mirror of
https://github.com/infiniflow/ragflow.git
synced 2026-01-23 11:36:38 +08:00
Added a guide on setting chat variables (#6904)
### What problem does this PR solve? ### Type of change - [x] Documentation Update
This commit is contained in:
23
docs/faq.mdx
23
docs/faq.mdx
@ -443,13 +443,26 @@ See [Upgrade RAGFlow](./guides/upgrade_ragflow.mdx) for more information.
|
||||
|
||||
To switch your document engine from Elasticsearch to [Infinity](https://github.com/infiniflow/infinity):
|
||||
|
||||
1. In **docker/.env**, set `DOC_ENGINE=${DOC_ENGINE:-infinity}`
|
||||
2. Restart your Docker image:
|
||||
1. Stop all running containers:
|
||||
|
||||
```bash
|
||||
$ docker compose -f docker-compose.yml up -d
|
||||
```
|
||||
```bash
|
||||
$ docker compose -f docker/docker-compose.yml down -v
|
||||
```
|
||||
:::caution WARNING
|
||||
`-v` will delete all Docker container volumes, and the existing data will be cleared.
|
||||
:::
|
||||
|
||||
2. In **docker/.env**, set `DOC_ENGINE=${DOC_ENGINE:-infinity}`
|
||||
3. Restart your Docker image:
|
||||
|
||||
```bash
|
||||
$ docker compose -f docker-compose.yml up -d
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### Where are my uploaded files stored in RAGFlow's image?
|
||||
|
||||
All uploaded files are stored in Minio, RAGFlow's object storage solution. For instance, if you upload your file directly to a knowledge base, it is located at `<knowledgebase_id>/filename`.
|
||||
|
||||
---
|
||||
@ -48,8 +48,8 @@ You can set global variables within the **Begin** component, which can be either
|
||||
|
||||
:::tip NOTE
|
||||
To pass in parameters from a client, call:
|
||||
- HTTP method [Converse with agent](../../references/http_api_reference.md#converse-with-agent), or
|
||||
- Python method [Converse with agent](../../referencespython_api_reference.md#converse-with-agent).
|
||||
- HTTP method [Converse with agent](../../../references/http_api_reference.md#converse-with-agent), or
|
||||
- Python method [Converse with agent](../../../referencespython_api_reference.md#converse-with-agent).
|
||||
:::
|
||||
|
||||
:::danger IMPORTANT
|
||||
|
||||
@ -20,7 +20,7 @@ Please note that some of your settings may consume a significant amount of time.
|
||||
Please note that rerank models are essential in certain scenarios. There is always a trade-off between speed and performance; you must weigh the pros against cons for your specific case.
|
||||
:::
|
||||
|
||||
- In the **Assistant Setting** tab of your **Chat Configuration** dialogue, disabling **Keyword analysis** will reduce the time to receive an answer from the LLM.
|
||||
- In the **Assistant settings** tab of your **Chat Configuration** dialogue, disabling **Keyword analysis** will reduce the time to receive an answer from the LLM.
|
||||
- When chatting with your chat assistant, click the light bulb icon above the *current* dialogue and scroll down the popup window to view the time taken for each task:
|
||||

|
||||
|
||||
|
||||
@ -15,11 +15,11 @@ From v0.17.0 onward, RAGFlow supports integrating agentic reasoning in an AI cha
|
||||
|
||||
To activate this feature:
|
||||
|
||||
1. Enable the **Reasoning** toggle under the **Prompt Engine** tab of your chat assistant dialogue.
|
||||
1. Enable the **Reasoning** toggle under the **Prompt engine** tab of your chat assistant dialogue.
|
||||
|
||||

|
||||
|
||||
2. Enter the correct Tavily API key under the **Assistant Setting** tab of your chat assistant dialogue to leverage Tavily-based web search
|
||||
2. Enter the correct Tavily API key under the **Assistant settings** tab of your chat assistant dialogue to leverage Tavily-based web search
|
||||
|
||||

|
||||
|
||||
|
||||
112
docs/guides/chat/set_chat_variables.md
Normal file
112
docs/guides/chat/set_chat_variables.md
Normal file
@ -0,0 +1,112 @@
|
||||
---
|
||||
sidebar_position: 4
|
||||
slug: /set_chat_variables
|
||||
---
|
||||
|
||||
# Set variables
|
||||
|
||||
Set variables to be used together with the system prompt for your LLM.
|
||||
|
||||
---
|
||||
|
||||
When configuring the system prompt for a chat model, variables play an important role in enhancing flexibility and reusability. With variables, you can dynamically adjust the system prompt to be sent to your model. In the context of RAGFlow, if you have defined variables in the **Chat Configuration** dialogue, except for the system's reserved variable `{knowledge}`, you are required to pass in values for them from RAGFlow's [HTTP API](../../references/http_api_reference.md#converse-with-chat-assistant) or through its [Python SDK](../../references/python_api_reference.md#converse-with-chat-assistant).
|
||||
|
||||
:::danger IMPORTANT
|
||||
In RAGFlow, variables are closely linked with the system prompt. When you add a variable in the **Variable** section, include it in the system prompt. Conversely, when deleting a variable, ensure it is removed from the system prompt; otherwise, an error would occur.
|
||||
:::
|
||||
|
||||
## Where to set variables
|
||||
|
||||
Hover your mouse over your chat assistant, click **Edit** to open its **Chat Configuration** dialogue, then click the **Prompt Engine** tab. Here, you can work on your variables in the **System prompt** field and the **Variable** section:
|
||||
|
||||
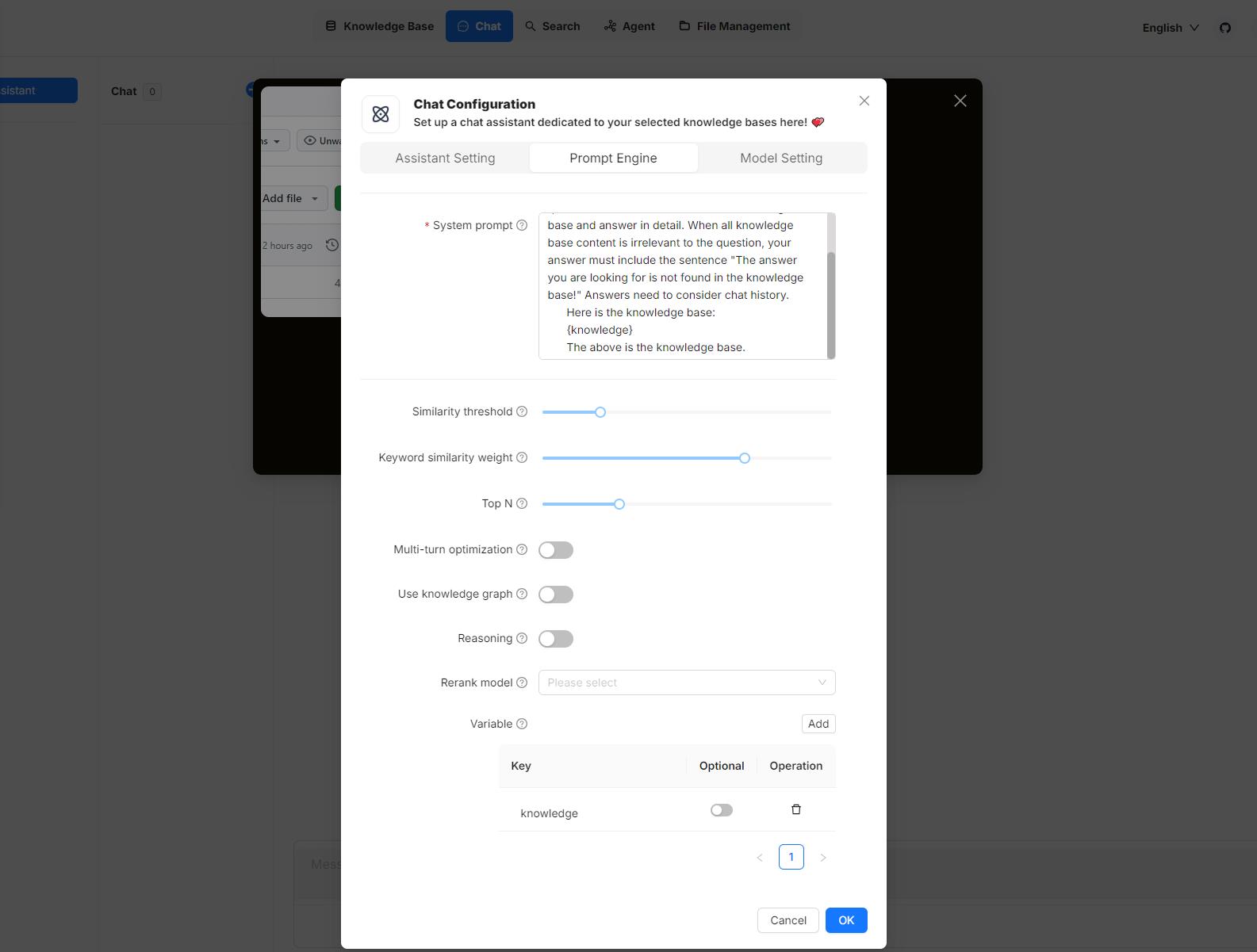
|
||||
|
||||
## 1. Manage variables
|
||||
|
||||
In the **Variable** section, you add, remove, or update variables.
|
||||
|
||||
### `{knowledge}` - a reserved variable
|
||||
|
||||
`{knowledge}` is the system's reserved variable, representing the chunks retrieved from the knowledge base(s) specified by **Knowledge bases** under the **Assistant settings** tab. If your chat assistant is associated with certain knowledge bases, you can keep it as is.
|
||||
|
||||
:::info NOTE
|
||||
It does not currently make a difference whether you set `{knowledge}` to optional or mandatory, but note that this design will be updated at a later point.
|
||||
:::
|
||||
|
||||
From v0.17.0 onward, you can start an AI chat without specifying knowledge bases. In this case, we recommend removing the `{knowledge}` variable to prevent unnecessary references and keeping the **Empty response** field empty to avoid errors.
|
||||
|
||||
### Custom variables
|
||||
|
||||
Besides `{knowledge}`, you can also define your own variables to pair with the system prompt. To use these custom variables, you must pass in their values through RAGFlow's official APIs. The **Optional** toggle determines whether these variables are required in the corresponding APIs:
|
||||
|
||||
- **Disabled** (Default): The variable is mandatory and must be provided.
|
||||
- **Enabled**: The variable is optional and can be omitted if not needed.
|
||||
|
||||
|
||||
|
||||
## 2. Update system prompt
|
||||
|
||||
After you add or remove variables in the **Variable** section, ensure your changes are reflected in the system prompt to avoid inconsistencies and errors. Here's an example:
|
||||
|
||||
```
|
||||
You are an intelligent assistant. Please answer the question by summarizing chunks from the specified knowledge base(s)...
|
||||
|
||||
Your answers should follow a professional and {style} style.
|
||||
|
||||
Here is the knowledge base:
|
||||
{knowledge}
|
||||
The above is the knowledge base.
|
||||
```
|
||||
|
||||
:::tip NOTE
|
||||
If you have removed `{knowledge}`, ensure that you thoroughly review and update the entire system prompt to achieve optimal results.
|
||||
:::
|
||||
|
||||
## APIs
|
||||
|
||||
The *only* way to pass in values for the custom variables defined in the **Chat Configuration** dialogue is to call RAGFlow's [HTTP API](../../references/http_api_reference.md#converse-with-chat-assistant) or through its [Python SDK](../../references/python_api_reference.md#converse-with-chat-assistant).
|
||||
|
||||
### HTTP API
|
||||
|
||||
See [Converse with chat assistant](../../references/http_api_reference.md#converse-with-chat-assistant). Here's an example:
|
||||
|
||||
```json {9}
|
||||
curl --request POST \
|
||||
--url http://{address}/api/v1/chats/{chat_id}/completions \
|
||||
--header 'Content-Type: application/json' \
|
||||
--header 'Authorization: Bearer <YOUR_API_KEY>' \
|
||||
--data-binary '
|
||||
{
|
||||
"question": "xxxxxxxxx",
|
||||
"stream": true,
|
||||
"style":"hilarious"
|
||||
}'
|
||||
```
|
||||
|
||||
### Python API
|
||||
|
||||
See [Converse with chat assistant](../../references/python_api_reference.md#converse-with-chat-assistant). Here's an example:
|
||||
|
||||
```python {18}
|
||||
from ragflow_sdk import RAGFlow
|
||||
|
||||
rag_object = RAGFlow(api_key="<YOUR_API_KEY>", base_url="http://<YOUR_BASE_URL>:9380")
|
||||
assistant = rag_object.list_chats(name="Miss R")
|
||||
assistant = assistant[0]
|
||||
session = assistant.create_session()
|
||||
|
||||
print("\n==================== Miss R =====================\n")
|
||||
print("Hello. What can I do for you?")
|
||||
|
||||
while True:
|
||||
question = input("\n==================== User =====================\n> ")
|
||||
style = input("Please enter your preferred style (e.g., formal, informal, hilarious): ")
|
||||
|
||||
print("\n==================== Miss R =====================\n")
|
||||
|
||||
cont = ""
|
||||
for ans in session.ask(question, stream=True, style=style):
|
||||
print(ans.content[len(cont):], end='', flush=True)
|
||||
cont = ans.content
|
||||
```
|
||||
|
||||
@ -19,7 +19,7 @@ You start an AI conversation by creating an assistant.
|
||||
|
||||
> RAGFlow offers you the flexibility of choosing a different chat model for each dialogue, while allowing you to set the default models in **System Model Settings**.
|
||||
|
||||
2. Update **Assistant Setting**:
|
||||
2. Update **Assistant Settings**:
|
||||
|
||||
- **Assistant name** is the name of your chat assistant. Each assistant corresponds to a dialogue with a unique combination of knowledge bases, prompts, hybrid search configurations, and large model settings.
|
||||
- **Empty response**:
|
||||
|
||||
@ -70,7 +70,7 @@ In a knowledge graph, a community is a cluster of entities linked by relationshi
|
||||
3. Click **Knowledge graph** to view the details of the generated graph.
|
||||
4. To use the created knowledge graph, do either of the following:
|
||||
|
||||
- In your **Chat Configuration** dialogue, click the **Assistant Setting** tab to add the corresponding knowledge base(s) and click the **Prompt Engine** tab to switch on the **Use knowledge graph** toggle.
|
||||
- In your **Chat Configuration** dialogue, click the **Assistant settings** tab to add the corresponding knowledge base(s) and click the **Prompt engine** tab to switch on the **Use knowledge graph** toggle.
|
||||
- If you are using an agent, click the **Retrieval** agent component to specify the knowledge base(s) and switch on the **Use knowledge graph** toggle.
|
||||
|
||||
## Frequently asked questions
|
||||
|
||||
@ -11,7 +11,7 @@ Use a tag set to tag chunks in your datasets.
|
||||
|
||||
Retrieval accuracy is the touchstone for a production-ready RAG framework. In addition to retrieval-enhancing approaches like auto-keyword, auto-question, and knowledge graph, RAGFlow introduces an auto-tagging feature to address semantic gaps. The auto-tagging feature automatically maps tags in the user-defined tag sets to relevant chunks within your knowledge base based on similarity with each chunk. This automation mechanism allows you to apply an additional "layer" of domain-specific knowledge to existing datasets, which is particularly useful when dealing with a large number of chunks.
|
||||
|
||||
To use this feature, ensure you have at least one properly configured tag set, specify the tag set(s) on the **Configuration** page of your knowledge base (dataset), and then re-parse your documents to initiate the auto-tag process. During this process, each chunk in your dataset is compared with every entry in the specified tag set(s), and tags are automatically applied based on similarity.
|
||||
To use this feature, ensure you have at least one properly configured tag set, specify the tag set(s) on the **Configuration** page of your knowledge base (dataset), and then re-parse your documents to initiate the auto-tagging process. During this process, each chunk in your dataset is compared with every entry in the specified tag set(s), and tags are automatically applied based on similarity.
|
||||
|
||||
:::caution NOTE
|
||||
The auto-tagging feature is *unavailable* on the [Infinity](https://github.com/infiniflow/infinity) document engine.
|
||||
@ -19,7 +19,7 @@ The auto-tagging feature is *unavailable* on the [Infinity](https://github.com/i
|
||||
|
||||
## Scenarios
|
||||
|
||||
Auto-tagging applies in situations where chunks are so similar to each other that the intended chunks cannot be distinguished from the rest. For example, when you have a few chunks about iPhone and a majority about iPhone case or iPhone accessaries, it becomes difficult to retrieve the iPhone-specific chunks without additional information.
|
||||
Auto-tagging applies in situations where chunks are so similar to each other that the intended chunks cannot be distinguished from the rest. For example, when you have a few chunks about iPhone and a majority about iPhone case or iPhone accessaries, it becomes difficult to retrieve those chunks about iPhone without additional information.
|
||||
|
||||
## Create tag set
|
||||
|
||||
|
||||
@ -7,7 +7,7 @@ slug: /manage_files
|
||||
|
||||
Knowledge base, hallucination-free chat, and file management are the three pillars of RAGFlow. RAGFlow's file management allows you to upload files individually or in bulk. You can then link an uploaded file to multiple target knowledge bases. This guide showcases some basic usages of the file management feature.
|
||||
|
||||
:::danger IMPORTANT
|
||||
:::info IMPORTANT
|
||||
Compared to uploading files directly to various knowledge bases, uploading them to RAGFlow's file management and then linking them to different knowledge bases is *not* an unnecessary step, particularly when you want to delete some parsed files or an entire knowledge base but retain the original files.
|
||||
:::
|
||||
|
||||
@ -17,7 +17,9 @@ RAGFlow's file management allows you to establish your file system with nested f
|
||||
|
||||

|
||||
|
||||
> Each knowledge base in RAGFlow has a corresponding folder under the **root/.knowledgebase** directory. You are not allowed to create a subfolder within it.
|
||||
:::caution NOTE
|
||||
Each knowledge base in RAGFlow has a corresponding folder under the **root/.knowledgebase** directory. You are not allowed to create a subfolder within it.
|
||||
:::
|
||||
|
||||
## Upload file
|
||||
|
||||
|
||||
@ -39,4 +39,4 @@ _After accepting the team invite, you should be able to view and update the team
|
||||
|
||||
## Leave a joined team
|
||||
|
||||

|
||||
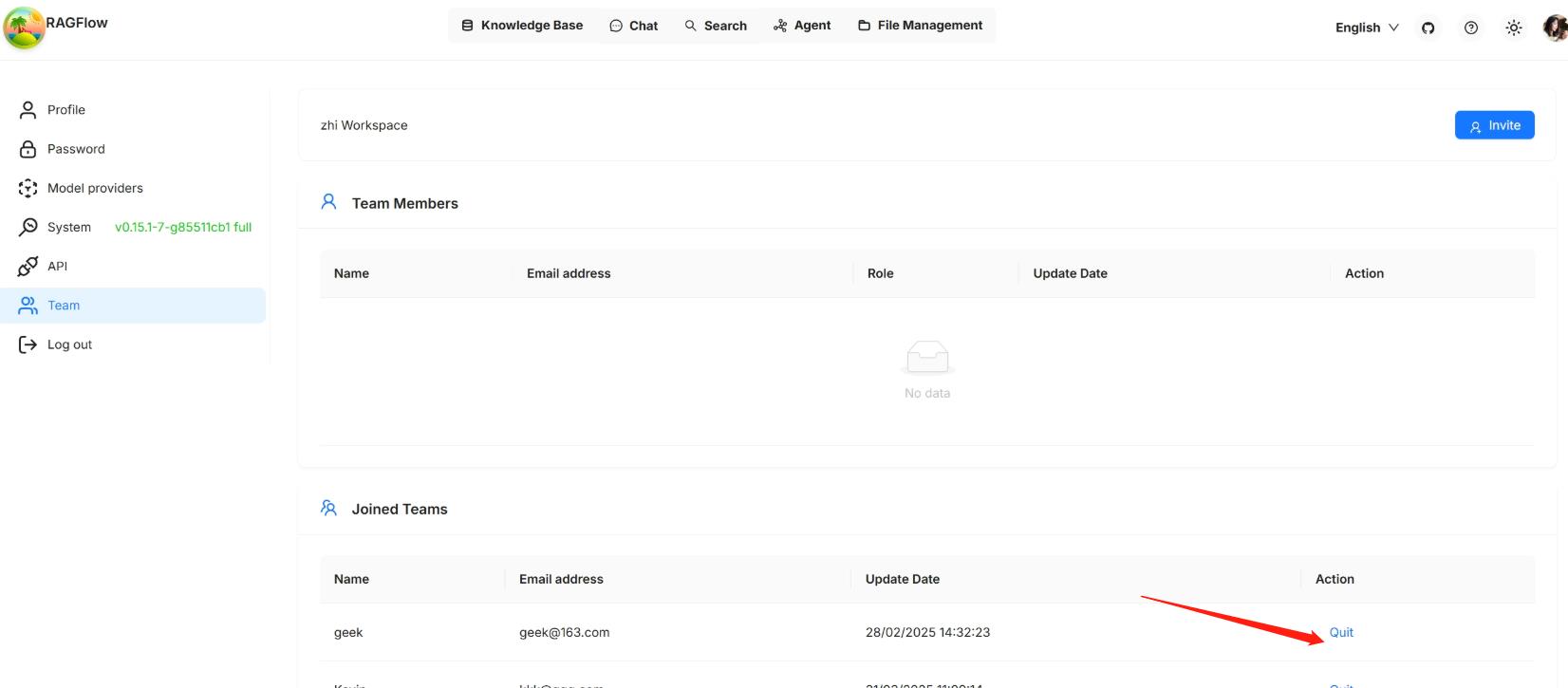
|
||||
@ -302,7 +302,7 @@ Once you have selected an embedding model and used it to parse a file, you are n
|
||||
_When the file parsing completes, its parsing status changes to **SUCCESS**._
|
||||
|
||||
:::caution NOTE
|
||||
- If your file parsing gets stuck at below 1%, see [this FAQ](./faq.mdxfaq#why-does-my-document-parsing-stall-at-under-one-percent).
|
||||
- If your file parsing gets stuck at below 1%, see [this FAQ](./faq.mdx#why-does-my-document-parsing-stall-at-under-one-percent).
|
||||
- If your file parsing gets stuck at near completion, see [this FAQ](./faq.mdx#why-does-my-pdf-parsing-stall-near-completion-while-the-log-does-not-show-any-error)
|
||||
:::
|
||||
|
||||
@ -339,16 +339,16 @@ Conversations in RAGFlow are based on a particular knowledge base or multiple kn
|
||||
1. Click the **Chat** tab in the middle top of the mage **>** **Create an assistant** to show the **Chat Configuration** dialogue *of your next dialogue*.
|
||||
> RAGFlow offer the flexibility of choosing a different chat model for each dialogue, while allowing you to set the default models in **System Model Settings**.
|
||||
|
||||
2. Update **Assistant Setting**:
|
||||
2. Update **Assistant settings**:
|
||||
|
||||
- Name your assistant and specify your knowledge bases.
|
||||
- **Empty response**:
|
||||
- If you wish to *confine* RAGFlow's answers to your knowledge bases, leave a response here. Then when it doesn't retrieve an answer, it *uniformly* responds with what you set here.
|
||||
- If you wish RAGFlow to *improvise* when it doesn't retrieve an answer from your knowledge bases, leave it blank, which may give rise to hallucinations.
|
||||
|
||||
3. Update **Prompt Engine** or leave it as is for the beginning.
|
||||
3. Update **Prompt engine** or leave it as is for the beginning.
|
||||
|
||||
4. Update **Model Setting**.
|
||||
4. Update **Model settings**.
|
||||
|
||||
5. Now, let's start the show:
|
||||
|
||||
|
||||
@ -403,7 +403,7 @@ curl --request POST \
|
||||
- `"chunk_token_count"`: Defaults to `128`.
|
||||
- `"layout_recognize"`: Defaults to `true`.
|
||||
- `"html4excel"`: Indicates whether to convert Excel documents into HTML format. Defaults to `false`.
|
||||
- `"delimiter"`: Defaults to `"\n!?。;!?"`.
|
||||
- `"delimiter"`: Defaults to `"\n"`.
|
||||
- `"task_page_size"`: Defaults to `12`. For PDF only.
|
||||
- `"raptor"`: Raptor-specific settings. Defaults to: `{"use_raptor": false}`.
|
||||
- If `"chunk_method"` is `"qa"`, `"manuel"`, `"paper"`, `"book"`, `"laws"`, or `"presentation"`, the `"parser_config"` object contains the following attribute:
|
||||
@ -411,7 +411,7 @@ curl --request POST \
|
||||
- If `"chunk_method"` is `"table"`, `"picture"`, `"one"`, or `"email"`, `"parser_config"` is an empty JSON object.
|
||||
- If `"chunk_method"` is `"knowledge_graph"`, the `"parser_config"` object contains the following attributes:
|
||||
- `"chunk_token_count"`: Defaults to `128`.
|
||||
- `"delimiter"`: Defaults to `"\n!?。;!?"`.
|
||||
- `"delimiter"`: Defaults to `"\n"`.
|
||||
- `"entity_types"`: Defaults to `["organization","person","location","event","time"]`
|
||||
|
||||
#### Response
|
||||
@ -436,7 +436,7 @@ Success:
|
||||
"name": "test_1",
|
||||
"parser_config": {
|
||||
"chunk_token_num": 128,
|
||||
"delimiter": "\\n!?;。;!?",
|
||||
"delimiter": "\\n",
|
||||
"html4excel": false,
|
||||
"layout_recognize": true,
|
||||
"raptor": {
|
||||
@ -658,7 +658,7 @@ Success:
|
||||
"chunk_method": "knowledge_graph",
|
||||
"parser_config": {
|
||||
"chunk_token_num": 8192,
|
||||
"delimiter": "\\n!?;。;!?",
|
||||
"delimiter": "\\n",
|
||||
"entity_types": [
|
||||
"organization",
|
||||
"person",
|
||||
@ -746,7 +746,7 @@ Success:
|
||||
"name": "1.txt",
|
||||
"parser_config": {
|
||||
"chunk_token_num": 128,
|
||||
"delimiter": "\\n!?;。;!?",
|
||||
"delimiter": "\\n",
|
||||
"html4excel": false,
|
||||
"layout_recognize": true,
|
||||
"raptor": {
|
||||
@ -835,7 +835,7 @@ curl --request PUT \
|
||||
- `"chunk_token_count"`: Defaults to `128`.
|
||||
- `"layout_recognize"`: Defaults to `true`.
|
||||
- `"html4excel"`: Indicates whether to convert Excel documents into HTML format. Defaults to `false`.
|
||||
- `"delimiter"`: Defaults to `"\n!?。;!?"`.
|
||||
- `"delimiter"`: Defaults to `"\n"`.
|
||||
- `"task_page_size"`: Defaults to `12`. For PDF only.
|
||||
- `"raptor"`: Raptor-specific settings. Defaults to: `{"use_raptor": false}`.
|
||||
- If `"chunk_method"` is `"qa"`, `"manuel"`, `"paper"`, `"book"`, `"laws"`, or `"presentation"`, the `"parser_config"` object contains the following attribute:
|
||||
@ -843,7 +843,7 @@ curl --request PUT \
|
||||
- If `"chunk_method"` is `"table"`, `"picture"`, `"one"`, or `"email"`, `"parser_config"` is an empty JSON object.
|
||||
- If `"chunk_method"` is `"knowledge_graph"`, the `"parser_config"` object contains the following attributes:
|
||||
- `"chunk_token_count"`: Defaults to `128`.
|
||||
- `"delimiter"`: Defaults to `"\n!?。;!?"`.
|
||||
- `"delimiter"`: Defaults to `"\n"`.
|
||||
- `"entity_types"`: Defaults to `["organization","person","location","event","time"]`
|
||||
|
||||
#### Response
|
||||
@ -978,7 +978,7 @@ Success:
|
||||
"name": "Test_2.txt",
|
||||
"parser_config": {
|
||||
"chunk_token_count": 128,
|
||||
"delimiter": "\n!?。;!?",
|
||||
"delimiter": "\n",
|
||||
"layout_recognize": true,
|
||||
"task_page_size": 12
|
||||
},
|
||||
@ -1335,7 +1335,7 @@ Success:
|
||||
"name": "1.txt",
|
||||
"parser_config": {
|
||||
"chunk_token_num": 128,
|
||||
"delimiter": "\\n!?;。;!?",
|
||||
"delimiter": "\\n",
|
||||
"html4excel": false,
|
||||
"layout_recognize": true,
|
||||
"raptor": {
|
||||
|
||||
@ -154,7 +154,7 @@ The chunking method of the dataset to create. Available options:
|
||||
The parser configuration of the dataset. A `ParserConfig` object's attributes vary based on the selected `chunk_method`:
|
||||
|
||||
- `chunk_method`=`"naive"`:
|
||||
`{"chunk_token_num":128,"delimiter":"\\n!?;。;!?","html4excel":False,"layout_recognize":True,"raptor":{"user_raptor":False}}`.
|
||||
`{"chunk_token_num":128,"delimiter":"\\n","html4excel":False,"layout_recognize":True,"raptor":{"user_raptor":False}}`.
|
||||
- `chunk_method`=`"qa"`:
|
||||
`{"raptor": {"user_raptor": False}}`
|
||||
- `chunk_method`=`"manuel"`:
|
||||
@ -174,7 +174,7 @@ The parser configuration of the dataset. A `ParserConfig` object's attributes va
|
||||
- `chunk_method`=`"one"`:
|
||||
`None`
|
||||
- `chunk_method`=`"knowledge-graph"`:
|
||||
`{"chunk_token_num":128,"delimiter":"\\n!?;。;!?","entity_types":["organization","person","location","event","time"]}`
|
||||
`{"chunk_token_num":128,"delimiter":"\\n","entity_types":["organization","person","location","event","time"]}`
|
||||
- `chunk_method`=`"email"`:
|
||||
`None`
|
||||
|
||||
@ -403,7 +403,7 @@ A dictionary representing the attributes to update, with the following keys:
|
||||
- `"email"`: Email
|
||||
- `"parser_config"`: `dict[str, Any]` The parsing configuration for the document. Its attributes vary based on the selected `"chunk_method"`:
|
||||
- `"chunk_method"`=`"naive"`:
|
||||
`{"chunk_token_num":128,"delimiter":"\\n!?;。;!?","html4excel":False,"layout_recognize":True,"raptor":{"user_raptor":False}}`.
|
||||
`{"chunk_token_num":128,"delimiter":"\\n","html4excel":False,"layout_recognize":True,"raptor":{"user_raptor":False}}`.
|
||||
- `chunk_method`=`"qa"`:
|
||||
`{"raptor": {"user_raptor": False}}`
|
||||
- `chunk_method`=`"manuel"`:
|
||||
@ -423,7 +423,7 @@ A dictionary representing the attributes to update, with the following keys:
|
||||
- `chunk_method`=`"one"`:
|
||||
`None`
|
||||
- `chunk_method`=`"knowledge-graph"`:
|
||||
`{"chunk_token_num":128,"delimiter":"\\n!?;。;!?","entity_types":["organization","person","location","event","time"]}`
|
||||
`{"chunk_token_num":128,"delimiter":"\\n","entity_types":["organization","person","location","event","time"]}`
|
||||
- `chunk_method`=`"email"`:
|
||||
`None`
|
||||
|
||||
@ -543,7 +543,7 @@ A `Document` object contains the following attributes:
|
||||
- `status`: `str` Reserved for future use.
|
||||
- `parser_config`: `ParserConfig` Configuration object for the parser. Its attributes vary based on the selected `chunk_method`:
|
||||
- `chunk_method`=`"naive"`:
|
||||
`{"chunk_token_num":128,"delimiter":"\\n!?;。;!?","html4excel":False,"layout_recognize":True,"raptor":{"user_raptor":False}}`.
|
||||
`{"chunk_token_num":128,"delimiter":"\\n","html4excel":False,"layout_recognize":True,"raptor":{"user_raptor":False}}`.
|
||||
- `chunk_method`=`"qa"`:
|
||||
`{"raptor": {"user_raptor": False}}`
|
||||
- `chunk_method`=`"manuel"`:
|
||||
@ -563,7 +563,7 @@ A `Document` object contains the following attributes:
|
||||
- `chunk_method`=`"one"`:
|
||||
`None`
|
||||
- `chunk_method`=`"knowledge-graph"`:
|
||||
`{"chunk_token_num":128,"delimiter": "\\n!?;。;!?","entity_types":["organization","person","location","event","time"]}`
|
||||
`{"chunk_token_num":128,"delimiter": "\\n","entity_types":["organization","person","location","event","time"]}`
|
||||
- `chunk_method`=`"email"`:
|
||||
`None`
|
||||
|
||||
|
||||
@ -75,7 +75,7 @@ Released on March 3, 2025.
|
||||
### New features
|
||||
|
||||
- AI chat: Implements Deep Research for agentic reasoning. To activate this, enable the **Reasoning** toggle under the **Prompt Engine** tab of your chat assistant dialogue.
|
||||
- AI chat: Leverages Tavily-based web search to enhance contexts in agentic reasoning. To activate this, enter the correct Tavily API key under the **Assistant Setting** tab of your chat assistant dialogue.
|
||||
- AI chat: Leverages Tavily-based web search to enhance contexts in agentic reasoning. To activate this, enter the correct Tavily API key under the **Assistant settings** tab of your chat assistant dialogue.
|
||||
- AI chat: Supports starting a chat without specifying knowledge bases.
|
||||
- AI chat: HTML files can also be previewed and referenced, in addition to PDF files.
|
||||
- Dataset: Adds a **PDF parser**, aka **Document parser**, dropdown menu to dataset configurations. This includes a DeepDoc model option, which is time-consuming, a much faster **naive** option (plain text), which skips DLA (Document Layout Analysis), OCR (Optical Character Recognition), and TSR (Table Structure Recognition) tasks, and several currently *experimental* large model options.
|
||||
|
||||
Reference in New Issue
Block a user