diff --git a/api/apps/conversation_app.py b/api/apps/conversation_app.py
index f4d327993..fe1047bc6 100644
--- a/api/apps/conversation_app.py
+++ b/api/apps/conversation_app.py
@@ -58,7 +58,7 @@ def set_conversation():
conv = {
"id": get_uuid(),
"dialog_id": req["dialog_id"],
- "name": "New conversation",
+ "name": req.get("name", "New conversation"),
"message": [{"role": "assistant", "content": dia.prompt_config["prologue"]}]
}
ConversationService.save(**conv)
@@ -102,7 +102,7 @@ def rm():
def list_convsersation():
dialog_id = request.args["dialog_id"]
try:
- convs = ConversationService.query(dialog_id=dialog_id)
+ convs = ConversationService.query(dialog_id=dialog_id, order_by=ConversationService.model.create_time, reverse=True)
convs = [d.to_dict() for d in convs]
return get_json_result(data=convs)
except Exception as e:
diff --git a/api/utils/file_utils.py b/api/utils/file_utils.py
index 1d6f15f33..7f8145971 100644
--- a/api/utils/file_utils.py
+++ b/api/utils/file_utils.py
@@ -185,5 +185,11 @@ def thumbnail(filename, blob):
pass
+def traversal_files(base):
+ for root, ds, fs in os.walk(base):
+ for f in fs:
+ fullname = os.path.join(root, f)
+ yield fullname
+
diff --git a/deepdoc/README.md b/deepdoc/README.md
index d6f397f44..5c7235566 100644
--- a/deepdoc/README.md
+++ b/deepdoc/README.md
@@ -11,7 +11,36 @@ English | [简体中文](./README_zh.md)
With a bunch of documents from various domains with various formats and along with diverse retrieval requirements,
an accurate analysis becomes a very challenge task. *Deep*Doc is born for that purpose.
-There 2 parts in *Deep*Doc so far: vision and parser.
+There are 2 parts in *Deep*Doc so far: vision and parser.
+You can run the flowing test programs if you're interested in our results of OCR, layout recognition and TSR.
+```bash
+python deepdoc/vision/t_ocr.py -h
+usage: t_ocr.py [-h] --inputs INPUTS [--output_dir OUTPUT_DIR]
+
+options:
+ -h, --help show this help message and exit
+ --inputs INPUTS Directory where to store images or PDFs, or a file path to a single image or PDF
+ --output_dir OUTPUT_DIR
+ Directory where to store the output images. Default: './ocr_outputs'
+```
+```bash
+python deepdoc/vision/t_recognizer.py -h
+usage: t_recognizer.py [-h] --inputs INPUTS [--output_dir OUTPUT_DIR] [--threshold THRESHOLD] [--mode {layout,tsr}]
+
+options:
+ -h, --help show this help message and exit
+ --inputs INPUTS Directory where to store images or PDFs, or a file path to a single image or PDF
+ --output_dir OUTPUT_DIR
+ Directory where to store the output images. Default: './layouts_outputs'
+ --threshold THRESHOLD
+ A threshold to filter out detections. Default: 0.5
+ --mode {layout,tsr} Task mode: layout recognition or table structure recognition
+```
+
+Our models are served on HuggingFace. If you have trouble downloading HuggingFace models, this might help!!
+```bash
+export HF_ENDPOINT=https://hf-mirror.com
+```
## 2. Vision
@@ -19,9 +48,14 @@ There 2 parts in *Deep*Doc so far: vision and parser.
We use vision information to resolve problems as human being.
- OCR. Since a lot of documents presented as images or at least be able to transform to image,
OCR is a very essential and fundamental or even universal solution for text extraction.
-
+ ```bash
+ python deepdoc/vision/t_ocr.py --inputs=path_to_images_or_pdfs --output_dir=path_to_store_result
+ ```
+ The inputs could be directory to images or PDF, or a image or PDF.
+ You can look into the folder 'path_to_store_result' where has images which demonstrate the positions of results,
+ txt files which contain the OCR text.
-

+

-

+

-
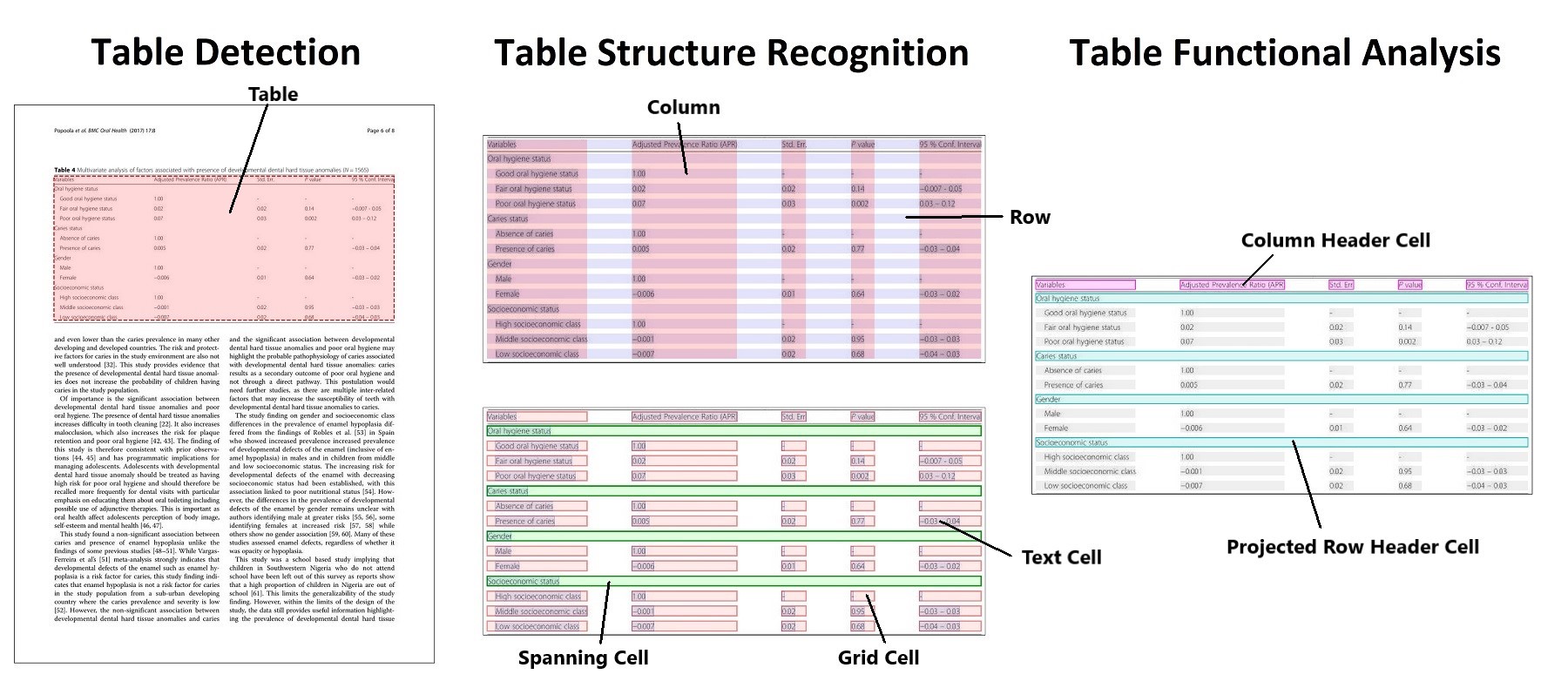
+

"
if cap:
@@ -339,8 +357,8 @@ class TableStructureRecognizer(Recognizer):
txt = ""
if arr:
h = min(np.min([c["bottom"] - c["top"] for c in arr]) / 2, 10)
- txt = "".join([c["text"]
- for c in self.sort_Y_firstly(arr, h)])
+ txt = " ".join([c["text"]
+ for c in Recognizer.sort_Y_firstly(arr, h)])
txts.append(txt)
sp = ""
if arr[0].get("colspan"):
@@ -366,7 +384,8 @@ class TableStructureRecognizer(Recognizer):
html += "\n
"
return html
- def __desc_table(self, cap, hdr_rowno, tbl, is_english):
+ @staticmethod
+ def __desc_table(cap, hdr_rowno, tbl, is_english):
# get text of every colomn in header row to become header text
clmno = len(tbl[0])
rowno = len(tbl)
@@ -469,7 +488,8 @@ class TableStructureRecognizer(Recognizer):
row_txt = [t + f"\t——{from_}“{cap}”" for t in row_txt]
return row_txt
- def __cal_spans(self, boxes, rows, cols, tbl, html=True):
+ @staticmethod
+ def __cal_spans(boxes, rows, cols, tbl, html=True):
# caculate span
clft = [np.mean([c.get("C_left", c["x0"]) for c in cln])
for cln in cols]
@@ -553,4 +573,3 @@ class TableStructureRecognizer(Recognizer):
tbl[rowspan[0]][colspan[0]] = arr
return tbl
-