||||||
icon: DatabaseZap,
|
// icon: DatabaseZap,
|
||||||
label: t(`knowledgeDetails.overview`),
|
// label: t(`knowledgeDetails.overview`),
|
||||||
key: Routes.DataSetOverview,
|
// key: Routes.DataSetOverview,
|
||||||
},
|
// },
|
||||||
{
|
{
|
||||||
icon: Database,
|
icon: Database,
|
||||||
label: t(`knowledgeDetails.dataset`),
|
label: t(`knowledgeDetails.dataset`),
|
||||||
|
|||||||
@ -17,16 +17,9 @@ import {
|
|||||||
import { Input } from '@/components/ui/input';
|
import { Input } from '@/components/ui/input';
|
||||||
import { IModalProps } from '@/interfaces/common';
|
import { IModalProps } from '@/interfaces/common';
|
||||||
import { zodResolver } from '@hookform/resolvers/zod';
|
import { zodResolver } from '@hookform/resolvers/zod';
|
||||||
import { useForm, useWatch } from 'react-hook-form';
|
import { useForm } from 'react-hook-form';
|
||||||
import { useTranslation } from 'react-i18next';
|
import { useTranslation } from 'react-i18next';
|
||||||
import { z } from 'zod';
|
import { z } from 'zod';
|
||||||
import {
|
|
||||||
DataExtractKnowledgeItem,
|
|
||||||
DataFlowItem,
|
|
||||||
EmbeddingModelItem,
|
|
||||||
ParseTypeItem,
|
|
||||||
TeamItem,
|
|
||||||
} from '../dataset/dataset-setting/configuration/common-item';
|
|
||||||
|
|
||||||
const FormId = 'dataset-creating-form';
|
const FormId = 'dataset-creating-form';
|
||||||
|
|
||||||
@ -54,10 +47,6 @@ export function InputForm({ onOk }: IModalProps<any>) {
|
|||||||
function onSubmit(data: z.infer<typeof FormSchema>) {
|
function onSubmit(data: z.infer<typeof FormSchema>) {
|
||||||
onOk?.(data.name);
|
onOk?.(data.name);
|
||||||
}
|
}
|
||||||
const parseType = useWatch({
|
|
||||||
control: form.control,
|
|
||||||
name: 'parseType',
|
|
||||||
});
|
|
||||||
return (
|
return (
|
||||||
<Form {...form}>
|
<Form {...form}>
|
||||||
<form
|
<form
|
||||||
@ -84,15 +73,6 @@ export function InputForm({ onOk }: IModalProps<any>) {
|
|||||||
</FormItem>
|
</FormItem>
|
||||||
)}
|
)}
|
||||||
/>
|
/>
|
||||||
<EmbeddingModelItem line={2} />
|
|
||||||
<ParseTypeItem />
|
|
||||||
{parseType === 2 && (
|
|
||||||
<>
|
|
||||||
<DataFlowItem />
|
|
||||||
<DataExtractKnowledgeItem />
|
|
||||||
<TeamItem />
|
|
||||||
</>
|
|
||||||
)}
|
|
||||||
</form>
|
</form>
|
||||||
</Form>
|
</Form>
|
||||||
);
|
);
|
||||||
|
|||||||
123
web/src/pages/datasets/dataset-dataflow-creating-dialog.tsx
Normal file
123
web/src/pages/datasets/dataset-dataflow-creating-dialog.tsx
Normal file
@ -0,0 +1,123 @@
|
|||||||
|
import { ButtonLoading } from '@/components/ui/button';
|
||||||
|
import {
|
||||||
|
Dialog,
|
||||||
|
DialogContent,
|
||||||
|
DialogFooter,
|
||||||
|
DialogHeader,
|
||||||
|
DialogTitle,
|
||||||
|
} from '@/components/ui/dialog';
|
||||||
|
import {
|
||||||
|
Form,
|
||||||
|
FormControl,
|
||||||
|
FormField,
|
||||||
|
FormItem,
|
||||||
|
FormLabel,
|
||||||
|
FormMessage,
|
||||||
|
} from '@/components/ui/form';
|
||||||
|
import { Input } from '@/components/ui/input';
|
||||||
|
import { IModalProps } from '@/interfaces/common';
|
||||||
|
import { zodResolver } from '@hookform/resolvers/zod';
|
||||||
|
import { useForm, useWatch } from 'react-hook-form';
|
||||||
|
import { useTranslation } from 'react-i18next';
|
||||||
|
import { z } from 'zod';
|
||||||
|
import {
|
||||||
|
DataExtractKnowledgeItem,
|
||||||
|
DataFlowItem,
|
||||||
|
EmbeddingModelItem,
|
||||||
|
ParseTypeItem,
|
||||||
|
TeamItem,
|
||||||
|
} from '../dataset/dataset-setting/configuration/common-item';
|
||||||
|
|
||||||
|
const FormId = 'dataset-creating-form';
|
||||||
|
|
||||||
|
export function InputForm({ onOk }: IModalProps<any>) {
|
||||||
|
const { t } = useTranslation();
|
||||||
|
|
||||||
|
const FormSchema = z.object({
|
||||||
|
name: z
|
||||||
|
.string()
|
||||||
|
.min(1, {
|
||||||
|
message: t('knowledgeList.namePlaceholder'),
|
||||||
|
})
|
||||||
|
.trim(),
|
||||||
|
parseType: z.number().optional(),
|
||||||
|
});
|
||||||
|
|
||||||
|
const form = useForm<z.infer<typeof FormSchema>>({
|
||||||
|
resolver: zodResolver(FormSchema),
|
||||||
|
defaultValues: {
|
||||||
|
name: '',
|
||||||
|
parseType: 1,
|
||||||
|
},
|
||||||
|
});
|
||||||
|
|
||||||
|
function onSubmit(data: z.infer<typeof FormSchema>) {
|
||||||
|
onOk?.(data.name);
|
||||||
|
}
|
||||||
|
const parseType = useWatch({
|
||||||
|
control: form.control,
|
||||||
|
name: 'parseType',
|
||||||
|
});
|
||||||
|
return (
|
||||||
|
<Form {...form}>
|
||||||
|
<form
|
||||||
|
onSubmit={form.handleSubmit(onSubmit)}
|
||||||
|
className="space-y-6"
|
||||||
|
id={FormId}
|
||||||
|
>
|
||||||
|
<FormField
|
||||||
|
control={form.control}
|
||||||
|
name="name"
|
||||||
|
render={({ field }) => (
|
||||||
|
<FormItem>
|
||||||
|
<FormLabel>
|
||||||
|
<span className="text-destructive mr-1"> *</span>
|
||||||
|
{t('knowledgeList.name')}
|
||||||
|
</FormLabel>
|
||||||
|
<FormControl>
|
||||||
|
<Input
|
||||||
|
placeholder={t('knowledgeList.namePlaceholder')}
|
||||||
|
{...field}
|
||||||
|
/>
|
||||||
|
</FormControl>
|
||||||
|
<FormMessage />
|
||||||
|
</FormItem>
|
||||||
|
)}
|
||||||
|
/>
|
||||||
|
<EmbeddingModelItem line={2} />
|
||||||
|
<ParseTypeItem />
|
||||||
|
{parseType === 2 && (
|
||||||
|
<>
|
||||||
|
<DataFlowItem />
|
||||||
|
<DataExtractKnowledgeItem />
|
||||||
|
<TeamItem />
|
||||||
|
</>
|
||||||
|
)}
|
||||||
|
</form>
|
||||||
|
</Form>
|
||||||
|
);
|
||||||
|
}
|
||||||
|
|
||||||
|
export function DatasetCreatingDialog({
|
||||||
|
hideModal,
|
||||||
|
onOk,
|
||||||
|
loading,
|
||||||
|
}: IModalProps<any>) {
|
||||||
|
const { t } = useTranslation();
|
||||||
|
|
||||||
|
return (
|
||||||
|
<Dialog open onOpenChange={hideModal}>
|
||||||
|
<DialogContent className="sm:max-w-[425px]">
|
||||||
|
<DialogHeader>
|
||||||
|
<DialogTitle>{t('knowledgeList.createKnowledgeBase')}</DialogTitle>
|
||||||
|
</DialogHeader>
|
||||||
|
<InputForm onOk={onOk}></InputForm>
|
||||||
|
<DialogFooter>
|
||||||
|
<ButtonLoading type="submit" form={FormId} loading={loading}>
|
||||||
|
{t('common.save')}
|
||||||
|
</ButtonLoading>
|
||||||
|
</DialogFooter>
|
||||||
|
</DialogContent>
|
||||||
|
</Dialog>
|
||||||
|
);
|
||||||
|
}
|
||||||
@ -37,6 +37,7 @@ const llmFactoryToUrlMap = {
|
|||||||
'https://huggingface.co/docs/text-embeddings-inference/quick_tour',
|
'https://huggingface.co/docs/text-embeddings-inference/quick_tour',
|
||||||
[LLMFactory.GPUStack]: 'https://docs.gpustack.ai/latest/quickstart',
|
[LLMFactory.GPUStack]: 'https://docs.gpustack.ai/latest/quickstart',
|
||||||
[LLMFactory.VLLM]: 'https://docs.vllm.ai/en/latest/',
|
[LLMFactory.VLLM]: 'https://docs.vllm.ai/en/latest/',
|
||||||
|
[LLMFactory.TokenPony]: 'https://docs.tokenpony.cn/#/',
|
||||||
};
|
};
|
||||||
type LlmFactory = keyof typeof llmFactoryToUrlMap;
|
type LlmFactory = keyof typeof llmFactoryToUrlMap;
|
||||||
|
|
||||||
|
|||||||
Reference in New Issue
Block a user