mirror of
https://github.com/infiniflow/ragflow.git
synced 2026-01-30 07:06:39 +08:00
docs: update docs icons (#12465)
### What problem does this PR solve? Update icons for docs. Trailing spaces are auto truncated by the editor, does not affect real content. ### Type of change - [x] Documentation Update
This commit is contained in:
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 0
|
||||
slug: /
|
||||
sidebar_custom_props: {
|
||||
sidebarIcon: LucideRocket
|
||||
}
|
||||
---
|
||||
|
||||
# Get started
|
||||
@ -12,9 +15,9 @@ RAGFlow is an open-source RAG (Retrieval-Augmented Generation) engine based on d
|
||||
|
||||
This quick start guide describes a general process from:
|
||||
|
||||
- Starting up a local RAGFlow server,
|
||||
- Creating a dataset,
|
||||
- Intervening with file parsing, to
|
||||
- Starting up a local RAGFlow server,
|
||||
- Creating a dataset,
|
||||
- Intervening with file parsing, to
|
||||
- Establishing an AI chat based on your datasets.
|
||||
|
||||
:::danger IMPORTANT
|
||||
@ -71,7 +74,7 @@ This section provides instructions on setting up the RAGFlow server on Linux. If
|
||||
:::caution WARNING
|
||||
This change will be reset after a system reboot. If you forget to update the value the next time you start up the server, you may get a `Can't connect to ES cluster` exception.
|
||||
:::
|
||||
|
||||
|
||||
1.3. To ensure your change remains permanent, add or update the `vm.max_map_count` value in **/etc/sysctl.conf** accordingly:
|
||||
|
||||
```bash
|
||||
@ -145,7 +148,7 @@ This section provides instructions on setting up the RAGFlow server on Linux. If
|
||||
```
|
||||
#### If you are on Windows with Docker Desktop WSL 2 backend, then use docker-desktop to set `vm.max_map_count`:
|
||||
|
||||
1.1. Run the following in WSL:
|
||||
1.1. Run the following in WSL:
|
||||
```bash
|
||||
$ wsl -d docker-desktop -u root
|
||||
$ sysctl -w vm.max_map_count=262144
|
||||
@ -172,7 +175,7 @@ This section provides instructions on setting up the RAGFlow server on Linux. If
|
||||
```
|
||||
|
||||
```bash
|
||||
# Append a line, which reads:
|
||||
# Append a line, which reads:
|
||||
vm.max_map_count = 262144
|
||||
```
|
||||
:::
|
||||
@ -227,13 +230,13 @@ This section provides instructions on setting up the RAGFlow server on Linux. If
|
||||
/ /_/ // /| | / / __ / /_ / // __ \| | /| / /
|
||||
/ _, _// ___ |/ /_/ // __/ / // /_/ /| |/ |/ /
|
||||
/_/ |_|/_/ |_|\____//_/ /_/ \____/ |__/|__/
|
||||
|
||||
|
||||
* Running on all addresses (0.0.0.0)
|
||||
```
|
||||
|
||||
:::danger IMPORTANT
|
||||
If you skip this confirmation step and directly log in to RAGFlow, your browser may prompt a `network anomaly` error because, at that moment, your RAGFlow may not be fully initialized.
|
||||
:::
|
||||
:::
|
||||
|
||||
5. In your web browser, enter the IP address of your server and log in to RAGFlow.
|
||||
|
||||
@ -245,24 +248,24 @@ This section provides instructions on setting up the RAGFlow server on Linux. If
|
||||
|
||||
RAGFlow is a RAG engine and needs to work with an LLM to offer grounded, hallucination-free question-answering capabilities. RAGFlow supports most mainstream LLMs. For a complete list of supported models, please refer to [Supported Models](./references/supported_models.mdx).
|
||||
|
||||
:::note
|
||||
RAGFlow also supports deploying LLMs locally using Ollama, Xinference, or LocalAI, but this part is not covered in this quick start guide.
|
||||
:::note
|
||||
RAGFlow also supports deploying LLMs locally using Ollama, Xinference, or LocalAI, but this part is not covered in this quick start guide.
|
||||
:::
|
||||
|
||||
To add and configure an LLM:
|
||||
To add and configure an LLM:
|
||||
|
||||
1. Click on your logo on the top right of the page **>** **Model providers**.
|
||||
|
||||
2. Click on the desired LLM and update the API key accordingly.
|
||||
|
||||
3. Click **System Model Settings** to select the default models:
|
||||
3. Click **System Model Settings** to select the default models:
|
||||
|
||||
- Chat model,
|
||||
- Embedding model,
|
||||
- Chat model,
|
||||
- Embedding model,
|
||||
- Image-to-text model,
|
||||
- and more.
|
||||
|
||||
> Some models, such as the image-to-text model **qwen-vl-max**, are subsidiary to a specific LLM. And you may need to update your API key to access these models.
|
||||
> Some models, such as the image-to-text model **qwen-vl-max**, are subsidiary to a specific LLM. And you may need to update your API key to access these models.
|
||||
|
||||
## Create your first dataset
|
||||
|
||||
@ -278,21 +281,21 @@ To create your first dataset:
|
||||
|
||||
|
||||
|
||||
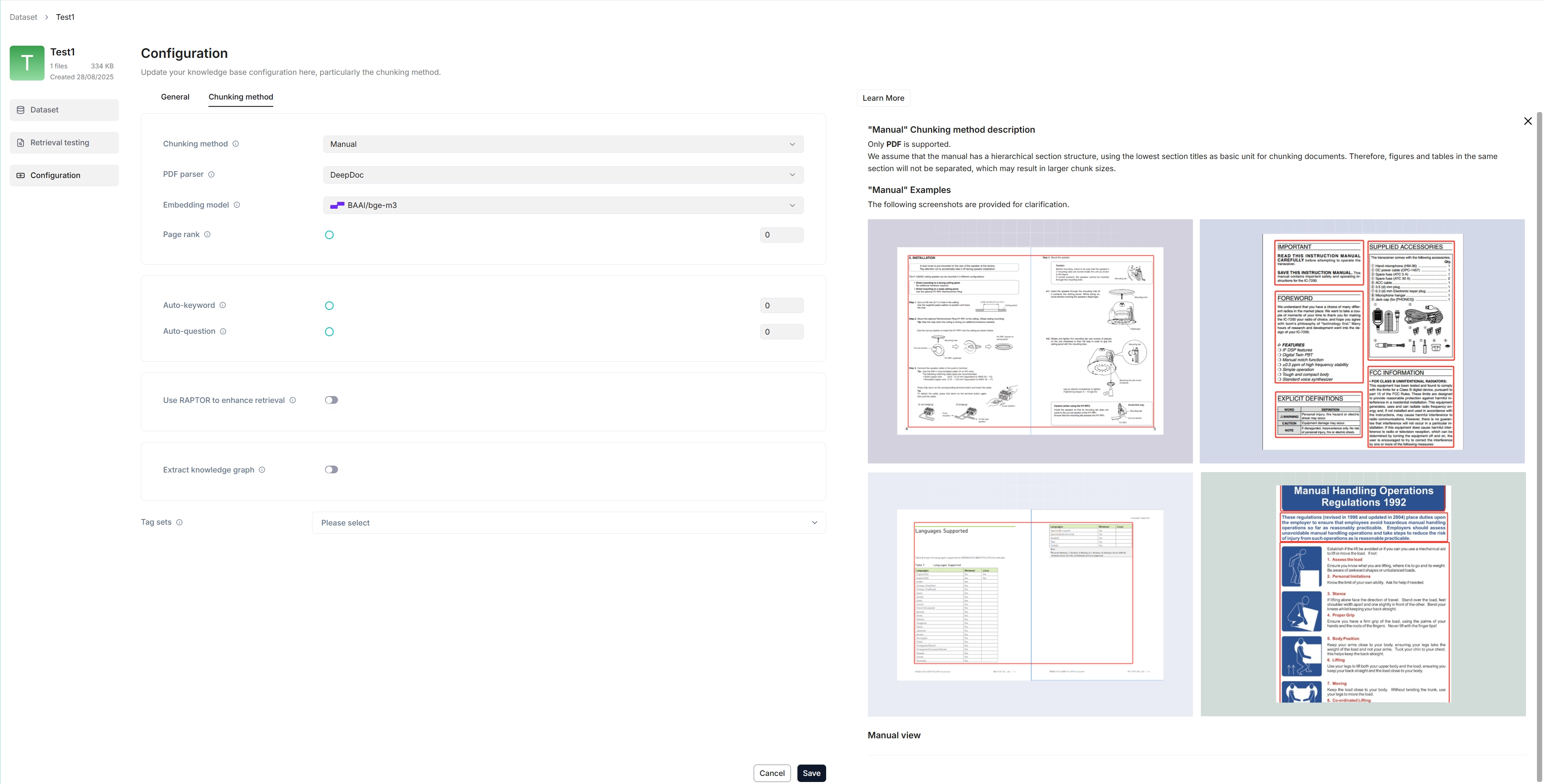
3. RAGFlow offers multiple chunk templates that cater to different document layouts and file formats. Select the embedding model and chunking method (template) for your dataset.
|
||||
3. RAGFlow offers multiple chunk templates that cater to different document layouts and file formats. Select the embedding model and chunking method (template) for your dataset.
|
||||
|
||||
:::danger IMPORTANT
|
||||
Once you have selected an embedding model and used it to parse a file, you are no longer allowed to change it. The obvious reason is that we must ensure that all files in a specific dataset are parsed using the *same* embedding model (ensure that they are being compared in the same embedding space).
|
||||
:::danger IMPORTANT
|
||||
Once you have selected an embedding model and used it to parse a file, you are no longer allowed to change it. The obvious reason is that we must ensure that all files in a specific dataset are parsed using the *same* embedding model (ensure that they are being compared in the same embedding space).
|
||||
:::
|
||||
|
||||
_You are taken to the **Dataset** page of your dataset._
|
||||
|
||||
4. Click **+ Add file** **>** **Local files** to start uploading a particular file to the dataset.
|
||||
4. Click **+ Add file** **>** **Local files** to start uploading a particular file to the dataset.
|
||||
|
||||
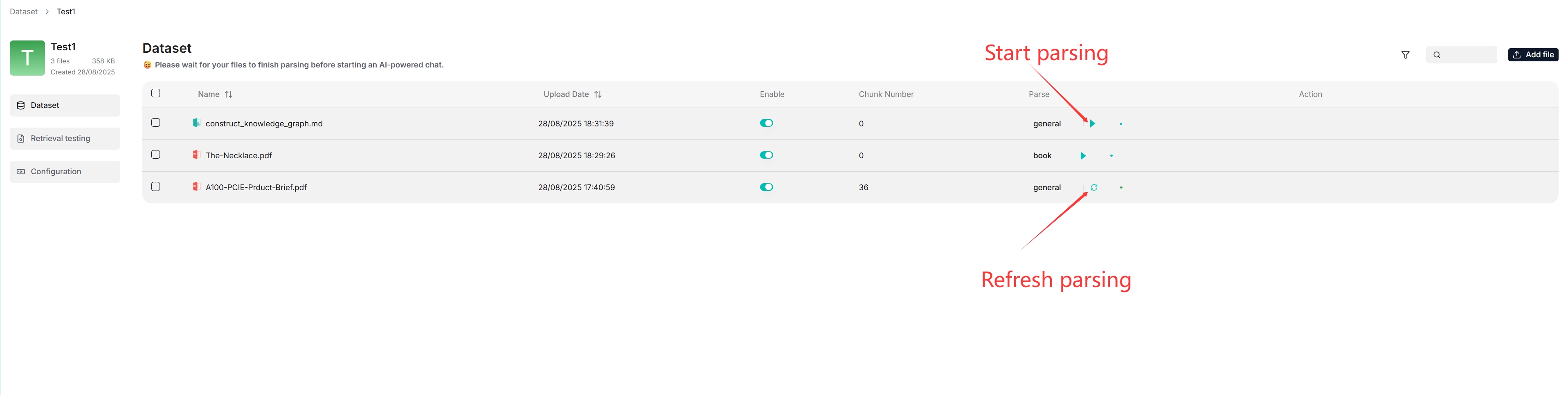
5. In the uploaded file entry, click the play button to start file parsing:
|
||||
|
||||
|
||||
|
||||
:::caution NOTE
|
||||
:::caution NOTE
|
||||
- If your file parsing gets stuck at below 1%, see [this FAQ](./faq.mdx#why-does-my-document-parsing-stall-at-under-one-percent).
|
||||
- If your file parsing gets stuck at near completion, see [this FAQ](./faq.mdx#why-does-my-pdf-parsing-stall-near-completion-while-the-log-does-not-show-any-error)
|
||||
:::
|
||||
|
||||
Reference in New Issue
Block a user