mirror of
https://github.com/infiniflow/ragflow.git
synced 2025-12-25 08:06:48 +08:00
Minor style changes (#11554)
### What problem does this PR solve? ### Type of change - [ ] Documentation Update
This commit is contained in:
@ -39,8 +39,10 @@ If you have not installed Docker on your local machine (Windows, Mac, or Linux),
|
||||
|
||||
This section provides instructions on setting up the RAGFlow server on Linux. If you are on a different operating system, no worries. Most steps are alike.
|
||||
|
||||
1. Ensure `vm.max_map_count` ≥ 262144.
|
||||
|
||||
<details>
|
||||
<summary>1. Ensure <code>vm.max_map_count</code> ≥ 262144:</summary>
|
||||
<summary>Expand to show details:</summary>
|
||||
|
||||
`vm.max_map_count`. This value sets the maximum number of memory map areas a process may have. Its default value is 65530. While most applications require fewer than a thousand maps, reducing this value can result in abnormal behaviors, and the system will throw out-of-memory errors when a process reaches the limitation.
|
||||
|
||||
@ -194,22 +196,22 @@ This section provides instructions on setting up the RAGFlow server on Linux. If
|
||||
$ docker compose -f docker-compose.yml up -d
|
||||
```
|
||||
|
||||
```mdx-code-block
|
||||
<APITable>
|
||||
```
|
||||
```mdx-code-block
|
||||
<APITable>
|
||||
```
|
||||
|
||||
| RAGFlow image tag | Image size (GB) | Stable? |
|
||||
| ------------------- | --------------- | ------------------------ |
|
||||
| v0.22.1 | ≈2 | Stable release |
|
||||
| nightly | ≈2 | _Unstable_ nightly build |
|
||||
| RAGFlow image tag | Image size (GB) | Stable? |
|
||||
| ------------------- | --------------- | ------------------------ |
|
||||
| v0.22.1 | ≈2 | Stable release |
|
||||
| nightly | ≈2 | _Unstable_ nightly build |
|
||||
|
||||
```mdx-code-block
|
||||
</APITable>
|
||||
```
|
||||
```mdx-code-block
|
||||
</APITable>
|
||||
```
|
||||
|
||||
:::tip NOTE
|
||||
The image size shown refers to the size of the *downloaded* Docker image, which is compressed. When Docker runs the image, it unpacks it, resulting in significantly greater disk usage. A Docker image will expand to around 7 GB once unpacked.
|
||||
:::
|
||||
:::tip NOTE
|
||||
The image size shown refers to the size of the *downloaded* Docker image, which is compressed. When Docker runs the image, it unpacks it, resulting in significantly greater disk usage. A Docker image will expand to around 7 GB once unpacked.
|
||||
:::
|
||||
|
||||
4. Check the server status after having the server up and running:
|
||||
|
||||
@ -229,15 +231,15 @@ The image size shown refers to the size of the *downloaded* Docker image, which
|
||||
* Running on all addresses (0.0.0.0)
|
||||
```
|
||||
|
||||
:::danger IMPORTANT
|
||||
If you skip this confirmation step and directly log in to RAGFlow, your browser may prompt a `network anomaly` error because, at that moment, your RAGFlow may not be fully initialized.
|
||||
:::
|
||||
:::danger IMPORTANT
|
||||
If you skip this confirmation step and directly log in to RAGFlow, your browser may prompt a `network anomaly` error because, at that moment, your RAGFlow may not be fully initialized.
|
||||
:::
|
||||
|
||||
5. In your web browser, enter the IP address of your server and log in to RAGFlow.
|
||||
|
||||
:::caution WARNING
|
||||
With the default settings, you only need to enter `http://IP_OF_YOUR_MACHINE` (**sans** port number) as the default HTTP serving port `80` can be omitted when using the default configurations.
|
||||
:::
|
||||
:::caution WARNING
|
||||
With the default settings, you only need to enter `http://IP_OF_YOUR_MACHINE` (**sans** port number) as the default HTTP serving port `80` can be omitted when using the default configurations.
|
||||
:::
|
||||
|
||||
## Configure LLMs
|
||||
|
||||
@ -278,9 +280,9 @@ To create your first dataset:
|
||||
|
||||
3. RAGFlow offers multiple chunk templates that cater to different document layouts and file formats. Select the embedding model and chunking method (template) for your dataset.
|
||||
|
||||
:::danger IMPORTANT
|
||||
Once you have selected an embedding model and used it to parse a file, you are no longer allowed to change it. The obvious reason is that we must ensure that all files in a specific dataset are parsed using the *same* embedding model (ensure that they are being compared in the same embedding space).
|
||||
:::
|
||||
:::danger IMPORTANT
|
||||
Once you have selected an embedding model and used it to parse a file, you are no longer allowed to change it. The obvious reason is that we must ensure that all files in a specific dataset are parsed using the *same* embedding model (ensure that they are being compared in the same embedding space).
|
||||
:::
|
||||
|
||||
_You are taken to the **Dataset** page of your dataset._
|
||||
|
||||
@ -290,10 +292,10 @@ Once you have selected an embedding model and used it to parse a file, you are n
|
||||
|
||||
|
||||
|
||||
:::caution NOTE
|
||||
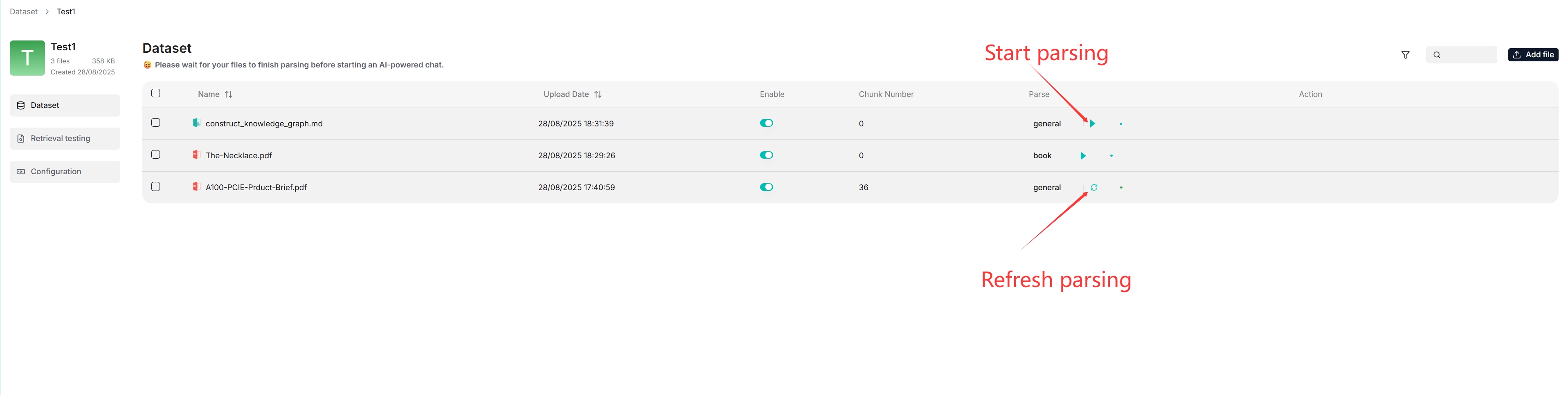
- If your file parsing gets stuck at below 1%, see [this FAQ](./faq.mdx#why-does-my-document-parsing-stall-at-under-one-percent).
|
||||
- If your file parsing gets stuck at near completion, see [this FAQ](./faq.mdx#why-does-my-pdf-parsing-stall-near-completion-while-the-log-does-not-show-any-error)
|
||||
:::
|
||||
:::caution NOTE
|
||||
- If your file parsing gets stuck at below 1%, see [this FAQ](./faq.mdx#why-does-my-document-parsing-stall-at-under-one-percent).
|
||||
- If your file parsing gets stuck at near completion, see [this FAQ](./faq.mdx#why-does-my-pdf-parsing-stall-near-completion-while-the-log-does-not-show-any-error)
|
||||
:::
|
||||
|
||||
## Intervene with file parsing
|
||||
|
||||
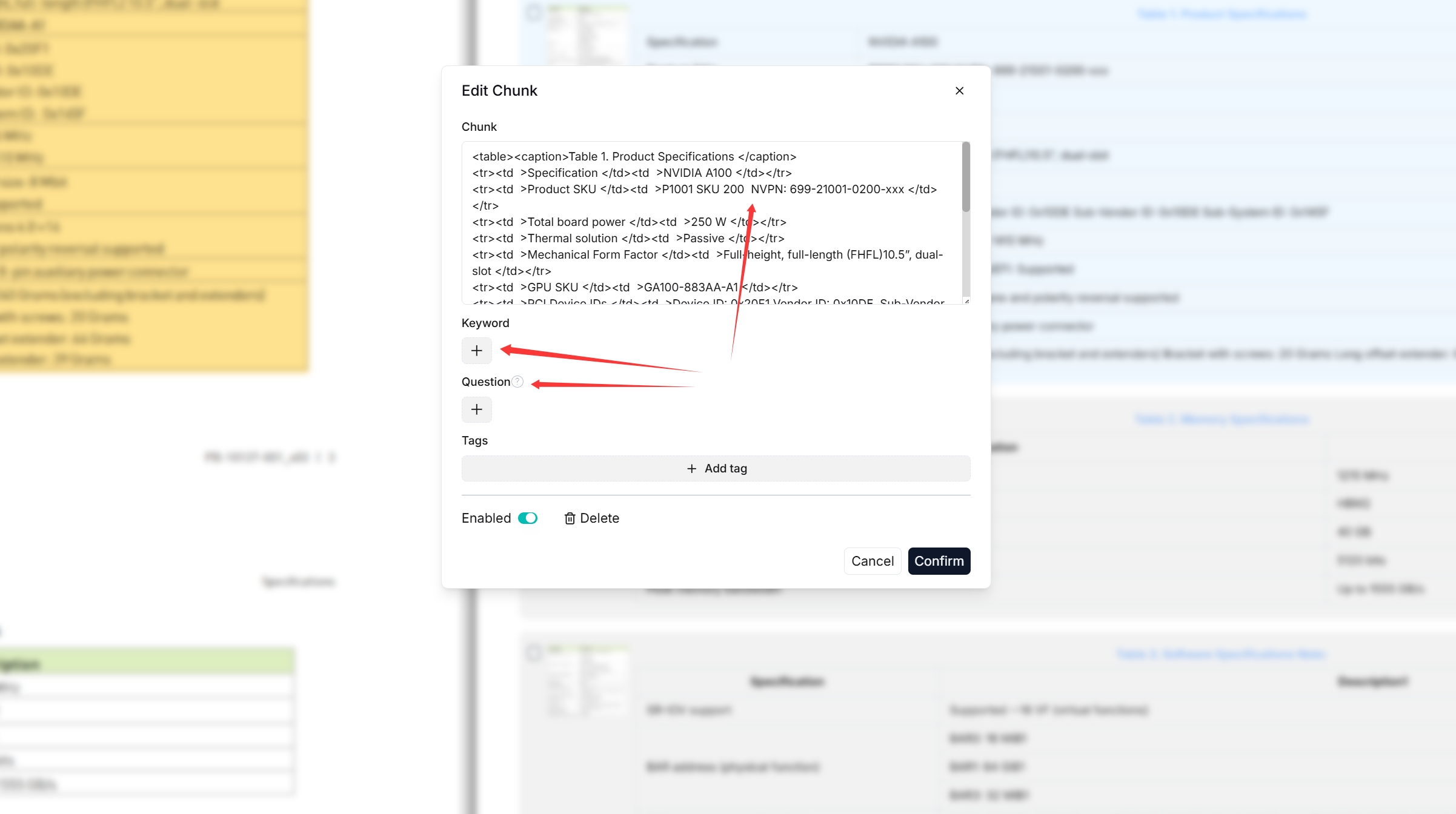
@ -311,9 +313,9 @@ RAGFlow features visibility and explainability, allowing you to view the chunkin
|
||||
|
||||
|
||||
|
||||
:::caution NOTE
|
||||
You can add keywords or questions to a file chunk to improve its ranking for queries containing those keywords. This action increases its keyword weight and can improve its position in search list.
|
||||
:::
|
||||
:::caution NOTE
|
||||
You can add keywords or questions to a file chunk to improve its ranking for queries containing those keywords. This action increases its keyword weight and can improve its position in search list.
|
||||
:::
|
||||
|
||||
4. In Retrieval testing, ask a quick question in **Test text** to double check if your configurations work:
|
||||
|
||||
|
||||
Reference in New Issue
Block a user