mirror of
https://github.com/infiniflow/ragflow.git
synced 2026-02-06 10:35:06 +08:00
Fix errors (#11804)
### What problem does this PR solve? 1. typos 2. grammar errors. ### Type of change - [x] Refactoring Signed-off-by: Jin Hai <haijin.chn@gmail.com>
This commit is contained in:
@ -478,7 +478,7 @@ class Canvas(Graph):
|
||||
})
|
||||
await _run_batch(idx, to)
|
||||
to = len(self.path)
|
||||
# post processing of components invocation
|
||||
# post-processing of components invocation
|
||||
for i in range(idx, to):
|
||||
cpn = self.get_component(self.path[i])
|
||||
cpn_obj = self.get_component_obj(self.path[i])
|
||||
|
||||
@ -75,7 +75,7 @@ class YahooFinance(ToolBase, ABC):
|
||||
@timeout(int(os.environ.get("COMPONENT_EXEC_TIMEOUT", 60)))
|
||||
def _invoke(self, **kwargs):
|
||||
if self.check_if_canceled("YahooFinance processing"):
|
||||
return
|
||||
return None
|
||||
|
||||
if not kwargs.get("stock_code"):
|
||||
self.set_output("report", "")
|
||||
@ -84,33 +84,33 @@ class YahooFinance(ToolBase, ABC):
|
||||
last_e = ""
|
||||
for _ in range(self._param.max_retries+1):
|
||||
if self.check_if_canceled("YahooFinance processing"):
|
||||
return
|
||||
return None
|
||||
|
||||
yohoo_res = []
|
||||
yahoo_res = []
|
||||
try:
|
||||
msft = yf.Ticker(kwargs["stock_code"])
|
||||
if self.check_if_canceled("YahooFinance processing"):
|
||||
return
|
||||
return None
|
||||
|
||||
if self._param.info:
|
||||
yohoo_res.append("# Information:\n" + pd.Series(msft.info).to_markdown() + "\n")
|
||||
yahoo_res.append("# Information:\n" + pd.Series(msft.info).to_markdown() + "\n")
|
||||
if self._param.history:
|
||||
yohoo_res.append("# History:\n" + msft.history().to_markdown() + "\n")
|
||||
yahoo_res.append("# History:\n" + msft.history().to_markdown() + "\n")
|
||||
if self._param.financials:
|
||||
yohoo_res.append("# Calendar:\n" + pd.DataFrame(msft.calendar).to_markdown() + "\n")
|
||||
yahoo_res.append("# Calendar:\n" + pd.DataFrame(msft.calendar).to_markdown() + "\n")
|
||||
if self._param.balance_sheet:
|
||||
yohoo_res.append("# Balance sheet:\n" + msft.balance_sheet.to_markdown() + "\n")
|
||||
yohoo_res.append("# Quarterly balance sheet:\n" + msft.quarterly_balance_sheet.to_markdown() + "\n")
|
||||
yahoo_res.append("# Balance sheet:\n" + msft.balance_sheet.to_markdown() + "\n")
|
||||
yahoo_res.append("# Quarterly balance sheet:\n" + msft.quarterly_balance_sheet.to_markdown() + "\n")
|
||||
if self._param.cash_flow_statement:
|
||||
yohoo_res.append("# Cash flow statement:\n" + msft.cashflow.to_markdown() + "\n")
|
||||
yohoo_res.append("# Quarterly cash flow statement:\n" + msft.quarterly_cashflow.to_markdown() + "\n")
|
||||
yahoo_res.append("# Cash flow statement:\n" + msft.cashflow.to_markdown() + "\n")
|
||||
yahoo_res.append("# Quarterly cash flow statement:\n" + msft.quarterly_cashflow.to_markdown() + "\n")
|
||||
if self._param.news:
|
||||
yohoo_res.append("# News:\n" + pd.DataFrame(msft.news).to_markdown() + "\n")
|
||||
self.set_output("report", "\n\n".join(yohoo_res))
|
||||
yahoo_res.append("# News:\n" + pd.DataFrame(msft.news).to_markdown() + "\n")
|
||||
self.set_output("report", "\n\n".join(yahoo_res))
|
||||
return self.output("report")
|
||||
except Exception as e:
|
||||
if self.check_if_canceled("YahooFinance processing"):
|
||||
return
|
||||
return None
|
||||
|
||||
last_e = e
|
||||
logging.exception(f"YahooFinance error: {e}")
|
||||
|
||||
@ -180,7 +180,7 @@ def login_user(user, remember=False, duration=None, force=False, fresh=True):
|
||||
user's `is_active` property is ``False``, they will not be logged in
|
||||
unless `force` is ``True``.
|
||||
|
||||
This will return ``True`` if the log in attempt succeeds, and ``False`` if
|
||||
This will return ``True`` if the login attempt succeeds, and ``False`` if
|
||||
it fails (i.e. because the user is inactive).
|
||||
|
||||
:param user: The user object to log in.
|
||||
|
||||
@ -552,7 +552,7 @@ def list_docs(dataset_id, tenant_id):
|
||||
create_time_from = int(q.get("create_time_from", 0))
|
||||
create_time_to = int(q.get("create_time_to", 0))
|
||||
|
||||
# map run status (accept text or numeric) - align with API parameter
|
||||
# map run status (text or numeric) - align with API parameter
|
||||
run_status_text_to_numeric = {"UNSTART": "0", "RUNNING": "1", "CANCEL": "2", "DONE": "3", "FAIL": "4"}
|
||||
run_status_converted = [run_status_text_to_numeric.get(v, v) for v in run_status]
|
||||
|
||||
@ -890,7 +890,7 @@ def list_chunks(tenant_id, dataset_id, document_id):
|
||||
type: string
|
||||
required: false
|
||||
default: ""
|
||||
description: Chunk Id.
|
||||
description: Chunk id.
|
||||
- in: header
|
||||
name: Authorization
|
||||
type: string
|
||||
|
||||
@ -126,7 +126,7 @@ class OnyxConfluence:
|
||||
def _renew_credentials(self) -> tuple[dict[str, Any], bool]:
|
||||
"""credential_json - the current json credentials
|
||||
Returns a tuple
|
||||
1. The up to date credentials
|
||||
1. The up-to-date credentials
|
||||
2. True if the credentials were updated
|
||||
|
||||
This method is intended to be used within a distributed lock.
|
||||
@ -179,8 +179,8 @@ class OnyxConfluence:
|
||||
credential_json["confluence_refresh_token"],
|
||||
)
|
||||
|
||||
# store the new credentials to redis and to the db thru the provider
|
||||
# redis: we use a 5 min TTL because we are given a 10 minute grace period
|
||||
# store the new credentials to redis and to the db through the provider
|
||||
# redis: we use a 5 min TTL because we are given a 10 minutes grace period
|
||||
# when keys are rotated. it's easier to expire the cached credentials
|
||||
# reasonably frequently rather than trying to handle strong synchronization
|
||||
# between the db and redis everywhere the credentials might be updated
|
||||
@ -690,7 +690,7 @@ class OnyxConfluence:
|
||||
) -> Iterator[dict[str, Any]]:
|
||||
"""
|
||||
This function will paginate through the top level query first, then
|
||||
paginate through all of the expansions.
|
||||
paginate through all the expansions.
|
||||
"""
|
||||
|
||||
def _traverse_and_update(data: dict | list) -> None:
|
||||
@ -863,7 +863,7 @@ def get_user_email_from_username__server(
|
||||
# For now, we'll just return None and log a warning. This means
|
||||
# we will keep retrying to get the email every group sync.
|
||||
email = None
|
||||
# We may want to just return a string that indicates failure so we dont
|
||||
# We may want to just return a string that indicates failure so we don't
|
||||
# keep retrying
|
||||
# email = f"FAILED TO GET CONFLUENCE EMAIL FOR {user_name}"
|
||||
_USER_EMAIL_CACHE[user_name] = email
|
||||
@ -912,7 +912,7 @@ def extract_text_from_confluence_html(
|
||||
confluence_object: dict[str, Any],
|
||||
fetched_titles: set[str],
|
||||
) -> str:
|
||||
"""Parse a Confluence html page and replace the 'user Id' by the real
|
||||
"""Parse a Confluence html page and replace the 'user id' by the real
|
||||
User Display Name
|
||||
|
||||
Args:
|
||||
|
||||
@ -76,7 +76,7 @@ ALL_ACCEPTED_FILE_EXTENSIONS = ACCEPTED_PLAIN_TEXT_FILE_EXTENSIONS + ACCEPTED_DO
|
||||
|
||||
MAX_RETRIEVER_EMAILS = 20
|
||||
CHUNK_SIZE_BUFFER = 64 # extra bytes past the limit to read
|
||||
# This is not a standard valid unicode char, it is used by the docs advanced API to
|
||||
# This is not a standard valid Unicode char, it is used by the docs advanced API to
|
||||
# represent smart chips (elements like dates and doc links).
|
||||
SMART_CHIP_CHAR = "\ue907"
|
||||
WEB_VIEW_LINK_KEY = "webViewLink"
|
||||
|
||||
@ -141,7 +141,7 @@ def crawl_folders_for_files(
|
||||
# Only mark a folder as done if it was fully traversed without errors
|
||||
# This usually indicates that the owner of the folder was impersonated.
|
||||
# In cases where this never happens, most likely the folder owner is
|
||||
# not part of the google workspace in question (or for oauth, the authenticated
|
||||
# not part of the Google Workspace in question (or for oauth, the authenticated
|
||||
# user doesn't own the folder)
|
||||
if found_files:
|
||||
update_traversed_ids_func(parent_id)
|
||||
@ -232,7 +232,7 @@ def get_files_in_shared_drive(
|
||||
**kwargs,
|
||||
):
|
||||
# If we found any files, mark this drive as traversed. When a user has access to a drive,
|
||||
# they have access to all the files in the drive. Also not a huge deal if we re-traverse
|
||||
# they have access to all the files in the drive. Also, not a huge deal if we re-traverse
|
||||
# empty drives.
|
||||
# NOTE: ^^ the above is not actually true due to folder restrictions:
|
||||
# https://support.google.com/a/users/answer/12380484?hl=en
|
||||
|
||||
@ -22,7 +22,7 @@ class GDriveMimeType(str, Enum):
|
||||
MARKDOWN = "text/markdown"
|
||||
|
||||
|
||||
# These correspond to The major stages of retrieval for google drive.
|
||||
# These correspond to The major stages of retrieval for Google Drive.
|
||||
# The stages for the oauth flow are:
|
||||
# get_all_files_for_oauth(),
|
||||
# get_all_drive_ids(),
|
||||
@ -117,7 +117,7 @@ class GoogleDriveCheckpoint(ConnectorCheckpoint):
|
||||
|
||||
class RetrievedDriveFile(BaseModel):
|
||||
"""
|
||||
Describes a file that has been retrieved from google drive.
|
||||
Describes a file that has been retrieved from Google Drive.
|
||||
user_email is the email of the user that the file was retrieved
|
||||
by impersonating. If an error worthy of being reported is encountered,
|
||||
error should be set and later propagated as a ConnectorFailure.
|
||||
|
||||
@ -29,8 +29,8 @@ class GmailService(Resource):
|
||||
|
||||
class RefreshableDriveObject:
|
||||
"""
|
||||
Running Google drive service retrieval functions
|
||||
involves accessing methods of the service object (ie. files().list())
|
||||
Running Google Drive service retrieval functions
|
||||
involves accessing methods of the service object (i.e. files().list())
|
||||
which can raise a RefreshError if the access token is expired.
|
||||
This class is a wrapper that propagates the ability to refresh the access token
|
||||
and retry the final retrieval function until execute() is called.
|
||||
|
||||
@ -120,7 +120,7 @@ def format_document_soup(
|
||||
# table is standard HTML element
|
||||
if e.name == "table":
|
||||
in_table = True
|
||||
# tr is for rows
|
||||
# TR is for rows
|
||||
elif e.name == "tr" and in_table:
|
||||
text += "\n"
|
||||
# td for data cell, th for header
|
||||
|
||||
@ -395,8 +395,7 @@ class AttachmentProcessingResult(BaseModel):
|
||||
|
||||
|
||||
class IndexingHeartbeatInterface(ABC):
|
||||
"""Defines a callback interface to be passed to
|
||||
to run_indexing_entrypoint."""
|
||||
"""Defines a callback interface to be passed to run_indexing_entrypoint."""
|
||||
|
||||
@abstractmethod
|
||||
def should_stop(self) -> bool:
|
||||
|
||||
@ -80,7 +80,7 @@ _TZ_OFFSET_PATTERN = re.compile(r"([+-])(\d{2})(:?)(\d{2})$")
|
||||
|
||||
|
||||
class JiraConnector(CheckpointedConnectorWithPermSync, SlimConnectorWithPermSync):
|
||||
"""Retrieve Jira issues and emit them as markdown documents."""
|
||||
"""Retrieve Jira issues and emit them as Markdown documents."""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
|
||||
@ -54,8 +54,8 @@ class ExternalAccess:
|
||||
A helper function that returns an *empty* set of external user-emails and group-ids, and sets `is_public` to `False`.
|
||||
This effectively makes the document in question "private" or inaccessible to anyone else.
|
||||
|
||||
This is especially helpful to use when you are performing permission-syncing, and some document's permissions aren't able
|
||||
to be determined (for whatever reason). Setting its `ExternalAccess` to "private" is a feasible fallback.
|
||||
This is especially helpful to use when you are performing permission-syncing, and some document's permissions can't
|
||||
be determined (for whatever reason). Setting its `ExternalAccess` to "private" is a feasible fallback.
|
||||
"""
|
||||
|
||||
return cls(
|
||||
|
||||
@ -61,7 +61,7 @@ def clean_markdown_block(text):
|
||||
str: Cleaned text with Markdown code block syntax removed, and stripped of surrounding whitespace
|
||||
|
||||
"""
|
||||
# Remove opening ```markdown tag with optional whitespace and newlines
|
||||
# Remove opening ```Markdown tag with optional whitespace and newlines
|
||||
# Matches: optional whitespace + ```markdown + optional whitespace + optional newline
|
||||
text = re.sub(r'^\s*```markdown\s*\n?', '', text)
|
||||
|
||||
|
||||
@ -51,7 +51,7 @@ We use vision information to resolve problems as human being.
|
||||
```bash
|
||||
python deepdoc/vision/t_ocr.py --inputs=path_to_images_or_pdfs --output_dir=path_to_store_result
|
||||
```
|
||||
The inputs could be directory to images or PDF, or a image or PDF.
|
||||
The inputs could be directory to images or PDF, or an image or PDF.
|
||||
You can look into the folder 'path_to_store_result' where has images which demonstrate the positions of results,
|
||||
txt files which contain the OCR text.
|
||||
<div align="center" style="margin-top:20px;margin-bottom:20px;">
|
||||
@ -78,7 +78,7 @@ We use vision information to resolve problems as human being.
|
||||
```bash
|
||||
python deepdoc/vision/t_recognizer.py --inputs=path_to_images_or_pdfs --threshold=0.2 --mode=layout --output_dir=path_to_store_result
|
||||
```
|
||||
The inputs could be directory to images or PDF, or a image or PDF.
|
||||
The inputs could be directory to images or PDF, or an image or PDF.
|
||||
You can look into the folder 'path_to_store_result' where has images which demonstrate the detection results as following:
|
||||
<div align="center" style="margin-top:20px;margin-bottom:20px;">
|
||||
<img src="https://github.com/infiniflow/ragflow/assets/12318111/07e0f625-9b28-43d0-9fbb-5bf586cd286f" width="1000"/>
|
||||
|
||||
@ -155,7 +155,7 @@ class TableStructureRecognizer(Recognizer):
|
||||
while i < len(boxes):
|
||||
if TableStructureRecognizer.is_caption(boxes[i]):
|
||||
if is_english:
|
||||
cap + " "
|
||||
cap += " "
|
||||
cap += boxes[i]["text"]
|
||||
boxes.pop(i)
|
||||
i -= 1
|
||||
|
||||
@ -4013,7 +4013,7 @@ Failure:
|
||||
|
||||
**DELETE** `/api/v1/agents/{agent_id}/sessions`
|
||||
|
||||
Deletes sessions of a agent by ID.
|
||||
Deletes sessions of an agent by ID.
|
||||
|
||||
#### Request
|
||||
|
||||
@ -4072,7 +4072,7 @@ Failure:
|
||||
|
||||
Generates five to ten alternative question strings from the user's original query to retrieve more relevant search results.
|
||||
|
||||
This operation requires a `Bearer Login Token`, which typically expires with in 24 hours. You can find the it in the Request Headers in your browser easily as shown below:
|
||||
This operation requires a `Bearer Login Token`, which typically expires with in 24 hours. You can find it in the Request Headers in your browser easily as shown below:
|
||||
|
||||
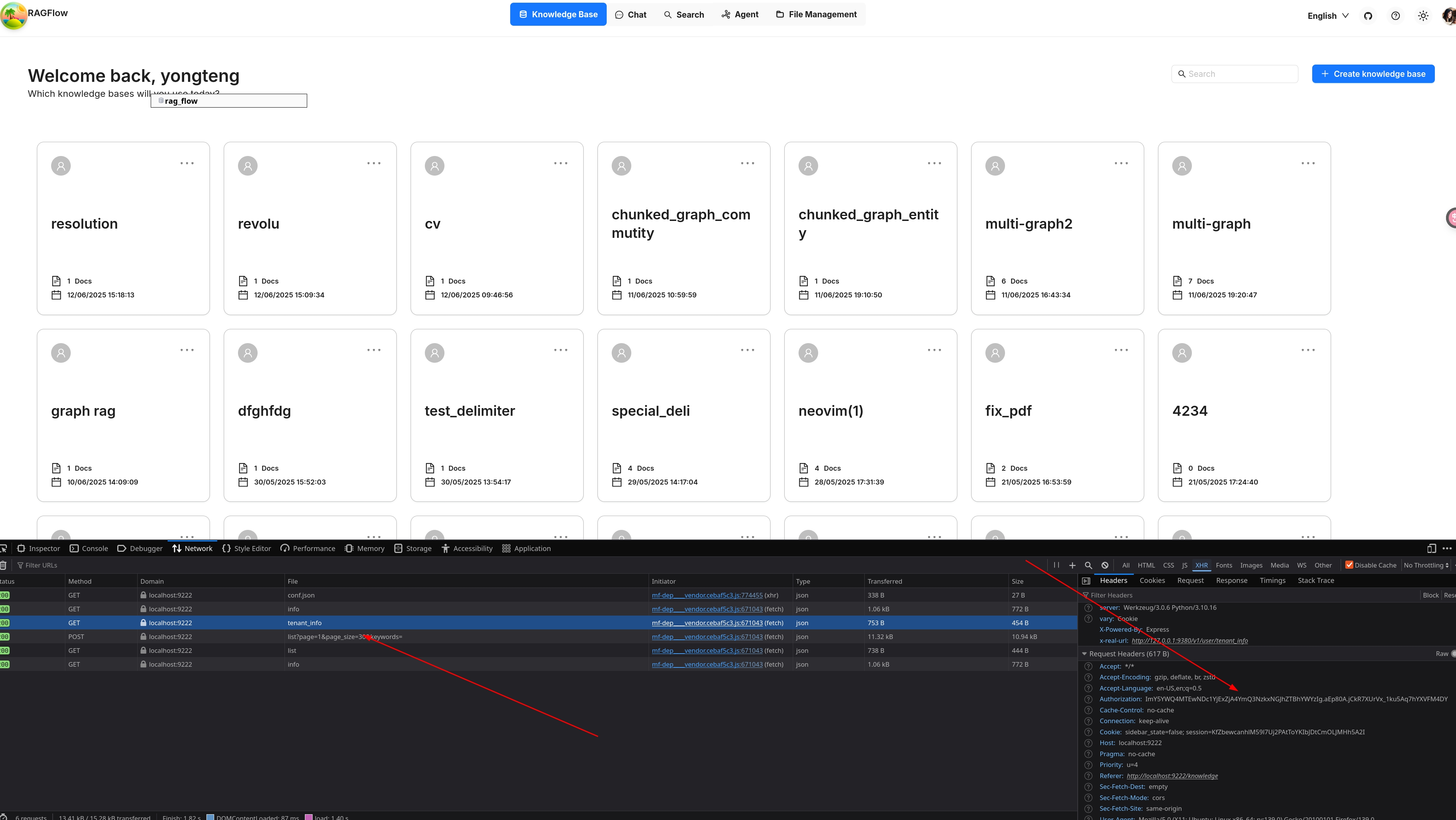
|
||||
|
||||
|
||||
@ -1740,7 +1740,7 @@ for session in sessions:
|
||||
Agent.delete_sessions(ids: list[str] = None)
|
||||
```
|
||||
|
||||
Deletes sessions of a agent by ID.
|
||||
Deletes sessions of an agent by ID.
|
||||
|
||||
#### Parameters
|
||||
|
||||
|
||||
@ -92,6 +92,6 @@ def get_metadata(cls) -> LLMToolMetadata:
|
||||
|
||||
The `get_metadata` method is a `classmethod`. It will provide the description of this tool to LLM.
|
||||
|
||||
The fields starts with `display` can use a special notation: `$t:xxx`, which will use the i18n mechanism in the RAGFlow frontend, getting text from the `llmTools` category. The frontend will display what you put here if you don't use this notation.
|
||||
The fields start with `display` can use a special notation: `$t:xxx`, which will use the i18n mechanism in the RAGFlow frontend, getting text from the `llmTools` category. The frontend will display what you put here if you don't use this notation.
|
||||
|
||||
Now our tool is ready. You can select it in the `Generate` component and try it out.
|
||||
|
||||
@ -5,7 +5,7 @@ from plugin.llm_tool_plugin import LLMToolMetadata, LLMToolPlugin
|
||||
class BadCalculatorPlugin(LLMToolPlugin):
|
||||
"""
|
||||
A sample LLM tool plugin, will add two numbers with 100.
|
||||
It only present for demo purpose. Do not use it in production.
|
||||
It only presents for demo purpose. Do not use it in production.
|
||||
"""
|
||||
_version_ = "1.0.0"
|
||||
|
||||
|
||||
@ -70,7 +70,7 @@ def chunk(filename, binary=None, from_page=0, to_page=100000,
|
||||
"""
|
||||
Supported file formats are docx, pdf, txt.
|
||||
Since a book is long and not all the parts are useful, if it's a PDF,
|
||||
please setup the page ranges for every book in order eliminate negative effects and save elapsed computing time.
|
||||
please set up the page ranges for every book in order eliminate negative effects and save elapsed computing time.
|
||||
"""
|
||||
parser_config = kwargs.get(
|
||||
"parser_config", {
|
||||
|
||||
@ -313,7 +313,7 @@ def mdQuestionLevel(s):
|
||||
def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", callback=None, **kwargs):
|
||||
"""
|
||||
Excel and csv(txt) format files are supported.
|
||||
If the file is in excel format, there should be 2 column question and answer without header.
|
||||
If the file is in Excel format, there should be 2 column question and answer without header.
|
||||
And question column is ahead of answer column.
|
||||
And it's O.K if it has multiple sheets as long as the columns are rightly composed.
|
||||
|
||||
|
||||
@ -37,7 +37,7 @@ def beAdoc(d, q, a, eng, row_num=-1):
|
||||
def chunk(filename, binary=None, lang="Chinese", callback=None, **kwargs):
|
||||
"""
|
||||
Excel and csv(txt) format files are supported.
|
||||
If the file is in excel format, there should be 2 column content and tags without header.
|
||||
If the file is in Excel format, there should be 2 column content and tags without header.
|
||||
And content column is ahead of tags column.
|
||||
And it's O.K if it has multiple sheets as long as the columns are rightly composed.
|
||||
|
||||
|
||||
@ -244,7 +244,7 @@ export interface JsonEditorOptions {
|
||||
timestampFormat?: string;
|
||||
|
||||
/**
|
||||
* If true, unicode characters are escaped. false by default.
|
||||
* If true, Unicode characters are escaped. false by default.
|
||||
*/
|
||||
escapeUnicode?: boolean;
|
||||
|
||||
|
||||
8
web/src/services/admin.service.d.ts
vendored
8
web/src/services/admin.service.d.ts
vendored
@ -66,7 +66,7 @@ declare module AdminService {
|
||||
title: string;
|
||||
};
|
||||
|
||||
export type TaskExectorHeartbeatItem = {
|
||||
export type TaskExecutorHeartbeatItem = {
|
||||
name: string;
|
||||
boot_at: string;
|
||||
now: string;
|
||||
@ -79,7 +79,7 @@ declare module AdminService {
|
||||
pid: number;
|
||||
};
|
||||
|
||||
export type TaskExecutorInfo = Record<string, TaskExectorHeartbeatItem[]>;
|
||||
export type TaskExecutorInfo = Record<string, TaskExecutorHeartbeatItem[]>;
|
||||
|
||||
export type ListServicesItem = {
|
||||
extra: Record<string, unknown>;
|
||||
@ -134,7 +134,7 @@ declare module AdminService {
|
||||
export type RoleDetail = {
|
||||
id: string;
|
||||
name: string;
|
||||
descrtiption: string;
|
||||
description: string;
|
||||
create_date: string;
|
||||
update_date: string;
|
||||
};
|
||||
@ -162,7 +162,7 @@ declare module AdminService {
|
||||
id: number;
|
||||
email: string;
|
||||
create_date: string;
|
||||
createt_time: number;
|
||||
create_time: number;
|
||||
update_date: string;
|
||||
update_time: number;
|
||||
};
|
||||
|
||||
Reference in New Issue
Block a user