mirror of
https://github.com/infiniflow/ragflow.git
synced 2026-02-07 02:55:08 +08:00
Compare commits
5 Commits
12979a3f21
...
856201c0f2
| Author | SHA1 | Date | |
|---|---|---|---|
| 856201c0f2 | |||
| 9d8b96c1d0 | |||
| 7c3c185038 | |||
| a9259917c6 | |||
| 8c28587821 |
@ -31,7 +31,7 @@ from api.db.services.file_service import FileService
|
||||
from api.utils.api_utils import get_json_result
|
||||
from api.utils.file_utils import filename_type
|
||||
from common import settings
|
||||
|
||||
from common.constants import RetCode
|
||||
|
||||
@manager.route('/file/upload', methods=['POST']) # noqa: F821
|
||||
@token_required
|
||||
@ -86,19 +86,19 @@ async def upload(tenant_id):
|
||||
pf_id = root_folder["id"]
|
||||
|
||||
if 'file' not in files:
|
||||
return get_json_result(data=False, message='No file part!', code=400)
|
||||
return get_json_result(data=False, message='No file part!', code=RetCode.BAD_REQUEST)
|
||||
file_objs = files.getlist('file')
|
||||
|
||||
for file_obj in file_objs:
|
||||
if file_obj.filename == '':
|
||||
return get_json_result(data=False, message='No selected file!', code=400)
|
||||
return get_json_result(data=False, message='No selected file!', code=RetCode.BAD_REQUEST)
|
||||
|
||||
file_res = []
|
||||
|
||||
try:
|
||||
e, pf_folder = FileService.get_by_id(pf_id)
|
||||
if not e:
|
||||
return get_json_result(data=False, message="Can't find this folder!", code=404)
|
||||
return get_json_result(data=False, message="Can't find this folder!", code=RetCode.NOT_FOUND)
|
||||
|
||||
for file_obj in file_objs:
|
||||
# Handle file path
|
||||
@ -114,13 +114,13 @@ async def upload(tenant_id):
|
||||
if file_len != len_id_list:
|
||||
e, file = FileService.get_by_id(file_id_list[len_id_list - 1])
|
||||
if not e:
|
||||
return get_json_result(data=False, message="Folder not found!", code=404)
|
||||
return get_json_result(data=False, message="Folder not found!", code=RetCode.NOT_FOUND)
|
||||
last_folder = FileService.create_folder(file, file_id_list[len_id_list - 1], file_obj_names,
|
||||
len_id_list)
|
||||
else:
|
||||
e, file = FileService.get_by_id(file_id_list[len_id_list - 2])
|
||||
if not e:
|
||||
return get_json_result(data=False, message="Folder not found!", code=404)
|
||||
return get_json_result(data=False, message="Folder not found!", code=RetCode.NOT_FOUND)
|
||||
last_folder = FileService.create_folder(file, file_id_list[len_id_list - 2], file_obj_names,
|
||||
len_id_list)
|
||||
|
||||
@ -202,7 +202,7 @@ async def create(tenant_id):
|
||||
|
||||
try:
|
||||
if not FileService.is_parent_folder_exist(pf_id):
|
||||
return get_json_result(data=False, message="Parent Folder Doesn't Exist!", code=400)
|
||||
return get_json_result(data=False, message="Parent Folder Doesn't Exist!", code=RetCode.BAD_REQUEST)
|
||||
if FileService.query(name=req["name"], parent_id=pf_id):
|
||||
return get_json_result(data=False, message="Duplicated folder name in the same folder.", code=409)
|
||||
|
||||
@ -306,13 +306,13 @@ def list_files(tenant_id):
|
||||
try:
|
||||
e, file = FileService.get_by_id(pf_id)
|
||||
if not e:
|
||||
return get_json_result(message="Folder not found!", code=404)
|
||||
return get_json_result(message="Folder not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
files, total = FileService.get_by_pf_id(tenant_id, pf_id, page_number, items_per_page, orderby, desc, keywords)
|
||||
|
||||
parent_folder = FileService.get_parent_folder(pf_id)
|
||||
if not parent_folder:
|
||||
return get_json_result(message="File not found!", code=404)
|
||||
return get_json_result(message="File not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
return get_json_result(data={"total": total, "files": files, "parent_folder": parent_folder.to_json()})
|
||||
except Exception as e:
|
||||
@ -392,7 +392,7 @@ def get_parent_folder():
|
||||
try:
|
||||
e, file = FileService.get_by_id(file_id)
|
||||
if not e:
|
||||
return get_json_result(message="Folder not found!", code=404)
|
||||
return get_json_result(message="Folder not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
parent_folder = FileService.get_parent_folder(file_id)
|
||||
return get_json_result(data={"parent_folder": parent_folder.to_json()})
|
||||
@ -439,7 +439,7 @@ def get_all_parent_folders(tenant_id):
|
||||
try:
|
||||
e, file = FileService.get_by_id(file_id)
|
||||
if not e:
|
||||
return get_json_result(message="Folder not found!", code=404)
|
||||
return get_json_result(message="Folder not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
parent_folders = FileService.get_all_parent_folders(file_id)
|
||||
parent_folders_res = [folder.to_json() for folder in parent_folders]
|
||||
@ -487,34 +487,34 @@ async def rm(tenant_id):
|
||||
for file_id in file_ids:
|
||||
e, file = FileService.get_by_id(file_id)
|
||||
if not e:
|
||||
return get_json_result(message="File or Folder not found!", code=404)
|
||||
return get_json_result(message="File or Folder not found!", code=RetCode.NOT_FOUND)
|
||||
if not file.tenant_id:
|
||||
return get_json_result(message="Tenant not found!", code=404)
|
||||
return get_json_result(message="Tenant not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
if file.type == FileType.FOLDER.value:
|
||||
file_id_list = FileService.get_all_innermost_file_ids(file_id, [])
|
||||
for inner_file_id in file_id_list:
|
||||
e, file = FileService.get_by_id(inner_file_id)
|
||||
if not e:
|
||||
return get_json_result(message="File not found!", code=404)
|
||||
return get_json_result(message="File not found!", code=RetCode.NOT_FOUND)
|
||||
settings.STORAGE_IMPL.rm(file.parent_id, file.location)
|
||||
FileService.delete_folder_by_pf_id(tenant_id, file_id)
|
||||
else:
|
||||
settings.STORAGE_IMPL.rm(file.parent_id, file.location)
|
||||
if not FileService.delete(file):
|
||||
return get_json_result(message="Database error (File removal)!", code=500)
|
||||
return get_json_result(message="Database error (File removal)!", code=RetCode.SERVER_ERROR)
|
||||
|
||||
informs = File2DocumentService.get_by_file_id(file_id)
|
||||
for inform in informs:
|
||||
doc_id = inform.document_id
|
||||
e, doc = DocumentService.get_by_id(doc_id)
|
||||
if not e:
|
||||
return get_json_result(message="Document not found!", code=404)
|
||||
return get_json_result(message="Document not found!", code=RetCode.NOT_FOUND)
|
||||
tenant_id = DocumentService.get_tenant_id(doc_id)
|
||||
if not tenant_id:
|
||||
return get_json_result(message="Tenant not found!", code=404)
|
||||
return get_json_result(message="Tenant not found!", code=RetCode.NOT_FOUND)
|
||||
if not DocumentService.remove_document(doc, tenant_id):
|
||||
return get_json_result(message="Database error (Document removal)!", code=500)
|
||||
return get_json_result(message="Database error (Document removal)!", code=RetCode.SERVER_ERROR)
|
||||
File2DocumentService.delete_by_file_id(file_id)
|
||||
|
||||
return get_json_result(data=True)
|
||||
@ -560,23 +560,23 @@ async def rename(tenant_id):
|
||||
try:
|
||||
e, file = FileService.get_by_id(req["file_id"])
|
||||
if not e:
|
||||
return get_json_result(message="File not found!", code=404)
|
||||
return get_json_result(message="File not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
if file.type != FileType.FOLDER.value and pathlib.Path(req["name"].lower()).suffix != pathlib.Path(
|
||||
file.name.lower()).suffix:
|
||||
return get_json_result(data=False, message="The extension of file can't be changed", code=400)
|
||||
return get_json_result(data=False, message="The extension of file can't be changed", code=RetCode.BAD_REQUEST)
|
||||
|
||||
for existing_file in FileService.query(name=req["name"], pf_id=file.parent_id):
|
||||
if existing_file.name == req["name"]:
|
||||
return get_json_result(data=False, message="Duplicated file name in the same folder.", code=409)
|
||||
|
||||
if not FileService.update_by_id(req["file_id"], {"name": req["name"]}):
|
||||
return get_json_result(message="Database error (File rename)!", code=500)
|
||||
return get_json_result(message="Database error (File rename)!", code=RetCode.SERVER_ERROR)
|
||||
|
||||
informs = File2DocumentService.get_by_file_id(req["file_id"])
|
||||
if informs:
|
||||
if not DocumentService.update_by_id(informs[0].document_id, {"name": req["name"]}):
|
||||
return get_json_result(message="Database error (Document rename)!", code=500)
|
||||
return get_json_result(message="Database error (Document rename)!", code=RetCode.SERVER_ERROR)
|
||||
|
||||
return get_json_result(data=True)
|
||||
except Exception as e:
|
||||
@ -606,13 +606,13 @@ async def get(tenant_id, file_id):
|
||||
description: File stream
|
||||
schema:
|
||||
type: file
|
||||
404:
|
||||
RetCode.NOT_FOUND:
|
||||
description: File not found
|
||||
"""
|
||||
try:
|
||||
e, file = FileService.get_by_id(file_id)
|
||||
if not e:
|
||||
return get_json_result(message="Document not found!", code=404)
|
||||
return get_json_result(message="Document not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
blob = settings.STORAGE_IMPL.get(file.parent_id, file.location)
|
||||
if not blob:
|
||||
@ -677,13 +677,13 @@ async def move(tenant_id):
|
||||
for file_id in file_ids:
|
||||
file = files_dict[file_id]
|
||||
if not file:
|
||||
return get_json_result(message="File or Folder not found!", code=404)
|
||||
return get_json_result(message="File or Folder not found!", code=RetCode.NOT_FOUND)
|
||||
if not file.tenant_id:
|
||||
return get_json_result(message="Tenant not found!", code=404)
|
||||
return get_json_result(message="Tenant not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
fe, _ = FileService.get_by_id(parent_id)
|
||||
if not fe:
|
||||
return get_json_result(message="Parent Folder not found!", code=404)
|
||||
return get_json_result(message="Parent Folder not found!", code=RetCode.NOT_FOUND)
|
||||
|
||||
FileService.move_file(file_ids, parent_id)
|
||||
return get_json_result(data=True)
|
||||
@ -705,7 +705,7 @@ async def convert(tenant_id):
|
||||
for file_id in file_ids:
|
||||
file = files_set[file_id]
|
||||
if not file:
|
||||
return get_json_result(message="File not found!", code=404)
|
||||
return get_json_result(message="File not found!", code=RetCode.NOT_FOUND)
|
||||
file_ids_list = [file_id]
|
||||
if file.type == FileType.FOLDER.value:
|
||||
file_ids_list = FileService.get_all_innermost_file_ids(file_id, [])
|
||||
@ -716,13 +716,13 @@ async def convert(tenant_id):
|
||||
doc_id = inform.document_id
|
||||
e, doc = DocumentService.get_by_id(doc_id)
|
||||
if not e:
|
||||
return get_json_result(message="Document not found!", code=404)
|
||||
return get_json_result(message="Document not found!", code=RetCode.NOT_FOUND)
|
||||
tenant_id = DocumentService.get_tenant_id(doc_id)
|
||||
if not tenant_id:
|
||||
return get_json_result(message="Tenant not found!", code=404)
|
||||
return get_json_result(message="Tenant not found!", code=RetCode.NOT_FOUND)
|
||||
if not DocumentService.remove_document(doc, tenant_id):
|
||||
return get_json_result(
|
||||
message="Database error (Document removal)!", code=404)
|
||||
message="Database error (Document removal)!", code=RetCode.NOT_FOUND)
|
||||
File2DocumentService.delete_by_file_id(id)
|
||||
|
||||
# insert
|
||||
@ -730,11 +730,11 @@ async def convert(tenant_id):
|
||||
e, kb = KnowledgebaseService.get_by_id(kb_id)
|
||||
if not e:
|
||||
return get_json_result(
|
||||
message="Can't find this knowledgebase!", code=404)
|
||||
message="Can't find this knowledgebase!", code=RetCode.NOT_FOUND)
|
||||
e, file = FileService.get_by_id(id)
|
||||
if not e:
|
||||
return get_json_result(
|
||||
message="Can't find this file!", code=404)
|
||||
message="Can't find this file!", code=RetCode.NOT_FOUND)
|
||||
|
||||
doc = DocumentService.insert({
|
||||
"id": get_uuid(),
|
||||
|
||||
@ -749,7 +749,7 @@ class Knowledgebase(DataBaseModel):
|
||||
|
||||
parser_id = CharField(max_length=32, null=False, help_text="default parser ID", default=ParserType.NAIVE.value, index=True)
|
||||
pipeline_id = CharField(max_length=32, null=True, help_text="Pipeline ID", index=True)
|
||||
parser_config = JSONField(null=False, default={"pages": [[1, 1000000]]})
|
||||
parser_config = JSONField(null=False, default={"pages": [[1, 1000000]], "table_context_size": 0, "image_context_size": 0})
|
||||
pagerank = IntegerField(default=0, index=False)
|
||||
|
||||
graphrag_task_id = CharField(max_length=32, null=True, help_text="Graph RAG task ID", index=True)
|
||||
@ -774,7 +774,7 @@ class Document(DataBaseModel):
|
||||
kb_id = CharField(max_length=256, null=False, index=True)
|
||||
parser_id = CharField(max_length=32, null=False, help_text="default parser ID", index=True)
|
||||
pipeline_id = CharField(max_length=32, null=True, help_text="pipeline ID", index=True)
|
||||
parser_config = JSONField(null=False, default={"pages": [[1, 1000000]]})
|
||||
parser_config = JSONField(null=False, default={"pages": [[1, 1000000]], "table_context_size": 0, "image_context_size": 0})
|
||||
source_type = CharField(max_length=128, null=False, default="local", help_text="where dose this document come from", index=True)
|
||||
type = CharField(max_length=32, null=False, help_text="file extension", index=True)
|
||||
created_by = CharField(max_length=32, null=False, help_text="who created it", index=True)
|
||||
|
||||
@ -923,7 +923,7 @@ def doc_upload_and_parse(conversation_id, file_objs, user_id):
|
||||
ParserType.AUDIO.value: audio,
|
||||
ParserType.EMAIL.value: email
|
||||
}
|
||||
parser_config = {"chunk_token_num": 4096, "delimiter": "\n!?;。;!?", "layout_recognize": "Plain Text"}
|
||||
parser_config = {"chunk_token_num": 4096, "delimiter": "\n!?;。;!?", "layout_recognize": "Plain Text", "table_context_size": 0, "image_context_size": 0}
|
||||
exe = ThreadPoolExecutor(max_workers=12)
|
||||
threads = []
|
||||
doc_nm = {}
|
||||
|
||||
@ -313,6 +313,10 @@ def get_parser_config(chunk_method, parser_config):
|
||||
chunk_method = "naive"
|
||||
|
||||
# Define default configurations for each chunking method
|
||||
base_defaults = {
|
||||
"table_context_size": 0,
|
||||
"image_context_size": 0,
|
||||
}
|
||||
key_mapping = {
|
||||
"naive": {
|
||||
"layout_recognize": "DeepDOC",
|
||||
@ -365,16 +369,19 @@ def get_parser_config(chunk_method, parser_config):
|
||||
|
||||
default_config = key_mapping[chunk_method]
|
||||
|
||||
# If no parser_config provided, return default
|
||||
# If no parser_config provided, return default merged with base defaults
|
||||
if not parser_config:
|
||||
return default_config
|
||||
if default_config is None:
|
||||
return deep_merge(base_defaults, {})
|
||||
return deep_merge(base_defaults, default_config)
|
||||
|
||||
# If parser_config is provided, merge with defaults to ensure required fields exist
|
||||
if default_config is None:
|
||||
return parser_config
|
||||
return deep_merge(base_defaults, parser_config)
|
||||
|
||||
# Ensure raptor and graphrag fields have default values if not provided
|
||||
merged_config = deep_merge(default_config, parser_config)
|
||||
merged_config = deep_merge(base_defaults, default_config)
|
||||
merged_config = deep_merge(merged_config, parser_config)
|
||||
|
||||
return merged_config
|
||||
|
||||
|
||||
@ -49,6 +49,7 @@ class RetCode(IntEnum, CustomEnum):
|
||||
RUNNING = 106
|
||||
PERMISSION_ERROR = 108
|
||||
AUTHENTICATION_ERROR = 109
|
||||
BAD_REQUEST = 400
|
||||
UNAUTHORIZED = 401
|
||||
SERVER_ERROR = 500
|
||||
FORBIDDEN = 403
|
||||
|
||||
@ -138,7 +138,6 @@ class RAGFlowHtmlParser:
|
||||
"metadata": {"table_id": table_id, "index": table_list.index(t)}})
|
||||
return table_info_list
|
||||
else:
|
||||
block_id = None
|
||||
if str.lower(element.name) in BLOCK_TAGS:
|
||||
block_id = str(uuid.uuid1())
|
||||
for child in element.children:
|
||||
@ -172,7 +171,7 @@ class RAGFlowHtmlParser:
|
||||
if tag_name == "table":
|
||||
table_info_list.append(item)
|
||||
else:
|
||||
current_content += (" " if current_content else "" + content)
|
||||
current_content += (" " if current_content else "") + content
|
||||
if current_content:
|
||||
block_content.append(current_content)
|
||||
return block_content, table_info_list
|
||||
|
||||
12
docs/faq.mdx
12
docs/faq.mdx
@ -323,9 +323,9 @@ The status of a Docker container status does not necessarily reflect the status
|
||||
|
||||
2. Follow [this document](./guides/run_health_check.md) to check the health status of the Elasticsearch service.
|
||||
|
||||
:::danger IMPORTANT
|
||||
The status of a Docker container status does not necessarily reflect the status of the service. You may find that your services are unhealthy even when the corresponding Docker containers are up running. Possible reasons for this include network failures, incorrect port numbers, or DNS issues.
|
||||
:::
|
||||
:::danger IMPORTANT
|
||||
The status of a Docker container status does not necessarily reflect the status of the service. You may find that your services are unhealthy even when the corresponding Docker containers are up running. Possible reasons for this include network failures, incorrect port numbers, or DNS issues.
|
||||
:::
|
||||
|
||||
3. If your container keeps restarting, ensure `vm.max_map_count` >= 262144 as per [this README](https://github.com/infiniflow/ragflow?tab=readme-ov-file#-start-up-the-server). Updating the `vm.max_map_count` value in **/etc/sysctl.conf** is required, if you wish to keep your change permanent. Note that this configuration works only for Linux.
|
||||
|
||||
@ -456,9 +456,9 @@ To switch your document engine from Elasticsearch to [Infinity](https://github.c
|
||||
```bash
|
||||
$ docker compose -f docker/docker-compose.yml down -v
|
||||
```
|
||||
:::caution WARNING
|
||||
`-v` will delete all Docker container volumes, and the existing data will be cleared.
|
||||
:::
|
||||
:::caution WARNING
|
||||
`-v` will delete all Docker container volumes, and the existing data will be cleared.
|
||||
:::
|
||||
|
||||
2. In **docker/.env**, set `DOC_ENGINE=${DOC_ENGINE:-infinity}`
|
||||
3. Restart your Docker image:
|
||||
|
||||
@ -22,7 +22,7 @@ An **Agent** component is essential when you need the LLM to assist with summari
|
||||
|
||||
1. Ensure you have a chat model properly configured:
|
||||
|
||||

|
||||

|
||||
|
||||
2. If your Agent involves dataset retrieval, ensure you [have properly configured your target dataset(s)](../../dataset/configure_knowledge_base.md).
|
||||
|
||||
@ -91,7 +91,7 @@ Update your MCP server's name, URL (including the API key), server type, and oth
|
||||
|
||||
*The target MCP server appears below your Agent component, and your Agent will autonomously decide when to invoke the available tools it offers.*
|
||||
|
||||
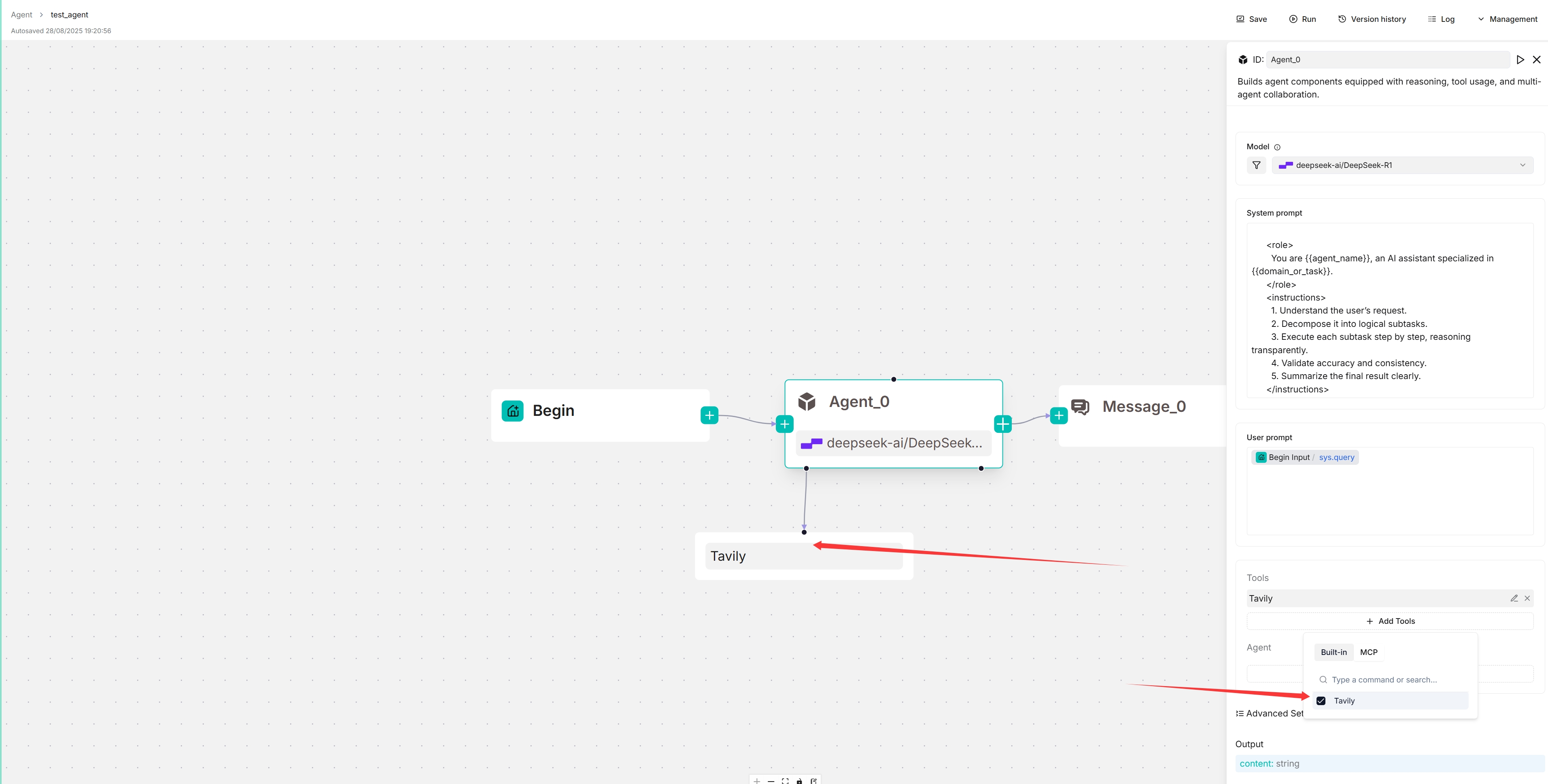
|
||||

|
||||
|
||||
### 5. Update system prompt to specify trigger conditions (Optional)
|
||||
|
||||
|
||||
@ -62,9 +62,9 @@ docker build -t sandbox-executor-manager:latest ./executor_manager
|
||||
|
||||
3. Add the following entry to your /etc/hosts file to resolve the executor manager service:
|
||||
|
||||
```bash
|
||||
127.0.0.1 es01 infinity mysql minio redis sandbox-executor-manager
|
||||
```
|
||||
```bash
|
||||
127.0.0.1 es01 infinity mysql minio redis sandbox-executor-manager
|
||||
```
|
||||
|
||||
4. Start the RAGFlow service as usual.
|
||||
|
||||
@ -74,24 +74,24 @@ docker build -t sandbox-executor-manager:latest ./executor_manager
|
||||
|
||||
1. Initialize the environment variables:
|
||||
|
||||
```bash
|
||||
cp .env.example .env
|
||||
```
|
||||
```bash
|
||||
cp .env.example .env
|
||||
```
|
||||
|
||||
2. Launch the sandbox services with Docker Compose:
|
||||
|
||||
```bash
|
||||
docker compose -f docker-compose.yml up
|
||||
```
|
||||
```bash
|
||||
docker compose -f docker-compose.yml up
|
||||
```
|
||||
|
||||
3. Test the sandbox setup:
|
||||
|
||||
```bash
|
||||
source .venv/bin/activate
|
||||
export PYTHONPATH=$(pwd)
|
||||
uv pip install -r executor_manager/requirements.txt
|
||||
uv run tests/sandbox_security_tests_full.py
|
||||
```
|
||||
```bash
|
||||
source .venv/bin/activate
|
||||
export PYTHONPATH=$(pwd)
|
||||
uv pip install -r executor_manager/requirements.txt
|
||||
uv run tests/sandbox_security_tests_full.py
|
||||
```
|
||||
|
||||
### Using Makefile
|
||||
|
||||
|
||||
@ -83,13 +83,13 @@ You start an AI conversation by creating an assistant.
|
||||
|
||||
1. Click the light bulb icon above the answer to view the expanded system prompt:
|
||||
|
||||
|
||||

|
||||
|
||||
*The light bulb icon is available only for the current dialogue.*
|
||||
|
||||
2. Scroll down the expanded prompt to view the time consumed for each task:
|
||||
|
||||

|
||||

|
||||
:::
|
||||
|
||||
## Update settings of an existing chat assistant
|
||||
|
||||
@ -56,9 +56,9 @@ Once a tag set is created, you can apply it to your dataset:
|
||||
1. Navigate to the **Configuration** page of your dataset.
|
||||
2. Select the tag set from the **Tag sets** dropdown and click **Save** to confirm.
|
||||
|
||||
:::tip NOTE
|
||||
If the tag set is missing from the dropdown, check that it has been created or configured correctly.
|
||||
:::
|
||||
:::tip NOTE
|
||||
If the tag set is missing from the dropdown, check that it has been created or configured correctly.
|
||||
:::
|
||||
|
||||
3. Re-parse your documents to start the auto-tagging process.
|
||||
_In an AI chat scenario using auto-tagged datasets, each query will be tagged using the corresponding tag set(s) and chunks with these tags will have a higher chance to be retrieved._
|
||||
|
||||
@ -39,8 +39,10 @@ If you have not installed Docker on your local machine (Windows, Mac, or Linux),
|
||||
|
||||
This section provides instructions on setting up the RAGFlow server on Linux. If you are on a different operating system, no worries. Most steps are alike.
|
||||
|
||||
1. Ensure `vm.max_map_count` ≥ 262144.
|
||||
|
||||
<details>
|
||||
<summary>1. Ensure <code>vm.max_map_count</code> ≥ 262144:</summary>
|
||||
<summary>Expand to show details:</summary>
|
||||
|
||||
`vm.max_map_count`. This value sets the maximum number of memory map areas a process may have. Its default value is 65530. While most applications require fewer than a thousand maps, reducing this value can result in abnormal behaviors, and the system will throw out-of-memory errors when a process reaches the limitation.
|
||||
|
||||
@ -194,22 +196,22 @@ This section provides instructions on setting up the RAGFlow server on Linux. If
|
||||
$ docker compose -f docker-compose.yml up -d
|
||||
```
|
||||
|
||||
```mdx-code-block
|
||||
<APITable>
|
||||
```
|
||||
```mdx-code-block
|
||||
<APITable>
|
||||
```
|
||||
|
||||
| RAGFlow image tag | Image size (GB) | Stable? |
|
||||
| ------------------- | --------------- | ------------------------ |
|
||||
| v0.22.1 | ≈2 | Stable release |
|
||||
| nightly | ≈2 | _Unstable_ nightly build |
|
||||
| RAGFlow image tag | Image size (GB) | Stable? |
|
||||
| ------------------- | --------------- | ------------------------ |
|
||||
| v0.22.1 | ≈2 | Stable release |
|
||||
| nightly | ≈2 | _Unstable_ nightly build |
|
||||
|
||||
```mdx-code-block
|
||||
</APITable>
|
||||
```
|
||||
```mdx-code-block
|
||||
</APITable>
|
||||
```
|
||||
|
||||
:::tip NOTE
|
||||
The image size shown refers to the size of the *downloaded* Docker image, which is compressed. When Docker runs the image, it unpacks it, resulting in significantly greater disk usage. A Docker image will expand to around 7 GB once unpacked.
|
||||
:::
|
||||
:::tip NOTE
|
||||
The image size shown refers to the size of the *downloaded* Docker image, which is compressed. When Docker runs the image, it unpacks it, resulting in significantly greater disk usage. A Docker image will expand to around 7 GB once unpacked.
|
||||
:::
|
||||
|
||||
4. Check the server status after having the server up and running:
|
||||
|
||||
@ -229,15 +231,15 @@ The image size shown refers to the size of the *downloaded* Docker image, which
|
||||
* Running on all addresses (0.0.0.0)
|
||||
```
|
||||
|
||||
:::danger IMPORTANT
|
||||
If you skip this confirmation step and directly log in to RAGFlow, your browser may prompt a `network anomaly` error because, at that moment, your RAGFlow may not be fully initialized.
|
||||
:::
|
||||
:::danger IMPORTANT
|
||||
If you skip this confirmation step and directly log in to RAGFlow, your browser may prompt a `network anomaly` error because, at that moment, your RAGFlow may not be fully initialized.
|
||||
:::
|
||||
|
||||
5. In your web browser, enter the IP address of your server and log in to RAGFlow.
|
||||
|
||||
:::caution WARNING
|
||||
With the default settings, you only need to enter `http://IP_OF_YOUR_MACHINE` (**sans** port number) as the default HTTP serving port `80` can be omitted when using the default configurations.
|
||||
:::
|
||||
:::caution WARNING
|
||||
With the default settings, you only need to enter `http://IP_OF_YOUR_MACHINE` (**sans** port number) as the default HTTP serving port `80` can be omitted when using the default configurations.
|
||||
:::
|
||||
|
||||
## Configure LLMs
|
||||
|
||||
@ -278,9 +280,9 @@ To create your first dataset:
|
||||
|
||||
3. RAGFlow offers multiple chunk templates that cater to different document layouts and file formats. Select the embedding model and chunking method (template) for your dataset.
|
||||
|
||||
:::danger IMPORTANT
|
||||
Once you have selected an embedding model and used it to parse a file, you are no longer allowed to change it. The obvious reason is that we must ensure that all files in a specific dataset are parsed using the *same* embedding model (ensure that they are being compared in the same embedding space).
|
||||
:::
|
||||
:::danger IMPORTANT
|
||||
Once you have selected an embedding model and used it to parse a file, you are no longer allowed to change it. The obvious reason is that we must ensure that all files in a specific dataset are parsed using the *same* embedding model (ensure that they are being compared in the same embedding space).
|
||||
:::
|
||||
|
||||
_You are taken to the **Dataset** page of your dataset._
|
||||
|
||||
@ -290,10 +292,10 @@ Once you have selected an embedding model and used it to parse a file, you are n
|
||||
|
||||
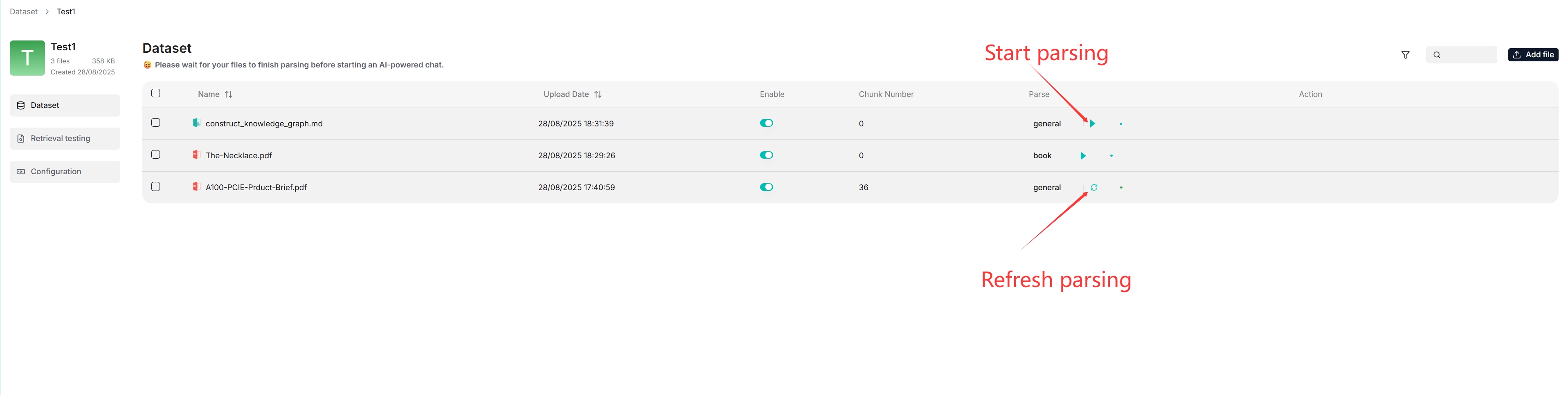
|
||||
|
||||
:::caution NOTE
|
||||
- If your file parsing gets stuck at below 1%, see [this FAQ](./faq.mdx#why-does-my-document-parsing-stall-at-under-one-percent).
|
||||
- If your file parsing gets stuck at near completion, see [this FAQ](./faq.mdx#why-does-my-pdf-parsing-stall-near-completion-while-the-log-does-not-show-any-error)
|
||||
:::
|
||||
:::caution NOTE
|
||||
- If your file parsing gets stuck at below 1%, see [this FAQ](./faq.mdx#why-does-my-document-parsing-stall-at-under-one-percent).
|
||||
- If your file parsing gets stuck at near completion, see [this FAQ](./faq.mdx#why-does-my-pdf-parsing-stall-near-completion-while-the-log-does-not-show-any-error)
|
||||
:::
|
||||
|
||||
## Intervene with file parsing
|
||||
|
||||
@ -311,9 +313,9 @@ RAGFlow features visibility and explainability, allowing you to view the chunkin
|
||||
|
||||
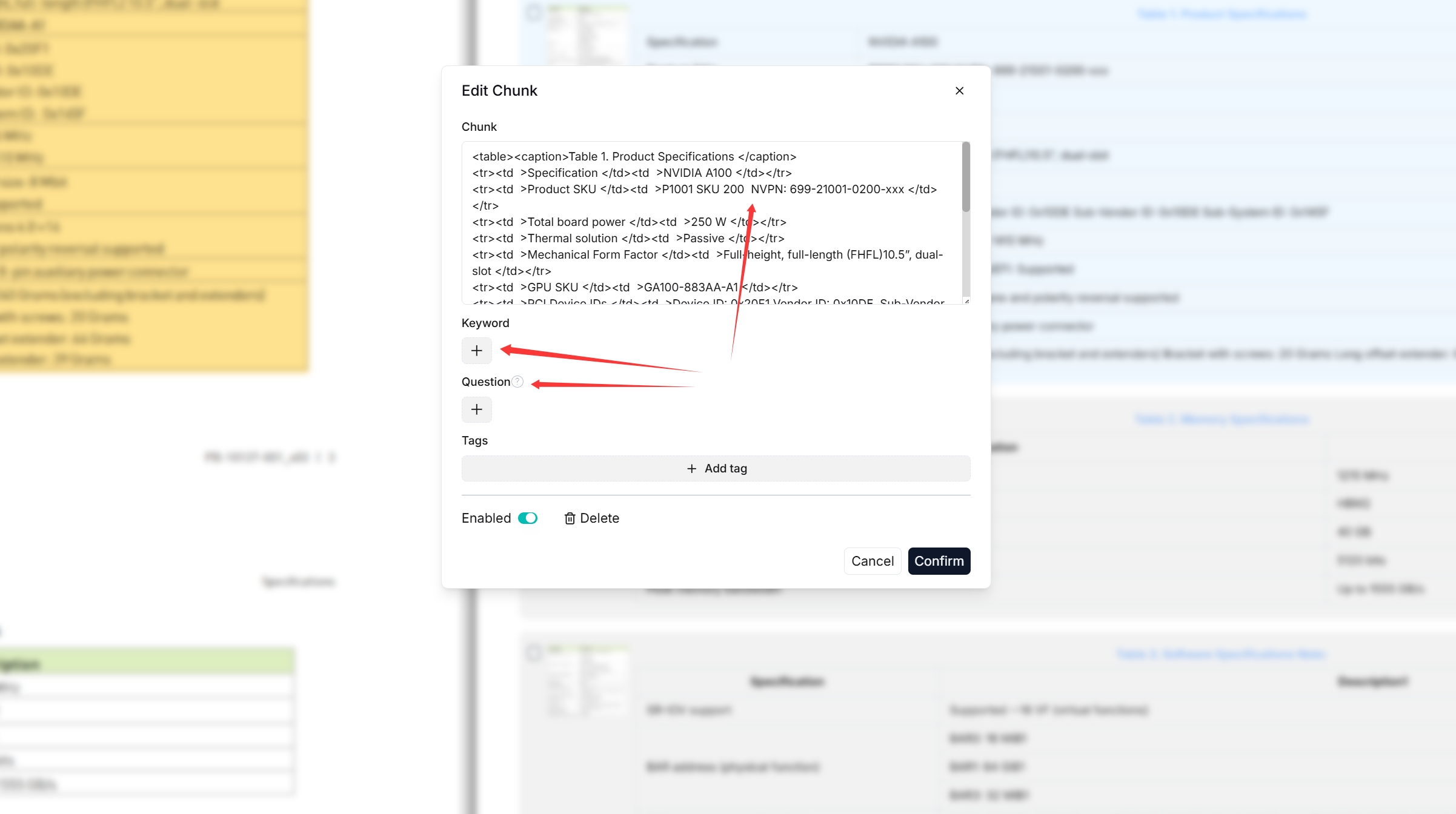
|
||||
|
||||
:::caution NOTE
|
||||
You can add keywords or questions to a file chunk to improve its ranking for queries containing those keywords. This action increases its keyword weight and can improve its position in search list.
|
||||
:::
|
||||
:::caution NOTE
|
||||
You can add keywords or questions to a file chunk to improve its ranking for queries containing those keywords. This action increases its keyword weight and can improve its position in search list.
|
||||
:::
|
||||
|
||||
4. In Retrieval testing, ask a quick question in **Test text** to double check if your configurations work:
|
||||
|
||||
|
||||
@ -23,7 +23,7 @@ from rag.app import naive
|
||||
from rag.app.naive import by_plaintext, PARSERS
|
||||
from rag.nlp import bullets_category, is_english,remove_contents_table, \
|
||||
hierarchical_merge, make_colon_as_title, naive_merge, random_choices, tokenize_table, \
|
||||
tokenize_chunks
|
||||
tokenize_chunks, attach_media_context
|
||||
from rag.nlp import rag_tokenizer
|
||||
from deepdoc.parser import PdfParser, HtmlParser
|
||||
from deepdoc.parser.figure_parser import vision_figure_parser_docx_wrapper
|
||||
@ -175,6 +175,10 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
|
||||
res = tokenize_table(tbls, doc, eng)
|
||||
res.extend(tokenize_chunks(chunks, doc, eng, pdf_parser))
|
||||
table_ctx = max(0, int(parser_config.get("table_context_size", 0) or 0))
|
||||
image_ctx = max(0, int(parser_config.get("image_context_size", 0) or 0))
|
||||
if table_ctx or image_ctx:
|
||||
attach_media_context(res, table_ctx, image_ctx)
|
||||
|
||||
return res
|
||||
|
||||
|
||||
@ -20,7 +20,7 @@ import re
|
||||
|
||||
from common.constants import ParserType
|
||||
from io import BytesIO
|
||||
from rag.nlp import rag_tokenizer, tokenize, tokenize_table, bullets_category, title_frequency, tokenize_chunks, docx_question_level
|
||||
from rag.nlp import rag_tokenizer, tokenize, tokenize_table, bullets_category, title_frequency, tokenize_chunks, docx_question_level, attach_media_context
|
||||
from common.token_utils import num_tokens_from_string
|
||||
from deepdoc.parser import PdfParser, DocxParser
|
||||
from deepdoc.parser.figure_parser import vision_figure_parser_pdf_wrapper,vision_figure_parser_docx_wrapper
|
||||
@ -155,7 +155,7 @@ class Docx(DocxParser):
|
||||
sum_question = '\n'.join(question_stack)
|
||||
if sum_question:
|
||||
ti_list.append((f'{sum_question}\n{last_answer}', last_image))
|
||||
|
||||
|
||||
tbls = []
|
||||
for tb in self.doc.tables:
|
||||
html= "<table>"
|
||||
@ -231,14 +231,14 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
if isinstance(poss, str):
|
||||
poss = pdf_parser.extract_positions(poss)
|
||||
first = poss[0] # tuple: ([pn], x1, x2, y1, y2)
|
||||
pn = first[0]
|
||||
pn = first[0]
|
||||
|
||||
if isinstance(pn, list):
|
||||
pn = pn[0] # [pn] -> pn
|
||||
poss[0] = (pn, *first[1:])
|
||||
|
||||
return (txt, layoutno, poss)
|
||||
|
||||
|
||||
|
||||
sections = [_normalize_section(sec) for sec in sections]
|
||||
|
||||
@ -247,7 +247,7 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
|
||||
if name in ["tcadp", "docling", "mineru"]:
|
||||
parser_config["chunk_token_num"] = 0
|
||||
|
||||
|
||||
callback(0.8, "Finish parsing.")
|
||||
|
||||
if len(sections) > 0 and len(pdf_parser.outlines) / len(sections) > 0.03:
|
||||
@ -310,6 +310,10 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
tbls=vision_figure_parser_pdf_wrapper(tbls=tbls,callback=callback,**kwargs)
|
||||
res = tokenize_table(tbls, doc, eng)
|
||||
res.extend(tokenize_chunks(chunks, doc, eng, pdf_parser))
|
||||
table_ctx = max(0, int(parser_config.get("table_context_size", 0) or 0))
|
||||
image_ctx = max(0, int(parser_config.get("image_context_size", 0) or 0))
|
||||
if table_ctx or image_ctx:
|
||||
attach_media_context(res, table_ctx, image_ctx)
|
||||
return res
|
||||
|
||||
elif re.search(r"\.docx?$", filename, re.IGNORECASE):
|
||||
@ -325,10 +329,14 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
d["doc_type_kwd"] = "image"
|
||||
tokenize(d, text, eng)
|
||||
res.append(d)
|
||||
table_ctx = max(0, int(parser_config.get("table_context_size", 0) or 0))
|
||||
image_ctx = max(0, int(parser_config.get("image_context_size", 0) or 0))
|
||||
if table_ctx or image_ctx:
|
||||
attach_media_context(res, table_ctx, image_ctx)
|
||||
return res
|
||||
else:
|
||||
raise NotImplementedError("file type not supported yet(pdf and docx supported)")
|
||||
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
import sys
|
||||
|
||||
@ -37,7 +37,7 @@ from deepdoc.parser.pdf_parser import PlainParser, VisionParser
|
||||
from deepdoc.parser.mineru_parser import MinerUParser
|
||||
from deepdoc.parser.docling_parser import DoclingParser
|
||||
from deepdoc.parser.tcadp_parser import TCADPParser
|
||||
from rag.nlp import concat_img, find_codec, naive_merge, naive_merge_with_images, naive_merge_docx, rag_tokenizer, tokenize_chunks, tokenize_chunks_with_images, tokenize_table
|
||||
from rag.nlp import concat_img, find_codec, naive_merge, naive_merge_with_images, naive_merge_docx, rag_tokenizer, tokenize_chunks, tokenize_chunks_with_images, tokenize_table, attach_media_context
|
||||
|
||||
def by_deepdoc(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", callback=None, pdf_cls = None ,**kwargs):
|
||||
callback = callback
|
||||
@ -616,6 +616,8 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
parser_config = kwargs.get(
|
||||
"parser_config", {
|
||||
"chunk_token_num": 512, "delimiter": "\n!?。;!?", "layout_recognize": "DeepDOC", "analyze_hyperlink": True})
|
||||
table_context_size = max(0, int(parser_config.get("table_context_size", 0) or 0))
|
||||
image_context_size = max(0, int(parser_config.get("image_context_size", 0) or 0))
|
||||
final_sections = False
|
||||
doc = {
|
||||
"docnm_kwd": filename,
|
||||
@ -686,6 +688,8 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
logging.info("naive_merge({}): {}".format(filename, timer() - st))
|
||||
res.extend(embed_res)
|
||||
res.extend(url_res)
|
||||
if table_context_size or image_context_size:
|
||||
attach_media_context(res, table_context_size, image_context_size)
|
||||
return res
|
||||
|
||||
elif re.search(r"\.pdf$", filename, re.IGNORECASE):
|
||||
@ -947,6 +951,8 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
res.extend(embed_res)
|
||||
if url_res:
|
||||
res.extend(url_res)
|
||||
if table_context_size or image_context_size:
|
||||
attach_media_context(res, table_context_size, image_context_size)
|
||||
return res
|
||||
|
||||
|
||||
|
||||
@ -20,7 +20,7 @@ import re
|
||||
|
||||
from deepdoc.parser.figure_parser import vision_figure_parser_pdf_wrapper
|
||||
from common.constants import ParserType
|
||||
from rag.nlp import rag_tokenizer, tokenize, tokenize_table, add_positions, bullets_category, title_frequency, tokenize_chunks
|
||||
from rag.nlp import rag_tokenizer, tokenize, tokenize_table, add_positions, bullets_category, title_frequency, tokenize_chunks, attach_media_context
|
||||
from deepdoc.parser import PdfParser
|
||||
import numpy as np
|
||||
from rag.app.naive import by_plaintext, PARSERS
|
||||
@ -150,7 +150,7 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
"chunk_token_num": 512, "delimiter": "\n!?。;!?", "layout_recognize": "DeepDOC"})
|
||||
if re.search(r"\.pdf$", filename, re.IGNORECASE):
|
||||
layout_recognizer = parser_config.get("layout_recognize", "DeepDOC")
|
||||
|
||||
|
||||
if isinstance(layout_recognizer, bool):
|
||||
layout_recognizer = "DeepDOC" if layout_recognizer else "Plain Text"
|
||||
|
||||
@ -234,6 +234,10 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
chunks.append(txt)
|
||||
last_sid = sec_id
|
||||
res.extend(tokenize_chunks(chunks, doc, eng, pdf_parser))
|
||||
table_ctx = max(0, int(parser_config.get("table_context_size", 0) or 0))
|
||||
image_ctx = max(0, int(parser_config.get("image_context_size", 0) or 0))
|
||||
if table_ctx or image_ctx:
|
||||
attach_media_context(res, table_ctx, image_ctx)
|
||||
return res
|
||||
|
||||
|
||||
|
||||
@ -20,11 +20,11 @@ import re
|
||||
import numpy as np
|
||||
from PIL import Image
|
||||
|
||||
from common.constants import LLMType
|
||||
from api.db.services.llm_service import LLMBundle
|
||||
from deepdoc.vision import OCR
|
||||
from rag.nlp import rag_tokenizer, tokenize
|
||||
from common.constants import LLMType
|
||||
from common.string_utils import clean_markdown_block
|
||||
from deepdoc.vision import OCR
|
||||
from rag.nlp import attach_media_context, rag_tokenizer, tokenize
|
||||
|
||||
ocr = OCR()
|
||||
|
||||
@ -39,9 +39,16 @@ def chunk(filename, binary, tenant_id, lang, callback=None, **kwargs):
|
||||
}
|
||||
eng = lang.lower() == "english"
|
||||
|
||||
parser_config = kwargs.get("parser_config", {}) or {}
|
||||
image_ctx = max(0, int(parser_config.get("image_context_size", 0) or 0))
|
||||
|
||||
if any(filename.lower().endswith(ext) for ext in VIDEO_EXTS):
|
||||
try:
|
||||
doc.update({"doc_type_kwd": "video"})
|
||||
doc.update(
|
||||
{
|
||||
"doc_type_kwd": "video",
|
||||
}
|
||||
)
|
||||
cv_mdl = LLMBundle(tenant_id, llm_type=LLMType.IMAGE2TEXT, lang=lang)
|
||||
ans = cv_mdl.chat(system="", history=[], gen_conf={}, video_bytes=binary, filename=filename)
|
||||
callback(0.8, "CV LLM respond: %s ..." % ans[:32])
|
||||
@ -64,7 +71,7 @@ def chunk(filename, binary, tenant_id, lang, callback=None, **kwargs):
|
||||
if (eng and len(txt.split()) > 32) or len(txt) > 32:
|
||||
tokenize(doc, txt, eng)
|
||||
callback(0.8, "OCR results is too long to use CV LLM.")
|
||||
return [doc]
|
||||
return attach_media_context([doc], 0, image_ctx)
|
||||
|
||||
try:
|
||||
callback(0.4, "Use CV LLM to describe the picture.")
|
||||
@ -76,7 +83,7 @@ def chunk(filename, binary, tenant_id, lang, callback=None, **kwargs):
|
||||
callback(0.8, "CV LLM respond: %s ..." % ans[:32])
|
||||
txt += "\n" + ans
|
||||
tokenize(doc, txt, eng)
|
||||
return [doc]
|
||||
return attach_media_context([doc], 0, image_ctx)
|
||||
except Exception as e:
|
||||
callback(prog=-1, msg=str(e))
|
||||
|
||||
@ -103,7 +110,7 @@ def vision_llm_chunk(binary, vision_model, prompt=None, callback=None):
|
||||
img_binary.seek(0)
|
||||
img_binary.truncate()
|
||||
img.save(img_binary, format="PNG")
|
||||
|
||||
|
||||
img_binary.seek(0)
|
||||
ans = clean_markdown_block(vision_model.describe_with_prompt(img_binary.read(), prompt))
|
||||
txt += "\n" + ans
|
||||
|
||||
@ -19,16 +19,16 @@ import random
|
||||
import re
|
||||
from functools import partial
|
||||
|
||||
import trio
|
||||
import numpy as np
|
||||
import trio
|
||||
from PIL import Image
|
||||
|
||||
from common.constants import LLMType
|
||||
from api.db.services.file2document_service import File2DocumentService
|
||||
from api.db.services.file_service import FileService
|
||||
from api.db.services.llm_service import LLMBundle
|
||||
from common import settings
|
||||
from common.constants import LLMType
|
||||
from common.misc_utils import get_uuid
|
||||
from rag.utils.base64_image import image2id
|
||||
from deepdoc.parser import ExcelParser
|
||||
from deepdoc.parser.mineru_parser import MinerUParser
|
||||
from deepdoc.parser.pdf_parser import PlainParser, RAGFlowPdfParser, VisionParser
|
||||
@ -37,7 +37,8 @@ from rag.app.naive import Docx
|
||||
from rag.flow.base import ProcessBase, ProcessParamBase
|
||||
from rag.flow.parser.schema import ParserFromUpstream
|
||||
from rag.llm.cv_model import Base as VLM
|
||||
from common import settings
|
||||
from rag.nlp import attach_media_context
|
||||
from rag.utils.base64_image import image2id
|
||||
|
||||
|
||||
class ParserParam(ProcessParamBase):
|
||||
@ -61,15 +62,18 @@ class ParserParam(ProcessParamBase):
|
||||
"json",
|
||||
],
|
||||
"image": [
|
||||
"text"
|
||||
"text",
|
||||
],
|
||||
"email": [
|
||||
"text",
|
||||
"json",
|
||||
],
|
||||
"email": ["text", "json"],
|
||||
"text&markdown": [
|
||||
"text",
|
||||
"json"
|
||||
"json",
|
||||
],
|
||||
"audio": [
|
||||
"json"
|
||||
"json",
|
||||
],
|
||||
"video": [],
|
||||
}
|
||||
@ -82,6 +86,8 @@ class ParserParam(ProcessParamBase):
|
||||
"pdf",
|
||||
],
|
||||
"output_format": "json",
|
||||
"table_context_size": 0,
|
||||
"image_context_size": 0,
|
||||
},
|
||||
"spreadsheet": {
|
||||
"parse_method": "deepdoc", # deepdoc/tcadp_parser
|
||||
@ -91,6 +97,8 @@ class ParserParam(ProcessParamBase):
|
||||
"xlsx",
|
||||
"csv",
|
||||
],
|
||||
"table_context_size": 0,
|
||||
"image_context_size": 0,
|
||||
},
|
||||
"word": {
|
||||
"suffix": [
|
||||
@ -98,18 +106,24 @@ class ParserParam(ProcessParamBase):
|
||||
"docx",
|
||||
],
|
||||
"output_format": "json",
|
||||
"table_context_size": 0,
|
||||
"image_context_size": 0,
|
||||
},
|
||||
"text&markdown": {
|
||||
"suffix": ["md", "markdown", "mdx", "txt"],
|
||||
"output_format": "json",
|
||||
"table_context_size": 0,
|
||||
"image_context_size": 0,
|
||||
},
|
||||
"slides": {
|
||||
"parse_method": "deepdoc", # deepdoc/tcadp_parser
|
||||
"suffix": [
|
||||
"pptx",
|
||||
"ppt"
|
||||
"ppt",
|
||||
],
|
||||
"output_format": "json",
|
||||
"table_context_size": 0,
|
||||
"image_context_size": 0,
|
||||
},
|
||||
"image": {
|
||||
"parse_method": "ocr",
|
||||
@ -121,13 +135,14 @@ class ParserParam(ProcessParamBase):
|
||||
},
|
||||
"email": {
|
||||
"suffix": [
|
||||
"eml", "msg"
|
||||
"eml",
|
||||
"msg",
|
||||
],
|
||||
"fields": ["from", "to", "cc", "bcc", "date", "subject", "body", "attachments", "metadata"],
|
||||
"output_format": "json",
|
||||
},
|
||||
"audio": {
|
||||
"suffix":[
|
||||
"suffix": [
|
||||
"da",
|
||||
"wave",
|
||||
"wav",
|
||||
@ -142,15 +157,15 @@ class ParserParam(ProcessParamBase):
|
||||
"realaudio",
|
||||
"vqf",
|
||||
"oggvorbis",
|
||||
"ape"
|
||||
"ape",
|
||||
],
|
||||
"output_format": "text",
|
||||
},
|
||||
"video": {
|
||||
"suffix":[
|
||||
"suffix": [
|
||||
"mp4",
|
||||
"avi",
|
||||
"mkv"
|
||||
"mkv",
|
||||
],
|
||||
"output_format": "text",
|
||||
},
|
||||
@ -253,7 +268,7 @@ class Parser(ProcessBase):
|
||||
markdown_image_response_type = conf.get("markdown_image_response_type", "1")
|
||||
tcadp_parser = TCADPParser(
|
||||
table_result_type=table_result_type,
|
||||
markdown_image_response_type=markdown_image_response_type
|
||||
markdown_image_response_type=markdown_image_response_type,
|
||||
)
|
||||
sections, _ = tcadp_parser.parse_pdf(
|
||||
filepath=name,
|
||||
@ -261,7 +276,7 @@ class Parser(ProcessBase):
|
||||
callback=self.callback,
|
||||
file_type="PDF",
|
||||
file_start_page=1,
|
||||
file_end_page=1000
|
||||
file_end_page=1000,
|
||||
)
|
||||
bboxes = []
|
||||
for section, position_tag in sections:
|
||||
@ -269,17 +284,20 @@ class Parser(ProcessBase):
|
||||
# Extract position information from TCADP's position tag
|
||||
# Format: @@{page_number}\t{x0}\t{x1}\t{top}\t{bottom}##
|
||||
import re
|
||||
|
||||
match = re.match(r"@@([0-9-]+)\t([0-9.]+)\t([0-9.]+)\t([0-9.]+)\t([0-9.]+)##", position_tag)
|
||||
if match:
|
||||
pn, x0, x1, top, bott = match.groups()
|
||||
bboxes.append({
|
||||
"page_number": int(pn.split('-')[0]), # Take the first page number
|
||||
"x0": float(x0),
|
||||
"x1": float(x1),
|
||||
"top": float(top),
|
||||
"bottom": float(bott),
|
||||
"text": section
|
||||
})
|
||||
bboxes.append(
|
||||
{
|
||||
"page_number": int(pn.split("-")[0]), # Take the first page number
|
||||
"x0": float(x0),
|
||||
"x1": float(x1),
|
||||
"top": float(top),
|
||||
"bottom": float(bott),
|
||||
"text": section,
|
||||
}
|
||||
)
|
||||
else:
|
||||
# If no position info, add as text without position
|
||||
bboxes.append({"text": section})
|
||||
@ -291,7 +309,30 @@ class Parser(ProcessBase):
|
||||
bboxes = []
|
||||
for t, poss in lines:
|
||||
for pn, x0, x1, top, bott in RAGFlowPdfParser.extract_positions(poss):
|
||||
bboxes.append({"page_number": int(pn[0]), "x0": float(x0), "x1": float(x1), "top": float(top), "bottom": float(bott), "text": t})
|
||||
bboxes.append(
|
||||
{
|
||||
"page_number": int(pn[0]),
|
||||
"x0": float(x0),
|
||||
"x1": float(x1),
|
||||
"top": float(top),
|
||||
"bottom": float(bott),
|
||||
"text": t,
|
||||
}
|
||||
)
|
||||
|
||||
for b in bboxes:
|
||||
text_val = b.get("text", "")
|
||||
has_text = isinstance(text_val, str) and text_val.strip()
|
||||
layout = b.get("layout_type")
|
||||
if layout == "figure" or (b.get("image") and not has_text):
|
||||
b["doc_type_kwd"] = "image"
|
||||
elif layout == "table":
|
||||
b["doc_type_kwd"] = "table"
|
||||
|
||||
table_ctx = conf.get("table_context_size", 0) or 0
|
||||
image_ctx = conf.get("image_context_size", 0) or 0
|
||||
if table_ctx or image_ctx:
|
||||
bboxes = attach_media_context(bboxes, table_ctx, image_ctx)
|
||||
|
||||
if conf.get("output_format") == "json":
|
||||
self.set_output("json", bboxes)
|
||||
@ -319,7 +360,7 @@ class Parser(ProcessBase):
|
||||
markdown_image_response_type = conf.get("markdown_image_response_type", "1")
|
||||
tcadp_parser = TCADPParser(
|
||||
table_result_type=table_result_type,
|
||||
markdown_image_response_type=markdown_image_response_type
|
||||
markdown_image_response_type=markdown_image_response_type,
|
||||
)
|
||||
if not tcadp_parser.check_installation():
|
||||
raise RuntimeError("TCADP parser not available. Please check Tencent Cloud API configuration.")
|
||||
@ -337,7 +378,7 @@ class Parser(ProcessBase):
|
||||
callback=self.callback,
|
||||
file_type=file_type,
|
||||
file_start_page=1,
|
||||
file_end_page=1000
|
||||
file_end_page=1000,
|
||||
)
|
||||
|
||||
# Process TCADP parser output based on configured output_format
|
||||
@ -365,7 +406,12 @@ class Parser(ProcessBase):
|
||||
# Add tables as text
|
||||
for table in tables:
|
||||
if table:
|
||||
result.append({"text": table})
|
||||
result.append({"text": table, "doc_type_kwd": "table"})
|
||||
|
||||
table_ctx = conf.get("table_context_size", 0) or 0
|
||||
image_ctx = conf.get("image_context_size", 0) or 0
|
||||
if table_ctx or image_ctx:
|
||||
result = attach_media_context(result, table_ctx, image_ctx)
|
||||
|
||||
self.set_output("json", result)
|
||||
|
||||
@ -400,7 +446,13 @@ class Parser(ProcessBase):
|
||||
if conf.get("output_format") == "json":
|
||||
sections, tbls = docx_parser(name, binary=blob)
|
||||
sections = [{"text": section[0], "image": section[1]} for section in sections if section]
|
||||
sections.extend([{"text": tb, "image": None} for ((_,tb), _) in tbls])
|
||||
sections.extend([{"text": tb, "image": None, "doc_type_kwd": "table"} for ((_, tb), _) in tbls])
|
||||
|
||||
table_ctx = conf.get("table_context_size", 0) or 0
|
||||
image_ctx = conf.get("image_context_size", 0) or 0
|
||||
if table_ctx or image_ctx:
|
||||
sections = attach_media_context(sections, table_ctx, image_ctx)
|
||||
|
||||
self.set_output("json", sections)
|
||||
elif conf.get("output_format") == "markdown":
|
||||
markdown_text = docx_parser.to_markdown(name, binary=blob)
|
||||
@ -420,7 +472,7 @@ class Parser(ProcessBase):
|
||||
markdown_image_response_type = conf.get("markdown_image_response_type", "1")
|
||||
tcadp_parser = TCADPParser(
|
||||
table_result_type=table_result_type,
|
||||
markdown_image_response_type=markdown_image_response_type
|
||||
markdown_image_response_type=markdown_image_response_type,
|
||||
)
|
||||
if not tcadp_parser.check_installation():
|
||||
raise RuntimeError("TCADP parser not available. Please check Tencent Cloud API configuration.")
|
||||
@ -439,7 +491,7 @@ class Parser(ProcessBase):
|
||||
callback=self.callback,
|
||||
file_type=file_type,
|
||||
file_start_page=1,
|
||||
file_end_page=1000
|
||||
file_end_page=1000,
|
||||
)
|
||||
|
||||
# Process TCADP parser output - PPT only supports json format
|
||||
@ -454,7 +506,12 @@ class Parser(ProcessBase):
|
||||
# Add tables as text
|
||||
for table in tables:
|
||||
if table:
|
||||
result.append({"text": table})
|
||||
result.append({"text": table, "doc_type_kwd": "table"})
|
||||
|
||||
table_ctx = conf.get("table_context_size", 0) or 0
|
||||
image_ctx = conf.get("image_context_size", 0) or 0
|
||||
if table_ctx or image_ctx:
|
||||
result = attach_media_context(result, table_ctx, image_ctx)
|
||||
|
||||
self.set_output("json", result)
|
||||
else:
|
||||
@ -469,6 +526,10 @@ class Parser(ProcessBase):
|
||||
# json
|
||||
assert conf.get("output_format") == "json", "have to be json for ppt"
|
||||
if conf.get("output_format") == "json":
|
||||
table_ctx = conf.get("table_context_size", 0) or 0
|
||||
image_ctx = conf.get("image_context_size", 0) or 0
|
||||
if table_ctx or image_ctx:
|
||||
sections = attach_media_context(sections, table_ctx, image_ctx)
|
||||
self.set_output("json", sections)
|
||||
|
||||
def _markdown(self, name, blob):
|
||||
@ -508,11 +569,15 @@ class Parser(ProcessBase):
|
||||
|
||||
json_results.append(json_result)
|
||||
|
||||
table_ctx = conf.get("table_context_size", 0) or 0
|
||||
image_ctx = conf.get("image_context_size", 0) or 0
|
||||
if table_ctx or image_ctx:
|
||||
json_results = attach_media_context(json_results, table_ctx, image_ctx)
|
||||
|
||||
self.set_output("json", json_results)
|
||||
else:
|
||||
self.set_output("text", "\n".join([section_text for section_text, _ in sections]))
|
||||
|
||||
|
||||
def _image(self, name, blob):
|
||||
from deepdoc.vision import OCR
|
||||
|
||||
@ -588,7 +653,7 @@ class Parser(ProcessBase):
|
||||
from email.parser import BytesParser
|
||||
|
||||
msg = BytesParser(policy=policy.default).parse(io.BytesIO(blob))
|
||||
email_content['metadata'] = {}
|
||||
email_content["metadata"] = {}
|
||||
# handle header info
|
||||
for header, value in msg.items():
|
||||
# get fields like from, to, cc, bcc, date, subject
|
||||
@ -600,6 +665,7 @@ class Parser(ProcessBase):
|
||||
# get body
|
||||
if "body" in target_fields:
|
||||
body_text, body_html = [], []
|
||||
|
||||
def _add_content(m, content_type):
|
||||
def _decode_payload(payload, charset, target_list):
|
||||
try:
|
||||
@ -641,14 +707,17 @@ class Parser(ProcessBase):
|
||||
if dispositions[0].lower() == "attachment":
|
||||
filename = part.get_filename()
|
||||
payload = part.get_payload(decode=True).decode(part.get_content_charset())
|
||||
attachments.append({
|
||||
"filename": filename,
|
||||
"payload": payload,
|
||||
})
|
||||
attachments.append(
|
||||
{
|
||||
"filename": filename,
|
||||
"payload": payload,
|
||||
}
|
||||
)
|
||||
email_content["attachments"] = attachments
|
||||
else:
|
||||
# handle msg file
|
||||
import extract_msg
|
||||
|
||||
print("handle a msg file.")
|
||||
msg = extract_msg.Message(blob)
|
||||
# handle header info
|
||||
@ -662,9 +731,9 @@ class Parser(ProcessBase):
|
||||
}
|
||||
email_content.update({k: v for k, v in basic_content.items() if k in target_fields})
|
||||
# get metadata
|
||||
email_content['metadata'] = {
|
||||
'message_id': msg.messageId,
|
||||
'in_reply_to': msg.inReplyTo,
|
||||
email_content["metadata"] = {
|
||||
"message_id": msg.messageId,
|
||||
"in_reply_to": msg.inReplyTo,
|
||||
}
|
||||
# get body
|
||||
if "body" in target_fields:
|
||||
@ -675,29 +744,31 @@ class Parser(ProcessBase):
|
||||
if "attachments" in target_fields:
|
||||
attachments = []
|
||||
for t in msg.attachments:
|
||||
attachments.append({
|
||||
"filename": t.name,
|
||||
"payload": t.data.decode("utf-8")
|
||||
})
|
||||
attachments.append(
|
||||
{
|
||||
"filename": t.name,
|
||||
"payload": t.data.decode("utf-8"),
|
||||
}
|
||||
)
|
||||
email_content["attachments"] = attachments
|
||||
|
||||
if conf["output_format"] == "json":
|
||||
self.set_output("json", [email_content])
|
||||
else:
|
||||
content_txt = ''
|
||||
content_txt = ""
|
||||
for k, v in email_content.items():
|
||||
if isinstance(v, str):
|
||||
# basic info
|
||||
content_txt += f'{k}:{v}' + "\n"
|
||||
content_txt += f"{k}:{v}" + "\n"
|
||||
elif isinstance(v, dict):
|
||||
# metadata
|
||||
content_txt += f'{k}:{json.dumps(v)}' + "\n"
|
||||
content_txt += f"{k}:{json.dumps(v)}" + "\n"
|
||||
elif isinstance(v, list):
|
||||
# attachments or others
|
||||
for fb in v:
|
||||
if isinstance(fb, dict):
|
||||
# attachments
|
||||
content_txt += f'{fb["filename"]}:{fb["payload"]}' + "\n"
|
||||
content_txt += f"{fb['filename']}:{fb['payload']}" + "\n"
|
||||
else:
|
||||
# str, usually plain text
|
||||
content_txt += fb
|
||||
|
||||
@ -318,6 +318,7 @@ def tokenize_table(tbls, doc, eng, batch_size=10):
|
||||
d = copy.deepcopy(doc)
|
||||
tokenize(d, rows, eng)
|
||||
d["content_with_weight"] = rows
|
||||
d["doc_type_kwd"] = "table"
|
||||
if img:
|
||||
d["image"] = img
|
||||
d["doc_type_kwd"] = "image"
|
||||
@ -330,6 +331,7 @@ def tokenize_table(tbls, doc, eng, batch_size=10):
|
||||
d = copy.deepcopy(doc)
|
||||
r = de.join(rows[i:i + batch_size])
|
||||
tokenize(d, r, eng)
|
||||
d["doc_type_kwd"] = "table"
|
||||
if img:
|
||||
d["image"] = img
|
||||
d["doc_type_kwd"] = "image"
|
||||
@ -338,6 +340,194 @@ def tokenize_table(tbls, doc, eng, batch_size=10):
|
||||
return res
|
||||
|
||||
|
||||
def attach_media_context(chunks, table_context_size=0, image_context_size=0):
|
||||
"""
|
||||
Attach surrounding text chunk content to media chunks (table/image).
|
||||
Best-effort ordering: if positional info exists on any chunk, use it to
|
||||
order chunks before collecting context; otherwise keep original order.
|
||||
"""
|
||||
if not chunks or (table_context_size <= 0 and image_context_size <= 0):
|
||||
return chunks
|
||||
|
||||
def is_image_chunk(ck):
|
||||
if ck.get("doc_type_kwd") == "image":
|
||||
return True
|
||||
|
||||
text_val = ck.get("content_with_weight") if isinstance(ck.get("content_with_weight"), str) else ck.get("text")
|
||||
has_text = isinstance(text_val, str) and text_val.strip()
|
||||
return bool(ck.get("image")) and not has_text
|
||||
|
||||
def is_table_chunk(ck):
|
||||
return ck.get("doc_type_kwd") == "table"
|
||||
|
||||
def is_text_chunk(ck):
|
||||
return not is_image_chunk(ck) and not is_table_chunk(ck)
|
||||
|
||||
def get_text(ck):
|
||||
if isinstance(ck.get("content_with_weight"), str):
|
||||
return ck["content_with_weight"]
|
||||
if isinstance(ck.get("text"), str):
|
||||
return ck["text"]
|
||||
return ""
|
||||
|
||||
def split_sentences(text):
|
||||
pattern = r"([.。!?!?;;::\n])"
|
||||
parts = re.split(pattern, text)
|
||||
sentences = []
|
||||
buf = ""
|
||||
for p in parts:
|
||||
if not p:
|
||||
continue
|
||||
if re.fullmatch(pattern, p):
|
||||
buf += p
|
||||
sentences.append(buf)
|
||||
buf = ""
|
||||
else:
|
||||
buf += p
|
||||
if buf:
|
||||
sentences.append(buf)
|
||||
return sentences
|
||||
|
||||
def trim_to_tokens(text, token_budget, from_tail=False):
|
||||
if token_budget <= 0 or not text:
|
||||
return ""
|
||||
sentences = split_sentences(text)
|
||||
if not sentences:
|
||||
return ""
|
||||
|
||||
collected = []
|
||||
remaining = token_budget
|
||||
seq = reversed(sentences) if from_tail else sentences
|
||||
for s in seq:
|
||||
tks = num_tokens_from_string(s)
|
||||
if tks <= 0:
|
||||
continue
|
||||
if tks > remaining:
|
||||
collected.append(s)
|
||||
break
|
||||
collected.append(s)
|
||||
remaining -= tks
|
||||
|
||||
if from_tail:
|
||||
collected = list(reversed(collected))
|
||||
return "".join(collected)
|
||||
|
||||
def extract_position(ck):
|
||||
pn = None
|
||||
top = None
|
||||
left = None
|
||||
try:
|
||||
if ck.get("page_num_int"):
|
||||
pn = ck["page_num_int"][0]
|
||||
elif ck.get("page_number") is not None:
|
||||
pn = ck.get("page_number")
|
||||
|
||||
if ck.get("top_int"):
|
||||
top = ck["top_int"][0]
|
||||
elif ck.get("top") is not None:
|
||||
top = ck.get("top")
|
||||
|
||||
if ck.get("position_int"):
|
||||
left = ck["position_int"][0][1]
|
||||
elif ck.get("x0") is not None:
|
||||
left = ck.get("x0")
|
||||
except Exception:
|
||||
pn = top = left = None
|
||||
return pn, top, left
|
||||
|
||||
indexed = list(enumerate(chunks))
|
||||
positioned_indices = []
|
||||
unpositioned_indices = []
|
||||
for idx, ck in indexed:
|
||||
pn, top, left = extract_position(ck)
|
||||
if pn is not None and top is not None:
|
||||
positioned_indices.append((idx, pn, top, left if left is not None else 0))
|
||||
else:
|
||||
unpositioned_indices.append(idx)
|
||||
|
||||
if positioned_indices:
|
||||
positioned_indices.sort(key=lambda x: (int(x[1]), int(x[2]), int(x[3]), x[0]))
|
||||
ordered_indices = [i for i, _, _, _ in positioned_indices] + unpositioned_indices
|
||||
else:
|
||||
ordered_indices = [idx for idx, _ in indexed]
|
||||
|
||||
total = len(ordered_indices)
|
||||
for sorted_pos, idx in enumerate(ordered_indices):
|
||||
ck = chunks[idx]
|
||||
token_budget = image_context_size if is_image_chunk(ck) else table_context_size if is_table_chunk(ck) else 0
|
||||
if token_budget <= 0:
|
||||
continue
|
||||
|
||||
prev_ctx = []
|
||||
remaining_prev = token_budget
|
||||
for prev_idx in range(sorted_pos - 1, -1, -1):
|
||||
if remaining_prev <= 0:
|
||||
break
|
||||
neighbor_idx = ordered_indices[prev_idx]
|
||||
if not is_text_chunk(chunks[neighbor_idx]):
|
||||
break
|
||||
txt = get_text(chunks[neighbor_idx])
|
||||
if not txt:
|
||||
continue
|
||||
tks = num_tokens_from_string(txt)
|
||||
if tks <= 0:
|
||||
continue
|
||||
if tks > remaining_prev:
|
||||
txt = trim_to_tokens(txt, remaining_prev, from_tail=True)
|
||||
tks = num_tokens_from_string(txt)
|
||||
prev_ctx.append(txt)
|
||||
remaining_prev -= tks
|
||||
prev_ctx.reverse()
|
||||
|
||||
next_ctx = []
|
||||
remaining_next = token_budget
|
||||
for next_idx in range(sorted_pos + 1, total):
|
||||
if remaining_next <= 0:
|
||||
break
|
||||
neighbor_idx = ordered_indices[next_idx]
|
||||
if not is_text_chunk(chunks[neighbor_idx]):
|
||||
break
|
||||
txt = get_text(chunks[neighbor_idx])
|
||||
if not txt:
|
||||
continue
|
||||
tks = num_tokens_from_string(txt)
|
||||
if tks <= 0:
|
||||
continue
|
||||
if tks > remaining_next:
|
||||
txt = trim_to_tokens(txt, remaining_next, from_tail=False)
|
||||
tks = num_tokens_from_string(txt)
|
||||
next_ctx.append(txt)
|
||||
remaining_next -= tks
|
||||
|
||||
if not prev_ctx and not next_ctx:
|
||||
continue
|
||||
|
||||
self_text = get_text(ck)
|
||||
pieces = [*prev_ctx]
|
||||
if self_text:
|
||||
pieces.append(self_text)
|
||||
pieces.extend(next_ctx)
|
||||
combined = "\n".join(pieces)
|
||||
|
||||
original = ck.get("content_with_weight")
|
||||
if "content_with_weight" in ck:
|
||||
ck["content_with_weight"] = combined
|
||||
elif "text" in ck:
|
||||
original = ck.get("text")
|
||||
ck["text"] = combined
|
||||
|
||||
if combined != original:
|
||||
if "content_ltks" in ck:
|
||||
ck["content_ltks"] = rag_tokenizer.tokenize(combined)
|
||||
if "content_sm_ltks" in ck:
|
||||
ck["content_sm_ltks"] = rag_tokenizer.fine_grained_tokenize(ck.get("content_ltks", rag_tokenizer.tokenize(combined)))
|
||||
|
||||
if positioned_indices:
|
||||
chunks[:] = [chunks[i] for i in ordered_indices]
|
||||
|
||||
return chunks
|
||||
|
||||
|
||||
def add_positions(d, poss):
|
||||
if not poss:
|
||||
return
|
||||
|
||||
@ -69,7 +69,7 @@ def convert_matching_field(field_weightstr: str) -> str:
|
||||
if field == "docnm_kwd" or field == "title_tks":
|
||||
field = "docnm@ft_docnm_rag_coarse"
|
||||
elif field == "title_sm_tks":
|
||||
field = "docnm@ft_title_rag_fine"
|
||||
field = "docnm@ft_docnm_rag_fine"
|
||||
elif field == "important_kwd":
|
||||
field = "important_keywords@ft_important_keywords_rag_coarse"
|
||||
elif field == "important_tks":
|
||||
|
||||
@ -42,6 +42,8 @@ DEFAULT_PARSER_CONFIG = {
|
||||
"auto_keywords": 0,
|
||||
"auto_questions": 0,
|
||||
"html4excel": False,
|
||||
"image_context_size": 0,
|
||||
"table_context_size": 0,
|
||||
"topn_tags": 3,
|
||||
"raptor": {
|
||||
"use_raptor": True,
|
||||
@ -62,4 +64,4 @@ DEFAULT_PARSER_CONFIG = {
|
||||
],
|
||||
"method": "light",
|
||||
},
|
||||
}
|
||||
}
|
||||
|
||||
Reference in New Issue
Block a user