mirror of
https://github.com/infiniflow/ragflow.git
synced 2026-02-02 16:45:08 +08:00
Doc: Added Long context RAG guide (#10591)
### What problem does this PR solve? ### Type of change - [x] Documentation Update
This commit is contained in:
@ -1,5 +1,5 @@
|
|||||||
---
|
---
|
||||||
sidebar_position: -1
|
sidebar_position: -10
|
||||||
slug: /configure_knowledge_base
|
slug: /configure_knowledge_base
|
||||||
---
|
---
|
||||||
|
|
||||||
@ -58,11 +58,8 @@ You can also change a file's chunking method on the **Files** page.
|
|||||||
|
|
||||||
|

|
||||||
|
|
||||||
:::tip NOTE
|
|
||||||
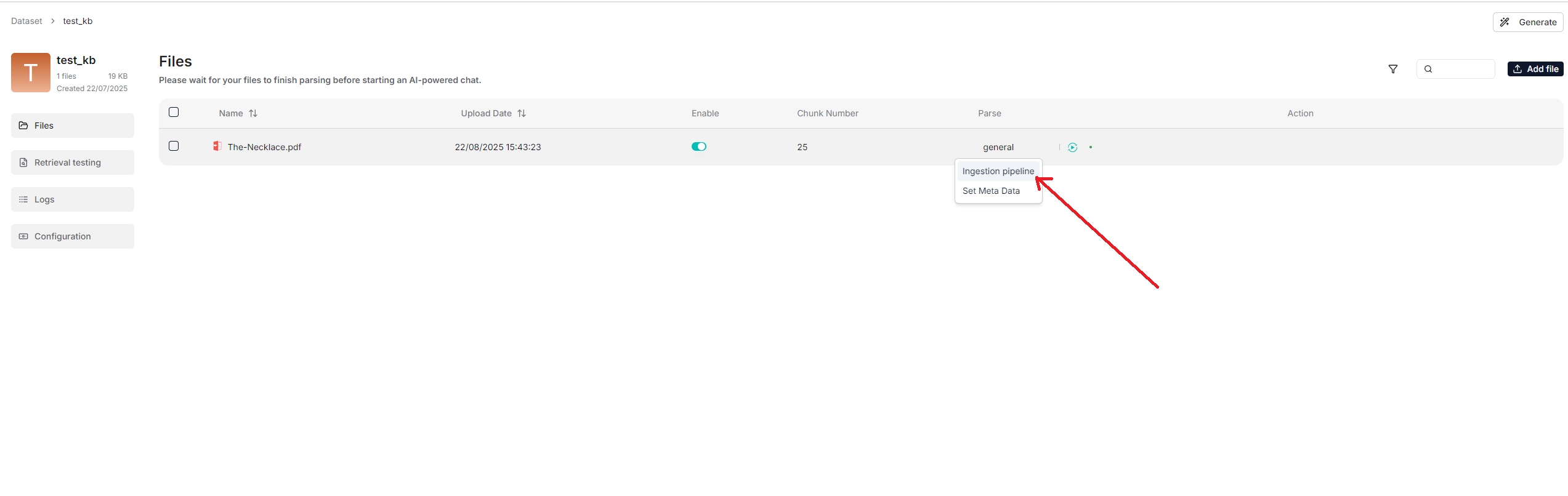
From v0.21.0, RAGFlow supports ingestion pipeline to allow for customized
|
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
<summary>From v0.21.0 onward, RAGFlow supports ingestion pipeline to allow for customized data ingestion and cleansing workflows.</summary>
|
<summary>From v0.21.0 onward, RAGFlow supports ingestion pipeline for customized data ingestion and cleansing workflows.</summary>
|
||||||
|
|
||||||
To use a customized data pipeline:
|
To use a customized data pipeline:
|
||||||
|
|
||||||
|
|||||||
39
docs/guides/dataset/extract_table_of_contents.md
Normal file
39
docs/guides/dataset/extract_table_of_contents.md
Normal file
@ -0,0 +1,39 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 4
|
||||||
|
slug: /enable_table_of_contents
|
||||||
|
---
|
||||||
|
|
||||||
|
# Extract table of contents
|
||||||
|
|
||||||
|
Extract table of contents (TOC) from documents to provide long context RAG and improve retrieval.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
During indexing, this technique uses LLM to extract and generate chapter information, which is added to each chunk to provide sufficient global context. At the retrieval stage, it first uses the chunks matched by search, then supplements missing chunks based on the table of contents structure. This addresses issues caused by chunk fragmentation and insufficient context, improving answer quality.
|
||||||
|
|
||||||
|
:::danger WARNING
|
||||||
|
Enabling TOC extraction requires significant memory, computational resources, and tokens.
|
||||||
|
:::
|
||||||
|
|
||||||
|
## Prerequisites
|
||||||
|
|
||||||
|
The system's default chat model is used to summarize clustered content. Before proceeding, ensure that you have a chat model properly configured:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## Quickstart
|
||||||
|
|
||||||
|
1. Navigate to the **Configuration** page.
|
||||||
|
|
||||||
|
2. Enable **TOC Enhance**.
|
||||||
|
|
||||||
|
3. To use this technique during retrieval, do either of the following:
|
||||||
|
|
||||||
|
- In the **Chat setting** panel of your chat app, switch on the **TOC Enhance** toggle.
|
||||||
|
- If you are using an agent, click the **Retrieval** agent component to specify the dataset(s) and switch on the **TOC Enhance** toggle.
|
||||||
|
|
||||||
|
## Frequently asked questions
|
||||||
|
|
||||||
|
### Will previously parsed files be searched using the TOC enhancement feature once I enable `TOC Enhance`?
|
||||||
|
|
||||||
|
No. Only files parsed after you enable **TOC Enhance** will be searched using the TOC enhancement feature. To apply this feature to files parsed before enabling **TOC Enhance**, you must reparse them.
|
||||||
@ -1,5 +1,5 @@
|
|||||||
---
|
---
|
||||||
sidebar_position: 1
|
sidebar_position: -4
|
||||||
slug: /select_pdf_parser
|
slug: /select_pdf_parser
|
||||||
---
|
---
|
||||||
|
|
||||||
@ -25,7 +25,7 @@ RAGFlow isn't one-size-fits-all. It is built for flexibility and supports deeper
|
|||||||
- **One**
|
- **One**
|
||||||
- To use a third-party visual model for parsing PDFs, ensure you have set a default img2txt model under **Set default models** on the **Model providers** page.
|
- To use a third-party visual model for parsing PDFs, ensure you have set a default img2txt model under **Set default models** on the **Model providers** page.
|
||||||
|
|
||||||
## Procedure
|
## Quickstart
|
||||||
|
|
||||||
1. On your dataset's **Configuration** page, select a chunking method, say **General**.
|
1. On your dataset's **Configuration** page, select a chunking method, say **General**.
|
||||||
|
|
||||||
|
|||||||
@ -1,5 +1,5 @@
|
|||||||
---
|
---
|
||||||
sidebar_position: 0
|
sidebar_position: -7
|
||||||
slug: /set_metada
|
slug: /set_metada
|
||||||
---
|
---
|
||||||
|
|
||||||
|
|||||||
@ -1,5 +1,5 @@
|
|||||||
---
|
---
|
||||||
sidebar_position: 2
|
sidebar_position: -2
|
||||||
slug: /set_page_rank
|
slug: /set_page_rank
|
||||||
---
|
---
|
||||||
|
|
||||||
|
|||||||
@ -42,8 +42,8 @@ A tag set is *not* involved in document indexing or retrieval. Do not specify a
|
|||||||
:::
|
:::
|
||||||
|
|
||||||
1. Click **+ Create dataset** to create a dataset.
|
1. Click **+ Create dataset** to create a dataset.
|
||||||
2. Navigate to the **Configuration** page of the created dataset and choose **Tag** as the default chunking method.
|
2. Navigate to the **Configuration** page of the created dataset, select **Built-in** in **Ingestion pipeline**, then choose **Tag** as the default chunking method from the **Built-in** drop-down menu.
|
||||||
3. Navigate to the **Dataset** page and upload and parse your table file in XLSX, CSV, or TXT formats.
|
3. Go back to the **Files** page and upload and parse your table file in XLSX, CSV, or TXT formats.
|
||||||
_A tag cloud appears under the **Tag view** section, indicating the tag set is created:_
|
_A tag cloud appears under the **Tag view** section, indicating the tag set is created:_
|
||||||

|

|
||||||
4. Click the **Table** tab to view the tag frequency table:
|
4. Click the **Table** tab to view the tag frequency table:
|
||||||
|
|||||||
Reference in New Issue
Block a user