mirror of
https://github.com/infiniflow/ragflow.git
synced 2026-01-31 23:55:06 +08:00
Docs: Updated dataset configuration, KG building and RAPTOR building for v0.21.0 (#10584)
### What problem does this PR solve? ### Type of change - [x] Documentation Update
This commit is contained in:
@ -37,7 +37,7 @@ This section covers the following topics:
|
||||
|
||||
### Select chunking method
|
||||
|
||||
RAGFlow offers multiple chunking template to facilitate chunking files of different layouts and ensure semantic integrity. In **Chunking method**, you can choose the default template that suits the layouts and formats of your files. The following table shows the descriptions and the compatible file formats of each supported chunk template:
|
||||
RAGFlow offers multiple built-in chunking template to facilitate chunking files of different layouts and ensure semantic integrity. From the **Built-in** chunking method dropdown under **Parse type**, you can choose the default template that suits the layouts and formats of your files. The following table shows the descriptions and the compatible file formats of each supported chunk template:
|
||||
|
||||
| **Template** | Description | File format |
|
||||
|--------------|-----------------------------------------------------------------------|-----------------------------------------------------------------------------------------------|
|
||||
@ -54,9 +54,26 @@ RAGFlow offers multiple chunking template to facilitate chunking files of differ
|
||||
| One | Each document is chunked in its entirety (as one). | DOCX, XLSX, XLS (Excel 97-2003), PDF, TXT |
|
||||
| Tag | The dataset functions as a tag set for the others. | XLSX, CSV/TXT |
|
||||
|
||||
You can also change a file's chunking method on the **Datasets** page.
|
||||
You can also change a file's chunking method on the **Files** page.
|
||||
|
||||
|
||||
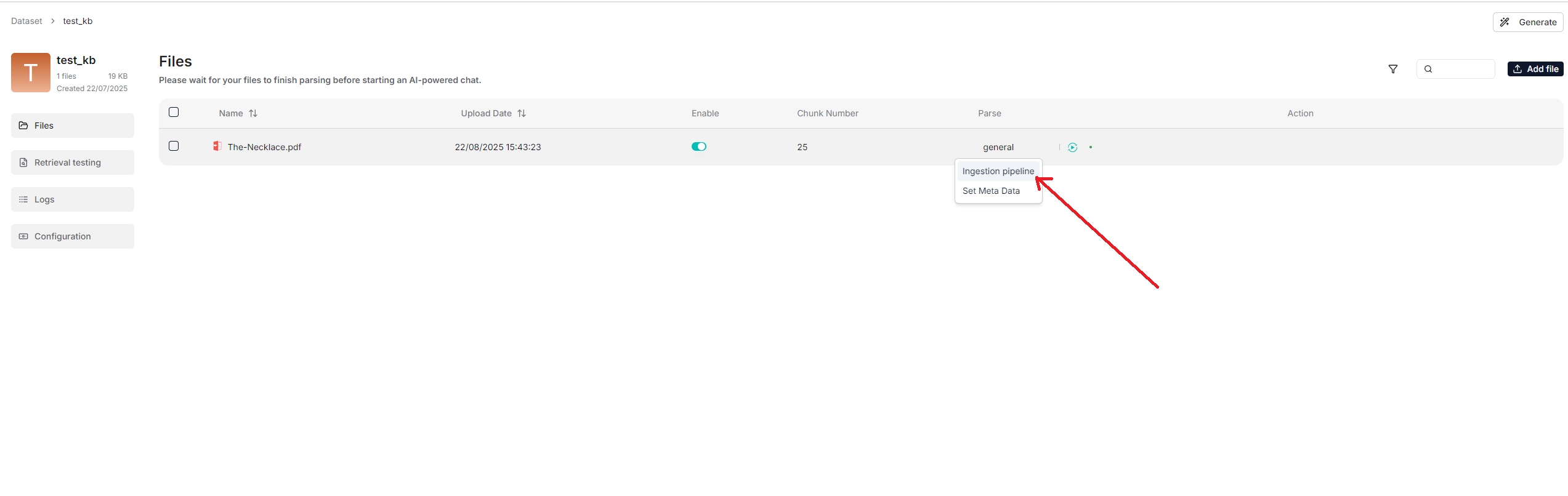
|
||||
|
||||
:::tip NOTE
|
||||
From v0.21.0, RAGFlow supports ingestion pipeline to allow for customized
|
||||
|
||||
<details>
|
||||
<summary>From v0.21.0 onward, RAGFlow supports ingestion pipeline to allow for customized data ingestion and cleansing workflows.</summary>
|
||||
|
||||
To use a customized data pipeline:
|
||||
|
||||
1. On the **Agent** page, click **+ Create agent** > **Create from blank**.
|
||||
2. Select **Ingestion pipeline** and name your data pipeline in the popup, then click **Save** to show the data pipeline canvas.
|
||||
3. After updating your data pipeline, click **Save** on the top right of the canvas.
|
||||
4. Navigate to the **Configuration** page of your dataset, select **Choose pipeline** in **Ingestion pipeline**.
|
||||
|
||||
*Your saved data pipeline will appear in the dropdown menu below.*
|
||||
|
||||
</details>
|
||||
|
||||
### Select embedding model
|
||||
|
||||
|
||||
@ -53,25 +53,31 @@ Whether to enable entity resolution. You can think of this as an entity deduplic
|
||||
- (Default) Disable entity resolution.
|
||||
- Enable entity resolution. This option consumes more tokens.
|
||||
|
||||
### Community report generation
|
||||
### Community reports
|
||||
|
||||
In a knowledge graph, a community is a cluster of entities linked by relationships. You can have the LLM generate an abstract for each community, known as a community report. See [here](https://www.microsoft.com/en-us/research/blog/graphrag-improving-global-search-via-dynamic-community-selection/) for more information. This indicates whether to generate community reports:
|
||||
|
||||
- Generate community reports. This option consumes more tokens.
|
||||
- (Default) Do not generate community reports.
|
||||
|
||||
## Procedure
|
||||
## Quickstart
|
||||
|
||||
1. On the **Configuration** page of your dataset, switch on **Extract knowledge graph** or adjust its settings as needed, and click **Save** to confirm your changes.
|
||||
1. Navigate to the **Configuration** page of your dataset and update:
|
||||
|
||||
- Entity types: *Required* - Specifies the entity types in the knowledge graph to generate. You don't have to stick with the default, but you need to customize them for your documents.
|
||||
- Method: *Optional*
|
||||
- Entity resolution: *Optional*
|
||||
- Community reports: *Optional*
|
||||
*The default knowledge graph configurations for your dataset are now set.*
|
||||
|
||||
- *The default knowledge graph configurations for your dataset are now set and files uploaded from this point onward will automatically use these settings during parsing.*
|
||||
- *Files parsed before this update will retain their original knowledge graph settings.*
|
||||
2. Navigate to the **Files** page of your dataset, click the **Generate** button on the top right corner of the page, then select **Knowledge graph** from the dropdown to initiate the knowledge graph generation process.
|
||||
|
||||
2. The knowledge graph of your dataset does *not* automatically update *until* a newly uploaded file is parsed.
|
||||
*You can click the pause button in the dropdown to halt the build process when necessary.*
|
||||
|
||||
_A **Knowledge graph** entry appears under **Configuration** once a knowledge graph is created._
|
||||
3. Go back to the **Configuration** page:
|
||||
|
||||
*Once a knowledge graph is generated, the **Knowledge graph** field changes from `Not generated` to `Generated at a specific timestamp`. You can delete it by clicking the recycle bin button to the right of the field.*
|
||||
|
||||
3. Click **Knowledge graph** to view the details of the generated graph.
|
||||
4. To use the created knowledge graph, do either of the following:
|
||||
|
||||
- In the **Chat setting** panel of your chat app, switch on the **Use knowledge graph** toggle.
|
||||
@ -79,17 +85,13 @@ In a knowledge graph, a community is a cluster of entities linked by relationshi
|
||||
|
||||
## Frequently asked questions
|
||||
|
||||
### Can I have different knowledge graph settings for different files in my dataset?
|
||||
|
||||
Yes, you can. Just one graph is generated per dataset. The smaller graphs of your files will be *combined* into one big, unified graph at the end of the graph extraction process.
|
||||
|
||||
### Does the knowledge graph automatically update when I remove a related file?
|
||||
|
||||
Nope. The knowledge graph does *not* automatically update *until* a newly uploaded document is parsed.
|
||||
Nope. The knowledge graph does *not* update *until* you regenerate a knowledge graph for your dataset.
|
||||
|
||||
### How to remove a generated knowledge graph?
|
||||
|
||||
To remove the generated knowledge graph, delete all related files in your dataset. Although the **Knowledge graph** entry will still be visible, the graph has actually been deleted.
|
||||
On the **Configuration** page of your dataset, find the **Knoweledge graph** field and click the recycle bin button to the right of the field.
|
||||
|
||||
### Where is the created knowledge graph stored?
|
||||
|
||||
|
||||
@ -72,3 +72,22 @@ The maximum number of clusters to create. Defaults to 64, with a maximum limit o
|
||||
### Random seed
|
||||
|
||||
A random seed. Click **+** to change the seed value.
|
||||
|
||||
## Quickstart
|
||||
|
||||
1. Navigate to the **Configuration** page of your dataset and update:
|
||||
|
||||
- Prompt: *Optional* - We recommend that you keep it as-is until you understand the mechanism behind.
|
||||
- Max token: *Optional*
|
||||
- Threshold: *Optional*
|
||||
- Max cluster: *Optional*
|
||||
|
||||
2. Navigate to the **Files** page of your dataset, click the **Generate** button on the top right corner of the page, then select **RAPTOR** from the dropdown to initiate the RAPTOR build process.
|
||||
|
||||
*You can click the pause button in the dropdown to halt the build process when necessary.*
|
||||
|
||||
3. Go back to the **Configuration** page:
|
||||
|
||||
*The **RAPTOR** field changes from `Not generated` to `Generated at a specific timestamp` when a RAPTOR hierarchical tree structure is generated. You can delete it by clicking the recycle bin button to the right of the field.*
|
||||
|
||||
4. Once a RAPTOR hierarchical tree structure is generated, your chat assistant and **Retrieval** agent component will use it for retrieval as a default.
|
||||
|
||||
Reference in New Issue
Block a user