📥 Model Download |
📄 Paper Link |
📄 Arxiv Paper Link |
DeepSeek-OCR: Contexts Optical Compression
Explore the boundaries of visual-text compression.
## Release
- [2025/10/23]🚀🚀🚀 DeepSeek-OCR is now officially supported in upstream [vLLM](https://docs.vllm.ai/projects/recipes/en/latest/DeepSeek/DeepSeek-OCR.html#installing-vllm). Thanks to the [vLLM](https://github.com/vllm-project/vllm) team for their help.
- [2025/10/20]🚀🚀🚀 We release DeepSeek-OCR, a model to investigate the role of vision encoders from an LLM-centric viewpoint.
## Contents
- [Install](#install)
- [vLLM Inference](#vllm-inference)
- [Transformers Inference](#transformers-inference)
## Install
>Our environment is cuda11.8+torch2.6.0.
1. Clone this repository and navigate to the DeepSeek-OCR folder
```bash
git clone https://github.com/deepseek-ai/DeepSeek-OCR.git
```
2. Conda
```Shell
conda create -n deepseek-ocr python=3.12.9 -y
conda activate deepseek-ocr
```
3. Packages
- download the vllm-0.8.5 [whl](https://github.com/vllm-project/vllm/releases/tag/v0.8.5)
```Shell
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118
pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl
pip install -r requirements.txt
pip install flash-attn==2.7.3 --no-build-isolation
```
**Note:** if you want vLLM and transformers codes to run in the same environment, you don't need to worry about this installation error like: vllm 0.8.5+cu118 requires transformers>=4.51.1
## vLLM-Inference
- VLLM:
>**Note:** change the INPUT_PATH/OUTPUT_PATH and other settings in the DeepSeek-OCR-master/DeepSeek-OCR-vllm/config.py
```Shell
cd DeepSeek-OCR-master/DeepSeek-OCR-vllm
```
1. image: streaming output
```Shell
python run_dpsk_ocr_image.py
```
2. pdf: concurrency ~2500tokens/s(an A100-40G)
```Shell
python run_dpsk_ocr_pdf.py
```
3. batch eval for benchmarks
```Shell
python run_dpsk_ocr_eval_batch.py
```
**[2025/10/23] The version of upstream [vLLM](https://docs.vllm.ai/projects/recipes/en/latest/DeepSeek/DeepSeek-OCR.html#installing-vllm):**
```shell
uv venv
source .venv/bin/activate
# Until v0.11.1 release, you need to install vLLM from nightly build
uv pip install -U vllm --pre --extra-index-url https://wheels.vllm.ai/nightly
```
```python
from vllm import LLM, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from PIL import Image
# Create model instance
llm = LLM(
model="deepseek-ai/DeepSeek-OCR",
enable_prefix_caching=False,
mm_processor_cache_gb=0,
logits_processors=[NGramPerReqLogitsProcessor]
)
# Prepare batched input with your image file
image_1 = Image.open("path/to/your/image_1.png").convert("RGB")
image_2 = Image.open("path/to/your/image_2.png").convert("RGB")
prompt = "\nFree OCR."
model_input = [
{
"prompt": prompt,
"multi_modal_data": {"image": image_1}
},
{
"prompt": prompt,
"multi_modal_data": {"image": image_2}
}
]
sampling_param = SamplingParams(
temperature=0.0,
max_tokens=8192,
# ngram logit processor args
extra_args=dict(
ngram_size=30,
window_size=90,
whitelist_token_ids={128821, 128822}, # whitelist: , |
),
skip_special_tokens=False,
)
# Generate output
model_outputs = llm.generate(model_input, sampling_param)
# Print output
for output in model_outputs:
print(output.outputs[0].text)
```
## Transformers-Inference
- Transformers
```python
from transformers import AutoModel, AutoTokenizer
import torch
import os
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
model_name = 'deepseek-ai/DeepSeek-OCR'
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(model_name, _attn_implementation='flash_attention_2', trust_remote_code=True, use_safetensors=True)
model = model.eval().cuda().to(torch.bfloat16)
# prompt = "\nFree OCR. "
prompt = "\n<|grounding|>Convert the document to markdown. "
image_file = 'your_image.jpg'
output_path = 'your/output/dir'
res = model.infer(tokenizer, prompt=prompt, image_file=image_file, output_path = output_path, base_size = 1024, image_size = 640, crop_mode=True, save_results = True, test_compress = True)
```
or you can
```Shell
cd DeepSeek-OCR-master/DeepSeek-OCR-hf
python run_dpsk_ocr.py
```
## Support-Modes
The current open-source model supports the following modes:
- Native resolution:
- Tiny: 512×512 (64 vision tokens)✅
- Small: 640×640 (100 vision tokens)✅
- Base: 1024×1024 (256 vision tokens)✅
- Large: 1280×1280 (400 vision tokens)✅
- Dynamic resolution
- Gundam: n×640×640 + 1×1024×1024 ✅
## Prompts examples
```python
# document: \n<|grounding|>Convert the document to markdown.
# other image: \n<|grounding|>OCR this image.
# without layouts: \nFree OCR.
# figures in document: \nParse the figure.
# general: \nDescribe this image in detail.
# rec: \nLocate <|ref|>xxxx<|/ref|> in the image.
# '先天下之忧而忧'
```
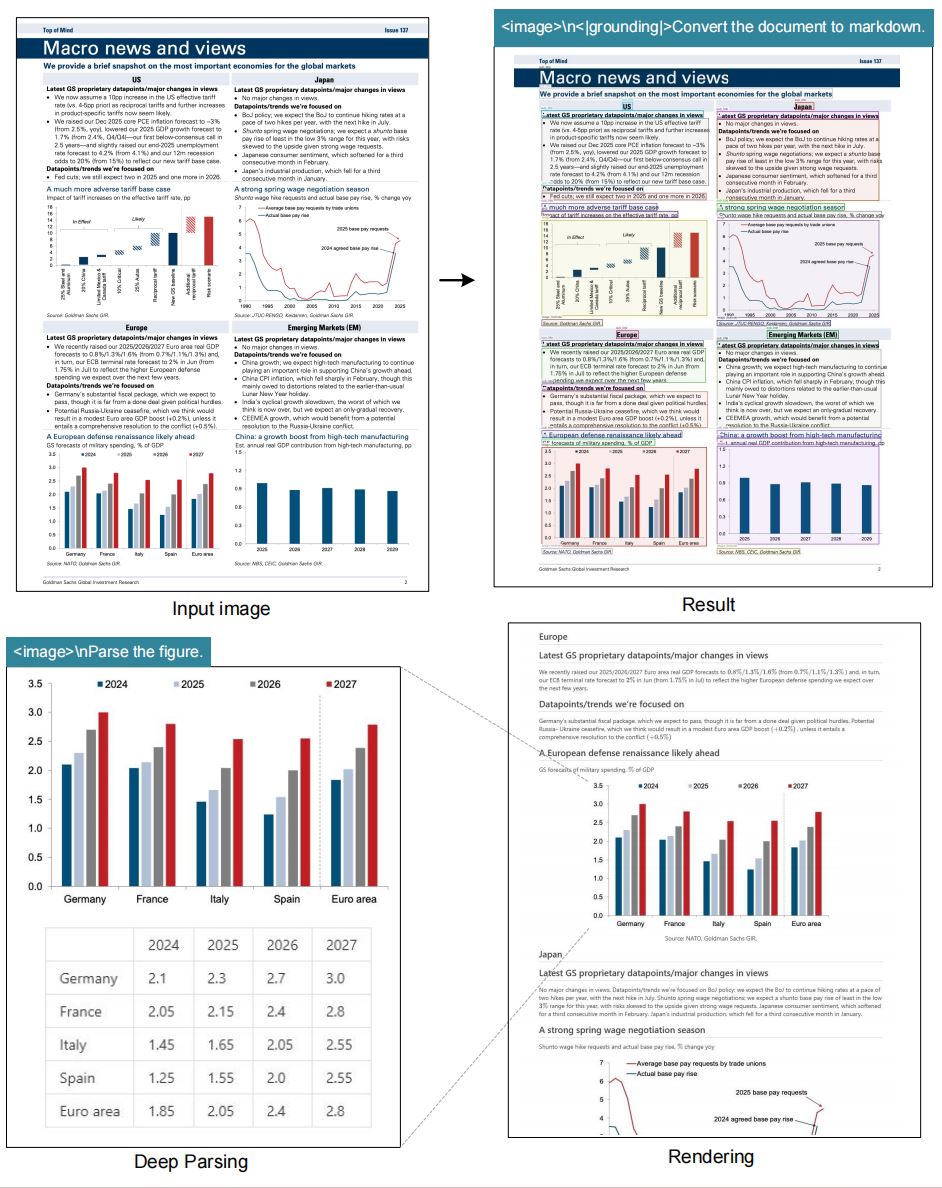
## Visualizations
## Acknowledgement
We would like to thank [Vary](https://github.com/Ucas-HaoranWei/Vary/), [GOT-OCR2.0](https://github.com/Ucas-HaoranWei/GOT-OCR2.0/), [MinerU](https://github.com/opendatalab/MinerU), [PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR), [OneChart](https://github.com/LingyvKong/OneChart), [Slow Perception](https://github.com/Ucas-HaoranWei/Slow-Perception) for their valuable models and ideas.
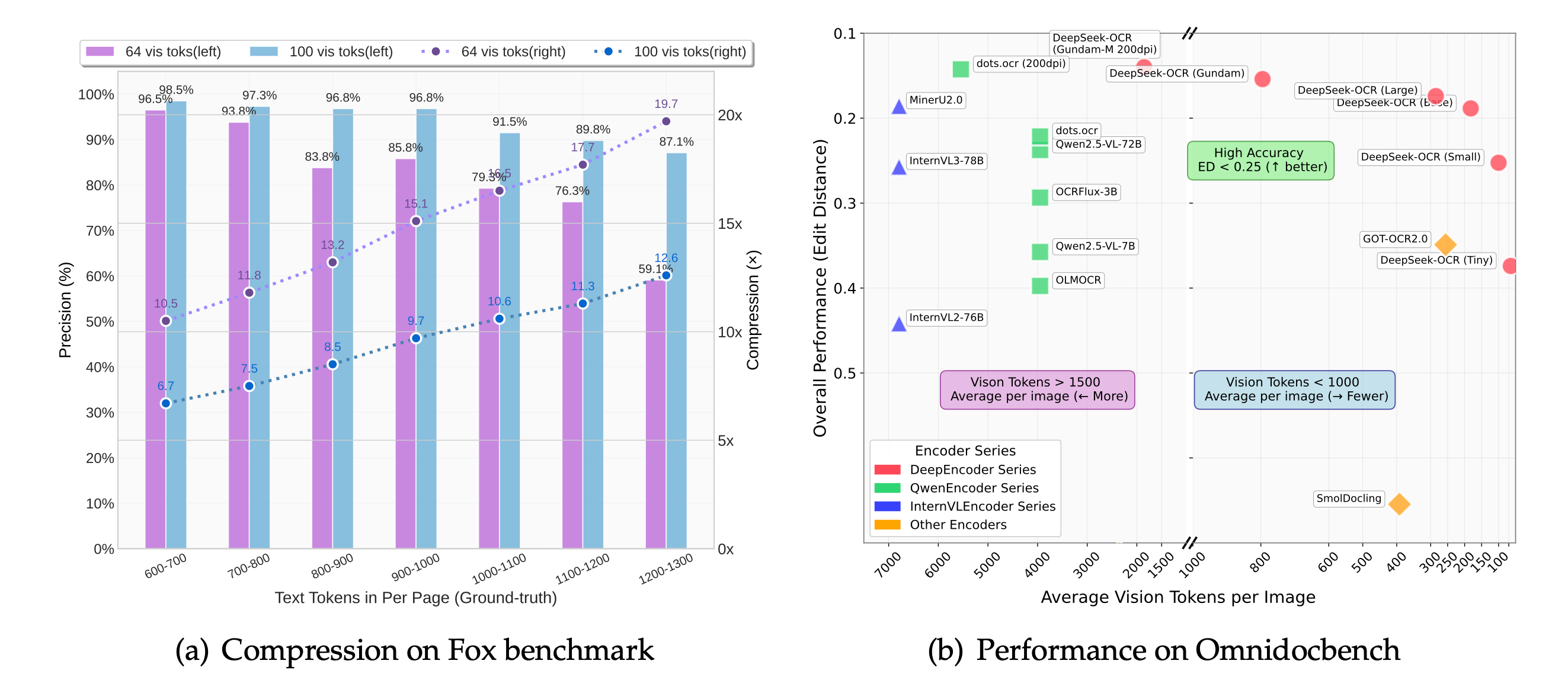
We also appreciate the benchmarks: [Fox](https://github.com/ucaslcl/Fox), [OminiDocBench](https://github.com/opendatalab/OmniDocBench).
## Citation
```bibtex
@article{wei2024deepseek-ocr,
title={DeepSeek-OCR: Contexts Optical Compression},
author={Wei, Haoran and Sun, Yaofeng and Li, Yukun},
journal={arXiv preprint arXiv:2510.18234},
year={2025}
}