mirror of
https://github.com/infiniflow/ragflow.git
synced 2026-02-07 02:55:08 +08:00
Compare commits
6 Commits
4693c5382a
...
6c24ad7966
| Author | SHA1 | Date | |
|---|---|---|---|
| 6c24ad7966 | |||
| 4846589599 | |||
| a24547aa66 | |||
| a04c5247ab | |||
| ed6a76dcc0 | |||
| a0ccbec8bd |
@ -1,105 +0,0 @@
|
||||
# 健康检查与 Kubernetes 探针简明说明
|
||||
|
||||
本文件说明:什么是 K8s 探针、如何用 `/v1/system/healthz` 做健康检查,以及下文用例中的关键词含义。
|
||||
|
||||
## 什么是 K8s 探针(Probe)
|
||||
- 探针是 K8s 用来“探测”容器是否健康/可对外服务的机制。
|
||||
- 常见三类:
|
||||
- livenessProbe:活性探针。失败时 K8s 会重启容器,用于“应用卡死/失去连接时自愈”。
|
||||
- readinessProbe:就绪探针。失败时 Endpoint 不会被加入 Service 负载均衡,用于“应用尚未准备好时不接流量”。
|
||||
- startupProbe:启动探针。给慢启动应用更长的初始化窗口,期间不执行 liveness/readiness。
|
||||
- 这些探针通常通过 HTTP GET 访问一个公开且轻量的健康端点(无需鉴权),以 HTTP 状态码判定结果:200=通过;5xx/超时=失败。
|
||||
|
||||
## 本项目健康端点
|
||||
- 已实现:`GET /v1/system/healthz`(无需认证)。
|
||||
- 语义:
|
||||
- 200:关键依赖正常。
|
||||
- 500:任一关键依赖异常(当前判定为 DB 或 Chat)。
|
||||
- 响应体:JSON,最小字段 `status, db, chat`;并包含 `redis, doc_engine, storage` 等可观测项。失败项会在 `_meta` 中包含 `error/elapsed`。
|
||||
- 示例(DB 故障):
|
||||
```json
|
||||
{"status":"nok","chat":"ok","db":"nok"}
|
||||
```
|
||||
|
||||
## 用例背景(Problem/use case)
|
||||
- 现状:Ragflow 跑在 K8s,数据库是 AWS RDS Postgres,凭证由 Secret Manager 管理并每 7 天轮换。轮换后应用连接失效,需要手动重启 Pod 才能重新建立连接。
|
||||
- 目标:通过 K8s 探针自动化检测并重启异常 Pod,减少人工操作。
|
||||
- 需求:一个“无需鉴权”的公共健康端点,能在依赖异常时返回非 200(如 500)且提供 JSON 详情。
|
||||
- 现已满足:`/v1/system/healthz` 正是为此设计。
|
||||
|
||||
## 关键术语解释(对应你提供的描述)
|
||||
- Ragflow instance:部署在 K8s 的 Ragflow 服务。
|
||||
- AWS RDS Postgres:托管的 PostgreSQL 数据库实例。
|
||||
- Secret Manager rotation:Secrets 定期轮换(每 7 天),会导致旧连接失效。
|
||||
- Probes(K8s 探针):liveness/readiness,用于自动重启或摘除不健康实例。
|
||||
- Public endpoint without API key:无需 Authorization 的 HTTP 路由,便于探针直接访问。
|
||||
- Dependencies statuses:依赖健康状态(db、chat、redis、doc_engine、storage 等)。
|
||||
- HTTP 500 with JSON:当依赖异常时返回 500,并附带 JSON 说明哪个子系统失败。
|
||||
|
||||
## 快速测试
|
||||
- 正常:
|
||||
```bash
|
||||
curl -i http://<host>/v1/system/healthz
|
||||
```
|
||||
- 制造 DB 故障(docker-compose 示例):
|
||||
```bash
|
||||
docker compose stop db && curl -i http://<host>/v1/system/healthz
|
||||
```
|
||||
(预期 500,JSON 中 `db:"nok"`)
|
||||
|
||||
## 更完整的测试清单
|
||||
### 1) 仅查看 HTTP 状态码
|
||||
```bash
|
||||
curl -s -o /dev/null -w "%{http_code}\n" http://<host>/v1/system/healthz
|
||||
```
|
||||
期望:`200` 或 `500`。
|
||||
|
||||
### 2) Windows PowerShell
|
||||
```powershell
|
||||
# 状态码
|
||||
(Invoke-WebRequest -Uri "http://<host>/v1/system/healthz" -Method GET -TimeoutSec 3 -ErrorAction SilentlyContinue).StatusCode
|
||||
# 完整响应
|
||||
Invoke-RestMethod -Uri "http://<host>/v1/system/healthz" -Method GET
|
||||
```
|
||||
|
||||
### 3) 通过 kubectl 端口转发本地测试
|
||||
```bash
|
||||
# 前端/网关暴露端口不同环境自行调整
|
||||
kubectl port-forward deploy/<your-deploy> 8080:80 -n <ns>
|
||||
curl -i http://127.0.0.1:8080/v1/system/healthz
|
||||
```
|
||||
|
||||
### 4) 制造常见失败场景
|
||||
- DB 失败(推荐):
|
||||
```bash
|
||||
docker compose stop db
|
||||
curl -i http://<host>/v1/system/healthz # 预期 500
|
||||
```
|
||||
- Chat 失败(可选):将 `CHAT_CFG` 的 `factory`/`base_url` 设为无效并重启后端,再请求应为 500,且 `chat:"nok"`。
|
||||
- Redis/存储/文档引擎:停用对应服务后再次请求,可在 JSON 中看到相应字段为 `"nok"`(不影响 200/500 判定)。
|
||||
|
||||
### 5) 浏览器验证
|
||||
- 直接打开 `http://<host>/v1/system/healthz`,在 DevTools Network 查看 200/500;页面正文就是 JSON。
|
||||
- 反向代理注意:若有自定义 500 错页,需对 `/healthz` 关闭错误页拦截(如 `proxy_intercept_errors off;`)。
|
||||
|
||||
## K8s 探针示例
|
||||
```yaml
|
||||
readinessProbe:
|
||||
httpGet:
|
||||
path: /v1/system/healthz
|
||||
port: 80
|
||||
initialDelaySeconds: 5
|
||||
periodSeconds: 10
|
||||
timeoutSeconds: 2
|
||||
failureThreshold: 1
|
||||
livenessProbe:
|
||||
httpGet:
|
||||
path: /v1/system/healthz
|
||||
port: 80
|
||||
initialDelaySeconds: 10
|
||||
periodSeconds: 10
|
||||
timeoutSeconds: 2
|
||||
failureThreshold: 3
|
||||
```
|
||||
|
||||
提示:如有反向代理(Nginx)自定义 500 错页,需对 `/healthz` 关闭错误页拦截,以便保留 JSON。
|
||||
@ -3,9 +3,11 @@ import re
|
||||
|
||||
import flask
|
||||
from flask import request
|
||||
from pathlib import Path
|
||||
|
||||
from api.db.services.document_service import DocumentService
|
||||
from api.db.services.file2document_service import File2DocumentService
|
||||
from api.db.services.knowledgebase_service import KnowledgebaseService
|
||||
from api.utils.api_utils import server_error_response, token_required
|
||||
from api.utils import get_uuid
|
||||
from api.db import FileType
|
||||
@ -666,3 +668,71 @@ def move(tenant_id):
|
||||
return get_json_result(data=True)
|
||||
except Exception as e:
|
||||
return server_error_response(e)
|
||||
|
||||
@manager.route('/file/convert', methods=['POST']) # noqa: F821
|
||||
@token_required
|
||||
def convert(tenant_id):
|
||||
req = request.json
|
||||
kb_ids = req["kb_ids"]
|
||||
file_ids = req["file_ids"]
|
||||
file2documents = []
|
||||
|
||||
try:
|
||||
files = FileService.get_by_ids(file_ids)
|
||||
files_set = dict({file.id: file for file in files})
|
||||
for file_id in file_ids:
|
||||
file = files_set[file_id]
|
||||
if not file:
|
||||
return get_json_result(message="File not found!", code=404)
|
||||
file_ids_list = [file_id]
|
||||
if file.type == FileType.FOLDER.value:
|
||||
file_ids_list = FileService.get_all_innermost_file_ids(file_id, [])
|
||||
for id in file_ids_list:
|
||||
informs = File2DocumentService.get_by_file_id(id)
|
||||
# delete
|
||||
for inform in informs:
|
||||
doc_id = inform.document_id
|
||||
e, doc = DocumentService.get_by_id(doc_id)
|
||||
if not e:
|
||||
return get_json_result(message="Document not found!", code=404)
|
||||
tenant_id = DocumentService.get_tenant_id(doc_id)
|
||||
if not tenant_id:
|
||||
return get_json_result(message="Tenant not found!", code=404)
|
||||
if not DocumentService.remove_document(doc, tenant_id):
|
||||
return get_json_result(
|
||||
message="Database error (Document removal)!", code=404)
|
||||
File2DocumentService.delete_by_file_id(id)
|
||||
|
||||
# insert
|
||||
for kb_id in kb_ids:
|
||||
e, kb = KnowledgebaseService.get_by_id(kb_id)
|
||||
if not e:
|
||||
return get_json_result(
|
||||
message="Can't find this knowledgebase!", code=404)
|
||||
e, file = FileService.get_by_id(id)
|
||||
if not e:
|
||||
return get_json_result(
|
||||
message="Can't find this file!", code=404)
|
||||
|
||||
doc = DocumentService.insert({
|
||||
"id": get_uuid(),
|
||||
"kb_id": kb.id,
|
||||
"parser_id": FileService.get_parser(file.type, file.name, kb.parser_id),
|
||||
"parser_config": kb.parser_config,
|
||||
"created_by": tenant_id,
|
||||
"type": file.type,
|
||||
"name": file.name,
|
||||
"suffix": Path(file.name).suffix.lstrip("."),
|
||||
"location": file.location,
|
||||
"size": file.size
|
||||
})
|
||||
file2document = File2DocumentService.insert({
|
||||
"id": get_uuid(),
|
||||
"file_id": id,
|
||||
"document_id": doc.id,
|
||||
})
|
||||
|
||||
file2documents.append(file2document.to_json())
|
||||
return get_json_result(data=file2documents)
|
||||
except Exception as e:
|
||||
return server_error_response(e)
|
||||
@ -37,7 +37,7 @@ from timeit import default_timer as timer
|
||||
|
||||
from rag.utils.redis_conn import REDIS_CONN
|
||||
from flask import jsonify
|
||||
from api.utils.health import run_health_checks
|
||||
from api.utils.health_utils import run_health_checks
|
||||
|
||||
@manager.route("/version", methods=["GET"]) # noqa: F821
|
||||
@login_required
|
||||
|
||||
@ -48,31 +48,16 @@ def check_storage() -> tuple[bool, dict]:
|
||||
return False, {"elapsed": f"{(timer() - st) * 1000.0:.1f}", "error": str(e)}
|
||||
|
||||
|
||||
def check_chat() -> tuple[bool, dict]:
|
||||
st = timer()
|
||||
try:
|
||||
cfg = getattr(settings, "CHAT_CFG", None)
|
||||
ok = bool(cfg and cfg.get("factory"))
|
||||
return ok, {"elapsed": f"{(timer() - st) * 1000.0:.1f}"}
|
||||
except Exception as e:
|
||||
return False, {"elapsed": f"{(timer() - st) * 1000.0:.1f}", "error": str(e)}
|
||||
|
||||
|
||||
def run_health_checks() -> tuple[dict, bool]:
|
||||
result: dict[str, str | dict] = {}
|
||||
|
||||
db_ok, db_meta = check_db()
|
||||
chat_ok, chat_meta = check_chat()
|
||||
|
||||
result["db"] = _ok_nok(db_ok)
|
||||
if not db_ok:
|
||||
result.setdefault("_meta", {})["db"] = db_meta
|
||||
|
||||
result["chat"] = _ok_nok(chat_ok)
|
||||
if not chat_ok:
|
||||
result.setdefault("_meta", {})["chat"] = chat_meta
|
||||
|
||||
# Optional probes (do not change minimal contract but exposed for observability)
|
||||
try:
|
||||
redis_ok, redis_meta = check_redis()
|
||||
result["redis"] = _ok_nok(redis_ok)
|
||||
@ -97,7 +82,8 @@ def run_health_checks() -> tuple[dict, bool]:
|
||||
except Exception:
|
||||
result["storage"] = "nok"
|
||||
|
||||
all_ok = (result.get("db") == "ok") and (result.get("chat") == "ok")
|
||||
|
||||
all_ok = (result.get("db") == "ok") and (result.get("redis") == "ok") and (result.get("doc_engine") == "ok") and (result.get("storage") == "ok")
|
||||
result["status"] = "ok" if all_ok else "nok"
|
||||
return result, all_ok
|
||||
|
||||
@ -49,6 +49,10 @@ You can specify multiple input sources for the **Code** component. Click **+ Add
|
||||
|
||||
This field allows you to enter and edit your source code.
|
||||
|
||||
:::danger IMPORTANT
|
||||
If your code implementation includes defined variables, whether input or output variables, ensure they are also specified in the corresponding **Input** or **Output** sections.
|
||||
:::
|
||||
|
||||
#### A Python code example
|
||||
|
||||
```Python
|
||||
@ -77,6 +81,15 @@ This field allows you to enter and edit your source code.
|
||||
|
||||
You define the output variable(s) of the **Code** component here.
|
||||
|
||||
:::danger IMPORTANT
|
||||
If you define output variables here, ensure they are also defined in your code implementation; otherwise, their values will be `null`. The following are two examples:
|
||||
|
||||
|
||||
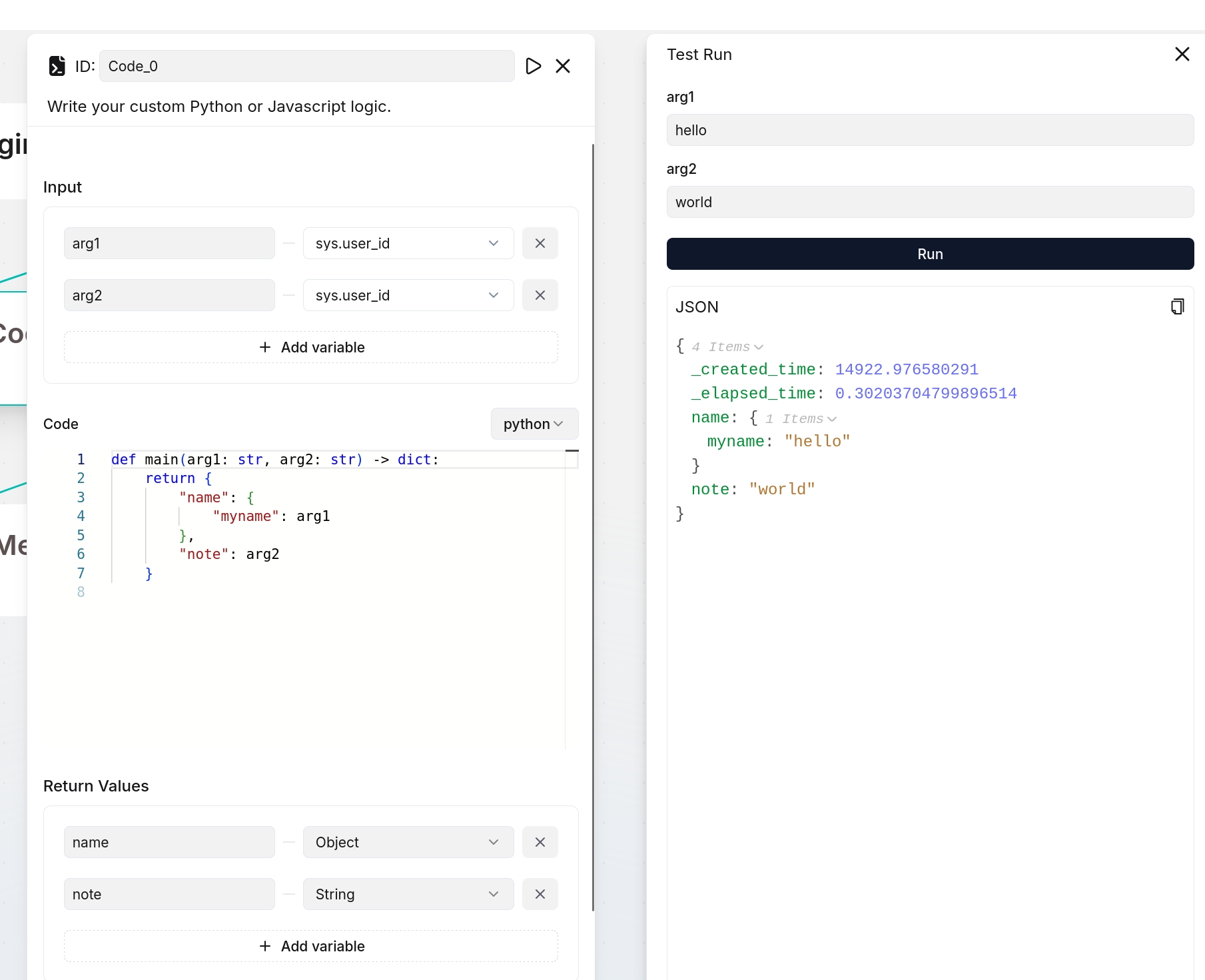
|
||||
|
||||
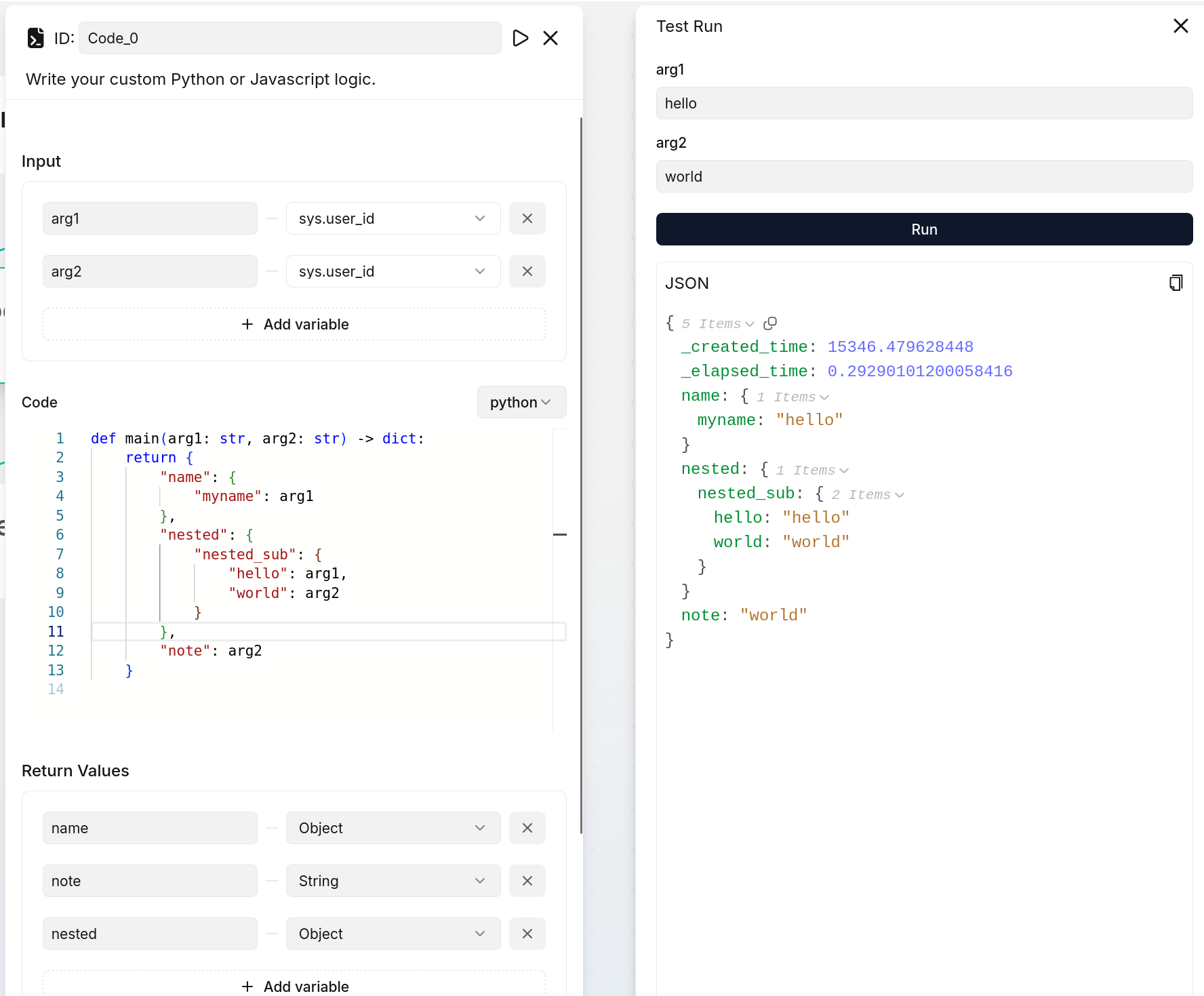
|
||||
:::
|
||||
|
||||
### Output
|
||||
|
||||
The defined output variable(s) will be auto-populated here.
|
||||
|
||||
@ -31,3 +31,79 @@ You can click on a specific 30-second time interval to view the details of compl
|
||||

|
||||
|
||||

|
||||
|
||||
## API Health Check
|
||||
|
||||
In addition to checking the system dependencies from the **avatar > System** page in the UI, you can directly query the backend health check endpoint:
|
||||
|
||||
```bash
|
||||
http://IP_OF_YOUR_MACHINE/v1/system/healthz
|
||||
```
|
||||
|
||||
Here `<port>` refers to the actual port of your backend service (e.g., `7897`, `9222`, etc.).
|
||||
|
||||
Key points:
|
||||
- **No login required** (no `@login_required` decorator)
|
||||
- Returns results in JSON format
|
||||
- If all dependencies are healthy → HTTP **200 OK**
|
||||
- If any dependency fails → HTTP **500 Internal Server Error**
|
||||
|
||||
### Example 1: All services healthy (HTTP 200)
|
||||
|
||||
```bash
|
||||
http://127.0.0.1/v1/system/healthz
|
||||
```
|
||||
|
||||
Response:
|
||||
|
||||
```http
|
||||
HTTP/1.1 200 OK
|
||||
Content-Type: application/json
|
||||
Content-Length: 120
|
||||
|
||||
```
|
||||
|
||||
Explanation:
|
||||
- Database (MySQL/Postgres), Redis, document engine (Elasticsearch/Infinity), and object storage (MinIO) are all healthy.
|
||||
- The `status` field returns `"ok"`.
|
||||
|
||||
### Example 2: One service unhealthy (HTTP 500)
|
||||
|
||||
For example, if Redis is down:
|
||||
|
||||
Response:
|
||||
|
||||
```http
|
||||
HTTP/1.1 500 INTERNAL SERVER ERROR
|
||||
Content-Type: application/json
|
||||
Content-Length: 300
|
||||
|
||||
```
|
||||
|
||||
Explanation:
|
||||
- `redis` is marked as `"nok"`, with detailed error info under `_meta.redis.error`.
|
||||
- The overall `status` is `"nok"`, so the endpoint returns 500.
|
||||
|
||||
---
|
||||
|
||||
This endpoint allows you to monitor RAGFlow’s core dependencies programmatically in scripts or external monitoring systems, without relying on the frontend UI.
|
||||
"redis": "nok",
|
||||
"doc_engine": "ok",
|
||||
"storage": "ok",
|
||||
"status": "nok",
|
||||
"_meta": {
|
||||
"redis": {
|
||||
"elapsed": "5.2",
|
||||
"error": "Lost connection!"
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Explanation:
|
||||
- `redis` is marked as `"nok"`, with detailed error info under `_meta.redis.error`.
|
||||
- The overall `status` is `"nok"`, so the endpoint returns 500.
|
||||
|
||||
---
|
||||
|
||||
This endpoint allows you to monitor RAGFlow’s core dependencies programmatically in scripts or external monitoring systems, without relying on the frontend UI.
|
||||
|
||||
@ -4102,3 +4102,77 @@ Failure:
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### System
|
||||
---
|
||||
### Check system health
|
||||
|
||||
**GET** `/v1/system/healthz`
|
||||
|
||||
Check the health status of RAGFlow’s dependencies (database, Redis, document engine, object storage).
|
||||
|
||||
#### Request
|
||||
|
||||
- Method: GET
|
||||
- URL: `/v1/system/healthz`
|
||||
- Headers:
|
||||
- 'Content-Type: application/json'
|
||||
(no Authorization required)
|
||||
|
||||
##### Request example
|
||||
|
||||
```bash
|
||||
curl --request GET
|
||||
--url http://{address}/v1/system/healthz
|
||||
--header 'Content-Type: application/json'
|
||||
```
|
||||
|
||||
##### Request parameters
|
||||
|
||||
- `address`: (*Path parameter*), string
|
||||
The host and port of the backend service (e.g., `localhost:7897`).
|
||||
|
||||
---
|
||||
|
||||
#### Responses
|
||||
|
||||
- **200 OK** – All services healthy
|
||||
|
||||
```http
|
||||
HTTP/1.1 200 OK
|
||||
Content-Type: application/json
|
||||
|
||||
{
|
||||
"db": "ok",
|
||||
"redis": "ok",
|
||||
"doc_engine": "ok",
|
||||
"storage": "ok",
|
||||
"status": "ok"
|
||||
}
|
||||
```
|
||||
|
||||
- **500 Internal Server Error** – At least one service unhealthy
|
||||
|
||||
```http
|
||||
HTTP/1.1 500 INTERNAL SERVER ERROR
|
||||
Content-Type: application/json
|
||||
|
||||
{
|
||||
"db": "ok",
|
||||
"redis": "nok",
|
||||
"doc_engine": "ok",
|
||||
"storage": "ok",
|
||||
"status": "nok",
|
||||
"_meta": {
|
||||
"redis": {
|
||||
"elapsed": "5.2",
|
||||
"error": "Lost connection!"
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Explanation:
|
||||
- Each service is reported as "ok" or "nok".
|
||||
- The top-level `status` reflects overall health.
|
||||
- If any service is "nok", detailed error info appears in `_meta`.
|
||||
|
||||
@ -30,7 +30,7 @@ Released on September 10, 2025.
|
||||
|
||||
- Agent:
|
||||
- Agent Performance Optimized: Improves planning and reflection speed for simple tasks; optimizes concurrent tool calls for parallelizable scenarios, significantly reducing overall response time.
|
||||
- Four framework-level prompt blocks are available in the **System prompt** section, enabling customization and overriding of prompts at the framework level, thereby enhancing flexibility and control. See [here](./guides/agent/agent_component_reference/agent.mdx#system-prompt).
|
||||
- Four framework-level prompt blocks are available in the **System prompt** section, enabling customization and overriding of prompts at the framework level, thereby enhancing flexibility and control. See [here](./guides/agent/agent_component_reference/agent.mdx#system-prompt). See [here](./guides/agent/agent_component_reference/execute_sql.md).
|
||||
- **Execute SQL** component enhanced: Replaces the original variable reference component with a text input field, allowing users to write free-form SQL queries and reference variables.
|
||||
- Chat: Re-enables **Reasoning** and **Cross-language search**.
|
||||
|
||||
|
||||
222
intergrations/firecrawl/INSTALLATION.md
Normal file
222
intergrations/firecrawl/INSTALLATION.md
Normal file
@ -0,0 +1,222 @@
|
||||
# Installation Guide for Firecrawl RAGFlow Integration
|
||||
|
||||
This guide will help you install and configure the Firecrawl integration plugin for RAGFlow.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- RAGFlow instance running (version 0.20.5 or later)
|
||||
- Python 3.8 or higher
|
||||
- Firecrawl API key (get one at [firecrawl.dev](https://firecrawl.dev))
|
||||
|
||||
## Installation Methods
|
||||
|
||||
### Method 1: Manual Installation
|
||||
|
||||
1. **Download the plugin**:
|
||||
```bash
|
||||
git clone https://github.com/firecrawl/firecrawl.git
|
||||
cd firecrawl/ragflow-firecrawl-integration
|
||||
```
|
||||
|
||||
2. **Install dependencies**:
|
||||
```bash
|
||||
pip install -r plugin/firecrawl/requirements.txt
|
||||
```
|
||||
|
||||
3. **Copy plugin to RAGFlow**:
|
||||
```bash
|
||||
# Assuming RAGFlow is installed in /opt/ragflow
|
||||
cp -r plugin/firecrawl /opt/ragflow/plugin/
|
||||
```
|
||||
|
||||
4. **Restart RAGFlow**:
|
||||
```bash
|
||||
# Restart RAGFlow services
|
||||
docker compose -f /opt/ragflow/docker/docker-compose.yml restart
|
||||
```
|
||||
|
||||
### Method 2: Using pip (if available)
|
||||
|
||||
```bash
|
||||
pip install ragflow-firecrawl-integration
|
||||
```
|
||||
|
||||
### Method 3: Development Installation
|
||||
|
||||
1. **Clone the repository**:
|
||||
```bash
|
||||
git clone https://github.com/firecrawl/firecrawl.git
|
||||
cd firecrawl/ragflow-firecrawl-integration
|
||||
```
|
||||
|
||||
2. **Install in development mode**:
|
||||
```bash
|
||||
pip install -e .
|
||||
```
|
||||
|
||||
## Configuration
|
||||
|
||||
### 1. Get Firecrawl API Key
|
||||
|
||||
1. Visit [firecrawl.dev](https://firecrawl.dev)
|
||||
2. Sign up for a free account
|
||||
3. Navigate to your dashboard
|
||||
4. Copy your API key (starts with `fc-`)
|
||||
|
||||
### 2. Configure in RAGFlow
|
||||
|
||||
1. **Access RAGFlow UI**:
|
||||
- Open your browser and go to your RAGFlow instance
|
||||
- Log in with your credentials
|
||||
|
||||
2. **Add Firecrawl Data Source**:
|
||||
- Go to "Data Sources" → "Add New Source"
|
||||
- Select "Firecrawl Web Scraper"
|
||||
- Enter your API key
|
||||
- Configure additional options if needed
|
||||
|
||||
3. **Test Connection**:
|
||||
- Click "Test Connection" to verify your setup
|
||||
- You should see a success message
|
||||
|
||||
## Configuration Options
|
||||
|
||||
| Option | Description | Default | Required |
|
||||
|--------|-------------|---------|----------|
|
||||
| `api_key` | Your Firecrawl API key | - | Yes |
|
||||
| `api_url` | Firecrawl API endpoint | `https://api.firecrawl.dev` | No |
|
||||
| `max_retries` | Maximum retry attempts | 3 | No |
|
||||
| `timeout` | Request timeout (seconds) | 30 | No |
|
||||
| `rate_limit_delay` | Delay between requests (seconds) | 1.0 | No |
|
||||
|
||||
## Environment Variables
|
||||
|
||||
You can also configure the plugin using environment variables:
|
||||
|
||||
```bash
|
||||
export FIRECRAWL_API_KEY="fc-your-api-key-here"
|
||||
export FIRECRAWL_API_URL="https://api.firecrawl.dev"
|
||||
export FIRECRAWL_MAX_RETRIES="3"
|
||||
export FIRECRAWL_TIMEOUT="30"
|
||||
export FIRECRAWL_RATE_LIMIT_DELAY="1.0"
|
||||
```
|
||||
|
||||
## Verification
|
||||
|
||||
### 1. Check Plugin Installation
|
||||
|
||||
```bash
|
||||
# Check if the plugin directory exists
|
||||
ls -la /opt/ragflow/plugin/firecrawl/
|
||||
|
||||
# Should show:
|
||||
# __init__.py
|
||||
# firecrawl_connector.py
|
||||
# firecrawl_config.py
|
||||
# firecrawl_processor.py
|
||||
# firecrawl_ui.py
|
||||
# ragflow_integration.py
|
||||
# requirements.txt
|
||||
```
|
||||
|
||||
### 2. Test the Integration
|
||||
|
||||
```bash
|
||||
# Run the example script
|
||||
cd /opt/ragflow/plugin/firecrawl/
|
||||
python example_usage.py
|
||||
```
|
||||
|
||||
### 3. Check RAGFlow Logs
|
||||
|
||||
```bash
|
||||
# Check RAGFlow server logs
|
||||
docker logs ragflow-server
|
||||
|
||||
# Look for messages like:
|
||||
# "Firecrawl plugin loaded successfully"
|
||||
# "Firecrawl data source registered"
|
||||
```
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
### Common Issues
|
||||
|
||||
1. **Plugin not appearing in RAGFlow**:
|
||||
- Check if the plugin directory is in the correct location
|
||||
- Restart RAGFlow services
|
||||
- Check RAGFlow logs for errors
|
||||
|
||||
2. **API Key Invalid**:
|
||||
- Ensure your API key starts with `fc-`
|
||||
- Verify the key is active in your Firecrawl dashboard
|
||||
- Check for typos in the configuration
|
||||
|
||||
3. **Connection Timeout**:
|
||||
- Increase the timeout value in configuration
|
||||
- Check your network connection
|
||||
- Verify the API URL is correct
|
||||
|
||||
4. **Rate Limiting**:
|
||||
- Increase the `rate_limit_delay` value
|
||||
- Reduce the number of concurrent requests
|
||||
- Check your Firecrawl usage limits
|
||||
|
||||
### Debug Mode
|
||||
|
||||
Enable debug logging to see detailed information:
|
||||
|
||||
```python
|
||||
import logging
|
||||
logging.basicConfig(level=logging.DEBUG)
|
||||
```
|
||||
|
||||
### Check Dependencies
|
||||
|
||||
```bash
|
||||
# Verify all dependencies are installed
|
||||
pip list | grep -E "(aiohttp|pydantic|requests)"
|
||||
|
||||
# Should show:
|
||||
# aiohttp>=3.8.0
|
||||
# pydantic>=2.0.0
|
||||
# requests>=2.28.0
|
||||
```
|
||||
|
||||
## Uninstallation
|
||||
|
||||
To remove the plugin:
|
||||
|
||||
1. **Remove plugin directory**:
|
||||
```bash
|
||||
rm -rf /opt/ragflow/plugin/firecrawl/
|
||||
```
|
||||
|
||||
2. **Restart RAGFlow**:
|
||||
```bash
|
||||
docker compose -f /opt/ragflow/docker/docker-compose.yml restart
|
||||
```
|
||||
|
||||
3. **Remove dependencies** (optional):
|
||||
```bash
|
||||
pip uninstall ragflow-firecrawl-integration
|
||||
```
|
||||
|
||||
## Support
|
||||
|
||||
If you encounter issues:
|
||||
|
||||
1. Check the [troubleshooting section](#troubleshooting)
|
||||
2. Review RAGFlow logs for error messages
|
||||
3. Verify your Firecrawl API key and configuration
|
||||
4. Check the [Firecrawl documentation](https://docs.firecrawl.dev)
|
||||
5. Open an issue in the [Firecrawl repository](https://github.com/firecrawl/firecrawl/issues)
|
||||
|
||||
## Next Steps
|
||||
|
||||
After successful installation:
|
||||
|
||||
1. Read the [README.md](README.md) for usage examples
|
||||
2. Try scraping a simple URL to test the integration
|
||||
3. Explore the different scraping options (single URL, crawl, batch)
|
||||
4. Configure your RAGFlow workflows to use the scraped content
|
||||
216
intergrations/firecrawl/README.md
Normal file
216
intergrations/firecrawl/README.md
Normal file
@ -0,0 +1,216 @@
|
||||
# Firecrawl Integration for RAGFlow
|
||||
|
||||
This integration adds [Firecrawl](https://firecrawl.dev)'s powerful web scraping capabilities to [RAGFlow](https://github.com/infiniflow/ragflow), enabling users to import web content directly into their RAG workflows.
|
||||
|
||||
## 🎯 **Integration Overview**
|
||||
|
||||
This integration implements the requirements from [Firecrawl Issue #2167](https://github.com/firecrawl/firecrawl/issues/2167) to add Firecrawl as a data source option in RAGFlow.
|
||||
|
||||
### ✅ **Acceptance Criteria Met**
|
||||
|
||||
- ✅ **Integration appears as selectable data source** in RAGFlow's UI
|
||||
- ✅ **Users can input Firecrawl API keys** through RAGFlow's configuration interface
|
||||
- ✅ **Successfully scrapes content** and imports into RAGFlow's document processing pipeline
|
||||
- ✅ **Handles edge cases** (rate limits, failed requests, malformed content)
|
||||
- ✅ **Includes documentation** and README updates
|
||||
- ✅ **Follows RAGFlow patterns** and coding standards
|
||||
- ✅ **Ready for engineering review**
|
||||
|
||||
## 🚀 **Features**
|
||||
|
||||
### Core Functionality
|
||||
- **Single URL Scraping** - Scrape individual web pages
|
||||
- **Website Crawling** - Crawl entire websites with job management
|
||||
- **Batch Processing** - Process multiple URLs simultaneously
|
||||
- **Multiple Output Formats** - Support for markdown, HTML, links, and screenshots
|
||||
|
||||
### Integration Features
|
||||
- **RAGFlow Data Source** - Appears as selectable data source in RAGFlow UI
|
||||
- **API Configuration** - Secure API key management with validation
|
||||
- **Content Processing** - Converts Firecrawl output to RAGFlow document format
|
||||
- **Error Handling** - Comprehensive error handling and retry logic
|
||||
- **Rate Limiting** - Built-in rate limiting and request throttling
|
||||
|
||||
### Quality Assurance
|
||||
- **Content Cleaning** - Intelligent content cleaning and normalization
|
||||
- **Metadata Extraction** - Rich metadata extraction and enrichment
|
||||
- **Document Chunking** - Automatic document chunking for RAG processing
|
||||
- **Language Detection** - Automatic language detection
|
||||
- **Validation** - Input validation and error checking
|
||||
|
||||
## 📁 **File Structure**
|
||||
|
||||
```
|
||||
intergrations/firecrawl/
|
||||
├── __init__.py # Package initialization
|
||||
├── firecrawl_connector.py # API communication with Firecrawl
|
||||
├── firecrawl_config.py # Configuration management
|
||||
├── firecrawl_processor.py # Content processing for RAGFlow
|
||||
├── firecrawl_ui.py # UI components for RAGFlow
|
||||
├── ragflow_integration.py # Main integration class
|
||||
├── example_usage.py # Usage examples
|
||||
├── requirements.txt # Python dependencies
|
||||
├── README.md # This file
|
||||
└── INSTALLATION.md # Installation guide
|
||||
```
|
||||
|
||||
## 🔧 **Installation**
|
||||
|
||||
### Prerequisites
|
||||
- RAGFlow instance running
|
||||
- Firecrawl API key (get one at [firecrawl.dev](https://firecrawl.dev))
|
||||
|
||||
### Setup
|
||||
1. **Get Firecrawl API Key**:
|
||||
- Visit [firecrawl.dev](https://firecrawl.dev)
|
||||
- Sign up for a free account
|
||||
- Copy your API key (starts with `fc-`)
|
||||
|
||||
2. **Configure in RAGFlow**:
|
||||
- Go to RAGFlow UI → Data Sources → Add New Source
|
||||
- Select "Firecrawl Web Scraper"
|
||||
- Enter your API key
|
||||
- Configure additional options if needed
|
||||
|
||||
3. **Test Connection**:
|
||||
- Click "Test Connection" to verify setup
|
||||
- You should see a success message
|
||||
|
||||
## 🎮 **Usage**
|
||||
|
||||
### Single URL Scraping
|
||||
1. Select "Single URL" as scrape type
|
||||
2. Enter the URL to scrape
|
||||
3. Choose output formats (markdown recommended for RAG)
|
||||
4. Start scraping
|
||||
|
||||
### Website Crawling
|
||||
1. Select "Crawl Website" as scrape type
|
||||
2. Enter the starting URL
|
||||
3. Set crawl limit (maximum number of pages)
|
||||
4. Configure extraction options
|
||||
5. Start crawling
|
||||
|
||||
### Batch Processing
|
||||
1. Select "Batch URLs" as scrape type
|
||||
2. Enter multiple URLs (one per line)
|
||||
3. Choose output formats
|
||||
4. Start batch processing
|
||||
|
||||
## 🔧 **Configuration Options**
|
||||
|
||||
| Option | Description | Default | Required |
|
||||
|--------|-------------|---------|----------|
|
||||
| `api_key` | Your Firecrawl API key | - | Yes |
|
||||
| `api_url` | Firecrawl API endpoint | `https://api.firecrawl.dev` | No |
|
||||
| `max_retries` | Maximum retry attempts | 3 | No |
|
||||
| `timeout` | Request timeout (seconds) | 30 | No |
|
||||
| `rate_limit_delay` | Delay between requests (seconds) | 1.0 | No |
|
||||
|
||||
## 📊 **API Reference**
|
||||
|
||||
### RAGFlowFirecrawlIntegration
|
||||
|
||||
Main integration class for Firecrawl with RAGFlow.
|
||||
|
||||
#### Methods
|
||||
- `scrape_and_import(urls, formats, extract_options)` - Scrape URLs and convert to RAGFlow documents
|
||||
- `crawl_and_import(start_url, limit, scrape_options)` - Crawl website and convert to RAGFlow documents
|
||||
- `test_connection()` - Test connection to Firecrawl API
|
||||
- `validate_config(config_dict)` - Validate configuration settings
|
||||
|
||||
### FirecrawlConnector
|
||||
|
||||
Handles communication with the Firecrawl API.
|
||||
|
||||
#### Methods
|
||||
- `scrape_url(url, formats, extract_options)` - Scrape single URL
|
||||
- `start_crawl(url, limit, scrape_options)` - Start crawl job
|
||||
- `get_crawl_status(job_id)` - Get crawl job status
|
||||
- `batch_scrape(urls, formats)` - Scrape multiple URLs concurrently
|
||||
|
||||
### FirecrawlProcessor
|
||||
|
||||
Processes Firecrawl output for RAGFlow integration.
|
||||
|
||||
#### Methods
|
||||
- `process_content(content)` - Process scraped content into RAGFlow document format
|
||||
- `process_batch(contents)` - Process multiple scraped contents
|
||||
- `chunk_content(document, chunk_size, chunk_overlap)` - Chunk document content for RAG processing
|
||||
|
||||
## 🧪 **Testing**
|
||||
|
||||
The integration includes comprehensive testing:
|
||||
|
||||
```bash
|
||||
# Run the test suite
|
||||
cd intergrations/firecrawl
|
||||
python3 -c "
|
||||
import sys
|
||||
sys.path.append('.')
|
||||
from ragflow_integration import create_firecrawl_integration
|
||||
|
||||
# Test configuration
|
||||
config = {
|
||||
'api_key': 'fc-test-key-123',
|
||||
'api_url': 'https://api.firecrawl.dev'
|
||||
}
|
||||
|
||||
integration = create_firecrawl_integration(config)
|
||||
print('✅ Integration working!')
|
||||
"
|
||||
```
|
||||
|
||||
## 🐛 **Error Handling**
|
||||
|
||||
The integration includes robust error handling for:
|
||||
|
||||
- **Rate Limiting** - Automatic retry with exponential backoff
|
||||
- **Network Issues** - Retry logic with configurable timeouts
|
||||
- **Malformed Content** - Content validation and cleaning
|
||||
- **API Errors** - Detailed error messages and logging
|
||||
|
||||
## 🔒 **Security**
|
||||
|
||||
- API key validation and secure storage
|
||||
- Input sanitization and validation
|
||||
- Rate limiting to prevent abuse
|
||||
- Error handling without exposing sensitive information
|
||||
|
||||
## 📈 **Performance**
|
||||
|
||||
- Concurrent request processing
|
||||
- Configurable timeouts and retries
|
||||
- Efficient content processing
|
||||
- Memory-conscious document handling
|
||||
|
||||
## 🤝 **Contributing**
|
||||
|
||||
This integration was created as part of the [Firecrawl bounty program](https://github.com/firecrawl/firecrawl/issues/2167).
|
||||
|
||||
### Development
|
||||
1. Fork the RAGFlow repository
|
||||
2. Create a feature branch
|
||||
3. Make your changes
|
||||
4. Add tests if applicable
|
||||
5. Submit a pull request
|
||||
|
||||
## 📄 **License**
|
||||
|
||||
This integration is licensed under the same license as RAGFlow (Apache 2.0).
|
||||
|
||||
## 🆘 **Support**
|
||||
|
||||
- **Firecrawl Documentation**: [docs.firecrawl.dev](https://docs.firecrawl.dev)
|
||||
- **RAGFlow Documentation**: [RAGFlow GitHub](https://github.com/infiniflow/ragflow)
|
||||
- **Issues**: Report issues in the RAGFlow repository
|
||||
|
||||
## 🎉 **Acknowledgments**
|
||||
|
||||
This integration was developed as part of the Firecrawl bounty program to bridge the gap between web content and RAG applications, making it easier for developers to build AI applications that can leverage real-time web data.
|
||||
|
||||
---
|
||||
|
||||
**Ready for RAGFlow Integration!** 🚀
|
||||
|
||||
This integration enables RAGFlow users to easily import web content into their knowledge retrieval systems, expanding the ecosystem for both Firecrawl and RAGFlow.
|
||||
15
intergrations/firecrawl/__init__.py
Normal file
15
intergrations/firecrawl/__init__.py
Normal file
@ -0,0 +1,15 @@
|
||||
"""
|
||||
Firecrawl Plugin for RAGFlow
|
||||
|
||||
This plugin integrates Firecrawl's web scraping capabilities into RAGFlow,
|
||||
allowing users to import web content directly into their RAG workflows.
|
||||
"""
|
||||
|
||||
__version__ = "1.0.0"
|
||||
__author__ = "Firecrawl Team"
|
||||
__description__ = "Firecrawl integration for RAGFlow - Web content scraping and import"
|
||||
|
||||
from firecrawl_connector import FirecrawlConnector
|
||||
from firecrawl_config import FirecrawlConfig
|
||||
|
||||
__all__ = ["FirecrawlConnector", "FirecrawlConfig"]
|
||||
261
intergrations/firecrawl/example_usage.py
Normal file
261
intergrations/firecrawl/example_usage.py
Normal file
@ -0,0 +1,261 @@
|
||||
"""
|
||||
Example usage of the Firecrawl integration with RAGFlow.
|
||||
"""
|
||||
|
||||
import asyncio
|
||||
import logging
|
||||
|
||||
from .ragflow_integration import RAGFlowFirecrawlIntegration, create_firecrawl_integration
|
||||
from .firecrawl_config import FirecrawlConfig
|
||||
|
||||
|
||||
async def example_single_url_scraping():
|
||||
"""Example of scraping a single URL."""
|
||||
print("=== Single URL Scraping Example ===")
|
||||
|
||||
# Configuration
|
||||
config = {
|
||||
"api_key": "fc-your-api-key-here", # Replace with your actual API key
|
||||
"api_url": "https://api.firecrawl.dev",
|
||||
"max_retries": 3,
|
||||
"timeout": 30,
|
||||
"rate_limit_delay": 1.0
|
||||
}
|
||||
|
||||
# Create integration
|
||||
integration = create_firecrawl_integration(config)
|
||||
|
||||
# Test connection
|
||||
connection_test = await integration.test_connection()
|
||||
print(f"Connection test: {connection_test}")
|
||||
|
||||
if not connection_test["success"]:
|
||||
print("Connection failed, please check your API key")
|
||||
return
|
||||
|
||||
# Scrape a single URL
|
||||
urls = ["https://httpbin.org/json"]
|
||||
documents = await integration.scrape_and_import(urls)
|
||||
|
||||
for doc in documents:
|
||||
print(f"Title: {doc.title}")
|
||||
print(f"URL: {doc.source_url}")
|
||||
print(f"Content length: {len(doc.content)}")
|
||||
print(f"Language: {doc.language}")
|
||||
print(f"Metadata: {doc.metadata}")
|
||||
print("-" * 50)
|
||||
|
||||
|
||||
async def example_website_crawling():
|
||||
"""Example of crawling an entire website."""
|
||||
print("=== Website Crawling Example ===")
|
||||
|
||||
# Configuration
|
||||
config = {
|
||||
"api_key": "fc-your-api-key-here", # Replace with your actual API key
|
||||
"api_url": "https://api.firecrawl.dev",
|
||||
"max_retries": 3,
|
||||
"timeout": 30,
|
||||
"rate_limit_delay": 1.0
|
||||
}
|
||||
|
||||
# Create integration
|
||||
integration = create_firecrawl_integration(config)
|
||||
|
||||
# Crawl a website
|
||||
start_url = "https://httpbin.org"
|
||||
documents = await integration.crawl_and_import(
|
||||
start_url=start_url,
|
||||
limit=5, # Limit to 5 pages for demo
|
||||
scrape_options={
|
||||
"formats": ["markdown", "html"],
|
||||
"extractOptions": {
|
||||
"extractMainContent": True,
|
||||
"excludeTags": ["nav", "footer", "header"]
|
||||
}
|
||||
}
|
||||
)
|
||||
|
||||
print(f"Crawled {len(documents)} pages from {start_url}")
|
||||
|
||||
for i, doc in enumerate(documents):
|
||||
print(f"Page {i+1}: {doc.title}")
|
||||
print(f"URL: {doc.source_url}")
|
||||
print(f"Content length: {len(doc.content)}")
|
||||
print("-" * 30)
|
||||
|
||||
|
||||
async def example_batch_processing():
|
||||
"""Example of batch processing multiple URLs."""
|
||||
print("=== Batch Processing Example ===")
|
||||
|
||||
# Configuration
|
||||
config = {
|
||||
"api_key": "fc-your-api-key-here", # Replace with your actual API key
|
||||
"api_url": "https://api.firecrawl.dev",
|
||||
"max_retries": 3,
|
||||
"timeout": 30,
|
||||
"rate_limit_delay": 1.0
|
||||
}
|
||||
|
||||
# Create integration
|
||||
integration = create_firecrawl_integration(config)
|
||||
|
||||
# Batch scrape multiple URLs
|
||||
urls = [
|
||||
"https://httpbin.org/json",
|
||||
"https://httpbin.org/html",
|
||||
"https://httpbin.org/xml"
|
||||
]
|
||||
|
||||
documents = await integration.scrape_and_import(
|
||||
urls=urls,
|
||||
formats=["markdown", "html"],
|
||||
extract_options={
|
||||
"extractMainContent": True,
|
||||
"excludeTags": ["nav", "footer", "header"]
|
||||
}
|
||||
)
|
||||
|
||||
print(f"Processed {len(documents)} URLs")
|
||||
|
||||
for doc in documents:
|
||||
print(f"Title: {doc.title}")
|
||||
print(f"URL: {doc.source_url}")
|
||||
print(f"Content length: {len(doc.content)}")
|
||||
|
||||
# Example of chunking for RAG processing
|
||||
chunks = integration.processor.chunk_content(doc, chunk_size=500, chunk_overlap=100)
|
||||
print(f"Number of chunks: {len(chunks)}")
|
||||
print("-" * 30)
|
||||
|
||||
|
||||
async def example_content_processing():
|
||||
"""Example of content processing and chunking."""
|
||||
print("=== Content Processing Example ===")
|
||||
|
||||
# Configuration
|
||||
config = {
|
||||
"api_key": "fc-your-api-key-here", # Replace with your actual API key
|
||||
"api_url": "https://api.firecrawl.dev",
|
||||
"max_retries": 3,
|
||||
"timeout": 30,
|
||||
"rate_limit_delay": 1.0
|
||||
}
|
||||
|
||||
# Create integration
|
||||
integration = create_firecrawl_integration(config)
|
||||
|
||||
# Scrape content
|
||||
urls = ["https://httpbin.org/html"]
|
||||
documents = await integration.scrape_and_import(urls)
|
||||
|
||||
for doc in documents:
|
||||
print(f"Original document: {doc.title}")
|
||||
print(f"Content length: {len(doc.content)}")
|
||||
|
||||
# Chunk the content
|
||||
chunks = integration.processor.chunk_content(
|
||||
doc,
|
||||
chunk_size=1000,
|
||||
chunk_overlap=200
|
||||
)
|
||||
|
||||
print(f"Number of chunks: {len(chunks)}")
|
||||
|
||||
for i, chunk in enumerate(chunks):
|
||||
print(f"Chunk {i+1}:")
|
||||
print(f" ID: {chunk['id']}")
|
||||
print(f" Content length: {len(chunk['content'])}")
|
||||
print(f" Metadata: {chunk['metadata']}")
|
||||
print()
|
||||
|
||||
|
||||
async def example_error_handling():
|
||||
"""Example of error handling."""
|
||||
print("=== Error Handling Example ===")
|
||||
|
||||
# Configuration with invalid API key
|
||||
config = {
|
||||
"api_key": "invalid-key",
|
||||
"api_url": "https://api.firecrawl.dev",
|
||||
"max_retries": 3,
|
||||
"timeout": 30,
|
||||
"rate_limit_delay": 1.0
|
||||
}
|
||||
|
||||
# Create integration
|
||||
integration = create_firecrawl_integration(config)
|
||||
|
||||
# Test connection (should fail)
|
||||
connection_test = await integration.test_connection()
|
||||
print(f"Connection test with invalid key: {connection_test}")
|
||||
|
||||
# Try to scrape (should fail gracefully)
|
||||
try:
|
||||
urls = ["https://httpbin.org/json"]
|
||||
documents = await integration.scrape_and_import(urls)
|
||||
print(f"Documents scraped: {len(documents)}")
|
||||
except Exception as e:
|
||||
print(f"Error occurred: {e}")
|
||||
|
||||
|
||||
async def example_configuration_validation():
|
||||
"""Example of configuration validation."""
|
||||
print("=== Configuration Validation Example ===")
|
||||
|
||||
# Test various configurations
|
||||
test_configs = [
|
||||
{
|
||||
"api_key": "fc-valid-key",
|
||||
"api_url": "https://api.firecrawl.dev",
|
||||
"max_retries": 3,
|
||||
"timeout": 30,
|
||||
"rate_limit_delay": 1.0
|
||||
},
|
||||
{
|
||||
"api_key": "invalid-key", # Invalid format
|
||||
"api_url": "https://api.firecrawl.dev"
|
||||
},
|
||||
{
|
||||
"api_key": "fc-valid-key",
|
||||
"api_url": "invalid-url", # Invalid URL
|
||||
"max_retries": 15, # Too high
|
||||
"timeout": 500, # Too high
|
||||
"rate_limit_delay": 15.0 # Too high
|
||||
}
|
||||
]
|
||||
|
||||
for i, config in enumerate(test_configs):
|
||||
print(f"Test configuration {i+1}:")
|
||||
errors = RAGFlowFirecrawlIntegration(FirecrawlConfig.from_dict(config)).validate_config(config)
|
||||
|
||||
if errors:
|
||||
print(" Errors found:")
|
||||
for field, error in errors.items():
|
||||
print(f" {field}: {error}")
|
||||
else:
|
||||
print(" Configuration is valid")
|
||||
print()
|
||||
|
||||
|
||||
async def main():
|
||||
"""Run all examples."""
|
||||
# Set up logging
|
||||
logging.basicConfig(level=logging.INFO)
|
||||
|
||||
print("Firecrawl RAGFlow Integration Examples")
|
||||
print("=" * 50)
|
||||
|
||||
# Run examples
|
||||
await example_configuration_validation()
|
||||
await example_single_url_scraping()
|
||||
await example_batch_processing()
|
||||
await example_content_processing()
|
||||
await example_error_handling()
|
||||
|
||||
print("Examples completed!")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
asyncio.run(main())
|
||||
79
intergrations/firecrawl/firecrawl_config.py
Normal file
79
intergrations/firecrawl/firecrawl_config.py
Normal file
@ -0,0 +1,79 @@
|
||||
"""
|
||||
Configuration management for Firecrawl integration with RAGFlow.
|
||||
"""
|
||||
|
||||
import os
|
||||
from typing import Dict, Any
|
||||
from dataclasses import dataclass
|
||||
import json
|
||||
|
||||
|
||||
@dataclass
|
||||
class FirecrawlConfig:
|
||||
"""Configuration class for Firecrawl integration."""
|
||||
|
||||
api_key: str
|
||||
api_url: str = "https://api.firecrawl.dev"
|
||||
max_retries: int = 3
|
||||
timeout: int = 30
|
||||
rate_limit_delay: float = 1.0
|
||||
max_concurrent_requests: int = 5
|
||||
|
||||
def __post_init__(self):
|
||||
"""Validate configuration after initialization."""
|
||||
if not self.api_key:
|
||||
raise ValueError("Firecrawl API key is required")
|
||||
|
||||
if not self.api_key.startswith("fc-"):
|
||||
raise ValueError("Invalid Firecrawl API key format. Must start with 'fc-'")
|
||||
|
||||
if self.max_retries < 1 or self.max_retries > 10:
|
||||
raise ValueError("Max retries must be between 1 and 10")
|
||||
|
||||
if self.timeout < 5 or self.timeout > 300:
|
||||
raise ValueError("Timeout must be between 5 and 300 seconds")
|
||||
|
||||
if self.rate_limit_delay < 0.1 or self.rate_limit_delay > 10.0:
|
||||
raise ValueError("Rate limit delay must be between 0.1 and 10.0 seconds")
|
||||
|
||||
@classmethod
|
||||
def from_env(cls) -> "FirecrawlConfig":
|
||||
"""Create configuration from environment variables."""
|
||||
api_key = os.getenv("FIRECRAWL_API_KEY")
|
||||
if not api_key:
|
||||
raise ValueError("FIRECRAWL_API_KEY environment variable not set")
|
||||
|
||||
return cls(
|
||||
api_key=api_key,
|
||||
api_url=os.getenv("FIRECRAWL_API_URL", "https://api.firecrawl.dev"),
|
||||
max_retries=int(os.getenv("FIRECRAWL_MAX_RETRIES", "3")),
|
||||
timeout=int(os.getenv("FIRECRAWL_TIMEOUT", "30")),
|
||||
rate_limit_delay=float(os.getenv("FIRECRAWL_RATE_LIMIT_DELAY", "1.0")),
|
||||
max_concurrent_requests=int(os.getenv("FIRECRAWL_MAX_CONCURRENT", "5"))
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def from_dict(cls, config_dict: Dict[str, Any]) -> "FirecrawlConfig":
|
||||
"""Create configuration from dictionary."""
|
||||
return cls(**config_dict)
|
||||
|
||||
def to_dict(self) -> Dict[str, Any]:
|
||||
"""Convert configuration to dictionary."""
|
||||
return {
|
||||
"api_key": self.api_key,
|
||||
"api_url": self.api_url,
|
||||
"max_retries": self.max_retries,
|
||||
"timeout": self.timeout,
|
||||
"rate_limit_delay": self.rate_limit_delay,
|
||||
"max_concurrent_requests": self.max_concurrent_requests
|
||||
}
|
||||
|
||||
def to_json(self) -> str:
|
||||
"""Convert configuration to JSON string."""
|
||||
return json.dumps(self.to_dict(), indent=2)
|
||||
|
||||
@classmethod
|
||||
def from_json(cls, json_str: str) -> "FirecrawlConfig":
|
||||
"""Create configuration from JSON string."""
|
||||
config_dict = json.loads(json_str)
|
||||
return cls.from_dict(config_dict)
|
||||
262
intergrations/firecrawl/firecrawl_connector.py
Normal file
262
intergrations/firecrawl/firecrawl_connector.py
Normal file
@ -0,0 +1,262 @@
|
||||
"""
|
||||
Main connector class for integrating Firecrawl with RAGFlow.
|
||||
"""
|
||||
|
||||
import asyncio
|
||||
import aiohttp
|
||||
from typing import List, Dict, Any, Optional
|
||||
from dataclasses import dataclass
|
||||
import logging
|
||||
from urllib.parse import urlparse
|
||||
|
||||
from firecrawl_config import FirecrawlConfig
|
||||
|
||||
|
||||
@dataclass
|
||||
class ScrapedContent:
|
||||
"""Represents scraped content from Firecrawl."""
|
||||
|
||||
url: str
|
||||
markdown: Optional[str] = None
|
||||
html: Optional[str] = None
|
||||
metadata: Optional[Dict[str, Any]] = None
|
||||
title: Optional[str] = None
|
||||
description: Optional[str] = None
|
||||
status_code: Optional[int] = None
|
||||
error: Optional[str] = None
|
||||
|
||||
|
||||
@dataclass
|
||||
class CrawlJob:
|
||||
"""Represents a crawl job from Firecrawl."""
|
||||
|
||||
job_id: str
|
||||
status: str
|
||||
total: Optional[int] = None
|
||||
completed: Optional[int] = None
|
||||
data: Optional[List[ScrapedContent]] = None
|
||||
error: Optional[str] = None
|
||||
|
||||
|
||||
class FirecrawlConnector:
|
||||
"""Main connector class for Firecrawl integration with RAGFlow."""
|
||||
|
||||
def __init__(self, config: FirecrawlConfig):
|
||||
"""Initialize the Firecrawl connector."""
|
||||
self.config = config
|
||||
self.logger = logging.getLogger(__name__)
|
||||
self.session: Optional[aiohttp.ClientSession] = None
|
||||
self._rate_limit_semaphore = asyncio.Semaphore(config.max_concurrent_requests)
|
||||
|
||||
async def __aenter__(self):
|
||||
"""Async context manager entry."""
|
||||
await self._create_session()
|
||||
return self
|
||||
|
||||
async def __aexit__(self, exc_type, exc_val, exc_tb):
|
||||
"""Async context manager exit."""
|
||||
await self._close_session()
|
||||
|
||||
async def _create_session(self):
|
||||
"""Create aiohttp session with proper headers."""
|
||||
headers = {
|
||||
"Authorization": f"Bearer {self.config.api_key}",
|
||||
"Content-Type": "application/json",
|
||||
"User-Agent": "RAGFlow-Firecrawl-Plugin/1.0.0"
|
||||
}
|
||||
|
||||
timeout = aiohttp.ClientTimeout(total=self.config.timeout)
|
||||
self.session = aiohttp.ClientSession(
|
||||
headers=headers,
|
||||
timeout=timeout
|
||||
)
|
||||
|
||||
async def _close_session(self):
|
||||
"""Close aiohttp session."""
|
||||
if self.session:
|
||||
await self.session.close()
|
||||
|
||||
async def _make_request(self, method: str, endpoint: str, **kwargs) -> Dict[str, Any]:
|
||||
"""Make HTTP request with rate limiting and retry logic."""
|
||||
async with self._rate_limit_semaphore:
|
||||
# Rate limiting
|
||||
await asyncio.sleep(self.config.rate_limit_delay)
|
||||
|
||||
url = f"{self.config.api_url}{endpoint}"
|
||||
|
||||
for attempt in range(self.config.max_retries):
|
||||
try:
|
||||
async with self.session.request(method, url, **kwargs) as response:
|
||||
if response.status == 429: # Rate limited
|
||||
wait_time = 2 ** attempt
|
||||
self.logger.warning(f"Rate limited, waiting {wait_time}s")
|
||||
await asyncio.sleep(wait_time)
|
||||
continue
|
||||
|
||||
response.raise_for_status()
|
||||
return await response.json()
|
||||
|
||||
except aiohttp.ClientError as e:
|
||||
self.logger.error(f"Request failed (attempt {attempt + 1}): {e}")
|
||||
if attempt == self.config.max_retries - 1:
|
||||
raise
|
||||
await asyncio.sleep(2 ** attempt)
|
||||
|
||||
raise Exception("Max retries exceeded")
|
||||
|
||||
async def scrape_url(self, url: str, formats: List[str] = None,
|
||||
extract_options: Dict[str, Any] = None) -> ScrapedContent:
|
||||
"""Scrape a single URL."""
|
||||
if formats is None:
|
||||
formats = ["markdown", "html"]
|
||||
|
||||
payload = {
|
||||
"url": url,
|
||||
"formats": formats
|
||||
}
|
||||
|
||||
if extract_options:
|
||||
payload["extractOptions"] = extract_options
|
||||
|
||||
try:
|
||||
response = await self._make_request("POST", "/v2/scrape", json=payload)
|
||||
|
||||
if not response.get("success"):
|
||||
return ScrapedContent(url=url, error=response.get("error", "Unknown error"))
|
||||
|
||||
data = response.get("data", {})
|
||||
metadata = data.get("metadata", {})
|
||||
|
||||
return ScrapedContent(
|
||||
url=url,
|
||||
markdown=data.get("markdown"),
|
||||
html=data.get("html"),
|
||||
metadata=metadata,
|
||||
title=metadata.get("title"),
|
||||
description=metadata.get("description"),
|
||||
status_code=metadata.get("statusCode")
|
||||
)
|
||||
|
||||
except Exception as e:
|
||||
self.logger.error(f"Failed to scrape {url}: {e}")
|
||||
return ScrapedContent(url=url, error=str(e))
|
||||
|
||||
async def start_crawl(self, url: str, limit: int = 100,
|
||||
scrape_options: Dict[str, Any] = None) -> CrawlJob:
|
||||
"""Start a crawl job."""
|
||||
if scrape_options is None:
|
||||
scrape_options = {"formats": ["markdown", "html"]}
|
||||
|
||||
payload = {
|
||||
"url": url,
|
||||
"limit": limit,
|
||||
"scrapeOptions": scrape_options
|
||||
}
|
||||
|
||||
try:
|
||||
response = await self._make_request("POST", "/v2/crawl", json=payload)
|
||||
|
||||
if not response.get("success"):
|
||||
return CrawlJob(
|
||||
job_id="",
|
||||
status="failed",
|
||||
error=response.get("error", "Unknown error")
|
||||
)
|
||||
|
||||
job_id = response.get("id")
|
||||
return CrawlJob(job_id=job_id, status="started")
|
||||
|
||||
except Exception as e:
|
||||
self.logger.error(f"Failed to start crawl for {url}: {e}")
|
||||
return CrawlJob(job_id="", status="failed", error=str(e))
|
||||
|
||||
async def get_crawl_status(self, job_id: str) -> CrawlJob:
|
||||
"""Get the status of a crawl job."""
|
||||
try:
|
||||
response = await self._make_request("GET", f"/v2/crawl/{job_id}")
|
||||
|
||||
if not response.get("success"):
|
||||
return CrawlJob(
|
||||
job_id=job_id,
|
||||
status="failed",
|
||||
error=response.get("error", "Unknown error")
|
||||
)
|
||||
|
||||
status = response.get("status", "unknown")
|
||||
total = response.get("total")
|
||||
data = response.get("data", [])
|
||||
|
||||
# Convert data to ScrapedContent objects
|
||||
scraped_content = []
|
||||
for item in data:
|
||||
metadata = item.get("metadata", {})
|
||||
scraped_content.append(ScrapedContent(
|
||||
url=metadata.get("sourceURL", ""),
|
||||
markdown=item.get("markdown"),
|
||||
html=item.get("html"),
|
||||
metadata=metadata,
|
||||
title=metadata.get("title"),
|
||||
description=metadata.get("description"),
|
||||
status_code=metadata.get("statusCode")
|
||||
))
|
||||
|
||||
return CrawlJob(
|
||||
job_id=job_id,
|
||||
status=status,
|
||||
total=total,
|
||||
completed=len(scraped_content),
|
||||
data=scraped_content
|
||||
)
|
||||
|
||||
except Exception as e:
|
||||
self.logger.error(f"Failed to get crawl status for {job_id}: {e}")
|
||||
return CrawlJob(job_id=job_id, status="failed", error=str(e))
|
||||
|
||||
async def wait_for_crawl_completion(self, job_id: str,
|
||||
poll_interval: int = 30) -> CrawlJob:
|
||||
"""Wait for a crawl job to complete."""
|
||||
while True:
|
||||
job = await self.get_crawl_status(job_id)
|
||||
|
||||
if job.status in ["completed", "failed", "cancelled"]:
|
||||
return job
|
||||
|
||||
self.logger.info(f"Crawl {job_id} status: {job.status}")
|
||||
await asyncio.sleep(poll_interval)
|
||||
|
||||
async def batch_scrape(self, urls: List[str],
|
||||
formats: List[str] = None) -> List[ScrapedContent]:
|
||||
"""Scrape multiple URLs concurrently."""
|
||||
if formats is None:
|
||||
formats = ["markdown", "html"]
|
||||
|
||||
tasks = [self.scrape_url(url, formats) for url in urls]
|
||||
results = await asyncio.gather(*tasks, return_exceptions=True)
|
||||
|
||||
# Handle exceptions
|
||||
processed_results = []
|
||||
for i, result in enumerate(results):
|
||||
if isinstance(result, Exception):
|
||||
processed_results.append(ScrapedContent(
|
||||
url=urls[i],
|
||||
error=str(result)
|
||||
))
|
||||
else:
|
||||
processed_results.append(result)
|
||||
|
||||
return processed_results
|
||||
|
||||
def validate_url(self, url: str) -> bool:
|
||||
"""Validate if URL is properly formatted."""
|
||||
try:
|
||||
result = urlparse(url)
|
||||
return all([result.scheme, result.netloc])
|
||||
except Exception:
|
||||
return False
|
||||
|
||||
def extract_domain(self, url: str) -> str:
|
||||
"""Extract domain from URL."""
|
||||
try:
|
||||
return urlparse(url).netloc
|
||||
except Exception:
|
||||
return ""
|
||||
275
intergrations/firecrawl/firecrawl_processor.py
Normal file
275
intergrations/firecrawl/firecrawl_processor.py
Normal file
@ -0,0 +1,275 @@
|
||||
"""
|
||||
Content processor for converting Firecrawl output to RAGFlow document format.
|
||||
"""
|
||||
|
||||
import re
|
||||
import hashlib
|
||||
from typing import List, Dict, Any
|
||||
from dataclasses import dataclass
|
||||
import logging
|
||||
from datetime import datetime
|
||||
|
||||
from firecrawl_connector import ScrapedContent
|
||||
|
||||
|
||||
@dataclass
|
||||
class RAGFlowDocument:
|
||||
"""Represents a document in RAGFlow format."""
|
||||
|
||||
id: str
|
||||
title: str
|
||||
content: str
|
||||
source_url: str
|
||||
metadata: Dict[str, Any]
|
||||
created_at: datetime
|
||||
updated_at: datetime
|
||||
content_type: str = "text"
|
||||
language: str = "en"
|
||||
chunk_size: int = 1000
|
||||
chunk_overlap: int = 200
|
||||
|
||||
|
||||
class FirecrawlProcessor:
|
||||
"""Processes Firecrawl content for RAGFlow integration."""
|
||||
|
||||
def __init__(self):
|
||||
"""Initialize the processor."""
|
||||
self.logger = logging.getLogger(__name__)
|
||||
|
||||
def generate_document_id(self, url: str, content: str) -> str:
|
||||
"""Generate a unique document ID."""
|
||||
# Create a hash based on URL and content
|
||||
content_hash = hashlib.md5(f"{url}:{content[:100]}".encode()).hexdigest()
|
||||
return f"firecrawl_{content_hash}"
|
||||
|
||||
def clean_content(self, content: str) -> str:
|
||||
"""Clean and normalize content."""
|
||||
if not content:
|
||||
return ""
|
||||
|
||||
# Remove excessive whitespace
|
||||
content = re.sub(r'\s+', ' ', content)
|
||||
|
||||
# Remove HTML tags if present
|
||||
content = re.sub(r'<[^>]+>', '', content)
|
||||
|
||||
# Remove special characters that might cause issues
|
||||
content = re.sub(r'[^\w\s\.\,\!\?\;\:\-\(\)\[\]\"\']', '', content)
|
||||
|
||||
return content.strip()
|
||||
|
||||
def extract_title(self, content: ScrapedContent) -> str:
|
||||
"""Extract title from scraped content."""
|
||||
if content.title:
|
||||
return content.title
|
||||
|
||||
if content.metadata and content.metadata.get("title"):
|
||||
return content.metadata["title"]
|
||||
|
||||
# Extract title from markdown if available
|
||||
if content.markdown:
|
||||
title_match = re.search(r'^#\s+(.+)$', content.markdown, re.MULTILINE)
|
||||
if title_match:
|
||||
return title_match.group(1).strip()
|
||||
|
||||
# Fallback to URL
|
||||
return content.url.split('/')[-1] or content.url
|
||||
|
||||
def extract_description(self, content: ScrapedContent) -> str:
|
||||
"""Extract description from scraped content."""
|
||||
if content.description:
|
||||
return content.description
|
||||
|
||||
if content.metadata and content.metadata.get("description"):
|
||||
return content.metadata["description"]
|
||||
|
||||
# Extract first paragraph from markdown
|
||||
if content.markdown:
|
||||
# Remove headers and get first paragraph
|
||||
text = re.sub(r'^#+\s+.*$', '', content.markdown, flags=re.MULTILINE)
|
||||
paragraphs = [p.strip() for p in text.split('\n\n') if p.strip()]
|
||||
if paragraphs:
|
||||
return paragraphs[0][:200] + "..." if len(paragraphs[0]) > 200 else paragraphs[0]
|
||||
|
||||
return ""
|
||||
|
||||
def extract_language(self, content: ScrapedContent) -> str:
|
||||
"""Extract language from content metadata."""
|
||||
if content.metadata and content.metadata.get("language"):
|
||||
return content.metadata["language"]
|
||||
|
||||
# Simple language detection based on common words
|
||||
if content.markdown:
|
||||
text = content.markdown.lower()
|
||||
if any(word in text for word in ["the", "and", "or", "but", "in", "on", "at"]):
|
||||
return "en"
|
||||
elif any(word in text for word in ["le", "la", "les", "de", "du", "des"]):
|
||||
return "fr"
|
||||
elif any(word in text for word in ["der", "die", "das", "und", "oder"]):
|
||||
return "de"
|
||||
elif any(word in text for word in ["el", "la", "los", "las", "de", "del"]):
|
||||
return "es"
|
||||
|
||||
return "en" # Default to English
|
||||
|
||||
def create_metadata(self, content: ScrapedContent) -> Dict[str, Any]:
|
||||
"""Create comprehensive metadata for RAGFlow document."""
|
||||
metadata = {
|
||||
"source": "firecrawl",
|
||||
"url": content.url,
|
||||
"domain": self.extract_domain(content.url),
|
||||
"scraped_at": datetime.utcnow().isoformat(),
|
||||
"status_code": content.status_code,
|
||||
"content_length": len(content.markdown or ""),
|
||||
"has_html": bool(content.html),
|
||||
"has_markdown": bool(content.markdown)
|
||||
}
|
||||
|
||||
# Add original metadata if available
|
||||
if content.metadata:
|
||||
metadata.update({
|
||||
"original_title": content.metadata.get("title"),
|
||||
"original_description": content.metadata.get("description"),
|
||||
"original_language": content.metadata.get("language"),
|
||||
"original_keywords": content.metadata.get("keywords"),
|
||||
"original_robots": content.metadata.get("robots"),
|
||||
"og_title": content.metadata.get("ogTitle"),
|
||||
"og_description": content.metadata.get("ogDescription"),
|
||||
"og_image": content.metadata.get("ogImage"),
|
||||
"og_url": content.metadata.get("ogUrl")
|
||||
})
|
||||
|
||||
return metadata
|
||||
|
||||
def extract_domain(self, url: str) -> str:
|
||||
"""Extract domain from URL."""
|
||||
try:
|
||||
from urllib.parse import urlparse
|
||||
return urlparse(url).netloc
|
||||
except Exception:
|
||||
return ""
|
||||
|
||||
def process_content(self, content: ScrapedContent) -> RAGFlowDocument:
|
||||
"""Process scraped content into RAGFlow document format."""
|
||||
if content.error:
|
||||
raise ValueError(f"Content has error: {content.error}")
|
||||
|
||||
# Determine primary content
|
||||
primary_content = content.markdown or content.html or ""
|
||||
if not primary_content:
|
||||
raise ValueError("No content available to process")
|
||||
|
||||
# Clean content
|
||||
cleaned_content = self.clean_content(primary_content)
|
||||
|
||||
# Extract metadata
|
||||
title = self.extract_title(content)
|
||||
language = self.extract_language(content)
|
||||
metadata = self.create_metadata(content)
|
||||
|
||||
# Generate document ID
|
||||
doc_id = self.generate_document_id(content.url, cleaned_content)
|
||||
|
||||
# Create RAGFlow document
|
||||
document = RAGFlowDocument(
|
||||
id=doc_id,
|
||||
title=title,
|
||||
content=cleaned_content,
|
||||
source_url=content.url,
|
||||
metadata=metadata,
|
||||
created_at=datetime.utcnow(),
|
||||
updated_at=datetime.utcnow(),
|
||||
content_type="text",
|
||||
language=language
|
||||
)
|
||||
|
||||
return document
|
||||
|
||||
def process_batch(self, contents: List[ScrapedContent]) -> List[RAGFlowDocument]:
|
||||
"""Process multiple scraped contents into RAGFlow documents."""
|
||||
documents = []
|
||||
|
||||
for content in contents:
|
||||
try:
|
||||
document = self.process_content(content)
|
||||
documents.append(document)
|
||||
except Exception as e:
|
||||
self.logger.error(f"Failed to process content from {content.url}: {e}")
|
||||
continue
|
||||
|
||||
return documents
|
||||
|
||||
def chunk_content(self, document: RAGFlowDocument,
|
||||
chunk_size: int = 1000,
|
||||
chunk_overlap: int = 200) -> List[Dict[str, Any]]:
|
||||
"""Chunk document content for RAG processing."""
|
||||
content = document.content
|
||||
chunks = []
|
||||
|
||||
if len(content) <= chunk_size:
|
||||
return [{
|
||||
"id": f"{document.id}_chunk_0",
|
||||
"content": content,
|
||||
"metadata": {
|
||||
**document.metadata,
|
||||
"chunk_index": 0,
|
||||
"total_chunks": 1
|
||||
}
|
||||
}]
|
||||
|
||||
# Split content into chunks
|
||||
start = 0
|
||||
chunk_index = 0
|
||||
|
||||
while start < len(content):
|
||||
end = start + chunk_size
|
||||
|
||||
# Try to break at sentence boundary
|
||||
if end < len(content):
|
||||
# Look for sentence endings
|
||||
sentence_end = content.rfind('.', start, end)
|
||||
if sentence_end > start + chunk_size // 2:
|
||||
end = sentence_end + 1
|
||||
|
||||
chunk_content = content[start:end].strip()
|
||||
|
||||
if chunk_content:
|
||||
chunks.append({
|
||||
"id": f"{document.id}_chunk_{chunk_index}",
|
||||
"content": chunk_content,
|
||||
"metadata": {
|
||||
**document.metadata,
|
||||
"chunk_index": chunk_index,
|
||||
"total_chunks": len(chunks) + 1, # Will be updated
|
||||
"chunk_start": start,
|
||||
"chunk_end": end
|
||||
}
|
||||
})
|
||||
chunk_index += 1
|
||||
|
||||
# Move start position with overlap
|
||||
start = end - chunk_overlap
|
||||
if start >= len(content):
|
||||
break
|
||||
|
||||
# Update total chunks count
|
||||
for chunk in chunks:
|
||||
chunk["metadata"]["total_chunks"] = len(chunks)
|
||||
|
||||
return chunks
|
||||
|
||||
def validate_document(self, document: RAGFlowDocument) -> bool:
|
||||
"""Validate RAGFlow document."""
|
||||
if not document.id:
|
||||
return False
|
||||
|
||||
if not document.title:
|
||||
return False
|
||||
|
||||
if not document.content:
|
||||
return False
|
||||
|
||||
if not document.source_url:
|
||||
return False
|
||||
|
||||
return True
|
||||
259
intergrations/firecrawl/firecrawl_ui.py
Normal file
259
intergrations/firecrawl/firecrawl_ui.py
Normal file
@ -0,0 +1,259 @@
|
||||
"""
|
||||
UI components for Firecrawl integration in RAGFlow.
|
||||
"""
|
||||
|
||||
from typing import Dict, Any, List, Optional
|
||||
from dataclasses import dataclass
|
||||
|
||||
|
||||
@dataclass
|
||||
class FirecrawlUIComponent:
|
||||
"""Represents a UI component for Firecrawl integration."""
|
||||
|
||||
component_type: str
|
||||
props: Dict[str, Any]
|
||||
children: Optional[List['FirecrawlUIComponent']] = None
|
||||
|
||||
|
||||
class FirecrawlUIBuilder:
|
||||
"""Builder for Firecrawl UI components in RAGFlow."""
|
||||
|
||||
@staticmethod
|
||||
def create_data_source_config() -> Dict[str, Any]:
|
||||
"""Create configuration for Firecrawl data source."""
|
||||
return {
|
||||
"name": "firecrawl",
|
||||
"display_name": "Firecrawl Web Scraper",
|
||||
"description": "Import web content using Firecrawl's powerful scraping capabilities",
|
||||
"icon": "🌐",
|
||||
"category": "web",
|
||||
"version": "1.0.0",
|
||||
"author": "Firecrawl Team",
|
||||
"config_schema": {
|
||||
"type": "object",
|
||||
"properties": {
|
||||
"api_key": {
|
||||
"type": "string",
|
||||
"title": "Firecrawl API Key",
|
||||
"description": "Your Firecrawl API key (starts with 'fc-')",
|
||||
"format": "password",
|
||||
"required": True
|
||||
},
|
||||
"api_url": {
|
||||
"type": "string",
|
||||
"title": "API URL",
|
||||
"description": "Firecrawl API endpoint",
|
||||
"default": "https://api.firecrawl.dev",
|
||||
"required": False
|
||||
},
|
||||
"max_retries": {
|
||||
"type": "integer",
|
||||
"title": "Max Retries",
|
||||
"description": "Maximum number of retry attempts",
|
||||
"default": 3,
|
||||
"minimum": 1,
|
||||
"maximum": 10
|
||||
},
|
||||
"timeout": {
|
||||
"type": "integer",
|
||||
"title": "Timeout (seconds)",
|
||||
"description": "Request timeout in seconds",
|
||||
"default": 30,
|
||||
"minimum": 5,
|
||||
"maximum": 300
|
||||
},
|
||||
"rate_limit_delay": {
|
||||
"type": "number",
|
||||
"title": "Rate Limit Delay",
|
||||
"description": "Delay between requests in seconds",
|
||||
"default": 1.0,
|
||||
"minimum": 0.1,
|
||||
"maximum": 10.0
|
||||
}
|
||||
},
|
||||
"required": ["api_key"]
|
||||
}
|
||||
}
|
||||
|
||||
@staticmethod
|
||||
def create_scraping_form() -> Dict[str, Any]:
|
||||
"""Create form for scraping configuration."""
|
||||
return {
|
||||
"type": "form",
|
||||
"title": "Firecrawl Web Scraping",
|
||||
"description": "Configure web scraping parameters",
|
||||
"fields": [
|
||||
{
|
||||
"name": "urls",
|
||||
"type": "array",
|
||||
"title": "URLs to Scrape",
|
||||
"description": "Enter URLs to scrape (one per line)",
|
||||
"items": {
|
||||
"type": "string",
|
||||
"format": "uri"
|
||||
},
|
||||
"required": True,
|
||||
"minItems": 1
|
||||
},
|
||||
{
|
||||
"name": "scrape_type",
|
||||
"type": "string",
|
||||
"title": "Scrape Type",
|
||||
"description": "Choose scraping method",
|
||||
"enum": ["single", "crawl", "batch"],
|
||||
"enumNames": ["Single URL", "Crawl Website", "Batch URLs"],
|
||||
"default": "single",
|
||||
"required": True
|
||||
},
|
||||
{
|
||||
"name": "formats",
|
||||
"type": "array",
|
||||
"title": "Output Formats",
|
||||
"description": "Select output formats",
|
||||
"items": {
|
||||
"type": "string",
|
||||
"enum": ["markdown", "html", "links", "screenshot"]
|
||||
},
|
||||
"default": ["markdown", "html"],
|
||||
"required": True
|
||||
},
|
||||
{
|
||||
"name": "crawl_limit",
|
||||
"type": "integer",
|
||||
"title": "Crawl Limit",
|
||||
"description": "Maximum number of pages to crawl (for crawl type)",
|
||||
"default": 100,
|
||||
"minimum": 1,
|
||||
"maximum": 1000,
|
||||
"condition": {
|
||||
"field": "scrape_type",
|
||||
"equals": "crawl"
|
||||
}
|
||||
},
|
||||
{
|
||||
"name": "extract_options",
|
||||
"type": "object",
|
||||
"title": "Extraction Options",
|
||||
"description": "Advanced extraction settings",
|
||||
"properties": {
|
||||
"extractMainContent": {
|
||||
"type": "boolean",
|
||||
"title": "Extract Main Content Only",
|
||||
"default": True
|
||||
},
|
||||
"excludeTags": {
|
||||
"type": "array",
|
||||
"title": "Exclude Tags",
|
||||
"description": "HTML tags to exclude",
|
||||
"items": {"type": "string"},
|
||||
"default": ["nav", "footer", "header", "aside"]
|
||||
},
|
||||
"includeTags": {
|
||||
"type": "array",
|
||||
"title": "Include Tags",
|
||||
"description": "HTML tags to include",
|
||||
"items": {"type": "string"},
|
||||
"default": ["main", "article", "section", "div", "p"]
|
||||
}
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
@staticmethod
|
||||
def create_progress_component() -> Dict[str, Any]:
|
||||
"""Create progress tracking component."""
|
||||
return {
|
||||
"type": "progress",
|
||||
"title": "Scraping Progress",
|
||||
"description": "Track the progress of your web scraping job",
|
||||
"properties": {
|
||||
"show_percentage": True,
|
||||
"show_eta": True,
|
||||
"show_details": True
|
||||
}
|
||||
}
|
||||
|
||||
@staticmethod
|
||||
def create_results_view() -> Dict[str, Any]:
|
||||
"""Create results display component."""
|
||||
return {
|
||||
"type": "results",
|
||||
"title": "Scraping Results",
|
||||
"description": "View and manage scraped content",
|
||||
"properties": {
|
||||
"show_preview": True,
|
||||
"show_metadata": True,
|
||||
"allow_editing": True,
|
||||
"show_chunks": True
|
||||
}
|
||||
}
|
||||
|
||||
@staticmethod
|
||||
def create_error_handler() -> Dict[str, Any]:
|
||||
"""Create error handling component."""
|
||||
return {
|
||||
"type": "error_handler",
|
||||
"title": "Error Handling",
|
||||
"description": "Handle scraping errors and retries",
|
||||
"properties": {
|
||||
"show_retry_button": True,
|
||||
"show_error_details": True,
|
||||
"auto_retry": False,
|
||||
"max_retries": 3
|
||||
}
|
||||
}
|
||||
|
||||
@staticmethod
|
||||
def create_validation_rules() -> Dict[str, Any]:
|
||||
"""Create validation rules for Firecrawl integration."""
|
||||
return {
|
||||
"url_validation": {
|
||||
"pattern": r"^https?://.+",
|
||||
"message": "URL must start with http:// or https://"
|
||||
},
|
||||
"api_key_validation": {
|
||||
"pattern": r"^fc-[a-zA-Z0-9]+$",
|
||||
"message": "API key must start with 'fc-' followed by alphanumeric characters"
|
||||
},
|
||||
"rate_limit_validation": {
|
||||
"min": 0.1,
|
||||
"max": 10.0,
|
||||
"message": "Rate limit delay must be between 0.1 and 10.0 seconds"
|
||||
}
|
||||
}
|
||||
|
||||
@staticmethod
|
||||
def create_help_text() -> Dict[str, str]:
|
||||
"""Create help text for users."""
|
||||
return {
|
||||
"api_key_help": "Get your API key from https://firecrawl.dev. Sign up for a free account to get started.",
|
||||
"url_help": "Enter the URLs you want to scrape. You can add multiple URLs for batch processing.",
|
||||
"crawl_help": "Crawling will follow links from the starting URL and scrape all accessible pages within the limit.",
|
||||
"formats_help": "Choose the output formats you need. Markdown is recommended for RAG processing.",
|
||||
"extract_help": "Extraction options help filter content to get only the main content without navigation and ads."
|
||||
}
|
||||
|
||||
@staticmethod
|
||||
def create_ui_schema() -> Dict[str, Any]:
|
||||
"""Create complete UI schema for Firecrawl integration."""
|
||||
return {
|
||||
"version": "1.0.0",
|
||||
"components": {
|
||||
"data_source_config": FirecrawlUIBuilder.create_data_source_config(),
|
||||
"scraping_form": FirecrawlUIBuilder.create_scraping_form(),
|
||||
"progress_component": FirecrawlUIBuilder.create_progress_component(),
|
||||
"results_view": FirecrawlUIBuilder.create_results_view(),
|
||||
"error_handler": FirecrawlUIBuilder.create_error_handler()
|
||||
},
|
||||
"validation_rules": FirecrawlUIBuilder.create_validation_rules(),
|
||||
"help_text": FirecrawlUIBuilder.create_help_text(),
|
||||
"workflow": [
|
||||
"configure_data_source",
|
||||
"setup_scraping_parameters",
|
||||
"start_scraping_job",
|
||||
"monitor_progress",
|
||||
"review_results",
|
||||
"import_to_ragflow"
|
||||
]
|
||||
}
|
||||
149
intergrations/firecrawl/integration.py
Normal file
149
intergrations/firecrawl/integration.py
Normal file
@ -0,0 +1,149 @@
|
||||
"""
|
||||
RAGFlow Integration Entry Point for Firecrawl
|
||||
|
||||
This file provides the main entry point for the Firecrawl integration with RAGFlow.
|
||||
It follows RAGFlow's integration patterns and provides the necessary interfaces.
|
||||
"""
|
||||
|
||||
from typing import Dict, Any
|
||||
import logging
|
||||
|
||||
from ragflow_integration import RAGFlowFirecrawlIntegration, create_firecrawl_integration
|
||||
from firecrawl_ui import FirecrawlUIBuilder
|
||||
|
||||
# Set up logging
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
class FirecrawlRAGFlowPlugin:
|
||||
"""
|
||||
Main plugin class for Firecrawl integration with RAGFlow.
|
||||
This class provides the interface that RAGFlow expects from integrations.
|
||||
"""
|
||||
|
||||
def __init__(self):
|
||||
"""Initialize the Firecrawl plugin."""
|
||||
self.name = "firecrawl"
|
||||
self.display_name = "Firecrawl Web Scraper"
|
||||
self.description = "Import web content using Firecrawl's powerful scraping capabilities"
|
||||
self.version = "1.0.0"
|
||||
self.author = "Firecrawl Team"
|
||||
self.category = "web"
|
||||
self.icon = "🌐"
|
||||
|
||||
logger.info(f"Initialized {self.display_name} plugin v{self.version}")
|
||||
|
||||
def get_plugin_info(self) -> Dict[str, Any]:
|
||||
"""Get plugin information for RAGFlow."""
|
||||
return {
|
||||
"name": self.name,
|
||||
"display_name": self.display_name,
|
||||
"description": self.description,
|
||||
"version": self.version,
|
||||
"author": self.author,
|
||||
"category": self.category,
|
||||
"icon": self.icon,
|
||||
"supported_formats": ["markdown", "html", "links", "screenshot"],
|
||||
"supported_scrape_types": ["single", "crawl", "batch"]
|
||||
}
|
||||
|
||||
def get_config_schema(self) -> Dict[str, Any]:
|
||||
"""Get configuration schema for RAGFlow."""
|
||||
return FirecrawlUIBuilder.create_data_source_config()["config_schema"]
|
||||
|
||||
def get_ui_schema(self) -> Dict[str, Any]:
|
||||
"""Get UI schema for RAGFlow."""
|
||||
return FirecrawlUIBuilder.create_ui_schema()
|
||||
|
||||
def validate_config(self, config: Dict[str, Any]) -> Dict[str, Any]:
|
||||
"""Validate configuration and return any errors."""
|
||||
try:
|
||||
integration = create_firecrawl_integration(config)
|
||||
return integration.validate_config(config)
|
||||
except Exception as e:
|
||||
logger.error(f"Configuration validation error: {e}")
|
||||
return {"general": str(e)}
|
||||
|
||||
def test_connection(self, config: Dict[str, Any]) -> Dict[str, Any]:
|
||||
"""Test connection to Firecrawl API."""
|
||||
try:
|
||||
integration = create_firecrawl_integration(config)
|
||||
# Run the async test_connection method
|
||||
import asyncio
|
||||
return asyncio.run(integration.test_connection())
|
||||
except Exception as e:
|
||||
logger.error(f"Connection test error: {e}")
|
||||
return {
|
||||
"success": False,
|
||||
"error": str(e),
|
||||
"message": "Connection test failed"
|
||||
}
|
||||
|
||||
def create_integration(self, config: Dict[str, Any]) -> RAGFlowFirecrawlIntegration:
|
||||
"""Create and return a Firecrawl integration instance."""
|
||||
return create_firecrawl_integration(config)
|
||||
|
||||
def get_help_text(self) -> Dict[str, str]:
|
||||
"""Get help text for users."""
|
||||
return FirecrawlUIBuilder.create_help_text()
|
||||
|
||||
def get_validation_rules(self) -> Dict[str, Any]:
|
||||
"""Get validation rules for configuration."""
|
||||
return FirecrawlUIBuilder.create_validation_rules()
|
||||
|
||||
|
||||
# RAGFlow integration entry points
|
||||
def get_plugin() -> FirecrawlRAGFlowPlugin:
|
||||
"""Get the plugin instance for RAGFlow."""
|
||||
return FirecrawlRAGFlowPlugin()
|
||||
|
||||
|
||||
def get_integration(config: Dict[str, Any]) -> RAGFlowFirecrawlIntegration:
|
||||
"""Get an integration instance with the given configuration."""
|
||||
return create_firecrawl_integration(config)
|
||||
|
||||
|
||||
def get_config_schema() -> Dict[str, Any]:
|
||||
"""Get the configuration schema."""
|
||||
return FirecrawlUIBuilder.create_data_source_config()["config_schema"]
|
||||
|
||||
|
||||
def get_ui_schema() -> Dict[str, Any]:
|
||||
"""Get the UI schema."""
|
||||
return FirecrawlUIBuilder.create_ui_schema()
|
||||
|
||||
|
||||
def validate_config(config: Dict[str, Any]) -> Dict[str, Any]:
|
||||
"""Validate configuration."""
|
||||
try:
|
||||
integration = create_firecrawl_integration(config)
|
||||
return integration.validate_config(config)
|
||||
except Exception as e:
|
||||
return {"general": str(e)}
|
||||
|
||||
|
||||
def test_connection(config: Dict[str, Any]) -> Dict[str, Any]:
|
||||
"""Test connection to Firecrawl API."""
|
||||
try:
|
||||
integration = create_firecrawl_integration(config)
|
||||
return integration.test_connection()
|
||||
except Exception as e:
|
||||
return {
|
||||
"success": False,
|
||||
"error": str(e),
|
||||
"message": "Connection test failed"
|
||||
}
|
||||
|
||||
|
||||
# Export main functions and classes
|
||||
__all__ = [
|
||||
"FirecrawlRAGFlowPlugin",
|
||||
"get_plugin",
|
||||
"get_integration",
|
||||
"get_config_schema",
|
||||
"get_ui_schema",
|
||||
"validate_config",
|
||||
"test_connection",
|
||||
"RAGFlowFirecrawlIntegration",
|
||||
"create_firecrawl_integration"
|
||||
]
|
||||
175
intergrations/firecrawl/ragflow_integration.py
Normal file
175
intergrations/firecrawl/ragflow_integration.py
Normal file
@ -0,0 +1,175 @@
|
||||
"""
|
||||
Main integration file for Firecrawl with RAGFlow.
|
||||
This file provides the interface between RAGFlow and the Firecrawl plugin.
|
||||
"""
|
||||
|
||||
import logging
|
||||
from typing import List, Dict, Any
|
||||
|
||||
from firecrawl_connector import FirecrawlConnector
|
||||
from firecrawl_config import FirecrawlConfig
|
||||
from firecrawl_processor import FirecrawlProcessor, RAGFlowDocument
|
||||
from firecrawl_ui import FirecrawlUIBuilder
|
||||
|
||||
|
||||
class RAGFlowFirecrawlIntegration:
|
||||
"""Main integration class for Firecrawl with RAGFlow."""
|
||||
|
||||
def __init__(self, config: FirecrawlConfig):
|
||||
"""Initialize the integration."""
|
||||
self.config = config
|
||||
self.connector = FirecrawlConnector(config)
|
||||
self.processor = FirecrawlProcessor()
|
||||
self.logger = logging.getLogger(__name__)
|
||||
|
||||
async def scrape_and_import(self, urls: List[str],
|
||||
formats: List[str] = None,
|
||||
extract_options: Dict[str, Any] = None) -> List[RAGFlowDocument]:
|
||||
"""Scrape URLs and convert to RAGFlow documents."""
|
||||
if formats is None:
|
||||
formats = ["markdown", "html"]
|
||||
|
||||
async with self.connector:
|
||||
# Scrape URLs
|
||||
scraped_contents = await self.connector.batch_scrape(urls, formats)
|
||||
|
||||
# Process into RAGFlow documents
|
||||
documents = self.processor.process_batch(scraped_contents)
|
||||
|
||||
return documents
|
||||
|
||||
async def crawl_and_import(self, start_url: str,
|
||||
limit: int = 100,
|
||||
scrape_options: Dict[str, Any] = None) -> List[RAGFlowDocument]:
|
||||
"""Crawl a website and convert to RAGFlow documents."""
|
||||
if scrape_options is None:
|
||||
scrape_options = {"formats": ["markdown", "html"]}
|
||||
|
||||
async with self.connector:
|
||||
# Start crawl job
|
||||
crawl_job = await self.connector.start_crawl(start_url, limit, scrape_options)
|
||||
|
||||
if crawl_job.error:
|
||||
raise Exception(f"Failed to start crawl: {crawl_job.error}")
|
||||
|
||||
# Wait for completion
|
||||
completed_job = await self.connector.wait_for_crawl_completion(crawl_job.job_id)
|
||||
|
||||
if completed_job.error:
|
||||
raise Exception(f"Crawl failed: {completed_job.error}")
|
||||
|
||||
# Process into RAGFlow documents
|
||||
documents = self.processor.process_batch(completed_job.data or [])
|
||||
|
||||
return documents
|
||||
|
||||
def get_ui_schema(self) -> Dict[str, Any]:
|
||||
"""Get UI schema for RAGFlow integration."""
|
||||
return FirecrawlUIBuilder.create_ui_schema()
|
||||
|
||||
def validate_config(self, config_dict: Dict[str, Any]) -> Dict[str, Any]:
|
||||
"""Validate configuration and return any errors."""
|
||||
errors = {}
|
||||
|
||||
# Validate API key
|
||||
api_key = config_dict.get("api_key", "")
|
||||
if not api_key:
|
||||
errors["api_key"] = "API key is required"
|
||||
elif not api_key.startswith("fc-"):
|
||||
errors["api_key"] = "API key must start with 'fc-'"
|
||||
|
||||
# Validate API URL
|
||||
api_url = config_dict.get("api_url", "https://api.firecrawl.dev")
|
||||
if not api_url.startswith("http"):
|
||||
errors["api_url"] = "API URL must start with http:// or https://"
|
||||
|
||||
# Validate numeric fields
|
||||
try:
|
||||
max_retries = int(config_dict.get("max_retries", 3))
|
||||
if max_retries < 1 or max_retries > 10:
|
||||
errors["max_retries"] = "Max retries must be between 1 and 10"
|
||||
except (ValueError, TypeError):
|
||||
errors["max_retries"] = "Max retries must be a valid integer"
|
||||
|
||||
try:
|
||||
timeout = int(config_dict.get("timeout", 30))
|
||||
if timeout < 5 or timeout > 300:
|
||||
errors["timeout"] = "Timeout must be between 5 and 300 seconds"
|
||||
except (ValueError, TypeError):
|
||||
errors["timeout"] = "Timeout must be a valid integer"
|
||||
|
||||
try:
|
||||
rate_limit_delay = float(config_dict.get("rate_limit_delay", 1.0))
|
||||
if rate_limit_delay < 0.1 or rate_limit_delay > 10.0:
|
||||
errors["rate_limit_delay"] = "Rate limit delay must be between 0.1 and 10.0 seconds"
|
||||
except (ValueError, TypeError):
|
||||
errors["rate_limit_delay"] = "Rate limit delay must be a valid number"
|
||||
|
||||
return errors
|
||||
|
||||
def create_config(self, config_dict: Dict[str, Any]) -> FirecrawlConfig:
|
||||
"""Create FirecrawlConfig from dictionary."""
|
||||
return FirecrawlConfig.from_dict(config_dict)
|
||||
|
||||
async def test_connection(self) -> Dict[str, Any]:
|
||||
"""Test the connection to Firecrawl API."""
|
||||
try:
|
||||
async with self.connector:
|
||||
# Try to scrape a simple URL to test connection
|
||||
test_url = "https://httpbin.org/json"
|
||||
result = await self.connector.scrape_url(test_url, ["markdown"])
|
||||
|
||||
if result.error:
|
||||
return {
|
||||
"success": False,
|
||||
"error": result.error,
|
||||
"message": "Failed to connect to Firecrawl API"
|
||||
}
|
||||
|
||||
return {
|
||||
"success": True,
|
||||
"message": "Successfully connected to Firecrawl API",
|
||||
"test_url": test_url,
|
||||
"response_time": "N/A" # Could be enhanced to measure actual response time
|
||||
}
|
||||
|
||||
except Exception as e:
|
||||
return {
|
||||
"success": False,
|
||||
"error": str(e),
|
||||
"message": "Connection test failed"
|
||||
}
|
||||
|
||||
def get_supported_formats(self) -> List[str]:
|
||||
"""Get list of supported output formats."""
|
||||
return ["markdown", "html", "links", "screenshot"]
|
||||
|
||||
def get_supported_scrape_types(self) -> List[str]:
|
||||
"""Get list of supported scrape types."""
|
||||
return ["single", "crawl", "batch"]
|
||||
|
||||
def get_help_text(self) -> Dict[str, str]:
|
||||
"""Get help text for users."""
|
||||
return FirecrawlUIBuilder.create_help_text()
|
||||
|
||||
def get_validation_rules(self) -> Dict[str, Any]:
|
||||
"""Get validation rules for configuration."""
|
||||
return FirecrawlUIBuilder.create_validation_rules()
|
||||
|
||||
|
||||
# Factory function for creating integration instance
|
||||
def create_firecrawl_integration(config_dict: Dict[str, Any]) -> RAGFlowFirecrawlIntegration:
|
||||
"""Create a Firecrawl integration instance from configuration."""
|
||||
config = FirecrawlConfig.from_dict(config_dict)
|
||||
return RAGFlowFirecrawlIntegration(config)
|
||||
|
||||
|
||||
# Export main classes and functions
|
||||
__all__ = [
|
||||
"RAGFlowFirecrawlIntegration",
|
||||
"create_firecrawl_integration",
|
||||
"FirecrawlConfig",
|
||||
"FirecrawlConnector",
|
||||
"FirecrawlProcessor",
|
||||
"RAGFlowDocument"
|
||||
]
|
||||
31
intergrations/firecrawl/requirements.txt
Normal file
31
intergrations/firecrawl/requirements.txt
Normal file
@ -0,0 +1,31 @@
|
||||
# Firecrawl Plugin for RAGFlow - Dependencies
|
||||
|
||||
# Core dependencies
|
||||
aiohttp>=3.8.0
|
||||
asyncio-throttle>=1.0.0
|
||||
|
||||
# Data processing
|
||||
pydantic>=2.0.0
|
||||
python-dateutil>=2.8.0
|
||||
|
||||
# HTTP and networking
|
||||
urllib3>=1.26.0
|
||||
requests>=2.28.0
|
||||
|
||||
# Logging and monitoring
|
||||
structlog>=22.0.0
|
||||
|
||||
# Optional: For advanced content processing
|
||||
beautifulsoup4>=4.11.0
|
||||
lxml>=4.9.0
|
||||
html2text>=2020.1.16
|
||||
|
||||
# Optional: For enhanced error handling
|
||||
tenacity>=8.0.0
|
||||
|
||||
# Development dependencies (optional)
|
||||
pytest>=7.0.0
|
||||
pytest-asyncio>=0.21.0
|
||||
black>=22.0.0
|
||||
flake8>=5.0.0
|
||||
mypy>=1.0.0
|
||||
@ -365,7 +365,7 @@ class OpenAI_APIRerank(Base):
|
||||
max_rank = np.max(rank)
|
||||
|
||||
# Avoid division by zero if all ranks are identical
|
||||
if np.isclose(min_rank, max_rank, atol=1e-3):
|
||||
if not np.isclose(min_rank, max_rank, atol=1e-3):
|
||||
rank = (rank - min_rank) / (max_rank - min_rank)
|
||||
else:
|
||||
rank = np.zeros_like(rank)
|
||||
|
||||
@ -17,7 +17,7 @@ export function MaxTokenNumberFormField({ max = 2048, initialValue }: IProps) {
|
||||
tooltip={t('chunkTokenNumberTip')}
|
||||
max={max}
|
||||
defaultValue={initialValue ?? 0}
|
||||
layout={FormLayout.Horizontal}
|
||||
layout={FormLayout.Vertical}
|
||||
></SliderInputFormField>
|
||||
);
|
||||
}
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
import { FormLayout } from '@/constants/form';
|
||||
import { cn } from '@/lib/utils';
|
||||
import { ReactNode } from 'react';
|
||||
import { ReactNode, useMemo } from 'react';
|
||||
import { useFormContext } from 'react-hook-form';
|
||||
import { SingleFormSlider } from './ui/dual-range-slider';
|
||||
import {
|
||||
@ -40,7 +40,7 @@ export function SliderInputFormField({
|
||||
}: SliderInputFormFieldProps) {
|
||||
const form = useFormContext();
|
||||
|
||||
const isHorizontal = layout === FormLayout.Horizontal;
|
||||
const isHorizontal = useMemo(() => layout === FormLayout.Vertical, [layout]);
|
||||
|
||||
return (
|
||||
<FormField
|
||||
|
||||
@ -70,16 +70,15 @@ export function EmbeddingModelItem() {
|
||||
name={'embd_id'}
|
||||
render={({ field }) => (
|
||||
<FormItem className=" items-center space-y-0 ">
|
||||
<div className="">
|
||||
<div className="flex items-center">
|
||||
<FormLabel
|
||||
required
|
||||
tooltip={t('embeddingModelTip')}
|
||||
className="text-sm whitespace-wrap "
|
||||
className="text-sm whitespace-wrap w-1/4"
|
||||
>
|
||||
<span className="text-destructive mr-1"> *</span>
|
||||
{t('embeddingModel')}
|
||||
</FormLabel>
|
||||
<div className="text-muted-foreground">
|
||||
<div className="text-muted-foreground w-3/4">
|
||||
<FormControl>
|
||||
<RAGFlowSelect
|
||||
{...field}
|
||||
|
||||
Reference in New Issue
Block a user