mirror of
https://github.com/infiniflow/ragflow.git
synced 2026-01-31 07:36:46 +08:00
Docs: Knowledge base renamed to dataset. (#10269)
### What problem does this PR solve? ### Type of change - [x] Documentation Update
This commit is contained in:
@ -3,28 +3,28 @@ sidebar_position: -1
|
||||
slug: /configure_knowledge_base
|
||||
---
|
||||
|
||||
# Configure knowledge base
|
||||
# Configure dataset
|
||||
|
||||
Knowledge base, hallucination-free chat, and file management are the three pillars of RAGFlow. RAGFlow's AI chats are based on knowledge bases. Each of RAGFlow's knowledge bases serves as a knowledge source, *parsing* files uploaded from your local machine and file references generated in **File Management** into the real 'knowledge' for future AI chats. This guide demonstrates some basic usages of the knowledge base feature, covering the following topics:
|
||||
Most of RAGFlow's chat assistants and Agents are based on datasets. Each of RAGFlow's datasets serves as a knowledge source, *parsing* files uploaded from your local machine and file references generated in **File Management** into the real 'knowledge' for future AI chats. This guide demonstrates some basic usages of the dataset feature, covering the following topics:
|
||||
|
||||
- Create a knowledge base
|
||||
- Configure a knowledge base
|
||||
- Search for a knowledge base
|
||||
- Delete a knowledge base
|
||||
- Create a dataset
|
||||
- Configure a dataset
|
||||
- Search for a dataset
|
||||
- Delete a dataset
|
||||
|
||||
## Create knowledge base
|
||||
## Create dataset
|
||||
|
||||
With multiple knowledge bases, you can build more flexible, diversified question answering. To create your first knowledge base:
|
||||
With multiple datasets, you can build more flexible, diversified question answering. To create your first dataset:
|
||||
|
||||
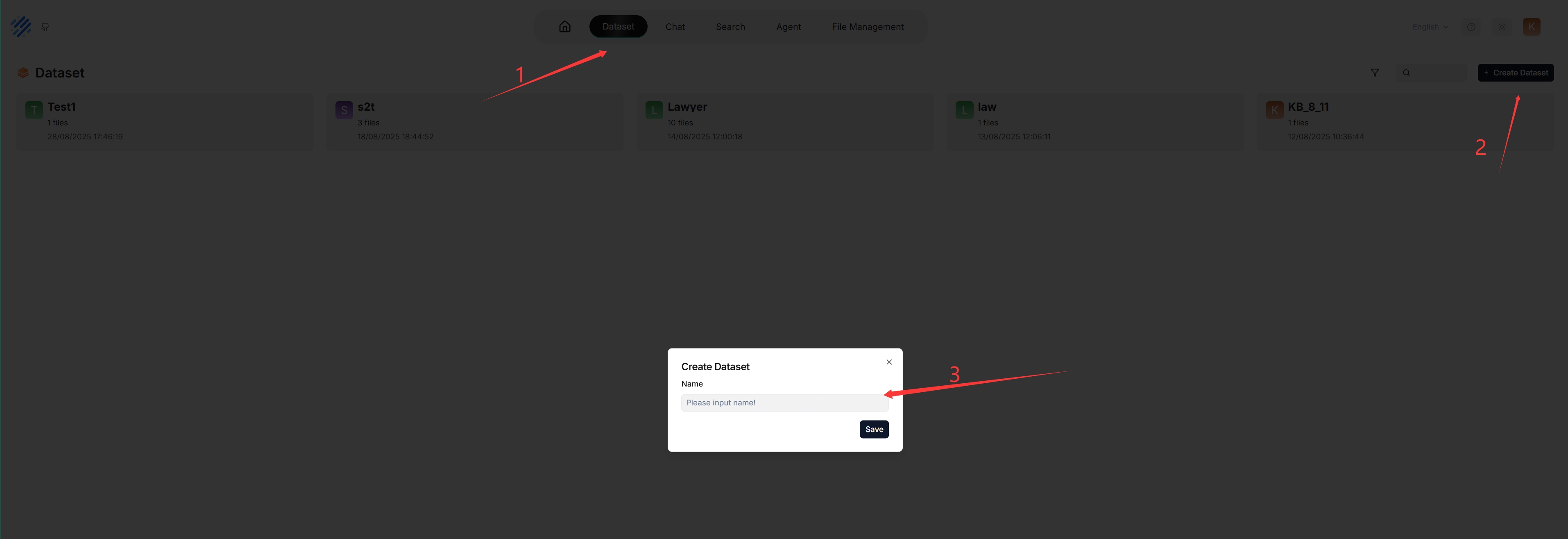
|
||||

|
||||
|
||||
_Each time a knowledge base is created, a folder with the same name is generated in the **root/.knowledgebase** directory._
|
||||
_Each time a dataset is created, a folder with the same name is generated in the **root/.knowledgebase** directory._
|
||||
|
||||
## Configure knowledge base
|
||||
## Configure dataset
|
||||
|
||||
The following screenshot shows the configuration page of a knowledge base. A proper configuration of your knowledge base is crucial for future AI chats. For example, choosing the wrong embedding model or chunking method would cause unexpected semantic loss or mismatched answers in chats.
|
||||
The following screenshot shows the configuration page of a dataset. A proper configuration of your dataset is crucial for future AI chats. For example, choosing the wrong embedding model or chunking method would cause unexpected semantic loss or mismatched answers in chats.
|
||||
|
||||
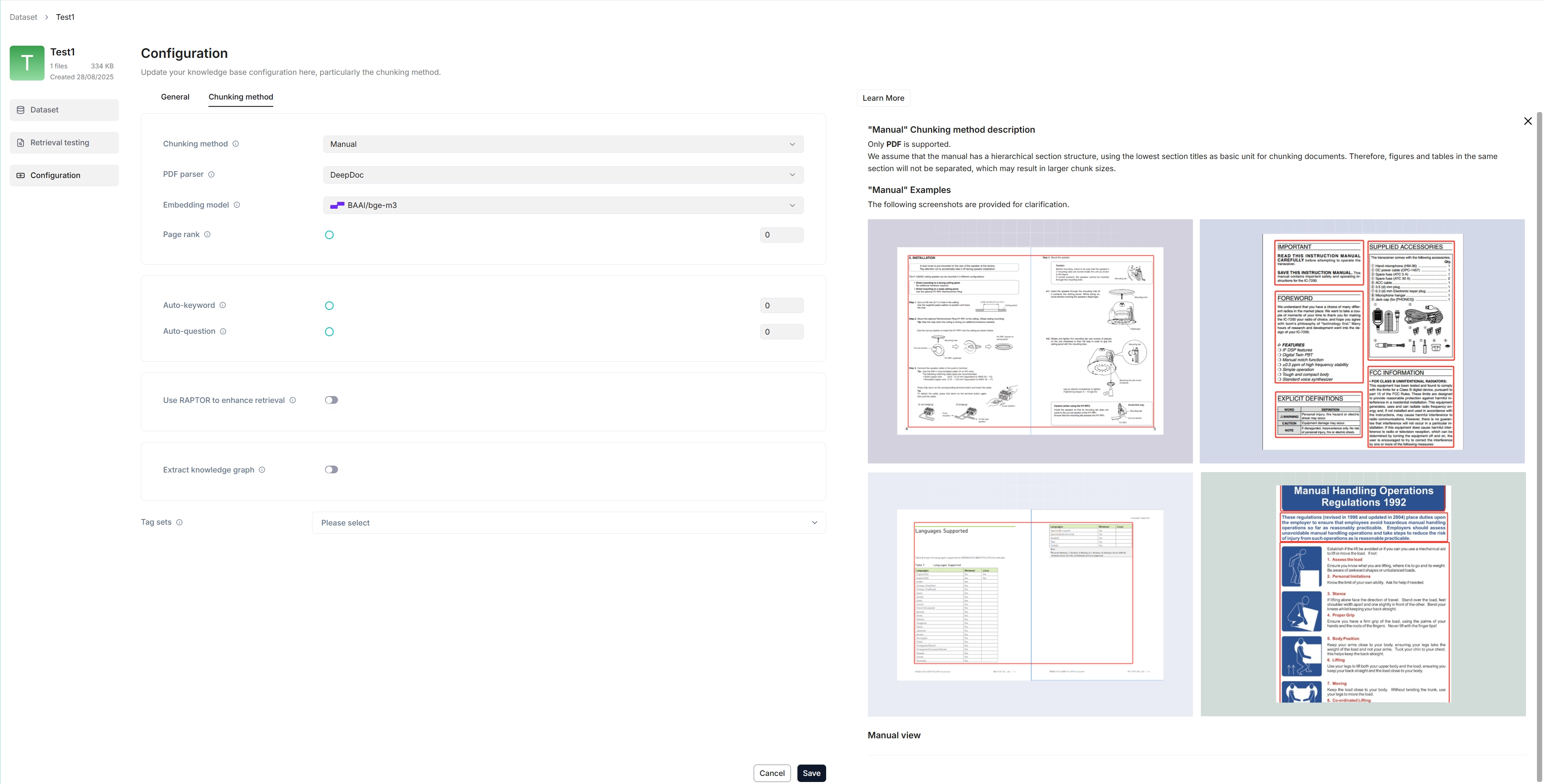
|
||||

|
||||
|
||||
This section covers the following topics:
|
||||
|
||||
@ -52,7 +52,7 @@ RAGFlow offers multiple chunking template to facilitate chunking files of differ
|
||||
| Presentation | | PDF, PPTX |
|
||||
| Picture | | JPEG, JPG, PNG, TIF, GIF |
|
||||
| One | Each document is chunked in its entirety (as one). | DOCX, XLSX, XLS (Excel 97-2003), PDF, TXT |
|
||||
| Tag | The knowledge base functions as a tag set for the others. | XLSX, CSV/TXT |
|
||||
| Tag | The dataset functions as a tag set for the others. | XLSX, CSV/TXT |
|
||||
|
||||
You can also change a file's chunking method on the **Datasets** page.
|
||||
|
||||
@ -60,7 +60,7 @@ You can also change a file's chunking method on the **Datasets** page.
|
||||
|
||||
### Select embedding model
|
||||
|
||||
An embedding model converts chunks into embeddings. It cannot be changed once the knowledge base has chunks. To switch to a different embedding model, you must delete all existing chunks in the knowledge base. The obvious reason is that we *must* ensure that files in a specific knowledge base are converted to embeddings using the *same* embedding model (ensure that they are compared in the same embedding space).
|
||||
An embedding model converts chunks into embeddings. It cannot be changed once the dataset has chunks. To switch to a different embedding model, you must delete all existing chunks in the dataset. The obvious reason is that we *must* ensure that files in a specific dataset are converted to embeddings using the *same* embedding model (ensure that they are compared in the same embedding space).
|
||||
|
||||
The following embedding models can be deployed locally:
|
||||
|
||||
@ -73,19 +73,19 @@ These two embedding models are optimized specifically for English and Chinese, s
|
||||
|
||||
### Upload file
|
||||
|
||||
- RAGFlow's **File Management** allows you to link a file to multiple knowledge bases, in which case each target knowledge base holds a reference to the file.
|
||||
- In **Knowledge Base**, you are also given the option of uploading a single file or a folder of files (bulk upload) from your local machine to a knowledge base, in which case the knowledge base holds file copies.
|
||||
- RAGFlow's **File Management** allows you to link a file to multiple datasets, in which case each target dataset holds a reference to the file.
|
||||
- In **Knowledge Base**, you are also given the option of uploading a single file or a folder of files (bulk upload) from your local machine to a dataset, in which case the dataset holds file copies.
|
||||
|
||||
While uploading files directly to a knowledge base seems more convenient, we *highly* recommend uploading files to **File Management** and then linking them to the target knowledge bases. This way, you can avoid permanently deleting files uploaded to the knowledge base.
|
||||
While uploading files directly to a dataset seems more convenient, we *highly* recommend uploading files to **File Management** and then linking them to the target datasets. This way, you can avoid permanently deleting files uploaded to the dataset.
|
||||
|
||||
### Parse file
|
||||
|
||||
File parsing is a crucial topic in knowledge base configuration. The meaning of file parsing in RAGFlow is twofold: chunking files based on file layout and building embedding and full-text (keyword) indexes on these chunks. After having selected the chunking method and embedding model, you can start parsing a file:
|
||||
File parsing is a crucial topic in dataset configuration. The meaning of file parsing in RAGFlow is twofold: chunking files based on file layout and building embedding and full-text (keyword) indexes on these chunks. After having selected the chunking method and embedding model, you can start parsing a file:
|
||||
|
||||
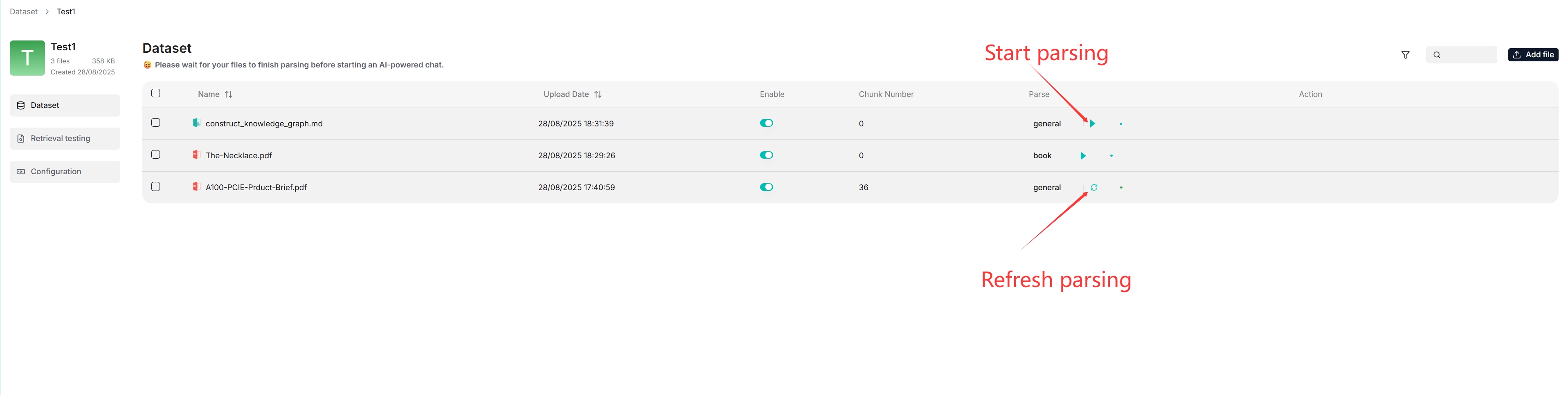
|
||||
|
||||
- As shown above, RAGFlow allows you to use a different chunking method for a particular file, offering flexibility beyond the default method.
|
||||
- As shown above, RAGFlow allows you to enable or disable individual files, offering finer control over knowledge base-based AI chats.
|
||||
- As shown above, RAGFlow allows you to enable or disable individual files, offering finer control over dataset-based AI chats.
|
||||
|
||||
### Intervene with file parsing results
|
||||
|
||||
@ -122,17 +122,17 @@ RAGFlow uses multiple recall of both full-text search and vector search in its c
|
||||
|
||||
See [Run retrieval test](./run_retrieval_test.md) for details.
|
||||
|
||||
## Search for knowledge base
|
||||
## Search for dataset
|
||||
|
||||
As of RAGFlow v0.20.5, the search feature is still in a rudimentary form, supporting only knowledge base search by name.
|
||||
As of RAGFlow v0.20.5, the search feature is still in a rudimentary form, supporting only dataset search by name.
|
||||
|
||||

|
||||

|
||||
|
||||
## Delete knowledge base
|
||||
## Delete dataset
|
||||
|
||||
You are allowed to delete a knowledge base. Hover your mouse over the three dot of the intended knowledge base card and the **Delete** option appears. Once you delete a knowledge base, the associated folder under **root/.knowledge** directory is AUTOMATICALLY REMOVED. The consequence is:
|
||||
You are allowed to delete a dataset. Hover your mouse over the three dot of the intended dataset card and the **Delete** option appears. Once you delete a dataset, the associated folder under **root/.knowledge** directory is AUTOMATICALLY REMOVED. The consequence is:
|
||||
|
||||
- The files uploaded directly to the knowledge base are gone;
|
||||
- The files uploaded directly to the dataset are gone;
|
||||
- The file references, which you created from within **File Management**, are gone, but the associated files still exist in **File Management**.
|
||||
|
||||

|
||||

|
||||
|
||||
Reference in New Issue
Block a user