mirror of
https://github.com/infiniflow/ragflow.git
synced 2026-02-01 16:15:07 +08:00
UI updates (#9836)
### What problem does this PR solve? ### Type of change - [x] Documentation Update
This commit is contained in:
@ -16,7 +16,7 @@ Knowledge base, hallucination-free chat, and file management are the three pilla
|
||||
|
||||
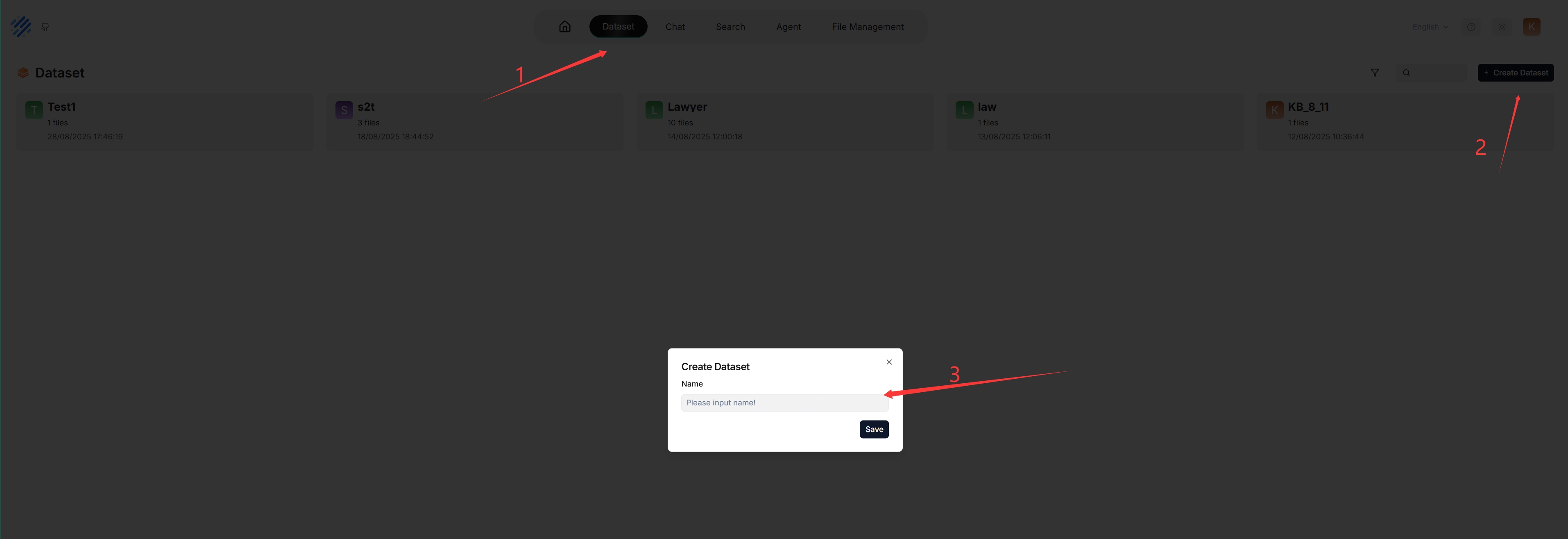
With multiple knowledge bases, you can build more flexible, diversified question answering. To create your first knowledge base:
|
||||
|
||||

|
||||
|
||||
|
||||
_Each time a knowledge base is created, a folder with the same name is generated in the **root/.knowledgebase** directory._
|
||||
|
||||
@ -24,7 +24,7 @@ _Each time a knowledge base is created, a folder with the same name is generated
|
||||
|
||||
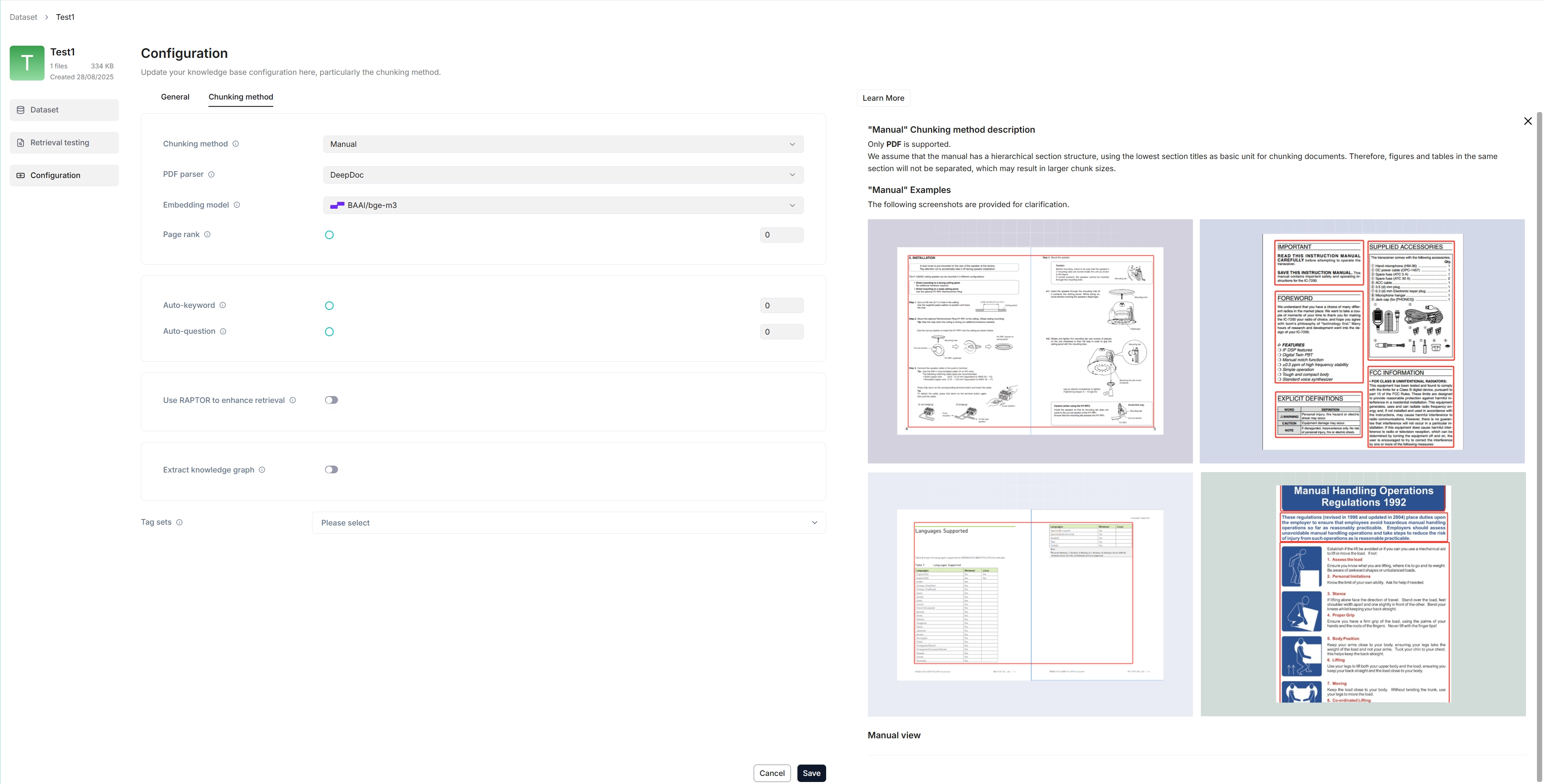
The following screenshot shows the configuration page of a knowledge base. A proper configuration of your knowledge base is crucial for future AI chats. For example, choosing the wrong embedding model or chunking method would cause unexpected semantic loss or mismatched answers in chats.
|
||||
|
||||

|
||||
|
||||
|
||||
This section covers the following topics:
|
||||
|
||||
@ -56,7 +56,7 @@ RAGFlow offers multiple chunking template to facilitate chunking files of differ
|
||||
|
||||
You can also change a file's chunking method on the **Datasets** page.
|
||||
|
||||

|
||||
|
||||
|
||||
### Select embedding model
|
||||
|
||||
@ -82,10 +82,8 @@ While uploading files directly to a knowledge base seems more convenient, we *hi
|
||||
|
||||
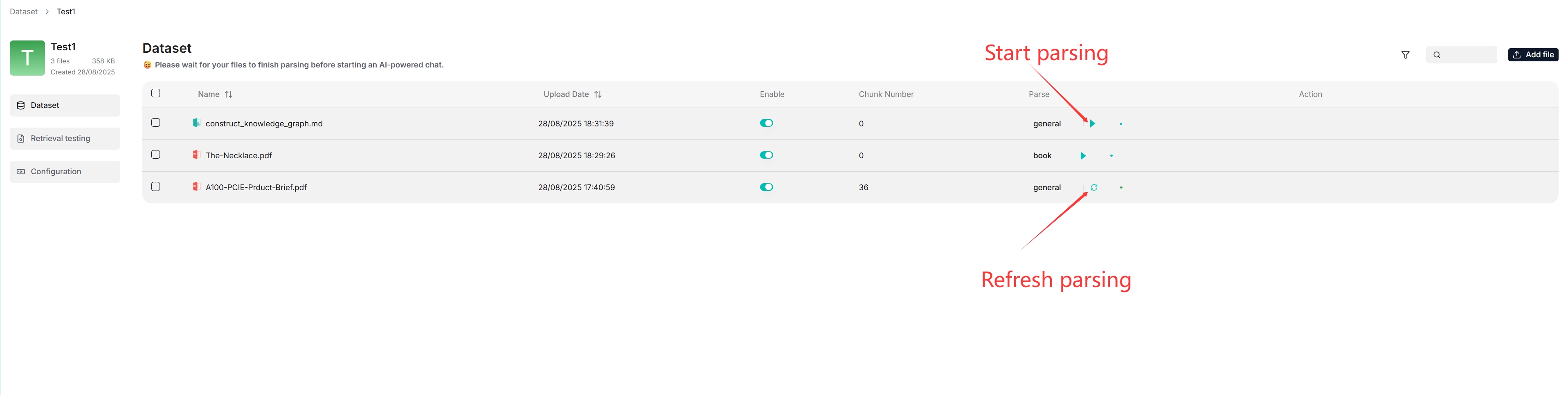
File parsing is a crucial topic in knowledge base configuration. The meaning of file parsing in RAGFlow is twofold: chunking files based on file layout and building embedding and full-text (keyword) indexes on these chunks. After having selected the chunking method and embedding model, you can start parsing a file:
|
||||
|
||||

|
||||
|
||||
|
||||
- Click the play button next to **UNSTART** to start file parsing.
|
||||
- Click the red-cross icon and then refresh, if your file parsing stalls for a long time.
|
||||
- As shown above, RAGFlow allows you to use a different chunking method for a particular file, offering flexibility beyond the default method.
|
||||
- As shown above, RAGFlow allows you to enable or disable individual files, offering finer control over knowledge base-based AI chats.
|
||||
|
||||
@ -97,13 +95,13 @@ RAGFlow features visibility and explainability, allowing you to view the chunkin
|
||||
|
||||
_You are taken to the **Chunk** page:_
|
||||
|
||||

|
||||
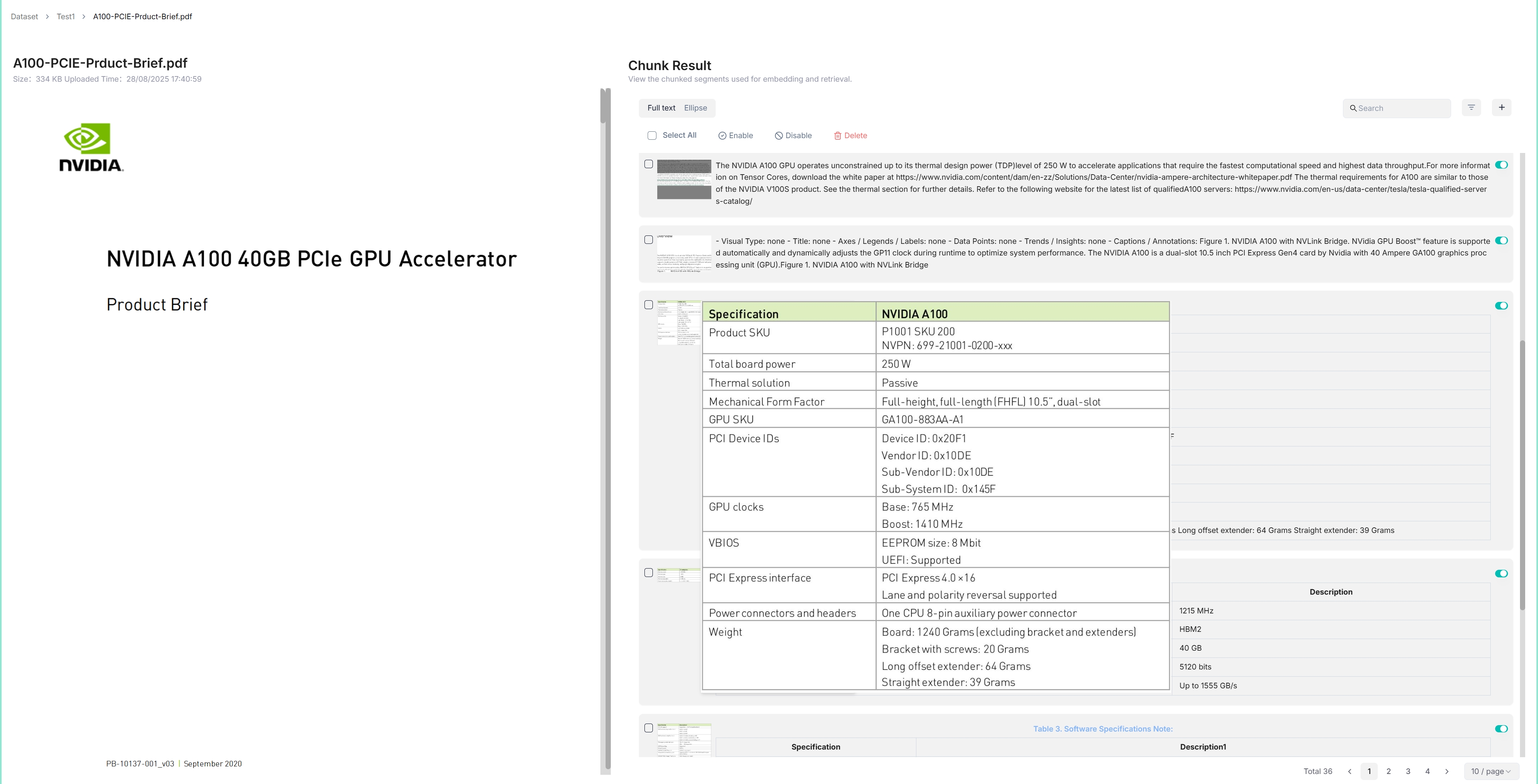
|
||||
|
||||
2. Hover over each snapshot for a quick view of each chunk.
|
||||
|
||||
3. Double-click the chunked texts to add keywords or make *manual* changes where necessary:
|
||||
3. Double-click the chunked texts to add keywords, questions, tags, or make *manual* changes where necessary:
|
||||
|
||||

|
||||
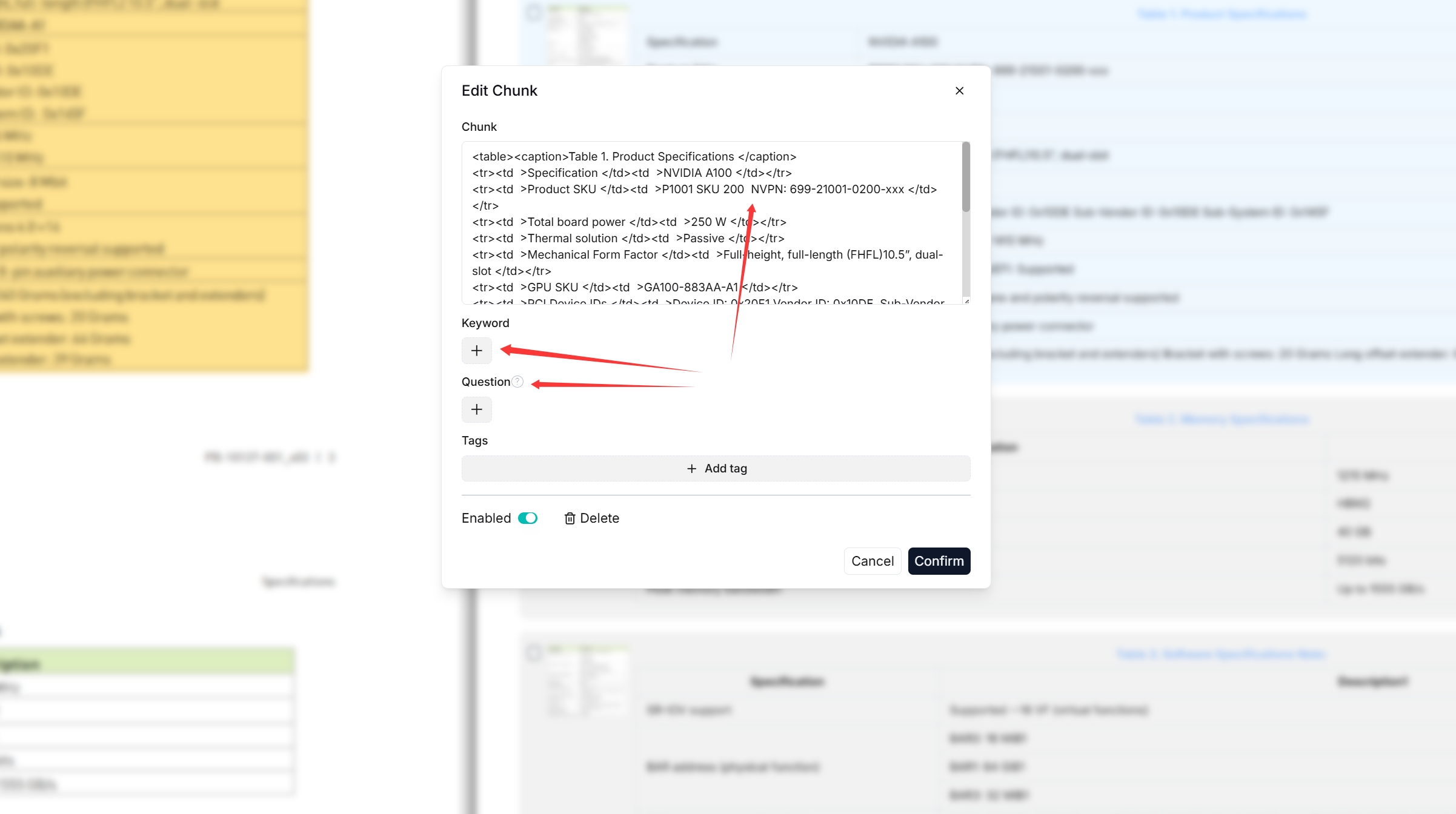
|
||||
|
||||
:::caution NOTE
|
||||
You can add keywords to a file chunk to increase its ranking for queries containing those keywords. This action increases its keyword weight and can improve its position in search list.
|
||||
@ -113,7 +111,7 @@ You can add keywords to a file chunk to increase its ranking for queries contain
|
||||
|
||||
_As you can tell from the following, RAGFlow responds with truthful citations._
|
||||
|
||||

|
||||
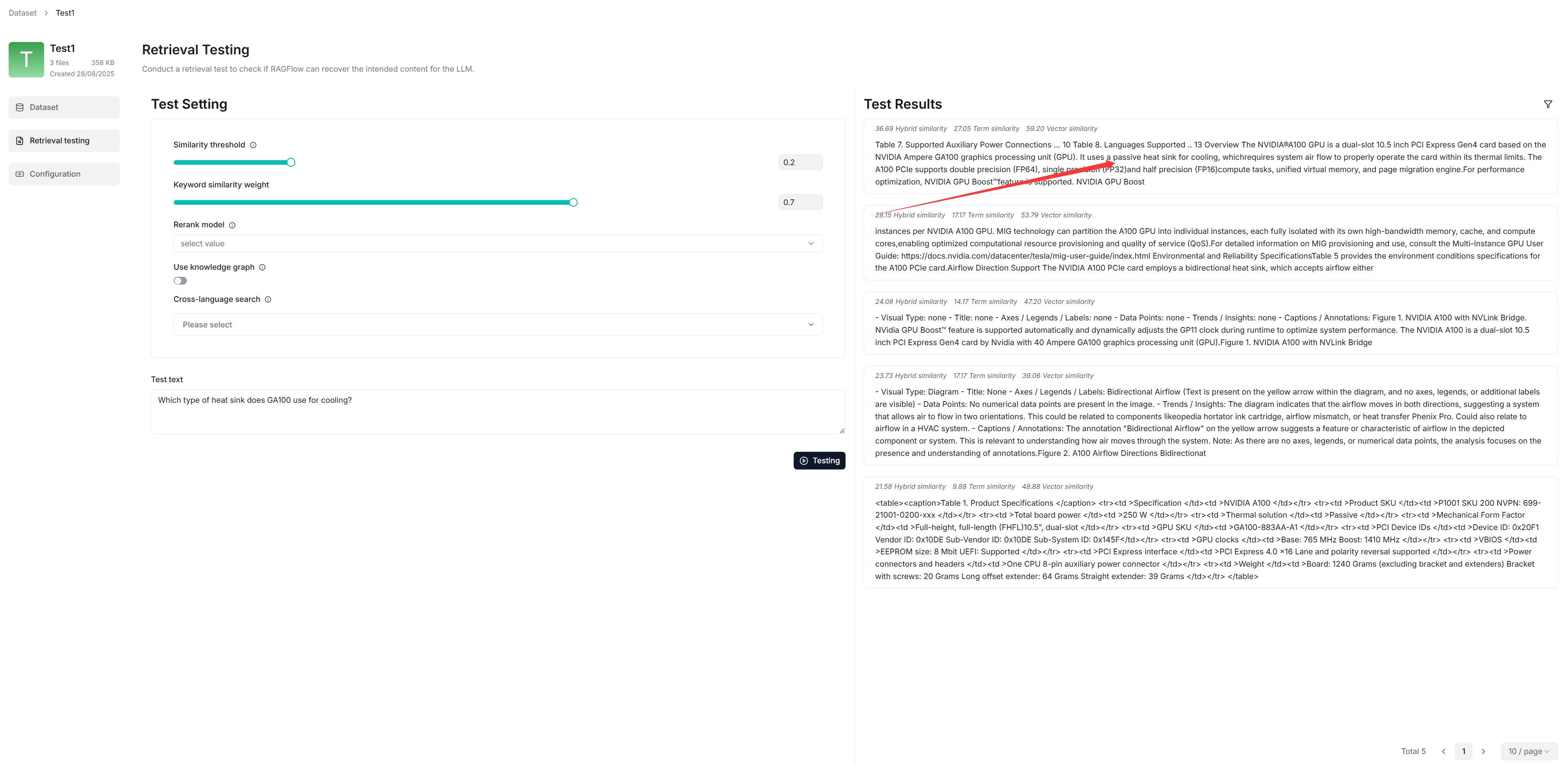
|
||||
|
||||
### Run retrieval testing
|
||||
|
||||
@ -124,13 +122,11 @@ RAGFlow uses multiple recall of both full-text search and vector search in its c
|
||||
|
||||
See [Run retrieval test](./run_retrieval_test.md) for details.
|
||||
|
||||

|
||||
|
||||
## Search for knowledge base
|
||||
|
||||
As of RAGFlow v0.20.4, the search feature is still in a rudimentary form, supporting only knowledge base search by name.
|
||||
|
||||

|
||||

|
||||
|
||||
## Delete knowledge base
|
||||
|
||||
@ -139,4 +135,4 @@ You are allowed to delete a knowledge base. Hover your mouse over the three dot
|
||||
- The files uploaded directly to the knowledge base are gone;
|
||||
- The file references, which you created from within **File Management**, are gone, but the associated files still exist in **File Management**.
|
||||
|
||||

|
||||

|
||||
|
||||
@ -31,7 +31,7 @@ RAPTOR (Recursive Abstractive Processing for Tree Organized Retrieval) can also
|
||||
|
||||
The system's default chat model is used to generate knowledge graph. Before proceeding, ensure that you have a chat model properly configured:
|
||||
|
||||

|
||||

|
||||
|
||||
## Configurations
|
||||
|
||||
@ -74,7 +74,7 @@ In a knowledge graph, a community is a cluster of entities linked by relationshi
|
||||
3. Click **Knowledge graph** to view the details of the generated graph.
|
||||
4. To use the created knowledge graph, do either of the following:
|
||||
|
||||
- In your **Chat Configuration** dialogue, click the **Assistant settings** tab to add the corresponding knowledge base(s) and click the **Prompt engine** tab to switch on the **Use knowledge graph** toggle.
|
||||
- In the **Chat setting** panel of your chat app, switch on the **Use knowledge graph** toggle.
|
||||
- If you are using an agent, click the **Retrieval** agent component to specify the knowledge base(s) and switch on the **Use knowledge graph** toggle.
|
||||
|
||||
## Frequently asked questions
|
||||
|
||||
@ -39,7 +39,7 @@ Knowledge graphs can also be used for multi-hop question-answering tasks. See [C
|
||||
|
||||
The system's default chat model is used to summarize clustered content. Before proceeding, ensure that you have a chat model properly configured:
|
||||
|
||||

|
||||

|
||||
|
||||
## Configurations
|
||||
|
||||
|
||||
@ -13,13 +13,13 @@ On the **Dataset** page of your knowledge base, you can add metadata to any uplo
|
||||
|
||||
For example, if you have a dataset of HTML files and want the LLM to cite the source URL when responding to your query, add a `"url"` parameter to each file's metadata.
|
||||
|
||||

|
||||

|
||||
|
||||
:::tip NOTE
|
||||
Ensure that your metadata is in JSON format; otherwise, your updates will not be applied.
|
||||
:::
|
||||
|
||||

|
||||
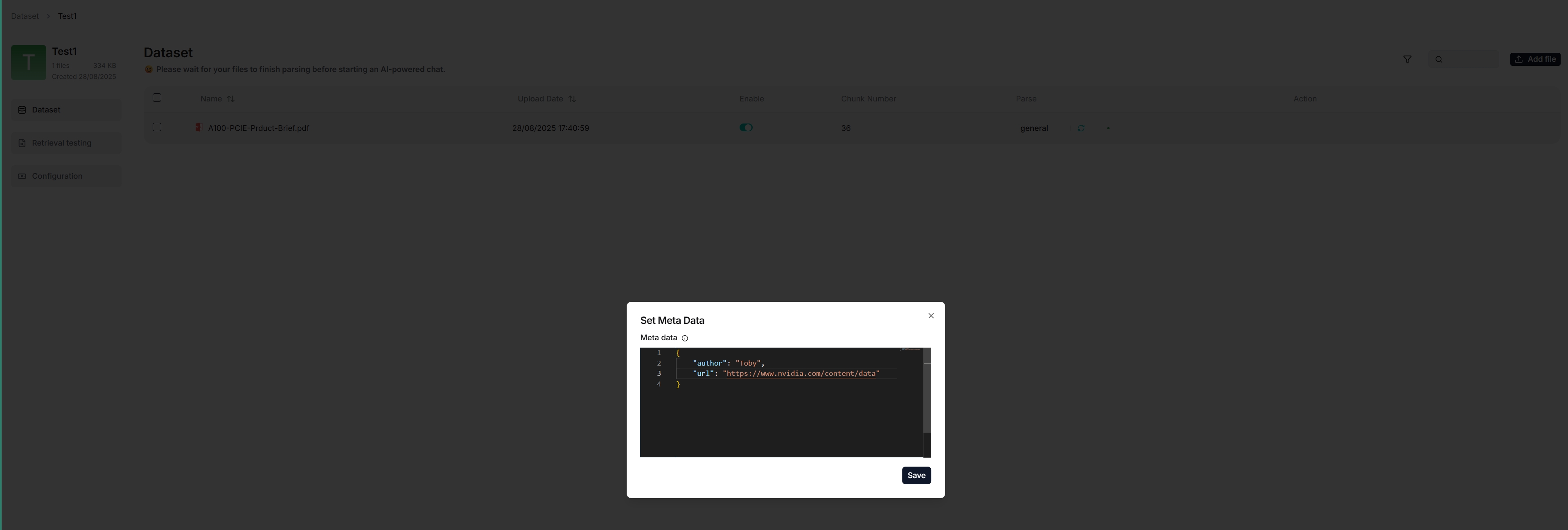
|
||||
|
||||
## Frequently asked questions
|
||||
|
||||
|
||||
Reference in New Issue
Block a user