mirror of
https://github.com/infiniflow/ragflow.git
synced 2026-01-23 11:36:38 +08:00
0519 pdfparser (#7747)
### What problem does this PR solve? ### Type of change - [x] Documentation Update
This commit is contained in:
@ -23,7 +23,7 @@ Once a connection is established, an MCP server communicates with its client in
|
||||
## Prerequisites
|
||||
|
||||
1. Ensure RAGFlow is upgraded to v0.18.0 or later.
|
||||
2. Have your RAGFlow API key ready. See [Acquire a RAGFlow API key](./acquire_ragflow_api_key.md).
|
||||
2. Have your RAGFlow API key ready. See [Acquire a RAGFlow API key](../acquire_ragflow_api_key.md).
|
||||
|
||||
:::tip INFO
|
||||
If you wish to try out our MCP server without upgrading RAGFlow, community contributor [yiminghub2024](https://github.com/yiminghub2024) 👏 shares their recommended steps [here](#launch-an-mcp-server-without-upgrading-ragflow).
|
||||
|
||||
@ -11,7 +11,7 @@ Switch your doc engine from Elasticsearch to Infinity.
|
||||
|
||||
RAGFlow uses Elasticsearch by default for storing full text and vectors. To switch to [Infinity](https://github.com/infiniflow/infinity/), follow these steps:
|
||||
|
||||
:::danger WARNING
|
||||
:::caution WARNING
|
||||
Switching to Infinity on a Linux/arm64 machine is not yet officially supported.
|
||||
:::
|
||||
|
||||
@ -21,7 +21,7 @@ Switching to Infinity on a Linux/arm64 machine is not yet officially supported.
|
||||
$ docker compose -f docker/docker-compose.yml down -v
|
||||
```
|
||||
|
||||
:::cautiion WARNING
|
||||
:::caution WARNING
|
||||
`-v` will delete the docker container volumes, and the existing data will be cleared.
|
||||
:::
|
||||
|
||||
|
||||
@ -25,7 +25,7 @@ When debugging your chat assistant, you can use AI search as a reference to veri
|
||||
|
||||
## Frequently asked questions
|
||||
|
||||
### key difference between an AI search and an AI chat?
|
||||
### Key difference between an AI search and an AI chat?
|
||||
|
||||
A chat is a multi-turn AI conversation where you can define your retrieval strategy (a weighted reranking score can be used to replace the weighted vector similarity in a hybrid search) and choose your chat model. In an AI chat, you can configure advanced RAG strategies, such as knowledge graphs, auto-keyword, and auto-question, for your specific case. Retrieved chunks are not displayed along with the answer.
|
||||
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
---
|
||||
sidebar_position: 0
|
||||
sidebar_position: -1
|
||||
slug: /configure_knowledge_base
|
||||
---
|
||||
|
||||
|
||||
53
docs/guides/dataset/select_pdf_parser.md
Normal file
53
docs/guides/dataset/select_pdf_parser.md
Normal file
@ -0,0 +1,53 @@
|
||||
---
|
||||
sidebar_position: 0
|
||||
slug: /select_pdf_parser
|
||||
---
|
||||
|
||||
# Select PDF parser
|
||||
|
||||
Select a visual model for parsing your PDFs.
|
||||
|
||||
---
|
||||
|
||||
RAGFlow isn't one-size-fits-all. It is built for flexibility and supports deeper customization to accommodate more complex use cases. From v0.17.0 onwards, RAGFlow decouples DeepDoc-specific data extraction tasks from chunking methods **for PDF files**. This separation enables you to autonomously select a visual model for OCR (Optical Character Recognition), TSR (Table Structure Recognition), and DLR (Document Layout Recognition) tasks that balances speed and performance to suit your specific use cases. If your PDFs contain only plain text, you can opt to skip these tasks by selecting the **Naive** option, to reduce the overall parsing time.
|
||||
|
||||
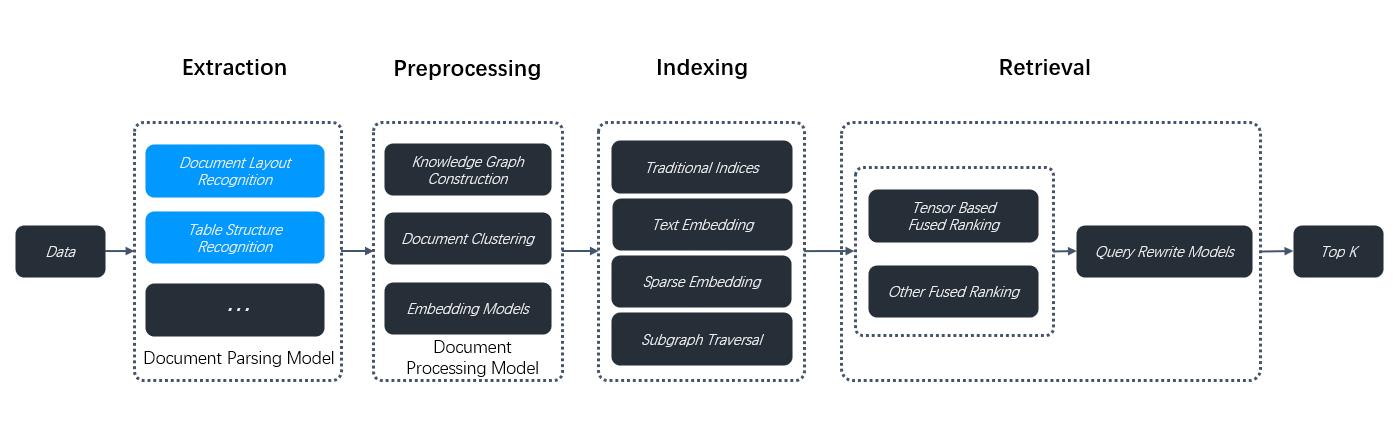
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- The PDF parser dropdown menu appears only when you select a chunking method compatible with PDFs, including:
|
||||
- **General**
|
||||
- **Manual**
|
||||
- **Paper**
|
||||
- **Book**
|
||||
- **Laws**
|
||||
- **Presentation**
|
||||
- **One**
|
||||
- To use a third-party visual model for parsing PDFs, ensure you have set a default image2txt model under **Set default models** on the **Model providers** page.
|
||||
|
||||
## Procedure
|
||||
|
||||
1. On your knowledge base's **Configuration** page, select a chunking method, say **General**.
|
||||
|
||||
_The **PDF parser** dropdown menu appears._
|
||||
|
||||
2. Select the option that works best with your scenario:
|
||||
|
||||
- DeepDoc: (Default) The default visual model for OCR, TSR, and DLR tasks.
|
||||
- Naive: Skip OCR, TSR, and DLR tasks if *all* your PDFs are plain text.
|
||||
- A third-party visual model provided by a specific model provider.
|
||||
|
||||
:::caution WARNING
|
||||
Third-party visual models are marked **Experimental**, because we have not fully tested these models for the aforementioned data extraction tasks.
|
||||
:::
|
||||
|
||||
## Frequently asked questions
|
||||
|
||||
### When should I select DeepDoc or a third-party visual model as the PDF parser?
|
||||
|
||||
Use a visual model to extract data if your PDFs contain formatted or image-based text rather than plain text. DeepDoc is the default visual model but can be time-consuming. You can also choose a lightweight or high-performance img2txt model depending on your needs and hardware capabilities.
|
||||
|
||||
### Can I select a visual model to parse my DOCX files?
|
||||
|
||||
No, you cannot. This dropdown menu is for PDFs only. To use this feature, convert your DOCX files to PDF first.
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
sidebar_position: 2
|
||||
slug: /set_metada
|
||||
---
|
||||
|
||||
|
||||
Reference in New Issue
Block a user