mirror of
https://github.com/infiniflow/ragflow.git
synced 2026-01-31 15:45:08 +08:00
docs: update docs icons (#12465)
### What problem does this PR solve? Update icons for docs. Trailing spaces are auto truncated by the editor, does not affect real content. ### Type of change - [x] Documentation Update
This commit is contained in:
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: -10
|
||||
slug: /configure_knowledge_base
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideCog
|
||||
}
|
||||
---
|
||||
|
||||
# Configure dataset
|
||||
@ -22,7 +25,7 @@ _Each time a dataset is created, a folder with the same name is generated in the
|
||||
|
||||
## Configure dataset
|
||||
|
||||
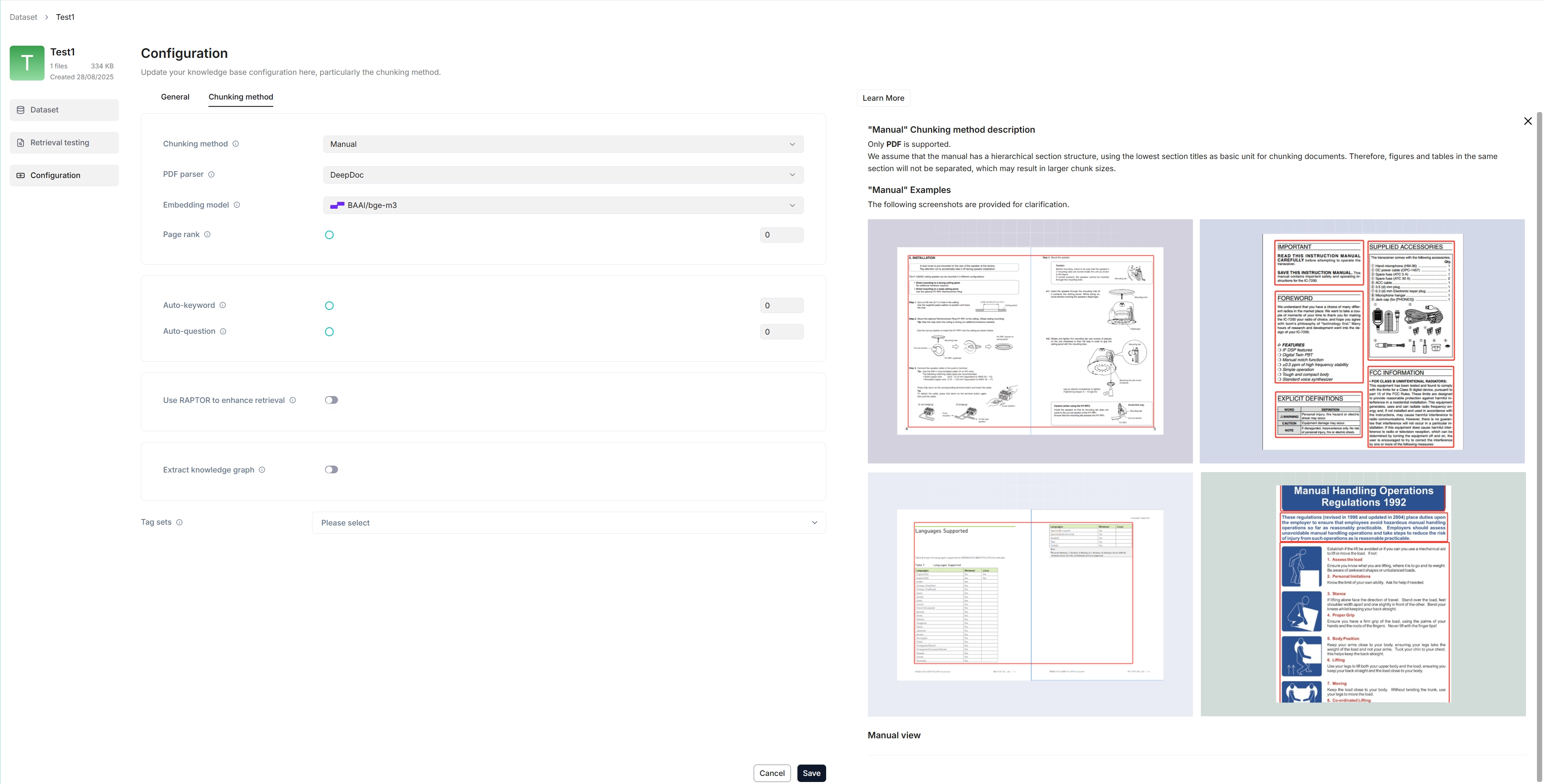
The following screenshot shows the configuration page of a dataset. A proper configuration of your dataset is crucial for future AI chats. For example, choosing the wrong embedding model or chunking method would cause unexpected semantic loss or mismatched answers in chats.
|
||||
The following screenshot shows the configuration page of a dataset. A proper configuration of your dataset is crucial for future AI chats. For example, choosing the wrong embedding model or chunking method would cause unexpected semantic loss or mismatched answers in chats.
|
||||
|
||||
|
||||
|
||||
@ -60,14 +63,14 @@ You can also change a file's chunking method on the **Files** page.
|
||||
|
||||
<details>
|
||||
<summary>From v0.21.0 onward, RAGFlow supports ingestion pipeline for customized data ingestion and cleansing workflows.</summary>
|
||||
|
||||
|
||||
To use a customized data pipeline:
|
||||
|
||||
1. On the **Agent** page, click **+ Create agent** > **Create from blank**.
|
||||
2. Select **Ingestion pipeline** and name your data pipeline in the popup, then click **Save** to show the data pipeline canvas.
|
||||
3. After updating your data pipeline, click **Save** on the top right of the canvas.
|
||||
4. Navigate to the **Configuration** page of your dataset, select **Choose pipeline** in **Ingestion pipeline**.
|
||||
|
||||
|
||||
*Your saved data pipeline will appear in the dropdown menu below.*
|
||||
|
||||
</details>
|
||||
@ -83,9 +86,9 @@ Some embedding models are optimized for specific languages, so performance may b
|
||||
### Upload file
|
||||
|
||||
- RAGFlow's File system allows you to link a file to multiple datasets, in which case each target dataset holds a reference to the file.
|
||||
- In **Knowledge Base**, you are also given the option of uploading a single file or a folder of files (bulk upload) from your local machine to a dataset, in which case the dataset holds file copies.
|
||||
- In **Knowledge Base**, you are also given the option of uploading a single file or a folder of files (bulk upload) from your local machine to a dataset, in which case the dataset holds file copies.
|
||||
|
||||
While uploading files directly to a dataset seems more convenient, we *highly* recommend uploading files to RAGFlow's File system and then linking them to the target datasets. This way, you can avoid permanently deleting files uploaded to the dataset.
|
||||
While uploading files directly to a dataset seems more convenient, we *highly* recommend uploading files to RAGFlow's File system and then linking them to the target datasets. This way, you can avoid permanently deleting files uploaded to the dataset.
|
||||
|
||||
### Parse file
|
||||
|
||||
@ -93,14 +96,14 @@ File parsing is a crucial topic in dataset configuration. The meaning of file pa
|
||||
|
||||
|
||||
|
||||
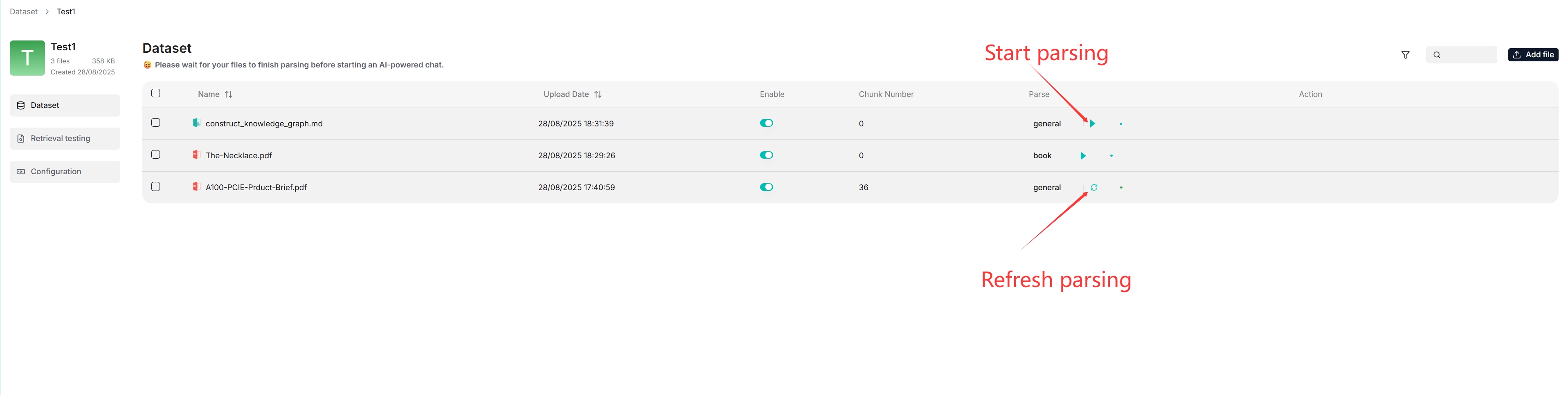
- As shown above, RAGFlow allows you to use a different chunking method for a particular file, offering flexibility beyond the default method.
|
||||
- As shown above, RAGFlow allows you to enable or disable individual files, offering finer control over dataset-based AI chats.
|
||||
- As shown above, RAGFlow allows you to use a different chunking method for a particular file, offering flexibility beyond the default method.
|
||||
- As shown above, RAGFlow allows you to enable or disable individual files, offering finer control over dataset-based AI chats.
|
||||
|
||||
### Intervene with file parsing results
|
||||
|
||||
RAGFlow features visibility and explainability, allowing you to view the chunking results and intervene where necessary. To do so:
|
||||
RAGFlow features visibility and explainability, allowing you to view the chunking results and intervene where necessary. To do so:
|
||||
|
||||
1. Click on the file that completes file parsing to view the chunking results:
|
||||
1. Click on the file that completes file parsing to view the chunking results:
|
||||
|
||||
_You are taken to the **Chunk** page:_
|
||||
|
||||
@ -113,7 +116,7 @@ RAGFlow features visibility and explainability, allowing you to view the chunkin
|
||||
|
||||
|
||||
:::caution NOTE
|
||||
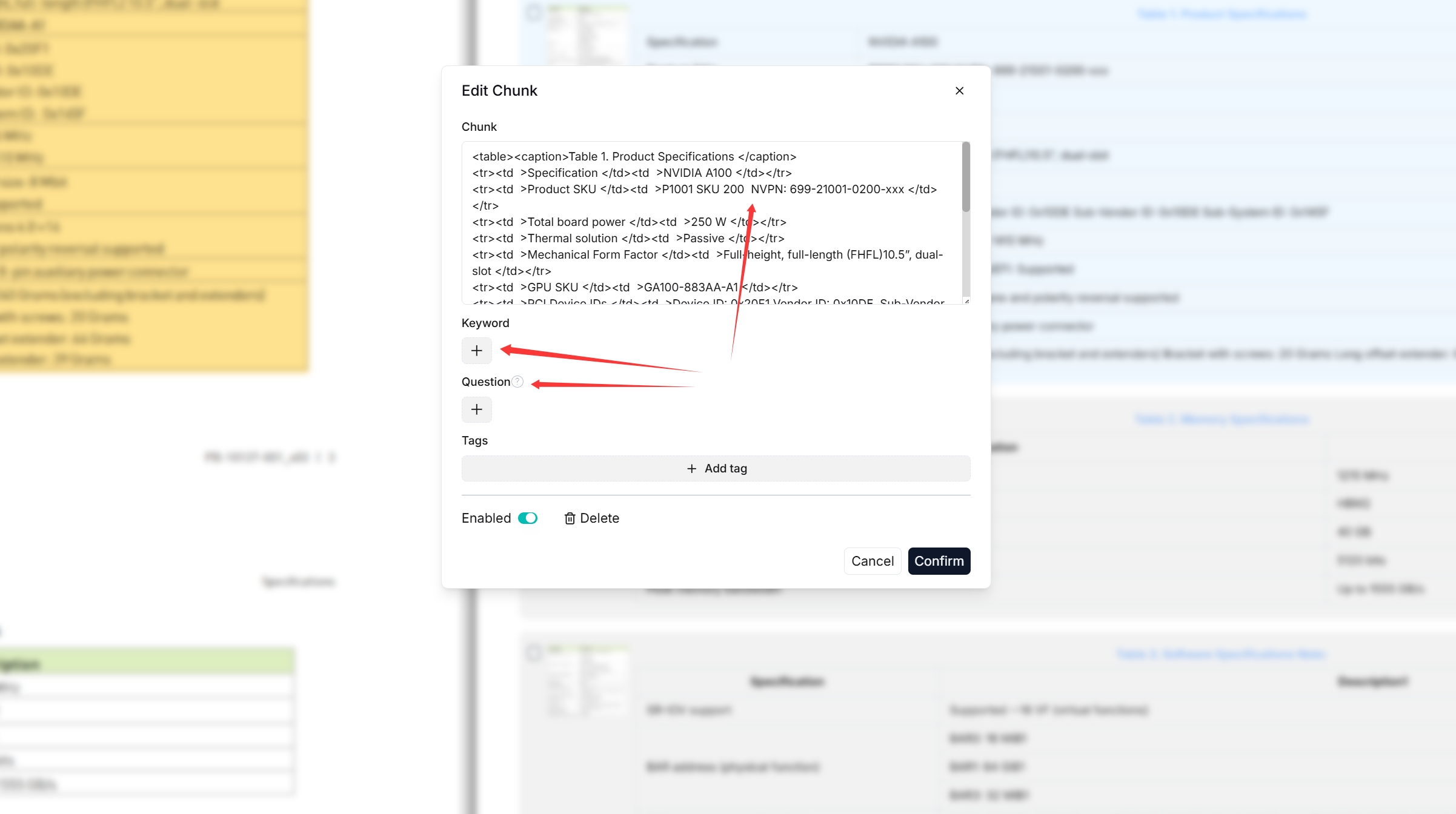
You can add keywords to a file chunk to increase its ranking for queries containing those keywords. This action increases its keyword weight and can improve its position in search list.
|
||||
You can add keywords to a file chunk to increase its ranking for queries containing those keywords. This action increases its keyword weight and can improve its position in search list.
|
||||
:::
|
||||
|
||||
4. In Retrieval testing, ask a quick question in **Test text** to double-check if your configurations work:
|
||||
@ -141,7 +144,7 @@ As of RAGFlow v0.23.1, the search feature is still in a rudimentary form, suppor
|
||||
|
||||
You are allowed to delete a dataset. Hover your mouse over the three dot of the intended dataset card and the **Delete** option appears. Once you delete a dataset, the associated folder under **root/.knowledge** directory is AUTOMATICALLY REMOVED. The consequence is:
|
||||
|
||||
- The files uploaded directly to the dataset are gone;
|
||||
- The file references, which you created from within RAGFlow's File system, are gone, but the associated files still exist.
|
||||
- The files uploaded directly to the dataset are gone;
|
||||
- The file references, which you created from within RAGFlow's File system, are gone, but the associated files still exist.
|
||||
|
||||

|
||||
|
||||
Reference in New Issue
Block a user