mirror of
https://github.com/infiniflow/ragflow.git
synced 2026-01-31 15:45:08 +08:00
docs: update docs icons (#12465)
### What problem does this PR solve? Update icons for docs. Trailing spaces are auto truncated by the editor, does not affect real content. ### Type of change - [x] Documentation Update
This commit is contained in:
@ -4,5 +4,8 @@
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "Guides on configuring a dataset."
|
||||
},
|
||||
"customProps": {
|
||||
"categoryIcon": "LucideDatabaseZap"
|
||||
}
|
||||
}
|
||||
|
||||
@ -4,5 +4,8 @@
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "Add various data sources"
|
||||
},
|
||||
"customProps": {
|
||||
"categoryIcon": "LucideServer"
|
||||
}
|
||||
}
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 3
|
||||
slug: /add_google_drive
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: SiGoogledrive
|
||||
}
|
||||
---
|
||||
|
||||
# Add Google Drive
|
||||
@ -10,9 +13,9 @@ slug: /add_google_drive
|
||||
You can either create a dedicated project for RAGFlow or use an existing
|
||||
Google Cloud external project.
|
||||
|
||||
**Steps:**
|
||||
**Steps:**
|
||||
1. Open the project creation page\
|
||||
`https://console.cloud.google.com/projectcreate`
|
||||
`https://console.cloud.google.com/projectcreate`
|
||||

|
||||
2. Select **External** as the Audience
|
||||

|
||||
@ -96,11 +99,11 @@ Navigate to the Google API Library:\
|
||||
|
||||
Enable the following APIs:
|
||||
|
||||
- Google Drive API
|
||||
- Admin SDK API
|
||||
- Google Sheets API
|
||||
- Google Drive API
|
||||
- Admin SDK API
|
||||
- Google Sheets API
|
||||
- Google Docs API
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
@ -126,7 +129,7 @@ Enable the following APIs:
|
||||

|
||||
|
||||
5. Click **Authorize with Google**
|
||||
A browser window will appear.
|
||||
A browser window will appear.
|
||||

|
||||
Click: - **Continue** - **Select All → Continue** - Authorization should
|
||||
succeed - Select **OK** to add the data source
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: -6
|
||||
slug: /auto_metadata
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideFileCodeCorner
|
||||
}
|
||||
---
|
||||
|
||||
# Auto-extract metadata
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 3
|
||||
slug: /autokeyword_autoquestion
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideSlidersHorizontal
|
||||
}
|
||||
---
|
||||
|
||||
# Auto-keyword Auto-question
|
||||
@ -20,14 +23,14 @@ Enabling this feature increases document indexing time and uses extra tokens, as
|
||||
|
||||
Auto-keyword refers to the auto-keyword generation feature of RAGFlow. It uses a chat model to generate a set of keywords or synonyms from each chunk to correct errors and enhance retrieval accuracy. This feature is implemented as a slider under **Page rank** on the **Configuration** page of your dataset.
|
||||
|
||||
**Values**:
|
||||
**Values**:
|
||||
|
||||
- 0: (Default) Disabled.
|
||||
- Between 3 and 5 (inclusive): Recommended if you have chunks of approximately 1,000 characters.
|
||||
- 30 (maximum)
|
||||
- 0: (Default) Disabled.
|
||||
- Between 3 and 5 (inclusive): Recommended if you have chunks of approximately 1,000 characters.
|
||||
- 30 (maximum)
|
||||
|
||||
:::tip NOTE
|
||||
- If your chunk size increases, you can increase the value accordingly. Please note, as the value increases, the marginal benefit decreases.
|
||||
- If your chunk size increases, you can increase the value accordingly. Please note, as the value increases, the marginal benefit decreases.
|
||||
- An Auto-keyword value must be an integer. If you set it to a non-integer, say 1.7, it will be rounded down to the nearest integer, which in this case is 1.
|
||||
:::
|
||||
|
||||
@ -37,12 +40,12 @@ Auto-question is a feature of RAGFlow that automatically generates questions fro
|
||||
|
||||
**Values**:
|
||||
|
||||
- 0: (Default) Disabled.
|
||||
- 1 or 2: Recommended if you have chunks of approximately 1,000 characters.
|
||||
- 0: (Default) Disabled.
|
||||
- 1 or 2: Recommended if you have chunks of approximately 1,000 characters.
|
||||
- 10 (maximum)
|
||||
|
||||
:::tip NOTE
|
||||
- If your chunk size increases, you can increase the value accordingly. Please note, as the value increases, the marginal benefit decreases.
|
||||
- If your chunk size increases, you can increase the value accordingly. Please note, as the value increases, the marginal benefit decreases.
|
||||
- An Auto-question value must be an integer. If you set it to a non-integer, say 1.7, it will be rounded down to the nearest integer, which in this case is 1.
|
||||
:::
|
||||
|
||||
|
||||
@ -4,5 +4,8 @@
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "Best practices on configuring a dataset."
|
||||
},
|
||||
"customProps": {
|
||||
"categoryIcon": "LucideStar"
|
||||
}
|
||||
}
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: -4
|
||||
slug: /configure_child_chunking_strategy
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideGroup
|
||||
}
|
||||
---
|
||||
|
||||
# Configure child chunking strategy
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: -10
|
||||
slug: /configure_knowledge_base
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideCog
|
||||
}
|
||||
---
|
||||
|
||||
# Configure dataset
|
||||
@ -22,7 +25,7 @@ _Each time a dataset is created, a folder with the same name is generated in the
|
||||
|
||||
## Configure dataset
|
||||
|
||||
The following screenshot shows the configuration page of a dataset. A proper configuration of your dataset is crucial for future AI chats. For example, choosing the wrong embedding model or chunking method would cause unexpected semantic loss or mismatched answers in chats.
|
||||
The following screenshot shows the configuration page of a dataset. A proper configuration of your dataset is crucial for future AI chats. For example, choosing the wrong embedding model or chunking method would cause unexpected semantic loss or mismatched answers in chats.
|
||||
|
||||
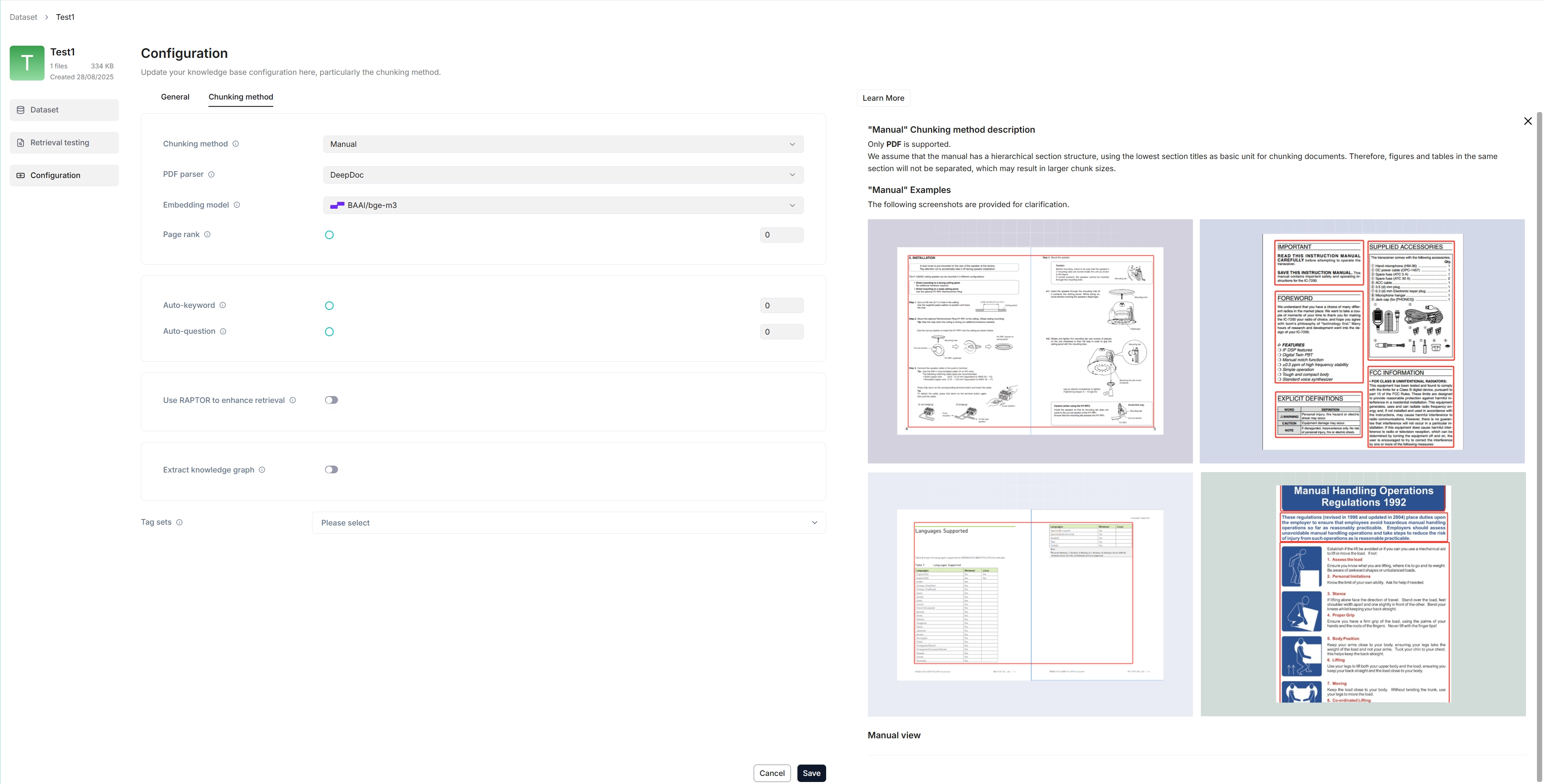
|
||||
|
||||
@ -60,14 +63,14 @@ You can also change a file's chunking method on the **Files** page.
|
||||
|
||||
<details>
|
||||
<summary>From v0.21.0 onward, RAGFlow supports ingestion pipeline for customized data ingestion and cleansing workflows.</summary>
|
||||
|
||||
|
||||
To use a customized data pipeline:
|
||||
|
||||
1. On the **Agent** page, click **+ Create agent** > **Create from blank**.
|
||||
2. Select **Ingestion pipeline** and name your data pipeline in the popup, then click **Save** to show the data pipeline canvas.
|
||||
3. After updating your data pipeline, click **Save** on the top right of the canvas.
|
||||
4. Navigate to the **Configuration** page of your dataset, select **Choose pipeline** in **Ingestion pipeline**.
|
||||
|
||||
|
||||
*Your saved data pipeline will appear in the dropdown menu below.*
|
||||
|
||||
</details>
|
||||
@ -83,9 +86,9 @@ Some embedding models are optimized for specific languages, so performance may b
|
||||
### Upload file
|
||||
|
||||
- RAGFlow's File system allows you to link a file to multiple datasets, in which case each target dataset holds a reference to the file.
|
||||
- In **Knowledge Base**, you are also given the option of uploading a single file or a folder of files (bulk upload) from your local machine to a dataset, in which case the dataset holds file copies.
|
||||
- In **Knowledge Base**, you are also given the option of uploading a single file or a folder of files (bulk upload) from your local machine to a dataset, in which case the dataset holds file copies.
|
||||
|
||||
While uploading files directly to a dataset seems more convenient, we *highly* recommend uploading files to RAGFlow's File system and then linking them to the target datasets. This way, you can avoid permanently deleting files uploaded to the dataset.
|
||||
While uploading files directly to a dataset seems more convenient, we *highly* recommend uploading files to RAGFlow's File system and then linking them to the target datasets. This way, you can avoid permanently deleting files uploaded to the dataset.
|
||||
|
||||
### Parse file
|
||||
|
||||
@ -93,14 +96,14 @@ File parsing is a crucial topic in dataset configuration. The meaning of file pa
|
||||
|
||||
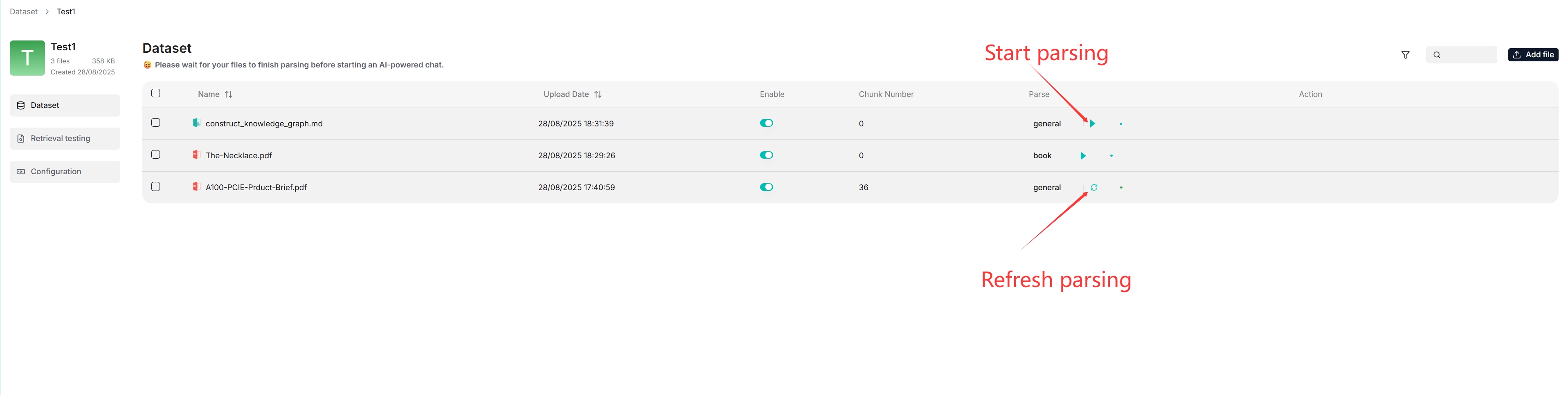
|
||||
|
||||
- As shown above, RAGFlow allows you to use a different chunking method for a particular file, offering flexibility beyond the default method.
|
||||
- As shown above, RAGFlow allows you to enable or disable individual files, offering finer control over dataset-based AI chats.
|
||||
- As shown above, RAGFlow allows you to use a different chunking method for a particular file, offering flexibility beyond the default method.
|
||||
- As shown above, RAGFlow allows you to enable or disable individual files, offering finer control over dataset-based AI chats.
|
||||
|
||||
### Intervene with file parsing results
|
||||
|
||||
RAGFlow features visibility and explainability, allowing you to view the chunking results and intervene where necessary. To do so:
|
||||
RAGFlow features visibility and explainability, allowing you to view the chunking results and intervene where necessary. To do so:
|
||||
|
||||
1. Click on the file that completes file parsing to view the chunking results:
|
||||
1. Click on the file that completes file parsing to view the chunking results:
|
||||
|
||||
_You are taken to the **Chunk** page:_
|
||||
|
||||
@ -113,7 +116,7 @@ RAGFlow features visibility and explainability, allowing you to view the chunkin
|
||||
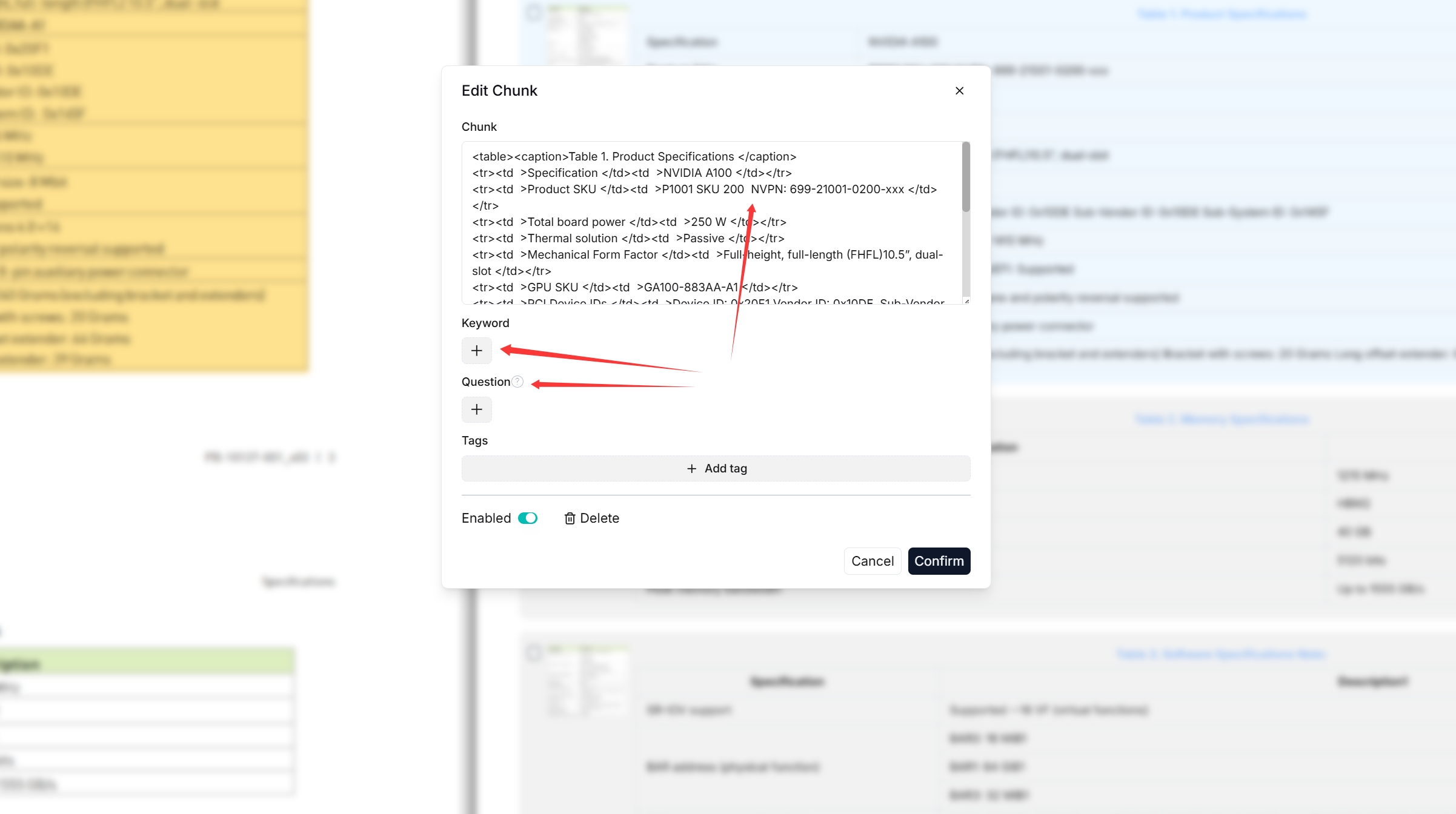
|
||||
|
||||
:::caution NOTE
|
||||
You can add keywords to a file chunk to increase its ranking for queries containing those keywords. This action increases its keyword weight and can improve its position in search list.
|
||||
You can add keywords to a file chunk to increase its ranking for queries containing those keywords. This action increases its keyword weight and can improve its position in search list.
|
||||
:::
|
||||
|
||||
4. In Retrieval testing, ask a quick question in **Test text** to double-check if your configurations work:
|
||||
@ -141,7 +144,7 @@ As of RAGFlow v0.23.1, the search feature is still in a rudimentary form, suppor
|
||||
|
||||
You are allowed to delete a dataset. Hover your mouse over the three dot of the intended dataset card and the **Delete** option appears. Once you delete a dataset, the associated folder under **root/.knowledge** directory is AUTOMATICALLY REMOVED. The consequence is:
|
||||
|
||||
- The files uploaded directly to the dataset are gone;
|
||||
- The file references, which you created from within RAGFlow's File system, are gone, but the associated files still exist.
|
||||
- The files uploaded directly to the dataset are gone;
|
||||
- The file references, which you created from within RAGFlow's File system, are gone, but the associated files still exist.
|
||||
|
||||

|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 8
|
||||
slug: /construct_knowledge_graph
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideWandSparkles
|
||||
}
|
||||
---
|
||||
|
||||
# Construct knowledge graph
|
||||
@ -63,7 +66,7 @@ In a knowledge graph, a community is a cluster of entities linked by relationshi
|
||||
## Quickstart
|
||||
|
||||
1. Navigate to the **Configuration** page of your dataset and update:
|
||||
|
||||
|
||||
- Entity types: *Required* - Specifies the entity types in the knowledge graph to generate. You don't have to stick with the default, but you need to customize them for your documents.
|
||||
- Method: *Optional*
|
||||
- Entity resolution: *Optional*
|
||||
@ -74,12 +77,12 @@ In a knowledge graph, a community is a cluster of entities linked by relationshi
|
||||
|
||||
*You can click the pause button in the dropdown to halt the build process when necessary.*
|
||||
|
||||
3. Go back to the **Configuration** page:
|
||||
|
||||
3. Go back to the **Configuration** page:
|
||||
|
||||
*Once a knowledge graph is generated, the **Knowledge graph** field changes from `Not generated` to `Generated at a specific timestamp`. You can delete it by clicking the recycle bin button to the right of the field.*
|
||||
|
||||
4. To use the created knowledge graph, do either of the following:
|
||||
|
||||
|
||||
- In the **Chat setting** panel of your chat app, switch on the **Use knowledge graph** toggle.
|
||||
- If you are using an agent, click the **Retrieval** agent component to specify the dataset(s) and switch on the **Use knowledge graph** toggle.
|
||||
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 4
|
||||
slug: /enable_excel2html
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideToggleRight
|
||||
}
|
||||
---
|
||||
|
||||
# Enable Excel2HTML
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 7
|
||||
slug: /enable_raptor
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideNetwork
|
||||
}
|
||||
---
|
||||
|
||||
# Enable RAPTOR
|
||||
@ -76,7 +79,7 @@ A random seed. Click **+** to change the seed value.
|
||||
## Quickstart
|
||||
|
||||
1. Navigate to the **Configuration** page of your dataset and update:
|
||||
|
||||
|
||||
- Prompt: *Optional* - We recommend that you keep it as-is until you understand the mechanism behind.
|
||||
- Max token: *Optional*
|
||||
- Threshold: *Optional*
|
||||
@ -86,8 +89,8 @@ A random seed. Click **+** to change the seed value.
|
||||
|
||||
*You can click the pause button in the dropdown to halt the build process when necessary.*
|
||||
|
||||
3. Go back to the **Configuration** page:
|
||||
|
||||
3. Go back to the **Configuration** page:
|
||||
|
||||
*The **RAPTOR** field changes from `Not generated` to `Generated at a specific timestamp` when a RAPTOR hierarchical tree structure is generated. You can delete it by clicking the recycle bin button to the right of the field.*
|
||||
|
||||
4. Once a RAPTOR hierarchical tree structure is generated, your chat assistant and **Retrieval** agent component will use it for retrieval as a default.
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 4
|
||||
slug: /enable_table_of_contents
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideTableOfContents
|
||||
}
|
||||
---
|
||||
|
||||
# Extract table of contents
|
||||
@ -28,7 +31,7 @@ The system's default chat model is used to summarize clustered content. Before p
|
||||
2. Enable **TOC Enhance**.
|
||||
|
||||
3. To use this technique during retrieval, do either of the following:
|
||||
|
||||
|
||||
- In the **Chat setting** panel of your chat app, switch on the **TOC Enhance** toggle.
|
||||
- If you are using an agent, click the **Retrieval** agent component to specify the dataset(s) and switch on the **TOC Enhance** toggle.
|
||||
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: -5
|
||||
slug: /manage_metadata
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideCode
|
||||
}
|
||||
---
|
||||
|
||||
# Manage metadata
|
||||
@ -19,7 +22,7 @@ From v0.23.0 onwards, RAGFlow allows you to manage metadata both at the dataset
|
||||
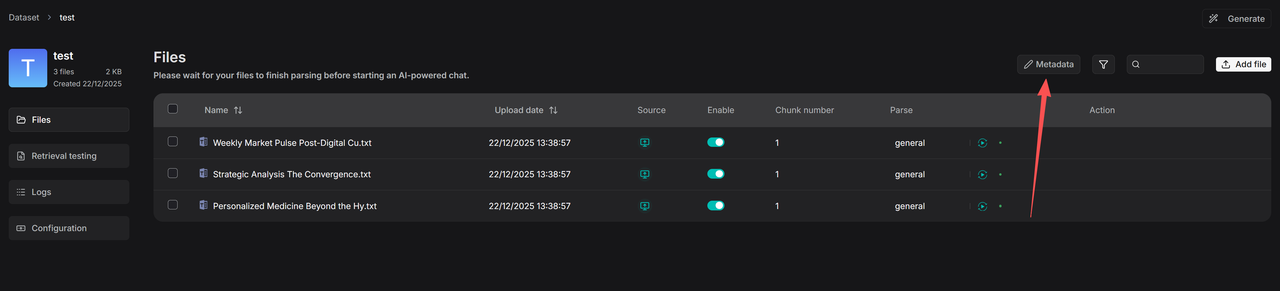
|
||||
|
||||
|
||||
2. On the **Manage Metadata** page, you can do either of the following:
|
||||
2. On the **Manage Metadata** page, you can do either of the following:
|
||||
- Edit Values: You can modify existing values. If you rename two values to be identical, they will be automatically merged.
|
||||
- Delete: You can delete specific values or entire fields. These changes will apply to all associated files.
|
||||
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 10
|
||||
slug: /run_retrieval_test
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideTextSearch
|
||||
}
|
||||
---
|
||||
|
||||
# Run retrieval test
|
||||
@ -53,7 +56,7 @@ The switch is disabled by default. When enabled, RAGFlow performs the following
|
||||
3. Find similar entities and their N-hop relationships from the graph using the embeddings of the extracted query entities.
|
||||
4. Retrieve similar relationships from the graph using the query embedding.
|
||||
5. Rank these retrieved entities and relationships by multiplying each one's PageRank value with its similarity score to the query, returning the top n as the final retrieval.
|
||||
6. Retrieve the report for the community involving the most entities in the final retrieval.
|
||||
6. Retrieve the report for the community involving the most entities in the final retrieval.
|
||||
*The retrieved entity descriptions, relationship descriptions, and the top 1 community report are sent to the LLM for content generation.*
|
||||
|
||||
:::danger IMPORTANT
|
||||
@ -78,10 +81,10 @@ This field is where you put in your testing query.
|
||||
1. Navigate to the **Retrieval testing** page of your dataset, enter your query in **Test text**, and click **Testing** to run the test.
|
||||
2. If the results are unsatisfactory, tune the options listed in the Configuration section and rerun the test.
|
||||
|
||||
*The following is a screenshot of a retrieval test conducted without using knowledge graph. It demonstrates a hybrid search combining weighted keyword similarity and weighted vector cosine similarity. The overall hybrid similarity score is 28.56, calculated as 25.17 (term similarity score) x 0.7 + 36.49 (vector similarity score) x 0.3:*
|
||||
*The following is a screenshot of a retrieval test conducted without using knowledge graph. It demonstrates a hybrid search combining weighted keyword similarity and weighted vector cosine similarity. The overall hybrid similarity score is 28.56, calculated as 25.17 (term similarity score) x 0.7 + 36.49 (vector similarity score) x 0.3:*
|
||||

|
||||
|
||||
*The following is a screenshot of a retrieval test conducted using a knowledge graph. It shows that only vector similarity is used for knowledge graph-generated chunks:*
|
||||
*The following is a screenshot of a retrieval test conducted using a knowledge graph. It shows that only vector similarity is used for knowledge graph-generated chunks:*
|
||||

|
||||
|
||||
:::caution WARNING
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: -3
|
||||
slug: /select_pdf_parser
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideFileText
|
||||
}
|
||||
---
|
||||
|
||||
# Select PDF parser
|
||||
@ -54,12 +57,12 @@ Starting from v0.22.0, RAGFlow includes MinerU (≥ 2.6.3) as an optional PDF p
|
||||
- `"vlm-mlx-engine"`
|
||||
- `"vlm-vllm-async-engine"`
|
||||
- `"vlm-lmdeploy-engine"`.
|
||||
- `MINERU_SERVER_URL`: (optional) The downstream vLLM HTTP server (e.g., `http://vllm-host:30000`). Applicable when `MINERU_BACKEND` is set to `"vlm-http-client"`.
|
||||
- `MINERU_SERVER_URL`: (optional) The downstream vLLM HTTP server (e.g., `http://vllm-host:30000`). Applicable when `MINERU_BACKEND` is set to `"vlm-http-client"`.
|
||||
- `MINERU_OUTPUT_DIR`: (optional) The local directory for holding the outputs of the MinerU API service (zip/JSON) before ingestion.
|
||||
- `MINERU_DELETE_OUTPUT`: Whether to delete temporary output when a temporary directory is used:
|
||||
- `1`: Delete.
|
||||
- `0`: Retain.
|
||||
3. In the web UI, navigate to your dataset's **Configuration** page and find the **Ingestion pipeline** section:
|
||||
3. In the web UI, navigate to your dataset's **Configuration** page and find the **Ingestion pipeline** section:
|
||||
- If you decide to use a chunking method from the **Built-in** dropdown, ensure it supports PDF parsing, then select **MinerU** from the **PDF parser** dropdown.
|
||||
- If you use a custom ingestion pipeline instead, select **MinerU** in the **PDF parser** section of the **Parser** component.
|
||||
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: -8
|
||||
slug: /set_context_window
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideListChevronsUpDown
|
||||
}
|
||||
---
|
||||
|
||||
# Set context window size
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: -7
|
||||
slug: /set_metadata
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideCode
|
||||
}
|
||||
---
|
||||
|
||||
# Set metadata
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: -2
|
||||
slug: /set_page_rank
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideStickyNote
|
||||
}
|
||||
---
|
||||
|
||||
# Set page rank
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 6
|
||||
slug: /use_tag_sets
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideTags
|
||||
}
|
||||
---
|
||||
|
||||
# Use tag set
|
||||
@ -43,10 +46,10 @@ A tag set is *not* involved in document indexing or retrieval. Do not specify a
|
||||
|
||||
1. Click **+ Create dataset** to create a dataset.
|
||||
2. Navigate to the **Configuration** page of the created dataset, select **Built-in** in **Ingestion pipeline**, then choose **Tag** as the default chunking method from the **Built-in** drop-down menu.
|
||||
3. Go back to the **Files** page and upload and parse your table file in XLSX, CSV, or TXT formats.
|
||||
_A tag cloud appears under the **Tag view** section, indicating the tag set is created:_
|
||||
3. Go back to the **Files** page and upload and parse your table file in XLSX, CSV, or TXT formats.
|
||||
_A tag cloud appears under the **Tag view** section, indicating the tag set is created:_
|
||||

|
||||
4. Click the **Table** tab to view the tag frequency table:
|
||||
4. Click the **Table** tab to view the tag frequency table:
|
||||

|
||||
|
||||
## 2. Tag chunks
|
||||
@ -60,12 +63,12 @@ Once a tag set is created, you can apply it to your dataset:
|
||||
If the tag set is missing from the dropdown, check that it has been created or configured correctly.
|
||||
:::
|
||||
|
||||
3. Re-parse your documents to start the auto-tagging process.
|
||||
3. Re-parse your documents to start the auto-tagging process.
|
||||
_In an AI chat scenario using auto-tagged datasets, each query will be tagged using the corresponding tag set(s) and chunks with these tags will have a higher chance to be retrieved._
|
||||
|
||||
## 3. Update tag set
|
||||
|
||||
Creating a tag set is *not* for once and for all. Oftentimes, you may find it necessary to update or delete existing tags or add new entries.
|
||||
Creating a tag set is *not* for once and for all. Oftentimes, you may find it necessary to update or delete existing tags or add new entries.
|
||||
|
||||
- You can update the existing tag set in the tag frequency table.
|
||||
- To add new entries, you can add and parse new table files in XLSX, CSV, or TXT formats.
|
||||
|
||||
Reference in New Issue
Block a user