mirror of
https://github.com/infiniflow/ragflow.git
synced 2026-02-07 02:55:08 +08:00
Fix typos (#11208)
### What problem does this PR solve? As title ### Type of change - [x] Documentation Update Signed-off-by: Jin Hai <haijin.chn@gmail.com>
This commit is contained in:
@ -58,7 +58,7 @@ The Auto-keyword or Auto-question values relate closely to the chunking size in
|
||||
|---------------------------------------------------------------------|---------------------------------|----------------------------|----------------------------|
|
||||
| Internal process guidance for employee handbook | Small, under 10 pages | 0 | 0 |
|
||||
| Customer service FAQs | Medium, 10–100 pages | 3–7 | 1–3 |
|
||||
| Technical whitepapers: Development standards, protocol details | Large, over 100 pages | 2–4 | 1–2 |
|
||||
| Technical white papers: Development standards, protocol details | Large, over 100 pages | 2–4 | 1–2 |
|
||||
| Contracts / Regulations / Legal clause retrieval | Large, over 50 pages | 2–5 | 0–1 |
|
||||
| Multi-repository layered new documents + old archive | Many | Adjust as appropriate |Adjust as appropriate |
|
||||
| Social media comment pool: multilingual & mixed spelling | Very large volume of short text | 8–12 | 0 |
|
||||
|
||||
@ -91,7 +91,7 @@ Nope. The knowledge graph does *not* update *until* you regenerate a knowledge g
|
||||
|
||||
### How to remove a generated knowledge graph?
|
||||
|
||||
On the **Configuration** page of your dataset, find the **Knoweledge graph** field and click the recycle bin button to the right of the field.
|
||||
On the **Configuration** page of your dataset, find the **Knowledge graph** field and click the recycle bin button to the right of the field.
|
||||
|
||||
### Where is the created knowledge graph stored?
|
||||
|
||||
|
||||
@ -12,7 +12,7 @@ Convert complex Excel spreadsheets into HTML tables.
|
||||
When using the **General** chunking method, you can enable the **Excel to HTML** toggle to convert spreadsheet files into HTML tables. If it is disabled, spreadsheet tables will be represented as key-value pairs. For complex tables that cannot be simply represented this way, you must enable this feature.
|
||||
|
||||
:::caution WARNING
|
||||
The feature is disabled by default. If your dataset contains spreadsheets with complex tables and you do not enable this feature, RAGFlow will not throw an error but your tables are likely to be garbled.
|
||||
The feature is disabled by default. If your dataset contains spreadsheets with complex tables, and you do not enable this feature, RAGFlow will not throw an error but your tables are likely to be garbled.
|
||||
:::
|
||||
|
||||
## Scenarios
|
||||
|
||||
@ -13,7 +13,7 @@ RAPTOR (Recursive Abstractive Processing for Tree Organized Retrieval) is an enh
|
||||
|
||||
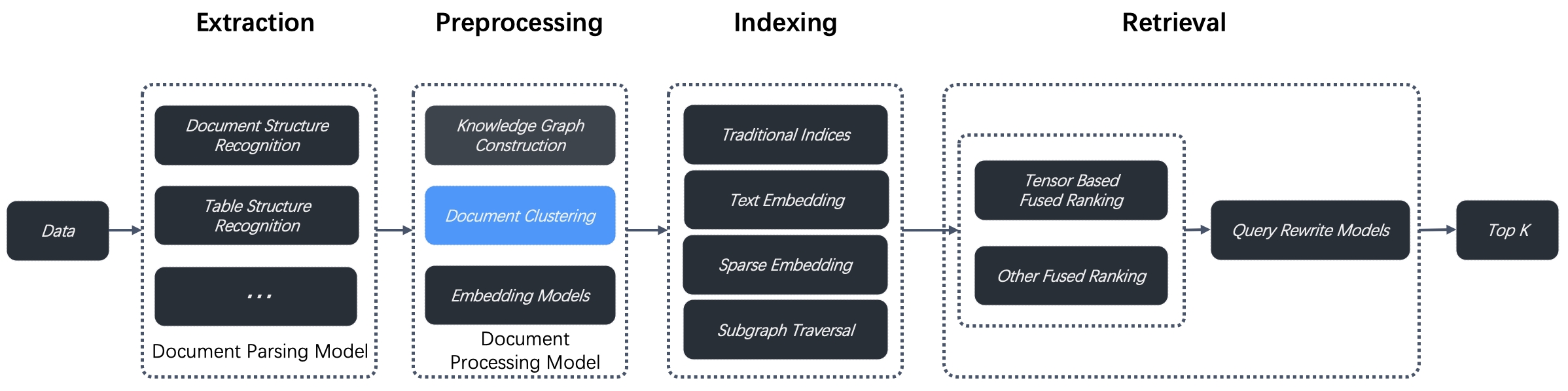
|
||||
|
||||
Our tests with this new approach demonstrate state-of-the-art (SOTA) results on question-answering tasks requiring complex, multi-step reasoning. By combining RAPTOR retrieval with our built-in chunking methods and/or other retrieval-augmented generation (RAG) approaches, you can further improve your question-answering accuracy.
|
||||
Our tests with this new approach demonstrate state-of-the-art (SOTA) results on question-answering tasks requiring complex, multistep reasoning. By combining RAPTOR retrieval with our built-in chunking methods and/or other retrieval-augmented generation (RAG) approaches, you can further improve your question-answering accuracy.
|
||||
|
||||
:::danger WARNING
|
||||
Enabling RAPTOR requires significant memory, computational resources, and tokens.
|
||||
@ -29,7 +29,7 @@ The recursive clustering and summarization capture a broad understanding (by the
|
||||
|
||||
## Scenarios
|
||||
|
||||
For multi-hop question-answering tasks involving complex, multi-step reasoning, a semantic gap often exists between the question and its answer. As a result, searching with the question often fails to retrieve the relevant chunks that contribute to the correct answer. RAPTOR addresses this challenge by providing the chat model with richer and more context-aware and relevant chunks to summarize, enabling a holistic understanding without losing granular details.
|
||||
For multi-hop question-answering tasks involving complex, multistep reasoning, a semantic gap often exists between the question and its answer. As a result, searching with the question often fails to retrieve the relevant chunks that contribute to the correct answer. RAPTOR addresses this challenge by providing the chat model with richer and more context-aware and relevant chunks to summarize, enabling a holistic understanding without losing granular details.
|
||||
|
||||
:::tip NOTE
|
||||
Knowledge graphs can also be used for multi-hop question-answering tasks. See [Construct knowledge graph](./construct_knowledge_graph.md) for details. You may use either approach or both, but ensure you understand the memory, computational, and token costs involved.
|
||||
|
||||
@ -23,7 +23,7 @@ RAGFlow isn't one-size-fits-all. It is built for flexibility and supports deeper
|
||||
- **Laws**
|
||||
- **Presentation**
|
||||
- **One**
|
||||
- To use a third-party visual model for parsing PDFs, ensure you have set a default img2txt model under **Set default models** on the **Model providers** page.
|
||||
- To use a third-party visual model for parsing PDFs, ensure you have set a default VLM under **Set default models** on the **Model providers** page.
|
||||
|
||||
## Quickstart
|
||||
|
||||
@ -39,7 +39,7 @@ RAGFlow isn't one-size-fits-all. It is built for flexibility and supports deeper
|
||||
- [Docling](https://github.com/docling-project/docling): (Experimental) An open-source document processing tool for gen AI.
|
||||
- A third-party visual model from a specific model provider.
|
||||
|
||||
:::danger IMPORTANG
|
||||
:::danger IMPORTANT
|
||||
MinerU PDF document parsing is available starting from v0.22.0. RAGFlow supports MinerU (>= 2.6.3) as an optional PDF parser with multiple backends. RAGFlow acts only as a client for MinerU, calling it to parse documents, reading the output files, and ingesting the parsed content. To use this feature, follow these steps:
|
||||
|
||||
1. Prepare MinerU:
|
||||
@ -90,7 +90,7 @@ MinerU PDF document parsing is available starting from v0.22.0. RAGFlow supports
|
||||
```
|
||||
|
||||
3. Restart the ragflow-server.
|
||||
4. In the web UI, navigate to the **Configuration** page of your dataset. Click **Built-in** in the **Ingestion pipeline** section, select a chunking method from the **Built-in** dropdown, which supports PDF parsing, and slect **MinerU** in **PDF parser**.
|
||||
4. In the web UI, navigate to the **Configuration** page of your dataset. Click **Built-in** in the **Ingestion pipeline** section, select a chunking method from the **Built-in** dropdown, which supports PDF parsing, and select **MinerU** in **PDF parser**.
|
||||
5. If you use a custom ingestion pipeline instead, you must also complete the first three steps before selecting **MinerU** in the **Parsing method** section of the **Parser** component.
|
||||
:::
|
||||
|
||||
@ -102,7 +102,7 @@ Third-party visual models are marked **Experimental**, because we have not fully
|
||||
|
||||
### When should I select DeepDoc or a third-party visual model as the PDF parser?
|
||||
|
||||
Use a visual model to extract data if your PDFs contain formatted or image-based text rather than plain text. DeepDoc is the default visual model but can be time-consuming. You can also choose a lightweight or high-performance img2txt model depending on your needs and hardware capabilities.
|
||||
Use a visual model to extract data if your PDFs contain formatted or image-based text rather than plain text. DeepDoc is the default visual model but can be time-consuming. You can also choose a lightweight or high-performance VLM depending on your needs and hardware capabilities.
|
||||
|
||||
### Can I select a visual model to parse my DOCX files?
|
||||
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
---
|
||||
sidebar_position: -7
|
||||
slug: /set_metada
|
||||
slug: /set_metadata
|
||||
---
|
||||
|
||||
# Set metadata
|
||||
|
||||
@ -73,7 +73,7 @@ Creating a tag set is *not* for once and for all. Oftentimes, you may find it ne
|
||||
### Update tag set in tag frequency table
|
||||
|
||||
1. Navigate to the **Configuration** page in your tag set.
|
||||
2. Click the **Table** tab under **Tag view** to view the tag frequncy table, where you can update tag names or delete tags.
|
||||
2. Click the **Table** tab under **Tag view** to view the tag frequency table, where you can update tag names or delete tags.
|
||||
|
||||
:::danger IMPORTANT
|
||||
When a tag set is updated, you must re-parse the documents in your dataset so that their tags can be updated accordingly.
|
||||
|
||||
Reference in New Issue
Block a user